Обсуждение: [HACKERS] Surjective functional indexes
Right now Postgres determines whether update operation touch index or not based only on set of the affected columns. But in case of functional indexes such policy quite frequently leads to unnecessary index updates. For example, functional index are widely use for indexing JSON data: info->>'name'. JSON data may contain multiple attributes and only few of them may be affected by update. Moreover, index is used to build for immutable attributes (like "id", "isbn", "name",...). Functions like (info->>'name') are named "surjective" ni mathematics. I have strong feeling that most of functional indexes are based on surjective functions. For such indexes current Postgresql index update policy is very inefficient. It cause disabling of hot updates and so leads to significant degrade of performance. Without this patch Postgres is slower than Mongo on YCSB benchmark with (50% update,50 % select) workload. And after applying this patch Postgres beats Mongo at all workloads. My proposal is to check value of function for functional indexes instead of just comparing set of effected attributes. Obviously, for some complex functions it may have negative effect on update speed. This is why I have added "surjective" option to index. By default it is switched on for all functional indexes (based on my assumption that most functions used in functional indexes are surjective). But it is possible to explicitly disable it and make decision weather index needs to be updated or not only based on set of effected attributes. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
Konstantin Knizhnik <k.knizhnik@postgrespro.ru> writes:
> My proposal is to check value of function for functional indexes instead
> of just comparing set of effected attributes.
> Obviously, for some complex functions it may have negative effect on
> update speed.
> This is why I have added "surjective" option to index.
This seems overcomplicated. We would have to compute the function
value at some point anyway. Can't we refactor to do that earlier?
regards, tom lane
On 2017-05-25 12:37:40 -0400, Tom Lane wrote: > Konstantin Knizhnik <k.knizhnik@postgrespro.ru> writes: > > My proposal is to check value of function for functional indexes instead > > of just comparing set of effected attributes. > > Obviously, for some complex functions it may have negative effect on > > update speed. > > This is why I have added "surjective" option to index. > > This seems overcomplicated. We would have to compute the function > value at some point anyway. Can't we refactor to do that earlier? Yea, that'd be good. Especially if we were to compute the expressions for all indexes in one go - doing that in other places (e.g. aggregate transition values) yielded a good amount of speedup. It'd be even larger if we get JITing of expressions. It seems feasible to do so for at least the nodeModifyTable case. I wonder if there's a chance to use such logic alsofor HOT update considerations, but that seems harder to do without larger layering violations. - Andres
On 25.05.2017 19:37, Tom Lane wrote: > Konstantin Knizhnik <k.knizhnik@postgrespro.ru> writes: >> My proposal is to check value of function for functional indexes instead >> of just comparing set of effected attributes. >> Obviously, for some complex functions it may have negative effect on >> update speed. >> This is why I have added "surjective" option to index. > This seems overcomplicated. We would have to compute the function > value at some point anyway. Can't we refactor to do that earlier? > > regards, tom lane Check for affected indexes/applicability of HOT update and update of indexes themselves is done in two completely different parts of code. And if we find out that values of indexed expressions are not changed, then we can use HOT update and indexes should not be updated (so calculated value of function is not needed). And it is expected to be most frequent case. Certainly, if value of indexed expression is changed, then we can avoid redundant calculation of function by storing result of calculations somewhere. But it will greatly complicate all logic of updating indexes. Please notice, that if we have several functional indexes and only one of them is actually changed, then in any case we can not use HOT and have to update all indexes. So we do not need to evaluate values of all indexed expressions. We just need to find first changed one. So we should somehow keep track values of which expression are calculated and which not. One more argument. Originally Postgres evaluates index expression only once (when inserting new version of tuple to the index). Now (with this patch) Postgres has to evaluate expression three times in the worst case: calculate the value of expression for old and new tuples to make a decision bout hot update, and the evaluate it once again when performing index update itself. Even if I managed to store somewhere calculated value of the expression, we still have to perform twice more evaluations than before. This is why for expensive functions or for functions defined for frequently updated attributes (in case of JSON) such policy should be disabled. And for non-expensive functions extra overhead is negligible. Also there is completely no overhead if indexed expression is not actually changed. And it is expected to be most frequent case. At least at the particular example with YCSB benchmark, our first try was just to disable index update by commenting correspondent check of updated fields mask. Obviously there are no extra function calculations in this case. Then I have implemented this patch. And performance is almost the same. This is why I think that simplicity and modularity of code is more important here than elimination of redundant function calculation. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 5/25/17 12:30, Konstantin Knizhnik wrote: > Functions like (info->>'name') are named "surjective" ni mathematics. A surjective function is one where each value in the output type can be obtained by some input value. That's not what you are after here. The behavior you are describing is a not-injective function. I think you are right that in practice most functions are not injective.But I think there is still quite some differencebetween a function like the one you showed that selects a component from a composite data structure and, for example, round(), where in practice any update is likely to change the result of the function. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 05/27/2017 09:50 PM, Peter Eisentraut wrote: > On 5/25/17 12:30, Konstantin Knizhnik wrote: >> Functions like (info->>'name') are named "surjective" ni mathematics. > A surjective function is one where each value in the output type can be > obtained by some input value. That's not what you are after here. The > behavior you are describing is a not-injective function. > > I think you are right that in practice most functions are not injective. > But I think there is still quite some difference between a function > like the one you showed that selects a component from a composite data > structure and, for example, round(), where in practice any update is > likely to change the result of the function. > Thank you, I will rename "surjective" parameter to "injective" with "false" as default value. Concerning "round" and other similar functions - obviously there are use cases when such functions are used for functional indexes. This is why I want to allow user to make a choice and this is the reason of introducing this parameter. The question is the default value of this parameter: should we by default preserve original Postgres behavior: check only affected set of keys or should we pay extra cost for calculating value of the function (even if we managed tostore calculated value of the indexes expression for new tuple, we still have to calculate it for old tuple, so function will becalculated at least twice more times). -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Re: Konstantin Knizhnik 2017-05-29 <592BBD90.3060104@postgrespro.ru> > On 05/27/2017 09:50 PM, Peter Eisentraut wrote: > > On 5/25/17 12:30, Konstantin Knizhnik wrote: > > > Functions like (info->>'name') are named "surjective" ni mathematics. > > A surjective function is one where each value in the output type can be > > obtained by some input value. That's not what you are after here. The > > behavior you are describing is a not-injective function. > > > > I think you are right that in practice most functions are not injective. > > But I think there is still quite some difference between a function > > like the one you showed that selects a component from a composite data > > structure and, for example, round(), where in practice any update is > > likely to change the result of the function. > > > Thank you, I will rename "surjective" parameter to "injective" with "false" as default value. I think the term you were looking for is "projection". https://en.wikipedia.org/wiki/Projection_(set_theory) Christoph
On 29.05.2017 19:21, Christoph Berg wrote: > I think the term you were looking for is "projection". > https://en.wikipedia.org/wiki/Projection_(set_theory) Maybe, I am seeing too much of a connection here but recently Raymond Hettinger held a very interesting talk [1] at PyCon 2017. For those without the time or bandwidth to watch: it describes the history of the modern dict in Python in several steps. 1) avoiding having a database scheme with columns and rows and indexes 2) introducing hashing with bucket lists 3...6) several improvements 7) in the end looks like a database table with indexes again ;) If you have the time, just go ahead and watch the 30 min video. He can explain things definitely better than me. In order to draw the line back on-topic, if I am not completely mistaken, his talks basically shows that over time even datastructures with different APIs such as dicts (hashes, maps, sets, etc.) internally converge towards a relational-database-y design because of performance and resources reasons. Thus let me think that also in the on-topic case, we might best be supporting the much narrow use-case of "Projection" (a term also used in relation database theory btw. ;-) ) instead of non-surjective functions. Cheers, Sven [1] https://www.youtube.com/watch?v=npw4s1QTmPg
On 29.05.2017 21:25, Sven R. Kunze wrote: > [...] non-surjective functions. non-injective of course
On 29.05.2017 20:21, Christoph Berg wrote: > > I think the term you were looking for is "projection". > > https://en.wikipedia.org/wiki/Projection_(set_theory) I have already renamed parameter from "surjective" to "injective". But I am ok to do do one more renaming to "projection" if it will be considered as better alternative.From my point of view, "projection" seems to be clearer for people without mathematical background, but IMHO this term is overloaded in DBMS context. The irony is that in Wikipedia "projection" is explained using "surjection" term:) > > Christoph -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Re: Konstantin Knizhnik 2017-05-30 <f97118e3-821c-10a8-85ec-0af3f1dfd01d@postgrespro.ru> > > > On 29.05.2017 20:21, Christoph Berg wrote: > > > > I think the term you were looking for is "projection". > > > > https://en.wikipedia.org/wiki/Projection_(set_theory) > > I have already renamed parameter from "surjective" to "injective". > But I am ok to do do one more renaming to "projection" if it will be > considered as better alternative. > From my point of view, "projection" seems to be clearer for people without > mathematical background, > but IMHO this term is overloaded in DBMS context. With mathematical background, I don't see how your indexes would exploit surjective or injective properties of the function used. What you are using is that ->> projects a json value to one of its components, i.e. the projection/function result does not depend on the other attributes contained. > The irony is that in Wikipedia "projection" is explained using > "surjection" term:) For the equivalence classes part, which isn't really connected to your application. Christoph
Attached please find rebased version of the patch. Now "projection" attribute is used instead of surjective/injective. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Fri, Jun 9, 2017 at 8:08 PM, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
> Attached please find rebased version of the patch.
> Now "projection" attribute is used instead of surjective/injective.
Hi Konstantin,
This still applies but it doesn't compile after commits 2cd70845 and
c6293249. You need to change this:
Form_pg_attribute att = RelationGetDescr(indexDesc)->attrs[i];
... to this:
Form_pg_attribute att = TupleDescAttr(RelationGetDescr(indexDesc), i);
Thanks!
--
Thomas Munro
http://www.enterprisedb.com
On 1 September 2017 at 05:40, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > On Fri, Jun 9, 2017 at 8:08 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> Attached please find rebased version of the patch. >> Now "projection" attribute is used instead of surjective/injective. > > Hi Konstantin, > > This still applies but it doesn't compile after commits 2cd70845 and > c6293249. You need to change this: > > Form_pg_attribute att = RelationGetDescr(indexDesc)->attrs[i]; > > ... to this: > > Form_pg_attribute att = TupleDescAttr(RelationGetDescr(indexDesc), i); > > Thanks! Does the patch work fully with that change? If so, I will review. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01.09.2017 09:25, Simon Riggs wrote: > On 1 September 2017 at 05:40, Thomas Munro > <thomas.munro@enterprisedb.com> wrote: >> On Fri, Jun 9, 2017 at 8:08 PM, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >>> Attached please find rebased version of the patch. >>> Now "projection" attribute is used instead of surjective/injective. >> Hi Konstantin, >> >> This still applies but it doesn't compile after commits 2cd70845 and >> c6293249. You need to change this: >> >> Form_pg_attribute att = RelationGetDescr(indexDesc)->attrs[i]; >> >> ... to this: >> >> Form_pg_attribute att = TupleDescAttr(RelationGetDescr(indexDesc), i); >> >> Thanks! > Does the patch work fully with that change? If so, I will review. > Attached please find rebased version of the patch. Yes, I checked that it works after this fix. Thank you in advance for review. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On 1 September 2017 at 09:47, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > On 01.09.2017 09:25, Simon Riggs wrote: >> >> On 1 September 2017 at 05:40, Thomas Munro >> <thomas.munro@enterprisedb.com> wrote: >>> >>> On Fri, Jun 9, 2017 at 8:08 PM, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >>>> >>>> Attached please find rebased version of the patch. >>>> Now "projection" attribute is used instead of surjective/injective. >>> >>> Hi Konstantin, >>> >>> This still applies but it doesn't compile after commits 2cd70845 and >>> c6293249. You need to change this: >>> >>> Form_pg_attribute att = RelationGetDescr(indexDesc)->attrs[i]; >>> >>> ... to this: >>> >>> Form_pg_attribute att = TupleDescAttr(RelationGetDescr(indexDesc), >>> i); >>> >>> Thanks! >> >> Does the patch work fully with that change? If so, I will review. >> > Attached please find rebased version of the patch. > Yes, I checked that it works after this fix. > Thank you in advance for review. Thanks for the patch. Overall looks sound and I consider that we are working towards commit for this. The idea is that we default "projection = on", and can turn it off in case the test is expensive. Why bother to have the option? (No docs at all then!) Why not just evaluate the test and autotune whether to make the test again in the future? That way we can avoid having an option completely. I am imagining collecting values on the relcache entry for the index. To implement autotuning we would need to instrument the execution. We could then display the collected value via EXPLAIN, so we could just then use EXPLAIN in your tests rather than implementing a special debug mode just for testing. We could also pass that information thru to stats as well. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 12.09.2017 19:28, Simon Riggs wrote: > On 1 September 2017 at 09:47, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 01.09.2017 09:25, Simon Riggs wrote: >>> On 1 September 2017 at 05:40, Thomas Munro >>> <thomas.munro@enterprisedb.com> wrote: >>>> On Fri, Jun 9, 2017 at 8:08 PM, Konstantin Knizhnik >>>> <k.knizhnik@postgrespro.ru> wrote: >>>>> Attached please find rebased version of the patch. >>>>> Now "projection" attribute is used instead of surjective/injective. >>>> Hi Konstantin, >>>> >>>> This still applies but it doesn't compile after commits 2cd70845 and >>>> c6293249. You need to change this: >>>> >>>> Form_pg_attribute att = RelationGetDescr(indexDesc)->attrs[i]; >>>> >>>> ... to this: >>>> >>>> Form_pg_attribute att = TupleDescAttr(RelationGetDescr(indexDesc), >>>> i); >>>> >>>> Thanks! >>> Does the patch work fully with that change? If so, I will review. >>> >> Attached please find rebased version of the patch. >> Yes, I checked that it works after this fix. >> Thank you in advance for review. > Thanks for the patch. Overall looks sound and I consider that we are > working towards commit for this. > > The idea is that we default "projection = on", and can turn it off in > case the test is expensive. Why bother to have the option? (No docs at > all then!) Why not just evaluate the test and autotune whether to make > the test again in the future? That way we can avoid having an option > completely. I am imagining collecting values on the relcache entry for > the index. Autotune is definitely good thing. But I do not think that excludes having explicit parameter for manual tuning. For some functional indexes DBA or programmer knows for sure that it doesn't perform projection. For example if it translates or changes encoding of original key. It seems to me that we should make it possible to declare this index as non-projective and do not rely on autotune. Also I have some doubts concerning using autotune in this case. First of all it is very hard to estimate complexity of test. How can we measure it? Calculate average execution time? It can vary for different systems and greatly depends on system load... Somehow calculate cost of indexed expression? It may be also not always produce expected result. Moreover, in some cases test may be not expensive, but still useless, if index expression specifies one-to-one mapping (for example function reversing key). Autotone will never be able to reliable determine that indexed expression is projection or not. It seems to be more precise to compare statistic for source column and index expression. If them are similar, then most likely index expression is not a projection... I will think more about it. > To implement autotuning we would need to instrument the execution. We > could then display the collected value via EXPLAIN, so we could just > then use EXPLAIN in your tests rather than implementing a special > debug mode just for testing. We could also pass that information thru > to stats as well. > -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Re: Konstantin Knizhnik 2017-09-01 <f530ede0-1bf6-879c-c362-34325514f692@postgrespro.ru> > + Functional index is based on on projection function: function which extract subset of its argument. > + In mathematic such functions are called non-injective. For injective function if any attribute used in the indexed > + expression is changed, then value of index expression is also changed. This is Just Wrong. I still think what you are doing here doesn't have anything to do with the function being injective or not. Christoph -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 13.09.2017 10:51, Christoph Berg wrote: > Re: Konstantin Knizhnik 2017-09-01 <f530ede0-1bf6-879c-c362-34325514f692@postgrespro.ru> >> + Functional index is based on on projection function: function which extract subset of its argument. >> + In mathematic such functions are called non-injective. For injective function if any attribute used in the indexed >> + expression is changed, then value of index expression is also changed. > This is Just Wrong. I still think what you are doing here doesn't have > anything to do with the function being injective or not. Sorry, can you please explain what is wrong? The problem I am trying to solve comes from particular use case: functional index on part of JSON column. Usually such index is built for persistent attributes, which are rarely changed, like ISBN... Right now any update of JSON column disables hot update. Even if such update doesn't really affect index. So instead of disabling HOT juts based on mask of modified attributes, I suggest to compare old and new value of index expression. Such behavior can significantly (several times) increase performance. But only for "projection" functions. There was long discussion in this thread about right notion for this function (subjective, non-injective, projection). But I think criteria is quite obvious. Simon propose eliminate "projection" property and use autotune to determine optimal behavior. I still think that such option will be useful, but we can really use statistic to compare number of unique values for index function and for it's argument(s). If them are similar, then most likely the function is injective, so it produce different result for different attributes. Then there is no sense to spend extra CPU time, calculating old and new values of the function. This is what I am going to implement now. So I will be please if you more precisely explain your concerns and suggestions (if you have one). -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Re: Konstantin Knizhnik 2017-09-13 <2393c4b3-2ec4-dc68-4ea9-670597b561fe@postgrespro.ru> > > > On 13.09.2017 10:51, Christoph Berg wrote: > > Re: Konstantin Knizhnik 2017-09-01 <f530ede0-1bf6-879c-c362-34325514f692@postgrespro.ru> > > > + Functional index is based on on projection function: function which extract subset of its argument. > > > + In mathematic such functions are called non-injective. For injective function if any attribute used in theindexed > > > + expression is changed, then value of index expression is also changed. > > This is Just Wrong. I still think what you are doing here doesn't have > > anything to do with the function being injective or not. > > Sorry, can you please explain what is wrong? I don't get why you are reasoning about "projection" -> "non-injective" -> "injective". Can't you try to explain what this functionality is about without abusing math terms that just mean something else in the rest of the world? Christoph -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 13.09.2017 13:14, Christoph Berg wrote: > Re: Konstantin Knizhnik 2017-09-13 <2393c4b3-2ec4-dc68-4ea9-670597b561fe@postgrespro.ru> >> >> On 13.09.2017 10:51, Christoph Berg wrote: >>> Re: Konstantin Knizhnik 2017-09-01 <f530ede0-1bf6-879c-c362-34325514f692@postgrespro.ru> >>>> + Functional index is based on on projection function: function which extract subset of its argument. >>>> + In mathematic such functions are called non-injective. For injective function if any attribute used in the indexed >>>> + expression is changed, then value of index expression is also changed. >>> This is Just Wrong. I still think what you are doing here doesn't have >>> anything to do with the function being injective or not. >> Sorry, can you please explain what is wrong? > I don't get why you are reasoning about "projection" -> > "non-injective" -> "injective". Can't you try to explain what this > functionality is about without abusing math terms that just mean > something else in the rest of the world? I tried to explain it in my previous e-mail. In most cases (it is just my filling, may be it is wrong), functional indexes are built for some complex types, like JSON, arrays, structs,... and index expression extracts some components of this compound value. It means that even if underlying column is changes, there is good chance that value of index function is not changed. So there is no need to update index and we can use HOT. It allows to several time increase performance. The only reason of all this discussion about terms is that I need to choose name for correspondent index option. Simon think that we do not need this option at all. In this case we should not worry about right term.From my point of view, "projection" is quite clear notion and not only for mathematics. It is also widely used in IT and especially in DBMSes. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 13 September 2017 at 11:30, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > The only reason of all this discussion about terms is that I need to choose > name for correspondent index option. > Simon think that we do not need this option at all. In this case we should > not worry about right term. > From my point of view, "projection" is quite clear notion and not only for > mathematics. It is also widely used in IT and especially in DBMSes. If we do have an option it won't be using fancy mathematical terminology at all, it would be described in terms of its function, e.g. recheck_on_update Yes, I'd rather not have an option at all, just some simple code with useful effect, like we have in many other places. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 13.09.2017 14:00, Simon Riggs wrote: > On 13 September 2017 at 11:30, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: > >> The only reason of all this discussion about terms is that I need to choose >> name for correspondent index option. >> Simon think that we do not need this option at all. In this case we should >> not worry about right term. >> From my point of view, "projection" is quite clear notion and not only for >> mathematics. It is also widely used in IT and especially in DBMSes. > If we do have an option it won't be using fancy mathematical > terminology at all, it would be described in terms of its function, > e.g. recheck_on_update > > Yes, I'd rather not have an option at all, just some simple code with > useful effect, like we have in many other places. > Yehhh, After more thinking I found out that my idea to use table/index statistic (particularity number of distinct values) to determine projection functions was wrong. Consider case column bookinfo of jsonb type and index expression (bookinfo->'ISBN'). Both can be considered as unique. But it is an obvious example of projection function, which value is not changed if we update other information related with this book. So this approach doesn't work. Looks like the only thing we can do to autotune is to collect own statistic: how frequently changing attribute(s) doesn't affect result of the function. By default we can considered function as projection and perform comparison of old/new function results. If after some number of comparisons fraction of hits (when value of function is not changed) is smaller than some threshold (0.5?, 0.9?,...) then we can mark index as non-projective and eliminate this checks in future. But it will require extending index statistic. Do we really need/want it? Despite to the possibility to implement autotune, I still think that we should have manual switch, doesn't mater how it is named. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 13.09.2017 14:00, Simon Riggs wrote:
> On 13 September 2017 at 11:30, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>
>> The only reason of all this discussion about terms is that I need to choose
>> name for correspondent index option.
>> Simon think that we do not need this option at all. In this case we should
>> not worry about right term.
>> From my point of view, "projection" is quite clear notion and not only for
>> mathematics. It is also widely used in IT and especially in DBMSes.
> If we do have an option it won't be using fancy mathematical
> terminology at all, it would be described in terms of its function,
> e.g. recheck_on_update
>
> Yes, I'd rather not have an option at all, just some simple code with
> useful effect, like we have in many other places.
>
Attached please find new version of projection functional index
optimization patch.
I have implemented very simple autotune strategy: now I use table
statistic to compare total number of updates with number of hot updates.
If fraction of hot updates is relatively small, then there is no sense
to spend time performing extra evaluation of index expression and
comparing its old and new values.
Right now the formula is the following:
#define MIN_UPDATES_THRESHOLD 10
#define HOT_RATIO_THRESHOLD 2
if (stat->tuples_updated > MIN_UPDATES_THRESHOLD
&& stat->tuples_updated >
stat->tuples_hot_updated*HOT_RATIO_THRESHOLD)
{
/* If percent of hot updates is small, then disable
projection index function
* optimization to eliminate overhead of extra index
expression evaluations.
*/
ii->ii_Projection = false;
}
This threshold values are pulled out of a hat: I am not sure if this
heuristic is right.
I will be please to get feedback if such approach to autotune is promising.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On 14 September 2017 at 10:42, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
>
>
> On 13.09.2017 14:00, Simon Riggs wrote:
>>
>> On 13 September 2017 at 11:30, Konstantin Knizhnik
>> <k.knizhnik@postgrespro.ru> wrote:
>>
>>> The only reason of all this discussion about terms is that I need to
>>> choose
>>> name for correspondent index option.
>>> Simon think that we do not need this option at all. In this case we
>>> should
>>> not worry about right term.
>>> From my point of view, "projection" is quite clear notion and not only
>>> for
>>> mathematics. It is also widely used in IT and especially in DBMSes.
>>
>> If we do have an option it won't be using fancy mathematical
>> terminology at all, it would be described in terms of its function,
>> e.g. recheck_on_update
>>
>> Yes, I'd rather not have an option at all, just some simple code with
>> useful effect, like we have in many other places.
>>
> Attached please find new version of projection functional index optimization
> patch.
> I have implemented very simple autotune strategy: now I use table statistic
> to compare total number of updates with number of hot updates.
> If fraction of hot updates is relatively small, then there is no sense to
> spend time performing extra evaluation of index expression and comparing its
> old and new values.
> Right now the formula is the following:
>
> #define MIN_UPDATES_THRESHOLD 10
> #define HOT_RATIO_THRESHOLD 2
>
> if (stat->tuples_updated > MIN_UPDATES_THRESHOLD
> && stat->tuples_updated >
> stat->tuples_hot_updated*HOT_RATIO_THRESHOLD)
> {
> /* If percent of hot updates is small, then disable projection
> index function
> * optimization to eliminate overhead of extra index expression
> evaluations.
> */
> ii->ii_Projection = false;
> }
>
> This threshold values are pulled out of a hat: I am not sure if this
> heuristic is right.
> I will be please to get feedback if such approach to autotune is promising.
Hmm, not really, but thanks for trying.
This works by looking at overall stats, and only looks at the overall
HOT %, so its too heavyweight and coarse.
I suggested storing stat info on the relcache and was expecting you
would look at how often the expression evaluates to new == old. If we
evaluate new against old many times, then if the success rate is low
we should stop attempting the comparison. (<10%?)
Another idea:
If we don't make a check when we should have done then we will get a
non-HOT update, so we waste time extra time difference between a HOT
and non-HOT update. If we check and fail we waste time take to perform
check. So the question is how expensive the check is against how
expensive a non-HOT update is. Could we simply say we don't bother to
check functions that have a cost higher than 10000? So if the user
doesn't want to perform the check they can just increase the cost of
the function above the check threshold?
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On 14.09.2017 13:19, Simon Riggs wrote:
> On 14 September 2017 at 10:42, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>>
>> On 13.09.2017 14:00, Simon Riggs wrote:
>>> On 13 September 2017 at 11:30, Konstantin Knizhnik
>>> <k.knizhnik@postgrespro.ru> wrote:
>>>
>>>> The only reason of all this discussion about terms is that I need to
>>>> choose
>>>> name for correspondent index option.
>>>> Simon think that we do not need this option at all. In this case we
>>>> should
>>>> not worry about right term.
>>>> From my point of view, "projection" is quite clear notion and not only
>>>> for
>>>> mathematics. It is also widely used in IT and especially in DBMSes.
>>> If we do have an option it won't be using fancy mathematical
>>> terminology at all, it would be described in terms of its function,
>>> e.g. recheck_on_update
>>>
>>> Yes, I'd rather not have an option at all, just some simple code with
>>> useful effect, like we have in many other places.
>>>
>> Attached please find new version of projection functional index optimization
>> patch.
>> I have implemented very simple autotune strategy: now I use table statistic
>> to compare total number of updates with number of hot updates.
>> If fraction of hot updates is relatively small, then there is no sense to
>> spend time performing extra evaluation of index expression and comparing its
>> old and new values.
>> Right now the formula is the following:
>>
>> #define MIN_UPDATES_THRESHOLD 10
>> #define HOT_RATIO_THRESHOLD 2
>>
>> if (stat->tuples_updated > MIN_UPDATES_THRESHOLD
>> && stat->tuples_updated >
>> stat->tuples_hot_updated*HOT_RATIO_THRESHOLD)
>> {
>> /* If percent of hot updates is small, then disable projection
>> index function
>> * optimization to eliminate overhead of extra index expression
>> evaluations.
>> */
>> ii->ii_Projection = false;
>> }
>>
>> This threshold values are pulled out of a hat: I am not sure if this
>> heuristic is right.
>> I will be please to get feedback if such approach to autotune is promising.
> Hmm, not really, but thanks for trying.
>
> This works by looking at overall stats, and only looks at the overall
> HOT %, so its too heavyweight and coarse.
>
> I suggested storing stat info on the relcache and was expecting you
> would look at how often the expression evaluates to new == old. If we
> evaluate new against old many times, then if the success rate is low
> we should stop attempting the comparison. (<10%?)
>
> Another idea:
> If we don't make a check when we should have done then we will get a
> non-HOT update, so we waste time extra time difference between a HOT
> and non-HOT update. If we check and fail we waste time take to perform
> check. So the question is how expensive the check is against how
> expensive a non-HOT update is. Could we simply say we don't bother to
> check functions that have a cost higher than 10000? So if the user
> doesn't want to perform the check they can just increase the cost of
> the function above the check threshold?
>
Attached pleased find one more patch which calculates hot update check
hit rate more precisely: I have to extended PgStat_StatTabEntry with two
new fields:
hot_update_hits and hot_update_misses.
Concerning your idea to check cost of index function: it certainly makes
sense.
The only problems: I do not understand now how to calculate this cost.
It can be easily calculated by optimizer when it is building query
execution plan.
But inside BuildIndexInfo I have just reference to Relation and have no
idea how
I can propagate here information about index expression cost from optimizer.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On 14 September 2017 at 16:37, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 14.09.2017 13:19, Simon Riggs wrote: >> This works by looking at overall stats, and only looks at the overall >> HOT %, so its too heavyweight and coarse. >> >> I suggested storing stat info on the relcache and was expecting you >> would look at how often the expression evaluates to new == old. If we >> evaluate new against old many times, then if the success rate is low >> we should stop attempting the comparison. (<10%?) >> >> Another idea: >> If we don't make a check when we should have done then we will get a >> non-HOT update, so we waste time extra time difference between a HOT >> and non-HOT update. If we check and fail we waste time take to perform >> check. So the question is how expensive the check is against how >> expensive a non-HOT update is. Could we simply say we don't bother to >> check functions that have a cost higher than 10000? So if the user >> doesn't want to perform the check they can just increase the cost of >> the function above the check threshold? >> > Attached pleased find one more patch which calculates hot update check hit > rate more precisely: I have to extended PgStat_StatTabEntry with two new > fields: > hot_update_hits and hot_update_misses. It's not going to work, as already mentioned above. Those stats are at table level and very little to do with this particular index. But you've not commented on the design I mention that can work: index relcache. > Concerning your idea to check cost of index function: it certainly makes > sense. > The only problems: I do not understand now how to calculate this cost. > It can be easily calculated by optimizer when it is building query execution > plan. > But inside BuildIndexInfo I have just reference to Relation and have no idea > how > I can propagate here information about index expression cost from optimizer. We could copy at create index, if we took that route. Or we can look up the cost for the index expression and cache it. Anyway, this is just jumping around because we still have a parameter and the idea was to remove the parameter entirely by autotuning, which I think is both useful and possible, just as HOT itself is autotuned. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 14.09.2017 18:53, Simon Riggs wrote: > >>> This works by looking at overall stats, and only looks at the overall >>> HOT %, so its too heavyweight and coarse. >>> >>> I suggested storing stat info on the relcache and was expecting you >>> would look at how often the expression evaluates to new == old. If we >>> evaluate new against old many times, then if the success rate is low >>> we should stop attempting the comparison. (<10%?) >>> >>> Another idea: >>> If we don't make a check when we should have done then we will get a >>> non-HOT update, so we waste time extra time difference between a HOT >>> and non-HOT update. If we check and fail we waste time take to perform >>> check. So the question is how expensive the check is against how >>> expensive a non-HOT update is. Could we simply say we don't bother to >>> check functions that have a cost higher than 10000? So if the user >>> doesn't want to perform the check they can just increase the cost of >>> the function above the check threshold? >>> >> Attached pleased find one more patch which calculates hot update check hit >> rate more precisely: I have to extended PgStat_StatTabEntry with two new >> fields: >> hot_update_hits and hot_update_misses. > It's not going to work, as already mentioned above. Those stats are at > table level and very little to do with this particular index. > > But you've not commented on the design I mention that can work: index relcache. Sorry, I do not completely agree with you. Yes, certainly whether functional index is projective or not is property of the index, not of the table. But the decision whether hot update is applicable or not is made for the whole table - for all indexes. If a value of just one indexed expressions is changed then we can not use hot update and have to update all indexes. Assume that we have table with "bookinfo" field of type JSONB. And we create several functional indexes on this column: (bookinfo->'isbn'), (bookinfo->'title'), (bookinfo->'author'), (bookinfo->'rating'). Probability that indexed expression is changed is case of updating "bookinfo" field my be different for all this three indexes. But there is completely no sense to check if 'isbn' is changed or not, if we already detect that most updates cause change of 'rating' attribute and so comparing old and new values of (bookinfo->'rating') is just waste of time. In this case we should not also compare (bookinfo->'isbn') and other indexed expressions because for already rejected possibility of hot update. So despite to the fact that this information depends on particular index, it affects behavior of the whole table and it is reasonable (and simpler) to collect it in table's statistic. >> Concerning your idea to check cost of index function: it certainly makes >> sense. >> The only problems: I do not understand now how to calculate this cost. >> It can be easily calculated by optimizer when it is building query execution >> plan. >> But inside BuildIndexInfo I have just reference to Relation and have no idea >> how >> I can propagate here information about index expression cost from optimizer. > We could copy at create index, if we took that route. Or we can look > up the cost for the index expression and cache it. > > > Anyway, this is just jumping around because we still have a parameter > and the idea was to remove the parameter entirely by autotuning, which > I think is both useful and possible, just as HOT itself is autotuned. > Hot update in almost all cases is preferable to normal update, causing update of indexes. There are can be some scenarios when hot updates reduce speed of some queries, but it is very difficult to predict such cases user level. But usually nature of index is well known by DBA or programmer. In almost all cases it is clear for person creating functional index whether it will perform projection or not and whether comparing old/new expression value makes sense or is just waste of time. We can guess it from autotune, but such decision may be wrong (just because of application business logic). Postgres indexes already have a lot of options. And I think that "projection" option (or whatever we name it) is also needed. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 14.09.2017 18:53, Simon Riggs wrote:
> It's not going to work, as already mentioned above. Those stats are at
> table level and very little to do with this particular index.
>
> But you've not commented on the design I mention that can work: index relcache.
>
>> Concerning your idea to check cost of index function: it certainly makes
>> sense.
>> The only problems: I do not understand now how to calculate this cost.
>> It can be easily calculated by optimizer when it is building query execution
>> plan.
>> But inside BuildIndexInfo I have just reference to Relation and have no idea
>> how
>> I can propagate here information about index expression cost from optimizer.
> We could copy at create index, if we took that route. Or we can look
> up the cost for the index expression and cache it.
>
>
> Anyway, this is just jumping around because we still have a parameter
> and the idea was to remove the parameter entirely by autotuning, which
> I think is both useful and possible, just as HOT itself is autotuned.
>
Attached please find yet another version of the patch.
I have to significantly rewrite it, because my first attempts to add
auto-tune were not correct.
New patch does it in correct way (I hope) and more efficiently.
I moved auto-tune code from BuildIndexInfo, which is called many times,
including heap_update (so at least once per update tuple).
to RelationGetIndexAttrBitmap which is called only when cached
RelationData is filled by backend.
The problem with my original implementation of auto-tune was that
switching off "projection" property of index, it doesn't update
attribute masks,
calculated by RelationGetIndexAttrBitmap.
I have also added check for maximal cost of indexed expression.
So now decision whether to apply projection index optimization (compare
old and new values of indexed expression)
is based on three sources:
1. Calculated hot update statistic: we compare number of hot updates
which are performed
because projection index check shows that index expression is not
changed with total
number of updates affecting attributes used in projection indexes.
If it is smaller than
some threshold (10%), then index is considered as non-projective.
2. Calculated cost of index expression: if it is higher than some
threshold (1000) then
extra comparison of index expression values is expected to be too
expensive.
3. "projection" index option explicitly set by user. This setting
overrides 1) and 2)
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On 15 September 2017 at 16:34, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > Attached please find yet another version of the patch. Thanks. I'm reviewing it. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Sep 13, 2017 at 7:00 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > If we do have an option it won't be using fancy mathematical > terminology at all, it would be described in terms of its function, > e.g. recheck_on_update +1. > Yes, I'd rather not have an option at all, just some simple code with > useful effect, like we have in many other places. I think the question we need to be able to answer is: What is the probability that an update that would otherwise be non-HOT can be made into a HOT update by performing a recheck to see whether the value has changed? It doesn't seem easy to figure that out from any of the statistics we have available today or could easily get, because it depends not only on the behavior of the expression which appears in the index definition but also on the application behavior. For example, consider a JSON blob representing a bank account. b->'balance' is likely to change most of the time, but b->'account_holder_name' only rarely. That's going to be hard for an automated system to determine. We should clearly check as many of the other criteria for a HOT update as possible before performing a recheck of this type, so that it only gets performed when it might help. For example, if column a is indexed and b->'foo' is indexed, there's no point in checking whether b->'foo' has changed if we know that a has changed. I don't know whether it would be feasible to postpone deciding whether to do a recheck until after we've figured out whether the page seems to contain enough free space to allow a HOT update. Turning non-HOT updates into HOT updates is really good, so it seems likely that the rechecks will often be worthwhile. If we avoid a HOT update in 25% of cases, that's probably easily worth the CPU overhead of a recheck assuming the function isn't something ridiculously expensive to compute; the extra CPU cost will be repaid by reduced bloat. However, if we avoid a HOT update only one time in a million, it's probably not worth the cost of recomputing the expression the other 999,999 times. I wonder where the crossover point is -- it seems like something that could be figured out by benchmarking. While I agree that it would be nice to have this be a completely automatic determination, I am not sure that will be practical. I oppose overloading some other marker (like function_cost>10000) for this; that's too magical. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, May 25, 2017 at 7:30 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > Right now Postgres determines whether update operation touch index or not > based only on set of the affected columns. > But in case of functional indexes such policy quite frequently leads to > unnecessary index updates. > For example, functional index are widely use for indexing JSON data: > info->>'name'. > > JSON data may contain multiple attributes and only few of them may be > affected by update. > Moreover, index is used to build for immutable attributes (like "id", > "isbn", "name",...). > > Functions like (info->>'name') are named "surjective" ni mathematics. > I have strong feeling that most of functional indexes are based on > surjective functions. > For such indexes current Postgresql index update policy is very inefficient. > It cause disabling of hot updates > and so leads to significant degrade of performance. > > Without this patch Postgres is slower than Mongo on YCSB benchmark with (50% > update,50 % select) workload. > And after applying this patch Postgres beats Mongo at all workloads. I confirm that the patch helps for workload A of YCSB, but actually just extends #clients, where postgres outperforms mongodb (see attached picture). If we increase #clients > 100 postgres quickly degrades not only for workload A, but even for workload B (5% updates), while mongodb and mysql behave much-much better, but this is another problem, we will discuss in different thread. > > My proposal is to check value of function for functional indexes instead of > just comparing set of effected attributes. > Obviously, for some complex functions it may have negative effect on update > speed. > This is why I have added "surjective" option to index. By default it is > switched on for all functional indexes (based on my assumption > that most functions used in functional indexes are surjective). But it is > possible to explicitly disable it and make decision weather index > needs to be updated or not only based on set of effected attributes. > > > -- > Konstantin Knizhnik > Postgres Professional: http://www.postgrespro.com > The Russian Postgres Company > > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers > -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Sep 28, 2017 at 11:24 PM, Oleg Bartunov <obartunov@gmail.com> wrote: > On Thu, May 25, 2017 at 7:30 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> Right now Postgres determines whether update operation touch index or not >> based only on set of the affected columns. >> But in case of functional indexes such policy quite frequently leads to >> unnecessary index updates. >> For example, functional index are widely use for indexing JSON data: >> info->>'name'. >> >> JSON data may contain multiple attributes and only few of them may be >> affected by update. >> Moreover, index is used to build for immutable attributes (like "id", >> "isbn", "name",...). >> >> Functions like (info->>'name') are named "surjective" ni mathematics. >> I have strong feeling that most of functional indexes are based on >> surjective functions. >> For such indexes current Postgresql index update policy is very inefficient. >> It cause disabling of hot updates >> and so leads to significant degrade of performance. >> >> Without this patch Postgres is slower than Mongo on YCSB benchmark with (50% >> update,50 % select) workload. >> And after applying this patch Postgres beats Mongo at all workloads. > > I confirm that the patch helps for workload A of YCSB, but actually > just extends #clients, where postgres outperforms mongodb (see > attached picture). If we increase #clients > 100 postgres quickly > degrades not only for workload A, but even for workload B (5% > updates), while mongodb and mysql behave much-much better, but this is > another problem, we will discuss in different thread. sorry, now with picture attached. -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
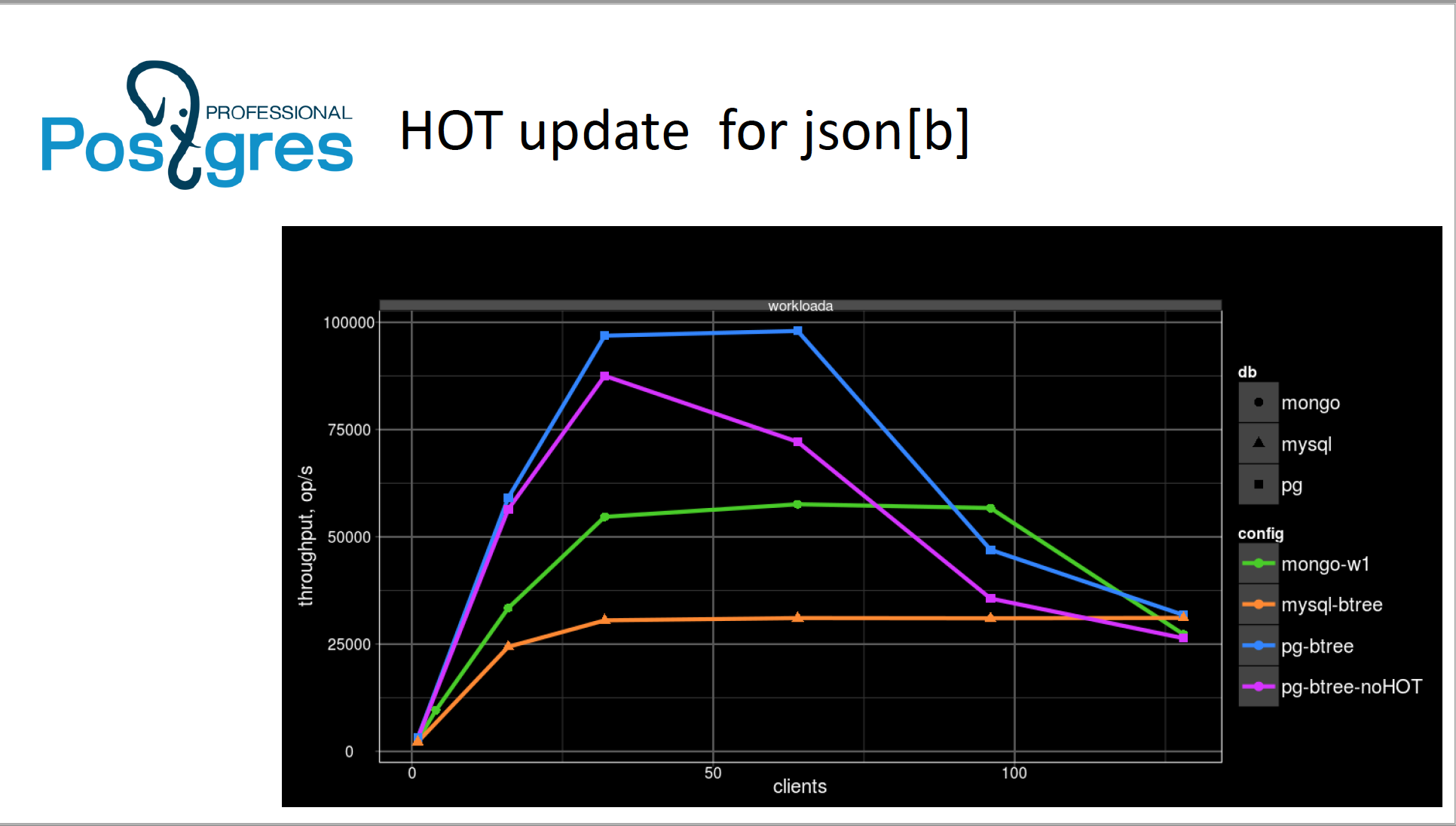{kind=link}
On 09/28/2017 10:10 PM, Robert Haas wrote: > On Wed, Sep 13, 2017 at 7:00 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> If we do have an option it won't be using fancy mathematical >> terminology at all, it would be described in terms of its function, >> e.g. recheck_on_update > +1. I have nothing against renaming "projection" option to "recheck_on_update" or whatever else is suggested. Just let me know the best version. From my point of view "recheck_on_update" is too verbose and still not self-explained(to understand the meaning of this option it is necessary to uunderstand how heap_update works). "projection"/"non-injective"/...are more declarative notions, explaining the characteristic of the index, while "recheck_on_update" is more procedural notion,explaining behavior of heap_update. > >> Yes, I'd rather not have an option at all, just some simple code with >> useful effect, like we have in many other places. > I think the question we need to be able to answer is: What is the > probability that an update that would otherwise be non-HOT can be made > into a HOT update by performing a recheck to see whether the value has > changed? It doesn't seem easy to figure that out from any of the > statistics we have available today or could easily get, because it > depends not only on the behavior of the expression which appears in > the index definition but also on the application behavior. For > example, consider a JSON blob representing a bank account. > b->'balance' is likely to change most of the time, but > b->'account_holder_name' only rarely. That's going to be hard for an > automated system to determine. > > We should clearly check as many of the other criteria for a HOT update > as possible before performing a recheck of this type, so that it only > gets performed when it might help. For example, if column a is > indexed and b->'foo' is indexed, there's no point in checking whether > b->'foo' has changed if we know that a has changed. I don't know > whether it would be feasible to postpone deciding whether to do a > recheck until after we've figured out whether the page seems to > contain enough free space to allow a HOT update. > > Turning non-HOT updates into HOT updates is really good, so it seems > likely that the rechecks will often be worthwhile. If we avoid a HOT > update in 25% of cases, that's probably easily worth the CPU overhead > of a recheck assuming the function isn't something ridiculously > expensive to compute; the extra CPU cost will be repaid by reduced > bloat. However, if we avoid a HOT update only one time in a million, > it's probably not worth the cost of recomputing the expression the > other 999,999 times. I wonder where the crossover point is -- it > seems like something that could be figured out by benchmarking. > > While I agree that it would be nice to have this be a completely > automatic determination, I am not sure that will be practical. I > oppose overloading some other marker (like function_cost>10000) for > this; that's too magical. > I almost agree with you. Just few remarks: indexes are rarely created for frequently changed attributes, like b->'balance'. So in case of proper database schema design it is possible to expect that most of updates are hot updates: do not actuallyaffect any index. But certainly different attributes may have different probability of been updated. Unfortunately we do not know before check which attribute of JSON field (or any other fields used in indexed expression)is changed. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Sep 27, 2017 at 4:07 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 15 September 2017 at 16:34, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: > >> Attached please find yet another version of the patch. > > Thanks. I'm reviewing it. Two months later, this patch is still waiting for a review (you are listed as well as a reviewer of this patch). The documentation of the patch has conflicts, please provide a rebased version. I am moving this patch to next CF with waiting on author as status. -- Michael
On 30.11.2017 05:02, Michael Paquier wrote: > On Wed, Sep 27, 2017 at 4:07 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On 15 September 2017 at 16:34, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >> >>> Attached please find yet another version of the patch. >> Thanks. I'm reviewing it. > Two months later, this patch is still waiting for a review (you are > listed as well as a reviewer of this patch). The documentation of the > patch has conflicts, please provide a rebased version. I am moving > this patch to next CF with waiting on author as status. Attached please find new patch with resolved documentation conflict. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On 4 December 2017 at 15:35, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > On 30.11.2017 05:02, Michael Paquier wrote: >> >> On Wed, Sep 27, 2017 at 4:07 PM, Simon Riggs <simon@2ndquadrant.com> >> wrote: >>> >>> On 15 September 2017 at 16:34, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >>> >>>> Attached please find yet another version of the patch. >>> >>> Thanks. I'm reviewing it. >> >> Two months later, this patch is still waiting for a review (you are >> listed as well as a reviewer of this patch). The documentation of the >> patch has conflicts, please provide a rebased version. I am moving >> this patch to next CF with waiting on author as status. > > Attached please find new patch with resolved documentation conflict. I’ve not posted a review because it was my hope that I could fix up the problems with this clever and useful patch and just commit it. I spent 2 days trying to do that but some problems remain and I’ve run out of time. Patch 3 has got some additional features that on balance I don’t think we need. Patch 1 didn’t actually work which was confusing when I tried to go back to that. Patch 3 Issues * Auto tuning added 2 extra items to Stats for each relation. That is too high a price to pay, so we should remove that. If we can’t do autotuning without that, please remove it. * Patch needs a proper test case added. We shouldn’t just have a DEBUG1 statement in there for testing - very ugly. Please rewrite tests using functions that show how many changes have occurred during the current statement/transaction. * Parameter coding was specific to that section of code. We need a capability to parse that parameter from other locations, just as we do with all other reloptions. It looks like it was coded that way because of difficulties with code placement. Please solve this with generic code, not just code that solves only the current issue. I’d personally be happier without any option at all, but if y’all want it, then please add the code in the right place. * The new coding for heap_update() uses the phrase “warm”, which is already taken by another patch. Please avoid confusing things by re-using the same term for different things. The use of these technical terms like projection and surjective doesn’t seem to add anything useful to the patch * Rename parameter to recheck_on_update * Remove random whitespace changes in the patch So at this stage the concept is good and works, but the patch is only just at the prototype stage and nowhere near committable. I hope you can correct these issues and if you do I will be happy to review and perhaps commit. Thanks -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thank you for review. On 13.12.2017 14:29, Simon Riggs wrote: > On 4 December 2017 at 15:35, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 30.11.2017 05:02, Michael Paquier wrote: >>> On Wed, Sep 27, 2017 at 4:07 PM, Simon Riggs <simon@2ndquadrant.com> >>> wrote: >>>> On 15 September 2017 at 16:34, Konstantin Knizhnik >>>> <k.knizhnik@postgrespro.ru> wrote: >>>> >>>>> Attached please find yet another version of the patch. >>>> Thanks. I'm reviewing it. >>> Two months later, this patch is still waiting for a review (you are >>> listed as well as a reviewer of this patch). The documentation of the >>> patch has conflicts, please provide a rebased version. I am moving >>> this patch to next CF with waiting on author as status. >> Attached please find new patch with resolved documentation conflict. > I’ve not posted a review because it was my hope that I could fix up > the problems with this clever and useful patch and just commit it. I > spent 2 days trying to do that but some problems remain and I’ve run > out of time. > > Patch 3 has got some additional features that on balance I don’t think > we need. Patch 1 didn’t actually work which was confusing when I tried > to go back to that. > > Patch 3 Issues > > * Auto tuning added 2 extra items to Stats for each relation. That is > too high a price to pay, so we should remove that. If we can’t do > autotuning without that, please remove it. Right now size of this structure is 168 bytes. Adding two extra fields increase it to 184 bytes - 9%. Is it really so critical? What is the typical/maximal number of relation in a database? I can not believe that there can be more than thousand non-temporary relations in any database. Certainly application can generate arbitrary number of temporary tables. But millions of such tables cause catalog bloating and will have awful impact on performance in any case. And for any reasonable number of relations (< million), extra memory used by this statistic is negligible. Also I think that these two fields can be useful not only for projection indexes. It can be also used by DBA and optimizer because them more precisely explain relation update pattern. I really love you idea with autotune and it will be pity to reject it just because of extra 16 bytes per relation. > * Patch needs a proper test case added. We shouldn’t just have a > DEBUG1 statement in there for testing - very ugly. Please rewrite > tests using functions that show how many changes have occurred during > the current statement/transaction. > > * Parameter coding was specific to that section of code. We need a > capability to parse that parameter from other locations, just as we do > with all other reloptions. It looks like it was coded that way because > of difficulties with code placement. Please solve this with generic > code, not just code that solves only the current issue. I’d personally > be happier without any option at all, but if y’all want it, then > please add the code in the right place. Sorry, I do not completely understand what you mean by "parameter coding". Do you mean IsProjectionFunctionalIndex function and filling relation options in it? It is the only reported issue which I do not understand how to fix. > * The new coding for heap_update() uses the phrase “warm”, which is > already taken by another patch. Please avoid confusing things by > re-using the same term for different things. > The use of these technical terms like projection and surjective > doesn’t seem to add anything useful to the patch > > * Rename parameter to recheck_on_update > > * Remove random whitespace changes in the patch > > So at this stage the concept is good and works, but the patch is only > just at the prototype stage and nowhere near committable. I hope you > can correct these issues and if you do I will be happy to review and > perhaps commit. Thank you once again for your efforts in improving this patch. I will fix all reported issues. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 13.12.2017 14:29, Simon Riggs wrote: > On 4 December 2017 at 15:35, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 30.11.2017 05:02, Michael Paquier wrote: >>> On Wed, Sep 27, 2017 at 4:07 PM, Simon Riggs <simon@2ndquadrant.com> >>> wrote: >>>> On 15 September 2017 at 16:34, Konstantin Knizhnik >>>> <k.knizhnik@postgrespro.ru> wrote: >>>> >>>>> Attached please find yet another version of the patch. >>>> Thanks. I'm reviewing it. >>> Two months later, this patch is still waiting for a review (you are >>> listed as well as a reviewer of this patch). The documentation of the >>> patch has conflicts, please provide a rebased version. I am moving >>> this patch to next CF with waiting on author as status. >> Attached please find new patch with resolved documentation conflict. > I’ve not posted a review because it was my hope that I could fix up > the problems with this clever and useful patch and just commit it. I > spent 2 days trying to do that but some problems remain and I’ve run > out of time. > > Patch 3 has got some additional features that on balance I don’t think > we need. Patch 1 didn’t actually work which was confusing when I tried > to go back to that. > > Patch 3 Issues > > * Auto tuning added 2 extra items to Stats for each relation. That is > too high a price to pay, so we should remove that. If we can’t do > autotuning without that, please remove it. > > * Patch needs a proper test case added. We shouldn’t just have a > DEBUG1 statement in there for testing - very ugly. Please rewrite > tests using functions that show how many changes have occurred during > the current statement/transaction. > > * Parameter coding was specific to that section of code. We need a > capability to parse that parameter from other locations, just as we do > with all other reloptions. It looks like it was coded that way because > of difficulties with code placement. Please solve this with generic > code, not just code that solves only the current issue. I’d personally > be happier without any option at all, but if y’all want it, then > please add the code in the right place. > > * The new coding for heap_update() uses the phrase “warm”, which is > already taken by another patch. Please avoid confusing things by > re-using the same term for different things. > The use of these technical terms like projection and surjective > doesn’t seem to add anything useful to the patch > > * Rename parameter to recheck_on_update > > * Remove random whitespace changes in the patch > > So at this stage the concept is good and works, but the patch is only > just at the prototype stage and nowhere near committable. I hope you > can correct these issues and if you do I will be happy to review and > perhaps commit. > > Thanks > Attached please find new patch which fix all the reported issues except disabling autotune. If you still thing that additional 16 bytes per relation in statistic is too high overhead, then I will also remove autotune. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On Wed, Dec 13, 2017 at 12:32 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > I can not believe that there can be more than thousand non-temporary > relations in any database. I ran across a cluster with more than 5 million non-temporary relations just this week. That's extreme, but having more than a thousand non-temporary tables is not particularly uncommon. I would guess that the percentage of EnterpriseDB's customers who have more than a thousand non-temporary tables in a database is in the double digits. That number is only going to go up as our partitioning capabilities improve. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Konstantin Knizhnik wrote: > If you still thing that additional 16 bytes per relation in statistic is too > high overhead, then I will also remove autotune. I think it's pretty clear that these additional bytes are excessive. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Dec 15, 2017 at 6:15 AM, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > Konstantin Knizhnik wrote: >> If you still thing that additional 16 bytes per relation in statistic is too >> high overhead, then I will also remove autotune. > > I think it's pretty clear that these additional bytes are excessive. The bar to add new fields in PgStat_TableCounts in very high, and one attempt to tackle its scaling problems with many relations is here by Horiguchi-san: https://www.postgresql.org/message-id/20171211.201523.24172046.horiguchi.kyotaro@lab.ntt.co.jp His patch may be worth a look if you need more fields for your feature. So it seems to me that the patch as currently presented has close to zero chance to be committed as long as you keep your changes to pgstat.c. -- Michael
On 15.12.2017 01:21, Michael Paquier wrote: > On Fri, Dec 15, 2017 at 6:15 AM, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: >> Konstantin Knizhnik wrote: >>> If you still thing that additional 16 bytes per relation in statistic is too >>> high overhead, then I will also remove autotune. >> I think it's pretty clear that these additional bytes are excessive. > The bar to add new fields in PgStat_TableCounts in very high, and one > attempt to tackle its scaling problems with many relations is here by > Horiguchi-san: > https://www.postgresql.org/message-id/20171211.201523.24172046.horiguchi.kyotaro@lab.ntt.co.jp > His patch may be worth a look if you need more fields for your > feature. So it seems to me that the patch as currently presented has > close to zero chance to be committed as long as you keep your changes > to pgstat.c. Ok, looks like everybody think that autotune based on statistic is bad idea. Attached please find patch without autotune. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
Greetings, * Konstantin Knizhnik (k.knizhnik@postgrespro.ru) wrote: > On 15.12.2017 01:21, Michael Paquier wrote: > >On Fri, Dec 15, 2017 at 6:15 AM, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > >>Konstantin Knizhnik wrote: > >>>If you still thing that additional 16 bytes per relation in statistic is too > >>>high overhead, then I will also remove autotune. > >>I think it's pretty clear that these additional bytes are excessive. > >The bar to add new fields in PgStat_TableCounts in very high, and one > >attempt to tackle its scaling problems with many relations is here by > >Horiguchi-san: > >https://www.postgresql.org/message-id/20171211.201523.24172046.horiguchi.kyotaro@lab.ntt.co.jp > >His patch may be worth a look if you need more fields for your > >feature. So it seems to me that the patch as currently presented has > >close to zero chance to be committed as long as you keep your changes > >to pgstat.c. > > Ok, looks like everybody think that autotune based on statistic is bad idea. > Attached please find patch without autotune. This patch appears to apply with a reasonable amount of fuzz, builds, and passes 'make check', at least, therefore I'm going to mark it 'Needs Review'. I will note that the documentation doesn't currently build due to this: /home/sfrost/git/pg/dev/cleanup/doc/src/sgml/ref/create_index.sgml:302: parser error : Opening and ending tag mismatch: literalline 302 and unparseable <term><literal>recheck_on_update</></term> but I don't think it makes sense for that to stand in the way of someone doing a review of the base patch. Still, please do fix the documentation build when you get a chance. Thanks! Stephen
Вложения
On 07.01.2018 01:59, Stephen Frost wrote: > Greetings, > > * Konstantin Knizhnik (k.knizhnik@postgrespro.ru) wrote: >> On 15.12.2017 01:21, Michael Paquier wrote: >>> On Fri, Dec 15, 2017 at 6:15 AM, Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: >>>> Konstantin Knizhnik wrote: >>>>> If you still thing that additional 16 bytes per relation in statistic is too >>>>> high overhead, then I will also remove autotune. >>>> I think it's pretty clear that these additional bytes are excessive. >>> The bar to add new fields in PgStat_TableCounts in very high, and one >>> attempt to tackle its scaling problems with many relations is here by >>> Horiguchi-san: >>> https://www.postgresql.org/message-id/20171211.201523.24172046.horiguchi.kyotaro@lab.ntt.co.jp >>> His patch may be worth a look if you need more fields for your >>> feature. So it seems to me that the patch as currently presented has >>> close to zero chance to be committed as long as you keep your changes >>> to pgstat.c. >> Ok, looks like everybody think that autotune based on statistic is bad idea. >> Attached please find patch without autotune. > This patch appears to apply with a reasonable amount of fuzz, builds, > and passes 'make check', at least, therefore I'm going to mark it > 'Needs Review'. > > I will note that the documentation doesn't currently build due to this: > > /home/sfrost/git/pg/dev/cleanup/doc/src/sgml/ref/create_index.sgml:302: parser error : Opening and ending tag mismatch:literal line 302 and unparseable > <term><literal>recheck_on_update</></term> > > but I don't think it makes sense for that to stand in the way of someone > doing a review of the base patch. Still, please do fix the > documentation build when you get a chance. > > Thanks! > > Stephen Sorry, issue with documentation is fixed. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On 10 January 2018 at 09:54, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
> Sorry, issue with documentation is fixed.
OK, thanks.
Patch appears to work cleanly now.
I'm wondering now about automatically inferring "recheck_on_update =
true" for certain common datatype/operators. It doesn't need to be an
exhaustive list, but it would be useful if we detected the main use
case of
(JSONB datatype column)->>CONSTANT
Seems like we could do a test to see if the index function is
FUNCTION(COLUMNNAME, CONSTANTs...)
{JSONB, ->>} or
{jsonb_object_field_text(Columnname, Constant)}
{substring(Columname, Constants...)}
It would be a shame if people had to remember to use this for the
common and obvious cases.
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 18.01.2018 11:38, Simon Riggs wrote:
> On 10 January 2018 at 09:54, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>
>> Sorry, issue with documentation is fixed.
> OK, thanks.
>
> Patch appears to work cleanly now.
>
> I'm wondering now about automatically inferring "recheck_on_update =
> true" for certain common datatype/operators. It doesn't need to be an
> exhaustive list, but it would be useful if we detected the main use
> case of
>
> (JSONB datatype column)->>CONSTANT
>
> Seems like we could do a test to see if the index function is
> FUNCTION(COLUMNNAME, CONSTANTs...)
> {JSONB, ->>} or
> {jsonb_object_field_text(Columnname, Constant)}
> {substring(Columname, Constants...)}
>
> It would be a shame if people had to remember to use this for the
> common and obvious cases.
>
Right now by default index is considered as projective. So even if you
do not specify "recheck_on_update" option, then recheck will be done.
This decision is based on the assumption that most of functional indexes
are actually projective and looks likes (JSONB datatype column)->>CONSTANT.
So do you think that this assumption is not correct and we should switch
disable recheck_on_update by default?
If not, then there is an opposite challenge: find out class of functions
which definitely are not projective and recheck on them will have no sense.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 18 January 2018 at 08:59, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
>
>
> On 18.01.2018 11:38, Simon Riggs wrote:
>>
>> On 10 January 2018 at 09:54, Konstantin Knizhnik
>> <k.knizhnik@postgrespro.ru> wrote:
>>
>>> Sorry, issue with documentation is fixed.
>>
>> OK, thanks.
>>
>> Patch appears to work cleanly now.
>>
>> I'm wondering now about automatically inferring "recheck_on_update =
>> true" for certain common datatype/operators. It doesn't need to be an
>> exhaustive list, but it would be useful if we detected the main use
>> case of
>>
>> (JSONB datatype column)->>CONSTANT
>>
>> Seems like we could do a test to see if the index function is
>> FUNCTION(COLUMNNAME, CONSTANTs...)
>> {JSONB, ->>} or
>> {jsonb_object_field_text(Columnname, Constant)}
>> {substring(Columname, Constants...)}
>>
>> It would be a shame if people had to remember to use this for the
>> common and obvious cases.
>>
> Right now by default index is considered as projective. So even if you do
> not specify "recheck_on_update" option, then recheck will be done.
That's good
> This decision is based on the assumption that most of functional indexes are
> actually projective and looks likes (JSONB datatype column)->>CONSTANT.
> So do you think that this assumption is not correct and we should switch
> disable recheck_on_update by default?
No thanks
> If not, then there is an opposite challenge: find out class of functions
> which definitely are not projective and recheck on them will have no sense.
If there are some.
Projective is not quite correct, since sin((col->>'angle')::numeric))
could stay same but the result is not a subset of the input.
I think it would be better to avoid the use of mathematical terms and
keep the description simple
"If the indexed value depends upon only a subset of the data, it is
possible that the function value will remain constant after an UPDATE
that changes the non-indexed data.
e.g.
If a column is updated from '/some/url/before' to '/some/url/after'
then the value of substing(col, 1, 5) will not change when updated
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 10 January 2018 at 09:54, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > (new version attached) Why this comment? Current implementation of projection optimization has to calculate index expression twice in case of hit (value of index expression is not changed) and three times if values are different. Old + New for check = 2 plus calculate again in index = 3 ? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 01.02.2018 03:10, Simon Riggs wrote: > On 10 January 2018 at 09:54, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: > >> (new version attached) > Why this comment? > > Current implementation of projection optimization has to calculate > index expression twice > in case of hit (value of index expression is not changed) and three > times if values are different. > > Old + New for check = 2 > plus calculate again in index = 3 > ? > Sorry, I do not completely understand your question. You do not agree with this statement or you think that this comment is irrelevant in this place? Or you just want to understand why index expression is calculated 2/3 times? If so, then you have answered this question yourself: > Old + New for check = 2 > plus calculate again in index = 3 Yes, we have to calculate the value of index expression for original and updated version of the record. If them are equal, then it is all we have to do with this index: hot update is applicable. In this case we calculate index expression twice. But if them are not equal, then hot update is not applicable and we have to update index. In this case expression will be calculated one more time. So totally three times. This is why, if calculation of index expression is very expensive, then effect of this optimization may be negative even if value of index expression is not changed. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 1 February 2018 at 08:49, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 01.02.2018 03:10, Simon Riggs wrote: >> >> On 10 January 2018 at 09:54, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >> >>> (new version attached) >> >> Why this comment? >> >> Current implementation of projection optimization has to calculate >> index expression twice >> in case of hit (value of index expression is not changed) and three >> times if values are different. >> >> Old + New for check = 2 >> plus calculate again in index = 3 >> ? >> > Sorry, I do not completely understand your question. > You do not agree with this statement or you think that this comment is > irrelevant in this place? > Or you just want to understand why index expression is calculated 2/3 times? > If so, then you have answered this question yourself: >> >> Old + New for check = 2 >> plus calculate again in index = 3 > > > Yes, we have to calculate the value of index expression for original and > updated version of the record. If them are equal, then it is all we have to > do with this index: hot update is applicable. > In this case we calculate index expression twice. > But if them are not equal, then hot update is not applicable and we have to > update index. In this case expression will be calculated one more time. So > totally three times. > This is why, if calculation of index expression is very expensive, then > effect of this optimization may be negative even if value of index > expression is not changed. OK, thanks. Just checking my understanding and will add to the comments in the patch. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 1 February 2018 at 09:32, Simon Riggs <simon@2ndquadrant.com> wrote: > OK, thanks. Just checking my understanding and will add to the > comments in the patch. I'm feeling good about ths now, but for personal reasons won't be committing this until late Feb/early March. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, I still don't think, as commented upon by Tom and me upthread, that we want this feature in the current form. Your arguments about layering violations seem to be counteracted by the fact that ProjectionIsNotChanged() basically appears to do purely executor work inside inside heapam.c. Greetings, Andres Freund
On 01.03.2018 22:48, Andres Freund wrote: > Hi, > > I still don't think, as commented upon by Tom and me upthread, that we > want this feature in the current form. > > Your arguments about layering violations seem to be counteracted by the > fact that ProjectionIsNotChanged() basically appears to do purely > executor work inside inside heapam.c. ProjectionIsNotChanged doesn't perform evaluation itslef, is calls FormIndexDatum. FormIndexDatum is also called in 13 other places in Postgres: analyze.c, constraint.c, index.c, tuplesort, execIndexing.c I still think that trying to store somewhere result odf index expression evaluation to be able to reuse in index update isnot so good idea: it complicates code and add extra dependencies between different modules. And benefits of such optimization are not obvious: is index expression evaluation is so expensive, then recheck_on_updateshould be prohibited for such index at all. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Please excuse my absence from this thread. On 2 March 2018 at 12:34, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 01.03.2018 22:48, Andres Freund wrote: >> >> Hi, >> >> I still don't think, as commented upon by Tom and me upthread, that we >> want this feature in the current form. The performance benefit of this patch is compelling. I don't see a comment from Tom along those lines, just a queston as to whether the code is in the right place. >> Your arguments about layering violations seem to be counteracted by the >> fact that ProjectionIsNotChanged() basically appears to do purely >> executor work inside inside heapam.c. > > > ProjectionIsNotChanged doesn't perform evaluation itslef, is calls > FormIndexDatum. > FormIndexDatum is also called in 13 other places in Postgres: > analyze.c, constraint.c, index.c, tuplesort, execIndexing.c > > I still think that trying to store somewhere result odf index expression > evaluation to be able to reuse in index update is not so good idea: > it complicates code and add extra dependencies between different modules. > And benefits of such optimization are not obvious: is index expression > evaluation is so expensive, then recheck_on_update should be prohibited for > such index at all. Agreed. What we are doing is trying to avoid HOT updates. We make the check for HOT update dynamically when it could be made statically in some cases. Simplicity says just test it dynamically. We could also do work to check for HOT update for functional indexes earlier but for the same reason, I don't think its worth adding. The patch itself is about as simple as it can be, so the code is in the right place. My problems with it have been around the actual user interface to request it. Index option handling has changed (and this needs rebase!), but other than that I think we want this and am planning to commit something early next week. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The rd_projidx (list of each nth element in the index list that is a projection index) thing looks odd. Wouldn't it make more sense to have a list of index OIDs that are projection indexes? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The whole IsProjectionFunctionalIndex looks kinda bogus/ugly to me. Set the boolean to false, but keep evaluating anyway? But then, I thought the idea was to do this based on the reloption, not by comparing the expression cost to a magical (unmodifiable) value? In RelationGetIndexAttrBitmap(), indexattrs no longer gets the columns corresponding to projection indexes. Isn't that weird/error prone/confusing? I think it'd be saner to add these bits to both bitmaps. Please update the comments ending in heapam.c:4188, and generally all comments that you should update. Please keep serial_schedule in sync with parallel_schedule. Also, pgindent. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 22.03.2018 23:37, Alvaro Herrera wrote: > The rd_projidx (list of each nth element in the index list that is a > projection index) thing looks odd. Wouldn't it make more sense to have > a list of index OIDs that are projection indexes? > rd_projidx is not a list, it is Bitmapset. It is just one of many bitmap sets in RelationData: Bitmapset *rd_indexattr; /* identifies columns used in indexes */ Bitmapset *rd_keyattr; /* cols that can be ref'd by foreign keys */ Bitmapset *rd_pkattr; /* cols included in primary key */ Bitmapset *rd_idattr; /* included in replica identity index */ Yes, it is possible to construct Oid list of projectional indexes instead of having bitmap which marks some indexes in projectional, but I am not sure that it will be more efficient both from CPU and memory footprint point of view (in most indexes bitmap will consists of just one integer). In any case, I do not think that it can have some measurable impact on performance or memory size: number of indexes and especially projectional indexes will very rarely exceed 10. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Konstantin Knizhnik wrote: > rd_projidx is not a list, it is Bitmapset. It is just one of many bitmap > sets in RelationData: Yes, but the other bitmapsets are of AttrNumber of the involved column. They new one is of list_nth() counters for items in the index list. That seems weird and it scares me -- do we use that coding pattern elsewhere? Maybe use an array of OIDs instead? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 23 March 2018 at 15:39, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 22.03.2018 23:37, Alvaro Herrera wrote: >> >> The rd_projidx (list of each nth element in the index list that is a >> projection index) thing looks odd. Wouldn't it make more sense to have >> a list of index OIDs that are projection indexes? >> > > rd_projidx is not a list, it is Bitmapset. It is just one of many bitmap > sets in RelationData: > > Bitmapset *rd_indexattr; /* identifies columns used in indexes */ > Bitmapset *rd_keyattr; /* cols that can be ref'd by foreign keys > */ > Bitmapset *rd_pkattr; /* cols included in primary key */ > Bitmapset *rd_idattr; /* included in replica identity index */ > > Yes, it is possible to construct Oid list of projectional indexes instead of > having bitmap which marks some indexes in projectional, but I am not sure > that > it will be more efficient both from CPU and memory footprint point of view > (in most indexes bitmap will consists of just one integer). In any case, I > do not think that it can have some measurable impact on performance or > memory size: > number of indexes and especially projectional indexes will very rarely > exceed 10. Alvaro's comment seems reasonable to me. The patch adds both rd_projindexattr and rd_projidx rd_projindexattr should be a Bitmapset, but rd_projidx looks strange now he mentions it. Above that in RelationData we have other structures that are List of OIDs, so Alvaro's proposal make sense. That would simplify the code in ProjectionIsNotChanged() by just looping over the list of projection indexes rather than the list of indexes So please could you make the change? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 22.03.2018 23:53, Alvaro Herrera wrote: > The whole IsProjectionFunctionalIndex looks kinda bogus/ugly to me. Set > the boolean to false, but keep evaluating anyway? But then, I thought > the idea was to do this based on the reloption, not by comparing the > expression cost to a magical (unmodifiable) value? The idea is very simple, I tried to explain it in the comments. Sorry if my explanation was not so clear. By default we assume all functional indexes as projectional. This is done by first assignment is_projection = true. Then we check cost of index function. I agree that "magical (unmodifiable) value" used as cost threshold is not a good idea. But I tried to avoid as much as possible adding yet another configuration parameter. I do no think that flexibility here is so important. I believe that in 99% cases functional indexes are projectional, and in all other cases DBA cna explicitly specify it using recheck_on_update index option. Which should override cost threshold: if DBA thinks that recheck is useful for this index, then it should be used despite to previsions guess based on index expression cost. This is why after setting "is_projection" to false because of too large cost of index expression, we continue work and check index options for explicitly specified value. > > In RelationGetIndexAttrBitmap(), indexattrs no longer gets the columns > corresponding to projection indexes. Isn't that weird/error > prone/confusing? I think it'd be saner to add these bits to both > bitmaps. This bitmap is needed only to mark attributes, which modification prevents hot update. Should I rename rd_indexattr to rd_hotindexattr or whatever else to avoid confusion? Please notice, that rd_indexattr is used only inside RelationGetIndexAttrBitmap and is not visible from outside. It is returned for INDEX_ATTR_BITMAP_HOT IndexAttrBitmapKind. > Please update the comments ending in heapam.c:4188, and generally all > comments that you should update. Sorry, did you apply projection-7.patch? I have checked all trailing spaces and other indentation issues. At least there is no trailing space at heapam.c:4188... > > Please keep serial_schedule in sync with parallel_schedule. Sorry, once again do not understand your complaint: I have added func_index both to serial and parallel schedule. > Also, pgindent. > -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 23.03.2018 18:45, Alvaro Herrera wrote: > Konstantin Knizhnik wrote: > >> rd_projidx is not a list, it is Bitmapset. It is just one of many bitmap >> sets in RelationData: > Yes, but the other bitmapsets are of AttrNumber of the involved column. > They new one is of list_nth() counters for items in the index list. > That seems weird and it scares me -- do we use that coding pattern > elsewhere? Maybe use an array of OIDs instead? > Using list or array instead of bitmap requires much more space... And bitmaps are much more efficient for many operations: check for element presence, combine, intersect,... Check in bitmap has O(0) complexity so iterating through list of all indexes or attributes with bitmap check doesn't add any essential overhead. Sorry, I do not understand this: "They new one is of list_nth() counters for items in the index list" -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 23 March 2018 at 15:54, Simon Riggs <simon@2ndquadrant.com> wrote: > So please could you make the change? Committed, but I still think that change would be good. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 27.03.2018 22:08, Simon Riggs wrote: > On 23 March 2018 at 15:54, Simon Riggs <simon@2ndquadrant.com> wrote: > >> So please could you make the change? > Committed, but I still think that change would be good. > Thank you. But I still not sure whether replacement of bitmap with List or array of Oids is really good idea. There are two aspects: size and speed. It seems to me that memory overhead is most important. At least you rejected your own idea about using autotune for this parameters because of presence of extra 16 bytes in statistic. But RelationData structure is even more space critical: its size is multiplied by number of relations and backends. Bitmap seems to provide the most compact representation of the projective index list. Concerning speed aspect, certainly iteration through the list of all indexes with checking presence of index in the bitmap is more expensive than just direct iteration through Oid list or array. But since check of bitmap can be done in constant time, both approaches have the same complexity. Also for typical case (< 5 normal indexes for a table and 1-2 functional indexes) difference in performance can not be measured. Also bitmap provides convenient interface for adding new members. To construct array of Oids I need first to determine number of indexes, so I have to perform two loops. So if you and Alvaro insist on this change, then I will definitely do it. But from my point of view, using bitmap here is acceptable solution. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Mar 1, 2018 at 2:48 PM, Andres Freund <andres@anarazel.de> wrote: > I still don't think, as commented upon by Tom and me upthread, that we > want this feature in the current form. Was this concern ever addressed, or did the patch just get committed anyway? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2018-05-10 23:25:58 -0400, Robert Haas wrote: > On Thu, Mar 1, 2018 at 2:48 PM, Andres Freund <andres@anarazel.de> wrote: > > I still don't think, as commented upon by Tom and me upthread, that we > > want this feature in the current form. > > Was this concern ever addressed, or did the patch just get committed anyway? No. Simon just claimed it's not actually a concern: https://www.postgresql.org/message-id/CANP8+j+vtskPhEp_GmqmEqdWaKSt2KbOtee0yz-my+Agh0aRPw@mail.gmail.com And yes, it got committed without doing squat to address the architectural concerns. Greetings, Andres Freund
On Thursday, February 1, 2018, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
Old + New for check = 2
plus calculate again in index = 3
Yes, we have to calculate the value of index expression for original and updated version of the record. If them are equal, then it is all we have to do with this index: hot update is applicable.
In this case we calculate index expression twice.
But if them are not equal, then hot update is not applicable and we have to update index. In this case expression will be calculated one more time. So totally three times.
This is why, if calculation of index expression is very expensive, then effect of this optimization may be negative even if value of index expression is not changed.
For the old/new comparison and the re-calculate if changed dynamics - is this a side effect of separation of concerns only or is there some other reason the old computed value already stored in the index isn't compared to the one and only function result of the new tuple which, if found to be different, is then stored. One function invocation, which has to happen anyway, and one extra equality check. Seems like this could be used for non-functional indexes too, so that mere presence in the update listing doesn't negate HOT if the column didn't actually change (if I'm not mis-remembering something here anyway...)
Also, create index page doc typo from site: "with an total" s/b "with a total" (expression cost less than 1000) - maybe add a comma for 1,000
David J.
On 11.05.2018 07:48, David G. Johnston wrote:
On Thursday, February 1, 2018, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:Old + New for check = 2
plus calculate again in index = 3
Yes, we have to calculate the value of index expression for original and updated version of the record. If them are equal, then it is all we have to do with this index: hot update is applicable.
In this case we calculate index expression twice.
But if them are not equal, then hot update is not applicable and we have to update index. In this case expression will be calculated one more time. So totally three times.
This is why, if calculation of index expression is very expensive, then effect of this optimization may be negative even if value of index expression is not changed.For the old/new comparison and the re-calculate if changed dynamics - is this a side effect of separation of concerns only or is there some other reason the old computed value already stored in the index isn't compared to the one and only function result of the new tuple which, if found to be different, is then stored. One function invocation, which has to happen anyway, and one extra equality check. Seems like this could be used for non-functional indexes too, so that mere presence in the update listing doesn't negate HOT if the column didn't actually change (if I'm not mis-remembering something here anyway...)Also, create index page doc typo from site: "with an total" s/b "with a total" (expression cost less than 1000) - maybe add a comma for 1,000David J.
Sorry, may be I do not completely understand you.
So whats happed before this patch:
- On update postgres compares old and new values of all changed attributes to determine whether them are actually changed.
- If value of some indexed attribute is changed, then hot update is not applicable and we have to rebuild indexed.
- Otherwise hot update is used and indexes should not be updated.
What is changed:
- When some of attributes, on which functional index depends, is changed, then we calculate value of index expression. It is done using existed FormIndexDatum function which stores calculated expression value in the provided slot. This evaluation of index expressions and their comparison is done in access/heap/heapam.c file.
- Only if old and new values of index expression are different, then hot update is really not applicable.
- In this case we have to rebuild indexes. It is done by ExecInsertIndexTuples in executor/execIndexing.c which calls FormIndexDatum once again to calculate index expression.
So in principle, it is certainly possible to store value of index expression calculated in ProjIndexIsUnchanged and reuse it ExecInsertIndexTuples.
But I do not know right place (context) where this value can be stored.
And also it will add some dependency between heapam and execIndexing modules. Also it is necessary to take in account that ProjIndexIsUnchanged is not always called. So index expression value may be not present.
Finally, most of practically used index expressions are not expensive. It is usually something like extraction of JSON component. Cost of execution of this function is much smaller than cost of extracting and unpacking toasted JSON value. So I do not think that such optimization will be really useful, while it is obvious that it significantly complicate code.
Also please notice that FormIndexDatum is used in some other places:
utils/adt/selfuncs.c
utils/sort/tuplesort.c
mmands/constraint.c
So this patch just adds two more calls of this function.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 11 May 2018 at 05:32, Andres Freund <andres@anarazel.de> wrote: > On 2018-05-10 23:25:58 -0400, Robert Haas wrote: >> On Thu, Mar 1, 2018 at 2:48 PM, Andres Freund <andres@anarazel.de> wrote: >> > I still don't think, as commented upon by Tom and me upthread, that we >> > want this feature in the current form. >> >> Was this concern ever addressed, or did the patch just get committed anyway? > > No. Simon just claimed it's not actually a concern: > https://www.postgresql.org/message-id/CANP8+j+vtskPhEp_GmqmEqdWaKSt2KbOtee0yz-my+Agh0aRPw@mail.gmail.com > > And yes, it got committed without doing squat to address the > architectural concerns. "Squat" means "zero, nothing" to me. So that comment would be inaccurate. I've spent a fair amount of time reviewing and grooming the patch, and I am happy that Konstantin has changed his patch significantly in response to those reviews, as well as explaining why the patch is fine as it is. It's a useful patch that PostgreSQL needs, so all good. I have no problem if you want to replace this with an even better design in a later release. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Sorry, may be I do not completely understand you.
So whats happed before this patch:
- On update postgres compares old and new values of all changed attributes to determine whether them are actually changed.
- If value of some indexed attribute is changed, then hot update is not applicable and we have to rebuild indexed.
- Otherwise hot update is used and indexes should not be updated.
What is changed:
- When some of attributes, on which functional index depends, is changed, then we calculate value of index expression. It is done using existed FormIndexDatum function which stores calculated expression value in the provided slot. This evaluation of index expressions and their comparison is done in access/heap/heapam.c file.
- Only if old and new values of index expression are different, then hot update is really not applicable.
Thanks.
So, in my version of layman's terms, before this patch we treated simple column referenced indexes and expression indexes differently because in a functional index we didn't actually compare the expression results, only the original values of the depended-on columns. With this patch both are treated the same - and in a manner that I would think would be normal/expected. Treating expression indexes this way, however, is potentially more costly than before and thus we want to provide the user a way to say "hey, PG, don't bother with the extra effort of comparing the entire expression, it ain't gonna matter since if I change the depended-on values odds are the expression result will change as well." Changing an option named "recheck_on_update" doesn't really communicate that to me (I dislike the word recheck, too implementation specific). Something like "only_compare_dependencies_on_update (default false)" would do a better job at that - tell me what the abnormal behavior is, not the normal, and lets me enable it instead of disabling the default behavior and not know what it is falling back to. The description for the parameter does a good job of describing this - just suggesting that the name match how the user might see things.
On the whole the change makes sense - and the general assumptions around runtime cost seem sound and support the trade-off simply re-computing the expression on the old tuple versus engineering an inexpensive way to retrieve the existing value from the index.
I don't have a problem with "total expression cost" being used as a heuristic - though maybe that would mean we should make this an enum with (off, on, never/always) with the third option overriding all heuristics.
David J.
On 2018-05-11 14:56:12 +0200, Simon Riggs wrote: > On 11 May 2018 at 05:32, Andres Freund <andres@anarazel.de> wrote: > > No. Simon just claimed it's not actually a concern: > > https://www.postgresql.org/message-id/CANP8+j+vtskPhEp_GmqmEqdWaKSt2KbOtee0yz-my+Agh0aRPw@mail.gmail.com > > > > And yes, it got committed without doing squat to address the > > architectural concerns. > > "Squat" means "zero, nothing" to me. So that comment would be inaccurate. Yes, I know it means that. And I don't see how it is inaccurate. > I have no problem if you want to replace this with an even better > design in a later release. Meh. The author / committer should get a patch into the right shape, not other people that are concerned with the consequences. Greetings, Andres Freund
On 11 May 2018 at 16:37, Andres Freund <andres@anarazel.de> wrote: > On 2018-05-11 14:56:12 +0200, Simon Riggs wrote: >> On 11 May 2018 at 05:32, Andres Freund <andres@anarazel.de> wrote: >> > No. Simon just claimed it's not actually a concern: >> > https://www.postgresql.org/message-id/CANP8+j+vtskPhEp_GmqmEqdWaKSt2KbOtee0yz-my+Agh0aRPw@mail.gmail.com >> > >> > And yes, it got committed without doing squat to address the >> > architectural concerns. >> >> "Squat" means "zero, nothing" to me. So that comment would be inaccurate. > > Yes, I know it means that. And I don't see how it is inaccurate. > > >> I have no problem if you want to replace this with an even better >> design in a later release. > > Meh. The author / committer should get a patch into the right shape They have done, at length. Claiming otherwise is just trash talk. As you pointed out, the design of the patch avoids layering violations that could have led to architectural objections. Are you saying I should have ignored your words and rewritten the patch to introduce a layering violation? What other objection do you think has not been addressed? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, May 11, 2018 at 11:01 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> I have no problem if you want to replace this with an even better >>> design in a later release. >> >> Meh. The author / committer should get a patch into the right shape > > They have done, at length. Claiming otherwise is just trash talk. Some people might call it "honest disagreement". -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes: > On Fri, May 11, 2018 at 11:01 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>>> I have no problem if you want to replace this with an even better >>>> design in a later release. >>> Meh. The author / committer should get a patch into the right shape >> They have done, at length. Claiming otherwise is just trash talk. > Some people might call it "honest disagreement". So where we are today is that this patch was lobotomized by commits 77366d90f/d06fe6ce2 as a result of this bug report: https://postgr.es/m/20181106185255.776mstcyehnc63ty@alvherre.pgsql We need to move forward, either by undertaking a more extensive clean-out, or by finding a path to a version of the code that is satisfactory. I wanted to enumerate my concerns while yesterday's events are still fresh in mind. (Andres or Robert might have more.) * I do not understand why this feature is on-by-default in the first place. It can only be a win for expression indexes that are many-to-one mappings; for indexes that are one-to-one or few-to-one, it's a pretty big loss. I see no reason to assume that most expression indexes fall into the first category. I suggest that the design ought to be to use this optimization only for indexes for which the user has explicitly enabled recheck_on_update. That would allow getting rid of the cost check in IsProjectionFunctionalIndex, about which we'd otherwise have to have an additional fight: I do not like its ad-hoc-ness, nor the modularity violation (and potential circularity) involved in having the relcache call cost_qual_eval. * Having heapam.c calling the executor also seems like a modularity/layering violation that will bite us in the future. * The implementation seems incredibly inefficient. ProjIndexIsUnchanged is doing creation/destruction of an EState, index_open/index_close (including acquisition of a lock we should already have), BuildIndexInfo, and expression compilation, all of which are completely redundant with work done elsewhere in the executor. And it's doing that *over again for every tuple*, which totally aside from wasted cycles probably means there are large query-lifespan memory leaks in an UPDATE affecting many rows. I think a minimum expectation should be that one-time work is done only one time; but ideally none of those things would happen at all because we could share work with the regular code path. Perhaps it's too much to hope that we could also avoid duplicate computation of the new index expression values, but as long as I'm listing complaints ... * As noted in the bug thread, the implementation of the new reloption is broken because (a) it fails to work for some built-in index AMs and (b) by design, it can't work for add-on AMs. I agree with Andres that that's not acceptable. * This seems like bad data structure design: + Bitmapset *rd_projidx; /* Oids of projection indexes */ That comment is a lie, although IMO it'd be better if it were true; a list of target index OIDs would be a far better design here. The use of rd_projidx as a set of indexes into the relation's indexlist is inefficient and overcomplicated, plus it creates an unnecessary and not very safe (even if it were documented) coupling between rd_indexlist and rd_projidx. * Having ProjIndexIsUnchanged examine relation->rd_projidx directly is broken by design anyway, both from a modularity standpoint and because its inner loop involves catalog accesses that could result in relcache flushes. I'm somewhat amazed that the regression tests passed on CLOBBER_CACHE_ALWAYS buildfarm animals, although possibly this is explained by the fact that they're only testing cases with a single expression index, so that the bitmap isn't checked again after the cache flush happens. Again, this could be fixed if what was returned was just a list of relevant index OIDs. * This bit of coding is unsafe, for the reason explained in the existing comment: /* * Now save copies of the bitmaps in the relcache entry. We intentionally * set rd_indexattr last, because that's the one that signals validity of * the values; if we run out of memory before making that copy, we won't * leave the relcache entry looking like the other ones are valid but * empty. */ oldcxt = MemoryContextSwitchTo(CacheMemoryContext); relation->rd_keyattr = bms_copy(uindexattrs); relation->rd_pkattr = bms_copy(pkindexattrs); relation->rd_idattr = bms_copy(idindexattrs); relation->rd_indexattr = bms_copy(indexattrs); + relation->rd_projindexattr = bms_copy(projindexattrs); + relation->rd_projidx = bms_copy(projindexes); MemoryContextSwitchTo(oldcxt); * There's a lot of other inattention to comments. For example, I noticed that this patch added new responsibilities to RelationGetIndexList without updating its header comment to mention them. * There's a lack of attention to terminology, too. I do not think that "projection index" is an appropriate term at all, nor do I think that "recheck_on_update" is a particularly helpful option name, though we may be stuck with the latter at this point. * I also got annoyed by minor sloppiness like not adding the new regression test in the same place in serial_schedule and parallel_schedule. The whole thing needed more careful review than it got. In short, it seems likely to me that large parts of this patch need to be pulled out, rewritten, and then put back in different places than they are today. I'm not sure if a complete revert is the best next step, or if we can make progress without that. regards, tom lane
On 07.11.2018 22:25, Tom Lane wrote:
First of all I am sorry for this bug. It's a pity that I was not involved in this investigation: I am not subscribed on "postgresql-general" list.Robert Haas <robertmhaas@gmail.com> writes:On Fri, May 11, 2018 at 11:01 AM, Simon Riggs <simon@2ndquadrant.com> wrote:I have no problem if you want to replace this with an even better design in a later release.Meh. The author / committer should get a patch into the right shapeThey have done, at length. Claiming otherwise is just trash talk.Some people might call it "honest disagreement".So where we are today is that this patch was lobotomized by commits 77366d90f/d06fe6ce2 as a result of this bug report: https://postgr.es/m/20181106185255.776mstcyehnc63ty@alvherre.pgsql We need to move forward, either by undertaking a more extensive clean-out, or by finding a path to a version of the code that is satisfactory. I wanted to enumerate my concerns while yesterday's events are still fresh in mind. (Andres or Robert might have more.) * I do not understand why this feature is on-by-default in the first place. It can only be a win for expression indexes that are many-to-one mappings; for indexes that are one-to-one or few-to-one, it's a pretty big loss. I see no reason to assume that most expression indexes fall into the first category. I suggest that the design ought to be to use this optimization only for indexes for which the user has explicitly enabled recheck_on_update. That would allow getting rid of the cost check in IsProjectionFunctionalIndex, about which we'd otherwise have to have an additional fight: I do not like its ad-hoc-ness, nor the modularity violation (and potential circularity) involved in having the relcache call cost_qual_eval. * Having heapam.c calling the executor also seems like a modularity/layering violation that will bite us in the future. * The implementation seems incredibly inefficient. ProjIndexIsUnchanged is doing creation/destruction of an EState, index_open/index_close (including acquisition of a lock we should already have), BuildIndexInfo, and expression compilation, all of which are completely redundant with work done elsewhere in the executor. And it's doing that *over again for every tuple*, which totally aside from wasted cycles probably means there are large query-lifespan memory leaks in an UPDATE affecting many rows. I think a minimum expectation should be that one-time work is done only one time; but ideally none of those things would happen at all because we could share work with the regular code path. Perhaps it's too much to hope that we could also avoid duplicate computation of the new index expression values, but as long as I'm listing complaints ... * As noted in the bug thread, the implementation of the new reloption is broken because (a) it fails to work for some built-in index AMs and (b) by design, it can't work for add-on AMs. I agree with Andres that that's not acceptable. * This seems like bad data structure design: + Bitmapset *rd_projidx; /* Oids of projection indexes */ That comment is a lie, although IMO it'd be better if it were true; a list of target index OIDs would be a far better design here. The use of rd_projidx as a set of indexes into the relation's indexlist is inefficient and overcomplicated, plus it creates an unnecessary and not very safe (even if it were documented) coupling between rd_indexlist and rd_projidx. * Having ProjIndexIsUnchanged examine relation->rd_projidx directly is broken by design anyway, both from a modularity standpoint and because its inner loop involves catalog accesses that could result in relcache flushes. I'm somewhat amazed that the regression tests passed on CLOBBER_CACHE_ALWAYS buildfarm animals, although possibly this is explained by the fact that they're only testing cases with a single expression index, so that the bitmap isn't checked again after the cache flush happens. Again, this could be fixed if what was returned was just a list of relevant index OIDs. * This bit of coding is unsafe, for the reason explained in the existing comment: /* * Now save copies of the bitmaps in the relcache entry. We intentionally * set rd_indexattr last, because that's the one that signals validity of * the values; if we run out of memory before making that copy, we won't * leave the relcache entry looking like the other ones are valid but * empty. */ oldcxt = MemoryContextSwitchTo(CacheMemoryContext); relation->rd_keyattr = bms_copy(uindexattrs); relation->rd_pkattr = bms_copy(pkindexattrs); relation->rd_idattr = bms_copy(idindexattrs); relation->rd_indexattr = bms_copy(indexattrs); + relation->rd_projindexattr = bms_copy(projindexattrs); + relation->rd_projidx = bms_copy(projindexes); MemoryContextSwitchTo(oldcxt); * There's a lot of other inattention to comments. For example, I noticed that this patch added new responsibilities to RelationGetIndexList without updating its header comment to mention them. * There's a lack of attention to terminology, too. I do not think that "projection index" is an appropriate term at all, nor do I think that "recheck_on_update" is a particularly helpful option name, though we may be stuck with the latter at this point. * I also got annoyed by minor sloppiness like not adding the new regression test in the same place in serial_schedule and parallel_schedule. The whole thing needed more careful review than it got. In short, it seems likely to me that large parts of this patch need to be pulled out, rewritten, and then put back in different places than they are today. I'm not sure if a complete revert is the best next step, or if we can make progress without that. regards, tom lane
I have found the same bug in yet another my code few month ago. Shame on me, but I didn't realized that values returned by FormIndexDatum
data doesn't match with descriptor of index relation, because AM may convert them to own types. By the way, I will be please if somebody can suggest the best
way of building proper tuple descriptor.
If the idea of "projection" index optimization is still considered as valuable by community, I can continue improvement of this patch.
Tom, thank you for the critics. But if it's not too brazen of me, I'd like to receive more constructive critics:
> Having heapam.c calling the executor also seems like a modularity/layering violation that will bite us in the future.
Function ProjIndexIsUnchanged is implemented and used in heapam.c because this is the place where decision weather to perform or no perform hot update is made.
Insertion of index is done later. So the only possibility is to somehow cache results of this operation to be able to reuse in future.
> The implementation seems incredibly inefficient. ProjIndexIsUnchanged is doing creation/destruction of an EState, index_open/index_close...
Well, please look for example at get_actual_variable_range function. It is doing almost the same. Is it also extremely inefficient?
Almost all functions dealing with indexes and calling FormIndexDatum are performing the same actions. But the main differences, is that most of them (like IndexCheckExclusion) initialize EState and create slot only once and then iterate through all tuples matching search condition. And ProjIndexIsUnchanged is doing it for each tuple. Once again, I will be pleased to receive from you (or somebody else) advice how to address this problem. I have no idea how it it possible to avoid to perform this check for each affected tuple. So the only solution I can imagine is to somehow cache and reused created executor state.
> Having ProjIndexIsUnchanged examine relation->rd_projidx directly is broken by design anyway, both from a modularity standpoint and because its inner loop involves catalog accesses that could result in relcache flushes.
Sorry, can you clarify it? As far as there are shared lock for correspondent relation and index, nobody else can alter this table or index. And there is rd_refcnt which should prevent destruction of Relation even if relcache is invalidated. There are a lot of other places where components of relation are accessed directly (most often relation->rd_rel stuff). I do not understand why replacing rd_projidx with list of Oid will solve the problem.
> There's a lack of attention to terminology, too. I do not think that "projection index" is an appropriate term at all, nor do I think that "recheck_on_update" is a particularly helpful option name, though we may be stuck with the latter at this point.
As I am not native english speaking, I will agree with any proposed terminology.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Tom Lane wrote: > I wanted to enumerate my concerns while yesterday's > events are still fresh in mind. (Andres or Robert might have more.) > > * I do not understand why this feature is on-by-default in the first > place. It can only be a win for expression indexes that are many-to-one > mappings; for indexes that are one-to-one or few-to-one, it's a pretty > big loss. I see no reason to assume that most expression indexes fall > into the first category. I suggest that the design ought to be to use > this optimization only for indexes for which the user has explicitly > enabled recheck_on_update. That would allow getting rid of the cost check > in IsProjectionFunctionalIndex, about which we'd otherwise have to have > an additional fight: I do not like its ad-hoc-ness, nor the modularity > violation (and potential circularity) involved in having the relcache call > cost_qual_eval. That was my impression too when I had a closer look at this feature. What about an option "hot_update_check" with values "off" (default), "on" and "always"? Yours, Laurenz Albe
On 08.11.2018 15:23, Laurenz Albe wrote: > Tom Lane wrote: >> I wanted to enumerate my concerns while yesterday's >> events are still fresh in mind. (Andres or Robert might have more.) >> >> * I do not understand why this feature is on-by-default in the first >> place. It can only be a win for expression indexes that are many-to-one >> mappings; for indexes that are one-to-one or few-to-one, it's a pretty >> big loss. I see no reason to assume that most expression indexes fall >> into the first category. I suggest that the design ought to be to use >> this optimization only for indexes for which the user has explicitly >> enabled recheck_on_update. That would allow getting rid of the cost check >> in IsProjectionFunctionalIndex, about which we'd otherwise have to have >> an additional fight: I do not like its ad-hoc-ness, nor the modularity >> violation (and potential circularity) involved in having the relcache call >> cost_qual_eval. > That was my impression too when I had a closer look at this feature. > > What about an option "hot_update_check" with values "off" (default), > "on" and "always"? > > Yours, > Laurenz Albe > Before doing any other refactoring of projection indexes I want to attach small bug fix patch which fixes the original problem (SIGSEGV) and also disables recheck_on_update by default. As Laurenz has suggested, I replaced boolean recheck_on_update option with "on","auto,"off" (default). -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On 2018-Nov-08, Konstantin Knizhnik wrote: > Before doing any other refactoring of projection indexes I want to attach > small bug fix patch which > fixes the original problem (SIGSEGV) and also disables recheck_on_update by > default. > As Laurenz has suggested, I replaced boolean recheck_on_update option with > "on","auto,"off" (default). I think this causes an ABI break for GenericIndexOpts. Not sure to what extent that is an actual problem (i.e. how many modules were compiled with 11.0 that are gonna be reading that struct with later Pg), but I think it should be avoided anyhow. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-11-07 14:25:54 -0500, Tom Lane wrote: > We need to move forward, either by undertaking a more extensive > clean-out, or by finding a path to a version of the code that is > satisfactory. > [...] > In short, it seems likely to me that large parts of this patch need to > be pulled out, rewritten, and then put back in different places than > they are today. I'm not sure if a complete revert is the best next > step, or if we can make progress without that. I think the feature has merit, but I don't think it makes that much sense to start with the current in-tree version. There's just too many architectural issues. So I think we should clean it out as much as we can, and then have the feature re-submitted with proper review etc. Greetings, Andres Freund
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> On 2018-Nov-08, Konstantin Knizhnik wrote:
>> Before doing any other refactoring of projection indexes I want to attach
>> small bug fix patch which
>> fixes the original problem (SIGSEGV) and also disables recheck_on_update by
>> default.
>> As Laurenz has suggested, I replaced boolean recheck_on_update option with
>> "on","auto,"off" (default).
> I think this causes an ABI break for GenericIndexOpts. Not sure to what
> extent that is an actual problem (i.e. how many modules were compiled
> with 11.0 that are gonna be reading that struct with later Pg), but I
> think it should be avoided anyhow.
I do not see the point of having more than a boolean option anyway,
if the default is going to be "off". If the user is going to the
trouble of marking a specific index for this feature, what else is
she likely to want other than having it "on"?
The bigger picture here, and the reason for my skepticism about having
any intelligence in the enabling logic, is that there is no scenario
in which this code can be smarter than the user about what to do.
We have no insight today, and are unlikely to have any in future, about
whether a specific index expression is many-to-one or not. I have
exactly no faith in cost-estimate-based logic either, because of the
extremely poor quality of our function cost estimates --- very little
effort has been put into assigning trustworthy procost numbers to the
built-in functions, and as for user-defined ones, it's probably much
worse. So that's why I'm on the warpath against the cost-based logic
that's there now; I think it's just garbage-in-garbage-out.
regards, tom lane
I wrote:
> The bigger picture here, and the reason for my skepticism about having
> any intelligence in the enabling logic, is that there is no scenario
> in which this code can be smarter than the user about what to do.
> We have no insight today, and are unlikely to have any in future, about
> whether a specific index expression is many-to-one or not.
Hmm ... actually, I take that back. Since we're only interested in this
for expression indexes, we can expect that statistics will be available
for the expression index, at least for tables that have been around
long enough that UPDATE performance is really an exciting topic.
So you could imagine pulling up the stadistinct numbers for the index
column(s) and the underlying column(s), and enabling the optimization
when their ratio is less than $something. Figuring out how to merge
numbers for multiple columns might be tricky, but it's not going to be
completely fact-free. (I still think that the cost-estimate logic is
quite bogus, however.)
Another issue in all this is the cost of doing this work over again
after any relcache flush. Maybe we could move the responsibility
into ANALYZE?
BTW, the existing code appears to be prepared to enable this logic
if *any* index column is an expression, but surely we should do so
only if they are *all* expressions?
regards, tom lane
On 09.11.2018 2:27, Tom Lane wrote: > I wrote: >> The bigger picture here, and the reason for my skepticism about having >> any intelligence in the enabling logic, is that there is no scenario >> in which this code can be smarter than the user about what to do. >> We have no insight today, and are unlikely to have any in future, about >> whether a specific index expression is many-to-one or not. > Hmm ... actually, I take that back. Since we're only interested in this > for expression indexes, we can expect that statistics will be available > for the expression index, at least for tables that have been around > long enough that UPDATE performance is really an exciting topic. > So you could imagine pulling up the stadistinct numbers for the index > column(s) and the underlying column(s), and enabling the optimization > when their ratio is less than $something. Figuring out how to merge > numbers for multiple columns might be tricky, but it's not going to be > completely fact-free. (I still think that the cost-estimate logic is > quite bogus, however.) > > Another issue in all this is the cost of doing this work over again > after any relcache flush. Maybe we could move the responsibility > into ANALYZE? > > BTW, the existing code appears to be prepared to enable this logic > if *any* index column is an expression, but surely we should do so > only if they are *all* expressions? > > regards, tom lane From my point of view "auto" value should be default, otherwise it has not so much sense. If somebody decides to switch on this optimization for some particular index, then it will set it to "on", not "auto". So I agree with your previous opinion, that if this optimization is disabled by default, then it is enough to have boolean parameter. Concerning muticolumn indexes: why we should apply this optimization only if *all* of index columns are expressions? Assume very simple example: we have some kind of document storage represented by the following table: create table document(owner integer, name text, last_updated timestamp, description json); So there are some static document attributes (name, date,...) and some dynamic, stored in json field. Consider that most frequently users will search among their own documents. So we may create index like this: create index by_title on documents(owner,(description->>'title')); Document description may include many attributes which are updated quite frequently, like "comments", "keywords",... But "title" is rarely changed, so this optimization will be very useful for such index. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 08.11.2018 22:05, Alvaro Herrera wrote: > On 2018-Nov-08, Konstantin Knizhnik wrote: > >> Before doing any other refactoring of projection indexes I want to attach >> small bug fix patch which >> fixes the original problem (SIGSEGV) and also disables recheck_on_update by >> default. >> As Laurenz has suggested, I replaced boolean recheck_on_update option with >> "on","auto,"off" (default). > I think this causes an ABI break for GenericIndexOpts. Not sure to what > extent that is an actual problem (i.e. how many modules were compiled > with 11.0 that are gonna be reading that struct with later Pg), but I > think it should be avoided anyhow. > Ok, I reverted back my change of reach_on_update option type. Now if reach_on_update option is not explicitly specified, then decision is made based on the expression cost. Patches becomes very small and fix only error in comparison of index tuple values. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On 2018-11-07 14:25:54 -0500, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: > > On Fri, May 11, 2018 at 11:01 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > >>>> I have no problem if you want to replace this with an even better > >>>> design in a later release. > > >>> Meh. The author / committer should get a patch into the right shape > > >> They have done, at length. Claiming otherwise is just trash talk. > > > Some people might call it "honest disagreement". > > So where we are today is that this patch was lobotomized by commits > 77366d90f/d06fe6ce2 as a result of this bug report: > > https://postgr.es/m/20181106185255.776mstcyehnc63ty@alvherre.pgsql > > We need to move forward, either by undertaking a more extensive > clean-out, or by finding a path to a version of the code that is > satisfactory. I wanted to enumerate my concerns while yesterday's > events are still fresh in mind. (Andres or Robert might have more.) > > * I do not understand why this feature is on-by-default in the first > place. It can only be a win for expression indexes that are many-to-one > mappings; for indexes that are one-to-one or few-to-one, it's a pretty > big loss. I see no reason to assume that most expression indexes fall > into the first category. I suggest that the design ought to be to use > this optimization only for indexes for which the user has explicitly > enabled recheck_on_update. That would allow getting rid of the cost check > in IsProjectionFunctionalIndex, about which we'd otherwise have to have > an additional fight: I do not like its ad-hoc-ness, nor the modularity > violation (and potential circularity) involved in having the relcache call > cost_qual_eval. > > * Having heapam.c calling the executor also seems like a > modularity/layering violation that will bite us in the future. > > * The implementation seems incredibly inefficient. ProjIndexIsUnchanged > is doing creation/destruction of an EState, index_open/index_close > (including acquisition of a lock we should already have), BuildIndexInfo, > and expression compilation, all of which are completely redundant with > work done elsewhere in the executor. And it's doing that *over again for > every tuple*, which totally aside from wasted cycles probably means there > are large query-lifespan memory leaks in an UPDATE affecting many rows. > I think a minimum expectation should be that one-time work is done only > one time; but ideally none of those things would happen at all because > we could share work with the regular code path. Perhaps it's too much > to hope that we could also avoid duplicate computation of the new index > expression values, but as long as I'm listing complaints ... > > * As noted in the bug thread, the implementation of the new reloption > is broken because (a) it fails to work for some built-in index AMs > and (b) by design, it can't work for add-on AMs. I agree with Andres > that that's not acceptable. > > * This seems like bad data structure design: > > + Bitmapset *rd_projidx; /* Oids of projection indexes */ > > That comment is a lie, although IMO it'd be better if it were true; > a list of target index OIDs would be a far better design here. The use > of rd_projidx as a set of indexes into the relation's indexlist is > inefficient and overcomplicated, plus it creates an unnecessary and not > very safe (even if it were documented) coupling between rd_indexlist and > rd_projidx. > > * Having ProjIndexIsUnchanged examine relation->rd_projidx directly is > broken by design anyway, both from a modularity standpoint and because > its inner loop involves catalog accesses that could result in relcache > flushes. I'm somewhat amazed that the regression tests passed on > CLOBBER_CACHE_ALWAYS buildfarm animals, although possibly this is > explained by the fact that they're only testing cases with a single > expression index, so that the bitmap isn't checked again after the cache > flush happens. Again, this could be fixed if what was returned was just > a list of relevant index OIDs. > > * This bit of coding is unsafe, for the reason explained in the existing > comment: > > /* > * Now save copies of the bitmaps in the relcache entry. We intentionally > * set rd_indexattr last, because that's the one that signals validity of > * the values; if we run out of memory before making that copy, we won't > * leave the relcache entry looking like the other ones are valid but > * empty. > */ > oldcxt = MemoryContextSwitchTo(CacheMemoryContext); > relation->rd_keyattr = bms_copy(uindexattrs); > relation->rd_pkattr = bms_copy(pkindexattrs); > relation->rd_idattr = bms_copy(idindexattrs); > relation->rd_indexattr = bms_copy(indexattrs); > + relation->rd_projindexattr = bms_copy(projindexattrs); > + relation->rd_projidx = bms_copy(projindexes); > MemoryContextSwitchTo(oldcxt); > > * There's a lot of other inattention to comments. For example, I noticed > that this patch added new responsibilities to RelationGetIndexList without > updating its header comment to mention them. > > * There's a lack of attention to terminology, too. I do not think that > "projection index" is an appropriate term at all, nor do I think that > "recheck_on_update" is a particularly helpful option name, though we > may be stuck with the latter at this point. > > * I also got annoyed by minor sloppiness like not adding the new > regression test in the same place in serial_schedule and > parallel_schedule. The whole thing needed more careful review > than it got. > > In short, it seems likely to me that large parts of this patch need to > be pulled out, rewritten, and then put back in different places than > they are today. I'm not sure if a complete revert is the best next > step, or if we can make progress without that. We've not really made progress on this. I continue to think that we ought to revert this feature, and then work to re-merge it an architecturally correct way afterwards. Other opinions? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2018-11-07 14:25:54 -0500, Tom Lane wrote:
>> In short, it seems likely to me that large parts of this patch need to
>> be pulled out, rewritten, and then put back in different places than
>> they are today. I'm not sure if a complete revert is the best next
>> step, or if we can make progress without that.
> We've not really made progress on this. I continue to think that we
> ought to revert this feature, and then work to re-merge it an
> architecturally correct way afterwards. Other opinions?
Given the lack of progress, I'd agree with a revert. It's probably
already going to be a bit painful to undo due to subsequent changes,
so we shouldn't wait too much longer.
Do we want to revert entirely, or leave the "recheck_on_update" option
present but nonfunctional?
regards, tom lane
Hi, On 2019-01-14 18:03:24 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2018-11-07 14:25:54 -0500, Tom Lane wrote: > >> In short, it seems likely to me that large parts of this patch need to > >> be pulled out, rewritten, and then put back in different places than > >> they are today. I'm not sure if a complete revert is the best next > >> step, or if we can make progress without that. > > > We've not really made progress on this. I continue to think that we > > ought to revert this feature, and then work to re-merge it an > > architecturally correct way afterwards. Other opinions? > > Given the lack of progress, I'd agree with a revert. It's probably > already going to be a bit painful to undo due to subsequent changes, > so we shouldn't wait too much longer. Yea, the reason I re-encountered this is cleaning up the pluggable storage patch. Which certainly would make this revert harder... > Do we want to revert entirely, or leave the "recheck_on_update" option > present but nonfunctional? I think it depends a bit on whether we want to revert in master or master and 11. If only master, I don't see much point in leaving the option around. If both, I think we should (need to?) leave it around in 11 only. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2019-01-14 18:03:24 -0500, Tom Lane wrote:
>> Do we want to revert entirely, or leave the "recheck_on_update" option
>> present but nonfunctional?
> I think it depends a bit on whether we want to revert in master or
> master and 11. If only master, I don't see much point in leaving the
> option around. If both, I think we should (need to?) leave it around in
> 11 only.
After a few minutes' more thought, I think that the most attractive
option is to leave v11 alone and do a full revert in HEAD. In this
way, if anyone's attached "recheck_on_update" options to their indexes,
it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be
able to migrate to v12 till they remove the options. That way we
aren't bound to the questionable design and naming of that storage
option if/when we try this again.
A revert in v11 would have ABI compatibility issues to think about,
and would also likely be a bunch more work on top of what we'll
have to do for HEAD, so leaving it as-is seems like a good idea.
regards, tom lane
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2019-01-14 18:03:24 -0500, Tom Lane wrote: > >> Do we want to revert entirely, or leave the "recheck_on_update" option > >> present but nonfunctional? > > > I think it depends a bit on whether we want to revert in master or > > master and 11. If only master, I don't see much point in leaving the > > option around. If both, I think we should (need to?) leave it around in > > 11 only. > > After a few minutes' more thought, I think that the most attractive > option is to leave v11 alone and do a full revert in HEAD. In this > way, if anyone's attached "recheck_on_update" options to their indexes, > it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be > able to migrate to v12 till they remove the options. That way we > aren't bound to the questionable design and naming of that storage > option if/when we try this again. So the plan is to add a check into pg_upgrade to complain if it comes across any cases where recheck_on_update is set during its pre-flight checks..? Or are you suggesting that pg_dump in v12+ would throw errors if it finds that set? Or that we'll dump it, but fail to allow it into a v12+ database? What if v12 sees "recheck_on_update='false'", as a v11 pg_dump might output today? To be clear, I'm in agreement with reverting this, just trying to think through what's going to happen and how users will be impacted. Thanks! Stephen
Вложения
On 2019-01-14 18:46:18 -0500, Stephen Frost wrote: > Greetings, > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > Andres Freund <andres@anarazel.de> writes: > > > On 2019-01-14 18:03:24 -0500, Tom Lane wrote: > > >> Do we want to revert entirely, or leave the "recheck_on_update" option > > >> present but nonfunctional? > > > > > I think it depends a bit on whether we want to revert in master or > > > master and 11. If only master, I don't see much point in leaving the > > > option around. If both, I think we should (need to?) leave it around in > > > 11 only. > > > > After a few minutes' more thought, I think that the most attractive > > option is to leave v11 alone and do a full revert in HEAD. In this > > way, if anyone's attached "recheck_on_update" options to their indexes, > > it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be > > able to migrate to v12 till they remove the options. That way we > > aren't bound to the questionable design and naming of that storage > > option if/when we try this again. > > So the plan is to add a check into pg_upgrade to complain if it comes > across any cases where recheck_on_update is set during its pre-flight > checks..? I don't think so. > Or are you suggesting that pg_dump in v12+ would throw errors if it > finds that set? Or that we'll dump it, but fail to allow it into a > v12+ database? What if v12 sees "recheck_on_update='false'", as a v11 > pg_dump might output today? It'll just error out on restore (including the internal one by pg_upgrade). I don't see much point in doing more, this isn't a widely used option by any stretch. Greetings, Andres Freund
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> After a few minutes' more thought, I think that the most attractive
>> option is to leave v11 alone and do a full revert in HEAD. In this
>> way, if anyone's attached "recheck_on_update" options to their indexes,
>> it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be
>> able to migrate to v12 till they remove the options. That way we
>> aren't bound to the questionable design and naming of that storage
>> option if/when we try this again.
> So the plan is to add a check into pg_upgrade to complain if it comes
> across any cases where recheck_on_update is set during its pre-flight
> checks..?
It wasn't my plan particularly. I think the number of databases with
that option set is probably negligible, not least because it was
on-by-default during its short lifespan. So there really has never been
a point where someone would have had a reason to turn it on explicitly.
Now if somebody else is excited enough to add such logic to pg_upgrade,
I wouldn't stand in their way. But I suspect just doing the revert is
already going to be painful enough :-(
> What if v12 sees "recheck_on_update='false'", as a v11
> pg_dump might output today?
It'll complain that that's an unknown option.
regards, tom lane
Greetings, * Andres Freund (andres@anarazel.de) wrote: > On 2019-01-14 18:46:18 -0500, Stephen Frost wrote: > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > > Andres Freund <andres@anarazel.de> writes: > > > > On 2019-01-14 18:03:24 -0500, Tom Lane wrote: > > > >> Do we want to revert entirely, or leave the "recheck_on_update" option > > > >> present but nonfunctional? > > > > > > > I think it depends a bit on whether we want to revert in master or > > > > master and 11. If only master, I don't see much point in leaving the > > > > option around. If both, I think we should (need to?) leave it around in > > > > 11 only. > > > > > > After a few minutes' more thought, I think that the most attractive > > > option is to leave v11 alone and do a full revert in HEAD. In this > > > way, if anyone's attached "recheck_on_update" options to their indexes, > > > it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be > > > able to migrate to v12 till they remove the options. That way we > > > aren't bound to the questionable design and naming of that storage > > > option if/when we try this again. > > > > So the plan is to add a check into pg_upgrade to complain if it comes > > across any cases where recheck_on_update is set during its pre-flight > > checks..? > > I don't think so. I could possibly see us just ignoring the option in pg_dump, but that goes against what Tom was suggesting, since users wouldn't see an error if we don't dump the option out.. > > Or are you suggesting that pg_dump in v12+ would throw errors if it > > finds that set? Or that we'll dump it, but fail to allow it into a > > v12+ database? What if v12 sees "recheck_on_update='false'", as a v11 > > pg_dump might output today? > > It'll just error out on restore (including the internal one by > pg_upgrade). I don't see much point in doing more, this isn't a widely > used option by any stretch. This.. doesn't actually make sense. The pg_upgrade will use v12+ pg_dump. You're saying that the v12+ pg_dump will dump out the option, but then the restore will fail to understand it? Thanks! Stephen
Вложения
Hi, On 2019-01-14 18:53:02 -0500, Tom Lane wrote: > But I suspect just doing the revert is already going to be painful > enough :-( I assume you're not particularly interested in doing that? I'm more than happy to leave this to others, but if nobody signals interest I'll give it a go, because it'll get a lot harder after the pluggable storage work (and it'd work even less usefully afterwards, given the location in heapam.c). Greetings, Andres Freund
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > >> After a few minutes' more thought, I think that the most attractive > >> option is to leave v11 alone and do a full revert in HEAD. In this > >> way, if anyone's attached "recheck_on_update" options to their indexes, > >> it'll continue to work^H^H^H^Hdo nothing in v11, though they won't be > >> able to migrate to v12 till they remove the options. That way we > >> aren't bound to the questionable design and naming of that storage > >> option if/when we try this again. > > > So the plan is to add a check into pg_upgrade to complain if it comes > > across any cases where recheck_on_update is set during its pre-flight > > checks..? > > It wasn't my plan particularly. I think the number of databases with > that option set is probably negligible, not least because it was > on-by-default during its short lifespan. So there really has never been > a point where someone would have had a reason to turn it on explicitly. > > Now if somebody else is excited enough to add such logic to pg_upgrade, > I wouldn't stand in their way. But I suspect just doing the revert is > already going to be painful enough :-( It seems like the thing to do would be to just ignore the option in v12+ pg_dump then, meaning that pg_dump wouldn't output it and pg_restore/v12+ wouldn't ever see it, and therefore users wouldn't get an error even if that option was used when they upgrade. I could live with that, but you seemed to be suggesting that something else would happen earlier. > > What if v12 sees "recheck_on_update='false'", as a v11 > > pg_dump might output today? > > It'll complain that that's an unknown option. Right, that's kinda what I figured. I'm not thrilled with that either, but hopefully it won't be too big a deal for users. Thanks! Stephen
Вложения
Hi, On 2019-01-14 18:55:18 -0500, Stephen Frost wrote: > * Andres Freund (andres@anarazel.de) wrote: > > > Or are you suggesting that pg_dump in v12+ would throw errors if it > > > finds that set? Or that we'll dump it, but fail to allow it into a > > > v12+ database? What if v12 sees "recheck_on_update='false'", as a v11 > > > pg_dump might output today? > > > > It'll just error out on restore (including the internal one by > > pg_upgrade). I don't see much point in doing more, this isn't a widely > > used option by any stretch. > > This.. doesn't actually make sense. The pg_upgrade will use v12+ > pg_dump. You're saying that the v12+ pg_dump will dump out the option, > but then the restore will fail to understand it? Why does that not make sense? With one exception the reloptions code in pg_dump doesn't have knowledge of individual reloptions. So without adding any special case code pg_dump will just continue to dump the option. And the server will just refuse to restore it, because it doesn't know it anymore. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2019-01-14 18:53:02 -0500, Tom Lane wrote:
>> But I suspect just doing the revert is already going to be painful
>> enough :-(
> I assume you're not particularly interested in doing that?
No, I'm willing to do it, and will do so tomorrow if there haven't
been objections.
What I'm not willing to do is write hacks for pg_upgrade or pg_dump
to mask cases where the option has been set on a v11 index. I judge
that it's not worth the trouble. If someone else disagrees, they
can do that work.
regards, tom lane
Greetings, * Andres Freund (andres@anarazel.de) wrote: > On 2019-01-14 18:55:18 -0500, Stephen Frost wrote: > > * Andres Freund (andres@anarazel.de) wrote: > > > > Or are you suggesting that pg_dump in v12+ would throw errors if it > > > > finds that set? Or that we'll dump it, but fail to allow it into a > > > > v12+ database? What if v12 sees "recheck_on_update='false'", as a v11 > > > > pg_dump might output today? > > > > > > It'll just error out on restore (including the internal one by > > > pg_upgrade). I don't see much point in doing more, this isn't a widely > > > used option by any stretch. > > > > This.. doesn't actually make sense. The pg_upgrade will use v12+ > > pg_dump. You're saying that the v12+ pg_dump will dump out the option, > > but then the restore will fail to understand it? > > Why does that not make sense? With one exception the reloptions code in > pg_dump doesn't have knowledge of individual reloptions. So without > adding any special case code pg_dump will just continue to dump the > option. And the server will just refuse to restore it, because it > doesn't know it anymore. Ugh, yeah, I was catching up to realize that we'd have to special-case add this into pg_dump to get it avoided; most things in pg_dump don't work that way. As that's the case, then I guess I'm thinking we really should make pg_upgrade complain if it finds it during the check phase. I really don't like having a case like this where the pg_upgrade will fail from something that we could have detected during the pre-flight check, that's what it's for, after all. Thanks, Stephen
Вложения
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2019-01-14 18:53:02 -0500, Tom Lane wrote: > >> But I suspect just doing the revert is already going to be painful > >> enough :-( > > > I assume you're not particularly interested in doing that? > > No, I'm willing to do it, and will do so tomorrow if there haven't > been objections. > > What I'm not willing to do is write hacks for pg_upgrade or pg_dump > to mask cases where the option has been set on a v11 index. I judge > that it's not worth the trouble. If someone else disagrees, they > can do that work. I'd love for there to be a better option beyond "just let people run the pg_upgrade and have it fail half-way through"... Particularly after someone's run the pg_upgrade check against the database... If there isn't, then I'll write the code to add the check to pg_upgrade. I'll also offer to add other such checks, if there's similar cases that people are aware of. Thanks, Stephen
Вложения
Hi, On 2019-01-14 19:04:07 -0500, Stephen Frost wrote: > As that's the case, then I guess I'm thinking we really should make > pg_upgrade complain if it finds it during the check phase. I really > don't like having a case like this where the pg_upgrade will fail from > something that we could have detected during the pre-flight check, > that's what it's for, after all. I suggest you write a separate patch for that in that case. Greetings, Andres Freund
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> What I'm not willing to do is write hacks for pg_upgrade or pg_dump
>> to mask cases where the option has been set on a v11 index. I judge
>> that it's not worth the trouble. If someone else disagrees, they
>> can do that work.
> I'd love for there to be a better option beyond "just let people run the
> pg_upgrade and have it fail half-way through"... Particularly after
> someone's run the pg_upgrade check against the database...
> If there isn't, then I'll write the code to add the check to pg_upgrade.
Go for it.
regards, tom lane