Обсуждение: [GSoC][Patch] Automatic Mode Detection V1
Dear all,
This is my first patch of my GSoC project, query tool automatic mode detection.
In this patch, the initial (basic) version of the project is implemented. In this version, query resultsets are updatable if and only if:
- All the columns belong to a single table
- No duplicate columns are available
- All the primary keys of the table are available
Inserts, updates and deletes work automatically when the resultset is updatable.
The 'save' button in the query tool works automatically to save the changes in the resultset if the query is the updatable, and saves the query to a file otherwise. The 'save as' button stays as is.
I will work on improving and adding features to this version throughout my work during the summer according to what has the highest priorities (supporting duplicate columns or columns produced by functions or aggregations as read-only columns in the results seems like a good next move).
Please give me your feedback of the changes I made, and any hints or comments that will improve my code in any aspect.
I also have a couple of questions,
- Should the save button in the query tool work the way I am using it now? or should there be a new dedicated button for saving the query to a file?
- What documentations or unit tests should I write? any guidelines here would be appreciated.
Thanks a lot!
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
This is a patch fixing a problem with the above patch that happened when:
- primary key columns are renamed.
- other columns are renamed to be like primary key columns.
This problem happened mainly because the primary keys are identified in the front-end by their names. This can be handled in a better way in a future update where columns that are primary keys are identified by the backend and sent to the frontend instead.
Also, renamed columns can be handled better by making them read-only in a future update (now they are editable but they cannot be updated as a column with the new name does not exist - it produces an error message to the user).
Waiting for your feedback. Thanks !
On Sat, Jun 15, 2019 at 8:48 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
Dear all,This is my first patch of my GSoC project, query tool automatic mode detection.In this patch, the initial (basic) version of the project is implemented. In this version, query resultsets are updatable if and only if:- All the columns belong to a single table- No duplicate columns are available- All the primary keys of the table are availableInserts, updates and deletes work automatically when the resultset is updatable.The 'save' button in the query tool works automatically to save the changes in the resultset if the query is the updatable, and saves the query to a file otherwise. The 'save as' button stays as is.I will work on improving and adding features to this version throughout my work during the summer according to what has the highest priorities (supporting duplicate columns or columns produced by functions or aggregations as read-only columns in the results seems like a good next move).Please give me your feedback of the changes I made, and any hints or comments that will improve my code in any aspect.I also have a couple of questions,- Should the save button in the query tool work the way I am using it now? or should there be a new dedicated button for saving the query to a file?- What documentations or unit tests should I write? any guidelines here would be appreciated.Thanks a lot!
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
Hi
On Sun, Jun 16, 2019 at 3:10 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
This is a patch fixing a problem with the above patch that happened when:- primary key columns are renamed.- other columns are renamed to be like primary key columns.This problem happened mainly because the primary keys are identified in the front-end by their names. This can be handled in a better way in a future update where columns that are primary keys are identified by the backend and sent to the frontend instead.Also, renamed columns can be handled better by making them read-only in a future update (now they are editable but they cannot be updated as a column with the new name does not exist - it produces an error message to the user).
Seems like a fairly low-impact problem. Most people probably don't rename columns whilst they're editing data in the same table. That said, if it's not overly invasive or complex, I see no reason not to fix it.
On Sat, Jun 15, 2019 at 8:48 AM Yosry Muhammad <yosrym93@gmail.com> wrote:Dear all,This is my first patch of my GSoC project, query tool automatic mode detection.In this patch, the initial (basic) version of the project is implemented. In this version, query resultsets are updatable if and only if:- All the columns belong to a single table- No duplicate columns are available- All the primary keys of the table are availableInserts, updates and deletes work automatically when the resultset is updatable.
Hmm, I wonder if I under-estimated the complexity of this task! There is more work to do of course, but it almost looks like you've done the hard part. Still, there are plenty of other related things that can be improved along the way.
The 'save' button in the query tool works automatically to save the changes in the resultset if the query is the updatable, and saves the query to a file otherwise. The 'save as' button stays as is.
Yeah, I think we'll have to have a second Save button. The current one would save the query text, whilst the new one would save changes to the data.
Do you want me to ask our design guy for an icon?
I will work on improving and adding features to this version throughout my work during the summer according to what has the highest priorities (supporting duplicate columns or columns produced by functions or aggregations as read-only columns in the results seems like a good next move).
I think handling read-only columns is most important, then duplicates.
Please give me your feedback of the changes I made, and any hints or comments that will improve my code in any aspect.
Well the first problem is that it doesn't actually work for me. This is what I get when running a simple "select * from pem.probe" (where pem.probe is a table with primary key and a few columns - see below) on a PG11 system (with both of your patches applied):
2019-06-17 10:56:44,610: SQL flask.app: Execute (void) for server #5 - CONN:3976967 (Query-id: 2391511):
BEGIN;
2019-06-17 10:56:44,610: SQL flask.app: Execute (async) for server #5 - CONN:3976967 (Query-id: 5707996):
select * from pem.probe
2019-06-17 10:56:44,614: INFO werkzeug: 127.0.0.1 - - [17/Jun/2019 10:56:44] "POST /sqleditor/query_tool/start/3781524 HTTP/1.1" 200 -
2019-06-17 10:56:44,631: SQL flask.app: Polling result for (Query-id: 5707996)
2019-06-17 10:56:44,635: SQL flask.app: Polling result for (Query-id: 5707996)
2019-06-17 10:56:44,639: SQL flask.app: Execute (dict) for server #5 - CONN:3976967 (Query-id: 5976248):
SELECT at.attname, ty.typname
FROM pg_attribute at LEFT JOIN pg_type ty ON (ty.oid = at.atttypid)
WHERE attrelid=17491::oid AND attnum = ANY (
(SELECT con.conkey FROM pg_class rel LEFT OUTER JOIN pg_constraint con ON con.conrelid=rel.oid
AND con.contype='p' WHERE rel.relkind IN ('r','s','t', 'p') AND rel.oid = 17491::oid)::oid[])
2019-06-17 10:56:44,641: ERROR flask.app: 'attnum'
Traceback (most recent call last):
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask_login/utils.py", line 261, in decorated_view
return func(*args, **kwargs)
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/__init__.py", line 462, in poll
trans_obj.check_for_updatable_resultset_and_primary_keys()
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/command.py", line 904, in check_for_updatable_resultset_and_primary_keys
is_query_resultset_updatable(conn, sql_path)
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py", line 75, in is_query_resultset_updatable
'column_number': row['attnum']
KeyError: 'attnum'
BEGIN;
2019-06-17 10:56:44,610: SQL flask.app: Execute (async) for server #5 - CONN:3976967 (Query-id: 5707996):
select * from pem.probe
2019-06-17 10:56:44,614: INFO werkzeug: 127.0.0.1 - - [17/Jun/2019 10:56:44] "POST /sqleditor/query_tool/start/3781524 HTTP/1.1" 200 -
2019-06-17 10:56:44,631: SQL flask.app: Polling result for (Query-id: 5707996)
2019-06-17 10:56:44,635: SQL flask.app: Polling result for (Query-id: 5707996)
2019-06-17 10:56:44,639: SQL flask.app: Execute (dict) for server #5 - CONN:3976967 (Query-id: 5976248):
SELECT at.attname, ty.typname
FROM pg_attribute at LEFT JOIN pg_type ty ON (ty.oid = at.atttypid)
WHERE attrelid=17491::oid AND attnum = ANY (
(SELECT con.conkey FROM pg_class rel LEFT OUTER JOIN pg_constraint con ON con.conrelid=rel.oid
AND con.contype='p' WHERE rel.relkind IN ('r','s','t', 'p') AND rel.oid = 17491::oid)::oid[])
2019-06-17 10:56:44,641: ERROR flask.app: 'attnum'
Traceback (most recent call last):
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/Users/dpage/.virtualenvs/pgadmin4/lib/python3.7/site-packages/flask_login/utils.py", line 261, in decorated_view
return func(*args, **kwargs)
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/__init__.py", line 462, in poll
trans_obj.check_for_updatable_resultset_and_primary_keys()
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/command.py", line 904, in check_for_updatable_resultset_and_primary_keys
is_query_resultset_updatable(conn, sql_path)
File "/Users/dpage/git/pgadmin4/web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py", line 75, in is_query_resultset_updatable
'column_number': row['attnum']
KeyError: 'attnum'
This is the table definition:
========
-- Table: pem.probe
-- DROP TABLE pem.probe;
CREATE TABLE pem.probe
(
id integer NOT NULL DEFAULT nextval('pem.probe_id_seq'::regclass),
display_name text COLLATE pg_catalog."default" NOT NULL,
internal_name text COLLATE pg_catalog."default" NOT NULL,
collection_method character(1) COLLATE pg_catalog."default" NOT NULL,
target_type_id integer NOT NULL,
applies_to_id integer NOT NULL,
agent_capability text COLLATE pg_catalog."default",
probe_code text COLLATE pg_catalog."default" NOT NULL,
enabled_by_default boolean NOT NULL,
default_execution_frequency integer NOT NULL,
default_lifetime integer NOT NULL,
any_server_version boolean NOT NULL,
force_enabled boolean NOT NULL DEFAULT false,
probe_key_list character varying[] COLLATE pg_catalog."default" NOT NULL DEFAULT '{}'::character varying[],
discard_history boolean NOT NULL DEFAULT false,
is_system_probe boolean NOT NULL DEFAULT true,
deleted boolean NOT NULL DEFAULT false,
deleted_time timestamp with time zone,
platform text COLLATE pg_catalog."default",
is_chartable boolean NOT NULL DEFAULT true,
jstid integer,
CONSTRAINT probe_pkey PRIMARY KEY (id),
CONSTRAINT probe_applies_to_id_fkey FOREIGN KEY (applies_to_id)
REFERENCES pem.probe_target_type (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_purge_jobstep_id_fkey FOREIGN KEY (jstid)
REFERENCES pem.jobstep (jstid) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_target_type_id_fkey FOREIGN KEY (target_type_id)
REFERENCES pem.probe_target_type (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_collection_method CHECK (collection_method = ANY (ARRAY['b'::bpchar, 's'::bpchar, 'i'::bpchar, 'w'::bpchar])),
CONSTRAINT probe_target_type_coherence CHECK (collection_method <> 's'::bpchar OR target_type_id <> 100)
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
ALTER TABLE pem.probe
OWNER to postgres;
COMMENT ON COLUMN pem.probe.default_lifetime
IS 'Default lifetime value in days';
-- Trigger: create_delete_purge_probe_jobstep_trigger
-- DROP TRIGGER create_delete_purge_probe_jobstep_trigger ON pem.probe;
CREATE TRIGGER create_delete_purge_probe_jobstep_trigger
AFTER INSERT OR DELETE
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.create_delete_probe_purge_jobstep();
-- Trigger: pem_custom_probe_deleted
-- DROP TRIGGER pem_custom_probe_deleted ON pem.probe;
CREATE TRIGGER pem_custom_probe_deleted
BEFORE UPDATE OF deleted
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.custom_probe_deleted();
-- Trigger: probe_preupdate
-- DROP TRIGGER probe_preupdate ON pem.probe;
CREATE TRIGGER probe_preupdate
BEFORE INSERT OR UPDATE
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.probe_preupdate();
-- Trigger: update_purge_jobs_on_insert_probe
-- DROP TRIGGER update_purge_jobs_on_insert_probe ON pem.probe;
CREATE TRIGGER update_purge_jobs_on_insert_probe
AFTER INSERT
ON pem.probe
FOR EACH STATEMENT
EXECUTE PROCEDURE pem.run_job_to_update_probe_objects_combo();
-- Trigger: update_purge_jobs_on_update_probe
-- DROP TRIGGER update_purge_jobs_on_update_probe ON pem.probe;
CREATE TRIGGER update_purge_jobs_on_update_probe
AFTER UPDATE OF default_lifetime
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.run_job_to_update_probe_objects_combo();
-- DROP TABLE pem.probe;
CREATE TABLE pem.probe
(
id integer NOT NULL DEFAULT nextval('pem.probe_id_seq'::regclass),
display_name text COLLATE pg_catalog."default" NOT NULL,
internal_name text COLLATE pg_catalog."default" NOT NULL,
collection_method character(1) COLLATE pg_catalog."default" NOT NULL,
target_type_id integer NOT NULL,
applies_to_id integer NOT NULL,
agent_capability text COLLATE pg_catalog."default",
probe_code text COLLATE pg_catalog."default" NOT NULL,
enabled_by_default boolean NOT NULL,
default_execution_frequency integer NOT NULL,
default_lifetime integer NOT NULL,
any_server_version boolean NOT NULL,
force_enabled boolean NOT NULL DEFAULT false,
probe_key_list character varying[] COLLATE pg_catalog."default" NOT NULL DEFAULT '{}'::character varying[],
discard_history boolean NOT NULL DEFAULT false,
is_system_probe boolean NOT NULL DEFAULT true,
deleted boolean NOT NULL DEFAULT false,
deleted_time timestamp with time zone,
platform text COLLATE pg_catalog."default",
is_chartable boolean NOT NULL DEFAULT true,
jstid integer,
CONSTRAINT probe_pkey PRIMARY KEY (id),
CONSTRAINT probe_applies_to_id_fkey FOREIGN KEY (applies_to_id)
REFERENCES pem.probe_target_type (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_purge_jobstep_id_fkey FOREIGN KEY (jstid)
REFERENCES pem.jobstep (jstid) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_target_type_id_fkey FOREIGN KEY (target_type_id)
REFERENCES pem.probe_target_type (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT probe_collection_method CHECK (collection_method = ANY (ARRAY['b'::bpchar, 's'::bpchar, 'i'::bpchar, 'w'::bpchar])),
CONSTRAINT probe_target_type_coherence CHECK (collection_method <> 's'::bpchar OR target_type_id <> 100)
)
WITH (
OIDS = FALSE
)
TABLESPACE pg_default;
ALTER TABLE pem.probe
OWNER to postgres;
COMMENT ON COLUMN pem.probe.default_lifetime
IS 'Default lifetime value in days';
-- Trigger: create_delete_purge_probe_jobstep_trigger
-- DROP TRIGGER create_delete_purge_probe_jobstep_trigger ON pem.probe;
CREATE TRIGGER create_delete_purge_probe_jobstep_trigger
AFTER INSERT OR DELETE
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.create_delete_probe_purge_jobstep();
-- Trigger: pem_custom_probe_deleted
-- DROP TRIGGER pem_custom_probe_deleted ON pem.probe;
CREATE TRIGGER pem_custom_probe_deleted
BEFORE UPDATE OF deleted
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.custom_probe_deleted();
-- Trigger: probe_preupdate
-- DROP TRIGGER probe_preupdate ON pem.probe;
CREATE TRIGGER probe_preupdate
BEFORE INSERT OR UPDATE
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.probe_preupdate();
-- Trigger: update_purge_jobs_on_insert_probe
-- DROP TRIGGER update_purge_jobs_on_insert_probe ON pem.probe;
CREATE TRIGGER update_purge_jobs_on_insert_probe
AFTER INSERT
ON pem.probe
FOR EACH STATEMENT
EXECUTE PROCEDURE pem.run_job_to_update_probe_objects_combo();
-- Trigger: update_purge_jobs_on_update_probe
-- DROP TRIGGER update_purge_jobs_on_update_probe ON pem.probe;
CREATE TRIGGER update_purge_jobs_on_update_probe
AFTER UPDATE OF default_lifetime
ON pem.probe
FOR EACH ROW
EXECUTE PROCEDURE pem.run_job_to_update_probe_objects_combo();
========
I also have a couple of questions,- Should the save button in the query tool work the way I am using it now? or should there be a new dedicated button for saving the query to a file?
See above :-)
- What documentations or unit tests should I write? any guidelines here would be appreciated.
We're aiming to add unit tests to give as much coverage as possible, focussing on Jasmine, Python/API and then feature tests in that order (fast -> slow execution, which is important). So we probably want
- one feature test to do basic end-to-end validation
- Python/API tests to exercise is_query_resultset_updatable, save_changed_data and anything else that seems relevant.
- Jasmine tests to ensure buttons are enabled/disabled as they should be, and that primary key and updatability data is tracked properly (this may not be feasible, but I'd still like it to be investigated and justified if not).
We're also a day or two away from committing a new test suite for exercising CRUD operations and the resulting reverse engineered SQL; if we can utilise that to test primary_keys.sql, that'd be good.
Once the in-place editing works, we'll need to rip out all the code related to the View/Edit data mode of the query tool. For example, there will be no need to have the Filter/Sort options any more as the user can edit the SQL directly (that one may be controversial - it's probably worth polling the users first). Of course, if they don't want it to be removed, we'll need to re-think how it works as then we'd have a dialogue that tries to edit arbitrary SQL strings.
When all that's done, the docs will need an overhaul to make them match the new design. That'll require new screenshots, and some non-trivial changes I suspect. You'll need to review what's there at the moment, and figure out what needs to be updated. It's possible we'll need to talk about structural changes as well, but we can do that nearer the time.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi
[please keep the maililng list CC'd]
On Mon, Jun 17, 2019 at 3:05 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
Do you want me to ask our design guy for an icon?That would be great to keep things clear and separated for the users.
I've asked Chethana (CC'd) to create one.
Please find attached a patch to fix the problem that happened with you. The problem is that I edited the primary_keys.sql file in web/tools/sqleditor/templates/sqleditor/sql/default/ only, while there was another one in ..../templates/sqleditor/sql/11_plus/. I wonder what happens with versions before 11? are the scripts in the default/ folder used if they are not found in that version folder?The patch also removes a few unnecessary lines of code that I found, not related to the problem.
Ahh, yes - that works :-). I haven't done a detailed code review yet as you're going to be whacking things around for a bit, but I didn't see any obvious styling issues except for:
(pgadmin4) dpage@hal:~/git/pgadmin4$ make check-pep8
pycodestyle --config=.pycodestyle docs/
pycodestyle --config=.pycodestyle pkg/
pycodestyle --config=.pycodestyle web/
web/pgadmin/tools/sqleditor/__init__.py:440: [E125] continuation line with same indent as next logical line
web/pgadmin/tools/sqleditor/command.py:929: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/command.py:977: [W391] blank line at end of file
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:53: [E501] line too long (92 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:74: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:81: [E501] line too long (97 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:83: [E501] line too long (84 > 79 characters)
1 E125 continuation line with same indent as next logical line
5 E501 line too long (80 > 79 characters)
1 W391 blank line at end of file
7
make: *** [check-pep8] Error 1
pycodestyle --config=.pycodestyle docs/
pycodestyle --config=.pycodestyle pkg/
pycodestyle --config=.pycodestyle web/
web/pgadmin/tools/sqleditor/__init__.py:440: [E125] continuation line with same indent as next logical line
web/pgadmin/tools/sqleditor/command.py:929: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/command.py:977: [W391] blank line at end of file
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:53: [E501] line too long (92 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:74: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:81: [E501] line too long (97 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:83: [E501] line too long (84 > 79 characters)
1 E125 continuation line with same indent as next logical line
5 E501 line too long (80 > 79 characters)
1 W391 blank line at end of file
7
make: *** [check-pep8] Error 1
All patches need to pass that (and all other) existing tests before they can be committed. Aside from that:
- When revising patches, please send an updated one for the whole thing, rather than incremental ones. Incrementals are more work to apply and don't give us any benefit in return.
- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.
- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).
- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.
- What documentations or unit tests should I write? any guidelines here would be appreciated.We're aiming to add unit tests to give as much coverage as possible, focussing on Jasmine, Python/API and then feature tests in that order (fast -> slow execution, which is important). So we probably want- one feature test to do basic end-to-end validation- Python/API tests to exercise is_query_resultset_updatable, save_changed_data and anything else that seems relevant.- Jasmine tests to ensure buttons are enabled/disabled as they should be, and that primary key and updatability data is tracked properly (this may not be feasible, but I'd still like it to be investigated and justified if not).We're also a day or two away from committing a new test suite for exercising CRUD operations and the resulting reverse engineered SQL; if we can utilise that to test primary_keys.sql, that'd be good.I am sorry but I don't understand what should be done exactly in those tests. Could you tell me where I can look at examples for feature tests, Python/API tests and Jasmine tests (preferably for features related to the query tool)?
They're all over the codebase to be honest. Some examples though:
Varions Jasmine tests: web/regression/javascript (e.g. history, slickgrid, sqleditor)
Various API tests: web/pgadmin/tools/sqleditor/tests
Feature tests: web/pgadmin/feature_tests (e.g. query_tool_*)
Once the in-place editing works, we'll need to rip out all the code related to the View/Edit data mode of the query tool. For example, there will be no need to have the Filter/Sort options any more as the user can edit the SQL directly (that one may be controversial - it's probably worth polling the users first). Of course, if they don't want it to be removed, we'll need to re-think how it works as then we'd have a dialogue that tries to edit arbitrary SQL strings.I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.
Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.
Good work - thanks!
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
I have been working all day to try to make this patch applicable.
On Tue, Jun 18, 2019 at 3:05 PM Dave Page <dpage@pgadmin.org> wrote:
Hi[please keep the maililng list CC'd]On Mon, Jun 17, 2019 at 3:05 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Do you want me to ask our design guy for an icon?That would be great to keep things clear and separated for the users.I've asked Chethana (CC'd) to create one.
Waiting for the icon, will set it up once it is ready.
Please find attached a patch to fix the problem that happened with you. The problem is that I edited the primary_keys.sql file in web/tools/sqleditor/templates/sqleditor/sql/default/ only, while there was another one in ..../templates/sqleditor/sql/11_plus/. I wonder what happens with versions before 11? are the scripts in the default/ folder used if they are not found in that version folder?The patch also removes a few unnecessary lines of code that I found, not related to the problem.Ahh, yes - that works :-). I haven't done a detailed code review yet as you're going to be whacking things around for a bit, but I didn't see any obvious styling issues except for:(pgadmin4) dpage@hal:~/git/pgadmin4$ make check-pep8
pycodestyle --config=.pycodestyle docs/
pycodestyle --config=.pycodestyle pkg/
pycodestyle --config=.pycodestyle web/
web/pgadmin/tools/sqleditor/__init__.py:440: [E125] continuation line with same indent as next logical line
web/pgadmin/tools/sqleditor/command.py:929: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/command.py:977: [W391] blank line at end of file
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:53: [E501] line too long (92 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:74: [E501] line too long (80 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:81: [E501] line too long (97 > 79 characters)
web/pgadmin/tools/sqleditor/utils/is_query_resultset_updatable.py:83: [E501] line too long (84 > 79 characters)
1 E125 continuation line with same indent as next logical line
5 E501 line too long (80 > 79 characters)
1 W391 blank line at end of file
7
make: *** [check-pep8] Error 1All patches need to pass that (and all other) existing tests before they can be committed. Aside from that:
I ran pep8 checks and JS tests on this patch, however I could not run python tests due to a problem with chromedriver (working on it), please let me know if any tests fail.
- When revising patches, please send an updated one for the whole thing, rather than incremental ones. Incrementals are more work to apply and don't give us any benefit in return.
The attached patch is a single patch including all old and new increments.
- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).
Both done, new rows are highlighted too.
- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?
That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:
INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;
I propose two solutions:
1- Hide pgadmin's generated sql from history (in both modes).
2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.
I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:
1- In View Data mode, same existing behavior.
2- In Query Tool mode:
- If auto-commit is on: the modifications are made and commited once save is pressed.
- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).
- What documentations or unit tests should I write? any guidelines here would be appreciated.We're aiming to add unit tests to give as much coverage as possible, focussing on Jasmine, Python/API and then feature tests in that order (fast -> slow execution, which is important). So we probably want- one feature test to do basic end-to-end validation- Python/API tests to exercise is_query_resultset_updatable, save_changed_data and anything else that seems relevant.- Jasmine tests to ensure buttons are enabled/disabled as they should be, and that primary key and updatability data is tracked properly (this may not be feasible, but I'd still like it to be investigated and justified if not).We're also a day or two away from committing a new test suite for exercising CRUD operations and the resulting reverse engineered SQL; if we can utilise that to test primary_keys.sql, that'd be good.I am sorry but I don't understand what should be done exactly in those tests. Could you tell me where I can look at examples for feature tests, Python/API tests and Jasmine tests (preferably for features related to the query tool)?They're all over the codebase to be honest. Some examples though:Varions Jasmine tests: web/regression/javascript (e.g. history, slickgrid, sqleditor)Various API tests: web/pgadmin/tools/sqleditor/testsFeature tests: web/pgadmin/feature_tests (e.g. query_tool_*)Once the in-place editing works, we'll need to rip out all the code related to the View/Edit data mode of the query tool. For example, there will be no need to have the Filter/Sort options any more as the user can edit the SQL directly (that one may be controversial - it's probably worth polling the users first). Of course, if they don't want it to be removed, we'll need to re-think how it works as then we'd have a dialogue that tries to edit arbitrary SQL strings.I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.
I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?
--Good work - thanks!Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Looking forward to your feedback. Thanks !
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
Hi
On Wed, Jun 19, 2019 at 6:18 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
Waiting for the icon, will set it up once it is ready.
It's underway :-)
I ran pep8 checks and JS tests on this patch, however I could not run python tests due to a problem with chromedriver (working on it), please let me know if any tests fail.
Take a look in the Makefile (or web/regression/README) and you'll see how you can run tests selectively - e.g. to avoid the feature tests when running the Python suite, you can do "python regression/runtests.py --exclude feature_tests"
As for chromedriver, there's a utility (tools/get_chromedriver.py) you can use to download and install the correct version. You should save it to somewhere in your path; I'd suggest the bin/ directory in your virtual environment.
- When revising patches, please send an updated one for the whole thing, rather than incremental ones. Incrementals are more work to apply and don't give us any benefit in return.The attached patch is a single patch including all old and new increments.
:-)
Aditya; can you do a quick code review please? Bear in mind it's a work in progress and there are no docs or tests etc. yet.
- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.
Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.
- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).
I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).
That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.
I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?
I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
Hi,
On Wed, Jun 19, 2019, 1:54 PM Dave Page <dpage@pgadmin.org> wrote:
.
- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.
Will do.
- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).
I can work on option 2 now and then work on
the checkbox if/when there is time.
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.
The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.
I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.
As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.
Thanks !
Hi
On Wed, Jun 19, 2019 at 2:47 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi,On Wed, Jun 19, 2019, 1:54 PM Dave Page <dpage@pgadmin.org> wrote:.- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.Will do.- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).I can work on option 2 now and then work onthe checkbox if/when there is time.
I'm pretty sure there will be time :-)
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.
Yeah, I agree removing the button for some modes only is weird. Maybe adding info to the notification, and having a more prominent "Your transaction is still in progress" notification will be enough.
Another thought - we also need to figure out what happens if the user edits data in the grid and when saving, an error occurs (e.g. trying to insert null into a not-null field). How does that tie into transaction control? For example, auto-rollback may then revert other changes made via SQL (which should have been atomic, with the data changes) - or having auto-rollback turned off may then require the user to explicitly start a new transaction before attempting to save the data again. Perhaps we need to precede data changes with a savepoint, and then roll back to that if there's an error?
I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.
Hmm, the point of this project (which has been a goal for maybe 20 years!) was to remove that mode entirely. There is an argument that users can use the "SELECT Script" option instead if they don't know SQL, but that would still require the Sort/Filter options.
What do other folks think?
Oh, and icon attached!
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
Hi there !
On Wed, Jun 19, 2019 at 4:11 PM Dave Page <dpage@pgadmin.org> wrote:
- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.Yeah, I agree removing the button for some modes only is weird. Maybe adding info to the notification, and having a more prominent "Your transaction is still in progress" notification will be enough.
Will work on adding a notification and making the transaction status more prominent.
Another thought - we also need to figure out what happens if the user edits data in the grid and when saving, an error occurs (e.g. trying to insert null into a not-null field). How does that tie into transaction control? For example, auto-rollback may then revert other changes made via SQL (which should have been atomic, with the data changes) - or having auto-rollback turned off may then require the user to explicitly start a new transaction before attempting to save the data again. Perhaps we need to precede data changes with a savepoint, and then roll back to that if there's an error?
I think the savepoint is an adequate solution.If any problems happen then rollback to the savepoint then release it, else just release the savepoint.
I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.Hmm, the point of this project (which has been a goal for maybe 20 years!) was to remove that mode entirely. There is an argument that users can use the "SELECT Script" option instead if they don't know SQL, but that would still require the Sort/Filter options.What do other folks think?
Waiting for other people's opinion on that matter.
Oh, and icon attached!
Will work on adding the new icon and switching the save functionality to it. I propose using this icon to save data in both View Data and Query Tool mode, and the existing save button for exclusively saving the query files (will be disabled in View Data mode).
On Wed, Jun 19, 2019 at 4:11 PM Dave Page <dpage@pgadmin.org> wrote:
HiOn Wed, Jun 19, 2019 at 2:47 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Hi,On Wed, Jun 19, 2019, 1:54 PM Dave Page <dpage@pgadmin.org> wrote:.- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.Will do.- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).I can work on option 2 now and then work onthe checkbox if/when there is time.I'm pretty sure there will be time :-)- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.Yeah, I agree removing the button for some modes only is weird. Maybe adding info to the notification, and having a more prominent "Your transaction is still in progress" notification will be enough.Another thought - we also need to figure out what happens if the user edits data in the grid and when saving, an error occurs (e.g. trying to insert null into a not-null field). How does that tie into transaction control? For example, auto-rollback may then revert other changes made via SQL (which should have been atomic, with the data changes) - or having auto-rollback turned off may then require the user to explicitly start a new transaction before attempting to save the data again. Perhaps we need to precede data changes with a savepoint, and then roll back to that if there's an error?I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.Hmm, the point of this project (which has been a goal for maybe 20 years!) was to remove that mode entirely. There is an argument that users can use the "SELECT Script" option instead if they don't know SQL, but that would still require the Sort/Filter options.What do other folks think?Oh, and icon attached!--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
On Thu, Jun 20, 2019 at 2:20 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi there !On Wed, Jun 19, 2019 at 4:11 PM Dave Page <dpage@pgadmin.org> wrote:- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.Yeah, I agree removing the button for some modes only is weird. Maybe adding info to the notification, and having a more prominent "Your transaction is still in progress" notification will be enough.Will work on adding a notification and making the transaction status more prominent.Another thought - we also need to figure out what happens if the user edits data in the grid and when saving, an error occurs (e.g. trying to insert null into a not-null field). How does that tie into transaction control? For example, auto-rollback may then revert other changes made via SQL (which should have been atomic, with the data changes) - or having auto-rollback turned off may then require the user to explicitly start a new transaction before attempting to save the data again. Perhaps we need to precede data changes with a savepoint, and then roll back to that if there's an error?I think the savepoint is an adequate solution.If any problems happen then rollback to the savepoint then release it, else just release the savepoint.I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.
+1
View data mode is quick & easy way for any novice user who want to interact with table data.
Hmm, the point of this project (which has been a goal for maybe 20 years!) was to remove that mode entirely. There is an argument that users can use the "SELECT Script" option instead if they don't know SQL, but that would still require the Sort/Filter options.What do other folks think?Waiting for other people's opinion on that matter.Oh, and icon attached!Will work on adding the new icon and switching the save functionality to it. I propose using this icon to save data in both View Data and Query Tool mode, and the existing save button for exclusively saving the query files (will be disabled in View Data mode).On Wed, Jun 19, 2019 at 4:11 PM Dave Page <dpage@pgadmin.org> wrote:HiOn Wed, Jun 19, 2019 at 2:47 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Hi,On Wed, Jun 19, 2019, 1:54 PM Dave Page <dpage@pgadmin.org> wrote:.- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.Will do.- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).I can work on option 2 now and then work onthe checkbox if/when there is time.I'm pretty sure there will be time :-)- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.The transaction status can be made more obvious and point out when a transaction is in progress that changes aren't commited. However, removing the save button when auto commit is off will cause us to a send a request and execute a query every time any cell is changed (which can be by accident or some kind of draft). I also think it will make more sense when there is a dedicated button, which can be named such that it is clear that it only executes some queries. Also, the pop up that shows after edits are succeesful can also state thar these changes are not yet commited.Yeah, I agree removing the button for some modes only is weird. Maybe adding info to the notification, and having a more prominent "Your transaction is still in progress" notification will be enough.Another thought - we also need to figure out what happens if the user edits data in the grid and when saving, an error occurs (e.g. trying to insert null into a not-null field). How does that tie into transaction control? For example, auto-rollback may then revert other changes made via SQL (which should have been atomic, with the data changes) - or having auto-rollback turned off may then require the user to explicitly start a new transaction before attempting to save the data again. Perhaps we need to precede data changes with a savepoint, and then roll back to that if there's an error?I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.As a user of pgAdmin I think this might not be the best option. Not all users of pgAdmin are developers or know SQL. I worked on several projects before where other people on the team (or frontend developers) would just want to take a look at some data or do simple edits using the GUI. Also, other management studios for other DBMSs also allow for this. In addition, the user can do sorting of data without knowing SQL. What I think can be done (potentially - maybe in the future) is limit the dependance on SQL knowledge when doing filters in View Data mode, while disabling filters and so in the Query Tool.Hmm, the point of this project (which has been a goal for maybe 20 years!) was to remove that mode entirely. There is an argument that users can use the "SELECT Script" option instead if they don't know SQL, but that would still require the Sort/Filter options.What do other folks think?Oh, and icon attached!--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
[forked the mail chain for code review]
Hi Yosry,
On Wed, Jun 19, 2019 at 5:24 PM Dave Page <dpage@pgadmin.org> wrote:
HiOn Wed, Jun 19, 2019 at 6:18 AM Yosry Muhammad <yosrym93@gmail.com> wrote:Waiting for the icon, will set it up once it is ready.It's underway :-)I ran pep8 checks and JS tests on this patch, however I could not run python tests due to a problem with chromedriver (working on it), please let me know if any tests fail.Take a look in the Makefile (or web/regression/README) and you'll see how you can run tests selectively - e.g. to avoid the feature tests when running the Python suite, you can do "python regression/runtests.py --exclude feature_tests"As for chromedriver, there's a utility (tools/get_chromedriver.py) you can use to download and install the correct version. You should save it to somewhere in your path; I'd suggest the bin/ directory in your virtual environment.- When revising patches, please send an updated one for the whole thing, rather than incremental ones. Incrementals are more work to apply and don't give us any benefit in return.The attached patch is a single patch including all old and new increments.:-)Aditya; can you do a quick code review please? Bear in mind it's a work in progress and there are no docs or tests etc. yet.
Nice work there. :)
I just had look on the code changes, and have few suggestions:
1) I found the code around primary key in the function check_for_updatable_resultset_and_primary_keys repeating. Try if you cpuld modify/reuse the get_primary_keys function.
2) The function name check_for_updatable_resultset_and_primary_keys could be shorter, something like check_updatabale_rset_pkeys. Same for __set_updatable_resultset_attributes to __set_updatable_rset_attr
3) You've used background: #f4f4f4; for .highlighted_grid_cells class. This should go to sqleditor.scss with appropriate color from web/pgadmin/static/scss/resources/_default.variables.scss. Hard coded color codes are highly discouraged.
2) The function name check_for_updatable_resultset_and_primary_keys could be shorter, something like check_updatabale_rset_pkeys. Same for __set_updatable_resultset_attributes to __set_updatable_rset_attr
3) You've used background: #f4f4f4; for .highlighted_grid_cells class. This should go to sqleditor.scss with appropriate color from web/pgadmin/static/scss/resources/_default.variables.scss. Hard coded color codes are highly discouraged.
Otherwise, looks good (didn't run and check)
--- We need to add a "do you want to continue" warning before actions like Execute or EXPLAIN are run, if there are unsaved changes in the grid.- I think we should make the text in any cells that has been edited bold until saved, so the user can see where changes have been made (as they can with deleted rows).Both done, new rows are highlighted too.Nice! I realise it's most likely not your code, but if you can fix the wrapping so it doesn't break mid-word, that would be good. See the attached screenshot to see what I mean.- If I make two data edits and then delete a row, I get 3 entries in the History panel, all showing the same delete. I would actually argue that data edit queries that pgAdmin generates should not go into the History at all, but maybe they should be added albeit with a flag to say they're internal queries and an option to hide them. Thoughts?That was a bug with the existing 'save changes' action of 'View Data', on which mine is based upon. I fixed the bug, now the queries are shown correctly. However, the queries are shown in the form in which they are sent from the backend to the database driver (without parameters - also an already existing bug in View Data Mode), for example:INSERT INTO public.kweek (
media_url, username, text, created_at) VALUES (
%(media_url)s::character varying, %(username)s::character varying, %(text)s::text, %(created_at)s::timestamp without time zone)
returning id;I propose two solutions:1- Hide pgadmin's generated sql from history (in both modes).2- Show the actual sql query that was executed after the parameters are plugged in (more understandable and potentially helpful).I like the idea of doing 2 - but I think we should have a checkbox on the history panel to show/hide generated queries (and we should include transaction control - BEGIN, COMMIT etc - in the generated query class).- We need to think about how data editing fits in with transaction control. Right now, it seems to happen entirely outside of it - for example, I tend to work with auto commit turned off, so my connection sits idle-in-transaction following an initial select, and remains un-affected by edits. Please think about this and suggest options for us to discuss.I integrated the data editing in the transaction control as you noted. Now the behavior is as follows:1- In View Data mode, same existing behavior.2- In Query Tool mode:- If auto-commit is on: the modifications are made and commited once save is pressed.- If auto-commit is off: the modifications are made as part of the ongoing transaction (or a new one if no transaction is ongoing), they are not commited unless the user executes a commit command (or rollback).That seems to work. I think we need to make it more obvious that there's a transaction in progress - especially as that can be the case after the user hits the Save button and thinks their data is safe (a side-thought is that perhaps we shouldn't require the Save button to be pressed when auto-commit is turned off, as that's just odd). We should highlight the transaction state more clearly to the user, and make sure we prompt for confirmation if they try to close the tab or the whole window.I think it makes more sense for filters to be disabled. I mean since the user is already writing SQL it would be more convenient to just edit it directly.Well we're not going to just disable them - we'll either remove them, or try to make them work. I'm leaning strongly towards just removing that code entirely.I meant disabling them in the query tool while keeping them in the View Data mode as the user cannot edit the sql in the View Data mode. Do you want to remove the feature from both modes completely?I think you misunderstand - I want to remove the View Data mode entirely. Your work should replace it.Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
On Thu, Jun 20, 2019 at 7:49 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:
[forked the mail chain for code review]Hi Yosry,On Wed, Jun 19, 2019 at 5:24 PM Dave Page <dpage@pgadmin.org> wrote:Aditya; can you do a quick code review please? Bear in mind it's a work in progress and there are no docs or tests etc. yet.Nice work there. :)I just had look on the code changes, and have few suggestions:1) I found the code around primary key in the function check_for_updatable_resultset_and_primary_keys repeating. Try if you cpuld modify/reuse the get_primary_keys function.
2) The function name check_for_updatable_resultset_and_primary_keys could be shorter, something like check_updatabale_rset_pkeys. Same for __set_updatable_resultset_attributes to __set_updatable_rset_attr
3) You've used background: #f4f4f4; for .highlighted_grid_cells class. This should go to sqleditor.scss with appropriate color from web/pgadmin/static/scss/resources/_default.variables.scss. Hard coded color codes are highly discouraged.Otherwise, looks good (didn't run and check)
I shortened both function names and fixed the hard-coded color. For #1, in the QueryToolCommand different processing of the primary keys occur in is_query_resultset_updatable function, where the attribute number of the primary keys is compared against columns and so. The only repeated part in check_for_updatable_resultset_and_primary_keys is the part where pk_names string is created in the required format (which is only a few lines of code). I could factor it out to a utility function - takes primary_keys dict and returns the pk_names string in the required format. What do you think?
These changes (together with other changes that I am working on) will be included in the next version of this patch.
Thanks !
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Hi all,
Please find attached a patch with all the changes (from the beginning of the project). What I added in this patch:
1- Fixed #1 and #2 that Mr. Toshniwal pointed out in his code review. Still waiting for a reply on #3.
2- When data is edited in Query Tool with auto-commit turned off, the notification message now tells the user that they need to commit these changes.
3- The new icon is added and the functionality of both icons are now completely separated as follows:
a) Save File button: exclusively for saving the query file (disabled in View Table mode).
b) Save Data Changes button: for saving changes in data grid in both modes.
I completely separated the 2 functionalities in all related files and modules. I also fixed an existing bug that went as follows:
- The user has unsaved edits (existed in View Table mode).
- The user tries to close the panel, they are asked if they want to save the changes.
- If they choose to save and the save failed (null in a non-null column for example), the panel closes anyway.
The panel now does not close if the save failed.
Something that is missing with the new button is the shortcut, I don't know how to modify the Preferences in the configuration database. I could not find the code responsible for adding data in the Preferences table and so. Any help?
4- A savepoint is now created before any attempts are made to save data changes, if the operation fails, the transaction is rolled back only till the savepoint, keeping the previous SQL in the same transaction unharmed. The whole transaction is rolled back if none existed in the first place.
5- Fixed a bug with all Alertiy.js confirm dialogs where line break would break words.
6- I re-implemented the code responsible for handling the panel close event in following way:
- The event used to handle one of two mutually exclusive events (or neither): exiting with unsaved changes in the query or exiting with unsaved changes in the data.
- As both can happen simultaneously now, I re-implemented this code to check for multiple cases and produce sequential dialogs for different cases (asynchronously to avoid freezing the page) . I also added a dialog that asks for user confirmation when exiting with an un-commited transaction (or data changes save).
I have several questions:
- How can I edit the data in the configuration database (specifically the preferences), what parts of the code are responsible for this?
- For running python tests, how should I produce an appropriate test_config.json.in file for my environment?
- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?
- When closing a panel in pgAdmin 4, my browser keeps asking me if I want to leave the page or stay which I think might be annoying to some users (specially when closing several tabs at once). We already produce dialogs if any changes are unsaved, the browsers' ones are unnecessary. Is this produces by our code or automatically by the browser? any way around it? I use Firefox.
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).
- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?
Here are things I think I might be working on next (share your thoughts):
- Make the transaction status more prominent.
- Handle cases where one or more columns can be made read-only for the remaining of the resultset to be updatable (for example: SELECT col1, col2, col1 || col2 as concat FROM some_table;). This will require modifying some of the data that is sent from the backend to the frontend and a lot o modifications (i think) in the front-end for handling columns individually.
Thanks everyone and sorry for the long email !
On Thu, Jun 20, 2019 at 4:54 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
On Thu, Jun 20, 2019 at 7:49 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:[forked the mail chain for code review]Hi Yosry,On Wed, Jun 19, 2019 at 5:24 PM Dave Page <dpage@pgadmin.org> wrote:Aditya; can you do a quick code review please? Bear in mind it's a work in progress and there are no docs or tests etc. yet.Nice work there. :)I just had look on the code changes, and have few suggestions:1) I found the code around primary key in the function check_for_updatable_resultset_and_primary_keys repeating. Try if you cpuld modify/reuse the get_primary_keys function.
2) The function name check_for_updatable_resultset_and_primary_keys could be shorter, something like check_updatabale_rset_pkeys. Same for __set_updatable_resultset_attributes to __set_updatable_rset_attr
3) You've used background: #f4f4f4; for .highlighted_grid_cells class. This should go to sqleditor.scss with appropriate color from web/pgadmin/static/scss/resources/_default.variables.scss. Hard coded color codes are highly discouraged.Otherwise, looks good (didn't run and check)I shortened both function names and fixed the hard-coded color. For #1, in the QueryToolCommand different processing of the primary keys occur in is_query_resultset_updatable function, where the attribute number of the primary keys is compared against columns and so. The only repeated part in check_for_updatable_resultset_and_primary_keys is the part where pk_names string is created in the required format (which is only a few lines of code). I could factor it out to a utility function - takes primary_keys dict and returns the pk_names string in the required format. What do you think?These changes (together with other changes that I am working on) will be included in the next version of this patch.Thanks !
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
Hi Yosry,
On Mon, Jun 24, 2019 at 11:08 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi all,Please find attached a patch with all the changes (from the beginning of the project). What I added in this patch:1- Fixed #1 and #2 that Mr. Toshniwal pointed out in his code review. Still waiting for a reply on #3.
What I meant for the color was to use existing colors defined which are based on a theme. The best fit for your work is $color-gray-lighter. Please use - $color-highlighted-grid-cell : $color-gray-lighter. Or may be remove $color-highlighted-grid-cell completely and use $color-gray-lighter in your class.
2- When data is edited in Query Tool with auto-commit turned off, the notification message now tells the user that they need to commit these changes.3- The new icon is added and the functionality of both icons are now completely separated as follows:a) Save File button: exclusively for saving the query file (disabled in View Table mode).b) Save Data Changes button: for saving changes in data grid in both modes.I completely separated the 2 functionalities in all related files and modules. I also fixed an existing bug that went as follows:- The user has unsaved edits (existed in View Table mode).- The user tries to close the panel, they are asked if they want to save the changes.- If they choose to save and the save failed (null in a non-null column for example), the panel closes anyway.The panel now does not close if the save failed.Something that is missing with the new button is the shortcut, I don't know how to modify the Preferences in the configuration database. I could not find the code responsible for adding data in the Preferences table and so. Any help?4- A savepoint is now created before any attempts are made to save data changes, if the operation fails, the transaction is rolled back only till the savepoint, keeping the previous SQL in the same transaction unharmed. The whole transaction is rolled back if none existed in the first place.5- Fixed a bug with all Alertiy.js confirm dialogs where line break would break words.6- I re-implemented the code responsible for handling the panel close event in following way:- The event used to handle one of two mutually exclusive events (or neither): exiting with unsaved changes in the query or exiting with unsaved changes in the data.- As both can happen simultaneously now, I re-implemented this code to check for multiple cases and produce sequential dialogs for different cases (asynchronously to avoid freezing the page) . I also added a dialog that asks for user confirmation when exiting with an un-commited transaction (or data changes save).I have several questions:- How can I edit the data in the configuration database (specifically the preferences), what parts of the code are responsible for this?
In the sqleditor __init__.py, you'll find a call - RegisterQueryToolPreferences (web/pgadmin/tools/sqleditor/utils/query_tool_preferences.py). Refer the code for btn_save_file
- For running python tests, how should I produce an appropriate test_config.json.in file for my environment?
Copy the test_config.json.in to test_config.json in the same directory. You just need to change the server details, sample below. You can add multiple servers to the list:
..."server_credentials": [
{
"name": "PostgreSQL 9.4",
"comment": "PostgreSQL 9.4 Server",
"db_username": "postgres",
"host": "localhost",
"db_password": "postgres",
"db_port": 5432,
"maintenance_db": "postgres",
"sslmode": "prefer",
"tablespace_path": "",
"enabled": true,
"default_binary_paths": {
"pg": "/Library/PostgreSQL/9.4/bin/",
"ppas": "",
"gpdb": ""
}
}
],
...
- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?
What command did you use, can you share the screenshot of the files changed?
- When closing a panel in pgAdmin 4, my browser keeps asking me if I want to leave the page or stay which I think might be annoying to some users (specially when closing several tabs at once). We already produce dialogs if any changes are unsaved, the browsers' ones are unnecessary. Is this produces by our code or automatically by the browser? any way around it? I use Firefox.
This can be disabled from Preferences -> Browser -> Display -> Confirm on close or refresh ?. Set it to false and you'll not get the browser warning.
This is particularly helpful if you open the query tool in a new browser tab and close the tab itself.
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).
@Dave Page is the right person to answer this.
- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?
Could you please share the query/screenshot ? The query history just stores the SQL text and fetches back to show in CodeMirror. No modifications/generation of queries is done by Query History.
Here are things I think I might be working on next (share your thoughts):- Make the transaction status more prominent.- Handle cases where one or more columns can be made read-only for the remaining of the resultset to be updatable (for example: SELECT col1, col2, col1 || col2 as concat FROM some_table;). This will require modifying some of the data that is sent from the backend to the frontend and a lot o modifications (i think) in the front-end for handling columns individually.
Thanks everyone and sorry for the long email !On Thu, Jun 20, 2019 at 4:54 PM Yosry Muhammad <yosrym93@gmail.com> wrote:On Thu, Jun 20, 2019 at 7:49 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:[forked the mail chain for code review]Hi Yosry,On Wed, Jun 19, 2019 at 5:24 PM Dave Page <dpage@pgadmin.org> wrote:Aditya; can you do a quick code review please? Bear in mind it's a work in progress and there are no docs or tests etc. yet.Nice work there. :)I just had look on the code changes, and have few suggestions:1) I found the code around primary key in the function check_for_updatable_resultset_and_primary_keys repeating. Try if you cpuld modify/reuse the get_primary_keys function.
2) The function name check_for_updatable_resultset_and_primary_keys could be shorter, something like check_updatabale_rset_pkeys. Same for __set_updatable_resultset_attributes to __set_updatable_rset_attr
3) You've used background: #f4f4f4; for .highlighted_grid_cells class. This should go to sqleditor.scss with appropriate color from web/pgadmin/static/scss/resources/_default.variables.scss. Hard coded color codes are highly discouraged.Otherwise, looks good (didn't run and check)I shortened both function names and fixed the hard-coded color. For #1, in the QueryToolCommand different processing of the primary keys occur in is_query_resultset_updatable function, where the attribute number of the primary keys is compared against columns and so. The only repeated part in check_for_updatable_resultset_and_primary_keys is the part where pk_names string is created in the required format (which is only a few lines of code). I could factor it out to a utility function - takes primary_keys dict and returns the pk_names string in the required format. What do you think?These changes (together with other changes that I am working on) will be included in the next version of this patch.Thanks !
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
Hi,
Please find attached a patch file with the following updates (last patch + updates) attached:
- Changed the color to $color-gray-lighter and added the shortcut for the new button.
- Added a preferences option to enable/disable prompting on uncommited transactions on exiting.
- Changed call_render_after_poll_specs test to be in sync with code changes, also fixed a mix up in the test descriptions in the same file.
- Fixed a bug with a recent patch 'Allow editing of data where a primary key column includes a % sign in the value.' that occurred when the primary key was a number.
- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?What command did you use, can you share the screenshot of the files changed?
I tried it again after a proper test_config.json as you mentioned and everything worked fine. All tests pass for this patch except for 3 feature tests that all fail because of a TimeoutException related to selenium. Please find a log file of the feature tests attached.
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.
Waiting for his reply :D
- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?Could you please share the query/screenshot ? The query history just stores the SQL text and fetches back to show in CodeMirror. No modifications/generation of queries is done by Query History.
By 'generated queries' I meant the querie that are generated by pgAdmin to save changes to the data grid to the database. Here is a screenshot from the released version (not the version I am working on).
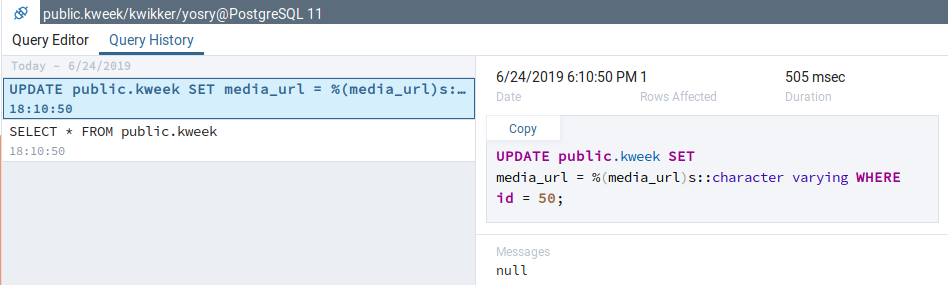
Scenario:
- Opened View Data on a table (public.kweek)
- Modified a cell in a column named media_url with a primary key (id = 50) to 'new link'
- Instead of showing 'new link' in the query %(media_url) is shown.
This can be fixed in save_changed_data() function in my patch but I need access to a cursor as previously mentioned. Thoughts?
Thanks a lot for your help!
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
Hi,
On Mon, Jun 24, 2019 at 10:13 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi,Please find attached a patch file with the following updates (last patch + updates) attached:- Changed the color to $color-gray-lighter and added the shortcut for the new button.- Added a preferences option to enable/disable prompting on uncommited transactions on exiting.- Changed call_render_after_poll_specs test to be in sync with code changes, also fixed a mix up in the test descriptions in the same file.- Fixed a bug with a recent patch 'Allow editing of data where a primary key column includes a % sign in the value.' that occurred when the primary key was a number.- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?What command did you use, can you share the screenshot of the files changed?I tried it again after a proper test_config.json as you mentioned and everything worked fine. All tests pass for this patch except for 3 feature tests that all fail because of a TimeoutException related to selenium. Please find a log file of the feature tests attached.- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.Waiting for his reply :D- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?Could you please share the query/screenshot ? The query history just stores the SQL text and fetches back to show in CodeMirror. No modifications/generation of queries is done by Query History.By 'generated queries' I meant the querie that are generated by pgAdmin to save changes to the data grid to the database. Here is a screenshot from the released version (not the version I am working on).Scenario:- Opened View Data on a table (public.kweek)- Modified a cell in a column named media_url with a primary key (id = 50) to 'new link'- Instead of showing 'new link' in the query %(media_url) is shown.
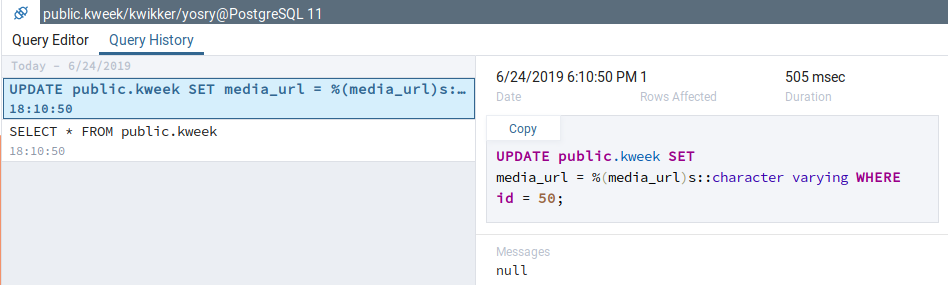
The update queries fired internally should not go to history. Queries fired by user only should go. That's what I think.
This can be fixed in save_changed_data() function in my patch but I need access to a cursor as previously mentioned. Thoughts?Thanks a lot for your help!
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
Вложения
Hi
On Mon, Jun 24, 2019 at 7:03 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.
It needs:
- A code complete feature (or infrastructure/refactoring ready for a feature), that is acceptable to us. Seems like this is 90% there for an initial commit.
- Documentation updates.
- Tests for the new feature to ensure it works without needing manual testing.
- To pass all existing tests (which may be modified if appropriate).
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Tue, Jun 25, 2019 at 7:09 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:
Hi,On Mon, Jun 24, 2019 at 10:13 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Hi,Please find attached a patch file with the following updates (last patch + updates) attached:- Changed the color to $color-gray-lighter and added the shortcut for the new button.- Added a preferences option to enable/disable prompting on uncommited transactions on exiting.- Changed call_render_after_poll_specs test to be in sync with code changes, also fixed a mix up in the test descriptions in the same file.- Fixed a bug with a recent patch 'Allow editing of data where a primary key column includes a % sign in the value.' that occurred when the primary key was a number.- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?What command did you use, can you share the screenshot of the files changed?I tried it again after a proper test_config.json as you mentioned and everything worked fine. All tests pass for this patch except for 3 feature tests that all fail because of a TimeoutException related to selenium. Please find a log file of the feature tests attached.- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.Waiting for his reply :D- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?Could you please share the query/screenshot ? The query history just stores the SQL text and fetches back to show in CodeMirror. No modifications/generation of queries is done by Query History.By 'generated queries' I meant the querie that are generated by pgAdmin to save changes to the data grid to the database. Here is a screenshot from the released version (not the version I am working on).Scenario:- Opened View Data on a table (public.kweek)- Modified a cell in a column named media_url with a primary key (id = 50) to 'new link'- Instead of showing 'new link' in the query %(media_url) is shown.The update queries fired internally should not go to history. Queries fired by user only should go. That's what I think.
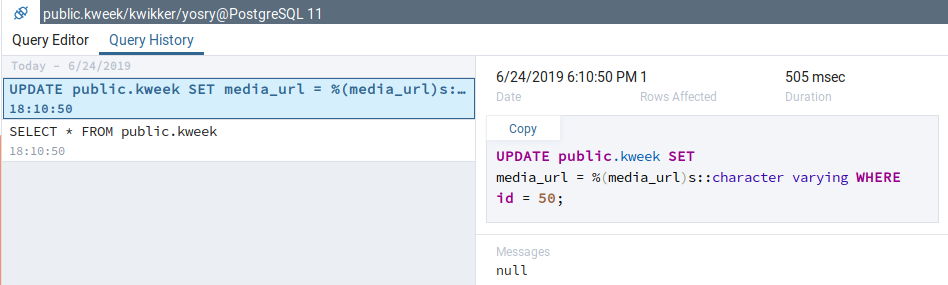
The conclusion I came to in previous discussion was that both should be available, with a checkbox (off by default) to include the internal queries, which would include any BEGIN/COMMITs etc.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
Hi,
On Tue, Jun 25, 2019 at 4:41 PM Dave Page <dpage@pgadmin.org> wrote:
On Tue, Jun 25, 2019 at 7:09 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:Hi,On Mon, Jun 24, 2019 at 10:13 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Hi,Please find attached a patch file with the following updates (last patch + updates) attached:- Changed the color to $color-gray-lighter and added the shortcut for the new button.- Added a preferences option to enable/disable prompting on uncommited transactions on exiting.- Changed call_render_after_poll_specs test to be in sync with code changes, also fixed a mix up in the test descriptions in the same file.- Fixed a bug with a recent patch 'Allow editing of data where a primary key column includes a % sign in the value.' that occurred when the primary key was a number.- After running python and feature tests, changes were made to nearly all the files (git status shows modifications in a ton of files), is there something I have done wrong?What command did you use, can you share the screenshot of the files changed?I tried it again after a proper test_config.json as you mentioned and everything worked fine. All tests pass for this patch except for 3 feature tests that all fail because of a TimeoutException related to selenium. Please find a log file of the feature tests attached.- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.Waiting for his reply :D- For the bug that I reported before (generated queries in Query History appear in a distorted way for the user), to get the actual query that is being executed I can use the mogirfy() function of psycopg2 but I need access to a cursor. I can get one directly in save_changed_data() function by using conn.conn.cursor() but then I would be bypassing the wrapper Connection class. Should I modify the wrapper Connection class and add a function that can provide a cursor (or a wrapper around cursor.mogrify() )? Thoughts?Could you please share the query/screenshot ? The query history just stores the SQL text and fetches back to show in CodeMirror. No modifications/generation of queries is done by Query History.By 'generated queries' I meant the querie that are generated by pgAdmin to save changes to the data grid to the database. Here is a screenshot from the released version (not the version I am working on).Scenario:- Opened View Data on a table (public.kweek)- Modified a cell in a column named media_url with a primary key (id = 50) to 'new link'- Instead of showing 'new link' in the query %(media_url) is shown.The update queries fired internally should not go to history. Queries fired by user only should go. That's what I think.The conclusion I came to in previous discussion was that both should be available, with a checkbox (off by default) to include the internal queries, which would include any BEGIN/COMMITs etc.
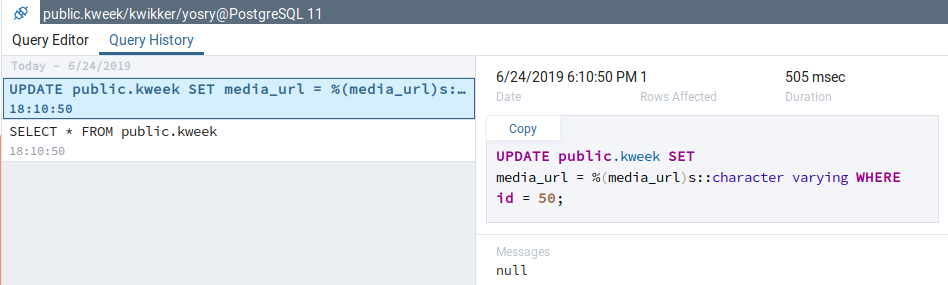
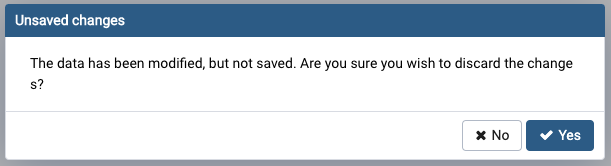{kind=link}
{kind=link}
OK. Yosry, How about storing the mogirfied query in the cookie/session when the query is executed and then modifying query history storing logic to use it when called ? This way you will not need to change any parsing when query history is displayed.
--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
Вложения
Hi,
OK. Yosry, How about storing the mogirfied query in the cookie/session when the query is executed and then modifying query history storing logic to use it when called ? This way you will not need to change any parsing when query history is displayed.--
My problem is not where to store the mogrified query, I can just replace the sql sent with the response to saving the data with the mogrified one. In order to produce the mogrified query in the first place I need a psycopg2.cursor object, but I only have access to a Connection object (the wrapper, not the actual psycopg2.connection object). Should I modify that wrapper Connection class to add a mogirfy function? or just get a cursor using the psycopg2.connection object like this: conn.conn.cursor() - which doesn't seem right. Thoughts?
Also, could you please help me with the selenium TimeoutException in the feature tests? 3 tests are failing because of that exception and I am not sure what is it related to. I am attaching the feature test log file in this email if you would like to take a look on it.
Thanks !
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Вложения
On Tue, Jun 25, 2019 at 1:09 PM Dave Page <dpage@pgadmin.org> wrote:
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.It needs:- A code complete feature (or infrastructure/refactoring ready for a feature), that is acceptable to us. Seems like this is 90% there for an initial commit.- Documentation updates.- Tests for the new feature to ensure it works without needing manual testing.- To pass all existing tests (which may be modified if appropriate).
Could you tell me what is missing from this patch (in terms of features - other than tests) to be acceptable? I will start working on the tests once the patch is complete. The patch passes all the existing tests except for 3 feature tests that fail due to a TimeoutException in selenium. I do not know what this is about I hope Aditya will help me with it.
Also, do you mean code documentation or documentation for the users? Could you point me towards the related parts?
Thanks a lot.
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Hi Yosry,
On Tue, Jun 25, 2019 at 8:46 PM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi,OK. Yosry, How about storing the mogirfied query in the cookie/session when the query is executed and then modifying query history storing logic to use it when called ? This way you will not need to change any parsing when query history is displayed.--My problem is not where to store the mogrified query, I can just replace the sql sent with the response to saving the data with the mogrified one. In order to produce the mogrified query in the first place I need a psycopg2.cursor object, but I only have access to a Connection object (the wrapper, not the actual psycopg2.connection object). Should I modify that wrapper Connection class to add a mogirfy function? or just get a cursor using the psycopg2.connection object like this: conn.conn.cursor() - which doesn't seem right. Thoughts?
That would be the way. But I think web/pgadmin/utils/driver/psycopg2/cursor.py will be corrrect place to add the mogrify function. Please note, psycopg2 does not support (,),% in the parameter names. So if the column names has any of these characters, mogrify might fail. Although it is handled with pgadmin_alias (line 493 - web/pgadmin/tools/sqleditor/__init__.py), please test this case as well.
Also, could you please help me with the selenium TimeoutException in the feature tests? 3 tests are failing because of that exception and I am not sure what is it related to. I am attaching the feature test log file in this email if you would like to take a look on it.
Can you check on latest chrome and chromdriver. You can check the chromedriver version as below. Your venv should have the chromedriver binary.
(pypg37) laptop207:pgadmin4 adityatoshniwal$ chromedriver --version
ChromeDriver 75.0.3770.8 (681f24ea911fe754973dda2fdc6d2a2e159dd300-refs/branch-heads/3770@{#40})
Thanks !
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
Hi,
On Wed, Jun 26, 2019 at 10:35 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:
Hi Yosry,On Tue, Jun 25, 2019 at 8:46 PM Yosry Muhammad <yosrym93@gmail.com> wrote:Hi,OK. Yosry, How about storing the mogirfied query in the cookie/session when the query is executed and then modifying query history storing logic to use it when called ? This way you will not need to change any parsing when query history is displayed.--My problem is not where to store the mogrified query, I can just replace the sql sent with the response to saving the data with the mogrified one. In order to produce the mogrified query in the first place I need a psycopg2.cursor object, but I only have access to a Connection object (the wrapper, not the actual psycopg2.connection object). Should I modify that wrapper Connection class to add a mogirfy function? or just get a cursor using the psycopg2.connection object like this: conn.conn.cursor() - which doesn't seem right. Thoughts?That would be the way. But I think web/pgadmin/utils/driver/psycopg2/cursor.py will be corrrect place to add the mogrify function. Please note, psycopg2 does not support (,),% in the parameter names. So if the column names has any of these characters, mogrify might fail. Although it is handled with pgadmin_alias (line 493 - web/pgadmin/tools/sqleditor/__init__.py), please test this case as well.
You can also get the last executed SQL in psycopg2 - http://initd.org/psycopg/docs/cursor.html#cursor.query. May be this can be used.
Also, could you please help me with the selenium TimeoutException in the feature tests? 3 tests are failing because of that exception and I am not sure what is it related to. I am attaching the feature test log file in this email if you would like to take a look on it.Can you check on latest chrome and chromdriver. You can check the chromedriver version as below. Your venv should have the chromedriver binary.(pypg37) laptop207:pgadmin4 adityatoshniwal$ chromedriver --version
ChromeDriver 75.0.3770.8 (681f24ea911fe754973dda2fdc6d2a2e159dd300-refs/branch-heads/3770@{#40})Thanks !
--Yosry Muhammad YosryComputer Engineering student,The Faculty of Engineering,Cairo University (2021).Class representative of CMP 2021.--Thanks and Regards,Aditya ToshniwalSoftware Engineer | EnterpriseDB India | Pune"Don't Complain about Heat, Plant a TREE"
Thanks and Regards,
Aditya Toshniwal
Software Engineer | EnterpriseDB India | Pune
"Don't Complain about Heat, Plant a TREE"
Hi
On Tue, Jun 25, 2019 at 11:20 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
On Tue, Jun 25, 2019 at 1:09 PM Dave Page <dpage@pgadmin.org> wrote:- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.It needs:- A code complete feature (or infrastructure/refactoring ready for a feature), that is acceptable to us. Seems like this is 90% there for an initial commit.- Documentation updates.- Tests for the new feature to ensure it works without needing manual testing.- To pass all existing tests (which may be modified if appropriate).Could you tell me what is missing from this patch (in terms of features - other than tests) to be acceptable? I will start working on the tests once the patch is complete. The patch passes all the existing tests except for 3 feature tests that fail due to a TimeoutException in selenium. I do not know what this is about I hope Aditya will help me with it.
Here are the issues I think should be fixed first:
- I think the Save button should be moved to the left of the Find button. It makes more sense to be near the Save Query button.
- Umm, that's about it, bar the history issue. The quick fix there might be to hide the internal queries for now as previously discussed, but I do this the checkbox to include them (in their mogrified state) should be included as part of the overall project.
Note that I haven't done in-depth testing. Once the patch is committed (and about now is a good time, as we're at the beginning of the release cycle), we'll get our QA guy to see if he can find any issues we've missed.
Also, do you mean code documentation or documentation for the users? Could you point me towards the related parts?
User documentation. I would expect at least one screenshot update due to the new button on the toolbar (probably more - please check for others that need updating), as well as updates to at least:
editgrid.rst
query_tool.rst
query_tool_toolbar.rst
Great work!
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
On Wed, Jun 26, 2019 at 1:01 PM Dave Page <dpage@pgadmin.org> wrote:
- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.It needs:- A code complete feature (or infrastructure/refactoring ready for a feature), that is acceptable to us. Seems like this is 90% there for an initial commit.- Documentation updates.- Tests for the new feature to ensure it works without needing manual testing.- To pass all existing tests (which may be modified if appropriate).Could you tell me what is missing from this patch (in terms of features - other than tests) to be acceptable? I will start working on the tests once the patch is complete. The patch passes all the existing tests except for 3 feature tests that fail due to a TimeoutException in selenium. I do not know what this is about I hope Aditya will help me with it.Here are the issues I think should be fixed first:- I think the Save button should be moved to the left of the Find button. It makes more sense to be near the Save Query button.- Umm, that's about it, bar the history issue. The quick fix there might be to hide the internal queries for now as previously discussed, but I do this the checkbox to include them (in their mogrified state) should be included as part of the overall project.Note that I haven't done in-depth testing. Once the patch is committed (and about now is a good time, as we're at the beginning of the release cycle), we'll get our QA guy to see if he can find any issues we've missed.Also, do you mean code documentation or documentation for the users? Could you point me towards the related parts?User documentation. I would expect at least one screenshot update due to the new button on the toolbar (probably more - please check for others that need updating), as well as updates to at least:editgrid.rstquery_tool.rstquery_tool_toolbar.rstGreat work!
I will disable the generated queries for now, then for the next patch I will work on (optionally) including them (mogrified). Should I send a patch with the completed work then start working on the tests and documentation (for it to get reviewed)? or wait until the patch is complete with tests and documentation?
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
On Wed, Jun 26, 2019 at 11:46 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:
Hi,On Wed, Jun 26, 2019 at 10:35 AM Aditya Toshniwal <aditya.toshniwal@enterprisedb.com> wrote:My problem is not where to store the mogrified query, I can just replace the sql sent with the response to saving the data with the mogrified one. In order to produce the mogrified query in the first place I need a psycopg2.cursor object, but I only have access to a Connection object (the wrapper, not the actual psycopg2.connection object). Should I modify that wrapper Connection class to add a mogirfy function? or just get a cursor using the psycopg2.connection object like this: conn.conn.cursor() - which doesn't seem right. Thoughts?That would be the way. But I think web/pgadmin/utils/driver/psycopg2/cursor.py will be corrrect place to add the mogrify function. Please note, psycopg2 does not support (,),% in the parameter names. So if the column names has any of these characters, mogrify might fail. Although it is handled with pgadmin_alias (line 493 - web/pgadmin/tools/sqleditor/__init__.py), please test this case as well.You can also get the last executed SQL in psycopg2 - http://initd.org/psycopg/docs/cursor.html#cursor.query. May be this can be used.
The cursor wrapper class (DictCursor) is exclusively used by the connection wrapper class (at web/pgadmin/utils/driver/psycopg2/connection.py) as a cursor factory. I think the mogrify function will need to be implemented in both classes, as the Connection class is the one that is used throughout the code - no code uses cursors directly. What do you think?
The use of cursor.query will not be possible as this is a property of the cursor, not the connection. I will need to call cursor.query on the exact cursor that was used to execute the query, which is not accessible in this case.
Thanks a lot for your help !
Also, could you please help me with the selenium TimeoutException in the feature tests? 3 tests are failing because of that exception and I am not sure what is it related to. I am attaching the feature test log file in this email if you would like to take a look on it.Can you check on latest chrome and chromdriver. You can check the chromedriver version as below. Your venv should have the chromedriver binary.(pypg37) laptop207:pgadmin4 adityatoshniwal$ chromedriver --version
ChromeDriver 75.0.3770.8 (681f24ea911fe754973dda2fdc6d2a2e159dd300-refs/branch-heads/3770@{#40})
The version I have is actually 75.0.3770.90. Could the more recent version be causing the problem ?
Thanks and regards.
--
Yosry Muhammad Yosry
Computer Engineering student,
The Faculty of Engineering,
Cairo University (2021).
Class representative of CMP 2021.
Hi
On Wed, Jun 26, 2019 at 8:20 AM Yosry Muhammad <yosrym93@gmail.com> wrote:
Hi,On Wed, Jun 26, 2019 at 1:01 PM Dave Page <dpage@pgadmin.org> wrote:- What else is missing from this patch to make it applicable ? I would like to produce a release-ready patch if possible. If so, I can continue working on the project on following patches, I just want to know what is the minimum amount of work needed to make this patch release-ready (especially that changes are being made in the master branch that require me to re-edit parts of the code that I have written before to keep things in-sync).@Dave Page is the right person to answer this.It needs:- A code complete feature (or infrastructure/refactoring ready for a feature), that is acceptable to us. Seems like this is 90% there for an initial commit.- Documentation updates.- Tests for the new feature to ensure it works without needing manual testing.- To pass all existing tests (which may be modified if appropriate).Could you tell me what is missing from this patch (in terms of features - other than tests) to be acceptable? I will start working on the tests once the patch is complete. The patch passes all the existing tests except for 3 feature tests that fail due to a TimeoutException in selenium. I do not know what this is about I hope Aditya will help me with it.Here are the issues I think should be fixed first:- I think the Save button should be moved to the left of the Find button. It makes more sense to be near the Save Query button.- Umm, that's about it, bar the history issue. The quick fix there might be to hide the internal queries for now as previously discussed, but I do this the checkbox to include them (in their mogrified state) should be included as part of the overall project.Note that I haven't done in-depth testing. Once the patch is committed (and about now is a good time, as we're at the beginning of the release cycle), we'll get our QA guy to see if he can find any issues we've missed.Also, do you mean code documentation or documentation for the users? Could you point me towards the related parts?User documentation. I would expect at least one screenshot update due to the new button on the toolbar (probably more - please check for others that need updating), as well as updates to at least:editgrid.rstquery_tool.rstquery_tool_toolbar.rstGreat work!I will disable the generated queries for now, then for the next patch I will work on (optionally) including them (mogrified). Should I send a patch with the completed work then start working on the tests and documentation (for it to get reviewed)? or wait until the patch is complete with tests and documentation?
We always want to commit the docs and tests along with the code so we don't get in a situation where they later get missed or omitted.
Thanks.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company