Обсуждение: row filtering for logical replication
Hi, The attached patches add support for filtering rows in the publisher. The output plugin will do the work if a filter was defined in CREATE PUBLICATION command. An optional WHERE clause can be added after the table name in the CREATE PUBLICATION such as: CREATE PUBLICATION foo FOR TABLE departments WHERE (id > 2000 AND id <= 3000); Row that doesn't match the WHERE clause will not be sent to the subscribers. Patches 0001 and 0002 are only refactors and can be applied independently. 0003 doesn't include row filtering on initial synchronization. Comments? -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
On Wed, Feb 28, 2018 at 08:03:02PM -0300, Euler Taveira wrote:
> Hi,
>
> The attached patches add support for filtering rows in the publisher.
> The output plugin will do the work if a filter was defined in CREATE
> PUBLICATION command. An optional WHERE clause can be added after the
> table name in the CREATE PUBLICATION such as:
>
> CREATE PUBLICATION foo FOR TABLE departments WHERE (id > 2000 AND id <= 3000);
>
> Row that doesn't match the WHERE clause will not be sent to the subscribers.
>
> Patches 0001 and 0002 are only refactors and can be applied
> independently. 0003 doesn't include row filtering on initial
> synchronization.
>
> Comments?
Great feature! I think a lot of people will like to have the option
of trading a little extra CPU on the pub side for a bunch of network
traffic and some work on the sub side.
I noticed that the WHERE clause applies to all tables in the
publication. Is that actually the right thing? I'm thinking of a
case where we have foo(id, ...) and bar(foo_id, ....). To slice that
correctly, we'd want to do the ids in the foo table and the foo_ids in
the bar table. In the system as written, that would entail, at least
potentially, writing a lot of publications by hand.
Something like
WHERE (
(table_1,..., table_N) HAS (/* WHERE clause here */) AND
(table_N+1,..., table_M) HAS (/* WHERE clause here */) AND
...
)
could be one way to specify.
I also noticed that in psql, \dRp+ doesn't show the WHERE clause,
which it probably should.
Does it need regression tests?
Best,
David.
--
David Fetter <david(at)fetter(dot)org> http://fetter.org/
Phone: +1 415 235 3778
Remember to vote!
Consider donating to Postgres: http://www.postgresql.org/about/donate
On 1 March 2018 at 07:03, Euler Taveira <euler@timbira.com.br> wrote:
Hi,
The attached patches add support for filtering rows in the publisher.
The output plugin will do the work if a filter was defined in CREATE
PUBLICATION command. An optional WHERE clause can be added after the
table name in the CREATE PUBLICATION such as:
CREATE PUBLICATION foo FOR TABLE departments WHERE (id > 2000 AND id <= 3000);
Row that doesn't match the WHERE clause will not be sent to the subscribers.
Patches 0001 and 0002 are only refactors and can be applied
independently. 0003 doesn't include row filtering on initial
synchronization.
Good idea. I haven't read this yet, but one thing to make sure you've handled is limiting the clause to referencing only the current tuple and the catalogs. user-catalog tables are OK, too, anything that is RelationIsAccessibleInLogicalDecoding().
It might be worth looking at the current logic for CHECK expressions, since the requirements are similar. In my opinion you could safely not bother with allowing access to user catalog tables in the filter expressions and limit them strictly to immutable functions and the tuple its self.
On 2018-03-01 00:03, Euler Taveira wrote: > The attached patches add support for filtering rows in the publisher. > 001-Refactor-function-create_estate_for_relation.patch > 0002-Rename-a-WHERE-node.patch > 0003-Row-filtering-for-logical-replication.patch > Comments? Very, very useful. I really do hope this patch survives the late-arrival-cull. I built this functionality into a test program I have been using and in simple cascading replication tests it works well. I did find what I think is a bug (a bug easy to avoid but also easy to run into): The test I used was to cascade 3 instances (all on one machine) from A->B->C I ran a pgbench session in instance A, and used: in A: alter publication pub0_6515 add table pgbench_accounts where (aid between 40000 and 60000-1); in B: alter publication pub1_6516 add table pgbench_accounts; The above worked well, but when I did the same but used the filter in both publications: in A: alter publication pub0_6515 add table pgbench_accounts where (aid between 40000 and 60000-1); in B: alter publication pub1_6516 add table pgbench_accounts where (aid between 40000 and 60000-1); then the replication only worked for (pgbench-)scale 1 (hence: very little data); with larger scales it became slow (taking many minutes where the above had taken less than 1 minute), and ended up using far too much memory (or blowing up/crashing altogether). Something not quite right there. Nevertheless, I am much in favour of acquiring this functionality as soon as possible. Thanks, Erik Rijkers
2018-02-28 21:47 GMT-03:00 David Fetter <david@fetter.org>: > I noticed that the WHERE clause applies to all tables in the > publication. Is that actually the right thing? I'm thinking of a > case where we have foo(id, ...) and bar(foo_id, ....). To slice that > correctly, we'd want to do the ids in the foo table and the foo_ids in > the bar table. In the system as written, that would entail, at least > potentially, writing a lot of publications by hand. > I didn't make it clear in my previous email and I think you misread the attached docs. Each table can have an optional WHERE clause. I'll made it clear when I rewrite the tests. Something like: CREATE PUBLICATION tap_pub FOR TABLE tab_rowfilter_1 WHERE (a > 1000 AND b <> 'filtered'), tab_rowfilter_2 WHERE (c % 2 = 0), tab_rowfilter_3; Such syntax will not block another future feature that will publish only few columns of the table. > I also noticed that in psql, \dRp+ doesn't show the WHERE clause, > which it probably should. > Yea, it could be added be I'm afraid of such long WHERE clauses. > Does it need regression tests? > I included some tests just to demonstrate the feature but I'm planning to add a separate test file for it. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On Thu, Mar 01, 2018 at 12:41:04PM -0300, Euler Taveira wrote: > 2018-02-28 21:47 GMT-03:00 David Fetter <david@fetter.org>: > > I noticed that the WHERE clause applies to all tables in the > > publication. Is that actually the right thing? I'm thinking of a > > case where we have foo(id, ...) and bar(foo_id, ....). To slice that > > correctly, we'd want to do the ids in the foo table and the foo_ids in > > the bar table. In the system as written, that would entail, at least > > potentially, writing a lot of publications by hand. > > > I didn't make it clear in my previous email and I think you misread > the attached docs. Each table can have an optional WHERE clause. I'll > made it clear when I rewrite the tests. Something like: Sorry I misunderstood. > CREATE PUBLICATION tap_pub FOR TABLE tab_rowfilter_1 WHERE (a > 1000 > AND b <> 'filtered'), tab_rowfilter_2 WHERE (c % 2 = 0), > tab_rowfilter_3; That's great! > Such syntax will not block another future feature that will publish > only few columns of the table. > > > I also noticed that in psql, \dRp+ doesn't show the WHERE clause, > > which it probably should. > > > Yea, it could be added be I'm afraid of such long WHERE clauses. I think of + as signifying, "I am ready to get a LOT of output in order to see more detail." Perhaps that's just me. > > Does it need regression tests? > > > I included some tests just to demonstrate the feature but I'm > planning to add a separate test file for it. Excellent. This feature looks like a nice big chunk of the user-space infrastructure needed for sharding, among other things. Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On 2018-03-01 16:27, Erik Rijkers wrote: > On 2018-03-01 00:03, Euler Taveira wrote: >> The attached patches add support for filtering rows in the publisher. > >> 001-Refactor-function-create_estate_for_relation.patch >> 0002-Rename-a-WHERE-node.patch >> 0003-Row-filtering-for-logical-replication.patch > >> Comments? > > Very, very useful. I really do hope this patch survives the > late-arrival-cull. > > I built this functionality into a test program I have been using and > in simple cascading replication tests it works well. > > I did find what I think is a bug (a bug easy to avoid but also easy to > run into): > The test I used was to cascade 3 instances (all on one machine) from > A->B->C > I ran a pgbench session in instance A, and used: > in A: alter publication pub0_6515 add table pgbench_accounts where > (aid between 40000 and 60000-1); > in B: alter publication pub1_6516 add table pgbench_accounts; > > The above worked well, but when I did the same but used the filter in > both publications: > in A: alter publication pub0_6515 add table pgbench_accounts where > (aid between 40000 and 60000-1); > in B: alter publication pub1_6516 add table pgbench_accounts where > (aid between 40000 and 60000-1); > > then the replication only worked for (pgbench-)scale 1 (hence: very > little data); with larger scales it became slow (taking many minutes > where the above had taken less than 1 minute), and ended up using far > too much memory (or blowing up/crashing altogether). Something not > quite right there. > > Nevertheless, I am much in favour of acquiring this functionality as > soon as possible. Attached is 'logrep_rowfilter.sh', a demonstration of above-described bug. The program runs initdb for 3 instances in /tmp (using ports 6515, 6516, and 6517) and sets up logical replication from 1->2->3. It can be made to work by removing de where-clause on the second 'create publication' ( i.e., outcomment the $where2 variable ). > Thanks, > > > Erik Rijkers
Вложения
Hi, On 2018-03-01 16:27:11 +0100, Erik Rijkers wrote: > Very, very useful. I really do hope this patch survives the > late-arrival-cull. FWIW, I don't think it'd be fair or prudent. There's definitely some issues (see e.g. Craig's reply), and I don't see why this patch'd deserve an exemption from the "nontrivial patches shouldn't be submitted to the last CF" policy? - Andres
Hi, On 3/1/18 4:27 PM, Andres Freund wrote: > On 2018-03-01 16:27:11 +0100, Erik Rijkers wrote: >> Very, very useful. I really do hope this patch survives the >> late-arrival-cull. > > FWIW, I don't think it'd be fair or prudent. There's definitely some > issues (see e.g. Craig's reply), and I don't see why this patch'd > deserve an exemption from the "nontrivial patches shouldn't be submitted > to the last CF" policy? I'm unable to find this in the CF under the title or author name. If it didn't get entered then it is definitely out. If it does have an entry, then I agree with Andres that it should be pushed to the next CF. -- -David david@pgmasters.net
2018-03-01 18:27 GMT-03:00 Andres Freund <andres@anarazel.de>: > FWIW, I don't think it'd be fair or prudent. There's definitely some > issues (see e.g. Craig's reply), and I don't see why this patch'd > deserve an exemption from the "nontrivial patches shouldn't be submitted > to the last CF" policy? > I forgot to mention but this feature is for v12. I know the rules and that is why I didn't add it to the in progress CF. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
2018-03-01 18:25 GMT-03:00 Erik Rijkers <er@xs4all.nl>: > Attached is 'logrep_rowfilter.sh', a demonstration of above-described bug. > Thanks for testing. I will figure out what is happening. There are some leaks around. I'll post another version when I fix some of those bugs. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
2018-02-28 21:54 GMT-03:00 Craig Ringer <craig@2ndquadrant.com>: > Good idea. I haven't read this yet, but one thing to make sure you've > handled is limiting the clause to referencing only the current tuple and the > catalogs. user-catalog tables are OK, too, anything that is > RelationIsAccessibleInLogicalDecoding(). > > This means only immutable functions may be invoked, since a stable or > volatile function might attempt to access a table. And views must be > prohibited or recursively checked. (We have tree walkers that would help > with this). > > It might be worth looking at the current logic for CHECK expressions, since > the requirements are similar. In my opinion you could safely not bother with > allowing access to user catalog tables in the filter expressions and limit > them strictly to immutable functions and the tuple its self. > IIRC implementation is similar to RLS expressions. I'll check all of these rules. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 3/1/18 6:00 PM, Euler Taveira wrote: > 2018-03-01 18:27 GMT-03:00 Andres Freund <andres@anarazel.de>: >> FWIW, I don't think it'd be fair or prudent. There's definitely some >> issues (see e.g. Craig's reply), and I don't see why this patch'd >> deserve an exemption from the "nontrivial patches shouldn't be submitted >> to the last CF" policy? >> > I forgot to mention but this feature is for v12. I know the rules and > that is why I didn't add it to the in progress CF. That was the right thing to do, thank you! -- -David david@pgmasters.net
On Thu, Mar 01, 2018 at 06:16:17PM -0500, David Steele wrote: > That was the right thing to do, thank you! This patch has been waiting on author for a couple of months and does not apply anymore, so I am marking as returned with feedback. If you can rebase, please feel free to resubmit. -- Michael
Вложения
Em qua, 28 de fev de 2018 às 20:03, Euler Taveira <euler@timbira.com.br> escreveu: > The attached patches add support for filtering rows in the publisher. > I rebased the patch. I added row filtering for initial synchronization, pg_dump support and psql support. 0001 removes unused code. 0002 reduces memory use. 0003 passes only structure member that is used in create_estate_for_relation. 0004 reuses a parser node for row filtering. 0005 is the feature. 0006 prints WHERE expression in psql. 0007 adds pg_dump support. 0008 is only for debug purposes (I'm not sure some of these messages will be part of the final patch). 0001, 0002, 0003 and 0008 are not mandatory for this feature. Comments? -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0004-Rename-a-WHERE-node.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- 0008-Debug-for-row-filtering.patch
On 2018-11-01 01:29, Euler Taveira wrote:
> Em qua, 28 de fev de 2018 às 20:03, Euler Taveira
> <euler@timbira.com.br> escreveu:
>> The attached patches add support for filtering rows in the publisher.
>>
I ran pgbench-over-logical-replication with a WHERE-clause and could not
get this to do a correct replication. Below is the output of the
attached test program.
$ ./logrep_rowfilter.sh
--
/home/aardvark/pg_stuff/pg_installations/pgsql.logrep_rowfilter/bin.fast/initdb
--pgdata=/tmp/cascade/instance1/data --encoding=UTF8 --pwfile=/tmp/bugs
--
/home/aardvark/pg_stuff/pg_installations/pgsql.logrep_rowfilter/bin.fast/initdb
--pgdata=/tmp/cascade/instance2/data --encoding=UTF8 --pwfile=/tmp/bugs
--
/home/aardvark/pg_stuff/pg_installations/pgsql.logrep_rowfilter/bin.fast/initdb
--pgdata=/tmp/cascade/instance3/data --encoding=UTF8 --pwfile=/tmp/bugs
sleep 3s
dropping old tables...
creating tables...
generating data...
100000 of 100000 tuples (100%) done (elapsed 0.09 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done.
create publication pub_6515_to_6516;
alter publication pub_6515_to_6516 add table pgbench_accounts where (aid
between 40000 and 60000-1) ; --> where 1
alter publication pub_6515_to_6516 add table pgbench_branches;
alter publication pub_6515_to_6516 add table pgbench_tellers;
alter publication pub_6515_to_6516 add table pgbench_history;
create publication pub_6516_to_6517;
alter publication pub_6516_to_6517 add table pgbench_accounts ; -- where
(aid between 40000 and 60000-1) ; --> where 2
alter publication pub_6516_to_6517 add table pgbench_branches;
alter publication pub_6516_to_6517 add table pgbench_tellers;
alter publication pub_6516_to_6517 add table pgbench_history;
create subscription pub_6516_from_6515 connection 'port=6515
application_name=rowfilter'
publication pub_6515_to_6516 with(enabled=false);
alter subscription pub_6516_from_6515 enable;
create subscription pub_6517_from_6516 connection 'port=6516
application_name=rowfilter'
publication pub_6516_to_6517 with(enabled=false);
alter subscription pub_6517_from_6516 enable;
-- pgbench -p 6515 -c 16 -j 8 -T 5 -n postgres # scale 1
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 16
number of threads: 8
duration: 5 s
number of transactions actually processed: 80
latency average = 1178.106 ms
tps = 13.581120 (including connections establishing)
tps = 13.597443 (excluding connections establishing)
accounts branches tellers history
--------- --------- --------- ---------
6515 6546b1f0f 2d328ed28 7406473b0 7c1351523 e8c07347b
6516 6546b1f0f 2d328ed28 d41d8cd98 d41d8cd98 e7235f541
6517 f7c0791c8 d9c63e471 d41d8cd98 d41d8cd98 30892eea1 NOK
6515 6546b1f0f 2d328ed28 7406473b0 7c1351523 e8c07347b
6516 6546b1f0f 2d328ed28 7406473b0 5a54cf7c5 191ae1af3
6517 6546b1f0f 2d328ed28 7406473b0 5a54cf7c5 191ae1af3 NOK
6515 6546b1f0f 2d328ed28 7406473b0 7c1351523 e8c07347b
6516 6546b1f0f 2d328ed28 7406473b0 5a54cf7c5 191ae1af3
6517 6546b1f0f 2d328ed28 7406473b0 5a54cf7c5 191ae1af3 NOK
[...]
I let that run for 10 minutes or so but that pgbench_history table
md5-values (of ports 6516 and 6517) do not change anymore, which shows
that it is and remains different from the original pgbench_history table
in 6515.
When there is a where-clause this goes *always* wrong.
Without a where-clause all logical replication tests were OK. Perhaps
the error is not in our patch but something in logical replication.
Attached is the test program (will need some tweaking of PATHs,
PG-variables (PGPASSFILE) etc). This is the same program I used in
march when you first posted a version of this patch alhough the error is
different.
thanks,
Erik Rijkers
Вложения
On 2018-11-01 08:56, Erik Rijkers wrote: > On 2018-11-01 01:29, Euler Taveira wrote: >> Em qua, 28 de fev de 2018 às 20:03, Euler Taveira >> <euler@timbira.com.br> escreveu: >>> The attached patches add support for filtering rows in the publisher. >>> > > I ran pgbench-over-logical-replication with a WHERE-clause and could > not get this to do a correct replication. Below is the output of the > attached test program. > > > $ ./logrep_rowfilter.sh I have noticed that the failure to replicate correctly can be avoided by putting a wait state of (on my machine) at least 3 seconds between the setting up of the subscription and the start of pgbench. See the bash program I attached in my previous mail. The bug can be avoided by a 'sleep 5' just before the start of the actual pgbench run. So it seems this bug is due to some timing error in your patch (or possibly in logical replication itself). Erik Rijkers
Em qui, 1 de nov de 2018 às 05:30, Erik Rijkers <er@xs4all.nl> escreveu:
> > I ran pgbench-over-logical-replication with a WHERE-clause and could
> > not get this to do a correct replication. Below is the output of the
> > attached test program.
> >
> >
> > $ ./logrep_rowfilter.sh
>
Erik, thanks for testing.
> So it seems this bug is due to some timing error in your patch (or
> possibly in logical replication itself).
>
It is a bug in the new synchronization code. I'm doing some code
cleanup/review and will post a new patchset after I finish it. If you
want to give it a try again, apply the following patch.
diff --git a/src/backend/replication/logical/tablesync.c
b/src/backend/replication/logical/tablesync.c
index e0eb73c..4797e0b 100644
--- a/src/backend/replication/logical/tablesync.c
+++ b/src/backend/replication/logical/tablesync.c
@@ -757,7 +757,7 @@ fetch_remote_table_info(char *nspname, char *relname,
/* Fetch row filtering info */
resetStringInfo(&cmd);
- appendStringInfo(&cmd, "SELECT pg_get_expr(prrowfilter,
prrelid) FROM pg_publication p INNER JOIN pg_publication_rel pr ON
(p.oid = pr.prpubid) WHERE pr.prrelid = %u AND p.pubname IN (",
MyLogicalRepWorker->relid);
+ appendStringInfo(&cmd, "SELECT pg_get_expr(prrowfilter,
prrelid) FROM pg_publication p INNER JOIN pg_publication_rel pr ON
(p.oid = pr.prpubid) WHERE pr.prrelid = %u AND p.pubname IN (",
lrel->remoteid);
--
Euler Taveira Timbira -
http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 2018-11-02 02:59, Euler Taveira wrote: > Em qui, 1 de nov de 2018 às 05:30, Erik Rijkers <er@xs4all.nl> > escreveu: >> > I ran pgbench-over-logical-replication with a WHERE-clause and could >> > not get this to do a correct replication. Below is the output of the >> > attached test program. >> > >> > >> > $ ./logrep_rowfilter.sh >> > Erik, thanks for testing. > >> So it seems this bug is due to some timing error in your patch (or >> possibly in logical replication itself). >> > It is a bug in the new synchronization code. I'm doing some code > cleanup/review and will post a new patchset after I finish it. If you > want to give it a try again, apply the following patch. > > diff --git a/src/backend/replication/logical/tablesync.c > b/src/backend/replication/logical/tablesync.c > index e0eb73c..4797e0b 100644 > --- a/src/backend/replication/logical/tablesync.c > +++ b/src/backend/replication/logical/tablesync.c > [...] That does indeed fix it. Thank you, Erik Rijkers
On 2018/11/01 0:29, Euler Taveira wrote: > Em qua, 28 de fev de 2018 às 20:03, Euler Taveira > <euler@timbira.com.br> escreveu: >> The attached patches add support for filtering rows in the publisher. >> > I rebased the patch. I added row filtering for initial > synchronization, pg_dump support and psql support. 0001 removes unused > code. 0002 reduces memory use. 0003 passes only structure member that > is used in create_estate_for_relation. 0004 reuses a parser node for > row filtering. 0005 is the feature. 0006 prints WHERE expression in > psql. 0007 adds pg_dump support. 0008 is only for debug purposes (I'm > not sure some of these messages will be part of the final patch). > 0001, 0002, 0003 and 0008 are not mandatory for this feature. > > Comments? > > Hi, I reviewed your patches and I found a bug when I tested ALTER PUBLICATION statement. In short, ALTER PUBLICATION SET with a WHERE clause does not applied new WHERE clause. I describe the outline of the test I did and my conclusion. [TEST] I show the test case I tried in below. (1)Publisher and Subscriber I executed each statement on the publisher and the subscriber. ``` testdb=# CREATE PUBLICATION pub_testdb_t FOR TABLE t WHERE (id > 10); CREATE PUBLICATION ``` ``` testdb=# CREATE SUBSCRIPTION sub_testdb_t CONNECTION 'dbname=testdb port=5432 user=postgres' PUBLICATION pub_testdb_t; NOTICE: created replication slot "sub_testdb_t" on publisher CREATE SUBSCRIPTION ``` (2)Publisher I executed these statements shown below. testdb=# INSERT INTO t VALUES (1,1); INSERT 0 1 testdb=# INSERT INTO t VALUES (11,11); INSERT 0 1 (3)Subscriber I confirmed that the CREATE PUBLICATION statement worked well. ``` testdb=# SELECT * FROM t; id | data ----+------ 11 | 11 (1 row) ``` (4)Publisher After that, I executed ALTER PUBLICATION with a WHERE clause and inserted a new row. ``` testdb=# ALTER PUBLICATION pub_testdb_t SET TABLE t WHERE (id > 5); ALTER PUBLICATION testdb=# INSERT INTO t VALUES (7,7); INSERT 0 1 testdb=# SELECT * FROM t; id | data ----+------ 1 | 1 11 | 11 7 | 7 (3 rows) ``` (5)Subscriber I confirmed that the change of WHERE clause set by ALTER PUBLICATION statement was ignored. ``` testdb=# SELECT * FROM t; id | data ----+------ 11 | 11 (1 row) ``` [Conclusion] I think AlterPublicationTables()@publicationcmds.c has a bug. In the foreach(oldlc, oldrelids) loop, oldrel must be appended to delrels if oldrel or newrel has a WHERE clause. However, the current implementation does not, therefore, old WHERE clause is not deleted and the new WHERE clause is ignored. This is my speculation. It may not be correct, but , at least, it is a fact that ALTER PUBLICATION with a WHERE clause is not functioned in my environment and my operation described in above. Best regards,
On 01/11/2018 01:29, Euler Taveira wrote:
> Em qua, 28 de fev de 2018 às 20:03, Euler Taveira
> <euler@timbira.com.br> escreveu:
>> The attached patches add support for filtering rows in the publisher.
>>
> I rebased the patch. I added row filtering for initial
> synchronization, pg_dump support and psql support. 0001 removes unused
> code. 0002 reduces memory use. 0003 passes only structure member that
> is used in create_estate_for_relation. 0004 reuses a parser node for
> row filtering. 0005 is the feature. 0006 prints WHERE expression in
> psql. 0007 adds pg_dump support. 0008 is only for debug purposes (I'm
> not sure some of these messages will be part of the final patch).
> 0001, 0002, 0003 and 0008 are not mandatory for this feature.
>
> Comments?
>
Hi,
I think there are two main topics that still need to be discussed about
this patch.
Firstly, I am not sure if it's wise to allow UDFs in the filter clause
for the table. The reason for that is that we can't record all necessary
dependencies there because the functions are black box for parser. That
means if somebody drops object that an UDF used in replication filter
depends on, that function will start failing. But unlike for user
sessions it will start failing during decoding (well processing in
output plugin). And that's not recoverable by reading the missing
object, the only way to get out of that is either to move slot forward
which means losing part of replication stream and need for manual resync
or full rebuild of replication. Neither of which are good IMHO.
Secondly, do we want to at least notify user on filters (or maybe even
disallow them) with combination of action + column where column value
will not be logged? I mean for example we do this when processing the
filter against a row:
> + ExecStoreHeapTuple(new_tuple ? new_tuple : old_tuple, ecxt->ecxt_scantuple, false);
But if user has expression on column which is not part of replica
identity that expression will always return NULL for DELETEs because
only replica identity is logged with actual values and everything else
in NULL in old_tuple. So if publication replicates deletes we should
check for this somehow.
Btw about code (you already fixed the wrong reloid in sync so skipping
that).
0002:
> + for (tupn = 0; tupn < walres->ntuples; tupn++)
> {
> - char *cstrs[MaxTupleAttributeNumber];
> + char **cstrs;
>
> CHECK_FOR_INTERRUPTS();
>
> /* Do the allocations in temporary context. */
> oldcontext = MemoryContextSwitchTo(rowcontext);
>
> + cstrs = palloc(nfields * sizeof(char *));
Not really sure that this is actually worth it given that we have to
allocate and free this in a loop now while before it was just sitting on
a stack.
0005:
> @@ -654,5 +740,10 @@ rel_sync_cache_publication_cb(Datum arg, int cacheid, uint32 hashvalue)
> */
> hash_seq_init(&status, RelationSyncCache);
> while ((entry = (RelationSyncEntry *) hash_seq_search(&status)) != NULL)
> + {
> entry->replicate_valid = false;
> + if (list_length(entry->row_filter) > 0)
> + list_free(entry->row_filter);
> + entry->row_filter = NIL;
> + }
Won't this leak memory? The list_free only frees the list cells, but not
the nodes you stored there before.
Also I think we should document here that the expression is run with the
session environment of the replication connection (so that it's more
obvious that things like CURRENT_USER will not return user which changed
tuple but the replication user).
It would be nice if 0006 had regression test and 0007 TAP test.
--
Petr Jelinek http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
Greetings, * Euler Taveira (euler@timbira.com.br) wrote: > 2018-02-28 21:54 GMT-03:00 Craig Ringer <craig@2ndquadrant.com>: > > Good idea. I haven't read this yet, but one thing to make sure you've > > handled is limiting the clause to referencing only the current tuple and the > > catalogs. user-catalog tables are OK, too, anything that is > > RelationIsAccessibleInLogicalDecoding(). > > > > This means only immutable functions may be invoked, since a stable or > > volatile function might attempt to access a table. And views must be > > prohibited or recursively checked. (We have tree walkers that would help > > with this). > > > > It might be worth looking at the current logic for CHECK expressions, since > > the requirements are similar. In my opinion you could safely not bother with > > allowing access to user catalog tables in the filter expressions and limit > > them strictly to immutable functions and the tuple its self. > > IIRC implementation is similar to RLS expressions. I'll check all of > these rules. Given the similarity to RLS and the nearby discussion about allowing non-superusers to create subscriptions, and probably publications later, I wonder if we shouldn't be somehow associating this with RLS policies instead of having the publication filtering be entirely independent.. Thanks! Stephen
Вложения
On 23/11/2018 03:02, Stephen Frost wrote: > Greetings, > > * Euler Taveira (euler@timbira.com.br) wrote: >> 2018-02-28 21:54 GMT-03:00 Craig Ringer <craig@2ndquadrant.com>: >>> Good idea. I haven't read this yet, but one thing to make sure you've >>> handled is limiting the clause to referencing only the current tuple and the >>> catalogs. user-catalog tables are OK, too, anything that is >>> RelationIsAccessibleInLogicalDecoding(). >>> >>> This means only immutable functions may be invoked, since a stable or >>> volatile function might attempt to access a table. And views must be >>> prohibited or recursively checked. (We have tree walkers that would help >>> with this). >>> >>> It might be worth looking at the current logic for CHECK expressions, since >>> the requirements are similar. In my opinion you could safely not bother with >>> allowing access to user catalog tables in the filter expressions and limit >>> them strictly to immutable functions and the tuple its self. >> >> IIRC implementation is similar to RLS expressions. I'll check all of >> these rules. > > Given the similarity to RLS and the nearby discussion about allowing > non-superusers to create subscriptions, and probably publications later, > I wonder if we shouldn't be somehow associating this with RLS policies > instead of having the publication filtering be entirely independent.. > I do see the appeal here, if you consider logical replication to be a streaming select it probably applies well. But given that this is happening inside output plugin which does not have full executor setup and has catalog-only snapshot I am not sure how feasible it is to try to merge these two things. As per my previous email it's possible that we'll have to be stricter about what we allow in expressions here. The other issue with merging this is that the use-case for filtering out the data in logical replication is not necessarily about security, but often about sending only relevant data. So it makes sense to have filter on publication without RLS enabled on table and if we'd force that, we'd limit usefulness of this feature. We definitely want to eventually create subscriptions as non-superuser but that has zero effect on this as everything here is happening on different server than where subscription lives (we already allow creation of publications with just CREATE privilege on database and ownership of the table). -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Em sex, 23 de nov de 2018 às 11:40, Petr Jelinek <petr.jelinek@2ndquadrant.com> escreveu: > But given that this is happening inside output plugin which does not > have full executor setup and has catalog-only snapshot I am not sure how > feasible it is to try to merge these two things. As per my previous > email it's possible that we'll have to be stricter about what we allow > in expressions here. > This feature should be as simple as possible. I don't want to introduce a huge overhead just for filtering some data. Data sharding generally uses simple expressions. > The other issue with merging this is that the use-case for filtering out > the data in logical replication is not necessarily about security, but > often about sending only relevant data. So it makes sense to have filter > on publication without RLS enabled on table and if we'd force that, we'd > limit usefulness of this feature. > Use the same infrastructure as RLS could be a good idea but use RLS for row filtering is not. RLS is complex. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek <petr.jelinek@2ndquadrant.com> escreveu: > Firstly, I am not sure if it's wise to allow UDFs in the filter clause > for the table. The reason for that is that we can't record all necessary > dependencies there because the functions are black box for parser. That > means if somebody drops object that an UDF used in replication filter > depends on, that function will start failing. But unlike for user > sessions it will start failing during decoding (well processing in > output plugin). And that's not recoverable by reading the missing > object, the only way to get out of that is either to move slot forward > which means losing part of replication stream and need for manual resync > or full rebuild of replication. Neither of which are good IMHO. > It is a foot gun but there are several ways to do bad things in postgres. CREATE PUBLICATION is restricted to superusers and role with CREATE privilege in current database. AFAICS a role with CREATE privilege cannot drop objects whose owner is not himself. I wouldn't like to disallow UDFs in row filtering expressions just because someone doesn't set permissions correctly. Do you have any other case in mind? > Secondly, do we want to at least notify user on filters (or maybe even > disallow them) with combination of action + column where column value > will not be logged? I mean for example we do this when processing the > filter against a row: > > > + ExecStoreHeapTuple(new_tuple ? new_tuple : old_tuple, ecxt->ecxt_scantuple, false); > We could emit a LOG message. That could possibly be an option but it could be too complex for the first version. > But if user has expression on column which is not part of replica > identity that expression will always return NULL for DELETEs because > only replica identity is logged with actual values and everything else > in NULL in old_tuple. So if publication replicates deletes we should > check for this somehow. > In this case, we should document this behavior. That is a recurring question in wal2json issues. Besides that we should explain that UPDATE/DELETE tuples doesn't log all columns (people think the behavior is equivalent to triggers; it is not unless you set REPLICA IDENTITY FULL). > Not really sure that this is actually worth it given that we have to > allocate and free this in a loop now while before it was just sitting on > a stack. > That is a experimentation code that should be in a separate patch. Don't you think low memory use is a good goal? I also think that MaxTupleAttributeNumber is an extreme value. I didn't some preliminary tests and didn't notice overheads. I'll leave these modifications in a separate patch. > Won't this leak memory? The list_free only frees the list cells, but not > the nodes you stored there before. > Good catch. It should be list_free_deep. > Also I think we should document here that the expression is run with the > session environment of the replication connection (so that it's more > obvious that things like CURRENT_USER will not return user which changed > tuple but the replication user). > Sure. > It would be nice if 0006 had regression test and 0007 TAP test. > Sure. Besides the problem presented by Hironobu-san, I'm doing some cleanup and improving docs. I also forget to declare pg_publication_rel TOAST table. Thanks for your review. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 2018-Nov-23, Euler Taveira wrote: > Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek > <petr.jelinek@2ndquadrant.com> escreveu: > > Won't this leak memory? The list_free only frees the list cells, but not > > the nodes you stored there before. > > Good catch. It should be list_free_deep. Actually, if the nodes have more structure (say you palloc one list item, but that list item also contains pointers to a Node) then a list_free_deep won't be enough either. I'd suggest to create a bespoke memory context, which you can delete afterwards. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Nov 23, 2018 at 12:03:27AM +0100, Petr Jelinek wrote: > On 01/11/2018 01:29, Euler Taveira wrote: > > Em qua, 28 de fev de 2018 às 20:03, Euler Taveira > > <euler@timbira.com.br> escreveu: > >> The attached patches add support for filtering rows in the publisher. > >> > > I rebased the patch. I added row filtering for initial > > synchronization, pg_dump support and psql support. 0001 removes unused > > code. 0002 reduces memory use. 0003 passes only structure member that > > is used in create_estate_for_relation. 0004 reuses a parser node for > > row filtering. 0005 is the feature. 0006 prints WHERE expression in > > psql. 0007 adds pg_dump support. 0008 is only for debug purposes (I'm > > not sure some of these messages will be part of the final patch). > > 0001, 0002, 0003 and 0008 are not mandatory for this feature. > > Hi, > > I think there are two main topics that still need to be discussed about > this patch. > > Firstly, I am not sure if it's wise to allow UDFs in the filter clause > for the table. The reason for that is that we can't record all necessary > dependencies there because the functions are black box for parser. Some UDFs are not a black box for the parser, namely ones written in SQL. Would it make sense at least not to foreclose the non-(black box) option? Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On 23/11/2018 17:39, David Fetter wrote: > On Fri, Nov 23, 2018 at 12:03:27AM +0100, Petr Jelinek wrote: >> On 01/11/2018 01:29, Euler Taveira wrote: >>> Em qua, 28 de fev de 2018 às 20:03, Euler Taveira >>> <euler@timbira.com.br> escreveu: >>>> The attached patches add support for filtering rows in the publisher. >>>> >>> I rebased the patch. I added row filtering for initial >>> synchronization, pg_dump support and psql support. 0001 removes unused >>> code. 0002 reduces memory use. 0003 passes only structure member that >>> is used in create_estate_for_relation. 0004 reuses a parser node for >>> row filtering. 0005 is the feature. 0006 prints WHERE expression in >>> psql. 0007 adds pg_dump support. 0008 is only for debug purposes (I'm >>> not sure some of these messages will be part of the final patch). >>> 0001, 0002, 0003 and 0008 are not mandatory for this feature. >> >> Hi, >> >> I think there are two main topics that still need to be discussed about >> this patch. >> >> Firstly, I am not sure if it's wise to allow UDFs in the filter clause >> for the table. The reason for that is that we can't record all necessary >> dependencies there because the functions are black box for parser. > > Some UDFs are not a black box for the parser, namely ones written in > SQL. Would it make sense at least not to foreclose the non-(black box) > option? > Yeah inlinable SQL functions should be fine, we just need the ability to extract dependencies. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 23/11/2018 17:15, Euler Taveira wrote: > Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek > <petr.jelinek@2ndquadrant.com> escreveu: >> Firstly, I am not sure if it's wise to allow UDFs in the filter clause >> for the table. The reason for that is that we can't record all necessary >> dependencies there because the functions are black box for parser. That >> means if somebody drops object that an UDF used in replication filter >> depends on, that function will start failing. But unlike for user >> sessions it will start failing during decoding (well processing in >> output plugin). And that's not recoverable by reading the missing >> object, the only way to get out of that is either to move slot forward >> which means losing part of replication stream and need for manual resync >> or full rebuild of replication. Neither of which are good IMHO. >> > It is a foot gun but there are several ways to do bad things in > postgres. CREATE PUBLICATION is restricted to superusers and role with > CREATE privilege in current database. AFAICS a role with CREATE > privilege cannot drop objects whose owner is not himself. I wouldn't > like to disallow UDFs in row filtering expressions just because > someone doesn't set permissions correctly. Do you have any other case > in mind? I don't think this has anything to do with security. Stupid example: user1: CREATE EXTENSION citext; user2: CREATE FUNCTION myfilter(col1 text, col2 text) returns boolean language plpgsql as $$BEGIN RETURN col1::citext = col2::citext; END;$$ user2: ALTER PUBLICATION mypub ADD TABLE mytab WHERE (myfilter(a,b)); [... replication happening ...] user1: DROP EXTENSION citext; And now replication is broken and unrecoverable without data loss. Recreating extension will not help because the changes happening in meantime will not see it in the historical snapshot. I don't think it's okay to do completely nothing about this. > >> Secondly, do we want to at least notify user on filters (or maybe even >> disallow them) with combination of action + column where column value >> will not be logged? I mean for example we do this when processing the >> filter against a row: >> >>> + ExecStoreHeapTuple(new_tuple ? new_tuple : old_tuple, ecxt->ecxt_scantuple, false); >> > We could emit a LOG message. That could possibly be an option but it > could be too complex for the first version. > Well, it needs walker which extracts Vars from the expression and checks them against replica identity columns. We already have a way to fetch replica identity columns and the walker could be something like simplified version of the find_expr_references_walker used by the recordDependencyOnSingleRelExpr (I don't think there is anything ready made already). >> But if user has expression on column which is not part of replica >> identity that expression will always return NULL for DELETEs because >> only replica identity is logged with actual values and everything else >> in NULL in old_tuple. So if publication replicates deletes we should >> check for this somehow. >> > In this case, we should document this behavior. That is a recurring > question in wal2json issues. Besides that we should explain that > UPDATE/DELETE tuples doesn't log all columns (people think the > behavior is equivalent to triggers; it is not unless you set REPLICA > IDENTITY FULL). > >> Not really sure that this is actually worth it given that we have to >> allocate and free this in a loop now while before it was just sitting on >> a stack. >> > That is a experimentation code that should be in a separate patch. > Don't you think low memory use is a good goal? I also think that > MaxTupleAttributeNumber is an extreme value. I didn't some preliminary > tests and didn't notice overheads. I'll leave these modifications in a > separate patch. > It's static memory and it's a few KB of it (it's just single array of pointers, not array of data, and does not depend on the number of rows). Palloc will definitely need more CPU cycles. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Nov 23, 2018 at 3:55 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote:
>
> On 23/11/2018 17:15, Euler Taveira wrote:
> > Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek
> > <petr.jelinek@2ndquadrant.com> escreveu:
> >> Firstly, I am not sure if it's wise to allow UDFs in the filter clause
> >> for the table. The reason for that is that we can't record all necessary
> >> dependencies there because the functions are black box for parser. That
> >> means if somebody drops object that an UDF used in replication filter
> >> depends on, that function will start failing. But unlike for user
> >> sessions it will start failing during decoding (well processing in
> >> output plugin). And that's not recoverable by reading the missing
> >> object, the only way to get out of that is either to move slot forward
> >> which means losing part of replication stream and need for manual resync
> >> or full rebuild of replication. Neither of which are good IMHO.
> >>
> > It is a foot gun but there are several ways to do bad things in
> > postgres. CREATE PUBLICATION is restricted to superusers and role with
> > CREATE privilege in current database. AFAICS a role with CREATE
> > privilege cannot drop objects whose owner is not himself. I wouldn't
> > like to disallow UDFs in row filtering expressions just because
> > someone doesn't set permissions correctly. Do you have any other case
> > in mind?
>
> I don't think this has anything to do with security. Stupid example:
>
> user1: CREATE EXTENSION citext;
>
> user2: CREATE FUNCTION myfilter(col1 text, col2 text) returns boolean
> language plpgsql as
> $$BEGIN
> RETURN col1::citext = col2::citext;
> END;$$
>
> user2: ALTER PUBLICATION mypub ADD TABLE mytab WHERE (myfilter(a,b));
>
> [... replication happening ...]
>
> user1: DROP EXTENSION citext;
>
> And now replication is broken and unrecoverable without data loss.
> Recreating extension will not help because the changes happening in
> meantime will not see it in the historical snapshot.
>
> I don't think it's okay to do completely nothing about this.
>
If carefully documented I see no problem with it... we already have an analogous problem with functional indexes.
Regards,
--
Fabrízio de Royes Mello Timbira - http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
>
> On 23/11/2018 17:15, Euler Taveira wrote:
> > Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek
> > <petr.jelinek@2ndquadrant.com> escreveu:
> >> Firstly, I am not sure if it's wise to allow UDFs in the filter clause
> >> for the table. The reason for that is that we can't record all necessary
> >> dependencies there because the functions are black box for parser. That
> >> means if somebody drops object that an UDF used in replication filter
> >> depends on, that function will start failing. But unlike for user
> >> sessions it will start failing during decoding (well processing in
> >> output plugin). And that's not recoverable by reading the missing
> >> object, the only way to get out of that is either to move slot forward
> >> which means losing part of replication stream and need for manual resync
> >> or full rebuild of replication. Neither of which are good IMHO.
> >>
> > It is a foot gun but there are several ways to do bad things in
> > postgres. CREATE PUBLICATION is restricted to superusers and role with
> > CREATE privilege in current database. AFAICS a role with CREATE
> > privilege cannot drop objects whose owner is not himself. I wouldn't
> > like to disallow UDFs in row filtering expressions just because
> > someone doesn't set permissions correctly. Do you have any other case
> > in mind?
>
> I don't think this has anything to do with security. Stupid example:
>
> user1: CREATE EXTENSION citext;
>
> user2: CREATE FUNCTION myfilter(col1 text, col2 text) returns boolean
> language plpgsql as
> $$BEGIN
> RETURN col1::citext = col2::citext;
> END;$$
>
> user2: ALTER PUBLICATION mypub ADD TABLE mytab WHERE (myfilter(a,b));
>
> [... replication happening ...]
>
> user1: DROP EXTENSION citext;
>
> And now replication is broken and unrecoverable without data loss.
> Recreating extension will not help because the changes happening in
> meantime will not see it in the historical snapshot.
>
> I don't think it's okay to do completely nothing about this.
>
If carefully documented I see no problem with it... we already have an analogous problem with functional indexes.
Regards,
--
Fabrízio de Royes Mello Timbira - http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 23/11/2018 19:05, Fabrízio de Royes Mello wrote: > On Fri, Nov 23, 2018 at 3:55 PM Petr Jelinek > <petr.jelinek@2ndquadrant.com <mailto:petr.jelinek@2ndquadrant.com>> wrote: >> >> On 23/11/2018 17:15, Euler Taveira wrote: >> > Em qui, 22 de nov de 2018 às 20:03, Petr Jelinek >> > <petr.jelinek@2ndquadrant.com <mailto:petr.jelinek@2ndquadrant.com>> > escreveu: >> >> Firstly, I am not sure if it's wise to allow UDFs in the filter clause >> >> for the table. The reason for that is that we can't record all > necessary >> >> dependencies there because the functions are black box for parser. That >> >> means if somebody drops object that an UDF used in replication filter >> >> depends on, that function will start failing. But unlike for user >> >> sessions it will start failing during decoding (well processing in >> >> output plugin). And that's not recoverable by reading the missing >> >> object, the only way to get out of that is either to move slot forward >> >> which means losing part of replication stream and need for manual > resync >> >> or full rebuild of replication. Neither of which are good IMHO. >> >> >> > It is a foot gun but there are several ways to do bad things in >> > postgres. CREATE PUBLICATION is restricted to superusers and role with >> > CREATE privilege in current database. AFAICS a role with CREATE >> > privilege cannot drop objects whose owner is not himself. I wouldn't >> > like to disallow UDFs in row filtering expressions just because >> > someone doesn't set permissions correctly. Do you have any other case >> > in mind? >> >> I don't think this has anything to do with security. Stupid example: >> >> user1: CREATE EXTENSION citext; >> >> user2: CREATE FUNCTION myfilter(col1 text, col2 text) returns boolean >> language plpgsql as >> $$BEGIN >> RETURN col1::citext = col2::citext; >> END;$$ >> >> user2: ALTER PUBLICATION mypub ADD TABLE mytab WHERE (myfilter(a,b)); >> >> [... replication happening ...] >> >> user1: DROP EXTENSION citext; >> >> And now replication is broken and unrecoverable without data loss. >> Recreating extension will not help because the changes happening in >> meantime will not see it in the historical snapshot. >> >> I don't think it's okay to do completely nothing about this. >> > > If carefully documented I see no problem with it... we already have an > analogous problem with functional indexes. The difference is that with functional indexes you can recreate the missing object and everything is okay again. With logical replication recreating the object will not help. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> wrote:
>
> >
> > If carefully documented I see no problem with it... we already have an
> > analogous problem with functional indexes.
>
> The difference is that with functional indexes you can recreate the
> missing object and everything is okay again. With logical replication
> recreating the object will not help.
>
In this case with logical replication you should rsync the object. That is the price of misunderstanding / bad use of the new feature.
> > If carefully documented I see no problem with it... we already have an
> > analogous problem with functional indexes.
>
> The difference is that with functional indexes you can recreate the
> missing object and everything is okay again. With logical replication
> recreating the object will not help.
>
In this case with logical replication you should rsync the object. That is the price of misunderstanding / bad use of the new feature.
As usual, there are no free beer ;-)
Regards,
--
Fabrízio de Royes Mello Timbira - http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Greetings, * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: > On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> > wrote: > > > If carefully documented I see no problem with it... we already have an > > > analogous problem with functional indexes. > > > > The difference is that with functional indexes you can recreate the > > missing object and everything is okay again. With logical replication > > recreating the object will not help. > > > > In this case with logical replication you should rsync the object. That is > the price of misunderstanding / bad use of the new feature. > > As usual, there are no free beer ;-) There's also certainly no shortage of other ways to break logical replication, including ways that would also be hard to recover from today other than doing a full resync. What that seems to indicate, to me at least, is that it'd be awful nice to have a way to resync the data which doesn't necessairly involve transferring all of it over again. Of course, it'd be nice if we could track those dependencies too, but that's yet another thing. In short, I'm not sure that I agree with the idea that we shouldn't allow this and instead I'd rather we realize it and put the logical replication into some kind of an error state that requires a resync. Thanks! Stephen
Вложения
On 23/11/2018 19:29, Fabrízio de Royes Mello wrote: > > On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek > <petr.jelinek@2ndquadrant.com <mailto:petr.jelinek@2ndquadrant.com>> wrote: >> >> > >> > If carefully documented I see no problem with it... we already have an >> > analogous problem with functional indexes. >> >> The difference is that with functional indexes you can recreate the >> missing object and everything is okay again. With logical replication >> recreating the object will not help. >> > > In this case with logical replication you should rsync the object. That > is the price of misunderstanding / bad use of the new feature. > > As usual, there are no free beer ;-) > Yeah but you have to resync whole subscription, not just single table (removing table from the publication will also not help), that's pretty severe punishment. What if you have triggers downstream that do calculations or logging which you can't recover by simply rebuilding replica? I think it's better to err on the side of no data loss. We could also try to figure out a way to recover from this that does not require resync, ie perhaps we could somehow temporarily force evaluation of the expression to have current snapshot. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 11/23/18 8:03 PM, Stephen Frost wrote: > Greetings, > > * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: >> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> >> wrote: >>>> If carefully documented I see no problem with it... we already have an >>>> analogous problem with functional indexes. >>> >>> The difference is that with functional indexes you can recreate the >>> missing object and everything is okay again. With logical replication >>> recreating the object will not help. >>> >> >> In this case with logical replication you should rsync the object. That is >> the price of misunderstanding / bad use of the new feature. >> >> As usual, there are no free beer ;-) > > There's also certainly no shortage of other ways to break logical > replication, including ways that would also be hard to recover from > today other than doing a full resync. > Sure, but that seems more like an argument against creating additional ones (and for preventing those that already exist). I'm not sure this particular feature is where we should draw the line, though. > What that seems to indicate, to me at least, is that it'd be awful > nice to have a way to resync the data which doesn't necessairly > involve transferring all of it over again. > > Of course, it'd be nice if we could track those dependencies too, > but that's yet another thing. Yep, that seems like a good idea in general. Both here and for functional indexes (although I suppose sure is a technical reason why it wasn't implemented right away for them). > > In short, I'm not sure that I agree with the idea that we shouldn't > allow this and instead I'd rather we realize it and put the logical > replication into some kind of an error state that requires a resync. > That would still mean a need to resync the data to recover, so I'm not sure it's really an improvement. And I suppose it'd require tracking the dependencies, because how else would you mark the subscription as requiring a resync? At which point we could decline the DROP without a CASCADE, just like we do elsewhere, no? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 11/23/18 8:14 PM, Petr Jelinek wrote: > On 23/11/2018 19:29, Fabrízio de Royes Mello wrote: >> >> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek >> <petr.jelinek@2ndquadrant.com <mailto:petr.jelinek@2ndquadrant.com>> wrote: >>> >>>> >>>> If carefully documented I see no problem with it... we already have an >>>> analogous problem with functional indexes. >>> >>> The difference is that with functional indexes you can recreate the >>> missing object and everything is okay again. With logical replication >>> recreating the object will not help. >>> >> >> In this case with logical replication you should rsync the object. That >> is the price of misunderstanding / bad use of the new feature. >> >> As usual, there are no free beer ;-) >> > > Yeah but you have to resync whole subscription, not just single table > (removing table from the publication will also not help), that's pretty > severe punishment. What if you have triggers downstream that do > calculations or logging which you can't recover by simply rebuilding > replica? I think it's better to err on the side of no data loss. > Yeah, having to resync everything because you accidentally dropped a function is quite annoying. Of course, you should notice that while testing the upgrade in a testing environment, but still ... > We could also try to figure out a way to recover from this that does not > require resync, ie perhaps we could somehow temporarily force evaluation > of the expression to have current snapshot. > That seems like huge a can of worms ... cheers -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Greetings, * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 23/11/2018 03:02, Stephen Frost wrote: > > * Euler Taveira (euler@timbira.com.br) wrote: > >> 2018-02-28 21:54 GMT-03:00 Craig Ringer <craig@2ndquadrant.com>: > >>> Good idea. I haven't read this yet, but one thing to make sure you've > >>> handled is limiting the clause to referencing only the current tuple and the > >>> catalogs. user-catalog tables are OK, too, anything that is > >>> RelationIsAccessibleInLogicalDecoding(). > >>> > >>> This means only immutable functions may be invoked, since a stable or > >>> volatile function might attempt to access a table. And views must be > >>> prohibited or recursively checked. (We have tree walkers that would help > >>> with this). > >>> > >>> It might be worth looking at the current logic for CHECK expressions, since > >>> the requirements are similar. In my opinion you could safely not bother with > >>> allowing access to user catalog tables in the filter expressions and limit > >>> them strictly to immutable functions and the tuple its self. > >> > >> IIRC implementation is similar to RLS expressions. I'll check all of > >> these rules. > > > > Given the similarity to RLS and the nearby discussion about allowing > > non-superusers to create subscriptions, and probably publications later, > > I wonder if we shouldn't be somehow associating this with RLS policies > > instead of having the publication filtering be entirely independent.. > > I do see the appeal here, if you consider logical replication to be a > streaming select it probably applies well. > > But given that this is happening inside output plugin which does not > have full executor setup and has catalog-only snapshot I am not sure how > feasible it is to try to merge these two things. As per my previous > email it's possible that we'll have to be stricter about what we allow > in expressions here. I can certainly understand the concern about trying to combine the implementation of this with that of RLS; perhaps that isn't a good fit due to the additional constraints put on logical decoding. That said, I still think it might make sense to consider these filters for logical decoding to be policies and, ideally, to allow users to use the same policy for both. In the end, the idea of having to build a single large and complex 'create publication' command which has a bunch of tables, each with their own filter clauses, just strikes me as pretty painful. > The other issue with merging this is that the use-case for filtering out > the data in logical replication is not necessarily about security, but > often about sending only relevant data. So it makes sense to have filter > on publication without RLS enabled on table and if we'd force that, we'd > limit usefulness of this feature. I definitely have a serious problem if we are going to say that you can't use this filtering for security-sensitive cases. > We definitely want to eventually create subscriptions as non-superuser > but that has zero effect on this as everything here is happening on > different server than where subscription lives (we already allow > creation of publications with just CREATE privilege on database and > ownership of the table). What I wasn't clear about above was the idea that we might allow a user other than the table owner to publish a given table, but that such a publication should certanily only be allowed to include the rows which that user has access to- as regulated by RLS. If the RLS policy is too complex to allow that then I would think we'd simply throw an error at the create publication time and the would-be publisher would need to figure that out with the table owner. I'll admit that this might seem like a stretch, but what happens today? Today, people write cronjobs to try to sync between tables with FDWs and you don't need to own a table to use it as the target of a foreign table. I do think that we'll need to have some additional privileges around who is allowed to create publications, I'm not entirely thrilled with that being combined with the ability to create schemas; the two seem quite different to me. * Euler Taveira (euler@timbira.com.br) wrote: > Em sex, 23 de nov de 2018 às 11:40, Petr Jelinek > <petr.jelinek@2ndquadrant.com> escreveu: > > But given that this is happening inside output plugin which does not > > have full executor setup and has catalog-only snapshot I am not sure how > > feasible it is to try to merge these two things. As per my previous > > email it's possible that we'll have to be stricter about what we allow > > in expressions here. > > This feature should be as simple as possible. I don't want to > introduce a huge overhead just for filtering some data. Data sharding > generally uses simple expressions. RLS often uses simple filters too. > > The other issue with merging this is that the use-case for filtering out > > the data in logical replication is not necessarily about security, but > > often about sending only relevant data. So it makes sense to have filter > > on publication without RLS enabled on table and if we'd force that, we'd > > limit usefulness of this feature. > > Use the same infrastructure as RLS could be a good idea but use RLS > for row filtering is not. RLS is complex. Right, this was along the lines I was thinking of- using the infrastructure and the policy system, in particular. Thanks! Stephen
Вложения
Greetings, * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > On 11/23/18 8:03 PM, Stephen Frost wrote: > > * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: > >> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> > >> wrote: > >>>> If carefully documented I see no problem with it... we already have an > >>>> analogous problem with functional indexes. > >>> > >>> The difference is that with functional indexes you can recreate the > >>> missing object and everything is okay again. With logical replication > >>> recreating the object will not help. > >>> > >> > >> In this case with logical replication you should rsync the object. That is > >> the price of misunderstanding / bad use of the new feature. > >> > >> As usual, there are no free beer ;-) > > > > There's also certainly no shortage of other ways to break logical > > replication, including ways that would also be hard to recover from > > today other than doing a full resync. > > Sure, but that seems more like an argument against creating additional > ones (and for preventing those that already exist). I'm not sure this > particular feature is where we should draw the line, though. I was actually going in the other direction- we should allow it because advanced users may know what they're doing better than we do and we shouldn't prevent things just because they might be misused or misunderstood by a user. > > What that seems to indicate, to me at least, is that it'd be awful > > nice to have a way to resync the data which doesn't necessairly > > involve transferring all of it over again. > > > > Of course, it'd be nice if we could track those dependencies too, > > but that's yet another thing. > > Yep, that seems like a good idea in general. Both here and for > functional indexes (although I suppose sure is a technical reason why it > wasn't implemented right away for them). We don't track function dependencies in general and I could certainly see cases where you really wouldn't want to do so, at least not in the same way that we track FKs or similar. I do wonder if maybe we didn't track function dependencies because we didn't (yet) have create or replace function and that now we should. We don't track dependencies inside a function either though. > > In short, I'm not sure that I agree with the idea that we shouldn't > > allow this and instead I'd rather we realize it and put the logical > > replication into some kind of an error state that requires a resync. > > That would still mean a need to resync the data to recover, so I'm not > sure it's really an improvement. And I suppose it'd require tracking the > dependencies, because how else would you mark the subscription as > requiring a resync? At which point we could decline the DROP without a > CASCADE, just like we do elsewhere, no? I was actually thinking more along the lines of just simply marking the publication/subscription as being in a 'failed' state when a failure actually happens, and maybe even at that point basically throwing away everything except the shell of the publication/subscription (so the user can see that it failed and come in and properly drop it); I'm thinking about this as perhaps similar to a transaction being aborted. Thanks! Stephen
Вложения
On 14/12/2018 16:38, Stephen Frost wrote: > Greetings, > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 23/11/2018 03:02, Stephen Frost wrote: >>> * Euler Taveira (euler@timbira.com.br) wrote: >>>> 2018-02-28 21:54 GMT-03:00 Craig Ringer <craig@2ndquadrant.com>: >>>>> Good idea. I haven't read this yet, but one thing to make sure you've >>>>> handled is limiting the clause to referencing only the current tuple and the >>>>> catalogs. user-catalog tables are OK, too, anything that is >>>>> RelationIsAccessibleInLogicalDecoding(). >>>>> >>>>> This means only immutable functions may be invoked, since a stable or >>>>> volatile function might attempt to access a table. And views must be >>>>> prohibited or recursively checked. (We have tree walkers that would help >>>>> with this). >>>>> >>>>> It might be worth looking at the current logic for CHECK expressions, since >>>>> the requirements are similar. In my opinion you could safely not bother with >>>>> allowing access to user catalog tables in the filter expressions and limit >>>>> them strictly to immutable functions and the tuple its self. >>>> >>>> IIRC implementation is similar to RLS expressions. I'll check all of >>>> these rules. >>> >>> Given the similarity to RLS and the nearby discussion about allowing >>> non-superusers to create subscriptions, and probably publications later, >>> I wonder if we shouldn't be somehow associating this with RLS policies >>> instead of having the publication filtering be entirely independent.. >> >> I do see the appeal here, if you consider logical replication to be a >> streaming select it probably applies well. >> >> But given that this is happening inside output plugin which does not >> have full executor setup and has catalog-only snapshot I am not sure how >> feasible it is to try to merge these two things. As per my previous >> email it's possible that we'll have to be stricter about what we allow >> in expressions here. > > I can certainly understand the concern about trying to combine the > implementation of this with that of RLS; perhaps that isn't a good fit > due to the additional constraints put on logical decoding. > > That said, I still think it might make sense to consider these filters > for logical decoding to be policies and, ideally, to allow users to use > the same policy for both. > I am not against that as long as it's possible to have policy for logical replication without having it for RLS and vice versa. I also wonder if policies are flexible enough to allow for specifying OLD and NEW - the replication filtering deals with DML, not with what's visible, it might very well depend on differences between these (that's something the current patch is missing as well BTW). > In the end, the idea of having to build a single large and complex > 'create publication' command which has a bunch of tables, each with > their own filter clauses, just strikes me as pretty painful. > >> The other issue with merging this is that the use-case for filtering out >> the data in logical replication is not necessarily about security, but >> often about sending only relevant data. So it makes sense to have filter >> on publication without RLS enabled on table and if we'd force that, we'd >> limit usefulness of this feature. > > I definitely have a serious problem if we are going to say that you > can't use this filtering for security-sensitive cases. I am saying it should not be tied to only security sensitive cases, because it has use cases that have nothing to do with security (ie, I don't want this to depend on RLS being enabled for a table). > >> We definitely want to eventually create subscriptions as non-superuser >> but that has zero effect on this as everything here is happening on >> different server than where subscription lives (we already allow >> creation of publications with just CREATE privilege on database and >> ownership of the table). > > What I wasn't clear about above was the idea that we might allow a user > other than the table owner to publish a given table, but that such a > publication should certanily only be allowed to include the rows which > that user has access to- as regulated by RLS. If the RLS policy is too > complex to allow that then I would think we'd simply throw an error at > the create publication time and the would-be publisher would need to > figure that out with the table owner. My opinion is that this is useful, but not necessarily something v1 patch needs to solve. Having too many publications and subscriptions to various places is not currently practical anyway due to decoding duplicating all the work for every connection. > > * Euler Taveira (euler@timbira.com.br) wrote: >> Em sex, 23 de nov de 2018 às 11:40, Petr Jelinek >> <petr.jelinek@2ndquadrant.com> escreveu: > >>> The other issue with merging this is that the use-case for filtering out >>> the data in logical replication is not necessarily about security, but >>> often about sending only relevant data. So it makes sense to have filter >>> on publication without RLS enabled on table and if we'd force that, we'd >>> limit usefulness of this feature. >> >> Use the same infrastructure as RLS could be a good idea but use RLS >> for row filtering is not. RLS is complex. > > Right, this was along the lines I was thinking of- using the > infrastructure and the policy system, in particular. > Yeah that part is definitely worth investigating. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 14/12/2018 16:56, Stephen Frost wrote: > Greetings, > > * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: >> On 11/23/18 8:03 PM, Stephen Frost wrote: >>> * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: >>>> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> >>>> wrote: >>>>>> If carefully documented I see no problem with it... we already have an >>>>>> analogous problem with functional indexes. >>>>> >>>>> The difference is that with functional indexes you can recreate the >>>>> missing object and everything is okay again. With logical replication >>>>> recreating the object will not help. >>>>> >>>> >>>> In this case with logical replication you should rsync the object. That is >>>> the price of misunderstanding / bad use of the new feature. >>>> >>>> As usual, there are no free beer ;-) >>> >>> There's also certainly no shortage of other ways to break logical >>> replication, including ways that would also be hard to recover from >>> today other than doing a full resync. >> >> Sure, but that seems more like an argument against creating additional >> ones (and for preventing those that already exist). I'm not sure this >> particular feature is where we should draw the line, though. > > I was actually going in the other direction- we should allow it because > advanced users may know what they're doing better than we do and we > shouldn't prevent things just because they might be misused or > misunderstood by a user. > That's all good, but we need good escape hatch for when things go south and we don't have it and IMHO it's not as easy to have one as you might think. That's why I would do the simple and safe way first before allowing more, otherwise we'll be discussing this for next couple of PG versions. >>> What that seems to indicate, to me at least, is that it'd be awful >>> nice to have a way to resync the data which doesn't necessairly >>> involve transferring all of it over again. >>> >>> Of course, it'd be nice if we could track those dependencies too, >>> but that's yet another thing. >> >> Yep, that seems like a good idea in general. Both here and for >> functional indexes (although I suppose sure is a technical reason why it >> wasn't implemented right away for them). > > We don't track function dependencies in general and I could certainly > see cases where you really wouldn't want to do so, at least not in the > same way that we track FKs or similar. I do wonder if maybe we didn't > track function dependencies because we didn't (yet) have create or > replace function and that now we should. We don't track dependencies > inside a function either though. Yeah we can't always have dependencies, it would break some perfectly valid usage scenarios. Also it's not exactly clear to me how we'd track dependencies of say plpython function... > >>> In short, I'm not sure that I agree with the idea that we shouldn't >>> allow this and instead I'd rather we realize it and put the logical >>> replication into some kind of an error state that requires a resync. >> >> That would still mean a need to resync the data to recover, so I'm not >> sure it's really an improvement. And I suppose it'd require tracking the >> dependencies, because how else would you mark the subscription as >> requiring a resync? At which point we could decline the DROP without a >> CASCADE, just like we do elsewhere, no? > > I was actually thinking more along the lines of just simply marking the > publication/subscription as being in a 'failed' state when a failure > actually happens, and maybe even at that point basically throwing away > everything except the shell of the publication/subscription (so the user > can see that it failed and come in and properly drop it); I'm thinking > about this as perhaps similar to a transaction being aborted. There are several problems with that. First this happens in historic snapshot which can't write and on top of that we are in the middle of error processing so we have our hands tied a bit, it's definitely going to need bit of creative thinking to do this. Second, and that's more soft issue (which is probably harder to solve) what do we do with the slot and subscription. There is one failed publication, but the subscription may be subscribed to 20 of them, do we kill the whole subscription because of single failed publication? If we don't do we continue replicating like nothing has happened but with data in the failed publication missing (which can be considered data loss/corruption from the view of user). If we stop replication, do we clean the slot so that we don't keep back wal/catalog xmin forever (which could lead to server stopping) or do we keep the slot so that user can somehow fix the issue (reconfigure subscription to not care about that publication for example) and continue replication without further loss? -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Greetings, * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 14/12/2018 16:38, Stephen Frost wrote: > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > >> I do see the appeal here, if you consider logical replication to be a > >> streaming select it probably applies well. > >> > >> But given that this is happening inside output plugin which does not > >> have full executor setup and has catalog-only snapshot I am not sure how > >> feasible it is to try to merge these two things. As per my previous > >> email it's possible that we'll have to be stricter about what we allow > >> in expressions here. > > > > I can certainly understand the concern about trying to combine the > > implementation of this with that of RLS; perhaps that isn't a good fit > > due to the additional constraints put on logical decoding. > > > > That said, I still think it might make sense to consider these filters > > for logical decoding to be policies and, ideally, to allow users to use > > the same policy for both. > > I am not against that as long as it's possible to have policy for > logical replication without having it for RLS and vice versa. RLS already is able to be enabled/disabled on a per-table basis. I could see how we might want to extend the existing policy system to have a way to enable/disable individual policies for RLS but that should be reasonably straight-forward to do, I would think. > I also wonder if policies are flexible enough to allow for specifying > OLD and NEW - the replication filtering deals with DML, not with what's > visible, it might very well depend on differences between these (that's > something the current patch is missing as well BTW). The policy system already has the notion of a 'visible' check and a 'does the new row match this' check (USING vs. WITH CHECK policies). Perhaps if you could outline the specific use-cases that you're thinking about, we could discuss them and make sure that they fit within those mechanisms- or, if not, discuss if such a use-case would make sense for RLS as well and, if so, figure out a way to support that for both. > > In the end, the idea of having to build a single large and complex > > 'create publication' command which has a bunch of tables, each with > > their own filter clauses, just strikes me as pretty painful. > > > >> The other issue with merging this is that the use-case for filtering out > >> the data in logical replication is not necessarily about security, but > >> often about sending only relevant data. So it makes sense to have filter > >> on publication without RLS enabled on table and if we'd force that, we'd > >> limit usefulness of this feature. > > > > I definitely have a serious problem if we are going to say that you > > can't use this filtering for security-sensitive cases. > > I am saying it should not be tied to only security sensitive cases, > because it has use cases that have nothing to do with security (ie, I > don't want this to depend on RLS being enabled for a table). I'm fine with this being able to be independently enabled/disabled, apart from RLS. > >> We definitely want to eventually create subscriptions as non-superuser > >> but that has zero effect on this as everything here is happening on > >> different server than where subscription lives (we already allow > >> creation of publications with just CREATE privilege on database and > >> ownership of the table). > > > > What I wasn't clear about above was the idea that we might allow a user > > other than the table owner to publish a given table, but that such a > > publication should certanily only be allowed to include the rows which > > that user has access to- as regulated by RLS. If the RLS policy is too > > complex to allow that then I would think we'd simply throw an error at > > the create publication time and the would-be publisher would need to > > figure that out with the table owner. > > My opinion is that this is useful, but not necessarily something v1 > patch needs to solve. Having too many publications and subscriptions to > various places is not currently practical anyway due to decoding > duplicating all the work for every connection. I agree that supporting this could be done in a later patch, however, I do feel that when we go to add support for non-owners to create publications then RLS needs to be supported at that point (and by more than just 'throw an error'). I can agree with incremental improvements but I don't want to get to a point where we've got a bunch of independent things only half of which work with other parts of the system. > > * Euler Taveira (euler@timbira.com.br) wrote: > >> Em sex, 23 de nov de 2018 às 11:40, Petr Jelinek > >> <petr.jelinek@2ndquadrant.com> escreveu: > > > >>> The other issue with merging this is that the use-case for filtering out > >>> the data in logical replication is not necessarily about security, but > >>> often about sending only relevant data. So it makes sense to have filter > >>> on publication without RLS enabled on table and if we'd force that, we'd > >>> limit usefulness of this feature. > >> > >> Use the same infrastructure as RLS could be a good idea but use RLS > >> for row filtering is not. RLS is complex. > > > > Right, this was along the lines I was thinking of- using the > > infrastructure and the policy system, in particular. > > Yeah that part is definitely worth investigating. Glad to hear that. Thanks! Stephen
Вложения
Greetings, * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: > On 14/12/2018 16:56, Stephen Frost wrote: > > * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > >> On 11/23/18 8:03 PM, Stephen Frost wrote: > >>> * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: > >>>> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> > >>>> wrote: > >>>>>> If carefully documented I see no problem with it... we already have an > >>>>>> analogous problem with functional indexes. > >>>>> > >>>>> The difference is that with functional indexes you can recreate the > >>>>> missing object and everything is okay again. With logical replication > >>>>> recreating the object will not help. > >>>>> > >>>> > >>>> In this case with logical replication you should rsync the object. That is > >>>> the price of misunderstanding / bad use of the new feature. > >>>> > >>>> As usual, there are no free beer ;-) > >>> > >>> There's also certainly no shortage of other ways to break logical > >>> replication, including ways that would also be hard to recover from > >>> today other than doing a full resync. > >> > >> Sure, but that seems more like an argument against creating additional > >> ones (and for preventing those that already exist). I'm not sure this > >> particular feature is where we should draw the line, though. > > > > I was actually going in the other direction- we should allow it because > > advanced users may know what they're doing better than we do and we > > shouldn't prevent things just because they might be misused or > > misunderstood by a user. > > That's all good, but we need good escape hatch for when things go south > and we don't have it and IMHO it's not as easy to have one as you might > think. We don't have a great solution but we should be able to at least drop and recreate the publication or subscription, even today, can't we? Sure, that means having to recopy everything, but that's what you get if you break your publication/subscription. If we allow the user to get to a point where the system can't be fixed then I agree that's a serious issue, but hopefully that isn't the case. > >>> What that seems to indicate, to me at least, is that it'd be awful > >>> nice to have a way to resync the data which doesn't necessairly > >>> involve transferring all of it over again. > >>> > >>> Of course, it'd be nice if we could track those dependencies too, > >>> but that's yet another thing. > >> > >> Yep, that seems like a good idea in general. Both here and for > >> functional indexes (although I suppose sure is a technical reason why it > >> wasn't implemented right away for them). > > > > We don't track function dependencies in general and I could certainly > > see cases where you really wouldn't want to do so, at least not in the > > same way that we track FKs or similar. I do wonder if maybe we didn't > > track function dependencies because we didn't (yet) have create or > > replace function and that now we should. We don't track dependencies > > inside a function either though. > > Yeah we can't always have dependencies, it would break some perfectly > valid usage scenarios. Also it's not exactly clear to me how we'd track > dependencies of say plpython function... Well, we could at leasts depend on the functions explicitly listed at the top level and I don't believe we even do that today. I can't think of any downside off-hand to that, given that we have create-or-replace function. > >>> In short, I'm not sure that I agree with the idea that we shouldn't > >>> allow this and instead I'd rather we realize it and put the logical > >>> replication into some kind of an error state that requires a resync. > >> > >> That would still mean a need to resync the data to recover, so I'm not > >> sure it's really an improvement. And I suppose it'd require tracking the > >> dependencies, because how else would you mark the subscription as > >> requiring a resync? At which point we could decline the DROP without a > >> CASCADE, just like we do elsewhere, no? > > > > I was actually thinking more along the lines of just simply marking the > > publication/subscription as being in a 'failed' state when a failure > > actually happens, and maybe even at that point basically throwing away > > everything except the shell of the publication/subscription (so the user > > can see that it failed and come in and properly drop it); I'm thinking > > about this as perhaps similar to a transaction being aborted. > > There are several problems with that. First this happens in historic > snapshot which can't write and on top of that we are in the middle of > error processing so we have our hands tied a bit, it's definitely going > to need bit of creative thinking to do this. We can't write to things inside the database in a historic snapshot and we do have to deal with the fact that we're in error processing. What about writing somewhere that's outside of the regular database system? Maybe a pg_logical/failed directory? There's all the usual complications from that around dealing with durable writes (if we need to worry about that and I'm not sure that we do... if we fail to persist a write saying "X failed" and we restart.. well, it's gonna fail again and we write it then), and cleaning things up as needed (but maybe this is handled as part of the DROP, and we WAL that, so we can re-do the removal of the failed marker file...), and if we need to think about what should happen on replicas (is there anything?). > Second, and that's more soft issue (which is probably harder to solve) > what do we do with the slot and subscription. There is one failed > publication, but the subscription may be subscribed to 20 of them, do we > kill the whole subscription because of single failed publication? If we > don't do we continue replicating like nothing has happened but with data > in the failed publication missing (which can be considered data > loss/corruption from the view of user). If we stop replication, do we > clean the slot so that we don't keep back wal/catalog xmin forever > (which could lead to server stopping) or do we keep the slot so that > user can somehow fix the issue (reconfigure subscription to not care > about that publication for example) and continue replication without > further loss? I would think we'd have to fail the whole publication if there's a failure for any part of it. Replicating a partial set definitely sounds wrong to me. Once we stop replication, yes, we should clean the slot and mark it failed so that we don't keep back WAL and so that we allow the catalog xmin to move forward so that the failed publication doesn't run the server out of disk space. If we really think there's a use-case for keeping the replication slot and allowing it to cause WAL to spool on the server and keep the catalog xmin back then I'd suggest we make this behavior configurable- so that users can choose on a publication if they want a failure to be considered a 'soft' fail or a 'hard' fail. A 'soft' fail would keep the slot and keep the WAL and keep the catalog xmin, with the expectation that the user will either drop the slot themselves or somehow fix it, while a 'hard' fail would clean everything up except the skeleton of the slot itself which the user would need to drop. Thanks! Stephen
Вложения
Hi, On 27/12/2018 20:05, Stephen Frost wrote: > Greetings, > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 14/12/2018 16:38, Stephen Frost wrote: >>> * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >>>> I do see the appeal here, if you consider logical replication to be a >>>> streaming select it probably applies well. >>>> >>>> But given that this is happening inside output plugin which does not >>>> have full executor setup and has catalog-only snapshot I am not sure how >>>> feasible it is to try to merge these two things. As per my previous >>>> email it's possible that we'll have to be stricter about what we allow >>>> in expressions here. >>> >>> I can certainly understand the concern about trying to combine the >>> implementation of this with that of RLS; perhaps that isn't a good fit >>> due to the additional constraints put on logical decoding. >>> >>> That said, I still think it might make sense to consider these filters >>> for logical decoding to be policies and, ideally, to allow users to use >>> the same policy for both. >> >> I am not against that as long as it's possible to have policy for >> logical replication without having it for RLS and vice versa. > > RLS already is able to be enabled/disabled on a per-table basis. I > could see how we might want to extend the existing policy system to have > a way to enable/disable individual policies for RLS but that should be > reasonably straight-forward to do, I would think. Sure, I was mostly referring to having ability of enable/disable this independently of enabling/disabling RLS which you are okay with based on bellow so no issue there from my side. > >> I also wonder if policies are flexible enough to allow for specifying >> OLD and NEW - the replication filtering deals with DML, not with what's >> visible, it might very well depend on differences between these (that's >> something the current patch is missing as well BTW). > > The policy system already has the notion of a 'visible' check and a > 'does the new row match this' check (USING vs. WITH CHECK policies). > Perhaps if you could outline the specific use-cases that you're thinking > about, we could discuss them and make sure that they fit within those > mechanisms- or, if not, discuss if such a use-case would make sense for > RLS as well and, if so, figure out a way to support that for both. So we'd use USING for old row images (UPDATE/DELETE) and WITH CHECK for new ones (UPDATE/INSERT)? I think OLD/NEW is somewhat more natural naming of this as there is no "SELECT" part of operation here, but as long as the functionality is there I don't mind syntax that much. > >>> In the end, the idea of having to build a single large and complex >>> 'create publication' command which has a bunch of tables, each with >>> their own filter clauses, just strikes me as pretty painful. >>> >>>> The other issue with merging this is that the use-case for filtering out >>>> the data in logical replication is not necessarily about security, but >>>> often about sending only relevant data. So it makes sense to have filter >>>> on publication without RLS enabled on table and if we'd force that, we'd >>>> limit usefulness of this feature. >>> >>> I definitely have a serious problem if we are going to say that you >>> can't use this filtering for security-sensitive cases. >> >> I am saying it should not be tied to only security sensitive cases, >> because it has use cases that have nothing to do with security (ie, I >> don't want this to depend on RLS being enabled for a table). > > I'm fine with this being able to be independently enabled/disabled, > apart from RLS. > Cool. >>>> We definitely want to eventually create subscriptions as non-superuser >>>> but that has zero effect on this as everything here is happening on >>>> different server than where subscription lives (we already allow >>>> creation of publications with just CREATE privilege on database and >>>> ownership of the table). >>> >>> What I wasn't clear about above was the idea that we might allow a user >>> other than the table owner to publish a given table, but that such a >>> publication should certanily only be allowed to include the rows which >>> that user has access to- as regulated by RLS. If the RLS policy is too >>> complex to allow that then I would think we'd simply throw an error at >>> the create publication time and the would-be publisher would need to >>> figure that out with the table owner. >> >> My opinion is that this is useful, but not necessarily something v1 >> patch needs to solve. Having too many publications and subscriptions to >> various places is not currently practical anyway due to decoding >> duplicating all the work for every connection. > > I agree that supporting this could be done in a later patch, however, I > do feel that when we go to add support for non-owners to create > publications then RLS needs to be supported at that point (and by more > than just 'throw an error'). I can agree with incremental improvements > but I don't want to get to a point where we've got a bunch of > independent things only half of which work with other parts of the > system. Yes, using RLS infrastructure now will make it easier to add support for publishing without being owner at some later point, just let's please not make publishing without being owner part of requirements for this. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On 27/12/2018 20:19, Stephen Frost wrote: > Greetings, > > * Petr Jelinek (petr.jelinek@2ndquadrant.com) wrote: >> On 14/12/2018 16:56, Stephen Frost wrote: >>> * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: >>>> On 11/23/18 8:03 PM, Stephen Frost wrote: >>>>> * Fabrízio de Royes Mello (fabriziomello@gmail.com) wrote: >>>>>> On Fri, Nov 23, 2018 at 4:13 PM Petr Jelinek <petr.jelinek@2ndquadrant.com> >>>>>> wrote: >>>>>>>> If carefully documented I see no problem with it... we already have an >>>>>>>> analogous problem with functional indexes. >>>>>>> >>>>>>> The difference is that with functional indexes you can recreate the >>>>>>> missing object and everything is okay again. With logical replication >>>>>>> recreating the object will not help. >>>>>>> >>>>>> >>>>>> In this case with logical replication you should rsync the object. That is >>>>>> the price of misunderstanding / bad use of the new feature. >>>>>> >>>>>> As usual, there are no free beer ;-) >>>>> >>>>> There's also certainly no shortage of other ways to break logical >>>>> replication, including ways that would also be hard to recover from >>>>> today other than doing a full resync. >>>> >>>> Sure, but that seems more like an argument against creating additional >>>> ones (and for preventing those that already exist). I'm not sure this >>>> particular feature is where we should draw the line, though. >>> >>> I was actually going in the other direction- we should allow it because >>> advanced users may know what they're doing better than we do and we >>> shouldn't prevent things just because they might be misused or >>> misunderstood by a user. >> >> That's all good, but we need good escape hatch for when things go south >> and we don't have it and IMHO it's not as easy to have one as you might >> think. > > We don't have a great solution but we should be able to at least drop > and recreate the publication or subscription, even today, can't we? Well we can drop thing always, yes, not having ability to drop things when they break would be bad design. I am debating ability to recover without rebuilding everything a there are cases where you simply can't rebuild everything (ie we allow filtering out deletes). I don't like disabling UDFs either as that means that user created types are unusable in filters, I just wonder if saying "sorry your replica is gone" is any better. > Sure, that means having to recopy everything, but that's what you get if > you break your publication/subscription. This is but off-topic here, but I really wonder how are you currently breaking your publications/subscriptions. >>>>> What that seems to indicate, to me at least, is that it'd be awful >>>>> nice to have a way to resync the data which doesn't necessairly >>>>> involve transferring all of it over again. >>>>> >>>>> Of course, it'd be nice if we could track those dependencies too, >>>>> but that's yet another thing. >>>> >>>> Yep, that seems like a good idea in general. Both here and for >>>> functional indexes (although I suppose sure is a technical reason why it >>>> wasn't implemented right away for them). >>> >>> We don't track function dependencies in general and I could certainly >>> see cases where you really wouldn't want to do so, at least not in the >>> same way that we track FKs or similar. I do wonder if maybe we didn't >>> track function dependencies because we didn't (yet) have create or >>> replace function and that now we should. We don't track dependencies >>> inside a function either though. >> >> Yeah we can't always have dependencies, it would break some perfectly >> valid usage scenarios. Also it's not exactly clear to me how we'd track >> dependencies of say plpython function... > > Well, we could at leasts depend on the functions explicitly listed at > the top level and I don't believe we even do that today. I can't think > of any downside off-hand to that, given that we have create-or-replace > function. > I dunno how much is that worth it TBH, the situations where I've seen this issue (pglogical has this feature for long time and suffers from the same lack of dependency tracking) is that somebody drops table/type used in a function that is used as filter. >>>>> In short, I'm not sure that I agree with the idea that we shouldn't >>>>> allow this and instead I'd rather we realize it and put the logical >>>>> replication into some kind of an error state that requires a resync. >>>> >>>> That would still mean a need to resync the data to recover, so I'm not >>>> sure it's really an improvement. And I suppose it'd require tracking the >>>> dependencies, because how else would you mark the subscription as >>>> requiring a resync? At which point we could decline the DROP without a >>>> CASCADE, just like we do elsewhere, no? >>> >>> I was actually thinking more along the lines of just simply marking the >>> publication/subscription as being in a 'failed' state when a failure >>> actually happens, and maybe even at that point basically throwing away >>> everything except the shell of the publication/subscription (so the user >>> can see that it failed and come in and properly drop it); I'm thinking >>> about this as perhaps similar to a transaction being aborted. >> >> There are several problems with that. First this happens in historic >> snapshot which can't write and on top of that we are in the middle of >> error processing so we have our hands tied a bit, it's definitely going >> to need bit of creative thinking to do this. > > We can't write to things inside the database in a historic snapshot and > we do have to deal with the fact that we're in error processing. What > about writing somewhere that's outside of the regular database system? > Maybe a pg_logical/failed directory? There's all the usual > complications from that around dealing with durable writes (if we need > to worry about that and I'm not sure that we do... if we fail to > persist a write saying "X failed" and we restart.. well, it's gonna fail > again and we write it then), and cleaning things up as needed (but maybe > this is handled as part of the DROP, and we WAL that, so we can re-do > the removal of the failed marker file...), and if we need to think about > what should happen on replicas (is there anything?). That sounds pretty reasonable. Given that this is corner-case user error we could perhaps do extra work to ensure things are fsynced even if it's all not too fast... > >> Second, and that's more soft issue (which is probably harder to solve) >> what do we do with the slot and subscription. There is one failed >> publication, but the subscription may be subscribed to 20 of them, do we >> kill the whole subscription because of single failed publication? If we >> don't do we continue replicating like nothing has happened but with data >> in the failed publication missing (which can be considered data >> loss/corruption from the view of user). If we stop replication, do we >> clean the slot so that we don't keep back wal/catalog xmin forever >> (which could lead to server stopping) or do we keep the slot so that >> user can somehow fix the issue (reconfigure subscription to not care >> about that publication for example) and continue replication without >> further loss? > > I would think we'd have to fail the whole publication if there's a > failure for any part of it. Replicating a partial set definitely sounds > wrong to me. Once we stop replication, yes, we should clean the slot > and mark it failed so that we don't keep back WAL and so that we allow > the catalog xmin to move forward so that the failed publication doesn't > run the server out of disk space. > I agree that continuing replication where some part of publication is broken seems wrong and that we should stop replication at that point. > If we really think there's a use-case for keeping the replication slot It's not so much about use-case as it is about complete change of behavior - there is no current error where we remove existing slot. The use case for keeping slot is a) investigation of the issue, b) just skipping the broken part of stream by advancing origin on subscription and continuing replication, with some luck that can mean only single table needs resyncing, which is better than rebuilding everything. I think some kind of automated slot cleanup is desirable, but likely separate feature that should be designed based on amount of outstanding wal or something. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Hi, On 2018-11-23 13:15:08 -0300, Euler Taveira wrote: > Besides the problem presented by Hironobu-san, I'm doing some cleanup > and improving docs. I also forget to declare pg_publication_rel TOAST > table. > > Thanks for your review. As far as I can tell, the patch has not been refreshed since. So I'm marking this as returned with feedback for now. Please resubmit once ready. Greetings, Andres Freund
Hi Euler, On 2019-02-03 13:14, Andres Freund wrote: > > On 2018-11-23 13:15:08 -0300, Euler Taveira wrote: >> Besides the problem presented by Hironobu-san, I'm doing some cleanup >> and improving docs. I also forget to declare pg_publication_rel TOAST >> table. >> >> Thanks for your review. > > As far as I can tell, the patch has not been refreshed since. So I'm > marking this as returned with feedback for now. Please resubmit once > ready. > Do you have any plans for continuing working on this patch and submitting it again on the closest September commitfest? There are only a few days left. Anyway, I will be glad to review the patch if you do submit it, though I didn't yet dig deeply into the code. I've rebased recently the entire patch set (attached) and it works fine. Your tap test is passed. Also I've added a new test case (see 0009 attached) with real life example of bidirectional replication (BDR) utilising this new WHERE clause. This naive BDR is implemented using is_cloud flag, which is set to TRUE/FALSE on cloud/remote nodes respectively. Although almost all new tests are passed, there is a problem with DELETE replication, so 1 out of 10 tests is failed. It isn't replicated if the record was created with is_cloud=TRUE on cloud, replicated to remote; then updated with is_cloud=FALSE on remote, replicated to cloud; then deleted on remote. Regards -- Alexey Kondratov Postgres Professional https://www.postgrespro.com Russian Postgres Company
Вложения
- v2-0001-Remove-unused-atttypmod-column-from-initial-table.patch
- v2-0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- v2-0003-Refactor-function-create_estate_for_relation.patch
- v2-0004-Rename-a-WHERE-node.patch
- v2-0005-Row-filtering-for-logical-replication.patch
- v2-0006-Print-publication-WHERE-condition-in-psql.patch
- v2-0007-Publication-where-condition-support-for-pg_dump.patch
- v2-0008-Debug-for-row-filtering.patch
- v2-0009-Add-simple-BDR-test-for-row-filtering.patch
Em dom, 3 de fev de 2019 às 07:14, Andres Freund <andres@anarazel.de> escreveu: > > As far as I can tell, the patch has not been refreshed since. So I'm > marking this as returned with feedback for now. Please resubmit once > ready. > I fix all of the bugs pointed in this thread. I decide to disallow UDFs in filters (it is safer for a first version). We can add this functionality later. However, I'll check if allow "safe" functions (aka builtin functions) are ok. I add more docs explaining that expressions are executed with the role used for replication connection and also that columns used in expressions must be part of PK or REPLICA IDENTITY. I add regression tests. Comments? -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0004-Rename-a-WHERE-node.patch
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0008-Debug-for-row-filtering.patch
Em ter, 27 de ago de 2019 às 18:10, <a.kondratov@postgrespro.ru> escreveu: > > Do you have any plans for continuing working on this patch and > submitting it again on the closest September commitfest? There are only > a few days left. Anyway, I will be glad to review the patch if you do > submit it, though I didn't yet dig deeply into the code. > Sure. See my last email to this thread. I appreciate if you can review it. > Although almost all new tests are passed, there is a problem with DELETE > replication, so 1 out of 10 tests is failed. It isn't replicated if the > record was created with is_cloud=TRUE on cloud, replicated to remote; > then updated with is_cloud=FALSE on remote, replicated to cloud; then > deleted on remote. > That's because you don't include is_cloud in PK or REPLICA IDENTITY. I add a small note in docs. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
I think that I also have found one shortcoming when using the setup described by Alexey Kondratov. The problem that I face is that if both (cloud and remote) tables already have data the moment I add the subscription, then the whole table is copied in both directions initially. Which leads to duplicated data and broken replication because COPY doesn't take into account the filtering condition. In case there are filters in a publication, the COPY command that is executed when adding a subscription (or altering one to refresh a publication) should also filter the data based on the same condition, e.g. COPY (SELECT * FROM ... WHERE ...) TO ...
The current workaround is to always use WITH copy_data = false when subscribing or refreshing, and then manually copy data with the above statement.
Alexey Zagarin
On 1 Sep 2019 12:11 +0700, Euler Taveira <euler@timbira.com.br>, wrote:
Em ter, 27 de ago de 2019 às 18:10, <a.kondratov@postgrespro.ru> escreveu:Sure. See my last email to this thread. I appreciate if you can review it.
Do you have any plans for continuing working on this patch and
submitting it again on the closest September commitfest? There are only
a few days left. Anyway, I will be glad to review the patch if you do
submit it, though I didn't yet dig deeply into the code.Although almost all new tests are passed, there is a problem with DELETEThat's because you don't include is_cloud in PK or REPLICA IDENTITY. I
replication, so 1 out of 10 tests is failed. It isn't replicated if the
record was created with is_cloud=TRUE on cloud, replicated to remote;
then updated with is_cloud=FALSE on remote, replicated to cloud; then
deleted on remote.
add a small note in docs.
--
Euler Taveira Timbira -
http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 2019-09-01 02:28, Euler Taveira wrote: > Em dom, 3 de fev de 2019 às 07:14, Andres Freund <andres@anarazel.de> > escreveu: >> >> As far as I can tell, the patch has not been refreshed since. So I'm >> marking this as returned with feedback for now. Please resubmit once >> ready. >> > I fix all of the bugs pointed in this thread. I decide to disallow > 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch > 0002-Store-number-of-tuples-in-WalRcvExecResult.patch > 0003-Refactor-function-create_estate_for_relation.patch > 0004-Rename-a-WHERE-node.patch > 0005-Row-filtering-for-logical-replication.patch > 0006-Print-publication-WHERE-condition-in-psql.patch > 0007-Publication-where-condition-support-for-pg_dump.patch > 0008-Debug-for-row-filtering.patch Hi, The first 4 of these apply without error, but I can't get 0005 to apply. This is what I use: patch --dry-run -b -l -F 5 -p 1 < /home/aardvark/download/pgpatches/0130/logrep_rowfilter/20190901/0005-Row-filtering-for-logical-replication.patch checking file doc/src/sgml/catalogs.sgml Hunk #1 succeeded at 5595 (offset 8 lines). checking file doc/src/sgml/ref/alter_publication.sgml checking file doc/src/sgml/ref/create_publication.sgml checking file src/backend/catalog/pg_publication.c checking file src/backend/commands/publicationcmds.c Hunk #1 succeeded at 352 (offset 8 lines). Hunk #2 succeeded at 381 (offset 8 lines). Hunk #3 succeeded at 539 (offset 8 lines). Hunk #4 succeeded at 570 (offset 8 lines). Hunk #5 succeeded at 601 (offset 8 lines). Hunk #6 succeeded at 626 (offset 8 lines). Hunk #7 succeeded at 647 (offset 8 lines). Hunk #8 succeeded at 679 (offset 8 lines). Hunk #9 succeeded at 693 (offset 8 lines). checking file src/backend/parser/gram.y checking file src/backend/parser/parse_agg.c checking file src/backend/parser/parse_expr.c Hunk #4 succeeded at 3571 (offset -2 lines). checking file src/backend/parser/parse_func.c Hunk #1 succeeded at 2516 (offset -13 lines). checking file src/backend/replication/logical/tablesync.c checking file src/backend/replication/logical/worker.c checking file src/backend/replication/pgoutput/pgoutput.c Hunk #1 FAILED at 12. Hunk #2 succeeded at 60 (offset 2 lines). Hunk #3 succeeded at 336 (offset 2 lines). Hunk #4 succeeded at 630 (offset 2 lines). Hunk #5 succeeded at 647 (offset 2 lines). Hunk #6 succeeded at 738 (offset 2 lines). 1 out of 6 hunks FAILED checking file src/include/catalog/pg_publication.h checking file src/include/catalog/pg_publication_rel.h checking file src/include/catalog/toasting.h checking file src/include/nodes/nodes.h checking file src/include/nodes/parsenodes.h Hunk #1 succeeded at 3461 (offset -1 lines). Hunk #2 succeeded at 3486 (offset -1 lines). checking file src/include/parser/parse_node.h checking file src/include/replication/logicalrelation.h checking file src/test/regress/expected/publication.out Hunk #1 succeeded at 116 (offset 9 lines). checking file src/test/regress/sql/publication.sql Hunk #1 succeeded at 69 with fuzz 1 (offset 9 lines). checking file src/test/subscription/t/013_row_filter.pl perhaps that can be fixed? thanks, Erik Rijkers
Em dom, 1 de set de 2019 às 06:09, Erik Rijkers <er@xs4all.nl> escreveu: > > The first 4 of these apply without error, but I can't get 0005 to apply. > This is what I use: > Erik, I generate a new patch set with patience diff algorithm. It seems it applies cleanly. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
- 0004-Rename-a-WHERE-node.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- 0008-Debug-for-row-filtering.patch
On 2019-09-02 01:43, Euler Taveira wrote:
> Em dom, 1 de set de 2019 às 06:09, Erik Rijkers <er@xs4all.nl>
> escreveu:
>>
>> The first 4 of these apply without error, but I can't get 0005 to
>> apply.
>> This is what I use:
>>
> Erik, I generate a new patch set with patience diff algorithm. It
> seems it applies cleanly.
>
It did apply cleanly, thanks.
But I can't get it to correctly do the partial replication in the
attached pgbench-script (similar versions of which script I also used
for earlier versions of the patch, last year).
There are complaints in the log (both pub and sub) like:
ERROR: trying to store a heap tuple into wrong type of slot
I have no idea what causes that.
I attach a zip:
$ unzip -l logrep_rowfilter.zip
Archive: logrep_rowfilter.zip
Length Date Time Name
--------- ---------- ----- ----
17942 2019-09-03 00:47 logfile.6525
10412 2019-09-03 00:47 logfile.6526
6913 2019-09-03 00:47 logrep_rowfilter_2_nodes.sh
3371 2019-09-03 00:47 output.txt
--------- -------
38638 4 files
That bash script runs 2 instances (as compiled on my local setup so it
will not run as-is) and tries for one minute to get a slice of the
pgbench_accounts table replicated. One minute is short but I wanted
short logfiles; I have tried the same up to 20 minutes without the
replication completing. I'll try even longer but in the meantime I hope
you can figure out why these errors occur.
thanks,
Erik Rijkers
Вложения
There are complaints in the log (both pub and sub) like:
ERROR: trying to store a heap tuple into wrong type of slot
I have no idea what causes that.
Yeah, I've seen that too. It was fixed by Alexey Kondratov, in line 955 of 0005-Row-filtering-for-logical-replication.patch it should be &TTSOpsHeapTuple instead of &TTSOpsVirtual.
Em ter, 3 de set de 2019 às 00:16, Alexey Zagarin <zagarin@gmail.com> escreveu: > > There are complaints in the log (both pub and sub) like: > ERROR: trying to store a heap tuple into wrong type of slot > > I have no idea what causes that. > > > Yeah, I've seen that too. It was fixed by Alexey Kondratov, in line 955 of 0005-Row-filtering-for-logical-replication.patchit should be &TTSOpsHeapTuple instead of &TTSOpsVirtual. > Ops... exact. That was an oversight while poking with different types of slots. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On 2019-09-03 05:32, Euler Taveira wrote: > Em ter, 3 de set de 2019 às 00:16, Alexey Zagarin <zagarin@gmail.com> > escreveu: >> >> There are complaints in the log (both pub and sub) like: >> ERROR: trying to store a heap tuple into wrong type of slot >> >> I have no idea what causes that. >> >> Yeah, I've seen that too. It was fixed by Alexey Kondratov, in line >> 955 of 0005-Row-filtering-for-logical-replication.patch it should be >> &TTSOpsHeapTuple instead of &TTSOpsVirtual. >> > Ops... exact. That was an oversight while poking with different types > of slots. OK, I'll consider Alexey Kondratov's set of patches as the current state-of-the-art then. (They still apply.) I found a problem where I'm not sure it's a bug: The attached bash script does a test by setting up pgbench tables on both master and replica, and then sets up logical replication for a slice of pgbench_accounts. Then it does a short pgbench run, and loops until the results become identical(ok) (or breaks out after a certain time (NOK=not ok)). It turns out this did not work until I added a wait state after the CREATE SUBSCRIPTION. It always fails without the wait state, and always works with the wait state. Do you agree this is a bug? thanks (also to both Alexeys :)) Erik Rijkers PS by the way, this script won't run as-is on other machines; it has stuff particular to my local setup.
Вложения
OK, I'll consider Alexey Kondratov's set of patches as the current
state-of-the-art then. (They still apply.)
Alexey's patch is the rebased version of previous Euler's patch set, with slot type mistake fixed, and adapted to current changes in the master branch. It also has testing improvements. On the other hand, the new patches from Euler include more fixes and the implementation of filtering in COPY (as far as I can tell from code) which addresses my particular pain point with BDR. Hope they'll be joined soon. :)
It turns out this did not work until I added a wait state after the
CREATE SUBSCRIPTION. It always fails without the wait state, and always
works with the wait state.
Do you agree this is a bug?
I'm not sure this is a bug as after the subscription is added (or a new table added to the publication and then the subscription is refreshed), the whole table is synchronized using COPY statement. Depending on size of the table it can take some time. You may want to check srsubstate in pg_subscription_rel instead of just sleep for more reliable implementation.
Alexey
Em ter, 3 de set de 2019 às 00:32, Euler Taveira <euler@timbira.com.br> escreveu: > > Ops... exact. That was an oversight while poking with different types of slots. > Here is a rebased version including this small fix. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0004-Rename-a-WHERE-node.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- 0008-Debug-for-row-filtering.patch
Hello
I find several problems as below when I test the patches:
1. There be some regression problem after apply 0001.patch~0005.patch
The regression problem is solved in 0006.patch
2. There be a data wrong after create subscription if the relation contains
inherits table, for example:
##########################
The Tables:
CREATE TABLE cities (
name text,
population float,
altitude int
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
Do on publication:
insert into cities values('aaa',123, 134);
insert into capitals values('bbb',123, 134);
create publication pub_tc for table cities where (altitude > 100 and altitude < 200);
postgres=# select * from cities ;
name | population | altitude
------+------------+----------
aaa | 123 | 134
bbb | 123 | 134
(2 rows)
Do on subscription:
create subscription sub_tc connection 'host=localhost port=5432 dbname=postgres' publication pub_tc;
postgres=# select * from cities ;
name | population | altitude
------+------------+----------
aaa | 123 | 134
bbb | 123 | 134
bbb | 123 | 134
(3 rows)
##########################
An unexcept row appears.
3. I am puzzled when I test the update.
Use the tables in problem 2 and test as below:
#########################
On publication:
postgres=# insert into cities values('t1',123, 34);
INSERT 0 1
postgres=# update cities SET altitude = 134 where altitude = 34;
UPDATE 1
postgres=# select * from cities ;
name | population | altitude
------+------------+----------
t1 | 123 | 134
(1 row)
On subscription:
postgres=# select * from cities ;
name | population | altitude
------+------------+----------
(0 rows)
On publication:
insert into cities values('t1',1,'135');
update cities set altitude=300 where altitude=135;
postgres=# table cities ;
name | population | altitude
------+------------+----------
t1 | 123 | 134
t1 | 1 | 300
(2 rows)
On subscription:
ostgres=# table cities ;
name | population | altitude
------+------------+----------
t1 | 1 | 135
(1 row)
#########################
Result1:Update a row that is not suitable the publication condition to
suitable, the subscription change nothing.
Result2: Update a row that is suitable for the publication condition to
not suitable, the subscription change nothing.
If it is a bug? Or there should be an explanation about it?
4. SQL splicing code in fetch_remote_table_info() function is too long
---
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead.li@highgo.ca
The new status of this patch is: Waiting on Author
Em seg, 23 de set de 2019 às 01:59, movead li <movead.li@highgo.ca> escreveu:
>
> I find several problems as below when I test the patches:
>
First of all, thanks for your review.
> 1. There be some regression problem after apply 0001.patch~0005.patch
> The regression problem is solved in 0006.patch
>
Which regression?
> 2. There be a data wrong after create subscription if the relation contains
> inherits table, for example:
>
Ouch. Good catch! Forgot about the ONLY in COPY with query. I will add
a test for it.
> 3. I am puzzled when I test the update.
> Use the tables in problem 2 and test as below:
> #########################
> On publication:
> postgres=# insert into cities values('t1',123, 34);
> INSERT 0 1
>
INSERT isn't replicated.
> postgres=# update cities SET altitude = 134 where altitude = 34;
> UPDATE 1
>
There should be an error because you don't have a PK or REPLICA IDENTITY.
postgres=# update cities SET altitude = 134 where altitude = 34;
ERROR: cannot update table "cities" because it does not have a
replica identity and publishes updates
HINT: To enable updating the table, set REPLICA IDENTITY using ALTER TABLE.
Even if you create a PK or REPLICA IDENTITY, it won't turn this UPDATE
into a INSERT and send it to the other node (indeed UPDATE will be
sent however there isn't a tuple to update). Also, filter columns must
be in PK or REPLICA IDENTITY. I explain this in documentation.
> 4. SQL splicing code in fetch_remote_table_info() function is too long
>
I split it into small pieces. I also run pgindent to improve code style.
I'll send a patchset later today.
Regards,
--
Euler Taveira Timbira -
http://www.timbira.com.br/
PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Em qua, 25 de set de 2019 às 08:08, Euler Taveira <euler@timbira.com.br> escreveu: > > I'll send a patchset later today. > ... and it is attached. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
Вложения
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0004-Rename-a-WHERE-node.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0008-Debug-for-row-filtering.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
>Which regression?
Apply the 0001.patch~0005.patch and then do a 'make check', then there be a
failed item. And when you apply the 0006.patch, the failed item disappeared.
>There should be an error because you don't have a PK or REPLICA IDENTITY.
No. I have done the 'ALTER TABLE cities REPLICA IDENTITY FULL'.
>Even if you create a PK or REPLICA IDENTITY, it won't turn this UPDATE
>into a INSERT and send it to the other node (indeed UPDATE will be
>sent however there isn't a tuple to update). Also, filter columns must
>be in PK or REPLICA IDENTITY. I explain this in documentation.
You should considered the Result2:
On publication:
insert into cities values('t1',1,135);
update cities set altitude=300 where altitude=135;
postgres=# table cities ;
name | population | altitude
------+------------+----------
t1 | 123 | 134
t1 | 1 | 300
(2 rows)
On subscription:
ostgres=# table cities ;
name | population | altitude
------+------------+----------
t1 | 1 | 135
The tuple ('t1',1,135) appeared in both publication and subscription,
but after an update on publication, the tuple is disappeared on
publication and change nothing on subscription.
The same with Result1, they puzzled me today and I think they will
puzzle the users in the future. It should have a more wonderful design,
for example, a log to notify users that there be a problem during replication
at least.
but after an update on publication, the tuple is disappeared on
publication and change nothing on subscription.
The same with Result1, they puzzled me today and I think they will
puzzle the users in the future. It should have a more wonderful design,
for example, a log to notify users that there be a problem during replication
at least.
---
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
Hi Euler,
Thanks for working on this. I have reviewed the patches, as I too am
working on a patch related to logical replication [1].
On Thu, Sep 26, 2019 at 8:20 AM Euler Taveira <euler@timbira.com.br> wrote:
>
> Em qua, 25 de set de 2019 às 08:08, Euler Taveira
> <euler@timbira.com.br> escreveu:
> >
> > I'll send a patchset later today.
> >
> ... and it is attached.
Needed to be rebased, which I did, to be able to test them; patches attached.
Some comments:
* 0001: seems a no-brainer
* 0002: seems, um, unnecessary? The only place ntuples will be used is here:
@@ -702,9 +702,8 @@ fetch_remote_table_info(char *nspname, char *relname,
(errmsg("could not fetch table info for table \"%s.%s\": %s",
nspname, relname, res->err)));
- /* We don't know the number of rows coming, so allocate enough space. */
- lrel->attnames = palloc0(MaxTupleAttributeNumber * sizeof(char *));
- lrel->atttyps = palloc0(MaxTupleAttributeNumber * sizeof(Oid));
+ lrel->attnames = palloc0(res->ntuples * sizeof(char *));
+ lrel->atttyps = palloc0(res->ntuples * sizeof(Oid));
but you might as well use tuplestore_tuple_count(res->tuplestore). My
point is that if ntuples that this patch is adding was widely useful
(as would be shown by the number of places that could be refactored to
use it), it would have been worthwhile to add it.
* 0003: seems fine to me.
* 0004: seems fine too, although maybe preproc.y should be updated too?
* 0005: naturally many comments here :)
+ <entry>Expression tree (in the form of a
+ <function>nodeToString()</function> representation) for the relation's
Minor nitpicking: "in the form of a" seems unnecessary. Other places
that mention nodeToString() just say "in
<function>nodeToString()</function> representation"
+ Columns used in the <literal>WHERE</literal> clause must be part of the
+ primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise
+ <command>UPDATE</command> and <command>DELETE</command> operations will not
+ be replicated.
+ </para>
Can you please explain the reasoning behind this restriction. Sorry
if this is already covered in the up-thread discussion.
/*
+ * Gets list of PublicationRelationQuals for a publication.
+ */
+List *
+GetPublicationRelationQuals(Oid pubid)
+{
...
+ relqual->relation = table_open(pubrel->prrelid,
ShareUpdateExclusiveLock);
I think it's a bad idea to open the table in one file and rely on
something else in the other file closing it. I know you're having it
to do it because you're using PublicationRelationQual to return
individual tables, but why not just store the table's OID in it and
only open and close the relation where it's needed. Keeping the
opening and closing of relation close to each other is better as long
as it doesn't need to be done many times over in many different
functions. In this case, pg_publication.c: publication_add_relation()
is the only place that needs to look at the open relation, so opening
and closing should both be done there. Nothing else needs to look at
the open relation.
Actually, OpenTableList() should also not open the relation. Then we
don't need CloseTableList(). I think it would be better to refactor
things around this and include the patch in this series.
+ /* Find all publications associated with the relation. */
+ pubrelsrel = table_open(PublicationRelRelationId, AccessShareLock);
I guess you meant:
/* Get all relations associated with this publication. */
+ relqual->whereClause = copyObject(qual_expr);
Is copying really necessary?
+ /*
+ * ALTER PUBLICATION ... DROP TABLE cannot contain a WHERE clause. Use
+ * publication_table_list node (that accepts a WHERE clause) but forbid
+ * the WHERE clause in it. The use of relation_expr_list node just for
+ * the DROP TABLE part does not worth the trouble.
+ */
This comment is not very helpful, as it's not clear what the various
names are referring to. I'd just just write:
/*
* Although ALTER PUBLICATION's grammar allows WHERE clause to be
* specified for DROP TABLE action, it doesn't makes sense to allow it.
* We implement that rule here, instead of complicating grammar to enforce
* it.
*/
+ errmsg("cannot use a WHERE clause for
removing table from publication \"%s\"",
I think: s/for/when/g
+ /*
+ * Remove publication / relation mapping iif (i) table is not
+ * found in the new list or (ii) table is found in the new list,
+ * however, its qual does not match the old one (in this case, a
+ * simple tuple update is not enough because of the dependencies).
+ */
Aside from the typo on the 1st line (iif), I suggest writing this as:
/*-----------
* Remove the publication-table mapping if:
*
* 1) Table is not found the new list of tables
*
* 2) Table is being re-added with a different qual expression
*
* For (2), simply updating the existing tuple is not enough,
* because of the qual expression's dependencies.
*/
+ errmsg("functions are not allowed in WHERE"),
Maybe:
functions are now allowed in publication WHERE expressions
+ err = _("cannot use subquery in publication WHERE expression");
s/expression/expressions/g
+ case EXPR_KIND_PUBLICATION_WHERE:
+ return "publication expression";
Maybe:
publication WHERE expression
or
publication qual
- int natt;
+ int n;
Are this and other related changes really needed?
+ appendStringInfoString(&cmd, "COPY (SELECT ");
+ /* list of attribute names */
+ first = true;
+ foreach(lc, attnamelist)
+ {
+ char *col = strVal(lfirst(lc));
+
+ if (first)
+ first = false;
+ else
+ appendStringInfoString(&cmd, ", ");
+ appendStringInfo(&cmd, "%s", quote_identifier(col));
+ }
Hmm, why wouldn't SELECT * suffice?
+ estate = create_estate_for_relation(relation);
+
+ /* prepare context per tuple */
+ ecxt = GetPerTupleExprContext(estate);
+ oldcxt = MemoryContextSwitchTo(estate->es_query_cxt);
+ ecxt->ecxt_scantuple = ExecInitExtraTupleSlot(estate,
tupdesc, &TTSOpsHeapTuple);
...
+ ExecDropSingleTupleTableSlot(ecxt->ecxt_scantuple);
+ FreeExecutorState(estate);
Creating and destroying the EState (that too with the ResultRelInfo
that is never used) for every tuple seems wasteful. You could store
the standalone ExprContext in RelationSyncEntry and use it for every
tuple.
+ /* evaluates row filter */
+ expr_type = exprType(qual);
+ expr = (Expr *) coerce_to_target_type(NULL, qual,
expr_type, BOOLOID, -1, COERCION_ASSIGNMENT, COERCE_IMPLICIT_CAST,
-1);
+ expr = expression_planner(expr);
+ expr_state = ExecInitExpr(expr, NULL);
Also, there appears to be no need to repeat this for every tuple? I
think this should be done only once, that is, RelationSyncEntry.qual
should cache ExprState nodes, not bare Expr nodes.
Given the above comments, the following seems unnecessary:
+extern EState *create_estate_for_relation(Relation rel);
By the way, make check doesn't pass. I see the following failure:
- "public.testpub_rf_tbl3" WHERE ((e > 300) AND (e < 500))
+ "public.testpub_rf_tbl3"
but I guess applying subsequent patches takes care of that.
* 0006 and 0007: small enough that I think it might be better to merge
them into 0005.
* 0008: no comments as it's not intended to be committed. :)
Thanks,
Amit
[1] https://commitfest.postgresql.org/25/2301/
On Mon, Nov 25, 2019 at 11:38 AM Amit Langote <amitlangote09@gmail.com> wrote: > Needed to be rebased, which I did, to be able to test them; patches attached. Oops, really attached this time. Thanks, Amit
Вложения
- 0002-Store-number-of-tuples-in-WalRcvExecResult.patch
- 0003-Refactor-function-create_estate_for_relation.patch
- 0001-Remove-unused-atttypmod-column-from-initial-table-sy.patch
- 0004-Rename-a-WHERE-node.patch
- 0005-Row-filtering-for-logical-replication.patch
- 0008-Debug-for-row-filtering.patch
- 0006-Print-publication-WHERE-condition-in-psql.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
On Mon, Nov 25, 2019 at 11:48:29AM +0900, Amit Langote wrote: > On Mon, Nov 25, 2019 at 11:38 AM Amit Langote <amitlangote09@gmail.com> wrote: >> Needed to be rebased, which I did, to be able to test them; patches attached. > > Oops, really attached this time. Euler, this thread is waiting for input from you regarding the latest comments from Amit. -- Michael
Вложения
On Thu, Nov 28, 2019 at 11:32:01AM +0900, Michael Paquier wrote: >On Mon, Nov 25, 2019 at 11:48:29AM +0900, Amit Langote wrote: >> On Mon, Nov 25, 2019 at 11:38 AM Amit Langote <amitlangote09@gmail.com> wrote: >>> Needed to be rebased, which I did, to be able to test them; patches attached. >> >> Oops, really attached this time. > >Euler, this thread is waiting for input from you regarding the latest >comments from Amit. Euler, this patch is still in "waiting on author" since 11/25. Do you plan to review changes made by Amit in the patches he submitted, or what are your plans with this patch? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Em qui., 16 de jan. de 2020 às 18:57, Tomas Vondra <tomas.vondra@2ndquadrant.com> escreveu: > > Euler, this patch is still in "waiting on author" since 11/25. Do you > plan to review changes made by Amit in the patches he submitted, or what > are your plans with this patch? > Yes, I'm working on Amit suggestions. I'll post a new patch as soon as possible. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte 24x7 e Treinamento
On Fri, 17 Jan 2020 at 07:58, Euler Taveira <euler@timbira.com.br> wrote: > > Em qui., 16 de jan. de 2020 às 18:57, Tomas Vondra > <tomas.vondra@2ndquadrant.com> escreveu: > > > > Euler, this patch is still in "waiting on author" since 11/25. Do you > > plan to review changes made by Amit in the patches he submitted, or what > > are your plans with this patch? > > > Yes, I'm working on Amit suggestions. I'll post a new patch as soon as possible. Great. I think this'd be nice to see. Were you able to fully address the following points that came up in the discussion? * Make sure row filters cannot access non-catalog, non-user-catalog relations i.e. can only use RelationIsAccessibleInLogicalDecoding rels * Prevent filters from attempting to access attributes that may not be WAL-logged in a given change record, or give them a way to test for this. Unchanged TOASTed atts are not logged. There's also REPLICA IDENTITY FULL to consider if exposing access to the old tuple in the filter. Also, while I'm not sure if it was raised earlier, experience with row filtering in pglogical has shown that error handling is challenging. Because row filters are read from a historic snapshot of the catalogs you cannot change them or any SQL or plpgsql functions they use if a problem causes an ERROR when executing the filter expression. You can fix the current snapshot's definition but the decoding session won't see it and will continue to ERROR. We don't really have a good answer for that yet in pglogical; right now you have to either intervene with low level tools or drop the subscription and re-create it. Neither of which is ideal. You can't just read the row filter from the current snapshot as the relation definition (atts etc) may not match. Plus that creates a variety of issues with which txns get which version of a row filter applied during decoding, consistency between multiple subscribers, etc. One option I've thought about was a GUC that allows users to specify what should be done for errors in row filter expressions: drop the row as if the filter rejected it; pass the row as if the filter matched; propagate the ERROR and end the decoding session (default). I'd welcome ideas about this one. I don't think it's a showstopper for accepting the feature either, we just have to document that great care is required with any operator or function that could raise an error in a row filter. But there are just so many often non-obvious ways you can land up with an ERROR being thrown that I think it's a bit of a user foot-gun. -- Craig Ringer http://www.2ndQuadrant.com/ 2ndQuadrant - PostgreSQL Solutions for the Enterprise
Hi Euler, On 1/21/20 2:32 AM, Craig Ringer wrote: > On Fri, 17 Jan 2020 at 07:58, Euler Taveira <euler@timbira.com.br> wrote: >> >> Em qui., 16 de jan. de 2020 às 18:57, Tomas Vondra >> <tomas.vondra@2ndquadrant.com> escreveu: >>> >>> Euler, this patch is still in "waiting on author" since 11/25. Do you >>> plan to review changes made by Amit in the patches he submitted, or what >>> are your plans with this patch? >>> >> Yes, I'm working on Amit suggestions. I'll post a new patch as soon as possible. > > Great. I think this'd be nice to see. The last CF for PG13 has started. Do you have a new patch ready? Regards, -- -David david@pgmasters.net
On 3/3/20 12:39 PM, David Steele wrote: > Hi Euler, > > On 1/21/20 2:32 AM, Craig Ringer wrote: >> On Fri, 17 Jan 2020 at 07:58, Euler Taveira <euler@timbira.com.br> wrote: >>> >>> Em qui., 16 de jan. de 2020 às 18:57, Tomas Vondra >>> <tomas.vondra@2ndquadrant.com> escreveu: >>>> >>>> Euler, this patch is still in "waiting on author" since 11/25. Do you >>>> plan to review changes made by Amit in the patches he submitted, or >>>> what >>>> are your plans with this patch? >>>> >>> Yes, I'm working on Amit suggestions. I'll post a new patch as soon >>> as possible. >> >> Great. I think this'd be nice to see. > > The last CF for PG13 has started. Do you have a new patch ready? I have marked this patch Returned with Feedback since no new patch has been posted. Please submit to a future CF when a new patch is available. Regards, -- -David david@pgmasters.net
Hi all,
I'm also interested in this patch. I rebased the changes to the current master branch and attached. The rebase had two issues. First, patch-8 was conflicting, and that seems only helpful for debugging purposes during development. So, I dropped it for simplicity. Second, the changes have a conflict with `publish_via_partition_root` changes. I tried to fix the issues, but ended-up having a limitation for now. The limitation is that "cannot create publication with WHERE clause on the partitioned table without publish_via_partition_root is set to true". This restriction can be lifted, though I left out for the sake of focusing on the some issues that I observed on this patch.
Please see my review:
+ if (list_length(relentry->qual) > 0)
+ {
+ HeapTuple old_tuple;
+ HeapTuple new_tuple;
+ TupleDesc tupdesc;
+ EState *estate;
+ ExprContext *ecxt;
+ MemoryContext oldcxt;
+ ListCell *lc;
+ bool matched = true;
+
+ old_tuple = change->data.tp.oldtuple ? &change->data.tp.oldtuple->tuple : NULL;
+ new_tuple = change->data.tp.newtuple ? &change->data.tp.newtuple->tuple : NULL;
+ tupdesc = RelationGetDescr(relation);
+ estate = create_estate_for_relation(relation);
+
+ /* prepare context per tuple */
+ ecxt = GetPerTupleExprContext(estate);
+ oldcxt = MemoryContextSwitchTo(estate->es_query_cxt);
+ ecxt->ecxt_scantuple = ExecInitExtraTupleSlot(estate, tupdesc, &TTSOpsHeapTuple);
+
+ ExecStoreHeapTuple(new_tuple ? new_tuple : old_tuple, ecxt->ecxt_scantuple, false);
+
+ foreach(lc, relentry->qual)
+ {
+ Node *qual;
+ ExprState *expr_state;
+ Expr *expr;
+ Oid expr_type;
+ Datum res;
+ bool isnull;
+
+ qual = (Node *) lfirst(lc);
+
+ /* evaluates row filter */
+ expr_type = exprType(qual);
+ expr = (Expr *) coerce_to_target_type(NULL, qual, expr_type, BOOLOID, -1, COERCION_ASSIGNMENT, COERCE_IMPLICIT_CAST, -1);
+ expr = expression_planner(expr);
+ expr_state = ExecInitExpr(expr, NULL);
+ res = ExecEvalExpr(expr_state, ecxt, &isnull);
+
+ /* if tuple does not match row filter, bail out */
+ if (!DatumGetBool(res) || isnull)
+ {
+ matched = false;
+ break;
+ }
+ }
+
+ MemoryContextSwitchTo(oldcxt);
+
The above part can be considered the core of the logic, executed per tuple. As far as I can see, it has two downsides.
First, calling `expression_planner()` for every tuple can be quite expensive. I created a sample table, loaded data and ran a quick benchmark to see its effect. I attached the very simple script that I used to reproduce the issue on my laptop. I'm pretty sure you can find nicer ways of doing similar perf tests, just sharing as a reference.
The idea of the test is to add a WHERE clause to a table, but none of the tuples are filtered out. They just go through this code-path and send it to the remote node.
#rows Patched | Master
1M 00:00:25.067536 | 00:00:16.633988
10M 00:04:50.770791 | 00:02:40.945358
So, it seems a significant overhead to me. What do you think?
Secondly, probably more importantly, allowing any operator is as dangerous as allowing any function as users can create/overload operator(s). For example, assume that users create an operator which modifies the table that is being filtered out:
```
CREATE OR REPLACE FUNCTION function_that_modifies_table(left_art INTEGER, right_arg INTEGER)
RETURNS BOOL AS
$$
BEGIN
INSERT INTO test SELECT * FROM test;
return left_art > right_arg;
END;
$$ LANGUAGE PLPGSQL VOLATILE;
CREATE OPERATOR >>= (
PROCEDURE = function_that_modifies_table,
LEFTARG = INTEGER,
RIGHTARG = INTEGER
);
CREATE PUBLICATION pub FOR TABLE test WHERE (key >>= 0);
``
With the above, we seem to be in trouble. Although the above is an extreme example, it felt useful to share to the extent of the problem. We probably cannot allow any free-form SQL to be on the filters.
To overcome these issues, one approach could be to rely on known safe operators and functions. I believe the btree and hash operators should provide a pretty strong coverage across many use cases. As far as I can see, the procs that the following query returns can be our baseline:
```
select DISTINCT amproc.amproc::regproc AS opfamily_procedure
from pg_am am,
pg_opfamily opf,
pg_amproc amproc
where opf.opfmethod = am.oid
and amproc.amprocfamily = opf.oid
order by
opfamily_procedure;
```
With that, we aim to prevent users easily shooting themselves by the foot.
The other problematic area was the performance, as calling `expression_planner()` for every tuple can be very expensive. To avoid that, it might be considered to ask users to provide a function instead of a free form WHERE clause, such that if the function returns true, the tuple is sent. The allowed functions need to be immutable SQL functions with bool return type. As we can parse the SQL functions, we should be able to allow only functions that rely on the above mentioned procs. We can apply as many restrictions (such as no modification query) as possible. For example, see below:
```
CREATE OR REPLACE function filter_tuples_for_test(int) returns bool as
$body$
select $1 > 100;
$body$
language sql immutable;
CREATE PUBLICATION pub FOR TABLE test FILTER = filter_tuples_for_tes(key);
```
In terms of performance, calling the function should avoid calling the `expression_planner()` and yield better performance. Though, this needs to be verified.
If such an approach makes sense, I'd be happy to work on the patch. Please provide me feedback.
Thanks,
Onder KALACI
Software Engineer at Microsoft &
Developing the Citus database extension for PostgreSQL
David Steele <david@pgmasters.net>, 16 Ara 2020 Çar, 21:43 tarihinde şunu yazdı:
On 3/3/20 12:39 PM, David Steele wrote:
> Hi Euler,
>
> On 1/21/20 2:32 AM, Craig Ringer wrote:
>> On Fri, 17 Jan 2020 at 07:58, Euler Taveira <euler@timbira.com.br> wrote:
>>>
>>> Em qui., 16 de jan. de 2020 às 18:57, Tomas Vondra
>>> <tomas.vondra@2ndquadrant.com> escreveu:
>>>>
>>>> Euler, this patch is still in "waiting on author" since 11/25. Do you
>>>> plan to review changes made by Amit in the patches he submitted, or
>>>> what
>>>> are your plans with this patch?
>>>>
>>> Yes, I'm working on Amit suggestions. I'll post a new patch as soon
>>> as possible.
>>
>> Great. I think this'd be nice to see.
>
> The last CF for PG13 has started. Do you have a new patch ready?
I have marked this patch Returned with Feedback since no new patch has
been posted.
Please submit to a future CF when a new patch is available.
Regards,
--
-David
david@pgmasters.net
Вложения
- 0001-Subject-PATCH-1-8-Remove-unused-atttypmod-column-fro.patch
- 0003-Subject-PATCH-3-8-Refactor-function-create_estate_fo.patch
- 0004-Subject-PATCH-4-8-Rename-a-WHERE-node.patch
- 0002-Subject-PATCH-2-8-Store-number-of-tuples-in-WalRcvEx.patch
- 0005-Subject-PATCH-5-8-Row-filtering-for-logical-replicat.patch
- 0006-Subject-PATCH-6-8-Print-publication-WHERE-condition-.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- commands_to_perf_test.sql
Hi Önder,
On Thu, Dec 17, 2020 at 3:43 PM Önder Kalacı <onderkalaci@gmail.com> wrote:
>
> Hi all,
>
> I'm also interested in this patch. I rebased the changes to the current master branch and attached. The rebase had
twoissues. First, patch-8 was conflicting, and that seems only helpful for debugging purposes during development. So, I
droppedit for simplicity. Second, the changes have a conflict with `publish_via_partition_root` changes. I tried to fix
theissues, but ended-up having a limitation for now. The limitation is that "cannot create publication with WHERE
clauseon the partitioned table without publish_via_partition_root is set to true". This restriction can be lifted,
thoughI left out for the sake of focusing on the some issues that I observed on this patch.
>
> Please see my review:
>
> + if (list_length(relentry->qual) > 0)
> + {
> + HeapTuple old_tuple;
> + HeapTuple new_tuple;
> + TupleDesc tupdesc;
> + EState *estate;
> + ExprContext *ecxt;
> + MemoryContext oldcxt;
> + ListCell *lc;
> + bool matched = true;
> +
> + old_tuple = change->data.tp.oldtuple ? &change->data.tp.oldtuple->tuple : NULL;
> + new_tuple = change->data.tp.newtuple ? &change->data.tp.newtuple->tuple : NULL;
> + tupdesc = RelationGetDescr(relation);
> + estate = create_estate_for_relation(relation);
> +
> + /* prepare context per tuple */
> + ecxt = GetPerTupleExprContext(estate);
> + oldcxt = MemoryContextSwitchTo(estate->es_query_cxt);
> + ecxt->ecxt_scantuple = ExecInitExtraTupleSlot(estate, tupdesc, &TTSOpsHeapTuple);
> +
> + ExecStoreHeapTuple(new_tuple ? new_tuple : old_tuple, ecxt->ecxt_scantuple, false);
> +
> + foreach(lc, relentry->qual)
> + {
> + Node *qual;
> + ExprState *expr_state;
> + Expr *expr;
> + Oid expr_type;
> + Datum res;
> + bool isnull;
> +
> + qual = (Node *) lfirst(lc);
> +
> + /* evaluates row filter */
> + expr_type = exprType(qual);
> + expr = (Expr *) coerce_to_target_type(NULL, qual, expr_type, BOOLOID, -1,
COERCION_ASSIGNMENT,COERCE_IMPLICIT_CAST, -1);
> + expr = expression_planner(expr);
> + expr_state = ExecInitExpr(expr, NULL);
> + res = ExecEvalExpr(expr_state, ecxt, &isnull);
> +
> + /* if tuple does not match row filter, bail out */
> + if (!DatumGetBool(res) || isnull)
> + {
> + matched = false;
> + break;
> + }
> + }
> +
> + MemoryContextSwitchTo(oldcxt);
> +
>
>
> The above part can be considered the core of the logic, executed per tuple. As far as I can see, it has two
downsides.
>
> First, calling `expression_planner()` for every tuple can be quite expensive. I created a sample table, loaded data
andran a quick benchmark to see its effect. I attached the very simple script that I used to reproduce the issue on my
laptop.I'm pretty sure you can find nicer ways of doing similar perf tests, just sharing as a reference.
>
> The idea of the test is to add a WHERE clause to a table, but none of the tuples are filtered out. They just go
throughthis code-path and send it to the remote node.
>
> #rows Patched | Master
> 1M 00:00:25.067536 | 00:00:16.633988
> 10M 00:04:50.770791 | 00:02:40.945358
>
>
> So, it seems a significant overhead to me. What do you think?
>
> Secondly, probably more importantly, allowing any operator is as dangerous as allowing any function as users can
create/overloadoperator(s). For example, assume that users create an operator which modifies the table that is being
filteredout:
>
> ```
> CREATE OR REPLACE FUNCTION function_that_modifies_table(left_art INTEGER, right_arg INTEGER)
> RETURNS BOOL AS
> $$
> BEGIN
>
> INSERT INTO test SELECT * FROM test;
>
> return left_art > right_arg;
> END;
> $$ LANGUAGE PLPGSQL VOLATILE;
>
> CREATE OPERATOR >>= (
> PROCEDURE = function_that_modifies_table,
> LEFTARG = INTEGER,
> RIGHTARG = INTEGER
> );
>
> CREATE PUBLICATION pub FOR TABLE test WHERE (key >>= 0);
> ``
>
> With the above, we seem to be in trouble. Although the above is an extreme example, it felt useful to share to the
extentof the problem. We probably cannot allow any free-form SQL to be on the filters.
>
> To overcome these issues, one approach could be to rely on known safe operators and functions. I believe the btree
andhash operators should provide a pretty strong coverage across many use cases. As far as I can see, the procs that
thefollowing query returns can be our baseline:
>
> ```
> select DISTINCT amproc.amproc::regproc AS opfamily_procedure
> from pg_am am,
> pg_opfamily opf,
> pg_amproc amproc
> where opf.opfmethod = am.oid
> and amproc.amprocfamily = opf.oid
> order by
> opfamily_procedure;
> ```
>
> With that, we aim to prevent users easily shooting themselves by the foot.
>
> The other problematic area was the performance, as calling `expression_planner()` for every tuple can be very
expensive.To avoid that, it might be considered to ask users to provide a function instead of a free form WHERE clause,
suchthat if the function returns true, the tuple is sent. The allowed functions need to be immutable SQL functions with
boolreturn type. As we can parse the SQL functions, we should be able to allow only functions that rely on the above
mentionedprocs. We can apply as many restrictions (such as no modification query) as possible. For example, see below:
> ```
>
> CREATE OR REPLACE function filter_tuples_for_test(int) returns bool as
> $body$
> select $1 > 100;
> $body$
> language sql immutable;
>
> CREATE PUBLICATION pub FOR TABLE test FILTER = filter_tuples_for_tes(key);
> ```
>
> In terms of performance, calling the function should avoid calling the `expression_planner()` and yield better
performance.Though, this needs to be verified.
>
> If such an approach makes sense, I'd be happy to work on the patch. Please provide me feedback.
>
You sent in your patch to pgsql-hackers on Dec 17, but you did not
post it to the next CommitFest[1] (I found the old entry of this
patch[2] but it's marked as "Returned with feedback"). If this was
intentional, then you need to take no action. However, if you want
your patch to be reviewed as part of the upcoming CommitFest, then you
need to add it yourself before 2021-01-01 AoE[3]. Thanks for your
contributions.
Regards,
[1] https://commitfest.postgresql.org/31/
[2] https://commitfest.postgresql.org/20/1862/
[2] https://en.wikipedia.org/wiki/Anywhere_on_Earth
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
Hi Masahiko,
You sent in your patch to pgsql-hackers on Dec 17, but you did not
post it to the next CommitFest[1] (I found the old entry of this
patch[2] but it's marked as "Returned with feedback"). If this was
intentional, then you need to take no action. However, if you want
your patch to be reviewed as part of the upcoming CommitFest, then you
need to add it yourself before 2021-01-01 AoE[3]. Thanks for your
contributions.
Thanks for letting me know of this, I added this patch to the next commit fest before 2021-01-01 AoE[3].
I'm also attaching the updated commits so that the tests pass on the CI.
Thanks,
Onder KALACI
Software Engineer at Microsoft &
Developing the Citus database extension for PostgreSQL
Вложения
- 0001-Subject-PATCH-1-8-Remove-unused-atttypmod-column-fro.patch
- 0004-Subject-PATCH-4-8-Rename-a-WHERE-node.patch
- 0002-Subject-PATCH-2-8-Store-number-of-tuples-in-WalRcvEx.patch
- 0003-Subject-PATCH-3-8-Refactor-function-create_estate_fo.patch
- 0005-Subject-PATCH-5-8-Row-filtering-for-logical-replicat.patch
- 0006-Subject-PATCH-6-8-Print-publication-WHERE-condition-.patch
- 0007-Publication-where-condition-support-for-pg_dump.patch
- commands_to_perf_test.sql
Hi, On 2020-12-17 09:43:30 +0300, Önder Kalacı wrote: > The above part can be considered the core of the logic, executed per tuple. > As far as I can see, it has two downsides. > > First, calling `expression_planner()` for every tuple can be quite > expensive. I created a sample table, loaded data and ran a quick benchmark > to see its effect. I attached the very simple script that I used to > reproduce the issue on my laptop. I'm pretty sure you can find nicer ways > of doing similar perf tests, just sharing as a reference. > > The idea of the test is to add a WHERE clause to a table, but none of the > tuples are filtered out. They just go through this code-path and send it to > the remote node. > > #rows Patched | Master > 1M 00:00:25.067536 | 00:00:16.633988 > 10M 00:04:50.770791 | 00:02:40.945358 > > > So, it seems a significant overhead to me. What do you think? That seems almost prohibitively expensive. I think at the very least some of this work would need to be done in a cached manner, e.g. via get_rel_sync_entry(). > Secondly, probably more importantly, allowing any operator is as dangerous > as allowing any function as users can create/overload operator(s). That's not safe, indeed. It's not even just create/overloading operators, as far as I can tell the expression can contain just plain function calls. The issue also isn't primarily that the user can overload functions, it's that logical decoding is a limited environment, and not everything is safe to do within. You e.g. only catalog tables can be accessed. Therefore I don't think we can allow arbitrary expressions. > The other problematic area was the performance, as calling > `expression_planner()` for every tuple can be very expensive. To avoid > that, it might be considered to ask users to provide a function instead of > a free form WHERE clause, such that if the function returns true, the tuple > is sent. The allowed functions need to be immutable SQL functions with bool > return type. As we can parse the SQL functions, we should be able to allow > only functions that rely on the above mentioned procs. We can apply as many > restrictions (such as no modification query) as possible. For example, see > below: > ``` I don't think that would get us very far. From a safety aspect: A function's body can be changed by the user at any time, therefore we cannot rely on analyses of the function's body. From a performance POV: SQL functions are planned at every invocation, so that'd not buy us much either. I think what you would have to do instead is to ensure that the expression is "simple enough", and then process it into a cheaply executable format in get_rel_sync_entry(). I'd suggest that in the first version you just allow a simple ANDed list of 'foo.bar op constant' expressions. Does that make sense? Greetings, Andres Freund
On Mon, Mar 16, 2020, at 10:58 AM, David Steele wrote:
Please submit to a future CF when a new patch is available.
Hi,
This is another version of the row filter patch. Patch summary:
0001: refactor to remove dead code
0002: grammar refactor for row filter
0003: core code, documentation, and tests
0004: psql code
0005: pg_dump support
0006: debug messages (only for test purposes)
0007: measure row filter overhead (only for test purposes)
From the previous version I incorporated Amit's suggestions [1], improve documentation and tests. I refactored to code to make it simple to read (break the row filter code into functions). This new version covers the new parameter publish_via_partition_root that was introduced (cf 83fd4532a7).
Regarding function prohibition, I wouldn't like to open a can of worms (see previous discussions in this thread). Simple expressions covers most of the use cases that I worked with until now. This prohibition can be removed in another patch after some careful analysis.
I did some limited tests and didn't observe some excessive CPU usage while testing this patch tough I agree with Andres that retain some expression context into a cache would certainly speed up this piece of code. I measured the row filter overhead in my i7 (see 0007) and got:
mean: 92.49 us
stddev: 32.63 us
median: 83.45 us
min-max: [11.13 .. 2731.55] us
percentile(95): 117.76 us
Вложения
- 0001-Remove-unused-column-from-initial-table-synchronizat.patch
- 0002-Rename-a-WHERE-node.patch
- 0003-Row-filter-for-logical-replication.patch
- 0004-Print-publication-WHERE-condition-in-psql.patch
- 0005-Publication-WHERE-condition-support-for-pg_dump.patch
- 0006-Debug-messages.patch
- 0007-Measure-row-filter-overhead.patch
On Mon, 01 Feb 2021 at 08:23, Euler Taveira <euler@eulerto.com> wrote:
> On Mon, Mar 16, 2020, at 10:58 AM, David Steele wrote:
>> Please submit to a future CF when a new patch is available.
> Hi,
>
> This is another version of the row filter patch. Patch summary:
>
> 0001: refactor to remove dead code
> 0002: grammar refactor for row filter
> 0003: core code, documentation, and tests
> 0004: psql code
> 0005: pg_dump support
> 0006: debug messages (only for test purposes)
> 0007: measure row filter overhead (only for test purposes)
>
Thanks for updating the patch. Here are some comments:
(1)
+ <para>
+ If this parameter is <literal>false</literal>, it uses the
+ <literal>WHERE</literal> clause from the partition; otherwise,the
+ <literal>WHERE</literal> clause from the partitioned table is used.
</para>
otherwise,the -> otherwise, the
(2)
+ <para>
+ Columns used in the <literal>WHERE</literal> clause must be part of the
+ primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise
+ <command>UPDATE</command> and <command>DELETE</command> operations will not
+ be replicated.
+ </para>
+
IMO we should indent one space here.
(3)
+
+ <para>
+ The <literal>WHERE</literal> clause expression is executed with the role used
+ for the replication connection.
+ </para>
Same as (2).
The documentation says:
> Columns used in the <literal>WHERE</literal> clause must be part of the
> primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise
> <command>UPDATE</command> and <command>DELETE</command> operations will not
> be replicated.
Why we need this limitation? Am I missing something?
When I tested, I find that the UPDATE can be replicated, while the DELETE
cannot be replicated. Here is my test-case:
-- 1. Create tables and publications on publisher
CREATE TABLE t1 (a int primary key, b int);
CREATE TABLE t2 (a int primary key, b int);
INSERT INTO t1 VALUES (1, 11);
INSERT INTO t2 VALUES (1, 11);
CREATE PUBLICATION mypub1 FOR TABLE t1;
CREATE PUBLICATION mypub2 FOR TABLE t2 WHERE (b > 10);
-- 2. Create tables and subscriptions on subscriber
CREATE TABLE t1 (a int primary key, b int);
CREATE TABLE t2 (a int primary key, b int);
CREATE SUBSCRIPTION mysub1 CONNECTION 'host=localhost port=8765 dbname=postgres' PUBLICATION mypub1;
CREATE SUBSCRIPTION mysub2 CONNECTION 'host=localhost port=8765 dbname=postgres' PUBLICATION mypub2;
-- 3. Check publications on publisher
postgres=# \dRp+
Publication mypub1
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
-------+------------+---------+---------+---------+-----------+----------
japin | f | t | t | t | t | f
Tables:
"public.t1"
Publication mypub2
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
-------+------------+---------+---------+---------+-----------+----------
japin | f | t | t | t | t | f
Tables:
"public.t2" WHERE (b > 10)
-- 4. Check initialization data on subscriber
postgres=# table t1;
a | b
---+----
1 | 11
(1 row)
postgres=# table t2;
a | b
---+----
1 | 11
(1 row)
-- 5. The update on publisher
postgres=# update t1 set b = 111 where b = 11;
UPDATE 1
postgres=# table t1;
a | b
---+-----
1 | 111
(1 row)
postgres=# update t2 set b = 111 where b = 11;
UPDATE 1
postgres=# table t2;
a | b
---+-----
1 | 111
(1 row)
-- 6. check the updated records on subscriber
postgres=# table t1;
a | b
---+-----
1 | 111
(1 row)
postgres=# table t2;
a | b
---+-----
1 | 111
(1 row)
-- 7. Delete records on publisher
postgres=# delete from t1 where b = 111;
DELETE 1
postgres=# table t1;
a | b
---+---
(0 rows)
postgres=# delete from t2 where b = 111;
DELETE 1
postgres=# table t2;
a | b
---+---
(0 rows)
-- 8. Check the deleted records on subscriber
postgres=# table t1;
a | b
---+---
(0 rows)
postgres=# table t2;
a | b
---+-----
1 | 111
(1 row)
I do a simple debug, and find that the pgoutput_row_filter() return false when I
execute "delete from t2 where b = 111;".
Does the publication only load the REPLICA IDENTITY columns into oldtuple when we
execute DELETE? So the pgoutput_row_filter() cannot find non REPLICA IDENTITY
columns, which cause it return false, right? If that's right, the UPDATE might
not be limitation by REPLICA IDENTITY, because all columns are in newtuple,
isn't it?
--
Regrads,
Japin Li.
ChengDu WenWu Information Technology Co.,Ltd.
On Mon, Feb 1, 2021, at 6:11 AM, japin wrote:
Thanks for updating the patch. Here are some comments:
Thanks for your review. I updated the documentation accordingly.
The documentation says:> Columns used in the <literal>WHERE</literal> clause must be part of the> primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise> <command>UPDATE</command> and <command>DELETE</command> operations will not> be replicated.
The UPDATE is an oversight from a previous version.
Does the publication only load the REPLICA IDENTITY columns into oldtuple when weexecute DELETE? So the pgoutput_row_filter() cannot find non REPLICA IDENTITYcolumns, which cause it return false, right? If that's right, the UPDATE mightnot be limitation by REPLICA IDENTITY, because all columns are in newtuple,isn't it?
No. oldtuple could possibly be available for UPDATE and DELETE. However, row
filter consider only one tuple for filtering. INSERT has only newtuple; row
filter uses it. UPDATE has newtuple and optionally oldtuple (if it has PK or
REPLICA IDENTITY); row filter uses newtuple. DELETE optionally has only
oldtuple; row filter uses it (if available). Keep in mind, if the expression
evaluates to NULL, it returns false and the row won't be replicated.
After the commit 3696a600e2, the last patch does not apply cleanly. I'm
attaching another version to address the documentation issues.
Вложения
- v10-0001-Remove-unused-column-from-initial-table-synchronizat.patch
- v10-0002-Rename-a-WHERE-node.patch
- v10-0003-Row-filter-for-logical-replication.patch
- v10-0004-Print-publication-WHERE-condition-in-psql.patch
- v10-0005-Publication-WHERE-condition-support-for-pg_dump.patch
- v10-0006-Debug-messages.patch
- v10-0007-Measure-row-filter-overhead.patch
On Mon, Feb 01, 2021 at 04:11:50PM -0300, Euler Taveira wrote: > After the commit 3696a600e2, the last patch does not apply cleanly. I'm > attaching another version to address the documentation issues. I have bumped into this thread, and applied 0001. My guess is that one of the patches developped originally for logical replication defined atttypmod in LogicalRepRelation, but has finished by not using it. Nice catch. -- Michael
Вложения
On Tue, 02 Feb 2021 at 03:11, Euler Taveira <euler@eulerto.com> wrote: > On Mon, Feb 1, 2021, at 6:11 AM, japin wrote: >> Thanks for updating the patch. Here are some comments: > Thanks for your review. I updated the documentation accordingly. > >> The documentation says: >> >> > Columns used in the <literal>WHERE</literal> clause must be part of the >> > primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise >> > <command>UPDATE</command> and <command>DELETE</command> operations will not >> > be replicated. > The UPDATE is an oversight from a previous version. > >> >> Does the publication only load the REPLICA IDENTITY columns into oldtuple when we >> execute DELETE? So the pgoutput_row_filter() cannot find non REPLICA IDENTITY >> columns, which cause it return false, right? If that's right, the UPDATE might >> not be limitation by REPLICA IDENTITY, because all columns are in newtuple, >> isn't it? > No. oldtuple could possibly be available for UPDATE and DELETE. However, row > filter consider only one tuple for filtering. INSERT has only newtuple; row > filter uses it. UPDATE has newtuple and optionally oldtuple (if it has PK or > REPLICA IDENTITY); row filter uses newtuple. DELETE optionally has only > oldtuple; row filter uses it (if available). Keep in mind, if the expression > evaluates to NULL, it returns false and the row won't be replicated. > Thanks for your clarification. -- Regrads, Japin Li. ChengDu WenWu Information Technology Co.,Ltd.
On Tue, 02 Feb 2021 at 13:02, Michael Paquier <michael@paquier.xyz> wrote: > On Mon, Feb 01, 2021 at 04:11:50PM -0300, Euler Taveira wrote: >> After the commit 3696a600e2, the last patch does not apply cleanly. I'm >> attaching another version to address the documentation issues. > > I have bumped into this thread, and applied 0001. My guess is that > one of the patches developped originally for logical replication > defined atttypmod in LogicalRepRelation, but has finished by not using > it. Nice catch. Since the 0001 patch already be commited (4ad31bb2ef), we can remove it. -- Regrads, Japin Li. ChengDu WenWu Information Technology Co.,Ltd.
On Tue, 02 Feb 2021 at 19:16, japin <japinli@hotmail.com> wrote: > On Tue, 02 Feb 2021 at 13:02, Michael Paquier <michael@paquier.xyz> wrote: >> On Mon, Feb 01, 2021 at 04:11:50PM -0300, Euler Taveira wrote: >>> After the commit 3696a600e2, the last patch does not apply cleanly. I'm >>> attaching another version to address the documentation issues. >> >> I have bumped into this thread, and applied 0001. My guess is that >> one of the patches developped originally for logical replication >> defined atttypmod in LogicalRepRelation, but has finished by not using >> it. Nice catch. > > Since the 0001 patch already be commited (4ad31bb2ef), we can remove it. In 0003 patch, function GetPublicationRelationQuals() has been defined, but it never used. So why should we define it? $ grep 'GetPublicationRelationQuals' -rn src/ src/include/catalog/pg_publication.h:116:extern List *GetPublicationRelationQuals(Oid pubid); src/backend/catalog/pg_publication.c:347:GetPublicationRelationQuals(Oid pubid) If we must keep it, here are some comments on it. (1) value_datum = heap_getattr(tup, Anum_pg_publication_rel_prqual, RelationGetDescr(pubrelsrel), &isnull); It looks too long, we can split it into two lines. (2) Since qual_value only used in "if (!isnull)" branch, so we can narrow it's scope. (3) Should we free the memory for qual_value? -- Regrads, Japin Li. ChengDu WenWu Information Technology Co.,Ltd.
On Tue, Feb 2, 2021, at 8:38 AM, japin wrote:
In 0003 patch, function GetPublicationRelationQuals() has been defined, but itnever used. So why should we define it?
Thanks for taking a look again. It is an oversight. It was introduced in an
attempt to refactor ALTER PUBLICATION SET TABLE. In AlterPublicationTables, we
could possibly keep some publication-table mappings that does not change,
however, since commit 3696a600e2, it is required to find the qual for all
inheritors (see GetPublicationRelations). I explain this decision in the
following comment:
/*
* Remove all publication-table mappings. We could possibly
* remove (i) tables that are not found in the new table list and
* (ii) tables that are being re-added with a different qual
* expression. For (ii), simply updating the existing tuple is not
* enough, because of qual expression dependencies.
*/
I will post a new patch set later.
Hi Euler,
+ Oid relid;
+ Relation relation;
Please find below some review comments,
1.
+
+ <row>
+ <entry><structfield>prqual</structfield></entry>
+ <entry><type>pg_node_tree</type></entry>
+ <entry></entry>
+ <entry>Expression tree (in <function>nodeToString()</function>
+ representation) for the relation's qualifying condition</entry>
+ </row>
+
+ <row>
+ <entry><structfield>prqual</structfield></entry>
+ <entry><type>pg_node_tree</type></entry>
+ <entry></entry>
+ <entry>Expression tree (in <function>nodeToString()</function>
+ representation) for the relation's qualifying condition</entry>
+ </row>
I think the docs are being incorrectly updated to add a column to pg_partitioned_table
instead of pg_publication_rel.
2. +typedef struct PublicationRelationQual
+{+ Oid relid;
+ Relation relation;
+ Node *whereClause;
+} PublicationRelationQual;
Can this be given a more generic name like PublicationRelationInfo, so that the same struct
can be used to store additional relation information in future, for ex. column names, if column filtering is introduced.
3. Also, in the above structure, it seems that we can do with storing just relid and derive relation information from it
+} PublicationRelationQual;
Can this be given a more generic name like PublicationRelationInfo, so that the same struct
can be used to store additional relation information in future, for ex. column names, if column filtering is introduced.
3. Also, in the above structure, it seems that we can do with storing just relid and derive relation information from it
using table_open when needed. Am I missing something?
4. Currently in logical replication, I noticed that an UPDATE is being applied on the subscriber even if the column values
4. Currently in logical replication, I noticed that an UPDATE is being applied on the subscriber even if the column values
are unchanged. Can row-filtering feature be used to change it such that, when all the OLD.columns = NEW.columns, filter out
the row from being sent to the subscriber. I understand this would need REPLICA IDENTITY FULL to work, but would be an
improvement from the existing state.
the row from being sent to the subscriber. I understand this would need REPLICA IDENTITY FULL to work, but would be an
improvement from the existing state.
On subscriber:
postgres=# select xmin, * from tab_rowfilter_1;
xmin | a | b
------+---+-------------
555 | 1 | unfiltered
(1 row)
On publisher:
postgres=# ALTER TABLE tab_rowfilter_1 REPLICA IDENTITY FULL;
ALTER TABLE
postgres=# update tab_rowfilter_1 SET b = 'unfiltered' where a = 1;
UPDATE 1
On Subscriber: The xmin has changed indicating the update from the publisher was applied
even though nothing changed.
postgres=# select xmin, * from tab_rowfilter_1;
xmin | a | b
------+---+-------------
556 | 1 | unfiltered
(1 row)
5. Currently, any existing rows that were not replicated, when updated to match the publication quals
using UPDATE tab SET pub_qual_column = 'not_filtered' where a = 1; won't be applied, as row
does not exist on the subscriber. It would be good if ALTER SUBSCRIBER REFRESH PUBLICATION
would help fetch such existing rows from publishers that match the qual now(either because the row changed
or the qual changed)
Thank you,
postgres=# select xmin, * from tab_rowfilter_1;
xmin | a | b
------+---+-------------
555 | 1 | unfiltered
(1 row)
On publisher:
postgres=# ALTER TABLE tab_rowfilter_1 REPLICA IDENTITY FULL;
ALTER TABLE
postgres=# update tab_rowfilter_1 SET b = 'unfiltered' where a = 1;
UPDATE 1
On Subscriber: The xmin has changed indicating the update from the publisher was applied
even though nothing changed.
postgres=# select xmin, * from tab_rowfilter_1;
xmin | a | b
------+---+-------------
556 | 1 | unfiltered
(1 row)
5. Currently, any existing rows that were not replicated, when updated to match the publication quals
using UPDATE tab SET pub_qual_column = 'not_filtered' where a = 1; won't be applied, as row
does not exist on the subscriber. It would be good if ALTER SUBSCRIBER REFRESH PUBLICATION
would help fetch such existing rows from publishers that match the qual now(either because the row changed
or the qual changed)
Thank you,
Rahila Syed
On Tue, Mar 9, 2021 at 8:35 PM Rahila Syed <rahilasyed90@gmail.com> wrote:
Hi Euler,Please find some comments below:
1. If the where clause contains non-replica identity columns, the delete performed on a replicated row
using DELETE from pub_tab where repl_ident_col = n;
is not being replicated, as logical replication does not have any info whether the column has
to be filtered or not.
Shouldn't a warning be thrown in this case to notify the user that the delete is not replicated.2. Same for update, even if I update a row to match the quals on publisher, it is still not being replicated tothe subscriber. (if the quals contain non-replica identity columns). I think for UPDATE at least, the new value
of the non-replicate identity column is available which can be used to filter and replicate the update.3. 0001.patch,+ memset(lrel, 0, sizeof(LogicalRepRelation));
Why is the name of the existing ExclusionWhereClause node being changed, if the exact same definition is being used?
For 0002.patch,
4. +
Is this needed, apart from the above, patch does not use or update lrel at all in that function.
5. PublicationRelationQual and PublicationTable have similar fields, can PublicationTable
be used in place of PublicationRelationQual instead of defining a new struct?
Thank you,
Rahila Syed
On Tue, Mar 9, 2021, at 12:05 PM, Rahila Syed wrote:
Please find some comments below:
Thanks for your review.
1. If the where clause contains non-replica identity columns, the delete performed on a replicated rowusing DELETE from pub_tab where repl_ident_col = n;is not being replicated, as logical replication does not have any info whether the column hasto be filtered or not.Shouldn't a warning be thrown in this case to notify the user that the delete is not replicated.
Isn't documentation enough? If you add a WARNING, it should be printed per row,
hence, a huge DELETE will flood the client with WARNING messages by default. If
you are thinking about LOG messages, it is a different story. However, we
should limit those messages to one per transaction. Even if we add such an aid,
it would impose a performance penalty while checking the DELETE is not
replicating because the row filter contains a column that is not part of the PK
or REPLICA IDENTITY. If I were to add any message, it would be to warn at the
creation time (CREATE PUBLICATION or ALTER PUBLICATION ... [ADD|SET] TABLE).
2. Same for update, even if I update a row to match the quals on publisher, it is still not being replicated tothe subscriber. (if the quals contain non-replica identity columns). I think for UPDATE at least, the new valueof the non-replicate identity column is available which can be used to filter and replicate the update.
Indeed, the row filter for UPDATE uses the new tuple. Maybe your non-replica
identity column contains NULL that evaluates the expression to false.
3. 0001.patch,Why is the name of the existing ExclusionWhereClause node being changed, if the exact same definition is being used?
Because this node ExclusionWhereClause is used for exclusion constraint. This
patch renames the node to made it clear it is a generic node that could be used
for other filtering features in the future.
For 0002.patch,4. ++ memset(lrel, 0, sizeof(LogicalRepRelation));Is this needed, apart from the above, patch does not use or update lrel at all in that function.
Good catch. It is a leftover from a previous patch. It will be fixed in the
next patch set.
5. PublicationRelationQual and PublicationTable have similar fields, can PublicationTablebe used in place of PublicationRelationQual instead of defining a new struct?
I don't think it is a good idea to have additional fields in a parse node. The
DDL commands use Relation (PublicationTableQual) and parse code uses RangeVar
(PublicationTable). publicationcmds.c uses Relation everywhere so I decided to
create a new struct to store Relation and qual as a list item. It also minimizes the places
you have to modify.
On Thu, Mar 18, 2021, at 7:51 AM, Rahila Syed wrote:
1.I think the docs are being incorrectly updated to add a column to pg_partitioned_tableinstead of pg_publication_rel.
Good catch.
2. +typedef struct PublicationRelationQual+{+ Oid relid;+ Relation relation;+ Node *whereClause;+} PublicationRelationQual;Can this be given a more generic name like PublicationRelationInfo, so that the same structcan be used to store additional relation information in future, for ex. column names, if column filtering is introduced.
Good idea. I rename it and it'll be in this next patch set.
3. Also, in the above structure, it seems that we can do with storing just relid and derive relation information from itusing table_open when needed. Am I missing something?
We need the Relation. See OpenTableList(). The way this code is organized, it
opens all publication tables and append each Relation to a list. This list is
used in PublicationAddTables() to update the catalog. I tried to minimize the
number of refactors while introducing this feature. We could probably revise
this code in the future (someone said in a previous discussion that it is weird
to open relations in one source code file -- publicationcmds.c -- and use it
into another one -- pg_publication.c).
4. Currently in logical replication, I noticed that an UPDATE is being applied on the subscriber even if the column valuesare unchanged. Can row-filtering feature be used to change it such that, when all the OLD.columns = NEW.columns, filter outthe row from being sent to the subscriber. I understand this would need REPLICA IDENTITY FULL to work, but would be animprovement from the existing state.
This is how Postgres works.
postgres=# create table foo (a integer, b integer);
CREATE TABLE
postgres=# insert into foo values(1, 100);
INSERT 0 1
postgres=# select ctid, xmin, xmax, a, b from foo;
ctid | xmin | xmax | a | b
-------+--------+------+---+-----
(0,1) | 488920 | 0 | 1 | 100
(1 row)
postgres=# update foo set b = 101 where a = 1;
UPDATE 1
postgres=# select ctid, xmin, xmax, a, b from foo;
ctid | xmin | xmax | a | b
-------+--------+------+---+-----
(0,2) | 488921 | 0 | 1 | 101
(1 row)
postgres=# update foo set b = 101 where a = 1;
UPDATE 1
postgres=# select ctid, xmin, xmax, a, b from foo;
ctid | xmin | xmax | a | b
-------+--------+------+---+-----
(0,3) | 488922 | 0 | 1 | 101
(1 row)
You could probably abuse this feature and skip some UPDATEs when old tuple is
identical to new tuple. The question is: why would someone issue the same
command multiple times? A broken application? I would say: don't do it. Besides
that, this feature could impose an overhead into a code path that already
consume substantial CPU time. I've seen some tables with RIF and dozens of
columns that would certainly contribute to increase the replication lag.
5. Currently, any existing rows that were not replicated, when updated to match the publication qualsusing UPDATE tab SET pub_qual_column = 'not_filtered' where a = 1; won't be applied, as rowdoes not exist on the subscriber. It would be good if ALTER SUBSCRIBER REFRESH PUBLICATIONwould help fetch such existing rows from publishers that match the qual now(either because the row changedor the qual changed)
I see. This should be addressed by a resynchronize feature. Such option is
useful when you have to change the row filter. It should certainly be implement
as an ALTER SUBSCRIPTION subcommand.
I attached a new patch set that addresses:
* fix documentation;
* rename PublicationRelationQual to PublicationRelationInfo;
* remove the memset that was leftover from a previous patch set;
* add new tests to improve coverage (INSERT/UPDATE/DELETE to exercise the row
filter code).
Вложения
On 22.03.21 03:15, Euler Taveira wrote: > I attached a new patch set that addresses: > > * fix documentation; > * rename PublicationRelationQual to PublicationRelationInfo; > * remove the memset that was leftover from a previous patch set; > * add new tests to improve coverage (INSERT/UPDATE/DELETE to exercise > the row > filter code). I have committed the 0001 patch. Attached are a few fixup patches that I recommend you integrate into your patch set. They address backward compatibility with PG13, and a few more stylistic issues. I suggest you combine your 0002, 0003, and 0004 patches into one. They can't be used separately, and for example the psql changes in patch 0003 already appear as regression test output changes in 0002, so this arrangement isn't useful. (0005 can be kept separately, since it's mostly for debugging right now.)
Вложения
- 0001-fixup-Row-filter-for-logical-replication.patch
- 0002-fixup-Row-filter-for-logical-replication.patch
- 0003-fixup-Row-filter-for-logical-replication.patch
- 0004-fixup-Row-filter-for-logical-replication.patch
- 0005-fixup-Publication-WHERE-condition-support-for-pg_dum.patch
- 0006-fixup-Print-publication-WHERE-condition-in-psql.patch
On Thu, Mar 25, 2021, at 8:15 AM, Peter Eisentraut wrote:
I have committed the 0001 patch.Attached are a few fixup patches that I recommend you integrate intoyour patch set. They address backward compatibility with PG13, and afew more stylistic issues.I suggest you combine your 0002, 0003, and 0004 patches into one. Theycan't be used separately, and for example the psql changes in patch 0003already appear as regression test output changes in 0002, so thisarrangement isn't useful. (0005 can be kept separately, since it'smostly for debugging right now.)
I appreciate your work on it. I split into psql and pg_dump support just
because it was developed after the main patch. I expect them to be combined
into the main patch (0002) before committing it. This new patch set integrates
them into the main patch.
I totally forgot about the backward compatibility support. Good catch. While
inspecting the code again, I did a small fix into the psql support. I added an
else as shown below so the query always returns the same number of columns and
we don't possibly have an issue while using a column number that is out of
range in PQgetisnull() a few lines later.
if (pset.sversion >= 140000)
appendPQExpBuffer(&buf,
", pg_get_expr(pr.prqual, c.oid)");
else
appendPQExpBuffer(&buf,
", NULL");
While testing the replication between v14 -> v10, I realized that even if the
tables in the publication have row filters, the data synchronization code won't
evaluate the row filter expressions. That's because the subscriber (v10) is
responsible to assemble the COPY command (possibly adding row filters) for data
synchronization and there is no such code in released versions. I added a new
sentence into copy_data parameter saying that row filters won't be used if
version is prior than 14. I also include this info into the commit message.
At this time, I didn't include the patch that changes the log_min_messages in
the row filter regression test. It was part of this patch set for testing
purposes only.
I don't expect the patch that measures row filter performance to be included
but I'm including it again in case someone wants to inspect the performance
numbers.
Вложения
Hi Euler,
While running some tests on v13 patches, I noticed that, in case the published table data
already exists on the subscriber database before creating the subscription, at the time of
While running some tests on v13 patches, I noticed that, in case the published table data
already exists on the subscriber database before creating the subscription, at the time of
CREATE subscription/table synchronization, an error as seen as follows
With the patch:
2021-03-29 14:32:56.265 IST [78467] STATEMENT: CREATE_REPLICATION_SLOT "pg_16406_sync_16390_6944995860755251708" LOGICAL pgoutput USE_SNAPSHOT
2021-03-29 14:32:56.279 IST [78467] LOG: could not send data to client: Broken pipe
2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT
2021-03-29 14:32:56.279 IST [78467] FATAL: connection to client lost
2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT
2021-03-29 14:33:01.302 IST [78470] LOG: logical decoding found consistent point at 0/4E2B8460
2021-03-29 14:33:01.302 IST [78470] DETAIL: There are no running transactions.
Without the patch:
2021-03-29 15:05:01.581 IST [79029] ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
2021-03-29 15:05:01.581 IST [79029] DETAIL: Key (bid)=(1) already exists.
2021-03-29 15:05:01.581 IST [79029] CONTEXT: COPY pgbench_branches, line 1
2021-03-29 15:05:01.583 IST [78538] LOG: background worker "logical replication worker" (PID 79029) exited with exit code 1
2021-03-29 15:05:06.593 IST [79031] LOG: logical replication table synchronization worker for subscription "test_sub2", table "pgbench_branches" has started
Without the patch the COPY command throws an ERROR, but with the patch, a similar scenario results in client connection being lost.
I didn't investigate it more, but looks like we should maintain the existing behaviour when table synchronization fails
due to duplicate data.
Thank you,
Rahila Syed
With the patch:
2021-03-29 14:32:56.265 IST [78467] STATEMENT: CREATE_REPLICATION_SLOT "pg_16406_sync_16390_6944995860755251708" LOGICAL pgoutput USE_SNAPSHOT
2021-03-29 14:32:56.279 IST [78467] LOG: could not send data to client: Broken pipe
2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT
2021-03-29 14:32:56.279 IST [78467] FATAL: connection to client lost
2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT
2021-03-29 14:33:01.302 IST [78470] LOG: logical decoding found consistent point at 0/4E2B8460
2021-03-29 14:33:01.302 IST [78470] DETAIL: There are no running transactions.
Without the patch:
2021-03-29 15:05:01.581 IST [79029] ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
2021-03-29 15:05:01.581 IST [79029] DETAIL: Key (bid)=(1) already exists.
2021-03-29 15:05:01.581 IST [79029] CONTEXT: COPY pgbench_branches, line 1
2021-03-29 15:05:01.583 IST [78538] LOG: background worker "logical replication worker" (PID 79029) exited with exit code 1
2021-03-29 15:05:06.593 IST [79031] LOG: logical replication table synchronization worker for subscription "test_sub2", table "pgbench_branches" has started
Without the patch the COPY command throws an ERROR, but with the patch, a similar scenario results in client connection being lost.
I didn't investigate it more, but looks like we should maintain the existing behaviour when table synchronization fails
due to duplicate data.
Thank you,
Rahila Syed
On Mon, Mar 29, 2021, at 6:45 AM, Rahila Syed wrote:
While running some tests on v13 patches, I noticed that, in case the published table dataalready exists on the subscriber database before creating the subscription, at the time ofCREATE subscription/table synchronization, an error as seen as followsWith the patch:2021-03-29 14:32:56.265 IST [78467] STATEMENT: CREATE_REPLICATION_SLOT "pg_16406_sync_16390_6944995860755251708" LOGICAL pgoutput USE_SNAPSHOT2021-03-29 14:32:56.279 IST [78467] LOG: could not send data to client: Broken pipe2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT2021-03-29 14:32:56.279 IST [78467] FATAL: connection to client lost2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT2021-03-29 14:33:01.302 IST [78470] LOG: logical decoding found consistent point at 0/4E2B84602021-03-29 14:33:01.302 IST [78470] DETAIL: There are no running transactions.
Rahila, I tried to reproduce this issue with the attached script but no luck. I always get
Without the patch:2021-03-29 15:05:01.581 IST [79029] ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"2021-03-29 15:05:01.581 IST [79029] DETAIL: Key (bid)=(1) already exists.2021-03-29 15:05:01.581 IST [79029] CONTEXT: COPY pgbench_branches, line 12021-03-29 15:05:01.583 IST [78538] LOG: background worker "logical replication worker" (PID 79029) exited with exit code 12021-03-29 15:05:06.593 IST [79031] LOG: logical replication table synchronization worker for subscription "test_sub2", table "pgbench_branches" has started
... this message. The code that reports this error is from the COPY command.
Row filter modifications has no control over it. It seems somehow your
subscriber close the replication connection causing this issue. Can you
reproduce it consistently? If so, please share your steps.
Вложения
Hi,
While running some tests on v13 patches, I noticed that, in case the published table dataalready exists on the subscriber database before creating the subscription, at the time ofCREATE subscription/table synchronization, an error as seen as followsWith the patch:2021-03-29 14:32:56.265 IST [78467] STATEMENT: CREATE_REPLICATION_SLOT "pg_16406_sync_16390_6944995860755251708" LOGICAL pgoutput USE_SNAPSHOT2021-03-29 14:32:56.279 IST [78467] LOG: could not send data to client: Broken pipe2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT2021-03-29 14:32:56.279 IST [78467] FATAL: connection to client lost2021-03-29 14:32:56.279 IST [78467] STATEMENT: COPY (SELECT aid, bid, abalance, filler FROM public.pgbench_accounts WHERE (aid > 0)) TO STDOUT2021-03-29 14:33:01.302 IST [78470] LOG: logical decoding found consistent point at 0/4E2B84602021-03-29 14:33:01.302 IST [78470] DETAIL: There are no running transactions.Rahila, I tried to reproduce this issue with the attached script but no luck. I always get
OK, Sorry for confusion. Actually both the errors are happening on different servers. *Broken pipe* error on publisher and
the following error on subscriber end. And the behaviour is consistent with or without row filtering.
the following error on subscriber end. And the behaviour is consistent with or without row filtering.
Without the patch:2021-03-29 15:05:01.581 IST [79029] ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"2021-03-29 15:05:01.581 IST [79029] DETAIL: Key (bid)=(1) already exists.2021-03-29 15:05:01.581 IST [79029] CONTEXT: COPY pgbench_branches, line 12021-03-29 15:05:01.583 IST [78538] LOG: background worker "logical replication worker" (PID 79029) exited with exit code 12021-03-29 15:05:06.593 IST [79031] LOG: logical replication table synchronization worker for subscription "test_sub2", table "pgbench_branches" has started... this message. The code that reports this error is from the COPY command.Row filter modifications has no control over it. It seems somehow yoursubscriber close the replication connection causing this issue. Can youreproduce it consistently? If so, please share your steps.
Please ignore the report.
Thank you,
Thank you,
Rahila Syed
On Mon, Mar 29, 2021 at 6:47 PM Euler Taveira <euler@eulerto.com> wrote:
>
Few comments:
==============
1. How can we specify row filters for multiple tables for a
publication? Consider a case as below:
postgres=# CREATE TABLE tab_rowfilter_1 (a int primary key, b text);
CREATE TABLE
postgres=# CREATE TABLE tab_rowfilter_2 (c int primary key);
CREATE TABLE
postgres=# CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1,
tab_rowfilter_2 WHERE (a > 1000 AND b <> 'filtered');
ERROR: column "a" does not exist
LINE 1: ...FOR TABLE tab_rowfilter_1, tab_rowfilter_2 WHERE (a > 1000 A...
^
postgres=# CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1,
tab_rowfilter_2 WHERE (c > 1000);
CREATE PUBLICATION
It gives an error when I tried to specify the columns corresponding to
the first relation but is fine for columns for the second relation.
Then, I tried few more combinations like below but that didn't work.
CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1 As t1,
tab_rowfilter_2 As t2 WHERE (t1.a > 1000 AND t1.b <> 'filtered');
Will users be allowed to specify join conditions among columns from
multiple tables?
2.
+ /*
+ * Although ALTER PUBLICATION grammar allows WHERE clause to be specified
+ * for DROP TABLE action, it doesn't make sense to allow it. We implement
+ * this restriction here, instead of complicating the grammar to enforce
+ * it.
+ */
+ if (stmt->tableAction == DEFELEM_DROP)
+ {
+ ListCell *lc;
+
+ foreach(lc, stmt->tables)
+ {
+ PublicationTable *t = lfirst(lc);
+
+ if (t->whereClause)
+ ereport(ERROR,
+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
+ errmsg("cannot use a WHERE clause when removing table from
publication \"%s\"",
+ NameStr(pubform->pubname))));
+ }
+ }
Is there a reason to deal with this here separately rather than in the
ALTER PUBLICATION grammar?
--
With Regards,
Amit Kapila.
On Tue, Mar 30, 2021, at 8:23 AM, Amit Kapila wrote:
On Mon, Mar 29, 2021 at 6:47 PM Euler Taveira <euler@eulerto.com> wrote:>Few comments:==============1. How can we specify row filters for multiple tables for apublication? Consider a case as below:
It is not possible. Row filter is a per table option. Isn't it clear from the
synopsis? The current design allows different row filter for tables in the same
publication. It is more flexible than a single row filter for a set of tables
(even if we would support such variant, there are some cases where the
condition should be different because the column names are not the same). You
can easily build a CREATE PUBLICATION command that adds the same row filter
multiple times using a DO block or use a similar approach in your favorite
language.
postgres=# CREATE TABLE tab_rowfilter_1 (a int primary key, b text);CREATE TABLEpostgres=# CREATE TABLE tab_rowfilter_2 (c int primary key);CREATE TABLEpostgres=# CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1,tab_rowfilter_2 WHERE (a > 1000 AND b <> 'filtered');ERROR: column "a" does not existLINE 1: ...FOR TABLE tab_rowfilter_1, tab_rowfilter_2 WHERE (a > 1000 A...^postgres=# CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1,tab_rowfilter_2 WHERE (c > 1000);CREATE PUBLICATIONIt gives an error when I tried to specify the columns corresponding tothe first relation but is fine for columns for the second relation.Then, I tried few more combinations like below but that didn't work.CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1 As t1,tab_rowfilter_2 As t2 WHERE (t1.a > 1000 AND t1.b <> 'filtered');Will users be allowed to specify join conditions among columns frommultiple tables?
It seems you are envisioning row filter as a publication property instead of a
publication-relation property. Due to the flexibility that the later approach
provides, I decided to use it because it covers more use cases. Regarding
allowing joins, it could possibly slow down a critical path, no? This code path
is executed by every change. If there are interest in the join support, we
might add it in a future patch.
2.+ /*+ * Although ALTER PUBLICATION grammar allows WHERE clause to be specified+ * for DROP TABLE action, it doesn't make sense to allow it. We implement+ * this restriction here, instead of complicating the grammar to enforce+ * it.+ */+ if (stmt->tableAction == DEFELEM_DROP)+ {+ ListCell *lc;++ foreach(lc, stmt->tables)+ {+ PublicationTable *t = lfirst(lc);++ if (t->whereClause)+ ereport(ERROR,+ (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),+ errmsg("cannot use a WHERE clause when removing table frompublication \"%s\"",+ NameStr(pubform->pubname))));+ }+ }Is there a reason to deal with this here separately rather than in theALTER PUBLICATION grammar?
Good question. IIRC the issue is that AlterPublicationStmt->tables has a list
element that was a relation_expr_list and was converted to
publication_table_list. If we share 'tables' with relation_expr_list (for ALTER
PUBLICATION ... DROP TABLE) and publication_table_list (for the other ALTER
PUBLICATION ... ADD|SET TABLE), the OpenTableList() has to know what list
element it is dealing with. I think I came to the conclusion that it is less
uglier to avoid changing OpenTableList() and CloseTableList().
[Doing some experimentation...]
Here is a patch that remove the referred code. It uses 2 distinct list
elements: relation_expr_list for ALTER PUBLICATION ... DROP TABLE and
publication_table_list for for ALTER PUBLICATION ... ADD|SET TABLE. A new
parameter was introduced to deal with the different elements of the list
'tables'.
Вложения
On Wed, Mar 31, 2021 at 7:17 AM Euler Taveira <euler@eulerto.com> wrote:
>
> On Tue, Mar 30, 2021, at 8:23 AM, Amit Kapila wrote:
>
> On Mon, Mar 29, 2021 at 6:47 PM Euler Taveira <euler@eulerto.com> wrote:
> >
> Few comments:
> ==============
> 1. How can we specify row filters for multiple tables for a
> publication? Consider a case as below:
>
> It is not possible. Row filter is a per table option. Isn't it clear from the
> synopsis?
>
Sorry, it seems I didn't read it properly earlier, now I got it.
>
> 2.
> + /*
> + * Although ALTER PUBLICATION grammar allows WHERE clause to be specified
> + * for DROP TABLE action, it doesn't make sense to allow it. We implement
> + * this restriction here, instead of complicating the grammar to enforce
> + * it.
> + */
> + if (stmt->tableAction == DEFELEM_DROP)
> + {
> + ListCell *lc;
> +
> + foreach(lc, stmt->tables)
> + {
> + PublicationTable *t = lfirst(lc);
> +
> + if (t->whereClause)
> + ereport(ERROR,
> + (errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
> + errmsg("cannot use a WHERE clause when removing table from
> publication \"%s\"",
> + NameStr(pubform->pubname))));
> + }
> + }
>
> Is there a reason to deal with this here separately rather than in the
> ALTER PUBLICATION grammar?
>
> Good question. IIRC the issue is that AlterPublicationStmt->tables has a list
> element that was a relation_expr_list and was converted to
> publication_table_list. If we share 'tables' with relation_expr_list (for ALTER
> PUBLICATION ... DROP TABLE) and publication_table_list (for the other ALTER
> PUBLICATION ... ADD|SET TABLE), the OpenTableList() has to know what list
> element it is dealing with. I think I came to the conclusion that it is less
> uglier to avoid changing OpenTableList() and CloseTableList().
>
> [Doing some experimentation...]
>
> Here is a patch that remove the referred code.
>
Thanks, few more comments:
1. In pgoutput_change, we are always sending schema even though we
don't send actual data because of row filters. It may not be a problem
in many cases but I guess for some odd cases we can avoid sending
extra information.
2. In get_rel_sync_entry(), we are caching the qual for rel_sync_entry
even though we won't publish it which seems unnecessary?
3.
@@ -1193,5 +1365,11 @@ rel_sync_cache_publication_cb(Datum arg, int
cacheid, uint32 hashvalue)
entry->pubactions.pubupdate = false;
entry->pubactions.pubdelete = false;
entry->pubactions.pubtruncate = false;
+
+ if (entry->qual != NIL)
+ list_free_deep(entry->qual);
Seeing one previous comment in this thread [1], I am wondering if
list_free_deep is enough here?
4. Can we write explicitly in the docs that row filters won't apply
for Truncate operation?
5. Getting some whitespace errors:
git am /d/PostgreSQL/Patches/logical_replication/row_filter/v14-0001-Row-filter-for-logical-replication.patch
.git/rebase-apply/patch:487: trailing whitespace.
warning: 1 line adds whitespace errors.
Applying: Row filter for logical replication
[1] - https://www.postgresql.org/message-id/20181123161933.jpepibtyayflz2xg%40alvherre.pgsql
--
With Regards,
Amit Kapila.
Hi,
As far as I can tell you have not *AT ALL* addressed that it is *NOT
SAFE* to evaluate arbitrary expressions from within an output
plugin. Despite that having been brought up multiple times.
> +static ExprState *
> +pgoutput_row_filter_prepare_expr(Node *rfnode, EState *estate)
> +{
> + ExprState *exprstate;
> + Oid exprtype;
> + Expr *expr;
> +
> + /* Prepare expression for execution */
> + exprtype = exprType(rfnode);
> + expr = (Expr *) coerce_to_target_type(NULL, rfnode, exprtype, BOOLOID, -1, COERCION_ASSIGNMENT,
COERCE_IMPLICIT_CAST,-1);
> +
> + if (expr == NULL)
> + ereport(ERROR,
> + (errcode(ERRCODE_CANNOT_COERCE),
> + errmsg("row filter returns type %s that cannot be coerced to the expected type %s",
> + format_type_be(exprtype),
> + format_type_be(BOOLOID)),
> + errhint("You will need to rewrite the row filter.")));
> +
> + exprstate = ExecPrepareExpr(expr, estate);
> +
> + return exprstate;
> +}
> +
> +/*
> + * Evaluates row filter.
> + *
> + * If the row filter evaluates to NULL, it is taken as false i.e. the change
> + * isn't replicated.
> + */
> +static inline bool
> +pgoutput_row_filter_exec_expr(ExprState *state, ExprContext *econtext)
> +{
> + Datum ret;
> + bool isnull;
> +
> + Assert(state != NULL);
> +
> + ret = ExecEvalExprSwitchContext(state, econtext, &isnull);
> +
> + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
> + DatumGetBool(ret) ? "true" : "false",
> + isnull ? "true" : "false");
> +
> + if (isnull)
> + return false;
> +
> + return DatumGetBool(ret);
> +}
> +/*
> + * Change is checked against the row filter, if any.
> + *
> + * If it returns true, the change is replicated, otherwise, it is not.
> + */
> +static bool
> +pgoutput_row_filter(Relation relation, HeapTuple oldtuple, HeapTuple newtuple, List *rowfilter)
> +{
> + TupleDesc tupdesc;
> + EState *estate;
> + ExprContext *ecxt;
> + MemoryContext oldcxt;
> + ListCell *lc;
> + bool result = true;
> +
> + /* Bail out if there is no row filter */
> + if (rowfilter == NIL)
> + return true;
> +
> + elog(DEBUG3, "table \"%s.%s\" has row filter",
> + get_namespace_name(get_rel_namespace(RelationGetRelid(relation))),
> + get_rel_name(relation->rd_id));
> +
> + tupdesc = RelationGetDescr(relation);
> +
> + estate = create_estate_for_relation(relation);
> +
> + /* Prepare context per tuple */
> + ecxt = GetPerTupleExprContext(estate);
> + oldcxt = MemoryContextSwitchTo(estate->es_query_cxt);
> + ecxt->ecxt_scantuple = ExecInitExtraTupleSlot(estate, tupdesc, &TTSOpsHeapTuple);
> + MemoryContextSwitchTo(oldcxt);
> +
> + ExecStoreHeapTuple(newtuple ? newtuple : oldtuple, ecxt->ecxt_scantuple, false);
> + /*
> + * If the subscription has multiple publications and the same table has a
> + * different row filter in these publications, all row filters must be
> + * matched in order to replicate this change.
> + */
> + foreach(lc, rowfilter)
> + {
> + Node *rfnode = (Node *) lfirst(lc);
> + ExprState *exprstate;
> +
> + /* Prepare for expression execution */
> + exprstate = pgoutput_row_filter_prepare_expr(rfnode, estate);
> +
> + /* Evaluates row filter */
> + result = pgoutput_row_filter_exec_expr(exprstate, ecxt);
Also, this still seems like an *extremely* expensive thing to do for
each tuple. It'll often be *vastly* faster to just send the data than to
the other side.
This just cannot be done once per tuple. It has to be cached.
I don't see how these issues can be addressed in the next 7 days,
therefore I think this unfortunately needs to be marked as returned with
feedback.
Greetings,
Andres Freund
On Wed, Mar 31, 2021 at 12:47 PM Euler Taveira <euler@eulerto.com> wrote: > .... > Good question. IIRC the issue is that AlterPublicationStmt->tables has a list > element that was a relation_expr_list and was converted to > publication_table_list. If we share 'tables' with relation_expr_list (for ALTER > PUBLICATION ... DROP TABLE) and publication_table_list (for the other ALTER > PUBLICATION ... ADD|SET TABLE), the OpenTableList() has to know what list > element it is dealing with. I think I came to the conclusion that it is less > uglier to avoid changing OpenTableList() and CloseTableList(). > > [Doing some experimentation...] > > Here is a patch that remove the referred code. It uses 2 distinct list > elements: relation_expr_list for ALTER PUBLICATION ... DROP TABLE and > publication_table_list for for ALTER PUBLICATION ... ADD|SET TABLE. A new > parameter was introduced to deal with the different elements of the list > 'tables'. AFAIK this is the latest patch available, but FYI it no longer applies cleanly on HEAD. git apply ../patches_misc/0001-Row-filter-for-logical-replication.patch ../patches_misc/0001-Row-filter-for-logical-replication.patch:518: trailing whitespace. error: patch failed: src/backend/parser/gram.y:426 error: src/backend/parser/gram.y: patch does not apply error: patch failed: src/backend/replication/logical/worker.c:340 error: src/backend/replication/logical/worker.c: patch does not apply -------- Kind Regards, Peter Smith. Fujitsu Australia.
On Mon, May 10, 2021, at 5:19 AM, Peter Smith wrote:
AFAIK this is the latest patch available, but FYI it no longer appliescleanly on HEAD.
Peter, the last patch is broken since f3b141c4825. I'm still working on it for
the next CF. I already addressed the points suggested by Amit in his last
review; however, I'm still working on a cache for evaluating expression as
suggested by Andres. I hope to post a new patch soon.
On Mon, May 10, 2021 at 11:42 PM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, May 10, 2021, at 5:19 AM, Peter Smith wrote: > > AFAIK this is the latest patch available, but FYI it no longer applies > cleanly on HEAD. > > Peter, the last patch is broken since f3b141c4825. I'm still working on it for > the next CF. I already addressed the points suggested by Amit in his last > review; however, I'm still working on a cache for evaluating expression as > suggested by Andres. I hope to post a new patch soon. Is there any ETA for your new patch? In the interim can you rebase the old patch just so it builds and I can try it? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jun 9, 2021 at 5:33 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Mon, May 10, 2021 at 11:42 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Mon, May 10, 2021, at 5:19 AM, Peter Smith wrote: > > > > AFAIK this is the latest patch available, but FYI it no longer applies > > cleanly on HEAD. > > > > Peter, the last patch is broken since f3b141c4825. I'm still working on it for > > the next CF. I already addressed the points suggested by Amit in his last > > review; however, I'm still working on a cache for evaluating expression as > > suggested by Andres. I hope to post a new patch soon. > > Is there any ETA for your new patch? > > In the interim can you rebase the old patch just so it builds and I can try it? > I have rebased the patch so that you can try it out. The main thing I have done is to remove changes in worker.c and created a specialized function to create estate for pgoutput.c as I don't think we need what is done in worker.c. Euler, do let me know if you are not happy with the change in pgoutput.c? -- With Regards, Amit Kapila.
Вложения
On Fri, Jun 18, 2021 at 9:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > [...] > I have rebased the patch so that you can try it out. The main thing I > have done is to remove changes in worker.c and created a specialized > function to create estate for pgoutput.c as I don't think we need what > is done in worker.c. Thanks for the recent rebase. - The v15 patch applies OK (albeit with whitespace warning) - make check is passing OK - the new TAP tests 020_row_filter is passing OK. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Jun 18, 2021, at 8:40 AM, Amit Kapila wrote:
I have rebased the patch so that you can try it out. The main thing Ihave done is to remove changes in worker.c and created a specializedfunction to create estate for pgoutput.c as I don't think we need whatis done in worker.c.Euler, do let me know if you are not happy with the change in pgoutput.c?
Amit, thanks for rebasing this patch. I already had a similar rebased patch in
my local tree. A recent patch broke your version v15 so I rebased it.
I like the idea of a simple create_estate_for_relation() function (I fixed an
oversight regarding GetCurrentCommandId(false) because it is used only for
read-only purposes). This patch also replaces all references to version 14.
Commit ef948050 made some changes in the snapshot handling. Set the current
active snapshot might not be required but future changes to allow functions
will need it.
As the previous patches, it includes commits (0002 and 0003) that are not
intended to be committed. They are available for test-only purposes.
Вложения
Hi.
I have been looking at the latest patch set (v16). Below are my review
comments and some patches.
The patches are:
v16-0001. This is identical to your previously posted 0001 patch. (I
only attached it again hoping it can allow the cfbot to keep working
OK).
v16-0002,0003. These are for demonstrating some of the review comments
v16-0004. This is a POC plan cache for your consideration.
//////////
REVIEW COMMENTS
===============
1. Patch 0001 comment - typo
you can optionally filter rows that does not satisfy a WHERE condition
typo: does/does
~~
2. Patch 0001 comment - typo
The WHERE clause should probably contain only columns that are part of
the primary key or that are covered by REPLICA IDENTITY. Otherwise,
and DELETEs won't be replicated.
typo: "Otherwise, and DELETEs" ??
~~
3. Patch 0001 comment - typo and clarification
If your publication contains partitioned table, the parameter
publish_via_partition_root determines if it uses the partition row filter (if
the parameter is false -- default) or the partitioned table row filter.
Typo: "contains partitioned table" -> "contains a partitioned table"
Also, perhaps the text "or the partitioned table row filter." should
say "or the root partitioned table row filter." to disambiguate the
case where there are more levels of partitions like A->B->C. e.g. What
filter does C use?
~~
4. src/backend/catalog/pg_publication.c - misleading names
-publication_add_relation(Oid pubid, Relation targetrel,
+publication_add_relation(Oid pubid, PublicationRelationInfo *targetrel,
bool if_not_exists)
Leaving this parameter name as "targetrel" seems a bit misleading now
in the function code. Maybe this should be called something like "pri"
which is consistent with other places where you have declared
PublicationRelationInfo.
Also, consider declaring some local variables so that the patch may
have less impact on existing code. e.g.
Oid relid = pri->relid
Relation *targetrel = relationinfo->relation
~~
5. src/backend/commands/publicationcmds.c - simplify code
- rels = OpenTableList(stmt->tables);
+ if (stmt->tableAction == DEFELEM_DROP)
+ rels = OpenTableList(stmt->tables, true);
+ else
+ rels = OpenTableList(stmt->tables, false);
Consider writing that code more simply as just:
rels = OpenTableList(stmt->tables, stmt->tableAction == DEFELEM_DROP);
~~
6. src/backend/commands/publicationcmds.c - bug?
- CloseTableList(rels);
+ CloseTableList(rels, false);
}
Is this a potential bug? When you called OpenTableList the 2nd param
was maybe true/false, so is it correct to be unconditionally false
here? I am not sure.
~~
7. src/backend/commands/publicationcmds.c - OpenTableList function comment.
* Open relations specified by a RangeVar list.
+ * AlterPublicationStmt->tables has a different list element, hence, is_drop
+ * indicates if it has a RangeVar (true) or PublicationTable (false).
* The returned tables are locked in ShareUpdateExclusiveLock mode in order to
* add them to a publication.
I am not sure about this. Should that comment instead say "indicates
if it has a Relation (true) or PublicationTable (false)"?
~~
8. src/backend/commands/publicationcmds.c - OpenTableList
- RangeVar *rv = castNode(RangeVar, lfirst(lc));
- bool recurse = rv->inh;
+ PublicationTable *t = NULL;
+ RangeVar *rv;
+ bool recurse;
Relation rel;
Oid myrelid;
+ if (is_drop)
+ {
+ rv = castNode(RangeVar, lfirst(lc));
+ }
+ else
+ {
+ t = lfirst(lc);
+ rv = castNode(RangeVar, t->relation);
+ }
+
+ recurse = rv->inh;
+
For some reason it feels kind of clunky to me for this function to be
processing the list differently according to the 2nd param. e.g. the
name "is_drop" seems quite unrelated to the function code, and more to
do with where it was called from. Sorry, I don't have any better ideas
for improvement atm.
~~
9. src/backend/commands/publicationcmds.c - OpenTableList bug?
- rels = lappend(rels, rel);
+ pri = palloc(sizeof(PublicationRelationInfo));
+ pri->relid = myrelid;
+ pri->relation = rel;
+ if (!is_drop)
+ pri->whereClause = t->whereClause;
+ rels = lappend(rels, pri);
I felt maybe this is a possible bug here because there seems no code
explicitly assigning the whereClause = NULL if "is_drop" is true so
maybe it can have a garbage value which could cause problems later.
Maybe this is fixed by using palloc0.
Same thing is 2x in this function.
~~
10. src/backend/commands/publicationcmds.c - CloseTableList function comment
@@ -587,16 +609,28 @@ OpenTableList(List *tables)
* Close all relations in the list.
*/
static void
-CloseTableList(List *rels)
+CloseTableList(List *rels, bool is_drop)
{
Probably the meaning of "is_drop" should be described in this function comment.
~~
11. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry signature.
-static RelationSyncEntry *get_rel_sync_entry(PGOutputData *data, Oid relid);
+static RelationSyncEntry *get_rel_sync_entry(PGOutputData *data, Relation rel);
I see that this function signature is modified but I did not see how
this parameter refactoring is actually related to the RowFilter patch.
Perhaps I am mistaken, but IIUC this only changes the relid =
RelationGetRelid(rel); to be done inside this function instead of
being done outside by the callers.
It impacts other code like in pgoutput_truncate:
@@ -689,12 +865,11 @@ pgoutput_truncate(LogicalDecodingContext *ctx,
ReorderBufferTXN *txn,
for (i = 0; i < nrelations; i++)
{
Relation relation = relations[i];
- Oid relid = RelationGetRelid(relation);
if (!is_publishable_relation(relation))
continue;
- relentry = get_rel_sync_entry(data, relid);
+ relentry = get_rel_sync_entry(data, relation);
if (!relentry->pubactions.pubtruncate)
continue;
@@ -704,10 +879,10 @@ pgoutput_truncate(LogicalDecodingContext *ctx,
ReorderBufferTXN *txn,
* root tables through it.
*/
if (relation->rd_rel->relispartition &&
- relentry->publish_as_relid != relid)
+ relentry->publish_as_relid != relentry->relid)
continue;
- relids[nrelids++] = relid;
+ relids[nrelids++] = relentry->relid;
maybe_send_schema(ctx, txn, change, relation, relentry);
}
So maybe this is a good refactor or maybe not, but I felt this should
not be included as part of the RowFilter patch unless it is really
necessary.
~~
12. src/backend/replication/pgoutput/pgoutput.c - missing function comments
The static functions create_estate_for_relation and
pgoutput_row_filter_prepare_expr probably should be commented.
~~
13. src/backend/replication/pgoutput/pgoutput.c -
pgoutput_row_filter_prepare_expr function name
+static ExprState *pgoutput_row_filter_prepare_expr(Node *rfnode,
EState *estate);
This function has an unfortunate name with the word "prepare" in it. I
wonder if a different name can be found for this function to avoid any
confusion with pgoutput functions (coming soon) which are related to
the two-phase commit "prepare".
~~
14. src/bin/psql/describe.c
+ if (!PQgetisnull(tabres, j, 2))
+ appendPQExpBuffer(&buf, " WHERE (%s)",
+ PQgetvalue(tabres, j, 2));
Because the where-clause value already has enclosing parentheses so
using " WHERE (%s)" seems overkill here. e.g. you can see the effect
in your src/test/regress/expected/publication.out file. I think this
should be changed to " WHERE %s" to give better output.
~~
15. src/include/catalog/pg_publication.h - new typedef
+typedef struct PublicationRelationInfo
+{
+ Oid relid;
+ Relation relation;
+ Node *whereClause;
+} PublicationRelationInfo;
+
The new PublicationRelationInfo should also be added
src/tools/pgindent/typedefs.list
~~
16. src/include/nodes/parsenodes.h - new typedef
+typedef struct PublicationTable
+{
+ NodeTag type;
+ RangeVar *relation; /* relation to be published */
+ Node *whereClause; /* qualifications */
+} PublicationTable;
The new PublicationTable should also be added src/tools/pgindent/typedefs.list
~~
17. sql/publication.sql - show more output
+CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1,
testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5);
+RESET client_min_messages;
+ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000
AND e < 2000);
+ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2;
+-- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (another
WHERE expression)
+ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300
AND e < 500);
+-- fail - functions disallowed
+ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl4 WHERE (length(g) < 6);
+-- fail - WHERE not allowed in DROP
+ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl3 WHERE (e < 27);
+\dRp+ testpub5
I felt that it would be better to have a "\dRp+ testpub5" after each
of the valid ALTER PUBLICATION steps to show the intermediate results
also; not just the final one at the end.
(PSA a temp patch showing what I mean by this review comment)
~~
18. src/test/subscription/t/020_row_filter.pl - rename file
I think this file should be renamed to 021_row_filter.pl as there is
already an 020 TAP test present.
~~
19. src/test/subscription/t/020_row_filter.pl - test comments
AFAIK the test cases are all OK, but it was really quite hard to
review these TAP tests to try to determine what the expected results
should be.
I found that I had to add my own comments to the file so I could
understand what was going on, so I think the TAP test can benefit lots
from having many more comments describing how the expected results are
determined.
Also, the filtering does not take place at the INSERT but really it is
affected only by which publications the subscription has subscribed
to. So I thought some of the existing comments (although correct) are
misplaced.
(PSA a temp patch showing what I mean by this review comment)
~~~
20. src/test/subscription/t/020_row_filter.pl - missing test case?
There are some partition tests, but I did not see any test that was
like 3 levels deep like A->B->C, so I was not sure if there is any
case C would ever make use of the filter of its parent B, or would it
only use the filter of the root A?
~~
21. src/test/subscription/t/020_row_filter.pl - missing test case?
If the same table is in multiple publications they can each have a row
filter. And a subscription might subscribe to some but not all of
those publications. I think this scenario is only partly tested.
e.g.
pub_1 has tableX with RowFilter1
pub_2 has tableX with RowFilter2
Then sub_12 subscribes to pub_1, pub_2
This is already tested in your TAP test (I think) and it makes sure
both filters are applied
But if there was also
pub_3 has tableX with RowFilter3
Then sub_12 still should only be checking the filtered RowFilter1 AND
RowFilter2 (but NOT row RowFilter3). I think this scenario is not
tested.
////////////////
POC PATCH FOR PLAN CACHE
========================
PSA a POC patch for a plan cache which gets used inside the
pgoutput_row_filter function instead of calling prepare for every row.
I think this is implementing something like Andes was suggesting a
while back [1].
Measurements with/without this plan cache:
Time spent processing within the pgoutput_row_filter function
- Data was captured using the same technique as the
0002-Measure-row-filter-overhead.patch.
- Inserted 1000 rows, sampled data for the first 100 times in this function.
not cached: average ~ 28.48 us
cached: average ~ 9.75 us
Replication times:
- Using tables and row filters same as in Onder's commands_to_test_perf.sql [2]
100K rows - not cached: ~ 42sec, 43sec, 44sec
100K rows - cached: ~ 41sec, 42sec, 42 sec.
There does seem to be a tiny gain achieved by having the plan cache,
but I think the gain might be a lot less than what people were
expecting.
Unless there are millions of rows the speedup may be barely noticeable.
--------
[1] https://www.postgresql.org/message-id/20210128022032.eq2qqc6zxkqn5syt%40alap3.anarazel.de
[2] https://www.postgresql.org/message-id/CACawEhW_iMnY9XK2tEb1ig%2BA%2BgKeB4cxdJcxMsoCU0SaKPExxg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Вложения
On Thu, Jul 1, 2021 at 10:43 AM Euler Taveira <euler@eulerto.com> wrote:
>
> Amit, thanks for rebasing this patch. I already had a similar rebased patch in
> my local tree. A recent patch broke your version v15 so I rebased it.
>
> I like the idea of a simple create_estate_for_relation() function (I fixed an
> oversight regarding GetCurrentCommandId(false) because it is used only for
> read-only purposes). This patch also replaces all references to version 14.
>
> Commit ef948050 made some changes in the snapshot handling. Set the current
> active snapshot might not be required but future changes to allow functions
> will need it.
>
> As the previous patches, it includes commits (0002 and 0003) that are not
> intended to be committed. They are available for test-only purposes.
>
I have some review comments on the "Row filter for logical replication" patch:
(1) Suggested update to patch comment:
(There are some missing words and things which could be better expressed)
This feature adds row filtering for publication tables.
When a publication is defined or modified, rows that don't satisfy a WHERE
clause may be optionally filtered out. This allows a database or set of
tables to be partially replicated. The row filter is per table, which allows
different row filters to be defined for different tables. A new row filter
can be added simply by specifying a WHERE clause after the table name.
The WHERE clause must be enclosed by parentheses.
The WHERE clause should probably contain only columns that are part of the
primary key or that are covered by REPLICA IDENTITY. Otherwise, any DELETEs
won't be replicated. DELETE uses the old row version (that is limited to
primary key or REPLICA IDENTITY) to evaluate the row filter. INSERT and UPDATE
use the new row version to evaluate the row filter, hence, you can use any
column. If the row filter evaluates to NULL, it returns false. For simplicity,
functions are not allowed; that could possibly be addressed in a future patch.
If you choose to do the initial table synchronization, only data that satisfies
the row filters is sent. If the subscription has several publications in which
a table has been published with different WHERE clauses, rows must satisfy all
expressions to be copied. If subscriber is a pre-15 version, data
synchronization won't use row filters if they are defined in the publisher.
Previous versions cannot handle row filters.
If your publication contains a partitioned table, the publication parameter
publish_via_partition_root determines if it uses the partition row filter (if
the parameter is false, the default) or the root partitioned table row filter.
(2) Some inconsistent error message wording:
Currently:
err = _("cannot use subquery in publication WHERE expression");
Suggest changing it to:
err = _("subqueries are not allowed in publication WHERE expressions");
Other examples from the patch:
err = _("aggregate functions are not allowed in publication WHERE expressions");
err = _("grouping operations are not allowed in publication WHERE expressions");
err = _("window functions are not allowed in publication WHERE expressions");
errmsg("functions are not allowed in publication WHERE expressions"),
err = _("set-returning functions are not allowed in publication WHERE
expressions");
(3) The current code still allows arbitrary code execution, e.g. via a
user-defined operator:
e.g.
publisher:
CREATE OR REPLACE FUNCTION myop(left_arg INTEGER, right_arg INTEGER)
RETURNS BOOL AS
$$
BEGIN
RAISE NOTICE 'I can do anything here!';
RETURN left_arg > right_arg;
END;
$$ LANGUAGE PLPGSQL VOLATILE;
CREATE OPERATOR >>>> (
PROCEDURE = myop,
LEFTARG = INTEGER,
RIGHTARG = INTEGER
);
CREATE PUBLICATION tap_pub FOR TABLE test_tab WHERE (a >>>> 5);
subscriber:
CREATE SUBSCRIPTION tap_sub CONNECTION 'host=localhost dbname=test_pub
application_name=tap_sub' PUBLICATION tap_pub;
Perhaps add the following after the existing shell error-check in make_op():
/* User-defined operators are not allowed in publication WHERE clauses */
if (pstate->p_expr_kind == EXPR_KIND_PUBLICATION_WHERE && opform->oid
>= FirstNormalObjectId)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("user-defined operators are not allowed in publication
WHERE expressions"),
parser_errposition(pstate, location)));
Also, I believe it's also allowing user-defined CASTs (so could add a
similar check to above in transformTypeCast()).
Ideally, it would be preferable to validate/check publication WHERE
expressions in one central place, rather than scattered all over the
place, but that might be easier said than done.
You need to update the patch comment accordingly.
(4) src/backend/replication/pgoutput/pgoutput.c
pgoutput_change()
The 3 added calls to pgoutput_row_filter() are returning from
pgoutput_change(), if false is returned, but instead they should break
from the switch, otherwise cleanup code is missed. This is surely a
bug.
e.g.
(3 similar cases of this)
+ if (!pgoutput_row_filter(relation, NULL, tuple, relentry->qual))
+ return;
should be:
+ if (!pgoutput_row_filter(relation, NULL, tuple, relentry->qual))
+ break;
Regards,
Greg Nancarrow
Fujitsu Australia
On Thu, Jul 1, 2021 at 10:43 AM Euler Taveira <euler@eulerto.com> wrote: > > > Amit, thanks for rebasing this patch. I already had a similar rebased patch in > my local tree. A recent patch broke your version v15 so I rebased it. > Hi, I did some testing of the performance of the row filtering, in the case of the publisher INSERTing 100,000 rows, using a similar test setup and timing as previously used in the “commands_to_perf_test.sql“ script posted by Önder Kalacı. I found that with the call to ExecInitExtraTupleSlot() in pgoutput_row_filter(), then the performance of pgoutput_row_filter() degrades considerably over the 100,000 invocations, and on my system it took about 43 seconds to filter and send to the subscriber. However, by caching the tuple table slot in RelationSyncEntry, this duration can be dramatically reduced by 38+ seconds. A further improvement can be made using this in combination with Peter's plan cache (v16-0004). I've attached a patch for this, which relies on the latest v16-0001 and v16-0004 patches posted by Peter Smith (noting that v16-0001 is identical to your previously-posted 0001 patch). Also attached is a graph (created by Peter Smith – thanks!) detailing the performance improvement. Regards, Greg Nancarrow Fujitsu Australia
Вложения
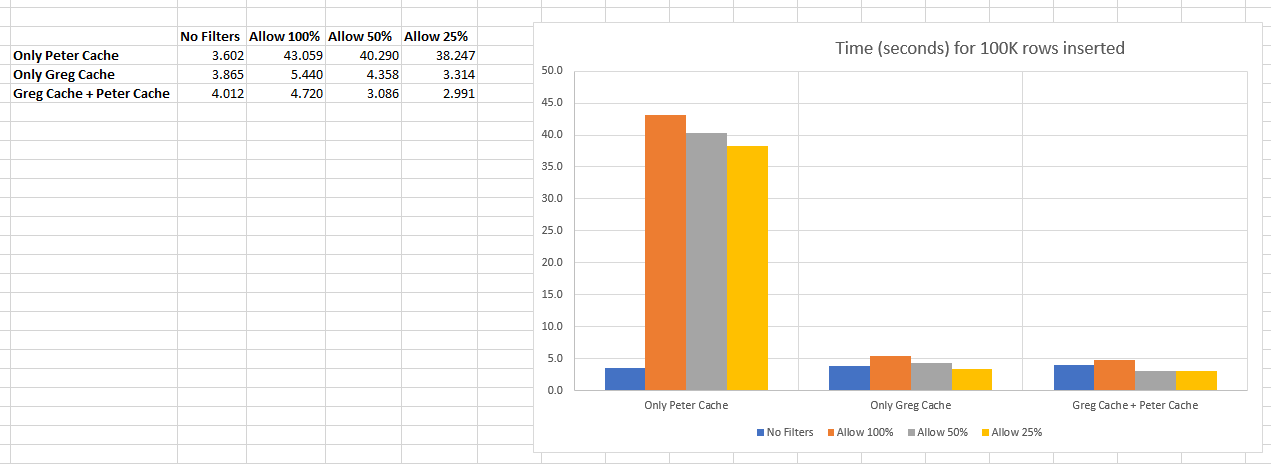{kind=link}
On Wed, Jul 7, 2021, at 2:24 AM, Greg Nancarrow wrote:
I found that with the call to ExecInitExtraTupleSlot() inpgoutput_row_filter(), then the performance of pgoutput_row_filter()degrades considerably over the 100,000 invocations, and on my systemit took about 43 seconds to filter and send to the subscriber.However, by caching the tuple table slot in RelationSyncEntry, thisduration can be dramatically reduced by 38+ seconds.A further improvement can be made using this in combination withPeter's plan cache (v16-0004).I've attached a patch for this, which relies on the latest v16-0001and v16-0004 patches posted by Peter Smith (noting that v16-0001 isidentical to your previously-posted 0001 patch).Also attached is a graph (created by Peter Smith – thanks!) detailingthe performance improvement.
Greg, I like your suggestion and already integrate it (I replaced
ExecAllocTableSlot() with MakeSingleTupleTableSlot() because we don't need the
List). I'm still working on a new version to integrate all suggestions that you
and Peter did. I have a similar code to Peter's plan cache and I'm working on
merging both ideas together. I'm done for today but I'll continue tomorrow.
On Thu, Jul 8, 2021 at 10:34 AM Euler Taveira <euler@eulerto.com> wrote: > > Greg, I like your suggestion and already integrate it (I replaced > ExecAllocTableSlot() with MakeSingleTupleTableSlot() because we don't need the > List). Yes I agree, I found the same thing, it's not needed. >I'm still working on a new version to integrate all suggestions that you > and Peter did. I have a similar code to Peter's plan cache and I'm working on > merging both ideas together. I'm done for today but I'll continue tomorrow. > I also realised that my 0005 patch wasn't handling RelationSyncEntry invalidation, so I've updated it. For completeness, I'm posting the complete patch set with the updates, so you can look at it and compare with yours, and also it'll keep the cfbot happy until you post your updated patch. Regards, Greg Nancarrow Fujitsu Australia
Вложения
On Fri, Jul 2, 2021, at 4:29 AM, Peter Smith wrote:
Hi.I have been looking at the latest patch set (v16). Below are my reviewcomments and some patches.
Peter, thanks for your detailed review. Comments are inline.
1. Patch 0001 comment - typoyou can optionally filter rows that does not satisfy a WHERE conditiontypo: does/does
Fixed.
2. Patch 0001 comment - typoThe WHERE clause should probably contain only columns that are part ofthe primary key or that are covered by REPLICA IDENTITY. Otherwise,and DELETEs won't be replicated.typo: "Otherwise, and DELETEs" ??
Fixed.
3. Patch 0001 comment - typo and clarificationIf your publication contains partitioned table, the parameterpublish_via_partition_root determines if it uses the partition row filter (ifthe parameter is false -- default) or the partitioned table row filter.Typo: "contains partitioned table" -> "contains a partitioned table"
Fixed.
Also, perhaps the text "or the partitioned table row filter." shouldsay "or the root partitioned table row filter." to disambiguate thecase where there are more levels of partitions like A->B->C. e.g. Whatfilter does C use?
I agree it can be confusing. BTW, CREATE PUBLICATION does not mention that the
root partitioned table is used. We should improve that sentence too.
4. src/backend/catalog/pg_publication.c - misleading names-publication_add_relation(Oid pubid, Relation targetrel,+publication_add_relation(Oid pubid, PublicationRelationInfo *targetrel,bool if_not_exists)Leaving this parameter name as "targetrel" seems a bit misleading nowin the function code. Maybe this should be called something like "pri"which is consistent with other places where you have declaredPublicationRelationInfo.Also, consider declaring some local variables so that the patch mayhave less impact on existing code. e.g.Oid relid = pri->relidRelation *targetrel = relationinfo->relation
Done.
5. src/backend/commands/publicationcmds.c - simplify code- rels = OpenTableList(stmt->tables);+ if (stmt->tableAction == DEFELEM_DROP)+ rels = OpenTableList(stmt->tables, true);+ else+ rels = OpenTableList(stmt->tables, false);Consider writing that code more simply as just:rels = OpenTableList(stmt->tables, stmt->tableAction == DEFELEM_DROP);
It is not a common pattern to use an expression as a function argument in
Postgres. I prefer to use a variable with a suggestive name.
6. src/backend/commands/publicationcmds.c - bug?- CloseTableList(rels);+ CloseTableList(rels, false);}Is this a potential bug? When you called OpenTableList the 2nd paramwas maybe true/false, so is it correct to be unconditionally falsehere? I am not sure.
Good catch.
7. src/backend/commands/publicationcmds.c - OpenTableList function comment.* Open relations specified by a RangeVar list.+ * AlterPublicationStmt->tables has a different list element, hence, is_drop+ * indicates if it has a RangeVar (true) or PublicationTable (false).* The returned tables are locked in ShareUpdateExclusiveLock mode in order to* add them to a publication.I am not sure about this. Should that comment instead say "indicatesif it has a Relation (true) or PublicationTable (false)"?
Fixed.
8. src/backend/commands/publicationcmds.c - OpenTableList
>8
For some reason it feels kind of clunky to me for this function to beprocessing the list differently according to the 2nd param. e.g. thename "is_drop" seems quite unrelated to the function code, and more todo with where it was called from. Sorry, I don't have any better ideasfor improvement atm.
My suggestion is to rename it to "pub_drop_table".
9. src/backend/commands/publicationcmds.c - OpenTableList bug?
>8
I felt maybe this is a possible bug here because there seems no codeexplicitly assigning the whereClause = NULL if "is_drop" is true somaybe it can have a garbage value which could cause problems later.Maybe this is fixed by using palloc0.
Fixed.
10. src/backend/commands/publicationcmds.c - CloseTableList function comment
>8
Probably the meaning of "is_drop" should be described in this function comment.
Done.
11. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry signature.-static RelationSyncEntry *get_rel_sync_entry(PGOutputData *data, Oid relid);+static RelationSyncEntry *get_rel_sync_entry(PGOutputData *data, Relation rel);I see that this function signature is modified but I did not see howthis parameter refactoring is actually related to the RowFilter patch.Perhaps I am mistaken, but IIUC this only changes the relid =RelationGetRelid(rel); to be done inside this function instead ofbeing done outside by the callers.
It is not critical for this patch so I removed it.
12. src/backend/replication/pgoutput/pgoutput.c - missing function commentsThe static functions create_estate_for_relation andpgoutput_row_filter_prepare_expr probably should be commented.
Done.
13. src/backend/replication/pgoutput/pgoutput.c -pgoutput_row_filter_prepare_expr function name+static ExprState *pgoutput_row_filter_prepare_expr(Node *rfnode,EState *estate);This function has an unfortunate name with the word "prepare" in it. Iwonder if a different name can be found for this function to avoid anyconfusion with pgoutput functions (coming soon) which are related tothe two-phase commit "prepare".
The word "prepare" is related to the executor context. The function name
contains "row_filter" that is sufficient to distinguish it from any other
function whose context is "prepare". I replaced "prepare" with "init".
14. src/bin/psql/describe.c+ if (!PQgetisnull(tabres, j, 2))+ appendPQExpBuffer(&buf, " WHERE (%s)",+ PQgetvalue(tabres, j, 2));Because the where-clause value already has enclosing parentheses sousing " WHERE (%s)" seems overkill here. e.g. you can see the effectin your src/test/regress/expected/publication.out file. I think thisshould be changed to " WHERE %s" to give better output.
Peter E suggested that extra parenthesis be added. See 0005 [1].
15. src/include/catalog/pg_publication.h - new typedef+typedef struct PublicationRelationInfo+{+ Oid relid;+ Relation relation;+ Node *whereClause;+} PublicationRelationInfo;+The new PublicationRelationInfo should also be addedsrc/tools/pgindent/typedefs.list
Patches usually don't update typedefs.list. Check src/tools/pgindent/README.
16. src/include/nodes/parsenodes.h - new typedef+typedef struct PublicationTable+{+ NodeTag type;+ RangeVar *relation; /* relation to be published */+ Node *whereClause; /* qualifications */+} PublicationTable;The new PublicationTable should also be added src/tools/pgindent/typedefs.list
Idem.
17. sql/publication.sql - show more output+CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1,testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5);+RESET client_min_messages;+ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000AND e < 2000);+ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2;+-- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (anotherWHERE expression)+ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300AND e < 500);+-- fail - functions disallowed+ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl4 WHERE (length(g) < 6);+-- fail - WHERE not allowed in DROP+ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl3 WHERE (e < 27);+\dRp+ testpub5I felt that it would be better to have a "\dRp+ testpub5" after eachof the valid ALTER PUBLICATION steps to show the intermediate resultsalso; not just the final one at the end.
Done.
18. src/test/subscription/t/020_row_filter.pl - rename fileI think this file should be renamed to 021_row_filter.pl as there isalready an 020 TAP test present.
Done.
19. src/test/subscription/t/020_row_filter.pl - test commentsAFAIK the test cases are all OK, but it was really quite hard toreview these TAP tests to try to determine what the expected resultsshould be.
I included your comments but heavily changed it.
20. src/test/subscription/t/020_row_filter.pl - missing test case?There are some partition tests, but I did not see any test that waslike 3 levels deep like A->B->C, so I was not sure if there is anycase C would ever make use of the filter of its parent B, or would itonly use the filter of the root A?
I didn't include it yet. There is an issue with initial synchronization and
partitioned table when you set publish_via_partition_root. I'll start another
thread for this issue.
21. src/test/subscription/t/020_row_filter.pl - missing test case?If the same table is in multiple publications they can each have a rowfilter. And a subscription might subscribe to some but not all ofthose publications. I think this scenario is only partly tested.
8<
e.g.pub_1 has tableX with RowFilter1pub_2 has tableX with RowFilter2Then sub_12 subscribes to pub_1, pub_2This is already tested in your TAP test (I think) and it makes sureboth filters are appliedBut if there was alsopub_3 has tableX with RowFilter3Then sub_12 still should only be checking the filtered RowFilter1 ANDRowFilter2 (but NOT row RowFilter3). I think this scenario is nottested.
I added a new publication tap_pub_not_used to cover this case.
POC PATCH FOR PLAN CACHE========================PSA a POC patch for a plan cache which gets used inside thepgoutput_row_filter function instead of calling prepare for every row.I think this is implementing something like Andes was suggesting awhile back [1].
I also had a WIP patch for it (that's very similar to your patch) so I merged
it.
This cache mechanism consists of caching ExprState and avoid calling
pgoutput_row_filter_init_expr() for every single row. Greg N suggested in
another email that tuple table slot should also be cached to avoid a few cycles
too. It is also included in this new patch.
Measurements with/without this plan cache:Time spent processing within the pgoutput_row_filter function- Data was captured using the same technique as the0002-Measure-row-filter-overhead.patch.- Inserted 1000 rows, sampled data for the first 100 times in this function.not cached: average ~ 28.48 uscached: average ~ 9.75 usReplication times:- Using tables and row filters same as in Onder's commands_to_test_perf.sql [2]100K rows - not cached: ~ 42sec, 43sec, 44sec100K rows - cached: ~ 41sec, 42sec, 42 sec.There does seem to be a tiny gain achieved by having the plan cache,but I think the gain might be a lot less than what people wereexpecting.
I did another measure using as baseline the previous patch (v16).
without cache (v16)
---------------------------
mean: 1.46 us
stddev: 2.13 us
median: 1.39 us
min-max: [0.69 .. 1456.69] us
percentile(99): 3.15 us
mode: 0.91 us
with cache (v18)
-----------------------
mean: 0.63 us
stddev: 1.07 us
median: 0.55 us
min-max: [0.29 .. 844.87] us
percentile(99): 1.38 us
mode: 0.41 us
It represents -57%. It is a really good optimization for just a few extra lines
of code.
Вложения
On Mon, Jul 5, 2021, at 12:14 AM, Greg Nancarrow wrote:
I have some review comments on the "Row filter for logical replication" patch:(1) Suggested update to patch comment:(There are some missing words and things which could be better expressed)
I incorporated all your wording suggestions.
(2) Some inconsistent error message wording:Currently:err = _("cannot use subquery in publication WHERE expression");Suggest changing it to:err = _("subqueries are not allowed in publication WHERE expressions");
The same expression "cannot use subquery in ..." is used in the other switch
cases. If you think this message can be improved, I suggest that you submit a
separate patch to change all sentences.
Other examples from the patch:err = _("aggregate functions are not allowed in publication WHERE expressions");err = _("grouping operations are not allowed in publication WHERE expressions");err = _("window functions are not allowed in publication WHERE expressions");errmsg("functions are not allowed in publication WHERE expressions"),err = _("set-returning functions are not allowed in publication WHEREexpressions");
This is a different function. I just followed the same wording from similar
sentences around it.
(3) The current code still allows arbitrary code execution, e.g. via auser-defined operator:
I fixed it in v18.
Perhaps add the following after the existing shell error-check in make_op():/* User-defined operators are not allowed in publication WHERE clauses */if (pstate->p_expr_kind == EXPR_KIND_PUBLICATION_WHERE && opform->oid>= FirstNormalObjectId)ereport(ERROR,(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),errmsg("user-defined operators are not allowed in publicationWHERE expressions"),parser_errposition(pstate, location)));
I'm still working on a way to accept built-in functions but while we don't have
it, let's forbid custom operators too.
Also, I believe it's also allowing user-defined CASTs (so could add asimilar check to above in transformTypeCast()).Ideally, it would be preferable to validate/check publication WHEREexpressions in one central place, rather than scattered all over theplace, but that might be easier said than done.You need to update the patch comment accordingly.
I forgot to mention it in the patch I sent a few minutes ago. I'm not sure we
need to mention every error condition (specially one that will be rarely used).
(4) src/backend/replication/pgoutput/pgoutput.cpgoutput_change()The 3 added calls to pgoutput_row_filter() are returning frompgoutput_change(), if false is returned, but instead they should breakfrom the switch, otherwise cleanup code is missed. This is surely abug.
Fixed.
In summary, v18 contains
* Peter Smith's review
* Greg Nancarrow's review
* cache ExprState
* cache TupleTableSlot
* forbid custom operators
* various fixes
Hi,
I took a look at this patch, which seems to be in CF since 2018. I have
only some basic comments and observations at this point:
1) alter_publication.sgml
I think "expression is executed" sounds a bit strange, perhaps
"evaluated" would be better?
2) create_publication.sgml
Why is the patch changing publish_via_partition_root docs? That seems
like a rather unrelated bit.
The <literal>WHERE</literal> clause should probably contain only
columns that are part of the primary key or be covered by
<literal>REPLICA ...
I'm not sure what exactly is this trying to say. What does "should
probably ..." mean in practice for the users? Does that mean something
bad will happen for other columns, or what? I'm sure this wording will
be quite confusing for users.
It may also be unclear whether the condition is evaluated on the old or
new row, so perhaps add an example illustrating that & more detailed
comment, or something. E.g. what will happen with
UPDATE departments SET active = false WHERE active;
3) publication_add_relation
Does this need to build the parse state even for whereClause == NULL?
4) AlterPublicationTables
I wonder if this new reworked code might have issues with subscriptions
containing many tables, but I haven't tried.
5) OpenTableList
I really dislike that the list can have two different node types
(Relation and PublicationTable). In principle we don't actually need the
extra flag, we can simply check the node type directly by IsA() and act
based on that. However, I think it'd be better to just use a single node
type from all places.
I don't see why not to set whereClause every time, I don't think the
extra if saves anything, it's just a bit more complex.
5) CloseTableList
The comment about node types seems pointless, this function has no flag
and the element type does not matter.
6) parse_agg.c
... are not allowed in publication WHERE expressions
I think all similar cases use "WHERE conditions" instead.
7) transformExprRecurse
The check at the beginning seems rather awkward / misplaced - it's way
too specific for this location (there are no other p_expr_kind
references in this function). Wouldn't transformFuncCall (or maybe
ParseFuncOrColumn) be a more appropriate place?
Initially I was wondering why not to allow function calls in WHERE
conditions, but I see that was discussed in the past as problematic. But
that reminds me that I don't see any docs describing what expressions
are allowed in WHERE conditions - maybe we should explicitly list what
expressions are allowed?
8) pgoutput.c
I have not reviewed this in detail yet, but there seems to be something
wrong because `make check-world` fails in subscription/010_truncate.pl
after hitting an assert (backtrace attached) during "START_REPLICATION
SLOT" in get_rel_sync_entry in this code:
/* Release tuple table slot */
if (entry->scantuple != NULL)
{
ExecDropSingleTupleTableSlot(entry->scantuple);
entry->scantuple = NULL;
}
So there seems to be something wrong with how the slot is created.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Sun, Jul 11, 2021, at 4:39 PM, Euler Taveira wrote:
with cache (v18)-----------------------mean: 0.63 usstddev: 1.07 usmedian: 0.55 usmin-max: [0.29 .. 844.87] uspercentile(99): 1.38 usmode: 0.41 usIt represents -57%. It is a really good optimization for just a few extra linesof code.
cfbot seems to be unhappy with v18 on some of the hosts. Cirrus/FreeBSD failed
in the test 010_truncate. It also failed in a Cirrus/Linux box. I failed to
reproduce in my local FreeBSD box. Since it passes appveyor and Cirrus/macos,
it could probably be a transient issue.
$ uname -a
FreeBSD freebsd12 12.2-RELEASE FreeBSD 12.2-RELEASE r366954 GENERIC amd64
$ PROVE_TESTS="t/010_truncate.pl" gmake check
gmake -C ../../../src/backend generated-headers
gmake[1]: Entering directory '/usr/home/euler/pglr-row-filter-v17/src/backend'
gmake -C catalog distprep generated-header-symlinks
gmake[2]: Entering directory '/usr/home/euler/pglr-row-filter-v17/src/backend/catalog'
gmake[2]: Nothing to be done for 'distprep'.
gmake[2]: Nothing to be done for 'generated-header-symlinks'.
gmake[2]: Leaving directory '/usr/home/euler/pglr-row-filter-v17/src/backend/catalog'
gmake -C utils distprep generated-header-symlinks
gmake[2]: Entering directory '/usr/home/euler/pglr-row-filter-v17/src/backend/utils'
gmake[2]: Nothing to be done for 'distprep'.
gmake[2]: Nothing to be done for 'generated-header-symlinks'.
gmake[2]: Leaving directory '/usr/home/euler/pglr-row-filter-v17/src/backend/utils'
gmake[1]: Leaving directory '/usr/home/euler/pglr-row-filter-v17/src/backend'
rm -rf '/home/euler/pglr-row-filter-v17'/tmp_install
/bin/sh ../../../config/install-sh -c -d '/home/euler/pglr-row-filter-v17'/tmp_install/log
gmake -C '../../..' DESTDIR='/home/euler/pglr-row-filter-v17'/tmp_install install >'/home/euler/pglr-row-filter-v17'/tmp_install/log/install.log 2>&1
gmake -j1 checkprep >>'/home/euler/pglr-row-filter-v17'/tmp_install/log/install.log 2>&1
rm -rf '/usr/home/euler/pglr-row-filter-v17/src/test/subscription'/tmp_check
/bin/sh ../../../config/install-sh -c -d '/usr/home/euler/pglr-row-filter-v17/src/test/subscription'/tmp_check
cd . && TESTDIR='/usr/home/euler/pglr-row-filter-v17/src/test/subscription' PATH="/home/euler/pglr-row-filter-v17/tmp_install/home/euler/pgrf18/bin:$PATH" LD_LIBRARY_PATH="/home/euler/pglr-row-filter-v17/tmp_install/home/euler/pgrf18/lib" LD_LIBRARY_PATH_RPATH=1 PGPORT='69999' PG_REGRESS='/usr/home/euler/pglr-row-filter-v17/src/test/subscription/../../../src/test/regress/pg_regress' /usr/local/bin/prove -I ../../../src/test/perl/ -I . t/010_truncate.pl
t/010_truncate.pl .. ok
All tests successful.
Files=1, Tests=14, 5 wallclock secs ( 0.02 usr 0.00 sys + 1.09 cusr 0.99 csys = 2.10 CPU)
Result: PASS
--
Euler Taveira
Hi Andres complained about the safety of doing general expression evaluation in pgoutput; that was first in https://postgr.es/m/20210128022032.eq2qqc6zxkqn5syt@alap3.anarazel.de where he described a possible approach to handle it by restricting expressions to have limited shape; and later in http://postgr.es/m/20210331191710.kqbiwe73lur7jo2e@alap3.anarazel.de I was just scanning the patch trying to see if some sort of protection had been added for this, but I couldn't find anything. (Some functions are under-commented, though). So, is it there already, and if so what is it? And if it isn't, then I think it should definitely be put there in some form. Thanks -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
On Mon, Jul 12, 2021 at 9:31 AM Euler Taveira <euler@eulerto.com> wrote:
>
> cfbot seems to be unhappy with v18 on some of the hosts. Cirrus/FreeBSD failed
> in the test 010_truncate. It also failed in a Cirrus/Linux box. I failed to
> reproduce in my local FreeBSD box. Since it passes appveyor and Cirrus/macos,
> it could probably be a transient issue.
>
I don't think it's a transient issue.
I also get a test failure in subscription/010_truncate.pl when I run
"make check-world" with the v18 patches applied.
The problem can be avoided with the following change (to match what
was originally in my v17-0005 performance-improvement patch):
diff --git a/src/backend/replication/pgoutput/pgoutput.c
b/src/backend/replication/pgoutput/pgoutput.c
index 08c018a300..800bae400b 100644
--- a/src/backend/replication/pgoutput/pgoutput.c
+++ b/src/backend/replication/pgoutput/pgoutput.c
@@ -1256,8 +1256,8 @@ get_rel_sync_entry(PGOutputData *data, Relation relation)
}
/* create a tuple table slot for row filter */
- tupdesc = RelationGetDescr(relation);
oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ tupdesc = CreateTupleDescCopy(RelationGetDescr(relation));
entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
MemoryContextSwitchTo(oldctx);
This creates a TupleDesc copy in CacheMemoryContext that is not
refcounted, so it side-steps the problem.
At this stage I am not sure why the original v18 patch code doesn't
work correctly for the TupleDesc refcounting here.
The TupleDesc refcount is zero when it's time to dealloc the tuple
slot (thus causing that Assert to fire), yet when the slot was
created, the TupleDesc refcount was incremented.- so it seems
something else has already decremented the refcount by the time it
comes to deallocate the slot. Perhaps there's an order-of-cleanup or
MemoryContext issue here or some buggy code somewhere, not sure yet.
Regards,
Greg Nancarrow
Fujitsu Australia
On Mon, Jul 12, 2021 at 7:19 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > Hi > > Andres complained about the safety of doing general expression > evaluation in pgoutput; that was first in > > https://postgr.es/m/20210128022032.eq2qqc6zxkqn5syt@alap3.anarazel.de > where he described a possible approach to handle it by restricting > expressions to have limited shape; and later in > http://postgr.es/m/20210331191710.kqbiwe73lur7jo2e@alap3.anarazel.de > > I was just scanning the patch trying to see if some sort of protection > had been added for this, but I couldn't find anything. (Some functions > are under-commented, though). So, is it there already, and if so what > is it? > I think the patch is trying to prohibit arbitrary expressions in the WHERE clause via transformWhereClause(..EXPR_KIND_PUBLICATION_WHERE..). You can notice that at various places the expressions are prohibited via EXPR_KIND_PUBLICATION_WHERE. I am not sure that the checks are correct and sufficient but I think there is some attempt to do it. For example, the below sort of ad-hoc check for func_call doesn't seem to be good idea. @@ -119,6 +119,13 @@ transformExprRecurse(ParseState *pstate, Node *expr) /* Guard against stack overflow due to overly complex expressions */ check_stack_depth(); + /* Functions are not allowed in publication WHERE clauses */ + if (pstate->p_expr_kind == EXPR_KIND_PUBLICATION_WHERE && nodeTag(expr) == T_FuncCall) + ereport(ERROR, + (errcode(ERRCODE_FEATURE_NOT_SUPPORTED), + errmsg("functions are not allowed in publication WHERE expressions"), + parser_errposition(pstate, exprLocation(expr)))); Now, the other idea I had in mind was to traverse the WHERE clause expression in publication_add_relation and identify if it contains anything other than the ANDed list of 'foo.bar op constant' expressions. OTOH, for index where clause expressions or policy check expressions, we use a technique similar to what we have in the patch to prohibit certain kinds of expressions. Do you have any preference on how this should be addressed? -- With Regards, Amit Kapila.
On 7/12/21 6:46 AM, Amit Kapila wrote: > On Mon, Jul 12, 2021 at 7:19 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: >> >> Hi >> >> Andres complained about the safety of doing general expression >> evaluation in pgoutput; that was first in >> >> https://postgr.es/m/20210128022032.eq2qqc6zxkqn5syt@alap3.anarazel.de >> where he described a possible approach to handle it by restricting >> expressions to have limited shape; and later in >> http://postgr.es/m/20210331191710.kqbiwe73lur7jo2e@alap3.anarazel.de >> >> I was just scanning the patch trying to see if some sort of protection >> had been added for this, but I couldn't find anything. (Some functions >> are under-commented, though). So, is it there already, and if so what >> is it? >> > > I think the patch is trying to prohibit arbitrary expressions in the > WHERE clause via > transformWhereClause(..EXPR_KIND_PUBLICATION_WHERE..). You can notice > that at various places the expressions are prohibited via > EXPR_KIND_PUBLICATION_WHERE. I am not sure that the checks are correct > and sufficient but I think there is some attempt to do it. For > example, the below sort of ad-hoc check for func_call doesn't seem to > be good idea. > > @@ -119,6 +119,13 @@ transformExprRecurse(ParseState *pstate, Node *expr) > /* Guard against stack overflow due to overly complex expressions */ > check_stack_depth(); > > + /* Functions are not allowed in publication WHERE clauses */ > + if (pstate->p_expr_kind == EXPR_KIND_PUBLICATION_WHERE && > nodeTag(expr) == T_FuncCall) > + ereport(ERROR, > + (errcode(ERRCODE_FEATURE_NOT_SUPPORTED), > + errmsg("functions are not allowed in publication WHERE expressions"), > + parser_errposition(pstate, exprLocation(expr)))); > Yes, I mentioned this bit of code in my review, although I was mostly wondering if this is the wrong place to make this check. > Now, the other idea I had in mind was to traverse the WHERE clause > expression in publication_add_relation and identify if it contains > anything other than the ANDed list of 'foo.bar op constant' > expressions. OTOH, for index where clause expressions or policy check > expressions, we use a technique similar to what we have in the patch > to prohibit certain kinds of expressions. > > Do you have any preference on how this should be addressed? > I don't think this is sufficient, because who knows where "op" comes from? It might be from an extension, in which case the problem pointed out by Petr Jelinek [1] would apply. OTOH I suppose we could allow expressions like (Var op Var), i.e. "a < b" or something like that. And then why not allow (a+b < c-10) and similar "more complex" expressions, as long as all the operators are built-in? In terms of implementation, I think there are two basic options - either we can define a new "expression" type in gram.y, which would be a subset of a_expr etc. Or we can do it as some sort of expression walker, kinda like what the transform* functions do now. regards [1] https://www.postgresql.org/message-id/92e5587d-28b8-5849-2374-5ca3863256f1%402ndquadrant.com -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jul 12, 2021 at 1:09 AM Euler Taveira <euler@eulerto.com> wrote:
>
> I did another measure using as baseline the previous patch (v16).
>
> without cache (v16)
> ---------------------------
>
> mean: 1.46 us
> stddev: 2.13 us
> median: 1.39 us
> min-max: [0.69 .. 1456.69] us
> percentile(99): 3.15 us
> mode: 0.91 us
>
> with cache (v18)
> -----------------------
>
> mean: 0.63 us
> stddev: 1.07 us
> median: 0.55 us
> min-max: [0.29 .. 844.87] us
> percentile(99): 1.38 us
> mode: 0.41 us
>
> It represents -57%. It is a really good optimization for just a few extra lines
> of code.
>
Good improvement but I think it is better to measure the performance
by using synchronous_replication by setting the subscriber as
standby_synchronous_names, which will provide the overall saving of
time. We can probably see when the timings when no rows are filtered,
when 10% rows are filtered when 30% are filtered and so on.
I think the way caching has been done in the patch is a bit
inefficient. Basically, it always invalidates and rebuilds the
expressions even though some unrelated operation has happened on
publication. For example, say publication has initially table t1 with
rowfilter r1 for which we have cached the state. Now you altered
publication and added table t2, it will invalidate the entire state of
t1 as well. I think we can avoid that if we invalidate the rowfilter
related state only on relcache invalidation i.e in
rel_sync_cache_relation_cb and save it the very first time we prepare
the expression. In that case, we don't need to do it in advance when
preparing relsyncentry, this will have the additional advantage that
we won't spend cycles on preparing state unless it is required (for
truncate we won't require row_filtering, so it won't be prepared).
Few other things, I have noticed:
1.
I am seeing tupledesc leak by following below steps:
ERROR: tupdesc reference 00000000008D7D18 is not owned by resource
owner TopTransaction
CONTEXT: slot "tap_sub", output plugin "pgoutput", in the change
callback, associated LSN 0/170BD50
Publisher
CREATE TABLE tab_rowfilter_1 (a int primary key, b text);
CREATE PUBLICATION tap_pub_1 FOR TABLE tab_rowfilter_1 WHERE (a > 1000
AND b <> 'filtered');
Subscriber
CREATE TABLE tab_rowfilter_1 (a int primary key, b text);
CREATE SUBSCRIPTION tap_sub
CONNECTION 'host=localhost port=5432 dbname=postgres'
PUBLICATION tap_pub_1;
Publisher
INSERT INTO tab_rowfilter_1 (a, b) VALUES (1980, 'not filtered');
Alter table tab_rowfilter_1 drop column b cascade;
INSERT INTO tab_rowfilter_1 (a) VALUES (1982);
2.
postgres=# Alter table tab_rowfilter_1 alter column b set data type varchar;
ERROR: unexpected object depending on column: publication of table
tab_rowfilter_1 in publication tap_pub_1
I think for this you need to change ATExecAlterColumnType to handle
the publication case.
--
With Regards,
Amit Kapila.
While looking at the other logrep patch [1] (column filtering) I noticed Alvaro's comment regarding a new parsenode (PublicationTable) not having read/out/equal/copy funcs. I'd bet the same thing applies here, so perhaps see if the patch needs the same fix. [1] https://www.postgresql.org/message-id/202107062342.eq6htmp2wgp2%40alvherre.pgsql -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jul 12, 2021, at 8:44 AM, Tomas Vondra wrote:
While looking at the other logrep patch [1] (column filtering) I noticedAlvaro's comment regarding a new parsenode (PublicationTable) not havingread/out/equal/copy funcs. I'd bet the same thing applies here, soperhaps see if the patch needs the same fix.
Good catch! I completely forgot about _copyPublicationTable() and
_equalPublicationTable().
On Mon, Jul 12, 2021 at 5:39 AM Euler Taveira <euler@eulerto.com> wrote:
>
> On Fri, Jul 2, 2021, at 4:29 AM, Peter Smith wrote:
>
> Hi.
>
> I have been looking at the latest patch set (v16). Below are my review
> comments and some patches.
>
> Peter, thanks for your detailed review. Comments are inline.
>
Hi Euler,
Thanks for addressing my previous review comments.
I have reviewed the latest v18 patch. Below are some more review
comments and patches.
(The patches 0003,0004 are just examples of what is mentioned in my
comments; The patches 0001,0002 are there only to try to keep cfbot
green).
//////////
1. Commit comment - wording
"When a publication is defined or modified, rows that don't satisfy a
WHERE clause may be
optionally filtered out."
=>
I think this means to say: "Rows that don't satisfy an optional WHERE
clause will be filtered out."
------
2. Commit comment - wording
"The row filter is per table, which allows different row filters to be
defined for different tables."
=>
I think all that is the same as just saying: "The row filter is per table."
------
3. PG docs - independent improvement
You wrote (ref [1] point 3):
"I agree it can be confusing. BTW, CREATE PUBLICATION does not mention that the
root partitioned table is used. We should improve that sentence too."
I agree, but that PG docs improvement is independent of your RowFilter
patch; please make another thread for that idea.
------
4. doc/src/sgml/ref/create_publication.sgml - independent improvement
@@ -131,9 +135,9 @@ CREATE PUBLICATION <replaceable
class="parameter">name</replaceable>
on its partitions) contained in the publication will be published
using the identity and schema of the partitioned table rather than
that of the individual partitions that are actually changed; the
- latter is the default. Enabling this allows the changes to be
- replicated into a non-partitioned table or a partitioned table
- consisting of a different set of partitions.
+ latter is the default (<literal>false</literal>). Enabling this
+ allows the changes to be replicated into a non-partitioned table or a
+ partitioned table consisting of a different set of partitions.
</para>
I think that Tomas wrote (ref [2] point 2) that this change seems
unrelated to your RowFilter patch.
I agree; I liked the change, but IMO you need to propose this one in
another thread too.
------
5. doc/src/sgml/ref/create_subscription.sgml - wording
@@ -102,7 +102,16 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
<para>
Specifies whether the existing data in the publications that are
being subscribed to should be copied once the replication starts.
- The default is <literal>true</literal>.
+ The default is <literal>true</literal>. If any table in the
+ publications has a <literal>WHERE</literal> clause, rows that do not
+ satisfy the <replaceable class="parameter">expression</replaceable>
+ will not be copied. If the subscription has several publications in
+ which a table has been published with different
+ <literal>WHERE</literal> clauses, rows must satisfy all expressions
+ to be copied. If any table in the publications has a
+ <literal>WHERE</literal> clause, data synchronization does not use it
+ if the subscriber is a <productname>PostgreSQL</productname> version
+ before 15.
I felt that the sentence: "If any table in the publications has a
<literal>WHERE</literal> clause, data synchronization does not use it
if the subscriber is a <productname>PostgreSQL</productname> version
before 15."
Could be expressed more simply like: "If the subscriber is a
<productname>PostgreSQL</productname> version before 15 then any row
filtering is ignored."
------
6. src/backend/commands/publicationcmds.c - wrong function comment
@@ -585,6 +611,9 @@ OpenTableList(List *tables)
/*
* Close all relations in the list.
+ *
+ * Publication node can have a different list element, hence, pub_drop_table
+ * indicates if it has a Relation (true) or PublicationTable (false).
*/
static void
CloseTableList(List *rels)
=>
The 2nd parameter does not exist in v18, so that comment about
pub_drop_table seems to be a cut/paste error from the OpenTableList.
------
src/backend/replication/logical/tablesync.c - bug ?
@@ -829,16 +883,23 @@ copy_table(Relation rel)
relmapentry = logicalrep_rel_open(lrel.remoteid, NoLock);
Assert(rel == relmapentry->localrel);
+ /* List of columns for COPY */
+ attnamelist = make_copy_attnamelist(relmapentry);
+
/* Start copy on the publisher. */
=>
I did not understand the above call to make_copy_attnamelist. The
result seems unused before it is overwritten later in this same
function (??)
------
7. src/backend/replication/logical/tablesync.c -
fetch_remote_table_info enhancement
+ /* Get relation qual */
+ if (walrcv_server_version(LogRepWorkerWalRcvConn) >= 150000)
+ {
+ resetStringInfo(&cmd);
+ appendStringInfo(&cmd,
+ "SELECT pg_get_expr(prqual, prrelid) "
+ " FROM pg_publication p "
+ " INNER JOIN pg_publication_rel pr "
+ " ON (p.oid = pr.prpubid) "
+ " WHERE pr.prrelid = %u "
+ " AND p.pubname IN (", lrel->remoteid);
=>
I think a small improvement is possible in this SQL.
If we change that to "SELECT DISTINCT pg_get_expr(prqual, prrelid)"...
then it avoids the copy SQL from having multiple WHERE clauses which
are all identical. This could happen when subscribed to multiple
publications which had the same filter for the same table.
I attached a tmp POC patch for this change and it works as expected.
For example, I subscribe to 3 publications, but 2 of them have the
same filter for the table.
BEFORE
COPY (SELECT key, value, data FROM public.test WHERE (key > 0) AND
(key > 1000) AND (key > 1000)) TO STDOUT
AFTER
COPY (SELECT key, value, data FROM public.test WHERE (key > 0) AND
(key > 1000) ) TO STDOUT
------
8. src/backend/replication/pgoutput/pgoutput.c - qual member is redundant
@@ -99,6 +108,9 @@ typedef struct RelationSyncEntry
bool replicate_valid;
PublicationActions pubactions;
+ List *qual; /* row filter */
+ List *exprstate; /* ExprState for row filter */
+ TupleTableSlot *scantuple; /* tuple table slot for row filter */
=>
Now that the exprstate is introduced I think that the other member
"qual" is redundant, so it can be removed.
FYI - I attached a tmp patch with all the qual references deleted and
everything is fine.
------
9. src/backend/replication/pgoutput/pgoutput.c - comment typo?
+ /*
+ * Cache ExprState using CacheMemoryContext. This is the same code as
+ * ExecPrepareExpr() but it is not used because it doesn't use an EState.
+ * It should probably be another function in the executor to handle the
+ * execution outside a normal Plan tree context.
+ */
=>
typo: it/that ?
I think it ought to say "This is the same code as ExecPrepareExpr()
but that is not used because"...
------
10. src/backend/replication/pgoutput/pgoutput.c - redundant debug logging?
+ /* Evaluates row filter */
+ result = pgoutput_row_filter_exec_expr(exprstate, ecxt);
+
+ elog(DEBUG3, "row filter %smatched", result ? "" : "not ");
The above debug logging is really only a repeat (with different
wording) of the same information already being logged inside the
pgoutput_row_filter_exec_expr function isn't it? Consider removing the
redundant logging.
e.g. This is already getting logged by pgoutput_row_filter_exec_expr:
elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
DatumGetBool(ret) ? "true" : "false",
isnull ? "true" : "false");
------
[1] https://www.postgresql.org/message-id/532a18d8-ce90-4444-8570-8a9fcf09f329%40www.fastmail.com
[2] https://www.postgresql.org/message-id/849ee491-bba3-c0ae-cc25-4fce1c03f105%40enterprisedb.com
[3] https://www.postgresql.org/message-id/532a18d8-ce90-4444-8570-8a9fcf09f329%40www.fastmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Вложения
On Mon, Jul 12, 2021 at 3:01 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/12/21 6:46 AM, Amit Kapila wrote: > > On Mon, Jul 12, 2021 at 7:19 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > Now, the other idea I had in mind was to traverse the WHERE clause > > expression in publication_add_relation and identify if it contains > > anything other than the ANDed list of 'foo.bar op constant' > > expressions. OTOH, for index where clause expressions or policy check > > expressions, we use a technique similar to what we have in the patch > > to prohibit certain kinds of expressions. > > > > Do you have any preference on how this should be addressed? > > > > I don't think this is sufficient, because who knows where "op" comes > from? It might be from an extension, in which case the problem pointed > out by Petr Jelinek [1] would apply. OTOH I suppose we could allow > expressions like (Var op Var), i.e. "a < b" or something like that. And > then why not allow (a+b < c-10) and similar "more complex" expressions, > as long as all the operators are built-in? > Yeah, and the patch already disallows the user-defined operators in filters. I think ideally if the operator doesn't refer to UDFs, we can allow to directly use such an OP in the filter as we can add a dependency for the same. > In terms of implementation, I think there are two basic options - either > we can define a new "expression" type in gram.y, which would be a subset > of a_expr etc. Or we can do it as some sort of expression walker, kinda > like what the transform* functions do now. > I think it is better to use some form of walker here rather than extending the grammar for this. However, the question is do we need some special kind of expression walker here or can we handle all required cases via transformWhereClause() call as the patch is trying to do. AFAIU, the main things we want to prohibit in the filter are: (a) it doesn't refer to any relation other than catalog in where clause, (b) it doesn't use UDFs in any way (in expressions, in user-defined operators, user-defined types, etc.), (c) the columns referred to in the filter should be part of PK or Replica Identity. Now, if all such things can be detected by the approach patch has taken then why do we need a special kind of expression walker? OTOH, if we can't detect some of this then probably we can use a special walker. I think in the long run one idea to allow UDFs is probably by explicitly allowing users to specify whether the function is publication predicate safe and if so, then we can allow such functions in the filter clause. -- With Regards, Amit Kapila.
Hi Euler, Greg noticed that your patch set was missing any implementation of the psql tab auto-complete for the new row filter WHERE syntax. So I have added a POC patch for this missing feature. Unfortunately, there is an existing HEAD problem overlapping with this exact same code. I reported this already in another thread [1]. So there are 2 patches attached here: 0001 - Fixes the other reported problem (I hope this may be pushed soon) 0002 - Adds the tab-completion code for your row filter WHERE's ------ [1] https://www.postgresql.org/message-id/CAHut+Ps-vkmnWAShWSRVCB3gx8aM=bFoDqWgBNTzofK0q1LpwA@mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia On Tue, Jul 13, 2021 at 1:25 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Mon, Jul 12, 2021 at 5:39 AM Euler Taveira <euler@eulerto.com> wrote: > > > > On Fri, Jul 2, 2021, at 4:29 AM, Peter Smith wrote: > > > > Hi. > > > > I have been looking at the latest patch set (v16). Below are my review > > comments and some patches. > > > > Peter, thanks for your detailed review. Comments are inline. > > > > Hi Euler, > > Thanks for addressing my previous review comments. > > I have reviewed the latest v18 patch. Below are some more review > comments and patches. > > (The patches 0003,0004 are just examples of what is mentioned in my > comments; The patches 0001,0002 are there only to try to keep cfbot > green). > > ////////// > > 1. Commit comment - wording > > "When a publication is defined or modified, rows that don't satisfy a > WHERE clause may be > optionally filtered out." > > => > > I think this means to say: "Rows that don't satisfy an optional WHERE > clause will be filtered out." > > ------ > > 2. Commit comment - wording > > "The row filter is per table, which allows different row filters to be > defined for different tables." > > => > > I think all that is the same as just saying: "The row filter is per table." > > ------ > > 3. PG docs - independent improvement > > You wrote (ref [1] point 3): > > "I agree it can be confusing. BTW, CREATE PUBLICATION does not mention that the > root partitioned table is used. We should improve that sentence too." > > I agree, but that PG docs improvement is independent of your RowFilter > patch; please make another thread for that idea. > > ------ > > 4. doc/src/sgml/ref/create_publication.sgml - independent improvement > > @@ -131,9 +135,9 @@ CREATE PUBLICATION <replaceable > class="parameter">name</replaceable> > on its partitions) contained in the publication will be published > using the identity and schema of the partitioned table rather than > that of the individual partitions that are actually changed; the > - latter is the default. Enabling this allows the changes to be > - replicated into a non-partitioned table or a partitioned table > - consisting of a different set of partitions. > + latter is the default (<literal>false</literal>). Enabling this > + allows the changes to be replicated into a non-partitioned table or a > + partitioned table consisting of a different set of partitions. > </para> > > I think that Tomas wrote (ref [2] point 2) that this change seems > unrelated to your RowFilter patch. > > I agree; I liked the change, but IMO you need to propose this one in > another thread too. > > ------ > > 5. doc/src/sgml/ref/create_subscription.sgml - wording > > @@ -102,7 +102,16 @@ CREATE SUBSCRIPTION <replaceable > class="parameter">subscription_name</replaceabl > <para> > Specifies whether the existing data in the publications that are > being subscribed to should be copied once the replication starts. > - The default is <literal>true</literal>. > + The default is <literal>true</literal>. If any table in the > + publications has a <literal>WHERE</literal> clause, rows that do not > + satisfy the <replaceable class="parameter">expression</replaceable> > + will not be copied. If the subscription has several publications in > + which a table has been published with different > + <literal>WHERE</literal> clauses, rows must satisfy all expressions > + to be copied. If any table in the publications has a > + <literal>WHERE</literal> clause, data synchronization does not use it > + if the subscriber is a <productname>PostgreSQL</productname> version > + before 15. > > I felt that the sentence: "If any table in the publications has a > <literal>WHERE</literal> clause, data synchronization does not use it > if the subscriber is a <productname>PostgreSQL</productname> version > before 15." > > Could be expressed more simply like: "If the subscriber is a > <productname>PostgreSQL</productname> version before 15 then any row > filtering is ignored." > > ------ > > 6. src/backend/commands/publicationcmds.c - wrong function comment > > @@ -585,6 +611,9 @@ OpenTableList(List *tables) > > /* > * Close all relations in the list. > + * > + * Publication node can have a different list element, hence, pub_drop_table > + * indicates if it has a Relation (true) or PublicationTable (false). > */ > static void > CloseTableList(List *rels) > > => > > The 2nd parameter does not exist in v18, so that comment about > pub_drop_table seems to be a cut/paste error from the OpenTableList. > > ------ > > src/backend/replication/logical/tablesync.c - bug ? > > @@ -829,16 +883,23 @@ copy_table(Relation rel) > relmapentry = logicalrep_rel_open(lrel.remoteid, NoLock); > Assert(rel == relmapentry->localrel); > > + /* List of columns for COPY */ > + attnamelist = make_copy_attnamelist(relmapentry); > + > /* Start copy on the publisher. */ > => > > I did not understand the above call to make_copy_attnamelist. The > result seems unused before it is overwritten later in this same > function (??) > > ------ > > 7. src/backend/replication/logical/tablesync.c - > fetch_remote_table_info enhancement > > + /* Get relation qual */ > + if (walrcv_server_version(LogRepWorkerWalRcvConn) >= 150000) > + { > + resetStringInfo(&cmd); > + appendStringInfo(&cmd, > + "SELECT pg_get_expr(prqual, prrelid) " > + " FROM pg_publication p " > + " INNER JOIN pg_publication_rel pr " > + " ON (p.oid = pr.prpubid) " > + " WHERE pr.prrelid = %u " > + " AND p.pubname IN (", lrel->remoteid); > > => > > I think a small improvement is possible in this SQL. > > If we change that to "SELECT DISTINCT pg_get_expr(prqual, prrelid)"... > then it avoids the copy SQL from having multiple WHERE clauses which > are all identical. This could happen when subscribed to multiple > publications which had the same filter for the same table. > > I attached a tmp POC patch for this change and it works as expected. > For example, I subscribe to 3 publications, but 2 of them have the > same filter for the table. > > BEFORE > COPY (SELECT key, value, data FROM public.test WHERE (key > 0) AND > (key > 1000) AND (key > 1000)) TO STDOUT > > AFTER > COPY (SELECT key, value, data FROM public.test WHERE (key > 0) AND > (key > 1000) ) TO STDOUT > > ------ > > 8. src/backend/replication/pgoutput/pgoutput.c - qual member is redundant > > @@ -99,6 +108,9 @@ typedef struct RelationSyncEntry > > bool replicate_valid; > PublicationActions pubactions; > + List *qual; /* row filter */ > + List *exprstate; /* ExprState for row filter */ > + TupleTableSlot *scantuple; /* tuple table slot for row filter */ > > => > > Now that the exprstate is introduced I think that the other member > "qual" is redundant, so it can be removed. > > FYI - I attached a tmp patch with all the qual references deleted and > everything is fine. > > ------ > > 9. src/backend/replication/pgoutput/pgoutput.c - comment typo? > > + /* > + * Cache ExprState using CacheMemoryContext. This is the same code as > + * ExecPrepareExpr() but it is not used because it doesn't use an EState. > + * It should probably be another function in the executor to handle the > + * execution outside a normal Plan tree context. > + */ > > => > > typo: it/that ? > > I think it ought to say "This is the same code as ExecPrepareExpr() > but that is not used because"... > > ------ > > 10. src/backend/replication/pgoutput/pgoutput.c - redundant debug logging? > > + /* Evaluates row filter */ > + result = pgoutput_row_filter_exec_expr(exprstate, ecxt); > + > + elog(DEBUG3, "row filter %smatched", result ? "" : "not "); > > The above debug logging is really only a repeat (with different > wording) of the same information already being logged inside the > pgoutput_row_filter_exec_expr function isn't it? Consider removing the > redundant logging. > > e.g. This is already getting logged by pgoutput_row_filter_exec_expr: > > elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > DatumGetBool(ret) ? "true" : "false", > isnull ? "true" : "false"); > > > ------ > [1] https://www.postgresql.org/message-id/532a18d8-ce90-4444-8570-8a9fcf09f329%40www.fastmail.com > [2] https://www.postgresql.org/message-id/849ee491-bba3-c0ae-cc25-4fce1c03f105%40enterprisedb.com > [3] https://www.postgresql.org/message-id/532a18d8-ce90-4444-8570-8a9fcf09f329%40www.fastmail.com > > Kind Regards, > Peter Smith. > Fujitsu Australia
Вложения
On Tue, Jul 13, 2021 at 10:24 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jul 12, 2021 at 3:01 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > In terms of implementation, I think there are two basic options - either > > we can define a new "expression" type in gram.y, which would be a subset > > of a_expr etc. Or we can do it as some sort of expression walker, kinda > > like what the transform* functions do now. > > > > I think it is better to use some form of walker here rather than > extending the grammar for this. However, the question is do we need > some special kind of expression walker here or can we handle all > required cases via transformWhereClause() call as the patch is trying > to do. AFAIU, the main things we want to prohibit in the filter are: > (a) it doesn't refer to any relation other than catalog in where > clause, (b) it doesn't use UDFs in any way (in expressions, in > user-defined operators, user-defined types, etc.), (c) the columns > referred to in the filter should be part of PK or Replica Identity. > Now, if all such things can be detected by the approach patch has > taken then why do we need a special kind of expression walker? OTOH, > if we can't detect some of this then probably we can use a special > walker. > > I think in the long run one idea to allow UDFs is probably by > explicitly allowing users to specify whether the function is > publication predicate safe and if so, then we can allow such functions > in the filter clause. > Another idea here could be to read the publication-related catalog with the latest snapshot instead of a historic snapshot. If we do that then if the user faces problems as described by Petr [1] due to missing dependencies via UDFs then she can Alter the Publication to remove/change the filter clause and after that, we would be able to recognize the updated filter clause and the system will be able to move forward. I might be missing something but reading publication catalogs with non-historic snapshots shouldn't create problems as we use the historic snapshots are required to decode WAL. I think the problem described by Petr[1] is also possible today if the user drops the publication and there is a corresponding subscription, basically, the system will stuck with error: "ERROR: publication "mypub" does not exist. I think allowing to use non-historic snapshots just for publications will resolve that problem as well. [1] - https://www.postgresql.org/message-id/92e5587d-28b8-5849-2374-5ca3863256f1%402ndquadrant.com -- With Regards, Amit Kapila.
On Tue, 2021-07-13 at 10:24 +0530, Amit Kapila wrote:
> to do. AFAIU, the main things we want to prohibit in the filter are:
> (a) it doesn't refer to any relation other than catalog in where
> clause,
Right, because the walsender is using a historical snapshot.
> (b) it doesn't use UDFs in any way (in expressions, in
> user-defined operators, user-defined types, etc.),
Is this a reasonable requirement? Postgres has a long history of
allowing UDFs nearly everywhere that a built-in is allowed. It feels
wrong to make built-ins special for this feature.
> (c) the columns
> referred to in the filter should be part of PK or Replica Identity.
Why?
Also:
* Andres also mentioned that the function should not leak memory.
* One use case for this feature is when sharding a table, so the
expression should allow things like "hashint8(x) between ...". I'd
really like to see this problem solved, as well.
> I think in the long run one idea to allow UDFs is probably by
> explicitly allowing users to specify whether the function is
> publication predicate safe and if so, then we can allow such
> functions
> in the filter clause.
This sounds like a better direction. We probably need some kind of
catalog information here to say what functions/operators are "safe" for
this kind of purpose. There are a couple questions:
1. Should this notion of safety be specific to this feature, or should
we try to generalize it so that other areas of the system might benefit
as well?
2. Should this marking be superuser-only, or user-specified?
3. Should it be related to the IMMUTABLE/STABLE/VOLATILE designation,
or completely separate?
Regards,
Jeff Davis
On 7/13/21 5:44 PM, Jeff Davis wrote: > On Tue, 2021-07-13 at 10:24 +0530, Amit Kapila wrote: >> to do. AFAIU, the main things we want to prohibit in the filter are: >> (a) it doesn't refer to any relation other than catalog in where >> clause, > > Right, because the walsender is using a historical snapshot. > >> (b) it doesn't use UDFs in any way (in expressions, in >> user-defined operators, user-defined types, etc.), > > Is this a reasonable requirement? Postgres has a long history of > allowing UDFs nearly everywhere that a built-in is allowed. It feels > wrong to make built-ins special for this feature. > Well, we can either prohibit UDF or introduce a massive foot-gun. The problem with functions in general (let's ignore SQL functions) is that they're black boxes, so we don't know what's inside. And if the function gets broken after an object gets dropped, the replication is broken and the only way to fix it is to recover the subscription. And this is not hypothetical issue, we've seen this repeatedly :-( So as much as I'd like to see support for UDFs here, I think it's better to disallow them - at least for now. And maybe relax that restriction later, if possible. >> (c) the columns >> referred to in the filter should be part of PK or Replica Identity. > > Why? > I'm not sure either. > > Also: > > * Andres also mentioned that the function should not leak memory. > * One use case for this feature is when sharding a table, so the > expression should allow things like "hashint8(x) between ...". I'd > really like to see this problem solved, as well. > I think built-in functions should be fine, because generally don't get dropped etc. (And if you drop built-in function, well - sorry.) Not sure about the memory leaks - I suppose we'd free memory for each row, so this shouldn't be an issue I guess ... >> I think in the long run one idea to allow UDFs is probably by >> explicitly allowing users to specify whether the function is >> publication predicate safe and if so, then we can allow such >> functions >> in the filter clause. > > This sounds like a better direction. We probably need some kind of > catalog information here to say what functions/operators are "safe" for > this kind of purpose. There are a couple questions: > Not sure. It's true it's a bit like volatile/stable/immutable categories where we can't guarantee those labels are correct, and it's up to the user to keep the pieces if they pick the wrong category. But we can achieve the same goal by introducing a simple GUC called dangerous_allow_udf_in_decoding, I think. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 7/13/21 12:57 PM, Amit Kapila wrote: > On Tue, Jul 13, 2021 at 10:24 AM Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> On Mon, Jul 12, 2021 at 3:01 PM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >> >>> In terms of implementation, I think there are two basic options - either >>> we can define a new "expression" type in gram.y, which would be a subset >>> of a_expr etc. Or we can do it as some sort of expression walker, kinda >>> like what the transform* functions do now. >>> >> >> I think it is better to use some form of walker here rather than >> extending the grammar for this. However, the question is do we need >> some special kind of expression walker here or can we handle all >> required cases via transformWhereClause() call as the patch is trying >> to do. AFAIU, the main things we want to prohibit in the filter are: >> (a) it doesn't refer to any relation other than catalog in where >> clause, (b) it doesn't use UDFs in any way (in expressions, in >> user-defined operators, user-defined types, etc.), (c) the columns >> referred to in the filter should be part of PK or Replica Identity. >> Now, if all such things can be detected by the approach patch has >> taken then why do we need a special kind of expression walker? OTOH, >> if we can't detect some of this then probably we can use a special >> walker. >> >> I think in the long run one idea to allow UDFs is probably by >> explicitly allowing users to specify whether the function is >> publication predicate safe and if so, then we can allow such functions >> in the filter clause. >> > > Another idea here could be to read the publication-related catalog > with the latest snapshot instead of a historic snapshot. If we do that > then if the user faces problems as described by Petr [1] due to > missing dependencies via UDFs then she can Alter the Publication to > remove/change the filter clause and after that, we would be able to > recognize the updated filter clause and the system will be able to > move forward. > > I might be missing something but reading publication catalogs with > non-historic snapshots shouldn't create problems as we use the > historic snapshots are required to decode WAL. > IMHO the best option for v1 is to just restrict the filters to known-safe expressions. That is, just built-in operators, no UDFs etc. Yes, it's not great, but both alternative proposals (allowing UDFs or using current snapshot) are problematic for various reasons. Even with those restrictions the row filtering seems quite useful, and we can relax those restrictions later if we find acceptable compromise and/or decide it's worth the risk. Seems better than having to introduce new restrictions later. > I think the problem described by Petr[1] is also possible today if the > user drops the publication and there is a corresponding subscription, > basically, the system will stuck with error: "ERROR: publication > "mypub" does not exist. I think allowing to use non-historic snapshots > just for publications will resolve that problem as well. > > [1] - https://www.postgresql.org/message-id/92e5587d-28b8-5849-2374-5ca3863256f1%402ndquadrant.com > That seems like a completely different problem, TBH. For example the slot is dropped too, which means the WAL is likely gone etc. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2021-Jul-13, Tomas Vondra wrote: > On 7/13/21 5:44 PM, Jeff Davis wrote: > > * Andres also mentioned that the function should not leak memory. > > * One use case for this feature is when sharding a table, so the > > expression should allow things like "hashint8(x) between ...". I'd > > really like to see this problem solved, as well. > > I think built-in functions should be fine, because generally don't get > dropped etc. (And if you drop built-in function, well - sorry.) > > Not sure about the memory leaks - I suppose we'd free memory for each row, > so this shouldn't be an issue I guess ... I'm not sure we need to be terribly strict about expression evaluation not leaking any memory here. I'd rather have a memory context that can be reset per row. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
On Tue, Jul 13, 2021, at 12:25 AM, Peter Smith wrote:
I have reviewed the latest v18 patch. Below are some more reviewcomments and patches.
Peter, thanks for quickly check the new patch. I'm attaching a new patch (v19)
that addresses (a) this new review, (b) Tomas' review and (c) Greg's review. I
also included the copy/equal node support for the new node (PublicationTable)
mentioned by Tomas in another email.
1. Commit comment - wording
8<
=>I think this means to say: "Rows that don't satisfy an optional WHEREclause will be filtered out."
Agreed.
2. Commit comment - wording"The row filter is per table, which allows different row filters to bedefined for different tables."=>I think all that is the same as just saying: "The row filter is per table."
Agreed.
3. PG docs - independent improvementYou wrote (ref [1] point 3):"I agree it can be confusing. BTW, CREATE PUBLICATION does not mention that theroot partitioned table is used. We should improve that sentence too."I agree, but that PG docs improvement is independent of your RowFilterpatch; please make another thread for that idea.
I will. And I will also include the next item that I removed from the patch.
4. doc/src/sgml/ref/create_publication.sgml - independent improvement@@ -131,9 +135,9 @@ CREATE PUBLICATION <replaceableclass="parameter">name</replaceable>on its partitions) contained in the publication will be publishedusing the identity and schema of the partitioned table rather thanthat of the individual partitions that are actually changed; the- latter is the default. Enabling this allows the changes to be- replicated into a non-partitioned table or a partitioned table- consisting of a different set of partitions.+ latter is the default (<literal>false</literal>). Enabling this+ allows the changes to be replicated into a non-partitioned table or a+ partitioned table consisting of a different set of partitions.</para>I think that Tomas wrote (ref [2] point 2) that this change seemsunrelated to your RowFilter patch.I agree; I liked the change, but IMO you need to propose this one inanother thread too.
Reverted.
5. doc/src/sgml/ref/create_subscription.sgml - wording
8<
I felt that the sentence: "If any table in the publications has a<literal>WHERE</literal> clause, data synchronization does not use itif the subscriber is a <productname>PostgreSQL</productname> versionbefore 15."Could be expressed more simply like: "If the subscriber is a<productname>PostgreSQL</productname> version before 15 then any rowfiltering is ignored."
Agreed.
6. src/backend/commands/publicationcmds.c - wrong function comment
8<
/** Close all relations in the list.+ *+ * Publication node can have a different list element, hence, pub_drop_table+ * indicates if it has a Relation (true) or PublicationTable (false).*/static voidCloseTableList(List *rels)=>The 2nd parameter does not exist in v18, so that comment aboutpub_drop_table seems to be a cut/paste error from the OpenTableList.
Oops. Removed.
src/backend/replication/logical/tablesync.c - bug ?@@ -829,16 +883,23 @@ copy_table(Relation rel)relmapentry = logicalrep_rel_open(lrel.remoteid, NoLock);Assert(rel == relmapentry->localrel);+ /* List of columns for COPY */+ attnamelist = make_copy_attnamelist(relmapentry);+/* Start copy on the publisher. */=>I did not understand the above call to make_copy_attnamelist. Theresult seems unused before it is overwritten later in this samefunction (??)
Good catch. This seems to be a leftover from an ancient version.
7. src/backend/replication/logical/tablesync.c -fetch_remote_table_info enhancement+ /* Get relation qual */+ if (walrcv_server_version(LogRepWorkerWalRcvConn) >= 150000)+ {+ resetStringInfo(&cmd);+ appendStringInfo(&cmd,+ "SELECT pg_get_expr(prqual, prrelid) "+ " FROM pg_publication p "+ " INNER JOIN pg_publication_rel pr "+ " ON (p.oid = pr.prpubid) "+ " WHERE pr.prrelid = %u "+ " AND p.pubname IN (", lrel->remoteid);=>I think a small improvement is possible in this SQL.If we change that to "SELECT DISTINCT pg_get_expr(prqual, prrelid)"...then it avoids the copy SQL from having multiple WHERE clauses whichare all identical. This could happen when subscribed to multiplepublications which had the same filter for the same table.
Good catch!
8. src/backend/replication/pgoutput/pgoutput.c - qual member is redundant@@ -99,6 +108,9 @@ typedef struct RelationSyncEntrybool replicate_valid;PublicationActions pubactions;+ List *qual; /* row filter */+ List *exprstate; /* ExprState for row filter */+ TupleTableSlot *scantuple; /* tuple table slot for row filter */=>Now that the exprstate is introduced I think that the other member"qual" is redundant, so it can be removed.
I was thinking about it for the next patch. Removed.
9. src/backend/replication/pgoutput/pgoutput.c - comment typo?
8<
typo: it/that ?I think it ought to say "This is the same code as ExecPrepareExpr()but that is not used because"...
Fixed.
10. src/backend/replication/pgoutput/pgoutput.c - redundant debug logging?+ /* Evaluates row filter */+ result = pgoutput_row_filter_exec_expr(exprstate, ecxt);++ elog(DEBUG3, "row filter %smatched", result ? "" : "not ");The above debug logging is really only a repeat (with differentwording) of the same information already being logged inside thepgoutput_row_filter_exec_expr function isn't it? Consider removing theredundant logging.
Agreed. Removed.
Вложения
On Sun, Jul 11, 2021, at 8:09 PM, Tomas Vondra wrote:
I took a look at this patch, which seems to be in CF since 2018. I haveonly some basic comments and observations at this point:
Tomas, thanks for reviewing this patch again.
1) alter_publication.sgmlI think "expression is executed" sounds a bit strange, perhaps"evaluated" would be better?
Fixed.
2) create_publication.sgmlWhy is the patch changing publish_via_partition_root docs? That seemslike a rather unrelated bit.
Removed. I will submit a separate patch for this.
The <literal>WHERE</literal> clause should probably contain onlycolumns that are part of the primary key or be covered by<literal>REPLICA ...I'm not sure what exactly is this trying to say. What does "shouldprobably ..." mean in practice for the users? Does that mean somethingbad will happen for other columns, or what? I'm sure this wording willbe quite confusing for users.
Reading again it seems "probably" is confusing. Let's remove it.
It may also be unclear whether the condition is evaluated on the old ornew row, so perhaps add an example illustrating that & more detailedcomment, or something. E.g. what will happen withUPDATE departments SET active = false WHERE active;
Yeah. I avoided to mention this internal detail about old/new row but it seems
better to be clear. How about the following paragraph?
<para>
The <literal>WHERE</literal> clause should contain only columns that are
part of the primary key or be covered by <literal>REPLICA
IDENTITY</literal> otherwise, <command>DELETE</command> operations will not
be replicated. That's because old row is used and it only contains primary
key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
and <command>UPDATE</command> operations, any column might be used in the
<literal>WHERE</literal> clause. New row is used and it contains all
columns. A <literal>NULL</literal> value causes the expression to evaluate
to false; avoid using columns without not-null constraints in the
<literal>WHERE</literal> clause. The <literal>WHERE</literal> clause does
not allow functions and user-defined operators.
</para>
3) publication_add_relationDoes this need to build the parse state even for whereClause == NULL?
No. Fixed.
4) AlterPublicationTablesI wonder if this new reworked code might have issues with subscriptionscontaining many tables, but I haven't tried.
This piece of code is already complicated. Amit complained about it too [1].
Are you envisioning any specific issue (other than open thousands of relations,
do some stuff, and close them all)? IMO the open/close relation should be
postponed for as long as possible.
5) OpenTableListI really dislike that the list can have two different node types(Relation and PublicationTable). In principle we don't actually need theextra flag, we can simply check the node type directly by IsA() and actbased on that. However, I think it'd be better to just use a single nodetype from all places.
Amit complained about having a runtime test for ALTER PUBLICATION ... DROP
TABLE in case user provides a WHERE clause [2]. I did that way (runtime test)
because it simplified the code. I would tend to avoid moving grammar task into
a runtime, that's why I agreed to change it. I didn't like the multi-node
argument handling for OpenTableList() (mainly because of the extra argument in
the function signature) but with your suggestion (IsA()) maybe it is
acceptable. What do you think? I included IsA() in v19.
I don't see why not to set whereClause every time, I don't think theextra if saves anything, it's just a bit more complex.
See runtime test in [2].
5) CloseTableListThe comment about node types seems pointless, this function has no flagand the element type does not matter.
Fixed.
6) parse_agg.c... are not allowed in publication WHERE expressionsI think all similar cases use "WHERE conditions" instead.
No. Policy, index, statistics, partition, column generation use expressions.
COPY and trigger use conditions. It is also referred as expression in the
synopsis.
7) transformExprRecurseThe check at the beginning seems rather awkward / misplaced - it's waytoo specific for this location (there are no other p_expr_kindreferences in this function). Wouldn't transformFuncCall (or maybeParseFuncOrColumn) be a more appropriate place?
Probably. I have to try the multiple possibilities to make sure it forbids all
cases.
Initially I was wondering why not to allow function calls in WHEREconditions, but I see that was discussed in the past as problematic. Butthat reminds me that I don't see any docs describing what expressionsare allowed in WHERE conditions - maybe we should explicitly list whatexpressions are allowed?
I started to investigate how to safely allow built-in functions. There is a
long discussion about using functions in a logical decoding context. As I said
during the last CF for v14, I prefer this to be a separate feature. I realized
that I mentioned that functions and user-defined operators are not allowed in
the commit message but forgot to mention it in the documentation.
8) pgoutput.cI have not reviewed this in detail yet, but there seems to be somethingwrong because `make check-world` fails in subscription/010_truncate.plafter hitting an assert (backtrace attached) during "START_REPLICATIONSLOT" in get_rel_sync_entry in this code:
That's because I didn't copy the TupleDesc in CacheMemoryContext. Greg pointed
it too in a previous email [3]. The new patch (v19) includes a fix for it.
On Tue, Jul 13, 2021, at 4:07 PM, Tomas Vondra wrote:
On 7/13/21 5:44 PM, Jeff Davis wrote:> On Tue, 2021-07-13 at 10:24 +0530, Amit Kapila wrote:
8<
>> (c) the columns>> referred to in the filter should be part of PK or Replica Identity.>> Why?>I'm not sure either.
This patch uses the old row for DELETE operations and new row for INSERT and
UPDATE operations. Since we usually don't use REPLICA IDENTITY FULL, all
columns in an old row that are not part of the PK or REPLICA IDENTITY are NULL.
The row filter evaluates NULL to false. Documentation says
<para>
The <literal>WHERE</literal> clause should contain only columns that are
part of the primary key or be covered by <literal>REPLICA
IDENTITY</literal> otherwise, <command>DELETE</command> operations will not
be replicated. That's because old row is used and it only contains primary
key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
and <command>UPDATE</command> operations, any column might be used in the
<literal>WHERE</literal> clause. New row is used and it contains all
columns. A <literal>NULL</literal> value causes the expression to evaluate
to false; avoid using columns without not-null constraints in the
<literal>WHERE</literal> clause. The <literal>WHERE</literal> clause does
not allow functions and user-defined operators.
</para>
On 2021-Jul-13, Euler Taveira wrote: > + <para> > + The <literal>WHERE</literal> clause should contain only columns that are > + part of the primary key or be covered by <literal>REPLICA > + IDENTITY</literal> otherwise, <command>DELETE</command> operations will not > + be replicated. That's because old row is used and it only contains primary > + key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the > + remaining columns are <literal>NULL</literal>. For <command>INSERT</command> > + and <command>UPDATE</command> operations, any column might be used in the > + <literal>WHERE</literal> clause. New row is used and it contains all > + columns. A <literal>NULL</literal> value causes the expression to evaluate > + to false; avoid using columns without not-null constraints in the > + <literal>WHERE</literal> clause. The <literal>WHERE</literal> clause does > + not allow functions and user-defined operators. > + </para> There's a couple of points in this paragraph .. 1. if you use REPLICA IDENTITY FULL, then the expressions would work even if they use any other column with DELETE. Maybe it would be reasonable to test for this in the code and raise an error if the expression requires a column that's not part of the replica identity. (But that could be relaxed if the publication does not publish updates/deletes.) 2. For UPDATE, does the expression apply to the old tuple or to the new tuple? You say it's the new tuple, but from the user point of view I think it would make more sense that it would apply to the old tuple. (Of course, if you're thinking that the R.I. is the PK and the PK is never changed, then you don't really care which one it is, but I bet that some people would not like that assumption.) I think it is sensible that it's the old tuple that is matched, not the new; consider what happens if you change the PK in the update and the replica already has that tuple. If you match on the new tuple and it doesn't match the expression (so you filter out the update), but the old tuple does match the expression, then the replica will retain the mismatching tuple forever. 3. You say that a NULL value in any of those columns causes the expression to become false and thus the tuple is not published. This seems pretty unfriendly, but maybe it would be useful to have examples of the behavior. Does ExecInitCheck() handle things in the other way, and if so does using a similar trick give more useful behavior? <para> The WHERE clause may only contain references to columns that are part of the table's replica identity. If <>DELETE</> or <>UPDATE</> operations are published, this restriction can be bypassed by making the replica identity be the whole row with <command>ALTER TABLE .. SET REPLICA IDENTITY FULL</command>. The <literal>WHERE</literal> clause does not allow functions or user-defined operators. </para> -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ "The Gord often wonders why people threaten never to come back after they've been told never to return" (www.actsofgord.com)
On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote:
1. if you use REPLICA IDENTITY FULL, then the expressions would workeven if they use any other column with DELETE. Maybe it would bereasonable to test for this in the code and raise an error if theexpression requires a column that's not part of the replica identity.(But that could be relaxed if the publication does not publishupdates/deletes.)
I thought about it but came to the conclusion that it doesn't worth it. Even
with REPLICA IDENTITY FULL expression evaluates to false if the column allows
NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER
TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY
because some row filter uses the column you want to remove from it.
2. For UPDATE, does the expression apply to the old tuple or to the newtuple? You say it's the new tuple, but from the user point of view Ithink it would make more sense that it would apply to the old tuple.(Of course, if you're thinking that the R.I. is the PK and the PK isnever changed, then you don't really care which one it is, but I betthat some people would not like that assumption.)
New tuple. The main reason is that new tuple is always there for UPDATEs.
Hence, row filter might succeed even if the row filter contains a column that
is not part of PK or REPLICA IDENTITY. pglogical also chooses to use new tuple
when it is available (e.g. for INSERT and UPDATE). If you don't like this
approach we can (a) create a new publication option to choose between old tuple
and new tuple for UPDATEs or (b) qualify columns using a special reference
(such as NEW.id or OLD.foo). Both options can provide flexibility but (a) is
simpler.
I think it is sensible that it's the old tuple that is matched, not thenew; consider what happens if you change the PK in the update and thereplica already has that tuple. If you match on the new tuple and itdoesn't match the expression (so you filter out the update), but the oldtuple does match the expression, then the replica will retain themismatching tuple forever.3. You say that a NULL value in any of those columns causes theexpression to become false and thus the tuple is not published. Thisseems pretty unfriendly, but maybe it would be useful to have examplesof the behavior. Does ExecInitCheck() handle things in the other way,and if so does using a similar trick give more useful behavior?
ExecInitCheck() is designed for CHECK constraints and SQL standard requires
taht NULL constraint conditions are not treated as errors. This feature uses a
WHERE clause and behaves like it. I mean, a NULL result does not return the
row. See ExecQual().
On Wed, Jul 14, 2021 at 6:28 AM Euler Taveira <euler@eulerto.com> wrote: > > On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote: > > 1. if you use REPLICA IDENTITY FULL, then the expressions would work > even if they use any other column with DELETE. Maybe it would be > reasonable to test for this in the code and raise an error if the > expression requires a column that's not part of the replica identity. > (But that could be relaxed if the publication does not publish > updates/deletes.) > +1. > I thought about it but came to the conclusion that it doesn't worth it. Even > with REPLICA IDENTITY FULL expression evaluates to false if the column allows > NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER > TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY > because some row filter uses the column you want to remove from it. > Yeah, that is required but is it not feasible to do so? > 2. For UPDATE, does the expression apply to the old tuple or to the new > tuple? You say it's the new tuple, but from the user point of view I > think it would make more sense that it would apply to the old tuple. > (Of course, if you're thinking that the R.I. is the PK and the PK is > never changed, then you don't really care which one it is, but I bet > that some people would not like that assumption.) > > New tuple. The main reason is that new tuple is always there for UPDATEs. > I am not sure if that is a very good reason to use a new tuple. -- With Regards, Amit Kapila.
On Wed, Jul 14, 2021 at 12:51 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2021-Jul-13, Tomas Vondra wrote: > > > On 7/13/21 5:44 PM, Jeff Davis wrote: > > > > * Andres also mentioned that the function should not leak memory. > > > * One use case for this feature is when sharding a table, so the > > > expression should allow things like "hashint8(x) between ...". I'd > > > really like to see this problem solved, as well. > > .. > > > > Not sure about the memory leaks - I suppose we'd free memory for each row, > > so this shouldn't be an issue I guess ... > > I'm not sure we need to be terribly strict about expression evaluation > not leaking any memory here. I'd rather have a memory context that can > be reset per row. > I also think that should be sufficient here and if I am reading correctly patch already evaluates the expression in per-tuple context and reset it for each tuple. Jeff, do you or Andres have something else in mind? -- With Regards, Amit Kapila.
On Wed, Jul 14, 2021 at 12:37 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/13/21 5:44 PM, Jeff Davis wrote: > > On Tue, 2021-07-13 at 10:24 +0530, Amit Kapila wrote: > > Also: > > > > * Andres also mentioned that the function should not leak memory. > > * One use case for this feature is when sharding a table, so the > > expression should allow things like "hashint8(x) between ...". I'd > > really like to see this problem solved, as well. > > > > I think built-in functions should be fine, because generally don't get > dropped etc. (And if you drop built-in function, well - sorry.) > I am not sure if all built-in functions are also safe. I think we can't allow volatile functions (ex. setval) that can update the database which doesn't seem to be allowed in the historic snapshot. Similarly, it might not be okay to invoke stable functions that access the database as those might expect current snapshot. I think immutable functions should be okay but that brings us to Jeff's question of can we tie the marking of functions that can be used here with IMMUTABLE/STABLE/VOLATILE designation? The UDFs might have a higher risk that something used in those functions can be dropped but I guess we can address that by using the current snapshot to access the publication catalog. > Not sure about the memory leaks - I suppose we'd free memory for each > row, so this shouldn't be an issue I guess ... > > >> I think in the long run one idea to allow UDFs is probably by > >> explicitly allowing users to specify whether the function is > >> publication predicate safe and if so, then we can allow such > >> functions > >> in the filter clause. > > > > This sounds like a better direction. We probably need some kind of > > catalog information here to say what functions/operators are "safe" for > > this kind of purpose. There are a couple questions: > > > > Not sure. It's true it's a bit like volatile/stable/immutable categories > where we can't guarantee those labels are correct, and it's up to the > user to keep the pieces if they pick the wrong category. > > But we can achieve the same goal by introducing a simple GUC called > dangerous_allow_udf_in_decoding, I think. > One guc for all UDFs sounds dangerous. -- With Regards, Amit Kapila.
On Wed, Jul 14, 2021 at 12:45 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/13/21 12:57 PM, Amit Kapila wrote: > > On Tue, Jul 13, 2021 at 10:24 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > I think the problem described by Petr[1] is also possible today if the > > user drops the publication and there is a corresponding subscription, > > basically, the system will stuck with error: "ERROR: publication > > "mypub" does not exist. I think allowing to use non-historic snapshots > > just for publications will resolve that problem as well. > > > > [1] - https://www.postgresql.org/message-id/92e5587d-28b8-5849-2374-5ca3863256f1%402ndquadrant.com > > > > That seems like a completely different problem, TBH. For example the > slot is dropped too, which means the WAL is likely gone etc. > I think if we can use WAL archive (if available) and re-create the slot, the system should move but recreating the publication won't allow the system to move. -- With Regards, Amit Kapila.
On 7/14/21 7:39 AM, Amit Kapila wrote: > On Wed, Jul 14, 2021 at 6:28 AM Euler Taveira <euler@eulerto.com> wrote: >> >> On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote: >> >> 1. if you use REPLICA IDENTITY FULL, then the expressions would work >> even if they use any other column with DELETE. Maybe it would be >> reasonable to test for this in the code and raise an error if the >> expression requires a column that's not part of the replica identity. >> (But that could be relaxed if the publication does not publish >> updates/deletes.) >> > > +1. > >> I thought about it but came to the conclusion that it doesn't worth it. Even >> with REPLICA IDENTITY FULL expression evaluates to false if the column allows >> NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER >> TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY >> because some row filter uses the column you want to remove from it. >> > > Yeah, that is required but is it not feasible to do so? > >> 2. For UPDATE, does the expression apply to the old tuple or to the new >> tuple? You say it's the new tuple, but from the user point of view I >> think it would make more sense that it would apply to the old tuple. >> (Of course, if you're thinking that the R.I. is the PK and the PK is >> never changed, then you don't really care which one it is, but I bet >> that some people would not like that assumption.) >> >> New tuple. The main reason is that new tuple is always there for UPDATEs. >> > > I am not sure if that is a very good reason to use a new tuple. > True. Perhaps we should look at other places with similar concept of WHERE conditions and old/new rows, and try to be consistent with those? I can think of: 1) updatable views with CHECK option 2) row-level security 3) triggers Is there some reasonable rule which of the old/new tuples (or both) to use for the WHERE condition? Or maybe it'd be handy to allow referencing OLD/NEW as in triggers? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 7/14/21 7:39 AM, Amit Kapila wrote: > > On Wed, Jul 14, 2021 at 6:28 AM Euler Taveira <euler@eulerto.com> wrote: > >> > >> On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote: > >> > >> 1. if you use REPLICA IDENTITY FULL, then the expressions would work > >> even if they use any other column with DELETE. Maybe it would be > >> reasonable to test for this in the code and raise an error if the > >> expression requires a column that's not part of the replica identity. > >> (But that could be relaxed if the publication does not publish > >> updates/deletes.) > >> > > > > +1. > > > >> I thought about it but came to the conclusion that it doesn't worth it. Even > >> with REPLICA IDENTITY FULL expression evaluates to false if the column allows > >> NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER > >> TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY > >> because some row filter uses the column you want to remove from it. > >> > > > > Yeah, that is required but is it not feasible to do so? > > > >> 2. For UPDATE, does the expression apply to the old tuple or to the new > >> tuple? You say it's the new tuple, but from the user point of view I > >> think it would make more sense that it would apply to the old tuple. > >> (Of course, if you're thinking that the R.I. is the PK and the PK is > >> never changed, then you don't really care which one it is, but I bet > >> that some people would not like that assumption.) > >> > >> New tuple. The main reason is that new tuple is always there for UPDATEs. > >> > > > > I am not sure if that is a very good reason to use a new tuple. > > > > True. Perhaps we should look at other places with similar concept of > WHERE conditions and old/new rows, and try to be consistent with those? > > I can think of: > > 1) updatable views with CHECK option > > 2) row-level security > > 3) triggers > > Is there some reasonable rule which of the old/new tuples (or both) to > use for the WHERE condition? Or maybe it'd be handy to allow referencing > OLD/NEW as in triggers? I think for insert we are only allowing those rows to replicate which are matching filter conditions, so if we updating any row then also we should maintain that sanity right? That means at least on the NEW rows we should apply the filter, IMHO. Said that, now if there is any row inserted which were satisfying the filter and replicated, if we update it with the new value which is not satisfying the filter then it will not be replicated, I think that makes sense because if an insert is not sending any row to a replica which is not satisfying the filter then why update has to do that, right? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jul 14, 2021 at 6:38 AM Euler Taveira <euler@eulerto.com> wrote:
>
> Peter, thanks for quickly check the new patch. I'm attaching a new patch (v19)
> that addresses (a) this new review, (b) Tomas' review and (c) Greg's review. I
> also included the copy/equal node support for the new node (PublicationTable)
> mentioned by Tomas in another email.
>
Some minor v19 patch review points you might consider for your next
patch version:
(I'm still considering the other issues raised about WHERE clauses and
filtering)
(1) src/backend/commands/publicationcmds.c
OpenTableList
Some suggested abbreviations:
BEFORE:
if (IsA(lfirst(lc), PublicationTable))
whereclause = true;
else
whereclause = false;
AFTER:
whereclause = IsA(lfirst(lc), PublicationTable);
BEFORE:
if (whereclause)
pri->whereClause = t->whereClause;
else
pri->whereClause = NULL;
AFTER:
pri->whereClause = whereclause? t->whereClause : NULL;
(2) src/backend/parser/parse_expr.c
I think that the check below:
/* Functions are not allowed in publication WHERE clauses */
if (pstate->p_expr_kind == EXPR_KIND_PUBLICATION_WHERE &&
nodeTag(expr) == T_FuncCall)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("functions are not allowed in publication WHERE expressions"),
parser_errposition(pstate, exprLocation(expr))));
should be moved down into the "T_FuncCall" case of the switch
statement below it, so that "if (pstate->p_expr_kind ==
EXPR_KIND_PUBLICATION_WHERE" doesn't get checked every call to
transformExprRecurse() regardless of the expression Node type.
(3) Save a nanosecond when entry->exprstate is already NIL:
BEFORE:
if (entry->exprstate != NIL)
list_free_deep(entry->exprstate);
entry->exprstate = NIL;
AFTER:
if (entry->exprstate != NIL)
{
list_free_deep(entry->exprstate);
entry->exprstate = NIL;
}
Regards,
Greg Nancarrow
Fujitsu Australia
On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/14/21 7:39 AM, Amit Kapila wrote: > > On Wed, Jul 14, 2021 at 6:28 AM Euler Taveira <euler@eulerto.com> wrote: > >> > >> On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote: > >> > >> 1. if you use REPLICA IDENTITY FULL, then the expressions would work > >> even if they use any other column with DELETE. Maybe it would be > >> reasonable to test for this in the code and raise an error if the > >> expression requires a column that's not part of the replica identity. > >> (But that could be relaxed if the publication does not publish > >> updates/deletes.) > >> > > > > +1. > > > >> I thought about it but came to the conclusion that it doesn't worth it. Even > >> with REPLICA IDENTITY FULL expression evaluates to false if the column allows > >> NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER > >> TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY > >> because some row filter uses the column you want to remove from it. > >> > > > > Yeah, that is required but is it not feasible to do so? > > > >> 2. For UPDATE, does the expression apply to the old tuple or to the new > >> tuple? You say it's the new tuple, but from the user point of view I > >> think it would make more sense that it would apply to the old tuple. > >> (Of course, if you're thinking that the R.I. is the PK and the PK is > >> never changed, then you don't really care which one it is, but I bet > >> that some people would not like that assumption.) > >> > >> New tuple. The main reason is that new tuple is always there for UPDATEs. > >> > > > > I am not sure if that is a very good reason to use a new tuple. > > > > True. Perhaps we should look at other places with similar concept of > WHERE conditions and old/new rows, and try to be consistent with those? > > I can think of: > > 1) updatable views with CHECK option > > 2) row-level security > > 3) triggers > > Is there some reasonable rule which of the old/new tuples (or both) to > use for the WHERE condition? Or maybe it'd be handy to allow referencing > OLD/NEW as in triggers? > I think apart from the above, it might be good if we can find what some other databases does in this regard? -- With Regards, Amit Kapila.
On 2021-Jul-14, Dilip Kumar wrote: > I think for insert we are only allowing those rows to replicate which > are matching filter conditions, so if we updating any row then also we > should maintain that sanity right? That means at least on the NEW rows > we should apply the filter, IMHO. Said that, now if there is any row > inserted which were satisfying the filter and replicated, if we update > it with the new value which is not satisfying the filter then it will > not be replicated, I think that makes sense because if an insert is > not sending any row to a replica which is not satisfying the filter > then why update has to do that, right? Right, that's a good aspect to think about. I think the guiding principle for which tuple to use for the filter is what is most useful to the potential user of the feature, rather than what is the easiest to implement. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ "La libertad es como el dinero; el que no la sabe emplear la pierde" (Álvarez)
On 7/14/21 4:01 PM, Alvaro Herrera wrote: > On 2021-Jul-14, Dilip Kumar wrote: > >> I think for insert we are only allowing those rows to replicate which >> are matching filter conditions, so if we updating any row then also we >> should maintain that sanity right? That means at least on the NEW rows >> we should apply the filter, IMHO. Said that, now if there is any row >> inserted which were satisfying the filter and replicated, if we update >> it with the new value which is not satisfying the filter then it will >> not be replicated, I think that makes sense because if an insert is >> not sending any row to a replica which is not satisfying the filter >> then why update has to do that, right? > > Right, that's a good aspect to think about. > I agree, that seems like a reasonable approach. The way I'm thinking about this is that for INSERT and DELETE it's clear which row version should be used (because there's just one). And for UPDATE we could see that as DELETE + INSERT, and apply the same rule to each action. On the other hand, I can imagine cases where it'd be useful to send the UPDATE when the old row matches the condition and new row does not. > I think the guiding principle for which tuple to use for the filter is > what is most useful to the potential user of the feature, rather than > what is the easiest to implement. > +1 -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 7/14/21 2:50 PM, Amit Kapila wrote: > On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 7/14/21 7:39 AM, Amit Kapila wrote: >>> On Wed, Jul 14, 2021 at 6:28 AM Euler Taveira <euler@eulerto.com> wrote: >>>> >>>> On Tue, Jul 13, 2021, at 6:06 PM, Alvaro Herrera wrote: >>>> >>>> 1. if you use REPLICA IDENTITY FULL, then the expressions would work >>>> even if they use any other column with DELETE. Maybe it would be >>>> reasonable to test for this in the code and raise an error if the >>>> expression requires a column that's not part of the replica identity. >>>> (But that could be relaxed if the publication does not publish >>>> updates/deletes.) >>>> >>> >>> +1. >>> >>>> I thought about it but came to the conclusion that it doesn't worth it. Even >>>> with REPLICA IDENTITY FULL expression evaluates to false if the column allows >>>> NULL values. Besides that REPLICA IDENTITY is changed via another DDL (ALTER >>>> TABLE) and you have to make sure you don't allow changing REPLICA IDENTITY >>>> because some row filter uses the column you want to remove from it. >>>> >>> >>> Yeah, that is required but is it not feasible to do so? >>> >>>> 2. For UPDATE, does the expression apply to the old tuple or to the new >>>> tuple? You say it's the new tuple, but from the user point of view I >>>> think it would make more sense that it would apply to the old tuple. >>>> (Of course, if you're thinking that the R.I. is the PK and the PK is >>>> never changed, then you don't really care which one it is, but I bet >>>> that some people would not like that assumption.) >>>> >>>> New tuple. The main reason is that new tuple is always there for UPDATEs. >>>> >>> >>> I am not sure if that is a very good reason to use a new tuple. >>> >> >> True. Perhaps we should look at other places with similar concept of >> WHERE conditions and old/new rows, and try to be consistent with those? >> >> I can think of: >> >> 1) updatable views with CHECK option >> >> 2) row-level security >> >> 3) triggers >> >> Is there some reasonable rule which of the old/new tuples (or both) to >> use for the WHERE condition? Or maybe it'd be handy to allow referencing >> OLD/NEW as in triggers? >> > > I think apart from the above, it might be good if we can find what > some other databases does in this regard? > Yeah, that might tell us what the users would like to do with it. I did some quick search, but haven't found much :-( The one thing I found is that Debezium [1] allows accessing both the "old" and "new" rows through value.before and value.after, and use both for filtering. I haven't found much about how this works in other databases, sadly. Perhaps the best way forward is to stick to the approach that INSERT uses new, DELETE uses old and UPDATE works as DELETE+INSERT (probably), and leave anything fancier (like being able to reference both versions of the row) for a future patch. [1] https://wanna-joke.com/wp-content/uploads/2015/01/german-translation-comics-science.jpg regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
{kind=link}
On Wed, Jul 14, 2021 at 8:04 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Perhaps the best way forward is to stick to the approach that INSERT > uses new, DELETE uses old and UPDATE works as DELETE+INSERT (probably), > and leave anything fancier (like being able to reference both versions > of the row) for a future patch. If UPDATE works as DELETE+ INSERT, does that mean both the OLD row and the NEW row should satisfy the filter, then only it will be sent? That means if we insert a row that is not satisfying the condition (which is not sent to the subscriber) and later if we update that row and change the values such that the modified value matches the filter then we will not send it because only the NEW row is satisfying the condition but OLD row doesn't. I am just trying to understand your idea. Or you are saying that in this case, we will not send anything for the OLD row as it was not satisfying the condition but the modified row will be sent as an INSERT operation because this is satisfying the condition? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On 2021-Jul-14, Tomas Vondra wrote: > The way I'm thinking about this is that for INSERT and DELETE it's clear > which row version should be used (because there's just one). And for UPDATE > we could see that as DELETE + INSERT, and apply the same rule to each > action. > > On the other hand, I can imagine cases where it'd be useful to send the > UPDATE when the old row matches the condition and new row does not. In any case, it seems to me that the condition expression should be scanned to see which columns are used in Vars (pull_varattnos?), and verify if those columns are in the REPLICA IDENTITY; and if they are not, raise an error. Most of the time the REPLICA IDENTITY is going to be the primary key; but if the user wants to use other columns in the expression, we can HINT that they can set REPLICA IDENTITY FULL. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ <Schwern> It does it in a really, really complicated way <crab> why does it need to be complicated? <Schwern> Because it's MakeMaker.
On 7/14/21 4:48 PM, Dilip Kumar wrote: > On Wed, Jul 14, 2021 at 8:04 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> > >> Perhaps the best way forward is to stick to the approach that INSERT >> uses new, DELETE uses old and UPDATE works as DELETE+INSERT (probably), >> and leave anything fancier (like being able to reference both versions >> of the row) for a future patch. > > If UPDATE works as DELETE+ INSERT, does that mean both the OLD row and > the NEW row should satisfy the filter, then only it will be sent? > That means if we insert a row that is not satisfying the condition > (which is not sent to the subscriber) and later if we update that row > and change the values such that the modified value matches the filter > then we will not send it because only the NEW row is satisfying the > condition but OLD row doesn't. I am just trying to understand your > idea. Or you are saying that in this case, we will not send anything > for the OLD row as it was not satisfying the condition but the > modified row will be sent as an INSERT operation because this is > satisfying the condition? > Good questions. I'm not sure, I probably have not thought it through. So yeah, I think we should probably stick to the principle that what we send needs to match the filter condition, which applied to this case would mean we should be looking at the new row version. The more elaborate scenarios can be added later by a patch allowing to explicitly reference the old/new row versions. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 7/14/21 4:52 PM, Alvaro Herrera wrote: > On 2021-Jul-14, Tomas Vondra wrote: > >> The way I'm thinking about this is that for INSERT and DELETE it's clear >> which row version should be used (because there's just one). And for UPDATE >> we could see that as DELETE + INSERT, and apply the same rule to each >> action. >> >> On the other hand, I can imagine cases where it'd be useful to send the >> UPDATE when the old row matches the condition and new row does not. > > In any case, it seems to me that the condition expression should be > scanned to see which columns are used in Vars (pull_varattnos?), and > verify if those columns are in the REPLICA IDENTITY; and if they are > not, raise an error. Most of the time the REPLICA IDENTITY is going to > be the primary key; but if the user wants to use other columns in the > expression, we can HINT that they can set REPLICA IDENTITY FULL. > Yeah, but AFAIK that's needed only when replicating DELETEs, so perhaps we could ignore this for subscriptions without DELETE. The other question is when to check/enforce this. I guess we'll have to do that during decoding, not just when the publication is being created, because the user can do ALTER TABLE later. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2021-Jul-14, Tomas Vondra wrote: > On 7/14/21 4:52 PM, Alvaro Herrera wrote: > > In any case, it seems to me that the condition expression should be > > scanned to see which columns are used in Vars (pull_varattnos?), and > > verify if those columns are in the REPLICA IDENTITY; and if they are > > not, raise an error. Most of the time the REPLICA IDENTITY is going to > > be the primary key; but if the user wants to use other columns in the > > expression, we can HINT that they can set REPLICA IDENTITY FULL. > > Yeah, but AFAIK that's needed only when replicating DELETEs, so perhaps we > could ignore this for subscriptions without DELETE. Yeah, I said that too in my older reply :-) > The other question is when to check/enforce this. I guess we'll have to do > that during decoding, not just when the publication is being created, > because the user can do ALTER TABLE later. ... if you're saying the user can change the replica identity after we have some publications with filters defined, then I think we should verify during ALTER TABLE and not allow the change if there's a publication that requires it. I mean, during decoding we should be able to simply assume that the tuple is correct for what we need at that point. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
On Wed, Jul 14, 2021, at 11:48 AM, Dilip Kumar wrote:
On Wed, Jul 14, 2021 at 8:04 PM Tomas Vondra<tomas.vondra@enterprisedb.com> wrote:>> Perhaps the best way forward is to stick to the approach that INSERT> uses new, DELETE uses old and UPDATE works as DELETE+INSERT (probably),> and leave anything fancier (like being able to reference both versions> of the row) for a future patch.If UPDATE works as DELETE+ INSERT, does that mean both the OLD row andthe NEW row should satisfy the filter, then only it will be sent?That means if we insert a row that is not satisfying the condition(which is not sent to the subscriber) and later if we update that rowand change the values such that the modified value matches the filterthen we will not send it because only the NEW row is satisfying thecondition but OLD row doesn't. I am just trying to understand youridea. Or you are saying that in this case, we will not send anythingfor the OLD row as it was not satisfying the condition but themodified row will be sent as an INSERT operation because this issatisfying the condition?
That's a fair argument for the default UPDATE behavior. It seems we have a
consensus that UPDATE operation will use old row. If there is no objections, I
will change it in the next version.
We can certainly discuss the possibilities for UPDATE operations. It can choose
which row to use: old, new or both (using an additional publication argument or
OLD and NEW placeholders to reference old and new rows are feasible ideas).
On Wed, Jul 14, 2021, at 12:08 PM, Tomas Vondra wrote:
Yeah, but AFAIK that's needed only when replicating DELETEs, so perhapswe could ignore this for subscriptions without DELETE.
... and UPDATE. It seems we have a consensus to use old row in the row filter
for UPDATEs. I think you meant publication.
The other question is when to check/enforce this. I guess we'll have todo that during decoding, not just when the publication is being created,because the user can do ALTER TABLE later.
I'm afraid this check during decoding has a considerable cost. If we want to
enforce this condition, I suggest that we add it to CREATE PUBLICATION, ALTER
PUBLICATION ... ADD|SET TABLE and ALTER TABLE ... REPLICA IDENTITY. Data are
being constantly modified; schema is not.
On Wed, Jul 14, 2021, at 8:21 AM, Greg Nancarrow wrote:
Some minor v19 patch review points you might consider for your nextpatch version:
Greg, thanks for another review. I agree with all of these changes. It will be
in the next patch.
On Wed, Jul 14, 2021 at 8:43 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2021-Jul-14, Tomas Vondra wrote: > > > The other question is when to check/enforce this. I guess we'll have to do > > that during decoding, not just when the publication is being created, > > because the user can do ALTER TABLE later. > > ... if you're saying the user can change the replica identity after we > have some publications with filters defined, then I think we should > verify during ALTER TABLE and not allow the change if there's a > publication that requires it. I mean, during decoding we should be able > to simply assume that the tuple is correct for what we need at that > point. > +1. -- With Regards, Amit Kapila.
On Wed, Jul 14, 2021 at 10:55 PM Euler Taveira <euler@eulerto.com> wrote: > > On Wed, Jul 14, 2021, at 12:08 PM, Tomas Vondra wrote: > > Yeah, but AFAIK that's needed only when replicating DELETEs, so perhaps > we could ignore this for subscriptions without DELETE. > > ... and UPDATE. It seems we have a consensus to use old row in the row filter > for UPDATEs. I think you meant publication. > If I read correctly people are suggesting to use a new row for updates but I still suggest completing the analysis (or at least spend some more time) Tomas and I requested in the few emails above and then conclude on this point. -- With Regards, Amit Kapila.
On Thu, Jul 15, 2021 at 7:37 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jul 14, 2021 at 10:55 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Wed, Jul 14, 2021, at 12:08 PM, Tomas Vondra wrote: > > > > Yeah, but AFAIK that's needed only when replicating DELETEs, so perhaps > > we could ignore this for subscriptions without DELETE. > > > > ... and UPDATE. It seems we have a consensus to use old row in the row filter > > for UPDATEs. I think you meant publication. > > > > If I read correctly people are suggesting to use a new row for updates Right > but I still suggest completing the analysis (or at least spend some > more time) Tomas and I requested in the few emails above and then > conclude on this point. +1 -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jul 14, 2021 at 10:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > I think apart from the above, it might be good if we can find what > some other databases does in this regard? > I did a bit of investigation in the case of Oracle Database and SQL Server. (purely from my interpretation of available documentation; I did not actually use the replication software) For Oracle (GoldenGate), it appears that it provides the ability for filters to reference both OLD and NEW rows in replication of UPDATEs: "For update operations, it can be advantageous to retrieve the before values of source columns: the values before the update occurred. These values are stored in the trail and can be used in filters and column mappings" It provides @BEFORE and @AFTER functions for this. For SQL Server, the available replication models seem quite different to that in PostgreSQL, and not all seem to support row filtering. For "snapshot replication", it seems that it effectively supports filtering rows on the NEW values. It seems that the snapshot is taken at a transactional boundary and rows included according to any filtering, and is then replicated. So to include the result of a particular UPDATE in the replication, the replication row filtering would effectively be done on the result (NEW) rows. Another type of replication that supports row filtering is "merge replication", which again seems to be effectively based on NEW rows: "For merge replication to process a row, the data in the row must satisfy the row filter, and it must have changed since the last synchronization" It's not clear to me if there is ANY way to filter on the OLD row values by using some option. If anybody has experience with the replication software for these other databases and I've interpreted the documentation for these incorrectly, please let me know. Regards, Greg Nancarrow Fujitsu Australia
On Thu, Jul 15, 2021 at 4:30 AM Euler Taveira <euler@eulerto.com> wrote: > > On Wed, Jul 14, 2021, at 8:21 AM, Greg Nancarrow wrote: > > Some minor v19 patch review points you might consider for your next > patch version: > > Greg, thanks for another review. I agree with all of these changes. It will be > in the next patch. Hi, here are a couple more minor review comments for the V19 patch. (The 2nd one overlaps a bit with one that Greg previously gave). ////// 1. doc/src/sgml/ref/create_publication.sgml + columns. A <literal>NULL</literal> value causes the expression to evaluate + to false; avoid using columns without not-null constraints in the + <literal>WHERE</literal> clause. The <literal>WHERE</literal> clause does + not allow functions and user-defined operators. + </para> => typo: "and user-defined operators." --> "or user-defined operators." ------ 2. src/backend/commands/publicationcmds.c - OpenTableList IsA logic IIUC the tables list can only consist of one kind of list element. Since there is no expected/permitted "mixture" of kinds then there is no need to check the IsA within the loop like v19 is doing; instead you can check only the list head element. If you want to, then you could Assert that every list element has a consistent kind as the initial kind, but maybe that is overkill too? PSA a small tmp patch to demonstrate what this comment is about. ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Wed, Jul 14, 2021 at 4:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > Is there some reasonable rule which of the old/new tuples (or both) to > > use for the WHERE condition? Or maybe it'd be handy to allow referencing > > OLD/NEW as in triggers? > > I think for insert we are only allowing those rows to replicate which > are matching filter conditions, so if we updating any row then also we > should maintain that sanity right? That means at least on the NEW rows > we should apply the filter, IMHO. Said that, now if there is any row > inserted which were satisfying the filter and replicated, if we update > it with the new value which is not satisfying the filter then it will > not be replicated, I think that makes sense because if an insert is > not sending any row to a replica which is not satisfying the filter > then why update has to do that, right? > There is another theory in this regard which is what if the old row (created by the previous insert) is not sent to the subscriber as that didn't match the filter but after the update, we decide to send it because the updated row (new row) matches the filter condition. In this case, I think it will generate an update conflict on the subscriber as the old row won't be present. As of now, we just skip the update but in the future, we might have some conflict handling there. If this is true then even if the new row matches the filter, there is no guarantee that it will be applied on the subscriber-side unless the old row also matches the filter. Sure, there could be a case where the user might have changed the filter between insert and update but maybe we can have a separate way to deal with such cases if required like providing some provision where the user can specify whether it would like to match old/new row in updates? -- With Regards, Amit Kapila.
On Fri, Jul 16, 2021 at 8:57 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jul 14, 2021 at 4:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > Is there some reasonable rule which of the old/new tuples (or both) to > > > use for the WHERE condition? Or maybe it'd be handy to allow referencing > > > OLD/NEW as in triggers? > > > > I think for insert we are only allowing those rows to replicate which > > are matching filter conditions, so if we updating any row then also we > > should maintain that sanity right? That means at least on the NEW rows > > we should apply the filter, IMHO. Said that, now if there is any row > > inserted which were satisfying the filter and replicated, if we update > > it with the new value which is not satisfying the filter then it will > > not be replicated, I think that makes sense because if an insert is > > not sending any row to a replica which is not satisfying the filter > > then why update has to do that, right? > > > > There is another theory in this regard which is what if the old row > (created by the previous insert) is not sent to the subscriber as that > didn't match the filter but after the update, we decide to send it > because the updated row (new row) matches the filter condition. In > this case, I think it will generate an update conflict on the > subscriber as the old row won't be present. As of now, we just skip > the update but in the future, we might have some conflict handling > there. If this is true then even if the new row matches the filter, > there is no guarantee that it will be applied on the subscriber-side > unless the old row also matches the filter. Yeah, it's a valid point. Sure, there could be a > case where the user might have changed the filter between insert and > update but maybe we can have a separate way to deal with such cases if > required like providing some provision where the user can specify > whether it would like to match old/new row in updates? Yeah, I think the best way is that users should get an option whether they want to apply the filter on the old row or on the new row, or both, in fact, they should be able to apply the different filters on old and new rows. I have one more thought in mind: currently, we are providing a filter for the publication table, doesn't it make sense to provide filters for operations of the publication table? I mean the different filters for Insert, delete, and the old row of update and the new row of the update. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Fri, Jul 16, 2021 at 10:11 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Jul 16, 2021 at 8:57 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Jul 14, 2021 at 4:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra > > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > > > Is there some reasonable rule which of the old/new tuples (or both) to > > > > use for the WHERE condition? Or maybe it'd be handy to allow referencing > > > > OLD/NEW as in triggers? > > > > > > I think for insert we are only allowing those rows to replicate which > > > are matching filter conditions, so if we updating any row then also we > > > should maintain that sanity right? That means at least on the NEW rows > > > we should apply the filter, IMHO. Said that, now if there is any row > > > inserted which were satisfying the filter and replicated, if we update > > > it with the new value which is not satisfying the filter then it will > > > not be replicated, I think that makes sense because if an insert is > > > not sending any row to a replica which is not satisfying the filter > > > then why update has to do that, right? > > > > > > > There is another theory in this regard which is what if the old row > > (created by the previous insert) is not sent to the subscriber as that > > didn't match the filter but after the update, we decide to send it > > because the updated row (new row) matches the filter condition. In > > this case, I think it will generate an update conflict on the > > subscriber as the old row won't be present. As of now, we just skip > > the update but in the future, we might have some conflict handling > > there. If this is true then even if the new row matches the filter, > > there is no guarantee that it will be applied on the subscriber-side > > unless the old row also matches the filter. > > Yeah, it's a valid point. > > Sure, there could be a > > case where the user might have changed the filter between insert and > > update but maybe we can have a separate way to deal with such cases if > > required like providing some provision where the user can specify > > whether it would like to match old/new row in updates? > > Yeah, I think the best way is that users should get an option whether > they want to apply the filter on the old row or on the new row, or > both, in fact, they should be able to apply the different filters on > old and new rows. > I am not so sure about different filters for old and new rows but it makes sense to by default apply the filter to both old and new rows. Then also provide a way for user to specify if the filter can be specified to just old or new row. > I have one more thought in mind: currently, we are > providing a filter for the publication table, doesn't it make sense to > provide filters for operations of the publication table? I mean the > different filters for Insert, delete, and the old row of update and > the new row of the update. > Hmm, I think this sounds a bit of a stretch but if there is any field use case then we can consider this in the future. -- With Regards, Amit Kapila.
On Fri, Jul 16, 2021 at 3:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > I am not so sure about different filters for old and new rows but it > makes sense to by default apply the filter to both old and new rows. > Then also provide a way for user to specify if the filter can be > specified to just old or new row. > I'm having some doubts and concerns about what is being suggested. My current thought and opinion is that the row filter should (initially, or at least by default) specify the condition of the row data at the publication boundary (i.e. what is actually sent to and received by the subscriber). That means for UPDATE, I think that the filter should operate on the new value. This has the clear advantage of knowing (from the WHERE expression) what restrictions are placed on the data that is actually published and what subscribers will actually receive. So it's more predictable. If we filter on OLD rows, then we would need to know exactly what is updated by the UPDATE in order to know what is actually published (for example, the UPDATE could modify the columns being checked in the publication WHERE expression). I'm not saying that's wrong, or a bad idea, but it's more complicated and potentially confusing. Maybe there could be an option for it. Also, even if we allowed OLD/NEW to be specified in the WHERE expression, OLD wouldn't make sense for INSERT and NEW wouldn't make sense for DELETE, so one WHERE expression with OLD/NEW references wouldn't seem valid to cover all operations INSERT, UPDATE and DELETE. I think that was what Dilip was essentially referring to, with his suggestion of using different filters for different operations (though I think that may be going too far for the initial implementation). Regards, Greg Nancarrow Fujitsu Australia
On 7/16/21 5:26 AM, Amit Kapila wrote: > On Wed, Jul 14, 2021 at 4:30 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: >> >> On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> >>> Is there some reasonable rule which of the old/new tuples (or both) to >>> use for the WHERE condition? Or maybe it'd be handy to allow referencing >>> OLD/NEW as in triggers? >> >> I think for insert we are only allowing those rows to replicate which >> are matching filter conditions, so if we updating any row then also we >> should maintain that sanity right? That means at least on the NEW rows >> we should apply the filter, IMHO. Said that, now if there is any row >> inserted which were satisfying the filter and replicated, if we update >> it with the new value which is not satisfying the filter then it will >> not be replicated, I think that makes sense because if an insert is >> not sending any row to a replica which is not satisfying the filter >> then why update has to do that, right? >> > > There is another theory in this regard which is what if the old row > (created by the previous insert) is not sent to the subscriber as that > didn't match the filter but after the update, we decide to send it > because the updated row (new row) matches the filter condition. In > this case, I think it will generate an update conflict on the > subscriber as the old row won't be present. As of now, we just skip > the update but in the future, we might have some conflict handling > there. Right. > If this is true then even if the new row matches the filter, > there is no guarantee that it will be applied on the subscriber-side > unless the old row also matches the filter. Sure, there could be a > case where the user might have changed the filterbetween insert and > update but maybe we can have a separate way to deal with such cases if > required like providing some provision where the user can specify > whether it would like to match old/new row in updates? > I think the best we can do for now is to document this. AFAICS it can't be solved without a conflict resolution that would turn the UPDATE to INSERT. And that would require REPLICA IDENTITY FULL, otherwise the UPDATE would not have data for all the columns. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2021-Jul-16, Greg Nancarrow wrote: > On Fri, Jul 16, 2021 at 3:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > I am not so sure about different filters for old and new rows but it > > makes sense to by default apply the filter to both old and new rows. > > Then also provide a way for user to specify if the filter can be > > specified to just old or new row. > > I'm having some doubts and concerns about what is being suggested. Yeah. I think the idea that some updates fail to reach the replica, leaving the downstream database in a different state than it would be if those updates had reached it, is unsettling. It makes me wish we raised an error at UPDATE time if both rows would not pass the filter test in the same way -- that is, if the old row passes the filter, then the new row must be a pass as well. Maybe a second option is to have replication change any UPDATE into either an INSERT or a DELETE, if the old or the new row do not pass the filter, respectively. That way, the databases would remain consistent. -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/ "You're _really_ hosed if the person doing the hiring doesn't understand relational systems: you end up with a whole raft of programmers, none of whom has had a Date with the clue stick." (Andrew Sullivan)
On Sat, Jul 17, 2021 at 3:05 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2021-Jul-16, Greg Nancarrow wrote: > > > On Fri, Jul 16, 2021 at 3:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > I am not so sure about different filters for old and new rows but it > > > makes sense to by default apply the filter to both old and new rows. > > > Then also provide a way for user to specify if the filter can be > > > specified to just old or new row. > > > > I'm having some doubts and concerns about what is being suggested. > > Yeah. I think the idea that some updates fail to reach the replica, > leaving the downstream database in a different state than it would be if > those updates had reached it, is unsettling. It makes me wish we raised > an error at UPDATE time if both rows would not pass the filter test in > the same way -- that is, if the old row passes the filter, then the new > row must be a pass as well. > Hmm, do you mean to say that raise an error in walsender while decoding if old or new doesn't match filter clause? How would walsender come out of that error? Even, if seeing the error user changed the filter clause for publication, I think it would still see the old ones due to historical snapshot and keep on getting the same error. One idea could be that we use the current snapshot to read the publications catalog table, then the user would probably change the filter or do something to move forward from this error. The other options could be: a. Just log it and move to the next row b. send to stats collector some info about this which can be displayed in a view and then move ahead c. just skip it like any other row that doesn't match the filter clause. I am not sure if there is any use of sending a row if one of the old/new rows doesn't match the filter. Because if the old row doesn't match but the new one matches the criteria, we will anyway just throw such a row on the subscriber instead of applying it. OTOH, if old matches but new doesn't match then it probably doesn't fit the analogy that new rows should behave similarly to Inserts. I am of opinion that we should do either (a) or (c) when one of the old or new rows doesn't match the filter clause. > Maybe a second option is to have replication change any UPDATE into > either an INSERT or a DELETE, if the old or the new row do not pass the > filter, respectively. That way, the databases would remain consistent. > I guess such things should be handled via conflict resolution on the subscriber side. -- With Regards, Amit Kapila.
On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > a. Just log it and move to the next row > b. send to stats collector some info about this which can be displayed > in a view and then move ahead > c. just skip it like any other row that doesn't match the filter clause. > > I am not sure if there is any use of sending a row if one of the > old/new rows doesn't match the filter. Because if the old row doesn't > match but the new one matches the criteria, we will anyway just throw > such a row on the subscriber instead of applying it. But at some time that will be true even if we skip the row based on (a) or (c) right. Suppose the OLD row was not satisfying the condition but the NEW row is satisfying the condition, now even if we skip this operation then in the next operation on the same row even if both OLD and NEW rows are satisfying the filter the operation will just be dropped by the subscriber right? because we did not send the previous row when it first updated to value which were satisfying the condition. So basically, any row is inserted which did not satisfy the condition first then post that no matter how many updates we do to that row either it will be skipped by the publisher because the OLD row was not satisfying the condition or it will be skipped by the subscriber as there was no matching row. > > Maybe a second option is to have replication change any UPDATE into > > either an INSERT or a DELETE, if the old or the new row do not pass the > > filter, respectively. That way, the databases would remain consistent. Yeah, I think this is the best way to keep the data consistent. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jul 14, 2021 at 8:03 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/14/21 2:50 PM, Amit Kapila wrote: > > On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra > > > > I think apart from the above, it might be good if we can find what > > some other databases does in this regard? > > > > Yeah, that might tell us what the users would like to do with it. I did > some quick search, but haven't found much :-( The one thing I found is > that Debezium [1] allows accessing both the "old" and "new" rows through > value.before and value.after, and use both for filtering. > Okay, but does it apply a filter to both rows for an Update event? > > [1] > https://wanna-joke.com/wp-content/uploads/2015/01/german-translation-comics-science.jpg > This link doesn't provide Debezium information, seems like a typo. -- With Regards, Amit Kapila.
On 7/19/21 1:00 PM, Dilip Kumar wrote: > On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: >> a. Just log it and move to the next row >> b. send to stats collector some info about this which can be displayed >> in a view and then move ahead >> c. just skip it like any other row that doesn't match the filter clause. >> >> I am not sure if there is any use of sending a row if one of the >> old/new rows doesn't match the filter. Because if the old row doesn't >> match but the new one matches the criteria, we will anyway just throw >> such a row on the subscriber instead of applying it. > > But at some time that will be true even if we skip the row based on > (a) or (c) right. Suppose the OLD row was not satisfying the > condition but the NEW row is satisfying the condition, now even if we > skip this operation then in the next operation on the same row even if > both OLD and NEW rows are satisfying the filter the operation will > just be dropped by the subscriber right? because we did not send the > previous row when it first updated to value which were satisfying the > condition. So basically, any row is inserted which did not satisfy > the condition first then post that no matter how many updates we do to > that row either it will be skipped by the publisher because the OLD > row was not satisfying the condition or it will be skipped by the > subscriber as there was no matching row. > I have a feeling it's getting overly complicated, to the extent that it'll be hard to explain to users and reason about. I don't think there's a "perfect" solution for cases when the filter expression gives different answers for old/new row - it'll always be surprising for some users :-( So maybe the best thing is to stick to the simple approach already used e.g. by pglogical, which simply user the new row when available (insert, update) and old one for deletes. I think that behaves more or less sensibly and it's easy to explain. All the other things (e.g. turning UPDATE to INSERT, advanced conflict resolution etc.) will require a lot of other stuff, and I see them as improvements of this simple approach. >>> Maybe a second option is to have replication change any UPDATE into >>> either an INSERT or a DELETE, if the old or the new row do not pass the >>> filter, respectively. That way, the databases would remain consistent. > > Yeah, I think this is the best way to keep the data consistent. > It'd also require REPLICA IDENTITY FULL, which seems like it'd add a rather significant overhead. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 7/19/21 1:30 PM, Amit Kapila wrote: > On Wed, Jul 14, 2021 at 8:03 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 7/14/21 2:50 PM, Amit Kapila wrote: >>> On Wed, Jul 14, 2021 at 3:58 PM Tomas Vondra >>> >>> I think apart from the above, it might be good if we can find what >>> some other databases does in this regard? >>> >> >> Yeah, that might tell us what the users would like to do with it. I did >> some quick search, but haven't found much :-( The one thing I found is >> that Debezium [1] allows accessing both the "old" and "new" rows through >> value.before and value.after, and use both for filtering. >> > > Okay, but does it apply a filter to both rows for an Update event? > >> >> [1] >> https://wanna-joke.com/wp-content/uploads/2015/01/german-translation-comics-science.jpg >> > > This link doesn't provide Debezium information, seems like a typo. > Uh, yeah - I copied a different link. I meant to send this one: https://debezium.io/documentation/reference/configuration/filtering.html regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jul 19, 2021 at 11:32 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > I have a feeling it's getting overly complicated, to the extent that > it'll be hard to explain to users and reason about. I don't think > there's a "perfect" solution for cases when the filter expression gives > different answers for old/new row - it'll always be surprising for some > users :-( > > So maybe the best thing is to stick to the simple approach already used > e.g. by pglogical, which simply user the new row when available (insert, > update) and old one for deletes. > > I think that behaves more or less sensibly and it's easy to explain. > > All the other things (e.g. turning UPDATE to INSERT, advanced conflict > resolution etc.) will require a lot of other stuff, and I see them as > improvements of this simple approach. > +1 My thoughts on this are very similar. Regards, Greg Nancarrow Fujitsu Australia
Hi, I am interested in this feature and took a quick a look at the patch. Here are a few comments. (1) + appendStringInfo(&cmd, "%s", q); We'd better use appendStringInfoString(&cmd, q); (2) + whereclause = transformWhereClause(pstate, + copyObject(pri->whereClause), + EXPR_KIND_PUBLICATION_WHERE, + "PUBLICATION"); + + /* Fix up collation information */ + assign_expr_collations(pstate, whereclause); Is it better to invoke eval_const_expressions or canonicalize_qual here to simplify the expression ? (3) + appendPQExpBuffer(&buf, + ", pg_get_expr(pr.prqual, c.oid)"); + else + appendPQExpBuffer(&buf, + ", NULL"); we'd better use appendPQExpBufferStr instead of appendPQExpBuffer here. (4) nodeTag(expr) == T_FuncCall) It might looks clearer to use IsA(expr, FuncCall) here. Best regards, Houzj
On 2021-Jul-19, Tomas Vondra wrote: > I have a feeling it's getting overly complicated, to the extent that > it'll be hard to explain to users and reason about. I don't think > there's a "perfect" solution for cases when the filter expression gives > different answers for old/new row - it'll always be surprising for some > users :-( > > So maybe the best thing is to stick to the simple approach already used > e.g. by pglogical, which simply user the new row when available (insert, > update) and old one for deletes. OK, no objection to that plan. -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/ "No es bueno caminar con un hombre muerto"
On Mon, Jul 19, 2021 at 4:31 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > Maybe a second option is to have replication change any UPDATE into > > > either an INSERT or a DELETE, if the old or the new row do not pass the > > > filter, respectively. That way, the databases would remain consistent. > > Yeah, I think this is the best way to keep the data consistent. > Today, while studying the behavior of this particular operation in other databases, I found that IBM's InfoSphere Data Replication does exactly this. See [1]. I think there is a merit if want to follow this idea. [1] - https://www.ibm.com/docs/en/idr/11.4.0?topic=rows-search-conditions -- With Regards, Amit Kapila.
On Mon, Jul 19, 2021 at 7:02 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/19/21 1:00 PM, Dilip Kumar wrote: > > On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > >> a. Just log it and move to the next row > >> b. send to stats collector some info about this which can be displayed > >> in a view and then move ahead > >> c. just skip it like any other row that doesn't match the filter clause. > >> > >> I am not sure if there is any use of sending a row if one of the > >> old/new rows doesn't match the filter. Because if the old row doesn't > >> match but the new one matches the criteria, we will anyway just throw > >> such a row on the subscriber instead of applying it. > > > > But at some time that will be true even if we skip the row based on > > (a) or (c) right. Suppose the OLD row was not satisfying the > > condition but the NEW row is satisfying the condition, now even if we > > skip this operation then in the next operation on the same row even if > > both OLD and NEW rows are satisfying the filter the operation will > > just be dropped by the subscriber right? because we did not send the > > previous row when it first updated to value which were satisfying the > > condition. So basically, any row is inserted which did not satisfy > > the condition first then post that no matter how many updates we do to > > that row either it will be skipped by the publisher because the OLD > > row was not satisfying the condition or it will be skipped by the > > subscriber as there was no matching row. > > > > I have a feeling it's getting overly complicated, to the extent that > it'll be hard to explain to users and reason about. I don't think > there's a "perfect" solution for cases when the filter expression gives > different answers for old/new row - it'll always be surprising for some > users :-( > It is possible but OTOH, the three replication solutions (Debezium, Oracle, IBM's InfoSphere Data Replication) which have this feature seems to filter based on both old and new rows in one or another way. Also, I am not sure if the simple approach of just filter based on the new row is very clear because it can also confuse users in a way that even if all the new rows matches the filters, they don't see anything on the subscriber and in fact, that can cause a lot of network overhead without any gain. > So maybe the best thing is to stick to the simple approach already used > e.g. by pglogical, which simply user the new row when available (insert, > update) and old one for deletes. > > I think that behaves more or less sensibly and it's easy to explain. > Okay, if nothing better comes up, then we can fall back to this option. > All the other things (e.g. turning UPDATE to INSERT, advanced conflict > resolution etc.) will require a lot of other stuff, > I have not evaluated this yet but I think spending some time thinking about turning Update to Insert/Delete (yesterday's suggestion by Alvaro) might be worth especially as that seems to be followed by some other replication solution as well. >and I see them as > improvements of this simple approach. > > >>> Maybe a second option is to have replication change any UPDATE into > >>> either an INSERT or a DELETE, if the old or the new row do not pass the > >>> filter, respectively. That way, the databases would remain consistent. > > > > Yeah, I think this is the best way to keep the data consistent. > > > > It'd also require REPLICA IDENTITY FULL, which seems like it'd add a > rather significant overhead. > Why? I think it would just need similar restrictions as we are planning for Delete operation such that filter columns must be either present in primary or replica identity columns. -- With Regards, Amit Kapila.
On Tue, Jul 20, 2021 at 2:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Today, while studying the behavior of this particular operation in
> other databases, I found that IBM's InfoSphere Data Replication does
> exactly this. See [1]. I think there is a merit if want to follow this
> idea.
>
So in this model (after initial sync of rows according to the filter),
for UPDATE, the OLD row is checked against the WHERE clause, to know
if the row had been previously published. If it hadn't, and the NEW
row satisfies the WHERE clause, then it needs to be published as an
INSERT. If it had been previously published, but the NEW row doesn't
satisfy the WHERE condition, then it needs to be published as a
DELETE. Otherwise, if both OLD and NEW rows satisfy the WHERE clause,
it needs to be published as an UPDATE.
At least, that seems to be the model when the WHERE clause refers to
the NEW (updated) values, as used in most of their samples (i.e. in
that database "the current log record", indicated by a ":" prefix on
the column name).
I think that allowing the OLD values ("old log record") to be
referenced in the WHERE clause, as that model does, could be
potentially confusing.
Regards,
Greg Nancarrow
Fujitsu Australia
On Tue, Jul 20, 2021 at 11:38 AM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> On Tue, Jul 20, 2021 at 2:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > Today, while studying the behavior of this particular operation in
> > other databases, I found that IBM's InfoSphere Data Replication does
> > exactly this. See [1]. I think there is a merit if want to follow this
> > idea.
> >
>
> So in this model (after initial sync of rows according to the filter),
> for UPDATE, the OLD row is checked against the WHERE clause, to know
> if the row had been previously published. If it hadn't, and the NEW
> row satisfies the WHERE clause, then it needs to be published as an
> INSERT. If it had been previously published, but the NEW row doesn't
> satisfy the WHERE condition, then it needs to be published as a
> DELETE. Otherwise, if both OLD and NEW rows satisfy the WHERE clause,
> it needs to be published as an UPDATE.
>
Yeah, this is what I also understood.
> At least, that seems to be the model when the WHERE clause refers to
> the NEW (updated) values, as used in most of their samples (i.e. in
> that database "the current log record", indicated by a ":" prefix on
> the column name).
> I think that allowing the OLD values ("old log record") to be
> referenced in the WHERE clause, as that model does, could be
> potentially confusing.
>
I think in terms of referring to old and new rows, we already have
terminology which we used at various other similar places. See Create
Rule docs [1]. For where clause, it says "Within condition and
command, the special table names NEW and OLD can be used to refer to
values in the referenced table. NEW is valid in ON INSERT and ON
UPDATE rules to refer to the new row being inserted or updated. OLD is
valid in ON UPDATE and ON DELETE rules to refer to the existing row
being updated or deleted.". We need similar things for the WHERE
clause in publication if we want special syntax to refer to old and
new rows.
I think if we use some existing way to refer to old/new values then it
shouldn't be confusing to users.
[1] - https://www.postgresql.org/docs/devel/sql-createrule.html
--
With Regards,
Amit Kapila.
On Tue, Jul 20, 2021 at 9:54 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jul 19, 2021 at 4:31 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > Maybe a second option is to have replication change any UPDATE into > > > > either an INSERT or a DELETE, if the old or the new row do not pass the > > > > filter, respectively. That way, the databases would remain consistent. > > > > Yeah, I think this is the best way to keep the data consistent. > > > > Today, while studying the behavior of this particular operation in > other databases, I found that IBM's InfoSphere Data Replication does > exactly this. See [1]. I think there is a merit if want to follow this > idea. > As per my initial analysis, there shouldn't be much difficulty in implementing this behavior. We need to change the filter API (pgoutput_row_filter) such that it tells us whether the filter is satisfied by the old row, new row or both and then the caller should be able to make a decision based on that. I think that should be sufficient to turn update to insert/delete when required. I might be missing something here but this doesn't appear to require any drastic changes in the patch. -- With Regards, Amit Kapila.
On Wed, Jul 14, 2021 at 2:08 AM Euler Taveira <euler@eulerto.com> wrote: > > On Tue, Jul 13, 2021, at 12:25 AM, Peter Smith wrote: > > I have reviewed the latest v18 patch. Below are some more review > comments and patches. > > Peter, thanks for quickly check the new patch. I'm attaching a new patch (v19). > The latest patch doesn't apply cleanly. Can you please rebase it and see if you can address some simpler comments till we reach a consensus on some of the remaining points? -- With Regards, Amit Kapila.
On 7/20/21 7:23 AM, Amit Kapila wrote: > On Mon, Jul 19, 2021 at 7:02 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 7/19/21 1:00 PM, Dilip Kumar wrote: >>> On Mon, Jul 19, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> a. Just log it and move to the next row >>>> b. send to stats collector some info about this which can be displayed >>>> in a view and then move ahead >>>> c. just skip it like any other row that doesn't match the filter clause. >>>> >>>> I am not sure if there is any use of sending a row if one of the >>>> old/new rows doesn't match the filter. Because if the old row doesn't >>>> match but the new one matches the criteria, we will anyway just throw >>>> such a row on the subscriber instead of applying it. >>> >>> But at some time that will be true even if we skip the row based on >>> (a) or (c) right. Suppose the OLD row was not satisfying the >>> condition but the NEW row is satisfying the condition, now even if we >>> skip this operation then in the next operation on the same row even if >>> both OLD and NEW rows are satisfying the filter the operation will >>> just be dropped by the subscriber right? because we did not send the >>> previous row when it first updated to value which were satisfying the >>> condition. So basically, any row is inserted which did not satisfy >>> the condition first then post that no matter how many updates we do to >>> that row either it will be skipped by the publisher because the OLD >>> row was not satisfying the condition or it will be skipped by the >>> subscriber as there was no matching row. >>> >> >> I have a feeling it's getting overly complicated, to the extent that >> it'll be hard to explain to users and reason about. I don't think >> there's a "perfect" solution for cases when the filter expression gives >> different answers for old/new row - it'll always be surprising for some >> users :-( >> > > > It is possible but OTOH, the three replication solutions (Debezium, > Oracle, IBM's InfoSphere Data Replication) which have this feature > seems to filter based on both old and new rows in one or another way. > Also, I am not sure if the simple approach of just filter based on the > new row is very clear because it can also confuse users in a way that > even if all the new rows matches the filters, they don't see anything > on the subscriber and in fact, that can cause a lot of network > overhead without any gain. > True. My point is that it's easier to explain than when using some combination of old/new row, and theapproach "replicate if the filter matches both rows" proposed in this thread would be confusing too. If the subscriber database can be modified, we kinda already have this issue already - the row can be deleted, and all UPDATEs will be lost. Yes, for read-only replicas that won't happen, but I think we're moving to use cases more advanced than that. I think there are only two ways to *guarantee* this does not happen: * prohibit updates of columns referenced in row filters * some sort of conflict resolution, turning UPDATE to INSERT etc. >> So maybe the best thing is to stick to the simple approach already used >> e.g. by pglogical, which simply user the new row when available (insert, >> update) and old one for deletes. >> >> I think that behaves more or less sensibly and it's easy to explain. >> > > Okay, if nothing better comes up, then we can fall back to this option. > >> All the other things (e.g. turning UPDATE to INSERT, advanced conflict >> resolution etc.) will require a lot of other stuff, >> > > I have not evaluated this yet but I think spending some time thinking > about turning Update to Insert/Delete (yesterday's suggestion by > Alvaro) might be worth especially as that seems to be followed by some > other replication solution as well. > I think that requires quite a bit of infrastructure, and I'd bet we'll need to handle other types of conflicts too. I don't have a clear opinion if that's required to get this patch working - I'd try getting the simplest implementation with reasonable behavior, with those more advanced things as future enhancements. >> and I see them as >> improvements of this simple approach. >> >>>>> Maybe a second option is to have replication change any UPDATE into >>>>> either an INSERT or a DELETE, if the old or the new row do not pass the >>>>> filter, respectively. That way, the databases would remain consistent. >>> >>> Yeah, I think this is the best way to keep the data consistent. >>> >> >> It'd also require REPLICA IDENTITY FULL, which seems like it'd add a >> rather significant overhead. >> > > Why? I think it would just need similar restrictions as we are > planning for Delete operation such that filter columns must be either > present in primary or replica identity columns. > How else would you turn UPDATE to INSERT? For UPDATE we only send the identity columns and modified columns, and the decision happens on the subscriber. So we need to send everything if there's a risk we'll need those columns. But it's early I only had one coffee, so I may be missing something glaringly obvious. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jul 20, 2021 at 2:39 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 7/20/21 7:23 AM, Amit Kapila wrote: > > On Mon, Jul 19, 2021 at 7:02 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > > >> So maybe the best thing is to stick to the simple approach already used > >> e.g. by pglogical, which simply user the new row when available (insert, > >> update) and old one for deletes. > >> > >> I think that behaves more or less sensibly and it's easy to explain. > >> > > > > Okay, if nothing better comes up, then we can fall back to this option. > > > >> All the other things (e.g. turning UPDATE to INSERT, advanced conflict > >> resolution etc.) will require a lot of other stuff, > >> > > > > I have not evaluated this yet but I think spending some time thinking > > about turning Update to Insert/Delete (yesterday's suggestion by > > Alvaro) might be worth especially as that seems to be followed by some > > other replication solution as well. > > > > I think that requires quite a bit of infrastructure, and I'd bet we'll > need to handle other types of conflicts too. > Hmm, I don't see why we need any additional infrastructure here if we do this at the publisher. I think this could be done without many changes to the patch as explained in one of my previous emails [1]. > I don't have a clear > opinion if that's required to get this patch working - I'd try getting > the simplest implementation with reasonable behavior, with those more > advanced things as future enhancements. > > >> and I see them as > >> improvements of this simple approach. > >> > >>>>> Maybe a second option is to have replication change any UPDATE into > >>>>> either an INSERT or a DELETE, if the old or the new row do not pass the > >>>>> filter, respectively. That way, the databases would remain consistent. > >>> > >>> Yeah, I think this is the best way to keep the data consistent. > >>> > >> > >> It'd also require REPLICA IDENTITY FULL, which seems like it'd add a > >> rather significant overhead. > >> > > > > Why? I think it would just need similar restrictions as we are > > planning for Delete operation such that filter columns must be either > > present in primary or replica identity columns. > > > > How else would you turn UPDATE to INSERT? For UPDATE we only send the > identity columns and modified columns, and the decision happens on the > subscriber. > Hmm, we log the entire new tuple and replica identity columns for the old tuple in WAL for Update. And, we are going to use a new tuple for Insert, so we have everything we need. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BAXEd5bO-qPp6L9Ptckk09nbWvP8V7q5UW4hg%2BkHjXwQ%40mail.gmail.com -- With Regards, Amit Kapila.
On Tue, Jul 20, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > Why? I think it would just need similar restrictions as we are > > > planning for Delete operation such that filter columns must be either > > > present in primary or replica identity columns. > > > > > > > How else would you turn UPDATE to INSERT? For UPDATE we only send the > > identity columns and modified columns, and the decision happens on the > > subscriber. > > > > Hmm, we log the entire new tuple and replica identity columns for the > old tuple in WAL for Update. And, we are going to use a new tuple for > Insert, so we have everything we need. > But for making that decision we need to apply the filter on the old rows as well right. So if we want to apply the filter on the old rows then either the filter should only be on the replica identity key or we need to use REPLICA IDENTITY FULL. I think that is what Tomas wants to point out. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Jul 20, 2021 at 3:19 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Jul 20, 2021 at 3:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > Why? I think it would just need similar restrictions as we are > > > > planning for Delete operation such that filter columns must be either > > > > present in primary or replica identity columns. > > > > > > > > > > How else would you turn UPDATE to INSERT? For UPDATE we only send the > > > identity columns and modified columns, and the decision happens on the > > > subscriber. > > > > > > > Hmm, we log the entire new tuple and replica identity columns for the > > old tuple in WAL for Update. And, we are going to use a new tuple for > > Insert, so we have everything we need. > > > > But for making that decision we need to apply the filter on the old > rows as well right. So if we want to apply the filter on the old rows > then either the filter should only be on the replica identity key or > we need to use REPLICA IDENTITY FULL. I think that is what Tomas > wants to point out. > I have already mentioned that for Updates the filter needs criteria similar to Deletes. This is exactly the requirement for Delete as well. -- With Regards, Amit Kapila.
On 7/20/21 11:42 AM, Amit Kapila wrote: > On Tue, Jul 20, 2021 at 2:39 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 7/20/21 7:23 AM, Amit Kapila wrote: >>> On Mon, Jul 19, 2021 at 7:02 PM Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >> >>>> So maybe the best thing is to stick to the simple approach already used >>>> e.g. by pglogical, which simply user the new row when available (insert, >>>> update) and old one for deletes. >>>> >>>> I think that behaves more or less sensibly and it's easy to explain. >>>> >>> >>> Okay, if nothing better comes up, then we can fall back to this option. >>> >>>> All the other things (e.g. turning UPDATE to INSERT, advanced conflict >>>> resolution etc.) will require a lot of other stuff, >>>> >>> >>> I have not evaluated this yet but I think spending some time thinking >>> about turning Update to Insert/Delete (yesterday's suggestion by >>> Alvaro) might be worth especially as that seems to be followed by some >>> other replication solution as well. >>> >> >> I think that requires quite a bit of infrastructure, and I'd bet we'll >> need to handle other types of conflicts too. >> > > Hmm, I don't see why we need any additional infrastructure here if we > do this at the publisher. I think this could be done without many > changes to the patch as explained in one of my previous emails [1]. > Oh, I see. I've been thinking about doing the "usual" conflict resolution on the subscriber side. I'm not sure about doing this on the publisher ... >> I don't have a clear >> opinion if that's required to get this patch working - I'd try getting >> the simplest implementation with reasonable behavior, with those more >> advanced things as future enhancements. >> >>>> and I see them as >>>> improvements of this simple approach. >>>> >>>>>>> Maybe a second option is to have replication change any UPDATE into >>>>>>> either an INSERT or a DELETE, if the old or the new row do not pass the >>>>>>> filter, respectively. That way, the databases would remain consistent. >>>>> >>>>> Yeah, I think this is the best way to keep the data consistent. >>>>> >>>> >>>> It'd also require REPLICA IDENTITY FULL, which seems like it'd add a >>>> rather significant overhead. >>>> >>> >>> Why? I think it would just need similar restrictions as we are >>> planning for Delete operation such that filter columns must be either >>> present in primary or replica identity columns. >>> >> >> How else would you turn UPDATE to INSERT? For UPDATE we only send the >> identity columns and modified columns, and the decision happens on the >> subscriber. >> > > Hmm, we log the entire new tuple and replica identity columns for the > old tuple in WAL for Update. And, we are going to use a new tuple for > Insert, so we have everything we need. > Do we log the TOAST-ed values that were not updated? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Do we log the TOAST-ed values that were not updated? No, we don't, I have submitted a patch sometime back to fix that [1] [1] https://commitfest.postgresql.org/33/3162/ -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Jul 20, 2021 at 6:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > I think in terms of referring to old and new rows, we already have > terminology which we used at various other similar places. See Create > Rule docs [1]. For where clause, it says "Within condition and > command, the special table names NEW and OLD can be used to refer to > values in the referenced table. NEW is valid in ON INSERT and ON > UPDATE rules to refer to the new row being inserted or updated. OLD is > valid in ON UPDATE and ON DELETE rules to refer to the existing row > being updated or deleted.". We need similar things for the WHERE > clause in publication if we want special syntax to refer to old and > new rows. > I have no doubt we COULD allow references to OLD and NEW in the WHERE clause, but do we actually want to? This is what I thought could cause confusion, when mixed with the model that I previously described. It's not entirely clear to me exactly how it works, when the WHERE clause is applied to the OLD and NEW rows, when the WHERE condition itself can refer to OLD and/or NEW (coupled with the fact that NEW doesn't make sense for DELETE and OLD doesn't make sense for INSERT). Combine that with the fact that a publication can have multiple tables each with their own WHERE clause, and tables can be dropped/(re)added to the publication with a different WHERE clause, and it starts to get a little complicated working out exactly what the result should be. Regards, Greg Nancarrow Fujitsu Australia
On Tue, Jul 20, 2021 at 5:13 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Tue, Jul 20, 2021 at 6:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > I think in terms of referring to old and new rows, we already have > > terminology which we used at various other similar places. See Create > > Rule docs [1]. For where clause, it says "Within condition and > > command, the special table names NEW and OLD can be used to refer to > > values in the referenced table. NEW is valid in ON INSERT and ON > > UPDATE rules to refer to the new row being inserted or updated. OLD is > > valid in ON UPDATE and ON DELETE rules to refer to the existing row > > being updated or deleted.". We need similar things for the WHERE > > clause in publication if we want special syntax to refer to old and > > new rows. > > > > I have no doubt we COULD allow references to OLD and NEW in the WHERE > clause, but do we actually want to? > This is what I thought could cause confusion, when mixed with the > model that I previously described. > It's not entirely clear to me exactly how it works, when the WHERE > clause is applied to the OLD and NEW rows, when the WHERE condition > itself can refer to OLD and/or NEW (coupled with the fact that NEW > doesn't make sense for DELETE and OLD doesn't make sense for INSERT). > It is not new, the same is true when they are used in RULES and probably in other places where we use them. -- With Regards, Amit Kapila.
On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > Do we log the TOAST-ed values that were not updated? > > No, we don't, I have submitted a patch sometime back to fix that [1] > That patch seems to log WAL for key unchanged columns. What about if unchanged non-key columns? Do they get logged as part of the new tuple or is there some other way we can get those? If not, then we need to probably think of restricting filter clause in some way. -- With Regards, Amit Kapila.
On Thu, Jul 22, 2021 at 5:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > Do we log the TOAST-ed values that were not updated? > > > > No, we don't, I have submitted a patch sometime back to fix that [1] > > > > That patch seems to log WAL for key unchanged columns. What about if > unchanged non-key columns? Do they get logged as part of the new tuple > or is there some other way we can get those? If not, then we need to > probably think of restricting filter clause in some way. But what sort of restrictions? I mean we can not put based on data type right that will be too restrictive, other option is only to allow replica identity keys columns in the filter condition? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Jul 22, 2021 at 8:06 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Thu, Jul 22, 2021 at 5:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra > > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > > > Do we log the TOAST-ed values that were not updated? > > > > > > No, we don't, I have submitted a patch sometime back to fix that [1] > > > > > > > That patch seems to log WAL for key unchanged columns. What about if > > unchanged non-key columns? Do they get logged as part of the new tuple > > or is there some other way we can get those? If not, then we need to > > probably think of restricting filter clause in some way. > > But what sort of restrictions? I mean we can not put based on data > type right that will be too restrictive, > Yeah, data type restriction sounds too restrictive and unless the data is toasted, the data will be anyway available. I think such kind of restriction should be the last resort but let's try to see if we can do something better. > other option is only to allow > replica identity keys columns in the filter condition? > Yes, that is what I had in mind because if key column(s) is changed then we will have data for both old and new tuples. But if it is not changed then we will have it probably for the old tuple unless we decide to fix the bug you mentioned in a different way in which case we might either need to log it for the purpose of this feature (but that will be any way for HEAD) or need to come up with some other solution here. I think we can't even fetch such columns data during decoding because we have catalog-only historic snapshots here. Do you have any better ideas? -- With Regards, Amit Kapila.
On Fri, Jul 23, 2021 at 8:29 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jul 22, 2021 at 8:06 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Thu, Jul 22, 2021 at 5:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra > > > > <tomas.vondra@enterprisedb.com> wrote: > > > > > > > > > > Do we log the TOAST-ed values that were not updated? > > > > > > > > No, we don't, I have submitted a patch sometime back to fix that [1] > > > > > > > > > > That patch seems to log WAL for key unchanged columns. What about if > > > unchanged non-key columns? Do they get logged as part of the new tuple > > > or is there some other way we can get those? If not, then we need to > > > probably think of restricting filter clause in some way. > > > > But what sort of restrictions? I mean we can not put based on data > > type right that will be too restrictive, > > > > Yeah, data type restriction sounds too restrictive and unless the data > is toasted, the data will be anyway available. I think such kind of > restriction should be the last resort but let's try to see if we can > do something better. > > > other option is only to allow > > replica identity keys columns in the filter condition? > > > > Yes, that is what I had in mind because if key column(s) is changed > then we will have data for both old and new tuples. But if it is not > changed then we will have it probably for the old tuple unless we > decide to fix the bug you mentioned in a different way in which case > we might either need to log it for the purpose of this feature (but > that will be any way for HEAD) or need to come up with some other > solution here. I think we can't even fetch such columns data during > decoding because we have catalog-only historic snapshots here. Do you > have any better ideas? > BTW, I wonder how pglogical can handle this because if these unchanged toasted values are not logged in WAL for the new tuple then how the comparison for such columns will work? Either they are forcing WAL in some way or don't allow WHERE clause on such columns or maybe they have dealt with it in some other way unless they are unaware of this problem. -- With Regards, Amit Kapila.
On Fri, Jul 23, 2021 at 8:36 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
On Fri, Jul 23, 2021 at 8:29 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Jul 22, 2021 at 8:06 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > On Thu, Jul 22, 2021 at 5:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> > > >
> > > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra
> > > > <tomas.vondra@enterprisedb.com> wrote:
> > > > >
> > > > > Do we log the TOAST-ed values that were not updated?
> > > >
> > > > No, we don't, I have submitted a patch sometime back to fix that [1]
> > > >
> > >
> > > That patch seems to log WAL for key unchanged columns. What about if
> > > unchanged non-key columns? Do they get logged as part of the new tuple
> > > or is there some other way we can get those? If not, then we need to
> > > probably think of restricting filter clause in some way.
> >
> > But what sort of restrictions? I mean we can not put based on data
> > type right that will be too restrictive,
> >
>
> Yeah, data type restriction sounds too restrictive and unless the data
> is toasted, the data will be anyway available. I think such kind of
> restriction should be the last resort but let's try to see if we can
> do something better.
>
> > other option is only to allow
> > replica identity keys columns in the filter condition?
> >
>
> Yes, that is what I had in mind because if key column(s) is changed
> then we will have data for both old and new tuples. But if it is not
> changed then we will have it probably for the old tuple unless we
> decide to fix the bug you mentioned in a different way in which case
> we might either need to log it for the purpose of this feature (but
> that will be any way for HEAD) or need to come up with some other
> solution here. I think we can't even fetch such columns data during
> decoding because we have catalog-only historic snapshots here. Do you
> have any better ideas?
>
BTW, I wonder how pglogical can handle this because if these unchanged
toasted values are not logged in WAL for the new tuple then how the
comparison for such columns will work? Either they are forcing WAL in
some way or don't allow WHERE clause on such columns or maybe they
have dealt with it in some other way unless they are unaware of this
problem.
The column comparison for row filtering happens before the unchanged toast
columns are filtered. Unchanged toast columns are filtered just before writing the tuple
to output stream. I think this is the case both for pglogical and the proposed patch.
So, I can't see why the not logging of unchanged toast columns would be a problem
for row filtering. Am I missing something?
Thank you,
columns are filtered. Unchanged toast columns are filtered just before writing the tuple
to output stream. I think this is the case both for pglogical and the proposed patch.
So, I can't see why the not logging of unchanged toast columns would be a problem
for row filtering. Am I missing something?
Thank you,
Rahila Syed
On Fri, Jul 23, 2021 at 2:27 PM Rahila Syed <rahilasyed90@gmail.com> wrote: > > On Fri, Jul 23, 2021 at 8:36 AM Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> On Fri, Jul 23, 2021 at 8:29 AM Amit Kapila <amit.kapila16@gmail.com> wrote: >> > >> > On Thu, Jul 22, 2021 at 8:06 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: >> > > >> > > On Thu, Jul 22, 2021 at 5:15 PM Amit Kapila <amit.kapila16@gmail.com> wrote: >> > > > >> > > > On Tue, Jul 20, 2021 at 4:33 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: >> > > > > >> > > > > On Tue, Jul 20, 2021 at 3:43 PM Tomas Vondra >> > > > > <tomas.vondra@enterprisedb.com> wrote: >> > > > > > >> > > > > > Do we log the TOAST-ed values that were not updated? >> > > > > >> > > > > No, we don't, I have submitted a patch sometime back to fix that [1] >> > > > > >> > > > >> > > > That patch seems to log WAL for key unchanged columns. What about if >> > > > unchanged non-key columns? Do they get logged as part of the new tuple >> > > > or is there some other way we can get those? If not, then we need to >> > > > probably think of restricting filter clause in some way. >> > > >> > > But what sort of restrictions? I mean we can not put based on data >> > > type right that will be too restrictive, >> > > >> > >> > Yeah, data type restriction sounds too restrictive and unless the data >> > is toasted, the data will be anyway available. I think such kind of >> > restriction should be the last resort but let's try to see if we can >> > do something better. >> > >> > > other option is only to allow >> > > replica identity keys columns in the filter condition? >> > > >> > >> > Yes, that is what I had in mind because if key column(s) is changed >> > then we will have data for both old and new tuples. But if it is not >> > changed then we will have it probably for the old tuple unless we >> > decide to fix the bug you mentioned in a different way in which case >> > we might either need to log it for the purpose of this feature (but >> > that will be any way for HEAD) or need to come up with some other >> > solution here. I think we can't even fetch such columns data during >> > decoding because we have catalog-only historic snapshots here. Do you >> > have any better ideas? >> > >> >> BTW, I wonder how pglogical can handle this because if these unchanged >> toasted values are not logged in WAL for the new tuple then how the >> comparison for such columns will work? Either they are forcing WAL in >> some way or don't allow WHERE clause on such columns or maybe they >> have dealt with it in some other way unless they are unaware of this >> problem. >> > > The column comparison for row filtering happens before the unchanged toast > columns are filtered. Unchanged toast columns are filtered just before writing the tuple > to output stream. > To perform filtering, you need to use the tuple from WAL and that tuple doesn't seem to have unchanged toast values, so how can we do filtering? I think it is a good idea to test this once. -- With Regards, Amit Kapila.
On July 23, 2021 6:16 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Fri, Jul 23, 2021 at 2:27 PM Rahila Syed <rahilasyed90@gmail.com> wrote:
> >
> > The column comparison for row filtering happens before the unchanged
> > toast columns are filtered. Unchanged toast columns are filtered just
> > before writing the tuple to output stream.
> >
>
> To perform filtering, you need to use the tuple from WAL and that tuple doesn't
> seem to have unchanged toast values, so how can we do filtering? I think it is a
> good idea to test this once.
I agreed.
Currently, both unchanged toasted key column and unchanged toasted non-key
column is not logged. So, we cannot get the toasted value directly for these
columns when doing row filtering.
I tested the current patch for toasted data and found a problem: In the current
patch, it will try to fetch the toast data from toast table when doing row
filtering[1]. But, it's unsafe to do that in walsender. We can see it use
HISTORIC snapshot in heap_fetch_toast_slice() and also the comments of
init_toast_snapshot() have said "Detoasting *must* happen in the same
transaction that originally fetched the toast pointer.". The toast data could
have been changed when doing row filtering. For exmaple, I tested the following
steps and get an error.
1) UPDATE a nonkey column in publisher.
2) Use debugger to block the walsender process in function
pgoutput_row_filter_exec_expr().
3) Open another psql to connect the publisher, and drop the table which updated
in 1).
4) Unblock the debugger in 2), and then I can see the following error:
---
ERROR: could not read block 0 in file "base/13675/16391"
---
[1]
(1)------publisher------
CREATE TABLE toasted_key (
id serial,
toasted_key text PRIMARY KEY,
toasted_col1 text,
toasted_col2 text
);
select repeat('9999999999', 200) as tvalue \gset
CREATE PUBLICATION pub FOR TABLE toasted_key WHERE (toasted_col2 = :'tvalue');
ALTER TABLE toasted_key REPLICA IDENTITY USING INDEX toasted_key_pkey;
ALTER TABLE toasted_key ALTER COLUMN toasted_key SET STORAGE EXTERNAL;
ALTER TABLE toasted_key ALTER COLUMN toasted_col1 SET STORAGE EXTERNAL;
ALTER TABLE toasted_key ALTER COLUMN toasted_col2 SET STORAGE EXTERNAL;
INSERT INTO toasted_key(toasted_key, toasted_col1, toasted_col2) VALUES(repeat('1234567890', 200), repeat('9876543210',
200),repeat('9999999999', 200));
(2)------subscriber------
CREATE TABLE toasted_key (
id serial,
toasted_key text PRIMARY KEY,
toasted_col1 text,
toasted_col2 text
);
CREATE SUBSCRIPTION sub CONNECTION 'dbname=postgres port=10000' PUBLICATION pub;
(3)------publisher------
UPDATE toasted_key SET toasted_col1 = repeat('1111113113', 200);
Based on the above steps, the row filter will ge through the following path
and fetch toast data in walsender.
------
pgoutput_row_filter_exec_expr
...
texteq
...
text *targ1 = DatumGetTextPP(arg1);
pg_detoast_datum_packed
detoast_attr
------
On Tue, Jul 27, 2021 at 6:21 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > 1) UPDATE a nonkey column in publisher. > 2) Use debugger to block the walsender process in function > pgoutput_row_filter_exec_expr(). > 3) Open another psql to connect the publisher, and drop the table which updated > in 1). > 4) Unblock the debugger in 2), and then I can see the following error: > --- > ERROR: could not read block 0 in file "base/13675/16391" Yeah, that's a big problem, seems like the expression evaluation machinery directly going and detoasting the externally stored data using some random snapshot. Ideally, in walsender we can never attempt to detoast the data because there is no guarantee that those data are preserved. Somehow before going to the expression evaluation machinery, I think we will have to deform that tuple and need to do something for the externally stored data otherwise it will be very difficult to control that inside the expression evaluation. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
FYI - v19 --> v20 (Only very minimal changes. Nothing functional) Changes: * The v19 patch was broken due to changes of commit [1] so I have rebased so the cfbot is happy. * I also renamed the TAP test 021_row_filter.pl ==> 023_row_filter.pl because commit [2] already added another TAP test numbered 021. ------ [1] https://github.com/postgres/postgres/commit/2b00db4fb0c7f02f000276bfadaab65a14059168 [2] https://github.com/postgres/postgres/commit/a8fd13cab0ba815e9925dc9676e6309f699b5f72 Kind Regards, Peter Smith. Fujitsu Australia
Вложения
FYI - v20 --> v21 (Only very minimal changes) * I noticed that the v20 TAP test (023_row_filter.pl) began failing due to a recent commit [1], so I have rebased it to keep the cfbot happy. ------ [1] https://github.com/postgres/postgres/commit/201a76183e2056c2217129e12d68c25ec9c559c8 Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Tue, Jul 27, 2021 at 9:56 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Jul 27, 2021 at 6:21 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > 1) UPDATE a nonkey column in publisher. > > 2) Use debugger to block the walsender process in function > > pgoutput_row_filter_exec_expr(). > > 3) Open another psql to connect the publisher, and drop the table which updated > > in 1). > > 4) Unblock the debugger in 2), and then I can see the following error: > > --- > > ERROR: could not read block 0 in file "base/13675/16391" > > Yeah, that's a big problem, seems like the expression evaluation > machinery directly going and detoasting the externally stored data > using some random snapshot. Ideally, in walsender we can never > attempt to detoast the data because there is no guarantee that those > data are preserved. Somehow before going to the expression evaluation > machinery, I think we will have to deform that tuple and need to do > something for the externally stored data otherwise it will be very > difficult to control that inside the expression evaluation. > True, I think it would be possible after we fix the issue reported in another thread [1] where we will log the key values as part of old_tuple_key for toast tuples even if they are not changed. We can have a restriction that in the WHERE clause that user can specify only Key columns for Updates similar to Deletes. Then, we have the data required for filter columns basically if the toasted key values are changed, then they will be anyway part of the old and new tuple and if they are not changed then they will be part of the old tuple. I have not checked the implementation part of it but theoretically, it seems possible. If my understanding is correct then it becomes necessary to solve the other bug [1] to solve this part of the problem for this patch. The other possibility is to disallow columns (datatypes) that can lead to toasted data (at least for Updates) which doesn't sound like a good idea to me. Do you have any other ideas for this problem? [1] - https://www.postgresql.org/message-id/OS0PR01MB611342D0A92D4F4BF26C0F47FB229%40OS0PR01MB6113.jpnprd01.prod.outlook.com -- With Regards, Amit Kapila.
v21 --> v22 (This small change is only to keep the patch up-to-date with HEAD) Changes: * A recent commit [1] added a new TAP subscription test file 023, so now this patch's test file (previously "023_row_filter.pl") has been bumped to "024_row_filter.pl". ------ [1] https://github.com/postgres/postgres/commit/63cf61cdeb7b0450dcf3b2f719c553177bac85a2 Kind Regards, Peter Smith. Fujitsu Australia
Вложения
v22 --> v23 Changes: * A rebase was needed (due to commit [1]) to keep the patch working with cfbot. ------ [1] https://github.com/postgres/postgres/commit/93d573d86571d148e2d14415166ec6981d34ea9d Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Tue, Aug 3, 2021 at 4:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jul 27, 2021 at 9:56 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > Yeah, that's a big problem, seems like the expression evaluation > > machinery directly going and detoasting the externally stored data > > using some random snapshot. Ideally, in walsender we can never > > attempt to detoast the data because there is no guarantee that those > > data are preserved. Somehow before going to the expression evaluation > > machinery, I think we will have to deform that tuple and need to do > > something for the externally stored data otherwise it will be very > > difficult to control that inside the expression evaluation. > > > > True, I think it would be possible after we fix the issue reported in > another thread [1] where we will log the key values as part of > old_tuple_key for toast tuples even if they are not changed. We can > have a restriction that in the WHERE clause that user can specify only > Key columns for Updates similar to Deletes. Then, we have the data > required for filter columns basically if the toasted key values are > changed, then they will be anyway part of the old and new tuple and if > they are not changed then they will be part of the old tuple. Right. I have > not checked the implementation part of it but theoretically, it seems > possible. Yeah, It would be possible to because at least after fixing [1] we would have the required column data. The only thing I am worried about is while applying the filter on the new tuple the toasted unchanged key data will not be a part of the new tuple. So we can not directly call the expression evaluation machinary, basically, somehow we need to deform the new tuple and then replace the data from the old tuple before passing it to expression evaluation. Anyways this is an implementation part so we can look into that while implementing. If my understanding is correct then it becomes necessary to > solve the other bug [1] to solve this part of the problem for this > patch. Right. The other possibility is to disallow columns (datatypes) that > can lead to toasted data (at least for Updates) which doesn't sound > like a good idea to me. Yeah, that will be a big limitation, then we won't be able to allow expression on any varlena types. Do you have any other ideas for this problem? As of now no other better idea to suggest. [1] - https://www.postgresql.org/message-id/OS0PR01MB611342D0A92D4F4BF26C0F47FB229%40OS0PR01MB6113.jpnprd01.prod.outlook.com -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Jul 12, 2021 at 7:35 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jul 12, 2021 at 1:09 AM Euler Taveira <euler@eulerto.com> wrote: > > > > I did another measure using as baseline the previous patch (v16). > > > > without cache (v16) > > --------------------------- > > > > mean: 1.46 us > > stddev: 2.13 us > > median: 1.39 us > > min-max: [0.69 .. 1456.69] us > > percentile(99): 3.15 us > > mode: 0.91 us > > > > with cache (v18) > > ----------------------- > > > > mean: 0.63 us > > stddev: 1.07 us > > median: 0.55 us > > min-max: [0.29 .. 844.87] us > > percentile(99): 1.38 us > > mode: 0.41 us > > > > It represents -57%. It is a really good optimization for just a few extra lines > > of code. > > > > Good improvement but I think it is better to measure the performance > by using synchronous_replication by setting the subscriber as > standby_synchronous_names, which will provide the overall saving of > time. We can probably see when the timings when no rows are filtered, > when 10% rows are filtered when 30% are filtered and so on. > > I think the way caching has been done in the patch is a bit > inefficient. Basically, it always invalidates and rebuilds the > expressions even though some unrelated operation has happened on > publication. For example, say publication has initially table t1 with > rowfilter r1 for which we have cached the state. Now you altered > publication and added table t2, it will invalidate the entire state of > t1 as well. I think we can avoid that if we invalidate the rowfilter > related state only on relcache invalidation i.e in > rel_sync_cache_relation_cb and save it the very first time we prepare > the expression. In that case, we don't need to do it in advance when > preparing relsyncentry, this will have the additional advantage that > we won't spend cycles on preparing state unless it is required (for > truncate we won't require row_filtering, so it won't be prepared). > I have used debug logging to confirm that what Amit wrote [1] is correct; the row-filter ExprState of *every* table's row_filter will be invalidated (and so subsequently gets rebuilt) when the user changes the PUBLICATION tables. This was a side-effect of the rel_sync_cache_publication_cb which is freeing the cached ExprState and setting the entry->replicate_valid = false; for *every* entry. So yes, the ExprCache is getting rebuilt for some situations where it is not strictly necessary to do so. But... 1. Although the ExprState cache is effective, in practice the performance improvement was not very much. My previous results [2] showed only about 2sec saving for 100K calls to the pgoutput_row_filter function. So I think eliminating just one or two unnecessary calls in the get_rel_sync_entry is going to make zero observable difference. 2. IMO it is safe to expect that the ALTER PUBLICATION is a rare operation relative to the number of times that pgoutput_row_filter will be called (the pgoutput_row_filter is quite a "hot" function since it is called for every INSERT/UPDATE/DELETE). It will be orders of magnitude difference 1:1000, 1:100000 etc. ~~ Anyway, I have implemented the suggested cache change because I agree it is probably theoretically superior, even if in practice there is almost no difference. PSA 2 new patches (v24*) Summary: 1. Now the rfnode_list row-filter cache is built 1 time only in function get_rel_sync_entry. 2. Now the ExprState list cache is lazy-built 1 time only when first needed in function pgoutput_row_filter 3. Now those caches are invalidated in function rel_sync_cache_relation_cb; Invalidation of one relation's caches will no longer cause the other relations' row-filter caches to be re-built. ------ I also ran performance tests to compare the old/new ExprState caching. These tests are inserting 1 million rows using different percentages of row filtering. Please refer to the attached result data/results. The main takeaway points from the test results are: 1. Using row-filter ExprState caching is slightly better than having no ExprState caching. 2. The old/new style ExprState caches have approximately the same performance. Essentially the *only* runtime difference with the old/new cache is the added condition in the pgouput_row_filter to check if the ExprState cache needs to be lazy-built or not. Over a million rows maybe this extra condition accounts for a tiny difference or maybe the small before/after differences can be attributed just to natural runtime variations. ------ [1] https://www.postgresql.org/message-id/CAA4eK1%2BxQb06NGs6Y7OzwMtKYYixEqR8tdWV5THAVE4SAqNrDg%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAHut%2BPs3GgPKUJ2npfY4bQdxAmYW%2ByQin%2BhQuBsMYvX%3DkBqEpA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
{kind=link}
On Tue, Aug 24, 2021, at 4:46 AM, Peter Smith wrote:
I have used debug logging to confirm that what Amit wrote [1] iscorrect; the row-filter ExprState of *every* table's row_filter willbe invalidated (and so subsequently gets rebuilt) when the userchanges the PUBLICATION tables. This was a side-effect of therel_sync_cache_publication_cb which is freeing the cached ExprStateand setting the entry->replicate_valid = false; for *every* entry.So yes, the ExprCache is getting rebuilt for some situations where itis not strictly necessary to do so.
I'm afraid we are overenginnering this feature. We already have a cache
mechanism that was suggested (that shows a small improvement). As you said the
gain for this new improvement is zero or minimal (it depends on your logical
replication setup/maintenance).
1. Although the ExprState cache is effective, in practice theperformance improvement was not very much. My previous results [2]showed only about 2sec saving for 100K calls to thepgoutput_row_filter function. So I think eliminating just one or twounnecessary calls in the get_rel_sync_entry is going to make zeroobservable difference.2. IMO it is safe to expect that the ALTER PUBLICATION is a rareoperation relative to the number of times that pgoutput_row_filterwill be called (the pgoutput_row_filter is quite a "hot" functionsince it is called for every INSERT/UPDATE/DELETE). It will be ordersof magnitude difference 1:1000, 1:100000 etc.~~Anyway, I have implemented the suggested cache change because I agreeit is probably theoretically superior, even if in practice there isalmost no difference.
I didn't inspect your patch carefully but it seems you add another List to
control this new cache mechanism. I don't like it. IMO if we can use the data
structures that we have now, let's implement your idea; otherwise, -1 for this
new micro optimization.
[By the way, it took some time to extract what you changed. Since we're trading
patches, I personally appreciate if you can send a patch on the top of the
current one. I have some changes too and it is time consuming incorporating
changes in the main patch.]
On Wed, Aug 25, 2021 at 5:52 AM Euler Taveira <euler@eulerto.com> wrote: > > On Tue, Aug 24, 2021, at 4:46 AM, Peter Smith wrote: > > I have used debug logging to confirm that what Amit wrote [1] is > correct; the row-filter ExprState of *every* table's row_filter will > be invalidated (and so subsequently gets rebuilt) when the user > changes the PUBLICATION tables. This was a side-effect of the > rel_sync_cache_publication_cb which is freeing the cached ExprState > and setting the entry->replicate_valid = false; for *every* entry. > > So yes, the ExprCache is getting rebuilt for some situations where it > is not strictly necessary to do so. > > I'm afraid we are overenginnering this feature. We already have a cache > mechanism that was suggested (that shows a small improvement). As you said the > gain for this new improvement is zero or minimal (it depends on your logical > replication setup/maintenance). > Hmm, I think the gain via caching is not visible because we are using simple expressions. It will be visible when we use somewhat complex expressions where expression evaluation cost is significant. Similarly, the impact of this change will magnify and it will also be visible when a publication has many tables. Apart from performance, this change is logically correct as well because it would be any way better if we don't invalidate the cached expressions unless required. > 1. Although the ExprState cache is effective, in practice the > performance improvement was not very much. My previous results [2] > showed only about 2sec saving for 100K calls to the > pgoutput_row_filter function. So I think eliminating just one or two > unnecessary calls in the get_rel_sync_entry is going to make zero > observable difference. > > 2. IMO it is safe to expect that the ALTER PUBLICATION is a rare > operation relative to the number of times that pgoutput_row_filter > will be called (the pgoutput_row_filter is quite a "hot" function > since it is called for every INSERT/UPDATE/DELETE). It will be orders > of magnitude difference 1:1000, 1:100000 etc. > > ~~ > > Anyway, I have implemented the suggested cache change because I agree > it is probably theoretically superior, even if in practice there is > almost no difference. > > I didn't inspect your patch carefully but it seems you add another List to > control this new cache mechanism. I don't like it. IMO if we can use the data > structures that we have now, let's implement your idea; otherwise, -1 for this > new micro optimization. > As mentioned above, without this we will invalidate many cached expressions even though it is not required. I don't deny that there might be a better way to achieve the same and if you or Peter have any ideas, I am all ears. If there are technical challenges to achieve the same or it makes the patch complex then certainly we can discuss but according to me, this should not introduce additional complexity. > [By the way, it took some time to extract what you changed. Since we're trading > patches, I personally appreciate if you can send a patch on the top of the > current one. > +1. -- With Regards, Amit Kapila.
On Wed, Aug 25, 2021 at 10:57 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Aug 25, 2021 at 5:52 AM Euler Taveira <euler@eulerto.com> wrote: > > > > On Tue, Aug 24, 2021, at 4:46 AM, Peter Smith wrote: > > > > Anyway, I have implemented the suggested cache change because I agree > > it is probably theoretically superior, even if in practice there is > > almost no difference. > > > > I didn't inspect your patch carefully but it seems you add another List to > > control this new cache mechanism. I don't like it. IMO if we can use the data > > structures that we have now, let's implement your idea; otherwise, -1 for this > > new micro optimization. > > > > As mentioned above, without this we will invalidate many cached > expressions even though it is not required. I don't deny that there > might be a better way to achieve the same and if you or Peter have any > ideas, I am all ears. > I see that the new list is added to store row_filter node which we later use to compute expression. This is not required for invalidation but for delaying the expression evaluation till it is required (for example, for truncate, we may not need the row evaluation, so there is no need to compute it). Can we try to postpone the syscache lookup to a later stage when we are actually doing row_filtering? If we can do that, then I think we can avoid having this extra list? -- With Regards, Amit Kapila.
On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > ... > > Hmm, I think the gain via caching is not visible because we are using > simple expressions. It will be visible when we use somewhat complex > expressions where expression evaluation cost is significant. > Similarly, the impact of this change will magnify and it will also be > visible when a publication has many tables. Apart from performance, > this change is logically correct as well because it would be any way > better if we don't invalidate the cached expressions unless required. Please tell me what is your idea of a "complex" row filter expression. Do you just mean a filter that has multiple AND conditions in it? I don't really know if few complex expressions would amount to any significant evaluation costs, so I would like to run some timing tests with some real examples to see the results. On Wed, Aug 25, 2021 at 6:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Aug 25, 2021 at 10:57 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Aug 25, 2021 at 5:52 AM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Tue, Aug 24, 2021, at 4:46 AM, Peter Smith wrote: > > > > > > > Anyway, I have implemented the suggested cache change because I agree > > > it is probably theoretically superior, even if in practice there is > > > almost no difference. > > > > > > I didn't inspect your patch carefully but it seems you add another List to > > > control this new cache mechanism. I don't like it. IMO if we can use the data > > > structures that we have now, let's implement your idea; otherwise, -1 for this > > > new micro optimization. > > > > > > > As mentioned above, without this we will invalidate many cached > > expressions even though it is not required. I don't deny that there > > might be a better way to achieve the same and if you or Peter have any > > ideas, I am all ears. > > > > I see that the new list is added to store row_filter node which we > later use to compute expression. This is not required for invalidation > but for delaying the expression evaluation till it is required (for > example, for truncate, we may not need the row evaluation, so there is > no need to compute it). Can we try to postpone the syscache lookup to > a later stage when we are actually doing row_filtering? If we can do > that, then I think we can avoid having this extra list? Yes, you are correct - that Node list was re-instated only because you had requested that the ExprState evaluation should be deferred until it is needed by the pgoutput_row_filter. Otherwise, the additional list would not be needed so everything would be much the same as in v23 except the invalidations would be more focussed on single tables. I don't think the syscache lookup can be easily postponed. That logic of get_rel_sync_entry processes the table filters of *all* publications, so moving that publications loop (including the partition logic) into the pgoutput_row_filter seems a bridge too far IMO. Furthermore, I am not yet convinced that this ExprState postponement is very useful. It may be true that for truncate there is no need to compute it, but consider that the user would never even define a row filter in the first place unless they intended there will be some CRUD operations. So even if the truncate does not need the filter, *something* is surely going to need it. In other words, IIUC this postponement is not going to save any time overall - it only shifting when the (one time) expression evaluation will happen. I feel it would be better to just remove the postponed evaluation of the ExprState added in v24. That will remove any need for the extra Node list (which I think is Euler's concern). The ExprState cache will still be slightly improved from how it was implemented before because it is "logically correct" that we don't invalidate the cached expressions unless required. Thoughts? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > ... > > > > Hmm, I think the gain via caching is not visible because we are using > > simple expressions. It will be visible when we use somewhat complex > > expressions where expression evaluation cost is significant. > > Similarly, the impact of this change will magnify and it will also be > > visible when a publication has many tables. Apart from performance, > > this change is logically correct as well because it would be any way > > better if we don't invalidate the cached expressions unless required. > > Please tell me what is your idea of a "complex" row filter expression. > Do you just mean a filter that has multiple AND conditions in it? I > don't really know if few complex expressions would amount to any > significant evaluation costs, so I would like to run some timing tests > with some real examples to see the results. > I think this means you didn't even understand or are convinced why the patch has cache in the first place. As per your theory, even if we didn't have cache, it won't matter but that is not true otherwise, the patch wouldn't have it. > On Wed, Aug 25, 2021 at 6:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Aug 25, 2021 at 10:57 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Wed, Aug 25, 2021 at 5:52 AM Euler Taveira <euler@eulerto.com> wrote: > > > > > > > > On Tue, Aug 24, 2021, at 4:46 AM, Peter Smith wrote: > > > > > > > > > > Anyway, I have implemented the suggested cache change because I agree > > > > it is probably theoretically superior, even if in practice there is > > > > almost no difference. > > > > > > > > I didn't inspect your patch carefully but it seems you add another List to > > > > control this new cache mechanism. I don't like it. IMO if we can use the data > > > > structures that we have now, let's implement your idea; otherwise, -1 for this > > > > new micro optimization. > > > > > > > > > > As mentioned above, without this we will invalidate many cached > > > expressions even though it is not required. I don't deny that there > > > might be a better way to achieve the same and if you or Peter have any > > > ideas, I am all ears. > > > > > > > I see that the new list is added to store row_filter node which we > > later use to compute expression. This is not required for invalidation > > but for delaying the expression evaluation till it is required (for > > example, for truncate, we may not need the row evaluation, so there is > > no need to compute it). Can we try to postpone the syscache lookup to > > a later stage when we are actually doing row_filtering? If we can do > > that, then I think we can avoid having this extra list? > > Yes, you are correct - that Node list was re-instated only because you > had requested that the ExprState evaluation should be deferred until > it is needed by the pgoutput_row_filter. Otherwise, the additional > list would not be needed so everything would be much the same as in > v23 except the invalidations would be more focussed on single tables. > > I don't think the syscache lookup can be easily postponed. That logic > of get_rel_sync_entry processes the table filters of *all* > publications, so moving that publications loop (including the > partition logic) into the pgoutput_row_filter seems a bridge too far > IMO. > Hmm, I don't think that is not true. You just need it for the relation to be processed. > Furthermore, I am not yet convinced that this ExprState postponement > is very useful. It may be true that for truncate there is no need to > compute it, but consider that the user would never even define a row > filter in the first place unless they intended there will be some CRUD > operations. So even if the truncate does not need the filter, > *something* is surely going to need it. > Sure, but we don't need to add additional computation until it is required. -- With Regards, Amit Kapila.
On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > ... > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > simple expressions. It will be visible when we use somewhat complex > > > expressions where expression evaluation cost is significant. > > > Similarly, the impact of this change will magnify and it will also be > > > visible when a publication has many tables. Apart from performance, > > > this change is logically correct as well because it would be any way > > > better if we don't invalidate the cached expressions unless required. > > > > Please tell me what is your idea of a "complex" row filter expression. > > Do you just mean a filter that has multiple AND conditions in it? I > > don't really know if few complex expressions would amount to any > > significant evaluation costs, so I would like to run some timing tests > > with some real examples to see the results. > > > > I think this means you didn't even understand or are convinced why the > patch has cache in the first place. As per your theory, even if we > didn't have cache, it won't matter but that is not true otherwise, the > patch wouldn't have it. I have never said there should be no caching. On the contrary, my performance test results [1] already confirmed that caching ExprState is of benefit for the millions of times it may be used in the pgoutput_row_filter function. My only doubts are in regard to how much observable impact there would be re-evaluating the filter expression just a few extra times by the get_rel_sync_entry function. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPs5j7mkO0xLmNW%3DkXh0eezGoKyzBCiQc9bfkCiM_MVDrg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Aug 26, 2021 at 9:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > ... > > > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > > simple expressions. It will be visible when we use somewhat complex > > > > expressions where expression evaluation cost is significant. > > > > Similarly, the impact of this change will magnify and it will also be > > > > visible when a publication has many tables. Apart from performance, > > > > this change is logically correct as well because it would be any way > > > > better if we don't invalidate the cached expressions unless required. > > > > > > Please tell me what is your idea of a "complex" row filter expression. > > > Do you just mean a filter that has multiple AND conditions in it? I > > > don't really know if few complex expressions would amount to any > > > significant evaluation costs, so I would like to run some timing tests > > > with some real examples to see the results. > > > > > > > I think this means you didn't even understand or are convinced why the > > patch has cache in the first place. As per your theory, even if we > > didn't have cache, it won't matter but that is not true otherwise, the > > patch wouldn't have it. > > I have never said there should be no caching. On the contrary, my > performance test results [1] already confirmed that caching ExprState > is of benefit for the millions of times it may be used in the > pgoutput_row_filter function. My only doubts are in regard to how much > observable impact there would be re-evaluating the filter expression > just a few extra times by the get_rel_sync_entry function. > I think it depends but why in the first place do you want to allow re-evaluation when there is a way for not doing that? -- With Regards, Amit Kapila.
On Wed, Aug 25, 2021 at 10:22 AM Euler Taveira <euler@eulerto.com> wrote: > .... > > [By the way, it took some time to extract what you changed. Since we're trading > patches, I personally appreciate if you can send a patch on the top of the > current one. I have some changes too and it is time consuming incorporating > changes in the main patch.] > OK. Sorry for causing you trouble. Here I am re-posting the ExprState cache changes as an incremental patch on top of the last rebased row-filter patch (v23). v25-0001 <--- v23 (last rebased main patch) v25-0002 ExprState cache mods v25-0002 ExprState cache extra debug logging (temp) Hopefully, this will make it easier to deal with this change in isolation. ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Aug 26, 2021 at 3:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 9:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > ... > > > > > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > > > simple expressions. It will be visible when we use somewhat complex > > > > > expressions where expression evaluation cost is significant. > > > > > Similarly, the impact of this change will magnify and it will also be > > > > > visible when a publication has many tables. Apart from performance, > > > > > this change is logically correct as well because it would be any way > > > > > better if we don't invalidate the cached expressions unless required. > > > > > > > > Please tell me what is your idea of a "complex" row filter expression. > > > > Do you just mean a filter that has multiple AND conditions in it? I > > > > don't really know if few complex expressions would amount to any > > > > significant evaluation costs, so I would like to run some timing tests > > > > with some real examples to see the results. > > > > > > > > > > I think this means you didn't even understand or are convinced why the > > > patch has cache in the first place. As per your theory, even if we > > > didn't have cache, it won't matter but that is not true otherwise, the > > > patch wouldn't have it. > > > > I have never said there should be no caching. On the contrary, my > > performance test results [1] already confirmed that caching ExprState > > is of benefit for the millions of times it may be used in the > > pgoutput_row_filter function. My only doubts are in regard to how much > > observable impact there would be re-evaluating the filter expression > > just a few extra times by the get_rel_sync_entry function. > > > > I think it depends but why in the first place do you want to allow > re-evaluation when there is a way for not doing that? Because the current code logic of having the "delayed" ExprState evaluation does come at some cost. And the cost is - a. Needing an extra condition and more code in the function pgoutput_row_filter b. Needing to maintain the additional Node list If we chose not to implement a delayed ExprState cache evaluation then there would still be a (one-time) ExprState cache evaluation but it would happen whenever get_rel_sync_entry is called (regardless of if pgoputput_row_filter is subsequently called). E.g. there can be some rebuilds of the ExprState cache if the user calls TRUNCATE. I guess I felt the only justification for implementing more sophisticated cache logic is if gives a performance gain. But if there is no observable difference, then maybe it's better to just keep the code simpler. That is why I have been questioning how much time a one-time ExprState cache evaluation really takes, and would a few extra ones even be noticeable. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Aug 26, 2021 at 3:41 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 3:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 9:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > ... > > > > > > > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > > > > simple expressions. It will be visible when we use somewhat complex > > > > > > expressions where expression evaluation cost is significant. > > > > > > Similarly, the impact of this change will magnify and it will also be > > > > > > visible when a publication has many tables. Apart from performance, > > > > > > this change is logically correct as well because it would be any way > > > > > > better if we don't invalidate the cached expressions unless required. > > > > > > > > > > Please tell me what is your idea of a "complex" row filter expression. > > > > > Do you just mean a filter that has multiple AND conditions in it? I > > > > > don't really know if few complex expressions would amount to any > > > > > significant evaluation costs, so I would like to run some timing tests > > > > > with some real examples to see the results. > > > > > > > > > > > > > I think this means you didn't even understand or are convinced why the > > > > patch has cache in the first place. As per your theory, even if we > > > > didn't have cache, it won't matter but that is not true otherwise, the > > > > patch wouldn't have it. > > > > > > I have never said there should be no caching. On the contrary, my > > > performance test results [1] already confirmed that caching ExprState > > > is of benefit for the millions of times it may be used in the > > > pgoutput_row_filter function. My only doubts are in regard to how much > > > observable impact there would be re-evaluating the filter expression > > > just a few extra times by the get_rel_sync_entry function. > > > > > > > I think it depends but why in the first place do you want to allow > > re-evaluation when there is a way for not doing that? > > Because the current code logic of having the "delayed" ExprState > evaluation does come at some cost. > So, now you mixed it with the second point. Here, I was talking about the need for correct invalidation but you started discussing when to first time evaluate the expression, both are different things. > And the cost is - > a. Needing an extra condition and more code in the function pgoutput_row_filter > b. Needing to maintain the additional Node list > I am not sure you need (b) above and I think (a) should make the overall code look clean. > If we chose not to implement a delayed ExprState cache evaluation then > there would still be a (one-time) ExprState cache evaluation but it > would happen whenever get_rel_sync_entry is called (regardless of if > pgoputput_row_filter is subsequently called). E.g. there can be some > rebuilds of the ExprState cache if the user calls TRUNCATE. > Apart from Truncate, it will also be a waste if any error happens before actually evaluating the filter, tomorrow there could be other operations like replication of sequences (I have checked that proposed patch for sequences uses get_rel_sync_entry) where we don't need to build ExprState (as filters might or might not be there). So, it would be better to avoid cache lookups in those cases if possible. I still think doing expensive things like preparing expressions should ideally be done only when it is required. -- With Regards, Amit Kapila.
On Thu, Aug 26, 2021 at 9:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 3:41 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 3:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Thu, Aug 26, 2021 at 9:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > > ... > > > > > > > > > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > > > > > simple expressions. It will be visible when we use somewhat complex > > > > > > > expressions where expression evaluation cost is significant. > > > > > > > Similarly, the impact of this change will magnify and it will also be > > > > > > > visible when a publication has many tables. Apart from performance, > > > > > > > this change is logically correct as well because it would be any way > > > > > > > better if we don't invalidate the cached expressions unless required. > > > > > > > > > > > > Please tell me what is your idea of a "complex" row filter expression. > > > > > > Do you just mean a filter that has multiple AND conditions in it? I > > > > > > don't really know if few complex expressions would amount to any > > > > > > significant evaluation costs, so I would like to run some timing tests > > > > > > with some real examples to see the results. > > > > > > > > > > > > > > > > I think this means you didn't even understand or are convinced why the > > > > > patch has cache in the first place. As per your theory, even if we > > > > > didn't have cache, it won't matter but that is not true otherwise, the > > > > > patch wouldn't have it. > > > > > > > > I have never said there should be no caching. On the contrary, my > > > > performance test results [1] already confirmed that caching ExprState > > > > is of benefit for the millions of times it may be used in the > > > > pgoutput_row_filter function. My only doubts are in regard to how much > > > > observable impact there would be re-evaluating the filter expression > > > > just a few extra times by the get_rel_sync_entry function. > > > > > > > > > > I think it depends but why in the first place do you want to allow > > > re-evaluation when there is a way for not doing that? > > > > Because the current code logic of having the "delayed" ExprState > > evaluation does come at some cost. > > > > So, now you mixed it with the second point. Here, I was talking about > the need for correct invalidation but you started discussing when to > first time evaluate the expression, both are different things. > > > And the cost is - > > a. Needing an extra condition and more code in the function pgoutput_row_filter > > b. Needing to maintain the additional Node list > > > > I am not sure you need (b) above and I think (a) should make the > overall code look clean. > > > If we chose not to implement a delayed ExprState cache evaluation then > > there would still be a (one-time) ExprState cache evaluation but it > > would happen whenever get_rel_sync_entry is called (regardless of if > > pgoputput_row_filter is subsequently called). E.g. there can be some > > rebuilds of the ExprState cache if the user calls TRUNCATE. > > > > Apart from Truncate, it will also be a waste if any error happens > before actually evaluating the filter, tomorrow there could be other > operations like replication of sequences (I have checked that proposed > patch for sequences uses get_rel_sync_entry) where we don't need to > build ExprState (as filters might or might not be there). So, it would > be better to avoid cache lookups in those cases if possible. I still > think doing expensive things like preparing expressions should ideally > be done only when it is required. OK. Per your suggestion, I will try to move as much of the row-filter cache code as possible out of the get_rel_sync_entry function and into the pgoutput_row_filter function. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Aug 27, 2021 at 3:31 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 9:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 3:41 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Apart from Truncate, it will also be a waste if any error happens > > before actually evaluating the filter, tomorrow there could be other > > operations like replication of sequences (I have checked that proposed > > patch for sequences uses get_rel_sync_entry) where we don't need to > > build ExprState (as filters might or might not be there). So, it would > > be better to avoid cache lookups in those cases if possible. I still > > think doing expensive things like preparing expressions should ideally > > be done only when it is required. > > OK. Per your suggestion, I will try to move as much of the row-filter > cache code as possible out of the get_rel_sync_entry function and into > the pgoutput_row_filter function. > I could think of more scenarios where doing this work in get_rel_sync_entry() could cost us without any actual need for it. Consider, the user has published only 'update' and 'delete' operation for a publication, then in the system there are inserts followed truncate or any ddl which generates invalidation, for such a case, for each change we need to rebuild the row_filters but we won't use it. Similarly, this can happen in any other combination of DML and DDL operations where the DML operation is not published. I don't want to say that this is the most common scenario but it is important to do expensive work when it is actually required, otherwise, there could be cases where it might hit us. -- With Regards, Amit Kapila.
On Fri, Aug 27, 2021 at 8:01 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Aug 26, 2021 at 9:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Aug 26, 2021 at 3:41 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Thu, Aug 26, 2021 at 3:00 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > On Thu, Aug 26, 2021 at 9:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > On Thu, Aug 26, 2021 at 1:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > On Thu, Aug 26, 2021 at 7:37 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > > > > > > > On Wed, Aug 25, 2021 at 3:28 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > > > > > > ... > > > > > > > > > > > > > > > > Hmm, I think the gain via caching is not visible because we are using > > > > > > > > simple expressions. It will be visible when we use somewhat complex > > > > > > > > expressions where expression evaluation cost is significant. > > > > > > > > Similarly, the impact of this change will magnify and it will also be > > > > > > > > visible when a publication has many tables. Apart from performance, > > > > > > > > this change is logically correct as well because it would be any way > > > > > > > > better if we don't invalidate the cached expressions unless required. > > > > > > > > > > > > > > Please tell me what is your idea of a "complex" row filter expression. > > > > > > > Do you just mean a filter that has multiple AND conditions in it? I > > > > > > > don't really know if few complex expressions would amount to any > > > > > > > significant evaluation costs, so I would like to run some timing tests > > > > > > > with some real examples to see the results. > > > > > > > > > > > > > > > > > > > I think this means you didn't even understand or are convinced why the > > > > > > patch has cache in the first place. As per your theory, even if we > > > > > > didn't have cache, it won't matter but that is not true otherwise, the > > > > > > patch wouldn't have it. > > > > > > > > > > I have never said there should be no caching. On the contrary, my > > > > > performance test results [1] already confirmed that caching ExprState > > > > > is of benefit for the millions of times it may be used in the > > > > > pgoutput_row_filter function. My only doubts are in regard to how much > > > > > observable impact there would be re-evaluating the filter expression > > > > > just a few extra times by the get_rel_sync_entry function. > > > > > > > > > > > > > I think it depends but why in the first place do you want to allow > > > > re-evaluation when there is a way for not doing that? > > > > > > Because the current code logic of having the "delayed" ExprState > > > evaluation does come at some cost. > > > > > > > So, now you mixed it with the second point. Here, I was talking about > > the need for correct invalidation but you started discussing when to > > first time evaluate the expression, both are different things. > > > > > And the cost is - > > > a. Needing an extra condition and more code in the function pgoutput_row_filter > > > b. Needing to maintain the additional Node list > > > > > > > I am not sure you need (b) above and I think (a) should make the > > overall code look clean. > > > > > If we chose not to implement a delayed ExprState cache evaluation then > > > there would still be a (one-time) ExprState cache evaluation but it > > > would happen whenever get_rel_sync_entry is called (regardless of if > > > pgoputput_row_filter is subsequently called). E.g. there can be some > > > rebuilds of the ExprState cache if the user calls TRUNCATE. > > > > > > > Apart from Truncate, it will also be a waste if any error happens > > before actually evaluating the filter, tomorrow there could be other > > operations like replication of sequences (I have checked that proposed > > patch for sequences uses get_rel_sync_entry) where we don't need to > > build ExprState (as filters might or might not be there). So, it would > > be better to avoid cache lookups in those cases if possible. I still > > think doing expensive things like preparing expressions should ideally > > be done only when it is required. > > OK. Per your suggestion, I will try to move as much of the row-filter > cache code as possible out of the get_rel_sync_entry function and into > the pgoutput_row_filter function. > Here are the new v26* patches. This is a refactoring of the row-filter caches to remove all the logic from the get_rel_sync_entry function and delay it until if/when needed in the pgoutput_row_filter function. This is now implemented per Amit's suggestion to move all the cache code [1]. It is a replacement for the v25* patches. The make check and TAP subscription tests are all OK. I have repeated the performance tests [2] and those results are good too. v26-0001 <--- v23 (base RF patch) v26-0002 <--- ExprState cache mods (refactored row filter caching) v26-0002 <--- ExprState cache extra debug logging (temp) ------ [1] https://www.postgresql.org/message-id/CAA4eK1%2Btio46goUKBUfAKFsFVxtgk8nOty%3DTxKoKH-gdLzHD2g%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAHut%2BPs5j7mkO0xLmNW%3DkXh0eezGoKyzBCiQc9bfkCiM_MVDrg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia.
Вложения
On Sun, Aug 29, 2021, at 11:14 PM, Peter Smith wrote:
Here are the new v26* patches. This is a refactoring of the row-filtercaches to remove all the logic from the get_rel_sync_entry functionand delay it until if/when needed in the pgoutput_row_filter function.This is now implemented per Amit's suggestion to move all the cachecode [1]. It is a replacement for the v25* patches.The make check and TAP subscription tests are all OK. I have repeatedthe performance tests [2] and those results are good too.v26-0001 <--- v23 (base RF patch)v26-0002 <--- ExprState cache mods (refactored row filter caching)v26-0002 <--- ExprState cache extra debug logging (temp)
Peter, I'm still reviewing this new cache mechanism. I will provide a feedback
as soon as I integrate it as part of this recent modification.
I'm attaching a new version that simply including Houzj review [1]. This is
based on v23.
There has been a discussion about which row should be used by row filter. We
don't have a unanimous choice, so I think it is prudent to provide a way for
the user to change it. I suggested in a previous email [2] that a publication
option should be added. Hence, row filter can be applied to old tuple, new
tuple, or both. This approach is simpler than using OLD/NEW references (less
code and avoid validation such as NEW reference for DELETEs and OLD reference
for INSERTs). I think about a reasonable default value and it seems _new_ tuple
is a good one because (i) it is always available and (ii) user doesn't have
to figure out that replication is broken due to a column that is not part
of replica identity. I'm attaching a POC that implements it. I'm still
polishing it. Add tests for multiple row filters and integrate Peter's caching
mechanism [3] are the next steps.
Вложения
On Wed, Sep 1, 2021 at 4:53 PM Euler Taveira <euler@eulerto.com> wrote: > > On Sun, Aug 29, 2021, at 11:14 PM, Peter Smith wrote: > > Here are the new v26* patches. This is a refactoring of the row-filter > caches to remove all the logic from the get_rel_sync_entry function > and delay it until if/when needed in the pgoutput_row_filter function. > This is now implemented per Amit's suggestion to move all the cache > code [1]. It is a replacement for the v25* patches. > > The make check and TAP subscription tests are all OK. I have repeated > the performance tests [2] and those results are good too. > > v26-0001 <--- v23 (base RF patch) > v26-0002 <--- ExprState cache mods (refactored row filter caching) > v26-0002 <--- ExprState cache extra debug logging (temp) > > Peter, I'm still reviewing this new cache mechanism. I will provide a feedback > as soon as I integrate it as part of this recent modification. > > I'm attaching a new version that simply including Houzj review [1]. This is > based on v23. > > There has been a discussion about which row should be used by row filter. We > don't have a unanimous choice, so I think it is prudent to provide a way for > the user to change it. I suggested in a previous email [2] that a publication > option should be added. Hence, row filter can be applied to old tuple, new > tuple, or both. This approach is simpler than using OLD/NEW references (less > code and avoid validation such as NEW reference for DELETEs and OLD reference > for INSERTs). I think about a reasonable default value and it seems _new_ tuple > is a good one because (i) it is always available and (ii) user doesn't have > to figure out that replication is broken due to a column that is not part > of replica identity. > I think this or any other similar solution for row filters (on updates) won't work till we solve the problem reported by Hou-San [1]. The main reason is that we don't have data for unchanged toast columns in WAL. For that, we have discussed some probable solutions in email [2], however, that also required us to solve one of the existing bugs[3]. [1] - https://www.postgresql.org/message-id/OS0PR01MB571618736E7E79309A723BBE94E99%40OS0PR01MB5716.jpnprd01.prod.outlook.com [2] - https://www.postgresql.org/message-id/CAA4eK1JLQqNZypOpN7h3%3DVt0JJW4Yb_FsLJS%3DT8J9J-WXgFMYg%40mail.gmail.com [3] - https://www.postgresql.org/message-id/OS0PR01MB611342D0A92D4F4BF26C0F47FB229@OS0PR01MB6113.jpnprd01.prod.outlook.com -- With Regards, Amit Kapila.
On Wed, Sep 1, 2021, at 9:36 AM, Amit Kapila wrote:
I think this or any other similar solution for row filters (onupdates) won't work till we solve the problem reported by Hou-San [1].The main reason is that we don't have data for unchanged toast columnsin WAL. For that, we have discussed some probable solutions in email[2], however, that also required us to solve one of the existingbugs[3].
I didn't mention but I'm working on it in parallel.
I agree with you that including TOAST values in the WAL is a possible solution
for this issue. This is a popular request for wal2json [1][2][3] and I think
other output plugins have the same request too. It is useful for CDC solutions.
I'm experimenting 2 approaches: (i) always include unchanged TOAST values to
new tuple if a GUC is set and (ii) include unchanged TOAST values to new tuple
iif it wasn't include in the old tuple. The advantage of the first option is
that you fix the problem adjusting a parameter in your configuration file.
However, the disadvantage is that, depending on your setup -- REPLICA IDENTITY
FULL, you might have the same TOAST value for a single change twice in the WAL.
The second option solves the disadvantage of (i) but it only works if you have
REPLICA IDENTITY FULL and Dilip's patch applied [4] (I expect to review it
soon). In the output plugin, (i) requires a simple modification (remove
restriction for unchanged TOAST values) but (ii) needs a more complex surgery.
On Wed, Sep 1, 2021 at 8:29 PM Euler Taveira <euler@eulerto.com> wrote: > > On Wed, Sep 1, 2021, at 9:36 AM, Amit Kapila wrote: > > I think this or any other similar solution for row filters (on > updates) won't work till we solve the problem reported by Hou-San [1]. > The main reason is that we don't have data for unchanged toast columns > in WAL. For that, we have discussed some probable solutions in email > [2], however, that also required us to solve one of the existing > bugs[3]. > > I didn't mention but I'm working on it in parallel. > > I agree with you that including TOAST values in the WAL is a possible solution > for this issue. This is a popular request for wal2json [1][2][3] and I think > other output plugins have the same request too. It is useful for CDC solutions. > > I'm experimenting 2 approaches: (i) always include unchanged TOAST values to > new tuple if a GUC is set and (ii) include unchanged TOAST values to new tuple > iif it wasn't include in the old tuple. > In the second approach, we will always end up having unchanged toast columns for non-key columns in the WAL which will be a significant overhead, so not sure if that can be acceptable if we want to do it by default. > The advantage of the first option is > that you fix the problem adjusting a parameter in your configuration file. > However, the disadvantage is that, depending on your setup -- REPLICA IDENTITY > FULL, you might have the same TOAST value for a single change twice in the WAL. > The second option solves the disadvantage of (i) but it only works if you have > REPLICA IDENTITY FULL and Dilip's patch applied [4] (I expect to review it > soon). > Thanks for offering the review of that patch. I think it will be good to get it committed. > In the output plugin, (i) requires a simple modification (remove > restriction for unchanged TOAST values) but (ii) needs a more complex surgery. > I think if get Dilip's patch then we can have a rule for filter columns such that it can contain only replica identity key columns. This rule is anyway required for Deletes and we can have it for Updates. At this stage, I haven't checked what it takes to implement such a solution but it would be worth investigating it. -- With Regards, Amit Kapila.
On Thu, Sep 2, 2021 at 1:43 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > ... > I think if get Dilip's patch then we can have a rule for filter > columns such that it can contain only replica identity key columns. > This rule is anyway required for Deletes and we can have it for > Updates. At this stage, I haven't checked what it takes to implement > such a solution but it would be worth investigating it. Yes, I have been experimenting with part of this puzzle. I have implemented already some POC code to extract the list of table columns contained within the row filter expression. I can share it after I clean it up some more if that is helpful. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Wed, Sep 1, 2021 at 9:23 PM Euler Taveira <euler@eulerto.com> wrote: > > On Sun, Aug 29, 2021, at 11:14 PM, Peter Smith wrote: ... > Peter, I'm still reviewing this new cache mechanism. I will provide a feedback > as soon as I integrate it as part of this recent modification. Hi Euler, for your next version can you please also integrate the tab-autocomplete change back into the main patch. This autocomplete change was originally posted quite a few weeks ago here [1] but seems to have gone overlooked. I've rebased it and it applied OK to your latest v27* set. PSA. Thanks! ------ [1] https://www.postgresql.org/message-id/CAHut%2BPuLoZuHD_A%3Dn8GshC84Nc%3D8guReDsTmV1RFsCYojssD8Q%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Wed, Sep 1, 2021 at 9:23 PM Euler Taveira <euler@eulerto.com> wrote: > > On Sun, Aug 29, 2021, at 11:14 PM, Peter Smith wrote: > > Here are the new v26* patches. This is a refactoring of the row-filter > caches to remove all the logic from the get_rel_sync_entry function > and delay it until if/when needed in the pgoutput_row_filter function. > This is now implemented per Amit's suggestion to move all the cache > code [1]. It is a replacement for the v25* patches. > > The make check and TAP subscription tests are all OK. I have repeated > the performance tests [2] and those results are good too. > > v26-0001 <--- v23 (base RF patch) > v26-0002 <--- ExprState cache mods (refactored row filter caching) > v26-0002 <--- ExprState cache extra debug logging (temp) > > Peter, I'm still reviewing this new cache mechanism. I will provide a feedback > as soon as I integrate it as part of this recent modification. > > I'm attaching a new version that simply including Houzj review [1]. This is > based on v23. > > There has been a discussion about which row should be used by row filter. We > don't have a unanimous choice, so I think it is prudent to provide a way for > the user to change it. I suggested in a previous email [2] that a publication > option should be added. Hence, row filter can be applied to old tuple, new > tuple, or both. This approach is simpler than using OLD/NEW references (less > code and avoid validation such as NEW reference for DELETEs and OLD reference > for INSERTs). I think about a reasonable default value and it seems _new_ tuple > is a good one because (i) it is always available and (ii) user doesn't have > to figure out that replication is broken due to a column that is not part > of replica identity. I'm attaching a POC that implements it. I'm still > polishing it. Add tests for multiple row filters and integrate Peter's caching > mechanism [3] are the next steps. > Assuming this _new_tuple option is enabled and 1. An UPDATE, where the new_tuple satisfies the row filter, but the old_tuple did not (not checked). Since the row filter check passed but the actual row never existed on the subscriber, would this patch convert the UPDATE to an INSERT or would this UPDATE be ignored? Based on the tests that I did, I see that it is ignored. 2. An UPDATE where the new tuple does not satisfy the row filter but the old_tuple did. Since the new_tuple did not match the row filter, wouldn't this row now remain divergent on the replica? Somehow this approach of either new_tuple or old_tuple doesn't seem to be very fruitful if the user requires that his replica is up-to-date based on the filter condition. For that, I think you will need to convert UPDATES to either INSERTS or DELETES if only new_tuple or old_tuple matches the filter condition but not both matches the filter condition. UPDATE old-row (match) new-row (no match) -> DELETE old-row (no match) new row (match) -> INSERT old-row (match) new row (match) -> UPDATE old-row (no match) new-row (no match) -> (drop change) regards, Ajin Cherian Fujitsu Australia
Hi Euler, As you probably know the "base" Row-Filter 27-0001 got seriously messed up by a recent commit that had lots of overlaps with your code [1]. e.g. It broke trying to apply on HEAD as follows: [postgres@CentOS7-x64 oss_postgres_RowFilter]$ git apply v27-0001-Row-filter-for-logical-replication.patch error: patch failed: src/backend/catalog/pg_publication.c:141 error: src/backend/catalog/pg_publication.c: patch does not apply error: patch failed: src/backend/commands/publicationcmds.c:384 error: src/backend/commands/publicationcmds.c: patch does not apply error: patch failed: src/backend/parser/gram.y:426 error: src/backend/parser/gram.y: patch does not apply error: patch failed: src/include/catalog/pg_publication.h:83 error: src/include/catalog/pg_publication.h: patch does not apply error: patch failed: src/include/nodes/nodes.h:490 error: src/include/nodes/nodes.h: patch does not apply error: patch failed: src/include/nodes/parsenodes.h:3625 error: src/include/nodes/parsenodes.h: patch does not apply error: patch failed: src/test/regress/expected/publication.out:158 error: src/test/regress/expected/publication.out: patch does not apply error: patch failed: src/test/regress/sql/publication.sql:93 error: src/test/regress/sql/publication.sql: patch does not apply ~~ I know you are having discussions in the other (Col-Filtering) thread about the names PublicationRelationInfo versus PublicationRelInfo etc, but meanwhile, I am in need of a working "base" Row-Filter patch so that I can post my incremental work, and so that the cfbot can continue to run ok. Since your v27 has been broken for several days already I've taken it upon myself to re-base it. PSA. v27-0001 --> v28-0001. (AFAIK this new v28 applies ok and passes all regression and TAP subscription tests) Note: This v28 patch was made only so that I can (soon) post some other small incremental patches on top of it, and also so the cfbot will be able to run them ok. If you do not like it then just overwrite it - I am happy to work with whatever latest "base" patch you provide so long as it is compatible with the current master code. ------ [1] https://github.com/postgres/postgres/commit/0c6828fa987b791744b9c8685aadf1baa21f8977# Kind Regards, Peter Smith. Fujitsu Australia
Вложения
PSA my new incremental patch (v28-0002) that introduces row filter validation for the publish mode "delete". The validation requires that any columns referred to in the filter expression must also be part of REPLICA IDENTITY or PK. [This v28-0001 is identical to the most recently posted rebased base patch. It is included again here only so the cfbot will be happy] ~~ A requirement for some filter validation like this has been mentioned several times in this thread [1][2][3][4][5]. I also added some test code for various kinds of replica identity. A couple of existing tests had to be modified so they could continue to work (e.g. changed publish = "insert" or REPLICA IDENTITY FULL) Feedback is welcome. ~~ NOTE: This validation currently only checks when the filters are first created. Probably there are many other scenarios that need to be properly handled. What to do if something which impacts the existing filter is changed? e.g. - what if the user changes the publish parameter using ALTER PUBLICATION set (publish="delete") etc? - what if the user changes the replication identity? - what if the user changes the filter using ALTER PUBLICATION in a way that is no longer compatible with the necessary cols? - what if the user changes the table (e.g. removes a column referred to by a filter)? - what if the user changes a referred column name? - more... (None of those are addressed yet - thoughts?) ------ [1] https://www.postgresql.org/message-id/92e5587d-28b8-5849-2374-5ca3863256f1%402ndquadrant.com [2] https://www.postgresql.org/message-id/CAA4eK1JL2q%2BHENgiCf1HLRU7nD9jCcttB9sEqV1tech4mMv_0A%40mail.gmail.com [3] https://www.postgresql.org/message-id/202107132106.wvjgvjgcyezo%40alvherre.pgsql [4] https://www.postgresql.org/message-id/202107141452.edncq4ot5zkg%40alvherre.pgsql [5] https://www.postgresql.org/message-id/CAA4eK1Kyax-qnVPcXzODu3JmA4vtgAjUSYPUK1Pm3vBL5gC81g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Sep 9, 2021 at 11:43 AM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA my new incremental patch (v28-0002) that introduces row filter > validation for the publish mode "delete". The validation requires that > any columns referred to in the filter expression must also be part of > REPLICA IDENTITY or PK. > > [This v28-0001 is identical to the most recently posted rebased base > patch. It is included again here only so the cfbot will be happy] > > ~~ > > A requirement for some filter validation like this has been mentioned > several times in this thread [1][2][3][4][5]. > > I also added some test code for various kinds of replica identity. > > A couple of existing tests had to be modified so they could continue > to work (e.g. changed publish = "insert" or REPLICA IDENTITY FULL) > > Feedback is welcome. > > ~~ > > NOTE: This validation currently only checks when the filters are first > created. Probably there are many other scenarios that need to be > properly handled. What to do if something which impacts the existing > filter is changed? > > e.g. > - what if the user changes the publish parameter using ALTER > PUBLICATION set (publish="delete") etc? > - what if the user changes the replication identity? > - what if the user changes the filter using ALTER PUBLICATION in a way > that is no longer compatible with the necessary cols? > - what if the user changes the table (e.g. removes a column referred > to by a filter)? > - what if the user changes a referred column name? > - more... > > (None of those are addressed yet - thoughts?) > I think we need to remove the filter or the table from publication in such cases. Now, one can think of just removing the condition related to the column being removed/changed in some way but I think that won't be appropriate because it would change the meaning of the filter. We are discussing similar stuff in the column filter thread and we might want to do the same for row filters as well. I would prefer to remove the table in both cases as Rahila has proposed in the column filter patch. -- With Regards, Amit Kapila.
I have attached a POC row-filter validation patch implemented using a
parse-tree 'walker' function.
PSA the incremental patch v28-0003.
v28-0001 --> v28-0001 (same as before - base patch)
v28-0002 --> v28-0002 (same as before - replica identity validation patch)
v28-0003 (NEW POC PATCH using "walker" validation)
~~
This kind of 'walker' validation has been proposed/recommended already
several times up-thread. [1][2][3].
For this POC patch, I have removed all the existing
EXPR_KIND_PUBLICATION_WHERE parser errors. I am not 100% sure this is
the best idea (see below), but for now, the parser errors are
temporarily #if 0 in the code. I will clean up this patch and re-post
later when there is some feedback/consensus on how to proceed.
~
1. PROS
1.1 Using a 'walker' validator allows the row filter expression
validation to be 'opt-in' instead of 'opt-out' checking logic. This
may be considered *safer* because now we can have a very
controlled/restricted set of allowed nodes - e.g. only allow simple
(Var op Const) expressions. This eliminates the risk that some
unforeseen dangerous loophole could be exploited.
1.2 It is convenient to have all the row-filter validation errors in
one place, instead of being scattered across the parser code based on
EXPR_KIND_PUBLICATION_WHERE. Indeed, there seems some confusion
already caused by the existing scattering of row-filter validation
(patch 0001). For example, I found some of the new "aggregate
functions are not allowed" errors are not even reachable because they
are shielded by the earlier "functions are not allowed" error.
2. CONS
2.1 Error messages thrown from the parser can include the character
location of the problem. Actually, this is also possible using the
'walker' (I have done it locally) but it requires passing the
ParseState into the walker code - something I thought seemed a bit
unusual, so I did not include that in this 0003 POC patch.
~~
Perhaps a hybrid validation is preferred. e.g. retain some/all of the
parser validation errors from the 0001 patch, but also keep the walker
validation as a 'catch-all' to trap anything unforeseen that may slip
through the parsing. Or perhaps this 'walker' validator is fine as the
only validator and all the current parser errors for
EXPR_KIND_PUBLICATION_WHERE can just be permanently removed.
I am not sure what is the best approach, so I am hoping for some
feedback and/or review comments.
------
[1] https://www.postgresql.org/message-id/33c033f7-be44-e241-5fdf-da1b328c288d%40enterprisedb.com
[2] https://www.postgresql.org/message-id/CAA4eK1Jumuio6jZK8AVQd6z7gpDsZydQhK6d%3DMUARxk3nS7%2BPw%40mail.gmail.com
[3] https://www.postgresql.org/message-id/CAA4eK1JL2q%2BHENgiCf1HLRU7nD9jCcttB9sEqV1tech4mMv_0A%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Вложения
Hi Euler, FYI - the last-known-good "main" patch has been broken in the cfbot for the last couple of days due to a recent commit [1] on the HEAD. To keep the cfbot happy I have re-based it. In this same post (so that they will not be misplaced and so they remain working with HEAD) I am also re-attaching all of my currently pending "incremental" patches. These are either awaiting merge back into the "main" patch and/or they are awaiting review. ~ PSA 5 patches: v29-0001 = the latest "main" patch (was v28-0001-Row-filter-for-logical-replication.patch from [2]) is now rebased to HEAD. v29-0002 = my tab auto-complete patch (was v1-0001-Add-tab-auto-complete-support-for-the-Row-Filter-.patch from [3]) awaiting merge. v29-0003 = my cache updates patch (was v26-0002-ExprState-cache-modifications.patch from [4]) awaiting merge. v29-0004 = my filter validation replica identity patch (was v28-0002-Row-filter-validation-replica-identity.patch from [5]) awaiting review/merge. v29-0005 = my filter validation walker POC patch (was v28-0003-POC-row-filter-walker-validation.patch from [6]) awaiting feedback. ~ It is getting increasingly time-consuming to maintain and track all these separate patches. If possible, please merge them back into the "main" patch. ------ [1] https://github.com/postgres/postgres/commit/1882d6cca161dcf9fa05ecab5abeb1a027a5cfd2 [2] https://www.postgresql.org/message-id/CAHut%2BPv-Gz_bA6djDOnTz0OT-fMykKwidsK6bLDU5mZ1KWX9KQ%40mail.gmail.com [3] https://www.postgresql.org/message-id/CAHut%2BPsi7EygLemHnQbdLSZhBqyxqHY-3Mov1RS5xFAR%3Dxg-wg%40mail.gmail.com [4] https://www.postgresql.org/message-id/CAHut%2BPsgRHymwLhJ9t3By6%2BKNaVDzfjf6Y4Aq%3DJRD-y8t1mEFg%40mail.gmail.com [5] https://www.postgresql.org/message-id/CAHut%2BPukNh_HsN1Au1p9YhG5KCOr3dH5jnwm%3DRmeX75BOtXTEg%40mail.gmail.com [6] https://www.postgresql.org/message-id/CAHut%2BPt6%2B%3Dw7_r%3DCHBCS%2ByZXk5V%2BtnrzHLi3b2ZOVP1LHL2W9w%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Wed, Sep 8, 2021 at 7:59 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Wed, Sep 1, 2021 at 9:23 PM Euler Taveira <euler@eulerto.com> wrote: > > > Somehow this approach of either new_tuple or old_tuple doesn't seem to > be very fruitful if the user requires that his replica is up-to-date > based on the filter condition. For that, I think you will need to > convert UPDATES to either INSERTS or DELETES if only new_tuple or > old_tuple matches the filter condition but not both matches the filter > condition. > > UPDATE > old-row (match) new-row (no match) -> DELETE > old-row (no match) new row (match) -> INSERT > old-row (match) new row (match) -> UPDATE > old-row (no match) new-row (no match) -> (drop change) > Adding a patch that strives to do the logic that I described above. For updates, the row filter is applied on both old_tuple and new_tuple. This patch assumes that the row filter only uses columns that are part of the REPLICA IDENTITY. (the current patch-set only restricts this for row-filters that are delete only) The old_tuple only has columns that are part of the old_tuple and have been changed, which is a problem while applying the row-filter. Since unchanged REPLICA IDENTITY columns are not present in the old_tuple, this patch creates a temporary old_tuple by getting such column values from the new_tuple and then applies the filter on this hand-created temp old_tuple. The way the old_tuple is created can be better optimised in future versions. This patch also handles the problem reported by Houz in [1]. The patch assumes a fix proposed by Dilip in [2]. This is the case where toasted unchanged RI columns are not detoasted in the new_tuple and has to be retrieved from disk during decoding. Dilip's fix involved updating the detoasted value in the old_tuple when writing to WAL. In the problem reported by Hou, when the row filter is applied on the new_tuple and the decoder attempts to detoast the value in the new_tuple and if the table was deleted at that time, the decode fails. To avoid this, in such a situation, the untoasted value in the old_tuple (fix by Dilip) is copied to the new_tuple before the row_filter is applied. I have also refactored the way Peter initializes the row_filter by moving it into a separate function before the insert/update/delete specific logic is applied. I have not changed any of the first 5 patches, just added my patch 006 at the end. Do let me know of any comments on this approach. [1] - https://www.postgresql.org/message-id/OS0PR01MB571618736E7E79309A723BBE94E99%40OS0PR01MB5716.jpnprd01.prod.outlook.com [2] - https://www.postgresql.org/message-id/OS0PR01MB611342D0A92D4F4BF26C0F47FB229@OS0PR01MB6113.jpnprd01.prod.outlook.com regards, Ajin Cherian Fujitsu Australia
Вложения
- v29-0001-Row-filter-for-logical-replication.patch
- v29-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v29-0003-PS-ExprState-cache-modifications.patch
- v29-0005-PS-POC-Row-filter-validation-walker.patch
- v29-0004-PS-Row-filter-validation-of-replica-identity.patch
- v29-0006-support-updates-based-on-old-and-new-tuple-in-ro.patch
On Mon, Sep 20, 2021 at 3:17 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Wed, Sep 8, 2021 at 7:59 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > On Wed, Sep 1, 2021 at 9:23 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > Somehow this approach of either new_tuple or old_tuple doesn't seem to > > be very fruitful if the user requires that his replica is up-to-date > > based on the filter condition. For that, I think you will need to > > convert UPDATES to either INSERTS or DELETES if only new_tuple or > > old_tuple matches the filter condition but not both matches the filter > > condition. > > > > UPDATE > > old-row (match) new-row (no match) -> DELETE > > old-row (no match) new row (match) -> INSERT > > old-row (match) new row (match) -> UPDATE > > old-row (no match) new-row (no match) -> (drop change) > > > > Adding a patch that strives to do the logic that I described above. > For updates, the row filter is applied on both old_tuple > and new_tuple. This patch assumes that the row filter only uses > columns that are part of the REPLICA IDENTITY. (the current patch-set > only > restricts this for row-filters that are delete only) > The old_tuple only has columns that are part of the old_tuple and have > been changed, which is a problem while applying the row-filter. Since > unchanged REPLICA IDENTITY columns > are not present in the old_tuple, this patch creates a temporary > old_tuple by getting such column values from the new_tuple and then > applies the filter on this hand-created temp old_tuple. The way the > old_tuple is created can be better optimised in future versions. > Yeah, this is the kind of idea which can work. One thing you might want to check is the overhead of the additional deform/form cycle. You might want to use Peter's tests above. I think you need to only form old/new tuples when you have changed something in it but on a quick look, it seems you are always re-forming both the tuples. -- With Regards, Amit Kapila.
On Mon, Sep 20, 2021 at 5:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > Adding a patch that strives to do the logic that I described above. > > For updates, the row filter is applied on both old_tuple > > and new_tuple. This patch assumes that the row filter only uses > > columns that are part of the REPLICA IDENTITY. (the current patch-set > > only > > restricts this for row-filters that are delete only) > > The old_tuple only has columns that are part of the old_tuple and have > > been changed, which is a problem while applying the row-filter. Since > > unchanged REPLICA IDENTITY columns > > are not present in the old_tuple, this patch creates a temporary > > old_tuple by getting such column values from the new_tuple and then > > applies the filter on this hand-created temp old_tuple. The way the > > old_tuple is created can be better optimised in future versions. I understand why this is done, but I have 2 concerns here 1) We are having extra deform and copying the field from new to old in case it is unchanged replica identity. 2) The same unchanged attribute values get qualified in the old tuple as well as in the new tuple. What exactly needs to be done is that the only updated field should be validated as part of the old as well as the new tuple, the unchanged field does not make sense to have redundant validation. For that we will have to change the filter for the old tuple to just validate the attributes which are actually modified and remaining unchanged and new values will anyway get validated in the new tuple. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 21, 2021 at 12:03 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Sep 20, 2021 at 5:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > > > Adding a patch that strives to do the logic that I described above. > > > For updates, the row filter is applied on both old_tuple > > > and new_tuple. This patch assumes that the row filter only uses > > > columns that are part of the REPLICA IDENTITY. (the current patch-set > > > only > > > restricts this for row-filters that are delete only) > > > The old_tuple only has columns that are part of the old_tuple and have > > > been changed, which is a problem while applying the row-filter. Since > > > unchanged REPLICA IDENTITY columns > > > are not present in the old_tuple, this patch creates a temporary > > > old_tuple by getting such column values from the new_tuple and then > > > applies the filter on this hand-created temp old_tuple. The way the > > > old_tuple is created can be better optimised in future versions. > > I understand why this is done, but I have 2 concerns here 1) We are > having extra deform and copying the field from new to old in case it > is unchanged replica identity. 2) The same unchanged attribute values > get qualified in the old tuple as well as in the new tuple. What > exactly needs to be done is that the only updated field should be > validated as part of the old as well as the new tuple, the unchanged > field does not make sense to have redundant validation. For that we > will have to change the filter for the old tuple to just validate the > attributes which are actually modified and remaining unchanged and new > values will anyway get validated in the new tuple. > But what if the filter expression depends on multiple columns, say (a+b) > 100 where a is unchanged while b is changed. Then we will still need both columns for applying the filter even though one is unchanged. Also, I am not aware of any mechanism by which we can apply a filter expression on individual attributes. The current mechanism does it on a tuple. Do let me know if you have any ideas there? Even if it were done, there would still be the overhead of deforming the tuple. I will run some performance tests like Amit suggested and see what the overhead is and try to minimise it. regards, Ajin Cherian Fujitsu Australia
On Tue, Sep 21, 2021 at 8:58 AM Ajin Cherian <itsajin@gmail.com> wrote: > > I understand why this is done, but I have 2 concerns here 1) We are > > having extra deform and copying the field from new to old in case it > > is unchanged replica identity. 2) The same unchanged attribute values > > get qualified in the old tuple as well as in the new tuple. What > > exactly needs to be done is that the only updated field should be > > validated as part of the old as well as the new tuple, the unchanged > > field does not make sense to have redundant validation. For that we > > will have to change the filter for the old tuple to just validate the > > attributes which are actually modified and remaining unchanged and new > > values will anyway get validated in the new tuple. > > > But what if the filter expression depends on multiple columns, say (a+b) > 100 > where a is unchanged while b is changed. Then we will still need both > columns for applying In such a case, we need to. > the filter even though one is unchanged. Also, I am not aware of any > mechanism by which > we can apply a filter expression on individual attributes. The current > mechanism does it > on a tuple. Do let me know if you have any ideas there? What I suggested is to modify the filter for the old tuple, e.g. filter is (a > 10 and b < 20 and c+d = 20), now only if a and c are modified then we can process the expression and we can transform this filter to (a > 10 and c+d=20). > > Even if it were done, there would still be the overhead of deforming the tuple. Suppose filter is just (a > 10 and b < 20) and only if the a is updated, and if we are able to modify the filter for the oldtuple to be just (a>10) then also do we need to deform? Even if we have to we can save a lot on avoiding duplicate expression evaluation. > I will run some performance tests like Amit suggested and see what the > overhead is and > try to minimise it. It is good to know, I think you must try with some worst-case scenarios, e.g. we have 10 text column and 1 int column in the REPLICA IDENTITY and only the int column get updated and all the text column are not updated, and you have a filter on all the columns. Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 21, 2021 at 9:54 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Sep 21, 2021 at 8:58 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > I understand why this is done, but I have 2 concerns here 1) We are > > > having extra deform and copying the field from new to old in case it > > > is unchanged replica identity. 2) The same unchanged attribute values > > > get qualified in the old tuple as well as in the new tuple. What > > > exactly needs to be done is that the only updated field should be > > > validated as part of the old as well as the new tuple, the unchanged > > > field does not make sense to have redundant validation. For that we > > > will have to change the filter for the old tuple to just validate the > > > attributes which are actually modified and remaining unchanged and new > > > values will anyway get validated in the new tuple. > > > > > But what if the filter expression depends on multiple columns, say (a+b) > 100 > > where a is unchanged while b is changed. Then we will still need both > > columns for applying > > In such a case, we need to. > > > the filter even though one is unchanged. Also, I am not aware of any > > mechanism by which > > we can apply a filter expression on individual attributes. The current > > mechanism does it > > on a tuple. Do let me know if you have any ideas there? > > What I suggested is to modify the filter for the old tuple, e.g. > filter is (a > 10 and b < 20 and c+d = 20), now only if a and c are > modified then we can process the expression and we can transform this > filter to (a > 10 and c+d=20). > If you have only a and c in the old tuple, how will it evaluate expression c + d? I think the point is if for some expression some values are in old tuple and others are in new then the idea proposed in the patch seems sane. Moreover, I think in your idea for each tuple we might need to build a new expression and sometimes twice that will beat the purpose of cache we have kept in the patch and I am not sure if it is less costly. See another example where splitting filter might not give desired results: Say filter expression: (a = 10 and b = 20 and c = 30) Now, old_tuple has values for columns a and c and say values are 10 and 30. So, the old_tuple will match the filter if we split it as per your suggestion. Now say new_tuple has values (a = 5, b = 15, c = 25). In such a situation dividing the filter will give us the result that the old_tuple is matching but new tuple is not matching which seems incorrect. I think dividing filter conditions among old and new tuples might not retain its sanctity. > > > > Even if it were done, there would still be the overhead of deforming the tuple. > > Suppose filter is just (a > 10 and b < 20) and only if the a is > updated, and if we are able to modify the filter for the oldtuple to > be just (a>10) then also do we need to deform? > Without deforming, how will you determine which columns are part of the old tuple? -- With Regards, Amit Kapila.
On Tue, Sep 21, 2021 at 10:41 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > If you have only a and c in the old tuple, how will it evaluate > expression c + d? Well, what I told is that if we have such dependency then we will have to copy that field to the old tuple, e.g. if we convert the filter for the old tuple from (a > 10 and b < 20 and c+d = 20) to (a > 10 and c+d=20), then we will not have to copy 'b' to the old tuple but we still have to copy 'd' because there is a dependency. I think the point is if for some expression some > values are in old tuple and others are in new then the idea proposed > in the patch seems sane. Moreover, I think in your idea for each tuple > we might need to build a new expression and sometimes twice that will > beat the purpose of cache we have kept in the patch and I am not sure > if it is less costly. Basically, expression initialization should happen only once in most cases so with my suggestion you might have to do it twice. But the overhead of extra expression evaluation is far less than doing duplicate evaluation because that will happen for sending each update operation right? > See another example where splitting filter might not give desired results: > > Say filter expression: (a = 10 and b = 20 and c = 30) > > Now, old_tuple has values for columns a and c and say values are 10 > and 30. So, the old_tuple will match the filter if we split it as per > your suggestion. Now say new_tuple has values (a = 5, b = 15, c = 25). > In such a situation dividing the filter will give us the result that > the old_tuple is matching but new tuple is not matching which seems > incorrect. I think dividing filter conditions among old and new tuples > might not retain its sanctity. Yeah that is a good example to apply a duplicate filter, basically some filters might not even get evaluated on new tuples as the above example and if we have removed such expression on the other tuple we might break something. Maybe for now this suggest that we might not be able to avoid the duplicate execution of the expression > > > > > > Even if it were done, there would still be the overhead of deforming the tuple. > > > > Suppose filter is just (a > 10 and b < 20) and only if the a is > > updated, and if we are able to modify the filter for the oldtuple to > > be just (a>10) then also do we need to deform? > > > > Without deforming, how will you determine which columns are part of > the old tuple? Okay, then we might have to deform, but at least are we ensuring that once we have deform the tuple for the expression evaluation then we are not doing that again while sending the tuple? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 21, 2021 at 11:16 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Sep 21, 2021 at 10:41 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > I think the point is if for some expression some > > values are in old tuple and others are in new then the idea proposed > > in the patch seems sane. Moreover, I think in your idea for each tuple > > we might need to build a new expression and sometimes twice that will > > beat the purpose of cache we have kept in the patch and I am not sure > > if it is less costly. > > Basically, expression initialization should happen only once in most > cases so with my suggestion you might have to do it twice. > No, the situation will be that we might have to do it twice per update where as now, it is just done at the very first operation on a relation. > But the > overhead of extra expression evaluation is far less than doing > duplicate evaluation because that will happen for sending each update > operation right? > Expression evaluation has to be done twice because every update can have a different set of values in the old and new tuple. > > See another example where splitting filter might not give desired results: > > > > Say filter expression: (a = 10 and b = 20 and c = 30) > > > > Now, old_tuple has values for columns a and c and say values are 10 > > and 30. So, the old_tuple will match the filter if we split it as per > > your suggestion. Now say new_tuple has values (a = 5, b = 15, c = 25). > > In such a situation dividing the filter will give us the result that > > the old_tuple is matching but new tuple is not matching which seems > > incorrect. I think dividing filter conditions among old and new tuples > > might not retain its sanctity. > > Yeah that is a good example to apply a duplicate filter, basically > some filters might not even get evaluated on new tuples as the above > example and if we have removed such expression on the other tuple we > might break something. > Right. > Maybe for now this suggest that we might not > be able to avoid the duplicate execution of the expression > So, IIUC, you agreed that let's proceed with the proposed approach and we can later do optimizations if possible or if we get better ideas. > > > > > > > > Even if it were done, there would still be the overhead of deforming the tuple. > > > > > > Suppose filter is just (a > 10 and b < 20) and only if the a is > > > updated, and if we are able to modify the filter for the oldtuple to > > > be just (a>10) then also do we need to deform? > > > > > > > Without deforming, how will you determine which columns are part of > > the old tuple? > > Okay, then we might have to deform, but at least are we ensuring that > once we have deform the tuple for the expression evaluation then we > are not doing that again while sending the tuple? > I think this is possible but we might want to be careful not to send extra unchanged values as we are doing now. -- With Regards, Amit Kapila.
On Tue, Sep 21, 2021 at 2:34 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Sep 21, 2021 at 11:16 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Sep 21, 2021 at 10:41 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > I think the point is if for some expression some > > > values are in old tuple and others are in new then the idea proposed > > > in the patch seems sane. Moreover, I think in your idea for each tuple > > > we might need to build a new expression and sometimes twice that will > > > beat the purpose of cache we have kept in the patch and I am not sure > > > if it is less costly. > > > > Basically, expression initialization should happen only once in most > > cases so with my suggestion you might have to do it twice. > > > > No, the situation will be that we might have to do it twice per update > where as now, it is just done at the very first operation on a > relation. Yeah right. Actually, I mean it will not get initialized for decoding each tuple, so instead of once it will be done twice, but anyway now we agree that we can not proceed in this direction because of the issue you pointed out. > > Maybe for now this suggest that we might not > > be able to avoid the duplicate execution of the expression > > > > So, IIUC, you agreed that let's proceed with the proposed approach and > we can later do optimizations if possible or if we get better ideas. Make sense. > > Okay, then we might have to deform, but at least are we ensuring that > > once we have deform the tuple for the expression evaluation then we > > are not doing that again while sending the tuple? > > > > I think this is possible but we might want to be careful not to send > extra unchanged values as we are doing now. Right. Some more comments, In pgoutput_row_filter_update(), first, we are deforming the tuple in local datum, then modifying the tuple, and then reforming the tuple. I think we can surely do better here. Currently, you are reforming the tuple so that you can store it in the scan slot by calling ExecStoreHeapTuple which will be used for expression evaluation. Instead of that what you need to do is to deform the tuple using tts_values of the scan slot and later call ExecStoreVirtualTuple(), so advantages are 1) you don't need to reform the tuple 2) the expression evaluation machinery doesn't need to deform again for fetching the value of the attribute, instead it can directly get from the value from the virtual tuple. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 21, 2021 at 4:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > Some more comments, > > In pgoutput_row_filter_update(), first, we are deforming the tuple in > local datum, then modifying the tuple, and then reforming the tuple. > I think we can surely do better here. Currently, you are reforming > the tuple so that you can store it in the scan slot by calling > ExecStoreHeapTuple which will be used for expression evaluation. > Instead of that what you need to do is to deform the tuple using > tts_values of the scan slot and later call ExecStoreVirtualTuple(), so > advantages are 1) you don't need to reform the tuple 2) the expression > evaluation machinery doesn't need to deform again for fetching the > value of the attribute, instead it can directly get from the value > from the virtual tuple. > I have one more question, while looking into the ExtractReplicaIdentity() function, it seems that if any of the "rep ident key" fields is changed then we will write all the key fields in the WAL as part of the old tuple, not just the changed fields. That means either the old tuple will be NULL or it will be having all the key attributes. So if we are supporting filter only on the "rep ident key fields" then is there any need to copy the fields from the new tuple to the old tuple? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Sep 21, 2021 at 9:42 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Sep 21, 2021 at 4:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > Some more comments, > > > > In pgoutput_row_filter_update(), first, we are deforming the tuple in > > local datum, then modifying the tuple, and then reforming the tuple. > > I think we can surely do better here. Currently, you are reforming > > the tuple so that you can store it in the scan slot by calling > > ExecStoreHeapTuple which will be used for expression evaluation. > > Instead of that what you need to do is to deform the tuple using > > tts_values of the scan slot and later call ExecStoreVirtualTuple(), so > > advantages are 1) you don't need to reform the tuple 2) the expression > > evaluation machinery doesn't need to deform again for fetching the > > value of the attribute, instead it can directly get from the value > > from the virtual tuple. > > > > I have one more question, while looking into the > ExtractReplicaIdentity() function, it seems that if any of the "rep > ident key" fields is changed then we will write all the key fields in > the WAL as part of the old tuple, not just the changed fields. That > means either the old tuple will be NULL or it will be having all the > key attributes. So if we are supporting filter only on the "rep ident > key fields" then is there any need to copy the fields from the new > tuple to the old tuple? > Yes, I just figured this out while testing. So we don't need to copy fields from the new tuple to the old tuple. But there is still the case of your fix for the unchanged toasted RI key fields in the new tuple which needs to be copied from the old tuple to the new tuple. This particular case seems to violate both rules that an old tuple will be present only when there are changed RI key fields and that if there is an old tuple it will contain all RI key fields. I think we still need to deform both old tuple and new tuple, just to handle this case. There is currently logic in ReorderBufferToastReplace() which already deforms the new tuple to detoast changed toasted fields in the new tuple. I think if we can enhance this logic for our purpose, then we can avoid an extra deform of the new tuple. But I think you had earlier indicated that having untoasted unchanged values in the new tuple can be bothersome. Any suggestions? regards, Ajin Cherian Fujitsu Australia regards, Ajin Cherian Fujitsu Australia
On Wed, Sep 22, 2021 at 6:42 AM Ajin Cherian <itsajin@gmail.com> wrote: > > On Tue, Sep 21, 2021 at 9:42 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Tue, Sep 21, 2021 at 4:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > I have one more question, while looking into the > > ExtractReplicaIdentity() function, it seems that if any of the "rep > > ident key" fields is changed then we will write all the key fields in > > the WAL as part of the old tuple, not just the changed fields. That > > means either the old tuple will be NULL or it will be having all the > > key attributes. So if we are supporting filter only on the "rep ident > > key fields" then is there any need to copy the fields from the new > > tuple to the old tuple? > > > > Yes, I just figured this out while testing. So we don't need to copy fields > from the new tuple to the old tuple. > > But there is still the case of your fix for the unchanged toasted RI > key fields in the new tuple > which needs to be copied from the old tuple to the new tuple. This > particular case > seems to violate both rules that an old tuple will be present only > when there are changed > RI key fields and that if there is an old tuple it will contain all RI > key fields. > Why do you think that the second assumption (if there is an old tuple it will contain all RI key fields.) is broken? It seems to me even when we are planning to include unchanged toast as part of old_key, it will contain all the key columns, isn't that true? > I think we > still need to deform both old tuple and new tuple, just to handle this case. > Yeah, but we will anyway talking about saving that cost for later if we decide to send that tuple. I think we can further try to optimize it by first checking whether the new tuple has any toasted value, if so then only we need this extra pass of deforming. > There is currently logic in ReorderBufferToastReplace() which already > deforms the new tuple > to detoast changed toasted fields in the new tuple. I think if we can > enhance this logic for our > purpose, then we can avoid an extra deform of the new tuple. > But I think you had earlier indicated that having untoasted unchanged > values in the new tuple > can be bothersome. > I think it will be too costly on the subscriber side during apply because it will update all the unchanged toasted values which will lead to extra writes both for WAL and data. -- With Regards, Amit Kapila.
On Wed, Sep 22, 2021 at 1:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Sep 22, 2021 at 6:42 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Why do you think that the second assumption (if there is an old tuple > it will contain all RI key fields.) is broken? It seems to me even > when we are planning to include unchanged toast as part of old_key, it > will contain all the key columns, isn't that true? Yes, I assumed wrongly. Just checked. What you say is correct. > > > I think we > > still need to deform both old tuple and new tuple, just to handle this case. > > > > Yeah, but we will anyway talking about saving that cost for later if > we decide to send that tuple. I think we can further try to optimize > it by first checking whether the new tuple has any toasted value, if > so then only we need this extra pass of deforming. Ok, I will go ahead with this approach. > > > There is currently logic in ReorderBufferToastReplace() which already > > deforms the new tuple > > to detoast changed toasted fields in the new tuple. I think if we can > > enhance this logic for our > > purpose, then we can avoid an extra deform of the new tuple. > > But I think you had earlier indicated that having untoasted unchanged > > values in the new tuple > > can be bothersome. > > > > I think it will be too costly on the subscriber side during apply > because it will update all the unchanged toasted values which will > lead to extra writes both for WAL and data. > Ok, agreed. regards, Ajin Cherian Fujitsu Australia
On Wed, Sep 22, 2021 at 9:20 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Sep 22, 2021 at 6:42 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > > On Tue, Sep 21, 2021 at 9:42 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > On Tue, Sep 21, 2021 at 4:29 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > I have one more question, while looking into the > > > ExtractReplicaIdentity() function, it seems that if any of the "rep > > > ident key" fields is changed then we will write all the key fields in > > > the WAL as part of the old tuple, not just the changed fields. That > > > means either the old tuple will be NULL or it will be having all the > > > key attributes. So if we are supporting filter only on the "rep ident > > > key fields" then is there any need to copy the fields from the new > > > tuple to the old tuple? > > > > > > > Yes, I just figured this out while testing. So we don't need to copy fields > > from the new tuple to the old tuple. > > > > But there is still the case of your fix for the unchanged toasted RI > > key fields in the new tuple > > which needs to be copied from the old tuple to the new tuple. Yes, we will have to do that. > > There is currently logic in ReorderBufferToastReplace() which already > > deforms the new tuple > > to detoast changed toasted fields in the new tuple. I think if we can > > enhance this logic for our > > purpose, then we can avoid an extra deform of the new tuple. > > But I think you had earlier indicated that having untoasted unchanged > > values in the new tuple > > can be bothersome. > > > > I think it will be too costly on the subscriber side during apply > because it will update all the unchanged toasted values which will > lead to extra writes both for WAL and data. Right we should not do that. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi,
I finally had time to take a closer look at the patch again, so here's
some review comments. The thread is moving fast, so chances are some of
the comments are obsolete or were already raised in the past.
1) I wonder if we should use WHERE or WHEN to specify the expression.
WHERE is not wrong, but WHEN (as used in triggers) might be better.
2) create_publication.sgml says:
A <literal>NULL</literal> value causes the expression to evaluate
to false; avoid using columns without not-null constraints in the
<literal>WHERE</literal> clause.
That's not quite correct, I think - doesn't the expression evaluate to
NULL (which is not TRUE, so it counts as mismatch)?
I suspect this whole paragraph (talking about NULL in old/new rows)
might be a bit too detailed / low-level for user docs.
3) create_subscription.sgml
<literal>WHERE</literal> clauses, rows must satisfy all expressions
to be copied. If the subscriber is a
I'm rather skeptical about the principle that all expressions have to
match - I'd have expected exactly the opposite behavior, actually.
I see a subscription as "a union of all publications". Imagine for
example you have a data set for all customers, and you create a
publication for different parts of the world, like
CREATE PUBLICATION customers_france
FOR TABLE customers WHERE (country = 'France');
CREATE PUBLICATION customers_germany
FOR TABLE customers WHERE (country = 'Germany');
CREATE PUBLICATION customers_usa
FOR TABLE customers WHERE (country = 'USA');
and now you want to subscribe to multiple publications, because you want
to replicate data for multiple countries (e.g. you want EU countries).
But if you do
CREATE SUBSCRIPTION customers_eu
PUBLICATION customers_france, customers_germany;
then you won't get anything, because each customer belongs to just a
single country. Yes, I could create multiple individual subscriptions,
one for each country, but that's inefficient and may have a different
set of issues (e.g. keeping them in sync when a customer moves between
countries).
I might have missed something, but I haven't found any explanation why
the requirement to satisfy all expressions is the right choice.
IMHO this should be 'satisfies at least one expression' i.e. we should
connect the expressions by OR, not AND.
4) pg_publication.c
It's a bit suspicious we're adding includes for parser to a place where
there were none before. I wonder if this might indicate some layering
issue, i.e. doing something in the wrong place ...
5) publicationcmds.c
I mentioned this in my last review [1] already, but I really dislike the
fact that OpenTableList accepts a list containing one of two entirely
separate node types (PublicationTable or Relation). It was modified to
use IsA() instead of a flag, but I still find it ugly, confusing and
possibly error-prone.
Also, not sure mentioning the two different callers explicitly in the
OpenTableList comment is a great idea - it's likely to get stale if
someone adds another caller.
6) parse_oper.c
I'm having some second thoughts about (not) allowing UDFs ...
Yes, I get that if the function starts failing, e.g. because querying a
dropped table or something, that breaks the replication and can't be
fixed without a resync.
That's pretty annoying, but maybe disallowing anything user-defined
(functions and operators) is maybe overly anxious? Also, extensibility
is one of the hallmarks of Postgres, and disallowing all custom UDF and
operators seems to contradict that ...
Perhaps just explaining that the expression can / can't do in the docs,
with clear warnings of the risks, would be acceptable.
7) exprstate_list
I'd just call the field / variable "exprstates", without indicating the
data type. I don't think we do that anywhere.
8) RfCol
Do we actually need this struct? Why not to track just name or attnum,
and lookup the other value in syscache when needed?
9) rowfilter_expr_checker
* Walk the parse-tree to decide if the row-filter is valid or not.
I don't see any clear explanation what does "valid" mean.
10) WHERE expression vs. data type
Seem ATExecAlterColumnType might need some changes, because changing a
data type for column referenced by the expression triggers this:
test=# alter table t alter COLUMN c type text;
ERROR: unexpected object depending on column: publication of
table t in publication p
11) extra (unnecessary) parens in the deparsed expression
test=# alter publication p add table t where ((b < 100) and (c < 100));
ALTER PUBLICATION
test=# \dRp+ p
Publication p
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
-------+------------+---------+---------+---------+-----------+----------
user | f | t | t | t | t | f
Tables:
"public.t" WHERE (((b < 100) AND (c < 100)))
12) WHERE expression vs. changing replica identity
Peter Smith already mentioned this in [3], but there's a bunch of places
that need to check the expression vs. replica identity. Consider for
example this:
test=# alter publication p add table t where (b < 100);
ERROR: cannot add relation "t" to publication
DETAIL: Row filter column "b" is not part of the REPLICA IDENTITY
test=# alter table t replica identity full;
ALTER TABLE
test=# alter publication p add table t where (b < 100);
ALTER PUBLICATION
test=# alter table t replica identity using INDEX t_pkey ;
ALTER TABLE
Which means the expression is not covered by the replica identity.
12) misuse of REPLICA IDENTITY
The more I think about this, the more I think we're actually misusing
REPLICA IDENTITY for something entirely different. The whole purpose of
RI was to provide a row identifier for the subscriber.
But now we're using it to ensure we have all the necessary columns,
which is entirely orthogonal to the original purpose. I predict this
will have rather negative consequences.
People will either switch everything to REPLICA IDENTITY FULL, or create
bogus unique indexes with extra columns. Which is really silly, because
it wastes network bandwidth (transfers more data) or local resources
(CPU and disk space to maintain extra indexes).
IMHO this needs more infrastructure to request extra columns to decode
(e.g. for the filter expression), and then remove them before sending
the data to the subscriber.
13) turning update into insert
I agree with Ajin Cherian [4] that looking at just old or new row for
updates is not the right solution, because each option will "break" the
replica in some case. So I think the goal "keeping the replica in sync"
is the right perspective, and converting the update to insert/delete if
needed seems appropriate.
This seems a somewhat similar to what pglogical does, because that may
also convert updates (although only to inserts, IIRC) when handling
replication conflicts. The difference is pglogical does all this on the
subscriber, while this makes the decision on the publisher.
I wonder if this might have some negative consequences, or whether
"moving" this to downstream would be useful for other purposes in the
fuure (e.g. it might be reused for handling other conflicts).
14) pgoutput_row_filter_update
The function name seems a bit misleading, as it suggests might seem like
it updates the row_filter, or something. Should indicate it's about
deciding what to do with the update.
15) pgoutput_row_filter initializing filter
I'm not sure I understand why the filter initialization gets moved from
get_rel_sync_entry. Presumably, most of what the replication does is
replicating rows, so I see little point in not initializing this along
with the rest of the rel_sync_entry.
regards
[1]
https://www.postgresql.org/message-id/849ee491-bba3-c0ae-cc25-4fce1c03f105%40enterprisedb.com
[2]
https://www.postgresql.org/message-id/7106a0fc-8017-c0fe-a407-9466c9407ff8%402ndquadrant.com
[3]
https://www.postgresql.org/message-id/CAHut%2BPukNh_HsN1Au1p9YhG5KCOr3dH5jnwm%3DRmeX75BOtXTEg%40mail.gmail.com
[4]
https://www.postgresql.org/message-id/CAFPTHDb7bpkuc4SxaL9B5vEvF2aEi0EOERdrG%2BxgVeAyMJsF%3DQ%40mail.gmail.com
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Sep 23, 2021 at 6:03 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 6) parse_oper.c > > I'm having some second thoughts about (not) allowing UDFs ... > > Yes, I get that if the function starts failing, e.g. because querying a > dropped table or something, that breaks the replication and can't be > fixed without a resync. > The other problem is that users can access/query any table inside the function and that also won't work in a logical decoding environment as we use historic snapshots using which we can access only catalog tables. > That's pretty annoying, but maybe disallowing anything user-defined > (functions and operators) is maybe overly anxious? Also, extensibility > is one of the hallmarks of Postgres, and disallowing all custom UDF and > operators seems to contradict that ... > > Perhaps just explaining that the expression can / can't do in the docs, > with clear warnings of the risks, would be acceptable. > I think the right way to support functions is by the explicit marking of functions and in one of the emails above Jeff Davis also agreed with the same. I think we should probably introduce a new marking for this. I feel this is important because without this it won't be safe to access even some of the built-in functions that can access/update database (non-immutable functions) due to logical decoding environment restrictions. > > 12) misuse of REPLICA IDENTITY > > The more I think about this, the more I think we're actually misusing > REPLICA IDENTITY for something entirely different. The whole purpose of > RI was to provide a row identifier for the subscriber. > > But now we're using it to ensure we have all the necessary columns, > which is entirely orthogonal to the original purpose. I predict this > will have rather negative consequences. > > People will either switch everything to REPLICA IDENTITY FULL, or create > bogus unique indexes with extra columns. Which is really silly, because > it wastes network bandwidth (transfers more data) or local resources > (CPU and disk space to maintain extra indexes). > > IMHO this needs more infrastructure to request extra columns to decode > (e.g. for the filter expression), and then remove them before sending > the data to the subscriber. > Yeah, but that would have an additional load on write operations and I am not sure at this stage but maybe there could be other ways to extend the current infrastructure wherein we build the snapshots using which we can access the user tables instead of only catalog tables. Such enhancements if feasible would be useful not only for allowing additional column access in row filters but for other purposes like allowing access to functions that access user tables. I feel we can extend this later as well seeing the usage and requests. For the first version, this doesn't sound too limiting to me. -- With Regards, Amit Kapila.
On Fri, Sep 24, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > 12) misuse of REPLICA IDENTITY > > > > The more I think about this, the more I think we're actually misusing > > REPLICA IDENTITY for something entirely different. The whole purpose of > > RI was to provide a row identifier for the subscriber. > > > > But now we're using it to ensure we have all the necessary columns, > > which is entirely orthogonal to the original purpose. I predict this > > will have rather negative consequences. > > > > People will either switch everything to REPLICA IDENTITY FULL, or create > > bogus unique indexes with extra columns. Which is really silly, because > > it wastes network bandwidth (transfers more data) or local resources > > (CPU and disk space to maintain extra indexes). > > > > IMHO this needs more infrastructure to request extra columns to decode > > (e.g. for the filter expression), and then remove them before sending > > the data to the subscriber. > > > > Yeah, but that would have an additional load on write operations and I > am not sure at this stage but maybe there could be other ways to > extend the current infrastructure wherein we build the snapshots using > which we can access the user tables instead of only catalog tables. > Such enhancements if feasible would be useful not only for allowing > additional column access in row filters but for other purposes like > allowing access to functions that access user tables. I feel we can > extend this later as well seeing the usage and requests. For the first > version, this doesn't sound too limiting to me. I agree with one point from Tomas, that if we bind the row filter with the RI, then if the user has to use the row filter on any column 1) they have to add an unnecessary column to the index 2) Since they have to add it to RI so now we will have to send it over the network as well. 3). We anyway have to WAL log it if it is modified because now we forced users to add some columns to RI because they wanted to use the row filter on that. Now suppose we remove that limitation and we somehow make these changes orthogonal to RI, i.e. if we have a row filter on some column then we WAL log it, so now the only extra cost we are paying is to just WAL log that column, but the user is not forced to add it to index, not forced to send it over the network. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 23, 2021 at 6:03 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 13) turning update into insert > > I agree with Ajin Cherian [4] that looking at just old or new row for > updates is not the right solution, because each option will "break" the > replica in some case. So I think the goal "keeping the replica in sync" > is the right perspective, and converting the update to insert/delete if > needed seems appropriate. > > This seems a somewhat similar to what pglogical does, because that may > also convert updates (although only to inserts, IIRC) when handling > replication conflicts. The difference is pglogical does all this on the > subscriber, while this makes the decision on the publisher. > > I wonder if this might have some negative consequences, or whether > "moving" this to downstream would be useful for other purposes in the > fuure (e.g. it might be reused for handling other conflicts). > Apart from additional traffic, I am not sure how will we handle all the conditions on subscribers, say if the new row doesn't match, how will subscribers know about this unless we pass row_filter or some additional information along with tuple. Previously, I have done some research and shared in one of the emails above that IBM's InfoSphere Data Replication [1] performs filtering in this way which also suggests that we won't be off here. > > > 15) pgoutput_row_filter initializing filter > > I'm not sure I understand why the filter initialization gets moved from > get_rel_sync_entry. Presumably, most of what the replication does is > replicating rows, so I see little point in not initializing this along > with the rest of the rel_sync_entry. > Sorry, IIRC, this has been suggested by me and I thought it was best to do any expensive computation the first time it is required. I have shared few cases like in [2] where it would lead to additional cost without any gain. Unless I am missing something, I don't see any downside of doing it in a delayed fashion. [1] - https://www.ibm.com/docs/en/idr/11.4.0?topic=rows-search-conditions [2] - https://www.postgresql.org/message-id/CAA4eK1JBHo2U2sZemFdJmcwEinByiJVii8wzGCDVMxOLYB3CUw%40mail.gmail.com -- With Regards, Amit Kapila.
On Fri, Sep 24, 2021 at 11:06 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Sep 24, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > 12) misuse of REPLICA IDENTITY > > > > > > The more I think about this, the more I think we're actually misusing > > > REPLICA IDENTITY for something entirely different. The whole purpose of > > > RI was to provide a row identifier for the subscriber. > > > > > > But now we're using it to ensure we have all the necessary columns, > > > which is entirely orthogonal to the original purpose. I predict this > > > will have rather negative consequences. > > > > > > People will either switch everything to REPLICA IDENTITY FULL, or create > > > bogus unique indexes with extra columns. Which is really silly, because > > > it wastes network bandwidth (transfers more data) or local resources > > > (CPU and disk space to maintain extra indexes). > > > > > > IMHO this needs more infrastructure to request extra columns to decode > > > (e.g. for the filter expression), and then remove them before sending > > > the data to the subscriber. > > > > > > > Yeah, but that would have an additional load on write operations and I > > am not sure at this stage but maybe there could be other ways to > > extend the current infrastructure wherein we build the snapshots using > > which we can access the user tables instead of only catalog tables. > > Such enhancements if feasible would be useful not only for allowing > > additional column access in row filters but for other purposes like > > allowing access to functions that access user tables. I feel we can > > extend this later as well seeing the usage and requests. For the first > > version, this doesn't sound too limiting to me. > > I agree with one point from Tomas, that if we bind the row filter with > the RI, then if the user has to use the row filter on any column 1) > they have to add an unnecessary column to the index 2) Since they have > to add it to RI so now we will have to send it over the network as > well. 3). We anyway have to WAL log it if it is modified because now > we forced users to add some columns to RI because they wanted to use > the row filter on that. Now suppose we remove that limitation and we > somehow make these changes orthogonal to RI, i.e. if we have a row > filter on some column then we WAL log it, so now the only extra cost > we are paying is to just WAL log that column, but the user is not > forced to add it to index, not forced to send it over the network. > I am not suggesting adding additional columns to RI just for using filter expressions. If most users that intend to publish delete/update wanted to use filter conditions apart from replica identity then we can later extend this functionality but not sure if the only way to accomplish that is to log additional data in WAL. I am just trying to see if we can provide meaningful functionality without extending too much the scope of this work. -- With Regards, Amit Kapila.
On Fri, Sep 24, 2021 at 11:52 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Sep 24, 2021 at 11:06 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Fri, Sep 24, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > 12) misuse of REPLICA IDENTITY > > > > > > > > The more I think about this, the more I think we're actually misusing > > > > REPLICA IDENTITY for something entirely different. The whole purpose of > > > > RI was to provide a row identifier for the subscriber. > > > > > > > > But now we're using it to ensure we have all the necessary columns, > > > > which is entirely orthogonal to the original purpose. I predict this > > > > will have rather negative consequences. > > > > > > > > People will either switch everything to REPLICA IDENTITY FULL, or create > > > > bogus unique indexes with extra columns. Which is really silly, because > > > > it wastes network bandwidth (transfers more data) or local resources > > > > (CPU and disk space to maintain extra indexes). > > > > > > > > IMHO this needs more infrastructure to request extra columns to decode > > > > (e.g. for the filter expression), and then remove them before sending > > > > the data to the subscriber. > > > > > > > > > > Yeah, but that would have an additional load on write operations and I > > > am not sure at this stage but maybe there could be other ways to > > > extend the current infrastructure wherein we build the snapshots using > > > which we can access the user tables instead of only catalog tables. > > > Such enhancements if feasible would be useful not only for allowing > > > additional column access in row filters but for other purposes like > > > allowing access to functions that access user tables. I feel we can > > > extend this later as well seeing the usage and requests. For the first > > > version, this doesn't sound too limiting to me. > > > > I agree with one point from Tomas, that if we bind the row filter with > > the RI, then if the user has to use the row filter on any column 1) > > they have to add an unnecessary column to the index 2) Since they have > > to add it to RI so now we will have to send it over the network as > > well. 3). We anyway have to WAL log it if it is modified because now > > we forced users to add some columns to RI because they wanted to use > > the row filter on that. Now suppose we remove that limitation and we > > somehow make these changes orthogonal to RI, i.e. if we have a row > > filter on some column then we WAL log it, so now the only extra cost > > we are paying is to just WAL log that column, but the user is not > > forced to add it to index, not forced to send it over the network. > > > > I am not suggesting adding additional columns to RI just for using > filter expressions. If most users that intend to publish delete/update > wanted to use filter conditions apart from replica identity then we > can later extend this functionality but not sure if the only way to > accomplish that is to log additional data in WAL. > One possibility in this regard could be that we enhance Replica Identity .. Include (column_list) where all the columns in the include list won't be sent but I think it is better to postpone such enhancements for a later version. Like, I suggested above, we might want to extend our infrastructure in a way where not only this extra columns request can be accomplished but we should be able to allow UDF's (where user tables can be accessed) and probably sub-queries as well. -- With Regards, Amit Kapila.
On Fri, Sep 24, 2021 at 12:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > One possibility in this regard could be that we enhance Replica > Identity .. Include (column_list) where all the columns in the include > list won't be sent Instead of RI's include column list why we can not think of row_filter's columns list? I mean like we log the old RI column can't we make similar things for the row filter columns? With that, we don't have to all the columns instead we only log the columns which are in row filter, or is this too hard to identify during write operation? So now the WAL logging requirement for RI and row filter is orthogonal and if some columns are common then we can log only once? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Fri, Sep 24, 2021 at 12:19 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Sep 24, 2021 at 12:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > One possibility in this regard could be that we enhance Replica > > Identity .. Include (column_list) where all the columns in the include > > list won't be sent > > Instead of RI's include column list why we can not think of > row_filter's columns list? I mean like we log the old RI column can't > we make similar things for the row filter columns? With that, we > don't have to all the columns instead we only log the columns which > are in row filter, or is this too hard to identify during write > operation? > Yeah, we can do that as well but my guess is that will have some additional work (to find common columns and log them only once) in heap_delete/update and then probably during decoding (to assemble the required filter and RI key). I am not very sure on this point, one has to write code and test. -- With Regards, Amit Kapila.
On 9/24/21 8:09 AM, Amit Kapila wrote: > On Thu, Sep 23, 2021 at 6:03 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> 13) turning update into insert >> >> I agree with Ajin Cherian [4] that looking at just old or new row for >> updates is not the right solution, because each option will "break" the >> replica in some case. So I think the goal "keeping the replica in sync" >> is the right perspective, and converting the update to insert/delete if >> needed seems appropriate. >> >> This seems a somewhat similar to what pglogical does, because that may >> also convert updates (although only to inserts, IIRC) when handling >> replication conflicts. The difference is pglogical does all this on the >> subscriber, while this makes the decision on the publisher. >> >> I wonder if this might have some negative consequences, or whether >> "moving" this to downstream would be useful for other purposes in the >> fuure (e.g. it might be reused for handling other conflicts). >> > > Apart from additional traffic, I am not sure how will we handle all > the conditions on subscribers, say if the new row doesn't match, how > will subscribers know about this unless we pass row_filter or some > additional information along with tuple. Previously, I have done some > research and shared in one of the emails above that IBM's InfoSphere > Data Replication [1] performs filtering in this way which also > suggests that we won't be off here. > I'm certainly not suggesting what we're doing is wrong. Given the design of built-in logical replication it makes sense doing it this way, I was just thinking aloud about what we might want to do in the future (e.g. pglogical uses this to deal with conflicts between multiple sources, and so on). >> >> >> 15) pgoutput_row_filter initializing filter >> >> I'm not sure I understand why the filter initialization gets moved from >> get_rel_sync_entry. Presumably, most of what the replication does is >> replicating rows, so I see little point in not initializing this along >> with the rest of the rel_sync_entry. >> > > Sorry, IIRC, this has been suggested by me and I thought it was best > to do any expensive computation the first time it is required. I have > shared few cases like in [2] where it would lead to additional cost > without any gain. Unless I am missing something, I don't see any > downside of doing it in a delayed fashion. > Not sure, but the arguments presented there seem a bit wonky ... Yes, the work would be wasted if we discard the cached data without using it (it might happen for truncate, I'm not sure). But how likely is it that such operations happen *in isolation*? I'd bet the workload is almost never just a stream of truncates - there are always some operations in between that would actually use this. Similarly for the errors - IIRC hitting an error means the replication restarts, which is orders of magnitude more expensive than anything we can save by this delayed evaluation. I'd keep it simple, for the sake of simplicity of the whole patch. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 9/24/21 7:20 AM, Amit Kapila wrote: > On Thu, Sep 23, 2021 at 6:03 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> 6) parse_oper.c >> >> I'm having some second thoughts about (not) allowing UDFs ... >> >> Yes, I get that if the function starts failing, e.g. because querying a >> dropped table or something, that breaks the replication and can't be >> fixed without a resync. >> > > The other problem is that users can access/query any table inside the > function and that also won't work in a logical decoding environment as > we use historic snapshots using which we can access only catalog > tables. > True. I always forget about some of these annoying issues. Let's document all of this in some comment / README. I see we still don't have src/backend/replication/logical/README which is a bit surprising, considering how complex this code is. >> That's pretty annoying, but maybe disallowing anything user-defined >> (functions and operators) is maybe overly anxious? Also, extensibility >> is one of the hallmarks of Postgres, and disallowing all custom UDF and >> operators seems to contradict that ... >> >> Perhaps just explaining that the expression can / can't do in the docs, >> with clear warnings of the risks, would be acceptable. >> > > I think the right way to support functions is by the explicit marking > of functions and in one of the emails above Jeff Davis also agreed > with the same. I think we should probably introduce a new marking for > this. I feel this is important because without this it won't be safe > to access even some of the built-in functions that can access/update > database (non-immutable functions) due to logical decoding environment > restrictions. > I agree that seems reasonable. Is there any reason why not to just use IMMUTABLE for this purpose? Seems like a good match to me. Yes, the user can lie and label something that is not really IMMUTABLE, but that's his fault. Yes, it's harder to fix than e.g. for indexes. >> >> 12) misuse of REPLICA IDENTITY >> >> The more I think about this, the more I think we're actually misusing >> REPLICA IDENTITY for something entirely different. The whole purpose of >> RI was to provide a row identifier for the subscriber. >> >> But now we're using it to ensure we have all the necessary columns, >> which is entirely orthogonal to the original purpose. I predict this >> will have rather negative consequences. >> >> People will either switch everything to REPLICA IDENTITY FULL, or create >> bogus unique indexes with extra columns. Which is really silly, because >> it wastes network bandwidth (transfers more data) or local resources >> (CPU and disk space to maintain extra indexes). >> >> IMHO this needs more infrastructure to request extra columns to decode >> (e.g. for the filter expression), and then remove them before sending >> the data to the subscriber. >> > > Yeah, but that would have an additional load on write operations and I > am not sure at this stage but maybe there could be other ways to > extend the current infrastructure wherein we build the snapshots using > which we can access the user tables instead of only catalog tables. > Such enhancements if feasible would be useful not only for allowing > additional column access in row filters but for other purposes like > allowing access to functions that access user tables. I feel we can > extend this later as well seeing the usage and requests. For the first > version, this doesn't sound too limiting to me. > I'm not really buying the argument that this means overhead for write operations. Well, it does, but the current RI approach is forcing users to either use RIF or add an index covering the filter attributes. Neither of those options is free, and I'd bet the extra overhead of adding just the row filter columns would be actually lower. If the argument is merely to limit the scope of this patch, fine. But I'd bet the amount of code we'd have to add to ExtractReplicaIdentity (or maybe somewhere close to it) would be fairly small. We'd need to cache which columns are needed (like RelationGetIndexAttrBitmap), and this might be a bit more complex, due to having to consider all the publications etc. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Sep 25, 2021 at 3:30 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 9/24/21 7:20 AM, Amit Kapila wrote: > > > > I think the right way to support functions is by the explicit marking > > of functions and in one of the emails above Jeff Davis also agreed > > with the same. I think we should probably introduce a new marking for > > this. I feel this is important because without this it won't be safe > > to access even some of the built-in functions that can access/update > > database (non-immutable functions) due to logical decoding environment > > restrictions. > > > > I agree that seems reasonable. Is there any reason why not to just use > IMMUTABLE for this purpose? Seems like a good match to me. > It will just solve one part of the puzzle (related to database access) but it is better to avoid the risk of broken replication by explicit marking especially for UDFs or other user-defined objects. You seem to be okay documenting such risk but I am not sure we have an agreement on that especially because that was one of the key points of discussions in this thread and various people told that we need to do something about it. I personally feel we should do something if we want to allow user-defined functions or operators because as reported in the thread this problem has been reported multiple times. I think we can go ahead with IMMUTABLE built-ins for the first version and then allow UDFs later or let's try to find a way for explicit marking. > Yes, the user can lie and label something that is not really IMMUTABLE, > but that's his fault. Yes, it's harder to fix than e.g. for indexes. > Agreed and I think we can't do anything about this. > >> > >> 12) misuse of REPLICA IDENTITY > >> > >> The more I think about this, the more I think we're actually misusing > >> REPLICA IDENTITY for something entirely different. The whole purpose of > >> RI was to provide a row identifier for the subscriber. > >> > >> But now we're using it to ensure we have all the necessary columns, > >> which is entirely orthogonal to the original purpose. I predict this > >> will have rather negative consequences. > >> > >> People will either switch everything to REPLICA IDENTITY FULL, or create > >> bogus unique indexes with extra columns. Which is really silly, because > >> it wastes network bandwidth (transfers more data) or local resources > >> (CPU and disk space to maintain extra indexes). > >> > >> IMHO this needs more infrastructure to request extra columns to decode > >> (e.g. for the filter expression), and then remove them before sending > >> the data to the subscriber. > >> > > > > Yeah, but that would have an additional load on write operations and I > > am not sure at this stage but maybe there could be other ways to > > extend the current infrastructure wherein we build the snapshots using > > which we can access the user tables instead of only catalog tables. > > Such enhancements if feasible would be useful not only for allowing > > additional column access in row filters but for other purposes like > > allowing access to functions that access user tables. I feel we can > > extend this later as well seeing the usage and requests. For the first > > version, this doesn't sound too limiting to me. > > > > I'm not really buying the argument that this means overhead for write > operations. Well, it does, but the current RI approach is forcing users > to either use RIF or add an index covering the filter attributes. > Neither of those options is free, and I'd bet the extra overhead of > adding just the row filter columns would be actually lower. > > If the argument is merely to limit the scope of this patch, fine. > Yeah, that is one and I am not sure that adding extra WAL is the best or only solution for this problem. As mentioned in my previous response, I think we eventually need to find a way to access user tables to support UDFs (that access database) or sub-query which other databases already support, and for that, we might need to enhance the current snapshot mechanism after which we might not need any additional WAL even for additional columns in row filter. I don't think anyone of us has evaluated in detail the different ways this problem can be solved and the pros/cons of each approach, so limiting the scope for this purpose doesn't seem like a bad idea to me. -- With Regards, Amit Kapila.
On Sat, Sep 25, 2021 at 3:07 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 9/24/21 8:09 AM, Amit Kapila wrote: > > On Thu, Sep 23, 2021 at 6:03 PM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> 13) turning update into insert > >> > >> I agree with Ajin Cherian [4] that looking at just old or new row for > >> updates is not the right solution, because each option will "break" the > >> replica in some case. So I think the goal "keeping the replica in sync" > >> is the right perspective, and converting the update to insert/delete if > >> needed seems appropriate. > >> > >> This seems a somewhat similar to what pglogical does, because that may > >> also convert updates (although only to inserts, IIRC) when handling > >> replication conflicts. The difference is pglogical does all this on the > >> subscriber, while this makes the decision on the publisher. > >> > >> I wonder if this might have some negative consequences, or whether > >> "moving" this to downstream would be useful for other purposes in the > >> fuure (e.g. it might be reused for handling other conflicts). > >> > > > > Apart from additional traffic, I am not sure how will we handle all > > the conditions on subscribers, say if the new row doesn't match, how > > will subscribers know about this unless we pass row_filter or some > > additional information along with tuple. Previously, I have done some > > research and shared in one of the emails above that IBM's InfoSphere > > Data Replication [1] performs filtering in this way which also > > suggests that we won't be off here. > > > > I'm certainly not suggesting what we're doing is wrong. Given the design > of built-in logical replication it makes sense doing it this way, I was > just thinking aloud about what we might want to do in the future (e.g. > pglogical uses this to deal with conflicts between multiple sources, and > so on). > Fair enough. > >> > >> > >> 15) pgoutput_row_filter initializing filter > >> > >> I'm not sure I understand why the filter initialization gets moved from > >> get_rel_sync_entry. Presumably, most of what the replication does is > >> replicating rows, so I see little point in not initializing this along > >> with the rest of the rel_sync_entry. > >> > > > > Sorry, IIRC, this has been suggested by me and I thought it was best > > to do any expensive computation the first time it is required. I have > > shared few cases like in [2] where it would lead to additional cost > > without any gain. Unless I am missing something, I don't see any > > downside of doing it in a delayed fashion. > > > > Not sure, but the arguments presented there seem a bit wonky ... > > Yes, the work would be wasted if we discard the cached data without > using it (it might happen for truncate, I'm not sure). But how likely is > it that such operations happen *in isolation*? I'd bet the workload is > almost never just a stream of truncates - there are always some > operations in between that would actually use this. > It could also happen with a mix of truncate and other operations as we decide whether to publish an operation or not after get_rel_sync_entry. > Similarly for the errors - IIRC hitting an error means the replication > restarts, which is orders of magnitude more expensive than anything we > can save by this delayed evaluation. > > I'd keep it simple, for the sake of simplicity of the whole patch. > The current version proposed by Peter is not reviewed yet and by looking at it I have some questions too which I'll clarify in a separate email. I am not sure if you are against delaying the expression initialization because of the current code or concept as a general because if it is later then we have other instances as well when we don't do all the work in get_rel_sync_entry like building tuple conversion map which is cached as well. -- With Regards, Amit Kapila.
On Mon, Sep 20, 2021 at 3:17 PM Ajin Cherian <itsajin@gmail.com> wrote: > > I have not changed any of the first 5 patches, just added my patch 006 > at the end. Do let me know of any comments on this approach. > I have a question regarding v29-0003-PS-ExprState-cache-modifications. In pgoutput_row_filter, for row_filter, we are traversing ancestors of a partition to find pub_relid but isn't that already available in RelationSyncEntry as publish_as_relid? -- With Regards, Amit Kapila.
On 9/25/21 6:23 AM, Amit Kapila wrote: > On Sat, Sep 25, 2021 at 3:30 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 9/24/21 7:20 AM, Amit Kapila wrote: >>> >>> I think the right way to support functions is by the explicit marking >>> of functions and in one of the emails above Jeff Davis also agreed >>> with the same. I think we should probably introduce a new marking for >>> this. I feel this is important because without this it won't be safe >>> to access even some of the built-in functions that can access/update >>> database (non-immutable functions) due to logical decoding environment >>> restrictions. >>> >> >> I agree that seems reasonable. Is there any reason why not to just use >> IMMUTABLE for this purpose? Seems like a good match to me. >> > > It will just solve one part of the puzzle (related to database access) > but it is better to avoid the risk of broken replication by explicit > marking especially for UDFs or other user-defined objects. You seem to > be okay documenting such risk but I am not sure we have an agreement > on that especially because that was one of the key points of > discussions in this thread and various people told that we need to do > something about it. I personally feel we should do something if we > want to allow user-defined functions or operators because as reported > in the thread this problem has been reported multiple times. I think > we can go ahead with IMMUTABLE built-ins for the first version and > then allow UDFs later or let's try to find a way for explicit marking. > Well, I know multiple people mentioned that issue. And I certainly agree just documenting the risk would not be an ideal solution. Requiring the functions to be labeled helps, but we've seen people marking volatile functions as immutable in order to allow indexing, so we'll have to document the risks anyway. All I'm saying is that allowing built-in functions/operators but not user-defined variants seems like an annoying break of extensibility. People are used that user-defined stuff can be used just like built-in functions and operators. >> Yes, the user can lie and label something that is not really IMMUTABLE, >> but that's his fault. Yes, it's harder to fix than e.g. for indexes. >> > > Agreed and I think we can't do anything about this. > >>>> >>>> 12) misuse of REPLICA IDENTITY >>>> >>>> The more I think about this, the more I think we're actually misusing >>>> REPLICA IDENTITY for something entirely different. The whole purpose of >>>> RI was to provide a row identifier for the subscriber. >>>> >>>> But now we're using it to ensure we have all the necessary columns, >>>> which is entirely orthogonal to the original purpose. I predict this >>>> will have rather negative consequences. >>>> >>>> People will either switch everything to REPLICA IDENTITY FULL, or create >>>> bogus unique indexes with extra columns. Which is really silly, because >>>> it wastes network bandwidth (transfers more data) or local resources >>>> (CPU and disk space to maintain extra indexes). >>>> >>>> IMHO this needs more infrastructure to request extra columns to decode >>>> (e.g. for the filter expression), and then remove them before sending >>>> the data to the subscriber. >>>> >>> >>> Yeah, but that would have an additional load on write operations and I >>> am not sure at this stage but maybe there could be other ways to >>> extend the current infrastructure wherein we build the snapshots using >>> which we can access the user tables instead of only catalog tables. >>> Such enhancements if feasible would be useful not only for allowing >>> additional column access in row filters but for other purposes like >>> allowing access to functions that access user tables. I feel we can >>> extend this later as well seeing the usage and requests. For the first >>> version, this doesn't sound too limiting to me. >>> >> >> I'm not really buying the argument that this means overhead for write >> operations. Well, it does, but the current RI approach is forcing users >> to either use RIF or add an index covering the filter attributes. >> Neither of those options is free, and I'd bet the extra overhead of >> adding just the row filter columns would be actually lower. >> >> If the argument is merely to limit the scope of this patch, fine. >> > > Yeah, that is one and I am not sure that adding extra WAL is the best > or only solution for this problem. As mentioned in my previous > response, I think we eventually need to find a way to access user > tables to support UDFs (that access database) or sub-query which other > databases already support, and for that, we might need to enhance the > current snapshot mechanism after which we might not need any > additional WAL even for additional columns in row filter. I don't > think anyone of us has evaluated in detail the different ways this > problem can be solved and the pros/cons of each approach, so limiting > the scope for this purpose doesn't seem like a bad idea to me. > Understood. I don't have a very good idea which of those options is the best one either, although I think enhancing the snapshot mechanism would be rather tricky. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Sep 25, 2021 at 3:36 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 9/25/21 6:23 AM, Amit Kapila wrote: > > On Sat, Sep 25, 2021 at 3:30 AM Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> On 9/24/21 7:20 AM, Amit Kapila wrote: > >>> > >>> I think the right way to support functions is by the explicit marking > >>> of functions and in one of the emails above Jeff Davis also agreed > >>> with the same. I think we should probably introduce a new marking for > >>> this. I feel this is important because without this it won't be safe > >>> to access even some of the built-in functions that can access/update > >>> database (non-immutable functions) due to logical decoding environment > >>> restrictions. > >>> > >> > >> I agree that seems reasonable. Is there any reason why not to just use > >> IMMUTABLE for this purpose? Seems like a good match to me. > >> > > > > It will just solve one part of the puzzle (related to database access) > > but it is better to avoid the risk of broken replication by explicit > > marking especially for UDFs or other user-defined objects. You seem to > > be okay documenting such risk but I am not sure we have an agreement > > on that especially because that was one of the key points of > > discussions in this thread and various people told that we need to do > > something about it. I personally feel we should do something if we > > want to allow user-defined functions or operators because as reported > > in the thread this problem has been reported multiple times. I think > > we can go ahead with IMMUTABLE built-ins for the first version and > > then allow UDFs later or let's try to find a way for explicit marking. > > > > Well, I know multiple people mentioned that issue. And I certainly agree > just documenting the risk would not be an ideal solution. Requiring the > functions to be labeled helps, but we've seen people marking volatile > functions as immutable in order to allow indexing, so we'll have to > document the risks anyway. > > All I'm saying is that allowing built-in functions/operators but not > user-defined variants seems like an annoying break of extensibility. > People are used that user-defined stuff can be used just like built-in > functions and operators. > I agree with you that allowing UDFs in some way would be good for this feature. I think once we get the base feature committed then we can discuss whether and how to allow UDFs. Do we want to have an additional label for it or can we come up with something which allows the user to continue replication even if she has dropped the object used in the function? It seems like we can limit the scope of base patch functionality to allow the use of immutable built-in functions in row filter expressions. -- With Regards, Amit Kapila.
Hi, I see no one responded to this important part of my review so far: On 9/23/21 2:33 PM, Tomas Vondra wrote: > 3) create_subscription.sgml > > <literal>WHERE</literal> clauses, rows must satisfy all expressions > to be copied. If the subscriber is a > > I'm rather skeptical about the principle that all expressions have to > match - I'd have expected exactly the opposite behavior, actually. > > I see a subscription as "a union of all publications". Imagine for > example you have a data set for all customers, and you create a > publication for different parts of the world, like > > CREATE PUBLICATION customers_france > FOR TABLE customers WHERE (country = 'France'); > > CREATE PUBLICATION customers_germany > FOR TABLE customers WHERE (country = 'Germany'); > > CREATE PUBLICATION customers_usa > FOR TABLE customers WHERE (country = 'USA'); > > and now you want to subscribe to multiple publications, because you want > to replicate data for multiple countries (e.g. you want EU countries). > But if you do > > CREATE SUBSCRIPTION customers_eu > PUBLICATION customers_france, customers_germany; > > then you won't get anything, because each customer belongs to just a > single country. Yes, I could create multiple individual subscriptions, > one for each country, but that's inefficient and may have a different > set of issues (e.g. keeping them in sync when a customer moves between > countries). > > I might have missed something, but I haven't found any explanation why > the requirement to satisfy all expressions is the right choice. > > IMHO this should be 'satisfies at least one expression' i.e. we should > connect the expressions by OR, not AND. Am I the only one finding the current behavior strange? What's the reasoning supporting the current approach? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Sep 27, 2021, at 10:34 AM, Tomas Vondra wrote:
Hi,I see no one responded to this important part of my review so far:
I'm still preparing a new patch and a summary.
Am I the only one finding the current behavior strange? What's thereasoning supporting the current approach?
I think it is an oversight from my side. It used to work the way you mentioned
but I changed it. I'll include this change in the next patch.
On Mon, Sep 27, 2021 at 7:19 PM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Sep 27, 2021, at 10:34 AM, Tomas Vondra wrote: > > Hi, > > I see no one responded to this important part of my review so far: > > I'm still preparing a new patch and a summary. > > Am I the only one finding the current behavior strange? What's the > reasoning supporting the current approach? > > I think it is an oversight from my side. It used to work the way you mentioned > but I changed it. I'll include this change in the next patch. > +1. -- With Regards, Amit Kapila.
On Wed, Sep 22, 2021 at 2:05 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Wed, Sep 22, 2021 at 1:50 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Sep 22, 2021 at 6:42 AM Ajin Cherian <itsajin@gmail.com> wrote: > > > > > > > Why do you think that the second assumption (if there is an old tuple > > it will contain all RI key fields.) is broken? It seems to me even > > when we are planning to include unchanged toast as part of old_key, it > > will contain all the key columns, isn't that true? > > Yes, I assumed wrongly. Just checked. What you say is correct. > > > > > > I think we > > > still need to deform both old tuple and new tuple, just to handle this case. > > > > > > > Yeah, but we will anyway talking about saving that cost for later if > > we decide to send that tuple. I think we can further try to optimize > > it by first checking whether the new tuple has any toasted value, if > > so then only we need this extra pass of deforming. > > Ok, I will go ahead with this approach. > > > > > > There is currently logic in ReorderBufferToastReplace() which already > > > deforms the new tuple > > > to detoast changed toasted fields in the new tuple. I think if we can > > > enhance this logic for our > > > purpose, then we can avoid an extra deform of the new tuple. > > > But I think you had earlier indicated that having untoasted unchanged > > > values in the new tuple > > > can be bothersome. > > > > > > > I think it will be too costly on the subscriber side during apply > > because it will update all the unchanged toasted values which will > > lead to extra writes both for WAL and data. > > Based on the discussion above, I've added two more slot pointers in the RelationSyncEntry structure to store tuples that have been deformed. Once the tuple (old and new) is deformed , then it is stored in the structure, where it can be retrieved while writing to the stream.I have also changed the logic so that the old tuple is not populated, as Dilip pointed out, it will have all the RI columns if it is changed. I've added two new APIs in proto.c for writing tuple cached and writing update cached. These are called if the the slots contain previously deformed tuples. I have for now also rebased the patch and merged the first 5 patches into 1, and added my changes for the above into the second patch. regards, Ajin Cherian Fujitsu Australia
Вложения
On Sat, Oct 2, 2021 at 5:44 PM Ajin Cherian <itsajin@gmail.com> wrote: > > I have for now also rebased the patch and merged the first 5 patches > into 1, and added my changes for the above into the second patch. I have split the patches back again, just to be consistent with the original state of the patches. Sorry for the inconvenience. regards, Ajin Cherian Fujitsu Australia
Вложения
- v31-0001-Row-filter-for-logical-replication.patch
- v31-0005-PS-POC-Row-filter-validation-walker.patch
- v31-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v31-0003-PS-ExprState-cache-modifications.patch
- v31-0004-PS-Row-filter-validation-of-replica-identity.patch
- v31-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Wed, Oct 6, 2021 at 2:33 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> On Sat, Oct 2, 2021 at 5:44 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > I have for now also rebased the patch and merged the first 5 patches
> > into 1, and added my changes for the above into the second patch.
>
> I have split the patches back again, just to be consistent with the
> original state of the patches. Sorry for the inconvenience.
Thanks for the updated version of the patch, I was looking into the
latest version and I have a few comments.
+ if ((att->attlen == -1 &&
VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i])) &&
+ (!old_slot->tts_isnull[i] &&
+ !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))))
+ {
+ tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
+ newtup_changed = true;
+ }
If the attribute is stored EXTERNAL_ONDIS on the new tuple and it is
not null in the old tuple then it must be logged completely in the old
tuple, so instead of checking
!(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]), it should be
asserted,
+ heap_deform_tuple(newtuple, desc, new_slot->tts_values,
new_slot->tts_isnull);
+ heap_deform_tuple(oldtuple, desc, old_slot->tts_values,
old_slot->tts_isnull);
+
+ if (newtup_changed)
+ tmpnewtuple = heap_form_tuple(desc, tmp_new_slot->tts_values,
new_slot->tts_isnull);
+
+ old_matched = pgoutput_row_filter(relation, NULL, oldtuple, entry);
+ new_matched = pgoutput_row_filter(relation, NULL,
+ newtup_changed ? tmpnewtuple :
newtuple, entry);
I do not like the fact that, first we have deformed the tuples and we
are again using the HeapTuple
for expression evaluation machinery and later the expression
evaluation we do the deform again.
So why don't you use the deformed tuple as it is to store as a virtual tuple?
Infact, if newtup_changed is true then you are forming back the tuple
just to get it deformed again
in the expression evaluation.
I think I have already given this comment on the last version.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 12, 2021 at 1:37 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Wed, Oct 6, 2021 at 2:33 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > On Sat, Oct 2, 2021 at 5:44 PM Ajin Cherian <itsajin@gmail.com> wrote:
> > >
> > > I have for now also rebased the patch and merged the first 5 patches
> > > into 1, and added my changes for the above into the second patch.
> >
> > I have split the patches back again, just to be consistent with the
> > original state of the patches. Sorry for the inconvenience.
>
> Thanks for the updated version of the patch, I was looking into the
> latest version and I have a few comments.
>
>
> + if ((att->attlen == -1 &&
> VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i])) &&
> + (!old_slot->tts_isnull[i] &&
> + !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))))
> + {
> + tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
> + newtup_changed = true;
> + }
>
> If the attribute is stored EXTERNAL_ONDIS on the new tuple and it is
> not null in the old tuple then it must be logged completely in the old
> tuple, so instead of checking
> !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]), it should be
> asserted,
>
>
> + heap_deform_tuple(newtuple, desc, new_slot->tts_values,
> new_slot->tts_isnull);
> + heap_deform_tuple(oldtuple, desc, old_slot->tts_values,
> old_slot->tts_isnull);
> +
> + if (newtup_changed)
> + tmpnewtuple = heap_form_tuple(desc, tmp_new_slot->tts_values,
> new_slot->tts_isnull);
> +
> + old_matched = pgoutput_row_filter(relation, NULL, oldtuple, entry);
> + new_matched = pgoutput_row_filter(relation, NULL,
> + newtup_changed ? tmpnewtuple :
> newtuple, entry);
>
> I do not like the fact that, first we have deformed the tuples and we
> are again using the HeapTuple
> for expression evaluation machinery and later the expression
> evaluation we do the deform again.
>
> So why don't you use the deformed tuple as it is to store as a virtual tuple?
>
> Infact, if newtup_changed is true then you are forming back the tuple
> just to get it deformed again
> in the expression evaluation.
>
> I think I have already given this comment on the last version.
Right, I only used the deformed tuple later when it was written to the
stream. I will modify this as well.
regards,
Ajin Cherian
Fujitsu Australia
On Tue, Oct 12, 2021 at 1:33 PM Ajin Cherian <itsajin@gmail.com> wrote: > > I do not like the fact that, first we have deformed the tuples and we > > are again using the HeapTuple > > for expression evaluation machinery and later the expression > > evaluation we do the deform again. > > > > So why don't you use the deformed tuple as it is to store as a virtual tuple? > > > > Infact, if newtup_changed is true then you are forming back the tuple > > just to get it deformed again > > in the expression evaluation. > > > > I think I have already given this comment on the last version. > > Right, I only used the deformed tuple later when it was written to the > stream. I will modify this as well. I have made the change to use the virtual slot for expression evaluation and avoided tuple deformation. regards, Ajin Cherian Fujitsu Australia
Вложения
- v32-0001-Row-filter-for-logical-replication.patch
- v32-0003-PS-ExprState-cache-modifications.patch
- v32-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v32-0005-PS-POC-Row-filter-validation-walker.patch
- v32-0004-PS-Row-filter-validation-of-replica-identity.patch
- v32-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Wed, Oct 13, 2021 at 10:00 PM Ajin Cherian <itsajin@gmail.com> wrote: > > I have made the change to use the virtual slot for expression > evaluation and avoided tuple deformation. > I started looking at the v32-0006 patch and have some initial comments. Shouldn't old_slot, new_slot and tmp_new_slot be cached in the RelationSyncEntry, similar to scantuple? Currently, these slots are always getting newly allocated each call to pgoutput_row_filter_update() - and also, seemingly never deallocated. We previously found that allocating slots each time for each row filtered (over 1000s of rows) had a huge performance overhead. As an example, scantuple was originally newly allocated each row filtered, and to filter 1,000,000 rows in a test case it was taking 40 seconds. Caching the allocation in RelationSyncEntry reduced it down to about 5 seconds. Regards, Greg Nancarrow Fujitsu Australia
On Fri, Oct 15, 2021 at 3:30 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> On Wed, Oct 13, 2021 at 10:00 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > I have made the change to use the virtual slot for expression
> > evaluation and avoided tuple deformation.
> >
>
> I started looking at the v32-0006 patch and have some initial comments.
> Shouldn't old_slot, new_slot and tmp_new_slot be cached in the
> RelationSyncEntry, similar to scantuple?
> Currently, these slots are always getting newly allocated each call to
> pgoutput_row_filter_update() - and also, seemingly never deallocated.
> We previously found that allocating slots each time for each row
> filtered (over 1000s of rows) had a huge performance overhead.
> As an example, scantuple was originally newly allocated each row
> filtered, and to filter 1,000,000 rows in a test case it was taking 40
> seconds. Caching the allocation in RelationSyncEntry reduced it down
> to about 5 seconds.
Thanks for the comment, I have modified patch 6 to cache old_tuple,
new_tuple and tmp_new_tuple.
On Tue, Oct 12, 2021 at 1:37 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> + if ((att->attlen == -1 &&
> VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i])) &&
> + (!old_slot->tts_isnull[i] &&
> + !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))))
> + {
> + tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
> + newtup_changed = true;
> + }
>
> If the attribute is stored EXTERNAL_ONDIS on the new tuple and it is
> not null in the old tuple then it must be logged completely in the old
> tuple, so instead of checking
> !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]), it should be
> asserted,
Sorry, I missed this in my last update
For this to be true, shouldn't the fix in [1] be committed? I will
change this once that change is committed.
[1] -
https://www.postgresql.org/message-id/OS0PR01MB611342D0A92D4F4BF26C0F47FB229@OS0PR01MB6113.jpnprd01.prod.outlook.com
regards,
Ajin Cherian
Fujitsu Australia
Вложения
- v33-0001-Row-filter-for-logical-replication.patch
- v33-0005-PS-POC-Row-filter-validation-walker.patch
- v33-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v33-0003-PS-ExprState-cache-modifications.patch
- v33-0004-PS-Row-filter-validation-of-replica-identity.patch
- v33-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 11) extra (unnecessary) parens in the deparsed expression > > test=# alter publication p add table t where ((b < 100) and (c < 100)); > ALTER PUBLICATION > test=# \dRp+ p > Publication p > Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root > -------+------------+---------+---------+---------+-----------+---------- > user | f | t | t | t | t | f > Tables: > "public.t" WHERE (((b < 100) AND (c < 100))) > I also reported the same as this some months back, but at that time it was rejected citing some pg_dump patch. (Please see [1] #14). ------ [1] https://www.postgresql.org/message-id/532a18d8-ce90-4444-8570-8a9fcf09f329%40www.fastmail.com Kind Regards, Peter Smith. Fujitsu Australia
PSA new set of patches: v34-0001 = the "main" patch from Euler. No change v34-0002 = tab auto-complete. No change v34-0003 = cache updates. Addresses Tomas review comment #3 [1]. v34-0004 = filter validation replica identity. Addresses Tomas review comment #8 and #9 [1]. v34-0005 = filter validation walker. Addresses Tomas review comment #6 [1] v34-0006 = support old/new tuple logic for row-filters. Modified, but no functional change. ------ [1] https://www.postgresql.org/message-id/574b4e78-2f35-acf3-4bdc-4b872582e739%40enterprisedb.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
- v34-0005-PS-Row-filter-validation-walker.patch
- v34-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v34-0003-PS-ExprState-cache-modifications.patch
- v34-0004-PS-Row-filter-validation-of-replica-identity.patch
- v34-0001-Row-filter-for-logical-replication.patch
- v34-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 7) exprstate_list > > I'd just call the field / variable "exprstates", without indicating the > data type. I don't think we do that anywhere. Fixed in v34. [1] > > > 8) RfCol > > Do we actually need this struct? Why not to track just name or attnum, > and lookup the other value in syscache when needed? > Fixed in v34. [1] > > 9) rowfilter_expr_checker > > * Walk the parse-tree to decide if the row-filter is valid or not. > > I don't see any clear explanation what does "valid" mean. > Updated comment in v34. [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvWk4w%2BNEAqB32YkQa75tSkXi50cq6suV9f3fASn5C9NA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia.
On Mon, Sep 27, 2021 at 2:02 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Sat, Sep 25, 2021 at 3:36 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > > > On 9/25/21 6:23 AM, Amit Kapila wrote: > > > On Sat, Sep 25, 2021 at 3:30 AM Tomas Vondra > > > <tomas.vondra@enterprisedb.com> wrote: > > >> > > >> On 9/24/21 7:20 AM, Amit Kapila wrote: > > >>> > > >>> I think the right way to support functions is by the explicit marking > > >>> of functions and in one of the emails above Jeff Davis also agreed > > >>> with the same. I think we should probably introduce a new marking for > > >>> this. I feel this is important because without this it won't be safe > > >>> to access even some of the built-in functions that can access/update > > >>> database (non-immutable functions) due to logical decoding environment > > >>> restrictions. > > >>> > > >> > > >> I agree that seems reasonable. Is there any reason why not to just use > > >> IMMUTABLE for this purpose? Seems like a good match to me. > > >> > > > > > > It will just solve one part of the puzzle (related to database access) > > > but it is better to avoid the risk of broken replication by explicit > > > marking especially for UDFs or other user-defined objects. You seem to > > > be okay documenting such risk but I am not sure we have an agreement > > > on that especially because that was one of the key points of > > > discussions in this thread and various people told that we need to do > > > something about it. I personally feel we should do something if we > > > want to allow user-defined functions or operators because as reported > > > in the thread this problem has been reported multiple times. I think > > > we can go ahead with IMMUTABLE built-ins for the first version and > > > then allow UDFs later or let's try to find a way for explicit marking. > > > > > > > Well, I know multiple people mentioned that issue. And I certainly agree > > just documenting the risk would not be an ideal solution. Requiring the > > functions to be labeled helps, but we've seen people marking volatile > > functions as immutable in order to allow indexing, so we'll have to > > document the risks anyway. > > > > All I'm saying is that allowing built-in functions/operators but not > > user-defined variants seems like an annoying break of extensibility. > > People are used that user-defined stuff can be used just like built-in > > functions and operators. > > > > I agree with you that allowing UDFs in some way would be good for this > feature. I think once we get the base feature committed then we can > discuss whether and how to allow UDFs. Do we want to have an > additional label for it or can we come up with something which allows > the user to continue replication even if she has dropped the object > used in the function? It seems like we can limit the scope of base > patch functionality to allow the use of immutable built-in functions > in row filter expressions. > OK, immutable system functions are now allowed in v34 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvWk4w%2BNEAqB32YkQa75tSkXi50cq6suV9f3fASn5C9NA%40mail.gmail.com Kind Regards, Peter Smith Fujitsu Australia
On Tue, Oct 26, 2021 at 3:24 PM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA new set of patches: > > v34-0001 = the "main" patch from Euler. No change > > v34-0002 = tab auto-complete. No change > > v34-0003 = cache updates. Addresses Tomas review comment #3 [1]. > > v34-0004 = filter validation replica identity. Addresses Tomas review > comment #8 and #9 [1]. > > v34-0005 = filter validation walker. Addresses Tomas review comment #6 [1] > > v34-0006 = support old/new tuple logic for row-filters. Modified, but > no functional change. > > ------ > [1] https://www.postgresql.org/message-id/574b4e78-2f35-acf3-4bdc-4b872582e739%40enterprisedb.com > A few comments for some things I have noticed so far: 1) scantuple cleanup seems to be missing since the v33-0001 patch. 2) I don't think that the ResetExprContext() calls (before FreeExecutorState()) are needed in the pgoutput_row_filter() and pgoutput_row_filter_virtual() functions. 3) make check-world fails, due to recent changes to PostgresNode.pm. I found that the following updates are needed: diff --git a/src/test/subscription/t/025_row_filter.pl b/src/test/subscription/t/025_row_filter.pl index 742bbbe8a8..3fc503f2e4 100644 --- a/src/test/subscription/t/025_row_filter.pl +++ b/src/test/subscription/t/025_row_filter.pl @@ -1,17 +1,17 @@ # Test logical replication behavior with row filtering use strict; use warnings; -use PostgresNode; -use TestLib; +use PostgreSQL::Test::Cluster; +use PostgreSQL::Test::Utils; use Test::More tests => 7; # create publisher node -my $node_publisher = PostgresNode->new('publisher'); +my $node_publisher = PostgreSQL::Test::Cluster->new('publisher'); $node_publisher->init(allows_streaming => 'logical'); $node_publisher->start; # create subscriber node -my $node_subscriber = PostgresNode->new('subscriber'); +my $node_subscriber = PostgreSQL::Test::Cluster->new('subscriber'); $node_subscriber->init(allows_streaming => 'logical'); $node_subscriber->start; Regards, Greg Nancarrow Fujitsu Australia
On Tue, Oct 26, 2021 at 3:24 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of patches:
>
> v34-0001 = the "main" patch from Euler. No change
>
> v34-0002 = tab auto-complete. No change
>
> v34-0003 = cache updates. Addresses Tomas review comment #3 [1].
>
> v34-0004 = filter validation replica identity. Addresses Tomas review
> comment #8 and #9 [1].
>
> v34-0005 = filter validation walker. Addresses Tomas review comment #6 [1]
>
> v34-0006 = support old/new tuple logic for row-filters. Modified, but
> no functional change.
>
Regarding the v34-0006 patch, shouldn't it also include an update to
the rowfilter_expr_checker() function added by the v34-0002 patch, for
validating the referenced row-filter columns in the case of UPDATE?
I was thinking something like the following (or is it more complex than this?):
diff --git a/src/backend/catalog/pg_publication.c
b/src/backend/catalog/pg_publication.c
index dc2f4597e6..579e727b10 100644
--- a/src/backend/catalog/pg_publication.c
+++ b/src/backend/catalog/pg_publication.c
@@ -162,12 +162,10 @@ rowfilter_expr_checker(Publication *pub,
ParseState *pstate, Node *rfnode, Relat
rowfilter_validator(relname, rfnode);
/*
- * Rule 2: For "delete", check that filter cols are also valid replica
- * identity cols.
- *
- * TODO - check later for publish "update" case.
+ * Rule 2: For "delete" and "update", check that filter cols are also
+ * valid replica identity cols.
*/
- if (pub->pubactions.pubdelete)
+ if (pub->pubactions.pubdelete || pub->pubactions.pubupdate)
{
char replica_identity = rel->rd_rel->relreplident;
Regards,
Greg Nancarrow
Fujitsu Australia
The v34* patch set is temporarily broken. It was impacted quite a lot by the recently committed "schema publication" patch [1]. We are actively fixing the full v34* patch set and will re-post it here as soon as the re-base hurdles can be overcome. Meanwhile, the small tab-complete patch (which is independent of the others) is the only patch currently working, so I am attaching it so at least the cfbot can have something to run. ------ [1] https://github.com/postgres/postgres/commit/5a2832465fd8984d089e8c44c094e6900d987fcd Kind Regards, Peter Smith. Fujitsu Australia
Вложения
Here's a rebase of the first 4 patches of the row-filter patch. Some issues still remain: 1. the following changes for adding OptWhereClause to the PublicationObjSpec has not been added as the test cases for this has not been yet rebased: PublicationObjSpec: ... + TABLE relation_expr OptWhereClause ... + | ColId OptWhereClause ... + | ColId indirection OptWhereClause ... + | extended_relation_expr OptWhereClause 2. Changes made to AlterPublicationTables() undid changes that were as part of the schema publication patch. This needs to be resolved with the correct approach. The patch 0005 and 0006 has not yet been rebased but will be updated in a few days. regards, Ajin Cherian
Вложения
On Tue, Nov 2, 2021 at 10:44 PM Ajin Cherian <itsajin@gmail.com> wrote: . > > The patch 0005 and 0006 has not yet been rebased but will be updated > in a few days. > Here's a rebase of all the 6 patches. Issue remaining: 1. Changes made to AlterPublicationTables() undid changes that were as part of the schema publication patch. This needs to be resolved with the correct approach. regards, Ajin Cherian Fujitsu Australia
Вложения
- v36-0001-Row-filter-for-logical-replication.patch
- v36-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v36-0005-PS-Row-filter-validation-walker.patch
- v36-0003-PS-ExprState-cache-modifications.patch
- v36-0004-PS-Row-filter-validation-of-replica-identity.patch
- v36-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Tue, Nov 2, 2021 at 10:44 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Here's a rebase of the first 4 patches of the row-filter patch. Some > issues still remain: > > 1. the following changes for adding OptWhereClause to the > PublicationObjSpec has not been added > as the test cases for this has not been yet rebased: > > PublicationObjSpec: > ... > + TABLE relation_expr OptWhereClause > ... > + | ColId OptWhereClause > ... > + | ColId indirection OptWhereClause > ... > + | extended_relation_expr OptWhereClause > This is addressed in the v36-0001 patch [1] ------ [1] https://www.postgresql.org/message-id/CAFPTHDYKfxTr2zpA-fC12u%2BhL2abCc%3D276OpJQUTyc6FBgYX9g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Hi.
During some ad-hoc filter testing I observed a quirk when there are
duplicate tables. I think we need to define/implement some proper
rules for this behaviour.
=====
BACKGROUND
When the same table appears multiple times in a CREATE PUBLICATION
then those duplicates are simply ignored. The end result is that the
table is only one time in the publication.
This is fine and makes no difference where there are no row-filters
(because the duplicates are all exactly the same as each other), but
if there *are* row-filters there there is a quirky behaviour.
=====
PROBLEM
Apparently it is the *first* of the occurrences that is used and all
the other duplicates are ignored.
In practice it looks like this.
ex.1)
DROP PUBLICATION
test_pub=# CREATE PUBLICATION p1 FOR TABLE t1 WHERE (a=1), t1 WHERE (a=2);
CREATE PUBLICATION
test_pub=# \dRp+ p1
Publication p1
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
----------+------------+---------+---------+---------+-----------+----------
postgres | f | t | t | t | t | f
Tables:
"public.t1" WHERE ((a = 1))
** Notice that the 2nd filter (a=2) was ignored
~
IMO ex1 is wrong behaviour. I think that any subsequent duplicate
table names should behave the same as if the CREATE was a combination
of CREATE PUBLICATION then ALTER PUBLICATION SET.
Like this:
ex.2)
test_pub=# CREATE PUBLICATION p1 FOR TABLE t1 WHERE (a=1);
CREATE PUBLICATION
test_pub=# ALTER PUBLICATION p1 SET TABLE t1 WHERE (a=2);
ALTER PUBLICATION
test_pub=# \dRp+ p1
Publication p1
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
----------+------------+---------+---------+---------+-----------+----------
postgres | f | t | t | t | t | f
Tables:
"public.t1" WHERE ((a = 2))
** Notice that the 2nd filter (a=2) overwrites the 1st filter (a=1) as expected.
~~
The current behaviour of duplicates becomes even more "unexpected" if
duplicate tables occur in a single ALTER PUBLICATION ... SET command.
ex.3)
test_pub=# CREATE PUBLICATION p1;
CREATE PUBLICATION
test_pub=# ALTER PUBLICATION p1 SET TABLE t1 WHERE (a=1), t1 WHERE (a=2);
ALTER PUBLICATION
test_pub=# \dRp+ p1
Publication p1
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
----------+------------+---------+---------+---------+-----------+----------
postgres | f | t | t | t | t | f
Tables:
"public.t1" WHERE ((a = 1))
** Notice the 2nd filter (a=2) did not overwrite the 1st filter (a=1).
I think a user would be quite surprised by this behaviour.
=====
PROPOSAL
I propose that we change the way duplicate tables are processed to
make it so that it is always the *last* one that takes effect (instead
of the *first* one). AFAIK doing this won't affect any current PG
behaviour, but doing this will let the new row-filter feature work in
a consistent/predictable/sane way.
Thoughts?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 4, 2021 at 8:17 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > PROPOSAL > > I propose that we change the way duplicate tables are processed to > make it so that it is always the *last* one that takes effect (instead > of the *first* one). > I don't have a good reason to prefer one over another but I think if we do this then we should document the chosen behavior. BTW, why not give an error if the duplicate table is present and any one of them or both have row-filters? I think the current behavior makes sense because it makes no difference if the table is present more than once in the list but with row-filter it can make difference so it seems to me that giving an error should be considered. -- With Regards, Amit Kapila.
On Wednesday, November 3, 2021 8:51 PM Ajin Cherian <itsajin@gmail.com> wrote:
> On Tue, Nov 2, 2021 at 10:44 PM Ajin Cherian <itsajin@gmail.com> wrote:
> .
> >
> > The patch 0005 and 0006 has not yet been rebased but will be updated
> > in a few days.
> >
>
> Here's a rebase of all the 6 patches. Issue remaining:
Thanks for the patches.
I started to review the patches and here are a few comments.
1)
/*
* ALTER PUBLICATION ... ADD TABLE provides a PublicationTable List
* (Relation, Where clause). ALTER PUBLICATION ... DROP TABLE provides
* a Relation List. Check the List element to be used.
*/
if (IsA(lfirst(lc), PublicationTable))
whereclause = true;
else
whereclause = false;
I am not sure about the comments here, wouldn't it be better to always provides
PublicationTable List which could be more consistent.
2)
+ if ($3)
+ {
+ $$->pubtable->whereClause = $3;
+ }
It seems we can remove the if ($3) check here.
3)
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ rfnode = stringToNode(TextDatumGetCString(rfdatum));
+ exprstate = pgoutput_row_filter_init_expr(rfnode);
+ entry->exprstates = lappend(entry->exprstates, exprstate);
+ MemoryContextSwitchTo(oldctx);
+ }
Currently in the patch, it save and execute each expression separately. I was
thinking it might be better if we can use "AND" to combine all the expressions
into one expression, then we can initialize and optimize the final expression
and execute it only once.
Best regards,
Hou zj
On Thu, Nov 4, 2021 at 2:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Nov 4, 2021 at 8:17 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > PROPOSAL > > > > I propose that we change the way duplicate tables are processed to > > make it so that it is always the *last* one that takes effect (instead > > of the *first* one). > > > > I don't have a good reason to prefer one over another but I think if > we do this then we should document the chosen behavior. BTW, why not > give an error if the duplicate table is present and any one of them or > both have row-filters? I think the current behavior makes sense > because it makes no difference if the table is present more than once > in the list but with row-filter it can make difference so it seems to > me that giving an error should be considered. Yes, giving an error if any duplicate table has a filter is also a good alternative solution. I only wanted to demonstrate the current problem, and get some consensus on the solution before implementing a fix. If others are happy to give an error for this case then that is fine by me too. ------ Kind Regards, Peter Smith. Fujitsu Australia.
PSA new set of v37* patches. This addresses some pending review comments as follows: v34-0001 = the "main" patch. - fixed Houz review comment #1 [1] - fixed Houz review comment #2 [1] - fixed Tomas review comment #5 [2] v34-0002 = tab auto-complete. - not changed v34-0003 = cache updates. - not changed v34-0004 = filter validation replica identity. - not changed v34-0005 = filter validation walker. - not changed v34-0006 = support old/new tuple logic for row-filters. - Ajin fixed Tomas review comment #14 [2] - Ajin fixed Greg review comment #1 [3] - Ajin fixed Greg review comment #2 [3] - Ajin fixed Greg review comment #3 [3] - Ajin fixed Greg review comment #1 [4] ------ [1] Houz 4/11 - https://www.postgresql.org/message-id/OS0PR01MB5716090A70A73ADF58C58950948D9%40OS0PR01MB5716.jpnprd01.prod.outlook.com [2] Tomas 23/9 - https://www.postgresql.org/message-id/574b4e78-2f35-acf3-4bdc-4b872582e739%40enterprisedb.com [3] Greg 26/10 - https://www.postgresql.org/message-id/CAJcOf-dNDy%3DrzUD%3D2H54J-VVUJCxq94o_2Sqc35RovFLKkSj7Q%40mail.gmail.com [4] Greg 27/10 - https://www.postgresql.org/message-id/CAJcOf-dViJh-F4oJkMQchAD19LELuCNbCqKfia5S7jsOASO6yA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
- v37-0004-PS-Row-filter-validation-of-replica-identity.patch
- v37-0005-PS-Row-filter-validation-walker.patch
- v37-0001-Row-filter-for-logical-replication.patch
- v37-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v37-0003-PS-ExprState-cache-modifications.patch
- v37-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 5) publicationcmds.c > > I mentioned this in my last review [1] already, but I really dislike the > fact that OpenTableList accepts a list containing one of two entirely > separate node types (PublicationTable or Relation). It was modified to > use IsA() instead of a flag, but I still find it ugly, confusing and > possibly error-prone. > > Also, not sure mentioning the two different callers explicitly in the > OpenTableList comment is a great idea - it's likely to get stale if > someone adds another caller. Fixed in v37-0001 [1] > 14) pgoutput_row_filter_update > > The function name seems a bit misleading, as it suggests might seem like > it updates the row_filter, or something. Should indicate it's about > deciding what to do with the update. Fixed in v37-0006 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtRdXzPpm3qv3cEYWWfVUkGT84EopEHxwt95eo_cG_3eQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Oct 26, 2021 at 6:26 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > A few comments for some things I have noticed so far: > > 1) scantuple cleanup seems to be missing since the v33-0001 patch. > > 2) I don't think that the ResetExprContext() calls (before > FreeExecutorState()) are needed in the pgoutput_row_filter() and > pgoutput_row_filter_virtual() functions. > > 3) make check-world fails, due to recent changes to PostgresNode.pm. These 3 comments all addressed in v37-0006 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtRdXzPpm3qv3cEYWWfVUkGT84EopEHxwt95eo_cG_3eQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia.
On Wed, Oct 27, 2021 at 7:21 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> Regarding the v34-0006 patch, shouldn't it also include an update to
> the rowfilter_expr_checker() function added by the v34-0002 patch, for
> validating the referenced row-filter columns in the case of UPDATE?
> I was thinking something like the following (or is it more complex than this?):
>
> diff --git a/src/backend/catalog/pg_publication.c
> b/src/backend/catalog/pg_publication.c
> index dc2f4597e6..579e727b10 100644
> --- a/src/backend/catalog/pg_publication.c
> +++ b/src/backend/catalog/pg_publication.c
> @@ -162,12 +162,10 @@ rowfilter_expr_checker(Publication *pub,
> ParseState *pstate, Node *rfnode, Relat
> rowfilter_validator(relname, rfnode);
>
> /*
> - * Rule 2: For "delete", check that filter cols are also valid replica
> - * identity cols.
> - *
> - * TODO - check later for publish "update" case.
> + * Rule 2: For "delete" and "update", check that filter cols are also
> + * valid replica identity cols.
> */
> - if (pub->pubactions.pubdelete)
> + if (pub->pubactions.pubdelete || pub->pubactions.pubupdate)
> {
> char replica_identity = rel->rd_rel->relreplident;
>
Fixed in v37-0006 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtRdXzPpm3qv3cEYWWfVUkGT84EopEHxwt95eo_cG_3eQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 4, 2021 at 2:21 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Thanks for the patches.
> I started to review the patches and here are a few comments.
>
> 1)
> /*
> * ALTER PUBLICATION ... ADD TABLE provides a PublicationTable List
> * (Relation, Where clause). ALTER PUBLICATION ... DROP TABLE provides
> * a Relation List. Check the List element to be used.
> */
> if (IsA(lfirst(lc), PublicationTable))
> whereclause = true;
> else
> whereclause = false;
>
> I am not sure about the comments here, wouldn't it be better to always provides
> PublicationTable List which could be more consistent.
Fixed in v37-0001 [1].
>
> 2)
> + if ($3)
> + {
> + $$->pubtable->whereClause = $3;
> + }
>
> It seems we can remove the if ($3) check here.
>
Fixed in v37-0001 [1].
>
> 3)
>
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> + rfnode = stringToNode(TextDatumGetCString(rfdatum));
> + exprstate = pgoutput_row_filter_init_expr(rfnode);
> + entry->exprstates = lappend(entry->exprstates, exprstate);
> + MemoryContextSwitchTo(oldctx);
> + }
>
> Currently in the patch, it save and execute each expression separately. I was
> thinking it might be better if we can use "AND" to combine all the expressions
> into one expression, then we can initialize and optimize the final expression
> and execute it only once.
Yes, thanks for this suggestion - it is an interesting idea. I had
thought the same as this some time ago but never acted on it. I will
try implementing this idea as a separate new patch because it probably
needs to be performance tested against the current code just in case
the extra effort to combine the expressions outweighs any execution
benefits.
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtRdXzPpm3qv3cEYWWfVUkGT84EopEHxwt95eo_cG_3eQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Fri, Nov 5, 2021 at 10:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of v37* patches.
>
Few comments about changes made to the patch to rebase it:
1.
+#if 1
+ // FIXME - can we do a better job if integrating this with the schema changes
+ /*
+ * Remove all publication-table mappings. We could possibly remove (i)
+ * tables that are not found in the new table list and (ii) tables that
+ * are being re-added with a different qual expression. For (ii),
+ * simply updating the existing tuple is not enough, because of qual
+ * expression dependencies.
+ */
+ foreach(oldlc, oldrelids)
+ {
+ Oid oldrelid = lfirst_oid(oldlc);
+ PublicationRelInfo *oldrel;
+
+ oldrel = palloc(sizeof(PublicationRelInfo));
+ oldrel->relid = oldrelid;
+ oldrel->whereClause = NULL;
+ oldrel->relation = table_open(oldrel->relid,
+ ShareUpdateExclusiveLock);
+ delrels = lappend(delrels, oldrel);
+ }
+#else
CheckObjSchemaNotAlreadyInPublication(rels, schemaidlist,
PUBLICATIONOBJ_TABLE);
I think for the correct merge you need to just call
CheckObjSchemaNotAlreadyInPublication() before this for loop. BTW, I
have a question regarding this implementation. Here, it has been
assumed that the new rel will always be specified with a different
qual, what if there is no qual or if the qual is the same?
2.
+preprocess_pubobj_list(List *pubobjspec_list, core_yyscan_t
yyscanner, bool alter_drop)
{
ListCell *cell;
PublicationObjSpec *pubobj;
@@ -17341,7 +17359,15 @@ preprocess_pubobj_list(List *pubobjspec_list,
core_yyscan_t yyscanner)
errcode(ERRCODE_SYNTAX_ERROR),
errmsg("invalid table name at or near"),
parser_errposition(pubobj->location));
- else if (pubobj->name)
+
+ /* cannot use WHERE w-filter for DROP TABLE from publications */
+ if (pubobj->pubtable && pubobj->pubtable->whereClause && alter_drop)
+ ereport(ERROR,
+ errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("invalid use of WHERE row-filter in ALTER PUBLICATION ... DROP TABLE"),
+ parser_errposition(pubobj->location));
+
This change looks a bit ad-hoc to me. Can we handle this at a later
point of time in publicationcmds.c?
3.
- | ColId
+ | ColId OptWhereClause
{
$$ = makeNode(PublicationObjSpec);
$$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
- $$->name = $1;
+ if ($2)
+ {
+ $$->pubtable = makeNode(PublicationTable);
+ $$->pubtable->relation = makeRangeVar(NULL, $1, @1);
+ $$->pubtable->whereClause = $2;
+ }
+ else
+ {
+ $$->name = $1;
+ }
Again this doesn't appear to be the right way. I think this should be
handled at a later point.
--
With Regards,
Amit Kapila.
On Fri, Nov 5, 2021 1:14 PM Peter Smith <smithpb2250@gmail.com> wrote:
> PSA new set of v37* patches.
Thanks for updating the patches.
Few comments:
1) v37-0001
I think it might be better to also show the filter expression in '\d+
tablename' command after publication description.
2) v37-0004
+ /* Scan the expression tree for referenceable objects */
+ find_expr_references_walker(expr, &context);
+
+ /* Remove any duplicates */
+ eliminate_duplicate_dependencies(context.addrs);
+
The 0004 patch currently use find_expr_references_walker to get all the
reference objects. I am thinking do we only need get the columns in the
expression ? I think maybe we can check the replica indentity like[1].
3) v37-0005
- no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr
I think there could be other node type which can also be considered as simple
expression, for exmaple T_NullIfExpr.
Personally, I think it's natural to only check the IMMUTABLE and
whether-user-defined in the new function rowfilter_walker. We can keep the
other row-filter errors which were thrown for EXPR_KIND_PUBLICATION_WHERE in
the 0001 patch.
[1]
rowfilter_expr_checker
...
if (replica_identity == REPLICA_IDENTITY_DEFAULT)
context.bms_replident = RelationGetIndexAttrBitmap(rel, INDEX_ATTR_BITMAP_PRIMARY_KEY);
else
context.bms_replident = RelationGetIndexAttrBitmap(rel, INDEX_ATTR_BITMAP_IDENTITY_KEY);
(void) rowfilter_expr_replident_walker(rfnode, &context);
...
static bool
rowfilter_expr_replident_walker(Node *node, rf_context *context)
{
if (node == NULL)
return false;
if (IsA(node, Var))
{
Oid relid = RelationGetRelid(context->rel);
Var *var = (Var *) node;
AttrNumber attnum = var->varattno - FirstLowInvalidHeapAttributeNumber;
if (!bms_is_member(attnum, context->bms_replident))
{
const char *colname = get_attname(relid, attnum, false);
ereport(ERROR,
(errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
errmsg("cannot add relation \"%s\" to publication",
RelationGetRelationName(context->rel)),
errdetail("Row filter column \"%s\" is not part of the REPLICA IDENTITY",
colname)));
return false;
}
return true;
}
return expression_tree_walker(node, rowfilter_expr_replident_walker,
(void *) context);
}
Best regards,
Hou zj
On Friday, November 5, 2021 1:14 PM, Peter Smith <smithpb2250@gmail.com> wrote: > > PSA new set of v37* patches. > Thanks for your patch. I have a problem when using this patch. The document about "create publication" in patch says: The <literal>WHERE</literal> clause should contain only columns that are part of the primary key or be covered by <literal>REPLICA IDENTITY</literal> otherwise, <command>DELETE</command> operations will not be replicated. But I tried this patch, the columns which could be contained in WHERE clause must be covered by REPLICA IDENTITY, but it doesn't matter if they are part of the primary key. (We can see it in Case 4 of publication.sql, too.) So maybe we should modify the document. Regards Tang
On Fri, Nov 5, 2021 4:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Fri, Nov 5, 2021 at 10:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > PSA new set of v37* patches.
> 3.
> - | ColId
> + | ColId OptWhereClause
> {
> $$ = makeNode(PublicationObjSpec);
> $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
> - $$->name = $1;
> + if ($2)
> + {
> + $$->pubtable = makeNode(PublicationTable); $$->pubtable->relation =
> + makeRangeVar(NULL, $1, @1); $$->pubtable->whereClause = $2; } else {
> + $$->name = $1; }
>
> Again this doesn't appear to be the right way. I think this should be handled at
> a later point.
I think the difficulty to handle this at a later point is that we need to make
sure we don't lose the whereclause. Currently, we can only save the whereclause
in PublicationTable structure and the PublicationTable is only used for TABLE,
but '| ColId' can be used for either a SCHEMA or TABLE. We cannot distinguish
the actual type at this stage, so we always need to save the whereclause if
it's NOT NULL.
I think the possible approaches to delay this check are:
(1) we can delete the PublicationTable structure and put all the vars(relation,
whereclause) in PublicationObjSpec. In this approach, we don't need check if
the whereclause is NULL in the '| ColId', we can check this at a later point.
Or
(2) Add a new pattern for whereclause in PublicationObjSpec:
The change could be:
PublicationObjSpec:
...
| ColId
...
+ | ColId WHERE '(' a_expr ')'
+ {
+ $$ = makeNode(PublicationObjSpec);
+ $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
+ $$->pubtable = makeNode(PublicationTable);
+ $$->pubtable->relation = makeRangeVar(NULL, $1, @1);
+ $$->pubtable->whereClause = $2;
+ }
In this approach, we also don't need the "if ($2)" check.
What do you think ?
Best regards,
Hou zj
PSA new set of v38* patches. This addresses some review comments as follows: v34-0001 = the "main" patch. - rebased to HEAD - fixed Amit review comment about ALTER DROP [1] - fixed Houz review comment about psql \d+ [2] v34-0002 = tab auto-complete. - not changed v34-0003 = cache updates. - fixed Houz review comment about combining multiple filters [3] v34-0004 = filter validation replica identity. - fixed Tang review comment about REPLICA IDENTITY docs [4] v34-0005 = filter validation walker. - not changed v34-0006 = support old/new tuple logic for row-filters. - not changed ------ [1] Amit 5/11 #2 - https://www.postgresql.org/message-id/CAA4eK1KN5gsTo6Qaomt-9vpC61cgw5ikgzLhOunf3o22G3uc_Q%40mail.gmail.com [2] Houz 8/11 #1 - https://www.postgresql.org/message-id/OS0PR01MB571625D4A5CC1DAB4045B2BB94919%40OS0PR01MB5716.jpnprd01.prod.outlook.com [3] Houz 4/11 #3 - https://www.postgresql.org/message-id/OS0PR01MB5716090A70A73ADF58C58950948D9%40OS0PR01MB5716.jpnprd01.prod.outlook.com [4] Tang 9/11 - https://www.postgresql.org/message-id/OS0PR01MB6113895D7964F03E9F57F9C7FB929%40OS0PR01MB6113.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
- v38-0003-PS-ExprState-cache-modifications.patch
- v38-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v38-0005-PS-Row-filter-validation-walker.patch
- v38-0004-PS-Row-filter-validation-of-replica-identity.patch
- v38-0001-Row-filter-for-logical-replication.patch
- v38-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Fri, Nov 5, 2021 at 7:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> 2.
> +preprocess_pubobj_list(List *pubobjspec_list, core_yyscan_t
> yyscanner, bool alter_drop)
> {
> ListCell *cell;
> PublicationObjSpec *pubobj;
> @@ -17341,7 +17359,15 @@ preprocess_pubobj_list(List *pubobjspec_list,
> core_yyscan_t yyscanner)
> errcode(ERRCODE_SYNTAX_ERROR),
> errmsg("invalid table name at or near"),
> parser_errposition(pubobj->location));
> - else if (pubobj->name)
> +
> + /* cannot use WHERE w-filter for DROP TABLE from publications */
> + if (pubobj->pubtable && pubobj->pubtable->whereClause && alter_drop)
> + ereport(ERROR,
> + errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("invalid use of WHERE row-filter in ALTER PUBLICATION ... DROP TABLE"),
> + parser_errposition(pubobj->location));
> +
>
> This change looks a bit ad-hoc to me. Can we handle this at a later
> point of time in publicationcmds.c?
>
Fixed in v38-0001 [1].
------
[1] https://www.postgresql.org/message-id/CAHut%2BPvWCS%2BW_OLV60AZJucY1RFpkXS%3DhfvYWwpwyMvifdJxiQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Fri, Nov 5, 2021 1:14 PM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA new set of v37* patches. > > Thanks for updating the patches. > Few comments: > > 1) v37-0001 > > I think it might be better to also show the filter expression in '\d+ > tablename' command after publication description. > Fixed in v38-0001 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvWCS%2BW_OLV60AZJucY1RFpkXS%3DhfvYWwpwyMvifdJxiQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Austrlalia
On Tue, Nov 9, 2021 at 2:03 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Friday, November 5, 2021 1:14 PM, Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA new set of v37* patches. > > > > Thanks for your patch. I have a problem when using this patch. > > The document about "create publication" in patch says: > > The <literal>WHERE</literal> clause should contain only columns that are > part of the primary key or be covered by <literal>REPLICA > IDENTITY</literal> otherwise, <command>DELETE</command> operations will not > be replicated. > > But I tried this patch, the columns which could be contained in WHERE clause must be > covered by REPLICA IDENTITY, but it doesn't matter if they are part of the primary key. > (We can see it in Case 4 of publication.sql, too.) So maybe we should modify the document. > PG Docs is changed in v38-0004 [1]. Please check if it is OK. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvWCS%2BW_OLV60AZJucY1RFpkXS%3DhfvYWwpwyMvifdJxiQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Nov 4, 2021 at 2:21 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > 3) > > + oldctx = MemoryContextSwitchTo(CacheMemoryContext); > + rfnode = stringToNode(TextDatumGetCString(rfdatum)); > + exprstate = pgoutput_row_filter_init_expr(rfnode); > + entry->exprstates = lappend(entry->exprstates, exprstate); > + MemoryContextSwitchTo(oldctx); > + } > > Currently in the patch, it save and execute each expression separately. I was > thinking it might be better if we can use "AND" to combine all the expressions > into one expression, then we can initialize and optimize the final expression > and execute it only once. > Fixed in v38-0003 [1]. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvWCS%2BW_OLV60AZJucY1RFpkXS%3DhfvYWwpwyMvifdJxiQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Thur, Nov 4, 2021 10:47 AM Peter Smith <smithpb2250@gmail.com> wrote: > PROPOSAL > > I propose that we change the way duplicate tables are processed to make it so > that it is always the *last* one that takes effect (instead of the *first* one). AFAIK > doing this won't affect any current PG behaviour, but doing this will let the new > row-filter feature work in a consistent/predictable/sane way. > > Thoughts? Last one take effect sounds reasonable to me. OTOH, I think we should make the behavior here consistent with Column Filter Patch in another thread. IIRC, in the current column filter patch, only the first one's filter takes effect. So, maybe better to get Rahila and Alvaro's thoughts on this. Best regards, Hou zj
On Tue, Nov 9, 2021 at 2:22 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Fri, Nov 5, 2021 4:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Fri, Nov 5, 2021 at 10:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > PSA new set of v37* patches.
> > 3.
> > - | ColId
> > + | ColId OptWhereClause
> > {
> > $$ = makeNode(PublicationObjSpec);
> > $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
> > - $$->name = $1;
> > + if ($2)
> > + {
> > + $$->pubtable = makeNode(PublicationTable); $$->pubtable->relation =
> > + makeRangeVar(NULL, $1, @1); $$->pubtable->whereClause = $2; } else {
> > + $$->name = $1; }
> >
> > Again this doesn't appear to be the right way. I think this should be handled at
> > a later point.
>
> I think the difficulty to handle this at a later point is that we need to make
> sure we don't lose the whereclause. Currently, we can only save the whereclause
> in PublicationTable structure and the PublicationTable is only used for TABLE,
> but '| ColId' can be used for either a SCHEMA or TABLE. We cannot distinguish
> the actual type at this stage, so we always need to save the whereclause if
> it's NOT NULL.
>
I see your point. But, I think we can add some comments here
indicating that the user might have mistakenly given where clause with
some schema which we will identify later and give an appropriate
error. Then, in preprocess_pubobj_list(), identify if the user has
given the where clause with schema name and give an appropriate error.
> I think the possible approaches to delay this check are:
>
> (1) we can delete the PublicationTable structure and put all the vars(relation,
> whereclause) in PublicationObjSpec. In this approach, we don't need check if
> the whereclause is NULL in the '| ColId', we can check this at a later point.
>
Yeah, we can do this but I don't think it will reduce any checks later
to identify if the user has given where clause only for tables. So,
let's keep this structure around as that will at least keep all things
related to the table together in one structure.
> Or
>
> (2) Add a new pattern for whereclause in PublicationObjSpec:
>
> The change could be:
>
> PublicationObjSpec:
> ...
> | ColId
> ...
> + | ColId WHERE '(' a_expr ')'
> + {
> + $$ = makeNode(PublicationObjSpec);
> + $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
> + $$->pubtable = makeNode(PublicationTable);
> + $$->pubtable->relation = makeRangeVar(NULL, $1, @1);
> + $$->pubtable->whereClause = $2;
> + }
>
> In this approach, we also don't need the "if ($2)" check.
>
This seems redundant and we still need same checks later to see if the
where clause is given with the table object.
--
With Regards,
Amit Kapila.
On Wed, Nov 10, 2021 10:48 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Nov 9, 2021 at 2:22 PM houzj.fnst@fujitsu.com wrote:
> >
> > On Fri, Nov 5, 2021 4:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > > On Fri, Nov 5, 2021 at 10:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > > >
> > > > PSA new set of v37* patches.
> > > 3.
> > > - | ColId
> > > + | ColId OptWhereClause
> > > {
> > > $$ = makeNode(PublicationObjSpec);
> > > $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
> > > - $$->name = $1;
> > > + if ($2)
> > > + {
> > > + $$->pubtable = makeNode(PublicationTable); $$->pubtable->relation
> > > + = makeRangeVar(NULL, $1, @1); $$->pubtable->whereClause = $2; }
> > > + else { $$->name = $1; }
> > >
> > > Again this doesn't appear to be the right way. I think this should
> > > be handled at a later point.
> >
> > I think the difficulty to handle this at a later point is that we need
> > to make sure we don't lose the whereclause. Currently, we can only
> > save the whereclause in PublicationTable structure and the
> > PublicationTable is only used for TABLE, but '| ColId' can be used for
> > either a SCHEMA or TABLE. We cannot distinguish the actual type at
> > this stage, so we always need to save the whereclause if it's NOT NULL.
> >
>
> I see your point. But, I think we can add some comments here indicating that
> the user might have mistakenly given where clause with some schema which we
> will identify later and give an appropriate error. Then, in
> preprocess_pubobj_list(), identify if the user has given the where clause with
> schema name and give an appropriate error.
>
OK, IIRC, in this approach, we need to set both $$->name and $$->pubtable in
'| ColId OptWhereClause'. And In preprocess_pubobj_list, we can add some check
if both name and pubtable is NOT NULL.
the grammar code could be:
| ColId OptWhereClause
{
$$ = makeNode(PublicationObjSpec);
$$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
$$->name = $1;
+ /* xxx */
+ $$->pubtable = makeNode(PublicationTable);
+ $$->pubtable->relation = makeRangeVar(NULL, $1, @1);
+ $$->pubtable->whereClause = $2;
$$->location = @1;
}
preprocess_pubobj_list
...
else if (pubobj->pubobjtype == PUBLICATIONOBJ_REL_IN_SCHEMA ||
pubobj->pubobjtype == PUBLICATIONOBJ_CURRSCHEMA)
{
...
+ if (pubobj->name &&
+ (!pubobj->pubtable || !pubobj->pubtable->whereClause))
pubobj->pubobjtype = PUBLICATIONOBJ_REL_IN_SCHEMA;
else if (!pubobj->name && !pubobj->pubtable)
pubobj->pubobjtype = PUBLICATIONOBJ_CURRSCHEMA;
else
ereport(ERROR,
errcode(ERRCODE_SYNTAX_ERROR),
errmsg("invalid schema name at or near"),
parser_errposition(pubobj->location));
}
Best regards,
Hou zj
On Wed, Nov 10, 2021 at 4:57 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wed, Nov 10, 2021 10:48 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Tue, Nov 9, 2021 at 2:22 PM houzj.fnst@fujitsu.com wrote:
> > >
> > > On Fri, Nov 5, 2021 4:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > > > On Fri, Nov 5, 2021 at 10:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > > > >
> > > > > PSA new set of v37* patches.
> > > > 3.
> > > > - | ColId
> > > > + | ColId OptWhereClause
> > > > {
> > > > $$ = makeNode(PublicationObjSpec);
> > > > $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
> > > > - $$->name = $1;
> > > > + if ($2)
> > > > + {
> > > > + $$->pubtable = makeNode(PublicationTable); $$->pubtable->relation
> > > > + = makeRangeVar(NULL, $1, @1); $$->pubtable->whereClause = $2; }
> > > > + else { $$->name = $1; }
> > > >
> > > > Again this doesn't appear to be the right way. I think this should
> > > > be handled at a later point.
> > >
> > > I think the difficulty to handle this at a later point is that we need
> > > to make sure we don't lose the whereclause. Currently, we can only
> > > save the whereclause in PublicationTable structure and the
> > > PublicationTable is only used for TABLE, but '| ColId' can be used for
> > > either a SCHEMA or TABLE. We cannot distinguish the actual type at
> > > this stage, so we always need to save the whereclause if it's NOT NULL.
> > >
> >
> > I see your point. But, I think we can add some comments here indicating that
> > the user might have mistakenly given where clause with some schema which we
> > will identify later and give an appropriate error. Then, in
> > preprocess_pubobj_list(), identify if the user has given the where clause with
> > schema name and give an appropriate error.
> >
>
> OK, IIRC, in this approach, we need to set both $$->name and $$->pubtable in
> '| ColId OptWhereClause'. And In preprocess_pubobj_list, we can add some check
> if both name and pubtable is NOT NULL.
>
> the grammar code could be:
>
> | ColId OptWhereClause
> {
> $$ = makeNode(PublicationObjSpec);
> $$->pubobjtype = PUBLICATIONOBJ_CONTINUATION;
>
> $$->name = $1;
> + /* xxx */
> + $$->pubtable = makeNode(PublicationTable);
> + $$->pubtable->relation = makeRangeVar(NULL, $1, @1);
> + $$->pubtable->whereClause = $2;
> $$->location = @1;
> }
>
> preprocess_pubobj_list
> ...
> else if (pubobj->pubobjtype == PUBLICATIONOBJ_REL_IN_SCHEMA ||
> pubobj->pubobjtype == PUBLICATIONOBJ_CURRSCHEMA)
> {
> ...
> + if (pubobj->name &&
> + (!pubobj->pubtable || !pubobj->pubtable->whereClause))
> pubobj->pubobjtype = PUBLICATIONOBJ_REL_IN_SCHEMA;
> else if (!pubobj->name && !pubobj->pubtable)
> pubobj->pubobjtype = PUBLICATIONOBJ_CURRSCHEMA;
> else
> ereport(ERROR,
> errcode(ERRCODE_SYNTAX_ERROR),
> errmsg("invalid schema name at or near"),
> parser_errposition(pubobj->location));
> }
>
Hi Hou-san. Actually, I have already implemented this part according
to my understanding of Amit's suggestion and it seems to be working
well.
Please wait for v39-0001, then feel free to post review comments about
it if you think there are still problems.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > 3) v37-0005 > > - no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr > > I think there could be other node type which can also be considered as simple > expression, for exmaple T_NullIfExpr. The current walker restrictions are from a previously agreed decision by Amit/Tomas [1] and from an earlier suggestion from Andres [2] to keep everything very simple for a first version. Yes, you are right, there might be some additional node types that might be fine, but at this time I don't want to add anything different without getting their approval to do so. Anyway, additions like this are all candidates for a future version of this row-filter feature. > > Personally, I think it's natural to only check the IMMUTABLE and > whether-user-defined in the new function rowfilter_walker. We can keep the > other row-filter errors which were thrown for EXPR_KIND_PUBLICATION_WHERE in > the 0001 patch. > YMMV. IMO it is much more convenient for all the filter validations to be centralized just in one walker function instead of scattered all over the place like they were in the 0001 patch. ----- [1] https://www.postgresql.org/message-id/CAA4eK1%2BXoD49bz5-2TtiD0ugq4PHSRX2D1sLPR_X4LNtdMc4OQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/20210128022032.eq2qqc6zxkqn5syt%40alap3.anarazel.de Kind Regards, Peter Smith. Fujitsu Australia
Attaching version 39- V39 fixes the following review comments: On Fri, Nov 5, 2021 at 7:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > CheckObjSchemaNotAlreadyInPublication(rels, schemaidlist, > PUBLICATIONOBJ_TABLE); > >I think for the correct merge you need to just call >CheckObjSchemaNotAlreadyInPublication() before this for loop. BTW, I >have a question regarding this implementation. Here, it has been >assumed that the new rel will always be specified with a different >qual, what if there is no qual or if the qual is the same? Actually with this code, no qual or a different qual does not matter, it recreates everything as specified by the ALTER SET command. I have added CheckObjSchemaNotAlreadyInPublication as you specified since this is required to match the schema patch behaviour. I've also added a test case that tests this particular case. On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > >2) v37-0004 > >+ /* Scan the expression tree for referenceable objects */ >+ find_expr_references_walker(expr, &context); >+ >+ /* Remove any duplicates */ >+ eliminate_duplicate_dependencies(context.addrs); >+ > >The 0004 patch currently use find_expr_references_walker to get all the >reference objects. I am thinking do we only need get the columns in the >expression ? I think maybe we can check the replica indentity like[1]. Changed as suggested. On Thu, Nov 4, 2021 at 2:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > >I see your point. But, I think we can add some comments here >indicating that the user might have mistakenly given where clause with >some schema which we will identify later and give an appropriate >error. Then, in preprocess_pubobj_list(), identify if the user has >given the where clause with schema name and give an appropriate erro Changed as suggested. On Thu, Nov 4, 2021 at 2:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > >BTW, why not give an error if the duplicate table is present and any one of them or >both have row-filters? I think the current behavior makes sense >because it makes no difference if the table is present more than once >in the list but with row-filter it can make difference so it seems to >me that giving an error should be considered. Changed as suggested, also added test cases for the same. regards, Ajin Cherian Fujitsu Australia
Вложения
- v39-0001-Row-filter-for-logical-replication.patch
- v39-0003-PS-ExprState-cache-modifications.patch
- v39-0004-PS-Row-filter-validation-of-replica-identity.patch
- v39-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v39-0005-PS-Row-filter-validation-walker.patch
- v39-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Fri, Nov 12, 2021 at 9:19 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching version 39-
Here are some review comments for v39-0006:
1)
@@ -261,9 +261,9 @@ rowfilter_expr_replident_walker(Node *node,
rf_context *context)
* Rule 1. Walk the parse-tree and reject anything other than very simple
* expressions (See rowfilter_validator for details on what is permitted).
*
- * Rule 2. If the publish operation contains "delete" then only columns that
- * are allowed by the REPLICA IDENTITY rules are permitted to be used in the
- * row-filter WHERE clause.
+ * Rule 2. If the publish operation contains "delete" or "delete" then only
+ * columns that are allowed by the REPLICA IDENTITY rules are permitted to
+ * be used in the row-filter WHERE clause.
*/
static void
rowfilter_expr_checker(Publication *pub, ParseState *pstate, Node
*rfnode, Relation rel)
@@ -276,12 +276,10 @@ rowfilter_expr_checker(Publication *pub,
ParseState *pstate, Node *rfnode, Relat
rowfilter_validator(relname, rfnode);
/*
- * Rule 2: For "delete", check that filter cols are also valid replica
+ * Rule 2: For "delete" and "update", check that filter cols are also
valid replica
* identity cols.
- *
- * TODO - check later for publish "update" case.
*/
- if (pub->pubactions.pubdelete)
1a)
Typo - the function comment: "delete" or "delete"; should say:
"delete" or "update"
1b)
I felt it would be better (for the comment in the function body) to
write it as "or" instead of "and" because then it matches with the
code "if ||" that follows this comment.
====
2)
@@ -746,6 +780,92 @@ logicalrep_read_typ(StringInfo in, LogicalRepTyp *ltyp)
}
/*
+ * Write a tuple to the outputstream using cached slot, in the most
efficient format possible.
+ */
+static void
+logicalrep_write_tuple_cached(StringInfo out, Relation rel,
TupleTableSlot *slot, bool binary)
The function logicalrep_write_tuple_cached seems to have almost all of
its function body in common with logicalrep_write_tuple. Is there any
good way to combine these functions to avoid ~80 lines mostly
duplicated code?
====
3)
+ if (!old_matched && !new_matched)
+ return false;
+
+ if (old_matched && new_matched)
+ *action = REORDER_BUFFER_CHANGE_UPDATE;
+ else if (old_matched && !new_matched)
+ *action = REORDER_BUFFER_CHANGE_DELETE;
+ else if (new_matched && !old_matched)
+ *action = REORDER_BUFFER_CHANGE_INSERT;
+
+ return true;
I felt it is slightly confusing to have inconsistent ordering of the
old_matched and new_matched in those above conditions.
I suggest to use the order like:
* old-row (no match) new-row (no match)
* old-row (no match) new row (match)
* old-row (match) new-row (no match)
* old-row (match) new row (match)
And then be sure to keep consistent ordering in all places it is mentioned:
* in the code
* in the function header comment
* in the commit comment
* in docs?
====
4)
+/*
+ * Change is checked against the row filter, if any.
+ *
+ * If it returns true, the change is replicated, otherwise, it is not.
+ */
+static bool
+pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
RelationSyncEntry *entry)
+{
+ EState *estate;
+ ExprContext *ecxt;
+ bool result = true;
+ Oid relid = RelationGetRelid(relation);
+
+ /* Bail out if there is no row filter */
+ if (!entry->exprstate)
+ return true;
+
+ elog(DEBUG3, "table \"%s.%s\" has row filter",
+ get_namespace_name(get_rel_namespace(relid)),
+ get_rel_name(relid));
It seems like that elog may consume unnecessary CPU most of the time.
I think it might be better to remove the relid declaration and rewrite
that elog as:
if (message_level_is_interesting(DEBUG3))
elog(DEBUG3, "table \"%s.%s\" has row filter",
get_namespace_name(get_rel_namespace(entry->relid)),
get_rel_name(entry->relid));
====
5)
diff --git a/src/include/replication/reorderbuffer.h
b/src/include/replication/reorderbuffer.h
index 5b40ff7..aec0059 100644
--- a/src/include/replication/reorderbuffer.h
+++ b/src/include/replication/reorderbuffer.h
@@ -51,7 +51,7 @@ typedef struct ReorderBufferTupleBuf
* respectively. They're used by INSERT .. ON CONFLICT .. UPDATE. Users of
* logical decoding don't have to care about these.
*/
-enum ReorderBufferChangeType
+typedef enum ReorderBufferChangeType
{
REORDER_BUFFER_CHANGE_INSERT,
REORDER_BUFFER_CHANGE_UPDATE,
@@ -65,7 +65,7 @@ enum ReorderBufferChangeType
REORDER_BUFFER_CHANGE_INTERNAL_SPEC_CONFIRM,
REORDER_BUFFER_CHANGE_INTERNAL_SPEC_ABORT,
REORDER_BUFFER_CHANGE_TRUNCATE
-};
+} ReorderBufferChangeType;
This new typedef can be added to src/tools/pgindent/typedefs.list.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wednesday, November 10, 2021 7:46 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, Nov 9, 2021 at 2:03 PM tanghy.fnst@fujitsu.com > <tanghy.fnst@fujitsu.com> wrote: > > > > On Friday, November 5, 2021 1:14 PM, Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > PSA new set of v37* patches. > > > > > > > Thanks for your patch. I have a problem when using this patch. > > > > The document about "create publication" in patch says: > > > > The <literal>WHERE</literal> clause should contain only columns that are > > part of the primary key or be covered by <literal>REPLICA > > IDENTITY</literal> otherwise, <command>DELETE</command> operations will > not > > be replicated. > > > > But I tried this patch, the columns which could be contained in WHERE clause > must be > > covered by REPLICA IDENTITY, but it doesn't matter if they are part of the > primary key. > > (We can see it in Case 4 of publication.sql, too.) So maybe we should modify the > document. > > > > PG Docs is changed in v38-0004 [1]. Please check if it is OK. > Thanks, this change looks good to me. Regards Tang
On Friday, November 12, 2021 6:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Attaching version 39- > Thanks for the new patch. I met a problem when using "ALTER PUBLICATION ... SET TABLE ... WHERE ...", the publisher was crashed after executing this statement. Here is some information about this problem. Steps to reproduce: -- publisher create table t(a int primary key, b int); create publication pub for table t where (a>5); -- subscriber create table t(a int primary key, b int); create subscription sub connection 'dbname=postgres port=5432' publication pub; -- publisher insert into t values (1, 2); alter publication pub set table t where (a>7); Publisher log: 2021-11-15 13:36:54.997 CST [3319891] LOG: logical decoding found consistent point at 0/15208B8 2021-11-15 13:36:54.997 CST [3319891] DETAIL: There are no running transactions. 2021-11-15 13:36:54.997 CST [3319891] STATEMENT: START_REPLICATION SLOT "sub" LOGICAL 0/0 (proto_version '3', publication_names'"pub"') double free or corruption (out) 2021-11-15 13:36:55.072 CST [3319746] LOG: received fast shutdown request 2021-11-15 13:36:55.073 CST [3319746] LOG: aborting any active transactions 2021-11-15 13:36:55.105 CST [3319746] LOG: background worker "logical replication launcher" (PID 3319874) exited with exitcode 1 2021-11-15 13:36:55.105 CST [3319869] LOG: shutting down 2021-11-15 13:36:55.554 CST [3319746] LOG: server process (PID 3319891) was terminated by signal 6: Aborted 2021-11-15 13:36:55.554 CST [3319746] DETAIL: Failed process was running: START_REPLICATION SLOT "sub" LOGICAL 0/0 (proto_version'3', publication_names '"pub"') 2021-11-15 13:36:55.554 CST [3319746] LOG: terminating any other active server processes Backtrace is attached. I think maybe the problem is related to the below change in 0003 patch: + free(entry->exprstate); Regards Tang
Вложения
On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Attaching version 39- > > V39 fixes the following review comments: > > On Fri, Nov 5, 2021 at 7:49 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > CheckObjSchemaNotAlreadyInPublication(rels, schemaidlist, > > PUBLICATIONOBJ_TABLE); > > > >I think for the correct merge you need to just call > >CheckObjSchemaNotAlreadyInPublication() before this for loop. BTW, I > >have a question regarding this implementation. Here, it has been > >assumed that the new rel will always be specified with a different > >qual, what if there is no qual or if the qual is the same? > > Actually with this code, no qual or a different qual does not matter, > it recreates everything as specified by the ALTER SET command. > I have added CheckObjSchemaNotAlreadyInPublication as you specified since this > is required to match the schema patch behaviour. I've also added > a test case that tests this particular case. > What I meant was that with this new code we have regressed the old behavior. Basically, imagine a case where no filter was given for any of the tables. Then after the patch, we will remove all the old tables whereas before the patch it will remove the oldrels only when they are not specified as part of new rels. If you agree with this, then we can retain the old behavior and for the new tables, we can always override the where clause for a SET variant of command. -- With Regards, Amit Kapila.
On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching version 39-
>
Some comments on 0006
--
/*
+ * Write UPDATE to the output stream using cached virtual slots.
+ * Cached updates will have both old tuple and new tuple.
+ */
+void
+logicalrep_write_update_cached(StringInfo out, TransactionId xid, Relation rel,
+ TupleTableSlot *oldtuple, TupleTableSlot *newtuple,
bool binary)
+{
Function, logicalrep_write_update_cached is exactly the same as
logicalrep_write_update, except calling logicalrep_write_tuple_cached
vs logicalrep_write_tuple. So I don't like the idea of making
complete duplicate copies. instead either we can keep a if check or we
can pass this logicalrep_write_tuple(_cached) as a function pointer.
--
Looking further, I realized that "logicalrep_write_tuple" and
"logicalrep_write_tuple_cached" are completely duplicate except first
one is calling "heap_deform_tuple" and then using local values[] array
and the second one is directly using the slot->values[] array, so in
fact we can pass this also as a parameter or we can put just one if
check the populate the values[] and null array, so if it is cached we
will point directly to the slot->values[] otherwise
heap_deform_tuple(), I think this should be just one simple check.
--
+
+/*
+ * Change is checked against the row filter, if any.
+ *
+ * If it returns true, the change is replicated, otherwise, it is not.
+ */
+static bool
+pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
RelationSyncEntry *entry)
IMHO, the comments should explain how it is different from the
pgoutput_row_filter function. Also comments are saying "If it returns
true, the change is replicated, otherwise, it is not" which is not
exactly true for this function, I mean based on that the caller will
change the action. So I think it is enough to say what this function
is doing but not required to say what the caller will do based on what
this function returns.
--
+ for (i = 0; i < desc->natts; i++)
+ {
+ Form_pg_attribute att = TupleDescAttr(desc, i);
+
+ /* if the column in the new_tuple is null, nothing to do */
+ if (tmp_new_slot->tts_isnull[i])
+ continue;
Put some comments over this loop about what it is trying to do, and
overall I think there are not sufficient comments in the
pgoutput_row_filter_update_check function.
--
+ /*
+ * Unchanged toasted replica identity columns are
+ * only detoasted in the old tuple, copy this over to the newtuple.
+ */
+ if ((att->attlen == -1 &&
VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i])) &&
+ (!old_slot->tts_isnull[i] &&
+ !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))))
Is it ever possible that if the attribute is not NULL in the old slot
still it is stored as VARATT_IS_EXTERNAL_ONDISK? I think no, so
instead of adding
this last condition in check it should be asserted inside the if check.
--
static bool
-pgoutput_row_filter(PGOutputData *data, Relation relation, HeapTuple
oldtuple, HeapTuple newtuple, RelationSyncEntry *entry)
+pgoutput_row_filter_update_check(Relation relation, HeapTuple
oldtuple, HeapTuple newtuple, RelationSyncEntry *entry,
ReorderBufferChangeType *action)
+{
This function definition header is too long to fit in one line, so
better to break it. I think running will be a good idea.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Mon, Nov 15, 2021 at 2:44 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > This function definition header is too long to fit in one line, so > better to break it. I think running will be a good idea. > It seems in the last line you are suggesting to run pgindent but it is not clear as the word 'pgindent' is missing? -- With Regards, Amit Kapila.
On Mon, 15 Nov 2021 at 3:07 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Mon, Nov 15, 2021 at 2:44 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
>
> This function definition header is too long to fit in one line, so
> better to break it. I think running will be a good idea.
>
It seems in the last line you are suggesting to run pgindent but it is
not clear as the word 'pgindent' is missing?
Yeah I intended to suggest pgindent
On Mon, Nov 15, 2021 at 5:09 PM tanghy.fnst@fujitsu.com
<tanghy.fnst@fujitsu.com> wrote:
>
> I met a problem when using "ALTER PUBLICATION ... SET TABLE ... WHERE ...", the
> publisher was crashed after executing this statement.
>
>
>
> Backtrace is attached. I think maybe the problem is related to the below change in 0003 patch:
>
> + free(entry->exprstate);
>
I had a look at this crash problem and could reproduce it.
I made the following changes and it seemed to resolve the problem:
diff --git a/src/backend/replication/pgoutput/pgoutput.c
b/src/backend/replication/pgoutput/pgoutput.c
index e7f2fd4bad..f0cb9b8265 100644
--- a/src/backend/replication/pgoutput/pgoutput.c
+++ b/src/backend/replication/pgoutput/pgoutput.c
@@ -969,8 +969,6 @@ pgoutput_row_filter_init(PGOutputData *data,
Relation relation, RelationSyncEntr
oldctx = MemoryContextSwitchTo(CacheMemoryContext);
rfnode = n_filters > 1 ? makeBoolExpr(AND_EXPR, rfnodes,
-1) : linitial(rfnodes);
entry->exprstate = pgoutput_row_filter_init_expr(rfnode);
-
- list_free(rfnodes);
}
entry->rowfilter_valid = true;
@@ -1881,7 +1879,7 @@ rel_sync_cache_relation_cb(Datum arg, Oid relid)
}
if (entry->exprstate != NULL)
{
- free(entry->exprstate);
+ pfree(entry->exprstate);
entry->exprstate = NULL;
}
}
Regards,
Greg Nancarrow
Fujitsu Australia
On Wed, Nov 10, 2021 at 12:36 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > 3) v37-0005
> >
> > - no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr
> >
> > I think there could be other node type which can also be considered as simple
> > expression, for exmaple T_NullIfExpr.
>
> The current walker restrictions are from a previously agreed decision
> by Amit/Tomas [1] and from an earlier suggestion from Andres [2] to
> keep everything very simple for a first version.
>
> Yes, you are right, there might be some additional node types that
> might be fine, but at this time I don't want to add anything different
> without getting their approval to do so. Anyway, additions like this
> are all candidates for a future version of this row-filter feature.
>
I think we can consider T_NullIfExpr unless you see any problem with the same.
> >
> > Personally, I think it's natural to only check the IMMUTABLE and
> > whether-user-defined in the new function rowfilter_walker. We can keep the
> > other row-filter errors which were thrown for EXPR_KIND_PUBLICATION_WHERE in
> > the 0001 patch.
> >
>
> YMMV. IMO it is much more convenient for all the filter validations to
> be centralized just in one walker function instead of scattered all
> over the place like they were in the 0001 patch.
>
+1.
Few comments on the latest set of patches (v39*)
=======================================
0001*
1.
ObjectAddress
-publication_add_relation(Oid pubid, PublicationRelInfo *targetrel,
+publication_add_relation(Oid pubid, PublicationRelInfo *pri,
bool if_not_exists)
{
Relation rel;
HeapTuple tup;
Datum values[Natts_pg_publication_rel];
bool nulls[Natts_pg_publication_rel];
- Oid relid = RelationGetRelid(targetrel->relation);
+ Relation targetrel = pri->relation;
I don't think such a renaming (targetrel-->pri) is warranted for this
patch. If we really want something like this, we can probably do it in
a separate patch but I suggest we can do that as a separate patch.
2.
+ * The OptWhereClause (row-filter) must be stored here
+ * but it is valid only for tables. If the ColId was
+ * mistakenly not a table this will be detected later
+ * in preprocess_pubobj_list() and an error thrown.
/error thrown/error is thrown
0003*
3. In pgoutput_row_filter(), the patch is finding pub_relid when it
should already be there in RelationSyncEntry->publish_as_relid found
during get_rel_sync_entry call. Is there a reason to do this work
again?
4. I think we should add some comments in pgoutput_row_filter() as to
why we are caching the row_filter here instead of
get_rel_sync_entry()? That has been discussed multiple times so it is
better to capture that in comments.
5. Why do you need a separate variable rowfilter_valid to indicate
whether a valid row filter exists? Why exprstate is not sufficient?
Can you update comments to indicate why we need this variable
separately?
0004*
6. In rowfilter_expr_checker(), the expression tree is traversed
twice, can't we traverse it once to detect all non-allowed stuff? It
can be sometimes costly to traverse the tree multiple times especially
when the expression is complex and it doesn't seem acceptable to do so
unless there is some genuine reason for the same.
7.
+static void
+rowfilter_expr_checker(Publication *pub, Node *rfnode, Relation rel)
Keep the rel argument before whereclause as that makes the function
signature better.
With Regards,
Amit Kapila.
On Fri, Nov 12, 2021 at 9:19 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Attaching version 39- > Thanks for the updated patch. Some review comments: doc/src/sgml/ref/create_publication.sgml (1) improve comment + /* Set up a pstate to parse with */ "pstate" is the variable name, better to use "ParseState". src/test/subscription/t/025_row_filter.pl (2) rename TAP test 025 to 026 I suggest that the t/025_row_filter.pl TAP test should be renamed to 026 now because 025 is being used by some schema TAP test. (3) whitespace errors The 0006 patch applies with several whitespace errors. (4) fix crash The pgoutput.c patch that I previously posted on this thread needs to be applied to fix the coredump issue reported by Tang-san. While that fixes the crash, I haven't tracked through to see where/whether the expression nodes are actually freed or whether now there is a possible memory leak issue that may need further investigation. Regards, Greg Nancarrow
On Friday, November 12, 2021 6:20 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching version 39-
>
I met another problem when filtering out with the operator '~'.
Data can't be replicated as expected.
For example:
-- publisher
create table t (a text primary key);
create publication pub for table t where (a ~ 'aaa');
-- subscriber
create table t (a text primary key);
create subscription sub connection 'port=5432' publication pub;
-- publisher
insert into t values ('aaaaab');
insert into t values ('aaaaabc');
postgres=# select * from t where (a ~ 'aaa');
a
---------
aaaaab
aaaaabc
(2 rows)
-- subscriber
postgres=# select * from t;
a
--------
aaaaab
(1 row)
The second record can’t be replicated.
By the way, when only applied 0001 patch, I couldn't reproduce this bug.
So, I think it was related to the later patches.
Regards
Tang
On Mon, Nov 15, 2021 at 2:44 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching version 39-
I have reviewed, 0001* and I have a few comments on it
---
>If you choose to do the initial table synchronization, only data that satisfies
>the row filters is sent.
I think this comment is not correct, I think the correct statement
would be "only data that satisfies the row filters is pulled by the
subscriber"
---
---
+ The <literal>WHERE</literal> clause should contain only columns that are
+ part of the primary key or be covered by <literal>REPLICA
+ IDENTITY</literal> otherwise, <command>DELETE</command> operations will not
+ be replicated. That's because old row is used and it only contains primary
+ key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
+ remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
+ and <command>UPDATE</command> operations, any column might be used in the
+ <literal>WHERE</literal> clause.
I think this message is not correct, because for update also we can
not have filters on the non-key attribute right? Even w.r.t the first
patch also if the non update non key toast columns are there we can
not apply filters on those. So this comment seems misleading to me.
---
- Oid relid = RelationGetRelid(targetrel->relation);
..
+ relid = RelationGetRelid(targetrel);
+
Why this change is required, I mean instead of fetching the relid
during the variable declaration why do we need to do it separately
now?
---
+ if (expr == NULL)
+ ereport(ERROR,
+ (errcode(ERRCODE_CANNOT_COERCE),
+ errmsg("row filter returns type %s that cannot be
coerced to the expected type %s",
Instead of "coerced to" can we use "cast to"? That will be in sync
with other simmilar kind od user exposed error message.
----
+static ExprState *
+pgoutput_row_filter_init_expr(Node *rfnode)
+{
.....
+ /*
+ * Cache ExprState using CacheMemoryContext. This is the same code as
+ * ExecPrepareExpr() but that is not used because it doesn't use an EState.
+ * It should probably be another function in the executor to handle the
+ * execution outside a normal Plan tree context.
+ */
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ expr = expression_planner(expr);
+ exprstate = ExecInitExpr(expr, NULL);
+ MemoryContextSwitchTo(oldctx);
+
+ return exprstate;
+}
I can see the caller of this function is already switching to
CacheMemoryContext, so what is the point in doing it again here?
Maybe if called is expected to do show we can Asssert on the
CurrentMemoryContext.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Nov 16, 2021 at 7:33 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > The second record can’t be replicated. > > By the way, when only applied 0001 patch, I couldn't reproduce this bug. > So, I think it was related to the later patches. > The problem seems to be caused by the 0006 patch (when I remove that patch, the problem doesn't occur). Still needs investigation. Regards, Greg Nancarrow Fujitsu Australia
On Tue, Nov 16, 2021 at 7:33 PM tanghy.fnst@fujitsu.com
<tanghy.fnst@fujitsu.com> wrote:
>
> On Friday, November 12, 2021 6:20 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching version 39-
> >
>
> I met another problem when filtering out with the operator '~'.
> Data can't be replicated as expected.
>
> For example:
> -- publisher
> create table t (a text primary key);
> create publication pub for table t where (a ~ 'aaa');
>
> -- subscriber
> create table t (a text primary key);
> create subscription sub connection 'port=5432' publication pub;
>
> -- publisher
> insert into t values ('aaaaab');
> insert into t values ('aaaaabc');
> postgres=# select * from t where (a ~ 'aaa');
> a
> ---------
> aaaaab
> aaaaabc
> (2 rows)
>
> -- subscriber
> postgres=# select * from t;
> a
> --------
> aaaaab
> (1 row)
>
> The second record can’t be replicated.
>
> By the way, when only applied 0001 patch, I couldn't reproduce this bug.
> So, I think it was related to the later patches.
>
I found that the problem was caused by allocating the WHERE clause
expression nodes in the wrong memory context (so they'd end up getting
freed after first-time use).
The following additions are needed in pgoutput_row_filter_init() - patch 0005.
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
rfnode = stringToNode(TextDatumGetCString(rfdatum));
rfnodes = lappend(rfnodes, rfnode);
+ MemoryContextSwitchTo(oldctx);
(these changes are needed in addition to the fixes I posted on this
thread for the crash problem that was previously reported)
Regards,
Greg Nancarrow
Fujitsu Australia
PSA new set of v40* patches. This addresses multiple review comments as follows: v40-0001 = the "main" patch - not changed v40-0002 = tab auto-complete. - not changed v40-0003 = cache updates. - fix memory bug reported by Tang, using Greg's fix [Tang 15/11] - fix unnecessary publish_as_relid code [Amit 15/11] #3 - add more comments about delayed caching [Amit 15/11] #4 - update comment for rowfilter_valid [Amit 15/11] #5 - fix regex bug reported by Tang, using Greg's fix [Tang 16/11] v40-0004 = combine using OR instead of AND - this is a new patch - new behavior. multiple filters now combine by OR instead of AND [Tomas 23/9] #3 v40-0005 = filter validation replica identity. - previously this was v39-0004 - rearrange args for rowfilter_expr_checker [Amit 15/11] #7 v40-0006 = filter validation walker. - previously this was v39-0005 - now allows NULLIF [Houz 8/11] #3 v40-0007 = support old/new tuple logic for row-filters. - previously this was v39-0006 - fix typos [Peter 15/11] #1 - function logicalrep_write_tuple_cached use more common code [Peter 15/11] #2, [Dilip 15/11] #1 - make order of old/new consistent [Peter 15/11] #3 - guard elog to be more efficient [Peter 15/11] #4 - update typedefs.list [Peter 15/11] #5 - update comment for pgoutput_row_filter_virtual function [Dilip 15/11] #2 - add more comments in pgoutput_row_filter_update_check [Dilip 15/11] #3 - add assertion [Dilip 15/11] #4 ------ [Tomas 23/9] https://www.postgresql.org/message-id/574b4e78-2f35-acf3-4bdc-4b872582e739%40enterprisedb.com [Houz 8/11] https://www.postgresql.org/message-id/OS0PR01MB571625D4A5CC1DAB4045B2BB94919%40OS0PR01MB5716.jpnprd01.prod.outlook.com [Tang 15/11] https://www.postgresql.org/message-id/OS0PR01MB61138751816E2BF9A0BD6EC9FB989%40OS0PR01MB6113.jpnprd01.prod.outlook.com [Amit 15/11] https://www.postgresql.org/message-id/CAA4eK1L4ddTpc%3D-3bq%3D%3DU8O-BJ%3DsvkAFefRDpATKCG4hKYKAig%40mail.gmail.com [Tang 16/11] https://www.postgresql.org/message-id/OS0PR01MB61132C0E4FFEE73D34AE9823FB999%40OS0PR01MB6113.jpnprd01.prod.outlook.com [Peter 15/11] https://www.postgresql.org/message-id/CAHut%2BPsZ2xsRZw4AyRQuLfO4gYiqCpNVNDRbv_RN1XUUo3KWsw%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
- v40-0001-Row-filter-for-logical-replication.patch
- v40-0004-PS-Combine-multiple-filters-with-OR-instead-of-A.patch
- v40-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v40-0003-PS-ExprState-cache-modifications.patch
- v40-0005-PS-Row-filter-validation-of-replica-identity.patch
- v40-0006-PS-Row-filter-validation-walker.patch
- v40-0007-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 3) create_subscription.sgml > > <literal>WHERE</literal> clauses, rows must satisfy all expressions > to be copied. If the subscriber is a > > I'm rather skeptical about the principle that all expressions have to > match - I'd have expected exactly the opposite behavior, actually. > > I see a subscription as "a union of all publications". Imagine for > example you have a data set for all customers, and you create a > publication for different parts of the world, like > > CREATE PUBLICATION customers_france > FOR TABLE customers WHERE (country = 'France'); > > CREATE PUBLICATION customers_germany > FOR TABLE customers WHERE (country = 'Germany'); > > CREATE PUBLICATION customers_usa > FOR TABLE customers WHERE (country = 'USA'); > > and now you want to subscribe to multiple publications, because you want > to replicate data for multiple countries (e.g. you want EU countries). > But if you do > > CREATE SUBSCRIPTION customers_eu > PUBLICATION customers_france, customers_germany; > > then you won't get anything, because each customer belongs to just a > single country. Yes, I could create multiple individual subscriptions, > one for each country, but that's inefficient and may have a different > set of issues (e.g. keeping them in sync when a customer moves between > countries). > > I might have missed something, but I haven't found any explanation why > the requirement to satisfy all expressions is the right choice. > > IMHO this should be 'satisfies at least one expression' i.e. we should > connect the expressions by OR, not AND. > Fixed in V40 [1] ----- [1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Nov 10, 2021 at 12:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > 3) v37-0005 > > > > > > - no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr > > > > > > I think there could be other node type which can also be considered as simple > > > expression, for exmaple T_NullIfExpr. > > > > The current walker restrictions are from a previously agreed decision > > by Amit/Tomas [1] and from an earlier suggestion from Andres [2] to > > keep everything very simple for a first version. > > > > Yes, you are right, there might be some additional node types that > > might be fine, but at this time I don't want to add anything different > > without getting their approval to do so. Anyway, additions like this > > are all candidates for a future version of this row-filter feature. > > > > I think we can consider T_NullIfExpr unless you see any problem with the same. Added in v40 [1] > Few comments on the latest set of patches (v39*) > ======================================= ... > 0003* > 3. In pgoutput_row_filter(), the patch is finding pub_relid when it > should already be there in RelationSyncEntry->publish_as_relid found > during get_rel_sync_entry call. Is there a reason to do this work > again? Fixed in v40 [1] > > 4. I think we should add some comments in pgoutput_row_filter() as to > why we are caching the row_filter here instead of > get_rel_sync_entry()? That has been discussed multiple times so it is > better to capture that in comments. Added comment in v40 [1] > > 5. Why do you need a separate variable rowfilter_valid to indicate > whether a valid row filter exists? Why exprstate is not sufficient? > Can you update comments to indicate why we need this variable > separately? I have improved the (existing) comment in v40 [1]. > > 0004* > 6. In rowfilter_expr_checker(), the expression tree is traversed > twice, can't we traverse it once to detect all non-allowed stuff? It > can be sometimes costly to traverse the tree multiple times especially > when the expression is complex and it doesn't seem acceptable to do so > unless there is some genuine reason for the same. I kind of doubt there would be any perceptible difference for 2 traverses instead of 1 because: a) filters are limited to simple expressions. Yes, a large boolean expression is possible but I don't think it is likely. b) the validation part is mostly a one-time execution only when the filter is created or changed. Anyway, I am happy to try to refactor the logic to a single traversal as suggested, but I'd like to combine those "validation" patches (v40-0005, v40-0006) first, so I can combine their walker logic. Is it OK? > > 7. > +static void > +rowfilter_expr_checker(Publication *pub, Node *rfnode, Relation rel) > > Keep the rel argument before whereclause as that makes the function > signature better. Fixed in v40 [1] ----- [1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Nov 15, 2021 at 5:09 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Friday, November 12, 2021 6:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Attaching version 39- > > > > Thanks for the new patch. > > I met a problem when using "ALTER PUBLICATION ... SET TABLE ... WHERE ...", the > publisher was crashed after executing this statement. > > Here is some information about this problem. > > Steps to reproduce: > -- publisher > create table t(a int primary key, b int); > create publication pub for table t where (a>5); > > -- subscriber > create table t(a int primary key, b int); > create subscription sub connection 'dbname=postgres port=5432' publication pub; > > -- publisher > insert into t values (1, 2); > alter publication pub set table t where (a>7); > > > Publisher log: > 2021-11-15 13:36:54.997 CST [3319891] LOG: logical decoding found consistent point at 0/15208B8 > 2021-11-15 13:36:54.997 CST [3319891] DETAIL: There are no running transactions. > 2021-11-15 13:36:54.997 CST [3319891] STATEMENT: START_REPLICATION SLOT "sub" LOGICAL 0/0 (proto_version '3', publication_names'"pub"') > double free or corruption (out) > 2021-11-15 13:36:55.072 CST [3319746] LOG: received fast shutdown request > 2021-11-15 13:36:55.073 CST [3319746] LOG: aborting any active transactions > 2021-11-15 13:36:55.105 CST [3319746] LOG: background worker "logical replication launcher" (PID 3319874) exited withexit code 1 > 2021-11-15 13:36:55.105 CST [3319869] LOG: shutting down > 2021-11-15 13:36:55.554 CST [3319746] LOG: server process (PID 3319891) was terminated by signal 6: Aborted > 2021-11-15 13:36:55.554 CST [3319746] DETAIL: Failed process was running: START_REPLICATION SLOT "sub" LOGICAL 0/0 (proto_version'3', publication_names '"pub"') > 2021-11-15 13:36:55.554 CST [3319746] LOG: terminating any other active server processes > > > Backtrace is attached. I think maybe the problem is related to the below change in 0003 patch: > > + free(entry->exprstate); > Fixed in V40 [1] using a fix provided by Greg Nancarrow. ----- [1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 16, 2021 at 7:33 PM tanghy.fnst@fujitsu.com
<tanghy.fnst@fujitsu.com> wrote:
>
> On Friday, November 12, 2021 6:20 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching version 39-
> >
>
> I met another problem when filtering out with the operator '~'.
> Data can't be replicated as expected.
>
> For example:
> -- publisher
> create table t (a text primary key);
> create publication pub for table t where (a ~ 'aaa');
>
> -- subscriber
> create table t (a text primary key);
> create subscription sub connection 'port=5432' publication pub;
>
> -- publisher
> insert into t values ('aaaaab');
> insert into t values ('aaaaabc');
> postgres=# select * from t where (a ~ 'aaa');
> a
> ---------
> aaaaab
> aaaaabc
> (2 rows)
>
> -- subscriber
> postgres=# select * from t;
> a
> --------
> aaaaab
> (1 row)
>
> The second record can’t be replicated.
>
> By the way, when only applied 0001 patch, I couldn't reproduce this bug.
> So, I think it was related to the later patches.
>
Fixed in V40-0003 [1] using a fix provided by Greg Nancarrow.
-----
[1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Nov 15, 2021 at 12:01 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Fri, Nov 12, 2021 at 9:19 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching version 39-
>
> Here are some review comments for v39-0006:
>
> 1)
> @@ -261,9 +261,9 @@ rowfilter_expr_replident_walker(Node *node,
> rf_context *context)
> * Rule 1. Walk the parse-tree and reject anything other than very simple
> * expressions (See rowfilter_validator for details on what is permitted).
> *
> - * Rule 2. If the publish operation contains "delete" then only columns that
> - * are allowed by the REPLICA IDENTITY rules are permitted to be used in the
> - * row-filter WHERE clause.
> + * Rule 2. If the publish operation contains "delete" or "delete" then only
> + * columns that are allowed by the REPLICA IDENTITY rules are permitted to
> + * be used in the row-filter WHERE clause.
> */
> static void
> rowfilter_expr_checker(Publication *pub, ParseState *pstate, Node
> *rfnode, Relation rel)
> @@ -276,12 +276,10 @@ rowfilter_expr_checker(Publication *pub,
> ParseState *pstate, Node *rfnode, Relat
> rowfilter_validator(relname, rfnode);
>
> /*
> - * Rule 2: For "delete", check that filter cols are also valid replica
> + * Rule 2: For "delete" and "update", check that filter cols are also
> valid replica
> * identity cols.
> - *
> - * TODO - check later for publish "update" case.
> */
> - if (pub->pubactions.pubdelete)
>
> 1a)
> Typo - the function comment: "delete" or "delete"; should say:
> "delete" or "update"
>
> 1b)
> I felt it would be better (for the comment in the function body) to
> write it as "or" instead of "and" because then it matches with the
> code "if ||" that follows this comment.
>
> ====
>
> 2)
> @@ -746,6 +780,92 @@ logicalrep_read_typ(StringInfo in, LogicalRepTyp *ltyp)
> }
>
> /*
> + * Write a tuple to the outputstream using cached slot, in the most
> efficient format possible.
> + */
> +static void
> +logicalrep_write_tuple_cached(StringInfo out, Relation rel,
> TupleTableSlot *slot, bool binary)
>
> The function logicalrep_write_tuple_cached seems to have almost all of
> its function body in common with logicalrep_write_tuple. Is there any
> good way to combine these functions to avoid ~80 lines mostly
> duplicated code?
>
> ====
>
> 3)
> + if (!old_matched && !new_matched)
> + return false;
> +
> + if (old_matched && new_matched)
> + *action = REORDER_BUFFER_CHANGE_UPDATE;
> + else if (old_matched && !new_matched)
> + *action = REORDER_BUFFER_CHANGE_DELETE;
> + else if (new_matched && !old_matched)
> + *action = REORDER_BUFFER_CHANGE_INSERT;
> +
> + return true;
>
> I felt it is slightly confusing to have inconsistent ordering of the
> old_matched and new_matched in those above conditions.
>
> I suggest to use the order like:
> * old-row (no match) new-row (no match)
> * old-row (no match) new row (match)
> * old-row (match) new-row (no match)
> * old-row (match) new row (match)
>
> And then be sure to keep consistent ordering in all places it is mentioned:
> * in the code
> * in the function header comment
> * in the commit comment
> * in docs?
>
> ====
>
> 4)
> +/*
> + * Change is checked against the row filter, if any.
> + *
> + * If it returns true, the change is replicated, otherwise, it is not.
> + */
> +static bool
> +pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
> RelationSyncEntry *entry)
> +{
> + EState *estate;
> + ExprContext *ecxt;
> + bool result = true;
> + Oid relid = RelationGetRelid(relation);
> +
> + /* Bail out if there is no row filter */
> + if (!entry->exprstate)
> + return true;
> +
> + elog(DEBUG3, "table \"%s.%s\" has row filter",
> + get_namespace_name(get_rel_namespace(relid)),
> + get_rel_name(relid));
>
> It seems like that elog may consume unnecessary CPU most of the time.
> I think it might be better to remove the relid declaration and rewrite
> that elog as:
>
> if (message_level_is_interesting(DEBUG3))
> elog(DEBUG3, "table \"%s.%s\" has row filter",
> get_namespace_name(get_rel_namespace(entry->relid)),
> get_rel_name(entry->relid));
>
> ====
>
> 5)
> diff --git a/src/include/replication/reorderbuffer.h
> b/src/include/replication/reorderbuffer.h
> index 5b40ff7..aec0059 100644
> --- a/src/include/replication/reorderbuffer.h
> +++ b/src/include/replication/reorderbuffer.h
> @@ -51,7 +51,7 @@ typedef struct ReorderBufferTupleBuf
> * respectively. They're used by INSERT .. ON CONFLICT .. UPDATE. Users of
> * logical decoding don't have to care about these.
> */
> -enum ReorderBufferChangeType
> +typedef enum ReorderBufferChangeType
> {
> REORDER_BUFFER_CHANGE_INSERT,
> REORDER_BUFFER_CHANGE_UPDATE,
> @@ -65,7 +65,7 @@ enum ReorderBufferChangeType
> REORDER_BUFFER_CHANGE_INTERNAL_SPEC_CONFIRM,
> REORDER_BUFFER_CHANGE_INTERNAL_SPEC_ABORT,
> REORDER_BUFFER_CHANGE_TRUNCATE
> -};
> +} ReorderBufferChangeType;
>
> This new typedef can be added to src/tools/pgindent/typedefs.list.
>
All above are fixed by Ajin Cherian in V40-0006 [1].
-----
[1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Nov 15, 2021 at 8:14 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> On Fri, Nov 12, 2021 at 3:49 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching version 39-
> >
>
> Some comments on 0006
>
> --
...
> --
>
> Looking further, I realized that "logicalrep_write_tuple" and
> "logicalrep_write_tuple_cached" are completely duplicate except first
> one is calling "heap_deform_tuple" and then using local values[] array
> and the second one is directly using the slot->values[] array, so in
> fact we can pass this also as a parameter or we can put just one if
> check the populate the values[] and null array, so if it is cached we
> will point directly to the slot->values[] otherwise
> heap_deform_tuple(), I think this should be just one simple check.
Fixed in v40 [1]
> --
> +
> +/*
> + * Change is checked against the row filter, if any.
> + *
> + * If it returns true, the change is replicated, otherwise, it is not.
> + */
> +static bool
> +pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
> RelationSyncEntry *entry)
>
> IMHO, the comments should explain how it is different from the
> pgoutput_row_filter function. Also comments are saying "If it returns
> true, the change is replicated, otherwise, it is not" which is not
> exactly true for this function, I mean based on that the caller will
> change the action. So I think it is enough to say what this function
> is doing but not required to say what the caller will do based on what
> this function returns.
Fixed in v40 [1].
>
>
> --
>
> + for (i = 0; i < desc->natts; i++)
> + {
> + Form_pg_attribute att = TupleDescAttr(desc, i);
> +
> + /* if the column in the new_tuple is null, nothing to do */
> + if (tmp_new_slot->tts_isnull[i])
> + continue;
>
> Put some comments over this loop about what it is trying to do, and
> overall I think there are not sufficient comments in the
> pgoutput_row_filter_update_check function.
Fixed in v40 [1].
>
> --
> + /*
> + * Unchanged toasted replica identity columns are
> + * only detoasted in the old tuple, copy this over to the newtuple.
> + */
> + if ((att->attlen == -1 &&
> VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i])) &&
> + (!old_slot->tts_isnull[i] &&
> + !(VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))))
>
> Is it ever possible that if the attribute is not NULL in the old slot
> still it is stored as VARATT_IS_EXTERNAL_ONDISK? I think no, so
> instead of adding
> this last condition in check it should be asserted inside the if check.
>
Fixed in v40 [1]
-----
[1] https://www.postgresql.org/message-id/CAHut%2BPv-D4rQseRO_OzfEz2dQsTKEnKjBCET9Z-iJppyT1XNMQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of v40* patches.
>
Thanks for the patch updates.
A couple of comments so far:
(1) compilation warning
WIth the patches applied, there's a single compilation warning when
Postgres is built:
pgoutput.c: In function ‘pgoutput_row_filter_init’:
pgoutput.c:854:8: warning: unused variable ‘relid’ [-Wunused-variable]
Oid relid = RelationGetRelid(relation);
^~~~~
> v40-0004 = combine using OR instead of AND
> - this is a new patch
> - new behavior. multiple filters now combine by OR instead of AND
> [Tomas 23/9] #3
>
(2) missing test case
It seems that the current tests are not testing the
multiple-row-filter case (n_filters > 1) in the following code in
pgoutput_row_filter_init():
rfnode = n_filters > 1 ? makeBoolExpr(OR_EXPR, rfnodes, -1) :
linitial(rfnodes);
I think a test needs to be added similar to the customers+countries
example that Tomas gave (where there is a single subscription to
multiple publications of the same table, each of which has a
row-filter).
Regards,
Greg Nancarrow
Fujitsu Australia
On Thu, Nov 18, 2021 at 11:02 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > 5. Why do you need a separate variable rowfilter_valid to indicate > > whether a valid row filter exists? Why exprstate is not sufficient? > > Can you update comments to indicate why we need this variable > > separately? > > I have improved the (existing) comment in v40 [1]. > > > > > 0004* > > 6. In rowfilter_expr_checker(), the expression tree is traversed > > twice, can't we traverse it once to detect all non-allowed stuff? It > > can be sometimes costly to traverse the tree multiple times especially > > when the expression is complex and it doesn't seem acceptable to do so > > unless there is some genuine reason for the same. > > I kind of doubt there would be any perceptible difference for 2 > traverses instead of 1 because: > a) filters are limited to simple expressions. Yes, a large boolean > expression is possible but I don't think it is likely. > But in such cases, it will be quite costly and more importantly, I don't see any good reason why we need to traverse it twice.. > b) the validation part is mostly a one-time execution only when the > filter is created or changed. > > Anyway, I am happy to try to refactor the logic to a single traversal > as suggested, but I'd like to combine those "validation" patches > (v40-0005, v40-0006) first, so I can combine their walker logic. Is it > OK? > That should be okay. You can combine the logic of v40-0005 and v40-0006, and then change it so that you need to traverse the expression once. -- With Regards, Amit Kapila.
On Thu, Nov 18, 2021 at 4:32 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Nov 10, 2021 at 12:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > 3) v37-0005 > > > > > > > > - no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr > > > > > > > > I think there could be other node type which can also be considered as simple > > > > expression, for exmaple T_NullIfExpr. > > > > > > The current walker restrictions are from a previously agreed decision > > > by Amit/Tomas [1] and from an earlier suggestion from Andres [2] to > > > keep everything very simple for a first version. > > > > > > Yes, you are right, there might be some additional node types that > > > might be fine, but at this time I don't want to add anything different > > > without getting their approval to do so. Anyway, additions like this > > > are all candidates for a future version of this row-filter feature. > > > > > > > I think we can consider T_NullIfExpr unless you see any problem with the same. > > Added in v40 [1] > I've noticed that row-filters that are testing NULL cannot pass the current expression validation restrictions. e.g.1 test_pub=# create publication ptest for table t1 where (a is null); ERROR: invalid publication WHERE expression for relation "t1" HINT: only simple expressions using columns, constants and immutable system functions are allowed e.g.2 test_pub=# create publication ptest for table t1 where (a is not null); ERROR: invalid publication WHERE expression for relation "t1" HINT: only simple expressions using columns, constants and immutable system functions are allowed So I think it would be useful to permit the NullTest also. Is it OK? ------ KInd Regards, Peter Smith. Fujitsu Australia
On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
...
>
> Few comments on the latest set of patches (v39*)
> =======================================
> 0001*
> 1.
> ObjectAddress
> -publication_add_relation(Oid pubid, PublicationRelInfo *targetrel,
> +publication_add_relation(Oid pubid, PublicationRelInfo *pri,
> bool if_not_exists)
> {
> Relation rel;
> HeapTuple tup;
> Datum values[Natts_pg_publication_rel];
> bool nulls[Natts_pg_publication_rel];
> - Oid relid = RelationGetRelid(targetrel->relation);
> + Relation targetrel = pri->relation;
>
> I don't think such a renaming (targetrel-->pri) is warranted for this
> patch. If we really want something like this, we can probably do it in
> a separate patch but I suggest we can do that as a separate patch.
>
The name "targetrel" implies it is a Relation. (and historically, this
arg once was "Relation *targetrel").
Then when the PublicationRelInfo struct was introduced the arg name
was not changed and it became "PublicationRelInfo *targetrel". But at
that time PublicationRelInfo was just a simple wrapper for a Relation
so that was probably ok.
But now this Row-Filter patch has added more new members to
PublicationRelInfo, so IMO the name change is helpful otherwise it
seems misleading to continue calling it like it was still just a
Relation.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Fri, Nov 19, 2021 at 3:16 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Nov 18, 2021 at 4:32 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Wed, Nov 10, 2021 at 12:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > On Mon, Nov 8, 2021 at 5:53 PM houzj.fnst@fujitsu.com > > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > > 3) v37-0005 > > > > > > > > > > - no parse nodes of any kind other than Var, OpExpr, Const, BoolExpr, FuncExpr > > > > > > > > > > I think there could be other node type which can also be considered as simple > > > > > expression, for exmaple T_NullIfExpr. > > > > > > > > The current walker restrictions are from a previously agreed decision > > > > by Amit/Tomas [1] and from an earlier suggestion from Andres [2] to > > > > keep everything very simple for a first version. > > > > > > > > Yes, you are right, there might be some additional node types that > > > > might be fine, but at this time I don't want to add anything different > > > > without getting their approval to do so. Anyway, additions like this > > > > are all candidates for a future version of this row-filter feature. > > > > > > > > > > I think we can consider T_NullIfExpr unless you see any problem with the same. > > > > Added in v40 [1] > > > > I've noticed that row-filters that are testing NULL cannot pass the > current expression validation restrictions. > > e.g.1 > test_pub=# create publication ptest for table t1 where (a is null); > ERROR: invalid publication WHERE expression for relation "t1" > HINT: only simple expressions using columns, constants and immutable > system functions are allowed > > e.g.2 > test_pub=# create publication ptest for table t1 where (a is not null); > ERROR: invalid publication WHERE expression for relation "t1" > HINT: only simple expressions using columns, constants and immutable > system functions are allowed > > So I think it would be useful to permit the NullTest also. Is it OK? > Yeah, I think such simple expressions should be okay but we need to test left-side expressions for simplicity. -- With Regards, Amit Kapila.
On Fri, Nov 19, 2021 at 5:35 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> ...
> >
> > Few comments on the latest set of patches (v39*)
> > =======================================
> > 0001*
> > 1.
> > ObjectAddress
> > -publication_add_relation(Oid pubid, PublicationRelInfo *targetrel,
> > +publication_add_relation(Oid pubid, PublicationRelInfo *pri,
> > bool if_not_exists)
> > {
> > Relation rel;
> > HeapTuple tup;
> > Datum values[Natts_pg_publication_rel];
> > bool nulls[Natts_pg_publication_rel];
> > - Oid relid = RelationGetRelid(targetrel->relation);
> > + Relation targetrel = pri->relation;
> >
> > I don't think such a renaming (targetrel-->pri) is warranted for this
> > patch. If we really want something like this, we can probably do it in
> > a separate patch but I suggest we can do that as a separate patch.
> >
>
> The name "targetrel" implies it is a Relation. (and historically, this
> arg once was "Relation *targetrel").
>
> Then when the PublicationRelInfo struct was introduced the arg name
> was not changed and it became "PublicationRelInfo *targetrel". But at
> that time PublicationRelInfo was just a simple wrapper for a Relation
> so that was probably ok.
>
> But now this Row-Filter patch has added more new members to
> PublicationRelInfo, so IMO the name change is helpful otherwise it
> seems misleading to continue calling it like it was still just a
> Relation.
>
Okay, that sounds reasonable.
--
With Regards,
Amit Kapila.
On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of v40* patches.
>
I notice that in the 0001 patch, it adds a "relid" member to the
PublicationRelInfo struct:
src/include/catalog/pg_publication.h
typedef struct PublicationRelInfo
{
+ Oid relid;
Relation relation;
+ Node *whereClause;
} PublicationRelInfo;
It appears that this new member is not actually required, as the relid
can be simply obtained from the existing "relation" member - using the
RelationGetRelid() macro.
Regards,
Greg Nancarrow
Fujitsu Australia
On Fri, Nov 19, 2021 at 4:15 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > PSA new set of v40* patches.
> >
>
> I notice that in the 0001 patch, it adds a "relid" member to the
> PublicationRelInfo struct:
>
> src/include/catalog/pg_publication.h
>
> typedef struct PublicationRelInfo
> {
> + Oid relid;
> Relation relation;
> + Node *whereClause;
> } PublicationRelInfo;
>
> It appears that this new member is not actually required, as the relid
> can be simply obtained from the existing "relation" member - using the
> RelationGetRelid() macro.
>
+1
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of v40* patches.
>
Another thing I noticed was in the 0004 patch, list_free_deep() should
be used instead of list_free() in the following code block, otherwise
the rfnodes themselves (allocated by stringToNode()) are not freed:
src/backend/replication/pgoutput/pgoutput.c
+ if (rfnodes)
+ {
+ list_free(rfnodes);
+ rfnodes = NIL;
+ }
Regards,
Greg Nancarrow
Fujitsu Australia
On Mon, Nov 22, 2021 at 7:14 AM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > PSA new set of v40* patches.
> >
I have a few more comments on 0007,
@@ -783,9 +887,28 @@ pgoutput_row_filter(PGOutputData *data, Relation
relation, HeapTuple oldtuple, H
ExecDropSingleTupleTableSlot(entry->scantuple);
entry->scantuple = NULL;
}
+ if (entry->old_tuple != NULL)
+ {
+ ExecDropSingleTupleTableSlot(entry->old_tuple);
+ entry->old_tuple = NULL;
+ }
+ if (entry->new_tuple != NULL)
+ {
+ ExecDropSingleTupleTableSlot(entry->new_tuple);
+ entry->new_tuple = NULL;
+ }
+ if (entry->tmp_new_tuple != NULL)
+ {
+ ExecDropSingleTupleTableSlot(entry->tmp_new_tuple);
+ entry->tmp_new_tuple = NULL;
+ }
in pgoutput_row_filter, we are dropping the slots if there are some
old slots in the RelationSyncEntry. But then I noticed that in
rel_sync_cache_relation_cb(), also we are doing that but only for the
scantuple slot. So IMHO, rel_sync_cache_relation_cb(), is only place
setting entry->rowfilter_valid to false; so why not drop all the slot
that time only and in pgoutput_row_filter(), you can just put an
assert?
2.
+static bool
+pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
RelationSyncEntry *entry)
+{
+ EState *estate;
+ ExprContext *ecxt;
pgoutput_row_filter_virtual and pgoutput_row_filter are exactly same
except, ExecStoreHeapTuple(), so why not just put one check based on
whether a slot is passed or not, instead of making complete duplicate
copy of the function.
3.
oldctx = MemoryContextSwitchTo(CacheMemoryContext);
tupdesc = CreateTupleDescCopy(tupdesc);
entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
Why do we need to copy the tupledesc? do we think that we need to have
this slot even if we close the relation, if so can you add the
comments explaining why we are making a copy here.
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Thursday, November 18, 2021 9:34 AM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA new set of v40* patches. > I found a problem on v40. The check for Replica Identity in WHERE clause is not working properly. For example: postgres=# create table tbl(a int primary key, b int); CREATE TABLE postgres=# create publication pub1 for table tbl where (a>10 and b>10); CREATE PUBLICATION I think it should report an error because column b is not part of Replica Identity. This seems due to "return true" in rowfilter_expr_replident_walker function, maybe we should remove it. Besides, a small comment on 0004 patch: + * Multiple row-filter expressions for the same publication will later be + * combined by the COPY using OR, but this means if any of the filters is Should we change it to: Multiple row-filter expressions for the same table ... Regards, Tang
On Tue, Nov 23, 2021 at 4:40 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Thursday, November 18, 2021 9:34 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA new set of v40* patches. > > > > I found a problem on v40. The check for Replica Identity in WHERE clause is not working properly. > > For example: > postgres=# create table tbl(a int primary key, b int); > CREATE TABLE > postgres=# create publication pub1 for table tbl where (a>10 and b>10); > CREATE PUBLICATION > > I think it should report an error because column b is not part of Replica Identity. > This seems due to "return true" in rowfilter_expr_replident_walker function, > maybe we should remove it. This has already been fixed in v41* updates. Please retest when v41* is posted. > > Besides, a small comment on 0004 patch: > > + * Multiple row-filter expressions for the same publication will later be > + * combined by the COPY using OR, but this means if any of the filters is > > Should we change it to: > Multiple row-filter expressions for the same table ... Yes, thanks for reporting. (added to my TODO list) ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA new set of v40* patches.
Few comments:
1) When a table is added to the publication, replica identity is
checked. But while modifying the publish action to include
delete/update, replica identity is not checked for the existing
tables. I felt it should be checked for the existing tables too.
@@ -315,6 +405,9 @@ publication_add_relation(Oid pubid, PublicationRelInfo *pri,
/* Fix up collation information */
assign_expr_collations(pstate, whereclause);
+
+ /* Validate the row-filter. */
+ rowfilter_expr_checker(pub, targetrel, whereclause);
postgres=# create publication pub1 for table t1 where ( c1 = 10);
ERROR: cannot add relation "t1" to publication
DETAIL: Row filter column "c1" is not part of the REPLICA IDENTITY
postgres=# create publication pub1 for table t1 where ( c1 = 10) with
(PUBLISH = INSERT);
CREATE PUBLICATION
postgres=# alter publication pub1 set (PUBLISH=DELETE);
ALTER PUBLICATION
2) Since the error message is because it publishes delete/update
operations, it should include publish delete/update in the error
message. Can we change the error message:
+ if (!bms_is_member(attnum -
FirstLowInvalidHeapAttributeNumber, context->bms_replident))
+ {
+ const char *colname = get_attname(relid, attnum, false);
+
+ ereport(ERROR,
+
(errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
+ errmsg("cannot add relation
\"%s\" to publication",
+
RelationGetRelationName(context->rel)),
+ errdetail("Row filter column
\"%s\" is not part of the REPLICA IDENTITY",
+ colname)));
+ }
To something like:
ereport(ERROR,
(errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
errmsg("cannot add relation \"%s\" to publication because row filter
column \"%s\" does not have a replica identity and publishes
deletes/updates",
RelationGetRelationName(context->rel), colname),
errhint("To enable deleting/updating from the table, set REPLICA
IDENTITY using ALTER TABLE")));
Regards,
Vignesh
On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote:
> On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com>
> wrote:
> >
> > PSA new set of v40* patches.
>
> Few comments:
> 1) When a table is added to the publication, replica identity is checked. But
> while modifying the publish action to include delete/update, replica identity is
> not checked for the existing tables. I felt it should be checked for the existing
> tables too.
In addition to this, I think we might also need some check to prevent user from
changing the REPLICA IDENTITY index which is used in the filter expression.
I was thinking is it possible do the check related to REPLICA IDENTITY in
function CheckCmdReplicaIdentity() or In GetRelationPublicationActions(). If we
move the REPLICA IDENTITY check to this function, it would be consistent with
the existing behavior about the check related to REPLICA IDENTITY(see the
comments in CheckCmdReplicaIdentity) and seems can cover all the cases
mentioned above.
Another comment about v40-0001 patch:
+ char *relname = pstrdup(RelationGetRelationName(rel));
+
table_close(rel, ShareUpdateExclusiveLock);
+
+ /* Disallow duplicate tables if there are any with row-filters. */
+ if (t->whereClause || list_member_oid(relids_with_rf, myrelid))
+ ereport(ERROR,
+ (errcode(ERRCODE_DUPLICATE_OBJECT),
+ errmsg("conflicting or redundant row-filters for \"%s\"",
+ relname)));
+ pfree(relname);
Maybe we can do the error check before table_close(), so that we don't need to
invoke pstrdup() and pfree().
Best regards,
Hou zj
On Thu, Nov 18, 2021 at 11:02 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> >
> > 4. I think we should add some comments in pgoutput_row_filter() as to
> > why we are caching the row_filter here instead of
> > get_rel_sync_entry()? That has been discussed multiple times so it is
> > better to capture that in comments.
>
> Added comment in v40 [1]
>
I think apart from truncate and error cases, it can also happen for
other operations because we decide whether to publish a change
(operation) after calling get_rel_sync_entry() in pgoutput_change. I
think we can reflect that as well in the comment.
> >
> > 5. Why do you need a separate variable rowfilter_valid to indicate
> > whether a valid row filter exists? Why exprstate is not sufficient?
> > Can you update comments to indicate why we need this variable
> > separately?
>
> I have improved the (existing) comment in v40 [1].
>
One more thing related to this code:
pgoutput_row_filter()
{
..
+ if (!entry->rowfilter_valid)
{
..
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ tupdesc = CreateTupleDescCopy(tupdesc);
+ entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
+ MemoryContextSwitchTo(oldctx);
..
}
Why do we need to initialize scantuple here unless we are sure that
the row filter is going to get associated with this relentry? I think
when there is no row filter then this allocation is not required.
--
With Regards,
Amit Kapila.
On Tue, Nov 23, 2021 at 1:29 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote: > > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com> > > wrote: > > > > > > PSA new set of v40* patches. > > > > Few comments: > > 1) When a table is added to the publication, replica identity is checked. But > > while modifying the publish action to include delete/update, replica identity is > > not checked for the existing tables. I felt it should be checked for the existing > > tables too. > > In addition to this, I think we might also need some check to prevent user from > changing the REPLICA IDENTITY index which is used in the filter expression. > > I was thinking is it possible do the check related to REPLICA IDENTITY in > function CheckCmdReplicaIdentity() or In GetRelationPublicationActions(). If we > move the REPLICA IDENTITY check to this function, it would be consistent with > the existing behavior about the check related to REPLICA IDENTITY(see the > comments in CheckCmdReplicaIdentity) and seems can cover all the cases > mentioned above. > Yeah, adding the replica identity check in CheckCmdReplicaIdentity() would cover all the above cases but I think that would put a premium on each update/delete operation. I think traversing the expression tree (it could be multiple traversals if the relation is part of multiple publications) during each update/delete would be costly. Don't you think so? -- With Regards, Amit Kapila.
Attaching a new patchset v41 which includes changes by both Peter and myself.
Patches v40-0005 and v40-0006 have been merged to create patch
v41-0005 which reduces the patches to 6 again.
This patch-set contains changes addressing the following review comments:
On Mon, Nov 15, 2021 at 5:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> What I meant was that with this new code we have regressed the old
> behavior. Basically, imagine a case where no filter was given for any
> of the tables. Then after the patch, we will remove all the old tables
> whereas before the patch it will remove the oldrels only when they are
> not specified as part of new rels. If you agree with this, then we can
> retain the old behavior and for the new tables, we can always override
> the where clause for a SET variant of command.
Fixed and modified the behaviour to match with what the schema patch
implemented.
On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> 2.
> + * The OptWhereClause (row-filter) must be stored here
> + * but it is valid only for tables. If the ColId was
> + * mistakenly not a table this will be detected later
> + * in preprocess_pubobj_list() and an error thrown.
>
> /error thrown/error is thrown
Fixed.
:
> 6. In rowfilter_expr_checker(), the expression tree is traversed
> twice, can't we traverse it once to detect all non-allowed stuff? It
> can be sometimes costly to traverse the tree multiple times especially
> when the expression is complex and it doesn't seem acceptable to do so
> unless there is some genuine reason for the same.
>
Fixed.
On Tue, Nov 16, 2021 at 7:24 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> doc/src/sgml/ref/create_publication.sgml
> (1) improve comment
> + /* Set up a pstate to parse with */
>
> "pstate" is the variable name, better to use "ParseState".
Fixed.
> src/test/subscription/t/025_row_filter.pl
> (2) rename TAP test 025 to 026
> I suggest that the t/025_row_filter.pl TAP test should be renamed to
> 026 now because 025 is being used by some schema TAP test.
>
Fixed
On Tue, Nov 16, 2021 at 7:50 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> ---
> >If you choose to do the initial table synchronization, only data that satisfies
> >the row filters is sent.
>
> I think this comment is not correct, I think the correct statement
> would be "only data that satisfies the row filters is pulled by the
> subscriber"
Fixed
>
> I think this message is not correct, because for update also we can
> not have filters on the non-key attribute right? Even w.r.t the first
> patch also if the non update non key toast columns are there we can
> not apply filters on those. So this comment seems misleading to me.
>
Fixed
>
> - Oid relid = RelationGetRelid(targetrel->relation);
> ..
> + relid = RelationGetRelid(targetrel);
> +
>
> Why this change is required, I mean instead of fetching the relid
> during the variable declaration why do we need to do it separately
> now?
>
Fixed
> + if (expr == NULL)
> + ereport(ERROR,
> + (errcode(ERRCODE_CANNOT_COERCE),
> + errmsg("row filter returns type %s that cannot be
> coerced to the expected type %s",
>
> Instead of "coerced to" can we use "cast to"? That will be in sync
> with other simmilar kind od user exposed error message.
> ----
Fixed
>
> I can see the caller of this function is already switching to
> CacheMemoryContext, so what is the point in doing it again here?
> Maybe if called is expected to do show we can Asssert on the
> CurrentMemoryContext.
>
Fixed.
On Thu, Nov 18, 2021 at 9:36 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> (2) missing test case
> It seems that the current tests are not testing the
> multiple-row-filter case (n_filters > 1) in the following code in
> pgoutput_row_filter_init():
>
> rfnode = n_filters > 1 ? makeBoolExpr(OR_EXPR, rfnodes, -1) :
> linitial(rfnodes);
>
> I think a test needs to be added similar to the customers+countries
> example that Tomas gave (where there is a single subscription to
> multiple publications of the same table, each of which has a
> row-filter).
Test case added.
On Fri, Nov 19, 2021 at 4:15 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> I notice that in the 0001 patch, it adds a "relid" member to the
> PublicationRelInfo struct:
>
> src/include/catalog/pg_publication.h
>
> typedef struct PublicationRelInfo
> {
> + Oid relid;
> Relation relation;
> + Node *whereClause;
> } PublicationRelInfo;
>
> It appears that this new member is not actually required, as the relid
> can be simply obtained from the existing "relation" member - using the
> RelationGetRelid() macro.
Fixed.
On Mon, Nov 22, 2021 at 12:44 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> Another thing I noticed was in the 0004 patch, list_free_deep() should
> be used instead of list_free() in the following code block, otherwise
> the rfnodes themselves (allocated by stringToNode()) are not freed:
>
> src/backend/replication/pgoutput/pgoutput.c
>
> + if (rfnodes)
> + {
> + list_free(rfnodes);
> + rfnodes = NIL;
> + }
Fixed.
We will be addressing the rest of the comments in the next patch.
regards,
Ajin Cherian
Fujitsu Australia
Вложения
- v41-0003-PS-ExprState-cache-modifications.patch
- v41-0002-PS-Add-tab-auto-complete-support-for-the-Row-Fil.patch
- v41-0005-PS-Row-filter-validation-walker.patch
- v41-0004-PS-Combine-multiple-filters-with-OR-instead-of-A.patch
- v41-0001-Row-filter-for-logical-replication.patch
- v41-0006-Support-updates-based-on-old-and-new-tuple-in-ro.patch
On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Attaching a new patchset v41 which includes changes by both Peter and myself. > In 0003 patch, why is below change required? --- a/src/backend/replication/pgoutput/pgoutput.c +++ b/src/backend/replication/pgoutput/pgoutput.c @@ -1,4 +1,4 @@ -/*------------------------------------------------------------------------- +/*------------------------------------------------------------------------ * * pgoutput.c I suggest at this stage we can combine 0001, 0003, and 0004. Then move pg_dump and psql (describe.c) related changes to 0002 and make 0002 as the last patch in the series. This will help review backend changes first and then we can look at client-side changes. After above, rearrange the code in pgoutput_row_filter(), so that two different checks related to 'rfisnull' (introduced by different patches) can be combined as if .. else check. -- With Regards, Amit Kapila.
On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching a new patchset v41 which includes changes by both Peter and myself.
Few comments on v41-0002 patch:
1) Tab completion should be handled for completion of "WITH(" in
"create publication pub1 for table t1 where (c1 > 10)":
@@ -2757,10 +2765,13 @@ psql_completion(const char *text, int start, int end)
else if (Matches("CREATE", "PUBLICATION", MatchAny, "FOR",
"ALL", "TABLES"))
COMPLETE_WITH("IN SCHEMA", "WITH (");
else if (Matches("CREATE", "PUBLICATION", MatchAny, "FOR",
"TABLE", MatchAny))
- COMPLETE_WITH("WITH (");
+ COMPLETE_WITH("WHERE (", "WITH (");
/* Complete "CREATE PUBLICATION <name> FOR TABLE" with "<table>, ..." */
else if (Matches("CREATE", "PUBLICATION", MatchAny, "FOR", "TABLE"))
COMPLETE_WITH_SCHEMA_QUERY(Query_for_list_of_tables, NULL);
+ /* "CREATE PUBLICATION <name> FOR TABLE <name> WHERE (" -
complete with table attributes */
+ else if (HeadMatches("CREATE", "PUBLICATION", MatchAny) &&
TailMatches("WHERE", "("))
+ COMPLETE_WITH_ATTR(prev3_wd, "");
2) Tab completion completes with "WHERE (" in case of "alter
publication pub1 add table t1,":
+ /* ALTER PUBLICATION <name> SET TABLE <name> */
+ /* ALTER PUBLICATION <name> ADD TABLE <name> */
+ else if (Matches("ALTER", "PUBLICATION", MatchAny, "SET|ADD",
"TABLE", MatchAny))
+ COMPLETE_WITH("WHERE (");
Should this be changed to:
+ /* ALTER PUBLICATION <name> SET TABLE <name> */
+ /* ALTER PUBLICATION <name> ADD TABLE <name> */
+ else if (Matches("ALTER", "PUBLICATION", MatchAny, "SET|ADD",
"TABLE", MatchAny) && (!ends_with(prev_wd, ','))
+ COMPLETE_WITH("WHERE (");
Regards,
Vignesh
On Tues, Nov 23, 2021 6:16 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Nov 23, 2021 at 1:29 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote: > > > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com> > > > wrote: > > > > > > > > PSA new set of v40* patches. > > > > > > Few comments: > > > 1) When a table is added to the publication, replica identity is checked. But > > > while modifying the publish action to include delete/update, replica identity is > > > not checked for the existing tables. I felt it should be checked for the existing > > > tables too. > > > > In addition to this, I think we might also need some check to prevent user from > > changing the REPLICA IDENTITY index which is used in the filter expression. > > > > I was thinking is it possible do the check related to REPLICA IDENTITY in > > function CheckCmdReplicaIdentity() or In GetRelationPublicationActions(). If we > > move the REPLICA IDENTITY check to this function, it would be consistent with > > the existing behavior about the check related to REPLICA IDENTITY(see the > > comments in CheckCmdReplicaIdentity) and seems can cover all the cases > > mentioned above. > > > > Yeah, adding the replica identity check in CheckCmdReplicaIdentity() > would cover all the above cases but I think that would put a premium > on each update/delete operation. I think traversing the expression > tree (it could be multiple traversals if the relation is part of > multiple publications) during each update/delete would be costly. > Don't you think so? Yes, I agreed that traversing the expression every time would be costly. I thought maybe we can cache the columns used in row filter or cache only the a flag(can_update|delete) in the relcache. I think every operation that affect the row-filter or replica-identity will invalidate the relcache and the cost of check seems acceptable with the cache. The reason that I thought it might be better do check in CheckCmdReplicaIdentity is that we might need to add duplicate check code for a couple of places otherwise, for example, we might need to check replica-identity when: [ALTER REPLICA IDENTITY | DROP INDEX | ALTER PUBLICATION ADD TABLE | ALTER PUBLICATION SET (pubaction)] Best regards, Hou zj
On Wed, Nov 24, 2021 at 6:51 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Tues, Nov 23, 2021 6:16 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Nov 23, 2021 at 1:29 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote: > > > > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com> > > > > wrote: > > > > > > > > > > PSA new set of v40* patches. > > > > > > > > Few comments: > > > > 1) When a table is added to the publication, replica identity is checked. But > > > > while modifying the publish action to include delete/update, replica identity is > > > > not checked for the existing tables. I felt it should be checked for the existing > > > > tables too. > > > > > > In addition to this, I think we might also need some check to prevent user from > > > changing the REPLICA IDENTITY index which is used in the filter expression. > > > > > > I was thinking is it possible do the check related to REPLICA IDENTITY in > > > function CheckCmdReplicaIdentity() or In GetRelationPublicationActions(). If we > > > move the REPLICA IDENTITY check to this function, it would be consistent with > > > the existing behavior about the check related to REPLICA IDENTITY(see the > > > comments in CheckCmdReplicaIdentity) and seems can cover all the cases > > > mentioned above. > > > > > > > Yeah, adding the replica identity check in CheckCmdReplicaIdentity() > > would cover all the above cases but I think that would put a premium > > on each update/delete operation. I think traversing the expression > > tree (it could be multiple traversals if the relation is part of > > multiple publications) during each update/delete would be costly. > > Don't you think so? > > Yes, I agreed that traversing the expression every time would be costly. > > I thought maybe we can cache the columns used in row filter or cache only the a > flag(can_update|delete) in the relcache. I think every operation that affect > the row-filter or replica-identity will invalidate the relcache and the cost of > check seems acceptable with the cache. > I think if we can cache this information especially as a bool flag then that should probably be better. -- With Regards, Amit Kapila.
On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching a new patchset v41 which includes changes by both Peter and myself.
>
> Patches v40-0005 and v40-0006 have been merged to create patch
> v41-0005 which reduces the patches to 6 again.
Few comments:
1) I'm not sure if we will be able to throw a better error message in
this case "ERROR: missing FROM-clause entry for table "t4"", if
possible you could change it.
+ if (pri->whereClause != NULL)
+ {
+ /* Set up a pstate to parse with */
+ pstate = make_parsestate(NULL);
+ pstate->p_sourcetext = nodeToString(pri->whereClause);
+
+ nsitem = addRangeTableEntryForRelation(pstate, targetrel,
+
AccessShareLock,
+
NULL, false, false);
+ addNSItemToQuery(pstate, nsitem, false, true, true);
+
+ whereclause = transformWhereClause(pstate,
+
copyObject(pri->whereClause),
+
EXPR_KIND_PUBLICATION_WHERE,
+
"PUBLICATION");
+
+ /* Fix up collation information */
+ assign_expr_collations(pstate, whereclause);
+ }
alter publication pub1 add table t5 where ( t4.c1 = 10);
ERROR: missing FROM-clause entry for table "t4"
LINE 1: alter publication pub1 add table t5 where ( t4.c1 = 10);
^
pstate->p_expr_kind is stored as EXPR_KIND_PUBLICATION_WHERE, we could
differentiate using expr_kind.
2) Should '"delete" or "delete"' be '"delete" or "update"'
--- a/src/backend/catalog/pg_publication.c
+++ b/src/backend/catalog/pg_publication.c
@@ -340,7 +340,7 @@ rowfilter_walker(Node *node, rf_context *context)
* 1. Only certain simple node types are permitted in the expression. See
* function rowfilter_walker for details.
*
- * 2. If the publish operation contains "delete" then only columns that
+ * 2. If the publish operation contains "delete" or "delete" then
only columns that
* are allowed by the REPLICA IDENTITY rules are permitted to be used in the
* row-filter WHERE clause.
*/
@@ -352,12 +352,10 @@ rowfilter_expr_checker(Publication *pub,
Relation rel, Node *rfnode)
context.rel = rel;
/*
- * For "delete", check that filter cols are also valid replica identity
+ * For "delete" or "update", check that filter cols are also
valid replica identity
* cols.
3) Should we include row filter condition in pg_publication_tables
view like in describe publication(\dRp+) , since the prqual is not
easily readable in pg_publication_rel table:
select * from pg_publication_tables ;
pubname | schemaname | tablename
---------+------------+-----------
pub1 | public | t1
(1 row)
select * from pg_publication_rel ;
oid | prpubid | prrelid |
prqual
-------+---------+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
16389 | 16388 | 16384 | {OPEXPR :opno 518 :opfuncid 144
:opresulttype 16 :opretset false :opcollid 0 :inputcollid 0 :args
({VAR :varno 1 :varattno 1 :vartype 23 :vartypmod -1 :varcollid 0
:varlevelsup 0 :va
rnosyn 1 :varattnosyn 1 :location 45} {CONST :consttype 23
:consttypmod -1 :constcollid 0 :constlen 4 :constbyval true
:constisnull false :location 51 :constvalue 4 [ 0 0 0 0 0 0 0 0 ]})
:location 48}
(1 row)
4) This should be included in typedefs.list, also we could add some
comments for this structure
+typedef struct {
+ Relation rel;
+ Bitmapset *bms_replident;
+}
+rf_context;
5) Few includes are not required. #include "miscadmin.h" not required
in pg_publication.c, #include "executor/executor.h" not required in
proto.c, #include "access/xact.h", #include "executor/executor.h" and
#include "replication/logicalrelation.h" not required in pgoutput.c
6) typo "filte" should be "filter":
+/*
+ * The row filte walker checks that the row filter expression is legal.
+ *
+ * Rules: Node-type validation
+ * ---------------------------
+ * Allow only simple or compound expressions like:
+ * - "(Var Op Const)" or
+ * - "(Var Op Const) Bool (Var Op Const)"
Regards,
Vignesh
On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> Attaching a new patchset v41 which includes changes by both Peter and myself.
>
> Patches v40-0005 and v40-0006 have been merged to create patch
> v41-0005 which reduces the patches to 6 again.
> This patch-set contains changes addressing the following review comments:
>
> On Mon, Nov 15, 2021 at 5:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > What I meant was that with this new code we have regressed the old
> > behavior. Basically, imagine a case where no filter was given for any
> > of the tables. Then after the patch, we will remove all the old tables
> > whereas before the patch it will remove the oldrels only when they are
> > not specified as part of new rels. If you agree with this, then we can
> > retain the old behavior and for the new tables, we can always override
> > the where clause for a SET variant of command.
>
> Fixed and modified the behaviour to match with what the schema patch
> implemented.
>
+
+ /*
+ * If the new relation or the old relation has a where clause,
+ * we need to remove it so that it can be added afresh later.
+ */
+ if (RelationGetRelid(newpubrel->relation) == oldrelid &&
+ newpubrel->whereClause == NULL && rfisnull)
Can't we use _equalPublicationTable() here? It compares the whereClause as well.
Few more comments:
=================
0001
1.
@@ -1039,10 +1081,11 @@ PublicationAddTables(Oid pubid, List *rels,
bool if_not_exists,
{
PublicationRelInfo *pub_rel = (PublicationRelInfo *) lfirst(lc);
Relation rel = pub_rel->relation;
+ Oid relid = RelationGetRelid(rel);
ObjectAddress obj;
/* Must be owner of the table or superuser. */
- if (!pg_class_ownercheck(RelationGetRelid(rel), GetUserId()))
+ if (!pg_class_ownercheck(relid, GetUserId()))
Here, you can directly use RelationGetRelid as was used in the
previous code without using an additional variable.
0005
2.
+typedef struct {
+ Relation rel;
+ bool check_replident;
+ Bitmapset *bms_replident;
+}
+rf_context;
Add rf_context in the same line where } ends.
3. In the function header comment of rowfilter_walker, you mentioned
the simple expressions allowed but we should write why we are doing
so. It has been discussed in detail in various emails in this thread.
AFAIR, below are the reasons:
A. We don't want to allow user-defined functions or operators because
(a) if the user drops such a function/operator or if there is any
other error via that function, the walsender won't be able to recover
from such an error even if we fix the function's problem because it
uses a historic snapshot to access row-filter; (b) any other table
could be accessed via a function which won't work because of historic
snapshots in logical decoding environment.
B. We don't allow anything other immutable built-in functions as those
can access database and would lead to the problem (b) mentioned in the
previous paragraph.
Don't we need to check for user-defined types similar to user-defined
functions and operators? If not why?
4.
+ * Rules: Node-type validation
+ * ---------------------------
+ * Allow only simple or compound expressions like:
+ * - "(Var Op Const)" or
It seems Var Op Var is allowed. I tried below and it works:
create publication pub for table t1 where (c1 < c2) WITH (publish = 'insert');
I think it should be okay to allow it provided we ensure that we never
access some other table/view etc. as part of the expression. Also, we
should document the behavior correctly.
--
With Regards,
Amit Kapila.
Thanks for all the review comments so far! We are endeavouring to keep pace with them. All feedback is being tracked and we will fix and/or reply to everything ASAP. Meanwhile, PSA the latest set of v42* patches. This version was mostly a patch restructuring exercise but it also addresses some minor review comments in passing. ~~ Patches have been merged and rearranged based on Amit's suggestions [Amit 23/11]. BEFORE: v41-0001 Euler's main patch v41-0002 Tab-complete v41-0003 ExprState cache v41-0004 OR/AND v41-0005 Validation walker v41-0006 new/old tuple updates AFTER: v42-0001 main patch <== v41-0001 + v41-0003 + v41-0004 v42-0002 validation walker <== v41-0005 v42-0003 new/old tuple updates <== v41-0006 v42-0004 tab-complete and pgdump <== v41-0002 (plus pgdump code from v41-0001) ~~ Some review comments were addressed as follows: v42-0001 main patch - improve comments about caching [Amit 15/Nov] #4. - fix comment typo [Tang 23/11] v42-0002 validation walker - fix comment typo [Vignesh 24/11] #2 - add comment for rf_context [Vignesh 24/11] #4 - fix comment typo [Vignesh 24/11] #6 - code formatting [Amit 24/11] #2 v42-0003 new/old tuple - fix compilation warning [Greg 18/11] #1 v42-0004 tab-complete and pgdump - NA ------ [Amit 15/11] https://www.postgresql.org/message-id/CAA4eK1L4ddTpc%3D-3bq%3D%3DU8O-BJ%3DsvkAFefRDpATKCG4hKYKAig%40mail.gmail.com [Amit 23/11] https://www.postgresql.org/message-id/CAA4eK1%2B7R_%3DLFXHvfjjR88m3oTLYeLV%3D2zdAZEH3n7n8nhj%3D%3Dw%40mail.gmail.com [Tang 23/11] https://www.postgresql.org/message-id/OS0PR01MB611389E3A5685B53930A4833FB609%40OS0PR01MB6113.jpnprd01.prod.outlook.com [Vignesh 24/11] https://www.postgresql.org/message-id/CALDaNm08Ynr_FzNg%2BdoHj%3D_nBet%2BKZAvNbqmkEEw7M2SPpPEAw%40mail.gmail.com [Amit 24/11] https://www.postgresql.org/message-id/CAA4eK1%2BXd%3DkM5D3jtXyN%2BW7J%2BwU-yyQAdyq66a6Wcq_PKRTbSw%40mail.gmail.com [Greg 18/11] https://www.postgresql.org/message-id/CAJcOf-fcDRsC4MYv2ZpUwFe68tPchbM-0fpb2z5ks%3DyLKDH2-g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Nov 18, 2021 at 9:35 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Thu, Nov 18, 2021 at 12:33 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA new set of v40* patches. > > > > Thanks for the patch updates. > > A couple of comments so far: > > (1) compilation warning > WIth the patches applied, there's a single compilation warning when > Postgres is built: > > pgoutput.c: In function ‘pgoutput_row_filter_init’: > pgoutput.c:854:8: warning: unused variable ‘relid’ [-Wunused-variable] > Oid relid = RelationGetRelid(relation); > ^~~~~ > Fixed in v42* [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsGZHvafa3K_RAJ0Agm28W2owjNN%2BqU0EUsSjBNbuXFsQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 23, 2021 at 8:02 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Nov 18, 2021 at 11:02 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Mon, Nov 15, 2021 at 9:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > 4. I think we should add some comments in pgoutput_row_filter() as to > > > why we are caching the row_filter here instead of > > > get_rel_sync_entry()? That has been discussed multiple times so it is > > > better to capture that in comments. > > > > Added comment in v40 [1] > > > > I think apart from truncate and error cases, it can also happen for > other operations because we decide whether to publish a change > (operation) after calling get_rel_sync_entry() in pgoutput_change. I > think we can reflect that as well in the comment. Fixed in v42* [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsGZHvafa3K_RAJ0Agm28W2owjNN%2BqU0EUsSjBNbuXFsQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 23, 2021 at 4:40 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Thursday, November 18, 2021 9:34 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA new set of v40* patches. > > > > Besides, a small comment on 0004 patch: > > + * Multiple row-filter expressions for the same publication will later be > + * combined by the COPY using OR, but this means if any of the filters is > > Should we change it to: > Multiple row-filter expressions for the same table ... Fixed in v42* [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsGZHvafa3K_RAJ0Agm28W2owjNN%2BqU0EUsSjBNbuXFsQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Nov 24, 2021 at 8:52 PM vignesh C <vignesh21@gmail.com> wrote:
>
> On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching a new patchset v41 which includes changes by both Peter and myself.
> >
> > Patches v40-0005 and v40-0006 have been merged to create patch
> > v41-0005 which reduces the patches to 6 again.
>
> Few comments:
...
> 2) Should '"delete" or "delete"' be '"delete" or "update"'
> --- a/src/backend/catalog/pg_publication.c
> +++ b/src/backend/catalog/pg_publication.c
> @@ -340,7 +340,7 @@ rowfilter_walker(Node *node, rf_context *context)
> * 1. Only certain simple node types are permitted in the expression. See
> * function rowfilter_walker for details.
> *
> - * 2. If the publish operation contains "delete" then only columns that
> + * 2. If the publish operation contains "delete" or "delete" then
> only columns that
> * are allowed by the REPLICA IDENTITY rules are permitted to be used in the
> * row-filter WHERE clause.
> */
> @@ -352,12 +352,10 @@ rowfilter_expr_checker(Publication *pub,
> Relation rel, Node *rfnode)
> context.rel = rel;
>
> /*
> - * For "delete", check that filter cols are also valid replica identity
> + * For "delete" or "update", check that filter cols are also
> valid replica identity
> * cols.
Fixed in v42* [1]
> 4) This should be included in typedefs.list, also we could add some
> comments for this structure
> +typedef struct {
> + Relation rel;
> + Bitmapset *bms_replident;
> +}
> +rf_context;
>
Fixed in v42* [1]
> 6) typo "filte" should be "filter":
> +/*
> + * The row filte walker checks that the row filter expression is legal.
> + *
> + * Rules: Node-type validation
> + * ---------------------------
> + * Allow only simple or compound expressions like:
> + * - "(Var Op Const)" or
> + * - "(Var Op Const) Bool (Var Op Const)"
Fixed in v42* [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPsGZHvafa3K_RAJ0Agm28W2owjNN%2BqU0EUsSjBNbuXFsQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 25, 2021 at 12:03 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching a new patchset v41 which includes changes by both Peter and myself.
> >
...
> Few more comments:
> =================
...
> 0005
> 2.
> +typedef struct {
> + Relation rel;
> + bool check_replident;
> + Bitmapset *bms_replident;
> +}
> +rf_context;
>
> Add rf_context in the same line where } ends.
>
Fixed in v42* [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPsGZHvafa3K_RAJ0Agm28W2owjNN%2BqU0EUsSjBNbuXFsQ%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Nov 23, 2021 at 10:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Attaching a new patchset v41 which includes changes by both Peter and myself. > > > ... > I suggest at this stage we can combine 0001, 0003, and 0004. Then move > pg_dump and psql (describe.c) related changes to 0002 and make 0002 as > the last patch in the series. This will help review backend changes > first and then we can look at client-side changes. > The patch combining and reordering was as suggested. BEFORE: v41-0001 Euler's main patch v41-0002 Tab-complete v41-0003 ExprState cache v41-0004 OR/AND v41-0005 Validation walker v41-0006 new/old tuple updates AFTER: v42-0001 main patch <== v41-0001 + v41-0003 + v41-0004 v42-0002 validation walker <== v41-0005 v42-0003 new/old tuple updates <== v41-0006 v42-0004 tab-complete and pgdump <== v41-0002 (plus pgdump code from v41-0001) ~ Please note, I did not remove the describe.c changes from the v42-0001 patch at this time. I left this as-is because I felt the ability for psql \d+ or \dRp+ etc to display the current row-filter is *essential* functionality to be able to test and debug the 0001 patch properly. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Nov 24, 2021 1:46 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Nov 24, 2021 at 6:51 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Tues, Nov 23, 2021 6:16 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > On Tue, Nov 23, 2021 at 1:29 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote: > > > > > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith > > > > > <smithpb2250@gmail.com> > > > > > wrote: > > > > > > > > > > > > PSA new set of v40* patches. > > > > > > > > > > Few comments: > > > > > 1) When a table is added to the publication, replica identity is > > > > > checked. But while modifying the publish action to include > > > > > delete/update, replica identity is not checked for the existing > > > > > tables. I felt it should be checked for the existing tables too. > > > > > > > > In addition to this, I think we might also need some check to > > > > prevent user from changing the REPLICA IDENTITY index which is used in > > > > the filter expression. > > > > > > > > I was thinking is it possible do the check related to REPLICA > > > > IDENTITY in function CheckCmdReplicaIdentity() or In > > > > GetRelationPublicationActions(). If we move the REPLICA IDENTITY > > > > check to this function, it would be consistent with the existing > > > > behavior about the check related to REPLICA IDENTITY(see the > > > > comments in CheckCmdReplicaIdentity) and seems can cover all the cases > > > > mentioned above. > > > > > > Yeah, adding the replica identity check in CheckCmdReplicaIdentity() > > > would cover all the above cases but I think that would put a premium > > > on each update/delete operation. I think traversing the expression > > > tree (it could be multiple traversals if the relation is part of > > > multiple publications) during each update/delete would be costly. > > > Don't you think so? > > > > Yes, I agreed that traversing the expression every time would be costly. > > > > I thought maybe we can cache the columns used in row filter or cache > > only the a > > flag(can_update|delete) in the relcache. I think every operation that > > affect the row-filter or replica-identity will invalidate the relcache > > and the cost of check seems acceptable with the cache. > > > > I think if we can cache this information especially as a bool flag then that should > probably be better. When researching and writing a top-up patch about this. I found a possible issue which I'd like to confirm first. It's possible the table is published in two publications A and B, publication A only publish "insert" , publication B publish "update". When UPDATE, both row filter in A and B will be executed. Is this behavior expected? For example: ---- Publication create table tbl1 (a int primary key, b int); create publication A for table tbl1 where (b<2) with(publish='insert'); create publication B for table tbl1 where (a>1) with(publish='update'); ---- Subscription create table tbl1 (a int primary key); CREATE SUBSCRIPTION sub CONNECTION 'dbname=postgres host=localhost port=10000' PUBLICATION A,B; ---- Publication update tbl1 set a = 2; The publication can be created, and when UPDATE, the rowfilter in A (b<2) will also been executed but the column in it is not part of replica identity. (I am not against this behavior just confirm) Best regards, Hou zj
On Thu, Nov 25, 2021, at 10:39 AM, houzj.fnst@fujitsu.com wrote:
When researching and writing a top-up patch about this.I found a possible issue which I'd like to confirm first.It's possible the table is published in two publications A and B, publication Aonly publish "insert" , publication B publish "update". When UPDATE, both rowfilter in A and B will be executed. Is this behavior expected?
Good question. No. The code should check the action before combining the
multiple row filters.
On Wednesday, November 24, 2021 1:46 PM Amit Kapila <amit.kapila16@gmail.com> > On Wed, Nov 24, 2021 at 6:51 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > > On Tues, Nov 23, 2021 6:16 PM Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > On Tue, Nov 23, 2021 at 1:29 PM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> > wrote: > > > > > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith > > > > > <smithpb2250@gmail.com> > > > > > wrote: > > > > > > > > > > > > PSA new set of v40* patches. > > > > > > > > > > Few comments: > > > > > 1) When a table is added to the publication, replica identity is > > > > > checked. But while modifying the publish action to include > > > > > delete/update, replica identity is not checked for the existing > > > > > tables. I felt it should be checked for the existing tables too. > > > > > > > > In addition to this, I think we might also need some check to > > > > prevent user from changing the REPLICA IDENTITY index which is used in > > > > the filter expression. > > > > > > > > I was thinking is it possible do the check related to REPLICA > > > > IDENTITY in function CheckCmdReplicaIdentity() or In > > > > GetRelationPublicationActions(). If we move the REPLICA IDENTITY > > > > check to this function, it would be consistent with the existing > > > > behavior about the check related to REPLICA IDENTITY(see the > > > > comments in CheckCmdReplicaIdentity) and seems can cover all the > > > > cases mentioned above. > > > > > > > > > > Yeah, adding the replica identity check in CheckCmdReplicaIdentity() > > > would cover all the above cases but I think that would put a premium > > > on each update/delete operation. I think traversing the expression > > > tree (it could be multiple traversals if the relation is part of > > > multiple publications) during each update/delete would be costly. > > > Don't you think so? > > > > Yes, I agreed that traversing the expression every time would be costly. > > > > I thought maybe we can cache the columns used in row filter or cache > > only the a > > flag(can_update|delete) in the relcache. I think every operation that > > affect the row-filter or replica-identity will invalidate the relcache > > and the cost of check seems acceptable with the cache. > > > > I think if we can cache this information especially as a bool flag then that should > probably be better. Based on this direction, I tried to write a top up POC patch(0005) which I'd like to share. The top up patch mainly did the following things. * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so that the invalidation is executed only when actual UPDATE or DELETE executed on the published relation. It's consistent with the existing check about replica identity. * Cache the results of the validation for row filter columns in relcache to reduce the cost of the validation. It's safe because every operation that change the row filter and replica identity will invalidate the relcache. Also attach the v42 patch set to keep cfbot happy. Best regards, Hou zj
Вложения
On Thu, Nov 25, 2021 at 7:39 PM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Nov 25, 2021, at 10:39 AM, houzj.fnst@fujitsu.com wrote: > > When researching and writing a top-up patch about this. > I found a possible issue which I'd like to confirm first. > > It's possible the table is published in two publications A and B, publication A > only publish "insert" , publication B publish "update". When UPDATE, both row > filter in A and B will be executed. Is this behavior expected? > > Good question. No. The code should check the action before combining the > multiple row filters. > Do you mean to say that we should give an error on Update/Delete if any of the publications contain table rowfilter that has columns that are not part of the primary key or replica identity? I think this is what Hou-san has implemented in his top-up patch and I also think this is the right behavior. -- With Regards, Amit Kapila.
On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Based on this direction, I tried to write a top up POC patch(0005) which I'd like to share.
>
I noticed a minor issue.
In the top-up patch, the following error message detail:
+ errdetail("Not all row filter columns are not part of the REPLICA
IDENTITY")));
should be:
+ errdetail("Not all row filter columns are part of the REPLICA IDENTITY")));
Regards,
Greg Nancarrow
Fujitsu Australia
On Fri, Nov 26, 2021 11:32 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Nov 25, 2021 at 7:39 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Thu, Nov 25, 2021, at 10:39 AM, houzj.fnst@fujitsu.com wrote: > > > > When researching and writing a top-up patch about this. > > I found a possible issue which I'd like to confirm first. > > > > It's possible the table is published in two publications A and B, > > publication A only publish "insert" , publication B publish "update". > > When UPDATE, both row filter in A and B will be executed. Is this behavior > expected? > > > > Good question. No. The code should check the action before combining > > the multiple row filters. > > > > Do you mean to say that we should give an error on Update/Delete if any of the > publications contain table rowfilter that has columns that are not part of the > primary key or replica identity? I think this is what Hou-san has implemented in > his top-up patch and I also think this is the right behavior. Yes, the top-up patch will give an error if the columns in row filter are not part of replica identity when UPDATE and DELETE. But the point I want to confirm is that: --- create publication A for table tbl1 where (b<2) with(publish='insert'); create publication B for table tbl1 where (a>1) with(publish='update'); --- When UPDATE on the table 'tbl1', is it correct to combine and execute both of the row filter in A(b<2) and B(a>1) ?(it's the current behavior) Because the filter in A has an unlogged column(b) and the publication A only publish "insert", so for UPDATE, should we skip the row filter in A and only execute the row filter in B ? Best regards, Hou zj
On Fri, Nov 26, 2021 at 4:05 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Fri, Nov 26, 2021 11:32 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Nov 25, 2021 at 7:39 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Thu, Nov 25, 2021, at 10:39 AM, houzj.fnst@fujitsu.com wrote: > > > > > > When researching and writing a top-up patch about this. > > > I found a possible issue which I'd like to confirm first. > > > > > > It's possible the table is published in two publications A and B, > > > publication A only publish "insert" , publication B publish "update". > > > When UPDATE, both row filter in A and B will be executed. Is this behavior > > expected? > > > > > > Good question. No. The code should check the action before combining > > > the multiple row filters. > > > > > > > Do you mean to say that we should give an error on Update/Delete if any of the > > publications contain table rowfilter that has columns that are not part of the > > primary key or replica identity? I think this is what Hou-san has implemented in > > his top-up patch and I also think this is the right behavior. > > Yes, the top-up patch will give an error if the columns in row filter are not part of > replica identity when UPDATE and DELETE. > > But the point I want to confirm is that: > > --- > create publication A for table tbl1 where (b<2) with(publish='insert'); > create publication B for table tbl1 where (a>1) with(publish='update'); > --- > > When UPDATE on the table 'tbl1', is it correct to combine and execute both of > the row filter in A(b<2) and B(a>1) ?(it's the current behavior) > > Because the filter in A has an unlogged column(b) and the publication A only > publish "insert", so for UPDATE, should we skip the row filter in A and only > execute the row filter in B ? > But since the filters are OR'ed together does it even matter? Now that your top-up patch now prevents invalid updates/deletes, this other point is only really a question about the cache performance, isn't it? ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Fri, Nov 26, 2021 at 4:18 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 4:05 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Fri, Nov 26, 2021 11:32 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > On Thu, Nov 25, 2021 at 7:39 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > > > On Thu, Nov 25, 2021, at 10:39 AM, houzj.fnst@fujitsu.com wrote: > > > > > > > > When researching and writing a top-up patch about this. > > > > I found a possible issue which I'd like to confirm first. > > > > > > > > It's possible the table is published in two publications A and B, > > > > publication A only publish "insert" , publication B publish "update". > > > > When UPDATE, both row filter in A and B will be executed. Is this behavior > > > expected? > > > > > > > > Good question. No. The code should check the action before combining > > > > the multiple row filters. > > > > > > > > > > Do you mean to say that we should give an error on Update/Delete if any of the > > > publications contain table rowfilter that has columns that are not part of the > > > primary key or replica identity? I think this is what Hou-san has implemented in > > > his top-up patch and I also think this is the right behavior. > > > > Yes, the top-up patch will give an error if the columns in row filter are not part of > > replica identity when UPDATE and DELETE. > > > > But the point I want to confirm is that: > > > > --- > > create publication A for table tbl1 where (b<2) with(publish='insert'); > > create publication B for table tbl1 where (a>1) with(publish='update'); > > --- > > > > When UPDATE on the table 'tbl1', is it correct to combine and execute both of > > the row filter in A(b<2) and B(a>1) ?(it's the current behavior) > > > > Because the filter in A has an unlogged column(b) and the publication A only > > publish "insert", so for UPDATE, should we skip the row filter in A and only > > execute the row filter in B ? > > > > But since the filters are OR'ed together does it even matter? > > Now that your top-up patch now prevents invalid updates/deletes, this > other point is only really a question about the cache performance, > isn't it? > Irrespective of replica identity I think there is still a functional behaviour question, right? e.g. create publication p1 for table census where (country = 'Aust') with (publish="update") create publication p2 for table census where (country = 'NZ') with (publish='insert') Should it be possible to UPDATE for country 'NZ' or not? Is this the same as your question Hou-san? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Nov 26, 2021 at 12:01 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 4:18 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Do you mean to say that we should give an error on Update/Delete if any of the > > > > publications contain table rowfilter that has columns that are not part of the > > > > primary key or replica identity? I think this is what Hou-san has implemented in > > > > his top-up patch and I also think this is the right behavior. > > > > > > Yes, the top-up patch will give an error if the columns in row filter are not part of > > > replica identity when UPDATE and DELETE. > > > > > > But the point I want to confirm is that: > > > Okay, I see your point now. > > > --- > > > create publication A for table tbl1 where (b<2) with(publish='insert'); > > > create publication B for table tbl1 where (a>1) with(publish='update'); > > > --- > > > > > > When UPDATE on the table 'tbl1', is it correct to combine and execute both of > > > the row filter in A(b<2) and B(a>1) ?(it's the current behavior) > > > > > > Because the filter in A has an unlogged column(b) and the publication A only > > > publish "insert", so for UPDATE, should we skip the row filter in A and only > > > execute the row filter in B ? > > > > > > > But since the filters are OR'ed together does it even matter? > > Even if it is OR'ed, if the value is not logged (as it was not part of replica identity or primary key) as per Hou-San's example, how will evaluate such a filter? > > Now that your top-up patch now prevents invalid updates/deletes, this > > other point is only really a question about the cache performance, > > isn't it? > > > > Irrespective of replica identity I think there is still a functional > behaviour question, right? > > e.g. > create publication p1 for table census where (country = 'Aust') with > (publish="update") > create publication p2 for table census where (country = 'NZ') with > (publish='insert') > > Should it be possible to UPDATE for country 'NZ' or not? > Is this the same as your question Hou-san? > I am not sure if it is the same because in Hou-San's example publications refer to different columns where one of the columns was part of PK and another was not whereas in your example both refer to the same column. I think in your example the error will happen at the time of update/delete whereas in Hou-San's example it won't happen at the time of update/delete. With Regards, Amit Kapila.
On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
...
> Based on this direction, I tried to write a top up POC patch(0005) which I'd like to share.
>
> The top up patch mainly did the following things.
>
> * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so that
> the invalidation is executed only when actual UPDATE or DELETE executed on the
> published relation. It's consistent with the existing check about replica
> identity.
>
> * Cache the results of the validation for row filter columns in relcache to
> reduce the cost of the validation. It's safe because every operation that
> change the row filter and replica identity will invalidate the relcache.
>
> Also attach the v42 patch set to keep cfbot happy.
Hi Hou-san.
Thanks for providing your "top-up" 0005 patch!
I suppose the goal will be to later merge this top-up with the current
0002 validation patch, but in the meantime here are my review comments
for 0005.
======
1) src/include/catalog/pg_publication.h - PublicationInfo
+typedef struct PublicationInfo
+{
+ PublicationActions pubactions;
+
+ /*
+ * True if pubactions don't include UPDATE and DELETE or
+ * all the columns in the row filter expression are part
+ * of replica identity.
+ */
+ bool rfcol_valid_for_replid;
+} PublicationInfo;
+
IMO "PublicationInfo" sounded too much like it is about the
Publication only, but IIUC it is really *per* Relation publication
info, right? So I thought perhaps it should be called more like struct
"RelationPubInfo".
======
2) src/include/catalog/pg_publication.h - PublicationInfo
The member "rfcol_valid_for_replid" also seems a little bit mis-named
because in some scenario (not UPDATE/DELETE) it can be true even if
there is not replica identity columns. So I thought perhaps it should
be called more like just "rfcols_valid"
Another thing - IIUC this is a kind of a "unified" boolean that covers
*all* filters for this Relation (across multiple publications). If
that is right., then the comment for this member should say something
about this.
======
3) src/include/catalog/pg_publication.h - PublicationInfo
This new typedef should be added to src/tools/pgindent/typedefs.list
======
4) src/backend/catalog/pg_publication.c - check_rowfilter_replident
+/*
+ * Check if all the columns used in the row-filter WHERE clause are part of
+ * REPLICA IDENTITY
+ */
+bool
+check_rowfilter_replident(Node *node, Bitmapset *bms_replident)
+{
IIUC here the false means "valid" and true means "invalid" which is
counter-intuitive to me. So at least true/false meaning ought to be
clarified in the function comment, and/or perhaps also rename the
function so that the return meaning is more obvious.
======
5) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
+ pubinfo = RelationGetPublicationInfo(rel);
+
IIUC this pubinfo* is palloced *every* time by
RelationGetPublicationInfo isn't it? If that is the case shouldn't
CheckCmdReplicaIdentity be doing a pfree(pubinfo)?
======
6) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
+ pubinfo = RelationGetPublicationInfo(rel);
+
+ /*
+ * if not all columns in the publication row filter are part of the REPLICA
+ * IDENTITY, then it's unsafe to execute it for UPDATE and DELETE.
+ */
+ if (!pubinfo->rfcol_valid_for_replid)
+ {
+ if (cmd == CMD_UPDATE)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
+ errmsg("cannot update table \"%s\"",
+ RelationGetRelationName(rel)),
+ errdetail("Not all row filter columns are not part of the REPLICA
IDENTITY")));
+ else if (cmd == CMD_DELETE)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
+ errmsg("cannot delete from table \"%s\"",
+ RelationGetRelationName(rel)),
+ errdetail("Not all row filter columns are not part of the REPLICA
IDENTITY")));
The comment seemed worded in a confusingly negative way.
Before:
+ * if not all columns in the publication row filter are part of the REPLICA
+ * IDENTITY, then it's unsafe to execute it for UPDATE and DELETE.
My Suggestion:
It is only safe to execute UPDATE/DELETE when all columns of the
publication row filters are part of the REPLICA IDENTITY.
~~
Also, is "publication row filter" really the correct terminology?
AFAIK it is more like *all* filters for this Relation across multiple
publications, but I have not got a good idea how to word that in a
comment. Anyway, I have a feeling this whole idea might be impacted by
other discussions in this RF thread.
======
7) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
Error messages have double negative wording? I think Greg already
commented on this same point.
+ errdetail("Not all row filter columns are not part of the REPLICA
IDENTITY")));
======
8) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
But which are the bad filter columns?
Previously the Row Filter column validation gave errors for the
invalid filter column, but in this top-up patch there is no indication
which column or which filter or which publication was the bad one -
only that "something" bad was detected. IMO this might make it very
difficult for the user to know enough about the cause of the problem
to be able to fix the offending filter.
======
9) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
/* If relation has replica identity we are always good. */
if (rel->rd_rel->relreplident == REPLICA_IDENTITY_FULL ||
OidIsValid(RelationGetReplicaIndex(rel)))
I was wondering if the check for REPLICA_IDENTITY_FULL should go
*before* your new call to pubinfo = RelationGetPublicationInfo(rel);
because IIUC if *every* column is a member of the replica identity
then the filter validation is not really necessary at all.
======
10) src/backend/utils/cache/relcache.c - function
GetRelationPublicationActions
@@ -5547,22 +5548,45 @@ RelationGetExclusionInfo(Relation indexRelation,
struct PublicationActions *
GetRelationPublicationActions(Relation relation)
{
- List *puboids;
- ListCell *lc;
- MemoryContext oldcxt;
- Oid schemaid;
- PublicationActions *pubactions = palloc0(sizeof(PublicationActions));
+ PublicationInfo *pubinfo;
+ PublicationActions *pubactions = palloc0(sizeof(PublicationInfo));
+
+ pubinfo = RelationGetPublicationInfo(relation);
Just assign pubinfo at the declaration instead of later in the function body.
======
11) src/backend/utils/cache/relcache.c - function
GetRelationPublicationActions
+ pubactions = memcpy(pubactions, relation->rd_pubinfo,
+ sizeof(PublicationActions));
Isn't that memcpy slightly incorrect and only working because the
pubactions happens to be the first member of the PublicationInfo? I
thought it should really be copying from
"&relation->rd_pubinfo->pubactions", right?
======
12) src/backend/utils/cache/relcache.c - function
GetRelationPublicationActions
Excessive blank lines following this function.
======
13). src/backend/utils/cache/relcache.c - function RelationGetPublicationInfo
+/*
+ * Get publication information for the given relation.
+ */
+struct PublicationInfo *
+RelationGetPublicationInfo(Relation relation)
+{
+ List *puboids;
+ ListCell *lc;
+ MemoryContext oldcxt;
+ Oid schemaid;
+ Bitmapset *bms_replident = NULL;
+ PublicationInfo *pubinfo = palloc0(sizeof(PublicationInfo));
+
+ pubinfo->rfcol_valid_for_replid = true;
It is not entirely clear to me why this function is always pallocing
the PublicationInfo and then returning a copy of what is stored in the
relation->rd_pubinfo. This then puts a burden on the callers (like the
GetRelationPublicationActions etc) to make sure to free that memory.
Why can't we just return the relation->rd_pubinfo directly And avoid
all the extra palloc/memcpy/free?
======
14). src/backend/utils/cache/relcache.c - function RelationGetPublicationInfo
+ /*
+ * Find what are the cols that are part of the REPLICA IDENTITY.
+ * Note that REPLICA IDENTIY DEFAULT means primary key or nothing.
+ */
typo "IDENTIY" -> "IDENTITY"
======
15). src/backend/utils/cache/relcache.c - function RelationGetPublicationInfo
/* Now save copy of the actions in the relcache entry. */
oldcxt = MemoryContextSwitchTo(CacheMemoryContext);
- relation->rd_pubactions = palloc(sizeof(PublicationActions));
- memcpy(relation->rd_pubactions, pubactions, sizeof(PublicationActions));
+ relation->rd_pubinfo = palloc(sizeof(PublicationInfo));
+ memcpy(relation->rd_pubinfo, pubinfo, sizeof(PublicationInfo));
MemoryContextSwitchTo(oldcxt);
The code comment looks a bit stale now. e.g. Perhaps now it should say
"save a copy of the info" instead of "save a copy of the actions".
======
16) Tests... CREATE PUBLICATION succeeds
I have not yet reviewed any of the 0005 tests, but there was some big
behaviour difference that I noticed.
I think now with the 0005 top-up patch the replica identify validation
is deferred to when UPDATE/DELETE is executed. I don’t know if this
will be very user friendly. It means now sometimes you can
successfully CREATE a PUBLICATION even though it will fail as soon as
you try to use it.
e.g. Below I create a publication with only pubaction "update", and
although it creates OK you cannot use it as intended.
test_pub=# create table t1(a int, b int, c int);
CREATE TABLE
test_pub=# create publication ptest for table t1 where (a > 3) with
(publish="update");
CREATE PUBLICATION
test_pub=# update t1 set a = 3;
ERROR: cannot update table "t1"
DETAIL: Not all row filter columns are not part of the REPLICA IDENTITY
Should we *also* be validating the replica identity at the time of
CREATE PUBLICATION so the user can be for-warned of problems?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Sun, Nov 28, 2021 at 6:17 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > ... > > Based on this direction, I tried to write a top up POC patch(0005) which I'd like to share. > > > > The top up patch mainly did the following things. > > > > * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so that > > the invalidation is executed only when actual UPDATE or DELETE executed on the > > published relation. It's consistent with the existing check about replica > > identity. > > > > * Cache the results of the validation for row filter columns in relcache to > > reduce the cost of the validation. It's safe because every operation that > > change the row filter and replica identity will invalidate the relcache. > > > > Also attach the v42 patch set to keep cfbot happy. > Now I looked at the patch 0005 test cases. Since this patch does the RI validation at UPDATE/DELETE execution instead of at the time of CREATE PUBLICATION it means that currently, the CREATE PUBLICATION is always going to succeed. So IIUC I think it is accidentally missing a DROP PUBLICATION for one of the tests because the "ERROR: publication "testpub6" already exists" should not be happening. Below is a fragment from the regression test publication.out I am referring to: CREATE PUBLICATION testpub6 FOR TABLE rf_tbl_abcd_pk WHERE (a > 99); -- fail - "a" is in PK but it is not part of REPLICA IDENTITY NOTHING UPDATE rf_tbl_abcd_pk set a = 1; ERROR: cannot update table "rf_tbl_abcd_pk" DETAIL: Not all row filter columns are not part of the REPLICA IDENTITY CREATE PUBLICATION testpub6 FOR TABLE rf_tbl_abcd_pk WHERE (c > 99); ERROR: publication "testpub6" already exists ------ Kind Regards, Peter Smith. Fujitsu Australia
On Sun, Nov 28, 2021 3:18 PM Peter Smith <smithpb2250@gmail.com> wrote:
> On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> >
> ...
> > Based on this direction, I tried to write a top up POC patch(0005) which I'd
> > like to share.
> >
> > The top up patch mainly did the following things.
> >
> > * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so
> > that the invalidation is executed only when actual UPDATE or DELETE executed on
> > the published relation. It's consistent with the existing check about replica
> > identity.
> >
> > * Cache the results of the validation for row filter columns in relcache to
> > reduce the cost of the validation. It's safe because every operation that
> > change the row filter and replica identity will invalidate the relcache.
> >
> > Also attach the v42 patch set to keep cfbot happy.
>
> Hi Hou-san.
>
> Thanks for providing your "top-up" 0005 patch!
>
> I suppose the goal will be to later merge this top-up with the current
> 0002 validation patch, but in the meantime here are my review comments
> for 0005.
Thanks for the review and many valuable comments !
> 8) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
>
> But which are the bad filter columns?
>
> Previously the Row Filter column validation gave errors for the
> invalid filter column, but in this top-up patch there is no indication
> which column or which filter or which publication was the bad one -
> only that "something" bad was detected. IMO this might make it very
> difficult for the user to know enough about the cause of the problem
> to be able to fix the offending filter.
If we want to report the invalid filter column, I can see two possibilities.
1) Instead of a bool flag, we cache a AttrNumber flag which indicates the
invalid column number(0 means all valid). We can report it in the error
message.
2) Everytime we decide to report an error, we traverse all the publications to
find the invalid column again and report it.
What do you think ?
> 13). src/backend/utils/cache/relcache.c - function RelationGetPublicationInfo
> +/*
> + * Get publication information for the given relation.
> + */
> +struct PublicationInfo *
> +RelationGetPublicationInfo(Relation relation)
> +{
> + List *puboids;
> + ListCell *lc;
> + MemoryContext oldcxt;
> + Oid schemaid;
> + Bitmapset *bms_replident = NULL;
> + PublicationInfo *pubinfo = palloc0(sizeof(PublicationInfo));
> +
> + pubinfo->rfcol_valid_for_replid = true;
>
> It is not entirely clear to me why this function is always pallocing
> the PublicationInfo and then returning a copy of what is stored in the
> relation->rd_pubinfo. This then puts a burden on the callers (like the
> GetRelationPublicationActions etc) to make sure to free that memory.
> Why can't we just return the relation->rd_pubinfo directly And avoid
> all the extra palloc/memcpy/free?
Normally, I think only the cache management function should change the data in
relcache. Return relation->xx directly might have a risk that user could
change the data in relcache. So, the management function usually return a copy
of cache data so that user is free to change it without affecting the real
cache data.
16) Tests... CREATE PUBLICATION succeeds
> I have not yet reviewed any of the 0005 tests, but there was some big
> behaviour difference that I noticed.
>
> I think now with the 0005 top-up patch the replica identify validation
> is deferred to when UPDATE/DELETE is executed. I don’t know if this
> will be very user friendly. It means now sometimes you can
> successfully CREATE a PUBLICATION even though it will fail as soon as
> you try to use it.
I am not sure, the initial idea here is to make the check of replica identity
consistent.
Currently, if user create a publication which publish "update" but the relation
in the publication didn't mark as replica identity, then user can create the
publication successfully. but the later UPDATE will report an error.
Best regards,
Hou zj
On Mon, Nov 29, 2021 at 1:54 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Sun, Nov 28, 2021 3:18 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> > >
> > ...
> > > Based on this direction, I tried to write a top up POC patch(0005) which I'd
> > > like to share.
> > >
> > > The top up patch mainly did the following things.
> > >
> > > * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so
> > > that the invalidation is executed only when actual UPDATE or DELETE executed on
> > > the published relation. It's consistent with the existing check about replica
> > > identity.
> > >
> > > * Cache the results of the validation for row filter columns in relcache to
> > > reduce the cost of the validation. It's safe because every operation that
> > > change the row filter and replica identity will invalidate the relcache.
> > >
> > > Also attach the v42 patch set to keep cfbot happy.
> >
> > Hi Hou-san.
> >
> > Thanks for providing your "top-up" 0005 patch!
> >
> > I suppose the goal will be to later merge this top-up with the current
> > 0002 validation patch, but in the meantime here are my review comments
> > for 0005.
>
> Thanks for the review and many valuable comments !
>
> > 8) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
> >
> > But which are the bad filter columns?
> >
> > Previously the Row Filter column validation gave errors for the
> > invalid filter column, but in this top-up patch there is no indication
> > which column or which filter or which publication was the bad one -
> > only that "something" bad was detected. IMO this might make it very
> > difficult for the user to know enough about the cause of the problem
> > to be able to fix the offending filter.
>
> If we want to report the invalid filter column, I can see two possibilities.
>
> 1) Instead of a bool flag, we cache a AttrNumber flag which indicates the
> invalid column number(0 means all valid). We can report it in the error
> message.
>
> 2) Everytime we decide to report an error, we traverse all the publications to
> find the invalid column again and report it.
>
> What do you think ?
Perhaps your idea #1 is good enough. At least if we provide just the
bad column name then the user can use psql \d+ to find all filter
publications that include that bad column. Maybe that can be a HINT
for the error message.
>
> > 13). src/backend/utils/cache/relcache.c - function RelationGetPublicationInfo
> > +/*
> > + * Get publication information for the given relation.
> > + */
> > +struct PublicationInfo *
> > +RelationGetPublicationInfo(Relation relation)
> > +{
> > + List *puboids;
> > + ListCell *lc;
> > + MemoryContext oldcxt;
> > + Oid schemaid;
> > + Bitmapset *bms_replident = NULL;
> > + PublicationInfo *pubinfo = palloc0(sizeof(PublicationInfo));
> > +
> > + pubinfo->rfcol_valid_for_replid = true;
> >
> > It is not entirely clear to me why this function is always pallocing
> > the PublicationInfo and then returning a copy of what is stored in the
> > relation->rd_pubinfo. This then puts a burden on the callers (like the
> > GetRelationPublicationActions etc) to make sure to free that memory.
> > Why can't we just return the relation->rd_pubinfo directly And avoid
> > all the extra palloc/memcpy/free?
>
> Normally, I think only the cache management function should change the data in
> relcache. Return relation->xx directly might have a risk that user could
> change the data in relcache. So, the management function usually return a copy
> of cache data so that user is free to change it without affecting the real
> cache data.
OK.
> 16) Tests... CREATE PUBLICATION succeeds
>
> > I have not yet reviewed any of the 0005 tests, but there was some big
> > behaviour difference that I noticed.
> >
> > I think now with the 0005 top-up patch the replica identify validation
> > is deferred to when UPDATE/DELETE is executed. I don’t know if this
> > will be very user friendly. It means now sometimes you can
> > successfully CREATE a PUBLICATION even though it will fail as soon as
> > you try to use it.
>
> I am not sure, the initial idea here is to make the check of replica identity
> consistent.
>
> Currently, if user create a publication which publish "update" but the relation
> in the publication didn't mark as replica identity, then user can create the
> publication successfully. but the later UPDATE will report an error.
>
OK. I see there is a different perspective; I will leave this to see
what other people think.
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Fri, Nov 26, 2021 at 12:40 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > When researching and writing a top-up patch about this. > I found a possible issue which I'd like to confirm first. > > It's possible the table is published in two publications A and B, publication A > only publish "insert" , publication B publish "update". When UPDATE, both row > filter in A and B will be executed. Is this behavior expected? > > For example: > ---- Publication > create table tbl1 (a int primary key, b int); > create publication A for table tbl1 where (b<2) with(publish='insert'); > create publication B for table tbl1 where (a>1) with(publish='update'); > > ---- Subscription > create table tbl1 (a int primary key); > CREATE SUBSCRIPTION sub CONNECTION 'dbname=postgres host=localhost > port=10000' PUBLICATION A,B; > > ---- Publication > update tbl1 set a = 2; > > The publication can be created, and when UPDATE, the rowfilter in A (b<2) will > also been executed but the column in it is not part of replica identity. > (I am not against this behavior just confirm) > There seems to be problems related to allowing the row filter to include columns that are not part of the replica identity (in the case of publish=insert). In your example scenario, the tbl1 WHERE clause "(b < 2)" for publication A, that publishes inserts only, causes a problem, because column "b" is not part of the replica identity. To see this, follow the simple example below: (and note, for the Subscription, the provided tbl1 definition has an error, it should also include the 2nd column "b int", same as in the publisher) ---- Publisher: INSERT INTO tbl1 VALUES (1,1); UPDATE tbl1 SET a = 2; Prior to the UPDATE above: On pub side, tbl1 contains (1,1). On sub side, tbl1 contains (1,1) After the above UPDATE: On pub side, tbl1 contains (2,1). On sub side, tbl1 contains (1,1), (2,1) So the UPDATE on the pub side has resulted in an INSERT of (2,1) on the sub side. This is because when (1,1) is UPDATEd to (2,1), it attempts to use the "insert" filter "(b<2)" to determine whether the old value had been inserted (published to subscriber), but finds there is no "b" value (because it only uses RI cols for UPDATE) and so has to assume the old tuple doesn't exist on the subscriber, hence the UPDATE ends up doing an INSERT. INow if the use of RI cols were enforced for the insert filter case, we'd properly know the answer as to whether the old row value had been published and it would have correctly performed an UPDATE instead of an INSERT in this case. Thoughts? Regards, Greg Nancarrow Fujitsu Australia
On Mon, Nov 29, 2021 at 12:10 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 12:40 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > When researching and writing a top-up patch about this. > > I found a possible issue which I'd like to confirm first. > > > > It's possible the table is published in two publications A and B, publication A > > only publish "insert" , publication B publish "update". When UPDATE, both row > > filter in A and B will be executed. Is this behavior expected? > > > > For example: > > ---- Publication > > create table tbl1 (a int primary key, b int); > > create publication A for table tbl1 where (b<2) with(publish='insert'); > > create publication B for table tbl1 where (a>1) with(publish='update'); > > > > ---- Subscription > > create table tbl1 (a int primary key); > > CREATE SUBSCRIPTION sub CONNECTION 'dbname=postgres host=localhost > > port=10000' PUBLICATION A,B; > > > > ---- Publication > > update tbl1 set a = 2; > > > > The publication can be created, and when UPDATE, the rowfilter in A (b<2) will > > also been executed but the column in it is not part of replica identity. > > (I am not against this behavior just confirm) > > > > There seems to be problems related to allowing the row filter to > include columns that are not part of the replica identity (in the case > of publish=insert). > In your example scenario, the tbl1 WHERE clause "(b < 2)" for > publication A, that publishes inserts only, causes a problem, because > column "b" is not part of the replica identity. > To see this, follow the simple example below: > (and note, for the Subscription, the provided tbl1 definition has an > error, it should also include the 2nd column "b int", same as in the > publisher) > > ---- Publisher: > INSERT INTO tbl1 VALUES (1,1); > UPDATE tbl1 SET a = 2; > > Prior to the UPDATE above: > On pub side, tbl1 contains (1,1). > On sub side, tbl1 contains (1,1) > > After the above UPDATE: > On pub side, tbl1 contains (2,1). > On sub side, tbl1 contains (1,1), (2,1) > > So the UPDATE on the pub side has resulted in an INSERT of (2,1) on > the sub side. > > This is because when (1,1) is UPDATEd to (2,1), it attempts to use the > "insert" filter "(b<2)" to determine whether the old value had been > inserted (published to subscriber), but finds there is no "b" value > (because it only uses RI cols for UPDATE) and so has to assume the old > tuple doesn't exist on the subscriber, hence the UPDATE ends up doing > an INSERT. > INow if the use of RI cols were enforced for the insert filter case, > we'd properly know the answer as to whether the old row value had been > published and it would have correctly performed an UPDATE instead of > an INSERT in this case. > I don't think it is a good idea to combine the row-filter from the publication that publishes just 'insert' with the row-filter that publishes 'updates'. We shouldn't apply the 'insert' filter for 'update' and similarly for publication operations. We can combine the filters when the published operations are the same. So, this means that we might need to cache multiple row-filters but I think that is better than having another restriction that publish operation 'insert' should also honor RI columns restriction. -- With Regards, Amit Kapila.
On Mon, Nov 29, 2021 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > ---- Publisher: > > INSERT INTO tbl1 VALUES (1,1); > > UPDATE tbl1 SET a = 2; > > > > Prior to the UPDATE above: > > On pub side, tbl1 contains (1,1). > > On sub side, tbl1 contains (1,1) > > > > After the above UPDATE: > > On pub side, tbl1 contains (2,1). > > On sub side, tbl1 contains (1,1), (2,1) > > > > So the UPDATE on the pub side has resulted in an INSERT of (2,1) on > > the sub side. > > > > This is because when (1,1) is UPDATEd to (2,1), it attempts to use the > > "insert" filter "(b<2)" to determine whether the old value had been > > inserted (published to subscriber), but finds there is no "b" value > > (because it only uses RI cols for UPDATE) and so has to assume the old > > tuple doesn't exist on the subscriber, hence the UPDATE ends up doing > > an INSERT. > > INow if the use of RI cols were enforced for the insert filter case, > > we'd properly know the answer as to whether the old row value had been > > published and it would have correctly performed an UPDATE instead of > > an INSERT in this case. > > > > I don't think it is a good idea to combine the row-filter from the > publication that publishes just 'insert' with the row-filter that > publishes 'updates'. We shouldn't apply the 'insert' filter for > 'update' and similarly for publication operations. We can combine the > filters when the published operations are the same. So, this means > that we might need to cache multiple row-filters but I think that is > better than having another restriction that publish operation 'insert' > should also honor RI columns restriction. I am just wondering that if we don't combine filter in the above case then what data we will send to the subscriber if the operation is "UPDATE tbl1 SET a = 2, b=3", so in this case, we will apply only the update filter i.e. a > 1 so as per that this will become the INSERT operation because the old row was not passing the filter. So now we will insert a new row in the subscriber-side with value (2,3). Looks a bit odd to me that the value b=3 would have been rejected with the direct insert but it is allowed due to indirect insert done by update. Is this behavior looks odd only to me? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Nov 29, 2021 at 8:24 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Sun, Nov 28, 2021 3:18 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > > > ... > > > Based on this direction, I tried to write a top up POC patch(0005) which I'd > > > like to share. > > > > > > The top up patch mainly did the following things. > > > > > > * Move the row filter columns invalidation to CheckCmdReplicaIdentity, so > > > that the invalidation is executed only when actual UPDATE or DELETE executed on > > > the published relation. It's consistent with the existing check about replica > > > identity. > > > > > > * Cache the results of the validation for row filter columns in relcache to > > > reduce the cost of the validation. It's safe because every operation that > > > change the row filter and replica identity will invalidate the relcache. > > > > > > Also attach the v42 patch set to keep cfbot happy. > > > > Hi Hou-san. > > > > Thanks for providing your "top-up" 0005 patch! > > > > I suppose the goal will be to later merge this top-up with the current > > 0002 validation patch, but in the meantime here are my review comments > > for 0005. > > Thanks for the review and many valuable comments ! > > > 8) src/backend/executor/execReplication.c - CheckCmdReplicaIdentity > > > > But which are the bad filter columns? > > > > Previously the Row Filter column validation gave errors for the > > invalid filter column, but in this top-up patch there is no indication > > which column or which filter or which publication was the bad one - > > only that "something" bad was detected. IMO this might make it very > > difficult for the user to know enough about the cause of the problem > > to be able to fix the offending filter. > > If we want to report the invalid filter column, I can see two possibilities. > > 1) Instead of a bool flag, we cache a AttrNumber flag which indicates the > invalid column number(0 means all valid). We can report it in the error > message. > > 2) Everytime we decide to report an error, we traverse all the publications to > find the invalid column again and report it. > > What do you think ? > I think we can probably give an error inside RelationGetPublicationInfo(we can change the name of the function based on changed functionality). Basically, if the row_filter is valid then we can copy publication info from relcache and return it in beginning, otherwise, allow it to check publications again. In error cases, it shouldn't matter much to not use the cached information. This is to some extent how the other parameters like rd_fkeyvalid and rd_partcheckvalid works. One more thing, similar to some of the other things isn't it better to manage pubactions and new bool flag directly in relation instead of using PublicationInfo? > 16) Tests... CREATE PUBLICATION succeeds > > > I have not yet reviewed any of the 0005 tests, but there was some big > > behaviour difference that I noticed. > > > > I think now with the 0005 top-up patch the replica identify validation > > is deferred to when UPDATE/DELETE is executed. I don’t know if this > > will be very user friendly. It means now sometimes you can > > successfully CREATE a PUBLICATION even though it will fail as soon as > > you try to use it. > > I am not sure, the initial idea here is to make the check of replica identity > consistent. > > Currently, if user create a publication which publish "update" but the relation > in the publication didn't mark as replica identity, then user can create the > publication successfully. but the later UPDATE will report an error. > Yeah, I think giving an error on Update/Delete should be okay. -- With Regards, Amit Kapila.
On Sun, Nov 28, 2021 at 12:48 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Fri, Nov 26, 2021 at 1:16 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
>
> 4) src/backend/catalog/pg_publication.c - check_rowfilter_replident
> +/*
> + * Check if all the columns used in the row-filter WHERE clause are part of
> + * REPLICA IDENTITY
> + */
> +bool
> +check_rowfilter_replident(Node *node, Bitmapset *bms_replident)
> +{
>
> IIUC here the false means "valid" and true means "invalid" which is
> counter-intuitive to me. So at least true/false meaning ought to be
> clarified in the function comment, and/or perhaps also rename the
> function so that the return meaning is more obvious.
>
+1 to rename the function in this case.
--
With Regards,
Amit Kapila.
On Mon, Nov 29, 2021 at 4:36 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Nov 29, 2021 at 3:41 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > ---- Publisher: > > > INSERT INTO tbl1 VALUES (1,1); > > > UPDATE tbl1 SET a = 2; > > > > > > Prior to the UPDATE above: > > > On pub side, tbl1 contains (1,1). > > > On sub side, tbl1 contains (1,1) > > > > > > After the above UPDATE: > > > On pub side, tbl1 contains (2,1). > > > On sub side, tbl1 contains (1,1), (2,1) > > > > > > So the UPDATE on the pub side has resulted in an INSERT of (2,1) on > > > the sub side. > > > > > > This is because when (1,1) is UPDATEd to (2,1), it attempts to use the > > > "insert" filter "(b<2)" to determine whether the old value had been > > > inserted (published to subscriber), but finds there is no "b" value > > > (because it only uses RI cols for UPDATE) and so has to assume the old > > > tuple doesn't exist on the subscriber, hence the UPDATE ends up doing > > > an INSERT. > > > INow if the use of RI cols were enforced for the insert filter case, > > > we'd properly know the answer as to whether the old row value had been > > > published and it would have correctly performed an UPDATE instead of > > > an INSERT in this case. > > > > > > > I don't think it is a good idea to combine the row-filter from the > > publication that publishes just 'insert' with the row-filter that > > publishes 'updates'. We shouldn't apply the 'insert' filter for > > 'update' and similarly for publication operations. We can combine the > > filters when the published operations are the same. So, this means > > that we might need to cache multiple row-filters but I think that is > > better than having another restriction that publish operation 'insert' > > should also honor RI columns restriction. > > I am just wondering that if we don't combine filter in the above case > then what data we will send to the subscriber if the operation is > "UPDATE tbl1 SET a = 2, b=3", so in this case, we will apply only the > update filter i.e. a > 1 so as per that this will become the INSERT > operation because the old row was not passing the filter. > If we want, I think for inserts (new row) we can consider the insert filter as well but that makes it tricky to explain. I feel we can change it later as well if there is a valid use case for this. What do you think? -- With Regards, Amit Kapila.
On Mon, Nov 29, 2021 at 5:40 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > I don't think it is a good idea to combine the row-filter from the > > > publication that publishes just 'insert' with the row-filter that > > > publishes 'updates'. We shouldn't apply the 'insert' filter for > > > 'update' and similarly for publication operations. We can combine the > > > filters when the published operations are the same. So, this means > > > that we might need to cache multiple row-filters but I think that is > > > better than having another restriction that publish operation 'insert' > > > should also honor RI columns restriction. > > > > I am just wondering that if we don't combine filter in the above case > > then what data we will send to the subscriber if the operation is > > "UPDATE tbl1 SET a = 2, b=3", so in this case, we will apply only the > > update filter i.e. a > 1 so as per that this will become the INSERT > > operation because the old row was not passing the filter. > > > > If we want, I think for inserts (new row) we can consider the insert > filter as well but that makes it tricky to explain. I feel we can > change it later as well if there is a valid use case for this. What do > you think? Yeah, that makes sense. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Mon, Nov 29, 2021, at 7:11 AM, Amit Kapila wrote:
I don't think it is a good idea to combine the row-filter from thepublication that publishes just 'insert' with the row-filter thatpublishes 'updates'. We shouldn't apply the 'insert' filter for'update' and similarly for publication operations. We can combine thefilters when the published operations are the same. So, this meansthat we might need to cache multiple row-filters but I think that isbetter than having another restriction that publish operation 'insert'should also honor RI columns restriction.
That's exactly what I meant to say but apparently I didn't explain in details.
If a subscriber has multiple publications and a table is part of these
publications with different row filters, it should check the publication action
*before* including it in the row filter list. It means that an UPDATE operation
cannot apply a row filter that is part of a publication that has only INSERT as
an action. Having said that we cannot always combine multiple row filter
expressions into one. Instead, it should cache individual row filter expression
and apply the OR during the row filter execution (as I did in the initial
patches before this caching stuff). The other idea is to have multiple caches
for each action. The main disadvantage of this approach is to create 4x
entries.
I'm experimenting the first approach that stores multiple row filters and its
publication action right now. Unfortunately we cannot use the
relentry->pubactions because it aggregates this information if you have
multiple entries. It seems a separate array should store this information that
will be used later while evaluating the row filter -- around
pgoutput_row_filter_exec_expr() call.
On Mon, Nov 29, 2021 6:11 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Nov 29, 2021 at 12:10 PM Greg Nancarrow <gregn4422@gmail.com> > wrote: > > > > On Fri, Nov 26, 2021 at 12:40 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > When researching and writing a top-up patch about this. > > > I found a possible issue which I'd like to confirm first. > > > > > > It's possible the table is published in two publications A and B, > > > publication A only publish "insert" , publication B publish > > > "update". When UPDATE, both row filter in A and B will be executed. Is this > behavior expected? > > > > > > For example: > > > ---- Publication > > > create table tbl1 (a int primary key, b int); create publication A > > > for table tbl1 where (b<2) with(publish='insert'); create > > > publication B for table tbl1 where (a>1) with(publish='update'); > > > > > > ---- Subscription > > > create table tbl1 (a int primary key); CREATE SUBSCRIPTION sub > > > CONNECTION 'dbname=postgres host=localhost port=10000' > PUBLICATION > > > A,B; > > > > > > ---- Publication > > > update tbl1 set a = 2; > > > > > > The publication can be created, and when UPDATE, the rowfilter in A > > > (b<2) will also been executed but the column in it is not part of replica > identity. > > > (I am not against this behavior just confirm) > > > > > > > There seems to be problems related to allowing the row filter to > > include columns that are not part of the replica identity (in the case > > of publish=insert). > > In your example scenario, the tbl1 WHERE clause "(b < 2)" for > > publication A, that publishes inserts only, causes a problem, because > > column "b" is not part of the replica identity. > > To see this, follow the simple example below: > > (and note, for the Subscription, the provided tbl1 definition has an > > error, it should also include the 2nd column "b int", same as in the > > publisher) > > > > ---- Publisher: > > INSERT INTO tbl1 VALUES (1,1); > > UPDATE tbl1 SET a = 2; > > > > Prior to the UPDATE above: > > On pub side, tbl1 contains (1,1). > > On sub side, tbl1 contains (1,1) > > > > After the above UPDATE: > > On pub side, tbl1 contains (2,1). > > On sub side, tbl1 contains (1,1), (2,1) > > > > So the UPDATE on the pub side has resulted in an INSERT of (2,1) on > > the sub side. > > > > This is because when (1,1) is UPDATEd to (2,1), it attempts to use the > > "insert" filter "(b<2)" to determine whether the old value had been > > inserted (published to subscriber), but finds there is no "b" value > > (because it only uses RI cols for UPDATE) and so has to assume the old > > tuple doesn't exist on the subscriber, hence the UPDATE ends up doing > > an INSERT. > > INow if the use of RI cols were enforced for the insert filter case, > > we'd properly know the answer as to whether the old row value had been > > published and it would have correctly performed an UPDATE instead of > > an INSERT in this case. > > > > I don't think it is a good idea to combine the row-filter from the publication > that publishes just 'insert' with the row-filter that publishes 'updates'. We > shouldn't apply the 'insert' filter for 'update' and similarly for publication > operations. We can combine the filters when the published operations are the > same. So, this means that we might need to cache multiple row-filters but I > think that is better than having another restriction that publish operation > 'insert' > should also honor RI columns restriction. Personally, I agreed that an UPDATE operation should only apply a row filter that is part of a publication that has only UPDATE. Best regards, Hou zj
On Thursday, November 25, 2021 11:22 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Thanks for all the review comments so far! We are endeavouring to keep > pace with them. > > All feedback is being tracked and we will fix and/or reply to everything ASAP. > > Meanwhile, PSA the latest set of v42* patches. > > This version was mostly a patch restructuring exercise but it also > addresses some minor review comments in passing. > Thanks for your patch. I have two comments on the document in 0001 patch. 1. + New row is used and it contains all columns. A <literal>NULL</literal> value + causes the expression to evaluate to false; avoid using columns without I don't quite understand this sentence 'A NULL value causes the expression to evaluate to false'. The expression contains NULL value can also return true. Could you be more specific? For example: postgres=# select null or true; ?column? ---------- t (1 row) 2. + at all then all other filters become redundant. If the subscriber is a + <productname>PostgreSQL</productname> version before 15 then any row filtering + is ignored. If the subscriber is a PostgreSQL version before 15, it seems row filtering will be ignored only when copying initial data, the later changes will not be ignored in row filtering. Should we make it clear in document? Regards, Tang
On Mon, Nov 29, 2021 at 8:40 PM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Nov 29, 2021, at 7:11 AM, Amit Kapila wrote: > > I don't think it is a good idea to combine the row-filter from the > publication that publishes just 'insert' with the row-filter that > publishes 'updates'. We shouldn't apply the 'insert' filter for > 'update' and similarly for publication operations. We can combine the > filters when the published operations are the same. So, this means > that we might need to cache multiple row-filters but I think that is > better than having another restriction that publish operation 'insert' > should also honor RI columns restriction. > > That's exactly what I meant to say but apparently I didn't explain in details. > If a subscriber has multiple publications and a table is part of these > publications with different row filters, it should check the publication action > *before* including it in the row filter list. It means that an UPDATE operation > cannot apply a row filter that is part of a publication that has only INSERT as > an action. Having said that we cannot always combine multiple row filter > expressions into one. Instead, it should cache individual row filter expression > and apply the OR during the row filter execution (as I did in the initial > patches before this caching stuff). The other idea is to have multiple caches > for each action. The main disadvantage of this approach is to create 4x > entries. > > I'm experimenting the first approach that stores multiple row filters and its > publication action right now. > We can try that way but I think we should still be able to combine in many cases like where all the operations are specified for publications having the table or maybe pubactions are same. So, we should not give up on those cases. We can do this new logic only when we find that pubactions are different and probably store them as independent expressions and corresponding pubactions for it at the current location in the v42* patch (in pgoutput_row_filter). It is okay to combine them at a later stage during execution when we can't do it at the time of forming cache entry. -- With Regards, Amit Kapila.
On Tue, Nov 30, 2021 at 10:26 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Nov 29, 2021 at 8:40 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Mon, Nov 29, 2021, at 7:11 AM, Amit Kapila wrote: > > > > I don't think it is a good idea to combine the row-filter from the > > publication that publishes just 'insert' with the row-filter that > > publishes 'updates'. We shouldn't apply the 'insert' filter for > > 'update' and similarly for publication operations. We can combine the > > filters when the published operations are the same. So, this means > > that we might need to cache multiple row-filters but I think that is > > better than having another restriction that publish operation 'insert' > > should also honor RI columns restriction. > > > > That's exactly what I meant to say but apparently I didn't explain in details. > > If a subscriber has multiple publications and a table is part of these > > publications with different row filters, it should check the publication action > > *before* including it in the row filter list. It means that an UPDATE operation > > cannot apply a row filter that is part of a publication that has only INSERT as > > an action. Having said that we cannot always combine multiple row filter > > expressions into one. Instead, it should cache individual row filter expression > > and apply the OR during the row filter execution (as I did in the initial > > patches before this caching stuff). The other idea is to have multiple caches > > for each action. The main disadvantage of this approach is to create 4x > > entries. > > > > I'm experimenting the first approach that stores multiple row filters and its > > publication action right now. > > > > We can try that way but I think we should still be able to combine in > many cases like where all the operations are specified for > publications having the table or maybe pubactions are same. So, we > should not give up on those cases. We can do this new logic only when > we find that pubactions are different and probably store them as > independent expressions and corresponding pubactions for it at the > current location in the v42* patch (in pgoutput_row_filter). It is > okay to combine them at a later stage during execution when we can't > do it at the time of forming cache entry. What about the initial table sync? during that, we are going to combine all the filters or we are going to apply only the insert filters? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 25, 2021 at 2:22 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Thanks for all the review comments so far! We are endeavouring to keep
> pace with them.
>
> All feedback is being tracked and we will fix and/or reply to everything ASAP.
>
> Meanwhile, PSA the latest set of v42* patches.
>
> This version was mostly a patch restructuring exercise but it also
> addresses some minor review comments in passing.
>
Addressed more review comments, in the attached patch-set v43. 5
patches carried forward from v42.
This patch-set contains the following fixes:
On Tue, Nov 23, 2021 at 1:28 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
> in pgoutput_row_filter, we are dropping the slots if there are some
> old slots in the RelationSyncEntry. But then I noticed that in
> rel_sync_cache_relation_cb(), also we are doing that but only for the
> scantuple slot. So IMHO, rel_sync_cache_relation_cb(), is only place
> setting entry->rowfilter_valid to false; so why not drop all the slot
> that time only and in pgoutput_row_filter(), you can just put an
> assert?
>
Moved all the dropping of slots to rel_sync_cache_relation_cb()
> +static bool
> +pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
> RelationSyncEntry *entry)
> +{
> + EState *estate;
> + ExprContext *ecxt;
>
>
> pgoutput_row_filter_virtual and pgoutput_row_filter are exactly same
> except, ExecStoreHeapTuple(), so why not just put one check based on
> whether a slot is passed or not, instead of making complete duplicate
> copy of the function.
Removed pgoutput_row_filter_virtual
> oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> tupdesc = CreateTupleDescCopy(tupdesc);
> entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
>
> Why do we need to copy the tupledesc? do we think that we need to have
> this slot even if we close the relation, if so can you add the
> comments explaining why we are making a copy here.
This code has been modified, and comments added.
On Tue, Nov 23, 2021 at 8:02 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> One more thing related to this code:
> pgoutput_row_filter()
> {
> ..
> + if (!entry->rowfilter_valid)
> {
> ..
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> + tupdesc = CreateTupleDescCopy(tupdesc);
> + entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
> + MemoryContextSwitchTo(oldctx);
> ..
> }
>
> Why do we need to initialize scantuple here unless we are sure that
> the row filter is going to get associated with this relentry? I think
> when there is no row filter then this allocation is not required.
>
Modified as suggested.
On Tue, Nov 23, 2021 at 10:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> In 0003 patch, why is below change required?
> --- a/src/backend/replication/pgoutput/pgoutput.c
> +++ b/src/backend/replication/pgoutput/pgoutput.c
> @@ -1,4 +1,4 @@
> -/*-------------------------------------------------------------------------
> +/*------------------------------------------------------------------------
> *
> * pgoutput.c
>
Removed.
>
> After above, rearrange the code in pgoutput_row_filter(), so that two
> different checks related to 'rfisnull' (introduced by different
> patches) can be combined as if .. else check.
>
Fixed.
On Thu, Nov 25, 2021 at 12:03 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> + * If the new relation or the old relation has a where clause,
> + * we need to remove it so that it can be added afresh later.
> + */
> + if (RelationGetRelid(newpubrel->relation) == oldrelid &&
> + newpubrel->whereClause == NULL && rfisnull)
>
> Can't we use _equalPublicationTable() here? It compares the whereClause as well.
>
Tried this, can't do this because one is an alter statement while the
other is a publication, the whereclause is not
the same Nodetype. In the statement, the whereclause is T_A_Expr,
while in the publication
catalog, it is T_OpExpr.
> /* Must be owner of the table or superuser. */
> - if (!pg_class_ownercheck(RelationGetRelid(rel), GetUserId()))
> + if (!pg_class_ownercheck(relid, GetUserId()))
>
> Here, you can directly use RelationGetRelid as was used in the
> previous code without using an additional variable.
>
Fixed.
> 2.
> +typedef struct {
> + Relation rel;
> + bool check_replident;
> + Bitmapset *bms_replident;
> +}
> +rf_context;
>
> Add rf_context in the same line where } ends.
Code has been modified, this comment no longer applies.
> 4.
> + * Rules: Node-type validation
> + * ---------------------------
> + * Allow only simple or compound expressions like:
> + * - "(Var Op Const)" or
>
> It seems Var Op Var is allowed. I tried below and it works:
> create publication pub for table t1 where (c1 < c2) WITH (publish = 'insert');
>
> I think it should be okay to allow it provided we ensure that we never
> access some other table/view etc. as part of the expression. Also, we
> should document the behavior correctly.
Fixed.
On Wed, Nov 24, 2021 at 8:52 PM vignesh C <vignesh21@gmail.com> wrote:
>
> 4) This should be included in typedefs.list, also we could add some
> comments for this structure
> +typedef struct {
> + Relation rel;
> + Bitmapset *bms_replident;
> +}
> +rf_context;
this has been removed in last patch, so comment no longer applies
> 5) Few includes are not required. #include "miscadmin.h" not required
> in pg_publication.c, #include "executor/executor.h" not required in
> proto.c, #include "access/xact.h", #include "executor/executor.h" and
> #include "replication/logicalrelation.h" not required in pgoutput.c
>
Optimized this. removed "executor/executor.h" from patch 0003, removed
"access/xact.h" from patch 0001
removed "replication/logicalrelation.h” from 0001. Others required.
> 6) typo "filte" should be "filter":
> +/*
> + * The row filte walker checks that the row filter expression is legal.
> + *
> + * Rules: Node-type validation
> + * ---------------------------
> + * Allow only simple or compound expressions like:
> + * - "(Var Op Const)" or
> + * - "(Var Op Const) Bool (Var Op Const)"
Fixed.
regards,
Ajin Cherian
Fujitsu Australia
Вложения
On Tue, Nov 30, 2021 at 11:37 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Nov 30, 2021 at 10:26 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Mon, Nov 29, 2021 at 8:40 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Mon, Nov 29, 2021, at 7:11 AM, Amit Kapila wrote: > > > > > > I don't think it is a good idea to combine the row-filter from the > > > publication that publishes just 'insert' with the row-filter that > > > publishes 'updates'. We shouldn't apply the 'insert' filter for > > > 'update' and similarly for publication operations. We can combine the > > > filters when the published operations are the same. So, this means > > > that we might need to cache multiple row-filters but I think that is > > > better than having another restriction that publish operation 'insert' > > > should also honor RI columns restriction. > > > > > > That's exactly what I meant to say but apparently I didn't explain in details. > > > If a subscriber has multiple publications and a table is part of these > > > publications with different row filters, it should check the publication action > > > *before* including it in the row filter list. It means that an UPDATE operation > > > cannot apply a row filter that is part of a publication that has only INSERT as > > > an action. Having said that we cannot always combine multiple row filter > > > expressions into one. Instead, it should cache individual row filter expression > > > and apply the OR during the row filter execution (as I did in the initial > > > patches before this caching stuff). The other idea is to have multiple caches > > > for each action. The main disadvantage of this approach is to create 4x > > > entries. > > > > > > I'm experimenting the first approach that stores multiple row filters and its > > > publication action right now. > > > > > > > We can try that way but I think we should still be able to combine in > > many cases like where all the operations are specified for > > publications having the table or maybe pubactions are same. So, we > > should not give up on those cases. We can do this new logic only when > > we find that pubactions are different and probably store them as > > independent expressions and corresponding pubactions for it at the > > current location in the v42* patch (in pgoutput_row_filter). It is > > okay to combine them at a later stage during execution when we can't > > do it at the time of forming cache entry. > > What about the initial table sync? during that, we are going to > combine all the filters or we are going to apply only the insert > filters? > AFAIK, currently, initial table sync doesn't respect publication actions so it should combine all the filters. What do you think? -- With Regards, Amit Kapila.
On Tue, Nov 30, 2021 at 3:55 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > We can try that way but I think we should still be able to combine in > > > many cases like where all the operations are specified for > > > publications having the table or maybe pubactions are same. So, we > > > should not give up on those cases. We can do this new logic only when > > > we find that pubactions are different and probably store them as > > > independent expressions and corresponding pubactions for it at the > > > current location in the v42* patch (in pgoutput_row_filter). It is > > > okay to combine them at a later stage during execution when we can't > > > do it at the time of forming cache entry. > > > > What about the initial table sync? during that, we are going to > > combine all the filters or we are going to apply only the insert > > filters? > > > > AFAIK, currently, initial table sync doesn't respect publication > actions so it should combine all the filters. What do you think? Yeah, I have the same opinion. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Nov 30, 2021 at 12:33 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> On Thu, Nov 25, 2021 at 2:22 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Thanks for all the review comments so far! We are endeavouring to keep
> > pace with them.
> >
> > All feedback is being tracked and we will fix and/or reply to everything ASAP.
> >
> > Meanwhile, PSA the latest set of v42* patches.
> >
> > This version was mostly a patch restructuring exercise but it also
> > addresses some minor review comments in passing.
> >
>
> Addressed more review comments, in the attached patch-set v43. 5
> patches carried forward from v42.
> This patch-set contains the following fixes:
>
> On Tue, Nov 23, 2021 at 1:28 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > in pgoutput_row_filter, we are dropping the slots if there are some
> > old slots in the RelationSyncEntry. But then I noticed that in
> > rel_sync_cache_relation_cb(), also we are doing that but only for the
> > scantuple slot. So IMHO, rel_sync_cache_relation_cb(), is only place
> > setting entry->rowfilter_valid to false; so why not drop all the slot
> > that time only and in pgoutput_row_filter(), you can just put an
> > assert?
> >
>
> Moved all the dropping of slots to rel_sync_cache_relation_cb()
>
> > +static bool
> > +pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
> > RelationSyncEntry *entry)
> > +{
> > + EState *estate;
> > + ExprContext *ecxt;
> >
> >
> > pgoutput_row_filter_virtual and pgoutput_row_filter are exactly same
> > except, ExecStoreHeapTuple(), so why not just put one check based on
> > whether a slot is passed or not, instead of making complete duplicate
> > copy of the function.
>
> Removed pgoutput_row_filter_virtual
>
> > oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> > tupdesc = CreateTupleDescCopy(tupdesc);
> > entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
> >
> > Why do we need to copy the tupledesc? do we think that we need to have
> > this slot even if we close the relation, if so can you add the
> > comments explaining why we are making a copy here.
>
> This code has been modified, and comments added.
>
> On Tue, Nov 23, 2021 at 8:02 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > One more thing related to this code:
> > pgoutput_row_filter()
> > {
> > ..
> > + if (!entry->rowfilter_valid)
> > {
> > ..
> > + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> > + tupdesc = CreateTupleDescCopy(tupdesc);
> > + entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
> > + MemoryContextSwitchTo(oldctx);
> > ..
> > }
> >
> > Why do we need to initialize scantuple here unless we are sure that
> > the row filter is going to get associated with this relentry? I think
> > when there is no row filter then this allocation is not required.
> >
>
> Modified as suggested.
>
> On Tue, Nov 23, 2021 at 10:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > In 0003 patch, why is below change required?
> > --- a/src/backend/replication/pgoutput/pgoutput.c
> > +++ b/src/backend/replication/pgoutput/pgoutput.c
> > @@ -1,4 +1,4 @@
> > -/*-------------------------------------------------------------------------
> > +/*------------------------------------------------------------------------
> > *
> > * pgoutput.c
> >
>
> Removed.
>
> >
> > After above, rearrange the code in pgoutput_row_filter(), so that two
> > different checks related to 'rfisnull' (introduced by different
> > patches) can be combined as if .. else check.
> >
> Fixed.
>
> On Thu, Nov 25, 2021 at 12:03 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > + * If the new relation or the old relation has a where clause,
> > + * we need to remove it so that it can be added afresh later.
> > + */
> > + if (RelationGetRelid(newpubrel->relation) == oldrelid &&
> > + newpubrel->whereClause == NULL && rfisnull)
> >
> > Can't we use _equalPublicationTable() here? It compares the whereClause as well.
> >
>
> Tried this, can't do this because one is an alter statement while the
> other is a publication, the whereclause is not
> the same Nodetype. In the statement, the whereclause is T_A_Expr,
> while in the publication
> catalog, it is T_OpExpr.
>
> > /* Must be owner of the table or superuser. */
> > - if (!pg_class_ownercheck(RelationGetRelid(rel), GetUserId()))
> > + if (!pg_class_ownercheck(relid, GetUserId()))
> >
> > Here, you can directly use RelationGetRelid as was used in the
> > previous code without using an additional variable.
> >
>
> Fixed.
>
> > 2.
> > +typedef struct {
> > + Relation rel;
> > + bool check_replident;
> > + Bitmapset *bms_replident;
> > +}
> > +rf_context;
> >
> > Add rf_context in the same line where } ends.
>
> Code has been modified, this comment no longer applies.
>
> > 4.
> > + * Rules: Node-type validation
> > + * ---------------------------
> > + * Allow only simple or compound expressions like:
> > + * - "(Var Op Const)" or
> >
> > It seems Var Op Var is allowed. I tried below and it works:
> > create publication pub for table t1 where (c1 < c2) WITH (publish = 'insert');
> >
> > I think it should be okay to allow it provided we ensure that we never
> > access some other table/view etc. as part of the expression. Also, we
> > should document the behavior correctly.
>
> Fixed.
>
> On Wed, Nov 24, 2021 at 8:52 PM vignesh C <vignesh21@gmail.com> wrote:
> >
> > 4) This should be included in typedefs.list, also we could add some
> > comments for this structure
> > +typedef struct {
> > + Relation rel;
> > + Bitmapset *bms_replident;
> > +}
> > +rf_context;
>
> this has been removed in last patch, so comment no longer applies
>
> > 5) Few includes are not required. #include "miscadmin.h" not required
> > in pg_publication.c, #include "executor/executor.h" not required in
> > proto.c, #include "access/xact.h", #include "executor/executor.h" and
> > #include "replication/logicalrelation.h" not required in pgoutput.c
> >
>
> Optimized this. removed "executor/executor.h" from patch 0003, removed
> "access/xact.h" from patch 0001
> removed "replication/logicalrelation.h” from 0001. Others required.
>
> > 6) typo "filte" should be "filter":
> > +/*
> > + * The row filte walker checks that the row filter expression is legal.
> > + *
> > + * Rules: Node-type validation
> > + * ---------------------------
> > + * Allow only simple or compound expressions like:
> > + * - "(Var Op Const)" or
> > + * - "(Var Op Const) Bool (Var Op Const)"
>
> Fixed.
Thanks for the updated patch, few comments:
1) Should this be changed to include non IMMUTABLE system functions
are not allowed:
+ not-null constraints in the <literal>WHERE</literal> clause. The
+ <literal>WHERE</literal> clause does not allow functions or user-defined
+ operators.
+ </para>
2) We can remove the #if 0 code if we don't plan to keep it in the final patch.
--- a/src/backend/parser/parse_agg.c
+++ b/src/backend/parser/parse_agg.c
@@ -552,11 +552,12 @@ check_agglevels_and_constraints(ParseState
*pstate, Node *expr)
break;
case EXPR_KIND_PUBLICATION_WHERE:
+#if 0
if (isAgg)
err = _("aggregate functions are not
allowed in publication WHERE expressions");
else
err = _("grouping operations are not
allowed in publication WHERE expressions");
-
+#endif
3) Can a user remove the row filter without removing the table from
the publication after creating the publication or should the user drop
the table and add the table in this case?
4) Should this be changed, since we error out if publisher without
replica identify performs delete or update:
+ The <literal>WHERE</literal> clause must contain only columns that are
+ covered by <literal>REPLICA IDENTITY</literal>, or are part of the primary
+ key (when <literal>REPLICA IDENTITY</literal> is not set), otherwise
+ <command>DELETE</command> or <command>UPDATE</command> operations will not
+ be replicated. That's because old row is used and it only contains primary
+ key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
+ remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
to:
+ The <literal>WHERE</literal> clause must contain only columns that are
+ covered by <literal>REPLICA IDENTITY</literal>, or are part of the primary
+ key (when <literal>REPLICA IDENTITY</literal> is not set), otherwise
+ <command>DELETE</command> or <command>UPDATE</command> operations will be
+ disallowed on those tables. That's because old row is used and it
only contains primary
+ key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
+ remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
Regards,
Vignesh
On Tue, Nov 30, 2021 at 12:33 PM Ajin Cherian <itsajin@gmail.com> wrote:
>
> On Thu, Nov 25, 2021 at 2:22 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Thanks for all the review comments so far! We are endeavouring to keep
> > pace with them.
> >
> > All feedback is being tracked and we will fix and/or reply to everything ASAP.
> >
> > Meanwhile, PSA the latest set of v42* patches.
> >
> > This version was mostly a patch restructuring exercise but it also
> > addresses some minor review comments in passing.
> >
>
> Addressed more review comments, in the attached patch-set v43. 5
> patches carried forward from v42.
> This patch-set contains the following fixes:
>
> On Tue, Nov 23, 2021 at 1:28 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:
> >
> > in pgoutput_row_filter, we are dropping the slots if there are some
> > old slots in the RelationSyncEntry. But then I noticed that in
> > rel_sync_cache_relation_cb(), also we are doing that but only for the
> > scantuple slot. So IMHO, rel_sync_cache_relation_cb(), is only place
> > setting entry->rowfilter_valid to false; so why not drop all the slot
> > that time only and in pgoutput_row_filter(), you can just put an
> > assert?
> >
>
> Moved all the dropping of slots to rel_sync_cache_relation_cb()
>
> > +static bool
> > +pgoutput_row_filter_virtual(Relation relation, TupleTableSlot *slot,
> > RelationSyncEntry *entry)
> > +{
> > + EState *estate;
> > + ExprContext *ecxt;
> >
> >
> > pgoutput_row_filter_virtual and pgoutput_row_filter are exactly same
> > except, ExecStoreHeapTuple(), so why not just put one check based on
> > whether a slot is passed or not, instead of making complete duplicate
> > copy of the function.
>
> Removed pgoutput_row_filter_virtual
>
> > oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> > tupdesc = CreateTupleDescCopy(tupdesc);
> > entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
> >
> > Why do we need to copy the tupledesc? do we think that we need to have
> > this slot even if we close the relation, if so can you add the
> > comments explaining why we are making a copy here.
>
> This code has been modified, and comments added.
>
> On Tue, Nov 23, 2021 at 8:02 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > One more thing related to this code:
> > pgoutput_row_filter()
> > {
> > ..
> > + if (!entry->rowfilter_valid)
> > {
> > ..
> > + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> > + tupdesc = CreateTupleDescCopy(tupdesc);
> > + entry->scantuple = MakeSingleTupleTableSlot(tupdesc, &TTSOpsHeapTuple);
> > + MemoryContextSwitchTo(oldctx);
> > ..
> > }
> >
> > Why do we need to initialize scantuple here unless we are sure that
> > the row filter is going to get associated with this relentry? I think
> > when there is no row filter then this allocation is not required.
> >
>
> Modified as suggested.
>
> On Tue, Nov 23, 2021 at 10:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > In 0003 patch, why is below change required?
> > --- a/src/backend/replication/pgoutput/pgoutput.c
> > +++ b/src/backend/replication/pgoutput/pgoutput.c
> > @@ -1,4 +1,4 @@
> > -/*-------------------------------------------------------------------------
> > +/*------------------------------------------------------------------------
> > *
> > * pgoutput.c
> >
>
> Removed.
>
> >
> > After above, rearrange the code in pgoutput_row_filter(), so that two
> > different checks related to 'rfisnull' (introduced by different
> > patches) can be combined as if .. else check.
> >
> Fixed.
>
> On Thu, Nov 25, 2021 at 12:03 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > + * If the new relation or the old relation has a where clause,
> > + * we need to remove it so that it can be added afresh later.
> > + */
> > + if (RelationGetRelid(newpubrel->relation) == oldrelid &&
> > + newpubrel->whereClause == NULL && rfisnull)
> >
> > Can't we use _equalPublicationTable() here? It compares the whereClause as well.
> >
>
> Tried this, can't do this because one is an alter statement while the
> other is a publication, the whereclause is not
> the same Nodetype. In the statement, the whereclause is T_A_Expr,
> while in the publication
> catalog, it is T_OpExpr.
Here we will not be able to do a direct comparison as we store the
transformed where clause in the pg_publication_rel table. We will have
to transform the where clause and then check. I have attached a patch
where we can check the transformed where clause and see if the where
clause is the same or not. If you are ok with this approach you could
make similar changes.
Regards,
Vignesh
Вложения
On Tue, Nov 30, 2021 at 9:34 PM vignesh C <vignesh21@gmail.com> wrote:
>
> 3) Can a user remove the row filter without removing the table from
> the publication after creating the publication or should the user drop
> the table and add the table in this case?
>
AFAIK to remove an existing filter use ALTER PUBLICATION ... SET TABLE
but do not specify any filter.
For example,
test_pub=# create table t1(a int primary key);
CREATE TABLE
test_pub=# create publication p1 for table t1 where (a > 1);
CREATE PUBLICATION
test_pub=# create publication p2 for table t1 where (a > 2);
CREATE PUBLICATION
test_pub=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage |
Compression | Stats target | Description
--------+---------+-----------+----------+---------+---------+-------------+--------------+-------------
a | integer | | not null | | plain |
| |
Indexes:
"t1_pkey" PRIMARY KEY, btree (a)
Publications:
"p1" WHERE ((a > 1))
"p2" WHERE ((a > 2))
Access method: heap
test_pub=# alter publication p1 set table t1;
ALTER PUBLICATION
test_pub=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage |
Compression | Stats target | Description
--------+---------+-----------+----------+---------+---------+-------------+--------------+-------------
a | integer | | not null | | plain |
| |
Indexes:
"t1_pkey" PRIMARY KEY, btree (a)
Publications:
"p1"
"p2" WHERE ((a > 2))
Access method: heap
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Nov 30, 2021, at 7:25 AM, Amit Kapila wrote:
On Tue, Nov 30, 2021 at 11:37 AM Dilip Kumar <dilipbalaut@gmail.com> wrote:>> What about the initial table sync? during that, we are going to> combine all the filters or we are going to apply only the insert> filters?>AFAIK, currently, initial table sync doesn't respect publicationactions so it should combine all the filters. What do you think?
I agree. If you think that it might need a row to apply DML commands (UPDATE,
DELETE) in the future or that due to a row filter that row should be available
in the subscriber (INSERT-only case), it makes sense to send all rows that
satisfies any row filter.
The current code already works this way. All row filter are combined into a
WHERE clause using OR. If any of the publications don't have a row filter,
there is no WHERE clause.
On Wed, Dec 1, 2021 at 6:55 AM Euler Taveira <euler@eulerto.com> wrote: > > On Tue, Nov 30, 2021, at 7:25 AM, Amit Kapila wrote: > > On Tue, Nov 30, 2021 at 11:37 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > What about the initial table sync? during that, we are going to > > combine all the filters or we are going to apply only the insert > > filters? > > > > AFAIK, currently, initial table sync doesn't respect publication > actions so it should combine all the filters. What do you think? > > I agree. If you think that it might need a row to apply DML commands (UPDATE, > DELETE) in the future or that due to a row filter that row should be available > in the subscriber (INSERT-only case), it makes sense to send all rows that > satisfies any row filter. > Right and Good point. -- With Regards, Amit Kapila.
PSA the v44* set of patches. The following review comments are addressed: v44-0001 main patch - Renamed the TAP test 026->027 due to clash caused by recent commit [1] - Refactored table_close [Houz 23/11] #2 - Alter compare where clauses [Amit 24/11] #0 - PG docs CREATE SUBSCRIPTION [Tang 30/11] #2 - PG docs CREATE PUBLICATION [Vignesh 30/11] #1, #4, [Tang 30/11] #1, [Tomas 23/9] #2 v44-0002 validation walker - Add NullTest support [Peter 18/11] - Update comments [Amit 24/11] #3 - Disallow user-defined types [Amit 24/11] #4 - Errmsg - skipped because handled by top-up [Vignesh 23/11] #2 - Removed #if 0 [Vignesh 30/11] #2 v44-0003 new/old tuple - NA v44-0004 tab-complete and pgdump - Handle table-list commas better [Vignesh 23/11] #2 v44-0005 top-up patch for validation - (This patch will be added again later) ------ [1] https://github.com/postgres/postgres/commit/8d74fc96db5fd547e077bf9bf4c3b67f821d71cd [Tomas 23/9] https://www.postgresql.org/message-id/574b4e78-2f35-acf3-4bdc-4b872582e739%40enterprisedb.com [Peter 18/11] https://www.postgresql.org/message-id/flat/CAFPTHDa67_H%3DsALy%2BEqXDGmUKm1MO-83apffZkO34RELjt_Prg%40mail.gmail.com#e5fb0d17564d7ffb11a64858598f5185 [Houz 23/11] https://www.postgresql.org/message-id/OS0PR01MB57162EB465A0E6BCFDF9B3F394609%40OS0PR01MB5716.jpnprd01.prod.outlook.com [Vignesh 23/11] https://www.postgresql.org/message-id/CALDaNm2bq-Zab3i5pvuA3UTxHvo3BqPwmgXbyznpw5vz4%3DfxpA%40mail.gmail.com [Amit 24/11] https://www.postgresql.org/message-id/CAA4eK1%2BXd%3DkM5D3jtXyN%2BW7J%2BwU-yyQAdyq66a6Wcq_PKRTbSw%40mail.gmail.com [Tang 30/11] https://www.postgresql.org/message-id/OS0PR01MB6113F2E024961A9C7F36BEADFB679%40OS0PR01MB6113.jpnprd01.prod.outlook.com [Vignesh 30/11] https://www.postgresql.org/message-id/CALDaNm2T3yXJkuKXARUUh%2B%3D_36Ry7gYxUqhpgW8AxECug9nH6Q%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > 2) create_publication.sgml says: > > A <literal>NULL</literal> value causes the expression to evaluate > to false; avoid using columns without not-null constraints in the > <literal>WHERE</literal> clause. > > That's not quite correct, I think - doesn't the expression evaluate to > NULL (which is not TRUE, so it counts as mismatch)? > > I suspect this whole paragraph (talking about NULL in old/new rows) > might be a bit too detailed / low-level for user docs. > Updated docs in v44 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 23, 2021 at 5:27 PM vignesh C <vignesh21@gmail.com> wrote:
>
> 2) Since the error message is because it publishes delete/update
> operations, it should include publish delete/update in the error
> message. Can we change the error message:
> + if (!bms_is_member(attnum -
> FirstLowInvalidHeapAttributeNumber, context->bms_replident))
> + {
> + const char *colname = get_attname(relid, attnum, false);
> +
> + ereport(ERROR,
> +
> (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
> + errmsg("cannot add relation
> \"%s\" to publication",
> +
> RelationGetRelationName(context->rel)),
> + errdetail("Row filter column
> \"%s\" is not part of the REPLICA IDENTITY",
> + colname)));
> + }
>
> To something like:
> ereport(ERROR,
> (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
> errmsg("cannot add relation \"%s\" to publication because row filter
> column \"%s\" does not have a replica identity and publishes
> deletes/updates",
> RelationGetRelationName(context->rel), colname),
> errhint("To enable deleting/updating from the table, set REPLICA
> IDENTITY using ALTER TABLE")));
>
The "top-up" patch 0005 (see v43*) is already addressing this now.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Nov 23, 2021 at 6:59 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tues, Nov 23, 2021 2:27 PM vignesh C <vignesh21@gmail.com> wrote:
> > On Thu, Nov 18, 2021 at 7:04 AM Peter Smith <smithpb2250@gmail.com>
> > wrote:
> > >
> > > PSA new set of v40* patches.
> >
> > Few comments:
...
> Another comment about v40-0001 patch:
>
>
> + char *relname = pstrdup(RelationGetRelationName(rel));
> +
> table_close(rel, ShareUpdateExclusiveLock);
> +
> + /* Disallow duplicate tables if there are any with row-filters. */
> + if (t->whereClause || list_member_oid(relids_with_rf, myrelid))
> + ereport(ERROR,
> + (errcode(ERRCODE_DUPLICATE_OBJECT),
> + errmsg("conflicting or redundant row-filters for \"%s\"",
> + relname)));
> + pfree(relname);
>
> Maybe we can do the error check before table_close(), so that we don't need to
> invoke pstrdup() and pfree().
>
Fixed in v44 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Nov 24, 2021 at 3:37 AM vignesh C <vignesh21@gmail.com> wrote:
>
> On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote:
> >
> > Attaching a new patchset v41 which includes changes by both Peter and myself.
>
> Few comments on v41-0002 patch:
...
> 2) Tab completion completes with "WHERE (" in case of "alter
> publication pub1 add table t1,":
> + /* ALTER PUBLICATION <name> SET TABLE <name> */
> + /* ALTER PUBLICATION <name> ADD TABLE <name> */
> + else if (Matches("ALTER", "PUBLICATION", MatchAny, "SET|ADD",
> "TABLE", MatchAny))
> + COMPLETE_WITH("WHERE (");
>
> Should this be changed to:
> + /* ALTER PUBLICATION <name> SET TABLE <name> */
> + /* ALTER PUBLICATION <name> ADD TABLE <name> */
> + else if (Matches("ALTER", "PUBLICATION", MatchAny, "SET|ADD",
> "TABLE", MatchAny) && (!ends_with(prev_wd, ','))
> + COMPLETE_WITH("WHERE (");
>
Fixed in v44 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Nov 25, 2021 at 12:03 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > Attaching a new patchset v41 which includes changes by both Peter and myself. > > > > Patches v40-0005 and v40-0006 have been merged to create patch > > v41-0005 which reduces the patches to 6 again. > > This patch-set contains changes addressing the following review comments: > > > > On Mon, Nov 15, 2021 at 5:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > What I meant was that with this new code we have regressed the old > > > behavior. Basically, imagine a case where no filter was given for any > > > of the tables. Then after the patch, we will remove all the old tables > > > whereas before the patch it will remove the oldrels only when they are > > > not specified as part of new rels. If you agree with this, then we can > > > retain the old behavior and for the new tables, we can always override > > > the where clause for a SET variant of command. > > > > Fixed and modified the behaviour to match with what the schema patch > > implemented. > > > > + > + /* > + * If the new relation or the old relation has a where clause, > + * we need to remove it so that it can be added afresh later. > + */ > + if (RelationGetRelid(newpubrel->relation) == oldrelid && > + newpubrel->whereClause == NULL && rfisnull) > > Can't we use _equalPublicationTable() here? It compares the whereClause as well. > Fixed in v44 [1] > Few more comments: > ================= > 0001 ... . > 3. In the function header comment of rowfilter_walker, you mentioned > the simple expressions allowed but we should write why we are doing > so. It has been discussed in detail in various emails in this thread. > AFAIR, below are the reasons: > A. We don't want to allow user-defined functions or operators because > (a) if the user drops such a function/operator or if there is any > other error via that function, the walsender won't be able to recover > from such an error even if we fix the function's problem because it > uses a historic snapshot to access row-filter; (b) any other table > could be accessed via a function which won't work because of historic > snapshots in logical decoding environment. > > B. We don't allow anything other immutable built-in functions as those > can access database and would lead to the problem (b) mentioned in the > previous paragraph. > Updated comment in v44 [1] > Don't we need to check for user-defined types similar to user-defined > functions and operators? If not why? Fixed in v44 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 30, 2021 at 2:49 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Thursday, November 25, 2021 11:22 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Thanks for all the review comments so far! We are endeavouring to keep > > pace with them. > > > > All feedback is being tracked and we will fix and/or reply to everything ASAP. > > > > Meanwhile, PSA the latest set of v42* patches. > > > > This version was mostly a patch restructuring exercise but it also > > addresses some minor review comments in passing. > > > > Thanks for your patch. > I have two comments on the document in 0001 patch. > > 1. > + New row is used and it contains all columns. A <literal>NULL</literal> value > + causes the expression to evaluate to false; avoid using columns without > > I don't quite understand this sentence 'A NULL value causes the expression to evaluate to false'. > The expression contains NULL value can also return true. Could you be more specific? > > For example: > > postgres=# select null or true; > ?column? > ---------- > t > (1 row) > Updated publication docs in v44 [1]. > > 2. > + at all then all other filters become redundant. If the subscriber is a > + <productname>PostgreSQL</productname> version before 15 then any row filtering > + is ignored. > > If the subscriber is a PostgreSQL version before 15, it seems row filtering will > be ignored only when copying initial data, the later changes will not be ignored in row > filtering. Should we make it clear in document? Updated subscription docs in v44 [1]. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Nov 30, 2021 at 9:34 PM vignesh C <vignesh21@gmail.com> wrote:
>
...
> Thanks for the updated patch, few comments:
> 1) Should this be changed to include non IMMUTABLE system functions
> are not allowed:
> + not-null constraints in the <literal>WHERE</literal> clause. The
> + <literal>WHERE</literal> clause does not allow functions or user-defined
> + operators.
> + </para>
>
Updated docs in v44 [1]
> 2) We can remove the #if 0 code if we don't plan to keep it in the final patch.
> --- a/src/backend/parser/parse_agg.c
> +++ b/src/backend/parser/parse_agg.c
> @@ -552,11 +552,12 @@ check_agglevels_and_constraints(ParseState
> *pstate, Node *expr)
>
> break;
> case EXPR_KIND_PUBLICATION_WHERE:
> +#if 0
> if (isAgg)
> err = _("aggregate functions are not
> allowed in publication WHERE expressions");
> else
> err = _("grouping operations are not
> allowed in publication WHERE expressions");
> -
> +#endif
>
Fixed in v44 [1]
> 4) Should this be changed, since we error out if publisher without
> replica identify performs delete or update:
> + The <literal>WHERE</literal> clause must contain only columns that are
> + covered by <literal>REPLICA IDENTITY</literal>, or are part of the primary
> + key (when <literal>REPLICA IDENTITY</literal> is not set), otherwise
> + <command>DELETE</command> or <command>UPDATE</command> operations will not
> + be replicated. That's because old row is used and it only contains primary
> + key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
> + remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
>
> to:
> + The <literal>WHERE</literal> clause must contain only columns that are
> + covered by <literal>REPLICA IDENTITY</literal>, or are part of the primary
> + key (when <literal>REPLICA IDENTITY</literal> is not set), otherwise
> + <command>DELETE</command> or <command>UPDATE</command> operations will be
> + disallowed on those tables. That's because old row is used and it
> only contains primary
> + key or columns that are part of the <literal>REPLICA IDENTITY</literal>; the
> + remaining columns are <literal>NULL</literal>. For <command>INSERT</command>
>
Updated docs in v44 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtjxzedJPbSZyb9pd72%2BUrGEj6HagQQbCdO0YJvr7OyJg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thursday, December 2, 2021 5:21 AM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA the v44* set of patches. > Thanks for the new patch. Few comments: 1. This is an example in publication doc, but in fact it's not allowed. Should we change this example? +CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE); postgres=# CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE); ERROR: invalid publication WHERE expression for relation "departments" HINT: only simple expressions using columns, constants and immutable system functions are allowed 2. A typo in 0002 patch. + * drops such a user-defnition or if there is any other error via its function, "user-defnition" should be "user-definition". Regards, Tang
On Thur, Dec 2, 2021 5:21 AM Peter Smith <smithpb2250@gmail.com> wrote: > PSA the v44* set of patches. > > The following review comments are addressed: > > v44-0001 main patch > - Renamed the TAP test 026->027 due to clash caused by recent commit [1] > - Refactored table_close [Houz 23/11] #2 > - Alter compare where clauses [Amit 24/11] #0 > - PG docs CREATE SUBSCRIPTION [Tang 30/11] #2 > - PG docs CREATE PUBLICATION [Vignesh 30/11] #1, #4, [Tang 30/11] #1, [Tomas > 23/9] #2 > > v44-0002 validation walker > - Add NullTest support [Peter 18/11] > - Update comments [Amit 24/11] #3 > - Disallow user-defined types [Amit 24/11] #4 > - Errmsg - skipped because handled by top-up [Vignesh 23/11] #2 > - Removed #if 0 [Vignesh 30/11] #2 > > v44-0003 new/old tuple > - NA > > v44-0004 tab-complete and pgdump > - Handle table-list commas better [Vignesh 23/11] #2 > > v44-0005 top-up patch for validation > - (This patch will be added again later) Attach the v44-0005 top-up patch. This version addressed all the comments received so far, mainly including the following changes: 1) rename rfcol_valid_for_replica to rfcol_valid 2) Remove the struct PublicationInfo and add the rfcol_valid flag directly in relation 3) report the invalid column number in the error message. 4) Rename some function to match the usage. 5) Fix some typos and add some code comments. 6) Fix a miss in testcase. Best regards, Hou zj
Вложения
On Wed, Dec 1, 2021 at 3:27 AM vignesh C <vignesh21@gmail.com> wrote: > > Here we will not be able to do a direct comparison as we store the > transformed where clause in the pg_publication_rel table. We will have > to transform the where clause and then check. I have attached a patch > where we can check the transformed where clause and see if the where > clause is the same or not. If you are ok with this approach you could > make similar changes. thanks for your patch, I have used the same logic with minor changes and shared it with Peter for v44. regards, Ajin Cherian Fujitsu Australia
On Tue, Nov 30, 2021 at 3:56 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Nov 29, 2021 at 8:40 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Mon, Nov 29, 2021, at 7:11 AM, Amit Kapila wrote: > > > > I don't think it is a good idea to combine the row-filter from the > > publication that publishes just 'insert' with the row-filter that > > publishes 'updates'. We shouldn't apply the 'insert' filter for > > 'update' and similarly for publication operations. We can combine the > > filters when the published operations are the same. So, this means > > that we might need to cache multiple row-filters but I think that is > > better than having another restriction that publish operation 'insert' > > should also honor RI columns restriction. > > > > That's exactly what I meant to say but apparently I didn't explain in details. > > If a subscriber has multiple publications and a table is part of these > > publications with different row filters, it should check the publication action > > *before* including it in the row filter list. It means that an UPDATE operation > > cannot apply a row filter that is part of a publication that has only INSERT as > > an action. Having said that we cannot always combine multiple row filter > > expressions into one. Instead, it should cache individual row filter expression > > and apply the OR during the row filter execution (as I did in the initial > > patches before this caching stuff). The other idea is to have multiple caches > > for each action. The main disadvantage of this approach is to create 4x > > entries. > > > > I'm experimenting the first approach that stores multiple row filters and its > > publication action right now. > > > > We can try that way but I think we should still be able to combine in > many cases like where all the operations are specified for > publications having the table or maybe pubactions are same. So, we > should not give up on those cases. We can do this new logic only when > we find that pubactions are different and probably store them as > independent expressions and corresponding pubactions for it at the > current location in the v42* patch (in pgoutput_row_filter). It is > okay to combine them at a later stage during execution when we can't > do it at the time of forming cache entry. > PSA a new v44* patch set. It includes a new patch 0006 which implements the idea above. ExprState cache logic is basically all the same as before (including all the OR combining), but there are now 4x ExprState caches keyed and separated by the 4x different pubactions. ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
- v44-0004-Tab-auto-complete-and-pgdump-support-for-Row-Fil.patch
- v44-0003-Support-updates-based-on-old-and-new-tuple-in-ro.patch
- v44-0002-PS-Row-filter-validation-walker.patch
- v44-0005-cache-the-result-of-row-filter-column-validation.patch
- v44-0001-Row-filter-for-logical-replication.patch
- v44-0006-Cache-ExprState-per-pubaction.patch
On Thu, Dec 2, 2021 at 9:29 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Thur, Dec 2, 2021 5:21 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > PSA the v44* set of patches.
> >
> > The following review comments are addressed:
> >
> > v44-0001 main patch
> > - Renamed the TAP test 026->027 due to clash caused by recent commit [1]
> > - Refactored table_close [Houz 23/11] #2
> > - Alter compare where clauses [Amit 24/11] #0
> > - PG docs CREATE SUBSCRIPTION [Tang 30/11] #2
> > - PG docs CREATE PUBLICATION [Vignesh 30/11] #1, #4, [Tang 30/11] #1, [Tomas
> > 23/9] #2
> >
> > v44-0002 validation walker
> > - Add NullTest support [Peter 18/11]
> > - Update comments [Amit 24/11] #3
> > - Disallow user-defined types [Amit 24/11] #4
> > - Errmsg - skipped because handled by top-up [Vignesh 23/11] #2
> > - Removed #if 0 [Vignesh 30/11] #2
> >
> > v44-0003 new/old tuple
> > - NA
> >
> > v44-0004 tab-complete and pgdump
> > - Handle table-list commas better [Vignesh 23/11] #2
> >
> > v44-0005 top-up patch for validation
> > - (This patch will be added again later)
>
> Attach the v44-0005 top-up patch.
Thanks for the updated patch, few comments:
1) Both testpub5a and testpub5c publication are same, one of them can be removed
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub5a FOR TABLE testpub_rf_tbl1 WHERE (a > 1)
WITH (publish="insert");
+CREATE PUBLICATION testpub5b FOR TABLE testpub_rf_tbl1;
+CREATE PUBLICATION testpub5c FOR TABLE testpub_rf_tbl1 WHERE (a > 3)
WITH (publish="insert");
+RESET client_min_messages;
+\d+ testpub_rf_tbl1
+DROP PUBLICATION testpub5a, testpub5b, testpub5c;
testpub5b will be covered in the earlier existing case above:
ALTER PUBLICATION testpib_ins_trunct ADD TABLE pub_test.testpub_nopk,
testpub_tbl1;
\d+ pub_test.testpub_nopk
\d+ testpub_tbl1
I felt test related to testpub5b is also not required
2) testpub5 and testpub_syntax2 are similar, one of them can be removed:
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1,
testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5);
+RESET client_min_messages;
+\dRp+ testpub5
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub_syntax2 FOR TABLE testpub_rf_tbl1,
testpub_rf_myschema.testpub_rf_tbl5 WHERE (h < 999);
+RESET client_min_messages;
+\dRp+ testpub_syntax2
+DROP PUBLICATION testpub_syntax2;
3) testpub7 can be renamed to testpub6 to maintain the continuity
since the previous testpub6 did not succeed:
+CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func, LEFTARG = integer,
RIGHTARG = integer);
+CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27);
+-- fail - WHERE not allowed in DROP
+ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl3 WHERE (e < 27);
+-- fail - cannot ALTER SET table which is a member of a pre-existing schema
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub7 FOR ALL TABLES IN SCHEMA testpub_rf_myschema1;
+ALTER PUBLICATION testpub7 SET ALL TABLES IN SCHEMA
testpub_rf_myschema1, TABLE testpub_rf_myschema1.testpub_rf_tb16;
+RESET client_min_messages;
4) Did this test intend to include where clause in testpub_rf_tb16, if
so it can be added:
+-- fail - cannot ALTER SET table which is a member of a pre-existing schema
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub7 FOR ALL TABLES IN SCHEMA testpub_rf_myschema1;
+ALTER PUBLICATION testpub7 SET ALL TABLES IN SCHEMA
testpub_rf_myschema1, TABLE testpub_rf_myschema1.testpub_rf_tb16;
+RESET client_min_messages;
5) It should be removed from typedefs.list too:
-/* For rowfilter_walker. */
-typedef struct {
- Relation rel;
- bool check_replident; /* check if Var is
bms_replident member? */
- Bitmapset *bms_replident;
-} rf_context;
-
Regards,
Vignesh
On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote:
PSA a new v44* patch set.It includes a new patch 0006 which implements the idea above.ExprState cache logic is basically all the same as before (includingall the OR combining), but there are now 4x ExprState caches keyed andseparated by the 4x different pubactions.
row filter is not applied for TRUNCATEs so it is just 3 operations.
On Fri, Dec 3, 2021 at 12:59 AM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote: > > PSA a new v44* patch set. > > It includes a new patch 0006 which implements the idea above. > > ExprState cache logic is basically all the same as before (including > all the OR combining), but there are now 4x ExprState caches keyed and > separated by the 4x different pubactions. > > row filter is not applied for TRUNCATEs so it is just 3 operations. > Correct. The patch 0006 comment/code will be updated for this point in the next version posted. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Dec 2, 2021 at 2:32 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Thursday, December 2, 2021 5:21 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA the v44* set of patches. > > > > Thanks for the new patch. Few comments: > > 1. This is an example in publication doc, but in fact it's not allowed. Should we > change this example? > > +CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE); > > postgres=# CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE); > ERROR: invalid publication WHERE expression for relation "departments" > HINT: only simple expressions using columns, constants and immutable system functions are allowed > Thanks for finding this. Actually, the documentation looks correct to me. The problem was the validation walker of patch 0002 was being overly restrictive. It needed to also allow a BooleanTest node. Now it works (locally) for me. For example. test_pub=# create table departments(depno int primary key, active boolean); CREATE TABLE test_pub=# create publication pdept for table departments where (active is true) with (publish="insert"); CREATE PUBLICATION test_pub=# create publication pdept2 for table departments where (active is false) with (publish="insert"); CREATE PUBLICATION This fix will be available in v45*. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Dec 2, 2021 at 6:18 PM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA a new v44* patch set. > Some initial comments: 0001 src/backend/replication/logical/tablesync.c (1) In fetch_remote_table_info update, "list_free(*qual);" should be "list_free_deep(*qual);" doc/src/sgml/ref/create_subscription.sgml (2) Refer to Notes Perhaps a link to the Notes section should be used here, as follows: - copied. Refer to the Notes section below. + copied. Refer to the <xref linkend="sql-createsubscription-notes"/> section below. - <refsect1> + <refsect1 id="sql-createsubscription-notes" xreflabel="Notes"> 0002 1) Typo in patch comment "Specifially" src/backend/catalog/pg_publication.c 2) bms_replident comment Member "Bitmapset *bms_replident;" in rf_context should have a comment, maybe something like "set of replica identity col indexes". 3) errdetail message In rowfilter_walker(), the "forbidden" errdetail message is loaded using gettext() in one instance, but just a raw formatted string in other cases. Shouldn't they all consistently be translated strings? 0003 src/backend/replication/logical/proto.c 1) logicalrep_write_tuple (i) if (slot == NULL || TTS_EMPTY(slot)) can be replaced with: if (TupIsNull(slot)) (ii) In the above case (where values and nulls are palloc'd), shouldn't the values and nulls be pfree()d at the end of the function? 0005 src/backend/utils/cache/relcache.c (1) RelationGetInvalRowFilterCol Shouldn't "rfnode" be pfree()d after use? Regards, Greg Nancarrow Fujitsu Australia
On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote:
PSA a new v44* patch set.
We are actively developing this feature for some months and we improved this
feature a lot. This has been a good team work. It seems a good time to provide
a retrospective for this feature based on the consensus we reached until now.
The current design has one row filter per publication-table mapping. It allows
flexible choices while using the same table for multiple replication purposes.
The WHERE clause was chosen as the syntax to declare the row filter expression
(enclosed by parentheses).
There was a lot of discussion about which columns are allowed to use in the row
filter expression. The consensus was that publications that publish UPDATE
and/or DELETE operations, should check if the columns in the row filter
expression is part of the replica identity. Otherwise, these DML operations
couldn't be replicated.
We also discussed about which expression would be allowed. We couldn't allow
all kind of expressions because the way logical decoding infrastructure was
designed, some expressions could break the replication. Hence, we decided to
allow only "simple expressions". By "simple expression", we mean to restrict
(a) user-defined objects (functions, operators, types) and (b) immutable
builtin functions.
A subscription can subscribe to multiple publications. These publication can
publish the same table. In this case, we have to combine the row filter
expression to decide if the row will be replicated or not. The consensus was to
replicate a row if any of the row filters returns true. It means that if one
publication-table mapping does not have a row filter, the row will be
replicated. There is an optimization for this case that provides an empty
expression for this table. Hence, it bails out and replicate the row without
running the row filter code.
The same logic applies to the initial table synchronization if there are
multiple row filters. Copy all rows that satisfies at least one row filter
expression. If the subscriber is a pre-15 version, data synchronization won't
use row filters if they are defined in the publisher.
If we are dealing with partitioned tables, the publication parameter
publish_via_partition_root determines if it uses the partition row filter
(false) or the root partitioned table row filter (true).
I used the last patch series (v44) posted by Peter Smith [1]. I did a lot of
improvements in this new version (v45). I merged 0001 (it is basically the main
patch I wrote) and 0004 (autocomplete). As I explained in [2], I implemented a
patch (that is incorporated in the v45-0001) to fix this issue. I saw that
Peter already proposed a slightly different patch (0006). I read this patch and
concludes that it would be better to keep the version I have. It fixes a few
things and also includes more comments. I attached another patch (v45-0002)
that includes the expression validation. It is based on 0002. I completely
overhaul it. There are additional expressions that was not supported by the
previous version (such as conditional expressions [CASE, COALESCE, NULLIF,
GREATEST, LEAST], array operators, XML operators). I probably didn't finish the
supported node list (there are a few primitive nodes that need to be checked).
However, the current "simple expression" routine seems promising. I plan to
integrate v45-0002 in the next patch version. I attached it here for comparison
purposes only.
My next step is to review 0003. As I said before it would like to treat it as a
separate feature. I know that it is useful for data consistency but this patch
is already too complex. Having said that, I didn't include it in this patch
series because it doesn't apply cleanly. If Ajin would like to provide a new
version, I would appreciate.
PS> I will update the commit message in the next version. I barely changed the
documentation to reflect the current behavior. I probably missed some changes
but I will fix in the next version.
Вложения
This is great work thanks for the Realisation Update.
Euler Taveira <euler@eulerto.com> schrieb am Sa., 4. Dez. 2021, 00:13:
On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote:PSA a new v44* patch set.We are actively developing this feature for some months and we improved thisfeature a lot. This has been a good team work. It seems a good time to providea retrospective for this feature based on the consensus we reached until now.The current design has one row filter per publication-table mapping. It allowsflexible choices while using the same table for multiple replication purposes.The WHERE clause was chosen as the syntax to declare the row filter expression(enclosed by parentheses).There was a lot of discussion about which columns are allowed to use in the rowfilter expression. The consensus was that publications that publish UPDATEand/or DELETE operations, should check if the columns in the row filterexpression is part of the replica identity. Otherwise, these DML operationscouldn't be replicated.We also discussed about which expression would be allowed. We couldn't allowall kind of expressions because the way logical decoding infrastructure wasdesigned, some expressions could break the replication. Hence, we decided toallow only "simple expressions". By "simple expression", we mean to restrict(a) user-defined objects (functions, operators, types) and (b) immutablebuiltin functions.A subscription can subscribe to multiple publications. These publication canpublish the same table. In this case, we have to combine the row filterexpression to decide if the row will be replicated or not. The consensus was toreplicate a row if any of the row filters returns true. It means that if onepublication-table mapping does not have a row filter, the row will bereplicated. There is an optimization for this case that provides an emptyexpression for this table. Hence, it bails out and replicate the row withoutrunning the row filter code.The same logic applies to the initial table synchronization if there aremultiple row filters. Copy all rows that satisfies at least one row filterexpression. If the subscriber is a pre-15 version, data synchronization won'tuse row filters if they are defined in the publisher.If we are dealing with partitioned tables, the publication parameterpublish_via_partition_root determines if it uses the partition row filter(false) or the root partitioned table row filter (true).I used the last patch series (v44) posted by Peter Smith [1]. I did a lot ofimprovements in this new version (v45). I merged 0001 (it is basically the mainpatch I wrote) and 0004 (autocomplete). As I explained in [2], I implemented apatch (that is incorporated in the v45-0001) to fix this issue. I saw thatPeter already proposed a slightly different patch (0006). I read this patch andconcludes that it would be better to keep the version I have. It fixes a fewthings and also includes more comments. I attached another patch (v45-0002)that includes the expression validation. It is based on 0002. I completelyoverhaul it. There are additional expressions that was not supported by theprevious version (such as conditional expressions [CASE, COALESCE, NULLIF,GREATEST, LEAST], array operators, XML operators). I probably didn't finish thesupported node list (there are a few primitive nodes that need to be checked).However, the current "simple expression" routine seems promising. I plan tointegrate v45-0002 in the next patch version. I attached it here for comparisonpurposes only.My next step is to review 0003. As I said before it would like to treat it as aseparate feature. I know that it is useful for data consistency but this patchis already too complex. Having said that, I didn't include it in this patchseries because it doesn't apply cleanly. If Ajin would like to provide a newversion, I would appreciate.PS> I will update the commit message in the next version. I barely changed thedocumentation to reflect the current behavior. I probably missed some changesbut I will fix in the next version.
On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote:
PS> I will update the commit message in the next version. I barely changed thedocumentation to reflect the current behavior. I probably missed some changesbut I will fix in the next version.
I realized that I forgot to mention a few things about the UPDATE behavior.
Regardless of 0003, we need to define which tuple will be used to evaluate the
row filter for UPDATEs. We already discussed it circa [1]. This current version
chooses *new* tuple. Is it the best choice?
Let's check all cases. There are 2 rows on the provider. One row satisfies the
row filter and the other one doesn't. For each case, I expect the initial rows
to be there (no modifications). The DDLs are:
CREATE TABLE foo (a integer, b text, PRIMARY KEY(a));
INSERT INTO foo (a, b) VALUES(10, 'abc'),(30, 'abc');
CREATE PUBLICATION bar FOR TABLE foo WHERE (a > 20);
The table describes what happen on the subscriber. BEFORE is the current row on
subscriber. OLD, NEW and OLD & NEW are action/row if we consider different ways
to evaluate the row filter.
-- case 1: old tuple (10, abc) ; new tuple (10, def)
UPDATE foo SET b = 'def' WHERE a = 10;
+-----------+--------------------+------------------+------------------+
| BEFORE | OLD | NEW | OLD & NEW |
+-----------+--------------------+------------------+------------------+
| NA | NA | NA | NA |
+-----------+--------------------+------------------+------------------+
If the old and new tuple don't satisfy the row filter, there is no issue.
-- case 2: old tuple (30, abc) ; new tuple (30, def)
UPDATE foo SET b = 'def' WHERE a = 30;
+-----------+--------------------+------------------+------------------+
| BEFORE | OLD | NEW | OLD & NEW |
+-----------+--------------------+------------------+------------------+
| (30, abc) | UPDATE (30, def) | UPDATE (30, def) | UPDATE (30, def) |
+-----------+--------------------+------------------+------------------+
If the old and new tuple satisfy the row filter, there is no issue.
-- case 3: old tuple (30, abc) ; new tuple (10, def)
UPDATE foo SET a = 10, b = 'def' WHERE a = 30;
+-----------+--------------------+------------------+------------------+
| BEFORE | OLD | NEW | OLD & NEW |
+-----------+--------------------+------------------+------------------+
| (30, abc) | UPDATE (10, def) * | KEEP (30, abc) * | KEEP (30, abc) * |
+-----------+--------------------+------------------+------------------+
If the old tuple satisfies the row filter but the new tuple doesn't, we have a
data consistency issue. Since the old tuple satisfies the row filter, the
initial table synchronization copies this row. However, after the UPDATE the
new tuple doesn't satisfy the row filter then, from the data consistency
perspective, that row should be removed on the subscriber.
The OLD sends the UPDATE because it satisfies the row filter (if it is a
sharding solution this new row should be moved to another node). The new row
would likely not be modified by replication again. That's a data inconsistency
according to the row filter.
The NEW and OLD & NEW don't send the UPDATE because it doesn't satisfy the row
filter. Keep the old row is undesirable because it doesn't reflect what we have
on the source. This row on the subscriber would likely not be modified by
replication again. If someone inserted a new row with a = 30, replication will
stop because there is already a row with that value.
-- case 4: old tuple (10, abc) ; new tuple (30, def)
UPDATE foo SET a = 30, b = 'def' WHERE a = 10;
+-----------+--------------------+------------------+------------------+
| BEFORE | OLD | NEW | OLD & NEW |
+-----------+--------------------+------------------+------------------+
| NA | NA ! | NA ! | NA |
+-----------+--------------------+------------------+------------------+
The OLD and OLD & NEW don't send the UPDATE because it doesn't satisfy the row
filter. The NEW sends the UPDATE because it satisfies the row filter but there
is no row to modify. The current behavior does nothing. However, it should
INSERT the new tuple. Subsequent UPDATE or DELETE have no effect. It could be a
surprise for an application that expects the same data set from the provider.
If we have to choose the default behavior I would say use the old tuple for
evaluates row filter. Why? The validation already restricts the columns to
replica identity so there isn't an issues with missing (NULL) columns. The case
3 updates the row with a value that is not consistent but keeping the old row
is worse because it could stop the replication if someone inserted the old key
in a new row on the provider. The case 4 ignores the UPDATE if it cannot find
the tuple but it could provide an error if there was an strict mode.
Since this change is very simple to revert, this new version contains this
modification. I also improve the documentation, remove extra parenthesis from
psql/pg_dump. As I said in the previous email, I merged the validation patch too.
FWIW in the previous version, I removed a code that compares nodes to decide if
it is necessary to remove the publication-relation entry. I had a similar code
in a ancient version of this patch but decided that the additional code is not
worth.
There is at least one issue in the current code that should be addressed: PK or
REPLICA IDENTITY modification could break the publication check for UPDATEs and
DELETEs.
Вложения
On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > PS> I will update the commit message in the next version. I barely changed the > documentation to reflect the current behavior. I probably missed some changes > but I will fix in the next version. > > I realized that I forgot to mention a few things about the UPDATE behavior. > Regardless of 0003, we need to define which tuple will be used to evaluate the > row filter for UPDATEs. We already discussed it circa [1]. This current version > chooses *new* tuple. Is it the best choice? But with 0003, we are using both the tuple for evaluating the row filter, so instead of fixing 0001, why we don't just merge 0003 with 0001? I mean eventually, 0003 is doing what is the agreed behavior, i.e. if just OLD is matching the filter then convert the UPDATE to DELETE OTOH if only new is matching the filter then convert the UPDATE to INSERT. Do you think that even we merge 0001 and 0003 then also there is an open issue regarding which row to select for the filter? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Sat, Dec 4, 2021 at 4:43 AM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote: > > PSA a new v44* patch set. > > We are actively developing this feature for some months and we improved this > feature a lot. This has been a good team work. It seems a good time to provide > a retrospective for this feature based on the consensus we reached until now. > > The current design has one row filter per publication-table mapping. It allows > flexible choices while using the same table for multiple replication purposes. > The WHERE clause was chosen as the syntax to declare the row filter expression > (enclosed by parentheses). > > There was a lot of discussion about which columns are allowed to use in the row > filter expression. The consensus was that publications that publish UPDATE > and/or DELETE operations, should check if the columns in the row filter > expression is part of the replica identity. Otherwise, these DML operations > couldn't be replicated. > > We also discussed about which expression would be allowed. We couldn't allow > all kind of expressions because the way logical decoding infrastructure was > designed, some expressions could break the replication. Hence, we decided to > allow only "simple expressions". By "simple expression", we mean to restrict > (a) user-defined objects (functions, operators, types) and (b) immutable > builtin functions. > I think what you said as (b) is wrong because we want to allow builtin immutable functions. See discussion [1]. > A subscription can subscribe to multiple publications. These publication can > publish the same table. In this case, we have to combine the row filter > expression to decide if the row will be replicated or not. The consensus was to > replicate a row if any of the row filters returns true. It means that if one > publication-table mapping does not have a row filter, the row will be > replicated. There is an optimization for this case that provides an empty > expression for this table. Hence, it bails out and replicate the row without > running the row filter code. > In addition to this, we have decided to have an exception/optimization where we need to consider publish actions while combining multiple filters as we can't combine insert/update filters. > The same logic applies to the initial table synchronization if there are > multiple row filters. Copy all rows that satisfies at least one row filter > expression. If the subscriber is a pre-15 version, data synchronization won't > use row filters if they are defined in the publisher. > > If we are dealing with partitioned tables, the publication parameter > publish_via_partition_root determines if it uses the partition row filter > (false) or the root partitioned table row filter (true). > > I used the last patch series (v44) posted by Peter Smith [1]. I did a lot of > improvements in this new version (v45). I merged 0001 (it is basically the main > patch I wrote) and 0004 (autocomplete). As I explained in [2], I implemented a > patch (that is incorporated in the v45-0001) to fix this issue. I saw that > Peter already proposed a slightly different patch (0006). I read this patch and > concludes that it would be better to keep the version I have. It fixes a few > things and also includes more comments. I attached another patch (v45-0002) > that includes the expression validation. It is based on 0002. I completely > overhaul it. There are additional expressions that was not supported by the > previous version (such as conditional expressions [CASE, COALESCE, NULLIF, > GREATEST, LEAST], array operators, XML operators). I probably didn't finish the > supported node list (there are a few primitive nodes that need to be checked). > However, the current "simple expression" routine seems promising. I plan to > integrate v45-0002 in the next patch version. I attached it here for comparison > purposes only. > > My next step is to review 0003. As I said before it would like to treat it as a > separate feature. > I don't think that would be right decision as we already had discussed that in detail and reach to the current conclusion based on which Ajin's 0003 patch is. > I know that it is useful for data consistency but this patch > is already too complex. > True, but that is the main reason the review and development are being done as separate sub-features. I suggest still keeping the similar separation till some of the reviews of each of the patches are done, otherwise, we need to rethink how to divide for easier review. We need to retain the 0005 patch because that handles many problems without which the main patch is incomplete and buggy w.r.t replica identity. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BXoD49bz5-2TtiD0ugq4PHSRX2D1sLPR_X4LNtdMc4OQ%40mail.gmail.com -- With Regards, Amit Kapila.
On Mon, Dec 6, 2021 at 12:06 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > > > PS> I will update the commit message in the next version. I barely changed the > > documentation to reflect the current behavior. I probably missed some changes > > but I will fix in the next version. > > > > I realized that I forgot to mention a few things about the UPDATE behavior. > > Regardless of 0003, we need to define which tuple will be used to evaluate the > > row filter for UPDATEs. We already discussed it circa [1]. This current version > > chooses *new* tuple. Is it the best choice? > > But with 0003, we are using both the tuple for evaluating the row > filter, so instead of fixing 0001, why we don't just merge 0003 with > 0001? > I agree that would be better than coming up with an entirely new approach especially when the current approach is discussed and agreed upon. > I mean eventually, 0003 is doing what is the agreed behavior, > i.e. if just OLD is matching the filter then convert the UPDATE to > DELETE OTOH if only new is matching the filter then convert the UPDATE > to INSERT. +1. > Do you think that even we merge 0001 and 0003 then also > there is an open issue regarding which row to select for the filter? > I think eventually we should merge 0001 and 0003 to avoid any sort of data consistency but it is better to keep them separate for the purpose of a review at this stage. If I am not wrong that still needs bug-fix we are discussing it as part of CF entry [1], right? If so, isn't it better to review that bug-fix patch and the 0003 patch being discussed here [2] to avoid missing any already reported issues in this thread? [1] - https://commitfest.postgresql.org/36/3162/ [2] - https://www.postgresql.org/message-id/CAHut%2BPtJnnM8MYQDf7xCyFAp13U_0Ya2dv-UQeFD%3DghixFLZiw%40mail.gmail.com -- With Regards, Amit Kapila.
On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > PS> I will update the commit message in the next version. I barely changed the > documentation to reflect the current behavior. I probably missed some changes > but I will fix in the next version. > > I realized that I forgot to mention a few things about the UPDATE behavior. > Regardless of 0003, we need to define which tuple will be used to evaluate the > row filter for UPDATEs. We already discussed it circa [1]. This current version > chooses *new* tuple. Is it the best choice? > Apart from the data inconsistency problems you outlined below, I think there is a major design problem with that w.r.t toast tuples as unchanged key values won't be part of *new* tuple. > Let's check all cases. There are 2 rows on the provider. One row satisfies the > row filter and the other one doesn't. For each case, I expect the initial rows > to be there (no modifications). The DDLs are: > > CREATE TABLE foo (a integer, b text, PRIMARY KEY(a)); > INSERT INTO foo (a, b) VALUES(10, 'abc'),(30, 'abc'); > CREATE PUBLICATION bar FOR TABLE foo WHERE (a > 20); > > The table describes what happen on the subscriber. BEFORE is the current row on > subscriber. OLD, NEW and OLD & NEW are action/row if we consider different ways > to evaluate the row filter. > > -- case 1: old tuple (10, abc) ; new tuple (10, def) > UPDATE foo SET b = 'def' WHERE a = 10; > > +-----------+--------------------+------------------+------------------+ > | BEFORE | OLD | NEW | OLD & NEW | > +-----------+--------------------+------------------+------------------+ > | NA | NA | NA | NA | > +-----------+--------------------+------------------+------------------+ > > If the old and new tuple don't satisfy the row filter, there is no issue. > > -- case 2: old tuple (30, abc) ; new tuple (30, def) > UPDATE foo SET b = 'def' WHERE a = 30; > > +-----------+--------------------+------------------+------------------+ > | BEFORE | OLD | NEW | OLD & NEW | > +-----------+--------------------+------------------+------------------+ > | (30, abc) | UPDATE (30, def) | UPDATE (30, def) | UPDATE (30, def) | > +-----------+--------------------+------------------+------------------+ > > If the old and new tuple satisfy the row filter, there is no issue. > > -- case 3: old tuple (30, abc) ; new tuple (10, def) > UPDATE foo SET a = 10, b = 'def' WHERE a = 30; > > +-----------+--------------------+------------------+------------------+ > | BEFORE | OLD | NEW | OLD & NEW | > +-----------+--------------------+------------------+------------------+ > | (30, abc) | UPDATE (10, def) * | KEEP (30, abc) * | KEEP (30, abc) * | > +-----------+--------------------+------------------+------------------+ > > If the old tuple satisfies the row filter but the new tuple doesn't, we have a > data consistency issue. Since the old tuple satisfies the row filter, the > initial table synchronization copies this row. However, after the UPDATE the > new tuple doesn't satisfy the row filter then, from the data consistency > perspective, that row should be removed on the subscriber. > This is the reason we decide to make such cases to transform UPDATE to DELETE. > The OLD sends the UPDATE because it satisfies the row filter (if it is a > sharding solution this new row should be moved to another node). The new row > would likely not be modified by replication again. That's a data inconsistency > according to the row filter. > > The NEW and OLD & NEW don't send the UPDATE because it doesn't satisfy the row > filter. Keep the old row is undesirable because it doesn't reflect what we have > on the source. This row on the subscriber would likely not be modified by > replication again. If someone inserted a new row with a = 30, replication will > stop because there is already a row with that value. > This shouldn't be a problem with the v44 patch version (0003 handles it). > -- case 4: old tuple (10, abc) ; new tuple (30, def) > UPDATE foo SET a = 30, b = 'def' WHERE a = 10; > > +-----------+--------------------+------------------+------------------+ > | BEFORE | OLD | NEW | OLD & NEW | > +-----------+--------------------+------------------+------------------+ > | NA | NA ! | NA ! | NA | > +-----------+--------------------+------------------+------------------+ > > The OLD and OLD & NEW don't send the UPDATE because it doesn't satisfy the row > filter. The NEW sends the UPDATE because it satisfies the row filter but there > is no row to modify. The current behavior does nothing. However, it should > INSERT the new tuple. Subsequent UPDATE or DELETE have no effect. It could be a > surprise for an application that expects the same data set from the provider. > Again this is addressed by V44 as an Insert would be performed in this case. > If we have to choose the default behavior I would say use the old tuple for > evaluates row filter. Why? The validation already restricts the columns to > replica identity so there isn't an issues with missing (NULL) columns. The case > 3 updates the row with a value that is not consistent but keeping the old row > is worse because it could stop the replication if someone inserted the old key > in a new row on the provider. The case 4 ignores the UPDATE if it cannot find > the tuple but it could provide an error if there was an strict mode. > Hmm, I think it is much better to translate Update to Delete in case-3 and Update to Insert in case-4 as there shouldn't be any data consistency issues after that. All these issues have been discussed in detail in this thread and based on that we decided to follow the v44 (0003) patch version approach. We have also investigated some other replication solutions and they were also doing the similar translations to avoid such issues. > Since this change is very simple to revert, this new version contains this > modification. I also improve the documentation, remove extra parenthesis from > psql/pg_dump. As I said in the previous email, I merged the validation patch too. > As said previously it might be better to keep those separate for easier review. It is anyway better to split such a big patch for ease of review even if in the end we combine all the work. > FWIW in the previous version, I removed a code that compares nodes to decide if > it is necessary to remove the publication-relation entry. I had a similar code > in a ancient version of this patch but decided that the additional code is not > worth. > > There is at least one issue in the current code that should be addressed: PK or > REPLICA IDENTITY modification could break the publication check for UPDATEs and > DELETEs. > Please see patch 0005 [1]. I think it tries to address the issues w.r.t Replica Identity interaction with this feature. Feel free to test/review and let us know if you see any issues. [1] - https://www.postgresql.org/message-id/CAHut%2BPtJnnM8MYQDf7xCyFAp13U_0Ya2dv-UQeFD%3DghixFLZiw%40mail.gmail.com -- With Regards, Amit Kapila.
On Sat, Dec 4, 2021 at 10:13 AM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Dec 2, 2021, at 4:18 AM, Peter Smith wrote: > > PSA a new v44* patch set. > ... > I used the last patch series (v44) posted by Peter Smith [1]. I did a lot of > improvements in this new version (v45). I merged 0001 (it is basically the main > patch I wrote) and 0004 (autocomplete). As I explained in [2], I implemented a > patch (that is incorporated in the v45-0001) to fix this issue. I saw that > Peter already proposed a slightly different patch (0006). I read this patch and > concludes that it would be better to keep the version I have. It fixes a few > things and also includes more comments. > [1] https://postgr.es/m/CAHut%2BPtJnnM8MYQDf7xCyFAp13U_0Ya2dv-UQeFD%3DghixFLZiw%40mail.gmail.com > [2] https://postgr.es/m/ca8d270d-f930-4d15-9f24-60f95b364173%40www.fastmail.com >> As I explained in [2], I implemented a patch (that is incorporated in the v45-0001) to fix this issue. I saw that Peter already proposed a slightly different patch (0006). I read this patch and concludes that it would be better to keep the version I have. It fixes a few things and also includes more comments. Your ExprState exprstate array code is essentially exactly the same logic that was int patch v44-0006 isn't it? The main difference I saw was 1. I pass the cache index (e.g. IDX_PUBACTION_DELETE etc) to the pgoutput_filter, but 2. You are passing in the ReorderBufferChangeType value. IMO the ability to directly access the cache array is more efficient. The function is called for every row operation (e.g. consider x 1 million rows) so I felt the overhead to have unnecessary if/else should be avoided. e.g. ------ if (action == REORDER_BUFFER_CHANGE_INSERT) result = pgoutput_row_filter_exec_expr(entry->exprstate[0], ecxt); else if (action == REORDER_BUFFER_CHANGE_UPDATE) result = pgoutput_row_filter_exec_expr(entry->exprstate[1], ecxt); else if (action == REORDER_BUFFER_CHANGE_DELETE) result = pgoutput_row_filter_exec_expr(entry->exprstate[2], ecxt); else Assert(false); ------ Why not just use a direct index like was in patch v44-0006 in the first place? e.g. ------ result = pgoutput_row_filter_exec_expr(entry->exprstate[idx_pubaction], ecxt); ------ Conveniently, those ReorderBufferChangeType first 3 enums are the ones you want so you can still pass them if you want. REORDER_BUFFER_CHANGE_INSERT, REORDER_BUFFER_CHANGE_UPDATE, REORDER_BUFFER_CHANGE_DELETE, Just use them to directly index into entry->exprstate[action] and so remove the excessive if/else. What do you think? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Dec 6, 2021, at 3:35 AM, Dilip Kumar wrote:
On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote:>> On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote:>> PS> I will update the commit message in the next version. I barely changed the> documentation to reflect the current behavior. I probably missed some changes> but I will fix in the next version.>> I realized that I forgot to mention a few things about the UPDATE behavior.> Regardless of 0003, we need to define which tuple will be used to evaluate the> row filter for UPDATEs. We already discussed it circa [1]. This current version> chooses *new* tuple. Is it the best choice?But with 0003, we are using both the tuple for evaluating the rowfilter, so instead of fixing 0001, why we don't just merge 0003 with0001? I mean eventually, 0003 is doing what is the agreed behavior,i.e. if just OLD is matching the filter then convert the UPDATE toDELETE OTOH if only new is matching the filter then convert the UPDATEto INSERT. Do you think that even we merge 0001 and 0003 then alsothere is an open issue regarding which row to select for the filter?
Maybe I was not clear. IIUC we are still discussing 0003 and I would like to
propose a different default based on the conclusion I came up. If we merged
0003, that's fine; this change will be useless. If we don't or it is optional,
it still has its merit.
Do we want to pay the overhead to evaluating both tuple for UPDATEs? I'm still
processing if it is worth it. If you think that in general the row filter
contains the primary key and it is rare to change it, it will waste cycles
evaluating the same expression twice. It seems this behavior could be
controlled by a parameter.
On Mon, Dec 6, 2021, at 3:44 AM, Amit Kapila wrote:
I think what you said as (b) is wrong because we want to allow builtinimmutable functions. See discussion [1].
It was a typo. I mean "non-immutable" function.
True, but that is the main reason the review and development are beingdone as separate sub-features. I suggest still keeping the similarseparation till some of the reviews of each of the patches are done,otherwise, we need to rethink how to divide for easier review. We needto retain the 0005 patch because that handles many problems withoutwhich the main patch is incomplete and buggy w.r.t replica identity.
IMO we should merge sub-features as soon as we reach consensus. Every new
sub-feature breaks comments, tests and documentation if you want to remove or
rearrange patches. It seems I misread 0005. I agree that it is important. I'll
check it.
On Mon, Dec 6, 2021 at 6:18 PM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Dec 6, 2021, at 3:44 AM, Amit Kapila wrote: > > True, but that is the main reason the review and development are being > done as separate sub-features. I suggest still keeping the similar > separation till some of the reviews of each of the patches are done, > otherwise, we need to rethink how to divide for easier review. We need > to retain the 0005 patch because that handles many problems without > which the main patch is incomplete and buggy w.r.t replica identity. > > IMO we should merge sub-features as soon as we reach consensus. Every new > sub-feature breaks comments, tests and documentation if you want to remove or > rearrange patches. > I agree that there is some effort but OTOH, it gives the flexibility to do a focussed review and as soon as some patch is ready or close to ready we can merge in the main patch. This was just a humble suggestion based on how this patch was making progress and how it has helped to keep some parts separate by allowing different people to work on different parts of the problem. > It seems I misread 0005. I agree that it is important. I'll > check it. > Okay, thanks! -- With Regards, Amit Kapila.
Hi Euler – As you know we have been posting patch update versions to the Row-Filter thread several times a week now for a few months. We are carefully tracking all open review comments of the thread and fixing as many as possible with each version posted. ~~ It is true that the multiple patches are difficult to maintain (particular for test cases impacting other patches), but - this is the arrangement that Amit preferred (without whose support as a committer this patch would likely be stalled). - separate patches have allowed us to spread the work across multiple people to improve the velocity (e.g. the Hou-san top-up patch 0005). - having multiple patches also allows the review comments to be more focused. ~~ We were mid-way putting together the next v45* when your latest attachment was posted over the weekend. So we will proceed with our original plan to post our v45* (tomorrow). After v45* is posted we will pause to find what are all the differences between your unified patch and our v45* patch set. Our intention is to integrate as many improvements as possible from your changes into the v46* etc that will follow tomorrow’s v45*. On some points, we will most likely need further discussion. With luck, soon everything can be more in sync again. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Friday, December 3, 2021 10:09 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Thu, Dec 2, 2021 at 2:32 PM tanghy.fnst@fujitsu.com > <tanghy.fnst@fujitsu.com> wrote: > > > > On Thursday, December 2, 2021 5:21 AM Peter Smith > <smithpb2250@gmail.com> wrote: > > > > > > PSA the v44* set of patches. > > > > > > > Thanks for the new patch. Few comments: > > > > 1. This is an example in publication doc, but in fact it's not allowed. Should we > > change this example? > > > > +CREATE PUBLICATION active_departments FOR TABLE departments WHERE > (active IS TRUE); > > > > postgres=# CREATE PUBLICATION active_departments FOR TABLE departments > WHERE (active IS TRUE); > > ERROR: invalid publication WHERE expression for relation "departments" > > HINT: only simple expressions using columns, constants and immutable system > functions are allowed > > > > Thanks for finding this. Actually, the documentation looks correct to > me. The problem was the validation walker of patch 0002 was being > overly restrictive. It needed to also allow a BooleanTest node. > > Now it works (locally) for me. For example. > > test_pub=# create table departments(depno int primary key, active boolean); > CREATE TABLE > test_pub=# create publication pdept for table departments where > (active is true) with (publish="insert"); > CREATE PUBLICATION > test_pub=# create publication pdept2 for table departments where > (active is false) with (publish="insert"); > CREATE PUBLICATION > > This fix will be available in v45*. > Thanks for looking into it. I have another problem with your patch. The document says: ... If the subscription has several publications in + which the same table has been published with different filters, those + expressions get OR'ed together so that rows satisfying any of the expressions + will be replicated. Notice this means if one of the publications has no filter + at all then all other filters become redundant. Then, what if one of the publications is specified as 'FOR ALL TABLES' or 'FOR ALL TABLES IN SCHEMA'. For example: create table tbl (a int primary key);" create publication p1 for table tbl where (a > 10); create publication p2 for all tables; create subscription sub connection 'dbname=postgres port=5432' publication p1, p2; I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be treated as no filter, and table tbl should have no filter in subscription sub. Thoughts? But for now, the filter(a > 10) works both when copying initial data and later changes. To fix it, I think we can check if the table is published in a 'FOR ALL TABLES' publication or published as part of schema in function pgoutput_row_filter_init (which was introduced in v44-0003 patch), also we need to make some changes in tablesync.c. Regards Tang
On Tue, Dec 7, 2021 at 12:18 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Friday, December 3, 2021 10:09 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Thu, Dec 2, 2021 at 2:32 PM tanghy.fnst@fujitsu.com > > <tanghy.fnst@fujitsu.com> wrote: > > > > > > On Thursday, December 2, 2021 5:21 AM Peter Smith > > <smithpb2250@gmail.com> wrote: > > > > > > > > PSA the v44* set of patches. > > > > > > > > > > Thanks for the new patch. Few comments: > > > > > > 1. This is an example in publication doc, but in fact it's not allowed. Should we > > > change this example? > > > > > > +CREATE PUBLICATION active_departments FOR TABLE departments WHERE > > (active IS TRUE); > > > > > > postgres=# CREATE PUBLICATION active_departments FOR TABLE departments > > WHERE (active IS TRUE); > > > ERROR: invalid publication WHERE expression for relation "departments" > > > HINT: only simple expressions using columns, constants and immutable system > > functions are allowed > > > > > > > Thanks for finding this. Actually, the documentation looks correct to > > me. The problem was the validation walker of patch 0002 was being > > overly restrictive. It needed to also allow a BooleanTest node. > > > > Now it works (locally) for me. For example. > > > > test_pub=# create table departments(depno int primary key, active boolean); > > CREATE TABLE > > test_pub=# create publication pdept for table departments where > > (active is true) with (publish="insert"); > > CREATE PUBLICATION > > test_pub=# create publication pdept2 for table departments where > > (active is false) with (publish="insert"); > > CREATE PUBLICATION > > > > This fix will be available in v45*. > > > > Thanks for looking into it. > > I have another problem with your patch. The document says: > > ... If the subscription has several publications in > + which the same table has been published with different filters, those > + expressions get OR'ed together so that rows satisfying any of the expressions > + will be replicated. Notice this means if one of the publications has no filter > + at all then all other filters become redundant. > > Then, what if one of the publications is specified as 'FOR ALL TABLES' or 'FOR > ALL TABLES IN SCHEMA'. > > For example: > create table tbl (a int primary key);" > create publication p1 for table tbl where (a > 10); > create publication p2 for all tables; > create subscription sub connection 'dbname=postgres port=5432' publication p1, p2; Thanks for the example. I was wondering about this case myself. > > I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be > treated as no filter, and table tbl should have no filter in subscription sub. Thoughts? > > But for now, the filter(a > 10) works both when copying initial data and later changes. > > To fix it, I think we can check if the table is published in a 'FOR ALL TABLES' > publication or published as part of schema in function pgoutput_row_filter_init > (which was introduced in v44-0003 patch), also we need to make some changes in > tablesync.c. In order to check "FOR ALL_TABLES", we might need to fetch publication metdata. Instead of that can we add a "TRUE" filter on all the tables which are part of FOR ALL TABLES publication? -- Best Wishes, Ashutosh Bapat
On Tue, Dec 7, 2021 at 6:31 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > On Tue, Dec 7, 2021 at 12:18 PM tanghy.fnst@fujitsu.com > <tanghy.fnst@fujitsu.com> wrote: > > > > I have another problem with your patch. The document says: > > > > ... If the subscription has several publications in > > + which the same table has been published with different filters, those > > + expressions get OR'ed together so that rows satisfying any of the expressions > > + will be replicated. Notice this means if one of the publications has no filter > > + at all then all other filters become redundant. > > > > Then, what if one of the publications is specified as 'FOR ALL TABLES' or 'FOR > > ALL TABLES IN SCHEMA'. > > > > For example: > > create table tbl (a int primary key);" > > create publication p1 for table tbl where (a > 10); > > create publication p2 for all tables; > > create subscription sub connection 'dbname=postgres port=5432' publication p1, p2; > > Thanks for the example. I was wondering about this case myself. > I think we should handle this case. > > > > I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be > > treated as no filter, and table tbl should have no filter in subscription sub. Thoughts? > > > > But for now, the filter(a > 10) works both when copying initial data and later changes. > > > > To fix it, I think we can check if the table is published in a 'FOR ALL TABLES' > > publication or published as part of schema in function pgoutput_row_filter_init > > (which was introduced in v44-0003 patch), also we need to make some changes in > > tablesync.c. > > In order to check "FOR ALL_TABLES", we might need to fetch publication > metadata. > Do we really need to perform a separate fetch for this? In get_rel_sync_entry(), we already have this information, can't we someway stash that in the corresponding RelationSyncEntry so that same can be used later for row filtering. > Instead of that can we add a "TRUE" filter on all the tables > which are part of FOR ALL TABLES publication? > How? We won't have an entry for such tables in pg_publication_rel where we store row_filter information. -- With Regards, Amit Kapila.
On Thu, Dec 2, 2021 at 2:59 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
...
> Attach the v44-0005 top-up patch.
> This version addressed all the comments received so far,
> mainly including the following changes:
> 1) rename rfcol_valid_for_replica to rfcol_valid
> 2) Remove the struct PublicationInfo and add the rfcol_valid flag directly in relation
> 3) report the invalid column number in the error message.
> 4) Rename some function to match the usage.
> 5) Fix some typos and add some code comments.
> 6) Fix a miss in testcase.
Below are my review comments for the most recent v44-0005 (top-up) patch:
======
1. src/backend/executor/execReplication.c
+ invalid_rfcol = RelationGetInvalRowFilterCol(rel);
+
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns of the row
+ * filters from publications which the relation is in are part of the
+ * REPLICA IDENTITY.
+ */
+ if (invalid_rfcol != InvalidAttrNumber)
+ {
It seemed confusing that when the invalid_rfcol is NOT invalid at all
then it is InvalidAttrNumber, so perhaps this code would be easier to
read if instead the condition was written just as:
---
if (invalid_rfcol)
{
...
}
---
====
2. invalid_rfcol var name
This variable name is used in a few places but I thought it was too
closely named with the "rfcol_valid" variable even though it has a
completely different meaning. IMO "invalid_rfcol" might be better
named "invalid_rfcolnum" or something like that to reinforce that it
is an AttributeNumber.
====
3. src/backend/utils/cache/relcache.c - function comment
+ * If not all the row filter columns are part of REPLICA IDENTITY, return the
+ * invalid column number, InvalidAttrNumber otherwise.
+ */
Minor rewording:
"InvalidAttrNumber otherwise." --> "otherwise InvalidAttrNumber."
====
4. src/backend/utils/cache/relcache.c - function name
+AttrNumber
+RelationGetInvalRowFilterCol(Relation relation)
IMO nothing was gained by saving 2 chars of the name.
"RelationGetInvalRowFilterCol" --> "RelationGetInvalidRowFilterCol"
====
5. src/backend/utils/cache/relcache.c
+/* For invalid_rowfilter_column_walker. */
+typedef struct {
+ AttrNumber invalid_rfcol;
+ Bitmapset *bms_replident;
+} rf_context;
+
The members should be commented.
====
6. src/include/utils/rel.h
/*
+ * true if the columns of row filters from all the publications the
+ * relation is in are part of replica identity.
+ */
+ bool rd_rfcol_valid;
I felt the member comment is not quite telling the full story. e.g.
IIUC this member is also true when pubaction is something other than
update/delete - but that case doesn't even do replica identity
checking at all. There might not even be any replica identity.
====
6. src/test/regress/sql/publication.sql
CREATE PUBLICATION testpub6 FOR TABLE rf_tbl_abcd_pk WHERE (a > 99);
+-- fail - "a" is in PK but it is not part of REPLICA IDENTITY INDEX
+update rf_tbl_abcd_pk set a = 1;
+DROP PUBLICATION testpub6;
-- ok - "c" is not in PK but it is part of REPLICA IDENTITY INDEX
-SET client_min_messages = 'ERROR';
CREATE PUBLICATION testpub6 FOR TABLE rf_tbl_abcd_pk WHERE (c > 99);
DROP PUBLICATION testpub6;
-RESET client_min_messages;
--- fail - "a" is not in REPLICA IDENTITY INDEX
CREATE PUBLICATION testpub6 FOR TABLE rf_tbl_abcd_nopk WHERE (a > 99);
+-- fail - "a" is not in REPLICA IDENTITY INDEX
+update rf_tbl_abcd_nopk set a = 1;
The "update" DML should be uppercase "UPDATE" for consistency with the
surrounding tests.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Dec 6, 2021 at 6:04 PM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Dec 6, 2021, at 3:35 AM, Dilip Kumar wrote: > > On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > > > PS> I will update the commit message in the next version. I barely changed the > > documentation to reflect the current behavior. I probably missed some changes > > but I will fix in the next version. > > > > I realized that I forgot to mention a few things about the UPDATE behavior. > > Regardless of 0003, we need to define which tuple will be used to evaluate the > > row filter for UPDATEs. We already discussed it circa [1]. This current version > > chooses *new* tuple. Is it the best choice? > > But with 0003, we are using both the tuple for evaluating the row > filter, so instead of fixing 0001, why we don't just merge 0003 with > 0001? I mean eventually, 0003 is doing what is the agreed behavior, > i.e. if just OLD is matching the filter then convert the UPDATE to > DELETE OTOH if only new is matching the filter then convert the UPDATE > to INSERT. Do you think that even we merge 0001 and 0003 then also > there is an open issue regarding which row to select for the filter? > > Maybe I was not clear. IIUC we are still discussing 0003 and I would like to > propose a different default based on the conclusion I came up. If we merged > 0003, that's fine; this change will be useless. If we don't or it is optional, > it still has its merit. > > Do we want to pay the overhead to evaluating both tuple for UPDATEs? I'm still > processing if it is worth it. If you think that in general the row filter > contains the primary key and it is rare to change it, it will waste cycles > evaluating the same expression twice. It seems this behavior could be > controlled by a parameter. > I think the first thing we should do in this regard is to evaluate the performance for both cases (when we apply a filter to both tuples vs. to one of the tuples). In case the performance difference is unacceptable, I think it would be better to still compare both tuples as default to avoid data inconsistency issues and have an option to allow comparing one of the tuples. -- With Regards, Amit Kapila.
On Wed, Dec 8, 2021 at 10:54 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Do we really need to perform a separate fetch for this? In > get_rel_sync_entry(), we already have this information, can't we > someway stash that in the corresponding RelationSyncEntry so that same > can be used later for row filtering. > > > Instead of that can we add a "TRUE" filter on all the tables > > which are part of FOR ALL TABLES publication? > > > > How? We won't have an entry for such tables in pg_publication_rel > where we store row_filter information. I missed that. Your solution works. Thanks. -- Best Wishes, Ashutosh Bapat
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > I finally had time to take a closer look at the patch again, so here's > some review comments. The thread is moving fast, so chances are some of > the comments are obsolete or were already raised in the past. > ... > 11) extra (unnecessary) parens in the deparsed expression > > test=# alter publication p add table t where ((b < 100) and (c < 100)); > ALTER PUBLICATION > test=# \dRp+ p > Publication p > Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root > -------+------------+---------+---------+---------+-----------+---------- > user | f | t | t | t | t | f > Tables: > "public.t" WHERE (((b < 100) AND (c < 100))) > Euler's fix for this was integrated into v45 [1] ------ [1] https://www.postgresql.org/message-id/CAFPTHDYB4nbxCMAFQGowJtDf7E6uBc%3D%3D_HupBKy7MaMhM%2B9QQA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Dec 8, 2021 7:52 PM Ajin Cherian <itsajin@gmail.com> wrote: > On Tue, Dec 7, 2021 at 5:36 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > We were mid-way putting together the next v45* when your latest > > attachment was posted over the weekend. So we will proceed with our > > original plan to post our v45* (tomorrow). > > > > After v45* is posted we will pause to find what are all the > > differences between your unified patch and our v45* patch set. Our > > intention is to integrate as many improvements as possible from your > > changes into the v46* etc that will follow tomorrow’s v45*. On some > > points, we will most likely need further discussion. > > > Posting an update for review comments, using contributions majorly from > Peter Smith. > I've also included changes based on Euler's combined patch, specially changes > to documentation and test cases. > I have left out Hou-san's 0005, in this patch-set. Hou-san will provide a rebased > update based on this. Attach the Top up patch(as 0006) which do the replica identity validation when actual UPDATE/DELETE happen. I adjusted the patch name to make the change clearer. The new version top up patch addressed all comments from Peter[1] and Greg[2]. I also fixed a validation issue of the top up patch reported by Tang. The fix is: If we add a partitioned table with filter and pubviaroot is true, we need to validate the parent table's row filter when UPDATE the child table and we should convert the parent table's column to the child's during validation in case the column order of parent table is different from the child table. [1] https://www.postgresql.org/message-id/CAHut%2BPuBdXGLw1%2BCBoNxXUp3bHcHcKYWHx1RSGF6tY5aSLu5ZA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAJcOf-dgxGmRs54nxQSZWDc0gaHZWFf3n%2BBhOChNXhi_cb8g9A%40mail.gmail.com Best regards, Hou zj
Вложения
- v45-0005-Cache-ExprState-per-pubaction.patch
- v45-0001-Row-filter-for-logical-replication.patch
- v45-0002-PS-Row-filter-validation-walker.patch
- v45-0003-Support-updates-based-on-old-and-new-tuple-in-ro.patch
- v45-0004-Tab-auto-complete-and-pgdump-support-for-Row-Fil.patch
- v45-0006-do-replica-identity-validation-when-UPDATE-or-DELETE.patch
On Wednesday, December 8, 2021 7:52 PM Ajin Cherian <itsajin@gmail.com>
> On Tue, Dec 7, 2021 at 5:36 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > We were mid-way putting together the next v45* when your latest
> > attachment was posted over the weekend. So we will proceed with our
> > original plan to post our v45* (tomorrow).
> >
> > After v45* is posted we will pause to find what are all the
> > differences between your unified patch and our v45* patch set. Our
> > intention is to integrate as many improvements as possible from your
> > changes into the v46* etc that will follow tomorrow’s v45*. On some
> > points, we will most likely need further discussion.
>
>
> Posting an update for review comments, using contributions majorly from
> Peter Smith.
> I've also included changes based on Euler's combined patch, specially changes
> to documentation and test cases.
> I have left out Hou-san's 0005, in this patch-set. Hou-san will provide a rebased
> update based on this.
>
> This patch addresses the following review comments:
Hi,
Thanks for updating the patch.
I noticed a possible issue.
+ /* Check row filter. */
+ if (!pgoutput_row_filter(data, relation, oldtuple, NULL, relentry))
+ break;
+
+ maybe_send_schema(ctx, change, relation, relentry);
+
/* Switch relation if publishing via root. */
if (relentry->publish_as_relid != RelationGetRelid(relation))
{
...
/* Convert tuple if needed. */
if (relentry->map)
tuple = execute_attr_map_tuple(tuple, relentry->map);
Currently, we execute the row filter before converting the tuple, I think it could
get wrong result if we are executing a parent table's row filter and the column
order of the parent table is different from the child table. For example:
----
create table parent(a int primary key, b int) partition by range (a);
create table child (b int, a int primary key);
alter table parent attach partition child default;
create publication pub for table parent where(a>10) with(PUBLISH_VIA_PARTITION_ROOT);
The column number of 'a' is '1' in filter expression while column 'a' is the
second one in the original tuple. I think we might need to execute the filter
expression after converting.
Best regards,
Hou zj
PSA the v46* patch set. Here are the main differences from v45: 0. Rebased to HEAD 1. Integrated many comments, docs, messages, code etc from Euler's patch [Euler 6/12] 2. Several bugfixes 3. Patches are merged/added ~~ Bugfix and Patch Merge details: v46-0001 (main) - Merged from v45-0001 (main) + v45-0005 (exprstate) - Fix for mem leak reported by Greg (off-list) v46-0002 (validation) - Merged from v45-0002 (node validation) + v45-0006 (replica identity validation) v46-0003 - Rebased from v45-0003 - Fix for partition column order [Houz 9/12] - Fix for core dump reported by Tang (off-list) v46-0004 (tab-complete and dump) - Rebased from v45-0004 v46-0005 (for all tables) - New patch - Fix for FOR ALL TABLES [Tang 7/12] ------ [Euler 6/12] https://www.postgresql.org/message-id/b676aef0-00c7-4c19-85f8-33786594e807%40www.fastmail.com [Tang 7/12] https://www.postgresql.org/message-id/OS0PR01MB6113D82113AA081ACF710D0CFB6E9%40OS0PR01MB6113.jpnprd01.prod.outlook.com [Houz 9/12] https://www.postgresql.org/message-id/OS0PR01MB5716EB3137D194030EB694F194709%40OS0PR01MB5716.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Dec 9, 2021 at 1:37 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wednesday, December 8, 2021 7:52 PM Ajin Cherian <itsajin@gmail.com>
> > On Tue, Dec 7, 2021 at 5:36 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > We were mid-way putting together the next v45* when your latest
> > > attachment was posted over the weekend. So we will proceed with our
> > > original plan to post our v45* (tomorrow).
> > >
> > > After v45* is posted we will pause to find what are all the
> > > differences between your unified patch and our v45* patch set. Our
> > > intention is to integrate as many improvements as possible from your
> > > changes into the v46* etc that will follow tomorrow’s v45*. On some
> > > points, we will most likely need further discussion.
> >
> >
> > Posting an update for review comments, using contributions majorly from
> > Peter Smith.
> > I've also included changes based on Euler's combined patch, specially changes
> > to documentation and test cases.
> > I have left out Hou-san's 0005, in this patch-set. Hou-san will provide a rebased
> > update based on this.
> >
> > This patch addresses the following review comments:
>
> Hi,
>
> Thanks for updating the patch.
> I noticed a possible issue.
>
> + /* Check row filter. */
> + if (!pgoutput_row_filter(data, relation, oldtuple, NULL, relentry))
> + break;
> +
> + maybe_send_schema(ctx, change, relation, relentry);
> +
> /* Switch relation if publishing via root. */
> if (relentry->publish_as_relid != RelationGetRelid(relation))
> {
> ...
> /* Convert tuple if needed. */
> if (relentry->map)
> tuple = execute_attr_map_tuple(tuple, relentry->map);
>
> Currently, we execute the row filter before converting the tuple, I think it could
> get wrong result if we are executing a parent table's row filter and the column
> order of the parent table is different from the child table. For example:
>
> ----
> create table parent(a int primary key, b int) partition by range (a);
> create table child (b int, a int primary key);
> alter table parent attach partition child default;
> create publication pub for table parent where(a>10) with(PUBLISH_VIA_PARTITION_ROOT);
>
> The column number of 'a' is '1' in filter expression while column 'a' is the
> second one in the original tuple. I think we might need to execute the filter
> expression after converting.
>
Fixed in v46* [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtoxjo6hpDFTya6WYH-zdspKQ5j%2BwZHBRc6EZkAkq7Nfw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Dec 7, 2021 at 5:48 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > ... > Thanks for looking into it. > > I have another problem with your patch. The document says: > > ... If the subscription has several publications in > + which the same table has been published with different filters, those > + expressions get OR'ed together so that rows satisfying any of the expressions > + will be replicated. Notice this means if one of the publications has no filter > + at all then all other filters become redundant. > > Then, what if one of the publications is specified as 'FOR ALL TABLES' or 'FOR > ALL TABLES IN SCHEMA'. > > For example: > create table tbl (a int primary key);" > create publication p1 for table tbl where (a > 10); > create publication p2 for all tables; > create subscription sub connection 'dbname=postgres port=5432' publication p1, p2; > > I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be > treated as no filter, and table tbl should have no filter in subscription sub. Thoughts? > > But for now, the filter(a > 10) works both when copying initial data and later changes. > > To fix it, I think we can check if the table is published in a 'FOR ALL TABLES' > publication or published as part of schema in function pgoutput_row_filter_init > (which was introduced in v44-0003 patch), also we need to make some changes in > tablesync.c. > Partly fixed in v46-0005 [1] NOTE - The initial COPY part of the tablesync does not take the publish operation into account so it means that if any of the subscribed publications have "puballtables" flag then all data will be copied sans filters. I guess this is consistent with the other decision to ignore publication operations [2]. TODO - Documentation - IIUC there is a similar case yet to be addressed - FOR ALL TABLES IN SCHEMA ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtoxjo6hpDFTya6WYH-zdspKQ5j%2BwZHBRc6EZkAkq7Nfw%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAA4eK1L3r%2BURSLFotOT5Y88ffscCskRoGC15H3CSAU1jj_0Rdg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Tue, Dec 7, 2021 at 5:48 PM tanghy.fnst@fujitsu.com
> <tanghy.fnst@fujitsu.com> wrote:
> >
> > I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be
> > treated as no filter, and table tbl should have no filter in subscription sub. Thoughts?
> >
> > But for now, the filter(a > 10) works both when copying initial data and later changes.
> >
> > To fix it, I think we can check if the table is published in a 'FOR ALL TABLES'
> > publication or published as part of schema in function pgoutput_row_filter_init
> > (which was introduced in v44-0003 patch), also we need to make some changes in
> > tablesync.c.
> >
>
> Partly fixed in v46-0005 [1]
>
> NOTE
> - The initial COPY part of the tablesync does not take the publish
> operation into account so it means that if any of the subscribed
> publications have "puballtables" flag then all data will be copied
> sans filters.
>
I think this should be okay but the way you have implemented it in the
patch doesn't appear to be the optimal way. Can't we fetch
allpubtables info and qual info as part of one query instead of using
separate queries?
> I guess this is consistent with the other decision to
> ignore publication operations [2].
>
> TODO
> - Documentation
> - IIUC there is a similar case yet to be addressed - FOR ALL TABLES IN SCHEMA
>
Yeah, "FOR ALL TABLES IN SCHEMA" should also be addressed. In this
case, the difference would be that we need to check the presence of
schema corresponding to the table (for which we are fetching
row_filter information) is there in pg_publication_namespace. If it
exists then we don't need to apply row_filter for the table. I feel it
is better to fetch all this information as part of the query which you
are using to fetch row_filter info. The idea is to avoid the extra
round-trip between subscriber and publisher.
Few other comments:
===================
1.
@@ -926,6 +928,22 @@ pgoutput_row_filter_init(PGOutputData *data,
Relation relation, RelationSyncEntr
bool rfisnull;
/*
+ * If the publication is FOR ALL TABLES then it is treated same as if this
+ * table has no filters (even if for some other publication it does).
+ */
+ if (pub->alltables)
+ {
+ if (pub->pubactions.pubinsert)
+ no_filter[idx_ins] = true;
+ if (pub->pubactions.pubupdate)
+ no_filter[idx_upd] = true;
+ if (pub->pubactions.pubdelete)
+ no_filter[idx_del] = true;
+
+ continue;
+ }
Is there a reason to continue checking the other publications if
no_filter is true for all kind of pubactions?
2.
+ * All row filter expressions will be discarded if there is one
+ * publication-relation entry without a row filter. That's because
+ * all expressions are aggregated by the OR operator. The row
+ * filter absence means replicate all rows so a single valid
+ * expression means publish this row.
This same comment is at two places, remove from one of the places. I
think keeping it atop for loop is better.
3.
+ {
+ int idx;
+ bool found_filters = false;
I am not sure if starting such ad-hoc braces in the code to localize
the scope of variables is a regular practice. Can we please remove
this?
--
With Regards,
Amit Kapila.
On Tue, Dec 14, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Few other comments: > =================== Few more comments: ================== v46-0001/0002 =============== 1. After rowfilter_walker() why do we need EXPR_KIND_PUBLICATION_WHERE? I thought this is primarily to identify the expressions that are not allowed in rowfilter which we are now able to detect upfront with the help of a walker. Can't we instead use EXPR_KIND_WHERE? 2. +Node * +GetTransformedWhereClause(ParseState *pstate, PublicationRelInfo *pri, + bool bfixupcollation) Can we add comments atop this function? 3. In GetTransformedWhereClause, can we change the name of variables (a) bfixupcollation to fixup_collation or assign_collation, (b) transformedwhereclause to whereclause. I think that will make the function more readable. v46-0002 ======== 4. + else if (IsA(node, List) || IsA(node, Const) || IsA(node, BoolExpr) || IsA(node, NullIfExpr) || + IsA(node, NullTest) || IsA(node, BooleanTest) || IsA(node, CoalesceExpr) || + IsA(node, CaseExpr) || IsA(node, CaseTestExpr) || IsA(node, MinMaxExpr) || + IsA(node, ArrayExpr) || IsA(node, ScalarArrayOpExpr) || IsA(node, XmlExpr)) Can we move this to a separate function say IsValidRowFilterExpr() or something on those lines and use Switch (nodetag(node)) to identify these nodes? -- With Regards, Amit Kapila.
On Tue, Dec 14, 2021 at 10:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 14, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Few other comments: > > =================== > > Few more comments: > ================== > v46-0001/0002 > =============== > 1. After rowfilter_walker() why do we need > EXPR_KIND_PUBLICATION_WHERE? I thought this is primarily to identify > the expressions that are not allowed in rowfilter which we are now > able to detect upfront with the help of a walker. Can't we instead use > EXPR_KIND_WHERE? FYI - I have tried this locally and all tests pass. ~~ If the EXPR_KIND_PUBLICATION_WHERE is removed then there will be some differences: - we would get errors for aggregate/grouping functions from the EXPR_KIND_WHERE - we would get errors for windows functions from the EXPR_KIND_WHERE - we would get errors for set-returning functions from the EXPR_KIND_WHERE Actually, IMO this would be a *good* change because AFAIK those are not all being checked by the row-filter walker. I think the only reason all tests pass is that there are no specific regression tests for these cases. OTOH, there would also be a difference where an error message would not be as nice. Please see the review comment from Vignesh. [1] The improved error message is only possible by checking the EXPR_KIND_PUBLICATION_WHERE. ~~ I think the best thing to do here is to leave the EXPR_KIND_PUBLICATION_WHERE but simplify code so that the improved error message remains as the *only* difference in behaviour from the EXPR_KIND_WHERE. i.e. we should let the other aggregate/grouping/windows/set function checks give errors exactly the same as for the EXPR_KIND_WHERE case. ------ [1] https://www.postgresql.org/message-id/CALDaNm08Ynr_FzNg%2BdoHj%3D_nBet%2BKZAvNbqmkEEw7M2SPpPEAw%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Dec 15, 2021 at 6:47 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, Dec 14, 2021 at 10:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Dec 14, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > Few other comments: > > > =================== > > > > Few more comments: > > ================== > > v46-0001/0002 > > =============== > > 1. After rowfilter_walker() why do we need > > EXPR_KIND_PUBLICATION_WHERE? I thought this is primarily to identify > > the expressions that are not allowed in rowfilter which we are now > > able to detect upfront with the help of a walker. Can't we instead use > > EXPR_KIND_WHERE? > > FYI - I have tried this locally and all tests pass. > > ~~ > > If the EXPR_KIND_PUBLICATION_WHERE is removed then there will be some > differences: > - we would get errors for aggregate/grouping functions from the EXPR_KIND_WHERE > - we would get errors for windows functions from the EXPR_KIND_WHERE > - we would get errors for set-returning functions from the EXPR_KIND_WHERE > > Actually, IMO this would be a *good* change because AFAIK those are > not all being checked by the row-filter walker. I think the only > reason all tests pass is that there are no specific regression tests > for these cases. > > OTOH, there would also be a difference where an error message would > not be as nice. Please see the review comment from Vignesh. [1] The > improved error message is only possible by checking the > EXPR_KIND_PUBLICATION_WHERE. > > ~~ > > I think the best thing to do here is to leave the > EXPR_KIND_PUBLICATION_WHERE but simplify code so that the improved > error message remains as the *only* difference in behaviour from the > EXPR_KIND_WHERE. i.e. we should let the other > aggregate/grouping/windows/set function checks give errors exactly the > same as for the EXPR_KIND_WHERE case. > I am not sure if "the better error message" is a good enough reason to introduce this new kind. I thought it is better to deal with that in rowfilter_walker. -- With Regards, Amit Kapila.
On Mon, Dec 13, 2021 at 8:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA the v46* patch set.
>
0001
(1)
"If a subscriber is a pre-15 version, the initial table
synchronization won't use row filters even if they are defined in the
publisher."
Won't this lead to data inconsistencies or errors that otherwise
wouldn't happen? Should such subscriptions be allowed?
(2) In the 0001 patch comment, the term "publication filter" is used
in one place, and in others "row filter" or "row-filter".
src/backend/catalog/pg_publication.c
(3) GetTransformedWhereClause() is missing a function comment.
(4)
The following comment seems incomplete:
+ /* Fix up collation information */
+ whereclause = GetTransformedWhereClause(pstate, pri, true);
src/backend/parser/parse_relation.c
(5)
wording? consistent?
Shouldn't it be "publication WHERE expression" for consistency?
+ errmsg("publication row-filter WHERE invalid reference to table \"%s\"",
+ relation->relname),
src/backend/replication/logical/tablesync.c
(6)
(i) Improve wording:
BEFORE:
/*
* Get information about remote relation in similar fashion the RELATION
- * message provides during replication.
+ * message provides during replication. This function also returns the relation
+ * qualifications to be used in COPY command.
*/
AFTER:
/*
- * Get information about remote relation in similar fashion the RELATION
- * message provides during replication.
+ * Get information about a remote relation, in a similar fashion to
how the RELATION
+ * message provides information during replication. This function
also returns the relation
+ * qualifications to be used in the COPY command.
*/
(ii) fetch_remote_table_info() doesn't currently account for ALL
TABLES and ALL TABLES IN SCHEMA.
src/backend/replication/pgoutput/pgoutput.c
(7) pgoutput_tow_filter()
I think that the "ExecDropSingleTupleTableSlot(entry->scantuple);" is
not needed in pgoutput_tow_filter() - I don't think it can be non-NULL
when entry->exprstate_valid is false
(8) I am a little unsure about this "combine filters on copy
(irrespective of pubaction)" functionality. What if a filter is
specified and the only pubaction is DELETE?
0002
src/backend/catalog/pg_publication.c
(1) rowfilter_walker()
One of the errdetail messages doesn't begin with an uppercase letter:
+ errdetail_msg = _("user-defined types are not allowed");
src/backend/executor/execReplication.c
(2) CheckCmdReplicaIdentity()
Strictly speaking, the following:
+ if (invalid_rfcolnum)
should be:
+ if (invalid_rfcolnum != InvalidAttrNumber)
0003
src/backend/replication/logical/tablesync.c
(1)
Column name in comment should be "puballtables" not "puballtable":
+ * If any publication has puballtable true then all row-filtering is
(2) pgoutput_row_filter_init()
There should be a space before the final "*/" (so the asterisks align).
Also, should say "... treated the same".
/*
+ * If the publication is FOR ALL TABLES then it is treated same as if this
+ * table has no filters (even if for some other publication it does).
+ */
Regards,
Greg Nancarrow
Fujitsu Australia
On Wed, Dec 15, 2021 at 10:20 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Mon, Dec 13, 2021 at 8:49 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA the v46* patch set. > > > > 0001 > > (1) > > "If a subscriber is a pre-15 version, the initial table > synchronization won't use row filters even if they are defined in the > publisher." > > Won't this lead to data inconsistencies or errors that otherwise > wouldn't happen? > How? The subscribers will get all the initial data. > Should such subscriptions be allowed? > I am not sure what you have in mind here? How can we change the already released code pre-15 for this new feature? -- With Regards, Amit Kapila.
On Wed, Dec 15, 2021 at 5:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> > "If a subscriber is a pre-15 version, the initial table
> > synchronization won't use row filters even if they are defined in the
> > publisher."
> >
> > Won't this lead to data inconsistencies or errors that otherwise
> > wouldn't happen?
> >
>
> How? The subscribers will get all the initial data.
>
But couldn't getting all the initial data (i.e. not filtering) break
the rules used by the old/new row processing (see v46-0003 patch)?
Those rules effectively assume rows have been previously published
with filtering.
So, for example, for the following case for UPDATE:
old-row (no match) new row (match) -> INSERT
the old-row check (no match) infers that the old row was never
published, but that row could in fact have been in the initial
unfiltered rows, so in that case an INSERT gets erroneously published
instead of an UPDATE, doesn't it?
> > Should such subscriptions be allowed?
> >
>
> I am not sure what you have in mind here? How can we change the
> already released code pre-15 for this new feature?
>
I was thinking such subscription requests could be rejected by the
server, based on the subscriber version and whether the publications
use filtering etc.
Regards,
Greg Nancarrow
Fujitsu Australia
On Wed, Dec 15, 2021 at 1:52 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Wed, Dec 15, 2021 at 5:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > "If a subscriber is a pre-15 version, the initial table > > > synchronization won't use row filters even if they are defined in the > > > publisher." > > > > > > Won't this lead to data inconsistencies or errors that otherwise > > > wouldn't happen? > > > > > > > How? The subscribers will get all the initial data. > > > > But couldn't getting all the initial data (i.e. not filtering) break > the rules used by the old/new row processing (see v46-0003 patch)? > Those rules effectively assume rows have been previously published > with filtering. > So, for example, for the following case for UPDATE: > old-row (no match) new row (match) -> INSERT > the old-row check (no match) infers that the old row was never > published, but that row could in fact have been in the initial > unfiltered rows, so in that case an INSERT gets erroneously published > instead of an UPDATE, doesn't it? > But this can happen even when both the publisher and subscriber are from v15, say if the user defines filter at some later point or change the filter conditions by Alter Publication. So, not sure if we need to invent something new for this. > > > Should such subscriptions be allowed? > > > > > > > I am not sure what you have in mind here? How can we change the > > already released code pre-15 for this new feature? > > > > I was thinking such subscription requests could be rejected by the > server, based on the subscriber version and whether the publications > use filtering etc. > Normally, the client sends some parameters to the server like (streaming, two_pc, etc.) based on which server can take such decisions. We may need to include some such thing which I am not sure is required for this particular case especially because that can happen otherwise as well. -- With Regards, Amit Kapila.
On Mon, Dec 13, 2021 5:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
> PSA the v46* patch set.
>
> Here are the main differences from v45:
> 0. Rebased to HEAD
> 1. Integrated many comments, docs, messages, code etc from Euler's patch
> [Euler 6/12] 2. Several bugfixes 3. Patches are merged/added
>
> ~~
>
> Bugfix and Patch Merge details:
>
> v46-0001 (main)
> - Merged from v45-0001 (main) + v45-0005 (exprstate)
> - Fix for mem leak reported by Greg (off-list)
>
> v46-0002 (validation)
> - Merged from v45-0002 (node validation) + v45-0006 (replica identity
> validation)
>
> v46-0003
> - Rebased from v45-0003
> - Fix for partition column order [Houz 9/12]
> - Fix for core dump reported by Tang (off-list)
>
> v46-0004 (tab-complete and dump)
> - Rebased from v45-0004
>
> v46-0005 (for all tables)
> - New patch
> - Fix for FOR ALL TABLES [Tang 7/12]
>
Thanks for updating the patch.
When reviewing the patch, I found the patch allows using system columns in
row filter expression.
---
create publication pub for table test WHERE ('(0,1)'::tid=ctid);
---
Since we can't create index on system column and most
existing expression feature(index expr,partition expr,table constr) doesn't
allow using system column, I think it might be better to disallow using system
column when creating or altering the publication. We can check like:
rowfilter_walker(Node *node, Relation relation)
...
if (var->varattno < 0)
ereport(ERROR,
errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
errmsg("cannot use system column \"%s\" in column generation expression",
...
Best regards,
Hou zj
Kindly do not change the mode of src/backend/parser/gram.y. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
PSA the v47* patch set. Main differences from v46: 0. Rebased to HEAD 1. Addressed multiple review comments ~~ Details: v47-0001 (main) - Quick loop exit if no filter for all pubactions [Amit 14/12] #1 - Remove duplicated comment [Amit 14/12] #2 - Remove code block parens [Amit 14/12] #3 - GetTransformedWhereClause add function comment [Amit 14/12] #2, [Greg 15/12] #3 - GetTransformedWhereClause change variable names [Amit 14/12] #3 - Commit comment wording [Greg 15/12] #2 - Fix incomplete comment [Greg 15/12] #4 - Wording of error message [Greg 15/12] #5 - Wording in tablesync comment [Greg 15/2] #6 - PG docs for FOR ALL TABLES - Added regression tests for aggregate functions v47-0002 (validation) - Remove EXPR_KIND_PUBLICATION_WHERE [Amit 14/12] #1 - Refactor function for simple nodes [Amit 14/12] #4 - Fix case of error message [Greg 15/12] #1 - Cleanup code not using InvalidAttrNumber [Greg 15/12] #2 v47-0003 (new/old tuple) - No change v47-0004 (tab-complete and dump) - No change v47-0005 (for all tables) - Fix comment in tablesync [Greg 15/12] #1 - Fix comment alignment [Greg 15/12] #2 - Add support for ALL TABLES IN SCHEMA [Amit 14/12] - Use a unified SQL in the tablesync COPY [Amit 14/12] - Quick loop exits if no filter for all pubactions [Amit 14/12] #1 - Added new TAP test case for FOR ALL TABLES - Added new TAP test case for ALL TABLES IN SCHEMA - Updated commit comment ------ [Amit 14/12] https://www.postgresql.org/message-id/CAA4eK1JdLzJEmxxzEEYAOg41Om3Y88uL%2B7CgXdvnAaj7hkw8BQ%40mail.gmail.com [Amit 14/12] https://www.postgresql.org/message-id/CAA4eK1%2BaiyjD4C1gohBZyZivrMruCE%3D9Mgmgtaq1gFvfRBU-wA%40mail.gmail.com [Greg 15/12] https://www.postgresql.org/message-id/CAJcOf-dFo_kTroR2_k1x80TqN%3D-3oZC_2BGYe1O6e5JinrLKYg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Fri, Dec 17, 2021 at 7:11 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > Kindly do not change the mode of src/backend/parser/gram.y. > Oops. Sorry that was not deliberate. I will correct that in the next version. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Dec 15, 2021 at 3:50 PM Greg Nancarrow <gregn4422@gmail.com> wrote:
>
> On Mon, Dec 13, 2021 at 8:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > PSA the v46* patch set.
> >
>
> 0001
>
...
> (2) In the 0001 patch comment, the term "publication filter" is used
> in one place, and in others "row filter" or "row-filter".
>
Fixed in v47 [1]
>
> src/backend/catalog/pg_publication.c
> (3) GetTransformedWhereClause() is missing a function comment.
>
Fixed in v47 [1]
> (4)
> The following comment seems incomplete:
>
> + /* Fix up collation information */
> + whereclause = GetTransformedWhereClause(pstate, pri, true);
>
>
Fixed in v47 [1]
> src/backend/parser/parse_relation.c
> (5)
> wording? consistent?
> Shouldn't it be "publication WHERE expression" for consistency?
>
In v47 [1] this message is removed when the KIND is removed.
> + errmsg("publication row-filter WHERE invalid reference to table \"%s\"",
> + relation->relname),
>
>
> src/backend/replication/logical/tablesync.c
> (6)
>
> (i) Improve wording:
>
> BEFORE:
> /*
> * Get information about remote relation in similar fashion the RELATION
> - * message provides during replication.
> + * message provides during replication. This function also returns the relation
> + * qualifications to be used in COPY command.
> */
>
> AFTER:
> /*
> - * Get information about remote relation in similar fashion the RELATION
> - * message provides during replication.
> + * Get information about a remote relation, in a similar fashion to
> how the RELATION
> + * message provides information during replication. This function
> also returns the relation
> + * qualifications to be used in the COPY command.
> */
>
Fixed in v47 [1]
> (ii) fetch_remote_table_info() doesn't currently account for ALL
> TABLES and ALL TABLES IN SCHEMA.
>
>
Fixed in v47 [1]
...
>
>
> 0002
>
> src/backend/catalog/pg_publication.c
> (1) rowfilter_walker()
> One of the errdetail messages doesn't begin with an uppercase letter:
>
> + errdetail_msg = _("user-defined types are not allowed");
>
>
Fixed in v47 [1]
> src/backend/executor/execReplication.c
> (2) CheckCmdReplicaIdentity()
>
> Strictly speaking, the following:
>
> + if (invalid_rfcolnum)
>
> should be:
>
> + if (invalid_rfcolnum != InvalidAttrNumber)
>
>
Fixed in v47 [1]
> 0003
>
> src/backend/replication/logical/tablesync.c
> (1)
> Column name in comment should be "puballtables" not "puballtable":
>
> + * If any publication has puballtable true then all row-filtering is
>
Fixed in v47 [1]
> (2) pgoutput_row_filter_init()
>
> There should be a space before the final "*/" (so the asterisks align).
> Also, should say "... treated the same".
>
> /*
> + * If the publication is FOR ALL TABLES then it is treated same as if this
> + * table has no filters (even if for some other publication it does).
> + */
>
>
Fixed in v47 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtjsj_OVMWEdYp2Wq19%3DH5D4Vgta43FbFVDYr2LuS_djg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Dec 14, 2021 at 4:20 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Tue, Dec 7, 2021 at 5:48 PM tanghy.fnst@fujitsu.com
> > <tanghy.fnst@fujitsu.com> wrote:
> > >
> > > I think for "FOR ALL TABLE" publication(p2 in my case), table tbl should be
> > > treated as no filter, and table tbl should have no filter in subscription sub. Thoughts?
> > >
> > > But for now, the filter(a > 10) works both when copying initial data and later changes.
> > >
> > > To fix it, I think we can check if the table is published in a 'FOR ALL TABLES'
> > > publication or published as part of schema in function pgoutput_row_filter_init
> > > (which was introduced in v44-0003 patch), also we need to make some changes in
> > > tablesync.c.
> > >
> >
> > Partly fixed in v46-0005 [1]
> >
> > NOTE
> > - The initial COPY part of the tablesync does not take the publish
> > operation into account so it means that if any of the subscribed
> > publications have "puballtables" flag then all data will be copied
> > sans filters.
> >
>
> I think this should be okay but the way you have implemented it in the
> patch doesn't appear to be the optimal way. Can't we fetch
> allpubtables info and qual info as part of one query instead of using
> separate queries?
Fixed in v47 [1]. Now code uses a unified SQL query provided by Vignesh.
>
> > I guess this is consistent with the other decision to
> > ignore publication operations [2].
> >
> > TODO
> > - Documentation
> > - IIUC there is a similar case yet to be addressed - FOR ALL TABLES IN SCHEMA
> >
>
> Yeah, "FOR ALL TABLES IN SCHEMA" should also be addressed. In this
> case, the difference would be that we need to check the presence of
> schema corresponding to the table (for which we are fetching
> row_filter information) is there in pg_publication_namespace. If it
> exists then we don't need to apply row_filter for the table. I feel it
> is better to fetch all this information as part of the query which you
> are using to fetch row_filter info. The idea is to avoid the extra
> round-trip between subscriber and publisher.
>
Fixed in v47 [1]. Added code and TAP test case for ALL TABLES IN SCHEMA.
> Few other comments:
> ===================
> 1.
> @@ -926,6 +928,22 @@ pgoutput_row_filter_init(PGOutputData *data,
> Relation relation, RelationSyncEntr
> bool rfisnull;
>
> /*
> + * If the publication is FOR ALL TABLES then it is treated same as if this
> + * table has no filters (even if for some other publication it does).
> + */
> + if (pub->alltables)
> + {
> + if (pub->pubactions.pubinsert)
> + no_filter[idx_ins] = true;
> + if (pub->pubactions.pubupdate)
> + no_filter[idx_upd] = true;
> + if (pub->pubactions.pubdelete)
> + no_filter[idx_del] = true;
> +
> + continue;
> + }
>
> Is there a reason to continue checking the other publications if
> no_filter is true for all kind of pubactions?
>
Fixed in v47 [1].
> 2.
> + * All row filter expressions will be discarded if there is one
> + * publication-relation entry without a row filter. That's because
> + * all expressions are aggregated by the OR operator. The row
> + * filter absence means replicate all rows so a single valid
> + * expression means publish this row.
>
> This same comment is at two places, remove from one of the places. I
> think keeping it atop for loop is better.
>
Fixed in v47 [1]
> 3.
> + {
> + int idx;
> + bool found_filters = false;
>
> I am not sure if starting such ad-hoc braces in the code to localize
> the scope of variables is a regular practice. Can we please remove
> this?
>
Fixed in v47 [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPtjsj_OVMWEdYp2Wq19%3DH5D4Vgta43FbFVDYr2LuS_djg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Dec 14, 2021 at 10:12 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 14, 2021 at 10:50 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Dec 14, 2021 at 4:44 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Few other comments: > > =================== > > Few more comments: > ================== > v46-0001/0002 > =============== > 1. After rowfilter_walker() why do we need > EXPR_KIND_PUBLICATION_WHERE? I thought this is primarily to identify > the expressions that are not allowed in rowfilter which we are now > able to detect upfront with the help of a walker. Can't we instead use > EXPR_KIND_WHERE? > Fixed in v47 [1] > 2. > +Node * > +GetTransformedWhereClause(ParseState *pstate, PublicationRelInfo *pri, > + bool bfixupcollation) > > Can we add comments atop this function? > Fixed in v47 [1] > 3. In GetTransformedWhereClause, can we change the name of variables > (a) bfixupcollation to fixup_collation or assign_collation, (b) > transformedwhereclause to whereclause. I think that will make the > function more readable. > Fixed in v47 [1] > > v46-0002 > ======== > 4. > + else if (IsA(node, List) || IsA(node, Const) || IsA(node, BoolExpr) > || IsA(node, NullIfExpr) || > + IsA(node, NullTest) || IsA(node, BooleanTest) || IsA(node, CoalesceExpr) || > + IsA(node, CaseExpr) || IsA(node, CaseTestExpr) || IsA(node, MinMaxExpr) || > + IsA(node, ArrayExpr) || IsA(node, ScalarArrayOpExpr) || IsA(node, XmlExpr)) > > Can we move this to a separate function say IsValidRowFilterExpr() or > something on those lines and use Switch (nodetag(node)) to identify > these nodes? > Fixed in v47 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPtjsj_OVMWEdYp2Wq19%3DH5D4Vgta43FbFVDYr2LuS_djg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Dec 17, 2021 at 9:41 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA the v47* patch set.
>
I found that even though there are now separately-maintained WHERE clauses per pubaction, there still seem to be problems when applying the old/new row rules for UPDATE.
A simple example of this was previously discussed in [1].
The example is repeated below:
---- Publication
create table tbl1 (a int primary key, b int);
create publication A for table tbl1 where (b<2) with(publish='insert');
create publication B for table tbl1 where (a>1) with(publish='update');
---- Subscription
create table tbl1 (a int primary key, b int);
create subscription sub connection 'dbname=postgres host=localhost port=10000' publication A,B;
---- Publication
insert into tbl1 values (1,1);
update tbl1 set a = 2;
So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), rather than an UPDATE of (1,1) to (2,1).
This is according to the 2nd UPDATE rule below, from patch 0003.
+ * old-row (no match) new-row (no match) -> (drop change)
+ * old-row (no match) new row (match) -> INSERT
+ * old-row (match) new-row (no match) -> DELETE
+ * old-row (match) new row (match) -> UPDATE
+ * old-row (no match) new row (match) -> INSERT
+ * old-row (match) new-row (no match) -> DELETE
+ * old-row (match) new row (match) -> UPDATE
This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does.
This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (and thus requires an INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously published via a different operation - INSERT (and using a different filter too).
I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previously UPDATEd (and published, or not published, according to the filter applicable to UPDATE), but this is not necessarily the case.
Or am I missing something?
----
Regards,
Greg Nancarrow
Fujitsu Australia
On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), rather thanan UPDATE of (1,1) to (2,1). > This is according to the 2nd UPDATE rule below, from patch 0003. > > + * old-row (no match) new-row (no match) -> (drop change) > + * old-row (no match) new row (match) -> INSERT > + * old-row (match) new-row (no match) -> DELETE > + * old-row (match) new row (match) -> UPDATE > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does. > This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (and thus requiresan INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously published viaa different operation - INSERT (and using a different filter too). > I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previously UPDATEd(and published, or not published, according to the filter applicable to UPDATE), but this is not necessarily the case. > Or am I missing something? But it need not be correct in assuming that the old-row was part of a previous INSERT either (and published, or not published according to the filter applicable to an INSERT). For example, change the sequence of inserts and updates prior to the last update: truncate tbl1 ; insert into tbl1 values (1,5); ==> not replicated since insert and ! (b < 2); update tbl1 set b = 1; ==> not replicated since update and ! (a > 1) update tbl1 set a = 2; ==> replicated and update converted to insert since (a > 1) In this case, the last update "update tbl1 set a = 2; " is updating a row that was previously updated and not inserted and not replicated to the subscriber. How does the replication logic differentiate between these two cases, and decide if the update was previously published or not? I think it's futile for the publisher side to try and figure out the history of published rows. In fact, if this level of logic is required then it is best implemented on the subscriber side, which then defeats the purpose of a publication filter. regards, Ajin Cherian Fujitsu Australia
On Fri, Dec 17, 2021 at 4:11 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> PSA the v47* patch set.
>
Few comments on v47-0002:
=======================
1. The handling to find rowfilter for ancestors in
RelationGetInvalidRowFilterCol seems complex. It seems you are
accumulating non-partition relations as well in toprelid_in_pub. Can
we simplify such that we find the ancestor only for 'pubviaroot'
publications?
2. I think the name RelationGetInvalidRowFilterCol is confusing
because the same function is also used to get publication actions. Can
we name it as GetRelationPublicationInfo() and pass a bool parameter
to indicate whether row_filter info needs to be built. We can get the
invalid_row_filter column as output from that function.
3.
+GetRelationPublicationActions(Relation relation)
{
..
+ if (!relation->rd_pubactions)
+ (void) RelationGetInvalidRowFilterCol(relation);
+
+ return memcpy(pubactions, relation->rd_pubactions,
+ sizeof(PublicationActions));
..
..
}
I think here we can reverse the check such that if actions are set
just do memcpy and return otherwise get the relationpublicationactions
info.
4.
invalid_rowfilter_column_walker
{
..
/*
* If pubviaroot is true, we need to convert the column number of
* parent to the column number of child relation first.
*/
if (context->pubviaroot)
{
char *colname = get_attname(context->parentid, attnum, false);
attnum = get_attnum(context->relid, colname);
}
Here, in the comments, you can tell why you need this conversion. Can
we name this function as rowfilter_column_walker()?
5.
+/* For invalid_rowfilter_column_walker. */
+typedef struct {
+ AttrNumber invalid_rfcolnum; /* invalid column number */
+ Bitmapset *bms_replident; /* bitset of replica identity col indexes */
+ bool pubviaroot; /* true if we are validating the parent
+ * relation's row filter */
+ Oid relid; /* relid of the relation */
+ Oid parentid; /* relid of the parent relation */
+} rf_context;
Normally, we declare structs at the beginning of the file and for the
formatting of struct declarations, see other nearby structs like
RelIdCacheEnt.
6. Can we name IsRowFilterSimpleNode() as IsRowFilterSimpleExpr()?
--
With Regards,
Amit Kapila.
On Fri, Dec 17, 2021 at 1:50 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), rather thanan UPDATE of (1,1) to (2,1). > > This is according to the 2nd UPDATE rule below, from patch 0003. > > > > + * old-row (no match) new-row (no match) -> (drop change) > > + * old-row (no match) new row (match) -> INSERT > > + * old-row (match) new-row (no match) -> DELETE > > + * old-row (match) new row (match) -> UPDATE > > > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does. > > This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (and thusrequires an INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously publishedvia a different operation - INSERT (and using a different filter too). > > I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previously UPDATEd(and published, or not published, according to the filter applicable to UPDATE), but this is not necessarily the case. > > Or am I missing something? > > But it need not be correct in assuming that the old-row was part of a > previous INSERT either (and published, or not published according to > the filter applicable to an INSERT). > For example, change the sequence of inserts and updates prior to the > last update: > > truncate tbl1 ; > insert into tbl1 values (1,5); ==> not replicated since insert and ! (b < 2); > update tbl1 set b = 1; ==> not replicated since update and ! (a > 1) > update tbl1 set a = 2; ==> replicated and update converted to insert > since (a > 1) > > In this case, the last update "update tbl1 set a = 2; " is updating a > row that was previously updated and not inserted and not replicated to > the subscriber. > How does the replication logic differentiate between these two cases, > and decide if the update was previously published or not? > I think it's futile for the publisher side to try and figure out the > history of published rows. > I also think so. One more thing, even if we want we might not be able to apply the insert filter as the corresponding values may not be logged. -- With Regards, Amit Kapila.
On Fri, Dec 17, 2021 at 7:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), rather thanan UPDATE of (1,1) to (2,1). > > This is according to the 2nd UPDATE rule below, from patch 0003. > > > > + * old-row (no match) new-row (no match) -> (drop change) > > + * old-row (no match) new row (match) -> INSERT > > + * old-row (match) new-row (no match) -> DELETE > > + * old-row (match) new row (match) -> UPDATE > > > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does. > > This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (and thusrequires an INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously publishedvia a different operation - INSERT (and using a different filter too). > > I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previously UPDATEd(and published, or not published, according to the filter applicable to UPDATE), but this is not necessarily the case. > > Or am I missing something? > > But it need not be correct in assuming that the old-row was part of a > previous INSERT either (and published, or not published according to > the filter applicable to an INSERT). > For example, change the sequence of inserts and updates prior to the > last update: > > truncate tbl1 ; > insert into tbl1 values (1,5); ==> not replicated since insert and ! (b < 2); > update tbl1 set b = 1; ==> not replicated since update and ! (a > 1) > update tbl1 set a = 2; ==> replicated and update converted to insert > since (a > 1) > > In this case, the last update "update tbl1 set a = 2; " is updating a > row that was previously updated and not inserted and not replicated to > the subscriber. > How does the replication logic differentiate between these two cases, > and decide if the update was previously published or not? > I think it's futile for the publisher side to try and figure out the > history of published rows. In fact, if this level of logic is required > then it is best implemented on the subscriber side, which then defeats > the purpose of a publication filter. > I think it's a concern, for such a basic example with only one row, getting unpredictable (and even wrong) replication results, depending upon the order of operations. Doesn't this problem result from allowing different WHERE clauses for different pubactions for the same table? My current thoughts are that this shouldn't be allowed, and also WHERE clauses for INSERTs should, like UPDATE and DELETE, be restricted to using only columns covered by the replica identity or primary key. Regards, Greg Nancarrow Fujitsu Australia
PSA the v48* patch set. Main differences from v47: 1. Addresses some review comments ~~ Details: v47-0001 (main) - Modify some regression tests [Vignesh 2/12] #1 (skipped), #4 - Remove redundant slot drop [Greg 15/12] #7 - Restore mode of gram.y file [Alvaro 16/12] v47-0002 (validation) - Modify some regression tests [Vignesh 2/12] #3 - Don't allow system columns in filters [Houz 16/12] v47-0003 (new/old tuple) - No change v47-0004 (tab-complete and dump) - No change v47-0005 (for all tables) - No change ------ [Vignesh 2/12] https://www.postgresql.org/message-id/CALDaNm2bMD%3DwxOzMvfnHQ7LeGTPyZWy_Fu_8G24k7MJ7k1UqHQ%40mail.gmail.com [Greg 15/12] https://www.postgresql.org/message-id/CAJcOf-dFo_kTroR2_k1x80TqN%3D-3oZC_2BGYe1O6e5JinrLKYg%40mail.gmail.com [Alvaro 16/12] https://www.postgresql.org/message-id/202112162011.iiyqqzuzpg4x%40alvherre.pgsql [Houz 16/12] https://www.postgresql.org/message-id/OS0PR01MB571694C3C0005B5D425CCB0694779%40OS0PR01MB5716.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Fri, Dec 17, 2021 at 5:29 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Fri, Dec 17, 2021 at 7:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > > So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), ratherthan an UPDATE of (1,1) to (2,1). > > > This is according to the 2nd UPDATE rule below, from patch 0003. > > > > > > + * old-row (no match) new-row (no match) -> (drop change) > > > + * old-row (no match) new row (match) -> INSERT > > > + * old-row (match) new-row (no match) -> DELETE > > > + * old-row (match) new row (match) -> UPDATE > > > > > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does. > > > This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (and thusrequires an INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously publishedvia a different operation - INSERT (and using a different filter too). > > > I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previously UPDATEd(and published, or not published, according to the filter applicable to UPDATE), but this is not necessarily the case. > > > Or am I missing something? > > > > But it need not be correct in assuming that the old-row was part of a > > previous INSERT either (and published, or not published according to > > the filter applicable to an INSERT). > > For example, change the sequence of inserts and updates prior to the > > last update: > > > > truncate tbl1 ; > > insert into tbl1 values (1,5); ==> not replicated since insert and ! (b < 2); > > update tbl1 set b = 1; ==> not replicated since update and ! (a > 1) > > update tbl1 set a = 2; ==> replicated and update converted to insert > > since (a > 1) > > > > In this case, the last update "update tbl1 set a = 2; " is updating a > > row that was previously updated and not inserted and not replicated to > > the subscriber. > > How does the replication logic differentiate between these two cases, > > and decide if the update was previously published or not? > > I think it's futile for the publisher side to try and figure out the > > history of published rows. In fact, if this level of logic is required > > then it is best implemented on the subscriber side, which then defeats > > the purpose of a publication filter. > > > > I think it's a concern, for such a basic example with only one row, > getting unpredictable (and even wrong) replication results, depending > upon the order of operations. > I am not sure how we can deduce that. The results are based on current and new values of row which is what I think we are expecting here. > Doesn't this problem result from allowing different WHERE clauses for > different pubactions for the same table? > My current thoughts are that this shouldn't be allowed, and also WHERE > clauses for INSERTs should, like UPDATE and DELETE, be restricted to > using only columns covered by the replica identity or primary key. > Hmm, even if we do that one could have removed the insert row filter by the time we are evaluating the update. So, we will get the same result. I think the behavior in your example is as we expect as per the specs defined by the patch and I don't see any problem, in this case, w.r.t replication results. Let us see what others think on this? -- With Regards, Amit Kapila.
On Sat, Dec 18, 2021 at 1:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Dec 17, 2021 at 5:29 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > On Fri, Dec 17, 2021 at 7:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > > > On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > > > > So using the v47 patch-set, I still find that the UPDATE above results in publication of an INSERT of (2,1), ratherthan an UPDATE of (1,1) to (2,1). > > > > This is according to the 2nd UPDATE rule below, from patch 0003. > > > > > > > > + * old-row (no match) new-row (no match) -> (drop change) > > > > + * old-row (no match) new row (match) -> INSERT > > > > + * old-row (match) new-row (no match) -> DELETE > > > > + * old-row (match) new row (match) -> UPDATE > > > > > > > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", but the new row (2,1) does. > > > > This functionality doesn't seem right to me. I don't think it can be assumed that (1,1) was never published (andthus requires an INSERT rather than UPDATE) based on these checks, because in this example, (1,1) was previously publishedvia a different operation - INSERT (and using a different filter too). > > > > I think the fundamental problem here is that these UPDATE rules assume that the old (current) row was previouslyUPDATEd (and published, or not published, according to the filter applicable to UPDATE), but this is not necessarilythe case. > > > > Or am I missing something? > > > > > > But it need not be correct in assuming that the old-row was part of a > > > previous INSERT either (and published, or not published according to > > > the filter applicable to an INSERT). > > > For example, change the sequence of inserts and updates prior to the > > > last update: > > > > > > truncate tbl1 ; > > > insert into tbl1 values (1,5); ==> not replicated since insert and ! (b < 2); > > > update tbl1 set b = 1; ==> not replicated since update and ! (a > 1) > > > update tbl1 set a = 2; ==> replicated and update converted to insert > > > since (a > 1) > > > > > > In this case, the last update "update tbl1 set a = 2; " is updating a > > > row that was previously updated and not inserted and not replicated to > > > the subscriber. > > > How does the replication logic differentiate between these two cases, > > > and decide if the update was previously published or not? > > > I think it's futile for the publisher side to try and figure out the > > > history of published rows. In fact, if this level of logic is required > > > then it is best implemented on the subscriber side, which then defeats > > > the purpose of a publication filter. > > > > > > > I think it's a concern, for such a basic example with only one row, > > getting unpredictable (and even wrong) replication results, depending > > upon the order of operations. > > > > I am not sure how we can deduce that. The results are based on current > and new values of row which is what I think we are expecting here. > > > Doesn't this problem result from allowing different WHERE clauses for > > different pubactions for the same table? > > My current thoughts are that this shouldn't be allowed, and also WHERE > > clauses for INSERTs should, like UPDATE and DELETE, be restricted to > > using only columns covered by the replica identity or primary key. > > > > Hmm, even if we do that one could have removed the insert row filter > by the time we are evaluating the update. So, we will get the same > result. I think the behavior in your example is as we expect as per > the specs defined by the patch and I don't see any problem, in this > case, w.r.t replication results. Let us see what others think on this? > I think currently there could be a problem with user perceptions. IMO a user would be mostly interested in predictability and getting results that are intuitive. So, even if all strange results can (after careful examination) be after-the-fact explained away as being "correct" according to a spec, I don't think that is going to make any difference. e.g. regardless of correctness, even if it just "appeared" to give unexpected results then a user may just decide that row-filtering is not worth their confusion... Perhaps there is a slightly dumbed-down RF design that can still be useful, but which can give much more comfort to the user because the replica will be more like what they were expecting? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Sat, Dec 18, 2021 at 1:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > I think it's a concern, for such a basic example with only one row, > > getting unpredictable (and even wrong) replication results, depending > > upon the order of operations. > > > > I am not sure how we can deduce that. The results are based on current > and new values of row which is what I think we are expecting here. > In the two simple cases presented, the publisher ends up with the same single row (2,1) in both cases, but in one of the cases the subscriber ends up with an extra row (1,1) that the publisher doesn't have. So, in using a "filter", a new row has been published that the publisher doesn't have. I'm not so sure a user would be expecting that. Not to mention that if (1,1) is subsequently INSERTed on the publisher side, it will result in a duplicate key error on the publisher. > > Doesn't this problem result from allowing different WHERE clauses for > > different pubactions for the same table? > > My current thoughts are that this shouldn't be allowed, and also WHERE > > clauses for INSERTs should, like UPDATE and DELETE, be restricted to > > using only columns covered by the replica identity or primary key. > > > > Hmm, even if we do that one could have removed the insert row filter > by the time we are evaluating the update. So, we will get the same > result. I think the behavior in your example is as we expect as per > the specs defined by the patch and I don't see any problem, in this > case, w.r.t replication results. Let us see what others think on this? > Here I'm talking about the typical use-case of setting the row-filtering WHERE clause up-front and not changing it thereafter. I think that dynamically changing filters after INSERT/UPDATE/DELETE operations is not the typical use-case, and IMHO it's another thing entirely (could result in all kinds of unpredictable, random results). Personally I think it would make more sense to: 1) Disallow different WHERE clauses on the same table, for different pubactions. 2) If only INSERTs are being published, allow any column in the WHERE clause, otherwise (as for UPDATE and DELETE) restrict the referenced columns to be part of the replica identity or primary key. Regards, Greg Nancarrow Fujitsu Australia
> -----Original Message----- > From: Amit Kapila <amit.kapila16@gmail.com> On Saturday, December 18, 2021 10:33 AM > On Fri, Dec 17, 2021 at 5:29 PM Greg Nancarrow <gregn4422@gmail.com> > wrote: > > > > On Fri, Dec 17, 2021 at 7:20 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > > > On Fri, Dec 17, 2021 at 5:46 PM Greg Nancarrow <gregn4422@gmail.com> > wrote: > > > > > > > So using the v47 patch-set, I still find that the UPDATE above results in > publication of an INSERT of (2,1), rather than an UPDATE of (1,1) to (2,1). > > > > This is according to the 2nd UPDATE rule below, from patch 0003. > > > > > > > > + * old-row (no match) new-row (no match) -> (drop change) > > > > + * old-row (no match) new row (match) -> INSERT > > > > + * old-row (match) new-row (no match) -> DELETE > > > > + * old-row (match) new row (match) -> UPDATE > > > > > > > > This is because the old row (1,1) doesn't match the UPDATE filter "(a>1)", > but the new row (2,1) does. > > > > This functionality doesn't seem right to me. I don't think it can be > assumed that (1,1) was never published (and thus requires an INSERT rather than > UPDATE) based on these checks, because in this example, (1,1) was previously > published via a different operation - INSERT (and using a different filter too). > > > > I think the fundamental problem here is that these UPDATE rules assume > that the old (current) row was previously UPDATEd (and published, or not > published, according to the filter applicable to UPDATE), but this is not > necessarily the case. > > > > Or am I missing something? > > > > > > But it need not be correct in assuming that the old-row was part of > > > a previous INSERT either (and published, or not published according > > > to the filter applicable to an INSERT). > > > For example, change the sequence of inserts and updates prior to the > > > last update: > > > > > > truncate tbl1 ; > > > insert into tbl1 values (1,5); ==> not replicated since insert and ! > > > (b < 2); update tbl1 set b = 1; ==> not replicated since update and > > > ! (a > 1) update tbl1 set a = 2; ==> replicated and update converted > > > to insert since (a > 1) > > > > > > In this case, the last update "update tbl1 set a = 2; " is updating > > > a row that was previously updated and not inserted and not > > > replicated to the subscriber. > > > How does the replication logic differentiate between these two > > > cases, and decide if the update was previously published or not? > > > I think it's futile for the publisher side to try and figure out the > > > history of published rows. In fact, if this level of logic is > > > required then it is best implemented on the subscriber side, which > > > then defeats the purpose of a publication filter. > > > > > > > I think it's a concern, for such a basic example with only one row, > > getting unpredictable (and even wrong) replication results, depending > > upon the order of operations. > > > > I am not sure how we can deduce that. The results are based on current and > new values of row which is what I think we are expecting here. > > > Doesn't this problem result from allowing different WHERE clauses for > > different pubactions for the same table? > > My current thoughts are that this shouldn't be allowed, and also WHERE > > clauses for INSERTs should, like UPDATE and DELETE, be restricted to > > using only columns covered by the replica identity or primary key. > > > > Hmm, even if we do that one could have removed the insert row filter by the > time we are evaluating the update. So, we will get the same result. I think the > behavior in your example is as we expect as per the specs defined by the patch > and I don't see any problem, in this case, w.r.t replication results. Let us see > what others think on this? I think it might not be hard to predict the current behavior. User only need to be aware of that: 1) pubaction and row filter on different publications are combined with 'OR'. 2) FOR UPDATE, we execute the fiter for both OLD and NEW tuple and would change the operation type accordingly. For the example mentioned: create table tbl1 (a int primary key, b int); create publication A for table tbl1 where (b<2) with(publish='insert'); create publication B for table tbl1 where (a>1) with(publish='update'); If we follow the rule 1) and 2), I feel we are able to predict the following conditions: -- WHERE (action = 'insert' AND b < 2) OR (action = 'update' AND a > 1) -- So, it seems acceptable to me. Personally, I think the current design could give user more flexibility to handle some complex scenario. If user want some simple setting for publication, they can also set same row filter for the same table in different publications. To avoid confusion, I think we can document about these rules clearly. BTW, From the document of IBM, I think IBM also support this kind of complex condition [1]. [1] https://www.ibm.com/docs/en/idr/11.4.0?topic=rows-log-record-variables Best regards, Hou zj
On Fri, Dec 17, 2021 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Fri, Dec 17, 2021 at 4:11 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > PSA the v47* patch set.
> >
>
> Few comments on v47-0002:
> =======================
> 1. The handling to find rowfilter for ancestors in
> RelationGetInvalidRowFilterCol seems complex. It seems you are
> accumulating non-partition relations as well in toprelid_in_pub. Can
> we simplify such that we find the ancestor only for 'pubviaroot'
> publications?
>
> 2. I think the name RelationGetInvalidRowFilterCol is confusing
> because the same function is also used to get publication actions. Can
> we name it as GetRelationPublicationInfo() and pass a bool parameter
> to indicate whether row_filter info needs to be built. We can get the
> invalid_row_filter column as output from that function.
>
> 3.
> +GetRelationPublicationActions(Relation relation)
> {
> ..
> + if (!relation->rd_pubactions)
> + (void) RelationGetInvalidRowFilterCol(relation);
> +
> + return memcpy(pubactions, relation->rd_pubactions,
> + sizeof(PublicationActions));
> ..
> ..
> }
>
> I think here we can reverse the check such that if actions are set
> just do memcpy and return otherwise get the relationpublicationactions
> info.
>
> 4.
> invalid_rowfilter_column_walker
> {
> ..
>
> /*
> * If pubviaroot is true, we need to convert the column number of
> * parent to the column number of child relation first.
> */
> if (context->pubviaroot)
> {
> char *colname = get_attname(context->parentid, attnum, false);
> attnum = get_attnum(context->relid, colname);
> }
>
> Here, in the comments, you can tell why you need this conversion. Can
> we name this function as rowfilter_column_walker()?
>
> 5.
> +/* For invalid_rowfilter_column_walker. */
> +typedef struct {
> + AttrNumber invalid_rfcolnum; /* invalid column number */
> + Bitmapset *bms_replident; /* bitset of replica identity col indexes */
> + bool pubviaroot; /* true if we are validating the parent
> + * relation's row filter */
> + Oid relid; /* relid of the relation */
> + Oid parentid; /* relid of the parent relation */
> +} rf_context;
>
> Normally, we declare structs at the beginning of the file and for the
> formatting of struct declarations, see other nearby structs like
> RelIdCacheEnt.
>
> 6. Can we name IsRowFilterSimpleNode() as IsRowFilterSimpleExpr()?
Thanks for the comments, I agree with all the comments.
Attach the V49 patch set, which addressed all the above comments on the 0002
patch.
Best regards,
Hou zj
Вложения
On Wednesday, December 8, 2021 2:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Dec 6, 2021 at 6:04 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Mon, Dec 6, 2021, at 3:35 AM, Dilip Kumar wrote: > > > > On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > > > > > PS> I will update the commit message in the next version. I barely changed the > > > documentation to reflect the current behavior. I probably missed some > changes > > > but I will fix in the next version. > > > > > > I realized that I forgot to mention a few things about the UPDATE behavior. > > > Regardless of 0003, we need to define which tuple will be used to evaluate the > > > row filter for UPDATEs. We already discussed it circa [1]. This current version > > > chooses *new* tuple. Is it the best choice? > > > > But with 0003, we are using both the tuple for evaluating the row > > filter, so instead of fixing 0001, why we don't just merge 0003 with > > 0001? I mean eventually, 0003 is doing what is the agreed behavior, > > i.e. if just OLD is matching the filter then convert the UPDATE to > > DELETE OTOH if only new is matching the filter then convert the UPDATE > > to INSERT. Do you think that even we merge 0001 and 0003 then also > > there is an open issue regarding which row to select for the filter? > > > > Maybe I was not clear. IIUC we are still discussing 0003 and I would like to > > propose a different default based on the conclusion I came up. If we merged > > 0003, that's fine; this change will be useless. If we don't or it is optional, > > it still has its merit. > > > > Do we want to pay the overhead to evaluating both tuple for UPDATEs? I'm still > > processing if it is worth it. If you think that in general the row filter > > contains the primary key and it is rare to change it, it will waste cycles > > evaluating the same expression twice. It seems this behavior could be > > controlled by a parameter. > > > > I think the first thing we should do in this regard is to evaluate the > performance for both cases (when we apply a filter to both tuples vs. > to one of the tuples). In case the performance difference is > unacceptable, I think it would be better to still compare both tuples > as default to avoid data inconsistency issues and have an option to > allow comparing one of the tuples. > I did some performance tests to see if 0003 patch has much overhead. With which I compared applying first two patches and applying first three patches in four cases: 1) only old rows match the filter. 2) only new rows match the filter. 3) both old rows and new rows match the filter. 4) neither old rows nor new rows match the filter. 0003 patch checks both old rows and new rows, and without 0003 patch, it only checks either old or new rows. We want to know whether it would take more time if we check the old rows. I ran the tests in asynchronous mode and compared the SQL execution time. I also tried some complex filters, to see if the difference could be more obvious. The result and the script are attached. I didn’t see big difference between the result of applying 0003 patch and the one not in all cases. So I think 0003 patch doesn’t have much overhead. Regards, Tang
Вложения
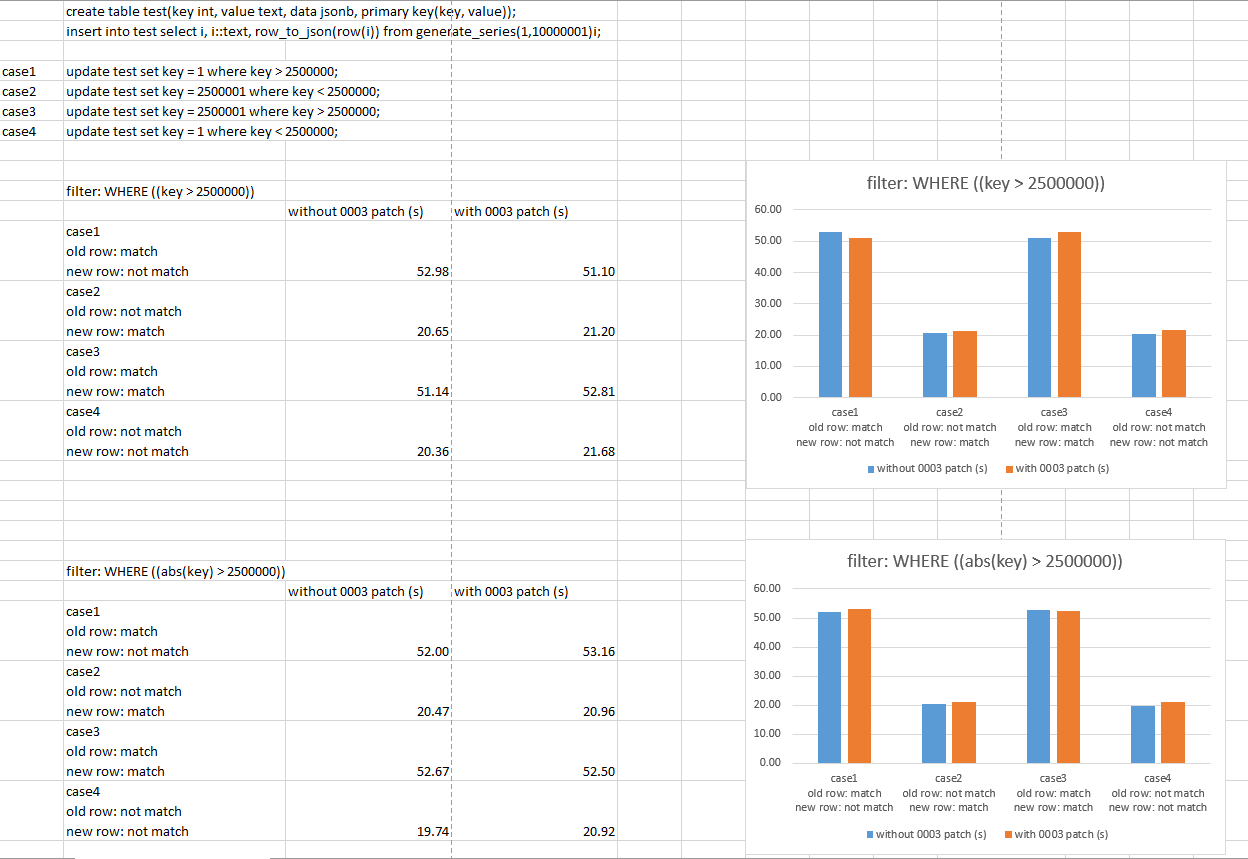{kind=link}
On Mon, Dec 20, 2021 at 6:07 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Sat, Dec 18, 2021 at 1:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > > I think it's a concern, for such a basic example with only one row, > > > getting unpredictable (and even wrong) replication results, depending > > > upon the order of operations. > > > > > > > I am not sure how we can deduce that. The results are based on current > > and new values of row which is what I think we are expecting here. > > > > In the two simple cases presented, the publisher ends up with the same > single row (2,1) in both cases, but in one of the cases the subscriber > ends up with an extra row (1,1) that the publisher doesn't have. So, > in using a "filter", a new row has been published that the publisher > doesn't have. I'm not so sure a user would be expecting that. Not to > mention that if (1,1) is subsequently INSERTed on the publisher side, > it will result in a duplicate key error on the publisher. > Personally, I feel users need to be careful in defining publications and subscriptions, otherwise, there are various ways "duplicate key error .." kind of issues can arise. Say, you different publications which publish the same table, and then you have different subscriptions on the subscriber which subscribe to those publications. > > > Doesn't this problem result from allowing different WHERE clauses for > > > different pubactions for the same table? > > > My current thoughts are that this shouldn't be allowed, and also WHERE > > > clauses for INSERTs should, like UPDATE and DELETE, be restricted to > > > using only columns covered by the replica identity or primary key. > > > > > > > Hmm, even if we do that one could have removed the insert row filter > > by the time we are evaluating the update. So, we will get the same > > result. I think the behavior in your example is as we expect as per > > the specs defined by the patch and I don't see any problem, in this > > case, w.r.t replication results. Let us see what others think on this? > > > > Here I'm talking about the typical use-case of setting the > row-filtering WHERE clause up-front and not changing it thereafter. > I think that dynamically changing filters after INSERT/UPDATE/DELETE > operations is not the typical use-case, and IMHO it's another thing > entirely (could result in all kinds of unpredictable, random results). > Yeah, that's what I also wanted to say that but users need to carefully define publications/subscriptions, otherwise, with up-front definition also leads to unpredictable results as shared in the explanation above. I feel Hou-San's latest email [1] explains the current rules very well and maybe we should document them in some way to avoid confusion. > Personally I think it would make more sense to: > 1) Disallow different WHERE clauses on the same table, for different pubactions. > 2) If only INSERTs are being published, allow any column in the WHERE > clause, otherwise (as for UPDATE and DELETE) restrict the referenced > columns to be part of the replica identity or primary key. > We can restrict in some way like you are saying or we can even restrict such that we "disallow specifying row filters unless pubactions have all the dml operations and allow row filter to have columns that are part of replica identity or primary key". I feel it is better to provide flexibility as the current patch does and document it to make users aware of the kind of problems that can arise with the wrong usage. [1] - https://www.postgresql.org/message-id/OS0PR01MB57168F4384D50656A4FC2DC5947B9%40OS0PR01MB5716.jpnprd01.prod.outlook.com -- With Regards, Amit Kapila.
On Mon, Dec 20, 2021 at 12:51 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > I think it might not be hard to predict the current behavior. User only need to be > aware of that: > 1) pubaction and row filter on different publications are combined with 'OR'. > 2) FOR UPDATE, we execute the fiter for both OLD and NEW tuple and would change > the operation type accordingly. > > For the example mentioned: > create table tbl1 (a int primary key, b int); > create publication A for table tbl1 where (b<2) with(publish='insert'); > create publication B for table tbl1 where (a>1) with(publish='update'); > > If we follow the rule 1) and 2), I feel we are able to predict the following > conditions: > -- > WHERE (action = 'insert' AND b < 2) OR (action = 'update' AND a > 1) > -- > > So, it seems acceptable to me. > > Personally, I think the current design could give user more flexibility to > handle some complex scenario. If user want some simple setting for publication, > they can also set same row filter for the same table in different publications. > To avoid confusion, I think we can document about these rules clearly. > > BTW, From the document of IBM, I think IBM also support this kind of complex > condition [1]. > [1] https://www.ibm.com/docs/en/idr/11.4.0?topic=rows-log-record-variables Yes, I agree with this. It's better to give users more flexibility while warning him on what the consequences are rather than restricting him with constraints. We could explain this in the documentation so that users can better predict the effect of having pubaction specific filters. regards, Ajin Cherian Fujitsu Australia
On Thu, Dec 2, 2021 at 7:40 PM vignesh C <vignesh21@gmail.com> wrote: > ... > Thanks for the updated patch, few comments: > 1) Both testpub5a and testpub5c publication are same, one of them can be removed > +SET client_min_messages = 'ERROR'; > +CREATE PUBLICATION testpub5a FOR TABLE testpub_rf_tbl1 WHERE (a > 1) > WITH (publish="insert"); > +CREATE PUBLICATION testpub5b FOR TABLE testpub_rf_tbl1; > +CREATE PUBLICATION testpub5c FOR TABLE testpub_rf_tbl1 WHERE (a > 3) > WITH (publish="insert"); > +RESET client_min_messages; > +\d+ testpub_rf_tbl1 > +DROP PUBLICATION testpub5a, testpub5b, testpub5c; > > testpub5b will be covered in the earlier existing case above: > ALTER PUBLICATION testpib_ins_trunct ADD TABLE pub_test.testpub_nopk, > testpub_tbl1; > > \d+ pub_test.testpub_nopk > \d+ testpub_tbl1 > > I felt test related to testpub5b is also not required Skipped. Strictly speaking you may be correct to say this code path is already tested elsewhere. But this test case was meant for \d+ so I wanted it to be "self-contained" and easy to observe it displaying both with and without a filters both at the same time. > 3) testpub7 can be renamed to testpub6 to maintain the continuity > since the previous testpub6 did not succeed: > +CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func, LEFTARG = integer, > RIGHTARG = integer); > +CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); > +-- fail - WHERE not allowed in DROP > +ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl3 WHERE (e < 27); > +-- fail - cannot ALTER SET table which is a member of a pre-existing schema > +SET client_min_messages = 'ERROR'; > +CREATE PUBLICATION testpub7 FOR ALL TABLES IN SCHEMA testpub_rf_myschema1; > +ALTER PUBLICATION testpub7 SET ALL TABLES IN SCHEMA > testpub_rf_myschema1, TABLE testpub_rf_myschema1.testpub_rf_tb16; > +RESET client_min_messages; > Fixed in v48 [1] > 4) Did this test intend to include where clause in testpub_rf_tb16, if > so it can be added: > +-- fail - cannot ALTER SET table which is a member of a pre-existing schema > +SET client_min_messages = 'ERROR'; > +CREATE PUBLICATION testpub7 FOR ALL TABLES IN SCHEMA testpub_rf_myschema1; > +ALTER PUBLICATION testpub7 SET ALL TABLES IN SCHEMA > testpub_rf_myschema1, TABLE testpub_rf_myschema1.testpub_rf_tb16; > +RESET client_min_messages; > Fixed in v48 [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPuHz1oFM7oaiHeqxMQqd0L70bV_hT7u_mDf3b8As5kwig%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Nov 24, 2021 at 3:22 PM vignesh C <vignesh21@gmail.com> wrote: > > On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > 3) Should we include row filter condition in pg_publication_tables > view like in describe publication(\dRp+) , since the prqual is not > easily readable in pg_publication_rel table: > How about exposing pubdef (or publicationdef) column via pg_publication_tables? In this, we will display the publication definition. This is similar to what we do for indexes via pg_indexes view: postgres=# select * from pg_indexes where tablename like '%t1%'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+-----------+------------+------------------------------------------------------------------- public | t1 | idx_t1 | | CREATE INDEX idx_t1 ON public.t1 USING btree (c1) WHERE (c1 < 10) (1 row) The one advantage I see with this is that we will avoid adding additional columns for the other patches like "column filter". Also, it might be convenient for users. What do you think? -- With Regards, Amit Kapila.
On Mon, Dec 20, 2021 at 4:13 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Nov 24, 2021 at 3:22 PM vignesh C <vignesh21@gmail.com> wrote: > > > > On Tue, Nov 23, 2021 at 4:58 PM Ajin Cherian <itsajin@gmail.com> wrote: > > > > > > > 3) Should we include row filter condition in pg_publication_tables > > view like in describe publication(\dRp+) , since the prqual is not > > easily readable in pg_publication_rel table: > > > > How about exposing pubdef (or publicationdef) column via > pg_publication_tables? In this, we will display the publication > definition. This is similar to what we do for indexes via pg_indexes > view: > postgres=# select * from pg_indexes where tablename like '%t1%'; > schemaname | tablename | indexname | tablespace | indexdef > ------------+-----------+-----------+------------+------------------------------------------------------------------- > public | t1 | idx_t1 | | CREATE INDEX idx_t1 ON public.t1 USING btree > (c1) WHERE (c1 < 10) > (1 row) > > The one advantage I see with this is that we will avoid adding > additional columns for the other patches like "column filter". Also, > it might be convenient for users. What do you think? > I think it is a good idea, particularly since there are already some precedents. OTOH maybe there is no immediate requirement for this feature because there are already alternative ways to conveniently display the filters (e.g. psql \d+ and \dRp+). Currently, there is no pg_get_pubdef function (analogous to the index's pg_get_indexdef) so that would need to be written from scratch. So I feel this is a good feature, but it could be implemented as an independent patch in another thread. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Monday, December 20, 2021 11:24 AM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> > > On Wednesday, December 8, 2021 2:29 PM Amit Kapila > <amit.kapila16@gmail.com> wrote: > > > > On Mon, Dec 6, 2021 at 6:04 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Mon, Dec 6, 2021, at 3:35 AM, Dilip Kumar wrote: > > > > > > On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > > > > > > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > > > > > > > PS> I will update the commit message in the next version. I barely changed > the > > > > documentation to reflect the current behavior. I probably missed some > > changes > > > > but I will fix in the next version. > > > > > > > > I realized that I forgot to mention a few things about the UPDATE behavior. > > > > Regardless of 0003, we need to define which tuple will be used to evaluate > the > > > > row filter for UPDATEs. We already discussed it circa [1]. This current version > > > > chooses *new* tuple. Is it the best choice? > > > > > > But with 0003, we are using both the tuple for evaluating the row > > > filter, so instead of fixing 0001, why we don't just merge 0003 with > > > 0001? I mean eventually, 0003 is doing what is the agreed behavior, > > > i.e. if just OLD is matching the filter then convert the UPDATE to > > > DELETE OTOH if only new is matching the filter then convert the UPDATE > > > to INSERT. Do you think that even we merge 0001 and 0003 then also > > > there is an open issue regarding which row to select for the filter? > > > > > > Maybe I was not clear. IIUC we are still discussing 0003 and I would like to > > > propose a different default based on the conclusion I came up. If we merged > > > 0003, that's fine; this change will be useless. If we don't or it is optional, > > > it still has its merit. > > > > > > Do we want to pay the overhead to evaluating both tuple for UPDATEs? I'm still > > > processing if it is worth it. If you think that in general the row filter > > > contains the primary key and it is rare to change it, it will waste cycles > > > evaluating the same expression twice. It seems this behavior could be > > > controlled by a parameter. > > > > > > > I think the first thing we should do in this regard is to evaluate the > > performance for both cases (when we apply a filter to both tuples vs. > > to one of the tuples). In case the performance difference is > > unacceptable, I think it would be better to still compare both tuples > > as default to avoid data inconsistency issues and have an option to > > allow comparing one of the tuples. > > > > I did some performance tests to see if 0003 patch has much overhead. > With which I compared applying first two patches and applying first three patches > in four cases: > 1) only old rows match the filter. > 2) only new rows match the filter. > 3) both old rows and new rows match the filter. > 4) neither old rows nor new rows match the filter. > > 0003 patch checks both old rows and new rows, and without 0003 patch, it only > checks either old or new rows. We want to know whether it would take more time > if we check the old rows. > > I ran the tests in asynchronous mode and compared the SQL execution time. I also > tried some complex filters, to see if the difference could be more obvious. > > The result and the script are attached. > I didn’t see big difference between the result of applying 0003 patch and the > one not in all cases. So I think 0003 patch doesn’t have much overhead. > In previous test, I ran 3 times and took the average value, which may be affected by performance fluctuations. So, to make the results more accurate, I tested them more times (10 times) and took the average value. The result is attached. In general, I can see the time difference is within 3.5%, which is in an reasonable performance range, I think. Regards, Tang
Вложения
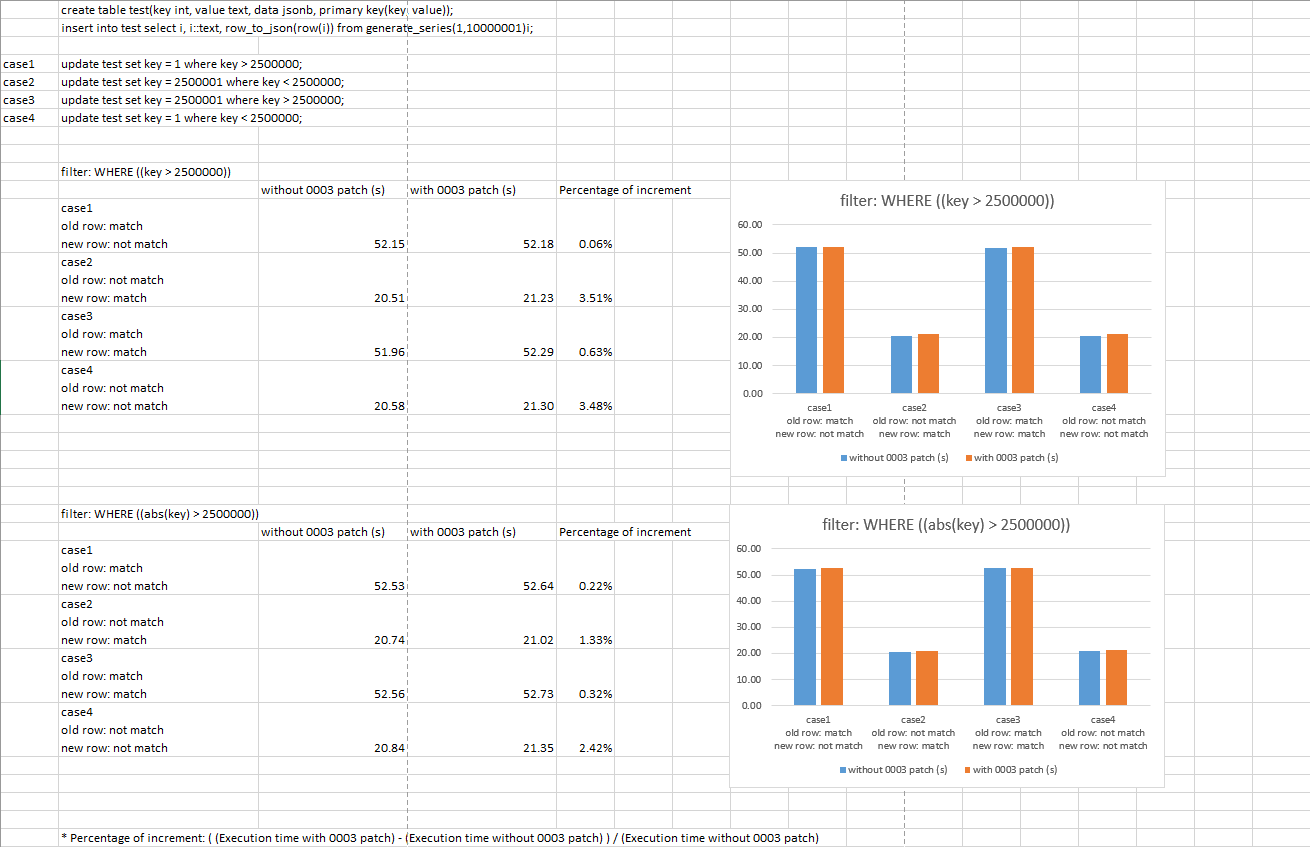{kind=link}
On Mon, Dec 20, 2021 at 8:41 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Thanks for the comments, I agree with all the comments.
> Attach the V49 patch set, which addressed all the above comments on the 0002
> patch.
>
Few comments/suugestions:
======================
1.
+ Oid publish_as_relid = InvalidOid;
+
+ /*
+ * For a partition, if pubviaroot is true, check if any of the
+ * ancestors are published. If so, note down the topmost ancestor
+ * that is published via this publication, the row filter
+ * expression on which will be used to filter the partition's
+ * changes. We could have got the topmost ancestor when collecting
+ * the publication oids, but that will make the code more
+ * complicated.
+ */
+ if (pubform->pubviaroot && relation->rd_rel->relispartition)
+ {
+ if (pubform->puballtables)
+ publish_as_relid = llast_oid(ancestors);
+ else
+ publish_as_relid = GetTopMostAncestorInPublication(pubform->oid,
+ ancestors);
+ }
+
+ if (publish_as_relid == InvalidOid)
+ publish_as_relid = relid;
I think you can initialize publish_as_relid as relid and then later
override it if required. That will save the additional check of
publish_as_relid.
2. I think your previous version code in GetRelationPublicationActions
was better as now we have to call memcpy at two places.
3.
+
+ if (list_member_oid(GetRelationPublications(ancestor),
+ puboid) ||
+ list_member_oid(GetSchemaPublications(get_rel_namespace(ancestor)),
+ puboid))
+ {
+ topmost_relid = ancestor;
+ }
I think here we don't need to use braces ({}) as there is just a
single statement in the condition.
4.
+#define IDX_PUBACTION_n 3
+ ExprState *exprstate[IDX_PUBACTION_n]; /* ExprState array for row filter.
+ One per publication action. */
..
..
I think we can have this define outside the structure. I don't like
this define name, can we name it NUM_ROWFILTER_TYPES or something like
that?
I think we can now merge 0001, 0002, and 0005. We are still evaluating
the performance for 0003, so it is better to keep it separate. We can
take the decision to merge it once we are done with our evaluation.
--
With Regards,
Amit Kapila.
On Tue, Dec 21, 2021 at 5:58 AM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Dec 20, 2021, at 12:10 AM, houzj.fnst@fujitsu.com wrote: > > Attach the V49 patch set, which addressed all the above comments on the 0002 > patch. > > I've been testing the latest versions of this patch set. I'm attaching a new > patch set based on v49. The suggested fixes are in separate patches after the > current one so it is easier to integrate them into the related patch. The > majority of these changes explains some decision to improve readability IMO. > > row-filter x row filter. I'm not a native speaker but "row filter" is widely > used in similar contexts so I suggest to use it. (I didn't adjust the commit > messages) > > An ancient patch use the term coerce but it was changed to cast. Coercion > implies an implicit conversion [1]. If you look at a few lines above you will > see that this expression expects an implicit conversion. > > I modified the query to obtain the row filter expressions to (i) add the schema > pg_catalog to some objects and (ii) use NOT EXISTS instead of subquery (it > reads better IMO). > > A detail message requires you to capitalize the first word of sentences and > includes a period at the end. > > It seems all server messages and documentation use the terminology "WHERE > clause". Let's adopt it instead of "row filter". > > I reviewed 0003. It uses TupleTableSlot instead of HeapTuple. I probably missed > the explanation but it requires more changes (logicalrep_write_tuple and 3 new > entries into RelationSyncEntry). I replaced this patch with a slightly > different one (0005 in this patch set) that uses HeapTuple instead. I didn't > only simple tests and it requires tests. I noticed that this patch does not > include a test to cover the case where TOASTed values are not included in the > new tuple. We should probably add one. > > I agree with Amit that it is a good idea to merge 0001, 0002, and 0005. I would > probably merge 0004 because it is just isolated changes. > > [1] https://en.wikipedia.org/wiki/Type_conversion > > Thanks for all the suggested fixes. Next, I plan to post a new v51* patch set which will be 1. Take your "fixes" patches, and wherever possible just merge them back into the main patches. 2. Merge the resulting main patches according to Amit's advice. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Tue, Dec 21, 2021 at 5:58 AM Euler Taveira <euler@eulerto.com> wrote: > > I reviewed 0003. It uses TupleTableSlot instead of HeapTuple. I probably missed > the explanation but it requires more changes (logicalrep_write_tuple and 3 new > entries into RelationSyncEntry). I replaced this patch with a slightly > different one (0005 in this patch set) that uses HeapTuple instead. I didn't > only simple tests and it requires tests. I noticed that this patch does not > include a test to cover the case where TOASTed values are not included in the > new tuple. We should probably add one. The reason I changed the code to use virtualtuple slots is to reduce tuple deforming overhead. Dilip raised this very valid comment in [1]: On Tue, Sep 21, 2021 at 4:29 PM Dilip Kumar <dilipbalaut(at)gmail(dot)com> wrote: > >In pgoutput_row_filter_update(), first, we are deforming the tuple in >local datum, then modifying the tuple, and then reforming the tuple. >I think we can surely do better here. Currently, you are reforming >the tuple so that you can store it in the scan slot by calling >ExecStoreHeapTuple which will be used for expression evaluation. >Instead of that what you need to do is to deform the tuple using >tts_values of the scan slot and later call ExecStoreVirtualTuple(), so >advantages are 1) you don't need to reform the tuple 2) the expression >evaluation machinery doesn't need to deform again for fetching the >value of the attribute, instead it can directly get from the value >from the virtual tuple. Storing the old tuple/new tuple in a slot and re-using the slot avoids the overhead of continuous deforming of tuple at multiple levels in the code. regards, Ajin Cherian [1] - https://www.postgresql.org/message-id/CAFiTN-vwBjy+eR+iodkO5UVN5cPv_xx1=s8ehzgCRJZA+AztAA@mail.gmail.com
On Tue, Dec 21, 2021 at 12:28 AM Euler Taveira <euler@eulerto.com> wrote: > > On Mon, Dec 20, 2021, at 12:10 AM, houzj.fnst@fujitsu.com wrote: > > Attach the V49 patch set, which addressed all the above comments on the 0002 > patch. > > I've been testing the latest versions of this patch set. I'm attaching a new > patch set based on v49. The suggested fixes are in separate patches after the > current one so it is easier to integrate them into the related patch. The > majority of these changes explains some decision to improve readability IMO. > > row-filter x row filter. I'm not a native speaker but "row filter" is widely > used in similar contexts so I suggest to use it. (I didn't adjust the commit > messages) > > An ancient patch use the term coerce but it was changed to cast. Coercion > implies an implicit conversion [1]. If you look at a few lines above you will > see that this expression expects an implicit conversion. > > I modified the query to obtain the row filter expressions to (i) add the schema > pg_catalog to some objects and (ii) use NOT EXISTS instead of subquery (it > reads better IMO). > Yeah, I think that reads better, but maybe we can once check the plan of both queries and see if there is any significant difference between one of those. > A detail message requires you to capitalize the first word of sentences and > includes a period at the end. > > It seems all server messages and documentation use the terminology "WHERE > clause". Let's adopt it instead of "row filter". > > I reviewed 0003. It uses TupleTableSlot instead of HeapTuple. I probably missed > the explanation but it requires more changes (logicalrep_write_tuple and 3 new > entries into RelationSyncEntry). I replaced this patch with a slightly > different one (0005 in this patch set) that uses HeapTuple instead. I didn't > only simple tests and it requires tests. I noticed that this patch does not > include a test to cover the case where TOASTed values are not included in the > new tuple. We should probably add one. > Yeah, it would be good to add such a test. -- With Regards, Amit Kapila.
On Mon, Dec 20, 2021 at 8:41 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Fri, Dec 17, 2021 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Dec 17, 2021 at 4:11 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > PSA the v47* patch set. > Thanks for the comments, I agree with all the comments. > Attach the V49 patch set, which addressed all the above comments on the 0002 > patch. While reviewing the patch, I was testing a scenario where we change the row filter condition and refresh the publication, in this case we do not identify the row filter change and the table data is not synced with the publisher. In case of setting the table, we sync the data from the publisher. I'm not sure if the behavior is right or not. Publisher session(setup publication): --------------------------------- create table t1(c1 int); insert into t1 values(11); insert into t1 values(12); insert into t1 values(1); select * from t1; c1 ---- 11 12 1 (3 rows) create publication pub1 for table t1 where ( c1 > 10); Subscriber session(setup subscription): --------------------------------- create table t1(c1 int); create subscription sub1 connection 'dbname=postgres host=localhost' publication pub1; select * from t1; c1 ---- 11 12 (2 rows) Publisher session(alter the row filter condition): --------------------------------- alter publication pub1 set table t1 where ( c1 < 10); Subscriber session(Refresh): --------------------------------- alter subscription sub1 refresh publication ; -- After refresh, c1 with 1 is not fetched select * from t1; c1 ---- 11 12 (2 rows) Should we do a table sync in this case, or should the user handle this scenario to take care of sync data from the publisher or should we throw an error to avoid confusion. If existing behavior is fine, we can document it. Thoughts? Regards, Vignesh
On Tue, Dec 21, 2021 at 6:17 AM Ajin Cherian <itsajin@gmail.com> wrote: > > On Tue, Dec 21, 2021 at 5:58 AM Euler Taveira <euler@eulerto.com> wrote: > > > >In pgoutput_row_filter_update(), first, we are deforming the tuple in > >local datum, then modifying the tuple, and then reforming the tuple. > >I think we can surely do better here. Currently, you are reforming > >the tuple so that you can store it in the scan slot by calling > >ExecStoreHeapTuple which will be used for expression evaluation. > >Instead of that what you need to do is to deform the tuple using > >tts_values of the scan slot and later call ExecStoreVirtualTuple(), so > >advantages are 1) you don't need to reform the tuple 2) the expression > >evaluation machinery doesn't need to deform again for fetching the > >value of the attribute, instead it can directly get from the value > >from the virtual tuple. > > Storing the old tuple/new tuple in a slot and re-using the slot avoids > the overhead of > continuous deforming of tuple at multiple levels in the code. > Yeah, deforming tuples again can have a significant cost but what is the need to maintain tmp_new_tuple in relsyncentry. I think that is required in rare cases, so we can probably allocate/deallocate when required. Few other comments: ================== 1. TupleTableSlot *scantuple; /* tuple table slot for row filter */ + TupleTableSlot *new_tuple; /* slot for storing deformed new tuple during updates */ + TupleTableSlot *old_tuple; /* slot for storing deformed old tuple during updates */ I think it is better to name these as scan_slot, new_slot, old_slot to avoid confusion with tuples. 2. +++ b/src/backend/replication/logical/proto.c @@ -19,6 +19,7 @@ #include "replication/logicalproto.h" #include "utils/lsyscache.h" #include "utils/syscache.h" +#include "executor/executor.h" The include is in wrong order. We keep includes in alphabatic order. 3. @@ -832,6 +847,7 @@ logicalrep_write_tuple(StringInfo out, Relation rel, HeapTuple tuple, bool binar ReleaseSysCache(typtup); } + } Spurious addition. 4. -logicalrep_write_tuple(StringInfo out, Relation rel, HeapTuple tuple, bool binary) +logicalrep_write_tuple(StringInfo out, Relation rel, HeapTuple tuple, TupleTableSlot *slot, +bool binary) The formatting is quite off. Please run pgindent. 5. If we decide to go with this approach then I feel let's merge the required comments from Euler's version. -- With Regards, Amit Kapila.
On Tue, Dec 21, 2021 at 10:53 AM vignesh C <vignesh21@gmail.com> wrote: > > On Mon, Dec 20, 2021 at 8:41 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Fri, Dec 17, 2021 6:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > On Fri, Dec 17, 2021 at 4:11 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > PSA the v47* patch set. > > Thanks for the comments, I agree with all the comments. > > Attach the V49 patch set, which addressed all the above comments on the 0002 > > patch. > > While reviewing the patch, I was testing a scenario where we change > the row filter condition and refresh the publication, in this case we > do not identify the row filter change and the table data is not synced > with the publisher. In case of setting the table, we sync the data > from the publisher. > We only sync data if the table is added after the last Refresh or Create Subscription. Even if we decide to sync the data again due to row filter change, it can easily create conflicts with already synced data. So, this seems expected behavior and we can probably document it. -- With Regards, Amit Kapila.
The current PG docs text for CREATE PUBLICATION (in the v54-0001 patch) has a part that says + A nullable column in the <literal>WHERE</literal> clause could cause the + expression to evaluate to false; avoid using columns without not-null + constraints in the <literal>WHERE</literal> clause. I felt that the caution to "avoid using" nullable columns is too strongly worded. AFAIK nullable columns will work perfectly fine so long as you take due care of them in the WHERE clause. In fact, it might be very useful sometimes to filter on nullable columns. Here is a small test example: // publisher test_pub=# create table t1 (id int primary key, msg text null); test_pub=# create publication p1 for table t1 where (msg != 'three'); // subscriber test_sub=# create table t1 (id int primary key, msg text null); test_sub=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=localhost dbname=test_pub application_name=sub1' PUBLICATION p1; // insert some data test_pub=# insert into t1 values (1, 'one'), (2, 'two'), (3, 'three'), (4, null), (5, 'five'); test_pub=# select * from t1; id | msg ----+------- 1 | one 2 | two 3 | three 4 | 5 | five (5 rows) // data at sub test_sub=# select * from t1; id | msg ----+------ 1 | one 2 | two 5 | five (3 rows) Notice the row 4 with the NULL is also not replicated. But, perhaps we were expecting it to be replicated (because NULL is not 'three'). To do this, simply rewrite the WHERE clause to properly account for nulls. // truncate both sides test_pub=# truncate table t1; test_sub=# truncate table t1; // alter the WHERE clause test_pub=# alter publication p1 set table t1 where (msg is null or msg != 'three'); // insert data at pub test_pub=# insert into t1 values (1, 'one'), (2, 'two'), (3, 'three'), (4, null), (5, 'five'); INSERT 0 5 test_pub=# select * from t1; id | msg ----+------- 1 | one 2 | two 3 | three 4 | 5 | five (5 rows) // data at sub (not it includes the row 4) test_sub=# select * from t1; id | msg ----+------ 1 | one 2 | two 4 | 5 | five (4 rows) ~~ So, IMO the PG docs wording for this part should be relaxed a bit. e.g. BEFORE: + A nullable column in the <literal>WHERE</literal> clause could cause the + expression to evaluate to false; avoid using columns without not-null + constraints in the <literal>WHERE</literal> clause. AFTER: + A nullable column in the <literal>WHERE</literal> clause could cause the + expression to evaluate to false. To avoid unexpected results, any possible + null values should be accounted for. Thoughts? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Dec 24, 2021 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote: > > The current PG docs text for CREATE PUBLICATION (in the v54-0001 > patch) has a part that says > > + A nullable column in the <literal>WHERE</literal> clause could cause the > + expression to evaluate to false; avoid using columns without not-null > + constraints in the <literal>WHERE</literal> clause. > > I felt that the caution to "avoid using" nullable columns is too > strongly worded. AFAIK nullable columns will work perfectly fine so > long as you take due care of them in the WHERE clause. In fact, it > might be very useful sometimes to filter on nullable columns. > > Here is a small test example: > > // publisher > test_pub=# create table t1 (id int primary key, msg text null); > test_pub=# create publication p1 for table t1 where (msg != 'three'); > // subscriber > test_sub=# create table t1 (id int primary key, msg text null); > test_sub=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=localhost > dbname=test_pub application_name=sub1' PUBLICATION p1; > > // insert some data > test_pub=# insert into t1 values (1, 'one'), (2, 'two'), (3, 'three'), > (4, null), (5, 'five'); > test_pub=# select * from t1; > id | msg > ----+------- > 1 | one > 2 | two > 3 | three > 4 | > 5 | five > (5 rows) > > // data at sub > test_sub=# select * from t1; > id | msg > ----+------ > 1 | one > 2 | two > 5 | five > (3 rows) > > Notice the row 4 with the NULL is also not replicated. But, perhaps we > were expecting it to be replicated (because NULL is not 'three'). To > do this, simply rewrite the WHERE clause to properly account for > nulls. > > // truncate both sides > test_pub=# truncate table t1; > test_sub=# truncate table t1; > > // alter the WHERE clause > test_pub=# alter publication p1 set table t1 where (msg is null or msg > != 'three'); > > // insert data at pub > test_pub=# insert into t1 values (1, 'one'), (2, 'two'), (3, 'three'), > (4, null), (5, 'five'); > INSERT 0 5 > test_pub=# select * from t1; > id | msg > ----+------- > 1 | one > 2 | two > 3 | three > 4 | > 5 | five > (5 rows) > > // data at sub (not it includes the row 4) > test_sub=# select * from t1; > id | msg > ----+------ > 1 | one > 2 | two > 4 | > 5 | five > (4 rows) > > ~~ > > So, IMO the PG docs wording for this part should be relaxed a bit. > > e.g. > BEFORE: > + A nullable column in the <literal>WHERE</literal> clause could cause the > + expression to evaluate to false; avoid using columns without not-null > + constraints in the <literal>WHERE</literal> clause. > AFTER: > + A nullable column in the <literal>WHERE</literal> clause could cause the > + expression to evaluate to false. To avoid unexpected results, any possible > + null values should be accounted for. > Your suggested wording sounds reasonable to me. Euler, others, any thoughts? -- With Regards, Amit Kapila.
On Sat, Dec 25, 2021, at 1:20 AM, Amit Kapila wrote:
On Fri, Dec 24, 2021 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote:>> So, IMO the PG docs wording for this part should be relaxed a bit.>> e.g.> BEFORE:> + A nullable column in the <literal>WHERE</literal> clause could cause the> + expression to evaluate to false; avoid using columns without not-null> + constraints in the <literal>WHERE</literal> clause.> AFTER:> + A nullable column in the <literal>WHERE</literal> clause could cause the> + expression to evaluate to false. To avoid unexpected results, any possible> + null values should be accounted for.>Your suggested wording sounds reasonable to me. Euler, others, any thoughts?
+1.
On 2021-Dec-26, Euler Taveira wrote: > On Sat, Dec 25, 2021, at 1:20 AM, Amit Kapila wrote: > > On Fri, Dec 24, 2021 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > So, IMO the PG docs wording for this part should be relaxed a bit. > > > > > > e.g. > > > BEFORE: > > > + A nullable column in the <literal>WHERE</literal> clause could cause the > > > + expression to evaluate to false; avoid using columns without not-null > > > + constraints in the <literal>WHERE</literal> clause. > > > AFTER: > > > + A nullable column in the <literal>WHERE</literal> clause could cause the > > > + expression to evaluate to false. To avoid unexpected results, any possible > > > + null values should be accounted for. Is this actually correct? I think a null value would cause the expression to evaluate to null, not false; the issue is that the filter considers a null value as not matching (right?). Maybe it's better to spell that out explicitly; both these wordings seem distracting. You have this elsewhere: + If the optional <literal>WHERE</literal> clause is specified, only rows + that satisfy the <replaceable class="parameter">expression</replaceable> + will be published. Note that parentheses are required around the + expression. It has no effect on <literal>TRUNCATE</literal> commands. Maybe this whole thing is clearer if you just say "If the optional WHERE clause is specified, rows for which the expression returns false or null will not be published." With that it should be fairly clear what happens if you have NULL values in the columns used in the expression, and you can just delete that phrase you're discussing. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/
On Sun, Dec 26, 2021, at 1:09 PM, Alvaro Herrera wrote:
On 2021-Dec-26, Euler Taveira wrote:> On Sat, Dec 25, 2021, at 1:20 AM, Amit Kapila wrote:> > On Fri, Dec 24, 2021 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote:> > >> > > So, IMO the PG docs wording for this part should be relaxed a bit.> > >> > > e.g.> > > BEFORE:> > > + A nullable column in the <literal>WHERE</literal> clause could cause the> > > + expression to evaluate to false; avoid using columns without not-null> > > + constraints in the <literal>WHERE</literal> clause.> > > AFTER:> > > + A nullable column in the <literal>WHERE</literal> clause could cause the> > > + expression to evaluate to false. To avoid unexpected results, any possible> > > + null values should be accounted for.Is this actually correct? I think a null value would cause theexpression to evaluate to null, not false; the issue is that the filterconsiders a null value as not matching (right?). Maybe it's better tospell that out explicitly; both these wordings seem distracting.
[Reading it again...] I think it is referring to the
pgoutput_row_filter_exec_expr() return. That's not accurate because it is
talking about the expression and the expression returns true, false and null.
However, the referred function returns only true or false. I agree that we
should explictily mention that a null return means the row won't be published.
You have this elsewhere:+ If the optional <literal>WHERE</literal> clause is specified, only rows+ that satisfy the <replaceable class="parameter">expression</replaceable>+ will be published. Note that parentheses are required around the+ expression. It has no effect on <literal>TRUNCATE</literal> commands.Maybe this whole thing is clearer if you just say "If the optional WHEREclause is specified, rows for which the expression returns false or nullwill not be published." With that it should be fairly clear whathappens if you have NULL values in the columns used in the expression,and you can just delete that phrase you're discussing.
Your proposal sounds good to me.
On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > Here is the v54* patch set: Attach the v55 patch set which add the following testcases in 0003 patch. 1. Added a test to cover the case where TOASTed values are not included in the new tuple. Suggested by Euler[1]. Note: this test is temporarily commented because it would fail without applying another bug fix patch in another thread[2] which log the detoasted value in old value. I have verified locally that the test pass after applying the bug fix patch[2]. 2. Add a test to cover the case that transform the UPDATE into INSERT. Provided by Tang. [1] https://www.postgresql.org/message-id/flat/6b6cf26d-bf74-4b39-bb07-c067e381d66d%40www.fastmail.com [2} https://postgr.es/m/OS0PR01MB611342D0A92D4F4BF26C0F47FB229@OS0PR01MB6113.jpnprd01.prod.outlook.com Best regards, Hou zj
Вложения
On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Here is the v54* patch set: > > Attach the v55 patch set which add the following testcases in 0003 patch. Sorry for the typo here, I mean the tests are added 0002 patch. Best regards, Hou zj
On Mon, Dec 27, 2021 9:19 PM Hou Zhijie <houzj.fnst@fujitsu.com> wrote: > On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > wrote: > > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > Here is the v54* patch set: > > > > Attach the v55 patch set which add the following testcases in 0002 patch. When reviewing the row filter patch, I found few things that could be improved. 1) We could transform the same row filter expression twice when ALTER PUBLICATION ... SET TABLE WHERE (...). Because we invoke GetTransformedWhereClause in both AlterPublicationTables() and publication_add_relation(). I was thinking it might be better if we only transform the expression once in AlterPublicationTables(). 2) When transforming the expression, we didn’t set the correct p_sourcetext. Since we need to transforming serval expressions which belong to different relations, I think it might be better to pass queryString down to the actual transform function and set p_sourcetext to the actual queryString. Attach a top up patch 0004 which did the above changes. Best regards, Hou zj
Вложения
On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > Here is the v54* patch set:
>
> Attach the v55 patch set which add the following testcases in 0003 patch.
> 1. Added a test to cover the case where TOASTed values are not included in the
> new tuple. Suggested by Euler[1].
>
> Note: this test is temporarily commented because it would fail without
> applying another bug fix patch in another thread[2] which log the detoasted
> value in old value. I have verified locally that the test pass after
> applying the bug fix patch[2].
>
> 2. Add a test to cover the case that transform the UPDATE into INSERT. Provided
> by Tang.
>
Thanks for updating the patches.
A few comments:
1) v55-0001
-/*
- * Gets the relations based on the publication partition option for a specified
- * relation.
- */
List *
GetPubPartitionOptionRelations(List *result, PublicationPartOpt pub_partopt,
Oid relid)
Do we need this change?
2) v55-0002
* Multiple ExprState entries might be used if there are multiple
* publications for a single table. Different publication actions don't
* allow multiple expressions to always be combined into one, so there is
- * one ExprSTate per publication action. Only 3 publication actions are
+ * one ExprState per publication action. Only 3 publication actions are
* used for row filtering ("insert", "update", "delete"). The exprstate
* array is indexed by ReorderBufferChangeType.
*/
I think this change can be merged into 0001 patch.
3) v55-0002
+static bool pgoutput_row_filter_update_check(enum ReorderBufferChangeType changetype, Relation relation,
+ HeapTuple oldtuple, HeapTuple newtuple,
+ RelationSyncEntry *entry, ReorderBufferChangeType *action);
Do we need parameter changetype here? I think it could only be
REORDER_BUFFER_CHANGE_UPDATE.
Regards,
Tang
On Mon, Dec 28, 2021 9:03 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> Attach a top up patch 0004 which did the above changes.
A few comments about v55-0001 and v55-0002.
v55-0001
1.
There is a typo at the last sentence of function(rowfilter_walker)'s comment.
* (b) a user-defined function can be used to access tables which could have
* unpleasant results because a historic snapshot is used. That's why only
- * non-immutable built-in functions are allowed in row filter expressions.
+ * immutable built-in functions are allowed in row filter expressions.
2.
There are two if statements at the end of fetch_remote_table_info.
+ if (!isnull)
+ *qual = lappend(*qual, makeString(TextDatumGetCString(rf)));
+
+ ExecClearTuple(slot);
+
+ /* Ignore filters and cleanup as necessary. */
+ if (isnull)
+ {
+ if (*qual)
+ {
+ list_free_deep(*qual);
+ *qual = NIL;
+ }
+ break;
+ }
What about using the format like following:
if (!isnull)
...
else
...
v55-0002
In function pgoutput_row_filter_init, I found almost whole function is in the if
statement written like this:
static void
pgoutput_row_filter_init()
{
Variable declaration and initialization;
if (!entry->exprstate_valid)
{
......
}
}
What about changing this if statement like following:
if (entry->exprstate_valid)
return;
Regards,
Wang wei
On Wed, Dec 29, 2021 11:16 AM Tang, Haiying <tanghy.fnst@fujitsu.com> wrote:
> On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
> wrote:
> >
> > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > > Here is the v54* patch set:
> >
> > Attach the v55 patch set which add the following testcases in 0003 patch.
> > 1. Added a test to cover the case where TOASTed values are not included in the
> > new tuple. Suggested by Euler[1].
> >
> > Note: this test is temporarily commented because it would fail without
> > applying another bug fix patch in another thread[2] which log the
> detoasted
> > value in old value. I have verified locally that the test pass after
> > applying the bug fix patch[2].
> >
> > 2. Add a test to cover the case that transform the UPDATE into INSERT.
> Provided
> > by Tang.
> >
>
> Thanks for updating the patches.
>
> A few comments:
>
> 1) v55-0001
>
> -/*
> - * Gets the relations based on the publication partition option for a specified
> - * relation.
> - */
> List *
> GetPubPartitionOptionRelations(List *result, PublicationPartOpt pub_partopt,
> Oid relid)
>
> Do we need this change?
Added the comment back.
> 2) v55-0002
> * Multiple ExprState entries might be used if there are multiple
> * publications for a single table. Different publication actions don't
> * allow multiple expressions to always be combined into one, so there is
> - * one ExprSTate per publication action. Only 3 publication actions are
> + * one ExprState per publication action. Only 3 publication actions
> +are
> * used for row filtering ("insert", "update", "delete"). The exprstate
> * array is indexed by ReorderBufferChangeType.
> */
>
> I think this change can be merged into 0001 patch.
Merged.
> 3) v55-0002
> +static bool pgoutput_row_filter_update_check(enum
> ReorderBufferChangeType changetype, Relation relation,
> +
> HeapTuple oldtuple, HeapTuple newtuple,
> +
> RelationSyncEntry *entry, ReorderBufferChangeType *action);
>
> Do we need parameter changetype here? I think it could only be
> REORDER_BUFFER_CHANGE_UPDATE.
I didn't change this, I think it might be better to wait for Ajin's opinion.
Attach the v56 patch set which address above comments and comments(1. 2.) from [1]
[1]
https://www.postgresql.org/message-id/OS3PR01MB62756D18BA0FA969D5255E369E459%40OS3PR01MB6275.jpnprd01.prod.outlook.com
Best regards,
Hou zj
Вложения
On Thur, Dec 30, 2021 9:40 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > Attach the v56 patch set which address above comments and comments(1. 2.) > from [1] > > [1] > https://www.postgresql.org/message-id/OS3PR01MB62756D18BA0FA969D5 > 255E369E459%40OS3PR01MB6275.jpnprd01.prod.outlook.com Rebased the patch set based on recent commit c9105dd. Best regards, Hou zj
Вложения
Here is the v58* patch set: Main changes from v57* are 1. Couple of review comments fixed ~~ Review comments (details) ========================= v58-0001 (main) - PG docs updated as suggested [Alvaro, Euler 26/12] v58-0002 (new/old tuple) - pgputput_row_filter_init refactored as suggested [Wangw 30/12] #3 - re-ran pgindent v58-0003 (tab, dump) - no change v58-0004 (refactor transformations) - minor changes to commit message ------ [Alvaro, Euler 26/12] https://www.postgresql.org/message-id/efac5ea8-d0c6-4c92-aa82-36ea45fd013a%40www.fastmail.com [Wangw 30/12] https://www.postgresql.org/message-id/OS3PR01MB62756D18BA0FA969D5255E369E459%40OS3PR01MB6275.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Dec 30, 2021 at 7:57 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Mon, Dec 28, 2021 9:03 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
> > Attach a top up patch 0004 which did the above changes.
>
> A few comments about v55-0001 and v55-0002.
...
> v55-0002
> In function pgoutput_row_filter_init, I found almost whole function is in the if
> statement written like this:
> static void
> pgoutput_row_filter_init()
> {
> Variable declaration and initialization;
> if (!entry->exprstate_valid)
> {
> ......
> }
> }
> What about changing this if statement like following:
> if (entry->exprstate_valid)
> return;
>
Modified in v58 [1] as suggested
------
[1] https://www.postgresql.org/message-id/CAHut%2BPvkswkGLqzYo7z9rwOoDeLtUk0PEha8kppNvZts0h22Hw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Dec 27, 2021 at 9:57 AM Euler Taveira <euler@eulerto.com> wrote: > > On Sun, Dec 26, 2021, at 1:09 PM, Alvaro Herrera wrote: > > On 2021-Dec-26, Euler Taveira wrote: > > > On Sat, Dec 25, 2021, at 1:20 AM, Amit Kapila wrote: > > > On Fri, Dec 24, 2021 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > > > > So, IMO the PG docs wording for this part should be relaxed a bit. > > > > > > > > e.g. > > > > BEFORE: > > > > + A nullable column in the <literal>WHERE</literal> clause could cause the > > > > + expression to evaluate to false; avoid using columns without not-null > > > > + constraints in the <literal>WHERE</literal> clause. > > > > AFTER: > > > > + A nullable column in the <literal>WHERE</literal> clause could cause the > > > > + expression to evaluate to false. To avoid unexpected results, any possible > > > > + null values should be accounted for. > > Is this actually correct? I think a null value would cause the > expression to evaluate to null, not false; the issue is that the filter > considers a null value as not matching (right?). Maybe it's better to > spell that out explicitly; both these wordings seem distracting. > > [Reading it again...] I think it is referring to the > pgoutput_row_filter_exec_expr() return. That's not accurate because it is > talking about the expression and the expression returns true, false and null. > However, the referred function returns only true or false. I agree that we > should explictily mention that a null return means the row won't be published. > > You have this elsewhere: > > + If the optional <literal>WHERE</literal> clause is specified, only rows > + that satisfy the <replaceable class="parameter">expression</replaceable> > + will be published. Note that parentheses are required around the > + expression. It has no effect on <literal>TRUNCATE</literal> commands. > > Maybe this whole thing is clearer if you just say "If the optional WHERE > clause is specified, rows for which the expression returns false or null > will not be published." With that it should be fairly clear what > happens if you have NULL values in the columns used in the expression, > and you can just delete that phrase you're discussing. > > Your proposal sounds good to me. Modified as suggested in v58 [1]. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPvkswkGLqzYo7z9rwOoDeLtUk0PEha8kppNvZts0h22Hw%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Dec 31, 2021 at 12:39 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Wed, Dec 29, 2021 11:16 AM Tang, Haiying <tanghy.fnst@fujitsu.com> wrote: > > On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > wrote: > > > > > > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here is the v54* patch set: > > > > > > Attach the v55 patch set which add the following testcases in 0003 patch. > > > 1. Added a test to cover the case where TOASTed values are not included in the > > > new tuple. Suggested by Euler[1]. > > > > > > Note: this test is temporarily commented because it would fail without > > > applying another bug fix patch in another thread[2] which log the > > detoasted > > > value in old value. I have verified locally that the test pass after > > > applying the bug fix patch[2]. > > > > > > 2. Add a test to cover the case that transform the UPDATE into INSERT. > > Provided > > > by Tang. > > > > > > > Thanks for updating the patches. > > > > A few comments: ... > > 3) v55-0002 > > +static bool pgoutput_row_filter_update_check(enum > > ReorderBufferChangeType changetype, Relation relation, > > + > > HeapTuple oldtuple, HeapTuple newtuple, > > + > > RelationSyncEntry *entry, ReorderBufferChangeType *action); > > > > Do we need parameter changetype here? I think it could only be > > REORDER_BUFFER_CHANGE_UPDATE. > > I didn't change this, I think it might be better to wait for Ajin's opinion. I agree with Tang. AFAIK there is no problem removing that redundant param as suggested. BTW - the Assert within that function is also incorrect because the only possible value is REORDER_BUFFER_CHANGE_UPDATE. I will make these fixes in a future version. ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Jan 4, 2022 at 00:54 PM Peter Smith <smithpb2250@gmail.com> wrote:
> Modified in v58 [1] as suggested
Thanks for updating the patches.
A few comments about v58-0001 and v58-0002.
v58-0001
1.
How about modifying the following loop in copy_table by using for_each_from
instead of foreach?
Like the invocation of for_each_from in function get_rule_expr.
from:
if (qual != NIL)
{
ListCell *lc;
bool first = true;
appendStringInfoString(&cmd, " WHERE ");
foreach(lc, qual)
{
char *q = strVal(lfirst(lc));
if (first)
first = false;
else
appendStringInfoString(&cmd, " OR ");
appendStringInfoString(&cmd, q);
}
list_free_deep(qual);
}
change to:
if (qual != NIL)
{
ListCell *lc;
char *q = strVal(linitial(qual));
appendStringInfo(&cmd, " WHERE %s", q);
for_each_from(lc, qual, 1)
{
q = strVal(lfirst(lc));
appendStringInfo(&cmd, " OR %s", q);
}
list_free_deep(qual);
}
2.
I find the API of get_rel_sync_entry is modified.
-get_rel_sync_entry(PGOutputData *data, Oid relid)
+get_rel_sync_entry(PGOutputData *data, Relation relation)
It looks like just moving the invocation of RelationGetRelid from outside into
function get_rel_sync_entry. I am not sure whether this modification is
necessary to this feature or not.
v58-0002
1.
In function pgoutput_row_filter_init, if no_filter is set, I think we do not
need to add row filter to list(rfnodes).
So how about changing three conditions when add row filter to rfnodes like this:
- if (pub->pubactions.pubinsert)
+ if (pub->pubactions.pubinsert && !no_filter[idx_ins])
{
rfnode = stringToNode(TextDatumGetCString(rfdatum));
rfnodes[idx_ins] = lappend(rfnodes[idx_ins], rfnode);
}
Regards,
Wang wei
On Tue, Jan 4, 2022 at 12:15 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Dec 31, 2021 at 12:39 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > 3) v55-0002 > > > +static bool pgoutput_row_filter_update_check(enum > > > ReorderBufferChangeType changetype, Relation relation, > > > + > > > HeapTuple oldtuple, HeapTuple newtuple, > > > + > > > RelationSyncEntry *entry, ReorderBufferChangeType *action); > > > > > > Do we need parameter changetype here? I think it could only be > > > REORDER_BUFFER_CHANGE_UPDATE. > > > > I didn't change this, I think it might be better to wait for Ajin's opinion. > > I agree with Tang. AFAIK there is no problem removing that redundant > param as suggested. BTW - the Assert within that function is also > incorrect because the only possible value is > REORDER_BUFFER_CHANGE_UPDATE. I will make these fixes in a future > version. > That sounds fine to me too. One more thing is that you don't need to modify the action in case it remains update as the caller has already set that value. Currently, we are modifying it as update at two places in this function, we can remove both of those and keep the comments intact for the later update. -- With Regards, Amit Kapila.
I have reviewed again the source code for v58-0001.
Below are my review comments.
Actually, I intend to fix most of these myself for v59*, so this post
is just for records.
v58-0001 Review Comments
========================
1. doc/src/sgml/ref/alter_publication.sgml - reword for consistency
+ name to explicitly indicate that descendant tables are included. If the
+ optional <literal>WHERE</literal> clause is specified, rows that do not
+ satisfy the <replaceable class="parameter">expression</replaceable> will
+ not be published. Note that parentheses are required around the
For consistency, it would be better to reword this sentence about the
expression to be more similar to the one in CREATE PUBLICATION, which
now says:
+ If the optional <literal>WHERE</literal> clause is specified, rows for
+ which the <replaceable class="parameter">expression</replaceable> returns
+ false or null will not be published. Note that parentheses are required
+ around the expression. It has no effect on <literal>TRUNCATE</literal>
+ commands.
~~
2. doc/src/sgml/ref/create_subscription.sgml - reword for consistency
@@ -319,6 +324,25 @@ CREATE SUBSCRIPTION <replaceable
class="parameter">subscription_name</replaceabl
the parameter <literal>create_slot = false</literal>. This is an
implementation restriction that might be lifted in a future release.
</para>
+
+ <para>
+ If any table in the publication has a <literal>WHERE</literal> clause, rows
+ that do not satisfy the <replaceable
class="parameter">expression</replaceable>
+ will not be published. If the subscription has several publications in which
For consistency, it would be better to reword this sentence about the
expression to be more similar to the one in CREATE PUBLICATION, which
now says:
+ If the optional <literal>WHERE</literal> clause is specified, rows for
+ which the <replaceable class="parameter">expression</replaceable> returns
+ false or null will not be published. Note that parentheses are required
+ around the expression. It has no effect on <literal>TRUNCATE</literal>
+ commands.
~~
3. src/backend/catalog/pg_publication.c - whitespace
+rowfilter_walker(Node *node, Relation relation)
+{
+ char *errdetail_msg = NULL;
+
+ if (node == NULL)
+ return false;
+
+
+ if (IsRowFilterSimpleExpr(node))
Remove the extra blank line.
~~
4. src/backend/executor/execReplication.c - move code
+ bad_rfcolnum = GetRelationPublicationInfo(rel, true);
+
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns referenced in
+ * the row filters from publications which the relation is in are valid,
+ * which means all referenced columns are part of REPLICA IDENTITY, or the
+ * table do not publish UPDATES or DELETES.
+ */
+ if (AttributeNumberIsValid(bad_rfcolnum))
I felt that the bad_rfcolnum assignment belongs below the large
comment explaining this logic.
~~
5. src/backend/executor/execReplication.c - fix typo
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns referenced in
+ * the row filters from publications which the relation is in are valid,
+ * which means all referenced columns are part of REPLICA IDENTITY, or the
+ * table do not publish UPDATES or DELETES.
+ */
Typo: "table do not publish" -> "table does not publish"
~~
6. src/backend/replication/pgoutput/pgoutput.c - fix typo
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ /* Gather the rfnodes per pubaction of this publiaction. */
+ if (pub->pubactions.pubinsert)
Typo: "publiaction" --> "publication"
~~
7. src/backend/utils/cache/relcache.c - fix comment case
@@ -267,6 +271,19 @@ typedef struct opclasscacheent
static HTAB *OpClassCache = NULL;
+/*
+ * Information used to validate the columns in the row filter expression. see
+ * rowfilter_column_walker for details.
+ */
Typo: "see" --> "See"
~~
8. src/backend/utils/cache/relcache.c - "row-filter"
For consistency with all other naming change all instances of
"row-filter" to "row filter" in this file.
~~
9. src/backend/utils/cache/relcache.c - fix typo
~~
10. src/backend/utils/cache/relcache.c - comment confused wording?
Function GetRelationPublicationInfo:
+ /*
+ * For a partition, if pubviaroot is true, check if any of the
+ * ancestors are published. If so, note down the topmost ancestor
+ * that is published via this publication, the row filter
+ * expression on which will be used to filter the partition's
+ * changes. We could have got the topmost ancestor when collecting
+ * the publication oids, but that will make the code more
+ * complicated.
+ */
Typo: Probably "on which' --> "of which" ?
~~
11. src/backend/utils/cache/relcache.c - GetRelationPublicationActions
Something seemed slightly fishy with the code doing the memcpy,
because IIUC is possible for the GetRelationPublicationInfo function
to return without setting the relation->rd_pubactions. Is it just
missing an Assert or maybe a comment to say such a scenario is not
possible in this case because the is_publishable_relation was already
tested?
Currently, it just seems a little bit too sneaky.
~~
12. src/include/parser/parse_node.h - This change is unrelated to row-filtering.
@@ -79,7 +79,7 @@ typedef enum ParseExprKind
EXPR_KIND_CALL_ARGUMENT, /* procedure argument in CALL */
EXPR_KIND_COPY_WHERE, /* WHERE condition in COPY FROM */
EXPR_KIND_GENERATED_COLUMN, /* generation expression for a column */
- EXPR_KIND_CYCLE_MARK, /* cycle mark value */
+ EXPR_KIND_CYCLE_MARK /* cycle mark value */
} ParseExprKind;
This change is unrelated to Row-Filtering so ought to be removed from
this patch. Soon I will post a separate thread to fix this
independently on HEAD.
~~
13. src/include/utils/rel.h - comment typos
@@ -164,6 +164,13 @@ typedef struct RelationData
PublicationActions *rd_pubactions; /* publication actions */
/*
+ * true if the columns referenced in row filters from all the publications
+ * the relation is in are part of replica identity, or the publication
+ * actions do not include UPDATE and DELETE.
+ */
Some minor rewording of the comment:
"true" --> "True".
"part of replica identity" --> "part of the replica identity"
"UPDATE and DELETE" --> "UPDATE or DELETE"
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Wed, Jan 5, 2022 at 4:34 PM Peter Smith <smithpb2250@gmail.com> wrote: > > I have reviewed again the source code for v58-0001. > > Below are my review comments. > > Actually, I intend to fix most of these myself for v59*, so this post > is just for records. > > v58-0001 Review Comments > ======================== > > ~~ > > 9. src/backend/utils/cache/relcache.c - fix typo > (Oops. The previous post omitted the detail for this comment #9) - * If we know everything is replicated, there is no point to check for - * other publications. + * If the publication action include UPDATE and DELETE and + * validate_rowfilter flag is true, validates that any columns + * referenced in the filter expression are part of REPLICA IDENTITY + * index. Typo: "If the publication action include UPDATE and DELETE" --> "If the publication action includes UPDATE or DELETE" ------ Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Dec 22, 2021 at 5:26 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Mon, Dec 20, 2021 at 9:30 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Mon, Dec 20, 2021 at 8:41 AM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > Thanks for the comments, I agree with all the comments.
> > > Attach the V49 patch set, which addressed all the above comments on the 0002
> > > patch.
> > >
> >
> > Few comments/suugestions:
> > ======================
> > 1.
> > + Oid publish_as_relid = InvalidOid;
> > +
> > + /*
> > + * For a partition, if pubviaroot is true, check if any of the
> > + * ancestors are published. If so, note down the topmost ancestor
> > + * that is published via this publication, the row filter
> > + * expression on which will be used to filter the partition's
> > + * changes. We could have got the topmost ancestor when collecting
> > + * the publication oids, but that will make the code more
> > + * complicated.
> > + */
> > + if (pubform->pubviaroot && relation->rd_rel->relispartition)
> > + {
> > + if (pubform->puballtables)
> > + publish_as_relid = llast_oid(ancestors);
> > + else
> > + publish_as_relid = GetTopMostAncestorInPublication(pubform->oid,
> > + ancestors);
> > + }
> > +
> > + if (publish_as_relid == InvalidOid)
> > + publish_as_relid = relid;
> >
> > I think you can initialize publish_as_relid as relid and then later
> > override it if required. That will save the additional check of
> > publish_as_relid.
> >
>
> Fixed in v51* [1]
>
> > 2. I think your previous version code in GetRelationPublicationActions
> > was better as now we have to call memcpy at two places.
> >
>
> Fixed in v51* [1]
>
> > 3.
> > +
> > + if (list_member_oid(GetRelationPublications(ancestor),
> > + puboid) ||
> > + list_member_oid(GetSchemaPublications(get_rel_namespace(ancestor)),
> > + puboid))
> > + {
> > + topmost_relid = ancestor;
> > + }
> >
> > I think here we don't need to use braces ({}) as there is just a
> > single statement in the condition.
> >
>
> Fixed in v51* [1]
>
> > 4.
> > +#define IDX_PUBACTION_n 3
> > + ExprState *exprstate[IDX_PUBACTION_n]; /* ExprState array for row filter.
> > + One per publication action. */
> > ..
> > ..
> >
> > I think we can have this define outside the structure. I don't like
> > this define name, can we name it NUM_ROWFILTER_TYPES or something like
> > that?
> >
>
> Partly fixed in v51* [1], I've changed the #define name but I did not
> move it. The adjacent comment talks about these ExprState caches and
> explains the reason why the number is 3. So if I move the #define then
> half that comment would have to move with it. I thought it is better
> to keep all the related parts grouped together with the one
> explanatory comment, but if you still want the #define moved please
> confirm and I can do it in a future version.
>
Yeah, I would prefer it to be moved. You can move the part of the
comment suggesting three pubactions can be used for row filtering.
--
With Regards,
Amit Kapila.
On Tue, Jan 4, 2022 at 9:58 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here is the v58* patch set:
>
> Main changes from v57* are
> 1. Couple of review comments fixed
>
> ~~
>
> Review comments (details)
> =========================
>
> v58-0001 (main)
> - PG docs updated as suggested [Alvaro, Euler 26/12]
>
> v58-0002 (new/old tuple)
> - pgputput_row_filter_init refactored as suggested [Wangw 30/12] #3
> - re-ran pgindent
>
> v58-0003 (tab, dump)
> - no change
>
> v58-0004 (refactor transformations)
> - minor changes to commit message
Few comments:
1) We could include namespace names along with the relation to make it
more clear to the user if the user had specified tables having same
table names from different schemas:
+ /* Disallow duplicate tables if there are any
with row filters. */
+ if (t->whereClause ||
list_member_oid(relids_with_rf, myrelid))
+ ereport(ERROR,
+
(errcode(ERRCODE_DUPLICATE_OBJECT),
+ errmsg("conflicting
or redundant WHERE clauses for table \"%s\"",
+
RelationGetRelationName(rel))));
2) Few includes are not required, I could compile without it:
#include "executor/executor.h" in pgoutput.c,
#include "parser/parse_clause.h",
#include "parser/parse_relation.h" and #include "utils/ruleutils.h" in
relcache.c and
#include "parser/parse_node.h" in pg_publication.h
3) I felt the 0004-Row-Filter-refactor-transformations can be merged
to 0001 patch, since most of the changes are from 0001 patch or the
functions which are moved from pg_publication.c to publicationcmds.c
can be handled in 0001 patch.
4) Should this be posted as a separate patch in a new thread, as it is
not part of row filtering:
--- a/src/include/parser/parse_node.h
+++ b/src/include/parser/parse_node.h
@@ -79,7 +79,7 @@ typedef enum ParseExprKind
EXPR_KIND_CALL_ARGUMENT, /* procedure argument in CALL */
EXPR_KIND_COPY_WHERE, /* WHERE condition in COPY FROM */
EXPR_KIND_GENERATED_COLUMN, /* generation expression for a column */
- EXPR_KIND_CYCLE_MARK, /* cycle mark value */
+ EXPR_KIND_CYCLE_MARK /* cycle mark value */
} ParseExprKind;
5) This log will be logged for each tuple, if there are millions of
records it will get logged millions of times, we could remove it:
+ /* update requires a new tuple */
+ Assert(newtuple);
+
+ elog(DEBUG3, "table \"%s.%s\" has row filter",
+
get_namespace_name(get_rel_namespace(RelationGetRelid(relation))),
+ get_rel_name(relation->rd_id));
Regards,
Vignesh
On Wed, Jan 5, 2022 at 11:04 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > 11. src/backend/utils/cache/relcache.c - GetRelationPublicationActions > > Something seemed slightly fishy with the code doing the memcpy, > because IIUC is possible for the GetRelationPublicationInfo function > to return without setting the relation->rd_pubactions. Is it just > missing an Assert or maybe a comment to say such a scenario is not > possible in this case because the is_publishable_relation was already > tested? > I think it would be good to have an Assert for a valid value of relation->rd_pubactions before doing memcpy. Alternatively, in function, GetRelationPublicationInfo(), we can have an Assert when rd_rfcol_valid is true. I think we can add comments atop GetRelationPublicationInfo about pubactions. > > 13. src/include/utils/rel.h - comment typos > > @@ -164,6 +164,13 @@ typedef struct RelationData > PublicationActions *rd_pubactions; /* publication actions */ > > /* > + * true if the columns referenced in row filters from all the publications > + * the relation is in are part of replica identity, or the publication > + * actions do not include UPDATE and DELETE. > + */ > > Some minor rewording of the comment: > ... > "UPDATE and DELETE" --> "UPDATE or DELETE" > The existing comment seems correct to me. Hou-San can confirm it once as I think this is written by him. -- With Regards, Amit Kapila.
On Wednesday, January 5, 2022 2:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 5, 2022 at 11:04 AM Peter Smith <smithpb2250@gmail.com> > wrote: > > > > > > 11. src/backend/utils/cache/relcache.c - GetRelationPublicationActions > > > > Something seemed slightly fishy with the code doing the memcpy, > > because IIUC is possible for the GetRelationPublicationInfo function > > to return without setting the relation->rd_pubactions. Is it just > > missing an Assert or maybe a comment to say such a scenario is not > > possible in this case because the is_publishable_relation was already > > tested? > > > > I think it would be good to have an Assert for a valid value of > relation->rd_pubactions before doing memcpy. Alternatively, in > function, GetRelationPublicationInfo(), we can have an Assert when > rd_rfcol_valid is true. I think we can add comments atop > GetRelationPublicationInfo about pubactions. > > > > > 13. src/include/utils/rel.h - comment typos > > > > @@ -164,6 +164,13 @@ typedef struct RelationData > > PublicationActions *rd_pubactions; /* publication actions */ > > > > /* > > + * true if the columns referenced in row filters from all the > > + publications > > + * the relation is in are part of replica identity, or the > > + publication > > + * actions do not include UPDATE and DELETE. > > + */ > > > > Some minor rewording of the comment: > > > ... > > "UPDATE and DELETE" --> "UPDATE or DELETE" > > > > The existing comment seems correct to me. Hou-San can confirm it once as I > think this is written by him. I think the code comment is trying to say "the publication does not include UPDATE and also does not include DELETE" I am not too sure about the grammar, I noticed there is some other places in the code use " no updates or deletes ", so maybe it's fine to change it to "UPDATE or DELETE" Best regards, Hou zj
On Tue, Dec 28, 2021 at 6:33 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Mon, Dec 27, 2021 9:19 PM Hou Zhijie <houzj.fnst@fujitsu.com> wrote:
> > On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
> > wrote:
> > > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > > > Here is the v54* patch set:
> > >
> > > Attach the v55 patch set which add the following testcases in 0002 patch.
>
> When reviewing the row filter patch, I found few things that could be improved.
> 1) We could transform the same row filter expression twice when
> ALTER PUBLICATION ... SET TABLE WHERE (...). Because we invoke
> GetTransformedWhereClause in both AlterPublicationTables() and
> publication_add_relation(). I was thinking it might be better if we only
> transform the expression once in AlterPublicationTables().
>
> 2) When transforming the expression, we didn’t set the correct p_sourcetext.
> Since we need to transforming serval expressions which belong to different
> relations, I think it might be better to pass queryString down to the actual
> transform function and set p_sourcetext to the actual queryString.
>
I have tried the following few examples to check the error_position
and it seems to be showing correct position without your 0004 patch.
postgres=# create publication pub for table t1 where (10);
ERROR: argument of PUBLICATION WHERE must be type boolean, not type integer
LINE 1: create publication pub for table t1 where (10);
^
Also, transformPubWhereClauses() seems to be returning the same list
as it was passed to it. Do we really need to return anything from
transformPubWhereClauses()?
--
With Regards,
Amit Kapila.
On Wed, Jan 5, 2022 at 2:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Dec 28, 2021 at 6:33 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > On Mon, Dec 27, 2021 9:19 PM Hou Zhijie <houzj.fnst@fujitsu.com> wrote: > > > On Mon, Dec 27, 2021 9:16 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > > wrote: > > > > On Thur, Dec 23, 2021 4:28 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > > Here is the v54* patch set: > > > > > > > > Attach the v55 patch set which add the following testcases in 0002 patch. > > > > When reviewing the row filter patch, I found few things that could be improved. > > 1) We could transform the same row filter expression twice when > > ALTER PUBLICATION ... SET TABLE WHERE (...). Because we invoke > > GetTransformedWhereClause in both AlterPublicationTables() and > > publication_add_relation(). I was thinking it might be better if we only > > transform the expression once in AlterPublicationTables(). > > > > 2) When transforming the expression, we didn’t set the correct p_sourcetext. > > Since we need to transforming serval expressions which belong to different > > relations, I think it might be better to pass queryString down to the actual > > transform function and set p_sourcetext to the actual queryString. > > > > I have tried the following few examples to check the error_position > and it seems to be showing correct position without your 0004 patch. > postgres=# create publication pub for table t1 where (10); > ERROR: argument of PUBLICATION WHERE must be type boolean, not type integer > LINE 1: create publication pub for table t1 where (10); > > ^ > I understand why the error position could vary even though it is showing the correct location in the above example after reading another related email [1]. > Also, transformPubWhereClauses() seems to be returning the same list > as it was passed to it. Do we really need to return anything from > transformPubWhereClauses()? > One more point about this function: the patch seems to be doing some work even when where clause is not specified which can be avoided. Another minor comment: +static bool pgoutput_row_filter(enum ReorderBufferChangeType changetype, Do we need to specify the 'enum' type before changetype parameter? [1] - https://www.postgresql.org/message-id/1513381.1640626456%40sss.pgh.pa.us -- With Regards, Amit Kapila.
BTW I think it's not great to commit with the presented split. We would have non-trivial short-lived changes for no good reason (0002 in particular). I think this whole series should be a single patch, with the commit message being a fusion of messages explaining in full what the functional change is, listing all the authors together. Having a commit message like in 0001 where all the distinct changes are explained in separate sections with each section listing its own author, does not sound very useful or helpful. -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ "Thou shalt not follow the NULL pointer, for chaos and madness await thee at its end." (2nd Commandment for C programmers)
FYI - v58 is currently known to be broken due to a recent commit [1]. I plan to post a v59* later today to address this as well as other recent review comments. ------ [1] https://github.com/postgres/postgres/commit/6ce16088bfed97f982f66a9dc17b8364df289e4d Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Jan 6, 2022 at 1:10 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > BTW I think it's not great to commit with the presented split. We would > have non-trivial short-lived changes for no good reason (0002 in > particular). I think this whole series should be a single patch, with Yes, we know that eventually these parts will be combined and committed as a single patch. What you see not is still a work-in-progress. The current separation has been mostly for helping multiple people collaborate without too much clashing. e.g., the 0002 patch has been kept separate just to help do performance testing of that part in isolation. > the commit message being a fusion of messages explaining in full what > the functional change is, listing all the authors together. Having a > commit message like in 0001 where all the distinct changes are explained > in separate sections with each section listing its own author, does not > sound very useful or helpful. > Yes, the current v58-0001 commit message is just a combination of previous historical patch comments as each of them got merged back into the main patch. This message format was just a quick/easy way to ensure that no information was accidentally lost along the way. We understand that prior to the final commit this will all need to be fused together just like you are suggesting. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jan 5, 2022 at 9:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > ... > Another minor comment: > +static bool pgoutput_row_filter(enum ReorderBufferChangeType changetype, > > Do we need to specify the 'enum' type before changetype parameter? > That is because there is currently no typedef for the enum ReorderBufferChangeType. Of course, it is easy to add a typedef and then this 'enum' is not needed in the signature, but I wasn't sure if adding a new typedef strictly belonged as part of this Row-Filter patch or not. ------ Kind Regards. Peter Smith. Fujitsu Australia.
On Thu, Jan 6, 2022 at 8:43 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Wed, Jan 5, 2022 at 9:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > ... > > > Another minor comment: > > +static bool pgoutput_row_filter(enum ReorderBufferChangeType changetype, > > > > Do we need to specify the 'enum' type before changetype parameter? > > > > That is because there is currently no typedef for the enum > ReorderBufferChangeType. > But I see that the 0002 patch is already adding the required typedef. > Of course, it is easy to add a typedef and then this 'enum' is not > needed in the signature, but I wasn't sure if adding a new typedef > strictly belonged as part of this Row-Filter patch or not. > I don't see any harm in doing so. -- With Regards, Amit Kapila.
On Thu, Jan 6, 2022 at 9:29 AM Peter Smith <smithpb2250@gmail.com> wrote: > > FYI - v58 is currently known to be broken due to a recent commit [1]. > > I plan to post a v59* later today to address this as well as other > recent review comments. > > ------ > [1] https://github.com/postgres/postgres/commit/6ce16088bfed97f982f66a9dc17b8364df289e4d > > Kind Regards, > Peter Smith. > Fujitsu Australia. Here is the v59* patch set: Main changes from v58* are 0. Rebase to HEAD (needed after recent commit [1]) 1. Multiple review comments addressed ~~ Details ======= v58-0001 (main) - Fixed some typos for commit message - Made PG docs wording more consistent [5/1 Peter] #1,#2 - Modified tablesync SQL using Vignesh improvements [22/12 Amit] and Tang improvements [internal] - Fixed whitespace [5/1 Peter] #3 - Moved code below comment [5/1 Peter] #4 - Fixed typos/wording in comments [5/1 Peter] #5,#6,#7,#8,#9,#10,#13 - Removed parse_node.h from this patch [5/1 Peter] #12, [5/1 Vignesh] #4 - Used for_each_from macro in tablesync [5/1 Wangw] #1 - Reverted unnecessary signature change of get_rel_sync_entry [5/1 Wangw] #2 - Moved #define outside of struct [5/1 Amit #define] v58-0002 (new/old tuple) - Modified signature of pgoutput_row_file_update_check [29/12 Tang] #3 - Removed unnecessary assignments of *action [5/1 Amit *action] v58-0003 (tab, dump) - no change v58-0004 (refactor transformations) - no change ------ [1] https://github.com/postgres/postgres/commit/6ce16088bfed97f982f66a9dc17b8364df289e4d [22/12 Amit] https://www.postgresql.org/message-id/CAA4eK1JNRE1dQR_xQT-2pFFHMTXzb%3DCf68Dw3N_5swvrz0D8tw%40mail.gmail.com [29/12 Tang] https://www.postgresql.org/message-id/OS0PR01MB611317903619FE04C42AD1ECFB449%40OS0PR01MB6113.jpnprd01.prod.outlook.com [5/1 Amit #define] https://www.postgresql.org/message-id/CAA4eK1K5%3DFZ47va1NjTrSJADCf91%3D251LtvqBxNjt4vtZGjPGw%40mail.gmail.com [5/1 Amit *action] https://www.postgresql.org/message-id/CAA4eK1Ktt5GrzM8hHWn9htg_Cfn-7y0VN6zFFyqQM4FxEjc5Rg%40mail.gmail.com [5/1 Peter] https://www.postgresql.org/message-id/CAHut%2BPvp_O%2BZQf11kOyhO80YHUQnPQZMDRrm2ce%2BryY36H_TPw%40mail.gmail.com [5/1 Vignesh] https://www.postgresql.org/message-id/CALDaNm13yVPH0EcObv4tCHLQfUwjfvPFh8c-nd3Ldg71Y9es7A%40mail.gmail.com [5/1 Wangw] https://www.postgresql.org/message-id/OS3PR01MB6275ADE2B0EDED067C136D539E4B9%40OS3PR01MB6275.jpnprd01.prod.outlook.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Thu, Jan 6, 2022, at 1:18 AM, Amit Kapila wrote:
On Thu, Jan 6, 2022 at 8:43 AM Peter Smith <smithpb2250@gmail.com> wrote:>> On Wed, Jan 5, 2022 at 9:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote:> >> ...>> > Another minor comment:> > +static bool pgoutput_row_filter(enum ReorderBufferChangeType changetype,> >> > Do we need to specify the 'enum' type before changetype parameter?> >>> That is because there is currently no typedef for the enum> ReorderBufferChangeType.>But I see that the 0002 patch is already adding the required typedef.
IMO we shouldn't reuse ReorderBufferChangeType. For a long-term solution, it is
fragile. ReorderBufferChangeType has values that do not matter for row filter
and it relies on the fact that REORDER_BUFFER_CHANGE_INSERT,
REORDER_BUFFER_CHANGE_UPDATE and REORDER_BUFFER_CHANGE_DELETE are the first 3
values from the enum, otherwise, it breaks rfnodes and no_filters in
pgoutput_row_filter(). I suggest a separate enum that contains only these 3
values.
enum RowFilterPublishAction {
PUBLISH_ACTION_INSERT,
PUBLISH_ACTION_UPDATE,
PUBLISH_ACTION_DELETE
};
On Wed, Jan 5, 2022 at 4:56 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > ... > > > 4. > > > +#define IDX_PUBACTION_n 3 > > > + ExprState *exprstate[IDX_PUBACTION_n]; /* ExprState array for row filter. > > > + One per publication action. */ > > > .. > > > .. > > > > > > I think we can have this define outside the structure. I don't like > > > this define name, can we name it NUM_ROWFILTER_TYPES or something like > > > that? > > > > > > > Partly fixed in v51* [1], I've changed the #define name but I did not > > move it. The adjacent comment talks about these ExprState caches and > > explains the reason why the number is 3. So if I move the #define then > > half that comment would have to move with it. I thought it is better > > to keep all the related parts grouped together with the one > > explanatory comment, but if you still want the #define moved please > > confirm and I can do it in a future version. > > > > Yeah, I would prefer it to be moved. You can move the part of the > comment suggesting three pubactions can be used for row filtering. > Fixed in v59* [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsiw9fbOUTpCMWirut1ZD5hbWk8_U9tZya4mG-YK%2Bfq8g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jan 5, 2022 at 4:26 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jan 4, 2022 at 12:15 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Dec 31, 2021 at 12:39 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > 3) v55-0002 > > > > +static bool pgoutput_row_filter_update_check(enum > > > > ReorderBufferChangeType changetype, Relation relation, > > > > + > > > > HeapTuple oldtuple, HeapTuple newtuple, > > > > + > > > > RelationSyncEntry *entry, ReorderBufferChangeType *action); > > > > > > > > Do we need parameter changetype here? I think it could only be > > > > REORDER_BUFFER_CHANGE_UPDATE. > > > > > > I didn't change this, I think it might be better to wait for Ajin's opinion. > > > > I agree with Tang. AFAIK there is no problem removing that redundant > > param as suggested. BTW - the Assert within that function is also > > incorrect because the only possible value is > > REORDER_BUFFER_CHANGE_UPDATE. I will make these fixes in a future > > version. > > > > That sounds fine to me too. One more thing is that you don't need to > modify the action in case it remains update as the caller has already > set that value. Currently, we are modifying it as update at two places > in this function, we can remove both of those and keep the comments > intact for the later update. > Fixed in v59* [1] ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsiw9fbOUTpCMWirut1ZD5hbWk8_U9tZya4mG-YK%2Bfq8g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jan 5, 2022 at 4:34 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> I have reviewed again the source code for v58-0001.
>
> Below are my review comments.
>
> Actually, I intend to fix most of these myself for v59*, so this post
> is just for records.
>
> v58-0001 Review Comments
> ========================
>
> 1. doc/src/sgml/ref/alter_publication.sgml - reword for consistency
>
> + name to explicitly indicate that descendant tables are included. If the
> + optional <literal>WHERE</literal> clause is specified, rows that do not
> + satisfy the <replaceable class="parameter">expression</replaceable> will
> + not be published. Note that parentheses are required around the
>
> For consistency, it would be better to reword this sentence about the
> expression to be more similar to the one in CREATE PUBLICATION, which
> now says:
>
> + If the optional <literal>WHERE</literal> clause is specified, rows for
> + which the <replaceable class="parameter">expression</replaceable> returns
> + false or null will not be published. Note that parentheses are required
> + around the expression. It has no effect on <literal>TRUNCATE</literal>
> + commands.
>
Updated in v59* [1]
> ~~
>
> 2. doc/src/sgml/ref/create_subscription.sgml - reword for consistency
>
> @@ -319,6 +324,25 @@ CREATE SUBSCRIPTION <replaceable
> class="parameter">subscription_name</replaceabl
> the parameter <literal>create_slot = false</literal>. This is an
> implementation restriction that might be lifted in a future release.
> </para>
> +
> + <para>
> + If any table in the publication has a <literal>WHERE</literal> clause, rows
> + that do not satisfy the <replaceable
> class="parameter">expression</replaceable>
> + will not be published. If the subscription has several publications in which
>
> For consistency, it would be better to reword this sentence about the
> expression to be more similar to the one in CREATE PUBLICATION, which
> now says:
>
> + If the optional <literal>WHERE</literal> clause is specified, rows for
> + which the <replaceable class="parameter">expression</replaceable> returns
> + false or null will not be published. Note that parentheses are required
> + around the expression. It has no effect on <literal>TRUNCATE</literal>
> + commands.
>
Updated in v59* [1]
> ~~
>
> 3. src/backend/catalog/pg_publication.c - whitespace
>
> +rowfilter_walker(Node *node, Relation relation)
> +{
> + char *errdetail_msg = NULL;
> +
> + if (node == NULL)
> + return false;
> +
> +
> + if (IsRowFilterSimpleExpr(node))
>
> Remove the extra blank line.
>
Fixed in v59* [1]
> ~~
>
> 4. src/backend/executor/execReplication.c - move code
>
> + bad_rfcolnum = GetRelationPublicationInfo(rel, true);
> +
> + /*
> + * It is only safe to execute UPDATE/DELETE when all columns referenced in
> + * the row filters from publications which the relation is in are valid,
> + * which means all referenced columns are part of REPLICA IDENTITY, or the
> + * table do not publish UPDATES or DELETES.
> + */
> + if (AttributeNumberIsValid(bad_rfcolnum))
>
> I felt that the bad_rfcolnum assignment belongs below the large
> comment explaining this logic.
>
Fixed in v59* [1]
> ~~
>
> 5. src/backend/executor/execReplication.c - fix typo
>
> + /*
> + * It is only safe to execute UPDATE/DELETE when all columns referenced in
> + * the row filters from publications which the relation is in are valid,
> + * which means all referenced columns are part of REPLICA IDENTITY, or the
> + * table do not publish UPDATES or DELETES.
> + */
>
> Typo: "table do not publish" -> "table does not publish"
>
Fixed in v59* [1]
> ~~
>
> 6. src/backend/replication/pgoutput/pgoutput.c - fix typo
>
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> + /* Gather the rfnodes per pubaction of this publiaction. */
> + if (pub->pubactions.pubinsert)
>
> Typo: "publiaction" --> "publication"
>
Fixed in v59* [1]
> ~~
>
> 7. src/backend/utils/cache/relcache.c - fix comment case
>
> @@ -267,6 +271,19 @@ typedef struct opclasscacheent
>
> static HTAB *OpClassCache = NULL;
>
> +/*
> + * Information used to validate the columns in the row filter expression. see
> + * rowfilter_column_walker for details.
> + */
>
> Typo: "see" --> "See"
>
Fixed in v59* [1]
> ~~
>
> 8. src/backend/utils/cache/relcache.c - "row-filter"
>
> For consistency with all other naming change all instances of
> "row-filter" to "row filter" in this file.
>
Fixed in v59* [1]
> ~~
>
> 9. src/backend/utils/cache/relcache.c - fix typo
>
Fixed in v59* [1]
> ~~
>
> 10. src/backend/utils/cache/relcache.c - comment confused wording?
>
> Function GetRelationPublicationInfo:
>
> + /*
> + * For a partition, if pubviaroot is true, check if any of the
> + * ancestors are published. If so, note down the topmost ancestor
> + * that is published via this publication, the row filter
> + * expression on which will be used to filter the partition's
> + * changes. We could have got the topmost ancestor when collecting
> + * the publication oids, but that will make the code more
> + * complicated.
> + */
>
> Typo: Probably "on which' --> "of which" ?
>
Fixed in v59* [1]
> ~~
>
> 11. src/backend/utils/cache/relcache.c - GetRelationPublicationActions
>
> Something seemed slightly fishy with the code doing the memcpy,
> because IIUC is possible for the GetRelationPublicationInfo function
> to return without setting the relation->rd_pubactions. Is it just
> missing an Assert or maybe a comment to say such a scenario is not
> possible in this case because the is_publishable_relation was already
> tested?
>
> Currently, it just seems a little bit too sneaky.
>
TODO
> ~~
>
> 12. src/include/parser/parse_node.h - This change is unrelated to row-filtering.
>
> @@ -79,7 +79,7 @@ typedef enum ParseExprKind
> EXPR_KIND_CALL_ARGUMENT, /* procedure argument in CALL */
> EXPR_KIND_COPY_WHERE, /* WHERE condition in COPY FROM */
> EXPR_KIND_GENERATED_COLUMN, /* generation expression for a column */
> - EXPR_KIND_CYCLE_MARK, /* cycle mark value */
> + EXPR_KIND_CYCLE_MARK /* cycle mark value */
> } ParseExprKind;
>
> This change is unrelated to Row-Filtering so ought to be removed from
> this patch. Soon I will post a separate thread to fix this
> independently on HEAD.
>
Fixed in v59* [1].
I started a separate thread for this problem.
See
https://www.postgresql.org/message-id/flat/CAHut%2BPsqr93nng7diTXxtUD636u7ytA%3DMq2duRphs0CBzpfDTA%40mail.gmail.com
> ~~
>
> 13. src/include/utils/rel.h - comment typos
>
> @@ -164,6 +164,13 @@ typedef struct RelationData
> PublicationActions *rd_pubactions; /* publication actions */
>
> /*
> + * true if the columns referenced in row filters from all the publications
> + * the relation is in are part of replica identity, or the publication
> + * actions do not include UPDATE and DELETE.
> + */
>
> Some minor rewording of the comment:
>
> "true" --> "True".
> "part of replica identity" --> "part of the replica identity"
> "UPDATE and DELETE" --> "UPDATE or DELETE"
>
Fixed in v59* [1]
------
[1] https://www.postgresql.org/message-id/CAHut%2BPsiw9fbOUTpCMWirut1ZD5hbWk8_U9tZya4mG-YK%2Bfq8g%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Jan 5, 2022 at 5:01 PM vignesh C <vignesh21@gmail.com> wrote: > ... > 4) Should this be posted as a separate patch in a new thread, as it is > not part of row filtering: > --- a/src/include/parser/parse_node.h > +++ b/src/include/parser/parse_node.h > @@ -79,7 +79,7 @@ typedef enum ParseExprKind > EXPR_KIND_CALL_ARGUMENT, /* procedure argument in CALL */ > EXPR_KIND_COPY_WHERE, /* WHERE condition in COPY FROM */ > EXPR_KIND_GENERATED_COLUMN, /* generation expression for a column */ > - EXPR_KIND_CYCLE_MARK, /* cycle mark value */ > + EXPR_KIND_CYCLE_MARK /* cycle mark value */ > } ParseExprKind; > Fixed in v59* [1] I started a new thread (with patch) for this one. See https://www.postgresql.org/message-id/flat/CAHut%2BPsqr93nng7diTXxtUD636u7ytA%3DMq2duRphs0CBzpfDTA%40mail.gmail.com ------ [1] https://www.postgresql.org/message-id/CAHut%2BPsiw9fbOUTpCMWirut1ZD5hbWk8_U9tZya4mG-YK%2Bfq8g%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jan 5, 2022 at 1:05 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Thu, Jan 4, 2022 at 00:54 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > Modified in v58 [1] as suggested
> Thanks for updating the patches.
> A few comments about v58-0001 and v58-0002.
>
> v58-0001
> 1.
> How about modifying the following loop in copy_table by using for_each_from
> instead of foreach?
> Like the invocation of for_each_from in function get_rule_expr.
> from:
> if (qual != NIL)
> {
> ListCell *lc;
> bool first = true;
>
> appendStringInfoString(&cmd, " WHERE ");
> foreach(lc, qual)
> {
> char *q = strVal(lfirst(lc));
>
> if (first)
> first = false;
> else
> appendStringInfoString(&cmd, " OR ");
> appendStringInfoString(&cmd, q);
> }
> list_free_deep(qual);
> }
> change to:
> if (qual != NIL)
> {
> ListCell *lc;
> char *q = strVal(linitial(qual));
>
> appendStringInfo(&cmd, " WHERE %s", q);
> for_each_from(lc, qual, 1)
> {
> q = strVal(lfirst(lc));
> appendStringInfo(&cmd, " OR %s", q);
> }
> list_free_deep(qual);
> }
>
Modified as suggested in v59* [1]
> 2.
> I find the API of get_rel_sync_entry is modified.
> -get_rel_sync_entry(PGOutputData *data, Oid relid)
> +get_rel_sync_entry(PGOutputData *data, Relation relation)
> It looks like just moving the invocation of RelationGetRelid from outside into
> function get_rel_sync_entry. I am not sure whether this modification is
> necessary to this feature or not.
>
Fixed in v59* [1]. Removed the unnecessary changes.
> v58-0002
> 1.
> In function pgoutput_row_filter_init, if no_filter is set, I think we do not
> need to add row filter to list(rfnodes).
> So how about changing three conditions when add row filter to rfnodes like this:
> - if (pub->pubactions.pubinsert)
> + if (pub->pubactions.pubinsert && !no_filter[idx_ins])
> {
> rfnode = stringToNode(TextDatumGetCString(rfdatum));
> rfnodes[idx_ins] = lappend(rfnodes[idx_ins], rfnode);
> }
>
TODO.
------
[1] https://www.postgresql.org/message-id/CAHut%2BPsiw9fbOUTpCMWirut1ZD5hbWk8_U9tZya4mG-YK%2Bfq8g%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thursday, January 6, 2022 8:10 PM Peter Smith <smithpb2250@gmail.com> wrote: > On Thu, Jan 6, 2022 at 9:29 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > FYI - v58 is currently known to be broken due to a recent commit [1]. > > > > I plan to post a v59* later today to address this as well as other > > recent review comments. > > > Here is the v59* patch set: Attach the v60 patch set. Note that the 0004 patch is merged to 0001 patch. Details ======= V60-0001 - Skip the transformation if where clause is not specified (Amit[1]) - Change the return type of transformPubWhereClauses to "void" (Amit[1]) - Merge 0004 patch to 0001 patch (Vignesh [2]) - Remove unnecessary includes (Vignesh [2]) - Add an Assert for a valid value of relation->rd_pubactions before doing memcpy in GetRelationPublicationActions() and add some comments atop GetRelationPublicationInfo () (Amit [3]) V60-0002 (new/old tuple) V60-0003 (tab, dump) - no change [1] https://www.postgresql.org/message-id/CAA4eK1Ky0z%3D%2BUznCUHOs--L%3DEs_EMmZ_rxNo8FH73%3D758sahsQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/CALDaNm13yVPH0EcObv4tCHLQfUwjfvPFh8c-nd3Ldg71Y9es7A%40mail.gmail.com [3] https://www.postgresql.org/message-id/CAA4eK1JgcNtmurzuTNw%3DFcNoJcODobx-y0FmohVQAce0-iitCA%40mail.gmail.com Best regards, Hou zj
Вложения
On Thu, Jan 6, 2022 at 6:42 PM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Jan 6, 2022, at 1:18 AM, Amit Kapila wrote: > > On Thu, Jan 6, 2022 at 8:43 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Wed, Jan 5, 2022 at 9:52 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > ... > > > > > Another minor comment: > > > +static bool pgoutput_row_filter(enum ReorderBufferChangeType changetype, > > > > > > Do we need to specify the 'enum' type before changetype parameter? > > > > > > > That is because there is currently no typedef for the enum > > ReorderBufferChangeType. > > > > But I see that the 0002 patch is already adding the required typedef. > > IMO we shouldn't reuse ReorderBufferChangeType. For a long-term solution, it is > fragile. ReorderBufferChangeType has values that do not matter for row filter > and it relies on the fact that REORDER_BUFFER_CHANGE_INSERT, > REORDER_BUFFER_CHANGE_UPDATE and REORDER_BUFFER_CHANGE_DELETE are the first 3 > values from the enum, otherwise, it breaks rfnodes and no_filters in > pgoutput_row_filter(). > I think you mean to say it will break in pgoutput_row_filter_init(). I see your point but OTOH, if we do what you are suggesting then don't we need an additional mapping between ReorderBufferChangeType and RowFilterPublishAction as row filter and pgoutput_change API need to use those values. -- With Regards, Amit Kapila.
On Wed, Jan 5, 2022 at 1:05 PM wangw.fnst@fujitsu.com
<wangw.fnst@fujitsu.com> wrote:
>
> On Thu, Jan 4, 2022 at 00:54 PM Peter Smith <smithpb2250@gmail.com> wrote:
> > Modified in v58 [1] as suggested
> Thanks for updating the patches.
> A few comments about v58-0001 and v58-0002.
>
> v58-0001
> 1.
> How about modifying the following loop in copy_table by using for_each_from
> instead of foreach?
> Like the invocation of for_each_from in function get_rule_expr.
> from:
> if (qual != NIL)
> {
> ListCell *lc;
> bool first = true;
>
> appendStringInfoString(&cmd, " WHERE ");
> foreach(lc, qual)
> {
> char *q = strVal(lfirst(lc));
>
> if (first)
> first = false;
> else
> appendStringInfoString(&cmd, " OR ");
> appendStringInfoString(&cmd, q);
> }
> list_free_deep(qual);
> }
> change to:
> if (qual != NIL)
> {
> ListCell *lc;
> char *q = strVal(linitial(qual));
>
> appendStringInfo(&cmd, " WHERE %s", q);
> for_each_from(lc, qual, 1)
> {
> q = strVal(lfirst(lc));
> appendStringInfo(&cmd, " OR %s", q);
> }
> list_free_deep(qual);
> }
>
> 2.
> I find the API of get_rel_sync_entry is modified.
> -get_rel_sync_entry(PGOutputData *data, Oid relid)
> +get_rel_sync_entry(PGOutputData *data, Relation relation)
> It looks like just moving the invocation of RelationGetRelid from outside into
> function get_rel_sync_entry. I am not sure whether this modification is
> necessary to this feature or not.
>
> v58-0002
> 1.
> In function pgoutput_row_filter_init, if no_filter is set, I think we do not
> need to add row filter to list(rfnodes).
> So how about changing three conditions when add row filter to rfnodes like this:
> - if (pub->pubactions.pubinsert)
> + if (pub->pubactions.pubinsert && !no_filter[idx_ins])
> {
> rfnode = stringToNode(TextDatumGetCString(rfdatum));
> rfnodes[idx_ins] = lappend(rfnodes[idx_ins], rfnode);
> }
>
I think currently there is no harm done with the current code because
even there was no_filter[xxx] then any gathered rfnodes[xxx] will be
later cleaned up and ignored anyway, so this change is not really
necessary.
OTOH your suggestion could be a tiny bit more efficient for some cases
if there are many publications. so LGTM.
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
On Fri, Jan 7, 2022 at 9:44 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 6, 2022 at 6:42 PM Euler Taveira <euler@eulerto.com> wrote: > > > > IMO we shouldn't reuse ReorderBufferChangeType. For a long-term solution, it is > > fragile. ReorderBufferChangeType has values that do not matter for row filter > > and it relies on the fact that REORDER_BUFFER_CHANGE_INSERT, > > REORDER_BUFFER_CHANGE_UPDATE and REORDER_BUFFER_CHANGE_DELETE are the first 3 > > values from the enum, otherwise, it breaks rfnodes and no_filters in > > pgoutput_row_filter(). > > > > I think you mean to say it will break in pgoutput_row_filter_init(). I > see your point but OTOH, if we do what you are suggesting then don't > we need an additional mapping between ReorderBufferChangeType and > RowFilterPublishAction as row filter and pgoutput_change API need to > use those values. > Can't we use 0,1,2 as indexes for rfnodes/no_filters based on change type as they are local variables as that will avoid the fragileness you are worried about. I am slightly hesitant to introduce new enum when we are already using reorder buffer change type in pgoutput.c. -- With Regards, Amit Kapila.
Below are some review comments for the v60 patches.
V60-0001 Review Comments
========================
1. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
unnecessary parens
+ /*
+ * NOTE: Multiple publication row filters have already been combined to a
+ * single exprstate (for this pubaction).
+ */
+ if (entry->exprstate[changetype])
+ {
+ /* Evaluates row filter */
+ result = pgoutput_row_filter_exec_expr(entry->exprstate[changetype], ecxt);
+ }
This is a single statement so it may be better to rearrange by
removing the unnecessary parens and moving the comment.
e.g.
/*
* Evaluate the row filter.
*
* NOTE: Multiple publication row filters have already been combined to a
* single exprstate (for this pubaction).
*/
if (entry->exprstate[changetype])
result = pgoutput_row_filter_exec_expr(entry->exprstate[changetype], ecxt);
v60-0002 Review Comments
========================
1. Commit Message
Some parts of this message could do with some minor re-wording. Here
are some suggestions:
1a.
BEFORE:
Also tuples that have been deformed will be cached in slots to avoid
multiple deforming of tuples.
AFTER:
Also, tuples that are deformed will be cached in slots to avoid unnecessarily
deforming again.
1b.
BEFORE:
However, after the UPDATE the new
tuple doesn't satisfy the row filter then, from the data consistency
perspective, that row should be removed on the subscriber.
AFTER:
However, after the UPDATE the new
tuple doesn't satisfy the row filter, so from a data consistency
perspective, that row should be removed on the subscriber.
1c.
BEFORE:
Keep this row on the subscriber is undesirable because it...
AFTER
Leaving this row on the subscriber is undesirable because it...
1d.
BEFORE:
However, after the UPDATE
the new tuple does satisfies the row filter then, from the data
consistency perspective, that row should inserted on the subscriber.
AFTER:
However, after the UPDATE
the new tuple does satisfy the row filter, so from a data
consistency perspective, that row should be inserted on the subscriber.
1e.
"Subsequent UPDATE or DELETE statements have no effect."
Why won't they have an effect? The first impression is the newly
updated tuple now matches the filter, I think this part seems to need
some more detailed explanation. I saw there are some slightly
different details in the header comment of the
pgoutput_row_filter_update_check function - does it help?
~~
2. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter decl
+static bool pgoutput_row_filter(enum ReorderBufferChangeType
changetype, EState *relation, Oid relid,
+ HeapTuple oldtuple, HeapTuple newtuple,
+ TupleTableSlot *slot, RelationSyncEntry *entry);
The 2nd parameter should be called "EState *estate" (not "EState *relation").
~~
3. src/backend/replication/pgoutput/pgoutput.c -
pgoutput_row_filter_update_check header comment
This function header comment looks very similar to an extract from the
0002 comment message. So any wording improvements made to the commit
message (see review comment #1) should be made here in this comment
too.
~~
4. src/backend/replication/pgoutput/pgoutput.c -
pgoutput_row_filter_update_check inconsistencies, typos, row-filter
4a. The comments here are mixing terms like "oldtuple" / "old tuple" /
"old_tuple", and "newtuple" / "new tuple" / "new_tuple". I feel it
would read better just saying "old tuple" and "new tuple" within the
comments.
4b. Typo: "row-filter" --> "row filter" (for consistency with every
other usage where the hyphen is removed)
~~
5. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
unnecessary parens
+ /*
+ * The default behavior for UPDATEs is to use the new tuple for row
+ * filtering. If the UPDATE requires a transformation, the new tuple will
+ * be replaced by the transformed tuple before calling this routine.
+ */
+ if (newtuple || oldtuple)
+ ExecStoreHeapTuple(newtuple ? newtuple : oldtuple,
ecxt->ecxt_scantuple, false);
+ else
+ {
+ ecxt->ecxt_scantuple = slot;
+ }
The else is a single statement so the parentheses are not needed here.
~~
6. src/include/replication/logicalproto.h
+extern void logicalrep_write_update_cached(StringInfo out,
TransactionId xid, Relation rel,
+ TupleTableSlot *oldtuple, TupleTableSlot *newtuple,
+ bool binary);
This extern seems unused ???
--------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Fri, Jan 7, 2022 at 12:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jan 7, 2022 at 9:44 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Jan 6, 2022 at 6:42 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > IMO we shouldn't reuse ReorderBufferChangeType. For a long-term solution, it is > > > fragile. ReorderBufferChangeType has values that do not matter for row filter > > > and it relies on the fact that REORDER_BUFFER_CHANGE_INSERT, > > > REORDER_BUFFER_CHANGE_UPDATE and REORDER_BUFFER_CHANGE_DELETE are the first 3 > > > values from the enum, otherwise, it breaks rfnodes and no_filters in > > > pgoutput_row_filter(). > > > > > > > I think you mean to say it will break in pgoutput_row_filter_init(). I > > see your point but OTOH, if we do what you are suggesting then don't > > we need an additional mapping between ReorderBufferChangeType and > > RowFilterPublishAction as row filter and pgoutput_change API need to > > use those values. > > > > Can't we use 0,1,2 as indexes for rfnodes/no_filters based on change > type as they are local variables as that will avoid the fragileness > you are worried about. I am slightly hesitant to introduce new enum > when we are already using reorder buffer change type in pgoutput.c. > Euler, I have one more question about this patch for you. I see that in the patch we are calling coerce_to_target_type() in pgoutput_row_filter_init_expr() but do we really need the same? We already do that via transformPubWhereClauses->transformWhereClause->coerce_to_boolean before storing where clause expression. It is not clear to me why that is required? We might want to add a comment if that is required. -- With Regards, Amit Kapila.
On Fri, Jan 7, 2022, at 3:35 AM, Amit Kapila wrote:
On Fri, Jan 7, 2022 at 9:44 AM Amit Kapila <amit.kapila16@gmail.com> wrote:>> On Thu, Jan 6, 2022 at 6:42 PM Euler Taveira <euler@eulerto.com> wrote:> >> > IMO we shouldn't reuse ReorderBufferChangeType. For a long-term solution, it is> > fragile. ReorderBufferChangeType has values that do not matter for row filter> > and it relies on the fact that REORDER_BUFFER_CHANGE_INSERT,> > REORDER_BUFFER_CHANGE_UPDATE and REORDER_BUFFER_CHANGE_DELETE are the first 3> > values from the enum, otherwise, it breaks rfnodes and no_filters in> > pgoutput_row_filter().> >>> I think you mean to say it will break in pgoutput_row_filter_init(). I> see your point but OTOH, if we do what you are suggesting then don't> we need an additional mapping between ReorderBufferChangeType and> RowFilterPublishAction as row filter and pgoutput_change API need to> use those values.>Can't we use 0,1,2 as indexes for rfnodes/no_filters based on changetype as they are local variables as that will avoid the fragilenessyou are worried about. I am slightly hesitant to introduce new enumwhen we are already using reorder buffer change type in pgoutput.c.
WFM. I used numbers + comments in a previous patch set [1]. I suggested the enum
because each command would be self explanatory.
On Fri, Jan 7, 2022, at 6:05 AM, Amit Kapila wrote:
Euler, I have one more question about this patch for you. I see thatin the patch we are calling coerce_to_target_type() inpgoutput_row_filter_init_expr() but do we really need the same? Wealready do that viatransformPubWhereClauses->transformWhereClause->coerce_to_booleanbefore storing where clause expression. It is not clear to me why thatis required? We might want to add a comment if that is required.
It is redundant. It seems an additional safeguard that we should be removed.
Good catch.
On Fri, Jan 7, 2022 at 11:20 PM Euler Taveira <euler@eulerto.com> wrote: > > On Fri, Jan 7, 2022, at 6:05 AM, Amit Kapila wrote: > > Euler, I have one more question about this patch for you. I see that > in the patch we are calling coerce_to_target_type() in > pgoutput_row_filter_init_expr() but do we really need the same? We > already do that via > transformPubWhereClauses->transformWhereClause->coerce_to_boolean > before storing where clause expression. It is not clear to me why that > is required? We might want to add a comment if that is required. > > It is redundant. It seems an additional safeguard that we should be removed. > Good catch. > Thanks for the confirmation. Actually, it was raised by Vignesh in his email [1]. [1] - https://www.postgresql.org/message-id/CALDaNm1_JVg_hqoGex_FVca_HPF46n9oDDB9dsp1SrPuaVpp-w%40mail.gmail.com -- With Regards, Amit Kapila.
On Friday, January 7, 2022 11:50 AM Hou, Zhijie wrote:
> Attach the v60 patch set.
> Note that the 0004 patch is merged to 0001 patch.
>
Attach the v61 patch set.
Details
=======
V61-0001
- Remove the redundant coerce_to_target_type() in
pgoutput_row_filter_init_expr(). (Vignesh)
- Check no_filter before adding row filter to list(rfnodes). (Wangw [1])
V61-0002
(Peter's comments 1 ~ 6 except 1e from [2])
- remove unnecessary parens in pgoutput_row_filter
- update commit message
- update code comments
- remove unused function declaretion
V61-0003
- handle the Tab completion of "WITH(" in
"create publication pub1 for table t1 where (c1 > 10)": (Vignesh)
[1] https://www.postgresql.org/message-id/CAHut%2BPtzEjqfzdSvouNPm1E60qzzF%2BDS%3DwcocLLDvPYCpLXB9g%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAHut%2BPvC7XFEJDFpEdaAneNUNv9Lo8O9SjEQyzUsBObrdkwTaw%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Friday, January 7, 2022 3:40 PM Peter Smith <smithpb2250@gmail.com> wrote: > Below are some review comments for the v60 patches. > > 1e. > "Subsequent UPDATE or DELETE statements have no effect." > > Why won't they have an effect? The first impression is the newly updated tuple > now matches the filter, I think this part seems to need some more detailed > explanation. I saw there are some slightly different details in the header > comment of the pgoutput_row_filter_update_check function - does it help? Thanks for the comments ! I have addressed all the comments except 1e which I will think over it and update in next version. Best regards, Hou zj
On Wednesday, January 5, 2022 2:01 PM vignesh C <vignesh21@gmail.com> wrote: > On Tue, Jan 4, 2022 at 9:58 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here is the v58* patch set: > > > > Main changes from v57* are > > 1. Couple of review comments fixed > > > > ~~ > > > > Review comments (details) > > ========================= > > > > v58-0001 (main) > > - PG docs updated as suggested [Alvaro, Euler 26/12] > > > > v58-0002 (new/old tuple) > > - pgputput_row_filter_init refactored as suggested [Wangw 30/12] #3 > > - re-ran pgindent > > > > v58-0003 (tab, dump) > > - no change > > > > v58-0004 (refactor transformations) > > - minor changes to commit message > > Few comments: Thanks for the comments! > 1) We could include namespace names along with the relation to make it more > clear to the user if the user had specified tables having same table names from > different schemas: Since most of the error message in publicationcmd.c and pg_publication.c doesn't include include namespace names along with the relation, I am not sure is it necessary to add this. So, I didn’t change this in the patch. > 5) This log will be logged for each tuple, if there are millions of records it will > get logged millions of times, we could remove it: > + /* update requires a new tuple */ > + Assert(newtuple); > + > + elog(DEBUG3, "table \"%s.%s\" has row filter", > + > get_namespace_name(get_rel_namespace(RelationGetRelid(relation))), > + get_rel_name(relation->rd_id)); Since the message is logged only in DEBUG3 and could be useful for some debugging purpose, so I didn't remove this in the new version patch. Best regards, Hou zj
On Mon, Jan 10, 2022 at 8:41 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the v61 patch set.
>
Few comments:
==============
1.
pgoutput_row_filter()
{
..
+
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+ rfnode = n_filters > 1 ? makeBoolExpr(OR_EXPR, rfnodes[idx], -1) :
linitial(rfnodes[idx]);
+ entry->exprstate[idx] = pgoutput_row_filter_init_expr(rfnode);
+ MemoryContextSwitchTo(oldctx);
..
}
rel_sync_cache_relation_cb()
{
..
+ if (entry->exprstate[idx] != NULL)
+ {
+ pfree(entry->exprstate[idx]);
+ entry->exprstate[idx] = NULL;
+ }
..
}
I think this can leak memory as just freeing 'exprstate' is not
sufficient. It contains other allocated memory as well like for
'steps'. Apart from that we might allocate other memory as well for
generating expression state. I think it would be better if we can have
another memory context (say cache_expr_cxt) in RelationSyncEntry and
allocate it the first time we need it and then reset it instead of
doing pfree of 'exprstate'. Also, we can free this new context in
pgoutput_shutdown before destroying RelationSyncCache.
2. If we do the above, we can use this new context at all other places
in the patch where it is using CacheMemoryContext.
3.
@@ -1365,6 +1785,7 @@ rel_sync_cache_publication_cb(Datum arg, int
cacheid, uint32 hashvalue)
{
HASH_SEQ_STATUS status;
RelationSyncEntry *entry;
+ MemoryContext oldctx;
/*
* We can get here if the plugin was used in SQL interface as the
@@ -1374,6 +1795,8 @@ rel_sync_cache_publication_cb(Datum arg, int
cacheid, uint32 hashvalue)
if (RelationSyncCache == NULL)
return;
+ oldctx = MemoryContextSwitchTo(CacheMemoryContext);
+
/*
* There is no way to find which entry in our cache the hash belongs to so
* mark the whole cache as invalid.
@@ -1392,6 +1815,8 @@ rel_sync_cache_publication_cb(Datum arg, int
cacheid, uint32 hashvalue)
entry->pubactions.pubdelete = false;
entry->pubactions.pubtruncate = false;
}
+
+ MemoryContextSwitchTo(oldctx);
}
Is there a reason for the above change?
4.
+#define SET_NO_FILTER_FOR_CURRENT_PUBACTIONS \
+ if (pub->pubactions.pubinsert) \
+ no_filter[idx_ins] = true; \
+ if (pub->pubactions.pubupdate) \
+ no_filter[idx_upd] = true; \
+ if (pub->pubactions.pubdelete) \
+ no_filter[idx_del] = true
I don't see the need for this macro and it makes code less readable. I
think we can instead move this code to a function to avoid duplicate
code.
5.
Multiple publications might have multiple row filters for
+ * this relation. Since row filter usage depends on the DML operation,
+ * there are multiple lists (one for each operation) which row filters
+ * will be appended.
There seems to be a typo in the above sentence.
/which row filters/to which row filters
6.
+ /*
+ * Find if there are any row filters for this relation. If there are,
+ * then prepare the necessary ExprState and cache it in
+ * entry->exprstate.
+ *
+ * NOTE: All publication-table mappings must be checked.
+ *
+ * NOTE: If the relation is a partition and pubviaroot is true, use
+ * the row filter of the topmost partitioned table instead of the row
+ * filter of its own partition.
+ *
+ * NOTE: Multiple publications might have multiple row filters for
+ * this relation. Since row filter usage depends on the DML operation,
+ * there are multiple lists (one for each operation) which row filters
+ * will be appended.
+ *
+ * NOTE: FOR ALL TABLES implies "don't use row filter expression" so
+ * it takes precedence.
+ *
+ * NOTE: ALL TABLES IN SCHEMA implies "don't use row filter
+ * expression" if the schema is the same as the table schema.
+ */
+ foreach(lc, data->publications)
Let's not add NOTE for each of these points but instead expand the
first sentence as "Find if there are any row filters for this
relation. If there are, then prepare the necessary ExprState and cache
it in entry->exprstate. To build an expression state, we need to
ensure the following:"
--
With Regards,
Amit Kapila.
On Thu, Sep 23, 2021 at 10:33 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> Hi,
>
> I finally had time to take a closer look at the patch again, so here's
> some review comments. The thread is moving fast, so chances are some of
> the comments are obsolete or were already raised in the past.
>
>
...
> 10) WHERE expression vs. data type
>
> Seem ATExecAlterColumnType might need some changes, because changing a
> data type for column referenced by the expression triggers this:
>
> test=# alter table t alter COLUMN c type text;
> ERROR: unexpected object depending on column: publication of
> table t in publication p
>
>
I reproduced this same error message using the following steps.
[postgres@CentOS7-x64 ~]$ psql -d test_pub
psql (15devel)
Type "help" for help.
test_pub=# create table t1(a text primary key);
CREATE TABLE
test_pub=# create publication p1 for table t1 where (a = '123');
CREATE PUBLICATION
test_pub=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats
target | Description
--------+------+-----------+----------+---------+----------+-------------+------
--------+-------------
a | text | | not null | | extended | |
|
Indexes:
"t1_pkey" PRIMARY KEY, btree (a)
Publications:
"p1" WHERE (a = '123'::text)
Access method: heap
test_pub=# alter table t1 alter column a type varchar;
2022-01-10 08:39:52.106 AEDT [2066] ERROR: unexpected object
depending on column: publication of table t1 in publication p1
2022-01-10 08:39:52.106 AEDT [2066] STATEMENT: alter table t1 alter
column a type varchar;
ERROR: unexpected object depending on column: publication of table t1
in publication p1
test_pub=#
~~
But the message looks OK. What exactly was your expectation for this
review comment?
------
Kind Regards,
Peter Smith.
Fujitsu Australia.
The current documentation updates (e.g. in the v61 patch) for the Row-Filter are good, but they are mostly about syntax changes and accompanying notes for the new WHERE clause etc. There are also notes for subscription tablesync behaviour etc. But these new docs feel a bit like scattered fragments - there is nowhere that gives an overview of this feature. IMO there should be some overview for the whole Row-Filtering feature. The overview text would be similar to the text of the 0001/0002 commit messages, and it would summarise how everything works, describe the UPDATE transformations (which currently seems not documented anywhere in PG docs?), and maybe include a few useful filtering examples. e.g. Perhaps there should be an entirely new page (section 31 ?) devoted just to "Logical Replication Filtering" - with subsections for "Row-Filtering" and "Col-Filtering". Thoughts? ------ Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Jan 10, 2022 2:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Mon, Jan 10, 2022 at 8:41 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the v61 patch set.
> >
>
> Few comments:
> ==============
> 1.
> pgoutput_row_filter()
> {
> ..
> +
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> + rfnode = n_filters > 1 ? makeBoolExpr(OR_EXPR, rfnodes[idx], -1) :
> linitial(rfnodes[idx]);
> + entry->exprstate[idx] = pgoutput_row_filter_init_expr(rfnode);
> + MemoryContextSwitchTo(oldctx);
> ..
> }
>
> rel_sync_cache_relation_cb()
> {
> ..
> + if (entry->exprstate[idx] != NULL)
> + {
> + pfree(entry->exprstate[idx]);
> + entry->exprstate[idx] = NULL;
> + }
> ..
> }
>
> I think this can leak memory as just freeing 'exprstate' is not
> sufficient. It contains other allocated memory as well like for
> 'steps'. Apart from that we might allocate other memory as well for
> generating expression state. I think it would be better if we can have
> another memory context (say cache_expr_cxt) in RelationSyncEntry and
> allocate it the first time we need it and then reset it instead of
> doing pfree of 'exprstate'. Also, we can free this new context in
> pgoutput_shutdown before destroying RelationSyncCache.
> 2. If we do the above, we can use this new context at all other places
> in the patch where it is using CacheMemoryContext.
Changed.
> 3.
> @@ -1365,6 +1785,7 @@ rel_sync_cache_publication_cb(Datum arg, int
> cacheid, uint32 hashvalue)
> {
> HASH_SEQ_STATUS status;
> RelationSyncEntry *entry;
> + MemoryContext oldctx;
>
> /*
> * We can get here if the plugin was used in SQL interface as the
> @@ -1374,6 +1795,8 @@ rel_sync_cache_publication_cb(Datum arg, int
> cacheid, uint32 hashvalue)
> if (RelationSyncCache == NULL)
> return;
>
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> +
> /*
> * There is no way to find which entry in our cache the hash belongs to so
> * mark the whole cache as invalid.
> @@ -1392,6 +1815,8 @@ rel_sync_cache_publication_cb(Datum arg, int
> cacheid, uint32 hashvalue)
> entry->pubactions.pubdelete = false;
> entry->pubactions.pubtruncate = false;
> }
> +
> + MemoryContextSwitchTo(oldctx);
> }
>
> Is there a reason for the above change?
Reverted this change.
> 4.
> +#define SET_NO_FILTER_FOR_CURRENT_PUBACTIONS \
> + if (pub->pubactions.pubinsert) \
> + no_filter[idx_ins] = true; \
> + if (pub->pubactions.pubupdate) \
> + no_filter[idx_upd] = true; \
> + if (pub->pubactions.pubdelete) \
> + no_filter[idx_del] = true
>
> I don't see the need for this macro and it makes code less readable. I
> think we can instead move this code to a function to avoid duplicate
> code.
I slightly refactor the code in this function to avoid duplicate code.
> 5.
> Multiple publications might have multiple row filters for
> + * this relation. Since row filter usage depends on the DML operation,
> + * there are multiple lists (one for each operation) which row filters
> + * will be appended.
>
> There seems to be a typo in the above sentence.
> /which row filters/to which row filters
Changed.
> 6.
> + /*
> + * Find if there are any row filters for this relation. If there are,
> + * then prepare the necessary ExprState and cache it in
> + * entry->exprstate.
> + *
> + * NOTE: All publication-table mappings must be checked.
> + *
> + * NOTE: If the relation is a partition and pubviaroot is true, use
> + * the row filter of the topmost partitioned table instead of the row
> + * filter of its own partition.
> + *
> + * NOTE: Multiple publications might have multiple row filters for
> + * this relation. Since row filter usage depends on the DML operation,
> + * there are multiple lists (one for each operation) which row filters
> + * will be appended.
> + *
> + * NOTE: FOR ALL TABLES implies "don't use row filter expression" so
> + * it takes precedence.
> + *
> + * NOTE: ALL TABLES IN SCHEMA implies "don't use row filter
> + * expression" if the schema is the same as the table schema.
> + */
> + foreach(lc, data->publications)
>
> Let's not add NOTE for each of these points but instead expand the
> first sentence as "Find if there are any row filters for this
> relation. If there are, then prepare the necessary ExprState and cache
> it in entry->exprstate. To build an expression state, we need to
> ensure the following:"
Changed.
Attach the v62 patch set which address the above comments and slightly
adjust the commit message in 0002 patch.
Best regards,
Hou zj
Вложения
On Tue, Jan 11, 2022 at 6:52 AM Peter Smith <smithpb2250@gmail.com> wrote: > > e.g. Perhaps there should be an entirely new page (section 31 ?) > devoted just to "Logical Replication Filtering" - with subsections for > "Row-Filtering" and "Col-Filtering". > +1. I think we need to be careful to avoid any duplicate updates in docs, other than that I think this will be helpful. -- With Regards, Amit Kapila.
On Tuesday, January 11, 2022 10:16 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> Attach the v62 patch set which address the above comments and slightly
> adjust the commit message in 0002 patch.
>
I saw a possible problem about Row-Filter tablesync SQL, which is related
to partition table.
If a parent table is published with publish_via_partition_root off, its child
table should be taken as no row filter when combining the row filters with OR.
But when using the current SQL, this publication is ignored.
For example:
create table parent (a int) partition by range (a);
create table child partition of parent default;
create publication puba for table parent with (publish_via_partition_root=false);
create publication pubb for table child where(a>10);
Using current SQL in patch:
(table child oid is 16387)
SELECT DISTINCT pg_get_expr(prqual, prrelid) FROM pg_publication p
INNER JOIN pg_publication_rel pr ON (p.oid = pr.prpubid)
WHERE pr.prrelid = 16387 AND p.pubname IN ( 'puba', 'pubb' )
AND NOT (select bool_or(puballtables)
FROM pg_publication
WHERE pubname in ( 'puba', 'pubb' ))
AND NOT EXISTS (SELECT 1
FROM pg_publication_namespace pn, pg_class c, pg_publication p
WHERE c.oid = 16387 AND c.relnamespace = pn.pnnspid AND p.oid = pn.pnpubid AND p.pubname IN ( 'puba', 'pubb' ));
pg_get_expr
-------------
(a > 10)
(1 row)
I think there should be no filter in this case, because "puba" publish table child
without row filter. Thoughts?
To fix this problem, we could use pg_get_publication_tables function in
tablesync SQL to filter which publications the table belongs to. How about the
following SQL, it would return NULL for "puba".
SELECT DISTINCT pg_get_expr(pr.prqual, pr.prrelid)
FROM pg_publication p
LEFT OUTER JOIN pg_publication_rel pr
ON (p.oid = pr.prpubid AND pr.prrelid = 16387),
LATERAL pg_get_publication_tables(p.pubname) GPT
WHERE GPT.relid = 16387 AND p.pubname IN ( 'puba', 'pubb' );
pg_get_expr
-------------
(a > 10)
(2 rows)
Regards,
Tang
On Tue, Jan 11, 2022 at 1:32 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Tuesday, January 11, 2022 10:16 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > > Attach the v62 patch set which address the above comments and slightly > > adjust the commit message in 0002 patch. > > > > I saw a possible problem about Row-Filter tablesync SQL, which is related > to partition table. > > If a parent table is published with publish_via_partition_root off, its child > table should be taken as no row filter when combining the row filters with OR. > But when using the current SQL, this publication is ignored. > > For example: > create table parent (a int) partition by range (a); > create table child partition of parent default; > create publication puba for table parent with (publish_via_partition_root=false); > create publication pubb for table child where(a>10); > > Using current SQL in patch: > (table child oid is 16387) > SELECT DISTINCT pg_get_expr(prqual, prrelid) FROM pg_publication p > INNER JOIN pg_publication_rel pr ON (p.oid = pr.prpubid) > WHERE pr.prrelid = 16387 AND p.pubname IN ( 'puba', 'pubb' ) > AND NOT (select bool_or(puballtables) > FROM pg_publication > WHERE pubname in ( 'puba', 'pubb' )) > AND NOT EXISTS (SELECT 1 > FROM pg_publication_namespace pn, pg_class c, pg_publication p > WHERE c.oid = 16387 AND c.relnamespace = pn.pnnspid AND p.oid = pn.pnpubid AND p.pubname IN ( 'puba', 'pubb' )); > pg_get_expr > ------------- > (a > 10) > (1 row) > > > I think there should be no filter in this case, because "puba" publish table child > without row filter. Thoughts? > I also think so. > To fix this problem, we could use pg_get_publication_tables function in > tablesync SQL to filter which publications the table belongs to. How about the > following SQL, it would return NULL for "puba". > > SELECT DISTINCT pg_get_expr(pr.prqual, pr.prrelid) > FROM pg_publication p > LEFT OUTER JOIN pg_publication_rel pr > ON (p.oid = pr.prpubid AND pr.prrelid = 16387), > LATERAL pg_get_publication_tables(p.pubname) GPT > WHERE GPT.relid = 16387 AND p.pubname IN ( 'puba', 'pubb' ); > pg_get_expr > ------------- > (a > 10) > > (2 rows) > One advantage of this query is that it seems to have simplified the original query by removing NOT conditions. I haven't tested this yet but logically it appears correct to me. -- With Regards, Amit Kapila.
I just looked at 0002 because of Justin Pryzby's comment in the column filtering thread, and realized that the pgoutput row filtering has a very strange API, which receives both heap tuples and slots; and we seem to convert to and from slots in seemingly unprincipled ways. I don't think this is going to fly. I think it's OK for the initial entry into pgoutput to be HeapTuple (but only because that's what ReorderBufferTupleBuf has), but it should be converted a slot right when it enters pgoutput, and then used as a slot throughout. I think this is mostly sensible in 0001 (which was evidently developed earlier), but 0002 makes a nonsensical change to the API, with poor results. (This is one of the reasons I've been saying that there patches should be squashed together -- so that we can see that the overall API transformation we're making are sensible.) -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
Here are my review comments for v62-0001
~~~
1. src/backend/catalog/pg_publication.c - GetTopMostAncestorInPublication
@@ -276,17 +276,46 @@ GetPubPartitionOptionRelations(List *result,
PublicationPartOpt pub_partopt,
}
/*
+ * Check if any of the ancestors are published in the publication. If so,
+ * return the relid of the topmost ancestor that is published via this
+ * publication, otherwise InvalidOid.
+ */
The GetTopMostAncestorInPublication function header comment seems to
be saying the same thing twice. I think it can be simplified
Suggested function comment:
"Return the relid of the topmost ancestor that is published via this
publication, otherwise return InvalidOid."
~~~
2. src/backend/commands/publicationcmds.c - AlterPublicationTables
- /* Calculate which relations to drop. */
+ /*
+ * In order to recreate the relation list for the publication, look
+ * for existing relations that need not be dropped.
+ */
Suggested minor rewording of comment:
"... look for existing relations that do not need to be dropped."
~~~
3. src/backend/commands/publicationcmds.c - AlterPublicationTables
+
+ /*
+ * Look if any of the new set of relations match with the
+ * existing relations in the publication. Additionally, if the
+ * relation has an associated where-clause, check the
+ * where-clauses also match. Drop the rest.
+ */
if (RelationGetRelid(newpubrel->relation) == oldrelid)
Suggested minor rewording of comment:
"Look if any..." --> "Check if any..."
~~~
4. src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns referenced in
+ * the row filters from publications which the relation is in are valid,
+ * which means all referenced columns are part of REPLICA IDENTITY, or the
+ * table does not publish UPDATES or DELETES.
+ */
Suggested minor rewording of comment:
"... in are valid, which means all ..." --> "... in are valid - i.e.
when all ..."
~~~
5. src/backend/parser/gram.y - ColId OptWhereClause
+ /*
+ * The OptWhereClause must be stored here but it is
+ * valid only for tables. If the ColId was mistakenly
+ * not a table this will be detected later in
+ * preprocess_pubobj_list() and an error is thrown.
+ */
Suggested minor rewording of comment:
"... and an error is thrown." --> "... and an error will be thrown."
~~~
6. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ * ALL TABLES IN SCHEMA implies "don't use row filter expression" if
+ * the schema is the same as the table schema.
+ */
+ foreach(lc, data->publications)
+ {
+ Publication *pub = lfirst(lc);
+ HeapTuple rftuple = NULL;
+ Datum rfdatum = 0;
+ bool rfisnull;
+ bool pub_no_filter = false;
+ List *schemarelids = NIL;
Not all of these variables need to be declared at the top of the loop
like this. Consider moving some of them (e.g. rfisnull, schemarelids)
lower down to declare only in the scope that uses them.
~~~
7. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ if (pub->pubactions.pubinsert)
+ no_filter[idx_ins] = true;
+ if (pub->pubactions.pubupdate)
+ no_filter[idx_upd] = true;
+ if (pub->pubactions.pubdelete)
+ no_filter[idx_del] = true;
This code can be simplified I think. e.g.
no_filter[idx_ins] |= pub->pubactions.pubinsert;
no_filter[idx_upd] |= pub->pubactions.pubupdate;
no_filter[idx_del] |= pub->pubactions.pubdelete;
~~~
8. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry
@@ -1245,9 +1650,6 @@ get_rel_sync_entry(PGOutputData *data, Oid relid)
entry->pubactions.pubtruncate |= pub->pubactions.pubtruncate;
}
- if (entry->pubactions.pubinsert && entry->pubactions.pubupdate &&
- entry->pubactions.pubdelete && entry->pubactions.pubtruncate)
- break;
}
I was not sure why that code was removed. Is it deliberate/correct?
~~~
9. src/backend/utils/cache/relcache.c - rowfilter_column_walker
@@ -5521,39 +5535,98 @@ RelationGetExclusionInfo(Relation indexRelation,
MemoryContextSwitchTo(oldcxt);
}
+
+
/*
- * Get publication actions for the given relation.
+ * Check if any columns used in the row filter WHERE clause are not part of
+ * REPLICA IDENTITY and save the invalid column number in
+ * rf_context::invalid_rfcolnum.
*/
There is an extra blank line before the function comment.
~~~
10. src/backend/utils/cache/relcache.c - GetRelationPublicationInfo
+ if (HeapTupleIsValid(rftuple))
+ {
+ Datum rfdatum;
+ bool rfisnull;
+ Node *rfnode;
+
+ context.pubviaroot = pubform->pubviaroot;
+ context.parentid = publish_as_relid;
+ context.relid = relid;
+
+ rfdatum = SysCacheGetAttr(PUBLICATIONRELMAP, rftuple,
+ Anum_pg_publication_rel_prqual,
+ &rfisnull);
+
+ if (!rfisnull)
+ {
+ rfnode = stringToNode(TextDatumGetCString(rfdatum));
+ rfcol_valid = !rowfilter_column_walker(rfnode, &context);
+ invalid_rfcolnum = context.invalid_rfcolnum;
+ pfree(rfnode);
+ }
+
+ ReleaseSysCache(rftuple);
+ }
Those 3 assignments to the context.pubviaroot/parentid/relid can be
moved to be inside the if (!rfisnull) block, because IIUC they don't
get used otherwise. Or, maybe better to just leave as-is; I am not
sure what is best. Please consider.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Here are some review comments for v62-0002 ~~~ 1. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_update_check + * If the change is to be replicated this function returns true, else false. + * + * Examples: Let's say the old tuple satisfies the row filter but the new tuple + * doesn't. Since the old tuple satisfies, the initial table synchronization + * copied this row (or another method was used to guarantee that there is data + * consistency). However, after the UPDATE the new tuple doesn't satisfy the The word "Examples:" should be on a line by itself; not merged with the 1st example "Let's say...". ~~~ 2. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_update_check + /* + * For updates, both the new tuple and old tuple needs to be checked + * against the row filter. The new tuple might not have all the replica + * identity columns, in which case it needs to be copied over from the old + * tuple. + */ Typo: "needs to be checked" --> "need to be checked" ~~~ 3. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init Missing blank line before a couple of block comments, here: bool pub_no_filter = false; List *schemarelids = NIL; /* * If the publication is FOR ALL TABLES then it is treated the * same as if this table has no row filters (even if for other * publications it does). */ if (pub->alltables) pub_no_filter = true; /* * If the publication is FOR ALL TABLES IN SCHEMA and it overlaps * with the current relation in the same schema then this is also * treated same as if this table has no row filters (even if for * other publications it does). */ else ~~~ 4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init This function was refactored out of the code from pgoutput_row_filter in the v62-0001 patch. So probably there are multiple comments from my earlier v62-0001 review [1] of that pgoutput_row_filter function, that now also apply to this pgoutput_row_filter_init function. ~~~ 5. src/tools/pgindent/typedefs.list - ReorderBufferChangeType Actually, the typedef for ReorderBufferChangeType was added in the 62-0001, so this typedef change should've been done in patch 0001 and it can be removed from patch 0002 ------ [1] https://www.postgresql.org/message-id/CAHut%2BPucFM3Bt-gaTT7Pr-Y_x%2BR0y%3DL7uqbhjPMUsSPhdLhRpA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, Jan 12, 2022 at 3:00 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I just looked at 0002 because of Justin Pryzby's comment in the column > filtering thread, and realized that the pgoutput row filtering has a > very strange API, which receives both heap tuples and slots; and we seem > to convert to and from slots in seemingly unprincipled ways. I don't > think this is going to fly. I think it's OK for the initial entry into > pgoutput to be HeapTuple (but only because that's what > ReorderBufferTupleBuf has), but it should be converted a slot right when > it enters pgoutput, and then used as a slot throughout. > One another thing that we can improve about 0002 is to unify the APIs for row filtering for update and insert/delete. I find having separate APIs a bit awkward. -- With Regards, Amit Kapila.
On Wed, Jan 12, 2022 5:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Jan 12, 2022 at 3:00 AM Alvaro Herrera <alvherre@alvh.no-ip.org> > wrote: > > > > I just looked at 0002 because of Justin Pryzby's comment in the column > > filtering thread, and realized that the pgoutput row filtering has a > > very strange API, which receives both heap tuples and slots; and we > > seem to convert to and from slots in seemingly unprincipled ways. I > > don't think this is going to fly. I think it's OK for the initial > > entry into pgoutput to be HeapTuple (but only because that's what > > ReorderBufferTupleBuf has), but it should be converted a slot right > > when it enters pgoutput, and then used as a slot throughout. > > > > One another thing that we can improve about 0002 is to unify the APIs for row > filtering for update and insert/delete. I find having separate APIs a bit awkward. Thanks for the comments. Attach the v63 patch set which include the following changes. Based on Alvaro and Amit's suggestions: - merged 0001 and 0002 into one patch. - did some initial refactorings for the interface of row_filter functions. For now, it receives only slots. - unify the APIs for row filtering for update and insert/delete And addressed some comments received earlier. - update some comments and some cosmetic changes. (Peter) - Add a new enum RowFilterPubAction use as the index of filter expression (Euler,Amit) array. - Fix a bug that when transform UPDATE to INSERT, the patch didn't pass the (Euler) transformed tuple to logicalrep_write_insert. Best regards, Hou zj
Вложения
Thanks for posting the merged v63.
Here are my review comments for the v63-0001 changes.
~~~
1. src/backend/replication/logical/proto.c - logicalrep_write_tuple
TupleDesc desc;
- Datum values[MaxTupleAttributeNumber];
- bool isnull[MaxTupleAttributeNumber];
+ Datum *values;
+ bool *isnull;
int i;
uint16 nliveatts = 0;
Those separate declarations for values / isnull are not strictly
needed anymore, so those vars could be deleted. IIRC those were only
added before when there were both slots and tuples. OTOH, maybe you
prefer to keep it this way just for code readability?
~~~
2. src/backend/replication/pgoutput/pgoutput.c - typedef
+typedef enum RowFilterPubAction
+{
+ PUBACTION_INSERT,
+ PUBACTION_UPDATE,
+ PUBACTION_DELETE,
+ NUM_ROWFILTER_PUBACTIONS /* must be last */
+} RowFilterPubAction;
This typedef is not currently used by any of the code.
So I think choices are:
- Option 1: remove the typedef, because nobody is using it.
- Option 2: keep the typedef, but use it! e.g. everywhere there is an
exprstate array index variable probably it should be declared as a
'RowFilterPubAction idx' instead of just 'int idx'.
I prefer option 2, but YMMV.
~~~
3. src/backend/replication/pgoutput/pgoutput.c - map_changetype_pubaction
After this recent v63 refactoring and merging of some APIs it seems
that the map_changetype_pubaction is now ONLY used by
pgoutput_row_filter function. So this can now be a static member of
pgoutput_row_filter function instead of being declared at file scope.
~~~
4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter comments
+
+/*
+ * Change is checked against the row filter, if any.
+ *
+ * If it returns true, the change is replicated, otherwise, it is not.
+ *
+ * FOR INSERT: evaluates the row filter for new tuple.
+ * FOR DELETE: evaluates the row filter for old tuple.
+ * For UPDATE: evaluates the row filter for old and new tuple. If both
+ * evaluations are true, it sends the UPDATE. If both evaluations are false, it
+ * doesn't send the UPDATE. If only one of the tuples matches the row filter
+ * expression, there is a data consistency issue. Fixing this issue requires a
+ * transformation.
+ *
+ * Transformations:
+ * Updates are transformed to inserts and deletes based on the
+ * old tuple and new tuple. The new action is updated in the
+ * action parameter. If not updated, action remains as update.
+ *
+ * Case 1: old-row (no match) new-row (no match) -> (drop change)
+ * Case 2: old-row (no match) new row (match) -> INSERT
+ * Case 3: old-row (match) new-row (no match) -> DELETE
+ * Case 4: old-row (match) new row (match) -> UPDATE
+ *
+ * If the change is to be replicated this function returns true, else false.
+ *
+ * Examples:
The function header comment says the same thing 2x about the return values.
The 1st text "If it returns true, the change is replicated, otherwise,
it is not." should be replaced by the better wording of the 2nd text
("If the change is to be replicated this function returns true, else
false."). Then, that 2nd text can be removed (from where it is later
in this same comment).
~~~
5. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ ExprContext *ecxt;
+ int filter_index = map_changetype_pubaction[*action];
+
+ /* *action is already assigned default by caller */
+ Assert(*action == REORDER_BUFFER_CHANGE_INSERT ||
+ *action == REORDER_BUFFER_CHANGE_UPDATE ||
+ *action == REORDER_BUFFER_CHANGE_DELETE);
+
Accessing the map_changetype_pubaction array should be done *after* the Assert.
~~~
6. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
Actually, instead of assigning the filter_insert and then referring to
entry->exprstate[filter_index] in multiple places, now the code might
be neater if we simply assign a local variable “filter_exprstate” like
below and use that instead.
ExprState *filter_exprstate;
...
filter_exprstate = entry->exprstate[map_changetype_pubaction[*action]];
Please consider what way you think is best.
~~~
7. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ /*
+ * For the following occasions where there is only one tuple, we can
+ * evaluates the row filter for the not null tuple and return.
+ *
+ * For INSERT: we only have new tuple.
+ *
+ * For UPDATE: if no old tuple, it means none of the replica identity
+ * columns changed and this would reduce to a simple update. we only need
+ * to evaluate the row filter for new tuple.
+ *
+ * FOR DELETE: we only have old tuple.
+ */
There are several things not quite right with that comment:
a. I thought now it should refer to "slots" instead of "tuples"
b. Some of the upper/lowercase is wonky
c. Maybe it reads better without the ":"
Suggested replacement comment:
/*
* For the following occasions where there is only one slot, we can
* evaluates the row filter for the not-null slot and return.
*
* For INSERT we only have the new slot.
*
* For UPDATE if no old slot, it means none of the replica identity
* columns changed and this would reduce to a simple update. We only need
* to evaluate the row filter for the new slot.
*
* For DELETE we only have the old slot.
*/
~~~
8. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ if (!new_slot || !old_slot)
+ {
+ ecxt->ecxt_scantuple = new_slot ? new_slot : old_slot;
+ result = pgoutput_row_filter_exec_expr(entry->exprstate[filter_index],
+ ecxt);
+
+ FreeExecutorState(estate);
+ PopActiveSnapshot();
+
+ return result;
+ }
+
+ tmp_new_slot = new_slot;
+ slot_getallattrs(new_slot);
+ slot_getallattrs(old_slot);
I think after this "if" condition then the INSERT, DELETE and simple
UPDATE are already handled. So, the remainder of the code is for
deciding what update transformation is needed etc.
I think there should be some block comment somewhere here to make that
more obvious.
~~~
9. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
Many of the comments in this function are still referring to old/new
"tuple". Now that all the params are slots instead of tuples maybe now
all the comments should also refer to "slots" instead of "tuples".
Please search all the comments - e.g. including all the "Case 1:" ...
"Case 4:" comments.
~~~
10. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
+ int idx_ins = PUBACTION_INSERT;
+ int idx_upd = PUBACTION_UPDATE;
+ int idx_del = PUBACTION_DELETE;
These variables are unnecessary now... They previously were added only
as short synonyms because the other enum names were too verbose (e.g.
REORDER_BUFFER_CHANGE_INSERT) but now that we have shorter enum names
like PUBACTION_INSERT we can just use those names directly
~~~
11. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
I felt that the code would seem more natural if the
pgoutput_row_filter_init function came *before* the
pgoutput_row_filter function in the source code.
~~~
12. src/backend/replication/pgoutput/pgoutput.c - pgoutput_change
@@ -634,6 +1176,9 @@ pgoutput_change(LogicalDecodingContext *ctx,
ReorderBufferTXN *txn,
RelationSyncEntry *relentry;
TransactionId xid = InvalidTransactionId;
Relation ancestor = NULL;
+ ReorderBufferChangeType modified_action = change->action;
+ TupleTableSlot *old_slot = NULL;
+ TupleTableSlot *new_slot = NULL;
It seemed a bit misleading to me to call this variable
'modified_action' since mostly it is not modified at all.
IMO it is better just to call this as 'action' but then add a comment
(above the "switch (modified_action)") to say the previous call to
pgoutput_row_filter may have transformed it to a different action.
~~~
13. src/tools/pgindent/typedefs.list - RowFilterPubAction
If you choose to keep the typedef for RowFilterPubAction (ref to
comment #1) then it should also be added to the typedefs.list.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Jan 13, 2022 at 12:19 PM Peter Smith <smithpb2250@gmail.com> wrote: > > 7. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter > > + /* > + * For the following occasions where there is only one tuple, we can > + * evaluates the row filter for the not null tuple and return. > + * > + * For INSERT: we only have new tuple. > + * > + * For UPDATE: if no old tuple, it means none of the replica identity > + * columns changed and this would reduce to a simple update. we only need > + * to evaluate the row filter for new tuple. > + * > + * FOR DELETE: we only have old tuple. > + */ > > There are several things not quite right with that comment: > a. I thought now it should refer to "slots" instead of "tuples" > I feel tuple still makes sense as it makes the comments/code easy to understand. -- With Regards, Amit Kapila.
> /*
> + * Only 3 publication actions are used for row filtering ("insert", "update",
> + * "delete"). See RelationSyncEntry.exprstate[].
> + */
> +typedef enum RowFilterPubAction
> +{
> + PUBACTION_INSERT,
> + PUBACTION_UPDATE,
> + PUBACTION_DELETE,
> + NUM_ROWFILTER_PUBACTIONS /* must be last */
> +} RowFilterPubAction;
Please do not add NUM_ROWFILTER_PUBACTIONS as an enum value. It's a bit
of a lie and confuses things, because your enum now has 4 possible
values, not 3. I suggest to
#define NUM_ROWFILTER_PUBACTIONS (PUBACTION_DELETE+1)
instead.
> + int idx_ins = PUBACTION_INSERT;
> + int idx_upd = PUBACTION_UPDATE;
> + int idx_del = PUBACTION_DELETE;
I don't understand the purpose of these variables; can't you just use
the constants?
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
"Hay que recordar que la existencia en el cosmos, y particularmente la
elaboración de civilizaciones dentro de él no son, por desgracia,
nada idílicas" (Ijon Tichy)
On Wed, Jan 12, 2022 at 7:19 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Wed, Jan 12, 2022 5:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Attach the v63 patch set which include the following changes.
>
Few comments:
=============
1.
+
+ <row>
+ <entry role="catalog_table_entry"><para role="column_definition">
+ <structfield>prqual</structfield> <type>pg_node_tree</type>
+ </para>
+ <para>Expression tree (in <function>nodeToString()</function>
+ representation) for the relation's qualifying condition</para></entry>
+ </row>
Let's slightly modify this as: "Expression tree (in
<function>nodeToString()</function> representation) for the relation's
qualifying condition. Null if there is no qualifying condition."
2.
+ A <literal>WHERE</literal> clause allows simple expressions. The simple
+ expression cannot contain any aggregate or window functions, non-immutable
+ functions, user-defined types, operators or functions.
This part in the docs should be updated to say something similar to
what we have in the commit message for this part or maybe additionally
in some way we can say which other forms of expressions are not
allowed.
3.
+ for which the <replaceable
class="parameter">expression</replaceable> returns
+ false or null will not be published.
+ If the subscription has several publications in which
+ the same table has been published with different <literal>WHERE</literal>
In the above text line spacing appears a bit odd to me. There doesn't
seem to be a need for extra space after line-2 and line-3 in
above-quoted text.
4.
/*
+ * Return the relid of the topmost ancestor that is published via this
We normally seem to use Returns in similar places.
5.
+ * The simple expression contains the following restrictions:
+ * - User-defined operators are not allowed;
+ * - User-defined functions are not allowed;
+ * - User-defined types are not allowed;
+ * - Non-immutable built-in functions are not allowed;
+ * - System columns are not allowed.
Why system columns are not allowed in the above context?
6.
+static void
+transformPubWhereClauses(List *tables, const char *queryString)
To keep the function naming similar to other nearby functions, it is
better to name this as TransformPubWhereClauses.
7. In AlterPublicationTables(), won't it better if we
transformPubWhereClauses() after
CheckObjSchemaNotAlreadyInPublication() to avoid extra processing in
case of errors.
8.
+ /*
+ * Check if the relation is member of the existing schema in the
+ * publication or member of the schema list specified.
+ */
CheckObjSchemaNotAlreadyInPublication(rels, schemaidlist,
PUBLICATIONOBJ_TABLE);
I don't see the above comment addition has anything to do with this
patch. Can we remove it?
9.
CheckCmdReplicaIdentity(Relation rel, CmdType cmd)
{
PublicationActions *pubactions;
+ AttrNumber bad_rfcolnum;
/* We only need to do checks for UPDATE and DELETE. */
if (cmd != CMD_UPDATE && cmd != CMD_DELETE)
return;
+ if (rel->rd_rel->relreplident == REPLICA_IDENTITY_FULL)
+ return;
+
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns referenced in
+ * the row filters from publications which the relation is in are valid -
+ * i.e. when all referenced columns are part of REPLICA IDENTITY, or the
+ * table does not publish UPDATES or DELETES.
+ */
+ bad_rfcolnum = GetRelationPublicationInfo(rel, true);
Can we name this variable as invalid_rf_column?
--
With Regards,
Amit Kapila.
On Thursday, January 13, 2022 6:23 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Wed, Jan 12, 2022 at 7:19 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Wed, Jan 12, 2022 5:38 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > Attach the v63 patch set which include the following changes.
> >
Thanks for the comments !
> Few comments:
> =============
> 1.
> +
> + <row>
> + <entry role="catalog_table_entry"><para role="column_definition">
> + <structfield>prqual</structfield> <type>pg_node_tree</type>
> + </para>
> + <para>Expression tree (in <function>nodeToString()</function>
> + representation) for the relation's qualifying condition</para></entry>
> + </row>
>
> Let's slightly modify this as: "Expression tree (in
> <function>nodeToString()</function> representation) for the relation's
> qualifying condition. Null if there is no qualifying condition."
Changed.
> 2.
> + A <literal>WHERE</literal> clause allows simple expressions. The simple
> + expression cannot contain any aggregate or window functions,
> non-immutable
> + functions, user-defined types, operators or functions.
>
> This part in the docs should be updated to say something similar to what we
> have in the commit message for this part or maybe additionally in some way we
> can say which other forms of expressions are not allowed.
Temporally used the description in commit message.
> 3.
> + for which the <replaceable
> class="parameter">expression</replaceable> returns
> + false or null will not be published.
> + If the subscription has several publications in which
> + the same table has been published with different
> + <literal>WHERE</literal>
>
> In the above text line spacing appears a bit odd to me. There doesn't seem to be
> a need for extra space after line-2 and line-3 in above-quoted text.
I adjusted these text lines.
> 4.
> /*
> + * Return the relid of the topmost ancestor that is published via this
>
> We normally seem to use Returns in similar places.
Changed
>
> 6.
> +static void
> +transformPubWhereClauses(List *tables, const char *queryString)
>
> To keep the function naming similar to other nearby functions, it is better to
> name this as TransformPubWhereClauses.
Changed.
> 7. In AlterPublicationTables(), won't it better if we
> transformPubWhereClauses() after
> CheckObjSchemaNotAlreadyInPublication() to avoid extra processing in case of
> errors.
Changed.
> 8.
> + /*
> + * Check if the relation is member of the existing schema in the
> + * publication or member of the schema list specified.
> + */
> CheckObjSchemaNotAlreadyInPublication(rels, schemaidlist,
> PUBLICATIONOBJ_TABLE);
>
> I don't see the above comment addition has anything to do with this patch. Can
> we remove it?
Removed.
> 9.
> CheckCmdReplicaIdentity(Relation rel, CmdType cmd) {
> PublicationActions *pubactions;
> + AttrNumber bad_rfcolnum;
>
> /* We only need to do checks for UPDATE and DELETE. */
> if (cmd != CMD_UPDATE && cmd != CMD_DELETE)
> return;
>
> + if (rel->rd_rel->relreplident == REPLICA_IDENTITY_FULL) return;
> +
> + /*
> + * It is only safe to execute UPDATE/DELETE when all columns referenced
> + in
> + * the row filters from publications which the relation is in are valid
> + -
> + * i.e. when all referenced columns are part of REPLICA IDENTITY, or
> + the
> + * table does not publish UPDATES or DELETES.
> + */
> + bad_rfcolnum = GetRelationPublicationInfo(rel, true);
>
> Can we name this variable as invalid_rf_column?
Changed.
Attach the V64 patch set which addressed Alvaro, Amit and Peter's comments.
The new version patch also include some other changes:
- Fix a table sync bug[1] by using the SQL suggested by Tang[1]
- Adjust the row filter initialize code related to FOR ALL TABLE IN SCHEMA to
make sure it gets the correct row filter.
- Update the documents.
- Rebased the patch based on recent commit 025b92
[1]
https://www.postgresql.org/message-id/OS0PR01MB6113BB510435B16E9F0B2A59FB519%40OS0PR01MB6113.jpnprd01.prod.outlook.com
Best regards,
Hou zj
Вложения
On Thur, Jan 13, 2022 5:22 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> > /*
> > + * Only 3 publication actions are used for row filtering ("insert",
> > +"update",
> > + * "delete"). See RelationSyncEntry.exprstate[].
> > + */
> > +typedef enum RowFilterPubAction
> > +{
> > + PUBACTION_INSERT,
> > + PUBACTION_UPDATE,
> > + PUBACTION_DELETE,
> > + NUM_ROWFILTER_PUBACTIONS /* must be last */ }
> RowFilterPubAction;
>
> Please do not add NUM_ROWFILTER_PUBACTIONS as an enum value. It's a bit
> of a lie and confuses things, because your enum now has 4 possible values, not
> 3. I suggest to #define NUM_ROWFILTER_PUBACTIONS
> (PUBACTION_DELETE+1) instead.
>
> > + int idx_ins = PUBACTION_INSERT;
> > + int idx_upd = PUBACTION_UPDATE;
> > + int idx_del = PUBACTION_DELETE;
>
> I don't understand the purpose of these variables; can't you just use the
> constants?
Thanks for the comments !
Changed the code as suggested.
Best regards,
Hou zj
On Thursday, January 13, 2022 2:49 PM Peter Smith <smithpb2250@gmail.com>
> Thanks for posting the merged v63.
>
> Here are my review comments for the v63-0001 changes.
>
> ~~~
Thanks for the comments!
> 1. src/backend/replication/logical/proto.c - logicalrep_write_tuple
>
> TupleDesc desc;
> - Datum values[MaxTupleAttributeNumber];
> - bool isnull[MaxTupleAttributeNumber];
> + Datum *values;
> + bool *isnull;
> int i;
> uint16 nliveatts = 0;
>
> Those separate declarations for values / isnull are not strictly
> needed anymore, so those vars could be deleted. IIRC those were only
> added before when there were both slots and tuples. OTOH, maybe you
> prefer to keep it this way just for code readability?
Yes, I prefer the current style for code readability.
>
> 2. src/backend/replication/pgoutput/pgoutput.c - typedef
>
> +typedef enum RowFilterPubAction
> +{
> + PUBACTION_INSERT,
> + PUBACTION_UPDATE,
> + PUBACTION_DELETE,
> + NUM_ROWFILTER_PUBACTIONS /* must be last */
> +} RowFilterPubAction;
>
> This typedef is not currently used by any of the code.
>
> So I think choices are:
>
> - Option 1: remove the typedef, because nobody is using it.
>
> - Option 2: keep the typedef, but use it! e.g. everywhere there is an
> exprstate array index variable probably it should be declared as a
> 'RowFilterPubAction idx' instead of just 'int idx'.
Thanks, I used the option 1.
>
> 3. src/backend/replication/pgoutput/pgoutput.c - map_changetype_pubaction
>
> After this recent v63 refactoring and merging of some APIs it seems
> that the map_changetype_pubaction is now ONLY used by
> pgoutput_row_filter function. So this can now be a static member of
> pgoutput_row_filter function instead of being declared at file scope.
>
Changed.
>
> 4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
> comments
> The function header comment says the same thing 2x about the return values.
>
Changed.
>
> ~~~
>
> 5. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
>
> + ExprContext *ecxt;
> + int filter_index = map_changetype_pubaction[*action];
> +
> + /* *action is already assigned default by caller */
> + Assert(*action == REORDER_BUFFER_CHANGE_INSERT ||
> + *action == REORDER_BUFFER_CHANGE_UPDATE ||
> + *action == REORDER_BUFFER_CHANGE_DELETE);
> +
>
> Accessing the map_changetype_pubaction array should be done *after* the
> Assert.
>
> ~~~
Changed.
>
> 6. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
>
> ExprState *filter_exprstate;
> ...
> filter_exprstate = entry->exprstate[map_changetype_pubaction[*action]];
>
> Please consider what way you think is best.
Changed as suggested.
>
> 7. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
> There are several things not quite right with that comment:
> a. I thought now it should refer to "slots" instead of "tuples"
>
> Suggested replacement comment:
Changed but I prefer "tuple" which is easy to understand.
> ~~~
>
> 8. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
>
> + if (!new_slot || !old_slot)
> + {
> + ecxt->ecxt_scantuple = new_slot ? new_slot : old_slot;
> + result = pgoutput_row_filter_exec_expr(entry->exprstate[filter_index],
> + ecxt);
> +
> + FreeExecutorState(estate);
> + PopActiveSnapshot();
> +
> + return result;
> + }
> +
> + tmp_new_slot = new_slot;
> + slot_getallattrs(new_slot);
> + slot_getallattrs(old_slot);
>
> I think after this "if" condition then the INSERT, DELETE and simple
> UPDATE are already handled. So, the remainder of the code is for
> deciding what update transformation is needed etc.
>
> I think there should be some block comment somewhere here to make that
> more obvious.
Changed.
> ~~
>
> 9. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
>
> Many of the comments in this function are still referring to old/new
> "tuple". Now that all the params are slots instead of tuples maybe now
> all the comments should also refer to "slots" instead of "tuples".
> Please search all the comments - e.g. including all the "Case 1:" ...
> "Case 4:" comments.
I also think tuple still makes sense, so I didn’t change this.
>
> 10. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
>
> + int idx_ins = PUBACTION_INSERT;
> + int idx_upd = PUBACTION_UPDATE;
> + int idx_del = PUBACTION_DELETE;
>
> These variables are unnecessary now... They previously were added only
> as short synonyms because the other enum names were too verbose (e.g.
> REORDER_BUFFER_CHANGE_INSERT) but now that we have shorter enum
> names
> like PUBACTION_INSERT we can just use those names directly
>
Changed.
>
> 11. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
>
> I felt that the code would seem more natural if the
> pgoutput_row_filter_init function came *before* the
> pgoutput_row_filter function in the source code.
>
Changed.
>
> 12. src/backend/replication/pgoutput/pgoutput.c - pgoutput_change
>
> @@ -634,6 +1176,9 @@ pgoutput_change(LogicalDecodingContext *ctx,
> ReorderBufferTXN *txn,
> RelationSyncEntry *relentry;
> TransactionId xid = InvalidTransactionId;
> Relation ancestor = NULL;
> + ReorderBufferChangeType modified_action = change->action;
> + TupleTableSlot *old_slot = NULL;
> + TupleTableSlot *new_slot = NULL;
>
> It seemed a bit misleading to me to call this variable
> 'modified_action' since mostly it is not modified at all.
>
> IMO it is better just to call this as 'action' but then add a comment
> (above the "switch (modified_action)") to say the previous call to
> pgoutput_row_filter may have transformed it to a different action.
>
Changed.
I have included these changes in v64 patch set.
Best regards,
Hou zj
On Thu, Jan 13, 2022 at 5:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Thanks for posting the merged v63.
>
> Here are my review comments for the v63-0001 changes.
>
...
> ~~~
>
> 4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter comments
>
> +
> +/*
> + * Change is checked against the row filter, if any.
> + *
> + * If it returns true, the change is replicated, otherwise, it is not.
> + *
> + * FOR INSERT: evaluates the row filter for new tuple.
> + * FOR DELETE: evaluates the row filter for old tuple.
> + * For UPDATE: evaluates the row filter for old and new tuple. If both
> + * evaluations are true, it sends the UPDATE. If both evaluations are false, it
> + * doesn't send the UPDATE. If only one of the tuples matches the row filter
> + * expression, there is a data consistency issue. Fixing this issue requires a
> + * transformation.
> + *
> + * Transformations:
> + * Updates are transformed to inserts and deletes based on the
> + * old tuple and new tuple. The new action is updated in the
> + * action parameter. If not updated, action remains as update.
> + *
> + * Case 1: old-row (no match) new-row (no match) -> (drop change)
> + * Case 2: old-row (no match) new row (match) -> INSERT
> + * Case 3: old-row (match) new-row (no match) -> DELETE
> + * Case 4: old-row (match) new row (match) -> UPDATE
> + *
> + * If the change is to be replicated this function returns true, else false.
> + *
> + * Examples:
>
> The function header comment says the same thing 2x about the return values.
>
> The 1st text "If it returns true, the change is replicated, otherwise,
> it is not." should be replaced by the better wording of the 2nd text
> ("If the change is to be replicated this function returns true, else
> false."). Then, that 2nd text can be removed (from where it is later
> in this same comment).
Hi Hou-san, thanks for all the v64 updates!
I think the above comment was only partly fixed.
The v64-0001 comment still says:
+ * If it returns true, the change is replicated, otherwise, it is not.
I thought the 2nd text is better:
"If the change is to be replicated this function returns true, else false."
But maybe it is best to rearrange the whole thing like:
"Returns true if the change is to be replicated, else false."
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Fri, Jan 14, 2022 at 5:48 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Thu, Jan 13, 2022 at 5:49 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > 4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter comments
> >
> > +
> > +/*
> > + * Change is checked against the row filter, if any.
> > + *
> > + * If it returns true, the change is replicated, otherwise, it is not.
> > + *
> > + * FOR INSERT: evaluates the row filter for new tuple.
> > + * FOR DELETE: evaluates the row filter for old tuple.
> > + * For UPDATE: evaluates the row filter for old and new tuple. If both
> > + * evaluations are true, it sends the UPDATE. If both evaluations are false, it
> > + * doesn't send the UPDATE. If only one of the tuples matches the row filter
> > + * expression, there is a data consistency issue. Fixing this issue requires a
> > + * transformation.
> > + *
> > + * Transformations:
> > + * Updates are transformed to inserts and deletes based on the
> > + * old tuple and new tuple. The new action is updated in the
> > + * action parameter. If not updated, action remains as update.
> > + *
> > + * Case 1: old-row (no match) new-row (no match) -> (drop change)
> > + * Case 2: old-row (no match) new row (match) -> INSERT
> > + * Case 3: old-row (match) new-row (no match) -> DELETE
> > + * Case 4: old-row (match) new row (match) -> UPDATE
> > + *
> > + * If the change is to be replicated this function returns true, else false.
> > + *
> > + * Examples:
> >
> > The function header comment says the same thing 2x about the return values.
> >
> > The 1st text "If it returns true, the change is replicated, otherwise,
> > it is not." should be replaced by the better wording of the 2nd text
> > ("If the change is to be replicated this function returns true, else
> > false."). Then, that 2nd text can be removed (from where it is later
> > in this same comment).
>
> Hi Hou-san, thanks for all the v64 updates!
>
> I think the above comment was only partly fixed.
>
> The v64-0001 comment still says:
> + * If it returns true, the change is replicated, otherwise, it is not.
>
...
...
>
> But maybe it is best to rearrange the whole thing like:
> "Returns true if the change is to be replicated, else false."
>
+1 to change as per this suggestion.
--
With Regards,
Amit Kapila.
Here are my review comments for v64-0001 (review of updates since v63-0001) ~~~ 1. doc/src/sgml/ref/create_publication.sgml - typo? + The <literal>WHERE</literal> clause allows simple expressions that don't have + user-defined functions, operators, non-immutable built-in functions. + </para> + I think there is a missing "or" after that Oxford comma. e.g. BEFORE "... operators, non-immutable built-in functions." AFTER "... operators, or non-immutable built-in functions." ~~ 2. commit message - typo You said that the above text (review comment 1) came from the 0001 commit message, so please make the same fix to the commit message. ~~ 3. src/backend/replication/logical/tablesync.c - redundant trailing ";" + /* Check for row filters. */ + resetStringInfo(&cmd); + appendStringInfo(&cmd, + "SELECT DISTINCT pg_get_expr(pr.prqual, pr.prrelid)" + " FROM pg_publication p" + " LEFT OUTER JOIN pg_publication_rel pr" + " ON (p.oid = pr.prpubid AND pr.prrelid = %u)," + " LATERAL pg_get_publication_tables(p.pubname) GPT" + " WHERE GPT.relid = %u" + " AND p.pubname IN ( %s );", + lrel->remoteid, + lrel->remoteid, + pub_names.data); I think that trailing ";" of the SQL is not needed, and nearby SQL execution code does not include one so maybe better to remove it for consistency. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Jan 13, 2022 at 6:46 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V64 patch set which addressed Alvaro, Amit and Peter's comments.
>
Few more comments:
===================
1.
"SELECT DISTINCT pg_get_expr(pr.prqual, pr.prrelid)"
+ " FROM pg_publication p"
+ " LEFT OUTER JOIN pg_publication_rel pr"
+ " ON (p.oid = pr.prpubid AND pr.prrelid = %u),"
+ " LATERAL pg_get_publication_tables(p.pubname) GPT"
+ " WHERE GPT.relid = %u"
+ " AND p.pubname IN ( %s );",
Use all aliases either in CAPS or in lower case. Seeing the nearby
code, it is better to use lower case for aliases.
2.
-
+extern Oid GetTopMostAncestorInPublication(Oid puboid, List *ancestors);
It seems like a spurious line removal. I think you should declare it
immediately after GetPubPartitionOptionRelations() to match the order
of functions as they are in pg_publication.c
3.
+ * It is only safe to execute UPDATE/DELETE when all columns referenced in
+ * the row filters from publications which the relation is in are valid -
+ * i.e. when all referenced columns are part of REPLICA IDENTITY, or the
There is no need for a comma after REPLICA IDENTITY.
4.
+ /*
+ * Find what are the cols that are part of the REPLICA IDENTITY.
Let's change this comment as: "Remember columns that are part of the
REPLICA IDENTITY."
5. The function name rowfilter_column_walker sounds goo generic for
its purpose. Can we rename it contain_invalid_rfcolumn_walker() and
move it to publicationcmds.c? Also, can we try to rearrange the code
in GetRelationPublicationInfo() such that row filter validation
related code is moved to a new function contain_invalid_rfcolumn()
which will internally call contain_invalid_rfcolumn_walker(). This new
functions can also be defined in publicationcmds.c.
6.
+ *
+ * If the cached validation result is true, we assume that the cached
+ * publication actions are also valid.
+ */
+AttrNumber
+GetRelationPublicationInfo(Relation relation, bool validate_rowfilter)
Instead of having the above comment, can we have an Assert for valid
relation->rd_pubactions when we are returning in the function due to
rd_rfcol_valid. Then, you can add a comment (publication actions must
be valid) before Assert.
7. I think we should have a function check_simple_rowfilter_expr()
which internally should call rowfilter_walker. See
check_nested_generated/check_nested_generated_walker. If you agree
with this, we can probably change the name of row_filter function to
check_simple_rowfilter_expr_walker().
8.
+ if (pubobj->pubtable && pubobj->pubtable->whereClause)
+ ereport(ERROR,
+ errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("WHERE clause for schema not allowed"),
Will it be better to write the above message as: "WHERE clause not
allowed for schema"?
9.
--- a/src/backend/replication/logical/proto.c
+++ b/src/backend/replication/logical/proto.c
@@ -15,6 +15,7 @@
#include "access/sysattr.h"
#include "catalog/pg_namespace.h"
#include "catalog/pg_type.h"
+#include "executor/executor.h"
Do we really need this include now? Please check includes in other
files as well and remove if anything is not required.
10.
/*
- * Get information about remote relation in similar fashion the RELATION
- * message provides during replication.
+ * Get information about a remote relation, in a similar fashion to how the
+ * RELATION message provides information during replication.
Why this part of the comment needs to be changed?
11.
/*
* For non-tables, we need to do COPY (SELECT ...), but we can't just
- * do SELECT * because we need to not copy generated columns.
+ * do SELECT * because we need to not copy generated columns.
I think here comment should say: "For non-tables and tables with row
filters, we need to do...."
Apart from the above, I have modified a few comments which you can
find in the attached patch v64-0002-Modify-comments. Kindly, review
those and if you are okay with them then merge those into the main
patch.
--
With Regards,
Amit Kapila.
Вложения
On Friday, January 14, 2022 7:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Thu, Jan 13, 2022 at 6:46 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the V64 patch set which addressed Alvaro, Amit and Peter's comments.
> >
>
> Few more comments:
> ===================
> 1.
> "SELECT DISTINCT pg_get_expr(pr.prqual, pr.prrelid)"
> + " FROM pg_publication p"
> + " LEFT OUTER JOIN pg_publication_rel pr"
> + " ON (p.oid = pr.prpubid AND pr.prrelid = %u),"
> + " LATERAL pg_get_publication_tables(p.pubname) GPT"
> + " WHERE GPT.relid = %u"
> + " AND p.pubname IN ( %s );",
>
> Use all aliases either in CAPS or in lower case. Seeing the nearby
> code, it is better to use lower case for aliases.
>
> 2.
> -
> +extern Oid GetTopMostAncestorInPublication(Oid puboid, List *ancestors);
>
> It seems like a spurious line removal. I think you should declare it
> immediately after GetPubPartitionOptionRelations() to match the order
> of functions as they are in pg_publication.c
>
> 3.
> + * It is only safe to execute UPDATE/DELETE when all columns referenced in
> + * the row filters from publications which the relation is in are valid -
> + * i.e. when all referenced columns are part of REPLICA IDENTITY, or the
>
> There is no need for a comma after REPLICA IDENTITY.
>
> 4.
> + /*
> + * Find what are the cols that are part of the REPLICA IDENTITY.
>
> Let's change this comment as: "Remember columns that are part of the
> REPLICA IDENTITY."
>
> 5. The function name rowfilter_column_walker sounds goo generic for
> its purpose. Can we rename it contain_invalid_rfcolumn_walker() and
> move it to publicationcmds.c? Also, can we try to rearrange the code
> in GetRelationPublicationInfo() such that row filter validation
> related code is moved to a new function contain_invalid_rfcolumn()
> which will internally call contain_invalid_rfcolumn_walker(). This new
> functions can also be defined in publicationcmds.c.
>
> 6.
> + *
> + * If the cached validation result is true, we assume that the cached
> + * publication actions are also valid.
> + */
> +AttrNumber
> +GetRelationPublicationInfo(Relation relation, bool validate_rowfilter)
>
> Instead of having the above comment, can we have an Assert for valid
> relation->rd_pubactions when we are returning in the function due to
> rd_rfcol_valid. Then, you can add a comment (publication actions must
> be valid) before Assert.
>
> 7. I think we should have a function check_simple_rowfilter_expr()
> which internally should call rowfilter_walker. See
> check_nested_generated/check_nested_generated_walker. If you agree
> with this, we can probably change the name of row_filter function to
> check_simple_rowfilter_expr_walker().
>
> 8.
> + if (pubobj->pubtable && pubobj->pubtable->whereClause)
> + ereport(ERROR,
> + errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("WHERE clause for schema not allowed"),
>
> Will it be better to write the above message as: "WHERE clause not
> allowed for schema"?
>
> 9.
> --- a/src/backend/replication/logical/proto.c
> +++ b/src/backend/replication/logical/proto.c
> @@ -15,6 +15,7 @@
> #include "access/sysattr.h"
> #include "catalog/pg_namespace.h"
> #include "catalog/pg_type.h"
> +#include "executor/executor.h"
>
> Do we really need this include now? Please check includes in other
> files as well and remove if anything is not required.
>
> 10.
> /*
> - * Get information about remote relation in similar fashion the RELATION
> - * message provides during replication.
> + * Get information about a remote relation, in a similar fashion to how the
> + * RELATION message provides information during replication.
>
> Why this part of the comment needs to be changed?
>
> 11.
> /*
> * For non-tables, we need to do COPY (SELECT ...), but we can't just
> - * do SELECT * because we need to not copy generated columns.
> + * do SELECT * because we need to not copy generated columns.
>
> I think here comment should say: "For non-tables and tables with row
> filters, we need to do...."
>
> Apart from the above, I have modified a few comments which you can
> find in the attached patch v64-0002-Modify-comments. Kindly, review
> those and if you are okay with them then merge those into the main
> patch.
Thanks for the comments.
Attach the V65 patch set which addressed the above comments and Peter's comments[1].
I also fixed some typos and removed some unused code.
[1] https://www.postgresql.org/message-id/CAHut%2BPvDKLrkT_nmPXd1cKfi7Cq8dVR7HGEKOyjrMwe65FdZ7Q%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Thu, Dec 2, 2021 at 7:40 PM vignesh C <vignesh21@gmail.com> wrote: > ... > > 2) testpub5 and testpub_syntax2 are similar, one of them can be removed: > +SET client_min_messages = 'ERROR'; > +CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1, > testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5); > +RESET client_min_messages; > +\dRp+ testpub5 > > +SET client_min_messages = 'ERROR'; > +CREATE PUBLICATION testpub_syntax2 FOR TABLE testpub_rf_tbl1, > testpub_rf_myschema.testpub_rf_tbl5 WHERE (h < 999); > +RESET client_min_messages; > +\dRp+ testpub_syntax2 > +DROP PUBLICATION testpub_syntax2; > To re-confirm my original motivation for adding the syntax2 test I coded some temporary logging into the different PublicationObjSpec cases. After I re-ran the regression tests, here are some extracts from the postmaster.log: (for testpub5) 2022-01-14 13:06:32.149 AEDT client backend[21853] pg_regress/publication LOG: !!> TABLE relation_expr OptWhereClause 2022-01-14 13:06:32.149 AEDT client backend[21853] pg_regress/publication STATEMENT: CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1, testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5) WITH (publish = 'insert'); 2022-01-14 13:06:32.149 AEDT client backend[21853] pg_regress/publication LOG: !!> ColId OptWhereClause 2022-01-14 13:06:32.149 AEDT client backend[21853] pg_regress/publication STATEMENT: CREATE PUBLICATION testpub5 FOR TABLE testpub_rf_tbl1, testpub_rf_tbl2 WHERE (c <> 'test' AND d < 5) WITH (publish = 'insert'); (for syntax2) 2022-01-14 13:06:32.186 AEDT client backend[21853] pg_regress/publication LOG: !!> TABLE relation_expr OptWhereClause 2022-01-14 13:06:32.186 AEDT client backend[21853] pg_regress/publication STATEMENT: CREATE PUBLICATION testpub_syntax2 FOR TABLE testpub_rf_tbl1, testpub_rf_schema1.testpub_rf_tbl5 WHERE (h < 999) WITH (publish = 'insert'); 2022-01-14 13:06:32.186 AEDT client backend[21853] pg_regress/publication LOG: !!> ColId indirection OptWhereClause 2022-01-14 13:06:32.186 AEDT client backend[21853] pg_regress/publication STATEMENT: CREATE PUBLICATION testpub_syntax2 FOR TABLE testpub_rf_tbl1, testpub_rf_schema1.testpub_rf_tbl5 WHERE (h < 999) WITH (publish = 'insert'); From those logs you can see although the SQLs looked to be similar they actually take different PublicationObjSpec execution paths in the gram.y: i.e. " ColId OptWhereClause" Versus " ColId indirection OptWhereClause" ~~ So this review comment can be skipped. Both tests should be retained. ------ Kind Regards, Peter Smith. Fujitsu Australia
Here are some review comments for v65-0001 (review of updates since v64-0001)
~~~
1. src/include/commands/publicationcmds.h - rename func
+extern bool contain_invalid_rfcolumn(Oid pubid, Relation relation,
+ List *ancestors,
+ AttrNumber *invalid_rfcolumn);
I thought that function should be called "contains_..." instead of
"contain_...".
~~~
2. src/backend/commands/publicationcmds.c - rename funcs
Suggested renaming (same as above #1).
"contain_invalid_rfcolumn_walker" --> "contains_invalid_rfcolumn_walker"
"contain_invalid_rfcolumn" --> "contains_invalid_rfcolumn"
Also, update it in the comment for rf_context:
+/*
+ * Information used to validate the columns in the row filter expression. See
+ * contain_invalid_rfcolumn_walker for details.
+ */
~~~
3. src/backend/commands/publicationcmds.c - bms
+ if (!rfisnull)
+ {
+ rf_context context = {0};
+ Node *rfnode;
+ Bitmapset *bms = NULL;
+
+ context.pubviaroot = pub->pubviaroot;
+ context.parentid = publish_as_relid;
+ context.relid = relid;
+
+ /*
+ * Remember columns that are part of the REPLICA IDENTITY. Note that
+ * REPLICA IDENTITY DEFAULT means primary key or nothing.
+ */
+ if (relation->rd_rel->relreplident == REPLICA_IDENTITY_DEFAULT)
+ bms = RelationGetIndexAttrBitmap(relation,
+ INDEX_ATTR_BITMAP_PRIMARY_KEY);
+ else if (relation->rd_rel->relreplident == REPLICA_IDENTITY_INDEX)
+ bms = RelationGetIndexAttrBitmap(relation,
+ INDEX_ATTR_BITMAP_IDENTITY_KEY);
+
+ context.bms_replident = bms;
There seems no need for a separate 'bms' variable here. Why not just
assign directly to context.bms_replident like the code used to do?
~~~
4. src/backend/utils/cache/relcache.c - typo?
/*
- * If we know everything is replicated, there is no point to check for
- * other publications.
+ * Check, if all columns referenced in the filter expression are part
+ * of the REPLICA IDENTITY index or not.
+ *
+ * If we already found the column in row filter which is not part of
+ * REPLICA IDENTITY index, skip the validation.
*/
Shouldn't that comment say "already found a column" instead of
"already found the column"?
~~~
5. src/backend/replication/pgoutput/pgoutput.c - map member
@@ -129,7 +169,7 @@ typedef struct RelationSyncEntry
* same as 'relid' or if unnecessary due to partition and the ancestor
* having identical TupleDesc.
*/
- TupleConversionMap *map;
+ AttrMap *map;
} RelationSyncEntry;
I wondered if you should also rename this member to something more
meaningful like 'attrmap' instead of just 'map'.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Sat, Jan 15, 2022 at 5:30 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the V65 patch set which addressed the above comments and Peter's comments[1]. > I also fixed some typos and removed some unused code. > I have several minor comments for the v65-0001 patch: doc/src/sgml/ref/alter_subscription.sgml (1) Suggest minor doc change: BEFORE: + Previously-subscribed tables are not copied, even if the table's row + filter <literal>WHERE</literal> clause had been modified. AFTER: + Previously-subscribed tables are not copied, even if a table's row + filter <literal>WHERE</literal> clause had been modified. src/backend/catalog/pg_publication.c (2) GetTopMostAncestorInPublication Is there a reason why there is no "break" after finding a topmost_relid? Why keep searching and potentially overwrite a previously-found topmost_relid? If it's intentional, I think that a comment should be added to explain it. src/backend/commands/publicationcmds.c (3) Grammar BEFORE: + * Returns true, if any of the columns used in row filter WHERE clause is not AFTER: + * Returns true, if any of the columns used in the row filter WHERE clause are not (4) contain_invalid_rfcolumn_walker Wouldn't this be better named "contains_invalid_rfcolumn_walker"? (and references to the functions be updated accordingly) src/backend/executor/execReplication.c (5) Comment is difficult to read Add commas to make the comment easier to read: BEFORE: + * It is only safe to execute UPDATE/DELETE when all columns referenced in + * the row filters from publications which the relation is in are valid - AFTER: + * It is only safe to execute UPDATE/DELETE when all columns, referenced in + * the row filters from publications which the relation is in, are valid - Regards, Greg Nancarrow Fujitsu Australia
On Sat, Jan 15, 2022 at 12:00 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Friday, January 14, 2022 7:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 13, 2022 at 6:46 PM houzj.fnst@fujitsu.com > > > > 9. > > --- a/src/backend/replication/logical/proto.c > > +++ b/src/backend/replication/logical/proto.c > > @@ -15,6 +15,7 @@ > > #include "access/sysattr.h" > > #include "catalog/pg_namespace.h" > > #include "catalog/pg_type.h" > > +#include "executor/executor.h" > > > > Do we really need this include now? Please check includes in other > > files as well and remove if anything is not required. > > ... .... > > Thanks for the comments. > Attach the V65 patch set which addressed the above comments and Peter's comments[1]. The above comment (#9) doesn't seem to be addressed. Also, please check other includes as well. I find below include also unnecessary. --- a/src/backend/replication/pgoutput/pgoutput.c +++ b/src/backend/replication/pgoutput/pgoutput.c ... ... +#include "nodes/nodeFuncs.h" Some other comments: ================== 1. /* + * If we know everything is replicated and some columns are not part + * of replica identity, there is no point to check for other + * publications. + */ + if (pubactions.pubinsert && pubactions.pubupdate && + pubactions.pubdelete && pubactions.pubtruncate && + (!validate_rowfilter || !rfcol_valid)) break; Why do we need to continue for other publications after we find there is an invalid column in row_filter? 2. * For initial synchronization, row filtering can be ignored in 2 cases: + * + * 1) one of the subscribed publications has puballtables set to true + * + * 2) one of the subscribed publications is declared as ALL TABLES IN + * SCHEMA that includes this relation Isn't there one more case (when one of the publications has a table without any filter) where row filtering be ignored? I see that point being mentioned later but it makes things unclear. I have tried to make things clear in the attached. Apart from the above, I have made a few other cosmetic changes atop v65-0001*.patch. Kindly review and merge into the main patch if you are okay with these changes. -- With Regards, Amit Kapila.
On Mon, Jan 17, 2022 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Some other comments:
> ==================
>
Few more comments:
==================
1.
+pgoutput_row_filter_init_expr(Node *rfnode)
+{
+ ExprState *exprstate;
+ Expr *expr;
+
+ /*
+ * This is the same code as ExecPrepareExpr() but that is not used because
+ * we have no EState to pass it.
Isn't it better to say "This is the same code as ExecPrepareExpr() but
that is not used because we want to cache the expression"? I feel if
we want we can allocate Estate as the patch is doing in
pgoutput_row_filter(), no?
2.
+ elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
+ DatumGetBool(ret) ? "true" : "false",
+ isnull ? "true" : "false");
+
+ if (isnull)
+ return false;
Won't the isnull condition's result in elog should be reversed?
3.
+ /*
+ * If the publication is FOR ALL TABLES IN SCHEMA and it overlaps
+ * with the current relation in the same schema then this is also
+ * treated same as if this table has no row filters (even if for
+ * other publications it does).
+ */
+ else if (list_member_oid(schemaPubids, pub->oid))
+ pub_no_filter = true;
The code will appear better if you can move the comments inside else
if. There are other places nearby this comment where we can follow the
same style.
4.
+ * Multiple ExprState entries might be used if there are multiple
+ * publications for a single table. Different publication actions don't
+ * allow multiple expressions to always be combined into one, so there is
+ * one ExprState per publication action. The exprstate array is indexed by
+ * ReorderBufferChangeType.
+ */
+ bool exprstate_valid;
+
+ /* ExprState array for row filter. One per publication action. */
+ ExprState *exprstate[NUM_ROWFILTER_PUBACTIONS];
It is not clear from comments here or at other places as to why we
need an array for row filter expressions? Can you please add comments
to explain the same? IIRC, it is primarily due to the reason that we
don't want to add the restriction that the publish operation 'insert'
should also honor RI columns restriction. If there are other reasons
then let's add those to comments as well.
--
With Regards,
Amit Kapila.
On Mon, Jan 17, 2022 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > Apart from the above, I have made a few other cosmetic changes atop > v65-0001*.patch. Kindly review and merge into the main patch if you > are okay with these changes. > Sorry, forgot to attach a top-up patch, sending it now. -- With Regards, Amit Kapila.
Вложения
On Mon, Jan 17, 2022 7:23 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Jan 17, 2022 at 3:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > Some other comments:
> > ==================
> >
>
> Few more comments:
> ==================
> 1.
> +pgoutput_row_filter_init_expr(Node *rfnode) { ExprState *exprstate;
> + Expr *expr;
> +
> + /*
> + * This is the same code as ExecPrepareExpr() but that is not used
> + because
> + * we have no EState to pass it.
>
> Isn't it better to say "This is the same code as ExecPrepareExpr() but that is not
> used because we want to cache the expression"? I feel if we want we can allocate
> Estate as the patch is doing in pgoutput_row_filter(), no?
Changed as suggested.
> 2.
> + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
> + DatumGetBool(ret) ? "true" : "false",
> + isnull ? "true" : "false");
> +
> + if (isnull)
> + return false;
>
> Won't the isnull condition's result in elog should be reversed?
Changed.
> 3.
> + /*
> + * If the publication is FOR ALL TABLES IN SCHEMA and it overlaps
> + * with the current relation in the same schema then this is also
> + * treated same as if this table has no row filters (even if for
> + * other publications it does).
> + */
> + else if (list_member_oid(schemaPubids, pub->oid)) pub_no_filter =
> + true;
>
> The code will appear better if you can move the comments inside else if. There
> are other places nearby this comment where we can follow the same style.
Changed.
> 4.
> + * Multiple ExprState entries might be used if there are multiple
> + * publications for a single table. Different publication actions don't
> + * allow multiple expressions to always be combined into one, so there
> + is
> + * one ExprState per publication action. The exprstate array is indexed
> + by
> + * ReorderBufferChangeType.
> + */
> + bool exprstate_valid;
> +
> + /* ExprState array for row filter. One per publication action. */
> + ExprState *exprstate[NUM_ROWFILTER_PUBACTIONS];
>
> It is not clear from comments here or at other places as to why we need an array
> for row filter expressions? Can you please add comments to explain the same?
> IIRC, it is primarily due to the reason that we don't want to add the restriction
> that the publish operation 'insert'
> should also honor RI columns restriction. If there are other reasons then let's add
> those to comments as well.
I will think over this and update in next version.
Attach the V66 patch set which addressed Amit, Peter and Greg's comments.
Best regards,
Hou zj
Вложения
On Mon, Jan 17, 2022 12:34 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v65-0001 (review of updates since
> v64-0001)
Thanks for the comments!
> ~~~
>
> 1. src/include/commands/publicationcmds.h - rename func
>
> +extern bool contain_invalid_rfcolumn(Oid pubid, Relation relation,
> +List *ancestors, AttrNumber *invalid_rfcolumn);
>
> I thought that function should be called "contains_..." instead of "contain_...".
>
> ~~~
>
> 2. src/backend/commands/publicationcmds.c - rename funcs
>
> Suggested renaming (same as above #1).
>
> "contain_invalid_rfcolumn_walker" --> "contains_invalid_rfcolumn_walker"
> "contain_invalid_rfcolumn" --> "contains_invalid_rfcolumn"
>
> Also, update it in the comment for rf_context:
> +/*
> + * Information used to validate the columns in the row filter
> +expression. See
> + * contain_invalid_rfcolumn_walker for details.
> + */
I am not sure about the name because many existing
functions are named contain_xxx_xxx.
(for example contain_mutable_functions)
>
> 3. src/backend/commands/publicationcmds.c - bms
>
> + if (!rfisnull)
> + {
> + rf_context context = {0};
> + Node *rfnode;
> + Bitmapset *bms = NULL;
> +
> + context.pubviaroot = pub->pubviaroot;
> + context.parentid = publish_as_relid;
> + context.relid = relid;
> +
> + /*
> + * Remember columns that are part of the REPLICA IDENTITY. Note that
> + * REPLICA IDENTITY DEFAULT means primary key or nothing.
> + */
> + if (relation->rd_rel->relreplident == REPLICA_IDENTITY_DEFAULT) bms =
> + RelationGetIndexAttrBitmap(relation,
> + INDEX_ATTR_BITMAP_PRIMARY_KEY);
> + else if (relation->rd_rel->relreplident == REPLICA_IDENTITY_INDEX) bms
> + = RelationGetIndexAttrBitmap(relation,
> + INDEX_ATTR_BITMAP_IDENTITY_KEY);
> +
> + context.bms_replident = bms;
>
> There seems no need for a separate 'bms' variable here. Why not just assign
> directly to context.bms_replident like the code used to do?
Because I found it made the code exceed 80 cols, so I personally
think use a shorter variable could make it looks better.
>
> 4. src/backend/utils/cache/relcache.c - typo?
>
> /*
> - * If we know everything is replicated, there is no point to check for
> - * other publications.
> + * Check, if all columns referenced in the filter expression are part
> + * of the REPLICA IDENTITY index or not.
> + *
> + * If we already found the column in row filter which is not part of
> + * REPLICA IDENTITY index, skip the validation.
> */
>
> Shouldn't that comment say "already found a column" instead of "already found
> the column"?
Adjusted the comments here.
>
> 5. src/backend/replication/pgoutput/pgoutput.c - map member
>
> @@ -129,7 +169,7 @@ typedef struct RelationSyncEntry
> * same as 'relid' or if unnecessary due to partition and the ancestor
> * having identical TupleDesc.
> */
> - TupleConversionMap *map;
> + AttrMap *map;
> } RelationSyncEntry;
>
> I wondered if you should also rename this member to something more
> meaningful like 'attrmap' instead of just 'map'.
Changed.
Best regards,
Hou zj
On Mon, Jan 17, 2022 12:35 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Sat, Jan 15, 2022 at 5:30 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > Attach the V65 patch set which addressed the above comments and Peter's > comments[1]. > > I also fixed some typos and removed some unused code. > > > > I have several minor comments for the v65-0001 patch: Thanks for the comments ! > doc/src/sgml/ref/alter_subscription.sgml > > (1) > Suggest minor doc change: > > BEFORE: > + Previously-subscribed tables are not copied, even if the table's row > + filter <literal>WHERE</literal> clause had been modified. > AFTER: > + Previously-subscribed tables are not copied, even if a table's row > + filter <literal>WHERE</literal> clause had been modified. > > > src/backend/catalog/pg_publication.c Changed. > (2) GetTopMostAncestorInPublication > Is there a reason why there is no "break" after finding a > topmost_relid? Why keep searching and potentially overwrite a > previously-found topmost_relid? If it's intentional, I think that a > comment should be added to explain it. The code was moved from get_rel_sync_entry, and was trying to get the last oid in the ancestor list which is published by the publication. Do you have some suggestions for the comment ? > > src/backend/commands/publicationcmds.c > > (3) Grammar > > BEFORE: > + * Returns true, if any of the columns used in row filter WHERE clause is not > AFTER: > + * Returns true, if any of the columns used in the row filter WHERE > clause are not Changed. > > (4) contain_invalid_rfcolumn_walker > Wouldn't this be better named "contains_invalid_rfcolumn_walker"? > (and references to the functions be updated accordingly) I am not sure about the name because many existing functions are named contain_xxx_xxx. (for example contain_mutable_functions) > > src/backend/executor/execReplication.c > > (5) Comment is difficult to read > Add commas to make the comment easier to read: > > BEFORE: > + * It is only safe to execute UPDATE/DELETE when all columns referenced in > + * the row filters from publications which the relation is in are valid - > AFTER: > + * It is only safe to execute UPDATE/DELETE when all columns, referenced in > + * the row filters from publications which the relation is in, are valid - > Changed. Best regards, Hou zj
Here are some review comments for v66-0001 (review of updates since v65-0001) ~~~ 1. src/backend/catalog/pg_publication.c - GetTopMostAncestorInPublication @@ -276,17 +276,45 @@ GetPubPartitionOptionRelations(List *result, PublicationPartOpt pub_partopt, } /* + * Returns the relid of the topmost ancestor that is published via this + * publication if any, otherwise return InvalidOid. + */ Suggestion: "otherwise return InvalidOid." --> "otherwise returns InvalidOid." ~~~ 2. src/backend/commands/publicationcmds.c - contain_invalid_rfcolumn_walker @@ -235,6 +254,337 @@ CheckObjSchemaNotAlreadyInPublication(List *rels, List *schemaidlist, } /* + * Returns true, if any of the columns used in the row filter WHERE clause are + * not part of REPLICA IDENTITY, false, otherwise. Suggestion: ", false, otherwise" --> ", otherwise returns false." ~~~ 3. src/backend/replication/logical/tablesync.c - fetch_remote_table_info + * We do need to copy the row even if it matches one of the publications, + * so, we later combine all the quals with OR. Suggestion: BEFORE * We do need to copy the row even if it matches one of the publications, * so, we later combine all the quals with OR. AFTER * We need to copy the row even if it matches just one of the publications, * so, we later combine all the quals with OR. ~~~ 4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_exec_expr + ret = ExecEvalExprSwitchContext(state, econtext, &isnull); + + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", + DatumGetBool(ret) ? "true" : "false", + isnull ? "false" : "true"); + + if (isnull) + return false; + + return DatumGetBool(ret); That change to the logging looks incorrect - the "(isnull: %s)" value is backwards now. I guess maybe the intent was to change it something like below: elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", isnull ? "false" : DatumGetBool(ret) ? "true" : "false", isnull ? "true" : "false"); ------ Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Jan 17, 2022 at 9:00 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Mon, Jan 17, 2022 12:34 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Here are some review comments for v65-0001 (review of updates since > > v64-0001) > > Thanks for the comments! > > > ~~~ > > > > 1. src/include/commands/publicationcmds.h - rename func > > > > +extern bool contain_invalid_rfcolumn(Oid pubid, Relation relation, > > +List *ancestors, AttrNumber *invalid_rfcolumn); > > > > I thought that function should be called "contains_..." instead of "contain_...". > > > > ~~~ > > > > 2. src/backend/commands/publicationcmds.c - rename funcs > > > > Suggested renaming (same as above #1). > > > > "contain_invalid_rfcolumn_walker" --> "contains_invalid_rfcolumn_walker" > > "contain_invalid_rfcolumn" --> "contains_invalid_rfcolumn" > > > > Also, update it in the comment for rf_context: > > +/* > > + * Information used to validate the columns in the row filter > > +expression. See > > + * contain_invalid_rfcolumn_walker for details. > > + */ > > I am not sure about the name because many existing > functions are named contain_xxx_xxx. > (for example contain_mutable_functions) > I also see many similar functions whose name start with contain_* like contain_var_clause, contain_agg_clause, contain_window_function, etc. So, it is probably okay to retain the name as it is in the patch. -- With Regards, Amit Kapila.
On Tue, Jan 18, 2022 at 2:31 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > (2) GetTopMostAncestorInPublication > > Is there a reason why there is no "break" after finding a > > topmost_relid? Why keep searching and potentially overwrite a > > previously-found topmost_relid? If it's intentional, I think that a > > comment should be added to explain it. > > The code was moved from get_rel_sync_entry, and was trying to get the > last oid in the ancestor list which is published by the publication. Do you > have some suggestions for the comment ? > Maybe the existing comment should be updated to just spell it out like that: /* * Find the "topmost" ancestor that is in this publication, by getting the * last Oid in the ancestors list which is published by the publication. */ Regards, Greg Nancarrow Fujitsu Australia
On Tue, Jan 18, 2022 at 8:41 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Tue, Jan 18, 2022 at 2:31 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > > (2) GetTopMostAncestorInPublication > > > Is there a reason why there is no "break" after finding a > > > topmost_relid? Why keep searching and potentially overwrite a > > > previously-found topmost_relid? If it's intentional, I think that a > > > comment should be added to explain it. > > > > The code was moved from get_rel_sync_entry, and was trying to get the > > last oid in the ancestor list which is published by the publication. Do you > > have some suggestions for the comment ? > > > > Maybe the existing comment should be updated to just spell it out like that: > > /* > * Find the "topmost" ancestor that is in this publication, by getting the > * last Oid in the ancestors list which is published by the publication. > */ > I am not sure that is helpful w.r.t what Peter is looking for as that is saying what code is doing and he wants to know why it is so? I think one can understand this by looking at get_partition_ancestors which will return the top-most ancestor as the last element. I feel either we can say see get_partition_ancestors or maybe explain how the ancestors are stored in this list. -- With Regards, Amit Kapila.
On Tue, Jan 18, 2022 at 2:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Jan 18, 2022 at 8:41 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > On Tue, Jan 18, 2022 at 2:31 AM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > (2) GetTopMostAncestorInPublication > > > > Is there a reason why there is no "break" after finding a > > > > topmost_relid? Why keep searching and potentially overwrite a > > > > previously-found topmost_relid? If it's intentional, I think that a > > > > comment should be added to explain it. > > > > > > The code was moved from get_rel_sync_entry, and was trying to get the > > > last oid in the ancestor list which is published by the publication. Do you > > > have some suggestions for the comment ? > > > > > > > Maybe the existing comment should be updated to just spell it out like that: > > > > /* > > * Find the "topmost" ancestor that is in this publication, by getting the > > * last Oid in the ancestors list which is published by the publication. > > */ > > > > I am not sure that is helpful w.r.t what Peter is looking for as that > is saying what code is doing and he wants to know why it is so? I > think one can understand this by looking at get_partition_ancestors > which will return the top-most ancestor as the last element. I feel > either we can say see get_partition_ancestors or maybe explain how the > ancestors are stored in this list. > (note: I asked the original question about why there is no "break", not Peter) Maybe instead, an additional comment could be added to the GetTopMostAncestorInPublication function to say "Note that the ancestors list is ordered such that the topmost ancestor is at the end of the list". Unfortunately the get_partition_ancestors function currently doesn't explicitly say that the topmost ancestors are returned at the end of the list (I guess you could conclude it by then looking at get_partition_ancestors_worker code which it calls). Also, this leads me to wonder if searching the ancestors list backwards might be better here, and break at the first match? Perhaps there is only a small gain in doing that ... Regards, Greg Nancarrow Fujitsu Australia
On Mon, Jan 17, 2022 at 8:58 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V66 patch set which addressed Amit, Peter and Greg's comments.
>
Thanks, some more comments, and suggestions:
1.
/*
+ * If no record in publication, check if the table is the partition
+ * of a published partitioned table. If so, the table has no row
+ * filter.
+ */
+ else if (!pub->pubviaroot)
+ {
+ List *schemarelids;
+ List *relids;
+
+ schemarelids = GetAllSchemaPublicationRelations(pub->oid,
+ PUBLICATION_PART_LEAF);
+ relids = GetPublicationRelations(pub->oid,
+ PUBLICATION_PART_LEAF);
+
+ if (list_member_oid(schemarelids, entry->publish_as_relid) ||
+ list_member_oid(relids, entry->publish_as_relid))
+ pub_no_filter = true;
+
+ list_free(schemarelids);
+ list_free(relids);
+
+ if (!pub_no_filter)
+ continue;
+ }
As far as I understand this handling is required only for partition
tables but it seems to be invoked for non-partition tables as well.
Please move the comment inside else if block and expand a bit more to
say why it is necessary to not directly set pub_no_filter here. Note,
that I think this can be improved (avoid cache lookups) if we maintain
a list of pubids in relsyncentry but I am not sure that is required
because this is a rare case and needs to be done only one time.
2.
static HTAB *OpClassCache = NULL;
-
/* non-export function prototypes */
Spurious line removal. I have added back in the attached top-up patch.
Apart from the above, I have made some modifications to other comments.
--
With Regards,
Amit Kapila.
Вложения
On Tue, Jan 18, 2022 at 6:05 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jan 17, 2022 at 8:58 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > Spurious line removal. I have added back in the attached top-up patch. > > Apart from the above, I have made some modifications to other comments. > Sorry, attached the wrong patch earlier. -- With Regards, Amit Kapila.
Вложения
On Tues, Jan 18, 2022 8:35 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Jan 17, 2022 at 8:58 PM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the V66 patch set which addressed Amit, Peter and Greg's comments.
> >
>
> Thanks, some more comments, and suggestions:
>
> 1.
> /*
> + * If no record in publication, check if the table is the partition
> + * of a published partitioned table. If so, the table has no row
> + * filter.
> + */
> + else if (!pub->pubviaroot)
> + {
> + List *schemarelids;
> + List *relids;
> +
> + schemarelids = GetAllSchemaPublicationRelations(pub->oid,
> + PUBLICATION_PART_LEAF);
> + relids = GetPublicationRelations(pub->oid,
> + PUBLICATION_PART_LEAF);
> +
> + if (list_member_oid(schemarelids, entry->publish_as_relid) ||
> + list_member_oid(relids, entry->publish_as_relid))
> + pub_no_filter = true;
> +
> + list_free(schemarelids);
> + list_free(relids);
> +
> + if (!pub_no_filter)
> + continue;
> + }
>
> As far as I understand this handling is required only for partition
> tables but it seems to be invoked for non-partition tables as well.
> Please move the comment inside else if block and expand a bit more to
> say why it is necessary to not directly set pub_no_filter here.
Changed.
> Note,
> that I think this can be improved (avoid cache lookups) if we maintain
> a list of pubids in relsyncentry but I am not sure that is required
> because this is a rare case and needs to be done only one time.
I will do some research about this.
> 2.
> static HTAB *OpClassCache = NULL;
>
> -
> /* non-export function prototypes */
>
> Spurious line removal. I have added back in the attached top-up patch.
>
> Apart from the above, I have made some modifications to other comments.
Thanks for the changes and comments.
Attach the V67 patch set which address the above comments.
The new version patch also includes:
- Some code comments update suggested by Peter [1] and Greg [2]
- Move the initialization of cached slot into a separate function because we now
use the cached slot even if there is no filter.
- Remove an unused parameter in pgoutput_row_filter_init.
- Improve the memory context initialization of row filter.
- Fix some tab-complete bugs (fix provided by Peter)
[1] https://www.postgresql.org/message-id/CAHut%2BPtPVqXVsqBHU3wTppU_cK5xuS7TkqT1XJLJmn%2BTpt905w%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJcOf-eWhCtdKXc9_5JASJ1sU0nGOSp%2B2nzLk01O2%3DZy7v1ApQ%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Tues, Jan 18, 2022 9:27 AM Peter Smith <smithpb2250@gmail.com> wrote: > Here are some review comments for v66-0001 (review of updates since > v65-0001) Thanks for the comments! > ~~~ > > 1. src/backend/catalog/pg_publication.c - GetTopMostAncestorInPublication > > @@ -276,17 +276,45 @@ GetPubPartitionOptionRelations(List *result, > PublicationPartOpt pub_partopt, } > > /* > + * Returns the relid of the topmost ancestor that is published via this > + * publication if any, otherwise return InvalidOid. > + */ > > Suggestion: > "otherwise return InvalidOid." --> "otherwise returns InvalidOid." > Changed. > > 2. src/backend/commands/publicationcmds.c - > contain_invalid_rfcolumn_walker > > @@ -235,6 +254,337 @@ CheckObjSchemaNotAlreadyInPublication(List > *rels, List *schemaidlist, > } > > /* > + * Returns true, if any of the columns used in the row filter WHERE > + clause are > + * not part of REPLICA IDENTITY, false, otherwise. > > Suggestion: > ", false, otherwise" --> ", otherwise returns false." > Changed. > > 3. src/backend/replication/logical/tablesync.c - fetch_remote_table_info > > + * We do need to copy the row even if it matches one of the > + publications, > + * so, we later combine all the quals with OR. > > Suggestion: > > BEFORE > * We do need to copy the row even if it matches one of the publications, > * so, we later combine all the quals with OR. > AFTER > * We need to copy the row even if it matches just one of the publications, > * so, we later combine all the quals with OR. > Changed. > > 4. src/backend/replication/pgoutput/pgoutput.c - > pgoutput_row_filter_exec_expr > > + ret = ExecEvalExprSwitchContext(state, econtext, &isnull); > + > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > + DatumGetBool(ret) ? "true" : "false", > + isnull ? "false" : "true"); > + > + if (isnull) > + return false; > + > + return DatumGetBool(ret); > > That change to the logging looks incorrect - the "(isnull: %s)" value is > backwards now. > > I guess maybe the intent was to change it something like below: > > elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", isnull ? "false" : > DatumGetBool(ret) ? "true" : "false", isnull ? "true" : "false"); I misread the previous comments. I think the original log is correct and I have reverted this change. Best regards, Hou zj
On Wed, Jan 19, 2022 at 1:15 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V67 patch set which address the above comments.
>
I noticed a problem in one of the error message errdetail messages
added by the patch:
(1) check_simple_rowfilter_expr_walker()
Non-immutable built-in functions are NOT allowed in expressions (i.e.
WHERE clauses).
Therefore, the error message should say that "Expressions only allow
... immutable built-in functions":
The following change is required:
BEFORE:
+ errdetail("Expressions only allow columns, constants, built-in
operators, built-in data types and non-immutable built-in functions.")
AFTER:
+ errdetail("Expressions only allow columns, constants, built-in
operators, built-in data types and immutable built-in functions.")
Regards,
Greg Nancarrow
Fujitsu Australia
On Wed, Jan 19, 2022 at 7:45 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Tues, Jan 18, 2022 8:35 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Attach the V67 patch set which address the above comments.
>
Some more comments and suggestions:
=================================
1. Can we do slot initialization in maybe_send_schema() instead of
introducing a new flag for it?
2.
+ * For updates if no old tuple, it means none of the replica identity
+ * columns changed and this would reduce to a simple update. We only need
+ * to evaluate the row filter for the new tuple.
Is it possible with the current version of the patch? I am asking
because, for updates, we now allow only RI columns in row filter, so
do we need to evaluate the row filter in this case? I think ideally,
we don't need to evaluate the row filter in this case as for updates
only replica identity columns are allowed but users can use constant
expressions in the row filter. So, we need to evaluate the row filter
in this case as well. Is my understanding correct?
3. + /* If no filter found, clean up the memory and return */
+ if (!has_filter)
+ {
+ if (entry->cache_expr_cxt != NULL)
+ MemoryContextDelete(entry->cache_expr_cxt);
I think this clean-up needs to be performed when we set
exprstate_valid to false. I have changed accordingly in the attached
patch.
Apart from the above, I have made quite a few changes in the code
comments in the attached top-up patch, kindly review those and merge
them into the main patch, if you are okay with it.
--
With Regards,
Amit Kapila.
Вложения
On Tue, Jan 18, 2022 at 10:23 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Tue, Jan 18, 2022 at 2:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Jan 18, 2022 at 8:41 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > > > On Tue, Jan 18, 2022 at 2:31 AM houzj.fnst@fujitsu.com > > > <houzj.fnst@fujitsu.com> wrote: > > > > > > > > > (2) GetTopMostAncestorInPublication > > > > > Is there a reason why there is no "break" after finding a > > > > > topmost_relid? Why keep searching and potentially overwrite a > > > > > previously-found topmost_relid? If it's intentional, I think that a > > > > > comment should be added to explain it. > > > > > > > > The code was moved from get_rel_sync_entry, and was trying to get the > > > > last oid in the ancestor list which is published by the publication. Do you > > > > have some suggestions for the comment ? > > > > > > > > > > Maybe the existing comment should be updated to just spell it out like that: > > > > > > /* > > > * Find the "topmost" ancestor that is in this publication, by getting the > > > * last Oid in the ancestors list which is published by the publication. > > > */ > > > > > > > I am not sure that is helpful w.r.t what Peter is looking for as that > > is saying what code is doing and he wants to know why it is so? I > > think one can understand this by looking at get_partition_ancestors > > which will return the top-most ancestor as the last element. I feel > > either we can say see get_partition_ancestors or maybe explain how the > > ancestors are stored in this list. > > > > (note: I asked the original question about why there is no "break", not Peter) > Okay. > Maybe instead, an additional comment could be added to the > GetTopMostAncestorInPublication function to say "Note that the > ancestors list is ordered such that the topmost ancestor is at the end > of the list". > I am fine with this and I see that Hou-San already used this in the latest version of patch. > Unfortunately the get_partition_ancestors function > currently doesn't explicitly say that the topmost ancestors are > returned at the end of the list (I guess you could conclude it by then > looking at get_partition_ancestors_worker code which it calls). > Also, this leads me to wonder if searching the ancestors list > backwards might be better here, and break at the first match? > I am not sure of the gains by doing that and anyway, that is a separate topic of discussion as it is an existing code. -- With Regards, Amit Kapila.
On Wednesday, January 19, 2022 5:56 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Jan 19, 2022 at 7:45 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Tues, Jan 18, 2022 8:35 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > Attach the V67 patch set which address the above comments.
> >
>
> Some more comments and suggestions:
> =================================
> 1. Can we do slot initialization in maybe_send_schema() instead of
> introducing a new flag for it?
>
> 2.
> + * For updates if no old tuple, it means none of the replica identity
> + * columns changed and this would reduce to a simple update. We only need
> + * to evaluate the row filter for the new tuple.
>
> Is it possible with the current version of the patch? I am asking
> because, for updates, we now allow only RI columns in row filter, so
> do we need to evaluate the row filter in this case? I think ideally,
> we don't need to evaluate the row filter in this case as for updates
> only replica identity columns are allowed but users can use constant
> expressions in the row filter. So, we need to evaluate the row filter
> in this case as well. Is my understanding correct?
>
> 3. + /* If no filter found, clean up the memory and return */
> + if (!has_filter)
> + {
> + if (entry->cache_expr_cxt != NULL)
> + MemoryContextDelete(entry->cache_expr_cxt);
>
> I think this clean-up needs to be performed when we set
> exprstate_valid to false. I have changed accordingly in the attached
> patch.
>
> Apart from the above, I have made quite a few changes in the code
> comments in the attached top-up patch, kindly review those and merge
> them into the main patch, if you are okay with it.
Thanks for the comments and changes.
Attach the V68 patch set which addressed the above comments and changes.
The version patch also fix the error message mentioned by Greg[1]
[1] https://www.postgresql.org/message-id/CAJcOf-f9DBXMvutsxW_DBLu7bepKP1e4BGw4bwiC%2BzwsK4Q0Wg%40mail.gmail.com
Best regards,
Hou zj
Вложения
Here are some review comments for v68-0001.
~~~
1. Commit message
"When a publication is defined or modified, rows that don't satisfy an
optional WHERE clause
will be filtered out."
That wording seems strange to me - it sounds like the filtering takes
place at the point of creating/altering.
Suggest reword something like:
"When a publication is defined or modified, an optional WHERE clause
can be specified. Rows that don't
satisfy this WHERE clause will be filtered out."
~~~
2. Commit message
"The WHERE clause allows simple expressions that don't have
user-defined functions, operators..."
Suggest adding the word ONLY:
"The WHERE clause only allows simple expressions that don't have
user-defined functions, operators..."
~~~
3. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
+ /* If no filter found, clean up the memory and return */
+ if (!has_filter)
+ {
+ if (entry->cache_expr_cxt != NULL)
+ MemoryContextDelete(entry->cache_expr_cxt);
+
+ entry->exprstate_valid = true;
+ return;
+ }
IMO this should be refactored to have if/else, so the function has
just a single point of return and a single point where the
exprstate_valid is set. e.g.
if (!has_filter)
{
/* If no filter found, clean up the memory and return */
...
}
else
{
/* Create or reset the memory context for row filters */
...
/*
* Now all the filters for all pubactions are known. Combine them when
* their pubactions are same.
...
}
entry->exprstate_valid = true;
~~~
4. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter comment
+ /*
+ * We need this map to avoid relying on changes in ReorderBufferChangeType
+ * enum.
+ */
+ static int map_changetype_pubaction[] = {
+ [REORDER_BUFFER_CHANGE_INSERT] = PUBACTION_INSERT,
+ [REORDER_BUFFER_CHANGE_UPDATE] = PUBACTION_UPDATE,
+ [REORDER_BUFFER_CHANGE_DELETE] = PUBACTION_DELETE
+ };
Suggest rewording comment and remove the double-spacing:
BEFORE:
"We need this map to avoid relying on changes in ReorderBufferChangeType enum."
AFTER:
"We need this map to avoid relying on ReorderBufferChangeType enums
having specific values."
~~~
5. DEBUG level 3
I found there are 3 debug logs in this patch and they all have DEBUG3 level.
IMO it is probably OK as-is, but just a comparison I noticed that the
most detailed logging for logical replication worker.c was DEBUG2.
Perhaps row-filter patch should be using DEBUG2 also?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Jan 20, 2022 at 7:51 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v68-0001.
>
>
> 3. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
>
> + /* If no filter found, clean up the memory and return */
> + if (!has_filter)
> + {
> + if (entry->cache_expr_cxt != NULL)
> + MemoryContextDelete(entry->cache_expr_cxt);
> +
> + entry->exprstate_valid = true;
> + return;
> + }
>
> IMO this should be refactored to have if/else, so the function has
> just a single point of return and a single point where the
> exprstate_valid is set. e.g.
>
> if (!has_filter)
> {
> /* If no filter found, clean up the memory and return */
> ...
> }
> else
> {
> /* Create or reset the memory context for row filters */
> ...
> /*
> * Now all the filters for all pubactions are known. Combine them when
> * their pubactions are same.
> ...
> }
>
> entry->exprstate_valid = true;
>
This part of the code is changed in v68 which makes the current code
more suitable as we don't need to deal with memory context in if part.
I am not sure if it is good to add the else block here but I think
that is just a matter of personal preference.
--
With Regards,
Amit Kapila.
On Thu, Jan 20, 2022 at 7:51 AM Peter Smith <smithpb2250@gmail.com> wrote: > > 5. DEBUG level 3 > > I found there are 3 debug logs in this patch and they all have DEBUG3 level. > > IMO it is probably OK as-is, > +1. > but just a comparison I noticed that the > most detailed logging for logical replication worker.c was DEBUG2. > Perhaps row-filter patch should be using DEBUG2 also? > OTOH, the other related files like reorderbuffer.c and snapbuild.c are using DEBUG3 for the detailed messages. So, I think it is probably okay to retain logs as is. -- With Regards, Amit Kapila.
On Thu, Jan 20, 2022 at 2:29 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Jan 20, 2022 at 7:51 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > Here are some review comments for v68-0001.
> >
> >
> > 3. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter_init
> >
> > + /* If no filter found, clean up the memory and return */
> > + if (!has_filter)
> > + {
> > + if (entry->cache_expr_cxt != NULL)
> > + MemoryContextDelete(entry->cache_expr_cxt);
> > +
> > + entry->exprstate_valid = true;
> > + return;
> > + }
> >
> > IMO this should be refactored to have if/else, so the function has
> > just a single point of return and a single point where the
> > exprstate_valid is set. e.g.
> >
> > if (!has_filter)
> > {
> > /* If no filter found, clean up the memory and return */
> > ...
> > }
> > else
> > {
> > /* Create or reset the memory context for row filters */
> > ...
> > /*
> > * Now all the filters for all pubactions are known. Combine them when
> > * their pubactions are same.
> > ...
> > }
> >
> > entry->exprstate_valid = true;
> >
>
> This part of the code is changed in v68 which makes the current code
> more suitable as we don't need to deal with memory context in if part.
> I am not sure if it is good to add the else block here but I think
> that is just a matter of personal preference.
>
Sorry, my mistake - I quoted the v67 source instead of the v68 source.
There is no else needed now at all. My suggestion becomes. e.g.
if (has_filter)
{
// deal with mem ctx ...
// combine filters ...
}
entry->exprstate_valid = true;
return;
------
Kind Regards,
Peter Smith
Fujitsu Australia
On Thu, Jan 20, 2022 at 6:42 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V68 patch set which addressed the above comments and changes.
>
Few comments and suggestions:
==========================
1.
/*
+ * For updates, if both the new tuple and old tuple are not null, then both
+ * of them need to be checked against the row filter.
+ */
+ tmp_new_slot = new_slot;
+ slot_getallattrs(new_slot);
+ slot_getallattrs(old_slot);
+
Isn't it better to add assert like
Assert(map_changetype_pubaction[*action] == PUBACTION_UPDATE); before
the above code? I have tried to change this part of the code in the
attached top-up patch.
2.
+ /*
+ * For updates, if both the new tuple and old tuple are not null, then both
+ * of them need to be checked against the row filter.
+ */
+ tmp_new_slot = new_slot;
+ slot_getallattrs(new_slot);
+ slot_getallattrs(old_slot);
+
+ /*
+ * The new tuple might not have all the replica identity columns, in which
+ * case it needs to be copied over from the old tuple.
+ */
+ for (i = 0; i < desc->natts; i++)
+ {
+ Form_pg_attribute att = TupleDescAttr(desc, i);
+
+ /*
+ * if the column in the new tuple or old tuple is null, nothing to do
+ */
+ if (tmp_new_slot->tts_isnull[i] || old_slot->tts_isnull[i])
+ continue;
+
+ /*
+ * Unchanged toasted replica identity columns are only detoasted in the
+ * old tuple, copy this over to the new tuple.
+ */
+ if (att->attlen == -1 &&
+ VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i]) &&
+ !VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))
+ {
+ if (tmp_new_slot == new_slot)
+ {
+ tmp_new_slot = MakeSingleTupleTableSlot(desc, &TTSOpsVirtual);
+ ExecClearTuple(tmp_new_slot);
+ ExecCopySlot(tmp_new_slot, new_slot);
+ }
+
+ tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
+ tmp_new_slot->tts_isnull[i] = old_slot->tts_isnull[i];
+ }
+ }
What is the need to assign new_slot to tmp_new_slot at the beginning
of this part of the code? Can't we do this when we found some
attribute that needs to be copied from the old tuple?
The other part which is not clear to me by looking at this code and
comments is how do we ensure that we cover all cases where the new
tuple doesn't have values?
Attached top-up patch with some minor changes. Kindly review.
--
With Regards,
Amit Kapila.
Вложения
On Thu, Jan 20, 2022 9:13 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > Attach the V68 patch set which addressed the above comments and changes. > The version patch also fix the error message mentioned by Greg[1] > I saw a problem about this patch, which is related to Replica Identity check. For example: -- publisher -- create table tbl (a int); create publication pub for table tbl where (a>10) with (publish='delete'); insert into tbl values (1); update tbl set a=a+1; postgres=# update tbl set a=a+1; ERROR: cannot update table "tbl" DETAIL: Column "a" used in the publication WHERE expression is not part of the replica identity. I think it shouldn't report the error because the publication didn't publish UPDATES. Thoughts? Regards, Tang
On Thu, Jan 20, 2022 at 5:03 PM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> wrote: > > On Thu, Jan 20, 2022 9:13 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the V68 patch set which addressed the above comments and changes. > > The version patch also fix the error message mentioned by Greg[1] > > > > I saw a problem about this patch, which is related to Replica Identity check. > > For example: > -- publisher -- > create table tbl (a int); > create publication pub for table tbl where (a>10) with (publish='delete'); > insert into tbl values (1); > update tbl set a=a+1; > > postgres=# update tbl set a=a+1; > ERROR: cannot update table "tbl" > DETAIL: Column "a" used in the publication WHERE expression is not part of the replica identity. > > I think it shouldn't report the error because the publication didn't publish UPDATES. > Right, I also don't see any reason why an error should be thrown in this case. The problem here is that the patch doesn't have any correspondence between the pubaction and RI column validation for a particular publication. I think we need to do that and cache that information unless the publication publishes both updates and deletes in which case it is okay to directly return invalid column in row filter as we are doing now. -- With Regards, Amit Kapila.
I was skimming this and the changes in CheckCmdReplicaIdentity caught my attention. "Is this code running at the publisher side or the subscriber side?" I wondered -- because the new error messages being added look intended to be thrown at the publisher side; but the existing error messages appear intended for the subscriber side. Apparently there is one caller at the publisher side (CheckValidResultRel) and three callers at the subscriber side. I'm not fully convinced that this is a problem, but I think it's not great to have it that way. Maybe it's okay with the current coding, but after this patch adds this new errors it is definitely weird. Maybe it should split in two routines, and document more explicitly which is one is for which side. And while wondering about that, I stumbled upon GetRelationPublicationActions(), which has a very weird API that it always returns a palloc'ed block -- but without saying so. And therefore, its only caller leaks that memory. Maybe not critical, but it looks ugly. I mean, if we're always going to do a memcpy, why not use a caller-supplied stack-allocated memory? Sounds like it'd be simpler. And the actual reason I was looking at this code, is that I had stumbled upon the new GetRelationPublicationInfo() function, which has an even weirder API: > * Get the publication information for the given relation. > * > * Traverse all the publications which the relation is in to get the > * publication actions and validate the row filter expressions for such > * publications if any. We consider the row filter expression as invalid if it > * references any column which is not part of REPLICA IDENTITY. > * > * To avoid fetching the publication information, we cache the publication > * actions and row filter validation information. > * > * Returns the column number of an invalid column referenced in a row filter > * expression if any, InvalidAttrNumber otherwise. > */ > AttrNumber > GetRelationPublicationInfo(Relation relation, bool validate_rowfilter) "Returns *an* invalid column referenced in a RF if any"? That sounds very strange. And exactly what info is it getting, given that there is no actual returned info? Maybe this was meant to be "validate RF expressions" and return, perhaps, a bitmapset of all invalid columns referenced? (What is an invalid column in the first place?) In many function comments you see things like "Check, if foo is bar" or "Returns true, if blah". These commas there needs to be removed. Thanks -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/ "I dream about dreams about dreams", sang the nightingale under the pale moon (Sandman)
On Thu, Jan 20, 2022 at 6:43 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > And the actual reason I was looking at this code, is that I had stumbled > upon the new GetRelationPublicationInfo() function, which has an even > weirder API: > > > * Get the publication information for the given relation. > > * > > * Traverse all the publications which the relation is in to get the > > * publication actions and validate the row filter expressions for such > > * publications if any. We consider the row filter expression as invalid if it > > * references any column which is not part of REPLICA IDENTITY. > > * > > * To avoid fetching the publication information, we cache the publication > > * actions and row filter validation information. > > * > > * Returns the column number of an invalid column referenced in a row filter > > * expression if any, InvalidAttrNumber otherwise. > > */ > > AttrNumber > > GetRelationPublicationInfo(Relation relation, bool validate_rowfilter) > > "Returns *an* invalid column referenced in a RF if any"? That sounds > very strange. And exactly what info is it getting, given that there is > no actual returned info? > It returns an invalid column referenced in an RF if any but if not then it helps to form pubactions which is anyway required at a later point in the caller. The idea is that when we are already traversing publications we should store/gather as much info as possible. I think probably the API name is misleading, maybe we should name it something like ValidateAndFetchPubInfo, ValidateAndRememberPubInfo, or something along these lines? > Maybe this was meant to be "validate RF > expressions" and return, perhaps, a bitmapset of all invalid columns > referenced? > Currently, we stop as soon as we find the first invalid column. > (What is an invalid column in the first place?) > A column that is referenced in the row filter but is not part of Replica Identity. -- With Regards, Amit Kapila.
On 2022-Jan-20, Amit Kapila wrote: > It returns an invalid column referenced in an RF if any but if not > then it helps to form pubactions which is anyway required at a later > point in the caller. The idea is that when we are already traversing > publications we should store/gather as much info as possible. I think this design isn't quite awesome. > I think probably the API name is misleading, maybe we should name it > something like ValidateAndFetchPubInfo, ValidateAndRememberPubInfo, or > something along these lines? Maybe RelationBuildReplicationPublicationDesc or just RelationBuildPublicationDesc are good names for a routine that fill in the publication aspect of the relcache entry, as a parallel to RelationBuildPartitionDesc. > > Maybe this was meant to be "validate RF > > expressions" and return, perhaps, a bitmapset of all invalid columns > > referenced? > > Currently, we stop as soon as we find the first invalid column. That seems quite strange. (And above you say "gather as much info as possible", so why stop at the first one?) > > (What is an invalid column in the first place?) > > A column that is referenced in the row filter but is not part of > Replica Identity. I do wonder how do these invalid columns reach the table definition in the first place. Shouldn't these be detected at DDL time and prohibited from getting into the definition? ... so if I do ADD TABLE foobar WHERE (col_not_in_replident = 42) then I should get an error immediately, rather than be forced to construct a relcache entry with "invalid" data in it. Likewise if I change the replica identity to one that causes one of these to be invalid. Isn't this the same approach we discussed for column filtering? -- Álvaro Herrera Valdivia, Chile — https://www.EnterpriseDB.com/ Voy a acabar con todos los humanos / con los humanos yo acabaré voy a acabar con todos (bis) / con todos los humanos acabaré ¡acabaré! (Bender)
On Fri, Jan 21, 2022 at 12:13 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
>
> And while wondering about that, I stumbled upon
> GetRelationPublicationActions(), which has a very weird API that it
> always returns a palloc'ed block -- but without saying so. And
> therefore, its only caller leaks that memory. Maybe not critical, but
> it looks ugly. I mean, if we're always going to do a memcpy, why not
> use a caller-supplied stack-allocated memory? Sounds like it'd be
> simpler.
>
+1
This issue exists on HEAD (i.e. was not introduced by the row filtering patch) and was already discussed on another thread ([1]) on which I posted a patch to correct the issue along the same lines that you're suggesting.
[1] https://postgr.es/m/CAJcOf-d0%3DvQx1Pzbf%2BLVarywejJFS5W%2BM6uR%2B2d0oeEJ2VQ%2BEw%40mail.gmail.com
Regards,
Greg Nancarrow
Fujitsu Australia
On Thu, Jan 20, 2022 at 7:56 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > Maybe this was meant to be "validate RF > > > expressions" and return, perhaps, a bitmapset of all invalid columns > > > referenced? > > > > Currently, we stop as soon as we find the first invalid column. > > That seems quite strange. (And above you say "gather as much info as > possible", so why stop at the first one?) > Because that is an error case, so, there doesn't seem to be any benefit in proceeding further. However, we can build all the required information by processing all publications (aka gather all information) and then later give an error if that idea appeals to you more. > > > (What is an invalid column in the first place?) > > > > A column that is referenced in the row filter but is not part of > > Replica Identity. > > I do wonder how do these invalid columns reach the table definition in > the first place. Shouldn't these be detected at DDL time and prohibited > from getting into the definition? > As mentioned by Peter E [1], there are two ways to deal with this: (a) The current approach is that the user can set the replica identity freely, and we decide later based on that what we can replicate (e.g., no updates). If we follow the same approach for this patch, we don't restrict what columns are part of the row filter, but we check what actions we can replicate based on the row filter. This is what is currently followed in the patch. (b) Add restrictions during DDL which is not as straightforward as it looks. For approach (b), we need to restrict quite a few DDLs like DROP INDEX/DROP PRIMARY/ALTER REPLICA IDENTITY/ATTACH PARTITION/CREATE TABLE PARTITION OF/ALTER PUBLICATION SET(publish='update')/ALTER PUBLICATION SET(publish_via_root), etc. We need to deal with partition table cases because newly added partitions automatically become part of publication if any of its ancestor tables is part of the publication. Now consider the case where the user needs to use CREATE TABLE PARTITION OF. The problem is that the user cannot specify the Replica Identity using an index when creating the table so we can't validate and it will lead to errors during replication if the parent table is published with a row filter. [1] - https://www.postgresql.org/message-id/2d6c8b74-bdef-767b-bdb6-29705985ed9c%40enterprisedb.com -- With Regards, Amit Kapila.
On Thursday, January 20, 2022 9:14 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I was skimming this and the changes in CheckCmdReplicaIdentity caught my > attention. "Is this code running at the publisher side or the subscriber side?" I > wondered -- because the new error messages being added look intended to > be thrown at the publisher side; but the existing error messages appear > intended for the subscriber side. Apparently there is one caller at the > publisher side (CheckValidResultRel) and three callers at the subscriber side. > I'm not fully convinced that this is a problem, but I think it's not great to have it > that way. Maybe it's okay with the current coding, but after this patch adds > this new errors it is definitely weird. Maybe it should split in two routines, and > document more explicitly which is one is for which side. I think the existing CheckCmdReplicaIdentity is intended to run at the publisher side. Although the CheckCmdReplicaIdentity is invoked in ExecSimpleRelationInsert which is at subscriber side, but I think that's because the subscriber side could be a publisher as well which need to check the RI. So, the new error message in the patch is consistent with the existing error message. (all for publisher sider) Best regards, Hou zj
On Thur, Jan 20, 2022 10:26 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2022-Jan-20, Amit Kapila wrote: > > > It returns an invalid column referenced in an RF if any but if not > > then it helps to form pubactions which is anyway required at a later > > point in the caller. The idea is that when we are already traversing > > publications we should store/gather as much info as possible. > > I think this design isn't quite awesome. > > > I think probably the API name is misleading, maybe we should name it > > something like ValidateAndFetchPubInfo, ValidateAndRememberPubInfo, or > > something along these lines? > > Maybe RelationBuildReplicationPublicationDesc or just > RelationBuildPublicationDesc are good names for a routine that fill in > the publication aspect of the relcache entry, as a parallel to > RelationBuildPartitionDesc. > > > > Maybe this was meant to be "validate RF > > > expressions" and return, perhaps, a bitmapset of all invalid columns > > > referenced? > > > > Currently, we stop as soon as we find the first invalid column. > > That seems quite strange. (And above you say "gather as much info as > possible", so why stop at the first one?) > > > > (What is an invalid column in the first place?) > > > > A column that is referenced in the row filter but is not part of > > Replica Identity. > > I do wonder how do these invalid columns reach the table definition in > the first place. Shouldn't these be detected at DDL time and prohibited > from getting into the definition? Personally, I'm a little hesitant to put the check at DDL level, because adding check at DDLs like ATTACH PARTITION/CREATE PARTITION OF ( [1] explained why we need to check these DDLs) looks a bit restrictive and user might also complain about that. Put the check in CheckCmdReplicaIdentity seems more acceptable because it is consistent with the existing behavior which has few complaints from users AFAIK. [1] https://www.postgresql.org/message-id/CAA4eK1%2Bm45Xyzx7AUY9TyFnB6CZ7_%2B_uooPb7WHSpp7UE%3DYmKg%40mail.gmail.com Best regards, Hou zj
On Thu, Jan 20, 2022 at 12:12 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the V68 patch set which addressed the above comments and changes. > The version patch also fix the error message mentioned by Greg[1] > Some review comments for the v68 patch, mostly nitpicking: (1) Commit message Minor suggested updates: BEFORE: Allow specifying row filter for logical replication of tables. AFTER: Allow specifying row filters for logical replication of tables. BEFORE: If you choose to do the initial table synchronization, only data that satisfies the row filters is pulled by the subscriber. AFTER: If you choose to do the initial table synchronization, only data that satisfies the row filters is copied to the subscriber. src/backend/executor/execReplication.c (2) BEFORE: + * table does not publish UPDATES or DELETES. AFTER: + * table does not publish UPDATEs or DELETEs. src/backend/replication/pgoutput/pgoutput.c (3) pgoutput_row_filter_exec_expr pgoutput_row_filter_exec_expr() returns false if "isnull" is true, otherwise (if "isnull" is false) returns the value of "ret" (true/false). So the following elog needs to be changed (Peter Smith previously pointed this out, but it didn't get completely changed): BEFORE: + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", + DatumGetBool(ret) ? "true" : "false", + isnull ? "true" : "false"); AFTER: + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", + isnull ? "false" : DatumGetBool(ret) ? "true" : "false", + isnull ? "true" : "false"); (4) pgoutput_row_filter_init BEFORE: + * we don't know yet if there is/isn't any row filters for this relation. AFTER: + * we don't know yet if there are/aren't any row filters for this relation. BEFORE: + * necessary at all. This avoids us to consume memory and spend CPU cycles + * when we don't need to. AFTER: + * necessary at all. So this allows us to avoid unnecessary memory + * consumption and CPU cycles. (5) pgoutput_row_filter BEFORE: + * evaluates the row filter for that tuple and return. AFTER: + * evaluate the row filter for that tuple and return. Regards, Greg Nancarrow Fujitsu Australia
On Thursday, January 20, 2022 8:53 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 20, 2022 at 5:03 PM tanghy.fnst@fujitsu.com > <tanghy.fnst@fujitsu.com> wrote: > > > > On Thu, Jan 20, 2022 9:13 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > Attach the V68 patch set which addressed the above comments and > changes. > > > The version patch also fix the error message mentioned by Greg[1] > > > > > > > I saw a problem about this patch, which is related to Replica Identity check. > > > > For example: > > -- publisher -- > > create table tbl (a int); > > create publication pub for table tbl where (a>10) with (publish='delete'); > > insert into tbl values (1); > > update tbl set a=a+1; > > > > postgres=# update tbl set a=a+1; > > ERROR: cannot update table "tbl" > > DETAIL: Column "a" used in the publication WHERE expression is not part of > the replica identity. > > > > I think it shouldn't report the error because the publication didn't publish > UPDATES. > > > > Right, I also don't see any reason why an error should be thrown in > this case. The problem here is that the patch doesn't have any > correspondence between the pubaction and RI column validation for a > particular publication. I think we need to do that and cache that > information unless the publication publishes both updates and deletes > in which case it is okay to directly return invalid column in row > filter as we are doing now. Attach the v69 patch set which fix this. The new version patch also addressed comments from Peter[1] and Amit[2]. I also added some testcases about partitioned table in the 027_row_filter.pl. Note that the comments from Alvaro[3] haven't been addressed because the discussion is still going on, I will address those comments soon. [1] https://www.postgresql.org/message-id/CAHut%2BPtUiaYaihtw6_SmqbwEBXtw6ryc7F%3DVEQkK%3D7HW18dGVg%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAA4eK1JzKYBC5Aos9QncZ%2BJksMLmZjpCcDmBJZQ1qC74AYggNg%40mail.gmail.com [3] https://www.postgresql.org/message-id/202201201313.zaceiqi4qb6h%40alvherre.pgsql Best regards, Hou zj
Вложения
On Thur, Jan 20, 2022 7:25 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Jan 20, 2022 at 6:42 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > Attach the V68 patch set which addressed the above comments and changes.
> >
>
> Few comments and suggestions:
> ==========================
> 1.
> /*
> + * For updates, if both the new tuple and old tuple are not null, then both
> + * of them need to be checked against the row filter.
> + */
> + tmp_new_slot = new_slot;
> + slot_getallattrs(new_slot);
> + slot_getallattrs(old_slot);
> +
>
> Isn't it better to add assert like
> Assert(map_changetype_pubaction[*action] == PUBACTION_UPDATE); before
> the above code? I have tried to change this part of the code in the
> attached top-up patch.
>
> 2.
> + /*
> + * For updates, if both the new tuple and old tuple are not null, then both
> + * of them need to be checked against the row filter.
> + */
> + tmp_new_slot = new_slot;
> + slot_getallattrs(new_slot);
> + slot_getallattrs(old_slot);
> +
> + /*
> + * The new tuple might not have all the replica identity columns, in which
> + * case it needs to be copied over from the old tuple.
> + */
> + for (i = 0; i < desc->natts; i++)
> + {
> + Form_pg_attribute att = TupleDescAttr(desc, i);
> +
> + /*
> + * if the column in the new tuple or old tuple is null, nothing to do
> + */
> + if (tmp_new_slot->tts_isnull[i] || old_slot->tts_isnull[i])
> + continue;
> +
> + /*
> + * Unchanged toasted replica identity columns are only detoasted in the
> + * old tuple, copy this over to the new tuple.
> + */
> + if (att->attlen == -1 &&
> + VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i]) &&
> + !VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))
> + {
> + if (tmp_new_slot == new_slot)
> + {
> + tmp_new_slot = MakeSingleTupleTableSlot(desc, &TTSOpsVirtual);
> + ExecClearTuple(tmp_new_slot);
> + ExecCopySlot(tmp_new_slot, new_slot);
> + }
> +
> + tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
> + tmp_new_slot->tts_isnull[i] = old_slot->tts_isnull[i];
> + }
> + }
>
>
> What is the need to assign new_slot to tmp_new_slot at the beginning
> of this part of the code? Can't we do this when we found some
> attribute that needs to be copied from the old tuple?
Thanks for the comments, Changed.
> The other part which is not clear to me by looking at this code and
> comments is how do we ensure that we cover all cases where the new
> tuple doesn't have values?
I will do some research about this and respond soon.
Best regards,
Hou zj
On Thu, Jan 20, 2022 at 4:54 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
+ /*
+ * Unchanged toasted replica identity columns are only detoasted in the
+ * old tuple, copy this over to the new tuple.
+ */
+ if (att->attlen == -1 &&
+ VARATT_IS_EXTERNAL_ONDISK(tmp_new_slot->tts_values[i]) &&
+ !VARATT_IS_EXTERNAL_ONDISK(old_slot->tts_values[i]))
+ {
+ if (tmp_new_slot == new_slot)
+ {
+ tmp_new_slot = MakeSingleTupleTableSlot(desc, &TTSOpsVirtual);
+ ExecClearTuple(tmp_new_slot);
+ ExecCopySlot(tmp_new_slot, new_slot);
+ }
+
+ tmp_new_slot->tts_values[i] = old_slot->tts_values[i];
+ tmp_new_slot->tts_isnull[i] = old_slot->tts_isnull[i];
+ }
+ }
What is the need to assign new_slot to tmp_new_slot at the beginning
of this part of the code? Can't we do this when we found some
attribute that needs to be copied from the old tuple?
The other part which is not clear to me by looking at this code and
comments is how do we ensure that we cover all cases where the new
tuple doesn't have values?
IMHO, the only part we are trying to handle is when the toasted attribute is not modified in the new tuple. And if we notice the update WAL the new tuple is written as it is in the WAL which is getting inserted into the heap page. That means if it is external it can only be in
VARATT_IS_EXTERNAL_ONDISK format. So I don't think we need to worry about any intermediate format which we use for the in-memory tuples. Sometimes in reorder buffer we do use the INDIRECT format as well which internally can store ON DISK format but we don't need to worry about that case either because that is only true when we have the complete toast tuple as part of the WAL and we recreate the tuple in memory in reorder buffer, so even if it can by ON DISK format inside INDIRECT format but we have complete tuple.
On 2022-Jan-21, houzj.fnst@fujitsu.com wrote: > Personally, I'm a little hesitant to put the check at DDL level, because > adding check at DDLs like ATTACH PARTITION/CREATE PARTITION OF ( [1] > explained why we need to check these DDLs) looks a bit restrictive and > user might also complain about that. Put the check in > CheckCmdReplicaIdentity seems more acceptable because it is consistent > with the existing behavior which has few complaints from users AFAIK. I think logical replication is currently so limited that there's very few people that can put it to real use. So I suggest we should not take the small number of complaints about the current behavior as very valuable, because it just means that not a lot of people are using logical replication in the first place. But once these new functionalities are introduced, it will start to become actually useful and it will be then when users will exercise and notice weird behavior. If ATTACH PARTITION or CREATE TABLE .. PARTITION OF don't let you specify replica identity, I suspect it's because both partitioning and logical replication were developed in parallel, and neither gave too much thought to the other. So these syntax corners went unnoticed. I suspect that a better way to attack this problem is to let ALTER TABLE ... ATTACH PARTITION and CREATE TABLE .. PARTITION OF specify a replica identity as necessary. My suggestion is to avoid painting us into a corner from which it will be impossible to get out later. -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/ "La espina, desde que nace, ya pincha" (Proverbio africano)
On Fri, Jan 21, 2022 at 8:19 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > If ATTACH PARTITION or CREATE TABLE .. PARTITION OF don't let you > specify replica identity, I suspect it's because both partitioning and > logical replication were developed in parallel, and neither gave too > much thought to the other. > I think the reason CREATE TABLE .. syntax form doesn't have a way to specify RI is that we need to have an index for RI. Consider the below example: ---- CREATE TABLE parent (a int primary key, b int not null, c varchar) PARTITION BY RANGE(a); CREATE TABLE child PARTITION OF parent FOR VALUES FROM (0) TO (250); CREATE UNIQUE INDEX b_index on child(b); ALTER TABLE child REPLICA IDENTITY using INDEX b_index; ---- In this, the parent table's replica identity is the primary key(default) and the child table's replica identity is the b_index. I think if we want we can come up with some syntax to combine these steps and allow to specify replica identity during the second step (Create ... Partition) but not sure if we have a convincing reason for this feature per se. > > I suspect that a better way to attack this problem is to let ALTER TABLE > ... ATTACH PARTITION and CREATE TABLE .. PARTITION OF specify a replica > identity as necessary. > > My suggestion is to avoid painting us into a corner from which it will > be impossible to get out later. > Apart from the above reason, here we are just following the current model of how the update/delete behaves w.r.t RI. Now, I think in the future we can also think of uplifting some of the restrictions related to RI for filters if we find a good way to have columns values that are not in WAL. We have discussed this previously in this thread and thought that it is sensible to have a RI restriction for updates/deletes as the patch is doing for the first version. I am not against inventing some new syntaxes for row/column filter patches but there doesn't seem to be a very convincing reason for it and there is a good chance that we won't be able to accomplish that for the current version. -- With Regards, Amit Kapila.
On 2022-Jan-22, Amit Kapila wrote: > CREATE TABLE parent (a int primary key, b int not null, c varchar) > PARTITION BY RANGE(a); > CREATE TABLE child PARTITION OF parent FOR VALUES FROM (0) TO (250); > CREATE UNIQUE INDEX b_index on child(b); > ALTER TABLE child REPLICA IDENTITY using INDEX b_index; > > In this, the parent table's replica identity is the primary > key(default) and the child table's replica identity is the b_index. Why is the partition's replica identity different from its parent's? Does that even make sense? -- Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/ "La verdad no siempre es bonita, pero el hambre de ella sí"
FYI - I noticed the cfbot is reporting a failed test case [1] for the latest v69 patch set. [21:09:32.183] # Failed test 'check replicated inserts on subscriber' [21:09:32.183] # at t/025_rep_changes_for_schema.pl line 202. [21:09:32.183] # got: '21|1|2139062143' [21:09:32.183] # expected: '21|1|21' [21:09:32.183] # Looks like you failed 1 test of 13. [21:09:32.183] [21:08:49] t/025_rep_changes_for_schema.pl .... ------ [1] https://cirrus-ci.com/task/6280873841524736?logs=test_world#L3970 Kind Regards, Peter Smith. Fujitsu Australia
On Sat, Jan 22, 2022 at 8:45 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2022-Jan-22, Amit Kapila wrote: > > > CREATE TABLE parent (a int primary key, b int not null, c varchar) > > PARTITION BY RANGE(a); > > CREATE TABLE child PARTITION OF parent FOR VALUES FROM (0) TO (250); > > CREATE UNIQUE INDEX b_index on child(b); > > ALTER TABLE child REPLICA IDENTITY using INDEX b_index; > > > > In this, the parent table's replica identity is the primary > > key(default) and the child table's replica identity is the b_index. > > Why is the partition's replica identity different from its parent's? > Does that even make sense? > Parent's RI doesn't matter as we always use a child's RI, so one may decide not to have RI for a parent. Also, when replicating, the user might have set up the partitioned table on the publisher-side and non-partitioned tables on the subscriber-side in which case also there could be different RI keys on child tables. -- With Regards, Amit Kapila.
On Fri, Jan 21, 2022 at 2:56 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Thu, Jan 20, 2022 at 12:12 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > (3) pgoutput_row_filter_exec_expr > pgoutput_row_filter_exec_expr() returns false if "isnull" is true, > otherwise (if "isnull" is false) returns the value of "ret" > (true/false). > So the following elog needs to be changed (Peter Smith previously > pointed this out, but it didn't get completely changed): > > BEFORE: > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > + DatumGetBool(ret) ? "true" : "false", > + isnull ? "true" : "false"); > AFTER: > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > + isnull ? "false" : DatumGetBool(ret) ? "true" : "false", > + isnull ? "true" : "false"); > Do you see any problem with the current? I find the current one easy to understand. -- With Regards, Amit Kapila.
On Mon, Jan 24, 2022 at 2:47 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> > (3) pgoutput_row_filter_exec_expr
> > pgoutput_row_filter_exec_expr() returns false if "isnull" is true,
> > otherwise (if "isnull" is false) returns the value of "ret"
> > (true/false).
> > So the following elog needs to be changed (Peter Smith previously
> > pointed this out, but it didn't get completely changed):
> >
> > BEFORE:
> > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
> > + DatumGetBool(ret) ? "true" : "false",
> > + isnull ? "true" : "false");
> > AFTER:
> > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)",
> > + isnull ? "false" : DatumGetBool(ret) ? "true" : "false",
> > + isnull ? "true" : "false");
> >
>
> Do you see any problem with the current? I find the current one easy
> to understand.
>
Yes, I see a problem. The logging doesn't match what the function code
actually returns when "isnull" is true.
When "isnull" is true, the function always returns false, not the
value of "ret".
For the current logging code to be correct, and match the function
return value, we should be able to change:
if (isnull)
return false;
to:
if (isnull)
return ret;
But regression tests fail when that code change is made (indicating
that there are cases when "isnull" is true but the function returns
true instead of false).
So the current logging code is NOT correct, and needs to be updated as
I indicated.
Regards,
Greg Nancarrow
Fujitsu Australia
On Mon, Jan 24, 2022 at 8:36 AM Peter Smith <smithpb2250@gmail.com> wrote: > > FYI - I noticed the cfbot is reporting a failed test case [1] for the > latest v69 patch set. > > [21:09:32.183] # Failed test 'check replicated inserts on subscriber' > [21:09:32.183] # at t/025_rep_changes_for_schema.pl line 202. > [21:09:32.183] # got: '21|1|2139062143' > [21:09:32.183] # expected: '21|1|21' > [21:09:32.183] # Looks like you failed 1 test of 13. > [21:09:32.183] [21:08:49] t/025_rep_changes_for_schema.pl .... > > ------ > [1] https://cirrus-ci.com/task/6280873841524736?logs=test_world#L3970 > 2139062143 is 0x7F7F7F7F, so it looks like a value from uninitialized memory (debug build) has been copied into the column, or something similar involving uninitialized memory. The problem is occurring on FreeBSD. I tried using similar build flags as that test environment, but couldn't reproduce the issue. Regards, Greg Nancarrow Fujitsu Australia
On Fri, Jan 21, 2022 at 2:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Jan 20, 2022 at 7:56 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > > > Maybe this was meant to be "validate RF > > > > expressions" and return, perhaps, a bitmapset of all invalid columns > > > > referenced? > > > > > > Currently, we stop as soon as we find the first invalid column. > > > > That seems quite strange. (And above you say "gather as much info as > > possible", so why stop at the first one?) > > > > Because that is an error case, so, there doesn't seem to be any > benefit in proceeding further. However, we can build all the required > information by processing all publications (aka gather all > information) and then later give an error if that idea appeals to you > more. > > > > > (What is an invalid column in the first place?) > > > > > > A column that is referenced in the row filter but is not part of > > > Replica Identity. > > > > I do wonder how do these invalid columns reach the table definition in > > the first place. Shouldn't these be detected at DDL time and prohibited > > from getting into the definition? > > > > As mentioned by Peter E [1], there are two ways to deal with this: (a) > The current approach is that the user can set the replica identity > freely, and we decide later based on that what we can replicate (e.g., > no updates). If we follow the same approach for this patch, we don't > restrict what columns are part of the row filter, but we check what > actions we can replicate based on the row filter. This is what is > currently followed in the patch. (b) Add restrictions during DDL which > is not as straightforward as it looks. FYI - I also wanted to highlight that doing the replica identity validation at update/delete time is not only following the "current approach", as mentioned above, but this is also consistent with the *documented* behaviour in PG docs (See [1] since PG v10), <QUOTE> If a table without a replica identity is added to a publication that replicates UPDATE or DELETE operations then subsequent UPDATE or DELETE operations will cause an error on the publisher. </QUOTE> Specifically, It does *not* say that the RI validation error will happen when a table is added to the publication at CREATE/ALTER PUBLICATION time. It says that *subsequent* "UPDATE or DELETE operations will cause an error". ~~ The point is that it is one thing to decide to change something that was never officially documented, but to change already *documented* behaviour is much more radical and has the potential to upset some users. ------ [1] https://www.postgresql.org/docs/devel/logical-replication-publication. Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Jan 24, 2022 at 4:53 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Jan 21, 2022 at 2:04 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Thu, Jan 20, 2022 at 7:56 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > > > > > Maybe this was meant to be "validate RF > > > > > expressions" and return, perhaps, a bitmapset of all invalid columns > > > > > referenced? > > > > > > > > Currently, we stop as soon as we find the first invalid column. > > > > > > That seems quite strange. (And above you say "gather as much info as > > > possible", so why stop at the first one?) > > > > > > > Because that is an error case, so, there doesn't seem to be any > > benefit in proceeding further. However, we can build all the required > > information by processing all publications (aka gather all > > information) and then later give an error if that idea appeals to you > > more. > > > > > > > (What is an invalid column in the first place?) > > > > > > > > A column that is referenced in the row filter but is not part of > > > > Replica Identity. > > > > > > I do wonder how do these invalid columns reach the table definition in > > > the first place. Shouldn't these be detected at DDL time and prohibited > > > from getting into the definition? > > > > > > > As mentioned by Peter E [1], there are two ways to deal with this: (a) > > The current approach is that the user can set the replica identity > > freely, and we decide later based on that what we can replicate (e.g., > > no updates). If we follow the same approach for this patch, we don't > > restrict what columns are part of the row filter, but we check what > > actions we can replicate based on the row filter. This is what is > > currently followed in the patch. (b) Add restrictions during DDL which > > is not as straightforward as it looks. > > FYI - I also wanted to highlight that doing the replica identity > validation at update/delete time is not only following the "current > approach", as mentioned above, but this is also consistent with the > *documented* behaviour in PG docs (See [1] since PG v10), > > <QUOTE> > If a table without a replica identity is added to a publication that > replicates UPDATE or DELETE operations then subsequent UPDATE or > DELETE operations will cause an error on the publisher. > </QUOTE> > > Specifically, > > It does *not* say that the RI validation error will happen when a > table is added to the publication at CREATE/ALTER PUBLICATION time. > > It says that *subsequent* "UPDATE or DELETE operations will cause an error". > > ~~ > > The point is that it is one thing to decide to change something that > was never officially documented, but to change already *documented* > behaviour is much more radical and has the potential to upset some > users. > > ------ (Sorry, fixed the broken link of the previous post) [1] https://www.postgresql.org/docs/current/logical-replication-publication.html ------ Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Jan 24, 2022 at 10:29 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Mon, Jan 24, 2022 at 2:47 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > (3) pgoutput_row_filter_exec_expr > > > pgoutput_row_filter_exec_expr() returns false if "isnull" is true, > > > otherwise (if "isnull" is false) returns the value of "ret" > > > (true/false). > > > So the following elog needs to be changed (Peter Smith previously > > > pointed this out, but it didn't get completely changed): > > > > > > BEFORE: > > > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > > > + DatumGetBool(ret) ? "true" : "false", > > > + isnull ? "true" : "false"); > > > AFTER: > > > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > > > + isnull ? "false" : DatumGetBool(ret) ? "true" : "false", > > > + isnull ? "true" : "false"); > > > > > > > Do you see any problem with the current? I find the current one easy > > to understand. > > > > Yes, I see a problem. > I tried by inserting NULL value in a column having row filter and the result it shows is: LOG: row filter evaluates to false (isnull: true) This is what is expected. > > But regression tests fail when that code change is made (indicating > that there are cases when "isnull" is true but the function returns > true instead of false). > But that is not what I am seeing in Logs with a test case where the row filter column has NULL values. Could you please try that see what is printed in LOG? You can change the code to make the elevel as LOG to get the results easily. The test case I tried is as follows: Node-1: postgres=# create table t1(c1 int, c2 int); CREATE TABLE postgres=# create publication pub for table t1 WHERE (c1 > 10); CREATE PUBLICATION Node-2: postgres=# create table t1(c1 int, c2 int); CREATE TABLE postgres=# create subscription sub connection 'dbname=postgres' publication pub; NOTICE: created replication slot "sub" on publisher CREATE SUBSCRIPTION After this on publisher-node, I see the LOG as "LOG: row filter evaluates to false (isnull: true)". I have verified that in the code as well (in slot_deform_heap_tuple), we set the value as 0 for isnull which matches above observation. -- With Regards, Amit Kapila.
On Mon, Jan 24, 2022 at 5:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jan 24, 2022 at 10:29 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > On Mon, Jan 24, 2022 at 2:47 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > > (3) pgoutput_row_filter_exec_expr > > > > pgoutput_row_filter_exec_expr() returns false if "isnull" is true, > > > > otherwise (if "isnull" is false) returns the value of "ret" > > > > (true/false). > > > > So the following elog needs to be changed (Peter Smith previously > > > > pointed this out, but it didn't get completely changed): > > > > > > > > BEFORE: > > > > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > > > > + DatumGetBool(ret) ? "true" : "false", > > > > + isnull ? "true" : "false"); > > > > AFTER: > > > > + elog(DEBUG3, "row filter evaluates to %s (isnull: %s)", > > > > + isnull ? "false" : DatumGetBool(ret) ? "true" : "false", > > > > + isnull ? "true" : "false"); > > > > > > > > > > Do you see any problem with the current? I find the current one easy > > > to understand. > > > > > > > Yes, I see a problem. > > > > I tried by inserting NULL value in a column having row filter and the > result it shows is: > > LOG: row filter evaluates to false (isnull: true) > > This is what is expected. > > > > > But regression tests fail when that code change is made (indicating > > that there are cases when "isnull" is true but the function returns > > true instead of false). > > > > But that is not what I am seeing in Logs with a test case where the > row filter column has NULL values. Could you please try that see what > is printed in LOG? > > You can change the code to make the elevel as LOG to get the results > easily. The test case I tried is as follows: > Node-1: > postgres=# create table t1(c1 int, c2 int); > CREATE TABLE > postgres=# create publication pub for table t1 WHERE (c1 > 10); > CREATE PUBLICATION > > Node-2: > postgres=# create table t1(c1 int, c2 int); > CREATE TABLE > postgres=# create subscription sub connection 'dbname=postgres' publication pub; > NOTICE: created replication slot "sub" on publisher > CREATE SUBSCRIPTION > > After this on publisher-node, I see the LOG as "LOG: row filter > evaluates to false (isnull: true)". I have verified that in the code > as well (in slot_deform_heap_tuple), we set the value as 0 for isnull > which matches above observation. > There are obviously multiple code paths under which a column can end up as NULL. Doing one NULL-column test case, and finding here that "DatumGetBool(ret)" is "false" when "isnull" is true, doesn't prove it will be like that for ALL possible cases. As I pointed out, the function is meant to always return false when "isnull" is true, so if the current logging code is correct (always logging "DatumGetBool(ret)" as the function return value), then to match the code to the current logging, we should be able to return "DatumGetBool(ret)" if "isnull" is true, instead of returning false as it currently does. But as I said, when I try that then I get a test failure (make check-world), proving that there is a case where "DatumGetBool(ret)" is true when "isnull" is true, and thus showing that the current logging is not correct because in that case the current log output would show the return value is true, which won't match the actual function return value of false. (I also added some extra logging for this isnull==true test failure case and found that ret==1) Regards, Greg Nancarrow Fujitsu Australia
Thanks for all the patches!
Here are my review comments for v69-0001
~~~
1. src/backend/executor/execReplication.c CheckCmdReplicaIdentity
call to RelationBuildPublicationDesc
+ /*
+ * It is only safe to execute UPDATE/DELETE when all columns, referenced in
+ * the row filters from publications which the relation is in, are valid -
+ * i.e. when all referenced columns are part of REPLICA IDENTITY or the
+ * table does not publish UPDATES or DELETES.
+ */
+ pubdesc = RelationBuildPublicationDesc(rel);
This code is leaky because never frees the palloc-ed memory for the pubdesc.
IMO change the RelationBuildPublicationDesc to pass in the
PublicationDesc* from the call stack then can eliminate the palloc and
risk of leaks.
~~~
2. src/include/utils/relcache.h - RelationBuildPublicationDesc
+struct PublicationDesc;
+extern struct PublicationDesc *RelationBuildPublicationDesc(Relation relation);
(Same as the previous comment #1). Suggest to change the function
signature to be void and pass the PublicationDesc* from stack instead
of palloc-ing it within the function
~~~
3. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
+RelationBuildPublicationDesc(Relation relation)
{
List *puboids;
ListCell *lc;
MemoryContext oldcxt;
Oid schemaid;
- PublicationActions *pubactions = palloc0(sizeof(PublicationActions));
+ List *ancestors = NIL;
+ Oid relid = RelationGetRelid(relation);
+ AttrNumber invalid_rfcolnum = InvalidAttrNumber;
+ PublicationDesc *pubdesc = palloc0(sizeof(PublicationDesc));
+ PublicationActions *pubactions = &pubdesc->pubactions;
+
+ pubdesc->rf_valid_for_update = true;
+ pubdesc->rf_valid_for_delete = true;
IMO it wold be better to change the "sense" of those variables.
e.g.
"rf_valid_for_update" --> "rf_invalid_for_update"
"rf_valid_for_delete" --> "rf_invalid_for_delete"
That way they have the same 'sense' as the AttrNumbers so it all reads
better to me.
Also, it means no special assignment is needed because the palloc0
will set them correctly
~~~
4. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
- if (relation->rd_pubactions)
+ if (relation->rd_pubdesc)
{
- pfree(relation->rd_pubactions);
- relation->rd_pubactions = NULL;
+ pfree(relation->rd_pubdesc);
+ relation->rd_pubdesc = NULL;
}
What is the purpose of this code? Can't it all just be removed?
e.g. Can't you Assert that relation->rd_pubdesc is NULL at this point?
(if it was not-null the function would have returned immediately from the top)
~~~
5. src/include/catalog/pg_publication.h - typedef struct PublicationDesc
+typedef struct PublicationDesc
+{
+ /*
+ * true if the columns referenced in row filters which are used for UPDATE
+ * or DELETE are part of the replica identity, or the publication actions
+ * do not include UPDATE or DELETE.
+ */
+ bool rf_valid_for_update;
+ bool rf_valid_for_delete;
+
+ AttrNumber invalid_rfcol_update;
+ AttrNumber invalid_rfcol_delete;
+
+ PublicationActions pubactions;
+} PublicationDesc;
+
I did not see any point really for the pairs of booleans and AttNumbers.
AFAIK both of them shared exactly the same validation logic so I think
you can get by using fewer members here.
e.g. (here I also reversed the sense of the bool flag, as per my suggestion #3)
typedef struct PublicationDesc
{
/*
* true if the columns referenced in row filters which are used for UPDATE
* or DELETE are part of the replica identity, or the publication actions
* do not include UPDATE or DELETE.
*/
bool rf_invalid_for_upd_del;
AttrNumber invalid_rfcol_upd_del;
PublicationActions pubactions;
} PublicationDesc;
~~~
6. src/tools/pgindent/typedefs.list
Missing the new typedef PublicationDesc
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Jan 24, 2022 at 1:19 PM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Mon, Jan 24, 2022 at 5:09 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > But that is not what I am seeing in Logs with a test case where the > > row filter column has NULL values. Could you please try that see what > > is printed in LOG? > > > > You can change the code to make the elevel as LOG to get the results > > easily. The test case I tried is as follows: > > Node-1: > > postgres=# create table t1(c1 int, c2 int); > > CREATE TABLE > > postgres=# create publication pub for table t1 WHERE (c1 > 10); > > CREATE PUBLICATION > > > > Node-2: > > postgres=# create table t1(c1 int, c2 int); > > CREATE TABLE > > postgres=# create subscription sub connection 'dbname=postgres' publication pub; > > NOTICE: created replication slot "sub" on publisher > > CREATE SUBSCRIPTION > > > > After this on publisher-node, I see the LOG as "LOG: row filter > > evaluates to false (isnull: true)". I have verified that in the code > > as well (in slot_deform_heap_tuple), we set the value as 0 for isnull > > which matches above observation. > > > > There are obviously multiple code paths under which a column can end up as NULL. > Doing one NULL-column test case, and finding here that > "DatumGetBool(ret)" is "false" when "isnull" is true, doesn't prove it > will be like that for ALL possible cases. > Sure, I just wanted to see the particular test which leads to failure so that I or others can know (or debug) why in some cases it behaves differently. Anyway, for others, the below test can show the results: CREATE TABLE tab_rowfilter_1 (a int primary key, b text); alter table tab_rowfilter_1 replica identity full ; INSERT INTO tab_rowfilter_1 (a, b) VALUES (1600, 'test 1600'); CREATE PUBLICATION pub FOR TABLE tab_rowfilter_1 WHERE (a > 1000 AND b <> 'filtered'); UPDATE tab_rowfilter_1 SET b = NULL WHERE a = 1600; So, we can change this DEBUG log. -- With Regards, Amit Kapila.
On Monday, January 24, 2022 4:38 PM Peter Smith <smithpb2250@gmail.com> > > Thanks for all the patches! > > Here are my review comments for v69-0001 Thanks for the comments! > ~~~ > > 1. src/backend/executor/execReplication.c CheckCmdReplicaIdentity call to > RelationBuildPublicationDesc > > + /* > + * It is only safe to execute UPDATE/DELETE when all columns, > + referenced in > + * the row filters from publications which the relation is in, are > + valid - > + * i.e. when all referenced columns are part of REPLICA IDENTITY or the > + * table does not publish UPDATES or DELETES. > + */ > + pubdesc = RelationBuildPublicationDesc(rel); > > This code is leaky because never frees the palloc-ed memory for the pubdesc. > > IMO change the RelationBuildPublicationDesc to pass in the > PublicationDesc* from the call stack then can eliminate the palloc and risk of > leaks. > > ~~~ > > 2. src/include/utils/relcache.h - RelationBuildPublicationDesc > > +struct PublicationDesc; > +extern struct PublicationDesc *RelationBuildPublicationDesc(Relation > +relation); > > (Same as the previous comment #1). Suggest to change the function signature > to be void and pass the PublicationDesc* from stack instead of palloc-ing it > within the function I agree with these changes and Greg has posted a separate patch[1] to change these. I think it might be better to change these after that separate patch get committed because some discussions are still going on in that thread. [1] https://postgr.es/m/CAJcOf-d0%3DvQx1Pzbf%2BLVarywejJFS5W%2BM6uR%2B2d0oeEJ2VQ%2BEw%40mail.gmail.com > > 3. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc > > +RelationBuildPublicationDesc(Relation relation) > { > List *puboids; > ListCell *lc; > MemoryContext oldcxt; > Oid schemaid; > - PublicationActions *pubactions = palloc0(sizeof(PublicationActions)); > + List *ancestors = NIL; > + Oid relid = RelationGetRelid(relation); AttrNumber invalid_rfcolnum = > + InvalidAttrNumber; PublicationDesc *pubdesc = > + palloc0(sizeof(PublicationDesc)); PublicationActions *pubactions = > + &pubdesc->pubactions; > + > + pubdesc->rf_valid_for_update = true; > + pubdesc->rf_valid_for_delete = true; > > IMO it wold be better to change the "sense" of those variables. > e.g. > > "rf_valid_for_update" --> "rf_invalid_for_update" > "rf_valid_for_delete" --> "rf_invalid_for_delete" > > That way they have the same 'sense' as the AttrNumbers so it all reads better to > me. > > Also, it means no special assignment is needed because the palloc0 will set > them correctly Since Alvaro also had some comments about the cached things and the discussion is still going on, I will note down this comment and change it later. > 4. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc > > - if (relation->rd_pubactions) > + if (relation->rd_pubdesc) > { > - pfree(relation->rd_pubactions); > - relation->rd_pubactions = NULL; > + pfree(relation->rd_pubdesc); > + relation->rd_pubdesc = NULL; > } > > What is the purpose of this code? Can't it all just be removed? > e.g. Can't you Assert that relation->rd_pubdesc is NULL at this point? > > (if it was not-null the function would have returned immediately from the top) I think it might be better to change this as a separate patch. > 5. src/include/catalog/pg_publication.h - typedef struct PublicationDesc > > +typedef struct PublicationDesc > +{ > + /* > + * true if the columns referenced in row filters which are used for > +UPDATE > + * or DELETE are part of the replica identity, or the publication > +actions > + * do not include UPDATE or DELETE. > + */ > + bool rf_valid_for_update; > + bool rf_valid_for_delete; > + > + AttrNumber invalid_rfcol_update; > + AttrNumber invalid_rfcol_delete; > + > + PublicationActions pubactions; > +} PublicationDesc; > + > > I did not see any point really for the pairs of booleans and AttNumbers. > AFAIK both of them shared exactly the same validation logic so I think you can > get by using fewer members here. the pairs of booleans are intended to fix the problem[2] reported earlier. [2] https://www.postgresql.org/message-id/OS0PR01MB611367BB85115707CDB2F40CFB5A9%40OS0PR01MB6113.jpnprd01.prod.outlook.com > > 6. src/tools/pgindent/typedefs.list > > Missing the new typedef PublicationDesc Added. Attach the V70 patch set which fixed above comments and Greg's comments[3]. [3] https://www.postgresql.org/message-id/CAJcOf-eUnXPSDR1smg9VFktr6OY5%3D8zAsCX-rqctBdfgoEavDA%40mail.gmail.com Best regards, Hou zj
Вложения
A couple more comments for the v69-0001 TAP tests.
~~~
1. src/test/subscription/t/027_row_filter.pl
+# The subscription of the ALL TABLES IN SCHEMA publication means
there should be
+# no filtering on the tablesync COPY, so all expect all 5 will be present.
+$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
FROM schema_rf_x.tab_rf_x");
+is($result, qq(5), 'check initial data copy from table tab_rf_x
should not be filtered');
+
+# Similarly, normal filtering after the initial phase will also have
not effect.
+# Expected:
+# tab_rf_x : 5 initial rows + 2 new rows = 7 rows
+# tab_rf_partition : 1 initial row + 1 new row = 2 rows
+$node_publisher->safe_psql('postgres', "INSERT INTO
schema_rf_x.tab_rf_x (x) VALUES (-99), (99)");
+$node_publisher->safe_psql('postgres', "INSERT INTO
schema_rf_x.tab_rf_partitioned (x) VALUES (5), (25)");
+$node_publisher->wait_for_catchup($appname);
+$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
FROM schema_rf_x.tab_rf_x");
+is($result, qq(7), 'check table tab_rf_x should not be filtered');
+$result = $node_subscriber->safe_psql('postgres', "SELECT * FROM
public.tab_rf_partition");
+is($result, qq(20
+25), 'check table tab_rf_partition should be filtered');
That comment ("Similarly, normal filtering after the initial phase
will also have not effect.") seems no good:
- it is too vague for the tab_rf_x tablesync
- it seems completely wrong for the tab_rf_partition table (because
that filter is working fine)
I'm not sure exactly what the comment should say, but possibly
something like this (??):
BEFORE:
Similarly, normal filtering after the initial phase will also have not effect.
AFTER:
Similarly, the table filter for tab_rf_x (after the initial phase) has
no effect when combined with the ALL TABLES IN SCHEMA. Meanwhile, the
filter for the tab_rf_partition does work because that partition
belongs to a different schema (and publish_via_partition_root =
false).
~~~
2. src/test/subscription/t/027_row_filter.pl
Here is a 2nd place with the same broken comment:
+# The subscription of the FOR ALL TABLES publication means there should be no
+# filtering on the tablesync COPY, so all expect all 5 will be present.
+my $result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
FROM tab_rf_x");
+is($result, qq(5), 'check initial data copy from table tab_rf_x
should not be filtered');
+
+# Similarly, normal filtering after the initial phase will also have
not effect.
+# Expected: 5 initial rows + 2 new rows = 7 rows
+$node_publisher->safe_psql('postgres', "INSERT INTO tab_rf_x (x)
VALUES (-99), (99)");
+$node_publisher->wait_for_catchup($appname);
+$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
FROM tab_rf_x");
+is($result, qq(7), 'check table tab_rf_x should not be filtered');
Here I also think the comment maybe should just say something like:
BEFORE:
Similarly, normal filtering after the initial phase will also have not effect.
AFTER:
Similarly, the table filter for tab_rf_x (after the initial phase) has
no effect when combined with the ALL TABLES IN SCHEMA.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Monday, January 24, 2022 5:36 AM Peter Smith <smithpb2250@gmail.com> > > FYI - I noticed the cfbot is reporting a failed test case [1] for the latest v69 patch > set. > > [21:09:32.183] # Failed test 'check replicated inserts on subscriber' > [21:09:32.183] # at t/025_rep_changes_for_schema.pl line 202. > [21:09:32.183] # got: '21|1|2139062143' > [21:09:32.183] # expected: '21|1|21' > [21:09:32.183] # Looks like you failed 1 test of 13. > [21:09:32.183] [21:08:49] t/025_rep_changes_for_schema.pl .... The test passed for the latest v70 patch set. I will keep an eye on the cfbot and if the error happen again in the future, I will continue to investigate this. Best regards, Hou zj
On Tuesday, January 25, 2022 1:55 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> A couple more comments for the v69-0001 TAP tests.
>
Thanks for the comments!
>
> 1. src/test/subscription/t/027_row_filter.pl
>
> +# The subscription of the ALL TABLES IN SCHEMA publication means
> there should be
> +# no filtering on the tablesync COPY, so all expect all 5 will be present.
> +$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
> FROM schema_rf_x.tab_rf_x");
> +is($result, qq(5), 'check initial data copy from table tab_rf_x
> should not be filtered');
> +
> +# Similarly, normal filtering after the initial phase will also have
> not effect.
> +# Expected:
> +# tab_rf_x : 5 initial rows + 2 new rows = 7 rows
> +# tab_rf_partition : 1 initial row + 1 new row = 2 rows
> +$node_publisher->safe_psql('postgres', "INSERT INTO
> schema_rf_x.tab_rf_x (x) VALUES (-99), (99)");
> +$node_publisher->safe_psql('postgres', "INSERT INTO
> schema_rf_x.tab_rf_partitioned (x) VALUES (5), (25)");
> +$node_publisher->wait_for_catchup($appname);
> +$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
> FROM schema_rf_x.tab_rf_x");
> +is($result, qq(7), 'check table tab_rf_x should not be filtered');
> +$result = $node_subscriber->safe_psql('postgres', "SELECT * FROM
> public.tab_rf_partition");
> +is($result, qq(20
> +25), 'check table tab_rf_partition should be filtered');
>
> That comment ("Similarly, normal filtering after the initial phase will also have
> not effect.") seems no good:
> - it is too vague for the tab_rf_x tablesync
> - it seems completely wrong for the tab_rf_partition table (because that filter is
> working fine)
>
> I'm not sure exactly what the comment should say, but possibly something like
> this (??):
>
> BEFORE:
> Similarly, normal filtering after the initial phase will also have not effect.
> AFTER:
> Similarly, the table filter for tab_rf_x (after the initial phase) has no effect when
> combined with the ALL TABLES IN SCHEMA. Meanwhile, the filter for the
> tab_rf_partition does work because that partition belongs to a different
> schema (and publish_via_partition_root = false).
>
Thanks, I think your change looks good. Changed.
>
> 2. src/test/subscription/t/027_row_filter.pl
>
> Here is a 2nd place with the same broken comment:
>
> +# The subscription of the FOR ALL TABLES publication means there should
> +be no # filtering on the tablesync COPY, so all expect all 5 will be present.
> +my $result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
> FROM tab_rf_x");
> +is($result, qq(5), 'check initial data copy from table tab_rf_x
> should not be filtered');
> +
> +# Similarly, normal filtering after the initial phase will also have
> not effect.
> +# Expected: 5 initial rows + 2 new rows = 7 rows
> +$node_publisher->safe_psql('postgres', "INSERT INTO tab_rf_x (x)
> VALUES (-99), (99)");
> +$node_publisher->wait_for_catchup($appname);
> +$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
> FROM tab_rf_x");
> +is($result, qq(7), 'check table tab_rf_x should not be filtered');
>
> Here I also think the comment maybe should just say something like:
>
> BEFORE:
> Similarly, normal filtering after the initial phase will also have not effect.
> AFTER:
> Similarly, the table filter for tab_rf_x (after the initial phase) has no effect when
> combined with the ALL TABLES IN SCHEMA.
Changed.
Attach the V71 patch set which addressed the above comments.
The patch also includes the changes:
- Changed the function RelationBuildPublicationDesc's signature to be void and
pass the PublicationDesc* from stack instead of palloc-ing it. [1]
- Removed the Push/Pop ActiveSnapshot related code. IIRC, these functions are
needed when we execute functions which will execute SQL(via SPI functions) to
access the database. I think we don't need the ActiveSnapshot for now as we
only support built-in immutable in the row filter which should only use the
argument values passed to the function.
- Adjusted some comments in pgoutput.c.
[1] https://www.postgresql.org/message-id/CAHut%2BPsRTtXoYQiRqxwvyrcmkDMm-kR4GkvD9-nAqNrk4A3aCQ%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Monday, January 24, 2022 4:38 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Thanks for all the patches!
>
> Here are my review comments for v69-0001
>
> ~~~
>
> 1. src/backend/executor/execReplication.c CheckCmdReplicaIdentity call to
> RelationBuildPublicationDesc
>
> + /*
> + * It is only safe to execute UPDATE/DELETE when all columns,
> + referenced in
> + * the row filters from publications which the relation is in, are
> + valid -
> + * i.e. when all referenced columns are part of REPLICA IDENTITY or the
> + * table does not publish UPDATES or DELETES.
> + */
> + pubdesc = RelationBuildPublicationDesc(rel);
>
> This code is leaky because never frees the palloc-ed memory for the pubdesc.
>
> IMO change the RelationBuildPublicationDesc to pass in the
> PublicationDesc* from the call stack then can eliminate the palloc and risk of
> leaks.
>
> ~~~
>
> 2. src/include/utils/relcache.h - RelationBuildPublicationDesc
>
> +struct PublicationDesc;
> +extern struct PublicationDesc *RelationBuildPublicationDesc(Relation
> +relation);
>
> (Same as the previous comment #1). Suggest to change the function signature
> to be void and pass the PublicationDesc* from stack instead of palloc-ing it
> within the function
Changed in V71.
>
> 3. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
>
> +RelationBuildPublicationDesc(Relation relation)
> {
> List *puboids;
> ListCell *lc;
> MemoryContext oldcxt;
> Oid schemaid;
> - PublicationActions *pubactions = palloc0(sizeof(PublicationActions));
> + List *ancestors = NIL;
> + Oid relid = RelationGetRelid(relation); AttrNumber invalid_rfcolnum =
> + InvalidAttrNumber; PublicationDesc *pubdesc =
> + palloc0(sizeof(PublicationDesc)); PublicationActions *pubactions =
> + &pubdesc->pubactions;
> +
> + pubdesc->rf_valid_for_update = true;
> + pubdesc->rf_valid_for_delete = true;
>
> IMO it wold be better to change the "sense" of those variables.
> e.g.
>
> "rf_valid_for_update" --> "rf_invalid_for_update"
> "rf_valid_for_delete" --> "rf_invalid_for_delete"
>
> That way they have the same 'sense' as the AttrNumbers so it all reads better to
> me.
>
> Also, it means no special assignment is needed because the palloc0 will set
> them correctly
Think again, I am not sure it's better to have an invalid_... flag.
It seems more natural to have a valid_... flag.
Best regards,
Hou zj
On Wednesday, January 26, 2022 9:43 AM I wrote: > On Tuesday, January 25, 2022 1:55 PM Peter Smith <smithpb2250@gmail.com> > wrote: > > Changed. > > Attach the V71 patch set which addressed the above comments. > The patch also includes the changes: > - Changed the function RelationBuildPublicationDesc's signature to be void > and > pass the PublicationDesc* from stack instead of palloc-ing it. [1] > - Removed the Push/Pop ActiveSnapshot related code. IIRC, these functions > are > needed when we execute functions which will execute SQL(via SPI functions) > to > access the database. I think we don't need the ActiveSnapshot for now as we > only support built-in immutable in the row filter which should only use the > argument values passed to the function. > - Adjusted some comments in pgoutput.c. There was a miss in the posted patch which didn't initialize the parameter in RelationBuildPublicationDesc, sorry for that. Attach the correct patch this time. Best regards, Hou zj
Вложения
On Wed, Jan 26, 2022 at 8:37 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 24, 2022 4:38 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> >
> > 3. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
> >
> > +RelationBuildPublicationDesc(Relation relation)
> > {
> > List *puboids;
> > ListCell *lc;
> > MemoryContext oldcxt;
> > Oid schemaid;
> > - PublicationActions *pubactions = palloc0(sizeof(PublicationActions));
> > + List *ancestors = NIL;
> > + Oid relid = RelationGetRelid(relation); AttrNumber invalid_rfcolnum =
> > + InvalidAttrNumber; PublicationDesc *pubdesc =
> > + palloc0(sizeof(PublicationDesc)); PublicationActions *pubactions =
> > + &pubdesc->pubactions;
> > +
> > + pubdesc->rf_valid_for_update = true;
> > + pubdesc->rf_valid_for_delete = true;
> >
> > IMO it wold be better to change the "sense" of those variables.
> > e.g.
> >
> > "rf_valid_for_update" --> "rf_invalid_for_update"
> > "rf_valid_for_delete" --> "rf_invalid_for_delete"
> >
> > That way they have the same 'sense' as the AttrNumbers so it all reads better to
> > me.
> >
> > Also, it means no special assignment is needed because the palloc0 will set
> > them correctly
>
> Think again, I am not sure it's better to have an invalid_... flag.
> It seems more natural to have a valid_... flag.
>
Can't we do without these valid_ flags? AFAICS, if we check for
"invalid_" attributes, it should serve our purpose because those can
have some attribute number only when the row filter contains some
column that is not part of RI. A few possible optimizations in
RelationBuildPublicationDesc:
a. It calls contain_invalid_rfcolumn with pubid and then does cache
lookup to again find a publication which its only caller has access
to, so can't we pass the same?
b. In RelationBuildPublicationDesc(), we call
GetRelationPublications() to get the list of publications and then
process those publications. I think if none of the publications has
row filter and the relation has replica identity then we don't need to
build the descriptor at all. If we do this optimization inside
RelationBuildPublicationDesc, we may want to rename function as
CheckAndBuildRelationPublicationDesc or something like that?
--
With Regards,
Amit Kapila.
On Tue, Jan 25, 2022 at 2:18 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 24, 2022 4:38 PM Peter Smith <smithpb2250@gmail.com>
> >
...
> > 5. src/include/catalog/pg_publication.h - typedef struct PublicationDesc
> >
> > +typedef struct PublicationDesc
> > +{
> > + /*
> > + * true if the columns referenced in row filters which are used for
> > +UPDATE
> > + * or DELETE are part of the replica identity, or the publication
> > +actions
> > + * do not include UPDATE or DELETE.
> > + */
> > + bool rf_valid_for_update;
> > + bool rf_valid_for_delete;
> > +
> > + AttrNumber invalid_rfcol_update;
> > + AttrNumber invalid_rfcol_delete;
> > +
> > + PublicationActions pubactions;
> > +} PublicationDesc;
> > +
> >
> > I did not see any point really for the pairs of booleans and AttNumbers.
> > AFAIK both of them shared exactly the same validation logic so I think you can
> > get by using fewer members here.
>
> the pairs of booleans are intended to fix the problem[2] reported earlier.
> [2]
https://www.postgresql.org/message-id/OS0PR01MB611367BB85115707CDB2F40CFB5A9%40OS0PR01MB6113.jpnprd01.prod.outlook.com
> >
OK. Thanks for the info.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Jan 26, 2022 at 2:08 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > There was a miss in the posted patch which didn't initialize the parameter in > RelationBuildPublicationDesc, sorry for that. Attach the correct patch this time. > A few comments for the v71-0001 patch: doc/src/sgml/catalogs.sgml (1) + + <row> + <entry role="catalog_table_entry"><para role="column_definition"> + <structfield>prqual</structfield> <type>pg_node_tree</type> + </para> + <para>Expression tree (in <function>nodeToString()</function> + representation) for the relation's qualifying condition. Null if + there is no qualifying condition.</para></entry> + </row> "qualifying condition" sounds a bit vague here. Wouldn't it be better to say "publication qualifying condition"? src/backend/commands/publicationcmds.c (2) check_simple_rowfilter_expr_walker In the function header: (i) "etc" should be "etc." (ii) Is + * - (Var Op Const) Bool (Var Op Const) meant to be: + * - (Var Op Const) Logical-Op (Var Op Const) ? It's not clear what "Bool" means here. (3) check_simple_rowfilter_expr_walker We should say "Built-in functions" instead of "System-functions": + * User-defined functions are not allowed. System-functions that are Regards, Greg Nancarrow Fujitsu Australia
On Wed, Jan 26, 2022 at 2:08 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > There was a miss in the posted patch which didn't initialize the parameter in > RelationBuildPublicationDesc, sorry for that. Attach the correct patch this time. > I have some additional doc update suggestions for the v71-0001 patch: (1) Patch commit comment BEFORE: row filter evaluates to NULL, it returns false. The WHERE clause only AFTER: row filter evaluates to NULL, it is regarded as "false". The WHERE clause only doc/src/sgml/catalogs.sgml (2) ALTER PUBLICATION BEFORE: + <replaceable class="parameter">expression</replaceable> returns false or null will AFTER: + <replaceable class="parameter">expression</replaceable> evaluates to false or null will doc/src/sgml/ref/alter_subscription.sgml (3) ALTER SUBSCRIPTION BEFORE: + filter <literal>WHERE</literal> clause had been modified. AFTER: + filter <literal>WHERE</literal> clause has since been modified. doc/src/sgml/ref/create_publication.sgml (4) CREATE PUBLICATION BEFORE: + which the <replaceable class="parameter">expression</replaceable> returns + false or null will not be published. Note that parentheses are required AFTER: + which the <replaceable class="parameter">expression</replaceable> evaluates + to false or null will not be published. Note that parentheses are required doc/src/sgml/ref/create_subscription.sgml (5) CREATE SUBSCRIPTION BEFORE: + returns false or null will not be published. If the subscription has several AFTER: + evaluates to false or null will not be published. If the subscription has several Regards, Greg Nancarrow Fujitsu Australia
On Thu, Jan 27, 2022 at 9:40 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Wed, Jan 26, 2022 at 2:08 PM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > > > There was a miss in the posted patch which didn't initialize the parameter in > > RelationBuildPublicationDesc, sorry for that. Attach the correct patch this time. > > > > A few comments for the v71-0001 patch: ... > (2) check_simple_rowfilter_expr_walker > > In the function header: > (i) "etc" should be "etc." > (ii) > Is > > + * - (Var Op Const) Bool (Var Op Const) > > meant to be: > > + * - (Var Op Const) Logical-Op (Var Op Const) > > ? > > It's not clear what "Bool" means here. The comment is only intended as a generic example of the kinds of acceptable expression format. The names in the comment used are roughly equivalent to the Node* tag names. This particular example is for an expression with AND/OR/NOT, which is handled by a BoolExpr. There is no such animal as LogicalOp, so rather than change like your suggestion I feel if this comment is going to change then it would be better to change to be "boolop" (because the BoolExpr struct has a boolop member). e.g. BEFORE + * - (Var Op Const) Bool (Var Op Const) AFTER + * - (Var Op Const) boolop (Var Op Const) ------ Kind Regards, Peter Smith. Fujitsu Australia.
On Thu, Jan 27, 2022 at 4:59 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Thu, Jan 27, 2022 at 9:40 AM Greg Nancarrow <gregn4422@gmail.com> wrote:
> >
> > On Wed, Jan 26, 2022 at 2:08 PM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > There was a miss in the posted patch which didn't initialize the parameter in
> > > RelationBuildPublicationDesc, sorry for that. Attach the correct patch this time.
> > >
> >
> > A few comments for the v71-0001 patch:
> ...
> > (2) check_simple_rowfilter_expr_walker
> >
> > In the function header:
> > (i) "etc" should be "etc."
> > (ii)
> > Is
> >
> > + * - (Var Op Const) Bool (Var Op Const)
> >
> > meant to be:
> >
> > + * - (Var Op Const) Logical-Op (Var Op Const)
> >
> > ?
> >
> > It's not clear what "Bool" means here.
>
> The comment is only intended as a generic example of the kinds of
> acceptable expression format.
>
> The names in the comment used are roughly equivalent to the Node* tag names.
>
> This particular example is for an expression with AND/OR/NOT, which is
> handled by a BoolExpr.
>
> There is no such animal as LogicalOp, so rather than change like your
> suggestion I feel if this comment is going to change then it would be
> better to change to be "boolop" (because the BoolExpr struct has a
> boolop member). e.g.
>
> BEFORE
> + * - (Var Op Const) Bool (Var Op Const)
> AFTER
> + * - (Var Op Const) boolop (Var Op Const)
>
My use of "LogicalOp" was just indicating that the use of "Bool" in that line was probably meant to mean "Logical Operator", and these are documented in "9.1 Logical Operators" here: https://www.postgresql.org/docs/14/functions-logical.html
(PostgreSQL docs don't refer to AND/OR etc. as boolean operators)
Perhaps, to make it clear, the change for the example compound expression could simply be:
+ * - (Var Op Const) AND/OR (Var Op Const)
or at least say something like " - where boolop is AND/OR".
Regards,
Greg Nancarrow
Fujitsu Australia
Here are some review comments for v71-0001
~~~
1. Commit Message - database
"...that don't satisfy this WHERE clause will be filtered out. This allows a
database or set of tables to be partially replicated. The row filter is
per table. A new row filter can be added simply by specifying a WHERE..."
I don't know what extra information is conveyed by saying "a
database". Isn't it sufficient to just say "This allows a set of
tables to be partially replicated." ?
~~~
2. Commit message - OR'ed
The row filters are applied before publishing the changes. If the
subscription has several publications in which the same table has been
published with different filters, those expressions get OR'ed together so
that rows satisfying any of the expressions will be replicated.
Shouldn't that say:
"with different filters," --> "with different filters (for the same
publish operation),"
~~~
3. Commit message - typo
This means all the other filters become redundant if (a) one of the
publications have no filter at all, (b) one of the publications was
created using FOR ALL TABLES, (c) one of the publications was created
using FOR ALL TABLES IN SCHEMA and the table belongs to that same schema.
Typo:
"have no filter" --> "has no filter"
~~~
4. Commit message - psql \d+
"Psql commands \dRp+ and \d+ will display any row filters."
Actually, just "\d" (without +) will also display row filters. You do
not need to say "\d+"
~~~
5. src/backend/executor/execReplication.c - CheckCmdReplicaIdentity
+ RelationBuildPublicationDesc(rel, &pubdesc);
+ if (!pubdesc.rf_valid_for_update && cmd == CMD_UPDATE)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
+ errmsg("cannot update table \"%s\"",
+ RelationGetRelationName(rel)),
+ errdetail("Column \"%s\" used in the publication WHERE expression is
not part of the replica identity.",
+ get_attname(RelationGetRelid(rel),
+ pubdesc.invalid_rfcol_update,
+ false))));
+ else if (!pubdesc.rf_valid_for_delete && cmd == CMD_DELETE)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_COLUMN_REFERENCE),
+ errmsg("cannot delete from table \"%s\"",
+ RelationGetRelationName(rel)),
+ errdetail("Column \"%s\" used in the publication WHERE expression is
not part of the replica identity.",
+ get_attname(RelationGetRelid(rel),
+ pubdesc.invalid_rfcol_delete,
+ false))));
IMO those conditions should be reversed because (a) it's more optimal
to test the other way around, and (b) for consistency with other code
in this function.
BEFORE
+ if (!pubdesc.rf_valid_for_update && cmd == CMD_UPDATE)
...
+ else if (!pubdesc.rf_valid_for_delete && cmd == CMD_DELETE)
AFTER
+ if (cmd == CMD_UPDATE && !pubdesc.rf_valid_for_update)
...
+ else if (cmd == CMD_DELETE && !pubdesc.rf_valid_for_delete)
~~~
6. src/backend/replication/pgoutput/pgoutput.c - pgoutput_row_filter
+ /*
+ * Unchanged toasted replica identity columns are only logged in the
+ * old tuple, copy this over to the new tuple. The changed (or WAL
+ * Logged) toast values are always assembled in memory and set as
+ * VARTAG_INDIRECT. See ReorderBufferToastReplace.
+ */
Something seems not quite right with the comma in that first sentence.
Maybe a period is better?
BEFORE
Unchanged toasted replica identity columns are only logged in the old
tuple, copy this over to the new tuple.
AFTER
Unchanged toasted replica identity columns are only logged in the old
tuple. Copy this over to the new tuple.
~~~
7. src/test/subscription/t/028_row_filter.pl - COPYRIGHT
This TAP file should have a copyright comment that is consistent with
all the other TAP files.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wednesday, January 26, 2022 6:57 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Jan 26, 2022 at 8:37 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Monday, January 24, 2022 4:38 PM Peter Smith
> <smithpb2250@gmail.com> wrote:
> > >
> > >
> > > 3. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
> > >
> > > +RelationBuildPublicationDesc(Relation relation)
> > > {
> > > List *puboids;
> > > ListCell *lc;
> > > MemoryContext oldcxt;
> > > Oid schemaid;
> > > - PublicationActions *pubactions = palloc0(sizeof(PublicationActions));
> > > + List *ancestors = NIL;
> > > + Oid relid = RelationGetRelid(relation); AttrNumber invalid_rfcolnum =
> > > + InvalidAttrNumber; PublicationDesc *pubdesc =
> > > + palloc0(sizeof(PublicationDesc)); PublicationActions *pubactions =
> > > + &pubdesc->pubactions;
> > > +
> > > + pubdesc->rf_valid_for_update = true;
> > > + pubdesc->rf_valid_for_delete = true;
> > >
> > > IMO it wold be better to change the "sense" of those variables.
> > > e.g.
> > >
> > > "rf_valid_for_update" --> "rf_invalid_for_update"
> > > "rf_valid_for_delete" --> "rf_invalid_for_delete"
> > >
> > > That way they have the same 'sense' as the AttrNumbers so it all reads better
> to
> > > me.
> > >
> > > Also, it means no special assignment is needed because the palloc0 will set
> > > them correctly
> >
> > Think again, I am not sure it's better to have an invalid_... flag.
> > It seems more natural to have a valid_... flag.
> >
Thanks for the comments !
> Can't we do without these valid_ flags? AFAICS, if we check for
> "invalid_" attributes, it should serve our purpose because those can
> have some attribute number only when the row filter contains some
> column that is not part of RI. A few possible optimizations in
> RelationBuildPublicationDesc:
I slightly refactored the logic here.
> a. It calls contain_invalid_rfcolumn with pubid and then does cache
> lookup to again find a publication which its only caller has access
> to, so can't we pass the same?
Adjusted the code here.
> b. In RelationBuildPublicationDesc(), we call
> GetRelationPublications() to get the list of publications and then
> process those publications. I think if none of the publications has
> row filter and the relation has replica identity then we don't need to
> build the descriptor at all. If we do this optimization inside
> RelationBuildPublicationDesc, we may want to rename function as
> CheckAndBuildRelationPublicationDesc or something like that?
After thinking more on this and considering Alvaro's comments. I did some
changes for the RelationBuildPublicationDesc function to try to
make it more natural.
- Make the function always collect the complete information instead of
returning immediately when find invalid rowfilter.
The reason for this change is: some extensions(3rd-part) might only care
about the cached publication actions, this approach can make sure they can
still get complete pulication actions as usual. Besides, this is also
consistent with the other existing cache management functions(like
RelationGetIndexAttrBitmap ...) which will always build complete information
even if user only want part of it.
- Only cache the flag rf_valid_for_[update|delete] flag in PublicationDesc
instead of the invalid rowfilter column.
Because it's a bit unnatural to me to store an invalid thing in relcache. Note
that now the patch doesn't report the column number in the error message. If we
later decide that the accurate column number or publication is useful, I
think it might be better to add a separate simple function(get_invalid_...)
to report the accurate column or publication instead of reusing the cache
management function.
Also address Peter's comments[1] and Greg's comments[2] [3]
[1] https://www.postgresql.org/message-id/CAHut%2BPsG1G80AoSYka7m1x05vHjKZAzKeVyK4b6CAm2-sTkadg%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJcOf-c7XrtsWSGppb96-eQxPbtg%2BAfssAtTXNYbT8QuhdyOYA%40mail.gmail.com
[3] https://www.postgresql.org/message-id/CAJcOf-f0kc%2B4xGEgkvqNLkbJxMf8Ff0E9gTO2biHDoSJnxyziA%40mail.gmail.com
Attach the V72 patch set which did the above changes.
Best regards,
Hou zj
Вложения
On Fri, Jan 28, 2022 at 2:26 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V72 patch set which did the above changes.
>
Thanks for updating the patch set.
One thing I noticed, in the patch commit comment it says:
Psql commands \dRp+ and \d will display any row filters.
However, "\d" by itself doesn't show any row filter information, so I
think it should say:
Psql commands "\dRp+" and "\d <table-name>" will display any row filters.
Regards,
Greg Nancarrow
Fujitsu Australia
I just pushed a change to tab-complete because of a comment in the
column-list patch series. I checked and your v72-0002 does not
conflict, but it doesn't fully work either; AFAICT you'll have to change
it so that the WHERE clause appears in the COMPLETE_WITH(",") line I
just added. As far as I tested it, with that change the completion
works fine.
Unrelated to these two patches:
Frankly I would prefer that these completions offer a ";" in addition to
the "," and "WHERE". But we have no precedent for doing that (offering
to end the command) anywhere in the completion rules, so I think it
would be a larger change that would merit more discussion.
And while we're talking of larger changes, I would love it if other
commands such as DROP TABLE offered a "," completion after a table name,
so that a command can be tab-completed to drop multiple tables. (Same
with other commands that process multiple comma-separated objects, of
course.)
--
Álvaro Herrera 39°49'30"S 73°17'W — https://www.EnterpriseDB.com/
"On the other flipper, one wrong move and we're Fatal Exceptions"
(T.U.X.: Term Unit X - http://www.thelinuxreview.com/TUX/)
Hi,
Are there any recent performance evaluations of the overhead of row filters? I
think it'd be good to get some numbers comparing:
1) $workload with master
2) $workload with patch, but no row filters
3) $workload with patch, row filter matching everything
4) $workload with patch, row filter matching few rows
For workload I think it'd be worth testing:
a) bulk COPY/INSERT into one table
b) Many transactions doing small modifications to one table
c) Many transactions targetting many different tables
d) Interspersed DDL + small changes to a table
> +/*
> + * Initialize for row filter expression execution.
> + */
> +static ExprState *
> +pgoutput_row_filter_init_expr(Node *rfnode)
> +{
> + ExprState *exprstate;
> + Expr *expr;
> +
> + /*
> + * This is the same code as ExecPrepareExpr() but that is not used because
> + * we want to cache the expression. There should probably be another
> + * function in the executor to handle the execution outside a normal Plan
> + * tree context.
> + */
> + expr = expression_planner((Expr *) rfnode);
> + exprstate = ExecInitExpr(expr, NULL);
> +
> + return exprstate;
> +}
In what memory context does this run? Are we taking care to deal with leaks?
I'm pretty sure the planner relies on cleanup via memory contexts.
> + memset(entry->exprstate, 0, sizeof(entry->exprstate));
> +
> + schemaId = get_rel_namespace(entry->publish_as_relid);
> + schemaPubids = GetSchemaPublications(schemaId);
Isn't this stuff that we've already queried before? If we re-fetch a lot of
information it's not clear to me that it's actually a good idea to defer
building the row filter.
> + am_partition = get_rel_relispartition(entry->publish_as_relid);
All this stuff likely can cause some memory "leakage" if you run it in a
long-lived memory context.
> + /*
> + * Find if there are any row filters for this relation. If there are,
> + * then prepare the necessary ExprState and cache it in
> + * entry->exprstate. To build an expression state, we need to ensure
> + * the following:
> + *
> + * All publication-table mappings must be checked.
> + *
> + * If the relation is a partition and pubviaroot is true, use the row
> + * filter of the topmost partitioned table instead of the row filter of
> + * its own partition.
> + *
> + * Multiple publications might have multiple row filters for this
> + * relation. Since row filter usage depends on the DML operation, there
> + * are multiple lists (one for each operation) to which row filters
> + * will be appended.
> + *
> + * FOR ALL TABLES implies "don't use row filter expression" so it takes
> + * precedence.
> + *
> + * ALL TABLES IN SCHEMA implies "don't use row filter expression" if
> + * the schema is the same as the table schema.
> + */
> + foreach(lc, data->publications)
> + {
> + Publication *pub = lfirst(lc);
> + HeapTuple rftuple = NULL;
> + Datum rfdatum = 0;
> + bool pub_no_filter = false;
> +
> + if (pub->alltables)
> + {
> + /*
> + * If the publication is FOR ALL TABLES then it is treated the
> + * same as if this table has no row filters (even if for other
> + * publications it does).
> + */
> + pub_no_filter = true;
> + }
> + else if (list_member_oid(schemaPubids, pub->oid))
> + {
> + /*
> + * If the publication is FOR ALL TABLES IN SCHEMA and it overlaps
> + * with the current relation in the same schema then this is also
> + * treated same as if this table has no row filters (even if for
> + * other publications it does).
> + */
> + pub_no_filter = true;
Isn't this basically O(schemas * publications)?
> + if (has_filter)
> + {
> + /* Create or reset the memory context for row filters */
> + if (entry->cache_expr_cxt == NULL)
> + entry->cache_expr_cxt = AllocSetContextCreate(CacheMemoryContext,
> + "Row filter expressions",
> + ALLOCSET_DEFAULT_SIZES);
> + else
> + MemoryContextReset(entry->cache_expr_cxt);
I see this started before this patch, but I don't think it's a great idea that
pgoutput does a bunch of stuff in CacheMemoryContext. That makes it
unnecessarily hard to debug leaks.
Seems like all this should live somwhere below ctx->context, allocated in
pgoutput_startup()?
Consider what happens in a long-lived replication connection, where
occasionally there's a transient error causing streaming to stop. At that
point you'll just loose all knowledge of entry->cache_expr_cxt, no?
> +
> +/* Inialitize the slot for storing new and old tuple */
> +static void
> +init_tuple_slot(Relation relation, RelationSyncEntry *entry)
> +{
> + MemoryContext oldctx;
> + TupleDesc oldtupdesc;
> + TupleDesc newtupdesc;
> +
> + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> +
> + /*
> + * Create tuple table slots. Create a copy of the TupleDesc as it needs to
> + * live as long as the cache remains.
> + */
> + oldtupdesc = CreateTupleDescCopy(RelationGetDescr(relation));
> + newtupdesc = CreateTupleDescCopy(RelationGetDescr(relation));
> +
> + entry->old_slot = MakeSingleTupleTableSlot(oldtupdesc, &TTSOpsHeapTuple);
> + entry->new_slot = MakeSingleTupleTableSlot(newtupdesc, &TTSOpsHeapTuple);
> +
> + MemoryContextSwitchTo(oldctx);
> +}
This *definitely* shouldn't be allocated in CacheMemoryContext. It's one thing
to have a named context below CacheMemoryContext, that's still somewhat
identifiable. But allocating directly in CacheMemoryContext is almost always a
bad idea.
What is supposed to clean any of this up in case of error?
I guess I'll start a separate thread about memory handling in pgoutput :/
> + /*
> + * We need this map to avoid relying on ReorderBufferChangeType enums
> + * having specific values.
> + */
> + static int map_changetype_pubaction[] = {
> + [REORDER_BUFFER_CHANGE_INSERT] = PUBACTION_INSERT,
> + [REORDER_BUFFER_CHANGE_UPDATE] = PUBACTION_UPDATE,
> + [REORDER_BUFFER_CHANGE_DELETE] = PUBACTION_DELETE
> + };
Why is this "static"? Function-local statics only really make sense for
variables that are changed and should survive between calls to a function.
> + Assert(*action == REORDER_BUFFER_CHANGE_INSERT ||
> + *action == REORDER_BUFFER_CHANGE_UPDATE ||
> + *action == REORDER_BUFFER_CHANGE_DELETE);
> +
> + Assert(new_slot || old_slot);
> +
> + /* Get the corresponding row filter */
> + filter_exprstate = entry->exprstate[map_changetype_pubaction[*action]];
> +
> + /* Bail out if there is no row filter */
> + if (!filter_exprstate)
> + return true;
> +
> + elog(DEBUG3, "table \"%s.%s\" has row filter",
> + get_namespace_name(RelationGetNamespace(relation)),
> + RelationGetRelationName(relation));
> +
> + estate = create_estate_for_relation(relation);
> + ecxt = GetPerTupleExprContext(estate);
So we do this for each filtered row? That's a *lot* of
overhead. CreateExecutorState() creates its own memory context, allocates an
EState, then GetPerTupleExprContext() allocates an ExprContext, which then
creates another memory context.
I don't really see any need to allocate this over-and-over?
> case REORDER_BUFFER_CHANGE_INSERT:
> {
> - HeapTuple tuple = &change->data.tp.newtuple->tuple;
> + /*
> + * Schema should be sent before the logic that replaces the
> + * relation because it also sends the ancestor's relation.
> + */
> + maybe_send_schema(ctx, change, relation, relentry);
> +
> + new_slot = relentry->new_slot;
> +
> + ExecClearTuple(new_slot);
> + ExecStoreHeapTuple(&change->data.tp.newtuple->tuple,
> + new_slot, false);
Why? This isn't free, and you're doing it unconditionally. I'd bet this alone
is noticeable slowdown over the current state.
Greetings,
Andres Freund
On 2022-Jan-28, Andres Freund wrote:
> > + foreach(lc, data->publications)
> > + {
> > + Publication *pub = lfirst(lc);
...
> Isn't this basically O(schemas * publications)?
Yeah, there are various places in the logical replication code that seem
pretty careless about this kind of thing -- most of it seems to assume
that there are going to be few publications, so it just looks things up
over and over with abandon, and I saw at least one place where it looped
up an inheritance hierarchy for partitioning doing indexscans at each
level(*). I think a lot more thought is going to be required to fix
these things in a thorough manner -- a log.repl.-specific caching
mechanism, I imagine.
(*) Before 025b920a3d45, psql was forced to seqscan pg_publication_rel
for one of the describe.c queries, and nobody seems to have noticed.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
Y una voz del caos me habló y me dijo
"Sonríe y sé feliz, podría ser peor".
Y sonreí. Y fui feliz.
Y fue peor.
PSA v73*. (A rebase was needed due to recent changes in tab-complete.c. Otherwise, v73* is the same as v72*). ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Monday, January 31, 2022 8:53 AM Peter Smith <smithpb2250@gmail.com> wrote: > > PSA v73*. > > (A rebase was needed due to recent changes in tab-complete.c. > Otherwise, v73* is the same as v72*). Thanks for the rebase. Attach the V74 patch set which did the following changes: v74-0000 ----- This patch is borrowed from[1] to fix the cfbot failure[2]. The reason of the cfbot failure is that: When rel_sync_cache_relation_cb does invalidate an entry, it immediately free the cached stuff(including the slot), even though that might still be in use. For the failed testcase, It received invalid message in logicalrep_write_tuple when invoking "SearchSysCache1(TYPEOID," and free the slot memory. So, it used the freed slot values to send which could cause the unexpected result. And this pending patch[1] fix this problem by move the memory free code from rel_sync_cache_relation_cb to get_rel_sync_entry. So, before this patch is committed, attach it here to make the cfbot happy. [1] https://www.postgresql.org/message-id/CAA4eK1JACZTJqu_pzTu_2Nf-zGAsupqyfk6KBqHe9puVZGQfvw%40mail.gmail.com [2] https://cirrus-ci.com/task/5450648090050560?logs=test_world#L3975 v74-0001 ----- - Cache the estate in RelationSyncEntry (Andres [3]) - Move the row filter init code to get_rel_sync_entry (Andres [3]) - Remove the static label of map_changetype_pubaction (Andres [3]) - Allocate memory for newly added cached stuff under a separate memory context which is below ctx->context (Andres [3]) - a commit message change. (Greg [4]) v74-0002 ----- - Add the WHERE clause in the COMPLETE_WITH(",") line. (Alvaro [5]) [3] https://www.postgresql.org/message-id/20220129003110.6ndrrpanem5sb4ee%40alap3.anarazel.de [4] https://www.postgresql.org/message-id/CAJcOf-d3zBMtpNwRuu23O%3DWeUz9FWBrTxeqtXUV_vyL103aW5A%40mail.gmail.com [5] https://www.postgresql.org/message-id/202201281351.clzyf4cs6vzb%40alvherre.pgsql Best regards, Hou zj
Вложения
On Saturday, January 29, 2022 8:31 AM Andres Freund <andres@anarazel.de> wrote:
>
> Hi,
>
> Are there any recent performance evaluations of the overhead of row filters? I
> think it'd be good to get some numbers comparing:
Thanks for looking at the patch! Will test it.
> 1) $workload with master
> 2) $workload with patch, but no row filters
> 3) $workload with patch, row filter matching everything
> 4) $workload with patch, row filter matching few rows
>
> For workload I think it'd be worth testing:
> a) bulk COPY/INSERT into one table
> b) Many transactions doing small modifications to one table
> c) Many transactions targetting many different tables
> d) Interspersed DDL + small changes to a table
> > +/*
> > + * Initialize for row filter expression execution.
> > + */
> > +static ExprState *
> > +pgoutput_row_filter_init_expr(Node *rfnode) {
> > + ExprState *exprstate;
> > + Expr *expr;
> > +
> > + /*
> > + * This is the same code as ExecPrepareExpr() but that is not used
> because
> > + * we want to cache the expression. There should probably be another
> > + * function in the executor to handle the execution outside a normal
> Plan
> > + * tree context.
> > + */
> > + expr = expression_planner((Expr *) rfnode);
> > + exprstate = ExecInitExpr(expr, NULL);
> > +
> > + return exprstate;
> > +}
>
> In what memory context does this run? Are we taking care to deal with leaks?
> I'm pretty sure the planner relies on cleanup via memory contexts.
It was running under entry->cache_expr_cxt.
> > + memset(entry->exprstate, 0, sizeof(entry->exprstate));
> > +
> > + schemaId = get_rel_namespace(entry->publish_as_relid);
> > + schemaPubids = GetSchemaPublications(schemaId);
>
> Isn't this stuff that we've already queried before? If we re-fetch a lot of
> information it's not clear to me that it's actually a good idea to defer building
> the row filter.
>
>
> > + am_partition = get_rel_relispartition(entry->publish_as_relid);
>
> All this stuff likely can cause some memory "leakage" if you run it in a long-lived
> memory context.
>
>
> > + /*
> > + * Find if there are any row filters for this relation. If there are,
> > + * then prepare the necessary ExprState and cache it in
> > + * entry->exprstate. To build an expression state, we need to ensure
> > + * the following:
...
> > + *
> > + * ALL TABLES IN SCHEMA implies "don't use row filter expression" if
> > + * the schema is the same as the table schema.
> > + */
> > + foreach(lc, data->publications)
...
> > + else if (list_member_oid(schemaPubids, pub->oid))
> > + {
> > + /*
> > + * If the publication is FOR ALL TABLES IN SCHEMA and
> it overlaps
> > + * with the current relation in the same schema then this
> is also
> > + * treated same as if this table has no row filters (even if
> for
> > + * other publications it does).
> > + */
> > + pub_no_filter = true;
>
> Isn't this basically O(schemas * publications)?
Moved the row filter initialization code to get_rel_sync_entry.
>
> > + if (has_filter)
> > + {
> > + /* Create or reset the memory context for row filters */
> > + if (entry->cache_expr_cxt == NULL)
> > + entry->cache_expr_cxt =
> AllocSetContextCreate(CacheMemoryContext,
> > +
> "Row filter expressions",
> > +
> ALLOCSET_DEFAULT_SIZES);
> > + else
> > + MemoryContextReset(entry->cache_expr_cxt);
>
> I see this started before this patch, but I don't think it's a great idea that
> pgoutput does a bunch of stuff in CacheMemoryContext. That makes it
> unnecessarily hard to debug leaks.
>
> Seems like all this should live somwhere below ctx->context, allocated in
> pgoutput_startup()?
>
> Consider what happens in a long-lived replication connection, where
> occasionally there's a transient error causing streaming to stop. At that point
> you'll just loose all knowledge of entry->cache_expr_cxt, no?
>
>
> > +
> > +/* Inialitize the slot for storing new and old tuple */ static void
> > +init_tuple_slot(Relation relation, RelationSyncEntry *entry) {
> > + MemoryContext oldctx;
> > + TupleDesc oldtupdesc;
> > + TupleDesc newtupdesc;
> > +
> > + oldctx = MemoryContextSwitchTo(CacheMemoryContext);
> > +
> > + /*
> > + * Create tuple table slots. Create a copy of the TupleDesc as it needs to
> > + * live as long as the cache remains.
> > + */
> > + oldtupdesc = CreateTupleDescCopy(RelationGetDescr(relation));
> > + newtupdesc = CreateTupleDescCopy(RelationGetDescr(relation));
> > +
> > + entry->old_slot = MakeSingleTupleTableSlot(oldtupdesc,
> &TTSOpsHeapTuple);
> > + entry->new_slot = MakeSingleTupleTableSlot(newtupdesc,
> > +&TTSOpsHeapTuple);
> > +
> > + MemoryContextSwitchTo(oldctx);
> > +}
>
> This *definitely* shouldn't be allocated in CacheMemoryContext. It's one thing
> to have a named context below CacheMemoryContext, that's still somewhat
> identifiable. But allocating directly in CacheMemoryContext is almost always a
> bad idea.
>
> What is supposed to clean any of this up in case of error?
>
>
> I guess I'll start a separate thread about memory handling in pgoutput :/
Thanks for the comments.
Added a separate memory context below ctx->context and
allocate all these newly added stuff under the separate memory context for now.
It seems you mean the existing stuff should also be put into a separate memory
context like this, do you think we can do it as a spearate patch or include
that change in row filter patch ?
> > + /*
> > + * We need this map to avoid relying on ReorderBufferChangeType
> enums
> > + * having specific values.
> > + */
> > + static int map_changetype_pubaction[] = {
> > + [REORDER_BUFFER_CHANGE_INSERT] = PUBACTION_INSERT,
> > + [REORDER_BUFFER_CHANGE_UPDATE] = PUBACTION_UPDATE,
> > + [REORDER_BUFFER_CHANGE_DELETE] = PUBACTION_DELETE
> > + };
>
> Why is this "static"? Function-local statics only really make sense for variables
> that are changed and should survive between calls to a function.
Removed the "static" label.
> > + Assert(*action == REORDER_BUFFER_CHANGE_INSERT ||
> > + *action == REORDER_BUFFER_CHANGE_UPDATE ||
> > + *action == REORDER_BUFFER_CHANGE_DELETE);
> > +
> > + Assert(new_slot || old_slot);
> > +
> > + /* Get the corresponding row filter */
> > + filter_exprstate =
> > +entry->exprstate[map_changetype_pubaction[*action]];
> > +
> > + /* Bail out if there is no row filter */
> > + if (!filter_exprstate)
> > + return true;
> > +
> > + elog(DEBUG3, "table \"%s.%s\" has row filter",
> > + get_namespace_name(RelationGetNamespace(relation)),
> > + RelationGetRelationName(relation));
> > +
> > + estate = create_estate_for_relation(relation);
> > + ecxt = GetPerTupleExprContext(estate);
>
> So we do this for each filtered row? That's a *lot* of overhead.
> CreateExecutorState() creates its own memory context, allocates an EState,
> then GetPerTupleExprContext() allocates an ExprContext, which then creates
> another memory context.
Cached the estate in the new version.
> I don't really see any need to allocate this over-and-over?
>
> > case REORDER_BUFFER_CHANGE_INSERT:
> > {
> > - HeapTuple tuple =
> &change->data.tp.newtuple->tuple;
> > + /*
> > + * Schema should be sent before the logic that
> replaces the
> > + * relation because it also sends the ancestor's
> relation.
> > + */
> > + maybe_send_schema(ctx, change, relation,
> relentry);
> > +
> > + new_slot = relentry->new_slot;
> > +
> > + ExecClearTuple(new_slot);
> > +
> ExecStoreHeapTuple(&change->data.tp.newtuple->tuple,
> > + new_slot,
> false);
>
> Why? This isn't free, and you're doing it unconditionally. I'd bet this alone is
> noticeable slowdown over the current state.
It was intended to avoid deform the tuple twice, once in row filter execution ,second time
in logicalrep_write_tuple. But I will test the performance impact of this and improve
this if needed.
Best regards,
Hou zj
On Mon, Jan 31, 2022 at 1:12 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> > > + /*
> > > + * We need this map to avoid relying on ReorderBufferChangeType
> > enums
> > > + * having specific values.
> > > + */
> > > + static int map_changetype_pubaction[] = {
> > > + [REORDER_BUFFER_CHANGE_INSERT] = PUBACTION_INSERT,
> > > + [REORDER_BUFFER_CHANGE_UPDATE] = PUBACTION_UPDATE,
> > > + [REORDER_BUFFER_CHANGE_DELETE] = PUBACTION_DELETE
> > > + };
> >
> > Why is this "static"? Function-local statics only really make sense for variables
> > that are changed and should survive between calls to a function.
>
> Removed the "static" label.
>
This array was only ever meant to be read-only, and visible only to
that function.
IMO removing "static" makes things worse because now that array gets
initialized each call to the function, which is unnecessary.
I think it should just be: "static const int map_changetype_pubaction[] = ..."
Regards,
Greg Nancarrow
Fujitsu Australia
On Mon, Jan 31, 2022 at 12:57 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the V74 patch set which did the following changes: > Hi, I tested psql and pg_dump after application of this patch, from the following perspectives: - "\dRp+" and "\d <table-name>" (added by the patch, for PostgreSQL 15) show row filters associated with publications and specified tables, respectively. - psql is able to connect to the same or older server version - pg_dump is able to dump from the same or older server version - dumps can be loaded into newer server versions than that of pg_dump - PostgreSQL v9 doesn't support publications - Only PostgreSQL v15 supports row filters (via the patch) So specifically I tested the following versions (built from the stable branch): 9.2, 9.6, 10, 11, 12, 13, 14 and 15 and used the following publication definitions: create table test1(i int primary key); create table test2(i int primary key, j text); create schema myschema; create table myschema.test3(i int primary key, j text, k text); create publication pub1 for all tables; create publication pub2 for table test1 [ where (i > 100); ] create publication pub3 for table test1 [ where (i > 50), test2 where (i > 100), myschema.test3 where (i > 200) ] with (publish = 'insert, update'); (note that for v9, only the above tables and schemas can be defined, as publications are not supported, and only the row filter "where" clauses can be defined on v15) I tested: - v15 psql connecting to same and older versions, and using "\dRp+" and "\d <table-name>" commands - v15 pg_dump, dumping the above definitions from the same or older server versions - Loading dumps from older or same (v15) server version into a v15 server. I did not detect any issues. Regards, Greg Nancarrow Fujitsu Australia
On Mon, Jan 31, 2022 at 7:27 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Monday, January 31, 2022 8:53 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > PSA v73*. > > > > (A rebase was needed due to recent changes in tab-complete.c. > > Otherwise, v73* is the same as v72*). > > Thanks for the rebase. > Attach the V74 patch set which did the following changes: > Few comments: ============= 1. /* Create or reset the memory context for row filters */ + entry->cache_expr_cxt = AllocSetContextCreate(cachectx, + "Row filter expressions", + ALLOCSET_DEFAULT_SIZES); + In the new code, we are no longer resetting it here, so we can probably remove "or reset" from the above comment. 2. You have changed some of the interfaces to pass memory context. Isn't it better to pass "PGOutputData *" and then use the required memory context. That will keep the interfaces consistent and we do something similar in ExecPrepareExpr. 3. + +/* + * Initialize the row filter, the first time. + */ +static void +pgoutput_row_filter_init(MemoryContext cachectx, List *publications, + RelationSyncEntry *entry) In the above comment, the first time doesn't seem to fit well after your changes because now that has been taken care of by the caller. -- With Regards, Amit Kapila.
On Mon, Jan 31, 2022 at 1:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Mon, Jan 31, 2022 at 7:27 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> > On Monday, January 31, 2022 8:53 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > PSA v73*.
> > >
> > > (A rebase was needed due to recent changes in tab-complete.c.
> > > Otherwise, v73* is the same as v72*).
> >
> > Thanks for the rebase.
> > Attach the V74 patch set which did the following changes:
> >
>
> Few comments:
> =============
>
Few more minor comments:
1.
+ if (relentry->attrmap)
+ {
+ TupleDesc tupdesc = RelationGetDescr(relation);
+ TupleTableSlot *tmp_slot = MakeTupleTableSlot(tupdesc,
+ &TTSOpsVirtual);
+
+ new_slot = execute_attr_map_slot(relentry->attrmap,
+ new_slot,
+ tmp_slot);
I think we don't need these additional variables tupdesc and tmp_slot.
You can directly use MakeTupleTableSlot instead of tmp_slot, which
will make this and nearby code look better.
2.
+ if (pubrinfo->pubrelqual)
+ appendPQExpBuffer(query, " WHERE (%s)", pubrinfo->pubrelqual);
+ appendPQExpBufferStr(query, ";\n");
Do we really need additional '()' for rwo filter expression here? See
the below output from pg_dump:
ALTER PUBLICATION pub1 ADD TABLE ONLY public.t1 WHERE ((c1 < 100));
3.
+ /* row filter (if any) */
+ if (pset.sversion >= 150000)
+ {
+ if (!PQgetisnull(result, i, 1))
+ appendPQExpBuffer(&buf, " WHERE %s", PQgetvalue(result, i, 1));
+ }
I don't think we need this version check if while forming query we use
NULL as the second column in the corresponding query for v < 150000.
--
With Regards,
Amit Kapila.
On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > Are there any recent performance evaluations of the overhead of row filters? I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table > I have gathered performance data for the workload case (a): HEAD 46743.75 v74 no filters 46929.15 v74 allow 100% 46926.09 v74 allow 75% 40617.74 v74 allow 50% 35744.17 v74 allow 25% 29468.93 v74 allow 0% 22540.58 PSA. This was tested using patch v74 and synchronous pub/sub. There are 1M INSERTS for publications using differing amounts of row filtering (or none). Observations: - There seems insignificant row-filter overheads (e.g. viz no filter and 100% allowed versus HEAD). - The elapsed time decreases linearly as there is less data getting replicated. I will post the results for other workload kinds (b, c, d) when I have them. ------ Kind Regards, Peter Smith. Fujitsu Australia.
Вложения
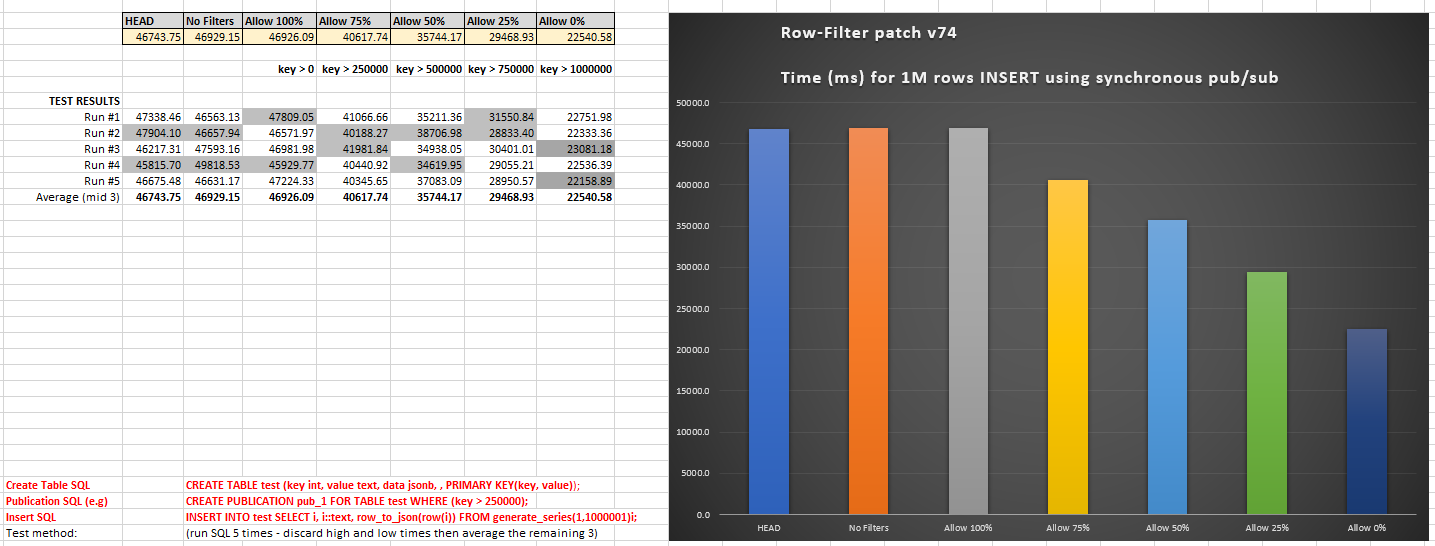{kind=link}
On 2022-01-31 14:12:38 +1100, Greg Nancarrow wrote: > This array was only ever meant to be read-only, and visible only to > that function. > IMO removing "static" makes things worse because now that array gets > initialized each call to the function, which is unnecessary. > I think it should just be: "static const int map_changetype_pubaction[] = ..." Yes, static const is good. static alone, not so much.
On Tue, Feb 1, 2022 at 12:07 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote: > > > > Hi, > > > > Are there any recent performance evaluations of the overhead of row filters? I > > think it'd be good to get some numbers comparing: > > > > 1) $workload with master > > 2) $workload with patch, but no row filters > > 3) $workload with patch, row filter matching everything > > 4) $workload with patch, row filter matching few rows > > > > For workload I think it'd be worth testing: > > a) bulk COPY/INSERT into one table > > b) Many transactions doing small modifications to one table > > c) Many transactions targetting many different tables > > d) Interspersed DDL + small changes to a table > > > > I have gathered performance data for the workload case (a): > > HEAD 46743.75 > v74 no filters 46929.15 > v74 allow 100% 46926.09 > v74 allow 75% 40617.74 > v74 allow 50% 35744.17 > v74 allow 25% 29468.93 > v74 allow 0% 22540.58 > > PSA. > > This was tested using patch v74 and synchronous pub/sub. There are 1M > INSERTS for publications using differing amounts of row filtering (or > none). > > Observations: > - There seems insignificant row-filter overheads (e.g. viz no filter > and 100% allowed versus HEAD). > - The elapsed time decreases linearly as there is less data getting replicated. > FYI - attached are the test steps I used in case anyone wants to try to reproduce these results. ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
On Sat, Jan 29, 2022 at 6:01 AM Andres Freund <andres@anarazel.de> wrote:
>
>
> > + if (has_filter)
> > + {
> > + /* Create or reset the memory context for row filters */
> > + if (entry->cache_expr_cxt == NULL)
> > + entry->cache_expr_cxt = AllocSetContextCreate(CacheMemoryContext,
> > +
"Rowfilter expressions",
> > +
ALLOCSET_DEFAULT_SIZES);
> > + else
> > + MemoryContextReset(entry->cache_expr_cxt);
>
> I see this started before this patch, but I don't think it's a great idea that
> pgoutput does a bunch of stuff in CacheMemoryContext. That makes it
> unnecessarily hard to debug leaks.
>
> Seems like all this should live somwhere below ctx->context, allocated in
> pgoutput_startup()?
>
Agreed.
> Consider what happens in a long-lived replication connection, where
> occasionally there's a transient error causing streaming to stop. At that
> point you'll just loose all knowledge of entry->cache_expr_cxt, no?
>
I think we will lose knowledge because the WALSender exits on ERROR
but that would be true even when we allocate it in this new allocated
context. Am, I missing something?
--
With Regards,
Amit Kapila.
On Mon, Jan 31, 2022 at 12:57 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > Attach the V74 patch set which did the following changes: > In the v74-0001 patch, I noticed the following code in get_rel_sync_entry(): + /* + * Tuple slots cleanups. (Will be rebuilt later if needed). + */ + oldctx = MemoryContextSwitchTo(data->cachectx); + + if (entry->old_slot) + ExecDropSingleTupleTableSlot(entry->old_slot); + if (entry->new_slot) + ExecDropSingleTupleTableSlot(entry->new_slot); + + entry->old_slot = NULL; + entry->new_slot = NULL; + + MemoryContextSwitchTo(oldctx); I don't believe the calls to MemoryContextSwitchTo() are required here, because within the context switch it's just freeing memory, not allocating it. Regards, Greg Nancarrow Fujitsu Australia
On Monday, January 31, 2022 9:02 PM Amit Kapila <amit.kapila16@gmail.com>
>
> On Mon, Jan 31, 2022 at 1:08 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Mon, Jan 31, 2022 at 7:27 AM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com> wrote:
> > >
> > > On Monday, January 31, 2022 8:53 AM Peter Smith
> <smithpb2250@gmail.com> wrote:
> > > >
> > > > PSA v73*.
> > > >
> > > > (A rebase was needed due to recent changes in tab-complete.c.
> > > > Otherwise, v73* is the same as v72*).
> > >
> > > Thanks for the rebase.
> > > Attach the V74 patch set which did the following changes:
> > >
> >
> > Few comments:
> > =============
> >
>
> Few more minor comments:
> 1.
> + if (relentry->attrmap)
> + {
> + TupleDesc tupdesc = RelationGetDescr(relation); TupleTableSlot
> + *tmp_slot = MakeTupleTableSlot(tupdesc,
> + &TTSOpsVirtual);
> +
> + new_slot = execute_attr_map_slot(relentry->attrmap,
> + new_slot,
> + tmp_slot);
>
> I think we don't need these additional variables tupdesc and tmp_slot.
> You can directly use MakeTupleTableSlot instead of tmp_slot, which will make
> this and nearby code look better.
Changed.
> 2.
> + if (pubrinfo->pubrelqual)
> + appendPQExpBuffer(query, " WHERE (%s)", pubrinfo->pubrelqual);
> + appendPQExpBufferStr(query, ";\n");
>
> Do we really need additional '()' for rwo filter expression here? See the below
> output from pg_dump:
>
> ALTER PUBLICATION pub1 ADD TABLE ONLY public.t1 WHERE ((c1 < 100));
I will investigate this and change this later if needed.
> 3.
> + /* row filter (if any) */
> + if (pset.sversion >= 150000)
> + {
> + if (!PQgetisnull(result, i, 1))
> + appendPQExpBuffer(&buf, " WHERE %s", PQgetvalue(result, i, 1)); }
>
> I don't think we need this version check if while forming query we use NULL as
> the second column in the corresponding query for v < 150000.
Changed.
Attach the V75 patch set which address the above, Amit's[1] and Greg's[2][3] comments.
The new version patch also includes the following changes:
- run pgindent
- adjust some comments
- remove some unnecessary ExecClearTuple
- slightly improve the row filter of toast case by removing some unnecessary
memory allocation and directly return the modified new slot instead of
copying it again.
[1] https://www.postgresql.org/message-id/CAA4eK1LjyiPkwOki3n%2BQfORmBQLUvsvBfifhZMh%2BquAJTuRU_w%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAJcOf-fR_BKHNuz7AXCWuk40ESVOr%3DDkXf3evbNNi4M4V_5agQ%40mail.gmail.com
[3] https://www.postgresql.org/message-id/CAJcOf-fR_BKHNuz7AXCWuk40ESVOr%3DDkXf3evbNNi4M4V_5agQ%40mail.gmail.com
Best regards,
Hou zj
Вложения
> On Saturday, January 29, 2022 8:31 AM Andres Freund <andres@anarazel.de>
> wrote:
> >
> > Hi,
> >
> > Are there any recent performance evaluations of the overhead of row
> > filters? I think it'd be good to get some numbers comparing:
>
> Thanks for looking at the patch! Will test it.
>
> > > case REORDER_BUFFER_CHANGE_INSERT:
> > > {
> > > - HeapTuple tuple = &change->data.tp.newtuple->tuple;
> > > + /*
> > > + * Schema should be sent before the logic that replaces the
> > > + * relation because it also sends the ancestor's relation.
> > > + */
> > > + maybe_send_schema(ctx, change, relation, relentry);
> > > +
> > > + new_slot = relentry->new_slot;
> > > +
> > > + ExecClearTuple(new_slot);
> > > + ExecStoreHeapTuple(&change->data.tp.newtuple->tuple,
> > > + new_slot, false);
> >
> > Why? This isn't free, and you're doing it unconditionally. I'd bet this alone is
> > noticeable slowdown over the current state.
>
> It was intended to avoid deform the tuple twice, once in row filter execution
> ,second time in logicalrep_write_tuple. But I will test the performance
> impact of this and improve this if needed.
I removed the unnecessary ExecClearTuple here, I think the ExecStoreHeapTuple
here doesn't allocate or free any memory and seems doesn't have a noticeable
impact from the perf result[1]. And we need this to avoid deforming the tuple
twice. So, it looks acceptable to me.
[1] 0.01% 0.00% postgres pgoutput.so [.] ExecStoreHeapTuple@plt
Best regards,
Hou zj
On Tue, Feb 1, 2022 at 2:45 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> Attach the V75 patch set which address the above, Amit's[1] and Greg's[2][3] comments.
>
In the v74-0001 patch (and now in the v75-001 patch) a change was made
in the GetTopMostAncestorInPublication() function, to get the relation
and schema publications lists (for the ancestor Oid) up-front:
+ List *apubids = GetRelationPublications(ancestor);
+ List *aschemaPubids = GetSchemaPublications(get_rel_namespace(ancestor));
+
+ if (list_member_oid(apubids, puboid) ||
+ list_member_oid(aschemaPubids, puboid))
+ topmost_relid = ancestor;
However, it seems that this makes it less efficient in the case a
match is found in the first list that is searched, since then there
was actually no reason to create the second list.
Instead of this, how about something like this:
List *apubids = GetRelationPublications(ancestor);
List *aschemaPubids = NULL;
if (list_member_oid(apubids, puboid) ||
list_member_oid(aschemaPubids =
GetSchemaPublications(get_rel_namespace(ancestor)), puboid))
topmost_relid = ancestor;
or, if that is considered a bit ugly due to the assignment within the
function parameters, alternatively:
List *apubids = GetRelationPublications(ancestor);
List *aschemaPubids = NULL;
if (list_member_oid(apubids, puboid))
topmost_relid = ancestor;
else
{
aschemaPubids = GetSchemaPublications(get_rel_namespace(ancestor));
if (list_member_oid(aschemaPubids, puboid))
topmost_relid = ancestor;
}
Regards,
Greg Nancarrow
Fujitsu Australia
On Tue, Feb 1, 2022 at 9:15 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 31, 2022 9:02 PM Amit Kapila <amit.kapila16@gmail.com>
> >
>
> > 3.
> > + /* row filter (if any) */
> > + if (pset.sversion >= 150000)
> > + {
> > + if (!PQgetisnull(result, i, 1))
> > + appendPQExpBuffer(&buf, " WHERE %s", PQgetvalue(result, i, 1)); }
> >
> > I don't think we need this version check if while forming query we use NULL as
> > the second column in the corresponding query for v < 150000.
>
> Changed.
>
But, I don't see a corresponding change in the else part of the query:
else
{
printfPQExpBuffer(&buf,
"SELECT pubname\n"
"FROM pg_catalog.pg_publication p\n"
"JOIN pg_catalog.pg_publication_rel pr ON p.oid = pr.prpubid\n"
"WHERE pr.prrelid = '%s'\n"
"UNION ALL\n"
"SELECT pubname\n"
"FROM pg_catalog.pg_publication p\n"
"WHERE p.puballtables AND pg_catalog.pg_relation_is_publishable('%s')\n"
"ORDER BY 1;",
oid, oid);
}
Don't we need to do that to keep it working with previous versions?
--
With Regards,
Amit Kapila.
On Tue, Feb 1, 2022 at 2:45 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 31, 2022 9:02 PM Amit Kapila <amit.kapila16@gmail.com>
> >
> > 2.
> > + if (pubrinfo->pubrelqual)
> > + appendPQExpBuffer(query, " WHERE (%s)", pubrinfo->pubrelqual);
> > + appendPQExpBufferStr(query, ";\n");
> >
> > Do we really need additional '()' for rwo filter expression here? See the below
> > output from pg_dump:
> >
> > ALTER PUBLICATION pub1 ADD TABLE ONLY public.t1 WHERE ((c1 < 100));
>
> I will investigate this and change this later if needed.
>
I don't think we can make this change (i.e. remove the additional parentheses), because then a "WHERE (TRUE)" row filter would result in invalid pg_dump output:
e.g. ALTER PUBLICATION pub1 ADD TABLE ONLY public.test1 WHERE TRUE;
(since currently, parentheses are required around the publication WHERE expression)
See also the following commit, which specifically added these parentheses and catered for WHERE TRUE:
Regards,
Greg Nancarrow
Fujitsu Australia
On Tue, Feb 1, 2022 at 9:15 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
> On Monday, January 31, 2022 9:02 PM Amit Kapila <amit.kapila16@gmail.com>
> >
Review Comments:
===============
1.
+ else if (IsA(node, OpExpr))
+ {
+ /* OK, except user-defined operators are not allowed. */
+ if (((OpExpr *) node)->opno >= FirstNormalObjectId)
+ errdetail_msg = _("User-defined operators are not allowed.");
+ }
Is it sufficient to check only the allowed operators for OpExpr? Don't
we need to check opfuncid to ensure that the corresponding function is
immutable? Also, what about opresulttype, opcollid, and inputcollid? I
think we don't want to allow user-defined types or collations but as
we are restricting the opexp to use a built-in operator, those should
not be present in such an expression. If that is the case, then I
think we can add a comment for the same.
2. Can we handle RelabelType node in
check_simple_rowfilter_expr_walker()? I think you need to check
resulttype and collation id to ensure that they are not user-defined.
There doesn't seem to be a need to check resulttypmod as that refers
to pg_attribute.atttypmod and that can't have anything unsafe. This
helps us to handle cases like the following which currently gives an
error:
create table t1(c1 int, c2 varchar(100));
create publication pub1 for table t1 where (c2 < 'john');
3. Similar to above, don't we need to consider disallowing
non-built-in collation of Var type nodes? Now, as we are only
supporting built-in types this might not be required. So, probably a
comment would suffice.
4.
A minor nitpick in tab-complete:
postgres=# Alter PUBLICATION pub1 ADD TABLE t2 WHERE ( c2 > 10)
, WHERE (
After the Where clause, it should not allow adding WHERE. This doesn't
happen for CREATE PUBLICATION case.
--
With Regards,
Amit Kapila.
On Tue, Feb 1, 2022 at 4:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Review Comments:
> ===============
> 1.
> + else if (IsA(node, OpExpr))
> + {
> + /* OK, except user-defined operators are not allowed. */
> + if (((OpExpr *) node)->opno >= FirstNormalObjectId)
> + errdetail_msg = _("User-defined operators are not allowed.");
> + }
>
> Is it sufficient to check only the allowed operators for OpExpr? Don't
> we need to check opfuncid to ensure that the corresponding function is
> immutable? Also, what about opresulttype, opcollid, and inputcollid? I
> think we don't want to allow user-defined types or collations but as
> we are restricting the opexp to use a built-in operator, those should
> not be present in such an expression. If that is the case, then I
> think we can add a comment for the same.
>
Today, I was looking at a few other nodes supported by the patch and I
have similar questions for those as well. As an example, the patch
allows T_ScalarArrayOpExpr and the node is as follows:
typedef struct ScalarArrayOpExpr
{
Expr xpr;
Oid opno; /* PG_OPERATOR OID of the operator */
Oid opfuncid; /* PG_PROC OID of comparison function */
Oid hashfuncid; /* PG_PROC OID of hash func or InvalidOid */
Oid negfuncid; /* PG_PROC OID of negator of opfuncid function
* or InvalidOid. See above */
bool useOr; /* true for ANY, false for ALL */
Oid inputcollid; /* OID of collation that operator should use */
List *args; /* the scalar and array operands */
int location; /* token location, or -1 if unknown */
} ScalarArrayOpExpr;
Don't we need to check pg_proc OIDs like hashfuncid to ensure that it
is immutable like the patch is doing for FuncExpr? Similarly for
ArrayExpr node, don't we need to check the array_collid to see if it
contains user-defined collation? I think some of these might be okay
to permit but then it is better to have some comments to explain.
--
With Regards,
Amit Kapila.
Hi Peter,
I just tried scenario b that Andres suggested:
For scenario b, I did some testing with row-filter-patch v74 and
various levels of filtering. 0% replicated to 100% rows replicated.
The times are in seconds, I did 5 runs each.
Results:
RUN HEAD "with patch 0%" "row-filter-patch 25%" "row-filter-patch
v74 50%" "row-filter-patch 75%" "row-filter-patch v74 100%"
1 17.26178 12.573736 12.869635 13.742167
17.977112 17.75814
2 17.522473 12.919554 12.640879 14.202737
14.515481 16.961836
3 17.124001 12.640879 12.706631 14.220245
15.686613 17.219355
4 17.24122 12.602345 12.674566 14.219423
15.564312 17.432765
5 17.25352 12.610657 12.689842 14.210725
15.613708 17.403821
As can see the performance seen on HEAD is similar to that which the
patch achieves with all rows (100%) replication. The performance
improves linearly with
more rows filtered.
The test scenario used was:
1. On publisher and subscriber:
CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value));
2. On publisher: (based on which scenario is being tested)
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed
3. On the subscriber:
CREATE SUBSCRIPTION sync_sub CONNECTION 'host=127.0.0.1 port=5432
dbname=postgres application_name=sync_sub' PUBLICATION pub_1;
4. now modify the postgresql.conf on the publisher side
synchronous_standby_names = 'sync_sub' and restart.
5. The test case:
DO
$do$
BEGIN
FOR i IN 1..1000001 BY 10 LOOP
INSERT INTO test VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test SET value = 'FOO' WHERE key = i;
IF I % 1000 = 0 THEN
COMMIT;
END IF;
END LOOP;
END
$do$;
regards,
Ajin Cherian
Fujitsu Australia
On Tue, Feb 1, 2022 at 12:07 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote:
> >
> > Hi,
> >
> > Are there any recent performance evaluations of the overhead of row filters? I
> > think it'd be good to get some numbers comparing:
> >
> > 1) $workload with master
> > 2) $workload with patch, but no row filters
> > 3) $workload with patch, row filter matching everything
> > 4) $workload with patch, row filter matching few rows
> >
> > For workload I think it'd be worth testing:
> > a) bulk COPY/INSERT into one table
> > b) Many transactions doing small modifications to one table
> > c) Many transactions targetting many different tables
> > d) Interspersed DDL + small changes to a table
> >
>
> I have gathered performance data for the workload case (a):
>
> HEAD 46743.75
> v74 no filters 46929.15
> v74 allow 100% 46926.09
> v74 allow 75% 40617.74
> v74 allow 50% 35744.17
> v74 allow 25% 29468.93
> v74 allow 0% 22540.58
>
> PSA.
>
> This was tested using patch v74 and synchronous pub/sub. There are 1M
> INSERTS for publications using differing amounts of row filtering (or
> none).
>
> Observations:
> - There seems insignificant row-filter overheads (e.g. viz no filter
> and 100% allowed versus HEAD).
> - The elapsed time decreases linearly as there is less data getting replicated.
>
> I will post the results for other workload kinds (b, c, d) when I have them.
>
> ------
> Kind Regards,
> Peter Smith.
> Fujitsu Australia.
On Wed, Feb 2, 2022 at 8:16 PM Ajin Cherian <itsajin@gmail.com> wrote: > > Hi Peter, > > I just tried scenario b that Andres suggested: > > For scenario b, I did some testing with row-filter-patch v74 and > various levels of filtering. 0% replicated to 100% rows replicated. > The times are in seconds, I did 5 runs each. > > Results: > > RUN HEAD "with patch 0%" "row-filter-patch 25%" "row-filter-patch > v74 50%" "row-filter-patch 75%" "row-filter-patch v74 100%" > 1 17.26178 12.573736 12.869635 13.742167 > 17.977112 17.75814 > 2 17.522473 12.919554 12.640879 14.202737 > 14.515481 16.961836 > 3 17.124001 12.640879 12.706631 14.220245 > 15.686613 17.219355 > 4 17.24122 12.602345 12.674566 14.219423 > 15.564312 17.432765 > 5 17.25352 12.610657 12.689842 14.210725 > 15.613708 17.403821 > > As can see the performance seen on HEAD is similar to that which the > patch achieves with all rows (100%) replication. The performance > improves linearly with > more rows filtered. > > The test scenario used was: > > 1. On publisher and subscriber: > CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); > > 2. On publisher: (based on which scenario is being tested) > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed > > 3. On the subscriber: > CREATE SUBSCRIPTION sync_sub CONNECTION 'host=127.0.0.1 port=5432 > dbname=postgres application_name=sync_sub' PUBLICATION pub_1; > > 4. now modify the postgresql.conf on the publisher side > synchronous_standby_names = 'sync_sub' and restart. > > 5. The test case: > > DO > $do$ > BEGIN > FOR i IN 1..1000001 BY 10 LOOP > INSERT INTO test VALUES(i,'BAH', row_to_json(row(i))); > UPDATE test SET value = 'FOO' WHERE key = i; > IF I % 1000 = 0 THEN > COMMIT; > END IF; > END LOOP; > END > $do$; > > Thanks! I have put your results as a bar chart same as for the previous workload case: HEAD 17.25 v74 no filters NA v74 allow 100% 17.35 v74 allow 75% 15.62 v74 allow 50% 14.21 v74 allow 25% 12.69 v74 allow 0% 12.62 PSA. ------ Kind Regards, Peter Smith. Fujitsu Australia.
Вложения
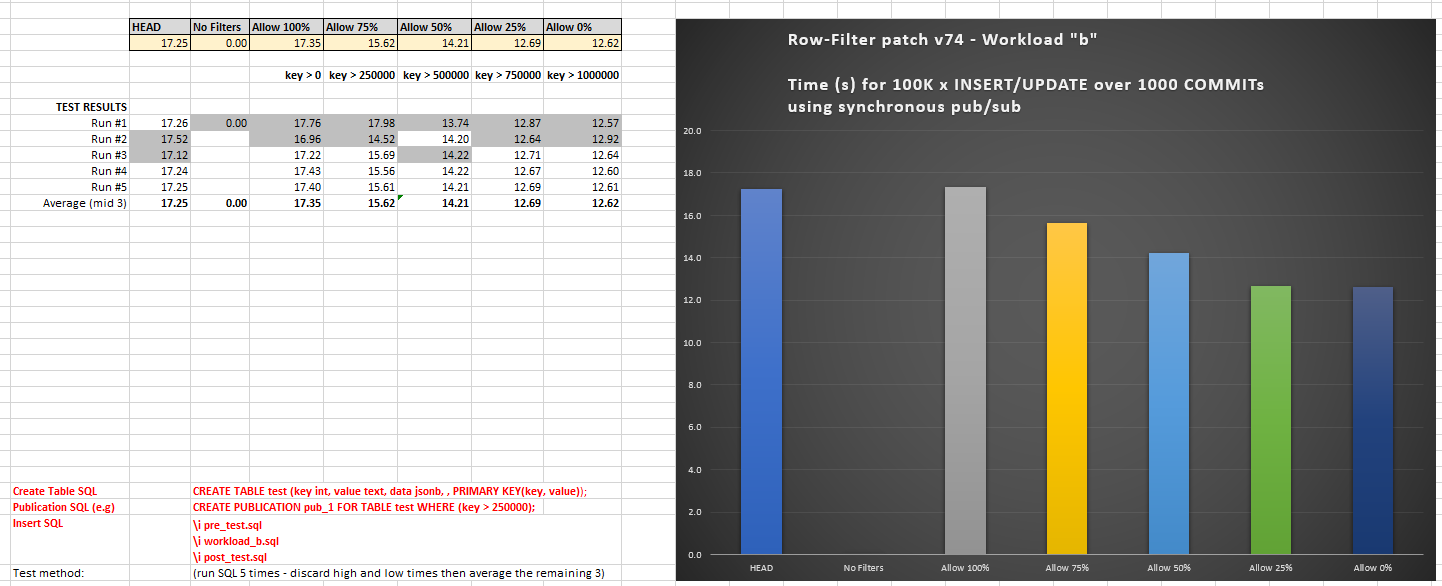{kind=link}
On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > Are there any recent performance evaluations of the overhead of row filters? I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table > Here are performance data results for the workload case (c): HEAD 105.75 v74 no filters 105.86 v74 allow 100% 104.94 v74 allow 75% 97.12 v74 allow 50% 78.92 v74 allow 25% 69.71 v74 allow 0% 59.70 This was tested using patch v74 and synchronous pub/sub. There are 100K INSERTS/UPDATES over 5 tables (all published) The PUBLICATIONS use differing amounts of row filtering (or none). Observations: - We see pretty much the same pattern as for workloads "a" and "b" - There seems insignificant row-filter overheads (e.g. viz no filter and 100% allowed versus HEAD). - The elapsed time decreases as more % data is filtered out (i.e as replication happens). PSA workload "c" test files for details. ------ Kind Regards, Peter Smith. Fujitsu Australia.
Вложения
{kind=link}
On Tuesday, February 1, 2022 7:22 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Tue, Feb 1, 2022 at 9:15 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
> wrote:
> >
> > On Monday, January 31, 2022 9:02 PM Amit Kapila
> > <amit.kapila16@gmail.com>
> > >
>
> Review Comments:
> ===============
> 1.
> + else if (IsA(node, OpExpr))
> + {
> + /* OK, except user-defined operators are not allowed. */ if (((OpExpr
> + *) node)->opno >= FirstNormalObjectId) errdetail_msg = _("User-defined
> + operators are not allowed."); }
>
> Is it sufficient to check only the allowed operators for OpExpr? Don't we need to
> check opfuncid to ensure that the corresponding function is immutable? Also,
> what about opresulttype, opcollid, and inputcollid? I think we don't want to allow
> user-defined types or collations but as we are restricting the opexp to use a
> built-in operator, those should not be present in such an expression. If that is the
> case, then I think we can add a comment for the same.
>
> 2. Can we handle RelabelType node in
> check_simple_rowfilter_expr_walker()? I think you need to check resulttype and
> collation id to ensure that they are not user-defined.
> There doesn't seem to be a need to check resulttypmod as that refers to
> pg_attribute.atttypmod and that can't have anything unsafe. This helps us to
> handle cases like the following which currently gives an
> error:
> create table t1(c1 int, c2 varchar(100)); create publication pub1 for table t1 where
> (c2 < 'john');
>
> 3. Similar to above, don't we need to consider disallowing non-built-in collation
> of Var type nodes? Now, as we are only supporting built-in types this might not
> be required. So, probably a comment would suffice.
I adjusted the code in check_simple_rowfilter_expr_walker to
handle the collation/type/function.
> 4.
> A minor nitpick in tab-complete:
> postgres=# Alter PUBLICATION pub1 ADD TABLE t2 WHERE ( c2 > 10)
> , WHERE (
>
> After the Where clause, it should not allow adding WHERE. This doesn't happen
> for CREATE PUBLICATION case.
I will look into this and change it soon.
Attach the V76 patch set which addressed above comments and comments from[1][2].
[1] https://www.postgresql.org/message-id/CAA4eK1L6hLRxFVphDO8mwuguc9kVdMu-DT2Dw2GXHwvprLoxrw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAA4eK1L6hLRxFVphDO8mwuguc9kVdMu-DT2Dw2GXHwvprLoxrw%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > Are there any recent performance evaluations of the overhead of row filters? I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table > Here's the performance data results for scenario d: HEAD "with patch no row filter" "with patch 0%" "row-filter-patch 25%" "row-filter-patch v74 50%" "row-filter-patch 75%" "row-filter-patch v74 100%" 1 65.397639 64.414034 5.919732 20.012096 36.35911 49.412548 64.508842 2 65.641783 65.255775 5.715082 20.157575 36.957403 51.355821 65.708444 3 65.096526 64.795163 6.146072 21.130709 37.679346 49.568513 66.602145 4 65.173569 64.644448 5.787197 20.784607 34.465133 55.397313 63.545337 5 65.791092 66.000412 5.642696 20.258802 36.493626 52.873252 63.511428 The performance is similar to the other scenarios. The script used is below: CREATE TABLE test (key int, value text, value1 text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed DO $do$ BEGIN FOR i IN 1..1000001 BY 4000 LOOP Alter table test alter column value1 TYPE varchar(30); INSERT INTO test VALUES(i,'BAH', row_to_json(row(i))); Alter table test ALTER COLUMN value1 TYPE text; UPDATE test SET value = 'FOO' WHERE key = i; COMMIT; END LOOP; END $do$; regards, Ajin Cherian Fujitsu Australia
Hi,
On 2022-02-01 13:31:36 +1100, Peter Smith wrote:
> TEST STEPS - Workload case a
>
> 1. Run initdb pub and sub and start both postgres instances (use the nosync postgresql.conf)
>
> 2. Run psql for both instances and create tables
> CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value));
>
> 3. create the PUBLISHER on pub instance (e.g. choose from below depending on filter)
> CREATE PUBLICATION pub_1 FOR TABLE test; -- 100% (no filter)
> CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed
> CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed
> CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed
> CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed
> CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed
>
> 4. create the SUBSCRIBER on sub instance
> CREATE SUBSCRIPTION sync_sub CONNECTION 'host=127.0.0.1 port=5432 dbname=postgres application_name=sync_sub'
PUBLICATIONpub_1;
>
> 5. On pub side modify the postgresql.conf on the publisher side and restart
> \q quite psql
> edit synchronous_standby_names = 'sync_sub'
> restart the pub instance
>
> 6. Run psql (pub side) and perform the test run.
> \timing
> INSERT INTO test SELECT i, i::text, row_to_json(row(i)) FROM generate_series(1,1000001)i;
> select count(*) from test;
> TRUNCATE test;
> select count(*) from test;
> repeat 6 for each test run.
I think think using syncrep as the mechanism for benchmarking the decoding
side makes the picture less clear than it could be - you're measuring a lot of
things other than the decoding. E.g. the overhead of applying those changes. I
think it'd be more accurate to do something like:
/* create publications, table, etc */
-- create a slot from before the changes
SELECT pg_create_logical_replication_slot('origin', 'pgoutput');
/* the changes you're going to measure */
-- save end LSN
SELECT pg_current_wal_lsn();
-- create a slot for pg_recvlogical to consume
SELECT * FROM pg_copy_logical_replication_slot('origin', 'consume');
-- benchmark, endpos is from pg_current_wal_lsn() above
time pg_recvlogical -S consume --endpos 0/2413A720 --start -o proto_version=3 -o publication_names=pub_1 -f /dev/null
-dpostgres
-- clean up
SELECT pg_drop_replication_slot('consume');
Then repeat this with the different publications and compare the time taken
for the pg_recvlogical. That way the WAL is exactly the same, there is no
overhead of actually doing anything with the data on the other side, etc.
Greetings,
Andres Freund
On Fri, Feb 4, 2022 at 2:26 AM Ajin Cherian <itsajin@gmail.com> wrote: > > On Sat, Jan 29, 2022 at 11:31 AM Andres Freund <andres@anarazel.de> wrote: > > > > Hi, > > > > Are there any recent performance evaluations of the overhead of row filters? I > > think it'd be good to get some numbers comparing: > > > > 1) $workload with master > > 2) $workload with patch, but no row filters > > 3) $workload with patch, row filter matching everything > > 4) $workload with patch, row filter matching few rows > > > > For workload I think it'd be worth testing: > > a) bulk COPY/INSERT into one table > > b) Many transactions doing small modifications to one table > > c) Many transactions targetting many different tables > > d) Interspersed DDL + small changes to a table > > > > Here's the performance data results for scenario d: > > HEAD "with patch no row filter" "with patch 0%" "row-filter-patch > 25%" "row-filter-patch v74 50%" "row-filter-patch 75%" > "row-filter-patch v74 100%" > 1 65.397639 64.414034 5.919732 20.012096 36.35911 49.412548 64.508842 > 2 65.641783 65.255775 5.715082 20.157575 36.957403 51.355821 65.708444 > 3 65.096526 64.795163 6.146072 21.130709 37.679346 49.568513 66.602145 > 4 65.173569 64.644448 5.787197 20.784607 34.465133 55.397313 63.545337 > 5 65.791092 66.000412 5.642696 20.258802 36.493626 52.873252 63.511428 > > The performance is similar to the other scenarios. > The script used is below: > > CREATE TABLE test (key int, value text, value1 text, data jsonb, > PRIMARY KEY(key, value)); > > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed > CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed > > DO > $do$ > BEGIN > FOR i IN 1..1000001 BY 4000 LOOP > Alter table test alter column value1 TYPE varchar(30); > INSERT INTO test VALUES(i,'BAH', row_to_json(row(i))); > Alter table test ALTER COLUMN value1 TYPE text; > UPDATE test SET value = 'FOO' WHERE key = i; > COMMIT; > END LOOP; > END > $do$; > Just for completeness, I have shown Ajin's workload "d" test results as a bar chart same as for the previous perf test posts: HEAD 65.40 v74 no filters 64.90 v74 allow 100% 64.59 v74 allow 75% 51.27 v74 allow 50% 35.97 v74 allow 25% 20.40 v74 allow 0% 5.78 PSA. ------ Kind Regards, Peter Smith. Fujitsu Australia
Вложения
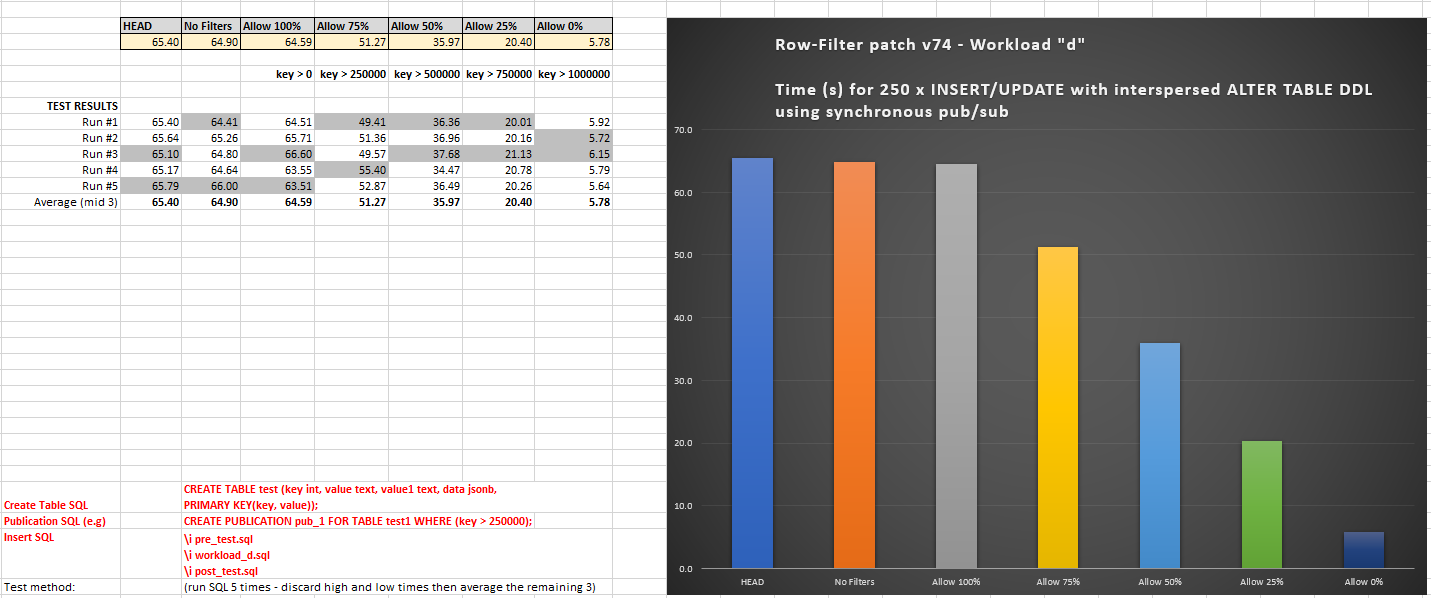{kind=link}
On Thursday, February 3, 2022 11:11 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
> On Tuesday, February 1, 2022 7:22 PM Amit Kapila <amit.kapila16@gmail.com>
> wrote:
> >
> > On Tue, Feb 1, 2022 at 9:15 AM houzj.fnst@fujitsu.com
> > <houzj.fnst@fujitsu.com>
> > wrote:
> > >
> > > On Monday, January 31, 2022 9:02 PM Amit Kapila
> > > <amit.kapila16@gmail.com>
> > > >
> >
> > Review Comments:
> > ===============
> > 1.
> > + else if (IsA(node, OpExpr))
> > + {
> > + /* OK, except user-defined operators are not allowed. */ if
> > + (((OpExpr
> > + *) node)->opno >= FirstNormalObjectId) errdetail_msg =
> > + _("User-defined operators are not allowed."); }
> >
> > Is it sufficient to check only the allowed operators for OpExpr? Don't
> > we need to check opfuncid to ensure that the corresponding function is
> > immutable? Also, what about opresulttype, opcollid, and inputcollid? I
> > think we don't want to allow user-defined types or collations but as
> > we are restricting the opexp to use a built-in operator, those should
> > not be present in such an expression. If that is the case, then I think we can
> add a comment for the same.
> >
> > 2. Can we handle RelabelType node in
> > check_simple_rowfilter_expr_walker()? I think you need to check
> > resulttype and collation id to ensure that they are not user-defined.
> > There doesn't seem to be a need to check resulttypmod as that refers
> > to pg_attribute.atttypmod and that can't have anything unsafe. This
> > helps us to handle cases like the following which currently gives an
> > error:
> > create table t1(c1 int, c2 varchar(100)); create publication pub1 for
> > table t1 where
> > (c2 < 'john');
> >
> > 3. Similar to above, don't we need to consider disallowing
> > non-built-in collation of Var type nodes? Now, as we are only
> > supporting built-in types this might not be required. So, probably a
> comment would suffice.
>
> I adjusted the code in check_simple_rowfilter_expr_walker to handle the
> collation/type/function.
>
> > 4.
> > A minor nitpick in tab-complete:
> > postgres=# Alter PUBLICATION pub1 ADD TABLE t2 WHERE ( c2 > 10)
> > , WHERE (
> >
> > After the Where clause, it should not allow adding WHERE. This doesn't
> > happen for CREATE PUBLICATION case.
>
> I will look into this and change it soon.
Since the v76-0000-clean-up-pgoutput-cache-invalidation.patch has been
committed, attach a new version patch set to make the cfbot happy. Also
addressed the above comments related to tab-complete in 0002 patch.
Best regards,
Hou zj
Вложения
> Are there any recent performance evaluations of the overhead of row filters? I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table > We have collected the performance data results for the workloads "a", "b", "c" (will do case "d" later). This time the tests were re-run now using pg_recvlogical and steps as Andres suggested [1]. Note - "Allow 100%" is included as a test case, but in practice, a user is unlikely to deliberately use a filter that allows everything to pass through it. PSA the bar charts of the results. All other details are below. ~~~~~ RESULTS - workload "a" ====================== HEAD 18.40 No Filters 18.86 Allow 100% 17.96 Allow 75% 16.39 Allow 50% 14.60 Allow 25% 11.23 Allow 0% 9.41 RESULTS - workload "b" ====================== HEAD 2.30 No Filters 1.96 Allow 100% 1.99 Allow 75% 1.65 Allow 50% 1.35 Allow 25% 1.17 Allow 0% 0.84 RESULTS - workload "c" ====================== HEAD 20.40 No Filters 19.85 Allow 100% 20.94 Allow 75% 17.26 Allow 50% 16.13 Allow 25% 13.32 Allow 0% 10.33 RESULTS - workload "d" ====================== (later) ~~~~~~ Details - workload "a" ======================= CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test; CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed INSERT INTO test SELECT i, i::text, row_to_json(row(i)) FROM generate_series(1,1000001)i; Details - workload "b" ====================== CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test; CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed DO $do$ BEGIN FOR i IN 0..1000001 BY 10 LOOP INSERT INTO test VALUES(i,'BAH', row_to_json(row(i))); UPDATE test SET value = 'FOO' WHERE key = i; IF I % 1000 = 0 THEN COMMIT; END IF; END LOOP; END $do$; Details - workload "c" ====================== CREATE TABLE test1 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test2 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test3 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test4 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test5 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test1, test2, test3, test4, test5; CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 0), test2 WHERE (key > 0), test3 WHERE (key > 0), test4 WHERE (key > 0), test5 WHERE (key > 0); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 250000), test2 WHERE (key > 250000), test3 WHERE (key > 250000), test4 WHERE (key > 250000), test5 WHERE (key > 250000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 500000), test2 WHERE (key > 500000), test3 WHERE (key > 500000), test4 WHERE (key > 500000), test5 WHERE (key > 500000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 750000), test2 WHERE (key > 750000), test3 WHERE (key > 750000), test4 WHERE (key > 750000), test5 WHERE (key > 750000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 1000000), test2 WHERE (key > 1000000), test3 WHERE (key > 1000000), test4 WHERE (key > 1000000), test5 WHERE (key > 1000000); DO $do$ BEGIN FOR i IN 0..1000001 BY 10 LOOP -- test1 INSERT INTO test1 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test1 SET value = 'FOO' WHERE key = i; -- test2 INSERT INTO test2 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test2 SET value = 'FOO' WHERE key = i; -- test3 INSERT INTO test3 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test3 SET value = 'FOO' WHERE key = i; -- test4 INSERT INTO test4 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test4 SET value = 'FOO' WHERE key = i; -- test5 INSERT INTO test5 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test5 SET value = 'FOO' WHERE key = i; IF I % 1000 = 0 THEN -- raise notice 'commit: %', i; COMMIT; END IF; END LOOP; END $do$; Details - workload "d" ====================== (later) ------ [1] https://www.postgresql.org/message-id/20220203182922.344fhhqzjp2ah6yp%40alap3.anarazel.de Kind Regards, Peter Smith. Fujitsu Australia
Вложения
{kind=link}
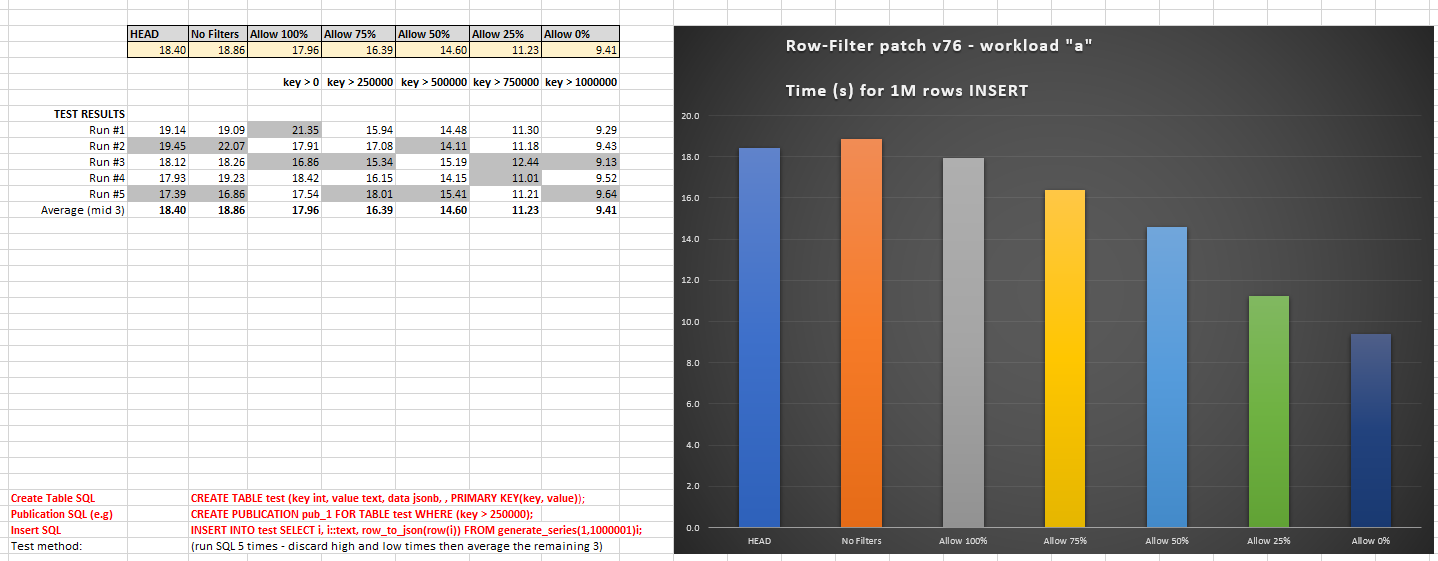{kind=link}
{kind=link}
On Fri, Feb 4, 2022 at 2:58 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Thursday, February 3, 2022 11:11 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > > Since the v76-0000-clean-up-pgoutput-cache-invalidation.patch has been > committed, attach a new version patch set to make the cfbot happy. Also > addressed the above comments related to tab-complete in 0002 patch. > I don't like some of the error message changes in this new version. For example: v75: +CREATE FUNCTION testpub_rf_func1(integer, integer) RETURNS boolean AS $$ SELECT hashint4($1) > $2 $$ LANGUAGE SQL; +CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func1, LEFTARG = integer, RIGHTARG = integer); +CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); +ERROR: invalid publication WHERE expression for relation "testpub_rf_tbl3" +DETAIL: User-defined operators are not allowed. v77 +CREATE FUNCTION testpub_rf_func1(integer, integer) RETURNS boolean AS $$ SELECT hashint4($1) > $2 $$ LANGUAGE SQL; +CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func1, LEFTARG = integer, RIGHTARG = integer); +CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); +ERROR: invalid publication WHERE expression +LINE 1: ...ICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); + ^ +DETAIL: User-defined or mutable functions are not allowed I think the detailed message by v75 "DETAIL: User-defined operators are not allowed." will be easier for users to understand. I have made some code changes and refactoring to make this behavior like previous without removing the additional checks you have added in v77. I have made a few changes to comments and error messages. Attached is a top-up patch on your v77 patch series. I suggest we can combine the 0001 and 0002 patches as well. -- With Regards, Amit Kapila.
Вложения
On Sat, Feb 5, 2022 7:51 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Feb 4, 2022 at 2:58 PM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> > wrote: > > > > On Thursday, February 3, 2022 11:11 PM houzj.fnst@fujitsu.com > > <houzj.fnst@fujitsu.com> > > > > Since the v76-0000-clean-up-pgoutput-cache-invalidation.patch has been > > committed, attach a new version patch set to make the cfbot happy. > > Also addressed the above comments related to tab-complete in 0002 patch. > > > > I don't like some of the error message changes in this new version. For example: > > v75: > +CREATE FUNCTION testpub_rf_func1(integer, integer) RETURNS boolean AS > $$ SELECT hashint4($1) > $2 $$ LANGUAGE SQL; > +CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func1, LEFTARG = integer, > RIGHTARG = integer); > +CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); > +ERROR: invalid publication WHERE expression for relation "testpub_rf_tbl3" > +DETAIL: User-defined operators are not allowed. > > v77 > +CREATE FUNCTION testpub_rf_func1(integer, integer) RETURNS boolean AS > $$ SELECT hashint4($1) > $2 $$ LANGUAGE SQL; > +CREATE OPERATOR =#> (PROCEDURE = testpub_rf_func1, LEFTARG = integer, > RIGHTARG = integer); > +CREATE PUBLICATION testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); > +ERROR: invalid publication WHERE expression LINE 1: ...ICATION > +testpub6 FOR TABLE testpub_rf_tbl3 WHERE (e =#> 27); > + ^ > +DETAIL: User-defined or mutable functions are not allowed > > I think the detailed message by v75 "DETAIL: User-defined operators are not > allowed." will be easier for users to understand. I have made some code changes > and refactoring to make this behavior like previous without removing the > additional checks you have added in v77. I have made a few changes to > comments and error messages. Attached is a top-up patch on your v77 patch > series. I suggest we can combine the > 0001 and 0002 patches as well. Thanks for the comments. Your changes look good to me. Attach the V78 patch which addressed the above changes and merged 0001 and 0002. Best regards, Hou zj
Вложения
Hi - I did a review of the v77 patches merged with Amit's v77 diff patch [1].
(Maybe this is equivalent to reviewing v78)
Below are my review comments:
======
1. doc/src/sgml/ref/create_publication.sgml - CREATE PUBLICATION
+ The <literal>WHERE</literal> clause allows simple expressions that
don't have
+ user-defined functions, operators, collations, non-immutable built-in
+ functions, or references to system columns.
+ </para>
That seems slightly ambiguous for operators and collations. It's only
the USER-DEFINED ones we don't support.
Perhaps it should be worded like:
"allows simple expressions that don't have user-defined
functions/operators/collations, non-immutable built-in functions..."
or like
"allows simple expressions that don't have user-defined functions,
user-defined operators, user-defined collations, non-immutable
built-in functions..."
~~~
2. src/backend/catalog/pg_publication.c - GetTopMostAncestorInPublication
+Oid
+GetTopMostAncestorInPublication(Oid puboid, List *ancestors)
+{
+ ListCell *lc;
+ Oid topmost_relid = InvalidOid;
+
+ /*
+ * Find the "topmost" ancestor that is in this publication.
+ */
+ foreach(lc, ancestors)
+ {
+ Oid ancestor = lfirst_oid(lc);
+ List *apubids = GetRelationPublications(ancestor);
+ List *aschemaPubids = NIL;
+
+ if (list_member_oid(apubids, puboid))
+ topmost_relid = ancestor;
+ else
+ {
+ aschemaPubids = GetSchemaPublications(get_rel_namespace(ancestor));
+ if (list_member_oid(aschemaPubids, puboid))
+ topmost_relid = ancestor;
+ }
+
+ list_free(apubids);
+ list_free(aschemaPubids);
+ }
+
+ return topmost_relid;
+}
Wouldn't it be better for the aschemaPubids to be declared and freed
inside the else block?
e.g.
else
{
List *aschemaPubids = GetSchemaPublications(get_rel_namespace(ancestor));
if (list_member_oid(aschemaPubids, puboid))
topmost_relid = ancestor;
list_free(aschemaPubids);
}
~~~
3. src/backend/commands/publicationcmds.c - contain_invalid_rfcolumn
+ if (pubviaroot && relation->rd_rel->relispartition)
+ {
+ publish_as_relid = GetTopMostAncestorInPublication(pubid, ancestors);
+
+ if (publish_as_relid == InvalidOid)
+ publish_as_relid = relid;
+ }
Consider using the macro code for the InvalidOid check. e.g.
if (!OidIsValid(publish_as_relid)
publish_as_relid = relid;
~~~
4. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (Tests)
+ switch (nodeTag(node))
+ {
+ case T_ArrayExpr:
+ case T_BooleanTest:
+ case T_BoolExpr:
+ case T_CaseExpr:
+ case T_CaseTestExpr:
+ case T_CoalesceExpr:
+ case T_CollateExpr:
+ case T_Const:
+ case T_FuncExpr:
+ case T_MinMaxExpr:
+ case T_NullTest:
+ case T_RelabelType:
+ case T_XmlExpr:
+ return true;
+ default:
+ return false;
+ }
I think there are several missing regression tests.
4a. There is a new message that says "User-defined collations are not
allowed." but I never saw any test case for it.
4b. There is also the RelabelType which seems to have no test case.
Amit previously provided [2] some SQL which would give an unexpected
error, so I guess that should be a new regression test case. e.g.
create table t1(c1 int, c2 varchar(100));
create publication pub1 for table t1 where (c2 < 'john');
~~~
5. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (Simple?)
+/*
+ * Is this a simple Node permitted within a row filter expression?
+ */
+static bool
+IsRowFilterSimpleExpr(Node *node)
+{
A lot has changed in this area recently and I feel that there is
something not quite 100% right with the naming and/or logic in this
expression validation. IMO there are several functions that seem to
depend too much on each other in special ways...
IIUC the "walker" logic now seems to be something like this:
a) Check for special cases of the supported nodes
b) Then check for supported (simple?) nodes (i.e.
IsRowFilterSimpleExpr is now acting as a "catch-all" after the special
case checks)
c) Then check for some unsupported node embedded within a supported
node (i.e. call expr_allowed_in_node)
d) If any of a,b,c was bad then give an error.
To achieve that logic the T_FuncExpr was added to the
"IsRowFilterSimpleExpr". Meanwhile, other nodes like
T_ScalarArrayOpExpr and T_NullIfExpr now are removed from
IsRowFilterSimpleExpr - I don't quite know why these got removed but
perhaps there is implicit knowledge that those node kinds were already
checked by the "walker" before the IsRowFilterSimpleExpr function ever
gets called.
So, although I trust that everything is working OK, I don't think
IsRowFilterSimpleExpr is really just about simple nodes anymore. It is
harder to see why some supported nodes are in there, and some
supported nodes are not. It seems tightly entwined with the logic of
check_simple_rowfilter_expr_walker; i.e. there seem to be assumptions
about exactly when it will be called and what was checked before and
what will be checked after calling it.
IMO probably all the nodes we are supporting should be in the
IsRowFilterSimpleExpr just for completeness (e.g. put T_NullIfExpr and
T_ScalarArrayOpExpr back in there...), and maybe the function should
be renamed (IsRowFilterAllowedNode?), and probably there need to be
more comments describing the validation logic (e.g. the a/b/c/d logic
I mentioned above).
~~~
6. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (T_List)
(From Amit's patch)
@@ -395,6 +397,7 @@ IsRowFilterSimpleExpr(Node *node)
case T_NullTest:
case T_RelabelType:
case T_XmlExpr:
+ case T_List:
return true;
default:
return false;
The case T_List should be moved to be alphabetical the same as all the
other cases.
~~~
7. src/backend/commands/publicationcmds.c -
contain_mutable_or_ud_functions_checker
+/* check_functions_in_node callback */
+static bool
+contain_mutable_or_ud_functions_checker(Oid func_id, void *context)
"ud" seems a strange name. Maybe better to name this function
"contain_mutable_or_user_functions_checker" ?
~~~
8. src/backend/commands/publicationcmds.c - expr_allowed_in_node (comment)
(From Amit's patch)
@@ -410,6 +413,37 @@ contain_mutable_or_ud_functions_checker(Oid
func_id, void *context)
}
/*
+ * Check, if the node contains any unallowed object in node. See
+ * check_simple_rowfilter_expr_walker.
+ *
+ * Returns the error detail meesage in errdetail_msg for unallowed expressions.
+ */
+static bool
+expr_allowed_in_node(Node *node, ParseState *pstate, char **errdetail_msg)
Remove the comma: "Check, if ..." --> "Check if ..."
Typo: "meesage" --> "message"
~~~
9. src/backend/commands/publicationcmds.c - expr_allowed_in_node (else)
(From Amit's patch)
+ if (exprType(node) >= FirstNormalObjectId)
+ *errdetail_msg = _("User-defined types are not allowed.");
+ if (check_functions_in_node(node, contain_mutable_or_ud_functions_checker,
+ (void*) pstate))
+ *errdetail_msg = _("User-defined or built-in mutable functions are
not allowed.");
+ else if (exprCollation(node) >= FirstNormalObjectId)
+ *errdetail_msg = _("User-defined collations are not allowed.");
+ else if (exprInputCollation(node) >= FirstNormalObjectId)
+ *errdetail_msg = _("User-defined collations are not allowed.");
Is that correct - isn't there a missing "else" on the 2nd "if"?
~~~
10. src/backend/commands/publicationcmds.c - expr_allowed_in_node (bool)
(From Amit's patch)
+static bool
+expr_allowed_in_node(Node *node, ParseState *pstate, char **errdetail_msg)
Why is this a boolean function? It can never return false (??)
~~~
11. src/backend/commands/publicationcmds.c -
check_simple_rowfilter_expr_walker (else)
(From Amit's patch)
@@ -500,12 +519,18 @@ check_simple_rowfilter_expr_walker(Node *node,
ParseState *pstate)
}
}
}
- else if (!IsRowFilterSimpleExpr(node))
+ else if (IsRowFilterSimpleExpr(node))
+ {
+ }
+ else
{
elog(DEBUG3, "row filter contains an unexpected expression
component: %s", nodeToString(node));
errdetail_msg = _("Expressions only allow columns, constants,
built-in operators, built-in data types, built-in collations and
immutable built-in functions.");
}
Why introduce a new code block that does nothing?
~~~
12. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry
+ /*
+ * Initialize the row filter after getting the final publish_as_relid
+ * as we only evaluate the row filter of the relation which we publish
+ * change as.
+ */
+ pgoutput_row_filter_init(data, active_publications, entry);
The comment "which we publish change as" seems strangely worded.
Perhaps it should be:
"... only evaluate the row filter of the relation which being published."
~~~
13. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc (release)
+ /*
+ * Check if all columns referenced in the filter expression are part of
+ * the REPLICA IDENTITY index or not.
+ *
+ * If the publication is FOR ALL TABLES then it means the table has no
+ * row filters and we can skip the validation.
+ */
+ if (!pubform->puballtables &&
+ (pubform->pubupdate || pubform->pubdelete) &&
+ contain_invalid_rfcolumn(pubid, relation, ancestors,
+ pubform->pubviaroot))
+ {
+ if (pubform->pubupdate)
+ pubdesc->rf_valid_for_update = false;
+ if (pubform->pubdelete)
+ pubdesc->rf_valid_for_delete = false;
+ }
ReleaseSysCache(tup);
This change has the effect of moving the location of the
"ReleaseSysCache(tup);" to much lower in the code but I think there is
no point to move it for the Row Filter patch, so it should be left
where it was before.
~~~
14. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
(if refactor)
- if (pubactions->pubinsert && pubactions->pubupdate &&
- pubactions->pubdelete && pubactions->pubtruncate)
+ if (pubdesc->pubactions.pubinsert && pubdesc->pubactions.pubupdate &&
+ pubdesc->pubactions.pubdelete && pubdesc->pubactions.pubtruncate &&
+ !pubdesc->rf_valid_for_update && !pubdesc->rf_valid_for_delete)
break;
I felt that the "rf_valid_for_update" and "rf_valid_for_delete" should
be checked first in that if condition. It is probably more optimal to
move them because then it can bail out early. All those other
pubaction flags are more likely to be true most of the time (because
that is the default case).
~~~
15. src/bin/psql/describe.c - SQL format
@@ -2898,12 +2902,12 @@ describeOneTableDetails(const char *schemaname,
else
{
printfPQExpBuffer(&buf,
- "SELECT pubname\n"
+ "SELECT pubname, NULL\n"
"FROM pg_catalog.pg_publication p\n"
"JOIN pg_catalog.pg_publication_rel pr ON p.oid = pr.prpubid\n"
"WHERE pr.prrelid = '%s'\n"
"UNION ALL\n"
- "SELECT pubname\n"
+ "SELECT pubname, NULL\n"
"FROM pg_catalog.pg_publication p\n"
I thought it may be better to reformat to put the NULL columns on a
different line for consistent format with the other SQL just above
this one. e.g.
printfPQExpBuffer(&buf,
"SELECT pubname\n"
+ " , NULL\n"
...
------
[1] https://www.postgresql.org/message-id/CAA4eK1LApUf%3DagS86KMstoosEBD74GD6%2BPPYGF419kwLw6fvrw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CAA4eK1KDtwUcuFHOJ4zCCTEY4%2B_-X3fKTjn%3DkyaZwBeeqRF-oA%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Mon, Feb 7, 2022 at 1:21 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 5. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (Simple?)
>
> +/*
> + * Is this a simple Node permitted within a row filter expression?
> + */
> +static bool
> +IsRowFilterSimpleExpr(Node *node)
> +{
>
> A lot has changed in this area recently and I feel that there is
> something not quite 100% right with the naming and/or logic in this
> expression validation. IMO there are several functions that seem to
> depend too much on each other in special ways...
>
> IIUC the "walker" logic now seems to be something like this:
> a) Check for special cases of the supported nodes
> b) Then check for supported (simple?) nodes (i.e.
> IsRowFilterSimpleExpr is now acting as a "catch-all" after the special
> case checks)
> c) Then check for some unsupported node embedded within a supported
> node (i.e. call expr_allowed_in_node)
> d) If any of a,b,c was bad then give an error.
>
> To achieve that logic the T_FuncExpr was added to the
> "IsRowFilterSimpleExpr". Meanwhile, other nodes like
> T_ScalarArrayOpExpr and T_NullIfExpr now are removed from
> IsRowFilterSimpleExpr - I don't quite know why these got removed
>
They are removed because those nodes need some special checks based on
which errors could be raised whereas other nodes don't need such
checks.
> but
> perhaps there is implicit knowledge that those node kinds were already
> checked by the "walker" before the IsRowFilterSimpleExpr function ever
> gets called.
>
> So, although I trust that everything is working OK, I don't think
> IsRowFilterSimpleExpr is really just about simple nodes anymore. It is
> harder to see why some supported nodes are in there, and some
> supported nodes are not. It seems tightly entwined with the logic of
> check_simple_rowfilter_expr_walker; i.e. there seem to be assumptions
> about exactly when it will be called and what was checked before and
> what will be checked after calling it.
>
> IMO probably all the nodes we are supporting should be in the
> IsRowFilterSimpleExpr just for completeness (e.g. put T_NullIfExpr and
> T_ScalarArrayOpExpr back in there...), and maybe the function should
> be renamed (IsRowFilterAllowedNode?),
>
I am not sure if that is a good idea because then instead of
true/false, we need to get an error message as well but I think we can
move back all the nodes handled in IsRowFilterSimpleExpr back to
check_simple_rowfilter_expr_walker() and change the handling to
switch..case
One more thing in this context is, in ScalarArrayOpExpr handling, we
are not checking a few parameters like hashfuncid. Can we please add a
comment that why some parameters are checked and others not?
>
> ~~~
>
> 6. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (T_List)
>
> (From Amit's patch)
>
> @@ -395,6 +397,7 @@ IsRowFilterSimpleExpr(Node *node)
> case T_NullTest:
> case T_RelabelType:
> case T_XmlExpr:
> + case T_List:
> return true;
> default:
> return false;
>
>
> The case T_List should be moved to be alphabetical the same as all the
> other cases.
>
Hmm, I have added based on the way it is defined in nodes.h. T_List is
defined after T_XmlExpr in nodes.h. I don't see they are handled in
alphabetical order in other places like in check_functions_in_node().
I think the nodes that need the same handling should be together and
again there also we can keep them in order as they are defined in
nodes.h and otherwise also all other nodes should be in the same order
as they are defined in nodes.h. That way we will be consistent.
--
With Regards,
Amit Kapila.
On Monday, February 7, 2022 3:51 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Hi - I did a review of the v77 patches merged with Amit's v77 diff patch [1].
>
> (Maybe this is equivalent to reviewing v78)
>
> Below are my review comments:
Thanks for the comments!
> ======
>
> 1. doc/src/sgml/ref/create_publication.sgml - CREATE PUBLICATION
>
> + The <literal>WHERE</literal> clause allows simple expressions that
> don't have
> + user-defined functions, operators, collations, non-immutable built-in
> + functions, or references to system columns.
> + </para>
>
> That seems slightly ambiguous for operators and collations. It's only
> the USER-DEFINED ones we don't support.
>
> Perhaps it should be worded like:
>
> "allows simple expressions that don't have user-defined functions,
> user-defined operators, user-defined collations, non-immutable
> built-in functions..."
Changed.
>
> 2. src/backend/catalog/pg_publication.c - GetTopMostAncestorInPublication
>
> +Oid
> +GetTopMostAncestorInPublication(Oid puboid, List *ancestors)
> +{
> + ListCell *lc;
> + Oid topmost_relid = InvalidOid;
> +
> + /*
> + * Find the "topmost" ancestor that is in this publication.
> + */
> + foreach(lc, ancestors)
> + {
> + Oid ancestor = lfirst_oid(lc);
> + List *apubids = GetRelationPublications(ancestor);
> + List *aschemaPubids = NIL;
> +
> + if (list_member_oid(apubids, puboid))
> + topmost_relid = ancestor;
> + else
> + {
> + aschemaPubids = GetSchemaPublications(get_rel_namespace(ancestor));
> + if (list_member_oid(aschemaPubids, puboid))
> + topmost_relid = ancestor;
> + }
> +
> + list_free(apubids);
> + list_free(aschemaPubids);
> + }
> +
> + return topmost_relid;
> +}
>
> Wouldn't it be better for the aschemaPubids to be declared and freed
> inside the else block?
I personally think the current code is clean and the code was borrowed from
Greg's comment[1]. So, I didn't change this.
[1] https://www.postgresql.org/message-id/CAJcOf-c2%2BWbjeP7NhwgcAEtsn9KdDnhrsowheafbZ9%2BQU9C8SQ%40mail.gmail.com
>
> 3. src/backend/commands/publicationcmds.c - contain_invalid_rfcolumn
>
> + if (pubviaroot && relation->rd_rel->relispartition)
> + {
> + publish_as_relid = GetTopMostAncestorInPublication(pubid, ancestors);
> +
> + if (publish_as_relid == InvalidOid)
> + publish_as_relid = relid;
> + }
>
> Consider using the macro code for the InvalidOid check. e.g.
>
> if (!OidIsValid(publish_as_relid)
> publish_as_relid = relid;
>
Changed.
>
> 4. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (Tests)
>
> + switch (nodeTag(node))
> + {
> + case T_ArrayExpr:
> + case T_BooleanTest:
> + case T_BoolExpr:
> + case T_CaseExpr:
> + case T_CaseTestExpr:
> + case T_CoalesceExpr:
> + case T_CollateExpr:
> + case T_Const:
> + case T_FuncExpr:
> + case T_MinMaxExpr:
> + case T_NullTest:
> + case T_RelabelType:
> + case T_XmlExpr:
> + return true;
> + default:
> + return false;
> + }
>
> I think there are several missing regression tests.
>
> 4a. There is a new message that says "User-defined collations are not
> allowed." but I never saw any test case for it.
>
> 4b. There is also the RelabelType which seems to have no test case.
> Amit previously provided [2] some SQL which would give an unexpected
> error, so I guess that should be a new regression test case. e.g.
> create table t1(c1 int, c2 varchar(100));
> create publication pub1 for table t1 where (c2 < 'john');
I added some tests to cover these nodes.
>
> 5. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr
> (Simple?)
>
> +/*
> + * Is this a simple Node permitted within a row filter expression?
> + */
> +static bool
> +IsRowFilterSimpleExpr(Node *node)
> +{
>
> A lot has changed in this area recently and I feel that there is
> something not quite 100% right with the naming and/or logic in this
> expression validation. IMO there are several functions that seem to
> depend too much on each other in special ways...
>
> IIUC the "walker" logic now seems to be something like this:
> a) Check for special cases of the supported nodes
> b) Then check for supported (simple?) nodes (i.e.
> IsRowFilterSimpleExpr is now acting as a "catch-all" after the special
> case checks)
> c) Then check for some unsupported node embedded within a supported
> node (i.e. call expr_allowed_in_node)
> d) If any of a,b,c was bad then give an error.
>
> To achieve that logic the T_FuncExpr was added to the
> "IsRowFilterSimpleExpr". Meanwhile, other nodes like
> T_ScalarArrayOpExpr and T_NullIfExpr now are removed from
> IsRowFilterSimpleExpr - I don't quite know why these got removed but
> perhaps there is implicit knowledge that those node kinds were already
> checked by the "walker" before the IsRowFilterSimpleExpr function ever
> gets called.
>
> So, although I trust that everything is working OK, I don't think
> IsRowFilterSimpleExpr is really just about simple nodes anymore. It is
> harder to see why some supported nodes are in there, and some
> supported nodes are not. It seems tightly entwined with the logic of
> check_simple_rowfilter_expr_walker; i.e. there seem to be assumptions
> about exactly when it will be called and what was checked before and
> what will be checked after calling it.
>
> IMO probably all the nodes we are supporting should be in the
> IsRowFilterSimpleExpr just for completeness (e.g. put T_NullIfExpr and
> T_ScalarArrayOpExpr back in there...), and maybe the function should
> be renamed (IsRowFilterAllowedNode?), and probably there need to be
> more comments describing the validation logic (e.g. the a/b/c/d logic
> I mentioned above).
I adjusted these codes by moving all the move back all the nodes handled in
IsRowFilterSimpleExpr back to check_simple_rowfilter_expr_walker() and change
the handling to switch..case.
>
> 6. src/backend/commands/publicationcmds.c - IsRowFilterSimpleExpr (T_List)
>
> (From Amit's patch)
>
> @@ -395,6 +397,7 @@ IsRowFilterSimpleExpr(Node *node)
> case T_NullTest:
> case T_RelabelType:
> case T_XmlExpr:
> + case T_List:
> return true;
> default:
> return false;
>
>
> The case T_List should be moved to be alphabetical the same as all the
> other cases.
I reordered these referring to the order as they are defined in nodes.h.
>
> 7. src/backend/commands/publicationcmds.c -
> contain_mutable_or_ud_functions_checker
>
> +/* check_functions_in_node callback */
> +static bool
> +contain_mutable_or_ud_functions_checker(Oid func_id, void *context)
>
> "ud" seems a strange name. Maybe better to name this function
> "contain_mutable_or_user_functions_checker" ?
>
Changed.
>
> 8. src/backend/commands/publicationcmds.c - expr_allowed_in_node
> (comment)
>
> (From Amit's patch)
>
> @@ -410,6 +413,37 @@ contain_mutable_or_ud_functions_checker(Oid
> func_id, void *context)
> }
>
> /*
> + * Check, if the node contains any unallowed object in node. See
> + * check_simple_rowfilter_expr_walker.
> + *
> + * Returns the error detail meesage in errdetail_msg for unallowed
> expressions.
> + */
> +static bool
> +expr_allowed_in_node(Node *node, ParseState *pstate, char
> **errdetail_msg)
>
> Remove the comma: "Check, if ..." --> "Check if ..."
> Typo: "meesage" --> "message"
>
Changed.
>
> 9. src/backend/commands/publicationcmds.c - expr_allowed_in_node (else)
>
> (From Amit's patch)
>
> + if (exprType(node) >= FirstNormalObjectId)
> + *errdetail_msg = _("User-defined types are not allowed.");
> + if (check_functions_in_node(node,
> contain_mutable_or_ud_functions_checker,
> + (void*) pstate))
> + *errdetail_msg = _("User-defined or built-in mutable functions are
> not allowed.");
> + else if (exprCollation(node) >= FirstNormalObjectId)
> + *errdetail_msg = _("User-defined collations are not allowed.");
> + else if (exprInputCollation(node) >= FirstNormalObjectId)
> + *errdetail_msg = _("User-defined collations are not allowed.");
>
> Is that correct - isn't there a missing "else" on the 2nd "if"?
>
Changed.
>
> 10. src/backend/commands/publicationcmds.c - expr_allowed_in_node (bool)
>
> (From Amit's patch)
>
> +static bool
> +expr_allowed_in_node(Node *node, ParseState *pstate, char
> **errdetail_msg)
>
> Why is this a boolean function? It can never return false (??)
>
Changed.
>
> 11. src/backend/commands/publicationcmds.c -
> check_simple_rowfilter_expr_walker (else)
>
> (From Amit's patch)
>
> @@ -500,12 +519,18 @@ check_simple_rowfilter_expr_walker(Node *node,
> ParseState *pstate)
> }
> }
> }
> - else if (!IsRowFilterSimpleExpr(node))
> + else if (IsRowFilterSimpleExpr(node))
> + {
> + }
> + else
> {
> elog(DEBUG3, "row filter contains an unexpected expression
> component: %s", nodeToString(node));
> errdetail_msg = _("Expressions only allow columns, constants,
> built-in operators, built-in data types, built-in collations and
> immutable built-in functions.");
> }
>
> Why introduce a new code block that does nothing?
>
Changed it to switch ... case which don’t have this problem.
>
> 12. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry
>
> + /*
> + * Initialize the row filter after getting the final publish_as_relid
> + * as we only evaluate the row filter of the relation which we publish
> + * change as.
> + */
> + pgoutput_row_filter_init(data, active_publications, entry);
>
> The comment "which we publish change as" seems strangely worded.
>
> Perhaps it should be:
> "... only evaluate the row filter of the relation which being published."
Changed.
>
> 13. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
> (release)
>
> + /*
> + * Check if all columns referenced in the filter expression are part of
> + * the REPLICA IDENTITY index or not.
> + *
> + * If the publication is FOR ALL TABLES then it means the table has no
> + * row filters and we can skip the validation.
> + */
> + if (!pubform->puballtables &&
> + (pubform->pubupdate || pubform->pubdelete) &&
> + contain_invalid_rfcolumn(pubid, relation, ancestors,
> + pubform->pubviaroot))
> + {
> + if (pubform->pubupdate)
> + pubdesc->rf_valid_for_update = false;
> + if (pubform->pubdelete)
> + pubdesc->rf_valid_for_delete = false;
> + }
>
> ReleaseSysCache(tup);
>
> This change has the effect of moving the location of the
> "ReleaseSysCache(tup);" to much lower in the code but I think there is
> no point to move it for the Row Filter patch, so it should be left
> where it was before.
The newly added code here refers to the 'pubform' which comes from the ' tup',
So I think we should release the tuple after these codes.
>
> 14. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
> (if refactor)
>
> - if (pubactions->pubinsert && pubactions->pubupdate &&
> - pubactions->pubdelete && pubactions->pubtruncate)
> + if (pubdesc->pubactions.pubinsert && pubdesc->pubactions.pubupdate
> &&
> + pubdesc->pubactions.pubdelete && pubdesc->pubactions.pubtruncate
> &&
> + !pubdesc->rf_valid_for_update && !pubdesc->rf_valid_for_delete)
> break;
>
> I felt that the "rf_valid_for_update" and "rf_valid_for_delete" should
> be checked first in that if condition. It is probably more optimal to
> move them because then it can bail out early. All those other
> pubaction flags are more likely to be true most of the time (because
> that is the default case).
I don't have a strong opinion on this, I feel it's fine to put the newly added
check at the end as it doesn't bring notable performance impact.
>
> 15. src/bin/psql/describe.c - SQL format
>
> @@ -2898,12 +2902,12 @@ describeOneTableDetails(const char
> *schemaname,
> else
> {
> printfPQExpBuffer(&buf,
> - "SELECT pubname\n"
> + "SELECT pubname, NULL\n"
> "FROM pg_catalog.pg_publication p\n"
> "JOIN pg_catalog.pg_publication_rel pr ON p.oid = pr.prpubid\n"
> "WHERE pr.prrelid = '%s'\n"
> "UNION ALL\n"
> - "SELECT pubname\n"
> + "SELECT pubname, NULL\n"
> "FROM pg_catalog.pg_publication p\n"
>
> I thought it may be better to reformat to put the NULL columns on a
> different line for consistent format with the other SQL just above
> this one. e.g.
>
> printfPQExpBuffer(&buf,
> "SELECT pubname\n"
> + " , NULL\n"
Changed.
Attach the V79 patch set which addressed the above comments and adjust some
comments related to expression check.
Best regards,
Hou zj
Вложения
On Tue, Feb 8, 2022 at 8:01 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > > > 12. src/backend/replication/pgoutput/pgoutput.c - get_rel_sync_entry > > > > + /* > > + * Initialize the row filter after getting the final publish_as_relid > > + * as we only evaluate the row filter of the relation which we publish > > + * change as. > > + */ > > + pgoutput_row_filter_init(data, active_publications, entry); > > > > The comment "which we publish change as" seems strangely worded. > > > > Perhaps it should be: > > "... only evaluate the row filter of the relation which being published." > > Changed. > I don't know if this change is an improvement. If you want to change then I don't think 'which' makes sense in the following part of the comment: "...relation which being published." Few other comments: ==================== 1. Can we save sending schema change messages if the row filter doesn't match by moving maybe_send_schema after row filter checks? 2. commit message/docs: "The WHERE clause only allows simple expressions that don't have user-defined functions, user-defined operators, user-defined collations, non-immutable built-in functions, or references to system columns." "user-defined types" is missing in this sentence. 3. + /* + * For all the supported nodes, check the functions and collations used in + * the nodes. + */ Again 'types' is missing in this comment. -- With Regards, Amit Kapila.
I did a review of the v79 patch. Below are my review comments:
======
1. doc/src/sgml/ref/create_publication.sgml - CREATE PUBLICATION
The commit message for v79-0001 says:
<quote>
If your publication contains a partitioned table, the publication parameter
publish_via_partition_root determines if it uses the partition row filter (if
the parameter is false, the default) or the root partitioned table row filter.
</quote>
I think that the same information should also be mentioned in the PG
DOCS for CREATE PUBLICATION note about the WHERE clause.
~~~
2. src/backend/commands/publicationcmds.c -
contain_mutable_or_ud_functions_checker
+/* check_functions_in_node callback */
+static bool
+contain_mutable_or_user_functions_checker(Oid func_id, void *context)
+{
+ return (func_volatile(func_id) != PROVOLATILE_IMMUTABLE ||
+ func_id >= FirstNormalObjectId);
+}
I was wondering why is the checking for user function and mutable
functions combined in one function like this. IMO it might be better
to have 2 "checker" callback functions instead of just one - then the
error messages can be split too so that only the relevant one is
displayed to the user.
BEFORE
contain_mutable_or_user_functions_checker --> "User-defined or
built-in mutable functions are not allowed."
AFTER
contain_user_functions_checker --> "User-defined functions are not allowed."
contain_mutable_function_checker --> "Built-in mutable functions are
not allowed."
~~~
3. src/backend/commands/publicationcmds.c - check_simple_rowfilter_expr_walker
+ case T_Const:
+ case T_FuncExpr:
+ case T_BoolExpr:
+ case T_RelabelType:
+ case T_CollateExpr:
+ case T_CaseExpr:
+ case T_CaseTestExpr:
+ case T_ArrayExpr:
+ case T_CoalesceExpr:
+ case T_MinMaxExpr:
+ case T_XmlExpr:
+ case T_NullTest:
+ case T_BooleanTest:
+ case T_List:
+ break;
Perhaps a comment should be added here simply saying "OK, supported"
just to make it more obvious?
~~~
4. src/test/regress/sql/publication.sql - test comment
+-- fail - user-defined types disallowed
For consistency with the nearby comments it would be better to reword this one:
"fail - user-defined types are not allowed"
~~~
5. src/test/regress/sql/publication.sql - test for \d
+-- test \d+ (now it displays filter information)
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub_dplus_rf_yes FOR TABLE testpub_rf_tbl1
WHERE (a > 1) WITH (publish = 'insert');
+CREATE PUBLICATION testpub_dplus_rf_no FOR TABLE testpub_rf_tbl1;
+RESET client_min_messages;
+\d+ testpub_rf_tbl1
Actually, the \d (without "+") will also display filters but I don't
think that has been tested anywhere. So suggest updating the comment
and adding one more test
AFTER
-- test \d+ <tablename> and \d <tablename> (now these display filter
information)
...
\d+ testpub_rf_tbl1
\d testpub_rf_tbl1
~~~
6. src/test/regress/sql/publication.sql - tests for partitioned table
+-- Tests for partitioned table
+ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (a > 99);
+ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
+-- ok - partition does not have row filter
+UPDATE rf_tbl_abcd_part_pk SET a = 1;
+ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
+-- ok - "a" is a OK col
+UPDATE rf_tbl_abcd_part_pk SET a = 1;
+ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (b > 99);
+ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
+-- ok - partition does not have row filter
+UPDATE rf_tbl_abcd_part_pk SET a = 1;
+ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
+-- fail - "b" is not in REPLICA IDENTITY INDEX
+UPDATE rf_tbl_abcd_part_pk SET a = 1;
Those comments and the way the code is arranged did not make it very
clear to me what exactly these tests are doing.
I think all the changes to the publish_via_partition_root belong BELOW
those test comments don't they?
Also the same comment "-- ok - partition does not have row filter"
appears 2 times so that can be made more clear too.
e.g. IIUC it should be changed to something a bit like this (Note - I
did not change the SQL, I only moved it a bit and changed the
comments):
AFTER (??)
-- Tests for partitioned table
ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (a > 99);
-- ok - PUBLISH_VIA_PARTITION_ROOT is false
-- Here the partition does not have a row filter
-- Col "a" is in replica identity.
ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
UPDATE rf_tbl_abcd_part_pk SET a = 1;
-- ok - PUBLISH_VIA_PARTITION_ROOT is true
-- Here the partition does not have a row filter, so the root filter
will be used.
-- Col "a" is in replica identity.
ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
UPDATE rf_tbl_abcd_part_pk SET a = 1;
-- Now change the root filter to use a column "b" (which is not in the
replica identity)
ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (b > 99);
-- ok - PUBLISH_VIA_PARTITION_ROOT is false
-- Here the partition does not have a row filter
-- Col "a" is in replica identity.
ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
UPDATE rf_tbl_abcd_part_pk SET a = 1;
-- fail - PUBLISH_VIA_PARTITION_ROOT is true
-- Here the root filter will be used, but the "b" referenced in the
root filter is not in replica identiy.
ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
UPDATE rf_tbl_abcd_part_pk SET a = 1;
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Feb 9, 2022 at 7:07 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> 2. src/backend/commands/publicationcmds.c -
> contain_mutable_or_ud_functions_checker
>
> +/* check_functions_in_node callback */
> +static bool
> +contain_mutable_or_user_functions_checker(Oid func_id, void *context)
> +{
> + return (func_volatile(func_id) != PROVOLATILE_IMMUTABLE ||
> + func_id >= FirstNormalObjectId);
> +}
>
> I was wondering why is the checking for user function and mutable
> functions combined in one function like this. IMO it might be better
> to have 2 "checker" callback functions instead of just one - then the
> error messages can be split too so that only the relevant one is
> displayed to the user.
>
For that, we need to invoke the checker function multiple times for a
node and or expression. So, not sure if it is worth it.
--
With Regards,
Amit Kapila.
> Are there any recent performance evaluations of the overhead of row filters? I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table > We have collected the performance data results for all the different workloads [*]. The test strategy is now using pg_recvlogical with steps as Andres suggested [1]. Note - "Allow 0%" and "Allow 100%" are included as tests cases, but in practice, a user is unlikely to deliberately use a filter that allows nothing to pass through it, or allows everything to pass through it. PSA the bar charts of the results. All other details are below. ~~~~~ RESULTS - workload "a" (v76) ====================== HEAD 18.40 No Filters 18.86 Allow 100% 17.96 Allow 75% 16.39 Allow 50% 14.60 Allow 25% 11.23 Allow 0% 9.41 Observations for "a": - Using row filters has minimal overhead in the worst case (compare HEAD versus "Allow 100%") - As more % data is filtered out (less is replicated) then the times decrease RESULTS - workload "b" (v76) ====================== HEAD 2.30 No Filters 1.96 Allow 100% 1.99 Allow 75% 1.65 Allow 50% 1.35 Allow 25% 1.17 Allow 0% 0.84 Observations for "b": - Using row filters has minimal overhead in the worst case (compare HEAD versus "Allow 100%") - As more % data is filtered out (less is replicated) then the times decrease RESULTS - workload "c" (v76) ====================== HEAD 20.40 No Filters 19.85 Allow 100% 20.94 Allow 75% 17.26 Allow 50% 16.13 Allow 25% 13.32 Allow 0% 10.33 Observations for "c": - Using row filters has minimal overhead in the worst case (compare HEAD versus "Allow 100%") - As more % data is filtered out (less is replicated) then the times decrease RESULTS - workload "d" (v80) ====================== HEAD 6.81 No Filters 6.85 Allow 100% 7.61 Allow 75% 7.80 Allow 50% 6.46 Allow 25% 6.35 Allow 0% 6.46 Observations for "d": - As more % data is filtered out (less is replicated) then the times became less than HEAD, but not much. - Improvements due to row filtering are less noticeable (e.g. HEAD versus "Allow 0%") for this workload; we attribute this to the fact that for this script there are fewer rows getting replicated in the 1st place so we are only comparing 1000 x INSERT/UPDATE against 0 x INSERT/UPDATE. ~~~~~~ Details - workload "a" ======================= CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test; CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed INSERT INTO test SELECT i, i::text, row_to_json(row(i)) FROM generate_series(1,1000001)i; Details - workload "b" ====================== CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test; CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed DO $do$ BEGIN FOR i IN 0..1000001 BY 10 LOOP INSERT INTO test VALUES(i,'BAH', row_to_json(row(i))); UPDATE test SET value = 'FOO' WHERE key = i; IF I % 1000 = 0 THEN COMMIT; END IF; END LOOP; END $do$; Details - workload "c" ====================== CREATE TABLE test1 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test2 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test3 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test4 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE TABLE test5 (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test1, test2, test3, test4, test5; CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 0), test2 WHERE (key > 0), test3 WHERE (key > 0), test4 WHERE (key > 0), test5 WHERE (key > 0); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 250000), test2 WHERE (key > 250000), test3 WHERE (key > 250000), test4 WHERE (key > 250000), test5 WHERE (key > 250000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 500000), test2 WHERE (key > 500000), test3 WHERE (key > 500000), test4 WHERE (key > 500000), test5 WHERE (key > 500000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 750000), test2 WHERE (key > 750000), test3 WHERE (key > 750000), test4 WHERE (key > 750000), test5 WHERE (key > 750000); CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 1000000), test2 WHERE (key > 1000000), test3 WHERE (key > 1000000), test4 WHERE (key > 1000000), test5 WHERE (key > 1000000); DO $do$ BEGIN FOR i IN 0..1000001 BY 10 LOOP -- test1 INSERT INTO test1 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test1 SET value = 'FOO' WHERE key = i; -- test2 INSERT INTO test2 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test2 SET value = 'FOO' WHERE key = i; -- test3 INSERT INTO test3 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test3 SET value = 'FOO' WHERE key = i; -- test4 INSERT INTO test4 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test4 SET value = 'FOO' WHERE key = i; -- test5 INSERT INTO test5 VALUES(i,'BAH', row_to_json(row(i))); UPDATE test5 SET value = 'FOO' WHERE key = i; IF I % 1000 = 0 THEN -- raise notice 'commit: %', i; COMMIT; END IF; END LOOP; END $do$; Details - workload "d" ====================== CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value)); CREATE PUBLICATION pub_1 FOR TABLE test; CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed DO $do$ BEGIN FOR i IN 0..1000000 BY 1000 LOOP ALTER TABLE test ALTER COLUMN value1 TYPE varchar(30); INSERT INTO test VALUES(i,'BAH','BAH', row_to_json(row(i))); ALTER TABLE test ALTER COLUMN value1 TYPE text; UPDATE test SET value = 'FOO' WHERE key = i; IF I % 10000 = 0 THEN COMMIT; END IF; END LOOP; END $do$; ------ [*] This post repeats some results for already sent for workloads "a","b","c"; this is so the complete set is now all here in one place [1] https://www.postgresql.org/message-id/20220203182922.344fhhqzjp2ah6yp%40alap3.anarazel.de Kind Regards, Peter Smith. Fujitsu Australia
Вложения
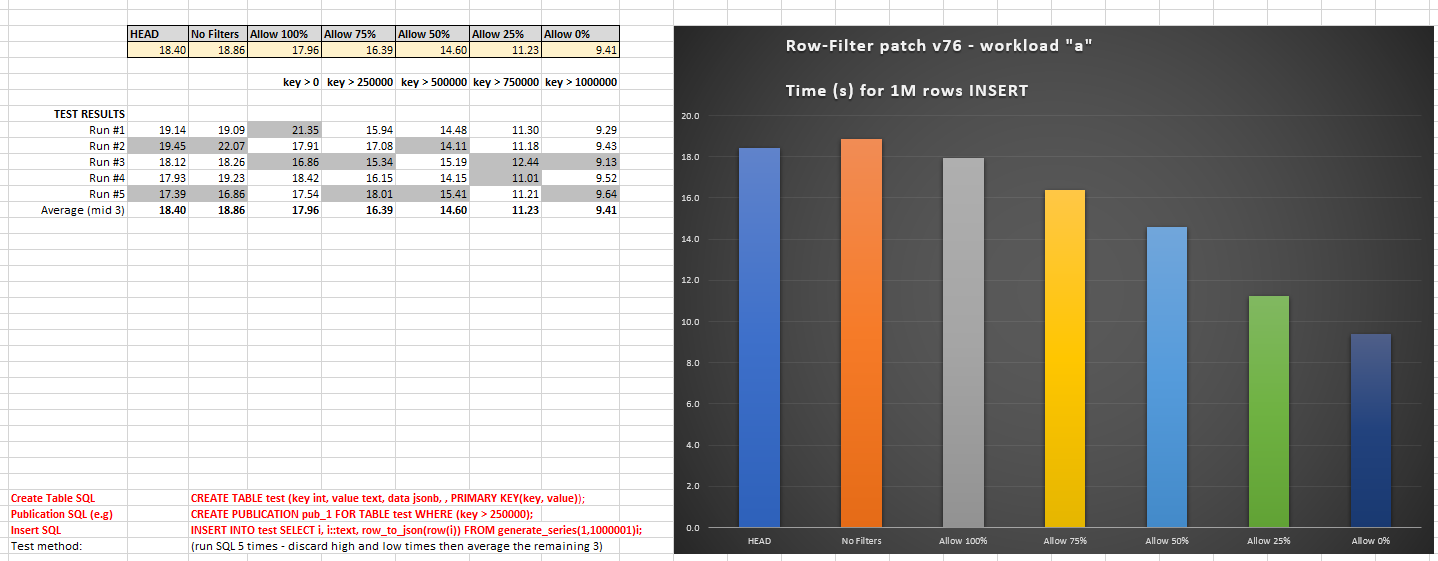{kind=link}
{kind=link}
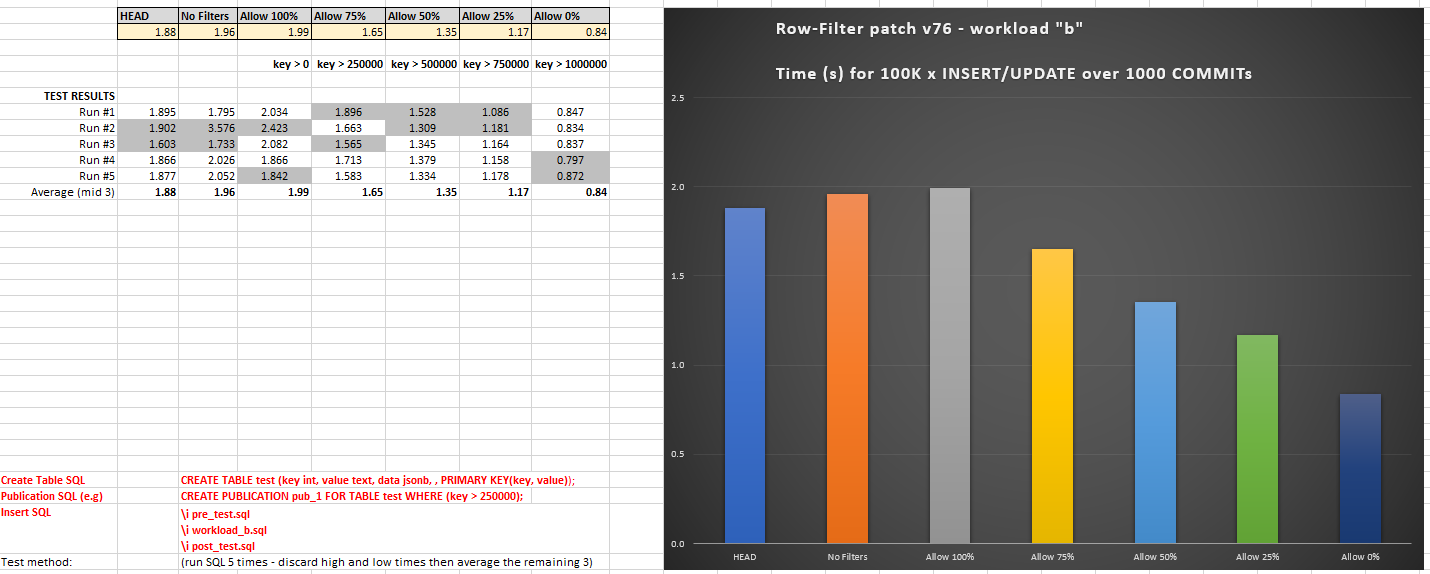{kind=link}
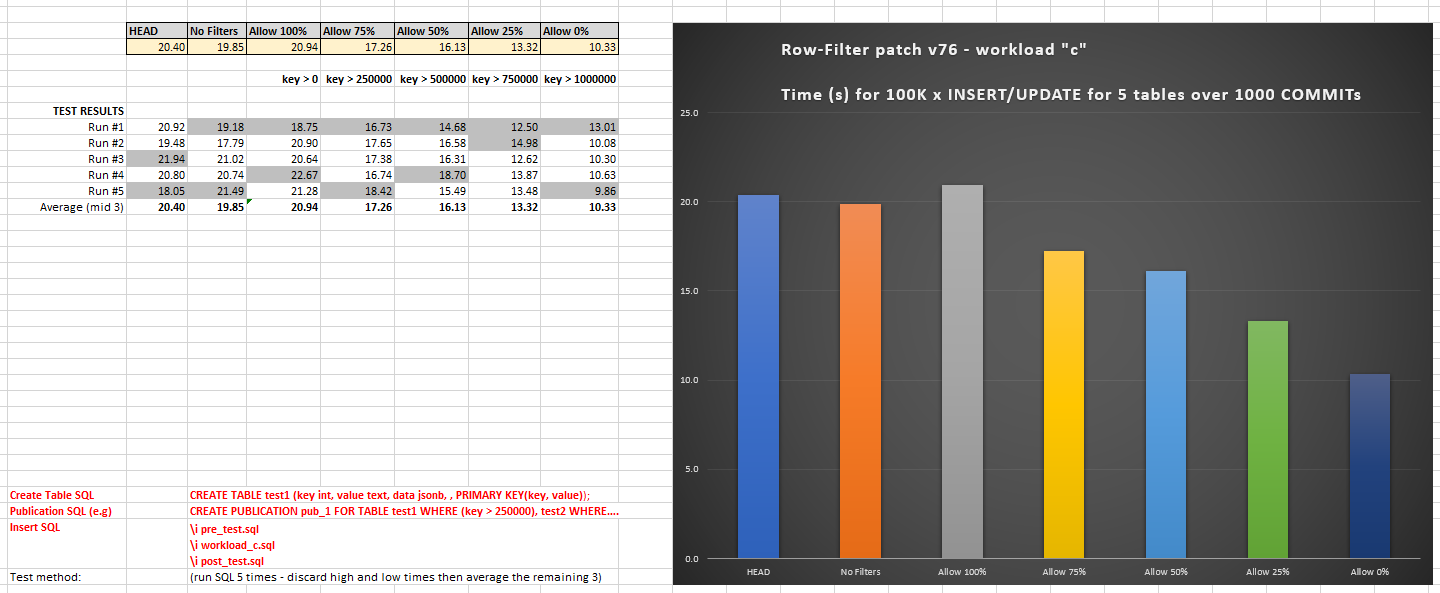{kind=link}
On Tue, Jan 25, 2022 at 2:18 PM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
...
> > 4. src/backend/utils/cache/relcache.c - RelationBuildPublicationDesc
> >
> > - if (relation->rd_pubactions)
> > + if (relation->rd_pubdesc)
> > {
> > - pfree(relation->rd_pubactions);
> > - relation->rd_pubactions = NULL;
> > + pfree(relation->rd_pubdesc);
> > + relation->rd_pubdesc = NULL;
> > }
> >
> > What is the purpose of this code? Can't it all just be removed?
> > e.g. Can't you Assert that relation->rd_pubdesc is NULL at this point?
> >
> > (if it was not-null the function would have returned immediately from the top)
>
> I think it might be better to change this as a separate patch.
OK. I have made a separate thread [1[ for discussing this one.
------
[1] https://www.postgresql.org/message-id/flat/1524753.1644453267%40sss.pgh.pa.us#1c40bbc4126daaf75b927a021526654a
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wednesday, February 9, 2022 9:37 AM Peter Smith <smithpb2250@gmail.com>
>
> I did a review of the v79 patch. Below are my review comments:
>
Thanks for the comments!
>
> 1. doc/src/sgml/ref/create_publication.sgml - CREATE PUBLICATION
>
> The commit message for v79-0001 says:
> <quote>
> If your publication contains a partitioned table, the publication parameter
> publish_via_partition_root determines if it uses the partition row filter (if
> the parameter is false, the default) or the root partitioned table row filter.
> </quote>
>
> I think that the same information should also be mentioned in the PG
> DOCS for CREATE PUBLICATION note about the WHERE clause.
>
Added this to the document.
>
> 2. src/backend/commands/publicationcmds.c -
> contain_mutable_or_ud_functions_checker
>
> +/* check_functions_in_node callback */
> +static bool
> +contain_mutable_or_user_functions_checker(Oid func_id, void *context)
> +{
> + return (func_volatile(func_id) != PROVOLATILE_IMMUTABLE ||
> + func_id >= FirstNormalObjectId);
> +}
>
> I was wondering why is the checking for user function and mutable
> functions combined in one function like this. IMO it might be better
> to have 2 "checker" callback functions instead of just one - then the
> error messages can be split too so that only the relevant one is
> displayed to the user.
>
> BEFORE
> contain_mutable_or_user_functions_checker --> "User-defined or
> built-in mutable functions are not allowed."
>
> AFTER
> contain_user_functions_checker --> "User-defined functions are not allowed."
> contain_mutable_function_checker --> "Built-in mutable functions are
> not allowed."
As Amit mentioned, I didn’t change this.
>
> 3. src/backend/commands/publicationcmds.c -
> check_simple_rowfilter_expr_walker
>
> + case T_Const:
> + case T_FuncExpr:
> + case T_BoolExpr:
> + case T_RelabelType:
> + case T_CollateExpr:
> + case T_CaseExpr:
> + case T_CaseTestExpr:
> + case T_ArrayExpr:
> + case T_CoalesceExpr:
> + case T_MinMaxExpr:
> + case T_XmlExpr:
> + case T_NullTest:
> + case T_BooleanTest:
> + case T_List:
> + break;
>
> Perhaps a comment should be added here simply saying "OK, supported"
> just to make it more obvious?
Added.
>
> 4. src/test/regress/sql/publication.sql - test comment
>
> +-- fail - user-defined types disallowed
>
> For consistency with the nearby comments it would be better to reword this
> one:
> "fail - user-defined types are not allowed"
Changed.
>
> 5. src/test/regress/sql/publication.sql - test for \d
>
> +-- test \d+ (now it displays filter information)
> +SET client_min_messages = 'ERROR';
> +CREATE PUBLICATION testpub_dplus_rf_yes FOR TABLE testpub_rf_tbl1
> WHERE (a > 1) WITH (publish = 'insert');
> +CREATE PUBLICATION testpub_dplus_rf_no FOR TABLE testpub_rf_tbl1;
> +RESET client_min_messages;
> +\d+ testpub_rf_tbl1
>
> Actually, the \d (without "+") will also display filters but I don't
> think that has been tested anywhere. So suggest updating the comment
> and adding one more test
>
> AFTER
> -- test \d+ <tablename> and \d <tablename> (now these display filter
> information)
> ...
> \d+ testpub_rf_tbl1
> \d testpub_rf_tbl1
Changed.
> 6. src/test/regress/sql/publication.sql - tests for partitioned table
>
> +-- Tests for partitioned table
> +ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (a >
> 99);
> +ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
> +-- ok - partition does not have row filter
> +UPDATE rf_tbl_abcd_part_pk SET a = 1;
> +ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
> +-- ok - "a" is a OK col
> +UPDATE rf_tbl_abcd_part_pk SET a = 1;
> +ALTER PUBLICATION testpub6 SET TABLE rf_tbl_abcd_part_pk WHERE (b >
> 99);
> +ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=0);
> +-- ok - partition does not have row filter
> +UPDATE rf_tbl_abcd_part_pk SET a = 1;
> +ALTER PUBLICATION testpub6 SET (PUBLISH_VIA_PARTITION_ROOT=1);
> +-- fail - "b" is not in REPLICA IDENTITY INDEX
> +UPDATE rf_tbl_abcd_part_pk SET a = 1;
>
> Those comments and the way the code is arranged did not make it very
> clear to me what exactly these tests are doing.
>
> I think all the changes to the publish_via_partition_root belong BELOW
> those test comments don't they?
> Also the same comment "-- ok - partition does not have row filter"
> appears 2 times so that can be made more clear too.
>
> e.g. IIUC it should be changed to something a bit like this (Note - I
> did not change the SQL, I only moved it a bit and changed the
> comments):
>
I think it might be better to put "-- ok" and "-- fail" before the DML as we
are testing the RI invalidation of DML here. But I added some comments
here to make it clearer.
Attach the V80 patch which addressed the above comments and
comments from Amit[1].
I also adjusted some code comments in the patch and fix the following
problems about inherited table:
- When subscriber is doing initial copy with row filter it will use "COPY
(SELECT ..) TO ..". If the target table is inherited parent table, SELECT
command will copy data from both the parent and child while we only need to
copy the parent table's data. So, Added a "ONLY" in this case to fix it.
- We didn't check the duplicate whereclause when speicifing both inherited
parent and child table with row filter in CRAETE PUBLICATION/ALTER
PUBLICATION. When adding a parent table we will also add all its child to the
list, so we need to check here if user already speicify the child with row
filter and report an error if yes.
Besides, added support for node RowExpr in row filter and added some testcases.
[1] https://www.postgresql.org/message-id/CAA4eK1JkXwu-dvOqEojnKUEZr2dXTLwz_QkQ5uJbmjiHs%3Dg0KQ%40mail.gmail.com
Best regards,
Hou zj
Вложения
On Thu, Feb 10, 2022 at 9:29 AM houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
>
>
> Attach the V80 patch which addressed the above comments and
> comments from Amit[1].
>
Thanks for the new version. Few minor/cosmetic comments:
1. Can we slightly change the below comment:
Before:
+ * To avoid fetching the publication information, we cache the publication
+ * actions and row filter validation information.
After:
To avoid fetching the publication information repeatedly, we cache the
publication actions and row filter validation information.
2.
+ /*
+ * For ordinary tables, make sure we don't copy data from child
+ * that inherits the named table.
+ */
+ if (lrel.relkind == RELKIND_RELATION)
+ appendStringInfoString(&cmd, " ONLY ");
I think we should mention the reason why we are doing so. So how about
something like: "For regular tables, make sure we don't copy data from
a child that inherits the named table as those will be copied
separately."
3.
Can we change the below comment?
Before:
+ /*
+ * Initialize the tuple slot, map and row filter that are only used
+ * when publishing inserts, updates or deletes.
+ */
After:
Initialize the tuple slot, map, and row filter. These are only used
when publishing inserts, updates, or deletes.
4.
+CREATE TABLE testpub_rf_tbl1 (a integer, b text);
+CREATE TABLE testpub_rf_tbl2 (c text, d integer);
Here, you can add a comment saying: "-- Test row filters" or something
on those lines.
5.
+-- test \d+ (now it displays filter information)
+SET client_min_messages = 'ERROR';
+CREATE PUBLICATION testpub_dplus_rf_yes FOR TABLE testpub_rf_tbl1
WHERE (a > 1) WITH (publish = 'insert');
+CREATE PUBLICATION testpub_dplus_rf_no FOR TABLE testpub_rf_tbl1;
+RESET client_min_messages;
+\d+ testpub_rf_tbl1
+ Table "public.testpub_rf_tbl1"
+ Column | Type | Collation | Nullable | Default | Storage | Stats
target | Description
+--------+---------+-----------+----------+---------+----------+--------------+-------------
+ a | integer | | | | plain | |
+ b | text | | | | extended | |
+Publications:
+ "testpub_dplus_rf_no"
+ "testpub_dplus_rf_yes" WHERE (a > 1)
I think here \d is sufficient to show row filters? I think it is
better to use table names such as testpub_rf_yes or testpub_rf_no in
this test.
6.
+# Similarly, the table filter for tab_rf_x (after the initial phase) has no
+# effect when combined with the ALL TABLES IN SCHEMA.
+# Expected: 5 initial rows + 2 new rows = 7 rows
+$node_publisher->safe_psql('postgres', "INSERT INTO tab_rf_x (x)
VALUES (-99), (99)");
+$node_publisher->wait_for_catchup($appname);
+$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
FROM tab_rf_x");
+is($result, qq(7), 'check table tab_rf_x should not be filtered');
I think the comment here should say "ALL TABLES." instead of "ALL
TABLES IN SCHEMA." as there is no publication before this test which
is created with "ALL TABLES IN SCHEMA" clause.
7.
+# The subscription of the ALL TABLES IN SCHEMA publication means
there should be
+# no filtering on the tablesync COPY, so all expect all 5 will be present.
It doesn't make sense to use 'all' twice in the above comment, the
first one can be removed.
8.
+
+# setup structure on publisher
+$node_publisher->safe_psql('postgres',
I think it will be good if we can add some generic comments explaining
the purpose of the tests following this. We can add "# Tests FOR TABLE
with row filter publications" before the current comment.
9. For the newly added test for tab_rowfilter_inherited, the patch has
a test case only for initial sync, can we add a test for replication
after initial sync for the same?
--
With Regards,
Amit Kapila.
On Thursday, February 10, 2022 6:18 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Feb 10, 2022 at 9:29 AM houzj.fnst@fujitsu.com
> <houzj.fnst@fujitsu.com> wrote:
> >
> >
> > Attach the V80 patch which addressed the above comments and
> > comments from Amit[1].
> >
>
> Thanks for the new version. Few minor/cosmetic comments:
Thanks for the comments !
> 1. Can we slightly change the below comment:
> Before:
> + * To avoid fetching the publication information, we cache the publication
> + * actions and row filter validation information.
>
> After:
> To avoid fetching the publication information repeatedly, we cache the
> publication actions and row filter validation information.
Changed.
> 2.
> + /*
> + * For ordinary tables, make sure we don't copy data from child
> + * that inherits the named table.
> + */
> + if (lrel.relkind == RELKIND_RELATION)
> + appendStringInfoString(&cmd, " ONLY ");
>
> I think we should mention the reason why we are doing so. So how about
> something like: "For regular tables, make sure we don't copy data from
> a child that inherits the named table as those will be copied
> separately."
Changed.
> 3.
> Can we change the below comment?
>
> Before:
> + /*
> + * Initialize the tuple slot, map and row filter that are only used
> + * when publishing inserts, updates or deletes.
> + */
>
> After:
> Initialize the tuple slot, map, and row filter. These are only used
> when publishing inserts, updates, or deletes.
Changed.
> 4.
> +CREATE TABLE testpub_rf_tbl1 (a integer, b text);
> +CREATE TABLE testpub_rf_tbl2 (c text, d integer);
>
> Here, you can add a comment saying: "-- Test row filters" or something
> on those lines.
Changed.
> 5.
> +-- test \d+ (now it displays filter information)
> +SET client_min_messages = 'ERROR';
> +CREATE PUBLICATION testpub_dplus_rf_yes FOR TABLE testpub_rf_tbl1
> WHERE (a > 1) WITH (publish = 'insert');
> +CREATE PUBLICATION testpub_dplus_rf_no FOR TABLE testpub_rf_tbl1;
> +RESET client_min_messages;
> +\d+ testpub_rf_tbl1
> + Table "public.testpub_rf_tbl1"
> + Column | Type | Collation | Nullable | Default | Storage | Stats
> target | Description
> +--------+---------+-----------+----------+---------+----------+------------
> --+-------------
> + a | integer | | | | plain | |
> + b | text | | | | extended | |
> +Publications:
> + "testpub_dplus_rf_no"
> + "testpub_dplus_rf_yes" WHERE (a > 1)
>
> I think here \d is sufficient to show row filters? I think it is
> better to use table names such as testpub_rf_yes or testpub_rf_no in
> this test.
Changed.
> 6.
> +# Similarly, the table filter for tab_rf_x (after the initial phase) has no
> +# effect when combined with the ALL TABLES IN SCHEMA.
> +# Expected: 5 initial rows + 2 new rows = 7 rows
> +$node_publisher->safe_psql('postgres', "INSERT INTO tab_rf_x (x)
> VALUES (-99), (99)");
> +$node_publisher->wait_for_catchup($appname);
> +$result = $node_subscriber->safe_psql('postgres', "SELECT count(x)
> FROM tab_rf_x");
> +is($result, qq(7), 'check table tab_rf_x should not be filtered');
>
> I think the comment here should say "ALL TABLES." instead of "ALL
> TABLES IN SCHEMA." as there is no publication before this test which
> is created with "ALL TABLES IN SCHEMA" clause.
Changed.
> 7.
> +# The subscription of the ALL TABLES IN SCHEMA publication means
> there should be
> +# no filtering on the tablesync COPY, so all expect all 5 will be present.
>
> It doesn't make sense to use 'all' twice in the above comment, the
> first one can be removed.
Changed.
> 8.
> +
> +# setup structure on publisher
> +$node_publisher->safe_psql('postgres',
>
> I think it will be good if we can add some generic comments explaining
> the purpose of the tests following this. We can add "# Tests FOR TABLE
> with row filter publications" before the current comment.
Added.
> 9. For the newly added test for tab_rowfilter_inherited, the patch has
> a test case only for initial sync, can we add a test for replication
> after initial sync for the same?
Added.
Attach the v81 patch which addressed above comments.
Best regards,
Hou zj
Вложения
On Saturday, January 29, 2022 9:31 AM, From: Andres Freund <andres@anarazel.de> > Hi, > > Are there any recent performance evaluations of the overhead of row filters? > I > think it'd be good to get some numbers comparing: > > 1) $workload with master > 2) $workload with patch, but no row filters > 3) $workload with patch, row filter matching everything > 4) $workload with patch, row filter matching few rows > > For workload I think it'd be worth testing: > a) bulk COPY/INSERT into one table > b) Many transactions doing small modifications to one table > c) Many transactions targetting many different tables > d) Interspersed DDL + small changes to a table I did the performance test for this patch in two ways: (1) using pg_recvlogical (2) using synchronous pub/sub The results are as below, also attach the bar charts and the details. Note that the result of performance test using pg_recvlogical is based on v80, and the one using synchronous pub/sub is based on v81. (I think v80 should have the same performance as V81 because V81 only fix some test related code compared with V80) (1) Using pg_recvlogical RESULTS - workload "a" ----------------------------- HEAD 4.350 No Filters 4.413 Allow 100% 4.463 Allow 75% 4.079 Allow 50% 3.765 Allow 25% 3.415 Allow 0% 3.104 RESULTS - workload "b" ----------------------------- HEAD 0.568 No Filters 0.569 Allow 100% 0.590 Allow 75% 0.510 Allow 50% 0.441 Allow 25% 0.370 Allow 0% 0.302 RESULTS - workload "c" ----------------------------- HEAD 2.752 No Filters 2.812 Allow 100% 2.846 Allow 75% 2.506 Allow 50% 2.147 Allow 25% 1.806 Allow 0% 1.448 RESULTS - workload "d" ----------------------------- HEAD 5.612 No Filters 5.645 Allow 100% 5.696 Allow 75% 5.648 Allow 50% 5.532 Allow 25% 5.379 Allow 0% 5.196 Summary of tests: (a) As more data is filtered out, less time is spend. (b) The case where no rows are filtered (worst case), there is a overhead of 1-4%. This should be okay as normally nobody will set up filters which doesn't filter any rows. (c) There is slight difference in HEAD and No filter (0-2%) case but some of that could also be attributed to run-to-run variation because in some runs no filter patch was taking lesser time and in other cases HEAD is taking lesser time. (2) Using synchronous pub/sub RESULTS - workload "a" ----------------------------- HEAD 9.671 No Filters 9.727 Allow 100% 10.336 Allow 75% 8.544 Allow 50% 7.598 Allow 25% 5.988 Allow 0% 4.542 RESULTS - workload "b" ----------------------------- HEAD 53.869 No Filters 53.531 Allow 100% 52.679 Allow 75% 39.782 Allow 50% 26.563 Allow 25% 13.506 Allow 0% 0.296 RESULTS - workload "c" ----------------------------- HEAD 52.378 No Filters 52.432 Allow 100% 51.974 Allow 75% 39.452 Allow 50% 26.604 Allow 25% 13.944 Allow 0% 1.194 RESULTS - workload "d" ----------------------------- HEAD 57.457 No Filters 57.385 Allow 100% 57.608 Allow 75% 43.575 Allow 50% 29.689 Allow 25% 15.786 Allow 0% 2.879 Summary of tests: (a) As more data is filtered out, less time is spend. (b) The case where no rows are filtered (worst case). There is a overhead in scenario a (bulk INSERT). This should be okay as normally nobody will set up filters which doesn't filter any rows. In other scenarios (doing small modifications to one table, targeting many different tables, and Interspersed DDL + small changes to a table), there is almost no overhead. (c) There is almost no time difference in HEAD and No filter. Regards, Tang
Вложения
{kind=link}
{kind=link}
{kind=link}
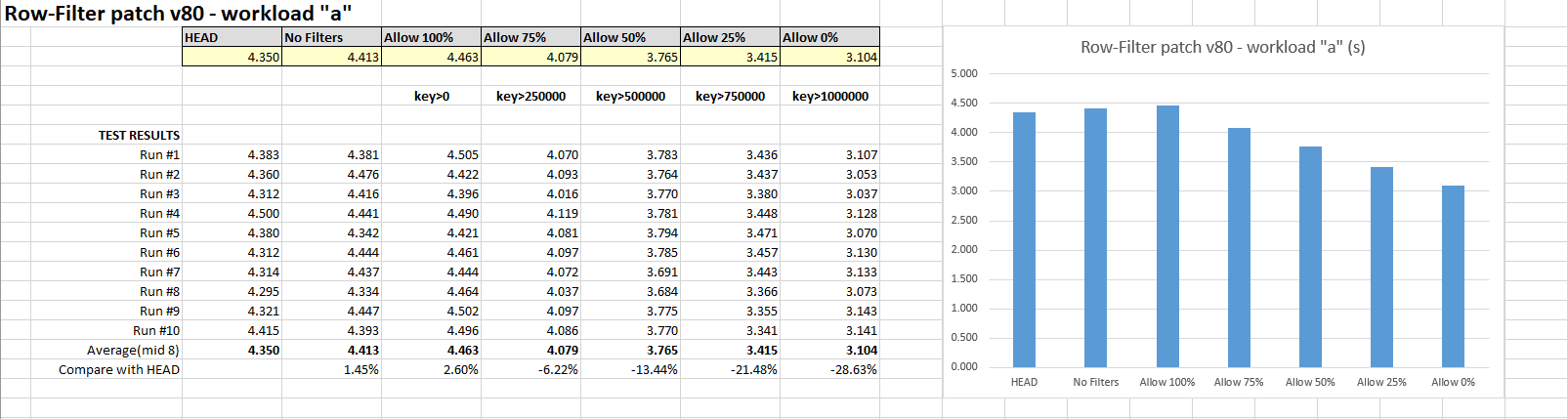{kind=link}
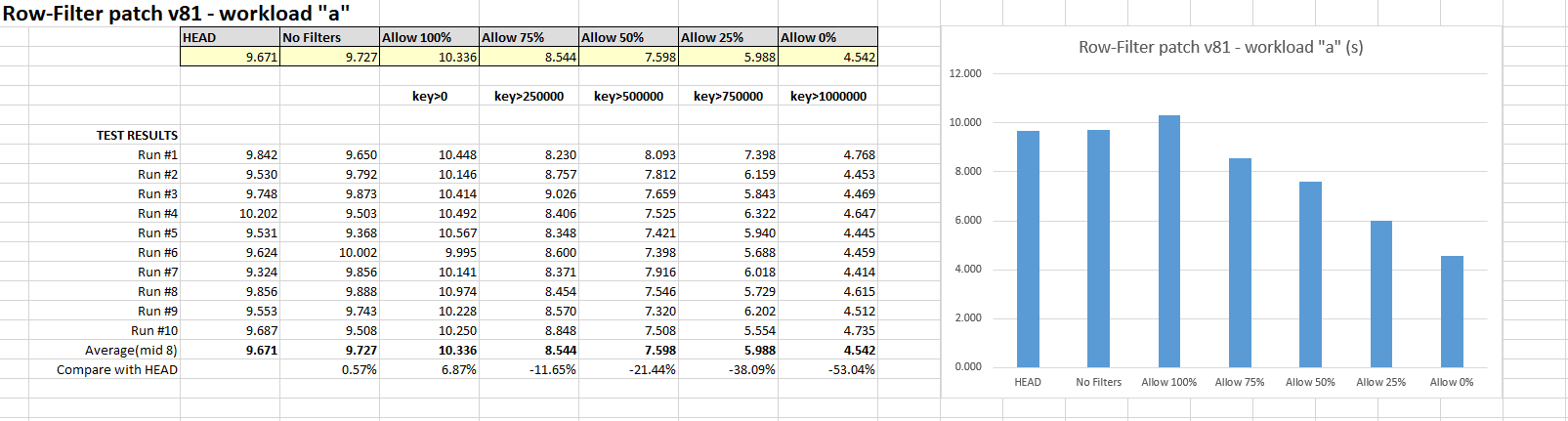{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Friday, February 11, 2022 5:02 PM houzj.fnst@fujitsu.com wrote: > > Attach the v81 patch which addressed above comments. Attach the v82 patch which was rebased based on recent commit. The new version patch also includes the following changes: - disallow specifying row filter for partitioned table if pubviaroot is false. Since only the partition's row filter would be used if pubviaroot is false, so disallow this case to avoid confusion. - some minor/cosmetic changes on comments, codes and testcases. - un-comment the testcases for unchanged toast key. - run pgindent and pgperltidy Best regards, Hou zj
Вложения
On Monday, February 14, 2022 8:56 PM houzj.fnst@fujitsu.com wrote: > > On Friday, February 11, 2022 5:02 PM houzj.fnst@fujitsu.com wrote: > > > > Attach the v81 patch which addressed above comments. > > Attach the v82 patch which was rebased based on recent commit. > > The new version patch also includes the following changes: > > - disallow specifying row filter for partitioned table if pubviaroot is false. > Since only the partition's row filter would be used if pubviaroot is false, > so disallow this case to avoid confusion. > - some minor/cosmetic changes on comments, codes and testcases. > - un-comment the testcases for unchanged toast key. > - run pgindent and pgperltidy Rebased the patch based on recent commit cfc7191d. Also fixed some typos. Best regards, Hou zj
Вложения
On Tue, Feb 15, 2022 at 7:57 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Monday, February 14, 2022 8:56 PM houzj.fnst@fujitsu.com wrote: > > > > On Friday, February 11, 2022 5:02 PM houzj.fnst@fujitsu.com wrote: > > > > > > Attach the v81 patch which addressed above comments. > > > > Attach the v82 patch which was rebased based on recent commit. > > > > The new version patch also includes the following changes: > > > > - disallow specifying row filter for partitioned table if pubviaroot is false. > > Since only the partition's row filter would be used if pubviaroot is false, > > so disallow this case to avoid confusion. I have slightly modified the error messages and checks for this change. Additionally, I changed a few comments and adapt the test case for changes in commit 549ec201d6132b7c7ee11ee90a4e02119259ba5b. The patch looks good to me. I am planning to commit this later this week (on Friday) unless there are any major comments. -- With Regards, Amit Kapila.
Вложения
On Tue, Feb 15, 2022 at 3:31 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Feb 15, 2022 at 7:57 AM houzj.fnst@fujitsu.com > <houzj.fnst@fujitsu.com> wrote: > > I have slightly modified the error messages and checks for this > change. Additionally, I changed a few comments and adapt the test case > for changes in commit 549ec201d6132b7c7ee11ee90a4e02119259ba5b. > > Attached is the version with a few changes: (a) make the WHERE expression in 'docs'/'code comments' consistent; (b) changed one of the error messages a bit, (c) use ObjectIdGetDatum instead of oid in one of the SearchSysCacheCopy1 calls. > The patch looks good to me. I am planning to commit this later this > week (on Friday) unless there are any major comments. > As there is a new version, I would like to wait for a few more days before committing. I am planning to commit this early next week (by Tuesday) unless others or I see any more things that can be improved. I would once like to mention the replica identity handling of the patch. Right now, (on HEAD) we are not checking the replica identity combination at DDL time, they are checked at execution time in CheckCmdReplicaIdentity(). This patch follows the same scheme and gives an error at the time of update/delete if the table publishes update/delete and the publication(s) has a row filter that contains non-replica-identity columns. We had earlier thought of handling it at DDL time but that won't follow the existing scheme and has a lot of complications as explained in emails [1][2]. Do let me know if you see any problem here? [1] - https://www.postgresql.org/message-id/CAA4eK1+m45Xyzx7AUY9TyFnB6CZ7_+_uooPb7WHSpp7UE=YmKg@mail.gmail.com [2] - https://www.postgresql.org/message-id/CAA4eK1+1DMkCip9SB3B0_u0Q6fGf-D3vgqQodkLfur0qkL482g@mail.gmail.com -- With Regards, Amit Kapila.
Вложения
On Thu, Feb 17, 2022 at 5:37 PM Amit Kapila <amit.kapila16@gmail.com> wrote: ... > As there is a new version, I would like to wait for a few more days > before committing. I am planning to commit this early next week (by > Tuesday) unless others or I see any more things that can be improved. I have no more review comments. This Row Filter patch v85 LGTM. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Feb 17, 2022, at 3:36 AM, Amit Kapila wrote:
As there is a new version, I would like to wait for a few more daysbefore committing. I am planning to commit this early next week (byTuesday) unless others or I see any more things that can be improved.
Amit, I don't have additional comments or suggestions. Let's move on. Next
topic. :-)
I would once like to mention the replica identity handling of thepatch. Right now, (on HEAD) we are not checking the replica identitycombination at DDL time, they are checked at execution time inCheckCmdReplicaIdentity(). This patch follows the same scheme andgives an error at the time of update/delete if the table publishesupdate/delete and the publication(s) has a row filter that containsnon-replica-identity columns. We had earlier thought of handling it atDDL time but that won't follow the existing scheme and has a lot ofcomplications as explained in emails [1][2]. Do let me know if you seeany problem here?
IMO it is not an issue that this patch needs to solve. The conclusion of
checking the RI at the DDL time vs execution time is that:
* the current patch just follows the same pattern used in the current logical
replication implementation;
* it is easier to check during execution time (a central point) versus a lot of
combinations for DDL commands;
* the check during DDL time might eventually break if new subcommands are
added;
* the execution time does not have the maintenance burden imposed by new DDL
subcommands;
* we might change the RI check to execute at DDL time if the current
implementation imposes a significant penalty in certain workloads.
Again, it is material for another patch.
Thanks for taking care of a feature that has been discussed for 4 years [1].
On Tue, Feb 22, 2022 at 4:47 AM Euler Taveira <euler@eulerto.com> wrote: > > On Thu, Feb 17, 2022, at 3:36 AM, Amit Kapila wrote: > > As there is a new version, I would like to wait for a few more days > before committing. I am planning to commit this early next week (by > Tuesday) unless others or I see any more things that can be improved. > > Amit, I don't have additional comments or suggestions. Let's move on. Next > topic. :-) > Pushed! -- With Regards, Amit Kapila.
Hi,
Thank you for developing of the great feature.
If multiple tables are specified when creating a PUBLICATION,
is it supposed that the WHERE clause condition is given to only one table?
I attached the operation log below.
--- operation log ---
postgres=> CREATE TABLE data1(c1 INT PRIMARY KEY, c2 VARCHAR(10));
CREATE TABLE
postgres=> CREATE TABLE data2(c1 INT PRIMARY KEY, c2 VARCHAR(10));
CREATE TABLE
postgres=> CREATE PUBLICATION pub1 FOR TABLE data1,data2 WHERE (c1 < 1000);
CREATE PUBLICATION
postgres=> \d data1
Table "public.data1"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
c1 | integer | | not null |
c2 | character varying(10) | | |
Indexes:
"data1_pkey" PRIMARY KEY, btree (c1)
Publications:
"pub1"
postgres=> \d data2
Table "public.data2"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
c1 | integer | | not null |
c2 | character varying(10) | | |
Indexes:
"data2_pkey" PRIMARY KEY, btree (c1)
Publications:
"pub1" WHERE (c1 < 1000)
postgres=> SELECT prrelid, prqual FROM pg_publication_rel;
prrelid | prqual
---------+-----------------------------------------------------------------------------
16408 |
16413 | {OPEXPR :opno 97 :opfuncid 66 :opresulttype 16 :opretset false :opcol
lid 0 :inputcollid 0 :args ({VAR :varno 1 :varattno 1 :vartype 23 :vartypmod -1
:varcollid 0 :varlevelsup 0 :varnosyn 1 :varattnosyn 1 :location 53} {CONST :con
sttype 23 :consttypmod -1 :constcollid 0 :constlen 4 :constbyval true :constisnu
ll false :location 58 :constvalue 4 [ -24 3 0 0 0 0 0 0 ]}) :location 56}
(2 rows)
Regards,
Noriyoshi Shinoda
-----Original Message-----
From: Amit Kapila <amit.kapila16@gmail.com>
Sent: Wednesday, February 23, 2022 11:06 AM
To: Euler Taveira <euler@eulerto.com>
Cc: houzj.fnst@fujitsu.com; Peter Smith <smithpb2250@gmail.com>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Greg
Nancarrow<gregn4422@gmail.com>; vignesh C <vignesh21@gmail.com>; Ajin Cherian <itsajin@gmail.com>;
tanghy.fnst@fujitsu.com;Dilip Kumar <dilipbalaut@gmail.com>; Rahila Syed <rahilasyed90@gmail.com>; Peter Eisentraut
<peter.eisentraut@enterprisedb.com>;Önder Kalacı <onderkalaci@gmail.com>; japin <japinli@hotmail.com>; Michael Paquier
<michael@paquier.xyz>;David Steele <david@pgmasters.net>; Craig Ringer <craig@2ndquadrant.com>; Amit Langote
<amitlangote09@gmail.com>;PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org>
Subject: Re: row filtering for logical replication
On Tue, Feb 22, 2022 at 4:47 AM Euler Taveira <euler@eulerto.com> wrote:
>
> On Thu, Feb 17, 2022, at 3:36 AM, Amit Kapila wrote:
>
> As there is a new version, I would like to wait for a few more days
> before committing. I am planning to commit this early next week (by
> Tuesday) unless others or I see any more things that can be improved.
>
> Amit, I don't have additional comments or suggestions. Let's move on.
> Next topic. :-)
>
Pushed!
--
With Regards,
Amit Kapila.
On Thu, Feb 24, 2022 at 7:43 AM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > > Hi, > Thank you for developing of the great feature. > If multiple tables are specified when creating a PUBLICATION, > is it supposed that the WHERE clause condition is given to only one table? > You can give it for multiple tables. See below as an example: > --- operation log --- > postgres=> CREATE TABLE data1(c1 INT PRIMARY KEY, c2 VARCHAR(10)); > CREATE TABLE > postgres=> CREATE TABLE data2(c1 INT PRIMARY KEY, c2 VARCHAR(10)); > CREATE TABLE > postgres=> CREATE PUBLICATION pub1 FOR TABLE data1,data2 WHERE (c1 < 1000); > CREATE PUBLICATION postgres=# CREATE PUBLICATION pub_data_1 FOR TABLE data1 WHERE (c1 > 10), data2 WHERE (c1 < 1000); CREATE PUBLICATION -- With Regards, Amit Kapila.
I noticed that there was a build-farm failure on the machine 'komodoensis' [1] # Failed test 'check replicated rows to tab_rowfilter_toast' # at t/028_row_filter.pl line 687. # got: '' # expected: 't|1' # Looks like you failed 1 test of 20. [18:21:24] t/028_row_filter.pl ................ Dubious, test returned 1 (wstat 256, 0x100) Failed 1/20 subtests That failure looks intermittent because from the history you can see the same machine already passed multiple times in this test case. When I investigated the test case I noticed there seems to be a missing "catchup" ($node_publisher->wait_for_catchup($appname);), so sometimes if the replication happens too slowly then the expected row might not be found on the subscriber side. I will post a patch to fix this shortly. ------ [1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=komodoensis&dt=2022-02-23%2016%3A12%3A03 Kind Regards, Peter Smith. Fujitsu Australia.
> You can give it for multiple tables. See below as an example: Thank you very much. I understood. Regards, Noriyoshi Shinoda -----Original Message----- From: Amit Kapila <amit.kapila16@gmail.com> Sent: Thursday, February 24, 2022 11:25 AM To: Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> Cc: Euler Taveira <euler@eulerto.com>; houzj.fnst@fujitsu.com; Peter Smith <smithpb2250@gmail.com>; Alvaro Herrera <alvherre@alvh.no-ip.org>;Greg Nancarrow <gregn4422@gmail.com>; vignesh C <vignesh21@gmail.com>; Ajin Cherian <itsajin@gmail.com>;tanghy.fnst@fujitsu.com; Dilip Kumar <dilipbalaut@gmail.com>; Rahila Syed <rahilasyed90@gmail.com>; PeterEisentraut <peter.eisentraut@enterprisedb.com>; Önder Kalacı <onderkalaci@gmail.com>; japin <japinli@hotmail.com>; MichaelPaquier <michael@paquier.xyz>; David Steele <david@pgmasters.net>; Craig Ringer <craig@2ndquadrant.com>; Amit Langote<amitlangote09@gmail.com>; PostgreSQL Hackers <pgsql-hackers@lists.postgresql.org> Subject: Re: row filtering for logical replication On Thu, Feb 24, 2022 at 7:43 AM Shinoda, Noriyoshi (PN Japan FSIP) <noriyoshi.shinoda@hpe.com> wrote: > > Hi, > Thank you for developing of the great feature. > If multiple tables are specified when creating a PUBLICATION, is it > supposed that the WHERE clause condition is given to only one table? > You can give it for multiple tables. See below as an example: > --- operation log --- > postgres=> CREATE TABLE data1(c1 INT PRIMARY KEY, c2 VARCHAR(10)); > CREATE TABLE postgres=> CREATE TABLE data2(c1 INT PRIMARY KEY, c2 > VARCHAR(10)); CREATE TABLE postgres=> CREATE PUBLICATION pub1 FOR > TABLE data1,data2 WHERE (c1 < 1000); CREATE PUBLICATION postgres=# CREATE PUBLICATION pub_data_1 FOR TABLE data1 WHERE (c1 > 10), data2 WHERE (c1 < 1000); CREATE PUBLICATION -- With Regards, Amit Kapila.
On Thu, Feb 24, 2022 at 7:57 AM Peter Smith <smithpb2250@gmail.com> wrote: > > I noticed that there was a build-farm failure on the machine 'komodoensis' [1] > > # Failed test 'check replicated rows to tab_rowfilter_toast' > # at t/028_row_filter.pl line 687. > # got: '' > # expected: 't|1' > # Looks like you failed 1 test of 20. > [18:21:24] t/028_row_filter.pl ................ > Dubious, test returned 1 (wstat 256, 0x100) > Failed 1/20 subtests > > That failure looks intermittent because from the history you can see > the same machine already passed multiple times in this test case. > > When I investigated the test case I noticed there seems to be a > missing "catchup" ($node_publisher->wait_for_catchup($appname);), so > sometimes if the replication happens too slowly then the expected row > might not be found on the subscriber side. > Your analysis seems correct to me and it is evident from the result as well. Reviewing the test, it seems other similar places already have the catchup but it is missed after this update test. > I will post a patch to fix this shortly. > Thanks. -- With Regards, Amit Kapila.
On Thu, Feb 24, 2022 at 1:33 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Thu, Feb 24, 2022 at 7:57 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > I noticed that there was a build-farm failure on the machine 'komodoensis' [1] > > > > # Failed test 'check replicated rows to tab_rowfilter_toast' > > # at t/028_row_filter.pl line 687. > > # got: '' > > # expected: 't|1' > > # Looks like you failed 1 test of 20. > > [18:21:24] t/028_row_filter.pl ................ > > Dubious, test returned 1 (wstat 256, 0x100) > > Failed 1/20 subtests > > > > That failure looks intermittent because from the history you can see > > the same machine already passed multiple times in this test case. > > > > When I investigated the test case I noticed there seems to be a > > missing "catchup" ($node_publisher->wait_for_catchup($appname);), so > > sometimes if the replication happens too slowly then the expected row > > might not be found on the subscriber side. > > > > Your analysis seems correct to me and it is evident from the result as > well. Reviewing the test, it seems other similar places already have > the catchup but it is missed after this update test. > > > I will post a patch to fix this shortly. > > > > Thanks. > PSA a patch to fix the observed [1] build-farm failure. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPv%3De9Qd1TSYo8Og6x6Abfz3b9_htwinLp4ENPgV45DACQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
Hi, While working on the column filtering patch, which touches about the same places, I noticed two minor gaps in testing: 1) The regression tests do perform multiple ALTER PUBLICATION commands, tweaking the row filter. But there are no checks the row filter was actually modified / stored in the catalog. It might be just thrown away and no one would notice. 2) There are no pg_dump tests. So attached are two trivial patched, addressing this. The first one adds a couple \dRp and \d commands, to show what the catalogs contain. The second one adds a simple pg_dump test. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
On Wed, Mar 2, 2022, at 8:45 AM, Tomas Vondra wrote:
While working on the column filtering patch, which touches about thesame places, I noticed two minor gaps in testing:1) The regression tests do perform multiple ALTER PUBLICATION commands,tweaking the row filter. But there are no checks the row filter wasactually modified / stored in the catalog. It might be just thrown awayand no one would notice.
The test that row filter was modified is available in a previous section. The
one that you modified (0001) is testing the supported objects.
153 ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000 AND e < 2000);
154 \dRp+ testpub5
155 ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2;
156 \dRp+ testpub5
157 -- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (another WHERE expression)
158 ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300 AND e < 500);
159 \dRp+ testpub5
IIRC this test was written before adding the row filter information into the
psql. We could add \d+ testpub_rf_tbl3 before and after the modification.
2) There are no pg_dump tests.
WFM.
On Wed, Mar 2, 2022 at 5:42 PM Euler Taveira <euler@eulerto.com> wrote: > > On Wed, Mar 2, 2022, at 8:45 AM, Tomas Vondra wrote: > > While working on the column filtering patch, which touches about the > same places, I noticed two minor gaps in testing: > > 1) The regression tests do perform multiple ALTER PUBLICATION commands, > tweaking the row filter. But there are no checks the row filter was > actually modified / stored in the catalog. It might be just thrown away > and no one would notice. > > The test that row filter was modified is available in a previous section. The > one that you modified (0001) is testing the supported objects. > Right. But if Tomas thinks it is good to add for these ones as well then I don't mind. > 153 ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000 AND e < 2000); > 154 \dRp+ testpub5 > 155 ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2; > 156 \dRp+ testpub5 > 157 -- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (another WHERE expression) > 158 ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300 AND e < 500); > 159 \dRp+ testpub5 > > IIRC this test was written before adding the row filter information into the > psql. We could add \d+ testpub_rf_tbl3 before and after the modification. > Agreed. We can use \d instead of \d+ as row filter is available with \d. > 2) There are no pg_dump tests. > > WFM. > This is a miss. I feel we can add a few more. -- With Regards, Amit Kapila.
On Thu, Mar 3, 2022 10:40 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Mar 2, 2022 at 5:42 PM Euler Taveira <euler@eulerto.com> wrote: > > > > On Wed, Mar 2, 2022, at 8:45 AM, Tomas Vondra wrote: > > > > While working on the column filtering patch, which touches about the > > same places, I noticed two minor gaps in testing: > > > > 1) The regression tests do perform multiple ALTER PUBLICATION commands, > > tweaking the row filter. But there are no checks the row filter was > > actually modified / stored in the catalog. It might be just thrown away > > and no one would notice. > > > > The test that row filter was modified is available in a previous section. The > > one that you modified (0001) is testing the supported objects. > > > > Right. But if Tomas thinks it is good to add for these ones as well > then I don't mind. > > > 153 ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000 > AND e < 2000); > > 154 \dRp+ testpub5 > > 155 ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2; > > 156 \dRp+ testpub5 > > 157 -- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (another WHERE > expression) > > 158 ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300 > AND e < 500); > > 159 \dRp+ testpub5 > > > > IIRC this test was written before adding the row filter information into the > > psql. We could add \d+ testpub_rf_tbl3 before and after the modification. > > > > > Agreed. We can use \d instead of \d+ as row filter is available with \d. > > > 2) There are no pg_dump tests. > > > > WFM. > > > > This is a miss. I feel we can add a few more. > Agree that we can add some tests, attach the patch which fixes these two points. Regards, Shi yu
Вложения
On Thu, Mar 3, 2022 at 11:18 AM shiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com> wrote: > > On Thu, Mar 3, 2022 10:40 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Mar 2, 2022 at 5:42 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Wed, Mar 2, 2022, at 8:45 AM, Tomas Vondra wrote: > > > > > > While working on the column filtering patch, which touches about the > > > same places, I noticed two minor gaps in testing: > > > > > > 1) The regression tests do perform multiple ALTER PUBLICATION commands, > > > tweaking the row filter. But there are no checks the row filter was > > > actually modified / stored in the catalog. It might be just thrown away > > > and no one would notice. > > > > > > The test that row filter was modified is available in a previous section. The > > > one that you modified (0001) is testing the supported objects. > > > > > > > Right. But if Tomas thinks it is good to add for these ones as well > > then I don't mind. > > > > > 153 ALTER PUBLICATION testpub5 ADD TABLE testpub_rf_tbl3 WHERE (e > 1000 > > AND e < 2000); > > > 154 \dRp+ testpub5 > > > 155 ALTER PUBLICATION testpub5 DROP TABLE testpub_rf_tbl2; > > > 156 \dRp+ testpub5 > > > 157 -- remove testpub_rf_tbl1 and add testpub_rf_tbl3 again (another WHERE > > expression) > > > 158 ALTER PUBLICATION testpub5 SET TABLE testpub_rf_tbl3 WHERE (e > 300 > > AND e < 500); > > > 159 \dRp+ testpub5 > > > > > > IIRC this test was written before adding the row filter information into the > > > psql. We could add \d+ testpub_rf_tbl3 before and after the modification. > > > > > > > > > Agreed. We can use \d instead of \d+ as row filter is available with \d. > > > > > 2) There are no pg_dump tests. > > > > > > WFM. > > > > > > > This is a miss. I feel we can add a few more. > > > > Agree that we can add some tests, attach the patch which fixes these two points. > LGTM. I'll push this tomorrow unless Tomas or Euler feels otherwise. -- With Regards, Amit Kapila.
On Thu, Mar 3, 2022, at 7:47 AM, Amit Kapila wrote:
LGTM. I'll push this tomorrow unless Tomas or Euler feels otherwise.
Sounds good to me.
On 3/3/22 21:07, Euler Taveira wrote: > On Thu, Mar 3, 2022, at 7:47 AM, Amit Kapila wrote: >> LGTM. I'll push this tomorrow unless Tomas or Euler feels otherwise. > Sounds good to me. > +1 -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Mar 7, 2022 at 12:50 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 3/3/22 21:07, Euler Taveira wrote: > > On Thu, Mar 3, 2022, at 7:47 AM, Amit Kapila wrote: > >> LGTM. I'll push this tomorrow unless Tomas or Euler feels otherwise. > > Sounds good to me. > > > > +1 > Thanks, Pushed (https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ceb57afd3ce177e897cb4c5b44aa683fc0036782). -- With Regards, Amit Kapila.
FYI, I was playing with row filters and partitions recently, and while doing something a bit unusual I received a cache leak warning. Below are the steps to reproduce it: test_pub=# CREATE TABLE parent(a int primary key) PARTITION BY RANGE(a); CREATE TABLE test_pub=# CREATE TABLE child PARTITION OF parent DEFAULT; CREATE TABLE test_pub=# CREATE PUBLICATION p4 FOR TABLE parent WHERE (a < 5), child WHERE (a >= 5) WITH (publish_via_partition_root=true); CREATE PUBLICATION test_pub=# ALTER PUBLICATION p4 SET TABLE parent, child WHERE (a >= 5); ALTER PUBLICATION test_pub=# ALTER PUBLICATION p4 SET (publish_via_partition_root = false); 2022-04-11 17:37:58.426 AEST [28152] WARNING: cache reference leak: cache pg_publication_rel (49), tuple 0/12 has count 1 WARNING: cache reference leak: cache pg_publication_rel (49), tuple 0/12 has count 1 ALTER PUBLICATION ------ Kind Regards, Peter Smith. Fujitsu Australia
On Tuesday, April 12, 2022 8:40 AM Peter Smith <smithpb2250@gmail.com> wrote: > > FYI, I was playing with row filters and partitions recently, and while doing > something a bit unusual I received a cache leak warning. > > Below are the steps to reproduce it: > > > test_pub=# CREATE TABLE parent(a int primary key) PARTITION BY RANGE(a); > CREATE TABLE > > test_pub=# CREATE TABLE child PARTITION OF parent DEFAULT; CREATE TABLE > > test_pub=# CREATE PUBLICATION p4 FOR TABLE parent WHERE (a < 5), child > WHERE (a >= 5) WITH (publish_via_partition_root=true); > CREATE PUBLICATION > > test_pub=# ALTER PUBLICATION p4 SET TABLE parent, child WHERE (a >= 5); > ALTER PUBLICATION > > test_pub=# ALTER PUBLICATION p4 SET (publish_via_partition_root = false); > 2022-04-11 17:37:58.426 AEST [28152] WARNING: cache reference leak: > cache pg_publication_rel (49), tuple 0/12 has count 1 > WARNING: cache reference leak: cache pg_publication_rel (49), tuple > 0/12 has count 1 > ALTER PUBLICATION Thanks for reporting. I think the reason is that we didn't invoke ReleaseSysCache when rftuple is valid and no filter exists. We need to release the tuple whenever the rftuple is valid. Attach a patch which fix this. Best regards, Hou zj
Вложения
On Tue, Apr 12, 2022 at 11:31 AM houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > On Tuesday, April 12, 2022 8:40 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > FYI, I was playing with row filters and partitions recently, and while doing > > something a bit unusual I received a cache leak warning. > > > > Below are the steps to reproduce it: > > > > > > test_pub=# CREATE TABLE parent(a int primary key) PARTITION BY RANGE(a); > > CREATE TABLE > > > > test_pub=# CREATE TABLE child PARTITION OF parent DEFAULT; CREATE TABLE > > > > test_pub=# CREATE PUBLICATION p4 FOR TABLE parent WHERE (a < 5), child > > WHERE (a >= 5) WITH (publish_via_partition_root=true); > > CREATE PUBLICATION > > > > test_pub=# ALTER PUBLICATION p4 SET TABLE parent, child WHERE (a >= 5); > > ALTER PUBLICATION > > > > test_pub=# ALTER PUBLICATION p4 SET (publish_via_partition_root = false); > > 2022-04-11 17:37:58.426 AEST [28152] WARNING: cache reference leak: > > cache pg_publication_rel (49), tuple 0/12 has count 1 > > WARNING: cache reference leak: cache pg_publication_rel (49), tuple > > 0/12 has count 1 > > ALTER PUBLICATION > > Thanks for reporting. > > I think the reason is that we didn't invoke ReleaseSysCache when rftuple is > valid and no filter exists. We need to release the tuple whenever the > rftuple is valid. Attach a patch which fix this. > Thanks! Your patch could be applied cleanly, and the reported problem now seems fixed. ------ Kind Regards, Peter Smith. Fujitsu Australia.
I understand that this is a minimal fix, and for that it seems OK, but I think the surrounding style is rather baroque. This code can be made simpler. Here's my take on it. I think it's also faster: we avoid looking up pg_publication_rel entries for rels that aren't partitioned tables. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Cuando mañana llegue pelearemos segun lo que mañana exija" (Mowgli)
Вложения
On Tue, Apr 12, 2022 at 2:35 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I understand that this is a minimal fix, and for that it seems OK, but I > think the surrounding style is rather baroque. This code can be made > simpler. Here's my take on it. > We don't have a lock on the relation, so if it gets dropped concurrently, it won't behave sanely. For example, get_rel_name() will return NULL which seems incorrect to me. > I think it's also faster: we avoid > looking up pg_publication_rel entries for rels that aren't partitioned > tables. > I am not sure about this as well because you will instead do a RELOID cache lookup even when there is no row filter or column list. -- With Regards, Amit Kapila.
On Tue, Apr 12, 2022 at 3:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Apr 12, 2022 at 2:35 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > > I understand that this is a minimal fix, and for that it seems OK, but I > > think the surrounding style is rather baroque. This code can be made > > simpler. Here's my take on it. > > > > We don't have a lock on the relation, so if it gets dropped > concurrently, it won't behave sanely. For example, get_rel_name() will > return NULL which seems incorrect to me. > It seems to me that we have a similar coding pattern in ExecGrant_Relation(). -- With Regards, Amit Kapila.
On 2022-Apr-12, Amit Kapila wrote: > On Tue, Apr 12, 2022 at 3:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > We don't have a lock on the relation, so if it gets dropped > > concurrently, it won't behave sanely. For example, get_rel_name() will > > return NULL which seems incorrect to me. Oh, oops ... a trap for the unwary? Anyway, yes, we can disregard the entry when get_rel_name returns null. Amended patch attached. > > I am not sure about this as well because you will instead do a RELOID > > cache lookup even when there is no row filter or column list. I guess my assumption is that the pg_class cache is typically more populated than other relcaches, but that's unsubstantiated. I'm not sure if we have any way to tell which one is the more common case. Anyway, let's do it the way you already had it. > It seems to me that we have a similar coding pattern in ExecGrant_Relation(). Not sure what you mean? In that function, when the syscache lookup returns NULL, an error is raised. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "El número de instalaciones de UNIX se ha elevado a 10, y se espera que este número aumente" (UPM, 1972)
Вложения
Sorry, I think I neglected to "git add" some late changes. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
Вложения
On Tue, Apr 12, 2022 at 5:12 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
>
> Sorry, I think I neglected to "git add" some late changes.
>
+ if (has_rowfilter)
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
+ errmsg("cannot set parameter \"%s\" to false for publication \"%s\"",
+ "publish_via_partition_root",
+ stmt->pubname),
+ errdetail("The publication contains a WHERE clause for partitioned
table \"%s\" which is not allowed when \"%s\" is false.",
+ get_rel_name(relid),
+ "publish_via_partition_root")));
It still has the same problem. The table can be dropped just before
this message and the get_rel_name will return NULL and we don't expect
that.
Also, is there a reason that you haven't kept the test case added by Hou-San?
--
With Regards,
Amit Kapila.
On Tue, Apr 12, 2022 at 5:01 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2022-Apr-12, Amit Kapila wrote: > > > On Tue, Apr 12, 2022 at 3:45 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > We don't have a lock on the relation, so if it gets dropped > > > concurrently, it won't behave sanely. For example, get_rel_name() will > > > return NULL which seems incorrect to me. > > Oh, oops ... a trap for the unwary? Anyway, yes, we can disregard the > entry when get_rel_name returns null. Amended patch attached. > > > > I am not sure about this as well because you will instead do a RELOID > > > cache lookup even when there is no row filter or column list. > > I guess my assumption is that the pg_class cache is typically more > populated than other relcaches, but that's unsubstantiated. I'm not > sure if we have any way to tell which one is the more common case. > Anyway, let's do it the way you already had it. > > > It seems to me that we have a similar coding pattern in ExecGrant_Relation(). > > Not sure what you mean? > I mean that it fetches the tuple from the RELOID cache and then performs relkind and other checks similar to what we are doing. I think it could also have used get_rel_relkind() but probably not done because it doesn't have a lock on the relation. -- With Regards, Amit Kapila.
On 2022-Apr-12, Amit Kapila wrote: > It still has the same problem. The table can be dropped just before > this message and the get_rel_name will return NULL and we don't expect > that. Ugh, I forgot to change the errmsg() parts to use the new variable, apologies. Fixed. > Also, is there a reason that you haven't kept the test case added by Hou-San? None. I put it back here. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
Вложения
On 2022-Apr-12, Amit Kapila wrote: > I mean that it fetches the tuple from the RELOID cache and then > performs relkind and other checks similar to what we are doing. I > think it could also have used get_rel_relkind() but probably not done > because it doesn't have a lock on the relation. Ah, but that one uses a lot more fields from the pg_class tuple in the non-error path. We only need relkind, up until we know the error is to be thrown. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
On Tue, Apr 12, 2022 at 6:16 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2022-Apr-12, Amit Kapila wrote: > > > It still has the same problem. The table can be dropped just before > > this message and the get_rel_name will return NULL and we don't expect > > that. > > Ugh, I forgot to change the errmsg() parts to use the new variable, > apologies. Fixed. > Thanks, this will work and fix the issue. I think this looks better than the current code, however, I am not sure if the handling for the concurrently dropped tables is better (both get_rel_relkind() and get_rel_name() can fail due to those reasons). I understand this won't fail because of the protection you have in the patch, so feel free to go ahead with this if you like this style better. -- With Regards, Amit Kapila.
On 2022-Apr-13, Amit Kapila wrote: > Thanks, this will work and fix the issue. I think this looks better > than the current code, Thanks for looking! Pushed. > however, I am not sure if the handling for the > concurrently dropped tables is better (both get_rel_relkind() and > get_rel_name() can fail due to those reasons). I understand this won't > fail because of the protection you have in the patch, Well, the point is that these routines return NULL if the relation cannot be found in the cache, so just doing "continue" (without raising any error) if any of those happens is sufficient for correct behavior. BTW I just noticed that AlterPublicationOptions acquires only ShareAccessLock on the publication object. I think this is too lax ... what if two of them run concurrently? (say to specify different published actions) Do they overwrite the other's update? I think it'd be better to acquire ShareUpdateExclusive to ensure only one is running at a time. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "This is a foot just waiting to be shot" (Andrew Dunstan)
On Wed, Apr 13, 2022 at 10:01 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > BTW I just noticed that AlterPublicationOptions acquires only > ShareAccessLock on the publication object. I think this is too lax ... > what if two of them run concurrently? (say to specify different > published actions) Do they overwrite the other's update? > No, they won't overwrite. Firstly the AccessShareLock on the publication object is not related to concurrent change of the publication object. They will be protected by normal update-row rules (like till the first transaction finishes, the other will wait). See an example below: Session-1 postgres=# Begin; BEGIN postgres=*# Alter publication pub1 set (publish = 'insert'); ALTER PUBLICATION Session-2: postgres=# Begin; BEGIN postgres=*# Alter publication pub1 set (publish = 'update'); The Alter in Session-2 will wait till we end the transaction in Session-1. -- With Regards, Amit Kapila.