Обсуждение: Hybrid Hash/Nested Loop joins and caching results from subplans
Hackers,
Over on [1], Heikki mentioned about the usefulness of caching results
from parameterized subplans so that they could be used again for
subsequent scans which have the same parameters as a previous scan.
On [2], I mentioned that parameterized nested loop joins could see
similar gains with such a cache. I suggested there that instead of
adding code that only allows this to work for subplans, that instead,
we add a new node type that can handle the caching for us. We can
then just inject that node type in places where it seems beneficial.
I've attached a patch which implements this. The new node type is
called "Result Cache". I'm not particularly wedded to keeping that
name, but if I change it, I only want to do it once. I've got a few
other names I mind, but I don't feel strongly or confident enough in
them to go and do the renaming.
How the caching works:
First off, it's only good for plugging in on top of parameterized
nodes that are rescanned with different parameters. The cache itself
uses a hash table using the simplehash.h implementation. The memory
consumption is limited to work_mem. The code maintains an LRU list and
when we need to add new entries but don't have enough space to do so,
we free off older items starting at the top of the LRU list. When we
get a cache hit, we move that entry to the end of the LRU list so that
it'll be the last to be evicted.
When should we cache:
For nested loop joins, the decision is made purely based on cost. The
costing model looks at the expected number of calls, the distinct
value estimate and work_mem size. It then determines how many items
can be cached and then goes on to estimate an expected cache hit ratio
and also an eviction ratio. It adjusts the input costs according to
those ratios and adds some additional charges for caching and cache
lookups.
For subplans, since we plan subplans before we're done planning the
outer plan, there's very little information to go on about the number
of times that the cache will be looked up. For now, I've coded things
so the cache is always used for EXPR_SUBLINK type subplans. There may
be other types of subplan that could support caching too, but I've not
really gone through them all yet to determine which. I certainly know
there's some that we can't cache for.
Why caching might be good:
With hash joins, it's sometimes not so great that we have to hash the
entire inner plan and only probe a very small number of values. If we
were able to only fill the hash table with values that are needed,
then then a lot of time and memory could be saved. Effectively, the
patch does exactly this with the combination of a parameterized nested
loop join with a Result Cache node above the inner scan.
For subplans, the gains can be more because often subplans are much
more expensive to execute than what might go on the inside of a
parameterized nested loop join.
Current problems and some ways to make it better:
The patch does rely heavily on good ndistinct estimates. One
unfortunate problem is that if the planner has no statistics for
whatever it's trying to estimate for, it'll default to returning
DEFAULT_NUM_DISTINCT (200). That may cause the Result Cache to appear
much more favourable than it should. One way I can think to work
around that would be to have another function similar to
estimate_num_groups() which accepts a default value which it will
return if it was unable to find statistics to use. In this case, such
a function could just be called passing the number of input rows as
the default, which would make the costing code think each value is
unique, which would not be favourable for caching. I've not done
anything like that in what I've attached here. That solution would
also do nothing if the ndistinct estimate was available, but was just
incorrect, as it often is.
There are currently a few compiler warnings with the patch due to the
scope of the simplehash.h hash table. Because the scope is static
rather than extern there's a load of unused function warnings. Not
sure yet the best way to deal with this. I don't want to change the
scope to extern just to keep compilers quiet.
Also during cache_reduce_memory(), I'm performing a hash table lookup
followed by a hash table delete. I already have the entry to delete,
but there's no simplehash.h function that allows deletion by element
pointer, only by key. This wastes a hash table lookup. I'll likely
make an adjustment to the simplehash.h code to export the delete code
as a separate function to fix this.
Demo:
# explain (analyze, costs off) select relname,(select count(*) from
pg_class c2 where c1.relkind = c2.relkind) from pg_class c1;
QUERY PLAN
----------------------------------------------------------------------------------------
Seq Scan on pg_class c1 (actual time=0.069..0.470 rows=391 loops=1)
SubPlan 1
-> Result Cache (actual time=0.001..0.001 rows=1 loops=391)
Cache Key: c1.relkind
Cache Hits: 387 Cache Misses: 4 Cache Evictions: 0 Cache
Overflows: 0
-> Aggregate (actual time=0.062..0.062 rows=1 loops=4)
-> Seq Scan on pg_class c2 (actual time=0.007..0.056
rows=98 loops=4)
Filter: (c1.relkind = relkind)
Rows Removed by Filter: 293
Planning Time: 0.047 ms
Execution Time: 0.536 ms
(11 rows)
# set enable_resultcache=0; -- disable result caching
SET
# explain (analyze, costs off) select relname,(select count(*) from
pg_class c2 where c1.relkind = c2.relkind) from pg_class c1;
QUERY PLAN
-------------------------------------------------------------------------------------
Seq Scan on pg_class c1 (actual time=0.070..24.619 rows=391 loops=1)
SubPlan 1
-> Aggregate (actual time=0.062..0.062 rows=1 loops=391)
-> Seq Scan on pg_class c2 (actual time=0.009..0.056
rows=120 loops=391)
Filter: (c1.relkind = relkind)
Rows Removed by Filter: 271
Planning Time: 0.042 ms
Execution Time: 24.653 ms
(8 rows)
-- Demo with parameterized nested loops
create table hundredk (hundredk int, tenk int, thousand int, hundred
int, ten int, one int);
insert into hundredk select x%100000,x%10000,x%1000,x%100,x%10,1 from
generate_Series(1,100000) x;
create table lookup (a int);
insert into lookup select x from generate_Series(1,100000)x,
generate_Series(1,100);
create index on lookup(a);
vacuum analyze lookup, hundredk;
# explain (analyze, costs off) select count(*) from hundredk hk inner
join lookup l on hk.thousand = l.a;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Aggregate (actual time=1876.710..1876.710 rows=1 loops=1)
-> Nested Loop (actual time=0.013..1371.690 rows=9990000 loops=1)
-> Seq Scan on hundredk hk (actual time=0.005..8.451
rows=100000 loops=1)
-> Result Cache (actual time=0.000..0.005 rows=100 loops=100000)
Cache Key: hk.thousand
Cache Hits: 99000 Cache Misses: 1000 Cache Evictions:
0 Cache Overflows: 0
-> Index Only Scan using lookup_a_idx on lookup l
(actual time=0.002..0.011 rows=100 loops=1000)
Index Cond: (a = hk.thousand)
Heap Fetches: 0
Planning Time: 0.113 ms
Execution Time: 1876.741 ms
(11 rows)
# set enable_resultcache=0;
SET
# explain (analyze, costs off) select count(*) from hundredk hk inner
join lookup l on hk.thousand = l.a;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Aggregate (actual time=2401.351..2401.352 rows=1 loops=1)
-> Merge Join (actual time=28.412..1890.905 rows=9990000 loops=1)
Merge Cond: (l.a = hk.thousand)
-> Index Only Scan using lookup_a_idx on lookup l (actual
time=0.005..10.170 rows=99901 loops=1)
Heap Fetches: 0
-> Sort (actual time=28.388..576.783 rows=9990001 loops=1)
Sort Key: hk.thousand
Sort Method: quicksort Memory: 7760kB
-> Seq Scan on hundredk hk (actual time=0.005..11.039
rows=100000 loops=1)
Planning Time: 0.123 ms
Execution Time: 2401.379 ms
(11 rows)
Cache Overflows:
You might have noticed "Cache Overflow" in the EXPLAIN ANALYZE output.
This happens if a single scan of the inner node exhausts the cache
memory. In this case, all the other entries will already have been
evicted in an attempt to make space for the current scan's tuples.
However, if we see an overflow then the size of the results from a
single scan alone must have exceeded work_mem. There might be some
tweaking to do here as it seems a shame that a single overly larger
scan would flush the entire cache. I doubt it would be too hard to
limit the flushing to some percentage of work_mem. Similar to how
large seqscans don't entirely flush shared_buffers.
Current Status:
I've spent quite a bit of time getting this working. I'd like to take
a serious go at making this happen for PG14. For now, it all seems to
work. I have some concerns about bad statistics causing nested loop
joins to be favoured more than they were previously due to the result
cache further lowering the cost of them when the cache hit ratio is
thought to be high.
For now, the node type is parallel_safe, but not parallel_aware. I can
see that a parallel_aware version would be useful, but I've not done
that here. Anything in that area will not be part of my initial
effort. The unfortunate part about that is the actual hit ratio will
drop with more parallel workers since the caches of each worker are
separate.
Some tests show a 10x speedup on TPC-H Q2.
I'm interested in getting feedback on this before doing much further work on it.
Does it seem like something we might want for PG14?
David
[1] https://www.postgresql.org/message-id/daceb327-9a20-51f4-fe6c-60b898692305%40iki.fi
[2] https://www.postgresql.org/message-id/CAKJS1f8oNXQ-LqjK%3DBOFDmxLc_7s3uFr_g4qi7Ncrjig0JOCiA%40mail.gmail.com
Вложения
On Wed, 20 May 2020 at 12:44, David Rowley <dgrowleyml@gmail.com> wrote:
Hackers,
Over on [1], Heikki mentioned about the usefulness of caching results
from parameterized subplans so that they could be used again for
subsequent scans which have the same parameters as a previous scan.
On [2], I mentioned that parameterized nested loop joins could see
similar gains with such a cache. I suggested there that instead of
adding code that only allows this to work for subplans, that instead,
we add a new node type that can handle the caching for us. We can
then just inject that node type in places where it seems beneficial.
Very cool
I've attached a patch which implements this. The new node type is
called "Result Cache". I'm not particularly wedded to keeping that
name, but if I change it, I only want to do it once. I've got a few
other names I mind, but I don't feel strongly or confident enough in
them to go and do the renaming.
How the caching works:
First off, it's only good for plugging in on top of parameterized
nodes that are rescanned with different parameters. The cache itself
uses a hash table using the simplehash.h implementation. The memory
consumption is limited to work_mem. The code maintains an LRU list and
when we need to add new entries but don't have enough space to do so,
we free off older items starting at the top of the LRU list. When we
get a cache hit, we move that entry to the end of the LRU list so that
it'll be the last to be evicted.
When should we cache:
For nested loop joins, the decision is made purely based on cost.
I thought the main reason to do this was the case when the nested loop subplan was significantly underestimated and we realize during execution that we should have built a hash table. So including this based on cost alone seems to miss a trick.
The patch does rely heavily on good ndistinct estimates.
Exactly. We know we seldom get those with many-way joins.
So +1 for adding this technique. My question is whether it should be added as an optional facility of a parameterised sub plan, rather than an always-needed full-strength node. That way the choice of whether to use it can happen at execution time once we notice that we've been called too many times.
On Thu, 21 May 2020 at 00:56, Simon Riggs <simon@2ndquadrant.com> wrote: > I thought the main reason to do this was the case when the nested loop subplan was significantly underestimated and werealize during execution that we should have built a hash table. So including this based on cost alone seems to miss atrick. Isn't that mostly because the planner tends to choose a non-parameterized nested loop when it thinks the outer side of the join has just 1 row? If so, I'd say that's a separate problem as Result Cache only deals with parameterized nested loops. Perhaps the problem you mention could be fixed by adding some "uncertainty degree" to the selectivity estimate function and have it return that along with the selectivity. We'd likely not want to choose an unparameterized nested loop when the uncertainly level is high. Multiplying the selectivity of different selectivity estimates could raise the uncertainty level a magnitude. For plans where the planner chooses to use a non-parameterized nested loop due to having just 1 row on the outer side of the loop, it's taking a huge risk. The cost of putting the 1 row on the inner side of a hash join would bearly cost anything extra during execution. Hashing 1 row is pretty cheap and performing a lookup on that hashed row is not much more expensive than evaluating the qual of the nested loop. Really just requires the additional hash function calls. Having the uncertainty degree I mentioned above would allow us to only have the planner do that when the uncertainty degree indicates it's not worth the risk. David
My question is whether it should be added as an optional facility of a parameterised sub plan, rather than an always-needed full-strength node. That way the choice of whether to use it can happen at execution time once we notice that we've been called too many times.
Actually I am not sure about what does the "parameterized sub plan" mean (I
treat is a SubPlan Node), so please correct me if I misunderstand you:) Because
the inner plan in nest loop not a SubPlan node actually. so if bind the
facility to SubPlan node, we may loss the chances for nest loop. And when we
consider the usage for nest loop, we can consider the below example, where this
feature will be more powerful.
treat is a SubPlan Node), so please correct me if I misunderstand you:) Because
the inner plan in nest loop not a SubPlan node actually. so if bind the
facility to SubPlan node, we may loss the chances for nest loop. And when we
consider the usage for nest loop, we can consider the below example, where this
feature will be more powerful.
select j1o.i, j2_v.sum_5
from j1 j1o
inner join lateral
(select im100, sum(im5) as sum_5
from j2
where j1o.im100 = im100
and j1o.i = 1
group by im100) j2_v
on true
where j1o.i = 1;
from j1 j1o
inner join lateral
(select im100, sum(im5) as sum_5
from j2
where j1o.im100 = im100
and j1o.i = 1
group by im100) j2_v
on true
where j1o.i = 1;
Best Regards
Andy Fan
On Fri, 22 May 2020 at 12:12, Andy Fan <zhihui.fan1213@gmail.com> wrote: > Actually I am not sure about what does the "parameterized sub plan" mean (I > treat is a SubPlan Node), so please correct me if I misunderstand you:) Because > the inner plan in nest loop not a SubPlan node actually. so if bind the > facility to SubPlan node, we may loss the chances for nest loop. A parameterized subplan would be a subquery that contains column reference to a query above its own level. The executor changes that column reference into a parameter and the subquery will need to be rescanned each time the parameter's value changes. > And when we > consider the usage for nest loop, we can consider the below example, where this > feature will be more powerful. I didn't quite get the LATERAL support quite done in the version I sent. For now, I'm not considering adding a Result Cache node if there are lateral vars in any location other than the inner side of the nested loop join. I think it'll just be a few lines to make it work though. I wanted to get some feedback before going to too much more trouble to make all cases work. I've now added this patch to the first commitfest of PG14. David
Today I tested the correctness & performance of this patch based on TPC-H
workload, the environment is setup based on [1]. Correctness is tested by
storing the result into another table when this feature is not introduced and
then enable this feature and comparing the result with the original ones. No
issue is found at this stage.
I also checked the performance gain for TPC-H workload, totally 4 out of the 22
queries uses this new path, 3 of them are subplan, 1 of them is nestloop. All of
changes gets a better result. You can check the attachments for reference.
normal.log is the data without this feature, patched.log is the data with the
feature. The data doesn't show the 10x performance gain, I think that's mainly
data size related.
At the code level, I mainly checked nestloop path and cost_resultcache_rescan,
everything looks good to me. I'd like to check the other parts in the following days.
-- workload, the environment is setup based on [1]. Correctness is tested by
storing the result into another table when this feature is not introduced and
then enable this feature and comparing the result with the original ones. No
issue is found at this stage.
I also checked the performance gain for TPC-H workload, totally 4 out of the 22
queries uses this new path, 3 of them are subplan, 1 of them is nestloop. All of
changes gets a better result. You can check the attachments for reference.
normal.log is the data without this feature, patched.log is the data with the
feature. The data doesn't show the 10x performance gain, I think that's mainly
data size related.
At the code level, I mainly checked nestloop path and cost_resultcache_rescan,
everything looks good to me. I'd like to check the other parts in the following days.
Best Regards
Andy Fan
Вложения
On Tue, 2 Jun 2020 at 21:05, Andy Fan <zhihui.fan1213@gmail.com> wrote: > Today I tested the correctness & performance of this patch based on TPC-H > workload, the environment is setup based on [1]. Correctness is tested by > storing the result into another table when this feature is not introduced and > then enable this feature and comparing the result with the original ones. No > issue is found at this stage. Thank you for testing it out. > I also checked the performance gain for TPC-H workload, totally 4 out of the 22 > queries uses this new path, 3 of them are subplan, 1 of them is nestloop. All of > changes gets a better result. You can check the attachments for reference. > normal.log is the data without this feature, patched.log is the data with the > feature. The data doesn't show the 10x performance gain, I think that's mainly > data size related. Thanks for running those tests. I had a quick look at the results and I think to say that all 4 are better is not quite right. One is actually a tiny bit slower and one is only faster due to a plan change. Here's my full analysis. Q2 uses a result cache for the subplan and has about a 37.5% hit ratio which reduces the execution time of the query down to 67% of the original. Q17 uses a result cache for the subplan and has about a 96.5% hit ratio which reduces the execution time of the query down to 24% of the original time. Q18 uses a result cache for 2 x nested loop joins and has a 0% hit ratio. The execution time is reduced to 91% of the original time only because the planner uses a different plan, which just happens to be faster by chance. Q20 uses a result cache for the subplan and has a 0% hit ratio. The execution time is 100.27% of the original time. There are 8620 cache misses. All other queries use the same plan with and without the patch. > At the code level, I mainly checked nestloop path and cost_resultcache_rescan, > everything looks good to me. I'd like to check the other parts in the following days. Great. > [1] https://ankane.org/tpc-h
Thanks for running those tests. I had a quick look at the results and
I think to say that all 4 are better is not quite right. One is
actually a tiny bit slower and one is only faster due to a plan
change.
Yes.. Thanks for pointing it out.
Q18 uses a result cache for 2 x nested loop joins and has a 0% hit
ratio. The execution time is reduced to 91% of the original time only
because the planner uses a different plan, which just happens to be
faster by chance.
Q20 uses a result cache for the subplan and has a 0% hit ratio. The
execution time is 100.27% of the original time. There are 8620 cache
misses.
Looks the case here is some statistics issue or cost model issue. I'd
like to check more about that. But before that, I upload the steps[1] I used
in case you want to reproduce it locally.
Best Regards
Andy Fan
On Wed, Jun 3, 2020 at 10:36 AM Andy Fan <zhihui.fan1213@gmail.com> wrote:
Thanks for running those tests. I had a quick look at the results and
I think to say that all 4 are better is not quite right. One is
actually a tiny bit slower and one is only faster due to a plan
change.Yes.. Thanks for pointing it out.
Q18 uses a result cache for 2 x nested loop joins and has a 0% hit
ratio. The execution time is reduced to 91% of the original time only
because the planner uses a different plan, which just happens to be
faster by chance.
This case should be caused by wrong rows estimations on condition
o_orderkey in (select l_orderkey from lineitem group by l_orderkey having
sum(l_quantity) > 312). The estimation is 123766 rows, but the fact is 10 rows.
sum(l_quantity) > 312). The estimation is 123766 rows, but the fact is 10 rows.
This estimation is hard and I don't think we should address this issue on this
patch.
Q20 uses a result cache for the subplan and has a 0% hit ratio. The
execution time is 100.27% of the original time. There are 8620 cache
misses.
This is by design for current implementation.
> For subplans, since we plan subplans before we're done planning the
> outer plan, there's very little information to go on about the number> of times that the cache will be looked up. For now, I've coded things
> so the cache is always used for EXPR_SUBLINK type subplans. "
I first tried to see if we can have a row estimation before the subplan
is created and it looks very complex. The subplan was created during
preprocess_qual_conditions, at that time, we even didn't create the base
RelOptInfo , to say nothing of join_rel which the rows estimation happens
much later.
Then I see if we can delay the cache decision until we have the rows estimation,
ExecInitSubPlan may be a candidate. At this time we can't add a new
ResutCache node, but we can add a cache function to SubPlan node with costed
based. However the num_of_distinct values for parameterized variable can't be
calculated which I still leave it as an open issue.
Best Regards
Andy Fan
On Fri, 12 Jun 2020 at 16:10, Andy Fan <zhihui.fan1213@gmail.com> wrote: > I first tried to see if we can have a row estimation before the subplan > is created and it looks very complex. The subplan was created during > preprocess_qual_conditions, at that time, we even didn't create the base > RelOptInfo , to say nothing of join_rel which the rows estimation happens > much later. > > Then I see if we can delay the cache decision until we have the rows estimation, > ExecInitSubPlan may be a candidate. At this time we can't add a new > ResutCache node, but we can add a cache function to SubPlan node with costed > based. However the num_of_distinct values for parameterized variable can't be > calculated which I still leave it as an open issue. I don't really like the idea of stuffing this feature into some existing node type. Doing so would seem pretty magical when looking at an EXPLAIN ANALYZE. There is of course overhead to pulling tuples through an additional node in the plan, but if you use that as an argument then there's some room to argue that we should only have 1 executor node type to get rid of that overhead. Tom mentioned in [1] that he's reconsidering his original thoughts on leaving the AlternativeSubPlan selection decision until execution time. If that were done late in planning, as Tom mentioned, then it would be possible to give a more accurate cost to the Result Cache as we'd have built the outer plan by that time and would be able to estimate the number of distinct calls to the correlated subplan. As that feature is today we'd be unable to delay making the decision until execution time as we don't have the required details to know how many distinct calls there will be to the Result Cache node. For now, I'm planning on changing things around a little in the Result Cache node to allow faster deletions from the cache. As of now, we must perform 2 hash lookups to perform a single delete. This is because we must perform the lookup to fetch the entry from the MRU list key, then an additional lookup in the hash delete code. I plan on changing the hash delete code to expose another function that allows us to delete an item directly if we've already looked it up. This should make a small reduction in the overheads of the node. Perhaps if the overhead is very small (say < 1%) when the cache is of no use then it might not be such a bad thing to just have a Result Cache for correlated subplans regardless of estimates. With the TPCH Q20 test, it appeared as if the overhead was 0.27% for that particular subplan. A more simple subplan would execute more quickly resulting the Result Cache overhead being a more significant portion of the overall subquery execution. I'd need to perform a worst-case overhead test to get an indication of what the percentage is. David [1] https://www.postgresql.org/message-id/1992952.1592785225@sss.pgh.pa.us
On Tue, 30 Jun 2020 at 11:57, David Rowley <dgrowleyml@gmail.com> wrote: > For now, I'm planning on changing things around a little in the Result > Cache node to allow faster deletions from the cache. As of now, we > must perform 2 hash lookups to perform a single delete. This is > because we must perform the lookup to fetch the entry from the MRU > list key, then an additional lookup in the hash delete code. I plan > on changing the hash delete code to expose another function that > allows us to delete an item directly if we've already looked it up. > This should make a small reduction in the overheads of the node. > Perhaps if the overhead is very small (say < 1%) when the cache is of > no use then it might not be such a bad thing to just have a Result > Cache for correlated subplans regardless of estimates. With the TPCH > Q20 test, it appeared as if the overhead was 0.27% for that particular > subplan. A more simple subplan would execute more quickly resulting > the Result Cache overhead being a more significant portion of the > overall subquery execution. I'd need to perform a worst-case overhead > test to get an indication of what the percentage is. I made the changes that I mention to speedup the cache deletes. The patch is now in 3 parts. The first two parts are additional work and the final part is the existing work with some small tweaks. 0001: Alters estimate_num_groups() to allow it to pass back a flags variable to indicate if the estimate used DEFAULT_NUM_DISTINCT. The idea here is to try and avoid using a Result Cache for a Nested Loop join when the statistics are likely to be unreliable. Because DEFAULT_NUM_DISTINCT is 200, if we estimate that number of distinct values then a Result Cache is likely to look highly favourable in some situations where it very well may not be. I've not given this patch a huge amount of thought, but so far I don't see anything too unreasonable about it. I'm prepared to be wrong about that though. 0002 Makes some adjustments to simplehash.h to expose a function which allows direct deletion of a hash table element when we already have a pointer to the bucket. I think this is a pretty good change as it reuses more simplehash.h code than without the patch. 0003 Is the result cache code. I've done another pass over this version and fixed a few typos and added a few comments. I've not yet added support for LATERAL joins. I plan to do that soon. For now, I just wanted to get something out there as I saw that the patch did need rebased. I did end up testing the overheads of having a Result Cache node on a very simple subplan that'll never see a cache hit. The overhead is quite a bit more than the 0.27% that we saw with TPCH Q20. Using a query that gets zero cache hits: $ cat bench.sql select relname,(select oid from pg_class c2 where c1.oid = c2.oid) from pg_Class c1 offset 1000000000; enable_resultcache = on: $ pgbench -n -f bench.sql -T 60 postgres latency average = 0.474 ms tps = 2110.431529 (including connections establishing) tps = 2110.503284 (excluding connections establishing) enable_resultcache = off: $ pgbench -n -f bench.sql -T 60 postgres latency average = 0.379 ms tps = 2640.534303 (including connections establishing) tps = 2640.620552 (excluding connections establishing) Which is about a 25% overhead in this very simple case. With more complex subqueries that overhead will drop significantly, but for that simple one, it does seem a quite a bit too high to be adding a Result Cache unconditionally for all correlated subqueries. I think based on that it's worth looking into the AlternativeSubPlan option that I mentioned earlier. I've attached the v2 patch series. David
Вложения
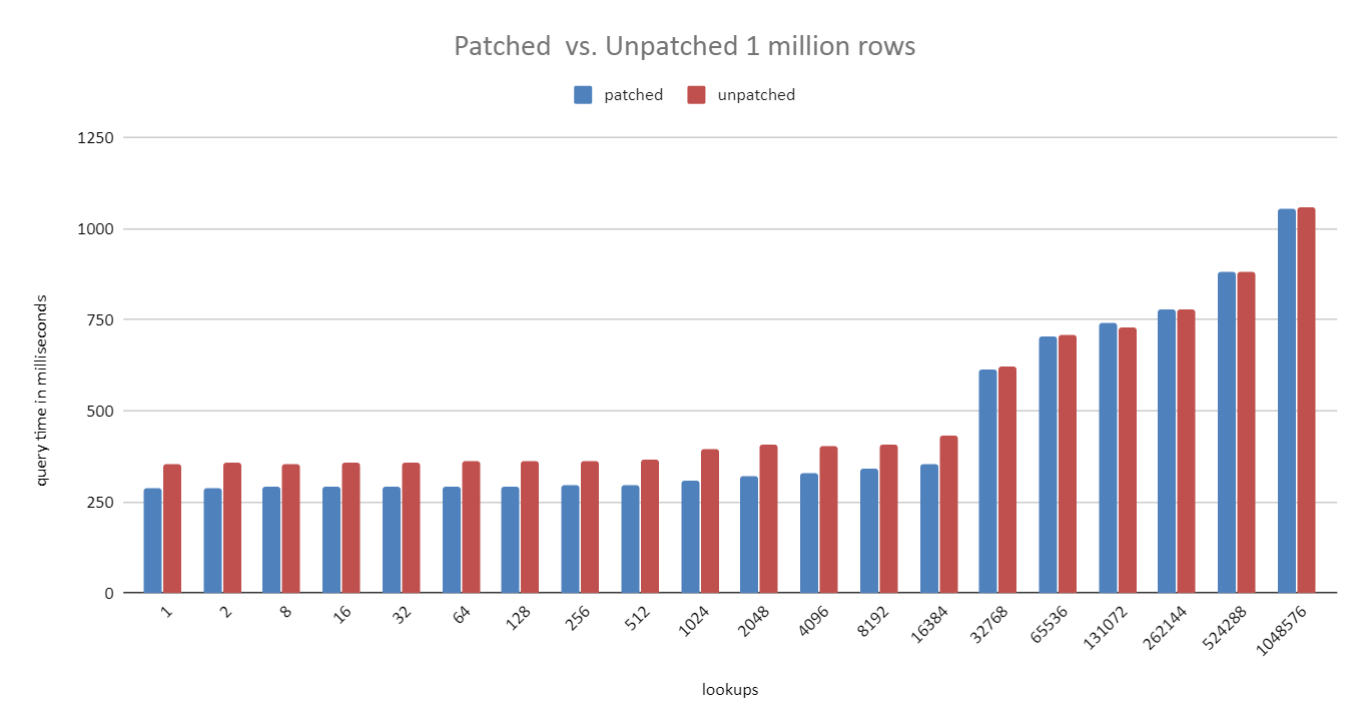
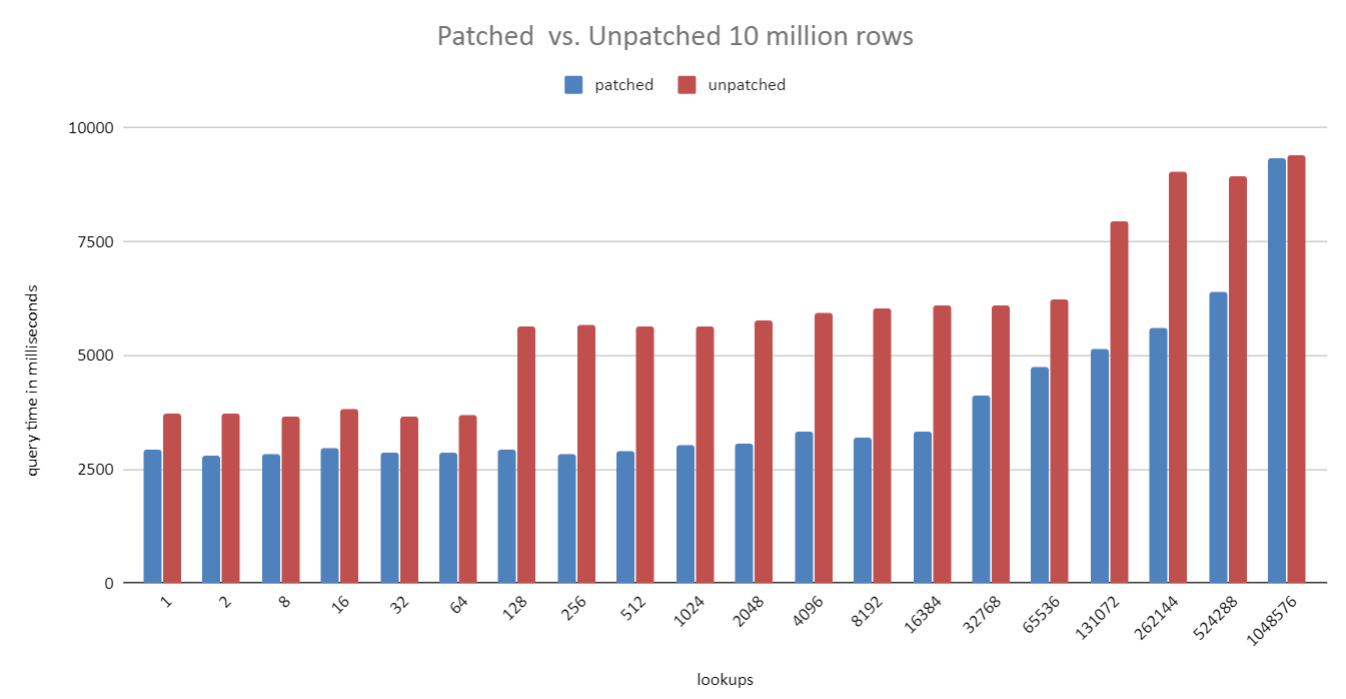
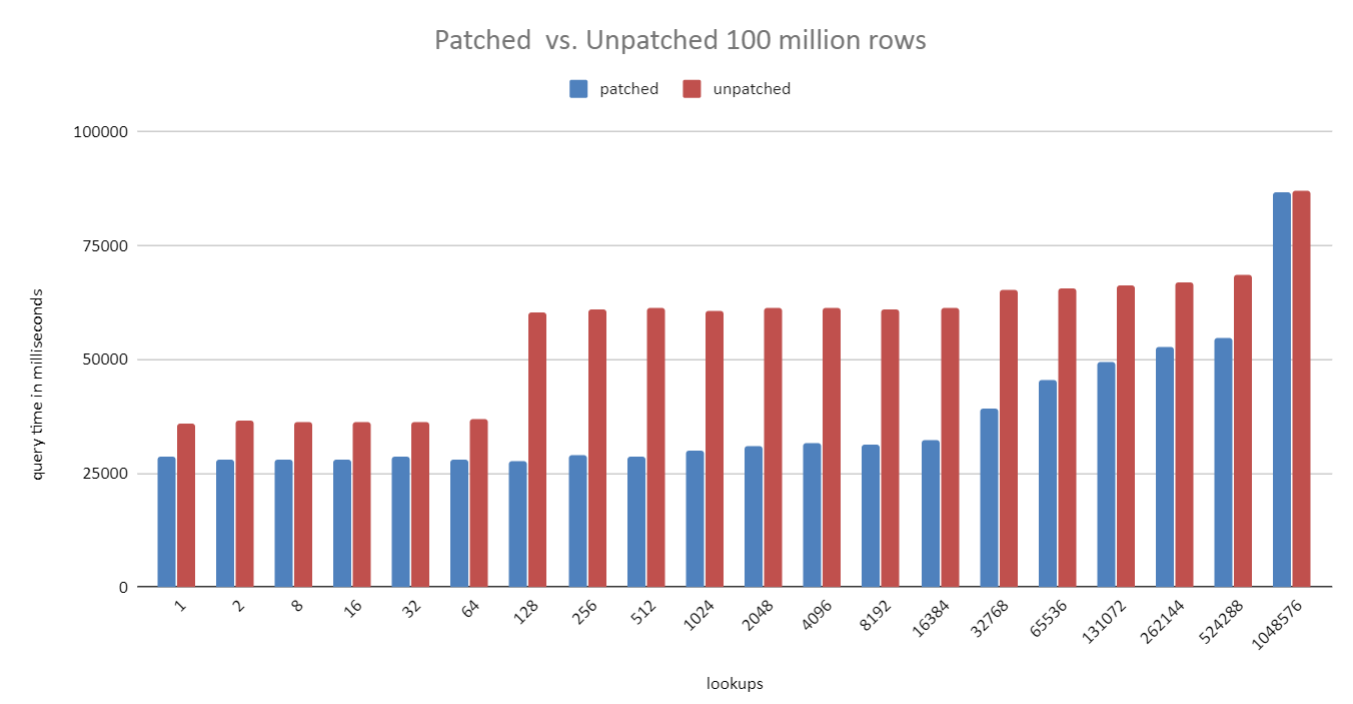
On Thu, 2 Jul 2020 at 22:57, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached the v2 patch series. There was a bug in v2 that caused the caching not to work properly when a unique join skipped to the next outer row after finding the first match. The cache was not correctly marked as complete in that case. Normally we only mark the cache entry complete when we read the scan to completion. Unique joins is a special case where we can mark it as complete early. I've also made a few more changes to reduce the size of the ResultCacheEntry struct, taking it from 40 bytes down to 24. That matters quite a bit when the cached tuple is very narrow. One of the tests in resultcache.out, because we can now fit more entries in the cache, it reports a 15% increase in cache hits. I also improved the costing regarding the estimate of how many cache entries we could fit in work mem. Previously I was not accounting for the size of the cache data structures in memory. v2 only accounted for the tuples themselves. It's important to count these as if we don't then it could cause the costing to think we could fit more entries than we actually could which meant the estimated number of cache evictions was off and could result in preferring a result cache plan when we perhaps shouldn't. I've attached v4. I've also attached a bunch of benchmark results which were based on v3 of the patch. I didn't send out v3, but the results of v4 should be almost the same for this test. The script to run the benchmark is contained in the resultcachebench.txt file. The benchmark just mocks up a "parts" table and a "sales" table. The parts table has 1 million rows in the 1 million test, as does the sales table. This goes up to 10 million and 100 million in the other two tests. What varies with each bar in the chart is the number of distinct parts in the sales table. I just started with 1 part then doubled that up to ~1 million. The unpatched version always uses a Hash Join, which is wasteful since only a subset of parts are looked up. In the 1 million test the planner switches to using a Hash Join in the patched version at 65k parts. It waits until the 1 million distinct parts test to switch over in the 10 million and 100 million test. The hash join costs are higher in that case due to multi-batching, which is why the crossover point is higher on the larger scale tests. I used 256MB work_mem for all tests. Looking closely at the 10 million test, you can see that the hash join starts taking longer from 128 parts onward. The hash table is the same each time here, so I can only suspect that the slowdown between 64 and 128 parts is due to CPU cache thrashing when getting the correct buckets from the overly large hash table. This is not really visible in the patched version as the resultcache hash table is much smaller. David
Вложения
{kind=link}
{kind=link}
{kind=link}
On Wed, 8 Jul 2020 at 00:32, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached v4. Thomas pointed out to me earlier that, per the CFbot, v4 was generating a new compiler warning. Andres pointed out to me that I could fix the warnings of the unused functions in simplehash.h by changing the scope from static to static inline. The attached v5 patch set fixes that. David
Вложения
Hi, On 2020-05-20 23:44:27 +1200, David Rowley wrote: > I've attached a patch which implements this. The new node type is > called "Result Cache". I'm not particularly wedded to keeping that > name, but if I change it, I only want to do it once. I've got a few > other names I mind, but I don't feel strongly or confident enough in > them to go and do the renaming. I'm not convinced it's a good idea to introduce a separate executor node for this. There's a fair bit of overhead in them, and they will only be below certain types of nodes afaict. It seems like it'd be better to pull the required calls into the nodes that do parametrized scans of subsidiary nodes. Have you considered that? Greetings, Andres Freund
On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote:
>
> On 2020-05-20 23:44:27 +1200, David Rowley wrote:
> > I've attached a patch which implements this. The new node type is
> > called "Result Cache". I'm not particularly wedded to keeping that
> > name, but if I change it, I only want to do it once. I've got a few
> > other names I mind, but I don't feel strongly or confident enough in
> > them to go and do the renaming.
>
> I'm not convinced it's a good idea to introduce a separate executor node
> for this. There's a fair bit of overhead in them, and they will only be
> below certain types of nodes afaict. It seems like it'd be better to
> pull the required calls into the nodes that do parametrized scans of
> subsidiary nodes. Have you considered that?
I see 41 different node types mentioned in ExecReScan(). I don't
really think it would be reasonable to change all those.
Here are a couple of examples, one with a Limit below the Result Cache
and one with a GroupAggregate.
postgres=# explain (costs off) select * from pg_Class c1 where relname
= (select relname from pg_Class c2 where c1.relname = c2.relname
offset 1 limit 1);
QUERY PLAN
-------------------------------------------------------------------------------------
Seq Scan on pg_class c1
Filter: (relname = (SubPlan 1))
SubPlan 1
-> Result Cache
Cache Key: c1.relname
-> Limit
-> Index Only Scan using pg_class_relname_nsp_index
on pg_class c2
Index Cond: (relname = c1.relname)
(8 rows)
postgres=# explain (costs off) select * from pg_Class c1 where relname
= (select relname from pg_Class c2 where c1.relname = c2.relname group
by 1 having count(*) > 1);
QUERY PLAN
-------------------------------------------------------------------------------------
Seq Scan on pg_class c1
Filter: (relname = (SubPlan 1))
SubPlan 1
-> Result Cache
Cache Key: c1.relname
-> GroupAggregate
Group Key: c2.relname
Filter: (count(*) > 1)
-> Index Only Scan using pg_class_relname_nsp_index
on pg_class c2
Index Cond: (relname = c1.relname)
(10 rows)
As for putting the logic somewhere like ExecReScan() then the first
paragraph in [1] are my thoughts on that.
David
[1] https://www.postgresql.org/message-id/CAApHDvr-yx9DEJ1Lc9aAy8QZkgEZkTP=3hBRBe83Vwo=kAndcA@mail.gmail.com
On Wed, 8 Jul 2020 at 15:37, David Rowley <dgrowleyml@gmail.com> wrote: > The attached v5 patch set fixes that. I've attached an updated set of patches for this per recent conflict. I'd like to push the 0002 patch quite soon as I think it's an improvement to simplehash.h regardless of if we get Result Cache. It reuses the SH_LOOKUP function for deletes. Also, if we ever get around to giving up performing a lookup if we get too far away from the optimal bucket, then that would only need to appear in one location rather than in two. Andres, or anyone, any objections to me pushing 0002? David
Вложения
Hi,
On 2020-08-04 10:05:25 +1200, David Rowley wrote:
> I'd like to push the 0002 patch quite soon as I think it's an
> improvement to simplehash.h regardless of if we get Result Cache. It
> reuses the SH_LOOKUP function for deletes. Also, if we ever get around
> to giving up performing a lookup if we get too far away from the
> optimal bucket, then that would only need to appear in one location
> rather than in two.
> Andres, or anyone, any objections to me pushing 0002?
I think it'd be good to add a warning that, unless one is very careful,
no other hashtable modifications are allowed between lookup and
modification. E.g. something like
a = foobar_lookup();foobar_insert();foobar_delete();
will occasionally go wrong...
> - /* TODO: return false; if distance too big */
> +/*
> + * Perform hash table lookup on 'key', delete the entry belonging to it and
> + * return true. Returns false if no item could be found relating to 'key'.
> + */
> +SH_SCOPE bool
> +SH_DELETE(SH_TYPE * tb, SH_KEY_TYPE key)
> +{
> + SH_ELEMENT_TYPE *entry = SH_LOOKUP(tb, key);
>
> - curelem = SH_NEXT(tb, curelem, startelem);
> + if (likely(entry != NULL))
> + {
> + /*
> + * Perform deletion and also the relocation of subsequent items which
> + * are not in their optimal position but can now be moved up.
> + */
> + SH_DELETE_ITEM(tb, entry);
> + return true;
> }
> +
> + return false; /* Can't find 'key' */
> }
You meantioned on IM that there's a slowdowns with gcc. I wonder if this
could partially be responsible. Does SH_DELETE inline LOOKUP and
DELETE_ITEM? And does the generated code end up reloading entry-> or
tb-> members?
When the SH_SCOPE isn't static *, then IIRC gcc on unixes can't rely on
the called function actually being the function defined in the same
translation unit (unless -fno-semantic-interposition is specified).
Hm, but you said that this happens in tidbitmap.c, and there all
referenced functions are local statics. So that's not quite the
explanation I was thinking it was...
Hm. Also wonder whether we currently (i.e. the existing code) we
unnecessarily end up reloading tb->data a bunch of times, because we do
the access to ->data as
SH_ELEMENT_TYPE *entry = &tb->data[curelem];
Think we should instead store tb->data in a local variable.
Greetings,
Andres Freund
On Wed, May 20, 2020 at 7:44 AM David Rowley <dgrowleyml@gmail.com> wrote: > I've attached a patch which implements this. The new node type is > called "Result Cache". I'm not particularly wedded to keeping that > name, but if I change it, I only want to do it once. I've got a few > other names I mind, but I don't feel strongly or confident enough in > them to go and do the renaming. This is cool work; I am going to bikeshed on the name for a minute. I don't think Result Cache is terrible, but I have two observations: 1. It might invite confusion with a feature of some other database systems where they cache the results of entire queries and try to reuse the entire result set. 2. The functionality reminds me a bit of a Materialize node, except that instead of overflowing to disk, we throw away cache entries, and instead of caching just one result, we potentially cache many. I can't really think of a way to work Materialize into the node name and I'm not sure it would be the right idea anyway. But I wonder if maybe a name like "Parameterized Cache" would be better? That would avoid confusion with any other use of the phrase "result cache"; also, an experienced PostgreSQL user might be more likely to guess how a "Parameterized Cache" is different from a "Materialize" node than they would be if it were called a "Result Cache". Just my $0.02, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, May 20, 2020 at 4:44 AM David Rowley <dgrowleyml@gmail.com> wrote: > Does it seem like something we might want for PG14? Minor terminology issue: "Hybrid Hash Join" is a specific hash join algorithm which is unrelated to what you propose to do here. I hope that confusion can be avoided, possibly by not using the word hybrid in the name. -- Peter Geoghegan
On Thu, 6 Aug 2020 at 08:13, Robert Haas <robertmhaas@gmail.com> wrote: > > This is cool work; I am going to bikeshed on the name for a minute. I > don't think Result Cache is terrible, but I have two observations: Thanks > 1. It might invite confusion with a feature of some other database > systems where they cache the results of entire queries and try to > reuse the entire result set. Yeah. I think "Cache" is good to keep, but I'm pretty much in favour of swapping "Result" for something else. It's a bit too close to the "Result" node in name, but too distant for everything else. > 2. The functionality reminds me a bit of a Materialize node, except > that instead of overflowing to disk, we throw away cache entries, and > instead of caching just one result, we potentially cache many. > > I can't really think of a way to work Materialize into the node name > and I'm not sure it would be the right idea anyway. But I wonder if > maybe a name like "Parameterized Cache" would be better? Yeah, I think that name is better. The only downside as far as I can see is the length of it. I'll hold off a bit before doing any renaming though to see what other people think. I just feel bikeshedding on the name is something that's going to take up quite a bit of time and effort with this. I plan to rename it at most once. Thanks for the comments David
On Thu, 6 Aug 2020 at 05:44, Andres Freund <andres@anarazel.de> wrote:
> > Andres, or anyone, any objections to me pushing 0002?
>
> I think it'd be good to add a warning that, unless one is very careful,
> no other hashtable modifications are allowed between lookup and
> modification. E.g. something like
> a = foobar_lookup();foobar_insert();foobar_delete();
> will occasionally go wrong...
Good point. I agree. An insert could grow the table. Additionally,
another delete could shuffle elements back to a more optimal position
so we couldn't do any inserts or deletes between the lookup of the
item to delete and the actual delete.
> > - /* TODO: return false; if distance too big */
> > +/*
> > + * Perform hash table lookup on 'key', delete the entry belonging to it and
> > + * return true. Returns false if no item could be found relating to 'key'.
> > + */
> > +SH_SCOPE bool
> > +SH_DELETE(SH_TYPE * tb, SH_KEY_TYPE key)
> > +{
> > + SH_ELEMENT_TYPE *entry = SH_LOOKUP(tb, key);
> >
> > - curelem = SH_NEXT(tb, curelem, startelem);
> > + if (likely(entry != NULL))
> > + {
> > + /*
> > + * Perform deletion and also the relocation of subsequent items which
> > + * are not in their optimal position but can now be moved up.
> > + */
> > + SH_DELETE_ITEM(tb, entry);
> > + return true;
> > }
> > +
> > + return false; /* Can't find 'key' */
> > }
>
> You meantioned on IM that there's a slowdowns with gcc. I wonder if this
> could partially be responsible. Does SH_DELETE inline LOOKUP and
> DELETE_ITEM? And does the generated code end up reloading entry-> or
> tb-> members?
Yeah both the SH_LOOKUP and SH_DELETE_ITEM are inlined.
I think the difference might be coming from the fact that I have to
calculate the bucket index from the bucket pointer using:
/* Calculate the index of 'entry' */
curelem = entry - &tb->data[0];
There is some slight change of instructions due to the change in the
hash lookup part of SH_DELETE, but for the guts of the code that's
generated for SH_DELETE_ITEM, there's a set of instructions that are
just additional:
subq %r10, %rax
sarq $4, %rax
imull $-1431655765, %eax, %eax
leal 1(%rax), %r8d
For testing sake, I changed the curelem = entry - &tb->data[0]; to
just be curelem = 10; and those 4 instructions disappear.
I can't really work out what the imull constant means. In binary, that
number is 10101010101010101010101010101011
I wonder if it might be easier if I just leave SH_DELETE alone and
just add a new function to delete with the known element.
> When the SH_SCOPE isn't static *, then IIRC gcc on unixes can't rely on
> the called function actually being the function defined in the same
> translation unit (unless -fno-semantic-interposition is specified).
>
>
> Hm, but you said that this happens in tidbitmap.c, and there all
> referenced functions are local statics. So that's not quite the
> explanation I was thinking it was...
>
>
> Hm. Also wonder whether we currently (i.e. the existing code) we
> unnecessarily end up reloading tb->data a bunch of times, because we do
> the access to ->data as
> SH_ELEMENT_TYPE *entry = &tb->data[curelem];
>
> Think we should instead store tb->data in a local variable.
At the start of SH_DELETE_ITEM I tried doing:
SH_ELEMENT_TYPE *buckets = tb->data;
then referencing that local var instead of tb->data in the body of the
loop. No meaningful improvements to the assembly. It just seems to
adjust which registers are used.
WIth the local var I see:
addq %r9, %rdx
but in the version without the local variable I see:
addq 24(%rdi), %rdx
the data array is 24 bytes into the SH_TYPE struct. So it appears like
we just calculate the offset to that field by adding 24 to the tb
field without the local var and just load the value from the register
that's storing the local var otherwise.
David
Hi, On 2020-07-09 10:25:14 +1200, David Rowley wrote: > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote: > > > > On 2020-05-20 23:44:27 +1200, David Rowley wrote: > > > I've attached a patch which implements this. The new node type is > > > called "Result Cache". I'm not particularly wedded to keeping that > > > name, but if I change it, I only want to do it once. I've got a few > > > other names I mind, but I don't feel strongly or confident enough in > > > them to go and do the renaming. > > > > I'm not convinced it's a good idea to introduce a separate executor node > > for this. There's a fair bit of overhead in them, and they will only be > > below certain types of nodes afaict. It seems like it'd be better to > > pull the required calls into the nodes that do parametrized scans of > > subsidiary nodes. Have you considered that? > > I see 41 different node types mentioned in ExecReScan(). I don't > really think it would be reasonable to change all those. But that's because we dispatch ExecReScan mechanically down to every single executor node. That doesn't determine how many nodes would need to modify to include explicit caching? What am I missing? Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c integration? Greetings, Andres Freund
On Tue, 11 Aug 2020 at 12:21, Andres Freund <andres@anarazel.de> wrote: > > On 2020-07-09 10:25:14 +1200, David Rowley wrote: > > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote: > > > I'm not convinced it's a good idea to introduce a separate executor node > > > for this. There's a fair bit of overhead in them, and they will only be > > > below certain types of nodes afaict. It seems like it'd be better to > > > pull the required calls into the nodes that do parametrized scans of > > > subsidiary nodes. Have you considered that? > > > > I see 41 different node types mentioned in ExecReScan(). I don't > > really think it would be reasonable to change all those. > > But that's because we dispatch ExecReScan mechanically down to every > single executor node. That doesn't determine how many nodes would need > to modify to include explicit caching? What am I missing? > > Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c > integration? hmm, I think you're right there about those two node types. I'm just not sure you're right about overloading these node types to act as a cache. How would you inform users via EXPLAIN ANALYZE of how many cache hits/misses occurred? What would you use to disable it for an escape hatch for when the planner makes a bad choice about caching? David
Hi, On 2020-08-11 17:23:42 +1200, David Rowley wrote: > On Tue, 11 Aug 2020 at 12:21, Andres Freund <andres@anarazel.de> wrote: > > > > On 2020-07-09 10:25:14 +1200, David Rowley wrote: > > > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote: > > > > I'm not convinced it's a good idea to introduce a separate executor node > > > > for this. There's a fair bit of overhead in them, and they will only be > > > > below certain types of nodes afaict. It seems like it'd be better to > > > > pull the required calls into the nodes that do parametrized scans of > > > > subsidiary nodes. Have you considered that? > > > > > > I see 41 different node types mentioned in ExecReScan(). I don't > > > really think it would be reasonable to change all those. > > > > But that's because we dispatch ExecReScan mechanically down to every > > single executor node. That doesn't determine how many nodes would need > > to modify to include explicit caching? What am I missing? > > > > Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c > > integration? > > hmm, I think you're right there about those two node types. I'm just > not sure you're right about overloading these node types to act as a > cache. I'm not 100% either, to be clear. I am just acutely aware that adding entire nodes is pretty expensive, and that there's, afaict, no need to have arbitrary (i.e. pointer to function) type callbacks to point to the cache. > How would you inform users via EXPLAIN ANALYZE of how many > cache hits/misses occurred? Similar to how we display memory for sorting etc. > What would you use to disable it for an > escape hatch for when the planner makes a bad choice about caching? Isn't that *easier* when embedding it into the node? There's no nice way to remove an intermediary executor node entirely, but it's trivial to have an if statement like if (node->cache && upsert_cache(node->cache, param)) Greetings, Andres Freund
On Tue, 11 Aug 2020 at 17:44, Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2020-08-11 17:23:42 +1200, David Rowley wrote: > > On Tue, 11 Aug 2020 at 12:21, Andres Freund <andres@anarazel.de> wrote: > > > > > > On 2020-07-09 10:25:14 +1200, David Rowley wrote: > > > > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote: > > > > > I'm not convinced it's a good idea to introduce a separate executor node > > > > > for this. There's a fair bit of overhead in them, and they will only be > > > > > below certain types of nodes afaict. It seems like it'd be better to > > > > > pull the required calls into the nodes that do parametrized scans of > > > > > subsidiary nodes. Have you considered that? > > > > > > > > I see 41 different node types mentioned in ExecReScan(). I don't > > > > really think it would be reasonable to change all those. > > > > > > But that's because we dispatch ExecReScan mechanically down to every > > > single executor node. That doesn't determine how many nodes would need > > > to modify to include explicit caching? What am I missing? > > > > > > Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c > > > integration? > > > > hmm, I think you're right there about those two node types. I'm just > > not sure you're right about overloading these node types to act as a > > cache. > > I'm not 100% either, to be clear. I am just acutely aware that adding > entire nodes is pretty expensive, and that there's, afaict, no need to > have arbitrary (i.e. pointer to function) type callbacks to point to the > cache. Perhaps you're right, but I'm just not convinced of it. I feel there's a certain air of magic involved in any node that has a good name and reputation for doing one thing that we suddenly add new functionality to which causes it to perform massively differently. A counterexample to your argument is that Materialize is a node type. There's only a limits number of places where that node is used. One of those places can be on the inside of a non-parameterized nested loop. Your argument of having Nested Loop do caching would also indicate that Materialize should be part of Nested Loop instead of a node itself. There's a few other places Materialize is used, e.g scrollable cursors, but in that regard, you could say that the caching should be handled in ExecutePlan(). I just don't think it should be, as I don't think Result Cache should be part of any other node or code. Another problem I see with overloading nodeSubplan and nodeNestloop is, we don't really document our executor nodes today, so unless this patch starts a new standard for that, then there's not exactly a good place to mention that parameterized nested loops may now cache results from the inner scan. I do understand what you mean with the additional node overhead. I saw that in my adventures of INNER JOIN removals a few years ago. I hope the fact that I've tried to code the planner so that for nested loops, it only uses a Result Cache node when it thinks it'll speed things up. That decision is of course based on having good statistics, which might not be the case. I don't quite have that luxury with subplans due to lack of knowledge of the outer plan when planning the subquery. > > How would you inform users via EXPLAIN ANALYZE of how many > > cache hits/misses occurred? > > Similar to how we display memory for sorting etc. I was more thinking of how bizarre it would be to see Nested Loop and SubPlan report cache statistics. It may appear quite magical to users to see EXPLAIN ANALYZE mentioning that their Nested Loop is now reporting something about cache hits. > > What would you use to disable it for an > > escape hatch for when the planner makes a bad choice about caching? > > Isn't that *easier* when embedding it into the node? There's no nice way > to remove an intermediary executor node entirely, but it's trivial to > have an if statement like > if (node->cache && upsert_cache(node->cache, param)) I was more meaning that it might not make sense to keep the enable_resultcache GUC if the caching were part of the existing nodes. I think people are pretty used to the enable_* GUCs corresponding to an executor whose name roughly matches the name of the GUC. In this case, without a Result Cache node, enable_resultcache would not assist in self-documenting. However, perhaps 2 new GUCs instead, enable_nestloop_caching and enable_subplan_caching. We're currently short of any other enable_* GUCs that are node modifiers. We did have enable_hashagg_disk until a few weeks ago. Nobody seemed to like that, but perhaps there were other reasons for people not to like it other than it was a node modifier GUC. I'm wondering if anyone else has any thoughts on this? David
On Mon, 25 May 2020 at 19:53, David Rowley <dgrowleyml@gmail.com> wrote:
> I didn't quite get the LATERAL support quite done in the version I
> sent. For now, I'm not considering adding a Result Cache node if there
> are lateral vars in any location other than the inner side of the
> nested loop join. I think it'll just be a few lines to make it work
> though. I wanted to get some feedback before going to too much more
> trouble to make all cases work.
I've now changed the patch so that it supports adding a Result Cache
node to LATERAL joins.
e.g.
regression=# explain analyze select count(*) from tenk1 t1, lateral
(select x from generate_Series(1,t1.twenty) x) gs;
QUERY
PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=150777.53..150777.54 rows=1 width=8) (actual
time=22.191..22.191 rows=1 loops=1)
-> Nested Loop (cost=0.01..125777.53 rows=10000000 width=0)
(actual time=0.010..16.980 rows=95000 loops=1)
-> Seq Scan on tenk1 t1 (cost=0.00..445.00 rows=10000
width=4) (actual time=0.003..0.866 rows=10000 loops=1)
-> Result Cache (cost=0.01..10.01 rows=1000 width=0)
(actual time=0.000..0.001 rows=10 loops=10000)
Cache Key: t1.twenty
Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Function Scan on generate_series x
(cost=0.00..10.00 rows=1000 width=0) (actual time=0.001..0.002 rows=10
loops=20)
Planning Time: 0.046 ms
Execution Time: 22.208 ms
(9 rows)
Time: 22.704 ms
regression=# set enable_resultcache=0;
SET
Time: 0.367 ms
regression=# explain analyze select count(*) from tenk1 t1, lateral
(select x from generate_Series(1,t1.twenty) x) gs;
QUERY
PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=225445.00..225445.01 rows=1 width=8) (actual
time=35.578..35.579 rows=1 loops=1)
-> Nested Loop (cost=0.00..200445.00 rows=10000000 width=0)
(actual time=0.008..30.196 rows=95000 loops=1)
-> Seq Scan on tenk1 t1 (cost=0.00..445.00 rows=10000
width=4) (actual time=0.002..0.905 rows=10000 loops=1)
-> Function Scan on generate_series x (cost=0.00..10.00
rows=1000 width=0) (actual time=0.001..0.002 rows=10 loops=10000)
Planning Time: 0.031 ms
Execution Time: 35.590 ms
(6 rows)
Time: 36.027 ms
v7 patch series attached.
I also modified the 0002 patch so instead of modifying simplehash.h's
SH_DELETE function to have it call SH_LOOKUP and the newly added
SH_DELETE_ITEM function, I've just added an entirely new
SH_DELETE_ITEM and left SH_DELETE untouched. Trying to remove the
code duplication without having a negative effect on performance was
tricky and it didn't save enough code to seem worthwhile enough.
I also did a round of polishing work, fixed a spelling mistake in a
comment and reworded a few other comments to make some meaning more
clear.
David
Вложения
On Tue, 18 Aug 2020 at 21:42, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 11 Aug 2020 at 17:44, Andres Freund <andres@anarazel.de> wrote:
> >
> > Hi,
> >
> > On 2020-08-11 17:23:42 +1200, David Rowley wrote:
> > > On Tue, 11 Aug 2020 at 12:21, Andres Freund <andres@anarazel.de> wrote:
> > > >
> > > > On 2020-07-09 10:25:14 +1200, David Rowley wrote:
> > > > > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote:
> > > > > > I'm not convinced it's a good idea to introduce a separate executor node
> > > > > > for this. There's a fair bit of overhead in them, and they will only be
> > > > > > below certain types of nodes afaict. It seems like it'd be better to
> > > > > > pull the required calls into the nodes that do parametrized scans of
> > > > > > subsidiary nodes. Have you considered that?
> > > > >
> > > > > I see 41 different node types mentioned in ExecReScan(). I don't
> > > > > really think it would be reasonable to change all those.
> > > >
> > > > But that's because we dispatch ExecReScan mechanically down to every
> > > > single executor node. That doesn't determine how many nodes would need
> > > > to modify to include explicit caching? What am I missing?
> > > >
> > > > Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c
> > > > integration?
> > >
> > > hmm, I think you're right there about those two node types. I'm just
> > > not sure you're right about overloading these node types to act as a
> > > cache.
> >
> > I'm not 100% either, to be clear. I am just acutely aware that adding
> > entire nodes is pretty expensive, and that there's, afaict, no need to
> > have arbitrary (i.e. pointer to function) type callbacks to point to the
> > cache.
>
> Perhaps you're right, but I'm just not convinced of it. I feel
> there's a certain air of magic involved in any node that has a good
> name and reputation for doing one thing that we suddenly add new
> functionality to which causes it to perform massively differently.
>
[ my long babble removed]
> I'm wondering if anyone else has any thoughts on this?
Just for anyone following along at home. The two variations would
roughly look like:
Current method:
regression=# explain (analyze, costs off, timing off, summary off)
select count(*) from tenk1 t1 inner join tenk1 t2 on
t1.twenty=t2.unique1;
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (actual rows=1 loops=1)
-> Nested Loop (actual rows=10000 loops=1)
-> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
-> Result Cache (actual rows=1 loops=10000)
Cache Key: t1.twenty
Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Index Scan using tenk1_unique1 on tenk1 t2 (actual
rows=1 loops=20)
Index Cond: (unique1 = t1.twenty)
(8 rows)
Andres' suggestion:
regression=# explain (analyze, costs off, timing off, summary off)
select count(*) from tenk1 t1 inner join tenk1 t2 on
t1.twenty=t2.unique1;
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (actual rows=1 loops=1)
-> Nested Loop (actual rows=10000 loops=1)
Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0
Overflows: 0
-> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
-> Index Scan using tenk1_unique1 on tenk1 t2 (actual rows=1 loops=20)
Index Cond: (unique1 = t1.twenty)
(6 rows)
and for subplans:
Current method:
regression=# explain (analyze, costs off, timing off, summary off)
select twenty, (select count(*) from tenk1 t2 where t1.twenty =
t2.twenty) from tenk1 t1;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
SubPlan 1
-> Result Cache (actual rows=1 loops=10000)
Cache Key: t1.twenty
Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Aggregate (actual rows=1 loops=20)
-> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
Filter: (t1.twenty = twenty)
Rows Removed by Filter: 9500
(9 rows)
Andres' suggestion:
regression=# explain (analyze, costs off, timing off, summary off)
select twenty, (select count(*) from tenk1 t2 where t1.twenty =
t2.twenty) from tenk1 t1;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
SubPlan 1
Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Aggregate (actual rows=1 loops=20)
-> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
Filter: (t1.twenty = twenty)
Rows Removed by Filter: 9500
(7 rows)
I've spoken to one other person off-list about this and they suggested
that they prefer Andres' suggestion on performance grounds that it's
less overhead to pull tuples through the plan and cheaper executor
startup/shutdowns due to fewer nodes.
I don't object to making the change. I just object to making it only
to put it back again later when someone else speaks up that they'd
prefer to keep nodes modular and not overload them in obscure ways.
So other input is welcome. Is it too weird to overload SubPlan and
Nested Loop this way? Or okay to do that if it squeezes out a dozen
or so nanoseconds per tuple?
I did some analysis into the overhead of pulling tuples through an
additional executor node in [1].
David
[1] https://www.postgresql.org/message-id/CAKJS1f9UXdk6ZYyqbJnjFO9a9hyHKGW7B%3DZRh-rxy9qxfPA5Gw%40mail.gmail.com
st 19. 8. 2020 v 5:48 odesílatel David Rowley <dgrowleyml@gmail.com> napsal:
On Tue, 18 Aug 2020 at 21:42, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 11 Aug 2020 at 17:44, Andres Freund <andres@anarazel.de> wrote:
> >
> > Hi,
> >
> > On 2020-08-11 17:23:42 +1200, David Rowley wrote:
> > > On Tue, 11 Aug 2020 at 12:21, Andres Freund <andres@anarazel.de> wrote:
> > > >
> > > > On 2020-07-09 10:25:14 +1200, David Rowley wrote:
> > > > > On Thu, 9 Jul 2020 at 04:53, Andres Freund <andres@anarazel.de> wrote:
> > > > > > I'm not convinced it's a good idea to introduce a separate executor node
> > > > > > for this. There's a fair bit of overhead in them, and they will only be
> > > > > > below certain types of nodes afaict. It seems like it'd be better to
> > > > > > pull the required calls into the nodes that do parametrized scans of
> > > > > > subsidiary nodes. Have you considered that?
> > > > >
> > > > > I see 41 different node types mentioned in ExecReScan(). I don't
> > > > > really think it would be reasonable to change all those.
> > > >
> > > > But that's because we dispatch ExecReScan mechanically down to every
> > > > single executor node. That doesn't determine how many nodes would need
> > > > to modify to include explicit caching? What am I missing?
> > > >
> > > > Wouldn't we need roughly just nodeNestloop.c and nodeSubplan.c
> > > > integration?
> > >
> > > hmm, I think you're right there about those two node types. I'm just
> > > not sure you're right about overloading these node types to act as a
> > > cache.
> >
> > I'm not 100% either, to be clear. I am just acutely aware that adding
> > entire nodes is pretty expensive, and that there's, afaict, no need to
> > have arbitrary (i.e. pointer to function) type callbacks to point to the
> > cache.
>
> Perhaps you're right, but I'm just not convinced of it. I feel
> there's a certain air of magic involved in any node that has a good
> name and reputation for doing one thing that we suddenly add new
> functionality to which causes it to perform massively differently.
>
[ my long babble removed]
> I'm wondering if anyone else has any thoughts on this?
Just for anyone following along at home. The two variations would
roughly look like:
Current method:
regression=# explain (analyze, costs off, timing off, summary off)
select count(*) from tenk1 t1 inner join tenk1 t2 on
t1.twenty=t2.unique1;
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (actual rows=1 loops=1)
-> Nested Loop (actual rows=10000 loops=1)
-> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
-> Result Cache (actual rows=1 loops=10000)
Cache Key: t1.twenty
Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Index Scan using tenk1_unique1 on tenk1 t2 (actual
rows=1 loops=20)
Index Cond: (unique1 = t1.twenty)
(8 rows)
Andres' suggestion:
regression=# explain (analyze, costs off, timing off, summary off)
select count(*) from tenk1 t1 inner join tenk1 t2 on
t1.twenty=t2.unique1;
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (actual rows=1 loops=1)
-> Nested Loop (actual rows=10000 loops=1)
Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0
Overflows: 0
-> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
-> Index Scan using tenk1_unique1 on tenk1 t2 (actual rows=1 loops=20)
Index Cond: (unique1 = t1.twenty)
(6 rows)
and for subplans:
Current method:
regression=# explain (analyze, costs off, timing off, summary off)
select twenty, (select count(*) from tenk1 t2 where t1.twenty =
t2.twenty) from tenk1 t1;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
SubPlan 1
-> Result Cache (actual rows=1 loops=10000)
Cache Key: t1.twenty
Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Aggregate (actual rows=1 loops=20)
-> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
Filter: (t1.twenty = twenty)
Rows Removed by Filter: 9500
(9 rows)
Andres' suggestion:
regression=# explain (analyze, costs off, timing off, summary off)
select twenty, (select count(*) from tenk1 t2 where t1.twenty =
t2.twenty) from tenk1 t1;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
SubPlan 1
Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
-> Aggregate (actual rows=1 loops=20)
-> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
Filter: (t1.twenty = twenty)
Rows Removed by Filter: 9500
(7 rows)
I've spoken to one other person off-list about this and they suggested
that they prefer Andres' suggestion on performance grounds that it's
less overhead to pull tuples through the plan and cheaper executor
startup/shutdowns due to fewer nodes.
I didn't do performance tests, that should be necessary, but I think Andres' variant is a little bit more readable.
The performance is most important, but readability of EXPLAIN is interesting too.
Regards
Pavel
I don't object to making the change. I just object to making it only
to put it back again later when someone else speaks up that they'd
prefer to keep nodes modular and not overload them in obscure ways.
So other input is welcome. Is it too weird to overload SubPlan and
Nested Loop this way? Or okay to do that if it squeezes out a dozen
or so nanoseconds per tuple?
I did some analysis into the overhead of pulling tuples through an
additional executor node in [1].
David
[1] https://www.postgresql.org/message-id/CAKJS1f9UXdk6ZYyqbJnjFO9a9hyHKGW7B%3DZRh-rxy9qxfPA5Gw%40mail.gmail.com
David Rowley <dgrowleyml@gmail.com> writes:
> I don't object to making the change. I just object to making it only
> to put it back again later when someone else speaks up that they'd
> prefer to keep nodes modular and not overload them in obscure ways.
> So other input is welcome. Is it too weird to overload SubPlan and
> Nested Loop this way? Or okay to do that if it squeezes out a dozen
> or so nanoseconds per tuple?
If you need somebody to blame it on, blame it on me - but I agree
that that is an absolutely horrid abuse of NestLoop. We might as
well reduce explain.c to a one-liner that prints "Here Be Dragons",
because no one will understand what this display is telling them.
I'm also quite skeptical that adding overhead to nodeNestloop.c
to support this would actually be a net win once you account for
what happens in plans where the caching is of no value.
regards, tom lane
On Wed, 19 Aug 2020 at 16:23, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I don't object to making the change. I just object to making it only > > to put it back again later when someone else speaks up that they'd > > prefer to keep nodes modular and not overload them in obscure ways. > > > So other input is welcome. Is it too weird to overload SubPlan and > > Nested Loop this way? Or okay to do that if it squeezes out a dozen > > or so nanoseconds per tuple? > > If you need somebody to blame it on, blame it on me - but I agree > that that is an absolutely horrid abuse of NestLoop. We might as > well reduce explain.c to a one-liner that prints "Here Be Dragons", > because no one will understand what this display is telling them. Thanks for chiming in. I'm relieved it's not me vs everyone else anymore. > I'm also quite skeptical that adding overhead to nodeNestloop.c > to support this would actually be a net win once you account for > what happens in plans where the caching is of no value. Agreed. David
On Wed, 19 Aug 2020 at 16:18, Pavel Stehule <pavel.stehule@gmail.com> wrote: > > > > st 19. 8. 2020 v 5:48 odesílatel David Rowley <dgrowleyml@gmail.com> napsal: >> Current method: >> >> regression=# explain (analyze, costs off, timing off, summary off) >> select twenty, (select count(*) from tenk1 t2 where t1.twenty = >> t2.twenty) from tenk1 t1; >> QUERY PLAN >> --------------------------------------------------------------------- >> Seq Scan on tenk1 t1 (actual rows=10000 loops=1) >> SubPlan 1 >> -> Result Cache (actual rows=1 loops=10000) >> Cache Key: t1.twenty >> Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0 >> -> Aggregate (actual rows=1 loops=20) >> -> Seq Scan on tenk1 t2 (actual rows=500 loops=20) >> Filter: (t1.twenty = twenty) >> Rows Removed by Filter: 9500 >> (9 rows) >> >> Andres' suggestion: >> >> regression=# explain (analyze, costs off, timing off, summary off) >> select twenty, (select count(*) from tenk1 t2 where t1.twenty = >> t2.twenty) from tenk1 t1; >> QUERY PLAN >> --------------------------------------------------------------------- >> Seq Scan on tenk1 t1 (actual rows=10000 loops=1) >> SubPlan 1 >> Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0 >> -> Aggregate (actual rows=1 loops=20) >> -> Seq Scan on tenk1 t2 (actual rows=500 loops=20) >> Filter: (t1.twenty = twenty) >> Rows Removed by Filter: 9500 >> (7 rows) > I didn't do performance tests, that should be necessary, but I think Andres' variant is a little bit more readable. Thanks for chiming in on this. I was just wondering about the readability part and what makes the one with the Result Cache node less readable? I can think of a couple of reasons you might have this view and just wanted to double-check what it is. David
On 2020-Aug-19, David Rowley wrote: > Andres' suggestion: > > regression=# explain (analyze, costs off, timing off, summary off) > select count(*) from tenk1 t1 inner join tenk1 t2 on > t1.twenty=t2.unique1; > QUERY PLAN > --------------------------------------------------------------------------------------- > Aggregate (actual rows=1 loops=1) > -> Nested Loop (actual rows=10000 loops=1) > Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0 > -> Seq Scan on tenk1 t1 (actual rows=10000 loops=1) > -> Index Scan using tenk1_unique1 on tenk1 t2 (actual rows=1 loops=20) > Index Cond: (unique1 = t1.twenty) > (6 rows) I think it doesn't look terrible in the SubPlan case -- it kinda makes sense there -- but for nested loop it appears really strange. On the performance aspect, I wonder what the overhead is, particularly considering Tom's point of making these nodes more expensive for cases with no caching. And also, as the JIT saga continues, aren't we going to get plan trees recompiled too, at which point it won't matter much? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, 20 Aug 2020 at 10:58, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On the performance aspect, I wonder what the overhead is, particularly > considering Tom's point of making these nodes more expensive for cases > with no caching. It's likely small. I've not written any code but only thought about it and I think it would be something like if (node->tuplecache != NULL). I imagine that in simple cases the branch predictor would likely realise the likely prediction fairly quickly and predict with 100% accuracy, once learned. But it's perhaps possible that some other branch shares the same slot in the branch predictor and causes some conflicting predictions. The size of the branch predictor cache is limited, of course. Certainly introducing new branches that mispredict and cause a pipeline stall during execution would be a very bad thing for performance. I'm unsure what would happen if there's say, 2 Nested loops, one with caching = on and one with caching = off where the number of tuples between the two is highly variable. I'm not sure a branch predictor would handle that well given that the two branches will be at the same address but have different predictions. However, if the predictor was to hash in the stack pointer too, then that might not be a problem. Perhaps someone with a better understanding of modern branch predictors can share their insight there. > And also, as the JIT saga continues, aren't we going > to get plan trees recompiled too, at which point it won't matter much? I was thinking batch execution would be our solution to the node overhead problem. We'll get there one day... we just need to finish with the infinite other optimisations there are to do first. David
čt 20. 8. 2020 v 0:04 odesílatel David Rowley <dgrowleyml@gmail.com> napsal:
On Wed, 19 Aug 2020 at 16:18, Pavel Stehule <pavel.stehule@gmail.com> wrote:
>
>
>
> st 19. 8. 2020 v 5:48 odesílatel David Rowley <dgrowleyml@gmail.com> napsal:
>> Current method:
>>
>> regression=# explain (analyze, costs off, timing off, summary off)
>> select twenty, (select count(*) from tenk1 t2 where t1.twenty =
>> t2.twenty) from tenk1 t1;
>> QUERY PLAN
>> ---------------------------------------------------------------------
>> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
>> SubPlan 1
>> -> Result Cache (actual rows=1 loops=10000)
>> Cache Key: t1.twenty
>> Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
>> -> Aggregate (actual rows=1 loops=20)
>> -> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
>> Filter: (t1.twenty = twenty)
>> Rows Removed by Filter: 9500
>> (9 rows)
>>
>> Andres' suggestion:
>>
>> regression=# explain (analyze, costs off, timing off, summary off)
>> select twenty, (select count(*) from tenk1 t2 where t1.twenty =
>> t2.twenty) from tenk1 t1;
>> QUERY PLAN
>> ---------------------------------------------------------------------
>> Seq Scan on tenk1 t1 (actual rows=10000 loops=1)
>> SubPlan 1
>> Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0
>> -> Aggregate (actual rows=1 loops=20)
>> -> Seq Scan on tenk1 t2 (actual rows=500 loops=20)
>> Filter: (t1.twenty = twenty)
>> Rows Removed by Filter: 9500
>> (7 rows)
> I didn't do performance tests, that should be necessary, but I think Andres' variant is a little bit more readable.
Thanks for chiming in on this. I was just wondering about the
readability part and what makes the one with the Result Cache node
less readable? I can think of a couple of reasons you might have this
view and just wanted to double-check what it is.
It is more compact - less rows, less nesting levels
David
Hi, On 2020-08-19 18:58:11 -0400, Alvaro Herrera wrote: > On 2020-Aug-19, David Rowley wrote: > > > Andres' suggestion: > > > > regression=# explain (analyze, costs off, timing off, summary off) > > select count(*) from tenk1 t1 inner join tenk1 t2 on > > t1.twenty=t2.unique1; > > QUERY PLAN > > --------------------------------------------------------------------------------------- > > Aggregate (actual rows=1 loops=1) > > -> Nested Loop (actual rows=10000 loops=1) > > Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0 > > -> Seq Scan on tenk1 t1 (actual rows=10000 loops=1) > > -> Index Scan using tenk1_unique1 on tenk1 t2 (actual rows=1 loops=20) > > Index Cond: (unique1 = t1.twenty) > > (6 rows) > > I think it doesn't look terrible in the SubPlan case -- it kinda makes > sense there -- but for nested loop it appears really strange. While I'm against introducing a separate node for the caching, I'm *not* against displaying a different node type when caching is present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd probably still want to display the 'Cache Key' similar to your example, but I don't see how it'd be better to display it with one more intermediary node. > On the performance aspect, I wonder what the overhead is, particularly > considering Tom's point of making these nodes more expensive for cases > with no caching. I doubt it, due to being a well predictable branch. But it's also easy enough to just have a different Exec* function for the caching and non-caching case, should that turn out to be a problem. > And also, as the JIT saga continues, aren't we going to get plan trees > recompiled too, at which point it won't matter much? That's a fair bit out, I think. And even then it'll only help for queries that run long enough (eventually also often enough, if we get prepared statement JITing) to be worth JITing. Greetings, Andres Freund
On Tue, 25 Aug 2020 at 08:26, Andres Freund <andres@anarazel.de> wrote: > While I'm against introducing a separate node for the caching, I'm *not* > against displaying a different node type when caching is > present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached > Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd > probably still want to display the 'Cache Key' similar to your example, > but I don't see how it'd be better to display it with one more > intermediary node. ...Well, this is difficult... For the record, in case anyone missed it, I'm pretty set on being against doing any node overloading for this. I think it's a pretty horrid modularity violation regardless of what text appears in EXPLAIN. I think if we merge these nodes then we may as well go further and merge in other simple nodes like LIMIT. Then after a few iterations of that, we end up with with a single node in EXPLAIN that nobody can figure out what it does. "Here Be Dragons", as Tom said. That might seem like a bit of an exaggeration, but it is important to understand that this would start us down that path, and the more steps you take down that path, the harder it is to return from it. Let's look at nodeProjectSet.c, for example, which I recall you spent quite a bit of time painfully extracting the scattered logic to get it into a single reusable node (69f4b9c85). I understand your motivation was for JIT compilation and not to modularise the code, however, I think the byproduct of that change of having all that code in one executor node was a good change, and I'm certainly a fan of what it allowed you to achieve with JIT. I really wouldn't like to put anyone else in a position of having to extract out some complex logic that we add to existing nodes in some future version of PostgreSQL. It might seem quite innocent today, but add a few more years of development and I'm sure things will get buried a little deeper. I'm sure you know better than most that the day will come where we go and start rewriting all of our executor node code to implement something like batch execution. I'd imagine you'd agree that this job would be easier if nodes were single-purpose, rather than overloaded with a bunch of needless complexity that only Heath Robinson himself could be proud of. I find it bizarre that on one hand, for non-parameterized nested loops, we can have the inner scan become materialized with a Materialize node (I don't recall complaints about that) However, on the other hand, for parameterized nested loops, we build the caching into the Nested Loop node itself. For the other arguments: I'm also struggling a bit to understand the arguments that it makes EXPLAIN easier to read due to reduced nesting depth. If that's the case, why don't we get rid of Hash below a Hash Join? It seems nobody has felt strongly enough about that to go to the trouble of writing the patch. We could certainly do work to reduce nesting depth in EXPLAIN provided you're not big on what the plan actually does. One line should be ok if you're not worried about what's happening to your tuples. Unfortunately, that does not seem very useful as it tends to be that people who do look at EXPLAIN do actually want to know what the planner has decided to do and are interested in what's happening to their tuples. Hiding away details that can significantly impact the performance of the plan does not seem like a great direction to be moving in. Also, just in case anyone is misunderstanding this Andres' argument. It's entirely based on the performance impact of having an additional node. However, given the correct planner choice, there will never be a gross slowdown due to having the extra node. The costing, the way it currently is designed will only choose to use a Result Cache if it thinks it'll be cheaper to do so and cheaper means having enough cache hits for the caching overhead to be worthwhile. If we get a good cache hit ratio then the additional node overhead does not exist during execution since we don't look any further than the cache during a cache hit. It would only be a cache miss that requires pulling the tuples through an additional node. Given perfect statistics (which of course is impossible) and costs, we'll never slow down the execution of a plan by having a separate Result Cache node. In reality, poor statistics, e.g, massive n_distinct underestimations, could cause slowdowns, but loading this into one node is not going to save us from that. All that your design will save us from is that 12 nanosecond per-tuple hop (measured on a 5-year-old laptop) to an additional node during cache misses. It seems like a strange thing to optimise for, given that the planner only chooses to use a Result Cache when there's a good number of expected cache hits. I understand that you've voiced your feelings about this, but what I want to know is, how strongly do you feel about overloading the node? Will you stand in my way if I want to push ahead with the separate node? Will anyone else? David
On 25/08/2020 20:48, David Rowley wrote: > On Tue, 25 Aug 2020 at 08:26, Andres Freund <andres@anarazel.de> wrote: >> While I'm against introducing a separate node for the caching, I'm *not* >> against displaying a different node type when caching is >> present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached >> Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd >> probably still want to display the 'Cache Key' similar to your example, >> but I don't see how it'd be better to display it with one more >> intermediary node. > ...Well, this is difficult... For the record, in case anyone missed > it, I'm pretty set on being against doing any node overloading for > this. I think it's a pretty horrid modularity violation regardless of > what text appears in EXPLAIN. I think if we merge these nodes then we > may as well go further and merge in other simple nodes like LIMIT. > Then after a few iterations of that, we end up with with a single node > in EXPLAIN that nobody can figure out what it does. "Here Be Dragons", > as Tom said. That might seem like a bit of an exaggeration, but it is > important to understand that this would start us down that path, and > the more steps you take down that path, the harder it is to return > from it. [...] > > I understand that you've voiced your feelings about this, but what I > want to know is, how strongly do you feel about overloading the node? > Will you stand in my way if I want to push ahead with the separate > node? Will anyone else? > > David > > From my own experience, and thinking about issues like this, I my thinking keeping them separate adds robustness wrt change. Presumably common code can be extracted out, to avoid excessive code duplication? -- Gavin
Hi, On 2020-08-25 20:48:37 +1200, David Rowley wrote: > On Tue, 25 Aug 2020 at 08:26, Andres Freund <andres@anarazel.de> wrote: > > While I'm against introducing a separate node for the caching, I'm *not* > > against displaying a different node type when caching is > > present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached > > Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd > > probably still want to display the 'Cache Key' similar to your example, > > but I don't see how it'd be better to display it with one more > > intermediary node. > > ...Well, this is difficult... For the record, in case anyone missed > it, I'm pretty set on being against doing any node overloading for > this. I think it's a pretty horrid modularity violation regardless of > what text appears in EXPLAIN. I think if we merge these nodes then we > may as well go further and merge in other simple nodes like LIMIT. Huh? That doesn't make any sense. LIMIT is applicable to every single node type with the exception of hash. The caching you talk about is applicable only to node types that parametrize their sub-nodes, of which there are exactly two instances. Limit doesn't shuttle through huge amounts of tuples normally. What you talk about does. > Also, just in case anyone is misunderstanding this Andres' argument. > It's entirely based on the performance impact of having an additional > node. Not entirely, no. It's also just that it doesn't make sense to have two nodes setting parameters that then half magically picked up by a special subsidiary node type and used as a cache key. This is pseudo modularity, not real modularity. And makes it harder to display useful information in explain etc. And makes it harder to e.g. clear the cache in cases we know that there's no further use of the current cache. At least without piercing the abstraction veil. > However, given the correct planner choice, there will never be > a gross slowdown due to having the extra node. There'll be a significant reduction in increase in performance. > I understand that you've voiced your feelings about this, but what I > want to know is, how strongly do you feel about overloading the node? > Will you stand in my way if I want to push ahead with the separate > node? Will anyone else? I feel pretty darn strongly about this. If there's plenty people on your side I'll not stand in your way, but I think this is a bad design based on pretty flimsy reasons. Greetings, Andres Freund
On Tue, Aug 25, 2020 at 11:53 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2020-08-25 20:48:37 +1200, David Rowley wrote:
> On Tue, 25 Aug 2020 at 08:26, Andres Freund <andres@anarazel.de> wrote:
> > While I'm against introducing a separate node for the caching, I'm *not*
> > against displaying a different node type when caching is
> > present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached
> > Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd
> > probably still want to display the 'Cache Key' similar to your example,
> > but I don't see how it'd be better to display it with one more
> > intermediary node.
>
> ...Well, this is difficult... For the record, in case anyone missed
> it, I'm pretty set on being against doing any node overloading for
> this. I think it's a pretty horrid modularity violation regardless of
> what text appears in EXPLAIN. I think if we merge these nodes then we
> may as well go further and merge in other simple nodes like LIMIT.
Huh? That doesn't make any sense. LIMIT is applicable to every single
node type with the exception of hash. The caching you talk about is
applicable only to node types that parametrize their sub-nodes, of which
there are exactly two instances.
Limit doesn't shuttle through huge amounts of tuples normally. What you
talk about does.
> Also, just in case anyone is misunderstanding this Andres' argument.
> It's entirely based on the performance impact of having an additional
> node.
Not entirely, no. It's also just that it doesn't make sense to have two
nodes setting parameters that then half magically picked up by a special
subsidiary node type and used as a cache key. This is pseudo modularity,
not real modularity. And makes it harder to display useful information
in explain etc. And makes it harder to e.g. clear the cache in cases we
know that there's no further use of the current cache. At least without
piercing the abstraction veil.
> However, given the correct planner choice, there will never be
> a gross slowdown due to having the extra node.
There'll be a significant reduction in increase in performance.
If this is a key blocking factor for this topic, I'd like to do a simple hack
to put the cache function into the subplan node, then do some tests to
show the real difference. But it is better to decide how much difference
can be thought of as a big difference. And for education purposes,
I'd like to understand where these differences come from. For my
current knowledge, my basic idea is it saves some function calls?
> I understand that you've voiced your feelings about this, but what I
> want to know is, how strongly do you feel about overloading the node?
> Will you stand in my way if I want to push ahead with the separate
> node? Will anyone else?
I feel pretty darn strongly about this. If there's plenty people on your
side I'll not stand in your way, but I think this is a bad design based on
pretty flimsy reasons.
Nice to see the different opinions from two great guys and interesting to
see how this can be resolved at last:)
Best Regards
Andy Fan
On Tue, Aug 25, 2020 at 11:53 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2020-08-25 20:48:37 +1200, David Rowley wrote:
> On Tue, 25 Aug 2020 at 08:26, Andres Freund <andres@anarazel.de> wrote:
> > While I'm against introducing a separate node for the caching, I'm *not*
> > against displaying a different node type when caching is
> > present. E.g. it'd be perfectly reasonable from my POV to have a 'Cached
> > Nested Loop' join and a plain 'Nested Loop' node in the above node. I'd
> > probably still want to display the 'Cache Key' similar to your example,
> > but I don't see how it'd be better to display it with one more
> > intermediary node.
>
> ...Well, this is difficult... For the record, in case anyone missed
> it, I'm pretty set on being against doing any node overloading for
> this. I think it's a pretty horrid modularity violation regardless of
> what text appears in EXPLAIN. I think if we merge these nodes then we
> may as well go further and merge in other simple nodes like LIMIT.
Huh? That doesn't make any sense. LIMIT is applicable to every single
node type with the exception of hash. The caching you talk about is
applicable only to node types that parametrize their sub-nodes, of which
there are exactly two instances.
Limit doesn't shuttle through huge amounts of tuples normally. What you
talk about does.
> Also, just in case anyone is misunderstanding this Andres' argument.
> It's entirely based on the performance impact of having an additional
> node.
Not entirely, no. It's also just that it doesn't make sense to have two
nodes setting parameters that then half magically picked up by a special
subsidiary node type and used as a cache key. This is pseudo modularity,
not real modularity. And makes it harder to display useful information
in explain etc. And makes it harder to e.g. clear the cache in cases we
know that there's no further use of the current cache. At least without
piercing the abstraction veil.
Sorry that I missed this when I replied to the last thread. I understand
this, I remain neutral about this.
> However, given the correct planner choice, there will never be
> a gross slowdown due to having the extra node.
There'll be a significant reduction in increase in performance.
> I understand that you've voiced your feelings about this, but what I
> want to know is, how strongly do you feel about overloading the node?
> Will you stand in my way if I want to push ahead with the separate
> node? Will anyone else?
I feel pretty darn strongly about this. If there's plenty people on your
side I'll not stand in your way, but I think this is a bad design based on
pretty flimsy reasons.
Greetings,
Andres Freund
Best Regards
Andy Fan
On Wed, 26 Aug 2020 at 05:18, Andy Fan <zhihui.fan1213@gmail.com> wrote:
>
>
> On Tue, Aug 25, 2020 at 11:53 PM Andres Freund <andres@anarazel.de> wrote:
>>
>> On 2020-08-25 20:48:37 +1200, David Rowley wrote:
>> > Also, just in case anyone is misunderstanding this Andres' argument.
>> > It's entirely based on the performance impact of having an additional
>> > node.
>>
>> Not entirely, no. It's also just that it doesn't make sense to have two
>> nodes setting parameters that then half magically picked up by a special
>> subsidiary node type and used as a cache key. This is pseudo modularity,
>> not real modularity. And makes it harder to display useful information
>> in explain etc. And makes it harder to e.g. clear the cache in cases we
>> know that there's no further use of the current cache. At least without
>> piercing the abstraction veil.
>>
>>
>> > However, given the correct planner choice, there will never be
>> > a gross slowdown due to having the extra node.
>>
>> There'll be a significant reduction in increase in performance.
>
>
> If this is a key blocking factor for this topic, I'd like to do a simple hack
> to put the cache function into the subplan node, then do some tests to
> show the real difference. But it is better to decide how much difference
> can be thought of as a big difference. And for education purposes,
> I'd like to understand where these differences come from. For my
> current knowledge, my basic idea is it saves some function calls?
If testing this, the cache hit ratio will be pretty key to the
results. You'd notice the overhead much less with a larger cache hit
ratio since you're not pulling the tuple from as deeply a nested node.
I'm unsure how you'd determine what is a good cache hit ratio to
test it with. The lower the cache expected cache hit ratio, the higher
the cost of the Result Cache node will be, so the planner has less
chance of choosing to use it. Maybe some experiments will find a
case where the planner picks a Result Cache plan with a low hit ratio
can be tested.
Say you find a case with the hit ratio of 90%. Going by [1] I found
pulling a tuple through an additional node to cost about 12
nanoseconds on an intel 4712HQ CPU. With a hit ratio of 90% we'll
only pull 10% of tuples through the additional node, so that's about
1.2 nanoseconds per tuple, or 1.2 milliseconds per million tuples. It
might become hard to measure above the noise. More costly inner scans
will have the planner choose to Result Cache with lower estimated hit
ratios, but in that case, pulling the tuple through the additional
node during a cache miss will be less noticeable due to the more
costly inner side of the join.
Likely you could test the overhead only in theory without going to the
trouble of adapting the code to make SubPlan and Nested Loop do the
caching internally. If you just modify ExecResultCache() to have it
simply return its subnode, then measure the performance with and
without enable_resultcache, you should get an idea of the per-tuple
overhead of pulling the tuple through the additional node on your CPU.
After you know that number, you could put the code back to what the
patches have and then experiment with a number of cases to find a case
that chooses Result Cache and gets a low hit ratio.
For example, from the plan I used in the initial email on this thread:
-> Index Only Scan using lookup_a_idx on lookup l
(actual time=0.002..0.011 rows=100 loops=1000)
Index Cond: (a = hk.thousand)
Heap Fetches: 0
Planning Time: 0.113 ms
Execution Time: 1876.741 ms
I don't have the exact per tuple overhead on the machine I ran that
on, but it's an AMD 3990x CPU, so I'll guess the overhead is about 8
nanoseconds per tuple, given I found it to be 12 nanoseconds on a 2014
CPU If that's right, then the overhead is something like 8 * 100
(rows) * 1000 (loops) = 800000 nanoseconds = 0.8 milliseconds. If I
compare that to the execution time of the query, it's about 0.04%.
I imagine we'll need to find something with a much worse hit ratio so
we can actually measure the overhead.
David
[1] https://www.postgresql.org/message-id/CAKJS1f9UXdk6ZYyqbJnjFO9a9hyHKGW7B%3DZRh-rxy9qxfPA5Gw%40mail.gmail.com
On Wed, Aug 26, 2020 at 8:14 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Wed, 26 Aug 2020 at 05:18, Andy Fan <zhihui.fan1213@gmail.com> wrote:
>
>
> On Tue, Aug 25, 2020 at 11:53 PM Andres Freund <andres@anarazel.de> wrote:
>>
>> On 2020-08-25 20:48:37 +1200, David Rowley wrote:
>> > Also, just in case anyone is misunderstanding this Andres' argument.
>> > It's entirely based on the performance impact of having an additional
>> > node.
>>
>> Not entirely, no. It's also just that it doesn't make sense to have two
>> nodes setting parameters that then half magically picked up by a special
>> subsidiary node type and used as a cache key. This is pseudo modularity,
>> not real modularity. And makes it harder to display useful information
>> in explain etc. And makes it harder to e.g. clear the cache in cases we
>> know that there's no further use of the current cache. At least without
>> piercing the abstraction veil.
>>
>>
>> > However, given the correct planner choice, there will never be
>> > a gross slowdown due to having the extra node.
>>
>> There'll be a significant reduction in increase in performance.
>
>
> If this is a key blocking factor for this topic, I'd like to do a simple hack
> to put the cache function into the subplan node, then do some tests to
> show the real difference. But it is better to decide how much difference
> can be thought of as a big difference. And for education purposes,
> I'd like to understand where these differences come from. For my
> current knowledge, my basic idea is it saves some function calls?
If testing this, the cache hit ratio will be pretty key to the
results. You'd notice the overhead much less with a larger cache hit
ratio since you're not pulling the tuple from as deeply a nested node.
I'm unsure how you'd determine what is a good cache hit ratio to
test it with.
I wanted to test the worst case where the cache hit ratio is 0. and then
compare the difference between putting the cache as a dedicated
node and in a SubPlan node. However, we have a better way
to test the difference based on your below message.
The lower the cache expected cache hit ratio, the higher
the cost of the Result Cache node will be, so the planner has less
chance of choosing to use it.
IIRC, we add the ResultCache for subplan nodes unconditionally now.
The main reason is we lack of ndistinct estimation during the subquery
planning. Tom suggested converting the AlternativeSubPlan to SubPlan
in setrefs.c [1], and I also ran into a case that can be resolved if we do
such conversion even earlier[2], the basic idea is we can do such conversation
once we can get the actual values for the subplan.
something like
if (bms_is_subset(subplan->deps_relids, rel->relids)
{
convert_alternativesubplans_to_subplan(rel);
}
you can see if that can be helpful for ResultCache in this user case. my
patch in [2] is still in a very PoC stage so it only takes care of subplan in
rel->reltarget.
Say you find a case with the hit ratio of 90%. Going by [1] I found
pulling a tuple through an additional node to cost about 12
nanoseconds on an intel 4712HQ CPU. With a hit ratio of 90% we'll
only pull 10% of tuples through the additional node, so that's about
1.2 nanoseconds per tuple, or 1.2 milliseconds per million tuples. It
might become hard to measure above the noise. More costly inner scans
will have the planner choose to Result Cache with lower estimated hit
ratios, but in that case, pulling the tuple through the additional
node during a cache miss will be less noticeable due to the more
costly inner side of the join.
Likely you could test the overhead only in theory without going to the
trouble of adapting the code to make SubPlan and Nested Loop do the
caching internally. If you just modify ExecResultCache() to have it
simply return its subnode, then measure the performance with and
without enable_resultcache, you should get an idea of the per-tuple
overhead of pulling the tuple through the additional node on your CPU.
Thanks for the hints. I think we can test it even easier with Limit node.
create table test_pull_tuples(a int);
insert into test_pull_tuples select i from generate_seri
insert into test_pull_tuples select i from generate_series(1, 100000)i;
-- test with pgbench.
insert into test_pull_tuples select i from generate_seri
insert into test_pull_tuples select i from generate_series(1, 100000)i;
-- test with pgbench.
select * from test_pull_tuples; 18.850 ms
select * from test_pull_tuples limit 100000; 20.500 ms
Basically it is 16 nanoseconds per tuple on my Intel(R) Xeon(R) CPU E5-2650.
select * from test_pull_tuples limit 100000; 20.500 ms
Basically it is 16 nanoseconds per tuple on my Intel(R) Xeon(R) CPU E5-2650.
Personally I'd say the performance difference is negligible unless I see some
different numbers.
Best Regards
Andy Fan
On Wed, 26 Aug 2020 at 03:52, Andres Freund <andres@anarazel.de> wrote: > > On 2020-08-25 20:48:37 +1200, David Rowley wrote: > > However, given the correct planner choice, there will never be > > a gross slowdown due to having the extra node. > > There'll be a significant reduction in increase in performance. So I did a very rough-cut change to the patch to have the caching be part of Nested Loop. It can be applied on top of the other 3 v7 patches. For the performance, the test I did results in the performance actually being reduced from having the Result Cache as a separate node. The reason for this is mostly because Nested Loop projects. Each time I fetch a MinimalTuple from the cache, the patch will deform it in order to store it in the virtual inner tuple slot for the nested loop. Having the Result Cache as a separate node can skip this step as it's result tuple slot is a TTSOpsMinimalTuple, so we can just store the cached MinimalTuple right into the slot without any deforming/copying. Here's an example of a query that's now slower: select count(*) from hundredk hk inner join lookup100 l on hk.one = l.a; In this case, the original patch does not have to deform the MinimalTuple from the cache as the count(*) does not require any Vars from it. With the rough patch that's attached, the MinimalTuple is deformed in during the transformation during ExecCopySlot(). The slowdown exists no matter which column of the hundredk table I join to (schema in [1]). Performance comparison is as follows: v7 (Result Cache as a separate node) postgres=# explain (analyze, timing off) select count(*) from hundredk hk inner join lookup l on hk.one = l.a; Execution Time: 652.582 ms v7 + attached rough patch postgres=# explain (analyze, timing off) select count(*) from hundredk hk inner join lookup l on hk.one = l.a; Execution Time: 843.566 ms I've not yet thought of any way to get rid of the needless MinimalTuple deform. I suppose the cache could just have already deformed tuples, but that requires more memory and would result in a worse cache hit ratios for workloads where the cache gets filled. I'm open to ideas to make the comparison fairer. (Renamed the patch file to .txt to stop the CFbot getting upset with me) David [1] https://www.postgresql.org/message-id/CAApHDvrPcQyQdWERGYWx8J+2DLUNgXu+fOSbQ1UscxrunyXyrQ@mail.gmail.com
Вложения
On Sat, 29 Aug 2020 at 02:54, David Rowley <dgrowleyml@gmail.com> wrote:
> I'm open to ideas to make the comparison fairer.
While on that, it's not just queries that don't require the cached
tuple to be deformed that are slower. Here's a couple of example that
do requite both patches to deform the cached tuple:
Some other results that do result in both patches deforming tuples
still slows that v7 is faster:
Query1:
v7 + attached patch
postgres=# explain (analyze, timing off) select count(l.a) from
hundredk hk inner join lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=378570.41..378570.42 rows=1 width=8) (actual rows=1 loops=1)
-> Nested Loop Cached (cost=0.43..353601.00 rows=9987763 width=4)
(actual rows=10000000 loops=1)
Cache Key: $0
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=4) (actual rows=100000 loops=1)
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.050 ms
Execution Time: 928.698 ms
(10 rows)
v7 only:
postgres=# explain (analyze, timing off) select count(l.a) from
hundredk hk inner join lookup100 l on hk.one = l.a;
QUERY
PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=152861.19..152861.20 rows=1 width=8) (actual rows=1 loops=1)
-> Nested Loop (cost=0.45..127891.79 rows=9987763 width=4)
(actual rows=10000000 loops=1)
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=4) (actual rows=100000 loops=1)
-> Result Cache (cost=0.45..2.53 rows=100 width=4) (actual
rows=100 loops=100000)
Cache Key: hk.one
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Index Only Scan using lookup100_a_idx on lookup100
l (cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.604 ms
Execution Time: 897.958 ms
(11 rows)
Query2:
v7 + attached patch
postgres=# explain (analyze, timing off) select * from hundredk hk
inner join lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Nested Loop Cached (cost=0.43..353601.00 rows=9987763 width=28)
(actual rows=10000000 loops=1)
Cache Key: $0
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=24) (actual rows=100000 loops=1)
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.621 ms
Execution Time: 883.610 ms
(9 rows)
v7 only:
postgres=# explain (analyze, timing off) select * from hundredk hk
inner join lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.45..127891.79 rows=9987763 width=28) (actual
rows=10000000 loops=1)
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=24) (actual rows=100000 loops=1)
-> Result Cache (cost=0.45..2.53 rows=100 width=4) (actual
rows=100 loops=100000)
Cache Key: hk.one
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.088 ms
Execution Time: 870.601 ms
(10 rows)
David
On Wed, Aug 19, 2020 at 6:58 PM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2020-Aug-19, David Rowley wrote: > > Andres' suggestion: > > regression=# explain (analyze, costs off, timing off, summary off) > > select count(*) from tenk1 t1 inner join tenk1 t2 on > > t1.twenty=t2.unique1; > > QUERY PLAN > > --------------------------------------------------------------------------------------- > > Aggregate (actual rows=1 loops=1) > > -> Nested Loop (actual rows=10000 loops=1) > > Cache Key: t1.twenty Hits: 9980 Misses: 20 Evictions: 0 Overflows: 0 > > -> Seq Scan on tenk1 t1 (actual rows=10000 loops=1) > > -> Index Scan using tenk1_unique1 on tenk1 t2 (actual rows=1 loops=20) > > Index Cond: (unique1 = t1.twenty) > > (6 rows) > > I think it doesn't look terrible in the SubPlan case -- it kinda makes > sense there -- but for nested loop it appears really strange. I disagree. I don't know why anyone should find this confusing, except that we're not used to seeing it. It seems to make a lot of sense that if you are executing the same plan tree with different parameters, you might want to cache results to avoid recomputation. So why wouldn't nodes that do this include a cache? This is not necessarily a vote for Andres's proposal. I don't know whether it's technically better to include the caching in the Nested Loop node or to make it a separate node, and I think we should do the one that's better. Getting pushed into an inferior design because we think the EXPLAIN output will be clearer does not make sense to me. I think David's points elsewhere on the thread about ProjectSet and Materialize nodes are interesting. It was never very clear to me why ProjectSet was handled separately in every node, adding quite a bit of complexity, and why Materialize was a separate node. Likewise, why are Hash Join and Hash two separate nodes instead of just one? Why do we not treat projection as a separate node type even when we're not projecting a set? In general, I've never really understood why we choose to include some functionality in other nodes and keep other things separate. Is there even an organizing principle, or is it just historical baggage? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Aug 29, 2020 at 3:33 AM Robert Haas <robertmhaas@gmail.com> wrote:
> I think David's points elsewhere on the thread about ProjectSet and
> Materialize nodes are interesting.
Indeed, I'm now finding it very difficult to look past the similarity with:
postgres=# explain select count(*) from t t1 cross join t t2;
QUERY PLAN
----------------------------------------------------------------------------
Aggregate (cost=1975482.56..1975482.57 rows=1 width=8)
-> Nested Loop (cost=0.00..1646293.50 rows=131675625 width=0)
-> Seq Scan on t t1 (cost=0.00..159.75 rows=11475 width=0)
-> Materialize (cost=0.00..217.12 rows=11475 width=0)
-> Seq Scan on t t2 (cost=0.00..159.75 rows=11475 width=0)
(5 rows)
I wonder what it would take to overcome the overheads of the separate
Result Cache node, with techniques to step out of the way or something
like that.
> [tricky philosophical questions about ancient and maybe in some cases arbitrary choices]
Ack.
Thanks for chipping in here. On Mon, 31 Aug 2020 at 17:57, Thomas Munro <thomas.munro@gmail.com> wrote: > I wonder what it would take to overcome the overheads of the separate > Result Cache node, with techniques to step out of the way or something > like that. So far it looks like there are more overheads to having the caching done inside nodeNestloop.c. See [1]. Perhaps there's something that can be done to optimise away the needless MinimalTuple deform that I mentioned there, but for now, performance-wise, we're better off having a separate node. David [1] https://www.postgresql.org/message-id/CAApHDvo2acQSogMCa3hB7moRntXWHO8G+WSwhyty2+c8vYRq3A@mail.gmail.com
On Sat, 29 Aug 2020 at 02:54, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Wed, 26 Aug 2020 at 03:52, Andres Freund <andres@anarazel.de> wrote:
> > There'll be a significant reduction in increase in performance.
>
> So I did a very rough-cut change to the patch to have the caching be
> part of Nested Loop. It can be applied on top of the other 3 v7
> patches.
>
> For the performance, the test I did results in the performance
> actually being reduced from having the Result Cache as a separate
> node. The reason for this is mostly because Nested Loop projects.
I spoke to Andres off-list this morning in regards to what can be done
to remove this performance regression over the separate Result Cache
node version of the patch. He mentioned that I could create another
ProjectionInfo for when reading from the cache's slot and use that to
project with.
I've hacked this up in the attached. It looks like another version of
the joinqual would also need to be created to that the MinimalTuple
from the cache is properly deformed. I've not done this yet.
The performance does improve this time. Using the same two test
queries from [1], I get:
v7 (Separate Result Cache node)
Query 1:
postgres=# explain (analyze, timing off) select count(l.a) from
hundredk hk inner join lookup100 l on hk.one = l.a;
QUERY
PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=152861.19..152861.20 rows=1 width=8) (actual rows=1 loops=1)
-> Nested Loop (cost=0.45..127891.79 rows=9987763 width=4)
(actual rows=10000000 loops=1)
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=4) (actual rows=100000 loops=1)
-> Result Cache (cost=0.45..2.53 rows=100 width=4) (actual
rows=100 loops=100000)
Cache Key: hk.one
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Index Only Scan using lookup100_a_idx on lookup100
l (cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.045 ms
Execution Time: 894.003 ms
(11 rows)
Query 2:
postgres=# explain (analyze, timing off) select * from hundredk hk
inner join lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.45..127891.79 rows=9987763 width=28) (actual
rows=10000000 loops=1)
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=24) (actual rows=100000 loops=1)
-> Result Cache (cost=0.45..2.53 rows=100 width=4) (actual
rows=100 loops=100000)
Cache Key: hk.one
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.077 ms
Execution Time: 854.950 ms
(10 rows)
v7 + hacks_V3 (caching done in Nested Loop)
Query 1:
explain (analyze, timing off) select count(l.a) from hundredk hk inner
join lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=378570.41..378570.42 rows=1 width=8) (actual rows=1 loops=1)
-> Nested Loop Cached (cost=0.43..353601.00 rows=9987763 width=4)
(actual rows=10000000 loops=1)
Cache Key: $0
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=4) (actual rows=100000 loops=1)
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.103 ms
Execution Time: 770.470 ms
(10 rows)
Query 2
explain (analyze, timing off) select * from hundredk hk inner join
lookup100 l on hk.one = l.a;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Nested Loop Cached (cost=0.43..353601.00 rows=9987763 width=28)
(actual rows=10000000 loops=1)
Cache Key: $0
Hits: 99999 Misses: 1 Evictions: 0 Overflows: 0
-> Seq Scan on hundredk hk (cost=0.00..1637.00 rows=100000
width=24) (actual rows=100000 loops=1)
-> Index Only Scan using lookup100_a_idx on lookup100 l
(cost=0.43..2.52 rows=100 width=4) (actual rows=100 loops=1)
Index Cond: (a = hk.one)
Heap Fetches: 0
Planning Time: 0.090 ms
Execution Time: 779.181 ms
(9 rows)
Also, I'd just like to reiterate that the attached is a very rough cut
implementation that I've put together just to use for performance
comparison in order to help move this conversation along. (I do know
that I'm breaking the const qualifier on PlanState's innerops.)
David
[1] https://www.postgresql.org/message-id/CAApHDvqt5U6VcKSm2G9Q1n4rsHejL-VX7QG9KToAQ0HyZymSzQ@mail.gmail.com
Вложения
On 2020-Sep-02, David Rowley wrote: > v7 (Separate Result Cache node) > Query 1: > Execution Time: 894.003 ms > > Query 2: > Execution Time: 854.950 ms > v7 + hacks_V3 (caching done in Nested Loop) > Query 1: > Execution Time: 770.470 ms > > Query 2 > Execution Time: 779.181 ms Wow, this is a *significant* change. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Thu, 3 Sep 2020 at 01:49, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > > On 2020-Sep-02, David Rowley wrote: > > > v7 (Separate Result Cache node) > > Query 1: > > Execution Time: 894.003 ms > > > > Query 2: > > Execution Time: 854.950 ms > > > v7 + hacks_V3 (caching done in Nested Loop) > > Query 1: > > Execution Time: 770.470 ms > > > > Query 2 > > Execution Time: 779.181 ms > > Wow, this is a *significant* change. Yeah, it's more than I thought it was going to be. It seems I misthought in [1] where I mentioned: > With a hit ratio of 90% we'll > only pull 10% of tuples through the additional node, so that's about > 1.2 nanoseconds per tuple, or 1.2 milliseconds per million tuples. It > might become hard to measure above the noise. More costly inner scans > will have the planner choose to Result Cache with lower estimated hit > ratios, but in that case, pulling the tuple through the additional > node during a cache miss will be less noticeable due to the more > costly inner side of the join. This wasn't technically wrong. I just failed to consider that a cache hit when the cache is built into Nested Loop requires looking at no other node. The tuples are right there in the cache, 90% of the time, in this example. No need to execute any nodes to get at them. I have come around a bit to Andres' idea. But we'd need to display the nested loop node as something like "Cacheable Nested Loop" in EXPLAIN so that we could easily identify what's going on. Not sure if the word "Hash" would be better to inject in the name somewhere rather than "Cacheable". I've not done any further work to shift the patch any further in that direction yet. I know it's going to be quite a bit of work and it sounds like there are still objections in both directions. I'd rather everyone agreed on something before I go to the trouble of trying to make something committable with Andres' way. Tom, I'm wondering if you'd still be against this if Nested Loop showed a different name in EXPLAIN when it was using caching? Or are you also concerned about adding unrelated code into nodeNestloop.c? If so, I'm wondering if adding a completely new node like nodeNestcacheloop.c. But that's going to add lots of boilerplate code that we'd get away with not having otherwise. In the meantime, I did change a couple of things with the current separate node version. It's just around how the path stuff works in the planner. I'd previously modified try_nestloop_path() to try a Result Cache, but I noticed more recently that's not how it's done for Materialize. So in the attached, I've just aligned it to how non-parameterized Nested Loops with a Materialized inner side work. David [1] https://www.postgresql.org/message-id/CAApHDvrX9o35_WUoL5c5arJ0XbJFN-cDHckjL57-PR-Keeypdw@mail.gmail.com
Вложения
On Tue, 15 Sep 2020 at 12:58, David Rowley <dgrowleyml@gmail.com> wrote: > > I've not done any further work to shift the patch any further in that > direction yet. I know it's going to be quite a bit of work and it > sounds like there are still objections in both directions. I'd rather > everyone agreed on something before I go to the trouble of trying to > make something committable with Andres' way. I spent some time converting the existing v8 to move the caching into the Nested Loop node instead of having an additional Result Cache node between the Nested Loop and the inner index scan. To minimise the size of this patch I've dropped support for caching Subplans, for now. I'd say the quality of this patch is still first draft. I just spent today getting some final things working again and spent a few hours trying to break it then another few hours running benchmarks on it and comparing it to the v8 patch, (v8 uses a separate Result Cache node). I'd say most of the patch is pretty good, but the changes I've made in nodeNestloop.c will need to be changed a bit. All the caching logic is in a new file named execMRUTupleCache.c. nodeNestloop.c is just a consumer of this. It can detect if the MRUTupleCache was a hit or a miss depending on which slot the tuple is returned in. So far I'm just using that to switch around the projection info and join quals for the ones I initialised to work with the MinimalTupleSlot from the cache. I'm not yet sure exactly how this should be improved, I just know what's there is not so great. So far benchmarking shows there's still a regression from the v8 version of the patch. This is using count(*). An earlier test [1] did show speedups when we needed to deform tuples returned by the nested loop node. I've not yet repeated that test again. I was disappointed to see v9 slower than v8 after having spent about 3 days rewriting the patch The setup for the test I did was: create table hundredk (hundredk int, tenk int, thousand int, hundred int, ten int, one int); insert into hundredk select x%100000,x%10000,x%1000,x%100,x%10,1 from generate_Series(1,100000) x; create table lookup (a int); insert into lookup select x from generate_Series(1,100000)x, generate_Series(1,100); create index on lookup(a); vacuum analyze lookup, hundredk; I then ran a query like; select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a; in pgbench for 60 seconds and then again after swapping the join column to hk.hundred, hk.ten and hk.one so that fewer index lookups were performed and more cache hits were seen. I did have enable_mergejoin = off when testing v8 and v9 on this test. The planner seemed to favour merge join over nested loop without that. Results in hundred_rows_per_rescan.png. I then reduced the lookup table so it only has 1 row to lookup instead of 100 for each value. truncate lookup; insert into lookup select x from generate_Series(1,100000)x; vacuum analyze lookup; and ran the tests again. Results in one_row_per_rescan.png. I also wanted to note that these small scale tests are not the best case for this patch. I've seen much more significant gains when an unpatched Hash join's hash table filled the L3 cache and started having to wait for RAM. Since my MRU cache was much smaller than the Hash join's hash table, it performed about 3x faster. What I'm trying to focus on here is the regression from v8 to v9. It seems to cast a bit more doubt as to whether v9 is any better than v8. I really would like to start moving this work towards a commit in the next month or two. So any comments about v8 vs v9 would be welcome as I'm still uncertain which patch is best to pursue. David [1] https://www.postgresql.org/message-id/CAApHDvpDdQDFSM+u19ROinT0qw41OX=MW4-B2mO003v6-X0AjA@mail.gmail.com
Вложения
{kind=link}
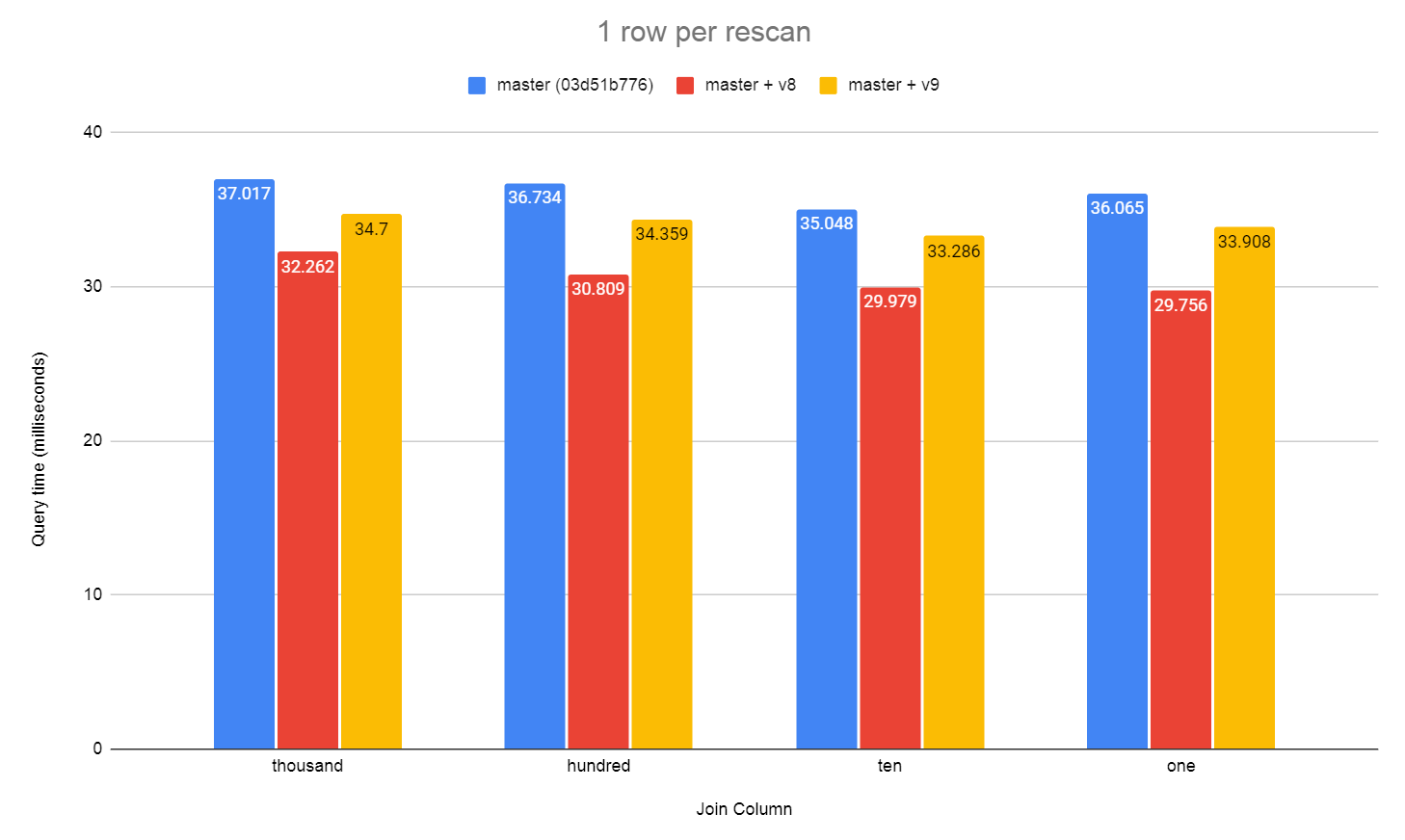{kind=link}
On Tue, 20 Oct 2020 at 22:30, David Rowley <dgrowleyml@gmail.com> wrote: > > So far benchmarking shows there's still a regression from the v8 > version of the patch. This is using count(*). An earlier test [1] did > show speedups when we needed to deform tuples returned by the nested > loop node. I've not yet repeated that test again. I was disappointed > to see v9 slower than v8 after having spent about 3 days rewriting the > patch I did some further tests this time with some tuple deforming. Again, it does seem that v9 is slower than v8. Graphs attached Looking at profiles, I don't really see any obvious reason as to why this is. I'm very much inclined to just pursue the v8 patch (separate Result Cache node) and just drop the v9 idea altogether. David
Вложения
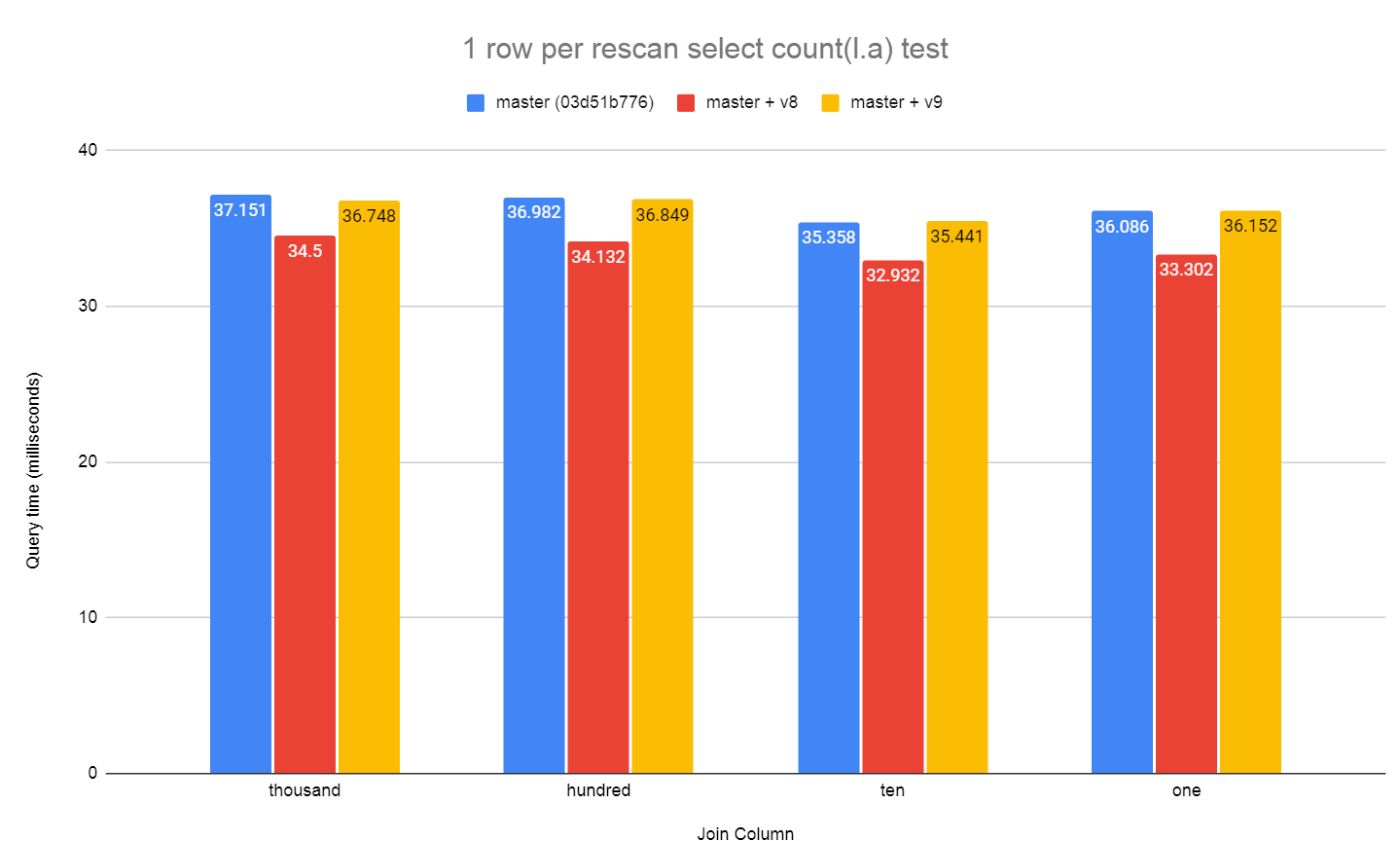{kind=link}
{kind=link}
On Mon, 2 Nov 2020 at 20:43, David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 20 Oct 2020 at 22:30, David Rowley <dgrowleyml@gmail.com> wrote: > I did some further tests this time with some tuple deforming. Again, > it does seem that v9 is slower than v8. > > Graphs attached > > Looking at profiles, I don't really see any obvious reason as to why > this is. I'm very much inclined to just pursue the v8 patch (separate > Result Cache node) and just drop the v9 idea altogether. Nobody raised any objections, so I'll start taking a more serious look at the v8 version (the patch with the separate Result Cache node). One thing that I had planned to come back to about now is the name "Result Cache". I admit to not thinking for too long on the best name and always thought it was something to come back to later when there's some actual code to debate a better name for. "Result Cache" was always a bit of a placeholder name. Some other names that I'd thought of were: "MRU Hash" "MRU Cache" "Parameterized Tuple Cache" (bit long) "Parameterized Cache" "Parameterized MRU Cache" I know Robert had shown some interest in using a different name. It would be nice to settle on something most people are happy with soon. David
On Fri, Nov 6, 2020 at 6:13 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Mon, 2 Nov 2020 at 20:43, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Tue, 20 Oct 2020 at 22:30, David Rowley <dgrowleyml@gmail.com> wrote:
> I did some further tests this time with some tuple deforming. Again,
> it does seem that v9 is slower than v8.
>
> Graphs attached
>
> Looking at profiles, I don't really see any obvious reason as to why
> this is. I'm very much inclined to just pursue the v8 patch (separate
> Result Cache node) and just drop the v9 idea altogether.
Nobody raised any objections, so I'll start taking a more serious look
at the v8 version (the patch with the separate Result Cache node).
One thing that I had planned to come back to about now is the name
"Result Cache". I admit to not thinking for too long on the best name
and always thought it was something to come back to later when there's
some actual code to debate a better name for. "Result Cache" was
always a bit of a placeholder name.
Some other names that I'd thought of were:
"MRU Hash"
"MRU Cache"
"Parameterized Tuple Cache" (bit long)
"Parameterized Cache"
"Parameterized MRU Cache"
I think "Tuple Cache" would be OK which means it is a cache for tuples.
Telling MRU/LRU would be too internal for an end user and "Parameterized"
looks redundant given that we have said "Cache Key" just below the node name.
Just my $0.01.
Best Regards
Andy Fan
On Mon, Nov 2, 2020 at 3:44 PM David Rowley <dgrowleyml@gmail.com> wrote:
On Tue, 20 Oct 2020 at 22:30, David Rowley <dgrowleyml@gmail.com> wrote:
>
> So far benchmarking shows there's still a regression from the v8
> version of the patch. This is using count(*). An earlier test [1] did
> show speedups when we needed to deform tuples returned by the nested
> loop node. I've not yet repeated that test again. I was disappointed
> to see v9 slower than v8 after having spent about 3 days rewriting the
> patch
I did some further tests this time with some tuple deforming. Again,
it does seem that v9 is slower than v8.
I run your test case on v8 and v9, I can produce a stable difference between them.
v8:
statement latencies in milliseconds:
1603.611 select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
statement latencies in milliseconds:
1603.611 select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
v9:
statement latencies in milliseconds:
1772.287 select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
1772.287 select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
then I did a perf on the 2 version, Is it possible that you called tts_minimal_clear twice in
the v9 version? Both ExecClearTuple and ExecStoreMinimalTuple called tts_minimal_clear
on the same slot.
With the following changes:
diff --git a/src/backend/executor/execMRUTupleCache.c b/src/backend/executor/execMRUTupleCache.c
index 3553dc26cb..b82d8e98b8 100644
--- a/src/backend/executor/execMRUTupleCache.c
+++ b/src/backend/executor/execMRUTupleCache.c
@@ -203,10 +203,9 @@ prepare_probe_slot(MRUTupleCache *mrucache, MRUCacheKey *key)
TupleTableSlot *tslot = mrucache->tableslot;
int numKeys = mrucache->nkeys;
- ExecClearTuple(pslot);
-
if (key == NULL)
{
+ ExecClearTuple(pslot);
/* Set the probeslot's values based on the current parameter values */
for (int i = 0; i < numKeys; i++)
pslot->tts_values[i] = ExecEvalExpr(mrucache->param_exprs[i],
@@ -641,7 +640,7 @@ ExecMRUTupleCacheFetch(MRUTupleCache *mrucache)
{
mrucache->state = MRUCACHE_FETCH_NEXT_TUPLE;
- ExecClearTuple(mrucache->cachefoundslot);
+ // ExecClearTuple(mrucache->cachefoundslot);
slot = mrucache->cachefoundslot;
ExecStoreMinimalTuple(mrucache->last_tuple->mintuple, slot, false);
return slot;
@@ -740,7 +739,7 @@ ExecMRUTupleCacheFetch(MRUTupleCache *mrucache)
return NULL;
}
- ExecClearTuple(mrucache->cachefoundslot);
+ // ExecClearTuple(mrucache->cachefoundslot);
slot = mrucache->cachefoundslot;
ExecStoreMinimalTuple(mrucache->last_tuple->mintuple, slot, false);
return slot;
index 3553dc26cb..b82d8e98b8 100644
--- a/src/backend/executor/execMRUTupleCache.c
+++ b/src/backend/executor/execMRUTupleCache.c
@@ -203,10 +203,9 @@ prepare_probe_slot(MRUTupleCache *mrucache, MRUCacheKey *key)
TupleTableSlot *tslot = mrucache->tableslot;
int numKeys = mrucache->nkeys;
- ExecClearTuple(pslot);
-
if (key == NULL)
{
+ ExecClearTuple(pslot);
/* Set the probeslot's values based on the current parameter values */
for (int i = 0; i < numKeys; i++)
pslot->tts_values[i] = ExecEvalExpr(mrucache->param_exprs[i],
@@ -641,7 +640,7 @@ ExecMRUTupleCacheFetch(MRUTupleCache *mrucache)
{
mrucache->state = MRUCACHE_FETCH_NEXT_TUPLE;
- ExecClearTuple(mrucache->cachefoundslot);
+ // ExecClearTuple(mrucache->cachefoundslot);
slot = mrucache->cachefoundslot;
ExecStoreMinimalTuple(mrucache->last_tuple->mintuple, slot, false);
return slot;
@@ -740,7 +739,7 @@ ExecMRUTupleCacheFetch(MRUTupleCache *mrucache)
return NULL;
}
- ExecClearTuple(mrucache->cachefoundslot);
+ // ExecClearTuple(mrucache->cachefoundslot);
slot = mrucache->cachefoundslot;
ExecStoreMinimalTuple(mrucache->last_tuple->mintuple, slot, false);
return slot;
v9 has the following result:
1608.048 select count(*) from hundredk hk inner join lookup l on hk.thousand = l.a;
Graphs attached
Looking at profiles, I don't really see any obvious reason as to why
this is. I'm very much inclined to just pursue the v8 patch (separate
Result Cache node) and just drop the v9 idea altogether.
David
Best Regards
Andy Fan
On Mon, 9 Nov 2020 at 03:52, Andy Fan <zhihui.fan1213@gmail.com> wrote:
> then I did a perf on the 2 version, Is it possible that you called tts_minimal_clear twice in
> the v9 version? Both ExecClearTuple and ExecStoreMinimalTuple called tts_minimal_clear
> on the same slot.
>
> With the following changes:
Thanks for finding that. After applying that fix I did a fresh set of
benchmarks on the latest master, latest master + v8 and latest master
+ v9 using the attached script. (resultcachebench2.sh.txt)
I ran this on my zen2 AMD64 machine and formatted the results into the
attached resultcache_master_vs_v8_vs_v9.csv file
If I load this into PostgreSQL:
# create table resultcache_bench (tbl text, target text, col text,
latency_master numeric(10,3), latency_v8 numeric(10,3), latency_v9
numeric(10,3));
# copy resultcache_bench from
'/path/to/resultcache_master_vs_v8_vs_v9.csv' with(format csv);
and run:
# select col,tbl,target, sum(latency_v8) v8, sum(latency_v9) v9,
round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9 from
resultcache_bench group by 1,2,3 order by 2,1,3;
I've attached the results of the above query. (resultcache_v8_vs_v9.txt)
Out of the 24 tests done on each branch, only 6 of 24 are better on v9
compared to v8. So v8 wins on 75% of the tests. v9 never wins using
the lookup1 table (1 row per lookup). It only runs on 50% of the
lookup100 queries (100 inner rows per outer row). However, despite the
draw in won tests for the lookup100 test, v8 takes less time overall,
as indicated by the following query:
postgres=# select round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9
from resultcache_bench where tbl='lookup100';
v8_vs_v9
----------
99.3
(1 row)
Ditching the WHERE clause and simply doing:
postgres=# select round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9
from resultcache_bench;
v8_vs_v9
----------
96.2
(1 row)
indicates that v8 is 3.8% faster than v9. Altering that query
accordingly indicates v8 is 11.5% faster than master and v9 is only 7%
faster than master.
Of course, scaling up the test will yield both versions being even
more favourable then master, but the point here is comparing v8 to v9.
David
Вложения
On Mon, Nov 9, 2020 at 10:07 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Mon, 9 Nov 2020 at 03:52, Andy Fan <zhihui.fan1213@gmail.com> wrote:
> then I did a perf on the 2 version, Is it possible that you called tts_minimal_clear twice in
> the v9 version? Both ExecClearTuple and ExecStoreMinimalTuple called tts_minimal_clear
> on the same slot.
>
> With the following changes:
Thanks for finding that. After applying that fix I did a fresh set of
benchmarks on the latest master, latest master + v8 and latest master
+ v9 using the attached script. (resultcachebench2.sh.txt)
I ran this on my zen2 AMD64 machine and formatted the results into the
attached resultcache_master_vs_v8_vs_v9.csv file
If I load this into PostgreSQL:
# create table resultcache_bench (tbl text, target text, col text,
latency_master numeric(10,3), latency_v8 numeric(10,3), latency_v9
numeric(10,3));
# copy resultcache_bench from
'/path/to/resultcache_master_vs_v8_vs_v9.csv' with(format csv);
and run:
# select col,tbl,target, sum(latency_v8) v8, sum(latency_v9) v9,
round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9 from
resultcache_bench group by 1,2,3 order by 2,1,3;
I've attached the results of the above query. (resultcache_v8_vs_v9.txt)
Out of the 24 tests done on each branch, only 6 of 24 are better on v9
compared to v8. So v8 wins on 75% of the tests.
I think either version is OK for me and I like this patch overall. However I believe v9
should be no worse than v8 all the time, Is there any theory to explain
your result?
v9 never wins using
the lookup1 table (1 row per lookup). It only runs on 50% of the
lookup100 queries (100 inner rows per outer row). However, despite the
draw in won tests for the lookup100 test, v8 takes less time overall,
as indicated by the following query:
postgres=# select round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9
from resultcache_bench where tbl='lookup100';
v8_vs_v9
----------
99.3
(1 row)
Ditching the WHERE clause and simply doing:
postgres=# select round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9
from resultcache_bench;
v8_vs_v9
----------
96.2
(1 row)
indicates that v8 is 3.8% faster than v9. Altering that query
accordingly indicates v8 is 11.5% faster than master and v9 is only 7%
faster than master.
Of course, scaling up the test will yield both versions being even
more favourable then master, but the point here is comparing v8 to v9.
David
Best Regards
Andy Fan
On Mon, 9 Nov 2020 at 16:29, Andy Fan <zhihui.fan1213@gmail.com> wrote:
> I think either version is OK for me and I like this patch overall.
That's good to know. Thanks.
> However I believe v9
> should be no worse than v8 all the time, Is there any theory to explain
> your result?
Nothing jumps out at me from looking at profiles. The only thing I
noticed was the tuple deforming is more costly with v9. I'm not sure
why.
The other part of v9 that I don't have a good solution for yet is the
code around the swapping of the projection info for the Nested Loop.
The cache always uses a MinimalTupleSlot, but we may have a
VirtualSlot when we get a cache miss. If we do then we need to
initialise 2 different projection infos so when we project from the
cache that we have the step to deform the minimal tuple. That step is
not required when the inner slot is a virtual slot.
I did some further testing on performance. Basically, I increased the
size of the tests by 2 orders of magnitude. Instead of 100k rows, I
used 10million rows. (See attached
resultcache_master_vs_v8_vs_v9_big.csv)
Loading that in with:
# create table resultcache_bench2 (tbl text, target text, col text,
latency_master numeric(10,3), latency_v8 numeric(10,3), latency_v9
numeric(10,3));
# copy resultcache_bench2 from
'/path/to/resultcache_master_vs_v8_vs_v9_big.csv' with(format csv);
I see that v8 still wins.
postgres=# select round(avg(latency_v8/latency_master)*100,1) as
v8_vs_master, round(avg(latency_v9/latency_master)*100,1) as
v9_vs_master, round(avg(latency_v8/latency_v9)*100,1) as v8_vs_v9 from
resultcache_bench2;
v8_vs_master | v9_vs_master | v8_vs_v9
--------------+--------------+----------
56.7 | 58.8 | 97.3
Execution for all tests for v8 runs in 56.7% of master, but v9 runs in
58.8% of master's time. Full results in
resultcache_master_v8_vs_v9_big.txt. v9 wins in 7 of 24 tests this
time. The best example test for v8 shows that v8 takes 90.6% of the
time of v9, but in the tests where v9 is faster, it only has a 4.3%
lead on v8 (95.7%). You can see that overall v8 is 2.7% faster than v9
for these tests.
David
Вложения
On 2020-Nov-10, David Rowley wrote: > On Mon, 9 Nov 2020 at 16:29, Andy Fan <zhihui.fan1213@gmail.com> wrote: > > However I believe v9 > > should be no worse than v8 all the time, Is there any theory to explain > > your result? > > Nothing jumps out at me from looking at profiles. The only thing I > noticed was the tuple deforming is more costly with v9. I'm not sure > why. Are you taking into account the possibility that generated machine code is a small percent slower out of mere bad luck? I remember someone suggesting that they can make code 2% faster or so by inserting random no-op instructions in the binary, or something like that. So if the difference between v8 and v9 is that small, then it might be due to this kind of effect. I don't know what is a good technique to test this hypothesis.
Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
> Are you taking into account the possibility that generated machine code
> is a small percent slower out of mere bad luck? I remember someone
> suggesting that they can make code 2% faster or so by inserting random
> no-op instructions in the binary, or something like that. So if the
> difference between v8 and v9 is that small, then it might be due to this
> kind of effect.
Yeah. I believe what this arises from is good or bad luck about relevant
tight loops falling within or across cache lines, and that sort of thing.
We've definitely seen performance changes up to a couple percent with
no apparent change to the relevant code.
regards, tom lane
On Tue, 10 Nov 2020 at 12:49, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Alvaro Herrera <alvherre@alvh.no-ip.org> writes: > > Are you taking into account the possibility that generated machine code > > is a small percent slower out of mere bad luck? I remember someone > > suggesting that they can make code 2% faster or so by inserting random > > no-op instructions in the binary, or something like that. So if the > > difference between v8 and v9 is that small, then it might be due to this > > kind of effect. > > Yeah. I believe what this arises from is good or bad luck about relevant > tight loops falling within or across cache lines, and that sort of thing. > We've definitely seen performance changes up to a couple percent with > no apparent change to the relevant code. It possibly is this issue. Normally how I build up my confidence in which is faster is why just rebasing on master as it advances and see if the winner ever changes. The theory here is if one patch is consistently the fastest, then there's more chance if there being a genuine reason for it. So far I've only rebased v9 twice. Both times it was slower than v8. Since the benchmarks are all scripted, it's simple enough to kick off another round to see if anything has changed. I do happen to prefer having the separate Result Cache node (v8), so from my point of view, even if the performance was equal, I'd rather have v8. I understand that some others feel different though. David
On Mon, Nov 9, 2020 at 3:49 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Alvaro Herrera <alvherre@alvh.no-ip.org> writes: > > Are you taking into account the possibility that generated machine code > > is a small percent slower out of mere bad luck? I remember someone > > suggesting that they can make code 2% faster or so by inserting random > > no-op instructions in the binary, or something like that. So if the > > difference between v8 and v9 is that small, then it might be due to this > > kind of effect. > > Yeah. I believe what this arises from is good or bad luck about relevant > tight loops falling within or across cache lines, and that sort of thing. > We've definitely seen performance changes up to a couple percent with > no apparent change to the relevant code. That was Andrew Gierth. And it was 5% IIRC. In theory it should be possible to control for this using a tool like stabilizer: https://github.com/ccurtsinger/stabilizer I am not aware of anybody having actually used the tool with Postgres, though. It looks rather inconvenient. -- Peter Geoghegan
On Tue, Nov 10, 2020 at 7:55 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Tue, 10 Nov 2020 at 12:49, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
> > Are you taking into account the possibility that generated machine code
> > is a small percent slower out of mere bad luck? I remember someone
> > suggesting that they can make code 2% faster or so by inserting random
> > no-op instructions in the binary, or something like that. So if the
> > difference between v8 and v9 is that small, then it might be due to this
> > kind of effect.
>
> Yeah. I believe what this arises from is good or bad luck about relevant
> tight loops falling within or across cache lines, and that sort of thing.
> We've definitely seen performance changes up to a couple percent with
> no apparent change to the relevant code.
I do happen to prefer having the separate Result Cache node (v8), so
from my point of view, even if the performance was equal, I'd rather
have v8. I understand that some others feel different though.
While I have interest about what caused the tiny difference, I admit that what direction
this patch should go is more important. Not sure if anyone is convinced that
v8 and v9 have a similar performance. The current data show it is similar. I want to
profile/read code more, but I don't know what part I should pay attention to. So I think
any hints on why v9 should be better at a noticeable level in theory should be very
helpful. After that, I'd like to read the code or profile more carefully.
Best Regards
Andy Fan
On Tue, 10 Nov 2020 at 15:38, Andy Fan <zhihui.fan1213@gmail.com> wrote: > While I have interest about what caused the tiny difference, I admit that what direction > this patch should go is more important. Not sure if anyone is convinced that > v8 and v9 have a similar performance. The current data show it is similar. I want to > profile/read code more, but I don't know what part I should pay attention to. So I think > any hints on why v9 should be better at a noticeable level in theory should be very > helpful. After that, I'd like to read the code or profile more carefully. It was thought by putting the cache code directly inside nodeNestloop.c that the overhead of fetching a tuple from a subnode could be eliminated when we get a cache hit. A cache hit on v8 looks like: Nest loop -> Fetch new outer row Nest loop -> Fetch inner row Result Cache -> cache hit return first cached tuple Nest loop -> eval qual and return tuple if matches With v9 it's more like: Nest Loop -> Fetch new outer row Nest loop -> cache hit return first cached tuple Nest loop -> eval qual and return tuple if matches So 1 less hop between nodes. In reality, the hop is not that expensive, so might not be a big enough factor to slow the execution down. There's some extra complexity in v9 around the slot type of the inner tuple. A cache hit means the slot type is Minimal. But a miss means the slot type is whatever type the inner node's slot is. So some code exists to switch the qual and projection info around depending on if we get a cache hit or a miss. I did some calculations on how costly pulling a tuple through a node in [1]. David [1] https://www.postgresql.org/message-id/CAKJS1f9UXdk6ZYyqbJnjFO9a9hyHKGW7B%3DZRh-rxy9qxfPA5Gw%40mail.gmail.com
On Tue, 10 Nov 2020 at 12:55, David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 10 Nov 2020 at 12:49, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > Alvaro Herrera <alvherre@alvh.no-ip.org> writes: > > > Are you taking into account the possibility that generated machine code > > > is a small percent slower out of mere bad luck? I remember someone > > > suggesting that they can make code 2% faster or so by inserting random > > > no-op instructions in the binary, or something like that. So if the > > > difference between v8 and v9 is that small, then it might be due to this > > > kind of effect. > > > > Yeah. I believe what this arises from is good or bad luck about relevant > > tight loops falling within or across cache lines, and that sort of thing. > > We've definitely seen performance changes up to a couple percent with > > no apparent change to the relevant code. > > It possibly is this issue. > > Normally how I build up my confidence in which is faster is why just > rebasing on master as it advances and see if the winner ever changes. > The theory here is if one patch is consistently the fastest, then > there's more chance if there being a genuine reason for it. I kicked off a script last night that ran benchmarks on master, v8 and v9 of the patch on 1 commit per day for the past 30 days since yesterday. The idea here is that as the code changes that if the performance differences are due to code alignment then there should be enough churn in 30 days to show if this is the case. The quickly put together script is attached. It would need quite a bit of modification to run on someone else's machine. This took about 20 hours to run. I found that v8 is faster on 28 out of 30 commits. In the two cases where v9 was faster, v9 took 99.8% and 98.5% of the time of v8. In the 28 cases where v8 was faster it was generally about 2-4% faster, but a couple of times 8-10% faster. Full results attached in .csv file. Also the query I ran to compare the results once loaded into Postgres. David
Вложения
Hi David:
I did a review on the v8, it looks great to me. Here are some tiny things noted,
just FYI.
1. modified src/include/utils/selfuncs.h
@@ -70,9 +70,9 @@* callers to provide further details about some assumptions which were made
* during the estimation.
*/
-#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one of
- * the DEFAULTs as defined above.
- */
+#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one
+ * of the DEFAULTs as defined
+ * above. */
Looks nothing has changed.
2. leading spaces is not necessary in comments.
/*
* ResultCacheTuple Stores an individually cached tuple
*/
typedef struct ResultCacheTuple
{
MinimalTuple mintuple; /* Cached tuple */
struct ResultCacheTuple *next; /* The next tuple with the same parameter
* values or NULL if it's the last one */
} ResultCacheTuple;
3. We define ResultCacheKey as below.
/*
* ResultCacheKey
* The hash table key for cached entries plus the LRU list link
*/
typedef struct ResultCacheKey
{
MinimalTuple params;
dlist_node lru_node; /* Pointer to next/prev key in LRU list */
} ResultCacheKey;
Since we store it as a MinimalTuple, we need some FETCH_INNER_VAR step for
each element during the ResultCacheHash_equal call. I am thinking if we can
store a "Datum *" directly to save these steps. exec_aggvalues/exec_aggnulls looks
a good candidate for me, except that the name looks not good. IMO, we can
rename exec_aggvalues/exec_aggnulls and try to merge
EEOP_AGGREF/EEOP_WINDOW_FUNC into a more generic step which can be
reused in this case.
4. I think the ExecClearTuple in prepare_probe_slot is not a must, since the
data tts_values/tts_flags/tts_nvalid are all reset later, and tts_tid is not
real used in our case. Since both prepare_probe_slot
and ResultCacheHash_equal are in pretty hot path, we may need to consider it.
static inline void
prepare_probe_slot(ResultCacheState *rcstate, ResultCacheKey *key)
{
...
ExecClearTuple(pslot);
static inline void
prepare_probe_slot(ResultCacheState *rcstate, ResultCacheKey *key)
{
...
ExecClearTuple(pslot);
...
}
static void
tts_virtual_clear(TupleTableSlot *slot)
{
if (unlikely(TTS_SHOULDFREE(slot)))
{
VirtualTupleTableSlot *vslot = (VirtualTupleTableSlot *) slot;
pfree(vslot->data);
vslot->data = NULL;
slot->tts_flags &= ~TTS_FLAG_SHOULDFREE;
}
slot->tts_nvalid = 0;
slot->tts_flags |= TTS_FLAG_EMPTY;
ItemPointerSetInvalid(&slot->tts_tid);
}
}
static void
tts_virtual_clear(TupleTableSlot *slot)
{
if (unlikely(TTS_SHOULDFREE(slot)))
{
VirtualTupleTableSlot *vslot = (VirtualTupleTableSlot *) slot;
pfree(vslot->data);
vslot->data = NULL;
slot->tts_flags &= ~TTS_FLAG_SHOULDFREE;
}
slot->tts_nvalid = 0;
slot->tts_flags |= TTS_FLAG_EMPTY;
ItemPointerSetInvalid(&slot->tts_tid);
}
--
Best Regards
Andy Fan
On Sun, Nov 22, 2020 at 9:21 PM Andy Fan <zhihui.fan1213@gmail.com> wrote:
Hi David:I did a review on the v8, it looks great to me. Here are some tiny things noted,just FYI.1. modified src/include/utils/selfuncs.h@@ -70,9 +70,9 @@
* callers to provide further details about some assumptions which were made
* during the estimation.
*/
-#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one of
- * the DEFAULTs as defined above.
- */
+#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one
+ * of the DEFAULTs as defined
+ * above. */
Looks nothing has changed.
2. leading spaces is not necessary in comments.
/*
* ResultCacheTuple Stores an individually cached tuple
*/
typedef struct ResultCacheTuple
{
MinimalTuple mintuple; /* Cached tuple */
struct ResultCacheTuple *next; /* The next tuple with the same parameter
* values or NULL if it's the last one */
} ResultCacheTuple;
3. We define ResultCacheKey as below.
/*
* ResultCacheKey
* The hash table key for cached entries plus the LRU list link
*/
typedef struct ResultCacheKey
{
MinimalTuple params;
dlist_node lru_node; /* Pointer to next/prev key in LRU list */
} ResultCacheKey;
Since we store it as a MinimalTuple, we need some FETCH_INNER_VAR step for
each element during the ResultCacheHash_equal call. I am thinking if we can
store a "Datum *" directly to save these steps. exec_aggvalues/exec_aggnulls looksa good candidate for me, except that the name looks not good. IMO, we canrename exec_aggvalues/exec_aggnulls and try to mergeEEOP_AGGREF/EEOP_WINDOW_FUNC into a more generic step which can bereused in this case.
4. I think the ExecClearTuple in prepare_probe_slot is not a must, since the
data tts_values/tts_flags/tts_nvalid are all reset later, and tts_tid is not
real used in our case. Since both prepare_probe_slotand ResultCacheHash_equal are in pretty hot path, we may need to consider it.
static inline void
prepare_probe_slot(ResultCacheState *rcstate, ResultCacheKey *key)
{
...
ExecClearTuple(pslot);...
}
static void
tts_virtual_clear(TupleTableSlot *slot)
{
if (unlikely(TTS_SHOULDFREE(slot)))
{
VirtualTupleTableSlot *vslot = (VirtualTupleTableSlot *) slot;
pfree(vslot->data);
vslot->data = NULL;
slot->tts_flags &= ~TTS_FLAG_SHOULDFREE;
}
slot->tts_nvalid = 0;
slot->tts_flags |= TTS_FLAG_EMPTY;
ItemPointerSetInvalid(&slot->tts_tid);
}--Best RegardsAndy Fan
1. I'd suggest adding Assert(false); in RC_END_OF_SCAN case to make the error clearer.
case RC_END_OF_SCAN:
/*
* We've already returned NULL for this scan, but just in case
* something call us again by mistake.
*/
return NULL;
2. Currently we handle the (!cache_store_tuple(node, outerslot))) case by set it
to RC_CACHE_BYPASS_MODE. The only reason for the cache_store_tuple failure is
we can't cache_reduce_memory. I guess if cache_reduce_memory
failed once, it would not succeed later(no more tuples can be stored,
nothing is changed). So I think we can record this state and avoid any new
cache_reduce_memory call.
/*
* If we failed to create the entry or failed to store the
* tuple in the entry, then go into bypass mode.
*/
if (unlikely(entry == NULL ||
!cache_store_tuple(node, outerslot)))
to
case RC_END_OF_SCAN:
/*
* We've already returned NULL for this scan, but just in case
* something call us again by mistake.
*/
return NULL;
2. Currently we handle the (!cache_store_tuple(node, outerslot))) case by set it
to RC_CACHE_BYPASS_MODE. The only reason for the cache_store_tuple failure is
we can't cache_reduce_memory. I guess if cache_reduce_memory
failed once, it would not succeed later(no more tuples can be stored,
nothing is changed). So I think we can record this state and avoid any new
cache_reduce_memory call.
/*
* If we failed to create the entry or failed to store the
* tuple in the entry, then go into bypass mode.
*/
if (unlikely(entry == NULL ||
!cache_store_tuple(node, outerslot)))
to
if (unlikely(entry == NULL || node->memory_cant_be_reduced ||
!cache_store_tuple(node, outerslot)))
--
Best Regards
Andy Fan
Thanks for having another look at this. > On Sun, Nov 22, 2020 at 9:21 PM Andy Fan <zhihui.fan1213@gmail.com> wrote: > add 2 more comments. > > 1. I'd suggest adding Assert(false); in RC_END_OF_SCAN case to make the error clearer. > > case RC_END_OF_SCAN: > /* > * We've already returned NULL for this scan, but just in case > * something call us again by mistake. > */ > return NULL; This just took some inspiration from nodeMaterial.c where it says: /* * If necessary, try to fetch another row from the subplan. * * Note: the eof_underlying state variable exists to short-circuit further * subplan calls. It's not optional, unfortunately, because some plan * node types are not robust about being called again when they've already * returned NULL. */ I'm not feeling a pressing need to put an Assert(false); in there as it's not what nodeMaterial.c does. nodeMaterial is nodeResultCache's sister node which can also be seen below Nested Loops. > 2. Currently we handle the (!cache_store_tuple(node, outerslot))) case by set it > to RC_CACHE_BYPASS_MODE. The only reason for the cache_store_tuple failure is > we can't cache_reduce_memory. I guess if cache_reduce_memory > failed once, it would not succeed later(no more tuples can be stored, > nothing is changed). So I think we can record this state and avoid any new > cache_reduce_memory call. > > /* > * If we failed to create the entry or failed to store the > * tuple in the entry, then go into bypass mode. > */ > if (unlikely(entry == NULL || > !cache_store_tuple(node, outerslot))) > > to > > if (unlikely(entry == NULL || node->memory_cant_be_reduced || > !cache_store_tuple(node, outerslot))) The reason for RC_CACHE_BYPASS_MODE is if there's a single set of parameters that have so many results that they, alone, don't fit in the cache. We call cache_reduce_memory() whenever we go over our memory budget. That function returns false if it was unable to free enough memory without removing the "specialkey", which in this case is the current cache entry that's being populated. Later, when we're caching some entry that isn't quite so large, we still want to be able to cache that. In that case, we'll have removed the remnants of the overly large entry that didn't fit to way for newer and, hopefully, smaller entries. No problems. I'm not sure why there's a need for another flag here. A bit more background. When caching a new entry, or finding an existing entry, we move that entry to the top of the MRU dlist. When adding entries or tuples to existing entries, if we've gone over memory budget, then we remove cache entries from the MRU list starting at the tail (lease recently used). If we begin caching tuples for an entry and need to free some space, then since we've put the current entry to the top of the MRU list, it'll be the last one to be removed. However, it's still possible that we run through the entire MRU list and end up at the most recently used item. So the entry we're populating can also be removed if freeing everything else was still not enough to give us enough free memory. The code refers to this as a cache overflow. This causes the state machine to move into RC_CACHE_BYPASS_MODE mode. We'll just read tuples directly from the subnode in that case, no need to attempt to cache them. They're not going to fit. We'll come out of RC_CACHE_BYPASS_MODE when doing the next rescan with a different set of parameters. This is our chance to try caching things again. The code does that. There might be far fewer tuples for the next parameter we're scanning for, or those tuples might be more narrow. So it makes sense to give caching them another try. Perhaps there's some point where we should give up doing that, but given good statistics, it's unlikely the planner would have thought a result cache would have been worth the trouble and would likely have picked some other way to execute the plan. The planner does estimate the average size of a cache entry and calculates how many of those fit into a hash_mem. If that number is too low then Result Caching the inner side won't be too appealing. Of course, calculating the average does not mean there are no outliers. We'll deal with the large side of the outliers with the bypass code. I currently don't really see what needs to be changed about that. David
On Fri, Nov 27, 2020 at 8:10 AM David Rowley <dgrowleyml@gmail.com> wrote:
Thanks for having another look at this.
> On Sun, Nov 22, 2020 at 9:21 PM Andy Fan <zhihui.fan1213@gmail.com> wrote:
> add 2 more comments.
>
> 1. I'd suggest adding Assert(false); in RC_END_OF_SCAN case to make the error clearer.
>
> case RC_END_OF_SCAN:
> /*
> * We've already returned NULL for this scan, but just in case
> * something call us again by mistake.
> */
> return NULL;
This just took some inspiration from nodeMaterial.c where it says:
/*
* If necessary, try to fetch another row from the subplan.
*
* Note: the eof_underlying state variable exists to short-circuit further
* subplan calls. It's not optional, unfortunately, because some plan
* node types are not robust about being called again when they've already
* returned NULL.
*/
I'm not feeling a pressing need to put an Assert(false); in there as
it's not what nodeMaterial.c does. nodeMaterial is nodeResultCache's
sister node which can also be seen below Nested Loops.
OK, even though I am not quite understanding the above now, I will try to figure it
by myself. I'm OK with this decision.
> 2. Currently we handle the (!cache_store_tuple(node, outerslot))) case by set it
> to RC_CACHE_BYPASS_MODE. The only reason for the cache_store_tuple failure is
> we can't cache_reduce_memory. I guess if cache_reduce_memory
> failed once, it would not succeed later(no more tuples can be stored,
> nothing is changed). So I think we can record this state and avoid any new
> cache_reduce_memory call.
>
> /*
> * If we failed to create the entry or failed to store the
> * tuple in the entry, then go into bypass mode.
> */
> if (unlikely(entry == NULL ||
> !cache_store_tuple(node, outerslot)))
>
> to
>
> if (unlikely(entry == NULL || node->memory_cant_be_reduced ||
> !cache_store_tuple(node, outerslot)))
The reason for RC_CACHE_BYPASS_MODE is if there's a single set of
parameters that have so many results that they, alone, don't fit in
the cache. We call cache_reduce_memory() whenever we go over our
memory budget. That function returns false if it was unable to free
enough memory without removing the "specialkey", which in this case is
the current cache entry that's being populated. Later, when we're
caching some entry that isn't quite so large, we still want to be able
to cache that. In that case, we'll have removed the remnants of the
overly large entry that didn't fit to way for newer and, hopefully,
smaller entries. No problems. I'm not sure why there's a need for
another flag here.
Thanks for the explanation, I'm sure I made some mistakes before at
this part.
Best Regards
Andy Fan
On Thu, 12 Nov 2020 at 15:36, David Rowley <dgrowleyml@gmail.com> wrote: > I kicked off a script last night that ran benchmarks on master, v8 and > v9 of the patch on 1 commit per day for the past 30 days since > yesterday. The idea here is that as the code changes that if the > performance differences are due to code alignment then there should be > enough churn in 30 days to show if this is the case. > > The quickly put together script is attached. It would need quite a bit > of modification to run on someone else's machine. > > This took about 20 hours to run. I found that v8 is faster on 28 out > of 30 commits. In the two cases where v9 was faster, v9 took 99.8% and > 98.5% of the time of v8. In the 28 cases where v8 was faster it was > generally about 2-4% faster, but a couple of times 8-10% faster. Full > results attached in .csv file. Also the query I ran to compare the > results once loaded into Postgres. Since running those benchmarks, Andres spent a little bit of time looking at the v9 patch and he pointed out that I can use the same projection info in the nested loop code with and without a cache hit. I just need to ensure that inneropsfixed is false so that the expression compilation includes a deform step when result caching is enabled. Making it work like that did make a small performance improvement, but further benchmarking showed that it was still not as fast as the v8 patch (separate Result Cache node). Due to that, I want to push forward with having the separate Result Cache node and just drop the idea of including the feature as part of the Nested Loop node. I've attached an updated patch, v10. This is v8 with a few further changes; I added the peak memory tracking and adjusted a few comments. I added a paragraph to explain what RC_CACHE_BYPASS_MODE is. I also noticed that the code I'd written to build the cache lookup expression included a step to deform the outer tuple. This was unnecessary and slowed down the expression evaluation. I'm fairly happy with patches 0001 to 0003. However, I ended up stripping out the subplan caching code out of 0003 and putting it in 0004. This part I'm not so happy with. The problem there is that when planning a correlated subquery we don't have any context to determine how many distinct values the subplan will be called with. For now, the 0004 patch just always includes a Result Cache for correlated subqueries. The reason I don't like that is that it could slow things down when the cache never gets a hit. The additional cost of adding tuples to the cache is going to slow things down. I'm not yet sure the best way to make 0004 better. I don't think using AlternativeSubplans is a good choice as it means having to build two subplans. Also determining the cheapest plan to use couldn't use the existing logic that's in fix_alternative_subplan(). It might be best left until we do some refactoring so instead of building subplans as soon as we've run the planner, instead have it keep a list of Paths around and then choose the best Path once the top-level plan has been planned. That's a pretty big change. On making another pass over this patchset, I feel there are two points that might still raise a few eyebrows: 1. In order to not have Nested Loops picked with an inner Result Cache when the inner index's parameters have no valid statistics, I modified estimate_num_groups() to add a new parameter that allows callers to pass an EstimationInfo struct to have the function set a flag to indicate of DEFAULT_NUM_DISTINCT was used. Callers which don't care about this can just pass NULL. I did once try adding a new parameter to clauselist_selectivity() in 2686ee1b. There was not much excitement about that we ended up removing it again. I don't see any alternative here. 2. Nobody really mentioned they didn't like the name Result Cache. I really used that as a placeholder name until I came up with something better. I mentioned a few other names in [1]. If nobody is objecting to Result Cache, I'll just keep it named that way. David [1] https://www.postgresql.org/message-id/CAApHDvoj_sH1H3JVXgHuwnxf1FQbjRVOqqgxzOgJX13NiA9-cg@mail.gmail.com
Вложения
Thanks for working on the new version.
On Fri, Dec 4, 2020 at 10:41 PM David Rowley <dgrowleyml@gmail.com> wrote:
I also
noticed that the code I'd written to build the cache lookup expression
included a step to deform the outer tuple. This was unnecessary and
slowed down the expression evaluation.
I thought it would be something like my 3rd suggestion on [1], however after
I read the code, it looked like no. Could you explain what changes it is?
I probably missed something.
--
Best Regards
Andy Fan
Thanks for this review. I somehow missed addressing what's mentioned
here for the v10 patch. Comments below.
On Mon, 23 Nov 2020 at 02:21, Andy Fan <zhihui.fan1213@gmail.com> wrote:
> 1. modified src/include/utils/selfuncs.h
> @@ -70,9 +70,9 @@
> * callers to provide further details about some assumptions which were made
> * during the estimation.
> */
> -#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one of
> - * the DEFAULTs as defined above.
> - */
> +#define SELFLAG_USED_DEFAULT (1 << 0) /* Estimation fell back on one
> + * of the DEFAULTs as defined
> + * above. */
>
> Looks nothing has changed.
I accidentally took the changes made by pgindent into the wrong patch.
Fixed that in v10.
> 2. leading spaces is not necessary in comments.
>
> /*
> * ResultCacheTuple Stores an individually cached tuple
> */
> typedef struct ResultCacheTuple
> {
> MinimalTuple mintuple; /* Cached tuple */
> struct ResultCacheTuple *next; /* The next tuple with the same parameter
> * values or NULL if it's the last one */
> } ResultCacheTuple;
OK, I've changed that so that they're on 1 line instead of 3.
> 3. We define ResultCacheKey as below.
>
> /*
> * ResultCacheKey
> * The hash table key for cached entries plus the LRU list link
> */
> typedef struct ResultCacheKey
> {
> MinimalTuple params;
> dlist_node lru_node; /* Pointer to next/prev key in LRU list */
> } ResultCacheKey;
>
> Since we store it as a MinimalTuple, we need some FETCH_INNER_VAR step for
> each element during the ResultCacheHash_equal call. I am thinking if we can
> store a "Datum *" directly to save these steps. exec_aggvalues/exec_aggnulls looks
> a good candidate for me, except that the name looks not good. IMO, we can
> rename exec_aggvalues/exec_aggnulls and try to merge
> EEOP_AGGREF/EEOP_WINDOW_FUNC into a more generic step which can be
> reused in this case.
I think this is along the lines of what I'd been thinking about and
mentioned internally to Thomas and Andres. I called it a MemTuple and
it was basically a contiguous block of memory with Datum and isnull
arrays and any varlena attributes at the end of the contiguous
allocation. These could quickly be copied into a VirtualSlot with
zero deforming. I've not given this too much thought yet, but if I
was to do this I'd be aiming to store the cached tuple this way to so
save having to deform it each time we get a cache hit. We'd use more
memory storing entries this way, but if we're not expecting the Result
Cache to fill work_mem, then perhaps it's another approach that the
planner could decide on. Perhaps the cached tuple pointer could be a
union to allow us to store either without making the struct any
larger.
However, FWIW, I'd prefer to think about this later though.
> 4. I think the ExecClearTuple in prepare_probe_slot is not a must, since the
> data tts_values/tts_flags/tts_nvalid are all reset later, and tts_tid is not
> real used in our case. Since both prepare_probe_slot
> and ResultCacheHash_equal are in pretty hot path, we may need to consider it.
I agree that it would be nice not to do the ExecClearTuple(), but the
only way I can see to get rid of it also requires getting rid of the
ExecStoreVirtualTuple(). The problem is ExecStoreVirtualTuple()
Asserts that the slot is empty, which it won't be the second time
around unless we ExecClearTuple it. It seems that to make that work
we'd have to manually set slot->tts_nvalid. I see other places in the
code doing this ExecClearTuple() / ExecStoreVirtualTuple() dance, so I
don't think it's going to be up to this patch to start making
optimisations just for this 1 case.
David
On Sun, 6 Dec 2020 at 03:52, Andy Fan <zhihui.fan1213@gmail.com> wrote: > > On Fri, Dec 4, 2020 at 10:41 PM David Rowley <dgrowleyml@gmail.com> wrote: >> >> I also >> noticed that the code I'd written to build the cache lookup expression >> included a step to deform the outer tuple. This was unnecessary and >> slowed down the expression evaluation. >> > > I thought it would be something like my 3rd suggestion on [1], however after > I read the code, it looked like no. Could you explain what changes it is? > I probably missed something. Basically, an extra argument in ExecBuildParamSetEqual() which allows the TupleTableSlotOps for the left and right side to be set individually. Previously I was passing a single TupleTableSlotOps of TTSOpsMinimalTuple. The probeslot is a TTSOpsVirtual tuple, so passing TTSOpsMinimalTuple causes the function to add a needless EEOP_OUTER_FETCHSOME step to the expression. David
I've attached another patchset that addresses some comments left by Zhihong Yu over on [1]. The version number got bumped to v12 instead of v11 as I still have a copy of the other version of the patch which I made some changes to and internally named v11. The patchset has grown 1 additional patch which is the 0004 patch. The review on the other thread mentioned that I should remove the code duplication for the full cache check that I had mostly duplicated between adding a new entry to the cache and adding tuple to an existing entry. I'm still a bit unsure that I like merging this into a helper function. One call needs the return value of the function to be a boolean value to know if it's still okay to use the cache. The other need the return value to be the cache entry. The patch makes the helper function return the entry and returns NULL to communicate the false value. I'm not a fan of the change and might drop it. The 0005 patch is now the only one that I think needs more work to make it good enough. This is Result Cache for subplans. I mentioned in [2] what my problem with that patch is. On Mon, 7 Dec 2020 at 12:50, David Rowley <dgrowleyml@gmail.com> wrote: > Basically, an extra argument in ExecBuildParamSetEqual() which allows > the TupleTableSlotOps for the left and right side to be set > individually. Previously I was passing a single TupleTableSlotOps of > TTSOpsMinimalTuple. The probeslot is a TTSOpsVirtual tuple, so > passing TTSOpsMinimalTuple causes the function to add a needless > EEOP_OUTER_FETCHSOME step to the expression. I also benchmarked that change and did see that it gives a small but notable improvement to the performance. David [1] https://www.postgresql.org/message-id/CALNJ-vRAgksPqjK-sAU+9gu3R44s_3jVPJ_5SDB++jjEkTntiA@mail.gmail.com [2] https://www.postgresql.org/message-id/CAApHDvpGX7RN+sh7Hn9HWZQKp53SjKaL=GtDzYheHWiEd-8moQ@mail.gmail.com
Вложения
On Tue, 8 Dec 2020 at 20:15, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached another patchset that addresses some comments left by > Zhihong Yu over on [1]. The version number got bumped to v12 instead > of v11 as I still have a copy of the other version of the patch which > I made some changes to and internally named v11. If anyone else wants to have a look at these, please do so soon. I'm planning on starting to take a serious look at getting 0001-0003 in early next week. David
On 09.12.2020 23:53, David Rowley wrote: > On Tue, 8 Dec 2020 at 20:15, David Rowley <dgrowleyml@gmail.com> wrote: >> I've attached another patchset that addresses some comments left by >> Zhihong Yu over on [1]. The version number got bumped to v12 instead >> of v11 as I still have a copy of the other version of the patch which >> I made some changes to and internally named v11. > If anyone else wants to have a look at these, please do so soon. I'm > planning on starting to take a serious look at getting 0001-0003 in > early next week. > > David > I tested the patched version of Postgres on JOBS benchmark: https://github.com/gregrahn/join-order-benchmark For most queries performance is the same, some queries are executed faster but one query is 150 times slower: explain analyze SELECT MIN(chn.name) AS character, MIN(t.title) AS movie_with_american_producer FROM char_name AS chn, cast_info AS ci, company_name AS cn, company_type AS ct, movie_companies AS mc, role_type AS rt, title AS t WHERE ci.note LIKE '%(producer)%' AND cn.country_code = '[us]' AND t.production_year > 1990 AND t.id = mc.movie_id AND t.id = ci.movie_id AND ci.movie_id = mc.movie_id AND chn.id = ci.person_role_id AND rt.id = ci.role_id AND cn.id = mc.company_id AND ct.id = mc.company_type_id; explain analyze SELECT MIN(cn.name) AS from_company, MIN(lt.link) AS movie_link_type, MIN(t.title) AS non_polish_sequel_movie FROM company_name AS cn, company_type AS ct, keyword AS k, link_type AS lt, movie_companies AS mc, movie_keyword AS mk, movie_link AS ml, title AS t WHERE cn.country_code !='[pl]' AND (cn.name LIKE '%Film%' OR cn.name LIKE '%Warner%') AND ct.kind ='production companies' AND k.keyword ='sequel' AND lt.link LIKE '%follow%' AND mc.note IS NULL AND t.production_year BETWEEN 1950 AND 2000 AND lt.id = ml.link_type_id AND ml.movie_id = t.id AND t.id = mk.movie_id AND mk.keyword_id = k.id AND t.id = mc.movie_id AND mc.company_type_id = ct.id AND mc.company_id = cn.id AND ml.movie_id = mk.movie_id AND ml.movie_id = mc.movie_id AND mk.movie_id = mc.movie_id; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------ Finalize Aggregate (cost=300131.43..300131.44 rows=1 width=64) (actual time=522985.919..522993.614 rows=1 loops=1) -> Gather (cost=300131.00..300131.41 rows=4 width=64) (actual time=522985.908..522993.606 rows=5 loops=1) Workers Planned: 4 Workers Launched: 4 -> Partial Aggregate (cost=299131.00..299131.01 rows=1 width=64) (actual time=522726.599..522726.606 rows=1 loops=5) -> Hash Join (cost=38559.78..298508.36 rows=124527 width=33) (actual time=301521.477..522726.592 rows=2 loops=5) Hash Cond: (ci.role_id = rt.id) -> Hash Join (cost=38558.51..298064.76 rows=124527 width=37) (actual time=301521.418..522726.529 rows=2 loops=5) Hash Cond: (mc.company_type_id = ct.id) -> Nested Loop (cost=38557.42..297390.45 rows=124527 width=41) (actual time=301521.392..522726.498 rows=2 loops=5) -> Nested Loop (cost=38556.98..287632.46 rows=255650 width=29) (actual time=235.183..4596.950 rows=156421 loops=5) Join Filter: (t.id = ci.movie_id) -> Parallel Hash Join (cost=38556.53..84611.99 rows=162109 width=29) (actual time=234.991..718.934 rows=119250 loops =5) Hash Cond: (t.id = mc.movie_id) -> Parallel Seq Scan on title t (cost=0.00..43899.19 rows=435558 width=21) (actual time=0.010..178.332 rows=34 9806 loops=5) Filter: (production_year > 1990) Rows Removed by Filter: 155856 -> Parallel Hash (cost=34762.05..34762.05 rows=303558 width=8) (actual time=234.282..234.285 rows=230760 loops =5) Buckets: 2097152 (originally 1048576) Batches: 1 (originally 1) Memory Usage: 69792kB -> Parallel Hash Join (cost=5346.12..34762.05 rows=303558 width=8) (actual time=11.846..160.085 rows=230 760 loops=5) Hash Cond: (mc.company_id = cn.id) -> Parallel Seq Scan on movie_companies mc (cost=0.00..27206.55 rows=841655 width=12) (actual time =0.013..40.426 rows=521826 loops=5) -> Parallel Hash (cost=4722.92..4722.92 rows=49856 width=4) (actual time=11.658..11.659 rows=16969 loops=5) Buckets: 131072 Batches: 1 Memory Usage: 4448kB -> Parallel Seq Scan on company_name cn (cost=0.00..4722.92 rows=49856 width=4) (actual time =0.014..8.324 rows=16969 loops=5) Filter: ((country_code)::text = '[us]'::text) Rows Removed by Filter: 30031 -> Result Cache (cost=0.45..1.65 rows=2 width=12) (actual time=0.019..0.030 rows=1 loops=596250) Cache Key: mc.movie_id Hits: 55970 Misses: 62602 Evictions: 0 Overflows: 0 Memory Usage: 6824kB Worker 0: Hits: 56042 Misses: 63657 Evictions: 0 Overflows: 0 Memory Usage: 6924kB Worker 1: Hits: 56067 Misses: 63659 Evictions: 0 Overflows: 0 Memory Usage: 6906kB Worker 2: Hits: 55947 Misses: 62171 Evictions: 0 Overflows: 0 Memory Usage: 6767kB Worker 3: Hits: 56150 Misses: 63985 Evictions: 0 Overflows: 0 Memory Usage: 6945kB -> Index Scan using cast_info_movie_id_idx on cast_info ci (cost=0.44..1.64 rows=2 width=12) (actual time=0.03 3..0.053 rows=1 loops=316074) Index Cond: (movie_id = mc.movie_id) Filter: ((note)::text ~~ '%(producer)%'::text) Rows Removed by Filter: 25 -> Result Cache (cost=0.44..0.59 rows=1 width=20) (actual time=3.311..3.311 rows=0 loops=782104) Cache Key: ci.person_role_id Hits: 5 Misses: 156294 Evictions: 0 Overflows: 0 Memory Usage: 9769kB Worker 0: Hits: 0 Misses: 156768 Evictions: 0 Overflows: 0 Memory Usage: 9799kB Worker 1: Hits: 1 Misses: 156444 Evictions: 0 Overflows: 0 Memory Usage: 9778kB Worker 2: Hits: 0 Misses: 156222 Evictions: 0 Overflows: 0 Memory Usage: 9764kB Worker 3: Hits: 0 Misses: 156370 Evictions: 0 Overflows: 0 Memory Usage: 9774kB -> Index Scan using char_name_pkey on char_name chn (cost=0.43..0.58 rows=1 width=20) (actual time=0.001..0.001 rows =0 loops=782098) Index Cond: (id = ci.person_role_id) -> Hash (cost=1.04..1.04 rows=4 width=4) (actual time=0.014..0.014 rows=4 loops=5) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on company_type ct (cost=0.00..1.04 rows=4 width=4) (actual time=0.012..0.012 rows=4 loops=5) -> Hash (cost=1.12..1.12 rows=12 width=4) (actual time=0.027..0.028 rows=12 loops=5) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Seq Scan on role_type rt (cost=0.00..1.12 rows=12 width=4) (actual time=0.022..0.023 rows=12 loops=5) Planning Time: 2.398 ms Execution Time: 523002.608 ms (55 rows) I attach file with times of query execution. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
Thanks a lot for testing this patch. It's good to see it run through a
benchmark that exercises quite a few join problems.
On Fri, 11 Dec 2020 at 05:44, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
> For most queries performance is the same, some queries are executed
> faster but
> one query is 150 times slower:
>
>
> explain analyze SELECT MIN(chn.name) AS character,
...
> Execution Time: 523002.608 ms
> I attach file with times of query execution.
I noticed the time reported in results.csv is exactly the same as the
one in the EXPLAIN ANALYZE above. One thing to note there that it
would be a bit fairer if the benchmark was testing the execution time
of the query instead of the time to EXPLAIN ANALYZE.
One of the reasons that the patch may look less favourable here is
that the timing overhead on EXPLAIN ANALYZE increases with additional
nodes.
If I just put this to the test by using the tables and query from [1].
# explain (analyze, costs off) select count(*) from hundredk hk inner
# join lookup l on hk.thousand = l.a;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Aggregate (actual time=1891.262..1891.263 rows=1 loops=1)
-> Nested Loop (actual time=0.312..1318.087 rows=9990000 loops=1)
-> Seq Scan on hundredk hk (actual time=0.299..15.753
rows=100000 loops=1)
-> Result Cache (actual time=0.000..0.004 rows=100 loops=100000)
Cache Key: hk.thousand
Hits: 99000 Misses: 1000 Evictions: 0 Overflows: 0
Memory Usage: 3579kB
-> Index Only Scan using lookup_a_idx on lookup l
(actual time=0.003..0.012 rows=100 loops=1000)
Index Cond: (a = hk.thousand)
Heap Fetches: 0
Planning Time: 3.471 ms
Execution Time: 1891.612 ms
(11 rows)
You can see here the query took 1.891 seconds to execute.
Same query without EXPLAIN ANALYZE.
postgres=# \timing
Timing is on.
postgres=# select count(*) from hundredk hk inner
postgres-# join lookup l on hk.thousand = l.a;
count
---------
9990000
(1 row)
Time: 539.449 ms
Or is it more accurate to say it took just 0.539 seconds?
Going through the same query after disabling; enable_resultcache,
enable_mergejoin, enable_nestloop, I can generate the following table
which compares the EXPLAIN ANALYZE time to the \timing on time.
postgres=# select type,ea_time,timing_time, round(ea_time::numeric /
timing_time::numeric,3) as ea_overhead from results order by
timing_time;
type | ea_time | timing_time | ea_overhead
----------------+----------+-------------+-------------
Nest loop + RC | 1891.612 | 539.449 | 3.507
Merge join | 2411.632 | 1008.991 | 2.390
Nest loop | 2484.82 | 1049.63 | 2.367
Hash join | 4969.284 | 3272.424 | 1.519
Result Cache will be hit a bit harder by this problem due to it having
additional nodes in the plan. The Hash Join query seems to suffer much
less from this problem.
However, saying that. It's certainly not the entire problem here:
Hits: 5 Misses: 156294 Evictions: 0 Overflows: 0 Memory Usage: 9769kB
The planner must have thought there'd be more hits than that or it
wouldn't have thought Result Caching would be a good plan. Estimating
the cache hit ratio using n_distinct becomes much less reliable when
there are joins and filters. A.K.A the real world.
David
[1] https://www.postgresql.org/message-id/CAApHDvrPcQyQdWERGYWx8J+2DLUNgXu+fOSbQ1UscxrunyXyrQ@mail.gmail.com
Thanks for having a look at this.
I've taken most of your suggestions. The things quoted below are just
the ones I didn't agree with or didn't understand.
On Thu, 28 Jan 2021 at 18:43, Justin Pryzby <pryzby@telsasoft.com> wrote:
>
> On Tue, Dec 08, 2020 at 08:15:52PM +1300, David Rowley wrote:
> > +typedef struct EstimationInfo
> > +{
> > + int flags; /* Flags, as defined above to mark special
> > + * properties of the estimation. */
>
> Maybe it should be a bits32 ?
I've changed this to uint32. There are a few examples in the code
base of bit flags using int. e.g PlannedStmt.jitFlags and
_mdfd_getseg()'s "behavior" parameter, there are also quite a few
using unsigned types.
> (Also, according to Michael, some people preferred 0x01 to 1<<0)
I'd rather keep the (1 << 0). I think that it gets much easier to
read when we start using more significant bits. Granted the codebase
has lots of examples of each. I just picked the one I prefer. If
there's some consensus that we switch the bit-shifting to hex
constants for other bitflag defines then I'll change it.
> I think "result cache nodes" should be added here:
>
> doc/src/sgml/config.sgml- <para>
> doc/src/sgml/config.sgml- Hash-based operations are generally more sensitive to memory
> doc/src/sgml/config.sgml- availability than equivalent sort-based operations. The
> doc/src/sgml/config.sgml- memory available for hash tables is computed by multiplying
> doc/src/sgml/config.sgml- <varname>work_mem</varname> by
> doc/src/sgml/config.sgml: <varname>hash_mem_multiplier</varname>. This makes it
> doc/src/sgml/config.sgml- possible for hash-based operations to use an amount of memory
> doc/src/sgml/config.sgml- that exceeds the usual <varname>work_mem</varname> base
> doc/src/sgml/config.sgml- amount.
> doc/src/sgml/config.sgml- </para>
I'd say it would be better to mention it in the previous paragraph.
I've done that. It now looks like:
Hash tables are used in hash joins, hash-based aggregation, result
cache nodes and hash-based processing of <literal>IN</literal>
subqueries.
</para>
Likely setops should be added to that list too, but not by this patch.
> Language fixen follow:
>
> > + * Initialize the hash table to empty.
>
> as empty
Perhaps, but I've kept the "to empty" as it's used in
nodeRecursiveunion.c and nodeSetOp.c to do the same thing. If you
propose a patch that gets transaction to change those instances then
I'll switch this one too.
I'm just in the middle of considering some other changes to the patch
and will post an updated version once I'm done with that.
David
On Fri, 11 Dec 2020 at 05:44, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > I tested the patched version of Postgres on JOBS benchmark: > > https://github.com/gregrahn/join-order-benchmark > > For most queries performance is the same, some queries are executed > faster but > one query is 150 times slower: I set up my AMD 3990x machine here to run the join order benchmark. I used a shared_buffers of 20GB so that all the data would fit in there. work_mem was set to 256MB. I used imdbpy2sql.py to parse the imdb database files and load the data into PostgreSQL. This seemed to work okay apart from the movie_info_idx table appeared to be missing. Many of the 113 join order benchmark queries need this table. Without that table, only 71 of the queries can run. I've not yet investigated why the table was not properly created and loaded. I performed 5 different sets of tests using master at 9522085a, and master with the attached series of patches applied. Tests: * Test 1 uses the standard setting of 100 for default_statistics_target and has parallel query disabled. * Test 2 again uses 100 for the default_statistics_target but enables parallel query. * Test 3 increases default_statistics_target to 10000 (then ANALYZE) and disables parallel query. * Test 4 as test 3 but with parallel query enabled. * Test 5 changes the cost model for Result Cache so that instead of using a result cache based on the estimated number of cache hits, the costing is simplified to inject a Result Cache node to a parameterised nested loop if the n_distinct estimate of the nested loop parameters is less than half the row estimate of the outer plan. I ran each query using pgbench for 20 seconds. Test 1: 18 of the 71 queries used a Result Cache node. Overall the runtime of those queries was reduced by 12.5% using v13 when compared to master. Over each of the 71 queries, the total time to parse/plan/execute each of the queries was reduced by 7.95%. Test 2: Again 18 queries used a Result Cache. The speedup was about 2.2% for just those 18 and 2.1% over the 71 queries. Test 3: 9 queries used a Result Cache. The speedup was 3.88% for those 9 queries and 0.79% over the 71 queries. Test 4: 8 of the 71 queries used a Result Cache. The speedup was 4.61% over those 8 queries and 4.53% over the 71 queries. Test 5: Saw 15 queries using a Result Cache node. These 15 ran 5.95% faster than master and over all of the 71 queries, the benchmark was 0.32% faster. I see some of the queries do take quite a bit of effort for the query planner due to the large number of joins. Some of the faster to execute queries here took a little longer due to this. The reason I increased the statistics targets to 10k was down to the fact that I noticed that in test 2 that queries 15c and 15d became slower. After checking the n_distinct estimate for the Result Cache key column I found that the estimate was significantly out when compared to the actual n_distinct. Manually correcting the n_distinct caused the planner to move away from using a Result Cache for those queries. However, I thought I'd check if increasing the statistics targets allowed a better n_distinct estimate due to the larger number of blocks being sampled. It did. I've attached a spreadsheet with the results of each of the tests. The attached file v13_costing_hacks.patch.txt is the quick and dirty patch I put together to run test 5. David
Вложения
- v13-0001-Allow-estimate_num_groups-to-pass-back-further-d.patch
- v13-0004-Remove-code-duplication-in-nodeResultCache.c.patch
- v13-0005-Use-a-Result-Cache-node-to-cache-results-from-su.patch
- v13-0002-Allow-users-of-simplehash.h-to-perform-direct-de.patch
- v13-0003-Add-Result-Cache-executor-node.patch
- Result_cache_v13_vs_master.ods
- v13_costing_hacks.patch.txt
On Wed, 3 Feb 2021 at 19:51, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached a spreadsheet with the results of each of the tests. > > The attached file v13_costing_hacks.patch.txt is the quick and dirty > patch I put together to run test 5. I've attached an updated set of patches. I'd forgotten to run make check-world with the 0005 patch and that was making the CF bot complain. I'm not intending 0005 for commit in the state that it's in, so I've just dropped it. I've also done some further performance testing with the attached set of patched, this time I focused solely on planner performance using the Join Order Benchmark. Some of the queries in this benchmark do give the planner quite a bit of exercise. Queries such as 29b take my 1-year old, fairly powerful AMD hardware about 78 ms to make a plan for. The attached spreadsheet shows the details of the results of these tests. Skip to the "Test6 no parallel 100 stats EXPLAIN only" sheet. To get these results I just ran pgbench for 10 seconds on each query prefixed with "EXPLAIN ". To summarise here, the planner performance gets a fair bit worse with the patched code. With master, summing the average planning time over each of the queries resulted in a total planning time of 765.7 ms. After patching, that went up to 1097.5 ms. I was pretty disappointed about that. On looking into why the performance gets worse, there's a few factors. One factor is that I'm adding a new path to consider and if that path sticks around then subsequent joins may consider that path. Changing things around so I only ever add the best path, the time went down to 1067.4 ms. add_path() does tend to ditch inferior paths anyway, so this may not really be a good thing to do. Another thing that I picked up on was the code that checks if a Result Cache Path is legal to use, it must check if the inner side of the join has any volatile functions. If I just comment out those checks, then the total planning time goes down to 985.6 ms. The estimate_num_groups() call that the costing for the ResultCache path must do to estimate the cache hit ratio is another factor. When replacing that call with a constant value the total planning time goes down to 905.7 ms. I can see perhaps ways that the volatile function checks could be optimised a bit further, but the other stuff really is needed, so it appears if we want this, then it seems like the planner is going to become slightly slower. That does not exactly fill me with joy. We currently have enable_partitionwise_aggregate and enable_partitionwise_join which are both disabled by default because of the possibility of slowing down the planner. One option could be to make enable_resultcache off by default too. I'm not really liking the idea of that much though since anyone who leaves the setting that way won't ever get any gains from caching the inner side of parameterised nested loop results. The idea I had to speed up the volatile function call checks was along similar lines to what parallel query does when it looks for parallel unsafe functions in the parse. Right now those checks are only done under a few conditions where we think that parallel query might actually be used. (See standard_planner()). However, with Result Cache, those could be used in many other cases too, so we don't really have any means to short circuit those checks. There might be gains to be had by checking the parse once rather than having to call contains_volatile_functions in the various places we do call it. I think both the parallel safety and volatile checks could then be done in the same tree traverse. Anyway. I've not done any hacking on this. It's just an idea so far. Does anyone have any particular thoughts on the planner slowdown? David
Вложения
On Mon, 15 Mar 2021 at 23:57, David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 12 Mar 2021 at 14:59, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > I'm -1 on doing it exactly that way, because you're expending > > the cost of those lookups without certainty that you need the answer. > > I had in mind something more like the way that we cache selectivity > > estimates in RestrictInfo, in which the value is cached when first > > demanded and then re-used on subsequent checks --- see in > > clause_selectivity_ext, around line 750. You do need a way for the > > field to have a "not known yet" value, but that's not hard. Moreover, > > this sort of approach can be less invasive than what you did here, > > because the caching behavior can be hidden inside > > contain_volatile_functions, rather than having all the call sites > > know about it explicitly. > > I coded up something more along the lines of what I think you had in > mind for the 0001 patch. I've now cleaned up the 0001 patch. I ended up changing a few places where we pass the RestrictInfo->clause to contain_volatile_functions() to instead pass the RestrictInfo itself so that there's a possibility of caching the volatility property for a subsequent call. I also made a pass over the remaining patches and for the 0004 patch, aside from the name, "Result Cache", I think that it's ready to go. We should consider before RC1 if we should have enable_resultcache switch on or off by default. Does anyone care to have a final look at these patches? I'd like to start pushing them fairly soon. David
Вложения
On Wed, 24 Mar 2021 at 00:42, David Rowley <dgrowleyml@gmail.com> wrote: > I've now cleaned up the 0001 patch. I ended up changing a few places > where we pass the RestrictInfo->clause to contain_volatile_functions() > to instead pass the RestrictInfo itself so that there's a possibility > of caching the volatility property for a subsequent call. > > I also made a pass over the remaining patches and for the 0004 patch, > aside from the name, "Result Cache", I think that it's ready to go. We > should consider before RC1 if we should have enable_resultcache switch > on or off by default. > > Does anyone care to have a final look at these patches? I'd like to > start pushing them fairly soon. I've now pushed the 0001 patch to cache the volatility of PathTarget and RestrictInfo. I'll be looking at the remaining patches over the next few days. Attached are a rebased set of patches on top of current master. The only change is to the 0003 patch (was 0004) which had an unstable regression test for parallel plan with a Result Cache. I've swapped the unstable test for something that shouldn't fail randomly depending on if a parallel worker did any work or not. David
Вложения
Hi,
For show_resultcache_info()
+ if (rcstate->shared_info != NULL)
+ {
+ {
The negated condition can be used with a return. This way, the loop can be unindented.
+ * ResultCache nodes are intended to sit above a parameterized node in the
+ * plan tree in order to cache results from them.
+ * plan tree in order to cache results from them.
Since the parameterized node is singular, it would be nice if 'them' can be expanded to refer to the source of result cache.
+ rcstate->mem_used -= freed_mem;
Should there be assertion that after the subtraction, mem_used stays non-negative ?
+ if (found && entry->complete)
+ {
+ node->stats.cache_hits += 1; /* stats update */
+ {
+ node->stats.cache_hits += 1; /* stats update */
Once inside the if block, we would return.
+ else
+ {
+ {
The else block can be unindented (dropping else keyword).
+ * return 1 row. XXX is this worth the check?
+ */
+ if (unlikely(entry->complete))
+ */
+ if (unlikely(entry->complete))
Since the check is on a flag (with minimal overhead), it seems the check can be kept, with the question removed.
Cheers
On Sun, Mar 28, 2021 at 7:21 PM David Rowley <dgrowleyml@gmail.com> wrote:
On Wed, 24 Mar 2021 at 00:42, David Rowley <dgrowleyml@gmail.com> wrote:
> I've now cleaned up the 0001 patch. I ended up changing a few places
> where we pass the RestrictInfo->clause to contain_volatile_functions()
> to instead pass the RestrictInfo itself so that there's a possibility
> of caching the volatility property for a subsequent call.
>
> I also made a pass over the remaining patches and for the 0004 patch,
> aside from the name, "Result Cache", I think that it's ready to go. We
> should consider before RC1 if we should have enable_resultcache switch
> on or off by default.
>
> Does anyone care to have a final look at these patches? I'd like to
> start pushing them fairly soon.
I've now pushed the 0001 patch to cache the volatility of PathTarget
and RestrictInfo.
I'll be looking at the remaining patches over the next few days.
Attached are a rebased set of patches on top of current master. The
only change is to the 0003 patch (was 0004) which had an unstable
regression test for parallel plan with a Result Cache. I've swapped
the unstable test for something that shouldn't fail randomly depending
on if a parallel worker did any work or not.
David
On Mon, 29 Mar 2021 at 15:56, Zhihong Yu <zyu@yugabyte.com> wrote:
> For show_resultcache_info()
>
> + if (rcstate->shared_info != NULL)
> + {
>
> The negated condition can be used with a return. This way, the loop can be unindented.
OK. I change that.
> + * ResultCache nodes are intended to sit above a parameterized node in the
> + * plan tree in order to cache results from them.
>
> Since the parameterized node is singular, it would be nice if 'them' can be expanded to refer to the source of result
cache.
I've done a bit of rewording in that paragraph.
> + rcstate->mem_used -= freed_mem;
>
> Should there be assertion that after the subtraction, mem_used stays non-negative ?
I'm not sure. I ended up adding one and also adjusting the #ifdef in
remove_cache_entry() which had some code to validate the memory
accounting so that it compiles when USE_ASSERT_CHECKING is defined.
I'm unsure if that's a bit too expensive to enable during debugs but I
didn't really want to leave the code in there unless it's going to get
some exercise on the buildfarm.
> + if (found && entry->complete)
> + {
> + node->stats.cache_hits += 1; /* stats update */
>
> Once inside the if block, we would return.
OK change.
> + else
> + {
> The else block can be unindented (dropping else keyword).
changed.
> + * return 1 row. XXX is this worth the check?
> + */
> + if (unlikely(entry->complete))
>
> Since the check is on a flag (with minimal overhead), it seems the check can be kept, with the question removed.
I changed the comment, but I did leave a mention that I'm still not
sure if it should be an Assert() or an elog.
The attached patch is an updated version of the Result Cache patch
containing the changes for the things you highlighted plus a few other
things.
I pushed the change to simplehash.h and the estimate_num_groups()
change earlier, so only 1 patch remaining.
Also, I noticed the CFBof found another unstable parallel regression
test. This was due to some code in show_resultcache_info() which
skipped parallel workers that appeared to not help out. It looks like
on my machine the worker never got a chance to do anything, but on one
of the CFbot's machines, it did. I ended up changing the EXPLAIN
output so that it shows the cache statistics regardless of if the
worker helped or not.
David
Вложения
Hi,
In paraminfo_get_equal_hashops(),
+ /* Reject if there are any volatile functions */
+ if (contain_volatile_functions(expr))
+ {
+ if (contain_volatile_functions(expr))
+ {
You can move the above code to just ahead of:
+ if (IsA(expr, Var))
+ var_relids = bms_make_singleton(((Var *) expr)->varno);
+ var_relids = bms_make_singleton(((Var *) expr)->varno);
This way, when we return early, var_relids doesn't need to be populated.
Cheers
On Tue, Mar 30, 2021 at 4:42 AM David Rowley <dgrowleyml@gmail.com> wrote:
On Mon, 29 Mar 2021 at 15:56, Zhihong Yu <zyu@yugabyte.com> wrote:
> For show_resultcache_info()
>
> + if (rcstate->shared_info != NULL)
> + {
>
> The negated condition can be used with a return. This way, the loop can be unindented.
OK. I change that.
> + * ResultCache nodes are intended to sit above a parameterized node in the
> + * plan tree in order to cache results from them.
>
> Since the parameterized node is singular, it would be nice if 'them' can be expanded to refer to the source of result cache.
I've done a bit of rewording in that paragraph.
> + rcstate->mem_used -= freed_mem;
>
> Should there be assertion that after the subtraction, mem_used stays non-negative ?
I'm not sure. I ended up adding one and also adjusting the #ifdef in
remove_cache_entry() which had some code to validate the memory
accounting so that it compiles when USE_ASSERT_CHECKING is defined.
I'm unsure if that's a bit too expensive to enable during debugs but I
didn't really want to leave the code in there unless it's going to get
some exercise on the buildfarm.
> + if (found && entry->complete)
> + {
> + node->stats.cache_hits += 1; /* stats update */
>
> Once inside the if block, we would return.
OK change.
> + else
> + {
> The else block can be unindented (dropping else keyword).
changed.
> + * return 1 row. XXX is this worth the check?
> + */
> + if (unlikely(entry->complete))
>
> Since the check is on a flag (with minimal overhead), it seems the check can be kept, with the question removed.
I changed the comment, but I did leave a mention that I'm still not
sure if it should be an Assert() or an elog.
The attached patch is an updated version of the Result Cache patch
containing the changes for the things you highlighted plus a few other
things.
I pushed the change to simplehash.h and the estimate_num_groups()
change earlier, so only 1 patch remaining.
Also, I noticed the CFBof found another unstable parallel regression
test. This was due to some code in show_resultcache_info() which
skipped parallel workers that appeared to not help out. It looks like
on my machine the worker never got a chance to do anything, but on one
of the CFbot's machines, it did. I ended up changing the EXPLAIN
output so that it shows the cache statistics regardless of if the
worker helped or not.
David
On Wed, 31 Mar 2021 at 05:34, Zhihong Yu <zyu@yugabyte.com> wrote:
>
> Hi,
> In paraminfo_get_equal_hashops(),
>
> + /* Reject if there are any volatile functions */
> + if (contain_volatile_functions(expr))
> + {
>
> You can move the above code to just ahead of:
>
> + if (IsA(expr, Var))
> + var_relids = bms_make_singleton(((Var *) expr)->varno);
>
> This way, when we return early, var_relids doesn't need to be populated.
Thanks for having another look. I did a bit more work in that area
and removed that code. I dug a little deeper and I can't see any way
that a lateral_var on a rel can refer to anything inside the rel. It
looks like that code was just a bit over paranoid about that.
I also added some additional caching in RestrictInfo to cache the hash
equality operator to use for the result cache. This saves checking
this each time we consider a join during the join search. In many
cases we would have used the value cached in
RestrictInfo.hashjoinoperator, however, for non-equaliy joins, that
would have be set to InvalidOid. We can still use Result Cache for
non-equality joins.
I've now pushed the main patch.
There's a couple of things I'm not perfectly happy with:
1. The name. There's a discussion on [1] if anyone wants to talk about that.
2. For lateral joins, there's no place to cache the hash equality
operator. Maybe there's some rework to do to add the ability to check
things for those like we use RestrictInfo for regular joins.
3. No ability to cache n_distinct estimates. This must be repeated
each time we consider a join. RestrictInfo allows caching for this to
speed up clauselist_selectivity() for other join types.
There was no consensus reached on the name of the node. "Tuple Cache"
seems like the favourite so far, but there's not been a great deal of
input. At least not enough that I was motivated to rename everything.
People will perhaps have more time to consider names during beta.
Thank you to everyone who gave input and reviewed this patch. It would
be great to get feedback on the performance with real workloads. As
mentioned in the commit message, there is a danger that it causes
performance regressions when n_distinct estimates are significantly
underestimated.
I'm off to look at the buildfarm now.
David
[1] https://www.postgresql.org/message-id/CAApHDvq=yQXr5kqhRviT2RhNKwToaWr9JAN5t+5_PzhuRJ3wvg@mail.gmail.com
On Thu, 1 Apr 2021 at 12:49, David Rowley <dgrowleyml@gmail.com> wrote: > I'm off to look at the buildfarm now. Well, it looks like the buildfarm didn't like the patch much. I had to revert the patch. It appears I overlooked some details in the EXPLAIN ANALYZE output when force_parallel_mode = regress is on. To make this work I had to change the EXPLAIN output so that it does not show the main process's cache Hit/Miss/Eviction details when there are zero misses. In the animals running force_parallel_mode = regress there was an additional line for the parallel worker containing the expected cache hits/misses/evictions as well as the one for the main process. The main process was not doing any work. I took inspiration from show_sort_info() which does not show the details for the main process when it did not help with the Sort. There was also an issue on florican [1] which appears to be due to that machine being 32-bit. I should have considered that when thinking of the cache eviction test. I originally tried to make the test as small as possible by lowering work_mem down to 64kB and only using enough rows to overflow that by a small amount. I think what's happening on florican is that due to all the pointer fields in the cache being 32-bits instead of 64-bits that more records fit into the cache and there are no evictions. I've scaled that test up a bit now to use 1200 rows instead of 800. The 32-bit machines also were reporting a different number of exact blocks in the bitmap heap scan. I've now just disabled bitmap scans for those tests. I've attached the updated patch. I'll let the CFbot grab this to ensure it's happy with it before I go looking to push it again. David [1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=florican&dt=2021-04-01%2000%3A28%3A12
Вложения
RE: Hybrid Hash/Nested Loop joins and caching results from subplans
От
"houzj.fnst@fujitsu.com"
Дата:
> I've attached the updated patch. I'll let the CFbot grab this to ensure it's
> happy with it before I go looking to push it again.
Hi,
I took a look into the patch and noticed some minor things.
1.
+ case T_ResultCache:
+ ptype = "ResultCache";
+ subpath = ((ResultCachePath *) path)->subpath;
+ break;
case T_UniquePath:
ptype = "Unique";
subpath = ((UniquePath *) path)->subpath;
should we use "case T_ResultCachePath" here?
2.
Is it better to add ResultCache's info to " src/backend/optimizer/README " ?
Something like:
NestPath - nested-loop joins
MergePath - merge joins
HashPath - hash joins
+ ResultCachePath - Result cache
Best regards,
Hou zhijie
On Thu, 1 Apr 2021 at 23:41, houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com> wrote: > > > I've attached the updated patch. I'll let the CFbot grab this to ensure it's > > happy with it before I go looking to push it again. > > Hi, > > I took a look into the patch and noticed some minor things. > > 1. > + case T_ResultCache: > + ptype = "ResultCache"; > + subpath = ((ResultCachePath *) path)->subpath; > + break; > case T_UniquePath: > ptype = "Unique"; > subpath = ((UniquePath *) path)->subpath; > should we use "case T_ResultCachePath" here? > > 2. > Is it better to add ResultCache's info to " src/backend/optimizer/README " ? > Something like: > NestPath - nested-loop joins > MergePath - merge joins > HashPath - hash joins > + ResultCachePath - Result cache Thanks for pointing those two things out. I've pushed the patch again with some updates to EXPLAIN to fix the issue from yesterday. I also disabled result cache in the partition_prune tests as I suspect that the parallel tests there might just be a bit too unstable in the buildfarm. The cache hit/miss/eviction line might disappear if the main process does not get a chance to do any work. Well, it's now time to watch the buildfarm again... David
On Fri, Mar 12, 2021 at 8:31 AM David Rowley <dgrowleyml@gmail.com> wrote:
Thanks for these suggestions.
On Mon, 22 Feb 2021 at 14:21, Justin Pryzby <pryzby@telsasoft.com> wrote:
>
> On Tue, Feb 16, 2021 at 11:15:51PM +1300, David Rowley wrote:
> > To summarise here, the planner performance gets a fair bit worse with
> > the patched code. With master, summing the average planning time over
> > each of the queries resulted in a total planning time of 765.7 ms.
> > After patching, that went up to 1097.5 ms. I was pretty disappointed
> > about that.
>
> I have a couple ideas;
I just checked the latest code, looks like we didn't improve this situation except
that we introduced a GUC to control it. Am I missing something? I don't have a
suggestion though.
> - default enable_resultcache=off seems okay. In plenty of cases, planning
> time is unimportant. This is the "low bar" - if we can do better and enable
> it by default, that's great.
I think that's reasonable. Teaching the planner to do new tricks is
never going to make the planner produce plans more quickly. When the
new planner trick gives us a more optimal plan, then great. When it
does not then it's wasted effort. Giving users the ability to switch
off the planner's new ability seems like a good way for people who
continually find it the additional effort costs more than it saves
seems like a good way to keep them happy.
> - Maybe this should be integrated into nestloop rather than being a separate
> plan node. That means that it could be dynamically enabled during
> execution, maybe after a few loops or after checking that there's at least
> some minimal number of repeated keys and cache hits. cost_nestloop would
> consider whether to use a result cache or not, and explain would show the
> cache stats as a part of nested loop. In this case, I propose there'd still
> be a GUC to disable it.
There was quite a bit of discussion on that topic already on this
thread. I don't really want to revisit that.
The main problem with that is that we'd be forced into costing a
Nested loop with a result cache exactly the same as we do for a plain
nested loop. If we were to lower the cost to account for the cache
hits then the planner is more likely to choose a nested loop over a
merge/hash join. If we then switched the caching off during execution
due to low cache hits then that does not magically fix the bad choice
of join method. The planner may have gone with a Hash Join if it had
known the cache hit ratio would be that bad. We'd still be left to
deal with the poor performing nested loop. What you'd really want
instead of turning the cache off would be to have nested loop ditch
the parameter scan and just morph itself into a Hash Join node. (I'm
not proposing we do that)
> - Maybe cost_resultcache() can be split into initial_cost and final_cost
> parts, same as for nestloop ? I'm not sure how it'd work, since
> initial_cost is supposed to return a lower bound, and resultcache tries to
> make things cheaper. initial_cost would just add some operator/tuple costs
> to make sure that resultcache of a unique scan is more expensive than
> nestloop alone. estimate_num_groups is at least O(n) WRT
> rcpath->param_exprs, so maybe you charge 100*list_length(param_exprs) *
> cpu_operator_cost in initial_cost and then call estimate_num_groups in
> final_cost. We'd be estimating the cost of estimating the cost...
The cost of the Result Cache is pretty dependant on the n_distinct
estimate. Low numbers of distinct values tend to estimate a high
number of cache hits, whereas large n_distinct values (relative to the
number of outer rows) is not going to estimate a large number of cache
hits.
I don't think feeding in a fake value would help us here. We'd
probably do better if we had a fast way to determine if a given Expr
is unique. (e.g UniqueKeys patch). Result Cache is never going to be
a win for a parameter that the value is never the same as some
previously seen value. This would likely allow us to skip considering
a Result Cache for the majority of OLTP type joins.
> - Maybe an initial implementation of this would only add a result cache if the
> best plan was already going to use a nested loop, even though a cached
> nested loop might be cheaper than other plans. This would avoid most
> planner costs, and give improved performance at execution time, but leaves
> something "on the table" for the future.
>
> > +cost_resultcache_rescan(PlannerInfo *root, ResultCachePath *rcpath,
> > + Cost *rescan_startup_cost, Cost *rescan_total_cost)
> > +{
> > + double tuples = rcpath->subpath->rows;
> > + double calls = rcpath->calls;
> ...
> > + /* estimate on the distinct number of parameter values */
> > + ndistinct = estimate_num_groups(root, rcpath->param_exprs, calls, NULL,
> > + &estinfo);
>
> Shouldn't this pass "tuples" and not "calls" ?
hmm. I don't think so. "calls" is the estimated number of outer side
rows. Here you're asking if the n_distinct estimate is relevant to
the inner side rows. It's not. If we expect to be called 1000 times by
the outer side of the nested loop, then we need to know our n_distinct
estimate for those 1000 rows. If the estimate comes back as 10
distinct values and we see that we're likely to be able to fit all the
tuples for those 10 distinct values in the cache, then the hit ratio
is going to come out at 99%. 10 misses, for the first time each value
is looked up and the remainder of the 990 calls will be hits. The
number of tuples (and the width of tuples) on the inside of the nested
loop is only relevant to calculating how many cache entries is likely
to fit into hash_mem. When we think cache entries will be evicted
then that makes the cache hit calculation more complex.
I've tried to explain what's going on in cost_resultcache_rescan() the
best I can with comments. I understand it's still pretty hard to
follow what's going on. I'm open to making it easier to understand if
you have suggestions.
David
Best Regards
Andy Fan (https://www.aliyun.com/)
On Wed, 26 May 2021 at 14:19, Andy Fan <zhihui.fan1213@gmail.com> wrote: > I just checked the latest code, looks like we didn't improve this situation except > that we introduced a GUC to control it. Am I missing something? I don't have a > suggestion though. Various extra caching was done to help speed it up. We now cache the volatility of RestrictInfo and PathTarget. I also added caching for the hash function in RestrictInfo so that we could more quickly determine if we can Result Cache or not. There's still a bit of caching left that I didn't do. This is around lateral_vars. I've nowhere to cache the hash function since that's just a list of vars. At the moment we need to check that each time we consider a result cache path. LATERAL joins are a bit less common so I didn't think that would be a huge issue. There's always enable_resultcache = off for people who cannot tolerate the overhead. Also, it's never going to be 100% as fast as it was. We're considering another path that we didn't consider before. Did you do some performance testing that caused you to bring this topic up? David