Обсуждение: what to revert
On Tue, May 3, 2016 at 11:36 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> There are a lot more than 2 patchsets that are busted at the moment, >> unfortunately, but I assume you are referring to "snapshot too old" >> and "Use Foreign Key relationships to infer multi-column join >> selectivity". > > Yeah, those are the ones I'm thinking of. I've not heard serious > proposals to revert any others, have you? Here's a list of what I think is currently broken in 9.6 that we might conceivably fix by reverting patches: - Snapshot Too Old. Tom, Andres, and Bruce want this reverted. It regresses performance significantly when turned on. It originally regressed performance significantly even when turned off, but that might be fixed now. Also, it seems to be broken for hash indexes, per Amit Kapila's report. - Atomic Pin/Unpin. There are two different open items related to this, both apparently relating to testing done by Jeff Janes. I am not sure whether they are really independent reports of different problems or just two reports of the same problem. But they sound like fairly serious breakage. - Predefined Roles. Neither you nor I liked Stephen's design. It slowed down pg_dump. It also broke pg_dump for non-superusers and something about bypassrls. None of these issues have been fixed despite considerable time having gone by. - Checkpoint Sorting and Flushing. Andres tried to fix the last report of problems with this in 72a98a639574d2e25ed94652848555900c81a799, but there were almost immediately new reports. - Foreign Keys and Multi-Column Outer Joins. You called for a revert, and the author responded with various thoughts and counterproposals. There are a few other open items, but I would consider reverting the antecedent patches as either impractical or disproportionate in those cases. Aside from the two cases you mentioned, I don't think that anyone's actually called for these other patches to be reverted, but I'm not sure that we shouldn't be considering it. What do you (and others) think? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, May 3, 2016 at 10:58 AM, Robert Haas <robertmhaas@gmail.com> wrote: > - Snapshot Too Old. Tom, Andres, and Bruce want this reverted. > It regresses performance significantly when turned on. When turned on, it improves performance in some cases and regresses performance in others. Don't forget it is currently back-patched to 9.4 and in use for production by users who could not use PostgreSQL without the feature. PostgreSQL failed their performance tests miserably without the feature, and passes with it. > It originally regressed performance significantly even when > turned off, Which was wildly exaggerated since most of the benchmarks purporting to show that actually had it turned on. I don't think the FUD from that has really evaporated. > but that might be fixed now. Certainly all evidence suggests that, FUD to the contrary. > Also, it seems to be broken for hash indexes, per Amit Kapila's > report. Yeah, with a fairly simple fix suggested immediately by Amit. I'm looking into a couple other angles for possible fixes, but certainly what he suggested could be done before beta1. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-05-03 11:58:34 -0400, Robert Haas wrote: > - Atomic Pin/Unpin. There are two different open items related to > this, both apparently relating to testing done by Jeff Janes. I am > not sure whether they are really independent reports of different > problems or just two reports of the same problem. But they sound like > fairly serious breakage. It's a bit hard to say, given the test take this long to run, but so far I've a fair amount of doubt that the bug report is actually related to the atomic pin/unpin. It appears to me - I'm in the process of trying to confirm (again long runs) that the pin/unpin patch merely changed the timing. > - Checkpoint Sorting and Flushing. Andres tried to fix the last > report of problems with this in > 72a98a639574d2e25ed94652848555900c81a799, but there were almost > immediately new reports. Yea, it's an issue with the 72a98a639574d2e25ed94652848555900c81a799, not checkpoint flushing itself. Turns out that mdsync() *wants/needs* to access deleted segments. Easily enough fixed. I've posted a patch, which I plan to commit unless somebody wants to give input on the flag design. > There are a few other open items, but I would consider reverting the > antecedent patches as either impractical or disproportionate in those > cases. Aside from the two cases you mentioned, I don't think that > anyone's actually called for these other patches to be reverted, but > I'm not sure that we shouldn't be considering it. What do you (and > others) think? I'm *really* doubtful about the logical timeline following patches. I think they're, as committed, over-complicated and pretty much unusable. Greetings, Andres Freund
On 2016-05-03 11:12:03 -0500, Kevin Grittner wrote: > On Tue, May 3, 2016 at 10:58 AM, Robert Haas <robertmhaas@gmail.com> wrote: > > > - Snapshot Too Old. Tom, Andres, and Bruce want this reverted. > > It regresses performance significantly when turned on. > > When turned on, it improves performance in some cases and regresses > performance in others. Don't forget it is currently back-patched > to 9.4 and in use for production by users who could not use > PostgreSQL without the feature. PostgreSQL failed their > performance tests miserably without the feature, and passes with > it. > > > It originally regressed performance significantly even when > > turned off, > > Which was wildly exaggerated since most of the benchmarks > purporting to show that actually had it turned on. I don't think > the FUD from that has really evaporated. Oh, ffs. The first report of the whole issue was *with default parameters*: http://archives.postgresql.org/message-id/CAPpHfdtMONZFOXSsw1HkrD9Eb4ozF8Q8oCqH4tkpH_girJPPuA%40mail.gmail.com The issue with 0 v. -1 (and 0 vs. > 0 makes a big performance difference, so it's not that surprising to interpret numbers that way) was immediately addressed by another round of benchmarks after you pointed it out. > > but that might be fixed now. > > Certainly all evidence suggests that, FUD to the contrary. So it's now FUD to report issues with a patch that obviously hasn't received sufficient benchmarking? Give me break. Andres
On Tue, May 3, 2016 at 12:22 PM, Andres Freund <andres@anarazel.de> wrote: >> > but that might be fixed now. >> >> Certainly all evidence suggests that, FUD to the contrary. > > So it's now FUD to report issues with a patch that obviously hasn't > received sufficient benchmarking? Give me break. Yeah, I don't think that's FUD. Kevin, since your last fix, we don't have a round of benchmarking on a big machine to show whether that fixed the issue or not. I think that to really know whether this is fixed, somebody would need to compare current master with current master after reverting snapshot too old on a big machine and see if there's a difference. If anyone has done that, they have not posted the results. So it's more accurate to say that we just don't know. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, May 3, 2016 at 11:22 AM, Andres Freund <andres@anarazel.de> wrote: > The issue with 0 v. -1 (and 0 vs. > 0 makes a big performance > difference, so it's not that surprising to interpret numbers that way) ... if you fail to read the documentation of the feature or the code implementing it before testing. > was immediately addressed by another round of benchmarks after you > pointed it out. Which showed a 4% maximum hit before moving the test for whether it was "off" inline. (I'm not clear from the posted results whether that was before or after skipping the spinlock when the feature was off.) All tests that I have done and that others have done (some on big NUMA machines) and shared with me show no regression now. I haven't been willing to declare victory on that basis without hearing back from others who were able to show a regression before. If there is still a regression found when "off", there is one more test of old_snapshot_threshold which could easily be shifted in-line; it just seems unnecessary given the other work done in that area unless there is evidence that it is really needed. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Andres Freund wrote: > I'm *really* doubtful about the logical timeline following patches. I > think they're, as committed, over-complicated and pretty much unusable. As its committer, I tend to agree about reverting that feature. Craig was just posting some more patches, and I have the pg_recvlogical changes here (--endpos) which after some testing are not quite looking ready to go -- plus we still have to write the actual Perl test scripts that would use it. Taken together, this is now looking to me a bit rushed, so I prefer to cut my losses here and revert the patch so that we can revisit it for 9.7. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, May 3, 2016 at 9:58 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > As its committer, I tend to agree about reverting that feature. Craig > was just posting some more patches, and I have the pg_recvlogical > changes here (--endpos) which after some testing are not quite looking > ready to go -- plus we still have to write the actual Perl test scripts > that would use it. Taken together, this is now looking to me a bit > rushed, so I prefer to cut my losses here and revert the patch so that > we can revisit it for 9.7. I think it's a positive development that we can take this attitude to reverting patches. It should not be seen as a big personal failure, because it isn't. Stigmatizing reverts incentivizes behavior that leads to bad outcomes. -- Peter Geoghegan
* Robert Haas (robertmhaas@gmail.com) wrote: > Here's a list of what I think is currently broken in 9.6 that we might > conceivably fix by reverting patches: [...] > - Predefined Roles. Neither you nor I liked Stephen's design. It > slowed down pg_dump. It also broke pg_dump for non-superusers and > something about bypassrls. None of these issues have been fixed > despite considerable time having gone by. The issues you list are not with predefined roles at all, but with the changes to dump ACLs defined against objects in pg_catalog. I've also got patches to address those issues already developed and (mostly) posted. I'll be posting a new set later today which addresses all of the known issues with dumping catalog ACLs. There is an ongoing thread where Noah and I have been discussing the dumping of catalog ACLs issues and the TAP test suite which I've been developing for pg_dump. Certainly, anyone is welcome to join in that discussion. As mentioned before, the concern raised about predefined roles are the checks which were added to make them unlike regular roles. I'll be posting a patch tomorrow to revert those checks, as I mentioned on another thread earlier today. Thanks! Stephen
On 2016-05-03 11:46:23 -0500, Kevin Grittner wrote: > > was immediately addressed by another round of benchmarks after you > > pointed it out. > > Which showed a 4% maximum hit before moving the test for whether it > was "off" inline. > (I'm not clear from the posted results whether that was before or > after skipping the spinlock when the feature was off.) They're from after the spinlock issue was resolved. Before that the issue was a lot worse (see mail linked two messages upthread). I'm pretty sure that I said that somewhere else at least once: But to be absolutely clear, I'm *not* really concerned with the performance with the feature turned off. I'm concerned about the performance with it turned on. Andres
On 2016-05-03 10:12:51 -0700, Peter Geoghegan wrote: > On Tue, May 3, 2016 at 9:58 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > As its committer, I tend to agree about reverting that feature. Craig > > was just posting some more patches, and I have the pg_recvlogical > > changes here (--endpos) which after some testing are not quite looking > > ready to go -- plus we still have to write the actual Perl test scripts > > that would use it. Taken together, this is now looking to me a bit > > rushed, so I prefer to cut my losses here and revert the patch so that > > we can revisit it for 9.7. > > I think it's a positive development that we can take this attitude to > reverting patches. It should not be seen as a big personal failure, > because it isn't. Stigmatizing reverts incentivizes behavior that > leads to bad outcomes. +1
On 05/03/2016 07:12 PM, Peter Geoghegan wrote: > On Tue, May 3, 2016 at 9:58 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: >> As its committer, I tend to agree about reverting that feature. Craig >> was just posting some more patches, and I have the pg_recvlogical >> changes here (--endpos) which after some testing are not quite looking >> ready to go -- plus we still have to write the actual Perl test scripts >> that would use it. Taken together, this is now looking to me a bit >> rushed, so I prefer to cut my losses here and revert the patch so that >> we can revisit it for 9.7. > > I think it's a positive development that we can take this attitude to > reverting patches. It should not be seen as a big personal failure, > because it isn't. Stigmatizing reverts incentivizes behavior that > leads to bad outcomes. > Absolutely +1 -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 05/03/2016 07:41 PM, Andres Freund wrote: > On 2016-05-03 11:46:23 -0500, Kevin Grittner wrote: >>> was immediately addressed by another round of benchmarks after you >>> pointed it out. >> >> Which showed a 4% maximum hit before moving the test for whether it >> was "off" inline. > >> (I'm not clear from the posted results whether that was before or >> after skipping the spinlock when the feature was off.) > > They're from after the spinlock issue was resolved. Before that the > issue was a lot worse (see mail linked two messages upthread). > > > I'm pretty sure that I said that somewhere else at least once: But to > be absolutely clear, I'm *not* really concerned with the performance > with the feature turned off. I'm concerned about the performance with > it turned on. If you tell me how to best test it, I do have a 4-socket server sitting idly in the corner (well, a corner reachable by SSH). I can get us some numbers, but I haven't been following the snapshot_too_old so I'll need some guidance on what to test. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, May 3, 2016 at 9:57 PM, Tomas Vondra
<tomas.vondra@2ndquadrant.com> wrote:
> If you tell me how to best test it, I do have a 4-socket server sitting idly
> in the corner (well, a corner reachable by SSH). I can get us some numbers,
> but I haven't been following the snapshot_too_old so I'll need some guidance
> on what to test.
I worry about two contention points with the current implementation.
The main one is the locking within MaintainOldSnapshotTimeMapping()
that gets called every time a snapshot is taken. AFAICS this should
show up by setting old_snapshot_threshold to any positive value and
then running a simple within shared buffers scale factor read only
pgbench at high concurrency (number of CPUs or a small multiple). On a
single socket system this does not show up.
The second one is probably a bit harder to hit,
GetOldSnapshotThresholdTimestamp() has a spinlock that gets hit
everytime a scan sees a page that has been modified after the snapshot
was taken. A workload that would tickle this is something that uses a
repeatable read snapshot, builds a non-temporary table and runs
reporting on it. Something like this would work:
BEGIN ISOLATION LEVEL REPEATABLE READ;
DROP TABLE IF EXISTS test_:client_id;
CREATE TABLE test_:client_id (x int, filler text);
INSERT INTO test_:client_id SELECT x, repeat(' ', 1000) AS filler
FROM generate_series(1,1000) x;
SELECT (SELECT COUNT(*) FROM test_:client_id WHERE x != y) FROM
generate_series(1,1000) y;
COMMIT;
With this script running with -c4 on a 4 core workstation I'm seeing
the following kind of contention and a >2x loss in throughput:
+ 14.77% postgres postgres [.] GetOldSnapshotThresholdTimestamp
- 8.01% postgres postgres [.] s_lock - s_lock + 88.15% GetOldSnapshotThresholdTimestamp +
10.47%TransactionIdLimitedForOldSnapshots + 0.71% TestForOldSnapshot_impl + 0.57% GetSnapshotCurrentTimestamp
Now this is kind of an extreme example, but I'm willing to bet that on
multi socket hosts similar issues can crop up with common real world
use cases.
Regards,
Ants Aasma
On 2016-05-04 00:01:20 +0300, Ants Aasma wrote: > On Tue, May 3, 2016 at 9:57 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: > > If you tell me how to best test it, I do have a 4-socket server sitting idly > > in the corner (well, a corner reachable by SSH). I can get us some numbers, > > but I haven't been following the snapshot_too_old so I'll need some guidance > > on what to test. > > I worry about two contention points with the current implementation. > > The main one is the locking within MaintainOldSnapshotTimeMapping() > that gets called every time a snapshot is taken. AFAICS this should > show up by setting old_snapshot_threshold to any positive value and > then running a simple within shared buffers scale factor read only > pgbench at high concurrency (number of CPUs or a small multiple). On a > single socket system this does not show up. On a two socket system it does, check the bottom of: http://archives.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq%40alap3.anarazel.de Note that this (accidentally) compares thresholds 0 and 10 (instead of -1 and 10), but that's actually interesting for this question because of the quick exit in MaintainOldSnapshotData:/* No further tracking needed for 0 (used for testing). */if (old_snapshot_threshold== 0) return; which happens before the lwlock is taken. > The second one is probably a bit harder to hit, > GetOldSnapshotThresholdTimestamp() has a spinlock that gets hit > everytime a scan sees a page that has been modified after the snapshot > was taken. A workload that would tickle this is something that uses a > repeatable read snapshot, builds a non-temporary table and runs > reporting on it. I'm not particularly concerned about that kind of issue - we can quite easily replace that spinlock with 64bit atomic reads/writes for which I've already proposed a patch. I'd expect that to go into 9.7. Greetings, Andres Freund
On 2016-05-03 20:57:13 +0200, Tomas Vondra wrote: > On 05/03/2016 07:41 PM, Andres Freund wrote: > >On 2016-05-03 11:46:23 -0500, Kevin Grittner wrote: > >>>was immediately addressed by another round of benchmarks after you > >>>pointed it out. > >> > >>Which showed a 4% maximum hit before moving the test for whether it > >>was "off" inline. > > > >>(I'm not clear from the posted results whether that was before or > >>after skipping the spinlock when the feature was off.) > > > >They're from after the spinlock issue was resolved. Before that the > >issue was a lot worse (see mail linked two messages upthread). > > > > > >I'm pretty sure that I said that somewhere else at least once: But to > >be absolutely clear, I'm *not* really concerned with the performance > >with the feature turned off. I'm concerned about the performance with > >it turned on. > > If you tell me how to best test it, I do have a 4-socket server sitting idly > in the corner (well, a corner reachable by SSH). I can get us some numbers, > but I haven't been following the snapshot_too_old so I'll need some guidance > on what to test. I think it'd be cool if you could test the effect of the feature in read-only (and additionally read-mostly?) workload with various client counts and snapshot_too_old values. For the latter maybe -1, 0, 10, 60 or such? I've done so (accidentally comparing 0 and 1 instead of -1 and 1) on a two socket machine in: www.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq@alap3.anarazel.de It'd be very interesting to see how big the penalty is on a bigger box.
On 4 May 2016 at 01:12, Peter Geoghegan <pg@heroku.com> wrote:
On Tue, May 3, 2016 at 9:58 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
> As its committer, I tend to agree about reverting that feature. Craig
> was just posting some more patches, and I have the pg_recvlogical
> changes here (--endpos) which after some testing are not quite looking
> ready to go -- plus we still have to write the actual Perl test scripts
> that would use it. Taken together, this is now looking to me a bit
> rushed, so I prefer to cut my losses here and revert the patch so that
> we can revisit it for 9.7.
I think it's a positive development that we can take this attitude to
reverting patches. It should not be seen as a big personal failure,
because it isn't. Stigmatizing reverts incentivizes behavior that
leads to bad outcomes.
Indeed. Being scared to revert also makes the barrier to committing something and getting it into more hands, for longer, under a variety of different conditions higher. Not a ton of help with this particular feature but quite important with others.
While I'm personally disappointed by this outcome, I also can't really disagree with it. The whole area is a bit of a mess and hard to work on, and as demonstrated my understanding of it when I wrote the original patch was incomplete. We could commit the rewritten function, but ... rewriting a feature just before beta1 probably says it's just not baked yet, right?
The upside of all this is that now I have a decent picture of how it should all look and how timeline following, failover capability etc can be introduced in a staged way. I'd also like to get rid of the use of various globals to pass timeline information "around" the walsender and share more of the logic between the code paths.
On Tue, May 3, 2016 at 9:28 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Tue, May 3, 2016 at 11:36 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> There are a lot more than 2 patchsets that are busted at the moment,
> >> unfortunately, but I assume you are referring to "snapshot too old"
> >> and "Use Foreign Key relationships to infer multi-column join
> >> selectivity".
> >
> > Yeah, those are the ones I'm thinking of. I've not heard serious
> > proposals to revert any others, have you?
>
> Here's a list of what I think is currently broken in 9.6 that we might
> conceivably fix by reverting patches:
>
Yes, that would be a way forward for 9.6 if we are not able to close blocking open items before beta1. However, I think it would be bad if we miss some of the below listed important features like snapshot_too_old or atomic pin/unpin for 9.6. Can we consider to postpone beta1, so that the patch authors get time to resolve blocking issues? I think there could be a strong argument that it is just a waste of time if the situation doesn't improve much even after delay, but it seems we can rely on people involved in those patch sets to make a progress.
>
> On Tue, May 3, 2016 at 11:36 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> There are a lot more than 2 patchsets that are busted at the moment,
> >> unfortunately, but I assume you are referring to "snapshot too old"
> >> and "Use Foreign Key relationships to infer multi-column join
> >> selectivity".
> >
> > Yeah, those are the ones I'm thinking of. I've not heard serious
> > proposals to revert any others, have you?
>
> Here's a list of what I think is currently broken in 9.6 that we might
> conceivably fix by reverting patches:
>
Yes, that would be a way forward for 9.6 if we are not able to close blocking open items before beta1. However, I think it would be bad if we miss some of the below listed important features like snapshot_too_old or atomic pin/unpin for 9.6. Can we consider to postpone beta1, so that the patch authors get time to resolve blocking issues? I think there could be a strong argument that it is just a waste of time if the situation doesn't improve much even after delay, but it seems we can rely on people involved in those patch sets to make a progress.
Amit Kapila <amit.kapila16@gmail.com> writes:
> Yes, that would be a way forward for 9.6 if we are not able to close
> blocking open items before beta1. However, I think it would be bad if we
> miss some of the below listed important features like snapshot_too_old or
> atomic pin/unpin for 9.6. Can we consider to postpone beta1, so that the
> patch authors get time to resolve blocking issues?
This was already considered and rejected by the release team. Most of
the patches in question went in very close to the feature freeze deadline
(all but one, in fact, in the last week) and there is every reason to
suspect that they were rushed rather than really being ready to commit.
We should not allow an entire year's worth of work to slide in the
possibly-vain hope that these few patches can get fixed up if they're
given more time.
The bigger picture here is that we'd all like to get back to development
sooner rather than later. The longer it takes to stabilize 9.6, the
longer it will be before the tree reopens for new development. That
consideration should make us very willing to revert problematic changes
and let their authors try again in the next cycle.
regards, tom lane
On 03-05-2016 20:25, Craig Ringer wrote: > On 4 May 2016 at 01:12, Peter Geoghegan <pg@heroku.com > <mailto:pg@heroku.com>> wrote: > > On Tue, May 3, 2016 at 9:58 AM, Alvaro Herrera > <alvherre@2ndquadrant.com <mailto:alvherre@2ndquadrant.com>> wrote: > > As its committer, I tend to agree about reverting that feature. Craig > > was just posting some more patches, and I have the pg_recvlogical > > changes here (--endpos) which after some testing are not quite looking > > ready to go -- plus we still have to write the actual Perl test scripts > > that would use it. Taken together, this is now looking to me a bit > > rushed, so I prefer to cut my losses here and revert the patch so that > > we can revisit it for 9.7. > > I think it's a positive development that we can take this attitude to > reverting patches. It should not be seen as a big personal failure, > because it isn't. Stigmatizing reverts incentivizes behavior that > leads to bad outcomes. > > > Indeed. Being scared to revert also makes the barrier to committing > something and getting it into more hands, for longer, under a variety of > different conditions higher. Not a ton of help with this particular > feature but quite important with others. > > While I'm personally disappointed by this outcome, I also can't really > disagree with it. The whole area is a bit of a mess and hard to work on, > and as demonstrated my understanding of it when I wrote the original > patch was incomplete. We could commit the rewritten function, but ... > rewriting a feature just before beta1 probably says it's just not baked > yet, right? > You said that in another thread... > The upside of all this is that now I have a decent picture of how it > should all look and how timeline following, failover capability etc can > be introduced in a staged way. I'd also like to get rid of the use of > various globals to pass timeline information "around" the walsender and > share more of the logic between the code paths. > Question is: is the actual code so useless that it can't even be a 1.0 release? A lot of (complex) features were introduced with the notion that will be improved in the next version. However, if the code is buggy or there are serious API problems, revert them. -- Euler Taveira Timbira - http://www.timbira.com.br/ PostgreSQL: Consultoria, Desenvolvimento, Suporte24x7 e Treinamento
On 4 May 2016 at 13:03, Euler Taveira <euler@timbira.com.br> wrote:
Question is: is the actual code so useless that it can't even be a 1.0
release?
What's committed suffers from a design problem and cannot work correctly, nor can it be fixed without an API change and significant revision. The revised version I posted yesterday is that fix, but it's new code just before beta1. It's pretty much equivalent to reverting the original patch and then adding a new, corrected implementation. If considered as a new feature it'd never be accepted at this stage of the release.
A lot of (complex) features were introduced with the notion
that will be improved in the next version.
Absolutely, and this is what Petr and I (and Andres, though less actively lately) have both been trying to do in terms of building on logical decoding to add logical replication support. This is one small piece of that work.
It's a pity since I'll have to maintain a patchset for 9.6 for people who need physical HA support for their logical decoding and replication clients. But it doesn't change the WAL format or catalogs, so it's pretty painless to swap into existing installations. It could be worse.
However, if the code is buggy
or there are serious API problems, revert them.
Exactly. That's the case here.
Craig Ringer wrote: > On 4 May 2016 at 13:03, Euler Taveira <euler@timbira.com.br> wrote: > > > Question is: is the actual code so useless that it can't even be a 1.0 > > release? > > What's committed suffers from a design problem and cannot work correctly, > nor can it be fixed without an API change and significant revision. The > revised version I posted yesterday is that fix, but it's new code just > before beta1. It's pretty much equivalent to reverting the original patch > and then adding a new, corrected implementation. If considered as a new > feature it'd never be accepted at this stage of the release. To make it worse, we don't have test code for a portion of the new functionality: it turned out that the test module only tests half of it. And in order to test the other half, we have a pending patch for some pg_recvlogical changes, but we still don't have the actual test script. So we would need to 1. commit the pg_recvlogical patch, assuming it's OK now. 2. write the test script to use that 3. commit the fix patch written a few days ago (which is still unreviewed). We could also commit the fix without the test, but that doesn't seem a great idea. As Craig, I am not happy with this outcome. But realistically I think it's the best decision at this point. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Andres Freund wrote: > On 2016-05-04 00:01:20 +0300, Ants Aasma wrote: > > On Tue, May 3, 2016 at 9:57 PM, Tomas Vondra > > <tomas.vondra@2ndquadrant.com> wrote: > > > If you tell me how to best test it, I do have a 4-socket server sitting idly > > > in the corner (well, a corner reachable by SSH). I can get us some numbers, > > > but I haven't been following the snapshot_too_old so I'll need some guidance > > > on what to test. > > > > I worry about two contention points with the current implementation. > > > > The main one is the locking within MaintainOldSnapshotTimeMapping() > > that gets called every time a snapshot is taken. AFAICS this should > > show up by setting old_snapshot_threshold to any positive value and > > then running a simple within shared buffers scale factor read only > > pgbench at high concurrency (number of CPUs or a small multiple). On a > > single socket system this does not show up. > > On a two socket system it does, check the bottom of: > http://archives.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq%40alap3.anarazel.de > Note that this (accidentally) compares thresholds 0 and 10 (instead of > -1 and 10), In other words, we expect that when the feature is disabled, no performance degradation occurs, because that function is not called at all. Honestly, I don't see any strong ground in which to base a revert threat for this feature. It doesn't scale as well as we would like in the case where a high-level is fully stressed with a read-only load -- okay. But that's unlikely to be a case where this feature is put to work. So I think accepting the promise that this feature would be improved in a future release to better support that case is good enough. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2016-05-04 13:35:02 -0300, Alvaro Herrera wrote: > Honestly, I don't see any strong ground in which to base a revert threat > for this feature. It's datastructures are badly designed. But releasing it there's no pressure to fix that. If this were an intrinsic cost - ok. But it's not. > It doesn't scale as well as we would like in the case > where a high-level is fully stressed with a read-only load -- okay. But > that's unlikely to be a case where this feature is put to work. It'll be just the same in a read mostly workload, which is part of the case for this feature. > So I think accepting the promise that this feature would be improved > in a future release to better support that case is good enough. I've not heard any such promise. Greetings, Andres Freund
On Wed, May 4, 2016 at 12:42 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-05-04 13:35:02 -0300, Alvaro Herrera wrote: >> Honestly, I don't see any strong ground in which to base a revert threat >> for this feature. > > It's datastructures are badly designed. But releasing it there's no > pressure to fix that. If this were an intrinsic cost - ok. But it's > not. I don't want to rule out the possibility that you are right, because you're frequently right about lots of things. However, you haven't provided much detail. AFAIK, the closest you've come to articulating a case for reverting this patch is to say that the tax ought to be paid by the write-side, rather than the read-side. I don't know exactly what that means, though. Snapshots are not stored in shared memory; writers can't iterate through all snapshots and whack the ones that are problematic - and even if they could, they can't know what tuples will be read in the future, which determines whether or not there is an actual problem. We could dispense with a lot of this machinery if we simply killed off transactions or sessions that stuck around too long, but the whole point of this feature is to avoid having to do that when it isn't really necessary. Surely nobody here is blind to the fact that holding back xmin often creates a lot of bloat for no reason - many or all of the retained old row versions may never be accessed. So I would like to hear more detail about why you think that the data structures are badly designed, and how they could be designed differently without changing what the patch does (which amounts to wishing that Kevin had implemented a different feature than the one you think he should have implemented). >> It doesn't scale as well as we would like in the case >> where a high-level is fully stressed with a read-only load -- okay. But >> that's unlikely to be a case where this feature is put to work. > > It'll be just the same in a read mostly workload, which is part of the > case for this feature. So what? SSI doesn't scale either, and nobody's saying we have to rip it out. It's still useful to people. pgbench is not the world. >> So I think accepting the promise that this feature would be improved >> in a future release to better support that case is good enough. > > I've not heard any such promise. The question Alvaro is raising isn't whether such a promise has been made but whether it would suffice. In fairness, such promises are not enforceable. Kevin can promise to work on this and then be run over by a rogue Mr. Softee truck tomorrow, and the work won't get done; or he can go to work for some non-PostgreSQL-supporting company and vanish. I hope neither of those things happens, but if we accept a promise to improve it, it's going to be contingent on certain things happening or not happening which are beyond the ability of the PostgreSQL community to effect or forestall. (FWIW, I believe I can safely say that EnterpriseDB will support his continued work on this feature for as long as the community has concerns about it and Kevin works for EnterpriseDB.) But personally, I generally agree with Alvaro's analysis. If this patch is slow when turned on, and you don't like that, don't use it. If you need to use it and want it to scale better, then you can write a patch to make it do that. Nobody is more qualified than you. I think it's a show-stopper if the patch regresses performance more than trivially when turned off, but we need fresh test results before reaching a conclusion about that. I also think it's a show-stopper if you can hold out specific design issues which we can generally agree are signs of serious flaws in Kevin's thinking. I do not think it's a show-stopper if you wish he'd worked harder on the performance under heavy concurrency with very short transactions. You could have raised that issue at any time, but instead waited until after feature freeze. If somebody had even hinted that such a problem might exist, Kevin probably would have fixed it before commit, but nobody did. As soon as it was raised, Kevin started working on it. That's about all you can ask, I think. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, May 4, 2016 at 1:25 PM, Robert Haas <robertmhaas@gmail.com> wrote: > If somebody had even hinted that such a problem might exist, Kevin > probably would have fixed it before commit, but nobody did. As soon > as it was raised, Kevin started working on it. That's about all you > can ask, I think. Right; I have not been ignoring the issue -- but I prioritized it below fixing correctness issues and performance issues when the feature is off. Since there are no known issues in either of those areas remaining once I push the patch I posted earlier today, I'm taking a close look at the three proposals from three different people about ways to address it (along with any other ideas that come to mind while working through those). Fortunately, the access problems to the EDB big NUMA machines have now been solved (by tweaking firewall settings), so I should have some sort of meaningful benchmarks of those three alternatives and anything else the comes to mind within a few days. (Until now I have been asking others to do some runs, which doesn't gather the data nearly as quickly as actually having access.) Amit's proof-of-concept patch is very small and safe and yielded a 3x to 4x performance improvement with the old_snapshot_threshold = 1 on a big NUMA machine with concurrency in the 32 to 64 client range. I don't know whether we can do better before beta1, but it is something. I'll be happy to try any other suggestions. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2016-05-04 14:25:14 -0400, Robert Haas wrote: > On Wed, May 4, 2016 at 12:42 PM, Andres Freund <andres@anarazel.de> wrote: > > On 2016-05-04 13:35:02 -0300, Alvaro Herrera wrote: > >> Honestly, I don't see any strong ground in which to base a revert threat > >> for this feature. > > > > It's datastructures are badly designed. But releasing it there's no > > pressure to fix that. If this were an intrinsic cost - ok. But it's > > not. > > I don't want to rule out the possibility that you are right, because > you're frequently right about lots of things. However, you haven't > provided much detail. AFAIK, the closest you've come to articulating > a case for reverting this patch is to say that the tax ought to be > paid by the write-side, rather than the read-side. I think I did go into some more detail than that, but let me explain here: My concern isn't performing checks at snapshot build time and at buffer access time. That seems fairly reasonable. My concern is that the time->xid mapping used to determine the xid horizon is built at snapshot access time. The relevant function for that is MaintainOldSnapshotTimeMapping() called by GetSnapshotData(), if you want to look at it. Building the mapping when building the snapshot requires that an exclusive lwlock is taken. Given that there's very few access patterns in which more xids are assigned than snapshots taken, that just doesn't make much sense; even leaving the fact that adding an exclusive lock in a function that's already one of the biggest bottlenecks in postgres, isn't a good idea. If we instead built the map somewhere around GetNewTransactionId() we'd only pay the cost when advancing an xid. It'd also make it possible to avoid another GetCurrentIntegerTimestamp() per snapshot, including the acquiration of oldSnapshotControl->mutex_current. In addition the data structure would be easier to maintain, because xids grow monotonically (yes, yes wraparound, but that's not a problem) - atm we need somwehat more complex logic to determine into which bucket an xid/timestamp pair has to be mapped to. So I'm really not just concerned with the performance, I think that's just fallout from choosing the wrong data representation. If you look at at bottom of http://www.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq@alap3.anarazel.de which shows performance numbers for old_snapshot_threshold=0 vs. old_snapshot_threshold=10. While that wasn't intended at the time, old_snapshot_threshold=0 shows the cost of the feature without maintaining the mapping, and old_snapshot_threshold=10 shows it while building the mapping. Pretty dramatic difference - that's really the cost of map maintenance. FWIW, it's not just me doubting the data structure here, Ants did as well. > Surely nobody here is blind to the fact that holding back xmin often > creates a lot of bloat for no reason - many or all of the retained old > row versions may never be accessed. Definitely. I *like* the feature. > So I would like to hear more detail about why you think that the data > structures are badly designed, and how they could be designed > differently without changing what the patch does (which amounts to > wishing that Kevin had implemented a different feature than the one > you think he should have implemented). Well, there'd be some minor differences what determines "too old" based on the above, but I think it'd just be a bit easier to explain. > >> It doesn't scale as well as we would like in the case > >> where a high-level is fully stressed with a read-only load -- okay. But > >> that's unlikely to be a case where this feature is put to work. > > > > It'll be just the same in a read mostly workload, which is part of the > > case for this feature. > > So what? SSI doesn't scale either, and nobody's saying we have to rip > it out. It's still useful to people. pgbench is not the world. Sure, pgbench is not the world. But this isn't a particularly pgbench specific issue. > >> So I think accepting the promise that this feature would be improved > >> in a future release to better support that case is good enough. > > > > I've not heard any such promise. > > The question Alvaro is raising isn't whether such a promise has been > made but whether it would suffice. In fairness, such promises are not > enforceable. Kevin can promise to work on this and then be run over > by a rogue Mr. Softee truck tomorrow, and the work won't get done; or > he can go to work for some non-PostgreSQL-supporting company and > vanish. Sure, it's not a guarantee. But I think a "promise" (signed in blood of course) of a senior contributor makes quite the difference. > But personally, I generally agree with Alvaro's analysis. If this > patch is slow when turned on, and you don't like that, don't use it. > If you need to use it and want it to scale better, then you can write > a patch to make it do that. Nobody is more qualified than you. I think that's what ticks me off about this. By introducing a feature implemented with the wrong structure, the onus of work is placed on others. It's imo perfectly reasonable not to unneccesarily perform micro-optimization before benchmarks show a problem, and if it were just a question of doing that in 9.7, I'd be fine. But what we're talking about is rewriting the central part of the feature. > I think it's a show-stopper if the patch regresses performance more > than trivially when turned off, but we need fresh test results before > reaching a conclusion about that. I'm not concerned about that at this stage. Kevin addressed those problems as far as I'm aware. > I also think it's a show-stopper if you can hold out specific design > issues which we can generally agree are signs of serious flaws in > Kevin's thinking. I think that's my issue. > I do not think it's a show-stopper if you wish he'd worked harder on > the performance under heavy concurrency with very short transactions. > You could have raised that issue at any time, but instead waited until > after feature freeze. Sorry, I don't buy that argument. There were senior community people giving feedback on the patch, the potential for performance regressions wasn't called out, the patch was updated pretty late in the CF. I find it really scary that review didn't call out the potential for regressions here, at the very least the ones with the feature disabled really should have been caught. Putting exclusive lwlocks and spinlocks in critical paths isn't a subtle, easy to miss, issue. Andres
On Wed, May 4, 2016 at 3:42 PM, Andres Freund <andres@anarazel.de> wrote: > My concern isn't performing checks at snapshot build time and at buffer > access time. That seems fairly reasonable. My concern is that the > time->xid mapping used to determine the xid horizon is built at snapshot > access time. The relevant function for that is > MaintainOldSnapshotTimeMapping() called by GetSnapshotData(), if you > want to look at it. Building the mapping when building the snapshot > requires that an exclusive lwlock is taken. Given that there's very few > access patterns in which more xids are assigned than snapshots taken, > that just doesn't make much sense; even leaving the fact that adding an > exclusive lock in a function that's already one of the biggest > bottlenecks in postgres, isn't a good idea. It seems to me that you are confusing the structure with the point from which the function to call it is filled (and how often). Some of the proposals involve fairly small tweaks to call MaintainOldSnapshotTimeMapping() from elsewhere or only when something changes (like crossing a minute boundary or seeing that a new TransactionId has been assigned). If you can disentangle those ideas, it might not look so bad. > If we instead built the map somewhere around GetNewTransactionId() we'd > only pay the cost when advancing an xid. It'd also make it possible to > avoid another GetCurrentIntegerTimestamp() per snapshot, including the > acquiration of oldSnapshotControl->mutex_current. In addition the data > structure would be easier to maintain, because xids grow monotonically > (yes, yes wraparound, but that's not a problem) - atm we need somwehat > more complex logic to determine into which bucket an xid/timestamp pair > has to be mapped to. Right. > So I'm really not just concerned with the performance, I think that's > just fallout from choosing the wrong data representation. Wrong. It's a matter of when the calls are made to maintain the structure. > If you look at at bottom of > http://www.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq@alap3.anarazel.de > which shows performance numbers for old_snapshot_threshold=0 > vs. old_snapshot_threshold=10. While that wasn't intended at the time, > old_snapshot_threshold=0 shows the cost of the feature without > maintaining the mapping, and old_snapshot_threshold=10 shows it while > building the mapping. Pretty dramatic difference - that's really the > cost of map maintenance. Right. > FWIW, it's not just me doubting the data structure here, Ants did as > well. It is true that the patch he posted added one more field to a struct. >> Surely nobody here is blind to the fact that holding back xmin often >> creates a lot of bloat for no reason - many or all of the retained old >> row versions may never be accessed. > > Definitely. I *like* the feature. And I think we have agreed in off-list discussions that even with these NUMA issues the patch, as it stands, would help some -- the poor choice of a call site for MaintainOldSnapshotTimeMapping() just unnecessarily limits how many workloads can benefit. Hopefully you can understand the reasons I chose to focus on the performance issues when it is disabled, and the hash index issue before moving on to this. >>>> So I think accepting the promise that this feature would be improved >>>> in a future release to better support that case is good enough. >>> >>> I've not heard any such promise. >> >> The question Alvaro is raising isn't whether such a promise has been >> made but whether it would suffice. In fairness, such promises are not >> enforceable. Kevin can promise to work on this and then be run over >> by a rogue Mr. Softee truck tomorrow, and the work won't get done; or >> he can go to work for some non-PostgreSQL-supporting company and >> vanish. > > Sure, it's not a guarantee. But I think a "promise" (signed in blood of > course) of a senior contributor makes quite the difference. How about we see where we are as we get closer to a go/no go point and see where performance has settled and what kind of promise would satisfy you. I'm uncomfortable with the demand for a rather non-specific promise, and find myself flashing back to some sections of the Catch 22 novel. >> But personally, I generally agree with Alvaro's analysis. If this >> patch is slow when turned on, and you don't like that, don't use it. > >> If you need to use it and want it to scale better, then you can write >> a patch to make it do that. Nobody is more qualified than you. > > I think that's what ticks me off about this. By introducing a feature > implemented with the wrong structure, the onus of work is placed on > others. It's imo perfectly reasonable not to unneccesarily perform > micro-optimization before benchmarks show a problem, and if it were just > a question of doing that in 9.7, I'd be fine. But what we're talking > about is rewriting the central part of the feature. If you see a need for more than adding a very small number of fields to any struct or function, please elaborate; if anyone else has proposed a solution that requires that, I've missed it. >> I also think it's a show-stopper if you can hold out specific design >> issues which we can generally agree are signs of serious flaws in >> Kevin's thinking. > > I think that's my issue. Amit's proof of concept patch reduced the problem by a factor of 3x to 4x with a local "if", without any structure changes, and Ants' proposal looks like it will reduce the locks to once per minute (potentially making them pretty hard to measure) by adding one field to one struct -- so I'm really having trouble understanding what you're getting at. Clarification welcome. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, May 4, 2016 at 1:42 PM, Andres Freund <andres@anarazel.de> wrote: >> Surely nobody here is blind to the fact that holding back xmin often >> creates a lot of bloat for no reason - many or all of the retained old >> row versions may never be accessed. > > Definitely. I *like* the feature. +1. >> I do not think it's a show-stopper if you wish he'd worked harder on >> the performance under heavy concurrency with very short transactions. >> You could have raised that issue at any time, but instead waited until >> after feature freeze. > > Sorry, I don't buy that argument. There were senior community people > giving feedback on the patch, the potential for performance regressions > wasn't called out, the patch was updated pretty late in the CF. I find > it really scary that review didn't call out the potential for > regressions here, at the very least the ones with the feature disabled > really should have been caught. Putting exclusive lwlocks and spinlocks > in critical paths isn't a subtle, easy to miss, issue. As one of the people that looked at the patch before it went in, perhaps I can shed some light. I focused exclusively on the correctness of the core mechanism. It simply didn't occur to me to check for problems of the type you describe, that affect the system even when the feature is disabled. I didn't check because Kevin is a committer, that I assumed wouldn't have made such an error. Also, time was limited. -- Peter Geoghegan
Hi, On 2016-05-04 16:22:41 -0500, Kevin Grittner wrote: > On Wed, May 4, 2016 at 3:42 PM, Andres Freund <andres@anarazel.de> wrote: > > > My concern isn't performing checks at snapshot build time and at buffer > > access time. That seems fairly reasonable. My concern is that the > > time->xid mapping used to determine the xid horizon is built at snapshot > > access time. The relevant function for that is > > MaintainOldSnapshotTimeMapping() called by GetSnapshotData(), if you > > want to look at it. Building the mapping when building the snapshot > > requires that an exclusive lwlock is taken. Given that there's very few > > access patterns in which more xids are assigned than snapshots taken, > > that just doesn't make much sense; even leaving the fact that adding an > > exclusive lock in a function that's already one of the biggest > > bottlenecks in postgres, isn't a good idea. > > It seems to me that you are confusing the structure with the point > from which the function to call it is filled (and how often). Well, you say tomato I say tomato. Sure we'd still use some form of mapping, but filling it from somewhere else, with somewhat different contents (xact timestamp presumably), with a somewhat different replacement policy wouldn't leave all that much of the current structure in place. But ok, let's then call it a question of where from and how the mapping is maintained. > Some of the proposals involve fairly small tweaks to call > MaintainOldSnapshotTimeMapping() from elsewhere or only when > something changes (like crossing a minute boundary or seeing that a > new TransactionId has been assigned). If you can disentangle those > ideas, it might not look so bad. Yea, if we can do that, I'm ok. I'm doubtful about releasing with the current state, even leaving performance aside, since fixing this will result in somewhat changed semantics, and I'm doubtful about significant development at this point of the release process. If it comes down to either one of those I'm clearly in favor of the latter. > >> Surely nobody here is blind to the fact that holding back xmin often > >> creates a lot of bloat for no reason - many or all of the retained old > >> row versions may never be accessed. > > > > Definitely. I *like* the feature. > > And I think we have agreed in off-list discussions that even with > these NUMA issues the patch, as it stands, would help some -- the > poor choice of a call site for MaintainOldSnapshotTimeMapping() > just unnecessarily limits how many workloads can benefit. Yes, totally. > Hopefully you can understand the reasons I chose to focus on the > performance issues when it is disabled, and the hash index issue > before moving on to this. Well, somewhat. For me addressing architectural issues (and where to fill the mapping from is that, independent of whether you call it a data structure issue) is pretty important too, because I personally don't believe we can release or even go to beta before that. But I'd not be all that bothered to release beta1 with a hash index issue that we know how to address. > > Sure, it's not a guarantee. But I think a "promise" (signed in blood of > > course) of a senior contributor makes quite the difference. > > How about we see where we are as we get closer to a go/no go point > and see where performance has settled and what kind of promise > would satisfy you. Hm. We're pretty close to a go/no go point, namely beta1. I don't want to be in the situation that we don't fix the issue before release, just because beta has passed. > I'm uncomfortable with the demand for a rather > non-specific promise, and find myself flashing back to some > sections of the Catch 22 novel. Gotta read that one day (ordered). Greetings, Andres Freund
On Wed, May 4, 2016 at 6:06 PM, Andres Freund <andres@anarazel.de> wrote: >> Some of the proposals involve fairly small tweaks to call >> MaintainOldSnapshotTimeMapping() from elsewhere or only when >> something changes (like crossing a minute boundary or seeing that a >> new TransactionId has been assigned). If you can disentangle those >> ideas, it might not look so bad. > > Yea, if we can do that, I'm ok. I'm doubtful about releasing with the > current state, even leaving performance aside, since fixing this will > result in somewhat changed semantics, and I'm doubtful about significant > development at this point of the release process. If it comes down to > either one of those I'm clearly in favor of the latter. How would the semantics change? > Hm. We're pretty close to a go/no go point, namely beta1. I don't want > to be in the situation that we don't fix the issue before release, just > because beta has passed. So, I was worried about this, too. But I think there is an overwhelming consensus on pgsql-release that getting a beta out early trumps all, and that if that results in somewhat more post-beta1 change than we've traditionally had, so be it. And I think that's pretty fair. We need to be really careful, as we get closer to release, about what impact the changes we make might have even on people not using the features in question, because otherwise we might invalidate the results of testing already performed. We also need to be careful about whether late changes are going to be stable, because instability at a late date will postpone the release. But I don't believe that rules out all meaningful change. I think we can decide to revert this feature, or rework it somewhat, after beta1, and that's OK. Similarly with the other commits that currently have multiple outstanding bugs. If they continue to breed bugs, we can shoot them later. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-05-04 18:22:27 -0400, Robert Haas wrote: > On Wed, May 4, 2016 at 6:06 PM, Andres Freund <andres@anarazel.de> wrote: > >> Some of the proposals involve fairly small tweaks to call > >> MaintainOldSnapshotTimeMapping() from elsewhere or only when > >> something changes (like crossing a minute boundary or seeing that a > >> new TransactionId has been assigned). If you can disentangle those > >> ideas, it might not look so bad. > > > > Yea, if we can do that, I'm ok. I'm doubtful about releasing with the > > current state, even leaving performance aside, since fixing this will > > result in somewhat changed semantics, and I'm doubtful about significant > > development at this point of the release process. If it comes down to > > either one of those I'm clearly in favor of the latter. > > How would the semantics change? Right now the time for computing the snapshot is relevant, if maintenance of xids is moved, it'll likely be tied to the time xids are assigned. That seems perfectly alright, but it'll change behaviour. > So, I was worried about this, too. But I think there is an > overwhelming consensus on pgsql-release that getting a beta out early > trumps all, and that if that results in somewhat more post-beta1 > change than we've traditionally had, so be it. *If* that's the policy - cool! I just don't want to see the issue not being fixed due to only wanting conservative changes. And the discussion around fixing spinlock related issues in the patch certainly made me think the RMT aimed to be conservative. Greetings, Andres Freund
On Wed, May 4, 2016 at 6:28 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-05-04 18:22:27 -0400, Robert Haas wrote: >> On Wed, May 4, 2016 at 6:06 PM, Andres Freund <andres@anarazel.de> wrote: >> >> Some of the proposals involve fairly small tweaks to call >> >> MaintainOldSnapshotTimeMapping() from elsewhere or only when >> >> something changes (like crossing a minute boundary or seeing that a >> >> new TransactionId has been assigned). If you can disentangle those >> >> ideas, it might not look so bad. >> > >> > Yea, if we can do that, I'm ok. I'm doubtful about releasing with the >> > current state, even leaving performance aside, since fixing this will >> > result in somewhat changed semantics, and I'm doubtful about significant >> > development at this point of the release process. If it comes down to >> > either one of those I'm clearly in favor of the latter. >> >> How would the semantics change? > > Right now the time for computing the snapshot is relevant, if > maintenance of xids is moved, it'll likely be tied to the time xids are > assigned. That seems perfectly alright, but it'll change behaviour. Not following. >> So, I was worried about this, too. But I think there is an >> overwhelming consensus on pgsql-release that getting a beta out early >> trumps all, and that if that results in somewhat more post-beta1 >> change than we've traditionally had, so be it. > > *If* that's the policy - cool! I just don't want to see the issue > not being fixed due to only wanting conservative changes. And the > discussion around fixing spinlock related issues in the patch certainly > made me think the RMT aimed to be conservative. Understand that I am conveying what I understand the sentiment of the community to be, not guaranteeing any specific outcome. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
<p dir="ltr">On 5 May 2016 1:28 a.m., "Andres Freund" <<a href="mailto:andres@anarazel.de">andres@anarazel.de</a>>wrote:<br /> > On 2016-05-04 18:22:27 -0400, Robert Haas wrote:<br/> > > How would the semantics change?<br /> ><br /> > Right now the time for computing the snapshotis relevant, if<br /> > maintenance of xids is moved, it'll likely be tied to the time xids are<br /> > assigned.That seems perfectly alright, but it'll change behaviour.<p dir="ltr">FWIW moving the maintenance to a clock tickprocess will not change user visible semantics in any significant way. The change could easily be made in the next release.<p dir="ltr">Regards,<br /> Ants Aasma
On 2016-05-05 06:08:39 +0300, Ants Aasma wrote: > On 5 May 2016 1:28 a.m., "Andres Freund" <andres@anarazel.de> wrote: > > On 2016-05-04 18:22:27 -0400, Robert Haas wrote: > > > How would the semantics change? > > > > Right now the time for computing the snapshot is relevant, if > > maintenance of xids is moved, it'll likely be tied to the time xids are > > assigned. That seems perfectly alright, but it'll change behaviour. > > FWIW moving the maintenance to a clock tick process will not change user > visible semantics in any significant way. The change could easily be made > in the next release. I'm not convinced of that - right now the timeout is computed as a offset to the time a snapshot with a certain xmin horizon is taken. Moving the computation to GetNewTransactionId() or a clock tick process will make it relative to the time an xid has been generated (minus a fuzz factor). That'll behave differently in a number of cases, no?
On Thu, May 5, 2016 at 8:44 AM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2016-05-05 06:08:39 +0300, Ants Aasma wrote:
> > On 5 May 2016 1:28 a.m., "Andres Freund" <andres@anarazel.de> wrote:
> > > On 2016-05-04 18:22:27 -0400, Robert Haas wrote:
> > > > How would the semantics change?
> > >
> > > Right now the time for computing the snapshot is relevant, if
> > > maintenance of xids is moved, it'll likely be tied to the time xids are
> > > assigned. That seems perfectly alright, but it'll change behaviour.
> >
> > FWIW moving the maintenance to a clock tick process will not change user
> > visible semantics in any significant way. The change could easily be made
> > in the next release.
>
> I'm not convinced of that - right now the timeout is computed as a
> offset to the time a snapshot with a certain xmin horizon is
> taken.
>
> On 2016-05-05 06:08:39 +0300, Ants Aasma wrote:
> > On 5 May 2016 1:28 a.m., "Andres Freund" <andres@anarazel.de> wrote:
> > > On 2016-05-04 18:22:27 -0400, Robert Haas wrote:
> > > > How would the semantics change?
> > >
> > > Right now the time for computing the snapshot is relevant, if
> > > maintenance of xids is moved, it'll likely be tied to the time xids are
> > > assigned. That seems perfectly alright, but it'll change behaviour.
> >
> > FWIW moving the maintenance to a clock tick process will not change user
> > visible semantics in any significant way. The change could easily be made
> > in the next release.
>
> I'm not convinced of that - right now the timeout is computed as a
> offset to the time a snapshot with a certain xmin horizon is
> taken.
Here are you talking about snapshot time (snapshot->whenTaken) which is updated at the time of GetSnapshotData()?
<p dir="ltr">5. mai 2016 6:14 AM kirjutas kuupäeval "Andres Freund" <<a href="mailto:andres@anarazel.de">andres@anarazel.de</a>>:<br/> ><br /> > On 2016-05-05 06:08:39 +0300, Ants Aasmawrote:<br /> > > On 5 May 2016 1:28 a.m., "Andres Freund" <<a href="mailto:andres@anarazel.de">andres@anarazel.de</a>>wrote:<br /> > > > On 2016-05-04 18:22:27 -0400, RobertHaas wrote:<br /> > > > > How would the semantics change?<br /> > > ><br /> > > > Rightnow the time for computing the snapshot is relevant, if<br /> > > > maintenance of xids is moved, it'll likelybe tied to the time xids are<br /> > > > assigned. That seems perfectly alright, but it'll change behaviour.<br/> > ><br /> > > FWIW moving the maintenance to a clock tick process will not change user<br />> > visible semantics in any significant way. The change could easily be made<br /> > > in the next release.<br/> ><br /> > I'm not convinced of that - right now the timeout is computed as a<br /> > offset to thetime a snapshot with a certain xmin horizon is<br /> > taken. Moving the computation to GetNewTransactionId() or aclock tick<br /> > process will make it relative to the time an xid has been generated<br /> > (minus a fuzz factor). That'll behave differently in a number of cases, no?<p dir="ltr">Timeout is calculated in TransactionIdLimitedForOldSnapshots()as GetSnapshotCurrentTimestamp() minus old_snapshot_timeout rounded down to previousminute. If the highest seen xmin in that minute is useful in raising cleanup xmin the threshold is bumped. Snapshotsswitch behavior when their whenTaken is past this threshold. Xid generation time has no effect on this timing, it'scompletely based on passage of time.<p dir="ltr">The needed invariant is, that no snapshot having whenTaken after timeouttimestamp can have xmin less than calculated bound. Moving the xmin calculation and storage to clock tick actuallymakes the bound tighter. The ordering between xmin calculation and clok update/read needs to be correct to ensurethe invariant.<p dir="ltr">Regards,<br /> Ants Aasma <br />
On Thu, May 5, 2016 at 3:39 AM, Ants Aasma <ants.aasma@eesti.ee> wrote: > 5. mai 2016 6:14 AM kirjutas kuupäeval "Andres Freund" <andres@anarazel.de>: >> >> On 2016-05-05 06:08:39 +0300, Ants Aasma wrote: >>> On 5 May 2016 1:28 a.m., "Andres Freund" <andres@anarazel.de> wrote: >>>> On 2016-05-04 18:22:27 -0400, Robert Haas wrote: >>>>> How would the semantics change? >>>> >>>> Right now the time for computing the snapshot is relevant, if >>>> maintenance of xids is moved, it'll likely be tied to the time xids >>>> are assigned. That seems perfectly alright, but it'll change behaviour. Basically this feature allows pruning or vacuuming rows that would still be visible to some snapshots, and then throws an error if one of those snapshots is used for a scan that would generate incorrect results because of the early cleanup. There are already several places that we relax the timings in such a way that it allows better performance by not being as aggressive as theoretically possible in the cleanup. From my perspective, the performance problems on NUMA when the feature is in use just show that this approach wasn't taken far enough, and the solutions don't do anything that isn't conceptually happening anyway. Some rows that currently get cleaned up in vacuum N will get cleaned up in vacuum N+1 with the proposed changes, but I don't see that as a semantic change. In many of those cases we might be able to add some locking and clean up the rows in vacuumm N-1, but nobody wants that. >>> FWIW moving the maintenance to a clock tick process will not change user >>> visible semantics in any significant way. The change could easily be >>> made in the next release. >> >> I'm not convinced of that - right now the timeout is computed as a >> offset to the time a snapshot with a certain xmin horizon is >> taken. Moving the computation to GetNewTransactionId() or a clock tick >> process will make it relative to the time an xid has been generated >> (minus a fuzz factor). That'll behave differently in a number of cases, >> no? Not in what I would consider any meaningful way. This feature is not about trying to provoke the error, it is about preventing bloat while minimizing errors. I have gotten many emails off-list from people asking whether the feature was broken because they had a case which was running with correct results but not generating any errors, and it often came down to such things as cursor use which had materialized a result set -- correct results were returned from the materialized cursor results, so no error was needed. As long as bloat is limited to something near the old_snapshot_threshold and incorrect results are never returned the contract of this feature is maintained. It's reaching a little bit as a metaphore, but we don't say that the semantics of autovacuum are changed in any significant way based slight variations in the timing of vacuums. > Timeout is calculated in TransactionIdLimitedForOldSnapshots() as > GetSnapshotCurrentTimestamp() minus old_snapshot_timeout rounded down to > previous minute. If the highest seen xmin in that minute is useful in > raising cleanup xmin the threshold is bumped. Snapshots switch behavior when > their whenTaken is past this threshold. Xid generation time has no effect on > this timing, it's completely based on passage of time. > > The needed invariant is, that no snapshot having whenTaken after timeout > timestamp can have xmin less than calculated bound. Moving the xmin > calculation and storage to clock tick actually makes the bound tighter. The > ordering between xmin calculation and clok update/read needs to be correct > to ensure the invariant. Right. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 05/04/2016 12:42 AM, Andres Freund wrote: > On 2016-05-03 20:57:13 +0200, Tomas Vondra wrote: >> On 05/03/2016 07:41 PM, Andres Freund wrote: ... >>> I'm pretty sure that I said that somewhere else at least once: But to >>> be absolutely clear, I'm *not* really concerned with the performance >>> with the feature turned off. I'm concerned about the performance with >>> it turned on. >> >> If you tell me how to best test it, I do have a 4-socket server sitting idly >> in the corner (well, a corner reachable by SSH). I can get us some numbers, >> but I haven't been following the snapshot_too_old so I'll need some guidance >> on what to test. > > I think it'd be cool if you could test the effect of the feature in > read-only (and additionally read-mostly?) workload with various client > counts and snapshot_too_old values. For the latter maybe -1, 0, 10, 60 > or such? I've done so (accidentally comparing 0 and 1 instead of -1 and > 1) on a two socket machine in: > www.postgresql.org/message-id/20160413171955.i53me46fqqhdlztq@alap3.anarazel.de > > It'd be very interesting to see how big the penalty is on a bigger box. OK. I do have results from mater with different values for the GUC (-1, 0, 10, 60), but I'm struggling with the reverts. Can you provide a patch against current master (commit 4bbc1a7e) that does the revert? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
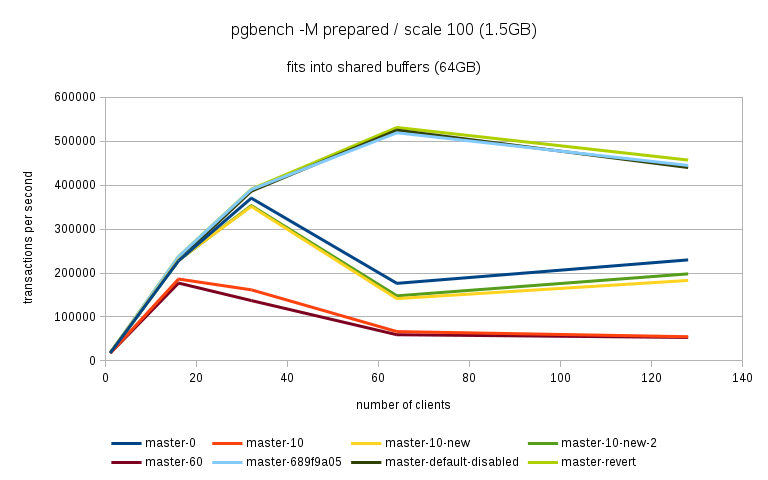
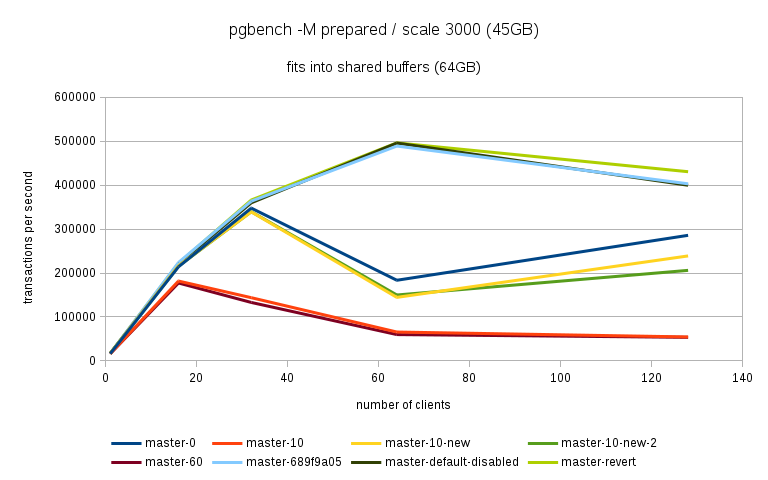
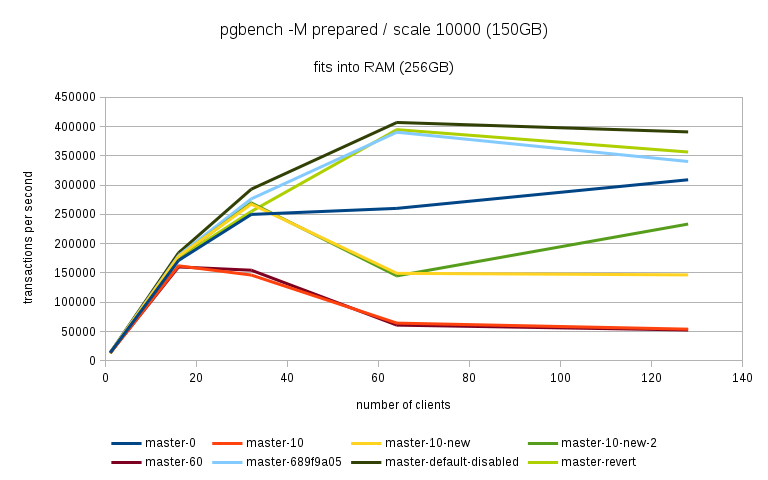
Hi, Over the past few days I've been running benchmarks on a fairly large NUMA box (4 sockets, 32 cores / 64 with HR, 256GB of RAM) to see the impact of the 'snapshot too old' - both when disabled and enabled with various values in the old_snapshot_threshold GUC. The full results are available here: https://drive.google.com/folderview?id=0BzigUP2Fn0XbR1dyOFA3dUxRaUU but let me explain how the benchmark was done and present a brief summary of the results as I understand them. The benchmark is a simple read-only pgbench with prepared statements, i.e. doing something like this: pgbench -S -M prepared -j N -c N This was done on three datasets with different scales - small (100), medium (3000) and large (10000). All of this fits into RAM, the two smaller data sets fit into shared_buffers. For each scale, the benchmark was run for 1, 16, 32, 64 and 128 clients, 5 runs for each client count, 5 minutes each. But only after a 2-hour warmup with 128 clients. So essentially something like this: for s in 100 3000 10000; do ... init + warmup for r in 1 2 3 4 5; do for c in 1 16 32 64 128; do pgbench -S -M prepared ... done done done The full results are available in the .tgz archive (as produced by run.sh included in it). The old_snap.csv contains just the extracted results, and there's also an ODS with some charts. The initial set of test was run on 4bbc1a7e which was the last commit in master when the benchmark was started. Then I've tested with 689f9a05 which is the last commit before the 'snapshot too old' got introduced, and 91fd1df4 which is the current master, including a commit that should improve performance in some cases. So in total there are data for these combinations master-0 - 4bbc1a7e + old_snapshot_threshold=0 master-10 - 4bbc1a7e + old_snapshot_threshold=10 master-10-new - 91fd1df4 + old_snapshot_threshold=10 master-10-new-2 - 91fd1df4 + old_snapshot_threshold=10 (rerun) master-60 - 4bbc1a7e + old_snapshot_threshold=60 master-689f9a05 - before the feature was added master-default-disabled - 4bbc1a7e + old_snapshot_threshold=-1 master-revert - 4bbc1a7e + revert.patch (reverts the feature) The results (average of the 5 runs) look like this (also see the charts attached to this post): scale=100 --------- dataset 1 16 32 64 128 master-0 18118 227615 370336 176435 229796 master-10 17741 186197 161655 66681 54977 master-10-new 18572 229685 351378 141624 183029 master-10-new-2 18366 228256 353420 148061 197953 master-60 17691 177053 137311 59508 53325 master-689f9a05 18630 237123 389782 519069 444732 master-disabled 17727 230818 386112 524981 440043 master-revert 18584 237383 390779 531075 457005 scale=3000 ---------- dataset 1 16 32 64 128 master-0 16480 214081 347689 183451 285729 master-10 16390 181683 143847 65614 54499 master-10-new 16821 216562 339106 144488 238851 master-10-new-2 17121 215423 339424 149910 206001 master-60 16372 177228 133013 59861 53599 master-689f9a05 16945 223894 363393 488892 402938 master-disabled 16635 220064 359686 495642 399728 master-revert 16963 221884 366086 496107 430518 scale=10000 ----------- dataset 1 16 32 64 128 master-0 13954 171378 249923 260291 309065 master-10 13513 162214 146458 64457 54159 master-10-new 13776 178255 267475 149335 146706 master-10-new-2 13188 176799 269629 145049 233515 master-60 14102 160247 154704 61015 52711 master-689f9a05 13896 179688 276487 390220 340206 master-disabled 13939 184222 293032 406846 390739 master-revert 12971 174562 254986 394569 356436 A few initial observations: * The results are a bit noisy, but I think in general this shows that for certain cases there's a clearly measurable difference (up to 5%) between the "disabled" and "reverted" cases. This is particularly visible on the smallest data set. * What's fairly strange is that on the largest dataset (scale 10000), the "disabled" case is actually consistently faster than "reverted" - that seems a bit suspicious, I think. It's possible that I did the revert wrong, though - the revert.patch is included in the tgz. This is why I also tested 689f9a05, but that's also slower than "disabled". * The performance impact with the feature enabled seems rather significant, especially once you exceed the number of physical cores (32 in this case). Then the drop is pretty clear - often ~50% or more. * 7e3da1c4 claims to bring the performance within 5% of the disabled case, but that seems not to be the case. What it however does is bringing the 'non-immediate' cases close to the immediate ones (before the performance drop came much sooner in these cases - at 16 clients). * It's also seems to me the feature greatly amplifies the variability of the results, somehow. It's not uncommon to see results like this: master-10-new-2 235516 331976 133316 155563 133396 where after the first runs (already fairly variable) the performance tanks to ~50%. This happens particularly with higher client counts, otherwise the max-min is within ~5% of the max. There are a few cases where this happens without the feature (i.e. old master, reverted or disabled), but it's usually much smaller than with it enabled (immediate, 10 or 60). See the 'summary' sheet in the ODS spreadsheet. I don't know what's the problem here - at first I thought that maybe something else was running on the machine, or that anti-wraparound autovacuum kicked in, but that seems not to be the case. There's nothing like that in the postgres log (also included in the .tgz). And the shell script interleaves runs for different client counts, so another process running on the system would affect the surrounding runs too (but that's not the case). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
{kind=link}
{kind=link}
{kind=link}
<div dir="ltr">On Mon, May 9, 2016 at 9:01 PM, Tomas Vondra <<a href="mailto:tomas.vondra@2ndquadrant.com">tomas.vondra@2ndquadrant.com</a>>wrote:<br /><br />> Over the past few daysI've been running benchmarks on a fairly<br />> large NUMA box (4 sockets, 32 cores / 64 with HR, 256GB of RAM)<br/>> to see the impact of the 'snapshot too old' - both when disabled<br />> and enabled with various valuesin the old_snapshot_threshold<br />> GUC.<br /><br />Thanks!<br /><br />> The benchmark is a simple read-onlypgbench with prepared<br />> statements, i.e. doing something like this:<br />><br />> pgbench -S -Mprepared -j N -c N<br /><br />Do you have any plans to benchmark cases where the patch can have a<br />benefit? (Clearly,nobody would be interested in using the feature<br />with a read-only load; so while that makes a good "worst case"<br/>scenario and is very valuable for testing the "off" versus<br />"reverted" comparison, it's not an intended useor one that's<br />likely to happen in production.)<br /><br />> master-10-new - 91fd1df4 + old_snapshot_threshold=10<br/>> master-10-new-2 - 91fd1df4 + old_snapshot_threshold=10 (rerun)<br /><br />So, these runswere with identical software on the same data? Any<br />differences are just noise?<br /><br />> * The results area bit noisy, but I think in general this shows<br />> that for certain cases there's a clearly measurable difference<br/>> (up to 5%) between the "disabled" and "reverted" cases. This is<br />> particularly visible on thesmallest data set.<br /><br />In some cases, the differences are in favor of disabled over<br />reverted.<br /><br />>* What's fairly strange is that on the largest dataset (scale<br />> 10000), the "disabled" case is actually consistentlyfaster than<br />> "reverted" - that seems a bit suspicious, I think. It's possible<br />> that I did therevert wrong, though - the revert.patch is<br />> included in the tgz. This is why I also tested 689f9a05, but<br />>that's also slower than "disabled".<br /><br />Since there is not a consistent win of disabled or reverted over<br/>the other, and what difference there is is often far less than the<br />difference between the two runs with identicalsoftware, is there<br />any reasonable interpretation of this except that the difference is<br />"in the noise"?<br/><br />> * The performance impact with the feature enabled seems rather<br />> significant, especially onceyou exceed the number of physical<br />> cores (32 in this case). Then the drop is pretty clear - often<br />>~50% or more.<br />><br />> * 7e3da1c4 claims to bring the performance within 5% of the<br />> disabled case,but that seems not to be the case.<br /><br />The commit comment says "At least in the tested case this brings<br />performancewithin 5% of when the feature is off, compared to<br />several times slower without this patch." The testedcase was a<br />read-write load, so your read-only tests do nothing to determine<br />whether this was the case ingeneral for this type of load.<br />Partly, the patch decreases chasing through HOT chains and<br />increases the numberof HOT updates, so there are compensating<br />benefits of performing early vacuum in a read-write load.<br /><br />>What it however does is bringing the 'non-immediate' cases close<br />> to the immediate ones (before the performancedrop came much<br />> sooner in these cases - at 16 clients).<br /><br />Right. This is, of course, just thefirst optimization, that we<br />were able to get in "under the wire" before beta, but the other<br />optimizations underconsideration would only tend to bring the<br />"enabled" cases closer together in performance, not make an enabled<br/>case perform the same as when the feature was off -- especially for<br />a read-only workload.<br /><br />>* It's also seems to me the feature greatly amplifies the<br />> variability of the results, somehow. It's not uncommonto see<br />> results like this:<br />><br />> master-10-new-2 235516 331976 133316 155563 133396<br />><br />> where after the first runs (already fairly variable) the<br />> performance tanksto ~50%. This happens particularly with higher<br />> client counts, otherwise the max-min is within ~5% of the max.<br/>> There are a few cases where this happens without the feature<br />> (i.e. old master, reverted or disabled),but it's usually much<br />> smaller than with it enabled (immediate, 10 or 60). See the<br />> 'summary'sheet in the ODS spreadsheet.<br />><br />> I don't know what's the problem here - at first I thought that<br/>> maybe something else was running on the machine, or that<br />> anti-wraparound autovacuum kicked in, butthat seems not to be <br />> the case. There's nothing like that in the postgres log (also <br />> included in the.tgz).<br /><br />I'm inclined to suspect NUMA effects. It would be interesting to<br />try with the NUMA patch and cpusetI submitted a while back or with<br />fixes in place for the Linux scheduler bugs which were reported<br />last month. Which kernel version was this?<br /><br />--<br />Kevin Grittner<br />EDB: <a href="http://www.enterprisedb.com">http://www.enterprisedb.com</a><br/>The Enterprise PostgreSQL Company<br /><br /></div>
<div dir="ltr">On Tue, May 10, 2016 at 3:29 AM, Kevin Grittner <<a href="mailto:kgrittn@gmail.com">kgrittn@gmail.com</a>>wrote:<br /><br />>> * The results are a bit noisy, but Ithink in general this shows<br />>> that for certain cases there's a clearly measurable difference<br />>> (upto 5%) between the "disabled" and "reverted" cases. This is<br />>> particularly visible on the smallest data set.<br/>><br />> In some cases, the differences are in favor of disabled over<br />> reverted.<br /><br />Therewere 75 samples each of "disabled" and "reverted" in the<br />spreadsheet. Averaging them all, I see this:<br /><br/>reverted: 290,660 TPS<br />disabled: 292,014 TPS<br /><br />That's a 0.46% overall increase in performance withthe patch,<br />disabled, compared to reverting it. I'm surprised that you<br />consider that to be a "clearly measurabledifference". I mean, it<br />was measured and it is a difference, but it seems to be well within<br />the noise. Even though it is based on 150 samples, I'm not sure we<br />should consider it statistically significant.<br /><br/>--<br />Kevin Grittner<br />EDB: <a href="http://www.enterprisedb.com">http://www.enterprisedb.com</a><br />The EnterprisePostgreSQL Company<br /></div>
Kevin Grittner <kgrittn@gmail.com> writes:
> There were 75 samples each of "disabled" and "reverted" in the
> spreadsheet. Averaging them all, I see this:
> reverted: 290,660 TPS
> disabled: 292,014 TPS
> That's a 0.46% overall increase in performance with the patch,
> disabled, compared to reverting it. I'm surprised that you
> consider that to be a "clearly measurable difference". I mean, it
> was measured and it is a difference, but it seems to be well within
> the noise. Even though it is based on 150 samples, I'm not sure we
> should consider it statistically significant.
You don't have to guess about that --- compare it to the standard
deviation within each group.
regards, tom lane
<div dir="ltr">On Tue, May 10, 2016 at 9:02 AM, Tom Lane <<a href="mailto:tgl@sss.pgh.pa.us">tgl@sss.pgh.pa.us</a>>wrote:<br />> Kevin Grittner <<a href="mailto:kgrittn@gmail.com">kgrittn@gmail.com</a>>writes:<br />>> There were 75 samples each of "disabled" and"reverted" in the<br />>> spreadsheet. Averaging them all, I see this:<br />><br />>> reverted: 290,660TPS<br />>> disabled: 292,014 TPS<br />><br />>> That's a 0.46% overall increase in performance withthe patch,<br />>> disabled, compared to reverting it. I'm surprised that you<br />>> consider that to bea "clearly measurable difference". I mean, it<br />>> was measured and it is a difference, but it seems to be wellwithin<br />>> the noise. Even though it is based on 150 samples, I'm not sure we<br />>> should considerit statistically significant.<br />><br />> You don't have to guess about that --- compare it to the standard<br/>> deviation within each group.<br /><br />My statistics skills are rusty, but I thought that just gives you<br/>an effect size, not any idea of whether the effect is statistically<br />significant.<br /><br />Does anyone withsharper skills in this area than I want to opine<br />on whether there is a statistically significant difference between<br/>the numbers on "master-default-disabled" lines and "master-revert"<br />lines in the old_snap.ods file attachedto an earlier post on this<br />thread?<br /><br />--<br />Kevin Grittner<br />EDB: <a href="http://www.enterprisedb.com">http://www.enterprisedb.com</a><br/>The Enterprise PostgreSQL Company</div>
Hi, On 05/10/2016 10:29 AM, Kevin Grittner wrote: > On Mon, May 9, 2016 at 9:01 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> wrote: > >> Over the past few days I've been running benchmarks on a fairly >> large NUMA box (4 sockets, 32 cores / 64 with HR, 256GB of RAM) >> to see the impact of the 'snapshot too old' - both when disabled >> and enabled with various values in the old_snapshot_threshold >> GUC. > > Thanks! > >> The benchmark is a simple read-only pgbench with prepared >> statements, i.e. doing something like this: >> >> pgbench -S -M prepared -j N -c N > > Do you have any plans to benchmark cases where the patch can have a > benefit? (Clearly, nobody would be interested in using the feature > with a read-only load; so while that makes a good "worst case" > scenario and is very valuable for testing the "off" versus > "reverted" comparison, it's not an intended use or one that's > likely to happen in production.) Yes, I'd like to repeat the tests with other workloads - I'm thinking about regular pgbench and perhaps something that'd qualify as 'mostly read-only' (not having a clear idea how that should work). Feel free to propose other tests. > >> master-10-new - 91fd1df4 + old_snapshot_threshold=10 >> master-10-new-2 - 91fd1df4 + old_snapshot_threshold=10 (rerun) > > So, these runs were with identical software on the same data? Any > differences are just noise? Yes, same config. The differences are either noise or something unexpected (like the sudden drops of tps with high client counts). >> * The results are a bit noisy, but I think in general this shows >> that for certain cases there's a clearly measurable difference >> (up to 5%) between the "disabled" and "reverted" cases. This is >> particularly visible on the smallest data set. > > In some cases, the differences are in favor of disabled over > reverted. Well, that's a good question. I think the results for higher client counts (>=64) are fairy noisy, so in those cases it may easily be just due to noise. For the lower client counts that seems to be much less noisy though. > >> * What's fairly strange is that on the largest dataset (scale >> 10000), the "disabled" case is actually consistently faster than >> "reverted" - that seems a bit suspicious, I think. It's possible >> that I did the revert wrong, though - the revert.patch is >> included in the tgz. This is why I also tested 689f9a05, but >> that's also slower than "disabled". > > Since there is not a consistent win of disabled or reverted over > the other, and what difference there is is often far less than the > difference between the two runs with identical software, is there > any reasonable interpretation of this except that the difference is > "in the noise"? Are we both looking at the results for scale 10000? I think there's pretty clear difference between "disabled" and "reverted" (or 68919a05, for that matter). The gap is also much larger compared to the two "identical" runs (ignoring the runs with 128 clients). > >> * The performance impact with the feature enabled seems rather >> significant, especially once you exceed the number of physical >> cores (32 in this case). Then the drop is pretty clear - often >> ~50% or more. >> >> * 7e3da1c4 claims to bring the performance within 5% of the >> disabled case, but that seems not to be the case. > > The commit comment says "At least in the tested case this brings > performance within 5% of when the feature is off, compared to > several times slower without this patch." The tested case was a > read-write load, so your read-only tests do nothing to determine > whether this was the case in general for this type of load. > Partly, the patch decreases chasing through HOT chains and > increases the number of HOT updates, so there are compensating > benefits of performing early vacuum in a read-write load. OK. Sadly the commit message does not mention what the tested case was, so I wasn't really sure ... > >> What it however does is bringing the 'non-immediate' cases close >> to the immediate ones (before the performance drop came much >> sooner in these cases - at 16 clients). > > Right. This is, of course, just the first optimization, that we > were able to get in "under the wire" before beta, but the other > optimizations under consideration would only tend to bring the > "enabled" cases closer together in performance, not make an enabled > case perform the same as when the feature was off -- especially for > a read-only workload. OK > >> * It's also seems to me the feature greatly amplifies the >> variability of the results, somehow. It's not uncommon to see >> results like this: >> >> master-10-new-2 235516 331976 133316 155563 133396 >> >> where after the first runs (already fairly variable) the >> performance tanks to ~50%. This happens particularly with higher >> client counts, otherwise the max-min is within ~5% of the max. >> There are a few cases where this happens without the feature >> (i.e. old master, reverted or disabled), but it's usually much >> smaller than with it enabled (immediate, 10 or 60). See the >> 'summary' sheet in the ODS spreadsheet. >> >> I don't know what's the problem here - at first I thought that >> maybe something else was running on the machine, or that >> anti-wraparound autovacuum kicked in, but that seems not to be >> the case. There's nothing like that in the postgres log (also >> included in the .tgz). > > I'm inclined to suspect NUMA effects. It would be interesting to > try with the NUMA patch and cpuset I submitted a while back or with > fixes in place for the Linux scheduler bugs which were reported > last month. Which kernel version was this? I can try that, sure. Can you point me to the last versions of the patches, possibly rebased to current master if needed? The kernel is 3.19.0-031900-generic regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Tomas Vondra wrote: > Yes, I'd like to repeat the tests with other workloads - I'm thinking about > regular pgbench and perhaps something that'd qualify as 'mostly read-only' > (not having a clear idea how that should work). You can use "-bselect-only@9 -bsimple-update@1" for a workload that's 10% the write transactions and 90% the read-only transactions. If you have custom .sql scripts you can use the @ with -f too. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 05/10/2016 03:04 PM, Kevin Grittner wrote:
> On Tue, May 10, 2016 at 3:29 AM, Kevin Grittner <kgrittn@gmail.com
> <mailto:kgrittn@gmail.com>> wrote:
>
>>> * The results are a bit noisy, but I think in general this shows
>>> that for certain cases there's a clearly measurable difference
>>> (up to 5%) between the "disabled" and "reverted" cases. This is
>>> particularly visible on the smallest data set.
>>
>> In some cases, the differences are in favor of disabled over
>> reverted.
>
> There were 75 samples each of "disabled" and "reverted" in the
> spreadsheet. Averaging them all, I see this:
>
> reverted: 290,660 TPS
> disabled: 292,014 TPS
Well, that kinda assumes it's one large group. I was wondering whether
the difference depends on some of the other factors (scale factor,
number of clients), which is why I mentioned "for certain cases".
The other problem is averaging the difference like this overweights the
results for large client counts. Also, it mixes results for different
scales, which I think is pretty important.
The following table shows the differences between the disabled and
reverted cases like this:
sum('reverted' results with N clients) ---------------------------------------- - 1.0 sum('disabled' results
withN clients)
for each scale/client count combination. So for example 4.83% means with
a single client on the smallest data set, the sum of the 5 runs for
reverted was about 1.0483x than for disabled.
scale 1 16 32 64 128 100 4.83% 2.84% 1.21% 1.16% 3.85% 3000
1.97% 0.83% 1.78% 0.09% 7.70% 10000 -6.94% -5.24% -12.98% -3.02% -8.78%
So in average for each scale;
scale revert/disable 100 2.78% 3000 2.47% 10000 -7.39%
Of course, it still might be due to noise. But looking at the two tables
that seems rather unlikely, I guess.
>
> That's a 0.46% overall increase in performance with the patch,
> disabled, compared to reverting it. I'm surprised that you
> consider that to be a "clearly measurable difference". I mean, it
> was measured and it is a difference, but it seems to be well within
> the noise. Even though it is based on 150 samples, I'm not sure we
> should consider it statistically significant.
Well, luckily we're in the position that we can collect more data.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, May 10, 2016 at 12:31 PM, Tomas Vondra
<tomas.vondra@2ndquadrant.com> wrote:
> The following table shows the differences between the disabled and reverted
> cases like this:
>
> sum('reverted' results with N clients)
> ---------------------------------------- - 1.0
> sum('disabled' results with N clients)
>
> for each scale/client count combination. So for example 4.83% means with a
> single client on the smallest data set, the sum of the 5 runs for reverted
> was about 1.0483x than for disabled.
>
> scale 1 16 32 64 128
> 100 4.83% 2.84% 1.21% 1.16% 3.85%
> 3000 1.97% 0.83% 1.78% 0.09% 7.70%
> 10000 -6.94% -5.24% -12.98% -3.02% -8.78%
/me scratches head.
That doesn't seem like noise, but I don't understand the
scale-factor-10000 results either. Reverting the patch makes the code
smaller and removes instructions from critical paths, so it should
speed things up at least nominally. The question is whether it makes
enough difference that anyone cares. However, removing unused code
shouldn't make the system *slower*, but that's what's happening here
at the higher scale factor.
I've seen cases where adding dummy instructions to critical paths
slows things down at 1 client and speeds them up with many clients.
That happens because the percentage of time active processes fighting
over the critical locks goes down, which reduces contention more than
enough to compensate for the cost of executing the dummy instructions.
If your results showed performance lower at 1 client and slightly
higher at many clients, I'd suspect an effect of that sort. But I
can't see why it should depend on the scale factor. That suggests
that, perhaps, it's having some effect on the impact of buffer
eviction, maybe due to a difference in shared memory layout. But I
thought we weren't supposed to have such artifacts any more now that
we start every allocation on a cache line boundary...
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
On 05/10/2016 07:36 PM, Robert Haas wrote:
> On Tue, May 10, 2016 at 12:31 PM, Tomas Vondra
> <tomas.vondra@2ndquadrant.com> wrote:
>> The following table shows the differences between the disabled and reverted
>> cases like this:
>>
>> sum('reverted' results with N clients)
>> ---------------------------------------- - 1.0
>> sum('disabled' results with N clients)
>>
>> for each scale/client count combination. So for example 4.83% means with a
>> single client on the smallest data set, the sum of the 5 runs for reverted
>> was about 1.0483x than for disabled.
>>
>> scale 1 16 32 64 128
>> 100 4.83% 2.84% 1.21% 1.16% 3.85%
>> 3000 1.97% 0.83% 1.78% 0.09% 7.70%
>> 10000 -6.94% -5.24% -12.98% -3.02% -8.78%
>
> /me scratches head.
>
> That doesn't seem like noise, but I don't understand the
> scale-factor-10000 results either. Reverting the patch makes the code
> smaller and removes instructions from critical paths, so it should
> speed things up at least nominally. The question is whether it makes
> enough difference that anyone cares. However, removing unused code
> shouldn't make the system *slower*, but that's what's happening here
> at the higher scale factor.
/me scratches head too
>
> I've seen cases where adding dummy instructions to critical paths
> slows things down at 1 client and speeds them up with many clients.
> That happens because the percentage of time active processes fighting
> over the critical locks goes down, which reduces contention more than
> enough to compensate for the cost of executing the dummy
> instructions. If your results showed performance lower at 1 client
> and slightly higher at many clients, I'd suspect an effect of that
> sort. But I can't see why it should depend on the scale factor. That
> suggests that, perhaps, it's having some effect on the impact of
> buffer eviction, maybe due to a difference in shared memory layout.
> But I thought we weren't supposed to have such artifacts any more
> now that we start every allocation on a cache line boundary...
>
I think we should look for issues in the testing procedure first,
perhaps try to reproduce it on a different system. Another possibility
is that the revert is not perfectly correct - the code compiles and does
not crash, but maybe there's a subtle issue somewhere.
I'll try to collect some additional info (detailed info from sar,
aggregated transaction log, ...) for further analysis. And also increase
the number of runs, so that we can better compare all the separate
combinations.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, May 10, 2016 at 11:13 AM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 05/10/2016 10:29 AM, Kevin Grittner wrote: >> On Mon, May 9, 2016 at 9:01 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>> * It's also seems to me the feature greatly amplifies the >>> variability of the results, somehow. It's not uncommon to see >>> results like this: >>> >>> master-10-new-2 235516 331976 133316 155563 133396 >>> >>> where after the first runs (already fairly variable) the >>> performance tanks to ~50%. This happens particularly with higher >>> client counts, otherwise the max-min is within ~5% of the max. >>> There are a few cases where this happens without the feature >>> (i.e. old master, reverted or disabled), but it's usually much >>> smaller than with it enabled (immediate, 10 or 60). See the >>> 'summary' sheet in the ODS spreadsheet. Just to quantify that with standard deviations: standard deviation - revert scale 1 16 32 64 128 100 386 1874 3661 8100 26587 3000 609 2236 4570 8974 41004 10000 257 4356 1350 891 12909 standard deviation - disabled scale 1 16 32 64 128 100 641 1924 2983 12575 9411 3000 206 2321 5477 2380 45779 10000 2236 10376 11439 9653 10436 >>> I don't know what's the problem here - at first I thought that >>> maybe something else was running on the machine, or that >>> anti-wraparound autovacuum kicked in, but that seems not to be >>> the case. There's nothing like that in the postgres log (also >>> included in the .tgz). >> >> I'm inclined to suspect NUMA effects. It would be interesting to >> try with the NUMA patch and cpuset I submitted a while back or with >> fixes in place for the Linux scheduler bugs which were reported >> last month. Which kernel version was this? > > I can try that, sure. Can you point me to the last versions of the > patches, possibly rebased to current master if needed? The initial thread (for explanation and discussion context) for my attempt to do something about some NUMA problems I ran into is at: http://www.postgresql.org/message-id/flat/1402267501.41111.YahooMailNeo@web122304.mail.ne1.yahoo.com Note that in my tests at the time, the cpuset configuration made a bigger difference than the patch, and both together typically only made about a 2% difference in the NUMA test environment I was using. I would sometimes see a difference as big as 20%, but had no idea how to repeat that. > The kernel is 3.19.0-031900-generic So that kernel is recent enough to have acquired the worst of the scheduling bugs, known to slow down one NASA high-concurrency benchmark by 138x. To quote from the recent paper by Lozi, et al[1]: | The Missing Scheduling Domains bug causes all threads of the | applications to run on a single node instead of eight. In some | cases, the performance impact is greater than the 8x slowdown | that one would expect, given that the threads are getting 8x less | CPU time than they would without the bug (they run on one node | instead of eight). lu, for example, runs 138x faster! | Super-linear slowdowns occur in cases where threads | frequently synchronize using locks or barriers: if threads spin | on a lock held by a descheduled thread, they will waste even more | CPU time, causing cascading effects on the entire application’s | performance. Some applications do not scale ideally to 64 cores | and are thus a bit less impacted by the bug. The minimum slowdown | is 4x. The bug is only encountered if cores are disabled and re-enabled, though, and I have no idea whether that might have happened on your machine. Since you're on a vulnerable kernel version, you might want to be aware of the issue and take care not to trigger the problem. You are only vulnerable to the Group Imbalance bug if you use autogroups. You are only vulnerable to the Scheduling Group Construction bug if you have more than one hop from any core to any memory segment (which seems quite unlikely with 4 sockets and 4 memory nodes). If you are vulnerable to any of the above, it might explain some of the odd variations. Let me know and I'll see if I can find more on workarounds or OS patches. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company [1] Jean-Pierre Lozi, Baptiste Lepers, Justin Funston, Fabien Gaud, Vivien Quéma, Alexandra Fedorova. The Linux Scheduler:a Decade of Wasted Cores. In Proceedings of the 11th European Conference on Computer Systems, EuroSys’16.April, 2016, London, UK. http://www.ece.ubc.ca/~sasha/papers/eurosys16-final29.pdf
On Tue, May 10, 2016 at 2:41 PM, Kevin Grittner <kgrittn@gmail.com> wrote: > http://www.postgresql.org/message-id/flat/1402267501.41111.YahooMailNeo@web122304.mail.ne1.yahoo.com Re-reading that thread I was reminded that I had more NUMA problems when data all landed in one memory node, as can happen with pgbench -i. Note that at scale 100 and 3000 all data would fit in one NUMA node, and very likely was all going through one CPU socket. The 2 hour warm-up might have rebalanced that to some degree or other, but as an alternative to the cpuset and NUMA patch, you could stop PostgreSQL after the initialize, discard OS cache, and start fresh before your warm-up. That should accomplish about the same thing -- to better balance the use of memory across the memory nodes and CPU sockets. On most NUMA systems you can use this command to see how much memory is in use on which nodes: numactl --hardware -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-05-10 13:36:32 -0400, Robert Haas wrote:
> On Tue, May 10, 2016 at 12:31 PM, Tomas Vondra
> <tomas.vondra@2ndquadrant.com> wrote:
> > The following table shows the differences between the disabled and reverted
> > cases like this:
> >
> > sum('reverted' results with N clients)
> > ---------------------------------------- - 1.0
> > sum('disabled' results with N clients)
> >
> > for each scale/client count combination. So for example 4.83% means with a
> > single client on the smallest data set, the sum of the 5 runs for reverted
> > was about 1.0483x than for disabled.
> >
> > scale 1 16 32 64 128
> > 100 4.83% 2.84% 1.21% 1.16% 3.85%
> > 3000 1.97% 0.83% 1.78% 0.09% 7.70%
> > 10000 -6.94% -5.24% -12.98% -3.02% -8.78%
>
> /me scratches head.
>
> That doesn't seem like noise, but I don't understand the
> scale-factor-10000 results either.
Hm. Could you change max_connections by 1 and 2 and run the 10k tests
again for each value? I wonder whether we're seing the affect of changed
shared memory alignment.
Greetings,
Andres Freund
On Tue, May 10, 2016 at 10:05:13AM -0500, Kevin Grittner wrote:
> On Tue, May 10, 2016 at 9:02 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > Kevin Grittner <kgrittn@gmail.com> writes:
> >> There were 75 samples each of "disabled" and "reverted" in the
> >> spreadsheet. Averaging them all, I see this:
> >
> >> reverted: 290,660 TPS
> >> disabled: 292,014 TPS
> >
> >> That's a 0.46% overall increase in performance with the patch,
> >> disabled, compared to reverting it. I'm surprised that you
> >> consider that to be a "clearly measurable difference". I mean, it
> >> was measured and it is a difference, but it seems to be well within
> >> the noise. Even though it is based on 150 samples, I'm not sure we
> >> should consider it statistically significant.
> >
> > You don't have to guess about that --- compare it to the standard
> > deviation within each group.
>
> My statistics skills are rusty, but I thought that just gives you
> an effect size, not any idea of whether the effect is statistically
> significant.
I discourage focusing on the statistical significance, because the hypothesis
in question ("Applying revert.patch to 4bbc1a7e decreases 'pgbench -S -M
prepared -j N -c N' tps by 0.46%.") is already an unreliable proxy for
anything we care about. PostgreSQL performance variation due to incidental,
ephemeral binary layout motion is roughly +/-5%. Assuming perfect confidence
that 4bbc1a7e+revert.patch is 0.46% slower than 4bbc1a7e, the long-term effect
of revert.patch could be anywhere from -5% to +4%.
If one wishes to make benchmark-driven decisions about single-digit
performance changes, one must control for binary layout effects:
http://www.postgresql.org/message-id/87vbitb2zp.fsf@news-spur.riddles.org.uk
http://www.postgresql.org/message-id/20160416204452.GA1910190@tornado.leadboat.com
nm
Hi,
I've repeated the tests with the read-only workload, with the number of
runs for each combination increased to 20 (so 4x higher compared to the
initial runs). Also, this time I've collected sar statistics so that
there's a chance of investigating the sudden tps drops observed in some
of the cases. All the tests were on 8ee29a19, i.e. the commit that
stamped 9.6beta1.
Attached is an ODS spreadsheet with the basic data, the full logs are
available in the same google drive folder as before (old_snapshot2.tgz):
https://drive.google.com/open?id=0BzigUP2Fn0XbR1dyOFA3dUxRaUU
The results (average tps) for the three scales (100, 3000 and 100000)
look like this (also see the three charts attached):
scale dataset 1 16 32 64 128
-------------------------------------------------------------------
100 disabled 18810 238813 390341 532965 452003
100 immediate 18792 229819 360048 141869 175624
100 revert 18458 235814 390306 524320 450595
scale dataset 1 16 32 64 128
-------------------------------------------------------------------
3000 disabled 17266 221723 366303 497338 413649
3000 immediate 17277 216554 342688 143374 256825
3000 revert 16893 220532 363965 494249 402798
scale dataset 1 16 32 64 128
-------------------------------------------------------------------
10000 disabled 14383 174992 270889 389629 344499
10000 immediate 14548 172316 257042 173671 200582
10000 revert 14109 162818 245688 370565 332799
And as a percentage vs. the "revert" case:
scale dataset 1 16 32 64 128
---------------------------------------------------------------
100 disabled 101.91% 101.27% 100.01% 101.65% 100.31%
100 immediate 101.81% 97.46% 92.25% 27.06% 38.98%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
3000 disabled 102.21% 100.54% 100.64% 100.62% 102.69%
3000 immediate 102.27% 98.20% 94.15% 29.01% 63.76%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
10000 disabled 101.94% 107.48% 110.26% 105.14% 103.52%
10000 immediate 103.11% 105.83% 104.62% 46.87% 60.27%
I do agree Noah is right that the small (~1-2%) differences may be
simply due to binary layout changes - I haven't taken any steps to
mitigate the influence of that.
The larger differences are however unlikely to be caused by this, I
guess. I mean, the significant performance drop with "immediate" config
and higher client counts is still there, and it's quite massive.
The strange speedup with the feature "disabled" (which gains up to ~10%
compared to the "revert" case with 32 clients) is also still there. I
find that a bit strange, not sure what's the cause here.
Overall, I think this shows that there seems to be no performance
penalty with "disabled" vs. "reverted" - i.e. even with the least
favorable (100% read-only) workload.
Let's see the impact of the patch on variability of results. First, the
(MAX-MIN)/MAX metric:
scale dataset 1 16 32 64 128
---------------------------------------------------------------
100 disabled 9.55% 3.18% 2.84% 4.16% 9.61%
immediate 4.92% 10.96% 4.39% 3.32% 58.95%
revert 4.43% 3.61% 3.01% 13.93% 10.25%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
3000 disabled 13.29% 4.19% 4.52% 9.06% 23.59%
immediate 7.86% 5.93% 3.15% 7.64% 50.41%
revert 12.34% 7.50% 3.99% 10.17% 16.95%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
10000 disabled 9.19% 17.21% 8.85% 8.01% 26.40%
immediate 7.74% 8.29% 8.53% 38.64% 46.09%
revert 4.42% 4.98% 6.58% 12.42% 18.68%
or as a STDDEV/AVERAGE:
scale dataset 1 16 32 64 128
---------------------------------------------------------------
100 disabled 2.34% 0.74% 1.00% 1.20% 2.65%
immediate 1.51% 2.65% 1.11% 0.69% 34.35%
revert 1.47% 0.94% 0.78% 3.22% 2.73%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
3000 disabled 2.93% 1.19% 1.06% 2.04% 6.99%
immediate 2.31% 1.34% 0.88% 1.72% 18.15%
revert 2.81% 1.51% 0.96% 2.64% 4.85%
scale dataset 1 16 32 64 128
---------------------------------------------------------------
10000 disabled 3.56% 4.51% 2.62% 1.73% 7.56%
immediate 2.53% 2.36% 2.82% 15.61% 18.20%
revert 1.41% 1.45% 1.69% 3.16% 6.39%
Whatever the metric is, I think it's fairly clear the patch makes the
results way more volatile - particularly with the "immediate" case and
higher client counts.
I'm not sure whether that's problem with NUMA or one of the bugs in the
kernel scheduler. But even if it is, we should not ignore that as it
will take a long time before most users migrate to fixed kernels.
AFAIK the system is not using autogroups, and I've rebooted it before
repeating the tests to make sure none of the cores were turned off
(e.g. during some experiments with hyper-threading or something). That
should eliminate the related scheduling bugs.
The end of the "numactl --hardware" output looks like this:
node distances:
node 0 1 2 3
0: 10 21 30 21
1: 21 10 21 30
2: 30 21 10 21
3: 21 30 21 10
Which I think means that there may be up to two hops, making the system
vulnerable to the "Scheduling Group Construction" bug. But it seems a
bit strange that it would only affect one of the cases ("immediate").
What I plan to do next, over the next week:
1) Wait for the second run of "immediate" to complete (should happen in
a few hours)
2) Do tests with other workloads (mostly read-only, read-write).
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
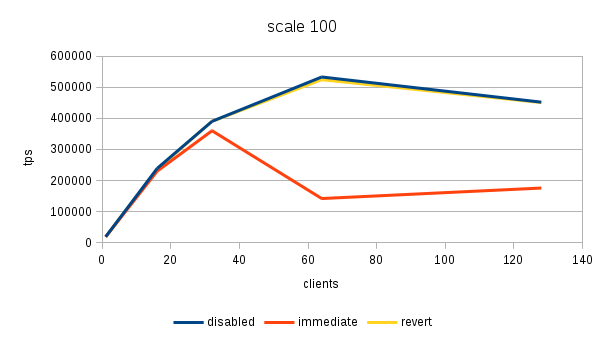{kind=link}
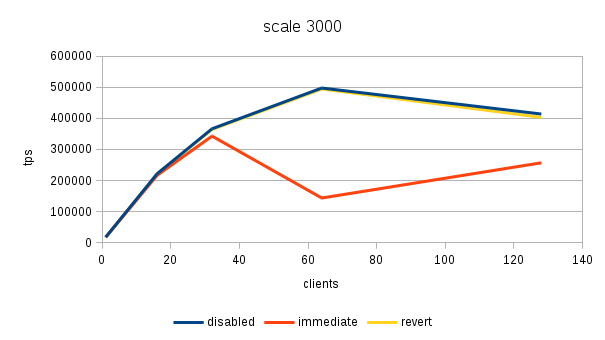{kind=link}
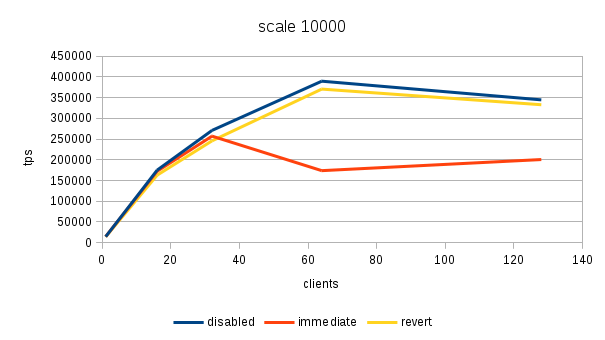{kind=link}
On Sun, May 15, 2016 at 4:06 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Overall, I think this shows that there seems to be no performance penalty > with "disabled" vs. "reverted" - i.e. even with the least favorable (100% > read-only) workload. OK, that's good, as far as it goes. > Whatever the metric is, I think it's fairly clear the patch makes the > results way more volatile - particularly with the "immediate" case and > higher client counts. I think you mean only when it is enabled. Right? Mithun and others at EnterpriseDB have been struggling with the problem of getting reproducible results on benchmarks, even read-only benchmarks that seem like they ought to be fairly stable, and they've been complaining to me about that problem - not specifically with respect to snapshot too old, but in general. I don't have a clear understanding at this point of why a particular piece of code might cause increased volatility, but I wish I did. In the past, I haven't paid much attention to this, but lately it's clear that it is becoming a significant problem when trying to benchmark, especially on many-socket machines. I suspect it might be a problem for actual users as well, but I know of any definite evidence that this is the case. It's probably an area that needs a bunch of work, but I don't understand the problem well enough to know what we should be doing. > What I plan to do next, over the next week: > > 1) Wait for the second run of "immediate" to complete (should happen in a > few hours) > > 2) Do tests with other workloads (mostly read-only, read-write). Sounds good. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 05/15/2016 10:06 PM, Tomas Vondra wrote:
...
> What I plan to do next, over the next week:
>
> 1) Wait for the second run of "immediate" to complete (should happen in
> a few hours)
>
> 2) Do tests with other workloads (mostly read-only, read-write).
I've finally had time to look at results from the additional read-write
runs. If needed, the whole archive (old_snapshot3.tgz) is available in
the same google drive folder as the previous results:
https://drive.google.com/open?id=0BzigUP2Fn0XbR1dyOFA3dUxRaUU
I've already analyzed the read-only results in the previous message on
15/5 and the additional "immediate" run was consistent with that, so I
have nothing to add at this point.
The read-write results (just the usual pgbench workload) suggest there's
not much difference - see the attached charts, where the data sets
almost merge into a single line.
The only exception seems to be the "small" data set where the
reverted/disabled cases seem to perform ~3-4% better than the
immediate/10 cases. But as Noah pointed out, this may just as well be
random noise or more likely due to binary layout differences.
What I still find a tiny bit annoying, though, is the volatility of the
read-only results with many clients. The last two sheets in the attached
spreadsheet measure this in two slightly different ways:
1: (MAX(x) - MIN(x)) / MAX(x)
2: STDDEV(x) / AVG(x)
The (1) formula is much more sensitive to outliers, of course, but in
general the conclusions are the same - there's a pretty clear increase
with the "immediate" setting on read-only.
Kevin mentioned possible kernel-related bugs - that may be the case, but
I'm not sure why that'd only affect this one case (and not for example
reverted case).
I'm however inclined to take this as a proof that running CPU-intensive
workloads 128 active clients on 32 physical cores is a bad idea. On
fewer client counts no such problems happen.
That being said, I'm done with benchmarking this feature, at least for
now - I'm personally convinced the performance impact is within noise. I
may run additional tests on request in the future, but probably not in
the next ~ month or so as the hw is busy with other stuff.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
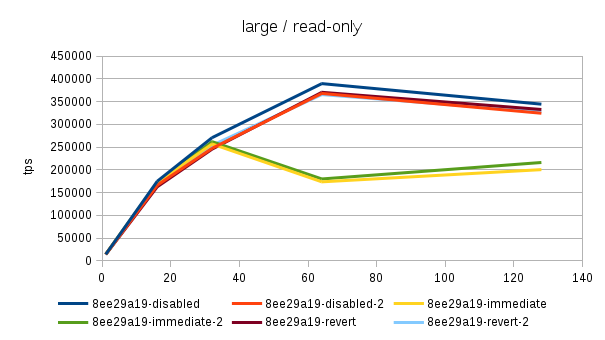{kind=link}
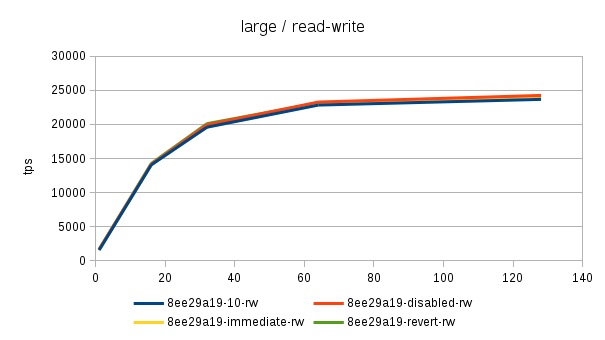{kind=link}
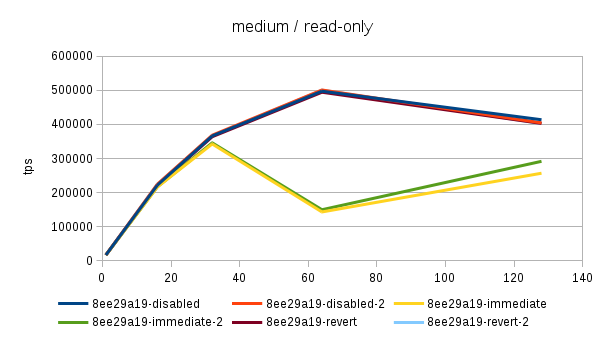{kind=link}
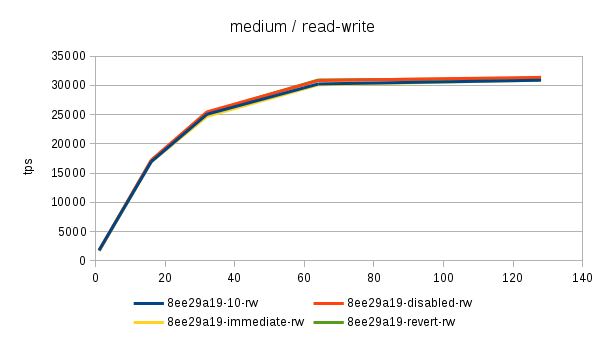{kind=link}
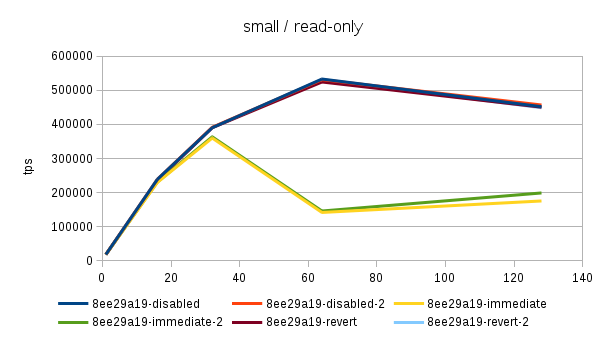{kind=link}
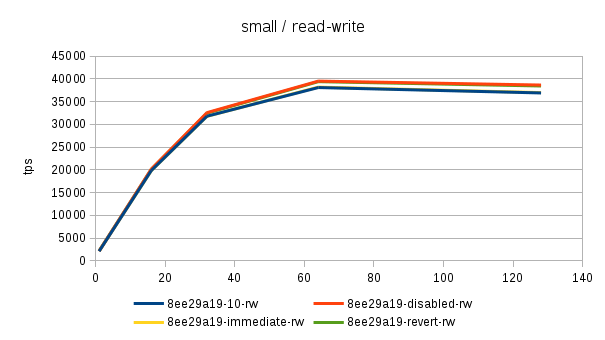{kind=link}