Обсуждение: Improving connection scalability: GetSnapshotData()
Hi,
I think postgres' issues with scaling to larger numbers of connections
is a serious problem in the field. While poolers can address some of
that, given the issues around prepared statements, transaction state,
etc, I don't think that's sufficient in many cases. It also adds
latency.
Nor do I think the argument that one shouldn't have more than a few
dozen connection holds particularly much water. As clients have think
time, and database results have to be sent/received (most clients don't
use pipelining), and as many applications have many application servers
with individual connection pools, it's very common to need more
connections than postgres can easily deal with.
The largest reason for that is GetSnapshotData(). It scales poorly to
larger connection counts. Part of that is obviously it's O(connections)
nature, but I always thought it had to be more. I've seen production
workloads spending > 98% of the cpu time n GetSnapshotData().
After a lot of analysis and experimentation I figured out that the
primary reason for this is PGXACT->xmin. Even the simplest transaction
modifies MyPgXact->xmin several times during its lifetime (IIRC twice
(snapshot & release) for exec_bind_message(), same for
exec_exec_message(), then again as part of EOXact processing). Which
means that a backend doing GetSnapshotData() on a system with a number
of other connections active, is very likely to hit PGXACT cachelines
that are owned by another cpu / set of cpus / socket. The larger the
system is, the worse the consequences of this are.
This problem is most prominent (and harder to fix) for xmin, but also
exists for the other fields in PGXACT. We rarely have xid, nxids,
overflow, or vacuumFlags set, yet constantly set them, leading to
cross-node traffic.
The second biggest problem is that the indirection through pgprocnos
that GetSnapshotData() has to do to go through to get each backend's
xmin is very unfriendly for a pipelined CPU (i.e. all that postgres runs
on). There's basically a stall at the end of every loop iteration -
which is exascerbated by there being so many cache misses.
It's fairly easy to avoid unnecessarily dirtying cachelines for all the
PGXACT fields except xmin. Because that actually needs to be visible to
other backends.
While it sounds almost trivial in hindsight, it took me a long while to
grasp a solution to a big part of this problem: We don't actually need
to look at PGXACT->xmin to compute a snapshot. The only reason that
GetSnapshotData() does so, is because it also computes
RecentGlobal[Data]Xmin.
But we don't actually need them all that frequently. They're primarily
used as a horizons for heap_page_prune_opt() etc. But for one, while
pruning is really important, it doesn't happen *all* the time. But more
importantly a RecentGlobalXmin from an earlier transaction is actually
sufficient for most pruning requests, especially when there is a larger
percentage of reading than updating transaction (very common).
By having GetSnapshotData() compute an accurate upper bound after which
we are certain not to be able to prune (basically the transaction's
xmin, slots horizons, etc), and a conservative lower bound below which
we are definitely able to prune, we can allow some pruning actions to
happen. If a pruning request (or something similar) encounters an xid
between those, an accurate lower bound can be computed.
That allows to avoid looking at PGXACT->xmin.
To address the second big problem (the indirection), we can instead pack
the contents of PGXACT tightly, just like we do for pgprocnos. In the
attached series, I introduced separate arrays for xids, vacuumFlags,
nsubxids.
The reason for splitting them is that they change at different rates,
and different sizes. In a read-mostly workload, most backends are not
going to have an xid, therefore making the xids array almost
constant. As long as all xids are unassigned, GetSnapshotData() doesn't
need to look at anything else, therefore making it sensible to check the
xid first.
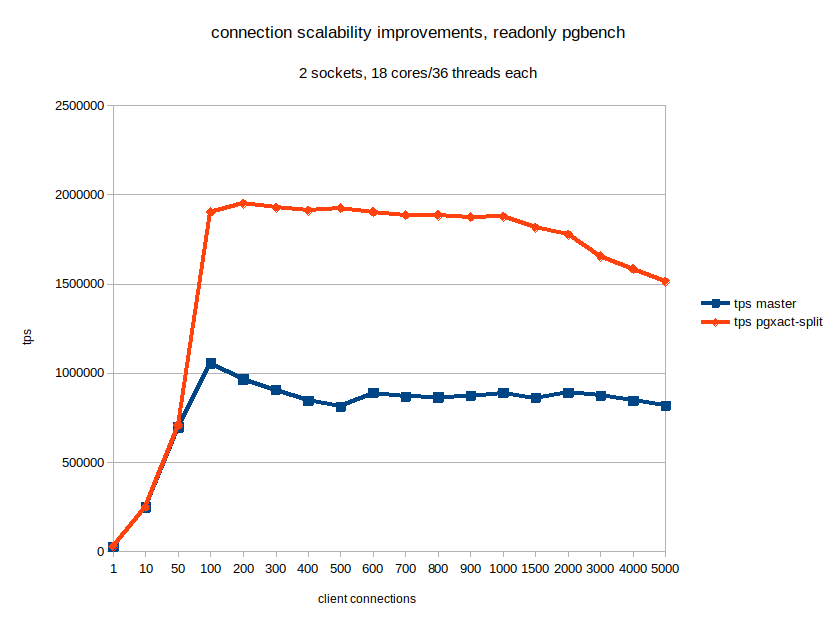
Here are some numbers for the submitted patch series. I'd to cull some
further improvements to make it more manageable, but I think the numbers
still are quite convincing.
The workload is a pgbench readonly, with pgbench -M prepared -c $conns
-j $conns -S -n for each client count. This is on a machine with 2
Intel(R) Xeon(R) Platinum 8168, but virtualized.
conns tps master tps pgxact-split
1 26842.492845 26524.194821
10 246923.158682 249224.782661
50 695956.539704 709833.746374
100 1054727.043139 1903616.306028
200 964795.282957 1949200.338012
300 906029.377539 1927881.231478
400 845696.690912 1911065.369776
500 812295.222497 1926237.255856
600 888030.104213 1903047.236273
700 866896.532490 1886537.202142
800 863407.341506 1883768.592610
900 871386.608563 1874638.012128
1000 887668.277133 1876402.391502
1500 860051.361395 1815103.564241
2000 890900.098657 1775435.271018
3000 874184.980039 1653953.817997
4000 845023.080703 1582582.316043
5000 817100.195728 1512260.802371
I think these are pretty nice results.
Note that the patchset currently does not implement snapshot_too_old,
the rest of the regression tests do pass.
One further cool recognition of the fact that GetSnapshotData()'s
results can be made to only depend on the set of xids in progress, is
that caching the results of GetSnapshotData() is almost trivial at that
point: We only need to recompute snapshots when a toplevel transaction
commits/aborts.
So we can avoid rebuilding snapshots when no commt has happened since it
was last built. Which amounts to assigning a current 'commit sequence
number' to the snapshot, and checking that against the current number
at the time of the next GetSnapshotData() call. Well, turns out there's
this "LSN" thing we assign to commits (there are some small issues with
that though). I've experimented with that, and it considerably further
improves the numbers above. Both with a higher peak throughput, but more
importantly it almost entirely removes the throughput regression from
2000 connections onwards.
I'm still working on cleaning that part of the patch up, I'll post it in
a bit.
The series currently consists out of:
0001-0005: Fixes and assert improvements that are independent of the patch, but
are hit by the new code (see also separate thread).
0006: Move delayChkpt from PGXACT to PGPROC it's rarely checked & frequently modified
0007: WIP: Introduce abstraction layer for "is tuple invisible" tests.
This is the most crucial piece. Instead of code directly using
RecentOldestXmin, there's a new set of functions for testing
whether an xid is visible (InvisibleToEveryoneTestXid() et al).
Those function use new horizon boundaries computed as part of
GetSnapshotData(), and recompute an accurate boundary when the
tested xid falls inbetween.
There's a bit more infrastructure needed - we need to limit how
often an accurate snapshot is computed. Probably to once per
snapshot? Or once per transaction?
To avoid issues with the lower boundary getting too old and
presenting a wraparound danger, I made all the xids be
FullTransactionIds. That imo is a good thing?
This patch currently breaks old_snapshot_threshold, as I've not
yet integrated it with the new functions. I think we can make the
old snapshot stuff a lot more precise with this - instead of
always triggering conflicts when a RecentGlobalXmin is too old, we
can do so only in the cases we actually remove a row. I ran out of
energy threading that through the heap_page_prune and
HeapTupleSatisfiesVacuum.
0008: Move PGXACT->xmin back to PGPROC.
Now that GetSnapshotData() doesn't access xmin anymore, we can
make it a normal field in PGPROC again.
0009: Improve GetSnapshotData() performance by avoiding indirection for xid access.
0010: Improve GetSnapshotData() performance by avoiding indirection for vacuumFlags
0011: Improve GetSnapshotData() performance by avoiding indirection for nsubxids access
These successively move the remaining PGXACT fields into separate
arrays in ProcGlobal, and adjust GetSnapshotData() to take
advantage. Those arrays are dense in the sense that they only
contain data for PGPROCs that are in use (i.e. when disconnecting,
the array is moved around)..
I think xid, and vacuumFlags are pretty reasonable. But need
cleanup, obviously:
- The biggest cleanup would be to add a few helper functions for
accessing the values, rather than open coding that.
- Perhaps we should call the ProcGlobal ones 'cached', and name
the PGPROC ones as the one true source of truth?
For subxid I thought it'd be nice to have nxids and overflow be
only one number. But that probably was the wrong call? Now
TransactionIdInProgress() cannot look at at the subxids that did
fit in PGPROC.subxid. I'm not sure that's important, given the
likelihood of misses? But I'd probably still have the subxid
array be one of {uint8 nsubxids; bool overflowed} instead.
To keep the arrays dense they copy the logic for pgprocnos. Which
means that ProcArrayAdd/Remove move things around. Unfortunately
that requires holding both ProcArrayLock and XidGenLock currently
(to avoid GetNewTransactionId() having to hold ProcArrayLock). But
that doesn't seem too bad?
0012: Remove now unused PGXACT.
There's no reason to have it anymore.
The patchseries is also available at
https://github.com/anarazel/postgres/tree/pgxact-split
Greetings,
Andres Freund
Вложения
- v1-0001-WIP-Ensure-snapshot-is-registered-within-ScanPgRe.patch.gz
- v1-0002-TMP-work-around-missing-snapshot-registrations.patch.gz
- v1-0003-TMP-don-t-build-snapshot_too_old-module-it-s-curr.patch.gz
- v1-0004-Improve-and-extend-asserts-for-a-snapshot-being-s.patch.gz
- v1-0005-Fix-unlikely-xid-wraparound-issue-in-heap_abort_s.patch.gz
- v1-0006-Move-delayChkpt-from-PGXACT-to-PGPROC-it-s-rarely.patch.gz
- v1-0007-WIP-Introduce-abstraction-layer-for-is-tuple-invi.patch.gz
- v1-0008-Move-PGXACT-xmin-back-to-PGPROC.patch.gz
- v1-0009-Improve-GetSnapshotData-performance-by-avoiding-i.patch.gz
- v1-0010-Improve-GetSnapshotData-performance-by-avoiding-i.patch.gz
- v1-0011-Improve-GetSnapshotData-performance-by-avoiding-i.patch.gz
- v1-0012-Remove-now-unused-PGXACT.patch.gz
Hi, On 2020-03-01 00:36:01 -0800, Andres Freund wrote: > conns tps master tps pgxact-split > > 1 26842.492845 26524.194821 > 10 246923.158682 249224.782661 > 50 695956.539704 709833.746374 > 100 1054727.043139 1903616.306028 > 200 964795.282957 1949200.338012 > 300 906029.377539 1927881.231478 > 400 845696.690912 1911065.369776 > 500 812295.222497 1926237.255856 > 600 888030.104213 1903047.236273 > 700 866896.532490 1886537.202142 > 800 863407.341506 1883768.592610 > 900 871386.608563 1874638.012128 > 1000 887668.277133 1876402.391502 > 1500 860051.361395 1815103.564241 > 2000 890900.098657 1775435.271018 > 3000 874184.980039 1653953.817997 > 4000 845023.080703 1582582.316043 > 5000 817100.195728 1512260.802371 > > I think these are pretty nice results. Attached as a graph as well.
Вложения
{kind=link}
On Sun, Mar 1, 2020 at 2:17 PM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2020-03-01 00:36:01 -0800, Andres Freund wrote: > > conns tps master tps pgxact-split > > > > 1 26842.492845 26524.194821 > > 10 246923.158682 249224.782661 > > 50 695956.539704 709833.746374 > > 100 1054727.043139 1903616.306028 > > 200 964795.282957 1949200.338012 > > 300 906029.377539 1927881.231478 > > 400 845696.690912 1911065.369776 > > 500 812295.222497 1926237.255856 > > 600 888030.104213 1903047.236273 > > 700 866896.532490 1886537.202142 > > 800 863407.341506 1883768.592610 > > 900 871386.608563 1874638.012128 > > 1000 887668.277133 1876402.391502 > > 1500 860051.361395 1815103.564241 > > 2000 890900.098657 1775435.271018 > > 3000 874184.980039 1653953.817997 > > 4000 845023.080703 1582582.316043 > > 5000 817100.195728 1512260.802371 > > > > I think these are pretty nice results. > Nice improvement. +1 for improving the scalability for higher connection count. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
Hi, On 2020-03-01 00:36:01 -0800, Andres Freund wrote: > Here are some numbers for the submitted patch series. I'd to cull some > further improvements to make it more manageable, but I think the numbers > still are quite convincing. > > The workload is a pgbench readonly, with pgbench -M prepared -c $conns > -j $conns -S -n for each client count. This is on a machine with 2 > Intel(R) Xeon(R) Platinum 8168, but virtualized. > > conns tps master tps pgxact-split > > 1 26842.492845 26524.194821 > 10 246923.158682 249224.782661 > 50 695956.539704 709833.746374 > 100 1054727.043139 1903616.306028 > 200 964795.282957 1949200.338012 > 300 906029.377539 1927881.231478 > 400 845696.690912 1911065.369776 > 500 812295.222497 1926237.255856 > 600 888030.104213 1903047.236273 > 700 866896.532490 1886537.202142 > 800 863407.341506 1883768.592610 > 900 871386.608563 1874638.012128 > 1000 887668.277133 1876402.391502 > 1500 860051.361395 1815103.564241 > 2000 890900.098657 1775435.271018 > 3000 874184.980039 1653953.817997 > 4000 845023.080703 1582582.316043 > 5000 817100.195728 1512260.802371 > > I think these are pretty nice results. > One further cool recognition of the fact that GetSnapshotData()'s > results can be made to only depend on the set of xids in progress, is > that caching the results of GetSnapshotData() is almost trivial at that > point: We only need to recompute snapshots when a toplevel transaction > commits/aborts. > > So we can avoid rebuilding snapshots when no commt has happened since it > was last built. Which amounts to assigning a current 'commit sequence > number' to the snapshot, and checking that against the current number > at the time of the next GetSnapshotData() call. Well, turns out there's > this "LSN" thing we assign to commits (there are some small issues with > that though). I've experimented with that, and it considerably further > improves the numbers above. Both with a higher peak throughput, but more > importantly it almost entirely removes the throughput regression from > 2000 connections onwards. > > I'm still working on cleaning that part of the patch up, I'll post it in > a bit. I triggered a longer run on the same hardware, that also includes numbers for the caching patch. nclients master pgxact-split pgxact-split-cache 1 29742.805074 29086.874404 28120.709885 2 58653.005921 56610.432919 57343.937924 3 116580.383993 115102.94057 117512.656103 4 150821.023662 154130.354635 152053.714824 5 186679.754357 189585.156519 191095.841847 6 219013.756252 223053.409306 224480.026711 7 256861.673892 256709.57311 262427.179555 8 291495.547691 294311.524297 296245.219028 9 332835.641015 333223.666809 335460.280487 10 367883.74842 373562.206447 375682.894433 15 561008.204553 578601.577916 587542.061911 20 748000.911053 794048.140682 810964.700467 25 904581.660543 1037279.089703 1043615.577083 30 999231.007768 1251113.123461 1288276.726489 35 1001274.289847 1438640.653822 1438508.432425 40 991672.445199 1518100.079695 1573310.171868 45 994427.395069 1575758.31948 1649264.339117 50 1017561.371878 1654776.716703 1715762.303282 60 993943.210188 1720318.989894 1789698.632656 70 971379.995255 1729836.303817 1819477.25356 80 966276.137538 1744019.347399 1842248.57152 90 901175.211649 1768907.069263 1847823.970726 100 803175.74326 1784636.397822 1865795.782943 125 664438.039582 1806275.514545 1870983.64688 150 623562.201749 1796229.009658 1876529.428419 175 680683.150597 1809321.487338 1910694.40987 200 668413.988251 1833457.942035 1878391.674828 225 682786.299485 1816577.462613 1884587.77743 250 727308.562076 1825796.324814 1864692.025853 275 676295.999761 1843098.107926 1908698.584573 300 698831.398432 1832068.168744 1892735.290045 400 661534.639489 1859641.983234 1898606.247281 500 645149.788352 1851124.475202 1888589.134422 600 740636.323211 1875152.669115 1880653.747185 700 858645.363292 1833527.505826 1874627.969414 800 858287.957814 1841914.668668 1892106.319085 900 882204.933544 1850998.221969 1868260.041595 1000 910988.551206 1836336.091652 1862945.18557 1500 917727.92827 1808822.338465 1864150.00307 2000 982137.053108 1813070.209217 1877104.342864 3000 1013514.639108 1753026.733843 1870416.924248 4000 1025476.80688 1600598.543635 1859908.314496 5000 1019889.160511 1534501.389169 1870132.571895 7500 968558.864242 1352137.828569 1853825.376742 10000 887558.112017 1198321.352461 1867384.381886 15000 687766.593628 950788.434914 1710509.977169 The odd dip for master between 90 and 700 connections looks like it's not directly related to GetSnapshotData(). It looks like it's related to the linux scheduler and virtiualization. When a pgbench thread and postgres backend need to swap who gets executed, and both are on different CPUs, the wakeup is more expensive when the target CPU is idle or isn't going to reschedule soon. In the expensive path a inter-process-interrupt (IPI) gets triggered, which requires to exit out of the VM (which is really expensive on azure, apparently). I can trigger similar behaviour for the other runs by renicing, albeit on a slightly smaller scale. I'll try to find a larger system that's not virtualized :/. Greetings, Andres Freund
Вложения
{kind=link}
On 3/1/20 3:36 AM, Andres Freund wrote: > > I think these are pretty nice results. Indeed they are. Is the target version PG13 or PG14? It seems like a pretty big patch to go in the last commitfest for PG13. Regards, -- -David david@pgmasters.net
Hi, Nice performance gains. On Sun, 1 Mar 2020 at 21:36, Andres Freund <andres@anarazel.de> wrote: > The series currently consists out of: > > 0001-0005: Fixes and assert improvements that are independent of the patch, but > are hit by the new code (see also separate thread). > > 0006: Move delayChkpt from PGXACT to PGPROC it's rarely checked & frequently modified > > 0007: WIP: Introduce abstraction layer for "is tuple invisible" tests. > > This is the most crucial piece. Instead of code directly using > RecentOldestXmin, there's a new set of functions for testing > whether an xid is visible (InvisibleToEveryoneTestXid() et al). > > Those function use new horizon boundaries computed as part of > GetSnapshotData(), and recompute an accurate boundary when the > tested xid falls inbetween. > > There's a bit more infrastructure needed - we need to limit how > often an accurate snapshot is computed. Probably to once per > snapshot? Or once per transaction? > > > To avoid issues with the lower boundary getting too old and > presenting a wraparound danger, I made all the xids be > FullTransactionIds. That imo is a good thing? > > > This patch currently breaks old_snapshot_threshold, as I've not > yet integrated it with the new functions. I think we can make the > old snapshot stuff a lot more precise with this - instead of > always triggering conflicts when a RecentGlobalXmin is too old, we > can do so only in the cases we actually remove a row. I ran out of > energy threading that through the heap_page_prune and > HeapTupleSatisfiesVacuum. > > > 0008: Move PGXACT->xmin back to PGPROC. > > Now that GetSnapshotData() doesn't access xmin anymore, we can > make it a normal field in PGPROC again. > > > 0009: Improve GetSnapshotData() performance by avoiding indirection for xid access. I've only looked at 0001-0009 so far. I'm not quite the expert in this area, so the review feels a bit superficial. Here's what I noted down during my pass. 0001 1. cant't -> can't * snapshot cant't change in the midst of a relcache build, so there's no 0002 2. I don't quite understand your change in UpdateSubscriptionRelState(). snap seems unused. Drilling down into SearchSysCacheCopy2, in SearchCatCacheMiss() the systable_beginscan() passes a NULL snapshot. the whole patch does this. I guess I don't understand why 0002 does this. 0004 3. This comment seems to have the line order swapped in bt_check_every_level /* * RecentGlobalXmin/B-Tree page deletion. * This assertion matches the one in index_getnext_tid(). See note on */ Assert(SnapshotSet()); 0006 4. Did you consider the location of 'delayChkpt' in PGPROC. Couldn't you slot it in somewhere it would fit in existing padding? 0007 5. GinPageIsRecyclable() has no comments at all. I know that ginvacuum.c is not exactly the modal citizen for function header comments, but likely this patch is no good reason to continue the trend. 6. The comment rearrangement in bt_check_every_level should be in the 0004 patch. 7. struct InvisibleToEveryoneState could do with some comments explaining the fields. 8. The header comment in GetOldestXminInt needs to be updated. It talks about "if rel = NULL and there are no transactions", but there's no parameter by that name now. Maybe the whole comment should be moved down to the external implementation of the function 9. I get the idea you don't intend to keep the debug message in InvisibleToEveryoneTestFullXid(), but if you do, then shouldn't it be using UINT64_FORMAT? 10. teh -> the * which is based on teh value computed when getting the current snapshot. 11. InvisibleToEveryoneCheckXid and InvisibleToEveryoneCheckFullXid seem to have their extern modifiers in the .c file. 0009 12. iare -> are * These iare separate from the main PGPROC array so that the most heavily 13. is -> are * accessed data is stored contiguously in memory in as few cache lines as 14. It doesn't seem to quite make sense to talk about "this proc" in: /* * TransactionId of top-level transaction currently being executed by this * proc, if running and XID is assigned; else InvalidTransactionId. * * Each PGPROC has a copy of its value in PGPROC.xidCopy. */ TransactionId *xids; maybe "this" can be replaced with "each" I will try to continue with the remaining patches soon. However, it would be good to get a more complete patchset. I feel there are quite a few XXX comments remaining for things you need to think about later, and ... it's getting late.
On Sun, Mar 1, 2020 at 9:36 PM Andres Freund <andres@anarazel.de> wrote:
> conns tps master tps pgxact-split
>
> 1 26842.492845 26524.194821
> 10 246923.158682 249224.782661
> 50 695956.539704 709833.746374
> 100 1054727.043139 1903616.306028
> 200 964795.282957 1949200.338012
> 300 906029.377539 1927881.231478
> 400 845696.690912 1911065.369776
> 500 812295.222497 1926237.255856
> 600 888030.104213 1903047.236273
> 700 866896.532490 1886537.202142
> 800 863407.341506 1883768.592610
> 900 871386.608563 1874638.012128
> 1000 887668.277133 1876402.391502
> 1500 860051.361395 1815103.564241
> 2000 890900.098657 1775435.271018
> 3000 874184.980039 1653953.817997
> 4000 845023.080703 1582582.316043
> 5000 817100.195728 1512260.802371
This will clearly be really big news for lots of PostgreSQL users.
> One further cool recognition of the fact that GetSnapshotData()'s
> results can be made to only depend on the set of xids in progress, is
> that caching the results of GetSnapshotData() is almost trivial at that
> point: We only need to recompute snapshots when a toplevel transaction
> commits/aborts.
>
> So we can avoid rebuilding snapshots when no commt has happened since it
> was last built. Which amounts to assigning a current 'commit sequence
> number' to the snapshot, and checking that against the current number
> at the time of the next GetSnapshotData() call. Well, turns out there's
> this "LSN" thing we assign to commits (there are some small issues with
> that though). I've experimented with that, and it considerably further
> improves the numbers above. Both with a higher peak throughput, but more
> importantly it almost entirely removes the throughput regression from
> 2000 connections onwards.
>
> I'm still working on cleaning that part of the patch up, I'll post it in
> a bit.
I looked at that part on your public pgxact-split branch. In that
version you used "CSN" rather than something based on LSNs, which I
assume avoids complications relating to WAL locking or something like
that. We should probably be careful to avoid confusion with the
pre-existing use of the term "commit sequence number" (CommitSeqNo,
CSN) that appears in predicate.c. This also calls to mind the
2013-2016 work by Ants Aasma and others[1] on CSN-based snapshots,
which is obviously a much more radical change, but really means what
it says (commits). The CSN in your patch set is used purely as a
level-change for snapshot cache invalidation IIUC, and it advances
also for aborts -- so maybe it should be called something like
completed_xact_count, using existing terminology from procarray.c.
+ if (snapshot->csn != 0 && MyProc->xidCopy == InvalidTransactionId &&
+ UINT64_ACCESS_ONCE(ShmemVariableCache->csn) == snapshot->csn)
Why is it OK to read ShmemVariableCache->csn without at least a read
barrier? I suppose this allows a cached snapshot to be used very soon
after a transaction commits and should be visible to you, but ...
hmmmrkwjherkjhg... I guess it must be really hard to observe any
anomaly. Let's see... maybe it's possible on a relaxed memory system
like POWER or ARM, if you use a shm flag to say "hey I just committed
a transaction", and the other guy sees the flag but can't yet see the
new CSN, so an SPI query can't see the transaction?
Another theoretical problem is the non-atomic read of a uint64 on some
32 bit platforms.
> 0007: WIP: Introduce abstraction layer for "is tuple invisible" tests.
>
> This is the most crucial piece. Instead of code directly using
> RecentOldestXmin, there's a new set of functions for testing
> whether an xid is visible (InvisibleToEveryoneTestXid() et al).
>
> Those function use new horizon boundaries computed as part of
> GetSnapshotData(), and recompute an accurate boundary when the
> tested xid falls inbetween.
>
> There's a bit more infrastructure needed - we need to limit how
> often an accurate snapshot is computed. Probably to once per
> snapshot? Or once per transaction?
>
>
> To avoid issues with the lower boundary getting too old and
> presenting a wraparound danger, I made all the xids be
> FullTransactionIds. That imo is a good thing?
+1, as long as we don't just move the wraparound danger to the places
where we convert xids to fxids!
+/*
+ * Be very careful about when to use this function. It can only safely be used
+ * when there is a guarantee that, at the time of the call, xid is within 2
+ * billion xids of rel. That e.g. can be guaranteed if the the caller assures
+ * a snapshot is held by the backend, and xid is from a table (where
+ * vacuum/freezing ensures the xid has to be within that range).
+ */
+static inline FullTransactionId
+FullXidViaRelative(FullTransactionId rel, TransactionId xid)
+{
+ uint32 rel_epoch = EpochFromFullTransactionId(rel);
+ TransactionId rel_xid = XidFromFullTransactionId(rel);
+ uint32 epoch;
+
+ /*
+ * TODO: A function to easily write an assertion ensuring that xid is
+ * between [oldestXid, nextFullXid) woudl be useful here, and in plenty
+ * other places.
+ */
+
+ if (xid > rel_xid)
+ epoch = rel_epoch - 1;
+ else
+ epoch = rel_epoch;
+
+ return FullTransactionIdFromEpochAndXid(epoch, xid);
+}
I hate it, but I don't have a better concrete suggestion right now.
Whatever I come up with amounts to the same thing on some level,
though I feel like it might be better to used an infrequently updated
oldestFxid as the lower bound in a conversion. An upper bound would
also seem better, though requires much trickier interlocking. What
you have means "it's near here!"... isn't that too prone to bugs that
are hidden because of the ambient fuzziness? A lower bound seems like
it could move extremely infrequently and therefore it'd be OK for it
to be protected by both proc array and xid gen locks (ie it'd be
recomputed when nextFxid needs to move too far ahead of it, so every
~2 billion xacts). I haven't looked at this long enough to have a
strong opinion, though.
On a more constructive note:
GetOldestXminInt() does:
LWLockAcquire(ProcArrayLock, LW_SHARED);
+ nextfxid = ShmemVariableCache->nextFullXid;
+
...
LWLockRelease(ProcArrayLock);
...
+ return FullXidViaRelative(nextfxid, result);
But nextFullXid is protected by XidGenLock; maybe that's OK from a
data freshness point of view (I'm not sure), but from an atomicity
point of view, you can't do that can you?
> This patch currently breaks old_snapshot_threshold, as I've not
> yet integrated it with the new functions. I think we can make the
> old snapshot stuff a lot more precise with this - instead of
> always triggering conflicts when a RecentGlobalXmin is too old, we
> can do so only in the cases we actually remove a row. I ran out of
> energy threading that through the heap_page_prune and
> HeapTupleSatisfiesVacuum.
CCing Kevin as an FYI.
> 0008: Move PGXACT->xmin back to PGPROC.
>
> Now that GetSnapshotData() doesn't access xmin anymore, we can
> make it a normal field in PGPROC again.
>
>
> 0009: Improve GetSnapshotData() performance by avoiding indirection for xid access.
> 0010: Improve GetSnapshotData() performance by avoiding indirection for vacuumFlags
> 0011: Improve GetSnapshotData() performance by avoiding indirection for nsubxids access
>
> These successively move the remaining PGXACT fields into separate
> arrays in ProcGlobal, and adjust GetSnapshotData() to take
> advantage. Those arrays are dense in the sense that they only
> contain data for PGPROCs that are in use (i.e. when disconnecting,
> the array is moved around)..
>
> I think xid, and vacuumFlags are pretty reasonable. But need
> cleanup, obviously:
> - The biggest cleanup would be to add a few helper functions for
> accessing the values, rather than open coding that.
> - Perhaps we should call the ProcGlobal ones 'cached', and name
> the PGPROC ones as the one true source of truth?
>
> For subxid I thought it'd be nice to have nxids and overflow be
> only one number. But that probably was the wrong call? Now
> TransactionIdInProgress() cannot look at at the subxids that did
> fit in PGPROC.subxid. I'm not sure that's important, given the
> likelihood of misses? But I'd probably still have the subxid
> array be one of {uint8 nsubxids; bool overflowed} instead.
>
>
> To keep the arrays dense they copy the logic for pgprocnos. Which
> means that ProcArrayAdd/Remove move things around. Unfortunately
> that requires holding both ProcArrayLock and XidGenLock currently
> (to avoid GetNewTransactionId() having to hold ProcArrayLock). But
> that doesn't seem too bad?
In the places where you now acquire both, I guess you also need to
release both in the error path?
[1]
https://www.postgresql.org/message-id/flat/CA%2BCSw_tEpJ%3Dmd1zgxPkjH6CWDnTDft4gBi%3D%2BP9SnoC%2BWy3pKdA%40mail.gmail.com
Hi,
Thanks for looking!
On 2020-03-20 18:23:03 +1300, Thomas Munro wrote:
> On Sun, Mar 1, 2020 at 9:36 PM Andres Freund <andres@anarazel.de> wrote:
> > I'm still working on cleaning that part of the patch up, I'll post it in
> > a bit.
>
> I looked at that part on your public pgxact-split branch. In that
> version you used "CSN" rather than something based on LSNs, which I
> assume avoids complications relating to WAL locking or something like
> that.
Right, I first tried to use LSNs, but after further tinkering found that
it's too hard to address the difference between visiblity order and LSN
order. I don't think there's an easy way to address the difference.
> We should probably be careful to avoid confusion with the
> pre-existing use of the term "commit sequence number" (CommitSeqNo,
> CSN) that appears in predicate.c.
I looked at that after you mentioned it on IM. But I find it hard to
grok what it's precisely defined at. There's basically no comments
explaining what it's really supposed to do, and I find the relevant code
far from easy to grok :(.
> This also calls to mind the 2013-2016 work by Ants Aasma and others[1]
> on CSN-based snapshots, which is obviously a much more radical change,
> but really means what it says (commits).
Well, I think you could actually build some form of more dense snapshots
ontop of "my" CSN, with a bit of effort (and lot of handwaving). I don't
think they're that different concepts.
> The CSN in your patch set is used purely as a level-change for
> snapshot cache invalidation IIUC, and it advances also for aborts --
> so maybe it should be called something like completed_xact_count,
> using existing terminology from procarray.c.
I expect it to be used outside of snapshots too, in the future, FWIW.
completed_xact_count sounds good to me.
> + if (snapshot->csn != 0 && MyProc->xidCopy == InvalidTransactionId &&
> + UINT64_ACCESS_ONCE(ShmemVariableCache->csn) == snapshot->csn)
>
> Why is it OK to read ShmemVariableCache->csn without at least a read
> barrier? I suppose this allows a cached snapshot to be used very soon
> after a transaction commits and should be visible to you, but ...
> hmmmrkwjherkjhg... I guess it must be really hard to observe any
> anomaly. Let's see... maybe it's possible on a relaxed memory system
> like POWER or ARM, if you use a shm flag to say "hey I just committed
> a transaction", and the other guy sees the flag but can't yet see the
> new CSN, so an SPI query can't see the transaction?
Yea, it does need more thought / comments. I can't really see an actual
correctness violation though. As far as I can tell you'd never be able
to get an "older" ShmemVariableCache->csn than one since *after* the
last lock acquired/released by the current backend - which then also
means a different "ordering" would have been possible allowing the
current backend to take the snapshot earlier.
> Another theoretical problem is the non-atomic read of a uint64 on some
> 32 bit platforms.
Yea, it probably should be a pg_atomic_uint64 to address that. I don't
think it really would cause problems, because I think it'd always end up
causing an unnecessary snapshot build. But there's no need to go there.
> > 0007: WIP: Introduce abstraction layer for "is tuple invisible" tests.
> >
> > This is the most crucial piece. Instead of code directly using
> > RecentOldestXmin, there's a new set of functions for testing
> > whether an xid is visible (InvisibleToEveryoneTestXid() et al).
> >
> > Those function use new horizon boundaries computed as part of
> > GetSnapshotData(), and recompute an accurate boundary when the
> > tested xid falls inbetween.
> >
> > There's a bit more infrastructure needed - we need to limit how
> > often an accurate snapshot is computed. Probably to once per
> > snapshot? Or once per transaction?
> >
> >
> > To avoid issues with the lower boundary getting too old and
> > presenting a wraparound danger, I made all the xids be
> > FullTransactionIds. That imo is a good thing?
>
> +1, as long as we don't just move the wraparound danger to the places
> where we convert xids to fxids!
>
> +/*
> + * Be very careful about when to use this function. It can only safely be used
> + * when there is a guarantee that, at the time of the call, xid is within 2
> + * billion xids of rel. That e.g. can be guaranteed if the the caller assures
> + * a snapshot is held by the backend, and xid is from a table (where
> + * vacuum/freezing ensures the xid has to be within that range).
> + */
> +static inline FullTransactionId
> +FullXidViaRelative(FullTransactionId rel, TransactionId xid)
> +{
> + uint32 rel_epoch = EpochFromFullTransactionId(rel);
> + TransactionId rel_xid = XidFromFullTransactionId(rel);
> + uint32 epoch;
> +
> + /*
> + * TODO: A function to easily write an assertion ensuring that xid is
> + * between [oldestXid, nextFullXid) woudl be useful here, and in plenty
> + * other places.
> + */
> +
> + if (xid > rel_xid)
> + epoch = rel_epoch - 1;
> + else
> + epoch = rel_epoch;
> +
> + return FullTransactionIdFromEpochAndXid(epoch, xid);
> +}
>
> I hate it, but I don't have a better concrete suggestion right now.
> Whatever I come up with amounts to the same thing on some level,
> though I feel like it might be better to used an infrequently updated
> oldestFxid as the lower bound in a conversion.
I am not sure it's as clearly correct to use oldestFxid in as many
cases. Normally PGPROC->xmin (PGXACT->xmin currently) should prevent the
"system wide" xid horizon to move too far relative to that, but I think
there are more plausible problems with the "oldest" xid horizon to move
concurrently with the a backend inspecting values.
It shouldn't be a problem here since the values are taken under a lock
preventing both from being moved I think, and since we're only comparing
those two values without taking anything else into account, the "global"
horizon changing concurrently wouldn't matter.
But it seems easier to understand the correctness when comparing to
nextXid?
What's the benefit of looking at an "infrequently updated" value
instead? I guess you can argue that it'd be more likely to be in cache,
but since all of this lives in a single cacheline...
> An upper bound would also seem better, though requires much trickier
> interlocking. What you have means "it's near here!"... isn't that too
> prone to bugs that are hidden because of the ambient fuzziness?
I can't follow the last sentence. Could you expand?
> On a more constructive note:
>
> GetOldestXminInt() does:
>
> LWLockAcquire(ProcArrayLock, LW_SHARED);
>
> + nextfxid = ShmemVariableCache->nextFullXid;
> +
> ...
> LWLockRelease(ProcArrayLock);
> ...
> + return FullXidViaRelative(nextfxid, result);
>
> But nextFullXid is protected by XidGenLock; maybe that's OK from a
> data freshness point of view (I'm not sure), but from an atomicity
> point of view, you can't do that can you?
Hm. Yea, I think it's not safe against torn 64bit reads, you're right.
> > This patch currently breaks old_snapshot_threshold, as I've not
> > yet integrated it with the new functions. I think we can make the
> > old snapshot stuff a lot more precise with this - instead of
> > always triggering conflicts when a RecentGlobalXmin is too old, we
> > can do so only in the cases we actually remove a row. I ran out of
> > energy threading that through the heap_page_prune and
> > HeapTupleSatisfiesVacuum.
>
> CCing Kevin as an FYI.
If anybody has an opinion on this sketch I'd be interested. I've started
to implement it, so ...
> > 0008: Move PGXACT->xmin back to PGPROC.
> >
> > Now that GetSnapshotData() doesn't access xmin anymore, we can
> > make it a normal field in PGPROC again.
> >
> >
> > 0009: Improve GetSnapshotData() performance by avoiding indirection for xid access.
> > 0010: Improve GetSnapshotData() performance by avoiding indirection for vacuumFlags
> > 0011: Improve GetSnapshotData() performance by avoiding indirection for nsubxids access
> >
> > These successively move the remaining PGXACT fields into separate
> > arrays in ProcGlobal, and adjust GetSnapshotData() to take
> > advantage. Those arrays are dense in the sense that they only
> > contain data for PGPROCs that are in use (i.e. when disconnecting,
> > the array is moved around)..
> >
> > I think xid, and vacuumFlags are pretty reasonable. But need
> > cleanup, obviously:
> > - The biggest cleanup would be to add a few helper functions for
> > accessing the values, rather than open coding that.
> > - Perhaps we should call the ProcGlobal ones 'cached', and name
> > the PGPROC ones as the one true source of truth?
> >
> > For subxid I thought it'd be nice to have nxids and overflow be
> > only one number. But that probably was the wrong call? Now
> > TransactionIdInProgress() cannot look at at the subxids that did
> > fit in PGPROC.subxid. I'm not sure that's important, given the
> > likelihood of misses? But I'd probably still have the subxid
> > array be one of {uint8 nsubxids; bool overflowed} instead.
> >
> >
> > To keep the arrays dense they copy the logic for pgprocnos. Which
> > means that ProcArrayAdd/Remove move things around. Unfortunately
> > that requires holding both ProcArrayLock and XidGenLock currently
> > (to avoid GetNewTransactionId() having to hold ProcArrayLock). But
> > that doesn't seem too bad?
>
> In the places where you now acquire both, I guess you also need to
> release both in the error path?
Hm. I guess you mean:
if (arrayP->numProcs >= arrayP->maxProcs)
{
/*
* Oops, no room. (This really shouldn't happen, since there is a
* fixed supply of PGPROC structs too, and so we should have failed
* earlier.)
*/
LWLockRelease(ProcArrayLock);
ereport(FATAL,
(errcode(ERRCODE_TOO_MANY_CONNECTIONS),
errmsg("sorry, too many clients already")));
}
I think we should just remove the LWLockRelease? At this point we
already have set up ProcKill(), which would release all lwlocks after
the error was thrown?
Greetings,
Andres Freund
Hi, On 2020-03-17 23:59:14 +1300, David Rowley wrote: > Nice performance gains. Thanks. > On Sun, 1 Mar 2020 at 21:36, Andres Freund <andres@anarazel.de> wrote: > 2. I don't quite understand your change in > UpdateSubscriptionRelState(). snap seems unused. Drilling down into > SearchSysCacheCopy2, in SearchCatCacheMiss() the systable_beginscan() > passes a NULL snapshot. > > the whole patch does this. I guess I don't understand why 0002 does this. See the thread at https://postgr.es/m/20200229052459.wzhqnbhrriezg4v2%40alap3.anarazel.de Basically, the way catalog snapshots are handled right now, it's not correct to much without a snapshot held. Any concurrent invalidation can cause the catalog snapshot to be released, which can reset the backend's xmin. Which in turn can allow for pruning etc to remove required data. This is part of this series only because I felt I needed to add stronger asserts to be confident in what's happening. And they started to trigger all over :( - and weren't related to the patchset :(. > 4. Did you consider the location of 'delayChkpt' in PGPROC. Couldn't > you slot it in somewhere it would fit in existing padding? > > 0007 Hm, maybe. I'm not sure what the best thing to do here is - there's some arguments to be made that we should keep the fields moved from PGXACT together on their own cacheline. Compared to some of the other stuff in PGPROC they're still accessed from other backends fairly frequently. > 5. GinPageIsRecyclable() has no comments at all. I know that > ginvacuum.c is not exactly the modal citizen for function header > comments, but likely this patch is no good reason to continue the > trend. Well, I basically just moved the code from the macro of the same name... I'll add something. > 9. I get the idea you don't intend to keep the debug message in > InvisibleToEveryoneTestFullXid(), but if you do, then shouldn't it be > using UINT64_FORMAT? Yea, I don't intend to keep them - they're way too verbose, even for DEBUG*. Note that there's some advantage in the long long cast approach - it's easier to deal with for translations IIRC. > 13. is -> are > > * accessed data is stored contiguously in memory in as few cache lines as Oh? 'data are stored' sounds wrong to me, somehow. Greetings, Andres Freund
On Sun, Mar 29, 2020 at 1:49 PM Andres Freund <andres@anarazel.de> wrote: > > 13. is -> are > > > > * accessed data is stored contiguously in memory in as few cache lines as > > Oh? 'data are stored' sounds wrong to me, somehow. In computer contexts it seems pretty well established that we treat "data" as an uncountable noun (like "air"), so I think "is" is right here. In maths or science contexts it's usually treated as a plural following Latin, which admittedly sounds cleverer, but it also has a slightly different meaning, not bits and bytes but something more like samples or (wince) datums.
On Sun, Mar 1, 2020 at 12:36 AM Andres Freund <andres@anarazel.de> wrote: > The workload is a pgbench readonly, with pgbench -M prepared -c $conns > -j $conns -S -n for each client count. This is on a machine with 2 > Intel(R) Xeon(R) Platinum 8168, but virtualized. > > conns tps master tps pgxact-split > > 1 26842.492845 26524.194821 > 10 246923.158682 249224.782661 > 50 695956.539704 709833.746374 > 100 1054727.043139 1903616.306028 > 200 964795.282957 1949200.338012 > 300 906029.377539 1927881.231478 > 400 845696.690912 1911065.369776 > 500 812295.222497 1926237.255856 > 600 888030.104213 1903047.236273 > 700 866896.532490 1886537.202142 > 800 863407.341506 1883768.592610 > 900 871386.608563 1874638.012128 > 1000 887668.277133 1876402.391502 > 1500 860051.361395 1815103.564241 > 2000 890900.098657 1775435.271018 > 3000 874184.980039 1653953.817997 > 4000 845023.080703 1582582.316043 > 5000 817100.195728 1512260.802371 > > I think these are pretty nice results. This scalability improvement is clearly very significant. There is little question that this is a strategically important enhancement for the Postgres project in general. I hope that you will ultimately be able to commit the patchset before feature freeze. I have heard quite a few complaints about the scalability of snapshot acquisition in Postgres. Generally from very large users that are not well represented on the mailing lists, for a variety of reasons. The GetSnapshotData() bottleneck is a *huge* problem for us. (As problems for Postgres users go, I would probably rank it second behind issues with VACUUM.) -- Peter Geoghegan
On Sat, Mar 28, 2020 at 06:39:32PM -0700, Peter Geoghegan wrote: > On Sun, Mar 1, 2020 at 12:36 AM Andres Freund <andres@anarazel.de> wrote: > > The workload is a pgbench readonly, with pgbench -M prepared -c $conns > > -j $conns -S -n for each client count. This is on a machine with 2 > > Intel(R) Xeon(R) Platinum 8168, but virtualized. > > > > conns tps master tps pgxact-split > > > > 1 26842.492845 26524.194821 > > 10 246923.158682 249224.782661 > > 50 695956.539704 709833.746374 > > 100 1054727.043139 1903616.306028 > > 200 964795.282957 1949200.338012 > > 300 906029.377539 1927881.231478 > > 400 845696.690912 1911065.369776 > > 500 812295.222497 1926237.255856 > > 600 888030.104213 1903047.236273 > > 700 866896.532490 1886537.202142 > > 800 863407.341506 1883768.592610 > > 900 871386.608563 1874638.012128 > > 1000 887668.277133 1876402.391502 > > 1500 860051.361395 1815103.564241 > > 2000 890900.098657 1775435.271018 > > 3000 874184.980039 1653953.817997 > > 4000 845023.080703 1582582.316043 > > 5000 817100.195728 1512260.802371 > > > > I think these are pretty nice results. > > This scalability improvement is clearly very significant. There is > little question that this is a strategically important enhancement for > the Postgres project in general. I hope that you will ultimately be > able to commit the patchset before feature freeze. +1 > I have heard quite a few complaints about the scalability of snapshot > acquisition in Postgres. Generally from very large users that are not > well represented on the mailing lists, for a variety of reasons. The > GetSnapshotData() bottleneck is a *huge* problem for us. (As problems > for Postgres users go, I would probably rank it second behind issues > with VACUUM.) +1 -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Hi, On 2020-03-28 18:39:32 -0700, Peter Geoghegan wrote: > I have heard quite a few complaints about the scalability of snapshot > acquisition in Postgres. Generally from very large users that are not > well represented on the mailing lists, for a variety of reasons. The > GetSnapshotData() bottleneck is a *huge* problem for us. (As problems > for Postgres users go, I would probably rank it second behind issues > with VACUUM.) Yea, I see it similarly. For busy databases, my experience is that vacuum is the big problem for write heavy workloads (or the write portion), and snapshot scalability the big problem for read heavy oltp workloads. > This scalability improvement is clearly very significant. There is > little question that this is a strategically important enhancement for > the Postgres project in general. I hope that you will ultimately be > able to commit the patchset before feature freeze. I've done a fair bit of cleanup, but I'm still fighting with how to implement old_snapshot_threshold in a good way. It's not hard to get it back to kind of working, but it requires some changes that go into the wrong direction. The problem basically is that the current old_snapshot_threshold implementation just reduces OldestXmin to whatever is indicated by old_snapshot_threshold, even if not necessary for pruning to do the specific cleanup that's about to be done. If OldestXmin < threshold, it'll set shared state that fails all older accesses. But that doesn't really work well with approach in the patch of using a lower/upper boundary for potentially valid xmin horizons. I thinkt he right approach would be to split TransactionIdLimitedForOldSnapshots() into separate parts. One that determines the most aggressive horizon that old_snapshot_threshold allows, and a separate part that increases the threshold after which accesses need to error out (i.e. SetOldSnapshotThresholdTimestamp()). Then we can only call SetOldSnapshotThresholdTimestamp() for exactly the xids that are removed, not for the most aggressive interpretation. Unfortunately I think that basically requires changing HeapTupleSatisfiesVacuum's signature, to take a more complex parameter than OldestXmin (to take InvisibleToEveryoneState *), which quickly increases the size of the patch. I'm currently doing that and seeing how the result makes me feel about the patch. Alternatively we also can just be less efficient and call GetOldestXmin() more aggressively when old_snapshot_threshold is set. That'd be easier to implement - but seems like an ugly gotcha. Greetings, Andres Freund
On Sun, Mar 29, 2020 at 4:40 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Sun, Mar 1, 2020 at 12:36 AM Andres Freund <andres@anarazel.de> wrote: > > The workload is a pgbench readonly, with pgbench -M prepared -c $conns > > -j $conns -S -n for each client count. This is on a machine with 2 > > Intel(R) Xeon(R) Platinum 8168, but virtualized. > > > > conns tps master tps pgxact-split > > > > 1 26842.492845 26524.194821 > > 10 246923.158682 249224.782661 > > 50 695956.539704 709833.746374 > > 100 1054727.043139 1903616.306028 > > 200 964795.282957 1949200.338012 > > 300 906029.377539 1927881.231478 > > 400 845696.690912 1911065.369776 > > 500 812295.222497 1926237.255856 > > 600 888030.104213 1903047.236273 > > 700 866896.532490 1886537.202142 > > 800 863407.341506 1883768.592610 > > 900 871386.608563 1874638.012128 > > 1000 887668.277133 1876402.391502 > > 1500 860051.361395 1815103.564241 > > 2000 890900.098657 1775435.271018 > > 3000 874184.980039 1653953.817997 > > 4000 845023.080703 1582582.316043 > > 5000 817100.195728 1512260.802371 > > > > I think these are pretty nice results. > > This scalability improvement is clearly very significant. There is > little question that this is a strategically important enhancement for > the Postgres project in general. I hope that you will ultimately be > able to commit the patchset before feature freeze. +1, this is really very cool results. Despite this patchset is expected to be clearly a big win on majority of workloads, I think we still need to investigate different workloads on different hardware to ensure there is no regression. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, On March 29, 2020 11:24:32 AM PDT, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > clearly a big win on majority >of workloads, I think we still need to investigate different workloads >on different hardware to ensure there is no regression. Definitely. Which workloads are you thinking of? I can think of those affected facets: snapshot speed, commit speed withwrites, connection establishment, prepared transaction speed. All in the small and large connection count cases. I did measurements on all of those but prepared xacts, fwiw. That definitely needs to be measured, due to the locking changesaround procarrayaddd/remove. I don't think regressions besides perhaps 2pc are likely - there's nothing really getting more expensive but procarray add/remove. Andres Regards, Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
On Sun, Mar 29, 2020 at 11:50:10AM -0700, Andres Freund wrote: >Hi, > >On March 29, 2020 11:24:32 AM PDT, Alexander Korotkov ><a.korotkov@postgrespro.ru> wrote: >> clearly a big win on majority >>of workloads, I think we still need to investigate different workloads >>on different hardware to ensure there is no regression. > >Definitely. Which workloads are you thinking of? I can think of those >affected facets: snapshot speed, commit speed with writes, connection >establishment, prepared transaction speed. All in the small and large >connection count cases. > >I did measurements on all of those but prepared xacts, fwiw. That >definitely needs to be measured, due to the locking changes around >procarrayaddd/remove. > >I don't think regressions besides perhaps 2pc are likely - there's >nothing really getting more expensive but procarray add/remove. > If I get some instructions what tests to do, I can run a bunch of tests on my machinees (not the largest boxes, but at least something). I don't have the bandwidth to come up with tests on my own, at the moment. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Mar 29, 2020 at 9:50 PM Andres Freund <andres@anarazel.de> wrote: > On March 29, 2020 11:24:32 AM PDT, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > clearly a big win on majority > >of workloads, I think we still need to investigate different workloads > >on different hardware to ensure there is no regression. > > Definitely. Which workloads are you thinking of? I can think of those affected facets: snapshot speed, commit speed withwrites, connection establishment, prepared transaction speed. All in the small and large connection count cases. Following pgbench scripts comes first to my mind: 1) SELECT txid_current(); (artificial but good for checking corner case) 2) Single insert statement (as example of very short transaction) 3) Plain pgbench read-write (you already did it for sure) 4) pgbench read-write script with increased amount of SELECTs. Repeat select from pgbench_accounts say 10 times with different aids. 5) 10% pgbench read-write, 90% of pgbench read-only > I did measurements on all of those but prepared xacts, fwiw Great, it would be nice to see the results in the thread. > That definitely needs to be measured, due to the locking changes around procarrayaddd/remove. > > I don't think regressions besides perhaps 2pc are likely - there's nothing really getting more expensive but procarrayadd/remove. I agree that ProcArrayAdd()/Remove() should be first subject of investigation, but other cases should be checked as well IMHO. Regarding 2pc I can following scenarios come to my mind: 1) pgbench read-write modified so that every transaction is prepared first, then commit prepared. 2) 10% of 2pc pgbench read-write, 90% normal pgbench read-write 3) 10% of 2pc pgbench read-write, 90% normal pgbench read-only ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi,
I'm still fighting with snapshot_too_old. The feature is just badly
undertested, underdocumented, and there's lots of other oddities. I've
now spent about as much time on that feature than on the whole rest of
the patchset.
As an example for under-documented, here's a definitely non-trivial
block of code without a single comment explaining what it's doing.
if (oldSnapshotControl->count_used > 0 &&
ts >= oldSnapshotControl->head_timestamp)
{
int offset;
offset = ((ts - oldSnapshotControl->head_timestamp)
/ USECS_PER_MINUTE);
if (offset > oldSnapshotControl->count_used - 1)
offset = oldSnapshotControl->count_used - 1;
offset = (oldSnapshotControl->head_offset + offset)
% OLD_SNAPSHOT_TIME_MAP_ENTRIES;
xlimit = oldSnapshotControl->xid_by_minute[offset];
if (NormalTransactionIdFollows(xlimit, recentXmin))
SetOldSnapshotThresholdTimestamp(ts, xlimit);
}
LWLockRelease(OldSnapshotTimeMapLock);
Also, SetOldSnapshotThresholdTimestamp() acquires a separate spinlock -
not great to call that with the lwlock held.
Then there's this comment:
/*
* Failsafe protection against vacuuming work of active transaction.
*
* This is not an assertion because we avoid the spinlock for
* performance, leaving open the possibility that xlimit could advance
* and be more current; but it seems prudent to apply this limit. It
* might make pruning a tiny bit less aggressive than it could be, but
* protects against data loss bugs.
*/
if (TransactionIdIsNormal(latest_xmin)
&& TransactionIdPrecedes(latest_xmin, xlimit))
xlimit = latest_xmin;
if (NormalTransactionIdFollows(xlimit, recentXmin))
return xlimit;
So this is not using lock, so the values aren't accurate, but it avoids
data loss bugs? I also don't know which spinlock is avoided on the path
here as mentioend - the acquisition is unconditional.
But more importantly - if this is about avoiding data loss bugs, how on
earth is it ok that we don't go through these checks in the
old_snapshot_threshold == 0 path?
/*
* Zero threshold always overrides to latest xmin, if valid. Without
* some heuristic it will find its own snapshot too old on, for
* example, a simple UPDATE -- which would make it useless for most
* testing, but there is no principled way to ensure that it doesn't
* fail in this way. Use a five-second delay to try to get useful
* testing behavior, but this may need adjustment.
*/
if (old_snapshot_threshold == 0)
{
if (TransactionIdPrecedes(latest_xmin, MyProc->xmin)
&& TransactionIdFollows(latest_xmin, xlimit))
xlimit = latest_xmin;
ts -= 5 * USECS_PER_SEC;
SetOldSnapshotThresholdTimestamp(ts, xlimit);
return xlimit;
}
This feature looks like it was put together by applying force until
something gave, and then stopping just there.
Greetings,
Andres Freund
Hi, On 2020-03-31 13:04:38 -0700, Andres Freund wrote: > I'm still fighting with snapshot_too_old. The feature is just badly > undertested, underdocumented, and there's lots of other oddities. I've > now spent about as much time on that feature than on the whole rest of > the patchset. To expand on this being under-tested: The whole time mapping infrastructure is not tested, because all of that is bypassed when old_snapshot_threshold = 0. And old_snapshot_threshold = 0 basically only exists for testing. The largest part of the complexity of this feature are TransactionIdLimitedForOldSnapshots() and MaintainOldSnapshotTimeMapping() - and none of the complexity is tested due to the tests running with old_snapshot_threshold = 0. So we have test only infrastructure that doesn't allow to actually test the feature. And the tests that we do have don't have a single comment explaining what the expected results are. Except for the newer sto_using_hash_index.spec, they just run all permutations. I don't know how those tests actually help, since it's not clear why any of the results are the way they are. And which just are the results of bugs. Ore not affected by s_t_o. Greetings, Andres Freund
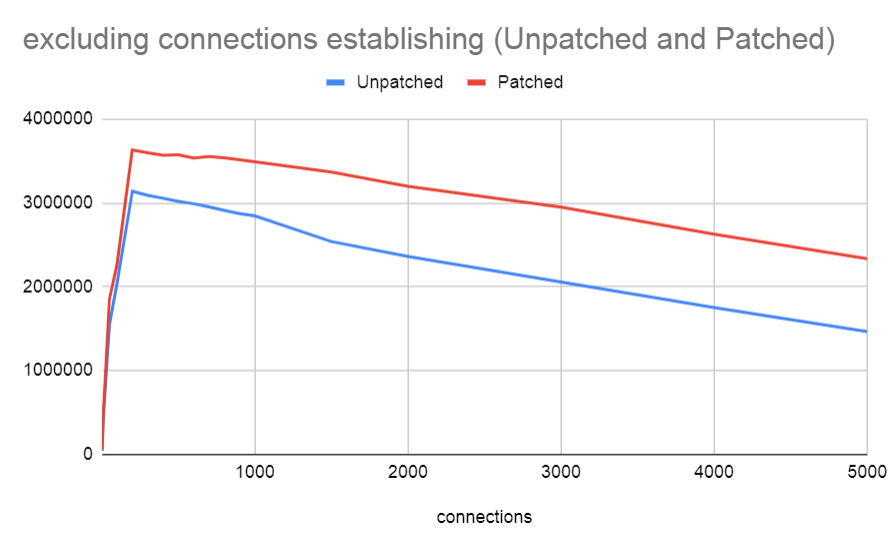
On Sun, 1 Mar 2020 at 21:47, Andres Freund <andres@anarazel.de> wrote: > On 2020-03-01 00:36:01 -0800, Andres Freund wrote: > > conns tps master tps pgxact-split > > > > 1 26842.492845 26524.194821 > > 10 246923.158682 249224.782661 > > 50 695956.539704 709833.746374 > > 100 1054727.043139 1903616.306028 > > 200 964795.282957 1949200.338012 > > 300 906029.377539 1927881.231478 > > 400 845696.690912 1911065.369776 > > 500 812295.222497 1926237.255856 > > 600 888030.104213 1903047.236273 > > 700 866896.532490 1886537.202142 > > 800 863407.341506 1883768.592610 > > 900 871386.608563 1874638.012128 > > 1000 887668.277133 1876402.391502 > > 1500 860051.361395 1815103.564241 > > 2000 890900.098657 1775435.271018 > > 3000 874184.980039 1653953.817997 > > 4000 845023.080703 1582582.316043 > > 5000 817100.195728 1512260.802371 > > > > I think these are pretty nice results. FWIW, I took this for a spin on an AMD 3990x: # setup pgbench -i postgres #benchmark #!/bin/bash for i in 1 10 50 100 200 300 400 500 600 700 800 900 1000 1500 2000 3000 4000 5000; do echo Testing with $i connections >> bench.log pgbench2 -M prepared -c $i -j $i -S -n -T 60 postgres >> bench.log done pgbench2 is your patched version pgbench. I got some pretty strange results with the unpatched version. Up to about 50 million tps for excluding connection establishing, which seems pretty farfetched connections Unpatched Patched 1 49062.24413 49834.64983 10 428673.1027 453290.5985 50 1552413.084 1849233.821 100 2039675.027 2261437.1 200 3139648.845 3632008.991 300 3091248.316 3597748.942 400 3056453.5 3567888.293 500 3019571.47 3574009.053 600 2991052.393 3537518.903 700 2952484.763 3553252.603 800 2910976.875 3539404.865 900 2873929.989 3514353.776 1000 2846859.499 3490006.026 1500 2540003.038 3370093.934 2000 2361799.107 3197556.738 3000 2056973.778 2949740.692 4000 1751418.117 2627174.81 5000 1464786.461 2334586.042 > Attached as a graph as well. Likewise. David
Вложения
{kind=link}
Hi, These benchmarks are on my workstation. The larger VM I used in the last round wasn't currently available. HW: 2 x Intel(R) Xeon(R) Gold 5215 (each 10 cores / 20 threads) 192GB Ram. data directory is on a Samsung SSD 970 PRO 1TB A bunch of terminals, emacs, mutt are open while the benchmark is running. No browser. Unless mentioned otherwise, relevant configuration options are: max_connections=1200 shared_buffers=8GB max_prepared_transactions=1000 synchronous_commit=local huge_pages=on fsync=off # to make it more likely to see scalability bottlenecks Independent of the effects of this patch (i.e. including master) I had a fairly hard time getting reproducible number for *low* client cases. I found the numbers to be more reproducible if I pinned server/pgbench onto the same core :(. I chose to do that for the -c1 cases, to benchmark the optimal behaviour, as that seemed to have the biggest potential for regressions. All numbers are best of three. Tests start in freshly created cluster each. On 2020-03-30 17:04:00 +0300, Alexander Korotkov wrote: > Following pgbench scripts comes first to my mind: > 1) SELECT txid_current(); (artificial but good for checking corner case) -M prepared -T 180 (did a few longer runs, but doesn't seem to matter much) clients tps master tps pgxact 1 46118 46027 16 377357 440233 40 373304 410142 198 103912 105579 btw, there's some pretty horrible cacheline bouncing in txid_current() because backends first ReadNextFullTransactionId() (acquires XidGenLock in shared mode, reads ShmemVariableCache->nextFullXid), then separately causes GetNewTransactionId() (acquires XidGenLock exclusively, reads & writes nextFullXid). With for fsync=off (and also for synchronous_commit=off) the numbers are, at lower client counts, severly depressed and variable due to walwriter going completely nuts (using more CPU than the backend doing the queries). Because WAL writes are so fast on my storage, individual XLogBackgroundFlush() calls are very quick. This leads to a *lot* of kill()s from the backend, from within XLogSetAsyncXactLSN(). There got to be a bug here. But unrelated. > 2) Single insert statement (as example of very short transaction) CREATE TABLE testinsert(c1 int not null, c2 int not null, c3 int not null, c4 int not null); INSERT INTO testinsert VALUES(1, 2, 3, 4); -M prepared -T 360 fsync on: clients tps master tps pgxact 1 653 658 16 5687 5668 40 14212 14229 198 60483 62420 fsync off: clients tps master tps pgxact 1 59356 59891 16 290626 299991 40 348210 355669 198 289182 291529 clients tps master tps pgxact 1024 47586 52135 -M simple fsync off: clients tps master tps pgxact 40 289077 326699 198 286011 299928 > 3) Plain pgbench read-write (you already did it for sure) -s 100 -M prepared -T 700 autovacuum=off, fsync on: clients tps master tps pgxact 1 474 479 16 4356 4476 40 8591 9309 198 20045 20261 1024 17986 18545 autovacuum=off, fsync off: clients tps master tps pgxact 1 7828 7719 16 49069 50482 40 68241 73081 198 73464 77801 1024 25621 28410 I chose autovacuum off because otherwise the results vary much more widely, and autovacuum isn't really needed for the workload. > 4) pgbench read-write script with increased amount of SELECTs. Repeat > select from pgbench_accounts say 10 times with different aids. I did intersperse all server-side statements in the script with two selects of other pgbench_account rows each. -s 100 -M prepared -T 700 autovacuum=off, fsync on: clients tps master tps pgxact 1 365 367 198 20065 21391 -s 1000 -M prepared -T 700 autovacuum=off, fsync on: clients tps master tps pgxact 16 2757 2880 40 4734 4996 198 16950 19998 1024 22423 24935 > 5) 10% pgbench read-write, 90% of pgbench read-only -s 100 -M prepared -T 100 -bselect-only@9 -btpcb-like@1 autovacuum=off, fsync on: clients tps master tps pgxact 16 37289 38656 40 81284 81260 198 189002 189357 1024 143986 164762 > > That definitely needs to be measured, due to the locking changes around procarrayaddd/remove. > > > > I don't think regressions besides perhaps 2pc are likely - there's nothing really getting more expensive but procarrayadd/remove. > > I agree that ProcArrayAdd()/Remove() should be first subject of > investigation, but other cases should be checked as well IMHO. I'm not sure I really see the point. If simple prepared tx doesn't show up as a negative difference, a more complex one won't either, since the ProcArrayAdd()/Remove() related bottlenecks will play smaller and smaller role. > Regarding 2pc I can following scenarios come to my mind: > 1) pgbench read-write modified so that every transaction is prepared > first, then commit prepared. The numbers here are -M simple, because I wanted to use PREPARE TRANSACTION 'ptx_:client_id'; COMMIT PREPARED 'ptx_:client_id'; -s 100 -M prepared -T 700 -f ~/tmp/pgbench-write-2pc.sql autovacuum=off, fsync on: clients tps master tps pgxact 1 251 249 16 2134 2174 40 3984 4089 198 6677 7522 1024 3641 3617 > 2) 10% of 2pc pgbench read-write, 90% normal pgbench read-write -s 100 -M prepared -T 100 -f ~/tmp/pgbench-write-2pc.sql@1 -btpcb-like@9 clients tps master tps pgxact 198 18625 18906 > 3) 10% of 2pc pgbench read-write, 90% normal pgbench read-only -s 100 -M prepared -T 100 -f ~/tmp/pgbench-write-2pc.sql@1 -bselect-only@9 clients tps master tps pgxact 198 84817 84350 I also benchmarked connection overhead, by using pgbench with -C executing SELECT 1. -T 10 clients tps master tps pgxact 1 572 587 16 2109 2140 40 2127 2136 198 2097 2129 1024 2101 2118 These numbers seem pretty decent to me. The regressions seem mostly within noise. The one possible exception to that is plain pgbench read/write with fsync=off and only a single session. I'll run more benchmarks around that tomorrow (but now it's 6am :(). Greetings, Andres Freund
Hi, On 2020-04-06 06:39:59 -0700, Andres Freund wrote: > These benchmarks are on my workstation. The larger VM I used in the last > round wasn't currently available. One way to reproduce the problem at smaller connection counts / smaller machines is to take more snapshots. Doesn't fully reproduce the problem, because resetting ->xmin without xact overhead is part of the problem, but it's helpful. I use a volatile function that loops over a trivial statement. There's probably an easier / more extreme way to reproduce the problem. But it's good enough. -- setup CREATE OR REPLACE FUNCTION snapme(p_ret int, p_loop int) RETURNS int VOLATILE LANGUAGE plpgsql AS $$BEGIN FOR x in 1..p_loopLOOP EXECUTE 'SELECT 1';END LOOP; RETURN p_ret; END;$$; -- statement executed in parallel SELECT snapme(17, 10000); before (all above 1.5%): + 37.82% postgres postgres [.] GetSnapshotData + 6.26% postgres postgres [.] AllocSetAlloc + 3.77% postgres postgres [.] base_yyparse + 3.04% postgres postgres [.] core_yylex + 1.94% postgres postgres [.] grouping_planner + 1.83% postgres libc-2.30.so [.] __strncpy_avx2 + 1.80% postgres postgres [.] palloc + 1.73% postgres libc-2.30.so [.] __memset_avx2_unaligned_erms after: + 5.75% postgres postgres [.] base_yyparse + 4.37% postgres postgres [.] palloc + 4.29% postgres postgres [.] AllocSetAlloc + 3.75% postgres postgres [.] expression_tree_walker.part.0 + 3.14% postgres postgres [.] core_yylex + 2.51% postgres postgres [.] subquery_planner + 2.48% postgres postgres [.] CheckExprStillValid + 2.45% postgres postgres [.] check_stack_depth + 2.42% postgres plpgsql.so [.] exec_stmt + 1.92% postgres libc-2.30.so [.] __memset_avx2_unaligned_erms + 1.91% postgres postgres [.] query_tree_walker + 1.88% postgres libc-2.30.so [.] __GI_____strtoll_l_internal + 1.86% postgres postgres [.] _SPI_execute_plan + 1.85% postgres postgres [.] assign_query_collations_walker + 1.84% postgres postgres [.] remove_useless_results_recurse + 1.83% postgres postgres [.] grouping_planner + 1.50% postgres postgres [.] set_plan_refs If I change the workload to be BEGIN; SELECT txid_current(); SELECT snapme(17, 1000); COMMIT; the difference reduces (because GetSnapshotData() only needs to look at procs with xids, and xids are assigned for much longer), but still is significant: before (all above 1.5%): + 35.89% postgres postgres [.] GetSnapshotData + 7.94% postgres postgres [.] AllocSetAlloc + 4.42% postgres postgres [.] base_yyparse + 3.62% postgres libc-2.30.so [.] __memset_avx2_unaligned_erms + 2.87% postgres postgres [.] LWLockAcquire + 2.76% postgres postgres [.] core_yylex + 2.30% postgres postgres [.] expression_tree_walker.part.0 + 1.81% postgres postgres [.] MemoryContextAllocZeroAligned + 1.80% postgres postgres [.] transformStmt + 1.66% postgres postgres [.] grouping_planner + 1.64% postgres postgres [.] subquery_planner after: + 24.59% postgres postgres [.] GetSnapshotData + 4.89% postgres postgres [.] base_yyparse + 4.59% postgres postgres [.] AllocSetAlloc + 3.00% postgres postgres [.] LWLockAcquire + 2.76% postgres postgres [.] palloc + 2.27% postgres postgres [.] MemoryContextAllocZeroAligned + 2.26% postgres postgres [.] check_stack_depth + 1.77% postgres postgres [.] core_yylex Greetings, Andres Freund
Hi, On 2020-04-06 06:39:59 -0700, Andres Freund wrote: > > 3) Plain pgbench read-write (you already did it for sure) > > -s 100 -M prepared -T 700 > > autovacuum=off, fsync on: > clients tps master tps pgxact > 1 474 479 > 16 4356 4476 > 40 8591 9309 > 198 20045 20261 > 1024 17986 18545 > > autovacuum=off, fsync off: > clients tps master tps pgxact > 1 7828 7719 > 16 49069 50482 > 40 68241 73081 > 198 73464 77801 > 1024 25621 28410 > > I chose autovacuum off because otherwise the results vary much more > widely, and autovacuum isn't really needed for the workload. > These numbers seem pretty decent to me. The regressions seem mostly > within noise. The one possible exception to that is plain pgbench > read/write with fsync=off and only a single session. I'll run more > benchmarks around that tomorrow (but now it's 6am :(). The "one possible exception" turned out to be a "real" regression, but one that was dead easy to fix: It was an DEBUG1 elog I had left in. The overhead seems to solely have been the increased code size + overhead of errstart(). After that there's no difference in the single client case anymore (I'd not expect a benefit). Greetings, Andres Freund
Hi, SEE BELOW: What, and what not, to do for v13. Attached is a substantially polished version of my patches. Note that the first three patches, as well as the last, are not intended to be committed at this time / in this form - they're there to make testing easier. There is a lot of polish, but also a few substantial changes: - To be compatible with old_snapshot_threshold I've revised the way heap_page_prune_opt() deals with old_snapshot_threshold. Now old_snapshot_threshold is only applied when we otherwise would have been unable to prune (both at the time of the pd_prune_xid check, and on individual tuples). This makes old_snapshot_threshold considerably cheaper and cause less conflicts. This required adding a version of HeapTupleSatisfiesVacuum that returns the horizon, rather than doing the horizon test itself; that way we can first test a tuple's horizon against the normal approximate threshold (making it an accurate threshold if needed) and only if that fails fall back to old_snapshot_threshold. The main reason here was not to improve old_snapshot_threshold, but to avoid a regression when its being used. Because we need a horizon to pass to old_snapshot_threshold, we'd have to fall back to computing an accurate horizon too often. - Previous versions of the patch had a TODO about computing horizons not just for one of shared / catalog / data tables, but all of them at once. To avoid potentially needing to determine xmin horizons multiple times within one transaction. For that I've renamed GetOldestXmin() to ComputeTransactionHorizons() and added wrapper functions instead of the different flag combinations we previously had for GetOldestXmin(). This allows us to get rid of the PROCARRAY_* flags, and PROC_RESERVED. - To address Thomas' review comment about not accessing nextFullXid without xidGenLock, I made latestCompletedXid a FullTransactionId (a fxid is needed to be able to infer 64bit xids for the horizons - otherwise there is some danger they could wrap). - Improving the comment around the snapshot caching, I decided that the justification for correctness around not taking ProcArrayLock is too complicated (in particular around setting MyProc->xmin). While avoiding ProcArrayLock alltogether is a substantial gain, the caching itself helps a lot already. Seems best to leave that for a later step. This means that the numbers for the very high connection counts aren't quite as good. - Plenty of small changes to address issues I found while benchmarking. The only one of real note is that I had released XidGenLock after ProcArrayLock in ProcArrayAdd/Remove. For 2pc that causes noticable unnecessary contention, because we'll wait for XidGenLock while holding ProcArrayLock... I think this is pretty close to being committable. But: This patch came in very late for v13, and it took me much longer to polish it up than I had hoped (partially distraction due to various bugs I found (in particular snapshot_too_old), partially covid19, partially "hell if I know"). The patchset touches core parts of the system. While both Thomas and David have done some review, they haven't for the latest version (mea culpa). In many other instances I would say that the above suggests slipping to v14, given the timing. The main reason I am considering pushing is that I think this patcheset addresses one of the most common critiques of postgres, as well as very common, hard to fix, real-world production issues. GetSnapshotData() has been a major bottleneck for about as long as I have been using postgres, and this addresses that to a significant degree. A second reason I am considering it is that, in my opinion, the changes are not all that complicated and not even that large. At least not for a change to a problem that we've long tried to improve. Obviously we all have a tendency to think our own work is important, and that we deserve a bit more leeway than others. So take the above with a grain of salt. Comments? Greetings, Andres Freund
Вложения
- v1-0001-TMP-work-around-missing-snapshot-registrations.patch
- v1-0002-Improve-and-extend-asserts-for-a-snapshot-being-s.patch
- v7-0001-TMP-work-around-missing-snapshot-registrations.patch
- v7-0002-Improve-and-extend-asserts-for-a-snapshot-being-s.patch
- v7-0003-Fix-xlogreader-fd-leak-encountered-with-twophase-.patch
- v7-0004-Move-delayChkpt-from-PGXACT-to-PGPROC-it-s-rarely.patch
- v7-0005-Change-the-way-backends-perform-tuple-is-invisibl.patch
- v7-0006-snapshot-scalability-Move-PGXACT-xmin-back-to-PGP.patch
- v7-0007-snapshot-scalability-Move-in-progress-xids-to-Pro.patch
- v7-0008-snapshot-scalability-Move-PGXACT-vacuumFlags-to-P.patch
- v7-0009-snapshot-scalability-Move-subxact-info-from-PGXAC.patch
- v7-0010-Remove-now-unused-PGXACT.patch
- v7-0011-snapshot-scalability-cache-snapshots-using-a-xact.patch
On 2020-04-07 05:15:03 -0700, Andres Freund wrote: > Attached is a substantially polished version of my patches. Note that > the first three patches, as well as the last, are not intended to be > committed at this time / in this form - they're there to make testing > easier. I didn't actually attached that last not-to-be-committed patch... It's just the pgbench patch that I had attached before (and started a thread about). Here it is again.
Вложения
On 4/7/20 8:15 AM, Andres Freund wrote: > I think this is pretty close to being committable. > > > But: This patch came in very late for v13, and it took me much longer to > polish it up than I had hoped (partially distraction due to various bugs > I found (in particular snapshot_too_old), partially covid19, partially > "hell if I know"). The patchset touches core parts of the system. While > both Thomas and David have done some review, they haven't for the latest > version (mea culpa). > > In many other instances I would say that the above suggests slipping to > v14, given the timing. > > The main reason I am considering pushing is that I think this patcheset > addresses one of the most common critiques of postgres, as well as very > common, hard to fix, real-world production issues. GetSnapshotData() has > been a major bottleneck for about as long as I have been using postgres, > and this addresses that to a significant degree. > > A second reason I am considering it is that, in my opinion, the changes > are not all that complicated and not even that large. At least not for a > change to a problem that we've long tried to improve. Even as recently as earlier this week there was a blog post making the rounds about the pain points running PostgreSQL with many simultaneous connections. Anything to help with that would go a long way, and looking at the benchmarks you ran (at least with a quick, nonthorough glance) this could and should be very positively impactful to a *lot* of PostgreSQL users. I can't comment on the "close to committable" aspect (at least not with an informed, confident opinion) but if it is indeed close to committable and you can put the work to finish polishing (read: "bug fixing" :-) and we have a plan both of testing and, if need be, to revert, I would be okay with including it, for whatever my vote is worth. Is the timing / situation ideal? No, but the way you describe it, it sounds like there is enough that can be done to ensure it's ready for Beta 1. From a RMT standpoint, perhaps this is one of the "Recheck at Mid-Beta" items, as well. Thanks, Jonathan
Вложения
Comments:
In 0002, the comments in SnapshotSet() are virtually incomprehensible.
There's no commit message so the reasons for the changes are unclear.
But mostly looks unproblematic.
0003 looks like a fairly unrelated bug fix that deserves to be
discussed on the thread related to the original patch. Probably should
be an open item.
0004 looks fine.
Regarding 0005:
There's sort of a mix of terminology here: are we pruning tuples or
removing tuples or testing whether things are invisible? It would be
better to be more consistent.
+ * State for testing whether tuple versions may be removed. To improve
+ * GetSnapshotData() performance we don't compute an accurate value whenever
+ * acquiring a snapshot. Instead we compute boundaries above/below which we
+ * know that row versions are [not] needed anymore. If at test time values
+ * falls in between the two, the boundaries can be recomputed (unless that
+ * just happened).
I don't like the wording here much. Maybe: State for testing whether
an XID is invisible to all current snapshots. If an XID precedes
maybe_needed_bound, it's definitely not visible to any current
snapshot. If it equals or follows definitely_needed_bound, that XID
isn't necessarily invisible to all snapshots. If it falls in between,
we're not sure. If, when testing a particular tuple, we see an XID
somewhere in the middle, we can try recomputing the boundaries to get
a more accurate answer (unless we've just done that). This is cheaper
than maintaining an accurate value all the time.
There's also the problem that this sorta contradicts the comment for
definitely_needed_bound. There it says intermediate values needed to
be tested against the ProcArray, whereas here it says we need to
recompute the bounds. That's kinda confusing.
ComputedHorizons seems like a fairly generic name. I think there's
some relationship between InvisibleToEveryoneState and
ComputedHorizons that should be brought out more clearly by the naming
and the comments.
+ /*
+ * The value of ShmemVariableCache->latestCompletedFullXid when
+ * ComputeTransactionHorizons() held ProcArrayLock.
+ */
+ FullTransactionId latest_completed;
+
+ /*
+ * The same for procArray->replication_slot_xmin and.
+ * procArray->replication_slot_catalog_xmin.
+ */
+ TransactionId slot_xmin;
+ TransactionId slot_catalog_xmin;
Department of randomly inconsistent names. In general I think it's
quite hard to grasp the relationship between the different fields in
ComputedHorizons.
+static inline bool OldSnapshotThresholdActive(void)
+{
+ return old_snapshot_threshold >= 0;
+}
Formatting.
+
+bool
+GinPageIsRecyclable(Page page)
Needs a comment. Or more than one.
- /*
- * If a transaction wrote a commit record in the gap between taking and
- * logging the snapshot then latestCompletedXid may already be higher than
- * the value from the snapshot, so check before we use the incoming value.
- */
- if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid,
- running->latestCompletedXid))
- ShmemVariableCache->latestCompletedXid = running->latestCompletedXid;
-
- Assert(TransactionIdIsNormal(ShmemVariableCache->latestCompletedXid));
-
- LWLockRelease(ProcArrayLock);
This code got relocated so that the lock is released later, but you
didn't add any comments explaining why. Somebody will move it back and
then you'll yet at them for doing it wrong. :-)
+ /*
+ * Must have called GetOldestVisibleTransactionId() if using SnapshotAny.
+ * Shouldn't have for an MVCC snapshot. (It's especially worth checking
+ * this for parallel builds, since ambuild routines that support parallel
+ * builds must work these details out for themselves.)
+ */
+ Assert(snapshot == SnapshotAny || IsMVCCSnapshot(snapshot));
+ Assert(snapshot == SnapshotAny ? TransactionIdIsValid(OldestXmin) :
+ !TransactionIdIsValid(OldestXmin));
+ Assert(snapshot == SnapshotAny || !anyvisible);
This looks like a gratuitous code relocation.
+HeapTupleSatisfiesVacuumHorizon(HeapTuple htup, Buffer buffer,
TransactionId *dead_after)
I don't much like the name dead_after, but I don't have a better
suggestion, either.
- * Deleter committed, but perhaps it was recent enough that some open
- * transactions could still see the tuple.
+ * Deleter committed, allow caller to check if it was recent enough that
+ * some open transactions could still see the tuple.
I think you could drop this change.
+ /*
+ * State related to determining whether a dead tuple is still needed.
+ */
+ InvisibleToEveryoneState *vistest;
+ TimestampTz limited_oldest_ts;
+ TransactionId limited_oldest_xmin;
+ /* have we made removal decision based on old_snapshot_threshold */
+ bool limited_oldest_committed;
Would benefit from more comments.
+ * accuring to prstate->vistest, but that can be removed based on
Typo.
Generally, heap_prune_satisfies_vacuum looks pretty good. The
limited_oldest_committed naming is confusing, but the comments make it
a lot clearer.
+ * If oldest btpo.xact in the deleted pages is invisible, then at
I'd say "invisible to everyone" here for clarity.
-latestCompletedXid variable. This allows GetSnapshotData to use
-latestCompletedXid + 1 as xmax for its snapshot: there can be no
+latestCompletedFullXid variable. This allows GetSnapshotData to use
+latestCompletedFullXid + 1 as xmax for its snapshot: there can be no
Is this fixing a preexisting README defect?
It might be useful if this README expanded on the new machinery a bit
instead of just updating the wording to account for it, but I'm not
sure exactly what that would look like or whether it would be too
duplicative of other things.
+void AssertTransactionIdMayBeOnDisk(TransactionId xid)
Formatting.
+ * Assert that xid is one that we could actually see on disk.
I don't know what this means. The whole purpose of this routine is
very unclear to me.
* the secondary effect that it sets RecentGlobalXmin. (This is critical
* for anything that reads heap pages, because HOT may decide to prune
* them even if the process doesn't attempt to modify any tuples.)
+ *
+ * FIXME: This comment is inaccurate / the code buggy. A snapshot that is
+ * not pushed/active does not reliably prevent HOT pruning (->xmin could
+ * e.g. be cleared when cache invalidations are processed).
Something needs to be done here... and in the other similar case.
Is this kind of review helpful?
...Robert
Hi, Thanks for the review! On 2020-04-07 12:41:07 -0400, Robert Haas wrote: > In 0002, the comments in SnapshotSet() are virtually incomprehensible. > There's no commit message so the reasons for the changes are unclear. > But mostly looks unproblematic. I was planning to drop that patch pre-commit, at least for now. I think there's a few live bugs here, but they're all older. I did send a few emails about the class of problem, unfortunately it was a fairly one-sided conversation so far ;) https://www.postgresql.org/message-id/20200407072418.ccvnyjbrktyi3rzc%40alap3.anarazel.de > 0003 looks like a fairly unrelated bug fix that deserves to be > discussed on the thread related to the original patch. Probably should > be an open item. There was some discussion in a separate thread: https://www.postgresql.org/message-id/20200406025651.fpzdb5yyb7qyhqko%40alap3.anarazel.de The only reason for including it in this patch stack is that I can't really execercise the patchset without the fix (it's a bit sad that this issue has gone unnoticed for months before I found it as part of the development of this patch). Think I'll push a minimal version now, and add an open item. > > Regarding 0005: > > There's sort of a mix of terminology here: are we pruning tuples or > removing tuples or testing whether things are invisible? It would be > better to be more consistent. > > + * State for testing whether tuple versions may be removed. To improve > + * GetSnapshotData() performance we don't compute an accurate value whenever > + * acquiring a snapshot. Instead we compute boundaries above/below which we > + * know that row versions are [not] needed anymore. If at test time values > + * falls in between the two, the boundaries can be recomputed (unless that > + * just happened). > > I don't like the wording here much. Maybe: State for testing whether > an XID is invisible to all current snapshots. If an XID precedes > maybe_needed_bound, it's definitely not visible to any current > snapshot. If it equals or follows definitely_needed_bound, that XID > isn't necessarily invisible to all snapshots. If it falls in between, > we're not sure. If, when testing a particular tuple, we see an XID > somewhere in the middle, we can try recomputing the boundaries to get > a more accurate answer (unless we've just done that). This is cheaper > than maintaining an accurate value all the time. I'll incorporate that, thanks. > There's also the problem that this sorta contradicts the comment for > definitely_needed_bound. There it says intermediate values needed to > be tested against the ProcArray, whereas here it says we need to > recompute the bounds. That's kinda confusing. For me those are the same. Computing an accurate bound is visitting the procarray. But I'll rephrase. > ComputedHorizons seems like a fairly generic name. I think there's > some relationship between InvisibleToEveryoneState and > ComputedHorizons that should be brought out more clearly by the naming > and the comments. I don't like the naming of ComputedHorizons, ComputeTransactionHorizons much... But I find it hard to come up with something that's meaningfully better. I'll add a comment. > + /* > + * The value of ShmemVariableCache->latestCompletedFullXid when > + * ComputeTransactionHorizons() held ProcArrayLock. > + */ > + FullTransactionId latest_completed; > + > + /* > + * The same for procArray->replication_slot_xmin and. > + * procArray->replication_slot_catalog_xmin. > + */ > + TransactionId slot_xmin; > + TransactionId slot_catalog_xmin; > > Department of randomly inconsistent names. In general I think it's > quite hard to grasp the relationship between the different fields in > ComputedHorizons. What's the inconsistency? The dropped replication_ vs dropped FullXid postfix? > + > +bool > +GinPageIsRecyclable(Page page) > > Needs a comment. Or more than one. Well, I started to write one a couple times. But it's really just moving the pre-existing code from the macro into a function and there weren't any comments around *any* of it before. All my comment attempts basically just were restating the code in so many words, or would have required more work than I saw justified in the context of just moving code. > - /* > - * If a transaction wrote a commit record in the gap between taking and > - * logging the snapshot then latestCompletedXid may already be higher than > - * the value from the snapshot, so check before we use the incoming value. > - */ > - if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid, > - running->latestCompletedXid)) > - ShmemVariableCache->latestCompletedXid = running->latestCompletedXid; > - > - Assert(TransactionIdIsNormal(ShmemVariableCache->latestCompletedXid)); > - > - LWLockRelease(ProcArrayLock); > > This code got relocated so that the lock is released later, but you > didn't add any comments explaining why. Somebody will move it back and > then you'll yet at them for doing it wrong. :-) I just moved it because the code now references ->nextFullXid, which was previously maintained after latestCompletedXid. > + /* > + * Must have called GetOldestVisibleTransactionId() if using SnapshotAny. > + * Shouldn't have for an MVCC snapshot. (It's especially worth checking > + * this for parallel builds, since ambuild routines that support parallel > + * builds must work these details out for themselves.) > + */ > + Assert(snapshot == SnapshotAny || IsMVCCSnapshot(snapshot)); > + Assert(snapshot == SnapshotAny ? TransactionIdIsValid(OldestXmin) : > + !TransactionIdIsValid(OldestXmin)); > + Assert(snapshot == SnapshotAny || !anyvisible); > > This looks like a gratuitous code relocation. I found it hard to understand the comments because the Asserts were done further away from where the relevant decisions they were made. And I think I have history to back me up: It looks to me that that that is because ab0dfc961b6a821f23d9c40c723d11380ce195a6 just put the progress related code between the if (!scan) and the Asserts. > +HeapTupleSatisfiesVacuumHorizon(HeapTuple htup, Buffer buffer, > TransactionId *dead_after) > > I don't much like the name dead_after, but I don't have a better > suggestion, either. > > - * Deleter committed, but perhaps it was recent enough that some open > - * transactions could still see the tuple. > + * Deleter committed, allow caller to check if it was recent enough that > + * some open transactions could still see the tuple. > > I think you could drop this change. Ok. Wasn't quite sure what to what to do with that comment. > Generally, heap_prune_satisfies_vacuum looks pretty good. The > limited_oldest_committed naming is confusing, but the comments make it > a lot clearer. I didn't like _committed much either. But couldn't come up with something short. _relied_upon? > + * If oldest btpo.xact in the deleted pages is invisible, then at > > I'd say "invisible to everyone" here for clarity. > > -latestCompletedXid variable. This allows GetSnapshotData to use > -latestCompletedXid + 1 as xmax for its snapshot: there can be no > +latestCompletedFullXid variable. This allows GetSnapshotData to use > +latestCompletedFullXid + 1 as xmax for its snapshot: there can be no > > Is this fixing a preexisting README defect? It's just adjusting for the changed name of latestCompletedXid to latestCompletedFullXid, as part of widening it to 64bits. I'm not really a fan of adding that to the variable name, but surrounding code already did it (cf VariableCache->nextFullXid), so I thought I'd follow suit. > It might be useful if this README expanded on the new machinery a bit > instead of just updating the wording to account for it, but I'm not > sure exactly what that would look like or whether it would be too > duplicative of other things. > +void AssertTransactionIdMayBeOnDisk(TransactionId xid) > > Formatting. > > + * Assert that xid is one that we could actually see on disk. > > I don't know what this means. The whole purpose of this routine is > very unclear to me. It's intended to be a double check against > * the secondary effect that it sets RecentGlobalXmin. (This is critical > * for anything that reads heap pages, because HOT may decide to prune > * them even if the process doesn't attempt to modify any tuples.) > + * > + * FIXME: This comment is inaccurate / the code buggy. A snapshot that is > + * not pushed/active does not reliably prevent HOT pruning (->xmin could > + * e.g. be cleared when cache invalidations are processed). > > Something needs to be done here... and in the other similar case. Indeed. I wrote a separate email about it yesterday: https://www.postgresql.org/message-id/20200407072418.ccvnyjbrktyi3rzc%40alap3.anarazel.de > Is this kind of review helpful? Yes! Greetings, Andres Freund
More review, since it sounds like you like it: 0006 - Boring. But I'd probably make this move both xmin and xid back, with related comment changes; see also next comment. 0007 - + TransactionId xidCopy; /* this backend's xid, a copy of this proc's + ProcGlobal->xids[] entry. */ Can we please NOT put Copy into the name like that? Pretty please? + int pgxactoff; /* offset into various ProcGlobal-> arrays + * NB: can change any time unless locks held! + */ I'm going to add the helpful comment "NB: can change any time unless locks held!" to every data structure in the backend that is in shared memory and not immutable. No need, of course, to mention WHICH locks... On a related note, PROC_HDR really, really, really needs comments explaining the locking regimen for the new xids field. + ProcGlobal->xids[pgxactoff] = InvalidTransactionId; Apparently this array is not dense in the sense that it excludes unused slots, but comments elsewhere don't seem to entirely agree. Maybe the comments discussing how it is "dense" need to be a little more precise about this. + for (int i = 0; i < nxids; i++) I miss my C89. Yeah, it's just me. - if (!suboverflowed) + if (suboverflowed) + continue; + Do we really need to do this kind of diddling in this patch? I mean yes to the idea, but no to things that are going to make it harder to understand what happened if this blows up. + uint32 TotalProcs = MaxBackends + NUM_AUXILIARY_PROCS + max_prepared_xacts; /* ProcGlobal */ size = add_size(size, sizeof(PROC_HDR)); - /* MyProcs, including autovacuum workers and launcher */ - size = add_size(size, mul_size(MaxBackends, sizeof(PGPROC))); - /* AuxiliaryProcs */ - size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(PGPROC))); - /* Prepared xacts */ - size = add_size(size, mul_size(max_prepared_xacts, sizeof(PGPROC))); - /* ProcStructLock */ + size = add_size(size, mul_size(TotalProcs, sizeof(PGPROC))); This seems like a bad idea. If we establish a precedent that it's OK to have sizing routines that don't use add_size() and mul_size(), people are going to cargo cult that into places where there is more risk of overflow than there is here. You've got a bunch of different places that talk about the new PGXACT array and they are somewhat redundant yet without saying exactly the same thing every time either. I think that needs cleanup. One thing I didn't see is any clear discussion of what happens if the two copies of the XID information don't agree with each other. That should be added someplace, either in an appropriate code comment or in a README or something. I *think* both are protected by the same locks, but there's also some unlocked access to those structure members, so it's not entirely a slam dunk. ...Robert
Hi, On 2020-04-07 10:51:12 -0700, Andres Freund wrote: > > +void AssertTransactionIdMayBeOnDisk(TransactionId xid) > > > > Formatting. > > > > + * Assert that xid is one that we could actually see on disk. > > > > I don't know what this means. The whole purpose of this routine is > > very unclear to me. > > It's intended to be a double check against forgetting things...? Err: It is intended to make it easier to detect cases where the passed TransactionId is not safe against wraparound. If there is protection against wraparound, then the xid a) may never be older than ShmemVariableCache->oldestXid (since otherwise the rel/datfrozenxid could not have advanced past the xid, and because oldestXid is what what prevents ->nextFullXid from advancing far enough to cause a wraparound) b) cannot be >= ShmemVariableCache->nextFullXid. If it is, it cannot recently have come from GetNewTransactionId(), and thus there is no anti-wraparound protection either. As full wraparounds are painful to exercise in testing, AssertTransactionIdMayBeOnDisk() is intended to make it easier to detect potential hazards. The reason for the *OnDisk naming is that [oldestXid, nextFullXid) is the appropriate check for values actually stored in tables. There could, and probably should, be a narrower assertion ensuring that a xid is protected against being pruned away (i.e. a PGPROC's xmin covering it). The reason for being concerned enough in the new code to add the new assertion helper (as well as a major motivating reason for making the horizons 64 bit xids) is that it's much harder to ensure that "global xmin" style horizons don't wrap around. By definition they include other backend's ->xmin, and those can be released without a lock at any time. As a lot of wraparound issues are triggered by very longrunning transactions, it is not even unlikely to hit such problems: At some point somebody is going to kill that old backend and ->oldestXid will advance very quickly. There is a lot of code that is pretty unsafe around wraparounds... They are getting easier and easier to hit on a regular schedule in production (plenty of databases that hit wraparounds multiple times a week). And I don't think we as PG developers often don't quite take that into account. Does that make some sense? Do you have a better suggestion for a name? Greetings, Andres Freund
On Tue, Apr 7, 2020 at 11:28 AM Andres Freund <andres@anarazel.de> wrote: > There is a lot of code that is pretty unsafe around wraparounds... They > are getting easier and easier to hit on a regular schedule in production > (plenty of databases that hit wraparounds multiple times a week). And I > don't think we as PG developers often don't quite take that into > account. It would be nice if there was high level documentation on wraparound hazards. Maybe even a dedicated README file. -- Peter Geoghegan
On Tue, Apr 7, 2020 at 2:28 PM Andres Freund <andres@anarazel.de> wrote:
> Does that make some sense? Do you have a better suggestion for a name?
I think it makes sense. I have two basic problems with the name. The
first is that "on disk" doesn't seem to be a very clear way of
describing what you're actually checking here, and it definitely
doesn't refer to an existing concept which sophisticated hackers can
be expected to understand. The second is that "may" is ambiguous in
English: it can either mean that something is permissible ("Johnny,
you may go to the bathroom") or that we do not have certain knowledge
of it ("Johnny may be in the bathroom"). When it is followed by "be",
it usually has the latter sense, although there are exceptions (e.g.
"She may be discharged from the hospital today if she wishes, but we
recommend that she stay for another day"). Consequently, I found that
use of "may be" in this context wicked confusing. What came to mind
was:
bool
RobertMayBeAGiraffe(void)
{
return true; // i mean, i haven't seen him since last week, so who knows?
}
So I suggest a name with "Is" or no verb, rather than one with
"MayBe." And I suggest something else instead of "OnDisk," e.g.
AssertTransactionIdIsInUsableRange() or
TransactionIdIsInAllowableRange() or
AssertTransactionIdWraparoundProtected(). I kind of like that last
one, but YMMV.
I wish to clarify that in sending these review emails I am taking no
position on whether or not it is prudent to commit any or all of them.
I do not think we can rule out the possibility that they will Break
Things, but neither do I wish to be seen as That Guy Who Stands In The
Way of Important Improvements. Time does not permit me a detailed
review anyway. So, these comments are provided in the hope that they
may be useful but without endorsement or acrimony. If other people
want to endorse or, uh, acrimoniate, based on my comments, that is up
to them.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Tue, Apr 7, 2020 at 1:51 PM Andres Freund <andres@anarazel.de> wrote: > > ComputedHorizons seems like a fairly generic name. I think there's > > some relationship between InvisibleToEveryoneState and > > ComputedHorizons that should be brought out more clearly by the naming > > and the comments. > > I don't like the naming of ComputedHorizons, ComputeTransactionHorizons > much... But I find it hard to come up with something that's meaningfully > better. It would help to stick XID in there, like ComputedXIDHorizons. What I find really baffling is that you seem to have two structures in the same file that have essentially the same purpose, but the second one (ComputedHorizons) has a lot more stuff in it. I can't understand why. > What's the inconsistency? The dropped replication_ vs dropped FullXid > postfix? Yeah, just having the member names be randomly different between the structs. Really harms greppability. > > Generally, heap_prune_satisfies_vacuum looks pretty good. The > > limited_oldest_committed naming is confusing, but the comments make it > > a lot clearer. > > I didn't like _committed much either. But couldn't come up with > something short. _relied_upon? oldSnapshotLimitUsed or old_snapshot_limit_used, like currentCommandIdUsed? > It's just adjusting for the changed name of latestCompletedXid to > latestCompletedFullXid, as part of widening it to 64bits. I'm not > really a fan of adding that to the variable name, but surrounding code > already did it (cf VariableCache->nextFullXid), so I thought I'd follow > suit. Oops, that was me misreading the diff. Sorry for the noise. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2020-04-07 14:28:09 -0400, Robert Haas wrote:
> More review, since it sounds like you like it:
>
> 0006 - Boring. But I'd probably make this move both xmin and xid back,
> with related comment changes; see also next comment.
>
> 0007 -
>
> + TransactionId xidCopy; /* this backend's xid, a copy of this proc's
> + ProcGlobal->xids[] entry. */
>
> Can we please NOT put Copy into the name like that? Pretty please?
Do you have a suggested naming scheme? Something indicating that it's
not the only place that needs to be updated?
> + int pgxactoff; /* offset into various ProcGlobal-> arrays
> + * NB: can change any time unless locks held!
> + */
>
> I'm going to add the helpful comment "NB: can change any time unless
> locks held!" to every data structure in the backend that is in shared
> memory and not immutable. No need, of course, to mention WHICH
> locks...
I think it's more on-point here, because we need to hold either of the
locks* even, for changes to a backend's own status that one reasonably
could expect would be safe to at least inspect. E.g looking at
ProcGlobal->xids[MyProc->pgxactoff]
doesn't look suspicious, but could very well return another backends
xid, if neither ProcArrayLock nor XidGenLock is held (because a
ProcArrayRemove() could have changed pgxactoff if a previous entry was
removed).
*see comment at PROC_HDR:
*
* Adding/Removing an entry into the procarray requires holding *both*
* ProcArrayLock and XidGenLock in exclusive mode (in that order). Both are
* needed because the dense arrays (see below) are accessed from
* GetNewTransactionId() and GetSnapshotData(), and we don't want to add
* further contention by both using one lock. Adding/Removing a procarray
* entry is much less frequent.
*/
typedef struct PROC_HDR
{
/* Array of PGPROC structures (not including dummies for prepared txns) */
PGPROC *allProcs;
/*
* Arrays with per-backend information that is hotly accessed, indexed by
* PGPROC->pgxactoff. These are in separate arrays for three reasons:
* First, to allow for as tight loops accessing the data as
* possible. Second, to prevent updates of frequently changing data from
* invalidating cachelines shared with less frequently changing
* data. Third to condense frequently accessed data into as few cachelines
* as possible.
*
* When entering a PGPROC for 2PC transactions with ProcArrayAdd(), those
* copies are used to provide the contents of the dense data, and will be
* transferred by ProcArrayAdd() while it already holds ProcArrayLock.
*/
there's also
* The various *Copy fields are copies of the data in ProcGlobal arrays that
* can be accessed without holding ProcArrayLock / XidGenLock (see PROC_HDR
* comments).
I had a more explicit warning/explanation about the dangers of accessing
the arrays without locks, but apparently went to far when reducing
duplicated comments.
> On a related note, PROC_HDR really, really, really needs comments
> explaining the locking regimen for the new xids field.
I'll expand the above, in particular highlighting the danger of
pgxactoff changing.
> + ProcGlobal->xids[pgxactoff] = InvalidTransactionId;
>
> Apparently this array is not dense in the sense that it excludes
> unused slots, but comments elsewhere don't seem to entirely agree.
What do you mean with "unused slots"? Backends that committed?
Dense is intended to describe that the arrays only contain currently
"live" entries. I.e. that the first procArray->numProcs entries in each
array have the data for all procs (including prepared xacts) that are
"connected". This is extending the concept that already existed for
procArray->pgprocnos.
Wheras the PGPROC/PGXACT arrays have "unused" entries interspersed.
This is what previously lead to the slow loop in GetSnapshotData(),
where we had to iterate over PGXACTs over an indirection in
procArray->pgprocnos. I.e. to only look at in-use PGXACTs we had to go
through allProcs[arrayP->pgprocnos[i]], which is, uh, suboptimal for
a performance critical routine holding a central lock.
I'll try to expand the comments around dense, but if you have a better
descriptor.
> Maybe the comments discussing how it is "dense" need to be a little
> more precise about this.
>
> + for (int i = 0; i < nxids; i++)
>
> I miss my C89. Yeah, it's just me.
Oh, dear god. I hate declaring variables like 'i' on function scope. The
bug that haunted me the longest in the development of this patch was in
XidCacheRemoveRunningXids, where there are both i and j, and a macro
XidCacheRemove(i), but the macro gets passed j as i.
> - if (!suboverflowed)
> + if (suboverflowed)
> + continue;
> +
>
> Do we really need to do this kind of diddling in this patch? I mean
> yes to the idea, but no to things that are going to make it harder to
> understand what happened if this blows up.
I can try to reduce those differences. Given the rest of the changes it
didn't seem likely to matter. I found it hard to keep the branches
nesting in my head when seeing:
}
}
}
}
}
> + uint32 TotalProcs = MaxBackends + NUM_AUXILIARY_PROCS + max_prepared_xacts;
>
> /* ProcGlobal */
> size = add_size(size, sizeof(PROC_HDR));
> - /* MyProcs, including autovacuum workers and launcher */
> - size = add_size(size, mul_size(MaxBackends, sizeof(PGPROC)));
> - /* AuxiliaryProcs */
> - size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(PGPROC)));
> - /* Prepared xacts */
> - size = add_size(size, mul_size(max_prepared_xacts, sizeof(PGPROC)));
> - /* ProcStructLock */
> + size = add_size(size, mul_size(TotalProcs, sizeof(PGPROC)));
>
> This seems like a bad idea. If we establish a precedent that it's OK
> to have sizing routines that don't use add_size() and mul_size(),
> people are going to cargo cult that into places where there is more
> risk of overflow than there is here.
Hm. I'm not sure I see the problem. Are you concerned that TotalProcs
would overflow due to too big MaxBackends or max_prepared_xacts? The
multiplication itself is still protected by add_size(). It didn't seem
correct to use add_size for the TotalProcs addition, since that's not
really a size. And since the limit for procs is much lower than
UINT32_MAX...
It seems worse to add a separate add_size calculation for each type of
proc entry, for for each of the individual arrays. We'd end up with
size = add_size(size, sizeof(PROC_HDR));
size = add_size(size, mul_size(MaxBackends, sizeof(PGPROC)));
size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(PGPROC)));
size = add_size(size, mul_size(max_prepared_xacts, sizeof(PGPROC)));
size = add_size(size, sizeof(slock_t));
size = add_size(size, mul_size(MaxBackends, sizeof(sizeof(*ProcGlobal->xids))));
size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(sizeof(*ProcGlobal->xids)));
size = add_size(size, mul_size(max_prepared_xacts, sizeof(sizeof(*ProcGlobal->xids))));
size = add_size(size, mul_size(MaxBackends, sizeof(sizeof(*ProcGlobal->subxidStates))));
size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(sizeof(*ProcGlobal->subxidStates)));
size = add_size(size, mul_size(max_prepared_xacts, sizeof(sizeof(*ProcGlobal->subxidStates))));
size = add_size(size, mul_size(MaxBackends, sizeof(sizeof(*ProcGlobal->vacuumFlags))));
size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(sizeof(*ProcGlobal->vacuumFlags)));
size = add_size(size, mul_size(max_prepared_xacts, sizeof(sizeof(*ProcGlobal->vacuumFlags))));
instead of
size = add_size(size, sizeof(PROC_HDR));
size = add_size(size, mul_size(TotalProcs, sizeof(PGPROC)));
size = add_size(size, sizeof(slock_t));
size = add_size(size, mul_size(TotalProcs, sizeof(*ProcGlobal->xids)));
size = add_size(size, mul_size(TotalProcs, sizeof(*ProcGlobal->subxidStates)));
size = add_size(size, mul_size(TotalProcs, sizeof(*ProcGlobal->vacuumFlags)));
which seems clearly worse.
> You've got a bunch of different places that talk about the new PGXACT
> array and they are somewhat redundant yet without saying exactly the
> same thing every time either. I think that needs cleanup.
Could you point out a few of those comments, I'm not entirely sure which
you're talking about?
> One thing I didn't see is any clear discussion of what happens if the
> two copies of the XID information don't agree with each other.
It should never happen. There's asserts that try to ensure that. For the
xid-less case:
ProcArrayEndTransaction(PGPROC *proc, TransactionId latestXid)
...
Assert(!TransactionIdIsValid(proc->xidCopy));
Assert(proc->subxidStatusCopy.count == 0);
and for the case of having an xid:
ProcArrayEndTransactionInternal(PGPROC *proc, TransactionId latestXid)
...
Assert(ProcGlobal->xids[pgxactoff] == proc->xidCopy);
...
Assert(ProcGlobal->subxidStates[pgxactoff].count == proc->subxidStatusCopy.count &&
ProcGlobal->subxidStates[pgxactoff].overflowed == proc->subxidStatusCopy.overflowed);
> That should be added someplace, either in an appropriate code comment
> or in a README or something. I *think* both are protected by the same
> locks, but there's also some unlocked access to those structure
> members, so it's not entirely a slam dunk.
Hm. I considered is allowed to modify those and when to really be
covered by the existing comments in transam/README. In particular in the
"Interlocking Transaction Begin, Transaction End, and Snapshots"
section.
Do you think that a comment explaining that the *Copy version has to be
kept up2date at all times (except when not yet added with ProcArrayAdd)
would ameliorate that concern?
Greetings,
Andres Freund
0008 - Here again, I greatly dislike putting Copy in the name. It makes little sense to pretend that either is the original and the other is the copy. You just have the same data in two places. If one of them is more authoritative, the place to explain that is in the comments, not by elongating the structure member name and supposing anyone will be able to make something of that. + * + * XXX: That's why this is using vacuumFlagsCopy. I am not sure there's any problem with the code that needs fixing here, so I might think about getting rid of this XXX. But this gets back to my complaint about the locking regime being unclear. What I think you need to do here is rephrase the previous paragraph so that it explains the reason for using this copy a bit better. Like "We read the copy of vacuumFlags from PGPROC rather than visiting the copy attached to ProcGlobal because we can do that without taking a lock. See fuller explanation in <place>." Or whatever. 0009, 0010 - I think you've got this whole series of things divided up too finely. Like, 0005 feels like the meat of it, and that has a bunch of things in it that could plausible be separated out as separate commits. 0007 also seems to do more than one kind of thing (see my comment regarding moving some of that into 0006). But whacking everything around like a crazy man in 0005 and a little more in 0007 and then doing the following cleanup in these little tiny steps seems pretty lame. Separating 0009 from 0010 is maybe the clearest example of that, but IMHO it's pretty unclear why both of these shouldn't be merged with 0008. To be clear, I exaggerate for effect. 0005 is not whacking everything around like a crazy man. But it is a non-minimal patch, whereas I consider 0009 and 0010 to be sub-minimal. My comments on the Copy naming apply here as well. I am also starting to wonder why exactly we need two copies of all this stuff. Perhaps I've just failed to absorb the idea for having read the patch too briefly, but I think that we need to make sure that it's super-clear why we're doing that. If we just needed it for one field because $REASONS, that would be one thing, but if we need it for all of them then there must be some underlying principle here that needs a good explanation in an easy-to-find and centrally located place. 0011 - + * Number of top-level transactions that completed in some form since the + * start of the server. This currently is solely used to check whether + * GetSnapshotData() needs to recompute the contents of the snapshot, or + * not. There are likely other users of this. Always above 1. Does it only count XID-bearing transactions? If so, best mention that. + * transactions completed since the last GetSnapshotData().. Too many periods. + /* Same with CSN */ + ShmemVariableCache->xactCompletionCount++; If I didn't know that CSN stood for commit sequence number from reading years of mailing list traffic, I'd be lost here. So I think this comment shouldn't use that term. +GetSnapshotDataFillTooOld(Snapshot snapshot) Uh... no clue what's going on here. Granted the code had no comments in the old place either, so I guess it's not worse, but even the name of the new function is pretty incomprehensible. + * Helper function for GetSnapshotData() that check if the bulk of the checks + * the fields that need to change and returns true. false is returned + * otherwise. Otherwise, it returns false. + * It is safe to re-enter the snapshot's xmin. This can't cause xmin to go I know what it means to re-enter a building, but I don't know what it means to re-enter the snapshot's xmin. This whole comment seems a bit murky. ...Robert
Hi,
On 2020-04-07 14:51:52 -0400, Robert Haas wrote:
> On Tue, Apr 7, 2020 at 2:28 PM Andres Freund <andres@anarazel.de> wrote:
> > Does that make some sense? Do you have a better suggestion for a name?
>
> I think it makes sense. I have two basic problems with the name. The
> first is that "on disk" doesn't seem to be a very clear way of
> describing what you're actually checking here, and it definitely
> doesn't refer to an existing concept which sophisticated hackers can
> be expected to understand. The second is that "may" is ambiguous in
> English: it can either mean that something is permissible ("Johnny,
> you may go to the bathroom") or that we do not have certain knowledge
> of it ("Johnny may be in the bathroom"). When it is followed by "be",
> it usually has the latter sense, although there are exceptions (e.g.
> "She may be discharged from the hospital today if she wishes, but we
> recommend that she stay for another day"). Consequently, I found that
> use of "may be" in this context wicked confusing.
Well, it *is* only a vague test :). It shouldn't ever have a false
positive, but there's plenty chance for false negatives (if wrapped
around far enough).
> So I suggest a name with "Is" or no verb, rather than one with
> "MayBe." And I suggest something else instead of "OnDisk," e.g.
> AssertTransactionIdIsInUsableRange() or
> TransactionIdIsInAllowableRange() or
> AssertTransactionIdWraparoundProtected(). I kind of like that last
> one, but YMMV.
Make sense - but they all seem to express a bit more certainty than I
think the test actually provides.
I explicitly did not want (and added a comment to that affect) have
something like TransactionIdIsInAllowableRange(), because there never
can be a safe use of its return value, as far as I can tell.
The "OnDisk" was intended to clarify that the range it verifies is
whether it'd be ok for the xid to have been found in a relation.
Greetings,
Andres Freund
Hi, On 2020-04-07 15:03:46 -0400, Robert Haas wrote: > On Tue, Apr 7, 2020 at 1:51 PM Andres Freund <andres@anarazel.de> wrote: > > > ComputedHorizons seems like a fairly generic name. I think there's > > > some relationship between InvisibleToEveryoneState and > > > ComputedHorizons that should be brought out more clearly by the naming > > > and the comments. > > > > I don't like the naming of ComputedHorizons, ComputeTransactionHorizons > > much... But I find it hard to come up with something that's meaningfully > > better. > > It would help to stick XID in there, like ComputedXIDHorizons. What I > find really baffling is that you seem to have two structures in the > same file that have essentially the same purpose, but the second one > (ComputedHorizons) has a lot more stuff in it. I can't understand why. ComputedHorizons are the various "accurate" horizons computed by ComputeTransactionHorizons(). That's used to determine a horizon for vacuuming (via GetOldestVisibleTransactionId()) and other similar use cases. The various InvisibleToEveryoneState variables contain the boundary based horizons, and are updated / initially filled by GetSnapshotData(). When the a tested value falls between the boundaries, we update the approximate boundaries using ComputeTransactionHorizons(). That briefly makes the boundaries in the InvisibleToEveryoneState accurate - but future GetSnapshotData() calls will increase the definitely_needed_bound (if transactions committed since). The ComputedHorizons fields could instead just be pointer based arguments to ComputeTransactionHorizons(), but that seems clearly worse. I'll change ComputedHorizons's comment to say that it's the result of ComputeTransactionHorizons(), not the "state". > > What's the inconsistency? The dropped replication_ vs dropped FullXid > > postfix? > > Yeah, just having the member names be randomly different between the > structs. Really harms greppability. The long names make it hard to keep line lengths in control, in particular when also involving the long macro names for TransactionId / FullTransactionId comparators... > > > Generally, heap_prune_satisfies_vacuum looks pretty good. The > > > limited_oldest_committed naming is confusing, but the comments make it > > > a lot clearer. > > > > I didn't like _committed much either. But couldn't come up with > > something short. _relied_upon? > > oldSnapshotLimitUsed or old_snapshot_limit_used, like currentCommandIdUsed? Will go for old_snapshot_limit_used, and rename the other variables to old_snapshot_limit_ts, old_snapshot_limit_xmin. Greetings, Andres Freund
On Tue, Apr 7, 2020 at 3:31 PM Andres Freund <andres@anarazel.de> wrote: > Well, it *is* only a vague test :). It shouldn't ever have a false > positive, but there's plenty chance for false negatives (if wrapped > around far enough). Sure, but I think you get my point. Asserting that something "might be" true isn't much of an assertion. Saying that it's in the correct range is not to say there can't be a problem - but we're saying that it IS in the expect range, not that it may or may not be. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Apr 7, 2020 at 3:24 PM Andres Freund <andres@anarazel.de> wrote: > > 0007 - > > > > + TransactionId xidCopy; /* this backend's xid, a copy of this proc's > > + ProcGlobal->xids[] entry. */ > > > > Can we please NOT put Copy into the name like that? Pretty please? > > Do you have a suggested naming scheme? Something indicating that it's > not the only place that needs to be updated? I don't think trying to indicate that in the structure member names is a useful idea. I think you should give them the same names, maybe with an "s" to pluralize the copy hanging off of ProcGlobal, and put a comment that says something like: We keep two copies of each of the following three fields. One copy is here in the PGPROC, and the other is in a more densely-packed array hanging off of PGXACT. Both copies of the value must always be updated at the same time and under the same locks, so that it is always the case that MyProc->xid == ProcGlobal->xids[MyProc->pgprocno] and similarly for vacuumFlags and WHATEVER. Note, however, that the arrays attached to ProcGlobal only contain entries for PGPROC structures that are currently part of the ProcArray (i.e. there is currently a backend for that PGPROC). We use those arrays when STUFF and the copies in the individual PGPROC when THINGS. > I think it's more on-point here, because we need to hold either of the > locks* even, for changes to a backend's own status that one reasonably > could expect would be safe to at least inspect. It's just too brief and obscure to be useful. > > + ProcGlobal->xids[pgxactoff] = InvalidTransactionId; > > > > Apparently this array is not dense in the sense that it excludes > > unused slots, but comments elsewhere don't seem to entirely agree. > > What do you mean with "unused slots"? Backends that committed? Backends that have no XID. You mean, I guess, that it is "dense" in the sense that only live backends are in there, not "dense" in the sense that only active write transactions are in there. It would be nice to nail that down better; the wording I suggested above might help. > > + uint32 TotalProcs = MaxBackends + NUM_AUXILIARY_PROCS + max_prepared_xacts; > > > > /* ProcGlobal */ > > size = add_size(size, sizeof(PROC_HDR)); > > - /* MyProcs, including autovacuum workers and launcher */ > > - size = add_size(size, mul_size(MaxBackends, sizeof(PGPROC))); > > - /* AuxiliaryProcs */ > > - size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(PGPROC))); > > - /* Prepared xacts */ > > - size = add_size(size, mul_size(max_prepared_xacts, sizeof(PGPROC))); > > - /* ProcStructLock */ > > + size = add_size(size, mul_size(TotalProcs, sizeof(PGPROC))); > > > > This seems like a bad idea. If we establish a precedent that it's OK > > to have sizing routines that don't use add_size() and mul_size(), > > people are going to cargo cult that into places where there is more > > risk of overflow than there is here. > > Hm. I'm not sure I see the problem. Are you concerned that TotalProcs > would overflow due to too big MaxBackends or max_prepared_xacts? The > multiplication itself is still protected by add_size(). It didn't seem > correct to use add_size for the TotalProcs addition, since that's not > really a size. And since the limit for procs is much lower than > UINT32_MAX... I'm concerned that there are 0 uses of add_size in any shared-memory sizing function, and I think it's best to keep it that way. If you initialize TotalProcs = add_size(MaxBackends, add_size(NUM_AUXILIARY_PROCS, max_prepared_xacts)) then I'm happy. I think it's a desperately bad idea to imagine that we can dispense with overflow checks here and be safe. It's just too easy for that to become false due to future code changes, or get copied to other places where it's unsafe now. > > You've got a bunch of different places that talk about the new PGXACT > > array and they are somewhat redundant yet without saying exactly the > > same thing every time either. I think that needs cleanup. > > Could you point out a few of those comments, I'm not entirely sure which > you're talking about? + /* + * Also allocate a separate arrays for data that is frequently (e.g. by + * GetSnapshotData()) accessed from outside a backend. There is one entry + * in each for every *live* PGPROC entry, and they are densely packed so + * that the first procArray->numProc entries are all valid. The entries + * for a PGPROC in those arrays are at PGPROC->pgxactoff. + * + * Note that they may not be accessed without ProcArrayLock held! Upon + * ProcArrayRemove() later entries will be moved. + * + * These are separate from the main PGPROC array so that the most heavily + * accessed data is stored contiguously in memory in as few cache lines as + * possible. This provides significant performance benefits, especially on + * a multiprocessor system. + */ + * Arrays with per-backend information that is hotly accessed, indexed by + * PGPROC->pgxactoff. These are in separate arrays for three reasons: + * First, to allow for as tight loops accessing the data as + * possible. Second, to prevent updates of frequently changing data from + * invalidating cachelines shared with less frequently changing + * data. Third to condense frequently accessed data into as few cachelines + * as possible. + * + * The various *Copy fields are copies of the data in ProcGlobal arrays that + * can be accessed without holding ProcArrayLock / XidGenLock (see PROC_HDR + * comments). + * Adding/Removing an entry into the procarray requires holding *both* + * ProcArrayLock and XidGenLock in exclusive mode (in that order). Both are + * needed because the dense arrays (see below) are accessed from + * GetNewTransactionId() and GetSnapshotData(), and we don't want to add + * further contention by both using one lock. Adding/Removing a procarray + * entry is much less frequent. I'm not saying these are all entirely redundant with each other; that's not so. But I don't think it gives a terribly clear grasp of the overall picture either, even taking all of them together. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi,
On 2020-04-07 15:26:36 -0400, Robert Haas wrote:
> 0008 -
>
> Here again, I greatly dislike putting Copy in the name. It makes
> little sense to pretend that either is the original and the other is
> the copy. You just have the same data in two places. If one of them is
> more authoritative, the place to explain that is in the comments, not
> by elongating the structure member name and supposing anyone will be
> able to make something of that.
Ok.
> 0009, 0010 -
>
> I think you've got this whole series of things divided up too finely.
> Like, 0005 feels like the meat of it, and that has a bunch of things
> in it that could plausible be separated out as separate commits. 0007
> also seems to do more than one kind of thing (see my comment regarding
> moving some of that into 0006). But whacking everything around like a
> crazy man in 0005 and a little more in 0007 and then doing the
> following cleanup in these little tiny steps seems pretty lame.
> Separating 0009 from 0010 is maybe the clearest example of that, but
> IMHO it's pretty unclear why both of these shouldn't be merged with
> 0008.
I found it a *lot* easier to review / evolve them this way. I e.g. had
an earlier version in which the subxid part of the change worked
substantially differently (it tried to elide the overflowed bool, by
definining -1 as the indicator for overflows), and it'd been way harder
to change that if I didn't have a patch with *just* the subxid changes.
I'd not push them separated by time, but I do think it'd make sense to
push them as separate commits. I think it's easier to review them in
case of a bug in a separate area.
> My comments on the Copy naming apply here as well. I am also starting
> to wonder why exactly we need two copies of all this stuff. Perhaps
> I've just failed to absorb the idea for having read the patch too
> briefly, but I think that we need to make sure that it's super-clear
> why we're doing that. If we just needed it for one field because
> $REASONS, that would be one thing, but if we need it for all of them
> then there must be some underlying principle here that needs a good
> explanation in an easy-to-find and centrally located place.
The main reason is that we want to be able to cheaply check the current
state of the variables (mostly when checking a backend's own state). We
can't access the "dense" ones without holding a lock, but we e.g. don't
want to make ProcArrayEndTransactionInternal() take a lock just to check
if vacuumFlags is set.
It turns out to also be good for performance to have the copy for
another reason: The "dense" arrays share cachelines with other
backends. That's worth it because it allows to make GetSnapshotData(),
by far the most frequent operation, touch fewer cache lines. But it also
means that it's more likely that a backend's "dense" array entry isn't
in a local cpu cache (it'll be pulled out of there when modified in
another backend). In many cases we don't need the shared entry at commit
etc time though, we just need to check if it is set - and most of the
time it won't be. The local entry allows to do that cheaply.
Basically it makes sense to access the PGPROC variable when checking a
single backend's data, especially when we have to look at the PGPROC for
other reasons already. It makes sense to look at the "dense" arrays if
we need to look at many / most entries, because we then benefit from the
reduced indirection and better cross-process cacheability.
> 0011 -
>
> + * Number of top-level transactions that completed in some form since the
> + * start of the server. This currently is solely used to check whether
> + * GetSnapshotData() needs to recompute the contents of the snapshot, or
> + * not. There are likely other users of this. Always above 1.
>
> Does it only count XID-bearing transactions? If so, best mention that.
Oh, good point.
> +GetSnapshotDataFillTooOld(Snapshot snapshot)
>
> Uh... no clue what's going on here. Granted the code had no comments
> in the old place either, so I guess it's not worse, but even the name
> of the new function is pretty incomprehensible.
It fills the old_snapshot_threshold fields of a Snapshot.
> + * It is safe to re-enter the snapshot's xmin. This can't cause xmin to go
>
> I know what it means to re-enter a building, but I don't know what it
> means to re-enter the snapshot's xmin.
Re-entering it into the procarray, thereby preventing rows that the
snapshot could see from being removed.
> This whole comment seems a bit murky.
How about:
/*
* If the current xactCompletionCount is still the same as it was at the
* time the snapshot was built, we can be sure that rebuilding the
* contents of the snapshot the hard way would result in the same snapshot
* contents:
*
* As explained in transam/README, the set of xids considered running by
* GetSnapshotData() cannot change while ProcArrayLock is held. Snapshot
* contents only depend on transactions with xids and xactCompletionCount
* is incremented whenever a transaction with an xid finishes (while
* holding ProcArrayLock) exclusively). Thus the xactCompletionCount check
* ensures we would detect if the snapshot would have changed.
*
* As the snapshot contents are the same as it was before, it is is safe
* to re-enter the snapshot's xmin into the PGPROC array. None of the rows
* visible under the snapshot could already have been removed (that'd
* require the set of running transactions to change) and it fulfills the
* requirement that concurrent GetSnapshotData() calls yield the same
* xmin.
*/
Greetings,
Andres Freund
Hi,
On 2020-04-07 16:13:07 -0400, Robert Haas wrote:
> On Tue, Apr 7, 2020 at 3:24 PM Andres Freund <andres@anarazel.de> wrote:
> > > + ProcGlobal->xids[pgxactoff] = InvalidTransactionId;
> > >
> > > Apparently this array is not dense in the sense that it excludes
> > > unused slots, but comments elsewhere don't seem to entirely agree.
> >
> > What do you mean with "unused slots"? Backends that committed?
>
> Backends that have no XID. You mean, I guess, that it is "dense" in
> the sense that only live backends are in there, not "dense" in the
> sense that only active write transactions are in there.
Correct.
I tried the "only active write transaction" approach, btw, and had a
hard time making it scale well (due to the much more frequent moving of
entries at commit/abort time). If we were to go to a 'only active
transactions' array at some point we'd imo still need pretty much all
the other changes made here - so I'm not worried about it for now.
> > > + uint32 TotalProcs = MaxBackends + NUM_AUXILIARY_PROCS + max_prepared_xacts;
> > >
> > > /* ProcGlobal */
> > > size = add_size(size, sizeof(PROC_HDR));
> > > - /* MyProcs, including autovacuum workers and launcher */
> > > - size = add_size(size, mul_size(MaxBackends, sizeof(PGPROC)));
> > > - /* AuxiliaryProcs */
> > > - size = add_size(size, mul_size(NUM_AUXILIARY_PROCS, sizeof(PGPROC)));
> > > - /* Prepared xacts */
> > > - size = add_size(size, mul_size(max_prepared_xacts, sizeof(PGPROC)));
> > > - /* ProcStructLock */
> > > + size = add_size(size, mul_size(TotalProcs, sizeof(PGPROC)));
> > >
> > > This seems like a bad idea. If we establish a precedent that it's OK
> > > to have sizing routines that don't use add_size() and mul_size(),
> > > people are going to cargo cult that into places where there is more
> > > risk of overflow than there is here.
> >
> > Hm. I'm not sure I see the problem. Are you concerned that TotalProcs
> > would overflow due to too big MaxBackends or max_prepared_xacts? The
> > multiplication itself is still protected by add_size(). It didn't seem
> > correct to use add_size for the TotalProcs addition, since that's not
> > really a size. And since the limit for procs is much lower than
> > UINT32_MAX...
>
> I'm concerned that there are 0 uses of add_size in any shared-memory
> sizing function, and I think it's best to keep it that way.
I can't make sense of that sentence?
We already have code like this, and have for a long time:
/* Size of the ProcArray structure itself */
#define PROCARRAY_MAXPROCS (MaxBackends + max_prepared_xacts)
adding NUM_AUXILIARY_PROCS doesn't really change that, does it?
> If you initialize TotalProcs = add_size(MaxBackends,
> add_size(NUM_AUXILIARY_PROCS, max_prepared_xacts)) then I'm happy.
Will do.
Greetings,
Andres Freund
Hi
On 2020-04-07 05:15:03 -0700, Andres Freund wrote:
> SEE BELOW: What, and what not, to do for v13.
>
> [ description of changes ]
>
> I think this is pretty close to being committable.
>
> But: This patch came in very late for v13, and it took me much longer to
> polish it up than I had hoped (partially distraction due to various bugs
> I found (in particular snapshot_too_old), partially covid19, partially
> "hell if I know"). The patchset touches core parts of the system. While
> both Thomas and David have done some review, they haven't for the latest
> version (mea culpa).
>
> In many other instances I would say that the above suggests slipping to
> v14, given the timing.
>
> The main reason I am considering pushing is that I think this patcheset
> addresses one of the most common critiques of postgres, as well as very
> common, hard to fix, real-world production issues. GetSnapshotData() has
> been a major bottleneck for about as long as I have been using postgres,
> and this addresses that to a significant degree.
>
> A second reason I am considering it is that, in my opinion, the changes
> are not all that complicated and not even that large. At least not for a
> change to a problem that we've long tried to improve.
>
>
> Obviously we all have a tendency to think our own work is important, and
> that we deserve a bit more leeway than others. So take the above with a
> grain of salt.
I tried hard, but came up short. It's 5 AM, and I am still finding
comments that aren't quite right. For a while I thought I'd be pushing a
few hours ... And even if it were ready now: This is too large a patch
to push this tired (but damn, I'd love to).
Unfortunately adressing Robert's comments made me realize I didn't like
some of my own naming. In particular I started to dislike
InvisibleToEveryone, and some of the procarray.c variables around
"visible". After trying about half a dozen schemes I think I found
something that makes some sense, although I am still not perfectly
happy.
I think the attached set of patches address most of Robert's review
comments, minus a few cases minor quibbles where I thought he was wrong
(fundamentally wrong of course). There are no *Copy fields in PGPROC
anymore, there's a lot more comments above PROC_HDR (not duplicated
elsewhere). I've reduced the interspersed changes to GetSnapshotData()
so those can be done separately.
There's also somewhat meaningful commit messages now. But
snapshot scalability: Move in-progress xids to ProcGlobal->xids[].
needs to be expanded to mention the changed locking requirements.
Realistically it still 2-3 hours of proof-reading.
This makes me sad :(
Вложения
- v9-0001-snapshot-scalability-Don-t-compute-global-horizon.patch
- v9-0002-snapshot-scalability-Move-PGXACT-xmin-back-to-PGP.patch
- v9-0003-snapshot-scalability-Move-in-progress-xids-to-Pro.patch
- v9-0004-snapshot-scalability-Move-PGXACT-vacuumFlags-to-P.patch
- v9-0005-snapshot-scalability-Move-subxact-info-to-ProcGlo.patch
- v9-0006-snapshot-scalability-cache-snapshots-using-a-xact.patch
On Wed, Apr 8, 2020 at 3:43 PM Andres Freund <andres@anarazel.de> wrote: > Realistically it still 2-3 hours of proof-reading. > > This makes me sad :( Can we ask RMT to extend feature freeze for this particular patchset? I think it's reasonable assuming extreme importance of this patchset. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Apr 7, 2020 at 4:27 PM Andres Freund <andres@anarazel.de> wrote: > The main reason is that we want to be able to cheaply check the current > state of the variables (mostly when checking a backend's own state). We > can't access the "dense" ones without holding a lock, but we e.g. don't > want to make ProcArrayEndTransactionInternal() take a lock just to check > if vacuumFlags is set. > > It turns out to also be good for performance to have the copy for > another reason: The "dense" arrays share cachelines with other > backends. That's worth it because it allows to make GetSnapshotData(), > by far the most frequent operation, touch fewer cache lines. But it also > means that it's more likely that a backend's "dense" array entry isn't > in a local cpu cache (it'll be pulled out of there when modified in > another backend). In many cases we don't need the shared entry at commit > etc time though, we just need to check if it is set - and most of the > time it won't be. The local entry allows to do that cheaply. > > Basically it makes sense to access the PGPROC variable when checking a > single backend's data, especially when we have to look at the PGPROC for > other reasons already. It makes sense to look at the "dense" arrays if > we need to look at many / most entries, because we then benefit from the > reduced indirection and better cross-process cacheability. That's a good explanation. I think it should be in the comments or a README somewhere. > How about: > /* > * If the current xactCompletionCount is still the same as it was at the > * time the snapshot was built, we can be sure that rebuilding the > * contents of the snapshot the hard way would result in the same snapshot > * contents: > * > * As explained in transam/README, the set of xids considered running by > * GetSnapshotData() cannot change while ProcArrayLock is held. Snapshot > * contents only depend on transactions with xids and xactCompletionCount > * is incremented whenever a transaction with an xid finishes (while > * holding ProcArrayLock) exclusively). Thus the xactCompletionCount check > * ensures we would detect if the snapshot would have changed. > * > * As the snapshot contents are the same as it was before, it is is safe > * to re-enter the snapshot's xmin into the PGPROC array. None of the rows > * visible under the snapshot could already have been removed (that'd > * require the set of running transactions to change) and it fulfills the > * requirement that concurrent GetSnapshotData() calls yield the same > * xmin. > */ That's nice and clear. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 4/8/20 8:59 AM, Alexander Korotkov wrote: > On Wed, Apr 8, 2020 at 3:43 PM Andres Freund <andres@anarazel.de> wrote: >> Realistically it still 2-3 hours of proof-reading. >> >> This makes me sad :( > > Can we ask RMT to extend feature freeze for this particular patchset? > I think it's reasonable assuming extreme importance of this patchset. One of the features of RMT responsibilities[1] is to be "hands off" as much as possible, so perhaps a reverse ask: how would people feel about this patch going into PG13, knowing that the commit would come after the feature freeze date? My 2¢, with RMT hat off: As mentioned earlier[2], we know that connection scalability is a major pain point with PostgreSQL and any effort that can help alleviate that is a huge win, even in incremental gains. Andres et al experimentation show that this is more than incremental gains, and will certainly make a huge difference in people's PostgreSQL experience. It is one of those features where you can "plug in and win" -- you get a performance benefit just by upgrading. That is not insignificant. However, I also want to ensure that we are fair: in the past there have also been other patches that have been "oh-so-close" to commit before feature freeze but have not made it in (an example escapes me at the moment). Therefore, we really need to have consensus among ourselves that the right decision is to allow this to go in after feature freeze. Did this come in (very) late into the development cycle? Yes, and I think normally that's enough to give cause for pause. But I could also argue that Andres is fixing a "bug" with PostgreSQL (probably several bugs ;) with PostgreSQL -- and perhaps the fixes can't be backpatched per se, but they do improve the overall stability and usability of PostgreSQL and it'd be a shame if we have to wait on them. Lastly, with the ongoing world events, perhaps time that could have been dedicated to this and other patches likely affected their completion. I know most things in my life take way longer than they used to (e.g. taking out the trash/recycles has gone from a 15s to 240s routine). The same could be said about other patches as well, but this one has a far greater impact (a double-edged sword, of course) given it's a feature that everyone uses in PostgreSQL ;) So with my RMT hat off, I say +1 to allowing this post feature freeze, though within a reasonable window. My 2¢, with RMT hat on: I believe in[2] I outlined a way a path for including the patch even at this stage in the game. If it is indeed committed, I think we immediately put it on the "Recheck a mid-Beta" list. I know it's not as trivial to change as something like "Determine if jit="on" by default" (not picking on Andres, I just remember that example from RMT 11), but it at least provides a notable reminder that we need to ensure we test this thoroughly, and point people to really hammer it during beta. So with my RMT hat on, I say +0 but with a ;) Thanks, Jonathan [1] https://wiki.postgresql.org/wiki/Release_Management_Team#History [2] https://www.postgresql.org/message-id/6be8c321-68ea-a865-d8d0-50a3af616463%40postgresql.org
Вложения
On Wed, Apr 8, 2020 at 9:27 AM Jonathan S. Katz <jkatz@postgresql.org> wrote: > One of the features of RMT responsibilities[1] is to be "hands off" as > much as possible, so perhaps a reverse ask: how would people feel about > this patch going into PG13, knowing that the commit would come after the > feature freeze date? Letting something be committed after feature freeze, or at any other time, is just a risk vs. reward trade-off. Every patch carries some chance of breaking stuff or making things worse. And every patch has a chance of making something better that people care about. On general principle, I would categorize this as a moderate-risk patch. It doesn't change SQL syntax like, e.g. MERGE, nor does it touch the on-disk format, like, e.g. INSERT .. ON CONFLICT UPDATE. The changes are relatively localized, unlike, e.g. parallel query. Those are all things that reduce risk. On the other hand, it's a brand new patch which has not been thoroughly reviewed by anyone. Moreover, shakedown time will be minimal because we're so late in the release cycle. if it has subtle synchronization problems or if it regresses performance badly in some cases, we might not find out about any of that until after release. While in theory we could revert it any time, since no SQL syntax or on-disk format is affected, in practice it will be difficult to do that if it's making life better for some people and worse for others. I don't know what the right thing to do is. I agree with everyone who says this is a very important problem, and I have the highest respect for Andres's technical ability. On the other hand, I have been around here long enough to know that deciding whether to allow late commits on the basis of how much we like the feature is a bad plan, because it takes into account only the upside of a commit, and ignores the possible downside risk. Typically, the commit is late because the feature was rushed to completion at the last minute, which can have an effect on quality. I can say, having read through the patches yesterday, that they don't suck, but I can't say that they're fully correct. That's not to say that we shouldn't decide to take them, but it is a concern to be taken seriously. We have made mistakes before in what we shipped that had serious implications for many users and for the project; we should all be wary of making more such mistakes. I am not trying to say that solving problems and making stuff better is NOT important, just that every coin has two sides. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, On 2020-04-08 09:24:13 -0400, Robert Haas wrote: > On Tue, Apr 7, 2020 at 4:27 PM Andres Freund <andres@anarazel.de> wrote: > > The main reason is that we want to be able to cheaply check the current > > state of the variables (mostly when checking a backend's own state). We > > can't access the "dense" ones without holding a lock, but we e.g. don't > > want to make ProcArrayEndTransactionInternal() take a lock just to check > > if vacuumFlags is set. > > > > It turns out to also be good for performance to have the copy for > > another reason: The "dense" arrays share cachelines with other > > backends. That's worth it because it allows to make GetSnapshotData(), > > by far the most frequent operation, touch fewer cache lines. But it also > > means that it's more likely that a backend's "dense" array entry isn't > > in a local cpu cache (it'll be pulled out of there when modified in > > another backend). In many cases we don't need the shared entry at commit > > etc time though, we just need to check if it is set - and most of the > > time it won't be. The local entry allows to do that cheaply. > > > > Basically it makes sense to access the PGPROC variable when checking a > > single backend's data, especially when we have to look at the PGPROC for > > other reasons already. It makes sense to look at the "dense" arrays if > > we need to look at many / most entries, because we then benefit from the > > reduced indirection and better cross-process cacheability. > > That's a good explanation. I think it should be in the comments or a > README somewhere. I had a briefer version in the PROC_HDR comment. I've just expanded it to: * * The denser separate arrays are beneficial for three main reasons: First, to * allow for as tight loops accessing the data as possible. Second, to prevent * updates of frequently changing data (e.g. xmin) from invalidating * cachelines also containing less frequently changing data (e.g. xid, * vacuumFlags). Third to condense frequently accessed data into as few * cachelines as possible. * * There are two main reasons to have the data mirrored between these dense * arrays and PGPROC. First, as explained above, a PGPROC's array entries can * only be accessed with either ProcArrayLock or XidGenLock held, whereas the * PGPROC entries do not require that (obviously there may still be locking * requirements around the individual field, separate from the concerns * here). That is particularly important for a backend to efficiently checks * it own values, which it often can safely do without locking. Second, the * PGPROC fields allow to avoid unnecessary accesses and modification to the * dense arrays. A backend's own PGPROC is more likely to be in a local cache, * whereas the cachelines for the dense array will be modified by other * backends (often removing it from the cache for other cores/sockets). At * commit/abort time a check of the PGPROC value can avoid accessing/dirtying * the corresponding array value. * * Basically it makes sense to access the PGPROC variable when checking a * single backend's data, especially when already looking at the PGPROC for * other reasons already. It makes sense to look at the "dense" arrays if we * need to look at many / most entries, because we then benefit from the * reduced indirection and better cross-process cache-ability. * * When entering a PGPROC for 2PC transactions with ProcArrayAdd(), the data * in the dense arrays is initialized from the PGPROC while it already holds Greetings, Andres Freund
On Wed, Apr 8, 2020 at 09:44:16AM -0400, Robert Haas wrote: > I don't know what the right thing to do is. I agree with everyone who > says this is a very important problem, and I have the highest respect > for Andres's technical ability. On the other hand, I have been around > here long enough to know that deciding whether to allow late commits > on the basis of how much we like the feature is a bad plan, because it > takes into account only the upside of a commit, and ignores the > possible downside risk. Typically, the commit is late because the > feature was rushed to completion at the last minute, which can have an > effect on quality. I can say, having read through the patches > yesterday, that they don't suck, but I can't say that they're fully > correct. That's not to say that we shouldn't decide to take them, but > it is a concern to be taken seriously. We have made mistakes before in > what we shipped that had serious implications for many users and for > the project; we should all be wary of making more such mistakes. I am > not trying to say that solving problems and making stuff better is NOT > important, just that every coin has two sides. If we don't commit this, where does this leave us with the old_snapshot_threshold feature? We remove it in back branches and have no working version in PG 13? That seems kind of bad. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Hi, On 2020-04-08 09:26:42 -0400, Jonathan S. Katz wrote: > On 4/8/20 8:59 AM, Alexander Korotkov wrote: > > On Wed, Apr 8, 2020 at 3:43 PM Andres Freund <andres@anarazel.de> wrote: > >> Realistically it still 2-3 hours of proof-reading. > >> > >> This makes me sad :( > > > > Can we ask RMT to extend feature freeze for this particular patchset? > > I think it's reasonable assuming extreme importance of this patchset. > One of the features of RMT responsibilities[1] is to be "hands off" as > much as possible, so perhaps a reverse ask: how would people feel about > this patch going into PG13, knowing that the commit would come after the > feature freeze date? I'm obviously biased, so I don't think there's much point in responding directly to that question. But I thought it could be helpful if I described what my thoughts about where the patchset is: What made me not commit it "earlier" yesterday was not that I had/have any substantial concerns about the technical details of the patch. But that there were a few too many comments that didn't yet sound quite right, that the commit messages didn't yet explain the architecture / benefits well enough, and that I noticed that a few variable names were too easy to be misunderstood by others. By 5 AM I had addressed most of that, except that some technical details weren't yet mentioned in the commit messages ([1], they are documented in the code). I also produce enough typos / odd grammar when fully awake, so even though I did proof read my changes, I thought that I need to do that again while awake. There have been no substantial code changes since yesterday. The variable renaming prompted by Robert (which I agree is an improvement), as well as reducing the diff size by deferring some readability improvements (probably also a good idea) did however produce quite a few conflicts in subsequent patches that I needed to resolve. Another awake read-through to confirm that I resolved them correctly seemed the responsible thing to do before a commit. > Lastly, with the ongoing world events, perhaps time that could have been > dedicated to this and other patches likely affected their completion. I > know most things in my life take way longer than they used to (e.g. > taking out the trash/recycles has gone from a 15s to 240s routine). The > same could be said about other patches as well, but this one has a far > greater impact (a double-edged sword, of course) given it's a feature > that everyone uses in PostgreSQL ;) I'm obviously not alone in that, so I agree that it's not an argument pro/con anything. But this definitely is the case for me. Leaving aside the general dread, not having a quiet home-office, nor good exercise, is definitely not helping. I'm really bummed that I didn't have the cycles to help the shared memory stats patch ready as well. It's clearly not yet there (but improved a lot during the CF). But it's been around for so long, and there's so many improvements blocked by the current stats infrastructure... [1] the "mirroring" of values beteween dense arrays and PGPROC, the changed locking regimen for ProcArrayAdd/Remove, the widening of lastCompletedXid to be a 64bit xid [2] https://www.postgresql.org/message-id/20200407121503.zltbpqmdesurflnm%40alap3.anarazel.de Greetings, Andres Freund
Hi, On 2020-04-08 09:44:16 -0400, Robert Haas wrote: > Moreover, shakedown time will be minimal because we're so late in the > release cycle My impression increasingly is that there's very little actual shakedown before beta :(. As e.g. evidenced by the fact that 2PC did basically not work for several months until I did new benchmarks for this patch. I don't know what to do about that, but... Greetings, Andres Freund
Hi, On 2020-04-08 18:06:23 -0400, Bruce Momjian wrote: > If we don't commit this, where does this leave us with the > old_snapshot_threshold feature? We remove it in back branches and have > no working version in PG 13? That seems kind of bad. I don't think this patch changes the situation for old_snapshot_threshold in a meaningful way. Sure, this patch makes old_snapshot_threshold scale better, and triggers fewer unnecessary query cancellations. But there still are wrong query results, the tests still don't test anything meaningful, and the determination of which query is cancelled is still wrong. - Andres
On Wed, Apr 8, 2020 at 03:25:34PM -0700, Andres Freund wrote: > Hi, > > On 2020-04-08 18:06:23 -0400, Bruce Momjian wrote: > > If we don't commit this, where does this leave us with the > > old_snapshot_threshold feature? We remove it in back branches and have > > no working version in PG 13? That seems kind of bad. > > I don't think this patch changes the situation for > old_snapshot_threshold in a meaningful way. > > Sure, this patch makes old_snapshot_threshold scale better, and triggers > fewer unnecessary query cancellations. But there still are wrong query > results, the tests still don't test anything meaningful, and the > determination of which query is cancelled is still wrong. Oh, OK, so it still needs to be disabled. I was hoping we could paint this as a fix. Based on Robert's analysis of the risk (no SQL syntax, no storage changes), I think, if you are willing to keep working at this until the final release, it is reasonable to apply it. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EnterpriseDB https://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Wed, Apr 08, 2020 at 03:17:41PM -0700, Andres Freund wrote: > On 2020-04-08 09:26:42 -0400, Jonathan S. Katz wrote: >> Lastly, with the ongoing world events, perhaps time that could have been >> dedicated to this and other patches likely affected their completion. I >> know most things in my life take way longer than they used to (e.g. >> taking out the trash/recycles has gone from a 15s to 240s routine). The >> same could be said about other patches as well, but this one has a far >> greater impact (a double-edged sword, of course) given it's a feature >> that everyone uses in PostgreSQL ;) > > I'm obviously not alone in that, so I agree that it's not an argument > pro/con anything. > > But this definitely is the case for me. Leaving aside the general dread, > not having a quiet home-office, nor good exercise, is definitely not > helping. Another factor to be careful of is that by committing a new feature in a release cycle, you actually need to think about the extra amount of resources you may need to address comments and issues about it in time during the beta/stability period, and that more care is likely needed if you commit something at the end of the cycle. On top of that, currently, that's a bit hard to plan one or two weeks ahead if help is needed to stabilize something you worked on. I am pretty sure that we'll be able to sort things out with a collective effort though. -- Michael
Вложения
Hello, hackers. Andres, nice work! Sorry for the off-top. Some of my work [1] related to the support of index hint bits on standby is highly interfering with this patch. Is it safe to consider it committed and start rebasing on top of the patches? Thanks, Michail. [1]: https://www.postgresql.org/message-id/CANtu0ojmkN_6P7CQWsZ%3DuEgeFnSmpCiqCxyYaHnhYpTZHj7Ubw%40mail.gmail.com
This patch no longer applies to HEAD, please submit a rebased version. I've marked it Waiting on Author in the meantime. cheers ./daniel
Hi, On 2020-07-01 14:42:59 +0200, Daniel Gustafsson wrote: > This patch no longer applies to HEAD, please submit a rebased version. I've > marked it Waiting on Author in the meantime. Thanks! Here's a rebased version. There's a good bit of commit message polishing and some code and comment cleanup compared to the last version. Oh, and obviously the conflicts are resolved. It could make sense to split the conversion of VariableCacheData->latestCompletedXid to FullTransactionId out from 0001 into is own commit. Not sure... I've played with splitting 0003, to have the "infrastructure" pieces separate, but I think it's not worth it. Without a user the changes look weird and it's hard to have the comment make sense. Greetings, Andres Freund
Вложения
- v11-0001-snapshot-scalability-Don-t-compute-global-horizo.patch
- v11-0002-snapshot-scalability-Move-PGXACT-xmin-back-to-PG.patch
- v11-0003-snapshot-scalability-Introduce-dense-array-of-in.patch
- v11-0004-snapshot-scalability-Move-PGXACT-vacuumFlags-to-.patch
- v11-0005-snapshot-scalability-Move-subxact-info-to-ProcGl.patch
- v11-0006-snapshot-scalability-cache-snapshots-using-a-xac.patch
On 2020-Jul-15, Andres Freund wrote: > It could make sense to split the conversion of > VariableCacheData->latestCompletedXid to FullTransactionId out from 0001 > into is own commit. Not sure... +1, the commit is large enough and that change can be had in advance. Note you forward-declare struct GlobalVisState twice in heapam.h. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2020-07-15 21:33:06 -0400, Alvaro Herrera wrote: > On 2020-Jul-15, Andres Freund wrote: > > > It could make sense to split the conversion of > > VariableCacheData->latestCompletedXid to FullTransactionId out from 0001 > > into is own commit. Not sure... > > +1, the commit is large enough and that change can be had in advance. I've done that in the attached. I wonder if somebody has an opinion on renaming latestCompletedXid to latestCompletedFullXid. That's the pattern we already had (cf nextFullXid), but it also leads to pretty long lines and quite a few comment etc changes. I'm somewhat inclined to remove the "Full" out of the variable, and to also do that for nextFullXid. I feel like including it in the variable name is basically a poor copy of the (also not great) C type system. If we hadn't made FullTransactionId a struct I'd see it differently (and thus incompatible with TransactionId), but we have ... > Note you forward-declare struct GlobalVisState twice in heapam.h. Oh, fixed, thanks. I've also fixed a correctness bug that Thomas's cfbot found (and he personally pointed out). There were occasional make check runs with vacuum erroring out. That turned out to be because it was possible for the horizon used to make decisions in heap_page_prune() and lazy_scan_heap() to differ a bit. I've started a thread about my concerns around the fragility of that logic [1]. The code around that can use a bit more polish, I think. I mainly wanted to post a new version so that the patch separated out above can be looked at. Greetings, Andres Freund [1] https://www.postgresql.org/message-id/20200723181018.neey2jd3u7rfrfrn%40alap3.anarazel.de
Вложения
- v12-0001-Track-latest-completed-xid-as-a-FullTransactionI.patch
- v12-0002-snapshot-scalability-Don-t-compute-global-horizo.patch
- v12-0003-snapshot-scalability-Move-PGXACT-xmin-back-to-PG.patch
- v12-0004-snapshot-scalability-Introduce-dense-array-of-in.patch
- v12-0005-snapshot-scalability-Move-PGXACT-vacuumFlags-to-.patch
- v12-0006-snapshot-scalability-Move-subxact-info-to-ProcGl.patch
- v12-0007-snapshot-scalability-cache-snapshots-using-a-xac.patch
Latest Postgres
Windows 64 bits
msvc 2019 64 bits
Patches applied v12-0001 to v12-0007:
C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,28): warning C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int [C:\dll\postgres C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,29): warning C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int [C:\dll\postgres\pg_visibility.
vcxproj]
C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pgstattuple.vcxproj]
C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pg_visibility.vcxproj]
C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pg_visibility.vcxproj]
vcxproj]
C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pgstattuple.vcxproj]
C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pg_visibility.vcxproj]
C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado [C:\dll\postgres\pg_visibility.vcxproj]
regards,
Ranier Vilela
On 2020-07-24 14:05:04 -0300, Ranier Vilela wrote: > Latest Postgres > Windows 64 bits > msvc 2019 64 bits > > Patches applied v12-0001 to v12-0007: > > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,28): warning C4013: > 'GetOldestXmin' indefinido; assumindo extern retornando int > [C:\dll\postgres > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,29): warning > C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int > [C:\dll\postgres\pg_visibility. > vcxproj] > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065: > 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado > [C:\dll\postgres\pgstattuple.vcxproj] > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado > [C:\dll\postgres\pg_visibility.vcxproj] > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado > [C:\dll\postgres\pg_visibility.vcxproj] I don't know that's about - there's no call to GetOldestXmin() in pgstatapprox and pg_visibility after patch 0002? And similarly, the PROCARRAY_* references are also removed in the same patch? Greetings, Andres Freund
Em sex., 24 de jul. de 2020 às 14:16, Andres Freund <andres@anarazel.de> escreveu:
On 2020-07-24 14:05:04 -0300, Ranier Vilela wrote:
> Latest Postgres
> Windows 64 bits
> msvc 2019 64 bits
>
> Patches applied v12-0001 to v12-0007:
>
> C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,28): warning C4013:
> 'GetOldestXmin' indefinido; assumindo extern retornando int
> [C:\dll\postgres
> C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,29): warning
> C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int
> [C:\dll\postgres\pg_visibility.
> vcxproj]
> C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065:
> 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> [C:\dll\postgres\pgstattuple.vcxproj]
> C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error
> C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> [C:\dll\postgres\pg_visibility.vcxproj]
> C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error
> C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> [C:\dll\postgres\pg_visibility.vcxproj]
I don't know that's about - there's no call to GetOldestXmin() in
pgstatapprox and pg_visibility after patch 0002? And similarly, the
PROCARRAY_* references are also removed in the same patch?
Maybe need to remove them from these places, not?
C:\dll\postgres\contrib>grep -d GetOldestXmin *.c
File pgstattuple\pgstatapprox.c:
OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
File pg_visibility\pg_visibility.c:
OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
* deadlocks, because surely GetOldestXmin() should never take
RecomputedOldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
File pgstattuple\pgstatapprox.c:
OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
File pg_visibility\pg_visibility.c:
OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
* deadlocks, because surely GetOldestXmin() should never take
RecomputedOldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
regards,
Ranier Vilela
On 2020-07-24 18:15:15 -0300, Ranier Vilela wrote:
> Em sex., 24 de jul. de 2020 às 14:16, Andres Freund <andres@anarazel.de>
> escreveu:
>
> > On 2020-07-24 14:05:04 -0300, Ranier Vilela wrote:
> > > Latest Postgres
> > > Windows 64 bits
> > > msvc 2019 64 bits
> > >
> > > Patches applied v12-0001 to v12-0007:
> > >
> > > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,28): warning
> > C4013:
> > > 'GetOldestXmin' indefinido; assumindo extern retornando int
> > > [C:\dll\postgres
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,29): warning
> > > C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int
> > > [C:\dll\postgres\pg_visibility.
> > > vcxproj]
> > > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065:
> > > 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pgstattuple.vcxproj]
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error
> > > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pg_visibility.vcxproj]
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error
> > > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pg_visibility.vcxproj]
> >
> > I don't know that's about - there's no call to GetOldestXmin() in
> > pgstatapprox and pg_visibility after patch 0002? And similarly, the
> > PROCARRAY_* references are also removed in the same patch?
> >
> Maybe need to remove them from these places, not?
> C:\dll\postgres\contrib>grep -d GetOldestXmin *.c
> File pgstattuple\pgstatapprox.c:
> OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
> File pg_visibility\pg_visibility.c:
> OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
> * deadlocks, because surely
> GetOldestXmin() should never take
> RecomputedOldestXmin = GetOldestXmin(NULL,
> PROCARRAY_FLAGS_VACUUM);
The 0002 patch changed those files:
diff --git a/contrib/pg_visibility/pg_visibility.c b/contrib/pg_visibility/pg_visibility.c
index 68d580ed1e0..37206c50a21 100644
--- a/contrib/pg_visibility/pg_visibility.c
+++ b/contrib/pg_visibility/pg_visibility.c
@@ -563,17 +563,14 @@ collect_corrupt_items(Oid relid, bool all_visible, bool all_frozen)
BufferAccessStrategy bstrategy = GetAccessStrategy(BAS_BULKREAD);
TransactionId OldestXmin = InvalidTransactionId;
- if (all_visible)
- {
- /* Don't pass rel; that will fail in recovery. */
- OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
- }
-
rel = relation_open(relid, AccessShareLock);
/* Only some relkinds have a visibility map */
check_relation_relkind(rel);
+ if (all_visible)
+ OldestXmin = GetOldestNonRemovableTransactionId(rel);
+
nblocks = RelationGetNumberOfBlocks(rel);
/*
@@ -679,11 +676,12 @@ collect_corrupt_items(Oid relid, bool all_visible, bool all_frozen)
* From a concurrency point of view, it sort of sucks to
* retake ProcArrayLock here while we're holding the buffer
* exclusively locked, but it should be safe against
- * deadlocks, because surely GetOldestXmin() should never take
- * a buffer lock. And this shouldn't happen often, so it's
- * worth being careful so as to avoid false positives.
+ * deadlocks, because surely GetOldestNonRemovableTransactionId()
+ * should never take a buffer lock. And this shouldn't happen
+ * often, so it's worth being careful so as to avoid false
+ * positives.
*/
- RecomputedOldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
+ RecomputedOldestXmin = GetOldestNonRemovableTransactionId(rel);
if (!TransactionIdPrecedes(OldestXmin, RecomputedOldestXmin))
record_corrupt_item(items, &tuple.t_self);
diff --git a/contrib/pgstattuple/pgstatapprox.c b/contrib/pgstattuple/pgstatapprox.c
index dbc0fa11f61..3a99333d443 100644
--- a/contrib/pgstattuple/pgstatapprox.c
+++ b/contrib/pgstattuple/pgstatapprox.c
@@ -71,7 +71,7 @@ statapprox_heap(Relation rel, output_type *stat)
BufferAccessStrategy bstrategy;
TransactionId OldestXmin;
- OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
+ OldestXmin = GetOldestNonRemovableTransactionId(rel);
bstrategy = GetAccessStrategy(BAS_BULKREAD);
nblocks = RelationGetNumberOfBlocks(rel);
Greetings,
Andres Freund
Em sex., 24 de jul. de 2020 às 21:00, Andres Freund <andres@anarazel.de> escreveu:
On 2020-07-24 18:15:15 -0300, Ranier Vilela wrote:
> Em sex., 24 de jul. de 2020 às 14:16, Andres Freund <andres@anarazel.de>
> escreveu:
>
> > On 2020-07-24 14:05:04 -0300, Ranier Vilela wrote:
> > > Latest Postgres
> > > Windows 64 bits
> > > msvc 2019 64 bits
> > >
> > > Patches applied v12-0001 to v12-0007:
> > >
> > > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,28): warning
> > C4013:
> > > 'GetOldestXmin' indefinido; assumindo extern retornando int
> > > [C:\dll\postgres
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,29): warning
> > > C4013: 'GetOldestXmin' indefinido; assumindo extern retornando int
> > > [C:\dll\postgres\pg_visibility.
> > > vcxproj]
> > > C:\dll\postgres\contrib\pgstattuple\pgstatapprox.c(74,56): error C2065:
> > > 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pgstattuple.vcxproj]
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(569,58): error
> > > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pg_visibility.vcxproj]
> > > C:\dll\postgres\contrib\pg_visibility\pg_visibility.c(686,70): error
> > > C2065: 'PROCARRAY_FLAGS_VACUUM': identificador nao declarado
> > > [C:\dll\postgres\pg_visibility.vcxproj]
> >
> > I don't know that's about - there's no call to GetOldestXmin() in
> > pgstatapprox and pg_visibility after patch 0002? And similarly, the
> > PROCARRAY_* references are also removed in the same patch?
> >
> Maybe need to remove them from these places, not?
> C:\dll\postgres\contrib>grep -d GetOldestXmin *.c
> File pgstattuple\pgstatapprox.c:
> OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
> File pg_visibility\pg_visibility.c:
> OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
> * deadlocks, because surely
> GetOldestXmin() should never take
> RecomputedOldestXmin = GetOldestXmin(NULL,
> PROCARRAY_FLAGS_VACUUM);
The 0002 patch changed those files:
diff --git a/contrib/pg_visibility/pg_visibility.c b/contrib/pg_visibility/pg_visibility.c
index 68d580ed1e0..37206c50a21 100644
--- a/contrib/pg_visibility/pg_visibility.c
+++ b/contrib/pg_visibility/pg_visibility.c
@@ -563,17 +563,14 @@ collect_corrupt_items(Oid relid, bool all_visible, bool all_frozen)
BufferAccessStrategy bstrategy = GetAccessStrategy(BAS_BULKREAD);
TransactionId OldestXmin = InvalidTransactionId;
- if (all_visible)
- {
- /* Don't pass rel; that will fail in recovery. */
- OldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
- }
-
rel = relation_open(relid, AccessShareLock);
/* Only some relkinds have a visibility map */
check_relation_relkind(rel);
+ if (all_visible)
+ OldestXmin = GetOldestNonRemovableTransactionId(rel);
+
nblocks = RelationGetNumberOfBlocks(rel);
/*
@@ -679,11 +676,12 @@ collect_corrupt_items(Oid relid, bool all_visible, bool all_frozen)
* From a concurrency point of view, it sort of sucks to
* retake ProcArrayLock here while we're holding the buffer
* exclusively locked, but it should be safe against
- * deadlocks, because surely GetOldestXmin() should never take
- * a buffer lock. And this shouldn't happen often, so it's
- * worth being careful so as to avoid false positives.
+ * deadlocks, because surely GetOldestNonRemovableTransactionId()
+ * should never take a buffer lock. And this shouldn't happen
+ * often, so it's worth being careful so as to avoid false
+ * positives.
*/
- RecomputedOldestXmin = GetOldestXmin(NULL, PROCARRAY_FLAGS_VACUUM);
+ RecomputedOldestXmin = GetOldestNonRemovableTransactionId(rel);
if (!TransactionIdPrecedes(OldestXmin, RecomputedOldestXmin))
record_corrupt_item(items, &tuple.t_self);
diff --git a/contrib/pgstattuple/pgstatapprox.c b/contrib/pgstattuple/pgstatapprox.c
index dbc0fa11f61..3a99333d443 100644
--- a/contrib/pgstattuple/pgstatapprox.c
+++ b/contrib/pgstattuple/pgstatapprox.c
@@ -71,7 +71,7 @@ statapprox_heap(Relation rel, output_type *stat)
BufferAccessStrategy bstrategy;
TransactionId OldestXmin;
- OldestXmin = GetOldestXmin(rel, PROCARRAY_FLAGS_VACUUM);
+ OldestXmin = GetOldestNonRemovableTransactionId(rel);
bstrategy = GetAccessStrategy(BAS_BULKREAD);
nblocks = RelationGetNumberOfBlocks(rel);
Obviously, the v12-0002-snapshot-scalability-Don-t-compute-global-horizo.patch patch needs to be rebased.
https://github.com/postgres/postgres/blob/master/contrib/pg_visibility/pg_visibility.c
1:
if (all_visible)
{
/ * Don't pass rel; that will fail in recovery. * /
OldestXmin = GetOldestXmin (NULL, PROCARRAY_FLAGS_VACUUM);
}
It is on line 566 in the current version of git, while the patch is on line 563.
2:
* deadlocks, because surely GetOldestXmin () should never take
* a buffer lock. And this shouldn't happen often, so it's
* worth being careful so as to avoid false positives.
* /
It is currently on line 682, while in the patch it is on line 679.
regards,
Ranier Vilela
https://github.com/postgres/postgres/blob/master/contrib/pg_visibility/pg_visibility.c
1:
if (all_visible)
{
/ * Don't pass rel; that will fail in recovery. * /
OldestXmin = GetOldestXmin (NULL, PROCARRAY_FLAGS_VACUUM);
}
It is on line 566 in the current version of git, while the patch is on line 563.
2:
* deadlocks, because surely GetOldestXmin () should never take
* a buffer lock. And this shouldn't happen often, so it's
* worth being careful so as to avoid false positives.
* /
It is currently on line 682, while in the patch it is on line 679.
regards,
Ranier Vilela
On Fri, Jul 24, 2020 at 1:11 PM Andres Freund <andres@anarazel.de> wrote: > On 2020-07-15 21:33:06 -0400, Alvaro Herrera wrote: > > On 2020-Jul-15, Andres Freund wrote: > > > It could make sense to split the conversion of > > > VariableCacheData->latestCompletedXid to FullTransactionId out from 0001 > > > into is own commit. Not sure... > > > > +1, the commit is large enough and that change can be had in advance. > > I've done that in the attached. + * pair with the memory barrier below. We do however accept xid to be <= + * to next_xid, instead of just <, as xid could be from the procarray, + * before we see the updated nextFullXid value. Tricky. Right, that makes sense. I like the range assertion. +static inline FullTransactionId +FullXidViaRelative(FullTransactionId rel, TransactionId xid) I'm struggling to find a better word for this than "relative". + return FullTransactionIdFromU64(U64FromFullTransactionId(rel) + + (int32) (xid - rel_xid)); I like your branch-free code for this. > I wonder if somebody has an opinion on renaming latestCompletedXid to > latestCompletedFullXid. That's the pattern we already had (cf > nextFullXid), but it also leads to pretty long lines and quite a few > comment etc changes. > > I'm somewhat inclined to remove the "Full" out of the variable, and to > also do that for nextFullXid. I feel like including it in the variable > name is basically a poor copy of the (also not great) C type system. If > we hadn't made FullTransactionId a struct I'd see it differently (and > thus incompatible with TransactionId), but we have ... Yeah, I'm OK with dropping the "Full". I've found it rather clumsy too.
On Wed, Jul 29, 2020 at 6:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > +static inline FullTransactionId > +FullXidViaRelative(FullTransactionId rel, TransactionId xid) > > I'm struggling to find a better word for this than "relative". The best I've got is "anchor" xid. It is an xid that is known to limit nextFullXid's range while the receiving function runs.
> On 24 Jul 2020, at 03:11, Andres Freund <andres@anarazel.de> wrote: > I've done that in the attached. As this is actively being reviewed but time is running short, I'm moving this to the next CF. cheers ./daniel
Hi, On 2020-07-29 19:20:04 +1200, Thomas Munro wrote: > On Wed, Jul 29, 2020 at 6:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > +static inline FullTransactionId > > +FullXidViaRelative(FullTransactionId rel, TransactionId xid) > > > > I'm struggling to find a better word for this than "relative". > > The best I've got is "anchor" xid. It is an xid that is known to > limit nextFullXid's range while the receiving function runs. Thinking about it, I think that relative is a good descriptor. It's just that 'via' is weird. How about: FullXidRelativeTo? Greetings, Andres Freund
On Wed, Aug 12, 2020 at 12:19 PM Andres Freund <andres@anarazel.de> wrote: > On 2020-07-29 19:20:04 +1200, Thomas Munro wrote: > > On Wed, Jul 29, 2020 at 6:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > +static inline FullTransactionId > > > +FullXidViaRelative(FullTransactionId rel, TransactionId xid) > > > > > > I'm struggling to find a better word for this than "relative". > > > > The best I've got is "anchor" xid. It is an xid that is known to > > limit nextFullXid's range while the receiving function runs. > > Thinking about it, I think that relative is a good descriptor. It's just > that 'via' is weird. How about: FullXidRelativeTo? WFM.
Hi, On 2020-08-12 12:24:52 +1200, Thomas Munro wrote: > On Wed, Aug 12, 2020 at 12:19 PM Andres Freund <andres@anarazel.de> wrote: > > On 2020-07-29 19:20:04 +1200, Thomas Munro wrote: > > > On Wed, Jul 29, 2020 at 6:15 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > +static inline FullTransactionId > > > > +FullXidViaRelative(FullTransactionId rel, TransactionId xid) > > > > > > > > I'm struggling to find a better word for this than "relative". > > > > > > The best I've got is "anchor" xid. It is an xid that is known to > > > limit nextFullXid's range while the receiving function runs. > > > > Thinking about it, I think that relative is a good descriptor. It's just > > that 'via' is weird. How about: FullXidRelativeTo? > > WFM. Cool, pushed. Attached are the rebased remainder of the series. Unless somebody protests, I plan to push 0001 after a bit more comment polishing and wait a buildfarm cycle, then push 0002-0005 and wait again, and finally push 0006. There's further optimizations, particularly after 0002 and after 0006, but that seems better done later. Greetings, Andres Freund
Вложения
- v13-0001-snapshot-scalability-Don-t-compute-global-horizo.patch
- v13-0002-snapshot-scalability-Move-PGXACT-xmin-back-to-PG.patch
- v13-0003-snapshot-scalability-Introduce-dense-array-of-in.patch
- v13-0004-snapshot-scalability-Move-PGXACT-vacuumFlags-to-.patch
- v13-0005-snapshot-scalability-Move-subxact-info-to-ProcGl.patch
- v13-0006-snapshot-scalability-cache-snapshots-using-a-xac.patch
We have two essentially identical buildfarm failures since these patches went in: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=damselfly&dt=2020-08-15%2011%3A27%3A32 https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=peripatus&dt=2020-08-15%2003%3A09%3A14 They're both in the same place in the freeze-the-dead isolation test: TRAP: FailedAssertion("!TransactionIdPrecedes(members[i].xid, cutoff_xid)", File: "heapam.c", Line: 6051) 0x9613eb <ExceptionalCondition+0x5b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x52d586 <heap_prepare_freeze_tuple+0x926> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x53bc7e <heap_vacuum_rel+0x100e> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x6949bb <vacuum_rel+0x25b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x694532 <vacuum+0x602> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x693d1c <ExecVacuum+0x37c> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres 0x8324b3 ... 2020-08-14 22:16:41.783 CDT [78410:4] LOG: server process (PID 80395) was terminated by signal 6: Abort trap 2020-08-14 22:16:41.783 CDT [78410:5] DETAIL: Failed process was running: VACUUM FREEZE tab_freeze; peripatus has successes since this failure, so it's not fully reproducible on that machine. I'm suspicious of a timing problem in computing vacuum's cutoff_xid. (I'm also wondering why the failing check is an Assert rather than a real test-and-elog. Assert doesn't seem like an appropriate way to check for plausible data corruption cases.) regards, tom lane
Hi, On 2020-08-15 11:10:51 -0400, Tom Lane wrote: > We have two essentially identical buildfarm failures since these patches > went in: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=damselfly&dt=2020-08-15%2011%3A27%3A32 > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=peripatus&dt=2020-08-15%2003%3A09%3A14 > > They're both in the same place in the freeze-the-dead isolation test: > TRAP: FailedAssertion("!TransactionIdPrecedes(members[i].xid, cutoff_xid)", File: "heapam.c", Line: 6051) > 0x9613eb <ExceptionalCondition+0x5b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x52d586 <heap_prepare_freeze_tuple+0x926> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x53bc7e <heap_vacuum_rel+0x100e> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x6949bb <vacuum_rel+0x25b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x694532 <vacuum+0x602> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x693d1c <ExecVacuum+0x37c> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > 0x8324b3 > ... > 2020-08-14 22:16:41.783 CDT [78410:4] LOG: server process (PID 80395) was terminated by signal 6: Abort trap > 2020-08-14 22:16:41.783 CDT [78410:5] DETAIL: Failed process was running: VACUUM FREEZE tab_freeze; > > peripatus has successes since this failure, so it's not fully reproducible > on that machine. I'm suspicious of a timing problem in computing vacuum's > cutoff_xid. Hm, maybe it's something around what I observed in https://www.postgresql.org/message-id/20200723181018.neey2jd3u7rfrfrn%40alap3.anarazel.de I.e. that somehow we end up with hot pruning and freezing coming to a different determination, and trying to freeze a hot tuple. I'll try to add a few additional asserts here, and burn some cpu tests trying to trigger the issue. I gotta escape the heat in the house for a few hours though (no AC here), so I'll not look at the results till later this afternoon, unless it triggers soon. > (I'm also wondering why the failing check is an Assert rather than a real > test-and-elog. Assert doesn't seem like an appropriate way to check for > plausible data corruption cases.) Robert, and to a lesser degree you, gave me quite a bit of grief over converting nearby asserts to elogs. I agree it'd be better if it were an assert, but ... Greetings, Andres Freund
Hi, On 2020-08-15 09:42:00 -0700, Andres Freund wrote: > On 2020-08-15 11:10:51 -0400, Tom Lane wrote: > > We have two essentially identical buildfarm failures since these patches > > went in: > > > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=damselfly&dt=2020-08-15%2011%3A27%3A32 > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=peripatus&dt=2020-08-15%2003%3A09%3A14 > > > > They're both in the same place in the freeze-the-dead isolation test: > > > TRAP: FailedAssertion("!TransactionIdPrecedes(members[i].xid, cutoff_xid)", File: "heapam.c", Line: 6051) > > 0x9613eb <ExceptionalCondition+0x5b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x52d586 <heap_prepare_freeze_tuple+0x926> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x53bc7e <heap_vacuum_rel+0x100e> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x6949bb <vacuum_rel+0x25b> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x694532 <vacuum+0x602> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x693d1c <ExecVacuum+0x37c> at /home/pgbuildfarm/buildroot/HEAD/inst/bin/postgres > > 0x8324b3 > > ... > > 2020-08-14 22:16:41.783 CDT [78410:4] LOG: server process (PID 80395) was terminated by signal 6: Abort trap > > 2020-08-14 22:16:41.783 CDT [78410:5] DETAIL: Failed process was running: VACUUM FREEZE tab_freeze; > > > > peripatus has successes since this failure, so it's not fully reproducible > > on that machine. I'm suspicious of a timing problem in computing vacuum's > > cutoff_xid. > > Hm, maybe it's something around what I observed in > https://www.postgresql.org/message-id/20200723181018.neey2jd3u7rfrfrn%40alap3.anarazel.de > > I.e. that somehow we end up with hot pruning and freezing coming to a > different determination, and trying to freeze a hot tuple. > > I'll try to add a few additional asserts here, and burn some cpu tests > trying to trigger the issue. > > I gotta escape the heat in the house for a few hours though (no AC > here), so I'll not look at the results till later this afternoon, unless > it triggers soon. 690 successful runs later, it didn't trigger for me :(. Seems pretty clear that there's another variable than pure chance, otherwise it seems like that number of runs should have hit the issue, given the number of bf hits vs bf runs. My current plan would is to push a bit of additional instrumentation to help narrow down the issue. We can afterwards decide what of that we'd like to keep longer term, and what not. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> 690 successful runs later, it didn't trigger for me :(. Seems pretty
> clear that there's another variable than pure chance, otherwise it seems
> like that number of runs should have hit the issue, given the number of
> bf hits vs bf runs.
It seems entirely likely that there's a timing component in this, for
instance autovacuum coming along at just the right time. It's not too
surprising that some machines would be more prone to show that than
others. (Note peripatus is FreeBSD, which we've already learned has
significantly different kernel scheduler behavior than Linux.)
> My current plan would is to push a bit of additional instrumentation to
> help narrow down the issue.
+1
regards, tom lane
On 2020-08-16 14:30:24 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > 690 successful runs later, it didn't trigger for me :(. Seems pretty > > clear that there's another variable than pure chance, otherwise it seems > > like that number of runs should have hit the issue, given the number of > > bf hits vs bf runs. > > It seems entirely likely that there's a timing component in this, for > instance autovacuum coming along at just the right time. It's not too > surprising that some machines would be more prone to show that than > others. (Note peripatus is FreeBSD, which we've already learned has > significantly different kernel scheduler behavior than Linux.) Yea. Interestingly there was a reproduction on linux since the initial reports you'd dug up: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=butterflyfish&dt=2020-08-15%2019%3A54%3A53 but that's likely a virtualized environment, so I guess the host scheduler behaviour could play a similar role. I'll run a few iterations with rr's chaos mode too, which tries to randomize scheduling decisions... I noticed that it's quite hard to actually hit the hot tuple path I mentioned earlier on my machine. Would probably be good to have a tests hitting it more reliably. But I'm not immediately seeing how we could force the necessarily serialization. Greetings, Andres Freund
I wrote:
> It seems entirely likely that there's a timing component in this, for
> instance autovacuum coming along at just the right time.
D'oh. The attached seems to make it 100% reproducible.
regards, tom lane
diff --git a/src/test/isolation/specs/freeze-the-dead.spec b/src/test/isolation/specs/freeze-the-dead.spec
index 915bf15b92..4100d9fc6f 100644
--- a/src/test/isolation/specs/freeze-the-dead.spec
+++ b/src/test/isolation/specs/freeze-the-dead.spec
@@ -32,6 +32,7 @@ session "s2"
step "s2_begin" { BEGIN; }
step "s2_key_share" { SELECT id FROM tab_freeze WHERE id = 3 FOR KEY SHARE; }
step "s2_commit" { COMMIT; }
+step "s2_wait" { select pg_sleep(60); }
step "s2_vacuum" { VACUUM FREEZE tab_freeze; }
session "s3"
@@ -49,6 +50,7 @@ permutation "s1_begin" "s2_begin" "s3_begin" # start transactions
"s1_update" "s2_key_share" "s3_key_share" # have xmax be a multi with an updater, updater being oldest xid
"s1_update" # create additional row version that has multis
"s1_commit" "s2_commit" # commit both updater and share locker
+ "s2_wait"
"s2_vacuum" # due to bug in freezing logic, we used to *not* prune updated row, and then froze it
"s1_selectone" # if hot chain is broken, the row can't be found via index scan
"s3_commit" # commit remaining open xact
Hi, On 2020-08-16 16:17:23 -0400, Tom Lane wrote: > I wrote: > > It seems entirely likely that there's a timing component in this, for > > instance autovacuum coming along at just the right time. > > D'oh. The attached seems to make it 100% reproducible. Great! It interestingly didn't work as the first item on the schedule, where I had duplicated it it to out of impatience. I guess there might be some need of concurrent autovacuum activity or something like that. I now luckily have a rr trace of the problem, so I hope I can narrow it down to the original problem fairly quickly. Thanks, Andres
Hi, On 2020-08-16 13:31:53 -0700, Andres Freund wrote: > I now luckily have a rr trace of the problem, so I hope I can narrow it > down to the original problem fairly quickly. Gna, I think I see the problem. In at least one place I wrongly accessed the 'dense' array of in-progress xids using the 'pgprocno', instead of directly using the [0...procArray->numProcs) index. Working on a fix, together with some improved asserts. Greetings, Andres Freund
Hi,
On 2020-08-16 13:52:58 -0700, Andres Freund wrote:
> On 2020-08-16 13:31:53 -0700, Andres Freund wrote:
> > I now luckily have a rr trace of the problem, so I hope I can narrow it
> > down to the original problem fairly quickly.
>
> Gna, I think I see the problem. In at least one place I wrongly
> accessed the 'dense' array of in-progress xids using the 'pgprocno',
> instead of directly using the [0...procArray->numProcs) index.
>
> Working on a fix, together with some improved asserts.
diff --git i/src/backend/storage/ipc/procarray.c w/src/backend/storage/ipc/procarray.c
index 8262abd42e6..96e4a878576 100644
--- i/src/backend/storage/ipc/procarray.c
+++ w/src/backend/storage/ipc/procarray.c
@@ -1663,7 +1663,7 @@ ComputeXidHorizons(ComputeXidHorizonsResult *h)
TransactionId xmin;
/* Fetch xid just once - see GetNewTransactionId */
- xid = UINT32_ACCESS_ONCE(other_xids[pgprocno]);
+ xid = UINT32_ACCESS_ONCE(other_xids[index]);
xmin = UINT32_ACCESS_ONCE(proc->xmin);
/*
indeed fixes the issue based on a number of iterations of your modified
test, and fixes a clear bug.
WRT better asserts: We could make ProcArrayRemove() and InitProcGlobal()
initialize currently unused procArray->pgprocnos,
procGlobal->{xids,subxidStates,vacuumFlags} to invalid values and/or
declare them as uninitialized using the valgrind helpers.
For the first, one issue is that there's no obviously good candidate for
an uninitialized xid. We could use something like FrozenTransactionId,
which may never be in the procarray. But it's not exactly pretty.
Opinions?
Greetings,
Andres Freund
Hi,
On 2020-08-16 14:11:46 -0700, Andres Freund wrote:
> On 2020-08-16 13:52:58 -0700, Andres Freund wrote:
> > On 2020-08-16 13:31:53 -0700, Andres Freund wrote:
> > Gna, I think I see the problem. In at least one place I wrongly
> > accessed the 'dense' array of in-progress xids using the 'pgprocno',
> > instead of directly using the [0...procArray->numProcs) index.
> >
> > Working on a fix, together with some improved asserts.
>
> diff --git i/src/backend/storage/ipc/procarray.c w/src/backend/storage/ipc/procarray.c
> index 8262abd42e6..96e4a878576 100644
> --- i/src/backend/storage/ipc/procarray.c
> +++ w/src/backend/storage/ipc/procarray.c
> @@ -1663,7 +1663,7 @@ ComputeXidHorizons(ComputeXidHorizonsResult *h)
> TransactionId xmin;
>
> /* Fetch xid just once - see GetNewTransactionId */
> - xid = UINT32_ACCESS_ONCE(other_xids[pgprocno]);
> + xid = UINT32_ACCESS_ONCE(other_xids[index]);
> xmin = UINT32_ACCESS_ONCE(proc->xmin);
>
> /*
>
> indeed fixes the issue based on a number of iterations of your modified
> test, and fixes a clear bug.
Pushed that much.
> WRT better asserts: We could make ProcArrayRemove() and InitProcGlobal()
> initialize currently unused procArray->pgprocnos,
> procGlobal->{xids,subxidStates,vacuumFlags} to invalid values and/or
> declare them as uninitialized using the valgrind helpers.
>
> For the first, one issue is that there's no obviously good candidate for
> an uninitialized xid. We could use something like FrozenTransactionId,
> which may never be in the procarray. But it's not exactly pretty.
>
> Opinions?
So we get some builfarm results while thinking about this.
Greetings,
Andres Freund
On Sun, Aug 16, 2020 at 2:11 PM Andres Freund <andres@anarazel.de> wrote: > For the first, one issue is that there's no obviously good candidate for > an uninitialized xid. We could use something like FrozenTransactionId, > which may never be in the procarray. But it's not exactly pretty. Maybe it would make sense to mark the fields as inaccessible or undefined to Valgrind. That has advantages and disadvantages that are obvious. If that isn't enough, it might not hurt to do this on top of whatever becomes the primary solution. An undefined value has the advantage of "spreading" when the value gets copied around. -- Peter Geoghegan
Andres Freund <andres@anarazel.de> writes:
> For the first, one issue is that there's no obviously good candidate for
> an uninitialized xid. We could use something like FrozenTransactionId,
> which may never be in the procarray. But it's not exactly pretty.
Huh? What's wrong with using InvalidTransactionId?
regards, tom lane
Hi, On 2020-08-16 17:28:46 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > For the first, one issue is that there's no obviously good candidate for > > an uninitialized xid. We could use something like FrozenTransactionId, > > which may never be in the procarray. But it's not exactly pretty. > > Huh? What's wrong with using InvalidTransactionId? It's a normal value for a backend when it doesn't have an xid assigned. Greetings, Andres Freund
On 2020-Aug-16, Peter Geoghegan wrote: > On Sun, Aug 16, 2020 at 2:11 PM Andres Freund <andres@anarazel.de> wrote: > > For the first, one issue is that there's no obviously good candidate for > > an uninitialized xid. We could use something like FrozenTransactionId, > > which may never be in the procarray. But it's not exactly pretty. > > Maybe it would make sense to mark the fields as inaccessible or > undefined to Valgrind. That has advantages and disadvantages that are > obvious. ... and perhaps making Valgrind complain about it is sufficient. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Aug 16, 2020 at 02:26:57PM -0700, Andres Freund wrote: > So we get some builfarm results while thinking about this. Andres, there is an entry in the CF for this thread: https://commitfest.postgresql.org/29/2500/ A lot of work has been committed with 623a9ba, 73487a6, 5788e25, etc. Now that PGXACT is done, how much work is remaining here? -- Michael
Вложения
On 03.09.2020 11:18, Michael Paquier wrote:
On Sun, Aug 16, 2020 at 02:26:57PM -0700, Andres Freund wrote:So we get some builfarm results while thinking about this.Andres, there is an entry in the CF for this thread: https://commitfest.postgresql.org/29/2500/ A lot of work has been committed with 623a9ba, 73487a6, 5788e25, etc. Now that PGXACT is done, how much work is remaining here? -- Michael
Andres, First of all a lot of thanks for this work. Improving Postgres connection scalability is very important. Reported results looks very impressive. But I tried to reproduce them and didn't observed similar behavior. So I am wondering what can be the difference and what I am doing wrong. I have tried two different systems. First one is IBM Power2 server with 384 cores and 8Tb of RAM. I run the same read-only pgbench test as you. I do not think that size of the database is matter, so I used scale 100 - it seems to be enough to avoid frequent buffer conflicts. Then I run the same scripts as you: for ((n=100; n < 1000; n+=100)); do echo $n; pgbench -M prepared -c $n -T 100 -j $n -M prepared -S -n postgres ; done for ((n=1000; n <= 5000; n+=1000)); do echo $n; pgbench -M prepared -c $n -T 100 -j $n -M prepared -S -n postgres ; done I have compared current master with version of Postgres prior to your commits with scalability improvements: a9a4a7ad56 For all number of connections older version shows slightly better results, for example for 500 clients: 475k TPS vs. 450k TPS for current master. This is quite exotic server and I do not have currently access to it. So I have repeated experiments at Intel server. It has 160 cores Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz and 256Gb of RAM. The same database, the same script, results are the following:
| Clients | old/inc | old/exl | new/inc | new/exl |
|---|---|---|---|---|
| 1000 | 1105750 | 1163292 | 1206105 | 1212701 |
| 2000 | 1050933 | 1124688 | 1149706 | 1164942 |
| 3000 | 1063667 | 1195158 | 1118087 | 1144216 |
| 4000 | 1040065 | 1290432 | 1107348 | 1163906 |
| 5000 | 943813 | 1258643 | 1103790 | 1160251 |
I have separately show results including/excluding connection connections establishing, because in new version there are almost no differences between them, but for old version gap between them is noticeable. Configuration file has the following differences with default postgres config: max_connections = 10000 # (change requires restart) shared_buffers = 8GB # min 128kB This results contradict with yours and makes me ask the following questions: 1. Why in your case performance is almost two times larger (2 millions vs 1)? The hardware in my case seems to be at least not worser than yours... May be there are some other improvements in the version you have tested which are not yet committed to master? 2. You wrote: This is on a machine with 2 Intel(R) Xeon(R) Platinum 8168, but virtualized (2 sockets of 18 cores/36 threads) According to Intel specification Intel® Xeon® Platinum 8168 Processor has 24 cores: https://ark.intel.com/content/www/us/en/ark/products/120504/intel-xeon-platinum-8168-processor-33m-cache-2-70-ghz.html And at your graph we can see almost linear increase of speed up to 40 connections. But most suspicious word for me is "virtualized". What is the actual hardware and how it is virtualized? Do you have any idea why in my case master version (with your commits) behaves almost the same as non-patched version? Below is yet another table showing scalability from 10 to 100 connections and combining your results (first two columns) and my results (last two columns):
| Clients | old master | pgxact-split-cache | current master | revision 9a4a7ad56 |
|---|---|---|---|---|
| 10 | 367883 | 375682 | 358984 | 347067 |
| 20 | 748000 | 810964 | 668631 | 630304 |
| 30 | 999231 | 1288276 | 920255 | 848244 |
| 40 | 991672 | 1573310 | 1100745 | 970717 |
| 50 | 1017561 | 1715762 | 1193928 | 1008755 |
| 60 | 993943 | 1789698 | 1255629 | 917788 |
| 70 | 971379 | 1819477 | 1277634 | 873022 |
| 80 | 966276 | 1842248 | 1266523 | 830197 |
| 90 | 901175 | 1847823 | 1255260 | 736550 |
| 100 | 803175 | 1865795 | 1241143 | 736756 |
May be it is because of more complex architecture of my server?
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, On 2020-09-03 17:18:29 +0900, Michael Paquier wrote: > On Sun, Aug 16, 2020 at 02:26:57PM -0700, Andres Freund wrote: > > So we get some builfarm results while thinking about this. > > Andres, there is an entry in the CF for this thread: > https://commitfest.postgresql.org/29/2500/ > > A lot of work has been committed with 623a9ba, 73487a6, 5788e25, etc. > Now that PGXACT is done, how much work is remaining here? I think it's best to close the entry. There's substantial further wins possible, in particular not acquiring ProcArrayLock in GetSnapshotData() when the cache is valid improves performance substantially. But it's non-trivial enough that it's probably best dealth with in a separate patch / CF entry. Closed. Greetings, Andres Freund
Hi, On 2020-09-04 18:24:12 +0300, Konstantin Knizhnik wrote: > Reported results looks very impressive. > But I tried to reproduce them and didn't observed similar behavior. > So I am wondering what can be the difference and what I am doing wrong. That is odd - I did reproduce it on quite a few systems by now. > Configuration file has the following differences with default postgres config: > > max_connections = 10000 # (change requires restart) > shared_buffers = 8GB # min 128kB I also used huge_pages=on / configured them on the OS level. Otherwise TLB misses will be a significant factor. Does it change if you initialize the test database using PGOPTIONS='-c vacuum_freeze_min_age=0' pgbench -i -s 100 or run a manual VACUUM FREEZE; after initialization? > I have tried two different systems. > First one is IBM Power2 server with 384 cores and 8Tb of RAM. > I run the same read-only pgbench test as you. I do not think that size of the database is matter, so I used scale 100 - > it seems to be enough to avoid frequent buffer conflicts. > Then I run the same scripts as you: > > for ((n=100; n < 1000; n+=100)); do echo $n; pgbench -M prepared -c $n -T 100 -j $n -M prepared -S -n postgres ; done > for ((n=1000; n <= 5000; n+=1000)); do echo $n; pgbench -M prepared -c $n -T 100 -j $n -M prepared -S -n postgres ; done > > > I have compared current master with version of Postgres prior to your commits with scalability improvements: a9a4a7ad56 Hm, it'd probably be good to compare commits closer to the changes, to avoid other changes showing up. Hm - did you verify if all the connections were actually established? Particularly without the patch applied? With an unmodified pgbench, I sometimes saw better numbers, but only because only half the connections were able to be established, due to ProcArrayLock contention. See https://www.postgresql.org/message-id/20200227180100.zyvjwzcpiokfsqm2%40alap3.anarazel.de There also is the issue that pgbench numbers for inclusive/exclusive are just about meaningless right now: https://www.postgresql.org/message-id/20200227202636.qaf7o6qcajsudoor%40alap3.anarazel.de (reminds me, need to get that fixed) One more thing worth investigating is whether your results change significantly when you start the server using numactl --interleave=all <start_server_cmdline>. Especially on larger systems the results otherwise can vary a lot from run-to-run, because the placement of shared buffers matters a lot. > So I have repeated experiments at Intel server. > It has 160 cores Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz and 256Gb of RAM. > > The same database, the same script, results are the following: > > Clients old/inc old/exl new/inc new/exl > 1000 1105750 1163292 1206105 1212701 > 2000 1050933 1124688 1149706 1164942 > 3000 1063667 1195158 1118087 1144216 > 4000 1040065 1290432 1107348 1163906 > 5000 943813 1258643 1103790 1160251 > I have separately show results including/excluding connection connections establishing, > because in new version there are almost no differences between them, > but for old version gap between them is noticeable. > > Configuration file has the following differences with default postgres config: > > max_connections = 10000 # (change requires restart) > shared_buffers = 8GB # min 128kB > > This results contradict with yours and makes me ask the following questions: > 1. Why in your case performance is almost two times larger (2 millions vs 1)? > The hardware in my case seems to be at least not worser than yours... > May be there are some other improvements in the version you have tested which are not yet committed to master? No, no uncommitted changes, except for the pgbench stuff mentioned above. However I found that the kernel version matters a fair bit, it's pretty easy to run into kernel scalability issues in a workload that is this heavy scheduler dependent. Did you connect via tcp or unix socket? Was pgbench running on the same machine? It was locally via unix socket for me (but it's also observable via two machines, just with lower overall throughput). Did you run a profile to see where the bottleneck is? There's a seperate benchmark that I found to be quite revealing that's far less dependent on scheduler behaviour. Run two pgbench instances: 1) With a very simply script '\sleep 1s' or such, and many connections (e.g. 100,1000,5000). That's to simulate connections that are currently idle. 2) With a normal pgbench read only script, and low client counts. Before the changes 2) shows a very sharp decline in performance when the count in 1) increases. Afterwards its pretty much linear. I think this benchmark actually is much more real world oriented - due to latency and client side overheads it's very normal to have a large fraction of connections idle in read mostly OLTP workloads. Here's the result on my workstation (2x Xeon Gold 5215 CPUs), testing 1f42d35a1d6144a23602b2c0bc7f97f3046cf890 against 07f32fcd23ac81898ed47f88beb569c631a2f223 which are the commits pre/post connection scalability changes. I used fairly short pgbench runs (15s), and the numbers are the best of three runs. I also had emacs and mutt open - some noise to be expected. But I also gotta work ;) | Idle Connections | Active Connections | TPS pre | TPS post | |-----------------:|-------------------:|--------:|---------:| | 0 | 1 | 33599 | 33406 | | 100 | 1 | 31088 | 33279 | | 1000 | 1 | 29377 | 33434 | | 2500 | 1 | 27050 | 33149 | | 5000 | 1 | 21895 | 33903 | | 10000 | 1 | 16034 | 33140 | | 0 | 48 | 1042005 | 1125104 | | 100 | 48 | 986731 | 1103584 | | 1000 | 48 | 854230 | 1119043 | | 2500 | 48 | 716624 | 1119353 | | 5000 | 48 | 553657 | 1119476 | | 10000 | 48 | 369845 | 1115740 | And a second version of this, where the idle connections are just less busy, using the following script: \sleep 100ms SELECT 1; | Mostly Idle Connections | Active Connections | TPS pre | TPS post | |------------------------:|-------------------:|--------:|---------------:| | 0 | 1 | 33837 | 34095.891429 | | 100 | 1 | 30622 | 31166.767491 | | 1000 | 1 | 25523 | 28829.313249 | | 2500 | 1 | 19260 | 24978.878822 | | 5000 | 1 | 11171 | 24208.146408 | | 10000 | 1 | 6702 | 29577.517084 | | 0 | 48 | 1022721 | 1133153.772338 | | 100 | 48 | 980705 | 1034235.255883 | | 1000 | 48 | 824668 | 1115965.638395 | | 2500 | 48 | 698510 | 1073280.930789 | | 5000 | 48 | 478535 | 1041931.158287 | | 10000 | 48 | 276042 | 953567.038634 | It's probably worth to call out that in the second test run here the run-to-run variability is huge. Presumably because it's very scheduler dependent much CPU time "active" backends and the "active" pgbench gets at higher "mostly idle" connection counts. > 2. You wrote: This is on a machine with 2 > Intel(R) Xeon(R) Platinum 8168, but virtualized (2 sockets of 18 cores/36 threads) > > According to Intel specification Intel® Xeon® Platinum 8168 Processor has 24 cores: > https://ark.intel.com/content/www/us/en/ark/products/120504/intel-xeon-platinum-8168-processor-33m-cache-2-70-ghz.html > > And at your graph we can see almost linear increase of speed up to 40 connections. > > But most suspicious word for me is "virtualized". What is the actual hardware and how it is virtualized? That was on an azure Fs72v2. I think that's hyperv virtualized, with all the "lost" cores dedicated to the hypervisor. But I did reproduce the speedups on my unvirtualized workstation (2x Xeon Gold 5215 CPUs) - the ceiling is lower, obviously. > May be it is because of more complex architecture of my server? Think we'll need profiles to know... Greetings, Andres Freund
On 2020-09-04 11:53:04 -0700, Andres Freund wrote: > There's a seperate benchmark that I found to be quite revealing that's > far less dependent on scheduler behaviour. Run two pgbench instances: > > 1) With a very simply script '\sleep 1s' or such, and many connections > (e.g. 100,1000,5000). That's to simulate connections that are > currently idle. > 2) With a normal pgbench read only script, and low client counts. > > Before the changes 2) shows a very sharp decline in performance when the > count in 1) increases. Afterwards its pretty much linear. > > I think this benchmark actually is much more real world oriented - due > to latency and client side overheads it's very normal to have a large > fraction of connections idle in read mostly OLTP workloads. > > Here's the result on my workstation (2x Xeon Gold 5215 CPUs), testing > 1f42d35a1d6144a23602b2c0bc7f97f3046cf890 against > 07f32fcd23ac81898ed47f88beb569c631a2f223 which are the commits pre/post > connection scalability changes. > > I used fairly short pgbench runs (15s), and the numbers are the best of > three runs. I also had emacs and mutt open - some noise to be > expected. But I also gotta work ;) > > | Idle Connections | Active Connections | TPS pre | TPS post | > |-----------------:|-------------------:|--------:|---------:| > | 0 | 1 | 33599 | 33406 | > | 100 | 1 | 31088 | 33279 | > | 1000 | 1 | 29377 | 33434 | > | 2500 | 1 | 27050 | 33149 | > | 5000 | 1 | 21895 | 33903 | > | 10000 | 1 | 16034 | 33140 | > | 0 | 48 | 1042005 | 1125104 | > | 100 | 48 | 986731 | 1103584 | > | 1000 | 48 | 854230 | 1119043 | > | 2500 | 48 | 716624 | 1119353 | > | 5000 | 48 | 553657 | 1119476 | > | 10000 | 48 | 369845 | 1115740 | Attached in graph form. Greetings, Andres Freund
Вложения
{kind=link}
{kind=link}
On Fri, Sep 04, 2020 at 10:35:19AM -0700, Andres Freund wrote: > I think it's best to close the entry. There's substantial further wins > possible, in particular not acquiring ProcArrayLock in GetSnapshotData() > when the cache is valid improves performance substantially. But it's > non-trivial enough that it's probably best dealth with in a separate > patch / CF entry. Cool, thanks for updating the CF entry. -- Michael
Вложения
On 04.09.2020 21:53, Andres Freund wrote: > > I also used huge_pages=on / configured them on the OS level. Otherwise > TLB misses will be a significant factor. As far as I understand there should not be no any TLB misses because size of the shared buffers (8Mb) as several order of magnitude smaler that available physical memory. > > Does it change if you initialize the test database using > PGOPTIONS='-c vacuum_freeze_min_age=0' pgbench -i -s 100 > or run a manual VACUUM FREEZE; after initialization? I tried it, but didn't see any improvement. > > Hm, it'd probably be good to compare commits closer to the changes, to > avoid other changes showing up. > > Hm - did you verify if all the connections were actually established? > Particularly without the patch applied? With an unmodified pgbench, I > sometimes saw better numbers, but only because only half the connections > were able to be established, due to ProcArrayLock contention. Yes, that really happen quite often at IBM Power2 server (specific of it's atomic implementation). I even have to patch pgbench by adding one second delay after connection has been established to make it possible for all clients to connect. But at Intel server I didn't see unconnected clients. And in any case - it happen only for large number of connections (> 1000). But the best performance was achieved at about 100 connections and still I can not reach 2k TPS performance a in your case. > Did you connect via tcp or unix socket? Was pgbench running on the same > machine? It was locally via unix socket for me (but it's also observable > via two machines, just with lower overall throughput). Pgbench was launched at the same machine and connected through unix sockets. > Did you run a profile to see where the bottleneck is? Sorry I do not have root privileges at this server and so can not use perf. > > There's a seperate benchmark that I found to be quite revealing that's > far less dependent on scheduler behaviour. Run two pgbench instances: > > 1) With a very simply script '\sleep 1s' or such, and many connections > (e.g. 100,1000,5000). That's to simulate connections that are > currently idle. > 2) With a normal pgbench read only script, and low client counts. > > Before the changes 2) shows a very sharp decline in performance when the > count in 1) increases. Afterwards its pretty much linear. > > I think this benchmark actually is much more real world oriented - due > to latency and client side overheads it's very normal to have a large > fraction of connections idle in read mostly OLTP workloads. > > Here's the result on my workstation (2x Xeon Gold 5215 CPUs), testing > 1f42d35a1d6144a23602b2c0bc7f97f3046cf890 against > 07f32fcd23ac81898ed47f88beb569c631a2f223 which are the commits pre/post > connection scalability changes. > > I used fairly short pgbench runs (15s), and the numbers are the best of > three runs. I also had emacs and mutt open - some noise to be > expected. But I also gotta work ;) > > | Idle Connections | Active Connections | TPS pre | TPS post | > |-----------------:|-------------------:|--------:|---------:| > | 0 | 1 | 33599 | 33406 | > | 100 | 1 | 31088 | 33279 | > | 1000 | 1 | 29377 | 33434 | > | 2500 | 1 | 27050 | 33149 | > | 5000 | 1 | 21895 | 33903 | > | 10000 | 1 | 16034 | 33140 | > | 0 | 48 | 1042005 | 1125104 | > | 100 | 48 | 986731 | 1103584 | > | 1000 | 48 | 854230 | 1119043 | > | 2500 | 48 | 716624 | 1119353 | > | 5000 | 48 | 553657 | 1119476 | > | 10000 | 48 | 369845 | 1115740 | Yes, there is also noticeable difference in my case | Idle Connections | Active Connections | TPS pre | TPS post | |-----------------:|-------------------:|--------:|---------:| | 5000 | 48 | 758914 | 1184085 | > Think we'll need profiles to know... I will try to obtain sudo permissions and do profiling.
On 04.09.2020 21:53, Andres Freund wrote: > >> May be it is because of more complex architecture of my server? > Think we'll need profiles to know... This is "perf top" of pgebch -c 100 -j 100 -M prepared -S 12.16% postgres [.] PinBuffer 11.92% postgres [.] LWLockAttemptLock 6.46% postgres [.] UnpinBuffer.constprop.11 6.03% postgres [.] LWLockRelease 3.14% postgres [.] BufferGetBlockNumber 3.04% postgres [.] ReadBuffer_common 2.13% [kernel] [k] _raw_spin_lock_irqsave 2.11% [kernel] [k] switch_mm_irqs_off 1.95% postgres [.] _bt_compare Looks like most of the time is pent in buffers locks. And which pgbench database scale factor you have used?
Hi, On 2020-09-05 16:58:31 +0300, Konstantin Knizhnik wrote: > On 04.09.2020 21:53, Andres Freund wrote: > > > > I also used huge_pages=on / configured them on the OS level. Otherwise > > TLB misses will be a significant factor. > > As far as I understand there should not be no any TLB misses because size of > the shared buffers (8Mb) as several order of magnitude smaler that available > physical memory. I assume you didn't mean 8MB but 8GB? If so, that's way large enough to be bigger than the TLB, particularly across processes (IIRC there's no optimization to keep shared mappings de-duplicated between processes from the view of the TLB). > Yes, there is also noticeable difference in my case > > | Idle Connections | Active Connections | TPS pre | TPS post | > |-----------------:|-------------------:|--------:|---------:| > | 5000 | 48 | 758914 | 1184085 | Sounds like you're somehow hitting another bottleneck around 1.2M TPS Greetings, Andres Freund
Hi, On 2020-09-06 14:05:35 +0300, Konstantin Knizhnik wrote: > On 04.09.2020 21:53, Andres Freund wrote: > > > > > May be it is because of more complex architecture of my server? > > Think we'll need profiles to know... > > This is "perf top" of pgebch -c 100 -j 100 -M prepared -S > > 12.16% postgres [.] PinBuffer > 11.92% postgres [.] LWLockAttemptLock > 6.46% postgres [.] UnpinBuffer.constprop.11 > 6.03% postgres [.] LWLockRelease > 3.14% postgres [.] BufferGetBlockNumber > 3.04% postgres [.] ReadBuffer_common > 2.13% [kernel] [k] _raw_spin_lock_irqsave > 2.11% [kernel] [k] switch_mm_irqs_off > 1.95% postgres [.] _bt_compare > > > Looks like most of the time is pent in buffers locks. Hm, that is interesting / odd. If you record a profile with call graphs (e.g. --call-graph dwarf), where are all the LWLockAttemptLock calls comming from? I assume the machine you're talking about is an 8 socket machine? What if you: a) start postgres and pgbench with numactl --interleave=all b) start postgres with numactl --interleave=0,1 --cpunodebind=0,1 --membind=0,1 in case you have 4 sockets, or 0,1,2,3 in case you have 8 sockets? > And which pgbench database scale factor you have used? 200 Another thing you could try is to run 2-4 pgench instances in different databases. Greetings, Andres Freund
On 06.09.2020 21:56, Andres Freund wrote: > > Hm, that is interesting / odd. If you record a profile with call graphs > (e.g. --call-graph dwarf), where are all the LWLockAttemptLock calls > comming from? > Attached. > I assume the machine you're talking about is an 8 socket machine? > > What if you: > a) start postgres and pgbench with numactl --interleave=all > b) start postgres with numactl --interleave=0,1 --cpunodebind=0,1 --membind=0,1 > in case you have 4 sockets, or 0,1,2,3 in case you have 8 sockets? > TPS for -c 100 --interleave=all 1168910 --interleave=0,1 1232557 --interleave=0,1,2,3 1254271 --cpunodebind=0,1,2,3 --membind=0,1,2,3 1237237 --cpunodebind=0,1 --membind=0,1 1420211 --cpunodebind=0 --membind=0 1101203 >> And which pgbench database scale factor you have used? > 200 > > Another thing you could try is to run 2-4 pgench instances in different > databases. I tried to reinitialize database with scale 200 but there was no significant improvement in performance.
Вложения
{kind=link}
On 06.09.2020 21:52, Andres Freund wrote: > Hi, > > On 2020-09-05 16:58:31 +0300, Konstantin Knizhnik wrote: >> On 04.09.2020 21:53, Andres Freund wrote: >>> I also used huge_pages=on / configured them on the OS level. Otherwise >>> TLB misses will be a significant factor. >> As far as I understand there should not be no any TLB misses because size of >> the shared buffers (8Mb) as several order of magnitude smaler that available >> physical memory. > I assume you didn't mean 8MB but 8GB? If so, that's way large enough to > be bigger than the TLB, particularly across processes (IIRC there's no > optimization to keep shared mappings de-duplicated between processes > from the view of the TLB). > > Sorry, certainly 8Gb. I tried huge pages, but it has almost no effect/
Hi, On Mon, Sep 7, 2020, at 07:20, Konstantin Knizhnik wrote: > >> And which pgbench database scale factor you have used? > > 200 > > > > Another thing you could try is to run 2-4 pgench instances in different > > databases. > I tried to reinitialize database with scale 200 but there was no > significant improvement in performance. If you're replying to the last bit I am quoting, I was talking about having four databases with separate pbench tables etc.To see how much of it is procarray contention, and how much it is contention of common buffers etc. > Attachments: > * pgbench.svg What numactl was used for this one?
On 2020/09/03 17:18, Michael Paquier wrote: > On Sun, Aug 16, 2020 at 02:26:57PM -0700, Andres Freund wrote: >> So we get some builfarm results while thinking about this. > > Andres, there is an entry in the CF for this thread: > https://commitfest.postgresql.org/29/2500/ > > A lot of work has been committed with 623a9ba, 73487a6, 5788e25, etc. I haven't seen it mentioned here, so apologies if I've overlooked something, but as of 623a9ba queries on standbys seem somewhat broken. Specifically, I maintain some code which does something like this: - connects to a standby - checks a particular row does not exist on the standby - connects to the primary - writes a row in the primary - polls the standby (using the same connection as above) to verify the row arrives on the standby As of recent HEAD it never sees the row arrive on the standby, even though it is verifiably there. I've traced this back to 623a9ba, which relies on "xactCompletionCount" being incremented to determine whether the snapshot can be reused, but that never happens on a standby, meaning this test in GetSnapshotDataReuse(): if (curXactCompletionCount != snapshot->snapXactCompletionCount) return false; will never return false, and the snapshot's xmin/xmax never get advanced. Which means the session on the standby is not able to see rows on the standby added after the session was started. It's simple enough to prevent that being an issue by just never calling GetSnapshotDataReuse() if the snapshot was taken during recovery (though obviously that means any performance benefits won't be available on standbys). I wonder if it's possible to increment "xactCompletionCount" during replay along these lines: *** a/src/backend/access/transam/xact.c --- b/src/backend/access/transam/xact.c *************** xact_redo_commit(xl_xact_parsed_commit * *** 5915,5920 **** --- 5915,5924 ---- */ if (XactCompletionApplyFeedback(parsed->xinfo)) XLogRequestWalReceiverReply(); + + LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE); + ShmemVariableCache->xactCompletionCount++; + LWLockRelease(ProcArrayLock); } which seems to work (though quite possibly I've overlooked something I don't know that I don't know about and it will all break horribly somewhere, etc. etc.). Regards Ian Barwick -- Ian Barwick https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Hi, On 2020-09-08 13:03:01 +0900, Ian Barwick wrote: > On 2020/09/03 17:18, Michael Paquier wrote: > > On Sun, Aug 16, 2020 at 02:26:57PM -0700, Andres Freund wrote: > > > So we get some builfarm results while thinking about this. > > > > Andres, there is an entry in the CF for this thread: > > https://commitfest.postgresql.org/29/2500/ > > > > A lot of work has been committed with 623a9ba, 73487a6, 5788e25, etc. > > I haven't seen it mentioned here, so apologies if I've overlooked > something, but as of 623a9ba queries on standbys seem somewhat > broken. > > Specifically, I maintain some code which does something like this: > > - connects to a standby > - checks a particular row does not exist on the standby > - connects to the primary > - writes a row in the primary > - polls the standby (using the same connection as above) > to verify the row arrives on the standby > > As of recent HEAD it never sees the row arrive on the standby, even > though it is verifiably there. Ugh, that's not good. > I've traced this back to 623a9ba, which relies on "xactCompletionCount" > being incremented to determine whether the snapshot can be reused, > but that never happens on a standby, meaning this test in > GetSnapshotDataReuse(): > > if (curXactCompletionCount != snapshot->snapXactCompletionCount) > return false; > > will never return false, and the snapshot's xmin/xmax never get advanced. > Which means the session on the standby is not able to see rows on the > standby added after the session was started. > > It's simple enough to prevent that being an issue by just never calling > GetSnapshotDataReuse() if the snapshot was taken during recovery > (though obviously that means any performance benefits won't be available > on standbys). Yea, that doesn't sound great. Nor is the additional branch welcome. > I wonder if it's possible to increment "xactCompletionCount" > during replay along these lines: > > *** a/src/backend/access/transam/xact.c > --- b/src/backend/access/transam/xact.c > *************** xact_redo_commit(xl_xact_parsed_commit * > *** 5915,5920 **** > --- 5915,5924 ---- > */ > if (XactCompletionApplyFeedback(parsed->xinfo)) > XLogRequestWalReceiverReply(); > + > + LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE); > + ShmemVariableCache->xactCompletionCount++; > + LWLockRelease(ProcArrayLock); > } > > which seems to work (though quite possibly I've overlooked something I don't > know that I don't know about and it will all break horribly somewhere, > etc. etc.). We'd also need the same in a few more places. Probably worth looking at the list where we increment it on the primary (particularly we need to also increment it for aborts, and 2pc commit/aborts). At first I was very confused as to why none of the existing tests have found this significant issue. But after thinking about it for a minute that's because they all use psql, and largely separate psql invocations for each query :(. Which means that there's no cached snapshot around... Do you want to try to write a patch? Greetings, Andres Freund
On 2020/09/08 13:11, Andres Freund wrote: > Hi, > > On 2020-09-08 13:03:01 +0900, Ian Barwick wrote: (...) >> I wonder if it's possible to increment "xactCompletionCount" >> during replay along these lines: >> >> *** a/src/backend/access/transam/xact.c >> --- b/src/backend/access/transam/xact.c >> *************** xact_redo_commit(xl_xact_parsed_commit * >> *** 5915,5920 **** >> --- 5915,5924 ---- >> */ >> if (XactCompletionApplyFeedback(parsed->xinfo)) >> XLogRequestWalReceiverReply(); >> + >> + LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE); >> + ShmemVariableCache->xactCompletionCount++; >> + LWLockRelease(ProcArrayLock); >> } >> >> which seems to work (though quite possibly I've overlooked something I don't >> know that I don't know about and it will all break horribly somewhere, >> etc. etc.). > > We'd also need the same in a few more places. Probably worth looking at > the list where we increment it on the primary (particularly we need to > also increment it for aborts, and 2pc commit/aborts). Yup. > At first I was very confused as to why none of the existing tests have > found this significant issue. But after thinking about it for a minute > that's because they all use psql, and largely separate psql invocations > for each query :(. Which means that there's no cached snapshot around... > > Do you want to try to write a patch? Sure, I'll give it a go as I have some time right now. Regards Ian Barwick -- Ian Barwick https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Sep 8, 2020 at 4:11 PM Andres Freund <andres@anarazel.de> wrote:
> At first I was very confused as to why none of the existing tests have
> found this significant issue. But after thinking about it for a minute
> that's because they all use psql, and largely separate psql invocations
> for each query :(. Which means that there's no cached snapshot around...
I prototyped a TAP test patch that could maybe do the sort of thing
you need, in patch 0006 over at [1]. Later versions of that patch set
dropped it, because I figured out how to use the isolation tester
instead, but I guess you can't do that for a standby test (at least
not until someone teaches the isolation tester to support multi-node
schedules, something that would be extremely useful...). Example:
+# start an interactive session that we can use to interleave statements
+my $session = PsqlSession->new($node, "postgres");
+$session->send("\\set PROMPT1 ''\n", 2);
+$session->send("\\set PROMPT2 ''\n", 1);
...
+# our snapshot is not too old yet, so we can still use it
+@lines = $session->send("select * from t order by i limit 1;\n", 2);
+shift @lines;
+$result = shift @lines;
+is($result, "1");
...
+# our snapshot is too old! the thing it wants to see has been removed
+@lines = $session->send("select * from t order by i limit 1;\n", 2);
+shift @lines;
+$result = shift @lines;
+is($result, "ERROR: snapshot too old");
[1] https://www.postgresql.org/message-id/CA%2BhUKG%2BFkUuDv-bcBns%3DZ_O-V9QGW0nWZNHOkEPxHZWjegRXvw%40mail.gmail.com
On 07.09.2020 23:45, Andres Freund wrote: > Hi, > > > On Mon, Sep 7, 2020, at 07:20, Konstantin Knizhnik wrote: >>>> And which pgbench database scale factor you have used? >>> 200 >>> >>> Another thing you could try is to run 2-4 pgench instances in different >>> databases. >> I tried to reinitialize database with scale 200 but there was no >> significant improvement in performance. > If you're replying to the last bit I am quoting, I was talking about having four databases with separate pbench tablesetc. To see how much of it is procarray contention, and how much it is contention of common buffers etc. > Sorry, I have tested hypothesis that the difference in performance in my and you cases can be explained by size of the table which can have influence on shared buffer contention. Thus is why I used the same scale as you, but there is no difference compatring with scale 100. And definitely Postgres performance in this test is limited by lock contention (most likely shared buffers locks, rather than procarray locks). If I create two instances of postgres, both with pgbench -s 200 database and run two pgbenches with 100 connections each, then each instance shows the same ~1million TPS (1186483) as been launched standalone. And total TPS is 2.3 millions. >> Attachments: >> * pgbench.svg > What numactl was used for this one? > None. I have not used numactl in this case. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi, On 2020-09-08 16:44:17 +1200, Thomas Munro wrote: > On Tue, Sep 8, 2020 at 4:11 PM Andres Freund <andres@anarazel.de> wrote: > > At first I was very confused as to why none of the existing tests have > > found this significant issue. But after thinking about it for a minute > > that's because they all use psql, and largely separate psql invocations > > for each query :(. Which means that there's no cached snapshot around... > > I prototyped a TAP test patch that could maybe do the sort of thing > you need, in patch 0006 over at [1]. Later versions of that patch set > dropped it, because I figured out how to use the isolation tester > instead, but I guess you can't do that for a standby test (at least > not until someone teaches the isolation tester to support multi-node > schedules, something that would be extremely useful...). Unfortunately proper multi-node isolationtester test basically is equivalent to building a global lock graph. I think, at least? Including a need to be able to correlate connections with their locks between the nodes. But for something like the bug at hand it'd probably sufficient to just "hack" something with dblink. In session 1) insert a row on the primary using dblink, return the LSN, wait for the LSN to have replicated and finally in session 2) check for row visibility. Greetings, Andres Freund
Hi, On 2020-06-07 11:24:50 +0300, Michail Nikolaev wrote: > Hello, hackers. > Andres, nice work! > > Sorry for the off-top. > > Some of my work [1] related to the support of index hint bits on > standby is highly interfering with this patch. > Is it safe to consider it committed and start rebasing on top of the patches? Sorry, I missed this email. Since they're now committed, yes, it is safe ;) Greetings, Andres Freund
On 2020/09/09 2:53, Andres Freund wrote: > Hi, > > On 2020-09-08 16:44:17 +1200, Thomas Munro wrote: >> On Tue, Sep 8, 2020 at 4:11 PM Andres Freund <andres@anarazel.de> wrote: >>> At first I was very confused as to why none of the existing tests have >>> found this significant issue. But after thinking about it for a minute >>> that's because they all use psql, and largely separate psql invocations >>> for each query :(. Which means that there's no cached snapshot around... >> >> I prototyped a TAP test patch that could maybe do the sort of thing >> you need, in patch 0006 over at [1]. Later versions of that patch set >> dropped it, because I figured out how to use the isolation tester >> instead, but I guess you can't do that for a standby test (at least >> not until someone teaches the isolation tester to support multi-node >> schedules, something that would be extremely useful...). > > Unfortunately proper multi-node isolationtester test basically is > equivalent to building a global lock graph. I think, at least? Including > a need to be able to correlate connections with their locks between the > nodes. > > But for something like the bug at hand it'd probably sufficient to just > "hack" something with dblink. In session 1) insert a row on the primary > using dblink, return the LSN, wait for the LSN to have replicated and > finally in session 2) check for row visibility. The attached seems to do the trick. Regards Ian Barwick -- Ian Barwick https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Вложения
On 2020/09/08 13:23, Ian Barwick wrote: > On 2020/09/08 13:11, Andres Freund wrote: >> Hi, >> >> On 2020-09-08 13:03:01 +0900, Ian Barwick wrote: > (...) >>> I wonder if it's possible to increment "xactCompletionCount" >>> during replay along these lines: >>> >>> *** a/src/backend/access/transam/xact.c >>> --- b/src/backend/access/transam/xact.c >>> *************** xact_redo_commit(xl_xact_parsed_commit * >>> *** 5915,5920 **** >>> --- 5915,5924 ---- >>> */ >>> if (XactCompletionApplyFeedback(parsed->xinfo)) >>> XLogRequestWalReceiverReply(); >>> + >>> + LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE); >>> + ShmemVariableCache->xactCompletionCount++; >>> + LWLockRelease(ProcArrayLock); >>> } >>> >>> which seems to work (though quite possibly I've overlooked something I don't >>> know that I don't know about and it will all break horribly somewhere, >>> etc. etc.). >> >> We'd also need the same in a few more places. Probably worth looking at >> the list where we increment it on the primary (particularly we need to >> also increment it for aborts, and 2pc commit/aborts). > > Yup. > >> At first I was very confused as to why none of the existing tests have >> found this significant issue. But after thinking about it for a minute >> that's because they all use psql, and largely separate psql invocations >> for each query :(. Which means that there's no cached snapshot around... >> >> Do you want to try to write a patch? > > Sure, I'll give it a go as I have some time right now. Attached, though bear in mind I'm not very familiar with parts of this, particularly 2PC stuff, so consider it educated guesswork. Regards Ian Barwick -- Ian Barwick https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Вложения
Hi, On 2020-09-09 17:02:58 +0900, Ian Barwick wrote: > Attached, though bear in mind I'm not very familiar with parts of this, > particularly 2PC stuff, so consider it educated guesswork. Thanks for this, and the test case! Your commit fixes the issues, but not quite correctly. Multixacts shouldn't matter, so we don't need to do anything there. And for the increases, I think they should be inside the already existing ProcArrayLock acquisition, as in the attached. I've also included a quite heavily revised version of your test. Instead of using dblink I went for having a long-running psql that I feed over stdin. The main reason for not liking the previous version is that it seems fragile, with the sleep and everything. I expanded it to cover 2PC is as well. The test probably needs a bit of cleanup, wrapping some of the redundancy around the pump_until calls. I think the approach of having a long running psql session is really useful, and probably would speed up some tests. Does anybody have a good idea for how to best, and without undue effort, to integrate this into PostgresNode.pm? I don't really have a great idea, so I think I'd leave it with a local helper in the new test? Regards, Andres
Вложения
Andres Freund <andres@anarazel.de> writes:
> I think the approach of having a long running psql session is really
> useful, and probably would speed up some tests. Does anybody have a good
> idea for how to best, and without undue effort, to integrate this into
> PostgresNode.pm? I don't really have a great idea, so I think I'd leave
> it with a local helper in the new test?
You could use the interactive_psql infrastructure that already exists
for psql/t/010_tab_completion.pl. That does rely on IO::Pty, but
I think I'd prefer to accept that dependency for such tests over rolling
our own IPC::Run, which is more or less what you've done here.
regards, tom lane
Hi, On 2020-09-14 20:14:48 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > I think the approach of having a long running psql session is really > > useful, and probably would speed up some tests. Does anybody have a good > > idea for how to best, and without undue effort, to integrate this into > > PostgresNode.pm? I don't really have a great idea, so I think I'd leave > > it with a local helper in the new test? > > You could use the interactive_psql infrastructure that already exists > for psql/t/010_tab_completion.pl. That does rely on IO::Pty, but > I think I'd prefer to accept that dependency for such tests over rolling > our own IPC::Run, which is more or less what you've done here. My test uses IPC::Run - although I'm indirectly 'use'ing, which I guess isn't pretty. Just as 013_crash_restart.pl already did (even before psql/t/010_tab_completion.pl). I am mostly wondering whether we could avoid copying the utility functions into multiple test files... Does IO::Pty work on windows? Given that currently the test doesn't use a pty and that there's no benefit I can see in requiring one, I'm a bit hesitant to go there? Greetings, Andres Freund
On Mon, Sep 14, 2020 at 05:42:51PM -0700, Andres Freund wrote: > My test uses IPC::Run - although I'm indirectly 'use'ing, which I guess > isn't pretty. Just as 013_crash_restart.pl already did (even before > psql/t/010_tab_completion.pl). I am mostly wondering whether we could > avoid copying the utility functions into multiple test files... > > Does IO::Pty work on windows? Given that currently the test doesn't use > a pty and that there's no benefit I can see in requiring one, I'm a bit > hesitant to go there? Per https://metacpan.org/pod/IO::Tty: "Windows is now supported, but ONLY under the Cygwin environment, see http://sources.redhat.com/cygwin/." So I would suggest to make stuff a soft dependency (as Tom is hinting?), and not worry about Windows specifically. It is not like what we are dealing with here is specific to Windows anyway, so you would have already sufficient coverage. I would not mind if any refactoring is done later, once we know that the proposed test is stable in the buildfarm as we would get a better image of what part of the facility overlaps across multiple tests. -- Michael
Вложения
Hi, On 2020-09-15 11:56:24 +0900, Michael Paquier wrote: > On Mon, Sep 14, 2020 at 05:42:51PM -0700, Andres Freund wrote: > > My test uses IPC::Run - although I'm indirectly 'use'ing, which I guess > > isn't pretty. Just as 013_crash_restart.pl already did (even before > > psql/t/010_tab_completion.pl). I am mostly wondering whether we could > > avoid copying the utility functions into multiple test files... > > > > Does IO::Pty work on windows? Given that currently the test doesn't use > > a pty and that there's no benefit I can see in requiring one, I'm a bit > > hesitant to go there? > > Per https://metacpan.org/pod/IO::Tty: > "Windows is now supported, but ONLY under the Cygwin environment, see > http://sources.redhat.com/cygwin/." > > So I would suggest to make stuff a soft dependency (as Tom is > hinting?), and not worry about Windows specifically. It is not like > what we are dealing with here is specific to Windows anyway, so you > would have already sufficient coverage. I would not mind if any > refactoring is done later, once we know that the proposed test is > stable in the buildfarm as we would get a better image of what part of > the facility overlaps across multiple tests. I'm confused - the test as posted should work on windows, and we already do this in an existing test (src/test/recovery/t/013_crash_restart.pl). What's the point in adding a platforms specific dependency here? Greetings, Andres Freund
Hi, On 2020-09-14 16:17:18 -0700, Andres Freund wrote: > I've also included a quite heavily revised version of your test. Instead > of using dblink I went for having a long-running psql that I feed over > stdin. The main reason for not liking the previous version is that it > seems fragile, with the sleep and everything. I expanded it to cover > 2PC is as well. > > The test probably needs a bit of cleanup, wrapping some of the > redundancy around the pump_until calls. > > I think the approach of having a long running psql session is really > useful, and probably would speed up some tests. Does anybody have a good > idea for how to best, and without undue effort, to integrate this into > PostgresNode.pm? I don't really have a great idea, so I think I'd leave > it with a local helper in the new test? Attached is an updated version of the test (better utility function, stricter regexes, bailing out instead of failing just the current when psql times out). I'm leaving it in this test for now, but it's fairly easy to use this way, in my opinion, so it may be worth moving to PostgresNode at some point. Greetings, Andres Freund
Вложения
On Tue, 15 Sep 2020 at 07:17, Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2020-09-09 17:02:58 +0900, Ian Barwick wrote: > > Attached, though bear in mind I'm not very familiar with parts of this, > > particularly 2PC stuff, so consider it educated guesswork. > > Thanks for this, and the test case! > > Your commit fixes the issues, but not quite correctly. Multixacts > shouldn't matter, so we don't need to do anything there. And for the > increases, I think they should be inside the already existing > ProcArrayLock acquisition, as in the attached. > > > I've also included a quite heavily revised version of your test. Instead > of using dblink I went for having a long-running psql that I feed over > stdin. The main reason for not liking the previous version is that it > seems fragile, with the sleep and everything. I expanded it to cover > 2PC is as well. > > The test probably needs a bit of cleanup, wrapping some of the > redundancy around the pump_until calls. > > I think the approach of having a long running psql session is really > useful, and probably would speed up some tests. Does anybody have a good > idea for how to best, and without undue effort, to integrate this into > PostgresNode.pm? I don't really have a great idea, so I think I'd leave > it with a local helper in the new test? 2ndQ has some infra for that and various other TAP enhancements that I'd like to try to upstream. I'll ask what I can share and how. -- Craig Ringer http://www.2ndQuadrant.com/ 2ndQuadrant - PostgreSQL Solutions for the Enterprise
Hi Ian, Andrew, All, On 2020-09-30 15:43:17 -0700, Andres Freund wrote: > Attached is an updated version of the test (better utility function, > stricter regexes, bailing out instead of failing just the current when > psql times out). I'm leaving it in this test for now, but it's fairly > easy to use this way, in my opinion, so it may be worth moving to > PostgresNode at some point. I pushed this yesterday. Ian, thanks again for finding this and helping with fixing & testing. Unfortunately currently some buildfarm animals don't like the test for reasons I don't quite understand. Looks like it's all windows + msys animals that run the tap tests. On jacana and fairywren the new test fails, but with a somewhat confusing problem: https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-10-01%2015%3A32%3A34 Bail out! aborting wait: program timed out # stream contents: >>data # (0 rows) # << # pattern searched for: (?m-xis:^\\(0 rows\\)$) https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2020-10-01%2014%3A12%3A13 Bail out! aborting wait: program timed out stream contents: >>data (0 rows) << pattern searched for: (?^m:^\\(0 rows\\)$) I don't know with the -xis indicates on jacana, and why it's not present on fairywren. Nor do I know why the pattern doesn't match in the first place, sure looks like it should? Andrew, do you have an insight into how mingw's regex match differs from native windows and proper unixoid systems? I guess it's somewhere around line endings or such? Jacana successfully deals with 013_crash_restart.pl, which does use the same mechanis as the new 021_row_visibility.pl - I think the only real difference is that I used ^ and $ in the regexes in the latter... Greetings, Andres Freund
On 10/1/20 2:26 PM, Andres Freund wrote: > Hi Ian, Andrew, All, > > On 2020-09-30 15:43:17 -0700, Andres Freund wrote: >> Attached is an updated version of the test (better utility function, >> stricter regexes, bailing out instead of failing just the current when >> psql times out). I'm leaving it in this test for now, but it's fairly >> easy to use this way, in my opinion, so it may be worth moving to >> PostgresNode at some point. > I pushed this yesterday. Ian, thanks again for finding this and helping > with fixing & testing. > > > Unfortunately currently some buildfarm animals don't like the test for > reasons I don't quite understand. Looks like it's all windows + msys > animals that run the tap tests. On jacana and fairywren the new test > fails, but with a somewhat confusing problem: > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=jacana&dt=2020-10-01%2015%3A32%3A34 > Bail out! aborting wait: program timed out > # stream contents: >>data > # (0 rows) > # << > # pattern searched for: (?m-xis:^\\(0 rows\\)$) > > https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=fairywren&dt=2020-10-01%2014%3A12%3A13 > Bail out! aborting wait: program timed out > stream contents: >>data > (0 rows) > << > pattern searched for: (?^m:^\\(0 rows\\)$) > > I don't know with the -xis indicates on jacana, and why it's not present > on fairywren. Nor do I know why the pattern doesn't match in the first > place, sure looks like it should? > > Andrew, do you have an insight into how mingw's regex match differs > from native windows and proper unixoid systems? I guess it's somewhere > around line endings or such? > > Jacana successfully deals with 013_crash_restart.pl, which does use the > same mechanis as the new 021_row_visibility.pl - I think the only real > difference is that I used ^ and $ in the regexes in the latter... My strong suspicion is that we're getting unwanted CRs. Note the presence of numerous instances of this in PostgresNode.pm: $stdout =~ s/\r\n/\n/g if $Config{osname} eq 'msys'; So you probably want something along those lines at the top of the loop in send_query_and_wait: $$psql{stdout} =~ s/\r\n/\n/g if $Config{osname} eq 'msys'; possibly also for stderr, just to make it more futureproof, and at the top of the file: use Config; Do you want me to test that first? The difference between the canonical way perl states the regex is due to perl version differences. It shouldn't matter. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
On 2020-10-01 16:00:20 -0400, Andrew Dunstan wrote:
> My strong suspicion is that we're getting unwanted CRs. Note the
> presence of numerous instances of this in PostgresNode.pm:
> $stdout =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
>
> So you probably want something along those lines at the top of the loop
> in send_query_and_wait:
>
> $$psql{stdout} =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
Yikes, that's ugly :(.
I assume it's not, as the comments says
# Note: on Windows, IPC::Run seems to convert \r\n to \n in program output
# if we're using native Perl, but not if we're using MSys Perl. So do it
# by hand in the latter case, here and elsewhere.
that IPC::Run converts things, but that native windows perl uses
https://perldoc.perl.org/perlrun#PERLIO
a PERLIO that includes :crlf, whereas msys probably doesn't?
Any chance you could run something like
perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");'
on both native and msys perl?
> possibly also for stderr, just to make it more futureproof, and at the
> top of the file:
>
> use Config;
>
>
> Do you want me to test that first?
That'd be awesome.
> The difference between the canonical way perl states the regex is due to
> perl version differences. It shouldn't matter.
Thanks!
Greetings,
Andres Freund
On 10/1/20 4:22 PM, Andres Freund wrote:
> Hi,
>
> On 2020-10-01 16:00:20 -0400, Andrew Dunstan wrote:
>> My strong suspicion is that we're getting unwanted CRs. Note the
>> presence of numerous instances of this in PostgresNode.pm:
>
>> $stdout =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
>>
>> So you probably want something along those lines at the top of the loop
>> in send_query_and_wait:
>>
>> $$psql{stdout} =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
> Yikes, that's ugly :(.
>
>
> I assume it's not, as the comments says
> # Note: on Windows, IPC::Run seems to convert \r\n to \n in program output
> # if we're using native Perl, but not if we're using MSys Perl. So do it
> # by hand in the latter case, here and elsewhere.
> that IPC::Run converts things, but that native windows perl uses
> https://perldoc.perl.org/perlrun#PERLIO
> a PERLIO that includes :crlf, whereas msys probably doesn't?
>
> Any chance you could run something like
> perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");'
> on both native and msys perl?
>
>
sys (jacana): stdio
native: unixcrlf
cheers
andrew
--
Andrew Dunstan https://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2020-10-01 16:44:03 -0400, Andrew Dunstan wrote: > > I assume it's not, as the comments says > > # Note: on Windows, IPC::Run seems to convert \r\n to \n in program output > > # if we're using native Perl, but not if we're using MSys Perl. So do it > > # by hand in the latter case, here and elsewhere. > > that IPC::Run converts things, but that native windows perl uses > > https://perldoc.perl.org/perlrun#PERLIO > > a PERLIO that includes :crlf, whereas msys probably doesn't? > > > > Any chance you could run something like > > perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");' > > on both native and msys perl? > > sys (jacana): stdio > > native: unixcrlf Interesting. That suggest we could get around needing the if msys branches in several places by setting PERLIO to unixcrlf somewhere centrally when using msys. Greetings, Andres Freund
On 10/1/20 4:22 PM, Andres Freund wrote:
> Hi,
>
> On 2020-10-01 16:00:20 -0400, Andrew Dunstan wrote:
>> My strong suspicion is that we're getting unwanted CRs. Note the
>> presence of numerous instances of this in PostgresNode.pm:
>
>> $stdout =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
>>
>> So you probably want something along those lines at the top of the loop
>> in send_query_and_wait:
>>
>> $$psql{stdout} =~ s/\r\n/\n/g if $Config{osname} eq 'msys';
> Yikes, that's ugly :(.
>
>
> I assume it's not, as the comments says
> # Note: on Windows, IPC::Run seems to convert \r\n to \n in program output
> # if we're using native Perl, but not if we're using MSys Perl. So do it
> # by hand in the latter case, here and elsewhere.
> that IPC::Run converts things, but that native windows perl uses
> https://perldoc.perl.org/perlrun#PERLIO
> a PERLIO that includes :crlf, whereas msys probably doesn't?
>
> Any chance you could run something like
> perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");'
> on both native and msys perl?
>
>
>> possibly also for stderr, just to make it more futureproof, and at the
>> top of the file:
>>
>> use Config;
>>
>>
>> Do you want me to test that first?
> That'd be awesome.
>
>
>
The change I suggested makes jacana happy.
cheers
andrew
--
Andrew Dunstan https://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2020/10/02 3:26, Andres Freund wrote: > Hi Ian, Andrew, All, > > On 2020-09-30 15:43:17 -0700, Andres Freund wrote: >> Attached is an updated version of the test (better utility function, >> stricter regexes, bailing out instead of failing just the current when >> psql times out). I'm leaving it in this test for now, but it's fairly >> easy to use this way, in my opinion, so it may be worth moving to >> PostgresNode at some point. > > I pushed this yesterday. Ian, thanks again for finding this and helping > with fixing & testing. Thanks! Apologies for not getting back to your earlier responses, have been distracted by Various Other Things. The tests I run which originally triggered the issue now run just fine. Regards Ian Barwick -- Ian Barwick https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Hi, On 2020-10-01 19:21:14 -0400, Andrew Dunstan wrote: > On 10/1/20 4:22 PM, Andres Freund wrote: > > # Note: on Windows, IPC::Run seems to convert \r\n to \n in program output > > # if we're using native Perl, but not if we're using MSys Perl. So do it > > # by hand in the latter case, here and elsewhere. > > that IPC::Run converts things, but that native windows perl uses > > https://perldoc.perl.org/perlrun#PERLIO > > a PERLIO that includes :crlf, whereas msys probably doesn't? > > > > Any chance you could run something like > > perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");' > > on both native and msys perl? > > > > > >> possibly also for stderr, just to make it more futureproof, and at the > >> top of the file: > >> > >> use Config; > >> > >> > >> Do you want me to test that first? > > That'd be awesome. > The change I suggested makes jacana happy. Thanks, pushed. Hopefully that fixes the mingw animals. I wonder if we instead should do something like # Have mingw perl treat CRLF the same way as perl on native windows does ifeq ($(build_os),mingw32) PROVE="PERLIO=unixcrlf $(PROVE)" endif in Makefile.global.in? Then we could remove these rexes from all the various places? Greetings, Andres Freund
On 10/5/20 10:33 PM, Andres Freund wrote: > Hi, > > On 2020-10-01 19:21:14 -0400, Andrew Dunstan wrote: >> On 10/1/20 4:22 PM, Andres Freund wrote: >>> # Note: on Windows, IPC::Run seems to convert \r\n to \n in program output >>> # if we're using native Perl, but not if we're using MSys Perl. So do it >>> # by hand in the latter case, here and elsewhere. >>> that IPC::Run converts things, but that native windows perl uses >>> https://perldoc.perl.org/perlrun#PERLIO >>> a PERLIO that includes :crlf, whereas msys probably doesn't? >>> >>> Any chance you could run something like >>> perl -mPerlIO -e 'print(PerlIO::get_layers(STDIN), "\n");' >>> on both native and msys perl? >>> >>> >>>> possibly also for stderr, just to make it more futureproof, and at the >>>> top of the file: >>>> >>>> use Config; >>>> >>>> >>>> Do you want me to test that first? >>> That'd be awesome. >> The change I suggested makes jacana happy. > Thanks, pushed. Hopefully that fixes the mingw animals. > I don't think we're out of the woods yet. This test is also have bad effects on bowerbird, which is an MSVC animal. It's hanging completely :-( Digging some more. cheers andrew -- Andrew Dunstan EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company