Обсуждение: Hash Indexes
For making hash indexes usable in production systems, we need to improve its concurrency and make them crash-safe by WAL logging them. The first problem I would like to tackle is improve the concurrency of hash indexes. First advantage, I see with improving concurrency of hash indexes is that it has the potential of out performing btree for "equal to" searches (with my WIP patch attached with this mail, I could see hash index outperform btree index by 20 to 30% for very simple cases which are mentioned later in this e-mail). Another advantage as explained by Robert [1] earlier is that if we remove heavy weight locks under which we perform arbitrarily large number of operations, it can help us to sensibly WAL log it. With this patch, I would also like to make hash indexes capable of completing the incomplete_splits which can occur due to interrupts (like cancel) or errors or crash.
% improvement between HEAD-Hash index vs Patch and HEAD-Btree index vs Patch-Hash index is:
This data shows that patch improves the performance of hash index upto 62.74 and it also makes hash-index faster than btree-index by ~20% (most client counts show the performance improvement in the range of 15~20%.
The performance with hash-index is ~30% better than Btree. Note, that for now, I have not taken the data for HEAD- Hash index. I think there will many more cases like when hash index is on char (20) column where the performance of hash-index can be much better than btree-index for equal to searches.
I have studied the concurrency problems of hash index and some of the solutions proposed for same previously and based on that came up with below solution which is based on idea by Robert [1], community discussion on thread [2] and some of my own thoughts.
Maintain a flag that can be set and cleared on the primary bucket page, call it split-in-progress, and a flag that can optionally be set on particular index tuples, call it moved-by-split. We will allow scans of all buckets and insertions into all buckets while the split is in progress, but (as now) we will not allow more than one split for a bucket to be in progress at the same time. We start the split by updating metapage to incrementing the number of buckets and set the split-in-progress flag in primary bucket pages for old and new buckets (lets number them as old bucket - N+1/2; new bucket - N + 1 for the matter of discussion). While the split-in-progress flag is set, any scans of N+1 will first scan that bucket, ignoring any tuples flagged moved-by-split, and then ALSO scan bucket N+1/2. To ensure that vacuum doesn't clean any tuples from old or new buckets till this scan is in progress, maintain a pin on both of the buckets (first pin on old bucket needs to be acquired). The moved-by-split flag never has any effect except when scanning the new bucket that existed at the start of that particular scan, and then only if the split-in-progress flag was also set at that time.
Once the split operation has set the split-in-progress flag, it will begin scanning bucket (N+1)/2. Every time it finds a tuple that properly belongs in bucket N+1, it will insert the tuple into bucket N+1 with the moved-by-split flag set. Tuples inserted by anything other than a split operation will leave this flag clear, and tuples inserted while the split is in progress will target the same bucket that they would hit if the split were already complete. Thus, bucket N+1 will end up with a mix of moved-by-split tuples, coming from bucket (N+1)/2, and unflagged tuples coming from parallel insertion activity. When the scan of bucket (N+1)/2 is complete, we know that bucket N+1 now contains all the tuples that are supposed to be there, so we clear the split-in-progress flag on both buckets. Future scans of both buckets can proceed normally. Split operation needs to take a cleanup lock on primary bucket to ensure that it doesn't start if there is any Insertion happening in the bucket. It will leave the lock on primary bucket, but not pin as it proceeds for next overflow page. Retaining pin on primary bucket will ensure that vacuum doesn't start on this bucket till the split is finished.
Insertion will happen by scanning the appropriate bucket and needs to retain pin on primary bucket to ensure that concurrent split doesn't happen, otherwise split might leave this tuple unaccounted.
Now for deletion of tuples from (N+1/2) bucket, we need to wait for the completion of any scans that began before we finished populating bucket N+1, because otherwise we might remove tuples that they're still expecting to find in bucket (N+1)/2. The scan will always maintain a pin on primary bucket and Vacuum can take a buffer cleanup lock (cleanup lock includes Exclusive lock on bucket and wait till all the pins on buffer becomes zero) on primary bucket for the buffer. I think we can relax the requirement for vacuum to take cleanup lock (instead take Exclusive Lock on buckets where no split has happened) with the additional flag has_garbage which will be set on primary bucket, if any tuples have been moved from that bucket, however I think for squeeze phase (in this phase, we try to move the tuples from later overflow pages to earlier overflow pages in the bucket and then if there are any empty overflow pages, then we move them to kind of a free pool) of vacuum, we need a cleanup lock, otherwise scan results might get effected.
Incomplete Splits
--------------------------
Incomplete splits can be completed either by vacuum or insert as both needs exclusive lock on bucket. If vacuum finds split-in-progress flag on a bucket then it will complete the split operation, vacuum won't see this flag if actually split is in progress on that bucket as vacuum needs cleanup lock and split retains pin till end of operation. To make it work for Insert operation, one simple idea could be that if insert finds split-in-progress flag, then it releases the current exclusive lock on bucket and tries to acquire a cleanup lock on bucket, if it gets cleanup lock, then it can complete the split and then the insertion of tuple, else it will have a exclusive lock on bucket and just perform the insertion of tuple. The disadvantage of trying to complete the split in vacuum is that split might require new pages and allocating new pages at time of vacuum is not advisable. The disadvantage of doing it at time of Insert is that Insert might skip it even if there is some scan on the bucket is going on as scan will also retain pin on the bucket, but I think that is not a big deal. The actual completion of split can be done in two ways: (a) scan the new bucket and build a hash table with all of the TIDs you find there. When copying tuples from the old bucket, first probe the hash table; if you find a match, just skip that tuple (idea suggested by Robert Haas offlist) (b) delete all the tuples that are marked as moved_by_split in the new bucket and perform the split operation from the beginning using old bucket.
Although, I don't think it is a very good idea to take any performance data with WIP patch, still I couldn't resist myself from doing so and below are the performance numbers. To get the performance data, I have dropped the primary key constraint on pgbench_accounts and created a hash index on aid column as below.
alter table pgbench_accounts drop constraint pgbench_accounts_pkey;
create index pgbench_accounts_pkey on pgbench_accounts using hash(aid);
Below data is for read-only pgbench test and is a median of 3 5-min runs. The performance tests are executed on a power-8 m/c.
Data fits in shared buffers
scale_factor - 300
shared_buffers - 8GB
| Patch_Ver/Client count | 1 | 8 | 16 | 32 | 64 | 72 | 80 | 88 | 96 | 128 |
| HEAD-Btree | 19397 | 122488 | 194433 | 344524 | 519536 | 527365 | 597368 | 559381 | 614321 | 609102 |
| HEAD-Hindex | 18539 | 141905 | 218635 | 363068 | 512067 | 522018 | 492103 | 484372 | 440265 | 393231 |
| Patch | 22504 | 146937 | 235948 | 419268 | 637871 | 637595 | 674042 | 669278 | 683704 | 639967 |
% improvement between HEAD-Hash index vs Patch and HEAD-Btree index vs Patch-Hash index is:
| Head-Hash vs Patch | 21.38 | 3.5 | 7.9 | 15.47 | 24.56 | 22.14 | 36.97 | 38.17 | 55.29 | 62.74 |
| Head-Btree vs. Patch | 16.01 | 19.96 | 21.35 | 21.69 | 22.77 | 20.9 | 12.83 | 19.64 | 11.29 | 5.06 |
This data shows that patch improves the performance of hash index upto 62.74 and it also makes hash-index faster than btree-index by ~20% (most client counts show the performance improvement in the range of 15~20%.
For the matter of comparison with btree, I think the impact of performance improvement of hash index will be more when the data doesn't fit shared buffers and the performance data for same is as below:
Data doesn't fits in shared buffers
scale_factor - 3000
shared_buffers - 8GB
| Client_Count/Patch | 16 | 64 | 96 |
| Head-Btree | 170042 | 463721 | 520656 |
| Patch-Hash | 227528 | 603594 | 659287 |
| % diff | 33.8 | 30.16 | 26.62 |
The performance with hash-index is ~30% better than Btree. Note, that for now, I have not taken the data for HEAD- Hash index. I think there will many more cases like when hash index is on char (20) column where the performance of hash-index can be much better than btree-index for equal to searches.
Note that this patch is a very-much WIP patch and I am posting it mainly to facilitate the discussion. Currently, it doesn't have any code to perform incomplete splits, the logic for locking/pins during Insert is yet to be done and many more things.
Вложения
On Tue, May 10, 2016 at 5:39 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
I have completed the patch with respect to incomplete splits and delayed cleanup of garbage tuples. For incomplete splits, I have used the option (a) as mentioned above. The incomplete splits are completed if the insertion sees split-in-progress flag in a bucket. The second major thing this new version of patch has achieved is cleanup of garbage tuples i.e the tuples that are left in old bucket during split. Currently (in HEAD), as part of a split operation, we clean the tuples from old bucket after moving them to new bucket, as we have heavy-weight locks on both old and new bucket till the whole split operation. In the new design, we need to take cleanup lock on old bucket and exclusive lock on new bucket to perform the split operation and we don't retain those locks till the end (release the lock as we move on to overflow buckets). Now to cleanup the tuples we need a cleanup lock on a bucket which we might not have at split-end. So I choose to perform the cleanup of garbage tuples during vacuum and when re-split of the bucket happens as during both the operations, we do hold cleanup lock. We can extend the cleanup of garbage to other operations as well if required.
Incomplete Splits--------------------------Incomplete splits can be completed either by vacuum or insert as both needs exclusive lock on bucket. If vacuum finds split-in-progress flag on a bucket then it will complete the split operation, vacuum won't see this flag if actually split is in progress on that bucket as vacuum needs cleanup lock and split retains pin till end of operation. To make it work for Insert operation, one simple idea could be that if insert finds split-in-progress flag, then it releases the current exclusive lock on bucket and tries to acquire a cleanup lock on bucket, if it gets cleanup lock, then it can complete the split and then the insertion of tuple, else it will have a exclusive lock on bucket and just perform the insertion of tuple. The disadvantage of trying to complete the split in vacuum is that split might require new pages and allocating new pages at time of vacuum is not advisable. The disadvantage of doing it at time of Insert is that Insert might skip it even if there is some scan on the bucket is going on as scan will also retain pin on the bucket, but I think that is not a big deal. The actual completion of split can be done in two ways: (a) scan the new bucket and build a hash table with all of the TIDs you find there. When copying tuples from the old bucket, first probe the hash table; if you find a match, just skip that tuple (idea suggested by Robert Haas offlist) (b) delete all the tuples that are marked as moved_by_split in the new bucket and perform the split operation from the beginning using old bucket.
I have completed the patch with respect to incomplete splits and delayed cleanup of garbage tuples. For incomplete splits, I have used the option (a) as mentioned above. The incomplete splits are completed if the insertion sees split-in-progress flag in a bucket. The second major thing this new version of patch has achieved is cleanup of garbage tuples i.e the tuples that are left in old bucket during split. Currently (in HEAD), as part of a split operation, we clean the tuples from old bucket after moving them to new bucket, as we have heavy-weight locks on both old and new bucket till the whole split operation. In the new design, we need to take cleanup lock on old bucket and exclusive lock on new bucket to perform the split operation and we don't retain those locks till the end (release the lock as we move on to overflow buckets). Now to cleanup the tuples we need a cleanup lock on a bucket which we might not have at split-end. So I choose to perform the cleanup of garbage tuples during vacuum and when re-split of the bucket happens as during both the operations, we do hold cleanup lock. We can extend the cleanup of garbage to other operations as well if required.
I have done some performance tests with this new version of patch and results are on same lines as in my previous e-mail. I have done some functional testing of the patch as well. I think more detailed testing is required, however it is better to do that once the design is discussed and agreed upon.
I have improved the code comments to make the new design clear, but still one can have questions related to locking decisions I have taken in patch. I think one of the important thing to verify in the patch is locking strategy used for different operations. I have changed heavy-weight locks to a light-weight read and write locks and a cleanup lock for vacuum and split operation.
Вложения
On Tue, May 10, 2016 at 8:09 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > > For making hash indexes usable in production systems, we need to improve its concurrency and make them crash-safe by WALlogging them. The first problem I would like to tackle is improve the concurrency of hash indexes. First advantage,I see with improving concurrency of hash indexes is that it has the potential of out performing btree for "equalto" searches (with my WIP patch attached with this mail, I could see hash index outperform btree index by 20 to 30%for very simple cases which are mentioned later in this e-mail). Another advantage as explained by Robert [1] earlieris that if we remove heavy weight locks under which we perform arbitrarily large number of operations, it can helpus to sensibly WAL log it. With this patch, I would also like to make hash indexes capable of completing the incomplete_splitswhich can occur due to interrupts (like cancel) or errors or crash. > > I have studied the concurrency problems of hash index and some of the solutions proposed for same previously and basedon that came up with below solution which is based on idea by Robert [1], community discussion on thread [2] and someof my own thoughts. > > Maintain a flag that can be set and cleared on the primary bucket page, call it split-in-progress, and a flag that canoptionally be set on particular index tuples, call it moved-by-split. We will allow scans of all buckets and insertionsinto all buckets while the split is in progress, but (as now) we will not allow more than one split for a bucketto be in progress at the same time. We start the split by updating metapage to incrementing the number of bucketsand set the split-in-progress flag in primary bucket pages for old and new buckets (lets number them as old bucket- N+1/2; new bucket - N + 1 for the matter of discussion). While the split-in-progress flag is set, any scans of N+1will first scan that bucket, ignoring any tuples flagged moved-by-split, and then ALSO scan bucket N+1/2. To ensure thatvacuum doesn't clean any tuples from old or new buckets till this scan is in progress, maintain a pin on both of thebuckets (first pin on old bucket needs to be acquired). The moved-by-split flag never has any effect except when scanningthe new bucket that existed at the start of that particular scan, and then only if the split-in-progress flag wasalso set at that time. You really need parentheses in (N+1)/2. Because you are not trying to add 1/2 to N. https://en.wikipedia.org/wiki/Order_of_operations > Once the split operation has set the split-in-progress flag, it will begin scanning bucket (N+1)/2. Every time it findsa tuple that properly belongs in bucket N+1, it will insert the tuple into bucket N+1 with the moved-by-split flag set. Tuples inserted by anything other than a split operation will leave this flag clear, and tuples inserted while the splitis in progress will target the same bucket that they would hit if the split were already complete. Thus, bucket N+1will end up with a mix of moved-by-split tuples, coming from bucket (N+1)/2, and unflagged tuples coming from parallelinsertion activity. When the scan of bucket (N+1)/2 is complete, we know that bucket N+1 now contains all the tuplesthat are supposed to be there, so we clear the split-in-progress flag on both buckets. Future scans of both bucketscan proceed normally. Split operation needs to take a cleanup lock on primary bucket to ensure that it doesn't startif there is any Insertion happening in the bucket. It will leave the lock on primary bucket, but not pin as it proceedsfor next overflow page. Retaining pin on primary bucket will ensure that vacuum doesn't start on this bucket tillthe split is finished. In the second-to-last sentence, I believe you have reversed the words "lock" and "pin". > Insertion will happen by scanning the appropriate bucket and needs to retain pin on primary bucket to ensure that concurrentsplit doesn't happen, otherwise split might leave this tuple unaccounted. What do you mean by "unaccounted"? > Now for deletion of tuples from (N+1/2) bucket, we need to wait for the completion of any scans that began before we finishedpopulating bucket N+1, because otherwise we might remove tuples that they're still expecting to find in bucket (N+1)/2.The scan will always maintain a pin on primary bucket and Vacuum can take a buffer cleanup lock (cleanup lock includesExclusive lock on bucket and wait till all the pins on buffer becomes zero) on primary bucket for the buffer. Ithink we can relax the requirement for vacuum to take cleanup lock (instead take Exclusive Lock on buckets where no splithas happened) with the additional flag has_garbage which will be set on primary bucket, if any tuples have been movedfrom that bucket, however I think for squeeze phase (in this phase, we try to move the tuples from later overflow pagesto earlier overflow pages in the bucket and then if there are any empty overflow pages, then we move them to kind ofa free pool) of vacuum, we need a cleanup lock, otherwise scan results might get effected. affected, not effected. I think this is basically correct, although I don't find it to be as clear as I think it could be. It seems very clear that any operation which potentially changes the order of tuples in the bucket chain, such as the squeeze phase as currently implemented, also needs to exclude all concurrent scans. However, I think that it's OK for vacuum to remove tuples from a given page with only an exclusive lock on that particular page. Also, I think that when cleaning up after a split, an exclusive lock is likewise sufficient to remove tuples from a particular page provided that we know that every scan currently in progress started after split-in-progress was set. If each scan holds a pin on the primary bucket and setting the split-in-progress flag requires a cleanup lock on that page, then this is always true. (Plain text email is preferred to HTML on this mailing list.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 16, 2016 at 3:28 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Incomplete splits can be completed either by vacuum or insert as both >> needs exclusive lock on bucket. If vacuum finds split-in-progress flag on a >> bucket then it will complete the split operation, vacuum won't see this flag >> if actually split is in progress on that bucket as vacuum needs cleanup lock >> and split retains pin till end of operation. To make it work for Insert >> operation, one simple idea could be that if insert finds split-in-progress >> flag, then it releases the current exclusive lock on bucket and tries to >> acquire a cleanup lock on bucket, if it gets cleanup lock, then it can >> complete the split and then the insertion of tuple, else it will have a >> exclusive lock on bucket and just perform the insertion of tuple. The >> disadvantage of trying to complete the split in vacuum is that split might >> require new pages and allocating new pages at time of vacuum is not >> advisable. The disadvantage of doing it at time of Insert is that Insert >> might skip it even if there is some scan on the bucket is going on as scan >> will also retain pin on the bucket, but I think that is not a big deal. The >> actual completion of split can be done in two ways: (a) scan the new bucket >> and build a hash table with all of the TIDs you find there. When copying >> tuples from the old bucket, first probe the hash table; if you find a match, >> just skip that tuple (idea suggested by Robert Haas offlist) (b) delete all >> the tuples that are marked as moved_by_split in the new bucket and perform >> the split operation from the beginning using old bucket. > > I have completed the patch with respect to incomplete splits and delayed > cleanup of garbage tuples. For incomplete splits, I have used the option > (a) as mentioned above. The incomplete splits are completed if the > insertion sees split-in-progress flag in a bucket. It seems to me that there is a potential performance problem here. If the split is still being performed, every insert will see the split-in-progress flag set. The in-progress split retains only a pin on the primary bucket, so other backends could also get an exclusive lock, which is all they need for an insert. It seems that under this algorithm they will now take the exclusive lock, release the exclusive lock, try to take a cleanup lock, fail, again take the exclusive lock. That seems like a lot of extra monkeying around. Wouldn't it be better to take the exclusive lock and then afterwards check if the pin count is 1? If so, even though we only intended to take an exclusive lock, it is actually a cleanup lock. If not, we can simply proceed with the insertion. This way you avoid unlocking and relocking the buffer repeatedly. > The second major thing > this new version of patch has achieved is cleanup of garbage tuples i.e the > tuples that are left in old bucket during split. Currently (in HEAD), as > part of a split operation, we clean the tuples from old bucket after moving > them to new bucket, as we have heavy-weight locks on both old and new bucket > till the whole split operation. In the new design, we need to take cleanup > lock on old bucket and exclusive lock on new bucket to perform the split > operation and we don't retain those locks till the end (release the lock as > we move on to overflow buckets). Now to cleanup the tuples we need a > cleanup lock on a bucket which we might not have at split-end. So I choose > to perform the cleanup of garbage tuples during vacuum and when re-split of > the bucket happens as during both the operations, we do hold cleanup lock. > We can extend the cleanup of garbage to other operations as well if > required. I think it's OK for the squeeze phase to be deferred until vacuum or a subsequent split, but simply removing dead tuples seems like it should be done earlier if possible. As I noted in my last email, it seems like any process that gets an exclusive lock can do that, and probably should. Otherwise, the index might become quite bloated. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 21, 2016 at 9:26 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Tue, May 10, 2016 at 8:09 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> > Once the split operation has set the split-in-progress flag, it will begin scanning bucket (N+1)/2. Every time it finds a tuple that properly belongs in bucket N+1, it will insert the tuple into bucket N+1 with the moved-by-split flag set. Tuples inserted by anything other than a split operation will leave this flag clear, and tuples inserted while the split is in progress will target the same bucket that they would hit if the split were already complete. Thus, bucket N+1 will end up with a mix of moved-by-split tuples, coming from bucket (N+1)/2, and unflagged tuples coming from parallel insertion activity. When the scan of bucket (N+1)/2 is complete, we know that bucket N+1 now contains all the tuples that are supposed to be there, so we clear the split-in-progress flag on both buckets. Future scans of both buckets can proceed normally. Split operation needs to take a cleanup lock on primary bucket to ensure that it doesn't start if there is any Insertion happening in the bucket. It will leave the lock on primary bucket, but not pin as it proceeds for next overflow page. Retaining pin on primary bucket will ensure that vacuum doesn't start on this bucket till the split is finished.
>
> In the second-to-last sentence, I believe you have reversed the words
> "lock" and "pin".
>
> > Insertion will happen by scanning the appropriate bucket and needs to retain pin on primary bucket to ensure that concurrent split doesn't happen, otherwise split might leave this tuple unaccounted.
>
> What do you mean by "unaccounted"?
>
> > Now for deletion of tuples from (N+1/2) bucket, we need to wait for the completion of any scans that began before we finished populating bucket N+1, because otherwise we might remove tuples that they're still expecting to find in bucket (N+1)/2. The scan will always maintain a pin on primary bucket and Vacuum can take a buffer cleanup lock (cleanup lock includes Exclusive lock on bucket and wait till all the pins on buffer becomes zero) on primary bucket for the buffer. I think we can relax the requirement for vacuum to take cleanup lock (instead take Exclusive Lock on buckets where no split has happened) with the additional flag has_garbage which will be set on primary bucket, if any tuples have been moved from that bucket, however I think for squeeze phase (in this phase, we try to move the tuples from later overflow pages to earlier overflow pages in the bucket and then if there are any empty overflow pages, then we move them to kind of a free pool) of vacuum, we need a cleanup lock, otherwise scan results might get effected.
>
> affected, not effected.
>
>
> On Tue, May 10, 2016 at 8:09 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> > Once the split operation has set the split-in-progress flag, it will begin scanning bucket (N+1)/2. Every time it finds a tuple that properly belongs in bucket N+1, it will insert the tuple into bucket N+1 with the moved-by-split flag set. Tuples inserted by anything other than a split operation will leave this flag clear, and tuples inserted while the split is in progress will target the same bucket that they would hit if the split were already complete. Thus, bucket N+1 will end up with a mix of moved-by-split tuples, coming from bucket (N+1)/2, and unflagged tuples coming from parallel insertion activity. When the scan of bucket (N+1)/2 is complete, we know that bucket N+1 now contains all the tuples that are supposed to be there, so we clear the split-in-progress flag on both buckets. Future scans of both buckets can proceed normally. Split operation needs to take a cleanup lock on primary bucket to ensure that it doesn't start if there is any Insertion happening in the bucket. It will leave the lock on primary bucket, but not pin as it proceeds for next overflow page. Retaining pin on primary bucket will ensure that vacuum doesn't start on this bucket till the split is finished.
>
> In the second-to-last sentence, I believe you have reversed the words
> "lock" and "pin".
>
Yes. What, I mean to say is release the lock, but retain the pin on primary bucket till end of operation.
> > Insertion will happen by scanning the appropriate bucket and needs to retain pin on primary bucket to ensure that concurrent split doesn't happen, otherwise split might leave this tuple unaccounted.
>
> What do you mean by "unaccounted"?
>
It means that split might leave this tuple in old bucket even if it can be moved to new bucket. Consider a case where insertion has to add a tuple on some intermediate overflow bucket in the bucket chain, if we allow split when insertion is in progress, split might not move this newly inserted tuple.
> > Now for deletion of tuples from (N+1/2) bucket, we need to wait for the completion of any scans that began before we finished populating bucket N+1, because otherwise we might remove tuples that they're still expecting to find in bucket (N+1)/2. The scan will always maintain a pin on primary bucket and Vacuum can take a buffer cleanup lock (cleanup lock includes Exclusive lock on bucket and wait till all the pins on buffer becomes zero) on primary bucket for the buffer. I think we can relax the requirement for vacuum to take cleanup lock (instead take Exclusive Lock on buckets where no split has happened) with the additional flag has_garbage which will be set on primary bucket, if any tuples have been moved from that bucket, however I think for squeeze phase (in this phase, we try to move the tuples from later overflow pages to earlier overflow pages in the bucket and then if there are any empty overflow pages, then we move them to kind of a free pool) of vacuum, we need a cleanup lock, otherwise scan results might get effected.
>
> affected, not effected.
>
> I think this is basically correct, although I don't find it to be as
> clear as I think it could be. It seems very clear that any operation
> which potentially changes the order of tuples in the bucket chain,
> such as the squeeze phase as currently implemented, also needs to
> exclude all concurrent scans. However, I think that it's OK for
> vacuum to remove tuples from a given page with only an exclusive lock
> on that particular page.
> clear as I think it could be. It seems very clear that any operation
> which potentially changes the order of tuples in the bucket chain,
> such as the squeeze phase as currently implemented, also needs to
> exclude all concurrent scans. However, I think that it's OK for
> vacuum to remove tuples from a given page with only an exclusive lock
> on that particular page.
>
How can we guarantee that it doesn't remove a tuple that is required by scan which is started after split-in-progress flag is set?
> Also, I think that when cleaning up after a
> split, an exclusive lock is likewise sufficient to remove tuples from
> a particular page provided that we know that every scan currently in
> progress started after split-in-progress was set.
> split, an exclusive lock is likewise sufficient to remove tuples from
> a particular page provided that we know that every scan currently in
> progress started after split-in-progress was set.
>
I think this could also have a similar issue as above, unless we have something which prevents concurrent scans.
>
> (Plain text email is preferred to HTML on this mailing list.)
>
If I turn to Plain text [1], then the signature of my e-mail also changes to Plain text which don't want. Is there a way, I can retain signature settings in Rich Text and mail content as Plain Text.
> (Plain text email is preferred to HTML on this mailing list.)
>
If I turn to Plain text [1], then the signature of my e-mail also changes to Plain text which don't want. Is there a way, I can retain signature settings in Rich Text and mail content as Plain Text.
On Tue, Jun 21, 2016 at 9:33 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Thu, Jun 16, 2016 at 3:28 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> Incomplete splits can be completed either by vacuum or insert as both
> >> needs exclusive lock on bucket. If vacuum finds split-in-progress flag on a
> >> bucket then it will complete the split operation, vacuum won't see this flag
> >> if actually split is in progress on that bucket as vacuum needs cleanup lock
> >> and split retains pin till end of operation. To make it work for Insert
> >> operation, one simple idea could be that if insert finds split-in-progress
> >> flag, then it releases the current exclusive lock on bucket and tries to
> >> acquire a cleanup lock on bucket, if it gets cleanup lock, then it can
> >> complete the split and then the insertion of tuple, else it will have a
> >> exclusive lock on bucket and just perform the insertion of tuple. The
> >> disadvantage of trying to complete the split in vacuum is that split might
> >> require new pages and allocating new pages at time of vacuum is not
> >> advisable. The disadvantage of doing it at time of Insert is that Insert
> >> might skip it even if there is some scan on the bucket is going on as scan
> >> will also retain pin on the bucket, but I think that is not a big deal. The
> >> actual completion of split can be done in two ways: (a) scan the new bucket
> >> and build a hash table with all of the TIDs you find there. When copying
> >> tuples from the old bucket, first probe the hash table; if you find a match,
> >> just skip that tuple (idea suggested by Robert Haas offlist) (b) delete all
> >> the tuples that are marked as moved_by_split in the new bucket and perform
> >> the split operation from the beginning using old bucket.
> >
> > I have completed the patch with respect to incomplete splits and delayed
> > cleanup of garbage tuples. For incomplete splits, I have used the option
> > (a) as mentioned above. The incomplete splits are completed if the
> > insertion sees split-in-progress flag in a bucket.
>
> It seems to me that there is a potential performance problem here. If
> the split is still being performed, every insert will see the
> split-in-progress flag set. The in-progress split retains only a pin
> on the primary bucket, so other backends could also get an exclusive
> lock, which is all they need for an insert. It seems that under this
> algorithm they will now take the exclusive lock, release the exclusive
> lock, try to take a cleanup lock, fail, again take the exclusive lock.
> That seems like a lot of extra monkeying around. Wouldn't it be
> better to take the exclusive lock and then afterwards check if the pin
> count is 1? If so, even though we only intended to take an exclusive
> lock, it is actually a cleanup lock. If not, we can simply proceed
> with the insertion. This way you avoid unlocking and relocking the
> buffer repeatedly.
>
> > The second major thing
> > this new version of patch has achieved is cleanup of garbage tuples i.e the
> > tuples that are left in old bucket during split. Currently (in HEAD), as
> > part of a split operation, we clean the tuples from old bucket after moving
> > them to new bucket, as we have heavy-weight locks on both old and new bucket
> > till the whole split operation. In the new design, we need to take cleanup
> > lock on old bucket and exclusive lock on new bucket to perform the split
> > operation and we don't retain those locks till the end (release the lock as
> > we move on to overflow buckets). Now to cleanup the tuples we need a
> > cleanup lock on a bucket which we might not have at split-end. So I choose
> > to perform the cleanup of garbage tuples during vacuum and when re-split of
> > the bucket happens as during both the operations, we do hold cleanup lock.
> > We can extend the cleanup of garbage to other operations as well if
> > required.
>
> I think it's OK for the squeeze phase to be deferred until vacuum or a
> subsequent split, but simply removing dead tuples seems like it should
> be done earlier if possible.
>
> On Thu, Jun 16, 2016 at 3:28 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> Incomplete splits can be completed either by vacuum or insert as both
> >> needs exclusive lock on bucket. If vacuum finds split-in-progress flag on a
> >> bucket then it will complete the split operation, vacuum won't see this flag
> >> if actually split is in progress on that bucket as vacuum needs cleanup lock
> >> and split retains pin till end of operation. To make it work for Insert
> >> operation, one simple idea could be that if insert finds split-in-progress
> >> flag, then it releases the current exclusive lock on bucket and tries to
> >> acquire a cleanup lock on bucket, if it gets cleanup lock, then it can
> >> complete the split and then the insertion of tuple, else it will have a
> >> exclusive lock on bucket and just perform the insertion of tuple. The
> >> disadvantage of trying to complete the split in vacuum is that split might
> >> require new pages and allocating new pages at time of vacuum is not
> >> advisable. The disadvantage of doing it at time of Insert is that Insert
> >> might skip it even if there is some scan on the bucket is going on as scan
> >> will also retain pin on the bucket, but I think that is not a big deal. The
> >> actual completion of split can be done in two ways: (a) scan the new bucket
> >> and build a hash table with all of the TIDs you find there. When copying
> >> tuples from the old bucket, first probe the hash table; if you find a match,
> >> just skip that tuple (idea suggested by Robert Haas offlist) (b) delete all
> >> the tuples that are marked as moved_by_split in the new bucket and perform
> >> the split operation from the beginning using old bucket.
> >
> > I have completed the patch with respect to incomplete splits and delayed
> > cleanup of garbage tuples. For incomplete splits, I have used the option
> > (a) as mentioned above. The incomplete splits are completed if the
> > insertion sees split-in-progress flag in a bucket.
>
> It seems to me that there is a potential performance problem here. If
> the split is still being performed, every insert will see the
> split-in-progress flag set. The in-progress split retains only a pin
> on the primary bucket, so other backends could also get an exclusive
> lock, which is all they need for an insert. It seems that under this
> algorithm they will now take the exclusive lock, release the exclusive
> lock, try to take a cleanup lock, fail, again take the exclusive lock.
> That seems like a lot of extra monkeying around. Wouldn't it be
> better to take the exclusive lock and then afterwards check if the pin
> count is 1? If so, even though we only intended to take an exclusive
> lock, it is actually a cleanup lock. If not, we can simply proceed
> with the insertion. This way you avoid unlocking and relocking the
> buffer repeatedly.
>
We can do it in the way as you are suggesting, but there is another thing which we need to consider here. As of now, the patch tries to finish the split if it finds split-in-progress flag in either old or new bucket. We need to lock both old and new buckets to finish the split, so it is quite possible that two different backends try to lock them in opposite order leading to a deadlock. I think the correct way to handle is to always try to lock the old bucket first and then new bucket. To achieve that, if the insertion on new bucket finds that split-in-progress flag is set on a bucket, it needs to release the lock and then acquire the lock first on old bucket, ensure pincount is 1 and then lock new bucket again and ensure that pincount is 1. I have already maintained the order of locks in scan (old bucket first and then new bucket; refer changes in _hash_first()). Alternatively, we can try to finish the splits only when someone tries to insert in old bucket.
> > The second major thing
> > this new version of patch has achieved is cleanup of garbage tuples i.e the
> > tuples that are left in old bucket during split. Currently (in HEAD), as
> > part of a split operation, we clean the tuples from old bucket after moving
> > them to new bucket, as we have heavy-weight locks on both old and new bucket
> > till the whole split operation. In the new design, we need to take cleanup
> > lock on old bucket and exclusive lock on new bucket to perform the split
> > operation and we don't retain those locks till the end (release the lock as
> > we move on to overflow buckets). Now to cleanup the tuples we need a
> > cleanup lock on a bucket which we might not have at split-end. So I choose
> > to perform the cleanup of garbage tuples during vacuum and when re-split of
> > the bucket happens as during both the operations, we do hold cleanup lock.
> > We can extend the cleanup of garbage to other operations as well if
> > required.
>
> I think it's OK for the squeeze phase to be deferred until vacuum or a
> subsequent split, but simply removing dead tuples seems like it should
> be done earlier if possible.
Yes, probably we can do it at time of insertion in a bucket, if we don't have concurrent scan issue.
On Wed, Jun 22, 2016 at 5:10 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> > Insertion will happen by scanning the appropriate bucket and needs to >> > retain pin on primary bucket to ensure that concurrent split doesn't happen, >> > otherwise split might leave this tuple unaccounted. >> >> What do you mean by "unaccounted"? > > It means that split might leave this tuple in old bucket even if it can be > moved to new bucket. Consider a case where insertion has to add a tuple on > some intermediate overflow bucket in the bucket chain, if we allow split > when insertion is in progress, split might not move this newly inserted > tuple. OK, that's a good point. >> > Now for deletion of tuples from (N+1/2) bucket, we need to wait for the >> > completion of any scans that began before we finished populating bucket N+1, >> > because otherwise we might remove tuples that they're still expecting to >> > find in bucket (N+1)/2. The scan will always maintain a pin on primary >> > bucket and Vacuum can take a buffer cleanup lock (cleanup lock includes >> > Exclusive lock on bucket and wait till all the pins on buffer becomes zero) >> > on primary bucket for the buffer. I think we can relax the requirement for >> > vacuum to take cleanup lock (instead take Exclusive Lock on buckets where no >> > split has happened) with the additional flag has_garbage which will be set >> > on primary bucket, if any tuples have been moved from that bucket, however I >> > think for squeeze phase (in this phase, we try to move the tuples from later >> > overflow pages to earlier overflow pages in the bucket and then if there are >> > any empty overflow pages, then we move them to kind of a free pool) of >> > vacuum, we need a cleanup lock, otherwise scan results might get effected. >> >> affected, not effected. >> >> I think this is basically correct, although I don't find it to be as >> clear as I think it could be. It seems very clear that any operation >> which potentially changes the order of tuples in the bucket chain, >> such as the squeeze phase as currently implemented, also needs to >> exclude all concurrent scans. However, I think that it's OK for >> vacuum to remove tuples from a given page with only an exclusive lock >> on that particular page. > > How can we guarantee that it doesn't remove a tuple that is required by scan > which is started after split-in-progress flag is set? If the tuple is being removed by VACUUM, it is dead. We can remove dead tuples right away, because no MVCC scan will see them. In fact, the only snapshot that will see them is SnapshotAny, and there's no problem with removing dead tuples while a SnapshotAny scan is in progress. It's no different than heap_page_prune() removing tuples that a SnapshotAny sequential scan was about to see. If the tuple is being removed because the bucket was split, it's only a problem if the scan predates setting the split-in-progress flag. But since your design involves out-waiting all scans currently in progress before setting that flag, there can't be any scan in progress that hasn't seen it. A scan that has seen the flag won't look at the tuple in any case. >> (Plain text email is preferred to HTML on this mailing list.) >> > > If I turn to Plain text [1], then the signature of my e-mail also changes to > Plain text which don't want. Is there a way, I can retain signature > settings in Rich Text and mail content as Plain Text. Nope, but I don't see what you are worried about. There's no HTML content in your signature anyway except for a link, and most mail-reading software will turn that into a hyperlink even without the HTML. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jun 22, 2016 at 5:14 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > We can do it in the way as you are suggesting, but there is another thing > which we need to consider here. As of now, the patch tries to finish the > split if it finds split-in-progress flag in either old or new bucket. We > need to lock both old and new buckets to finish the split, so it is quite > possible that two different backends try to lock them in opposite order > leading to a deadlock. I think the correct way to handle is to always try > to lock the old bucket first and then new bucket. To achieve that, if the > insertion on new bucket finds that split-in-progress flag is set on a > bucket, it needs to release the lock and then acquire the lock first on old > bucket, ensure pincount is 1 and then lock new bucket again and ensure that > pincount is 1. I have already maintained the order of locks in scan (old > bucket first and then new bucket; refer changes in _hash_first()). > Alternatively, we can try to finish the splits only when someone tries to > insert in old bucket. Yes, I think locking buckets in increasing order is a good solution. I also think it's fine to only try to finish the split when the insert targets the old bucket. Finishing the split enables us to remove tuples from the old bucket, which lets us reuse space instead of accelerating more. So there is at least some potential benefit to the backend inserting into the old bucket. On the other hand, a process inserting into the new bucket derives no direct benefit from finishing the split. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jun 22, 2016 at 8:44 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 22, 2016 at 5:10 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> >>> I think this is basically correct, although I don't find it to be as >>> clear as I think it could be. It seems very clear that any operation >>> which potentially changes the order of tuples in the bucket chain, >>> such as the squeeze phase as currently implemented, also needs to >>> exclude all concurrent scans. However, I think that it's OK for >>> vacuum to remove tuples from a given page with only an exclusive lock >>> on that particular page. >> >> How can we guarantee that it doesn't remove a tuple that is required by scan >> which is started after split-in-progress flag is set? > > If the tuple is being removed by VACUUM, it is dead. We can remove > dead tuples right away, because no MVCC scan will see them. In fact, > the only snapshot that will see them is SnapshotAny, and there's no > problem with removing dead tuples while a SnapshotAny scan is in > progress. It's no different than heap_page_prune() removing tuples > that a SnapshotAny sequential scan was about to see. > > If the tuple is being removed because the bucket was split, it's only > a problem if the scan predates setting the split-in-progress flag. > But since your design involves out-waiting all scans currently in > progress before setting that flag, there can't be any scan in progress > that hasn't seen it. > For above cases, just an exclusive lock will work. > A scan that has seen the flag won't look at the > tuple in any case. > Why so? Assume that scan started on new bucket where split-in-progress flag was set, now it will not look at tuples that are marked as moved-by-split in this bucket, as it will assume to find all such tuples in old bucket. Now, if allow Vacuum or someone else to remove tuples from old with just an Exclusive lock, it is quite possible that scan miss the tuple in old bucket which got removed by vacuum. >>> (Plain text email is preferred to HTML on this mailing list.) >>> >> >> If I turn to Plain text [1], then the signature of my e-mail also changes to >> Plain text which don't want. Is there a way, I can retain signature >> settings in Rich Text and mail content as Plain Text. > > Nope, but I don't see what you are worried about. There's no HTML > content in your signature anyway except for a link, and most > mail-reading software will turn that into a hyperlink even without the > HTML. > Okay, I didn't knew that mail-reading software does that. Thanks for pointing out. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Jun 22, 2016 at 8:48 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 22, 2016 at 5:14 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> We can do it in the way as you are suggesting, but there is another thing >> which we need to consider here. As of now, the patch tries to finish the >> split if it finds split-in-progress flag in either old or new bucket. We >> need to lock both old and new buckets to finish the split, so it is quite >> possible that two different backends try to lock them in opposite order >> leading to a deadlock. I think the correct way to handle is to always try >> to lock the old bucket first and then new bucket. To achieve that, if the >> insertion on new bucket finds that split-in-progress flag is set on a >> bucket, it needs to release the lock and then acquire the lock first on old >> bucket, ensure pincount is 1 and then lock new bucket again and ensure that >> pincount is 1. I have already maintained the order of locks in scan (old >> bucket first and then new bucket; refer changes in _hash_first()). >> Alternatively, we can try to finish the splits only when someone tries to >> insert in old bucket. > > Yes, I think locking buckets in increasing order is a good solution. Okay. > I also think it's fine to only try to finish the split when the insert > targets the old bucket. Finishing the split enables us to remove > tuples from the old bucket, which lets us reuse space instead of > accelerating more. So there is at least some potential benefit to the > backend inserting into the old bucket. On the other hand, a process > inserting into the new bucket derives no direct benefit from finishing > the split. > makes sense, will change that way and will add a comment why we are just doing it for old bucket. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Jun 22, 2016 at 10:13 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> A scan that has seen the flag won't look at the >> tuple in any case. > > Why so? Assume that scan started on new bucket where > split-in-progress flag was set, now it will not look at tuples that > are marked as moved-by-split in this bucket, as it will assume to find > all such tuples in old bucket. Now, if allow Vacuum or someone else > to remove tuples from old with just an Exclusive lock, it is quite > possible that scan miss the tuple in old bucket which got removed by > vacuum. Oh, you're right. So we really need to CLEAR the split-in-progress flag before removing any tuples from the old bucket. Does that sound right? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 23, 2016 at 10:56 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 22, 2016 at 10:13 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> A scan that has seen the flag won't look at the >>> tuple in any case. >> >> Why so? Assume that scan started on new bucket where >> split-in-progress flag was set, now it will not look at tuples that >> are marked as moved-by-split in this bucket, as it will assume to find >> all such tuples in old bucket. Now, if allow Vacuum or someone else >> to remove tuples from old with just an Exclusive lock, it is quite >> possible that scan miss the tuple in old bucket which got removed by >> vacuum. > > Oh, you're right. So we really need to CLEAR the split-in-progress > flag before removing any tuples from the old bucket. > I think that alone is not sufficient, we also need to out-wait any scan that has started when the flag is set and till it is cleared. Before vacuum starts cleaning particular bucket, we can certainly detect if it has to clean garbage tuples (the patch sets has_garbage flag in old bucket for split operation) and only for that case we can out-wait the scans. So probably, how it can work is during vacuum, take Exclusive lock on bucket, check if has_garbage flag is set and split-in-progress flag is cleared on bucket, if so then wait till the pin-count on bucket is 1, else if has_garbage is not set, then just proceed with clearing dead tuples from bucket. This will reduce the requirement of having cleanup lock only when it is required (namely when bucket has garbage tuples). -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Jun 16, 2016 at 12:58 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
+ /*
+ * Conditionally get the lock on primary bucket page for search while
+ * holding lock on meta page. If we have to wait, then release the meta
+ * page lock and retry it in a hard way.
+ */
+ bucket = _hash_hashkey2bucket(hashkey,
+ metap->hashm_maxbucket,
+ metap->hashm_highmask,
+ metap->hashm_lowmask);
+
+ blkno = BUCKET_TO_BLKNO(metap, bucket);
+
+ /* Fetch the primary bucket page for the bucket */
+ buf = ReadBuffer(rel, blkno);
+ if (!ConditionalLockBufferShared(buf))
Here we try to take lock on bucket page but I think if successful we do not recheck whether any split happened before taking lock. Is this not necessary now?
Also below "if" is always true as we enter here only when outer "if (retry)" is true.
+ if (retry)
+ {
+ if (oldblkno == blkno)
+ break;
+ _hash_relbuf(rel, buf);
+ }
--
On Fri, Jun 24, 2016 at 2:38 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
> On Thu, Jun 16, 2016 at 12:58 PM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>
> I have a question regarding code changes in _hash_first.
>
> + /*
> + * Conditionally get the lock on primary bucket page for search
> while
> + * holding lock on meta page. If we have to wait, then release the
> meta
> + * page lock and retry it in a hard way.
> + */
> + bucket = _hash_hashkey2bucket(hashkey,
> +
> metap->hashm_maxbucket,
> +
> metap->hashm_highmask,
> +
> metap->hashm_lowmask);
> +
> + blkno = BUCKET_TO_BLKNO(metap, bucket);
> +
> + /* Fetch the primary bucket page for the bucket */
> + buf = ReadBuffer(rel, blkno);
> + if (!ConditionalLockBufferShared(buf))
>
> Here we try to take lock on bucket page but I think if successful we do not
> recheck whether any split happened before taking lock. Is this not necessary
> now?
>
Yes, now that is not needed, because we are doing that by holding the
read lock on metapage. Split happens by having a write lock on
metapage. The basic idea of this optimization is that if we get the
lock immediately, then do so by holding metapage lock, else if we
decide to wait for getting a lock on bucket page then we still
fallback to previous kind of mechanism.
> Also below "if" is always true as we enter here only when outer "if
> (retry)" is true.
> + if (retry)
> + {
> + if (oldblkno == blkno)
> + break;
> + _hash_relbuf(rel, buf);
> + }
>
Good catch, I think we don't need this retry check now. We do need
similar change in _hash_doinsert().
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Wed, Jun 22, 2016 at 8:44 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 22, 2016 at 5:10 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> > Insertion will happen by scanning the appropriate bucket and needs to >>> > retain pin on primary bucket to ensure that concurrent split doesn't happen, >>> > otherwise split might leave this tuple unaccounted. >>> >>> What do you mean by "unaccounted"? >> >> It means that split might leave this tuple in old bucket even if it can be >> moved to new bucket. Consider a case where insertion has to add a tuple on >> some intermediate overflow bucket in the bucket chain, if we allow split >> when insertion is in progress, split might not move this newly inserted >> tuple. > >>> I think this is basically correct, although I don't find it to be as >>> clear as I think it could be. It seems very clear that any operation >>> which potentially changes the order of tuples in the bucket chain, >>> such as the squeeze phase as currently implemented, also needs to >>> exclude all concurrent scans. However, I think that it's OK for >>> vacuum to remove tuples from a given page with only an exclusive lock >>> on that particular page. >> >> How can we guarantee that it doesn't remove a tuple that is required by scan >> which is started after split-in-progress flag is set? > > If the tuple is being removed by VACUUM, it is dead. We can remove > dead tuples right away, because no MVCC scan will see them. In fact, > the only snapshot that will see them is SnapshotAny, and there's no > problem with removing dead tuples while a SnapshotAny scan is in > progress. It's no different than heap_page_prune() removing tuples > that a SnapshotAny sequential scan was about to see. > While again thinking about this case, it seems to me that we need a cleanup lock even for dead tuple removal. The reason for the same is that scans that return multiple tuples always restart the scan from the previous offset number from which they have returned last tuple. Now, consider the case where the first tuple is returned from offset number-3 in page and after that another backend removes the corresponding tuple from heap and vacuum also removes the dead tuple corresponding to offset-3. When the scan will try to get the next tuple, it will start from offset-3 which can lead to incorrect results. Now, one way to solve above problem could be if we change scan for hash indexes such that it works page at a time like we do for btree scans (refer BTScanPosData and comments on top of it). This has an additional advantage that it will reduce lock/unlock calls for retrieving tuples from a page. However, I think this solution can only work for MVCC scans. For non-MVCC scans, still there is a problem, because after fetching all the tuples from a page, when it tries to check the validity of tuples in heap, we won't be able to detect if the old tuple is deleted and a new tuple has been placed at that location in heap. I think what we can do to solve this for non-MVCC scans is that allow vacuum to always take a cleanup lock on a bucket and MVCC-scans will release both the lock and pin as it proceeds. Non-MVCC scans and scans that are started during split-in-progress will release the lock, but not a pin on primary bucket. This way, we can allow vacuum to proceed even if there is a MVCC-scan going on a bucket if it is not started during a bucket split operation. For btree code, we do something similar, which means that vacuum always take cleanup lock on a bucket and non-MVCC scan retains a pin on the bucket. The insertions should work as they are currently in patch, that is they always need to retain a pin on primary bucket to avoid the concurrent split problem as mentioned above (refer the first paragraph discussion of this mail). Thoughts? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Jun 22, 2016 at 8:48 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 22, 2016 at 5:14 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> We can do it in the way as you are suggesting, but there is another thing >> which we need to consider here. As of now, the patch tries to finish the >> split if it finds split-in-progress flag in either old or new bucket. We >> need to lock both old and new buckets to finish the split, so it is quite >> possible that two different backends try to lock them in opposite order >> leading to a deadlock. I think the correct way to handle is to always try >> to lock the old bucket first and then new bucket. To achieve that, if the >> insertion on new bucket finds that split-in-progress flag is set on a >> bucket, it needs to release the lock and then acquire the lock first on old >> bucket, ensure pincount is 1 and then lock new bucket again and ensure that >> pincount is 1. I have already maintained the order of locks in scan (old >> bucket first and then new bucket; refer changes in _hash_first()). >> Alternatively, we can try to finish the splits only when someone tries to >> insert in old bucket. > > Yes, I think locking buckets in increasing order is a good solution. > I also think it's fine to only try to finish the split when the insert > targets the old bucket. Finishing the split enables us to remove > tuples from the old bucket, which lets us reuse space instead of > accelerating more. So there is at least some potential benefit to the > backend inserting into the old bucket. On the other hand, a process > inserting into the new bucket derives no direct benefit from finishing > the split. > Okay, following this suggestion, I have updated the patch so that only insertion into old-bucket can try to finish the splits. Apart from that, I have fixed the issue reported by Mithun upthread. I have updated the README to explain the locking used in patch. Also, I have changed the locking around vacuum, so that it can work with concurrent scans when ever possible. In previous patch version, vacuum used to take cleanup lock on a bucket to remove the dead tuples, moved-due-to-split tuples and squeeze operation, also it holds the lock on bucket till end of cleanup. Now, also it takes cleanup lock on a bucket to out-wait scans, but it releases the lock as it proceeds to clean the overflow pages. The idea is first we need to lock the next bucket page and then release the lock on current bucket page. This ensures that any concurrent scan started after we start cleaning the bucket will always be behind the cleanup. Allowing scans to cross vacuum will allow it to remove tuples required for sanctity of scan. Also for squeeze-phase we are just checking if the pincount of buffer is one (we already have Exclusive lock on buffer of bucket by that time), then only proceed, else will try to squeeze next time the cleanup is required for that bucket. Thoughts/Suggestions? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
I did some basic testing of same. In that I found one issue with cursor.
closing the cursor comes with the warning which say we forgot to unpin the buffer.+BEGIN;
+SET enable_seqscan = OFF;
+SET enable_bitmapscan = OFF;
+CREATE FUNCTION declares_cursor(int)
+ RETURNS void
+ AS 'DECLARE c CURSOR FOR SELECT * from con_hash_index_table WHERE keycol = $1;'
+LANGUAGE SQL;
+
+SELECT declares_cursor(1);
+MOVE FORWARD ALL FROM c;
+MOVE BACKWARD 10000 FROM c;
+ CLOSE c;
+ WARNING: buffer refcount leak: [5835] (rel=base/16384/30537, blockNum=327, flags=0x93800000, refcount=1 1)
ROLLBACK;
[1] Some tests to cover hash_index.
On Thu, Jul 14, 2016 at 4:33 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Jun 22, 2016 at 8:48 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Wed, Jun 22, 2016 at 5:14 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> We can do it in the way as you are suggesting, but there is another thing
>> which we need to consider here. As of now, the patch tries to finish the
>> split if it finds split-in-progress flag in either old or new bucket. We
>> need to lock both old and new buckets to finish the split, so it is quite
>> possible that two different backends try to lock them in opposite order
>> leading to a deadlock. I think the correct way to handle is to always try
>> to lock the old bucket first and then new bucket. To achieve that, if the
>> insertion on new bucket finds that split-in-progress flag is set on a
>> bucket, it needs to release the lock and then acquire the lock first on old
>> bucket, ensure pincount is 1 and then lock new bucket again and ensure that
>> pincount is 1. I have already maintained the order of locks in scan (old
>> bucket first and then new bucket; refer changes in _hash_first()).
>> Alternatively, we can try to finish the splits only when someone tries to
>> insert in old bucket.
>
> Yes, I think locking buckets in increasing order is a good solution.
> I also think it's fine to only try to finish the split when the insert
> targets the old bucket. Finishing the split enables us to remove
> tuples from the old bucket, which lets us reuse space instead of
> accelerating more. So there is at least some potential benefit to the
> backend inserting into the old bucket. On the other hand, a process
> inserting into the new bucket derives no direct benefit from finishing
> the split.
>
Okay, following this suggestion, I have updated the patch so that only
insertion into old-bucket can try to finish the splits. Apart from
that, I have fixed the issue reported by Mithun upthread. I have
updated the README to explain the locking used in patch. Also, I
have changed the locking around vacuum, so that it can work with
concurrent scans when ever possible. In previous patch version,
vacuum used to take cleanup lock on a bucket to remove the dead
tuples, moved-due-to-split tuples and squeeze operation, also it holds
the lock on bucket till end of cleanup. Now, also it takes cleanup
lock on a bucket to out-wait scans, but it releases the lock as it
proceeds to clean the overflow pages. The idea is first we need to
lock the next bucket page and then release the lock on current bucket
page. This ensures that any concurrent scan started after we start
cleaning the bucket will always be behind the cleanup. Allowing scans
to cross vacuum will allow it to remove tuples required for sanctity
of scan. Also for squeeze-phase we are just checking if the pincount
of buffer is one (we already have Exclusive lock on buffer of bucket
by that time), then only proceed, else will try to squeeze next time
the cleanup is required for that bucket.
Thoughts/Suggestions?
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
--
On Thu, Aug 4, 2016 at 8:02 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > I did some basic testing of same. In that I found one issue with cursor. > Thanks for the testing. The reason for failure was that the patch didn't take into account the fact that for scrolling cursors, scan can reacquire the lock and pin on bucket buffer multiple times. I have fixed it such that we release the pin on bucket buffers after we scan the last overflow page in bucket. Attached patch fixes the issue for me, let me know if you still see the issue. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On 08/05/2016 07:36 AM, Amit Kapila wrote: > On Thu, Aug 4, 2016 at 8:02 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: >> I did some basic testing of same. In that I found one issue with cursor. >> > > Thanks for the testing. The reason for failure was that the patch > didn't take into account the fact that for scrolling cursors, scan can > reacquire the lock and pin on bucket buffer multiple times. I have > fixed it such that we release the pin on bucket buffers after we scan > the last overflow page in bucket. Attached patch fixes the issue for > me, let me know if you still see the issue. > Needs a rebase. hashinsert.c + * reuse the space. There is no such apparent benefit from finsihing the -> finishing hashpage.c + * retrun the buffer, else return InvalidBuffer. -> return + if (blkno == P_NEW) + elog(ERROR, "hash AM does not use P_NEW"); Left over ? + * for unlocking it. -> for unlocking them. hashsearch.c + * bucket, but not pin, then acuire the lock on new bucket and again -> acquire hashutil.c + * half. It is mainly required to finsh the incomplete splits where we are -> finish Ran some tests on a CHAR() based column which showed good results. Will have to compare with a run with the WAL patch applied. make check-world passes. Best regards, Jesper
On Thu, Sep 1, 2016 at 11:33 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > On 08/05/2016 07:36 AM, Amit Kapila wrote: > > Needs a rebase. > Done. > > + if (blkno == P_NEW) > + elog(ERROR, "hash AM does not use P_NEW"); > > Left over ? > No. We need this check similar to all other _hash_*buf API's, as we never expect caller of those API's to pass P_NEW. The new buckets (blocks) are created during split and it uses different mechanism to allocate blocks in bulk. I have fixed all other issues you have raised. Updated patch is attached with this mail. > > Ran some tests on a CHAR() based column which showed good results. Will have > to compare with a run with the WAL patch applied. > Okay, Thanks for testing. I think WAL patch is still not ready for performance testing, I am fixing few issues in that patch, but you can do the design or code level review of that patch at this stage. I think it is fine even if you share the performance numbers with this and or Mithun's patch [1]. [1] - https://commitfest.postgresql.org/10/715/ -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On Thu, Sep 1, 2016 at 8:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
I have fixed all other issues you have raised. Updated patch is
attached with this mail.
I am finding the comments (particularly README) quite hard to follow. There are many references to an "overflow bucket", or similar phrases. I think these should be "overflow pages". A bucket is a conceptual thing consisting of a primary page for that bucket and zero or more overflow pages for the same bucket. There are no overflow buckets, unless you are referring to the new bucket to which things are being moved.
Was maintaining on-disk compatibility a major concern for this patch? Would you do things differently if that were not a concern? If we would benefit from a break in format, I think it would be better to do that now while hash indexes are still discouraged, rather than in a future release.
In particular, I am thinking about the need for every insert to exclusive-content-lock the meta page to increment the index-wide tuple count. I think that this is going to be a huge bottleneck on update intensive workloads (which I don't believe have been performance tested as of yet). I was wondering if we might not want to change that so that each bucket keeps a local count, and sweeps that up to the meta page only when it exceeds a threshold. But this would require the bucket page to have an area to hold such a count. Another idea would to keep not a count of tuples, but of buckets with at least one overflow page, and split when there are too many of those. I bring it up now because it would be a shame to ignore it until 10.0 is out the door, and then need to break things in 11.0.
Cheers,
Jeff
On Wed, Sep 7, 2016 at 11:49 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
> On Thu, Sep 1, 2016 at 8:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>>
>> I have fixed all other issues you have raised. Updated patch is
>> attached with this mail.
>
>
> I am finding the comments (particularly README) quite hard to follow. There
> are many references to an "overflow bucket", or similar phrases. I think
> these should be "overflow pages". A bucket is a conceptual thing consisting
> of a primary page for that bucket and zero or more overflow pages for the
> same bucket. There are no overflow buckets, unless you are referring to the
> new bucket to which things are being moved.
>
Hmm. I think page or block is a concept of database systems and
buckets is a general concept used in hashing technology. I think the
difference is that there are primary buckets and overflow buckets. I
have checked how they are referred in one of the wiki pages [1],
search for overflow on that wiki page. Now, I think we shouldn't be
inconsistent in using them. I will change to make it same if I find
any inconsistency based on what you or other people think is the
better way to refer overflow space.
> Was maintaining on-disk compatibility a major concern for this patch? Would
> you do things differently if that were not a concern?
>
I would not have done much differently from what it is now, however
one thing I have considered during development was to change the hash
index tuple structure as below to mark the index tuples as
move-by-split:
typedef struct
{
IndexTuple entry; /* tuple to insert */
bool moved_by_split;
} HashEntryData;
The other alternative was to use the (unused) bit in IndexTupleData->tinfo.
I have chosen the later approach, now one could definitely argue that
it is the last available bit in IndexTuple and using it for hash
indexes might or might not be best thing to do. However, I think it
is also not advisable to break the compatibility if we can use some
existing bit. In any case, the same question can arise whenever
anyone wants to use it for some other purpose.
> In particular, I am thinking about the need for every insert to
> exclusive-content-lock the meta page to increment the index-wide tuple
> count.
This is not what this patch has changed. The main purpose of this
patch is to change heavy-weight locking to light-weight locking and
provide a way to handle the in-complete splits, both of which are
required to sensibly write WAL for hash-indexes. Having said that, I
agree with your point that we can improve the insertion logic, so that
we don't need to Write-lock the meta-page at each insert. I have
noticed some other improvements in hash indexes as well during this
work like caching the meta page, reduce lock/unlock calls for
retrieving tuples from a page by making hash index scans work a page
at a time as we do for btree scans, kill_prior_tuple mechanism is
current quite naive and needs improvement and the biggest improvement
is needed in create index logic where we are inserting tuple-by-tuple
whereas btree operates at page level and also by-passes the shared
buffers. One of such improvements (cache the meta page) is already
being worked upon by my colleague and the patch [2] for same is in CF.
The main point I want to high light is that apart from what this patch
does, there are number of other potential areas which needs
improvements in hash indexes and I think it is better to do those as
separate enhancements rather than as a single patch.
> I think that this is going to be a huge bottleneck on update
> intensive workloads (which I don't believe have been performance tested as
> of yet).
I have done some performance testing with this patch and I find there
was a significant improvement as compare to what we have now in hash
indexes even for read-write workload. I think the better idea is to
compare it with btree, but in any case, even if this proves to be a
bottleneck, we should try to improve it in a separate patch rather
than as a part of this patch.
> I was wondering if we might not want to change that so that each
> bucket keeps a local count, and sweeps that up to the meta page only when it
> exceeds a threshold. But this would require the bucket page to have an area
> to hold such a count. Another idea would to keep not a count of tuples, but
> of buckets with at least one overflow page, and split when there are too
> many of those.
I think both of these ideas could lead to change the point (tuple
count) where we currently split. This might impact the search speed
and space usage. Yet another alternative could be to change
hashm_ntuples to 64bit and use 64-bit atomics to operate on it or may
be use a separate spin-lock to protect it. However, whatever we
decide to do with it, I think it is a matter of separate patch.
Thanks for looking into patch.
[1] - https://en.wikipedia.org/wiki/Linear_hashing
[2] - https://commitfest.postgresql.org/10/715/
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On 09/01/2016 11:55 PM, Amit Kapila wrote: > I have fixed all other issues you have raised. Updated patch is > attached with this mail. > The following script hangs on idx_val creation - just with v5, WAL patch not applied. Best regards, Jesper
Вложения
On 13/09/16 01:20, Jesper Pedersen wrote: > On 09/01/2016 11:55 PM, Amit Kapila wrote: >> I have fixed all other issues you have raised. Updated patch is >> attached with this mail. >> > > The following script hangs on idx_val creation - just with v5, WAL patch > not applied. Are you sure it is actually hanging? I see 100% cpu for a few minutes but the index eventually completes ok for me (v5 patch applied to today's master). Cheers Mark
On Tue, Sep 13, 2016 at 3:58 AM, Mark Kirkwood <mark.kirkwood@catalyst.net.nz> wrote: > On 13/09/16 01:20, Jesper Pedersen wrote: >> >> On 09/01/2016 11:55 PM, Amit Kapila wrote: >>> >>> I have fixed all other issues you have raised. Updated patch is >>> attached with this mail. >>> >> >> The following script hangs on idx_val creation - just with v5, WAL patch >> not applied. > > > Are you sure it is actually hanging? I see 100% cpu for a few minutes but > the index eventually completes ok for me (v5 patch applied to today's > master). > It completed for me as well. The second index creation is taking more time and cpu, because it is just inserting duplicate values which need lot of overflow pages. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Attached, new version of patch which contains the fix for problem reported on write-ahead-log of hash index thread [1]. [1] - https://www.postgresql.org/message-id/CAA4eK1JuKt%3D-%3DY0FheiFL-i8Z5_5660%3D3n8JUA8s3zG53t_ArQ%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On 09/12/2016 10:42 PM, Amit Kapila wrote: >>> The following script hangs on idx_val creation - just with v5, WAL patch >>> not applied. >> >> >> Are you sure it is actually hanging? I see 100% cpu for a few minutes but >> the index eventually completes ok for me (v5 patch applied to today's >> master). >> > > It completed for me as well. The second index creation is taking more > time and cpu, because it is just inserting duplicate values which need > lot of overflow pages. > Yeah, sorry for the false alarm. It just took 3m45s to complete on my machine. Best regards, Jesper
On Thu, Sep 8, 2016 at 12:32 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Hmm. I think page or block is a concept of database systems and > buckets is a general concept used in hashing technology. I think the > difference is that there are primary buckets and overflow buckets. I > have checked how they are referred in one of the wiki pages [1], > search for overflow on that wiki page. Now, I think we shouldn't be > inconsistent in using them. I will change to make it same if I find > any inconsistency based on what you or other people think is the > better way to refer overflow space. In the existing source code, the terminology 'overflow page' is clearly preferred to 'overflow bucket'. [rhaas pgsql]$ git grep 'overflow page' | wc -l 75 [rhaas pgsql]$ git grep 'overflow bucket' | wc -l 1 In our off-list conversations, I too have found it very confusing when you've made reference to an overflow bucket. A hash table has a fixed number of buckets, and depending on the type of hash table the storage for each bucket may be linked together into some kind of a chain; here, a chain of pages. The 'bucket' logically refers to all of the entries that have hash codes such that (hc % nbuckets) == bucketno, regardless of which pages contain them. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Sep 7, 2016 at 9:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
========
in _hash_splitbucket comments, this needs updating:
* The caller must hold exclusive locks on both buckets to ensure that
* no one else is trying to access them (see README).
On Wed, Sep 7, 2016 at 11:49 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
> On Thu, Sep 1, 2016 at 8:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>>
>> I have fixed all other issues you have raised. Updated patch is
>> attached with this mail.
>
>
> I am finding the comments (particularly README) quite hard to follow. There
> are many references to an "overflow bucket", or similar phrases. I think
> these should be "overflow pages". A bucket is a conceptual thing consisting
> of a primary page for that bucket and zero or more overflow pages for the
> same bucket. There are no overflow buckets, unless you are referring to the
> new bucket to which things are being moved.
>
Hmm. I think page or block is a concept of database systems and
buckets is a general concept used in hashing technology. I think the
difference is that there are primary buckets and overflow buckets. I
have checked how they are referred in one of the wiki pages [1],
search for overflow on that wiki page.
That page seems to use "slot" to refer to the primary bucket/page and all the overflow buckets/pages which cover the same post-masked values. I don't think that would be an improvement for us, because "slot" is already pretty well-used for other things. Their use of "bucket" does seem to be mostly the same as "page" (or maybe "buffer" or "block"?) but I don't think we gain anything from creating yet another synonym for page/buffer/block. I think the easiest thing would be to keep using the meanings which the existed committed code uses, so that we at least have internal consistency.
Now, I think we shouldn't be
inconsistent in using them. I will change to make it same if I find
any inconsistency based on what you or other people think is the
better way to refer overflow space.
I think just "overflow page" or "buffer containing the overflow page".
Here are some more notes I've taken, mostly about the README and comments.
It took me a while to understand that once a tuple is marked as moved by split, it stays that way forever. It doesn't mean "recently moved by split", but "ever moved by split". Which works, but is rather subtle. Perhaps this deserves a parenthetical comment in the README the first time the flag is mentioned.
========
#define INDEX_SIZE_MASK 0x1FFF
/* bit 0x2000 is not used at present */
========
ensures that scan will always be behind cleanup.
Above, the abrupt transition from splits (first sentence) to cleanup is confusing. If the cleanup referred to is vacuuming, it should be a new paragraph or at least have a transition sentence. Or is it referring to clean-up locks used for control purposes, rather than for actual vacuum clean-up? I think it is the first one, the vacuum. (I find the committed version of this comment confusing as well--how in the committed code would a tuple be visited twice, and why does that not do harm in the committed coding? So maybe the issue here is me, not the comment.)
=======
+Vacuum acquires cleanup lock on bucket to remove the dead tuples and or tuples
+that are moved due to split. The need for cleanup lock to remove dead tuples
+is to ensure that scans' returns correct results. Scan that returns multiple
+tuples from the same bucket page always restart the scan from the previous
+offset number from which it has returned last tuple.
========
#define INDEX_SIZE_MASK 0x1FFF
/* bit 0x2000 is not used at present */
This is no longer true, maybe:
/* bit 0x2000 is reserved for index-AM specific usage */
========
Note that this is designed to allow concurrent splits and scans. If a
split occurs, tuples relocated into the new bucket will be visited twice
by the scan, but that does no harm. As we are releasing the locks during
scan of a bucket, it will allow concurrent scan to start on a bucket andensures that scan will always be behind cleanup.
Above, the abrupt transition from splits (first sentence) to cleanup is confusing. If the cleanup referred to is vacuuming, it should be a new paragraph or at least have a transition sentence. Or is it referring to clean-up locks used for control purposes, rather than for actual vacuum clean-up? I think it is the first one, the vacuum. (I find the committed version of this comment confusing as well--how in the committed code would a tuple be visited twice, and why does that not do harm in the committed coding? So maybe the issue here is me, not the comment.)
=======
+Vacuum acquires cleanup lock on bucket to remove the dead tuples and or tuples
+that are moved due to split. The need for cleanup lock to remove dead tuples
+is to ensure that scans' returns correct results. Scan that returns multiple
+tuples from the same bucket page always restart the scan from the previous
+offset number from which it has returned last tuple.
Perhaps it would be better to teach scans to restart anywhere on the page, than to force more cleanup locks to be taken?
=======
This comment no longer seems accurate (as long as it is just an ERROR and not a PANIC):
* XXX we have a problem here if we fail to get space for a
* new overflow page: we'll error out leaving the bucket split
* only partially complete, meaning the index is corrupt,
* since searches may fail to find entries they should find.
The split will still be marked as being in progress, so any scanner will have to scan the old page and see the tuple there.=======
This comment no longer seems accurate (as long as it is just an ERROR and not a PANIC):
* XXX we have a problem here if we fail to get space for a
* new overflow page: we'll error out leaving the bucket split
* only partially complete, meaning the index is corrupt,
* since searches may fail to find entries they should find.
========
in _hash_splitbucket comments, this needs updating:
* The caller must hold exclusive locks on both buckets to ensure that
* no one else is trying to access them (see README).
The true prereq here is a buffer clean up lock (pin plus exclusive buffer content lock), correct?
And then:
* Split needs to hold pin on primary bucket pages of both old and new
* buckets till end of operation.
* Split needs to hold pin on primary bucket pages of both old and new
* buckets till end of operation.
'retain' is probably better than 'hold', to emphasize that we are dropping the buffer content lock part of the clean-up lock, but that the pin part of it is kept continuously (this also matches the variable name used in the code). Also, the paragraph after that one seems to be obsolete and contradictory with the newly added comments.
===========
/*
* Acquiring cleanup lock to clear the split-in-progress flag ensures that
* there is no pending scan that has seen the flag after it is cleared.
*/
===========
/*
* Acquiring cleanup lock to clear the split-in-progress flag ensures that
* there is no pending scan that has seen the flag after it is cleared.
*/
But, we are not acquiring a clean up lock. We already have a pin, and we do acquire a write buffer-content lock, but don't observe that our pin is the only one. I don't see why it is necessary to have a clean up lock (what harm is done if a under-way scan thinks it is scanning a bucket that is being split when it actually just finished the split?), but if it is necessary then I think this code is wrong. If not necessary, the comment is wrong.
Also, why must we hold a write lock on both old and new primary bucket pages simultaneously? Is this in anticipation of the WAL patch? The contract for the function does say that it returns both pages write locked, but I don't see a reason for that part of the contract at the moment.
=========
To avoid deadlock between readers and inserters, whenever there is a need
to lock multiple buckets, we always take in the order suggested in Locking
Definitions above. This algorithm allows them a very high degree of
concurrency.
The section referred to is actually spelled "Lock Definitions", no "ing".
The Lock Definitions sections doesn't mention the meta page at all. I think there needs be something added to it about how the meta page gets locked and why that is deadlock free. (But we could be optimistic and assume the patch to implement caching of the metapage will go in and will take care of that).
=========
And an operational question on this: A lot of stuff is done conditionally here. Under high concurrency, do splits ever actually occur? It seems like they could easily be permanently starved.
Cheers,
Jeff
On 09/13/2016 07:26 AM, Amit Kapila wrote: > Attached, new version of patch which contains the fix for problem > reported on write-ahead-log of hash index thread [1]. > I have been testing patch in various scenarios, and it has a positive performance impact in some cases. This is especially seen in cases where the values of the indexed column are unique - SELECTs can see a 40-60% benefit over a similar query using b-tree. UPDATE also sees an improvement. In cases where the indexed column value isn't unique, it takes a long time to build the index due to the overflow page creation. Also in cases where the index column is updated with a high number of clients, ala -- ddl.sql -- CREATE TABLE test AS SELECT generate_series(1, 10) AS id, 0 AS val; CREATE INDEX IF NOT EXISTS idx_id ON test USING hash (id); CREATE INDEX IF NOT EXISTS idx_val ON test USING hash (val); ANALYZE; -- test.sql -- \set id random(1,10) \set val random(0,10) BEGIN; UPDATE test SET val = :val WHERE id = :id; COMMIT; w/ 100 clients - it takes longer than the b-tree counterpart (2921 tps for hash, and 10062 tps for b-tree). Jeff mentioned upthread the idea of moving the lock to a bucket meta page instead of having it on the main meta page. Likely a question for the assigned committer. Thanks for working on this ! Best regards, Jesper
On Tue, Sep 13, 2016 at 5:46 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Sep 8, 2016 at 12:32 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Hmm. I think page or block is a concept of database systems and >> buckets is a general concept used in hashing technology. I think the >> difference is that there are primary buckets and overflow buckets. I >> have checked how they are referred in one of the wiki pages [1], >> search for overflow on that wiki page. Now, I think we shouldn't be >> inconsistent in using them. I will change to make it same if I find >> any inconsistency based on what you or other people think is the >> better way to refer overflow space. > > In the existing source code, the terminology 'overflow page' is > clearly preferred to 'overflow bucket'. > Okay, point taken. Will update it in next version of patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 14, 2016 at 12:29 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > On 09/13/2016 07:26 AM, Amit Kapila wrote: >> >> Attached, new version of patch which contains the fix for problem >> reported on write-ahead-log of hash index thread [1]. >> > > I have been testing patch in various scenarios, and it has a positive > performance impact in some cases. > > This is especially seen in cases where the values of the indexed column are > unique - SELECTs can see a 40-60% benefit over a similar query using b-tree. > Here, I think it is better if we have the data comparing the situation of hash index with respect to HEAD as well. What I mean to say is that you are claiming that after the hash index improvements SELECT workload is 40-60% better, but where do we stand as of HEAD? > UPDATE also sees an improvement. > Can you explain this more? Is it more compare to HEAD or more as compare to Btree? Isn't this contradictory to what the test in below mail shows? > In cases where the indexed column value isn't unique, it takes a long time > to build the index due to the overflow page creation. > > Also in cases where the index column is updated with a high number of > clients, ala > > -- ddl.sql -- > CREATE TABLE test AS SELECT generate_series(1, 10) AS id, 0 AS val; > CREATE INDEX IF NOT EXISTS idx_id ON test USING hash (id); > CREATE INDEX IF NOT EXISTS idx_val ON test USING hash (val); > ANALYZE; > > -- test.sql -- > \set id random(1,10) > \set val random(0,10) > BEGIN; > UPDATE test SET val = :val WHERE id = :id; > COMMIT; > > w/ 100 clients - it takes longer than the b-tree counterpart (2921 tps for > hash, and 10062 tps for b-tree). > Thanks for doing the tests. Have you applied both concurrent index and cache the meta page patch for these tests? So from above tests, we can say that after these set of patches read-only workloads will be significantly improved even better than btree in quite-a-few useful cases. However when the indexed column is updated, there is still a large gap as compare to btree (what about the case when the indexed column is not updated in read-write transaction as in our pgbench read-write transactions, by any chance did you ran any such test?). I think we need to focus on improving cases where index columns are updated, but it is better to do that work as a separate patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hi, On 09/14/2016 07:24 AM, Amit Kapila wrote: > On Wed, Sep 14, 2016 at 12:29 AM, Jesper Pedersen > <jesper.pedersen@redhat.com> wrote: >> On 09/13/2016 07:26 AM, Amit Kapila wrote: >>> >>> Attached, new version of patch which contains the fix for problem >>> reported on write-ahead-log of hash index thread [1]. >>> >> >> I have been testing patch in various scenarios, and it has a positive >> performance impact in some cases. >> >> This is especially seen in cases where the values of the indexed column are >> unique - SELECTs can see a 40-60% benefit over a similar query using b-tree. >> > > Here, I think it is better if we have the data comparing the situation > of hash index with respect to HEAD as well. What I mean to say is > that you are claiming that after the hash index improvements SELECT > workload is 40-60% better, but where do we stand as of HEAD? > The tests I have done are with a copy of a production database using the same queries sent with a b-tree index for the primary key, and the same with a hash index. Those are seeing a speed-up of the mentioned 40-60% in execution time - some involve JOINs. Largest of those tables is 390Mb with a CHAR() based primary key. >> UPDATE also sees an improvement. >> > > Can you explain this more? Is it more compare to HEAD or more as > compare to Btree? Isn't this contradictory to what the test in below > mail shows? > Same thing here - where the fields involving the hash index aren't updated. >> In cases where the indexed column value isn't unique, it takes a long time >> to build the index due to the overflow page creation. >> >> Also in cases where the index column is updated with a high number of >> clients, ala >> >> -- ddl.sql -- >> CREATE TABLE test AS SELECT generate_series(1, 10) AS id, 0 AS val; >> CREATE INDEX IF NOT EXISTS idx_id ON test USING hash (id); >> CREATE INDEX IF NOT EXISTS idx_val ON test USING hash (val); >> ANALYZE; >> >> -- test.sql -- >> \set id random(1,10) >> \set val random(0,10) >> BEGIN; >> UPDATE test SET val = :val WHERE id = :id; >> COMMIT; >> >> w/ 100 clients - it takes longer than the b-tree counterpart (2921 tps for >> hash, and 10062 tps for b-tree). >> > > Thanks for doing the tests. Have you applied both concurrent index > and cache the meta page patch for these tests? So from above tests, > we can say that after these set of patches read-only workloads will be > significantly improved even better than btree in quite-a-few useful > cases. Agreed. > However when the indexed column is updated, there is still a > large gap as compare to btree (what about the case when the indexed > column is not updated in read-write transaction as in our pgbench > read-write transactions, by any chance did you ran any such test?). I have done a run to look at the concurrency / TPS aspect of the implementation - to try something different than Mark's work on testing the pgbench setup. With definitions as above, with SELECT as -- select.sql -- \set id random(1,10) BEGIN; SELECT * FROM test WHERE id = :id; COMMIT; and UPDATE/Indexed with an index on 'val', and finally UPDATE/Nonindexed w/o one. [1] [2] [3] is new_hash - old_hash is the existing hash implementation on master. btree is master too. Machine is a 28C/56T with 256Gb RAM with 2 x RAID10 SSD for data + wal. Clients ran with -M prepared. [1] https://www.postgresql.org/message-id/CAA4eK1+ERbP+7mdKkAhJZWQ_dTdkocbpt7LSWFwCQvUHBXzkmA@mail.gmail.com [2] https://www.postgresql.org/message-id/CAD__OujvYghFX_XVkgRcJH4VcEbfJNSxySd9x=1Wp5VyLvkf8Q@mail.gmail.com [3] https://www.postgresql.org/message-id/CAA4eK1JUYr_aB7BxFnSg5+JQhiwgkLKgAcFK9bfD4MLfFK6Oqw@mail.gmail.com Don't know if you find this useful due to the small number of rows, but let me know if there are other tests I can run, f.ex. bump the number of rows. > I > think we need to focus on improving cases where index columns are > updated, but it is better to do that work as a separate patch. > Ok. Best regards, Jesper
Вложения
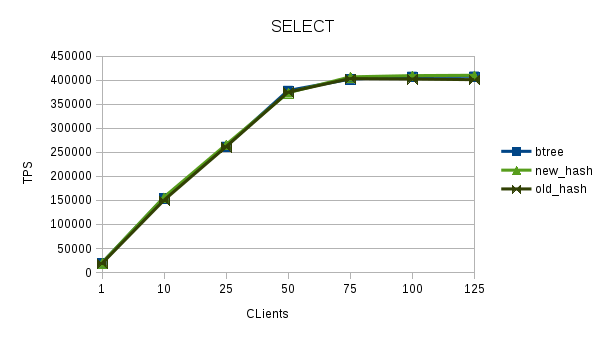{kind=link}
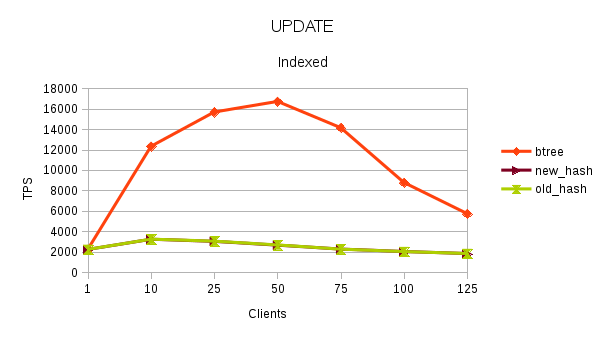{kind=link}
{kind=link}
On Tue, Sep 13, 2016 at 9:31 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
=======
+Vacuum acquires cleanup lock on bucket to remove the dead tuples and or tuples
+that are moved due to split. The need for cleanup lock to remove dead tuples
+is to ensure that scans' returns correct results. Scan that returns multiple
+tuples from the same bucket page always restart the scan from the previous
+offset number from which it has returned last tuple.Perhaps it would be better to teach scans to restart anywhere on the page, than to force more cleanup locks to be taken?
Commenting on one of my own questions:
This won't work when the vacuum removes the tuple which an existing scan is currently examining and thus will be used to re-find it's position when it realizes it is not visible and so takes up the scan again.
The index tuples in a page are stored sorted just by hash value, not by the combination of (hash value, tid). If they were sorted by both, we could re-find our position even if the tuple had been removed, because we would know to start at the slot adjacent to where the missing tuple would be were it not removed. But unless we are willing to break pg_upgrade, there is no feasible way to change that now.
Cheers,
Jeff
On Tue, May 10, 2016 at 5:09 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
598.2
Although, I don't think it is a very good idea to take any performance data with WIP patch, still I couldn't resist myself from doing so and below are the performance numbers. To get the performance data, I have dropped the primary key constraint on pgbench_accounts and created a hash index on aid column as below.alter table pgbench_accounts drop constraint pgbench_accounts_pkey;create index pgbench_accounts_pkey on pgbench_accounts using hash(aid);
To be rigorously fair, you should probably replace the btree primary key with a non-unique btree index and use that in the btree comparison case. I don't know how much difference that would make, probably none at all for a read-only case.
Below data is for read-only pgbench test and is a median of 3 5-min runs. The performance tests are executed on a power-8 m/c.
With pgbench -S where everything fits in shared_buffers and the number of cores I have at my disposal, I am mostly benchmarking interprocess communication between pgbench and the backend. I am impressed that you can detect any difference at all.
For this type of thing, I like to create a server side function for use in benchmarking:
create or replace function pgbench_query(scale integer,size integer)
RETURNS integer AS $$
DECLARE sum integer default 0;
amount integer;
account_id integer;
BEGIN FOR i IN 1..size LOOP
account_id=1+floor(random()*scale);
SELECT abalance into strict amount FROM pgbench_accounts
WHERE aid = account_id;
sum := sum + amount;
END LOOP;
return sum;
END $$ LANGUAGE plpgsql;
And then run using a command like this:
pgbench -f <(echo 'select pgbench_query(40,1000)') -c$j -j$j -T 300
Where the first argument ('40', here) must be manually set to the same value as the scale-factor.
With 8 cores and 8 clients, the values I get are, for btree, hash-head, hash-concurrent, hash-concurrent-cache, respectively:
577.4
668.7
664.6
(each transaction involves 1000 select statements)
So I do see that the concurrency patch is quite an improvement. The cache patch does not produce a further improvement, which was somewhat surprising to me (I thought that that patch would really shine in a read-write workload, but I expected at least improvement in read only)
I've run this was 128MB shared_buffers and scale factor 40. Not everything fits in shared_buffers, but quite easily fits in RAM, and there is no meaningful IO caused by the benchmark.
Cheers,
Jeff
On Tue, Sep 13, 2016 at 10:01 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Wed, Sep 7, 2016 at 9:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> > > >> >> Now, I think we shouldn't be >> inconsistent in using them. I will change to make it same if I find >> any inconsistency based on what you or other people think is the >> better way to refer overflow space. > > > I think just "overflow page" or "buffer containing the overflow page". > Okay changed to overflow page. > > Here are some more notes I've taken, mostly about the README and comments. > > It took me a while to understand that once a tuple is marked as moved by > split, it stays that way forever. It doesn't mean "recently moved by > split", but "ever moved by split". Which works, but is rather subtle. > Perhaps this deserves a parenthetical comment in the README the first time > the flag is mentioned. > I have added an additional paragraph explaining move-by-split flag along with the explanation of split operation. > ======== > > #define INDEX_SIZE_MASK 0x1FFF > /* bit 0x2000 is not used at present */ > > This is no longer true, maybe: > /* bit 0x2000 is reserved for index-AM specific usage */ > Changed as per suggestion. > ======== > > Note that this is designed to allow concurrent splits and scans. If a > split occurs, tuples relocated into the new bucket will be visited twice > by the scan, but that does no harm. As we are releasing the locks during > scan of a bucket, it will allow concurrent scan to start on a bucket and > ensures that scan will always be behind cleanup. > > Above, the abrupt transition from splits (first sentence) to cleanup is > confusing. If the cleanup referred to is vacuuming, it should be a new > paragraph or at least have a transition sentence. Or is it referring to > clean-up locks used for control purposes, rather than for actual vacuum > clean-up? I think it is the first one, the vacuum. > Yes, it is first one. > (I find the committed > version of this comment confusing as well--how in the committed code would a > tuple be visited twice, and why does that not do harm in the committed > coding? So maybe the issue here is me, not the comment.) > You have to read this scan as scan during vacuum. Whatever is written in committed code is right, let me try to explain with example. Suppose, there are two buckets at the start of vacuum, after it completes the vacuuming of first bucket and before or during vacuum for second bucket, a split for first bucket occurs. Now we have three buckets. If you notice in code (hashbulkdelete), after completing the vacuum for first and second bucket, if there is a split it will perform the vacuum for third bucket as well. This is the reason why readme mention's that tuples relocated into the new bucket will be visited twice. This whole explanation is in garbage collection section, so to me it looks clear. However, I have changed some wording, see if it makes sense to you now. > > ======= > > +Vacuum acquires cleanup lock on bucket to remove the dead tuples and or > tuples > +that are moved due to split. The need for cleanup lock to remove dead > tuples > +is to ensure that scans' returns correct results. Scan that returns > multiple > +tuples from the same bucket page always restart the scan from the previous > +offset number from which it has returned last tuple. > > Perhaps it would be better to teach scans to restart anywhere on the page, > than to force more cleanup locks to be taken? > Yeah, we can do that by making hash index scans work-a-page-at-a-time as we do for btree scans. However, as mentioned earlier, this is in my Todo list and I think it is better to do it as a separate patch based on this work. Do you think thats reasonable or do you have some strong reason why we should consider it as part of this patch only? > ======= > This comment no longer seems accurate (as long as it is just an ERROR and > not a PANIC): > > * XXX we have a problem here if we fail to get space for a > * new overflow page: we'll error out leaving the bucket > split > * only partially complete, meaning the index is corrupt, > * since searches may fail to find entries they should find. > > The split will still be marked as being in progress, so any scanner will > have to scan the old page and see the tuple there. > I have removed that part of comment. I think for PANIC case anyway hash index will be corrupt, so we might not need to mention anything about it. > ======== > in _hash_splitbucket comments, this needs updating: > > * The caller must hold exclusive locks on both buckets to ensure that > * no one else is trying to access them (see README). > > The true prereq here is a buffer clean up lock (pin plus exclusive buffer > content lock), correct? > Right and I have changed it accordingly. > And then: > > * Split needs to hold pin on primary bucket pages of both old and new > * buckets till end of operation. > > 'retain' is probably better than 'hold', to emphasize that we are dropping > the buffer content lock part of the clean-up lock, but that the pin part of > it is kept continuously (this also matches the variable name used in the > code). Okay, changed to retain. > Also, the paragraph after that one seems to be obsolete and > contradictory with the newly added comments. > Are you talking about: * In addition, the caller must have created the new bucket's base page, .. If yes, then I think that is valid. That paragraph mainly highlights two points. First is the new bucket's base page should be pinned, write-locked before calling this API and both will be released in this API. Second is we must do _hash_getnewbuf() before releasing the metapage write lock. Both the points still seems to be valid. > =========== > > /* > * Acquiring cleanup lock to clear the split-in-progress flag ensures > that > * there is no pending scan that has seen the flag after it is cleared. > */ > > But, we are not acquiring a clean up lock. We already have a pin, and we do > acquire a write buffer-content lock, but don't observe that our pin is the > only one. I don't see why it is necessary to have a clean up lock (what > harm is done if a under-way scan thinks it is scanning a bucket that is > being split when it actually just finished the split?), but if it is > necessary then I think this code is wrong. If not necessary, the comment is > wrong. > The comment is wrong and I have removed it. This is ramanant of some previous idea which I wanted to try but found problems in it and didin't pursued it. > Also, why must we hold a write lock on both old and new primary bucket pages > simultaneously? Is this in anticipation of the WAL patch? Yes, clearing the flag on both the buckets needs to be an atomic operation. Otherwise also, it is not good to write two different WAL records (one for clearing the flag on old bucket and other on new bucket). > The contract for > the function does say that it returns both pages write locked, but I don't > see a reason for that part of the contract at the moment. > Just refer it's usage in _hash_finish_split() cleanup flow. The reason is that we need to retain the lock in one of the buckets depending on the case. > ========= > > To avoid deadlock between readers and inserters, whenever there is a need > to lock multiple buckets, we always take in the order suggested in > Locking > Definitions above. This algorithm allows them a very high degree of > concurrency. > > The section referred to is actually spelled "Lock Definitions", no "ing". > > The Lock Definitions sections doesn't mention the meta page at all. Okay, changed. > I think > there needs be something added to it about how the meta page gets locked and > why that is deadlock free. (But we could be optimistic and assume the patch > to implement caching of the metapage will go in and will take care of that). > I don't think caching the meta page will eliminate the need to lock the meta page. However, this patch has not changed anything relavant in meta page locking that can impact deadlock detection. I have thought about it but not sure what more to write other than what is already mentioned at different places about meta page in README. Let me know, if you have something specific in mind. > ========= > > And an operational question on this: A lot of stuff is done conditionally > here. Under high concurrency, do splits ever actually occur? It seems like > they could easily be permanently starved. > May be, but the situation won't be worse than what we have in head. Under high concurrency also, it can arise only if there is always a reader for a bucket, before we try to split. Point to note here is once the split is started, concurrent readers are allowed which was not allowed previously. I think the same argument can be applied to other places where readers and writers contend for same lock, example procarraylock. In such cases theoretically readers can starve writers for ever, but practically such situations are rare. Apart from fixing above review comments, I have fixed the issue reported by Ashutosh Sharma [1]. Many thanks Jeff for the detailed review. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BfMUpJoAp5MXKRSv9193JXn25qtG%2BZrYUwb4dUuqmHrA%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On Thu, Sep 15, 2016 at 4:04 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Tue, Sep 13, 2016 at 9:31 AM, Jeff Janes <jeff.janes@gmail.com> wrote: >> >> ======= >> >> +Vacuum acquires cleanup lock on bucket to remove the dead tuples and or >> tuples >> +that are moved due to split. The need for cleanup lock to remove dead >> tuples >> +is to ensure that scans' returns correct results. Scan that returns >> multiple >> +tuples from the same bucket page always restart the scan from the >> previous >> +offset number from which it has returned last tuple. >> >> Perhaps it would be better to teach scans to restart anywhere on the page, >> than to force more cleanup locks to be taken? > > > Commenting on one of my own questions: > > This won't work when the vacuum removes the tuple which an existing scan is > currently examining and thus will be used to re-find it's position when it > realizes it is not visible and so takes up the scan again. > > The index tuples in a page are stored sorted just by hash value, not by the > combination of (hash value, tid). If they were sorted by both, we could > re-find our position even if the tuple had been removed, because we would > know to start at the slot adjacent to where the missing tuple would be were > it not removed. But unless we are willing to break pg_upgrade, there is no > feasible way to change that now. > I think it is possible without breaking pg_upgrade, if we match all items of a page at once (and save them as local copy), rather than matching item-by-item as we do now. We are already doing similar for btree, refer explanation of BTScanPosItem and BTScanPosData in nbtree.h. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 15, 2016 at 4:44 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
> On Tue, May 10, 2016 at 5:09 AM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>>
>>
>> Although, I don't think it is a very good idea to take any performance
>> data with WIP patch, still I couldn't resist myself from doing so and below
>> are the performance numbers. To get the performance data, I have dropped
>> the primary key constraint on pgbench_accounts and created a hash index on
>> aid column as below.
>>
>> alter table pgbench_accounts drop constraint pgbench_accounts_pkey;
>> create index pgbench_accounts_pkey on pgbench_accounts using hash(aid);
>
>
>
> To be rigorously fair, you should probably replace the btree primary key
> with a non-unique btree index and use that in the btree comparison case. I
> don't know how much difference that would make, probably none at all for a
> read-only case.
>
>>
>>
>>
>> Below data is for read-only pgbench test and is a median of 3 5-min runs.
>> The performance tests are executed on a power-8 m/c.
>
>
> With pgbench -S where everything fits in shared_buffers and the number of
> cores I have at my disposal, I am mostly benchmarking interprocess
> communication between pgbench and the backend. I am impressed that you can
> detect any difference at all.
>
> For this type of thing, I like to create a server side function for use in
> benchmarking:
>
> create or replace function pgbench_query(scale integer,size integer)
> RETURNS integer AS $$
> DECLARE sum integer default 0;
> amount integer;
> account_id integer;
> BEGIN FOR i IN 1..size LOOP
> account_id=1+floor(random()*scale);
> SELECT abalance into strict amount FROM pgbench_accounts
> WHERE aid = account_id;
> sum := sum + amount;
> END LOOP;
> return sum;
> END $$ LANGUAGE plpgsql;
>
> And then run using a command like this:
>
> pgbench -f <(echo 'select pgbench_query(40,1000)') -c$j -j$j -T 300
>
> Where the first argument ('40', here) must be manually set to the same value
> as the scale-factor.
>
> With 8 cores and 8 clients, the values I get are, for btree, hash-head,
> hash-concurrent, hash-concurrent-cache, respectively:
>
> 598.2
> 577.4
> 668.7
> 664.6
>
> (each transaction involves 1000 select statements)
>
> So I do see that the concurrency patch is quite an improvement. The cache
> patch does not produce a further improvement, which was somewhat surprising
> to me (I thought that that patch would really shine in a read-write
> workload, but I expected at least improvement in read only)
>
To see the benefit from cache meta page patch, you might want to test
with clients more than the number of cores, atleast that is what data
by Mithun [1] indicates or probably in somewhat larger m/c.
[1] - https://www.postgresql.org/message-id/CAD__OugX0aOa7qopz3d-nbBAoVmvSmdFJOX4mv5tFRpijqH47A%40mail.gmail.com
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 15, 2016 at 12:43 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > Hi, > > On 09/14/2016 07:24 AM, Amit Kapila wrote: > >>> UPDATE also sees an improvement. >>> >> >> Can you explain this more? Is it more compare to HEAD or more as >> compare to Btree? Isn't this contradictory to what the test in below >> mail shows? >> > > Same thing here - where the fields involving the hash index aren't updated. > Do you mean that for such cases also you see 40-60% gain? > > I have done a run to look at the concurrency / TPS aspect of the > implementation - to try something different than Mark's work on testing the > pgbench setup. > > With definitions as above, with SELECT as > > -- select.sql -- > \set id random(1,10) > BEGIN; > SELECT * FROM test WHERE id = :id; > COMMIT; > > and UPDATE/Indexed with an index on 'val', and finally UPDATE/Nonindexed w/o > one. > > [1] [2] [3] is new_hash - old_hash is the existing hash implementation on > master. btree is master too. > > Machine is a 28C/56T with 256Gb RAM with 2 x RAID10 SSD for data + wal. > Clients ran with -M prepared. > > [1] > https://www.postgresql.org/message-id/CAA4eK1+ERbP+7mdKkAhJZWQ_dTdkocbpt7LSWFwCQvUHBXzkmA@mail.gmail.com > [2] > https://www.postgresql.org/message-id/CAD__OujvYghFX_XVkgRcJH4VcEbfJNSxySd9x=1Wp5VyLvkf8Q@mail.gmail.com > [3] > https://www.postgresql.org/message-id/CAA4eK1JUYr_aB7BxFnSg5+JQhiwgkLKgAcFK9bfD4MLfFK6Oqw@mail.gmail.com > > Don't know if you find this useful due to the small number of rows, but let > me know if there are other tests I can run, f.ex. bump the number of rows. > It might be useful to test with higher number of rows because with so less data contention is not visible, but I think in general with your, jeff's and mine own tests it is clear that there is significant win for read-only cases and for read-write cases where index column is not updated. Also, we don't find any regression as compare to HEAD which is sufficient to prove the worth of patch. I think we should not forget that one of the other main reason for this patch is to allow WAL logging for hash indexes. I think for now, we have done sufficient tests for this patch to ensure it's benefit, now if any committer wants to see something more we can surely do it. I think the important thing at this stage is to find out what more (if anything) is left to make this patch as "ready for committer". -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
One other point, I would like to discuss is that currently, we have a concept for tracking active hash scans (hashscan.c) which I think is mainly to protect splits when the backend which is trying to split has some scan open. You can read "Other Notes" section of access/hash/README for further details. I think after this patch we don't need that mechanism for splits because we always retain a pin on bucket buffer till all the tuples are fetched or scan is finished which will defend against a split by our own backend which tries to ensure cleanup lock on bucket. However, we might need it for vacuum (hashbulkdelete), if we want to get rid of cleanup lock in vacuum, once we have a page-at-a-time scan mode implemented for hash indexes. If you agree with above analysis, then we can remove the checks for _hash_has_active_scan from both vacuum and split path and also remove corresponding code from hashbegin/end scan, but retain that hashscan.c for future improvements. I am posting this as a separate mail to avoid it getting lost as one of the points in long list of review points discussed. Thoughts? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 15, 2016 at 2:13 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > One other point, I would like to discuss is that currently, we have a > concept for tracking active hash scans (hashscan.c) which I think is > mainly to protect splits when the backend which is trying to split has > some scan open. You can read "Other Notes" section of > access/hash/README for further details. I think after this patch we > don't need that mechanism for splits because we always retain a pin on > bucket buffer till all the tuples are fetched or scan is finished > which will defend against a split by our own backend which tries to > ensure cleanup lock on bucket. Hmm, yeah. It seems like we can remove it. > However, we might need it for vacuum > (hashbulkdelete), if we want to get rid of cleanup lock in vacuum, > once we have a page-at-a-time scan mode implemented for hash indexes. > If you agree with above analysis, then we can remove the checks for > _hash_has_active_scan from both vacuum and split path and also remove > corresponding code from hashbegin/end scan, but retain that hashscan.c > for future improvements. Do you have a plan for that? I'd be inclined to just blow away hashscan.c if we don't need it any more, unless you're pretty sure it's going to get reused. It's not like we can't pull it back out of git if we decide we want it back after all. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 15, 2016 at 1:41 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I think it is possible without breaking pg_upgrade, if we match all > items of a page at once (and save them as local copy), rather than > matching item-by-item as we do now. We are already doing similar for > btree, refer explanation of BTScanPosItem and BTScanPosData in > nbtree.h. If ever we want to sort hash buckets by TID, it would be best to do that in v10 since we're presumably going to be recommending a REINDEX anyway. But is that a good thing to do? That's a little harder to say. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2016-05-10 17:39:22 +0530, Amit Kapila wrote: > For making hash indexes usable in production systems, we need to improve > its concurrency and make them crash-safe by WAL logging them. One earlier question about this is whether that is actually a worthwhile goal. Are the speed and space benefits big enough in the general case? Could those benefits not be achieved in a more maintainable manner by adding a layer that uses a btree over hash(columns), and adds appropriate rechecks after heap scans? Note that I'm not saying that hash indexes are not worthwhile, I'm just doubtful that question has been explored sufficiently. Greetings, Andres Freund
On 09/15/2016 02:03 AM, Amit Kapila wrote: >> Same thing here - where the fields involving the hash index aren't updated. >> > > Do you mean that for such cases also you see 40-60% gain? > No, UPDATEs are around 10-20% for our cases. >> >> I have done a run to look at the concurrency / TPS aspect of the >> implementation - to try something different than Mark's work on testing the >> pgbench setup. >> >> With definitions as above, with SELECT as >> >> -- select.sql -- >> \set id random(1,10) >> BEGIN; >> SELECT * FROM test WHERE id = :id; >> COMMIT; >> >> and UPDATE/Indexed with an index on 'val', and finally UPDATE/Nonindexed w/o >> one. >> >> [1] [2] [3] is new_hash - old_hash is the existing hash implementation on >> master. btree is master too. >> >> Machine is a 28C/56T with 256Gb RAM with 2 x RAID10 SSD for data + wal. >> Clients ran with -M prepared. >> >> [1] >> https://www.postgresql.org/message-id/CAA4eK1+ERbP+7mdKkAhJZWQ_dTdkocbpt7LSWFwCQvUHBXzkmA@mail.gmail.com >> [2] >> https://www.postgresql.org/message-id/CAD__OujvYghFX_XVkgRcJH4VcEbfJNSxySd9x=1Wp5VyLvkf8Q@mail.gmail.com >> [3] >> https://www.postgresql.org/message-id/CAA4eK1JUYr_aB7BxFnSg5+JQhiwgkLKgAcFK9bfD4MLfFK6Oqw@mail.gmail.com >> >> Don't know if you find this useful due to the small number of rows, but let >> me know if there are other tests I can run, f.ex. bump the number of rows. >> > > It might be useful to test with higher number of rows because with so > less data contention is not visible, Attached is a run with 1000 rows. > but I think in general with your, > jeff's and mine own tests it is clear that there is significant win > for read-only cases and for read-write cases where index column is not > updated. Also, we don't find any regression as compare to HEAD which > is sufficient to prove the worth of patch. Very much agreed. > I think we should not > forget that one of the other main reason for this patch is to allow > WAL logging for hash indexes. Absolutely. There are scenarios that will have a benefit of switching to a hash index. > I think for now, we have done > sufficient tests for this patch to ensure it's benefit, now if any > committer wants to see something more we can surely do it. Ok. > I think > the important thing at this stage is to find out what more (if > anything) is left to make this patch as "ready for committer". > I think for CHI is would be Robert's and others feedback. For WAL, there is [1]. [1] https://www.postgresql.org/message-id/5f8b4681-1229-92f4-4315-57d780d9c128%40redhat.com Best regards, Jesper
Вложения
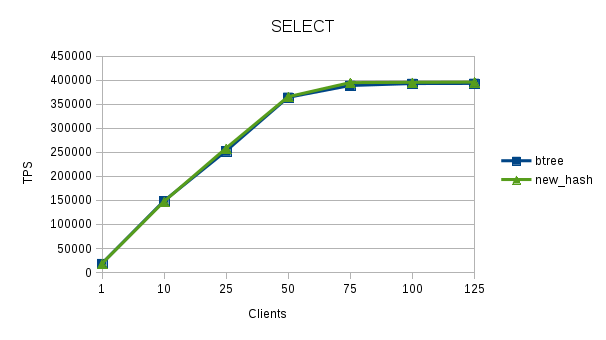{kind=link}
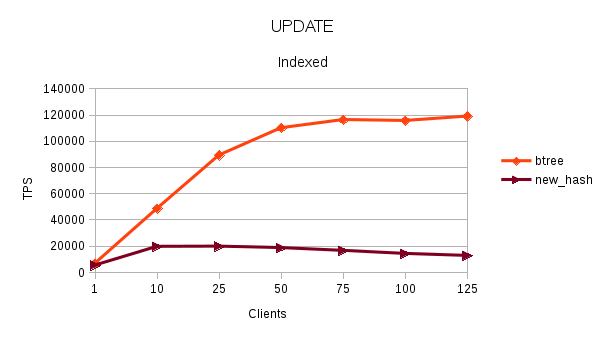{kind=link}
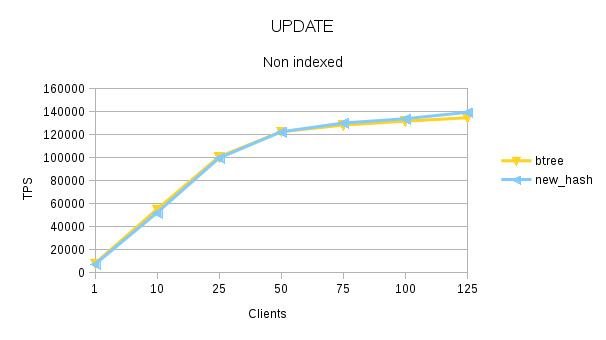{kind=link}
On Thu, Sep 15, 2016 at 7:25 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Sep 15, 2016 at 2:13 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> One other point, I would like to discuss is that currently, we have a >> concept for tracking active hash scans (hashscan.c) which I think is >> mainly to protect splits when the backend which is trying to split has >> some scan open. You can read "Other Notes" section of >> access/hash/README for further details. I think after this patch we >> don't need that mechanism for splits because we always retain a pin on >> bucket buffer till all the tuples are fetched or scan is finished >> which will defend against a split by our own backend which tries to >> ensure cleanup lock on bucket. > > Hmm, yeah. It seems like we can remove it. > >> However, we might need it for vacuum >> (hashbulkdelete), if we want to get rid of cleanup lock in vacuum, >> once we have a page-at-a-time scan mode implemented for hash indexes. >> If you agree with above analysis, then we can remove the checks for >> _hash_has_active_scan from both vacuum and split path and also remove >> corresponding code from hashbegin/end scan, but retain that hashscan.c >> for future improvements. > > Do you have a plan for that? I'd be inclined to just blow away > hashscan.c if we don't need it any more, unless you're pretty sure > it's going to get reused. It's not like we can't pull it back out of > git if we decide we want it back after all. > I do want to work on it, but it is always possible that due to some other work this might get delayed. Also, I think there is always a chance that while doing that work, we face some problem due to which we might not be able to use that optimization. So I will go with your suggestion of removing hashscan.c and it's usage for now and then if required we will pull it back. If nobody else thinks otherwise, I will update this in next patch version. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 15, 2016 at 7:53 PM, Andres Freund <andres@anarazel.de> wrote: > Hi, > > On 2016-05-10 17:39:22 +0530, Amit Kapila wrote: >> For making hash indexes usable in production systems, we need to improve >> its concurrency and make them crash-safe by WAL logging them. > > One earlier question about this is whether that is actually a worthwhile > goal. Are the speed and space benefits big enough in the general case? > I think there will surely by speed benefits w.r.t reads for larger indexes. All our measurements till now have shown that there is a benefit varying from 30~60% (for reads) with hash index as compare to btree, and I think it could be even more if we further increase the size of index. On space front, I have not done any detailed study, so it is not right to conclude anything, but it appears to me that if the index is on char/varchar column where size of key is 10 or 20 bytes, hash indexes should be beneficial as they store just hash-key. > Could those benefits not be achieved in a more maintainable manner by > adding a layer that uses a btree over hash(columns), and adds > appropriate rechecks after heap scans? > I don't think it can be faster for reads than using real hash index, but surely one can have that as a workaround. > Note that I'm not saying that hash indexes are not worthwhile, I'm just > doubtful that question has been explored sufficiently. > I think theoretically hash indexes are faster than btree considering logarithmic complexity (O(1) vs. O(logn)), also the results after recent optimizations indicate that hash indexes are faster than btree for equal to searches. I am not saying after the recent set of patches proposed for hash indexes they will be better in all kind of cases. It could be beneficial for cases where indexed columns are not updated heavily. I think one can definitely argue that we can some optimizations in btree and make them equivalent or better than hash indexes, but I am not sure if it is possible for all-kind of use-cases. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 16/09/16 18:35, Amit Kapila wrote: > On Thu, Sep 15, 2016 at 7:53 PM, Andres Freund <andres@anarazel.de> wrote: >> Hi, >> >> On 2016-05-10 17:39:22 +0530, Amit Kapila wrote: >>> For making hash indexes usable in production systems, we need to improve >>> its concurrency and make them crash-safe by WAL logging them. >> One earlier question about this is whether that is actually a worthwhile >> goal. Are the speed and space benefits big enough in the general case? >> > I think there will surely by speed benefits w.r.t reads for larger > indexes. All our measurements till now have shown that there is a > benefit varying from 30~60% (for reads) with hash index as compare to > btree, and I think it could be even more if we further increase the > size of index. On space front, I have not done any detailed study, so > it is not right to conclude anything, but it appears to me that if the > index is on char/varchar column where size of key is 10 or 20 bytes, > hash indexes should be beneficial as they store just hash-key. > >> Could those benefits not be achieved in a more maintainable manner by >> adding a layer that uses a btree over hash(columns), and adds >> appropriate rechecks after heap scans? >> > I don't think it can be faster for reads than using real hash index, > but surely one can have that as a workaround. > >> Note that I'm not saying that hash indexes are not worthwhile, I'm just >> doubtful that question has been explored sufficiently. >> > I think theoretically hash indexes are faster than btree considering > logarithmic complexity (O(1) vs. O(logn)), also the results after > recent optimizations indicate that hash indexes are faster than btree > for equal to searches. I am not saying after the recent set of > patches proposed for hash indexes they will be better in all kind of > cases. It could be beneficial for cases where indexed columns are not > updated heavily. > > I think one can definitely argue that we can some optimizations in > btree and make them equivalent or better than hash indexes, but I am > not sure if it is possible for all-kind of use-cases. > I think having the choice for a more equality optimized index design is desirable. Now that they are wal logged they are first class citizens so to speak. I suspect that there are a lot of further speed optimizations that can be considered to tease out the best performance - now that the basics of reliability have been sorted. I think this patch/set of patches is/are important! regards Mark
On Thu, Sep 15, 2016 at 10:38 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > On 09/15/2016 02:03 AM, Amit Kapila wrote: >>> >>> Same thing here - where the fields involving the hash index aren't >>> updated. >>> >> >> Do you mean that for such cases also you see 40-60% gain? >> > > No, UPDATEs are around 10-20% for our cases. > Okay, good to know. >> >> It might be useful to test with higher number of rows because with so >> less data contention is not visible, > > > Attached is a run with 1000 rows. > I think 1000 is also less, you probably want to run it for 100,000 or more rows. I suspect that the reason why you are seeing the large difference between btree and hash index is that the range of values is narrow and there may be many overflow pages. >> > > I think for CHI is would be Robert's and others feedback. For WAL, there is > [1]. > I have fixed your feedback for WAL and posted the patch. I think the remaining thing to handle for Concurrent Hash Index patch is to remove the usage of hashscan.c from code if no one objects to it, do let me know if I am missing something here. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 15, 2016 at 7:23 AM, Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2016-05-10 17:39:22 +0530, Amit Kapila wrote:
> For making hash indexes usable in production systems, we need to improve
> its concurrency and make them crash-safe by WAL logging them.
One earlier question about this is whether that is actually a worthwhile
goal. Are the speed and space benefits big enough in the general case?
Could those benefits not be achieved in a more maintainable manner by
adding a layer that uses a btree over hash(columns), and adds
appropriate rechecks after heap scans?
Note that I'm not saying that hash indexes are not worthwhile, I'm just
doubtful that question has been explored sufficiently.
I think that exploring it well requires good code. If the code is good, why not commit it? I would certainly be unhappy to try to compare WAL logged concurrent hash indexes to btree-over-hash indexes, if I had to wait a few years for the latter to appear, and then dig up the patches for the former and clean up the bitrot, and juggle multiple patch sets, in order to have something to compare.
Cheers,
Jeff
On 2016-09-16 09:12:22 -0700, Jeff Janes wrote: > On Thu, Sep 15, 2016 at 7:23 AM, Andres Freund <andres@anarazel.de> wrote: > > One earlier question about this is whether that is actually a worthwhile > > goal. Are the speed and space benefits big enough in the general case? > > Could those benefits not be achieved in a more maintainable manner by > > adding a layer that uses a btree over hash(columns), and adds > > appropriate rechecks after heap scans? > > > > Note that I'm not saying that hash indexes are not worthwhile, I'm just > > doubtful that question has been explored sufficiently. > I think that exploring it well requires good code. If the code is good, > why not commit it? Because getting there requires a lot of effort, debugging it afterwards would take effort, and maintaining it would also takes a fair amount? Adding code isn't free. I'm rather unenthused about having a hash index implementation that's mildly better in some corner cases, but otherwise doesn't have much benefit. That'll mean we'll have to step up our user education a lot, and we'll have to maintain something for little benefit. Andres
On 09/16/2016 03:18 AM, Amit Kapila wrote: >> Attached is a run with 1000 rows. >> > > I think 1000 is also less, you probably want to run it for 100,000 or > more rows. I suspect that the reason why you are seeing the large > difference between btree and hash index is that the range of values is > narrow and there may be many overflow pages. > Attached is 100,000. >> I think for CHI is would be Robert's and others feedback. For WAL, there is >> [1]. >> > > I have fixed your feedback for WAL and posted the patch. Thanks ! > I think the > remaining thing to handle for Concurrent Hash Index patch is to remove > the usage of hashscan.c from code if no one objects to it, do let me > know if I am missing something here. > Like Robert said, hashscan.c can always come back, and it would take a call-stack out of the 'am' methods. Best regards, Jesper
Вложения
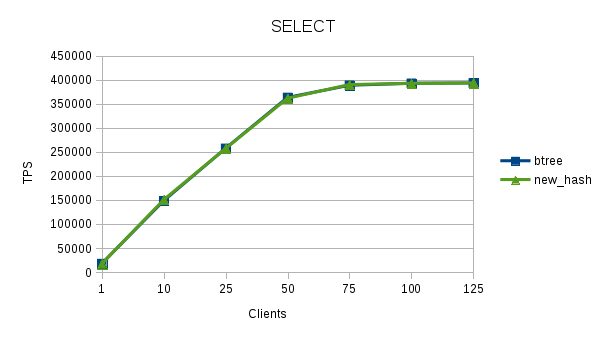{kind=link}
{kind=link}
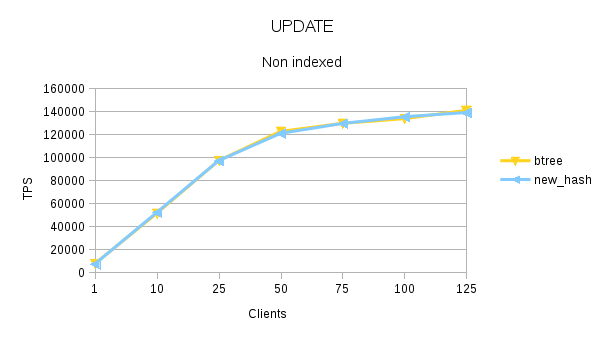{kind=link}
On 17/09/16 06:38, Andres Freund wrote: > On 2016-09-16 09:12:22 -0700, Jeff Janes wrote: >> On Thu, Sep 15, 2016 at 7:23 AM, Andres Freund <andres@anarazel.de> wrote: >>> One earlier question about this is whether that is actually a worthwhile >>> goal. Are the speed and space benefits big enough in the general case? >>> Could those benefits not be achieved in a more maintainable manner by >>> adding a layer that uses a btree over hash(columns), and adds >>> appropriate rechecks after heap scans? >>> >>> Note that I'm not saying that hash indexes are not worthwhile, I'm just >>> doubtful that question has been explored sufficiently. >> I think that exploring it well requires good code. If the code is good, >> why not commit it? > Because getting there requires a lot of effort, debugging it afterwards > would take effort, and maintaining it would also takes a fair amount? > Adding code isn't free. > > I'm rather unenthused about having a hash index implementation that's > mildly better in some corner cases, but otherwise doesn't have much > benefit. That'll mean we'll have to step up our user education a lot, > and we'll have to maintain something for little benefit. > While I see the point of what you are saying here, I recall all previous discussions about has indexes tended to go a bit like this: - until WAL logging of hash indexes is written it is not worthwhile trying to make improvements to them - WAL logging will be a lot of work, patches 1st please Now someone has done that work, and we seem to be objecting that because they are not improved then the patches are (maybe) not worthwhile. I think that is - essentially - somewhat unfair. regards Mark
On Mon, Sep 19, 2016 at 11:20 AM, Mark Kirkwood <mark.kirkwood@catalyst.net.nz> wrote: > > > On 17/09/16 06:38, Andres Freund wrote: >> >> On 2016-09-16 09:12:22 -0700, Jeff Janes wrote: >>> >>> On Thu, Sep 15, 2016 at 7:23 AM, Andres Freund <andres@anarazel.de> >>> wrote: >>>> >>>> One earlier question about this is whether that is actually a worthwhile >>>> goal. Are the speed and space benefits big enough in the general case? >>>> Could those benefits not be achieved in a more maintainable manner by >>>> adding a layer that uses a btree over hash(columns), and adds >>>> appropriate rechecks after heap scans? >>>> >>>> Note that I'm not saying that hash indexes are not worthwhile, I'm just >>>> doubtful that question has been explored sufficiently. >>> >>> I think that exploring it well requires good code. If the code is good, >>> why not commit it? >> >> Because getting there requires a lot of effort, debugging it afterwards >> would take effort, and maintaining it would also takes a fair amount? >> Adding code isn't free. >> >> I'm rather unenthused about having a hash index implementation that's >> mildly better in some corner cases, but otherwise doesn't have much >> benefit. That'll mean we'll have to step up our user education a lot, >> and we'll have to maintain something for little benefit. >> > > While I see the point of what you are saying here, I recall all previous > discussions about has indexes tended to go a bit like this: > > - until WAL logging of hash indexes is written it is not worthwhile trying > to make improvements to them > - WAL logging will be a lot of work, patches 1st please > > Now someone has done that work, and we seem to be objecting that because > they are not improved then the patches are (maybe) not worthwhile. > I think saying hash indexes are not improved after proposed set of patches is an understatement. The read performance has improved by more than 80% as compare to HEAD [1] (refer data in Mithun's mail). Also, tests by Mithun and Jesper has indicated that in multiple workloads, they are better than BTREE by 30~60% (in fact Jesper mentioned that he is seeing 40~60% benefit on production database, Jesper correct me if I am wrong.). I agree that when index column is updated they are much worse than btree as of now, but no work has been done improve it and I am sure that it can be improved for those cases as well. In general, I thought the tests done till now are sufficient to prove the importance of work, but if still Andres and others have doubt and they want to test some specific cases, then sure we can do more performance benchmarking. Mark, thanks for supporting the case for improving Hash Indexes. [1] - https://www.postgresql.org/message-id/CAD__OugX0aOa7qopz3d-nbBAoVmvSmdFJOX4mv5tFRpijqH47A%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Sep 19, 2016 at 12:14:26PM +0530, Amit Kapila wrote: > On Mon, Sep 19, 2016 at 11:20 AM, Mark Kirkwood > <mark.kirkwood@catalyst.net.nz> wrote: > > > > > > On 17/09/16 06:38, Andres Freund wrote: > >> > >> On 2016-09-16 09:12:22 -0700, Jeff Janes wrote: > >>> > >>> On Thu, Sep 15, 2016 at 7:23 AM, Andres Freund <andres@anarazel.de> > >>> wrote: > >>>> > >>>> One earlier question about this is whether that is actually a worthwhile > >>>> goal. Are the speed and space benefits big enough in the general case? > >>>> Could those benefits not be achieved in a more maintainable manner by > >>>> adding a layer that uses a btree over hash(columns), and adds > >>>> appropriate rechecks after heap scans? > >>>> > >>>> Note that I'm not saying that hash indexes are not worthwhile, I'm just > >>>> doubtful that question has been explored sufficiently. > >>> > >>> I think that exploring it well requires good code. If the code is good, > >>> why not commit it? > >> > >> Because getting there requires a lot of effort, debugging it afterwards > >> would take effort, and maintaining it would also takes a fair amount? > >> Adding code isn't free. > >> > >> I'm rather unenthused about having a hash index implementation that's > >> mildly better in some corner cases, but otherwise doesn't have much > >> benefit. That'll mean we'll have to step up our user education a lot, > >> and we'll have to maintain something for little benefit. > >> > > > > While I see the point of what you are saying here, I recall all previous > > discussions about has indexes tended to go a bit like this: > > > > - until WAL logging of hash indexes is written it is not worthwhile trying > > to make improvements to them > > - WAL logging will be a lot of work, patches 1st please > > > > Now someone has done that work, and we seem to be objecting that because > > they are not improved then the patches are (maybe) not worthwhile. > > > > I think saying hash indexes are not improved after proposed set of > patches is an understatement. The read performance has improved by > more than 80% as compare to HEAD [1] (refer data in Mithun's mail). > Also, tests by Mithun and Jesper has indicated that in multiple > workloads, they are better than BTREE by 30~60% (in fact Jesper > mentioned that he is seeing 40~60% benefit on production database, > Jesper correct me if I am wrong.). I agree that when index column is > updated they are much worse than btree as of now, but no work has been > done improve it and I am sure that it can be improved for those cases > as well. > > In general, I thought the tests done till now are sufficient to prove > the importance of work, but if still Andres and others have doubt and > they want to test some specific cases, then sure we can do more > performance benchmarking. > > Mark, thanks for supporting the case for improving Hash Indexes. > > > [1] - https://www.postgresql.org/message-id/CAD__OugX0aOa7qopz3d-nbBAoVmvSmdFJOX4mv5tFRpijqH47A%40mail.gmail.com > -- > With Regards, > Amit Kapila. > EnterpriseDB: http://www.enterprisedb.com > +1 Throughout the years, I have seen benchmarks that demonstrated the performance advantages of even the initial hash index (without WAL) over the btree of a hash variant. It is pretty hard to dismiss the O(1) versus O(log(n)) difference. There are classes of problems for which a hash index is the best solution. Lack of WAL has hamstrung development in those areas for years. Regards, Ken
On Sun, Sep 18, 2016 at 11:44 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Mon, Sep 19, 2016 at 11:20 AM, Mark Kirkwood
<mark.kirkwood@catalyst.net.nz> wrote:
> On 17/09/16 06:38, Andres Freund wrote:
>
> While I see the point of what you are saying here, I recall all previous
> discussions about has indexes tended to go a bit like this:
>
> - until WAL logging of hash indexes is written it is not worthwhile trying
> to make improvements to them
> - WAL logging will be a lot of work, patches 1st please
>
> Now someone has done that work, and we seem to be objecting that because
> they are not improved then the patches are (maybe) not worthwhile.
>
+1
I think saying hash indexes are not improved after proposed set of
patches is an understatement. The read performance has improved by
more than 80% as compare to HEAD [1] (refer data in Mithun's mail).
Also, tests by Mithun and Jesper has indicated that in multiple
workloads, they are better than BTREE by 30~60% (in fact Jesper
mentioned that he is seeing 40~60% benefit on production database,
Jesper correct me if I am wrong.). I agree that when index column is
updated they are much worse than btree as of now,
Has anyone tested that with the relcache patch applied? I would expect that to improve things by a lot (compared to hash-HEAD, not necessarily compared to btree-HEAD), but if I am following the emails correctly, that has not been done.
but no work has been
done improve it and I am sure that it can be improved for those cases
as well.
In general, I thought the tests done till now are sufficient to prove
the importance of work, but if still Andres and others have doubt and
they want to test some specific cases, then sure we can do more
performance benchmarking.
I think that a precursor to WAL is enough to justify it even if the verified performance improvements were not impressive. But they are pretty impressive, at least for some situations.
Cheers,
Jeff
On Fri, Sep 16, 2016 at 2:38 PM, Andres Freund <andres@anarazel.de> wrote: >> I think that exploring it well requires good code. If the code is good, >> why not commit it? > > Because getting there requires a lot of effort, debugging it afterwards > would take effort, and maintaining it would also takes a fair amount? > Adding code isn't free. Of course not, but nobody's saying you have to be the one to put in any of that effort. I was a bit afraid that nobody outside of EnterpriseDB was going to take any interest in this patch, and I'm really pretty pleased by the amount of interest that it's generated. It's pretty clear that multiple smart people are working pretty hard to break this, and Amit is fixing it, and at least for me that makes me a lot less scared that the final result will be horribly broken. It will probably have some bugs, but they probably won't be worse than the status quo: WARNING: hash indexes are not WAL-logged and their use is discouraged Personally, I think it's outright embarrassing that we've had that limitation for years; it boils down to "hey, we have this feature but it doesn't work", which is a pretty crummy position for the world's most advanced open-source database to take. > I'm rather unenthused about having a hash index implementation that's > mildly better in some corner cases, but otherwise doesn't have much > benefit. That'll mean we'll have to step up our user education a lot, > and we'll have to maintain something for little benefit. If it turns out that it has little benefit, then we don't really need to step up our user education. People can just keep using btree like they do now and that will be fine. The only time we *really* need to step up our user education is if it *does* have a benefit. I think that's a real possibility, because it's pretty clear to me - based in part on off-list conversations with Amit - that the hash index code has gotten very little love compared to btree, and there are lots of optimizations that have been done for btree that have not been done for hash indexes, but which could be done. So I think there's a very good chance that once we fix hash indexes to the point where they can realistically be used, there will be further patches - either from Amit or others - which improve performance even more. Even the preliminary results are not bad, though. Also, Oracle offers hash indexes, and SQL Server offers them for memory-optimized tables. DB2 offers a "hash access path" which is not described as an index but seems to work like one. MySQL, like SQL Server, offers them only for memory-optimized tables. When all of the other database products that we're competing against offer something, it's not crazy to think that we should have it, too - and that it should actually work, rather than being some kind of half-supported wart. By the way, I think that one thing which limits the performance improvement we can get from hash indexes is the overall slowness of the executor. You can't save more by speeding something up than the percentage of time you were spending on it in the first place. IOW, if you're spending all of your time in src/backend/executor then you can't be spending it in src/backend/access, so making src/backend/access faster doesn't help much. However, as the executor gets faster, which I hope it will, the potential gains from a faster index go up. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Sep 19, 2016 at 05:50:13PM +1200, Mark Kirkwood wrote: > >I'm rather unenthused about having a hash index implementation that's > >mildly better in some corner cases, but otherwise doesn't have much > >benefit. That'll mean we'll have to step up our user education a lot, > >and we'll have to maintain something for little benefit. > > While I see the point of what you are saying here, I recall all previous > discussions about has indexes tended to go a bit like this: > > - until WAL logging of hash indexes is written it is not worthwhile trying > to make improvements to them > - WAL logging will be a lot of work, patches 1st please > > Now someone has done that work, and we seem to be objecting that because > they are not improved then the patches are (maybe) not worthwhile. I think > that is - essentially - somewhat unfair. My understanding of hash indexes is that they'd be good for indexing random(esque) data (such as UUIDs or, well, hashes like shaX). If so then I've got a DB that'll be rather big that is the very embodiment of such a use case. It indexes such data for equality comparisons and runs on SELECT, INSERT and, eventually, DELETE. Lack of WAL and that big warning in the docs is why I haven't used it. Given the above, many lamentations from me that it wont be available for 9.6. :( When 10.0 comes I'd probably go to the bother of re-indexing with hash indexes. Andrew
On Fri, Sep 16, 2016 at 11:22 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > > I do want to work on it, but it is always possible that due to some > other work this might get delayed. Also, I think there is always a > chance that while doing that work, we face some problem due to which > we might not be able to use that optimization. So I will go with your > suggestion of removing hashscan.c and it's usage for now and then if > required we will pull it back. If nobody else thinks otherwise, I > will update this in next patch version. > In the attached patch, I have removed the support of hashscans. I think it might improve performance by few percentage (especially for single row fetch transactions) as we have registration and destroy of hashscans. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On Thu, Sep 15, 2016 at 11:11:41AM +0530, Amit Kapila wrote: > I think it is possible without breaking pg_upgrade, if we match all > items of a page at once (and save them as local copy), rather than > matching item-by-item as we do now. We are already doing similar for > btree, refer explanation of BTScanPosItem and BTScanPosData in > nbtree.h. FYI, pg_upgrade has code to easily mark indexes as invalid and create a script the use can run to recreate the indexes as valid. I have received no complaints when this was used. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Mon, Sep 19, 2016 at 03:50:38PM -0400, Robert Haas wrote: > It will probably have some bugs, but they probably won't be worse than > the status quo: > > WARNING: hash indexes are not WAL-logged and their use is discouraged > > Personally, I think it's outright embarrassing that we've had that > limitation for years; it boils down to "hey, we have this feature but > it doesn't work", which is a pretty crummy position for the world's > most advanced open-source database to take. No question. We inherited the technical dept of hash indexes 20 years ago and haven't really solved it yet. We keep making incremental improvements, which keeps it from being removed, but hash is still far behind other index types. > > I'm rather unenthused about having a hash index implementation that's > > mildly better in some corner cases, but otherwise doesn't have much > > benefit. That'll mean we'll have to step up our user education a lot, > > and we'll have to maintain something for little benefit. > > If it turns out that it has little benefit, then we don't really need > to step up our user education. People can just keep using btree like The big problem is people coming from other databases and assuming our hash indexes have the same benefits over btree that exist in some other database software. The 9.5 warning at least helps with that. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Tue, Sep 20, 2016 at 7:55 PM, Bruce Momjian <bruce@momjian.us> wrote: >> If it turns out that it has little benefit, then we don't really need >> to step up our user education. People can just keep using btree like > > The big problem is people coming from other databases and assuming our > hash indexes have the same benefits over btree that exist in some other > database software. The 9.5 warning at least helps with that. I'd be curious what benefits people expect to get. For example, I searched for "Oracle hash indexes" using Google and found this page: http://logicalread.solarwinds.com/oracle-11g-hash-indexes-mc02/ It implies that their hash indexes are actually clustered indexes; that is, the table data is physically organized into contiguous chunks by hash bucket. Also, they can't split buckets on the fly. I think the DB2 implementation is similar. So our hash indexes, even once we add write-ahead logging and better concurrency, will be somewhat different from those products. However, I'm not actually sure how widely-used those index types are. I wonder if people who use hash indexes in PostgreSQL are even likely to be familiar with those technologies, and what expectations they might have. For PostgreSQL, I expect the benefits of improving hash indexes to be (1) slightly better raw performance for equality comparisons and (2) better concurrency. The details aren't very clear at this stage. We know that write performance is bad right now, even with Amit's patches, but that's without the kill_prior_tuple optimization which is probably extremely important but which has never been implemented for hash indexes. Read performance is good, but there are still further optimizations that haven't been done there, too, so it may be even better by the time Amit gets done working in this area. Of course, if we want to implement clustered indexes, that's going to require significant changes to the heap format ... or the ability to support multiple heap storage formats. I'm not opposed to that, but I think it makes sense to fix the existing implementation first. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
21.09.2016, 15:29, Robert Haas kirjoitti: > For PostgreSQL, I expect the benefits of improving hash indexes to be > (1) slightly better raw performance for equality comparisons and (2) > better concurrency. There's a third benefit: with large columns a hash index is a lot smaller on disk than a btree index. This is the biggest reason I've seen people want to use hash indexes instead of btrees. hashtext() btrees are a workaround, but they require all queries to be adjusted which is a pain. / Oskari
On Thu, Sep 15, 2016 at 7:13 AM, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Sep 15, 2016 at 1:41 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> I think it is possible without breaking pg_upgrade, if we match all
> items of a page at once (and save them as local copy), rather than
> matching item-by-item as we do now. We are already doing similar for
> btree, refer explanation of BTScanPosItem and BTScanPosData in
> nbtree.h.
If ever we want to sort hash buckets by TID, it would be best to do
that in v10 since we're presumably going to be recommending a REINDEX
anyway.
We are? I thought we were trying to preserve on-disk compatibility so that we didn't have to rebuild the indexes.
Is the concern that lack of WAL logging has generated some subtle unrecognized on disk corruption?
If I were using hash indexes on a production system and I experienced a crash, I would surely reindex immediately after the crash, not wait until the next pg_upgrade.
But is that a good thing to do? That's a little harder to
say.
How could we go about deciding that? Do you think anything short of coding it up and seeing how it works would suffice? I agree that if we want to do it, v10 is the time. But we have about 6 months yet on that.
Cheers,
Jeff
On Wed, Sep 21, 2016 at 08:29:59AM -0400, Robert Haas wrote: > Of course, if we want to implement clustered indexes, that's going to > require significant changes to the heap format ... or the ability to > support multiple heap storage formats. I'm not opposed to that, but I > think it makes sense to fix the existing implementation first. For me, there are several measurements for indexes: Build timeINSERT / UPDATE overheadStorage sizeAccess speed I am guessing people make conclusions based on their Computer Science education. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Wed, Sep 21, 2016 at 2:11 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > We are? I thought we were trying to preserve on-disk compatibility so that > we didn't have to rebuild the indexes. Well, that was my initial idea, but ... > Is the concern that lack of WAL logging has generated some subtle > unrecognized on disk corruption? ...this is a consideration in the other direction. > If I were using hash indexes on a production system and I experienced a > crash, I would surely reindex immediately after the crash, not wait until > the next pg_upgrade. You might be more responsible, and more knowledgeable, than our typical user. >> But is that a good thing to do? That's a little harder to >> say. > > How could we go about deciding that? Do you think anything short of coding > it up and seeing how it works would suffice? I agree that if we want to do > it, v10 is the time. But we have about 6 months yet on that. Yes, I think some experimentation will be needed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 21 September 2016 at 13:29, Robert Haas <robertmhaas@gmail.com> wrote: > I'd be curious what benefits people expect to get. An edge case I came across the other day was a unique index on a large string: postgresql popped up and told me that I couldn't insert a value into the field because the BTREE-index-based constraint wouldn't support the size of string, and that I should use a HASH index instead. Which, of course, I can't, because it's fairly clearly deprecated in the documentation...
<div dir="ltr"><div class="gmail_extra"><div class="gmail_quote">On Wed, Sep 21, 2016 at 12:44 PM, Geoff Winkless <span
dir="ltr"><<ahref="mailto:pgsqladmin@geoff.dj" target="_blank">pgsqladmin@geoff.dj</a>></span> wrote:<br
/><blockquoteclass="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex"><span
class="">On21 September 2016 at 13:29, Robert Haas <<a
href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>>wrote:<br /> > I'd be curious what benefits people
expectto get.<br /><br /></span>An edge case I came across the other day was a unique index on a large<br /> string:
postgresqlpopped up and told me that I couldn't insert a<br /> value into the field because the BTREE-index-based
constraintwouldn't<br /> support the size of string, and that I should use a HASH index<br /> instead. Which, of
course,I can't, because it's fairly clearly<br /> deprecated in the documentation...<br /></blockquote></div><br
/></div><divclass="gmail_extra">Yes, this large string issue is why I argued against removing hash indexes the last
coupletimes people proposed removing them. I'd rather be able to use something that gets the job done, even if it is
deprecated.</div><divclass="gmail_extra"><br /></div><div class="gmail_extra">You could use btree indexes over hashes
ofthe strings. But then you would have to rewrite all your queries to inject an additional qualification, something
like:</div><divclass="gmail_extra"><br /></div><div class="gmail_extra">Where value = 'really long string' and
md5(value)=md5('reallylong string').</div><div class="gmail_extra"><br /></div><div class="gmail_extra">Alas, it still
wouldn'tsupport unique indexes. I don't think you can even use an excluding constraint, because you would have to
excludeon the hash value alone, not the original value, and so it would also forbid false-positive
collisions.</div><divclass="gmail_extra"><br /></div><div class="gmail_extra">There has been discussion to make
btree-over-hashjust work without needing to rewrite the queries, but discussions aren't patches...</div><div
class="gmail_extra"><br/></div><div class="gmail_extra">Cheers,</div><div class="gmail_extra"><br /></div><div
class="gmail_extra">Jeff</div></div>
On 2016-09-21 19:49:15 +0300, Oskari Saarenmaa wrote: > 21.09.2016, 15:29, Robert Haas kirjoitti: > > For PostgreSQL, I expect the benefits of improving hash indexes to be > > (1) slightly better raw performance for equality comparisons and (2) > > better concurrency. > > There's a third benefit: with large columns a hash index is a lot smaller on > disk than a btree index. This is the biggest reason I've seen people want > to use hash indexes instead of btrees. hashtext() btrees are a workaround, > but they require all queries to be adjusted which is a pain. Sure. But that can be addressed, with a lot less effort than fixing and maintaining the hash indexes, by adding the ability to do that transparently using btree indexes + a recheck internally. How that compares efficiency-wise is unclear as of now. But I do think it's something we should measure before committing the new code. Andres
Andres Freund <andres@anarazel.de> writes:
> Sure. But that can be addressed, with a lot less effort than fixing and
> maintaining the hash indexes, by adding the ability to do that
> transparently using btree indexes + a recheck internally. How that
> compares efficiency-wise is unclear as of now. But I do think it's
> something we should measure before committing the new code.
TBH, I think we should reject that argument out of hand. If someone
wants to spend time developing a hash-wrapper-around-btree AM, they're
welcome to do so. But to kick the hash AM as such to the curb is to say
"sorry, there will never be O(1) index lookups in Postgres".
It's certainly conceivable that it's impossible to get decent performance
out of hash indexes, but I do not agree that we should simply stop trying.
Even if I granted the unproven premise that use-a-btree-on-hash-codes will
always be superior, I don't see how it follows that we should refuse to
commit work that's already been done. Is committing it somehow going to
prevent work on the btree-wrapper approach?
regards, tom lane
On 2016-09-21 22:23:27 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Sure. But that can be addressed, with a lot less effort than fixing and > > maintaining the hash indexes, by adding the ability to do that > > transparently using btree indexes + a recheck internally. How that > > compares efficiency-wise is unclear as of now. But I do think it's > > something we should measure before committing the new code. > > TBH, I think we should reject that argument out of hand. If someone > wants to spend time developing a hash-wrapper-around-btree AM, they're > welcome to do so. But to kick the hash AM as such to the curb is to say > "sorry, there will never be O(1) index lookups in Postgres". Note that I'm explicitly *not* saying that. I just would like to see actual comparisons being made before investing significant amounts of code and related effort being invested in fixing the current hash table implementation. And I haven't seen a lot of that. If the result of that comparison is that hash-indexes actually perform very well: Great! > always be superior, I don't see how it follows that we should refuse to > commit work that's already been done. Is committing it somehow going to > prevent work on the btree-wrapper approach? The necessary work seems a good bit from finished. Greetings, Andres Freund
On Thu, Sep 22, 2016 at 8:03 AM, Andres Freund <andres@anarazel.de> wrote: > On 2016-09-21 22:23:27 -0400, Tom Lane wrote: >> Andres Freund <andres@anarazel.de> writes: >> > Sure. But that can be addressed, with a lot less effort than fixing and >> > maintaining the hash indexes, by adding the ability to do that >> > transparently using btree indexes + a recheck internally. How that >> > compares efficiency-wise is unclear as of now. But I do think it's >> > something we should measure before committing the new code. >> >> TBH, I think we should reject that argument out of hand. If someone >> wants to spend time developing a hash-wrapper-around-btree AM, they're >> welcome to do so. But to kick the hash AM as such to the curb is to say >> "sorry, there will never be O(1) index lookups in Postgres". > > Note that I'm explicitly *not* saying that. I just would like to see > actual comparisons being made before investing significant amounts of > code and related effort being invested in fixing the current hash table > implementation. And I haven't seen a lot of that. > I think it can be deduced from testing done till now. Basically, by having index (btree/hash) on integer column can do the fair comparison. The size of key will be same in both hash and btree index. In such a case, if we know that hash index is performing better in certain cases, then it is indication that it will perform better in the scheme you are suggesting because it doesn't have extra recheck in btree code which will further worsen the case for btree. > If the result of that > comparison is that hash-indexes actually perform very well: Great! > > >> always be superior, I don't see how it follows that we should refuse to >> commit work that's already been done. Is committing it somehow going to >> prevent work on the btree-wrapper approach? > > The necessary work seems a good bit from finished. > Are you saying this about WAL patch? If yes, then even if it is still away from being in shape to committed, there is a lot of effort being put in to taking into its current stage and it is not in bad shape either. It has survived lot of testing, there are still some bugs which we are fixing. One more thing, I want to say that don't assume that all people involved in current development of hash indexes or further development on it will run away once the code is committed and the responsibility of maintenance will be on other senior members of community. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 21, 2016 at 08:44:15PM +0100, Geoff Winkless wrote: > On 21 September 2016 at 13:29, Robert Haas <robertmhaas@gmail.com> wrote: > > I'd be curious what benefits people expect to get. > > An edge case I came across the other day was a unique index on a large > string: postgresql popped up and told me that I couldn't insert a > value into the field because the BTREE-index-based constraint wouldn't > support the size of string, and that I should use a HASH index > instead. Which, of course, I can't, because it's fairly clearly > deprecated in the documentation... Thanks for that. Forgot about that bit of nastiness. I came across the above migrating a MySQL app to PostgreSQL. MySQL, I believe, handles this by silently truncating the string on index. PostgreSQL by telling you it can't index. :( So, as a result, AFAIK, I had a choice between a trigger that did a left() on the string and inserts it into a new column on the table that I can then index or do an index on left(). Either way you wind up re-writing a whole bunch of queries. If I wanted to avoid the re-writes I had the option of making the DB susceptible to poor recovery from crashes, et all. No matter which option I chose, the end result was going to be ugly. It would be good not to have to go ugly in such situations. Sometimes one size does not fit all. For me this would be a second major case where I'd use usable hashed indexes the moment they showed up. Andrew
On Wed, Sep 21, 2016 at 10:33 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-09-21 22:23:27 -0400, Tom Lane wrote: >> Andres Freund <andres@anarazel.de> writes: >> > Sure. But that can be addressed, with a lot less effort than fixing and >> > maintaining the hash indexes, by adding the ability to do that >> > transparently using btree indexes + a recheck internally. How that >> > compares efficiency-wise is unclear as of now. But I do think it's >> > something we should measure before committing the new code. >> >> TBH, I think we should reject that argument out of hand. If someone >> wants to spend time developing a hash-wrapper-around-btree AM, they're >> welcome to do so. But to kick the hash AM as such to the curb is to say >> "sorry, there will never be O(1) index lookups in Postgres". > > Note that I'm explicitly *not* saying that. I just would like to see > actual comparisons being made before investing significant amounts of > code and related effort being invested in fixing the current hash table > implementation. And I haven't seen a lot of that. If the result of that > comparison is that hash-indexes actually perform very well: Great! Yeah, I just don't agree with that. I don't think we have any policy that you can't develop A and get it committed unless you try every alternative that some other community member thinks might be better in the long run first. If we adopt such a policy, we'll have no developers and no new features. Also, in this particular case, I think there's no evidence that the alternative you are proposing would actually be better or less work to maintain. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-09-23 15:19:14 -0400, Robert Haas wrote: > On Wed, Sep 21, 2016 at 10:33 PM, Andres Freund <andres@anarazel.de> wrote: > > On 2016-09-21 22:23:27 -0400, Tom Lane wrote: > >> Andres Freund <andres@anarazel.de> writes: > >> > Sure. But that can be addressed, with a lot less effort than fixing and > >> > maintaining the hash indexes, by adding the ability to do that > >> > transparently using btree indexes + a recheck internally. How that > >> > compares efficiency-wise is unclear as of now. But I do think it's > >> > something we should measure before committing the new code. > >> > >> TBH, I think we should reject that argument out of hand. If someone > >> wants to spend time developing a hash-wrapper-around-btree AM, they're > >> welcome to do so. But to kick the hash AM as such to the curb is to say > >> "sorry, there will never be O(1) index lookups in Postgres". > > > > Note that I'm explicitly *not* saying that. I just would like to see > > actual comparisons being made before investing significant amounts of > > code and related effort being invested in fixing the current hash table > > implementation. And I haven't seen a lot of that. If the result of that > > comparison is that hash-indexes actually perform very well: Great! > > Yeah, I just don't agree with that. I don't think we have any policy > that you can't develop A and get it committed unless you try every > alternative that some other community member thinks might be better in > the long run first. Huh. I think we make such arguments *ALL THE TIME*. Anyway, I don't see much point in continuing to discuss this, I'm clearly in the minority.
On Thu, Sep 22, 2016 at 3:23 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > But to kick the hash AM as such to the curb is to say > "sorry, there will never be O(1) index lookups in Postgres". Well there's plenty of halfway solutions for that. We could move hash indexes to contrib or even have them in core as experimental_hash or unlogged_hash until the day they achieve their potential. We definitely shouldn't discourage people from working on hash indexes but we probably shouldn't have released ten years worth of a feature marked "please don't use this" that's guaranteed to corrupt your database and cause weird problems if you use it a any of a number of supported situations (including non-replicated system recovery that has been a bedrock feature of Postgres for over a decade). Arguably adding a hashed btree opclass and relegating the existing code to an experimental state would actually encourage development since a) Users would actually be likely to use the hashed btree opclass so any work on a real hash opclass would have a real userbase ready and waiting for delivery, b) delivering a real hash opclass wouldn't involve convincing users to unlearn a million instructions warning not to use this feature and c) The fear of breaking existing users use cases and databases would be less and pg_upgrade would be an ignorable problem at least until the day comes for the big cutover of the default to the new opclass. -- greg
Greg Stark <stark@mit.edu> writes:
> On Thu, Sep 22, 2016 at 3:23 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> But to kick the hash AM as such to the curb is to say
>> "sorry, there will never be O(1) index lookups in Postgres".
> Well there's plenty of halfway solutions for that. We could move hash
> indexes to contrib or even have them in core as experimental_hash or
> unlogged_hash until the day they achieve their potential.
> We definitely shouldn't discourage people from working on hash indexes
> but we probably shouldn't have released ten years worth of a feature
> marked "please don't use this" that's guaranteed to corrupt your
> database and cause weird problems if you use it a any of a number of
> supported situations (including non-replicated system recovery that
> has been a bedrock feature of Postgres for over a decade).
Obviously that has not been a good situation, but we lack a time
machine to retroactively make it better, so I don't see much point
in fretting over what should have been done in the past.
> Arguably adding a hashed btree opclass and relegating the existing
> code to an experimental state would actually encourage development
> since a) Users would actually be likely to use the hashed btree
> opclass so any work on a real hash opclass would have a real userbase
> ready and waiting for delivery, b) delivering a real hash opclass
> wouldn't involve convincing users to unlearn a million instructions
> warning not to use this feature and c) The fear of breaking existing
> users use cases and databases would be less and pg_upgrade would be an
> ignorable problem at least until the day comes for the big cutover of
> the default to the new opclass.
I'm not following your point here. There is no hash-over-btree AM and
nobody (including Andres) has volunteered to create one. Meanwhile,
we have a patch in hand to WAL-enable the hash AM. Why would we do
anything other than apply that patch and stop saying hash is deprecated?
regards, tom lane
On Sat, Sep 24, 2016 at 10:49 PM, Greg Stark <stark@mit.edu> wrote: > On Thu, Sep 22, 2016 at 3:23 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> But to kick the hash AM as such to the curb is to say >> "sorry, there will never be O(1) index lookups in Postgres". > > Well there's plenty of halfway solutions for that. We could move hash > indexes to contrib or even have them in core as experimental_hash or > unlogged_hash until the day they achieve their potential. > > We definitely shouldn't discourage people from working on hash indexes > Okay, but to me it appears that naming it as experimental_hash or moving it to contrib could discourage people or at the very least people will be less motivated. Thinking on those lines a year or so back would have been a wise direction, but now when already there is lot of work done (patches to make it wal-enabled, more concurrent and performant, page inspect module are available) for hash indexes and still more is in progress, that sounds like a step backward then step forward. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 25/09/16 18:18, Amit Kapila wrote: > On Sat, Sep 24, 2016 at 10:49 PM, Greg Stark <stark@mit.edu> wrote: >> On Thu, Sep 22, 2016 at 3:23 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> But to kick the hash AM as such to the curb is to say >>> "sorry, there will never be O(1) index lookups in Postgres". >> Well there's plenty of halfway solutions for that. We could move hash >> indexes to contrib or even have them in core as experimental_hash or >> unlogged_hash until the day they achieve their potential. >> >> We definitely shouldn't discourage people from working on hash indexes >> > Okay, but to me it appears that naming it as experimental_hash or > moving it to contrib could discourage people or at the very least > people will be less motivated. Thinking on those lines a year or so > back would have been a wise direction, but now when already there is > lot of work done (patches to make it wal-enabled, more concurrent and > performant, page inspect module are available) for hash indexes and > still more is in progress, that sounds like a step backward then step > forward. > +1 I think so too - I've seen many email threads over the years on this list that essentially state "we need hash indexes wal logged to make progress with them"...and Amit et al has/have done this (more than this obviously - made 'em better too) and I'm astonished that folk are suggesting anything other than 'commit this great patch now!'... regards Mark
On 09/20/2016 09:02 AM, Amit Kapila wrote: > On Fri, Sep 16, 2016 at 11:22 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> I do want to work on it, but it is always possible that due to some >> other work this might get delayed. Also, I think there is always a >> chance that while doing that work, we face some problem due to which >> we might not be able to use that optimization. So I will go with your >> suggestion of removing hashscan.c and it's usage for now and then if >> required we will pull it back. If nobody else thinks otherwise, I >> will update this in next patch version. >> > > In the attached patch, I have removed the support of hashscans. I > think it might improve performance by few percentage (especially for > single row fetch transactions) as we have registration and destroy of > hashscans. > > I have been running various tests, and applications with this patch together with the WAL v5 patch [1]. As I havn't seen any failures and doesn't currently have additional feedback I'm moving this patch to "Ready for Committer" for their feedback. If others have comments, move the patch status back in the CommitFest application, please. [1] https://www.postgresql.org/message-id/CAA4eK1KE%3D%2BkkowyYD0vmch%3Dph4ND3H1tViAB%2B0cWTHqjZDDfqg%40mail.gmail.com Best regards, Jesper
On Tue, Sep 27, 2016 at 3:06 PM, Jesper Pedersen
<jesper.pedersen@redhat.com> wrote:
> I have been running various tests, and applications with this patch together
> with the WAL v5 patch [1].
>
> As I havn't seen any failures and doesn't currently have additional feedback
> I'm moving this patch to "Ready for Committer" for their feedback.
Cool! Thanks for reviewing.
Amit, can you please split the buffer manager changes in this patch
into a separate patch? I think those changes can be committed first
and then we can try to deal with the rest of it. Instead of adding
ConditionalLockBufferShared, I think we should add an "int mode"
argument to the existing ConditionalLockBuffer() function. That way
is more consistent with LockBuffer(). It means an API break for any
third-party code that's calling this function, but that doesn't seem
like a big problem. There are only 10 callers of
ConditionalLockBuffer() in our source tree and only one of those is in
contrib, so probably there isn't much third-party code that will be
affected by this, and I think it's worth it for the long-term
cleanliness.
As for CheckBufferForCleanup, I think that looks OK, but: (1) please
add an Assert() that we hold an exclusive lock on the buffer, using
LWLockHeldByMeInMode; and (2) I think we should rename it to something
like IsBufferCleanupOK. Then, when it's used, it reads like English:
if (IsBufferCleanupOK(buf)) { /* clean up the buffer */ }.
I'll write another email with my thoughts about the rest of the patch.
For the record, Amit and I have had extensive discussions about this
effort off-list, and as Amit noted in his original post, the design is
based on suggestions which I previously posted to the list suggesting
how the issues with hash indexes might get fixed. Therefore, I don't
expect to have too many basic disagreements regarding the design of
the patch; if anyone else does, please speak up. Andres already
stated that he things working on btree-over-hash would be more
beneficial than fixing hash, but at this point it seems like he's the
only one who takes that position. Even if we accept that working on
the hash AM is a reasonable thing to do, it doesn't follow that the
design Amit has adopted here is ideal. I think it's reasonably good,
but that's only to be expected considering that I drafted the original
version of it and have been involved in subsequent discussions;
someone else might dislike something that I thought was OK, and any
such opinions certainly deserve a fair hearing. To be clear, It's
been a long time since I've looked at any of the actual code in this
patch and I have at no point studied it deeply, so I expect that I may
find a fair number of things that I'm not happy with in detail, and
I'll write those up along with any design-level concerns that I do
have. This should in no way forestall review from anyone else who
wants to get involved.
Thanks,
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2016-09-28 15:04:30 -0400, Robert Haas wrote: > Andres already > stated that he things working on btree-over-hash would be more > beneficial than fixing hash, but at this point it seems like he's the > only one who takes that position. Note that I did *NOT* take that position. I was saying that I think we should evaluate whether that's not a better approach, doing some simple performance comparisons. Greetings, Andres Freund
On Wed, Sep 28, 2016 at 3:06 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-09-28 15:04:30 -0400, Robert Haas wrote: >> Andres already >> stated that he things working on btree-over-hash would be more >> beneficial than fixing hash, but at this point it seems like he's the >> only one who takes that position. > > Note that I did *NOT* take that position. I was saying that I think we > should evaluate whether that's not a better approach, doing some simple > performance comparisons. OK, sorry. I evidently misunderstood your position, for which I apologize. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> I'll write another email with my thoughts about the rest of the patch.
I think that the README changes for this patch need a fairly large
amount of additional work. Here are a few things I notice:
- The confusion between buckets and pages hasn't been completely
cleared up. If you read the beginning of the README, the terminology
is clearly set forth. It says:
>> A hash index consists of two or more "buckets", into which tuples are placed whenever their hash key maps to the
bucketnumber. Each bucket in the hash index comprises one or more index pages. The bucket's first page is permanently
assignedto it when the bucket is created. Additional pages, called "overflow pages", are added if the bucket receives
toomany tuples to fit in the primary bucket page."
But later on, you say:
>> Scan will take a lock in shared mode on the primary bucket or on one of the overflow page.
So the correct terminology here would be "primary bucket page" not
"primary bucket".
- In addition, notice that there are two English errors in this
sentence: the word "the" needs to be added to the beginning of the
sentence, and the last word needs to be "pages" rather than "page".
There are a considerable number of similar minor errors; if you can't
fix them, I'll make a pass over it and clean it up.
- The whole "lock definitions" section seems to me to be pretty loose
and imprecise about what is happening. For example, it uses the term
"split-in-progress" without first defining it. The sentence quoted
above says that scans take a lock in shared mode either on the primary
page or on one of the overflow pages, but it's not to document code by
saying that it will do either A or B without explaining which one! In
fact, I think that a scan will take a content lock first on the
primary bucket page and then on each overflow page in sequence,
retaining a pin on the primary buffer page throughout the scan. So it
is not one or the other but both in a particular sequence, and that
can and should be explained.
Another problem with this section is that even when it's precise about
what is going on, it's probably duplicating what is or should be in
the following sections where the algorithms for each operation are
explained. In the original wording, this section explains what each
lock protects, and then the following sections explain the algorithms
in the context of those definitions. Now, this section contains a
sketch of the algorithm, and then the following sections lay it out
again in more detail. The question of what each lock protects has
been lost. Here's an attempt at some text to replace what you have
here:
===
Concurrency control for hash indexes is provided using buffer content
locks, buffer pins, and cleanup locks. Here as elsewhere in
PostgreSQL, cleanup lock means that we hold an exclusive lock on the
buffer and have observed at some point after acquiring the lock that
we hold the only pin on that buffer. For hash indexes, a cleanup lock
on a primary bucket page represents the right to perform an arbitrary
reorganization of the entire bucket, while a cleanup lock on an
overflow page represents the right to perform a reorganization of just
that page. Therefore, scans retain a pin on both the primary bucket
page and the overflow page they are currently scanning, if any.
Splitting a bucket requires a cleanup lock on both the old and new
primary bucket pages. VACUUM therefore takes a cleanup lock on every
bucket page in turn order to remove tuples. It can also remove tuples
copied to a new bucket by any previous split operation, because the
cleanup lock taken on the primary bucket page guarantees that no scans
which started prior to the most recent split can still be in progress.
After cleaning each page individually, it attempts to take a cleanup
lock on the primary bucket page in order to "squeeze" the bucket down
to the minimum possible number of pages.
===
As I was looking at the old text regarding deadlock risk, I realized
what may be a serious problem. Suppose process A is performing a scan
of some hash index. While the scan is suspended, it attempts to take
a lock and is blocked by process B. Process B, meanwhile, is running
VACUUM on that hash index. Eventually, it will do
LockBufferForCleanup() on the hash bucket on which process A holds a
buffer pin, resulting in an undetected deadlock. In the current
coding, A would hold a heavyweight lock and B would attempt to acquire
a conflicting heavyweight lock, and the deadlock detector would kill
one of them. This patch probably breaks that. I notice that that's
the only place where we attempt to acquire a buffer cleanup lock
unconditionally; every place else, we acquire the lock conditionally,
so there's no deadlock risk. Once we resolve this problem, the
paragraph about deadlock risk in this section should be revised to
explain whatever solution we come up with.
By the way, since VACUUM must run in its own transaction, B can't be
holding arbitrary locks, but that doesn't seem quite sufficient to get
us out of the woods. It will at least hold ShareUpdateExclusiveLock
on the relation being vacuumed, and process A could attempt to acquire
that same lock.
Also in regards to deadlock, I notice that you added a paragraph
saying that we lock higher-numbered buckets before lower-numbered
buckets. That's fair enough, but what about the metapage? The reader
algorithm suggests that the metapage must lock must be taken after the
bucket locks, because it tries to grab the bucket lock conditionally
after acquiring the metapage lock, but that's not documented here.
The reader algorithm itself seems to be a bit oddly explained.
pin meta page and take buffer content lock in shared mode
+ compute bucket number for target hash key
+ read and pin the primary bucket page
So far, I'm with you.
+ conditionally get the buffer content lock in shared mode on
primary bucket page for search
+ if we didn't get the lock (need to wait for lock)
"didn't get the lock" and "wait for the lock" are saying the same
thing, so this is redundant, and the statement that it is "for search"
on the previous line is redundant with the introductory text
describing this as the reader algorithm.
+ release the buffer content lock on meta page
+ acquire buffer content lock on primary bucket page in shared mode
+ acquire the buffer content lock in shared mode on meta page
OK...
+ to check for possibility of split, we need to recompute the bucket and
+ verify, if it is a correct bucket; set the retry flag
This makes it sound like we set the retry flag whether it was the
correct bucket or not, which isn't sensible.
+ else if we get the lock, then we can skip the retry path
This line is totally redundant. If we don't set the retry flag, then
of course we can skip the part guarded by if (retry).
+ if (retry)
+ loop:
+ compute bucket number for target hash key
+ release meta page buffer content lock
+ if (correct bucket page is already locked)
+ break
+ release any existing content lock on bucket page (if a
concurrent split happened)
+ pin primary bucket page and take shared buffer content lock
+ retake meta page buffer content lock in shared mode
This is the part I *really* don't understand. It makes sense to me
that we need to loop until we get the correct bucket locked with no
concurrent splits, but why is this retry loop separate from the
previous bit of code that set the retry flag. In other words, why is
not something like this?
pin the meta page and take shared content lock on it
compute bucket number for target hash key
if (we can't get a shared content lock on the target bucket without blocking) loop: release meta page content
lock take a shared content lock on the target primary bucket page take a shared content lock on the metapage
if (previously-computed target bucket has not been split) break;
Another thing I don't quite understand about this algorithm is that in
order to conditionally lock the target primary bucket page, we'd first
need to read and pin it. And that doesn't seem like a good thing to
do while we're holding a shared content lock on the metapage, because
of the principle that we don't want to hold content locks across I/O.
-- then, per read request: release pin on metapage
- read current page of bucket and take shared buffer content lock
- step to next page if necessary (no chaining of locks)
+ if the split is in progress for current bucket and this is a new bucket
+ release the buffer content lock on current bucket page
+ pin and acquire the buffer content lock on old bucket in shared mode
+ release the buffer content lock on old bucket, but not pin
+ retake the buffer content lock on new bucket
+ mark the scan such that it skips the tuples that are marked
as moved by split
Aren't these steps done just once per scan? If so, I think they
should appear before "-- then, per read request" which AIUI is
intended to imply a loop over tuples.
+ step to next page if necessary (no chaining of locks)
+ if the scan indicates moved by split, then move to old bucket
after the scan
+ of current bucket is finished get tuple release buffer content lock and pin on current page-- at scan
shutdown:
- release bucket share-lock
Don't we have a pin to release at scan shutdown in the new system?
Well, I was hoping to get through the whole patch in one email, but
I'm not even all the way through the README. However, it's late, so
I'm stopping here for now.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> I'll write another email with my thoughts about the rest of the patch. > > I think that the README changes for this patch need a fairly large > amount of additional work. Here are a few things I notice: > > - The confusion between buckets and pages hasn't been completely > cleared up. If you read the beginning of the README, the terminology > is clearly set forth. It says: > >>> A hash index consists of two or more "buckets", into which tuples are placed whenever their hash key maps to the bucketnumber. Each bucket in the hash index comprises one or more index pages. The bucket's first page is permanently assignedto it when the bucket is created. Additional pages, called "overflow pages", are added if the bucket receives toomany tuples to fit in the primary bucket page." > > But later on, you say: > >>> Scan will take a lock in shared mode on the primary bucket or on one of the overflow page. > > So the correct terminology here would be "primary bucket page" not > "primary bucket". > > - In addition, notice that there are two English errors in this > sentence: the word "the" needs to be added to the beginning of the > sentence, and the last word needs to be "pages" rather than "page". > There are a considerable number of similar minor errors; if you can't > fix them, I'll make a pass over it and clean it up. > > - The whole "lock definitions" section seems to me to be pretty loose > and imprecise about what is happening. For example, it uses the term > "split-in-progress" without first defining it. The sentence quoted > above says that scans take a lock in shared mode either on the primary > page or on one of the overflow pages, but it's not to document code by > saying that it will do either A or B without explaining which one! In > fact, I think that a scan will take a content lock first on the > primary bucket page and then on each overflow page in sequence, > retaining a pin on the primary buffer page throughout the scan. So it > is not one or the other but both in a particular sequence, and that > can and should be explained. > > Another problem with this section is that even when it's precise about > what is going on, it's probably duplicating what is or should be in > the following sections where the algorithms for each operation are > explained. In the original wording, this section explains what each > lock protects, and then the following sections explain the algorithms > in the context of those definitions. Now, this section contains a > sketch of the algorithm, and then the following sections lay it out > again in more detail. The question of what each lock protects has > been lost. Here's an attempt at some text to replace what you have > here: > > === > Concurrency control for hash indexes is provided using buffer content > locks, buffer pins, and cleanup locks. Here as elsewhere in > PostgreSQL, cleanup lock means that we hold an exclusive lock on the > buffer and have observed at some point after acquiring the lock that > we hold the only pin on that buffer. For hash indexes, a cleanup lock > on a primary bucket page represents the right to perform an arbitrary > reorganization of the entire bucket, while a cleanup lock on an > overflow page represents the right to perform a reorganization of just > that page. Therefore, scans retain a pin on both the primary bucket > page and the overflow page they are currently scanning, if any. > I don't think we take cleanup lock on overflow page, so I will edit that part. > Splitting a bucket requires a cleanup lock on both the old and new > primary bucket pages. VACUUM therefore takes a cleanup lock on every > bucket page in turn order to remove tuples. It can also remove tuples > copied to a new bucket by any previous split operation, because the > cleanup lock taken on the primary bucket page guarantees that no scans > which started prior to the most recent split can still be in progress. > After cleaning each page individually, it attempts to take a cleanup > lock on the primary bucket page in order to "squeeze" the bucket down > to the minimum possible number of pages. > === > > As I was looking at the old text regarding deadlock risk, I realized > what may be a serious problem. Suppose process A is performing a scan > of some hash index. While the scan is suspended, it attempts to take > a lock and is blocked by process B. Process B, meanwhile, is running > VACUUM on that hash index. Eventually, it will do > LockBufferForCleanup() on the hash bucket on which process A holds a > buffer pin, resulting in an undetected deadlock. In the current > coding, A would hold a heavyweight lock and B would attempt to acquire > a conflicting heavyweight lock, and the deadlock detector would kill > one of them. This patch probably breaks that. I notice that that's > the only place where we attempt to acquire a buffer cleanup lock > unconditionally; every place else, we acquire the lock conditionally, > so there's no deadlock risk. Once we resolve this problem, the > paragraph about deadlock risk in this section should be revised to > explain whatever solution we come up with. > > By the way, since VACUUM must run in its own transaction, B can't be > holding arbitrary locks, but that doesn't seem quite sufficient to get > us out of the woods. It will at least hold ShareUpdateExclusiveLock > on the relation being vacuumed, and process A could attempt to acquire > that same lock. > Right, I think there is a danger of deadlock in above situation. Needs some more thoughts. > Also in regards to deadlock, I notice that you added a paragraph > saying that we lock higher-numbered buckets before lower-numbered > buckets. That's fair enough, but what about the metapage? The reader > algorithm suggests that the metapage must lock must be taken after the > bucket locks, because it tries to grab the bucket lock conditionally > after acquiring the metapage lock, but that's not documented here. > That is for efficiency. This patch haven't changed anything in metapage locking which can directly impact deadlock. > The reader algorithm itself seems to be a bit oddly explained. > > pin meta page and take buffer content lock in shared mode > + compute bucket number for target hash key > + read and pin the primary bucket page > > So far, I'm with you. > > + conditionally get the buffer content lock in shared mode on > primary bucket page for search > + if we didn't get the lock (need to wait for lock) > > "didn't get the lock" and "wait for the lock" are saying the same > thing, so this is redundant, and the statement that it is "for search" > on the previous line is redundant with the introductory text > describing this as the reader algorithm. > > + release the buffer content lock on meta page > + acquire buffer content lock on primary bucket page in shared mode > + acquire the buffer content lock in shared mode on meta page > > OK... > > + to check for possibility of split, we need to recompute the bucket and > + verify, if it is a correct bucket; set the retry flag > > This makes it sound like we set the retry flag whether it was the > correct bucket or not, which isn't sensible. > > + else if we get the lock, then we can skip the retry path > > This line is totally redundant. If we don't set the retry flag, then > of course we can skip the part guarded by if (retry). > Will change as per suggestions. > + if (retry) > + loop: > + compute bucket number for target hash key > + release meta page buffer content lock > + if (correct bucket page is already locked) > + break > + release any existing content lock on bucket page (if a > concurrent split happened) > + pin primary bucket page and take shared buffer content lock > + retake meta page buffer content lock in shared mode > > This is the part I *really* don't understand. It makes sense to me > that we need to loop until we get the correct bucket locked with no > concurrent splits, but why is this retry loop separate from the > previous bit of code that set the retry flag. In other words, why is > not something like this? > > pin the meta page and take shared content lock on it > compute bucket number for target hash key > if (we can't get a shared content lock on the target bucket without blocking) > loop: > release meta page content lock > take a shared content lock on the target primary bucket page > take a shared content lock on the metapage > if (previously-computed target bucket has not been split) > break; > I think we can write it the way you are suggesting, but I don't want to change much in the existing for loop in code, which uses _hash_getbuf() to acquire the pin and lock together. > Another thing I don't quite understand about this algorithm is that in > order to conditionally lock the target primary bucket page, we'd first > need to read and pin it. And that doesn't seem like a good thing to > do while we're holding a shared content lock on the metapage, because > of the principle that we don't want to hold content locks across I/O. > I think we can release metapage content lock before reading the buffer. > -- then, per read request: > release pin on metapage > - read current page of bucket and take shared buffer content lock > - step to next page if necessary (no chaining of locks) > + if the split is in progress for current bucket and this is a new bucket > + release the buffer content lock on current bucket page > + pin and acquire the buffer content lock on old bucket in shared mode > + release the buffer content lock on old bucket, but not pin > + retake the buffer content lock on new bucket > + mark the scan such that it skips the tuples that are marked > as moved by split > > Aren't these steps done just once per scan? If so, I think they > should appear before "-- then, per read request" which AIUI is > intended to imply a loop over tuples. > As per code, there is no such intention (loop over tuples). It is about reading the page and getting the tuple. > + step to next page if necessary (no chaining of locks) > + if the scan indicates moved by split, then move to old bucket > after the scan > + of current bucket is finished > get tuple > release buffer content lock and pin on current page > -- at scan shutdown: > - release bucket share-lock > > Don't we have a pin to release at scan shutdown in the new system? > Yes, it is mentioned in line below: + release any pin we hold on current buffer, old bucket buffer, new bucket buffer + > Well, I was hoping to get through the whole patch in one email, but > I'm not even all the way through the README. However, it's late, so > I'm stopping here for now. > Thanks for the review! -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 28, 2016 at 8:06 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-09-28 15:04:30 -0400, Robert Haas wrote: >> Andres already >> stated that he things working on btree-over-hash would be more >> beneficial than fixing hash, but at this point it seems like he's the >> only one who takes that position. > > Note that I did *NOT* take that position. I was saying that I think we > should evaluate whether that's not a better approach, doing some simple > performance comparisons. I, for one, agree with this position. -- Peter Geoghegan
On Thu, Sep 29, 2016 at 8:07 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Wed, Sep 28, 2016 at 8:06 PM, Andres Freund <andres@anarazel.de> wrote: >> On 2016-09-28 15:04:30 -0400, Robert Haas wrote: >>> Andres already >>> stated that he things working on btree-over-hash would be more >>> beneficial than fixing hash, but at this point it seems like he's the >>> only one who takes that position. >> >> Note that I did *NOT* take that position. I was saying that I think we >> should evaluate whether that's not a better approach, doing some simple >> performance comparisons. > > I, for one, agree with this position. Well, I, for one, find it frustrating. It seems pretty unhelpful to bring this up only after the code has already been written. The first post on this thread was on May 10th. The first version of the patch was posted on June 16th. This position was first articulated on September 15th. But, by all means, please feel free to do the performance comparison and post the results. I'd be curious to see them myself. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-09-29 20:14:40 -0400, Robert Haas wrote: > On Thu, Sep 29, 2016 at 8:07 PM, Peter Geoghegan <pg@heroku.com> wrote: > > On Wed, Sep 28, 2016 at 8:06 PM, Andres Freund <andres@anarazel.de> wrote: > >> On 2016-09-28 15:04:30 -0400, Robert Haas wrote: > >>> Andres already > >>> stated that he things working on btree-over-hash would be more > >>> beneficial than fixing hash, but at this point it seems like he's the > >>> only one who takes that position. > >> > >> Note that I did *NOT* take that position. I was saying that I think we > >> should evaluate whether that's not a better approach, doing some simple > >> performance comparisons. > > > > I, for one, agree with this position. > > Well, I, for one, find it frustrating. It seems pretty unhelpful to > bring this up only after the code has already been written. I brought this up in person at pgcon too.
On Thu, Sep 29, 2016 at 8:16 PM, Andres Freund <andres@anarazel.de> wrote: >> Well, I, for one, find it frustrating. It seems pretty unhelpful to >> bring this up only after the code has already been written. > > I brought this up in person at pgcon too. To whom? In what context? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On September 29, 2016 5:28:00 PM PDT, Robert Haas <robertmhaas@gmail.com> wrote: >On Thu, Sep 29, 2016 at 8:16 PM, Andres Freund <andres@anarazel.de> >wrote: >>> Well, I, for one, find it frustrating. It seems pretty unhelpful to >>> bring this up only after the code has already been written. >> >> I brought this up in person at pgcon too. > >To whom? In what context? Amit, over dinner. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Fri, Sep 30, 2016 at 1:29 AM, Andres Freund <andres@anarazel.de> wrote: >>To whom? In what context? > > Amit, over dinner. In case it matters, I also talked to Amit about this privately. -- Peter Geoghegan
On Fri, Sep 30, 2016 at 1:14 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> I, for one, agree with this position. > > Well, I, for one, find it frustrating. It seems pretty unhelpful to > bring this up only after the code has already been written. The first > post on this thread was on May 10th. The first version of the patch > was posted on June 16th. This position was first articulated on > September 15th. Really, what do we have to lose at this point? It's not very difficult to do what Andres proposes. -- Peter Geoghegan
On Thu, Sep 29, 2016 at 8:29 PM, Andres Freund <andres@anarazel.de> wrote: > On September 29, 2016 5:28:00 PM PDT, Robert Haas <robertmhaas@gmail.com> wrote: >>On Thu, Sep 29, 2016 at 8:16 PM, Andres Freund <andres@anarazel.de> >>wrote: >>>> Well, I, for one, find it frustrating. It seems pretty unhelpful to >>>> bring this up only after the code has already been written. >>> >>> I brought this up in person at pgcon too. >> >>To whom? In what context? > > Amit, over dinner. OK, well, I can't really comment on that, then, except to say that if you waited three months to follow up on the mailing list, you probably can't blame Amit if he thought that it was more of a casual suggestion than a serious objection. Maybe it was? I don't know. For my part, I don't really understand how you think that we could find anything out via relatively simple tests. The hash index code is horribly under-maintained, which is why Amit is able to get large performance improvements out of improving it. If you compare it to btree in some way, it's probably going to lose. But I don't think that answers the question of whether a hash AM that somebody's put some work into will win or lose against a hypothetical hash-over-btree AM that nobody's written. Even if it wins, is that really a reason to leave the hash index code itself in a state of disrepair? We probably would have removed it already except that the infrastructure is used for hash joins and hash aggregation, so we really can't. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 29, 2016 at 8:53 PM, Peter Geoghegan <pg@heroku.com> wrote: > On Fri, Sep 30, 2016 at 1:14 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> I, for one, agree with this position. >> >> Well, I, for one, find it frustrating. It seems pretty unhelpful to >> bring this up only after the code has already been written. The first >> post on this thread was on May 10th. The first version of the patch >> was posted on June 16th. This position was first articulated on >> September 15th. > > Really, what do we have to lose at this point? It's not very difficult > to do what Andres proposes. Well, first of all, I can't, because I don't really understand what tests he has in mind. Maybe somebody else does, in which case perhaps they could do the work and post the results. If the tests really are simple, that shouldn't be much of a burden. But, second, suppose we do the tests and find out that the hash-over-btree idea completely trounces hash indexes. What then? I don't think that would really prove anything because, as I said in my email to Andres, the current hash index code is severely under-optimized, so it's not really an apples-to-apples comparison. But even if it did prove something, is the idea then that Amit (with help from Mithun and Ashutosh Sharma) should throw away the ~8 months of development work that's been done on hash indexes in favor of starting all over with a new and probably harder project to build a whole new AM, and just leave hash indexes broken? That doesn't seem like a very reasonable think to ask. Leaving hash indexes broken fixes no problem that we have. On the other hand, applying those patches (after they've been suitably reviewed and fixed up) does fix several things. For one thing, we can stop shipping a totally broken feature in release after release. For another thing, those hash indexes do in fact outperform btree on some workloads, and with more work they can probably beat btree on more workloads. And if somebody later wants to write hash-over-btree and that turns out to be better still, great! I'm not blocking anyone from doing that. The only argument that's been advanced for not fixing hash indexes is that we'd then have to give people accurate guidance on whether to choose hash or btree, but that would also be true of a hypothetical hash-over-btree AM. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
<p dir="ltr">On 30-Sep-2016 6:24 AM, "Robert Haas" <<a href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>>wrote:<br /> ><br /> > On Thu, Sep 29, 2016 at 8:29PM, Andres Freund <<a href="mailto:andres@anarazel.de">andres@anarazel.de</a>> wrote:<br /> > > On September29, 2016 5:28:00 PM PDT, Robert Haas <<a href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>> wrote:<br/> > >>On Thu, Sep 29, 2016 at 8:16 PM, Andres Freund <<a href="mailto:andres@anarazel.de">andres@anarazel.de</a>><br/> > >>wrote:<br /> > >>>> Well, I,for one, find it frustrating. It seems pretty unhelpful to<br /> > >>>> bring this up only after the codehas already been written.<br /> > >>><br /> > >>> I brought this up in person at pgcon too.<br/> > >><br /> > >>To whom? In what context?<br /> > ><br /> > > Amit, over dinner.<br/> ><br /> > OK, well, I can't really comment on that, then, except to say that if<br /> > you waitedthree months to follow up on the mailing list, you probably<br /> > can't blame Amit if he thought that it was moreof a casual suggestion<br /> > than a serious objection. Maybe it was? I don't know.<br /> ><p dir="ltr">Bothof them have talked about hash indexes with me offline. Peter mentioned that it would be better to improvebtree rather than hash indexes. IIRC, Andres asked me mainly about what use cases I have in mind for hash indexesand then we do have some further discussion on the same thing where he was not convinced that there is any big usecase for hash indexes even though there may be some cases. In that discussion, as he is saying and I don't doubt him,he would have told me the alternative, but it was not apparent to me that he is expecting some sort of comparison.<pdir="ltr">What I got from both the discussions was a friendly gesture that it might be a better use of my time,if I work on some other problem. I really respect suggestions from both of them, but it was no where clear to me thatany one of them is expecting any comparison of other approach.<p dir="ltr">Considering, I have missed the real intentionof their suggestions, I think such a serious objection on any work should be discussed on list. To answer the actualobjection, I have already mentioned upthread that we can deduce from the current tests done by Jesper and Mithun thatthere are some cases where hash index will be better than hash-over-btree (tests done over integer columns). I thinkany discussion on whether we should consider not to improve current hash indexes is only meaningful if some one hasa code which can prove both theoretically and practically that it is better than hash indexes for all usages.<p dir="ltr">Note- excuse me for formatting of this email as I am on travel and using my phone.<p dir="ltr">With Regards, <br/> Amit Kapila.<br />
On Fri, Sep 30, 2016 at 9:07 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Considering, I have missed the real intention of their suggestions, I think > such a serious objection on any work should be discussed on list. To answer > the actual objection, I have already mentioned upthread that we can deduce > from the current tests done by Jesper and Mithun that there are some cases > where hash index will be better than hash-over-btree (tests done over > integer columns). I think any discussion on whether we should consider not > to improve current hash indexes is only meaningful if some one has a code > which can prove both theoretically and practically that it is better than > hash indexes for all usages. I cannot speak for Andres, but you judged my intent here correctly. I have no firm position on any of this just yet; I haven't even read the patch. I just think that it is worth doing some simple analysis of a hash-over-btree implementation, with simple prototyping and a simple test-case. I would consider that a due-diligence thing, because, honestly, it seems obvious to me that it should be at least checked out informally. I wasn't aware that there was already some analysis of this. Robert did just acknowledge that it is *possible* that "the hash-over-btree idea completely trounces hash indexes", so the general tone of this thread suggested to me that there was little or no analysis of hash-over-btree. I'm willing to believe that I'm wrong to be dismissive of the hash AM in general, and I'm even willing to be flexible on crediting the hash AM with being less optimized overall (assuming we can see a way past that). My only firm position is that it wouldn't be very hard to investigate hash-over-btree to Andres' satisfaction, say, so, why not? I'm surprised that this has caused consternation -- ISTM that Andres' suggestion is *perfectly* reasonable. It doesn't appear to be an objection to anything in particular. -- Peter Geoghegan
On Fri, Sep 30, 2016 at 7:47 AM, Peter Geoghegan <pg@heroku.com> wrote: > My only firm position is that it wouldn't be very hard to investigate > hash-over-btree to Andres' satisfaction, say, so, why not? I'm > surprised that this has caused consternation -- ISTM that Andres' > suggestion is *perfectly* reasonable. It doesn't appear to be an > objection to anything in particular. I would just be very disappointed if, after the amount of work that Amit and others have put into this project, the code gets rejected because somebody thinks a different project would have been more worth doing. As Tom said upthread: $$But to kick the hash AM as such to the curb is to say "sorry, there will never be O(1) index lookups in Postgres".$$ I think that's correct and a sufficiently-good reason to pursue this work, regardless of the merits (or lack of merits) of hash-over-btree. The fact that we have hash indexes already and cannot remove them because too much other code depends on hash opclasses is also, in my opinion, a sufficiently good reason to pursue improving them. I don't think the project needs the additional justification of outperforming a hash-over-btree in order to exist, even if such a comparison could be done fairly, which I suspect is harder than you're crediting. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I would just be very disappointed if, after the amount of work that > Amit and others have put into this project, the code gets rejected > because somebody thinks a different project would have been more worth > doing. I wouldn't presume to tell anyone else how to spend their time, and am not concerned about this making the hash index code any less useful from the user's perspective. If this is how we remove the wart of hash indexes not being WAL-logged, that's fine by me. I am trying to be helpful. > As Tom said upthread: $But to kick the hash AM as such to the > curb is to say > "sorry, there will never be O(1) index lookups in Postgres".$ I > think that's correct and a sufficiently-good reason to pursue this > work, regardless of the merits (or lack of merits) of hash-over-btree. I don't think that "O(1) index lookups" is a useful guarantee with a very expensive constant factor. Amit said: "I think any discussion on whether we should consider not to improve current hash indexes is only meaningful if some one has a code which can prove both theoretically and practically that it is better than hash indexes for all usages", so I think that he shares this view. > The fact that we have hash indexes already and cannot remove them > because too much other code depends on hash opclasses is also, in my > opinion, a sufficiently good reason to pursue improving them. I think that Andres was suggesting that hash index opclasses would be usable with hash-over-btree, so you might still not end up with the wart of having hash opclasses without hash indexes (an idea that has been proposed and rejected at least once before now). Andres? To be clear: I haven't expressed any opinion on this patch. -- Peter Geoghegan
On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I would just be very disappointed if, after the amount of work that > Amit and others have put into this project, the code gets rejected > because somebody thinks a different project would have been more worth > doing. I wouldn't presume to tell anyone else how to spend their time, and am not concerned about this patch making the hash index code any less useful from the user's perspective. If this is how we remove the wart of hash indexes not being WAL-logged, that's fine by me. I'm trying to be helpful. > As Tom said upthread: $But to kick the hash AM as such to the > curb is to say > "sorry, there will never be O(1) index lookups in Postgres".$ I > think that's correct and a sufficiently-good reason to pursue this > work, regardless of the merits (or lack of merits) of hash-over-btree. I don't think that "O(1) index lookups" is a useful guarantee with a very expensive constant factor. Amit seemed to agree with this, since he spoke of the importance of both theoretical performance benefits and practically realizable performance benefits. > The fact that we have hash indexes already and cannot remove them > because too much other code depends on hash opclasses is also, in my > opinion, a sufficiently good reason to pursue improving them. I think that Andres was suggesting that hash index opclasses would be usable with hash-over-btree, so you might still not end up with the wart of having hash opclasses without hash indexes (an idea that has been proposed and rejected at least once before). -- Peter Geoghegan
Peter Geoghegan <pg@heroku.com> writes:
> On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> The fact that we have hash indexes already and cannot remove them
>> because too much other code depends on hash opclasses is also, in my
>> opinion, a sufficiently good reason to pursue improving them.
> I think that Andres was suggesting that hash index opclasses would be
> usable with hash-over-btree, so you might still not end up with the
> wart of having hash opclasses without hash indexes (an idea that has
> been proposed and rejected at least once before now). Andres?
That's an interesting point. If we were to flat-out replace the hash AM
with a hash-over-btree AM, the existing hash opclasses would just migrate
to that unchanged. But if someone wanted to add hash-over-btree alongside
the hash AM, it would be necessary to clone all those opclass entries,
or else find a way for the two AMs to share pg_opclass etc entries.
Either one of those is kind of annoying. (Although if we did do the work
of implementing the latter, it might come in handy in future; you could
certainly imagine that there will be cases like a next-generation GIST AM
wanting to reuse the opclasses of existing GIST, say.)
But having said that, I remain opposed to removing the hash AM.
If someone wants to implement hash-over-btree, that's cool with me,
but I'd much rather put it in beside plain hash and let them duke
it out in the field.
regards, tom lane
On 2016-09-30 17:39:04 +0100, Peter Geoghegan wrote:
> On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> > I would just be very disappointed if, after the amount of work that
> > Amit and others have put into this project, the code gets rejected
> > because somebody thinks a different project would have been more worth
> > doing.
>
> I wouldn't presume to tell anyone else how to spend their time, and am
> not concerned about this making the hash index code any less useful
> from the user's perspective.
Me neither.
I'm concerned that this is a heck of a lot of work, and I don't think
we've reached the end of it by a good bit. I think it would have, and
probably still is, a more efficient use of time to go for the
hash-via-btree method, and rip out the current hash indexes. But that's
just me.
I find it more than a bit odd to be accused of trying to waste others
time by saying this, and that this is too late because time has already
been invested. Especially the latter never has been a standard in the
community, and while excruciatingly painful when one is the person(s)
having invested the time, it probably shouldn't be.
> > The fact that we have hash indexes already and cannot remove them
> > because too much other code depends on hash opclasses is also, in my
> > opinion, a sufficiently good reason to pursue improving them.
>
> I think that Andres was suggesting that hash index opclasses would be
> usable with hash-over-btree, so you might still not end up with the
> wart of having hash opclasses without hash indexes (an idea that has
> been proposed and rejected at least once before now). Andres?
Yes, that was what I was pretty much thinking. I was kind of guessing
that this might be easiest implemented as a separate AM ("hash2" ;))
that's just a layer ontop of nbtree.
Greetings,
Andres Freund
<p dir="ltr">On 30-Sep-2016 10:26 PM, "Peter Geoghegan" <<a href="mailto:pg@heroku.com">pg@heroku.com</a>> wrote:<br/> ><br /> > On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <<a href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>>wrote:<br /> > > I would just be very disappointedif, after the amount of work that<br /> > > Amit and others have put into this project, the code gets rejected<br/> > > because somebody thinks a different project would have been more worth<br /> > > doing.<br/> ><br /> > I wouldn't presume to tell anyone else how to spend their time, and am<br /> > not concernedabout this patch making the hash index code any less<br /> > useful from the user's perspective. If this is howwe remove the wart<br /> > of hash indexes not being WAL-logged, that's fine by me. I'm trying to<br /> > be helpful.<br/> ><p dir="ltr">If that is fine, then I think we should do that. I want to bring it to your notice that wehave already seen and reported that with proposed set of patches, hash indexes are good bit faster than btree, so thatadds additional value in making them WAL-logged.<p dir="ltr">> > As Tom said upthread: $But to kick the hash AMas such to the<br /> > > curb is to say<br /> > > "sorry, there will never be O(1) index lookups in Postgres".$ I<br /> > > think that's correct and a sufficiently-good reason to pursue this<br /> > > work, regardlessof the merits (or lack of merits) of hash-over-btree.<br /> ><br /> > I don't think that "O(1) index lookups"is a useful guarantee with a<br /> > very expensive constant factor.<p dir="ltr">The constant factor doesn't playmuch role when data doesn't have duplicates or have lesser duplicates.<p dir="ltr"> Amit seemed to agree with this, since<br/> > he spoke of the importance of both theoretical performance benefits<br /> > and practically realizableperformance benefits.<br /> ><p dir="ltr">No, I don't agree with that rather I think hash indexes are theoreticallyfaster than btree and we have seen that practically as well for quite a few cases (for read workloads - whenused with unique data and also in nest loops).<p dir="ltr">With Regards,<br /> Amit Kapila <br />
Andres Freund <andres@anarazel.de>:
> On 2016-09-30 17:39:04 +0100, Peter Geoghegan wrote:
>> On Fri, Sep 30, 2016 at 4:46 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> > I would just be very disappointed if, after the amount of work that
>> > Amit and others have put into this project, the code gets rejected
>> > because somebody thinks a different project would have been more worth
>> > doing.
>>
>> I wouldn't presume to tell anyone else how to spend their time, and am
>> not concerned about this making the hash index code any less useful
>> from the user's perspective.
>
> Me neither.
>
> I'm concerned that this is a heck of a lot of work, and I don't think
> we've reached the end of it by a good bit. I think it would have, and
> probably still is, a more efficient use of time to go for the
> hash-via-btree method, and rip out the current hash indexes. But that's
> just me.
>
> I find it more than a bit odd to be accused of trying to waste others
> time by saying this, and that this is too late because time has already
> been invested. Especially the latter never has been a standard in the
> community, and while excruciatingly painful when one is the person(s)
> having invested the time, it probably shouldn't be.
>
>
>> > The fact that we have hash indexes already and cannot remove them
>> > because too much other code depends on hash opclasses is also, in my
>> > opinion, a sufficiently good reason to pursue improving them.
>>
>> I think that Andres was suggesting that hash index opclasses would be
>> usable with hash-over-btree, so you might still not end up with the
>> wart of having hash opclasses without hash indexes (an idea that has
>> been proposed and rejected at least once before now). Andres?
>
> Yes, that was what I was pretty much thinking. I was kind of guessing
> that this might be easiest implemented as a separate AM ("hash2" ;))
> that's just a layer ontop of nbtree.
>
> Greetings,
>
> Andres Freund
Hi,
There have been benchmarks posted over the years were even the non-WAL
logged hash out performed the btree usage variant. You cannot argue
against O(1) algorithm behavior. We need to have a usable hash index
so that others can help improve it.
My 2 cents.
Regards,
Ken
On Fri, Sep 30, 2016 at 2:11 AM, Robert Haas <robertmhaas@gmail.com> wrote: > For one thing, we can stop shipping a totally broken feature in release after release For what it's worth I'm for any patch that can accomplish that. In retrospect I think we should have done the hash-over-btree thing ten years ago but we didn't and if Amit's patch makes hash indexes recoverable today then go for it. -- greg
On Sun, Oct 2, 2016 at 3:31 AM, Greg Stark <stark@mit.edu> wrote: > On Fri, Sep 30, 2016 at 2:11 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> For one thing, we can stop shipping a totally broken feature in release after release > > For what it's worth I'm for any patch that can accomplish that. > > In retrospect I think we should have done the hash-over-btree thing > ten years ago but we didn't and if Amit's patch makes hash indexes > recoverable today then go for it. +1. -- Michael
2016-10-02 12:40 GMT+02:00 Michael Paquier <michael.paquier@gmail.com>:
On Sun, Oct 2, 2016 at 3:31 AM, Greg Stark <stark@mit.edu> wrote:
> On Fri, Sep 30, 2016 at 2:11 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> For one thing, we can stop shipping a totally broken feature in release after release
>
> For what it's worth I'm for any patch that can accomplish that.
>
> In retrospect I think we should have done the hash-over-btree thing
> ten years ago but we didn't and if Amit's patch makes hash indexes
> recoverable today then go for it.
+1.
+1
Pavel
--
Michael
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On Mon, Oct 3, 2016 at 12:42 AM, Pavel Stehule <pavel.stehule@gmail.com> wrote: > > > 2016-10-02 12:40 GMT+02:00 Michael Paquier <michael.paquier@gmail.com>: >> >> On Sun, Oct 2, 2016 at 3:31 AM, Greg Stark <stark@mit.edu> wrote: >> > On Fri, Sep 30, 2016 at 2:11 AM, Robert Haas <robertmhaas@gmail.com> >> > wrote: >> >> For one thing, we can stop shipping a totally broken feature in release >> >> after release >> > >> > For what it's worth I'm for any patch that can accomplish that. >> > >> > In retrospect I think we should have done the hash-over-btree thing >> > ten years ago but we didn't and if Amit's patch makes hash indexes >> > recoverable today then go for it. >> >> +1. > > +1 And moved to next CF to make it breath. -- Michael
On Thu, Sep 29, 2016 at 5:14 PM, Robert Haas <robertmhaas@gmail.com> wrote:
I run 'pgbench -c16 -j16 -T 900 -M prepared' on an 8 core machine with a scale of 40. All the data fits in RAM, but not in shared_buffers (128MB).
On Thu, Sep 29, 2016 at 8:07 PM, Peter Geoghegan <pg@heroku.com> wrote:
> On Wed, Sep 28, 2016 at 8:06 PM, Andres Freund <andres@anarazel.de> wrote:
>> On 2016-09-28 15:04:30 -0400, Robert Haas wrote:
>>> Andres already
>>> stated that he things working on btree-over-hash would be more
>>> beneficial than fixing hash, but at this point it seems like he's the
>>> only one who takes that position.
>>
>> Note that I did *NOT* take that position. I was saying that I think we
>> should evaluate whether that's not a better approach, doing some simple
>> performance comparisons.
>
> I, for one, agree with this position.
Well, I, for one, find it frustrating. It seems pretty unhelpful to
bring this up only after the code has already been written. The first
post on this thread was on May 10th. The first version of the patch
was posted on June 16th. This position was first articulated on
September 15th.
But, by all means, please feel free to do the performance comparison
and post the results. I'd be curious to see them myself.
I've done a simple comparison using pgbench's default transaction, in which all the primary keys have been dropped and replaced with indexes of either hash or btree type, alternating over many rounds.
I find a 4% improvement for hash indexes over btree indexes, 9324.744 vs 9727.766. The difference is significant at p-value of 1.9e-9.
The four versions of hash indexes (HEAD, concurrent, wal, cache, applied cumulatively) have no statistically significant difference in performance from each other.
I certainly don't see how btree-over-hash-over-integer could be better than direct btree-over-integer.
I think I don't see improvement in hash performance with the concurrent and cache patches because I don't have enough cores to get to the contention that those patches are targeted at. But since the concurrent patch is a prerequisite to the wal patch, that is enough to justify it even without a demonstrated performance boost. A 4% gain is not astonishing, but is nice to have provided we can get it without giving up crash safety.
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> I've done a simple comparison using pgbench's default transaction, in which
> all the primary keys have been dropped and replaced with indexes of either
> hash or btree type, alternating over many rounds.
> I run 'pgbench -c16 -j16 -T 900 -M prepared' on an 8 core machine with a
> scale of 40. All the data fits in RAM, but not in shared_buffers (128MB).
> I find a 4% improvement for hash indexes over btree indexes, 9324.744
> vs 9727.766. The difference is significant at p-value of 1.9e-9.
Thanks for doing this work!
> The four versions of hash indexes (HEAD, concurrent, wal, cache, applied
> cumulatively) have no statistically significant difference in performance
> from each other.
Interesting.
> I think I don't see improvement in hash performance with the concurrent and
> cache patches because I don't have enough cores to get to the contention
> that those patches are targeted at.
Possibly. However, if the cache patch is not a prerequisite to the WAL
fixes, IMO somebody would have to demonstrate that it has a measurable
performance benefit before it would get in. It certainly doesn't look
like it's simplifying the code, so I wouldn't take it otherwise.
I think, though, that this is enough to put to bed the argument that
we should toss the hash AM entirely. If it's already competitive with
btree today, despite the lack of attention that it's gotten, there is
reason to hope that it will be a significant win (for some use-cases,
obviously) in future. We should now get back to reviewing these patches
on their own merits.
regards, tom lane
On Thu, Sep 29, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> As I was looking at the old text regarding deadlock risk, I realized >> what may be a serious problem. Suppose process A is performing a scan >> of some hash index. While the scan is suspended, it attempts to take >> a lock and is blocked by process B. Process B, meanwhile, is running >> VACUUM on that hash index. Eventually, it will do >> LockBufferForCleanup() on the hash bucket on which process A holds a >> buffer pin, resulting in an undetected deadlock. In the current >> coding, A would hold a heavyweight lock and B would attempt to acquire >> a conflicting heavyweight lock, and the deadlock detector would kill >> one of them. This patch probably breaks that. I notice that that's >> the only place where we attempt to acquire a buffer cleanup lock >> unconditionally; every place else, we acquire the lock conditionally, >> so there's no deadlock risk. Once we resolve this problem, the >> paragraph about deadlock risk in this section should be revised to >> explain whatever solution we come up with. >> >> By the way, since VACUUM must run in its own transaction, B can't be >> holding arbitrary locks, but that doesn't seem quite sufficient to get >> us out of the woods. It will at least hold ShareUpdateExclusiveLock >> on the relation being vacuumed, and process A could attempt to acquire >> that same lock. >> > > Right, I think there is a danger of deadlock in above situation. > Needs some more thoughts. > I think one way to avoid the risk of deadlock in above scenario is to take the cleanup lock conditionally, if we get the cleanup lock then we will delete the items as we are doing in patch now, else it will just mark the tuples as dead and ensure that it won't try to remove tuples that are moved-by-split. Now, I think the question is how will these dead tuples be removed. We anyway need a separate mechanism to clear dead tuples for hash indexes as during scans we are marking the tuples as dead if corresponding tuple in heap is dead which are not removed later. This is already taken care in btree code via kill_prior_tuple optimization. So I think clearing of dead tuples can be handled by a separate patch. I have also thought about using page-scan-at-a-time idea which has been discussed upthread[1], but I think we can't completely eliminate the need to out-wait scans (cleanup lock requirement) for scans that are started when split-in-progress or for non-MVCC scans as described in that e-mail [1]. We might be able to find some way to solve the problem with this approach, but I think it will be slightly complicated and much more work is required as compare to previous approach. What is your preference among above approaches to resolve this problem or let me know if you have a better idea to solve it? [1] - https://www.postgresql.org/message-id/CAA4eK1Jj1UqneTXrywr%3DGg87vgmnMma87LuscN_r3hKaHd%3DL2g%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 4, 2016 at 10:06 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Sep 29, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> >>> As I was looking at the old text regarding deadlock risk, I realized >>> what may be a serious problem. Suppose process A is performing a scan >>> of some hash index. While the scan is suspended, it attempts to take >>> a lock and is blocked by process B. Process B, meanwhile, is running >>> VACUUM on that hash index. Eventually, it will do >>> LockBufferForCleanup() on the hash bucket on which process A holds a >>> buffer pin, resulting in an undetected deadlock. In the current >>> coding, A would hold a heavyweight lock and B would attempt to acquire >>> a conflicting heavyweight lock, and the deadlock detector would kill >>> one of them. This patch probably breaks that. I notice that that's >>> the only place where we attempt to acquire a buffer cleanup lock >>> unconditionally; every place else, we acquire the lock conditionally, >>> so there's no deadlock risk. Once we resolve this problem, the >>> paragraph about deadlock risk in this section should be revised to >>> explain whatever solution we come up with. >>> >>> By the way, since VACUUM must run in its own transaction, B can't be >>> holding arbitrary locks, but that doesn't seem quite sufficient to get >>> us out of the woods. It will at least hold ShareUpdateExclusiveLock >>> on the relation being vacuumed, and process A could attempt to acquire >>> that same lock. >>> >> >> Right, I think there is a danger of deadlock in above situation. >> Needs some more thoughts. >> > > I think one way to avoid the risk of deadlock in above scenario is to > take the cleanup lock conditionally, if we get the cleanup lock then > we will delete the items as we are doing in patch now, else it will > just mark the tuples as dead and ensure that it won't try to remove > tuples that are moved-by-split. Now, I think the question is how will > these dead tuples be removed. We anyway need a separate mechanism to > clear dead tuples for hash indexes as during scans we are marking the > tuples as dead if corresponding tuple in heap is dead which are not > removed later. This is already taken care in btree code via > kill_prior_tuple optimization. So I think clearing of dead tuples can > be handled by a separate patch. > I think we can also remove the dead tuples next time when vacuum visits the bucket and is able to acquire the cleanup lock. Right now, we are just checking if the corresponding heap tuple is dead, we can have an additional check as well to ensure if the current item is dead in index, then consider it in list of deletable items. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I think one way to avoid the risk of deadlock in above scenario is to > take the cleanup lock conditionally, if we get the cleanup lock then > we will delete the items as we are doing in patch now, else it will > just mark the tuples as dead and ensure that it won't try to remove > tuples that are moved-by-split. Now, I think the question is how will > these dead tuples be removed. We anyway need a separate mechanism to > clear dead tuples for hash indexes as during scans we are marking the > tuples as dead if corresponding tuple in heap is dead which are not > removed later. This is already taken care in btree code via > kill_prior_tuple optimization. So I think clearing of dead tuples can > be handled by a separate patch. That seems like it could work. The hash scan code will need to be made smart enough to ignore any tuples marked dead, if it isn't already. More aggressive cleanup can be left for another patch. > I have also thought about using page-scan-at-a-time idea which has > been discussed upthread[1], but I think we can't completely eliminate > the need to out-wait scans (cleanup lock requirement) for scans that > are started when split-in-progress or for non-MVCC scans as described > in that e-mail [1]. We might be able to find some way to solve the > problem with this approach, but I think it will be slightly > complicated and much more work is required as compare to previous > approach. There are several levels of aggressiveness here with different locking requirements: 1. Mark line items dead without reorganizing the page. Needs an exclusive content lock, no more. Even a shared content lock may be OK, as for other opportunistic bit-flipping. 2. Mark line items dead and compact the tuple data. If a pin is sufficient to look at tuple data, as it is for the heap, then a cleanup lock is required here. But if we always hold a shared content lock when looking at the tuple data, it might be possible to do this with just an exclusive content lock. 3. Remove dead line items completely, compacting the tuple data and the item-pointer array. Doing this with only an exclusive content lock certainly needs page-at-a-time mode because otherwise a searcher that resumes a scan later might resume from the wrong place. It also needs the guarantee mentioned for point #2, namely that nobody will be examining the tuple data without a shared content lock. 4. Squeezing the bucket. This is probably always going to require a cleanup lock, because otherwise it's pretty unclear how a concurrent scan could be made safe. I suppose the scan could remember every TID it has seen, somehow detect that a squeeze had happened, and rescan the whole bucket ignoring TIDs already returned, but that seems to require the client to use potentially unbounded amounts of memory to remember already-returned TIDs, plus an as-yet-uninvented mechanism for detecting that a squeeze has happened. So this seems like a dead-end to me. I think that it is very much worthwhile to reduce the required lock strength from cleanup-lock to exclusive-lock in as many cases as possible, but I don't think it will be possible to completely eliminate the need to take the cleanup lock in some cases. However, if we can always take the cleanup lock conditionally and never be in a situation where it's absolutely required, we should be OK - and even level (1) gives you that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Oct 5, 2016 at 10:22 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> I think one way to avoid the risk of deadlock in above scenario is to
>> take the cleanup lock conditionally, if we get the cleanup lock then
>> we will delete the items as we are doing in patch now, else it will
>> just mark the tuples as dead and ensure that it won't try to remove
>> tuples that are moved-by-split. Now, I think the question is how will
>> these dead tuples be removed. We anyway need a separate mechanism to
>> clear dead tuples for hash indexes as during scans we are marking the
>> tuples as dead if corresponding tuple in heap is dead which are not
>> removed later. This is already taken care in btree code via
>> kill_prior_tuple optimization. So I think clearing of dead tuples can
>> be handled by a separate patch.
>
> That seems like it could work. The hash scan code will need to be
> made smart enough to ignore any tuples marked dead, if it isn't
> already.
>
It already takes care of ignoring killed tuples in below code, though
the way is much less efficient as compare to btree. Basically, it
fetches the matched tuple and then check if it is dead where as in
btree while matching the key, it does the same check. It might be
efficient to do it before matching the hashkey, but I think it is a
matter of separate patch.
hashgettuple()
{
..
/*
* Skip killed tuples if asked to.
*/
if (scan->ignore_killed_tuples)
}
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Thu, Sep 29, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: > >> Another thing I don't quite understand about this algorithm is that in >> order to conditionally lock the target primary bucket page, we'd first >> need to read and pin it. And that doesn't seem like a good thing to >> do while we're holding a shared content lock on the metapage, because >> of the principle that we don't want to hold content locks across I/O. >> > Aren't we already doing this during BufferAlloc() when the buffer selected by StrategyGetBuffer() is dirty? > I think we can release metapage content lock before reading the buffer. > On thinking about this again, if we release the metapage content lock before reading and pinning the primary bucket page, then we need to take it again to verify if the split has happened during the time we don't have a lock on a metapage. Releasing and again taking content lock on metapage is not good from the performance aspect. Do you have some other idea for this? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Oct 10, 2016 at 5:55 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Thu, Sep 29, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>> Another thing I don't quite understand about this algorithm is that in
>> order to conditionally lock the target primary bucket page, we'd first
>> need to read and pin it. And that doesn't seem like a good thing to
>> do while we're holding a shared content lock on the metapage, because
>> of the principle that we don't want to hold content locks across I/O.
>>
>
Aren't we already doing this during BufferAlloc() when the buffer
selected by StrategyGetBuffer() is dirty?
Right, you probably shouldn't allocate another buffer while holding a content lock on a different one, if you can help it. But, BufferAlloc doesn't do that internally, does it? It is only a problem if you make it be one by the way you use it. Am I missing something?
> I think we can release metapage content lock before reading the buffer.
>
On thinking about this again, if we release the metapage content lock
before reading and pinning the primary bucket page, then we need to
take it again to verify if the split has happened during the time we
don't have a lock on a metapage. Releasing and again taking content
lock on metapage is not
good from the performance aspect. Do you have some other idea for this?
Doesn't the relcache patch effectively deal wit hthis? If this is a sticking point, maybe the relcache patch could be incorporated into this one.
Cheers,
Jeff
On Mon, Oct 10, 2016 at 10:07 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
> On Mon, Oct 10, 2016 at 5:55 AM, Amit Kapila <amit.kapila16@gmail.com>
> wrote:
>>
>> On Thu, Sep 29, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com>
>> wrote:
>> > On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com>
>> > wrote:
>> >
>> >> Another thing I don't quite understand about this algorithm is that in
>> >> order to conditionally lock the target primary bucket page, we'd first
>> >> need to read and pin it. And that doesn't seem like a good thing to
>> >> do while we're holding a shared content lock on the metapage, because
>> >> of the principle that we don't want to hold content locks across I/O.
>> >>
>> >
>>
>> Aren't we already doing this during BufferAlloc() when the buffer
>> selected by StrategyGetBuffer() is dirty?
>
>
> Right, you probably shouldn't allocate another buffer while holding a
> content lock on a different one, if you can help it.
>
I don't see the problem in that, but I guess the simple rule is that
we should not hold content locks for longer duration, which could
happen if we do I/O, or need to allocate a new buffer.
> But, BufferAlloc
> doesn't do that internally, does it?
>
You are right that BufferAlloc() doesn't allocate a new buffer while
holding content lock on another buffer, but it does perform I/O while
holding content lock.
> It is only a problem if you make it be
> one by the way you use it. Am I missing something?
>
>>
>>
>> > I think we can release metapage content lock before reading the buffer.
>> >
>>
>> On thinking about this again, if we release the metapage content lock
>> before reading and pinning the primary bucket page, then we need to
>> take it again to verify if the split has happened during the time we
>> don't have a lock on a metapage. Releasing and again taking content
>> lock on metapage is not
>> good from the performance aspect. Do you have some other idea for this?
>
>
> Doesn't the relcache patch effectively deal wit hthis? If this is a
> sticking point, maybe the relcache patch could be incorporated into this
> one.
>
Yeah, relcache patch would eliminate the need for metapage locking,
but that is not a blocking point. As this patch is mainly to enable
WAL logging, so there is no urgency to incorporate relcache patch,
even if we have to go with an algorithm where we need to take the
metapage lock twice to verify the splits. Having said that, I am
okay, if Robert and or others are also in favour of combining the two
patches (patch in this thread and cache the metapage patch). If we
don't want to hold content lock across another ReadBuffer call, then
another option could be to modify the read algorithm as below:
read the metapage
compute bucket number for target hash key based on metapage contents
read the required block
loop:
acquire shared content lock on metapage
recompute bucket number for target hash key based on metapage contents if the recomputed block number is not same as
theblock number we read release meta page content lock read the recomputed block number else break;
if (we can't get a shared content lock on the target bucket without blocking) loop: release meta page content
lock take a shared content lock on the target primary bucket page take a shared content lock on the metapage
if (previously-computed target bucket has not been split) break;
The basic change here is that first we compute the target block number
*without* locking metapage and then after locking the metapage, if
both doesn't match, then we need to again read the computed block
number.
Thoughts?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 5, 2016 at 10:22 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I think one way to avoid the risk of deadlock in above scenario is to >> take the cleanup lock conditionally, if we get the cleanup lock then >> we will delete the items as we are doing in patch now, else it will >> just mark the tuples as dead and ensure that it won't try to remove >> tuples that are moved-by-split. Now, I think the question is how will >> these dead tuples be removed. We anyway need a separate mechanism to >> clear dead tuples for hash indexes as during scans we are marking the >> tuples as dead if corresponding tuple in heap is dead which are not >> removed later. This is already taken care in btree code via >> kill_prior_tuple optimization. So I think clearing of dead tuples can >> be handled by a separate patch. > > That seems like it could work. > I have implemented this idea and it works for MVCC scans. However, I think this might not work for non-MVCC scans. Consider a case where in Process-1, hash scan has returned one row and before it could check it's validity in heap, vacuum marks that tuple as dead and removed the entry from heap and some new tuple has been placed at that offset in heap. Now when Process-1 checks the validity in heap, it will check for different tuple then what the index tuple was suppose to check. If we want, we can make it work similar to what btree does as being discussed on thread [1], but for that we need to introduce page-scan mode as well in hash indexes. However, do we really want to solve this problem as part of this patch when this exists for other index am as well? [1] - https://www.postgresql.org/message-id/CACjxUsNtBXe1OfRp%3DacB%2B8QFAVWJ%3Dnr55_HMmqQYceCzVGF4tQ%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 18, 2016 at 5:37 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Oct 5, 2016 at 10:22 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> I think one way to avoid the risk of deadlock in above scenario is to >>> take the cleanup lock conditionally, if we get the cleanup lock then >>> we will delete the items as we are doing in patch now, else it will >>> just mark the tuples as dead and ensure that it won't try to remove >>> tuples that are moved-by-split. Now, I think the question is how will >>> these dead tuples be removed. We anyway need a separate mechanism to >>> clear dead tuples for hash indexes as during scans we are marking the >>> tuples as dead if corresponding tuple in heap is dead which are not >>> removed later. This is already taken care in btree code via >>> kill_prior_tuple optimization. So I think clearing of dead tuples can >>> be handled by a separate patch. >> >> That seems like it could work. > > I have implemented this idea and it works for MVCC scans. However, I > think this might not work for non-MVCC scans. Consider a case where > in Process-1, hash scan has returned one row and before it could check > it's validity in heap, vacuum marks that tuple as dead and removed the > entry from heap and some new tuple has been placed at that offset in > heap. Oops, that's bad. > Now when Process-1 checks the validity in heap, it will check > for different tuple then what the index tuple was suppose to check. > If we want, we can make it work similar to what btree does as being > discussed on thread [1], but for that we need to introduce page-scan > mode as well in hash indexes. However, do we really want to solve > this problem as part of this patch when this exists for other index am > as well? For what other index AM does this problem exist? Kevin has been careful not to create this problem for btree, or at least I think he has. That's why the pin still has to be held on the index page when it's a non-MVCC scan. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Oct 18, 2016 at 5:37 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> I have implemented this idea and it works for MVCC scans. However, I
>> think this might not work for non-MVCC scans. Consider a case where
>> in Process-1, hash scan has returned one row and before it could check
>> it's validity in heap, vacuum marks that tuple as dead and removed the
>> entry from heap and some new tuple has been placed at that offset in
>> heap.
> Oops, that's bad.
Do we care? Under what circumstances would a hash index be used for a
non-MVCC scan?
regards, tom lane
On 2016-10-18 13:38:14 -0400, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > On Tue, Oct 18, 2016 at 5:37 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > >> I have implemented this idea and it works for MVCC scans. However, I > >> think this might not work for non-MVCC scans. Consider a case where > >> in Process-1, hash scan has returned one row and before it could check > >> it's validity in heap, vacuum marks that tuple as dead and removed the > >> entry from heap and some new tuple has been placed at that offset in > >> heap. > > > Oops, that's bad. > > Do we care? Under what circumstances would a hash index be used for a > non-MVCC scan? Uniqueness checks, are the most important one that comes to mind. Andres
On Tue, Oct 18, 2016 at 10:52 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Oct 18, 2016 at 5:37 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Wed, Oct 5, 2016 at 10:22 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> I think one way to avoid the risk of deadlock in above scenario is to >>>> take the cleanup lock conditionally, if we get the cleanup lock then >>>> we will delete the items as we are doing in patch now, else it will >>>> just mark the tuples as dead and ensure that it won't try to remove >>>> tuples that are moved-by-split. Now, I think the question is how will >>>> these dead tuples be removed. We anyway need a separate mechanism to >>>> clear dead tuples for hash indexes as during scans we are marking the >>>> tuples as dead if corresponding tuple in heap is dead which are not >>>> removed later. This is already taken care in btree code via >>>> kill_prior_tuple optimization. So I think clearing of dead tuples can >>>> be handled by a separate patch. >>> >>> That seems like it could work. >> >> I have implemented this idea and it works for MVCC scans. However, I >> think this might not work for non-MVCC scans. Consider a case where >> in Process-1, hash scan has returned one row and before it could check >> it's validity in heap, vacuum marks that tuple as dead and removed the >> entry from heap and some new tuple has been placed at that offset in >> heap. > > Oops, that's bad. > >> Now when Process-1 checks the validity in heap, it will check >> for different tuple then what the index tuple was suppose to check. >> If we want, we can make it work similar to what btree does as being >> discussed on thread [1], but for that we need to introduce page-scan >> mode as well in hash indexes. However, do we really want to solve >> this problem as part of this patch when this exists for other index am >> as well? > > For what other index AM does this problem exist? > By this problem, I mean to say deadlocks for suspended scans, that can happen in btree for non-Mvcc or other type of scans where we don't release pin during scan. In my mind, we have below options: a. problem of deadlocks for suspended scans should be tackled as a separate patch as it exists for other indexes (at least for some type of scans). b. Implement page-scan mode and then we won't have deadlock problem for MVCC scans. c. Let's not care for non-MVCC scans unless we have some way to hit those for hash indexes and proceed with Dead tuple marking idea. I think even if we don't care for non-MVCC scans, we might hit this problem (deadlocks) when the index relation is unlogged. Here, even if we want to go with (b), I think we can handle it in a separate patch, unless you think otherwise. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Oct 19, 2016 at 5:57 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Oct 18, 2016 at 10:52 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Oct 18, 2016 at 5:37 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> On Wed, Oct 5, 2016 at 10:22 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>>> On Tue, Oct 4, 2016 at 12:36 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>>> I think one way to avoid the risk of deadlock in above scenario is to >>>>> take the cleanup lock conditionally, if we get the cleanup lock then >>>>> we will delete the items as we are doing in patch now, else it will >>>>> just mark the tuples as dead and ensure that it won't try to remove >>>>> tuples that are moved-by-split. Now, I think the question is how will >>>>> these dead tuples be removed. We anyway need a separate mechanism to >>>>> clear dead tuples for hash indexes as during scans we are marking the >>>>> tuples as dead if corresponding tuple in heap is dead which are not >>>>> removed later. This is already taken care in btree code via >>>>> kill_prior_tuple optimization. So I think clearing of dead tuples can >>>>> be handled by a separate patch. >>>> >>>> That seems like it could work. >>> >>> I have implemented this idea and it works for MVCC scans. However, I >>> think this might not work for non-MVCC scans. Consider a case where >>> in Process-1, hash scan has returned one row and before it could check >>> it's validity in heap, vacuum marks that tuple as dead and removed the >>> entry from heap and some new tuple has been placed at that offset in >>> heap. >> >> Oops, that's bad. >> >>> Now when Process-1 checks the validity in heap, it will check >>> for different tuple then what the index tuple was suppose to check. >>> If we want, we can make it work similar to what btree does as being >>> discussed on thread [1], but for that we need to introduce page-scan >>> mode as well in hash indexes. However, do we really want to solve >>> this problem as part of this patch when this exists for other index am >>> as well? >> >> For what other index AM does this problem exist? >> > > By this problem, I mean to say deadlocks for suspended scans, that can > happen in btree for non-Mvcc or other type of scans where we don't > release pin during scan. In my mind, we have below options: > > a. problem of deadlocks for suspended scans should be tackled as a > separate patch as it exists for other indexes (at least for some type > of scans). > b. Implement page-scan mode and then we won't have deadlock problem > for MVCC scans. > c. Let's not care for non-MVCC scans unless we have some way to hit > those for hash indexes and proceed with Dead tuple marking idea. I > think even if we don't care for non-MVCC scans, we might hit this > problem (deadlocks) when the index relation is unlogged. > oops, my last sentence is wrong. What I wanted to say is: "I think even if we don't care for non-MVCC scans, we might hit the problem of TIDs reuse when the index relation is unlogged." -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Oct 18, 2016 at 8:27 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > By this problem, I mean to say deadlocks for suspended scans, that can > happen in btree for non-Mvcc or other type of scans where we don't > release pin during scan. In my mind, we have below options: > > a. problem of deadlocks for suspended scans should be tackled as a > separate patch as it exists for other indexes (at least for some type > of scans). > b. Implement page-scan mode and then we won't have deadlock problem > for MVCC scans. > c. Let's not care for non-MVCC scans unless we have some way to hit > those for hash indexes and proceed with Dead tuple marking idea. I > think even if we don't care for non-MVCC scans, we might hit this > problem (deadlocks) when the index relation is unlogged. > > Here, even if we want to go with (b), I think we can handle it in a > separate patch, unless you think otherwise. After some off-list discussion with Amit, I think I get his point here: the deadlock hazard which is introduced by this patch already exists for btree and has for a long time, and nobody's gotten around to fixing it (although 2ed5b87f96d473962ec5230fd820abfeaccb2069 improved things). So it's probably OK for hash indexes to have the same issue. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> Amit, can you please split the buffer manager changes in this patch
> into a separate patch?
>
Sure, attached patch extend_bufmgr_api_for_hash_index_v1.patch does that.
> I think those changes can be committed first
> and then we can try to deal with the rest of it. Instead of adding
> ConditionalLockBufferShared, I think we should add an "int mode"
> argument to the existing ConditionalLockBuffer() function. That way
> is more consistent with LockBuffer(). It means an API break for any
> third-party code that's calling this function, but that doesn't seem
> like a big problem.
That was the reason I have chosen to write separate API, but now I
have changed it as per your suggestion.
> As for CheckBufferForCleanup, I think that looks OK, but: (1) please
> add an Assert() that we hold an exclusive lock on the buffer, using
> LWLockHeldByMeInMode; and (2) I think we should rename it to something
> like IsBufferCleanupOK. Then, when it's used, it reads like English:
> if (IsBufferCleanupOK(buf)) { /* clean up the buffer */ }.
Changed as per suggestion.
>> I'll write another email with my thoughts about the rest of the patch.
>
> I think that the README changes for this patch need a fairly large
> amount of additional work. Here are a few things I notice:
>
> - The confusion between buckets and pages hasn't been completely
> cleared up. If you read the beginning of the README, the terminology
> is clearly set forth. It says:
>
>>> A hash index consists of two or more "buckets", into which tuples are placed whenever their hash key maps to the
bucketnumber. Each bucket in the hash index comprises one or more index pages. The bucket's first page is permanently
assignedto it when the bucket is created. Additional pages, called "overflow pages", are added if the bucket receives
toomany tuples to fit in the primary bucket page."
>
> But later on, you say:
>
>>> Scan will take a lock in shared mode on the primary bucket or on one of the overflow page.
>
> So the correct terminology here would be "primary bucket page" not
> "primary bucket".
>
> - In addition, notice that there are two English errors in this
> sentence: the word "the" needs to be added to the beginning of the
> sentence, and the last word needs to be "pages" rather than "page".
> There are a considerable number of similar minor errors; if you can't
> fix them, I'll make a pass over it and clean it up.
>
I have tried to fix as per above suggestion, but I think may be some
more work is needed.
> - The whole "lock definitions" section seems to me to be pretty loose
> and imprecise about what is happening. For example, it uses the term
> "split-in-progress" without first defining it. The sentence quoted
> above says that scans take a lock in shared mode either on the primary
> page or on one of the overflow pages, but it's not to document code by
> saying that it will do either A or B without explaining which one! In
> fact, I think that a scan will take a content lock first on the
> primary bucket page and then on each overflow page in sequence,
> retaining a pin on the primary buffer page throughout the scan. So it
> is not one or the other but both in a particular sequence, and that
> can and should be explained.
>
> Another problem with this section is that even when it's precise about
> what is going on, it's probably duplicating what is or should be in
> the following sections where the algorithms for each operation are
> explained. In the original wording, this section explains what each
> lock protects, and then the following sections explain the algorithms
> in the context of those definitions. Now, this section contains a
> sketch of the algorithm, and then the following sections lay it out
> again in more detail. The question of what each lock protects has
> been lost. Here's an attempt at some text to replace what you have
> here:
>
> ===
> Concurrency control for hash indexes is provided using buffer content
> locks, buffer pins, and cleanup locks. Here as elsewhere in
> PostgreSQL, cleanup lock means that we hold an exclusive lock on the
> buffer and have observed at some point after acquiring the lock that
> we hold the only pin on that buffer. For hash indexes, a cleanup lock
> on a primary bucket page represents the right to perform an arbitrary
> reorganization of the entire bucket, while a cleanup lock on an
> overflow page represents the right to perform a reorganization of just
> that page. Therefore, scans retain a pin on both the primary bucket
> page and the overflow page they are currently scanning, if any.
> Splitting a bucket requires a cleanup lock on both the old and new
> primary bucket pages. VACUUM therefore takes a cleanup lock on every
> bucket page in turn order to remove tuples. It can also remove tuples
> copied to a new bucket by any previous split operation, because the
> cleanup lock taken on the primary bucket page guarantees that no scans
> which started prior to the most recent split can still be in progress.
> After cleaning each page individually, it attempts to take a cleanup
> lock on the primary bucket page in order to "squeeze" the bucket down
> to the minimum possible number of pages.
> ===
>
Changed as per suggestion.
> As I was looking at the old text regarding deadlock risk, I realized
> what may be a serious problem. Suppose process A is performing a scan
> of some hash index. While the scan is suspended, it attempts to take
> a lock and is blocked by process B. Process B, meanwhile, is running
> VACUUM on that hash index. Eventually, it will do
> LockBufferForCleanup() on the hash bucket on which process A holds a
> buffer pin, resulting in an undetected deadlock. In the current
> coding, A would hold a heavyweight lock and B would attempt to acquire
> a conflicting heavyweight lock, and the deadlock detector would kill
> one of them. This patch probably breaks that. I notice that that's
> the only place where we attempt to acquire a buffer cleanup lock
> unconditionally; every place else, we acquire the lock conditionally,
> so there's no deadlock risk. Once we resolve this problem, the
> paragraph about deadlock risk in this section should be revised to
> explain whatever solution we come up with.
>
> By the way, since VACUUM must run in its own transaction, B can't be
> holding arbitrary locks, but that doesn't seem quite sufficient to get
> us out of the woods. It will at least hold ShareUpdateExclusiveLock
> on the relation being vacuumed, and process A could attempt to acquire
> that same lock.
>
As discussed [1] that this risk exists for btree, so leaving it as it
is for now.
> Also in regards to deadlock, I notice that you added a paragraph
> saying that we lock higher-numbered buckets before lower-numbered
> buckets. That's fair enough, but what about the metapage?
>
Updated README with regard to metapage as well.
The reader
> algorithm suggests that the metapage must lock must be taken after the
> bucket locks, because it tries to grab the bucket lock conditionally
> after acquiring the metapage lock, but that's not documented here.
>
> The reader algorithm itself seems to be a bit oddly explained.
>
> pin meta page and take buffer content lock in shared mode
> + compute bucket number for target hash key
> + read and pin the primary bucket page
>
> So far, I'm with you.
>
> + conditionally get the buffer content lock in shared mode on
> primary bucket page for search
> + if we didn't get the lock (need to wait for lock)
>
> "didn't get the lock" and "wait for the lock" are saying the same
> thing, so this is redundant, and the statement that it is "for search"
> on the previous line is redundant with the introductory text
> describing this as the reader algorithm.
>
> + release the buffer content lock on meta page
> + acquire buffer content lock on primary bucket page in shared mode
> + acquire the buffer content lock in shared mode on meta page
>
> OK...
>
> + to check for possibility of split, we need to recompute the bucket and
> + verify, if it is a correct bucket; set the retry flag
>
> This makes it sound like we set the retry flag whether it was the
> correct bucket or not, which isn't sensible.
>
> + else if we get the lock, then we can skip the retry path
>
> This line is totally redundant. If we don't set the retry flag, then
> of course we can skip the part guarded by if (retry).
>
> + if (retry)
> + loop:
> + compute bucket number for target hash key
> + release meta page buffer content lock
> + if (correct bucket page is already locked)
> + break
> + release any existing content lock on bucket page (if a
> concurrent split happened)
> + pin primary bucket page and take shared buffer content lock
> + retake meta page buffer content lock in shared mode
>
> This is the part I *really* don't understand. It makes sense to me
> that we need to loop until we get the correct bucket locked with no
> concurrent splits, but why is this retry loop separate from the
> previous bit of code that set the retry flag. In other words, why is
> not something like this?
>
> pin the meta page and take shared content lock on it
> compute bucket number for target hash key
> if (we can't get a shared content lock on the target bucket without blocking)
> loop:
> release meta page content lock
> take a shared content lock on the target primary bucket page
> take a shared content lock on the metapage
> if (previously-computed target bucket has not been split)
> break;
>
> Another thing I don't quite understand about this algorithm is that in
> order to conditionally lock the target primary bucket page, we'd first
> need to read and pin it. And that doesn't seem like a good thing to
> do while we're holding a shared content lock on the metapage, because
> of the principle that we don't want to hold content locks across I/O.
>
I have changed it such that we don't perform I/O across content lock,
but that needs to lock metapage twice which will hurt performance, but
we can buy back that performance with caching the metapage [2].
Updated the readme accordingly.
> -- then, per read request:
> release pin on metapage
> - read current page of bucket and take shared buffer content lock
> - step to next page if necessary (no chaining of locks)
> + if the split is in progress for current bucket and this is a new bucket
> + release the buffer content lock on current bucket page
> + pin and acquire the buffer content lock on old bucket in shared mode
> + release the buffer content lock on old bucket, but not pin
> + retake the buffer content lock on new bucket
> + mark the scan such that it skips the tuples that are marked
> as moved by split
>
> Aren't these steps done just once per scan? If so, I think they
> should appear before "-- then, per read request" which AIUI is
> intended to imply a loop over tuples.
>
> + step to next page if necessary (no chaining of locks)
> + if the scan indicates moved by split, then move to old bucket
> after the scan
> + of current bucket is finished
> get tuple
> release buffer content lock and pin on current page
> -- at scan shutdown:
> - release bucket share-lock
>
> Don't we have a pin to release at scan shutdown in the new system?
>
Already replied to this point in previous e-mail.
> Well, I was hoping to get through the whole patch in one email, but
> I'm not even all the way through the README. However, it's late, so
> I'm stopping here for now.
>
Thanks for the valuable feedback.
[1] - https://www.postgresql.org/message-id/CA%2BTgmoZWH0L%3DmEq9-7%2Bo-yogbXqDhF35nERcK4HgjCoFKVbCkA%40mail.gmail.com
[2] - https://commitfest.postgresql.org/11/715/
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Вложения
On Mon, Oct 24, 2016 at 8:00 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Sep 29, 2016 at 6:04 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Sep 28, 2016 at 3:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: > > > Thanks for the valuable feedback. > Forgot to mention that in addition to fixing the review comments, I had made an additional change to skip the dead tuple while copying tuples from old bucket to new bucket during split. This was previously not possible because split and scan were blocking operations (split used to take Exclusive lock on bucket and Scan used to hold Share lock on bucket till the operation ends), but now it is possible and during scan some of the tuples can be marked as dead. Similarly during squeeze operation, skipping dead tuples while moving tuples across buckets. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Amit, can you please split the buffer manager changes in this patch >> into a separate patch? > > Sure, attached patch extend_bufmgr_api_for_hash_index_v1.patch does that. The additional argument to ConditionalLockBuffer() doesn't seem to be used anywhere in the main patch. Do we actually need it? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Oct 28, 2016 at 2:52 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> Amit, can you please split the buffer manager changes in this patch >>> into a separate patch? >> >> Sure, attached patch extend_bufmgr_api_for_hash_index_v1.patch does that. > > The additional argument to ConditionalLockBuffer() doesn't seem to be > used anywhere in the main patch. Do we actually need it? > No, with latest patch of concurrent hash index, we don't need it. I have forgot to remove it. Please find updated patch attached. The usage of second parameter for ConditionalLockBuffer() is removed as we don't want to allow I/O across content locks, so the patch is changed to fallback to twice locking the metapage. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> [ new patches ]
I looked over parts of this today, mostly the hashinsert.c changes.
+ /*
+ * Copy bucket mapping info now; The comment in _hash_expandtable where
+ * we copy this information and calls _hash_splitbucket explains why this
+ * is OK.
+ */
So, I went and tried to find the comments to which this comment is
referring and didn't have much luck. At the point this code is
running, we have a pin but no lock on the metapage, so this is only
safe if changing any of these fields requires a cleanup lock on the
metapage. If that's true, it seems like you could just make the
comment say that; if it's false, you've got problems.
This code seems rather pointless anyway, the way it's written. All of
these local variables are used in exactly one place, which is here:
+ _hash_finish_split(rel, metabuf, buf, nbuf, maxbucket,
+ highmask, lowmask);
But you hold the same locks at the point where you copy those values
into local variables and the point where that code runs. So if the
code is safe as written, you could instead just pass
metap->hashm_maxbucket, metap->hashm_highmask, and
metap->hashm_lowmask to that function instead of having these local
variables. Or, for that matter, you could just let that function read
the data itself: it's got metabuf, after all.
+ * In future, if we want to finish the splits during insertion in new
+ * bucket, we must ensure the locking order such that old bucket is locked
+ * before new bucket.
Not if the locks are conditional anyway.
+ nblkno = _hash_get_newblk(rel, pageopaque);
I think this is not a great name for this function. It's not clear
what "new blocks" refers to, exactly. I suggest
FIND_SPLIT_BUCKET(metap, bucket) or OLD_BUCKET_TO_NEW_BUCKET(metap,
bucket) returning a new bucket number. I think that macro can be
defined as something like this: bucket + (1 <<
(fls(metap->hashm_maxbucket) - 1)). Then do nblkno =
BUCKET_TO_BLKNO(metap, newbucket) to get the block number. That'd all
be considerably simpler than what you have for hash_get_newblk().
Here's some test code I wrote, which seems to work:
#include <stdio.h>
#include <stdlib.h>
#include <strings.h>
#include <assert.h>
int
newbucket(int bucket, int nbuckets)
{
assert(bucket < nbuckets);
return bucket + (1 << (fls(nbuckets) - 1));
}
int
main(int argc, char **argv)
{
int nbuckets = 1;
int restartat = 1;
int splitbucket = 0;
while (splitbucket < 32)
{
printf("old bucket %d splits to new bucket %d\n", splitbucket,
newbucket(splitbucket, nbuckets));
if (++splitbucket >= restartat)
{
splitbucket = 0;
restartat *= 2;
}
++nbuckets;
}
exit(0);
}
Moving on ...
/*
* ovfl page exists; go get it. if it doesn't have room, we'll
- * find out next pass through the loop test above.
+ * find out next pass through the loop test above. Retain the
+ * pin, if it is a primary bucket page.
*/
- _hash_relbuf(rel, buf);
+ if (pageopaque->hasho_flag & LH_BUCKET_PAGE)
+ _hash_chgbufaccess(rel, buf, HASH_READ, HASH_NOLOCK);
+ else
+ _hash_relbuf(rel, buf);
It seems like it would be cheaper, safer, and clearer to test whether
buf != bucket_buf here, rather than examining the page opaque data.
That's what you do down at the bottom of the function when you ensure
that the pin on the primary bucket page gets released, and it seems
like it should work up here, too.
+ bool retain_pin = false;
+
+ /* page flags must be accessed before releasing lock on a page. */
+ retain_pin = pageopaque->hasho_flag & LH_BUCKET_PAGE;
Similarly.
I have also attached a patch with some suggested comment changes.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Wed, Nov 2, 2016 at 6:39 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> [ new patches ] > > I looked over parts of this today, mostly the hashinsert.c changes. > > + /* > + * Copy bucket mapping info now; The comment in _hash_expandtable where > + * we copy this information and calls _hash_splitbucket explains why this > + * is OK. > + */ > > So, I went and tried to find the comments to which this comment is > referring and didn't have much luck. > I guess you have just tried to find it in the patch. However, the comment I am referring above is an existing comment in _hash_expandtable(). Refer below comment: /* * Copy bucket mapping info now; this saves re-accessing the meta page * inside _hash_splitbucket's inner loop. ... > At the point this code is > running, we have a pin but no lock on the metapage, so this is only > safe if changing any of these fields requires a cleanup lock on the > metapage. If that's true, > No that's not true, we need just Exclusive content lock to update those fields and these fields should be copied when we have Share content lock on metapage. In version-8 of patch, it was correct, but in last version, it seems during code re-arrangement, I have moved it. I will change it such that these values are copied under matapage share content lock. I think moving it just before the preceding for loop should be okay, let me know if you think otherwise. > + nblkno = _hash_get_newblk(rel, pageopaque); > > I think this is not a great name for this function. It's not clear > what "new blocks" refers to, exactly. I suggest > FIND_SPLIT_BUCKET(metap, bucket) or OLD_BUCKET_TO_NEW_BUCKET(metap, > bucket) returning a new bucket number. I think that macro can be > defined as something like this: bucket + (1 << > (fls(metap->hashm_maxbucket) - 1)). > I think such a macro would not work for the usage of incomplete splits. The reason is that by the time we try to complete the split of the current old bucket, the table half (lowmask, highmask, maxbucket) would have changed and it could give you the bucket in new table half. > Then do nblkno = > BUCKET_TO_BLKNO(metap, newbucket) to get the block number. That'd all > be considerably simpler than what you have for hash_get_newblk(). > I think to use BUCKET_TO_BLKNO we need either a share or exclusive lock on metapage and as we need a lock on metapage to find new block from old block, I thought it is better to do inside _hash_get_newblk(). > > Moving on ... > > /* > * ovfl page exists; go get it. if it doesn't have room, we'll > - * find out next pass through the loop test above. > + * find out next pass through the loop test above. Retain the > + * pin, if it is a primary bucket page. > */ > - _hash_relbuf(rel, buf); > + if (pageopaque->hasho_flag & LH_BUCKET_PAGE) > + _hash_chgbufaccess(rel, buf, HASH_READ, HASH_NOLOCK); > + else > + _hash_relbuf(rel, buf); > > It seems like it would be cheaper, safer, and clearer to test whether > buf != bucket_buf here, rather than examining the page opaque data. > That's what you do down at the bottom of the function when you ensure > that the pin on the primary bucket page gets released, and it seems > like it should work up here, too. > > + bool retain_pin = false; > + > + /* page flags must be accessed before releasing lock on a page. */ > + retain_pin = pageopaque->hasho_flag & LH_BUCKET_PAGE; > > Similarly. > Agreed, will change the usage as per your suggestion. > I have also attached a patch with some suggested comment changes. > I will include it in next version of patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 3, 2016 at 6:25 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> + nblkno = _hash_get_newblk(rel, pageopaque); >> >> I think this is not a great name for this function. It's not clear >> what "new blocks" refers to, exactly. I suggest >> FIND_SPLIT_BUCKET(metap, bucket) or OLD_BUCKET_TO_NEW_BUCKET(metap, >> bucket) returning a new bucket number. I think that macro can be >> defined as something like this: bucket + (1 << >> (fls(metap->hashm_maxbucket) - 1)). >> > > I think such a macro would not work for the usage of incomplete > splits. The reason is that by the time we try to complete the split > of the current old bucket, the table half (lowmask, highmask, > maxbucket) would have changed and it could give you the bucket in new > table half. Can you provide an example of the scenario you are talking about here? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Oct 28, 2016 at 12:33 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Oct 28, 2016 at 2:52 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> Amit, can you please split the buffer manager changes in this patch >>>> into a separate patch? >>> >>> Sure, attached patch extend_bufmgr_api_for_hash_index_v1.patch does that. >> >> The additional argument to ConditionalLockBuffer() doesn't seem to be >> used anywhere in the main patch. Do we actually need it? >> > > No, with latest patch of concurrent hash index, we don't need it. I > have forgot to remove it. Please find updated patch attached. The > usage of second parameter for ConditionalLockBuffer() is removed as we > don't want to allow I/O across content locks, so the patch is changed > to fallback to twice locking the metapage. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Nov 1, 2016 at 9:09 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> [ new patches ]
>
> I looked over parts of this today, mostly the hashinsert.c changes.
Some more review...
@@ -656,6 +678,10 @@ _hash_squeezebucket(Relation rel,
IndexTuple itup;
Size itemsz;
+ /* skip dead tuples */
+ if (ItemIdIsDead(PageGetItemId(rpage, roffnum)))
+ continue;
Is this an optimization independent of the rest of the patch, or is
there something in this patch that necessitates it? i.e. Could this
small change be committed independently? If not, then I think it
needs a better comment explaining why it is now mandatory.
- * Caller must hold exclusive lock on the target bucket. This allows
+ * Caller must hold cleanup lock on the target bucket. This allows
* us to safely lock multiple pages in the bucket.
The notion of a lock on a bucket no longer really exists; with this
patch, we'll now properly speak of a lock on a primary bucket page.
Also, I think the bit about safely locking multiple pages is bizarre
-- that's not the issue at all: the problem is that reorganizing a
bucket might confuse concurrent scans into returning wrong answers.
I've included a broader updating of that comment, and some other
comment changes, in the attached incremental patch, which also
refactors your changes to _hash_freeovflpage() a bit to avoid some
code duplication. Please consider this for inclusion in your next
version.
In hashutil.c, I think that _hash_msb() is just a reimplementation of
fls(), which you can rely on being present because we have our own
implementation in src/port. It's quite similar to yours but slightly
shorter. :-) Also, some systems have a builtin fls() function which
actually optimizes down to a single machine instruction, and which is
therefore much faster than either version.
I don't like the fact that _hash_get_newblk() and _hash_get_oldblk()
are working out the bucket number by using the HashOpaque structure
within the bucket page they're examining. First, it seems weird to
pass the whole structure when you only need the bucket number out of
it. More importantly, the caller really ought to know what bucket
they care about without having to discover it.
For example, in _hash_doinsert(), we figure out the bucket into which
we need to insert, and we store that in a variable called "bucket".
Then from there we work out the primary bucket page's block number,
which we store in "blkno". We read the page into "buf" and put a
pointer to that buffer's contents into "page" from which we discover
the HashOpaque, a pointer to which we store into "pageopaque". Then
we pass that to _hash_get_newblk() which will go look into that
structure to find the bucket number ... but couldn't we have just
passed "bucket" instead? Similarly, _hash_expandtable() has the value
available in the variable "old_bucket".
The only caller of _hash_get_oldblk() is _hash_first(), which has the
bucket number available in a variable called "bucket".
So it seems to me that these functions could be simplified to take the
bucket number as an argument directly instead of the HashOpaque.
Generally, this pattern recurs throughout the patch. Every time you
use the data in the page to figure something out which the caller
already knew, you're introducing a risk of bugs: what if the answers
don't match? I think you should try to root out as much of that from
this code as you can.
As you may be able to tell, I'm working my way into this patch
gradually, starting with peripheral parts and working toward the core
of it. Generally, I think it's in pretty good shape, but I still have
quite a bit left to study.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Fri, Nov 4, 2016 at 6:37 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Nov 3, 2016 at 6:25 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> + nblkno = _hash_get_newblk(rel, pageopaque); >>> >>> I think this is not a great name for this function. It's not clear >>> what "new blocks" refers to, exactly. I suggest >>> FIND_SPLIT_BUCKET(metap, bucket) or OLD_BUCKET_TO_NEW_BUCKET(metap, >>> bucket) returning a new bucket number. I think that macro can be >>> defined as something like this: bucket + (1 << >>> (fls(metap->hashm_maxbucket) - 1)). >>> >> >> I think such a macro would not work for the usage of incomplete >> splits. The reason is that by the time we try to complete the split >> of the current old bucket, the table half (lowmask, highmask, >> maxbucket) would have changed and it could give you the bucket in new >> table half. > > Can you provide an example of the scenario you are talking about here? > Consider a case as below: First half of table 0 1 2 3 Second half of table 4 5 6 7 Now when split of bucket 2 (corresponding new bucket will be 6) is in progress, system crashes and after restart it splits bucket number 3 (corresponding bucket will be 7). Now after that, it will try to form a new table half with buckets ranging from 8,9,..15. Assume it creates bucket 8 by splitting from bucket 0 and next if it tries to split bucket 2, it will find an incomplete split and will attempt to finish it. At that time if it tries to calculate new bucket from old bucket (2), it will calculate it as 10 (value of metap->hashm_maxbucket will be 8 for third table half and if try it with the above macro, it will calculate it as 10) whereas we need 6. That is why you will see a check (if (new_bucket > metap->hashm_maxbucket)) in _hash_get_newblk() which will ensure that it returns the bucket number from previous half. The basic idea is that if there is an incomplete split from current bucket, it can't do a new split from that bucket, so the check in _hash_get_newblk() will give us correct value. I can try to explain again if above is not clear enough. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Nov 4, 2016 at 9:37 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Nov 1, 2016 at 9:09 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> [ new patches ] >> >> I looked over parts of this today, mostly the hashinsert.c changes. > > Some more review... > > @@ -656,6 +678,10 @@ _hash_squeezebucket(Relation rel, > IndexTuple itup; > Size itemsz; > > + /* skip dead tuples */ > + if (ItemIdIsDead(PageGetItemId(rpage, roffnum))) > + continue; > > Is this an optimization independent of the rest of the patch, or is > there something in this patch that necessitates it? > This specific case is independent of rest of patch, but the same optimization is used in function _hash_splitbucket_guts() which is mandatory, because otherwise it will make a copy of that tuple without copying dead flag. > i.e. Could this > small change be committed independently? Both the places _hash_squeezebucket() and _hash_splitbucket can use this optimization irrespective of rest of the patch. I will prepare a separate patch for these and send along with main patch after some testing. > If not, then I think it > needs a better comment explaining why it is now mandatory. > > - * Caller must hold exclusive lock on the target bucket. This allows > + * Caller must hold cleanup lock on the target bucket. This allows > * us to safely lock multiple pages in the bucket. > > The notion of a lock on a bucket no longer really exists; with this > patch, we'll now properly speak of a lock on a primary bucket page. > Also, I think the bit about safely locking multiple pages is bizarre > -- that's not the issue at all: the problem is that reorganizing a > bucket might confuse concurrent scans into returning wrong answers. > > I've included a broader updating of that comment, and some other > comment changes, in the attached incremental patch, which also > refactors your changes to _hash_freeovflpage() a bit to avoid some > code duplication. Please consider this for inclusion in your next > version. > Your modifications looks good to me, so will include it in next version. > In hashutil.c, I think that _hash_msb() is just a reimplementation of > fls(), which you can rely on being present because we have our own > implementation in src/port. It's quite similar to yours but slightly > shorter. :-) Also, some systems have a builtin fls() function which > actually optimizes down to a single machine instruction, and which is > therefore much faster than either version. > Agreed, will change as per suggestion. > I don't like the fact that _hash_get_newblk() and _hash_get_oldblk() > are working out the bucket number by using the HashOpaque structure > within the bucket page they're examining. First, it seems weird to > pass the whole structure when you only need the bucket number out of > it. More importantly, the caller really ought to know what bucket > they care about without having to discover it. > > For example, in _hash_doinsert(), we figure out the bucket into which > we need to insert, and we store that in a variable called "bucket". > Then from there we work out the primary bucket page's block number, > which we store in "blkno". We read the page into "buf" and put a > pointer to that buffer's contents into "page" from which we discover > the HashOpaque, a pointer to which we store into "pageopaque". Then > we pass that to _hash_get_newblk() which will go look into that > structure to find the bucket number ... but couldn't we have just > passed "bucket" instead? > Yes, it can be done. However, note that pageopaque is not only retrieved for passing to _hash_get_newblk(), rather it is used in below code as well, so we can't remove that. > Similarly, _hash_expandtable() has the value > available in the variable "old_bucket". > > The only caller of _hash_get_oldblk() is _hash_first(), which has the > bucket number available in a variable called "bucket". > > So it seems to me that these functions could be simplified to take the > bucket number as an argument directly instead of the HashOpaque. > Okay, I agree that it is better to use bucket number in both the API's, so will change it accordingly. > Generally, this pattern recurs throughout the patch. Every time you > use the data in the page to figure something out which the caller > already knew, you're introducing a risk of bugs: what if the answers > don't match? I think you should try to root out as much of that from > this code as you can. > Okay, I will review the patch once with this angle and see if I can improve it. > As you may be able to tell, I'm working my way into this patch > gradually, starting with peripheral parts and working toward the core > of it. Generally, I think it's in pretty good shape, but I still have > quite a bit left to study. > Thanks. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 3, 2016 at 3:55 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Nov 2, 2016 at 6:39 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Mon, Oct 24, 2016 at 10:30 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> [ new patches ] >> >> I looked over parts of this today, mostly the hashinsert.c changes. >> > >> At the point this code is >> running, we have a pin but no lock on the metapage, so this is only >> safe if changing any of these fields requires a cleanup lock on the >> metapage. If that's true, >> > > No that's not true, we need just Exclusive content lock to update > those fields and these fields should be copied when we have Share > content lock on metapage. In version-8 of patch, it was correct, but > in last version, it seems during code re-arrangement, I have moved it. > I will change it such that these values are copied under matapage > share content lock. > Fixed as mentioned. > > >> + nblkno = _hash_get_newblk(rel, pageopaque); >> >> I think this is not a great name for this function. It's not clear >> what "new blocks" refers to, exactly. I suggest >> FIND_SPLIT_BUCKET(metap, bucket) or OLD_BUCKET_TO_NEW_BUCKET(metap, >> bucket) returning a new bucket number. I think that macro can be >> defined as something like this: bucket + (1 << >> (fls(metap->hashm_maxbucket) - 1)). >> > > I think such a macro would not work for the usage of incomplete > splits. The reason is that by the time we try to complete the split > of the current old bucket, the table half (lowmask, highmask, > maxbucket) would have changed and it could give you the bucket in new > table half. > I have changed the function name to _hash_get_oldbucket_newblock() and passed the Bucket as a second parameter. > >> >> Moving on ... >> >> /* >> * ovfl page exists; go get it. if it doesn't have room, we'll >> - * find out next pass through the loop test above. >> + * find out next pass through the loop test above. Retain the >> + * pin, if it is a primary bucket page. >> */ >> - _hash_relbuf(rel, buf); >> + if (pageopaque->hasho_flag & LH_BUCKET_PAGE) >> + _hash_chgbufaccess(rel, buf, HASH_READ, HASH_NOLOCK); >> + else >> + _hash_relbuf(rel, buf); >> >> It seems like it would be cheaper, safer, and clearer to test whether >> buf != bucket_buf here, rather than examining the page opaque data. >> That's what you do down at the bottom of the function when you ensure >> that the pin on the primary bucket page gets released, and it seems >> like it should work up here, too. >> >> + bool retain_pin = false; >> + >> + /* page flags must be accessed before releasing lock on a page. */ >> + retain_pin = pageopaque->hasho_flag & LH_BUCKET_PAGE; >> >> Similarly. >> > > Agreed, will change the usage as per your suggestion. > Changed as discussed. I have changed the similar usage at few other places in patch. >> I have also attached a patch with some suggested comment changes. >> > > I will include it in next version of patch. > Included in new version of patch. >> Some more review... >> >> @@ -656,6 +678,10 @@ _hash_squeezebucket(Relation rel, >> IndexTuple itup; >> Size itemsz; >> >> + /* skip dead tuples */ >> + if (ItemIdIsDead(PageGetItemId(rpage, roffnum))) >> + continue; >> >> Is this an optimization independent of the rest of the patch, or is >> there something in this patch that necessitates it? >> > > This specific case is independent of rest of patch, but the same > optimization is used in function _hash_splitbucket_guts() which is > mandatory, because otherwise it will make a copy of that tuple without > copying dead flag. > >> i.e. Could this >> small change be committed independently? > > Both the places _hash_squeezebucket() and _hash_splitbucket can use > this optimization irrespective of rest of the patch. I will prepare a > separate patch for these and send along with main patch after some > testing. > Done as a separate patch skip_dead_tups_hash_index-v1.patch. >> If not, then I think it >> needs a better comment explaining why it is now mandatory. >> >> - * Caller must hold exclusive lock on the target bucket. This allows >> + * Caller must hold cleanup lock on the target bucket. This allows >> * us to safely lock multiple pages in the bucket. >> >> The notion of a lock on a bucket no longer really exists; with this >> patch, we'll now properly speak of a lock on a primary bucket page. >> Also, I think the bit about safely locking multiple pages is bizarre >> -- that's not the issue at all: the problem is that reorganizing a >> bucket might confuse concurrent scans into returning wrong answers. >> >> I've included a broader updating of that comment, and some other >> comment changes, in the attached incremental patch, which also >> refactors your changes to _hash_freeovflpage() a bit to avoid some >> code duplication. Please consider this for inclusion in your next >> version. >> > > Your modifications looks good to me, so will include it in next version. > Included in new version of patch. >> In hashutil.c, I think that _hash_msb() is just a reimplementation of >> fls(), which you can rely on being present because we have our own >> implementation in src/port. It's quite similar to yours but slightly >> shorter. :-) Also, some systems have a builtin fls() function which >> actually optimizes down to a single machine instruction, and which is >> therefore much faster than either version. >> > > Agreed, will change as per suggestion. > Changed as per suggestion. >> I don't like the fact that _hash_get_newblk() and _hash_get_oldblk() >> are working out the bucket number by using the HashOpaque structure >> within the bucket page they're examining. First, it seems weird to >> pass the whole structure when you only need the bucket number out of >> it. More importantly, the caller really ought to know what bucket >> they care about without having to discover it. >> >> >> So it seems to me that these functions could be simplified to take the >> bucket number as an argument directly instead of the HashOpaque. >> > > Okay, I agree that it is better to use bucket number in both the > API's, so will change it accordingly. > Changed as per suggestion. >> Generally, this pattern recurs throughout the patch. Every time you >> use the data in the page to figure something out which the caller >> already knew, you're introducing a risk of bugs: what if the answers >> don't match? I think you should try to root out as much of that from >> this code as you can. >> > > Okay, I will review the patch once with this angle and see if I can improve it. > I have reviewed and found multiple places like hashbucketcleanup(), _hash_readnext(), _hash_readprev() where such pattern was used. Changed all such places to ensure that the caller passes the information if it already has. Thanks to Ashutosh Sharma who has helped me in ensuring that the latest patches didn't introduce any concurrency hazards (by testing with pgbench at high client counts). -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Вложения
On Mon, Nov 7, 2016 at 9:51 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Both the places _hash_squeezebucket() and _hash_splitbucket can use >> this optimization irrespective of rest of the patch. I will prepare a >> separate patch for these and send along with main patch after some >> testing. > > Done as a separate patch skip_dead_tups_hash_index-v1.patch. Thanks. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Nov 7, 2016 at 9:51 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> [ new patches ]
Attached is yet another incremental patch with some suggested changes.
+ * This expects that the caller has acquired a cleanup lock on the target
+ * bucket (primary page of a bucket) and it is reponsibility of caller to
+ * release that lock.
This is confusing, because it makes it sound like we retain the lock
through the entire execution of the function, which isn't always true.
I would say that caller must acquire a cleanup lock on the target
primary bucket page before calling this function, and that on return
that page will again be write-locked. However, the lock might be
temporarily released in the meantime, which visiting overflow pages.
(Attached patch has a suggested rewrite.)
+ * During scan of overflow pages, first we need to lock the next bucket and
+ * then release the lock on current bucket. This ensures that any concurrent
+ * scan started after we start cleaning the bucket will always be behind the
+ * cleanup. Allowing scans to cross vacuum will allow it to remove tuples
+ * required for sanctity of scan.
This comment says that it's bad if other scans can pass our cleanup
scan, but it doesn't explain why. I think it's because we don't have
page-at-a-time mode yet, and cleanup might decrease the TIDs for
existing index entries. (Attached patch has a suggested rewrite, but
might need further adjustment if my understanding of the reasons is
incomplete.)
+ if (delay)
+ vacuum_delay_point();
You don't really need "delay". If we're not in a cost-accounted
VACUUM, vacuum_delay_point() just turns into CHECK_FOR_INTERRUPTS(),
which should be safe (and a good idea) regardless. (Fixed in
attached.)
+ if (callback && callback(htup, callback_state))
+ {
+ /* mark the item for deletion */
+ deletable[ndeletable++] = offno;
+ if (tuples_removed)
+ *tuples_removed += 1;
+ }
+ else if (bucket_has_garbage)
+ {
+ /* delete the tuples that are moved by split. */
+ bucket = _hash_hashkey2bucket(_hash_get_indextuple_hashkey(itup
),
+ maxbucket,
+ highmask,
+ lowmask);
+ /* mark the item for deletion */
+ if (bucket != cur_bucket)
+ {
+ /*
+ * We expect tuples to either belong to curent bucket or
+ * new_bucket. This is ensured because we don't allow
+ * further splits from bucket that contains garbage. See
+ * comments in _hash_expandtable.
+ */
+ Assert(bucket == new_bucket);
+ deletable[ndeletable++] = offno;
+ }
+ else if (num_index_tuples)
+ *num_index_tuples += 1;
+ }
+ else if (num_index_tuples)
+ *num_index_tuples += 1;
+ }
OK, a couple things here. First, it seems like we could also delete
any tuples where ItemIdIsDead, and that seems worth doing. In fact, I
think we should check it prior to invoking the callback, because it's
probably quite substantially cheaper than the callback. Second,
repeating deletable[ndeletable++] = offno and *num_index_tuples += 1
doesn't seem very clean to me; I think we should introduce a new bool
to track whether we're keeping the tuple or killing it, and then use
that to drive which of those things we do. (Fixed in attached.)
+ if (H_HAS_GARBAGE(bucket_opaque) &&
+ !H_INCOMPLETE_SPLIT(bucket_opaque))
This is the only place in the entire patch that use
H_INCOMPLETE_SPLIT(), and I'm wondering if that's really correct even
here. Don't you really want H_OLD_INCOMPLETE_SPLIT() here? (And
couldn't we then remove H_INCOMPLETE_SPLIT() itself?) There's no
garbage to be removed from the "new" bucket until the next split, when
it will take on the role of the "old" bucket.
I think it would be a good idea to change this so that
LH_BUCKET_PAGE_HAS_GARBAGE doesn't get set until
LH_BUCKET_OLD_PAGE_SPLIT is cleared. The current way is confusing,
because those tuples are NOT garbage until the split is completed!
Moreover, both of the places that care about
LH_BUCKET_PAGE_HAS_GARBAGE need to make sure that
LH_BUCKET_OLD_PAGE_SPLIT is clear before they do anything about
LH_BUCKET_PAGE_HAS_GARBAGE, so the change I am proposing would
actually simplify the code very slightly.
+#define H_OLD_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
LH_BUCKET_OLD_PAGE_SPLIT)
+#define H_NEW_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
LH_BUCKET_NEW_PAGE_SPLIT)
The code isn't consistent about the use of these macros, or at least
not in a good way. When you care about LH_BUCKET_OLD_PAGE_SPLIT, you
test it using the macro; when you care about H_NEW_INCOMPLETE_SPLIT,
you ignore the macro and test it directly. Either get rid of both
macros and always test directly, or keep both macros and use both of
them. Using a macro for one but not the other is strange.
I wonder if we should rename these flags and macros. Maybe
LH_BUCKET_OLD_PAGE_SPLIT -> LH_BEING_SPLIT and
LH_BUCKET_NEW_PAGE_SPLIT -> LH_BEING_POPULATED. I think that might be
clearer. When LH_BEING_POPULATED is set, the bucket is being filled -
that is, populated - from the old bucket. And maybe
LH_BUCKET_PAGE_HAS_GARBAGE -> LH_NEEDS_SPLIT_CLEANUP, too.
+ * Copy bucket mapping info now; The comment in _hash_expandtable
+ * where we copy this information and calls _hash_splitbucket explains
+ * why this is OK.
After a semicolon, the next word should not be capitalized. There
shouldn't be two spaces after a semicolon, either. Also,
_hash_splitbucket appears to have a verb before it (calls) and a verb
after it (explains) and I have no idea what that means.
+ for (;;)
+ {
+ mask = lowmask + 1;
+ new_bucket = old_bucket | mask;
+ if (new_bucket > metap->hashm_maxbucket)
+ {
+ lowmask = lowmask >> 1;
+ continue;
+ }
+ blkno = BUCKET_TO_BLKNO(metap, new_bucket);
+ break;
+ }
I can't help feeling that it should be possible to do this without
looping. Can we ever loop more than once? How? Can we just use an
if-then instead of a for-loop?
Can't _hash_get_oldbucket_newblock call _hash_get_oldbucket_newbucket
instead of duplicating the logic?
I still don't like the names of these functions very much. If you
said "get X from Y", it would be clear that you put in Y and you get
out X. If you say "X 2 Y", it would be clear that you put in X and
you get out Y. As it is, it's not very clear which is the input and
which is the output.
+ bool primary_buc_page)
I think we could just go with "primary_page" here. (Fixed in attached.)
+ /*
+ * Acquiring cleanup lock to clear the split-in-progress flag ensures that
+ * there is no pending scan that has seen the flag after it is cleared.
+ */
+ _hash_chgbufaccess(rel, bucket_obuf, HASH_NOLOCK, HASH_WRITE);
+ opage = BufferGetPage(bucket_obuf);
+ oopaque = (HashPageOpaque) PageGetSpecialPointer(opage);
I don't understand the comment, because the code *isn't* acquiring a
cleanup lock.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Wed, Nov 9, 2016 at 1:23 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Nov 7, 2016 at 9:51 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> [ new patches ]
>
> Attached is yet another incremental patch with some suggested changes.
>
> + * This expects that the caller has acquired a cleanup lock on the target
> + * bucket (primary page of a bucket) and it is reponsibility of caller to
> + * release that lock.
>
> This is confusing, because it makes it sound like we retain the lock
> through the entire execution of the function, which isn't always true.
> I would say that caller must acquire a cleanup lock on the target
> primary bucket page before calling this function, and that on return
> that page will again be write-locked. However, the lock might be
> temporarily released in the meantime, which visiting overflow pages.
> (Attached patch has a suggested rewrite.)
>
+ * This function expects that the caller has acquired a cleanup lock on the
+ * primary bucket page, and will with a write lock again held on the primary
+ * bucket page. The lock won't necessarily be held continuously, though,
+ * because we'll release it when visiting overflow pages.
Looks like typo in above comment. /will with a write lock/will
return with a write lock
> + * During scan of overflow pages, first we need to lock the next bucket and
> + * then release the lock on current bucket. This ensures that any concurrent
> + * scan started after we start cleaning the bucket will always be behind the
> + * cleanup. Allowing scans to cross vacuum will allow it to remove tuples
> + * required for sanctity of scan.
>
> This comment says that it's bad if other scans can pass our cleanup
> scan, but it doesn't explain why. I think it's because we don't have
> page-at-a-time mode yet,
>
Right.
> and cleanup might decrease the TIDs for
> existing index entries.
>
I think the reason is that cleanup might move tuples around during
which it might move previously returned TID to a position earlier than
its current position. This is a problem because it restarts the scan
from previously returned offset and try to find previously returned
tuples TID. This has been mentioned in README as below:
+ It is must to
+keep scans behind cleanup, else vacuum could remove tuples that are required
+to complete the scan as the scan that returns multiple tuples from the same
+bucket page always restart the scan from the previous offset number from which
+it has returned last tuple.
We might want to slightly improve the README so that the reason is
more clear and then mention in comments to refer README, but I am open
either way, let me know which way you prefer?
>
> + if (delay)
> + vacuum_delay_point();
>
> You don't really need "delay". If we're not in a cost-accounted
> VACUUM, vacuum_delay_point() just turns into CHECK_FOR_INTERRUPTS(),
> which should be safe (and a good idea) regardless. (Fixed in
> attached.)
>
Okay, that makes sense.
> + if (callback && callback(htup, callback_state))
> + {
> + /* mark the item for deletion */
> + deletable[ndeletable++] = offno;
> + if (tuples_removed)
> + *tuples_removed += 1;
> + }
> + else if (bucket_has_garbage)
> + {
> + /* delete the tuples that are moved by split. */
> + bucket = _hash_hashkey2bucket(_hash_get_indextuple_hashkey(itup
> ),
> + maxbucket,
> + highmask,
> + lowmask);
> + /* mark the item for deletion */
> + if (bucket != cur_bucket)
> + {
> + /*
> + * We expect tuples to either belong to curent bucket or
> + * new_bucket. This is ensured because we don't allow
> + * further splits from bucket that contains garbage. See
> + * comments in _hash_expandtable.
> + */
> + Assert(bucket == new_bucket);
> + deletable[ndeletable++] = offno;
> + }
> + else if (num_index_tuples)
> + *num_index_tuples += 1;
> + }
> + else if (num_index_tuples)
> + *num_index_tuples += 1;
> + }
>
> OK, a couple things here. First, it seems like we could also delete
> any tuples where ItemIdIsDead, and that seems worth doing.
I think we can't do that because here we want to strictly rely on
callback function for vacuum similar to btree. The reason is explained
as below comment in function btvacuumpage().
/*
* During Hot Standby we currently assume that
* XLOG_BTREE_VACUUM records do not produce conflicts. That is
* only true as long as the callback function depends only
* upon whether the index tuple refers to heap tuples removed
* in the initial heap scan. ...
..
> In fact, I
> think we should check it prior to invoking the callback, because it's
> probably quite substantially cheaper than the callback. Second,
> repeating deletable[ndeletable++] = offno and *num_index_tuples += 1
> doesn't seem very clean to me; I think we should introduce a new bool
> to track whether we're keeping the tuple or killing it, and then use
> that to drive which of those things we do. (Fixed in attached.)
>
This looks okay to me. So if you agree with my reasoning for not
including first part, then I can take that out and keep this part in
next patch.
> + if (H_HAS_GARBAGE(bucket_opaque) &&
> + !H_INCOMPLETE_SPLIT(bucket_opaque))
>
> This is the only place in the entire patch that use
> H_INCOMPLETE_SPLIT(), and I'm wondering if that's really correct even
> here. Don't you really want H_OLD_INCOMPLETE_SPLIT() here? (And
> couldn't we then remove H_INCOMPLETE_SPLIT() itself?)
You are right. Will remove it in next version.
>
> I think it would be a good idea to change this so that
> LH_BUCKET_PAGE_HAS_GARBAGE doesn't get set until
> LH_BUCKET_OLD_PAGE_SPLIT is cleared. The current way is confusing,
> because those tuples are NOT garbage until the split is completed!
> Moreover, both of the places that care about
> LH_BUCKET_PAGE_HAS_GARBAGE need to make sure that
> LH_BUCKET_OLD_PAGE_SPLIT is clear before they do anything about
> LH_BUCKET_PAGE_HAS_GARBAGE, so the change I am proposing would
> actually simplify the code very slightly.
>
Not an issue. We can do that way.
> +#define H_OLD_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
> LH_BUCKET_OLD_PAGE_SPLIT)
> +#define H_NEW_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
> LH_BUCKET_NEW_PAGE_SPLIT)
>
> The code isn't consistent about the use of these macros, or at least
> not in a good way. When you care about LH_BUCKET_OLD_PAGE_SPLIT, you
> test it using the macro; when you care about H_NEW_INCOMPLETE_SPLIT,
> you ignore the macro and test it directly. Either get rid of both
> macros and always test directly, or keep both macros and use both of
> them. Using a macro for one but not the other is strange.
>
I will like to use a macro at both places.
> I wonder if we should rename these flags and macros. Maybe
> LH_BUCKET_OLD_PAGE_SPLIT -> LH_BEING_SPLIT and
> LH_BUCKET_NEW_PAGE_SPLIT -> LH_BEING_POPULATED.
>
I think keeping BUCKET (LH_BUCKET_*) in define indicates in some way
about the type of page being split. Hash index has multiple type of
pages. That seems to be taken care in existing defines as below.
#define LH_OVERFLOW_PAGE (1 << 0)
#define LH_BUCKET_PAGE (1 << 1)
#define LH_BITMAP_PAGE (1 << 2)
#define LH_META_PAGE (1 << 3)
> I think that might be
> clearer. When LH_BEING_POPULATED is set, the bucket is being filled -
> that is, populated - from the old bucket.
>
How about LH_BUCKET_BEING_POPULATED or may LH_BP_BEING_SPLIT where BP
indicates Bucket page?
I think keeping Split work in these defines might make more sense like
LH_BP_SPLIT_OLD/LH_BP_SPLIT_FORM_NEW.
> And maybe
> LH_BUCKET_PAGE_HAS_GARBAGE -> LH_NEEDS_SPLIT_CLEANUP, too.
>
How about LH_BUCKET_NEEDS_SPLIT_CLEANUP or LH_BP_NEEDS_SPLIT_CLEANUP?
I am slightly inclined to keep Bucket word, but let me know if you
think it will make the length longer.
> + * Copy bucket mapping info now; The comment in _hash_expandtable
> + * where we copy this information and calls _hash_splitbucket explains
> + * why this is OK.
>
> After a semicolon, the next word should not be capitalized. There
> shouldn't be two spaces after a semicolon, either.
>
Will fix.
> Also,
> _hash_splitbucket appears to have a verb before it (calls) and a verb
> after it (explains) and I have no idea what that means.
>
I think conjuction is required there. Let me try to rewrite as below:
refer the comment in _hash_expandtable where we copy this information
before calling _hash_splitbucket to see why this is ok.
If you have better words to explain it, then let me know.
> + for (;;)
> + {
> + mask = lowmask + 1;
> + new_bucket = old_bucket | mask;
> + if (new_bucket > metap->hashm_maxbucket)
> + {
> + lowmask = lowmask >> 1;
> + continue;
> + }
> + blkno = BUCKET_TO_BLKNO(metap, new_bucket);
> + break;
> + }
>
> I can't help feeling that it should be possible to do this without
> looping. Can we ever loop more than once?
>
No.
> How? Can we just use an
> if-then instead of a for-loop?
>
I could see below two possibilities:
First way -
retry:
mask = lowmask + 1;
new_bucket = old_bucket | mask;
if (new_bucket > maxbucket)
{
lowmask = lowmask >> 1;
goto retry;
}
Second way -
new_bucket = CALC_NEW_BUCKET(old_bucket,lowmask);
if (new_bucket > maxbucket)
{
lowmask = lowmask >> 1;
new_bucket = CALC_NEW_BUCKET(old_bucket, lowmask);
}
#define CALC_NEW_BUCKET(old_bucket, lowmask) \
new_bucket = old_bucket | (lowmask + 1)
Do you have something else in mind?
> Can't _hash_get_oldbucket_newblock call _hash_get_oldbucket_newbucket
> instead of duplicating the logic?
>
Will change in next version of patch.
> I still don't like the names of these functions very much. If you
> said "get X from Y", it would be clear that you put in Y and you get
> out X. If you say "X 2 Y", it would be clear that you put in X and
> you get out Y. As it is, it's not very clear which is the input and
> which is the output.
>
Whatever exists earlier is input and the later one is output. For
example in existing function _hash_get_indextuple_hashkey(). However,
feel free to suggest better names here. How about
_hash_get_oldbucket2newblock() or _hash_get_newblock_from_oldbucket()
or simply _hash_get_newblock()?
> + /*
> + * Acquiring cleanup lock to clear the split-in-progress flag ensures that
> + * there is no pending scan that has seen the flag after it is cleared.
> + */
> + _hash_chgbufaccess(rel, bucket_obuf, HASH_NOLOCK, HASH_WRITE);
> + opage = BufferGetPage(bucket_obuf);
> + oopaque = (HashPageOpaque) PageGetSpecialPointer(opage);
>
> I don't understand the comment, because the code *isn't* acquiring a
> cleanup lock.
>
Oops, this is ramnant from one of the design approach to clear these
flags which was later discarded due to issues. I will change this to
indicate Exclusive lock.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Wed, Nov 9, 2016 at 9:04 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> + * This function expects that the caller has acquired a cleanup lock on the
> + * primary bucket page, and will with a write lock again held on the primary
> + * bucket page. The lock won't necessarily be held continuously, though,
> + * because we'll release it when visiting overflow pages.
>
> Looks like typo in above comment. /will with a write lock/will
> return with a write lock
Oh, yes. Thanks.
>> + * During scan of overflow pages, first we need to lock the next bucket and
>> + * then release the lock on current bucket. This ensures that any concurrent
>> + * scan started after we start cleaning the bucket will always be behind the
>> + * cleanup. Allowing scans to cross vacuum will allow it to remove tuples
>> + * required for sanctity of scan.
>>
>> This comment says that it's bad if other scans can pass our cleanup
>> scan, but it doesn't explain why. I think it's because we don't have
>> page-at-a-time mode yet,
>>
>
> Right.
>
>> and cleanup might decrease the TIDs for
>> existing index entries.
>>
>
> I think the reason is that cleanup might move tuples around during
> which it might move previously returned TID to a position earlier than
> its current position. This is a problem because it restarts the scan
> from previously returned offset and try to find previously returned
> tuples TID. This has been mentioned in README as below:
>
> + It is must to
> +keep scans behind cleanup, else vacuum could remove tuples that are required
> +to complete the scan as the scan that returns multiple tuples from the same
> +bucket page always restart the scan from the previous offset number from which
> +it has returned last tuple.
>
> We might want to slightly improve the README so that the reason is
> more clear and then mention in comments to refer README, but I am open
> either way, let me know which way you prefer?
I think we can give a brief explanation right in the code comment. I
referred to "decreasing the TIDs"; you are referring to "moving tuples
around". But I think that moving the tuples to different locations is
not the problem. I think the problem is that a tuple might be
assigned a lower spot in the item pointer array - i.e. the TID
decreases.
>> OK, a couple things here. First, it seems like we could also delete
>> any tuples where ItemIdIsDead, and that seems worth doing.
>
> I think we can't do that because here we want to strictly rely on
> callback function for vacuum similar to btree. The reason is explained
> as below comment in function btvacuumpage().
OK, I see. It would probably be good to comment this, then, so that
someone later doesn't get confused as I did.
> This looks okay to me. So if you agree with my reasoning for not
> including first part, then I can take that out and keep this part in
> next patch.
Cool.
>> I think that might be
>> clearer. When LH_BEING_POPULATED is set, the bucket is being filled -
>> that is, populated - from the old bucket.
>
> How about LH_BUCKET_BEING_POPULATED or may LH_BP_BEING_SPLIT where BP
> indicates Bucket page?
LH_BUCKET_BEING_POPULATED seems good to me.
>> And maybe
>> LH_BUCKET_PAGE_HAS_GARBAGE -> LH_NEEDS_SPLIT_CLEANUP, too.
>>
>
> How about LH_BUCKET_NEEDS_SPLIT_CLEANUP or LH_BP_NEEDS_SPLIT_CLEANUP?
> I am slightly inclined to keep Bucket word, but let me know if you
> think it will make the length longer.
LH_BUCKET_NEEDS_SPLIT_CLEANUP seems good to me.
>> How? Can we just use an
>> if-then instead of a for-loop?
>
> I could see below two possibilities:
> First way -
>
> retry:
> mask = lowmask + 1;
> new_bucket = old_bucket | mask;
> if (new_bucket > maxbucket)
> {
> lowmask = lowmask >> 1;
> goto retry;
> }
>
> Second way -
> new_bucket = CALC_NEW_BUCKET(old_bucket,lowmask);
> if (new_bucket > maxbucket)
> {
> lowmask = lowmask >> 1;
> new_bucket = CALC_NEW_BUCKET(old_bucket, lowmask);
> }
>
> #define CALC_NEW_BUCKET(old_bucket, lowmask) \
> new_bucket = old_bucket | (lowmask + 1)
>
> Do you have something else in mind?
Second one would be my preference.
>> I still don't like the names of these functions very much. If you
>> said "get X from Y", it would be clear that you put in Y and you get
>> out X. If you say "X 2 Y", it would be clear that you put in X and
>> you get out Y. As it is, it's not very clear which is the input and
>> which is the output.
>
> Whatever exists earlier is input and the later one is output. For
> example in existing function _hash_get_indextuple_hashkey(). However,
> feel free to suggest better names here. How about
> _hash_get_oldbucket2newblock() or _hash_get_newblock_from_oldbucket()
> or simply _hash_get_newblock()?
The problem with _hash_get_newblock() is that it sounds like you are
getting a new block in the relation, not the new bucket (or
corresponding block) for some old bucket. The name isn't specific
enough to know what "new" means.
In general, I think "new" and "old" are not very good terminology
here. It's not entirely intuitive what they mean, and as soon as it
becomes unclear that you are speaking of something happening *in the
context of a bucket split* then it becomes much less clear. I don't
really have any ideas here that are altogether good; either of your
other two suggestions (not _hash_get_newblock()) seem OK.
>> + /*
>> + * Acquiring cleanup lock to clear the split-in-progress flag ensures that
>> + * there is no pending scan that has seen the flag after it is cleared.
>> + */
>> + _hash_chgbufaccess(rel, bucket_obuf, HASH_NOLOCK, HASH_WRITE);
>> + opage = BufferGetPage(bucket_obuf);
>> + oopaque = (HashPageOpaque) PageGetSpecialPointer(opage);
>>
>> I don't understand the comment, because the code *isn't* acquiring a
>> cleanup lock.
>
> Oops, this is ramnant from one of the design approach to clear these
> flags which was later discarded due to issues. I will change this to
> indicate Exclusive lock.
Of course, an exclusive lock doesn't guarantee anything like that...
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Nov 9, 2016 at 9:10 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Nov 9, 2016 at 9:04 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > > I think we can give a brief explanation right in the code comment. I > referred to "decreasing the TIDs"; you are referring to "moving tuples > around". But I think that moving the tuples to different locations is > not the problem. I think the problem is that a tuple might be > assigned a lower spot in the item pointer array > I think we both understand the problem and it is just matter of using different words. I will go with your suggestion and will try to slightly adjust the README as well so that both places use same terminology. >>> + /* >>> + * Acquiring cleanup lock to clear the split-in-progress flag ensures that >>> + * there is no pending scan that has seen the flag after it is cleared. >>> + */ >>> + _hash_chgbufaccess(rel, bucket_obuf, HASH_NOLOCK, HASH_WRITE); >>> + opage = BufferGetPage(bucket_obuf); >>> + oopaque = (HashPageOpaque) PageGetSpecialPointer(opage); >>> >>> I don't understand the comment, because the code *isn't* acquiring a >>> cleanup lock. >> >> Oops, this is ramnant from one of the design approach to clear these >> flags which was later discarded due to issues. I will change this to >> indicate Exclusive lock. > > Of course, an exclusive lock doesn't guarantee anything like that... > Right, but we don't need that guarantee (there is no pending scan that has seen the flag after it is cleared) to clear the flags. It was written in one of the previous patches where I was exploring the idea of using cleanup lock to clear the flags and then don't use the same during vacuum. However, there were some problems in that design and I have changed the code, but forgot to update the comment. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Nov 9, 2016 at 11:41 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Nov 9, 2016 at 9:10 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Nov 9, 2016 at 9:04 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I think we can give a brief explanation right in the code comment. I >> referred to "decreasing the TIDs"; you are referring to "moving tuples >> around". But I think that moving the tuples to different locations is >> not the problem. I think the problem is that a tuple might be >> assigned a lower spot in the item pointer array > > I think we both understand the problem and it is just matter of using > different words. I will go with your suggestion and will try to > slightly adjust the README as well so that both places use same > terminology. Yes, I think we're on the same page. > Right, but we don't need that guarantee (there is no pending scan that > has seen the flag after it is cleared) to clear the flags. It was > written in one of the previous patches where I was exploring the idea > of using cleanup lock to clear the flags and then don't use the same > during vacuum. However, there were some problems in that design and I > have changed the code, but forgot to update the comment. OK, got it, thanks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Nov 9, 2016 at 12:11 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Wed, Nov 9, 2016 at 11:41 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> On Wed, Nov 9, 2016 at 9:10 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>>> On Wed, Nov 9, 2016 at 9:04 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>> I think we can give a brief explanation right in the code comment. I
>>> referred to "decreasing the TIDs"; you are referring to "moving tuples
>>> around". But I think that moving the tuples to different locations is
>>> not the problem. I think the problem is that a tuple might be
>>> assigned a lower spot in the item pointer array
>>
>> I think we both understand the problem and it is just matter of using
>> different words. I will go with your suggestion and will try to
>> slightly adjust the README as well so that both places use same
>> terminology.
>
> Yes, I think we're on the same page.
Some more review:
The API contract of _hash_finish_split seems a bit unfortunate. The
caller is supposed to have obtained a cleanup lock on both the old and
new buffers, but the first thing it does is walk the entire new bucket
chain, completely ignoring the old one. That means holding a cleanup
lock on the old buffer across an unbounded number of I/O operations --
which also means that you can't interrupt the query by pressing ^C,
because an LWLock (on the old buffer) is held. Moreover, the
requirement to hold a lock on the new buffer isn't convenient for
either caller; they both have to go do it, so why not move it into the
function? Perhaps the function should be changed so that it
guarantees that a pin is held on the primary page of the existing
bucket, but no locks are held.
Where _hash_finish_split does LockBufferForCleanup(bucket_nbuf),
should it instead be trying to get the lock conditionally and
returning immediately if it doesn't get the lock? Seems like a good
idea...
* We're at the end of the old bucket chain, so we're done partitioning * the tuples. Mark the old and new
bucketsto indicate split is * finished. * * To avoid deadlocks due to locking order of buckets, first lock the
old * bucket and then the new bucket.
These comments have drifted too far from the code to which they refer.
The first part is basically making the same point as the
slightly-later comment /* indicate that split is finished */.
The use of _hash_relbuf, _hash_wrtbuf, and _hash_chgbufaccess is
coming to seem like a horrible idea to me. That's not your fault - it
was like this before - but maybe in a followup patch we should
consider ripping all of that out and just calling MarkBufferDirty(),
ReleaseBuffer(), LockBuffer(), UnlockBuffer(), and/or
UnlockReleaseBuffer() as appropriate. As far as I can see, the
current style is just obfuscating the code.
itupsize = new_itup->t_info & INDEX_SIZE_MASK; new_itup->t_info &= ~INDEX_SIZE_MASK;
new_itup->t_info |= INDEX_MOVED_BY_SPLIT_MASK; new_itup->t_info |= itupsize;
If I'm not mistaken, you could omit the first, second, and fourth
lines here and keep only the third one, and it would do exactly the
same thing. The first line saves the bits in INDEX_SIZE_MASK. The
second line clears the bits in INDEX_SIZE_MASK. The fourth line
re-sets the bits that were originally saved.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Nov 10, 2016 at 2:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: > > Some more review: > > The API contract of _hash_finish_split seems a bit unfortunate. The > caller is supposed to have obtained a cleanup lock on both the old and > new buffers, but the first thing it does is walk the entire new bucket > chain, completely ignoring the old one. That means holding a cleanup > lock on the old buffer across an unbounded number of I/O operations -- > which also means that you can't interrupt the query by pressing ^C, > because an LWLock (on the old buffer) is held. > I see the problem you are talking about, but it was done to ensure locking order, old bucket first and then new bucket, else there could be a deadlock risk. However, I think we can avoid holding the cleanup lock on old bucket till we scan the new bucket to form a hash table of TIDs. > Moreover, the > requirement to hold a lock on the new buffer isn't convenient for > either caller; they both have to go do it, so why not move it into the > function? > Yeah, we can move the locking of new bucket entirely into new function. > Perhaps the function should be changed so that it > guarantees that a pin is held on the primary page of the existing > bucket, but no locks are held. > Okay, so we can change the locking order as follows: a. ensure a cleanup lock on old bucket and check if the bucket (old) has pending split. b. if there is a pending split, release the lock on old bucket, but not pin. below steps will be performed by _hash_finish_split(): c. acquire the read content lock on new bucket and form the hash table of TIDs and in the process of forming hash table, we need to traverse whole bucket chain. While traversing bucket chain, release the lock on previous bucket (both lock and pin if not a primary bucket page). d. After the hash table is formed, acquire cleanup lock on old and new buckets conditionaly; if we are not able to get cleanup lock on either, then just return from there. e. Perform split operation. f. release the lock and pin on new bucket g. release the lock on old bucket. We don't want to release the pin on old bucket as the caller has ensure it before passing it to _hash_finish_split(), so releasing pin should be resposibility of caller. Now, both the callers need to ensure that they restart the operation from begining as after we release lock on old bucket, somebody might have split the bucket. Does the above change in locking strategy sounds okay? > Where _hash_finish_split does LockBufferForCleanup(bucket_nbuf), > should it instead be trying to get the lock conditionally and > returning immediately if it doesn't get the lock? Seems like a good > idea... > Yeah, we can take a cleanup lock conditionally, but it would waste the effort of forming hash table, if we don't get cleanup lock immediately. Considering incomplete splits to be a rare operation, may be this the wasted effort is okay, but I am not sure. Don't you think we should avoid that effort? > * We're at the end of the old bucket chain, so we're done partitioning > * the tuples. Mark the old and new buckets to indicate split is > * finished. > * > * To avoid deadlocks due to locking order of buckets, first lock the old > * bucket and then the new bucket. > > These comments have drifted too far from the code to which they refer. > The first part is basically making the same point as the > slightly-later comment /* indicate that split is finished */. > I think we can remove the second comment /* indicate that split is finished */. Apart from that, I think the above comment you have quoted seems to be inline with current code. At that point, we have finished partitioning the tuples, so I don't understand what makes you think that it is drifted from the code? Is it because of second part of comment (To avoid deadlocks ...)? If so, I think we can move it to few lines down where we actually performs the locking on old and new bucket? > The use of _hash_relbuf, _hash_wrtbuf, and _hash_chgbufaccess is > coming to seem like a horrible idea to me. That's not your fault - it > was like this before - but maybe in a followup patch we should > consider ripping all of that out and just calling MarkBufferDirty(), > ReleaseBuffer(), LockBuffer(), UnlockBuffer(), and/or > UnlockReleaseBuffer() as appropriate. As far as I can see, the > current style is just obfuscating the code. > Okay, we can do some study and try to change it in the way you are suggesting. It seems partially this has been derived from btree code where we have function _bt_relbuf(). I am sure that we don't need _hash_wrtbuf after WAL patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Nov 9, 2016 at 1:23 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Mon, Nov 7, 2016 at 9:51 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> [ new patches ]
>
> Attached is yet another incremental patch with some suggested changes.
>
> + * This expects that the caller has acquired a cleanup lock on the target
> + * bucket (primary page of a bucket) and it is reponsibility of caller to
> + * release that lock.
>
> This is confusing, because it makes it sound like we retain the lock
> through the entire execution of the function, which isn't always true.
> I would say that caller must acquire a cleanup lock on the target
> primary bucket page before calling this function, and that on return
> that page will again be write-locked. However, the lock might be
> temporarily released in the meantime, which visiting overflow pages.
> (Attached patch has a suggested rewrite.)
>
> + * During scan of overflow pages, first we need to lock the next bucket and
> + * then release the lock on current bucket. This ensures that any concurrent
> + * scan started after we start cleaning the bucket will always be behind the
> + * cleanup. Allowing scans to cross vacuum will allow it to remove tuples
> + * required for sanctity of scan.
>
> This comment says that it's bad if other scans can pass our cleanup
> scan, but it doesn't explain why. I think it's because we don't have
> page-at-a-time mode yet, and cleanup might decrease the TIDs for
> existing index entries. (Attached patch has a suggested rewrite, but
> might need further adjustment if my understanding of the reasons is
> incomplete.)
>
Okay, I have included your changes with minor typo fix and updated
README to use similar language.
> + if (delay)
> + vacuum_delay_point();
>
> You don't really need "delay". If we're not in a cost-accounted
> VACUUM, vacuum_delay_point() just turns into CHECK_FOR_INTERRUPTS(),
> which should be safe (and a good idea) regardless. (Fixed in
> attached.)
>
New patch contains this fix.
> + if (callback && callback(htup, callback_state))
> + {
> + /* mark the item for deletion */
> + deletable[ndeletable++] = offno;
> + if (tuples_removed)
> + *tuples_removed += 1;
> + }
> + else if (bucket_has_garbage)
> + {
> + /* delete the tuples that are moved by split. */
> + bucket = _hash_hashkey2bucket(_hash_get_indextuple_hashkey(itup
> ),
> + maxbucket,
> + highmask,
> + lowmask);
> + /* mark the item for deletion */
> + if (bucket != cur_bucket)
> + {
> + /*
> + * We expect tuples to either belong to curent bucket or
> + * new_bucket. This is ensured because we don't allow
> + * further splits from bucket that contains garbage. See
> + * comments in _hash_expandtable.
> + */
> + Assert(bucket == new_bucket);
> + deletable[ndeletable++] = offno;
> + }
> + else if (num_index_tuples)
> + *num_index_tuples += 1;
> + }
> + else if (num_index_tuples)
> + *num_index_tuples += 1;
> + }
>
> OK, a couple things here. First, it seems like we could also delete
> any tuples where ItemIdIsDead, and that seems worth doing. In fact, I
> think we should check it prior to invoking the callback, because it's
> probably quite substantially cheaper than the callback. Second,
> repeating deletable[ndeletable++] = offno and *num_index_tuples += 1
> doesn't seem very clean to me; I think we should introduce a new bool
> to track whether we're keeping the tuple or killing it, and then use
> that to drive which of those things we do. (Fixed in attached.)
>
As discussed up thread, I have included your changes apart from the
change related to ItemIsDead.
> + if (H_HAS_GARBAGE(bucket_opaque) &&
> + !H_INCOMPLETE_SPLIT(bucket_opaque))
>
> This is the only place in the entire patch that use
> H_INCOMPLETE_SPLIT(), and I'm wondering if that's really correct even
> here. Don't you really want H_OLD_INCOMPLETE_SPLIT() here? (And
> couldn't we then remove H_INCOMPLETE_SPLIT() itself?) There's no
> garbage to be removed from the "new" bucket until the next split, when
> it will take on the role of the "old" bucket.
>
Fixed.
> I think it would be a good idea to change this so that
> LH_BUCKET_PAGE_HAS_GARBAGE doesn't get set until
> LH_BUCKET_OLD_PAGE_SPLIT is cleared. The current way is confusing,
> because those tuples are NOT garbage until the split is completed!
> Moreover, both of the places that care about
> LH_BUCKET_PAGE_HAS_GARBAGE need to make sure that
> LH_BUCKET_OLD_PAGE_SPLIT is clear before they do anything about
> LH_BUCKET_PAGE_HAS_GARBAGE, so the change I am proposing would
> actually simplify the code very slightly.
>
Yeah, I have changed as per above suggestion. However, I think with
this change we can only check for garbage flag during vacuum. For
now, I am checking both incomplete split and garbage flag in the
vacuum just to be extra sure, but if you also feel that we can remove
the incomplete split check, then I will do so.
> +#define H_OLD_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
> LH_BUCKET_OLD_PAGE_SPLIT)
> +#define H_NEW_INCOMPLETE_SPLIT(opaque) ((opaque)->hasho_flag &
> LH_BUCKET_NEW_PAGE_SPLIT)
>
> The code isn't consistent about the use of these macros, or at least
> not in a good way. When you care about LH_BUCKET_OLD_PAGE_SPLIT, you
> test it using the macro; when you care about H_NEW_INCOMPLETE_SPLIT,
> you ignore the macro and test it directly. Either get rid of both
> macros and always test directly, or keep both macros and use both of
> them. Using a macro for one but not the other is strange.
>
Used macro for both.
> I wonder if we should rename these flags and macros. Maybe
> LH_BUCKET_OLD_PAGE_SPLIT -> LH_BEING_SPLIT and
> LH_BUCKET_NEW_PAGE_SPLIT -> LH_BEING_POPULATED. I think that might be
> clearer. When LH_BEING_POPULATED is set, the bucket is being filled -
> that is, populated - from the old bucket. And maybe
> LH_BUCKET_PAGE_HAS_GARBAGE -> LH_NEEDS_SPLIT_CLEANUP, too.
>
Changed the names as per discussion up thread.
> + * Copy bucket mapping info now; The comment in _hash_expandtable
> + * where we copy this information and calls _hash_splitbucket explains
> + * why this is OK.
>
> After a semicolon, the next word should not be capitalized. There
> shouldn't be two spaces after a semicolon, either. Also,
> _hash_splitbucket appears to have a verb before it (calls) and a verb
> after it (explains) and I have no idea what that means.
>
Fixed.
> + for (;;)
> + {
> + mask = lowmask + 1;
> + new_bucket = old_bucket | mask;
> + if (new_bucket > metap->hashm_maxbucket)
> + {
> + lowmask = lowmask >> 1;
> + continue;
> + }
> + blkno = BUCKET_TO_BLKNO(metap, new_bucket);
> + break;
> + }
>
> I can't help feeling that it should be possible to do this without
> looping. Can we ever loop more than once? How? Can we just use an
> if-then instead of a for-loop?
>
> Can't _hash_get_oldbucket_newblock call _hash_get_oldbucket_newbucket
> instead of duplicating the logic?
>
Changed as per discussion up thread.
> I still don't like the names of these functions very much. If you
> said "get X from Y", it would be clear that you put in Y and you get
> out X. If you say "X 2 Y", it would be clear that you put in X and
> you get out Y. As it is, it's not very clear which is the input and
> which is the output.
>
Changed as per discussion up thread.
> + bool primary_buc_page)
>
> I think we could just go with "primary_page" here. (Fixed in attached.)
>
Included the change in attached version of the patch.
> + /*
> + * Acquiring cleanup lock to clear the split-in-progress flag ensures that
> + * there is no pending scan that has seen the flag after it is cleared.
> + */
> + _hash_chgbufaccess(rel, bucket_obuf, HASH_NOLOCK, HASH_WRITE);
> + opage = BufferGetPage(bucket_obuf);
> + oopaque = (HashPageOpaque) PageGetSpecialPointer(opage);
>
> I don't understand the comment, because the code *isn't* acquiring a
> cleanup lock.
>
Removed this comment.
>> Some more review:
>>
>> The API contract of _hash_finish_split seems a bit unfortunate. The
>> caller is supposed to have obtained a cleanup lock on both the old and
>> new buffers, but the first thing it does is walk the entire new bucket
>> chain, completely ignoring the old one. That means holding a cleanup
>> lock on the old buffer across an unbounded number of I/O operations --
>> which also means that you can't interrupt the query by pressing ^C,
>> because an LWLock (on the old buffer) is held.
>>
>
Fixed in attached patch as per algorithm proposed few lines down in this mail.
> I see the problem you are talking about, but it was done to ensure
> locking order, old bucket first and then new bucket, else there could
> be a deadlock risk. However, I think we can avoid holding the cleanup
> lock on old bucket till we scan the new bucket to form a hash table of
> TIDs.
>
>> Moreover, the
>> requirement to hold a lock on the new buffer isn't convenient for
>> either caller; they both have to go do it, so why not move it into the
>> function?
>>
>
> Yeah, we can move the locking of new bucket entirely into new function.
>
Done.
>> Perhaps the function should be changed so that it
>> guarantees that a pin is held on the primary page of the existing
>> bucket, but no locks are held.
>>
>
> Okay, so we can change the locking order as follows:
> a. ensure a cleanup lock on old bucket and check if the bucket (old)
> has pending split.
> b. if there is a pending split, release the lock on old bucket, but not pin.
>
> below steps will be performed by _hash_finish_split():
>
> c. acquire the read content lock on new bucket and form the hash table
> of TIDs and in the process of forming hash table, we need to traverse
> whole bucket chain. While traversing bucket chain, release the lock
> on previous bucket (both lock and pin if not a primary bucket page).
> d. After the hash table is formed, acquire cleanup lock on old and new
> buckets conditionaly; if we are not able to get cleanup lock on
> either, then just return from there.
> e. Perform split operation..
> f. release the lock and pin on new bucket
> g. release the lock on old bucket. We don't want to release the pin
> on old bucket as the caller has ensure it before passing it to
> _hash_finish_split(), so releasing pin should be resposibility of
> caller.
>
> Now, both the callers need to ensure that they restart the operation
> from begining as after we release lock on old bucket, somebody might
> have split the bucket.
>
> Does the above change in locking strategy sounds okay?
>
I have changed the locking strategy as per above description by me and
accordingly changed the prototype of _hash_finish_split.
>> Where _hash_finish_split does LockBufferForCleanup(bucket_nbuf),
>> should it instead be trying to get the lock conditionally and
>> returning immediately if it doesn't get the lock? Seems like a good
>> idea...
>>
>
> Yeah, we can take a cleanup lock conditionally, but it would waste the
> effort of forming hash table, if we don't get cleanup lock
> immediately. Considering incomplete splits to be a rare operation,
> may be this the wasted effort is okay, but I am not sure. Don't you
> think we should avoid that effort?
>
Changed it to conditional lock.
>> * We're at the end of the old bucket chain, so we're done partitioning
>> * the tuples. Mark the old and new buckets to indicate split is
>> * finished.
>> *
>> * To avoid deadlocks due to locking order of buckets, first lock the old
>> * bucket and then the new bucket.
>>
>> These comments have drifted too far from the code to which they refer.
>> The first part is basically making the same point as the
>> slightly-later comment /* indicate that split is finished */.
>>
>
> I think we can remove the second comment /* indicate that split is
> finished */.
Removed this comment.
> itupsize = new_itup->t_info & INDEX_SIZE_MASK;
> new_itup->t_info &= ~INDEX_SIZE_MASK;
> new_itup->t_info |= INDEX_MOVED_BY_SPLIT_MASK;
> new_itup->t_info |= itupsize;
>
> If I'm not mistaken, you could omit the first, second, and fourth
> lines here and keep only the third one, and it would do exactly the
> same thing. The first line saves the bits in INDEX_SIZE_MASK. The
> second line clears the bits in INDEX_SIZE_MASK. The fourth line
> re-sets the bits that were originally saved.
>
You are right and I have changed the code as per your suggestion.
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Вложения
On Sat, Nov 12, 2016 at 12:49 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> You are right and I have changed the code as per your suggestion.
So...
+ /*
+ * We always maintain the pin on bucket page for whole scan operation,
+ * so releasing the additional pin we have acquired here.
+ */
+ if ((*opaquep)->hasho_flag & LH_BUCKET_PAGE)
+ _hash_dropbuf(rel, *bufp);
This relies on the page contents to know whether we took a pin; that
seems like a bad plan. We need to know intrinsically whether we took
a pin.
+ * If the bucket split is in progress, then we need to skip tuples that
+ * are moved from old bucket. To ensure that vacuum doesn't clean any
+ * tuples from old or new buckets till this scan is in progress, maintain
+ * a pin on both of the buckets. Here, we have to be cautious about
It wouldn't be a problem if VACUUM removed tuples from the new bucket,
because they'd have to be dead anyway. It also wouldn't be a problem
if it removed tuples from the old bucket that were actually dead. The
real issue isn't vacuum anyway, but the process of cleaning up after a
split. We need to hold the pin so that tuples being moved from the
old bucket to the new bucket by the split don't get removed from the
old bucket until our scan is done.
+ old_blkno = _hash_get_oldblock_from_newbucket(rel,
opaque->hasho_bucket);
Couldn't you pass "bucket" here instead of "hasho->opaque_bucket"? I
feel like I'm repeating this ad nauseum, but I really think it's bad
to rely on the special space instead of our own local variables!
- /* we ran off the end of the bucket without finding a match */
+ /*
+ * We ran off the end of the bucket without finding a match.
+ * Release the pin on bucket buffers. Normally, such pins are
+ * released at end of scan, however scrolling cursors can
+ * reacquire the bucket lock and pin in the same scan multiple
+ * times.
+ */ *bufP = so->hashso_curbuf = InvalidBuffer; ItemPointerSetInvalid(current);
+ _hash_dropscanbuf(rel, so);
I think this comment is saying that we'll release the pin on the
primary bucket page for now, and then reacquire it later if the user
reverses the scan direction. But that doesn't sound very safe,
because the bucket could be split in the meantime and the order in
which tuples are returned could change. I think we want that to
remain stable within a single query execution.
+ _hash_readnext(rel, &buf, &page, &opaque,
+ (opaque->hasho_flag & LH_BUCKET_PAGE) ? true : false);
Same comment: don't rely on the special space to figure this out.
Keep track. Also != 0 would be better than ? true : false.
+ /*
+ * setting hashso_skip_moved_tuples to false
+ * ensures that we don't check for tuples that are
+ * moved by split in old bucket and it also
+ * ensures that we won't retry to scan the old
+ * bucket once the scan for same is finished.
+ */
+ so->hashso_skip_moved_tuples = false;
I think you've got a big problem here. Suppose the user starts the
scan in the new bucket and runs it forward until they end up in the
old bucket. Then they turn around and run the scan backward. When
they reach the beginning of the old bucket, they're going to stop, not
move back to the new bucket, AFAICS. Oops.
_hash_first() has a related problem: a backward scan starts at the end
of the new bucket and moves backward, but it should start at the end
of the old bucket, and then when it reaches the beginning, flip to the
new bucket and move backward through that one. Otherwise, a backward
scan and a forward scan don't return tuples in opposite order, which
they should.
I think what you need to do to fix both of these problems is a more
thorough job gluing the two buckets together. I'd suggest that the
responsibility for switching between the two buckets should probably
be given to _hash_readprev() and _hash_readnext(), because every place
that needs to advance to the next or previous page that cares about
this. Right now you are trying to handle it mostly in the functions
that call those functions, but that is prone to errors of omission.
Also, I think that so->hashso_skip_moved_tuples is badly designed.
There are two separate facts you need to know: (1) whether you are
scanning a bucket that was still being populated at the start of your
scan and (2) if yes, whether you are scanning the bucket being
populated or whether you are instead scanning the corresponding "old"
bucket. You're trying to keep track of that using one Boolean, but
one Boolean only has two states and there are three possible states
here.
+ if (H_BUCKET_BEING_SPLIT(pageopaque) && IsBufferCleanupOK(buf))
+ {
+
+ /* release the lock on bucket buffer, before completing the split. */
Extra blank line.
+moved-by-split flag on a tuple indicates that tuple is moved from old to new
+bucket. The concurrent scans can skip such tuples till the split operation is
+finished. Once the tuple is marked as moved-by-split, it will remain
so forever
+but that does no harm. We have intentionally not cleared it as that
can generate
+an additional I/O which is not necessary.
The first sentence needs to start with "the" but the second sentence shouldn't.
It would be good to adjust this part a bit to more clearly explain
that the split-in-progress and split-cleanup flags are bucket-level
flags, while moved-by-split is a per-tuple flag. It's possible to
figure this out from what you've written, but I think it could be more
clear. Another thing that is strange is that the code uses THREE
flags, bucket-being-split, bucket-being-populated, and
needs-split-cleanup, but the README conflates the first two and uses a
different name.
+previously-acquired content lock, but not pin and repeat the process using the
s/but not pin/but not the pin,/
A problem is that if a split fails partway through (eg due to insufficient
-disk space) the index is left corrupt. The probability of that could be
-made quite low if we grab a free page or two before we update the meta
-page, but the only real solution is to treat a split as a WAL-loggable,
+disk space or crash) the index is left corrupt. The probability of that
+could be made quite low if we grab a free page or two before we update the
+meta page, but the only real solution is to treat a split as a WAL-loggable,must-complete action. I'm not planning to
teachhash about WAL in this
-go-round.
+go-round. However, we do try to finish the incomplete splits during insert
+and split.
I think this paragraph needs a much heavier rewrite explaining the new
incomplete split handling. It's basically wrong now. Perhaps replace
it with something like this:
--
If a split fails partway through (e.g. due to insufficient disk space
or an interrupt), the index will not be corrupted. Instead, we'll
retry the split every time a tuple is inserted into the old bucket
prior to inserting the new tuple; eventually, we should succeed. The
fact that a split is left unfinished doesn't prevent subsequent
buckets from being split, but we won't try to split the bucket again
until the prior split is finished. In other words, a bucket can be in
the middle of being split for some time, but ti can't be in the middle
of two splits at the same time.
Although we can survive a failure to split a bucket, a crash is likely
to corrupt the index, since hash indexes are not yet WAL-logged.
--
+ Acquire cleanup lock on target bucket
+ Scan and remove tuples
+ For overflow page, first we need to lock the next page and then
+ release the lock on current bucket or overflow page
+ Ensure to have buffer content lock in exclusive mode on bucket page
+ If buffer pincount is one, then compact free space as needed
+ Release lock
I don't think this summary is particularly correct. You would never
guess from this that we lock each bucket page in turn and then go back
and try to relock the primary bucket page at the end. It's more like:
acquire cleanup lock on primary bucket page
loop: scan and remove tuples if this is the last bucket page, break out of loop pin and x-lock next page
releaseprior lock and pin (except keep pin on primary bucket page)
if the page we have locked is not the primary bucket page: release lock and take exclusive lock on primary bucket
page
if there are no other pins on the primary bucket page: squeeze the bucket to remove free space
Come to think of it, I'm a little worried about the locking in
_hash_squeezebucket(). It seems like we drop the lock on each "write"
bucket page before taking the lock on the next one. So a concurrent
scan could get ahead of the cleanup process. That would be bad,
wouldn't it?
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Nov 17, 2016 at 3:08 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Sat, Nov 12, 2016 at 12:49 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> You are right and I have changed the code as per your suggestion. > > So... > > + /* > + * We always maintain the pin on bucket page for whole scan operation, > + * so releasing the additional pin we have acquired here. > + */ > + if ((*opaquep)->hasho_flag & LH_BUCKET_PAGE) > + _hash_dropbuf(rel, *bufp); > > This relies on the page contents to know whether we took a pin; that > seems like a bad plan. We need to know intrinsically whether we took > a pin. > Okay, I think we can do that as we have bucket buffer information (hashso_bucket_buf) in HashScanOpaqueData. We might need to pass this information in _hash_readprev. > + * If the bucket split is in progress, then we need to skip tuples that > + * are moved from old bucket. To ensure that vacuum doesn't clean any > + * tuples from old or new buckets till this scan is in progress, maintain > + * a pin on both of the buckets. Here, we have to be cautious about > > It wouldn't be a problem if VACUUM removed tuples from the new bucket, > because they'd have to be dead anyway. It also wouldn't be a problem > if it removed tuples from the old bucket that were actually dead. The > real issue isn't vacuum anyway, but the process of cleaning up after a > split. We need to hold the pin so that tuples being moved from the > old bucket to the new bucket by the split don't get removed from the > old bucket until our scan is done. > Are you expecting a comment change here? > + old_blkno = _hash_get_oldblock_from_newbucket(rel, > opaque->hasho_bucket); > > Couldn't you pass "bucket" here instead of "hasho->opaque_bucket"? I > feel like I'm repeating this ad nauseum, but I really think it's bad > to rely on the special space instead of our own local variables! > Sure, we can pass bucket as well. However, if you see few lines below (while (BlockNumberIsValid(opaque->hasho_nextblkno))), we are already relying on special space to pass variables. In general, we are using special space to pass variables to functions in many other places in the code. What exactly are you bothered about in accessing special space, if it is safe to do? > - /* we ran off the end of the bucket without finding a match */ > + /* > + * We ran off the end of the bucket without finding a match. > + * Release the pin on bucket buffers. Normally, such pins are > + * released at end of scan, however scrolling cursors can > + * reacquire the bucket lock and pin in the same scan multiple > + * times. > + */ > *bufP = so->hashso_curbuf = InvalidBuffer; > ItemPointerSetInvalid(current); > + _hash_dropscanbuf(rel, so); > > I think this comment is saying that we'll release the pin on the > primary bucket page for now, and then reacquire it later if the user > reverses the scan direction. But that doesn't sound very safe, > because the bucket could be split in the meantime and the order in > which tuples are returned could change. I think we want that to > remain stable within a single query execution. > Isn't that possible even without the patch? Basically, after reaching end of forward scan and for doing backward *all* scan, we need to perform portal rewind which will in turn call hashrescan where we will drop the lock on bucket and then again when we try to move cursor forward we acquire lock in _hash_first(), so in between when we don't have the lock, the split could happen and next scan results could differ. Also, in the documentation, it is mentioned that "The SQL standard says that it is implementation-dependent whether cursors are sensitive to concurrent updates of the underlying data by default. In PostgreSQL, cursors are insensitive by default, and can be made sensitive by specifying FOR UPDATE." which I think indicates that results can't be guaranteed for forward and backward scans. So, even if we try to come up with some solution for stable results in some scenarios, I am not sure that can be guaranteed for all scenarios. > + /* > + * setting hashso_skip_moved_tuples to false > + * ensures that we don't check for tuples that are > + * moved by split in old bucket and it also > + * ensures that we won't retry to scan the old > + * bucket once the scan for same is finished. > + */ > + so->hashso_skip_moved_tuples = false; > > I think you've got a big problem here. Suppose the user starts the > scan in the new bucket and runs it forward until they end up in the > old bucket. Then they turn around and run the scan backward. When > they reach the beginning of the old bucket, they're going to stop, not > move back to the new bucket, AFAICS. Oops. > After the scan has finished old bucket and turned back, it will actually restart the scan (_hash_first) and will start from the end of the new bucket. That is also a problem and it should actually start from the end of the old bucket which is actually what you have mentioned as next problem. So, I think if we fix the next problem, we are okay. > _hash_first() has a related problem: a backward scan starts at the end > of the new bucket and moves backward, but it should start at the end > of the old bucket, and then when it reaches the beginning, flip to the > new bucket and move backward through that one. Otherwise, a backward > scan and a forward scan don't return tuples in opposite order, which > they should. > > I think what you need to do to fix both of these problems is a more > thorough job gluing the two buckets together. I'd suggest that the > responsibility for switching between the two buckets should probably > be given to _hash_readprev() and _hash_readnext(), because every place > that needs to advance to the next or previous page that cares about > this. Right now you are trying to handle it mostly in the functions > that call those functions, but that is prone to errors of omission. > It seems like a better way, so will change accordingly. > Also, I think that so->hashso_skip_moved_tuples is badly designed. > There are two separate facts you need to know: (1) whether you are > scanning a bucket that was still being populated at the start of your > scan and (2) if yes, whether you are scanning the bucket being > populated or whether you are instead scanning the corresponding "old" > bucket. You're trying to keep track of that using one Boolean, but > one Boolean only has two states and there are three possible states > here. > So do you prefer to have two booleans to track those facts or have an uint8 with a tri-state value or something else? > > acquire cleanup lock on primary bucket page > loop: > scan and remove tuples > if this is the last bucket page, break out of loop > pin and x-lock next page > release prior lock and pin (except keep pin on primary bucket page) > if the page we have locked is not the primary bucket page: > release lock and take exclusive lock on primary bucket page > if there are no other pins on the primary bucket page: > squeeze the bucket to remove free space > > Come to think of it, I'm a little worried about the locking in > _hash_squeezebucket(). It seems like we drop the lock on each "write" > bucket page before taking the lock on the next one. So a concurrent > scan could get ahead of the cleanup process. That would be bad, > wouldn't it? > Yeah, that would be bad if it happens, but no concurrent scan can happen during squeeze phase because we take an exclusive lock on a bucket page and maintain it throughout the operation. Thanks for such a detailed review. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 17, 2016 at 12:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Are you expecting a comment change here? > >> + old_blkno = _hash_get_oldblock_from_newbucket(rel, >> opaque->hasho_bucket); >> >> Couldn't you pass "bucket" here instead of "hasho->opaque_bucket"? I >> feel like I'm repeating this ad nauseum, but I really think it's bad >> to rely on the special space instead of our own local variables! >> > > Sure, we can pass bucket as well. However, if you see few lines below > (while (BlockNumberIsValid(opaque->hasho_nextblkno))), we are already > relying on special space to pass variables. In general, we are using > special space to pass variables to functions in many other places in > the code. What exactly are you bothered about in accessing special > space, if it is safe to do? I don't want to rely on the special space to know which buffers we have locked or pinned. We obviously need the special space to find the next and previous buffers in the block chain -- there's no other way to know that. However, we should be more careful about locks and pins. If the special space is corrupted in some way, we still shouldn't get confused about which buffers we have locked or pinned. >> I think this comment is saying that we'll release the pin on the >> primary bucket page for now, and then reacquire it later if the user >> reverses the scan direction. But that doesn't sound very safe, >> because the bucket could be split in the meantime and the order in >> which tuples are returned could change. I think we want that to >> remain stable within a single query execution. > > Isn't that possible even without the patch? Basically, after reaching > end of forward scan and for doing backward *all* scan, we need to > perform portal rewind which will in turn call hashrescan where we will > drop the lock on bucket and then again when we try to move cursor > forward we acquire lock in _hash_first(), so in between when we don't > have the lock, the split could happen and next scan results could > differ. Well, the existing code doesn't drop the heavyweight lock at that location, but your patch does drop the pin that serves the same function, so I feel like there must be some difference. >> Also, I think that so->hashso_skip_moved_tuples is badly designed. >> There are two separate facts you need to know: (1) whether you are >> scanning a bucket that was still being populated at the start of your >> scan and (2) if yes, whether you are scanning the bucket being >> populated or whether you are instead scanning the corresponding "old" >> bucket. You're trying to keep track of that using one Boolean, but >> one Boolean only has two states and there are three possible states >> here. > > So do you prefer to have two booleans to track those facts or have an > uint8 with a tri-state value or something else? I don't currently have a preference. >> Come to think of it, I'm a little worried about the locking in >> _hash_squeezebucket(). It seems like we drop the lock on each "write" >> bucket page before taking the lock on the next one. So a concurrent >> scan could get ahead of the cleanup process. That would be bad, >> wouldn't it? > > Yeah, that would be bad if it happens, but no concurrent scan can > happen during squeeze phase because we take an exclusive lock on a > bucket page and maintain it throughout the operation. Well, that's completely unacceptable. A major reason the current code uses heavyweight locks is because you can't hold lightweight locks across arbitrary amounts of work -- because, just to take one example, a process holding or waiting for an LWLock isn't interruptible. The point of this redesign was to get rid of that, so that LWLocks are only held for short periods. I dislike the lock-chaining approach (take the next lock before releasing the previous one) quite a bit and really would like to find a way to get rid of that, but the idea of holding a buffer lock across a complete traversal of an unbounded number of overflow buckets is far worse. We've got to come up with a design that doesn't require that, or else completely redesign the bucket-squeezing stuff. (Would it make any sense to change the order of the hash index patches we've got outstanding? For instance, if we did the page-at-a-time stuff first, it would make life simpler for this patch in several ways, possibly including this issue.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Nov 17, 2016 at 10:54 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Nov 17, 2016 at 12:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > >>> I think this comment is saying that we'll release the pin on the >>> primary bucket page for now, and then reacquire it later if the user >>> reverses the scan direction. But that doesn't sound very safe, >>> because the bucket could be split in the meantime and the order in >>> which tuples are returned could change. I think we want that to >>> remain stable within a single query execution. >> >> Isn't that possible even without the patch? Basically, after reaching >> end of forward scan and for doing backward *all* scan, we need to >> perform portal rewind which will in turn call hashrescan where we will >> drop the lock on bucket and then again when we try to move cursor >> forward we acquire lock in _hash_first(), so in between when we don't >> have the lock, the split could happen and next scan results could >> differ. > > Well, the existing code doesn't drop the heavyweight lock at that > location, but your patch does drop the pin that serves the same > function, so I feel like there must be some difference. > Yes, but I am not sure if existing code is right. Consider below scenario, Session-1 Begin; Declare c cursor for select * from t4 where c1=1; Fetch forward all from c; --here shared heavy-weight lock count becomes 1 Fetch prior from c; --here shared heavy-weight lock count becomes 2 close c; -- here, lock release will reduce the lock count and shared heavy-weight lock count becomes 1 Now, if we try to insert from another session, such that it leads to bucket-split of the bucket for which session-1 had used a cursor, it will wait for session-1. The insert can only proceed after session-1 performs the commit. I think after the cursor is closed in session-1, the insert from another session should succeed, don't you think so? >>> Come to think of it, I'm a little worried about the locking in >>> _hash_squeezebucket(). It seems like we drop the lock on each "write" >>> bucket page before taking the lock on the next one. So a concurrent >>> scan could get ahead of the cleanup process. That would be bad, >>> wouldn't it? >> >> Yeah, that would be bad if it happens, but no concurrent scan can >> happen during squeeze phase because we take an exclusive lock on a >> bucket page and maintain it throughout the operation. > > Well, that's completely unacceptable. A major reason the current code > uses heavyweight locks is because you can't hold lightweight locks > across arbitrary amounts of work -- because, just to take one example, > a process holding or waiting for an LWLock isn't interruptible. The > point of this redesign was to get rid of that, so that LWLocks are > only held for short periods. I dislike the lock-chaining approach > (take the next lock before releasing the previous one) quite a bit and > really would like to find a way to get rid of that, but the idea of > holding a buffer lock across a complete traversal of an unbounded > number of overflow buckets is far worse. We've got to come up with a > design that doesn't require that, or else completely redesign the > bucket-squeezing stuff. > I think we can use the idea of lock-chaining (take the next lock before releasing the previous one) for squeeze-phase to solve this issue. Basically for squeeze operation, what we need to take care is that there shouldn't be any scan before we start the squeeze and then afterward if the scan starts, it should be always behind write-end of a squeeze. If we follow this, then there shouldn't be any problem even for backward scans because to start backward scans, it needs to start with the first bucket and reach last bucket page by locking each bucket page in read mode. > (Would it make any sense to change the order of the hash index patches > we've got outstanding? For instance, if we did the page-at-a-time > stuff first, it would make life simpler for this patch in several > ways, possibly including this issue.) > I agree that page-at-a-time can help hash indexes, but I don't think it can help with this particular issue of squeeze operation. While cleaning dead-tuples, it would be okay even if scan went ahead of cleanup (considering we have page-at-a-time mode), but for squeeze, we can't afford that because it can move some tuples to a prior bucket page and scan would miss those tuples. Also, page-at-a-time will help cleaning tuples only for MVCC scans (it might not help for unlogged tables scan or non-MVCC scans). Another point is that we don't have a patch for page-at-a-time scan ready at this stage. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Nov 18, 2016 at 12:11 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Nov 17, 2016 at 10:54 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, Nov 17, 2016 at 12:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> >>>> I think this comment is saying that we'll release the pin on the >>>> primary bucket page for now, and then reacquire it later if the user >>>> reverses the scan direction. But that doesn't sound very safe, >>>> because the bucket could be split in the meantime and the order in >>>> which tuples are returned could change. I think we want that to >>>> remain stable within a single query execution. >>> >>> Isn't that possible even without the patch? Basically, after reaching >>> end of forward scan and for doing backward *all* scan, we need to >>> perform portal rewind which will in turn call hashrescan where we will >>> drop the lock on bucket and then again when we try to move cursor >>> forward we acquire lock in _hash_first(), so in between when we don't >>> have the lock, the split could happen and next scan results could >>> differ. >> >> Well, the existing code doesn't drop the heavyweight lock at that >> location, but your patch does drop the pin that serves the same >> function, so I feel like there must be some difference. >> > > Yes, but I am not sure if existing code is right. Consider below scenario, > > Session-1 > > Begin; > Declare c cursor for select * from t4 where c1=1; > Fetch forward all from c; --here shared heavy-weight lock count becomes 1 > Fetch prior from c; --here shared heavy-weight lock count becomes 2 > close c; -- here, lock release will reduce the lock count and shared > heavy-weight lock count becomes 1 > > Now, if we try to insert from another session, such that it leads to > bucket-split of the bucket for which session-1 had used a cursor, it > will wait for session-1. > It will not wait, but just skip the split because we are using try lock, however, the point remains that select should not hold bucket level locks even after the cursor is closed. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Nov 17, 2016 at 3:08 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Sat, Nov 12, 2016 at 12:49 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> You are right and I have changed the code as per your suggestion.
>
> So...
>
> + /*
> + * We always maintain the pin on bucket page for whole scan operation,
> + * so releasing the additional pin we have acquired here.
> + */
> + if ((*opaquep)->hasho_flag & LH_BUCKET_PAGE)
> + _hash_dropbuf(rel, *bufp);
>
> This relies on the page contents to know whether we took a pin; that
> seems like a bad plan. We need to know intrinsically whether we took
> a pin.
>
Okay, changed to not rely on page contents.
> + * If the bucket split is in progress, then we need to skip tuples that
> + * are moved from old bucket. To ensure that vacuum doesn't clean any
> + * tuples from old or new buckets till this scan is in progress, maintain
> + * a pin on both of the buckets. Here, we have to be cautious about
>
> It wouldn't be a problem if VACUUM removed tuples from the new bucket,
> because they'd have to be dead anyway. It also wouldn't be a problem
> if it removed tuples from the old bucket that were actually dead. The
> real issue isn't vacuum anyway, but the process of cleaning up after a
> split. We need to hold the pin so that tuples being moved from the
> old bucket to the new bucket by the split don't get removed from the
> old bucket until our scan is done.
>
Updated comments to explain clearly.
> + old_blkno = _hash_get_oldblock_from_newbucket(rel,
> opaque->hasho_bucket);
>
> Couldn't you pass "bucket" here instead of "hasho->opaque_bucket"? I
> feel like I'm repeating this ad nauseum, but I really think it's bad
> to rely on the special space instead of our own local variables!
>
Okay, changed as per suggestion.
> - /* we ran off the end of the bucket without finding a match */
> + /*
> + * We ran off the end of the bucket without finding a match.
> + * Release the pin on bucket buffers. Normally, such pins are
> + * released at end of scan, however scrolling cursors can
> + * reacquire the bucket lock and pin in the same scan multiple
> + * times.
> + */
> *bufP = so->hashso_curbuf = InvalidBuffer;
> ItemPointerSetInvalid(current);
> + _hash_dropscanbuf(rel, so);
>
> I think this comment is saying that we'll release the pin on the
> primary bucket page for now, and then reacquire it later if the user
> reverses the scan direction. But that doesn't sound very safe,
> because the bucket could be split in the meantime and the order in
> which tuples are returned could change. I think we want that to
> remain stable within a single query execution.
>
As explained [1], this shouldn't be a problem.
> + _hash_readnext(rel, &buf, &page, &opaque,
> + (opaque->hasho_flag & LH_BUCKET_PAGE) ? true : false);
>
> Same comment: don't rely on the special space to figure this out.
> Keep track. Also != 0 would be better than ? true : false.
>
After gluing scan of old and new buckets in _hash_read* API's, this is
no more required.
> + /*
> + * setting hashso_skip_moved_tuples to false
> + * ensures that we don't check for tuples that are
> + * moved by split in old bucket and it also
> + * ensures that we won't retry to scan the old
> + * bucket once the scan for same is finished.
> + */
> + so->hashso_skip_moved_tuples = false;
>
> I think you've got a big problem here. Suppose the user starts the
> scan in the new bucket and runs it forward until they end up in the
> old bucket. Then they turn around and run the scan backward. When
> they reach the beginning of the old bucket, they're going to stop, not
> move back to the new bucket, AFAICS. Oops.
>
> _hash_first() has a related problem: a backward scan starts at the end
> of the new bucket and moves backward, but it should start at the end
> of the old bucket, and then when it reaches the beginning, flip to the
> new bucket and move backward through that one. Otherwise, a backward
> scan and a forward scan don't return tuples in opposite order, which
> they should.
>
> I think what you need to do to fix both of these problems is a more
> thorough job gluing the two buckets together. I'd suggest that the
> responsibility for switching between the two buckets should probably
> be given to _hash_readprev() and _hash_readnext(), because every place
> that needs to advance to the next or previous page that cares about
> this. Right now you are trying to handle it mostly in the functions
> that call those functions, but that is prone to errors of omission.
>
Changed as per this idea to change the API's and fix the problem.
> Also, I think that so->hashso_skip_moved_tuples is badly designed.
> There are two separate facts you need to know: (1) whether you are
> scanning a bucket that was still being populated at the start of your
> scan and (2) if yes, whether you are scanning the bucket being
> populated or whether you are instead scanning the corresponding "old"
> bucket. You're trying to keep track of that using one Boolean, but
> one Boolean only has two states and there are three possible states
> here.
>
Updated patch is using two boolean variables to track the bucket state.
> + if (H_BUCKET_BEING_SPLIT(pageopaque) && IsBufferCleanupOK(buf))
> + {
> +
> + /* release the lock on bucket buffer, before completing the split. */
>
> Extra blank line.
>
Removed.
> +moved-by-split flag on a tuple indicates that tuple is moved from old to new
> +bucket. The concurrent scans can skip such tuples till the split operation is
> +finished. Once the tuple is marked as moved-by-split, it will remain
> so forever
> +but that does no harm. We have intentionally not cleared it as that
> can generate
> +an additional I/O which is not necessary.
>
> The first sentence needs to start with "the" but the second sentence shouldn't.
>
Changed.
> It would be good to adjust this part a bit to more clearly explain
> that the split-in-progress and split-cleanup flags are bucket-level
> flags, while moved-by-split is a per-tuple flag. It's possible to
> figure this out from what you've written, but I think it could be more
> clear. Another thing that is strange is that the code uses THREE
> flags, bucket-being-split, bucket-being-populated, and
> needs-split-cleanup, but the README conflates the first two and uses a
> different name.
>
Updated patch to use bucket-being-split and bucket-being-populated to
explain the split operation in README. I have also changed the readme
to clearly indicate which the bucket and tuple level flags.
> +previously-acquired content lock, but not pin and repeat the process using the
>
> s/but not pin/but not the pin,/
>
Changed.
> A problem is that if a split fails partway through (eg due to insufficient
> -disk space) the index is left corrupt. The probability of that could be
> -made quite low if we grab a free page or two before we update the meta
> -page, but the only real solution is to treat a split as a WAL-loggable,
> +disk space or crash) the index is left corrupt. The probability of that
> +could be made quite low if we grab a free page or two before we update the
> +meta page, but the only real solution is to treat a split as a WAL-loggable,
> must-complete action. I'm not planning to teach hash about WAL in this
> -go-round.
> +go-round. However, we do try to finish the incomplete splits during insert
> +and split.
>
> I think this paragraph needs a much heavier rewrite explaining the new
> incomplete split handling. It's basically wrong now. Perhaps replace
> it with something like this:
>
> --
> If a split fails partway through (e.g. due to insufficient disk space
> or an interrupt), the index will not be corrupted. Instead, we'll
> retry the split every time a tuple is inserted into the old bucket
> prior to inserting the new tuple; eventually, we should succeed. The
> fact that a split is left unfinished doesn't prevent subsequent
> buckets from being split, but we won't try to split the bucket again
> until the prior split is finished. In other words, a bucket can be in
> the middle of being split for some time, but ti can't be in the middle
> of two splits at the same time.
>
> Although we can survive a failure to split a bucket, a crash is likely
> to corrupt the index, since hash indexes are not yet WAL-logged.
> --
>
s/ti/it
Fixed the typo and used the suggested text in README.
> + Acquire cleanup lock on target bucket
> + Scan and remove tuples
> + For overflow page, first we need to lock the next page and then
> + release the lock on current bucket or overflow page
> + Ensure to have buffer content lock in exclusive mode on bucket page
> + If buffer pincount is one, then compact free space as needed
> + Release lock
>
> I don't think this summary is particularly correct. You would never
> guess from this that we lock each bucket page in turn and then go back
> and try to relock the primary bucket page at the end. It's more like:
>
> acquire cleanup lock on primary bucket page
> loop:
> scan and remove tuples
> if this is the last bucket page, break out of loop
> pin and x-lock next page
> release prior lock and pin (except keep pin on primary bucket page)
> if the page we have locked is not the primary bucket page:
> release lock and take exclusive lock on primary bucket page
> if there are no other pins on the primary bucket page:
> squeeze the bucket to remove free space
>
Yeah, it is clear, so I have used it in README.
> Come to think of it, I'm a little worried about the locking in
> _hash_squeezebucket(). It seems like we drop the lock on each "write"
> bucket page before taking the lock on the next one. So a concurrent
> scan could get ahead of the cleanup process. That would be bad,
> wouldn't it?
>
As discussed [2], I have changed the code to use lock-chaining during
squeeze phase.
Apart from above, I have fixed a bug in calculation of lowmask in
_hash_get_oldblock_from_newbucket().
[1] - https://www.postgresql.org/message-id/CAA4eK1JJDWFY0_Ezs4ZxXgnrGtTn48vFuXniOLmL7FOWX-tKNw%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAA4eK1J%2B0OYWKswWYNEjrBk3LfGpGJ9iSV8bYPQ3M%3D-qpkMtwQ
%40mail.gmail.com
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Вложения
Hi All,
I have executed few test-cases to validate the v12 patch for
concurrent hash index shared upthread and have found no issues. Below
are some of the test-cases i ran,
1) pgbench test on a read-write workload with following configuration
(This was basically to validate the locking strategy not for
performance testing)
postgresql non-default configuration:
----------------------------------------------------
min_wal_size=15GB
max_wal_size=20GB
checkpoint_timeout=900
maintenance_work_mem=1GB
checkpoint_completion_target=0.9
max_connections=200
shared buffer=8GB
pgbench settings:
-------------------------
Scale Factor=300
run time= 30 mins
pgbench -c $thread -j $thread -T $time_for_reading -M prepared postgres
2) As v12 patch mainly has locking changes related to bucket squeezing
in hash index, I have ran a small test-case to build hash index with
good number of overflow pages and then ran deletion operation to see
if the bucket squeezing has happened. The test script
"test_squeezeb_hindex.sh" used for this testing is attached with this
mail and the results are shown below:
=====Number of bucket and overflow pages before delete=====
274671 Tuples only is on.
148390
131263 bucket
17126 overflow
1 bitmap
=====Number of bucket and overflow pages after delete=====
274671 Tuples only is on.
141240
131263 bucket
9976 overflow
1 bitmap
With Regards,
Ashutosh Sharma
EnterpriseDB: http://www.enterprisedb.com
On Wed, Nov 23, 2016 at 7:20 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Thu, Nov 17, 2016 at 3:08 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>> On Sat, Nov 12, 2016 at 12:49 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>> You are right and I have changed the code as per your suggestion.
>>
>> So...
>>
>> + /*
>> + * We always maintain the pin on bucket page for whole scan operation,
>> + * so releasing the additional pin we have acquired here.
>> + */
>> + if ((*opaquep)->hasho_flag & LH_BUCKET_PAGE)
>> + _hash_dropbuf(rel, *bufp);
>>
>> This relies on the page contents to know whether we took a pin; that
>> seems like a bad plan. We need to know intrinsically whether we took
>> a pin.
>>
>
> Okay, changed to not rely on page contents.
>
>> + * If the bucket split is in progress, then we need to skip tuples that
>> + * are moved from old bucket. To ensure that vacuum doesn't clean any
>> + * tuples from old or new buckets till this scan is in progress, maintain
>> + * a pin on both of the buckets. Here, we have to be cautious about
>>
>> It wouldn't be a problem if VACUUM removed tuples from the new bucket,
>> because they'd have to be dead anyway. It also wouldn't be a problem
>> if it removed tuples from the old bucket that were actually dead. The
>> real issue isn't vacuum anyway, but the process of cleaning up after a
>> split. We need to hold the pin so that tuples being moved from the
>> old bucket to the new bucket by the split don't get removed from the
>> old bucket until our scan is done.
>>
>
> Updated comments to explain clearly.
>
>> + old_blkno = _hash_get_oldblock_from_newbucket(rel,
>> opaque->hasho_bucket);
>>
>> Couldn't you pass "bucket" here instead of "hasho->opaque_bucket"? I
>> feel like I'm repeating this ad nauseum, but I really think it's bad
>> to rely on the special space instead of our own local variables!
>>
>
> Okay, changed as per suggestion.
>
>> - /* we ran off the end of the bucket without finding a match */
>> + /*
>> + * We ran off the end of the bucket without finding a match.
>> + * Release the pin on bucket buffers. Normally, such pins are
>> + * released at end of scan, however scrolling cursors can
>> + * reacquire the bucket lock and pin in the same scan multiple
>> + * times.
>> + */
>> *bufP = so->hashso_curbuf = InvalidBuffer;
>> ItemPointerSetInvalid(current);
>> + _hash_dropscanbuf(rel, so);
>>
>> I think this comment is saying that we'll release the pin on the
>> primary bucket page for now, and then reacquire it later if the user
>> reverses the scan direction. But that doesn't sound very safe,
>> because the bucket could be split in the meantime and the order in
>> which tuples are returned could change. I think we want that to
>> remain stable within a single query execution.
>>
>
> As explained [1], this shouldn't be a problem.
>
>> + _hash_readnext(rel, &buf, &page, &opaque,
>> + (opaque->hasho_flag & LH_BUCKET_PAGE) ? true : false);
>>
>> Same comment: don't rely on the special space to figure this out.
>> Keep track. Also != 0 would be better than ? true : false.
>>
>
> After gluing scan of old and new buckets in _hash_read* API's, this is
> no more required.
>
>> + /*
>> + * setting hashso_skip_moved_tuples to false
>> + * ensures that we don't check for tuples that are
>> + * moved by split in old bucket and it also
>> + * ensures that we won't retry to scan the old
>> + * bucket once the scan for same is finished.
>> + */
>> + so->hashso_skip_moved_tuples = false;
>>
>> I think you've got a big problem here. Suppose the user starts the
>> scan in the new bucket and runs it forward until they end up in the
>> old bucket. Then they turn around and run the scan backward. When
>> they reach the beginning of the old bucket, they're going to stop, not
>> move back to the new bucket, AFAICS. Oops.
>>
>> _hash_first() has a related problem: a backward scan starts at the end
>> of the new bucket and moves backward, but it should start at the end
>> of the old bucket, and then when it reaches the beginning, flip to the
>> new bucket and move backward through that one. Otherwise, a backward
>> scan and a forward scan don't return tuples in opposite order, which
>> they should.
>>
>> I think what you need to do to fix both of these problems is a more
>> thorough job gluing the two buckets together. I'd suggest that the
>> responsibility for switching between the two buckets should probably
>> be given to _hash_readprev() and _hash_readnext(), because every place
>> that needs to advance to the next or previous page that cares about
>> this. Right now you are trying to handle it mostly in the functions
>> that call those functions, but that is prone to errors of omission.
>>
>
> Changed as per this idea to change the API's and fix the problem.
>
>> Also, I think that so->hashso_skip_moved_tuples is badly designed.
>> There are two separate facts you need to know: (1) whether you are
>> scanning a bucket that was still being populated at the start of your
>> scan and (2) if yes, whether you are scanning the bucket being
>> populated or whether you are instead scanning the corresponding "old"
>> bucket. You're trying to keep track of that using one Boolean, but
>> one Boolean only has two states and there are three possible states
>> here.
>>
>
> Updated patch is using two boolean variables to track the bucket state.
>
>> + if (H_BUCKET_BEING_SPLIT(pageopaque) && IsBufferCleanupOK(buf))
>> + {
>> +
>> + /* release the lock on bucket buffer, before completing the split. */
>>
>> Extra blank line.
>>
>
> Removed.
>
>> +moved-by-split flag on a tuple indicates that tuple is moved from old to new
>> +bucket. The concurrent scans can skip such tuples till the split operation is
>> +finished. Once the tuple is marked as moved-by-split, it will remain
>> so forever
>> +but that does no harm. We have intentionally not cleared it as that
>> can generate
>> +an additional I/O which is not necessary.
>>
>> The first sentence needs to start with "the" but the second sentence shouldn't.
>>
>
> Changed.
>
>> It would be good to adjust this part a bit to more clearly explain
>> that the split-in-progress and split-cleanup flags are bucket-level
>> flags, while moved-by-split is a per-tuple flag. It's possible to
>> figure this out from what you've written, but I think it could be more
>> clear. Another thing that is strange is that the code uses THREE
>> flags, bucket-being-split, bucket-being-populated, and
>> needs-split-cleanup, but the README conflates the first two and uses a
>> different name.
>>
>
> Updated patch to use bucket-being-split and bucket-being-populated to
> explain the split operation in README. I have also changed the readme
> to clearly indicate which the bucket and tuple level flags.
>
>> +previously-acquired content lock, but not pin and repeat the process using the
>>
>> s/but not pin/but not the pin,/
>>
>
> Changed.
>
>> A problem is that if a split fails partway through (eg due to insufficient
>> -disk space) the index is left corrupt. The probability of that could be
>> -made quite low if we grab a free page or two before we update the meta
>> -page, but the only real solution is to treat a split as a WAL-loggable,
>> +disk space or crash) the index is left corrupt. The probability of that
>> +could be made quite low if we grab a free page or two before we update the
>> +meta page, but the only real solution is to treat a split as a WAL-loggable,
>> must-complete action. I'm not planning to teach hash about WAL in this
>> -go-round.
>> +go-round. However, we do try to finish the incomplete splits during insert
>> +and split.
>>
>> I think this paragraph needs a much heavier rewrite explaining the new
>> incomplete split handling. It's basically wrong now. Perhaps replace
>> it with something like this:
>>
>> --
>> If a split fails partway through (e.g. due to insufficient disk space
>> or an interrupt), the index will not be corrupted. Instead, we'll
>> retry the split every time a tuple is inserted into the old bucket
>> prior to inserting the new tuple; eventually, we should succeed. The
>> fact that a split is left unfinished doesn't prevent subsequent
>> buckets from being split, but we won't try to split the bucket again
>> until the prior split is finished. In other words, a bucket can be in
>> the middle of being split for some time, but ti can't be in the middle
>> of two splits at the same time.
>>
>> Although we can survive a failure to split a bucket, a crash is likely
>> to corrupt the index, since hash indexes are not yet WAL-logged.
>> --
>>
>
> s/ti/it
> Fixed the typo and used the suggested text in README.
>
>> + Acquire cleanup lock on target bucket
>> + Scan and remove tuples
>> + For overflow page, first we need to lock the next page and then
>> + release the lock on current bucket or overflow page
>> + Ensure to have buffer content lock in exclusive mode on bucket page
>> + If buffer pincount is one, then compact free space as needed
>> + Release lock
>>
>> I don't think this summary is particularly correct. You would never
>> guess from this that we lock each bucket page in turn and then go back
>> and try to relock the primary bucket page at the end. It's more like:
>>
>> acquire cleanup lock on primary bucket page
>> loop:
>> scan and remove tuples
>> if this is the last bucket page, break out of loop
>> pin and x-lock next page
>> release prior lock and pin (except keep pin on primary bucket page)
>> if the page we have locked is not the primary bucket page:
>> release lock and take exclusive lock on primary bucket page
>> if there are no other pins on the primary bucket page:
>> squeeze the bucket to remove free space
>>
>
> Yeah, it is clear, so I have used it in README.
>
>> Come to think of it, I'm a little worried about the locking in
>> _hash_squeezebucket(). It seems like we drop the lock on each "write"
>> bucket page before taking the lock on the next one. So a concurrent
>> scan could get ahead of the cleanup process. That would be bad,
>> wouldn't it?
>>
>
> As discussed [2], I have changed the code to use lock-chaining during
> squeeze phase.
>
>
> Apart from above, I have fixed a bug in calculation of lowmask in
> _hash_get_oldblock_from_newbucket().
>
> [1] - https://www.postgresql.org/message-id/CAA4eK1JJDWFY0_Ezs4ZxXgnrGtTn48vFuXniOLmL7FOWX-tKNw%40mail.gmail.com
> [2] - https://www.postgresql.org/message-id/CAA4eK1J%2B0OYWKswWYNEjrBk3LfGpGJ9iSV8bYPQ3M%3D-qpkMtwQ
> %40mail.gmail.com
>
>
> --
> With Regards,
> Amit Kapila.
> EnterpriseDB: http://www.enterprisedb.com
>
>
> --
> Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
> To make changes to your subscription:
> http://www.postgresql.org/mailpref/pgsql-hackers
>
Вложения
On Wed, Nov 23, 2016 at 8:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > [ new patch ] Committed with some further cosmetic changes. I guess I won't be very surprised if this turns out to have a few bugs yet, but I think it's in fairly good shape at this point. I think it would be worth testing this code with very long overflow chains by hacking the fill factor up to 1000 or something of that sort, so that we get lots and lots of overflow pages before we start splitting. I think that might find some bugs that aren't obvious right now because most buckets get split before they even have a single overflow bucket. Also, the deadlock hazards that we talked about upthread should probably be documented in the README somewhere, along with why we're OK with accepting those hazards. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 1, 2016 at 2:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Nov 23, 2016 at 8:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> [ new patch ] > > Committed with some further cosmetic changes. > Thank you very much. > I think it would be worth testing this code with very long overflow > chains by hacking the fill factor up to 1000 > 1000 is not a valid value for fill factor. Do you intend to say 100? or something of that > sort, so that we get lots and lots of overflow pages before we start > splitting. I think that might find some bugs that aren't obvious > right now because most buckets get split before they even have a > single overflow bucket. > > Also, the deadlock hazards that we talked about upthread should > probably be documented in the README somewhere, along with why we're > OK with accepting those hazards. > That makes sense. I will send a patch along that lines. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Dec 1, 2016 at 12:43 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Dec 1, 2016 at 2:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Nov 23, 2016 at 8:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> [ new patch ] >> >> Committed with some further cosmetic changes. > > Thank you very much. > >> I think it would be worth testing this code with very long overflow >> chains by hacking the fill factor up to 1000 > > 1000 is not a valid value for fill factor. Do you intend to say 100? No. IIUC, 100 would mean split when the average bucket contains 1 page worth of tuples. I want to split when the average bucket contains 10 pages worth of tuples. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 1, 2016 at 8:56 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Dec 1, 2016 at 12:43 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Thu, Dec 1, 2016 at 2:18 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Wed, Nov 23, 2016 at 8:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> [ new patch ] >>> >>> Committed with some further cosmetic changes. >> >> Thank you very much. >> >>> I think it would be worth testing this code with very long overflow >>> chains by hacking the fill factor up to 1000 >> >> 1000 is not a valid value for fill factor. Do you intend to say 100? > > No. IIUC, 100 would mean split when the average bucket contains 1 > page worth of tuples. > I also think so. > I want to split when the average bucket > contains 10 pages worth of tuples. > oh, I think what you mean to say is hack the code to bump fill factor and then test it. I was confused that how can user can do that from SQL command. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Dec 2, 2016 at 1:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I want to split when the average bucket >> contains 10 pages worth of tuples. > > oh, I think what you mean to say is hack the code to bump fill factor > and then test it. I was confused that how can user can do that from > SQL command. Yes, that's why I said "hacking the fill factor up to 1000" when I originally mentioned it. Actually, for hash indexes, there's no reason why we couldn't allow fillfactor settings greater than 100, and it might be useful. Possibly it should be the default. Not 1000, certainly, but I'm not sure that the current value of 75 is at all optimal. The optimal value might be 100 or 125 or 150 or something like that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Dec 3, 2016 at 12:13 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Dec 2, 2016 at 1:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> I want to split when the average bucket >>> contains 10 pages worth of tuples. >> >> oh, I think what you mean to say is hack the code to bump fill factor >> and then test it. I was confused that how can user can do that from >> SQL command. > > Yes, that's why I said "hacking the fill factor up to 1000" when I > originally mentioned it. > > Actually, for hash indexes, there's no reason why we couldn't allow > fillfactor settings greater than 100, and it might be useful. > Yeah, I agree with that, but as of now, it might be tricky to support the different range of fill factor for one of the indexes. Another idea could be to have an additional storage parameter like split_bucket_length or something like that for hash indexes which indicate that split will occur after the average bucket contains "split_bucket_length * page" worth of tuples. We do have additional storage parameters for other types of indexes, so having one for the hash index should not be a problem. I think this is important because split immediately increases the hash index space by approximately 2 times. We might want to change that algorithm someday, but the above idea will prevent that in many cases. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Dec 2, 2016 at 10:54 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Sat, Dec 3, 2016 at 12:13 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Fri, Dec 2, 2016 at 1:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> I want to split when the average bucket >>>> contains 10 pages worth of tuples. >>> >>> oh, I think what you mean to say is hack the code to bump fill factor >>> and then test it. I was confused that how can user can do that from >>> SQL command. >> >> Yes, that's why I said "hacking the fill factor up to 1000" when I >> originally mentioned it. >> >> Actually, for hash indexes, there's no reason why we couldn't allow >> fillfactor settings greater than 100, and it might be useful. > > Yeah, I agree with that, but as of now, it might be tricky to support > the different range of fill factor for one of the indexes. Another > idea could be to have an additional storage parameter like > split_bucket_length or something like that for hash indexes which > indicate that split will occur after the average bucket contains > "split_bucket_length * page" worth of tuples. We do have additional > storage parameters for other types of indexes, so having one for the > hash index should not be a problem. Agreed. > I think this is important because split immediately increases the hash > index space by approximately 2 times. We might want to change that > algorithm someday, but the above idea will prevent that in many cases. Also agreed. But the first thing is that you should probably do some testing in that area via a quick hack to see if anything breaks in an obvious way. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 1, 2016 at 10:54 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Thu, Dec 1, 2016 at 8:56 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> On Thu, Dec 1, 2016 at 12:43 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> On Thu, Dec 1, 2016 at 2:18 AM, Robert Haas <robertmhaas@gmail.com> wrote:
>>> On Wed, Nov 23, 2016 at 8:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>>> [ new patch ]
>>>
>>> Committed with some further cosmetic changes.
>>
>> Thank you very much.
>>
>>> I think it would be worth testing this code with very long overflow
>>> chains by hacking the fill factor up to 1000
>>
>> 1000 is not a valid value for fill factor. Do you intend to say 100?
>
> No. IIUC, 100 would mean split when the average bucket contains 1
> page worth of tuples.
>
I also think so.
> I want to split when the average bucket
> contains 10 pages worth of tuples.
>
oh, I think what you mean to say is hack the code to bump fill factor
and then test it. I was confused that how can user can do that from
SQL command.
I just occasionally insert a bunch of equal tuples, which have to be in overflow pages no matter how much splitting happens.
I am getting vacuum errors against HEAD, after about 20 minutes or so (8 cores).
49233 XX002 2016-12-05 23:06:44.087 PST:ERROR: index "foo_index_idx" contains unexpected zero page at block 64941
49233 XX002 2016-12-05 23:06:44.087 PST:HINT: Please REINDEX it.
49233 XX002 2016-12-05 23:06:44.087 PST:CONTEXT: automatic vacuum of table "jjanes.public.foo"
Testing harness is attached. It includes a lot of code to test crash recovery, but all of that stuff is turned off in this instance. No patches need to be applied to the server to get this one to run.
With the latest HASH WAL patch applied, I get different but apparently related errors
41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:ERROR: index "foo_index_idx" contains corrupted page at block 27602
41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:HINT: Please REINDEX it.
41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:STATEMENT: update foo set count=count+1 where index=$1
Cheers,
Jeff
Вложения
On Tue, Dec 6, 2016 at 1:29 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > > > I just occasionally insert a bunch of equal tuples, which have to be in > overflow pages no matter how much splitting happens. > > I am getting vacuum errors against HEAD, after about 20 minutes or so (8 > cores). > > 49233 XX002 2016-12-05 23:06:44.087 PST:ERROR: index "foo_index_idx" > contains unexpected zero page at block 64941 > 49233 XX002 2016-12-05 23:06:44.087 PST:HINT: Please REINDEX it. > 49233 XX002 2016-12-05 23:06:44.087 PST:CONTEXT: automatic vacuum of table > "jjanes.public.foo" > Thanks for the report. This can happen due to vacuum trying to access a new page. Vacuum can do so if (a) the calculation for maxbuckets (in metapage) is wrong or (b) it is trying to free the overflow page twice. Offhand, I don't see that can happen in code. I will investigate further to see if there is any another reason why vacuum can access the new page. BTW, have you done the test after commit 2f4193c3, that doesn't appear to be the cause of this problem, but still, it is better to test after that fix. I am trying to reproduce the issue, but in the meantime, if by anychance, you have a callstack, then please share the same. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Dec 6, 2016 at 4:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Tue, Dec 6, 2016 at 1:29 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
>
>
> I just occasionally insert a bunch of equal tuples, which have to be in
> overflow pages no matter how much splitting happens.
>
> I am getting vacuum errors against HEAD, after about 20 minutes or so (8
> cores).
>
> 49233 XX002 2016-12-05 23:06:44.087 PST:ERROR: index "foo_index_idx"
> contains unexpected zero page at block 64941
> 49233 XX002 2016-12-05 23:06:44.087 PST:HINT: Please REINDEX it.
> 49233 XX002 2016-12-05 23:06:44.087 PST:CONTEXT: automatic vacuum of table
> "jjanes.public.foo"
>
Thanks for the report. This can happen due to vacuum trying to access
a new page. Vacuum can do so if (a) the calculation for maxbuckets
(in metapage) is wrong or (b) it is trying to free the overflow page
twice. Offhand, I don't see that can happen in code. I will
investigate further to see if there is any another reason why vacuum
can access the new page. BTW, have you done the test after commit
2f4193c3, that doesn't appear to be the cause of this problem, but
still, it is better to test after that fix. I am trying to reproduce
the issue, but in the meantime, if by anychance, you have a callstack,
then please share the same.
It looks like I compiled the code for testing a few minutes before 2f4193c3 went in.
I've run it again with cb9dcbc1eebd8, after promoting the ERROR in _hash_checkpage, hashutil.c:174 to a PANIC so that I can get a coredump to feed to gdb.
This time it was an INSERT, not autovac, that got the error:
35495 INSERT XX002 2016-12-06 09:25:09.517 PST:PANIC: XX002: index "foo_index_idx" contains unexpected zero page at block 202328
35495 INSERT XX002 2016-12-06 09:25:09.517 PST:HINT: Please REINDEX it.
35495 INSERT XX002 2016-12-06 09:25:09.517 PST:LOCATION: _hash_checkpage, hashutil.c:174
35495 INSERT XX002 2016-12-06 09:25:09.517 PST:STATEMENT: insert into foo (index) select $1 from generate_series(1,10000)
#0 0x0000003838c325e5 in raise (sig=6) at ../nptl/sysdeps/unix/sysv/linux/raise.c:64
64 return INLINE_SYSCALL (tgkill, 3, pid, selftid, sig);
(gdb) bt
#0 0x0000003838c325e5 in raise (sig=6) at ../nptl/sysdeps/unix/sysv/linux/raise.c:64
#1 0x0000003838c33dc5 in abort () at abort.c:92
#2 0x00000000007d6adf in errfinish (dummy=<value optimized out>) at elog.c:557
#3 0x0000000000498d93 in _hash_checkpage (rel=0x7f4d030906a0, buf=<value optimized out>, flags=<value optimized out>) at hashutil.c:169
#4 0x00000000004967cf in _hash_getbuf_with_strategy (rel=0x7f4d030906a0, blkno=<value optimized out>, access=2, flags=1, bstrategy=<value optimized out>)
at hashpage.c:234
#5 0x0000000000493dbb in hashbucketcleanup (rel=0x7f4d030906a0, cur_bucket=14544, bucket_buf=7801, bucket_blkno=22864, bstrategy=0x0, maxbucket=276687,
highmask=524287, lowmask=262143, tuples_removed=0x0, num_index_tuples=0x0, split_cleanup=1 '\001', callback=0, callback_state=0x0) at hash.c:799
#6 0x0000000000497921 in _hash_expandtable (rel=0x7f4d030906a0, metabuf=7961) at hashpage.c:668
#7 0x0000000000495596 in _hash_doinsert (rel=0x7f4d030906a0, itup=0x1f426b0) at hashinsert.c:236
#8 0x0000000000494830 in hashinsert (rel=0x7f4d030906a0, values=<value optimized out>, isnull=<value optimized out>, ht_ctid=0x7f4d03076404,
heapRel=<value optimized out>, checkUnique=<value optimized out>) at hash.c:247
#9 0x00000000005c81bc in ExecInsertIndexTuples (slot=0x1f28940, tupleid=0x7f4d03076404, estate=0x1f28280, noDupErr=0 '\000', specConflict=0x0,
arbiterIndexes=0x0) at execIndexing.c:389
#10 0x00000000005e74ad in ExecInsert (node=0x1f284d0) at nodeModifyTable.c:496
#11 ExecModifyTable (node=0x1f284d0) at nodeModifyTable.c:1511
#12 0x00000000005cc9d8 in ExecProcNode (node=0x1f284d0) at execProcnode.c:396
#13 0x00000000005ca53a in ExecutePlan (queryDesc=0x1f21a30, direction=<value optimized out>, count=0) at execMain.c:1567
#14 standard_ExecutorRun (queryDesc=0x1f21a30, direction=<value optimized out>, count=0) at execMain.c:338
#15 0x00007f4d0c1a6dfb in pgss_ExecutorRun (queryDesc=0x1f21a30, direction=ForwardScanDirection, count=0) at pg_stat_statements.c:877
#16 0x00000000006dfc8a in ProcessQuery (plan=<value optimized out>, sourceText=0x1f21990 "insert into foo (index) select $1 from generate_series(1,10000)",
params=0x1f219e0, dest=0xc191c0, completionTag=0x7ffe82a959d0 "") at pquery.c:185
#17 0x00000000006dfeda in PortalRunMulti (portal=0x1e86900, isTopLevel=1 '\001', setHoldSnapshot=0 '\000', dest=0xc191c0, altdest=0xc191c0,
completionTag=0x7ffe82a959d0 "") at pquery.c:1299
#18 0x00000000006e056c in PortalRun (portal=0x1e86900, count=9223372036854775807, isTopLevel=1 '\001', dest=0x1eec870, altdest=0x1eec870,
completionTag=0x7ffe82a959d0 "") at pquery.c:813
#19 0x00000000006de832 in exec_execute_message (argc=<value optimized out>, argv=<value optimized out>, dbname=0x1e933b8 "jjanes",
username=<value optimized out>) at postgres.c:1977
#20 PostgresMain (argc=<value optimized out>, argv=<value optimized out>, dbname=0x1e933b8 "jjanes", username=<value optimized out>) at postgres.c:4132
#21 0x000000000067e8a4 in BackendRun (argc=<value optimized out>, argv=<value optimized out>) at postmaster.c:4274
#22 BackendStartup (argc=<value optimized out>, argv=<value optimized out>) at postmaster.c:3946
#23 ServerLoop (argc=<value optimized out>, argv=<value optimized out>) at postmaster.c:1704
#24 PostmasterMain (argc=<value optimized out>, argv=<value optimized out>) at postmaster.c:1312
#25 0x0000000000606388 in main (argc=2, argv=0x1e68320) at main.c:228
Attached is the 'bt full' output.
Cheers,
Jeff
Вложения
On Wed, Dec 7, 2016 at 2:02 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Tue, Dec 6, 2016 at 4:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> On Tue, Dec 6, 2016 at 1:29 PM, Jeff Janes <jeff.janes@gmail.com> wrote: >> > >> > >> > I just occasionally insert a bunch of equal tuples, which have to be in >> > overflow pages no matter how much splitting happens. >> > >> > I am getting vacuum errors against HEAD, after about 20 minutes or so (8 >> > cores). >> > >> > 49233 XX002 2016-12-05 23:06:44.087 PST:ERROR: index "foo_index_idx" >> > contains unexpected zero page at block 64941 >> > 49233 XX002 2016-12-05 23:06:44.087 PST:HINT: Please REINDEX it. >> > 49233 XX002 2016-12-05 23:06:44.087 PST:CONTEXT: automatic vacuum of >> > table >> > "jjanes.public.foo" >> > >> >> Thanks for the report. This can happen due to vacuum trying to access >> a new page. Vacuum can do so if (a) the calculation for maxbuckets >> (in metapage) is wrong or (b) it is trying to free the overflow page >> twice. Offhand, I don't see that can happen in code. I will >> investigate further to see if there is any another reason why vacuum >> can access the new page. BTW, have you done the test after commit >> 2f4193c3, that doesn't appear to be the cause of this problem, but >> still, it is better to test after that fix. I am trying to reproduce >> the issue, but in the meantime, if by anychance, you have a callstack, >> then please share the same. > > > It looks like I compiled the code for testing a few minutes before 2f4193c3 > went in. > > I've run it again with cb9dcbc1eebd8, after promoting the ERROR in > _hash_checkpage, hashutil.c:174 to a PANIC so that I can get a coredump to > feed to gdb. > > This time it was an INSERT, not autovac, that got the error: > The reason for this and the similar error in vacuum was that in one of the corner cases after freeing the overflow page and updating the link for the previous bucket, we were not marking the buffer as dirty. So, due to concurrent activity, the buffer containing the updated links got evicted and then later when we tried to access the same buffer, it brought back the old copy which contains a link to freed overflow page. Apart from above issue, Kuntal has noticed that there is assertion failure (Assert(bucket == new_bucket);) in hashbucketcleanup with the same test as provided by you. The reason for that problem was that after deleting tuples in hashbucketcleanup, we were not marking the buffer as dirty due to which the old copy of the overflow page was re-appearing and causing that failure. After fixing the above problem, it has been noticed that there is another assertion failure (Assert(bucket == obucket);) in _hash_splitbucket_guts. The reason for this problem was that after the split, vacuum failed to remove tuples from the old bucket that are moved due to split. Now, during next split from the same old bucket, we don't expect old bucket to contain tuples from the previous split. To fix this whenever vacuum needs to perform split cleanup, it should update the metapage values (masks required to calculate bucket number), so that it shouldn't miss cleaning the tuples. I believe this is the same assertion what Andreas has reported in another thread [1]. The next problem we encountered is that after running the same test for somewhat longer, inserts were failing with error "unexpected zero page at block ..". After some analysis, I have found that the lock chain (lock next overflow bucket page before releasing the previous bucket page) was broken in one corner case in _hash_freeovflpage due to which insert went ahead than squeeze bucket operation and accessed the freed overflow page before the link for the same has been updated. With above fixes, the test ran successfully for more than a day. Many thanks to Kuntal and Dilip for helping me in analyzing and testing the fixes for these problems. [1] - https://www.postgresql.org/message-id/87y3zrzbu5.fsf_-_%40ansel.ydns.eu -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Sun, Dec 11, 2016 at 11:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Dec 7, 2016 at 2:02 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > > With above fixes, the test ran successfully for more than a day. > There was a small typo in the previous patch which is fixed in attached. I don't think it will impact the test results if you have already started the test with the previous patch, but if not, then it is better to test with attached. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Tue, Dec 6, 2016 at 1:29 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Thu, Dec 1, 2016 at 10:54 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: > > With the latest HASH WAL patch applied, I get different but apparently > related errors > > 41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:ERROR: index "foo_index_idx" > contains corrupted page at block 27602 > 41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:HINT: Please REINDEX it. > 41993 UPDATE XX002 2016-12-05 22:28:45.333 PST:STATEMENT: update foo set > count=count+1 where index=$1 > This is not the problem of WAL patch per se. It should be fixed with the hash index bug fix patch I sent upthread. However, after the bug fix patch, WAL patch needs to be rebased which I will do and send it after verification. In the meantime, it would be great if you can verify the fix posted. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sun, Dec 11, 2016 at 8:37 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Sun, Dec 11, 2016 at 11:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Wed, Dec 7, 2016 at 2:02 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
>
> With above fixes, the test ran successfully for more than a day.
>
There was a small typo in the previous patch which is fixed in
attached. I don't think it will impact the test results if you have
already started the test with the previous patch, but if not, then it
is better to test with attached.
Thanks, I've already been running the previous one for several hours, and so far it looks good. I've tried forward porting it to the WAL patch to test that as well, but didn't have any luck doing so.
Cheers,
Jeff
On Mon, Dec 12, 2016 at 10:25 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Sun, Dec 11, 2016 at 8:37 PM, Amit Kapila <amit.kapila16@gmail.com> > wrote: >> >> On Sun, Dec 11, 2016 at 11:54 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > On Wed, Dec 7, 2016 at 2:02 AM, Jeff Janes <jeff.janes@gmail.com> wrote: >> > >> > With above fixes, the test ran successfully for more than a day. >> > >> >> There was a small typo in the previous patch which is fixed in >> attached. I don't think it will impact the test results if you have >> already started the test with the previous patch, but if not, then it >> is better to test with attached. > > > Thanks, I've already been running the previous one for several hours, and > so far it looks good. > Thanks. > I've tried forward porting it to the WAL patch to > test that as well, but didn't have any luck doing so. > I think we can verify WAL patch separately. I am already working on it. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sun, Dec 11, 2016 at 1:24 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > The reason for this and the similar error in vacuum was that in one of > the corner cases after freeing the overflow page and updating the link > for the previous bucket, we were not marking the buffer as dirty. So, > due to concurrent activity, the buffer containing the updated links > got evicted and then later when we tried to access the same buffer, it > brought back the old copy which contains a link to freed overflow > page. > > Apart from above issue, Kuntal has noticed that there is assertion > failure (Assert(bucket == new_bucket);) in hashbucketcleanup with the > same test as provided by you. The reason for that problem was that > after deleting tuples in hashbucketcleanup, we were not marking the > buffer as dirty due to which the old copy of the overflow page was > re-appearing and causing that failure. > > After fixing the above problem, it has been noticed that there is > another assertion failure (Assert(bucket == obucket);) in > _hash_splitbucket_guts. The reason for this problem was that after > the split, vacuum failed to remove tuples from the old bucket that are > moved due to split. Now, during next split from the same old bucket, > we don't expect old bucket to contain tuples from the previous split. > To fix this whenever vacuum needs to perform split cleanup, it should > update the metapage values (masks required to calculate bucket > number), so that it shouldn't miss cleaning the tuples. > I believe this is the same assertion what Andreas has reported in > another thread [1]. > > The next problem we encountered is that after running the same test > for somewhat longer, inserts were failing with error "unexpected zero > page at block ..". After some analysis, I have found that the lock > chain (lock next overflow bucket page before releasing the previous > bucket page) was broken in one corner case in _hash_freeovflpage due > to which insert went ahead than squeeze bucket operation and accessed > the freed overflow page before the link for the same has been updated. > > With above fixes, the test ran successfully for more than a day. Instead of doing this: + _hash_chgbufaccess(rel, bucket_buf, HASH_WRITE, HASH_NOLOCK); + _hash_chgbufaccess(rel, bucket_buf, HASH_NOLOCK, HASH_WRITE); ...wouldn't it be better to just do MarkBufferDirty()? There's no real reason to release the lock only to reacquire it again, is there? I don't think we should be afraid to call MarkBufferDirty() instead of going through these (fairly stupid) hasham-specific APIs. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 13, 2016 at 2:51 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Dec 11, 2016 at 1:24 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> With above fixes, the test ran successfully for more than a day. > > Instead of doing this: > > + _hash_chgbufaccess(rel, bucket_buf, HASH_WRITE, HASH_NOLOCK); > + _hash_chgbufaccess(rel, bucket_buf, HASH_NOLOCK, HASH_WRITE); > > ...wouldn't it be better to just do MarkBufferDirty()? There's no > real reason to release the lock only to reacquire it again, is there? > The reason is to make the operations consistent in master and standby. In WAL patch, for clearing the SPLIT_CLEANUP flag, we write a WAL and if we don't release the lock after writing a WAL, the operation can appear on standby even before on master. Currently, without WAL, there is no benefit of doing so and we can fix by using MarkBufferDirty, however, I thought it might be simpler to keep it this way as this is required for enabling WAL. OTOH, we can leave that for WAL patch. Let me know which way you prefer? > I don't think we should be afraid to call MarkBufferDirty() instead of > going through these (fairly stupid) hasham-specific APIs. > Right and anyway we need to use it at many more call sites when we enable WAL for hash index. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 12/11/2016 11:37 PM, Amit Kapila wrote: > On Sun, Dec 11, 2016 at 11:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Wed, Dec 7, 2016 at 2:02 AM, Jeff Janes <jeff.janes@gmail.com> wrote: >> >> With above fixes, the test ran successfully for more than a day. >> > There was a small typo in the previous patch which is fixed in > attached. I don't think it will impact the test results if you have > already started the test with the previous patch, but if not, then it > is better to test with attached. > A mix work load (INSERT, DELETE and VACUUM primarily) is successful here too using _v2. Thanks ! Best regards, Jesper
On Mon, Dec 12, 2016 at 9:21 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > The reason is to make the operations consistent in master and standby. > In WAL patch, for clearing the SPLIT_CLEANUP flag, we write a WAL and > if we don't release the lock after writing a WAL, the operation can > appear on standby even before on master. Currently, without WAL, > there is no benefit of doing so and we can fix by using > MarkBufferDirty, however, I thought it might be simpler to keep it > this way as this is required for enabling WAL. OTOH, we can leave > that for WAL patch. Let me know which way you prefer? It's not required for enabling WAL. You don't *have* to release and reacquire the buffer lock; in fact, that just adds overhead. You *do* have to be aware that the standby will perhaps see the intermediate state, because it won't hold the lock throughout. But that does not mean that the master must release the lock. >> I don't think we should be afraid to call MarkBufferDirty() instead of >> going through these (fairly stupid) hasham-specific APIs. > > Right and anyway we need to use it at many more call sites when we > enable WAL for hash index. I propose the attached patch, which removes _hash_wrtbuf() and causes those functions which previously called it to do MarkBufferDirty() directly. Aside from hopefully fixing the bug we're talking about here, this makes the logic in several places noticeably less contorted. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Tue, Dec 13, 2016 at 11:30 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Mon, Dec 12, 2016 at 9:21 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> The reason is to make the operations consistent in master and standby. >> In WAL patch, for clearing the SPLIT_CLEANUP flag, we write a WAL and >> if we don't release the lock after writing a WAL, the operation can >> appear on standby even before on master. Currently, without WAL, >> there is no benefit of doing so and we can fix by using >> MarkBufferDirty, however, I thought it might be simpler to keep it >> this way as this is required for enabling WAL. OTOH, we can leave >> that for WAL patch. Let me know which way you prefer? > > It's not required for enabling WAL. You don't *have* to release and > reacquire the buffer lock; in fact, that just adds overhead. > If we don't release the lock, then it will break the general coding pattern of writing WAL (Acquire pin and an exclusive lock, Markbufferdirty, Write WAL, Release Lock). Basically, I think it is to ensure that we don't hold it for multiple atomic operations or in this case avoid calling MarkBufferDirty multiple times. > You *do* > have to be aware that the standby will perhaps see the intermediate > state, because it won't hold the lock throughout. But that does not > mean that the master must release the lock. > Okay, but I think that will be avoided to a great extent because we do follow the practice of releasing the lock immediately after writing the WAL. >>> I don't think we should be afraid to call MarkBufferDirty() instead of >>> going through these (fairly stupid) hasham-specific APIs. >> >> Right and anyway we need to use it at many more call sites when we >> enable WAL for hash index. > > I propose the attached patch, which removes _hash_wrtbuf() and causes > those functions which previously called it to do MarkBufferDirty() > directly. > It is possible that we can MarkBufferDirty multiple times (twice in hashbucketcleanup and then in _hash_squeezebucket) while holding the lock. I don't think that is a big problem as of now but wanted to avoid it as I thought we need it for WAL patch. > Aside from hopefully fixing the bug we're talking about > here, this makes the logic in several places noticeably less > contorted. > Yeah, it will fix the problem in hashbucketcleanup, but there are two other problems that need to be fixed for which I can send a separate patch. By the way, as mentioned to you earlier that WAL patch already takes care of removing _hash_wrtbuf and simplified the logic wherever possible without introducing the logic of MarkBufferDirty multiple times under one lock. However, if you want to proceed with the current patch, then I can send you separate patches for the remaining problems as addressed in bug fix patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Wed, Dec 14, 2016 at 4:27 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> It's not required for enabling WAL. You don't *have* to release and >> reacquire the buffer lock; in fact, that just adds overhead. > > If we don't release the lock, then it will break the general coding > pattern of writing WAL (Acquire pin and an exclusive lock, > Markbufferdirty, Write WAL, Release Lock). Basically, I think it is > to ensure that we don't hold it for multiple atomic operations or in > this case avoid calling MarkBufferDirty multiple times. I think you're being too pedantic. Yes, the general rule is to release the lock after each WAL record, but no harm comes if we take the lock, emit TWO WAL records, and then release it. > It is possible that we can MarkBufferDirty multiple times (twice in > hashbucketcleanup and then in _hash_squeezebucket) while holding the > lock. I don't think that is a big problem as of now but wanted to > avoid it as I thought we need it for WAL patch. I see no harm in calling MarkBufferDirty multiple times, either now or after the WAL patch. Of course we don't want to end up with tons of extra calls - it's not totally free - but it's pretty cheap. >> Aside from hopefully fixing the bug we're talking about >> here, this makes the logic in several places noticeably less >> contorted. > > Yeah, it will fix the problem in hashbucketcleanup, but there are two > other problems that need to be fixed for which I can send a separate > patch. By the way, as mentioned to you earlier that WAL patch already > takes care of removing _hash_wrtbuf and simplified the logic wherever > possible without introducing the logic of MarkBufferDirty multiple > times under one lock. However, if you want to proceed with the > current patch, then I can send you separate patches for the remaining > problems as addressed in bug fix patch. That sounds good. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 14, 2016 at 10:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Dec 14, 2016 at 4:27 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> >> Yeah, it will fix the problem in hashbucketcleanup, but there are two >> other problems that need to be fixed for which I can send a separate >> patch. By the way, as mentioned to you earlier that WAL patch already >> takes care of removing _hash_wrtbuf and simplified the logic wherever >> possible without introducing the logic of MarkBufferDirty multiple >> times under one lock. However, if you want to proceed with the >> current patch, then I can send you separate patches for the remaining >> problems as addressed in bug fix patch. > > That sounds good. > Attached are the two patches on top of remove-hash-wrtbuf. Patch fix_dirty_marking_v1.patch allows to mark the buffer dirty in one of the corner cases in _hash_freeovflpage() and avoids to mark dirty without need in _hash_squeezebucket(). I think this can be combined with remove-hash-wrtbuf patch. fix_lock_chaining_v1.patch fixes the chaining behavior (lock next overflow bucket page before releasing the previous bucket page) was broken in _hash_freeovflpage(). These patches can be applied in series, first remove-hash-wrtbuf, then fix_dirst_marking_v1.patch and then fix_lock_chaining_v1.patch. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Thu, Dec 15, 2016 at 11:33 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> Attached are the two patches on top of remove-hash-wrtbuf. Patch
> fix_dirty_marking_v1.patch allows to mark the buffer dirty in one of
> the corner cases in _hash_freeovflpage() and avoids to mark dirty
> without need in _hash_squeezebucket(). I think this can be combined
> with remove-hash-wrtbuf patch. fix_lock_chaining_v1.patch fixes the
> chaining behavior (lock next overflow bucket page before releasing the
> previous bucket page) was broken in _hash_freeovflpage(). These
> patches can be applied in series, first remove-hash-wrtbuf, then
> fix_dirst_marking_v1.patch and then fix_lock_chaining_v1.patch.
I committed remove-hash-wrtbuf and fix_dirty_marking_v1 but I've got
some reservations about fix_lock_chaining_v1. ISTM that the natural
fix here would be to change the API contract for _hash_freeovflpage so
that it doesn't release the lock on the write buffer. Why does it
even do that? I think that the only reason why _hash_freeovflpage
should be getting wbuf as an argument is so that it can handle the
case where wbuf happens to be the previous block correctly. Aside
from that there's no reason for it to touch wbuf. If you fix it like
that then you should be able to avoid this rather ugly wart:
* XXX Here, we are moving to next overflow page for writing without * ensuring if the previous write page is
full. This is annoying, but * should not hurt much in practice as that space will anyway be consumed * by future
inserts.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, Dec 16, 2016 at 9:57 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Dec 15, 2016 at 11:33 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> Attached are the two patches on top of remove-hash-wrtbuf. Patch >> fix_dirty_marking_v1.patch allows to mark the buffer dirty in one of >> the corner cases in _hash_freeovflpage() and avoids to mark dirty >> without need in _hash_squeezebucket(). I think this can be combined >> with remove-hash-wrtbuf patch. fix_lock_chaining_v1.patch fixes the >> chaining behavior (lock next overflow bucket page before releasing the >> previous bucket page) was broken in _hash_freeovflpage(). These >> patches can be applied in series, first remove-hash-wrtbuf, then >> fix_dirst_marking_v1.patch and then fix_lock_chaining_v1.patch. > > I committed remove-hash-wrtbuf and fix_dirty_marking_v1 but I've got > some reservations about fix_lock_chaining_v1. ISTM that the natural > fix here would be to change the API contract for _hash_freeovflpage so > that it doesn't release the lock on the write buffer. Why does it > even do that? I think that the only reason why _hash_freeovflpage > should be getting wbuf as an argument is so that it can handle the > case where wbuf happens to be the previous block correctly. > Yeah, as of now that is the only case, but for WAL patch, I think we need to ensure that the action of moving all the tuples to the page being written and the overflow page being freed needs to be logged together as an atomic operation. Now apart from that, it is theoretically possible that write page will remain locked for multiple overflow pages being freed (when the page being written has enough space that it can accommodate tuples from multiple overflow pages). I am not sure if it is worth worrying about such a case because practically it might happen rarely. So, I have prepared a patch to retain a lock on wbuf in _hash_freeovflpage() as suggested by you. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Sun, Dec 18, 2016 at 8:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I committed remove-hash-wrtbuf and fix_dirty_marking_v1 but I've got >> some reservations about fix_lock_chaining_v1. ISTM that the natural >> fix here would be to change the API contract for _hash_freeovflpage so >> that it doesn't release the lock on the write buffer. Why does it >> even do that? I think that the only reason why _hash_freeovflpage >> should be getting wbuf as an argument is so that it can handle the >> case where wbuf happens to be the previous block correctly. > > Yeah, as of now that is the only case, but for WAL patch, I think we > need to ensure that the action of moving all the tuples to the page > being written and the overflow page being freed needs to be logged > together as an atomic operation. Not really. We can have one operation that empties the overflow page and another that unlinks it and makes it free. > Now apart from that, it is > theoretically possible that write page will remain locked for multiple > overflow pages being freed (when the page being written has enough > space that it can accommodate tuples from multiple overflow pages). I > am not sure if it is worth worrying about such a case because > practically it might happen rarely. So, I have prepared a patch to > retain a lock on wbuf in _hash_freeovflpage() as suggested by you. Committed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Dec 19, 2016 at 11:05 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Sun, Dec 18, 2016 at 8:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> I committed remove-hash-wrtbuf and fix_dirty_marking_v1 but I've got >>> some reservations about fix_lock_chaining_v1. ISTM that the natural >>> fix here would be to change the API contract for _hash_freeovflpage so >>> that it doesn't release the lock on the write buffer. Why does it >>> even do that? I think that the only reason why _hash_freeovflpage >>> should be getting wbuf as an argument is so that it can handle the >>> case where wbuf happens to be the previous block correctly. >> >> Yeah, as of now that is the only case, but for WAL patch, I think we >> need to ensure that the action of moving all the tuples to the page >> being written and the overflow page being freed needs to be logged >> together as an atomic operation. > > Not really. We can have one operation that empties the overflow page > and another that unlinks it and makes it free. > We have mainly four actions for squeeze operation, add tuples to the write page, empty overflow page, unlinks overflow page, make it free by setting the corresponding bit in overflow page. Now, if we don't log the changes to write page and freeing of overflow page as one operation, then won't query on standby can either see duplicate tuples or miss the tuples which are freed in overflow page. >> Now apart from that, it is >> theoretically possible that write page will remain locked for multiple >> overflow pages being freed (when the page being written has enough >> space that it can accommodate tuples from multiple overflow pages). I >> am not sure if it is worth worrying about such a case because >> practically it might happen rarely. So, I have prepared a patch to >> retain a lock on wbuf in _hash_freeovflpage() as suggested by you. > > Committed. > Thanks. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Dec 20, 2016 at 4:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > We have mainly four actions for squeeze operation, add tuples to the > write page, empty overflow page, unlinks overflow page, make it free > by setting the corresponding bit in overflow page. Now, if we don't > log the changes to write page and freeing of overflow page as one > operation, then won't query on standby can either see duplicate tuples > or miss the tuples which are freed in overflow page. No, I think you could have two operations: 1. Move tuples from the "read" page to the "write" page. 2. Unlink the overflow page from the chain and mark it free. If we fail after step 1, the bucket chain might end with an empty overflow page, but that's OK. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 20, 2016 at 7:11 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Dec 20, 2016 at 4:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> We have mainly four actions for squeeze operation, add tuples to the >> write page, empty overflow page, unlinks overflow page, make it free >> by setting the corresponding bit in overflow page. Now, if we don't >> log the changes to write page and freeing of overflow page as one >> operation, then won't query on standby can either see duplicate tuples >> or miss the tuples which are freed in overflow page. > > No, I think you could have two operations: > > 1. Move tuples from the "read" page to the "write" page. > > 2. Unlink the overflow page from the chain and mark it free. > > If we fail after step 1, the bucket chain might end with an empty > overflow page, but that's OK. > If there is an empty page in bucket chain, access to that page will give an error (In WAL patch we are initializing the page instead of making it completely empty, so we might not see an error in such a case). What advantage do you see by splitting the operation? Anyway, I think it is better to discuss this in WAL patch thread. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Dec 20, 2016 at 9:01 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Dec 20, 2016 at 7:11 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Dec 20, 2016 at 4:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> We have mainly four actions for squeeze operation, add tuples to the >>> write page, empty overflow page, unlinks overflow page, make it free >>> by setting the corresponding bit in overflow page. Now, if we don't >>> log the changes to write page and freeing of overflow page as one >>> operation, then won't query on standby can either see duplicate tuples >>> or miss the tuples which are freed in overflow page. >> >> No, I think you could have two operations: >> >> 1. Move tuples from the "read" page to the "write" page. >> >> 2. Unlink the overflow page from the chain and mark it free. >> >> If we fail after step 1, the bucket chain might end with an empty >> overflow page, but that's OK. > > If there is an empty page in bucket chain, access to that page will > give an error (In WAL patch we are initializing the page instead of > making it completely empty, so we might not see an error in such a > case). It wouldn't be a new, uninitialized page. It would be empty of tuples, not all-zeroes. > What advantage do you see by splitting the operation? It's simpler. The code here is very complicated and trying to merge too many things into a single operation may make it even more complicated, increasing the risk of bugs and making the code hard to maintain without necessarily buying much performance. > Anyway, I think it is better to discuss this in WAL patch thread. OK. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 20, 2016 at 7:44 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Dec 20, 2016 at 9:01 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Tue, Dec 20, 2016 at 7:11 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Tue, Dec 20, 2016 at 4:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> We have mainly four actions for squeeze operation, add tuples to the >>>> write page, empty overflow page, unlinks overflow page, make it free >>>> by setting the corresponding bit in overflow page. Now, if we don't >>>> log the changes to write page and freeing of overflow page as one >>>> operation, then won't query on standby can either see duplicate tuples >>>> or miss the tuples which are freed in overflow page. >>> >>> No, I think you could have two operations: >>> >>> 1. Move tuples from the "read" page to the "write" page. >>> >>> 2. Unlink the overflow page from the chain and mark it free. >>> >>> If we fail after step 1, the bucket chain might end with an empty >>> overflow page, but that's OK. >> >> If there is an empty page in bucket chain, access to that page will >> give an error (In WAL patch we are initializing the page instead of >> making it completely empty, so we might not see an error in such a >> case). > > It wouldn't be a new, uninitialized page. It would be empty of > tuples, not all-zeroes. > AFAIU we initialize page as all-zeros, but I think you are envisioning that we need to change it to a new uninitialized page. >> What advantage do you see by splitting the operation? > > It's simpler. The code here is very complicated and trying to merge > too many things into a single operation may make it even more > complicated, increasing the risk of bugs and making the code hard to > maintain without necessarily buying much performance. > Sure, if you find that way better, then we can change it, but the current patch treats it as a single operation. If after looking the patch you find it is better to change it into two operations, I will do so. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com