Обсуждение: Default setting for enable_hashagg_disk
This is just a placeholder thread for an open item that I'm adding to
the Open Items list. We can make a decision later.
Now that we have Disk-based Hash Aggregation, there are a lot more
situations where the planner can choose HashAgg. The
enable_hashagg_disk GUC, if set to true, chooses HashAgg based on
costing. If false, it only generates a HashAgg path if it thinks it
will fit in work_mem, similar to the old behavior (though it wlil now
spill to disk if the planner was wrong about it fitting in work_mem).
The current default is true.
I expect this to be a win in a lot of cases, obviously. But as with any
planner change, it will be wrong sometimes. We may want to be
conservative and set the default to false depending on the experience
during beta. I'm inclined to leave it as true for now though, because
that will give us better information upon which to base any decision.
Regards,
Jeff Davis
On Tue, Apr 07, 2020 at 11:20:46AM -0700, Jeff Davis wrote: > The enable_hashagg_disk GUC, if set to true, chooses HashAgg based on > costing. If false, it only generates a HashAgg path if it thinks it will fit > in work_mem, similar to the old behavior (though it wlil now spill to disk if > the planner was wrong about it fitting in work_mem). The current default is > true. Are there any other GUCs that behave like that ? It's confusing to me when I see "Disk Usage: ... kB", despite setting it to "disable", and without the usual disable_cost. I realize that postgres chose the plan on the hypothesis that it would *not* exceed work_mem, and that spilling to disk is considered preferable to ignoring the setting, and that "going back" to planning phase isn't a possibility. template1=# explain (analyze, costs off, summary off) SELECT a, COUNT(1) FROM generate_series(1,999999) a GROUP BY 1 ; HashAggregate (actual time=1370.945..2877.250 rows=999999 loops=1) Group Key: a Peak Memory Usage: 5017 kB Disk Usage: 22992 kB HashAgg Batches: 84 -> Function Scan on generate_series a (actual time=314.507..741.517 rows=999999 loops=1) A previous version of the docs said this, which I thought was confusing, and you removed it. But I guess this is the behavior it was trying to .. explain. + <term><varname>enable_hashagg_disk</varname> (<type>boolean</type>) + ... This only affects the planner choice; + execution time may still require using disk-based hash + aggregation. The default is <literal>on</literal>. I suggest that should be reworded and then re-introduced, unless there's some further behavior change allowing the previous behavior of might-exceed-work-mem. "This setting determines whether the planner will elect to use a hash plan which it expects will exceed work_mem and spill to disk. During execution, hash nodes which exceed work_mem will spill to disk even if this setting is disabled. To avoid spilling to disk, either increase work_mem (or set enable_hashagg=off)." For sure the release notes should recommend re-calibrating work_mem. -- Justin
On Tue, Apr 07, 2020 at 05:39:01PM -0500, Justin Pryzby wrote: >On Tue, Apr 07, 2020 at 11:20:46AM -0700, Jeff Davis wrote: >> The enable_hashagg_disk GUC, if set to true, chooses HashAgg based on >> costing. If false, it only generates a HashAgg path if it thinks it will fit >> in work_mem, similar to the old behavior (though it wlil now spill to disk if >> the planner was wrong about it fitting in work_mem). The current default is >> true. > >Are there any other GUCs that behave like that ? It's confusing to me when I >see "Disk Usage: ... kB", despite setting it to "disable", and without the >usual disable_cost. I realize that postgres chose the plan on the hypothesis >that it would *not* exceed work_mem, and that spilling to disk is considered >preferable to ignoring the setting, and that "going back" to planning phase >isn't a possibility. > It it really any different from our enable_* GUCs? Even if you do e.g. enable_sort=off, we may still do a sort. Same for enable_groupagg etc. >template1=# explain (analyze, costs off, summary off) SELECT a, COUNT(1) FROM generate_series(1,999999) a GROUP BY 1 ; > HashAggregate (actual time=1370.945..2877.250 rows=999999 loops=1) > Group Key: a > Peak Memory Usage: 5017 kB > Disk Usage: 22992 kB > HashAgg Batches: 84 > -> Function Scan on generate_series a (actual time=314.507..741.517 rows=999999 loops=1) > >A previous version of the docs said this, which I thought was confusing, and you removed it. >But I guess this is the behavior it was trying to .. explain. > >+ <term><varname>enable_hashagg_disk</varname> (<type>boolean</type>) >+ ... This only affects the planner choice; >+ execution time may still require using disk-based hash >+ aggregation. The default is <literal>on</literal>. > >I suggest that should be reworded and then re-introduced, unless there's some >further behavior change allowing the previous behavior of >might-exceed-work-mem. > Yeah, it would be good to mention this is a best-effort setting. >"This setting determines whether the planner will elect to use a hash plan >which it expects will exceed work_mem and spill to disk. During execution, >hash nodes which exceed work_mem will spill to disk even if this setting is >disabled. To avoid spilling to disk, either increase work_mem (or set >enable_hashagg=off)." > >For sure the release notes should recommend re-calibrating work_mem. > I don't follow. Why would the recalibrating be needed? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Apr 09, 2020 at 01:48:55PM +0200, Tomas Vondra wrote: > On Tue, Apr 07, 2020 at 05:39:01PM -0500, Justin Pryzby wrote: > > On Tue, Apr 07, 2020 at 11:20:46AM -0700, Jeff Davis wrote: > > > The enable_hashagg_disk GUC, if set to true, chooses HashAgg based on > > > costing. If false, it only generates a HashAgg path if it thinks it will fit > > > in work_mem, similar to the old behavior (though it wlil now spill to disk if > > > the planner was wrong about it fitting in work_mem). The current default is > > > true. > > > > Are there any other GUCs that behave like that ? It's confusing to me when I > > see "Disk Usage: ... kB", despite setting it to "disable", and without the > > usual disable_cost. I realize that postgres chose the plan on the hypothesis > > that it would *not* exceed work_mem, and that spilling to disk is considered > > preferable to ignoring the setting, and that "going back" to planning phase > > isn't a possibility. > > It it really any different from our enable_* GUCs? Even if you do e.g. > enable_sort=off, we may still do a sort. Same for enable_groupagg etc. Those show that the GUC was disabled by showing disable_cost. That's what's different about this one. Also.. there's no such thing as enable_groupagg? Unless I've been missing out on something. > > "This setting determines whether the planner will elect to use a hash plan > > which it expects will exceed work_mem and spill to disk. During execution, > > hash nodes which exceed work_mem will spill to disk even if this setting is > > disabled. To avoid spilling to disk, either increase work_mem (or set > > enable_hashagg=off)." > > > > For sure the release notes should recommend re-calibrating work_mem. > > I don't follow. Why would the recalibrating be needed? Because HashAgg plans which used to run fine (because they weren't prevented from overflowing work_mem) might now run poorly after spilling to disk (because of overflowing work_mem). -- Justin
On Thu, 2020-04-09 at 12:24 -0500, Justin Pryzby wrote:
> Also.. there's no such thing as enable_groupagg? Unless I've been
> missing out
> on something.
I thought about adding that, and went so far as to make a patch. But it
didn't seem right to me -- the grouping isn't what takes the time, it's
the sorting. So what would the point of such a GUC be? To disable
GroupAgg when the input data is already sorted? Or a strange way to
disable Sort?
> Because HashAgg plans which used to run fine (because they weren't
> prevented
> from overflowing work_mem) might now run poorly after spilling to
> disk (because
> of overflowing work_mem).
It's probably worth a mention in the release notes, but I wouldn't word
it too strongly. Typically the performance difference is not a lot if
the workload still fits in system memory.
Regards,
Jeff Davis
On Thu, Apr 9, 2020 at 7:49 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > It it really any different from our enable_* GUCs? Even if you do e.g. > enable_sort=off, we may still do a sort. Same for enable_groupagg etc. I think it's actually pretty different. All of the other enable_* GUCs disable an entire type of plan node, except for cases where that would otherwise result in planning failure. This just disables a portion of the planning logic for a certain kind of node, without actually disabling the whole node type. I'm not sure that's a bad idea, but it definitely seems to be inconsistent with what we've done in the past. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 2020-04-09 at 15:26 -0400, Robert Haas wrote:
> I think it's actually pretty different. All of the other enable_*
> GUCs
> disable an entire type of plan node, except for cases where that
> would
> otherwise result in planning failure. This just disables a portion of
> the planning logic for a certain kind of node, without actually
> disabling the whole node type. I'm not sure that's a bad idea, but it
> definitely seems to be inconsistent with what we've done in the past.
The patch adds two GUCs. Both are slightly weird, to be honest, but let
me explain the reasoning. I am open to other suggestions.
1. enable_hashagg_disk (default true):
This is essentially there just to get some of the old behavior back, to
give people an escape hatch if they see bad plans while we are tweaking
the costing. The old behavior was weird, so this GUC is also weird.
Perhaps we can make this a compatibility GUC that we eventually drop? I
don't necessarily think this GUC would make sense, say, 5 versions from
now. I'm just trying to be conservative because I know that, even if
the plans are faster for 90% of people, the other 10% will be unhappy
and want a way to work around it.
2. enable_groupingsets_hash_disk (default false):
This is about how we choose which grouping sets to hash and which to
sort when generating mixed mode paths.
Even before this patch, there are quite a few paths that could be
generated. It tries to estimate the size of each grouping set's hash
table, and then see how many it can fit in work_mem (knapsack), while
also taking advantage of any path keys, etc.
With Disk-based Hash Aggregation, in principle we can generate paths
representing any combination of hashing and sorting for the grouping
sets. But that would be overkill (and grow to a huge number of paths if
we have more than a handful of grouping sets). So I think the existing
planner logic for grouping sets is fine for now. We might come up with
a better approach later.
But that created a testing problem, because if the planner estimates
correctly, no hashed grouping sets will spill, and the spilling code
won't be exercised. This GUC makes the planner disregard which grouping
sets' hash tables will fit, making it much easier to exercise the
spilling code. Is there a better way I should be testing this code
path?
Regards,
Jeff Davis
On Thu, Apr 9, 2020 at 1:02 PM Jeff Davis <pgsql@j-davis.com> wrote:
2. enable_groupingsets_hash_disk (default false):
This is about how we choose which grouping sets to hash and which to
sort when generating mixed mode paths.
Even before this patch, there are quite a few paths that could be
generated. It tries to estimate the size of each grouping set's hash
table, and then see how many it can fit in work_mem (knapsack), while
also taking advantage of any path keys, etc.
With Disk-based Hash Aggregation, in principle we can generate paths
representing any combination of hashing and sorting for the grouping
sets. But that would be overkill (and grow to a huge number of paths if
we have more than a handful of grouping sets). So I think the existing
planner logic for grouping sets is fine for now. We might come up with
a better approach later.
But that created a testing problem, because if the planner estimates
correctly, no hashed grouping sets will spill, and the spilling code
won't be exercised. This GUC makes the planner disregard which grouping
sets' hash tables will fit, making it much easier to exercise the
spilling code. Is there a better way I should be testing this code
path?
So, I was catching up on email and noticed the last email in this
thread.
I think I am not fully understanding what enable_groupingsets_hash_disk
does. Is it only for testing?
Using the tests you added to src/test/regress/sql/groupingsets.sql, I
did get a plan that looks like hashagg is spilling to disk (goes through
hashagg_spill_tuple() code path and has number of batches reported in
Explain) in a MixedAgg plan for a grouping sets query even with
enable_groupingsets_hash_disk set to false. You don't have the exact
query I tried (below) in the test suite, but it is basically what is
already there, so I must be missing something.
set enable_hashagg_disk = true;
SET enable_groupingsets_hash_disk = false;
SET work_mem='64kB';
set enable_hashagg = true;
set jit_above_cost = 0;
drop table if exists gs_hash_1;
create table gs_hash_1 as
select g1000, g100, g10, sum(g::numeric), count(*), max(g::text) from
(select g%1000 as g1000, g%100 as g100, g%10 as g10, g
from generate_series(0,199999) g) s
group by cube (g1000,g100,g10);
explain (analyze, costs off, timing off)
select g1000, g100, g10
from gs_hash_1 group by cube (g1000,g100,g10);
QUERY PLAN
--------------------------------------------------------------
MixedAggregate (actual rows=9648 loops=1)
Hash Key: g10
Hash Key: g10, g1000
Hash Key: g100
Hash Key: g100, g10
Group Key: g1000, g100, g10
Group Key: g1000, g100
Group Key: g1000
Group Key: ()
Peak Memory Usage: 233 kB
Disk Usage: 1600 kB
HashAgg Batches: 2333
-> Sort (actual rows=4211 loops=1)
Sort Key: g1000, g100, g10
Sort Method: external merge Disk: 384kB
-> Seq Scan on gs_hash_1 (actual rows=4211 loops=1)
Anyway, when I throw in the stats trick that is used in join_hash.sql:
alter table gs_hash_1 set (autovacuum_enabled = 'false');
update pg_class set reltuples = 10 where relname = 'gs_hash_1';
I get a MixedAgg plan that doesn't have any Sort below and uses much
more disk.
QUERY PLAN
----------------------------------------------------------
MixedAggregate (actual rows=4211 loops=1)
Hash Key: g1000, g100, g10
Hash Key: g1000, g100
Hash Key: g1000
Hash Key: g100, g10
Hash Key: g100
Hash Key: g10, g1000
Hash Key: g10
Group Key: ()
Peak Memory Usage: 405 kB
Disk Usage: 59712 kB
HashAgg Batches: 4209
-> Seq Scan on gs_hash_1 (actual rows=200000 loops=1)
I'm not sure if this is more what you were looking for--or maybe I am
misunderstanding the guc.
-- thread.
I think I am not fully understanding what enable_groupingsets_hash_disk
does. Is it only for testing?
Using the tests you added to src/test/regress/sql/groupingsets.sql, I
did get a plan that looks like hashagg is spilling to disk (goes through
hashagg_spill_tuple() code path and has number of batches reported in
Explain) in a MixedAgg plan for a grouping sets query even with
enable_groupingsets_hash_disk set to false. You don't have the exact
query I tried (below) in the test suite, but it is basically what is
already there, so I must be missing something.
set enable_hashagg_disk = true;
SET enable_groupingsets_hash_disk = false;
SET work_mem='64kB';
set enable_hashagg = true;
set jit_above_cost = 0;
drop table if exists gs_hash_1;
create table gs_hash_1 as
select g1000, g100, g10, sum(g::numeric), count(*), max(g::text) from
(select g%1000 as g1000, g%100 as g100, g%10 as g10, g
from generate_series(0,199999) g) s
group by cube (g1000,g100,g10);
explain (analyze, costs off, timing off)
select g1000, g100, g10
from gs_hash_1 group by cube (g1000,g100,g10);
QUERY PLAN
--------------------------------------------------------------
MixedAggregate (actual rows=9648 loops=1)
Hash Key: g10
Hash Key: g10, g1000
Hash Key: g100
Hash Key: g100, g10
Group Key: g1000, g100, g10
Group Key: g1000, g100
Group Key: g1000
Group Key: ()
Peak Memory Usage: 233 kB
Disk Usage: 1600 kB
HashAgg Batches: 2333
-> Sort (actual rows=4211 loops=1)
Sort Key: g1000, g100, g10
Sort Method: external merge Disk: 384kB
-> Seq Scan on gs_hash_1 (actual rows=4211 loops=1)
Anyway, when I throw in the stats trick that is used in join_hash.sql:
alter table gs_hash_1 set (autovacuum_enabled = 'false');
update pg_class set reltuples = 10 where relname = 'gs_hash_1';
I get a MixedAgg plan that doesn't have any Sort below and uses much
more disk.
QUERY PLAN
----------------------------------------------------------
MixedAggregate (actual rows=4211 loops=1)
Hash Key: g1000, g100, g10
Hash Key: g1000, g100
Hash Key: g1000
Hash Key: g100, g10
Hash Key: g100
Hash Key: g10, g1000
Hash Key: g10
Group Key: ()
Peak Memory Usage: 405 kB
Disk Usage: 59712 kB
HashAgg Batches: 4209
-> Seq Scan on gs_hash_1 (actual rows=200000 loops=1)
I'm not sure if this is more what you were looking for--or maybe I am
misunderstanding the guc.
Melanie Plageman
On Tue, Jun 09, 2020 at 06:20:13PM -0700, Melanie Plageman wrote: > On Thu, Apr 9, 2020 at 1:02 PM Jeff Davis <pgsql@j-davis.com> wrote: > > > 2. enable_groupingsets_hash_disk (default false): > > > > This is about how we choose which grouping sets to hash and which to > > sort when generating mixed mode paths. > > > > Even before this patch, there are quite a few paths that could be > > generated. It tries to estimate the size of each grouping set's hash > > table, and then see how many it can fit in work_mem (knapsack), while > > also taking advantage of any path keys, etc. > > > > With Disk-based Hash Aggregation, in principle we can generate paths > > representing any combination of hashing and sorting for the grouping > > sets. But that would be overkill (and grow to a huge number of paths if > > we have more than a handful of grouping sets). So I think the existing > > planner logic for grouping sets is fine for now. We might come up with > > a better approach later. > > > > But that created a testing problem, because if the planner estimates > > correctly, no hashed grouping sets will spill, and the spilling code > > won't be exercised. This GUC makes the planner disregard which grouping > > sets' hash tables will fit, making it much easier to exercise the > > spilling code. Is there a better way I should be testing this code > > path? > > So, I was catching up on email and noticed the last email in this > thread. > > I think I am not fully understanding what enable_groupingsets_hash_disk > does. Is it only for testing? If so, it should be in category: "Developer Options". > Using the tests you added to src/test/regress/sql/groupingsets.sql, I > did get a plan that looks like hashagg is spilling to disk (goes through > hashagg_spill_tuple() code path and has number of batches reported in > Explain) in a MixedAgg plan for a grouping sets query even with > enable_groupingsets_hash_disk set to false. > I'm not sure if this is more what you were looking for--or maybe I am > misunderstanding the guc. The behavior of the GUC is inconsistent with the other GUCs, which is confusing. See also Robert's comments in this thread. https://www.postgresql.org/message-id/20200407223900.GT2228%40telsasoft.com The old (pre-13) behavior was: - work_mem is the amount of RAM to which each query node tries to constrain itself, and the planner will reject a plan if it's expected to exceed that. ...But a chosen plan might exceed work_mem anyway. The new behavior in v13 seems to be: - HashAgg now respects work_mem, but instead enable*hash_disk are opportunisitic. A node which is *expected* to spill to disk will be rejected. ...But at execution time, a node which exceeds work_mem will be spilled. If someone sees a plan which spills to disk and wants to improve performance by avoid spilling, they might SET enable_hashagg_disk=off, which might do what they want (if the plan is rejected at plan time), or it might not, which I think will be a surprise every time. If someone agrees, I suggest to add this as an Opened Item. Maybe some combination of these would be an improvement: - change documentation to emphasize behavior; - change EXPLAIN ouput to make it obvious this isn't misbehaving; - rename the GUC to not start with enable_* (work_mem_exceed?) - rename the GUC *values* to something other than on/off. On/Planner? - change the GUC to behave like it sounds like it should, which means "off" would allow the pre-13 behavior of exceeding work_mem. - Maybe make it ternary, like: exceed_work_mem: {spill_disk, planner_reject, allow} -- Justin
On Tue, Jun 9, 2020 at 7:15 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
On Tue, Jun 09, 2020 at 06:20:13PM -0700, Melanie Plageman wrote:
> On Thu, Apr 9, 2020 at 1:02 PM Jeff Davis <pgsql@j-davis.com> wrote:
>
> > 2. enable_groupingsets_hash_disk (default false):
> >
> > This is about how we choose which grouping sets to hash and which to
> > sort when generating mixed mode paths.
> >
> > Even before this patch, there are quite a few paths that could be
> > generated. It tries to estimate the size of each grouping set's hash
> > table, and then see how many it can fit in work_mem (knapsack), while
> > also taking advantage of any path keys, etc.
> >
> > With Disk-based Hash Aggregation, in principle we can generate paths
> > representing any combination of hashing and sorting for the grouping
> > sets. But that would be overkill (and grow to a huge number of paths if
> > we have more than a handful of grouping sets). So I think the existing
> > planner logic for grouping sets is fine for now. We might come up with
> > a better approach later.
> >
> > But that created a testing problem, because if the planner estimates
> > correctly, no hashed grouping sets will spill, and the spilling code
> > won't be exercised. This GUC makes the planner disregard which grouping
> > sets' hash tables will fit, making it much easier to exercise the
> > spilling code. Is there a better way I should be testing this code
> > path?
>
> So, I was catching up on email and noticed the last email in this
> thread.
>
> I think I am not fully understanding what enable_groupingsets_hash_disk
> does. Is it only for testing?
If so, it should be in category: "Developer Options".
> Using the tests you added to src/test/regress/sql/groupingsets.sql, I
> did get a plan that looks like hashagg is spilling to disk (goes through
> hashagg_spill_tuple() code path and has number of batches reported in
> Explain) in a MixedAgg plan for a grouping sets query even with
> enable_groupingsets_hash_disk set to false.
> I'm not sure if this is more what you were looking for--or maybe I am
> misunderstanding the guc.
The behavior of the GUC is inconsistent with the other GUCs, which is
confusing. See also Robert's comments in this thread.
https://www.postgresql.org/message-id/20200407223900.GT2228%40telsasoft.com
The old (pre-13) behavior was:
- work_mem is the amount of RAM to which each query node tries to constrain
itself, and the planner will reject a plan if it's expected to exceed that.
...But a chosen plan might exceed work_mem anyway.
The new behavior in v13 seems to be:
- HashAgg now respects work_mem, but instead enable*hash_disk are
opportunisitic. A node which is *expected* to spill to disk will be
rejected.
...But at execution time, a node which exceeds work_mem will be spilled.
If someone sees a plan which spills to disk and wants to improve performance by
avoid spilling, they might SET enable_hashagg_disk=off, which might do what
they want (if the plan is rejected at plan time), or it might not, which I
think will be a surprise every time.
But I thought that the enable_groupingsets_hash_disk GUC allows us to
test the following scenario:
The following is true:
- planner thinks grouping sets' hashtables table would fit in memory
(spilling is *not* expected)
- user is okay with spilling
- some grouping keys happen to be sortable and some hashable
The following happens:
- Planner generates some HashAgg grouping sets paths
- A MixedAgg plan is created
- During execution of the MixedAgg plan, one or more grouping sets'
hashtables would exceed work_mem, so the executor spills those tuples
to disk instead of exceeding work_mem
Especially given the code and comment:
/*
* If we have sortable columns to work with (gd->rollups is non-empty)
* and enable_groupingsets_hash_disk is disabled, don't generate
* hash-based paths that will exceed work_mem.
*/
if (!enable_groupingsets_hash_disk &&
hashsize > work_mem * 1024L && gd->rollups)
return; /* nope, won't fit */
If this is the scenario that the GUC is designed to test, it seems like
you could exercise it without the enable_groupingsets_hash_disk GUC by
lying about the stats, no?
test the following scenario:
The following is true:
- planner thinks grouping sets' hashtables table would fit in memory
(spilling is *not* expected)
- user is okay with spilling
- some grouping keys happen to be sortable and some hashable
The following happens:
- Planner generates some HashAgg grouping sets paths
- A MixedAgg plan is created
- During execution of the MixedAgg plan, one or more grouping sets'
hashtables would exceed work_mem, so the executor spills those tuples
to disk instead of exceeding work_mem
Especially given the code and comment:
/*
* If we have sortable columns to work with (gd->rollups is non-empty)
* and enable_groupingsets_hash_disk is disabled, don't generate
* hash-based paths that will exceed work_mem.
*/
if (!enable_groupingsets_hash_disk &&
hashsize > work_mem * 1024L && gd->rollups)
return; /* nope, won't fit */
If this is the scenario that the GUC is designed to test, it seems like
you could exercise it without the enable_groupingsets_hash_disk GUC by
lying about the stats, no?
--
Melanie Plageman
On Tue, 2020-06-09 at 18:20 -0700, Melanie Plageman wrote:
> So, I was catching up on email and noticed the last email in this
> thread.
>
> I think I am not fully understanding what
> enable_groupingsets_hash_disk
> does. Is it only for testing?
It's mostly for testing. I could imagine cases where it would be useful
to force groupingsets to use the disk, but I mainly wanted the setting
there for testing the grouping sets hash disk code path.
> Using the tests you added to src/test/regress/sql/groupingsets.sql, I
> did get a plan that looks like hashagg is spilling to disk (goes
> through
I had something that worked as a test for a while, but then when I
tweaked the costing, it started using the Sort path (therefore not
testing my grouping sets hash disk code at all) and a bug crept in. So
I thought it would be best to have a more forceful knob.
Perhaps I should just get rid of that GUC and use the stats trick?
Regards,
Jeff Davis
On Tue, 2020-06-09 at 21:15 -0500, Justin Pryzby wrote: > The behavior of the GUC is inconsistent with the other GUCs, which is > confusing. See also Robert's comments in this thread. > https://www.postgresql.org/message-id/20200407223900.GT2228%40telsasoft.com enable_* GUCs are planner GUCs, so it would be confusing to me if they affected execution-time behavior. I think the point of confusion is that it's not enabling/disabling an entire execution node; it only "disables" HashAgg if it thinks it will spill. I agree that is a difference with the other GUCs, and could cause confusion. Stepping back, I was trying to solve two problems with these GUCs: 1. Testing the spilling of hashed grouping sets: I'm inclined to just get rid of enable_groupingsets_hash_disk and use Melanie's stats- hacking approach instead. 2. Trying to provide an escape hatch for someone who experiences a performance regression and wants something like the old behavior back. There are two aspects of the old behavior that a user could potentially want back: a. Don't choose HashAgg if it's expected to have more groups than fit into a work_mem-sized hashtable. b. If executing HashAgg, and the hash table exceeds work_mem, just keep going. The behavior in v13 master is, by default, analagous to Sort or anything else that adapts at runtime to spill. If we had spillable HashAgg the whole time, we wouldn't be worried about #2 at all. But, out of conservatism, I am trying to accommodate users who want an escape hatch, at least for a release or two until users feel more comfortable with disk-based HashAgg. Setting enable_hash_disk=false implements 2(a). This name apparently causes confusion, but it's hard to come up with a better one because the v12 behavior has nuance that's hard to express succinctly. I don't think the names you suggested quite fit, but the idea to use a more interesting GUC value might help express the behavior. Perhaps making enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word "reject" is too definite for the planner, which is working with imperfect information. In master, there is no explicit way to get 2(b), but you can just set work_mem higher in a lot of cases. If enough people want 2(b), I can add it easily. Perhaps hashagg_overflow=on|off, which would control execution time behavior? Regards, Jeff Davis
On Tue, 2020-04-07 at 11:20 -0700, Jeff Davis wrote: > Now that we have Disk-based Hash Aggregation, there are a lot more > situations where the planner can choose HashAgg. The > enable_hashagg_disk GUC, if set to true, chooses HashAgg based on > costing. If false, it only generates a HashAgg path if it thinks it > will fit in work_mem, similar to the old behavior (though it wlil now > spill to disk if the planner was wrong about it fitting in work_mem). > The current default is true. > > I expect this to be a win in a lot of cases, obviously. But as with > any > planner change, it will be wrong sometimes. We may want to be > conservative and set the default to false depending on the experience > during beta. I'm inclined to leave it as true for now though, because > that will give us better information upon which to base any decision. A compromise may be to multiply the disk costs for HashAgg by, e.g. a 1.5 - 2X penalty. That would make the plan changes less abrupt, and may mitigate some of the concerns about I/O patterns that Tomas raised here: https://www.postgresql.org/message-id/20200519151202.u2p2gpiawoaznsv2@development The issues were improved a lot, but it will take us a while to really tune the IO behavior as well as Sort. Regards, Jeff Davis
On Wed, Jun 10, 2020 at 10:39 AM Jeff Davis <pgsql@j-davis.com> wrote:
On Tue, 2020-06-09 at 18:20 -0700, Melanie Plageman wrote:
> So, I was catching up on email and noticed the last email in this
> thread.
>
> I think I am not fully understanding what
> enable_groupingsets_hash_disk
> does. Is it only for testing?
It's mostly for testing. I could imagine cases where it would be useful
to force groupingsets to use the disk, but I mainly wanted the setting
there for testing the grouping sets hash disk code path.
> Using the tests you added to src/test/regress/sql/groupingsets.sql, I
> did get a plan that looks like hashagg is spilling to disk (goes
> through
I had something that worked as a test for a while, but then when I
tweaked the costing, it started using the Sort path (therefore not
testing my grouping sets hash disk code at all) and a bug crept in. So
I thought it would be best to have a more forceful knob.
Perhaps I should just get rid of that GUC and use the stats trick?
throw in that other trick that is used in groupingsets.sql and make some
of the grouping columns unhashable and some unsortable so you know that
you will not pick only the Sort Path and do just a GroupAgg.
This slight modification of my previous example will probably yield
consistent results:
set enable_hashagg_disk = true;
SET enable_groupingsets_hash_disk = false;
SET work_mem='64kB';
SET enable_hashagg = true;
drop table if exists gs_hash_1;
create table gs_hash_1 as
select g%1000 as g1000, g%100 as g100, g%10 as g10, g,
g::text::xid as g_unsortable, g::bit(4) as g_unhashable
from generate_series(0,199999) g;
analyze gs_hash_1;
alter table gs_hash_1 set (autovacuum_enabled = 'false');
update pg_class set reltuples = 10 where relname = 'gs_hash_1';
explain (analyze, costs off, timing off)
select g1000, g100, g10
from gs_hash_1
group by grouping sets ((g1000,g100), (g10, g_unhashable), (g100, g_unsortable));
QUERY PLAN
----------------------------------------------------------------
MixedAggregate (actual rows=201080 loops=1)
Hash Key: g100, g_unsortable
Group Key: g1000, g100
Sort Key: g10, g_unhashable
Group Key: g10, g_unhashable
Peak Memory Usage: 109 kB
Disk Usage: 13504 kB
HashAgg Batches: 10111
-> Sort (actual rows=200000 loops=1)
Sort Key: g1000, g100
Sort Method: external merge Disk: 9856kB
-> Seq Scan on gs_hash_1 (actual rows=200000 loops=1)
While we are on the topic of the tests, I was wondering if you had
considered making a user defined type that had a lot of padding so that
the tests could use fewer rows. I did this for adaptive hashjoin and it
helped me with iteration time.
I don't know if that would still be the kind of test you are looking for
since a user probably wouldn't have a couple hundred really fat
untoasted tuples, but, I just thought I would check if that would be
useful.
--
Melanie Plageman
On Wed, 2020-06-10 at 11:39 -0700, Jeff Davis wrote:
> 1. Testing the spilling of hashed grouping sets: I'm inclined to just
> get rid of enable_groupingsets_hash_disk and use Melanie's stats-
> hacking approach instead.
Fixed in 92c58fd9.
> think the names you suggested quite fit, but the idea to use a more
> interesting GUC value might help express the behavior. Perhaps making
> enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word
> "reject" is too definite for the planner, which is working with
> imperfect information.
I renamed enable_hashagg_disk to hashagg_avoid_disk_plan, which I think
satisfies the concerns raised here. Also in 92c58fd9.
There is still the original topic of this thread, which is whether we
need to change the default value of this GUC, or penalize disk-based
HashAgg in some way, to be more conservative about plan changes in v13.
I think we can wait a little longer to make a decision there.
Regards,
Jeff Davis
On Thu, Jun 11, 2020 at 01:22:57PM -0700, Jeff Davis wrote: > On Wed, 2020-06-10 at 11:39 -0700, Jeff Davis wrote: > > 1. Testing the spilling of hashed grouping sets: I'm inclined to just > > get rid of enable_groupingsets_hash_disk and use Melanie's stats- > > hacking approach instead. > > Fixed in 92c58fd9. > > > think the names you suggested quite fit, but the idea to use a more > > interesting GUC value might help express the behavior. Perhaps making > > enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word > > "reject" is too definite for the planner, which is working with > > imperfect information. > > I renamed enable_hashagg_disk to hashagg_avoid_disk_plan, which I think > satisfies the concerns raised here. Also in 92c58fd9. Thanks for considering :) I saw you updated the Open Items page, but put the items into "Older Bugs / Fixed". I moved them underneath "Resolved" since they're all new in v13. https://wiki.postgresql.org/index.php?title=PostgreSQL_13_Open_Items&diff=34995&oldid=34994 -- Justin
On Thu, 9 Apr 2020 at 13:24, Justin Pryzby <pryzby@telsasoft.com> wrote:
On Thu, Apr 09, 2020 at 01:48:55PM +0200, Tomas Vondra wrote:
> It it really any different from our enable_* GUCs? Even if you do e.g.
> enable_sort=off, we may still do a sort. Same for enable_groupagg etc.
Those show that the GUC was disabled by showing disable_cost. That's what's
different about this one.
Fwiw in the past this was seen not so much as a positive thing but a bug to be fixed. We've talked about carrying a boolean "disabled plan" flag which would be treated as a large cost penalty but not actually be added to the cost in the plan.
The problems with the disable_cost in the cost are (at least):
1) It causes the resulting costs to be useless for comparing the plan costs with other plans.
2) It can cause other planning decisions to be distorted in strange non-linear ways.
greg
On Thu, Jun 11, 2020 at 01:22:57PM -0700, Jeff Davis wrote: > > think the names you suggested quite fit, but the idea to use a more > > interesting GUC value might help express the behavior. Perhaps making > > enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word > > "reject" is too definite for the planner, which is working with > > imperfect information. > > I renamed enable_hashagg_disk to hashagg_avoid_disk_plan, which I think > satisfies the concerns raised here. Also in 92c58fd9. I think this should be re-arranged to be in alphabetical order https://www.postgresql.org/docs/devel/runtime-config-query.html -- Justin
On Wed, Jun 10, 2020 at 2:39 PM Jeff Davis <pgsql@j-davis.com> wrote: > The behavior in v13 master is, by default, analagous to Sort or > anything else that adapts at runtime to spill. If we had spillable > HashAgg the whole time, we wouldn't be worried about #2 at all. But, > out of conservatism, I am trying to accommodate users who want an > escape hatch, at least for a release or two until users feel more > comfortable with disk-based HashAgg. > > Setting enable_hash_disk=false implements 2(a). This name apparently > causes confusion, but it's hard to come up with a better one because > the v12 behavior has nuance that's hard to express succinctly. I don't > think the names you suggested quite fit, but the idea to use a more > interesting GUC value might help express the behavior. Perhaps making > enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word > "reject" is too definite for the planner, which is working with > imperfect information. > > In master, there is no explicit way to get 2(b), but you can just set > work_mem higher in a lot of cases. If enough people want 2(b), I can > add it easily. Perhaps hashagg_overflow=on|off, which would control > execution time behavior? Planner GUCs are a pretty blunt instrument for solving problems that users may have with planner features. There's no guarantee that the experience a user has with one query will be the same as the experience they have with another query, or even that you couldn't have a single query which contains two different nodes where the optimal behavior is different for one than it is for the other. In the first case, changing the value of the GUC on a per-query basis is pretty painful; in the second case, even that is not good enough. So, as Tom has said before, the only really good choice in a case like this is for the planner to figure out the right things automatically; anything that boils down to a user-provided hint pretty well sucks. So I feel like the really important thing here is to fix the cases that don't come out well with default settings. If we can't do that, then the feature is half-baked and maybe should not have been committed in the first place. If we can, then we don't really need the GUC, let alone multiple GUCs. I understand that some of the reason you added these was out of paranoia, and I get that: it's hard to be sure that any feature of this complexity isn't going to have some rough patches, especially given how defective work_mem is as a model in general. Still, we don't want to end up with 50 planner GUCs enabling and disabling individual bits of various planner nodes, or at least I don't think we do, so I'm very skeptical of the idea that we need 2 just for this feature. That doesn't feel scalable. I think the right number is 0 or 1, and if it's 1, very few people should be changing the default. If anything else is the case, then IMHO the feature isn't ready to ship. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jun 22, 2020 at 10:52:37AM -0400, Robert Haas wrote: > On Wed, Jun 10, 2020 at 2:39 PM Jeff Davis <pgsql@j-davis.com> wrote: > > The behavior in v13 master is, by default, analagous to Sort or > > anything else that adapts at runtime to spill. If we had spillable > > HashAgg the whole time, we wouldn't be worried about #2 at all. But, > > out of conservatism, I am trying to accommodate users who want an > > escape hatch, at least for a release or two until users feel more > > comfortable with disk-based HashAgg. > > > > Setting enable_hash_disk=false implements 2(a). This name apparently > > causes confusion, but it's hard to come up with a better one because > > the v12 behavior has nuance that's hard to express succinctly. I don't > > think the names you suggested quite fit, but the idea to use a more > > interesting GUC value might help express the behavior. Perhaps making > > enable_hashagg a ternary "enable_hashagg=on|off|avoid_disk"? The word > > "reject" is too definite for the planner, which is working with > > imperfect information. > > > > In master, there is no explicit way to get 2(b), but you can just set > > work_mem higher in a lot of cases. If enough people want 2(b), I can > > add it easily. Perhaps hashagg_overflow=on|off, which would control > > execution time behavior? > > don't think we do, so I'm very skeptical of the idea that we need 2 > just for this feature. That doesn't feel scalable. I think the right > number is 0 or 1, and if it's 1, very few people should be changing > the default. If anything else is the case, then IMHO the feature isn't > ready to ship. This was addressed in 92c58fd94801dd5c81ee20e26c5bb71ad64552a8 https://wiki.postgresql.org/index.php?title=PostgreSQL_13_Open_Items&diff=34994&oldid=34993 -- Justin
On Mon, Jun 22, 2020 at 11:06 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > This was addressed in 92c58fd94801dd5c81ee20e26c5bb71ad64552a8 > https://wiki.postgresql.org/index.php?title=PostgreSQL_13_Open_Items&diff=34994&oldid=34993 I mean, that's fine, but I am trying to make a more general point about priorities. Getting the GUCs right is a lot less important than getting the feature right. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 2020-06-22 at 10:52 -0400, Robert Haas wrote:
> So I feel like the really important thing here is to fix the cases
> that don't come out well with default settings.
...with the caveat that perfection is not something to expect from our
planner.
> If we can't do that,
> then the feature is half-baked and maybe should not have been
> committed in the first place.
HashAgg started out half-baked at the dawn of time, and stayed that way
through version 12. Disk-based HashAgg was designed to fix it.
Other major planner features generally offer a way to turn them off
(e.g. parallelism, JIT), and we don't call those half-baked.
I agree that the single GUC added in v13 (hashagg_avoid_disk_plan) is
weird because it's half of a disable switch. But it's not weird because
of my changes in v13; it's weird because the planner behavior in v12
was weird. I hope not many people need to set it, and I hope we can
remove it soon.
If you think we will never be able to remove the GUC, then we should
think a little harder about whether we really need it. I am open to
that discussion, but I don't think the presence of this GUC implies
that disk-based hashagg is half-baked.
Regards,
Jeff Davis
On Mon, 2020-06-22 at 11:17 -0400, Robert Haas wrote:
> I mean, that's fine, but I am trying to make a more general point
> about priorities. Getting the GUCs right is a lot less important than
> getting the feature right.
What about the feature you are worried that we're getting wrong?
Regards,
Jeff Davis
On Mon, Jun 22, 2020 at 1:30 PM Jeff Davis <pgsql@j-davis.com> wrote: > On Mon, 2020-06-22 at 10:52 -0400, Robert Haas wrote: > > So I feel like the really important thing here is to fix the cases > > that don't come out well with default settings. > > ...with the caveat that perfection is not something to expect from our > planner. +1. > > If we can't do that, > > then the feature is half-baked and maybe should not have been > > committed in the first place. > > HashAgg started out half-baked at the dawn of time, and stayed that way > through version 12. Disk-based HashAgg was designed to fix it. > > Other major planner features generally offer a way to turn them off > (e.g. parallelism, JIT), and we don't call those half-baked. Sure, and I'm not calling this half-baked either, but there is a difference. JIT and parallelism are discrete features to a far greater extent than this is. I think we can explain to people the pros and cons of those things and ask them to make an intelligent choice about whether they want them. You can say things like "well, JIT is liable to make your queries run faster once they get going, but it adds to the startup time and creates a dependency on LLVM" and the user can decide whether they want that or not. At least to me, something like this isn't so easy to consider as a separate feature. As you say: > I agree that the single GUC added in v13 (hashagg_avoid_disk_plan) is > weird because it's half of a disable switch. But it's not weird because > of my changes in v13; it's weird because the planner behavior in v12 > was weird. I hope not many people need to set it, and I hope we can > remove it soon. The weirdness is the problem here, at least for me. Generally, I don't like GUCs of the form give_me_the_old_strange_behavior=true, because either they tend to be either unnecessary (because nobody wants the old strange behavior) or hard to eliminate (because the new behavior is also strange and is not categorically better). > If you think we will never be able to remove the GUC, then we should > think a little harder about whether we really need it. I am open to > that discussion, but I don't think the presence of this GUC implies > that disk-based hashagg is half-baked. I don't think it necessarily implies that either. I do however have some concerns about people using the GUC as a crutch. I am slightly worried that this is going to have hard-to-fix problems and that we'll be stuck with the GUC for that reason. Now if that is the case, is removing the GUC any better? Maybe not. These decisions are hard, and I am not trying to pretend like I have all the answers. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 2020-06-22 at 15:28 -0400, Robert Haas wrote:
> The weirdness is the problem here, at least for me. Generally, I
> don't
> like GUCs of the form give_me_the_old_strange_behavior=true
I agree with all of that in general.
> I don't think it necessarily implies that either. I do however have
> some concerns about people using the GUC as a crutch.
Another way of looking at it is that the weird behavior is already
there in v12, so there are already users relying on this weird behavior
as a crutch for some other planner mistake. The question is whether we
want to:
(a) take the weird behavior away now as a consequence of implementing
disk-based HashAgg; or
(b) support the weird behavior forever; or
(c) introduce a GUC now to help transition away from the weird behavior
The danger with (c) is that it gives users more time to become more
reliant on the weird behavior; and worse, a GUC could be seen as an
endorsement of the weird behavior rather than a path to eliminating it.
So we could intend to do (c) and end up with (b). We can mitigate this
with documentation warnings, perhaps.
> I am slightly
> worried that this is going to have hard-to-fix problems and that
> we'll
> be stuck with the GUC for that reason.
Without the GUC, it's basically a normal cost-based decision, with all
of the good and bad that comes with that.
> Now if that is the case, is
> removing the GUC any better? Maybe not. These decisions are hard, and
> I am not trying to pretend like I have all the answers.
I agree that there is no easy answer.
My philosophy here is: if a user does experience a plan regression due
to my change, would it be reasonable to tell them that we don't have
any escape hatch or transition period at all? That would be a tough
sell for such a common plan type.
Regards,
Jeff Davis
On Tue, 23 Jun 2020 at 08:24, Jeff Davis <pgsql@j-davis.com> wrote: > Another way of looking at it is that the weird behavior is already > there in v12, so there are already users relying on this weird behavior > as a crutch for some other planner mistake. The question is whether we > want to: > > (a) take the weird behavior away now as a consequence of implementing > disk-based HashAgg; or > (b) support the weird behavior forever; or > (c) introduce a GUC now to help transition away from the weird behavior > > The danger with (c) is that it gives users more time to become more > reliant on the weird behavior; and worse, a GUC could be seen as an > endorsement of the weird behavior rather than a path to eliminating it. > So we could intend to do (c) and end up with (b). We can mitigate this > with documentation warnings, perhaps. So, I have a few thoughts on this subject. I understand both problem cases have been mentioned before on this thread, but just to reiterate the two problem cases that we really would rather people didn't hit. They are: 1. Statistics underestimation can cause hashagg to be selected. The executor will spill to disk in PG13. Users may find performance suffers as previously the query may have just overshot work_mem without causing any OOM issues. Their I/O performance might be terrible. 2. We might now choose to hash aggregate where pre PG13, we didn't choose that because the hash table was estimated to be bigger than work_mem. Hash agg might not be the best plan for the job. For #1. We know users are forced to run smaller work_mems than they might like as they need to allow for that random moment where all backends happen to be doing that 5-way hash join all at the same time. It seems reasonable that someone might want the old behaviour. They may well be sitting on a timebomb that's about to OOM, but it would be sad if someone's upgrade to PG13 was blocked on this, especially if it's just due to some query that runs once per month but needs to perform quickly. For #2. This seems like a very legitimate requirement to me. If a user is unhappy that PG13 now hashaggs where before it sorted and group aggregated, but they're unhappy, not because there's some issue with hashagg spilling, but because that causes the node above the agg to becomes a Hash Join rather than a Merge Join and that's bad for some existing reason. Our planner doing the wrong thing based on either; lack of, inaccurate or out-of-date statistics is not Jeff's fault. Having the ability to switch off a certain planner feature is just following along with what we do today for many other node types. As for GUCs to try to help the group of users who, *I'm certain*, will have problems with PG13's plan choice. I think the overloaded enable_hashagg option is a really nice compromise. We don't really have any other executor node type that has multiple GUCs controlling its behaviour, so I believe it would be nice to keep it that way. How about: enable_hashagg = "on" -- enables hashagg allowing it to freely spill to disk as it pleases. enable_hashagg = "trynospill" -- Planner will only choose hash_agg if it thinks it won't spill (pre PG13 planner behaviour) enable_hashagg = "neverspill" -- executor will *never* spill to disk and can still OOM (NOT RECOMMENDED, but does give pre PG13 planner and executor behaviour) enable_hashagg = "off" -- planner does not consider hash agg, ever. Same as what PG12 did for this setting. Now, it's a bit weird to have "neverspill" as this is controlling what's done in the executor from a planner GUC. Likely we can just work around that by having a new "allowhashspill" bool field in the "Agg" struct that's set by the planner, say during createplan that controls if nodeAgg.c is allowed to spill or not. That'll also allow PREPAREd plans to continue to do what they had planned to do already. The thing I like about doing it this way is that: a) it does not add any new GUCs b) it semi hides the weird values that we really wish nobody would ever have to set in a GUC that people have become used it just allowing the values "on" and "off". The thing I don't quite like about this idea is: a) I wish the planner was perfect and we didn't need to do this. b) It's a bit weird to overload a GUC that has a very booleanish name to not be bool. However, I also think it's pretty lightweight to support this. I imagine a dozen lines of docs and likely about half a dozen lines per GUC option in the planner. And in the future, when our planner is perfect*, we can easily just remove the enum values from the GUC that we no longer want to support. David * Yes I know that will never happen.
On Wed, Jun 24, 2020 at 02:11:57PM +1200, David Rowley wrote: > On Tue, 23 Jun 2020 at 08:24, Jeff Davis <pgsql@j-davis.com> wrote: > > Another way of looking at it is that the weird behavior is already > > there in v12, so there are already users relying on this weird behavior > > as a crutch for some other planner mistake. The question is whether we > > want to: Yea - "behavior change" is a scenario for which it's hard to anticipate well all the range of consequences. > How about: > > enable_hashagg = "on" -- enables hashagg allowing it to freely spill > to disk as it pleases. > enable_hashagg = "trynospill" -- Planner will only choose hash_agg if > it thinks it won't spill (pre PG13 planner behaviour) > enable_hashagg = "neverspill" -- executor will *never* spill to disk > and can still OOM (NOT RECOMMENDED, but does give pre PG13 planner and > executor behaviour) > enable_hashagg = "off" -- planner does not consider hash agg, ever. > Same as what PG12 did for this setting. +1 I like that this allows the new behavior as an *option* one *can* use rather than a "behavior change" which is imposed on users and which users then *have* to accomodate in postgres. -- Justin
On Wed, Jun 24, 2020 at 02:11:57PM +1200, David Rowley wrote:
> On Tue, 23 Jun 2020 at 08:24, Jeff Davis <pgsql@j-davis.com> wrote:
> > Another way of looking at it is that the weird behavior is already
> > there in v12, so there are already users relying on this weird behavior
> > as a crutch for some other planner mistake. The question is whether we
> > want to:
> >
> > (a) take the weird behavior away now as a consequence of implementing
> > disk-based HashAgg; or
> > (b) support the weird behavior forever; or
> > (c) introduce a GUC now to help transition away from the weird behavior
> >
> > The danger with (c) is that it gives users more time to become more
> > reliant on the weird behavior; and worse, a GUC could be seen as an
> > endorsement of the weird behavior rather than a path to eliminating it.
> > So we could intend to do (c) and end up with (b). We can mitigate this
> > with documentation warnings, perhaps.
>
> So, I have a few thoughts on this subject. I understand both problem
> cases have been mentioned before on this thread, but just to reiterate
> the two problem cases that we really would rather people didn't hit.
I appreciated this summary since I wasn't fully following the issues.
> As for GUCs to try to help the group of users who, *I'm certain*, will
> have problems with PG13's plan choice. I think the overloaded
> enable_hashagg option is a really nice compromise. We don't really
> have any other executor node type that has multiple GUCs controlling
> its behaviour, so I believe it would be nice to keep it that way.
So, in trying to anticipate how users will be affected by an API change,
I try to look at similar cases where we already have this behavior, and
how users react to this. Looking at the available join methods, I think
we have one. We currently support:
* nested loop with sequential scan
* nested loop with index scan
* hash join
* merge join
It would seem merge join has almost the same complexities as the new
hash join code, since it can spill to disk doing sorts for merge joins,
and adjusting work_mem is the only way to control that spill to disk. I
don't remember anyone complaining about spills to disk during merge
join, so I am unclear why we would need a such control for hash join.
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EnterpriseDB https://enterprisedb.com
The usefulness of a cup is in its emptiness, Bruce Lee
On Wed, 24 Jun 2020 at 21:06, Bruce Momjian <bruce@momjian.us> wrote: > I > don't remember anyone complaining about spills to disk during merge > join, so I am unclear why we would need a such control for hash join. Hash aggregate, you mean? The reason is that upgrading to PG13 can cause a performance regression for an underestimated ndistinct on the GROUP BY clause and cause hash aggregate to spill to disk where it previously did everything in RAM. Sure, that behaviour was never what we wanted to happen, Jeff has fixed that now, but the fact remains that this does happen in the real world quite often and people often get away with it, likey because work_mem is generally set to some very conservative value. Of course, there's also a bunch of people that have been bitten by OOM due to this too. The "neverspill" wouldn't be for those people. Certainly, it's possible that we just tell these people to increase work_mem for this query, that way they can set it to something reasonable and still get spilling if it's really needed to save them from OOM, but the problem there is that it's not very easy to go and set work_mem for a certain query. FWIW, I wish that I wasn't suggesting we do this, but I am because it seems simple enough to implement and it removes a pretty big roadblock that might exist for a small subset of people wishing to upgrade to PG13. It seems lightweight enough to maintain, at least until we invent some better management of how many executor nodes we can have allocating work_mem at once. The suggestion I made was just based on asking myself the following set of questions: Since Hash Aggregate has been able to overflow work_mem since day 1, and now that we've completely changed that fact in PG13, is that likely to upset anyone? If so, should we go to the trouble of giving those people a way of getting the old behaviour back? If we do want to help those people, what's the best way to make those options available to them in a way that we can remove the special options with the least pain in some future version of PostgreSQL? I'd certainly be interested in hearing how other people would answer those question. David
On Wed, Jun 24, 2020 at 05:06:28AM -0400, Bruce Momjian wrote: > On Wed, Jun 24, 2020 at 02:11:57PM +1200, David Rowley wrote: > > On Tue, 23 Jun 2020 at 08:24, Jeff Davis <pgsql@j-davis.com> wrote: > > > Another way of looking at it is that the weird behavior is already > > > there in v12, so there are already users relying on this weird behavior > > > as a crutch for some other planner mistake. The question is whether we > > > want to: > > > > > > (a) take the weird behavior away now as a consequence of implementing > > > disk-based HashAgg; or > > > (b) support the weird behavior forever; or > > > (c) introduce a GUC now to help transition away from the weird behavior > > > > > > The danger with (c) is that it gives users more time to become more > > > reliant on the weird behavior; and worse, a GUC could be seen as an > > > endorsement of the weird behavior rather than a path to eliminating it. > > > So we could intend to do (c) and end up with (b). We can mitigate this > > > with documentation warnings, perhaps. > > > > So, I have a few thoughts on this subject. I understand both problem > > cases have been mentioned before on this thread, but just to reiterate > > the two problem cases that we really would rather people didn't hit. > > I appreciated this summary since I wasn't fully following the issues. > > > As for GUCs to try to help the group of users who, *I'm certain*, will > > have problems with PG13's plan choice. I think the overloaded > > enable_hashagg option is a really nice compromise. We don't really > > have any other executor node type that has multiple GUCs controlling > > its behaviour, so I believe it would be nice to keep it that way. ... > It would seem merge join has almost the same complexities as the new > hash join code, since it can spill to disk doing sorts for merge joins, > and adjusting work_mem is the only way to control that spill to disk. I > don't remember anyone complaining about spills to disk during merge > join, so I am unclear why we would need a such control for hash join. It loooks like merge join was new in 8.3. I don't think that's a good analogy, since the old behavior was still available with enable_mergejoin=off. I think a better analogy would be if we now changed sort nodes beneath merge join to use at most 0.5*work_mem, with no way of going back to using 1.0*work_mem. -- Justin
On Wed, Jun 24, 2020 at 07:38:43AM -0500, Justin Pryzby wrote: > On Wed, Jun 24, 2020 at 05:06:28AM -0400, Bruce Momjian wrote: > > It would seem merge join has almost the same complexities as the new > > hash join code, since it can spill to disk doing sorts for merge joins, > > and adjusting work_mem is the only way to control that spill to disk. I > > don't remember anyone complaining about spills to disk during merge > > join, so I am unclear why we would need a such control for hash join. > > It loooks like merge join was new in 8.3. I don't think that's a good analogy, > since the old behavior was still available with enable_mergejoin=off. Uh, we don't gurantee backward compatibility in the optimizer. You can turn off hashagg if you want. That doesn't get you to PG 13 behavior, but we don't gurantee that. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Thu, Jun 25, 2020 at 12:24:29AM +1200, David Rowley wrote: > On Wed, 24 Jun 2020 at 21:06, Bruce Momjian <bruce@momjian.us> wrote: > > I > > don't remember anyone complaining about spills to disk during merge > > join, so I am unclear why we would need a such control for hash join. > > Hash aggregate, you mean? The reason is that upgrading to PG13 can Yes, sorry. > cause a performance regression for an underestimated ndistinct on the > GROUP BY clause and cause hash aggregate to spill to disk where it > previously did everything in RAM. Sure, that behaviour was never > what we wanted to happen, Jeff has fixed that now, but the fact > remains that this does happen in the real world quite often and people > often get away with it, likey because work_mem is generally set to > some very conservative value. Of course, there's also a bunch of > people that have been bitten by OOM due to this too. The "neverspill" > wouldn't be for those people. Certainly, it's possible that we just > tell these people to increase work_mem for this query, that way they > can set it to something reasonable and still get spilling if it's > really needed to save them from OOM, but the problem there is that > it's not very easy to go and set work_mem for a certain query. Well, my point is that merge join works that way, and no one has needed a knob to avoid mergejoin if it is going to spill to disk. If they are adjusting work_mem to prevent spill of merge join, they can do the same for hash agg. We just need to document this in the release notes. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
Justin Pryzby <pryzby@telsasoft.com> writes:
> On Wed, Jun 24, 2020 at 05:06:28AM -0400, Bruce Momjian wrote:
>> It would seem merge join has almost the same complexities as the new
>> hash join code, since it can spill to disk doing sorts for merge joins,
>> and adjusting work_mem is the only way to control that spill to disk. I
>> don't remember anyone complaining about spills to disk during merge
>> join, so I am unclear why we would need a such control for hash join.
> It loooks like merge join was new in 8.3. I don't think that's a good analogy,
> since the old behavior was still available with enable_mergejoin=off.
Uh, what? A look into our git history shows immediately that
nodeMergejoin.c has been there since the initial code import in 1996.
I tend to agree with Bruce that it's not very obvious that we need
another GUC knob here ... especially not one as ugly as this.
I'm especially against the "neverspill" option, because that makes a
single GUC that affects both the planner and executor independently.
If we feel we need something to let people have the v12 behavior
back, let's have
(1) enable_hashagg on/off --- controls planner, same as it ever was
(2) enable_hashagg_spill on/off --- controls executor by disabling spill
But I'm not really convinced that we need (2).
regards, tom lane
On Wed, Jun 24, 2020 at 01:29:56PM -0400, Tom Lane wrote: >Justin Pryzby <pryzby@telsasoft.com> writes: >> On Wed, Jun 24, 2020 at 05:06:28AM -0400, Bruce Momjian wrote: >>> It would seem merge join has almost the same complexities as the new >>> hash join code, since it can spill to disk doing sorts for merge joins, >>> and adjusting work_mem is the only way to control that spill to disk. I >>> don't remember anyone complaining about spills to disk during merge >>> join, so I am unclear why we would need a such control for hash join. > >> It loooks like merge join was new in 8.3. I don't think that's a good analogy, >> since the old behavior was still available with enable_mergejoin=off. > >Uh, what? A look into our git history shows immediately that >nodeMergejoin.c has been there since the initial code import in 1996. > >I tend to agree with Bruce that it's not very obvious that we need >another GUC knob here ... especially not one as ugly as this. >I'm especially against the "neverspill" option, because that makes a >single GUC that affects both the planner and executor independently. > >If we feel we need something to let people have the v12 behavior >back, let's have >(1) enable_hashagg on/off --- controls planner, same as it ever was >(2) enable_hashagg_spill on/off --- controls executor by disabling spill > What if a user specifies enable_hashagg = on enable_hashagg_spill = off and the estimates say the hashagg would need to spill to disk. Should that disable the query (in which case the second GUC affects both executor and planner) or run it (in which case we knowingly ignore work_mem, which seems wrong). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> On Wed, Jun 24, 2020 at 01:29:56PM -0400, Tom Lane wrote:
>> If we feel we need something to let people have the v12 behavior
>> back, let's have
>> (1) enable_hashagg on/off --- controls planner, same as it ever was
>> (2) enable_hashagg_spill on/off --- controls executor by disabling spill
> What if a user specifies
> enable_hashagg = on
> enable_hashagg_spill = off
It would probably be reasonable for the planner to behave as it did
pre-v13, that is not choose hashagg if it estimates that work_mem
would be exceeded. (So, okay, that means enable_hashagg_spill
affects both planner and executor ... but ISTM it's just one
behavior not two.)
regards, tom lane
Hi, On 2020-06-24 14:11:57 +1200, David Rowley wrote: > 1. Statistics underestimation can cause hashagg to be selected. The > executor will spill to disk in PG13. Users may find performance > suffers as previously the query may have just overshot work_mem > without causing any OOM issues. Their I/O performance might be > terrible. > 2. We might now choose to hash aggregate where pre PG13, we didn't > choose that because the hash table was estimated to be bigger than > work_mem. Hash agg might not be the best plan for the job. > For #1. We know users are forced to run smaller work_mems than they > might like as they need to allow for that random moment where all > backends happen to be doing that 5-way hash join all at the same time. > It seems reasonable that someone might want the old behaviour. They > may well be sitting on a timebomb that's about to OOM, but it would be > sad if someone's upgrade to PG13 was blocked on this, especially if > it's just due to some query that runs once per month but needs to > perform quickly. I'm quite concerned about this one. I think this isn't just going to hit when the planner mis-estimates ndistinct, but also when transition values use a bit more space. We'll now start spilling in cases the < v13 planner did everything right. That's great for cases where we'd otherwise OOM, but for a lot of other cases where there actually is more than sufficient RAM to overrun work_mem by a single-digit factor, it can cause a pretty massive increase of IO over < v13. FWIW, my gut feeling is that we'll end up have to separate the "execution time" spilling from using plain work mem, because it'll trigger spilling too often. E.g. if the plan isn't expected to spill, only spill at 10 x work_mem or something like that. Or we'll need better management of temp file data when there's plenty memory available. > For #2. This seems like a very legitimate requirement to me. If a > user is unhappy that PG13 now hashaggs where before it sorted and > group aggregated, but they're unhappy, not because there's some issue > with hashagg spilling, but because that causes the node above the agg > to becomes a Hash Join rather than a Merge Join and that's bad for > some existing reason. Our planner doing the wrong thing based on > either; lack of, inaccurate or out-of-date statistics is not Jeff's > fault. Having the ability to switch off a certain planner feature is > just following along with what we do today for many other node types. This one concerns me a bit less, fwiw. There's a lot more "pressure" in the planner to choose hash agg or sorted agg, compared to e.g. a bunch of aggregate states taking up a bit more space (can't estimate that at all for ma. > As for GUCs to try to help the group of users who, *I'm certain*, will > have problems with PG13's plan choice. I think the overloaded > enable_hashagg option is a really nice compromise. We don't really > have any other executor node type that has multiple GUCs controlling > its behaviour, so I believe it would be nice to keep it that way. > > How about: > > enable_hashagg = "on" -- enables hashagg allowing it to freely spill > to disk as it pleases. > enable_hashagg = "trynospill" -- Planner will only choose hash_agg if > it thinks it won't spill (pre PG13 planner behaviour) > enable_hashagg = "neverspill" -- executor will *never* spill to disk > and can still OOM (NOT RECOMMENDED, but does give pre PG13 planner and > executor behaviour) > enable_hashagg = "off" -- planner does not consider hash agg, ever. > Same as what PG12 did for this setting. > > Now, it's a bit weird to have "neverspill" as this is controlling > what's done in the executor from a planner GUC. Likely we can just > work around that by having a new "allowhashspill" bool field in the > "Agg" struct that's set by the planner, say during createplan that > controls if nodeAgg.c is allowed to spill or not. That'll also allow > PREPAREd plans to continue to do what they had planned to do already. > > The thing I like about doing it this way is that: > > a) it does not add any new GUCs > b) it semi hides the weird values that we really wish nobody would > ever have to set in a GUC that people have become used it just > allowing the values "on" and "off". > > The thing I don't quite like about this idea is: > a) I wish the planner was perfect and we didn't need to do this. > b) It's a bit weird to overload a GUC that has a very booleanish name > to not be bool. > > However, I also think it's pretty lightweight to support this. I > imagine a dozen lines of docs and likely about half a dozen lines per > GUC option in the planner. That'd work for me, but I honestly don't particularly care about the specific naming, as long as we provide users an escape hatch from the increased amount of IO. Greetings, Andres Freund
Hi, On 2020-06-24 13:12:03 -0400, Bruce Momjian wrote: > Well, my point is that merge join works that way, and no one has needed > a knob to avoid mergejoin if it is going to spill to disk. If they are > adjusting work_mem to prevent spill of merge join, they can do the same > for hash agg. We just need to document this in the release notes. I don't think this is comparable. For starters, the IO indirectly triggered by mergejoin actually leads to plenty people just straight out disabling it. For lots of workloads there's never a valid reason to use a mergejoin (and often the planner will never choose one). Secondly, the planner has better information about estimating the memory usage for the to-be-sorted data than it has about the size of the transition values. And lastly, there's a difference between a long existing cause for bad IO behaviour and one that's suddenly kicks in after a major version upgrade, to which there's no escape hatch (it's rarely realistic to disable hash aggs, in contrast to merge joins). Greetings, Andres Freund
On Wed, Jun 24, 2020 at 3:14 PM Andres Freund <andres@anarazel.de> wrote: > FWIW, my gut feeling is that we'll end up have to separate the > "execution time" spilling from using plain work mem, because it'll > trigger spilling too often. E.g. if the plan isn't expected to spill, > only spill at 10 x work_mem or something like that. Or we'll need > better management of temp file data when there's plenty memory > available. So, I don't think we can wire in a constant like 10x. That's really unprincipled and I think it's a bad idea. What we could do, though, is replace the existing Boolean-valued GUC with a new GUC that controls the size at which the aggregate spills. The default could be -1, meaning work_mem, but a user could configure a larger value if desired (presumably, we would just treat a value smaller than work_mem as work_mem, and document the same). I think that's actually pretty appealing. Separating the memory we plan to use from the memory we're willing to use before spilling seems like a good idea in general, and I think we should probably also do it in other places - like sorts. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2020-06-24 14:40:50 -0400, Tom Lane wrote:
> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> > On Wed, Jun 24, 2020 at 01:29:56PM -0400, Tom Lane wrote:
> >> If we feel we need something to let people have the v12 behavior
> >> back, let's have
> >> (1) enable_hashagg on/off --- controls planner, same as it ever was
> >> (2) enable_hashagg_spill on/off --- controls executor by disabling spill
>
> > What if a user specifies
> > enable_hashagg = on
> > enable_hashagg_spill = off
>
> It would probably be reasonable for the planner to behave as it did
> pre-v13, that is not choose hashagg if it estimates that work_mem
> would be exceeded. (So, okay, that means enable_hashagg_spill
> affects both planner and executor ... but ISTM it's just one
> behavior not two.)
There's two different reasons for spilling in the executor right now:
1) The planner estimated that we'd need to spill, and that turns out to
be true. There seems no reason to not spill in that case (as long as
it's enabled/chosen in the planner).
2) The planner didn't think we'd need to spill, but we end up using more
than work_mem memory.
nodeAgg.c already treats those separately:
void
hash_agg_set_limits(double hashentrysize, uint64 input_groups, int used_bits,
Size *mem_limit, uint64 *ngroups_limit,
int *num_partitions)
{
int npartitions;
Size partition_mem;
/* if not expected to spill, use all of work_mem */
if (input_groups * hashentrysize < work_mem * 1024L)
{
if (num_partitions != NULL)
*num_partitions = 0;
*mem_limit = work_mem * 1024L;
*ngroups_limit = *mem_limit / hashentrysize;
return;
}
We can't sensibly disable spilling when chosen at plan time, because
that'd lead to *more* OOMS than in v12.
ISTM that we should have one option that controls whether 1) is done,
and one that controls whether 2) is done. Even if the option for 2 is
off, we still should spill when the option for 1) chooses a spilling
plan. I don't think it makes sense for one of those options to
influence the other implicitly.
So maybe enable_hashagg_spilling_plan for 1) and
hashagg_spill_on_exhaust for 2).
Greetings,
Andres Freund
Hi, On 2020-06-24 15:28:47 -0400, Robert Haas wrote: > On Wed, Jun 24, 2020 at 3:14 PM Andres Freund <andres@anarazel.de> wrote: > > FWIW, my gut feeling is that we'll end up have to separate the > > "execution time" spilling from using plain work mem, because it'll > > trigger spilling too often. E.g. if the plan isn't expected to spill, > > only spill at 10 x work_mem or something like that. Or we'll need > > better management of temp file data when there's plenty memory > > available. > > So, I don't think we can wire in a constant like 10x. That's really > unprincipled and I think it's a bad idea. What we could do, though, is > replace the existing Boolean-valued GUC with a new GUC that controls > the size at which the aggregate spills. The default could be -1, > meaning work_mem, but a user could configure a larger value if desired > (presumably, we would just treat a value smaller than work_mem as > work_mem, and document the same). To be clear, I wasn't actually thinking of hard-coding 10x, but having a config option that specifies a factor of work_mem. A factor seems better because it'll work reasonably for different values of work_mem, whereas a concrete size wouldn't. > I think that's actually pretty appealing. Separating the memory we > plan to use from the memory we're willing to use before spilling seems > like a good idea in general, and I think we should probably also do it > in other places - like sorts. Indeed. And then perhaps we could eventually add some reporting / monitoring infrastructure for the cases where plan time and execution time memory estimate/usage widely differs. Greetings, Andres Freund
On Wed, Jun 24, 2020 at 12:36:24PM -0700, Andres Freund wrote: >Hi, > >On 2020-06-24 15:28:47 -0400, Robert Haas wrote: >> On Wed, Jun 24, 2020 at 3:14 PM Andres Freund <andres@anarazel.de> wrote: >> > FWIW, my gut feeling is that we'll end up have to separate the >> > "execution time" spilling from using plain work mem, because it'll >> > trigger spilling too often. E.g. if the plan isn't expected to spill, >> > only spill at 10 x work_mem or something like that. Or we'll need >> > better management of temp file data when there's plenty memory >> > available. >> >> So, I don't think we can wire in a constant like 10x. That's really >> unprincipled and I think it's a bad idea. What we could do, though, is >> replace the existing Boolean-valued GUC with a new GUC that controls >> the size at which the aggregate spills. The default could be -1, >> meaning work_mem, but a user could configure a larger value if desired >> (presumably, we would just treat a value smaller than work_mem as >> work_mem, and document the same). > >To be clear, I wasn't actually thinking of hard-coding 10x, but having a >config option that specifies a factor of work_mem. A factor seems better >because it'll work reasonably for different values of work_mem, whereas >a concrete size wouldn't. > I'm not quite convinced we need/should introduce a new memory limit. It's true keping it equal to work_mem by default makes this less of an issue, but it's still another moving part the users will need to learn how to use. But if we do introduce a new limit, I very much think it should be a plain limit, not a factor. That just makes it even more complicated, and we don't have any such limit yet. > >> I think that's actually pretty appealing. Separating the memory we >> plan to use from the memory we're willing to use before spilling seems >> like a good idea in general, and I think we should probably also do it >> in other places - like sorts. > >Indeed. And then perhaps we could eventually add some reporting / >monitoring infrastructure for the cases where plan time and execution >time memory estimate/usage widely differs. > I wouldn't mind something like that in general - not just for hashagg, but for various other nodes. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Jun 24, 2020 at 11:02:10PM +0200, Tomas Vondra wrote: > > Indeed. And then perhaps we could eventually add some reporting / > > monitoring infrastructure for the cases where plan time and execution > > time memory estimate/usage widely differs. > > > > I wouldn't mind something like that in general - not just for hashagg, > but for various other nodes. Well, other than worrying about problems with pre-13 queries, how is this different from any other spill to disk when we exceed work_mem, like sorts for merge join. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Wed, Jun 24, 2020 at 12:19:00PM -0700, Andres Freund wrote: > Hi, > > On 2020-06-24 13:12:03 -0400, Bruce Momjian wrote: > > Well, my point is that merge join works that way, and no one has needed > > a knob to avoid mergejoin if it is going to spill to disk. If they are > > adjusting work_mem to prevent spill of merge join, they can do the same > > for hash agg. We just need to document this in the release notes. > > I don't think this is comparable. For starters, the IO indirectly > triggered by mergejoin actually leads to plenty people just straight out > disabling it. For lots of workloads there's never a valid reason to use > a mergejoin (and often the planner will never choose one). Secondly, the > planner has better information about estimating the memory usage for the > to-be-sorted data than it has about the size of the transition > values. And lastly, there's a difference between a long existing cause > for bad IO behaviour and one that's suddenly kicks in after a major > version upgrade, to which there's no escape hatch (it's rarely realistic > to disable hash aggs, in contrast to merge joins). Well, this sounds like an issue of degree, rather than kind. It sure sounds like "ignore work_mem for this join type, but not the other". -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Wed, Jun 24, 2020 at 07:18:10PM -0400, Bruce Momjian wrote: > On Wed, Jun 24, 2020 at 12:19:00PM -0700, Andres Freund wrote: > > Hi, > > > > On 2020-06-24 13:12:03 -0400, Bruce Momjian wrote: > > > Well, my point is that merge join works that way, and no one has needed > > > a knob to avoid mergejoin if it is going to spill to disk. If they are > > > adjusting work_mem to prevent spill of merge join, they can do the same > > > for hash agg. We just need to document this in the release notes. > > > > I don't think this is comparable. For starters, the IO indirectly > > triggered by mergejoin actually leads to plenty people just straight out > > disabling it. For lots of workloads there's never a valid reason to use > > a mergejoin (and often the planner will never choose one). Secondly, the > > planner has better information about estimating the memory usage for the > > to-be-sorted data than it has about the size of the transition > > values. And lastly, there's a difference between a long existing cause > > for bad IO behaviour and one that's suddenly kicks in after a major > > version upgrade, to which there's no escape hatch (it's rarely realistic > > to disable hash aggs, in contrast to merge joins). > > Well, this sounds like an issue of degree, rather than kind. It sure > sounds like "ignore work_mem for this join type, but not the other". I think my main point is that work_mem was not being honored for hash-agg before, but now that PG 13 can do it, we are again allowing work_mem not to apply in certain cases. I am wondering if our hard limit for work_mem is the issue, and we should make that more flexible for all uses. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Wed, Jun 24, 2020 at 7:38 PM Bruce Momjian <bruce@momjian.us> wrote: > I think my main point is that work_mem was not being honored for > hash-agg before, but now that PG 13 can do it, we are again allowing > work_mem not to apply in certain cases. I am wondering if our hard > limit for work_mem is the issue, and we should make that more flexible > for all uses. I mean, that's pretty much what we're talking about here, isn't it? It seems like in your previous two replies you were opposed to separating the plan-type limit from the execution-time limit, but that idea is precisely a way of being more flexible (and extending it to other plan nodes is a way of making it more flexible for more use cases). As I think you know, if you have a system where the workload varies a lot, you may sometimes be using 0 copies of work_mem and at other times 1000 or more copies, so the value has to be chosen conservatively as a percentage of system memory, else you start swapping or the OOM killer gets involved. On the other hand, some plan nodes get a lot less efficient when the amount of memory available falls below some threshold, so you can't just set this to a tiny value and forget about it. Because the first problem is so bad, most people set the value relatively conservatively and just live with the performance consequences. But this also means that they have memory left over most of the time, so the idea of letting a node burst above its work_mem allocation when something unexpected happens isn't crazy: as long as only a few nodes do that here and there, rather than, say, all the nodes doing it all at the same time, it's actually fine. If we had a smarter system that could dole out more work_mem to nodes that would really benefit from it and less to nodes where it isn't likely to make much difference, that would be similar in spirit but even better. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, 2020-06-24 at 15:28 -0400, Robert Haas wrote:
> On Wed, Jun 24, 2020 at 3:14 PM Andres Freund <andres@anarazel.de>
> wrote:
> > FWIW, my gut feeling is that we'll end up have to separate the
> > "execution time" spilling from using plain work mem, because it'll
> > trigger spilling too often. E.g. if the plan isn't expected to
> > spill,
> > only spill at 10 x work_mem or something like that. Or we'll need
> > better management of temp file data when there's plenty memory
> > available.
...
> I think that's actually pretty appealing. Separating the memory we
> plan to use from the memory we're willing to use before spilling
> seems
> like a good idea in general, and I think we should probably also do
> it
> in other places - like sorts.
I'm trying to make sense of this. Let's say there are two GUCs:
planner_work_mem=16MB and executor_work_mem=32MB.
And let's say a query comes along and generates a HashAgg path, and the
planner (correctly) thinks if you put all the groups in memory at once,
it would be 24MB. Then the planner, using planner_work_mem, would think
spilling was necessary, and generate a cost that involves spilling.
Then it's going to generate a Sort+Group path, as well. And perhaps it
estimates that sorting all of the tuples in memory would also take
24MB, so it generates a cost that involves spilling to disk.
But it has to choose one of them. We've penalized plans at risk of
spilling to disk, but what's the point? The planner needs to choose one
of them, and both are at risk of spilling to disk.
Regards,
Jeff Davis
On Wed, 2020-06-24 at 12:14 -0700, Andres Freund wrote:
> E.g. if the plan isn't expected to spill,
> only spill at 10 x work_mem or something like that.
Let's say you have work_mem=32MB and a query that's expected to use
16MB of memory. In reality, it uses 64MB of memory. So you are saying
this query would get to use all 64MB of memory, right?
But then you run ANALYZE. Now the query is (correctly) expected to use
64MB of memory. Are you saying this query, executed again with better
stats, would only get to use 32MB of memory, and therefore run slower?
Regards,
Jeff Davis
On 2020-06-25 09:24:52 -0700, Jeff Davis wrote: > On Wed, 2020-06-24 at 12:14 -0700, Andres Freund wrote: > > E.g. if the plan isn't expected to spill, > > only spill at 10 x work_mem or something like that. > > Let's say you have work_mem=32MB and a query that's expected to use > 16MB of memory. In reality, it uses 64MB of memory. So you are saying > this query would get to use all 64MB of memory, right? > > But then you run ANALYZE. Now the query is (correctly) expected to use > 64MB of memory. Are you saying this query, executed again with better > stats, would only get to use 32MB of memory, and therefore run slower? Yes. I think that's ok, because it was taken into account from a costing perspective int he second case.
On Wed, 2020-06-24 at 12:31 -0700, Andres Freund wrote:
> nodeAgg.c already treats those separately:
>
> void
> hash_agg_set_limits(double hashentrysize, uint64 input_groups, int
> used_bits,
> Size *mem_limit, uint64
> *ngroups_limit,
> int *num_partitions)
> {
> int npartitions;
> Size partition_mem;
>
> /* if not expected to spill, use all of work_mem */
> if (input_groups * hashentrysize < work_mem * 1024L)
> {
> if (num_partitions != NULL)
> *num_partitions = 0;
> *mem_limit = work_mem * 1024L;
> *ngroups_limit = *mem_limit / hashentrysize;
> return;
> }
The reason this code exists is to decide how much of work_mem to set
aside for spilling (each spill partition needs an IO buffer).
The alternative would be to fix the number of partitions before
processing a batch, which didn't seem ideal. Or, we could just ignore
the memory required for IO buffers, like HashJoin.
Granted, this is an example where an underestimate can give an
advantage, but I don't think we want to extend the concept into other
areas.
Regards,
Jeff Davis
On Thu, 2020-06-25 at 11:46 -0400, Robert Haas wrote:
> Because the first problem is so bad, most people
> set the value relatively conservatively and just live with the
> performance consequences. But this also means that they have memory
> left over most of the time, so the idea of letting a node burst above
> its work_mem allocation when something unexpected happens isn't
> crazy:
> as long as only a few nodes do that here and there, rather than, say,
> all the nodes doing it all at the same time, it's actually fine.
Unexpected things (meaning underestimates) are not independent. All the
queries are based on the same stats, so if you have a lot of similar
queries, they will all get the same underestimate at once, and all be
surprised when they need to spill at once, and then all decide they are
entitled to ignore work_mem at once.
> If we
> had a smarter system that could dole out more work_mem to nodes that
> would really benefit from it and less to nodes where it isn't likely
> to make much difference, that would be similar in spirit but even
> better.
That sounds more useful and probably not too hard to implement in a
crude form. Just have a shared counter in memory representing GB. If a
node is about to spill, it could try to decrement the counter by N, and
if it succeeds, it gets to exceed work_mem by N more GB.
Regards,
Jeff Davis
On Thu, Jun 25, 2020 at 11:46:54AM -0400, Robert Haas wrote:
> On Wed, Jun 24, 2020 at 7:38 PM Bruce Momjian <bruce@momjian.us> wrote:
> > I think my main point is that work_mem was not being honored for
> > hash-agg before, but now that PG 13 can do it, we are again allowing
> > work_mem not to apply in certain cases. I am wondering if our hard
> > limit for work_mem is the issue, and we should make that more flexible
> > for all uses.
>
> I mean, that's pretty much what we're talking about here, isn't it? It
> seems like in your previous two replies you were opposed to separating
> the plan-type limit from the execution-time limit, but that idea is
> precisely a way of being more flexible (and extending it to other plan
> nodes is a way of making it more flexible for more use cases).
I think it is was Tom who was complaining about plan vs. execution time
control.
> As I think you know, if you have a system where the workload varies a
> lot, you may sometimes be using 0 copies of work_mem and at other
> times 1000 or more copies, so the value has to be chosen
> conservatively as a percentage of system memory, else you start
> swapping or the OOM killer gets involved. On the other hand, some plan
> nodes get a lot less efficient when the amount of memory available
> falls below some threshold, so you can't just set this to a tiny value
> and forget about it. Because the first problem is so bad, most people
> set the value relatively conservatively and just live with the
> performance consequences. But this also means that they have memory
> left over most of the time, so the idea of letting a node burst above
> its work_mem allocation when something unexpected happens isn't crazy:
> as long as only a few nodes do that here and there, rather than, say,
> all the nodes doing it all at the same time, it's actually fine. If we
> had a smarter system that could dole out more work_mem to nodes that
> would really benefit from it and less to nodes where it isn't likely
> to make much difference, that would be similar in spirit but even
> better.
I think the issue is that in PG 13 work_mem controls sorts and hashes
with a new hard limit for hash aggregation:
https://www.postgresql.org/docs/12/runtime-config-resource.html#RUNTIME-CONFIG-RESOURCE-MEMORY
Sort operations are used for ORDER BY, DISTINCT, and merge joins. Hash
tables are used in hash joins, hash-based aggregation, and hash-based
processing of IN subqueries.
In pre-PG 13, we "controlled" it by avoiding hash-based aggregation if
was expected it to exceed work_mem, but if we assumed it would be less
than work_mem and it was more, we exceeded work_mem allocation for that
node. In PG 13, we "limit" memory to work_mem and spill to disk if we
exceed it.
We should really have always documented that hash agg could exceed
work_mem for misestimation, and if we add a hash_agg work_mem
misestimation bypass setting we should document this setting in work_mem
as well.
But then the question is why do we allow this bypass only for hash agg?
Should work_mem have a settings for ORDER BY, merge join, hash join, and
hash agg, e.g.:
work_mem = 'order_by=10MB, hash_join=20MB, hash_agg=100MB'
Yeah, crazy syntax, but you get the idea. I understand some nodes are
more sensitive to disk spill than others, so shouldn't we be controlling
this at the work_mem level, rather than for a specific node type like
hash agg? We could allow for misestimation over allocation of hash agg
work_mem by splitting up the hash agg values:
work_mem = 'order_by=10MB, hash_join=20MB, hash_agg=100MB hash_agg_max=200MB'
but _avoiding_ hash agg if it is estimated to exceed work mem and spill
to disk is not something to logically control at the work mem level,
which leads so something like David Rowley suggested, but with different
names:
enable_hashagg = on | soft | avoid | off
where 'on' and 'off' are the current PG 13 behavior, 'soft' means to
treat work_mem as a soft limit and allow it to exceed work mem for
misestimation, and 'avoid' means to avoid hash agg if it is estimated to
exceed work mem. Both 'soft' and 'avoid' don't spill to disk.
David's original terms of "trynospill" and "neverspill" were focused on
spilling, not on its interaction with work_mem, and I found that
confusing.
Frankly, if it took me this long to get my head around this, I am
unclear how many people will understand this tuning feature enough to
actually use it.
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EnterpriseDB https://enterprisedb.com
The usefulness of a cup is in its emptiness, Bruce Lee
On Thu, 2020-06-25 at 09:37 -0700, Andres Freund wrote:
> > Let's say you have work_mem=32MB and a query that's expected to use
> > 16MB of memory. In reality, it uses 64MB of memory. So you are
> > saying
> > this query would get to use all 64MB of memory, right?
> >
> > But then you run ANALYZE. Now the query is (correctly) expected to
> > use
> > 64MB of memory. Are you saying this query, executed again with
> > better
> > stats, would only get to use 32MB of memory, and therefore run
> > slower?
>
> Yes. I think that's ok, because it was taken into account from a
> costing
> perspective int he second case.
What do you mean by "taken into account"?
There are only two possible paths: HashAgg and Sort+Group, and we need
to pick one. If the planner expects one to spill, it is likely to
expect the other to spill. If one spills in the executor, then the
other is likely to spill, too. (I'm ignoring the case with a lot of
tuples and few groups because that doesn't seem relevant.)
Imagine that there was only one path available to choose. Would you
suggest the same thing, that unexpected spills can exceed work_mem but
expected spills can't?
Regards,
Jeff Davis
On Thu, Jun 25, 2020 at 1:15 PM Jeff Davis <pgsql@j-davis.com> wrote: > Unexpected things (meaning underestimates) are not independent. All the > queries are based on the same stats, so if you have a lot of similar > queries, they will all get the same underestimate at once, and all be > surprised when they need to spill at once, and then all decide they are > entitled to ignore work_mem at once. Yeah, that's a risk. But what is proposed is a configuration setting, so people can adjust it depending on what they think is likely to happen in their environment. > That sounds more useful and probably not too hard to implement in a > crude form. Just have a shared counter in memory representing GB. If a > node is about to spill, it could try to decrement the counter by N, and > if it succeeds, it gets to exceed work_mem by N more GB. That's a neat idea, although GB seems too coarse. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, 2020-06-25 at 13:17 -0400, Bruce Momjian wrote:
> Frankly, if it took me this long to get my head around this, I am
> unclear how many people will understand this tuning feature enough to
> actually use it.
The way I think about it is that v13 HashAgg is much more consistent
with the way we do everything else: the planner costs it (including any
spilling that is expected), and the executor executes it (including any
spilling that is required to obey work_mem).
In earlier versions, HashAgg was weird. If we add GUCs to get that
weird behavior back, then the GUCs will necessarily be weird; and
therefore hard to document.
I would feel more comfortable with some kind of GUC escape hatch (or
two). GROUP BY is just too common, and I don't think we can ignore the
potential for users experiencing a regression of some type (even if, in
principle, the v13 version is better).
If we have the GUCs there, then at least if someone comes to the
mailing list with a problem, we can offer them a temporary solution,
and have time to try to avoid the problem in a future release (tweaking
estimates, cost model, defaults, etc.).
One idea is to have undocumented GUCs. That way we don't have to
support them forever, and we are more likely to hear problem reports.
Regards,
Jeff Davis
On Wed, 2020-06-24 at 13:29 -0400, Tom Lane wrote:
> If we feel we need something to let people have the v12 behavior
> back, let's have
> (1) enable_hashagg on/off --- controls planner, same as it ever was
> (2) enable_hashagg_spill on/off --- controls executor by disabling
> spill
>
> But I'm not really convinced that we need (2).
If we're not going to have a planner GUC, one alternative is to just
penalize the disk costs of HashAgg for a release or two. It would only
affect the cost of HashAgg paths that are expected to spill, which
weren't even generated in previous releases.
In other words, multiply the disk costs by enough that the planner will
usually not choose HashAgg if expected to spill unless the average
group size is quite large (i.e. there are a lot more tuples than
groups, but still enough groups to spill).
As we learn more and optimize more, we can reduce or eliminate the
penalty in a future release. I'm not sure exactly what the penalty
would be, though.
Regards,
Jeff Davis
Hi, On 2020-06-25 10:44:42 -0700, Jeff Davis wrote: > There are only two possible paths: HashAgg and Sort+Group, and we need > to pick one. If the planner expects one to spill, it is likely to > expect the other to spill. If one spills in the executor, then the > other is likely to spill, too. (I'm ignoring the case with a lot of > tuples and few groups because that doesn't seem relevant.) There's also ordered index scan + Group. Which will often be vastly better than Sort+Group, but still slower than HashAgg. > Imagine that there was only one path available to choose. Would you > suggest the same thing, that unexpected spills can exceed work_mem but > expected spills can't? I'm not saying what I propose is perfect, but I've yet to hear a better proposal. Given that there *are* different ways to implement aggregation, and that we use expected costs to choose, I think the assumed costs are relevant. Greetings, Andres Freund
On Thu, Jun 25, 2020 at 11:02:30AM -0700, Jeff Davis wrote: > If we have the GUCs there, then at least if someone comes to the > mailing list with a problem, we can offer them a temporary solution, > and have time to try to avoid the problem in a future release (tweaking > estimates, cost model, defaults, etc.). > > One idea is to have undocumented GUCs. That way we don't have to > support them forever, and we are more likely to hear problem reports. Uh, our track record of adding GUCs just in case is not good, and removing them is even harder. Undocumented sounds interesting but then how do we even document when we remove it? I don't think we want to go there. Oracle has done that, and I don't think the user experience is good. Maybe we should just continue though beta, add an incompatibility item to the PG 13 release notes, and see what feedback we get. We know increasing work_mem gets us the exceed work_mem behavior, but that affects other nodes too, and I can't think of a way to avoid if spill is predicted except to disable hash agg for that query. I am still trying to get my head around why the spill is going to be so much work to adjust for hash agg than our other spillable nodes. What are people doing for those cases already? Do we have an real-world queries that are a problem in PG 13 for this? -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Thu, Jun 25, 2020 at 11:10:58AM -0700, Jeff Davis wrote: > On Wed, 2020-06-24 at 13:29 -0400, Tom Lane wrote: > > If we feel we need something to let people have the v12 behavior > > back, let's have > > (1) enable_hashagg on/off --- controls planner, same as it ever was > > (2) enable_hashagg_spill on/off --- controls executor by disabling > > spill > > > > But I'm not really convinced that we need (2). > > If we're not going to have a planner GUC, one alternative is to just > penalize the disk costs of HashAgg for a release or two. It would only > affect the cost of HashAgg paths that are expected to spill, which > weren't even generated in previous releases. > > In other words, multiply the disk costs by enough that the planner will > usually not choose HashAgg if expected to spill unless the average > group size is quite large (i.e. there are a lot more tuples than > groups, but still enough groups to spill). Well, the big question is whether this costing is actually more accurate than what we have now. What I am hearing is that spilling hash agg is expensive, so whatever we can do to reflect the actual costs seems like a win. If it can be done, it certainly seems better than a cost setting few people will use. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Thu, Jun 25, 2020 at 03:24:42PM -0400, Bruce Momjian wrote: > On Thu, Jun 25, 2020 at 11:10:58AM -0700, Jeff Davis wrote: > > On Wed, 2020-06-24 at 13:29 -0400, Tom Lane wrote: > > > If we feel we need something to let people have the v12 behavior > > > back, let's have > > > (1) enable_hashagg on/off --- controls planner, same as it ever was > > > (2) enable_hashagg_spill on/off --- controls executor by disabling > > > spill > > > > > > But I'm not really convinced that we need (2). > > > > If we're not going to have a planner GUC, one alternative is to just > > penalize the disk costs of HashAgg for a release or two. It would only > > affect the cost of HashAgg paths that are expected to spill, which > > weren't even generated in previous releases. > > > > In other words, multiply the disk costs by enough that the planner will > > usually not choose HashAgg if expected to spill unless the average > > group size is quite large (i.e. there are a lot more tuples than > > groups, but still enough groups to spill). > > Well, the big question is whether this costing is actually more accurate > than what we have now. What I am hearing is that spilling hash agg is > expensive, so whatever we can do to reflect the actual costs seems like > a win. If it can be done, it certainly seems better than a cost setting > few people will use. It is my understanding that spill of sorts is mostly read sequentially, while hash reads are random. Is that right? Is that not being costed properly? That doesn't fix the misestimation case, but increasing work mem does allow pre-PG 13 behavior there. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
Hi, On 2020-06-25 14:25:12 -0400, Bruce Momjian wrote: > I am still trying to get my head around why the spill is going to be so > much work to adjust for hash agg than our other spillable nodes. Aggregates are the classical case used to process large amounts of data. For larger amounts of data sorted input (be it via explicit sort or ordered index scan) isn't an attractive option. IOW hash-agg is the common case. There's also fewer stats for halfway accurately estimating the number of groups and the size of the transition state - a sort / hash join doesn't have an equivalent to the variably sized transition value. > What are people doing for those cases already? Do we have an > real-world queries that are a problem in PG 13 for this? I don't know about real world, but it's pretty easy to come up with examples. query: SELECT a, array_agg(b) FROM (SELECT generate_series(1, 10000)) a(a), (SELECT generate_series(1, 10000)) b(b) GROUP BY a HAVINGarray_length(array_agg(b), 1) = 0; work_mem = 4MB 12 18470.012 ms HEAD 44635.210 ms HEAD causes ~2.8GB of file IO, 12 doesn't cause any. If you're IO bandwidth constrained, this could be quite bad. Obviously this is contrived, and a pretty extreme case. But if you imagine this happening on a system where disk IO isn't super fast (e.g. just about any cloud provider). An even more extreme version of the above is this: query: SELECT a, array_agg(b) FROM (SELECT generate_series(1, 50000)) a(a), (SELECT generate_series(1, 10000)) b(b) GROUPBY a HAVING array_length(array_agg(b), 1) = 0; work_mem = 16MB 12 81598.965 ms HEAD 210772.360 ms temporary tablespace on magnetic disk (raid 0 of two 7.2k server spinning disks) 12 81136.530 ms HEAD 225182.560 ms The disks are busy in some periods, but still keep up. If I however make the transition state a bit bigger: query: SELECT a, array_agg(b), count(c), max(d),max(e) FROM (SELECT generate_series(1, 10000)) a(a), (SELECT generate_series(1,5000)::text, repeat(random()::text, 10), repeat(random()::text, 10), repeat(random()::text, 10)) b(b,c,d,e)GROUP BY a HAVING array_length(array_agg(b), 1) = 0; 12 28164.865 ms fast ssd: HEAD 92520.680 ms magnetic: HEAD 183968.538 ms (no reads, there's plenty enough memory. Just writes because the age / amount thresholds for dirty data are reached) In the magnetic case we're IO bottlenecked nearly the whole time. Just to be clear: I think this is a completely over-the-top example. But I do think it shows the problem to some degree at least. Greetings, Andres Freund
On Thu, 2020-06-25 at 15:56 -0400, Bruce Momjian wrote: > It is my understanding that spill of sorts is mostly read > sequentially, > while hash reads are random. Is that right? Is that not being > costed > properly? I don't think there's a major problem with the cost model, but it could probably use some tweaking. Hash writes are random. The hash reads should be mostly sequential (for large partitions it will be 128-block extents, or 1MB). The cost model assumes 50% sequential and 50% random. Sorts are written sequentially and read randomly, but there's prefetching to keep the reads from being too random. The cost model assumes 75% sequential and 25% random. Overall, the IO pattern is better for Sort, but not dramatically so. Tomas Vondra did some nice analysis here: https://www.postgresql.org/message-id/20200525021045.dilgcsmgiu4l5jpa@development That resulted in getting the prealloc and projection patches in. Regards, Jeff Davis
On 2020-Jun-25, Andres Freund wrote: > > What are people doing for those cases already? Do we have an > > real-world queries that are a problem in PG 13 for this? > > I don't know about real world, but it's pretty easy to come up with > examples. > > query: > SELECT a, array_agg(b) FROM (SELECT generate_series(1, 10000)) a(a), (SELECT generate_series(1, 10000)) b(b) GROUP BY aHAVING array_length(array_agg(b), 1) = 0; > > work_mem = 4MB > > 12 18470.012 ms > HEAD 44635.210 ms > > HEAD causes ~2.8GB of file IO, 12 doesn't cause any. If you're IO > bandwidth constrained, this could be quite bad. ... however, you can pretty much get the previous performance back by increasing work_mem. I just tried your example here, and I get 32 seconds of runtime for work_mem 4MB, and 13.5 seconds for work_mem 1GB (this one spills about 800 MB); if I increase that again to 1.7GB I get no spilling and 9 seconds of runtime. (For comparison, 12 takes 15.7 seconds regardless of work_mem). My point here is that maybe we don't need to offer a GUC to explicitly turn spilling off; it seems sufficient to let users change work_mem so that spilling will naturally not occur. Why do we need more? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On June 25, 2020 3:44:22 PM PDT, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >On 2020-Jun-25, Andres Freund wrote: > >> > What are people doing for those cases already? Do we have an >> > real-world queries that are a problem in PG 13 for this? >> >> I don't know about real world, but it's pretty easy to come up with >> examples. >> >> query: >> SELECT a, array_agg(b) FROM (SELECT generate_series(1, 10000)) a(a), >(SELECT generate_series(1, 10000)) b(b) GROUP BY a HAVING >array_length(array_agg(b), 1) = 0; >> >> work_mem = 4MB >> >> 12 18470.012 ms >> HEAD 44635.210 ms >> >> HEAD causes ~2.8GB of file IO, 12 doesn't cause any. If you're IO >> bandwidth constrained, this could be quite bad. > >... however, you can pretty much get the previous performance back by >increasing work_mem. I just tried your example here, and I get 32 >seconds of runtime for work_mem 4MB, and 13.5 seconds for work_mem 1GB >(this one spills about 800 MB); if I increase that again to 1.7GB I get >no spilling and 9 seconds of runtime. (For comparison, 12 takes 15.7 >seconds regardless of work_mem). > >My point here is that maybe we don't need to offer a GUC to explicitly >turn spilling off; it seems sufficient to let users change work_mem so >that spilling will naturally not occur. Why do we need more? That's not really a useful escape hatch, because I'll often lead to other nodes using more memory. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On 2020-Jun-25, Andres Freund wrote: > >My point here is that maybe we don't need to offer a GUC to explicitly > >turn spilling off; it seems sufficient to let users change work_mem so > >that spilling will naturally not occur. Why do we need more? > > That's not really a useful escape hatch, because I'll often lead to > other nodes using more memory. Ah -- other nodes in the same query -- you're right, that's not good. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jun 25, 2020 at 02:28:02PM -0700, Jeff Davis wrote: >On Thu, 2020-06-25 at 15:56 -0400, Bruce Momjian wrote: >> It is my understanding that spill of sorts is mostly read >> sequentially, >> while hash reads are random. Is that right? Is that not being >> costed >> properly? > >I don't think there's a major problem with the cost model, but it could >probably use some tweaking. > >Hash writes are random. The hash reads should be mostly sequential (for >large partitions it will be 128-block extents, or 1MB). The cost model >assumes 50% sequential and 50% random. > The important bit here is that while the logical writes are random, those are effectively combined in page cache and the physical writes are pretty sequential. So I think the cost model is fairly reasonable. Note: Judging by iosnoop stats shared in the thread linked by Jeff. >Sorts are written sequentially and read randomly, but there's >prefetching to keep the reads from being too random. The cost model >assumes 75% sequential and 25% random. > >Overall, the IO pattern is better for Sort, but not dramatically so. >Tomas Vondra did some nice analysis here: > > >https://www.postgresql.org/message-id/20200525021045.dilgcsmgiu4l5jpa@development > >That resulted in getting the prealloc and projection patches in. > >Regards, > Jeff Davis > > regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jun 25, 2020 at 11:16:23AM -0700, Andres Freund wrote: >Hi, > >On 2020-06-25 10:44:42 -0700, Jeff Davis wrote: >> There are only two possible paths: HashAgg and Sort+Group, and we need >> to pick one. If the planner expects one to spill, it is likely to >> expect the other to spill. If one spills in the executor, then the >> other is likely to spill, too. (I'm ignoring the case with a lot of >> tuples and few groups because that doesn't seem relevant.) > >There's also ordered index scan + Group. Which will often be vastly >better than Sort+Group, but still slower than HashAgg. > > >> Imagine that there was only one path available to choose. Would you >> suggest the same thing, that unexpected spills can exceed work_mem but >> expected spills can't? > >I'm not saying what I propose is perfect, but I've yet to hear a better >proposal. Given that there *are* different ways to implement >aggregation, and that we use expected costs to choose, I think the >assumed costs are relevant. > I share Jeff's opinion that this is quite counter-intuitive and we'll have a hard time explaining it to users. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jun 25, 2020 at 09:42:33AM -0700, Jeff Davis wrote:
>On Wed, 2020-06-24 at 12:31 -0700, Andres Freund wrote:
>> nodeAgg.c already treats those separately:
>>
>> void
>> hash_agg_set_limits(double hashentrysize, uint64 input_groups, int
>> used_bits,
>> Size *mem_limit, uint64
>> *ngroups_limit,
>> int *num_partitions)
>> {
>> int npartitions;
>> Size partition_mem;
>>
>> /* if not expected to spill, use all of work_mem */
>> if (input_groups * hashentrysize < work_mem * 1024L)
>> {
>> if (num_partitions != NULL)
>> *num_partitions = 0;
>> *mem_limit = work_mem * 1024L;
>> *ngroups_limit = *mem_limit / hashentrysize;
>> return;
>> }
>
>The reason this code exists is to decide how much of work_mem to set
>aside for spilling (each spill partition needs an IO buffer).
>
>The alternative would be to fix the number of partitions before
>processing a batch, which didn't seem ideal. Or, we could just ignore
>the memory required for IO buffers, like HashJoin.
>
I think the conclusion from the recent HashJoin discussions is that not
accounting for BufFiles is an issue, and we want to fix it. So repeating
that for HashAgg would be a mistake, IMHO.
>Granted, this is an example where an underestimate can give an
>advantage, but I don't think we want to extend the concept into other
>areas.
>
I agree.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jun 25, 2020 at 01:17:56PM -0400, Bruce Momjian wrote: >On Thu, Jun 25, 2020 at 11:46:54AM -0400, Robert Haas wrote: >> On Wed, Jun 24, 2020 at 7:38 PM Bruce Momjian <bruce@momjian.us> wrote: >> > I think my main point is that work_mem was not being honored for >> > hash-agg before, but now that PG 13 can do it, we are again allowing >> > work_mem not to apply in certain cases. I am wondering if our hard >> > limit for work_mem is the issue, and we should make that more flexible >> > for all uses. >> >> I mean, that's pretty much what we're talking about here, isn't it? It >> seems like in your previous two replies you were opposed to separating >> the plan-type limit from the execution-time limit, but that idea is >> precisely a way of being more flexible (and extending it to other plan >> nodes is a way of making it more flexible for more use cases). > >I think it is was Tom who was complaining about plan vs. execution time >control. > >> As I think you know, if you have a system where the workload varies a >> lot, you may sometimes be using 0 copies of work_mem and at other >> times 1000 or more copies, so the value has to be chosen >> conservatively as a percentage of system memory, else you start >> swapping or the OOM killer gets involved. On the other hand, some plan >> nodes get a lot less efficient when the amount of memory available >> falls below some threshold, so you can't just set this to a tiny value >> and forget about it. Because the first problem is so bad, most people >> set the value relatively conservatively and just live with the >> performance consequences. But this also means that they have memory >> left over most of the time, so the idea of letting a node burst above >> its work_mem allocation when something unexpected happens isn't crazy: >> as long as only a few nodes do that here and there, rather than, say, >> all the nodes doing it all at the same time, it's actually fine. If we >> had a smarter system that could dole out more work_mem to nodes that >> would really benefit from it and less to nodes where it isn't likely >> to make much difference, that would be similar in spirit but even >> better. > >I think the issue is that in PG 13 work_mem controls sorts and hashes >with a new hard limit for hash aggregation: > > https://www.postgresql.org/docs/12/runtime-config-resource.html#RUNTIME-CONFIG-RESOURCE-MEMORY > > Sort operations are used for ORDER BY, DISTINCT, and merge joins. Hash > tables are used in hash joins, hash-based aggregation, and hash-based > processing of IN subqueries. > >In pre-PG 13, we "controlled" it by avoiding hash-based aggregation if >was expected it to exceed work_mem, but if we assumed it would be less >than work_mem and it was more, we exceeded work_mem allocation for that >node. In PG 13, we "limit" memory to work_mem and spill to disk if we >exceed it. > >We should really have always documented that hash agg could exceed >work_mem for misestimation, and if we add a hash_agg work_mem >misestimation bypass setting we should document this setting in work_mem >as well. > I don't think that would change anything, really. For the users the consequences would be still exactly the same, and they wouldn't even be in position to check if they are affected. So just documenting that hashagg does not respect work_mem at runtime would be nice, but it would not make any difference for v13, just like documenting a bug is not really the same thing as fixing it. >But then the question is why do we allow this bypass only for hash agg? >Should work_mem have a settings for ORDER BY, merge join, hash join, and >hash agg, e.g.: > > work_mem = 'order_by=10MB, hash_join=20MB, hash_agg=100MB' > >Yeah, crazy syntax, but you get the idea. I understand some nodes are >more sensitive to disk spill than others, so shouldn't we be controlling >this at the work_mem level, rather than for a specific node type like >hash agg? We could allow for misestimation over allocation of hash agg >work_mem by splitting up the hash agg values: > > work_mem = 'order_by=10MB, hash_join=20MB, hash_agg=100MB hash_agg_max=200MB' > >but _avoiding_ hash agg if it is estimated to exceed work mem and spill >to disk is not something to logically control at the work mem level, >which leads so something like David Rowley suggested, but with different >names: > > enable_hashagg = on | soft | avoid | off > >where 'on' and 'off' are the current PG 13 behavior, 'soft' means to >treat work_mem as a soft limit and allow it to exceed work mem for >misestimation, and 'avoid' means to avoid hash agg if it is estimated to >exceed work mem. Both 'soft' and 'avoid' don't spill to disk. > >David's original terms of "trynospill" and "neverspill" were focused on >spilling, not on its interaction with work_mem, and I found that >confusing. > >Frankly, if it took me this long to get my head around this, I am >unclear how many people will understand this tuning feature enough to >actually use it. > Yeah. I agree with Andres we this may be a real issue, and that adding some sort of "escape hatch" for v13 would be good. But I'm not convinced adding a whole lot of new memory limits for every node that might spill is the way to go. What exactly would be our tuning advice to users? Of course, we could keep it set to work_mem by default, but we all know engineers - we can't resist tuning a know when we get one. I'm not saying it's not beneficial to use different limits for different nodes. Some nodes are less sensitive to the size (e.g. sorting often gets faster with smaller work_mem). But I think we should instead have a per-session limit, and the planner should "distribute" the memory to different nodes. It's a hard problem, of course. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jun 26, 2020 at 01:53:57AM +0200, Tomas Vondra wrote: > I'm not saying it's not beneficial to use different limits for different > nodes. Some nodes are less sensitive to the size (e.g. sorting often > gets faster with smaller work_mem). But I think we should instead have a > per-session limit, and the planner should "distribute" the memory to > different nodes. It's a hard problem, of course. Yeah, I am actually confused why we haven't developed a global memory allocation strategy and continue to use per-session work_mem. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jun 26, 2020 at 12:02:10AM -0400, Bruce Momjian wrote: >On Fri, Jun 26, 2020 at 01:53:57AM +0200, Tomas Vondra wrote: >> I'm not saying it's not beneficial to use different limits for different >> nodes. Some nodes are less sensitive to the size (e.g. sorting often >> gets faster with smaller work_mem). But I think we should instead have a >> per-session limit, and the planner should "distribute" the memory to >> different nodes. It's a hard problem, of course. > >Yeah, I am actually confused why we haven't developed a global memory >allocation strategy and continue to use per-session work_mem. > I think it's pretty hard problem, actually. One of the reasons is that the costing of a node depends on the amount of memory available to the node, but as we're building the plan bottom-up, we have no information about the nodes above us. So we don't know if there are operations that will need memory, how sensitive they are, etc. And so far the per-node limit served us pretty well, I think. So I'm not very confused we don't have the per-session limit yet, TBH. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jun 26, 2020 at 04:44:14PM +0200, Tomas Vondra wrote:
> On Fri, Jun 26, 2020 at 12:02:10AM -0400, Bruce Momjian wrote:
> > On Fri, Jun 26, 2020 at 01:53:57AM +0200, Tomas Vondra wrote:
> > > I'm not saying it's not beneficial to use different limits for different
> > > nodes. Some nodes are less sensitive to the size (e.g. sorting often
> > > gets faster with smaller work_mem). But I think we should instead have a
> > > per-session limit, and the planner should "distribute" the memory to
> > > different nodes. It's a hard problem, of course.
> >
> > Yeah, I am actually confused why we haven't developed a global memory
> > allocation strategy and continue to use per-session work_mem.
> >
>
> I think it's pretty hard problem, actually. One of the reasons is that
Yes, it is a hard problem, because it is balancing memory for shared
buffers, work_mem, and kernel buffers:
https://momjian.us/main/blogs/pgblog/2018.html#December_7_2018
I think the big problem is that the work_mem value is not one value but
a floating value that is different per query and session, and concurrent
session activity.
> the costing of a node depends on the amount of memory available to the
> node, but as we're building the plan bottom-up, we have no information
> about the nodes above us. So we don't know if there are operations that
> will need memory, how sensitive they are, etc.
>
> And so far the per-node limit served us pretty well, I think. So I'm not
> very confused we don't have the per-session limit yet, TBH.
I was thinking more of being able to allocate a single value to be
shared by all active sesions.
Also, doesn't this blog entry also show that spiling to disk for ORDER
BY is similarly slow compared to hash aggs?
https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EnterpriseDB https://enterprisedb.com
The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jun 26, 2020 at 12:37:26PM -0400, Bruce Momjian wrote: >On Fri, Jun 26, 2020 at 04:44:14PM +0200, Tomas Vondra wrote: >> On Fri, Jun 26, 2020 at 12:02:10AM -0400, Bruce Momjian wrote: >> > On Fri, Jun 26, 2020 at 01:53:57AM +0200, Tomas Vondra wrote: >> > > I'm not saying it's not beneficial to use different limits for different >> > > nodes. Some nodes are less sensitive to the size (e.g. sorting often >> > > gets faster with smaller work_mem). But I think we should instead have a >> > > per-session limit, and the planner should "distribute" the memory to >> > > different nodes. It's a hard problem, of course. >> > >> > Yeah, I am actually confused why we haven't developed a global memory >> > allocation strategy and continue to use per-session work_mem. >> > >> >> I think it's pretty hard problem, actually. One of the reasons is that > >Yes, it is a hard problem, because it is balancing memory for shared >buffers, work_mem, and kernel buffers: > > https://momjian.us/main/blogs/pgblog/2018.html#December_7_2018 > >I think the big problem is that the work_mem value is not one value but >a floating value that is different per query and session, and concurrent >session activity. > >> the costing of a node depends on the amount of memory available to the >> node, but as we're building the plan bottom-up, we have no information >> about the nodes above us. So we don't know if there are operations that >> will need memory, how sensitive they are, etc. >> >> And so far the per-node limit served us pretty well, I think. So I'm not >> very confused we don't have the per-session limit yet, TBH. > >I was thinking more of being able to allocate a single value to be >shared by all active sesions. > Not sure I understand. What "single value" do you mean? Wasn't the idea was to replace work_mem with something like query_mem? That'd be nice, but I think it's inherently circular - we don't know how to distribute this to different nodes until we know which nodes will need a buffer, but the buffer size is important for costing (so we need it when constructing the paths). Plus then there's the question whether all nodes should get the same fraction, or less sensitive nodes should get smaller chunks, etc. Ultimately this would be based on costing too, I think, but it makes it soe much complex ... >Also, doesn't this blog entry also show that spiling to disk for ORDER >BY is similarly slow compared to hash aggs? > > https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012 > The post does not mention hashagg at all, so I'm not sure how could it show that? But I think you're right the spilling itself is not that far away, in most cases (thanks to the recent fixes made by Jeff). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, Jun 25, 2020 at 1:36 PM Andres Freund <andres@anarazel.de> wrote: > 12 28164.865 ms > > fast ssd: > HEAD 92520.680 ms > > magnetic: > HEAD 183968.538 ms > > (no reads, there's plenty enough memory. Just writes because the age / > amount thresholds for dirty data are reached) > > In the magnetic case we're IO bottlenecked nearly the whole time. I agree with almost everything you've said on this thread, but at the same time I question the emphasis on I/O here. You've shown that spinning rust is about twice as slow as a fast SSD here. Fair enough, but to me the real story is that spilling is clearly a lot slower in general, regardless of how fast the storage subsystem happens to be (I wonder how fast it is with a ramdisk). To me, it makes more sense to think of the problem here as the fact that v13 will *not* do aggregation using the fast strategy (i.e. in-memory) -- as opposed to the problem being that v13 does the aggregation using the slow strategy (which is assumed to be slow because it involves I/O instead of memory buffers). I get approximately the same query runtimes with your "make the transition state a bit bigger" test case. With "set enable_hashagg = off", I get a group aggregate + sort. It spills to disk, even with 'work_mem = '15GB'" -- leaving 4 runs to merge at the end. That takes 63702.992 ms on v13. But if I reduce the amount of work_mem radically, to only 16MB (a x960 decrease!), then the run time only increases by ~30% -- it's only 83123.926 ms. So we're talking about a ~200% increase (for hash aggregate) versus a ~30% increase (for groupagg + sort) on fast SSDs. Changing the cost of I/O in the context of hashaggregate seems like it misses the point. Jeff recently said "Overall, the IO pattern is better for Sort, but not dramatically so". Whatever the IO pattern may be, I think that it's pretty clear that the performance characteristics of hash aggregation with limited memory are very different to groupaggregate + sort, at least when only a fraction of the optimal amount of memory we'd like is available. It's true that hash aggregate was weird among plan nodes in v12, and is now in some sense less weird among plan nodes. And yet we have a new problem now -- so where does that leave that whole "weirdness" framing? ISTM that the work_mem framework was and is the main problem. We seem to have lost a crutch that ameliorated the problem before now, even though that amelioration was kind of an accident. Or a thing that user apps evolved to rely on. -- Peter Geoghegan
On Fri, Jun 26, 2020 at 07:45:13PM +0200, Tomas Vondra wrote: > On Fri, Jun 26, 2020 at 12:37:26PM -0400, Bruce Momjian wrote: > > I was thinking more of being able to allocate a single value to be > > shared by all active sesions. > > Not sure I understand. What "single value" do you mean? I was thinking of a full-cluster work_mem maximum allocation that could be given to various backends that request it. Imagine we set the cluster-wide total of work_mem to 1GB. If a session asks for 100MB, if there are no other active sessions, it can grant the entire 100MB. If there are other sessions running, and 500MB has already been allocated, maybe it is only given an active per-node work_mem of 50MB. As the amount of unallocated cluster-wide work_mem gets smaller, requests are granted smaller actual allocations. What we do now makes little sense, because we might have lots of free memory, but we force nodes to spill to disk when they exceed a fixed work_mem. I realize this is very imprecise, because you don't know what future work_mem requests are coming, or how long until existing allocations are freed, but it seems it would have to be better than what we do now. > Wasn't the idea was to replace work_mem with something like query_mem? > That'd be nice, but I think it's inherently circular - we don't know how > to distribute this to different nodes until we know which nodes will > need a buffer, but the buffer size is important for costing (so we need > it when constructing the paths). > > Plus then there's the question whether all nodes should get the same > fraction, or less sensitive nodes should get smaller chunks, etc. > Ultimately this would be based on costing too, I think, but it makes it > soe much complex ... Since work_mem affect the optimizer choices, I can imagine it getting complex since nodes would have to ask the global work_mem allocator how much memory it _might_ get, but then ask for final work_mem during execution, and they might differ. Still, our spill costs are so high for so many node types, that reducing spills seems like it would be a win, even if it sometimes causes poorer plans. > > Also, doesn't this blog entry also show that spiling to disk for ORDER > > BY is similarly slow compared to hash aggs? > > > > https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012 > > The post does not mention hashagg at all, so I'm not sure how could it > show that? But I think you're right the spilling itself is not that far > away, in most cases (thanks to the recent fixes made by Jeff). Yeah, I was just measuring ORDER BY spill, but it seems to be a similar overhead to hashagg spill, which is being singled out in this discussion as particularly expensive, and I am questioning that. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jun 26, 2020 at 4:00 PM Bruce Momjian <bruce@momjian.us> wrote: > Imagine we set the cluster-wide total of work_mem to 1GB. If a session > asks for 100MB, if there are no other active sessions, it can grant the > entire 100MB. If there are other sessions running, and 500MB has > already been allocated, maybe it is only given an active per-node > work_mem of 50MB. As the amount of unallocated cluster-wide work_mem > gets smaller, requests are granted smaller actual allocations. I think that that's the right approach long term. But right now the DBA has no way to give hash-based nodes more memory, even though it's clear that that's where it's truly needed in most cases, across almost workloads. I think that that's the really glaring problem. This is just the intrinsic nature of hash-based aggregation and hash join vs sort-based aggregation and merge join (roughly speaking). It's much more valuable to be able to do hash-based aggregation in one pass, especially in cases where hashing already did particularly well in Postgres v12. > What we do now makes little sense, because we might have lots of free > memory, but we force nodes to spill to disk when they exceed a fixed > work_mem. I realize this is very imprecise, because you don't know what > future work_mem requests are coming, or how long until existing > allocations are freed, but it seems it would have to be better than what > we do now. Postgres 13 made hash aggregate respect work_mem. Perhaps it would have made more sense to teach work_mem to respect hash aggregate, though. Hash aggregate cannot consume an unbounded amount of memory in v13, since the old behavior was clearly unreasonable. Which is great. But it may be even more unreasonable to force users to conservatively set the limit on the size of the hash table in an artificial, generic way. > Since work_mem affect the optimizer choices, I can imagine it getting > complex since nodes would have to ask the global work_mem allocator how > much memory it _might_ get, but then ask for final work_mem during > execution, and they might differ. Still, our spill costs are so high > for so many node types, that reducing spills seems like it would be a > win, even if it sometimes causes poorer plans. I don't think it's really about the spill costs, at least in one important sense. If performing a hash aggregate in memory uses twice as much memory as spilling (with either sorting or hashing), but the operation completes in one third the time, you have actually saved memory in the aggregate (no pun intended). Also, the query is 3x faster, which is a nice bonus! I don't think that this kind of scenario is rare. -- Peter Geoghegan
On Fri, Jun 26, 2020 at 01:53:05PM -0700, Peter Geoghegan wrote:
> On Thu, Jun 25, 2020 at 1:36 PM Andres Freund <andres@anarazel.de> wrote:
> > 12 28164.865 ms
> >
> > fast ssd:
> > HEAD 92520.680 ms
> >
> > magnetic:
> > HEAD 183968.538 ms
> >
> > (no reads, there's plenty enough memory. Just writes because the age /
> > amount thresholds for dirty data are reached)
> >
> > In the magnetic case we're IO bottlenecked nearly the whole time.
>
> I agree with almost everything you've said on this thread, but at the
> same time I question the emphasis on I/O here. You've shown that
> spinning rust is about twice as slow as a fast SSD here. Fair enough,
> but to me the real story is that spilling is clearly a lot slower in
> general, regardless of how fast the storage subsystem happens to be (I
> wonder how fast it is with a ramdisk). To me, it makes more sense to
This blog entry shows ORDER BY using ram disk, SSD, and magnetic:
https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012
It is from 2012, but I can re-run the test if you want.
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EnterpriseDB https://enterprisedb.com
The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jun 26, 2020 at 07:00:20PM -0400, Bruce Momjian wrote: >On Fri, Jun 26, 2020 at 07:45:13PM +0200, Tomas Vondra wrote: >> On Fri, Jun 26, 2020 at 12:37:26PM -0400, Bruce Momjian wrote: >> > I was thinking more of being able to allocate a single value to be >> > shared by all active sesions. >> >> Not sure I understand. What "single value" do you mean? > >I was thinking of a full-cluster work_mem maximum allocation that could >be given to various backends that request it. > >Imagine we set the cluster-wide total of work_mem to 1GB. If a session >asks for 100MB, if there are no other active sessions, it can grant the >entire 100MB. If there are other sessions running, and 500MB has >already been allocated, maybe it is only given an active per-node >work_mem of 50MB. As the amount of unallocated cluster-wide work_mem >gets smaller, requests are granted smaller actual allocations. > >What we do now makes little sense, because we might have lots of free >memory, but we force nodes to spill to disk when they exceed a fixed >work_mem. I realize this is very imprecise, because you don't know what >future work_mem requests are coming, or how long until existing >allocations are freed, but it seems it would have to be better than what >we do now. > >> Wasn't the idea was to replace work_mem with something like query_mem? >> That'd be nice, but I think it's inherently circular - we don't know how >> to distribute this to different nodes until we know which nodes will >> need a buffer, but the buffer size is important for costing (so we need >> it when constructing the paths). >> >> Plus then there's the question whether all nodes should get the same >> fraction, or less sensitive nodes should get smaller chunks, etc. >> Ultimately this would be based on costing too, I think, but it makes it >> soe much complex ... > >Since work_mem affect the optimizer choices, I can imagine it getting >complex since nodes would have to ask the global work_mem allocator how >much memory it _might_ get, but then ask for final work_mem during >execution, and they might differ. Still, our spill costs are so high >for so many node types, that reducing spills seems like it would be a >win, even if it sometimes causes poorer plans. > I may not understand what you mean by "poorer plans" here, but I find it hard to accept that reducing spills is generally worth poorer plans. I agree larger work_mem for hashagg (and thus less spilling) may mean lower work_mem for so some other nodes that are less sensitive to this. But I think this needs to be formulated as a cost-based decision, although I don't know how to do that for the reasons I explained before (bottom-up plan construction vs. distributing the memory budget). FWIW some databases already do something like this - SQL Server has something called "memory grant" which I think mostly does what you described here. >> > Also, doesn't this blog entry also show that spiling to disk for ORDER >> > BY is similarly slow compared to hash aggs? >> > >> > https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012 >> >> The post does not mention hashagg at all, so I'm not sure how could it >> show that? But I think you're right the spilling itself is not that far >> away, in most cases (thanks to the recent fixes made by Jeff). > >Yeah, I was just measuring ORDER BY spill, but it seems to be a similar >overhead to hashagg spill, which is being singled out in this discussion >as particularly expensive, and I am questioning that. > The difference between sort and hashagg spills is that for sorts there is no behavior change. Plans that did (not) spill in v12 will behave the same way on v13, modulo some random perturbation. For hashagg that's not the case - some queries that did not spill before will spill now. So even if the hashagg spills are roughly equal to sort spills, both are significantly more expensive than not spilling. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jun 27, 2020 at 01:58:50AM +0200, Tomas Vondra wrote: > > Since work_mem affect the optimizer choices, I can imagine it getting > > complex since nodes would have to ask the global work_mem allocator how > > much memory it _might_ get, but then ask for final work_mem during > > execution, and they might differ. Still, our spill costs are so high > > for so many node types, that reducing spills seems like it would be a > > win, even if it sometimes causes poorer plans. > > > > I may not understand what you mean by "poorer plans" here, but I find it > hard to accept that reducing spills is generally worth poorer plans. We might cost a plan based on a work_mem that the global allocator things it will give us when we are in the executor, but that might change when we are in the executor. We could code is to an optimizer request is always honored in the executor, but prepared plans would be a problem, or perhaps already are if you prepare a plan and change work_mem before EXECUTE. > I agree larger work_mem for hashagg (and thus less spilling) may mean > lower work_mem for so some other nodes that are less sensitive to this. > But I think this needs to be formulated as a cost-based decision, > although I don't know how to do that for the reasons I explained before > (bottom-up plan construction vs. distributing the memory budget). > > FWIW some databases already do something like this - SQL Server has > something called "memory grant" which I think mostly does what you > described here. Yep, something like that. > > > > Also, doesn't this blog entry also show that spiling to disk for ORDER > > > > BY is similarly slow compared to hash aggs? > > > > > > > > https://momjian.us/main/blogs/pgblog/2012.html#February_2_2012 > > > > > > The post does not mention hashagg at all, so I'm not sure how could it > > > show that? But I think you're right the spilling itself is not that far > > > away, in most cases (thanks to the recent fixes made by Jeff). > > > > Yeah, I was just measuring ORDER BY spill, but it seems to be a similar > > overhead to hashagg spill, which is being singled out in this discussion > > as particularly expensive, and I am questioning that. > > > > The difference between sort and hashagg spills is that for sorts there > is no behavior change. Plans that did (not) spill in v12 will behave the > same way on v13, modulo some random perturbation. For hashagg that's not > the case - some queries that did not spill before will spill now. Well, my point is that we already had ORDER BY problems, and if hash agg now has them too in PG 13, I am fine with that. We don't guarantee no problems in major versions. If we want to add a general knob that says, "Hey allow this node to exceed work_mem by X%," I don't see the point --- just increase work_mem, or have different work_mem settings for different node types, as I outlined previously. > So even if the hashagg spills are roughly equal to sort spills, both are > significantly more expensive than not spilling. Yes, but that means we need a more general fix and worrying about hash agg is not addressing the core issue. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jun 26, 2020 at 4:59 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I agree larger work_mem for hashagg (and thus less spilling) may mean > lower work_mem for so some other nodes that are less sensitive to this. > But I think this needs to be formulated as a cost-based decision, > although I don't know how to do that for the reasons I explained before > (bottom-up plan construction vs. distributing the memory budget). Why do you think that it needs to be formulated as a cost-based decision? That's probably true of a scheme that allocates memory very intelligently, but what about an approach that's slightly better than work_mem? What problems do you foresee (if any) with adding a hash_mem GUC that gets used for both planning and execution for hash aggregate and hash join nodes, in about the same way as work_mem is now? > FWIW some databases already do something like this - SQL Server has > something called "memory grant" which I think mostly does what you > described here. Same is true of Oracle. But Oracle also has simple work_mem-like settings for sorting and hashing. People don't really use them anymore, but apparently it was once common for the DBA to explicitly give over more memory to hashing -- much like the hash_mem setting I asked about. IIRC the same is true of DB2. > The difference between sort and hashagg spills is that for sorts there > is no behavior change. Plans that did (not) spill in v12 will behave the > same way on v13, modulo some random perturbation. For hashagg that's not > the case - some queries that did not spill before will spill now. > > So even if the hashagg spills are roughly equal to sort spills, both are > significantly more expensive than not spilling. Just to make sure we're on the same page: both are significantly more expensive than a hash aggregate not spilling *specifically*. OTOH, a group aggregate may not be much slower when it spills compared to an in-memory sort group aggregate. It may even be noticeably faster, due to caching effects, as you mentioned at one point upthread. This is the property that makes hash aggregate special, and justifies giving it more memory than other nodes on a system-wide basis (the same thing applies to hash join). This could even work as a multiplier of work_mem. -- Peter Geoghegan
On Thu, Jun 25, 2020 at 12:59 AM Robert Haas <robertmhaas@gmail.com> wrote: > > So, I don't think we can wire in a constant like 10x. That's really > unprincipled and I think it's a bad idea. What we could do, though, is > replace the existing Boolean-valued GUC with a new GUC that controls > the size at which the aggregate spills. The default could be -1, > meaning work_mem, but a user could configure a larger value if desired > (presumably, we would just treat a value smaller than work_mem as > work_mem, and document the same). > > I think that's actually pretty appealing. Separating the memory we > plan to use from the memory we're willing to use before spilling seems > like a good idea in general, and I think we should probably also do it > in other places - like sorts. > +1. I also think GUC on these lines could help not only the problem being discussed here but in other cases as well. However, I think the real question is do we want to design/implement it for PG13? It seems to me at this stage we don't have a clear understanding of what percentage of real-world cases will get impacted due to the new behavior of hash aggregates. We want to provide some mechanism as a safety net to avoid problems that users might face which is not a bad idea but what if we wait and see the real impact of this? Is it too bad to provide a GUC later in back-branch if we see users face such problems quite often? I think the advantage of delaying it is that we might see some real problems (like where hash aggregate is not a good choice) which can be fixed via the costing model. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Jun 26, 2020 at 05:24:36PM -0700, Peter Geoghegan wrote: >On Fri, Jun 26, 2020 at 4:59 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> I agree larger work_mem for hashagg (and thus less spilling) may mean >> lower work_mem for so some other nodes that are less sensitive to this. >> But I think this needs to be formulated as a cost-based decision, >> although I don't know how to do that for the reasons I explained before >> (bottom-up plan construction vs. distributing the memory budget). > >Why do you think that it needs to be formulated as a cost-based >decision? That's probably true of a scheme that allocates memory very >intelligently, but what about an approach that's slightly better than >work_mem? > Well, there are multiple ideas discussed in this (sub)thread, one of them being a per-query memory limit. That requires decisions how much memory should different nodes get, which I think would need to be cost-based. >What problems do you foresee (if any) with adding a hash_mem GUC that >gets used for both planning and execution for hash aggregate and hash >join nodes, in about the same way as work_mem is now? > Of course, a simpler scheme like this would not require that. And maybe introducing hash_mem is a good idea - I'm not particularly opposed to that, actually. But I think we should not introduce separate memory limits for each node type, which was also mentioned earlier. The problem of course is that hash_mem does not really solve the issue discussed at the beginning of this thread, i.e. regressions due to underestimates and unexpected spilling at execution time. The thread is getting a rather confusing mix of proposals how to fix that for v13 and proposals how to improve our configuration of memory limits :-( >> FWIW some databases already do something like this - SQL Server has >> something called "memory grant" which I think mostly does what you >> described here. > >Same is true of Oracle. But Oracle also has simple work_mem-like >settings for sorting and hashing. People don't really use them anymore, >but apparently it was once common for the DBA to explicitly give over >more memory to hashing -- much like the hash_mem setting I asked about. >IIRC the same is true of DB2. > Interesting. What is not entirely clear to me how do these databases decide how much should each node get during planning. With the separate work_mem-like settings it's fairly obvious, but how do they do that with the global limit (either per-instance or per-query)? >> The difference between sort and hashagg spills is that for sorts >> there is no behavior change. Plans that did (not) spill in v12 will >> behave the same way on v13, modulo some random perturbation. For >> hashagg that's not the case - some queries that did not spill before >> will spill now. >> >> So even if the hashagg spills are roughly equal to sort spills, both >> are significantly more expensive than not spilling. > >Just to make sure we're on the same page: both are significantly more >expensive than a hash aggregate not spilling *specifically*. OTOH, a >group aggregate may not be much slower when it spills compared to an >in-memory sort group aggregate. It may even be noticeably faster, due >to caching effects, as you mentioned at one point upthread. > >This is the property that makes hash aggregate special, and justifies >giving it more memory than other nodes on a system-wide basis (the same >thing applies to hash join). This could even work as a multiplier of >work_mem. > Yes, I agree. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jun 27, 2020 at 3:00 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > I think the advantage of delaying it is that we > might see some real problems (like where hash aggregate is not a good > choice) which can be fixed via the costing model. I think any problem that might come up with the costing is best thought of as a distinct problem. This thread is mostly about the problem of users getting fewer in-memory hash aggregates compared to a previous release running the same application (though there has been some discussion of the other problem, too [1], but it's thought to be less serious). The problem is that affected users were theoretically never entitled to the performance they came to rely on, and yet there is good reason to think that hash aggregate really should be entitled to more memory. They won't care that they were theoretically never entitled to that performance, though -- they *liked* the fact that hash agg could cheat. And they'll dislike the fact that this cannot be corrected by tuning work_mem, since that affects all node types that consume work_mem, not just hash aggregate -- that could cause OOMs for them. There are two or three similar ideas under discussion that might fix the problem. They all seem to involve admitting that hash aggregate's "cheating" might actually have been a good thing all along (even though giving hash aggregate much much more memory than other nodes is terrible), and giving hash aggregate license to "cheat openly". Note that the problem isn't exactly a problem with the hash aggregate spilling patch. You could think of the problem as a pre-existing issue -- a failure to give more memory to hash aggregate, which really should be entitled to more memory. Jeff's patch just made the issue more obvious. [1] https://postgr.es/m/20200624191433.5gnqgrxfmucexldm@alap3.anarazel.de -- Peter Geoghegan
On Sat, Jun 27, 2020 at 3:41 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Well, there are multiple ideas discussed in this (sub)thread, one of > them being a per-query memory limit. That requires decisions how much > memory should different nodes get, which I think would need to be > cost-based. A design like that probably makes sense. But it's way out of scope for Postgres 13, and not something that should be discussed further on this thread IMV. > Of course, a simpler scheme like this would not require that. And maybe > introducing hash_mem is a good idea - I'm not particularly opposed to > that, actually. But I think we should not introduce separate memory > limits for each node type, which was also mentioned earlier. I had imagined that hash_mem would apply to hash join and hash aggregate only. A GUC that either represents a multiple of work_mem, or an absolute work_mem-style KB value. > The problem of course is that hash_mem does not really solve the issue > discussed at the beginning of this thread, i.e. regressions due to > underestimates and unexpected spilling at execution time. Like Andres, I suspect that that's a smaller problem in practice. A hash aggregate that spills often has performance characteristics somewhat like a group aggregate + sort, anyway. I'm worried about cases where an *in-memory* hash aggregate is naturally far far faster than other strategies, and yet we can't use it -- despite the fact that Postgres 12 could "safely" do so. (It probably doesn't matter whether the slow plan that you get in Postgres 13 is a hash aggregate that spills, or something else -- this is not really a costing problem.) Besides, hash_mem *can* solve that problem to some extent. Other cases (cases where the estimates are so bad that hash_mem won't help) seem like less of a concern to me. To some extent, that's the price you pay to avoid the risk of an OOM. > The thread is getting a rather confusing mix of proposals how to fix > that for v13 and proposals how to improve our configuration of memory > limits :-( As I said to Amit in my last message, I think that all of the ideas that are worth pursuing involve giving hash aggregate nodes license to use more memory than other nodes. One variant involves doing so only at execution time, while the hash_mem idea involves formalizing and documenting that hash-based nodes are special -- and taking that into account during both planning and execution. > Interesting. What is not entirely clear to me how do these databases > decide how much should each node get during planning. With the separate > work_mem-like settings it's fairly obvious, but how do they do that with > the global limit (either per-instance or per-query)? I don't know, but that seems like a much more advanced way of approaching the problem. It isn't in scope here. Perhaps I'm not considering some unintended consequence of the planner giving hash-based nodes extra memory "for free" in the common case where hash_mem exceeds work_mem (by 2x, say). But my guess is that that won't be a significant problem that biases the planner in some obviously undesirable way. -- Peter Geoghegan
On Mon, Jun 29, 2020 at 10:20:14AM -0700, Peter Geoghegan wrote: >On Mon, Jun 29, 2020 at 8:07 AM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> Not sure I follow. Which cases do you mean when you say that 12 could >> safely do them, but 13 won't? I see the following two cases: > >> a) Planner in 12 and 13 disagree about whether the hash table will fit >> into work_mem. >> >> I don't quite see why this would be the case (given the same cardinality >> estimates etc.), though. That is, if 12 says "will fit" I'd expect 13 to >> end up with the same conclusion. But maybe 13 has higher per-tuple >> overhead or something? I know we set aside some memory for BufFiles, but >> not when we expect the whole hash table to fit into memory. > >I have no reason to believe that the planner is any more or any less >likely to conclude that the hash table will fit in memory in v13 as >things stand (I don't know if the BufFile issue matters). > >In general, grouping estimates probably aren't very good compared to >join estimates. I imagine that in either v12 or v13 the planner is >likely to incorrectly believe that it'll all fit in memory fairly >often. v12 was much too permissive about what could happen. But v13 is >too conservative. > Can you give and example of what you mean by being too permissive or too conservative? Do you mean the possibility of unlimited memory usage in v12, and strict enforcement in v13? IMO enforcing the work_mem limit (in v13) is right in principle, but I do understand the concerns about unexpected regressions compared to v12. >> b) Planner believes the hash table will fit, due to underestimate. >> >> On 12, we'd just let the hash table overflow, which may be a win when >> there's enough RAM and the estimate is not "too wrong". But it may >> easily end with a sad OOM. > >It might end up with an OOM on v12 due to an underestimate -- but >probably not! The fact that a hash aggregate is faster than a group >aggregate ameliorates the higher memory usage. You might actually use >less memory this way. > I don't understand what you mean by "less memory" when the whole issue is significantly exceeding work_mem? I don't think the OOM is the only negative performance here - using a lot of memory also forces eviction of data from page cache (although writing a lot of temporary files may have similar effect). >> On 13, we'll just start spilling. True - people tend to use conservative >> work_mem values exactly because of cases like this (which is somewhat >> futile as the underestimate may be arbitrarily wrong) and also because >> they don't know how many work_mem instances the query will use. >> >> So yeah, I understand why people may not want to increase work_mem too >> much, and maybe hash_work would be a way to get the "no spill" behavior. > >Andres wanted to increase the amount of memory that could be used at >execution time, without changing planning. You could say that hash_mem >is a more ambitious proposal than that. It's changing the behavior >across the board -- though in a way that makes sense anyway. It has >the additional benefit of making it more likely that an in-memory hash >aggregate will be used. That isn't a problem that we're obligated to >solve now, so this may seem odd. But if the more ambitious plan is >actually easier to implement and support, why not pursue it? > >hash_mem seems a lot easier to explain and reason about than having >different work_mem budgets during planning and execution, which is >clearly a kludge. hash_mem makes sense generally, and more or less >solves the problems raised on this thread. > I agree with this, and I'm mostly OK with having hash_mem. In fact, from the proposals in this thread I like it the most - as long as it's used both during planning and execution. It's a pretty clear solution. It's not a perfect solution in the sense that it does not reintroduce the v12 behavior perfectly (i.e. we'll still spill after reaching hash_mem) but that may be good enougn. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 29, 2020 at 01:31:40PM -0400, Bruce Momjian wrote: >On Mon, Jun 29, 2020 at 10:20:14AM -0700, Peter Geoghegan wrote: >> I have no reason to believe that the planner is any more or any less >> likely to conclude that the hash table will fit in memory in v13 as >> things stand (I don't know if the BufFile issue matters). >> >> In general, grouping estimates probably aren't very good compared to >> join estimates. I imagine that in either v12 or v13 the planner is >> likely to incorrectly believe that it'll all fit in memory fairly >> often. v12 was much too permissive about what could happen. But v13 is >> too conservative. > >FYI, we have improved planner statistics estimates for years, which must >have affected node spill behavior on many node types (except hash_agg), >and don't remember any complaints about it. > I think misestimates for GROUP BY are quite common and very hard to fix. Firstly, our ndistinct estimator may give pretty bad results depending e.g. on how is the table correlated. I've been running some TPC-H benchmarks, and for partsupp.ps_partkey our estimate was 4338776, when the actual value is 15000000, i.e. ~3.5x higher. This was with statistics target increased to 1000. I can easily imagine even worse estimates with lower values. This ndistinct estimator is used even for extended statistics, so that can't quite save us. Moreover, the grouping may be on top of a join, in which case using ndistinct coefficients may not be possible :-( So I think this is a quite real problem ... regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 29, 2020 at 2:22 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Can you give and example of what you mean by being too permissive or too > conservative? Do you mean the possibility of unlimited memory usage in > v12, and strict enforcement in v13? Yes -- that's all I meant. > IMO enforcing the work_mem limit (in v13) is right in principle, but I > do understand the concerns about unexpected regressions compared to v12. Yeah. Both of these two things are true at the same time. > I don't understand what you mean by "less memory" when the whole issue > is significantly exceeding work_mem? I was just reiterating what I said a few times already: Not using an in-memory hash aggregate when the amount of memory required is high but not prohibitively high is penny wise, pound foolish. It's easy to imagine this actually using up more memory when an entire workload is considered. This observation does not apply to a system that only ever has one active connection at a time, but who cares about that? > I don't think the OOM is the only negative performance here - using a > lot of memory also forces eviction of data from page cache (although > writing a lot of temporary files may have similar effect). True. > I agree with this, and I'm mostly OK with having hash_mem. In fact, from > the proposals in this thread I like it the most - as long as it's used > both during planning and execution. It's a pretty clear solution. Great. It's not trivial to write the patch, since there are a few tricky cases. For example, maybe there is some subtlety in nodeAgg.c with AGG_MIXED cases. Is there somebody else that knows that code better than I do that wants to have a go at writing a patch? -- Peter Geoghegan
On Mon, Jun 29, 2020 at 2:46 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Jun 29, 2020 at 2:22 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > I agree with this, and I'm mostly OK with having hash_mem. In fact, from > > the proposals in this thread I like it the most - as long as it's used > > both during planning and execution. It's a pretty clear solution. > > Great. > > It's not trivial to write the patch, since there are a few tricky > cases. For example, maybe there is some subtlety in nodeAgg.c with > AGG_MIXED cases. Attached is an attempt at this. I have not been particularly thorough, since it is still not completely clear that the hash_mem proposal has a serious chance of resolving the "many users rely on hashagg exceeding work_mem, regardless of whether or not that is the intended behavior in Postgres 12" problem. But at least we have a patch now, and so have some idea of how invasive this will have to be. We also have something to test. Note that I created a new open item for this "maybe we need something like a hash_mem GUC now" problem today. To recap, this thread started out being a discussion about the enable_hashagg_disk GUC, which seems like a distinct problem to me. It won't make much sense to return to discussing the original problem before we have a solution to this other problem (the problem that I propose to address by inventing hash_mem). About the patch: The patch adds hash_mem, which is just another work_mem-like GUC that the patch has us use in certain cases -- cases where the work area is a hash table (but not when it's a sort, or some kind of bitset, or anything else). I still think that the new GUC should work as a multiplier of work_mem, or something else along those lines, though for now it's just an independent work_mem used for hashing. I bring it up again because I'm concerned about users that upgrade to Postgres 13 incautiously, and find that hashing uses *less* memory than before. Many users probably get away with setting work_mem quite high across the board. At the very least, hash_mem should be ignored when it's set to below work_mem (which isn't what the patch does). It might have made more sense to call the new GUC hash_work_mem instead of hash_mem. I don't feel strongly about the name. Again, this is just a starting point for further discussion. -- Peter Geoghegan
Вложения
On Thu, Jul 2, 2020 at 8:00 PM Bruce Momjian <bruce@momjian.us> wrote: > Also, I feel this is all out of scope for PG 13, frankly. I think our > only option is to revert the hash spill entirely, and return to PG 13 > behavior, if people are too worried about hash performance regression. But the problem isn't really the hashaggs-that-spill patch itself. Rather, the problem is the way that work_mem is supposed to behave in general, and the impact that that has on hash aggregate now that it has finally been brought into line with every other kind of executor node. There just isn't much reason to think that we should give the same amount of memory to a groupagg + sort as a hash aggregate. The patch more or less broke an existing behavior that is itself officially broken. That is, the problem that we're trying to fix here is only a problem to the extent that the previous scheme isn't really operating as intended (because grouping estimates are inherently very hard). A revert doesn't seem like it helps anyone. I accept that the idea of inventing hash_mem to fix this problem now is unorthodox. In a certain sense it solves problems beyond the problems that we're theoretically obligated to solve now. But any "more conservative" approach that I can think of seems like a big mess. -- Peter Geoghegan
On Thu, Jul 2, 2020 at 7:46 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > Thanks for putting it together, I agree that hash_mem seems to be an obvious > "escape hatch" that generalizes existing GUCs and independently useful. It is independently useful. It's a natural consequence of "being honest" about work_mem and hashing. > I feel it should same as work_mem, as it's written, and not a multiplier. > > And actually I don't think a lower value should be ignored: "mechanism not > policy". Do we refuse atypical values of maintenance_work_mem < work_mem ? I see your point, but AFAIK maintenance_work_mem was not retrofit like this. It seems different. (Unless we add the -1 behavior, perhaps) > I assumed that hash_mem would default to -1, which would mean "fall back to > work_mem". We'd then advise users to increase it if they have an issue in v13 > with performance of hashes spilled to disk. (And maybe in other cases, too.) Yeah, this kind of -1 behavior could make sense. > I read the argument that hash tables are a better use of RAM than sort. > However it seems like setting the default to greater than work_mem is a > separate change than providing the mechanism allowing user to do so. I guess > the change in default is intended to mitigate the worst possible behavior > change someone might experience in v13 hashing, and might be expected to > improve "out of the box" performance. I'm not opposed to it, but it's not an > essential part of the patch. That's true. > In nodeHash.c, you missed an underscore: > + * Target in-memory hashtable size is hashmem kilobytes. Got it; thanks. -- Peter Geoghegan
On Thu, Jul 2, 2020 at 08:35:40PM -0700, Peter Geoghegan wrote: > But the problem isn't really the hashaggs-that-spill patch itself. > Rather, the problem is the way that work_mem is supposed to behave in > general, and the impact that that has on hash aggregate now that it > has finally been brought into line with every other kind of executor > node. There just isn't much reason to think that we should give the > same amount of memory to a groupagg + sort as a hash aggregate. The > patch more or less broke an existing behavior that is itself > officially broken. That is, the problem that we're trying to fix here > is only a problem to the extent that the previous scheme isn't really > operating as intended (because grouping estimates are inherently very > hard). A revert doesn't seem like it helps anyone. > > I accept that the idea of inventing hash_mem to fix this problem now > is unorthodox. In a certain sense it solves problems beyond the > problems that we're theoretically obligated to solve now. But any > "more conservative" approach that I can think of seems like a big > mess. Well, the bottom line is that we are designing features during beta. People are supposed to be testing PG 13 behavior during beta, including optimizer behavior. We don't even have a user report yet of a regression compared to PG 12, or one that can't be fixed by increasing work_mem. If we add a new behavior to PG 13, we then have the pre-PG 13 behavior, the pre-patch behavior, and the post-patch behavior. How are people supposed to test all of that? Add to that that some don't even feel we need a new behavior, which is delaying any patch from being applied. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Fri, Jul 03, 2020 at 10:08:08AM -0400, Bruce Momjian wrote: > On Thu, Jul 2, 2020 at 08:35:40PM -0700, Peter Geoghegan wrote: > > But the problem isn't really the hashaggs-that-spill patch itself. > > Rather, the problem is the way that work_mem is supposed to behave in > > general, and the impact that that has on hash aggregate now that it > > has finally been brought into line with every other kind of executor > > node. There just isn't much reason to think that we should give the > > same amount of memory to a groupagg + sort as a hash aggregate. The > > patch more or less broke an existing behavior that is itself > > officially broken. That is, the problem that we're trying to fix here > > is only a problem to the extent that the previous scheme isn't really > > operating as intended (because grouping estimates are inherently very > > hard). A revert doesn't seem like it helps anyone. > > > > I accept that the idea of inventing hash_mem to fix this problem now > > is unorthodox. In a certain sense it solves problems beyond the > > problems that we're theoretically obligated to solve now. But any > > "more conservative" approach that I can think of seems like a big > > mess. > > Well, the bottom line is that we are designing features during beta. > People are supposed to be testing PG 13 behavior during beta, including > optimizer behavior. We don't even have a user report yet of a > regression compared to PG 12, or one that can't be fixed by increasing > work_mem. > > If we add a new behavior to PG 13, we then have the pre-PG 13 behavior, > the pre-patch behavior, and the post-patch behavior. How are people > supposed to test all of that? Add to that that some don't even feel we > need a new behavior, which is delaying any patch from being applied. If we default hash_mem=-1, the post-patch behavior by default would be same as the pre-patch behavior. Actually, another reason it should be -1 is simply to reduce the minimum, essential number of GUCs everyone has to change or review on a new installs of a dedicated or nontrivial instance. shared_buffers, max_wal_size, checkpoint_timeout, eff_cache_size, work_mem. I don't think anybody said it before, but now it occurs to me that one advantage of making hash_mem a multiplier (I'm thinking of hash_mem_scale_factor) rather than an absolute is that one wouldn't need to remember to increase hash_mem every time they increase work_mem. Otherwise, this is kind of a foot-gun: hash_mem would default to 16MB, and people experiencing poor performance would increase work_mem to 256MB like they've been doing for decades, and see no effect. Or someone would increase work_mem from 4MB to 256MB, which exceeds hash_mem default of 16MB, so then (if Peter has his way) hash_mem is ignored. Due to these behaviors, I'll retract my previous preference: | "I feel it should same as work_mem, as it's written, and not a multiplier." I think the better ideas are: - hash_mem=-1 - hash_mem_scale_factor=1 ? Maybe as a separate patch we'd set default hash_mem_scale_factor=4, possibly only in master not and v13. -- Justin
On 2020-Jul-03, Bruce Momjian wrote: > Well, the bottom line is that we are designing features during beta. Well, we're designing a way for users to interact the new feature. The feature itself is already in, and it works well in general terms. I expect that the new behavior is a win in the majority of cases, and the problem being discussed here will only manifest as a regression in corner cases. (I don't have data to back this up, but if this weren't the case we would have realized much earlier). It seem to me we're designing a solution to a problem that was found during testing, which seems perfectly acceptable to me. I don't see grounds for reverting the behavior and I haven't seen anyone suggesting that it would be an appropriate solution to the issue. > If we add a new behavior to PG 13, we then have the pre-PG 13 behavior, > the pre-patch behavior, and the post-patch behavior. How are people > supposed to test all of that? They don't have to. We tell them that we added some new tweak for a new pg13 feature in beta3 and that's it. > Add to that that some don't even feel we > need a new behavior, which is delaying any patch from being applied. If we don't need any new behavior, then we would just close the open item and call the current state good, no? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 3, 2020 at 7:38 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Thu, Jul 2, 2020 at 08:35:40PM -0700, Peter Geoghegan wrote: > > But the problem isn't really the hashaggs-that-spill patch itself. > > Rather, the problem is the way that work_mem is supposed to behave in > > general, and the impact that that has on hash aggregate now that it > > has finally been brought into line with every other kind of executor > > node. There just isn't much reason to think that we should give the > > same amount of memory to a groupagg + sort as a hash aggregate. The > > patch more or less broke an existing behavior that is itself > > officially broken. That is, the problem that we're trying to fix here > > is only a problem to the extent that the previous scheme isn't really > > operating as intended (because grouping estimates are inherently very > > hard). A revert doesn't seem like it helps anyone. > > > > I accept that the idea of inventing hash_mem to fix this problem now > > is unorthodox. In a certain sense it solves problems beyond the > > problems that we're theoretically obligated to solve now. But any > > "more conservative" approach that I can think of seems like a big > > mess. > > We don't even have a user report yet of a > regression compared to PG 12, or one that can't be fixed by increasing > work_mem. > Yeah, this is exactly the same point I have raised above. I feel we should wait before designing any solution to match pre-13 behavior for hashaggs to see what percentage of users face problems related to this and how much is a problem for them to increase work_mem to avoid regression. Say, if only less than 1% of users face this problem and some of them are happy by just increasing work_mem then we might not need to do anything. OTOH, if 10% users face this problem and most of them don't want to increase work_mem then it would be evident that we need to do something about it and we can probably provide a guc at that stage for them to revert to old behavior and do some advanced solution in the master branch. I am not sure what is the right thing to do here but it seems to me we are designing a solution based on the assumption that we will have a lot of users who will be hit by this problem and would be unhappy by the new behavior. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sat, 2020-07-04 at 14:49 +0530, Amit Kapila wrote:
> > We don't even have a user report yet of a
> > regression compared to PG 12, or one that can't be fixed by
> > increasing
> > work_mem.
> >
>
> Yeah, this is exactly the same point I have raised above. I feel we
> should wait before designing any solution to match pre-13 behavior
> for
> hashaggs to see what percentage of users face problems related to
> this
> and how much is a problem for them to increase work_mem to avoid
> regression.
I agree that it's good to wait for actual problems. But the challenge
is that we can't backport an added GUC. Are there other, backportable
changes we could potentially make if a lot of users have a problem with
v13 after release? Or will any users who experience a problem need to
wait for v14?
I'm OK not having a GUC, but we need consensus around what our response
will be if a user experiences a regression. If our only answer is
"tweak X, Y, and Z; and if that doesn't work, wait for v14" then I'd
like almost everyone to be on board with that. If we have some
backportable potential solutions, that gives us a little more
confidence that we can still get that user onto v13 (even if they have
to wait for a point release).
Without some backportable potential solutions, I'm inclined to ship
with either one or two escape-hatch GUCs, with warnings that they
should be used as a last resort. Hopefully users will complain on the
lists (so we understand the problem) before setting them.
It's not very principled, and we may be stuck with some cruft, but it
mitigates the risk a lot. There's a good chance we can remove them
later, especially if it's part of a larger overhall of
work_mem/hash_mem (which might happen fairly soon, given the interest
in this thread), or if we change something about HashAgg that makes the
GUCs harder to maintain.
Regards,
Jeff Davis
On Sat, Jul 4, 2020 at 1:54 PM Jeff Davis <pgsql@j-davis.com> wrote: > I agree that it's good to wait for actual problems. But the challenge > is that we can't backport an added GUC. Are there other, backportable > changes we could potentially make if a lot of users have a problem with > v13 after release? I doubt that there are. > I'm OK not having a GUC, but we need consensus around what our response > will be if a user experiences a regression. If our only answer is > "tweak X, Y, and Z; and if that doesn't work, wait for v14" then I'd > like almost everyone to be on board with that. I'm practically certain that there will be users that complain about regressions. It's all but inevitable given that in general grouping estimates are often wrong by orders of magnitude. > Without some backportable potential solutions, I'm inclined to ship > with either one or two escape-hatch GUCs, with warnings that they > should be used as a last resort. Hopefully users will complain on the > lists (so we understand the problem) before setting them. Where does that leave the hash_mem idea (or some other similar proposal)? I think that we should offer something like hash_mem that can work as a multiple of work_mem, for the reason that Justin mentioned recently. This can be justified as something that more or less maintains some kind of continuity with the old design. I think that it should affect hash join too, though I suppose that that part might be controversial -- that is certainly more than an escape hatch for this particular problem. Any thoughts on that? > It's not very principled, and we may be stuck with some cruft, but it > mitigates the risk a lot. There's a good chance we can remove them > later, especially if it's part of a larger overhall of > work_mem/hash_mem (which might happen fairly soon, given the interest > in this thread), or if we change something about HashAgg that makes the > GUCs harder to maintain. There are several reasons to get rid of work_mem entirely in the medium to long term. Some relatively obvious, others less so. An example in the latter category is "hash teams" [1]: a design that teaches multiple hash operations (e.g. a hash join and a hash aggregate that hash on the same columns) to cooperate in processing their inputs. It's more or less the hashing equivalent of what are sometimes called "interesting sort orders" (e.g. cases where the same sort/sort order is used by both a merge join and a group aggregate). The hash team controls spilling behavior for related hash nodes as a whole. That's the most sensible way of thinking about the related hash nodes, to enable a slew of optimizations. For example, I think that it enables bushy plans with multiple hash joins that can have much lower high watermark memory consumption. This hash teams business seems quite important in general, but it is fundamentally incompatible with the work_mem model, which supposes that each node exists on its own in a vacuum. (I suspect you already knew about this, Jeff, but not everyone will.) [1] http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.114.3183&rep=rep1&type=pdf -- Peter Geoghegan
On Sun, Jul 5, 2020 at 2:24 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Sat, 2020-07-04 at 14:49 +0530, Amit Kapila wrote: > > > We don't even have a user report yet of a > > > regression compared to PG 12, or one that can't be fixed by > > > increasing > > > work_mem. > > > > > > > Yeah, this is exactly the same point I have raised above. I feel we > > should wait before designing any solution to match pre-13 behavior > > for > > hashaggs to see what percentage of users face problems related to > > this > > and how much is a problem for them to increase work_mem to avoid > > regression. > > I agree that it's good to wait for actual problems. But the challenge > is that we can't backport an added GUC. > Is it because we won't be able to edit existing postgresql.conf file or for some other reasons? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, 2020-07-06 at 15:59 +0530, Amit Kapila wrote:
> I agree that it's good to wait for actual problems. But the
> > challenge
> > is that we can't backport an added GUC.
> >
>
> Is it because we won't be able to edit existing postgresql.conf file
> or for some other reasons?
Perhaps "can't" was too strong of a word, but I think it would be
unprecedented to introduce a GUC in a minor version. It could be a
source of confusion.
If others think that adding a GUC in a minor version would be
acceptable, please let me know.
Regards,
Jeff Davis
On Sun, 2020-07-05 at 16:47 -0700, Peter Geoghegan wrote: > Where does that leave the hash_mem idea (or some other similar > proposal)? hash_mem is acceptable to me if the consensus is moving toward that, but I'm not excited about it. It would be one thing if hash_mem was a nice clean solution. But it doesn't seem like a clean solution to me; and it's likely that it will get in the way of the next person who tries to improve the work_mem situation. > I think that we should offer something like hash_mem that can work as > a multiple of work_mem, for the reason that Justin mentioned > recently. > This can be justified as something that more or less maintains some > kind of continuity with the old design. Didn't Justin argue against using a multiplier? https://postgr.es/m/20200703024649.GJ4107@telsasoft.com > I think that it should affect hash join too, though I suppose that > that part might be controversial -- that is certainly more than an > escape hatch for this particular problem. Any thoughts on that? If it's called hash_mem, then I guess it needs to affect HJ. If not, it should have a different name. > There are several reasons to get rid of work_mem entirely in the > medium to long term. Some relatively obvious, others less so. Agreed. It seems like the only argument against the escape hatch GUCs is that they are cruft and we will end up stuck with them. But if we are dispensing with work_mem in a few releases, surely we'd need to dispense with hash_mem or the proposed escape-hatch GUCs anyway. > An example in the latter category is "hash teams" [1]: a design that > teaches multiple hash operations (e.g. a hash join and a hash > aggregate that hash on the same columns) to cooperate in processing > their inputs. Cool! It would certainly be nice to share the partitioning work between a HashAgg and a HJ. Regards, Jeff Davis
On Tue, Jul 7, 2020 at 9:18 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Mon, 2020-07-06 at 15:59 +0530, Amit Kapila wrote: > > I agree that it's good to wait for actual problems. But the > > > challenge > > > is that we can't backport an added GUC. > > > > > > > Is it because we won't be able to edit existing postgresql.conf file > > or for some other reasons? > > Perhaps "can't" was too strong of a word, but I think it would be > unprecedented to introduce a GUC in a minor version. > I don't think this is true. We seem to have introduced three new guc variables in a 9.3.3 minor release. See the following entry in 9.3.3 release notes [1]: "Create separate GUC parameters to control multixact freezing.... Introduce new settings vacuum_multixact_freeze_min_age, vacuum_multixact_freeze_table_age, and autovacuum_multixact_freeze_max_age to control when to freeze multixacts." Apart from this, we have asked users to not only edit postgresql.conf file but also update system catalogs. See the fix for "Cope with the Windows locale named "Norwegian (Bokmål)" [2] in 9.4.1 release. There are other instances where we also suggest users to set gucs, create new system objects (like views), perform DDL, DMLs, run REINDEX on various indexes, etc. in the minor release. [1] - https://www.postgresql.org/docs/release/9.3.3/ [2] - https://wiki.postgresql.org/wiki/Changes_To_Norwegian_Locale -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, 7 Jul 2020 at 16:57, Jeff Davis <pgsql@j-davis.com> wrote: > > On Sun, 2020-07-05 at 16:47 -0700, Peter Geoghegan wrote: > > Where does that leave the hash_mem idea (or some other similar > > proposal)? > > hash_mem is acceptable to me if the consensus is moving toward that, > but I'm not excited about it. FWIW, I'm not a fan of the hash_mem idea. It was my impression that we aimed to provide an escape hatch for people we have become accustomed to <= PG12 behaviour and hash_mem sounds like it's not that. Surely a GUC by that name would control what Hash Join does too? Otherwise, it would be called hashagg_mem. I'd say changing the behaviour of Hash join is not well aligned to the goal of allowing users to get something closer to what PG12 did. I know there has been talk over the years to improve how work_mem works. I see Tomas mentioned memory grants on the other thread [1]. I do imagine this is the long term solution to the problem where users must choose very conservative values for work_mem. We're certainly not going to get that for PG13, so I do think what we need here is just a simple escape hatch. I mentioned my thoughts in [2], so won't go over it again here. Once we've improved the situation in some future version of postgres, perhaps along the lines of what Tomas mentioned, then we can get rid of the escape hatch. Here are my reasons for not liking the hash_mem idea: 1. if it also increases the amount of memory that Hash Join can use then that makes the partition-wise hash join problem of hash_mem * npartitions even bigger when users choose to set hash_mem higher than work_mem to get Hash Agg doing what they're used to. 2. Someone will one day ask for sort_mem and then materialize_mem. Maybe then cte_mem. Once those are done we might as well just add a GUC to control every executor node that uses work_mem. 3. I'm working on a Result cache node [3]. It uses a hash table internally. Should it constraint its memory consumption according to hash_mem or work_mem? It's not really that obvious to people that it internally uses a hash table. "Hash" does not appear in the node name. Do people need to look that up in the documents? David [1] https://www.postgresql.org/message-id/20200626235850.gvl3lpfyeobu4evi@development [2] https://www.postgresql.org/message-id/CAApHDvqFZikXhAGW=UKZKq1_FzHy+XzmUzAJiNj6RWyTHH4UfA@mail.gmail.com [3] https://www.postgresql.org/message-id/CAApHDvrPcQyQdWERGYWx8J+2DLUNgXu+fOSbQ1UscxrunyXyrQ@mail.gmail.com
út 7. 7. 2020 v 14:55 odesílatel David Rowley <dgrowleyml@gmail.com> napsal:
On Tue, 7 Jul 2020 at 16:57, Jeff Davis <pgsql@j-davis.com> wrote:
>
> On Sun, 2020-07-05 at 16:47 -0700, Peter Geoghegan wrote:
> > Where does that leave the hash_mem idea (or some other similar
> > proposal)?
>
> hash_mem is acceptable to me if the consensus is moving toward that,
> but I'm not excited about it.
FWIW, I'm not a fan of the hash_mem idea. It was my impression that we
aimed to provide an escape hatch for people we have become accustomed
to <= PG12 behaviour and hash_mem sounds like it's not that. Surely a
GUC by that name would control what Hash Join does too? Otherwise, it
would be called hashagg_mem. I'd say changing the behaviour of Hash
join is not well aligned to the goal of allowing users to get
something closer to what PG12 did.
I know there has been talk over the years to improve how work_mem
works. I see Tomas mentioned memory grants on the other thread [1]. I
do imagine this is the long term solution to the problem where users
must choose very conservative values for work_mem. We're certainly not
going to get that for PG13, so I do think what we need here is just a
simple escape hatch. I mentioned my thoughts in [2], so won't go over
it again here. Once we've improved the situation in some future
version of postgres, perhaps along the lines of what Tomas mentioned,
then we can get rid of the escape hatch.
Here are my reasons for not liking the hash_mem idea:
1. if it also increases the amount of memory that Hash Join can use
then that makes the partition-wise hash join problem of hash_mem *
npartitions even bigger when users choose to set hash_mem higher than
work_mem to get Hash Agg doing what they're used to.
2. Someone will one day ask for sort_mem and then materialize_mem.
Maybe then cte_mem. Once those are done we might as well just add a
GUC to control every executor node that uses work_mem.
3. I'm working on a Result cache node [3]. It uses a hash table
internally. Should it constraint its memory consumption according to
hash_mem or work_mem? It's not really that obvious to people that it
internally uses a hash table. "Hash" does not appear in the node name.
Do people need to look that up in the documents?
+1
I share your opinion.
David
[1] https://www.postgresql.org/message-id/20200626235850.gvl3lpfyeobu4evi@development
[2] https://www.postgresql.org/message-id/CAApHDvqFZikXhAGW=UKZKq1_FzHy+XzmUzAJiNj6RWyTHH4UfA@mail.gmail.com
[3] https://www.postgresql.org/message-id/CAApHDvrPcQyQdWERGYWx8J+2DLUNgXu+fOSbQ1UscxrunyXyrQ@mail.gmail.com
Hi, On 2020-07-03 10:08:08 -0400, Bruce Momjian wrote: > Well, the bottom line is that we are designing features during beta. > People are supposed to be testing PG 13 behavior during beta, including > optimizer behavior. I think it makes no too much sense to plan invent something like hash_mem for v13, it's clearly too much work. That's a seperate discussion from having something like it for v14. > We don't even have a user report yet of a > regression compared to PG 12, or one that can't be fixed by increasing > work_mem. I posted a repro, and no you can't fix it by increasing work_mem without increasing memory usage in the whole query / all queries. > If we add a new behavior to PG 13, we then have the pre-PG 13 behavior, > the pre-patch behavior, and the post-patch behavior. How are people > supposed to test all of that? I don't really buy this as a problem. It's not like the pre-13 behaviour would be all new. It's how PG has behaved approximately forever. My conclusion about this topic is that I think we'll be doing our users a disservice by not providing an escape hatch, but that I also don't have the energy / time to fight for it further. This is a long thread already, and I sense little movement towards a conclusion. Greetings, Andres Freund
On Tue, Jul 7, 2020 at 5:55 AM David Rowley <dgrowleyml@gmail.com> wrote: > FWIW, I'm not a fan of the hash_mem idea. It was my impression that we > aimed to provide an escape hatch for people we have become accustomed > to <= PG12 behaviour and hash_mem sounds like it's not that. The exact scope of the problem is unclear. If it was clear, then we'd be a lot closer to a resolution than we seem to be. Determining the scope of the problem is the hardest part of the problem. All that is ~100% clear now is that some users will experience what they'll call a regression. Those users will be unhappy, even if and when they come to understand that technically they're just "living within their means" for the first time, and were theoretically not entitled to the performance from earlier versions all along. That's bad, and we should try our best to avoid or mitigate it. Sometimes the more ambitious plan (in this case hash_mem) actually has a greater chance of succeeding, despite solving more problems than the immediate problem. I don't think that it's reasonable to hold that against my proposal. It may be that hash_mem is a bad idea based on the costs and benefits, or the new risks, in which case it should be rejected. But if it's the best proposal on the table by a clear margin, then it shouldn't be disqualified for not satisfying the original framing of the problem. > Surely a > GUC by that name would control what Hash Join does too? Otherwise, it > would be called hashagg_mem. I'd say changing the behaviour of Hash > join is not well aligned to the goal of allowing users to get > something closer to what PG12 did. My tentative hash_mem proposal assumed that hash join would be affected alongside hash agg, in the obvious way. Yes, that's clearly beyond the scope of the open item. The history of some other database systems is instructive. At least a couple of these systems had something like a work_mem/sort_mem GUC, as well as a separate hash_mem-like GUC that only affects hashing. It's sloppy, but nevertheless better than completely ignoring the fundamental ways in which hashing really is special. This is a way of papering-over one of the main deficiencies of the general idea of a work_mem style per-node allocation. Yes, that's pretty ugly. I think that work_mem would be a lot easier to tune if you assume that hash-based nodes don't exist (i.e. only merge joins and nestloop joins are available, plus group aggregate for aggregation). You don't need to do this as a thought experiment. That really was how things were up until about the mid-1980s, when increasing memory capacities made hash join and hash agg in database systems feasible for the first time. Hashing came after most of the serious work on cost-based optimizers had already been done. This argues for treating hash-based nodes as special now, if only to extend work_mem beyond its natural life as a pragmatic short-term measure. Separately, it argues for a *total rethink* of how memory is used in the executor in the long term -- it shouldn't be per-node in a few important cases (I'm thinking of the "hash teams" design I mentioned on this thread recently, which seems like a fundamentally better way of doing it). > We're certainly not > going to get that for PG13, so I do think what we need here is just a > simple escape hatch. I mentioned my thoughts in [2], so won't go over > it again here. Once we've improved the situation in some future > version of postgres, perhaps along the lines of what Tomas mentioned, > then we can get rid of the escape hatch. If it really has to be a simple escape hatch in Postgres 13, then I could live with a hard disabling of spilling at execution time. That seems like the most important thing that is addressed by your proposal. I'm concerned that way too many users will have to use the escape hatch, and that that misses the opportunity to provide a smoother experience. > Here are my reasons for not liking the hash_mem idea: I'm sure that your objections are valid to varying degrees. But they could almost be thought of as problems with work_mem itself. I am trying to come up with a practical way of ameliorating the downsides of work_mem. I don't for a second imagine that this won't create new problems. I think that it's the least worst thing right now. I have my misgivings. -- Peter Geoghegan
On 2020-Jul-07, Amit Kapila wrote: > I don't think this is true. We seem to have introduced three new guc > variables in a 9.3.3 minor release. Yeah, backporting GUCs is not a big deal. Sure, the GUC won't appear in postgresql.conf files generated by initdb prior to the release that introduces it. But users that need it can just edit their .confs and add the appropriate line, or just do ALTER SYSTEM after the minor upgrade. For people that don't need it, it would have a reasonable default (probably work_mem, so that behavior doesn't change on the minor upgrade). -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jul 7, 2020 at 1:18 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Yeah, backporting GUCs is not a big deal. Sure, the GUC won't appear in > postgresql.conf files generated by initdb prior to the release that > introduces it. But users that need it can just edit their .confs and > add the appropriate line, or just do ALTER SYSTEM after the minor > upgrade. I don't buy that argument myself. At a minimum, if we do it then we ought to feel bad about it. It should be rare. The fact that you can have a replica on an earlier point release enforces the idea that it ought to be broadly compatible. Technically users are not guaranteed that this will work, just like there are no guarantees about WAL compatibility across point releases. We nevertheless tacitly provide a "soft" guarantee that we won't break WAL -- and that we won't add entirely new GUCs in a point release. -- Peter Geoghegan
On 2020-Jul-07, Peter Geoghegan wrote: > On Tue, Jul 7, 2020 at 1:18 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Yeah, backporting GUCs is not a big deal. Sure, the GUC won't appear in > > postgresql.conf files generated by initdb prior to the release that > > introduces it. But users that need it can just edit their .confs and > > add the appropriate line, or just do ALTER SYSTEM after the minor > > upgrade. > > I don't buy that argument myself. At a minimum, if we do it then we > ought to feel bad about it. It should be rare. Judging history, it's pretty clear that it *is* rare. I'm not suggesting we do it now. I'm just contesting the assertion that it's impossible. > The fact that you can have a replica on an earlier point release > enforces the idea that it ought to be broadly compatible. A replica without hash_mem is not going to fail if the primary is upgraded to a version with hash_mem, so I'm not sure this argument means anything in this case. In any case, when we add WAL message types in minor releases, users are suggested to upgrade the replicas first; if they fail to do so, the replicas shut down when they reach a WAL point where the primary emitted the new message. Generally speaking, we *don't* promise that running a replica with an older minor always works, though obviously it does work most of the time. > Technically > users are not guaranteed that this will work, just like there are no > guarantees about WAL compatibility across point releases. We > nevertheless tacitly provide a "soft" guarantee that we won't break > WAL -- and that we won't add entirely new GUCs in a point release. Agreed, we do provide those guarantees. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jul 7, 2020 at 10:12 AM Andres Freund <andres@anarazel.de> wrote: > I think it makes no too much sense to plan invent something like > hash_mem for v13, it's clearly too much work. That's a seperate > discussion from having something like it for v14. Can you explain why you believe that to be the case? It seems quite possible that there is some subtlety that I missed in grouping sets or something like that. I would like to know the specifics, if there are any specifics. > My conclusion about this topic is that I think we'll be doing our users > a disservice by not providing an escape hatch, but that I also don't > have the energy / time to fight for it further. This is a long thread > already, and I sense little movement towards a conclusion. An escape hatch seems necessary. I accept that a hard disabling of spilling at execution time meets that standard, and that may be enough for Postgres 13. But I am concerned that an uncomfortably large proportion of our users will end up needing this. (Perhaps I should say a large proportion of the subset of users that might be affected either way. You get the idea.) I have to wonder if this escape hatch is an escape hatch for our users, or an escape hatch for us. There is a difference. -- Peter Geoghegan
On Wed, 8 Jul 2020 at 07:25, Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Jul 7, 2020 at 5:55 AM David Rowley <dgrowleyml@gmail.com> wrote: > > We're certainly not > > going to get that for PG13, so I do think what we need here is just a > > simple escape hatch. I mentioned my thoughts in [2], so won't go over > > it again here. Once we've improved the situation in some future > > version of postgres, perhaps along the lines of what Tomas mentioned, > > then we can get rid of the escape hatch. > > If it really has to be a simple escape hatch in Postgres 13, then I > could live with a hard disabling of spilling at execution time. That > seems like the most important thing that is addressed by your > proposal. I'm concerned that way too many users will have to use the > escape hatch, and that that misses the opportunity to provide a > smoother experience. Yeah. It's a valid concern. I'd rather nobody would ever have to exit through the escape hatch either. I don't think anyone here actually wants that to happen. It's only been proposed to allow users a method to escape the new behaviour and get back what they're used to. I think the smoother experience will come in some future version of PostgreSQL with generally better memory management for work_mem all round. It's certainly been talked about enough and I don't think anyone here disagrees that there is a problem with N being unbounded when it comes to N * work_mem. I'd really like to see this thread move forward to a solution and I'm not sure how best to do that. I started by reading back over both this thread and the original one and tried to summarise what people have suggested. I understand some people did change their minds along the way, so I may have made some mistakes. I could have assumed the latest mindset overruled, but it was harder to determine that due to the thread being split. For hash_mem = Justin [16], PeterG [15], Tomas [7] hash_mem out of scope for PG13 = Bruce [8], Andres [9] Wait for reports from users = Amit [10] Escape hatch that can be removed later when we get something better = Jeff [11], David [12], Pavel [13], Andres [14], Justin [1] Add enable_hashagg_spill = Tom [2] (I'm unclear on this proposal. Does it affect the planner or executor or both?) Maybe do nothing until we see how things go during beta = Bruce [3] Just let users set work_mem = Alvaro [4] (I think he changed his mind after Andres pointed out that changes other nodes in the plan too) Swap enable_hashagg for a GUC that specifies when spilling should occur. -1 means work_mem = Robert [17], Amit [18] hash_mem does not solve the problem = Tomas [6] David [1] https://www.postgresql.org/message-id/20200624031443.GV4107@telsasoft.com [2] https://www.postgresql.org/message-id/2214502.1593019796@sss.pgh.pa.us [3] https://www.postgresql.org/message-id/20200625182512.GC12486@momjian.us [4] https://www.postgresql.org/message-id/20200625224422.GA9653@alvherre.pgsql [5] https://www.postgresql.org/message-id/CAA4eK1K0cgk_8hRyxsvppgoh_Z-NY+UZTcFWB2we6baJ9DXCQw@mail.gmail.com [6] https://www.postgresql.org/message-id/20200627104141.gq7d3hm2tvoqgjjs@development [7] https://www.postgresql.org/message-id/20200629212229.n3afgzq6xpxrr4cu@development [8] https://www.postgresql.org/message-id/20200703030001.GD26235@momjian.us [9] https://www.postgresql.org/message-id/20200707171216.jqxrld2jnxwf5ozv@alap3.anarazel.de [10] https://www.postgresql.org/message-id/CAA4eK1KfPi6iz0hWxBLZzfVOG_NvOVJL=9UQQirWLpaN=kANTQ@mail.gmail.com [11] https://www.postgresql.org/message-id/8bff2e4e8020c3caa16b61a46918d21b573eaf78.camel@j-davis.com [12] https://www.postgresql.org/message-id/CAApHDvqFZikXhAGW=UKZKq1_FzHy+XzmUzAJiNj6RWyTHH4UfA@mail.gmail.com [13] https://www.postgresql.org/message-id/CAFj8pRBf1w4ndz-ynd+mUpTfiZfbs7+CPjc4ob8v9d3X0MscCg@mail.gmail.com [14] https://www.postgresql.org/message-id/20200624191433.5gnqgrxfmucexldm@alap3.anarazel.de [15] https://www.postgresql.org/message-id/CAH2-WzmD+i1pG6rc1+Cjc4V6EaFJ_qSuKCCHVnH=oruqD-zqow@mail.gmail.com [16] https://www.postgresql.org/message-id/20200703024649.GJ4107@telsasoft.com [17] https://www.postgresql.org/message-id/CA+TgmobyV9+T-Wjx-cTPdQuRCgt1THz1mL3v1NXC4m4G-H6Rcw@mail.gmail.com [18] https://www.postgresql.org/message-id/CAA4eK1K0cgk_8hRyxsvppgoh_Z-NY+UZTcFWB2we6baJ9DXCQw@mail.gmail.com
On Wed, Jul 8, 2020 at 7:28 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
>
> I'd really like to see this thread move forward to a solution and I'm
> not sure how best to do that. I started by reading back over both this
> thread and the original one and tried to summarise what people have
> suggested.
>
Thanks, I think this might help us in reaching some form of consensus
by seeing what most people prefer.
> I understand some people did change their minds along the way, so I
> may have made some mistakes. I could have assumed the latest mindset
> overruled, but it was harder to determine that due to the thread being
> split.
>
> For hash_mem = Justin [16], PeterG [15], Tomas [7]
> hash_mem out of scope for PG13 = Bruce [8], Andres [9]
>
+1 for hash_mem out of scope for PG13. Apart from the reasons you
have mentioned above, the other reason is if this is a way to allow
users to get a smooth experience for hash aggregates, then I think the
idea proposed by Robert is not yet ruled out and we should see which
one is better. OTOH, if we want to see this as a way to give smooth
experience for current use cases for hash aggregates and improve the
situation for hash joins as well then I think this seems to be a new
behavior which should be discussed for PG14. Having said that, I am
not saying this is not a good idea but just I don't think we should
pursue it for PG13.
> Wait for reports from users = Amit [10]
I think this is mostly inline with Bruce is intending to say ("Maybe
do nothing until we see how things go during beta"). So, probably we
can club the votes.
> Escape hatch that can be removed later when we get something better =
> Jeff [11], David [12], Pavel [13], Andres [14], Justin [1]
> Add enable_hashagg_spill = Tom [2] (I'm unclear on this proposal. Does
> it affect the planner or executor or both?)
> Maybe do nothing until we see how things go during beta = Bruce [3]
> Just let users set work_mem = Alvaro [4] (I think he changed his mind
> after Andres pointed out that changes other nodes in the plan too)
> Swap enable_hashagg for a GUC that specifies when spilling should
> occur. -1 means work_mem = Robert [17], Amit [18]
> hash_mem does not solve the problem = Tomas [6]
>
[1] - https://www.postgresql.org/message-id/CA+TgmobyV9+T-Wjx-cTPdQuRCgt1THz1mL3v1NXC4m4G-H6Rcw@mail.gmail.com
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Greetings, * Alvaro Herrera (alvherre@2ndquadrant.com) wrote: > On 2020-Jun-25, Andres Freund wrote: > > > >My point here is that maybe we don't need to offer a GUC to explicitly > > >turn spilling off; it seems sufficient to let users change work_mem so > > >that spilling will naturally not occur. Why do we need more? > > > > That's not really a useful escape hatch, because I'll often lead to > > other nodes using more memory. > > Ah -- other nodes in the same query -- you're right, that's not good. It's exactly how the system has been operating for, basically, forever, for everything. Yes, it'd be good to have a way to manage the overall amount of memory that a query is allowed to use but that's a huge change and inventing some new 'hash_mem' or some such GUC doesn't strike me as a move in the right direction- are we going to have sort_mem next? What if having one large hash table for aggregation would be good, but having the other aggregate use a lot of memory would run the system out of memory? Yes, we need to do better, but inventing new node_mem GUCs isn't the direction to go in. That HashAgg previously didn't care that it was going wayyyyy over work_mem was, if anything, a bug. Inventing new GUCs late in the cycle like this under duress seems like a *really* bad idea. Yes, people are going to have to adjust work_mem if they want these queries to continue using a ton of memory to run when the planner didn't think it'd actually take that much memory- but then, in lots of the kinds of cases that I think you're worrying about, the stats aren't actually that far off and people did increase work_mem to get the HashAgg plan in the first place. I'm also in support of having enable_hashagg_disk set to true as the default, just like all of the other enable_*'s. Thanks, Stephen
Вложения
On Wed, 2020-07-08 at 10:00 -0400, Stephen Frost wrote:
> That HashAgg previously didn't care that it was going wayyyyy over
> work_mem was, if anything, a bug.
I think we all agree about that, but some people may be depending on
that bug.
> Inventing new GUCs late in the
> cycle like this under duress seems like a *really* bad idea.
Are you OK with escape-hatch GUCs that allow the user to opt for v12
behavior in the event that they experience a regression?
The one for the planner is already there, and it looks like we need one
for the executor as well (to tell HashAgg to ignore the memory limit
just like v12).
Regards,
Jeff Davis
Greetings, * Jeff Davis (pgsql@j-davis.com) wrote: > On Wed, 2020-07-08 at 10:00 -0400, Stephen Frost wrote: > > That HashAgg previously didn't care that it was going wayyyyy over > > work_mem was, if anything, a bug. > > I think we all agree about that, but some people may be depending on > that bug. That's why we don't make these kinds of changes in a minor release and instead have major releases. > > Inventing new GUCs late in the > > cycle like this under duress seems like a *really* bad idea. > > Are you OK with escape-hatch GUCs that allow the user to opt for v12 > behavior in the event that they experience a regression? The enable_* options aren't great, and the one added for this is even stranger since it's an 'enable' option for a particular capability of a node rather than just a costing change for a node, but I feel like people generally understand that they shouldn't be messing with the enable_* options and that they're not really intended for end users. > The one for the planner is already there, and it looks like we need one > for the executor as well (to tell HashAgg to ignore the memory limit > just like v12). No, ignoring the limit set was, as agreed above, a bug, and I don't think it makes sense to add some new user tunable for this. If folks want to let HashAgg use more memory then they can set work_mem higher, just the same as if they want a Sort node to use more memory or a HashJoin. Yes, that comes with potential knock-on effects about other nodes (possibly) using more memory but that's pretty well understood for all the other cases and I don't think that it makes sense to have a special case for HashAgg when the only justification is that "well, you see, it used to have this bug, so...". Thanks, Stephen
Вложения
On Thu, Jul 9, 2020 at 7:03 AM Stephen Frost <sfrost@snowman.net> wrote: > > The one for the planner is already there, and it looks like we need one > > for the executor as well (to tell HashAgg to ignore the memory limit > > just like v12). > > No, ignoring the limit set was, as agreed above, a bug, and I don't > think it makes sense to add some new user tunable for this. It makes more sense than simply ignoring what our users will see as a simple regression. (Though I still lean towards fixing the problem by introducing hash_mem, which at least tries to fix the problem head on.) > If folks > want to let HashAgg use more memory then they can set work_mem higher, > just the same as if they want a Sort node to use more memory or a > HashJoin. Yes, that comes with potential knock-on effects about other > nodes (possibly) using more memory but that's pretty well understood for > all the other cases and I don't think that it makes sense to have a > special case for HashAgg when the only justification is that "well, you > see, it used to have this bug, so...". That's not the only justification. The other justification is that it's generally reasonable to prefer giving hash aggregate more memory. This would even be true in a world where all grouping estimates were somehow magically accurate. These two justifications coincide in a way that may seem a bit too convenient to truly be an accident of history. And if they do: I agree. It's no accident. It seems likely that we have been "complicit" in enabling "applications that live beyond their means", work_mem-wise. We knew that hash aggregate had this "bug" forever, and yet we were reasonably happy to have it be the common case for years. It's very fast, and didn't actually explode most of the time (even though grouping estimates are often pretty poor). Hash agg was and is the common case. Yes, we were concerned about the risk of OOM for many years, but it was considered a risk worth taking. We knew what the trade-off was. We never quite admitted it, but what does it matter? Our own tacit attitude towards hash agg + work_mem mirrors that of our users (or at least the users that will be affected by this issue, of which there will be plenty). Declaring this behavior a bug with no redeeming qualities now seems a bit rich. -- Peter Geoghegan
Greetings, * Peter Geoghegan (pg@bowt.ie) wrote: > On Thu, Jul 9, 2020 at 7:03 AM Stephen Frost <sfrost@snowman.net> wrote: > > > The one for the planner is already there, and it looks like we need one > > > for the executor as well (to tell HashAgg to ignore the memory limit > > > just like v12). > > > > No, ignoring the limit set was, as agreed above, a bug, and I don't > > think it makes sense to add some new user tunable for this. > > It makes more sense than simply ignoring what our users will see as a > simple regression. (Though I still lean towards fixing the problem by > introducing hash_mem, which at least tries to fix the problem head > on.) The presumption that this will always end up resulting in a regression really doesn't seem sensible to me. We could rip out the logic in Sort that spills to disk and see how much faster it gets- as long as we don't actually run out of memory, but that's kind of the entire point of having some kind of limit on the amount of memory we use, isn't it? > > If folks > > want to let HashAgg use more memory then they can set work_mem higher, > > just the same as if they want a Sort node to use more memory or a > > HashJoin. Yes, that comes with potential knock-on effects about other > > nodes (possibly) using more memory but that's pretty well understood for > > all the other cases and I don't think that it makes sense to have a > > special case for HashAgg when the only justification is that "well, you > > see, it used to have this bug, so...". > > That's not the only justification. The other justification is that > it's generally reasonable to prefer giving hash aggregate more memory. Sure, and it's generally reasonably to prefer giving Sorts more memory too... as long as you've got it available. > This would even be true in a world where all grouping estimates were > somehow magically accurate. These two justifications coincide in a way > that may seem a bit too convenient to truly be an accident of history. > And if they do: I agree. It's no accident. I disagree that the lack of HashAgg's ability to spill to disk was because, for this one particular node, we should always just give it however much memory it needs, regardless of if it's anywhere near how much we thought it'd need or not. > It seems likely that we have been "complicit" in enabling > "applications that live beyond their means", work_mem-wise. We knew > that hash aggregate had this "bug" forever, and yet we were reasonably > happy to have it be the common case for years. It's very fast, and > didn't actually explode most of the time (even though grouping > estimates are often pretty poor). Hash agg was and is the common case. I disagree that we were reasonably happy with this bug or that it somehow makes sense to retain it. HashAgg is certainly commonly used, but that's not really relevant- it's still going to be used quite a bit, it's just that, now, when our estimates are far wrong, we won't just gobble up all the memory available and instead will spill to disk- just like we do with the other nodes. > Yes, we were concerned about the risk of OOM for many years, but it > was considered a risk worth taking. We knew what the trade-off was. We > never quite admitted it, but what does it matter? This is not some well designed feature of HashAgg that had a lot of thought put into it, whereby the community agreed that we should just let it be and hope no one noticed or got bit by it- I certainly have managed to kill servers by a HashAgg gone bad and I seriously doubt I'm alone in that. > Our own tacit attitude towards hash agg + work_mem mirrors that of our > users (or at least the users that will be affected by this issue, of > which there will be plenty). Declaring this behavior a bug with no > redeeming qualities now seems a bit rich. No, I disagree entirely. Thanks, Stephen
Вложения
On Thu, Jul 9, 2020 at 3:58 PM Stephen Frost <sfrost@snowman.net> wrote: > > That's not the only justification. The other justification is that > > it's generally reasonable to prefer giving hash aggregate more memory. > > Sure, and it's generally reasonably to prefer giving Sorts more memory > too... as long as you've got it available. Did you actually read any of the discussion? The value of doing a hash aggregate all in memory is generally far greater than the value of doing a sort all in memory. They're just very different situations, owing to the fundamental laws-of-physics principles that apply in each case. Even to the extent that sometimes an external sort can actually be slightly *faster* (it's not really supposed to be, but it is). Try it out yourself. I'm not going to repeat this in full again. The thread is already long enough. > > This would even be true in a world where all grouping estimates were > > somehow magically accurate. These two justifications coincide in a way > > that may seem a bit too convenient to truly be an accident of history. > > And if they do: I agree. It's no accident. > > I disagree that the lack of HashAgg's ability to spill to disk was > because, for this one particular node, we should always just give it > however much memory it needs, regardless of if it's anywhere near how > much we thought it'd need or not. This is a straw man. It's possible to give hash agg an amount of memory that exceeds work_mem, but is less than infinity. That's more or less what I propose to enable by inventing a new hash_mem GUC, in fact. There is also the separate "escape hatch" idea that David Rowley proposed, that I consider to be a plausible way of resolving the problem. That wouldn't "always give it [hash agg] however much memory it asks for", either. It would only do that when the setting indicated that hash agg should be given however much memory it asks for. > I disagree that we were reasonably happy with this bug or that it > somehow makes sense to retain it. While we're far from resolving this open item, I think that you'll find that most people agree that it's reasonable to think of hash agg as special -- at least in some contexts. The central disagreement seems to be on the question of how to maintain some kind of continuity with the old behavior, how ambitious our approach should be in Postgres 13, etc. > > Yes, we were concerned about the risk of OOM for many years, but it > > was considered a risk worth taking. We knew what the trade-off was. We > > never quite admitted it, but what does it matter? > > This is not some well designed feature of HashAgg that had a lot of > thought put into it, whereby the community agreed that we should just > let it be and hope no one noticed or got bit by it- I certainly have > managed to kill servers by a HashAgg gone bad and I seriously doubt I'm > alone in that. I was talking about the evolutionary pressures that led to this curious state of affairs, where hashagg's overuse of memory was often actually quite desirable. I understand that it also sometimes causes OOMs, and that OOMs are bad. Both beliefs are compatible, just as a design that takes both into account is possible. If it isn't practical to do that in Postgres 13, then an escape hatch is highly desirable, if not essential. -- Peter Geoghegan
On Thu, Jul 9, 2020 at 3:58 PM Stephen Frost <sfrost@snowman.net> wrote:
> > If folks
> > want to let HashAgg use more memory then they can set work_mem higher,
> > just the same as if they want a Sort node to use more memory or a
> > HashJoin. Yes, that comes with potential knock-on effects about other
> > nodes (possibly) using more memory but that's pretty well understood for
> > all the other cases and I don't think that it makes sense to have a
> > special case for HashAgg when the only justification is that "well, you
> > see, it used to have this bug, so...".
>
> That's not the only justification. The other justification is that
> it's generally reasonable to prefer giving hash aggregate more memory.
Sure, and it's generally reasonably to prefer giving Sorts more memory
too... as long as you've got it available.
Looking at the docs for work_mem it was decided to put "such as" before "sort" and "hash table" even though the rest of the paragraph then only talks about those two. Are there other things possible that warrant the "such as" qualifier or can we write "specifically, a sort, or a hash table"?
For me, as a user that doesn't presently need to deal with all this, I'd rather have a multiplier GUC for max_hash_work_mem_units defaulting to something like 4. The planner would then use that multiple. We've closed the "bug" while still giving me a region of utility that emulates the v12 reality without me touching anything, or even being aware of the bug that is being fixed.
I cannot see myself wanting to globally revert to v12 behavior on the execution side as the OOM side-effect is definitely more unpleasant than slowed queries. If I have to go into a specific query anyway I'd go for a measured change on the work_mem or multiplier rather than choosing to consume as much memory as needed.
David J.
Greetings, * Peter Geoghegan (pg@bowt.ie) wrote: > On Thu, Jul 9, 2020 at 3:58 PM Stephen Frost <sfrost@snowman.net> wrote: > > > That's not the only justification. The other justification is that > > > it's generally reasonable to prefer giving hash aggregate more memory. > > > > Sure, and it's generally reasonably to prefer giving Sorts more memory > > too... as long as you've got it available. > > The value of doing a hash aggregate all in memory is generally far > greater than the value of doing a sort all in memory. They're just > very different situations, owing to the fundamental laws-of-physics > principles that apply in each case. Even to the extent that sometimes > an external sort can actually be slightly *faster* (it's not really > supposed to be, but it is). Try it out yourself. I didn't, and don't, think it particularly relevant to the discussion, but if you don't like the comparison to Sort then we could compare it to a HashJoin instead- the point is that, yes, if you are willing to give more memory to a given operation, it's going to go faster, and the way users tell us that they'd like the query to use more memory is already well-defined and understood to be through work_mem. We do not do them a service by ignoring that. > > > This would even be true in a world where all grouping estimates were > > > somehow magically accurate. These two justifications coincide in a way > > > that may seem a bit too convenient to truly be an accident of history. > > > And if they do: I agree. It's no accident. > > > > I disagree that the lack of HashAgg's ability to spill to disk was > > because, for this one particular node, we should always just give it > > however much memory it needs, regardless of if it's anywhere near how > > much we thought it'd need or not. > > This is a straw man. It's really not- the system has been quite intentionally designed, and documented, to work within the constraints given to it (even if they're not very well defined, this is still the case) and this particular node didn't. That isn't a feature. > It's possible to give hash agg an amount of memory that exceeds > work_mem, but is less than infinity. That's more or less what I > propose to enable by inventing a new hash_mem GUC, in fact. We already have a GUC that we've documented and explained to users that is there specifically to control this exact thing, and that's work_mem. How would we document this? "work_mem is used to control the amount of memory a given node can consider using- oh, except for this one particular kind of node called a HashAgg, then you have to use this other variable; no, there's no other node-specific tunable like that, and no, you can't control how much memory is used for a given HashAgg or for a given node". Sure, I'm going over the top here to show my point, but I don't think I'm far from the mark on how this would look. > There is also the separate "escape hatch" idea that David Rowley > proposed, that I consider to be a plausible way of resolving the > problem. That wouldn't "always give it [hash agg] however much memory > it asks for", either. It would only do that when the setting indicated > that hash agg should be given however much memory it asks for. Where's the setting for HashJoin or for Sort, to do the same thing? Would we consider it sensible to set everything to "use as much memory as you want?" I disagree with this notion that HashAgg is so very special that it must have an independent set of tunables like this. > > I disagree that we were reasonably happy with this bug or that it > > somehow makes sense to retain it. > > While we're far from resolving this open item, I think that you'll > find that most people agree that it's reasonable to think of hash agg > as special -- at least in some contexts. The central disagreement > seems to be on the question of how to maintain some kind of continuity > with the old behavior, how ambitious our approach should be in > Postgres 13, etc. The old behavior was buggy and we are providing quite enough continuity through the fact that we've got major versions which will be maintained for the next 5 years that folks can run as they test out newer versions. Inventing hacks to preserve bug-compatibility across major versions is not a good direction to go in. > > > Yes, we were concerned about the risk of OOM for many years, but it > > > was considered a risk worth taking. We knew what the trade-off was. We > > > never quite admitted it, but what does it matter? > > > > This is not some well designed feature of HashAgg that had a lot of > > thought put into it, whereby the community agreed that we should just > > let it be and hope no one noticed or got bit by it- I certainly have > > managed to kill servers by a HashAgg gone bad and I seriously doubt I'm > > alone in that. > > I was talking about the evolutionary pressures that led to this > curious state of affairs, where hashagg's overuse of memory was often > actually quite desirable. I understand that it also sometimes causes > OOMs, and that OOMs are bad. Both beliefs are compatible, just as a > design that takes both into account is possible. I don't agree that evolution of the system led us to have a HashAgg node that overused memory- certainly it wasn't intentional as it only happened when we thought it wouldn't based on what information we had at plan time, a fact that has certainly led a lot of folks to increase work_mem to get the HashAgg that they wanted and who, most likely, won't actually end up being hit by this at all. > If it isn't practical to do that in Postgres 13, then an escape hatch > is highly desirable, if not essential. We have a parameter which already drives this and which users are welcome to (and quite often do) tune. I disagree that anything further is either essential or particularly desirable. I'm really rather astounded at the direction this has been going in. Thanks, Stephen
Вложения
On Thu, Jul 9, 2020 at 5:08 PM Stephen Frost <sfrost@snowman.net> wrote: > I didn't, and don't, think it particularly relevant to the discussion, > but if you don't like the comparison to Sort then we could compare it to > a HashJoin instead- the point is that, yes, if you are willing to give > more memory to a given operation, it's going to go faster, and the way > users tell us that they'd like the query to use more memory is already > well-defined and understood to be through work_mem. We do not do them a > service by ignoring that. The hash_mem design (as it stands) would affect both hash join and hash aggregate. I believe that it makes most sense to have hash-based nodes under the control of a single GUC. I believe that this granularity will cause the least problems. It certainly represents a trade-off. work_mem is less of a problem with hash join, primarily because join estimates are usually a lot better than grouping estimates. But it is nevertheless something that it makes sense to put in the same conceptual bucket as hash aggregate, pending a future root and branch redesign of work_mem. > > This is a straw man. > > It's really not- the system has been quite intentionally designed, and > documented, to work within the constraints given to it (even if they're > not very well defined, this is still the case) and this particular node > didn't. That isn't a feature. I don't think that it was actually designed, so much as it evolved -- at least in this particular respect. But it hardly matters now. > We already have a GUC that we've documented and explained to users that > is there specifically to control this exact thing, and that's work_mem. > How would we document this? hash_mem would probably work as a multiplier of work_mem when negated, or as an absolute KB value, like work_mem. It would apply to nodes that use hashing, currently defined as hash agg and hash join. We might make the default -2, meaning twice whatever work_mem was (David Johnson suggested 4x just now, which seems a little on the aggressive side to me). Yes, that is a new burden for users that need to tune work_mem. Similar settings exist in other DB systems (or did before they finally replaced the equivalent of work_mem with something fundamentally better). All of the choices on the table have significant downsides. Nobody can claim the mantle of prudent conservative by proposing that we do nothing here. To do so is to ignore predictable significant negative consequences for our users. That much isn't really in question. I'm pretty sure that Andres, Robert, David Rowley, Alvaro, Justin, and Tomas will all agree with that statement (I'm sure that I'm forgetting somebody else, though). If this seems strange or unlikely, then look back over the thread. > Where's the setting for HashJoin or for Sort, to do the same thing? > Would we consider it sensible to set everything to "use as much memory > as you want?" I disagree with this notion that HashAgg is so very > special that it must have an independent set of tunables like this. Regardless of what we do now, the fact is that the economic case for giving hash agg more memory (relative to most other executor nodes) when the system as a whole is short on memory is very strong. It does not follow that the current hash_mem proposal is the best way forward now, of course, but I don't see why you don't at least agree with me about that much. It seems rather obvious to me. > The old behavior was buggy and we are providing quite enough continuity > through the fact that we've got major versions which will be maintained > for the next 5 years that folks can run as they test out newer versions. > Inventing hacks to preserve bug-compatibility across major versions is > not a good direction to go in. Like I said, the escape hatch GUC is not my preferred solution. But at least it acknowledges the problem. I don't think that anyone (or anyone else) believes that work_mem doesn't have serious limitations. > We have a parameter which already drives this and which users are > welcome to (and quite often do) tune. I disagree that anything further > is either essential or particularly desirable. This is a user hostile attitude. > I'm really rather astounded at the direction this has been going in. Why? -- Peter Geoghegan
On Thu, 2020-07-09 at 19:18 -0500, Justin Pryzby wrote:
> Maybe pretend that Jeff implemented something called CashAgg, which
> does
> everything HashAgg does but implemented from scratch. Users would be
> able to
> tune it or disable it, and we could talk about removing HashAgg for
> the next 3
> years.
That's kind of what we'd have if we had the two escape-hatch GUCs.
Default gives new behavior, changing the GUCs would give the v12
behavior.
In principle, Stephen is right: the v12 behavior is a bug, lots of
people are unhappy about it, it causes real problems, and it would not
be acceptable if proposed today. Otherwise I wouldn't have spent the
time to fix it.
Similarly, potential regressions are not the "fault" of my feature --
they are the fault of the limitations of work_mem, the limitations of
the planner, the wrong expectations from customers, or just
happenstance.
But at a certain point, I have to weigh the potential anger of
customers hitting regressions versus the potential anger of hackers
seeing a couple extra GUCs. I have to say that I am more worried about
the former.
If there is some more serious consequence of adding a GUC that I missed
in this thread, please let me know. Otherwise, I intend to commit a new
GUC shortly that will enable users to bypass work_mem for HashAgg, just
as in v12.
Regards,
Jeff Davis
Greetings, * Peter Geoghegan (pg@bowt.ie) wrote: > On Thu, Jul 9, 2020 at 5:08 PM Stephen Frost <sfrost@snowman.net> wrote: > > I didn't, and don't, think it particularly relevant to the discussion, > > but if you don't like the comparison to Sort then we could compare it to > > a HashJoin instead- the point is that, yes, if you are willing to give > > more memory to a given operation, it's going to go faster, and the way > > users tell us that they'd like the query to use more memory is already > > well-defined and understood to be through work_mem. We do not do them a > > service by ignoring that. > > The hash_mem design (as it stands) would affect both hash join and > hash aggregate. I believe that it makes most sense to have hash-based > nodes under the control of a single GUC. I believe that this > granularity will cause the least problems. It certainly represents a > trade-off. So, now this has moved from being a hack to deal with a possible regression for a small number of users due to new behavior in one node, to a change that has impacts on other nodes that hadn't been changed, all happening during beta. No, I don't agree with this. Now is not the time for designing new features for v13. > work_mem is less of a problem with hash join, primarily because join > estimates are usually a lot better than grouping estimates. But it is > nevertheless something that it makes sense to put in the same > conceptual bucket as hash aggregate, pending a future root and branch > redesign of work_mem. I'm still not thrilled with the 'hash_mem' kind of idea as it's going in the wrong direction because what's actually needed is a way to properly consider and track overall memory usage- a redesign of work_mem (or some new parameter, but it wouldn't be 'hash_mem') as you say, but all of this discussion should be targeting v14. > Like I said, the escape hatch GUC is not my preferred solution. But at > least it acknowledges the problem. I don't think that anyone (or > anyone else) believes that work_mem doesn't have serious limitations. work_mem obviously has serious limitations, but that's not novel or new or unexpected by anyone. > > We have a parameter which already drives this and which users are > > welcome to (and quite often do) tune. I disagree that anything further > > is either essential or particularly desirable. > > This is a user hostile attitude. I don't find that argument convincing, at all. > > I'm really rather astounded at the direction this has been going in. > > Why? Due to the fact that we're in beta and now is not the time to be redesigning this feature. What Jeff implemented was done in a way that follows the existing structure for how all of the other nodes work and how HashAgg was *intended* to work (as in- if we thought the HashAgg would go over work_mem, we wouldn't pick it and would do a GroupAgg instead). If there's bugs in his implementation (which I doubt, but it can happen, of course) then that'd be useful to discuss and look at fixing, but this discussion isn't appropriate for beta. Thanks, Stephen
Вложения
On Fri, Jul 10, 2020 at 7:17 AM Stephen Frost <sfrost@snowman.net> wrote: > > The hash_mem design (as it stands) would affect both hash join and > > hash aggregate. I believe that it makes most sense to have hash-based > > nodes under the control of a single GUC. I believe that this > > granularity will cause the least problems. It certainly represents a > > trade-off. > > So, now this has moved from being a hack to deal with a possible > regression for a small number of users due to new behavior in one node, > to a change that has impacts on other nodes that hadn't been changed, > all happening during beta. The common goal is ameliorating or avoiding predictable negative consequences for our users. One proposal is an ambitious and comprehensive way of dealing with that, that certainly has unique risks. The other is much less ambitious, and clearly a kludge -- but it's also much less risky. The discussion hasn't really moved at all. > I'm still not thrilled with the 'hash_mem' kind of idea as it's going in > the wrong direction because what's actually needed is a way to properly > consider and track overall memory usage- a redesign of work_mem (or some > new parameter, but it wouldn't be 'hash_mem') as you say, but all of > this discussion should be targeting v14. It's certainly possible that hash_mem is too radical, and yet not radical enough -- in any timeframe (i.e. a total redesign of work_mem is the only thing that will be acceptable). I don't understand why you refuse to engage with the idea at all, though. The mere fact that hash_mem could in theory fix this problem comprehensively *usefully frames the problem*. This is the kind of issue where developing a shared understanding is very important. Andres said to me privately that hash_mem could be a good idea, even though he opposes it as a fix to the open item for Postgres 13. I understand that proposing such a thing during beta is controversial, whatever the specifics are. It is a proposal made in the spirit of trying to move things forward. Hand wringing about ignoring the community's process is completely counterproductive. There are about 3 general approaches to addressing this problem, and hash_mem is one of them. Am I not allowed to point that out? I have been completely open and honest about the risks. > > Like I said, the escape hatch GUC is not my preferred solution. But at > > least it acknowledges the problem. I don't think that anyone (or > > anyone else) believes that work_mem doesn't have serious limitations. > > work_mem obviously has serious limitations, but that's not novel or new > or unexpected by anyone. In your other email from this morning, you wrote: "And those workloads would be addressed by increasing work_mem, no? Why are we inventing something new here for something that'll only impact a small fraction of users in a small fraction of cases and where there's already a perfectly workable way to address the issue?" Which one is it? > > > I'm really rather astounded at the direction this has been going in. > > > > Why? > > Due to the fact that we're in beta and now is not the time to be > redesigning this feature. Did you read the discussion? -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes:
> On Fri, Jul 10, 2020 at 7:17 AM Stephen Frost <sfrost@snowman.net> wrote:
>> Due to the fact that we're in beta and now is not the time to be
>> redesigning this feature.
> Did you read the discussion?
Beta is when we fix problems that testing exposes in new features.
Obviously, we'd rather not design new APIs at this point, but if it's
the only reasonable way to resolve a problem, that's what we've got
to do. I don't think anyone is advocating for reverting the hashagg
spill feature, and "do nothing" is not an attractive option either.
On the other hand, it's surely too late to engage in any massive
redesigns such as some of this thread has speculated about.
I looked over Peter's patch in [1], and it seems generally pretty
sane to me, though I concur with the idea that it'd be better to
define the GUC as a multiplier for work_mem. (For one thing, we could
then easily limit it to be at least 1.0, ensuring sanity; also, if
work_mem does eventually become more dynamic than it is now, we might
still be able to salvage this knob as something useful. Or if not,
we just rip it out.) So my vote is for moving in that direction.
regards, tom lane
[1] https://www.postgresql.org/message-id/CAH2-WzmD%2Bi1pG6rc1%2BCjc4V6EaFJ_qSuKCCHVnH%3DoruqD-zqow%40mail.gmail.com
On Fri, 2020-07-10 at 13:46 -0400, Tom Lane wrote:
> I looked over Peter's patch in [1], and it seems generally pretty
> sane to me, though I concur with the idea that it'd be better to
> define the GUC as a multiplier for work_mem. (For one thing, we
> could
> then easily limit it to be at least 1.0, ensuring sanity; also, if
> work_mem does eventually become more dynamic than it is now, we might
> still be able to salvage this knob as something useful. Or if not,
> we just rip it out.) So my vote is for moving in that direction.
In that case, I will hold off on my "escape-hatch" GUC.
Regards,
Jeff Davis
On Fri, Jul 10, 2020 at 10:47 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I looked over Peter's patch in [1], and it seems generally pretty > sane to me, though I concur with the idea that it'd be better to > define the GUC as a multiplier for work_mem. (For one thing, we could > then easily limit it to be at least 1.0, ensuring sanity; also, if > work_mem does eventually become more dynamic than it is now, we might > still be able to salvage this knob as something useful. Or if not, > we just rip it out.) So my vote is for moving in that direction. Cool. I agree that it makes sense to constrain the effective value to be at least work_mem in all cases. With that in mind, I propose that this new GUC have the following characteristics: * It should be named "hash_mem_multiplier", a floating point GUC (somewhat like bgwriter_lru_multiplier). * The default value is 2.0. * The minimum allowable value is 1.0, to protect users from accidentally giving less memory to hash-based nodes. * The maximum allowable value is 100.0, to protect users from accidentally setting hash_mem_multiplier to a value intended to work like a work_mem-style KB value (you can't provide an absolute value like that directly). This maximum is absurdly high. I think that it's possible that a small number of users will find it useful to set the value of hash_mem_multiplier as high as 5.0. That is a very aggressive value, but one that could still make sense with certain workloads. Thoughts? -- Peter Geoghegan
On 2020-Jul-10, Peter Geoghegan wrote: > * The maximum allowable value is 100.0, to protect users from > accidentally setting hash_mem_multiplier to a value intended to work > like a work_mem-style KB value (you can't provide an absolute value > like that directly). This maximum is absurdly high. > > I think that it's possible that a small number of users will find it > useful to set the value of hash_mem_multiplier as high as 5.0. That is > a very aggressive value, but one that could still make sense with > certain workloads. I'm not sure about this bit; sounds a bit like what has been qualified as "nannyism" elsewhere. Suppose I want to give a hash table 2GB of memory for whatever reason. If my work_mem is default (4MB) then I cannot possibly achieve that without altering both settings. So I propose that maybe we do want a maximum value, but if so it should be higher than what you propose. I think 10000 is acceptable in that it doesn't get in the way. Another point is that if you specify a unit for the multiplier (which is what users are likely to do for larger values), it'll fail anyway, so I'm not sure this is such terrible a problem. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 10, 2020 at 11:34 AM Jeff Davis <pgsql@j-davis.com> wrote: > On Fri, 2020-07-10 at 13:46 -0400, Tom Lane wrote: > > I looked over Peter's patch in [1], and it seems generally pretty > > sane to me, though I concur with the idea that it'd be better to > > define the GUC as a multiplier for work_mem. (For one thing, we > > could > > then easily limit it to be at least 1.0, ensuring sanity; also, if > > work_mem does eventually become more dynamic than it is now, we might > > still be able to salvage this knob as something useful. Or if not, > > we just rip it out.) So my vote is for moving in that direction. > > In that case, I will hold off on my "escape-hatch" GUC. It now seems likely that the hash_mem/hash_mem_multiplier proposal has the support it needs to get into Postgres 13. Assuming that the proposal doesn't lose momentum, then it's about time to return to the original question you posed at the start of the thread: What should we do with the hashagg_avoid_disk_plan GUC (formerly known as the enable_hashagg_disk GUC), if anything? I myself think that there is a case to be made for removing it entirely. But if we keep it then we should also not change the default. In other words, by default the planner should *not* try to avoid hash aggs that spill. AFAICT there is no particular reason to be concerned about that now, since nobody has expressed any concerns about any of the possibly-relevant cost models. That said, I don't feel strongly about this hashagg_avoid_disk_plan question. It seems *much* less important. -- Peter Geoghegan
On Fri, Jul 10, 2020 at 2:10 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > I'm not sure about this bit; sounds a bit like what has been qualified > as "nannyism" elsewhere. Suppose I want to give a hash table 2GB of > memory for whatever reason. If my work_mem is default (4MB) then I > cannot possibly achieve that without altering both settings. > > So I propose that maybe we do want a maximum value, but if so it should > be higher than what you propose. I think 10000 is acceptable in that it > doesn't get in the way. That's a good point. I amend my proposal: the maximum allowable value of hash_mem_multiplier should be 10000.0 (i.e., ten thousand times whatever work_mem is set to, which is subject to the existing work_mem sizing restrictions). -- Peter Geoghegan
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> On 2020-Jul-10, Peter Geoghegan wrote:
>> * The maximum allowable value is 100.0, to protect users from
>> accidentally setting hash_mem_multiplier to a value intended to work
>> like a work_mem-style KB value (you can't provide an absolute value
>> like that directly). This maximum is absurdly high.
> I'm not sure about this bit; sounds a bit like what has been qualified
> as "nannyism" elsewhere. Suppose I want to give a hash table 2GB of
> memory for whatever reason. If my work_mem is default (4MB) then I
> cannot possibly achieve that without altering both settings.
> So I propose that maybe we do want a maximum value, but if so it should
> be higher than what you propose. I think 10000 is acceptable in that it
> doesn't get in the way.
I was kind of thinking 1000 as the limit ;-). In any case, the code
will need to internally clamp the product to not exceed whatever the
work_mem physical limit is these days.
regards, tom lane
Peter Geoghegan <pg@bowt.ie> writes:
> It now seems likely that the hash_mem/hash_mem_multiplier proposal has
> the support it needs to get into Postgres 13. Assuming that the
> proposal doesn't lose momentum, then it's about time to return to the
> original question you posed at the start of the thread:
> What should we do with the hashagg_avoid_disk_plan GUC (formerly known
> as the enable_hashagg_disk GUC), if anything?
> I myself think that there is a case to be made for removing it
> entirely.
+0.5 or so for removing it. It seems too confusing and dubiously
useful.
regards, tom lane
Greetings, * Peter Geoghegan (pg@bowt.ie) wrote: > On Fri, Jul 10, 2020 at 7:17 AM Stephen Frost <sfrost@snowman.net> wrote: > > > The hash_mem design (as it stands) would affect both hash join and > > > hash aggregate. I believe that it makes most sense to have hash-based > > > nodes under the control of a single GUC. I believe that this > > > granularity will cause the least problems. It certainly represents a > > > trade-off. > > > > So, now this has moved from being a hack to deal with a possible > > regression for a small number of users due to new behavior in one node, > > to a change that has impacts on other nodes that hadn't been changed, > > all happening during beta. > > The common goal is ameliorating or avoiding predictable negative > consequences for our users. One proposal is an ambitious and > comprehensive way of dealing with that, that certainly has unique > risks. The other is much less ambitious, and clearly a kludge -- but > it's also much less risky. The discussion hasn't really moved at all. Neither seem to be going in a direction which looks appropriate for a beta-time change, particuarly given that none of this is *actually* new territory. Having to increase work_mem to get a HashAgg or HashJoin that hasn't got a bunch of batches is routine and while it'd be nicer if PG had a way to, overall, manage memory usage to stay within some particular value, we don't. When we start going in that direction it'll be interesting to discuss how much we should favor trying to do an in-memory HashAgg by reducing the amount of memory allocated to a Sort node. > > I'm still not thrilled with the 'hash_mem' kind of idea as it's going in > > the wrong direction because what's actually needed is a way to properly > > consider and track overall memory usage- a redesign of work_mem (or some > > new parameter, but it wouldn't be 'hash_mem') as you say, but all of > > this discussion should be targeting v14. > > It's certainly possible that hash_mem is too radical, and yet not > radical enough -- in any timeframe (i.e. a total redesign of work_mem > is the only thing that will be acceptable). I don't understand why you > refuse to engage with the idea at all, though. The mere fact that > hash_mem could in theory fix this problem comprehensively *usefully > frames the problem*. This is the kind of issue where developing a > shared understanding is very important. I don't see hash_mem as being any kind of proper fix- it's just punting to the user saying "we can't figure this out, how about you do it" and, worse, it's in conflict with how we already ask the user that question. Turning it into a multiplier doesn't change that either. > Andres said to me privately that hash_mem could be a good idea, even > though he opposes it as a fix to the open item for Postgres 13. I > understand that proposing such a thing during beta is controversial, > whatever the specifics are. It is a proposal made in the spirit of > trying to move things forward. Hand wringing about ignoring the > community's process is completely counterproductive. I disagree that caring about the fact that we're in beta is counterproductive. Saying that we should ignore that we're in beta isn't appropriate and I could say that's counterproductive- though that hardly seems to be helpful, so I wonder why that comment was chosen. > There are about 3 general approaches to addressing this problem, and > hash_mem is one of them. Am I not allowed to point that out? I have > been completely open and honest about the risks. I don't think I said at any point that you weren't allowed to suggest something. I do think, and continue to feel, that not enough consideration is being given to the fact that we're well past the point where this kind of development should be happening- and commenting on how leveling that concern at your proposed solution is mere 'hand wringing' certainly doesn't reduce my feeling that we're being far too cavalier with this. > > > Like I said, the escape hatch GUC is not my preferred solution. But at > > > least it acknowledges the problem. I don't think that anyone (or > > > anyone else) believes that work_mem doesn't have serious limitations. > > > > work_mem obviously has serious limitations, but that's not novel or new > > or unexpected by anyone. > > In your other email from this morning, you wrote: > > "And those workloads would be addressed by increasing work_mem, no? > Why are we inventing something new here for something that'll only > impact a small fraction of users in a small fraction of cases and > where there's already a perfectly workable way to address the issue?" > > Which one is it? Uh, it's clearly both. Those two statements are not contractictory at all- I agree that work_mem isn't good, and it has limitations, but this isn't one of those- people can increase work_mem and get the same HashAgg they got before and have it use all that memory just as it did before if they want to. > > > > I'm really rather astounded at the direction this has been going in. > > > > > > Why? > > > > Due to the fact that we're in beta and now is not the time to be > > redesigning this feature. > > Did you read the discussion? This is not productive to the discussion. I'd ask that you stop. Nothing of what you've said thus far has shown me that there were material bits of the discussion that I've missed. No, that other people feel differently or have made comments supporting one thing or another isn't what I would consider material- I'm as allowed my opinions as much as others, even when I disagree with the majority (or so claimed anyhow- I've not gone back to count, but I don't claim it to be otherwise either). Thanks, Stephen
Вложения
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Peter Geoghegan <pg@bowt.ie> writes: > > It now seems likely that the hash_mem/hash_mem_multiplier proposal has > > the support it needs to get into Postgres 13. Assuming that the > > proposal doesn't lose momentum, then it's about time to return to the > > original question you posed at the start of the thread: > > > What should we do with the hashagg_avoid_disk_plan GUC (formerly known > > as the enable_hashagg_disk GUC), if anything? > > > I myself think that there is a case to be made for removing it > > entirely. > > +0.5 or so for removing it. It seems too confusing and dubiously > useful. I agree that it shouldn't exist. Thanks, Stephen
Вложения
Stephen Frost <sfrost@snowman.net> writes:
> I don't see hash_mem as being any kind of proper fix- it's just punting
> to the user saying "we can't figure this out, how about you do it" and,
> worse, it's in conflict with how we already ask the user that question.
> Turning it into a multiplier doesn't change that either.
Have you got a better proposal that is reasonably implementable for v13?
(I do not accept the argument that "do nothing" is a better proposal.)
I agree that hash_mem is a stopgap, whether it's a multiplier or no,
but at this point it seems difficult to avoid inventing a stopgap.
Getting rid of the process-global work_mem setting is a research project,
and one I wouldn't even count on having results from for v14. In the
meantime, it seems dead certain that there are applications for which
the current behavior will be problematic. hash_mem seems like a cleaner
and more useful stopgap than the "escape hatch" approach, at least to me.
regards, tom lane
On Fri, Jul 10, 2020 at 2:50 PM Stephen Frost <sfrost@snowman.net> wrote: > Nothing of what you've said thus far has shown me that there were > material bits of the discussion that I've missed. Maybe that's just because you missed those bits too? > No, that other people > feel differently or have made comments supporting one thing or another > isn't what I would consider material- I'm as allowed my opinions as much > as others, even when I disagree with the majority (or so claimed anyhow- > I've not gone back to count, but I don't claim it to be otherwise > either). You are of course entitled to your opinion. The problem we're trying to address here is paradoxical, in a certain sense. The HashAggs-that-spill patch is somehow not at fault on the one hand, but on the other hand has created this urgent need to ameliorate what is for all intents and purposes a regression. Everything is intertwined. Yes -- this *is* weird! And, I admit that the hash_mem proposal is unorthodox, even ugly -- in fact, I've said words to that effect on perhaps a dozen occasions at this point. This is also weird. I pointed out that my hash_mem proposal was popular because it seemed like it might save time. When I see somebody I know proposing something strange, my first thought is "why are they proposing that?". I might only realize some time later that there are special circumstances that make the proposal much more reasonable than it seemed at first (maybe even completely reasonable). There is no inherent reason why other people supporting the proposal makes it more valid, but in general it does suggest that special circumstances might apply. It guides me in the direction of looking for and understanding what they might be sooner. -- Peter Geoghegan
On Sat, 11 Jul 2020 at 10:00, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Stephen Frost <sfrost@snowman.net> writes: > > I don't see hash_mem as being any kind of proper fix- it's just punting > > to the user saying "we can't figure this out, how about you do it" and, > > worse, it's in conflict with how we already ask the user that question. > > Turning it into a multiplier doesn't change that either. > > Have you got a better proposal that is reasonably implementable for v13? > (I do not accept the argument that "do nothing" is a better proposal.) > > I agree that hash_mem is a stopgap, whether it's a multiplier or no, > but at this point it seems difficult to avoid inventing a stopgap. > Getting rid of the process-global work_mem setting is a research project, > and one I wouldn't even count on having results from for v14. In the > meantime, it seems dead certain that there are applications for which > the current behavior will be problematic. hash_mem seems like a cleaner > and more useful stopgap than the "escape hatch" approach, at least to me. If we're going to end up going down the route of something like hash_mem for PG13, wouldn't it be better to have something more like hashagg_mem that only adjusts the memory limits for Hash Agg only? Stephen mentions in [1] that: > Users who are actually hit by this in a negative way > have an option- increase work_mem to reflect what was actually happening > already. Peter is not a fan of that idea, which can only be due to the fact that will also increase the maximum memory consumption allowed by other nodes in the plan too. My concern is that if we do hash_mem and have that control the memory allowances for Hash Joins and Hash Aggs, then that solution is just as good as Stephen's idea when the plan only contains Hash Joins and Hash Aggs. As much as I do want to see us get something to allow users some reasonable way to get the same performance as they're used to, I'm concerned that giving users something that works for many of the use cases is not really going to be as good as giving them something that works in all their use cases. A user who has a partitioned table with a good number of partitions and partition-wise joins enabled might not like it if their Hash Join plan suddenly consumes hash_mem * nPartitions when they've set hash_mem to 10x of work_mem due to some other plan that requires that to maintain PG12's performance in PG13. If that user is unable to adjust hash_mem due to that then they're not going to be very satisfied that we've added hash_mem to allow their query to perform as well as it did in PG12. They'll be at the same OOM risk that they were exposed to in PG12 if they were to increase hash_mem here. David [1] https://www.postgresql.org/message-id/20200710143415.GJ12375@tamriel.snowman.net
On Fri, Jul 10, 2020 at 5:16 PM David Rowley <dgrowleyml@gmail.com> wrote:
Stephen mentions in [1] that:
> Users who are actually hit by this in a negative way
> have an option- increase work_mem to reflect what was actually happening
> already.
Peter is not a fan of that idea, which can only be due to the fact
that will also increase the maximum memory consumption allowed by
other nodes in the plan too.
That isn't the only reason for me - the main advantage of hash_mem is that we get to set a default to some multiple greater than 1.0 so that an upgrade to v13 has a region where behavior similar to v12 is effectively maintained. I have no feel for whether that should be 2.0, 4.0, or something else, but 2.0 seemed small and I chose to use a power of 2.
My concern is that if we do hash_mem and
have that control the memory allowances for Hash Joins and Hash Aggs,
then that solution is just as good as Stephen's idea when the plan
only contains Hash Joins and Hash Aggs.
As much as I do want to see us get something to allow users some
reasonable way to get the same performance as they're used to, I'm
concerned that giving users something that works for many of the use
cases is not really going to be as good as giving them something that
works in all their use cases. A user who has a partitioned table
with a good number of partitions and partition-wise joins enabled
might not like it if their Hash Join plan suddenly consumes hash_mem *
nPartitions when they've set hash_mem to 10x of work_mem due to some
other plan that requires that to maintain PG12's performance in PG13.
I don't know enough about the hash join dynamic to comment there but if an admin goes in and changes the system default to 10x in lieu of a targeted fix for a query that actually needs work_mem to be increased to 10 times its current value to work properly I'd say that would be a poor decision. Absent hash_mem they wouldn't update work_mem on their system to 10x its current value in order to upgrade to v13, they'd set work_mem for that query specifically. The same should happen here.
Frankly, if admins are on top of their game and measuring and monitoring query performance and memory consumption they would be able to operate in our "do nothing" mode by setting the default for hash_mem to 1.0 and just dole out memory via work_mem as they have always done. Though setting hash_mem to 10x for that single query would reduce their risk of OOM (none of the work_mem consulting nodes would be increased) so having the GUC would be a net win should they avail themselves of it.
The multiplier seems strictly better than "rely on work_mem alone, i.e., do nothing"; the detracting factor being one more GUC. Even if one wants to argue the solution is ugly or imperfect the current state seems worse and a more perfect option doesn't seem worth waiting for. The multiplier won't make every single upgrade a non-event but it provides a more than sufficient amount of control and in the worse case can be effectively ignored by setting it to 1.0.
Is there some reason to think that having this multiplier with a conservative default of 2.0 would cause an actual problem - and would that scenario have likely caused an OOM anyway in v12? Given that "work_mem can be used many many times in a single query" I'm having trouble imagining such a problem.
David J.
On Sat, 11 Jul 2020 at 12:47, David G. Johnston <david.g.johnston@gmail.com> wrote: > The multiplier seems strictly better than "rely on work_mem alone, i.e., do nothing"; the detracting factor being one moreGUC. Even if one wants to argue the solution is ugly or imperfect the current state seems worse and a more perfect optiondoesn't seem worth waiting for. The multiplier won't make every single upgrade a non-event but it provides a morethan sufficient amount of control and in the worse case can be effectively ignored by setting it to 1.0. My argument wasn't related to if the new GUC should be a multiplier of work_mem or an absolute amount of memory. The point I was trying to make was that the solution to add a GUC to allow users to increase the memory Hash Join and Hash Agg for plans which don't contain any other nodes types that use work_mem is the same as doing nothing. As of today, those people could just increase work_mem. If we get hash_mem or some variant that is a multiplier of work_mem, then that user is in exactly the same situation for that plan. i.e there's no ability to increase the memory allowances for Hash Agg alone. If we have to have a new GUC, my preference would be hashagg_mem, where -1 means use work_mem and a value between 64 and MAX_KILOBYTES would mean use that value. We'd need some sort of check hook to disallow 0-63. I really am just failing to comprehend why we're contemplating changing the behaviour of Hash Join here. Of course, I understand that that node type also uses a hash table, but why does that give it the right to be involved in a change that we're making to try and give users the ability to avoid possible regressions with Hash Agg? David
On Fri, Jul 10, 2020 at 6:19 PM David Rowley <dgrowleyml@gmail.com> wrote:
If we have to have a new GUC, my preference would be hashagg_mem,
where -1 means use work_mem and a value between 64 and MAX_KILOBYTES
would mean use that value. We'd need some sort of check hook to
disallow 0-63. I really am just failing to comprehend why we're
contemplating changing the behaviour of Hash Join here.
If we add a setting that defaults to work_mem then the benefit is severely reduced. You still have to modify individual queries, but the change can simply be more targeted than changing work_mem alone. I truly desire to have whatever we do provide that ability as well as a default value that is greater than the current work_mem value - which in v12 was being ignored and thus production usages saw memory consumption greater than work_mem. Only a multiplier does this. A multiplier-only solution fixes the problem at hand. A multiplier-or-memory solution adds complexity but provides flexibility. If adding that flexibility is straight-forward I don't see any serious downside other than the complexity of having the meaning of a single GUC's value dependent upon its magnitude.
Of course, I
understand that that node type also uses a hash table, but why does
that give it the right to be involved in a change that we're making to
try and give users the ability to avoid possible regressions with Hash
Agg?
If Hash Join isn't affected by the "was allowed to use unlimited amounts of execution memory but now isn't" change then it probably should continue to consult work_mem instead of being changed to use the calculated value (work_mem x multiplier).
David J.
On Sat, 11 Jul 2020 at 13:36, David G. Johnston <david.g.johnston@gmail.com> wrote: > If we add a setting that defaults to work_mem then the benefit is severely reduced. You still have to modify individualqueries, but the change can simply be more targeted than changing work_mem alone. I think the idea is that this is an escape hatch to allow users to get something closer to what PG12 did, but only if they really need it. I can't quite understand why we need to leave the escape hatch open and push them halfway through it. I find escape hatches are best left closed until you really have no choice but to use them. David
On Fri, Jul 10, 2020 at 6:43 PM David Rowley <dgrowleyml@gmail.com> wrote:
On Sat, 11 Jul 2020 at 13:36, David G. Johnston
<david.g.johnston@gmail.com> wrote:
> If we add a setting that defaults to work_mem then the benefit is severely reduced. You still have to modify individual queries, but the change can simply be more targeted than changing work_mem alone.
I think the idea is that this is an escape hatch to allow users to get
something closer to what PG12 did, but only if they really need it. I
can't quite understand why we need to leave the escape hatch open and
push them halfway through it. I find escape hatches are best left
closed until you really have no choice but to use them.
The escape hatch dynamic is "the user senses a problem, goes into their query, and modifies some GUCs to make the problem go away". As a user I'd much rather have the odds of my needing to use that escape hatch reduced - especially if that reduction can be done without risk and without any action on my part.
It's like having someone in a box right now, and then turning up the heat. We can give them an opening to get out of the box if they need it but we can also give them A/C. For some the A/C may be unnecessary, but also not harmful, while a smaller group will stay in the margin, while for the others it's not enough and use the opening (which they would have done anyway without the A/C).
David J.
On Fri, Jul 10, 2020 at 6:19 PM David Rowley <dgrowleyml@gmail.com> wrote: > If we get hash_mem > or some variant that is a multiplier of work_mem, then that user is in > exactly the same situation for that plan. i.e there's no ability to > increase the memory allowances for Hash Agg alone. That's true, of course. > If we have to have a new GUC, my preference would be hashagg_mem, > where -1 means use work_mem and a value between 64 and MAX_KILOBYTES > would mean use that value. We'd need some sort of check hook to > disallow 0-63. I really am just failing to comprehend why we're > contemplating changing the behaviour of Hash Join here. I don't understand why parititonwise hash join consumes work_mem in the way it does. I assume that the reason is something like "because that behavior was the easiest to explain", or perhaps "people that use partitioning ought to be able to tune their database well". Or even "this design avoids an epic pgsql-hackers thread, because of course every hash table should get its own work_mem". > Of course, I > understand that that node type also uses a hash table, but why does > that give it the right to be involved in a change that we're making to > try and give users the ability to avoid possible regressions with Hash > Agg? It doesn't, exactly. The idea of hash_mem came from similar settings in another database system that you'll have heard of, that affect all nodes that use a hash table. I read about this long ago, and thought that it might make sense to do something similar as a way to improving work_mem (without replacing it with something completely different to enable things like the "hash teams" design, which should be the long term goal). It's unusual that it took this hashaggs-that-spill issue to make the work_mem situation come to a head, and it's unusual that the proposal on the table doesn't just target hash agg. But it's not *that* unusual. I believe that it makes sense on balance to lump together hash aggregate and hash join, with the expectation that the user might want to tune them for the system as a whole. This is not an escape hatch -- it's something that adds granularity to how work_mem can be tuned in a way that makes sense (but doesn't make perfect sense). It doesn't reflect reality, but I think that it comes closer to reflecting reality than other variations that I can think of, including your hashagg_mem compromise proposal (which is still much better than plain work_mem). In short, hash_mem is relatively conceptually clean, and doesn't unduly burden the user. I understand that you only want to add an escape hatch, which is what hashagg_mem still amounts to. There are negative consequences to the setting affecting hash join, which I am not unconcerned about. On the other hand, hashagg_mem is an escape hatch, and that's ugly in a way that hash_mem isn't. I'm also concerned about that. In the end, I think that the "hash_mem vs. hashagg_mem" question is fundamentally a matter of opinion. -- Peter Geoghegan
On Sat, 11 Jul 2020 at 14:02, Peter Geoghegan <pg@bowt.ie> wrote: > > On Fri, Jul 10, 2020 at 6:19 PM David Rowley <dgrowleyml@gmail.com> wrote: > > If we have to have a new GUC, my preference would be hashagg_mem, > > where -1 means use work_mem and a value between 64 and MAX_KILOBYTES > > would mean use that value. We'd need some sort of check hook to > > disallow 0-63. I really am just failing to comprehend why we're > > contemplating changing the behaviour of Hash Join here. > > I don't understand why parititonwise hash join consumes work_mem in > the way it does. I assume that the reason is something like "because > that behavior was the easiest to explain", or perhaps "people that use > partitioning ought to be able to tune their database well". Or even > "this design avoids an epic pgsql-hackers thread, because of course > every hash table should get its own work_mem". hmm yeah. It's unfortunate, but I'm not sure how I'd have implemented it differently. The problem is made worse by the fact that we'll only release the memory for the hash table during ExecEndHashJoin(). If the planner had some ability to provide the executor with knowledge that the node would never be rescanned, then the executor could release the memory for the hash table after the join is complete. For now, we'll need to live with the fact that an Append containing many children doing hash joins will mean holding onto all that memory until the executor is shutdown :-( There's room to make improvements there, for sure, but not for PG13. > > Of course, I > > understand that that node type also uses a hash table, but why does > > that give it the right to be involved in a change that we're making to > > try and give users the ability to avoid possible regressions with Hash > > Agg? > > It doesn't, exactly. The idea of hash_mem came from similar settings > in another database system that you'll have heard of, that affect all > nodes that use a hash table. I read about this long ago, and thought > that it might make sense to do something similar as a way to improving > work_mem It sounds interesting, but it also sounds like a new feature post-beta. Perhaps it's better we minimise the scope of the change to be a minimal fix just for the behaviour we predict some users might not like. David
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > I don't see hash_mem as being any kind of proper fix- it's just punting > > to the user saying "we can't figure this out, how about you do it" and, > > worse, it's in conflict with how we already ask the user that question. > > Turning it into a multiplier doesn't change that either. > > Have you got a better proposal that is reasonably implementable for v13? > (I do not accept the argument that "do nothing" is a better proposal.) > > I agree that hash_mem is a stopgap, whether it's a multiplier or no, > but at this point it seems difficult to avoid inventing a stopgap. > Getting rid of the process-global work_mem setting is a research project, > and one I wouldn't even count on having results from for v14. In the > meantime, it seems dead certain that there are applications for which > the current behavior will be problematic. hash_mem seems like a cleaner > and more useful stopgap than the "escape hatch" approach, at least to me. Have we heard from people running actual applications where there is a problem with raising work_mem to simply match what's already happening with the v12 behavior? Sure, there's been some examples on this thread of people who know the backend well showing how the default work_mem will cause the v13 HashAgg to spill to disk when given a query which has poor estimates, and that's slower than v12 where it ignored work_mem and used a bunch of memory, but it was also shown that raising work_mem addresses that issue and brings v12 and v13 back in line. There was a concern raised that other nodes might then use more memory- but there's nothing new there, if you wanted to avoid batching with a HashJoin in v12 you'd have exactly the same issue, and yet folks raise work_mem all the time to address this, and to get that HashAgg plan in the first place too when the estimates aren't so far off. There now seems to be some suggestions that not only should we have a new GUC, but we should default to having it not be equal to work_mem (or 1.0 or whatever) and instead by higher, to be *twice* or larger whatever the existing work_mem setting is- meaning that people whose systems are working just fine and have good estimates that represent their workload and who get the plans they want may then start seeing differences and increased memory utilization in places that they *don't* want that, all because we're scared that someone, somewhere, might see a regression due to HashAgg spilling to disk. So, no, I don't agree that 'do nothing' (except ripping out the one GUC that was already added) is a worse proposal than adding another work_mem like thing that's only for some nodes types. There's no way that we'd even be considering such an approach during the regular development cycle either- there would be calls for a proper wholistic view, at least to the point where every node type that could possibly allocate a reasonable chunk of memory would be covered. Thanks, Stephen
Вложения
David Rowley <dgrowleyml@gmail.com> writes:
> hmm yeah. It's unfortunate, but I'm not sure how I'd have implemented
> it differently. The problem is made worse by the fact that we'll only
> release the memory for the hash table during ExecEndHashJoin(). If the
> planner had some ability to provide the executor with knowledge that
> the node would never be rescanned, then the executor could release the
> memory for the hash table after the join is complete.
EXEC_FLAG_REWIND seems to fit the bill already?
regards, tom lane
On Sat, Jul 11, 2020 at 7:22 AM Stephen Frost <sfrost@snowman.net> wrote:
There now seems to be some suggestions that not only should we have a
new GUC, but we should default to having it not be equal to work_mem (or
1.0 or whatever) and instead by higher, to be *twice* or larger whatever
the existing work_mem setting is- meaning that people whose systems are
working just fine and have good estimates that represent their workload
and who get the plans they want may then start seeing differences and
increased memory utilization in places that they *don't* want that, all
because we're scared that someone, somewhere, might see a regression due
to HashAgg spilling to disk.
If that increased memory footprint allows the planner to give me a better plan with faster execution and with no OOM I'd be very happy that this change happened. While having a more flexible memory allocation framework is not a primary goal in and of itself it is a nice side-effect. I'm not going to say "let's only set work_mem to 32MB instead of 48MB so I can avoid this faster HashAgg node and instead execute a nested loop (or whatever)". More probable is the user whose current nested loop plan is fast enough and doesn't even realize that with a bit more memory they could get an HashAgg that performs 15% faster. For them this is a win on its face.
I don't believe this negatively impacts the super-admin in our user-base and is a decent win for the average and below average admin.
Do we really have an issue with plans being chosen while having access to more memory being slower than plans chosen while having less memory?
The main risk here is that we choose for a user to consume more memory than they expected and they report OOM issues to us. We tell them to set this new GUC to 1.0. But that implies they are getting many non-HashAgg plans produced when with a bit more memory those HashAgg plans would have been chosen. If they get those faster plans without OOM it's a win, if it OOMs it's a loss. I'm feeling optimistic here and we'll get considerably more wins than losses. How loss-averse do we need to be here though? Npte we can give the upgrading user advance notice of our loss-aversion level and they can simply disagree and set it to 1.0 and/or perform more thorough testing. So being optimistic feels like the right choice.
David J.
On Sat, Jul 11, 2020 at 7:22 AM Stephen Frost <sfrost@snowman.net> wrote: > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > Have you got a better proposal that is reasonably implementable for v13? > > (I do not accept the argument that "do nothing" is a better proposal.) > So, no, I don't agree that 'do nothing' (except ripping out the one GUC > that was already added) is a worse proposal than adding another work_mem > like thing that's only for some nodes types. The question was "Have you got a better proposal that is reasonably implementable for v13?". This is anecdotal, but just today somebody on Twitter reported *increasing* work_mem to stop getting OOMs from group aggregate + sort: https://twitter.com/theDressler/status/1281942941133615104 It was possible to fix the problem in this instance, since evidently there wasn't anything else that really did try to consume ~5 GB of work_mem memory. Evidently the memory isn't available in any general sense, so there are no OOMs now. Nevertheless, we can expect OOMs on this server just as soon as there is a real need to do a ~5GB sort, regardless of anything else. I don't think that this kind of perverse effect is uncommon. Hash aggregate can naturally be far faster than group agg + sort, Hash agg can naturally use a lot less memory in many cases, and we have every reason to think that grouping estimates are regularly totally wrong. You're significantly underestimating the risk. -- Peter Geoghegan
On Sat, Jul 11, 2020 at 09:49:43AM -0700, Peter Geoghegan wrote: >On Sat, Jul 11, 2020 at 7:22 AM Stephen Frost <sfrost@snowman.net> wrote: >> * Tom Lane (tgl@sss.pgh.pa.us) wrote: >> > Have you got a better proposal that is reasonably implementable for v13? >> > (I do not accept the argument that "do nothing" is a better proposal.) > >> So, no, I don't agree that 'do nothing' (except ripping out the one GUC >> that was already added) is a worse proposal than adding another work_mem >> like thing that's only for some nodes types. > >The question was "Have you got a better proposal that is reasonably >implementable for v13?". > >This is anecdotal, but just today somebody on Twitter reported >*increasing* work_mem to stop getting OOMs from group aggregate + >sort: > >https://twitter.com/theDressler/status/1281942941133615104 > >It was possible to fix the problem in this instance, since evidently >there wasn't anything else that really did try to consume ~5 GB of >work_mem memory. Evidently the memory isn't available in any general >sense, so there are no OOMs now. Nevertheless, we can expect OOMs on >this server just as soon as there is a real need to do a ~5GB sort, >regardless of anything else. > I find that example rather suspicious. I mean, what exactly in the GroupAgg plan would consume this memory? Surely it'd have to be some node below the grouping, but sort shouldn't do that, no? Seems strange. >I don't think that this kind of perverse effect is uncommon. Hash >aggregate can naturally be far faster than group agg + sort, Hash agg >can naturally use a lot less memory in many cases, and we have every >reason to think that grouping estimates are regularly totally wrong. >You're significantly underestimating the risk. > I agree grouping estimates are often quite off, and I kinda agree with introducing hash_mem (or at least with the concept that hashing is more sensitive to amount of memory than sort). Not sure it's the right espace hatch to the hashagg spill problem, but maybe it is. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 10, 2020 at 10:00 PM David Rowley <dgrowleyml@gmail.com> wrote: > hmm yeah. It's unfortunate, but I'm not sure how I'd have implemented > it differently. The problem is made worse by the fact that we'll only > release the memory for the hash table during ExecEndHashJoin(). If the > planner had some ability to provide the executor with knowledge that > the node would never be rescanned, then the executor could release the > memory for the hash table after the join is complete. For now, we'll > need to live with the fact that an Append containing many children > doing hash joins will mean holding onto all that memory until the > executor is shutdown :-( > > There's room to make improvements there, for sure, but not for PG13. I think that we're stuck with the idea that partitionwise join uses up to one work_mem allocation per partition until we deprecate work_mem as a concept. Anyway, I only talked about partitionwise join because that was your example. I could just as easily have picked on parallel hash join instead, which is something that I was involved in myself (kind of). This is more or less a negative consequence of the incremental approach we have taken here, which is a collective failure. I have difficulty accepting that something like hash_mem_multiplier cannot be accepted because it risks making the consequence of questionable designs even worse. The problem remains that the original assumption just isn't very robust, and isn't something that the user has granular control over. In general it makes sense that a design in a stable branch is assumed to be the norm that new things need to respect, and not the other way around. But there must be some limit to how far that's taken. > It sounds interesting, but it also sounds like a new feature > post-beta. Perhaps it's better we minimise the scope of the change to > be a minimal fix just for the behaviour we predict some users might > not like. That's an understandable interpretation of the hash_mem/hash_mem_multiplier proposal on the table, and yet one that I disagree with. I consider it highly desirable to have a GUC that can be tuned in a generic and high level way, on general principle. We don't really do escape hatches, and I'd rather avoid adding one now (though it's far preferable to doing nothing, which I consider totally out of the question). Pursuing what you called hashagg_mem is a compromise that will make neither of us happy. It seems like an escape hatch by another name. I would rather just go with your original proposal instead, especially if that's the only thing that'll resolve the problem in front of us. -- Peter Geoghegan
On Sat, Jul 11, 2020 at 4:23 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I find that example rather suspicious. I mean, what exactly in the > GroupAgg plan would consume this memory? Surely it'd have to be some > node below the grouping, but sort shouldn't do that, no? > > Seems strange. Well, I imagine hash aggregate manages to use much less memory than the equivalent groupagg's sort, even though to the optimizer it appears as if hash agg should end up using more memory (which is not allowed by the optimizer when it exceeds work_mem, regardless of whether or not it's faster). It may also be relevant that Hash agg can use less memory simply by being faster. Going faster could easily reduce the memory usage for the system as a whole, even when you assume individual group agg nodes use more memory for as long as they run. So in-memory hash agg is effectively less memory hungry. It's not a great example of a specific case that we'd regress by not having hash_mem/hash_mem_multiplier. It's an overestimate where older releases accidentally got a bad, slow plan, not an underestimate where older releases "lived beyond their means but got away with it" by getting a good, fast plan. ISTM that the example is a good example of the strange dynamics involved. > I agree grouping estimates are often quite off, and I kinda agree with > introducing hash_mem (or at least with the concept that hashing is more > sensitive to amount of memory than sort). Not sure it's the right espace > hatch to the hashagg spill problem, but maybe it is. The hash_mem/hash_mem_multiplier proposal aims to fix the problem directly, and not be an escape hatch, because we don't like escape hatches. I think that that probably fixes many or most of the problems in practice, at least assuming that the admin is willing to tune it. But a small number of remaining installations may still need a "true" escape hatch. There is an argument for having both, though I hope that the escape hatch can be avoided. -- Peter Geoghegan
On Sat, Jul 11, 2020 at 09:02:43AM -0700, David G. Johnston wrote: >On Sat, Jul 11, 2020 at 7:22 AM Stephen Frost <sfrost@snowman.net> wrote: > >> There now seems to be some suggestions that not only should we have a >> new GUC, but we should default to having it not be equal to work_mem (or >> 1.0 or whatever) and instead by higher, to be *twice* or larger whatever >> the existing work_mem setting is- meaning that people whose systems are >> working just fine and have good estimates that represent their workload >> and who get the plans they want may then start seeing differences and >> increased memory utilization in places that they *don't* want that, all >> because we're scared that someone, somewhere, might see a regression due >> to HashAgg spilling to disk. >> > >If that increased memory footprint allows the planner to give me a better >plan with faster execution and with no OOM I'd be very happy that this >change happened. While having a more flexible memory allocation framework >is not a primary goal in and of itself it is a nice side-effect. I'm not >going to say "let's only set work_mem to 32MB instead of 48MB so I can >avoid this faster HashAgg node and instead execute a nested loop (or >whatever)". More probable is the user whose current nested loop plan is >fast enough and doesn't even realize that with a bit more memory they could >get an HashAgg that performs 15% faster. For them this is a win on its >face. > >I don't believe this negatively impacts the super-admin in our user-base >and is a decent win for the average and below average admin. > >Do we really have an issue with plans being chosen while having access to >more memory being slower than plans chosen while having less memory? > >The main risk here is that we choose for a user to consume more memory than >they expected and they report OOM issues to us. We tell them to set this >new GUC to 1.0. But that implies they are getting many non-HashAgg plans >produced when with a bit more memory those HashAgg plans would have been >chosen. If they get those faster plans without OOM it's a win, if it OOMs >it's a loss. I'm feeling optimistic here and we'll get considerably more >wins than losses. How loss-averse do we need to be here though? Npte we >can give the upgrading user advance notice of our loss-aversion level and >they can simply disagree and set it to 1.0 and/or perform more thorough >testing. So being optimistic feels like the right choice. > I don't know, but one of the main arguments against simply suggesting people to bump up work_mem (if they're hit by the hashagg spill in v13) was that it'd increase overall memory usage for them. It seems strange to then propose a new GUC set to a default that would result in higher memory usage *for everyone*. Of course, having such GUC with a default a multiple of work_mem might be a win overall - or maybe not. I don't have a very good idea how many people will get bitten by this, and how many will get speedup (and how significant the speedup would be). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> I don't know, but one of the main arguments against simply suggesting
> people to bump up work_mem (if they're hit by the hashagg spill in v13)
> was that it'd increase overall memory usage for them. It seems strange
> to then propose a new GUC set to a default that would result in higher
> memory usage *for everyone*.
It seems like a lot of the disagreement here is focused on Peter's
proposal to make hash_mem_multiplier default to 2.0. But it doesn't
seem to me that that's a critical element of the proposal. Why not just
make it default to 1.0, thus keeping the default behavior identical
to what it is now?
If we find that's a poor default, we can always change it later;
but it seems to me that the evidence for a higher default is
a bit thin at this point.
regards, tom lane
I would be okay with a default of 1.0.
Peter Geoghegan
(Sent from my phone)
(Sent from my phone)
On Sun, Jul 12, 2020 at 2:27 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > David Rowley <dgrowleyml@gmail.com> writes: > > hmm yeah. It's unfortunate, but I'm not sure how I'd have implemented > > it differently. The problem is made worse by the fact that we'll only > > release the memory for the hash table during ExecEndHashJoin(). If the > > planner had some ability to provide the executor with knowledge that > > the node would never be rescanned, then the executor could release the > > memory for the hash table after the join is complete. > > EXEC_FLAG_REWIND seems to fit the bill already? FWIW I have a patch that does exactly that, which I was planning to submit for CF2 along with some other patches that estimate and measure peak executor memory usage.
On Sat, Jul 11, 2020 at 5:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> I don't know, but one of the main arguments against simply suggesting
> people to bump up work_mem (if they're hit by the hashagg spill in v13)
> was that it'd increase overall memory usage for them. It seems strange
> to then propose a new GUC set to a default that would result in higher
> memory usage *for everyone*.
It seems like a lot of the disagreement here is focused on Peter's
proposal to make hash_mem_multiplier default to 2.0. But it doesn't
seem to me that that's a critical element of the proposal. Why not just
make it default to 1.0, thus keeping the default behavior identical
to what it is now?
If we don't default it to something other than 1.0 we might as well just make it memory units and let people decide precisely what they want to use instead of adding the complexity of a multiplier.
If we find that's a poor default, we can always change it later;
but it seems to me that the evidence for a higher default is
a bit thin at this point.
So "your default is 1.0 unless you installed the new database on or after 13.4 in which case it's 2.0"?
I'd rather have it be just memory units defaulting to -1 meaning "use work_mem". In the unlikely scenario we decide post-release to want a multiplier > 1.0 we can add the GUC with that default at that point. The multiplier would want to be ignored if hash_mem if set to anything other than -1.
David J.
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Sat, Jul 11, 2020 at 5:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> It seems like a lot of the disagreement here is focused on Peter's
>> proposal to make hash_mem_multiplier default to 2.0. But it doesn't
>> seem to me that that's a critical element of the proposal. Why not just
>> make it default to 1.0, thus keeping the default behavior identical
>> to what it is now?
> If we don't default it to something other than 1.0 we might as well just
> make it memory units and let people decide precisely what they want to use
> instead of adding the complexity of a multiplier.
Not sure how that follows? The advantage of a multiplier is that it
tracks whatever people might do to work_mem automatically. In general
I'd view work_mem as the base value that people twiddle to control
executor memory consumption. Having to also twiddle this other value
doesn't seem especially user-friendly.
>> If we find that's a poor default, we can always change it later;
>> but it seems to me that the evidence for a higher default is
>> a bit thin at this point.
> So "your default is 1.0 unless you installed the new database on or after
> 13.4 in which case it's 2.0"?
What else would be new? See e.g. 848ae330a. (Note I'm not suggesting
that we'd change it in a minor release.)
regards, tom lane
On Saturday, July 11, 2020, Tom Lane <tgl@sss.pgh.pa.us> wrote:
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> On Sat, Jul 11, 2020 at 5:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> It seems like a lot of the disagreement here is focused on Peter's
>> proposal to make hash_mem_multiplier default to 2.0. But it doesn't
>> seem to me that that's a critical element of the proposal. Why not just
>> make it default to 1.0, thus keeping the default behavior identical
>> to what it is now?
> If we don't default it to something other than 1.0 we might as well just
> make it memory units and let people decide precisely what they want to use
> instead of adding the complexity of a multiplier.
Not sure how that follows? The advantage of a multiplier is that it
tracks whatever people might do to work_mem automatically.
I was thinking that setting -1 would basically do that.
In general
I'd view work_mem as the base value that people twiddle to control
executor memory consumption. Having to also twiddle this other value
doesn't seem especially user-friendly.
I’ll admit I don’t have a feel for what is or is not user-friendly when setting these GUCs in a session to override the global defaults. But as far as the global defaults I say it’s a wash between (32mb, -1) -> (32mb, 48mb) and (32mb, 1.0) -> (32mb, 1.5)
If you want 96mb for the session/query hash setting it to 96mb is invariant, whilesetting it to 3.0 means it can change in the future if the system work_mem changes. Knowing the multiplier is 1.5 and choosing 64mb for work_mem in the session is possible but also mutable and has side-effects. If the user is going to set both values to make it invariant we are back to it being a wash.
I don’t believe using a multiplier will promote better comprehension for why this setting exists compared to “-1 means use work_mem but you can override a subset if you want.”
Is having a session level memory setting be mutable something we want to introduce?
Is it more user-friendly?
>> If we find that's a poor default, we can always change it later;
>> but it seems to me that the evidence for a higher default is
>> a bit thin at this point.
> So "your default is 1.0 unless you installed the new database on or after
> 13.4 in which case it's 2.0"?
What else would be new? See e.g. 848ae330a. (Note I'm not suggesting
that we'd change it in a minor release.)
Minor release update is what I had thought, and to an extent was making possible by not using the multiplier upfront.
I agree options are wide open come v14 and beyond.
David J.
On Sat, Jul 11, 2020 at 08:47:54PM -0400, Tom Lane wrote: >Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> I don't know, but one of the main arguments against simply suggesting >> people to bump up work_mem (if they're hit by the hashagg spill in v13) >> was that it'd increase overall memory usage for them. It seems strange >> to then propose a new GUC set to a default that would result in higher >> memory usage *for everyone*. > >It seems like a lot of the disagreement here is focused on Peter's >proposal to make hash_mem_multiplier default to 2.0. But it doesn't >seem to me that that's a critical element of the proposal. Why not just >make it default to 1.0, thus keeping the default behavior identical >to what it is now? > >If we find that's a poor default, we can always change it later; >but it seems to me that the evidence for a higher default is >a bit thin at this point. > You're right, I was specifically pushing against that aspect of the proposal. Sorry for not making that clearer, I assumed it's clear from the context of this (sub)thread. I agree making it 1.0 (or equal to work_mem, if it's not a multiplier) by default, but allowing it to be increased if needed would address most of the spilling issues. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jul 11, 2020 at 10:26:22PM -0700, David G. Johnston wrote: >On Saturday, July 11, 2020, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> "David G. Johnston" <david.g.johnston@gmail.com> writes: >> > On Sat, Jul 11, 2020 at 5:47 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: >> >> It seems like a lot of the disagreement here is focused on Peter's >> >> proposal to make hash_mem_multiplier default to 2.0. But it doesn't >> >> seem to me that that's a critical element of the proposal. Why not just >> >> make it default to 1.0, thus keeping the default behavior identical >> >> to what it is now? >> >> > If we don't default it to something other than 1.0 we might as well just >> > make it memory units and let people decide precisely what they want to >> use >> > instead of adding the complexity of a multiplier. >> >> Not sure how that follows? The advantage of a multiplier is that it >> tracks whatever people might do to work_mem automatically. > > >> >I was thinking that setting -1 would basically do that. > I think Tom meant that the multiplier would automatically track any changes to work_mem, and adjust the hash_mem accordingly. With -1 (and the GUC in units) you could only keep it exactly equal to work_mem, but then as soon as you change it you'd have to update both. >> In general >> I'd view work_mem as the base value that people twiddle to control >> executor memory consumption. Having to also twiddle this other value >> doesn't seem especially user-friendly. > > >I’ll admit I don’t have a feel for what is or is not user-friendly when >setting these GUCs in a session to override the global defaults. But as >far as the global defaults I say it’s a wash between (32mb, -1) -> (32mb, >48mb) and (32mb, 1.0) -> (32mb, 1.5) > >If you want 96mb for the session/query hash setting it to 96mb is >invariant, whilesetting it to 3.0 means it can change in the future if the >system work_mem changes. Knowing the multiplier is 1.5 and choosing 64mb >for work_mem in the session is possible but also mutable and has >side-effects. If the user is going to set both values to make it invariant >we are back to it being a wash. > >I don’t believe using a multiplier will promote better comprehension for >why this setting exists compared to “-1 means use work_mem but you can >override a subset if you want.” > >Is having a session level memory setting be mutable something we want to >introduce? > >Is it more user-friendly? > I still think it should be in simple units, TBH. We already have somewhat similar situation with cost parameters, where we often say that seq_page_cost = 1.0 is the baseline for the other cost parameters, yet we have not coded that as multipliers. >>> If we find that's a poor default, we can always change it later; >> >> but it seems to me that the evidence for a higher default is >> >> a bit thin at this point. >> >> > So "your default is 1.0 unless you installed the new database on or after >> > 13.4 in which case it's 2.0"? >> >> What else would be new? See e.g. 848ae330a. (Note I'm not suggesting >> that we'd change it in a minor release.) >> > >Minor release update is what I had thought, and to an extent was making >possible by not using the multiplier upfront. > >I agree options are wide open come v14 and beyond. > >David J. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jul 11, 2020 at 3:30 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Stephen Frost <sfrost@snowman.net> writes: > > I don't see hash_mem as being any kind of proper fix- it's just punting > > to the user saying "we can't figure this out, how about you do it" and, > > worse, it's in conflict with how we already ask the user that question. > > Turning it into a multiplier doesn't change that either. > > Have you got a better proposal that is reasonably implementable for v13? > (I do not accept the argument that "do nothing" is a better proposal.) > > I agree that hash_mem is a stopgap, whether it's a multiplier or no, > but at this point it seems difficult to avoid inventing a stopgap. > Getting rid of the process-global work_mem setting is a research project, > and one I wouldn't even count on having results from for v14. In the > meantime, it seems dead certain that there are applications for which > the current behavior will be problematic. > If this is true then certainly it adds more weight to the argument for having a solution like hash_mem or some other escape-hatch. I know it would be difficult to get the real-world data but why not try TPC-H or similar workloads at a few different scale_factor/size? I was checking some old results with me for TPC-H runs and I found that many of the plans were using Finalize GroupAggregate and Partial GroupAggregate kinds of plans, there were few where I saw Partial HashAggregate being used but it appears on a random check that GroupAggregate seems to be used more. It could be that after parallelism GroupAggregate plans are getting preference but I am not sure about this. However, even if that is not true, I think after the parallel aggregates the memory-related thing is taken care of to some extent automatically because I think after that each worker doing partial aggregation can be allowed to consume work_mem memory. So, probably the larger aggregates which are going to give better performance by consuming more memory would already be parallelized and would have given the desired results. Now, allowing aggregates to use more memory via hash_mem kind of thing is beneficial in non-parallel cases but for cases where parallelism is used it could be worse because now each work will be entitled to use more memory. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2020-04-07 20:20, Jeff Davis wrote: > Now that we have Disk-based Hash Aggregation, there are a lot more > situations where the planner can choose HashAgg. The > enable_hashagg_disk GUC, if set to true, chooses HashAgg based on > costing. If false, it only generates a HashAgg path if it thinks it > will fit in work_mem, similar to the old behavior (though it wlil now > spill to disk if the planner was wrong about it fitting in work_mem). > The current default is true. I have an anecdote that might be related to this discussion. I was running an unrelated benchmark suite. With PostgreSQL 12, one query ran out of memory. With PostgreSQL 13, the same query instead ran out of disk space. I bisected this to the introduction of disk-based hash aggregation. Of course, the very point of that feature is to eliminate the out of memory and make use of disk space instead. But running out of disk space is likely to be a worse experience than running out of memory. Also, while it's relatively easy to limit memory use both in PostgreSQL and in the kernel, it is difficult or impossible to limit disk space use in a similar way. I don't have a solution or proposal here, I just want to mention this as a possibility and suggest that we look out for similar experiences. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, 13 Jul 2020 at 23:51, Peter Eisentraut <peter.eisentraut@2ndquadrant.com> wrote: > I have an anecdote that might be related to this discussion. > > I was running an unrelated benchmark suite. With PostgreSQL 12, one > query ran out of memory. With PostgreSQL 13, the same query instead ran > out of disk space. I bisected this to the introduction of disk-based > hash aggregation. Of course, the very point of that feature is to > eliminate the out of memory and make use of disk space instead. But > running out of disk space is likely to be a worse experience than > running out of memory. Also, while it's relatively easy to limit memory > use both in PostgreSQL and in the kernel, it is difficult or impossible > to limit disk space use in a similar way. Isn't that what temp_file_limit is for? David
Greetings, * Peter Geoghegan (pg@bowt.ie) wrote: > On Sat, Jul 11, 2020 at 7:22 AM Stephen Frost <sfrost@snowman.net> wrote: > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > > Have you got a better proposal that is reasonably implementable for v13? > > > (I do not accept the argument that "do nothing" is a better proposal.) > > > So, no, I don't agree that 'do nothing' (except ripping out the one GUC > > that was already added) is a worse proposal than adding another work_mem > > like thing that's only for some nodes types. > > The question was "Have you got a better proposal that is reasonably > implementable for v13?". > > This is anecdotal, but just today somebody on Twitter reported > *increasing* work_mem to stop getting OOMs from group aggregate + > sort: > > https://twitter.com/theDressler/status/1281942941133615104 Yes, increasing work_mem isn't unusual, at all. What that tweet shows that I don't think folks who are suggesting things like setting this factor to 2.0 is that people may have a work_mem configured in the gigabytes- meaning that a 2.0 value would result in a work_mem of 5GB and a hash_mem of 10GB. Now, I'm all for telling people to review their configurations between major versions, but that's a large difference that's going to be pretty deeply hidden in a 'multiplier' setting. I'm still wholly unconvinced that we need such a setting, just to be clear, but I don't think there's any way it'd be reasonable to have it set to something other than "whatever work_mem is" by default- and it needs to actually be "what work_mem is" and not "have the same default value" or *everyone* would have to configure it. > It was possible to fix the problem in this instance, since evidently > there wasn't anything else that really did try to consume ~5 GB of > work_mem memory. Evidently the memory isn't available in any general > sense, so there are no OOMs now. Nevertheless, we can expect OOMs on > this server just as soon as there is a real need to do a ~5GB sort, > regardless of anything else. Eh? That's not at all what it looks like- they were getting OOM's because they set work_mem to be higher than the actual amount of memory they had and the Sort before the GroupAgg was actually trying to use all that memory. The HashAgg ended up not needing that much memory because the aggregated set wasn't actually that large. If anything, this shows exactly what Jeff's fine work here is (hopefully) going to give us- the option to plan a HashAgg in such cases, since we can accept spilling to disk if we end up underestimate, or take advantage of that HashAgg being entirely in memory if we overestimate. > I don't think that this kind of perverse effect is uncommon. Hash > aggregate can naturally be far faster than group agg + sort, Hash agg > can naturally use a lot less memory in many cases, and we have every > reason to think that grouping estimates are regularly totally wrong. I'm confused as to why we're talking about the relative performance of a HashAgg vs. a Sort+GroupAgg- of course the HashAgg is going to be faster if it's got enough memory, but that's a constraint we have to consider and deal with because, otherwise, the query can end up failing and potentially impacting other queries or activity on the system, including resulting in the entire database system falling over due to the OOM Killer firing and killing a process and the database ending up restarting and going through crash recovery, which is going to be quite a bit worse than performance maybe not being great. > You're significantly underestimating the risk. Of... what? That we'll end up getting worse performance because we underestimated the size of the result set and we end up spilling to disk with the HashAgg? I think I'm giving that risk the amount of concern it deserves- which is, frankly, not very much. Users who run into that issue, as this tweet *also* showed, are familiar with work_mem and can tune it to address that. This reaction to demand a new GUC to break up work_mem into pieces strikes me as unjustified, and doing so during beta makes it that much worse. Having looked back, I'm not sure that I'm really in the minority regarding the proposal to add this at this time either- there's been a few different comments that it's too late for v13 and/or that we should see if we actually end up with users seriously complaining about the lack of a separate way to specify the memory for a given node type, and/or that if we're going to do this then we should have a broader set of options covering other nodes types too, all of which are positions that I agree with. Thanks, Stephen
Вложения
On 2020-07-13 14:16, David Rowley wrote: > Isn't that what temp_file_limit is for? Yeah, I guess that is so rarely used that I had forgotten about it. So maybe that is also something that more users will want to be aware of. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 13, 2020 at 01:51:42PM +0200, Peter Eisentraut wrote: >On 2020-04-07 20:20, Jeff Davis wrote: >>Now that we have Disk-based Hash Aggregation, there are a lot more >>situations where the planner can choose HashAgg. The >>enable_hashagg_disk GUC, if set to true, chooses HashAgg based on >>costing. If false, it only generates a HashAgg path if it thinks it >>will fit in work_mem, similar to the old behavior (though it wlil now >>spill to disk if the planner was wrong about it fitting in work_mem). >>The current default is true. > >I have an anecdote that might be related to this discussion. > >I was running an unrelated benchmark suite. With PostgreSQL 12, one >query ran out of memory. With PostgreSQL 13, the same query instead >ran out of disk space. I bisected this to the introduction of >disk-based hash aggregation. Of course, the very point of that >feature is to eliminate the out of memory and make use of disk space >instead. But running out of disk space is likely to be a worse >experience than running out of memory. Also, while it's relatively >easy to limit memory use both in PostgreSQL and in the kernel, it is >difficult or impossible to limit disk space use in a similar way. > Why is running out of disk space worse experience than running out of memory? Sure, it'll take longer and ultimately the query fails (and if it fills the device used by the WAL then it may also cause shutdown of the main instance due to inability to write WAL). But that can be prevented by moving the temp tablespace and/or setting the temp file limit, as already mentioned. With OOM, if the kernel OOM killer decides to act, it may easily bring down the instance too, and there are much less options to prevent that. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, 14 Jul 2020 at 01:13, Stephen Frost <sfrost@snowman.net> wrote: > Yes, increasing work_mem isn't unusual, at all. What that tweet shows > that I don't think folks who are suggesting things like setting this > factor to 2.0 is that people may have a work_mem configured in the > gigabytes- meaning that a 2.0 value would result in a work_mem of 5GB > and a hash_mem of 10GB. Now, I'm all for telling people to review their > configurations between major versions, but that's a large difference > that's going to be pretty deeply hidden in a 'multiplier' setting. I think Peter seems to be fine with setting the default to 1.0, per [0]. This thread did split off a while back into "Default setting for enable_hashagg_disk (hash_mem)", I did try and summarise who sits where on this in [19]. I think it would be good if we could try to move towards getting consensus here rather than reiterating our arguments over and over. Updated summary: * For hash_mem = Tomas [7], Justin [16] * For hash_mem_multiplier with a default > 1.0 = DavidG [21] * For hash_mem_multiplier with default = 1.0 = PeterG [15][0], Tom [20][24] * hash_mem out of scope for PG13 = Bruce [8], Andres [9] * hashagg_mem default to -1 meaning use work_mem = DavidR [23] (2nd preference) * Escape hatch that can be removed later when we get something better = Jeff [11], DavidR [12], Pavel [13], Andres [14], Justin [1] * Add enable_hashagg_spill = Tom [2] (I'm unclear on this proposal. Does it affect the planner or executor or both?) (updated opinion in [20]) * Maybe do nothing until we see how things go during beta = Bruce [3], Amit [10] * Just let users set work_mem = Stephen [21], Alvaro [4] (Alvaro changed his mind after Andres pointed out that changes other nodes in the plan too [25]) * Swap enable_hashagg for a GUC that specifies when spilling should occur. -1 means work_mem = Robert [17], Amit [18] * hash_mem does not solve the problem = Tomas [6] (changed his mind in [7]) Perhaps people who have managed to follow this thread but not chip in yet can reply quoting the option above that they'd be voting for. Or if you're ok changing your mind to some option that has more votes than the one your name is already against. That might help move this along. David [0] https://www.postgresql.org/message-id/CAH2-Wz=VV6EKFGUJDsHEqyvRk7pCO36BvEoF5sBQry_O6R2=nw@mail.gmail.com [1] https://www.postgresql.org/message-id/20200624031443.GV4107@telsasoft.com [2] https://www.postgresql.org/message-id/2214502.1593019796@sss.pgh.pa.us [3] https://www.postgresql.org/message-id/20200625182512.GC12486@momjian.us [4] https://www.postgresql.org/message-id/20200625224422.GA9653@alvherre.pgsql [5] https://www.postgresql.org/message-id/CAA4eK1K0cgk_8hRyxsvppgoh_Z-NY+UZTcFWB2we6baJ9DXCQw@mail.gmail.com [6] https://www.postgresql.org/message-id/20200627104141.gq7d3hm2tvoqgjjs@development [7] https://www.postgresql.org/message-id/20200629212229.n3afgzq6xpxrr4cu@development [8] https://www.postgresql.org/message-id/20200703030001.GD26235@momjian.us [9] https://www.postgresql.org/message-id/20200707171216.jqxrld2jnxwf5ozv@alap3.anarazel.de [10] https://www.postgresql.org/message-id/CAA4eK1KfPi6iz0hWxBLZzfVOG_NvOVJL=9UQQirWLpaN=kANTQ@mail.gmail.com [11] https://www.postgresql.org/message-id/8bff2e4e8020c3caa16b61a46918d21b573eaf78.camel@j-davis.com [12] https://www.postgresql.org/message-id/CAApHDvqFZikXhAGW=UKZKq1_FzHy+XzmUzAJiNj6RWyTHH4UfA@mail.gmail.com [13] https://www.postgresql.org/message-id/CAFj8pRBf1w4ndz-ynd+mUpTfiZfbs7+CPjc4ob8v9d3X0MscCg@mail.gmail.com [14] https://www.postgresql.org/message-id/20200624191433.5gnqgrxfmucexldm@alap3.anarazel.de [15] https://www.postgresql.org/message-id/CAH2-WzmD+i1pG6rc1+Cjc4V6EaFJ_qSuKCCHVnH=oruqD-zqow@mail.gmail.com [16] https://www.postgresql.org/message-id/20200703024649.GJ4107@telsasoft.com [17] https://www.postgresql.org/message-id/CA+TgmobyV9+T-Wjx-cTPdQuRCgt1THz1mL3v1NXC4m4G-H6Rcw@mail.gmail.com [18] https://www.postgresql.org/message-id/CAA4eK1K0cgk_8hRyxsvppgoh_Z-NY+UZTcFWB2we6baJ9DXCQw@mail.gmail.com [19] https://www.postgresql.org/message-id/CAApHDvrP1FiEv4AQL2ZscbHi32W+Gp01j+qnhwou7y7p-QFj_w@mail.gmail.com [20] https://www.postgresql.org/message-id/2107841.1594403217@sss.pgh.pa.us [21] https://www.postgresql.org/message-id/20200710141714.GI12375@tamriel.snowman.net [22] https://www.postgresql.org/message-id/CAKFQuwa2gwLa0b%2BmQv5r5A_Q0XWsA2%3D1zQ%2BZ5m4pQprxh-aM4Q%40mail.gmail.com [23] https://www.postgresql.org/message-id/CAApHDvpxbHHP566rRjJWgnfS0YOxR53EZTz5LHH-jcEKvqdj4g@mail.gmail.com [24] https://www.postgresql.org/message-id/2463591.1594514874@sss.pgh.pa.us [25] https://www.postgresql.org/message-id/20200625225853.GA11137%40alvherre.pgsql
On Tue, 2020-07-14 at 02:25 +1200, David Rowley wrote:
> Updated summary:
> * For hash_mem = Tomas [7], Justin [16]
> * For hash_mem_multiplier with a default > 1.0 = DavidG [21]
> * For hash_mem_multiplier with default = 1.0 = PeterG [15][0], Tom
> [20][24]
I am OK with these options, but I still prefer a simple escape hatch.
> * Maybe do nothing until we see how things go during beta = Bruce
> [3], Amit [10]
> * Just let users set work_mem = Stephen [21], Alvaro [4] (Alvaro
> changed his mind after Andres pointed out that changes other nodes in
> the plan too [25])
I am not on board with these options.
Regards,
Jeff Davis
On 2020-07-13 16:11, Tomas Vondra wrote: > Why is running out of disk space worse experience than running out of > memory? > > Sure, it'll take longer and ultimately the query fails (and if it fills > the device used by the WAL then it may also cause shutdown of the main > instance due to inability to write WAL). But that can be prevented by > moving the temp tablespace and/or setting the temp file limit, as > already mentioned. > > With OOM, if the kernel OOM killer decides to act, it may easily bring > down the instance too, and there are much less options to prevent that. Well, that's an interesting point. Depending on the OS setup, by default an out of memory might actually be worse if the OOM killer strikes in an unfortunate way. That didn't happen to me in my tests, so the OS must have been configured differently by default. So maybe a lesson here is that just like we have been teaching users to adjust the OOM killer, we have to teach them now that setting the temp file limit might become more important. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 13, 2020 at 6:13 AM Stephen Frost <sfrost@snowman.net> wrote: > Yes, increasing work_mem isn't unusual, at all. It's unusual as a way of avoiding OOMs! > Eh? That's not at all what it looks like- they were getting OOM's > because they set work_mem to be higher than the actual amount of memory > they had and the Sort before the GroupAgg was actually trying to use all > that memory. The HashAgg ended up not needing that much memory because > the aggregated set wasn't actually that large. If anything, this shows > exactly what Jeff's fine work here is (hopefully) going to give us- the > option to plan a HashAgg in such cases, since we can accept spilling to > disk if we end up underestimate, or take advantage of that HashAgg > being entirely in memory if we overestimate. I very specifically said that it wasn't a case where something like hash_mem would be expected to make all the difference. > Having looked back, I'm not sure that I'm really in the minority > regarding the proposal to add this at this time either- there's been a > few different comments that it's too late for v13 and/or that we should > see if we actually end up with users seriously complaining about the > lack of a separate way to specify the memory for a given node type, > and/or that if we're going to do this then we should have a broader set > of options covering other nodes types too, all of which are positions > that I agree with. By proposing to do nothing at all, you are very clearly in a small minority. While (for example) I might have debated the details with David Rowley a lot recently, and you couldn't exactly say that we're in agreement, our two positions are nevertheless relatively close together. AFAICT, the only other person that has argued that we should do nothing (have no new GUC) is Bruce, which was a while ago now. (Amit said something similar, but has since softened his opinion [1]). [1] https://postgr.es.m/m/CAA4eK1+KMSQuOq5Gsj-g-pYec_8zgGb4K=xRznbCccnaumFqSA@mail.gmail.com -- Peter Geoghegan
On 2020-Jul-13, Jeff Davis wrote: > On Tue, 2020-07-14 at 02:25 +1200, David Rowley wrote: > > Updated summary: > > * For hash_mem = Tomas [7], Justin [16] > > * For hash_mem_multiplier with a default > 1.0 = DavidG [21] > > * For hash_mem_multiplier with default = 1.0 = PeterG [15][0], Tom > > [20][24] > > I am OK with these options, but I still prefer a simple escape hatch. I'm in favor of hash_mem_multiplier. I think a >1 default is more sensible than =1 in the long run, but if strategic vote is what we're doing, then I support the =1 option. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> I'm in favor of hash_mem_multiplier. I think a >1 default is more
> sensible than =1 in the long run, but if strategic vote is what we're
> doing, then I support the =1 option.
FWIW, I also think that we'll eventually end up with >1 default.
But the evidence to support that isn't really there yet, so
I'm good with 1.0 default to start with.
regards, tom lane
On Mon, Jul 13, 2020 at 7:25 AM David Rowley <dgrowleyml@gmail.com> wrote: > I think it would be good if we could try to move towards getting > consensus here rather than reiterating our arguments over and over. +1 > Updated summary: > * For hash_mem = Tomas [7], Justin [16] > * For hash_mem_multiplier with a default > 1.0 = DavidG [21] > * For hash_mem_multiplier with default = 1.0 = PeterG [15][0], Tom [20][24] > * hash_mem out of scope for PG13 = Bruce [8], Andres [9] > * hashagg_mem default to -1 meaning use work_mem = DavidR [23] (2nd preference) > * Escape hatch that can be removed later when we get something better > = Jeff [11], DavidR [12], Pavel [13], Andres [14], Justin [1] > * Add enable_hashagg_spill = Tom [2] (I'm unclear on this proposal. > Does it affect the planner or executor or both?) (updated opinion in > [20]) > * Maybe do nothing until we see how things go during beta = Bruce [3], Amit [10] > * Just let users set work_mem = Stephen [21], Alvaro [4] (Alvaro > changed his mind after Andres pointed out that changes other nodes in > the plan too [25]) > * Swap enable_hashagg for a GUC that specifies when spilling should > occur. -1 means work_mem = Robert [17], Amit [18] > * hash_mem does not solve the problem = Tomas [6] (changed his mind in [7]) I don't think that hashagg_mem needs to be considered here, because you were the only one that spoke out in favor of that idea, and it's your second preference in any case (maybe Tom was in favor of such a thing at one point, but he clearly favors hash_mem/hash_mem_multiplier now so it hardly matters). I don't think that hashagg_mem represents a meaningful compromise between the escape hatch and hash_mem/hash_mem_multiplier in any case. (I would *prefer* the escape hatch to hashagg_mem, since at least the escape hatch is an "honest" escape hatch.) ISTM that there are three basic approaches to resolving this open item that remain: 1. Do nothing. 2. Add an escape hatch. 3. Add hash_mem/hash_mem_multiplier. Many people (e.g., Tom, Jeff, you, Andres, myself) have clearly indicated that doing nothing is simply a non-starter. It's not just that it doesn't get a lot of votes -- it's something that is strongly opposed. We can rule it out right away. This is where it gets harder. Many of us have views that are won't easily fit into buckets. For example, even though I myself proposed hash_mem/hash_mem_multiplier, I've said that I can live with the escape hatch. Similarly, Jeff favors the escape hatch, but has said that he can live with hash_mem/hash_mem_multiplier. And, Andres said to me privately that he thinks that hash_mem could be a good idea, even though he opposes it now due to release management considerations. Even still, I think that it's possible to divide people into two camps on this without grossly misrepresenting anybody. Primarily in favor of escape hatch: Jeff, DavidR, Pavel, Andres, Robert ??, Amit ?? Primarily in favor of hash_mem/hash_mem_multiplier: PeterG, Tom, Alvaro, Tomas, Justin, DavidG, Jonathan Katz There are clear problems with this summary, including for example the fact that Robert weighed in before the hash_mem/hash_mem_multiplier proposal was even on the table. What he actually said about it [1] seems closer to hash_mem, so I feel that putting him in that bucket is a conservative assumption on my part. Same goes for Amit, who warmed to the idea of hash_mem_multiplier recently. (Though I probably got some detail wrong, in which case please correct me.) ISTM that there is a majority of opinion in favor of hash_mem/hash_mem_multiplier. If you assume that I have this wrong, and that we're simply deadlocked, then it becomes a matter for the RMT. I strongly doubt that that changes the overall outcome, since this year's RMT members happen to all be in favor of the hash_mem/hash_mem_multiplier proposal on an individual basis. [1] https://www.postgresql.org/message-id/CA+TgmobyV9+T-Wjx-cTPdQuRCgt1THz1mL3v1NXC4m4G-H6Rcw@mail.gmail.com -- Peter Geoghegan
On Mon, Jul 13, 2020 at 11:50 AM Peter Geoghegan <pg@bowt.ie> wrote:
Primarily in favor of escape hatch:
Jeff,
DavidR,
Pavel,
Andres,
Robert ??,
Amit ??
To be clear, by "escape hatch" you mean "add a GUC that instructs the PostgreSQL executor to ignore hash_mem when deciding whether to spill the contents of the hash table to disk - IOW to never spill the contents of a hash table to disk"? If so that seems separate from whether to add a hash_mem GUC to provide finer grained control - people may well want both.
Primarily in favor of hash_mem/hash_mem_multiplier:
PeterG,
Tom,
Alvaro,
Tomas,
Justin,
DavidG,
Jonathan Katz
I would prefer DavidJ as an abbreviation - my middle initial can be dropped when referring to me.
David J.
On Mon, Jul 13, 2020 at 12:57 PM David G. Johnston <david.g.johnston@gmail.com> wrote: > To be clear, by "escape hatch" you mean "add a GUC that instructs the PostgreSQL executor to ignore hash_mem when decidingwhether to spill the contents of the hash table to disk - IOW to never spill the contents of a hash table to disk"? Yes, that's what that means. > If so that seems separate from whether to add a hash_mem GUC to provide finer grained control - people may well want both. They might want the escape hatch too, as an additional measure, but my assumption is that anybody in favor of the hash_mem/hash_mem_multiplier proposal takes that position because they think that it's the principled solution. That's the kind of subtlety that is bound to get lost when summarizing general sentiment at a high level. In any case no individual has seriously argued that there is a simultaneous need for both -- at least not yet. This thread is already enormous, and very hard to keep up with. I'm trying to draw a line under the discussion. For my part, I have compromised on the important question of the default value of hash_mem_multiplier -- I am writing a new version of the patch that makes the default 1.0 (i.e. no behavioral changes by default). > I would prefer DavidJ as an abbreviation - my middle initial can be dropped when referring to me. Sorry about that. -- Peter Geoghegan
"David G. Johnston" <david.g.johnston@gmail.com> writes:
> To be clear, by "escape hatch" you mean "add a GUC that instructs the
> PostgreSQL executor to ignore hash_mem when deciding whether to spill the
> contents of the hash table to disk - IOW to never spill the contents of a
> hash table to disk"? If so that seems separate from whether to add a
> hash_mem GUC to provide finer grained control - people may well want both.
If we define the problem narrowly as "allow people to get back exactly
the pre-v13 behavior", then yeah you'd need an escape hatch of that
sort. We should not, however, forget that the pre-v13 behavior is
pretty darn problematic. It's hard to see why anyone would really
want to get back exactly "never spill even if it leads to OOM".
The proposals for allowing a higher-than-work_mem, but not infinite,
spill boundary seem to me to be a reasonable way to accommodate cases
where the old behavior is accidentally preferable to what v13 does
right now. Moreover, such a knob seems potentially useful in its
own right, at least as a stopgap until we figure out how to generalize
or remove work_mem. (Which might be a long time.)
I'm not unalterably opposed to providing an escape hatch of the other
sort, but right now I think the evidence for needing it isn't there.
If we get field complaints that can't be resolved with the "raise the
spill threshold by X" approach, we could reconsider. But that approach
seems a whole lot less brittle than "raise the spill threshold to
infinity", so I think we should start with the former type of fix.
regards, tom lane
On Mon, Jul 13, 2020 at 9:50 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Jul 13, 2020 at 6:13 AM Stephen Frost <sfrost@snowman.net> wrote: > > Yes, increasing work_mem isn't unusual, at all. > > It's unusual as a way of avoiding OOMs! > > > Eh? That's not at all what it looks like- they were getting OOM's > > because they set work_mem to be higher than the actual amount of memory > > they had and the Sort before the GroupAgg was actually trying to use all > > that memory. The HashAgg ended up not needing that much memory because > > the aggregated set wasn't actually that large. If anything, this shows > > exactly what Jeff's fine work here is (hopefully) going to give us- the > > option to plan a HashAgg in such cases, since we can accept spilling to > > disk if we end up underestimate, or take advantage of that HashAgg > > being entirely in memory if we overestimate. > > I very specifically said that it wasn't a case where something like > hash_mem would be expected to make all the difference. > > > Having looked back, I'm not sure that I'm really in the minority > > regarding the proposal to add this at this time either- there's been a > > few different comments that it's too late for v13 and/or that we should > > see if we actually end up with users seriously complaining about the > > lack of a separate way to specify the memory for a given node type, > > and/or that if we're going to do this then we should have a broader set > > of options covering other nodes types too, all of which are positions > > that I agree with. > > By proposing to do nothing at all, you are very clearly in a small > minority. While (for example) I might have debated the details with > David Rowley a lot recently, and you couldn't exactly say that we're > in agreement, our two positions are nevertheless relatively close > together. > > AFAICT, the only other person that has argued that we should do > nothing (have no new GUC) is Bruce, which was a while ago now. (Amit > said something similar, but has since softened his opinion [1]). > To be clear, my vote for PG13 is not to do anything till we have clear evidence of regressions. In the email you quoted, I was trying to say that due to parallelism we might not have the problem for which we are planning to provide an escape-hatch or hash_mem GUC. I think the reason for the delay in getting to the agreement is that there is no clear evidence for the problem (user-reported cases or results of some benchmarks like TPC-H) unless I have missed something. Having said that, I understand that we have to reach some conclusion to close this open item and if the majority of people are in-favor of escape-hatch or hash_mem solution then we have to do one of those. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Jul 13, 2020 at 2:50 PM Peter Geoghegan <pg@bowt.ie> wrote: > Primarily in favor of escape hatch: > > Jeff, > DavidR, > Pavel, > Andres, > Robert ??, > Amit ?? > > Primarily in favor of hash_mem/hash_mem_multiplier: > > PeterG, > Tom, > Alvaro, > Tomas, > Justin, > DavidG, > Jonathan Katz > > There are clear problems with this summary, including for example the > fact that Robert weighed in before the hash_mem/hash_mem_multiplier > proposal was even on the table. What he actually said about it [1] > seems closer to hash_mem, so I feel that putting him in that bucket is > a conservative assumption on my part. Same goes for Amit, who warmed > to the idea of hash_mem_multiplier recently. (Though I probably got > some detail wrong, in which case please correct me.) My view is: - I thought the problem we were trying to solve here was that, in v12, if the planner thinks that your hashagg will fit in memory when really it doesn't, you will get good performance because we'll cheat; in v13, you'll get VERY bad performance because we won't. - So, if hash_mem_multiplier affects both planning and execution, it doesn't really solve the problem. Neither does adjusting the existing work_mem setting. Imagine that you have two queries. The planner thinks Q1 will use 1GB of memory for a HashAgg but it will actually need 2GB. It thinks Q2 will use 1.5GB for a HashAgg but it will actually need 3GB. If you plan using a 1GB memory limit, Q1 will pick a HashAgg and perform terribly when it spills. Q2 will pick a GroupAggregate which will be OK but not great. If you plan with a 2GB memory limit, Q1 will pick a HashAgg and will not spill so now it will be in great shape. But Q2 will pick a HashAgg and then spill so it will stink. Oops. - An escape hatch that prevents spilling at execution time *does* solve this problem, but now suppose we add a Q3 which the planner thinks will use 512MB of memory but at execution time it will actually consume 512GB due to the row count estimate being 1024x off. So if you enable the escape hatch to get back to a situation where Q1 and Q2 both perform acceptably, then Q3 makes your system OOM. - If you were to instead introduce a GUC like what I proposed before, which allows the execution-time memory usage to exceed what was planned, but only by a certain margin, then you can set hash_mem_execution_overrun_multiplier_thingy=2.5 and call it a day. Now, no matter how you set work_mem, you're fine. Depending on the value you choose for work_mem, you may get group aggregates for some of the queries. If you set it large enough that you get hash aggregates, then Q1 and Q2 will avoid spilling (which works but is slow) because the overrun is less than 2x. Q3 will spill, so you won't OOM. Wahoo! - I do agree in general that it makes more sense to allow hash_work_mem > sort_work_mem, and even to make that the default. Allowing the same budget for both is unreasonable, because I think we have good evidence that inadequate memory has a severe impact on hashing operations but usually only a fairly mild effect on sorting operations, except in the case where the underrun is severe. That is, if you need 1GB of memory for a sort and you only get 768MB, the slowdown is much much less severe than if the same thing happens for a hash. If you have 10MB of memory, both are going to suck, but that's kinda unavoidable. - If you hold my feet to the fire and ask me to choose between a Boolean escape hatch (rather than a multiplier-based one) and hash_mem_multiplier, gosh, I don't know. I guess the Boolean escape hatch? I mean it's a pretty bad solution, but at least if I have that I can get both Q1 and Q2 to perform well at the same time, and I guess I'm no worse off than I was in v12. The hash_mem_multiplier thing, assuming it affects both planning and execution, seems like a very good idea in general, but I guess I don't see how it helps with this problem. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jul 14, 2020 at 12:46 PM Robert Haas <robertmhaas@gmail.com> wrote: > - I thought the problem we were trying to solve here was that, in v12, > if the planner thinks that your hashagg will fit in memory when really > it doesn't, you will get good performance because we'll cheat; in v13, > you'll get VERY bad performance because we won't. That is the problem we started out with. I propose to solve a broader problem that I believe mostly encompasses the original problem (it's an "inventor's paradox" situation). Although the exact degree to which it truly addresses the original problem will vary across installations, I believe that it will go a very long way towards cutting down on problems for users upgrading to Postgres 13 generally. > - So, if hash_mem_multiplier affects both planning and execution, it > doesn't really solve the problem. Neither does adjusting the existing > work_mem setting. Imagine that you have two queries. The planner > thinks Q1 will use 1GB of memory for a HashAgg but it will actually > need 2GB. It thinks Q2 will use 1.5GB for a HashAgg but it will > actually need 3GB. If you plan using a 1GB memory limit, Q1 will pick > a HashAgg and perform terribly when it spills. Q2 will pick a > GroupAggregate which will be OK but not great. If you plan with a 2GB > memory limit, Q1 will pick a HashAgg and will not spill so now it will > be in great shape. But Q2 will pick a HashAgg and then spill so it > will stink. Oops. Maybe I missed your point here. The problem is not so much that we'll get HashAggs that spill -- there is nothing intrinsically wrong with that. While it's true that the I/O pattern is not as sequential as a similar group agg + sort, that doesn't seem like the really important factor here. The really important factor is that in-memory HashAggs can be blazingly fast relative to *any* alternative strategy -- be it a HashAgg that spills, or a group aggregate + sort that doesn't spill, whatever. We're mostly concerned about keeping the one available fast strategy than we are about getting a new, generally slow strategy. There will be no problems at all unless and until we're short on memory, because you can just increase work_mem and everything works out, regardless of the details. Obviously the general problems we anticipate only crop up when increasing work_mem stops being a viable DBA strategy. By teaching the system to have at least a crude appreciation of the value of memory when hashing vs when sorting, the system is often able to give much more memory to Hash aggs (and hash joins). Increasing hash_mem_multiplier (maybe while also decreasing work_mem) will be beneficial when we take memory from things that don't really need so much, like sorts (or even CTE tuplestores) -- we reduce the memory pressure without paying a commensurate price in system throughput (maybe even only a very small hit). As a bonus, everything going faster may actually *reduce* the memory usage for the system as a whole, even as individual queries use more memory. Under this scheme, it may well not matter that you cannot cheat (Postgres 12 style) anymore, because you'll be able to use the memory that is available sensibly -- regardless of whether or not the group estimates are very good (we have to have more than zero faith in the estimates -- they can be bad without being terrible). Maybe no amount of tuning can ever restore the desirable Postgres 12 performance characteristics you came to rely on, but remaining "regressions" are probably cases where the user was flying pretty close to the sun OOM-wise all along. They may have been happy with Postgres 12, but at a certain point that really is something that you have to view as a fool's paradise, even if like me you happen to be a memory Keynesian. Really big outliers tend to be rare and therefore something that the user can afford to have go slower. It's the constant steady stream of medium-sized hash aggs that we mostly need to worry about. To the extent that that's true, hash_mem_multiplier addresses the problem on the table. > - An escape hatch that prevents spilling at execution time *does* > solve this problem, but now suppose we add a Q3 which the planner > thinks will use 512MB of memory but at execution time it will actually > consume 512GB due to the row count estimate being 1024x off. So if you > enable the escape hatch to get back to a situation where Q1 and Q2 > both perform acceptably, then Q3 makes your system OOM. Right. Nothing stops these two things from being true at the same time. > - If you were to instead introduce a GUC like what I proposed before, > which allows the execution-time memory usage to exceed what was > planned, but only by a certain margin, then you can set > hash_mem_execution_overrun_multiplier_thingy=2.5 and call it a day. > Now, no matter how you set work_mem, you're fine. Depending on the > value you choose for work_mem, you may get group aggregates for some > of the queries. If you set it large enough that you get hash > aggregates, then Q1 and Q2 will avoid spilling (which works but is > slow) because the overrun is less than 2x. Q3 will spill, so you won't > OOM. Wahoo! But we'll have to live with that kludge for a long time, and haven't necessarily avoided any risk compared to the hash_mem_multiplier alternative. I think that having a shadow memory limit for the executor is pretty ugly. I'm trying to come up with a setting that can sensibly be tuned at the system level. Not an escape hatch, which seems worth avoiding. Admittedly, this is not without its downsides. > - If you hold my feet to the fire and ask me to choose between a > Boolean escape hatch (rather than a multiplier-based one) and > hash_mem_multiplier, gosh, I don't know. I guess the Boolean escape > hatch? I mean it's a pretty bad solution, but at least if I have that > I can get both Q1 and Q2 to perform well at the same time, and I guess > I'm no worse off than I was in v12. Fortunately you don't have to choose. Doing both together might make sense, to cover any remaining user apps that still experience problems after tuning hash_mem_multiplier. We can take a wait and see approach to this, as Tom suggested recently. -- Peter Geoghegan
On Mon, Jul 13, 2020 at 9:47 AM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > I'm in favor of hash_mem_multiplier. I think a >1 default is more > sensible than =1 in the long run, but if strategic vote is what we're > doing, then I support the =1 option. Attached is a WIP patch implementing hash_mem_multiplier, with 1.0 as the GUC's default value (i.e. the patch introduces no behavioral changes by default). The first patch in the series renames some local variables whose name is made ambiguous by the second, main patch. Since the patch doesn't add a new work_mem-style GUC, but existing consumers of work_mem expect something like that, the code is structured in a way that allows the planner and executor to pretend that there really is a work_mem-style GUC called hash_mem, which they can determine the value of by calling the get_hash_mem() function. This seemed like the simplest approach overall. I placed the get_hash_mem() function in nodeHash.c, which is a pretty random place for it. If anybody has any better ideas about where it should live, please say so. ISTM that the planner changes are where there's mostly likely to be problems. Reviewers should examine consider_groupingsets_paths() in detail. -- Peter Geoghegan
Вложения
On Tue, 2020-07-14 at 21:12 -0700, Peter Geoghegan wrote:
> Attached is a WIP patch implementing hash_mem_multiplier, with 1.0 as
> the GUC's default value (i.e. the patch introduces no behavioral
> changes by default). The first patch in the series renames some local
> variables whose name is made ambiguous by the second, main patch.
The idea is growing on me a bit. It doesn't give exactly v12 behavior,
but it does offer another lever that might tackle a lot of the
practical cases. If I were making the decision alone, I'd still choose
the escape hatch based on simplicity, but I'm fine with this approach
as well.
The patch itself looks reasonable to me. I don't see a lot of obvious
dangers, but perhaps someone would like to take a closer look at the
planner changes as you suggest.
Regards,
Jeff Davis
On Fri, Jul 17, 2020 at 5:13 PM Jeff Davis <pgsql@j-davis.com> wrote: > The idea is growing on me a bit. It doesn't give exactly v12 behavior, > but it does offer another lever that might tackle a lot of the > practical cases. Cool. > If I were making the decision alone, I'd still choose > the escape hatch based on simplicity, but I'm fine with this approach > as well. There is also the separate question of what to do about the hashagg_avoid_disk_plan GUC (this is a separate open item that requires a separate resolution). Tom leans slightly towards removing it now. Is your position about the same as before? > The patch itself looks reasonable to me. I don't see a lot of obvious > dangers, but perhaps someone would like to take a closer look at the > planner changes as you suggest. It would be good to get further input on the patch from somebody else, particularly the planner aspects. My intention is to commit the patch myself. I was the primary advocate for hash_mem_multiplier, so it seems as if I should own it. (You may have noticed that I just pushed the preparatory local-variable-renaming patch, to get that piece out of the way.) -- Peter Geoghegan
On Fri, 2020-07-17 at 18:38 -0700, Peter Geoghegan wrote:
> There is also the separate question of what to do about the
> hashagg_avoid_disk_plan GUC (this is a separate open item that
> requires a separate resolution). Tom leans slightly towards removing
> it now. Is your position about the same as before?
Yes, I think we should have that GUC (hashagg_avoid_disk_plan) for at
least one release.
Clealy, a lot of plans will change. For any GROUP BY where there are a
lot of groups, there was only one choice in v12 and now there are two
choices in v13. Obviously I think most of those changes will be for the
better, but some regressions are bound to happen. Giving users some
time to adjust, and for us to tune the cost model based on user
feedback, seems prudent.
Are there other examples of widespread changes in plans where we
*didn't* have a GUC? There are many GUCs for controlling parallism,
JIT, etc.
Regards,
Jeff Davis
Jeff Davis <pgsql@j-davis.com> writes:
> On Fri, 2020-07-17 at 18:38 -0700, Peter Geoghegan wrote:
>> There is also the separate question of what to do about the
>> hashagg_avoid_disk_plan GUC (this is a separate open item that
>> requires a separate resolution). Tom leans slightly towards removing
>> it now. Is your position about the same as before?
> Yes, I think we should have that GUC (hashagg_avoid_disk_plan) for at
> least one release.
You'e being optimistic about it being possible to remove a GUC once
we ship it. That seems to be a hard sell most of the time.
I'm honestly a bit baffled about the level of fear being expressed
around this feature. We have *frequently* made changes that would
change query plans, perhaps not 100.00% for the better, and never
before have we had this kind of bikeshedding about whether it was
necessary to be able to turn it off. I think the entire discussion
is way out ahead of any field evidence that we need such a knob.
In the absence of evidence, our default position ought to be to
keep it simple, not to accumulate backwards-compatibility kluges.
(The only reason I'm in favor of heap_mem[_multiplier] is that it
seems like it might be possible to use it to get *better* plans
than before. I do not see it as a backwards-compatibility knob.)
regards, tom lane
On Sat, Jul 18, 2020 at 11:30 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Jeff Davis <pgsql@j-davis.com> writes: > > Yes, I think we should have that GUC (hashagg_avoid_disk_plan) for at > > least one release. > > You'e being optimistic about it being possible to remove a GUC once > we ship it. That seems to be a hard sell most of the time. You've said that you're +0.5 on removing this GUC, while Jeff seems to be about -0.5 (at least that's my take). It's hard to see a way towards closing out the hashagg_avoid_disk_plan open item if that's our starting point. The "do we need to keep hashagg_avoid_disk_plan?" question is fundamentally a value judgement IMV. I believe that you both understand each other's perspectives. I also suspect that no pragmatic compromise will be possible -- we can either have the hashagg_avoid_disk_plan GUC or not have it. ISTM that we're deadlocked, at least in a technical or procedural sense. Does that understanding seem accurate to you both? -- Peter Geoghegan
On Sat, 2020-07-18 at 14:30 -0400, Tom Lane wrote:
> You'e being optimistic about it being possible to remove a GUC once
> we ship it. That seems to be a hard sell most of the time.
If nothing else, a repeat of this thread in a year or two to discuss
removing a GUC doesn't seem appealing.
> I think the entire discussion
> is way out ahead of any field evidence that we need such a knob.
> In the absence of evidence, our default position ought to be to
> keep it simple, not to accumulate backwards-compatibility kluges.
Fair enough. I think that was where Stephen and Amit were coming from,
as well.
What is your opinion about pessimizing the HashAgg disk costs (not
affecting HashAgg plans expected to stay in memory)? Tomas Vondra
presented some evidence that Sort had some better IO patterns in some
cases that weren't easily reflected in a principled way in the cost
model.
That would lessen the number of changed plans, but we could easily
remove the pessimization without controversy later if it turned out to
be unnecessary, or if we further optimize HashAgg IO.
Regards,
Jeff Davis
Jeff Davis <pgsql@j-davis.com> writes:
> What is your opinion about pessimizing the HashAgg disk costs (not
> affecting HashAgg plans expected to stay in memory)? Tomas Vondra
> presented some evidence that Sort had some better IO patterns in some
> cases that weren't easily reflected in a principled way in the cost
> model.
Hm, was that in some other thread? I didn't find any such info
in a quick look through this one.
> That would lessen the number of changed plans, but we could easily
> remove the pessimization without controversy later if it turned out to
> be unnecessary, or if we further optimize HashAgg IO.
Trying to improve our cost models under-the-hood seems like a
perfectly reasonable activity to me.
regards, tom lane
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Jeff Davis <pgsql@j-davis.com> writes: > > On Fri, 2020-07-17 at 18:38 -0700, Peter Geoghegan wrote: > >> There is also the separate question of what to do about the > >> hashagg_avoid_disk_plan GUC (this is a separate open item that > >> requires a separate resolution). Tom leans slightly towards removing > >> it now. Is your position about the same as before? > > > Yes, I think we should have that GUC (hashagg_avoid_disk_plan) for at > > least one release. > > You'e being optimistic about it being possible to remove a GUC once > we ship it. That seems to be a hard sell most of the time. Agreed. > I'm honestly a bit baffled about the level of fear being expressed > around this feature. We have *frequently* made changes that would > change query plans, perhaps not 100.00% for the better, and never > before have we had this kind of bikeshedding about whether it was > necessary to be able to turn it off. I think the entire discussion > is way out ahead of any field evidence that we need such a knob. > In the absence of evidence, our default position ought to be to > keep it simple, not to accumulate backwards-compatibility kluges. +100 > (The only reason I'm in favor of heap_mem[_multiplier] is that it > seems like it might be possible to use it to get *better* plans > than before. I do not see it as a backwards-compatibility knob.) I still don't think a hash_mem-type thing is really the right direction to go in, even if making a distinction between memory used for sorting and memory used for hashing is, and I'm of the general opinion that we'd be thinking about doing something better and more appropriate- except for the fact that we're talking about adding this in during beta. In other words, if we'd stop trying to shoehorn something in, which we're doing because we're in beta, we'd very likely be talking about all of this in a very different way and probably be contemplating something like a query_mem that provides for an overall memory limit and which favors memory for hashing over memory for sorting, etc. Thanks, Stephen
Вложения
Stephen Frost <sfrost@snowman.net> writes:
> In other words, if we'd stop trying to shoehorn something in, which
> we're doing because we're in beta, we'd very likely be talking about all
> of this in a very different way and probably be contemplating something
> like a query_mem that provides for an overall memory limit and which
> favors memory for hashing over memory for sorting, etc.
Even if we were at the start of the dev cycle rather than its end,
I'm not sure I agree. Yes, replacing work_mem with some more-holistic
approach would be great. But that's a research project, one that
we can't be sure will yield fruit on any particular schedule. (Seeing
that we've understood this to be a problem for *decades*, I would tend
to bet on a longer not shorter time frame for a solution.)
I think that if we are worried about hashagg-spill behavior in the near
term, we have to have some fix that's not conditional on solving that
very large problem. The only other practical alternative is "do
nothing for v13", and I agree with the camp that doesn't like that.
regards, tom lane
On Sun, Jul 19, 2020 at 4:38 AM Stephen Frost <sfrost@snowman.net> wrote:
> (The only reason I'm in favor of heap_mem[_multiplier] is that it
> seems like it might be possible to use it to get *better* plans
> than before. I do not see it as a backwards-compatibility knob.)
I still don't think a hash_mem-type thing is really the right direction
to go in, even if making a distinction between memory used for sorting
and memory used for hashing is, and I'm of the general opinion that we'd
be thinking about doing something better and more appropriate- except
for the fact that we're talking about adding this in during beta.
In other words, if we'd stop trying to shoehorn something in, which
we're doing because we're in beta, we'd very likely be talking about all
of this in a very different way and probably be contemplating something
like a query_mem that provides for an overall memory limit and which
favors memory for hashing over memory for sorting, etc.
At minimum we'd need a patch we would be happy with dropping in should there be user complaints. And once this conversation ends with that in hand I have my doubts whether there will be interest, or even project desirability, in working toward a "better" solution should this one prove itself "good enough". And as it seems unlikely that this patch would foreclose on other promising solutions, combined with there being a non-trivial behavioral change that we've made, suggests to me that we might as well just deploy whatever short-term solution we come up with now.
As for hashagg_avoid_disk_plan...
The physical processes we are modelling here:
1. Processing D amount of records takes M amount of memory
2. Processing D amount of records in-memory takes T time per record while doing the same on-disk takes V time per record
3. Processing D amount of records via some other plan has an effective cost U
3. V >> T (is strictly greater than)
4. Having chosen a value for M that ensures T it is still possible for V to end up used
Thus:
If we get D wrong the user can still tweak the system by changing the hash_mem_multiplier (this is strictly better than v12 which used work_mem)
Setting hashagg_avoid_disk_plan = off provides a means to move V infinitely far away from T (set to on by default, off reverts to v12 behavior).
There is no way for the user to move V's relative position toward T (n/a in v12)
The only way to move T is to make it infinitely large by setting enable_hashagg = off (same as in v12)
Is hashagg_disk_cost_multiplier = [0.0, 1,000,000,000.0] i.e., (T * hashagg_disk_cost_multiplier == V) doable?
It has a nice symmetry with hash_mem_multiplier and can move V both toward and away from T. To the extent T is tunable or not in v12 it can remain the same in v13.
David J.
On Sat, 2020-07-18 at 21:15 -0400, Tom Lane wrote: > Jeff Davis <pgsql@j-davis.com> writes: > > What is your opinion about pessimizing the HashAgg disk costs (not > > affecting HashAgg plans expected to stay in memory)? Tomas Vondra > > presented some evidence that Sort had some better IO patterns in > > some > > cases that weren't easily reflected in a principled way in the cost > > model. > > Hm, was that in some other thread? I didn't find any such info > in a quick look through this one. https://www.postgresql.org/message-id/2df2e0728d48f498b9d6954b5f9080a34535c385.camel%40j-davis.com Regards, Jeff Davis
On Sat, Jul 18, 2020 at 3:04 PM Jeff Davis <pgsql@j-davis.com> wrote: > > I think the entire discussion > > is way out ahead of any field evidence that we need such a knob. > > In the absence of evidence, our default position ought to be to > > keep it simple, not to accumulate backwards-compatibility kluges. > > Fair enough. I think that was where Stephen and Amit were coming from, > as well. > That would lessen the number of changed plans, but we could easily > remove the pessimization without controversy later if it turned out to > be unnecessary, or if we further optimize HashAgg IO. Does this mean that we've reached a final conclusion on hashagg_avoid_disk_plan for Postgres 13, which is that it should be removed? If so, I'd appreciate it if you took care of it. I don't think that we need to delay its removal until the details of the HashAgg cost pessimization are finalized. (I expect that that will be totally uncontroversial.) Thanks -- Peter Geoghegan
On Sun, Jul 19, 2020 at 02:17:15PM -0700, Jeff Davis wrote: >On Sat, 2020-07-18 at 21:15 -0400, Tom Lane wrote: >> Jeff Davis <pgsql@j-davis.com> writes: >> > What is your opinion about pessimizing the HashAgg disk costs (not >> > affecting HashAgg plans expected to stay in memory)? Tomas Vondra >> > presented some evidence that Sort had some better IO patterns in >> > some >> > cases that weren't easily reflected in a principled way in the cost >> > model. >> >> Hm, was that in some other thread? I didn't find any such info >> in a quick look through this one. > > >https://www.postgresql.org/message-id/2df2e0728d48f498b9d6954b5f9080a34535c385.camel%40j-davis.com > FWIW the two messages to look at are these two: 1) report with initial data https://www.postgresql.org/message-id/20200519151202.u2p2gpiawoaznsv2%40development 2) updated stats, with the block pre-allocation and tlist projection https://www.postgresql.org/message-id/20200521001255.kfaihp3afv6vy6uq%40development But I'm not convinced we actually need to tweak the costing - we've ended up fixing two things, and I think a lot of the differences in I/O patterns disappeared thanks to this. For sort, the stats of request sizes look like this: type | bytes | count | pct ------+---------+-------+------- RA | 131072 | 26034 | 59.92 RA | 16384 | 6160 | 14.18 RA | 8192 | 3636 | 8.37 RA | 32768 | 3406 | 7.84 RA | 65536 | 3270 | 7.53 RA | 24576 | 361 | 0.83 ... W | 1310720 | 8070 | 34.26 W | 262144 | 1213 | 5.15 W | 524288 | 1056 | 4.48 W | 1056768 | 689 | 2.93 W | 786432 | 292 | 1.24 W | 802816 | 199 | 0.84 ... And for the hashagg, it looks like this: type | bytes | count | pct ------+---------+--------+-------- RA | 131072 | 200816 | 70.93 RA | 8192 | 23640 | 8.35 RA | 16384 | 19324 | 6.83 RA | 32768 | 19279 | 6.81 RA | 65536 | 19273 | 6.81 ... W | 1310720 | 18000 | 65.91 W | 524288 | 2074 | 7.59 W | 1048576 | 660 | 2.42 W | 8192 | 409 | 1.50 W | 786432 | 354 | 1.30 ... so it's actually a tad better than sort, because larger proportion of both reads and writes is in larger chunks (reads 128kB, writes 1280kB). I think the device had default read-ahead setting, which I assume explains the 128kB. For the statistics of deltas between requests - for sort type | block_delta | count | pct ------+-------------+-------+------- RA | 256 | 13432 | 30.91 RA | 16 | 3291 | 7.57 RA | 32 | 3272 | 7.53 RA | 64 | 3266 | 7.52 RA | 128 | 2877 | 6.62 RA | 1808 | 1278 | 2.94 RA | -2320 | 483 | 1.11 RA | 28928 | 386 | 0.89 ... W | 2560 | 7856 | 33.35 W | 2064 | 4921 | 20.89 W | 2080 | 586 | 2.49 W | 30960 | 300 | 1.27 W | 2160 | 253 | 1.07 W | 1024 | 248 | 1.05 ... and for hashagg: type | block_delta | count | pct ------+-------------+--------+------- RA | 256 | 180955 | 63.91 RA | 32 | 19274 | 6.81 RA | 64 | 19273 | 6.81 RA | 128 | 19264 | 6.80 RA | 16 | 19203 | 6.78 RA | 30480 | 9835 | 3.47 At first this might look worse than sort, but 256 sectors matches the 128kB from the request size stats, and it's good match (64% vs. 70%). There's a minor problem here, though - these stats were collected before we fixed the tlist issue, so hashagg was spilling about 10x the amount of data compared to sort+groupagg. So maybe that's the first thing we should do, before contemplating changes to the costing - collecting fresh data. I can do that, if needed. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> There's a minor problem here, though - these stats were collected before
> we fixed the tlist issue, so hashagg was spilling about 10x the amount
> of data compared to sort+groupagg. So maybe that's the first thing we
> should do, before contemplating changes to the costing - collecting
> fresh data. I can do that, if needed.
+1. I'm not sure if we still need to do anything, but we definitely
can't tell on the basis of data that doesn't reliably reflect what
the code does now.
regards, tom lane
On Mon, Jul 20, 2020 at 09:17:21AM -0400, Tom Lane wrote: >Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> There's a minor problem here, though - these stats were collected before >> we fixed the tlist issue, so hashagg was spilling about 10x the amount >> of data compared to sort+groupagg. So maybe that's the first thing we >> should do, before contemplating changes to the costing - collecting >> fresh data. I can do that, if needed. > >+1. I'm not sure if we still need to do anything, but we definitely >can't tell on the basis of data that doesn't reliably reflect what >the code does now. > OK, will do. The hardware is busy doing something else at the moment, but I'll do the tests and report results in a couple days. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jul 14, 2020 at 03:49:40PM -0700, Peter Geoghegan wrote: > Maybe I missed your point here. The problem is not so much that we'll > get HashAggs that spill -- there is nothing intrinsically wrong with > that. While it's true that the I/O pattern is not as sequential as a > similar group agg + sort, that doesn't seem like the really important > factor here. The really important factor is that in-memory HashAggs > can be blazingly fast relative to *any* alternative strategy -- be it > a HashAgg that spills, or a group aggregate + sort that doesn't spill, > whatever. We're mostly concerned about keeping the one available fast > strategy than we are about getting a new, generally slow strategy. Do we have any data that in-memory HashAggs are "blazingly fast relative to *any* alternative strategy?" The data I have tested myself and what I saw from Tomas was that spilling sort or spilling hash are both 2.5x slower. Are we sure the quoted statement is true? -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee
On Tue, Jul 14, 2020 at 6:49 PM Peter Geoghegan <pg@bowt.ie> wrote: > Maybe I missed your point here. The problem is not so much that we'll > get HashAggs that spill -- there is nothing intrinsically wrong with > that. While it's true that the I/O pattern is not as sequential as a > similar group agg + sort, that doesn't seem like the really important > factor here. The really important factor is that in-memory HashAggs > can be blazingly fast relative to *any* alternative strategy -- be it > a HashAgg that spills, or a group aggregate + sort that doesn't spill, > whatever. We're mostly concerned about keeping the one available fast > strategy than we are about getting a new, generally slow strategy. I don't know; it depends. Like, if the less-sequential I/O pattern that is caused by a HashAgg is not really any slower than a Sort+GroupAgg, then whatever. The planner might as well try a HashAgg - because it will be fast if it stays in memory - and if it doesn't work out, we've lost little by trying. But if a Sort+GroupAgg is noticeably faster than a HashAgg that ends up spilling, then there is a potential regression. I thought we had evidence that this was a real problem, but if that's not the case, then I think we're fine as far as v13 goes. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jul 21, 2020 at 1:30 PM Bruce Momjian <bruce@momjian.us> wrote: > On Tue, Jul 14, 2020 at 03:49:40PM -0700, Peter Geoghegan wrote: > > Maybe I missed your point here. The problem is not so much that we'll > > get HashAggs that spill -- there is nothing intrinsically wrong with > > that. While it's true that the I/O pattern is not as sequential as a > > similar group agg + sort, that doesn't seem like the really important > > factor here. The really important factor is that in-memory HashAggs > > can be blazingly fast relative to *any* alternative strategy -- be it > > a HashAgg that spills, or a group aggregate + sort that doesn't spill, > > whatever. We're mostly concerned about keeping the one available fast > > strategy than we are about getting a new, generally slow strategy. > > Do we have any data that in-memory HashAggs are "blazingly fast relative > to *any* alternative strategy?" The data I have tested myself and what > I saw from Tomas was that spilling sort or spilling hash are both 2.5x > slower. Are we sure the quoted statement is true? I admit that I was unclear in the remarks you quote here. I placed too much emphasis on the precise cross-over point at which a hash agg that didn't spill in Postgres 12 spills now. That was important to Andres, who was concerned about the added I/O, especially with things like cloud providers [1] -- it's not desirable to go from no I/O to lots of I/O when upgrading, regardless of how fast your disks for temp files are. But that was not the point I was trying to make (though it's a good point, and one that I agree with). I'll take another shot at it. I'll use with Andres' test case in [1]. Specifically this query (I went with this example because it was convenient): SELECT a, array_agg(b) FROM (SELECT generate_series(1, 10000)) a(a), (SELECT generate_series(1, 10000)) b(b) GROUP BY a HAVING array_length(array_agg(b), 1) = 0; The planner generally prefers a hashagg here, though it's not a particularly sympathetic case for hash agg. For one thing the input to the sort is already sorted. For another, there isn't skew. But the planner seems to have it right, at least when everything fits in memory, because that takes ~17.6 seconds with a group agg + sort vs ~13.2 seconds with an in-memory hash agg. Importantly, hash agg's peak memory usage is 1443558kB (once we get to the point that no spilling is required), whereas for the sort we're using 7833229kB for the quicksort. Don't forget that in-memory hash agg is using ~5.4x less memory in this case on account of the way hash agg represents things. It's faster, and much much more efficient once you take a holistic view (i.e. something like work done per second per KB of memory). Clearly the precise "query operation spills" cross-over point isn't that relevant to query execution time (on my server with a fast nvme SSD), because if I give the sort 95% - 99% of the memory it needs to be an in-memory quicksort then it makes a noticeable difference, but not a huge difference. I get one big run and one tiny run in the tuplesort. The query itself takes ~23.4 seconds -- higher than 17.6 seconds, but not all that much higher considering we have to write and read ~7GB of data. If I try to do approximately the same thing with hash agg (give it very slightly less than optimal memory) I find that the difference is smaller -- it takes ~14.1 seconds (up from ~13.2 seconds). It looks like my original remarks are totally wrong so far, because it's as if the performance hit is entirely explainable as the extra temp file I/O (right down to the fact that hash agg takes a smaller hit because it has much less to write out to disk). But let's keep going. = Sort vs Hash = We'll focus on how the group agg + sort case behaves as we take memory away. What I notice is that it literally doesn't matter how much memory I take away any more (now that the sort has started to spill). I said that it was ~23.4 seconds when we have two runs, but if I keep taking memory away so that we get 10 runs it takes 23.2 seconds. If there are 36 runs it takes 22.8 seconds. And if there are 144 runs (work_mem is 50MB, down from the "optimal" required for the sort to be internal, ~7GB) then it takes 21.9 seconds. So it gets slightly faster, not slower. We really don't need very much memory to do the sort in one pass, and it pretty much doesn't matter how many runs we need to merge provided it doesn't get into the thousands, which is quite rare (when random I/O from multiple passes finally starts to bite). Now for hash agg -- this is where it gets interesting. If we give it about half the memory it needs (work_mem 700MB) we still have 4 batches and it hardly changes -- it takes 19.8 seconds, which is slower than the 4 batch case that took 14.1 seconds but not that surprising. 300MB still gets 4 batches which now takes ~23.5 seconds. 200MB gets 2424 batches and takes ~27.7 seconds -- a big jump! With 100MB it takes ~31.1 seconds (3340 batches). 50MB it's ~32.8 seconds (3591 batches). With 5MB it's ~33.8 seconds, and bizarrely has a drop in the number of batches to only 1028. If I put it down to 1MB it's ~40.7 seconds and has 5604 batches (the number of batches goes up again). (And yes, the planner still chooses a hash agg when work_mem is only 1MB.) = Observations = Hash aggs that have lots of memory (which could still be somewhat less than all the memory they could possibly make use of) *are* significantly faster in general, and particularly when you consider memory efficiency. They tend to use less memory but be much more sensitive to memory availability. And, we see really sharp discontinuities at certain points as memory is taken away: weird behavior around the number of batches, etc. Group agg + sort, in contrast, is slower initially/with more memory but remarkably insensitive to how much memory it gets, and remarkably predictable overall (it actually gets a bit faster with less memory here, but I think it's fair to assume no change once the tuplesort can merge all the runs produced in one merge pass). The important point here for me is that a hash agg will almost always benefit from more memory (until everything fits in a single batch and we don't spill at all) -- even a small additional amount consistently makes a difference. Whereas there is a huge "memory availability range" for the sort where it just does not make a bit of difference. We are highly incentivized to give hash agg more memory in general, because it's bound to be faster that way (and usually uses *less* memory, as we see here). But it's not just faster -- it's also more predictable and insensitive to an underestimate of the number of groupings. It can therefore ameliorate the problem we have here with users depending on Postgres 12 fast in-memory hash aggregates, without any escape hatch kludges. I don't think that the hash_mem_multiplier patch deserves "extra credit" for being generally useful. But I also don't think that it should be punished for it. [1] https://postgr.es/m/20200625203629.7m6yvut7eqblgmfo@alap3.anarazel.de -- Peter Geoghegan
On Fri, Jul 17, 2020 at 5:13 PM Jeff Davis <pgsql@j-davis.com> wrote: > The patch itself looks reasonable to me. I don't see a lot of obvious > dangers, but perhaps someone would like to take a closer look at the > planner changes as you suggest. Attached is v3 of the hash_mem_multiplier patch series, which now has a preparatory patch that removes hashagg_avoid_disk_plan. What do you think of this approach, Jeff? It seems as if removing hashagg_avoid_disk_plan will necessitate removing various old bits of planner.c that were concerned with avoiding hash aggs that spill (the bits that hashagg_avoid_disk_plan skips in the common case where it's turned off). This makes v3-0001-* a bit trickier than I imagined it would have to be. At least it lowers the footprint of the hash_mem_multiplier code added by v3-0002-* (compared to the last version of the patch). I find the partial group paths stuff added to planner.c by commit 4f15e5d09de rather confusing (that commit was preparatory work for the main feature commit e2f1eb0e). Hopefully the hash_mem_multiplier-removal patch didn't get anything wrong in this area. Perhaps Robert can comment on this as the committer of record for partition-wise grouping/aggregation. I would like to commit this patch series by next week, and close out the two relevant open items. Separately, I suspect that we'll also need to update the cost model for hash aggs that spill, but that now seems like a totally unrelated matter. I'm waiting to hear back from Tomas about that. Tomas? Thanks -- Peter Geoghegan
Вложения
On Mon, Jul 20, 2020 at 07:25:39PM +0200, Tomas Vondra wrote:
>On Mon, Jul 20, 2020 at 09:17:21AM -0400, Tom Lane wrote:
>>Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
>>>There's a minor problem here, though - these stats were collected before
>>>we fixed the tlist issue, so hashagg was spilling about 10x the amount
>>>of data compared to sort+groupagg. So maybe that's the first thing we
>>>should do, before contemplating changes to the costing - collecting
>>>fresh data. I can do that, if needed.
>>
>>+1. I'm not sure if we still need to do anything, but we definitely
>>can't tell on the basis of data that doesn't reliably reflect what
>>the code does now.
>>
>
>OK, will do. The hardware is busy doing something else at the moment,
>but I'll do the tests and report results in a couple days.
>
Hi,
So let me share some fresh I/O statistics collected on the current code
using iosnoop. I've done the tests on two different machines using the
"aggregate part" of TPC-H Q17, i.e. essentially this:
SELECT * FROM (
SELECT
l_partkey AS agg_partkey,
0.2 * avg(l_quantity) AS avg_quantity
FROM lineitem GROUP BY l_partkey OFFSET 1000000000
) part_agg;
The OFFSET is there just to ensure we don't need to send anything to
the client, etc.
On the first machine (i5-2500k, 8GB RAM) data was located on a RAID
of SSD devices, and the temp tablespace was placed on a separate SSD
device. This makes it easy to isolate the I/O requests related to the
spilling, which is the interesting thing. The data set here is scale
32GB, most of it in the lineitem table.
On the second machine (xeon e5-2620, 64GB RAM) was using scale 75GB,
and I've done two different tests. First, the data was on a SATA RAID
while the temp tablespace was on a NVMe SSD - this allows isolating
the I/O requests just like on the first machine, but the durations are
not very interesting because the SATA RAID is the bottleneck. Then I've
switched the locations (data on SSD, temp files on SATA RAID), which
gives us some interesting query durations but the multiple devices make
it difficult to analyze the I/O patterns. So I'll present patterns from
the first setup and timings from the second one, hopefully it's not
completely bogus.
In all cases I've ran the query with a range of work_mem values and
enable_sort/enable_hashagg settings, and enabled/disabled parallelism,
collecting the iosnoop data, query durations, information about cost
and disk usage. Attached are the explain plans, summary of iosnoop
stats etc.
I also have a couple observations about hashagg vs. groupagg, and the
recent hashagg fixes.
1) hashagg vs. groupagg
If you look at the query duration charts comparing hashagg and groupagg,
you can see that in both cases the hashagg is stable and mostly not
dependent on work_mem. It initially (for low work_mem values) wins, but
the sort+groupagg gradually improves and eventually gets faster.
Note: This does not include work_mem large enough to eliminate the need
for spilling, which would probably make hashagg much faster.
For the parallel case the difference is much smaller and groupagg gets
faster much sooner. This is probably due to the large number of groups
in this particular data set.
Now, the I/O patterns - if you look into the iosnoop summaries, there
are two tables for each config - block stats (request sizes) and delta
stats (gaps between requests). These tables need to be interpreted in
combination - ideally, the blocks should be larger and the gaps should
match the block size.
IIRC it was suggested hashagg does more random I/O than sort, but I
don't think the iosnoop data really show that - in fact, the requests
tend to be larger than for sort, and the deltas match the request sizes
better I think. At least for lower work_mem values. With larger values
it kinda inverts and sort gets more sequential, but I don't think the
difference is very big.
Also, had it been more random it'd be very obvious from durations with
temp tablespace on the SATA RAID, I think.
So I'm not sure we need to tweak the hashagg costing for this reason.
2) hashagg vs. CP_SMALL_TLIST vs. groupagg
I was a bit puzzled because the hashagg timings seemed higher compared
to the last runs with the CP_SMALL_TLIST fix (which was now reverted
and replaced by projection right before spilling). But the explanation
is pretty simple - we spill significantly more data than with the
CP_SMALL_TLIST patch. And what's also interesting is that in both cases
we spill much more data than sort.
This is illustrated on the "disk usage" charts, but let me show some
numbers here. These are the "Disk Usage" values from explain analyze
(measured in GB):
2MB 4MB 8MB 64MB 256MB
-----------------------------------------------------------
hash 6.71 6.70 6.73 6.44 5.81
hash CP_SMALL_TLIST 5.28 5.26 5.24 5.04 4.54
sort 3.41 3.41 3.41 3.57 3.45
So sort writes ~3.4GB of data, give or take. But hashagg/master writes
almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the
original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still
much more than the 3.4GB of data written by sort (which has to spill
everything, while hashagg only spills rows not covered by the groups
that fit into work_mem).
I initially assumed this is due to writing the hash value to the tapes,
and the rows are fairly narrow (only about 40B per row), so a 4B hash
could make a difference - but certainly not this much. Moreover, that
does not explain the difference between master and the now-reverted
CP_SMALL_TLIST, I think.
3) costing
What I find really surprising is the costing - despite writing about
twice as much data, the hashagg cost is estimated to be much lower than
the sort. For example on the i5 machine, the hashagg cost is ~10M, while
sort cost is almost 42M. Despite using almost twice as much disk. And
the costing is exactly the same for master and the CP_SMALL_TLIST.
I was wondering if this might be due to random_page_cost being too low
or something, but I very much doubt that. Firstly - this is on SSDs,
so I really don't want it very high. Secondly, increasing random_page
cost actually increases both costs.
So I'm wondering why the hashagg cost is so low, but I haven't looked
into that yet.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
- xeon-temp-on-ssd.tgz
- xeon-temp-on-sata.tgz
- i5.tgz
- iosnoop-xeon.txt
- iosnoop-i5.txt
- i5-noparallel-duration.png
- i5-noparallel-cost.png
- i5-noparallel-disk-usage.png
- i5-parallel-duration.png
- i5-parallel-cost.png
- i5-parallel-disk-usage.png
- xeon-noparallel-duration.png
- xeon-noparallel-cost.png
- xeon-noparallel-disk-usage.png
- xeon-parallel-duration.png
- xeon-parallel-cost.png
- xeon-parallel-disk-usage.png
- cp-small-tlist-query-duration.png
- cp-small-tlist-query-cost.png
- cp-small-tlist-disk-usage.png
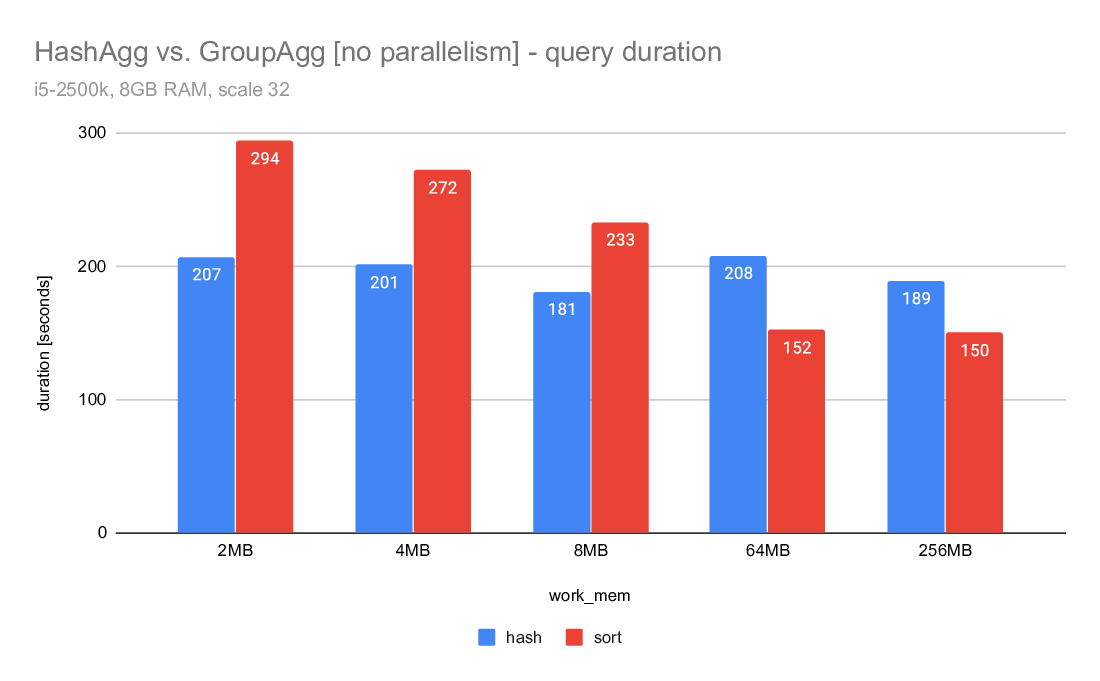{kind=link}
{kind=link}
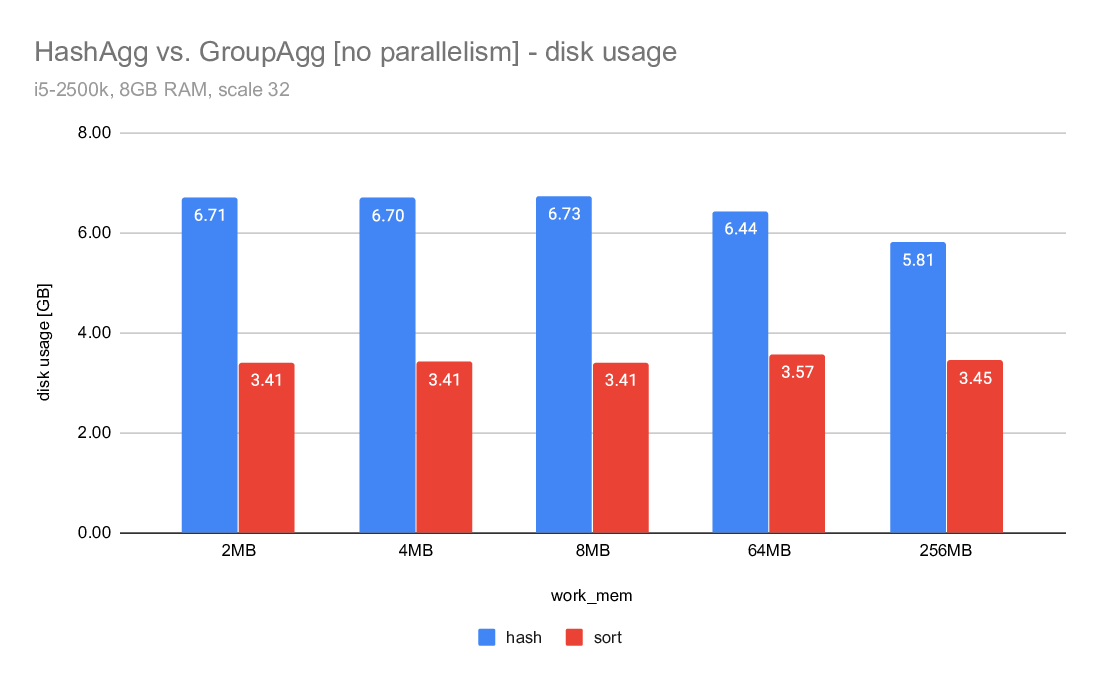{kind=link}
{kind=link}
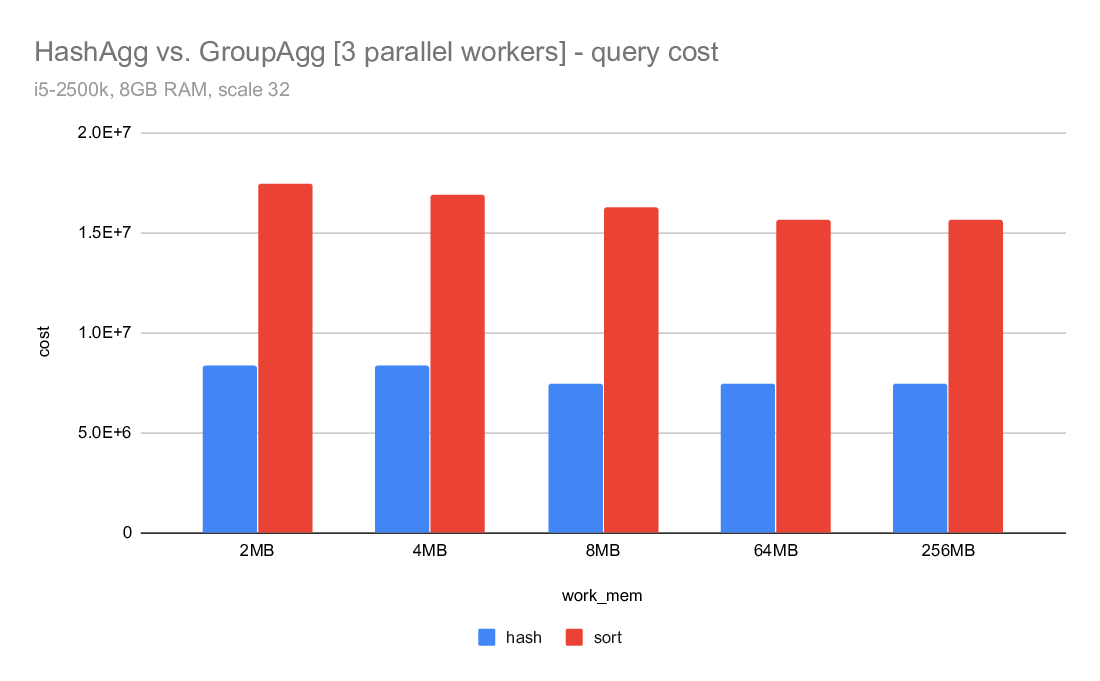{kind=link}
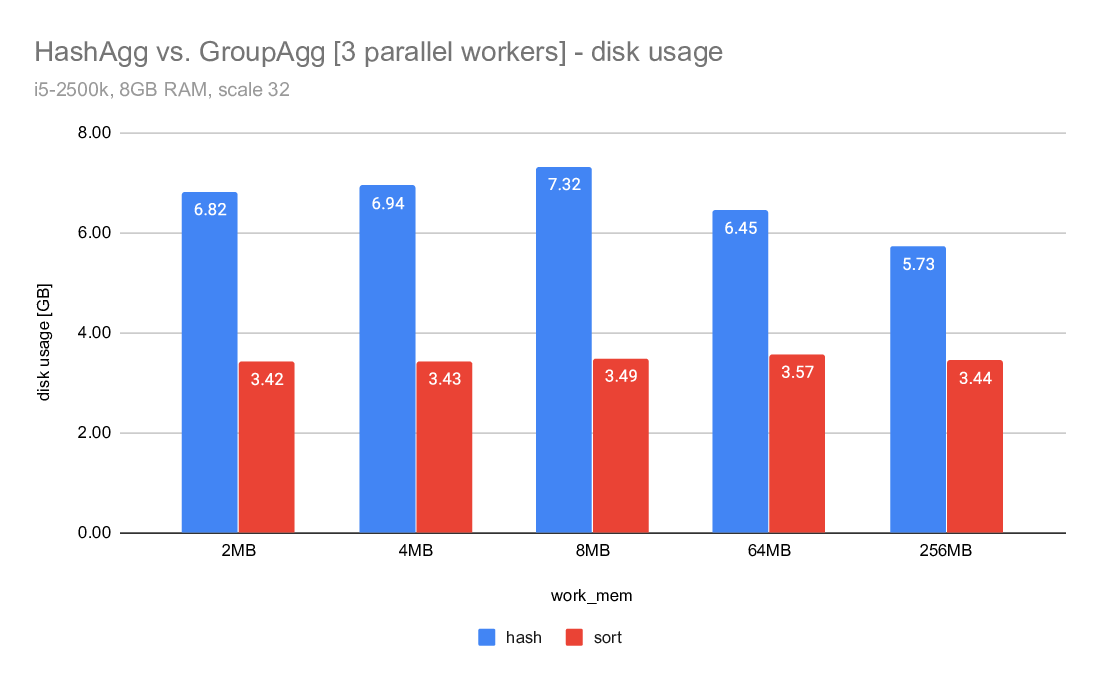{kind=link}
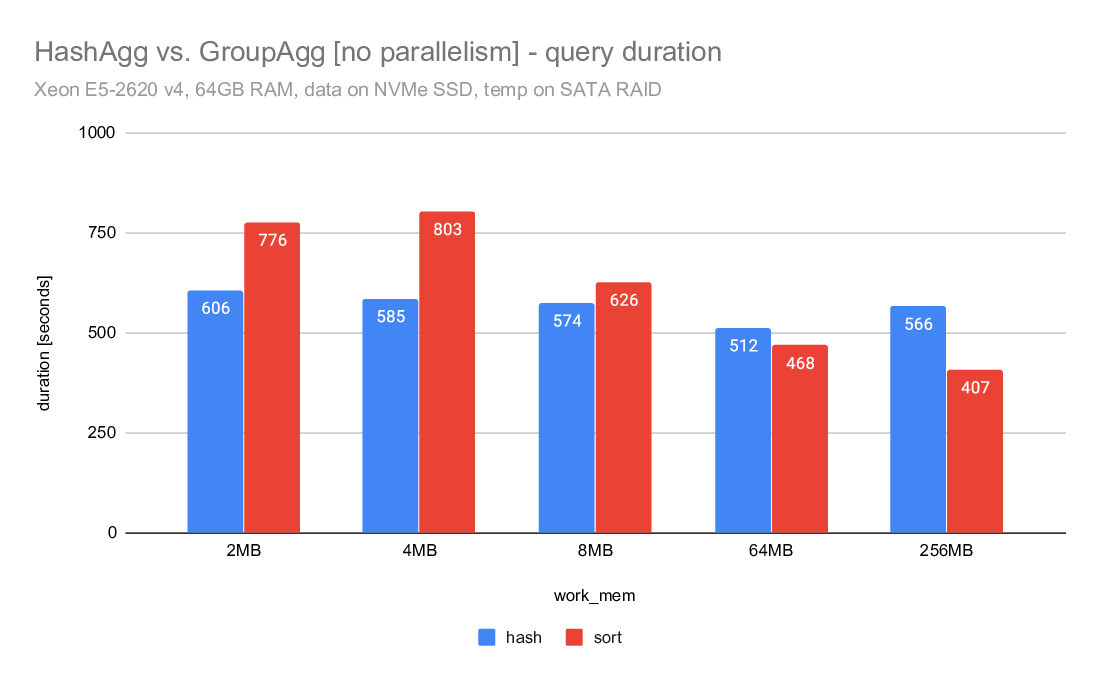{kind=link}
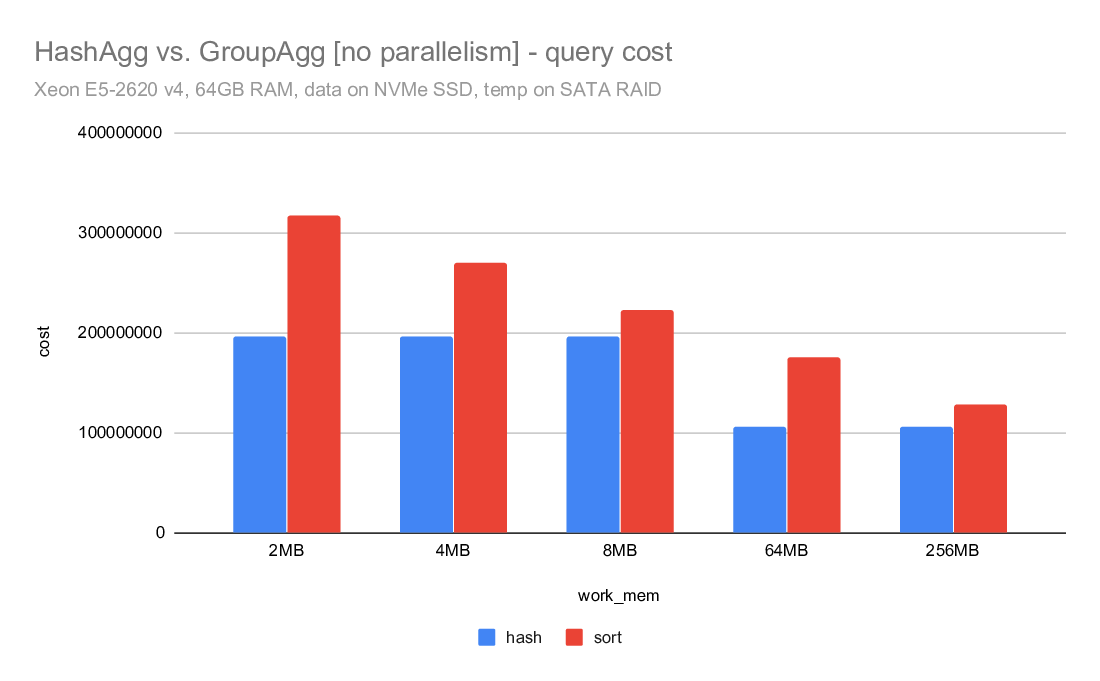{kind=link}
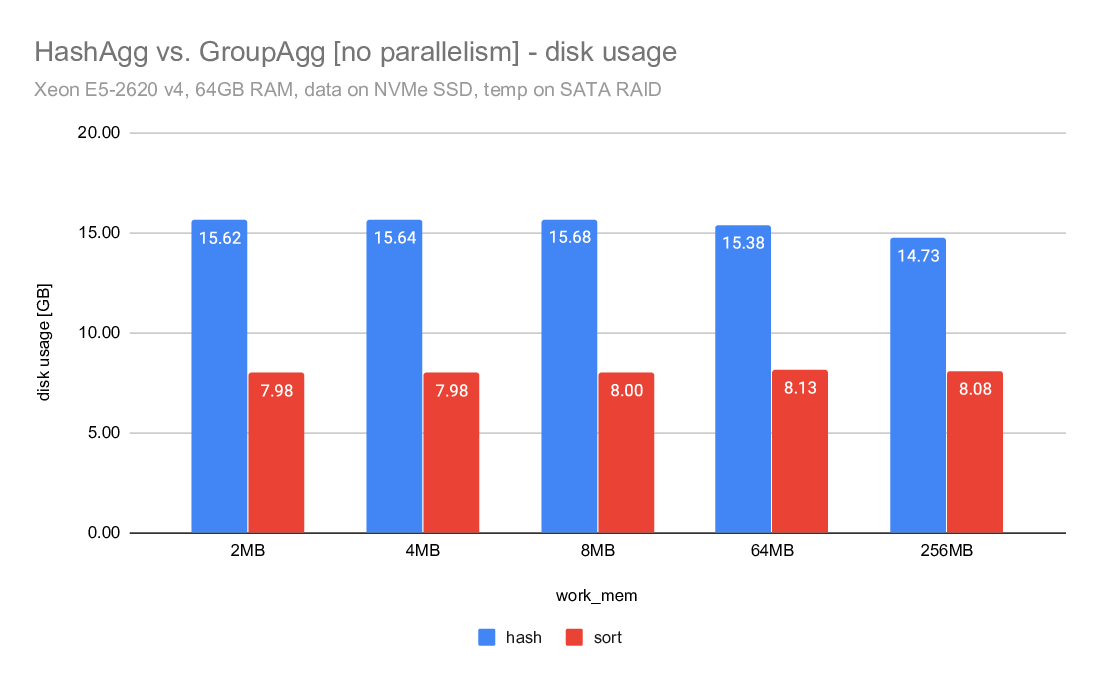{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
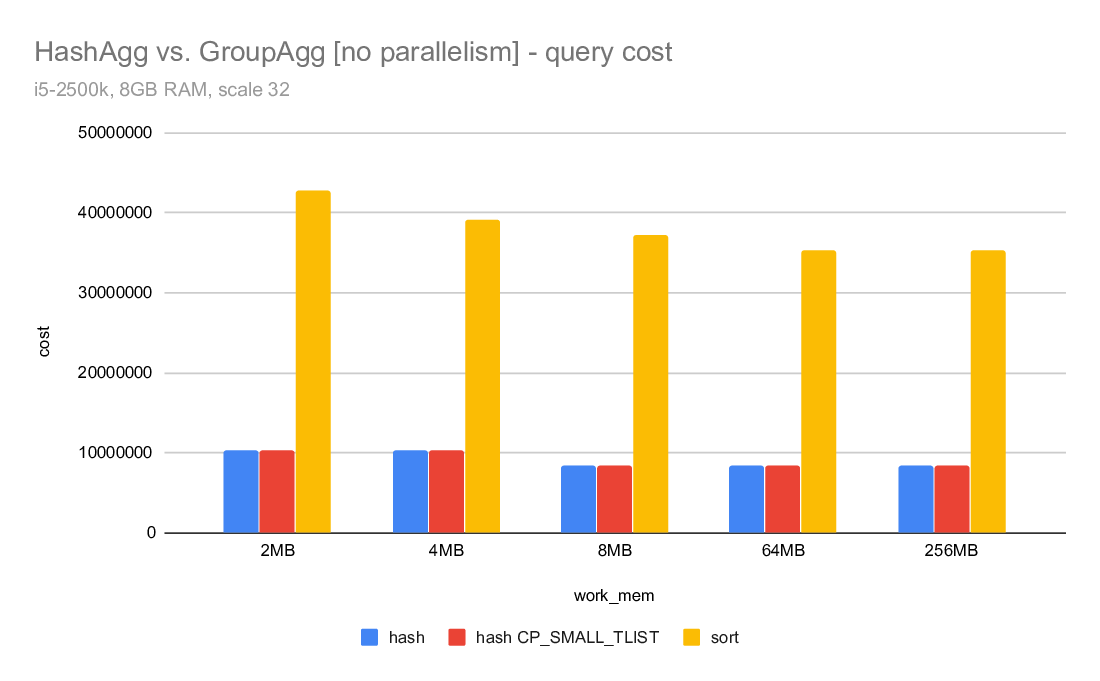{kind=link}
{kind=link}
On Thu, Jul 23, 2020 at 6:22 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > So let me share some fresh I/O statistics collected on the current code > using iosnoop. I've done the tests on two different machines using the > "aggregate part" of TPC-H Q17, i.e. essentially this: > > SELECT * FROM ( > SELECT > l_partkey AS agg_partkey, > 0.2 * avg(l_quantity) AS avg_quantity > FROM lineitem GROUP BY l_partkey OFFSET 1000000000 > ) part_agg; > > The OFFSET is there just to ensure we don't need to send anything to > the client, etc. Thanks for testing this. > So sort writes ~3.4GB of data, give or take. But hashagg/master writes > almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the > original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still > much more than the 3.4GB of data written by sort (which has to spill > everything, while hashagg only spills rows not covered by the groups > that fit into work_mem). What I find when I run your query (with my own TPC-H DB that is smaller than what you used here -- 59,986,052 lineitem tuples) is that the sort required about 7x more memory than the hash agg to do everything in memory: 4,384,711KB for the quicksort vs 630,801KB peak hash agg memory usage. I'd be surprised if the ratio was very different for you -- but can you check? I think that there is something pathological about this spill behavior, because it sounds like the precise opposite of what you might expect when you make a rough extrapolation of what disk I/O will be based on the memory used in no-spill cases (as reported by EXPLAIN ANALYZE). > What I find really surprising is the costing - despite writing about > twice as much data, the hashagg cost is estimated to be much lower than > the sort. For example on the i5 machine, the hashagg cost is ~10M, while > sort cost is almost 42M. Despite using almost twice as much disk. And > the costing is exactly the same for master and the CP_SMALL_TLIST. That does make it sound like the costs of the hash agg aren't being represented. I suppose it isn't clear if this is a costing issue because it isn't clear if the execution time performance itself is pathological or is instead something that must be accepted as the cost of spilling the hash agg in a general kind of way. -- Peter Geoghegan
On Thu, Jul 23, 2020 at 07:33:45PM -0700, Peter Geoghegan wrote:
>On Thu, Jul 23, 2020 at 6:22 PM Tomas Vondra
><tomas.vondra@2ndquadrant.com> wrote:
>> So let me share some fresh I/O statistics collected on the current code
>> using iosnoop. I've done the tests on two different machines using the
>> "aggregate part" of TPC-H Q17, i.e. essentially this:
>>
>> SELECT * FROM (
>> SELECT
>> l_partkey AS agg_partkey,
>> 0.2 * avg(l_quantity) AS avg_quantity
>> FROM lineitem GROUP BY l_partkey OFFSET 1000000000
>> ) part_agg;
>>
>> The OFFSET is there just to ensure we don't need to send anything to
>> the client, etc.
>
>Thanks for testing this.
>
>> So sort writes ~3.4GB of data, give or take. But hashagg/master writes
>> almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the
>> original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still
>> much more than the 3.4GB of data written by sort (which has to spill
>> everything, while hashagg only spills rows not covered by the groups
>> that fit into work_mem).
>
>What I find when I run your query (with my own TPC-H DB that is
>smaller than what you used here -- 59,986,052 lineitem tuples) is that
>the sort required about 7x more memory than the hash agg to do
>everything in memory: 4,384,711KB for the quicksort vs 630,801KB peak
>hash agg memory usage. I'd be surprised if the ratio was very
>different for you -- but can you check?
>
I can check, but it's not quite clear to me what are we looking for?
Increase work_mem until there's no need to spill in either case?
>I think that there is something pathological about this spill
>behavior, because it sounds like the precise opposite of what you
>might expect when you make a rough extrapolation of what disk I/O will
>be based on the memory used in no-spill cases (as reported by EXPLAIN
>ANALYZE).
>
Maybe, not sure what exactly you think is pathological? The trouble is
hashagg has to spill input tuples but the memory used in no-spill case
represents aggregated groups, so I'm not sure how you could extrapolate
from that ...
FWIW one more suspicious thing that I forgot to mention is the behavior
of the "planned partitions" depending on work_mem, which looks like
this:
2MB Planned Partitions: 64 HashAgg Batches: 4160
4MB Planned Partitions: 128 HashAgg Batches: 16512
8MB Planned Partitions: 256 HashAgg Batches: 21488
64MB Planned Partitions: 32 HashAgg Batches: 2720
256MB Planned Partitions: 8 HashAgg Batches: 8
I'd expect the number of planned partitions to decrease (slowly) as
work_mem increases, but it seems to increase initially. Seems a bit
strange, but maybe it's expected.
>> What I find really surprising is the costing - despite writing about
>> twice as much data, the hashagg cost is estimated to be much lower than
>> the sort. For example on the i5 machine, the hashagg cost is ~10M, while
>> sort cost is almost 42M. Despite using almost twice as much disk. And
>> the costing is exactly the same for master and the CP_SMALL_TLIST.
>
>That does make it sound like the costs of the hash agg aren't being
>represented. I suppose it isn't clear if this is a costing issue
>because it isn't clear if the execution time performance itself is
>pathological or is instead something that must be accepted as the cost
>of spilling the hash agg in a general kind of way.
>
Not sure, but I think we need to spill roughly as much as sort, so it
seems a bit strange that (a) we're spilling 2x as much data and yet the
cost is so much lower.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 24, 2020 at 10:40:47AM +0200, Tomas Vondra wrote: >On Thu, Jul 23, 2020 at 07:33:45PM -0700, Peter Geoghegan wrote: >>On Thu, Jul 23, 2020 at 6:22 PM Tomas Vondra >><tomas.vondra@2ndquadrant.com> wrote: >>>So let me share some fresh I/O statistics collected on the current code >>>using iosnoop. I've done the tests on two different machines using the >>>"aggregate part" of TPC-H Q17, i.e. essentially this: >>> >>> SELECT * FROM ( >>> SELECT >>> l_partkey AS agg_partkey, >>> 0.2 * avg(l_quantity) AS avg_quantity >>> FROM lineitem GROUP BY l_partkey OFFSET 1000000000 >>> ) part_agg; >>> >>>The OFFSET is there just to ensure we don't need to send anything to >>>the client, etc. >> >>Thanks for testing this. >> >>>So sort writes ~3.4GB of data, give or take. But hashagg/master writes >>>almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the >>>original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still >>>much more than the 3.4GB of data written by sort (which has to spill >>>everything, while hashagg only spills rows not covered by the groups >>>that fit into work_mem). >> >>What I find when I run your query (with my own TPC-H DB that is >>smaller than what you used here -- 59,986,052 lineitem tuples) is that >>the sort required about 7x more memory than the hash agg to do >>everything in memory: 4,384,711KB for the quicksort vs 630,801KB peak >>hash agg memory usage. I'd be surprised if the ratio was very >>different for you -- but can you check? >> > >I can check, but it's not quite clear to me what are we looking for? >Increase work_mem until there's no need to spill in either case? > FWIW the hashagg needs about 4775953kB and the sort 33677586kB. So yeah, that's about 7x more. I think that's probably built into the TPC-H data set. It'd be easy to construct cases with much higher/lower factors. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
On Thu, Jul 23, 2020 at 9:22 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > 2MB 4MB 8MB 64MB 256MB > ----------------------------------------------------------- > hash 6.71 6.70 6.73 6.44 5.81 > hash CP_SMALL_TLIST 5.28 5.26 5.24 5.04 4.54 > sort 3.41 3.41 3.41 3.57 3.45 > > So sort writes ~3.4GB of data, give or take. But hashagg/master writes > almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the > original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still > much more than the 3.4GB of data written by sort (which has to spill > everything, while hashagg only spills rows not covered by the groups > that fit into work_mem). > > I initially assumed this is due to writing the hash value to the tapes, > and the rows are fairly narrow (only about 40B per row), so a 4B hash > could make a difference - but certainly not this much. Moreover, that > does not explain the difference between master and the now-reverted > CP_SMALL_TLIST, I think. This is all really good analysis, I think, but this seems like the key finding. It seems like we don't really understand what's actually getting written. Whether we use hash or sort doesn't seem like it should have this kind of impact on how much data gets written, and whether we use CP_SMALL_TLIST or project when needed doesn't seem like it should matter like this either. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Jul 24, 2020 at 11:18:48AM -0400, Robert Haas wrote: >On Thu, Jul 23, 2020 at 9:22 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> 2MB 4MB 8MB 64MB 256MB >> ----------------------------------------------------------- >> hash 6.71 6.70 6.73 6.44 5.81 >> hash CP_SMALL_TLIST 5.28 5.26 5.24 5.04 4.54 >> sort 3.41 3.41 3.41 3.57 3.45 >> >> So sort writes ~3.4GB of data, give or take. But hashagg/master writes >> almost 6-7GB of data, i.e. almost twice as much. Meanwhile, with the >> original CP_SMALL_TLIST we'd write "only" ~5GB of data. That's still >> much more than the 3.4GB of data written by sort (which has to spill >> everything, while hashagg only spills rows not covered by the groups >> that fit into work_mem). >> >> I initially assumed this is due to writing the hash value to the tapes, >> and the rows are fairly narrow (only about 40B per row), so a 4B hash >> could make a difference - but certainly not this much. Moreover, that >> does not explain the difference between master and the now-reverted >> CP_SMALL_TLIST, I think. > >This is all really good analysis, I think, but this seems like the key >finding. It seems like we don't really understand what's actually >getting written. Whether we use hash or sort doesn't seem like it >should have this kind of impact on how much data gets written, and >whether we use CP_SMALL_TLIST or project when needed doesn't seem like >it should matter like this either. > I think for CP_SMALL_TLIST at least some of the extra data can be attributed to writing the hash value along with the tuple, which sort obviously does not do. With the 32GB data set (the i5 machine), there are ~20M rows in the lineitem table, and with 4B hash values that's about 732MB of extra data. That's about the 50% of the difference between sort and CP_SMALL_TLIST, and I'd dare to speculate the other 50% is due to LogicalTape internals (pointers to the next block, etc.) The question is why master has 2x the overhead of CP_SMALL_TLIST, if it's meant to write the same set of columns etc. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 24, 2020 at 8:19 AM Robert Haas <robertmhaas@gmail.com> wrote: > This is all really good analysis, I think, but this seems like the key > finding. It seems like we don't really understand what's actually > getting written. Whether we use hash or sort doesn't seem like it > should have this kind of impact on how much data gets written, and > whether we use CP_SMALL_TLIST or project when needed doesn't seem like > it should matter like this either. Isn't this more or less the expected behavior in the event of partitions that are spilled recursively? The case that Tomas tested were mostly cases where work_mem was tiny relative to the data being aggregated. The following is an extract from commit 1f39bce0215 showing some stuff added to the beginning of nodeAgg.c: + * We also specify a min and max number of partitions per spill. Too few might + * mean a lot of wasted I/O from repeated spilling of the same tuples. Too + * many will result in lots of memory wasted buffering the spill files (which + * could instead be spent on a larger hash table). + */ +#define HASHAGG_PARTITION_FACTOR 1.50 +#define HASHAGG_MIN_PARTITIONS 4 +#define HASHAGG_MAX_PARTITIONS 1024 -- Peter Geoghegan
On Fri, Jul 24, 2020 at 1:40 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Maybe, not sure what exactly you think is pathological? The trouble is > hashagg has to spill input tuples but the memory used in no-spill case > represents aggregated groups, so I'm not sure how you could extrapolate > from that ... Yeah, but when hash agg enters spill mode it will continue to advance the transition states for groups already in the hash table, which could be quite a significant effect. The peak memory usage for an equivalent no-spill hash agg is therefore kind of related to the amount of I/O needed for spilling. I suppose that you mostly tested cases where memory was in very short supply, where that breaks down completely. Perhaps it wasn't helpful for me to bring that factor into this discussion -- it's not as if there is any doubt that hash agg is spilling a lot more here in any case. > Not sure, but I think we need to spill roughly as much as sort, so it > seems a bit strange that (a) we're spilling 2x as much data and yet the > cost is so much lower. ISTM that the amount of I/O that hash agg performs can vary *very* widely for the same data. This is mostly determined by work_mem, but there are second order effects. OTOH, the amount of I/O that a sort must do is practically fixed. You can quibble with that characterisation a bit because of multi-pass sorts, but not really -- multi-pass sorts are generally quite rare. I think that we need a more sophisticated cost model for this in cost_agg(). Maybe the "pages_written" calculation could be pessimized. However, it doesn't seem like this is precisely an issue with I/O costs. -- Peter Geoghegan
On Fri, Jul 24, 2020 at 11:03:54AM -0700, Peter Geoghegan wrote:
>On Fri, Jul 24, 2020 at 8:19 AM Robert Haas <robertmhaas@gmail.com> wrote:
>> This is all really good analysis, I think, but this seems like the key
>> finding. It seems like we don't really understand what's actually
>> getting written. Whether we use hash or sort doesn't seem like it
>> should have this kind of impact on how much data gets written, and
>> whether we use CP_SMALL_TLIST or project when needed doesn't seem like
>> it should matter like this either.
>
>Isn't this more or less the expected behavior in the event of
>partitions that are spilled recursively? The case that Tomas tested
>were mostly cases where work_mem was tiny relative to the data being
>aggregated.
>
>The following is an extract from commit 1f39bce0215 showing some stuff
>added to the beginning of nodeAgg.c:
>
>+ * We also specify a min and max number of partitions per spill. Too few might
>+ * mean a lot of wasted I/O from repeated spilling of the same tuples. Too
>+ * many will result in lots of memory wasted buffering the spill files (which
>+ * could instead be spent on a larger hash table).
>+ */
>+#define HASHAGG_PARTITION_FACTOR 1.50
>+#define HASHAGG_MIN_PARTITIONS 4
>+#define HASHAGG_MAX_PARTITIONS 1024
>
Maybe, but we're nowhere close to these limits. See this table which I
posted earlier:
2MB Planned Partitions: 64 HashAgg Batches: 4160
4MB Planned Partitions: 128 HashAgg Batches: 16512
8MB Planned Partitions: 256 HashAgg Batches: 21488
64MB Planned Partitions: 32 HashAgg Batches: 2720
256MB Planned Partitions: 8 HashAgg Batches: 8
This is from the non-parallel runs on the i5 machine with 32GB data set,
the first column is work_mem. We're nowhere near the 1024 limit, and the
cardinality estimates are pretty good.
OTOH the number o batches is much higher, so clearly there was some
recursive spilling happening. What I find strange is that this grows
with work_mem and only starts dropping after 64MB.
Also, how could the amount of I/O be almost constant in all these cases?
Surely more recursive spilling should do more I/O, but the Disk Usage
reported by explain analyze does not show anything like ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 24, 2020 at 12:16 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Maybe, but we're nowhere close to these limits. See this table which I > posted earlier: > > 2MB Planned Partitions: 64 HashAgg Batches: 4160 > 4MB Planned Partitions: 128 HashAgg Batches: 16512 > 8MB Planned Partitions: 256 HashAgg Batches: 21488 > 64MB Planned Partitions: 32 HashAgg Batches: 2720 > 256MB Planned Partitions: 8 HashAgg Batches: 8 > > This is from the non-parallel runs on the i5 machine with 32GB data set, > the first column is work_mem. We're nowhere near the 1024 limit, and the > cardinality estimates are pretty good. > > OTOH the number o batches is much higher, so clearly there was some > recursive spilling happening. What I find strange is that this grows > with work_mem and only starts dropping after 64MB. Could that be caused by clustering in the data? If the input data is in totally random order then we have a good chance of never having to spill skewed "common" values. That is, we're bound to encounter common values before entering spill mode, and so those common values will continue to be usefully aggregated until we're done with the initial groups (i.e. until the in-memory hash table is cleared in order to process spilled input tuples). This is great because the common values get aggregated without ever spilling, and most of the work is done before we even begin with spilled tuples. If, on the other hand, the common values are concentrated together in the input... Assuming that I have this right, then I would also expect simply having more memory to ameliorate the problem. If you only have/need 4 or 8 partitions then you can fit a higher proportion of the total number of groups for the whole dataset in the hash table (at the point when you first enter spill mode). I think it follows that the "nailed" hash table entries/groupings will "better characterize" the dataset as a whole. > Also, how could the amount of I/O be almost constant in all these cases? > Surely more recursive spilling should do more I/O, but the Disk Usage > reported by explain analyze does not show anything like ... Not sure, but might that just be because of the fact that logtape.c can recycle disk space? As I said in my last e-mail, it's pretty reasonable to assume that the vast majority of external sorts are one-pass. It follows that disk usage can be thought of as almost the same thing as total I/O for tuplesort. But the same heuristic isn't reasonable when thinking about hash agg. Hash agg might write out much less data than the total memory used for the equivalent "peak optimal nospill" hash agg case -- or much more. (Again, reiterating what I said in my last e-mail.) -- Peter Geoghegan
On Fri, 2020-07-24 at 21:16 +0200, Tomas Vondra wrote:
> Surely more recursive spilling should do more I/O, but the Disk Usage
> reported by explain analyze does not show anything like ...
I suspect that's because of disk reuse in logtape.c.
Regards,
Jeff Davis
On Fri, Jul 24, 2020 at 12:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > Could that be caused by clustering in the data? > > If the input data is in totally random order then we have a good > chance of never having to spill skewed "common" values. That is, we're > bound to encounter common values before entering spill mode, and so > those common values will continue to be usefully aggregated until > we're done with the initial groups (i.e. until the in-memory hash > table is cleared in order to process spilled input tuples). This is > great because the common values get aggregated without ever spilling, > and most of the work is done before we even begin with spilled tuples. > > If, on the other hand, the common values are concentrated together in > the input... I still don't know if that was a factor in your example, but I can clearly demonstrate that the clustering of data can matter a lot to hash aggs in Postgres 13. I attach a contrived example where it makes a *huge* difference. I find that the sorted version of the aggregate query takes significantly longer to finish, and has the following spill characteristics: "Peak Memory Usage: 205086kB Disk Usage: 2353920kB HashAgg Batches: 2424" Note that the planner doesn't expect any partitions here, but we still get 2424 batches -- so the planner seems to get it totally wrong. OTOH, the same query against a randomized version of the same data (no longer in sorted order, no clustering) works perfectly with the same work_mem (200MB): "Peak Memory Usage: 1605334kB" Hash agg avoids spilling entirely (so the planner gets it right this time around). It even uses notably less memory. -- Peter Geoghegan
Вложения
On Sat, Jul 25, 2020 at 9:39 AM Peter Geoghegan <pg@bowt.ie> wrote: > "Peak Memory Usage: 1605334kB" > > Hash agg avoids spilling entirely (so the planner gets it right this > time around). It even uses notably less memory. I guess that this is because the reported memory usage doesn't reflect the space used for transition state, which is presumably most of the total -- array_agg() is used in the query. -- Peter Geoghegan
On Fri, 2020-07-24 at 10:40 +0200, Tomas Vondra wrote:
> FWIW one more suspicious thing that I forgot to mention is the
> behavior
> of the "planned partitions" depending on work_mem, which looks like
> this:
>
> 2MB Planned Partitions: 64 HashAgg Batches: 4160
> 4MB Planned Partitions: 128 HashAgg Batches: 16512
> 8MB Planned Partitions: 256 HashAgg Batches: 21488
> 64MB Planned Partitions: 32 HashAgg Batches: 2720
> 256MB Planned Partitions: 8 HashAgg Batches: 8
>
> I'd expect the number of planned partitions to decrease (slowly) as
> work_mem increases, but it seems to increase initially. Seems a bit
> strange, but maybe it's expected.
The space for open-partition buffers is also limited to about 25% of
memory. Each open partition takes BLCKSZ memory, so those numbers are
exactly what I'd expect (64*8192 = 512kB).
There's also another effect at work that can cause the total number of
batches to be higher for larger work_mem values: when we do recurse, we
again need to estimate the number of partitions needed. Right now, we
overestimate the number of partitions needed (to be conservative),
which leads to a wider fan-out and lots of tiny partitions, and
therefore more batches.
I think we can improve this by using something like a HyperLogLog on
the hash values of the spilled tuples to get a better estimate for the
number of groups (and therefore the number of partitions) that we need
when we recurse, which would reduce the number of overall batches at
higher work_mem settings. But I didn't get a chance to implement that
yet.
Regards,
Jeff Davis
On Thu, 2020-07-23 at 19:33 -0700, Peter Geoghegan wrote:
> That does make it sound like the costs of the hash agg aren't being
> represented. I suppose it isn't clear if this is a costing issue
> because it isn't clear if the execution time performance itself is
> pathological or is instead something that must be accepted as the
> cost
> of spilling the hash agg in a general kind of way.
I have a feeling that this is mostly a costing problem. Sort uses its
memory in two different phases:
1. when writing the sorted runs, it needs the memory to hold the run
before sorting it, and only a single buffer for the output tape; and
2. when merging, it needs a lot of read buffers
But in HashAgg, it needs to hold all of the groups in memory *at the
same time* as it needs a lot of output buffers (one for each
partition). This doesn't matter a lot at high values of work_mem,
because the buffers will only be 8MB at most.
I did attempt to cost this properly: hash_agg_set_limits() takes into
account the memory the partitions will use, and the remaining memory is
what's used in cost_agg(). But there's a lot of room for error in
there.
If someone sees an obvious error in the costing, please let me know.
Otherwise, I think it will just take some time to make it better
reflect reality in a variety of cases. For v13, and we will either need
to live with it, or pessimize the costing for HashAgg until we get it
right.
Many costing issues can deal with a lot of slop -- e.g. HashJoin vs
MergeJoin -- because a small factor often doesn't make the difference
between plans. But HashAgg and Sort are more competitive with each
other, so costing needs to be more precise.
Regards,
Jeff Davis
On Sat, Jul 25, 2020 at 10:23 AM Jeff Davis <pgsql@j-davis.com> wrote:
> There's also another effect at work that can cause the total number of
> batches to be higher for larger work_mem values: when we do recurse, we
> again need to estimate the number of partitions needed. Right now, we
> overestimate the number of partitions needed (to be conservative),
> which leads to a wider fan-out and lots of tiny partitions, and
> therefore more batches.
What worries me a bit is the sharp discontinuities when spilling with
significantly less work_mem than the "optimal" amount. For example,
with Tomas' TPC-H query (against my smaller TPC-H dataset), I find
that setting work_mem to 6MB looks like this:
-> HashAggregate (cost=2700529.47..3020654.22 rows=1815500
width=40) (actual time=21039.788..32278.703 rows=2000000 loops=1)
Output: lineitem.l_partkey, (0.2 * avg(lineitem.l_quantity))
Group Key: lineitem.l_partkey
Planned Partitions: 128 Peak Memory Usage: 6161kB Disk
Usage: 2478080kB HashAgg Batches: 128
(And we have a sensible looking number of batches that match the
number of planned partitions with higher work_mem settings, too.)
However, if I set work_mem to 5MB (or less), it looks like this:
-> HashAggregate (cost=2700529.47..3020654.22 rows=1815500
width=40) (actual time=20849.490..37027.533 rows=2000000 loops=1)
Output: lineitem.l_partkey, (0.2 * avg(lineitem.l_quantity))
Group Key: lineitem.l_partkey
Planned Partitions: 128 Peak Memory Usage: 5393kB Disk
Usage: 2482152kB HashAgg Batches: 11456
So the number of partitions is still 128, but the number of batches
explodes to 11,456 all at once. My guess that this is because the
recursive hash aggregation misbehaves in a self-similar fashion once a
certain tipping point has been reached. I expect that the exact nature
of that tipping point is very complicated, and generally dependent on
the dataset, clustering, etc. But I don't think that this kind of
effect will be uncommon.
(FWIW this example requires ~620MB work_mem to complete without
spilling at all -- so it's kind of extreme, though not quite as
extreme as many of the similar test results from Tomas.)
--
Peter Geoghegan
On Sat, 2020-07-25 at 11:05 -0700, Peter Geoghegan wrote:
> What worries me a bit is the sharp discontinuities when spilling with
> significantly less work_mem than the "optimal" amount. For example,
> with Tomas' TPC-H query (against my smaller TPC-H dataset), I find
> that setting work_mem to 6MB looks like this:
...
> Planned Partitions: 128 Peak Memory Usage: 6161kB Disk
> Usage: 2478080kB HashAgg Batches: 128
...
> Planned Partitions: 128 Peak Memory Usage: 5393kB Disk
> Usage: 2482152kB HashAgg Batches: 11456
...
> My guess that this is because the
> recursive hash aggregation misbehaves in a self-similar fashion once
> a
> certain tipping point has been reached.
It looks like it might be fairly easy to use HyperLogLog as an
estimator for the recursive step. That should reduce the
overpartitioning, which I believe is the cause of this discontinuity.
It's not clear to me that overpartitioning is a real problem in this
case -- but I think the fact that it's causing confusion is enough
reason to see if we can fix it.
Regards,
Jeff Davis
On Sat, Jul 25, 2020 at 1:10 PM Jeff Davis <pgsql@j-davis.com> wrote: > On Sat, 2020-07-25 at 11:05 -0700, Peter Geoghegan wrote: > > What worries me a bit is the sharp discontinuities when spilling with > > significantly less work_mem than the "optimal" amount. For example, > > with Tomas' TPC-H query (against my smaller TPC-H dataset), I find > > that setting work_mem to 6MB looks like this: > > ... > > > Planned Partitions: 128 Peak Memory Usage: 6161kB Disk > > Usage: 2478080kB HashAgg Batches: 128 > > ... > > > Planned Partitions: 128 Peak Memory Usage: 5393kB Disk > > Usage: 2482152kB HashAgg Batches: 11456 > It's not clear to me that overpartitioning is a real problem in this > case -- but I think the fact that it's causing confusion is enough > reason to see if we can fix it. I'm not sure about that either. FWIW I notice that when I reduce work_mem a little further (to 3MB) with the same query, the number of partitions is still 128, while the number of run time batches is 16,512 (an increase from 11,456 from 6MB work_mem). I notice that 16512/128 is 129, which hints at the nature of what's going on with the recursion. I guess it would be ideal if the growth in batches was more gradual as I subtract memory. -- Peter Geoghegan
On Sat, 2020-07-25 at 13:27 -0700, Peter Geoghegan wrote:
> It's not clear to me that overpartitioning is a real problem in
> > this
> > case -- but I think the fact that it's causing confusion is enough
> > reason to see if we can fix it.
>
> I'm not sure about that either.
>
> FWIW I notice that when I reduce work_mem a little further (to 3MB)
> with the same query, the number of partitions is still 128, while the
> number of run time batches is 16,512 (an increase from 11,456 from
> 6MB
> work_mem). I notice that 16512/128 is 129, which hints at the nature
> of what's going on with the recursion. I guess it would be ideal if
> the growth in batches was more gradual as I subtract memory.
I wrote a quick patch to use HyperLogLog to estimate the number of
groups contained in a spill file. It seems to reduce the
overpartitioning effect, and is a more principled approach than what I
was doing before.
It does seem to hurt the runtime slightly when spilling to disk in some
cases. I haven't narrowed down whether this is because we end up
recursing multiple times, or if it's just more efficient to
overpartition, or if the cost of doing the HLL itself is significant.
Regards,
Jeff Davis
Вложения
On Sat, Jul 25, 2020 at 10:07:37AM -0700, Peter Geoghegan wrote: >On Sat, Jul 25, 2020 at 9:39 AM Peter Geoghegan <pg@bowt.ie> wrote: >> "Peak Memory Usage: 1605334kB" >> >> Hash agg avoids spilling entirely (so the planner gets it right this >> time around). It even uses notably less memory. > >I guess that this is because the reported memory usage doesn't reflect >the space used for transition state, which is presumably most of the >total -- array_agg() is used in the query. > I'm not sure what you mean by "reported memory usage doesn't reflect the space used for transition state"? Surely it does include that, we've built the memory accounting stuff pretty much exactly to do that. I think it's pretty clear what's happening - in the sorted case there's only a single group getting new values at any moment, so when we decide to spill we'll only add rows to that group and everything else will be spilled to disk. In the unsorted case however we manage to initialize all groups in the hash table, but at that point the groups are tiny an fit into work_mem. As we process more and more data the groups grow, but we can't evict them - at the moment we don't have that capability. So we end up processing everything in memory, but significantly exceeding work_mem. FWIW all my tests are done on the same TPC-H data set clustered by l_shipdate (so probably random with respect to other columns). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jul 25, 2020 at 5:05 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > I'm not sure what you mean by "reported memory usage doesn't reflect the > space used for transition state"? Surely it does include that, we've > built the memory accounting stuff pretty much exactly to do that. > > I think it's pretty clear what's happening - in the sorted case there's > only a single group getting new values at any moment, so when we decide > to spill we'll only add rows to that group and everything else will be > spilled to disk. Right. > In the unsorted case however we manage to initialize all groups in the > hash table, but at that point the groups are tiny an fit into work_mem. > As we process more and more data the groups grow, but we can't evict > them - at the moment we don't have that capability. So we end up > processing everything in memory, but significantly exceeding work_mem. work_mem was set to 200MB, which is more than the reported "Peak Memory Usage: 1605334kB". So either the random case significantly exceeds work_mem and the "Peak Memory Usage" accounting is wrong (because it doesn't report this excess), or the random case really doesn't exceed work_mem but has a surprising advantage over the sorted case. -- Peter Geoghegan
On Sat, Jul 25, 2020 at 4:56 PM Jeff Davis <pgsql@j-davis.com> wrote: > I wrote a quick patch to use HyperLogLog to estimate the number of > groups contained in a spill file. It seems to reduce the > overpartitioning effect, and is a more principled approach than what I > was doing before. This pretty much fixes the issue that I observed with overparitioning. At least in the sense that the number of partitions grows more predictably -- even when the number of partitions planned is reduced the change in the number of batches seems smooth-ish. It "looks nice". > It does seem to hurt the runtime slightly when spilling to disk in some > cases. I haven't narrowed down whether this is because we end up > recursing multiple times, or if it's just more efficient to > overpartition, or if the cost of doing the HLL itself is significant. I'm glad that this better principled approach is possible. It's hard to judge how much of a problem this really is, though. We'll need to think about this aspect some more. Thanks -- Peter Geoghegan
On Sat, Jul 25, 2020 at 5:31 PM Peter Geoghegan <pg@bowt.ie> wrote: > I'm glad that this better principled approach is possible. It's hard > to judge how much of a problem this really is, though. We'll need to > think about this aspect some more. BTW, your HLL patch ameliorates the problem with my extreme "sorted vs random input" test case from this morning [1] (the thing that I just discussed with Tomas). Without the HLL patch the sorted case had 2424 batches. With the HLL patch it has 20. That at least seems like a notable improvement. [1] https://postgr.es/m/CAH2-Wz=ur7MQKpaUZJP=Adtg0TPMx5M_WoNE=ke2vUU=amdjPQ@mail.gmail.com -- Peter Geoghegan
On Sat, Jul 25, 2020 at 05:13:00PM -0700, Peter Geoghegan wrote: >On Sat, Jul 25, 2020 at 5:05 PM Tomas Vondra ><tomas.vondra@2ndquadrant.com> wrote: >> I'm not sure what you mean by "reported memory usage doesn't reflect the >> space used for transition state"? Surely it does include that, we've >> built the memory accounting stuff pretty much exactly to do that. >> >> I think it's pretty clear what's happening - in the sorted case there's >> only a single group getting new values at any moment, so when we decide >> to spill we'll only add rows to that group and everything else will be >> spilled to disk. > >Right. > >> In the unsorted case however we manage to initialize all groups in the >> hash table, but at that point the groups are tiny an fit into work_mem. >> As we process more and more data the groups grow, but we can't evict >> them - at the moment we don't have that capability. So we end up >> processing everything in memory, but significantly exceeding work_mem. > >work_mem was set to 200MB, which is more than the reported "Peak >Memory Usage: 1605334kB". So either the random case significantly That's 1.6GB, if I read it right. Which is more than 200MB ;-) >exceeds work_mem and the "Peak Memory Usage" accounting is wrong >(because it doesn't report this excess), or the random case really >doesn't exceed work_mem but has a surprising advantage over the sorted >case. > >-- >Peter Geoghegan -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Jul 26, 2020 at 11:34 AM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > That's 1.6GB, if I read it right. Which is more than 200MB ;-) Sigh. That solves that "mystery": the behavior that my sorted vs random example exhibited is a known limitation in hash aggs that spill (and an acceptable one). The memory usage is reported on accurately by EXPLAIN ANALYZE. -- Peter Geoghegan
On 2020-Jul-23, Peter Geoghegan wrote: > Attached is v3 of the hash_mem_multiplier patch series, which now has > a preparatory patch that removes hashagg_avoid_disk_plan. I notice you put the prototype for get_hash_mem in nodeHash.h. This would be fine if not for the fact that optimizer needs to call the function too, which means now optimizer have to include executor headers -- not a great thing. I'd move the prototype elsewhere to avoid this, and I think miscadmin.h is a decent place for the prototype, next to work_mem and m_w_m. It remains strange to have the function in executor implementation, but I don't offhand see a better place, so maybe it's okay where it is. Other than that admittedly trivial complaint, I found nothing to complain about in this patch. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 27, 2020 at 10:30 AM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2020-Jul-23, Peter Geoghegan wrote: > I notice you put the prototype for get_hash_mem in nodeHash.h. This > would be fine if not for the fact that optimizer needs to call the > function too, which means now optimizer have to include executor headers > -- not a great thing. I'd move the prototype elsewhere to avoid this, > and I think miscadmin.h is a decent place for the prototype, next to > work_mem and m_w_m. The location of get_hash_mem() is awkward, but there is no obvious alternative. Are you proposing that I just put the prototype in miscadmin.h, while leaving the implementation where it is (in nodeHash.c)? Maybe that sounds like an odd question, but bear in mind that the natural place to put the implementation of a function declared in miscadmin.h is either utils/init/postinit.c or utils/init/miscinit.c -- moving the implementation of get_hash_mem() to either of those two files seems worse to me. That said, there is an existing oddball case in miscadmin.h, right at the end -- the two functions whose implementation is in access/transam/xlog.c. So I can see an argument for adding another oddball case (i.e. moving the prototype to the end of miscadmin.h without changing anything else). > Other than that admittedly trivial complaint, I found nothing to > complain about in this patch. Great. Thanks for the review. My intention is to commit hash_mem_multiplier on Wednesday. We need to move on from this, and get the release out the door. -- Peter Geoghegan
On 2020-Jul-27, Peter Geoghegan wrote: > On Mon, Jul 27, 2020 at 10:30 AM Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > On 2020-Jul-23, Peter Geoghegan wrote: > > I notice you put the prototype for get_hash_mem in nodeHash.h. This > > would be fine if not for the fact that optimizer needs to call the > > function too, which means now optimizer have to include executor headers > > -- not a great thing. I'd move the prototype elsewhere to avoid this, > > and I think miscadmin.h is a decent place for the prototype, next to > > work_mem and m_w_m. > > The location of get_hash_mem() is awkward, Yes. > but there is no obvious alternative. Agreed. > Are you proposing that I just put the prototype in miscadmin.h, while > leaving the implementation where it is (in nodeHash.c)? Yes, that's in the part of my reply you didn't quote: : It remains strange to have the function in executor : implementation, but I don't offhand see a better place, so maybe it's : okay where it is. > [...] moving the implementation of get_hash_mem() to either of those > two files seems worse to me. Sure. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 27, 2020 at 11:24 AM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > Are you proposing that I just put the prototype in miscadmin.h, while > > leaving the implementation where it is (in nodeHash.c)? > > Yes, that's in the part of my reply you didn't quote: > > : It remains strange to have the function in executor > : implementation, but I don't offhand see a better place, so maybe it's > : okay where it is. Got it. I tried putting the prototype in miscadmin.h, and I now agree that that's the best way to do it -- that's how I do it in the attached revision. No other changes. The v4-0001-Remove-hashagg_avoid_disk_plan-GUC.patch changes are surprisingly complicated. It would be nice if you could take a look at that aspect (or confirm that it's included in your review). -- Peter Geoghegan
Вложения
On 2020-Jul-27, Peter Geoghegan wrote: > The v4-0001-Remove-hashagg_avoid_disk_plan-GUC.patch changes are > surprisingly complicated. It would be nice if you could take a look at > that aspect (or confirm that it's included in your review). I think you mean "it replaces surprisingly complicated code with straightforward code". Right? Because in the previous code, there was a lot of effort going into deciding whether the path needed to be generated; the new code just generates the path always. Similarly the code to decide allow_hash in create_distinct_path, which used to be nontrivial, could (if you wanted) be simplified down to a single boolean condition. Previously, it was nontrivial only because it needed to consider memory usage -- not anymore. But maybe you're talking about something more subtle that I'm just too blind to see. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 27, 2020 at 12:52 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2020-Jul-27, Peter Geoghegan wrote: > > The v4-0001-Remove-hashagg_avoid_disk_plan-GUC.patch changes are > > surprisingly complicated. It would be nice if you could take a look at > > that aspect (or confirm that it's included in your review). > > I think you mean "it replaces surprisingly complicated code with > straightforward code". Right? Because in the previous code, there was > a lot of effort going into deciding whether the path needed to be > generated; the new code just generates the path always. Yes, that's what I meant. It's a bit tricky. For example, I have removed a redundant "cheapest_total_path != NULL" test in create_partial_grouping_paths() (two, actually). But these two tests were always redundant. I have to wonder if I missed the point. Though it seems likely that that was just an accident. Accretions of code over time made the code work like that; nothing more. -- Peter Geoghegan
On Mon, 2020-07-27 at 11:30 -0700, Peter Geoghegan wrote:
> The v4-0001-Remove-hashagg_avoid_disk_plan-GUC.patch changes are
> surprisingly complicated. It would be nice if you could take a look
> at
> that aspect (or confirm that it's included in your review).
I noticed that one of the conditionals, "cheapest_total_path != NULL",
was already redundant with the outer conditional before your patch. I
guess that was just a mistake which your patch corrects along the way?
Anyway, the patch looks good to me. We can have a separate discussion
about pessimizing the costing, if necessary.
Regards,
Jeff Davis
On Mon, Jul 27, 2020 at 5:10 PM Jeff Davis <pgsql@j-davis.com> wrote: > I noticed that one of the conditionals, "cheapest_total_path != NULL", > was already redundant with the outer conditional before your patch. I > guess that was just a mistake which your patch corrects along the way? Makes sense. > Anyway, the patch looks good to me. We can have a separate discussion > about pessimizing the costing, if necessary. Pushed the hashagg_avoid_disk_plan patch -- thanks! -- Peter Geoghegan
On Sat, 2020-07-25 at 17:52 -0700, Peter Geoghegan wrote:
> BTW, your HLL patch ameliorates the problem with my extreme "sorted
> vs
> random input" test case from this morning [1] (the thing that I just
> discussed with Tomas). Without the HLL patch the sorted case had 2424
> batches. With the HLL patch it has 20. That at least seems like a
> notable improvement.
Committed.
Though I did notice some overhead for spilled-but-still-in-memory cases
due to addHyperLogLog() itself. It seems that it can be mostly
eliminated with [1], though I'll wait to see if there's an objection
because that would affect other users of HLL.
Regards,
Jeff Davis
[1]
https://www.postgresql.org/message-id/17068336d300fab76dd6131cbe1996df450dde38.camel@j-davis.com
On Mon, Jul 27, 2020 at 5:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > Pushed the hashagg_avoid_disk_plan patch -- thanks! Pushed the hash_mem_multiplier patch as well -- thanks again! As I've said before, I am not totally opposed to adding a true escape hatch. That has not proven truly necessary just yet. For now, my working assumption is that the problem on the table has been addressed. -- Peter Geoghegan