Обсуждение: Why is src/test/modules/committs/t/002_standby.pl flaky?
Hi,
There's a wait for replay that is open coded (instead of using the
wait_for_catchup() routine), and sometimes the second of two such
waits at line 51 (in master) times out after 3 minutes with "standby
never caught up". It's happening on three particular Windows boxes,
but once also happened on the AIX box "tern".
branch | animal | count
---------------+-----------+-------
HEAD | drongo | 1
HEAD | fairywren | 8
REL_10_STABLE | drongo | 3
REL_10_STABLE | fairywren | 10
REL_10_STABLE | jacana | 3
REL_11_STABLE | drongo | 1
REL_11_STABLE | fairywren | 4
REL_11_STABLE | jacana | 3
REL_12_STABLE | drongo | 2
REL_12_STABLE | fairywren | 5
REL_12_STABLE | jacana | 1
REL_12_STABLE | tern | 1
REL_13_STABLE | fairywren | 3
REL_14_STABLE | drongo | 2
REL_14_STABLE | fairywren | 6
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-30%2014:42:30
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-30%2013:13:22
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-30%2006:03:07
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-22%2011:37:37
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-22%2010:46:07
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-22%2009:03:06
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-17%2004:59:17
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-17%2003:59:51
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-16%2004:37:58
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-15%2009:57:14
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-15%2002:38:43
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-14%2020:42:15
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-14%2012:08:41
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-14%2000:35:32
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-13%2023:40:11
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-13%2022:47:25
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-09%2006:59:10
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-09%2006:04:04
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-09%2001:36:09
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-08%2019:20:35
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-08%2018:04:28
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-08%2014:12:32
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-12-08%2011:15:58
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2021-12-08%2004:04:22
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2021-12-03%2017:31:49
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-11-11%2015:58:55
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-10-02%2022:00:17
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-09-09%2005:16:43
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-08-24%2004:45:09
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=tern&dt=2021-07-17%2010:57:49
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2021-06-12%2016:05:32
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2021-02-07%2012:59:43
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-03-24%2012:49:50
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-02-01%2018:00:27
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-02-01%2017:26:27
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-01-30%2023:49:49
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2019-12-22%2014:19:02
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-12-13%2000:12:11
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-12-09%2006:02:05
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-12-06%2003:07:42
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-11-02%2014:41:04
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-25%2013:12:08
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-24%2013:12:41
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-23%2023:10:00
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-23%2018:00:39
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-22%2015:05:57
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-18%2013:29:49
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-16%2014:54:46
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-15%2014:21:11
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-14%2013:15:07
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-13%2014:19:41
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=drongo&dt=2019-10-12%2016:32:06
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2019-10-10%2013:12:09
On 12/30/21 15:01, Thomas Munro wrote: > Hi, > > There's a wait for replay that is open coded (instead of using the > wait_for_catchup() routine), and sometimes the second of two such > waits at line 51 (in master) times out after 3 minutes with "standby > never caught up". It's happening on three particular Windows boxes, > but once also happened on the AIX box "tern". > > branch | animal | count > ---------------+-----------+------- > HEAD | drongo | 1 > HEAD | fairywren | 8 > REL_10_STABLE | drongo | 3 > REL_10_STABLE | fairywren | 10 > REL_10_STABLE | jacana | 3 > REL_11_STABLE | drongo | 1 > REL_11_STABLE | fairywren | 4 > REL_11_STABLE | jacana | 3 > REL_12_STABLE | drongo | 2 > REL_12_STABLE | fairywren | 5 > REL_12_STABLE | jacana | 1 > REL_12_STABLE | tern | 1 > REL_13_STABLE | fairywren | 3 > REL_14_STABLE | drongo | 2 > REL_14_STABLE | fairywren | 6 > > FYI, drongo and fairywren are run on the same AWS/EC2 Windows Server 2019 instance. Nothing else runs on it. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Andrew Dunstan <andrew@dunslane.net> writes:
> On 12/30/21 15:01, Thomas Munro wrote:
>> There's a wait for replay that is open coded (instead of using the
>> wait_for_catchup() routine), and sometimes the second of two such
>> waits at line 51 (in master) times out after 3 minutes with "standby
>> never caught up". It's happening on three particular Windows boxes,
>> but once also happened on the AIX box "tern".
> FYI, drongo and fairywren are run on the same AWS/EC2 Windows Server
> 2019 instance. Nothing else runs on it.
I spent a little time looking into this just now. There are similar
failures in both 002_standby.pl and 003_standby_2.pl, which is
unsurprising because there are essentially-identical test sequences
in both. What I've realized is that the issue is triggered by
this sequence:
$standby->start;
...
$primary->restart;
$primary->safe_psql('postgres', 'checkpoint');
my $primary_lsn =
$primary->safe_psql('postgres', 'select pg_current_wal_lsn()');
$standby->poll_query_until('postgres',
qq{SELECT '$primary_lsn'::pg_lsn <= pg_last_wal_replay_lsn()})
or die "standby never caught up";
(the failing poll_query_until is at line 51 in 002_standby.pl, or
line 37 in 003_standby_2.pl). That is, we have forced a primary
restart since the standby first connected to the primary, and
now we have to wait for the standby to reconnect and catch up.
*These two tests seem to be the only TAP tests that do that*.
So I think there's not really anything specific to commit_ts testing
involved, it's just a dearth of primary restarts elsewhere.
Looking at the logs in the failing cases, there's no evidence
that the standby has even detected the primary's disconnection,
which explains why it hasn't attempted to reconnect. For
example, in the most recent HEAD failure,
https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2022-01-03%2018%3A04%3A41
the standby reports successful connection:
2022-01-03 18:58:04.920 UTC [179700:1] LOG: started streaming WAL from primary at 0/3000000 on timeline 1
(which we can also see in the primary's log), but after that
there's no log traffic at all except the test script's vain
checks of pg_last_wal_replay_lsn(). In the same animal's
immediately preceding successful run,
https://buildfarm.postgresql.org/cgi-bin/show_stage_log.pl?nm=fairywren&dt=2022-01-03%2015%3A04%3A41&stg=module-commit_ts-check
we see:
2022-01-03 15:59:24.186 UTC [176664:1] LOG: started streaming WAL from primary at 0/3000000 on timeline 1
2022-01-03 15:59:25.003 UTC [176664:2] LOG: replication terminated by primary server
2022-01-03 15:59:25.003 UTC [176664:3] DETAIL: End of WAL reached on timeline 1 at 0/3030CB8.
2022-01-03 15:59:25.003 UTC [176664:4] FATAL: could not send end-of-streaming message to primary: server closed the
connectionunexpectedly
This probably means the server terminated abnormally
before or while processing the request.
no COPY in progress
2022-01-03 15:59:25.005 UTC [177092:5] LOG: invalid record length at 0/3030CB8: wanted 24, got 0
...
2022-01-03 15:59:25.564 UTC [177580:1] LOG: started streaming WAL from primary at 0/3000000 on timeline 1
So for some reason, on these machines detection of walsender-initiated
connection close is unreliable ... or maybe, the walsender didn't close
the connection, but is somehow still hanging around? Don't have much idea
where to dig beyond that, but maybe someone else will. I wonder in
particular if this could be related to our recent discussions about
whether to use shutdown(2) on Windows --- could we need to do the
equivalent of 6051857fc/ed52c3707 on walsender connections?
regards, tom lane
I wrote: > So for some reason, on these machines detection of walsender-initiated > connection close is unreliable ... or maybe, the walsender didn't close > the connection, but is somehow still hanging around? Don't have much idea > where to dig beyond that, but maybe someone else will. I wonder in > particular if this could be related to our recent discussions about > whether to use shutdown(2) on Windows --- could we need to do the > equivalent of 6051857fc/ed52c3707 on walsender connections? ... wait a minute. After some more study of the buildfarm logs, it was brought home to me that these failures started happening just after 6051857fc went in: https://buildfarm.postgresql.org/cgi-bin/show_failures.pl?max_days=90&branch=&member=&stage=module-commit_tsCheck&filter=Submit The oldest matching failure is jacana's on 2021-12-03. (The above sweep finds an unrelated-looking failure on 2021-11-11, but no others before 6051857fc went in on 2021-12-02. Also, it looks likely that ed52c3707 on 2021-12-07 made the failure more probable, because jacana's is the only matching failure before 12-07.) So I'm now thinking it's highly likely that those commits are causing it somehow, but how? regards, tom lane
Hello Tom, 09.01.2022 04:17, Tom Lane wrote: >> So for some reason, on these machines detection of walsender-initiated >> connection close is unreliable ... or maybe, the walsender didn't close >> the connection, but is somehow still hanging around? Don't have much idea >> where to dig beyond that, but maybe someone else will. I wonder in >> particular if this could be related to our recent discussions about >> whether to use shutdown(2) on Windows --- could we need to do the >> equivalent of 6051857fc/ed52c3707 on walsender connections? > ... wait a minute. After some more study of the buildfarm logs, > it was brought home to me that these failures started happening > just after 6051857fc went in: > > https://buildfarm.postgresql.org/cgi-bin/show_failures.pl?max_days=90&branch=&member=&stage=module-commit_tsCheck&filter=Submit > > The oldest matching failure is jacana's on 2021-12-03. > (The above sweep finds an unrelated-looking failure on 2021-11-11, > but no others before 6051857fc went in on 2021-12-02. Also, it > looks likely that ed52c3707 on 2021-12-07 made the failure more > probable, because jacana's is the only matching failure before 12-07.) > > So I'm now thinking it's highly likely that those commits are > causing it somehow, but how? > I've managed to reproduce this failure too. Removing "shutdown(MyProcPort->sock, SD_SEND);" doesn't help here, so the culprit is exactly "closesocket(MyProcPort->sock);". I've added `system("netstat -ano");` before die() in 002_standby.pl and see: # Postmaster PID for node "primary" is 944 Proto Local Address Foreign Address State PID ... TCP 127.0.0.1:58545 127.0.0.1:61995 FIN_WAIT_2 944 ... TCP 127.0.0.1:61995 127.0.0.1:58545 CLOSE_WAIT 1352 (Replacing SD_SEND with SD_BOTH doesn't change the behaviour.) Looking at the libpqwalreceiver.c: /* Now that we've consumed some input, try again */ rawlen = PQgetCopyData(conn->streamConn, &conn->recvBuf, 1); here we get -1 on the primary disconnection. Then we get COMMAND_OK here: res = libpqrcv_PQgetResult(conn->streamConn); if (PQresultStatus(res) == PGRES_COMMAND_OK) and finally just hang at: /* Verify that there are no more results. */ res = libpqrcv_PQgetResult(conn->streamConn); until the standby gets interrupted by the TAP test. (That call can also return NULL and then the test completes successfully.) Going down through the call chain, I see that at the end of it WaitForMultipleObjects() hangs while waiting for the primary connection socket event. So it looks like the socket, that is closed by the primary, can get into a state unsuitable for WaitForMultipleObjects(). I tried to check the socket state with the WSAPoll() function and discovered that it returns POLLHUP for the "problematic" socket. The following draft addition in latch.c: int WaitLatchOrSocket(Latch *latch, int wakeEvents, pgsocket sock, long timeout, uint32 wait_event_info) { int ret = 0; int rc; WaitEvent event; #ifdef WIN32 if (wakeEvents & WL_SOCKET_MASK) { WSAPOLLFD pollfd; pollfd.fd = sock; pollfd.events = POLLRDNORM | POLLWRNORM; pollfd.revents = 0; int rc = WSAPoll(&pollfd, 1, 0); if ((rc == 1) && (pollfd.revents & POLLHUP)) { elog(WARNING, "WaitLatchOrSocket: A stream-oriented connection was either disconnected or aborted."); return WL_SOCKET_MASK; } } #endif makes the test 002_stanby.pl pass (100 of 100 iterations, while without the fix I get failures roughly on each third). I'm not sure where to place this check, maybe it's better to move it up to libpqrcv_PQgetResult() to minimize it's footprint or to find less Windows-specific approach, but I'd prefer a client-side fix anyway, as graceful closing a socket by a server seems a legitimate action. Best regards, Alexander
Alexander Lakhin <exclusion@gmail.com> writes:
> 09.01.2022 04:17, Tom Lane wrote:
>> ... wait a minute. After some more study of the buildfarm logs,
>> it was brought home to me that these failures started happening
>> just after 6051857fc went in:
> I've managed to reproduce this failure too.
> Removing "shutdown(MyProcPort->sock, SD_SEND);" doesn't help here, so
> the culprit is exactly "closesocket(MyProcPort->sock);".
Ugh. Did you try removing the closesocket and keeping shutdown?
I don't recall if we tried that combination before.
> ... I'm not sure where to
> place this check, maybe it's better to move it up to
> libpqrcv_PQgetResult() to minimize it's footprint or to find less
> Windows-specific approach, but I'd prefer a client-side fix anyway, as
> graceful closing a socket by a server seems a legitimate action.
What concerns me here is whether this implies that other clients
(libpq, jdbc, etc) are going to need changes as well. Maybe
libpq is okay, because we've not seen failures of the isolation
tests that use pg_cancel_backend(), but still it's worrisome.
I'm not entirely sure whether the isolationtester would notice
that a connection that should have died didn't.
regards, tom lane
On Mon, Jan 10, 2022 at 12:00 AM Alexander Lakhin <exclusion@gmail.com> wrote: > Going down through the call chain, I see that at the end of it > WaitForMultipleObjects() hangs while waiting for the primary connection > socket event. So it looks like the socket, that is closed by the > primary, can get into a state unsuitable for WaitForMultipleObjects(). I wonder if FD_CLOSE is edge-triggered, and it's already told us once. I think that's what these Python Twisted guys are saying: https://stackoverflow.com/questions/7598936/how-can-a-disconnected-tcp-socket-be-reliably-detected-using-msgwaitformultipleo > I tried to check the socket state with the WSAPoll() function and > discovered that it returns POLLHUP for the "problematic" socket. Good discovery. I guess if the above theory is right, there's a memory somewhere that makes this level-triggered as expected by users of poll().
On Mon, Jan 10, 2022 at 8:06 AM Thomas Munro <thomas.munro@gmail.com> wrote: > On Mon, Jan 10, 2022 at 12:00 AM Alexander Lakhin <exclusion@gmail.com> wrote: > > Going down through the call chain, I see that at the end of it > > WaitForMultipleObjects() hangs while waiting for the primary connection > > socket event. So it looks like the socket, that is closed by the > > primary, can get into a state unsuitable for WaitForMultipleObjects(). > > I wonder if FD_CLOSE is edge-triggered, and it's already told us once. Can you reproduce it with this patch?
Вложения
10.01.2022 05:00, Thomas Munro wrote: > On Mon, Jan 10, 2022 at 8:06 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> On Mon, Jan 10, 2022 at 12:00 AM Alexander Lakhin <exclusion@gmail.com> wrote: >>> Going down through the call chain, I see that at the end of it >>> WaitForMultipleObjects() hangs while waiting for the primary connection >>> socket event. So it looks like the socket, that is closed by the >>> primary, can get into a state unsuitable for WaitForMultipleObjects(). >> I wonder if FD_CLOSE is edge-triggered, and it's already told us once. > Can you reproduce it with this patch? Unfortunately, this fix (with the correction "(cur_event & WL_SOCKET_MASK)" -> "(cur_event->events & WL_SOCKET_MASK") doesn't work, because we have two separate calls to libpqrcv_PQgetResult(): > Then we get COMMAND_OK here: > res = libpqrcv_PQgetResult(conn->streamConn); > if (PQresultStatus(res) == PGRES_COMMAND_OK) > and finally just hang at: > /* Verify that there are no more results. */ > res = libpqrcv_PQgetResult(conn->streamConn); The libpqrcv_PQgetResult function, in turn, invokes WaitLatchOrSocket() where WaitEvents are defined locally, and the closed flag set on the first invocation but expected to be checked on second. >> I've managed to reproduce this failure too. >> Removing "shutdown(MyProcPort->sock, SD_SEND);" doesn't help here, so >> the culprit is exactly "closesocket(MyProcPort->sock);". >> > Ugh. Did you try removing the closesocket and keeping shutdown? > I don't recall if we tried that combination before. Even with shutdown() only I still observe WaitForMultipleObjects() hanging (and WSAPoll() returns POLLHUP for the socket). As to your concern regarding other clients, I suspect that this issue is caused by libpqwalreceiver' specific call pattern and may be other clients just don't do that. I need some more time to analyze this. Best regards, Alexander
On Mon, Jan 10, 2022 at 8:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > The libpqrcv_PQgetResult function, in turn, invokes WaitLatchOrSocket() > where WaitEvents are defined locally, and the closed flag set on the > first invocation but expected to be checked on second. D'oh, right. There's also a WaitLatchOrSocket call in walreceiver.c. We'd need a long-lived WaitEventSet common across all of these sites, which is hard here (because the socket might change under you, as discussed in other threads that introduced long lived WaitEventSets to other places but not here). /me wonders if it's possible that graceful FD_CLOSE is reported only once, but abortive/error FD_CLOSE is reported multiple times...
On Mon, Jan 10, 2022 at 10:20 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Mon, Jan 10, 2022 at 8:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > The libpqrcv_PQgetResult function, in turn, invokes WaitLatchOrSocket() > > where WaitEvents are defined locally, and the closed flag set on the > > first invocation but expected to be checked on second. > > D'oh, right. There's also a WaitLatchOrSocket call in walreceiver.c. > We'd need a long-lived WaitEventSet common across all of these sites, > which is hard here (because the socket might change under you, as > discussed in other threads that introduced long lived WaitEventSets to > other places but not here). This is super quick-and-dirty code (and doesn't handle some errors or socket changes correctly), but does it detect the closed socket?
Вложения
10.01.2022 12:40, Thomas Munro wrote: > This is super quick-and-dirty code (and doesn't handle some errors or > socket changes correctly), but does it detect the closed socket? Yes, it fixes the behaviour and makes the 002_standby test pass (100 of 100 iterations). I'm yet to find out whether the other WaitLatchOrSocket' users (e. g. postgres_fdw) can suffer from the disconnected socket state, but this approach definitely works for walreceiver. Best regards, Alexander
On Tue, Jan 11, 2022 at 6:00 AM Alexander Lakhin <exclusion@gmail.com> wrote: > 10.01.2022 12:40, Thomas Munro wrote: > > This is super quick-and-dirty code (and doesn't handle some errors or > > socket changes correctly), but does it detect the closed socket? > Yes, it fixes the behaviour and makes the 002_standby test pass (100 of > 100 iterations). Thanks for testing. That result does seem to confirm the hypothesis that FD_CLOSE is reported only once for the socket on graceful shutdown (that is, it's edge-triggered and incidentally you won't get FD_READ), so you need to keep track of it carefully. Incidentally, another observation is that your WSAPoll() test appears to be returning POLLHUP where at least Linux, FreeBSD and Solaris would not: a socket that is only half shut down (the primary shut down its end gracefully, but walreceiver did not), so I suspect Windows' POLLHUP might have POLLRDHUP semantics. > I'm yet to find out whether the other > WaitLatchOrSocket' users (e. g. postgres_fdw) can suffer from the > disconnected socket state, but this approach definitely works for > walreceiver. I see where you're going: there might be safe call sequences and unsafe call sequences, and maybe walreceiver is asking for trouble by double-polling. I'm not sure about that; I got the impression recently that it's possible to get FD_CLOSE while you still have buffered data to read, so then the next recv() will return > 0 and then we don't have any state left anywhere to remember that we saw FD_CLOSE, even if you're careful to poll and read in the ideal sequence. I could be wrong, and it would be nice if there is an easy fix along those lines... The documentation around FD_CLOSE is unclear. I do plan to make a higher quality patch like the one I showed (material from earlier unfinished work[1] that needs a bit more infrastructure), but to me that's new feature/efficiency work, not something we'd want to back-patch. Hmm, one thing I'm still unclear on: did this problem really start with 6051857fc/ed52c3707? My initial email in this thread lists similar failures going back further, doesn't it? (And what's tern doing mixed up in this mess?) [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGJPaygh-6WHEd0FnH89GrkTpVyN_ew9ckv3%2BnwjmLcSeg%40mail.gmail.com#aa33ec3e7ad85499f35dd1434a139c3f
On 1/10/22 15:52, Thomas Munro wrote: > > Hmm, one thing I'm still unclear on: did this problem really start > with 6051857fc/ed52c3707? My initial email in this thread lists > similar failures going back further, doesn't it? (And what's tern > doing mixed up in this mess?) Your list contains at least some false positives. e.g. <https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2019-12-22%2014:19:02> which has a different script failing. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Thomas Munro <thomas.munro@gmail.com> writes: > Hmm, one thing I'm still unclear on: did this problem really start > with 6051857fc/ed52c3707? My initial email in this thread lists > similar failures going back further, doesn't it? (And what's tern > doing mixed up in this mess?) Well, those earlier ones may be committs failures, but a lot of them contain different-looking symptoms, eg pg_ctl failures. tern's failure at https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=tern&dt=2021-07-17+10%3A57%3A49 does look similar, but we can see in its log that the standby *did* notice the primary disconnection and then reconnect: 2021-07-17 16:29:08.248 UTC [17498380:2] LOG: replication terminated by primary server 2021-07-17 16:29:08.248 UTC [17498380:3] DETAIL: End of WAL reached on timeline 1 at 0/30378F8. 2021-07-17 16:29:08.248 UTC [17498380:4] FATAL: could not send end-of-streaming message to primary: no COPY in progress 2021-07-17 16:29:08.248 UTC [25166230:5] LOG: invalid record length at 0/30378F8: wanted 24, got 0 2021-07-17 16:29:08.350 UTC [16318578:1] FATAL: could not connect to the primary server: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. 2021-07-17 16:29:36.369 UTC [7077918:1] FATAL: could not connect to the primary server: FATAL: the database system is startingup 2021-07-17 16:29:36.380 UTC [11338028:1] FATAL: could not connect to the primary server: FATAL: the database system isstarting up ... 2021-07-17 16:29:36.881 UTC [17367092:1] LOG: started streaming WAL from primary at 0/3000000 on timeline 1 So I'm not sure what happened there, but it's not an instance of this problem. One thing that looks a bit suspicious is this in the primary's log: 2021-07-17 16:26:47.832 UTC [12386550:1] LOG: using stale statistics instead of current ones because stats collector isnot responding which makes me wonder if the timeout is down to out-of-date pg_stats data. The loop in 002_standby.pl doesn't appear to depend on the stats collector: my $primary_lsn = $primary->safe_psql('postgres', 'select pg_current_wal_lsn()'); $standby->poll_query_until('postgres', qq{SELECT '$primary_lsn'::pg_lsn <= pg_last_wal_replay_lsn()}) or die "standby never caught up"; but maybe I'm missing the connection. Apropos of that, it's worth noting that wait_for_catchup *is* dependent on up-to-date stats, and here's a recent run where it sure looks like the timeout cause is AWOL stats collector: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=sungazer&dt=2022-01-10%2004%3A51%3A34 I wonder if we should refactor wait_for_catchup to probe the standby directly instead of relying on the upstream's view. regards, tom lane
10.01.2022 23:52, Thomas Munro wrote: >> I'm yet to find out whether the other >> WaitLatchOrSocket' users (e. g. postgres_fdw) can suffer from the >> disconnected socket state, but this approach definitely works for >> walreceiver. > I see where you're going: there might be safe call sequences and > unsafe call sequences, and maybe walreceiver is asking for trouble by > double-polling. I'm not sure about that; I got the impression > recently that it's possible to get FD_CLOSE while you still have > buffered data to read, so then the next recv() will return > 0 and > then we don't have any state left anywhere to remember that we saw > FD_CLOSE, even if you're careful to poll and read in the ideal > sequence. I could be wrong, and it would be nice if there is an easy > fix along those lines... The documentation around FD_CLOSE is > unclear. I had no strong opinion regarding unsafe sequence, though initially I suspected that exactly the second libpqrcv_PQgetResult call could cause the issue. But after digging into WaitLatchOrSocket I'd inclined to put the fix deeper to satisfy all possible callers. At the other hand, I've shared Tom's concerns regarding other clients, that can stuck on WaitForMultipleObjects() just as walreceiver does, and hoped that only walreceiver suffer from a graceful server socket closing. So to get these doubts cleared, I've made a simple test for postgres_fdw (please look at the attachment; you can put it into contrib/postgres_fdw/t and run `vcregress taptest contrib\postgres_fdw`). This test shows for me: === ... t/001_disconnection.pl .. # 12:13:39.481084 executing query... # 12:13:43.245277 result: 0 # 0|0 # 12:13:43.246342 executing query... # 12:13:46.525924 result: 0 # 0|0 # 12:13:46.527097 executing query... # 12:13:47.745176 result: 3 # # psql:<stdin>:1: WARNING: no connection to the server # psql:<stdin>:1: ERROR: FATAL: terminating connection due to administrator co mmand # server closed the connection unexpectedly # This probably means the server terminated abnormally # before or while processing the request. # CONTEXT: remote SQL command: FETCH 100 FROM c1 # 12:13:47.794612 executing query... # 12:13:51.073318 result: 0 # 0|0 # 12:13:51.074347 executing query... === With the simple logging added to connection.c: /* Sleep until there's something to do */ elog(LOG, "pgfdw_get_result before WaitLatchOrSocket"); wc = WaitLatchOrSocket(MyLatch, WL_LATCH_SET | WL_SOCKET_READABLE | WL_EXIT_ON_PM_DEATH, PQsocket(conn), -1L, PG_WAIT_EXTENSION); elog(LOG, "pgfdw_get_result after WaitLatchOrSocket"); I see in 001_disconnection_local.log: ... 2022-01-11 15:13:52.875 MSK|Administrator|postgres|61dd747f.5e4|LOG: pgfdw_get_result after WaitLatchOrSocket 2022-01-11 15:13:52.875 MSK|Administrator|postgres|61dd747f.5e4|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-11 15:13:52.875 MSK|Administrator|postgres|61dd747f.5e4|LOG: pgfdw_get_result before WaitLatchOrSocket 2022-01-11 15:13:52.875 MSK|Administrator|postgres|61dd747f.5e4|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-11 15:14:36.976 MSK|||61dd74ac.840|DEBUG: autovacuum: processing database "postgres" 2022-01-11 15:14:51.088 MSK|Administrator|postgres|61dd747f.5e4|LOG: pgfdw_get_result after WaitLatchOrSocket 2022-01-11 15:14:51.088 MSK|Administrator|postgres|61dd747f.5e4|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-11 15:14:51.089 MSK|Administrator|postgres|61dd747f.5e4|LOG: pgfdw_get_result before WaitLatchOrSocket 2022-01-11 15:14:51.089 MSK|Administrator|postgres|61dd747f.5e4|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-11 15:15:37.006 MSK|||61dd74e9.9e8|DEBUG: autovacuum: processing database "postgres" 2022-01-11 15:16:37.116 MSK|||61dd7525.ad0|DEBUG: autovacuum: processing database "postgres" 2022-01-11 15:17:37.225 MSK|||61dd7561.6a0|DEBUG: autovacuum: processing database "postgres" 2022-01-11 15:18:36.916 MSK|||61dd7470.704|LOG: checkpoint starting: time ... 2022-01-11 15:36:38.225 MSK|||61dd79d6.2a0|DEBUG: autovacuum: processing database "postgres" ... So here we get similar hanging on WaitLatchOrSocket(). Just to make sure that it's indeed the same issue, I've removed socket shutdown&close and the test executed to the end (several times). Argh. Best regards, Alexander
Вложения
On Wed, Jan 12, 2022 at 4:00 AM Alexander Lakhin <exclusion@gmail.com> wrote:
> So here we get similar hanging on WaitLatchOrSocket().
> Just to make sure that it's indeed the same issue, I've removed socket
> shutdown&close and the test executed to the end (several times). Argh.
Ouch. I think our options at this point are:
1. Revert 6051857fc (and put it back when we have a working
long-lived WES as I showed). This is not very satisfying, now that we
understand the bug, because even without that change I guess you must
be able to reach the hanging condition by using Windows postgres_fdw
to talk to a non-Windows server (ie a normal TCP stack with graceful
shutdown/linger on process exit).
2. Put your poll() check into the READABLE side. There's some
precedent for that sort of kludge on the WRITEABLE side (and a
rejection of the fragile idea that clients of latch.c should only
perform "safe" sequences):
/*
* Windows does not guarantee to log an FD_WRITE network event
* indicating that more data can be sent unless the previous send()
* failed with WSAEWOULDBLOCK. While our caller might well have made
* such a call, we cannot assume that here. Therefore, if waiting for
* write-ready, force the issue by doing a dummy send(). If the dummy
* send() succeeds, assume that the socket is in fact write-ready, and
* return immediately. Also, if it fails with something other than
* WSAEWOULDBLOCK, return a write-ready indication to let our caller
* deal with the error condition.
*/
Thomas Munro <thomas.munro@gmail.com> writes:
> Ouch. I think our options at this point are:
> 1. Revert 6051857fc (and put it back when we have a working
> long-lived WES as I showed). This is not very satisfying, now that we
> understand the bug, because even without that change I guess you must
> be able to reach the hanging condition by using Windows postgres_fdw
> to talk to a non-Windows server (ie a normal TCP stack with graceful
> shutdown/linger on process exit).
It'd be worth checking, perhaps. One thing I've been wondering all
along is how much of this behavior is specific to the local-loopback
case where Windows can see both ends of the connection. You'd think
that they couldn't long get away with such blatant violations of the
TCP specs when talking to external servers, because the failures
would be visible to everyone with a web browser.
regards, tom lane
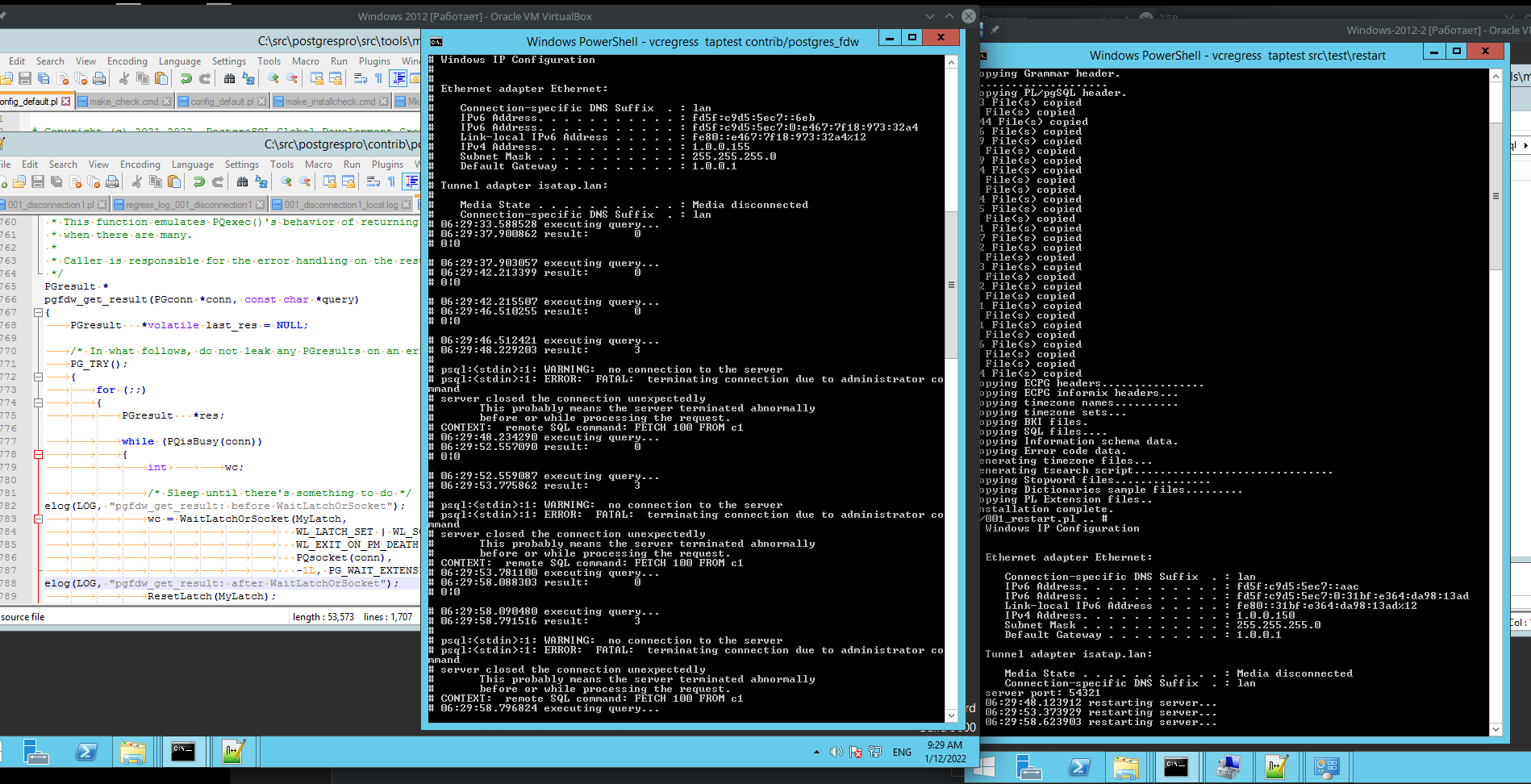
> 11.01.2022 23:16, Tom Lane wrote: >> Thomas Munro <thomas.munro@gmail.com> writes: >>> Ouch. I think our options at this point are: >>> 1. Revert 6051857fc (and put it back when we have a working >>> long-lived WES as I showed). This is not very satisfying, now that we >>> understand the bug, because even without that change I guess you must >>> be able to reach the hanging condition by using Windows postgres_fdw >>> to talk to a non-Windows server (ie a normal TCP stack with graceful >>> shutdown/linger on process exit). >> It'd be worth checking, perhaps. One thing I've been wondering all >> along is how much of this behavior is specific to the local-loopback >> case where Windows can see both ends of the connection. You'd think >> that they couldn't long get away with such blatant violations of the >> TCP specs when talking to external servers, because the failures >> would be visible to everyone with a web browser. I've split my test (both parts attached) and run it on two virtual machines with clean builds from master (ac7c8075) on both (just the debugging output added to connection.c). I provide probably redundant info (also see attached screenshot) just to make sure that I didn't make a mistake. The excerpt from 001_disconnection1_local.log: ... 2022-01-12 09:29:48.099 MSK|Administrator|postgres|61de755a.a54|LOG: pgfdw_get_result: before WaitLatchOrSocket 2022-01-12 09:29:48.099 MSK|Administrator|postgres|61de755a.a54|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|LOG: pgfdw_get_result: after WaitLatchOrSocket 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|LOG: pgfdw_get_result: before WaitLatchOrSocket 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|LOG: pgfdw_get_result: after WaitLatchOrSocket 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|STATEMENT: SELECT * FROM large WHERE a = fx2(a) 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|ERROR: FATAL: terminating connection due to administrator command server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|CONTEXT: remote SQL command: FETCH 100 FROM c1 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|WARNING: no connection to the server 2022-01-12 09:29:48.100 MSK|Administrator|postgres|61de755a.a54|CONTEXT: remote SQL command: ABORT TRANSACTION 2022-01-12 09:29:48.107 MSK|Administrator|postgres|61de755a.a54|LOG: disconnection: session time: 0:00:01.577 user=Administrator database=postgres host=127.0.0.1 port=49752 2022-01-12 09:29:48.257 MSK|[unknown]|[unknown]|61de755c.a4c|LOG: connection received: host=127.0.0.1 port=49754 2022-01-12 09:29:48.261 MSK|Administrator|postgres|61de755c.a4c|LOG: connection authenticated: identity="WIN-FCPSOVMM1JC\Administrator" method=sspi (C:/src/postgrespro/contrib/postgres_fdw/tmp_check/t_001_disconnection1_local_data/pgdata/pg_hba.conf:2) 2022-01-12 09:29:48.261 MSK|Administrator|postgres|61de755c.a4c|LOG: connection authorized: user=Administrator database=postgres application_name=001_disconnection1.pl 2022-01-12 09:29:48.263 MSK|Administrator|postgres|61de755c.a4c|LOG: statement: SELECT * FROM large WHERE a = fx2(a) 2022-01-12 09:29:48.285 MSK|Administrator|postgres|61de755c.a4c|LOG: pgfdw_get_result: before WaitLatchOrSocket 2022-01-12 09:29:48.285 MSK|Administrator|postgres|61de755c.a4c|STATEMENT: SELECT * FROM large WHERE a = fx2(a) ... By the look of things, you are right and this is the localhost-only issue. I've rechecked that the test 001_disconnection.pl (local-loopback version) hangs on both machines while 001_disconnection1.pl performs successfully in both directions. I'm not sure whether the Windows client and non-Windows server or reverse combinations are of interest in light of the above. Best regards, Alexander
Вложения
{kind=link}
On Wed, Jan 12, 2022 at 8:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > By the look of things, you are right and this is the localhost-only issue. But can't that be explained with timing races? You change some stuff around and it becomes less likely that you get a FIN to arrive in a super narrow window, which I'm guessing looks something like: recv -> EWOULDBLOCK, [receive FIN], wait -> FD_CLOSE, wait [hangs]. Note that it's not happening on several Windows BF animals, and the ones it is happening on only do it only every few weeks. Here's a draft attempt at a fix. First I tried to use recv(fd, &c, 1, MSG_PEEK) == 0 to detect EOF, which seemed to me to be a reasonable enough candidate, but somehow it corrupts the stream (!?), so I used Alexander's POLLHUP idea, except I pushed it down to a more principled place IMHO. Then I suppressed it after the initial check because then the logic from my earlier patch takes over, so stuff like FeBeWaitSet doesn't suffer from extra calls, only these two paths that haven't been converted to long-lived WESes yet. Does this pass the test? I wonder if this POLLHUP technique is reliable enough (I know that wouldn't work on other systems[1], which is why I was trying to make MSG_PEEK work...). What about environment variable PG_TEST_USE_UNIX_SOCKETS=1, does it reproduce with that set, and does the patch fix it? I'm hoping that explains some Windows CI failures from a nearby thread[2]. [1] https://illumos.topicbox.com/groups/developer/T5576767e764aa26a-Maf8f3460c2866513b0ac51bf [2] https://www.postgresql.org/message-id/flat/CALT9ZEG%3DC%3DJSypzt2gz6NoNtx-ew2tYHbwiOfY_xNo%2ByBY_%3Djw%40mail.gmail.com
Вложения
13.01.2022 09:36, Thomas Munro wrote: > On Wed, Jan 12, 2022 at 8:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: >> By the look of things, you are right and this is the localhost-only issue. > But can't that be explained with timing races? You change some stuff > around and it becomes less likely that you get a FIN to arrive in a > super narrow window, which I'm guessing looks something like: recv -> > EWOULDBLOCK, [receive FIN], wait -> FD_CLOSE, wait [hangs]. Note that > it's not happening on several Windows BF animals, and the ones it is > happening on only do it only every few weeks. But I still see the issue when I run both test parts on a single machine: first instance is `vcregress taptest src\test\restart` and the second `set NO_TEMP_INSTALL=1 & vcregress taptest contrib/postgres_fdw` (see attachment). I'll try new tests and continue investigation later today/tomorrow. Thanks! Best regards, Alexander
Вложения
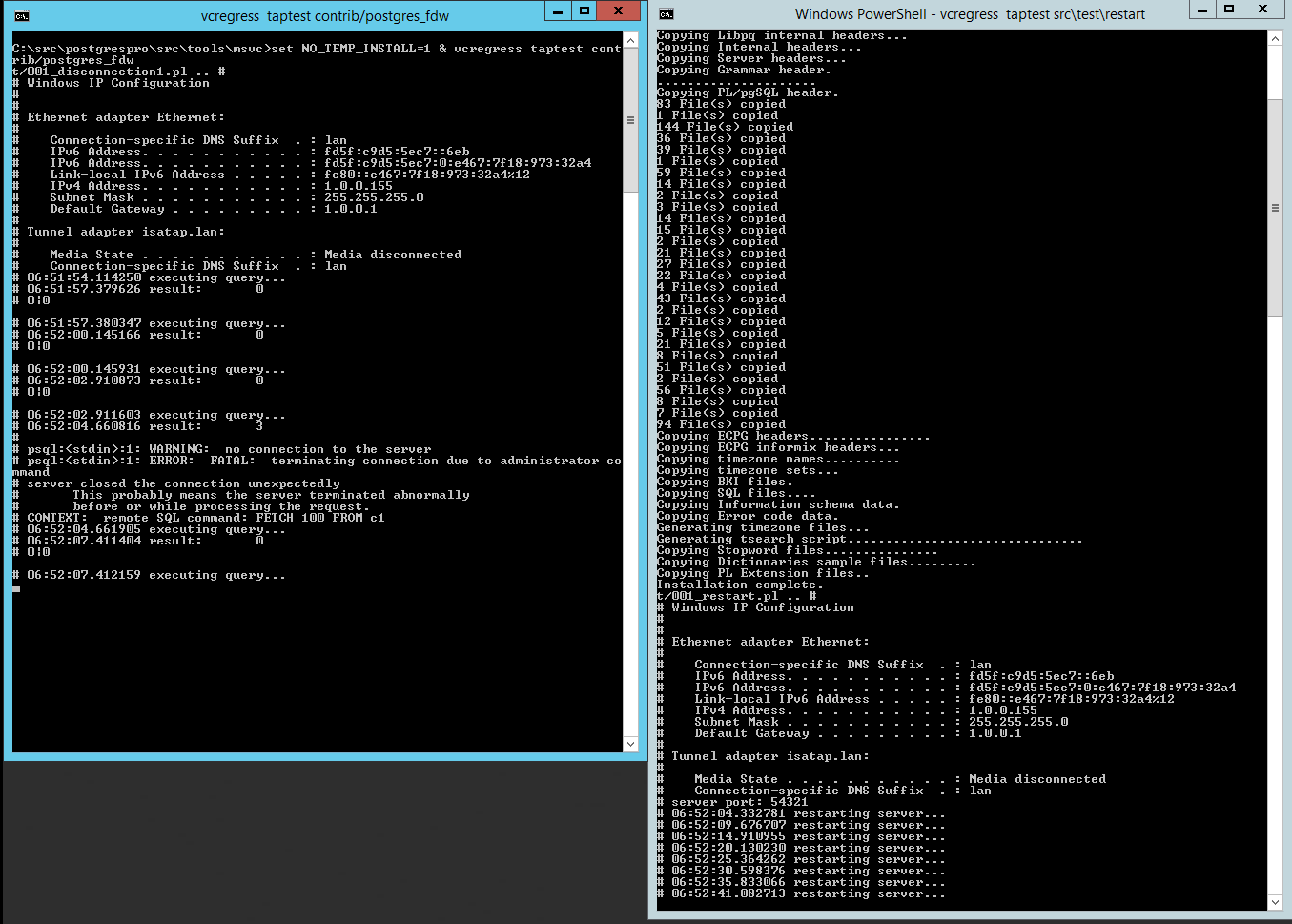{kind=link}
On Thu, Jan 13, 2022 at 7:36 PM Thomas Munro <thomas.munro@gmail.com> wrote: > ... First I tried to use recv(fd, &c, 1, > MSG_PEEK) == 0 to detect EOF, which seemed to me to be a reasonable > enough candidate, but somehow it corrupts the stream (!?), Ahh, that'd be because recv() and friends are redirected to our wrappers in socket.c, where we use the overlapped Winsock API (that is, async network IO), which is documented as not supporting MSG_PEEK. OK then. Andres and I chatted about this stuff off list and he pointed out something else about the wrappers in socket.c: there are more paths in there that work with socket events, which means more ways to lose the precious FD_CLOSE event. I don't know if any of those paths are reachable in the relevant cases, but it does look a little bit like the lack of graceful shutdown might have been hiding a whole class of event tracking bug.
13.01.2022 09:36, Thomas Munro wrote: > Here's a draft attempt at a fix. First I tried to use recv(fd, &c, 1, > MSG_PEEK) == 0 to detect EOF, which seemed to me to be a reasonable > enough candidate, but somehow it corrupts the stream (!?), so I used > Alexander's POLLHUP idea, except I pushed it down to a more principled > place IMHO. Then I suppressed it after the initial check because then > the logic from my earlier patch takes over, so stuff like FeBeWaitSet > doesn't suffer from extra calls, only these two paths that haven't > been converted to long-lived WESes yet. Does this pass the test? Yes, this fix eliminates the flakiness for me. The test commit_ts (with 002_standby and 003_standby_2) passed 2x200 iterations. It also makes my test postgres_fdw/001_disconnection pass reliably. > I wonder if this POLLHUP technique is reliable enough (I know that > wouldn't work on other systems[1], which is why I was trying to make > MSG_PEEK work...). > > What about environment variable PG_TEST_USE_UNIX_SOCKETS=1, does it > reproduce with that set, and does the patch fix it? I'm hoping that > explains some Windows CI failures from a nearby thread[2]. With PG_TEST_USE_UNIX_SOCKETS=1 the test commit_ts/002_standby fails on the unpatched HEAD: t/002_standby.pl .... 1/4 # poll_query_until timed out executing this query: # SELECT '0/303C628'::pg_lsn <= pg_last_wal_replay_lsn() # expecting this output: # t # last actual query output: # f # with stderr: # Looks like your test exited with 25 just after 1. t/002_standby.pl .... Dubious, test returned 25 (wstat 6400, 0x1900) 002_standby_primary.log contains: 2022-01-13 18:57:32.925 PST [1448] LOG: starting PostgreSQL 15devel, compiled by Visual C++ build 1928, 64-bit 2022-01-13 18:57:32.926 PST [1448] LOG: listening on Unix socket "C:/Users/1/AppData/Local/Temp/yOKQPH1FoO/.s.PGSQL.62733" The same with my postgres_fdw test: # 03:41:12.533246 result: 0 # 0|0 # 03:41:12.534758 executing query... # 03:41:14.267594 result: 3 # # psql:<stdin>:1: WARNING: no connection to the server # psql:<stdin>:1: ERROR: FATAL: terminating connection due to administrator command # server closed the connection unexpectedly # This probably means the server terminated abnormally # before or while processing the request. # CONTEXT: remote SQL command: FETCH 100 FROM c1 # 03:41:14.270449 executing query... # 03:41:14.334437 result: 3 # # psql:<stdin>:1: ERROR: could not connect to server "fpg" # DETAIL: connection to server on socket "C:/Users/1/AppData/Local/Temp/hJWD9mzPHM/.s.PGSQL.57414" failed: Connection refused (0x0000274D/10061) # Is the server running locally and accepting connections on that socket? # 03:41:14.336918 executing query... # 03:41:14.422381 result: 3 # # psql:<stdin>:1: ERROR: could not connect to server "fpg" # DETAIL: connection to server on socket "C:/Users/1/AppData/Local/Temp/hJWD9mzPHM/.s.PGSQL.57414" failed: Connection refused (0x0000274D/10061) # Is the server running locally and accepting connections on that socket? # 03:41:14.425628 executing query... ...hang... With the patch these tests pass successfully. I can also confirm that on Windows 10 20H2 (previous tests were performed on Windows Server 2012) the unpatched HEAD + PG_TEST_USE_UNIX_SOCKETS=1 hangs on src\test\recovery\001_stream_rep (on iterations 1, 1, 4 for me). (v9-0001-Add-option-for-amcheck-and-pg_amcheck-to-check-un.patch [1] not required to see that.) 001_stream_rep_primary.log contains: ... 2022-01-13 19:46:48.287 PST [1364] LOG: listening on Unix socket "C:/Users/1/AppData/Local/Temp/EWzapwiXjV/.s.PGSQL.58248" 2022-01-13 19:46:48.317 PST [6736] LOG: database system was shut down at 2022-01-13 19:46:37 PST 2022-01-13 19:46:48.331 PST [1364] LOG: database system is ready to accept connections 2022-01-13 19:46:49.536 PST [1088] 001_stream_rep.pl LOG: statement: CREATE TABLE tab_int AS SELECT generate_series(1,1002) AS a 2022-01-13 19:46:49.646 PST [3028] 001_stream_rep.pl LOG: statement: SELECT pg_current_wal_insert_lsn() 2022-01-13 19:46:49.745 PST [3360] 001_stream_rep.pl LOG: statement: SELECT '0/3023268' <= replay_lsn AND state = 'streaming' FROM pg_catalog.pg_stat_replication WHERE application_name = 'standby_1'; ... 2022-01-13 19:50:39.755 PST [4924] 001_stream_rep.pl LOG: statement: SELECT '0/3023268' <= replay_lsn AND state = 'streaming' FROM pg_catalog.pg_stat_replication WHERE application_name = 'standby_1'; 2022-01-13 19:50:39.928 PST [5924] 001_stream_rep.pl LOG: statement: SELECT '0/3023268' <= replay_lsn AND state = 'streaming' FROM pg_catalog.pg_stat_replication WHERE application_name = 'standby_1'; Without PG_TEST_USE_UNIX_SOCKETS=1 and without the fix the 001_stream_rep hangs too (but on iterations 3, 8, 2). So it seems that using unix sockets increases the fail rate. With the fix 100 iterations with PG_TEST_USE_UNIX_SOCKETS=1 and 40 (and still counting) iterations without PG_TEST_USE_UNIX_SOCKETS pass. So the fix looks as absolutely working to me with the tests that we have for now. [1] https://www.postgresql.org/message-id/CALT9ZEHx2%2B9rqAeAANkUXJCsTueQqdx2Tt6ypaig9tozJkWvkQ%40mail.gmail.com
Hi, On 2022-01-14 20:31:22 +1300, Thomas Munro wrote: > Andres and I chatted about this stuff off list and he pointed out > something else about the wrappers in socket.c: there are more paths in > there that work with socket events, which means more ways to lose the > precious FD_CLOSE event. I think it doesn't even need to touch socket.c to cause breakage. Using two different WaitEventSets is enough. https://docs.microsoft.com/en-us/windows/win32/api/winsock2/nf-winsock2-wsaeventselect says: > The FD_CLOSE network event is recorded when a close indication is received > for the virtual circuit corresponding to the socket. In TCP terms, this > means that the FD_CLOSE is recorded when the connection goes into the TIME > WAIT or CLOSE WAIT states. This results from the remote end performing a > shutdown on the send side or a closesocket. FD_CLOSE being posted after all > data is read from a socket So FD_CLOSE is *recorded* internally when the connection is closed. But only posted to the visible event once all data is read. All good so far. But combine that with: > Issuing a WSAEventSelect for a socket cancels any previous WSAAsyncSelect or > WSAEventSelect for the same socket and clears the internal network event > record. Note the bit about clearing the internal network event record. Which seems to pretty precisely explain why we're loosing FD_CLOSEs? And it does also explain why this is more likely after the shutdown changes: It's more likely the network stack knows it has readable data *and* that the connection closed. Which is recorded in the "internal network event record". But once all the data is read, walsender.c will do another WaitLatchOrSocket(), which does WSAEventSelect(), clearing the "internal event record" and loosing the FD_CLOSE. My first inclination was that we ought to wrap the socket created for windows in pgwin32_socket() in a custom type with some additional data - including information about already received events, an EVENT, etc. I think that might help to remove a lot of the messy workarounds we have in socket.c etc. But: It wouldn't do much good here, because the socket is not a socket created by socket.c but by libpq :(. Greetings, Andres Freund
Hi,
On 2022-01-14 12:28:48 -0800, Andres Freund wrote:
> But once all the data is read, walsender.c will do another
> WaitLatchOrSocket(), which does WSAEventSelect(), clearing the "internal event
> record" and loosing the FD_CLOSE.
Walreceiver only started using WES in
2016-03-29 [314cbfc5d] Add new replication mode synchronous_commit = 'remote_ap
With that came the following comment:
/*
* Ideally we would reuse a WaitEventSet object repeatedly
* here to avoid the overheads of WaitLatchOrSocket on epoll
* systems, but we can't be sure that libpq (or any other
* walreceiver implementation) has the same socket (even if
* the fd is the same number, it may have been closed and
* reopened since the last time). In future, if there is a
* function for removing sockets from WaitEventSet, then we
* could add and remove just the socket each time, potentially
* avoiding some system calls.
*/
Assert(wait_fd != PGINVALID_SOCKET);
rc = WaitLatchOrSocket(MyLatch,
WL_EXIT_ON_PM_DEATH | WL_SOCKET_READABLE |
WL_TIMEOUT | WL_LATCH_SET,
wait_fd,
NAPTIME_PER_CYCLE,
WAIT_EVENT_WAL_RECEIVER_MAIN);
I don't really see how libpq could have changed the socket underneath us, as
long as we get it the first time after the connection successfully was
established? I mean, there's a running command that we're processing the
result of? Nor do I understand what "any other walreceiver implementation"
refers to?
Thomas, I think you wrote that?
Greetings,
Andres Freund
On Sat, Jan 15, 2022 at 9:28 AM Andres Freund <andres@anarazel.de> wrote: > I think it doesn't even need to touch socket.c to cause breakage. Using two > different WaitEventSets is enough. Right. I was interested in your observation because so far we'd *only* been considering the two-consecutive-WaitEventSets case, which we could grok experimentally. The patch Alexander tested most recently uses a tri-state eof flag, so (1) the WES event starts out in "unknown" state and polls with WSAPoll() to figure out whether the socket was already closed when it wasn't looking, and then (2) it switches to believing that we'll definitely get an FD_CLOSE so we don't need to make the extra call on every wait. That does seem to do the job, but if there are *other* places that can eat FD_CLOSE event once we've switched to believing that it will come, that might be fatal to the second part of that idea, and we might have to assume "unknown" all the time, which would be somewhat similar to the way we do a dummy WSASend() every time when waiting for WRITEABLE. (That patch is assuming that we're looking for something simple to back-patch, in the event that we decide not to just revert the graceful shutdown patch from back branches. Reverting might be a better idea for now, and then we could fix all this stuff going forward.) > > Issuing a WSAEventSelect for a socket cancels any previous WSAAsyncSelect or > > WSAEventSelect for the same socket and clears the internal network event > > record. > > Note the bit about clearing the internal network event record. Which seems to > pretty precisely explain why we're loosing FD_CLOSEs? Indeed. > And it does also explain why this is more likely after the shutdown changes: > It's more likely the network stack knows it has readable data *and* that the > connection closed. Which is recorded in the "internal network event > record". But once all the data is read, walsender.c will do another > WaitLatchOrSocket(), which does WSAEventSelect(), clearing the "internal event > record" and loosing the FD_CLOSE. Yeah.
On Sat, Jan 15, 2022 at 10:59 AM Thomas Munro <thomas.munro@gmail.com> wrote: > (That patch is assuming that we're looking for something simple to > back-patch, in the event that we decide not to just revert the > graceful shutdown patch from back branches. Reverting might be a > better idea for now, and then we could fix all this stuff going > forward.) (Though, as mentioned already, reverting isn't really enough either, because other OSes that Windows might be talking to use lingering sockets... and there may still be ways for this to break...)
Hi, On 2022-01-15 10:59:00 +1300, Thomas Munro wrote: > On Sat, Jan 15, 2022 at 9:28 AM Andres Freund <andres@anarazel.de> wrote: > > I think it doesn't even need to touch socket.c to cause breakage. Using two > > different WaitEventSets is enough. > > Right. I was interested in your observation because so far we'd > *only* been considering the two-consecutive-WaitEventSets case, which > we could grok experimentally. There likely are further problems in other parts, but I think socket.c is unlikely to be involved in walreceiver case - there shouldn't be any socket.c style socket in walreceiver itself, nor do I think we are doing a send/recv/select backed by socket.c. > The patch Alexander tested most recently uses a tri-state eof flag [...] What about instead giving WalReceiverConn an internal WaitEventSet, and using that consistently? I've attached a draft for that. Alexander, could you test with that patch applied? Greetings, Andres Freund
Вложения
Thomas Munro <thomas.munro@gmail.com> writes:
> (That patch is assuming that we're looking for something simple to
> back-patch, in the event that we decide not to just revert the
> graceful shutdown patch from back branches. Reverting might be a
> better idea for now, and then we could fix all this stuff going
> forward.)
FWIW, I'm just fine with reverting, particularly in the back branches.
It seems clear that this dank corner of Windows contains even more
creepy-crawlies than we thought.
regards, tom lane
On Sat, Jan 15, 2022 at 11:44 AM Andres Freund <andres@anarazel.de> wrote: > > The patch Alexander tested most recently uses a tri-state eof flag [...] > > What about instead giving WalReceiverConn an internal WaitEventSet, and using > that consistently? I've attached a draft for that. > > Alexander, could you test with that patch applied? Isn't your patch nearly identical to one that I already posted, that Alexander tested and reported success with here? https://www.postgresql.org/message-id/5d507424-13ce-d19f-2f5d-ab4c6a987316%40gmail.com I can believe that fixes walreceiver (if we're sure that there isn't a libpq-changes-the-socket problem), but AFAICS the same problem exists for postgres_fdw and async append. That's why I moved to trying to fix the multiple-WES thing (though of course I agree we should be using long lived WESes wherever possible, I just didn't think that seemed back-patchable, so it's more of a feature patch for the future).
On Sat, Jan 15, 2022 at 9:47 AM Andres Freund <andres@anarazel.de> wrote: > Walreceiver only started using WES in > 2016-03-29 [314cbfc5d] Add new replication mode synchronous_commit = 'remote_ap > > With that came the following comment: > > /* > * Ideally we would reuse a WaitEventSet object repeatedly > * here to avoid the overheads of WaitLatchOrSocket on epoll > * systems, but we can't be sure that libpq (or any other > * walreceiver implementation) has the same socket (even if > * the fd is the same number, it may have been closed and > * reopened since the last time). In future, if there is a > * function for removing sockets from WaitEventSet, then we > * could add and remove just the socket each time, potentially > * avoiding some system calls. > */ > Assert(wait_fd != PGINVALID_SOCKET); > rc = WaitLatchOrSocket(MyLatch, > WL_EXIT_ON_PM_DEATH | WL_SOCKET_READABLE | > WL_TIMEOUT | WL_LATCH_SET, > wait_fd, > NAPTIME_PER_CYCLE, > WAIT_EVENT_WAL_RECEIVER_MAIN); > > I don't really see how libpq could have changed the socket underneath us, as > long as we get it the first time after the connection successfully was > established? I mean, there's a running command that we're processing the > result of? Erm, I didn't analyse the situation much back then, I just knew that libpq could reconnect in early phases. I can see that once you reach that stage you can count on socket stability though, so yeah that should work as long as you can handle it correctly in the earlier connection phase (probably using the other patch I posted and Alexander tested), it should all work nicely. You'd probably want to formalise the interface/documentation on that point. > Nor do I understand what "any other walreceiver implementation" > refers to? I think I meant that it goes via function pointers to talk to libpqwalreceiver.c, but I know now that we don't actually support using that to switch to different code, it's just a solution to a backend/frontend linking problem. The comment was probably just paranoia based on the way the interface works.
Hi, On 2022-01-15 13:19:42 +1300, Thomas Munro wrote: > On Sat, Jan 15, 2022 at 11:44 AM Andres Freund <andres@anarazel.de> wrote: > > > The patch Alexander tested most recently uses a tri-state eof flag [...] > > > > What about instead giving WalReceiverConn an internal WaitEventSet, and using > > that consistently? I've attached a draft for that. > > > > Alexander, could you test with that patch applied? > > Isn't your patch nearly identical to one that I already posted, that > Alexander tested and reported success with here? Sorry, somehow I missed that across the many patches in the thread... And yes, it does look remarkably similar. > https://www.postgresql.org/message-id/5d507424-13ce-d19f-2f5d-ab4c6a987316%40gmail.com > > I can believe that fixes walreceiver One thing that still bothers me around this is that we didn't detect the problem of the dead walreceiver connection, even after missing the FD_CLOSE. There's plenty other ways that a connection can get stalled for prolonged was, that we'd not get notified about either. That's why there's wal_receiver_timeout, after all. But from what I can see wal_receiver_timeout doesn't work even halfway reliably, because of all the calls down to libpqrcv_PQgetResult, where we just block indefinitely? This actually seems like a significant issue to me, and not just on windows. > (if we're sure that there isn't a libpq-changes-the-socket problem) I just don't see what that problem could be, once connection is established. The only way a the socket fd could change is a reconnect, which doesn't happen automatically. I actually was searching the archives for threads on it, but I didn't find much besides the references around [1]. And I didn't see a concrete risk explained there? > but AFAICS the same problem exists for postgres_fdw and async append. Perhaps - but I suspect it'll matter far less with them than with walreceiver. > That's why I moved to trying to > fix the multiple-WES thing (though of course I agree we should be > using long lived WESes wherever possible That approach seems like a very very leaky bandaid, with a decent potential for unintended consequences. Perhaps there's nothing better that we can do, but I'd rather try to fix the problem closer to the root... > I just didn't think that seemed back-patchable, so it's more of a feature > patch for the future). Hm, it doesn't seem crazy invasive to me. But I guess we might be looking at a revert of the shutdown changes for now anyway? In that case we should be fixing this anyway, but we might be able to afford doing it in master only? Greetings, Andres Freund [1] https://www.postgresql.org/message-id/CA%2BhUKG%2BzCNJZBXcURPdQvdY-tjyD0y7Li2wZEC6XChyUej1S5w%40mail.gmail.com
Hello Andres, 15.01.2022 01:44, Andres Freund wrote: > What about instead giving WalReceiverConn an internal WaitEventSet, and using > that consistently? I've attached a draft for that. > > Alexander, could you test with that patch applied? Unfortunately, this patch doesn't fix the issue. The test commit_ts/002_standby still fails (on iterations 3, 1, 8 for me). With the debugging logging added: ... elog(LOG, "libpqrcv_wait() before WaitEventSetWait(%p)", conn->wes); nevents = WaitEventSetWait(conn->wes, timeout, &event, 1, wait_event_info); elog(LOG, "libpqrcv_wait() after WaitEventSetWait"); ... elog(LOG, "WaitEventSetWaitBlock before WaitForMultipleObjects(%p)", set->handles); rc = WaitForMultipleObjects(set->nevents + 1, set->handles, FALSE, cur_timeout); elog(LOG, "WaitEventSetWaitBlock aftet WaitForMultipleObjects"); ... and so on. I see in 002_standby_standby.log ... 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_receive PQgetCopyData returned: 145 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_receive PQgetCopyData returned: 0 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_wait() before WaitEventSetWait(000000000063ABA8) 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWait before WaitEventSetWaitBlock(000000000063ABA8) 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWaitBlock before WaitForMultipleObjects(000000000063AC30) 2022-01-16 13:31:36.244 MSK [2820] LOG: WaitEventSetWaitBlock aftet WaitForMultipleObjects 2022-01-16 13:31:36.244 MSK [2820] LOG: WaitEventSetWait after WaitEventSetWaitBlock 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWaitBlock aftet WaitForMultipleObjects 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWait after WaitEventSetWaitBlock 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_wait() after WaitEventSetWait 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_receive PQgetCopyData returned: 0 2022-01-16 13:31:36.244 MSK [1336] LOG: libpqrcv_wait() before WaitEventSetWait(000000000063ABA8) 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWait before WaitEventSetWaitBlock(000000000063ABA8) 2022-01-16 13:31:36.244 MSK [1336] LOG: WaitEventSetWaitBlock before WaitForMultipleObjects(000000000063AC30) 2022-01-16 13:31:36.244 MSK [2820] LOG: WaitEventSetWait before WaitEventSetWaitBlock(0000000000649FB8) 2022-01-16 13:31:36.244 MSK [2820] LOG: WaitEventSetWaitBlock before WaitForMultipleObjects(000000000064A020) 2022-01-16 13:31:36.247 MSK [1336] LOG: WaitEventSetWaitBlock aftet WaitForMultipleObjects 2022-01-16 13:31:36.247 MSK [1336] LOG: WaitEventSetWait after WaitEventSetWaitBlock 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_wait() after WaitEventSetWait 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_receive PQgetCopyData returned: -1 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_receive before libpqrcv_PQgetResult(1) 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_receive libpqrcv_PQgetResult(1) returned 0000000000692400 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_receive before libpqrcv_PQgetResult(2) 2022-01-16 13:31:36.247 MSK [1336] LOG: libpqrcv_wait() before WaitEventSetWait(000000000063ABA8) 2022-01-16 13:31:36.247 MSK [1336] LOG: WaitEventSetWait before WaitEventSetWaitBlock(000000000063ABA8) 2022-01-16 13:31:36.247 MSK [1336] LOG: WaitEventSetWaitBlock before WaitForMultipleObjects(000000000063AC30) 2022-01-16 13:31:36.368 MSK [984] LOG: WaitEventSetWaitBlock aftet WaitForMultipleObjects 2022-01-16 13:31:36.368 MSK [984] LOG: WaitEventSetWait after WaitEventSetWaitBlock ... After that, the process 1336 hangs till shutdown. Best regards, Alexander
Hi, On 2022-01-14 17:51:52 -0500, Tom Lane wrote: > FWIW, I'm just fine with reverting, particularly in the back branches. > It seems clear that this dank corner of Windows contains even more > creepy-crawlies than we thought. Seems we should revert now-ish? There's a minor release coming up and I think it'd be bad to ship these changes to users. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-01-14 17:51:52 -0500, Tom Lane wrote:
>> FWIW, I'm just fine with reverting, particularly in the back branches.
>> It seems clear that this dank corner of Windows contains even more
>> creepy-crawlies than we thought.
> Seems we should revert now-ish? There's a minor release coming up and I think
> it'd be bad to ship these changes to users.
Sure. Do we want to revert in HEAD too?
regards, tom lane
Hi, On 2022-01-24 15:35:25 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2022-01-14 17:51:52 -0500, Tom Lane wrote: > >> FWIW, I'm just fine with reverting, particularly in the back branches. > >> It seems clear that this dank corner of Windows contains even more > >> creepy-crawlies than we thought. > > > Seems we should revert now-ish? There's a minor release coming up and I think > > it'd be bad to ship these changes to users. > > Sure. Do we want to revert in HEAD too? Not sure. I'm also OK with trying to go with Thomas' patch to walreceiver and try a bit longer to get all this working. Thomas? Greetings, Andres Freund
On Tue, Jan 25, 2022 at 10:28 AM Andres Freund <andres@anarazel.de> wrote: > On 2022-01-24 15:35:25 -0500, Tom Lane wrote: > > Andres Freund <andres@anarazel.de> writes: > > > On 2022-01-14 17:51:52 -0500, Tom Lane wrote: > > >> FWIW, I'm just fine with reverting, particularly in the back branches. > > >> It seems clear that this dank corner of Windows contains even more > > >> creepy-crawlies than we thought. > > > > > Seems we should revert now-ish? There's a minor release coming up and I think > > > it'd be bad to ship these changes to users. > > > > Sure. Do we want to revert in HEAD too? > > Not sure. I'm also OK with trying to go with Thomas' patch to walreceiver and > try a bit longer to get all this working. Thomas? I vote for reverting in release branches only. I'll propose a better WES patch set for master that hopefully also covers async append etc (which I was already planning to do before we knew about this Windows problem). More soon.
Thomas Munro <thomas.munro@gmail.com> writes:
> On Tue, Jan 25, 2022 at 10:28 AM Andres Freund <andres@anarazel.de> wrote:
>> On 2022-01-24 15:35:25 -0500, Tom Lane wrote:
>>> Sure. Do we want to revert in HEAD too?
>> Not sure. I'm also OK with trying to go with Thomas' patch to walreceiver and
>> try a bit longer to get all this working. Thomas?
> I vote for reverting in release branches only. I'll propose a better
> WES patch set for master that hopefully also covers async append etc
> (which I was already planning to do before we knew about this Windows
> problem). More soon.
WFM, but we'll have to remember to revert this in v15 if we don't
have a solid fix by then.
It's kinda late here, so I'll push the reverts tomorrow.
regards, tom lane
On Tue, Jan 25, 2022 at 3:50 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Thomas Munro <thomas.munro@gmail.com> writes:
> > I vote for reverting in release branches only. I'll propose a better
> > WES patch set for master that hopefully also covers async append etc
> > (which I was already planning to do before we knew about this Windows
> > problem). More soon.
>
> WFM, but we'll have to remember to revert this in v15 if we don't
> have a solid fix by then.
Phew, after a couple of days of very slow compile/test cycles on
Windows exploring a couple of different ideas, I finally have
something new. First let me recap the three main ideas in this
thread:
1. It sounds like no one really loves the WSAPoll() kludge, even
though it apparently works for simple cases. It's not totally clear
that it really works in enough cases, for one thing. It doesn't allow
for a socket to be in two WESes at the same time, and I'm not sure I
want to bank on Winsock's WSAPoll() being guaranteed to report POLLHUP
when half closed (as mentioned, no other OS does AFAIK).
2. The long-lived-WaitEventSets-everywhere concept was initially
appealling to me and solves the walreceiver problem (when combined
with a sticky seen_fd_close flag), and I've managed to get that
working correctly across libpq reconnects. As mentioned, I also have
some toy patches along those lines for the equivalent but more complex
problem in postgres_fdw, because I've been studying how to make
parallel append generate a tidy stream of epoll_wait()/kevent() calls,
instead of a quadratic explosion of setup/teardown spam. I'll write
some more about those patches and hopefully propose them soon anyway,
but on reflection I don't really want that Unix efficiency problem to
be tangled up with this Windows correctness problem. That'd require a
programming rule that I don't want to burden us with forever: you'd
*never* be able to use a socket in more than one WaitEventSet, and
WaitLatchOrSocket() would have to be removed.
3. The real solution to this problem is to recognise that we just
have the event objects in the wrong place. WaitEventSets shouldn't
own them: they need to be 1:1 with sockets, or Winsock will eat
events. Likewise for the flag you need for edge->level conversion, or
*we'll* eat events. Having now tried that, it's starting to feel like
the best way forward, even though my initial prototype (see attached)
is maybe a tad cumbersome with bookkeeping. I believe it means that
all existing coding patterns *should* now be safe (not yet confirmed
by testing), and we're free to put sockets in multiple WESes even at
the same time if the need arises.
The basic question is: how should a socket user find the associated
event handle and flags? Some answers:
1. "pgsocket" could become a pointer to a heap-allocated wrapper
object containing { socket, event, flags } on Windows, or something
like that, but that seems a bit invasive and tangled up with public
APIs like libpq, which put me off trying that. I'm willing to explore
it if people object to my other idea.
2. "pgsocket" could stay unchanged, but we could have a parallel
array with extra socket state, indexed by file descriptor. We could
use new socket()/close() libpq events so that libpq's sockets could be
registered in this scheme without libpq itself having to know anything
about that. That worked pretty nicely when I developed it on my
FreeBSD box, but on Windows I soon learned that SOCKET is really yet
another name for HANDLE, so it's not a dense number space anchored at
0 like Unix file descriptors. The array could be prohibitively big.
3. I tried the same as #2 but with a hash table, and ran into another
small problem when putting it all together: we probably don't want to
longjump out of libpq callbacks on allocation failure. So, I modified
simplehash to add a no-OOM behaviour. That's the POC patch set I'm
attaching for show-and-tell. Some notes and TODOs in the commit
messages and comments.
Thoughts?
Вложения
Hi,
On 2022-02-01 18:02:34 +1300, Thomas Munro wrote:
> 1. It sounds like no one really loves the WSAPoll() kludge, even
> though it apparently works for simple cases.
Yea, at least I don't :)
> 2. The long-lived-WaitEventSets-everywhere concept was initially
> appealling to me and solves the walreceiver problem (when combined
> with a sticky seen_fd_close flag), and I've managed to get that
> working correctly across libpq reconnects. As mentioned, I also have
> some toy patches along those lines for the equivalent but more complex
> problem in postgres_fdw, because I've been studying how to make
> parallel append generate a tidy stream of epoll_wait()/kevent() calls,
> instead of a quadratic explosion of setup/teardown spam. I'll write
> some more about those patches and hopefully propose them soon anyway,
> but on reflection I don't really want that Unix efficiency problem to
> be tangled up with this Windows correctness problem. That'd require a
> programming rule that I don't want to burden us with forever: you'd
> *never* be able to use a socket in more than one WaitEventSet, and
> WaitLatchOrSocket() would have to be removed.
Which seems like a bad direction to go in.
> 3. The real solution to this problem is to recognise that we just
> have the event objects in the wrong place. WaitEventSets shouldn't
> own them: they need to be 1:1 with sockets, or Winsock will eat
> events. Likewise for the flag you need for edge->level conversion, or
> *we'll* eat events. Having now tried that, it's starting to feel like
> the best way forward, even though my initial prototype (see attached)
> is maybe a tad cumbersome with bookkeeping. I believe it means that
> all existing coding patterns *should* now be safe (not yet confirmed
> by testing), and we're free to put sockets in multiple WESes even at
> the same time if the need arises.
Agreed.
> The basic question is: how should a socket user find the associated
> event handle and flags? Some answers:
>
> 1. "pgsocket" could become a pointer to a heap-allocated wrapper
> object containing { socket, event, flags } on Windows, or something
> like that, but that seems a bit invasive and tangled up with public
> APIs like libpq, which put me off trying that. I'm willing to explore
> it if people object to my other idea.
I'm not sure if the libpq aspect really is a problem. We're not going to have
to do that conversion repeatedly, I think.
> 2. "pgsocket" could stay unchanged, but we could have a parallel
> array with extra socket state, indexed by file descriptor. We could
> use new socket()/close() libpq events so that libpq's sockets could be
> registered in this scheme without libpq itself having to know anything
> about that. That worked pretty nicely when I developed it on my
> FreeBSD box, but on Windows I soon learned that SOCKET is really yet
> another name for HANDLE, so it's not a dense number space anchored at
> 0 like Unix file descriptors. The array could be prohibitively big.
Yes, that seems like a no-go. It also doesn't seem like it'd gain much in the
robustness department over 1) - you'd not know if a socket had been closed and
a new one with the same integer value had been created.
> 3. I tried the same as #2 but with a hash table, and ran into another
> small problem when putting it all together: we probably don't want to
> longjump out of libpq callbacks on allocation failure. So, I modified
> simplehash to add a no-OOM behaviour. That's the POC patch set I'm
> attaching for show-and-tell. Some notes and TODOs in the commit
> messages and comments.
1) seems more plausible to me, but I can see this working as well.
> From bdd90aeb65d82ecae8fe58b441d25a1e1b129bf3 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Sat, 29 Jan 2022 02:15:10 +1300
> Subject: [PATCH 1/3] Add low level socket events for libpq.
>
> Provide a way to get a callback when a socket is created or closed.
>
> XXX TODO handle callback failure
> XXX TODO investigate overheads/other implications of having a callback
> installed
What do we need this for? I still don't understand what kind of reconnects we
need to automatically need to detect.
> +#ifdef SH_RAW_ALLOCATOR_NOZERO
> + memset(tb, 0, sizeof(SH_TYPE));
> +#endif
...
> +#ifdef SH_RAW_ALLOCATOR_NOZERO
> + memset(newdata, 0, sizeof(SH_ELEMENT_TYPE) * newsize);
> +#endif
Seems like this should be handled in an allocator wrapper, rather than in
multiple places in the simplehash code?
> +#if defined(WIN32) || defined(USE_ASSERT_CHECKING)
> +static socktab_hash *socket_table;
> +#endif
Perhaps a separate #define for this would be appropriate? So we don't have to
spell the exact condition out every time.
> +ExtraSocketState *
> +SocketTableAdd(pgsocket sock, bool no_oom)
> +{
> +#if defined(WIN32) || defined(USE_ASSERT_CHECKING)
> + SocketTableEntry *ste;
> + ExtraSocketState *ess;
Given there's goto targets that test for ess != NULL, it seems nicer to
initialize it to NULL. I don't think there's problematic paths right now, but
it seems unnecessary to "risk" that changing over time.
> +#if !defined(FRONTEND)
> +struct ExtraSocketState
> +{
> +#ifdef WIN32
> + HANDLE event_handle; /* one event for the life of the socket */
> + int flags; /* most recent WSAEventSelect() flags */
> + bool seen_fd_close; /* has FD_CLOSE been received? */
> +#else
> + int dummy; /* none of this is needed for Unix */
> +#endif
> +};
Seems like we might want to track more readiness events than just close? If we
e.g. started tracking whether we've seen writes blocking / write readiness,
we could get rid of cruft like
/*
* Windows does not guarantee to log an FD_WRITE network event
* indicating that more data can be sent unless the previous send()
* failed with WSAEWOULDBLOCK. While our caller might well have made
* such a call, we cannot assume that here. Therefore, if waiting for
* write-ready, force the issue by doing a dummy send(). If the dummy
* send() succeeds, assume that the socket is in fact write-ready, and
* return immediately. Also, if it fails with something other than
* WSAEWOULDBLOCK, return a write-ready indication to let our caller
* deal with the error condition.
*/
that seems likely to just make bugs less likely, rather than actually fix them...
Greetings,
Andres Freund
On Wed, Feb 2, 2022 at 6:38 AM Andres Freund <andres@anarazel.de> wrote:
> On 2022-02-01 18:02:34 +1300, Thomas Munro wrote:
> > 1. "pgsocket" could become a pointer to a heap-allocated wrapper
> > object containing { socket, event, flags } on Windows, or something
> > like that, but that seems a bit invasive and tangled up with public
> > APIs like libpq, which put me off trying that. I'm willing to explore
> > it if people object to my other idea.
>
> I'm not sure if the libpq aspect really is a problem. We're not going to have
> to do that conversion repeatedly, I think.
Alright, I'm prototyping that variant today.
> > Provide a way to get a callback when a socket is created or closed.
> >
> > XXX TODO handle callback failure
> > XXX TODO investigate overheads/other implications of having a callback
> > installed
>
> What do we need this for? I still don't understand what kind of reconnects we
> need to automatically need to detect.
libpq makes new sockets in various cases like when trying multiple
hosts/ports (the easiest test to set up) or in some SSL and GSSAPI
cases. In the model shown in the most recent patch where there is a
hash table holding ExtraSocketState objects that libpq doesn't even
know about, we have to do SocketTableDrop(old socket),
SocketTableAdd(new socket) at those times, which is why I introduced
that callback.
If we switch to the model where a socket is really a pointer to a
wrapper struct (which I'm about to prototype), the need for all that
bookkeeping goes away, no callbacks, no hash table, but now libpq has
to participate knowingly in a socket wrapping scheme to help the
backend while also somehow providing unwrapped SOCKET for client API
stability. Trying some ideas, more on that soon.
> > +#if !defined(FRONTEND)
> > +struct ExtraSocketState
> > +{
> > +#ifdef WIN32
> > + HANDLE event_handle; /* one event for the life of the socket */
> > + int flags; /* most recent WSAEventSelect() flags */
> > + bool seen_fd_close; /* has FD_CLOSE been received? */
> > +#else
> > + int dummy; /* none of this is needed for Unix */
> > +#endif
> > +};
>
> Seems like we might want to track more readiness events than just close? If we
> e.g. started tracking whether we've seen writes blocking / write readiness,
> we could get rid of cruft like
>
> /*
> * Windows does not guarantee to log an FD_WRITE network event
> * indicating that more data can be sent unless the previous send()
> * failed with WSAEWOULDBLOCK. While our caller might well have made
> * such a call, we cannot assume that here. Therefore, if waiting for
> * write-ready, force the issue by doing a dummy send(). If the dummy
> * send() succeeds, assume that the socket is in fact write-ready, and
> * return immediately. Also, if it fails with something other than
> * WSAEWOULDBLOCK, return a write-ready indication to let our caller
> * deal with the error condition.
> */
>
> that seems likely to just make bugs less likely, rather than actually fix them...
Yeah. Unlike FD_CLOSE, FD_WRITE is a non-terminal condition so would
also need to be cleared, which requires seeing all
send()/sendto()/write() calls with wrapper functions, but we already
do stuff like that. Looking into it...
Hi, Over in another thread I made some wild unsubstantiated guesses that the windows issues could have been made much more likely by a somewhat odd bit of code in PQisBusy(): https://postgr.es/m/1959196.1644544971%40sss.pgh.pa.us Alexander, any chance you'd try if that changes the likelihood of the problem occurring, without any other fixes / reverts applied? Greetings, Andres Freund
Hello Andres, 11.02.2022 05:22, Andres Freund wrote: > Over in another thread I made some wild unsubstantiated guesses that the > windows issues could have been made much more likely by a somewhat odd bit of > code in PQisBusy(): > > https://postgr.es/m/1959196.1644544971%40sss.pgh.pa.us > > Alexander, any chance you'd try if that changes the likelihood of the problem > occurring, without any other fixes / reverts applied? Unfortunately I haven't seen an improvement for the test in question. With the PQisBusy-fix.patch from [1] and without any other changes on the master branch (52377bb8) it still fails (on iterations 13, 5, 2, 2 for me). The diagnostic logging (in attachment) added: 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_receive: PQgetCopyData returned 0 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_receive: PQgetCopyData 2 returned -1 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_receive: end-of-streaming or error: -1 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_PQgetResult: streamConn->asyncStatus: 1 && streamConn->status: 0 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_receive libpqrcv_PQgetResult returned 10551584, 1 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_receive libpqrcv_PQgetResult PGRES_COMMAND_OK 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_PQgetResult: streamConn->asyncStatus: 1 && streamConn->status: 0 2022-02-12 01:04:16.341 PST [4912] LOG: libpqrcv_PQgetResult loop before WaitLatchOrSocket 2022-02-12 01:04:16.341 PST [4912] LOG: WSAEventSelect event->fd: 948, flags: 21 2022-02-12 01:04:16.341 PST [4912] LOG: WaitLatchOrSocket before WaitEventSetWait 2022-02-12 01:04:16.341 PST [4912] LOG: WaitEventSetWait before WaitEventSetWaitBlock 2022-02-12 01:04:16.341 PST [4912] LOG: WaitEventSetWaitBlock before WaitForMultipleObjects: 3 ... shows that before the doomed WaitForMultipleObjects() call the field conn->status is 0 (CONNECTION_OK). [1] https://www.postgresql.org/message-id/2187263.1644616494%40sss.pgh.pa.us Best regards, Alexander
Вложения
Alexander Lakhin <exclusion@gmail.com> writes: > 11.02.2022 05:22, Andres Freund wrote: >> Over in another thread I made some wild unsubstantiated guesses that the >> windows issues could have been made much more likely by a somewhat odd bit of >> code in PQisBusy(): >> https://postgr.es/m/1959196.1644544971%40sss.pgh.pa.us >> Alexander, any chance you'd try if that changes the likelihood of the problem >> occurring, without any other fixes / reverts applied? > Unfortunately I haven't seen an improvement for the test in question. Yeah, that's what I expected, sadly. While I think this PQisBusy behavior is definitely a bug, it will not lead to an infinite loop, just to write failures being reported in a less convenient fashion than intended. I wonder whether it would help to put a PQconsumeInput call *before* the PQisBusy loop, so that any pre-existing EOF condition will be detected. If you don't like duplicating code, we could restructure the loop as for (;;) { int rc; /* Consume whatever data is available from the socket */ if (PQconsumeInput(streamConn) == 0) { /* trouble; return NULL */ return NULL; } /* Done? */ if (!PQisBusy(streamConn)) break; /* Wait for more data */ rc = WaitLatchOrSocket(MyLatch, WL_EXIT_ON_PM_DEATH | WL_SOCKET_READABLE | WL_LATCH_SET, PQsocket(streamConn), 0, WAIT_EVENT_LIBPQWALRECEIVER_RECEIVE); /* Interrupted? */ if (rc & WL_LATCH_SET) { ResetLatch(MyLatch); ProcessWalRcvInterrupts(); } } /* Now we can collect and return the next PGresult */ return PQgetResult(streamConn); In combination with the PQisBusy fix, this might actually help ... regards, tom lane
Hi, On 2022-02-12 11:47:20 -0500, Tom Lane wrote: > Alexander Lakhin <exclusion@gmail.com> writes: > > 11.02.2022 05:22, Andres Freund wrote: > >> Over in another thread I made some wild unsubstantiated guesses that the > >> windows issues could have been made much more likely by a somewhat odd bit of > >> code in PQisBusy(): > >> https://postgr.es/m/1959196.1644544971%40sss.pgh.pa.us > >> Alexander, any chance you'd try if that changes the likelihood of the problem > >> occurring, without any other fixes / reverts applied? > > > Unfortunately I haven't seen an improvement for the test in question. Thanks for testing! > Yeah, that's what I expected, sadly. While I think this PQisBusy behavior > is definitely a bug, it will not lead to an infinite loop, just to write > failures being reported in a less convenient fashion than intended. FWIW, I didn't think it'd end up looping indefinitely, but that there's a chance it could end up waiting indefinitely. The WaitLatchOrSocket() doesn't have a timeout, and if I understand the windows FD_CLOSE stuff correctly, you're not guaranteed to get an event if you do WaitForMultipleObjects if FD_CLOSE was already consumed and if there isn't any data to read. ISTM that it's not a great idea for libpqrcv_receive() to do blocking IO at all. The caller expects it to not block... > I wonder whether it would help to put a PQconsumeInput call *before* > the PQisBusy loop, so that any pre-existing EOF condition will be > detected. If you don't like duplicating code, we could restructure > the loop as That does look a bit saner. Even leaving EOF and windows issues aside, it seems weird to do a WaitLatchOrSocket() without having tried to read more data. Greetings, Andres Freund
On Mon, Jan 10, 2022 at 04:25:27PM -0500, Tom Lane wrote: > Apropos of that, it's worth noting that wait_for_catchup *is* > dependent on up-to-date stats, and here's a recent run where > it sure looks like the timeout cause is AWOL stats collector: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=sungazer&dt=2022-01-10%2004%3A51%3A34 > > I wonder if we should refactor wait_for_catchup to probe the > standby directly instead of relying on the upstream's view. It would be nice. For logical replication tests, do we have a monitoring API independent of the stats collector? If not and we don't want to add one, a hacky alternative might be for wait_for_catchup to run a WAL-writing command every ~20s. That way, if the stats collector misses the datagram about the standby reaching a certain LSN, the stats collector would have more chances.
I have a new socket abstraction patch that should address the known Windows socket/event bugs, but it's a little bigger than I thought it would be, not quite ready, and now too late to expect people to review for 15, so I think it should go into the next cycle. I've bounced https://commitfest.postgresql.org/37/3523/ into the next CF. We'll need to do something like 75674c7e for master.
Thomas Munro <thomas.munro@gmail.com> writes: > I have a new socket abstraction patch that should address the known > Windows socket/event bugs, but it's a little bigger than I thought it > would be, not quite ready, and now too late to expect people to review > for 15, so I think it should go into the next cycle. I've bounced > https://commitfest.postgresql.org/37/3523/ into the next CF. We'll > need to do something like 75674c7e for master. OK. You want me to push 75674c7e to HEAD? regards, tom lane
On Tue, Mar 22, 2022 at 4:13 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Thomas Munro <thomas.munro@gmail.com> writes: > > I have a new socket abstraction patch that should address the known > > Windows socket/event bugs, but it's a little bigger than I thought it > > would be, not quite ready, and now too late to expect people to review > > for 15, so I think it should go into the next cycle. I've bounced > > https://commitfest.postgresql.org/37/3523/ into the next CF. We'll > > need to do something like 75674c7e for master. > > OK. You want me to push 75674c7e to HEAD? Thanks, yes, please do.
Thomas Munro <thomas.munro@gmail.com> writes:
> On Tue, Mar 22, 2022 at 4:13 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> OK. You want me to push 75674c7e to HEAD?
> Thanks, yes, please do.
Done.
regards, tom lane
Here is a new attempt to fix this mess. Disclaimer: this based entirely on reading the manual and vicariously hacking a computer I don't have via CI. The two basic ideas are: * keep per-socket event handles in a hash table * add our own level-triggered event memory The socket table entries are reference counted, and exist as long as the socket is currently in at least one WaitEventSet. When creating a new entry, extra polling logic re-checks the initial level-triggered state (an overhead that we had in an ad-hoc way already, and that can be avoided by more widespread use of long lived WaitEventSet). You are not allowed to close a socket while it's in a WaitEventSet, because then a new socket could be allocated with the same number and chaos would ensue. For example, if we revive the idea of hooking libpq connections up to long-lived WaitEventSets, we'll probably need to invent a libpq event callback that says 'I am going to close socket X!', so you have a chance to remove the socket from any WaitEventSet *before* it's closed, to maintain that invariant. Other lazier ideas are possible, but probably become impossible in a hypothetical multi-threaded future. With these changes, AFAIK it should be safe to reinstate graceful socket shutdowns, to fix the field complaints about FATAL error messages being eaten by a grue and the annoying random CI/BF failures. Here are some other ideas that I considered but rejected for now: 1. We could throw the WAIT_USE_WIN32 code away, and hack WAIT_USE_POLL to use WSAPoll() on Windows; we could create a 'self-pipe' using a pair of connected AF_UNIX sockets to implement latches and fake signals. It seems like a lot of work, and makes latches a bit worse (instead of "everything is an event!" we have "everything is a socket!" with a helper thread, and we don't even have socketpair() on this OS). Blah. 2. We could figure out how to do fancy asynchronous sockets and IOCP. That's how NT really wants to talk to the world, it doesn't really want to pretend to be Unix. I expect that is where we'll get to eventually but it's a much bigger cross-platform R&D job. 3. Maybe there is a kind of partial step towards idea 2 that Andres mentioned on another thread somewhere: one could use an IOCP, and then use event callbacks that run on system threads to post IOCP messages (a bit like we do for our fake waitpid()). What I have here is the simplest way I could see to patch up what we already have, with the idea that in the fullness of time we'll eventually get around to idea 2, once someone is ready to do the press-ups. Review/poking-with-a-stick/trying-to-break-it most welcome.
Вложения
- v2-0001-simplehash-Allow-raw-memory-to-be-freed.patch
- v2-0002-simplehash-Allow-raw-allocation-to-fail.patch
- v2-0003-Redesign-Windows-socket-event-management.patch
- v2-0004-Remove-pgwin32_select.patch
- v2-0005-Refactor-pgwin32_waitforsinglesocket-to-share-eve.patch
- v2-0006-Reinstate-graceful-shutdown-changes-for-Windows.patch
Hello Thomas,
10.11.2023 06:31, Thomas Munro wrote:
10.11.2023 06:31, Thomas Munro wrote:
Here is a new attempt to fix this mess. Disclaimer: this based entirely on reading the manual and vicariously hacking a computer I don't have via CI.
As it also might (and I would like it to) be the final attempt, I decided
to gather information and all the cases that we had on this topic.
At least, for the last 5 years we've seen:
[1] 2019-01-18: Re: BUG #15598: PostgreSQL Error Code is not reported when connection terminated due to idle-in-transaction timeout
test 099_case_15598 made (in attachment)
no commit
[2] 2019-01-22: Rare SSL failures on eelpout
references [1]
test 099_rare_ssl_failures made (in attachment)
commit 2019-03-19 1f39a1c06: Restructure libpq's hqandling of send failures.
[3] 2019-11-28: pgsql: Add tests for '-f' option in dropdb utility.
test 051_dropdb_force was proposed (included in the attachment)
commit 2019-11-30 98a9b37ba: Revert commits 290acac92b and 8a7e9e9dad.
[4] 2019-12-06: closesocket behavior in different platforms
references [1], [2], [3]; a documentation change proposed
no commit
[5] 2020-06-03: libpq copy error handling busted
test 099_pgbench_with_server_off made (in attachment)
commit 2020-06-07 7247e243a: Try to read data from the socket in pqSendSome's write_failed paths. (a fix for 1f39a1c06)
[6] 2020-10-19: BUG #16678: The ecpg connect/test5 test sometimes fails on Windows
no commit
[7] 2021-11-17: Windows: Wrong error message at connection termination
references [6]
commit: 2021-12-02 6051857fc: On Windows, close the client socket explicitly during backend shutdown.
[8] 2021-12-05 17:03:18: MSVC SSL test failure
commit: 2021-12-07 ed52c3707: On Windows, also call shutdown() while closing the client socket.
[9] 2021-12-30: Why is src/test/modules/committs/t/002_standby.pl flaky?
additional test 099_postgres_fdw_disconnect
commit 2022-01-26 75674c7ec: Revert "graceful shutdown" changes for Windows, in back branches only. (REL_14_STABLE)
commit 2022-03-22 29992a6a5: Revert "graceful shutdown" changes for Windows. (master)
[10] 2022-02-02 19:19:22: BUG #17391: While using --with-ssl=openssl and PG_TEST_EXTRA='ssl' options, SSL tests fail on OpenBSD 7.0
commit 2022-02-12 335fa5a26: Fix thinko in PQisBusy(). (a fix for 1f39a1c06)
commit 2022-02-12 faa189c93: Move libpq's write_failed mechanism down to pqsecure_raw_write(). (a fix for 1f39a1c06)
As it becomes difficult to test/check all those cases scattered around, I
decided to retell the whole story by means of tests. Please look at the
script win-sock-tests-01.cmd attached, which can be executed both on
Windows (as regular cmd) and on Linux (bash win-sock-tests-01.cmd).
At the end of the script we can see several things.
First, the last patchset you posted, applied to b282fa88d~1, fixes the
issue discussed in this thread (it eliminates failures of
commit_ts_002_standby (and also 099_postgres_fdw_disconnect)).
Second, with the sleep added (see [6]), I had the same results of
`meson test` on Windows and on Linux.
Namely, there are some tests failing (see win-sock-tests-01.cmd) due to
walsender preventing server stop.
I describe this issue separately (see details in walsender-cannot-exit.txt;
maybe it's worth to discuss it in a separate thread) as it's kind of
off-topic. With the supplementary sleep() added to WalSndLoop(), the
complete `meson test` passes successfully both on Windows and on Linux.
Third, cases [1] and [3] are still broken, due to a Windows peculiarity.
Please see server.c and client.c attached, which demonstrate:
Case "no shutdown/closesocket" on Windows:
C:\src>server
Listening for incoming connections...
C:\src>client
Client connected: 127.0.0.1:64395
Connection to server established. Enter message: msg
Client message: msg
Sending message...
Sleeping...
Exiting...
C:\src>
Calling recv()...
recv() failed
Case "no shutdown/closesocket" on Linux:
$ server
Listening for incoming connections...
$ client
Client connected: 127.0.0.1:33044
Connection to server established. Enter message: msg
Client message: msg
Sending message...
Sleeping...
Exiting...
$
Calling recv()...
Server message: MESSAGE
Case "shutdown/closesocket" on Windows:
C:\src>server shutdown closesocket
Listening for incoming connections...
C:\src>client
Client connected: 127.0.0.1:64396
Connection to server established. Enter message: msg
Client message: msg
Sending message...
Sleeping...
Calling shutdown()...
Calling closesocket()...
Exiting...
C:\src>
Calling recv()...
Server message: MESSAGE
That's okay so far, but what makes cases [1]/[3] different from all cases
in the whole existing test suite, which now performed successfully, is
that psql calls send() before recv() on a socket closed and abandoned by
the server.
Those programs show on Windows:
C:\src>server shutdown closesocket
Listening for incoming connections...
C:\src>client send_before_recv
Client connected: 127.0.0.1:64397
Connection to server established. Enter message: msg
Client message: msg
Sending message...
Sleeping...
Calling shutdown()...
Calling closesocket()...
Exiting...
C:\src>
send() returned 4
Calling recv()...
recv() failed
As known, on Linux the same scenario works just fine.
Fourth, tests 099_rare_ssl_failures (and 001_ssl_tests, though more rarely)
fail for me with the latest patches (only on Windows again):
...
8/10 postgresql:ssl_1 / ssl_1/099_rare_ssl_failures ERROR 141.34s exit status 3
...
9/10 postgresql:ssl_7 / ssl_7/099_rare_ssl_failures OK 142.52s 2000 subtests passed
10/10 postgresql:ssl_6 / ssl_6/099_rare_ssl_failures OK 143.00s 2000 subtests passed
Ok: 2
Expected Fail: 0
Fail: 8
ssl_1\099_rare_ssl_failures\log\regress_log_099_rare_ssl_failures.txt:
...
iteration 354
[20:57:06.984](0.106s) ok 707 - certificate authorization fails with revoked client cert with server-side CRL directory
[20:57:06.984](0.000s) ok 708 - certificate authorization fails with revoked client cert with server-side CRL directory: matches
iteration 355
[20:57:07.156](0.172s) ok 709 - certificate authorization fails with revoked client cert with server-side CRL directory
[20:57:07.156](0.001s) not ok 710 - certificate authorization fails with revoked client cert with server-side CRL directory: matches
[20:57:07.159](0.003s) # Failed test 'certificate authorization fails with revoked client cert with server-side CRL directory: matches'
# at .../src/test/ssl_1/t/099_rare_ssl_failures.pl line 88.
[20:57:07.159](0.000s) # 'psql: error: connection to server at "127.0.0.1", port 59843 failed: could not receive data from server: Software caused connection abort (0x00002745/10053)
# SSL SYSCALL error: Software caused connection abort (0x00002745/10053)'
# doesn't match '(?^:SSL error: sslv3 alert certificate revoked)'
...
It seems to me that it can have the same explanation (if openssl can call
send() before recv() under the hood), but maybe it should be investigated
further.
Review/poking-with-a-stick/trying-to-break-it most welcome.
I could not find anything suspicious in the code, except for maybe a typo
"The are ...".
[1] https://www.postgresql.org/message-id/flat/87k1iy44fd.fsf%40news-spur.riddles.org.uk#ba0c07f13c300d42fd537855dd95dd2b
[2] https://www.postgresql.org/message-id/flat/CAEepm%3D2n6Nv%2B5tFfe8YnkUm1fXgvxR0Mm1FoD%2BQKG-vLNGLyKg%40mail.gmail.com
[3] https://www.postgresql.org/message-id/flat/E1iaD8h-0004us-K9@gemulon.postgresql.org
[4] https://www.postgresql.org/message-id/flat/CALDaNm2tEvr_Kum7SyvFn0%3D6H3P0P-Zkhnd%3DdkkX%2BQ%3DwKutZ%3DA%40mail.gmail.com
[5] https://www.postgresql.org/message-id/flat/20200603201242.ofvm4jztpqytwfye%40alap3.anarazel.de
[6] https://www.postgresql.org/message-id/16678-253e48d34dc0c376@postgresql.org
[7] https://www.postgresql.org/message-id/flat/90b34057-4176-7bb0-0dbb-9822a5f6425b%40greiz-reinsdorf.de
[8] https://www.postgresql.org/message-id/flat/af5e0bf3-6a61-bb97-6cba-061ddf22ff6b%40dunslane.net
[9] https://www.postgresql.org/message-id/flat/CA%2BhUKG%2BOeoETZQ%3DQw5Ub5h3tmwQhBmDA%3DnuNO3KG%3DzWfUypFAw%40mail.gmail.com
[10] https://www.postgresql.org/message-id/flat/17391-304f81bcf724b58b%40postgresql.org
Best regards,
Alexander
Вложения
On Thu, Nov 9, 2023 at 10:32 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Here is a new attempt to fix this mess. Disclaimer: this based > entirely on reading the manual and vicariously hacking a computer I > don't have via CI. I'd first like to congratulate this thread on reaching its second birthday. The CommitFest entry hasn't quite made it to the two year mark yet - expect that in another month or so - but thread itself is over the line. Regarding 0001, I don't know if we really need SH_RAW_FREE. You can just define your own SH_FREE implementation in userspace. That doesn't work for SH_RAW_ALLOCATOR because there's code in simplehash.h that knows about memory contexts apart from the actual definition of SH_ALLOCATE - e.g. we include a MemoryContext pointer in SH_TYPE, and in the signature of SH_CREATE. But SH_FREE doesn't seem to have any similar issues. Maybe it's still worth doing for convenience -- I haven't thought about that very hard -- but it doesn't seem to be required in the same way that SH_RAW_ALLOCATOR was. I wonder whether we really want 0002. It seems like a pretty significant behavior change -- now everybody using simplehash has to worry about whether failure cases are possible. And maybe there's some performance overhead. And most of the changes are restricted to the SH_RAW_ALLOCATOR case, but the changes to SH_GROW are not. And making this contingent on SH_RAW_ALLOCATOR doesn't seem principled. I kind of wonder whether trying to handle OOM here is the wrong direction to go. What if we just bail out hard if we can't insert into the hash table? I think that we don't expect the hash table to ever be very large (right?) and we don't install these kinds of defenses everywhere that OOM on a small memory allocation is a possibility (or at least I don't think we do). I'm actually sort of unclear about why you're trying to force this to use raw malloc/free instead of palloc/pfree. Do we need to use this on the frontend side? Do we need it on the backend side prior to the memory context infrastructure being up? -- Robert Haas EDB: http://www.enterprisedb.com
2024-01 Commitfest. Hi, This patch has a CF status of "Needs Review" [1], but it seems like there were CFbot test failures last time it was run [1]. Please have a look and post an updated version if necessary. ====== 1[] https://commitfest.postgresql.org/46/3523/ [1] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest/46/3523
On Mon, 22 Jan 2024 at 09:56, Peter Smith <smithpb2250@gmail.com> wrote: > > 2024-01 Commitfest. > > Hi, This patch has a CF status of "Needs Review" [1], but it seems > like there were CFbot test failures last time it was run [1]. Please > have a look and post an updated version if necessary. The patch which you submitted has been awaiting your attention for quite some time now. As such, we have moved it to "Returned with Feedback" and removed it from the reviewing queue. Depending on timing, this may be reversible. Kindly address the feedback you have received, and resubmit the patch to the next CommitFest. Regards, Vignesh