Обсуждение: Yet another fast GiST build
Hi! In many cases GiST index can be build fast using z-order sorting. I've looked into proof of concept by Nikita Glukhov [0] and it looks very interesting. So, I've implemented yet another version of B-tree-like GiST build. It's main use case and benefits can be summarized with small example: postgres=# create table x as select point (random(),random()) from generate_series(1,3000000,1); SELECT 3000000 Time: 5061,967 ms (00:05,062) postgres=# create index ON x using gist (point ) with (fast_build_sort_function=gist_point_sortsupport); CREATE INDEX Time: 6140,227 ms (00:06,140) postgres=# create index ON x using gist (point ); CREATE INDEX Time: 32061,200 ms (00:32,061) As you can see, Z-order build is on order of magnitude faster. Select performance is roughly the same. Also, index is significantlysmaller. Nikita's PoC is faster because it uses parallel build, but it intervenes into B-tree code a lot (for reuse). This patchsetis GiST-isolated. My biggest concern is that passing function to relation option seems a bit hacky. You can pass there any function matchingsort support signature. Embedding this function into opclass makes no sense: it does not affect scan anyhow. In current version, docs and tests are not implemented. I want to discuss overall design. Do we really want yet another GiSTbuild, if it is 3-10 times faster? Thanks! Best regards, Andrey Borodin. [0] https://github.com/postgres/postgres/compare/master...glukhovn:gist_btree_build
Вложения
Hello,
This is very interesting. In my pipeline currently GiST index rebuild is the biggest time consuming step.
I believe introducing optional concept of order in the GiST opclass will be beneficial not only for fast build, but for other tasks later:
- CLUSTER can order the table using that notion, in parallel way.
- btree_gist can be even closer to btree by getting the tuples sorted inside page.
- tree descend on insertion in future can traverse the list in more opportunistic way, calculating penalty for siblings-by-order first.
This is very interesting. In my pipeline currently GiST index rebuild is the biggest time consuming step.
I believe introducing optional concept of order in the GiST opclass will be beneficial not only for fast build, but for other tasks later:
- CLUSTER can order the table using that notion, in parallel way.
- btree_gist can be even closer to btree by getting the tuples sorted inside page.
- tree descend on insertion in future can traverse the list in more opportunistic way, calculating penalty for siblings-by-order first.
I believe everywhere the idea of ordering is needed it's provided by giving a btree opclass.
How about giving a link to btree opclass inside a gist opclass?
How about giving a link to btree opclass inside a gist opclass?
On Mon, Aug 26, 2019 at 10:59 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote:
Hi!
In many cases GiST index can be build fast using z-order sorting.
I've looked into proof of concept by Nikita Glukhov [0] and it looks very interesting.
So, I've implemented yet another version of B-tree-like GiST build.
It's main use case and benefits can be summarized with small example:
postgres=# create table x as select point (random(),random()) from generate_series(1,3000000,1);
SELECT 3000000
Time: 5061,967 ms (00:05,062)
postgres=# create index ON x using gist (point ) with (fast_build_sort_function=gist_point_sortsupport);
CREATE INDEX
Time: 6140,227 ms (00:06,140)
postgres=# create index ON x using gist (point );
CREATE INDEX
Time: 32061,200 ms (00:32,061)
As you can see, Z-order build is on order of magnitude faster. Select performance is roughly the same. Also, index is significantly smaller.
Nikita's PoC is faster because it uses parallel build, but it intervenes into B-tree code a lot (for reuse). This patchset is GiST-isolated.
My biggest concern is that passing function to relation option seems a bit hacky. You can pass there any function matching sort support signature.
Embedding this function into opclass makes no sense: it does not affect scan anyhow.
In current version, docs and tests are not implemented. I want to discuss overall design. Do we really want yet another GiST build, if it is 3-10 times faster?
Thanks!
Best regards, Andrey Borodin.
[0] https://github.com/postgres/postgres/compare/master...glukhovn:gist_btree_build
Darafei Praliaskouski
Support me: http://patreon.com/komzpa
On 26/08/2019 10:59, Andrey Borodin wrote: > Hi! > > In many cases GiST index can be build fast using z-order sorting. > > I've looked into proof of concept by Nikita Glukhov [0] and it looks very interesting. > So, I've implemented yet another version of B-tree-like GiST build. Cool! > My biggest concern is that passing function to relation option seems > a bit hacky. You can pass there any function matching sort support > signature. Embedding this function into opclass makes no sense: it > does not affect scan anyhow. I think it should be a new, optional, GiST "AM support function", in pg_amproc. That's how the sort support functions are defined for B-tree opfamilies, too. - Heikki
On Mon, Aug 26, 2019 at 10:59 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > In many cases GiST index can be build fast using z-order sorting. > > I've looked into proof of concept by Nikita Glukhov [0] and it looks very interesting. > So, I've implemented yet another version of B-tree-like GiST build. > It's main use case and benefits can be summarized with small example: > > postgres=# create table x as select point (random(),random()) from generate_series(1,3000000,1); > SELECT 3000000 > Time: 5061,967 ms (00:05,062) > postgres=# create index ON x using gist (point ) with (fast_build_sort_function=gist_point_sortsupport); > CREATE INDEX > Time: 6140,227 ms (00:06,140) > postgres=# create index ON x using gist (point ); > CREATE INDEX > Time: 32061,200 ms (00:32,061) > > As you can see, Z-order build is on order of magnitude faster. Select performance is roughly the same. Also, index is significantlysmaller. Cool! These experiments bring me to following thoughts. Can we not only build, but also maintain GiST indexes in B-tree-like manner? If we put Z-value together with MBR to the non-leaf keys, that should be possible. Maintaining it in B-tree-like manner would have a lot of advantages. 1) Binary search in non-leaf pages instead of probing each key is much faster. 2) Split algorithm is also simpler and faster. 3) We can refind existing index tuple in predictable time of O(log N). And this doesn't depend on MBR overlapping degree. This is valuable for future table AMs, which would have notion of deleting individual index tuples (for instance, zheap promises to eventually support delete-marking indexes). Eventually, we may come to the idea of B-tree indexes with user-defined additional keys in non-leaf tuples, which could be used for scanning. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Aug 29, 2019 at 3:48 PM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > As you can see, Z-order build is on order of magnitude faster. Select performance is roughly the same. Also, index issignificantly smaller. > > Cool! These experiments bring me to following thoughts. Can we not > only build, but also maintain GiST indexes in B-tree-like manner? If > we put Z-value together with MBR to the non-leaf keys, that should be > possible. Maintaining it in B-tree-like manner would have a lot of > advantages. I'm not an expert on GiST, but that seems like it would have a lot of advantages in the long term. It is certainly theoretically appealing. Could this make it easier to use merge join with containment operators? I'm thinking of things like geospatial joins, which can generally only be performed as nested loop joins at the moment. This is often wildly inefficient. -- Peter Geoghegan
On Fri, Aug 30, 2019 at 2:34 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Aug 29, 2019 at 3:48 PM Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > > As you can see, Z-order build is on order of magnitude faster. Select performance is roughly the same. Also, indexis significantly smaller. > > > > Cool! These experiments bring me to following thoughts. Can we not > > only build, but also maintain GiST indexes in B-tree-like manner? If > > we put Z-value together with MBR to the non-leaf keys, that should be > > possible. Maintaining it in B-tree-like manner would have a lot of > > advantages. > > I'm not an expert on GiST, but that seems like it would have a lot of > advantages in the long term. It is certainly theoretically appealing. > > Could this make it easier to use merge join with containment > operators? I'm thinking of things like geospatial joins, which can > generally only be performed as nested loop joins at the moment. This > is often wildly inefficient. AFAICS, spatial joins aren't going to be as easy as just merge joins on Z-value. When searching for close points in two datasets (closer than given threshold) we can scan some ranges of Z-value in one dataset while iterating on another. But dealing with prolonged spatial objects in not that easy. In order to determine if there are matching values in given Z-range you also need to be aware on size of objects inside that Z-range. So, before merge-like join you need to not only sort, but build some index-like structure. Alternatively you can encode size in Z-value. But this increases dimensionality of space and decreases efficiency of join. Also, spatial join can be made using two indexes, even just current GiST without Z-values. We've prototyped that, see [1]. Links 1. https://github.com/pgsphere/pgsphere/blob/crossmatch_cnode/crossmatch.c ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Aug 29, 2019 at 8:22 PM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Alternatively you can encode size in Z-value. But this increases > dimensionality of space and decreases efficiency of join. Also, > spatial join can be made using two indexes, even just current GiST > without Z-values. We've prototyped that, see [1]. I'm pretty sure that spatial joins generally need two spatial indexes (usually R-Trees). There seems to have been quite a lot of research in it in the 1990s. -- Peter Geoghegan
30 авг. 2019 г., в 3:47, Alexander Korotkov <a.korotkov@postgrespro.ru> написал(а):
1) Binary search in non-leaf pages instead of probing each key is much faster.
for two sets of tuples X and Y
if for any i,o from N, Xi < Yo
does not guaranty union(X) < union (Y)
For example consider this z-ordered keyspace (picture attached)
union(5, 9) is z-order-smaller than union(4,4)
I'm not even sure we can use sorted search for choosing subtree for insertion.
How do you think, should I supply GiST-build patch with docs and tests and add it to CF? Or do we need more design discussion before?
Best regards, Andrey Borodin.
Вложения
> 30 авг. 2019 г., в 16:44, Andrey Borodin <x4mmm@yandex-team.ru> написал(а):
>
>
> How do you think, should I supply GiST-build patch with docs and tests and add it to CF? Or do we need more design
discussionbefore?
PFA v2: now sort support is part of opclass.
There's a problem with Z-ordering NaN which causes regression tests to fail. So I decided not to add patch to CF
(despitehaving few minutes to do so).
How to correctly Z-order NaN? So that it would be consistent with semantics of union() and consistent() functions. If
oneof values is NaN, then we consider all it's bits to be 1?
BTW patch uses
union {
float f;
uint32 i;
}
I hope it's OK, because AFAIK we do not have non-IEEE-754 platforms now.
Thanks!
Best regards, Andrey Borodin.
Вложения
On Fri, Aug 30, 2019 at 2:44 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > 30 авг. 2019 г., в 3:47, Alexander Korotkov <a.korotkov@postgrespro.ru> написал(а): > > 1) Binary search in non-leaf pages instead of probing each key is much faster. > > > That's a neat idea, but key union breaks ordering, even for z-order. > for two sets of tuples X and Y > if for any i,o from N, Xi < Yo > does not guaranty union(X) < union (Y) > > For example consider this z-ordered keyspace (picture attached) > > union(5, 9) is z-order-smaller than union(4,4) > > I'm not even sure we can use sorted search for choosing subtree for insertion. Sorry, I didn't explain my proposal in enough details. I didn't mean B-tree separator keys would be the same as union key (MBR). I mean B-tree on Z-values, which maintains union key in addition to separator keys. So, you select downlink to insert using separator Z-values and then also extend union key (if needed). It's probably still not enough detail yet. I'll try to spend more time for more detailed description later. > > How do you think, should I supply GiST-build patch with docs and tests and add it to CF? Or do we need more design discussionbefore? +1 for adding to CF. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Aug 30, 2019 at 6:28 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Aug 29, 2019 at 8:22 PM Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > Alternatively you can encode size in Z-value. But this increases > > dimensionality of space and decreases efficiency of join. Also, > > spatial join can be made using two indexes, even just current GiST > > without Z-values. We've prototyped that, see [1]. > > I'm pretty sure that spatial joins generally need two spatial indexes > (usually R-Trees). There seems to have been quite a lot of research in > it in the 1990s. Sure, our prototype was an implementation of one of such papers. My point is that advantages of Z-value ordered GiST for spatial joins are not yet clear for me. Except faster build and smaller index, which are general advantages. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
> 1 сент. 2019 г., в 15:53, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): > > > <v2-0001-Add-sort-support-for-point-gist_point_sortsupport.patch><v2-0002-Implement-GiST-build-using-sort-support.patch> Here's V3 of the patch set. Changes: 1. Added some documentation of new sort support routines 2. Fixed bug with dirty pages I did not add sort support procs to built-in boxes, circles and polys, since it may be not optimal index for them. However,for points Z-order is quite good as a default. Tests only pass with fixes for GiST KNN from Alexander in other thread. Thanks! Best regards, Andrey Borodin.
Вложения
On Sun, Sep 08, 2019 at 01:54:35PM +0500, Andrey Borodin wrote: > Here's V3 of the patch set. > Changes: > 1. Added some documentation of new sort support routines > 2. Fixed bug with dirty pages > > I did not add sort support procs to built-in boxes, circles and > polys, since it may be not optimal index for them. However, for > points Z-order is quite good as a defaul t. The latest patch does not apply. Could you send a rebase? I have moved the patch to next CF, waiting on author for now. -- Michael
Вложения
> 1 дек. 2019 г., в 7:06, Michael Paquier <michael@paquier.xyz> написал(а): > > On Sun, Sep 08, 2019 at 01:54:35PM +0500, Andrey Borodin wrote: >> Here's V3 of the patch set. >> Changes: >> 1. Added some documentation of new sort support routines >> 2. Fixed bug with dirty pages >> >> I did not add sort support procs to built-in boxes, circles and >> polys, since it may be not optimal index for them. However, for >> points Z-order is quite good as a defaul t. > > The latest patch does not apply. Could you send a rebase? I have > moved the patch to next CF, waiting on author for now. Thanks, Michael! PFA rebased patch. Best regards, Andrey Borodin.
Вложения
On Mon, Dec 30, 2019 at 7:43 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote:
> PFA rebased patch.
Hi Andrey,
This looks really interesting, and I am sure there are a lot of GIS
people who would love to see dramatically faster and smaller indexes
in PG13. I don't know enough to comment on the details, but here are
some superficial comments:
+ method is also optional and is used diring fast GiST build.
-> during
+ /* esteblish order between x and y */
-> establish
+/* Compute Z-oder for point */
static inline uint64
point_zorder_internal(Point *p)
-> order
Could this function please have a comment that explains why it works?
I mean, just a breadcrumb... the name of the technique or something...
so that uninitiated hackers can google their way to a clue (is it
"Morton encoding"?)
MSVC says:
src/backend/access/gist/gistproc.c(1582): error C2065: 'INT32_MAX' :
undeclared identifier
GCC says:
gistbuild.c: In function ‘gist_indexsortbuild’:
gistbuild.c:256:4: error: ISO C90 forbids mixed declarations and code
[-Werror=declaration-after-statement]
IndexTuple *itvec = gistextractpage(lower_page, &vect_len);
^
On Wed, Feb 19, 2020 at 8:00 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> Could this function please have a comment that explains why it works?
> I mean, just a breadcrumb... the name of the technique or something...
> so that uninitiated hackers can google their way to a clue (is it
> "Morton encoding"?)
Ok I think I get it now after doing some homework.
1. We expect floats to be in IEEE format, and the sort order of IEEE
floats is mostly correlated to the binary sort order of the bits
reinterpreted as an int. It isn't in some special cases, but for this
use case we don't really care about that, we're just trying to
encourage locality.
2. We generate a Morton code that interleaves the bits of N integers
to produce a single integer that preserves locality: things that were
close in the N dimensional space are close in the resulting integer.
Cool.
+static int
+my_fastcmp(Datum x, Datum y, SortSupport ssup)
+{
+ /* esteblish order between x and y */
+
+ return z1 == z2 ? 0 : z1 > z2 ? 1 : -1;
+}
This example code from the documentation looks wrong, probably missing
eg int64 z1 = DatumGetInt64(x).
On Thu, Feb 20, 2020 at 10:14 AM Thomas Munro <thomas.munro@gmail.com> wrote: > 1. We expect floats to be in IEEE format, and the sort order of IEEE > floats is mostly correlated to the binary sort order of the bits > reinterpreted as an int. It isn't in some special cases, but for this > use case we don't really care about that, we're just trying to > encourage locality. I suppose there is a big jump in integer value (whether signed or unsigned) as you cross from positive to negative floats, and then the sort order is reversed. I have no idea if either of those things is a problem worth fixing. That made me wonder if there might also be an endianness problem. It seems from some quick googling that all current architectures have integers and floats of the same endianness. Apparently this wasn't always the case, and some ARMs have a weird half-flipped arrangement for 64 bit floats, but not 32 bit floats as you are using here.
Hi Thomas! Thanks for looking into this! I’ll fix your notices asap. > On 24 февр. 2020 г., at 01:58, Thomas Munro <thomas.munro@gmail.com> wrote: > > On Thu, Feb 20, 2020 at 10:14 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> 1. We expect floats to be in IEEE format, and the sort order of IEEE >> floats is mostly correlated to the binary sort order of the bits >> reinterpreted as an int. It isn't in some special cases, but for this >> use case we don't really care about that, we're just trying to >> encourage locality. > > I suppose there is a big jump in integer value (whether signed or > unsigned) as you cross from positive to negative floats, and then the > sort order is reversed. I have no idea if either of those things is a > problem worth fixing. That made me wonder if there might also be an > endianness problem. It seems from some quick googling that all > current architectures have integers and floats of the same endianness. > Apparently this wasn't always the case, and some ARMs have a weird > half-flipped arrangement for 64 bit floats, but not 32 bit floats as > you are using here. Yes, this leap is a problem for point as generic data type. And I do not know how to fix it. It can cause inefficient Index Scans when searching near (0,0) and query window touches simultaneously all quadrants (4x slower). But everything will be just fine when all data is in 2nd quadrant. Actually, we do not need to add this hacky code to core: we can provide colum-wise ordering or something similar as an example. This feature is aimed at PostGIS and they already possess bit tricks tricks [0]. I’ve taken this union code from PostGIS. Thanks! Best regards, Andrey Borodin. [0] https://github.com/postgis/postgis/blob/master/postgis/gserialized_gist_nd.c#L1150
Hi! > On 24 февр. 2020 г., at 13:50, Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > > Hi Thomas! > > Thanks for looking into this! I’ll fix your notices asap. PFA v5. Thomas, I've used your wording almost exactly with explanation how point_zorder_internal() works. It has more explanation power than my attempts to compose good comment. There is one design decision that worries me most: should we use opclass function or index option to provide this sorting information? It is needed only during index creation, actually. And having extra i-class only for fast build seems excessive. I think we can provide both ways and let opclass developers decide? Thanks! Best regards, Andrey Borodin.
Вложения
On 2020-02-29 13:13, Andrey M. Borodin wrote: > Hi! > >> On 24 февр. 2020 г., at 13:50, Andrey M. Borodin >> <x4mmm@yandex-team.ru> wrote: >> >> Hi Thomas! >> >> Thanks for looking into this! I’ll fix your notices asap. > > PFA v5. > Thomas, I've used your wording almost exactly with explanation how > point_zorder_internal() works. It has more explanation power than my > attempts > to compose good comment. Small typo alert: In v5-0002-Implement-GiST-build-using-sort-support.patch there is: + method is also optional and is used diring fast GiST build. 'diring' should be 'during'
> On 29 февр. 2020 г., at 17:20, Erik Rijkers <er@xs4all.nl> wrote: > > Small typo alert: > In v5-0002-Implement-GiST-build-using-sort-support.patch there is: > > + method is also optional and is used diring fast GiST build. > > 'diring' should be 'during' > Thanks! I've fixed this and added patch with GiST reloption to provide sort support function. Best regards, Andrey Borodin.
Вложения
Hello, Thanks for the patch and working on GiST infrastructure, it's really valuable for PostGIS use cases and I wait to see this improvement in PG13. On Sat, Feb 29, 2020 at 3:13 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > Thomas, I've used your wording almost exactly with explanation how > point_zorder_internal() works. It has more explanation power than my attempts > to compose good comment. PostGIS uses this trick to ensure locality. In PostGIS 3 we enhanced that trick to have the Hilbert curve instead of Z Order curve. For visual representation have a look at these links: - http://blog.cleverelephant.ca/2019/08/postgis-3-sorting.html - as it's implemented in PostGIS btree sorting opclass - https://observablehq.com/@mourner/hilbert-curve-packing - to explore general approach. Indeed if it feels insecure to work with bit magic that implementation can be left out to extensions. > There is one design decision that worries me most: > should we use opclass function or index option to provide this sorting information? > It is needed only during index creation, actually. And having extra i-class only for fast build > seems excessive. > I think we can provide both ways and let opclass developers decide? Reloption variant looks dirty. It won't cover an index on (id uuid, geom geometry) where id is duplicated (say, tracked car identifier) but present in every query - no way to pass such thing as reloption. I'm also concerned about security of passing a sortsupport function manually during index creation (what if that's not from the same extension or even (wrong-)user defined something). We know for sure it's a good idea for all btree_gist types and geometry and I don't see a case where user would want to disable it. Just make it part of operator class, and that would also allow fast creation of multi-column index. Thanks. -- Darafei Praliaskouski Support me: http://patreon.com/komzpa
Awesome addition! Would it make sense to use x86's BMI2's PDEP instruction, or is the interleave computation too small ofa percentage to introduce not-so-easy-to-port code? Also, I think it needs a bit more documentation to explain the logic,i.e. a link to https://stackoverflow.com/questions/39490345/interleave-bits-efficiently ? Thx for making it faster:)
Hello Yuri, PDEP is indeed first thing that comes up when you start googling z-curve and bit interleaving :) We had the code with z-curve generating PDEP instruction in PostGIS, and dropped it since. In sorting, we now utilize sort support / prefix search, and key generated as Hilbert curve, with fine tuning it for different projections' geometric properties. From this patch the most valuable thing for us is the sorting build infrastructure itself. Maybe to get it a bit more understandable for people not deep in geometry it makes sense to first expose the btree_gist datatypes to this thing? So that btree_gist index on integer will be built exactly the same way the btree index on integer is built. This will also get everyone a reference point on the bottlenecks and optimality of patch. On Fri, Apr 3, 2020 at 10:56 AM Yuri Astrakhan <yuriastrakhan@gmail.com> wrote: > > Awesome addition! Would it make sense to use x86's BMI2's PDEP instruction, or is the interleave computation too smallof a percentage to introduce not-so-easy-to-port code? Also, I think it needs a bit more documentation to explain thelogic, i.e. a link to https://stackoverflow.com/questions/39490345/interleave-bits-efficiently ? Thx for making it faster:) -- Darafei Praliaskouski Support me: http://patreon.com/komzpa
> On 29 Feb 2020, at 18:24, Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > I've fixed this and added patch with GiST reloption to provide sort support function. 0002 in this patchset fails to apply, please submit a rebased version. I've marked the entry Waiting for Author in the meantime. cheers ./daniel
> 1 июля 2020 г., в 17:05, Daniel Gustafsson <daniel@yesql.se> написал(а): > >> On 29 Feb 2020, at 18:24, Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > >> I've fixed this and added patch with GiST reloption to provide sort support function. > > 0002 in this patchset fails to apply, please submit a rebased version. I've > marked the entry Waiting for Author in the meantime. Thanks, Daniel! PFA v7. Best regards, Andrey Borodin.
Вложения
> 6 июля 2020 г., в 17:55, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): > > > >> 1 июля 2020 г., в 17:05, Daniel Gustafsson <daniel@yesql.se> написал(а): >> >>> On 29 Feb 2020, at 18:24, Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: >> >>> I've fixed this and added patch with GiST reloption to provide sort support function. >> >> 0002 in this patchset fails to apply, please submit a rebased version. I've >> marked the entry Waiting for Author in the meantime. > > Thanks, Daniel! > > PFA v7. Oops. I've mismerged docs and did not notice this with check world. PFA v8 with fixed docs. Best regards, Andrey Borodin.
Вложения
On Tue, Jul 7, 2020 at 7:03 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > Oops. I've mismerged docs and did not notice this with check world. PFA v8 with fixed docs. It looks like point_zorder_internal() has the check for NaN in the wrong place.
> 10 июля 2020 г., в 10:53, Thomas Munro <thomas.munro@gmail.com> написал(а): > > On Tue, Jul 7, 2020 at 7:03 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: >> Oops. I've mismerged docs and did not notice this with check world. PFA v8 with fixed docs. > > It looks like point_zorder_internal() has the check for NaN in the wrong place. Thanks! Fixed. Best regards, Andrey Borodin.
Вложения
On Fri, Jul 10, 2020 at 6:55 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > Thanks! Fixed. It's not a bug, but I think those 64 bit constants should be wrapped in UINT64CONST(), following our convention. I'm confused about these two patches: 0001 introduces gist_point_fastcmp(), but then 0002 changes it to gist_bbox_fastcmp(). Maybe you intended to keep both of them? Also 0002 seems to have fixups for 0001 squashed into it.
> 30 июля 2020 г., в 06:26, Thomas Munro <thomas.munro@gmail.com> написал(а): > > On Fri, Jul 10, 2020 at 6:55 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: >> Thanks! Fixed. > > It's not a bug, but I think those 64 bit constants should be wrapped > in UINT64CONST(), following our convention. Thanks, fixed! > I'm confused about these two patches: 0001 introduces > gist_point_fastcmp(), but then 0002 changes it to gist_bbox_fastcmp(). > Maybe you intended to keep both of them? Also 0002 seems to have > fixups for 0001 squashed into it. Indeed, that were fixups: point converted to GiST representation is a bbox already, and the function expects only bboxes. Also I've fixed some mismerges in documentation. Thanks! Best regards, Andrey Borodin.
Вложения
I see this feature quite useful in concept and decided to test it.
On a real database of 7 million rows I observed speedup of 4 times in case of single column index on points only and 2.5 times speedup in case of index on points with several included columns. Standard deviation between in series of measurements being of 10%. Index size saving was of 1.7-1.5 times respectively. Points were in all four quadrants.
On random points same as query in the original message it was observer 3 times speedup with the patch. Then I generated same points set but so they will get into one quadrant didn't observe a difference with the previous case. So probably anomaly in Morton curve not so big to induce noticeable slowdown in a whole random set. But as the ordering is done only for index and not used outside index it seems to me possible to introduce shifting floating point coordinates respective to leftmost-bottom corner point and thus make all of them positive to avoid anomaly of Morton curve near quadrants transitions.
Of course speed measurements depend on machine and configuration a lot, but I am sure anyway there is a noticeable difference in index build time and this is quite valuable for end-user who build GiSt index on point type of data. Furthermore same speedup is also for REBUILD INDEX CONCURRENTLY. There short rebuild time also mean fewer user modified table rows during rebuild which should be integrated in a newer index after rebuild.
This patch can be also seen as a step to futher introduce the other ordering algoritms e.g. Gilbert curve and I consider this feature is useful and is worth to be committed.
Both patches 0001 and 0002 when applied on version 14dev compile and work cleanly. Regression tests are passed.
Code seems clean and legible for me.
In declaration I see little bit different style in similar argument pointers/arrays:
extern IndexTuple gistFormTuple(GISTSTATE *giststate, Relation r, Datum *attdata, bool *isnull, bool isleaf);
extern IndexTuple gistCompressValusAndFormTuple(GISTSTATE *giststate, Relation r, Datum attdata[], bool isnull[], bool isleaf, Datum compatt[]);I suppose this is because gistFormTuple previously had different style in declaration and definition. Maybe it would be nice to change them to one style in all code, I propose pointers instead of [].
In a big comment
/*
+ * In this function we need to compute Morton codes for non-integral
+ * components p->x and p->y. But Morton codes are defined only for
+ * integral values.
+ * In this function we need to compute Morton codes for non-integral
+ * components p->x and p->y. But Morton codes are defined only for
+ * integral values.
i don't quite caught meaning of "non-integral" and "integral" and propose to replace it to "float" and "integers".
Also there are some extra spaces before line
"prev_level_start = level_start;"
and after
"The argument is a pointer to a <structname>SortSupport</structname> struct."
Overall I see the patch useful and almost ready for commit.
вт, 4 авг. 2020 г. в 21:28, Andrey M. Borodin <x4mmm@yandex-team.ru>:
> 30 июля 2020 г., в 06:26, Thomas Munro <thomas.munro@gmail.com> написал(а):
>
> On Fri, Jul 10, 2020 at 6:55 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:
>> Thanks! Fixed.
>
> It's not a bug, but I think those 64 bit constants should be wrapped
> in UINT64CONST(), following our convention.
Thanks, fixed!
> I'm confused about these two patches: 0001 introduces
> gist_point_fastcmp(), but then 0002 changes it to gist_bbox_fastcmp().
> Maybe you intended to keep both of them? Also 0002 seems to have
> fixups for 0001 squashed into it.
Indeed, that were fixups: point converted to GiST representation is a bbox already, and the function expects only bboxes.
Also I've fixed some mismerges in documentation.
Thanks!
Best regards, Andrey Borodin.
The following review has been posted through the commitfest application: make installcheck-world: tested, passed Implements feature: tested, passed Spec compliant: not tested Documentation: not tested I consider this patch almost ready for commit with minor corrections (see previous message) The new status of this patch is: Waiting on Author
> 14 авг. 2020 г., в 14:21, Pavel Borisov <pashkin.elfe@gmail.com> написал(а): > > I see this feature quite useful in concept and decided to test it. Thanks for reviewing and benchmarking, Pavel! I agree with your suggestions. PFA patch with relevant changes. Thanks a lot. Best regards, Andrey Borodin.
Вложения
> 23 авг. 2020 г., в 14:39, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): > > Thanks for reviewing and benchmarking, Pavel! Pavel sent me few typos offlist. PFA v12 fixing these typos. Thanks! Best regards, Andrey Borodin.
Вложения
Pavel sent me few typos offlist. PFA v12 fixing these typos.
Thanks!
Now I consider the patch ready to be committed and mark it so on CF.
Thank you!
On 30/08/2020 15:04, Andrey M. Borodin wrote: >> 23 авг. 2020 г., в 14:39, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): >> >> Thanks for reviewing and benchmarking, Pavel! > > Pavel sent me few typos offlist. PFA v12 fixing these typos. In gist_indexsortbuild(), you first build all the leaf pages. Then, you read through all the index pages you just built, to form the tuples for the next level, and repeat for all the upper levels. That seems inefficient, it would be more better to form the tuples for the downlinks as you go, when you build the leaf pages in the first place. That's how nbtsort.c works. Also, you could WAL-log the pages as you go. In gist_indexsortbuild_flush(), can't you just memcpy() the page from memory to the buffer? - Heikki
> 3 сент. 2020 г., в 23:40, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 30/08/2020 15:04, Andrey M. Borodin wrote: >>> 23 авг. 2020 г., в 14:39, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): >>> >>> Thanks for reviewing and benchmarking, Pavel! >> Pavel sent me few typos offlist. PFA v12 fixing these typos. > > In gist_indexsortbuild(), you first build all the leaf pages. Then, you read through all the index pages you just built,to form the tuples for the next level, and repeat for all the upper levels. That seems inefficient, it would be morebetter to form the tuples for the downlinks as you go, when you build the leaf pages in the first place. That's how nbtsort.cworks. Also, you could WAL-log the pages as you go. > > In gist_indexsortbuild_flush(), can't you just memcpy() the page from > memory to the buffer? > > - Heikki Thanks for ideas, Heikki. Please see v13 with proposed changes. But I've found out that logging page-by-page slows down GiST build by approximately 15% (when CPU constrained). Though In think that this is IO-wise. Thanks! Best regards, Andrey Borodin.
Вложения
On 05/09/2020 14:53, Andrey M. Borodin wrote: > Thanks for ideas, Heikki. Please see v13 with proposed changes. Thanks, that was quick! > But I've found out that logging page-by-page slows down GiST build by > approximately 15% (when CPU constrained). Though In think that this > is IO-wise. Hmm, any ideas why that is? log_newpage_range() writes one WAL record for 32 pages, while now you're writing one record per page, so you'll have a little bit more overhead from that. But 15% seems like a lot. - Heikki
> 6 сент. 2020 г., в 18:26, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 05/09/2020 14:53, Andrey M. Borodin wrote: >> Thanks for ideas, Heikki. Please see v13 with proposed changes. > > Thanks, that was quick! > >> But I've found out that logging page-by-page slows down GiST build by >> approximately 15% (when CPU constrained). Though In think that this >> is IO-wise. > Hmm, any ideas why that is? log_newpage_range() writes one WAL record for 32 pages, while now you're writing one recordper page, so you'll have a little bit more overhead from that. But 15% seems like a lot. I do not know. I guess this can be some effect of pglz compression during cold stage. It can be slower and less compressivethan pglz with cache table? But this is pointing into the sky. Nevertheless, here's the patch identical to v13, but with 3rd part: log flushed pages with bunches of 32. This brings CPU performance back and slightly better than before page-by-page logging. Some details about test: MacOS, 6-core i7 psql -c '\timing' -c "create table x as select point (random(),random()) from generate_series(1,10000000,1);" -c "createindex on x using gist (point);" With patch v13 this takes 20,567 seconds, with v14 18,149 seconds, v12 ~18,3s (which is closer to 10% btw, sorry for miscomputation).This was not statistically significant testing, just a quick laptop benchmark with 2-3 tests to verify stability. Best regards, Andrey Borodin.
Вложения
> 6 сент. 2020 г., в 18:26, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 05/09/2020 14:53, Andrey M. Borodin wrote: >> Thanks for ideas, Heikki. Please see v13 with proposed changes. > > Thanks, that was quick! > >> But I've found out that logging page-by-page slows down GiST build by >> approximately 15% (when CPU constrained). Though In think that this >> is IO-wise. > Hmm, any ideas why that is? log_newpage_range() writes one WAL record for 32 pages, while now you're writing one recordper page, so you'll have a little bit more overhead from that. But 15% seems like a lot. Hmm, this works for B-tree too. this index creation psql -c '\timing' -c "create table x as select random() from generate_series(1,10000000,1);" -c "create index ON x (random);" takes 7 seconds on may machine, but with one weird patch it takes only 6 :) Maybe I'm missing something? Like forgot to log 10% of pages, or something like that... Best regards, Andrey Borodin.
Вложения
> 7 сент. 2020 г., в 12:14, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): > > Maybe I'm missing something? Like forgot to log 10% of pages, or something like that... Indeed, there was a bug. I've fixed it, and I still observe same performance gain. Best regards, Andrey Borodin.
Вложения
On 24/02/2020 10:50, Andrey M. Borodin wrote: >> On 24 февр. 2020 г., at 01:58, Thomas Munro <thomas.munro@gmail.com> wrote: >> >> On Thu, Feb 20, 2020 at 10:14 AM Thomas Munro <thomas.munro@gmail.com> wrote: >>> 1. We expect floats to be in IEEE format, and the sort order of IEEE >>> floats is mostly correlated to the binary sort order of the bits >>> reinterpreted as an int. It isn't in some special cases, but for this >>> use case we don't really care about that, we're just trying to >>> encourage locality. >> >> I suppose there is a big jump in integer value (whether signed or >> unsigned) as you cross from positive to negative floats, and then the >> sort order is reversed. I have no idea if either of those things is a >> problem worth fixing. That made me wonder if there might also be an >> endianness problem. It seems from some quick googling that all >> current architectures have integers and floats of the same endianness. >> Apparently this wasn't always the case, and some ARMs have a weird >> half-flipped arrangement for 64 bit floats, but not 32 bit floats as >> you are using here. > > Yes, this leap is a problem for point as generic data type. And I do not know > how to fix it. It can cause inefficient Index Scans when searching near (0,0) and query > window touches simultaneously all quadrants (4x slower). I took a stab at fixing this, see attached patch (applies on top of your patch v14). To evaluate this, I used the other attached patch to expose the zorder function to SQL, and plotted points around zero with gnuplot. See the attached two images, one with patch v14, and the other one with this patch. I'll continue looking at these patches in whole tomorrow. I think it's getting close to a committable state. > But everything will be just fine when all data is in 2nd quadrant. Simon Riggs and friends would agree :-) - Heikki
Вложения
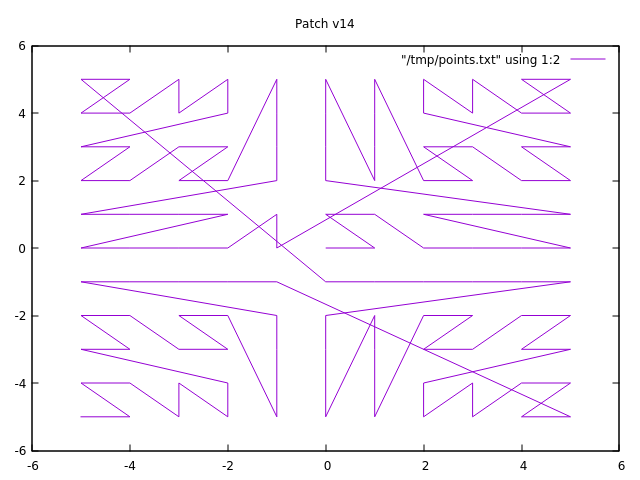{kind=link}
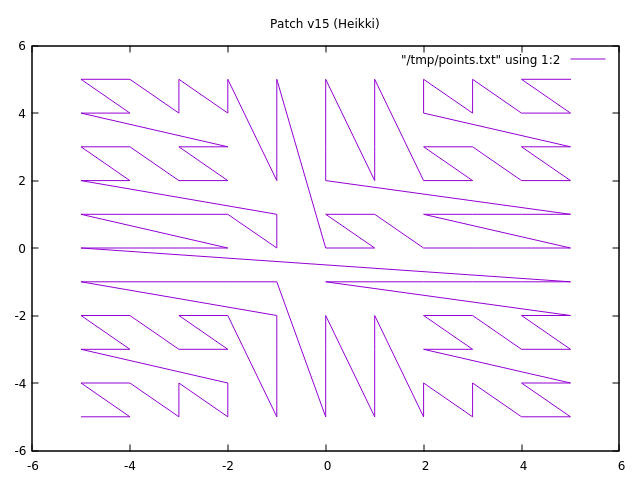{kind=link}
>> I suppose there is a big jump in integer value (whether signed or
>> unsigned) as you cross from positive to negative floats, and then the
>> sort order is reversed. I have no idea if either of those things is a
>> problem worth fixing. That made me wonder if there might also be an
I took a stab at fixing this, see attached patch (applies on top of your
patch v14).
To evaluate this, I used the other attached patch to expose the zorder
function to SQL, and plotted points around zero with gnuplot. See the
attached two images, one with patch v14, and the other one with this patch.
I'd made testing of sorted SpGist build in cases of points distributed only in 2d quadrant and points in all 4 quadrants and it appears that this abnormality doesn't affect as much as Andrey supposed. But Heikki's patch is really nice way to avoid what can be avoided and I'd like it is included together with Andrey's patch.
Pavel.
On 07/09/2020 13:59, Pavel Borisov wrote: >>>> I suppose there is a big jump in integer value (whether signed or >>>> unsigned) as you cross from positive to negative floats, and then the >>>> sort order is reversed. I have no idea if either of those things is a >>>> problem worth fixing. That made me wonder if there might also be an >> >> I took a stab at fixing this, see attached patch (applies on top of your >> patch v14). >> >> To evaluate this, I used the other attached patch to expose the zorder >> function to SQL, and plotted points around zero with gnuplot. See the >> attached two images, one with patch v14, and the other one with this patch. > > I'd made testing of sorted SpGist build in cases of points distributed only > in 2d quadrant and points in all 4 quadrants and it appears that this > abnormality doesn't affect as much as Andrey supposed. But Heikki's patch > is really nice way to avoid what can be avoided and I'd like it is included > together with Andrey's patch. Thanks! Did you measure the quality of the built index somehow? The ordering shouldn't make any difference to the build speed, but it affects the shape of the resulting index and the speed of queries against it. I played with some simple queries like this: explain (analyze, buffers) select count(*) from points_good where p <@ box(point(50, 50), point(75, 75)); and looking at the "Buffers" line for how many pages were accessed. There doesn't seem to be any consistent difference between v14 and my fix. So I concur it doesn't seem to matter much. I played some more with plotting the curve. I wrote a little python program to make an animation of it, and also simulated how the points would be divided into pages, assuming that each GiST page can hold 200 tuples (I think the real number is around 150 with default page size). In the animation, the leaf pages appear as rectangles as it walks through the Z-order curve. This is just a simulation by splitting all the points into batches of 200 and drawing a bounding box around each batch. I haven't checked the actual pages as the GiST creates, but I think this gives a good idea of how it works. The animation shows that there's quite a lot of overlap between the pages. It's not necessarily this patch's business to try to improve that, and the non-sorting index build isn't perfect either. But it occurs to me that there's maybe one pretty simple trick we could do: instead of blindly filling the leaf pages in Z-order, collect tuples into a larger buffer, in Z-order. I'm thinking 32 pages worth of tuples, or something in that ballpark, or maybe go all the way up to work_mem. When the buffer fills up, call the picksplit code to divide the buffer into the actual pages, and flush them to disk. If you look at the animation and imagine that you would take a handful of pages in the order they're created, and re-divide the points with the split algorithm, there would be much less overlap. - Heikki
Вложения
> 7 сент. 2020 г., в 19:10, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 07/09/2020 13:59, Pavel Borisov wrote: >>>>> I suppose there is a big jump in integer value (whether signed or >>>>> unsigned) as you cross from positive to negative floats, and then the >>>>> sort order is reversed. I have no idea if either of those things is a >>>>> problem worth fixing. That made me wonder if there might also be an >>> >>> I took a stab at fixing this, see attached patch (applies on top of your >>> patch v14). >>> >>> To evaluate this, I used the other attached patch to expose the zorder >>> function to SQL, and plotted points around zero with gnuplot. See the >>> attached two images, one with patch v14, and the other one with this patch. >> >> I'd made testing of sorted SpGist build in cases of points distributed only >> in 2d quadrant and points in all 4 quadrants and it appears that this >> abnormality doesn't affect as much as Andrey supposed. But Heikki's patch >> is really nice way to avoid what can be avoided and I'd like it is included >> together with Andrey's patch. > > Thanks! Did you measure the quality of the built index somehow? The > ordering shouldn't make any difference to the build speed, but it > affects the shape of the resulting index and the speed of queries > against it. I've tried to benchmark the difference between build time v14 and v15. v15 seems to be slightly slower, but with negligibledifference. > I played with some simple queries like this: > > explain (analyze, buffers) select count(*) from points_good where p <@ > box(point(50, 50), point(75, 75)); To observe IndexScan difference query should touch 4 quadrants. i.e. search within ((-25,-25),point(25,25)) > and looking at the "Buffers" line for how many pages were accessed. > There doesn't seem to be any consistent difference between v14 and my > fix. So I concur it doesn't seem to matter much. > > > I played some more with plotting the curve. I wrote a little python > program to make an animation of it, and also simulated how the points > would be divided into pages, assuming that each GiST page can hold 200 > tuples (I think the real number is around 150 with default page size). > In the animation, the leaf pages appear as rectangles as it walks > through the Z-order curve. This is just a simulation by splitting all > the points into batches of 200 and drawing a bounding box around each > batch. I haven't checked the actual pages as the GiST creates, but I > think this gives a good idea of how it works. > The animation shows that there's quite a lot of overlap between the > pages. It's not necessarily this patch's business to try to improve > that, and the non-sorting index build isn't perfect either. But it > occurs to me that there's maybe one pretty simple trick we could do: > instead of blindly filling the leaf pages in Z-order, collect tuples > into a larger buffer, in Z-order. I'm thinking 32 pages worth of tuples, > or something in that ballpark, or maybe go all the way up to work_mem. > When the buffer fills up, call the picksplit code to divide the buffer > into the actual pages, and flush them to disk. If you look at the > animation and imagine that you would take a handful of pages in the > order they're created, and re-divide the points with the split > algorithm, there would be much less overlap. Animation looks cool! It really pins the inefficiency of resulting MBRs. But in R*-tree one of Beckman's points was that overlap optimisation worth doing on higher levels, not lower. But we can do this for splits on each level, I think. We do not know tree depth in advance to divide maintenance workmemamong level.. But, probably we don't need to, let's allocate half to first level, quarter to second, 1/8 to thirdetc until it's one page. Should we take allocations inside picksplit() into account? The more I think about it the cooler idea seem to me. BTW I've found one more bug in the patch: it writes WAL even for unlogged tables. I'm not sending a patch because changesare trivial and currently we already have lengthy patchset in different messages. Also, to avoid critical section we can use log_new_page() instead of log_buffer(). Thanks! Best regards, Andrey Borodin.
> Thanks! Did you measure the quality of the built index somehow? The
> ordering shouldn't make any difference to the build speed, but it
> affects the shape of the resulting index and the speed of queries
> against it.
Again I've tried random select tests near axes and haven't noticed any performance difference between ordinary gist build and z-ordered one. The same is for selects far from axes. Theoretically, there may be a possible slowdown for particular points inside the MBR which crosses the axis but I haven't tried to dig so deep and haven't tested performance as a function of coordinate.
So I feel this patch is not about select speed optimization.
On 08/09/2020 21:33, Pavel Borisov wrote: > > Thanks! Did you measure the quality of the built index somehow? The > > ordering shouldn't make any difference to the build speed, but it > > affects the shape of the resulting index and the speed of queries > > against it. > > Again I've tried random select tests near axes and haven't noticed any > performance difference between ordinary gist build and z-ordered one. > The same is for selects far from axes. Theoretically, there may be a > possible slowdown for particular points inside the MBR which crosses the > axis but I haven't tried to dig so deep and haven't tested performance > as a function of coordinate. > > So I feel this patch is not about select speed optimization. Ok, thank for confirming. I've been reviewing the patch today. The biggest changes I've made have been in restructuring the code in gistbuild.c for readability, but there are a bunch of smaller changes throughout. Attached is what I've got so far, squashed into one patch. I'm continuing to review it, but a couple of questions so far: In the gistBuildCallback(), you're skipping the tuple if 'tupleIsAlive == false'. That seems fishy, surely we need to index recently-dead tuples, too. The normal index build path isn't skipping them either. How does the 'sortsupport' routine interact with 'compress'/'decompress'? Which representation is passed to the comparator routine: the original value from the table, the compressed representation, or the decompressed representation? Do the comparetup_index_btree() and readtup_index() routines agree with that? - Heikki
Вложения
> 9 сент. 2020 г., в 00:05, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > I've been reviewing the patch today. The biggest changes I've made have been in restructuring the code in gistbuild.c forreadability, but there are a bunch of smaller changes throughout. Attached is what I've got so far, squashed into onepatch. Thanks! > I'm continuing to review it, but a couple of questions so far: > > In the gistBuildCallback(), you're skipping the tuple if 'tupleIsAlive == false'. That seems fishy, surely we need to indexrecently-dead tuples, too. The normal index build path isn't skipping them either. That's an oversight. > > How does the 'sortsupport' routine interact with 'compress'/'decompress'? Which representation is passed to the comparatorroutine: the original value from the table, the compressed representation, or the decompressed representation?Do the comparetup_index_btree() and readtup_index() routines agree with that? Currently we pass compressed values, which seems not very good. But there was a request from PostGIS maintainers to pass values before decompression. Darafei, please, correct me if I'm wrong. Also can you please provide link on PostGIS B-tree sorting functions? Thanks! Best regards, Andrey Borodin.
Hi,
On Wed, Sep 9, 2020 at 9:43 AM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:
> 9 сент. 2020 г., в 00:05, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> I've been reviewing the patch today. The biggest changes I've made have been in restructuring the code in gistbuild.c for readability, but there are a bunch of smaller changes throughout. Attached is what I've got so far, squashed into one patch.
Thanks!
> I'm continuing to review it, but a couple of questions so far:
>
> In the gistBuildCallback(), you're skipping the tuple if 'tupleIsAlive == false'. That seems fishy, surely we need to index recently-dead tuples, too. The normal index build path isn't skipping them either.
That's an oversight.
>
> How does the 'sortsupport' routine interact with 'compress'/'decompress'? Which representation is passed to the comparator routine: the original value from the table, the compressed representation, or the decompressed representation? Do the comparetup_index_btree() and readtup_index() routines agree with that?
Currently we pass compressed values, which seems not very good.
But there was a request from PostGIS maintainers to pass values before decompression.
Darafei, please, correct me if I'm wrong. Also can you please provide link on PostGIS B-tree sorting functions?
We were expecting to reuse btree opclass for this thing. This way btree_gist extension will become a lot thinner. :)
Core routine for current sorting implementation is Hilbert curve, which is based on 2D center of a box - and used for abbreviated sort:
https://github.com/postgis/postgis/blob/2a7ebd0111b02aed3aa24752aad0ba89aef5d431/liblwgeom/gbox.c#L893
https://github.com/postgis/postgis/blob/2a7ebd0111b02aed3aa24752aad0ba89aef5d431/liblwgeom/gbox.c#L893
All the btree functions are wrappers around gserialized_cmp which just adds a bunch of tiebreakers that don't matter in practice:
https://github.com/postgis/postgis/blob/2a7ebd0111b02aed3aa24752aad0ba89aef5d431/liblwgeom/gserialized.c#L313
Base representation for index compressed datatype is GIDX, which is also a box. We can make it work on top of it instead of the original representation.
There is no such thing as "decompressed representation" unfortunately as compression is lossy.
https://github.com/postgis/postgis/blob/2a7ebd0111b02aed3aa24752aad0ba89aef5d431/liblwgeom/gserialized.c#L313
Base representation for index compressed datatype is GIDX, which is also a box. We can make it work on top of it instead of the original representation.
There is no such thing as "decompressed representation" unfortunately as compression is lossy.
Thanks Darafei! > 9 сент. 2020 г., в 12:05, Darafei Komяpa Praliaskouski <me@komzpa.net> написал(а): > > > How does the 'sortsupport' routine interact with 'compress'/'decompress'? Which representation is passed to the comparatorroutine: the original value from the table, the compressed representation, or the decompressed representation?Do the comparetup_index_btree() and readtup_index() routines agree with that? > > Currently we pass compressed values, which seems not very good. > But there was a request from PostGIS maintainers to pass values before decompression. > Darafei, please, correct me if I'm wrong. Also can you please provide link on PostGIS B-tree sorting functions? > > We were expecting to reuse btree opclass for this thing. This way btree_gist extension will become a lot thinner. :) I think if we aim at reusing B-tree sort support functions we have to pass uncompressed values. They can be a lot biggerand slower in case of PostGIS. We will be sorting actual geometries instead of MBRs. In my view it's better to implement GiST-specific sort support in btree_gist, rather than trying to reuse existing sort supports. Best regards, Andrey Borodin.
On 09/09/2020 13:28, Andrey M. Borodin wrote: > Thanks Darafei! > >> 9 сент. 2020 г., в 12:05, Darafei Komяpa Praliaskouski >> <me@komzpa.net> написал(а): >> >>> How does the 'sortsupport' routine interact with >>> 'compress'/'decompress'? Which representation is passed to the >>> comparator routine: the original value from the table, the >>> compressed representation, or the decompressed representation? Do >>> the comparetup_index_btree() and readtup_index() routines agree >>> with that? >> >> Currently we pass compressed values, which seems not very good. But >> there was a request from PostGIS maintainers to pass values before >> decompression. Darafei, please, correct me if I'm wrong. Also can >> you please provide link on PostGIS B-tree sorting functions? >> >> We were expecting to reuse btree opclass for this thing. This way >> btree_gist extension will become a lot thinner. :) > > I think if we aim at reusing B-tree sort support functions we have to > pass uncompressed values. They can be a lot bigger and slower in case > of PostGIS. We will be sorting actual geometries instead of MBRs. > > In my view it's better to implement GiST-specific sort support in > btree_gist, rather than trying to reuse existing sort supports. Yeah, I don't think reusing existing sortsupport functions directly is important. The comparison function should be short anyway for performance reasons, so it won't be a lot of code to copy-paste. And if there are some common subroutines, you can put them in a separate internal functions for reuse. Using the 'compressed' format seems reasonable to me. It's natural to the gistbuild.c code, and the comparison routine can 'decompress' itself if it wishes. If the decompressions is somewhat expensive, it's unfortunate if you need to do it repeatedly in the comparator, but tuplesort.c would need pretty big changes to keep around a separate in-memory representation compare. However, you could use the sort "abbreviation" functionality to mitigate that. Come to think of it, the point z-order comparator could benefit a lot from key abbreviation, too. You could do the point -> zorder conversion in the abbreviation routine. - Heikki
On Wed, Sep 9, 2020 at 3:09 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote:
On 09/09/2020 13:28, Andrey M. Borodin wrote:
> Thanks Darafei!
>
>> 9 сент. 2020 г., в 12:05, Darafei Komяpa Praliaskouski
>> <me@komzpa.net> написал(а):
>>
>>> How does the 'sortsupport' routine interact with
>>> 'compress'/'decompress'? Which representation is passed to the
>>> comparator routine: the original value from the table, the
>>> compressed representation, or the decompressed representation? Do
>>> the comparetup_index_btree() and readtup_index() routines agree
>>> with that?
>>
....
Come to think of it, the point z-order comparator could benefit a lot
from key abbreviation, too. You could do the point -> zorder conversion
in the abbreviation routine.
That's how it works in PostGIS, only that we moved to more effecient Hilbert curve:
https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171
https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171
On 09/09/2020 15:20, Darafei "Komяpa" Praliaskouski wrote: > On Wed, Sep 9, 2020 at 3:09 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > >> Come to think of it, the point z-order comparator could benefit a lot >> from key abbreviation, too. You could do the point -> zorder conversion >> in the abbreviation routine. > > That's how it works in PostGIS, only that we moved to more > effecient Hilbert curve: > https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171 Thanks, that's interesting. I implemented the abbreviated keys for the point opclass, too, and noticed that the patch as it was never used it. I reworked the patch so that tuplesort_begin_index_gist() is responsible for looking up the sortsupport function, like tuplesort_begin_index_btree() does, and uses abbreviation when possible. I think this is pretty much ready for commit now. I'll do a bit more testing (do we have regression test coverage for this?), also on a SIZEOF_DATUM==4 system since the abbreviation works differently with that, and push if nothing new comes up. And clarify the documentation and/or comments that the sortsupport function sees "compressed" values. I wonder if we could use sorting to also speed up building tsvector indexes? The values stored there are bit signatures, what would be a good sort order for those? - Heikki
On 09/09/2020 15:20, Darafei "Komяpa" Praliaskouski wrote: > On Wed, Sep 9, 2020 at 3:09 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > >> Come to think of it, the point z-order comparator could benefit a lot >> from key abbreviation, too. You could do the point -> zorder conversion >> in the abbreviation routine. > > That's how it works in PostGIS, only that we moved to more > effecient Hilbert curve: > https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171 Thanks, that's interesting. I implemented the abbreviated keys for the point opclass, too, and noticed that the patch as it was never used it. I reworked the patch so that tuplesort_begin_index_gist() is responsible for looking up the sortsupport function, like tuplesort_begin_index_btree() does, and uses abbreviation when possible. I think this is pretty much ready for commit now. I'll do a bit more testing (do we have regression test coverage for this?), also on a SIZEOF_DATUM==4 system since the abbreviation works differently with that, and push if nothing new comes up. And clarify the documentation and/or comments that the sortsupport function sees "compressed" values. I wonder if we could use sorting to also speed up building tsvector indexes? The values stored there are bit signatures, what would be a good sort order for those? - Heikki
Вложения
> 9 сент. 2020 г., в 20:39, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 09/09/2020 15:20, Darafei "Komяpa" Praliaskouski wrote: >> On Wed, Sep 9, 2020 at 3:09 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> Come to think of it, the point z-order comparator could benefit a lot >>> from key abbreviation, too. You could do the point -> zorder conversion >>> in the abbreviation routine. >> That's how it works in PostGIS, only that we moved to more >> effecient Hilbert curve: >> https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171 > > Thanks, that's interesting. > > I implemented the abbreviated keys for the point opclass, too, and noticed that the patch as it was never used it. I reworkedthe patch so that tuplesort_begin_index_gist() is responsible for looking up the sortsupport function, like tuplesort_begin_index_btree()does, and uses abbreviation when possible. Wow, abbreviated sort made gist for points construction even 1.5x faster! btw there is small typo in arg names in gist_bbox_zorder_cmp_abbrev(); z1,z2 -> a,b > do we have regression test coverage for this? Yes, sorting build for points is tested in point.sql, but with small dataset. index_including_gist.sql seems to be workingwith boxes, but triggers point paths too. > , also on a SIZEOF_DATUM==4 system since the abbreviation works differently with that, and push if nothing new comes up.And clarify the documentation and/or comments that the sortsupport function sees "compressed" values. > > I wonder if we could use sorting to also speed up building tsvector indexes? The values stored there are bit signatures,what would be a good sort order for those? We need an order so that nearby values have a lot of bits in common. What is the length of this signature? For each 4 bytes we can compute number of 1s in it's binary representation. Then z-order these dwords as values 0-32. This will be very inefficient grouping, but it will tend to keep empty and dense 4-byte regions apart. Thanks for working on this! Best regards, Andrey Borodin.
On Mon, Sep 7, 2020 at 7:50 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > On 07/09/2020 13:59, Pavel Borisov wrote: > >>>> I suppose there is a big jump in integer value (whether signed or > >>>> unsigned) as you cross from positive to negative floats, and then the > >>>> sort order is reversed. I have no idea if either of those things is a > >>>> problem worth fixing. That made me wonder if there might also be an > >> > >> I took a stab at fixing this, see attached patch (applies on top of your > >> patch v14). > >> > >> To evaluate this, I used the other attached patch to expose the zorder > >> function to SQL, and plotted points around zero with gnuplot. See the > >> attached two images, one with patch v14, and the other one with this patch. > > > > I'd made testing of sorted SpGist build in cases of points distributed only > > in 2d quadrant and points in all 4 quadrants and it appears that this > > abnormality doesn't affect as much as Andrey supposed. But Heikki's patch > > is really nice way to avoid what can be avoided and I'd like it is included > > together with Andrey's patch. > > Thanks! Did you measure the quality of the built index somehow? The > ordering shouldn't make any difference to the build speed, but it > affects the shape of the resulting index and the speed of queries > against it. > > I played with some simple queries like this: > > explain (analyze, buffers) select count(*) from points_good where p <@ > box(point(50, 50), point(75, 75)); > > and looking at the "Buffers" line for how many pages were accessed. > There doesn't seem to be any consistent difference between v14 and my > fix. So I concur it doesn't seem to matter much. > > > I played some more with plotting the curve. I wrote a little python > program to make an animation of it, and also simulated how the points > would be divided into pages, assuming that each GiST page can hold 200 > tuples (I think the real number is around 150 with default page size). > In the animation, the leaf pages appear as rectangles as it walks > through the Z-order curve. This is just a simulation by splitting all > the points into batches of 200 and drawing a bounding box around each > batch. I haven't checked the actual pages as the GiST creates, but I > think this gives a good idea of how it works. Heikki, you may use our gevel extension to visualize index tree http://www.sai.msu.su/~megera/wiki/Gevel I used it to investigate rtree index http://www.sai.msu.su/~megera/wiki/Rtree_Index > > The animation shows that there's quite a lot of overlap between the > pages. It's not necessarily this patch's business to try to improve > that, and the non-sorting index build isn't perfect either. But it > occurs to me that there's maybe one pretty simple trick we could do: > instead of blindly filling the leaf pages in Z-order, collect tuples > into a larger buffer, in Z-order. I'm thinking 32 pages worth of tuples, > or something in that ballpark, or maybe go all the way up to work_mem. > When the buffer fills up, call the picksplit code to divide the buffer > into the actual pages, and flush them to disk. If you look at the > animation and imagine that you would take a handful of pages in the > order they're created, and re-divide the points with the split > algorithm, there would be much less overlap. Interesting to see also the size of index, it should be several times less. > > - Heikki -- Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Interesting to see also the size of index, it should be several times less.
I've tested this above in CF thread and got ordered GiST index ~1.7 times smaller than non-ordered one for single column of real points.
On 09/09/2020 19:50, Andrey M. Borodin wrote: >> 9 сент. 2020 г., в 20:39, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): >> >> On 09/09/2020 15:20, Darafei "Komяpa" Praliaskouski wrote: >>> On Wed, Sep 9, 2020 at 3:09 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>>> Come to think of it, the point z-order comparator could benefit a lot >>>> from key abbreviation, too. You could do the point -> zorder conversion >>>> in the abbreviation routine. >>> That's how it works in PostGIS, only that we moved to more >>> effecient Hilbert curve: >>> https://github.com/postgis/postgis/blob/54399b9f6b0f02e8db9444f9f042b8d4ca6d4fa4/postgis/lwgeom_btree.c#L171 >> >> Thanks, that's interesting. >> >> I implemented the abbreviated keys for the point opclass, too, and noticed that the patch as it was never used it. I reworkedthe patch so that tuplesort_begin_index_gist() is responsible for looking up the sortsupport function, like tuplesort_begin_index_btree()does, and uses abbreviation when possible. > Wow, abbreviated sort made gist for points construction even 1.5x faster! > btw there is small typo in arg names in gist_bbox_zorder_cmp_abbrev(); z1,z2 -> a,b One more patch version attached. I fixed some memory leaks, and fixed the abbreviation on 32-bit systems, and a bunch of small comment changes and such. - Heikki
Вложения
> 10 сент. 2020 г., в 17:43, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > One more patch version attached. I fixed some memory leaks, and fixed the abbreviation on 32-bit systems, and a bunch ofsmall comment changes and such. > > - Heikki > <v18-0001-Add-support-for-building-GiST-index-by-sorting.patch> The patch looks fine to me. On my machine GiST for points is builded 10x faster than before the patch. Future action items: 1. Sort support for gist_btree data types 2. Better page borders with split and fillfactor 3. Consider sort build for tsvector I'll certainly do 1 before next CF and most probably 2. Item 1 is basically a lot of similar code for many many different types. In Item 2 I plan to use Oleg's gevel to evaluation possibilities of MBR overlap reduction. Item 3 seems tricky and need deeper evaluation: chances are sort build will decrease IndexScan performance in this case. Thanks, Heikki! Best regards, Andrey Borodin,
On 11/09/2020 09:02, Andrey M. Borodin wrote: >> 10 сент. 2020 г., в 17:43, Heikki Linnakangas <hlinnaka@iki.fi> >> написал(а): >> >> One more patch version attached. I fixed some memory leaks, and >> fixed the abbreviation on 32-bit systems, and a bunch of small >> comment changes and such. >> >> <v18-0001-Add-support-for-building-GiST-index-by-sorting.patch> > > The patch looks fine to me. On my machine GiST for points is builded > 10x faster than before the patch. Another patch version, fixed a few small bugs pointed out by assertion failures in the regression tests. - Heikki
Вложения
> 15 сент. 2020 г., в 16:36, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> Another patch version, fixed a few small bugs pointed out by assertion failures in the regression tests.
>
> - Heikki
> <v19-0001-Add-support-for-building-GiST-index-by-sorting.patch>
These changes in create_index.out do not seem correct to me
SELECT * FROM point_tbl ORDER BY f1 <-> '0,1';
f1
-------------------
- (0,0)
(1e-300,-1e-300)
+ (0,0)
I did not figure out the root cause yet. We do not touch anything related to distance computation..
Best regards, Andrey Borodin.
On 15/09/2020 19:46, Andrey M. Borodin wrote:
>
>
>> 15 сент. 2020 г., в 16:36, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>>
>> Another patch version, fixed a few small bugs pointed out by assertion failures in the regression tests.
>>
>> - Heikki
>> <v19-0001-Add-support-for-building-GiST-index-by-sorting.patch>
>
> These changes in create_index.out do not seem correct to me
>
> SELECT * FROM point_tbl ORDER BY f1 <-> '0,1';
> f1
> -------------------
> - (0,0)
> (1e-300,-1e-300)
> + (0,0)
>
> I did not figure out the root cause yet. We do not touch anything related to distance computation..
Ah yeah, that's subtle. Those rows are considered to be equally distant
from (0, 1), given the precision of the <-> operator:
regression=# SELECT f1, f1 <-> '0,1' FROM point_tbl ORDER BY f1 <-> '0,1';
f1 | ?column?
-------------------+------------------
(0,0) | 1
(1e-300,-1e-300) | 1
(-3,4) | 4.24264068711929
(-10,0) | 10.0498756211209
(10,10) | 13.4536240470737
(-5,-12) | 13.9283882771841
(5.1,34.5) | 33.885985303662
(1e+300,Infinity) | Infinity
(NaN,NaN) | NaN
|
(10 rows)
It is arbitrary which one you get first.
It's not very nice to have a not-well defined order of rows in the
expected output, as it could change in the future if we change the index
build algorithm again. But we have plenty of cases that depend on the
physical row order, and it's not like this changes very often, so I
think it's ok to just memorize the new order in the expected output.
- Heikki
> 15 сент. 2020 г., в 22:07, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > regression=# SELECT f1, f1 <-> '0,1' FROM point_tbl ORDER BY f1 <-> '0,1'; > f1 | ?column? > -------------------+------------------ > (0,0) | 1 > (1e-300,-1e-300) | 1 > (-3,4) | 4.24264068711929 > (-10,0) | 10.0498756211209 > (10,10) | 13.4536240470737 > (-5,-12) | 13.9283882771841 > (5.1,34.5) | 33.885985303662 > (1e+300,Infinity) | Infinity > (NaN,NaN) | NaN > | > (10 rows) > > It is arbitrary which one you get first. > > It's not very nice to have a not-well defined order of rows in the expected output, as it could change in the future ifwe change the index build algorithm again. But we have plenty of cases that depend on the physical row order, and it'snot like this changes very often, so I think it's ok to just memorize the new order in the expected output. I think this is valid reasoning. GiST choose subtree algorithm is not deterministic, it calls random(), but not in testedpaths. I was thinking that machine epsilon is near 1e-300, but I was wrong. It's actually near 1e-15. Actually, I just want to understand what changes between v18 and v19 changed on-page order of items. I look into patch diffand cannot figure it out. There are only logging changes. How this affects scan? Best regards, Andrey Borodin.
On 16/09/2020 10:27, Andrey M. Borodin wrote: > Actually, I just want to understand what changes between v18 and v19 > changed on-page order of items. I look into patch diff and cannot > figure it out. There are only logging changes. How this affects > scan? The test was failing with v18 too. - Heikki
At Wed, 16 Sep 2020 12:27:09 +0500, "Andrey M. Borodin" <x4mmm@yandex-team.ru> wrote in > I was thinking that machine epsilon is near 1e-300, but I was > wrong. It's actually near 1e-15. FWIW, the mantissa of double is effectively 52+1 bits, about 15.9 digits. so 1+(1e-16) is basically indistincitve from 1+(2e-16). Actually two double precisions 1+2e-16 and 1+3e-16 are indistinctive from each other. > Actually, I just want to understand what changes between v18 and v19 changed on-page order of items. I look into patchdiff and cannot figure it out. There are only logging changes. How this affects scan? FWIW, I saw the same symptom by my another patch after adding a value to POINT_TBL. (But I didn't pursue the cause further..) regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On 15/09/2020 14:36, Heikki Linnakangas wrote: > Another patch version, fixed a few small bugs pointed out by assertion > failures in the regression tests. Pushed. Thanks everyone! - Heikki
> 17 сент. 2020 г., в 13:38, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 15/09/2020 14:36, Heikki Linnakangas wrote: >> Another patch version, fixed a few small bugs pointed out by assertion >> failures in the regression tests. > > Pushed. Thanks everyone! That's wonderful! Thank you, Heikki! Best regards, Andrey Borodin.
Heikki Linnakangas <hlinnaka@iki.fi> writes: > Pushed. Thanks everyone! It appears that hyrax (CLOBBER_CACHE_ALWAYS) is not very happy with this: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=hyrax&dt=2020-09-19%2021%3A27%3A23 We have a recent pass from prion, showing that -DRELCACHE_FORCE_RELEASE -DCATCACHE_FORCE_RELEASE doesn't cause a problem, so maybe hyrax's result is just random cosmic rays or something. But I doubt it. regards, tom lane
I wrote: > It appears that hyrax (CLOBBER_CACHE_ALWAYS) is not very happy > with this: > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=hyrax&dt=2020-09-19%2021%3A27%3A23 I reproduced that and traced it to a missing RelationOpenSmgr call. Fixed now. regards, tom lane
Justin Pryzby <pryzby@telsasoft.com> writes:
> This also appears to break checksums.
I was wondering about that, because the typical pattern for use of
smgrextend for indexes seems to be
RelationOpenSmgr(rel);
PageSetChecksumInplace(page, lastblock);
smgrextend(rel->rd_smgr, MAIN_FORKNUM, lastblock, zerobuf.data, false);
and gist_indexsortbuild wasn't doing either of the first two things.
gist_indexsortbuild_flush_ready_pages looks like it might be
a few bricks shy of a load too. But my local CLOBBER_CACHE_ALWAYS
run hasn't gotten to anything except the pretty-trivial index
made in point.sql, so I don't have evidence about it.
Another interesting point is that all the other index AMs seem to WAL-log
the new page before the smgrextend call, whereas this code is doing it
in the other order. I strongly doubt that both patterns are equally
correct. Could be that the other AMs are in the wrong though.
regards, tom lane
On 21/09/2020 02:06, Tom Lane wrote: > Justin Pryzby <pryzby@telsasoft.com> writes: >> This also appears to break checksums. Thanks, I'll go fix it. > I was wondering about that, because the typical pattern for use of > smgrextend for indexes seems to be > > RelationOpenSmgr(rel); > PageSetChecksumInplace(page, lastblock); > smgrextend(rel->rd_smgr, MAIN_FORKNUM, lastblock, zerobuf.data, false); > > and gist_indexsortbuild wasn't doing either of the first two things. > > gist_indexsortbuild_flush_ready_pages looks like it might be > a few bricks shy of a load too. But my local CLOBBER_CACHE_ALWAYS > run hasn't gotten to anything except the pretty-trivial index > made in point.sql, so I don't have evidence about it. I don't think a relcache invalidation can happen on the index we're building. Other similar callers call RelationOpenSmgr(rel) before every write though (e.g. _bt_blwritepage()), so perhaps it's better to copy that pattern here too. > Another interesting point is that all the other index AMs seem to WAL-log > the new page before the smgrextend call, whereas this code is doing it > in the other order. I strongly doubt that both patterns are equally > correct. Could be that the other AMs are in the wrong though. My thinking was that it's better to call smgrextend() first, so that if you run out of disk space, you get the error before WAL-logging it. That reduces the chance that WAL replay will run out of disk space. A lot of things are different during WAL replay, so it's quite likely that WAL replay runs out of disk space anyway if you're living on the edge, but still. I didn't notice that the other callers are doing it the other way round, though. I think they need to, so that they can stamp the page with the LSN of the WAL record. But GiST build is special in that regard, because it stamps all pages with GistBuildLSN. - Heikki
On 21/09/2020 11:08, Heikki Linnakangas wrote: > I think they need to, so that they can stamp the page with the LSN of > the WAL record. But GiST build is special in that regard, because it > stamps all pages with GistBuildLSN. Actually, don't we have a problem with that, even before this patch? Even though we set the LSN to the magic GistBuildLSN value when we build the index, WAL replay will write the LSN of the record instead. That would mess with the LSN-NSN interlock. After WAL replay (or in a streaming replica), a scan on the GiST index might traverse right-links unnecessarily. - Heikki
> 21 сент. 2020 г., в 13:45, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 21/09/2020 11:08, Heikki Linnakangas wrote: >> I think they need to, so that they can stamp the page with the LSN of >> the WAL record. But GiST build is special in that regard, because it >> stamps all pages with GistBuildLSN. > > Actually, don't we have a problem with that, even before this patch? Even though we set the LSN to the magic GistBuildLSNvalue when we build the index, WAL replay will write the LSN of the record instead. That would mess with theLSN-NSN interlock. After WAL replay (or in a streaming replica), a scan on the GiST index might traverse right-links unnecessarily. I think we don't set rightlinks during index build. Best regards, Andrey Borodin.
On 21/09/2020 02:06, Tom Lane wrote: > Justin Pryzby <pryzby@telsasoft.com> writes: >> This also appears to break checksums. Fixed, thanks for the report! > I was wondering about that, because the typical pattern for use of > smgrextend for indexes seems to be > > RelationOpenSmgr(rel); > PageSetChecksumInplace(page, lastblock); > smgrextend(rel->rd_smgr, MAIN_FORKNUM, lastblock, zerobuf.data, false); > > and gist_indexsortbuild wasn't doing either of the first two things. > > gist_indexsortbuild_flush_ready_pages looks like it might be > a few bricks shy of a load too. But my local CLOBBER_CACHE_ALWAYS > run hasn't gotten to anything except the pretty-trivial index > made in point.sql, so I don't have evidence about it. I added a RelationOpenSmgr() call there too, although it's not needed currently. It seems to be enough to do it before the first smgrextend() call. But if you removed or refactored the first call someohow, so it was not the first call anymore, it would be easy to miss that you'd still need the RelationOpenSmgr() call there. It's more consistent with the code in nbtsort.c now, too. - Heikki
On 21/09/2020 12:06, Andrey M. Borodin wrote: >> 21 сент. 2020 г., в 13:45, Heikki Linnakangas <hlinnaka@iki.fi> >> написал(а): >> >> Actually, don't we have a problem with that, even before this >> patch? Even though we set the LSN to the magic GistBuildLSN value >> when we build the index, WAL replay will write the LSN of the >> record instead. That would mess with the LSN-NSN interlock. After >> WAL replay (or in a streaming replica), a scan on the GiST index >> might traverse right-links unnecessarily. > > I think we don't set rightlinks during index build. The new GiST sorting code does not, but the regular insert-based code does. That's a bit questionable in the new code actually. Was that a conscious decision? The right-links are only needed when there are concurrent page splits, so I think it's OK, but the checks for InvalidBlockNumber in gistScanPage() and gistFindPage() have comment "/* sanity check */". Comment changes are needed, at least. - Heikki
> 21 сент. 2020 г., в 17:15, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > On 21/09/2020 12:06, Andrey M. Borodin wrote >> >> I think we don't set rightlinks during index build. > > The new GiST sorting code does not, but the regular insert-based code does. > > That's a bit questionable in the new code actually. Was that a conscious > decision? The right-links are only needed when there are concurrent page > splits, so I think it's OK, but the checks for InvalidBlockNumber in > gistScanPage() and gistFindPage() have comment "/* sanity check */". > Comment changes are needed, at least. It was a conscious decision with incorrect motivation. I was thinking that it will help to reduce number of "false positive"inspecting right pages. But now I see that: 1. There should be no such "false positives" that we can avoid 2. Valid rightlinks could help to do amcheck verification in future But thing that bothers me now: when we vacuum leaf page, we bump it's NSN. But we do not bump internal page LSN. Does thismeans we will follow rightlinks after vacuum? It seems superflous. And btw we did not adjust internal page tuples aftervacuum... Best regards, Andrey Borodin.
> 21 сент. 2020 г., в 18:29, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): > > It was a conscious decision with incorrect motivation. I was thinking that it will help to reduce number of "false positive"inspecting right pages. But now I see that: > 1. There should be no such "false positives" that we can avoid > 2. Valid rightlinks could help to do amcheck verification in future Well, point number 2 here is invalid. There exist one leaf page p, so that if we start traversing rightlink from p we willreach all leaf pages. But we practically have no means to find this page. This makes rightlinks not very helpful in amcheckfor GiST. But for consistency I think it worth to install them. Thanks! Best regards, Andrey Borodin.
Вложения
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> On 21/09/2020 02:06, Tom Lane wrote:
>> Another interesting point is that all the other index AMs seem to WAL-log
>> the new page before the smgrextend call, whereas this code is doing it
>> in the other order. I strongly doubt that both patterns are equally
>> correct. Could be that the other AMs are in the wrong though.
> My thinking was that it's better to call smgrextend() first, so that if
> you run out of disk space, you get the error before WAL-logging it. That
> reduces the chance that WAL replay will run out of disk space. A lot of
> things are different during WAL replay, so it's quite likely that WAL
> replay runs out of disk space anyway if you're living on the edge, but
> still.
Yeah. access/transam/README points out that such failures need to be
planned for, and explains what we do for heap pages;
1. Adding a disk page to an existing table.
This action isn't WAL-logged at all. We extend a table by writing a page
of zeroes at its end. We must actually do this write so that we are sure
the filesystem has allocated the space. If the write fails we can just
error out normally. Once the space is known allocated, we can initialize
and fill the page via one or more normal WAL-logged actions. Because it's
possible that we crash between extending the file and writing out the WAL
entries, we have to treat discovery of an all-zeroes page in a table or
index as being a non-error condition. In such cases we can just reclaim
the space for re-use.
So GIST seems to be acting according to that design. (Someday we need
to update this para to acknowledge that not all filesystems behave as
it's assuming.)
> I didn't notice that the other callers are doing it the other way round,
> though. I think they need to, so that they can stamp the page with the
> LSN of the WAL record. But GiST build is special in that regard, because
> it stamps all pages with GistBuildLSN.
Kind of unpleasant; that means they risk what the README points out:
In all of these cases, if WAL replay fails to redo the original action
we must panic and abort recovery. The DBA will have to manually clean up
(for instance, free up some disk space or fix directory permissions) and
then restart recovery. This is part of the reason for not writing a WAL
entry until we've successfully done the original action.
I'm not sufficiently motivated to go and change it right now, though.
regards, tom lane
On 21/09/2020 16:29, Andrey M. Borodin wrote: > But thing that bothers me now: when we vacuum leaf page, we bump it's > NSN. But we do not bump internal page LSN. Does this means we will > follow rightlinks after vacuum? It seems superflous. Sorry, I did not understand what you said above. Vacuum doesn't update any NSNs, only LSNs. Can you elaborate? > And btw we did not adjust internal page tuples after vacuum... What do you mean by that? - Heikki
On 21/09/2020 17:19, Andrey M. Borodin wrote:
>> 21 сент. 2020 г., в 18:29, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а):
>>
>> It was a conscious decision with incorrect motivation. I was thinking that it will help to reduce number of "false
positive"inspecting right pages. But now I see that:
>> 1. There should be no such "false positives" that we can avoid
>> 2. Valid rightlinks could help to do amcheck verification in future
>
> Well, point number 2 here is invalid. There exist one leaf page p, so that if we start traversing rightlink from p we
willreach all leaf pages. But we practically have no means to find this page. This makes rightlinks not very helpful in
amcheckfor GiST.
Well, if you store all the right links in a hash table or something, you
can "connect the dots" after you have scanned all the pages to see that
the chain is unbroken. Probably would not be worth the trouble, since
the rightlinks are not actually needed after concurrent scans have
completed.
> But for consistency I think it worth to install them.
I agree. I did some testing with your patch. It seems that the
rightlinks are still not always set. I didn't try to debug why.
I wrote a couple of 'pageinspect' function to inspect GiST pages for
this. See attached. I then created a test table and index like this:
create table points (p point);
insert into points select point(x,y) from generate_series(-2000, 2000)
x, generate_series(-2000, 2000) y;
create index points_idx on points using gist (p);
And this is what the root page looks like:
postgres=# select * from gist_page_items(get_raw_page('points_idx', 0));
itemoffset | ctid | itemlen
------------+---------------+---------
1 | (27891,65535) | 40
2 | (55614,65535) | 40
3 | (83337,65535) | 40
4 | (97019,65535) | 40
(4 rows)
And the right links on the next level:
postgres=# select * from (VALUES (27891), (55614), (83337), (97019)) b
(blkno), lateral gist_page_opaque_info(get_raw_page('points_idx', blkno));
blkno | lsn | nsn | rightlink | flags
-------+-----+-----+------------+-------
27891 | 0/1 | 0/0 | 4294967295 | {}
55614 | 0/1 | 0/0 | 4294967295 | {}
83337 | 0/1 | 0/0 | 27891 | {}
97019 | 0/1 | 0/0 | 55614 | {}
(4 rows)
I expected there to be only one page with invalid right link, but there
are two.
- Heikki
Вложения
> 28 сент. 2020 г., в 13:12, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> On 21/09/2020 17:19, Andrey M. Borodin wrote:
>>> 21 сент. 2020 г., в 18:29, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а):
>>>
>>> It was a conscious decision with incorrect motivation. I was thinking that it will help to reduce number of "false
positive"inspecting right pages. But now I see that:
>>> 1. There should be no such "false positives" that we can avoid
>>> 2. Valid rightlinks could help to do amcheck verification in future
>> Well, point number 2 here is invalid. There exist one leaf page p, so that if we start traversing rightlink from p
wewill reach all leaf pages. But we practically have no means to find this page. This makes rightlinks not very helpful
inamcheck for GiST.
>
> Well, if you store all the right links in a hash table or something, you can "connect the dots" after you have
scannedall the pages to see that the chain is unbroken. Probably would not be worth the trouble, since the rightlinks
arenot actually needed after concurrent scans have completed.
>
>> But for consistency I think it worth to install them.
>
> I agree. I did some testing with your patch. It seems that the rightlinks are still not always set. I didn't try to
debugwhy.
>
> I wrote a couple of 'pageinspect' function to inspect GiST pages for this. See attached. I then created a test table
andindex like this:
>
> create table points (p point);
> insert into points select point(x,y) from generate_series(-2000, 2000) x, generate_series(-2000, 2000) y;
> create index points_idx on points using gist (p);
>
> And this is what the root page looks like:
>
> postgres=# select * from gist_page_items(get_raw_page('points_idx', 0));
> itemoffset | ctid | itemlen
> ------------+---------------+---------
> 1 | (27891,65535) | 40
> 2 | (55614,65535) | 40
> 3 | (83337,65535) | 40
> 4 | (97019,65535) | 40
> (4 rows)
>
> And the right links on the next level:
>
> postgres=# select * from (VALUES (27891), (55614), (83337), (97019)) b (blkno), lateral
gist_page_opaque_info(get_raw_page('points_idx',blkno));
> blkno | lsn | nsn | rightlink | flags
> -------+-----+-----+------------+-------
> 27891 | 0/1 | 0/0 | 4294967295 | {}
> 55614 | 0/1 | 0/0 | 4294967295 | {}
> 83337 | 0/1 | 0/0 | 27891 | {}
> 97019 | 0/1 | 0/0 | 55614 | {}
> (4 rows)
>
> I expected there to be only one page with invalid right link, but there are two.
Yes, there is a bug. Now it seems to me so obvious, yet it took some time to understand that links were shifted by one
extrajump. PFA fixed rightlinks installation.
BTW some one more small thing: we initialise page buffers with palloc() and palloc0(), while first one is sufficient
forgistinitpage().
Also I'm working on btree_gist opclasses and found out that new sortsupport function is not mentioned in
gistadjustmembers().I think this can be fixed with gist_btree patch.
Your pageinspect patch seems very useful. How do you think, should we provide a way to find invalid tuples in GiST
withingist_page_items()? At some point we will have to ask user to reindex GiSTs with invalid tuples.
> 28 сент. 2020 г., в 11:53, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> On 21/09/2020 16:29, Andrey M. Borodin wrote:
>> But thing that bothers me now: when we vacuum leaf page, we bump it's
>> NSN. But we do not bump internal page LSN. Does this means we will
>> follow rightlinks after vacuum? It seems superflous.
>
> Sorry, I did not understand what you said above. Vacuum doesn't update any NSNs, only LSNs. Can you elaborate?
I've misunderstood difference between NSN and LSN. Seems like everything is fine.
>
>> And btw we did not adjust internal page tuples after vacuum...
> What do you mean by that?
When we delete rows from table internal tuples in GiST stay wide.
Thanks!
Best regards, Andrey Borodin.
Вложения
On 29/09/2020 21:04, Andrey M. Borodin wrote:
> 28 сент. 2020 г., в 13:12, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>> I did some testing with your patch. It seems that the rightlinks
>> are still not always set. I didn't try to debug why.
>
> Yes, there is a bug. Now it seems to me so obvious, yet it took some
> time to understand that links were shifted by one extra jump. PFA
> fixed rightlinks installation.
Ah, that was simple. I propose adding a comment on it:
--- a/src/backend/access/gist/gistbuild.c
+++ b/src/backend/access/gist/gistbuild.c
@@ -540,6 +540,19 @@ gist_indexsortbuild_pagestate_flush(GISTBuildState
*state,
/* Re-initialize the page buffer for next page on this level. */
pagestate->page = palloc(BLCKSZ);
gistinitpage(pagestate->page, isleaf ? F_LEAF : 0);
+
+ /*
+ * Set the right link to point to the previous page. This is just for
+ * debugging purposes: GiST only follows the right link if a page is split
+ * concurrently to a scan, and that cannot happen during index build.
+ *
+ * It's a bit counterintuitive that we set the right link on the new page
+ * to point to the previous page, and not the other way round. But GiST
+ * pages are not ordered like B-tree pages are, so as long as the
+ * right-links form a chain through all the pages in the same level, the
+ * order doesn't matter.
+ */
+ GistPageGetOpaque(pagestate->page)->rightlink = blkno;
}
> BTW some one more small thing: we initialise page buffers with
> palloc() and palloc0(), while first one is sufficient for
> gistinitpage().
Hmm. Only the first one, in gist_indexsortbuild(), but that needs to be
palloc0, because it's used to write an all-zeros placeholder for the
root page.
> Also I'm working on btree_gist opclasses and found out that new
> sortsupport function is not mentioned in gistadjustmembers(). I think
> this can be fixed with gist_btree patch.
Thanks!
> Your pageinspect patch seems very useful. How do you think, should we
> provide a way to find invalid tuples in GiST within
> gist_page_items()? At some point we will have to ask user to reindex
> GiSTs with invalid tuples.
You mean invalid tuples created by crash on PostgreSQL version 9.0 or
below, and pg_upgraded? I doubt there are any of those still around in
the wild. We have to keep the code to detect them, though.
It would be nice to improve gist_page_items() to display more
information about the items, although I wouldn't worry much about
invalid tuples. The 'gevel' extension that Oleg mentioned upthread does
more, it would be nice to incorporate that into pageinspect somehow.
- Heikki
I've been making tests with memory sanitizer and got one another error in regression test create_index:
CREATE INDEX gpointind ON point_tbl USING gist (f1);
server closed the connection unexpectedly
with logfile:
gistproc.c:1714:28: runtime error: 1e+300 is outside the range of representable values of type 'float'
SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior gistproc.c:1714:28
SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior gistproc.c:1714:28
gistproc.c:
1714 z = point_zorder_internal(p->x, p->y);
Consider this a minor issue but unrelated to the other issues discussed. It is reproduced on the last master commit 0a3c864c32751fd29d021929cf70af421fd27370 after all changes into Gist committed.
cflags="-DUSE_VALGRIND -Og -O0 -fsanitize=address -fsanitize=undefined -fno-sanitize-recover=all -fno-sanitize=alignment -fstack-protector"
On 06/10/2020 14:05, Pavel Borisov wrote: > I've been making tests with memory sanitizer Thanks! > and got one another error > in regression test create_index: > CREATE INDEX gpointind ON point_tbl USING gist (f1); > server closed the connection unexpectedly > > with logfile: > gistproc.c:1714:28: runtime error: 1e+300 is outside the range of > representable values of type 'float' > SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior gistproc.c:1714:28 > > gistproc.c: > 1714 z = point_zorder_internal(p->x, p->y); > > Consider this a minor issue but unrelated to the other issues discussed. > It is reproduced on the last master > commit 0a3c864c32751fd29d021929cf70af421fd27370 after all changes into > Gist committed. > > cflags="-DUSE_VALGRIND -Og -O0 -fsanitize=address -fsanitize=undefined > -fno-sanitize-recover=all -fno-sanitize=alignment -fstack-protector" You get the same error with: select (float8 '1e+300')::float4; float.c:1204:11: runtime error: 1e+300 is outside the range of representable values of type 'float' SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior float.c:1204:11 in It boils down to casting a C double to float, when the value doesn't fit in float. I'm surprised that's undefined behavior, but I'm no C99 lawyer. The code in dtof() expects it to yield Inf. I'm inclined to shrug this off and say that the sanitizer is being over-zealous. Is there some compiler flag we should be setting, to tell it that we require specific behavior? Any other ideas? - Heikki
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> You get the same error with:
> select (float8 '1e+300')::float4;
> float.c:1204:11: runtime error: 1e+300 is outside the range of
> representable values of type 'float'
> SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior float.c:1204:11 in
> It boils down to casting a C double to float, when the value doesn't fit
> in float. I'm surprised that's undefined behavior, but I'm no C99
> lawyer. The code in dtof() expects it to yield Inf.
I think UBSan read C99 6.3.1.5:
[#2] When a double is demoted to float or a long double to
double or float, if the value being converted is outside the
range of values that can be represented, the behavior is
undefined.
and stopped reading at that point, which they should not have.
If you go on to read the portions around, particularly, <fenv.h>,
you get a different picture of affairs. If we're relying on IEEE
float semantics in other places, which we are, we're perfectly
entitled to assume that the cast will yield Inf (and a floating
point exception flag, which we ignore). I think the "undefined"
here is just meant to say that there's no single behavior promised
across all possible C implementations. They'd have been better to
write "implementation-defined", though.
> I'm inclined to shrug this off and say that the sanitizer is being
> over-zealous. Is there some compiler flag we should be setting, to tell
> it that we require specific behavior? Any other ideas?
If UBSan doesn't have a flag to tell it to assume IEEE math,
I'd say that makes it next door to worthless for our purposes.
regards, tom lane
It became normal with
-fsanitize=signed-integer-overflow,null,alignmentinstead of
-fsanitize=undefined
(which is strictly a 'default' list of needed and unnecessary things to check, can be overridden anyway but needed some reading for it)
Thanks!
> 29 сент. 2020 г., в 23:04, Andrey M. Borodin <x4mmm@yandex-team.ru> написал(а): > > > Also I'm working on btree_gist opclasses and found out that new sortsupport function is not mentioned in gistadjustmembers().I think this can be fixed with gist_btree patch. Here's draft patch with implementation of sortsupport for ints and floats. Thanks! Best regards, Andrey Borodin.
Вложения
On 07/10/2020 15:27, Andrey Borodin wrote:
> Here's draft patch with implementation of sortsupport for ints and floats.
> +static int
> +gbt_int4_cmp(Datum a, Datum b, SortSupport ssup)
> +{
> + int32KEY *ia = (int32KEY *) DatumGetPointer(a);
> + int32KEY *ib = (int32KEY *) DatumGetPointer(b);
> +
> + if (ia->lower == ib->lower)
> + {
> + if (ia->upper == ib->upper)
> + return 0;
> +
> + return (ia->upper > ib->upper) ? 1 : -1;
> + }
> +
> + return (ia->lower > ib->lower) ? 1 : -1;
> +}
We're only dealing with leaf items during index build, so the 'upper'
and 'lower' should always be equal here, right? Maybe add a comment and
an assertion on that.
(It's pretty sad that the on-disk representation is identical for leaf
and internal items, because that wastes a lot of disk space, but that's
way out of scope for this patch.)
- Heikki
> 7 окт. 2020 г., в 17:38, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> On 07/10/2020 15:27, Andrey Borodin wrote:
>> Here's draft patch with implementation of sortsupport for ints and floats.
>
>> +static int
>> +gbt_int4_cmp(Datum a, Datum b, SortSupport ssup)
>> +{
>> + int32KEY *ia = (int32KEY *) DatumGetPointer(a);
>> + int32KEY *ib = (int32KEY *) DatumGetPointer(b);
>> +
>> + if (ia->lower == ib->lower)
>> + {
>> + if (ia->upper == ib->upper)
>> + return 0;
>> +
>> + return (ia->upper > ib->upper) ? 1 : -1;
>> + }
>> +
>> + return (ia->lower > ib->lower) ? 1 : -1;
>> +}
>
> We're only dealing with leaf items during index build, so the 'upper' and 'lower' should always be equal here, right?
Maybeadd a comment and an assertion on that.
>
> (It's pretty sad that the on-disk representation is identical for leaf and internal items, because that wastes a lot
ofdisk space, but that's way out of scope for this patch.)
Thanks, I've added assert() where is was easy to test equalty.
PFA patch with all types.
I had a plan to implement and test one type each day. I did not quite understood how rich our type system is.
Thanks!
Best regards, Andrey Borodin.
Вложения
>> + return (ia->lower > ib->lower) ? 1 : -1;
>> +}
>
> We're only dealing with leaf items during index build, so the 'upper' and 'lower' should always be equal here, right? Maybe add a comment and an assertion on that.
>
> (It's pretty sad that the on-disk representation is identical for leaf and internal items, because that wastes a lot of disk space, but that's way out of scope for this patch.)
Thanks, I've added assert() where is was easy to test equalty.
PFA patch with all types.
I had a plan to implement and test one type each day. I did not quite understood how rich our type system is.
Cool, thanks!
BTW there is a somewhat parallel discussion on this gist patch in pgsql-bugs which you may miss
The main point is that buffering build is better to be enforced with buffering=on as otherwise buffering build becomes hard to test in the presence of sort support.
On 21/10/2020 20:13, Andrey Borodin wrote:
>> 7 окт. 2020 г., в 17:38, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>>
>> On 07/10/2020 15:27, Andrey Borodin wrote:
>>> Here's draft patch with implementation of sortsupport for ints and floats.
>>
>>> +static int
>>> +gbt_int4_cmp(Datum a, Datum b, SortSupport ssup)
>>> +{
>>> + int32KEY *ia = (int32KEY *) DatumGetPointer(a);
>>> + int32KEY *ib = (int32KEY *) DatumGetPointer(b);
>>> +
>>> + if (ia->lower == ib->lower)
>>> + {
>>> + if (ia->upper == ib->upper)
>>> + return 0;
>>> +
>>> + return (ia->upper > ib->upper) ? 1 : -1;
>>> + }
>>> +
>>> + return (ia->lower > ib->lower) ? 1 : -1;
>>> +}
>>
>> We're only dealing with leaf items during index build, so the 'upper' and 'lower' should always be equal here,
right?Maybe add a comment and an assertion on that.
>>
>> (It's pretty sad that the on-disk representation is identical for leaf and internal items, because that wastes a lot
ofdisk space, but that's way out of scope for this patch.)
>
> Thanks, I've added assert() where is was easy to test equalty.
>
> PFA patch with all types.
gbt_ts_cmp(), gbt_time_cmp_sort() and gbt_date_cmp_sort() still have the
above issue, they still compare "upper" for no good reason.
> +static Datum
> +gbt_bit_abbrev_convert(Datum original, SortSupport ssup)
> +{
> + return (Datum) 0;
> +}
> +
> +static int
> +gbt_bit_cmp_abbrev(Datum z1, Datum z2, SortSupport ssup)
> +{
> + return 0;
> +}
If an abbreviated key is not useful, just don't define abbrev functions
and don't set SortSupport->abbrev_converter in the first place.
> static bool
> gbt_inet_abbrev_abort(int memtupcount, SortSupport ssup)
> {
> #if SIZEOF_DATUM == 8
> return false;
> #else
> return true;
> #endif
> }
Better to not set the 'abbrev_converter' function in the first place. Or
would it be better to cast the float8 to float4 if SIZEOF_DATUM == 4?
> I had a plan to implement and test one type each day. I did not quite understood how rich our type system is.
:-)
- Heikki
Thanks!
> 27 окт. 2020 г., в 16:43, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>
> gbt_ts_cmp(), gbt_time_cmp_sort() and gbt_date_cmp_sort() still have the above issue, they still compare "upper" for
nogood reason.
Fixed.
>> +static Datum
>> +gbt_bit_abbrev_convert(Datum original, SortSupport ssup)
>> +{
>> + return (Datum) 0;
>> +}
>> +
>> +static int
>> +gbt_bit_cmp_abbrev(Datum z1, Datum z2, SortSupport ssup)
>> +{
>> + return 0;
>> +}
>
> If an abbreviated key is not useful, just don't define abbrev functions and don't set SortSupport->abbrev_converter
inthe first place.
Fixed.
>
>> static bool
>> gbt_inet_abbrev_abort(int memtupcount, SortSupport ssup)
>> {
>> #if SIZEOF_DATUM == 8
>> return false;
>> #else
>> return true;
>> #endif
>> }
>
> Better to not set the 'abbrev_converter' function in the first place. Or would it be better to cast the float8 to
float4if SIZEOF_DATUM == 4?
Ok, now for 4 bytes Datum we do return (Datum) Float4GetDatum((float) z);
How do you think, should this patch and patch with pageinspect GiST functions be registered on commitfest?
Thanks!
Best regards, Andrey Borodin.
Вложения
On 30/10/2020 20:20, Andrey Borodin wrote:
>> 27 окт. 2020 г., в 16:43, Heikki Linnakangas <hlinnaka@iki.fi> написал(а):
>>> static bool
>>> gbt_inet_abbrev_abort(int memtupcount, SortSupport ssup)
>>> {
>>> #if SIZEOF_DATUM == 8
>>> return false;
>>> #else
>>> return true;
>>> #endif
>>> }
>>
>> Better to not set the 'abbrev_converter' function in the first place. Or would it be better to cast the float8 to
float4if SIZEOF_DATUM == 4?
> Ok, now for 4 bytes Datum we do return (Datum) Float4GetDatum((float) z);
A few quick comments:
* Currently with float8, you immediately abort abbreviation if
SIZEOF_DATUM == 4. Like in the 'inet' above, you could convert the
float8 to float4 instead.
* Some of the ALTER OPERATOR FAMILY commands in btree_gist--1.6--1.7.sql
are copy-pasted wrong. Here's one example:
ALTER OPERATOR FAMILY gist_timestamptz_ops USING gist ADD
FUNCTION 11 (text, text) gbt_text_sortsupport;
* It's easy to confuse the new comparison functions with the existing
comparisons used by the picksplit functions. Some comments and/or naming
changes would be good to clarify how they're different.
* It would be straightforward to have abbreviated functions for macaddr
and macaddr8 too.
> How do you think, should this patch and patch with pageinspect GiST functions be registered on commitfest?
Yeah, that'd be good.
- Heikki
> 2 нояб. 2020 г., в 19:45, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > >> How do you think, should this patch and patch with pageinspect GiST functions be registered on commitfest? > > Yeah, that'd be good. I've registered both patches on January CF. pageinspect patch's code looks goot to me (besides TODO item there), but it lacks docs and tests. I can add some info andcalls in future reviews. > > On 30/10/2020 20:20, Andrey Borodin wrote: > A few quick comments: > > * Currently with float8, you immediately abort abbreviation if SIZEOF_DATUM == 4. Like in the 'inet' above, you could convertthe float8 to float4 instead. > > * Some of the ALTER OPERATOR FAMILY commands in btree_gist--1.6--1.7.sql are copy-pasted wrong. Here's one example: > > ALTER OPERATOR FAMILY gist_timestamptz_ops USING gist ADD > FUNCTION 11 (text, text) gbt_text_sortsupport; > > * It's easy to confuse the new comparison functions with the existing comparisons used by the picksplit functions. Somecomments and/or naming changes would be good to clarify how they're different. > > * It would be straightforward to have abbreviated functions for macaddr and macaddr8 too. I'll fix these issues soon. But things like this bother me a lot: > ALTER OPERATOR FAMILY gist_timestamptz_ops USING gist ADD > FUNCTION 11 (text, text) gbt_text_sortsupport; To test that functions are actually called for sorting build we should support directive sorting build like "CREATE INDEXON A USING GIST(B) WITH(sorting=surely,and fail if not)". If we have unconditional sorting build and unconditional buffered build we can check opclasses code better. The problem is current reloption is called "buffering". It would be strange if we gave this enum possible value like "notbuffering, but very much like buffering, just another way". How do you think, is it ok to add reloption "buffering=sorting" to enhance tests? Best regards, Andrey Borodin.
> 5 нояб. 2020 г., в 22:20, Justin Pryzby <pryzby@telsasoft.com> написал(а): > > On Thu, Nov 05, 2020 at 10:11:52PM +0500, Andrey Borodin wrote: >> To test that functions are actually called for sorting build we should support directive sorting build like "CREATE INDEXON A USING GIST(B) WITH(sorting=surely,and fail if not)". > > Maybe you could add a DEBUG1 message for that, and include that in regression > tests, which would then fail if sorting wasn't used. That's a good idea. Thanks! > > Maybe you'd need to make it consistent by setting GUCs like work_mem / > max_parallel_maintenance_workers / ?? > > Similar to this > > postgres=# SET client_min_messages =debug; > postgres=# CREATE INDEX ON A USING GIST(i) WITH(buffering=off); > DEBUG: building index "a_i_idx2" on table "a" serially > CREATE INDEX Currently, only B-tree uses parallel build, so no need to tweak GUCs except client_min_messages. Before these tests, actually, ~20% of opclasses were not working as expected. Despite I've checked each one by hand. I have PFA patch with fixed comments from Heikki. Thanks! Best regards, Andrey Borodin.
Вложения
> 28 сент. 2020 г., в 13:12, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > I wrote a couple of 'pageinspect' function to inspect GiST pages for this. See attached. > <0001-Add-functions-to-pageinspect-to-inspect-GiST-indexes.patch> Here's version with tests and docs. I still have no idea how to print some useful information about tuples keys. Thanks! Best regards, Andrey Borodin.
Вложения
On Mon, Dec 7, 2020 at 2:05 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > Here's version with tests and docs. I still have no idea how to print some useful information about tuples keys. I suggest calling BuildIndexValueDescription() from your own custom debug instrumentation code. -- Peter Geoghegan
> 7 дек. 2020 г., в 23:56, Peter Geoghegan <pg@bowt.ie> написал(а): > > On Mon, Dec 7, 2020 at 2:05 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: >> Here's version with tests and docs. I still have no idea how to print some useful information about tuples keys. > > I suggest calling BuildIndexValueDescription() from your own custom > debug instrumentation code. Thanks for the hint, Peter! This function does exactly what I want to do. But I have no Relation inside gist_page_items(bytea) function... probably,I'll add gist_page_items(relname, blockno) overload to fetch keys. Thanks! Best regards, Andrey Borodin.
> 9 дек. 2020 г., в 14:47, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): > > > >> 7 дек. 2020 г., в 23:56, Peter Geoghegan <pg@bowt.ie> написал(а): >> >> On Mon, Dec 7, 2020 at 2:05 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: >>> Here's version with tests and docs. I still have no idea how to print some useful information about tuples keys. >> >> I suggest calling BuildIndexValueDescription() from your own custom >> debug instrumentation code. > Thanks for the hint, Peter! > This function does exactly what I want to do. But I have no Relation inside gist_page_items(bytea) function... probably,I'll add gist_page_items(relname, blockno) overload to fetch keys. PFA patch with implementation. Best regards, Andrey Borodin.
Вложения
On 10/12/2020 12:16, Andrey Borodin wrote: >> 9 дек. 2020 г., в 14:47, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): >>> 7 дек. 2020 г., в 23:56, Peter Geoghegan <pg@bowt.ie> написал(а): >>> >>> On Mon, Dec 7, 2020 at 2:05 AM Andrey Borodin <x4mmm@yandex-team.ru> wrote: >>>> Here's version with tests and docs. I still have no idea how to print some useful information about tuples keys. >>> >>> I suggest calling BuildIndexValueDescription() from your own custom >>> debug instrumentation code. >> Thanks for the hint, Peter! >> This function does exactly what I want to do. But I have no Relation inside gist_page_items(bytea) function... probably,I'll add gist_page_items(relname, blockno) overload to fetch keys. > > PFA patch with implementation. I did a bit of cleanup on the function signature. The .sql script claimed that gist_page_items() took bytea as argument, but in reality it was a relation name, as text. I changed it so that it takes a page image as argument, instead of reading the block straight from the index. Mainly to make it consistent with brin_page_items(), if it wasn't for that precedence I might've gone either way on it. Fixed the docs accordingly, and ran pgindent. New patch version attached. - Heikki
Вложения
> 12 янв. 2021 г., в 18:49, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > >> PFA patch with implementation. > > I did a bit of cleanup on the function signature. The .sql script claimed that gist_page_items() took bytea as argument,but in reality it was a relation name, as text. I changed it so that it takes a page image as argument, insteadof reading the block straight from the index. Mainly to make it consistent with brin_page_items(), if it wasn't forthat precedence I might've gone either way on it. bt_page_items() takes relation name and block number, that was a reason for doing so. But all others *_page_items() (heap,brin, hash) are doing as in v4. So I think it's more common way. > > Fixed the docs accordingly, and ran pgindent. New patch version attached. Thanks! Looks good to me. One more question: will bytea tests run correctly on 32bit\different-endian systems? Best regards, Andrey Borodin.
On 12/01/2021 18:19, Andrey Borodin wrote: >> 12 янв. 2021 г., в 18:49, Heikki Linnakangas <hlinnaka@iki.fi> >> написал(а): >> >> Fixed the docs accordingly, and ran pgindent. New patch version >> attached. > > Thanks! Looks good to me. Pushed, thanks! > One more question: will bytea tests run correctly on > 32bit\different-endian systems? Good question. Somehow I thought we were printing esseantilly text values as bytea. But they are Points, which consists of float8's. Since I already pushed this, I'm going to just wait and see what the buildfarm says, and fix if needed. I think the fix is going to be to just remove the test for the bytea-variant, it doesn't seem that important to test. - Heikki
> 13 янв. 2021 г., в 13:41, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > >> One more question: will bytea tests run correctly on >> 32bit\different-endian systems? > > Good question. Somehow I thought we were printing esseantilly text values as bytea. But they are Points, which consistsof float8's. Since I already pushed this, I'm going to just wait and see what the buildfarm says, and fix if needed.I think the fix is going to be to just remove the test for the bytea-variant, it doesn't seem that important to test. Maybe we can just omit key_data from tests? Best regards, Andrey Borodin.
On 13/01/2021 11:46, Andrey Borodin wrote: >> 13 янв. 2021 г., в 13:41, Heikki Linnakangas <hlinnaka@iki.fi> >> написал(а): >> >>> One more question: will bytea tests run correctly on >>> 32bit\different-endian systems? >> >> Good question. Somehow I thought we were printing esseantilly text >> values as bytea. But they are Points, which consists of float8's. >> Since I already pushed this, I'm going to just wait and see what >> the buildfarm says, and fix if needed. I think the fix is going to >> be to just remove the test for the bytea-variant, it doesn't seem >> that important to test. > > Maybe we can just omit key_data from tests? Make sense, fixed it that way. Thanks! - Heikki
On 13/01/2021 12:34, Heikki Linnakangas wrote:
> On 13/01/2021 11:46, Andrey Borodin wrote:
>>> 13 янв. 2021 г., в 13:41, Heikki Linnakangas <hlinnaka@iki.fi>
>>> написал(а):
>>>
>>>> One more question: will bytea tests run correctly on
>>>> 32bit\different-endian systems?
>>>
>>> Good question. Somehow I thought we were printing esseantilly text
>>> values as bytea. But they are Points, which consists of float8's.
>>> Since I already pushed this, I'm going to just wait and see what
>>> the buildfarm says, and fix if needed. I think the fix is going to
>>> be to just remove the test for the bytea-variant, it doesn't seem
>>> that important to test.
>>
>> Maybe we can just omit key_data from tests?
>
> Make sense, fixed it that way. Thanks!
Buildfarm animal thorntail is still not happy:
> --- /home/nm/farm/sparc64_deb10_gcc_64_ubsan/HEAD/pgsql.build/../pgsql/contrib/pageinspect/expected/gist.out
2021-01-1313:38:09.721752365 +0300
> +++ /home/nm/farm/sparc64_deb10_gcc_64_ubsan/HEAD/pgsql.build/contrib/pageinspect/results/gist.out 2021-01-13
14:12:21.540046507+0300
> @@ -3,21 +3,21 @@
> CREATE INDEX test_gist_idx ON test_gist USING gist (p);
> -- Page 0 is the root, the rest are leaf pages
> SELECT * FROM gist_page_opaque_info(get_raw_page('test_gist_idx', 0));
> - lsn | nsn | rightlink | flags
> ------+-----+------------+-------
> - 0/1 | 0/0 | 4294967295 | {}
> + lsn | nsn | rightlink | flags
> +------------+-----+------------+-------
> + 0/1B8357F8 | 0/0 | 4294967295 | {}
> (1 row)
Looks like the LSN on the page is not set to GistBuildLSN as expected.
Weird.
Thorntail is a sparc64 system, so little-endian, but the other
little-endian buildfarm members are not reporting this error. Any idea
what might be going on?
- Heikki
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> On 13/01/2021 11:46, Andrey Borodin wrote:
>> Maybe we can just omit key_data from tests?
> Make sense, fixed it that way. Thanks!
thorntail, at least, is still unhappy.
regards, tom lane
On 13 January 2021 13:53:39 EET, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>Buildfarm animal thorntail is still not happy:
>
>> --- /home/nm/farm/sparc64_deb10_gcc_64_ubsan/HEAD/pgsql.build/../pgsql/contrib/pageinspect/expected/gist.out
2021-01-1313:38:09.721752365 +0300
>> +++ /home/nm/farm/sparc64_deb10_gcc_64_ubsan/HEAD/pgsql.build/contrib/pageinspect/results/gist.out 2021-01-13
14:12:21.540046507+0300
>> @@ -3,21 +3,21 @@
>> CREATE INDEX test_gist_idx ON test_gist USING gist (p);
>> -- Page 0 is the root, the rest are leaf pages
>> SELECT * FROM gist_page_opaque_info(get_raw_page('test_gist_idx', 0));
>> - lsn | nsn | rightlink | flags
>> ------+-----+------------+-------
>> - 0/1 | 0/0 | 4294967295 | {}
>> + lsn | nsn | rightlink | flags
>> +------------+-----+------------+-------
>> + 0/1B8357F8 | 0/0 | 4294967295 | {}
>> (1 row)
>
>Looks like the LSN on the page is not set to GistBuildLSN as expected.
>Weird.
>
>Thorntail is a sparc64 system, so little-endian, but the other
>little-endian buildfarm members are not reporting this error. Any idea
>what might be going on?
Status update on this: I am building Postgres in a qemu sparc64 emulated virtual machine, hoping to be able to
reproducethis. It's very slow, so it will take hours still to complete.
I don't think this is a problem with the test, or with the new pageinspect functions, but a genuine bug in the gist
building code. Or there is something special on that animal that causes the just-created index pages to be dirtied. It
doesseem to happen consistently on thorntail, but not on other animals.
- Heikki
On 13 January 2021 20:04:10 EET, Heikki Linnakangas <hlinnaka@gmail.com> wrote: > > >On 13 January 2021 13:53:39 EET, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>Looks like the LSN on the page is not set to GistBuildLSN as expected. >>Weird. >> >>Thorntail is a sparc64 system, so little-endian, but the other >>little-endian buildfarm members are not reporting this error. Any idea >>what might be going on? > >Status update on this: I am building Postgres in a qemu sparc64 emulated virtual machine, hoping to be able to reproducethis. It's very slow, so it will take hours still to complete. > >I don't think this is a problem with the test, or with the new pageinspect functions, but a genuine bug in the gist building code. Or there is something special on that animal that causes the just-created index pages to be dirtied. It doesseem to happen consistently on thorntail, but not on other animals. Ah, silly me. Thorntail uses "wal_level=minimal". With that, I can readily reproduce this. I'm still not sure why it happens, but now it should be straightforward to debug. - Heikki
On Tue, Jan 12, 2021 at 5:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > I did a bit of cleanup on the function signature. The .sql script > claimed that gist_page_items() took bytea as argument, but in reality it > was a relation name, as text. I changed it so that it takes a page image > as argument, instead of reading the block straight from the index. > Mainly to make it consistent with brin_page_items(), if it wasn't for > that precedence I might've gone either way on it. BTW it would be nice if gist_page_items() had a "dead" boolean output argument for the item's LP_DEAD bit, just like bt_page_items(). I plan on adding some testing for GiST's opportunistic index deletion soon. I may also add some of the same enhancements that nbtree got today (following commit d168b666). This feature was originally heavily based on the nbtree LP_DEAD deletion mechanism (now called simple deletion), and I see no reason (or at least no good reason) why it shouldn't be possible to keep it in sync (except maybe with bottom-up deletion, where that it at least isn't straightforward/mechanical). -- Peter Geoghegan
> 14 янв. 2021 г., в 04:47, Peter Geoghegan <pg@bowt.ie> написал(а): > > On Tue, Jan 12, 2021 at 5:49 AM Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> I did a bit of cleanup on the function signature. The .sql script >> claimed that gist_page_items() took bytea as argument, but in reality it >> was a relation name, as text. I changed it so that it takes a page image >> as argument, instead of reading the block straight from the index. >> Mainly to make it consistent with brin_page_items(), if it wasn't for >> that precedence I might've gone either way on it. > > BTW it would be nice if gist_page_items() had a "dead" boolean output > argument for the item's LP_DEAD bit, just like bt_page_items(). +1. PFA patch. > I plan > on adding some testing for GiST's opportunistic index deletion soon. I > may also add some of the same enhancements that nbtree got today > (following commit d168b666). > > This feature was originally heavily based on the nbtree LP_DEAD > deletion mechanism (now called simple deletion), and I see no reason > (or at least no good reason) why it shouldn't be possible to keep it > in sync (except maybe with bottom-up deletion, where that it at least > isn't straightforward/mechanical). Sound great! Best regards, Andrey Borodin.
Вложения
On 2021-01-12 14:49, Heikki Linnakangas wrote: >>>> I suggest calling BuildIndexValueDescription() from your own custom >>>> debug instrumentation code. >>> Thanks for the hint, Peter! >>> This function does exactly what I want to do. But I have no Relation inside gist_page_items(bytea) function... probably,I'll add gist_page_items(relname, blockno) overload to fetch keys. >> >> PFA patch with implementation. > > I did a bit of cleanup on the function signature. The .sql script > claimed that gist_page_items() took bytea as argument, but in reality it > was a relation name, as text. I changed it so that it takes a page image > as argument, instead of reading the block straight from the index. > Mainly to make it consistent with brin_page_items(), if it wasn't for > that precedence I might've gone either way on it. I noticed this patch while working on another patch for pageinspect [0], and this one appears to introduce a problem similar to the one the other patch attempts to fix: The "itemlen" output parameters are declared to be of type smallint, but the underlying C data is of type uint16 (OffsetNumber). I don't know the details of gist enough to determine whether overflow is possible here. If not, perhaps a check or at least a comment would be useful. Otherwise, these parameters should be of type int in SQL. [0]: https://www.postgresql.org/message-id/09e2dd82-4eb6-bba1-271a-d2b58bf6c71f@enterprisedb.com
> 15 янв. 2021 г., в 10:24, Peter Eisentraut <peter.eisentraut@enterprisedb.com> написал(а): > > I noticed this patch while working on another patch for pageinspect [0], and this one appears to introduce a problem similarto the one the other patch attempts to fix: The "itemlen" output parameters are declared to be of type smallint, butthe underlying C data is of type uint16 (OffsetNumber). I don't know the details of gist enough to determine whetheroverflow is possible here. If not, perhaps a check or at least a comment would be useful. Otherwise, these parametersshould be of type int in SQL. Item offsets cannot exceed maximum block size of 32768. And even 32768/sizeof(ItemId). Thus overflow is impossible. Interesting question is wether pageinspect should protect itself from corrupted input? Generating description from bogus tuple, probably, can go wrong. Best regards, Andrey Borodin.
Heikki Linnakangas <hlinnaka@iki.fi> writes:
> On 12/01/2021 18:19, Andrey Borodin wrote:
>> Thanks! Looks good to me.
> Pushed, thanks!
I noticed that gist_page_items() thinks it can hold inter_call_data->rel
open across a series of calls. That's completely unsafe: the executor
might not run the call series to completion (see LIMIT), resulting in
relcache leak complaints. I suspect that it might have cache-flush
hazards even without that. I think this code needs to be rewritten to do
all the interesting work in the first call. Or maybe better, return the
results as a tuplestore so you don't have to do multiple calls at all.
regards, tom lane
On Sun, Jan 17, 2021 at 12:50 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > I noticed that gist_page_items() thinks it can hold inter_call_data->rel > open across a series of calls. That's completely unsafe: the executor > might not run the call series to completion (see LIMIT), resulting in > relcache leak complaints. It also has the potential to run into big problems should the user input a raw page image with an regclass-argument-incompatible tuple descriptor. Maybe that's okay (this is a tool for experts), but it certainly is a consideration. -- Peter Geoghegan
On 18/01/2021 00:35, Peter Geoghegan wrote: > On Sun, Jan 17, 2021 at 12:50 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: >> I noticed that gist_page_items() thinks it can hold inter_call_data->rel >> open across a series of calls. That's completely unsafe: the executor >> might not run the call series to completion (see LIMIT), resulting in >> relcache leak complaints. Fixed, thanks! I changed it to return a tuplestore. > It also has the potential to run into big problems should the user > input a raw page image with an regclass-argument-incompatible tuple > descriptor. Maybe that's okay (this is a tool for experts), but it > certainly is a consideration. I'm not sure I understand. It's true that the raw page image can contain data from a different index, or any garbage really. And the function will behave badly if you do that. That's an accepted risk with pageinspect functions, that's why they're superuser-only, although some of them are more tolerant of corrupt pages than others. The gist_page_items_bytea() variant doesn't try to parse the key data and is less likely to crash on bad input. - Heikki
On Sun, Jan 17, 2021 at 2:52 PM Heikki Linnakangas <hlinnaka@iki.fi> wrote: > I'm not sure I understand. It's true that the raw page image can contain > data from a different index, or any garbage really. And the function > will behave badly if you do that. That's an accepted risk with > pageinspect functions, that's why they're superuser-only, although some > of them are more tolerant of corrupt pages than others. The > gist_page_items_bytea() variant doesn't try to parse the key data and is > less likely to crash on bad input. I personally agree with you - it's not like there aren't other ways for superusers to crash the server (most of which seem very similar to this gist_page_items() issue, in fact). I just think that it's worth being clear about that being a trade-off that we've accepted. -- Peter Geoghegan
On Sun, Jan 17, 2021 at 3:04 PM Peter Geoghegan <pg@bowt.ie> wrote: > I personally agree with you - it's not like there aren't other ways > for superusers to crash the server (most of which seem very similar to > this gist_page_items() issue, in fact). I just think that it's worth > being clear about that being a trade-off that we've accepted. Can we rename gist_page_items_bytea() to gist_page_items(), and at the same time rename the current gist_page_items() -- perhaps call it gist_page_items_output()? That way we could add a bt_page_items_output() function later, while leaving everything consistent (actually not quite, since bt_page_items() outputs text instead of bytea -- but that seems worth fixing too). This also has the merit of making the unsafe "output" variant into the special case. -- Peter Geoghegan
On 18/01/2021 01:10, Peter Geoghegan wrote: > On Sun, Jan 17, 2021 at 3:04 PM Peter Geoghegan <pg@bowt.ie> wrote: >> I personally agree with you - it's not like there aren't other ways >> for superusers to crash the server (most of which seem very similar to >> this gist_page_items() issue, in fact). I just think that it's worth >> being clear about that being a trade-off that we've accepted. > > Can we rename gist_page_items_bytea() to gist_page_items(), and at the > same time rename the current gist_page_items() -- perhaps call it > gist_page_items_output()? > > That way we could add a bt_page_items_output() function later, while > leaving everything consistent (actually not quite, since > bt_page_items() outputs text instead of bytea -- but that seems worth > fixing too). This also has the merit of making the unsafe "output" > variant into the special case. bt_page_items() and bt_page_items_bytea() exist already. And brin_page_items() also calls the output functions (there's no bytea version of that). Perhaps it would've been better to make the bytea-variants the default, but I'm afraid that ship has already sailed. We're not terribly consistent; heap_page_items(), hash_page_items() and gin_page_items() don't attempt to call the output functions. Then again, I don't think we need to worry much about backwards compatibility in pageinspect, so I guess we could rename them all. It doesn't bother me enough to make me do it, but I won't object if you want to. - Heikki
On 08/03/2021 19:06, Andrey Borodin wrote:
> There were numerous GiST-build-related patches in this thread. Yet uncommitted is a patch with sortsupport routines
forbtree_gist contrib module.
> Here's its version which needs review.
Reviewing this now again. One thing caught my eye:
> +static int
> +gbt_bit_sort_build_cmp(Datum a, Datum b, SortSupport ssup)
> +{
> + return DatumGetInt32(DirectFunctionCall2(byteacmp,
> + PointerGetDatum(a),
> + PointerGetDatum(b)));
> +}
That doesn't quite match the sort order used by the comparison
functions, gbt_bitlt and such. The comparison functions compare the bits
first, and use the length as a tie-breaker. Using byteacmp() will
compare the "bit length" first. However, gbt_bitcmp() also uses
byteacmp(), so I'm a bit confused. So, huh?
- Heikki
On 07/04/2021 09:00, Heikki Linnakangas wrote:
> On 08/03/2021 19:06, Andrey Borodin wrote:
>> There were numerous GiST-build-related patches in this thread. Yet uncommitted is a patch with sortsupport routines
forbtree_gist contrib module.
>> Here's its version which needs review.
Committed with small fixes. I changed the all functions to use
*GetDatum() and DatumGet*() macros, instead of just comparing Datums
with < and >. Datum is unsigned, while int2, int4, int8 and money are
signed, so that changes the sort order around 0 for those types to be
the same as the picksplit and picksplit functions use. Not a correctness
issue, the sorting only affects the quality of the index, but let's be tidy.
This issue remains:
> Reviewing this now again. One thing caught my eye:
>
>> +static int
>> +gbt_bit_sort_build_cmp(Datum a, Datum b, SortSupport ssup)
>> +{
>> + return DatumGetInt32(DirectFunctionCall2(byteacmp,
>> + PointerGetDatum(a),
>> + PointerGetDatum(b)));
>> +}
>
> That doesn't quite match the sort order used by the comparison
> functions, gbt_bitlt and such. The comparison functions compare the bits
> first, and use the length as a tie-breaker. Using byteacmp() will
> compare the "bit length" first. However, gbt_bitcmp() also uses
> byteacmp(), so I'm a bit confused. So, huh?
Since we used byteacmp() previously for picksplit, too, this is
consistent with the order you got previously. It still seems wrong to me
and should be investigated, but it doesn't need to block this patch.
- Heikki
On 07/04/2021 09:00, Heikki Linnakangas wrote:
> On 08/03/2021 19:06, Andrey Borodin wrote:
>> There were numerous GiST-build-related patches in this thread. Yet uncommitted is a patch with sortsupport routines
forbtree_gist contrib module.
>> Here's its version which needs review.
>
> Reviewing this now again. One thing caught my eye:
>
>> +static int
>> +gbt_bit_sort_build_cmp(Datum a, Datum b, SortSupport ssup)
>> +{
>> + return DatumGetInt32(DirectFunctionCall2(byteacmp,
>> + PointerGetDatum(a),
>> + PointerGetDatum(b)));
>> +}
>
> That doesn't quite match the sort order used by the comparison
> functions, gbt_bitlt and such. The comparison functions compare the bits
> first, and use the length as a tie-breaker. Using byteacmp() will
> compare the "bit length" first. However, gbt_bitcmp() also uses
> byteacmp(), so I'm a bit confused. So, huh?
Ok, I think I understand that now. In btree_gist, the *_cmp() function
operates on non-leaf values, and *_lt(), *_gt() et al operate on leaf
values. For all other datatypes, the leaf and non-leaf representation is
the same, but for bit/varbit, the non-leaf representation is different.
The leaf representation is VarBit, and non-leaf is just the bits without
the 'bit_len' field. That's why it is indeed correct for gbt_bitcmp() to
just use byteacmp(), whereas gbt_bitlt() et al compares the 'bit_len'
field separately. That's subtle, and 100% uncommented.
What that means for this patch is that gbt_bit_sort_build_cmp() should
*not* call byteacmp(), but bitcmp(). Because it operates on the original
datatype stored in the table.
- Heikki
> 7 апр. 2021 г., в 13:23, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > Committed with small fixes. Thanks! > 7 апр. 2021 г., в 14:56, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > > Ok, I think I understand that now. In btree_gist, the *_cmp() function operates on non-leaf values, and *_lt(), *_gt()et al operate on leaf values. For all other datatypes, the leaf and non-leaf representation is the same, but for bit/varbit,the non-leaf representation is different. The leaf representation is VarBit, and non-leaf is just the bits withoutthe 'bit_len' field. That's why it is indeed correct for gbt_bitcmp() to just use byteacmp(), whereas gbt_bitlt()et al compares the 'bit_len' field separately. That's subtle, and 100% uncommented. > > What that means for this patch is that gbt_bit_sort_build_cmp() should *not* call byteacmp(), but bitcmp(). Because itoperates on the original datatype stored in the table. +1 Thanks for investigating this. If I understand things right, adding test values with different lengths of bit sequences would not uncover the problem anyway? Best regards, Andrey Borodin.
On 07/04/2021 15:12, Andrey Borodin wrote: >> 7 апр. 2021 г., в 14:56, Heikki Linnakangas <hlinnaka@iki.fi> >> написал(а): >> >> Ok, I think I understand that now. In btree_gist, the *_cmp() >> function operates on non-leaf values, and *_lt(), *_gt() et al >> operate on leaf values. For all other datatypes, the leaf and >> non-leaf representation is the same, but for bit/varbit, the >> non-leaf representation is different. The leaf representation is >> VarBit, and non-leaf is just the bits without the 'bit_len' field. >> That's why it is indeed correct for gbt_bitcmp() to just use >> byteacmp(), whereas gbt_bitlt() et al compares the 'bit_len' field >> separately. That's subtle, and 100% uncommented. >> >> What that means for this patch is that gbt_bit_sort_build_cmp() >> should *not* call byteacmp(), but bitcmp(). Because it operates on >> the original datatype stored in the table. > > +1 Thanks for investigating this. If I understand things right, > adding test values with different lengths of bit sequences would not > uncover the problem anyway? That's right, the only consequence of a "wrong" sort order is that the quality of the tree suffers, and scans need to scan more pages unnecessarily. I tried to investigate this by creating a varbit index with and without sorting, and compared them with pageinspect, but in quick testing, I wasn't able to find cases where the sorted version was badly ordered. I guess I didn't find the right data set yet. - Heikki
> 7 апр. 2021 г., в 16:18, Heikki Linnakangas <hlinnaka@iki.fi> написал(а): > I see there is a problem with "SET client_min_messages = DEBUG1;" on buildfarm. I think these checks were necessary to makesure test paths are triggered. When we know that code paths are tested, maybe we can omit checks? Best regards, Andrey Borodin.
On 07/04/2021 22:41, Andrey Borodin wrote:
> I see there is a problem with "SET client_min_messages = DEBUG1;" on
> buildfarm. I think these checks were necessary to make sure test
> paths are triggered. When we know that code paths are tested, maybe
> we can omit checks?
Yeah. We don't have very reliable coverage of different GiST build
methods, as noted earlier in this thread. But that's not this patch's fault.
I've been investigating the varbit issue, and realized that all the
comparison functions in this patch for varlen datatypes are broken. The
representation that the sortsupport function sees is the one that the
'compress' function returns. The fixed-length versions got this right,
but the varlen versions assume that the input is a Datum of the original
datatype. It happens to not crash, because the representation returned
by gbt_var_compress() is also a varlena, and all of the comparison
functions tolerate the garbage inputs, but it's bogus. The correct
pattern would be something like this (without the debugging NOTICE, of
course):
> static int
> gbt_text_sort_build_cmp(Datum a, Datum b, SortSupport ssup)
> {
> GBT_VARKEY_R ra = gbt_var_key_readable((GBT_VARKEY *) PG_DETOAST_DATUM(a));
> GBT_VARKEY_R rb = gbt_var_key_readable((GBT_VARKEY *) PG_DETOAST_DATUM(b));
>
> int x = DatumGetInt32(DirectFunctionCall2Coll(bttextcmp,
> ssup->ssup_collation,
> PointerGetDatum(a),
> PointerGetDatum(b)));
> elog(NOTICE, "cmp: %s vs %s: %d",
> TextDatumGetCString(ra.lower),
> TextDatumGetCString(rb.lower),
> x);
> return x;
> }
- Heikki
Thanks for the investigation, Heikki.
> 8 апр. 2021 г., в 01:18, Heikki Linnakangas <hlinnaka@iki.fi> написThe correct pattern would be something like this
(withoutthe debugging NOTICE, of course):
>
>> static int
>> gbt_text_sort_build_cmp(Datum a, Datum b, SortSupport ssup)
>> {
>> GBT_VARKEY_R ra = gbt_var_key_readable((GBT_VARKEY *) PG_DETOAST_DATUM(a));
>> GBT_VARKEY_R rb = gbt_var_key_readable((GBT_VARKEY *) PG_DETOAST_DATUM(b));
>> int x = DatumGetInt32(DirectFunctionCall2Coll(bttextcmp,
>> ssup->ssup_collation,
>> PointerGetDatum(a),
>> PointerGetDatum(b)));
>> elog(NOTICE, "cmp: %s vs %s: %d",
>> TextDatumGetCString(ra.lower),
>> TextDatumGetCString(rb.lower),
>> x);
>> return x;
>> }
>
In this pattern I flipped PointerGetDatum(a) to PointerGetDatum(ra.lower), because it seems to me correct. I've
followedrule of thumb: every sort function must extract and user "lower" somehow. Though I suspect numeric a bit. Is it
regularvarlena?
PFA patchset with v6 intact + two fixes of discovered issues.
Thanks!
Best regards, Andrey Borodin.
Вложения
I tried reviewing the remaining patches. It seems to work correctly, and passes the tests on my laptop. > In this pattern I flipped PointerGetDatum(a) to PointerGetDatum(ra.lower), because it seems to me correct. I've followedrule of thumb: every sort function must extract and use "lower" somehow. Though I suspect numeric a bit. Is it regularvarlena? As far as I understand, we cannot use the sortsupport functions from the btree operator classes because the btree_gist extension handles things differently. This is unfortunate and a source of bugs [1], but we cannot do anything about it. Given that the lower and upper datums must be the same for the leaf nodes, it makes sense to me to compare one of them. Using numeric_cmp() for numeric in line with using bttextcmp() for text. > + /* > + * Numeric has abbreviation routines in numeric.c, but we don't try to use > + * them here. Maybe later. > + */ This is also true for text. Perhaps we should also add a comment there. > PFA patchset with v6 intact + two fixes of discovered issues. > + /* Use byteacmp(), like gbt_bitcmp() does */ We can improve this comment by incorporating Heikki's previous email: > Ok, I think I understand that now. In btree_gist, the *_cmp() function > operates on non-leaf values, and *_lt(), *_gt() et al operate on leaf > values. For all other datatypes, the leaf and non-leaf representation is > the same, but for bit/varbit, the non-leaf representation is different. > The leaf representation is VarBit, and non-leaf is just the bits without > the 'bit_len' field. That's why it is indeed correct for gbt_bitcmp() to > just use byteacmp(), whereas gbt_bitlt() et al compares the 'bit_len' > field separately. That's subtle, and 100% uncommented. I think patch number 3 should be squashed to patch number 1. I couldn't understand patch number 2 "Remove DEBUG1 verification". It seems like something rather useful. [1] https://www.postgresql.org/message-id/flat/201010112055.o9BKtZf7011251%40wwwmaster.postgresql.org
> On 5 Jul 2021, at 08:27, Emre Hasegeli <emre@hasegeli.com> wrote: > ... > > I couldn't understand patch number 2 "Remove DEBUG1 verification". It > seems like something rather useful. These questions have gone unanswered since July, and the patch fails to apply anymore. Is there an updated version on the way? -- Daniel Gustafsson https://vmware.com/
> 17 нояб. 2021 г., в 16:33, Daniel Gustafsson <daniel@yesql.se> написал(а): > >> On 5 Jul 2021, at 08:27, Emre Hasegeli <emre@hasegeli.com> wrote: > >> ... >> >> I couldn't understand patch number 2 "Remove DEBUG1 verification". It >> seems like something rather useful. Emre, thanks for the review! And sorry for this delay. Properly answering questions is still in my queue. > > These questions have gone unanswered since July, and the patch fails to apply > anymore. Is there an updated version on the way? Yes. In future versions I also want to address IOS vs pinned buffers issue[0]. And, probably, sort items on leaf pages. And,maybe, split pages more intelligently. I hope to get to this in December. I'll post rebased version ASAP. Best regards, Andrey Borodin. [0] https://www.postgresql.org/message-id/CAH2-Wz=PqOziyRSrnN5jAtfXWXY7-BJcHz9S355LH8Dt=5qxWQ@mail.gmail.com
Hi Emre! Thank you for the review. > I tried reviewing the remaining patches. It seems to work correctly, > and passes the tests on my laptop. > >> In this pattern I flipped PointerGetDatum(a) to PointerGetDatum(ra.lower), because it seems to me correct. I've followedrule of thumb: every sort function must extract and use "lower" somehow. Though I suspect numeric a bit. Is it regularvarlena? > > As far as I understand, we cannot use the sortsupport functions from > the btree operator classes because the btree_gist extension handles > things differently. This is unfortunate and a source of bugs [1], but > we cannot do anything about it. > > Given that the lower and upper datums must be the same for the leaf > nodes, it makes sense to me to compare one of them. > > Using numeric_cmp() for numeric in line with using bttextcmp() for text. OK. >> + /* >> + * Numeric has abbreviation routines in numeric.c, but we don't try to use >> + * them here. Maybe later. >> + */ > > This is also true for text. Perhaps we should also add a comment there. Done. > >> PFA patchset with v6 intact + two fixes of discovered issues. > >> + /* Use byteacmp(), like gbt_bitcmp() does */ > > We can improve this comment by incorporating Heikki's previous email: > >> Ok, I think I understand that now. In btree_gist, the *_cmp() function >> operates on non-leaf values, and *_lt(), *_gt() et al operate on leaf >> values. For all other datatypes, the leaf and non-leaf representation is >> the same, but for bit/varbit, the non-leaf representation is different. >> The leaf representation is VarBit, and non-leaf is just the bits without >> the 'bit_len' field. That's why it is indeed correct for gbt_bitcmp() to >> just use byteacmp(), whereas gbt_bitlt() et al compares the 'bit_len' >> field separately. That's subtle, and 100% uncommented. > Done. > I think patch number 3 should be squashed to patch number 1. All patches in the patchset expected to be squashed into 1 during commit. > > I couldn't understand patch number 2 "Remove DEBUG1 verification". It > seems like something rather useful. If failed on buildfarm on some nodes. There were somewhat extroneous error messages. Currently Step 1 and 2 are separete to ensure that opclasses are used correctly. Thanks! Best regards, Andrey Borodin.