RE: row filtering for logical replication
| От | tanghy.fnst@fujitsu.com |
|---|---|
| Тема | RE: row filtering for logical replication |
| Дата | |
| Msg-id | OS0PR01MB6113B69179C075A12CCD8EC0FB7B9@OS0PR01MB6113.jpnprd01.prod.outlook.com обсуждение исходный текст |
| Ответ на | RE: row filtering for logical replication ("tanghy.fnst@fujitsu.com" <tanghy.fnst@fujitsu.com>) |
| Список | pgsql-hackers |
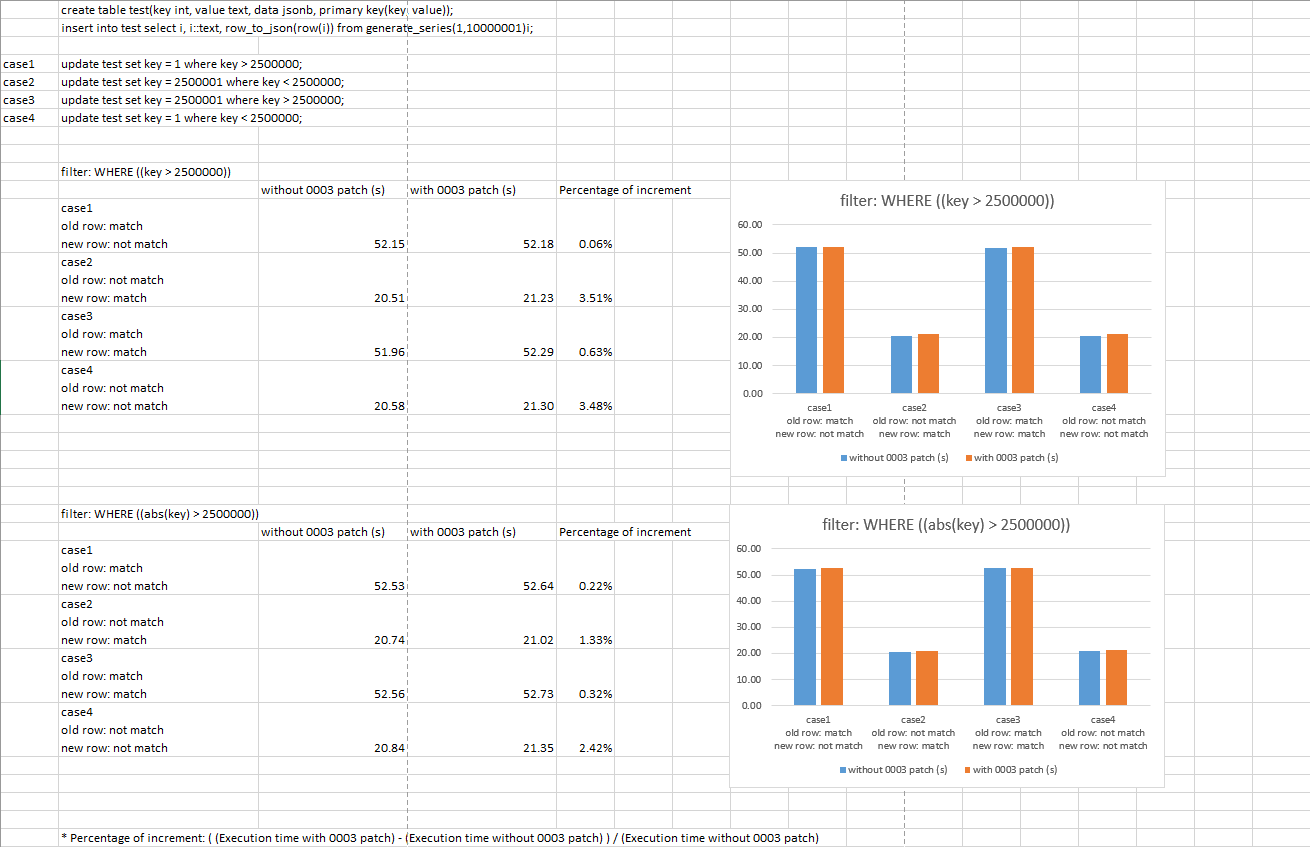
On Monday, December 20, 2021 11:24 AM tanghy.fnst@fujitsu.com <tanghy.fnst@fujitsu.com> > > On Wednesday, December 8, 2021 2:29 PM Amit Kapila > <amit.kapila16@gmail.com> wrote: > > > > On Mon, Dec 6, 2021 at 6:04 PM Euler Taveira <euler@eulerto.com> wrote: > > > > > > On Mon, Dec 6, 2021, at 3:35 AM, Dilip Kumar wrote: > > > > > > On Mon, Dec 6, 2021 at 6:49 AM Euler Taveira <euler@eulerto.com> wrote: > > > > > > > > On Fri, Dec 3, 2021, at 8:12 PM, Euler Taveira wrote: > > > > > > > > PS> I will update the commit message in the next version. I barely changed > the > > > > documentation to reflect the current behavior. I probably missed some > > changes > > > > but I will fix in the next version. > > > > > > > > I realized that I forgot to mention a few things about the UPDATE behavior. > > > > Regardless of 0003, we need to define which tuple will be used to evaluate > the > > > > row filter for UPDATEs. We already discussed it circa [1]. This current version > > > > chooses *new* tuple. Is it the best choice? > > > > > > But with 0003, we are using both the tuple for evaluating the row > > > filter, so instead of fixing 0001, why we don't just merge 0003 with > > > 0001? I mean eventually, 0003 is doing what is the agreed behavior, > > > i.e. if just OLD is matching the filter then convert the UPDATE to > > > DELETE OTOH if only new is matching the filter then convert the UPDATE > > > to INSERT. Do you think that even we merge 0001 and 0003 then also > > > there is an open issue regarding which row to select for the filter? > > > > > > Maybe I was not clear. IIUC we are still discussing 0003 and I would like to > > > propose a different default based on the conclusion I came up. If we merged > > > 0003, that's fine; this change will be useless. If we don't or it is optional, > > > it still has its merit. > > > > > > Do we want to pay the overhead to evaluating both tuple for UPDATEs? I'm still > > > processing if it is worth it. If you think that in general the row filter > > > contains the primary key and it is rare to change it, it will waste cycles > > > evaluating the same expression twice. It seems this behavior could be > > > controlled by a parameter. > > > > > > > I think the first thing we should do in this regard is to evaluate the > > performance for both cases (when we apply a filter to both tuples vs. > > to one of the tuples). In case the performance difference is > > unacceptable, I think it would be better to still compare both tuples > > as default to avoid data inconsistency issues and have an option to > > allow comparing one of the tuples. > > > > I did some performance tests to see if 0003 patch has much overhead. > With which I compared applying first two patches and applying first three patches > in four cases: > 1) only old rows match the filter. > 2) only new rows match the filter. > 3) both old rows and new rows match the filter. > 4) neither old rows nor new rows match the filter. > > 0003 patch checks both old rows and new rows, and without 0003 patch, it only > checks either old or new rows. We want to know whether it would take more time > if we check the old rows. > > I ran the tests in asynchronous mode and compared the SQL execution time. I also > tried some complex filters, to see if the difference could be more obvious. > > The result and the script are attached. > I didn’t see big difference between the result of applying 0003 patch and the > one not in all cases. So I think 0003 patch doesn’t have much overhead. > In previous test, I ran 3 times and took the average value, which may be affected by performance fluctuations. So, to make the results more accurate, I tested them more times (10 times) and took the average value. The result is attached. In general, I can see the time difference is within 3.5%, which is in an reasonable performance range, I think. Regards, Tang
Вложения
В списке pgsql-hackers по дате отправления: