Обсуждение: Move PinBuffer and UnpinBuffer to atomics
Hello hackers! Continuing the theme: http://www.postgresql.org/message-id/3368228.mTSz6V0Jsq@dinodell This time, we fairly rewrote 'refcount' and 'usage_count' to atomic in PinBuffer and UnpinBuffer (but save lock for buffer flags in Unpin). In the same time it doesn't affect to correctness of buffer manager because that variables already have LWLock on top of them (for partition of hashtable). If someone pinned buffer after the call StrategyGetBuffer we just try again (in BufferAlloc). Also in the code there is one more check before deleting the old buffer, where changes can be rolled back. The other functions where it is checked 'refcount' and 'usage_count' put exclusive locks. Also stress test with 256 KB shared memory ended successfully. Without patch we have 417523 TPS and with patch 965821 TPS for big x86 server. All details here: https://gist.github.com/stalkerg/773a81b79a27b4d5d63f Thank you. -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
Hi, On 2015-09-11 13:23:24 +0300, YUriy Zhuravlev wrote: > Continuing the theme: http://www.postgresql.org/message-id/3368228.mTSz6V0Jsq@dinodell Please don't just start new threads for a new version of the patch. > This time, we fairly rewrote 'refcount' and 'usage_count' to atomic in > PinBuffer and UnpinBuffer (but save lock for buffer flags in Unpin). Hm. > In the same time it doesn't affect to correctness of buffer manager > because that variables already have LWLock on top of them (for partition of > hashtable). Note that there's a pending patch that removes the buffer mapping locks entirely. > If someone pinned buffer after the call StrategyGetBuffer we just try > again (in BufferAlloc). Also in the code there is one more check > before deleting the old buffer, where changes can be rolled back. The > other functions where it is checked 'refcount' and 'usage_count' put > exclusive locks. I don't think this is correct. This way we can leave the for (;;) loop in BufferAlloc() thinking that the buffer is unused (and can't be further pinned because of the held spinlock!) while it actually has been pinned since by PinBuffer(). Additionally oldFlags can get out of sync there. I don't think the approach of making some of the fields atomics but not really caring about the rest is going to work. My suggestion is to add a single 'state' 32bit atomic. This 32bit state is subdivided into: 10bit for flags, 3bit for usage_count, 16bit for refcount then turn each operation that currently uses one of these fields into corresponding accesses (just different values for flags, bit-shiftery & mask for reading usage count, bit mask for reading refcount). The trick then is to add a *new* flag value BM_LOCKED. This can then act as a sort of a 'one bit' spinlock. That should roughly look like (more or less pseudocode): void LockBufHdr(BufferDesc *desc) { int state = pg_atomic_read_u32(&desc->state); for (;;) { /* wait till lock is free */ while (unlikely(state & BM_LOCKED)) { pg_spin_delay(); state = pg_atomic_read_u32(&desc->state); /* add exponential backoff? Should seldomly be contended tho. */ } /* and try to get lock */ if (pg_atomic_compare_exchange_u32(&desc->state, &state, state | BM_LOCKED)) break; } } static bool PinBuffer(volatile BufferDesc *buf, BufferAccessStrategy strategy) { ... if (ref == NULL) { ReservePrivateRefCountEntry(); ref = NewPrivateRefCountEntry(b); ... int state = pg_atomic_read_u32(&desc->state); int oldstate = state; while (true) { /* spin-wait till lock is free */ while (unlikely(state & BM_LOCKED)) { pg_spin_delay(); state = pg_atomic_read_u32(&desc->state); } /* increase refcount */ state += 1; /* increase usagecount unless already max */ if ((state & USAGE_COUNT_MASK) != BM_MAX_USAGE_COUNT) state += BM_USAGE_COUNT_ONE; result = (state & BM_VALID) != 0; if (pg_atomic_compare_exchange_u32(&desc->state, &oldstate, state)) break; /* get ready for next loop, oldstate has been updated by cas */ state = oldstate; } ... } other callsites can either just plainly continue to use LockBufHdr/UnlockBufHdr or converted similarly to PinBuffer(). Greetings, Andres Freund
On 11 September 2015 at 22:23, YUriy Zhuravlev <u.zhuravlev@postgrespro.ru> wrote:
Without patch we have 417523 TPS and with patch 965821 TPS for big x86 server.
All details here: https://gist.github.com/stalkerg/773a81b79a27b4d5d63f
Impressive!
I've run this on a single CPU server and don't see any speedup, so I assume I'm not getting enough contention.
As soon as our 4 socket machine is free I'll try a pgbench run with that.
Just for fun, what's the results if you use -M prepared ?
Regards
David Rowley
--
David Rowley http://www.2ndQuadrant.com/
David Rowley http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
On Friday 11 September 2015 18:14:21 Andres Freund wrote: > This way we can leave the for (;;) loop > in BufferAlloc() thinking that the buffer is unused (and can't be further > pinned because of the held spinlock!) We lost lock after PinBuffer_Locked in BufferAlloc. Therefore, in essence, nothing has changed. -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2015-09-11 19:33:26 +0300, YUriy Zhuravlev wrote:
> On Friday 11 September 2015 18:14:21 Andres Freund wrote:
> > This way we can leave the for (;;) loop
> > in BufferAlloc() thinking that the buffer is unused (and can't be further
> > pinned because of the held spinlock!)
>
> We lost lock after PinBuffer_Locked in BufferAlloc. Therefore, in essence,
> nothing has changed.
The relevant piece of code is: /* * Need to lock the buffer header too in order to change its tag. */
LockBufHdr(buf);
/* * Somebody could have pinned or re-dirtied the buffer while we were * doing the I/O and making the new
hashtableentry. If so, we can't * recycle this buffer; we must undo everything we've done and start * over
witha new victim buffer. */ oldFlags = buf->flags; if (buf->refcount == 1 && !(oldFlags & BM_DIRTY))
break;
UnlockBufHdr(buf); BufTableDelete(&newTag, newHash); if ((oldFlags & BM_TAG_VALID) && oldPartitionLock
!=newPartitionLock) LWLockRelease(oldPartitionLock); LWLockRelease(newPartitionLock); UnpinBuffer(buf,
true);}
/* * Okay, it's finally safe to rename the buffer. * * Clearing BM_VALID here is necessary, clearing the dirtybits is
just* paranoia. We also reset the usage_count since any recency of use of * the old content is no longer relevant.
(Theusage_count starts out at * 1 so that the buffer can survive one clock-sweep pass.) */buf->tag = newTag;buf->flags
&=~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED | BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT);if (relpersistence ==
RELPERSISTENCE_PERMANENT) buf->flags |= BM_TAG_VALID | BM_PERMANENT;else buf->flags |=
BM_TAG_VALID;buf->usage_count= 1;
UnlockBufHdr(buf);
so unless I'm missing something, no, we haven't lost the lock.
Greetings,
Andres Freund
On Friday 11 September 2015 18:37:00 you wrote: > so unless I'm missing something, no, we haven't lost the lock. This section is protected by like LWLockAcquire(newPartitionLock, LW_EXCLUSIVE); before it (and we can't get this buffer from hash table). -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2015-09-11 19:46:02 +0300, YUriy Zhuravlev wrote: > On Friday 11 September 2015 18:37:00 you wrote: > > so unless I'm missing something, no, we haven't lost the lock. > This section is protected by like LWLockAcquire(newPartitionLock, > LW_EXCLUSIVE); before it (and we can't get this buffer from hash table). a) As I said upthread there's a patch to remove these locks entirely b) It doesn't matter anyway. Not every pin goes through the buffer mapping table. StrategyGetBuffer(), SyncOneBuffer(),... Greetings, Andres Freund
On Friday 11 September 2015 18:50:35 you wrote: > a) As I said upthread there's a patch to remove these locks entirely It is very interesting. Could you provide a link? And it's not very good, since there is a bottleneck PinBuffer / UnpinBuffer instead of LWLocks. > b) It doesn't matter anyway. Not every pin goes through the buffer > mapping table. StrategyGetBuffer(), SyncOneBuffer(), ... StrategyGetBuffer call only from BufferAlloc . SyncOneBuffer not problem too because: PinBuffer_Locked(bufHdr); LWLockAcquire(bufHdr->content_lock, LW_SHARED); And please read comment before LockBufHdr(bufHdr) in SyncOneBuffer. We checked all functions with refcount and usage_count. Thanks! ^_^ -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2015-09-14 13:16:46 +0300, YUriy Zhuravlev wrote: > On Friday 11 September 2015 18:50:35 you wrote: > > a) As I said upthread there's a patch to remove these locks entirely > It is very interesting. Could you provide a link? http://archives.postgresql.org/message-id/CA%2BTgmoYE4t-Pt%2Bv08kMO5u_XN-HNKBWtfMgcUXEGBrQiVgdV9Q%40mail.gmail.com > And it's not very good, > since there is a bottleneck PinBuffer / UnpinBuffer instead of > LWLocks. Where the bottleneck is entirely depends on your workload. If you have a high cache replacement ratio the mapping partition locks are frequently going to be held exclusively. > > b) It doesn't matter anyway. Not every pin goes through the buffer > > mapping table. StrategyGetBuffer(), SyncOneBuffer(), ... > StrategyGetBuffer call only from BufferAlloc . It gets called without buffer mapping locks held. And it can (and frequently will!) access all the buffers in the buffer pool. > SyncOneBuffer not problem too because: > PinBuffer_Locked(bufHdr); Which you made ineffective because PinBuffer() doesn't take a lock anymore. Mutual exclusion through locks only works if all participants take the locks. > We checked all functions with refcount and usage_count. Adding lockless behaviour by just taking out locks without analyzing the whole isn't going to fly. You either need to provide backward compatibility (a LockBuffer that provides actual exclusion) or you actually need to go carefully through all relevant code and make it lock-free. I pointed out how you can actually make this safely lock-free giving you the interesting code. Greetings, Andres Freund
On 2015-09-14 17:41:42 +0200, Andres Freund wrote: > I pointed out how you can actually make this safely lock-free giving you > the interesting code. And here's an actual implementation of that approach. It's definitely work-in-progress and could easily be optimized further. Don't have any big machines to play around with right now tho. Andres
Вложения
On Tuesday 15 September 2015 04:06:25 Andres Freund wrote: > And here's an actual implementation of that approach. It's definitely > work-in-progress and could easily be optimized further. Don't have any > big machines to play around with right now tho. Thanks. Interesting. We had a version like your patch. But this is only half the work. Example: state = pg_atomic_read_u32(&buf->state); if ((state & BUF_REFCOUNT_MASK) == 0 && (state & BUF_USAGECOUNT_MASK) == 0) After the first command somebody can change buf->state and local state not actual. In this embodiment, there is no significant difference between the two patches. For honest work will need used the CAS for all IF statement. Thanks! Hope for understanding. ^_^ -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Saturday 12 September 2015 04:15:43 David Rowley wrote: > I've run this on a single CPU server and don't see any speedup, so I assume > I'm not getting enough contention. > As soon as our 4 socket machine is free I'll try a pgbench run with that. Excellent! Will wait. > Just for fun, what's the results if you use -M prepared ? Unfortunately now we can not check. :( -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Sep 14, 2015 at 9:06 PM, Andres Freund <andres@anarazel.de> wrote: > On 2015-09-14 17:41:42 +0200, Andres Freund wrote: >> I pointed out how you can actually make this safely lock-free giving you >> the interesting code. > > And here's an actual implementation of that approach. It's definitely > work-in-progress and could easily be optimized further. Don't have any > big machines to play around with right now tho. Are you confident this is faster across all workloads? Pin/Unpin are probably faster but this comes at a cost of extra atomic ops during the clock sweep loop. I wonder if this will degrade results under heavy contention. Also, I'm curious about your introduction of __builtin_expect() macros. Did you measure any gain from them? I bet there are other places they could be used -- for example the mvcc hint bit checks on xmin. merlin
On 2015-09-15 12:51:24 +0300, YUriy Zhuravlev wrote: > We had a version like your patch. But this is only half the work. Example: > state = pg_atomic_read_u32(&buf->state); > if ((state & BUF_REFCOUNT_MASK) == 0 > && (state & BUF_USAGECOUNT_MASK) == 0) > After the first command somebody can change buf->state and local state not > actual. No, they can't in a a relevant manner. We hold the buffer header lock. > In this embodiment, there is no significant difference between the two > patches. For honest work will need used the CAS for all IF statement. What? > Thanks! Hope for understanding. ^_^ There's pretty little understanding left at this point. You're posting things for review and you seem completely unwilling to actually respond to points raised. Greetings, Andres Freund
On 2015-09-15 08:07:57 -0500, Merlin Moncure wrote: > Are you confident this is faster across all workloads? No. This is a proof of concept I just wrote & posted because I didn't see the patch moving in the right direction. But I do think it can be made faster in all relevant workloads. > Pin/Unpin are probably faster but this comes at a cost of extra atomic > ops during the clock sweep loop. I wonder if this will degrade > results under heavy contention. I think it's actually going to be faster under contention, and the situation where it's slower is uncontended workloads where you a very very low cache hit ratio. > Also, I'm curious about your introduction of __builtin_expect() > macros. Did you measure any gain from them? I introduced them because I was bothered by the generated assembler ;) But a bit more seriously, I do think there's some benefit in influencing the code like that. I personally also find they *increase* readability in cases like this where the likely() branch should be taken just about all the time. > I bet there are other places they could be used -- for example the > mvcc hint bit checks on xmin. I don't think those are good candidates, there's too many cases where it's common to have the majority of cases go the other way. Greetings, Andres Freund
On Tue, Sep 15, 2015 at 9:56 AM, Andres Freund <andres@anarazel.de> wrote: > On 2015-09-15 08:07:57 -0500, Merlin Moncure wrote: >> Also, I'm curious about your introduction of __builtin_expect() >> macros. Did you measure any gain from them? > > I introduced them because I was bothered by the generated assembler ;) > > But a bit more seriously, I do think there's some benefit in influencing > the code like that. I personally also find they *increase* readability > in cases like this where the likely() branch should be taken just about > all the time. right. For posterity, I agree with this. >> I bet there are other places they could be used -- for example the >> mvcc hint bit checks on xmin. > > I don't think those are good candidates, there's too many cases where > it's common to have the majority of cases go the other way. Maybe, but, consider that penalty vs win is asymmetric. If the hint bit isn't set, you're doing a lot of other work anyways such that the branch penalty falls away to noise while if you win the benefits are significant against the tight tuple scan loop. Anyways, as it pertains to *this* patch, +1 for adding that feature. merlin
On Tuesday 15 September 2015 16:50:44 Andres Freund wrote: > No, they can't in a a relevant manner. We hold the buffer header lock. I'm sorry, I did not notice of a LockBufHdr. In this embodiment, your approach seems to be very similar to s_lock. Cycle in PinBuffer behaves like s_lock. In LockBufHdr: if (pg_atomic_compare_exchange_u32(&desc->state, &state, state | BM_LOCKED)) conflict with: while (unlikely(state & BM_LOCKED)) from PinBuffer. Thus your patch does not remove the problem of competition for PinBuffer. We will try check your patch this week. >You're posting >things for review and you seem completely unwilling to actually respond >to points raised. I think we're just talking about different things. -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2015-09-15 19:43:28 +0300, YUriy Zhuravlev wrote: > On Tuesday 15 September 2015 16:50:44 Andres Freund wrote: > > No, they can't in a a relevant manner. We hold the buffer header lock. > I'm sorry, I did not notice of a LockBufHdr. > > In this embodiment, your approach seems to be very similar to s_lock. Cycle in > PinBuffer behaves like s_lock. > In LockBufHdr: > if (pg_atomic_compare_exchange_u32(&desc->state, &state, state | BM_LOCKED)) > > conflict with: > while (unlikely(state & BM_LOCKED)) > from PinBuffer. > Thus your patch does not remove the problem of competition for PinBuffer. > We will try check your patch this week. That path is only taken if somebody else has already locked the buffer (e.g. BufferAlloc()). If you have contention in PinBuffer() your workload will be mostly cache resident and neither PinBuffer() nor UnpinBuffer() set BM_LOCKED. Greetings, Andres Freund
> That path is only taken if somebody else has already locked the buffer > (e.g. BufferAlloc()). If you have contention in PinBuffer() your > workload will be mostly cache resident and neither PinBuffer() nor > UnpinBuffer() set BM_LOCKED. Thanks. Now I understand everything. It might work. We will be tested. >your workload Simple pgbench -S for NUMA. -- YUriy Zhuravlev Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 2015-09-15 20:16:10 +0300, YUriy Zhuravlev wrote: > We will be tested. Did you have a chance to run some benchmarks? Andres
On Thu, Sep 24, 2015 at 6:32 PM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2015-09-15 20:16:10 +0300, YUriy Zhuravlev wrote:
> We will be tested.
Did you have a chance to run some benchmarks?
Yes, we now have 60 physical cores intel server and we're running benchmarks on it.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Thu, Sep 24, 2015 at 6:36 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Thu, Sep 24, 2015 at 6:32 PM, Andres Freund <andres@anarazel.de> wrote:On 2015-09-15 20:16:10 +0300, YUriy Zhuravlev wrote:
> We will be tested.
Did you have a chance to run some benchmarks?Yes, we now have 60 physical cores intel server and we're running benchmarks on it.
We got a consensus with Andres that we should commit the CAS version first and look to other optimizations.
Refactored version of atomic state patch is attached. The changes are following:
1) Macros are used for access refcount and usagecount.
2) likely/unlikely were removed. I think introducing of likely/unlikely should be a separate patch since it touches portability. Also, I didn't see any performance effect of this.
3) LockBufHdr returns the state after taking lock. Without using atomic increments it still can save some loops on skip atomic value reading.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Thu, Oct 29, 2015 at 8:18 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Thu, Sep 24, 2015 at 6:36 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Thu, Sep 24, 2015 at 6:32 PM, Andres Freund <andres@anarazel.de> wrote:On 2015-09-15 20:16:10 +0300, YUriy Zhuravlev wrote:
> We will be tested.
Did you have a chance to run some benchmarks?Yes, we now have 60 physical cores intel server and we're running benchmarks on it.We got a consensus with Andres that we should commit the CAS version first and look to other optimizations.Refactored version of atomic state patch is attached. The changes are following:1) Macros are used for access refcount and usagecount.2) likely/unlikely were removed. I think introducing of likely/unlikely should be a separate patch since it touches portability. Also, I didn't see any performance effect of this.3) LockBufHdr returns the state after taking lock. Without using atomic increments it still can save some loops on skip atomic value reading.
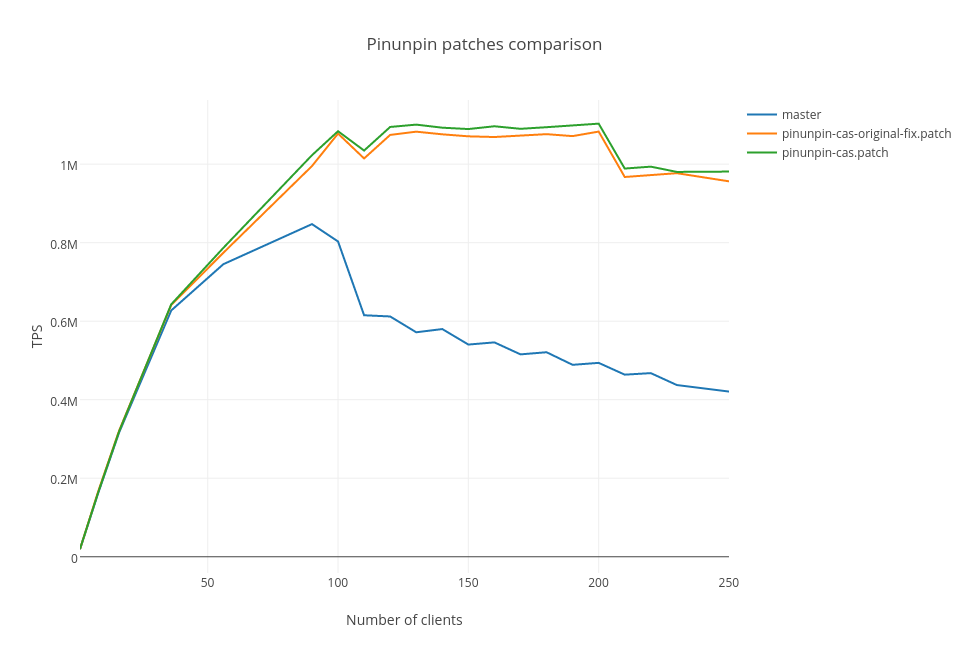
pinunpin-cas-original-fix.patch is just original patch by Andres Freund with fixed bug which causes hang.
Performance comparison on 72-cores Intel server in attached. On this machine we see no regression in version of patch in previous letter.
------
Вложения
{kind=link}
Hi, Thanks for benchmarking! On 2015-10-30 16:28:22 +0300, Alexander Korotkov wrote: > pinunpin-cas-original-fix.patch is just original patch by Andres Freund > with fixed bug which causes hang. > Performance comparison on 72-cores Intel server in attached. On this > machine we see no regression in version of patch in previous letter. So pinunpin-cas-original-fix is my version with a bug fixed, and pinunpin-cas is what exactly? Your earlier version with the xadd + cmpxchg? The results look pretty good. Could you give a few more details about the hardware and workload (i.e. cpu model number + scale)? So the plan would be to finish cleaning this up into a committable shape? Greetings, Andres Freund
Hi!
On Fri, Oct 30, 2015 at 5:12 PM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2015-10-30 16:28:22 +0300, Alexander Korotkov wrote:
> pinunpin-cas-original-fix.patch is just original patch by Andres Freund
> with fixed bug which causes hang.
> Performance comparison on 72-cores Intel server in attached. On this
> machine we see no regression in version of patch in previous letter.
So pinunpin-cas-original-fix is my version with a bug fixed, and
pinunpin-cas is what exactly? Your earlier version with the xadd +
cmpxchg?
pinunpin-cas is still just cmpxchg with no xadd. It contain just minor changes:
Refactored version of atomic state patch is attached. The changes are following:
1) Macros are used for access refcount and usagecount.
2) likely/unlikely were removed. I think introducing of likely/unlikely should be a separate patch since it touches portability. Also, I didn't see any performance effect of this.
3) LockBufHdr returns the state after taking lock. Without using atomic increments it still can save some loops on skip atomic value reading.
I compare them just to show there is no regression because of these changes.
The results look pretty good. Could you give a few more details about
the hardware and workload (i.e. cpu model number + scale)?
It is 4 socket Intel(R) Xeon(R) CPU E7-8890 v3 @ 2.50GHz, 2 Tb of memory, all data in shared_buffers, 1000 scale factor, -M prepared, pgbench runs on the same maching through unix socket.
So the plan would be to finish cleaning this up into a committable
shape?
Yes.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
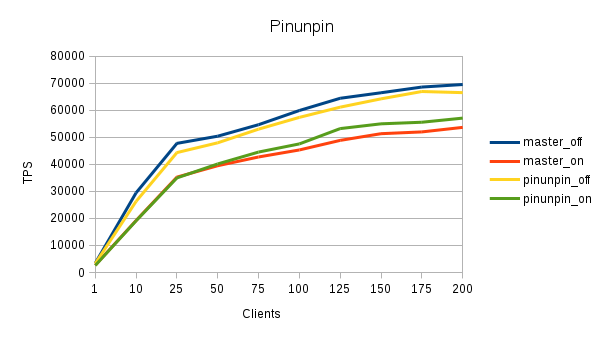
On 10/29/2015 01:18 PM, Alexander Korotkov wrote: > We got a consensus with Andres that we should commit the CAS version first > and look to other optimizations. > Refactored version of atomic state patch is attached. The changes are > following: > 1) Macros are used for access refcount and usagecount. > 2) likely/unlikely were removed. I think introducing of likely/unlikely > should be a separate patch since it touches portability. Also, I didn't see > any performance effect of this. > 3) LockBufHdr returns the state after taking lock. Without using atomic > increments it still can save some loops on skip atomic value reading. > I have been testing this on a smaller system than yours - 2 socket Intel(R) Xeon(R) CPU E5-2683 v3 w/ 2 x RAID10 SSD disks (data + xlog), so focused on a smaller number of clients. While I saw an improvement for the 'synchronous_commit = on' case - there is a small regression for 'off', using -M prepared + Unix Domain Socket. If that is something that should be considered right now. Maybe it is worth to update the README to mention that the flags are maintained in an atomic uint32 now. BTW, there are two CommitFest entries for this submission: https://commitfest.postgresql.org/7/370/ https://commitfest.postgresql.org/7/408/ Best regards, Jesper
Вложения
{kind=link}
Hi, On November 6, 2015 9:31:37 PM GMT+01:00, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: >I have been testing this on a smaller system than yours - 2 socket >Intel(R) Xeon(R) CPU E5-2683 v3 w/ 2 x RAID10 SSD disks (data + xlog), >so focused on a smaller number of clients. Thanks for running tests! >While I saw an improvement for the 'synchronous_commit = on' case - >there is a small regression for 'off', using -M prepared + Unix Domain >Socket. If that is something that should be considered right now. What tests where you running, in which order? I presume it's a read/write pgbench? What scale, shared buffers? I right now can't see any reason sc on/off should be relevant for the patch. Could it be an artifact of the order you rantests in? Did you initdb between tests? Pgbench -i? Restart the database? Andres --- Please excuse brevity and formatting - I am writing this on my mobile phone.
Hi, On 11/06/2015 03:38 PM, Andres Freund wrote: >> While I saw an improvement for the 'synchronous_commit = on' case - >> there is a small regression for 'off', using -M prepared + Unix Domain >> Socket. If that is something that should be considered right now. > > What tests where you running, in which order? I presume it's a read/write pgbench? What scale, shared buffers? > Scale is 3000, and shared buffer is 64Gb, effective is 160Gb. Order was master/off -> master/on -> pinunpin/off -> pinunpin/on. > I right now can't see any reason sc on/off should be relevant for the patch. Could it be an artifact of the order you rantests in? > I was puzzled too, hence the post. > Did you initdb between tests? Pgbench -i? Restart the database? I didn't initdb / pgbench -i between the tests, so that it is likely it. I'll redo. Best regards, Jesper
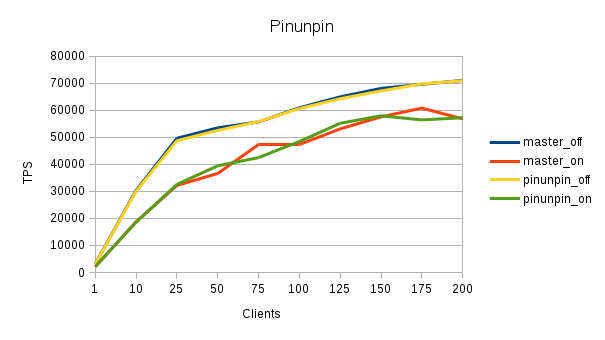
Hi, On 11/06/2015 03:47 PM, Jesper Pedersen wrote: >> Did you initdb between tests? Pgbench -i? Restart the database? > > I didn't initdb / pgbench -i between the tests, so that it is likely it. > Each graph has a full initdb + pgbench -i cycle now. I know, I have a brown paper bag somewhere. Best regards, Jesper
Вложения
{kind=link}
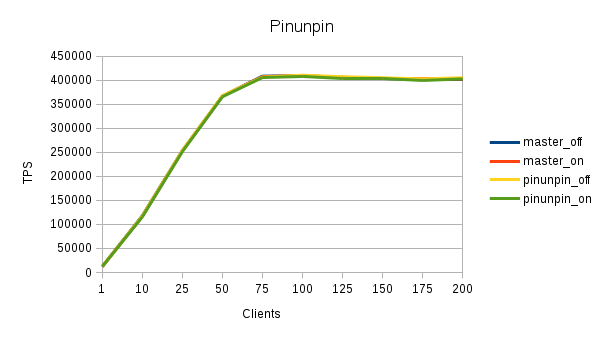
On 2015-11-09 11:54:59 -0500, Jesper Pedersen wrote: > Hi, > > On 11/06/2015 03:47 PM, Jesper Pedersen wrote: > >>Did you initdb between tests? Pgbench -i? Restart the database? > > > >I didn't initdb / pgbench -i between the tests, so that it is likely it. > > > > Each graph has a full initdb + pgbench -i cycle now. That looks about as we'd expect: the lock-free pinning doesn't matter and ssynchronous commit is beneficial. I think our bottlenecks in write workloads are sufficiently elsewhere that it's unlikely that buffer pins make a lot of difference. You could try a readonly pgbench workload (i.e. -S), to see whether a difference is visible there. For a pgbench -S workload it's more likely that you only see significant contention on larger machines. If you've a workload that touches more cached buffers, it'd be visible earlier. > I know, I have a brown paper bag somewhere. Why? This looks as expected, and the issues from the previous run were easy to make mistakes? Greetings, Andres Freund
Hi, On 11/09/2015 05:10 PM, Andres Freund wrote: >> Each graph has a full initdb + pgbench -i cycle now. > > That looks about as we'd expect: the lock-free pinning doesn't matter > and ssynchronous commit is beneficial. I think our bottlenecks in write > workloads are sufficiently elsewhere that it's unlikely that buffer pins > make a lot of difference. > Using https://commitfest.postgresql.org/7/373/ shows that the CLog queue is max'ed out on the number of client connections. > You could try a readonly pgbench workload (i.e. -S), to see whether a > difference is visible there. For a pgbench -S workload it's more likely > that you only see significant contention on larger machines. If you've a > workload that touches more cached buffers, it'd be visible earlier. > Yeah, basically no difference between the 4 -S runs on this setup. >> I know, I have a brown paper bag somewhere. > > Why? This looks as expected, and the issues from the previous run were > easy to make mistakes? > I should have known to do the full cycle of initdb / pgbench -i in the first place. Best regards, Jesper
Вложения
{kind=link}
Hi, Andres!
server
. At first, I'd like to mentioned that we did experiments with atomic increment on power8, despite it doesn't have native atomic increment. Let me explain why. CAS operation in power8 assembly looks like this.
.L1: lwarx 9,0,5
cmpw 0,9,3
bne- 0,.L2
stwcx. 4,0,5
bne- 0,.L1 .L2: isync
So, it's a loop until value isn't changed between lwarx and stwcx. When you put CAS inside loop it becomes loop inside loop. Atomic increment is a single loop like CAS.
add 9,9,3
stwcx. 9,0,5
bne- 0,.L1
isyncThis is why atomic increment *could be* cheaper than loop over CAS and, it worth having experiments. Another idea is that we can put arbitrary logic between lwarx and stwcx. Thus, we can implement PinBuffer using single loop of lwarx and stwcx which could be better than loop of CAS.
Tested patches are following:
1) pinunpin-cas.patch – moves pin/unpin buffer to atomic operations with buffer state. PinBuffer uses loop of CAS. Same as upthread, but rebased with current master.
2) pinunpin-increment.patch (based on pinunpin-cas.patch) – PinBuffer changes state using atomic increment operation instead of loop of CAS. Both refcount and usagecount are incremented at once. There is not enough bits in 32 bit state to guarantee that usagecount doesn't overflow. I moved usagecount to higher bits of state, thus overflow of usagecount doesn't affect other bits. Therefore, this patch doesn't pretend to be correct. However, we can use it to check if we should try moving this direction.
3) lwlock-increment.patch – LWLockAttemptLock change state using atomic increment operation instead of loop of CAS. This patch does it for LWLockAttemptLock like pinunpin-increment.patch does for PinBuffer. Actually, this patch is not directly related to buffer manager. However, it's nice to test loop of CAS vs atomic increment in different places.
4) pinunpin-ibm-asm.patch (based on pinunpin-cas.patch) – assembly optimizations of PinBuffer and LWLockAttemptLock which makes both of them use single loop of lwarx and stwcx.
The following versions were compared in our benchmark.
1) 9.4
2) 9.5
3) master
4) pinunpin-cas – pinunpin-cas.patch
5) pinunpin-increment – pinunpin-cas.patch + pinunpin-increment.patch
6
) pinunpin-cas-lwlock-increment – pinunpin-cas.patch + lwlock-increment.patch7
) pinunpin-cas-lwlock-increment – pinunpin-cas.patch + pinunpin-increment.patch +
lwlock-increment.patch8) pinunpin-lwlock-asm – pinunpin-cas.patch + pinunpin-ibm-asm.patch
See results in ibm-scalability.png. We can see that there is almost no effect of pinunpin-increment.patch. So, atomic increment in PinBuffer doesn't give benefit on power8. I will publish test results on Intel platform a bit later, but I can say there is no much effect too. So, I think, we can throw this idea away.
However, effect of lwlock-increment.patch is huge. It gives almost same effect as assembly optimizations. I think it worth having separate thread for discussing lwlock optimization. It's likely we can do something much better than current lwlock-increment.patch does.
For this thread, I think we can focus on pinunpin-cas.patch without thinking about atomic increment.
------
Вложения
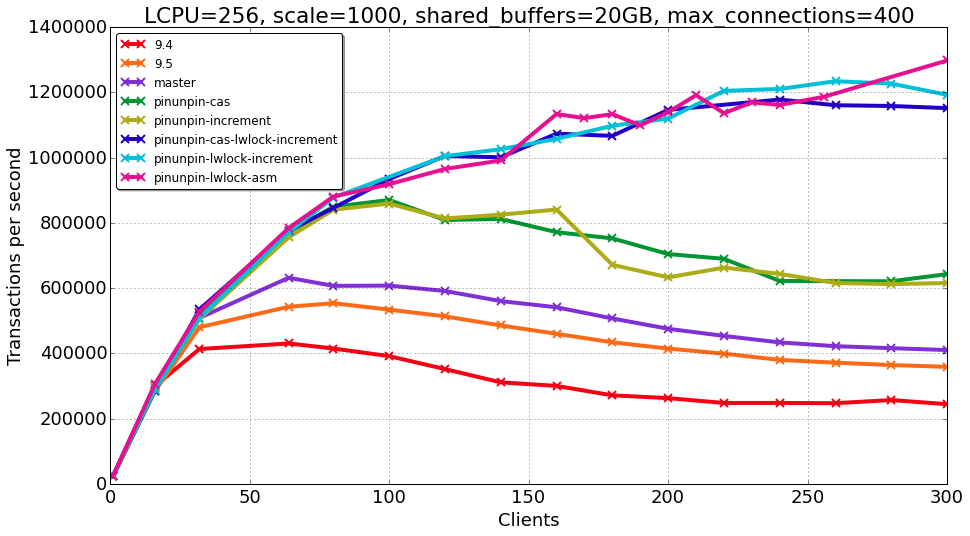{kind=link}
Hi, On 2015-12-08 12:53:49 +0300, Alexander Korotkov wrote: > This is why atomic increment *could be* cheaper than loop over CAS and, it > worth having experiments. Another idea is that we can put arbitrary logic > between lwarx and stwcx. Thus, we can implement PinBuffer using single loop > of lwarx and stwcx which could be better than loop of CAS. You can't really put that much between an ll/sc - the hardware is only able to track a very limited number of cacheline references. > 3) lwlock-increment.patch – LWLockAttemptLock change state using atomic > increment operation instead of loop of CAS. This patch does it for > LWLockAttemptLock like pinunpin-increment.patch does for PinBuffer. > Actually, this patch is not directly related to buffer manager. However, > it's nice to test loop of CAS vs atomic increment in different places. Yea, that's a worthwhile improvement. Actually it's how the first versions of the lwlock patches worked - unfortunately I couldn't see big differences on hardware I had available at the time. There's some more trickyness required than what you have in your patch (afaics at least). The problem is that when you 'optimistically' increment by LW_VAL_SHARED and notice that there actually was another locker, you possibly, until you've 'fixed' the state, are blocking new exclusive lockers from acquiring the locks. So you additionally need to do special handling in these cases, and check the queue more. Greetings, Andres Freund
On Tue, Dec 8, 2015 at 1:04 PM, Andres Freund <andres@anarazel.de> wrote:
On 2015-12-08 12:53:49 +0300, Alexander Korotkov wrote:
> This is why atomic increment *could be* cheaper than loop over CAS and, it
> worth having experiments. Another idea is that we can put arbitrary logic
> between lwarx and stwcx. Thus, we can implement PinBuffer using single loop
> of lwarx and stwcx which could be better than loop of CAS.
You can't really put that much between an ll/sc - the hardware is only
able to track a very limited number of cacheline references.
I have some doubts about this, but I didn't find the place where it's
explicitly documented. In the case of LWLockAttemptLock it not very much between
lwarx/stwcx: 4 instructions while CAS have 2 instructions.
Could you please share some link to docs, if any?> 3) lwlock-increment.patch – LWLockAttemptLock change state using atomic
> increment operation instead of loop of CAS. This patch does it for
> LWLockAttemptLock like pinunpin-increment.patch does for PinBuffer.
> Actually, this patch is not directly related to buffer manager. However,
> it's nice to test loop of CAS vs atomic increment in different places.
Yea, that's a worthwhile improvement. Actually it's how the first
versions of the lwlock patches worked - unfortunately I couldn't see big
differences on hardware I had available at the time.
There's some more trickyness required than what you have in your patch
(afaics at least). The problem is that when you 'optimistically'
increment by LW_VAL_SHARED and notice that there actually was another
locker, you possibly, until you've 'fixed' the state, are blocking new
exclusive lockers from acquiring the locks. So you additionally need to
do special handling in these cases, and check the queue more.
Agree. This patch need to be carefully verified. Current experiments just show that it is promising direction for improvement. I'll come with better version of this patch.
Also, after testing on large machines I have another observation to share. For now, LWLock doesn't guarantee that exclusive lock would be ever acquired (assuming each shared lock duration is finite). It because when there is no exclusive lock, new shared locks aren't queued and LWLock state is changed directly. Thus, process which tries to acquire exclusive lock have to wait for gap in shared locks. But with high concurrency for shared lock that could happen very rare, say never.
We did see this on big Intel machine in practice. pgbench -S gets shared ProcArrayLock very frequently. Since some number of connections is achieved, new connections hangs on getting exclusive ProcArrayLock. I think we could do some workaround for this problem. For instance, when exclusive lock waiter have some timeout it could set some special bit which prevents others to get new shared locks.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Dec 8, 2015 at 3:56 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
Agree. This patch need to be carefully verified. Current experiments just show that it is promising direction for improvement. I'll come with better version of this patch.Also, after testing on large machines I have another observation to share. For now, LWLock doesn't guarantee that exclusive lock would be ever acquired (assuming each shared lock duration is finite). It because when there is no exclusive lock, new shared locks aren't queued and LWLock state is changed directly. Thus, process which tries to acquire exclusive lock have to wait for gap in shared locks.
I think this has the potential to starve exclusive lockers in worst case.
But with high concurrency for shared lock that could happen very rare, say never.We did see this on big Intel machine in practice. pgbench -S gets shared ProcArrayLock very frequently. Since some number of connections is achieved, new connections hangs on getting exclusive ProcArrayLock. I think we could do some workaround for this problem. For instance, when exclusive lock waiter have some timeout it could set some special bit which prevents others to get new shared locks.
I think timeout based solution would lead to giving priority to
exclusive lock waiters (assume a case where each of exclusive
lock waiter timesout one after another) and make shared lockers
wait and a timer based solution might turn out to be costly for
general cases where wait is not so long. Another way could be to
check if the Exclusive locker needs to go for repeated wait for a
couple of times, then we can set such a bit.
On Tue, Dec 8, 2015 at 6:00 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Tue, Dec 8, 2015 at 3:56 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Agree. This patch need to be carefully verified. Current experiments just show that it is promising direction for improvement. I'll come with better version of this patch.Also, after testing on large machines I have another observation to share. For now, LWLock doesn't guarantee that exclusive lock would be ever acquired (assuming each shared lock duration is finite). It because when there is no exclusive lock, new shared locks aren't queued and LWLock state is changed directly. Thus, process which tries to acquire exclusive lock have to wait for gap in shared locks.I think this has the potential to starve exclusive lockers in worst case.But with high concurrency for shared lock that could happen very rare, say never.We did see this on big Intel machine in practice. pgbench -S gets shared ProcArrayLock very frequently. Since some number of connections is achieved, new connections hangs on getting exclusive ProcArrayLock. I think we could do some workaround for this problem. For instance, when exclusive lock waiter have some timeout it could set some special bit which prevents others to get new shared locks.I think timeout based solution would lead to giving priority toexclusive lock waiters (assume a case where each of exclusivelock waiter timesout one after another) and make shared lockerswait and a timer based solution might turn out to be costly forgeneral cases where wait is not so long.
Since all lwlock waiters are ordered in the queue, we can let only first waiter to set this bit.
Anyway, once bit is set, shared lockers would be added to the queue. They would get the lock in queue order.
Another way could be tocheck if the Exclusive locker needs to go for repeated wait for acouple of times, then we can set such a bit.
I'm not sure what do you mean by repeated wait. Do you mean exclusive locker was waked twice up by timeout? Because now, without timeout, exclusive locker wouldn't be waked up until all shared locks are released.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Wed, Dec 9, 2015 at 2:17 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Tue, Dec 8, 2015 at 6:00 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:On Tue, Dec 8, 2015 at 3:56 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Agree. This patch need to be carefully verified. Current experiments just show that it is promising direction for improvement. I'll come with better version of this patch.Also, after testing on large machines I have another observation to share. For now, LWLock doesn't guarantee that exclusive lock would be ever acquired (assuming each shared lock duration is finite). It because when there is no exclusive lock, new shared locks aren't queued and LWLock state is changed directly. Thus, process which tries to acquire exclusive lock have to wait for gap in shared locks.I think this has the potential to starve exclusive lockers in worst case.But with high concurrency for shared lock that could happen very rare, say never.We did see this on big Intel machine in practice. pgbench -S gets shared ProcArrayLock very frequently. Since some number of connections is achieved, new connections hangs on getting exclusive ProcArrayLock. I think we could do some workaround for this problem. For instance, when exclusive lock waiter have some timeout it could set some special bit which prevents others to get new shared locks.I think timeout based solution would lead to giving priority toexclusive lock waiters (assume a case where each of exclusivelock waiter timesout one after another) and make shared lockerswait and a timer based solution might turn out to be costly forgeneral cases where wait is not so long.Since all lwlock waiters are ordered in the queue, we can let only first waiter to set this bit.
Thats okay, but still every time an Exclusive locker woke up, the
threshold time for its wait might be already over and it will set the
bit. In theory, that looks okay, but as compare to current algorithm
it will make more shared lockers to be added into wait queue.
Anyway, once bit is set, shared lockers would be added to the queue. They would get the lock in queue order.
Ye thats right, but I think in general the solution to this problem
should be don't let any Exclusive locker to starve and still allow
as many shared lockers as possible. I think here it is important
how we define starving, should it be based on time or something
else? I find timer based solution somewhat less suitable, but may
be it is okay, if there is no other better way.
Another way could be tocheck if the Exclusive locker needs to go for repeated wait for acouple of times, then we can set such a bit.I'm not sure what do you mean by repeated wait. Do you mean exclusive locker was waked twice up by timeout?
I mean to say once the Exclusive locker is woken up, it again
re-tries to acquire the lock as it does today, but if it finds that the
number of retries is greater than certain threshold (let us say 10),
then we sit the bit.
Because now, without timeout, exclusive locker wouldn't be waked up until all shared locks are released.
Does LWLockWakeup() work that way? I thought it works such
that once an Exclusive locker is encountered in the wait queue, it
just wakes that and won't try to wake any further waiters.
On Thu, Dec 10, 2015 at 9:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Wed, Dec 9, 2015 at 2:17 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Tue, Dec 8, 2015 at 6:00 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:On Tue, Dec 8, 2015 at 3:56 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Agree. This patch need to be carefully verified. Current experiments just show that it is promising direction for improvement. I'll come with better version of this patch.Also, after testing on large machines I have another observation to share. For now, LWLock doesn't guarantee that exclusive lock would be ever acquired (assuming each shared lock duration is finite). It because when there is no exclusive lock, new shared locks aren't queued and LWLock state is changed directly. Thus, process which tries to acquire exclusive lock have to wait for gap in shared locks.I think this has the potential to starve exclusive lockers in worst case.But with high concurrency for shared lock that could happen very rare, say never.We did see this on big Intel machine in practice. pgbench -S gets shared ProcArrayLock very frequently. Since some number of connections is achieved, new connections hangs on getting exclusive ProcArrayLock. I think we could do some workaround for this problem. For instance, when exclusive lock waiter have some timeout it could set some special bit which prevents others to get new shared locks.I think timeout based solution would lead to giving priority toexclusive lock waiters (assume a case where each of exclusivelock waiter timesout one after another) and make shared lockerswait and a timer based solution might turn out to be costly forgeneral cases where wait is not so long.Since all lwlock waiters are ordered in the queue, we can let only first waiter to set this bit.Thats okay, but still every time an Exclusive locker woke up, thethreshold time for its wait might be already over and it will set thebit. In theory, that looks okay, but as compare to current algorithmit will make more shared lockers to be added into wait queue.Anyway, once bit is set, shared lockers would be added to the queue. They would get the lock in queue order.Ye thats right, but I think in general the solution to this problemshould be don't let any Exclusive locker to starve and still allowas many shared lockers as possible. I think here it is importanthow we define starving, should it be based on time or somethingelse? I find timer based solution somewhat less suitable, but maybe it is okay, if there is no other better way.
Yes, we probably should find something better.
Another way could be tocheck if the Exclusive locker needs to go for repeated wait for acouple of times, then we can set such a bit.I'm not sure what do you mean by repeated wait. Do you mean exclusive locker was waked twice up by timeout?I mean to say once the Exclusive locker is woken up, it againre-tries to acquire the lock as it does today, but if it finds that thenumber of retries is greater than certain threshold (let us say 10),then we sit the bit.
Yes, there is a cycle with retries in LWLockAcquire function. The case of retry is when waiter is waked up, but someone other steal the lock before him. Lock waiter is waked up by lock releaser only when lock becomes free. But in the case of high concurrency for shared lock, it almost never becomes free. So, exclusive locker would be never waked up. I'm pretty sure this happens on big Intel machine while we do the benchmark. So, relying on number of retries wouldn't work in this case.
I'll do the tests to verify if retries happens in our case.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2015-12-11 15:56:46 +0300, Alexander Korotkov wrote: > On Thu, Dec 10, 2015 at 9:26 AM, Amit Kapila <amit.kapila16@gmail.com> > wrote: > >>>> We did see this on big Intel machine in practice. pgbench -S gets > >>>> shared ProcArrayLock very frequently. Since some number of connections is > >>>> achieved, new connections hangs on getting exclusive ProcArrayLock. I think > >>>> we could do some workaround for this problem. For instance, when exclusive > >>>> lock waiter have some timeout it could set some special bit which prevents > >>>> others to get new shared locks. > > Ye thats right, but I think in general the solution to this problem > > should be don't let any Exclusive locker to starve and still allow > > as many shared lockers as possible. I think here it is important > > how we define starving, should it be based on time or something > > else? I find timer based solution somewhat less suitable, but may > > be it is okay, if there is no other better way. > > > > Yes, we probably should find something better. > Another way could be to > >>> check if the Exclusive locker needs to go for repeated wait for a > >>> couple of times, then we can set such a bit. > >>> > >> > >> I'm not sure what do you mean by repeated wait. Do you mean exclusive > >> locker was waked twice up by timeout? > >> > > > > I mean to say once the Exclusive locker is woken up, it again > > re-tries to acquire the lock as it does today, but if it finds that the > > number of retries is greater than certain threshold (let us say 10), > > then we sit the bit. > > > > Yes, there is a cycle with retries in LWLockAcquire function. The case of > retry is when waiter is waked up, but someone other steal the lock before > him. Lock waiter is waked up by lock releaser only when lock becomes free. > But in the case of high concurrency for shared lock, it almost never > becomes free. So, exclusive locker would be never waked up. I'm pretty sure > this happens on big Intel machine while we do the benchmark. So, relying on > number of retries wouldn't work in this case. > I'll do the tests to verify if retries happens in our case. I seriously doubt that making lwlocks fairer is the right way to go here. In my testing the "unfairness" is essential to performance - the number of context switches otherwise increases massively. I think in this case its better to work on making the lock less contended, rather than making micro-optimizations around the locking behaviour. Andres
On Fri, Dec 11, 2015 at 6:34 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2015-12-11 15:56:46 +0300, Alexander Korotkov wrote:
> >
> > Yes, there is a cycle with retries in LWLockAcquire function. The case of
> > retry is when waiter is waked up, but someone other steal the lock before
> > him. Lock waiter is waked up by lock releaser only when lock becomes free.
> > But in the case of high concurrency for shared lock, it almost never
> > becomes free. So, exclusive locker would be never waked up. I'm pretty sure
> > this happens on big Intel machine while we do the benchmark. So, relying on
> > number of retries wouldn't work in this case.
> > I'll do the tests to verify if retries happens in our case.
>
> On 2015-12-11 15:56:46 +0300, Alexander Korotkov wrote:
> >
> > Yes, there is a cycle with retries in LWLockAcquire function. The case of
> > retry is when waiter is waked up, but someone other steal the lock before
> > him. Lock waiter is waked up by lock releaser only when lock becomes free.
> > But in the case of high concurrency for shared lock, it almost never
> > becomes free. So, exclusive locker would be never waked up. I'm pretty sure
> > this happens on big Intel machine while we do the benchmark. So, relying on
> > number of retries wouldn't work in this case.
> > I'll do the tests to verify if retries happens in our case.
makes sense and if retries never happen, then I think changing LWLockRelease()
such that it should wake the waiters if there are waiters on a lock and it has not
waked them for some threshold number of times or something like that might
work.
>
> I seriously doubt that making lwlocks fairer is the right way to go
> here. In my testing the "unfairness" is essential to performance - the
> number of context switches otherwise increases massively.
>
Agreed, if the change being discussed hurts in any kind of scenario, then
we should better not do it, OTOH the case described by Alexander seems
to be genuine and I have seen similar complaint by customer in the past
for another database I worked with and the reason for the problem is same.
On Sun, Dec 13, 2015 at 11:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Dec 11, 2015 at 6:34 PM, Andres Freund <andres@anarazel.de> wrote: >> >> On 2015-12-11 15:56:46 +0300, Alexander Korotkov wrote: >> > >> > Yes, there is a cycle with retries in LWLockAcquire function. The case >> > of >> > retry is when waiter is waked up, but someone other steal the lock >> > before >> > him. Lock waiter is waked up by lock releaser only when lock becomes >> > free. >> > But in the case of high concurrency for shared lock, it almost never >> > becomes free. So, exclusive locker would be never waked up. I'm pretty >> > sure >> > this happens on big Intel machine while we do the benchmark. So, relying >> > on >> > number of retries wouldn't work in this case. >> > I'll do the tests to verify if retries happens in our case. > > makes sense and if retries never happen, then I think changing > LWLockRelease() > such that it should wake the waiters if there are waiters on a lock and it > has not > waked them for some threshold number of times or something like that might > work. > >> >> I seriously doubt that making lwlocks fairer is the right way to go >> here. In my testing the "unfairness" is essential to performance - the >> number of context switches otherwise increases massively. >> > > Agreed, if the change being discussed hurts in any kind of scenario, then > we should better not do it, OTOH the case described by Alexander seems > to be genuine and I have seen similar complaint by customer in the past > for another database I worked with and the reason for the problem is same. I have moved this patch to next CF.. -- Michael
On Thu, Dec 24, 2015 at 8:26 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
I was looking into this patch, overall patch looks good to me, I want to
know what is the current state of this patch, is there some pending task in
this patch ?
Patch was not applying on head so i have re based it and re based version is
attached in the mail.
I have done some performance testing also..
Summary:
---------------
1. In my test for readonly workload i have observed some improvement for scale factor 1000.
2. I have also observed some regression with scale factor 300 (I can't say
it's actual regression or just run to run variance), I thought that may be problem with lower scale factor so tested with scale factor 100 but with s.f. 100 looks fine.
Non Default Parameter:
------------------------
Shared Buffer= 30GB
max_wal_size= 10GB
max_connections=500
Test1:
pgbench -i -s 1000 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 19753 19493
32 344059 336773
64 495708 540425
128 564358 685212
256 466562 639059
Test2:
pgbench -i -s 300 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 20555 19404
32 375919 332670
64 509067 440680
128 431346 415121
256 380926 379176
Test3:
pgbench -i -s 100 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 20555 19404
32 375919 332670
64 509067 440680
128 431346 415121
256 380926 379176
--
On Sun, Dec 13, 2015 at 11:05 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Fri, Dec 11, 2015 at 6:34 PM, Andres Freund <andres@anarazel.de> wrote:
I was looking into this patch, overall patch looks good to me, I want to
know what is the current state of this patch, is there some pending task in
this patch ?
Patch was not applying on head so i have re based it and re based version is
attached in the mail.
I have done some performance testing also..
Summary:
---------------
1. In my test for readonly workload i have observed some improvement for scale factor 1000.
2. I have also observed some regression with scale factor 300 (I can't say
it's actual regression or just run to run variance), I thought that may be problem with lower scale factor so tested with scale factor 100 but with s.f. 100 looks fine.
Machine Detail:
cpu : POWER8
cpu : POWER8
cores: 24 (192 with HT)
Non Default Parameter:
------------------------
Shared Buffer= 30GB
max_wal_size= 10GB
max_connections=500
Test1:
pgbench -i -s 1000 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 19753 19493
32 344059 336773
64 495708 540425
128 564358 685212
256 466562 639059
Test2:
pgbench -i -s 300 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 20555 19404
32 375919 332670
64 509067 440680
128 431346 415121
256 380926 379176
Test3:
pgbench -i -s 100 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 20555 19404
32 375919 332670
64 509067 440680
128 431346 415121
256 380926 379176
--
Вложения
On Tue, Jan 19, 2016 at 7:31 PM, Dilip Kumar wrote: > Test2: > pgbench -i -s 300 postgres > pgbench -c$ -j$ -Mprepared -S postgres > > Client Base Pached > > 1 20555 19404 > 32 375919 332670 > 64 509067 440680 > 128 431346 415121 > 256 380926 379176 > > Test3: > pgbench -i -s 100 postgres > pgbench -c$ -j$ -Mprepared -S postgres > > Client Base Pached > > 1 20555 19404 > 32 375919 332670 > 64 509067 440680 > 128 431346 415121 > 256 380926 379176 It seems like you did a copy-paste of the results with s=100 and s=300. Both are showing the exact same numbers. -- Michael
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Tue, Jan 19, 2016 at 5:44 PM, Michael Paquier <spandir="ltr"><<a href="mailto:michael.paquier@gmail.com" target="_blank">michael.paquier@gmail.com</a>></span> wrote:<br/><blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"><spanclass="">> Test3:<br /> > pgbench -i -s 100 postgres<br /> > pgbench -c$-j$ -Mprepared -S postgres<br /> ><br /> > Client Base Pached<br /> ><br />> 1 20555 19404<br /> > 32 375919 332670<br/> > 64 509067 440680<br /> > 128 431346 415121<br /> > 256 380926 379176<br /><br /></span>It seems like you did a copy-pasteof the results with s=100 and<br /> s=300. Both are showing the exact same numbers.</blockquote></div><br /></div><divclass="gmail_extra">Oops, my mistake, re-pasting the correct results for s=100<br /><br />pgbench -i -s 100 postgres<br/>pgbench -c$ -j$ -Mprepared -S postgres<br /><br />Client Base Pached<br /><br/>1 20548 20791<br />32 372633 355356<br />64 532052 552148<br />128 412755 478826<br />256 346701 372057 <br /></div><div class="gmail_extra"><br clear="all" /><br />-- <br /><divclass="gmail_signature"><div dir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">Dilip Kumar</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><a href="http://www.enterprisedb.com/"style="color:rgb(17,85,204);font-size:12.8px" target="_blank">http://www.enterprisedb.com</a><br/></div></div></div></div>
Hi, Dilip!
On Tue, Jan 19, 2016 at 6:00 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Tue, Jan 19, 2016 at 5:44 PM, Michael Paquier <michael.paquier@gmail.com> wrote:> Test3:
> pgbench -i -s 100 postgres
> pgbench -c$ -j$ -Mprepared -S postgres
>
> Client Base Pached
>
> 1 20555 19404
> 32 375919 332670
> 64 509067 440680
> 128 431346 415121
> 256 380926 379176
It seems like you did a copy-paste of the results with s=100 and
s=300. Both are showing the exact same numbers.Oops, my mistake, re-pasting the correct results for s=100
pgbench -i -s 100 postgres
pgbench -c$ -j$ -Mprepared -S postgres
Client Base Pached
1 20548 20791
32 372633 355356
64 532052 552148
128 412755 478826
256 346701 372057
Could you please re-run these tests few times?
Just to be sure it's a reproducible regression with s=300 and not a statistical error.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Jan 29, 2016 at 3:17 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Hi, Dilip! > > On Tue, Jan 19, 2016 at 6:00 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote: >> >> >> On Tue, Jan 19, 2016 at 5:44 PM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >>> >>> > Test3: >>> > pgbench -i -s 100 postgres >>> > pgbench -c$ -j$ -Mprepared -S postgres >>> > >>> > Client Base Pached >>> > >>> > 1 20555 19404 >>> > 32 375919 332670 >>> > 64 509067 440680 >>> > 128 431346 415121 >>> > 256 380926 379176 >>> >>> It seems like you did a copy-paste of the results with s=100 and >>> s=300. Both are showing the exact same numbers. >> >> >> Oops, my mistake, re-pasting the correct results for s=100 >> >> pgbench -i -s 100 postgres >> pgbench -c$ -j$ -Mprepared -S postgres >> >> Client Base Pached >> >> 1 20548 20791 >> 32 372633 355356 >> 64 532052 552148 >> 128 412755 478826 >> 256 346701 372057 > > > Could you please re-run these tests few times? > Just to be sure it's a reproducible regression with s=300 and not a > statistical error. Probably want to run for at least 5 minutes via -T 300 merlin
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Sat, Jan 30, 2016 at 3:05 AM, Merlin Moncure <spandir="ltr"><<a href="mailto:mmoncure@gmail.com" target="_blank">mmoncure@gmail.com</a>></span> wrote:<br /><blockquoteclass="gmail_quote" style="margin:0 0 0 .8ex;border-left:1px #ccc solid;padding-left:1ex">Probably want to runfor at least 5 minutes via -T 300</blockquote></div><br /></div><div class="gmail_extra">Last time i run for 5 minutesand taken median of three runs, just missed mentioning "-T 300" in the mail..<br /><br /></div><div class="gmail_extra">Bylooking at the results with scale factor 1000 and 100 i don't see any reason why it will regress withscale factor 300.<br /><br /></div><div class="gmail_extra">So I will run the test again with scale factor 300 and thistime i am planning to run 2 cases. <br />1. when data fits in shared buffer<br />2. when data doesn't fit in shared buffer.<br/><br />-- <br /><div class="gmail_signature"><div dir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><brstyle="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">DilipKumar</span><br style="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><ahref="http://www.enterprisedb.com/" style="color:rgb(17,85,204);font-size:12.8px"target="_blank">http://www.enterprisedb.com</a><br /></div></div></div></div>
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Sun, Jan 31, 2016 at 11:44 AM, Dilip Kumar <spandir="ltr"><<a href="mailto:dilipbalaut@gmail.com" target="_blank">dilipbalaut@gmail.com</a>></span> wrote:<br/><blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"><divclass="gmail_extra">By looking at the results with scale factor 1000 and 100 i don'tsee any reason why it will regress with scale factor 300.<br /><br /></div><div class="gmail_extra">So I will run thetest again with scale factor 300 and this time i am planning to run 2 cases. <br />1. when data fits in shared buffer<br/>2. when data doesn't fit in shared buffer.</div></blockquote></div><br /></div><div class="gmail_extra">I haverun the test again with 300 S.F and found no regression, in fact there is improvement with the patch like we saw with1000 scale factor.<br /><br />Shared Buffer= 8GB <br />max_connections=150 <br />Scale Factor=300 <br /> <br />./pgbench -j$ -c$ -T300 -M prepared -S postgres <br /> <br />Client Base Patch<br />1 19744 19382<br />8 125923 126395<br />32 313931 333351<br />64 387339 496830<br/>128 306412 350610<br /> <br />Shared Buffer= 512MB <br />max_connections=150 <br />ScaleFactor=300 <br /> <br />./pgbench -j$ -c$ -T300 -M prepared -S postgres <br /> <br />Client Base Patch<br />1 17169 16454<br />8 108547 105559<br />32 241619 262818<br />64 206868 233606<br />128 137084 217013 <br /></div><div class="gmail_extra"><br clear="all" /><br />-- <br /><divclass="gmail_signature"><div dir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">Dilip Kumar</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><a href="http://www.enterprisedb.com/"style="color:rgb(17,85,204);font-size:12.8px" target="_blank">http://www.enterprisedb.com</a><br/></div></div></div></div>
On Mon, Feb 1, 2016 at 7:05 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Sun, Jan 31, 2016 at 11:44 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:By looking at the results with scale factor 1000 and 100 i don't see any reason why it will regress with scale factor 300.So I will run the test again with scale factor 300 and this time i am planning to run 2 cases.
1. when data fits in shared buffer
2. when data doesn't fit in shared buffer.I have run the test again with 300 S.F and found no regression, in fact there is improvement with the patch like we saw with 1000 scale factor.
Shared Buffer= 8GB
max_connections=150
Scale Factor=300
./pgbench -j$ -c$ -T300 -M prepared -S postgres
Client Base Patch
1 19744 19382
8 125923 126395
32 313931 333351
64 387339 496830
128 306412 350610
Shared Buffer= 512MB
max_connections=150
Scale Factor=300
./pgbench -j$ -c$ -T300 -M prepared -S postgres
Client Base Patch
1 17169 16454
8 108547 105559
32 241619 262818
64 206868 233606
128 137084 217013
Great, thanks!
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Feb 1, 2016 at 11:34 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Mon, Feb 1, 2016 at 7:05 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:On Sun, Jan 31, 2016 at 11:44 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:By looking at the results with scale factor 1000 and 100 i don't see any reason why it will regress with scale factor 300.So I will run the test again with scale factor 300 and this time i am planning to run 2 cases.
1. when data fits in shared buffer
2. when data doesn't fit in shared buffer.I have run the test again with 300 S.F and found no regression, in fact there is improvement with the patch like we saw with 1000 scale factor.
Shared Buffer= 8GB
max_connections=150
Scale Factor=300
./pgbench -j$ -c$ -T300 -M prepared -S postgres
Client Base Patch
1 19744 19382
8 125923 126395
32 313931 333351
64 387339 496830
128 306412 350610
Shared Buffer= 512MB
max_connections=150
Scale Factor=300
./pgbench -j$ -c$ -T300 -M prepared -S postgres
Client Base Patch
1 17169 16454
8 108547 105559
32 241619 262818
64 206868 233606
128 137084 217013Great, thanks!
Attached patch is rebased and have better comments.
Also, there is one comment which survive since original version by Andres.
/* Add exponential backoff? Should seldomly be contended tho. */
Andres, did you mean we should twice the delay with each unsuccessful try to lock?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
Alexander Korotkov wrote: > Attached patch is rebased and have better comments. > Also, there is one comment which survive since original version by Andres. > > /* Add exponential backoff? Should seldomly be contended tho. */ > > > Andres, did you mean we should twice the delay with each unsuccessful try > to lock? This is probably a tough patch to review; trying to break it with low number of shared buffers and high concurrency might be an interesting exercise. I know Andres is already pretty busy with the checkpoint flush patch and I very much doubt he will be able to give this patch a lot of attention in the short term. Moving to next CF. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2016-02-01 13:06:57 +0300, Alexander Korotkov wrote: > On Mon, Feb 1, 2016 at 11:34 AM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > >> Client Base Patch > >> 1 19744 19382 > >> 8 125923 126395 > >> 32 313931 333351 > >> 64 387339 496830 > >> 128 306412 350610 > >> > >> Shared Buffer= 512MB > >> max_connections=150 > >> Scale Factor=300 > >> > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres > >> > >> Client Base Patch > >> 1 17169 16454 > >> 8 108547 105559 > >> 32 241619 262818 > >> 64 206868 233606 > >> 128 137084 217013 So, there's a small regression on low client counts. That's worth addressing. > Attached patch is rebased and have better comments. > Also, there is one comment which survive since original version by Andres. > > /* Add exponential backoff? Should seldomly be contended tho. */ > > > Andres, did you mean we should twice the delay with each unsuccessful try > to lock? Spinning on a lock as fast as possible leads to rapid cacheline bouncing without anybody making progress. See s_lock() in s_lock.c. Greetings, Andres Freund
On 2016-02-01 22:35:06 +0100, Alvaro Herrera wrote: > I know Andres is already pretty busy with the checkpoint flush patch and > I very much doubt he will be able to give this patch a lot of attention > in the short term. Moving to next CF. Yea, there's no realistic chance I'll be able to take care of this in the next couple days.
On Tue, Feb 2, 2016 at 12:43 AM, Andres Freund <andres@anarazel.de> wrote:
On 2016-02-01 13:06:57 +0300, Alexander Korotkov wrote:
> On Mon, Feb 1, 2016 at 11:34 AM, Alexander Korotkov <
> a.korotkov@postgrespro.ru> wrote:
> >> Client Base Patch
> >> 1 19744 19382
> >> 8 125923 126395
> >> 32 313931 333351
> >> 64 387339 496830
> >> 128 306412 350610
> >>
> >> Shared Buffer= 512MB
> >> max_connections=150
> >> Scale Factor=300
> >>
> >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres
> >>
> >> Client Base Patch
> >> 1 17169 16454
> >> 8 108547 105559
> >> 32 241619 262818
> >> 64 206868 233606
> >> 128 137084 217013
So, there's a small regression on low client counts. That's worth
addressing.
Interesting. I'll try to reproduce it.
> Attached patch is rebased and have better comments.
> Also, there is one comment which survive since original version by Andres.
>
> /* Add exponential backoff? Should seldomly be contended tho. */
>
>
> Andres, did you mean we should twice the delay with each unsuccessful try
> to lock?
Spinning on a lock as fast as possible leads to rapid cacheline bouncing
without anybody making progress. See s_lock() in s_lock.c.
I didn't notice that s_lock() behaves so. Thank you.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-02-02 13:12:50 +0300, Alexander Korotkov wrote: > On Tue, Feb 2, 2016 at 12:43 AM, Andres Freund <andres@anarazel.de> wrote: > > > On 2016-02-01 13:06:57 +0300, Alexander Korotkov wrote: > > > On Mon, Feb 1, 2016 at 11:34 AM, Alexander Korotkov < > > > a.korotkov@postgrespro.ru> wrote: > > > >> Client Base Patch > > > >> 1 19744 19382 > > > >> 8 125923 126395 > > > >> 32 313931 333351 > > > >> 64 387339 496830 > > > >> 128 306412 350610 > > > >> > > > >> Shared Buffer= 512MB > > > >> max_connections=150 > > > >> Scale Factor=300 > > > >> > > > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres > > > >> > > > >> Client Base Patch > > > >> 1 17169 16454 > > > >> 8 108547 105559 > > > >> 32 241619 262818 > > > >> 64 206868 233606 > > > >> 128 137084 217013 > > > > So, there's a small regression on low client counts. That's worth > > addressing. > > > > Interesting. I'll try to reproduce it. Any progress here? Regards, Andres
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Sat, Feb 27, 2016 at 5:14 AM, Andres Freund <spandir="ltr"><<a href="mailto:andres@anarazel.de" target="_blank">andres@anarazel.de</a>></span> wrote:<br /><blockquoteclass="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"><spanclass="">> > > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres<br/> > > > >><br /> > > > >> Client Base Patch<br /> > > > >>1 17169 16454<br /> > > > >> 8 108547 105559<br /> > > > >> 32 241619 262818<br /> > > > >> 64 206868 233606<br /> > > > >> 128 137084 217013<br/> > ><br /> > > So, there's a small regression on low client counts. That's worth<br /> > > addressing.<br/> > ><br /> ><br /> > Interesting. I'll try to reproduce it.<br /><br /></span>Any progress here?</blockquote></div><br/></div><div class="gmail_extra">In Multi socket machine with 8 sockets and 64 cores, I have seenmore regression compared to my previous run in power8 with 2 socket, currently I tested Read only workload for 5 minsRun, When I get time, I will run for longer time and confirm again.<br /><br /><span class="im">Shared Buffer= 8GB<br/> Scale Factor=300</span><br /><br /><span class="">./pgbench -j$ -c$ -T300 -M prepared -S postgres</span><br />client base patch<br />1 7057 5230<br />2 10043 9573<br />4 20140 18188<br /></div><div class="gmail_extra"><br clear="all" /><br />-- <br /><div class="gmail_signature"><divdir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">Dilip Kumar</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><a href="http://www.enterprisedb.com/"style="color:rgb(17,85,204);font-size:12.8px" target="_blank">http://www.enterprisedb.com</a><br/></div></div></div></div>
On Sun, Feb 28, 2016 at 9:05 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
>
>
> On Sat, Feb 27, 2016 at 5:14 AM, Andres Freund <andres@anarazel.de> wrote:
>>
>> > > > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres
>> > > > >>
>> > > > >> Client Base Patch
>> > > > >> 1 17169 16454
>> > > > >> 8 108547 105559
>> > > > >> 32 241619 262818
>> > > > >> 64 206868 233606
>> > > > >> 128 137084 217013
>> > >
>> > > So, there's a small regression on low client counts. That's worth
>> > > addressing.
>> > >
>> >
>> > Interesting. I'll try to reproduce it.
>>
>> Any progress here?
>
>
> In Multi socket machine with 8 sockets and 64 cores, I have seen more regression compared to my previous run in power8 with 2 socket, currently I tested Read only workload for 5 mins Run, When I get time, I will run for longer time and confirm again.
>
>
>
> On Sat, Feb 27, 2016 at 5:14 AM, Andres Freund <andres@anarazel.de> wrote:
>>
>> > > > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres
>> > > > >>
>> > > > >> Client Base Patch
>> > > > >> 1 17169 16454
>> > > > >> 8 108547 105559
>> > > > >> 32 241619 262818
>> > > > >> 64 206868 233606
>> > > > >> 128 137084 217013
>> > >
>> > > So, there's a small regression on low client counts. That's worth
>> > > addressing.
>> > >
>> >
>> > Interesting. I'll try to reproduce it.
>>
>> Any progress here?
>
>
> In Multi socket machine with 8 sockets and 64 cores, I have seen more regression compared to my previous run in power8 with 2 socket, currently I tested Read only workload for 5 mins Run, When I get time, I will run for longer time and confirm again.
>
Have you tried by reverting the commits 6150a1b0 and ac1d794, which I think effects read-only performance and sometimes create variation in TPS across different runs, here second might have less impact, but first one could impact performance? Is it possible for you to get perf data with and without patch and share with others?
On Mon, Feb 29, 2016 at 8:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
Have you tried by reverting the commits 6150a1b0 and ac1d794, which I think effects read-only performance and sometimes create variation in TPS across different runs, here second might have less impact, but first one could impact performance? Is it possible for you to get perf data with and without patch and share with others?
I only reverted ac1d794 commit in my test, In my next run I will revert 6150a1b0 also and test.
On Sat, Feb 27, 2016 at 2:44 AM, Andres Freund <andres@anarazel.de> wrote:
On 2016-02-02 13:12:50 +0300, Alexander Korotkov wrote:
> On Tue, Feb 2, 2016 at 12:43 AM, Andres Freund <andres@anarazel.de> wrote:
>
> > On 2016-02-01 13:06:57 +0300, Alexander Korotkov wrote:
> > > On Mon, Feb 1, 2016 at 11:34 AM, Alexander Korotkov <
> > > a.korotkov@postgrespro.ru> wrote:
> > > >> Client Base Patch
> > > >> 1 19744 19382
> > > >> 8 125923 126395
> > > >> 32 313931 333351
> > > >> 64 387339 496830
> > > >> 128 306412 350610
> > > >>
> > > >> Shared Buffer= 512MB
> > > >> max_connections=150
> > > >> Scale Factor=300
> > > >>
> > > >> ./pgbench -j$ -c$ -T300 -M prepared -S postgres
> > > >>
> > > >> Client Base Patch
> > > >> 1 17169 16454
> > > >> 8 108547 105559
> > > >> 32 241619 262818
> > > >> 64 206868 233606
> > > >> 128 137084 217013
> >
> > So, there's a small regression on low client counts. That's worth
> > addressing.
> >
>
> Interesting. I'll try to reproduce it.
Any progress here?
I didn't reproduce the regression. I had access to multicore machine but didn't see either regression on low clients or improvements on high clients.
In the attached path spinlock delay was exposed in s_lock.h and used in LockBufHdr().
Dilip, could you try this version of patch? Could you also run perf or other profiler in the case of regression. It would be nice to compare profiles with and without patch. We probably could find the cause of regression.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Mon, Feb 29, 2016 at 5:18 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
I didn't reproduce the regression. I had access to multicore machine but didn't see either regression on low clients or improvements on high clients.In the attached path spinlock delay was exposed in s_lock.h and used in LockBufHdr().Dilip, could you try this version of patch? Could you also run perf or other profiler in the case of regression. It would be nice to compare profiles with and without patch. We probably could find the cause of regression.
OK, I will test it, sometime in this week.
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Tue, Mar 1, 2016 at 10:19 AM, Dilip Kumar <spandir="ltr"><<a href="mailto:dilipbalaut@gmail.com" target="_blank">dilipbalaut@gmail.com</a>></span> wrote:<br/><blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"><divclass="gmail_extra"><br /></div><div class="gmail_extra">OK, I will test it, sometimein this week.</div></blockquote></div><br /></div><div class="gmail_extra">I have tested this patch in my laptop,and there i did not see any regression at 1 client<br /><br />Shared buffer 10GB, 5 mins run with pgbench, read-onlytest<br /><br /> base patch<br />run1 22187 24334<br />run2 26288 27440<br />run3 26306 27411<br /></div><div class="gmail_extra"><br /><br /></div><div class="gmail_extra">May be in a day or 2 I will testit in the same machine where I reported the regression, and if regression is there I will check the instruction usingCall grind.<br clear="all" /></div><div class="gmail_extra"><br />-- <br /><div class="gmail_signature"><div dir="ltr"><spanstyle="color:rgb(80,0,80);font-size:12.8px">Regards,</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">Dilip Kumar</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><a href="http://www.enterprisedb.com/"style="color:rgb(17,85,204);font-size:12.8px" target="_blank">http://www.enterprisedb.com</a><br/></div></div></div></div>
On March 1, 2016 8:41:33 PM PST, Dilip Kumar <dilipbalaut@gmail.com> wrote: >On Tue, Mar 1, 2016 at 10:19 AM, Dilip Kumar <dilipbalaut@gmail.com> >wrote: > >> >> OK, I will test it, sometime in this week. >> > >I have tested this patch in my laptop, and there i did not see any >regression at 1 client > >Shared buffer 10GB, 5 mins run with pgbench, read-only test > > base patch >run1 22187 24334 >run2 26288 27440 >run3 26306 27411 > > >May be in a day or 2 I will test it in the same machine where I >reported >the regression, and if regression is there I will check the instruction >using Call grind. Sounds like a ppc vs. x86 issue. The regression was on the former, right? Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Wed, Mar 2, 2016 at 10:39 AM, Andres Freund <spandir="ltr"><<a href="mailto:andres@anarazel.de" target="_blank">andres@anarazel.de</a>></span> wrote:<br /><blockquoteclass="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex">Soundslike a ppc vs. x86 issue. The regression was on the former, right?</blockquote></div><br/></div><div class="gmail_extra">Well, Regression what I reported last two time, out of thatone was on X86 and other was on PPC.<br /><br /><br />Copied from older Threads<br />--------------------------------------<br/>On PPC<br /><span class="im">>> > > > >> ./pgbench -j$-c$ -T300 -M prepared -S postgres<br />>> > > > >><br />>> > > > >> Client Base Patch<br />>> > > > >> 1 17169 16454<br />>> > > > >> 8 108547 105559<br />>> > > > >> 32 241619 262818<br />>> > > > >> 64 206868 233606<br />>> > > > >> 128 137084 217013</span><br /><br /></div><div class="gmail_extra">OnX86<br /><span><span class="im">>> > > > >></span>Shared Buffer= 8GB<br /></span><span><spanclass="im">>> > > > >></span>Scale Factor=300</span><span class="im"><br /><br /><span></span></span><spanclass="im"><span><span class="im">>> > > > >></span>./pgbench -j$ -c$ -T300-M prepared -S postgres</span><br /></span><span class="im">>> > > > >></span>client base patch<br /><span class="im">>> > > > >></span>1 7057 5230<br /><spanclass="im">>> > > > >></span>2 10043 9573<br /><span class="im">>>> > > >></span>4 20140 18188<br /></div><div class="gmail_extra"><br/><br /></div><div class="gmail_extra">And this latest result (no regression) is on X86 but on mylocal machine.<br /><br /></div><div class="gmail_extra">I did not exactly saw what this new version of patch is doingdifferent, so I will test this version in other machines also and see the results. <br /></div><div class="gmail_extra"><brclear="all" /><br />-- <br /><div class="gmail_signature"><div dir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><brstyle="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">DilipKumar</span><br style="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><ahref="http://www.enterprisedb.com/" style="color:rgb(17,85,204);font-size:12.8px"target="_blank">http://www.enterprisedb.com</a><br /></div></div></div></div>
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Wed, Mar 2, 2016 at 11:05 AM, Dilip Kumar <spandir="ltr"><<a href="mailto:dilipbalaut@gmail.com" target="_blank">dilipbalaut@gmail.com</a>></span> wrote:<br/><blockquote class="gmail_quote" style="margin:0px 0px 0px 0.8ex;border-left:1px solid rgb(204,204,204);padding-left:1ex"><divclass="gmail_extra">And this latest result (no regression) is on X86 but on my localmachine.<br /><br /></div><div class="gmail_extra">I did not exactly saw what this new version of patch is doing different,so I will test this version in other machines also and see the results. </div></blockquote></div><br /></div><divclass="gmail_extra">I tested this on PPC again, This time in various order (sometime patch first and then basefirst).<br /> I tested with latest patch <b>pinunpin-cas-2.patch</b> on Power8.<br /><br />Shared Buffer = 8GB<br /><spanclass="im"><span>./pgbench -j$ -c$ -T300 -M prepared -S postgres<br /><br />BASE<br />-----<br />Clients run1 run2 run3<br />1 21200 18754 20537<br />2 40331 39520 38746<br /> <br/><br />Patch<br />-----<br />Clients run1 run2 run3<br />1 20225 19806 19778<br />2 39830 41898 36620<br /><br /></span></span></div><div class="gmail_extra"><span class="im"><span>I think,here we can not see any regression, (If I take median then it may looks low with patch so posting all 3 reading).<br/></span></span></div><div class="gmail_extra"><span class="im"><span><br /></span></span>Note: reverted onlyac1d794 commit in my test.<br /><br />-- <br /><div class="gmail_signature"><div dir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><brstyle="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">DilipKumar</span><br style="color:rgb(80,0,80);font-size:12.8px" /><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><ahref="http://www.enterprisedb.com/" style="color:rgb(17,85,204);font-size:12.8px"target="_blank">http://www.enterprisedb.com</a><br /></div></div></div></div>
On Sat, Mar 5, 2016 at 7:22 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: > On Wed, Mar 2, 2016 at 11:05 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote: >> And this latest result (no regression) is on X86 but on my local machine. >> >> I did not exactly saw what this new version of patch is doing different, >> so I will test this version in other machines also and see the results. > > > I tested this on PPC again, This time in various order (sometime patch first > and then base first). > I tested with latest patch pinunpin-cas-2.patch on Power8. > > Shared Buffer = 8GB > ./pgbench -j$ -c$ -T300 -M prepared -S postgres > > BASE > ----- > Clients run1 run2 run3 > 1 21200 18754 20537 > 2 40331 39520 38746 > > > Patch > ----- > Clients run1 run2 run3 > 1 20225 19806 19778 > 2 39830 41898 36620 > > I think, here we can not see any regression, (If I take median then it may > looks low with patch so posting all 3 reading). If the median looks low, how is that not a regression? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Mar 7, 2016 at 6:19 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Sat, Mar 5, 2016 at 7:22 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> On Wed, Mar 2, 2016 at 11:05 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
>> And this latest result (no regression) is on X86 but on my local machine.
>>
>> I did not exactly saw what this new version of patch is doing different,
>> so I will test this version in other machines also and see the results.
>
>
> I tested this on PPC again, This time in various order (sometime patch first
> and then base first).
> I tested with latest patch pinunpin-cas-2.patch on Power8.
>
> Shared Buffer = 8GB
> ./pgbench -j$ -c$ -T300 -M prepared -S postgres
>
> BASE
> -----
> Clients run1 run2 run3
> 1 21200 18754 20537
> 2 40331 39520 38746
>
>
> Patch
> -----
> Clients run1 run2 run3
> 1 20225 19806 19778
> 2 39830 41898 36620
>
> I think, here we can not see any regression, (If I take median then it may
> looks low with patch so posting all 3 reading).
If the median looks low, how is that not a regression?
I don't think we can rely on median that much if we have only 3 runs.
For 3 runs we can only apply Kornfeld method which claims that confidence interval should be between lower and upper values.
Since confidence intervals for master and patched versions are overlapping we can't conclude that expected TPS numbers are different.
Dilip, could you do more runs? 10, for example. Using such statistics we would be able to conclude something.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Thu, Mar 10, 2016 at 8:26 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
I don't think we can rely on median that much if we have only 3 runs.For 3 runs we can only apply Kornfeld method which claims that confidence interval should be between lower and upper values.Since confidence intervals for master and patched versions are overlapping we can't conclude that expected TPS numbers are different.Dilip, could you do more runs? 10, for example. Using such statistics we would be able to conclude something.
Here is the reading for 10 runs....
Median Result
-----------------------
-----------------------
Client Base Patch
-------------------------------------------
-------------------------------------------
1 19873 19739
2 38658 38276
4 68812 62075
2 38658 38276
4 68812 62075
Full Results of 10 runs...
Base
-------------
Runs 1 Client 2 Client 4 Client
-----------------------------------------------------
1 19442 34866 49023
2 19605 35139 51695
3 19726 37104 53899
4 19835 38439 55708
5 19866 38638 67473
6 19880 38679 70152
7 19973 38720 70920
8 20048 38737 71342
9 20057 38815 71403
10 20344 41423 77953
-----------------------------------------------------
Patch
-----------
Runs 1 Client 2 Client 4 Client
------------------------------------------------------
1 18881 30161 54928
2 19415 32031 59741
3 19564 35022 61060
4 19627 36712 61839
5 19670 37659 62011
6 19808 38894 62139
7 19857 39081 62983
8 19910 39923 75358
9 20169 39937 77481
10 20181 40003 78462
------------------------------------------------------
On Fri, Mar 11, 2016 at 7:08 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Thu, Mar 10, 2016 at 8:26 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:I don't think we can rely on median that much if we have only 3 runs.For 3 runs we can only apply Kornfeld method which claims that confidence interval should be between lower and upper values.Since confidence intervals for master and patched versions are overlapping we can't conclude that expected TPS numbers are different.Dilip, could you do more runs? 10, for example. Using such statistics we would be able to conclude something.Here is the reading for 10 runs....Median Result
-----------------------Client Base Patch
-------------------------------------------1 19873 19739
2 38658 38276
4 68812 62075Full Results of 10 runs...
Base
-------------
Runs 1 Client 2 Client 4 Client
-----------------------------------------------------
1 19442 34866 49023
2 19605 35139 51695
3 19726 37104 53899
4 19835 38439 55708
5 19866 38638 67473
6 19880 38679 70152
7 19973 38720 70920
8 20048 38737 71342
9 20057 38815 71403
10 20344 41423 77953
-----------------------------------------------------
Patch
-----------
Runs 1 Client 2 Client 4 Client
------------------------------------------------------
1 18881 30161 54928
2 19415 32031 59741
3 19564 35022 61060
4 19627 36712 61839
5 19670 37659 62011
6 19808 38894 62139
7 19857 39081 62983
8 19910 39923 75358
9 20169 39937 77481
10 20181 40003 78462
------------------------------------------------------
I've drawn graphs for these measurements. The variation doesn't look random here. TPS is going higher from measurement to measurement. I bet you did measurements sequentially.
I think we should do more measurements until TPS stop growing and beyond to see accumulate average statistics. Could you please do the same tests but 50 runs.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
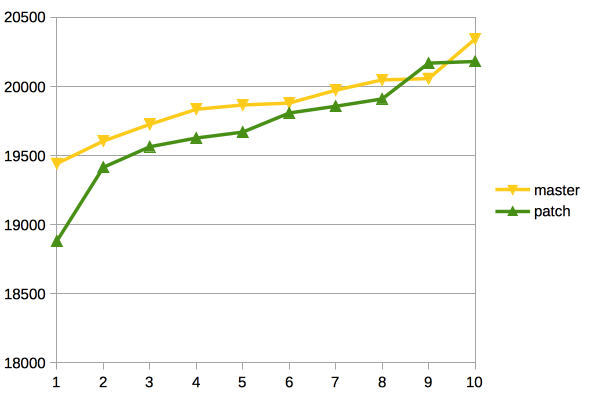{kind=link}
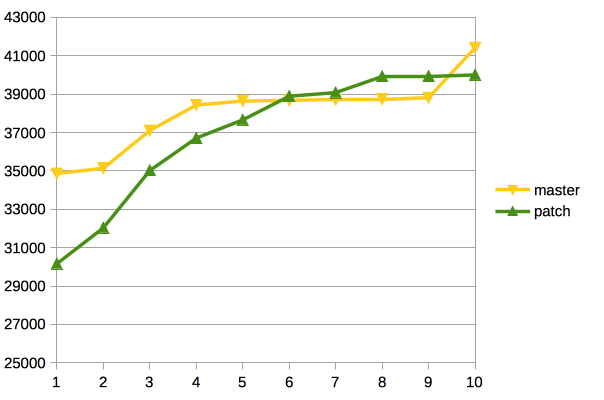{kind=link}
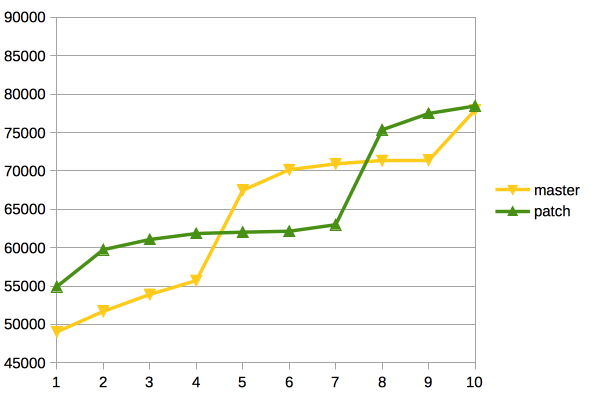{kind=link}
On Mon, Mar 14, 2016 at 3:09 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
I've drawn graphs for these measurements. The variation doesn't look random here. TPS is going higher from measurement to measurement. I bet you did measurements sequentially.I think we should do more measurements until TPS stop growing and beyond to see accumulate average statistics. Could you please do the same tests but 50 runs.
I have taken reading at different client count (1,2 and 4)
1. Avg: Is taken average after discarding lowest 5 and highest 5 readings.
2. With 4 client I have only 30 reading.
Summary:
Summary:
I think if we check avg or median atleast at 1 or 2 client head always looks winner, but same is not the case with 4 clients. And with 4 clients I can see much more fluctuation in the reading.
| Head(1 Client) | Patch (1 Client) | Head (2 Client) | Patch (2 Client) | Head (4 Client) | Patch (4 Client) | |||
| Avg: | 19628 | 19578 | 37180 | 36536 | 70044 | 70731 | ||
| Median: | 19663 | 19581 | 37967 | 37484 | 73003 | 75376 |
Below is all the reading. (Arranged in sorted order)
| Runs | Head (1 Client) | Patch (1 Client) | Head (2 Client) | Patch (2 Client) | Head (4 Client) | Patch (4 Client) | ||
| 1 | 18191 | 18153 | 29454 | 26128 | 49931 | 47210 | ||
| 2 | 18365 | 18768 | 31218 | 26956 | 53358 | 47287 | ||
| 3 | 19053 | 18769 | 31808 | 29286 | 53575 | 55458 | ||
| 4 | 19128 | 18915 | 31860 | 30558 | 54282 | 55794 | ||
| 5 | 19160 | 18948 | 32411 | 30945 | 56629 | 56253 | ||
| 6 | 19177 | 19055 | 32453 | 31316 | 57595 | 58147 | ||
| 7 | 19351 | 19232 | 32571 | 31703 | 59490 | 58543 | ||
| 8 | 19353 | 19239 | 33294 | 32029 | 63887 | 58990 | ||
| 9 | 19361 | 19255 | 33936 | 32217 | 64718 | 60233 | ||
| 10 | 19390 | 19297 | 34361 | 32767 | 65737 | 68210 | ||
| 11 | 19452 | 19368 | 34563 | 34487 | 65881 | 71409 | ||
| 12 | 19478 | 19387 | 36110 | 34907 | 67151 | 72108 | ||
| 13 | 19488 | 19388 | 36221 | 34936 | 70974 | 73977 | ||
| 14 | 19490 | 19395 | 36461 | 35068 | 72212 | 74891 | ||
| 15 | 19512 | 19406 | 36712 | 35298 | 73003 | 75376 | ||
| 16 | 19538 | 19450 | 37104 | 35492 | 74842 | 75468 | ||
| 17 | 19547 | 19487 | 37246 | 36648 | 75400 | 75515 | ||
| 18 | 19592 | 19521 | 37567 | 37263 | 75573 | 75626 | ||
| 19 | 19627 | 19536 | 37707 | 37430 | 75798 | 75745 | ||
| 20 | 19661 | 19556 | 37958 | 37461 | 75834 | 75868 | ||
| 21 | 19666 | 19607 | 37976 | 37507 | 76240 | 76161 | ||
| 22 | 19701 | 19624 | 38060 | 37557 | 76426 | 76162 | ||
| 23 | 19708 | 19643 | 38244 | 37717 | 76770 | 76333 | ||
| 24 | 19748 | 19684 | 38272 | 38285 | 77011 | 77009 | ||
| 25 | 19751 | 19694 | 38467 | 38294 | 77114 | 77168 | ||
| 26 | 19776 | 19695 | 38524 | 38469 | 77630 | 77318 | ||
| 27 | 19781 | 19709 | 38625 | 38642 | 77865 | 77550 | ||
| 28 | 19786 | 19765 | 38756 | 38643 | 77912 | 77904 | ||
| 29 | 19796 | 19823 | 38939 | 38649 | 78242 | 78736 | ||
| 30 | 19826 | 19847 | 39139 | 38659 | ||||
| 31 | 19837 | 19899 | 39208 | 38713 | ||||
| 32 | 19849 | 19909 | 39211 | 38837 | ||||
| 33 | 19854 | 19932 | 39230 | 38876 | ||||
| 34 | 19867 | 19949 | 39249 | 39088 | ||||
| 35 | 19891 | 19990 | 39259 | 39148 | ||||
| 36 | 20038 | 20085 | 39286 | 39453 | ||||
| 37 | 20083 | 20128 | 39435 | 39563 | ||||
| 38 | 20143 | 20166 | 39448 | 39959 | ||||
| 39 | 20191 | 20198 | 39475 | 40495 | ||||
| 40 | 20437 | 20455 | 40375 | 40664 |
--
On Sat, Mar 19, 2016 at 3:22 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Mon, Mar 14, 2016 at 3:09 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:I've drawn graphs for these measurements. The variation doesn't look random here. TPS is going higher from measurement to measurement. I bet you did measurements sequentially.I think we should do more measurements until TPS stop growing and beyond to see accumulate average statistics. Could you please do the same tests but 50 runs.I have taken reading at different client count (1,2 and 4)1. Avg: Is taken average after discarding lowest 5 and highest 5 readings.2. With 4 client I have only 30 reading.
Summary:I think if we check avg or median atleast at 1 or 2 client head always looks winner, but same is not the case with 4 clients. And with 4 clients I can see much more fluctuation in the reading.
Head(1 Client) Patch (1 Client) Head (2 Client) Patch (2 Client) Head (4 Client) Patch (4 Client) Avg: 19628 19578 37180 36536 70044 70731 Median: 19663 19581 37967 37484 73003 75376 Below is all the reading. (Arranged in sorted order)
Runs Head (1 Client) Patch (1 Client) Head (2 Client) Patch (2 Client) Head (4 Client) Patch (4 Client) 1 18191 18153 29454 26128 49931 47210 2 18365 18768 31218 26956 53358 47287 3 19053 18769 31808 29286 53575 55458 4 19128 18915 31860 30558 54282 55794 5 19160 18948 32411 30945 56629 56253 6 19177 19055 32453 31316 57595 58147 7 19351 19232 32571 31703 59490 58543 8 19353 19239 33294 32029 63887 58990 9 19361 19255 33936 32217 64718 60233 10 19390 19297 34361 32767 65737 68210 11 19452 19368 34563 34487 65881 71409 12 19478 19387 36110 34907 67151 72108 13 19488 19388 36221 34936 70974 73977 14 19490 19395 36461 35068 72212 74891 15 19512 19406 36712 35298 73003 75376 16 19538 19450 37104 35492 74842 75468 17 19547 19487 37246 36648 75400 75515 18 19592 19521 37567 37263 75573 75626 19 19627 19536 37707 37430 75798 75745 20 19661 19556 37958 37461 75834 75868 21 19666 19607 37976 37507 76240 76161 22 19701 19624 38060 37557 76426 76162 23 19708 19643 38244 37717 76770 76333 24 19748 19684 38272 38285 77011 77009 25 19751 19694 38467 38294 77114 77168 26 19776 19695 38524 38469 77630 77318 27 19781 19709 38625 38642 77865 77550 28 19786 19765 38756 38643 77912 77904 29 19796 19823 38939 38649 78242 78736 30 19826 19847 39139 38659 31 19837 19899 39208 38713 32 19849 19909 39211 38837 33 19854 19932 39230 38876 34 19867 19949 39249 39088 35 19891 19990 39259 39148 36 20038 20085 39286 39453 37 20083 20128 39435 39563 38 20143 20166 39448 39959 39 20191 20198 39475 40495 40 20437 20455 40375 40664
So, I think it's really some regression here on small number clients. I have following hypothesis about that. In some cases we use more atomic operations than before. For instace, in BufferAlloc we have following block of code. Previous code deals with that without atomic operations relying on spinlock. So, we have 2 extra atomic operations here, and similar situation in other places.
pg_atomic_fetch_and_u32(&buf->state, ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED | BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT | BUF_USAGECOUNT_MASK)); if (relpersistence == RELPERSISTENCE_PERMANENT) pg_atomic_fetch_or_u32(&buf->state, BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE); else pg_atomic_fetch_or_u32(&buf->state, BM_TAG_VALID | BUF_USAGECOUNT_ONE);
Actually, we behave like old code and do such modifications without increasing number of atomic operations. We can just calculate new value of state (including unset of BM_LOCKED flag) and write it to the buffer. In this case we don't require more atomic operations. However, it becomes not safe to use atomic decrement in UnpinBuffer(). We can use there loop of CAS which wait buffer header to be unlocked like PinBuffer() does. I'm not sure if this affects multicore scalability, but I think it worth trying.
So, this idea is implemented in attached patch. Please, try it for both regression on lower number of clients and scalability on large number of clients.
Other changes in this patch:
1) PinBuffer() and UnpinBuffer() use exponential backoff in spindealy like LockBufHdr() does.
2) Previous patch contained revert of ac1d7945f866b1928c2554c0f80fd52d7f977772. This was not intentional. No, it doesn't contains this revert.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Sun, Mar 20, 2016 at 4:10 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
Actually, we behave like old code and do such modifications without increasing number of atomic operations. We can just calculate new value of state (including unset of BM_LOCKED flag) and write it to the buffer. In this case we don't require more atomic operations. However, it becomes not safe to use atomic decrement in UnpinBuffer(). We can use there loop of CAS which wait buffer header to be unlocked like PinBuffer() does. I'm not sure if this affects multicore scalability, but I think it worth trying.So, this idea is implemented in attached patch. Please, try it for both regression on lower number of clients and scalability on large number of clients.
Good, seems like we have reduced some instructions, I will test it soon.
Other changes in this patch:1) PinBuffer() and UnpinBuffer() use exponential backoff in spindealy like LockBufHdr() does.2) Previous patch contained revert of ac1d7945f866b1928c2554c0f80fd52d7f977772. This was not intentional. No, it doesn't contains this revert.
*************** ReadBuffer_common(SMgrRelation smgr, cha
*** 828,837 ****
*/
do
{
! LockBufHdr(bufHdr);
! Assert(bufHdr->flags & BM_VALID);
! bufHdr->flags &= ~BM_VALID;
! UnlockBufHdr(bufHdr);
} while (!StartBufferIO(bufHdr, true));
}
}
--- 826,834 ----
*/
do
{
! uint32 state = LockBufHdr(bufHdr);
! state &= ~(BM_VALID | BM_LOCKED);
! pg_atomic_write_u32(&bufHdr->state, state);
} while (!StartBufferIO(bufHdr, true));
Better Write some comment, about we clearing the BM_LOCKED from stage directly and need not to call UnlockBufHdr explicitly.
otherwise its confusing.
On Tue, Mar 22, 2016 at 12:31 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
! pg_atomic_write_u32(&bufHdr->state, state);} while (!StartBufferIO(bufHdr, true));Better Write some comment, about we clearing the BM_LOCKED from stage directly and need not to call UnlockBufHdr explicitly.otherwise its confusing.
Few more comments..
*** 828,837 ****
*/
do
{
! LockBufHdr(bufHdr);
! Assert(bufHdr->flags & BM_VALID);
! bufHdr->flags &= ~BM_VALID;
! UnlockBufHdr(bufHdr);
} while (!StartBufferIO(bufHdr, true));
}
}
--- 826,834 ----
*/
do
{
! uint32 state = LockBufHdr(bufHdr);
! state &= ~(BM_VALID | BM_LOCKED);
! pg_atomic_write_u32(&bufHdr->state, state);
} while (!StartBufferIO(bufHdr, true));
1. Previously there was a Assert, any reason why we removed it ?
Assert(bufHdr->flags & BM_VALID);
2. And also if we don't need assert then can't we directly clear BM_VALID flag from state variable (if not locked) like pin/unpin buffer does, without taking buffer header lock?
On Tue, Mar 22, 2016 at 7:57 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Tue, Mar 22, 2016 at 12:31 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:! pg_atomic_write_u32(&bufHdr->state, state);} while (!StartBufferIO(bufHdr, true));Better Write some comment, about we clearing the BM_LOCKED from stage directly and need not to call UnlockBufHdr explicitly.otherwise its confusing.
Few more comments..*** 828,837 *****/do{! LockBufHdr(bufHdr);! Assert(bufHdr->flags & BM_VALID);! bufHdr->flags &= ~BM_VALID;! UnlockBufHdr(bufHdr);} while (!StartBufferIO(bufHdr, true));}}--- 826,834 ----*/do{! uint32 state = LockBufHdr(bufHdr);! state &= ~(BM_VALID | BM_LOCKED);! pg_atomic_write_u32(&bufHdr->state, state);} while (!StartBufferIO(bufHdr, true));1. Previously there was a Assert, any reason why we removed it ?Assert(bufHdr->flags & BM_VALID);
It was missed. In the attached patch I've put it back.
2. And also if we don't need assert then can't we directly clear BM_VALID flag from state variable (if not locked) like pin/unpin buffer does, without taking buffer header lock?
In this version of patch it could be also done as loop of CAS operation. But I'm not intended to it so because it would significantly complicate code. It's not yes clear that traffic in this place is high enough to make such optimizations.
Since v4 patch implements slightly different approach. Could you please test it? We need to check that this approach worth putting more efforts on it. Or through it away otherwise.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Tue, Mar 22, 2016 at 1:08 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Tue, Mar 22, 2016 at 7:57 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:On Tue, Mar 22, 2016 at 12:31 PM, Dilip Kumar <dilipbalaut@gmail.com> wrote:! pg_atomic_write_u32(&bufHdr->state, state);} while (!StartBufferIO(bufHdr, true));Better Write some comment, about we clearing the BM_LOCKED from stage directly and need not to call UnlockBufHdr explicitly.otherwise its confusing.
Few more comments..*** 828,837 *****/do{! LockBufHdr(bufHdr);! Assert(bufHdr->flags & BM_VALID);! bufHdr->flags &= ~BM_VALID;! UnlockBufHdr(bufHdr);} while (!StartBufferIO(bufHdr, true));}}--- 826,834 ----*/do{! uint32 state = LockBufHdr(bufHdr);! state &= ~(BM_VALID | BM_LOCKED);! pg_atomic_write_u32(&bufHdr->state, state);} while (!StartBufferIO(bufHdr, true));1. Previously there was a Assert, any reason why we removed it ?Assert(bufHdr->flags & BM_VALID);It was missed. In the attached patch I've put it back.2. And also if we don't need assert then can't we directly clear BM_VALID flag from state variable (if not locked) like pin/unpin buffer does, without taking buffer header lock?In this version of patch it could be also done as loop of CAS operation. But I'm not intended to it so because it would significantly complicate code. It's not yes clear that traffic in this place is high enough to make such optimizations.Since v4 patch implements slightly different approach. Could you please test it? We need to check that this approach worth putting more efforts on it. Or through it away otherwise.
Could anybody run benchmarks? Feature freeze is soon, but it would be *very nice* to fit it into 9.6 release cycle, because it greatly improves scalability on large machines. Without this patch PostgreSQL 9.6 will be significantly behind competitors like MySQL 5.7.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
<div dir="ltr"><div class="gmail_extra"><br /><div class="gmail_quote">On Fri, Mar 25, 2016 at 8:09 PM, Alexander Korotkov<span dir="ltr"><<a href="mailto:a.korotkov@postgrespro.ru" target="_blank">a.korotkov@postgrespro.ru</a>></span>wrote:<br /><blockquote class="gmail_quote" style="margin:0px 0px0px 0.8ex;border-left-width:1px;border-left-color:rgb(204,204,204);border-left-style:solid;padding-left:1ex">Could anybodyrun benchmarks? Feature freeze is soon, but it would be *very nice* to fit it into 9.6 release cycle, because itgreatly improves scalability on large machines. Without this patch PostgreSQL 9.6 will be significantly behind competitorslike MySQL 5.7.</blockquote></div><br />I have run the performance and here are the results.. With latest patchI did not see any regression at lower client count (median of 3 reading).</div><div class="gmail_extra"><br /></div><divclass="gmail_extra">scale factor 1000 shared buffer 8GB readonly<span class="" style="white-space:pre"> </span><br/></div><div class="gmail_extra"><div class="gmail_extra"><span class="" style="white-space:pre"> </span></div><divclass="gmail_extra"><b>Client<span class="" style="white-space:pre"> </span>Base<span class="" style="white-space:pre"></span>patch</b></div><div class="gmail_extra">1<span class="" style="white-space:pre"> </span>12957<spanclass="" style="white-space:pre"> </span>13068</div><div class="gmail_extra">2<span class="" style="white-space:pre"></span>24931<span class="" style="white-space:pre"> </span>25816</div><div class="gmail_extra">4<spanclass="" style="white-space:pre"> </span>46311<span class="" style="white-space:pre"> </span>48767</div><divclass="gmail_extra">32<span class="" style="white-space:pre"> </span>300921<span class="" style="white-space:pre"></span>310062</div><div class="gmail_extra">64<span class="" style="white-space:pre"> </span>387623<spanclass="" style="white-space:pre"> </span>493843</div><div class="gmail_extra">128<span class="" style="white-space:pre"></span>249635<span class="" style="white-space:pre"> </span>583513</div><div class="gmail_extra"><spanclass="" style="white-space:pre"> </span></div><div class="gmail_extra"><span class="" style="white-space:pre"></span></div><div class="gmail_extra">scale factor 300 shared buffer 8GB readonly<span class="" style="white-space:pre"></span></div><div class="gmail_extra"><span class="" style="white-space:pre"> </span></div><div class="gmail_extra"><b>Client<spanclass="" style="white-space:pre"> </span>Base<span class="" style="white-space:pre"> </span>patch</b></div><divclass="gmail_extra">1<span class="" style="white-space:pre"> </span>14537<span class="" style="white-space:pre"></span>14586 --> one thread number looks little less, generally I get ~18000 (will recheck).</div><divclass="gmail_extra">2<span class="" style="white-space:pre"> </span>34703<span class="" style="white-space:pre"></span>33929 --> may be run to run variance (once I get time, will recheck)</div><div class="gmail_extra">4<spanclass="" style="white-space:pre"> </span>67744<span class="" style="white-space:pre"> </span>69069</div><divclass="gmail_extra">32<span class="" style="white-space:pre"> </span>312575<span class="" style="white-space:pre"></span>336012</div><div class="gmail_extra">64<span class="" style="white-space:pre"> </span>213312<spanclass="" style="white-space:pre"> </span>539056</div><div class="gmail_extra">128<span class="" style="white-space:pre"></span>190139<span class="" style="white-space:pre"> </span>380122</div><div class="gmail_extra"><br/></div><div class="gmail_extra"><b>Summary:</b></div><div class="gmail_extra"><br /></div><div class="gmail_extra">Actuallywith 64 client we have seen ~470,000 TPS with head also, by revering commit 6150a1b0.</div><divclass="gmail_extra">refer this thread: (<a href="http://www.postgresql.org/message-id/CAA4eK1+ZeB8PMwwktf+3bRS0Pt4Ux6Rs6Aom0uip8c6shJWmyg@mail.gmail.com">http://www.postgresql.org/message-id/CAA4eK1+ZeB8PMwwktf+3bRS0Pt4Ux6Rs6Aom0uip8c6shJWmyg@mail.gmail.com</a>)</div><div class="gmail_extra"><br/></div><div class="gmail_extra">I haven't tested this patch by reverting commit 6150a1b0, so notsure can this patch give even better performance ?</div><div class="gmail_extra"><br /></div><div class="gmail_extra">Italso points to the case, what Andres has mentioned in this thread.</div><div class="gmail_extra"><br/></div><div class="gmail_extra"><a href="http://www.postgresql.org/message-id/20160226191158.3vidtk3ktcmhimdu@alap3.anarazel.de">http://www.postgresql.org/message-id/20160226191158.3vidtk3ktcmhimdu@alap3.anarazel.de</a></div><div class="gmail_extra"><spanstyle="color:rgb(80,0,80);font-size:12.8px"><br /></span></div><div class="gmail_extra"><span style="color:rgb(80,0,80);font-size:12.8px">Regards,</span><br/></div></div><div class="gmail_extra"><div class="gmail_signature"><divdir="ltr"><span style="color:rgb(80,0,80);font-size:12.8px">Dilip Kumar</span><br style="color:rgb(80,0,80);font-size:12.8px"/><span style="color:rgb(80,0,80);font-size:12.8px">EnterpriseDB: </span><a href="http://www.enterprisedb.com/"style="color:rgb(17,85,204);font-size:12.8px" target="_blank">http://www.enterprisedb.com</a><br/></div></div></div></div>
On Fri, Mar 25, 2016 at 8:09 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Could anybody run benchmarks? Feature freeze is soon, but it would be *very nice* to fit it into 9.6 release cycle, because it greatly improves scalability on large machines. Without this patch PostgreSQL 9.6 will be significantly behind competitors like MySQL 5.7.
I have run the performance and here are the results.. With latest patch I did not see any regression at lower client count (median of 3 reading).scale factor 1000 shared buffer 8GB readonlyClient Base patch1 12957 130682 24931 258164 46311 4876732 300921 31006264 387623 493843128 249635 583513scale factor 300 shared buffer 8GB readonlyClient Base patch1 14537 14586 --> one thread number looks little less, generally I get ~18000 (will recheck).2 34703 33929 --> may be run to run variance (once I get time, will recheck)4 67744 6906932 312575 33601264 213312 539056128 190139 380122Summary:Actually with 64 client we have seen ~470,000 TPS with head also, by revering commit 6150a1b0.refer this thread: (http://www.postgresql.org/message-id/CAA4eK1+ZeB8PMwwktf+3bRS0Pt4Ux6Rs6Aom0uip8c6shJWmyg@mail.gmail.com)I haven't tested this patch by reverting commit 6150a1b0, so not sure can this patch give even better performance ?It also points to the case, what Andres has mentioned in this thread.
Thank you very much for testing!
I also got access to 4 x 18 Intel server with 144 threads. I'm going to post results of tests on this server in next Monday.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sat, Mar 26, 2016 at 1:26 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
Thank you very much for testing!I also got access to 4 x 18 Intel server with 144 threads. I'm going to post results of tests on this server in next Monday.
I've run pgbench tests on this machine: pgbench -s 1000 -c $clients -j 100 -M prepared -T 300.
See results in the table and chart.
clients master v3 v5
1 11671 12507 12679
2 24650 26005 25010
4 49631 48863 49811
8 96790 96441 99946
10 121275 119928 124100
20 243066 243365 246432
30 359616 342241 357310
40 431375 415310 441619
50 489991 489896 500590
60 538057 636473 554069
70 588659 714426 738535
80 405008 923039 902632
90 295443 1181247 1155918
100 258695 1323125 1325019
110 238842 1393767 1410274
120 226018 1432504 1474982
130 215102 1465459 1503241
140 206415 1470454 1505380
150 197850 1475479 1519908
160 190935 1420915 1484868
170 185835 1438965 1453128
180 182519 1416252 1453098
My conclusions are following:
1) We don't observe any regression in v5 in comparison to master.
2) v5 in most of cases slightly outperforms v3.
I'm going to do some code cleanup of v5 in Monday
------
Alexander KorotkovPostgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
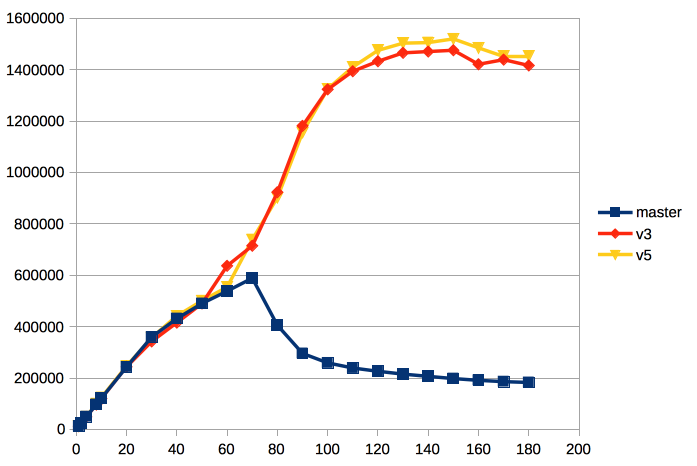{kind=link}
On 2016-03-25 23:02:11 +0530, Dilip Kumar wrote: > On Fri, Mar 25, 2016 at 8:09 PM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > > > Could anybody run benchmarks? Feature freeze is soon, but it would be > > *very nice* to fit it into 9.6 release cycle, because it greatly improves > > scalability on large machines. Without this patch PostgreSQL 9.6 will be > > significantly behind competitors like MySQL 5.7. > > > I have run the performance and here are the results.. With latest patch I > did not see any regression at lower client count (median of 3 reading). > > scale factor 1000 shared buffer 8GB readonly > *Client Base patch* > 1 12957 13068 > 2 24931 25816 > 4 46311 48767 > 32 300921 310062 > 64 387623 493843 > 128 249635 583513 > scale factor 300 shared buffer 8GB readonly > *Client Base patch* > 1 14537 14586 --> one thread number looks little less, generally I get > ~18000 (will recheck). > 2 34703 33929 --> may be run to run variance (once I get time, will > recheck) > 4 67744 69069 > 32 312575 336012 > 64 213312 539056 > 128 190139 380122 > > *Summary:* > > Actually with 64 client we have seen ~470,000 TPS with head also, by > revering commit 6150a1b0. > refer this thread: ( > http://www.postgresql.org/message-id/CAA4eK1+ZeB8PMwwktf+3bRS0Pt4Ux6Rs6Aom0uip8c6shJWmyg@mail.gmail.com > ) > > I haven't tested this patch by reverting commit 6150a1b0, so not sure can > this patch give even better performance ? > > It also points to the case, what Andres has mentioned in this thread. > > http://www.postgresql.org/message-id/20160226191158.3vidtk3ktcmhimdu@alap3.anarazel.de On what hardware did you run these tests? Thanks, Andres
On 2016-03-27 12:38:25 +0300, Alexander Korotkov wrote: > On Sat, Mar 26, 2016 at 1:26 AM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > > > Thank you very much for testing! > > I also got access to 4 x 18 Intel server with 144 threads. I'm going to > > post results of tests on this server in next Monday. > > > > I've run pgbench tests on this machine: pgbench -s 1000 -c $clients -j 100 > -M prepared -T 300. > See results in the table and chart. > > clients master v3 v5 > 1 11671 12507 12679 > 2 24650 26005 25010 > 4 49631 48863 49811 > 8 96790 96441 99946 > 10 121275 119928 124100 > 20 243066 243365 246432 > 30 359616 342241 357310 > 40 431375 415310 441619 > 50 489991 489896 500590 > 60 538057 636473 554069 > 70 588659 714426 738535 > 80 405008 923039 902632 > 90 295443 1181247 1155918 > 100 258695 1323125 1325019 > 110 238842 1393767 1410274 > 120 226018 1432504 1474982 > 130 215102 1465459 1503241 > 140 206415 1470454 1505380 > 150 197850 1475479 1519908 > 160 190935 1420915 1484868 > 170 185835 1438965 1453128 > 180 182519 1416252 1453098 > > My conclusions are following: > 1) We don't observe any regression in v5 in comparison to master. > 2) v5 in most of cases slightly outperforms v3. What commit did you base these tests on? I guess something recent, after 98a64d0bd? > I'm going to do some code cleanup of v5 in Monday Ok, I'll try to do a review and possibly commit after that. Greetings, Andres Freund
On Sun, Mar 27, 2016 at 5:37 PM, Andres Freund <andres@anarazel.de> wrote:
On what hardware did you run these tests?
IBM POWER 8 MACHINE.
Architecture: ppc64le
Byte Order: Little Endian
CPU(s): 192
Thread(s) per core: 8
Core(s) per socket: 1
Socket(s): 24
NUMA node(s): 4
On 2016-03-27 17:45:52 +0530, Dilip Kumar wrote: > On Sun, Mar 27, 2016 at 5:37 PM, Andres Freund <andres@anarazel.de> wrote: > > > On what hardware did you run these tests? > > > IBM POWER 8 MACHINE. > > Architecture: ppc64le > Byte Order: Little Endian > CPU(s): 192 > Thread(s) per core: 8 > Core(s) per socket: 1 > Socket(s): 24 > NUMA node(s): 4 What's sizeof(BufferDesc) after applying these patches? It should better be <= 64... Andres
On Sun, Mar 27, 2016 at 3:10 PM, Andres Freund <andres@anarazel.de> wrote:
What commit did you base these tests on? I guess something recent, afterOn 2016-03-27 12:38:25 +0300, Alexander Korotkov wrote:
> On Sat, Mar 26, 2016 at 1:26 AM, Alexander Korotkov <
> a.korotkov@postgrespro.ru> wrote:
>
> > Thank you very much for testing!
> > I also got access to 4 x 18 Intel server with 144 threads. I'm going to
> > post results of tests on this server in next Monday.
> >
>
> I've run pgbench tests on this machine: pgbench -s 1000 -c $clients -j 100
> -M prepared -T 300.
> See results in the table and chart.
>
> clients master v3 v5
> 1 11671 12507 12679
> 2 24650 26005 25010
> 4 49631 48863 49811
> 8 96790 96441 99946
> 10 121275 119928 124100
> 20 243066 243365 246432
> 30 359616 342241 357310
> 40 431375 415310 441619
> 50 489991 489896 500590
> 60 538057 636473 554069
> 70 588659 714426 738535
> 80 405008 923039 902632
> 90 295443 1181247 1155918
> 100 258695 1323125 1325019
> 110 238842 1393767 1410274
> 120 226018 1432504 1474982
> 130 215102 1465459 1503241
> 140 206415 1470454 1505380
> 150 197850 1475479 1519908
> 160 190935 1420915 1484868
> 170 185835 1438965 1453128
> 180 182519 1416252 1453098
>
> My conclusions are following:
> 1) We don't observe any regression in v5 in comparison to master.
> 2) v5 in most of cases slightly outperforms v3.
98a64d0bd?
Yes, more recent than 98a64d0bd. It was based on 676265eb7b.
> I'm going to do some code cleanup of v5 in Monday
Ok, I'll try to do a review and possibly commit after that.
Sounds good.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, Mar 27, 2016 at 5:48 PM, Andres Freund <andres@anarazel.de> wrote:
What's sizeof(BufferDesc) after applying these patches? It should better
be <= 64...
It is 72.
On Sun, Mar 27, 2016 at 4:31 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sun, Mar 27, 2016 at 3:10 PM, Andres Freund <andres@anarazel.de> wrote:What commit did you base these tests on? I guess something recent, afterOn 2016-03-27 12:38:25 +0300, Alexander Korotkov wrote:
> On Sat, Mar 26, 2016 at 1:26 AM, Alexander Korotkov <
> a.korotkov@postgrespro.ru> wrote:
>
> > Thank you very much for testing!
> > I also got access to 4 x 18 Intel server with 144 threads. I'm going to
> > post results of tests on this server in next Monday.
> >
>
> I've run pgbench tests on this machine: pgbench -s 1000 -c $clients -j 100
> -M prepared -T 300.
> See results in the table and chart.
>
> clients master v3 v5
> 1 11671 12507 12679
> 2 24650 26005 25010
> 4 49631 48863 49811
> 8 96790 96441 99946
> 10 121275 119928 124100
> 20 243066 243365 246432
> 30 359616 342241 357310
> 40 431375 415310 441619
> 50 489991 489896 500590
> 60 538057 636473 554069
> 70 588659 714426 738535
> 80 405008 923039 902632
> 90 295443 1181247 1155918
> 100 258695 1323125 1325019
> 110 238842 1393767 1410274
> 120 226018 1432504 1474982
> 130 215102 1465459 1503241
> 140 206415 1470454 1505380
> 150 197850 1475479 1519908
> 160 190935 1420915 1484868
> 170 185835 1438965 1453128
> 180 182519 1416252 1453098
>
> My conclusions are following:
> 1) We don't observe any regression in v5 in comparison to master.
> 2) v5 in most of cases slightly outperforms v3.
98a64d0bd?Yes, more recent than 98a64d0bd. It was based on 676265eb7b.> I'm going to do some code cleanup of v5 in Monday
Ok, I'll try to do a review and possibly commit after that.Sounds good.
There is next revision of patch. It contains mostly cosmetic changes. Comment are adjusted to reflect changes of behaviour.
I also changed atomic AND/OR for local buffers to read/write pair which would be cheaper I suppose. However, I don't insist on it, and it could be reverted.
The patch is ready for your review. It's especially interesting what do you think about the way I abstracted exponential back off of spinlock.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On 2016-03-28 11:48:46 +0530, Dilip Kumar wrote: > On Sun, Mar 27, 2016 at 5:48 PM, Andres Freund <andres@anarazel.de> wrote: > > > > > What's sizeof(BufferDesc) after applying these patches? It should better > > be <= 64... > > > > It is 72. Ah yes, miscalculated the required alignment. Hm. So we got to get this smaller. I see three approaches: 1) Reduce the spinlock size on ppc. That actually might just work by replacing "unsigned int" by "unsigned char" 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid embedding the spinlock, and actually might allowto avoid one atomic op in a number of cases. 3) Shrink the size of BufferDesc by removing buf_id; that'd bring it to 64byte. I'm a bit hesitant to go for 3), because it'd likely end up adding a bit of arithmetic to a number of places in bufmgr.c. Robert, what do you think? Andres
On 2016-03-28 15:46:43 +0300, Alexander Korotkov wrote:
> diff --git a/src/backend/storage/buffer/bufmnew file mode 100644
> index 6dd7c6e..fe6fb9c
> --- a/src/backend/storage/buffer/bufmgr.c
> +++ b/src/backend/storage/buffer/bufmgr.c
> @@ -52,7 +52,6 @@
> #include "utils/resowner_private.h"
> #include "utils/timestamp.h"
>
> -
> /* Note: these two macros only work on shared buffers, not local ones! */
> #define BufHdrGetBlock(bufHdr) ((Block) (BufferBlocks + ((Size) (bufHdr)->buf_id) * BLCKSZ))
> #define BufferGetLSN(bufHdr) (PageGetLSN(BufHdrGetBlock(bufHdr)))
spurious
> @@ -848,7 +852,7 @@ ReadBuffer_common(SMgrRelation smgr, cha
> * it's not been recycled) but come right back here to try smgrextend
> * again.
> */
> - Assert(!(bufHdr->flags & BM_VALID)); /* spinlock not needed */
> + Assert(!(pg_atomic_read_u32(&bufHdr->state) & BM_VALID)); /* header lock not needed */
>
> bufBlock = isLocalBuf ? LocalBufHdrGetBlock(bufHdr) : BufHdrGetBlock(bufHdr);
>
> @@ -932,8 +936,13 @@ ReadBuffer_common(SMgrRelation smgr, cha
>
> if (isLocalBuf)
> {
> - /* Only need to adjust flags */
> - bufHdr->flags |= BM_VALID;
> + /*
> + * Only need to adjust flags. Since it's local buffer, there is no
> + * concurrency. We assume read/write pair to be cheaper than atomic OR.
> + */
> + uint32 state = pg_atomic_read_u32(&bufHdr->state);
> + state |= BM_VALID;
> + pg_atomic_write_u32(&bufHdr->state, state);
I'm not a fan of repeating that comment in multiple places. Hm.
> }
> else
> {
> @@ -987,10 +996,11 @@ BufferAlloc(SMgrRelation smgr, char relp
> BufferTag oldTag; /* previous identity of selected buffer */
> uint32 oldHash; /* hash value for oldTag */
> LWLock *oldPartitionLock; /* buffer partition lock for it */
> - BufFlags oldFlags;
> + uint32 oldFlags;
> int buf_id;
> BufferDesc *buf;
> bool valid;
> + uint32 state;
>
> /* create a tag so we can lookup the buffer */
> INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum);
> @@ -1050,23 +1060,23 @@ BufferAlloc(SMgrRelation smgr, char relp
> for (;;)
> {
> /*
> - * Ensure, while the spinlock's not yet held, that there's a free
> + * Ensure, while the header lock isn't yet held, that there's a free
> * refcount entry.
> */
> ReservePrivateRefCountEntry();
>
> /*
> * Select a victim buffer. The buffer is returned with its header
> - * spinlock still held!
> + * lock still held!
> */
> - buf = StrategyGetBuffer(strategy);
> + buf = StrategyGetBuffer(strategy, &state);
The new thing really still is a spinlock, not sure if it's worth
changing the comments that way.
> @@ -1319,7 +1330,7 @@ BufferAlloc(SMgrRelation smgr, char relp
> * InvalidateBuffer -- mark a shared buffer invalid and return it to the
> * freelist.
> *
> - * The buffer header spinlock must be held at entry. We drop it before
> + * The buffer header lock must be held at entry. We drop it before
> * returning. (This is sane because the caller must have locked the
> * buffer in order to be sure it should be dropped.)
> *
Ok, by now I'm pretty sure that I don't want this to be changed
everywhere, just makes reviewing harder.
> @@ -1433,6 +1443,7 @@ void
> MarkBufferDirty(Buffer buffer)
> {
> BufferDesc *bufHdr;
> + uint32 state;
>
> if (!BufferIsValid(buffer))
> elog(ERROR, "bad buffer ID: %d", buffer);
> @@ -1449,14 +1460,14 @@ MarkBufferDirty(Buffer buffer)
> /* unfortunately we can't check if the lock is held exclusively */
> Assert(LWLockHeldByMe(BufferDescriptorGetContentLock(bufHdr)));
>
> - LockBufHdr(bufHdr);
> + state = LockBufHdr(bufHdr);
>
> - Assert(bufHdr->refcount > 0);
> + Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
>
> /*
> * If the buffer was not dirty already, do vacuum accounting.
> */
> - if (!(bufHdr->flags & BM_DIRTY))
> + if (!(state & BM_DIRTY))
> {
> VacuumPageDirty++;
> pgBufferUsage.shared_blks_dirtied++;
> @@ -1464,9 +1475,9 @@ MarkBufferDirty(Buffer buffer)
> VacuumCostBalance += VacuumCostPageDirty;
> }
>
> - bufHdr->flags |= (BM_DIRTY | BM_JUST_DIRTIED);
> -
> - UnlockBufHdr(bufHdr);
> + state |= BM_DIRTY | BM_JUST_DIRTIED;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&bufHdr->state, state);
> }
Hm, this is a routine I think we should avoid taking the lock in; it's
often called quite frequently. Also doesn't look very hard.
> static bool
> PinBuffer(BufferDesc *buf, BufferAccessStrategy strategy)
> @@ -1547,23 +1563,44 @@ PinBuffer(BufferDesc *buf, BufferAccessS
>
> if (ref == NULL)
> {
> + /* loop of CAS operations */
> + uint32 state;
> + uint32 oldstate;
> + SpinDelayStatus delayStatus;
> ReservePrivateRefCountEntry();
> ref = NewPrivateRefCountEntry(b);
>
> - LockBufHdr(buf);
> - buf->refcount++;
> - if (strategy == NULL)
> - {
> - if (buf->usage_count < BM_MAX_USAGE_COUNT)
> - buf->usage_count++;
> - }
> - else
> + state = pg_atomic_read_u32(&buf->state);
> + oldstate = state;
> +
> + init_spin_delay(&delayStatus, (Pointer)buf, __FILE__, __LINE__);
Hm. This way we're calling this on every iteration. That doesn't seem
like a good idea. How about making delayStatus a static, and
init_spin_delay a macro which returns a {struct, member, one, two} type
literal?
> + while (true)
> {
> - if (buf->usage_count == 0)
> - buf->usage_count = 1;
> + /* spin-wait till lock is free */
> + while (state & BM_LOCKED)
> + {
> + make_spin_delay(&delayStatus);
> + state = pg_atomic_read_u32(&buf->state);
> + oldstate = state;
> + }
Maybe we should abstract that to pg_atomic_wait_bit_unset_u32()? It
seems quite likely we need this in other places (e.g. lwlock.c itself).
> + /* increase refcount */
> + state += BUF_REFCOUNT_ONE;
> +
> + /* increase usagecount unless already max */
> + if (BUF_STATE_GET_USAGECOUNT(state) != BM_MAX_USAGE_COUNT)
> + state += BUF_USAGECOUNT_ONE;
> +
> + /* try to do CAS, exit on success */
Seems like a somewhat obvious comment?
> @@ -1603,15 +1640,22 @@ PinBuffer_Locked(BufferDesc *buf)
> {
> Assert(GetPrivateRefCountEntry(BufferDescriptorGetBuffer(buf), false) == NULL);
>
> - buf->refcount++;
> - UnlockBufHdr(buf);
> + /*
> + * Since we assume to held buffer header lock, we can update the buffer
> + * state in a single write operation.
> + */
> + state = pg_atomic_read_u32(&buf->state);
> + state += 1;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&buf->state, state);
Te comment should probably mention that we're releasing the
spinlock. And the += 1 should be a BUF_REFCOUNT_ONE, otherwise it's hard
to understand.
> @@ -1646,30 +1690,66 @@ UnpinBuffer(BufferDesc *buf, bool fixOwn
> ref->refcount--;
> if (ref->refcount == 0)
> {
> +
> + /* Support LockBufferForCleanup() */
> + if (state & BM_PIN_COUNT_WAITER)
> + {
> + state = LockBufHdr(buf);
> +
> + if (state & BM_PIN_COUNT_WAITER && BUF_STATE_GET_REFCOUNT(state) == 1)
> + {
> + /* we just released the last pin other than the waiter's */
> + int wait_backend_pid = buf->wait_backend_pid;
>
> + state &= ~(BM_PIN_COUNT_WAITER | BM_LOCKED);
> + pg_atomic_write_u32(&buf->state, state);
> + ProcSendSignal(wait_backend_pid);
> + }
> + else
> + UnlockBufHdr(buf);
> + }
I think it's quite confusing to use UnlockBufHdr and direct bit
expressions in one branch.
Thinking about it I also don't think the pg_atomic_write_u32 variant is
correct without adding a write barrier; the other side might not see the
values yet.
I think we can just redefine UnlockBufHdr() to be a
pg_atomic_write_u32() and pg_write_memory_barrier()?
> * BM_PERMANENT can't be changed while we hold a pin on the buffer, so we
> - * need not bother with the buffer header spinlock. Even if someone else
> + * need not bother with the buffer header lock. Even if someone else
> * changes the buffer header flags while we're doing this, we assume that
> * changing an aligned 2-byte BufFlags value is atomic, so we'll read the
> * old value or the new value, but not random garbage.
> */
The rest of the comment is outdated, BufFlags isn't a 2 byte value
anymore.
> @@ -3078,7 +3168,7 @@ FlushRelationBuffers(Relation rel)
> localpage,
> false);
>
> - bufHdr->flags &= ~(BM_DIRTY | BM_JUST_DIRTIED);
> + pg_atomic_fetch_and_u32(&bufHdr->state, ~(BM_DIRTY | BM_JUST_DIRTIED));
Hm, in other places you replaced atomics on local buffers with plain
writes.
> lsn = XLogSaveBufferForHint(buffer, buffer_std);
> }
>
> - LockBufHdr(bufHdr);
> - Assert(bufHdr->refcount > 0);
> - if (!(bufHdr->flags & BM_DIRTY))
> + state = LockBufHdr(bufHdr);
> +
> + Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
> +
> + if (!(state & BM_DIRTY))
> {
> dirtied = true; /* Means "will be dirtied by this action" */
It's again worthwhile to try make this work without taking the lock.
> - buf->flags |= BM_IO_IN_PROGRESS;
> -
> - UnlockBufHdr(buf);
> + state |= BM_IO_IN_PROGRESS;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&buf->state, state);
How about making UnlockBufHdr() take a new state parameter, and
internally unset BM_LOCKED?
> /*
> + * Lock buffer header - set BM_LOCKED in buffer state.
> + */
> +uint32
> +LockBufHdr(volatile BufferDesc *desc)
> +{
> + SpinDelayStatus delayStatus;
> + uint32 state;
> +
> + init_spin_delay(&delayStatus, (Pointer)desc, __FILE__, __LINE__);
> +
> + state = pg_atomic_read_u32(&desc->state);
> +
> + for (;;)
> + {
> + /* wait till lock is free */
> + while (state & BM_LOCKED)
> + {
> + make_spin_delay(&delayStatus);
> + state = pg_atomic_read_u32(&desc->state);
> + /* Add exponential backoff? Should seldomly be contended tho. */
Outdated comment.
> +/*
> + * Unlock buffer header - unset BM_LOCKED in buffer state.
> + */
> +void
> +UnlockBufHdr(volatile BufferDesc *desc)
> +{
> + Assert(pg_atomic_read_u32(&desc->state) & BM_LOCKED);
> +
> + pg_atomic_sub_fetch_u32(&desc->state, BM_LOCKED);
> +}
As suggested above, there's likely no need to use an actual atomic op
here.
Greetings,
Andres Freund
Andres Freund wrote:
> On 2016-03-28 15:46:43 +0300, Alexander Korotkov wrote:
> > @@ -932,8 +936,13 @@ ReadBuffer_common(SMgrRelation smgr, cha
> >
> > if (isLocalBuf)
> > {
> > - /* Only need to adjust flags */
> > - bufHdr->flags |= BM_VALID;
> > + /*
> > + * Only need to adjust flags. Since it's local buffer, there is no
> > + * concurrency. We assume read/write pair to be cheaper than atomic OR.
> > + */
> > + uint32 state = pg_atomic_read_u32(&bufHdr->state);
> > + state |= BM_VALID;
> > + pg_atomic_write_u32(&bufHdr->state, state);
>
> I'm not a fan of repeating that comment in multiple places. Hm.
Perhaps a set of macros should be offered that do "read, set some flag,
write". Then the comments can be attached to the macro instead of to
each callsite.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Mar 28, 2016 at 9:09 AM, Andres Freund <andres@anarazel.de> wrote: > On 2016-03-28 11:48:46 +0530, Dilip Kumar wrote: >> On Sun, Mar 27, 2016 at 5:48 PM, Andres Freund <andres@anarazel.de> wrote: >> > What's sizeof(BufferDesc) after applying these patches? It should better >> > be <= 64... >> > >> >> It is 72. > > Ah yes, miscalculated the required alignment. Hm. So we got to get this > smaller. I see three approaches: > > 1) Reduce the spinlock size on ppc. That actually might just work by > replacing "unsigned int" by "unsigned char" > 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid > embedding the spinlock, and actually might allow to avoid one atomic > op in a number of cases. > 3) Shrink the size of BufferDesc by removing buf_id; that'd bring it to > 64byte. > > I'm a bit hesitant to go for 3), because it'd likely end up adding a bit > of arithmetic to a number of places in bufmgr.c. Robert, what do you > think? I don't have a clear idea what's going to be better here. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-03-29 13:09:05 -0400, Robert Haas wrote: > On Mon, Mar 28, 2016 at 9:09 AM, Andres Freund <andres@anarazel.de> wrote: > > On 2016-03-28 11:48:46 +0530, Dilip Kumar wrote: > >> On Sun, Mar 27, 2016 at 5:48 PM, Andres Freund <andres@anarazel.de> wrote: > >> > What's sizeof(BufferDesc) after applying these patches? It should better > >> > be <= 64... > >> > > >> > >> It is 72. > > > > Ah yes, miscalculated the required alignment. Hm. So we got to get this > > smaller. I see three approaches: > > > > 1) Reduce the spinlock size on ppc. That actually might just work by > > replacing "unsigned int" by "unsigned char" > > 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid > > embedding the spinlock, and actually might allow to avoid one atomic > > op in a number of cases. > > 3) Shrink the size of BufferDesc by removing buf_id; that'd bring it to > > 64byte. > > > > I'm a bit hesitant to go for 3), because it'd likely end up adding a bit > > of arithmetic to a number of places in bufmgr.c. Robert, what do you > > think? > > I don't have a clear idea what's going to be better here. My gut feeling is that we should do both 1) and 2). Dilip, could you test performance of reducing ppc's spinlock to 1 byte? Cross-compiling suggest that doing so "just works". I.e. replace the #if defined(__ppc__) typedef from an int to a char. Regards, Andres
Hi, Andres!
Please, find next revision of patch in attachment.
On Mon, Mar 28, 2016 at 4:59 PM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2016-03-28 15:46:43 +0300, Alexander Korotkov wrote:
> diff --git a/src/backend/storage/buffer/bufmnew file mode 100644
> index 6dd7c6e..fe6fb9c
> --- a/src/backend/storage/buffer/bufmgr.c
> +++ b/src/backend/storage/buffer/bufmgr.c
> @@ -52,7 +52,6 @@
> #include "utils/resowner_private.h"
> #include "utils/timestamp.h"
>
> -
> /* Note: these two macros only work on shared buffers, not local ones! */
> #define BufHdrGetBlock(bufHdr) ((Block) (BufferBlocks + ((Size) (bufHdr)->buf_id) * BLCKSZ))
> #define BufferGetLSN(bufHdr) (PageGetLSN(BufHdrGetBlock(bufHdr)))
spurious
Fixed.
> @@ -848,7 +852,7 @@ ReadBuffer_common(SMgrRelation smgr, cha
> * it's not been recycled) but come right back here to try smgrextend
> * again.
> */
> - Assert(!(bufHdr->flags & BM_VALID)); /* spinlock not needed */
> + Assert(!(pg_atomic_read_u32(&bufHdr->state) & BM_VALID)); /* header lock not needed */
>
> bufBlock = isLocalBuf ? LocalBufHdrGetBlock(bufHdr) : BufHdrGetBlock(bufHdr);
>
> @@ -932,8 +936,13 @@ ReadBuffer_common(SMgrRelation smgr, cha
>
> if (isLocalBuf)
> {
> - /* Only need to adjust flags */
> - bufHdr->flags |= BM_VALID;
> + /*
> + * Only need to adjust flags. Since it's local buffer, there is no
> + * concurrency. We assume read/write pair to be cheaper than atomic OR.
> + */
> + uint32 state = pg_atomic_read_u32(&bufHdr->state);
> + state |= BM_VALID;
> + pg_atomic_write_u32(&bufHdr->state, state);
I'm not a fan of repeating that comment in multiple places. Hm.
Moved comments into single place where macros for CAS loop is defined (see my comments below).
> }
> else
> {
> @@ -987,10 +996,11 @@ BufferAlloc(SMgrRelation smgr, char relp
> BufferTag oldTag; /* previous identity of selected buffer */
> uint32 oldHash; /* hash value for oldTag */
> LWLock *oldPartitionLock; /* buffer partition lock for it */
> - BufFlags oldFlags;
> + uint32 oldFlags;
> int buf_id;
> BufferDesc *buf;
> bool valid;
> + uint32 state;
>
> /* create a tag so we can lookup the buffer */
> INIT_BUFFERTAG(newTag, smgr->smgr_rnode.node, forkNum, blockNum);
> @@ -1050,23 +1060,23 @@ BufferAlloc(SMgrRelation smgr, char relp
> for (;;)
> {
> /*
> - * Ensure, while the spinlock's not yet held, that there's a free
> + * Ensure, while the header lock isn't yet held, that there's a free
> * refcount entry.
> */
> ReservePrivateRefCountEntry();
>
> /*
> * Select a victim buffer. The buffer is returned with its header
> - * spinlock still held!
> + * lock still held!
> */
> - buf = StrategyGetBuffer(strategy);
> + buf = StrategyGetBuffer(strategy, &state);
The new thing really still is a spinlock, not sure if it's worth
changing the comments that way.
> @@ -1319,7 +1330,7 @@ BufferAlloc(SMgrRelation smgr, char relp
> * InvalidateBuffer -- mark a shared buffer invalid and return it to the
> * freelist.
> *
> - * The buffer header spinlock must be held at entry. We drop it before
> + * The buffer header lock must be held at entry. We drop it before
> * returning. (This is sane because the caller must have locked the
> * buffer in order to be sure it should be dropped.)
> *
Ok, by now I'm pretty sure that I don't want this to be changed
everywhere, just makes reviewing harder.
Fixed.
> @@ -1433,6 +1443,7 @@ void
> MarkBufferDirty(Buffer buffer)
> {
> BufferDesc *bufHdr;
> + uint32 state;
>
> if (!BufferIsValid(buffer))
> elog(ERROR, "bad buffer ID: %d", buffer);
> @@ -1449,14 +1460,14 @@ MarkBufferDirty(Buffer buffer)
> /* unfortunately we can't check if the lock is held exclusively */
> Assert(LWLockHeldByMe(BufferDescriptorGetContentLock(bufHdr)));
>
> - LockBufHdr(bufHdr);
> + state = LockBufHdr(bufHdr);
>
> - Assert(bufHdr->refcount > 0);
> + Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
>
> /*
> * If the buffer was not dirty already, do vacuum accounting.
> */
> - if (!(bufHdr->flags & BM_DIRTY))
> + if (!(state & BM_DIRTY))
> {
> VacuumPageDirty++;
> pgBufferUsage.shared_blks_dirtied++;
> @@ -1464,9 +1475,9 @@ MarkBufferDirty(Buffer buffer)
> VacuumCostBalance += VacuumCostPageDirty;
> }
>
> - bufHdr->flags |= (BM_DIRTY | BM_JUST_DIRTIED);
> -
> - UnlockBufHdr(bufHdr);
> + state |= BM_DIRTY | BM_JUST_DIRTIED;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&bufHdr->state, state);
> }
Hm, this is a routine I think we should avoid taking the lock in; it's
often called quite frequently. Also doesn't look very hard.
Done.
> static bool
> PinBuffer(BufferDesc *buf, BufferAccessStrategy strategy)
> @@ -1547,23 +1563,44 @@ PinBuffer(BufferDesc *buf, BufferAccessS
>
> if (ref == NULL)
> {
> + /* loop of CAS operations */
> + uint32 state;
> + uint32 oldstate;
> + SpinDelayStatus delayStatus;
> ReservePrivateRefCountEntry();
> ref = NewPrivateRefCountEntry(b);
>
> - LockBufHdr(buf);
> - buf->refcount++;
> - if (strategy == NULL)
> - {
> - if (buf->usage_count < BM_MAX_USAGE_COUNT)
> - buf->usage_count++;
> - }
> - else
> + state = pg_atomic_read_u32(&buf->state);
> + oldstate = state;
> +
> + init_spin_delay(&delayStatus, (Pointer)buf, __FILE__, __LINE__);
Hm. This way we're calling this on every iteration. That doesn't seem
like a good idea. How about making delayStatus a static, and
init_spin_delay a macro which returns a {struct, member, one, two} type
literal?
Done.
> + while (true)
> {
> - if (buf->usage_count == 0)
> - buf->usage_count = 1;
> + /* spin-wait till lock is free */
> + while (state & BM_LOCKED)
> + {
> + make_spin_delay(&delayStatus);
> + state = pg_atomic_read_u32(&buf->state);
> + oldstate = state;
> + }
Maybe we should abstract that to pg_atomic_wait_bit_unset_u32()? It
seems quite likely we need this in other places (e.g. lwlock.c itself).
I have some doubts about such function. At first, I can't find a place for it in lwlock.c. It doesn't run explicit spin delays yet. Is it related to some changes you're planning for lwlock.c.
At second, I doubt about it's signature. It would be logical if it would be "uint32 pg_atomic_wait_bit_unset_u32(pg_atomic_u32 *var, uint32 mask)". But in this case we have to do extra pg_atomic_read_u32 after unsuccessful CAS. And it causes some small regression. Especially unpleasant that it's also regression in comparison with master on low clients.
But there is code duplication which would be very nice to evade. I end up with macros which encapsulates CAS loop.
BEGIN_BUFSTATE_CAS_LOOP(buf);
state |= BM_LOCKED;
END_BUFSTATE_CAS_LOOP(buf);
For me, it simplifies readability a lot.
> + /* increase refcount */
> + state += BUF_REFCOUNT_ONE;
> +
> + /* increase usagecount unless already max */
> + if (BUF_STATE_GET_USAGECOUNT(state) != BM_MAX_USAGE_COUNT)
> + state += BUF_USAGECOUNT_ONE;
> +
> + /* try to do CAS, exit on success */
Seems like a somewhat obvious comment?
Comment removed.
> @@ -1603,15 +1640,22 @@ PinBuffer_Locked(BufferDesc *buf)
> {
> Assert(GetPrivateRefCountEntry(BufferDescriptorGetBuffer(buf), false) == NULL);
>
> - buf->refcount++;
> - UnlockBufHdr(buf);
> + /*
> + * Since we assume to held buffer header lock, we can update the buffer
> + * state in a single write operation.
> + */
> + state = pg_atomic_read_u32(&buf->state);
> + state += 1;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&buf->state, state);
Te comment should probably mention that we're releasing the
spinlock. And the += 1 should be a BUF_REFCOUNT_ONE, otherwise it's hard
to understand.
Fixed.
> @@ -1646,30 +1690,66 @@ UnpinBuffer(BufferDesc *buf, bool fixOwn
> ref->refcount--;
> if (ref->refcount == 0)
> {
> +
> + /* Support LockBufferForCleanup() */
> + if (state & BM_PIN_COUNT_WAITER)
> + {
> + state = LockBufHdr(buf);
> +
> + if (state & BM_PIN_COUNT_WAITER && BUF_STATE_GET_REFCOUNT(state) == 1)
> + {
> + /* we just released the last pin other than the waiter's */
> + int wait_backend_pid = buf->wait_backend_pid;
>
> + state &= ~(BM_PIN_COUNT_WAITER | BM_LOCKED);
> + pg_atomic_write_u32(&buf->state, state);
> + ProcSendSignal(wait_backend_pid);
> + }
> + else
> + UnlockBufHdr(buf);
> + }
I think it's quite confusing to use UnlockBufHdr and direct bit
expressions in one branch.
Thinking about it I also don't think the pg_atomic_write_u32 variant is
correct without adding a write barrier; the other side might not see the
values yet.
I think we can just redefine UnlockBufHdr() to be a
pg_atomic_write_u32() and pg_write_memory_barrier()?
Done.
> * BM_PERMANENT can't be changed while we hold a pin on the buffer, so we
> - * need not bother with the buffer header spinlock. Even if someone else
> + * need not bother with the buffer header lock. Even if someone else
> * changes the buffer header flags while we're doing this, we assume that
> * changing an aligned 2-byte BufFlags value is atomic, so we'll read the
> * old value or the new value, but not random garbage.
> */
The rest of the comment is outdated, BufFlags isn't a 2 byte value
anymore.
Fixed.
> @@ -3078,7 +3168,7 @@ FlushRelationBuffers(Relation rel)
> localpage,
> false);
>
> - bufHdr->flags &= ~(BM_DIRTY | BM_JUST_DIRTIED);
> + pg_atomic_fetch_and_u32(&bufHdr->state, ~(BM_DIRTY | BM_JUST_DIRTIED));
Hm, in other places you replaced atomics on local buffers with plain
writes.
Fixed.
> lsn = XLogSaveBufferForHint(buffer, buffer_std);
> }
>
> - LockBufHdr(bufHdr);
> - Assert(bufHdr->refcount > 0);
> - if (!(bufHdr->flags & BM_DIRTY))
> + state = LockBufHdr(bufHdr);
> +
> + Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
> +
> + if (!(state & BM_DIRTY))
> {
> dirtied = true; /* Means "will be dirtied by this action" */
It's again worthwhile to try make this work without taking the lock.
Comment there claims.
/*
* Set the page LSN if we wrote a backup block. We aren't supposed
* to set this when only holding a share lock but as long as we
* serialise it somehow we're OK. We choose to set LSN while
* holding the buffer header lock, which causes any reader of an
* LSN who holds only a share lock to also obtain a buffer header
* lock before using PageGetLSN(), which is enforced in
* BufferGetLSNAtomic().
Thus, buffer header lock is used for write serialization. I don't think it would be correct to remove the lock here.
> - buf->flags |= BM_IO_IN_PROGRESS;
> -
> - UnlockBufHdr(buf);
> + state |= BM_IO_IN_PROGRESS;
> + state &= ~BM_LOCKED;
> + pg_atomic_write_u32(&buf->state, state);
How about making UnlockBufHdr() take a new state parameter, and
internally unset BM_LOCKED?
Done.
> /*
> + * Lock buffer header - set BM_LOCKED in buffer state.
> + */
> +uint32
> +LockBufHdr(volatile BufferDesc *desc)
> +{
> + SpinDelayStatus delayStatus;
> + uint32 state;
> +
> + init_spin_delay(&delayStatus, (Pointer)desc, __FILE__, __LINE__);
> +
> + state = pg_atomic_read_u32(&desc->state);
> +
> + for (;;)
> + {
> + /* wait till lock is free */
> + while (state & BM_LOCKED)
> + {
> + make_spin_delay(&delayStatus);
> + state = pg_atomic_read_u32(&desc->state);
> + /* Add exponential backoff? Should seldomly be contended tho. */
Outdated comment.
Fixed.
> +/*
> + * Unlock buffer header - unset BM_LOCKED in buffer state.
> + */
> +void
> +UnlockBufHdr(volatile BufferDesc *desc)
> +{
> + Assert(pg_atomic_read_u32(&desc->state) & BM_LOCKED);
> +
> + pg_atomic_sub_fetch_u32(&desc->state, BM_LOCKED);
> +}
As suggested above, there's likely no need to use an actual atomic op
here.
Fixed. Actually, this function is removed now.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
Andres Freund <andres@anarazel.de> writes:
> Dilip, could you test performance of reducing ppc's spinlock to 1 byte?
> Cross-compiling suggest that doing so "just works". I.e. replace the
> #if defined(__ppc__) typedef from an int to a char.
AFAICS, lwarx/stwcx are specifically *word* wide.
regards, tom lane
On 2016-03-29 13:24:40 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Dilip, could you test performance of reducing ppc's spinlock to 1 byte? > > Cross-compiling suggest that doing so "just works". I.e. replace the > > #if defined(__ppc__) typedef from an int to a char. > > AFAICS, lwarx/stwcx are specifically *word* wide. Ah, x86 gcc is just too convenient, with it automatically adjusting instruction types :( There's actually lbarx/stbcx - but it's not present in all ISAs. So I guess it's clear where to go. Andres Freund
On 2016-03-29 20:22:00 +0300, Alexander Korotkov wrote:
> > > + while (true)
> > > {
> > > - if (buf->usage_count == 0)
> > > - buf->usage_count = 1;
> > > + /* spin-wait till lock is free */
> > > + while (state & BM_LOCKED)
> > > + {
> > > + make_spin_delay(&delayStatus);
> > > + state = pg_atomic_read_u32(&buf->state);
> > > + oldstate = state;
> > > + }
> >
> > Maybe we should abstract that to pg_atomic_wait_bit_unset_u32()? It
> > seems quite likely we need this in other places (e.g. lwlock.c itself).
> >
>
> I have some doubts about such function. At first, I can't find a place for
> it in lwlock.c. It doesn't run explicit spin delays yet. Is it related to
> some changes you're planning for lwlock.c.
Yes, see http://www.postgresql.org/message-id/20160328130904.4mhugvkf4f3wg4qb@awork2.anarazel.de
> > > lsn = XLogSaveBufferForHint(buffer, buffer_std);
> > > }
> > >
> > > - LockBufHdr(bufHdr);
> > > - Assert(bufHdr->refcount > 0);
> > > - if (!(bufHdr->flags & BM_DIRTY))
> > > + state = LockBufHdr(bufHdr);
> > > +
> > > + Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
> > > +
> > > + if (!(state & BM_DIRTY))
> > > {
> > > dirtied = true; /* Means "will be dirtied
> > by this action" */
> >
> > It's again worthwhile to try make this work without taking the lock.
> >
>
> Comment there claims.
>
> /*
> * Set the page LSN if we wrote a backup block. We aren't supposed
> * to set this when only holding a share lock but as long as we
> * serialise it somehow we're OK. We choose to set LSN while
> * holding the buffer header lock, which causes any reader of an
> * LSN who holds only a share lock to also obtain a buffer header
> * lock before using PageGetLSN(), which is enforced in
> * BufferGetLSNAtomic().
>
> Thus, buffer header lock is used for write serialization. I don't think it
> would be correct to remove the lock here.
Gah, I forgot about this uglyness. Man, the checksumming commit sure
made a number of things really ugly.
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2016-03-29 13:24:40 -0400, Tom Lane wrote:
>> AFAICS, lwarx/stwcx are specifically *word* wide.
> There's actually lbarx/stbcx - but it's not present in all ISAs. So I
> guess it's clear where to go.
Hm. We could certainly add a configure test to see if the local assembler
knows these instructions --- but it's not clear that we should depend on
compile-time environment to match run-time.
Googling suggests that these instructions came in with PPC ISA 2.06
which seems to date to 2010. So there's undoubtedly still production
hardware without them.
In the department of not-production hardware, I checked this on prairiedog
and got
/var/tmp/ccbQy9uG.s:1722:Invalid mnemonic 'lbarx'
/var/tmp/ccbQy9uG.s:1726:Invalid mnemonic 'stbcx.'
regards, tom lane
On 2016-03-29 14:09:42 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > There's actually lbarx/stbcx - but it's not present in all ISAs. So I > > guess it's clear where to go. > > Hm. We could certainly add a configure test to see if the local assembler > knows these instructions --- but it's not clear that we should depend on > compile-time environment to match run-time. I think it'd be easier to continue using lwarx/stwcx, but be careful about only testing/setting the lowest byte, if we want to go there. But that then likely would require hints about alignment to the compiler... i've no experience writing ppc assembly, but it doesn't look too hard. but i think it's easier to just remove the spinlock from struct lwlock then - and it also improves the situation for other architectures with wider spinlocks. i think that's beneficial for some future things anyway. > Googling suggests that these instructions came in with PPC ISA 2.06 > which seems to date to 2010. So there's undoubtedly still production > hardware without them. > > In the department of not-production hardware, I checked this on prairiedog > and got > /var/tmp/ccbQy9uG.s:1722:Invalid mnemonic 'lbarx' > /var/tmp/ccbQy9uG.s:1726:Invalid mnemonic 'stbcx.' Heh. Thanks for testing. Andres
On Tue, Mar 29, 2016 at 10:43 PM, Andres Freund <andres@anarazel.de> wrote:
My gut feeling is that we should do both 1) and 2).
Dilip, could you test performance of reducing ppc's spinlock to 1 byte?
Cross-compiling suggest that doing so "just works". I.e. replace the
#if defined(__ppc__) typedef from an int to a char.
I set that, but after that it hangs, even Initdb hangs..
int
│164 s_lock(volatile slock_t *lock, const char *file, int line)
│165 {
│166 SpinDelayStatus delayStatus;
│167
│168 init_spin_delay(&delayStatus, (Pointer)lock, file, line);
│169
│170 while (TAS_SPIN(lock))
│171 {
>│172 make_spin_delay(&delayStatus);
│173 }
│174
I clean build multiple times but problem persist,
Does it have dependency of some other variable of defined under PPC in some other place ? I don't know..
/* PowerPC */
#if defined(__ppc__) || defined(__powerpc__) || defined(__ppc64__) || defined(__powerpc64__)
#define HAS_TEST_AND_SET
typedef unsigned int slock_t; --> changed like this
#define TAS(lock) tas(lock)
On 2016-03-30 07:13:16 +0530, Dilip Kumar wrote: > On Tue, Mar 29, 2016 at 10:43 PM, Andres Freund <andres@anarazel.de> wrote: > > > My gut feeling is that we should do both 1) and 2). > > > > Dilip, could you test performance of reducing ppc's spinlock to 1 byte? > > Cross-compiling suggest that doing so "just works". I.e. replace the > > #if defined(__ppc__) typedef from an int to a char. > > > > I set that, but after that it hangs, even Initdb hangs.. Yea, as Tom pointed out that's not going to work. I'll try to write a patch for approach 1). Andres
On Wed, Mar 30, 2016 at 10:16 AM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2016-03-30 07:13:16 +0530, Dilip Kumar wrote:
> On Tue, Mar 29, 2016 at 10:43 PM, Andres Freund <andres@anarazel.de> wrote:
>
> > My gut feeling is that we should do both 1) and 2).
> >
> > Dilip, could you test performance of reducing ppc's spinlock to 1 byte?
> > Cross-compiling suggest that doing so "just works". I.e. replace the
> > #if defined(__ppc__) typedef from an int to a char.
> >
>
> I set that, but after that it hangs, even Initdb hangs..
Yea, as Tom pointed out that's not going to work. I'll try to write a
patch for approach 1).
Great! Do you need any improvements for pinunpin-cas-7.patch from me?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Wed, Mar 30, 2016 at 3:16 AM, Andres Freund <andres@anarazel.de> wrote: > On 2016-03-30 07:13:16 +0530, Dilip Kumar wrote: >> On Tue, Mar 29, 2016 at 10:43 PM, Andres Freund <andres@anarazel.de> wrote: >> >> > My gut feeling is that we should do both 1) and 2). >> > >> > Dilip, could you test performance of reducing ppc's spinlock to 1 byte? >> > Cross-compiling suggest that doing so "just works". I.e. replace the >> > #if defined(__ppc__) typedef from an int to a char. >> > >> >> I set that, but after that it hangs, even Initdb hangs.. > > Yea, as Tom pointed out that's not going to work. I'll try to write a > patch for approach 1). Does this mean that any platform that wants to perform well will now need a sub-4-byte spinlock implementation? That's has a somewhat uncomfortable sound to it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-03-31 06:54:02 -0400, Robert Haas wrote: > On Wed, Mar 30, 2016 at 3:16 AM, Andres Freund <andres@anarazel.de> wrote: > > Yea, as Tom pointed out that's not going to work. I'll try to write a > > patch for approach 1). > > Does this mean that any platform that wants to perform well will now > need a sub-4-byte spinlock implementation? That's has a somewhat > uncomfortable sound to it. Oh. I confused my approaches. I was thinking about going for 2): > 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid > embedding the spinlock, and actually might allow to avoid one atomic > op in a number of cases. precisely because of that concern.
On 2016-03-31 12:58:55 +0200, Andres Freund wrote: > On 2016-03-31 06:54:02 -0400, Robert Haas wrote: > > On Wed, Mar 30, 2016 at 3:16 AM, Andres Freund <andres@anarazel.de> wrote: > > > Yea, as Tom pointed out that's not going to work. I'll try to write a > > > patch for approach 1). > > > > Does this mean that any platform that wants to perform well will now > > need a sub-4-byte spinlock implementation? That's has a somewhat > > uncomfortable sound to it. > > Oh. I confused my approaches. I was thinking about going for 2): > > > 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid > > embedding the spinlock, and actually might allow to avoid one atomic > > op in a number of cases. > > precisely because of that concern. Here's a WIP patch to evaluate. Dilip/Ashutosh, could you perhaps run some benchmarks, to see whether this addresses the performance issues? I guess it'd both be interesting to compare master with master + patch, and this thread's latest patch with the patch additionally applied. Thanks! Andres
Вложения
On Tue, Mar 29, 2016 at 10:52 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
Hi, Andres!Please, find next revision of patch in attachment.
Couple of minor comments:
+ * The following two macroses
is macroses right word to be used here?
+ * of this loop. It should be used as fullowing:
/fullowing/following
+ * For local buffers usage of these macros shouldn't be used.
isn't it better to write it as
For local buffers, these macros shouldn't be used.
static int ts_ckpt_progress_comparator(Datum a, Datum b, void *arg);
-
Spurious line deletion.
+ * Since buffers are pinned/unpinned very frequently, this functions tries
+ * to pin buffer as cheap as possible.
/this functions tries
which functions are you referring here? Comment seems to be slightly unclear.
! if (XLogHintBitIsNeeded() && (pg_atomic_read_u32(&bufHdr->state) & BM_PERMANENT))
Is there a reason that you have kept macro's to read refcount and usagecount, but not for flags?
Apart from this, I have verified that patch compiles on Windows and passed regressions (make check)!
Nice work!
Andres Freund <andres@anarazel.de> writes:
> Oh. I confused my approaches. I was thinking about going for 2):
>> 2) Replace the lwlock spinlock by a bit in LWLock->state. That'd avoid
>> embedding the spinlock, and actually might allow to avoid one atomic
>> op in a number of cases.
> precisely because of that concern.
Oh, okay, ignore my comment just now in the other thread.
regards, tom lane
Hi!
On Thu, Mar 31, 2016 at 4:59 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Tue, Mar 29, 2016 at 10:52 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:Hi, Andres!Please, find next revision of patch in attachment.Couple of minor comments:+ * The following two macrosesis macroses right word to be used here?+ * of this loop. It should be used as fullowing:/fullowing/following+ * For local buffers usage of these macros shouldn't be used.isn't it better to write it asFor local buffers, these macros shouldn't be used.static int ts_ckpt_progress_comparator(Datum a, Datum b, void *arg);-Spurious line deletion.
All of above is fixed.
+ * Since buffers are pinned/unpinned very frequently, this functions tries+ * to pin buffer as cheap as possible./this functions trieswhich functions are you referring here? Comment seems to be slightly unclear.
I meant just PinBuffer() there. UnpinBuffer() has another comment in the body. Fixed.
! if (XLogHintBitIsNeeded() && (pg_atomic_read_u32(&bufHdr->state) & BM_PERMANENT))Is there a reason that you have kept macro's to read refcount and usagecount, but not for flags?
We could change dealing with flags to GET/SET macros. But I guess such change would make review more complicated, because it would touch some places which are unchanged for now. I think it could be done in a separate refactoring patch.
Apart from this, I have verified that patch compiles on Windows and passed regressions (make check)!
Thank you! I didn't manage to try this on Windows.
Nice work!
Thank you!
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
Hi,
> +/*
> + * The following two macros are aimed to simplify buffer state modification
> + * in CAS loop. It's assumed that variable "uint32 state" is defined outside
> + * of this loop. It should be used as following:
> + *
> + * BEGIN_BUFSTATE_CAS_LOOP(bufHdr);
> + * modifications of state variable;
> + * END_BUFSTATE_CAS_LOOP(bufHdr);
> + *
> + * For local buffers, these macros shouldn't be used.. Since there is
> + * no cuncurrency, local buffer state could be chaged directly by atomic
> + * read/write operations.
> + */
> +#define BEGIN_BUFSTATE_CAS_LOOP(bufHdr) \
> + do { \
> + SpinDelayStatus delayStatus = init_spin_delay((Pointer)(bufHdr)); \
> + uint32 oldstate; \
> + oldstate = pg_atomic_read_u32(&(bufHdr)->state); \
> + for (;;) { \
> + while (oldstate & BM_LOCKED) \
> + { \
> + make_spin_delay(&delayStatus); \
> + oldstate = pg_atomic_read_u32(&(bufHdr)->state); \
> + } \
> + state = oldstate
> +
> +#define END_BUFSTATE_CAS_LOOP(bufHdr) \
> + if (pg_atomic_compare_exchange_u32(&bufHdr->state, &oldstate, state)) \
> + break; \
> + } \
> + finish_spin_delay(&delayStatus); \
> + } while (0)
Hm. Not sure if that's not too much magic. Will think about it.
> /*
> + * Lock buffer header - set BM_LOCKED in buffer state.
> + */
> + uint32
> + LockBufHdr(BufferDesc *desc)
> + {
> + uint32 state;
> +
> + BEGIN_BUFSTATE_CAS_LOOP(desc);
> + state |= BM_LOCKED;
> + END_BUFSTATE_CAS_LOOP(desc);
> +
> + return state;
> + }
> +
Hm. It seems a bit over the top to do the full round here. How about
uint32 oldstate;
while (true)
{ oldstate = pg_atomic_fetch_or(..., BM_LOCKED); if (!(oldstate & BM_LOCKED) break; perform_spin_delay();
}
return oldstate | BM_LOCKED;
Especially if we implement atomic xor on x86, that'd likely be a good
bit more efficient.
> typedef struct BufferDesc
> {
> BufferTag tag; /* ID of page contained in buffer */
> - BufFlags flags; /* see bit definitions above */
> - uint8 usage_count; /* usage counter for clock sweep code */
> - slock_t buf_hdr_lock; /* protects a subset of fields, see above */
> - unsigned refcount; /* # of backends holding pins on buffer */
> - int wait_backend_pid; /* backend PID of pin-count waiter */
>
> + /* state of the tag, containing flags, refcount and usagecount */
> + pg_atomic_uint32 state;
> +
> + int wait_backend_pid; /* backend PID of pin-count waiter */
> int buf_id; /* buffer's index number (from 0) */
> int freeNext; /* link in freelist chain */
Hm. Won't matter on most platforms, but it seems like a good idea to
move to an 8 byte aligned boundary. Move buf_id up?
> +/*
> + * Support for spin delay which could be useful in other places where
> + * spinlock-like procedures take place.
> + */
> +typedef struct
> +{
> + int spins;
> + int delays;
> + int cur_delay;
> + Pointer ptr;
> + const char *file;
> + int line;
> +} SpinDelayStatus;
> +
> +#define init_spin_delay(ptr) {0, 0, 0, (ptr), __FILE__, __LINE__}
> +
> +void make_spin_delay(SpinDelayStatus *status);
> +void finish_spin_delay(SpinDelayStatus *status);
> +
> #endif /* S_LOCK_H */
s/make_spin_delay/perform_spin_delay/? The former sounds like it's
allocating something or such.
Regards,
Andres
On Thu, Mar 31, 2016 at 7:14 PM, Andres Freund <andres@anarazel.de> wrote:
> +/*
> + * The following two macros are aimed to simplify buffer state modification
> + * in CAS loop. It's assumed that variable "uint32 state" is defined outside
> + * of this loop. It should be used as following:
> + *
> + * BEGIN_BUFSTATE_CAS_LOOP(bufHdr);
> + * modifications of state variable;
> + * END_BUFSTATE_CAS_LOOP(bufHdr);
> + *
> + * For local buffers, these macros shouldn't be used.. Since there is
> + * no cuncurrency, local buffer state could be chaged directly by atomic
> + * read/write operations.
> + */
> +#define BEGIN_BUFSTATE_CAS_LOOP(bufHdr) \
> + do { \
> + SpinDelayStatus delayStatus = init_spin_delay((Pointer)(bufHdr)); \
> + uint32 oldstate; \
> + oldstate = pg_atomic_read_u32(&(bufHdr)->state); \
> + for (;;) { \
> + while (oldstate & BM_LOCKED) \
> + { \
> + make_spin_delay(&delayStatus); \
> + oldstate = pg_atomic_read_u32(&(bufHdr)->state); \
> + } \
> + state = oldstate
> +
> +#define END_BUFSTATE_CAS_LOOP(bufHdr) \
> + if (pg_atomic_compare_exchange_u32(&bufHdr->state, &oldstate, state)) \
> + break; \
> + } \
> + finish_spin_delay(&delayStatus); \
> + } while (0)
Hm. Not sure if that's not too much magic. Will think about it.
I'm not sure too...
> /*
> + * Lock buffer header - set BM_LOCKED in buffer state.
> + */
> + uint32
> + LockBufHdr(BufferDesc *desc)
> + {
> + uint32 state;
> +
> + BEGIN_BUFSTATE_CAS_LOOP(desc);
> + state |= BM_LOCKED;
> + END_BUFSTATE_CAS_LOOP(desc);
> +
> + return state;
> + }
> +
Hm. It seems a bit over the top to do the full round here. How about
uint32 oldstate;
while (true)
{
oldstate = pg_atomic_fetch_or(..., BM_LOCKED);
if (!(oldstate & BM_LOCKED)
break;
perform_spin_delay();
}
return oldstate | BM_LOCKED;
Especially if we implement atomic xor on x86, that'd likely be a good
bit more efficient.
Nice idea. Done.
> typedef struct BufferDesc
> {
> BufferTag tag; /* ID of page contained in buffer */
> - BufFlags flags; /* see bit definitions above */
> - uint8 usage_count; /* usage counter for clock sweep code */
> - slock_t buf_hdr_lock; /* protects a subset of fields, see above */
> - unsigned refcount; /* # of backends holding pins on buffer */
> - int wait_backend_pid; /* backend PID of pin-count waiter */
>
> + /* state of the tag, containing flags, refcount and usagecount */
> + pg_atomic_uint32 state;
> +
> + int wait_backend_pid; /* backend PID of pin-count waiter */
> int buf_id; /* buffer's index number (from 0) */
> int freeNext; /* link in freelist chain */
Hm. Won't matter on most platforms, but it seems like a good idea to
move to an 8 byte aligned boundary. Move buf_id up?
I think so. Done.
> +/*
> + * Support for spin delay which could be useful in other places where
> + * spinlock-like procedures take place.
> + */
> +typedef struct
> +{
> + int spins;
> + int delays;
> + int cur_delay;
> + Pointer ptr;
> + const char *file;
> + int line;
> +} SpinDelayStatus;
> +
> +#define init_spin_delay(ptr) {0, 0, 0, (ptr), __FILE__, __LINE__}
> +
> +void make_spin_delay(SpinDelayStatus *status);
> +void finish_spin_delay(SpinDelayStatus *status);
> +
> #endif /* S_LOCK_H */
s/make_spin_delay/perform_spin_delay/? The former sounds like it's
allocating something or such.
Done.
I think these changes worth running benchmark again. I'm going to run it on 4x18 Intel.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Thu, Mar 31, 2016 at 8:21 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
I think these changes worth running benchmark again. I'm going to run it on 4x18 Intel.
The results are following.
clients master v3 v5 v9
1 11671 12507 12679 12408
2 24650 26005 25010 25495
4 49631 48863 49811 50150
8 96790 96441 99946 98383
10 121275 119928 124100 124180
20 243066 243365 246432 248723
30 359616 342241 357310 378881
40 431375 415310 441619 425653
50 489991 489896 500590 502549
60 538057 636473 554069 685010
70 588659 714426 738535 719383
80 405008 923039 902632 909126
90 295443 1181247 1155918 1179163
100 258695 1323125 1325019 1351578
110 238842 1393767 1410274 1421531
120 226018 1432504 1474982 1497122
130 215102 1465459 1503241 1521619
140 206415 1470454 1505380 1541816
150 197850 1475479 1519908 1515017
160 190935 1420915 1484868 1523150
170 185835 1438965 1453128 1499913
180 182519 1416252 1453098 1472945
It appears that atomic OR for LockBufHdr() gives small but measurable effect. Great idea, Andres!
The Russian Postgres Company
Вложения
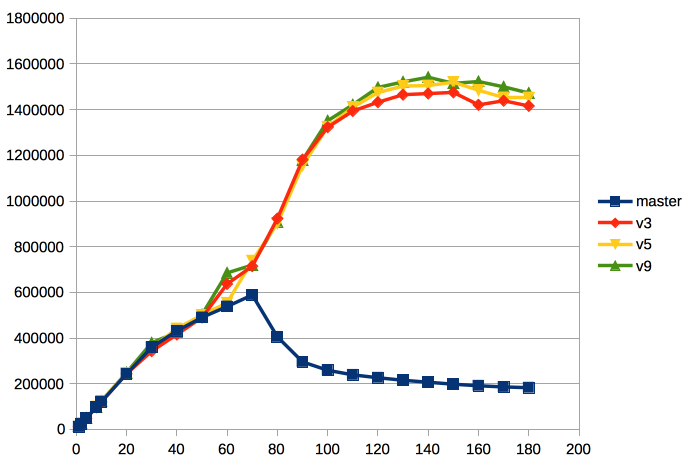{kind=link}
On Thu, Mar 31, 2016 at 5:52 PM, Andres Freund <andres@anarazel.de> wrote:
Here's a WIP patch to evaluate. Dilip/Ashutosh, could you perhaps run
some benchmarks, to see whether this addresses the performance issues?
I guess it'd both be interesting to compare master with master + patch,
and this thread's latest patch with the patch additionally applied.
I tested it in Power and seen lot of fluctuations in the reading, From this reading I could not reach to any conclusion.
only we can say that with (patch + pinunpin), we can reach more than 600000.
I think it needs more number of runs.. After seeing this results I did not run head+pinunpin,
Head 64 Client 128 Client
-----------------------------------------------------
Run1 434860 356945
Run2 275815 275815
Run3 437872 366560
Patch 64 Client 128 Client
-----------------------------------------------------
Run1 429520 372958
Run2 446249 167189
Run3 431066 381592
Patch+Pinunpin 64 Client 128 Client
----------------------------------------------------------
Run1 338298 642535
Run2 406240 644187
Run3 595439 285420
--
On 2016-04-01 13:50:10 +0530, Dilip Kumar wrote: > I think it needs more number of runs.. After seeing this results I did not > run head+pinunpin, > > Head 64 Client 128 Client > ----------------------------------------------------- > Run1 434860 356945 > Run2 275815 *275815* > Run3 437872 366560 > Patch 64 Client 128 Client > ----------------------------------------------------- > Run1 429520 372958 > Run2 446249 *167189* > Run3 431066 381592 > Patch+Pinunpin 64 Client 128 Client > ---------------------------------------------------------- > Run1 338298 642535 > Run2 406240 644187 > Run3 595439 *285420 * Could you describe the exact setup a bit more? Postgres settings, pgbench parameters, etc. What's the size of BufferDesc after applying the patch? Thanks, Andres
On 2016-04-01 10:35:18 +0200, Andres Freund wrote: > On 2016-04-01 13:50:10 +0530, Dilip Kumar wrote: > > I think it needs more number of runs.. After seeing this results I did not > > run head+pinunpin, > > > > Head 64 Client 128 Client > > ----------------------------------------------------- > > Run1 434860 356945 > > Run2 275815 *275815* > > Run3 437872 366560 > > Patch 64 Client 128 Client > > ----------------------------------------------------- > > Run1 429520 372958 > > Run2 446249 *167189* > > Run3 431066 381592 > > Patch+Pinunpin 64 Client 128 Client > > ---------------------------------------------------------- > > Run1 338298 642535 > > Run2 406240 644187 > > Run3 595439 *285420 * > > Could you describe the exact setup a bit more? Postgres settings, > pgbench parameters, etc. > > What's the size of BufferDesc after applying the patch? One interesting thing to do would be to use -P1 during the test and see how much the performance varies over time. Greetings, Andres Freund
On Fri, Apr 1, 2016 at 2:09 PM, Andres Freund <andres@anarazel.de> wrote:
One interesting thing to do would be to use -P1 during the test and see
how much the performance varies over time.
I have run with -P option, I ran for 1200 second and set -P as 30 second, and what I observed is that when its low its low throughout the run and when its high, Its high for complete run.
Non Default Parameter:
--------------------------------
shared_buffer 8GB
Max Connections 150
./pgbench -c $threads -j $threads -T 1200 -M prepared -S -P 30 postgres
Test results are attached in result.tar file.
File details:
------------------
1. head_run1.txt --> 20 mins run on head reading 1
2. head_run2.txt --> 20 mins run on head reading 2
3. head_patch_run1.txt --> 20 mins run on head + patch reading 1
4. head_patch_run2.txt --> 20 mins run on head + patch reading 2
5. head_pinunpin.txt --> 20 mins run on head + pinunpin-cas-8.patch
6. head_pinunpin_patch.txt --> 20 mins run on head + pinunpin-cas-8.patch + patch reading
--
Вложения
On Sun, Apr 3, 2016 at 9:55 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Fri, Apr 1, 2016 at 2:09 PM, Andres Freund <andres@anarazel.de> wrote:One interesting thing to do would be to use -P1 during the test and see
how much the performance varies over time.
I have run with -P option, I ran for 1200 second and set -P as 30 second, and what I observed is that when its low its low throughout the run and when its high, Its high for complete run.
What is the conclusion of this test? As far as I see, with the patch (0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect), the performance degradation is not fixed, but with pin-unpin patch, the performance seems to be better in most of the runs, however still you see less performance in some of the runs. Is that right? Can you answer some of the questions asked by Andres upthread[1]?
On Sun, Apr 3, 2016 at 2:28 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
What is the conclusion of this test? As far as I see, with the patch (0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect), the performance degradation is not fixed, but with pin-unpin patch, the performance seems to be better in most of the runs, however still you see less performance in some of the runs. Is that right?
Summary Of the Run:
-----------------------------
1. Throughout one run if we observe TPS every 30 seconds its stable in one run.
2. With Head 64 client run vary between ~250,000 to ~450000. you can see below results.
run1: 434860 (5min)
run2: 275815 (5min)
run3: 437872 (5min)
run4: 237033 (5min)
run5: 347611 (10min)
run6: 435933 (20min)
3. With Head + 0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect with 64 client I always saw ~450,000 TPS
run1: 429520 (5min)
run2: 446249 (5min)
run3: 431066 (5min)
run4: 441280 (10min)
run5: 429844 (20 mins)
4. With Head+ 0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect with 128 Client something performance is as low as ~150,000 which is never observed with Head (with head it is constantly ~ 350,000 TPS).
run1: 372958 (5min)
run2: 167189 (5min)
run3: 381592 (5min)
run4: 441280 (10min)
run5: 362742 (20 min)
5. With Head+pinunpin-cas-8, with 64 client its ~ 550,000 TPS and with 128 client ~650,000 TPS.
6. With Head+ pinunpin-cas-8 + 0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect performance is almost same as with
Head+pinunpin-cas-8, only sometime performance at 128 client is low (~250,000 instead of 650,000)
Seems like Head+ pinunpin-cas-8 is giving best performance and without much fluctuation.
Can you answer some of the questions asked by Andres upthread[1]?
Non Default Parameter:
--------------------------------
shared_buffer 8GB
Max Connections 150
./pgbench -c $threads -j $threads -T 1200 -M prepared -S -P 30 postgres
BufferDesc Size:
------------------------
Head: 80 Bytes
Head+0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect : 72Bytes
Head+0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect+ Pinunpin-cas-8 : 64 Bytes
Hi, On 2016-04-03 16:47:49 +0530, Dilip Kumar wrote: > 6. With Head+ pinunpin-cas-8 + > 0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect performance is > almost same as with > Head+pinunpin-cas-8, only sometime performance at 128 client is low > (~250,000 instead of 650,000) Hm, interesting. I suspect that's because of the missing backoff in my experimental patch. If you apply the attached patch ontop of that (requires infrastructure from pinunpin), how does performance develop? Regards, Andres
Вложения
On Mon, Apr 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:
Hm, interesting. I suspect that's because of the missing backoff in my
experimental patch. If you apply the attached patch ontop of that
(requires infrastructure from pinunpin), how does performance develop?
I have applied this patch also, but still results are same, I mean around 550,000 with 64 threads and 650,000 with 128 client with lot of fluctuations..
128 client (head+0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect +pinunpin-cas-9+backoff)
run1 645769
run2 643161
run3 285546
run4 289421
run5 630772
run6 284363
On Tue, Apr 5, 2016 at 10:26 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Mon, Apr 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:Hm, interesting. I suspect that's because of the missing backoff in my
experimental patch. If you apply the attached patch ontop of that
(requires infrastructure from pinunpin), how does performance develop?
I have applied this patch also, but still results are same, I mean around 550,000 with 64 threads and 650,000 with 128 client with lot of fluctuations..128 client (head+0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect +pinunpin-cas-9+backoff)run1 645769run2 643161run3 285546run4 289421run5 630772run6 284363
Could the reason be that we're increasing concurrency for LWLock state atomic variable by placing queue spinlock there?
But I wonder why this could happen during "pgbench -S", because it doesn't seem to have high traffic of exclusive LWLocks.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-04-05 17:36:49 +0300, Alexander Korotkov wrote: > Could the reason be that we're increasing concurrency for LWLock state > atomic variable by placing queue spinlock there? Don't think so, it's the same cache-line either way. > But I wonder why this could happen during "pgbench -S", because it doesn't > seem to have high traffic of exclusive LWLocks. Yea, that confuses me too. I suspect there's some mis-aligned datastructures somewhere. It's hard to investigate such things without access to hardware. (FWIW, I'm working on getting pinunpin committed) Greetings, Andres Freund
On Tue, Apr 5, 2016 at 8:15 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-05 17:36:49 +0300, Alexander Korotkov wrote:
> > Could the reason be that we're increasing concurrency for LWLock state
> > atomic variable by placing queue spinlock there?
>
> Don't think so, it's the same cache-line either way.
>
> > But I wonder why this could happen during "pgbench -S", because it doesn't
> > seem to have high traffic of exclusive LWLocks.
>
> Yea, that confuses me too. I suspect there's some mis-aligned
> datastructures somewhere. It's hard to investigate such things without
> access to hardware.
>
>
> On 2016-04-05 17:36:49 +0300, Alexander Korotkov wrote:
> > Could the reason be that we're increasing concurrency for LWLock state
> > atomic variable by placing queue spinlock there?
>
> Don't think so, it's the same cache-line either way.
>
> > But I wonder why this could happen during "pgbench -S", because it doesn't
> > seem to have high traffic of exclusive LWLocks.
>
> Yea, that confuses me too. I suspect there's some mis-aligned
> datastructures somewhere. It's hard to investigate such things without
> access to hardware.
>
This fluctuation started appearing after commit 6150a1b0 which we have discussed in another thread [1] and a colleague of mine is working on to write a patch to try to revert it on current HEAD and then see the results.
> (FWIW, I'm working on getting pinunpin committed)
>
Good to know, but I am slightly worried that it will make the problem harder to detect as it will reduce the reproducibility. I understand that we are running short of time and committing this patch is important, so we should proceed with it as this is not a problem of this patch. After this patch gets committed, we always need to revert it locally to narrow down the problem due to commit 6150a1b0.
On 2016-04-05 20:56:31 +0530, Amit Kapila wrote: > This fluctuation started appearing after commit 6150a1b0 which we have > discussed in another thread [1] and a colleague of mine is working on to > write a patch to try to revert it on current HEAD and then see the results. I don't see what that buys us. That commit is a good win on x86... Greetings, Andres Freund
On Tue, Apr 5, 2016 at 9:00 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-05 20:56:31 +0530, Amit Kapila wrote:
> > This fluctuation started appearing after commit 6150a1b0 which we have
> > discussed in another thread [1] and a colleague of mine is working on to
> > write a patch to try to revert it on current HEAD and then see the results.
>
> I don't see what that buys us. That commit is a good win on x86...
>
>
> On 2016-04-05 20:56:31 +0530, Amit Kapila wrote:
> > This fluctuation started appearing after commit 6150a1b0 which we have
> > discussed in another thread [1] and a colleague of mine is working on to
> > write a patch to try to revert it on current HEAD and then see the results.
>
> I don't see what that buys us. That commit is a good win on x86...
>
At least, that way we can see the results of pin-unpin without fluctuation. I agree that we need to narrow down why even after reducing BufferDesc size, we are seeing performance fluctuation.
On Tue, Apr 5, 2016 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote: > On 2016-04-05 20:56:31 +0530, Amit Kapila wrote: >> This fluctuation started appearing after commit 6150a1b0 which we have >> discussed in another thread [1] and a colleague of mine is working on to >> write a patch to try to revert it on current HEAD and then see the results. > > I don't see what that buys us. That commit is a good win on x86... Maybe. But I wouldn't be surprised to find out that that is an overgeneralization. Based on some results Mithun Cy showed me this morning, I think that some of this enormous run-to-run fluctuation that we're seeing is due to NUMA effects. So some runs we get two things that are frequently accessed together on the same NUMA node and other times they get placed on different NUMA nodes and then everything sucks. I don't think we fully understand what's going on here yet - and I think we're committing changes in this area awfully quickly - but I see no reason to believe that x86 is immune to such effects. They may just happen in different scenarios than what we see on POWER. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-04-05 12:14:35 -0400, Robert Haas wrote:
> On Tue, Apr 5, 2016 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote:
> > On 2016-04-05 20:56:31 +0530, Amit Kapila wrote:
> >> This fluctuation started appearing after commit 6150a1b0 which we have
> >> discussed in another thread [1] and a colleague of mine is working on to
> >> write a patch to try to revert it on current HEAD and then see the results.
> >
> > I don't see what that buys us. That commit is a good win on x86...
>
> Maybe. But I wouldn't be surprised to find out that that is an
> overgeneralization. Based on some results Mithun Cy showed me this
> morning, I think that some of this enormous run-to-run fluctuation
> that we're seeing is due to NUMA effects. So some runs we get two
> things that are frequently accessed together on the same NUMA node and
> other times they get placed on different NUMA nodes and then
> everything sucks. I don't think we fully understand what's going on
> here yet - and I think we're committing changes in this area awfully
> quickly - but I see no reason to believe that x86 is immune to such
> effects. They may just happen in different scenarios than what we see
> on POWER.
I'm not really following - we were talking about 6150a1b0 ("Move buffer
I/O and content LWLocks out of the main tranche.") made four months
ago. Afaics the atomic buffer pin patch is a pretty clear win on both
ppc and x86?
I agree that there's numa effects we don't understand. I think
re-considering Kevin's patch that did explicit numa hinting on linux
would be rather worthwhile. It makes a lot of sense to force shmem to be
force-interleaved, but make backend local memory, uh, local.
Greetings,
Andres Freund
On Tue, Apr 5, 2016 at 1:04 PM, Andres Freund <andres@anarazel.de> wrote:
> On 2016-04-05 12:14:35 -0400, Robert Haas wrote:
>> On Tue, Apr 5, 2016 at 11:30 AM, Andres Freund <andres@anarazel.de> wrote:
>> > On 2016-04-05 20:56:31 +0530, Amit Kapila wrote:
>> >> This fluctuation started appearing after commit 6150a1b0 which we have
>> >> discussed in another thread [1] and a colleague of mine is working on to
>> >> write a patch to try to revert it on current HEAD and then see the results.
>> >
>> > I don't see what that buys us. That commit is a good win on x86...
>>
>> Maybe. But I wouldn't be surprised to find out that that is an
>> overgeneralization. Based on some results Mithun Cy showed me this
>> morning, I think that some of this enormous run-to-run fluctuation
>> that we're seeing is due to NUMA effects. So some runs we get two
>> things that are frequently accessed together on the same NUMA node and
>> other times they get placed on different NUMA nodes and then
>> everything sucks. I don't think we fully understand what's going on
>> here yet - and I think we're committing changes in this area awfully
>> quickly - but I see no reason to believe that x86 is immune to such
>> effects. They may just happen in different scenarios than what we see
>> on POWER.
>
> I'm not really following - we were talking about 6150a1b0 ("Move buffer
> I/O and content LWLocks out of the main tranche.") made four months
> ago. Afaics the atomic buffer pin patch is a pretty clear win on both
> ppc and x86?
The point is that the testing Amit's team is doing can't tell the
answer to that question one way or another. 6150a1b0 completely
destabilized performance on our test systems to the point where
testing subsequent patches is extremely difficult.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Tue, Apr 5, 2016 at 5:45 PM, Andres Freund <andres@anarazel.de> wrote:
On 2016-04-05 17:36:49 +0300, Alexander Korotkov wrote:
> Could the reason be that we're increasing concurrency for LWLock state
> atomic variable by placing queue spinlock there?
Don't think so, it's the same cache-line either way.
Yes, it's very unlikely.
> But I wonder why this could happen during "pgbench -S", because it doesn't
> seem to have high traffic of exclusive LWLocks.
Yea, that confuses me too. I suspect there's some mis-aligned
datastructures somewhere. It's hard to investigate such things without
access to hardware.
But it's quite easy to check if it is alignment issue. We can try your patch but without removing mutex from LWLock struct. If it's alignment issue, then TPS should become stable again.
(FWIW, I'm working on getting pinunpin committed)
Sounds good.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-04-05 12:56:46 +0530, Dilip Kumar wrote: > On Mon, Apr 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote: > > > Hm, interesting. I suspect that's because of the missing backoff in my > > experimental patch. If you apply the attached patch ontop of that > > (requires infrastructure from pinunpin), how does performance develop? > > > > I have applied this patch also, but still results are same, I mean around > 550,000 with 64 threads and 650,000 with 128 client with lot of > fluctuations.. > > *128 client > **(head+**0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect > +pinunpin-cas-9+backoff)* > > run1 645769 > run2 643161 > run3 *285546* > run4 *289421* > run5 630772 > run6 *284363* I wonder what http://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=09adc9a8c09c9640de05c7023b27fb83c761e91c does to all these numbers. It seems entirely possible that "this" is mainly changing the alignment of some common datastructures... - Andres
Hi, On 2016-04-03 16:47:49 +0530, Dilip Kumar wrote: > Summary Of the Run: > ----------------------------- > 1. Throughout one run if we observe TPS every 30 seconds its stable in one > run. > 2. With Head 64 client run vary between ~250,000 to ~450000. you can see > below results. > > run1: 434860 (5min) > run2: 275815 (5min) > run3: 437872 (5min) > run4: 237033 (5min) > run5: 347611 (10min) > run6: 435933 (20min) > > [1] - > > http://www.postgresql.org/message-id/20160401083518.GE9074@awork2.anarazel.de > > > > > Non Default Parameter: > -------------------------------- > shared_buffer 8GB > Max Connections 150 > > ./pgbench -c $threads -j $threads -T 1200 -M prepared -S -P 30 postgres Which scale did you initialize with? I'm trying to reproduce the workload on hydra as precisely as possible... Greetings, Andres Freund
On 2016-04-06 11:52:28 +0200, Andres Freund wrote: > Hi, > > On 2016-04-03 16:47:49 +0530, Dilip Kumar wrote: > > > Summary Of the Run: > > ----------------------------- > > 1. Throughout one run if we observe TPS every 30 seconds its stable in one > > run. > > 2. With Head 64 client run vary between ~250,000 to ~450000. you can see > > below results. > > > > run1: 434860 (5min) > > run2: 275815 (5min) > > run3: 437872 (5min) > > run4: 237033 (5min) > > run5: 347611 (10min) > > run6: 435933 (20min) > > > > [1] - > > > http://www.postgresql.org/message-id/20160401083518.GE9074@awork2.anarazel.de > > > > > > > > > Non Default Parameter: > > -------------------------------- > > shared_buffer 8GB > > Max Connections 150 > > > > ./pgbench -c $threads -j $threads -T 1200 -M prepared -S -P 30 postgres > > Which scale did you initialize with? I'm trying to reproduce the > workload on hydra as precisely as possible... On hydra, even after a fair amount of tinkering, I cannot reprodue such variability. Pin/Unpin only has a minor effect itself, reducing the size of lwlock on-top improves performance (378829 to 409914 TPS) in intentionally short 15s tests (warm cache) with 128 clients; as well as to a lower degree in 120s tests (415921 to 420487). It appears, over 5 runs, that the alignment fix shortens the rampup phase from about 100s to about 8; interesting. Andres
On Wed, Apr 6, 2016 at 3:22 PM, Andres Freund <andres@anarazel.de> wrote:
Which scale did you initialize with? I'm trying to reproduce the
workload on hydra as precisely as possible...
I tested with scale factor 300, shared buffer 8GB.
My test script is attached with the mail (perf_pgbench_ro.sh).
I have done some more test on power (same machine)
Test1:
--------
head + pinunpin-cas-9.patch + BufferDesc content lock to pointer (patch attached: buffer_content_lock_ptr**.patch)
Ashutosh helped me in generating this patch (this is just temp patch to see the pin/unpin behaviour if content lock is pointer)
64 client
run1 497684
run2 543366
run3 476988
128 Client
run1 740301
run2 482676
run3 474530
run4 480971
run5 757779
Summary:
1. With 64 client I think whether we apply only
pinunpin-cas-9.patch or we apply pinunpin-cas-9.patch + buffer_content_lock_ptr_rebased_head_temp.patch
max TPS is ~550,000 and some fluctuations.
2. With 128, we saw in earlier post that with pinunpin we were getting max TPS was 650,000 (even after converting BufferDesc to 64 bytes it was 650,000. Now after converting content lock to pointer on top of pinunpin I get max as ~750,000.
- One more point to be noted, earlier it was varying from 250,000 to 650,000 but after converting content lock to pointer its varying from 450,000 to 750000.
Test2:
Head + buffer_content_lock_ptr_rebased_head_temp.patch
1. With this test reading is same as head, and can see same variance in performance.
Вложения
On Wed, Apr 6, 2016 at 10:04 AM, Dilip Kumar <dilipbalaut@gmail.com> wrote:
> On Wed, Apr 6, 2016 at 3:22 PM, Andres Freund <andres@anarazel.de> wrote:
>> Which scale did you initialize with? I'm trying to reproduce the
>> workload on hydra as precisely as possible...
>
> I tested with scale factor 300, shared buffer 8GB.
>
> My test script is attached with the mail (perf_pgbench_ro.sh).
>
> I have done some more test on power (same machine)
I spent a lot of time testing things on power2 today and also
discussed with Andres via IM. Andres came up with a few ideas to
reduce the variability, which I tried. One of those was to run the
server under numactl --interleave=all (that is, numactl
--interleave=all pg_ctl start etc.) and another was to set
kernel.numa_balancing = 0 (it was set to 1). Neither of those things
seemed to prevent the problem of run-to-run variability. Andres also
suggested running pgbench with "-P 1", which revealed that it was
generally possible to tell what the overall performance of a run was
going to be like within 10-20 seconds. Runs that started out fast
stayed fast, and those that started out slower remained slower.
Therefore, long runs didn't seem to be necessary for testing, so I
switched to using 2-minute test runs launched via pgbench -T 120 -c 64
-j 64 -n -M prepared -S -P1.
After quite a bit of experimentation, Andres hit on an idea that did
succeed in drastically reducing the run-to-run variation: prewarming
all of the relations in a deterministic order before starting the
test. I used this query:
psql -c "select sum(x.x) from (select pg_prewarm(oid) as x from
pg_class where relkind in ('i', 'r') order by oid) x;"
With that change to my test script, the results became much more
stable. I tested four different builds of the server: commit 3fed4174
(that is, the one just before where you have been reporting the
variability to have begun), commit 6150a1b0 (the one you reported that
the variability actually did begin), master as of this morning
(actually commit cac0e366), and master + pinunpin-cas-9.patch +
0001-WIP-Avoid-the-use-of-a-separate-spinlock-to-protect-.patch +
backoff.patch (herein called "andres"). The first and last of these
have 64-byte BufferDescs, and the others have 80-byte BufferDescs.
Without prewarming, I see high and low results on *all* of these
builds, even 3fed4174. I did nine test runs with each configuration
with and without prewarming, and here are the results. With each
result I have reported the raw numbers, plus the median and the range
(highest result - lowest result).
-- without prewarming --
3fed4174
tps by run: 249165.928992 300958.039880 501281.083247
488073.289603 251033.038275 272086.063197
522287.023374 528855.922328 266057.502255
median: 300958.039880, range: 206687.132100
6150a1b0
tps by run: 455853.061092 438628.888369 353643.017507
419850.232715 424353.870515 440219.581180
431805.001465 237528.175877 431789.666417
median: 431789.666417, range: 218324.885215
master
tps by run: 427808.559919 366625.640433 376165.188508
441349.141152 363381.095198 352925.252345
348975.712841 446626.284308 444633.921009
median: 376165.188508, range: 97650.571467
andres
tps by run: 391123.866928 423525.415037 496103.017599
346707.246825 531194.321999 466100.337795
517708.470146 355392.837942 510817.921728
median: 466100.337795, range: 184487.075174
-- with prewarming --
3fed4174
tps by run: 413239.471751 428996.202541 488206.103941
493788.533491 497953.728875 498074.092686
501719.406720 508880.505416 509868.266778
median: 497953.728875, range: 96628.795027
6150a1b0
tps by run: 421589.299889 438765.851782 440601.270742
440649.818900 443033.460295 447317.269583
452831.480337 456387.316178 460140.159903
median: 443033.460295, range: 38550.860014
master
tps by run: 427211.917303 427796.174209 435601.396857
436581.431219 442329.269335 446438.814270
449970.003595 450085.123059 456231.229966
median: 442329.269335, range: 29019.312663
andres
tps by run: 425513.771259 429219.907952 433838.084721
451354.257738 494735.045808 495301.319716
517166.054466 531655.887669 546984.476602
median: 494735.045808, range: 121470.705343
My belief is that the first set of numbers has so much jigger that you
can't really draw any meaningful conclusions. For two of the four
branches, the range is more than 50% of the median, which is enormous.
You could probably draw some conclusions if you took enough
measurements, but it's pretty hard. Notice that that set of numbers
makes 6150a1b0 look like a performance improvement, whereas the second
set makes it pretty clear that 6150a1b0 was a regression.
Also, the patch set is clearly winning here. It picks up 90k TPS
median on the first set of numbers and 50k TPS median on the second
set.
It's fairly mysterious to me why there is so much jitter in the
results on this machine. By doing prewarming in a consistent fashion,
we make sure that every disk run puts the same disk blocks in the same
buffers. Andres guessed that maybe the degree of associativity of the
CPU caches comes into play here: depending on where the hot data is we
either get the important cache lines in places where they can all be
cached at once, or we get them in places where they can't all be
cached at once. But if that's really what is going on here, it's
shocking that it makes this much difference.
However, my conclusion based on these results is that (1) the patch is
a win and (2) the variability on this machine didn't begin with
6150a1b0. YMMV, of course, but that's what I think.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi, On 2016-04-06 21:58:50 -0400, Robert Haas wrote: > I spent a lot of time testing things on power2 today Thanks for that! > It's fairly mysterious to me why there is so much jitter in the > results on this machine. By doing prewarming in a consistent fashion, > we make sure that every disk run puts the same disk blocks in the same > buffers. Andres guessed that maybe the degree of associativity of the > CPU caches comes into play here: depending on where the hot data is we > either get the important cache lines in places where they can all be > cached at once, or we get them in places where they can't all be > cached at once. But if that's really what is going on here, it's > shocking that it makes this much difference. I'm not sure at all that that is indeed the reason. I think it'd be quite worthwhile to a) collect perf stat -ddd of a slow and a fast run, compare b) collect a perf profile of a slow and fast run, run perf diff c) add perf probes for lwlocks and spinlocks where we ended up sleeping, check whether the two runs have different distributionof which locks ended up sleeping. I'm also wondering if the idea from http://archives.postgresql.org/message-id/20160407082711.q7iq3ykffqxcszkv%40alap3.anarazel.de both with/without preloading, changes variability. Greetings, Andres Freund
On 2016-03-31 20:21:02 +0300, Alexander Korotkov wrote: > ! BEGIN_BUFSTATE_CAS_LOOP(bufHdr); > > ! Assert(BUF_STATE_GET_REFCOUNT(state) > 0); > ! wasDirty = (state & BM_DIRTY) ? true : false; > ! state |= BM_DIRTY | BM_JUST_DIRTIED; > ! if (state == oldstate) > ! break; I'm doubtful that this early exit is entirely safe. None of the preceding operations imply a memory barrier. The buffer could previously have been marked dirty, but cleaned since. It's pretty critical that we re-set the dirty bit (there's no danger of loosing it with a barrier, because we hold an exclusive content lock). Practically the risk seems fairly low, because acquiring the exclusive content lock will have implied a barrier. But it seems unlikely to have a measurable performance effect to me, so I'd rather not add the early exit. Andres
On Thu, Apr 7, 2016 at 4:41 PM, Andres Freund <andres@anarazel.de> wrote:
On 2016-03-31 20:21:02 +0300, Alexander Korotkov wrote:
> ! BEGIN_BUFSTATE_CAS_LOOP(bufHdr);
>
> ! Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
> ! wasDirty = (state & BM_DIRTY) ? true : false;
> ! state |= BM_DIRTY | BM_JUST_DIRTIED;
> ! if (state == oldstate)
> ! break;
I'm doubtful that this early exit is entirely safe. None of the
preceding operations imply a memory barrier. The buffer could previously
have been marked dirty, but cleaned since. It's pretty critical that we
re-set the dirty bit (there's no danger of loosing it with a barrier,
because we hold an exclusive content lock).
Oh, I get it.
Practically the risk seems fairly low, because acquiring the exclusive
content lock will have implied a barrier. But it seems unlikely to have
a measurable performance effect to me, so I'd rather not add the early
exit.
Ok, let's just remove it.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-04-07 16:50:44 +0300, Alexander Korotkov wrote: > On Thu, Apr 7, 2016 at 4:41 PM, Andres Freund <andres@anarazel.de> wrote: > > > On 2016-03-31 20:21:02 +0300, Alexander Korotkov wrote: > > > ! BEGIN_BUFSTATE_CAS_LOOP(bufHdr); > > > > > > ! Assert(BUF_STATE_GET_REFCOUNT(state) > 0); > > > ! wasDirty = (state & BM_DIRTY) ? true : false; > > > ! state |= BM_DIRTY | BM_JUST_DIRTIED; > > > ! if (state == oldstate) > > > ! break; > > > > I'm doubtful that this early exit is entirely safe. None of the > > preceding operations imply a memory barrier. The buffer could previously > > have been marked dirty, but cleaned since. It's pretty critical that we > > re-set the dirty bit (there's no danger of loosing it with a barrier, > > because we hold an exclusive content lock). > > > > Oh, I get it. > > > > Practically the risk seems fairly low, because acquiring the exclusive > > content lock will have implied a barrier. But it seems unlikely to have > > a measurable performance effect to me, so I'd rather not add the early > > exit. > > > > Ok, let's just remove it. Here's my updated version of the patch. I've updated this on an intercontinental flight, after a otherwise hectic week (moving from SF to Berlin); so I'm planning to look over this once more before pushing (. I've decided that the cas-loop macros are too obfuscating for my taste. To avoid duplicating the wait part I've introduced WaitBufHdrUnlocked(). As you can see in http://archives.postgresql.org/message-id/CA%2BTgmoaeRbN%3DZ4oWENLvgGLeHEvGZ_S_Z3KGrdScyKiSvNt3oA%40mail.gmail.com I'm planning to apply this sometime this weekend, after running some tests and going over the patch again. Any chance you could have a look over this? Regards, Andres
Вложения
On Fri, Apr 8, 2016 at 7:39 PM, Andres Freund <andres@anarazel.de> wrote:
On 2016-04-07 16:50:44 +0300, Alexander Korotkov wrote:
> On Thu, Apr 7, 2016 at 4:41 PM, Andres Freund <andres@anarazel.de> wrote:
>
> > On 2016-03-31 20:21:02 +0300, Alexander Korotkov wrote:
> > > ! BEGIN_BUFSTATE_CAS_LOOP(bufHdr);
> > >
> > > ! Assert(BUF_STATE_GET_REFCOUNT(state) > 0);
> > > ! wasDirty = (state & BM_DIRTY) ? true : false;
> > > ! state |= BM_DIRTY | BM_JUST_DIRTIED;
> > > ! if (state == oldstate)
> > > ! break;
> >
> > I'm doubtful that this early exit is entirely safe. None of the
> > preceding operations imply a memory barrier. The buffer could previously
> > have been marked dirty, but cleaned since. It's pretty critical that we
> > re-set the dirty bit (there's no danger of loosing it with a barrier,
> > because we hold an exclusive content lock).
> >
>
> Oh, I get it.
>
>
> > Practically the risk seems fairly low, because acquiring the exclusive
> > content lock will have implied a barrier. But it seems unlikely to have
> > a measurable performance effect to me, so I'd rather not add the early
> > exit.
> >
>
> Ok, let's just remove it.
Here's my updated version of the patch. I've updated this on an
intercontinental flight, after a otherwise hectic week (moving from SF
to Berlin); so I'm planning to look over this once more before pushing (.
Ok.
I've decided that the cas-loop macros are too obfuscating for my
taste. To avoid duplicating the wait part I've introduced
WaitBufHdrUnlocked().
That's OK for me. Cas-loop macros looks cute, but too magic.
As you can see in
http://archives.postgresql.org/message-id/CA%2BTgmoaeRbN%3DZ4oWENLvgGLeHEvGZ_S_Z3KGrdScyKiSvNt3oA%40mail.gmail.com
I'm planning to apply this sometime this weekend, after running some
tests and going over the patch again.
Any chance you could have a look over this?
I took a look at this. Changes you made look good for me.
I also run test on 4x18 Intel server.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, Apr 8, 2016 at 10:19 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Fri, Apr 8, 2016 at 7:39 PM, Andres Freund <andres@anarazel.de> wrote:As you can see inhttp://archives.postgresql.org/message-id/CA%2BTgmoaeRbN%3DZ4oWENLvgGLeHEvGZ_S_Z3KGrdScyKiSvNt3oA%40mail.gmail.com
I'm planning to apply this sometime this weekend, after running some
tests and going over the patch again.
Any chance you could have a look over this?I took a look at this. Changes you made look good for me.I also run test on 4x18 Intel server.
On the top of current master results are following:
clients TPS
1 12562
2 25604
4 52661
8 103209
10 128599
20 256872
30 365718
40 432749
50 513528
60 684943
70 696050
80 923350
90 1119776
100 1208027
110 1229429
120 1163356
130 1107924
140 1084344
150 1014064
160 961730
170 980743
180 968419
The results are quite discouraging because previously we had about 1.5M TPS in the peak while we have only about 1.2M now. I found that it's not related to the changes you made in the patch, but it's related to 5364b357 "Increase maximum number of clog buffers". I'm making same benchmark with 5364b357 reverted.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sat, Apr 9, 2016 at 11:24 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Fri, Apr 8, 2016 at 10:19 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Fri, Apr 8, 2016 at 7:39 PM, Andres Freund <andres@anarazel.de> wrote:As you can see inhttp://archives.postgresql.org/message-id/CA%2BTgmoaeRbN%3DZ4oWENLvgGLeHEvGZ_S_Z3KGrdScyKiSvNt3oA%40mail.gmail.com
I'm planning to apply this sometime this weekend, after running some
tests and going over the patch again.
Any chance you could have a look over this?I took a look at this. Changes you made look good for me.I also run test on 4x18 Intel server.On the top of current master results are following:clients TPS1 125622 256044 526618 10320910 12859920 25687230 36571840 43274950 51352860 68494370 69605080 92335090 1119776100 1208027110 1229429120 1163356130 1107924140 1084344150 1014064160 961730170 980743180 968419The results are quite discouraging because previously we had about 1.5M TPS in the peak while we have only about 1.2M now. I found that it's not related to the changes you made in the patch, but it's related to 5364b357 "Increase maximum number of clog buffers". I'm making same benchmark with 5364b357 reverted.
There are results with 5364b357 reverted.
clients TPS
1 12980
2 27105
4 51969
8 105507
10 132811
20 256888
30 368573
40 467605
50 544231
60 590898
70 799094
80 967569
90 1211662
100 1352427
110 1432561
120 1480324
130 1486624
140 1492092
150 1461681
160 1426733
170 1409081
180 1366199
It's much closer to what we had before.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote: > There are results with 5364b357 reverted. Crazy that this has such a negative impact. Amit, can you reproduce that? Alexander, I guess for r/w workload 5364b357 is a benefit on that machine as well? > It's much closer to what we had before. I'm going to apply this later then. If there's some micro optimization for large x86, we can look into that later. Greetings, Andres Freund
On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> wrote: >On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote: >> There are results with 5364b357 reverted. > >Crazy that this has such a negative impact. Amit, can you reproduce >that? Alexander, I guess for r/w workload 5364b357 is a benefit on that >machine as well? How sure are you about these measurements? Because there really shouldn't be clog lookups one a steady state is reached... Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Sun, Apr 10, 2016 at 1:13 AM, Andres Freund <andres@anarazel.de> wrote:
With Regards,
Amit Kapila.
On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
> There are results with 5364b357 reverted.
What exactly is this test?
I think assuming it is a read-only -M prepared pgbench run where data fits in shared buffers. However if you can share exact details, then I can try the similar test.
Crazy that this has such a negative impact. Amit, can you reproduce
that?
I will try it.
Alexander, I guess for r/w workload 5364b357 is a benefit on that
machine as well?
I also think so. Alexander, if try read-write workload with unlogged tables, then we should see an improvement.
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote:
On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> wrote:
>On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
>> There are results with 5364b357 reverted.
>
>Crazy that this has such a negative impact. Amit, can you reproduce
>that? Alexander, I guess for r/w workload 5364b357 is a benefit on that
>machine as well?
How sure are you about these measurements?
I'm pretty sure. I've retried it multiple times by hand before re-run the script.
Because there really shouldn't be clog lookups one a steady state is reached...
Hm... I'm also surprised. There shouldn't be clog lookups once hint bits are set.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, Apr 10, 2016 at 7:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Sun, Apr 10, 2016 at 1:13 AM, Andres Freund <andres@anarazel.de> wrote:On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
> There are results with 5364b357 reverted.What exactly is this test?I think assuming it is a read-only -M prepared pgbench run where data fits in shared buffers. However if you can share exact details, then I can try the similar test.
Yes, the test is:
pgbench -s 1000 -c $clients -j 100 -M prepared -S -T 300 (shared_buffers=24GB)
Crazy that this has such a negative impact. Amit, can you reproduce
that?I will try it.
Good.
Alexander, I guess for r/w workload 5364b357 is a benefit on that
machine as well?I also think so. Alexander, if try read-write workload with unlogged tables, then we should see an improvement.
I'll try read-write workload.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, Apr 10, 2016 at 8:36 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote:
On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> wrote:
>On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
>> There are results with 5364b357 reverted.
>
>Crazy that this has such a negative impact. Amit, can you reproduce
>that? Alexander, I guess for r/w workload 5364b357 is a benefit on that
>machine as well?
How sure are you about these measurements?I'm pretty sure. I've retried it multiple times by hand before re-run the script.Because there really shouldn't be clog lookups one a steady state is reached...Hm... I'm also surprised. There shouldn't be clog lookups once hint bits are set.
I also tried to run perf top during pgbench and get some interesting results.
Without 5364b357:
5,69% postgres [.] GetSnapshotData
4,47% postgres [.] LWLockAttemptLock
3,81% postgres [.] _bt_compare
3,42% postgres [.] hash_search_with_hash_value
3,08% postgres [.] LWLockRelease
2,49% postgres [.] PinBuffer.isra.3
1,58% postgres [.] AllocSetAlloc
1,17% [kernel] [k] __schedule
1,15% postgres [.] PostgresMain
1,13% libc-2.17.so [.] vfprintf
1,01% libc-2.17.so [.] __memcpy_ssse3_back
18,54% postgres [.] GetSnapshotData
3,45% postgres [.] LWLockRelease
3,27% postgres [.] LWLockAttemptLock
3,21% postgres [.] _bt_compare
2,93% postgres [.] hash_search_with_hash_value
2,00% postgres [.] PinBuffer.isra.3
1,32% postgres [.] AllocSetAlloc
1,10% libc-2.17.so [.] vfprintf
Very surprising. It appears that after 5364b357, GetSnapshotData consumes more time. But I can't see anything depending on clog buffers in GetSnapshotData code...
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, Apr 10, 2016 at 11:33 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sun, Apr 10, 2016 at 8:36 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote:
On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> wrote:
>On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
>> There are results with 5364b357 reverted.
>
>Crazy that this has such a negative impact. Amit, can you reproduce
>that? Alexander, I guess for r/w workload 5364b357 is a benefit on that
>machine as well?
How sure are you about these measurements?I'm pretty sure. I've retried it multiple times by hand before re-run the script.Because there really shouldn't be clog lookups one a steady state is reached...Hm... I'm also surprised. There shouldn't be clog lookups once hint bits are set.I also tried to run perf top during pgbench and get some interesting results.Without 5364b357:5,69% postgres [.] GetSnapshotData4,47% postgres [.] LWLockAttemptLock3,81% postgres [.] _bt_compare3,42% postgres [.] hash_search_with_hash_value3,08% postgres [.] LWLockRelease2,49% postgres [.] PinBuffer.isra.31,58% postgres [.] AllocSetAlloc1,17% [kernel] [k] __schedule1,15% postgres [.] PostgresMain1,13% libc-2.17.so [.] vfprintf1,01% libc-2.17.so [.] __memcpy_ssse3_backWith 5364b357:18,54% postgres [.] GetSnapshotData3,45% postgres [.] LWLockRelease3,27% postgres [.] LWLockAttemptLock3,21% postgres [.] _bt_compare2,93% postgres [.] hash_search_with_hash_value2,00% postgres [.] PinBuffer.isra.31,32% postgres [.] AllocSetAlloc1,10% libc-2.17.so [.] vfprintfVery surprising. It appears that after 5364b357, GetSnapshotData consumes more time. But I can't see anything depending on clog buffers in GetSnapshotData code...
There is a related fact presented by Mithun C Y as well [1] which suggests that Andres's idea of reducing the cost of snapshot shows noticeable gain after increasing the clog buffers. If you read that thread you will notice that initially we didn't notice much gain by that idea, but with increased clog buffers, it started showing noticeable gain. If by any chance, you can apply that patch and see the results (latest patch is at [2]).
On Sun, Apr 10, 2016 at 11:10 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sun, Apr 10, 2016 at 7:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:On Sun, Apr 10, 2016 at 1:13 AM, Andres Freund <andres@anarazel.de> wrote:On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
> There are results with 5364b357 reverted.What exactly is this test?I think assuming it is a read-only -M prepared pgbench run where data fits in shared buffers. However if you can share exact details, then I can try the similar test.Yes, the test is:pgbench -s 1000 -c $clients -j 100 -M prepared -S -T 300 (shared_buffers=24GB)Crazy that this has such a negative impact. Amit, can you reproduce
that?I will try it.Good.
Okay, I have done some performance testing of read-only tests with configuration suggested by you to see the impact
pin_unpin - latest version of pin unpin patch on top of HEAD.
pin_unpin_clog_32 - pin_unpin + change clog buffers to 32
| Client_Count/Patch_ver | 64 | 128 |
| pin_unpin | 330280 | 133586 |
| pin_unpin_clog_32 | 388244 | 132388 |
This shows that at 64 client count, the performance is better with 32 clog buffers. However, I think this is more attributed towards the fact that contention seems to shifted to procarraylock as to an extent indicated in Alexandar's mail. I will try once with cache the snapshot patch as well and with clog buffers as 64.
On Sun, Apr 10, 2016 at 6:15 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Sun, Apr 10, 2016 at 11:10 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Sun, Apr 10, 2016 at 7:26 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:On Sun, Apr 10, 2016 at 1:13 AM, Andres Freund <andres@anarazel.de> wrote:On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
> There are results with 5364b357 reverted.What exactly is this test?I think assuming it is a read-only -M prepared pgbench run where data fits in shared buffers. However if you can share exact details, then I can try the similar test.Yes, the test is:pgbench -s 1000 -c $clients -j 100 -M prepared -S -T 300 (shared_buffers=24GB)Crazy that this has such a negative impact. Amit, can you reproduce
that?I will try it.Good.Okay, I have done some performance testing of read-only tests with configuration suggested by you to see the impactpin_unpin - latest version of pin unpin patch on top of HEAD.pin_unpin_clog_32 - pin_unpin + change clog buffers to 32
Client_Count/Patch_ver 64 128 pin_unpin 330280 133586 pin_unpin_clog_32 388244 132388 This shows that at 64 client count, the performance is better with 32 clog buffers. However, I think this is more attributed towards the fact that contention seems to shifted to procarraylock as to an extent indicated in Alexandar's mail. I will try once with cache the snapshot patch as well and with clog buffers as 64.
I went ahead and tried with Cache the snapshot patch and with clog buffers as 64 and below is performance data:
Description of patches
pin_unpin - latest version of pin unpin patch on top of HEAD.
pin_unpin_clog_32 - pin_unpin + change clog buffers to 32
pin_unpin_cache_snapshot - pin_unpin + Cache the snapshot
pin_unpin_clog_64 - pin_unpin + change clog buffers to 64
| Client_Count/Patch_ver | 64 | 128 |
| pin_unpin | 330280 | 133586 |
| pin_unpin_clog_32 | 388244 | 132388 |
| pin_unpin_cache_snapshot | 412149 | 144799 |
| pin_unpin_clog_64 | 391472 | 132951 |
Above data seems to indicate that cache the snapshot patch will make performance go further up with clog buffers as 128 (HEAD). I will take the performance data with pin_unpin + clog buffers as 32 + cache the snapshot, but above seems a good enough indication that making clog buffers as 128 is a good move considering we will one day improve GetSnapshotData either by Cache the snapshot technique or some other way. Also making clog buffers as 64 instead of 128 seems to address the regression (at the very least in above tests), but for read-write performance, clog buffers as 128 has better numbers, though the difference between 64 and 128 is not very high.
On 2016-04-10 09:03:37 +0300, Alexander Korotkov wrote: > On Sun, Apr 10, 2016 at 8:36 AM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > > > On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote: > > > >> > >> > >> On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> > >> wrote: > >> >On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote: > >> >> There are results with 5364b357 reverted. > >> > > >> >Crazy that this has such a negative impact. Amit, can you reproduce > >> >that? Alexander, I guess for r/w workload 5364b357 is a benefit on that > >> >machine as well? > >> > >> How sure are you about these measurements? > > > > > > I'm pretty sure. I've retried it multiple times by hand before re-run the > > script. > > > > > >> Because there really shouldn't be clog lookups one a steady state is > >> reached... > >> > > > > Hm... I'm also surprised. There shouldn't be clog lookups once hint bits > > are set. > > > > I also tried to run perf top during pgbench and get some interesting > results. > > Without 5364b357: > 5,69% postgres [.] GetSnapshotData > 4,47% postgres [.] LWLockAttemptLock > 3,81% postgres [.] _bt_compare > 3,42% postgres [.] hash_search_with_hash_value > 3,08% postgres [.] LWLockRelease > 2,49% postgres [.] PinBuffer.isra.3 > 1,58% postgres [.] AllocSetAlloc > 1,17% [kernel] [k] __schedule > 1,15% postgres [.] PostgresMain > 1,13% libc-2.17.so [.] vfprintf > 1,01% libc-2.17.so [.] __memcpy_ssse3_back > > With 5364b357: > 18,54% postgres [.] GetSnapshotData > 3,45% postgres [.] LWLockRelease > 3,27% postgres [.] LWLockAttemptLock > 3,21% postgres [.] _bt_compare > 2,93% postgres [.] hash_search_with_hash_value > 2,00% postgres [.] PinBuffer.isra.3 > 1,32% postgres [.] AllocSetAlloc > 1,10% libc-2.17.so [.] vfprintf > > Very surprising. It appears that after 5364b357, GetSnapshotData consumes > more time. But I can't see anything depending on clog buffers > in GetSnapshotData code... Could you retry after applying the attached series of patches? - Andres
Вложения
On Sun, Apr 10, 2016 at 2:24 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Sun, Apr 10, 2016 at 11:33 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Sun, Apr 10, 2016 at 8:36 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote:
On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de> wrote:
>On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
>> There are results with 5364b357 reverted.
>
>Crazy that this has such a negative impact. Amit, can you reproduce
>that? Alexander, I guess for r/w workload 5364b357 is a benefit on that
>machine as well?
How sure are you about these measurements?I'm pretty sure. I've retried it multiple times by hand before re-run the script.Because there really shouldn't be clog lookups one a steady state is reached...Hm... I'm also surprised. There shouldn't be clog lookups once hint bits are set.I also tried to run perf top during pgbench and get some interesting results.Without 5364b357:5,69% postgres [.] GetSnapshotData4,47% postgres [.] LWLockAttemptLock3,81% postgres [.] _bt_compare3,42% postgres [.] hash_search_with_hash_value3,08% postgres [.] LWLockRelease2,49% postgres [.] PinBuffer.isra.31,58% postgres [.] AllocSetAlloc1,17% [kernel] [k] __schedule1,15% postgres [.] PostgresMain1,13% libc-2.17.so [.] vfprintf1,01% libc-2.17.so [.] __memcpy_ssse3_backWith 5364b357:18,54% postgres [.] GetSnapshotData3,45% postgres [.] LWLockRelease3,27% postgres [.] LWLockAttemptLock3,21% postgres [.] _bt_compare2,93% postgres [.] hash_search_with_hash_value2,00% postgres [.] PinBuffer.isra.31,32% postgres [.] AllocSetAlloc1,10% libc-2.17.so [.] vfprintfVery surprising. It appears that after 5364b357, GetSnapshotData consumes more time. But I can't see anything depending on clog buffers in GetSnapshotData code...There is a related fact presented by Mithun C Y as well [1] which suggests that Andres's idea of reducing the cost of snapshot shows noticeable gain after increasing the clog buffers. If you read that thread you will notice that initially we didn't notice much gain by that idea, but with increased clog buffers, it started showing noticeable gain. If by any chance, you can apply that patch and see the results (latest patch is at [2]).
I took a look at this thread but I still didn't get why number of clog buffers affects read-only benchmark.
Could you please explain it to me in more details?
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Apr 11, 2016 at 8:10 AM, Andres Freund <andres@anarazel.de> wrote:
Could you retry after applying the attached series of patches?On 2016-04-10 09:03:37 +0300, Alexander Korotkov wrote:
> On Sun, Apr 10, 2016 at 8:36 AM, Alexander Korotkov <
> a.korotkov@postgrespro.ru> wrote:
>
> > On Sat, Apr 9, 2016 at 10:49 PM, Andres Freund <andres@anarazel.de> wrote:
> >
> >>
> >>
> >> On April 9, 2016 12:43:03 PM PDT, Andres Freund <andres@anarazel.de>
> >> wrote:
> >> >On 2016-04-09 22:38:31 +0300, Alexander Korotkov wrote:
> >> >> There are results with 5364b357 reverted.
> >> >
> >> >Crazy that this has such a negative impact. Amit, can you reproduce
> >> >that? Alexander, I guess for r/w workload 5364b357 is a benefit on that
> >> >machine as well?
> >>
> >> How sure are you about these measurements?
> >
> >
> > I'm pretty sure. I've retried it multiple times by hand before re-run the
> > script.
> >
> >
> >> Because there really shouldn't be clog lookups one a steady state is
> >> reached...
> >>
> >
> > Hm... I'm also surprised. There shouldn't be clog lookups once hint bits
> > are set.
> >
>
> I also tried to run perf top during pgbench and get some interesting
> results.
>
> Without 5364b357:
> 5,69% postgres [.] GetSnapshotData
> 4,47% postgres [.] LWLockAttemptLock
> 3,81% postgres [.] _bt_compare
> 3,42% postgres [.] hash_search_with_hash_value
> 3,08% postgres [.] LWLockRelease
> 2,49% postgres [.] PinBuffer.isra.3
> 1,58% postgres [.] AllocSetAlloc
> 1,17% [kernel] [k] __schedule
> 1,15% postgres [.] PostgresMain
> 1,13% libc-2.17.so [.] vfprintf
> 1,01% libc-2.17.so [.] __memcpy_ssse3_back
>
> With 5364b357:
> 18,54% postgres [.] GetSnapshotData
> 3,45% postgres [.] LWLockRelease
> 3,27% postgres [.] LWLockAttemptLock
> 3,21% postgres [.] _bt_compare
> 2,93% postgres [.] hash_search_with_hash_value
> 2,00% postgres [.] PinBuffer.isra.3
> 1,32% postgres [.] AllocSetAlloc
> 1,10% libc-2.17.so [.] vfprintf
>
> Very surprising. It appears that after 5364b357, GetSnapshotData consumes
> more time. But I can't see anything depending on clog buffers
> in GetSnapshotData code...
Yes, I will try with these patches and snapshot too old reverted.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Apr 11, 2016 at 5:04 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Mon, Apr 11, 2016 at 8:10 AM, Andres Freund <andres@anarazel.de> wrote:Could you retry after applying the attached series of patches?Yes, I will try with these patches and snapshot too old reverted.
I've run the same benchmark with 279d86af and 848ef42b reverted. I've tested of all 3 patches from you applied and, for comparison, 3 patches + clog buffers reverted back to 32.
clients patches patches + clog_32
1 12594 12556
2 26705 26258
4 50985 53254
8 103234 104416
10 135321 130893
20 268675 267648
30 370437 409710
40 486512 482382
50 539910 525667
60 616401 672230
70 667864 660853
80 924606 737768
90 1217435 799581
100 1326054 863066
110 1446380 980206
120 1484920 1000963
130 1512440 1058852
140 1536181 1088958
150 1504750 1134354
160 1461513 1132173
170 1453943 1158656
180 1426288 1120511
I hardly can understand how clog buffers influence read-only benchmark. It even harder for me why influence of clog buffers change its direction after applying your patches. But the results are following. And I've rechecked some values manually to verify that there is no error. I would be very thankful for any explanation.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2016-04-11 22:08:15 +0300, Alexander Korotkov wrote: > On Mon, Apr 11, 2016 at 5:04 PM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > > > On Mon, Apr 11, 2016 at 8:10 AM, Andres Freund <andres@anarazel.de> wrote: > > > >> Could you retry after applying the attached series of patches? > >> > > > > Yes, I will try with these patches and snapshot too old reverted. > > > > I've run the same benchmark with 279d86af and 848ef42b reverted. I've > tested of all 3 patches from you applied and, for comparison, 3 patches + > clog buffers reverted back to 32. > > clients patches patches + clog_32 > 1 12594 12556 > 2 26705 26258 > 4 50985 53254 > 8 103234 104416 > 10 135321 130893 > 20 268675 267648 > 30 370437 409710 > 40 486512 482382 > 50 539910 525667 > 60 616401 672230 > 70 667864 660853 > 80 924606 737768 > 90 1217435 799581 > 100 1326054 863066 > 110 1446380 980206 > 120 1484920 1000963 > 130 1512440 1058852 > 140 1536181 1088958 > 150 1504750 1134354 > 160 1461513 1132173 > 170 1453943 1158656 > 180 1426288 1120511 > > I hardly can understand how clog buffers influence read-only > benchmark. My guess is that the number of buffers influences some alignment; causing a lot of false sharing or something. I.e. the number of clog buffers itself doesn't play a role, it's just a question of how it change the memory layout. > It even harder for me why influence of clog buffers change its > direction after applying your patches. But the results are following. > And I've rechecked some values manually to verify that there is no > error. > I would be very thankful for any explanation. Hm. Possibly this patches influenced alignment, but didn't make things sufficiently stable to guarantee that we're always correctly aligned, thus the 32bit case now regresses. Any chance that I could run some tests on that machine myself? It's very hard to investigate that kind of issue without access; the only thing I otherwise can do is lob patches at you, till we find the relevant memory. If not, one of the things to do is to use perf to compare where cache misses is happening between the fast and the slow case. Greetings, Andres Freund
On 2016-04-11 12:17:20 -0700, Andres Freund wrote: > On 2016-04-11 22:08:15 +0300, Alexander Korotkov wrote: > > On Mon, Apr 11, 2016 at 5:04 PM, Alexander Korotkov < > > a.korotkov@postgrespro.ru> wrote: > > > > > On Mon, Apr 11, 2016 at 8:10 AM, Andres Freund <andres@anarazel.de> wrote: > > > > > >> Could you retry after applying the attached series of patches? > > >> > > > > > > Yes, I will try with these patches and snapshot too old reverted. > > > > > > > I've run the same benchmark with 279d86af and 848ef42b reverted. I've > > tested of all 3 patches from you applied and, for comparison, 3 patches + > > clog buffers reverted back to 32. > > > > clients patches patches + clog_32 > > 1 12594 12556 > > 2 26705 26258 > > 4 50985 53254 > > 8 103234 104416 > > 10 135321 130893 > > 20 268675 267648 > > 30 370437 409710 > > 40 486512 482382 > > 50 539910 525667 > > 60 616401 672230 > > 70 667864 660853 > > 80 924606 737768 > > 90 1217435 799581 > > 100 1326054 863066 > > 110 1446380 980206 > > 120 1484920 1000963 > > 130 1512440 1058852 > > 140 1536181 1088958 > > 150 1504750 1134354 > > 160 1461513 1132173 > > 170 1453943 1158656 > > 180 1426288 1120511 > Any chance that I could run some tests on that machine myself? It's very > hard to investigate that kind of issue without access; the only thing I > otherwise can do is lob patches at you, till we find the relevant > memory. I did get access to the machine (thanks!). My testing shows that performance is sensitive to various parameters influencing memory allocation. E.g. twiddling with max_connections changes performance. With max_connections=400 and the previous patches applied I get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're dealing with an alignment/sharing related issue. Padding PGXACT to a full cache-line seems to take care of the largest part of the performance irregularity. I looked at perf profiles and saw that most cache misses stem from there, and that the percentage (not absolute amount!) changes between fast/slow settings. To me it makes intuitive sense why you'd want PGXACTs to be on separate cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed making it immediately return propels performance up to 1720000, without other changes. Additionally cacheline-padding PGXACT speeds things up to 1750000 tps. But I'm unclear why the magnitude of the effect depends on other allocations. With the previously posted patches allPgXact is always cacheline-aligned. Greetings, Andres Freund
On 2016-04-11 14:40:29 -0700, Andres Freund wrote: > On 2016-04-11 12:17:20 -0700, Andres Freund wrote: > > On 2016-04-11 22:08:15 +0300, Alexander Korotkov wrote: > > > On Mon, Apr 11, 2016 at 5:04 PM, Alexander Korotkov < > > > a.korotkov@postgrespro.ru> wrote: > > > > > > > On Mon, Apr 11, 2016 at 8:10 AM, Andres Freund <andres@anarazel.de> wrote: > > > > > > > >> Could you retry after applying the attached series of patches? > > > >> > > > > > > > > Yes, I will try with these patches and snapshot too old reverted. > > > > > > > > > > I've run the same benchmark with 279d86af and 848ef42b reverted. I've > > > tested of all 3 patches from you applied and, for comparison, 3 patches + > > > clog buffers reverted back to 32. > > > > > > clients patches patches + clog_32 > > > 1 12594 12556 > > > 2 26705 26258 > > > 4 50985 53254 > > > 8 103234 104416 > > > 10 135321 130893 > > > 20 268675 267648 > > > 30 370437 409710 > > > 40 486512 482382 > > > 50 539910 525667 > > > 60 616401 672230 > > > 70 667864 660853 > > > 80 924606 737768 > > > 90 1217435 799581 > > > 100 1326054 863066 > > > 110 1446380 980206 > > > 120 1484920 1000963 > > > 130 1512440 1058852 > > > 140 1536181 1088958 > > > 150 1504750 1134354 > > > 160 1461513 1132173 > > > 170 1453943 1158656 > > > 180 1426288 1120511 > > > Any chance that I could run some tests on that machine myself? It's very > > hard to investigate that kind of issue without access; the only thing I > > otherwise can do is lob patches at you, till we find the relevant > > memory. > > I did get access to the machine (thanks!). My testing shows that > performance is sensitive to various parameters influencing memory > allocation. E.g. twiddling with max_connections changes > performance. With max_connections=400 and the previous patches applied I > get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're > dealing with an alignment/sharing related issue. > > Padding PGXACT to a full cache-line seems to take care of the largest > part of the performance irregularity. I looked at perf profiles and saw > that most cache misses stem from there, and that the percentage (not > absolute amount!) changes between fast/slow settings. > > To me it makes intuitive sense why you'd want PGXACTs to be on separate > cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed > making it immediately return propels performance up to 1720000, without > other changes. Additionally cacheline-padding PGXACT speeds things up to > 1750000 tps. > > But I'm unclear why the magnitude of the effect depends on other > allocations. With the previously posted patches allPgXact is always > cacheline-aligned. Oh, one more thing: The volatile on PGXACT in GetSnapshotData() costs us about 100k tps on that machine; without, afaics, any point but force pgxact->xmin to only be loaded once (which a *((volatile TransactionId)&pgxact->xmin) does just as well). Greetings, Andres Freund
On 2016-04-11 14:40:29 -0700, Andres Freund wrote: > On 2016-04-11 12:17:20 -0700, Andres Freund wrote: > I did get access to the machine (thanks!). My testing shows that > performance is sensitive to various parameters influencing memory > allocation. E.g. twiddling with max_connections changes > performance. With max_connections=400 and the previous patches applied I > get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're > dealing with an alignment/sharing related issue. > > Padding PGXACT to a full cache-line seems to take care of the largest > part of the performance irregularity. I looked at perf profiles and saw > that most cache misses stem from there, and that the percentage (not > absolute amount!) changes between fast/slow settings. > > To me it makes intuitive sense why you'd want PGXACTs to be on separate > cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed > making it immediately return propels performance up to 1720000, without > other changes. Additionally cacheline-padding PGXACT speeds things up to > 1750000 tps. > > But I'm unclear why the magnitude of the effect depends on other > allocations. With the previously posted patches allPgXact is always > cacheline-aligned. I've spent considerable amount experimenting around this. The alignment of allPgXact does *not* apear to play a significant role; rather it apears to be the the "distance" between the allPgXact and pgprocno arrays. Alexander, could you post dmidecode output, and install numactl & numastat on the machine? I wonder if the box has cluster-on-die activated or not. Do I see correctly that this is a system that could potentially have 8 sockets, but actually has only four? Because I see physical id : 3 in /proc/cpuinfo only going up to three (from zero), not 7? And there's only 144 processorcs, while each E7-8890 v3 should have 36 threads. Greetings, Andres Freund
On Mon, Apr 11, 2016 at 7:33 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sun, Apr 10, 2016 at 2:24 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:I also tried to run perf top during pgbench and get some interesting results.Without 5364b357:5,69% postgres [.] GetSnapshotData4,47% postgres [.] LWLockAttemptLock3,81% postgres [.] _bt_compare3,42% postgres [.] hash_search_with_hash_value3,08% postgres [.] LWLockRelease2,49% postgres [.] PinBuffer.isra.31,58% postgres [.] AllocSetAlloc1,17% [kernel] [k] __schedule1,15% postgres [.] PostgresMain1,13% libc-2.17.so [.] vfprintf1,01% libc-2.17.so [.] __memcpy_ssse3_backWith 5364b357:18,54% postgres [.] GetSnapshotData3,45% postgres [.] LWLockRelease3,27% postgres [.] LWLockAttemptLock3,21% postgres [.] _bt_compare2,93% postgres [.] hash_search_with_hash_value2,00% postgres [.] PinBuffer.isra.31,32% postgres [.] AllocSetAlloc1,10% libc-2.17.so [.] vfprintfVery surprising. It appears that after 5364b357, GetSnapshotData consumes more time. But I can't see anything depending on clog buffers in GetSnapshotData code...There is a related fact presented by Mithun C Y as well [1] which suggests that Andres's idea of reducing the cost of snapshot shows noticeable gain after increasing the clog buffers. If you read that thread you will notice that initially we didn't notice much gain by that idea, but with increased clog buffers, it started showing noticeable gain. If by any chance, you can apply that patch and see the results (latest patch is at [2]).I took a look at this thread but I still didn't get why number of clog buffers affects read-only benchmark.Could you please explain it to me in more details?
As already pointed out by Andres, that this is mainly due to shared memory alignment issues. We have observed that changing some shared memory
arrangement (structures) some times causes huge differences in performance. I guess that is the reason why with Cache the snapshot patch, I am seeing the performance gets restored (mainly because it is changing shared memory structures). I think the right way to fix this is to find which shared structure/structure's needs padding, so that we don't see such fluctuations every time we change some thing is shared memory.
arrangement (structures) some times causes huge differences in performance. I guess that is the reason why with Cache the snapshot patch, I am seeing the performance gets restored (mainly because it is changing shared memory structures). I think the right way to fix this is to find which shared structure/structure's needs padding, so that we don't see such fluctuations every time we change some thing is shared memory.
On Tue, Apr 12, 2016 at 5:39 AM, Andres Freund <andres@anarazel.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2016-04-11 14:40:29 -0700, Andres Freund wrote:
> On 2016-04-11 12:17:20 -0700, Andres Freund wrote:
> I did get access to the machine (thanks!). My testing shows that
> performance is sensitive to various parameters influencing memory
> allocation. E.g. twiddling with max_connections changes
> performance. With max_connections=400 and the previous patches applied I
> get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're
> dealing with an alignment/sharing related issue.
>
> Padding PGXACT to a full cache-line seems to take care of the largest
> part of the performance irregularity. I looked at perf profiles and saw
> that most cache misses stem from there, and that the percentage (not
> absolute amount!) changes between fast/slow settings.
>
> To me it makes intuitive sense why you'd want PGXACTs to be on separate
> cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed
> making it immediately return propels performance up to 1720000, without
> other changes. Additionally cacheline-padding PGXACT speeds things up to
> 1750000 tps.
>
> But I'm unclear why the magnitude of the effect depends on other
> allocations. With the previously posted patches allPgXact is always
> cacheline-aligned.
I've spent considerable amount experimenting around this. The alignment
of allPgXact does *not* apear to play a significant role; rather it
apears to be the the "distance" between the allPgXact and pgprocno
arrays.
Alexander, could you post dmidecode output, and install numactl &
numastat on the machine? I wonder if the box has cluster-on-die
activated or not.
Dmidecode output is in the attachment. Numactl & numastat are installed.
Do I see correctly that this is a system that could
potentially have 8 sockets, but actually has only four? Because I see
physical id : 3 in /proc/cpuinfo only going up to three (from zero),
not 7? And there's only 144 processorcs, while each E7-8890 v3 should
have 36 threads.
There are definitely 4 of used sockets. I'm not sure about potential count though.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
On Tue, Apr 12, 2016 at 12:40 AM, Andres Freund <andres@anarazel.de> wrote:
performance is sensitive to various parameters influencing memoryI did get access to the machine (thanks!). My testing shows that
allocation. E.g. twiddling with max_connections changes
performance. With max_connections=400 and the previous patches applied I
get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're
dealing with an alignment/sharing related issue.
Padding PGXACT to a full cache-line seems to take care of the largest
part of the performance irregularity. I looked at perf profiles and saw
that most cache misses stem from there, and that the percentage (not
absolute amount!) changes between fast/slow settings.
To me it makes intuitive sense why you'd want PGXACTs to be on separate
cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed
making it immediately return propels performance up to 1720000, without
other changes. Additionally cacheline-padding PGXACT speeds things up to
1750000 tps.
------
On Tue, Apr 12, 2016 at 3:48 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Tue, Apr 12, 2016 at 12:40 AM, Andres Freund <andres@anarazel.de> wrote:performance is sensitive to various parameters influencing memoryI did get access to the machine (thanks!). My testing shows that
allocation. E.g. twiddling with max_connections changes
performance. With max_connections=400 and the previous patches applied I
get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're
dealing with an alignment/sharing related issue.
Padding PGXACT to a full cache-line seems to take care of the largest
part of the performance irregularity. I looked at perf profiles and saw
that most cache misses stem from there, and that the percentage (not
absolute amount!) changes between fast/slow settings.
To me it makes intuitive sense why you'd want PGXACTs to be on separate
cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed
making it immediately return propels performance up to 1720000, without
other changes. Additionally cacheline-padding PGXACT speeds things up to
1750000 tps.It seems like padding PGXACT to a full cache-line is a great improvement. We have not so many PGXACTs to care about bytes wasted to padding.
Yes, it seems generally it is a good idea, but not sure if it is a complete fix for variation in performance we are seeing when we change shared memory structures. Andres suggested me on IM to take performance data on x86 m/c by padding PGXACT and the data for the same is as below:
median of 3, 5-min runs
| Client_Count/Patch_ver | 8 | 64 | 128 |
| HEAD | 59708 | 329560 | 173655 |
| PATCH | 61480 | 379798 | 157580 |
Here, at 128 client-count the performance with patch still seems to have variation. The highest tps with patch (170363) is close to HEAD (175718). This could be run-to-run variation, but I think it indicates that there are more places where we might need such padding or may be optimize them, so that they are aligned.
I can do some more experiments on similar lines, but I am out on vacation and might not be able to access the m/c for 3-4 days.
Вложения
On 2016-04-12 19:42:11 +0530, Amit Kapila wrote: > Yes, it seems generally it is a good idea, but not sure if it is a complete > fix for variation in performance we are seeing when we change shared memory > structures. I didn't suspect it would be. More whether it'd be beneficial performance wise. FWIW, I haven't seen the variations you're observing on any machine so far. I think at high concurrency levels we're quite likely to interact with the exact strategy used for the last-level/l3 cache. pgprocno, allPgXact, BufferDescs are all arrays with a regular stride that we access across several numa nodes, at a very high rate. At some point that makes very likely that cache conflicts occur in set associative caches. > Andres suggested me on IM to take performance data on x86 m/c > by padding PGXACT and the data for the same is as below: > > median of 3, 5-min runs Thanks for running these. I presume these were *without* pg_prewarming the contents? It'd be interesting to do the same with prewarming; aligning these structures should be unrelated to the separate issue of bufferdesc order having a rather massive performance effect. Greetings, Andres Freund
On Tue, Apr 12, 2016 at 5:12 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On Tue, Apr 12, 2016 at 3:48 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Tue, Apr 12, 2016 at 12:40 AM, Andres Freund <andres@anarazel.de> wrote:performance is sensitive to various parameters influencing memoryI did get access to the machine (thanks!). My testing shows that
allocation. E.g. twiddling with max_connections changes
performance. With max_connections=400 and the previous patches applied I
get ~1220000 tps, with 402 ~1620000 tps. This sorta confirms that we're
dealing with an alignment/sharing related issue.
Padding PGXACT to a full cache-line seems to take care of the largest
part of the performance irregularity. I looked at perf profiles and saw
that most cache misses stem from there, and that the percentage (not
absolute amount!) changes between fast/slow settings.
To me it makes intuitive sense why you'd want PGXACTs to be on separate
cachelines - they're constantly dirtied via SnapshotResetXmin(). Indeed
making it immediately return propels performance up to 1720000, without
other changes. Additionally cacheline-padding PGXACT speeds things up to
1750000 tps.It seems like padding PGXACT to a full cache-line is a great improvement. We have not so many PGXACTs to care about bytes wasted to padding.Yes, it seems generally it is a good idea, but not sure if it is a complete fix for variation in performance we are seeing when we change shared memory structures. Andres suggested me on IM to take performance data on x86 m/c by padding PGXACT and the data for the same is as below:median of 3, 5-min runs
Client_Count/Patch_ver 8 64 128 HEAD 59708 329560 173655 PATCH 61480 379798 157580 Here, at 128 client-count the performance with patch still seems to have variation. The highest tps with patch (170363) is close to HEAD (175718). This could be run-to-run variation, but I think it indicates that there are more places where we might need such padding or may be optimize them, so that they are aligned.I can do some more experiments on similar lines, but I am out on vacation and might not be able to access the m/c for 3-4 days.
Could share details of hardware you used? I could try to find something similar to reproduce this.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Apr 12, 2016 at 9:32 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-12 19:42:11 +0530, Amit Kapila wrote:
> > Andres suggested me on IM to take performance data on x86 m/c
> > by padding PGXACT and the data for the same is as below:
> >
> > median of 3, 5-min runs
>
> Thanks for running these.
>
> I presume these were *without* pg_prewarming the contents?
>
> On 2016-04-12 19:42:11 +0530, Amit Kapila wrote:
> > Andres suggested me on IM to take performance data on x86 m/c
> > by padding PGXACT and the data for the same is as below:
> >
> > median of 3, 5-min runs
>
> Thanks for running these.
>
> I presume these were *without* pg_prewarming the contents?
>
Yes.
> It'd be
> interesting to do the same with prewarming;
> interesting to do the same with prewarming;
What you want to see by prewarming? Will it have safe effect, if the tests are run for 10 or 15 mins rather than 5 mins?
> Could share details of hardware you used? I could try to find something similar to reproduce this.
Processor related information (using lscpu)
----------------------------------------------------------------
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
Stepping: 2
CPU MHz: 1064.000
BogoMIPS: 4266.62
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 24576K
NUMA node0 CPU(s): 0,65-71,96-103
NUMA node1 CPU(s): 72-79,104-111
NUMA node2 CPU(s): 80-87,112-119
NUMA node3 CPU(s): 88-95,120-127
NUMA node4 CPU(s): 1-8,33-40
NUMA node5 CPU(s): 9-16,41-48
NUMA node6 CPU(s): 17-24,49-56
NUMA node7 CPU(s): 25-32,57-64
On 2016-04-14 07:59:07 +0530, Amit Kapila wrote: > What you want to see by prewarming? Prewarming appears to greatly reduce the per-run variance on that machine, making it a lot easier to get meaningful results. Thus it'd make it easier to compare pre/post padding numbers. > Will it have safe effect, if the tests are run for 10 or 15 mins > rather than 5 mins? s/safe/same/? If so, no, I doesn't look that way. The order of buffers appears to play a large role; and it won't change in a memory resident workload over one run. Greetings, Andres Freund
On Thu, Apr 14, 2016 at 5:35 AM, Andres Freund <andres@anarazel.de> wrote:
On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> What you want to see by prewarming?
Prewarming appears to greatly reduce the per-run variance on that
machine, making it a lot easier to get meaningful results. Thus it'd
make it easier to compare pre/post padding numbers.
> Will it have safe effect, if the tests are run for 10 or 15 mins
> rather than 5 mins?
s/safe/same/? If so, no, I doesn't look that way. The order of buffers
appears to play a large role; and it won't change in a memory resident
workload over one run.
I've tried to run read-only benchmark of pad_pgxact_v1.patch on 4x18 Intel machine. The results are following.
clients no-pad pad
1 12997 13381
2 26728 25645
4 52539 51738
8 103785 102337
10 132606 126174
20 255844 252143
30 371359 357629
40 450429 443053
50 497705 488250
60 564385 564877
70 718860 725149
80 934170 931218
90 1152961 1146498
100 1240055 1300369
110 1207727 1375706
120 1167681 1417032
130 1120891 1448408
140 1085904 1449027
150 1022160 1437545
160 976487 1441720
170 978120 1435848
180 953843 1414925
snapshot_too_old patch was reverted in the both cases.
On high number of clients padding gives very significant benefit. However, on low number of clients there is small regression. I think this regression could be caused by alignment of other data structures.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Вложения
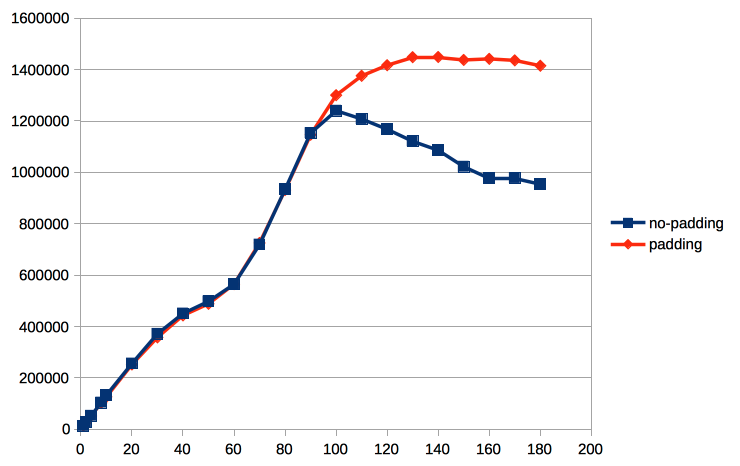{kind=link}
On Thu, Apr 14, 2016 at 8:05 AM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> > What you want to see by prewarming?
>
> Prewarming appears to greatly reduce the per-run variance on that
> machine, making it a lot easier to get meaningful results.
>
>
> On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> > What you want to see by prewarming?
>
> Prewarming appears to greatly reduce the per-run variance on that
> machine, making it a lot easier to get meaningful results.
>
I think you are referring the tests done by Robert on power-8 m/c, but the performance results I have reported were on intel x86. In last two days, I have spent quite some effort to do the performance testing of this patch with pre-warming by using the same query [1] as used by Robert in his tests. The tests are done such that first it start server, pre-warms the relations, ran read-only test, stop server, again repeat this for next test. I have observed that the variance in run-to-run performance still occurs especially at higher client count (128). Below are results for 128 client count both when the tests ran first with patch and then with HEAD and vice versa.
Test-1
----------
client count - 128 (basically -c 128 -j 128)
first tests ran with patch and then with HEAD
| Patch_ver/Runs | HEAD (commit -70715e6a) | Patch |
| Run-1 | 156748 | 174640 |
| Run-2 | 151352 | 150115 |
| Run-3 | 177940 | 165269 |
Test-2
----------
client count - 128 (basically -c 128 -j 128)
first tests ran with HEAD and then with patch
| Patch_ver/Runs | HEAD (commit -70715e6a) | Patch |
| Run-1 | 173063 | 151282 |
| Run-2 | 173187 | 140676 |
| Run-3 | 177046 | 166726 |
I think this patch (padding pgxact) certainly is beneficial as reported above thread. At very high client count some variation in performance is observed with and without patch, but I feel in general it is a win.
[1] - psql -c "select sum(x.x) from (select pg_prewarm(oid) as x from pg_class where relkind in ('i', 'r') order by oid) x;"
On Fri, Apr 15, 2016 at 1:59 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
These results indicates that the patch is a win. Are these results median of 3 runs or single run data. By the way can you share the output of lscpu command on this m/c.
On Thu, Apr 14, 2016 at 5:35 AM, Andres Freund <andres@anarazel.de> wrote:On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> What you want to see by prewarming?
Prewarming appears to greatly reduce the per-run variance on that
machine, making it a lot easier to get meaningful results. Thus it'd
make it easier to compare pre/post padding numbers.
> Will it have safe effect, if the tests are run for 10 or 15 mins
> rather than 5 mins?
s/safe/same/? If so, no, I doesn't look that way. The order of buffers
appears to play a large role; and it won't change in a memory resident
workload over one run.I've tried to run read-only benchmark of pad_pgxact_v1.patch on 4x18 Intel machine. The results are following.clients no-pad pad1 12997 133812 26728 256454 52539 517388 103785 10233710 132606 12617420 255844 25214330 371359 35762940 450429 44305350 497705 48825060 564385 56487770 718860 72514980 934170 93121890 1152961 1146498100 1240055 1300369110 1207727 1375706120 1167681 1417032130 1120891 1448408140 1085904 1449027150 1022160 1437545160 976487 1441720170 978120 1435848180 953843 1414925snapshot_too_old patch was reverted in the both cases.On high number of clients padding gives very significant benefit.
These results indicates that the patch is a win. Are these results median of 3 runs or single run data. By the way can you share the output of lscpu command on this m/c.
On Sun, Apr 17, 2016 at 7:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
On Thu, Apr 14, 2016 at 8:05 AM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> > What you want to see by prewarming?
>
> Prewarming appears to greatly reduce the per-run variance on that
> machine, making it a lot easier to get meaningful results.
>I think you are referring the tests done by Robert on power-8 m/c, but the performance results I have reported were on intel x86. In last two days, I have spent quite some effort to do the performance testing of this patch with pre-warming by using the same query [1] as used by Robert in his tests. The tests are done such that first it start server, pre-warms the relations, ran read-only test, stop server, again repeat this for next test.
What did you include into single run: test of single version (HEAD or Patch) or test of both of them?
I have observed that the variance in run-to-run performance still occurs especially at higher client count (128). Below are results for 128 client count both when the tests ran first with patch and then with HEAD and vice versa.Test-1----------client count - 128 (basically -c 128 -j 128)first tests ran with patch and then with HEAD
Patch_ver/Runs HEAD (commit -70715e6a) Patch Run-1 156748 174640 Run-2 151352 150115 Run-3 177940 165269 Test-2----------client count - 128 (basically -c 128 -j 128)first tests ran with HEAD and then with patch
Patch_ver/Runs HEAD (commit -70715e6a) Patch Run-1 173063 151282 Run-2 173187 140676 Run-3 177046 166726 I think this patch (padding pgxact) certainly is beneficial as reported above thread. At very high client count some variation in performance is observed with and without patch, but I feel in general it is a win.
So, what hardware did you use for these tests: power-8 or x86? How long was single run?
Per-run variation seems quite high. It also seems that it depends on which version runs first. But that could be a coincidence.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Apr 25, 2016 at 6:04 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sun, Apr 17, 2016 at 7:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:On Thu, Apr 14, 2016 at 8:05 AM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-04-14 07:59:07 +0530, Amit Kapila wrote:
> > What you want to see by prewarming?
>
> Prewarming appears to greatly reduce the per-run variance on that
> machine, making it a lot easier to get meaningful results.
>I think you are referring the tests done by Robert on power-8 m/c, but the performance results I have reported were on intel x86. In last two days, I have spent quite some effort to do the performance testing of this patch with pre-warming by using the same query [1] as used by Robert in his tests. The tests are done such that first it start server, pre-warms the relations, ran read-only test, stop server, again repeat this for next test.What did you include into single run: test of single version (HEAD or Patch) or test of both of them?
single run includes single version (either HEAD or Patch).
I have observed that the variance in run-to-run performance still occurs especially at higher client count (128). Below are results for 128 client count both when the tests ran first with patch and then with HEAD and vice versa.Test-1----------client count - 128 (basically -c 128 -j 128)first tests ran with patch and then with HEAD
Patch_ver/Runs HEAD (commit -70715e6a) Patch Run-1 156748 174640 Run-2 151352 150115 Run-3 177940 165269 Test-2----------client count - 128 (basically -c 128 -j 128)first tests ran with HEAD and then with patch
Patch_ver/Runs HEAD (commit -70715e6a) Patch Run-1 173063 151282 Run-2 173187 140676 Run-3 177046 166726 I think this patch (padding pgxact) certainly is beneficial as reported above thread. At very high client count some variation in performance is observed with and without patch, but I feel in general it is a win.So, what hardware did you use for these tests: power-8 or x86?
x86
How long was single run?
hi all:
In Document "Table 59-1. Built-in GiST Operator Classes":
"range_ops any range type && &> &< >> << <@ -|- = @> @>", exist double "@>",
Should be "<@ @>" ?
On Sun, Aug 2, 2020 at 8:17 PM osdba <mailtch@163.com> wrote:
hi all:In Document "Table 59-1. Built-in GiST Operator Classes":"range_ops any range type && &> &< >> << <@ -|- = @> @>", exist double "@>",Should be "<@ @>" ?
It helps to reference the current version of the page (or provide a url link) as that section seems to have migrated to Chapter 64 - though it is unchanged even on the main development branch.
The table itself is extremely difficult to read: it would be more easily readable if the font was monospaced, but its not.
I'm reasonably confident that the equal sign is part of the second-to-last operator while the lone @> is the final operator. Mostly I say this because GiST doesn't do straight equality so a lone equal operator isn't valid.
David J.
you can see url: https://www.postgresql.org/docs/12/gist-builtin-opclasses.html
you can see screen snapshot:

在 2020-08-03 11:43:53,"David G. Johnston" <david.g.johnston@gmail.com> 写道:
On Sun, Aug 2, 2020 at 8:17 PM osdba <mailtch@163.com> wrote:hi all:In Document "Table 59-1. Built-in GiST Operator Classes":"range_ops any range type && &> &< >> << <@ -|- = @> @>", exist double "@>",Should be "<@ @>" ?It helps to reference the current version of the page (or provide a url link) as that section seems to have migrated to Chapter 64 - though it is unchanged even on the main development branch.The table itself is extremely difficult to read: it would be more easily readable if the font was monospaced, but its not.I'm reasonably confident that the equal sign is part of the second-to-last operator while the lone @> is the final operator. Mostly I say this because GiST doesn't do straight equality so a lone equal operator isn't valid.David J.
Вложения
On Sun, Aug 2, 2020 at 08:43:53PM -0700, David G. Johnston wrote:
> On Sun, Aug 2, 2020 at 8:17 PM osdba <mailtch@163.com> wrote:
>
> hi all:
>
> In Document "Table 59-1. Built-in GiST Operator Classes":
>
> "range_ops any range type && &> &< >> << <@ -|- = @> @>", exist double "@>
> ",
>
> Should be "<@ @>" ?
>
>
>
> It helps to reference the current version of the page (or provide a url link)
> as that section seems to have migrated to Chapter 64 - though it is unchanged
> even on the main development branch.
>
> The table itself is extremely difficult to read: it would be more easily
> readable if the font was monospaced, but its not.
>
> I'm reasonably confident that the equal sign is part of the second-to-last
> operator while the lone @> is the final operator. Mostly I say this because
> GiST doesn't do straight equality so a lone equal operator isn't valid.
I dug into this. This query I think explains why the duplicate is
there:
SELECT oprname, oprleft::regtype, oprright::regtype, oprresult::regtype
FROM pg_am
JOIN pg_opclass ON opcmethod = pg_am.oid
JOIN pg_amop ON opcfamily = pg_amop.amopfamily
JOIN pg_operator ON amopopr = pg_operator.oid
WHERE amname = 'gist'
AND opcname = 'range_ops'
ORDER BY 1
oprname | oprleft | oprright | oprresult
---------+----------+------------+-----------
&& | anyrange | anyrange | boolean
&< | anyrange | anyrange | boolean
&> | anyrange | anyrange | boolean
-|- | anyrange | anyrange | boolean
<< | anyrange | anyrange | boolean
<@ | anyrange | anyrange | boolean
= | anyrange | anyrange | boolean
>> | anyrange | anyrange | boolean
--> @> | anyrange | anyrange | boolean
--> @> | anyrange | anyelement | boolean
Notice that @> appears twice. (I am not sure why @> appears twice in
the SQL output, while <@ appears only once.) The PG docs explain the
duplicate:
https://www.postgresql.org/docs/12/functions-range.html
@> contains range int4range(2,4) @> int4range(2,3) t
@> contains element '[2011-01-01,2011-03-01)'::tsrange @> '2011-01-10'::timestamp t
<@ range is contained by int4range(2,4) <@ int4range(1,7) t
<@ element is contained by 42 <@ int4range(1,7) f
There is an anyrange/anyrange version, and an anyrange/anyelement
version of @> and <@. Anyway, for the docs, I think we can either
remove the duplicate entry, or modify it to clarify one is for
anyrange/anyrange and another is for anyrange/anyelement. I suggest the
first option.
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EnterpriseDB https://enterprisedb.com
The usefulness of a cup is in its emptiness, Bruce Lee
Ah, seems Tom has even more detail so we will continue to discuss on that thread. --------------------------------------------------------------------------- On Mon, Aug 3, 2020 at 07:51:51PM -0400, Bruce Momjian wrote: > On Sun, Aug 2, 2020 at 08:43:53PM -0700, David G. Johnston wrote: > > On Sun, Aug 2, 2020 at 8:17 PM osdba <mailtch@163.com> wrote: > > > > hi all: > > > > In Document "Table 59-1. Built-in GiST Operator Classes": > > > > "range_ops any range type && &> &< >> << <@ -|- = @> @>", exist double "@> > > ", > > > > Should be "<@ @>" ? > > > > > > > > It helps to reference the current version of the page (or provide a url link) > > as that section seems to have migrated to Chapter 64 - though it is unchanged > > even on the main development branch. > > > > The table itself is extremely difficult to read: it would be more easily > > readable if the font was monospaced, but its not. > > > > I'm reasonably confident that the equal sign is part of the second-to-last > > operator while the lone @> is the final operator. Mostly I say this because > > GiST doesn't do straight equality so a lone equal operator isn't valid. > > I dug into this. This query I think explains why the duplicate is > there: > > SELECT oprname, oprleft::regtype, oprright::regtype, oprresult::regtype > FROM pg_am > JOIN pg_opclass ON opcmethod = pg_am.oid > JOIN pg_amop ON opcfamily = pg_amop.amopfamily > JOIN pg_operator ON amopopr = pg_operator.oid > WHERE amname = 'gist' > AND opcname = 'range_ops' > ORDER BY 1 > > oprname | oprleft | oprright | oprresult > ---------+----------+------------+----------- > && | anyrange | anyrange | boolean > &< | anyrange | anyrange | boolean > &> | anyrange | anyrange | boolean > -|- | anyrange | anyrange | boolean > << | anyrange | anyrange | boolean > <@ | anyrange | anyrange | boolean > = | anyrange | anyrange | boolean > >> | anyrange | anyrange | boolean > --> @> | anyrange | anyrange | boolean > --> @> | anyrange | anyelement | boolean > > Notice that @> appears twice. (I am not sure why @> appears twice in > the SQL output, while <@ appears only once.) The PG docs explain the > duplicate: > > https://www.postgresql.org/docs/12/functions-range.html > > @> contains range int4range(2,4) @> int4range(2,3) t > @> contains element '[2011-01-01,2011-03-01)'::tsrange @> '2011-01-10'::timestamp t > <@ range is contained by int4range(2,4) <@ int4range(1,7) t > <@ element is contained by 42 <@ int4range(1,7) f > > There is an anyrange/anyrange version, and an anyrange/anyelement > version of @> and <@. Anyway, for the docs, I think we can either > remove the duplicate entry, or modify it to clarify one is for > anyrange/anyrange and another is for anyrange/anyelement. I suggest the > first option. > > -- > Bruce Momjian <bruce@momjian.us> https://momjian.us > EnterpriseDB https://enterprisedb.com > > The usefulness of a cup is in its emptiness, Bruce Lee > > > -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com The usefulness of a cup is in its emptiness, Bruce Lee