Обсуждение: gaussian distribution pgbench
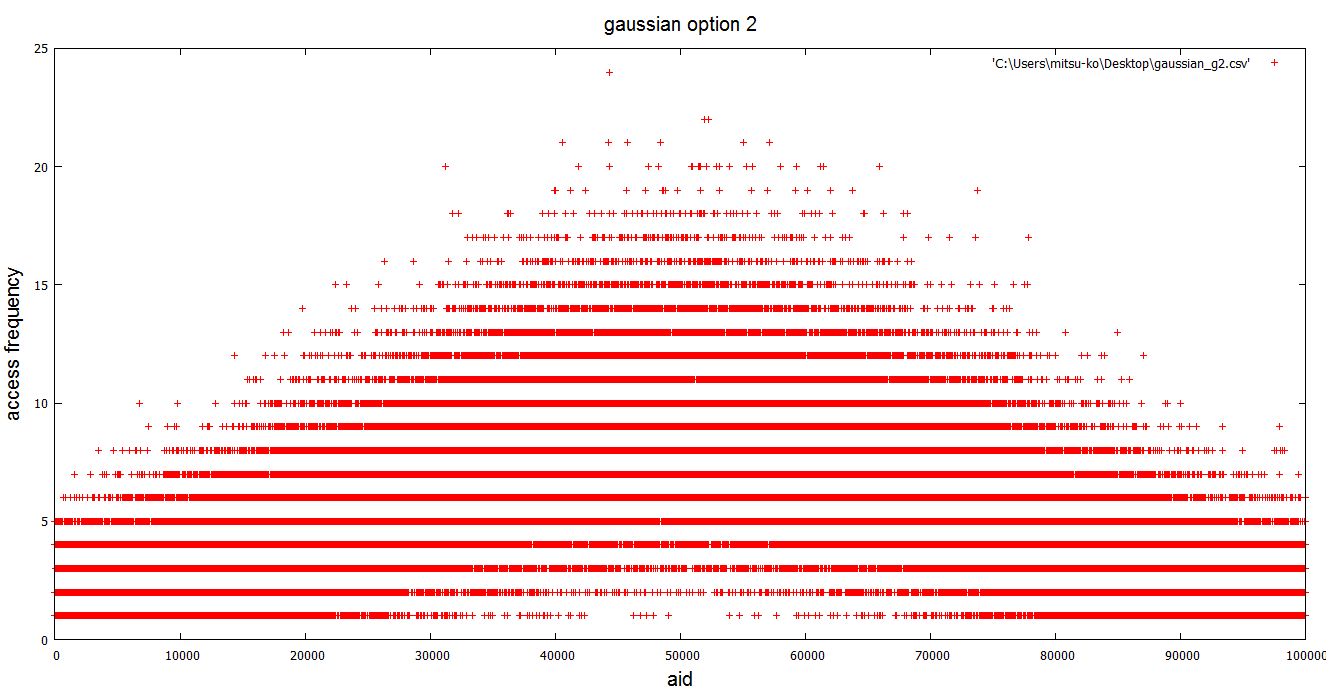
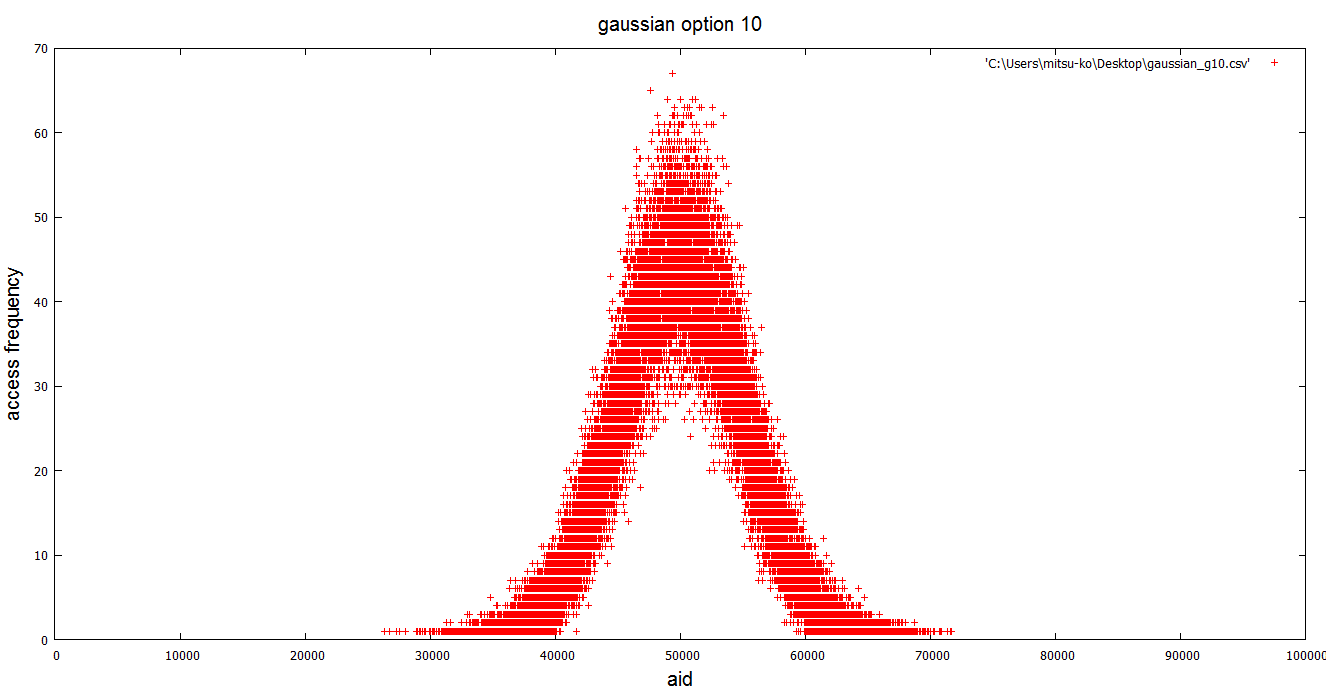
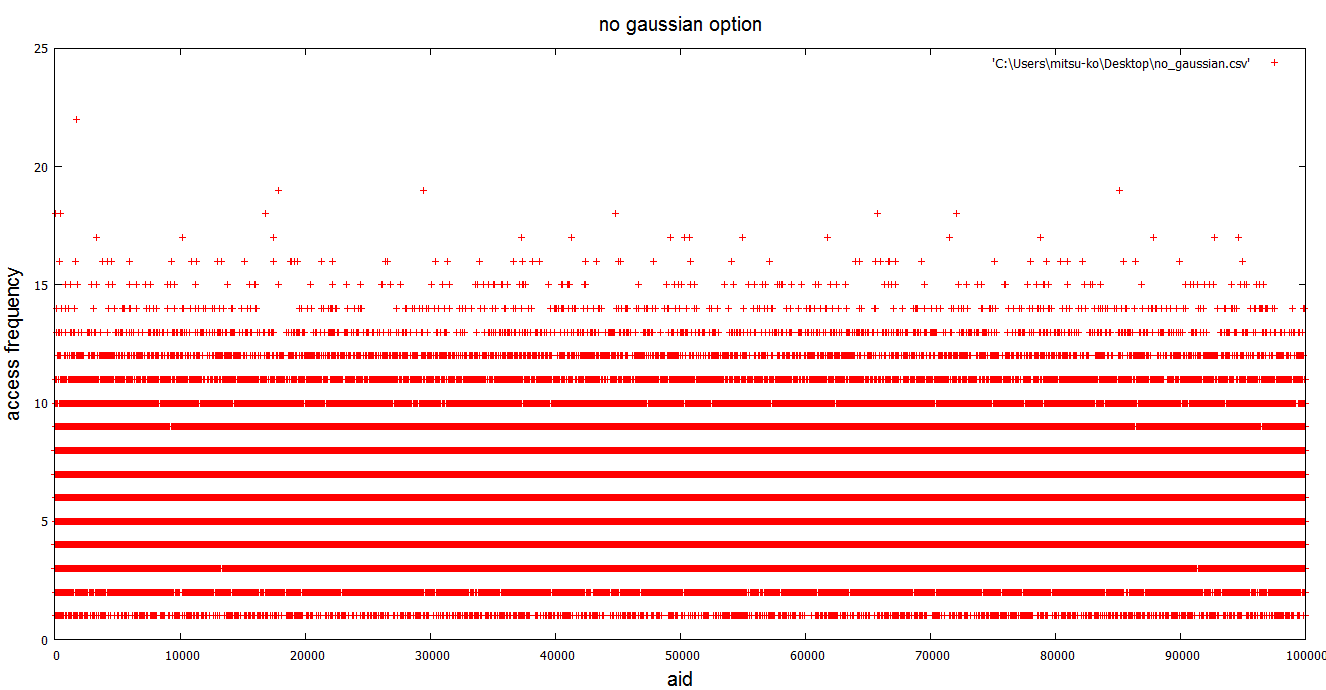
Hello, I create gaussinan distribution pgbench patch that can access records with gaussian frequency. And I submit this commit fest. * Purpose this patch In the general transaction situation, clients access for all records equally is hard to happen. I think gaussian distribution access patterns are most of transaction petterns in general. My patch realizes neary this access pattern. I think that not only it can simulate a general access pattern as an effect of this patch, but also it is useful for new development features such as effective use and free of shared_buffers, the readahead optimization in the OS, and the speed-up of the tuple level lock. * Usage It is easy to use, only put -g with standard deviation threshold parameter. If we set larger standard deviation threshold, pgbench access patern limited more specific records. Min standard deviation threshold is 2. Execution example command is here. > [mitsu-ko@localhost postgresql]$ bin/pgbench -g 10 -c 16 -j 8 -T 300 > starting vacuum...end. > transaction type: TPC-B (sort of) > scaling factor: 1 > standard deviation threshold: 10.00000 > access probability of top 20%, 10% and 5% records: 0.95450 0.68269 0.38292 > query mode: simple > number of clients: 16 > number of threads: 8 > duration: 300 s > number of transactions actually processed: 566367 > tps = 1887.821409 (including connections establishing) > tps = 1887.949390 (excluding connections establishing) "access probability" indicates top N access probability in this benchmark. If we set larger standard deviation threshold parameter, it become more large. Attached png files which are "gausian_2.png" and "gaussian_10.png" indicate gaussian distribution access patern by my patch. "no_gaussian.png" is not with -g option (normal). I think my patch realize gaussian distribution access patern. * Approach It replaces uniform random number generator to gaussian distribution random number generator using by box-muller tansform method. Then, I use standard deviation threshold parameter for mapping a normal distribution access pattern in each record and normalization. It is linear mappping method that is a floating point to an integer value. * other I also create another patches that can get more accurate benchmark result in pgbench, and will submit them this commit fest. They are like that I submitted checkpoint patch in the past. They are all right, too! Any question? Best regards, -- Mitsumasa KONDO NTT Open Source Software Center
Вложения
{kind=link}
{kind=link}
{kind=link}
KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > I create gaussinan distribution pgbench patch that can access > records with gaussian frequency. And I submit this commit fest. Thanks! I have moved this to the Open CommitFest, though. https://commitfest.postgresql.org/action/commitfest_view/open You had accidentally added to the CF In Progress. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Mitsumasa, > In the general transaction situation, clients access for all records equally is > hard to happen. I think gaussian distribution access patterns are most of > transaction petterns in general. My patch realizes neary this access pattern. That is great! I was just looking for something like that! I have not looked at the patch yet, but from the plots you sent, it seems that it is a gaussian distribution over the keys. However this pattern induces stronger cache effects which are maybe not too realistic, because neighboring keys in the middle are more likely to be chosen. It seems to me that this is not desirable. Have you considered adding a "randomization" layer, that is once you have a key in [1 .. n] centered around n/2, then you perform a pseudo-random transformation into the same domain so that key values are scattered over the whole domain? -- Fabien.
<div dir="ltr"><p class="">> You had accidentally added to the CF In Progress.<p class="" style="style">Oh, I had completely mistookthis CF schedule :-)<p class="" style="style">Maybe, Horiguchi-san is same situation...<p class="" style="style"><br/><p class="" style="style">However, because of your moving, I become first submitter in next CF.<p class=""style="style">Thank you for moving :-)<p class="" style="style">--<p class="" style="style">Mitsumasa KONDO</div>
> However this pattern induces stronger cache effects which are maybe not too realistic,
> because neighboring keys in the middle are more likely to be chosen.
I think that your opinion is right. However, in effect, it is a paseudo-benchmark, so that I think that such a simple mechanism is also necessary.
> Have you considered adding a "randomization" layer, that is once you have a key in [1 .. > n] centered around n/2, then you perform a pseudo-random transformation into the same > domain so that key values are scattered over the whole domain?
Yes. I also consider this patch. It can realize by adding linear mapping array which is created by random generator. However, current erand48 algorithm is not high accuracy and fossil algorithm, I do not know whether it works well. If we realize it, we may need more accurate random generator algorithm which is like Mersenne Twister.
Regards,
--
Mitsumasa KONDO
On 9/20/13 2:42 AM, KONDO Mitsumasa wrote: > I create gaussinan distribution pgbench patch that can access records with > gaussian frequency. And I submit this commit fest. This patch no longer applies.
Sorry for my delay reply. Since I have had vacation last week, I replyed from gmail. However, it was stalled post to pgsql-hackers:-( (2013/09/21 6:05), Kevin Grittner wrote:> You had accidentally added to the CF In Progress. Oh, I had completely mistook this CF schedule :-) Maybe, Horiguchi-san is same situation... However, because of your moving, I become first submitter in next CF. Thank you for moving ! -- Mitsumasa KONDO NTT Open Source Software Center
Sorry for my delay reply. Since I have had vacation last week, I replied from gmail. However, it was stalled post to pgsql-hackers:-( (2013/09/21 7:54), Fabien COELHO wrote: > However this pattern induces stronger cache effects which are maybe not too realistic, > because neighboring keys in the middle are more likely to be chosen. I think that your opinion is right. However, in effect, it is a paseudo-benchmark, so that I think that such a simple mechanism is also necessary. > Have you considered adding a "randomization" layer, that is once you have a key in [1 .. > n] centered around n/2, thenyou perform a pseudo-random transformation into the same > domain so that key values are scattered over the whole domain? Yes. I also consider this patch. It can realize by adding linear mapping array which is created by random generator. However, current erand48 algorithm is not high accuracy and fossil algorithm, I do not know whether it works well. If we realize it, we may need more accurate random generator algorithm which is like Mersenne Twister. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
(2013/09/27 5:29), Peter Eisentraut wrote: > This patch no longer applies. I will try to create this patch in next commit fest. If you have nice idea, please send me! Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On 30.09.2013 07:12, KONDO Mitsumasa wrote: > (2013/09/27 5:29), Peter Eisentraut wrote: >> This patch no longer applies. > I will try to create this patch in next commit fest. > If you have nice idea, please send me! A few thoughts on this: 1. DBT-2 uses a non-uniform distribution. You can use that instead of pgbench. 2. Do we really want to add everything and the kitchen sink to pgbench? Every addition is small when considered alone, but we'll soon end with a monster. So I'm inclined to reject this patch on those grounds. 3. That said, this could be handy. But it would be even more handy if you could get Gaussian random numbers with \setrandom, so that you could use this with custom scripts. And once you implement that, do we actually need the -g flag anymore? If you want TPC-B transactions with gaussian distribution, you can write a custom script to do that. The documentation includes a full script that corresponds to the built-in TPC-B script. So what I'd actually like to see is \setgaussian, for use in custom scripts. - Heikki
> 3. That said, this could be handy. But it would be even more handy if you > could get Gaussian random numbers with \setrandom, so that you could use this > with custom scripts. And once you implement that, do we actually need the -g > flag anymore? If you want TPC-B transactions with gaussian distribution, you > can write a custom script to do that. The documentation includes a full > script that corresponds to the built-in TPC-B script. > > So what I'd actually like to see is \setgaussian, for use in custom scripts. Indeed, great idea! That looks pretty elegant! It would be something like: \setgauss var min max sigma I'm not sure whether sigma should be relative to max-min, or absolute. I would say relative is better... A concerned I raised is that what one should really want is a "pseudo randomized" (discretized) gaussian, i.e. you want the probability of each value along a gaussian distribution, *but* no direct frequency correlation between neighbors. Otherwise, you may have unwanted/unrealistic positive cache effects. Maybe this could be achieved by an independent built-in, say either: \randomize var min max [parameter ?] \randomize var min max val [parameter] Which would mean take variable var which must be in [min,max], and apply a pseudo-random transformation which results is also in [min,max]. From a probabilistic point of view, it seems to me that a randomized (discretized) exponential would be more significant to model a server load. \setexp var min max lambda... -- Fabien.
On Thu, Nov 21, 2013 at 9:13 AM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > So what I'd actually like to see is \setgaussian, for use in custom scripts. +1. I'd really like to be able to run a benchmark with a Gaussian and uniform distribution side-by-side for comparative purposes - we need to know that we're not optimizing one at the expense of the other. Sure, DBT-2 gets you a non-uniform distribution, but it has serious baggage from it being a tool primarily intended for measuring the relative performance of different database systems. pgbench would be pretty worthless for measuring the relative strengths and weaknesses of different database systems, but it is not bad at informing the optimization efforts of hackers. pgbench is a defacto standard for that kind of thing, so we should make it incrementally better for that kind of thing. No standard industry benchmark is likely to replace it for this purpose, because such optimizations require relatively narrow focus. Sometimes I want to maximally pessimize the number of FPIs generated. Other times I do not. Getting a sense of how something affects a variety of distributions would be very valuable, not least since normal distributions abound in nature. -- Peter Geoghegan
On 20/12/13 09:36, Peter Geoghegan wrote: > On Thu, Nov 21, 2013 at 9:13 AM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> So what I'd actually like to see is \setgaussian, for use in custom scripts. > +1. I'd really like to be able to run a benchmark with a Gaussian and > uniform distribution side-by-side for comparative purposes - we need > to know that we're not optimizing one at the expense of the other. > Sure, DBT-2 gets you a non-uniform distribution, but it has serious > baggage from it being a tool primarily intended for measuring the > relative performance of different database systems. pgbench would be > pretty worthless for measuring the relative strengths and weaknesses > of different database systems, but it is not bad at informing the > optimization efforts of hackers. pgbench is a defacto standard for > that kind of thing, so we should make it incrementally better for that > kind of thing. No standard industry benchmark is likely to replace it > for this purpose, because such optimizations require relatively narrow > focus. > > Sometimes I want to maximally pessimize the number of FPIs generated. > Other times I do not. Getting a sense of how something affects a > variety of distributions would be very valuable, not least since > normal distributions abound in nature. > > Curious, wouldn't the common usage pattern tend to favour a skewed distribution, such as the Poisson Distribution (it has been over 40 years since I studied this area, so there may be better candidates). Just that gut feeling & experience tends to make me think that the "Normal" distribution may often not be the best for database access simulation. Cheers, Gavin
On 12/19/13 5:52 PM, Gavin Flower wrote: > Curious, wouldn't the common usage pattern tend to favour a skewed > distribution, such as the Poisson Distribution (it has been over 40 > years since I studied this area, so there may be better candidates). > Some people like database load testing with a "Pareto principle" distribution, where 80% of the activity hammers 20% of the rows such that locking becomes important. (That's one specific form of Pareto distribution) The standard pgbench load indirectly gets you quite a bit of that due to all the contention on the branches table. Targeting all of that at a single table can be more realistic. My last round of reviewing a pgbench change left me pretty worn out with wanting to extend that code much further. Adding in some new probability distributions would be fine though, that's a narrow change. We shouldn't get too excited about pgbench remaining a great tool for too much longer though. pgbench is fast approaching a wall nowadays, where it's hard for any single client server to fully overload today's larger server. You basically need a second large server to generate load, whereas what people really want is a bunch of coordinated small clients. (That sort of wall was in early versions too, it just got pushed upward a lot by the multi-worker changes in 9.0 coming around the same time desktop core counts really skyrocketed) pgbench started as a clone of a now abandoned Java project called JDBCBench. I've been seriously considering a move back toward that direction lately. Nowadays spinning up ten machines to run load generation is trivial. The idea of extending pgbench's C code to support multiple clients running at the same time and collating all of their results is not a project I'd be excited about. It should remain a perfectly fine tool for PostgreSQL developers to find code hotspots, but that's only so useful. (At this point someone normally points out Tsung solved all of those problems years ago if you'd only give it a chance. I think it's kind of telling that work on sysbench is rewriting the whole thing so you can use Lua for your test scripts.)
Hi,
I revise my gaussian pgbench patch which wss requested from community.
* Changes
- Support custom script.
- "\setgaussian" is generating gaussian distribute random number.
- ex) \setgaussian [var] [min] [max] [stddev_threshold]
- We can use mixture model in multiple custom scripts.
- Delete short option "-g", and add long options ”--gaussian"
- Refactoring getrand() interface
> - getrand(TState *thread, int64 min, int64 max)
> + getrand(TState *thread, int64 min, int64 max, DistType dist_type, double value1)
- We can easy to add other random distribution algorithms. Please see detail
design in attached patch.
Febien COELHO wrote:
>> From a probabilistic point of view, it seems to me that a randomized
> (discretized) exponential would be more significant to model a server load.
>
> \setexp var min max lambda...
I can create randomized exponential distribution under following. It is very easy.
double rand_exp( double lambda ){
return -log(Uniform(0,1))/lambda;
}
If community wants this, I will add this function in my patch.
Gavin Flower wrote:
> Curious, wouldn't the common usage pattern tend to favour a skewed distribution,
> such as the Poisson Distribution (it has been over 40 years since I studied
> this area, so there may be better candidates).
The difference between Poisson distribution and Gaussian distribution is discrete
or not.
In my gaussian algorithm, first generating continuos gaussian distribution, next
projection to integer values which are each record, it will be discrete value.
Therefore, it will be almost simular with Poisson distribution. And when we set
larger standard deviations(higher 10), it will be created better approximation of
Poisson distribution.
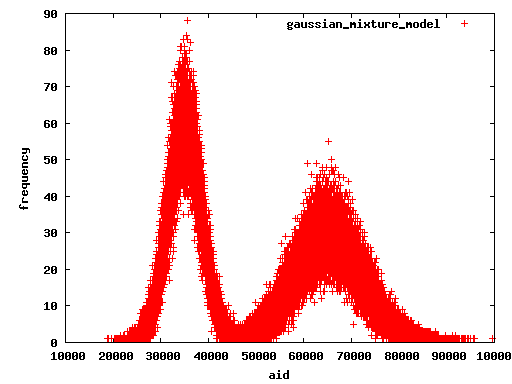
Attached sql files are for custom scripts which are different distribution. It
realize mixture distribuion benchmark. And attached graph is the result.
[example command]
$pgbench -f file1.sql file2.sql
If you have more some comment, please send me.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Вложения
{kind=link}
Hello,
> I revise my gaussian pgbench patch which wss requested from community.
With a lot of delay for which I apologise, please find hereafter the
review.
Gaussian Pgbench v3 patch by Mitsumasa KONDO review
* The purpose of the patch is to allow a pgbench script to draw from normally distributed integer values instead of
uniformlydistributed.
This is a valuable contribution to enable pgbench to generate more realistic loads, which is seldom uniform in
practice.
However, ISTM that other distributions such an exponantial one would make more sense, and also the values should be
furtherrandomized so that neighboring values are not more likely to be drawn. The latest point is non trivial.
* Compilation
The patch applies and compiles against current head. It works as expected, although there is few feedback from the
scriptto show that.
* Mathematical soundness
We want to derive a discrete normal distribution from a uniform one. Well, normal distributions are for continuous
variables...Anyway, this is done by computing a continuous normal distribution which is then projected onto integers.
I'mbasically fine with that.
The system uses a Box-Muller transform (1958) to do this transformation. The Ziggurat method seems to be prefered
forthis purpose, *but* it would require precalculated tables which depends on the target values. So I'm fine with the
Box-Mullertransform for pgbench.
The BM method uses 2 uniformly distributed numbers to derive 2 normally distributed numbers. The implementation
computesone of these, and loops over till one match a threshold criterion.
More explanations, at least in comments, are needed about this threshold and its meaning. It is required to be more
than2. I guess is that it allows to limit the number of iterations of the while loop, but in what proportion is
unclear.The documentation does not also help the user to understand this value and its meaning.
What I think it is: it is the deviation for the FURTHEST point around the mean, that is the actual deviation
associatedto the "min" and "max" target values. The 2 minimum value induces that there is a least 4 stddev lengths
betweenmin & max, with the most likely mean in the middle.
If the threshold test fails, one of the 2 uniform number is redrawn, a new candidate value is tested. I'm not at
easeabout why only 1 value is redrawn and not both, some explanations would be welcome. Also, on the other hand, why
nottest the other possible value (with cos) if the first one fails?
Also, as suggested above, I would like some explanations about how much this while loop may iterate without success,
saywith the expected average number of iterations with its explanation in a comment.
* Implementation
Random values : double rand1 = 1.0 - rand; // instead of the LONG_MAX computation & limits.h rand2 should be in (0,
1],but it is in [0, 1), use "1.0 - ..." as well?!
What is called "stdev*" in getrand() is really the chosen deviation from the target mean, so it would make more
senseto name it "dev".
I do not think that the getrand refactoring was such a good idea. I'm sorry if I may have suggested that in a
previouscomment. The new getrand possibly ignores its parameters, hmmmm. ISTM that it would be much simpler in the
codeto have a separate and clean "getrand_normal" or "getrand_gauss" called for "\setgaussian", and that's it. This
would allow to get rid of DistType and all of getrand changes in the code.
There are heavy constants computations (sqrt(log()) within the while loop which would be moved out of the loop.
ISTM that the while condition would be easier to read as:
while ( dev < - threshold || threshold < dev )
Maybe the \\setgaussian argument handling may be transformed into a function, so that it could be used easily later
forsome other distribution (say some setexp:-)
* Options
ISTM that the test options would be better if made orthogonal, i.e. not to have three --gaussian* options. I would
suggestto have only one --gaussian=NUM which would trigger gaussian tests with this threshold, and --gaussian=3.5
--select-onlywould use the select-only variant, and so on.
* Typos
gausian -> gaussian patern -> pattern
* Conclusion :
- this is a valuable patch to help create more realistic load and make pgbench a more useful tool. I'm greatly in
favorof having such a functionality.
- it seems to me that the patch should be further improved before being committed, in particular I would suggest:
(1) improve the explanations in the code and in the documentation, especially about what is the "deviation
threshold"and its precise link to generated values.
(2) simplify the code with a separate gaussian getrand, and simpler or more efficient code here and there, see
commentsabove.
(3) use only one option to trigger gaussian tests.
(bonus) \setexp would be a nice:-)
--
Fabien.
Hi Febien,
Thank you very much for your very detail and useful comments!
I read your comment, I agree most of your advice:)
Attached patch is fixed for your comment. That are...
- Remove redundant long-option.
- We can use "--gaussian=NUM -S" or "--gaussian=NUMN -N" options.
- Add sentence in document
- Separate two random generate function which are uniform and gaussian.
- getGaussianrand() is created.
- Fix ranged random number more strictly, ex. (0,1) or [0,1).
- Please see comment of source code in detail:).
- Fix typo.
- Use cos() and sin() function when we generate gaussian random number.
- Add fast sqrt calculation algorithm.
- Reuse sqrt result and pre generate random number for reducing calculation cost.
- Experience of this method is under following. It will be little-bit faster
than non-reuse method. And distribution of gaussian is still good.
* Settings
shared_buffers = 1024MB
* Test script
pgbench -i -s 1
pgbench --gaussian=2 -T 30 -S -c8 -j4 -n
pgbench --gaussian=2 -T 30 -S -c8 -j4 -n
pgbench --gaussian=2 -T 30 -S -c8 -j4 -n
* Result
method | try1 | try2 | try3 |
--------------------------------------------|
reuse method | 44189 | 44453 | 44013 |
non-reuse method | 43567 | 43635 | 43508 |
(2014/02/09 21:32), Fabien COELHO wrote:
> This is a valuable contribution to enable pgbench to generate more realistic
> loads, which is seldom uniform in practice.
Thanks!
> However, ISTM that other distributions such an exponantial one would make
> more sense,
I can easy to create exponential distribution. Here, I assume exponential
distribution that is f(x) = lambda * exp^(-lambda * x) in general.
What do you think under following interface?
custom script: \setexp [varname] min max threshold
command : --exponential=NUM(threshold)
I don't want to use lambda variable for simple implementation. So lambda is
always 1. Because it can enough to control distribution by threshold. Threshold
parameter is f(x) value. And using created distribution projects to 'aid' by same
method. If you think OK, I will impliment under followings tomorrow, and also
create parseing part of this function...
do
{
rand = 1.0 - pg_erand48(thread->random_state);
rand = -log(rand);
}while( rand > exp_threshold)
return rand / exp_threshold;
> and also the values should be further randomized so that
> neighboring values are not more likely to be drawn. The latest point is non
> trivial.
That's right, but I worry about gaussian randomness and benchmark reproducibility
might be disappeared when we re-randomized access pattern, because Postgres
storage method manages records by each pages and it is difficult to realize
access randomness in whole pages, not record. If we solve this problem, we have
to need algorithm for smart shuffule projection function that is still having
gaussian randomized. I think it will be difficult, and it have to impement in
another patch in the future.
> * Mathematical soundness
>
> We want to derive a discrete normal distribution from a uniform one.
> Well, normal distributions are for continuous variables... Anyway, this is
> done by computing a continuous normal distribution which is then projected
> onto integers. I'm basically fine with that.
>
> The system uses a Box-Muller transform (1958) to do this transformation.
> The Ziggurat method seems to be prefered for this purpose, *but* it would
> require precalculated tables which depends on the target values. So I'm
> fine with the Box-Muller transform for pgbench.
Yes, that's right. I selected simple and relatively faster algorithm, that is
Box-Muller transform.
> The BM method uses 2 uniformly distributed numbers to derive 2 normally
> distributed numbers. The implementation computes one of these, and loops
> over till one match a threshold criterion.
>
> More explanations, at least in comments, are needed about this threshold
> and its meaning. It is required to be more than 2. I guess is that it allows
> to limit the number of iterations of the while loop,
Yes. This loop could not almost go on, because min stdev_threshold is 2.
The possibility of retry-loop is under 4 percent. It might not be problem.
> but in what proportion
> is unclear. The documentation does not also help the user to understand
> this value and its meaning.
Yes, it is huristic method. So I added the comments in document.
> What I think it is: it is the deviation for the FURTHEST point around the
> mean, that is the actual deviation associated to the "min" and "max" target
> values. The 2 minimum value induces that there is a least 4 stddev lengths
> between min & max, with the most likely mean in the middle.
Correct!
> If the threshold test fails, one of the 2 uniform number is redrawn, a new
> candidate value is tested. I'm not at ease about why only 1 value is redrawn
> and not both, some explanations would be welcome. Also, on the other hand,
> why not test the other possible value (with cos) if the first one fails?
Yes, I think so too. So I fixed this partan and it will be better. Past
implementations are not good:(
> Also, as suggested above, I would like some explanations about how much this
> while loop may iterate without success, say with the expected average number
> of iterations with its explanation in a comment.
I add my comments in source code.
> * Implementation
>
> Random values :
> double rand1 = 1.0 - rand; // instead of the LONG_MAX computation & limits.h
> rand2 should be in (0, 1], but it is in [0, 1), use "1.0 - ..." as well?!
It's more smart method. I change to this method.
> What is called "stdev*" in getrand() is really the chosen deviation from
> the target mean, so it would make more sense to name it "dev".
Hmm, I like stdev*. Short variable makes us more confuse:( And it's not big problem.
> I do not think that the getrand refactoring was such a good idea. I'm sorry
> if I may have suggested that in a previous comment.
> The new getrand possibly ignores its parameters, hmmmm. ISTM that it would
> be much simpler in the code to have a separate and clean "getrand_normal"
> or "getrand_gauss" called for "\setgaussian", and that's it. This would
> allow to get rid of DistType and all of getrand changes in the code.
I separate two function that are getrand() and getGaussianrand(), it becomes more
clear I think.
> There are heavy constants computations (sqrt(log()) within the while
> loop which would be moved out of the loop.
>
> ISTM that the while condition would be easier to read as:
>
> while ( dev < - threshold || threshold < dev )
OK, fixed.
>
> Maybe the \\setgaussian argument handling may be transformed into a function,
> so that it could be used easily later for some other distribution (say some
> setexp:-)
> * Options
>
> ISTM that the test options would be better if made orthogonal, i.e. not to
> have three --gaussian* options. I would suggest to have only one
> --gaussian=NUM which would trigger gaussian tests with this threshold,
> and --gaussian=3.5 --select-only would use the select-only variant,
> and so on.
Agreed. Fixed.
> * Typos
>
> gausian -> gaussian
> patern -> pattern
Oh, fixed.
> * Conclusion :
>
> - this is a valuable patch to help create more realistic load and make pgbench
> a more useful tool. I'm greatly in favor of having such a functionality.
>
> - it seems to me that the patch should be further improved before being
> committed, in particular I would suggest:
>
> (1) improve the explanations in the code and in the documentation, especially
> about what is the "deviation threshold" and its precise link to generated
> values.
>
> (2) simplify the code with a separate gaussian getrand, and simpler or
> more efficient code here and there, see comments above.
>
> (3) use only one option to trigger gaussian tests.
>
> (bonus) \setexp would be a nice:-)
Thank you for your comments. They make my patch more polished:)
I think my patch is fixed for supporting all your comments, but it might not be fixed
as you think. And if you notice other part, please send me.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Вложения
Sorry, previos attached patch has small bug. Please use latest one. > 134 - return min + (int64) (max - min + 1) * rand; > 134 + return min + (int64)((max - min + 1) * rand); Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Вложения
Вложения
{kind=link}
Gaussian Pgbench v6 patch by Mitsumasa KONDO review & patch v7. * The purpose of the patch is to allow a pgbench script to draw from normally distributed or exponentially distributed integervalues instead of uniformly distributed. This is a valuable contribution to enable pgbench to generate more realistic loads, which is seldom uniform in practice. * Changes I have updated the patch (v7) based on Mitsumasa latest v6: - some code simplifications & formula changes. - I've addedexplicit looping probability computations in comments to show the (low) looping probability of the iterative search. - I've tried to clarify the sgml documentation. - I've removed the 5.0 default value as it was not used anymore. - I've renamed some variables to match the naming style around. * Compilation The patch applies and compiles against current head. It works as expected, although there is few feedback from the scriptto show that. By looking at the "aid" distribution in the "pgbench_history" table after a run, I could check thatthe aid values are indeed skewed, depending on the parameters. * Mathematical soundness I've checked again the mathematical soundness for the methods involved. After further thoughts, I'm not that sure that there is not a bias induced by taking the second value based on "cos" whenthe first based on "sin" as failed the test. So I removed the cos computation for the gaussian version, and simplifiedthe code accordingly. This mean that it may be a little less efficient, but I'm more confident that there is nobias. * Conclusion If Mitsumasa-san is okay with the changes I have made, I would suggest to accept this patch. -- Fabien.
(2014/02/16 7:38), Fabien COELHO wrote: > I have updated the patch (v7) based on Mitsumasa latest v6: > - some code simplifications & formula changes. > - I've added explicit looping probability computations in comments > to show the (low) looping probability of the iterative search. > - I've tried to clarify the sgml documentation. > - I've removed the 5.0 default value as it was not used anymore. > - I've renamed some variables to match the naming style around. Thank you for yor detail review and fix some code! I checked your modification version, it seems better than previos version and very helpful for documents. > * Mathematical soundness > > I've checked again the mathematical soundness for the methods involved. > > After further thoughts, I'm not that sure that there is not a bias induced > by taking the second value based on "cos" when the first based on "sin" > as failed the test. So I removed the cos computation for the gaussian version, > and simplified the code accordingly. This mean that it may be a little > less efficient, but I'm more confident that there is no bias. I tried to confirm which method is better. However, at the end of the day, it is not a problem because other part of implementations have bigger overhead in pgbench client. We like simple implementaion so I agree with your modification version. And I tested this version, there is no overhead in creating gaussian and exponential random number with minimum threshold that is most overhead situation. > * Conclusion > > If Mitsumasa-san is okay with the changes I have made, I would suggest > to accept this patch. Attached patch based on v7 is added output that is possibility of access record when we use exponential option in the end of pgbench result. It is caluculated by a definite integral method for e^-x. If you check it and think no problem, please mark it ready for commiter. Ishii-san will review this patch:) Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Вложения
Gaussian Pgbench v8 patch by Mitsumasa KONDO review & patch v9. * The purpose of the patch is to allow a pgbench script to draw from normally distributed or exponentially distributed integervalues instead of uniformly distributed. This is a valuable contribution to enable pgbench to generate more realistic loads, which is seldom uniform in practice. * Very minor change I have updated the patch (v9) based on Mitsumasa latest v8: - remove one spurious space in the help message. * Compilation The patch applies cleanly and compiles against current head. * Check I have checked that the aid values are skewed depending on the parameters by looking at the "aid" distribution in the"pgbench_history" table after a run. * Mathematical soundness I've checked the mathematical soundness of the methods involved. I'm fine with casting doubles to integers for having the expected distribution on integers. Although there is a retry loop for finding a suitable, the looping probability is low thanks to the minimum thresholdparameter required. * Conclusion I suggest to apply this patch which provide a useful and more realistic testing capability to pgbench. -- Fabien.
Seems that in the review so far, Fabien has focused mainly in the mathematical properties of the new random number generation. That seems perfectly fine, but no comment has been made about the chosen UI for the feature. Per the few initial messages in the thread, in the patch as submitted you ask for a gaussian random number by using \setgaussian, and exponential via \setexp. Is this the right UI? Currently you get an evenly distributed number with \setrandom. There is nothing that makes it obvious on \setgaussian by itself that it produces random numbers. Perhaps we should simply add a new argument to \setrandom, instead of creating new commands for each distribution? I would guess that, in the future, we're going to want other distributions as well. Not sure what it would look like; perhaps \setrandom foo 1 10 gaussian or \setrandom foo 1 10 dist=gaussian or \setrandom(gaussian) foo 1 10 or \setrandom(dist=gaussian) foo 1 10 I think we could easily support \set distrib gaussian \setrandom(dist=:distrib) foo 1 10 so that it can be changed for a bunch of commands easily. Or maybe I'm going overboard, everybody else is happy with \setgaussian, and should just use that? -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> Seems that in the review so far, Fabien has focused mainly in the
> mathematical properties of the new random number generation. That seems
> perfectly fine, but no comment has been made about the chosen UI for the
> feature. Per the few initial messages in the thread, in the patch as
> submitted you ask for a gaussian random number by using \setgaussian,
> and exponential via \setexp. Is this the right UI? Currently you get
> an evenly distributed number with \setrandom. There is nothing that
> makes it obvious on \setgaussian by itself that it produces random
> numbers. Perhaps we should simply add a new argument to \setrandom,
> instead of creating new commands for each distribution? I would guess
> that, in the future, we're going to want other distributions as well.
+1 for an argument to \setrandom instead of separate commands.
> Not sure what it would look like; perhaps
> \setrandom foo 1 10 gaussian
FWIW, I think this style is sufficient; the others seem overcomplicated
for not much gain. I'm not strongly attached to that position though.
regards, tom lane
Hello Alvaro & Tom, > Alvaro Herrera <alvherre@2ndquadrant.com> writes: >> Seems that in the review so far, Fabien has focused mainly in the >> mathematical properties of the new random number generation. That seems >> perfectly fine, but no comment has been made about the chosen UI for the >> feature. >> Per the few initial messages in the thread, in the patch as submitted >> you ask for a gaussian random number by using \setgaussian, and >> exponential via \setexp. Is this the right UI? I thought it would be both concise & clear to have that as another form of \set*. If I had it designed from the start, I think I may have put only "\set" with some functions such as "uniform", "gaussian" and so on. but once there is a set and a setrandom for uniform, this suggested other settings would have their own set commands as well. Also, the number of expected arguments is not the same, so it may make the parsing code less obvious. Finally, this is not a "language" heavily used, so I would emphasize simpler code over more elegant features, for once. >> Currently you get an evenly distributed number with \setrandom. There >> is nothing that makes it obvious on \setgaussian by itself that it >> produces random numbers. Well, "gaussian" or "exp" are kind of a clue, at least to my mathematically-oriented mind. >> Perhaps we should simply add a new argument to \setrandom, instead of >> creating new commands for each distribution? I would guess that, in >> the future, we're going to want other distributions as well. > > +1 for an argument to \setrandom instead of separate commands. >> Not sure what it would look like; perhaps >> \setrandom foo 1 10 gaussian There is an additional argument expected. That would make: \setrandom foo 1 10 [uniform] \setrandom foo 1 :size gaussian 3.6 \setrandom foo 1 100 exponential 7.2 > FWIW, I think this style is sufficient; the others seem overcomplicated > for not much gain. I'm not strongly attached to that position though. If there is a change, I agree that one simple style is enough, especially as the parsing code is rather low-level already. So I'm basically fine with the current status of the patch, but I would be okay with a \setrandom as well. -- Fabien.
(2014/03/02 22:32), Fabien COELHO wrote: >> Alvaro Herrera <alvherre@2ndquadrant.com> writes: >>> Seems that in the review so far, Fabien has focused mainly in the >>> mathematical properties of the new random number generation. That seems >>> perfectly fine, but no comment has been made about the chosen UI for the >>> feature. >>> Per the few initial messages in the thread, in the patch as submitted you ask >>> for a gaussian random number by using \setgaussian, and exponential via >>> \setexp. Is this the right UI? > I thought it would be both concise & clear to have that as another form of \set*. Yeah, but we got only two or three? concise. So I agree with discussing about UI. > There is an additional argument expected. That would make: > > \setrandom foo 1 10 [uniform] > \setrandom foo 1 :size gaussian 3.6 > \setrandom foo 1 100 exponential 7.2 It's good design. I think it will become more low overhead at part of parsing in pgbench, because comparison of strings will be redeced(maybe). And I'd like to remove [uniform], beacause we have to have compatibility for old scripts, and random function always gets uniform distribution in common sense of programming. However, new grammer is little bit long in user script. It seems trade-off that are visibility of scripts and user writing cost. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
>> \setrandom foo 1 10 [uniform] >> \setrandom foo 1 :size gaussian 3.6 >> \setrandom foo 1 100 exponential 7.2 > It's good design. I think it will become more low overhead at part of parsing > in pgbench, because comparison of strings will be redeced(maybe). And I'd > like to remove [uniform], beacause we have to have compatibility for old > scripts, and random function always gets uniform distribution in common sense > of programming. I just put "uniform" as an optional default, hence the brackets. Otherwise, what I would have in mind if this would be designed from scratch: \set foo 124 \set foo "string value" (?) \set foo :variable \set foo 12 + :shift And then \set foo uniform 1 10 \set foo gaussian 1 10 4.2 \set foo exponential 1 100 5.2 or maybe functions could be repended with something like "&uniform". But that would be for another life:-) > However, new grammer is little bit long in user script. It seems trade-off > that are visibility of scripts and user writing cost. Yep. -- Fabien.
(2014/03/03 16:51), Fabien COELHO wrote:>>> \setrandom foo 1 10 [uniform]>>> \setrandom foo 1 :size gaussian 3.6>>> \setrandom foo 1 100 exponential 7.2>> It's good design. I think it will become more low overhead at part of parsing>>in pgbench, because comparison of strings will be redeced(maybe). And I'd like>> to remove [uniform], beacause wehave to have compatibility for old scripts,>> and random function always gets uniform distribution in common sense of>>programming.>> I just put "uniform" as an optional default, hence the brackets. All right. I was misunderstanding. However, if we select this format, I'd like to remove it. Because pgbench needs to check counts of argment number. If we allow brackets, it will not be simple. > Otherwise, what I would have in mind if this would be designed from scratch:>> \set foo 124> \set foo "string value"(?)> \set foo :variable> \set foo 12 + :shift>> And then>> \set foo uniform 1 10> \set foo gaussian 1 104.2> \set foo exponential 1 100 5.2>> or maybe functions could be repended with something like "&uniform".> But thatwould be for another life:-) I don't agree with that.. They are more overhead in parsing part and more complex for user. >> However, new grammer is little bit long in user script. It seems trade-off that>> are visibility of scripts and user writingcost.>> Yep. OK. I'm not sure which idia is the best. So I wait for comments in community:) Regards, -- Mitsumasa KONDO NTT Open Source Software Center
> OK. I'm not sure which idia is the best. So I wait for comments in > community:) Hmmm. Maybe you can do what Tom voted for, he is the committer:-) -- Fabien.
(2014/03/04 17:28), Fabien COELHO wrote: >> OK. I'm not sure which idia is the best. So I wait for comments in community:) > Hmmm. Maybe you can do what Tom voted for, he is the committer:-) Yeah, but he might change his mind by our disscuttion. So I wait untill tomorrow, and if nothing to comment, I will start to fix what Tom voted for. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Hi,
(2014/03/04 17:42), KONDO Mitsumasa wrote:> (2014/03/04 17:28), Fabien COELHO wrote:
>>> OK. I'm not sure which idia is the best. So I wait for comments in community:)
>> Hmmm. Maybe you can do what Tom voted for, he is the committer:-)
> Yeah, but he might change his mind by our disscuttion. So I wait untill tomorrow,
> and if nothing to comment, I will start to fix what Tom voted for.
I create the patch which is fixed UI. If we agree with this interface,
I also start to fix the document.
New "\setrandom" interface is here.
\setrandom var min max [gaussian threshold | exponential threshold]
Attached patch realizes this interface, but it has little bit ugly codeing in
executeStatement() and process_commands().. That is under following.
if(argc == 4)
{
... /* uniform */
}
else if (argv[4]== gaussian or exponential)
{
... /* gaussian or exponential */
}
else
{
... /* uniform with extra argments */
}
It is beacause pgbench custom script allows extra comments or extra argument in
its file. For example, under following cases are no problem case.
\setrandom var min max #hoge --> uniform random
\setrandom var min max #hoge1 #hoge2 --> uniform random
\setrandom var min max gaussian threshold #hoge -->gaussian random
And other cases are classified under following.
\setrandom var min max gaussian #hoge --> uniform
\setrandom var min max max2 gaussian threshold --> uniform
\setrandom var min gaussian #hoge --> ERROR
However, if we wrong grammer in pgbench custom script,
pgbench outputs error log on user terminal. So I think it is especially no problem.
What do you think?
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Вложения
(2014/03/07 16:02), KONDO Mitsumasa wrote: > And other cases are classified under following. > \setrandom var min max gaussian #hoge --> uniform Oh, it's wrong... It will be.. \setrandom var min max gaussian #hoge --> ERROR Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Hello Mitsumasa-san, > New "\setrandom" interface is here. > \setrandom var min max [gaussian threshold | exponential threshold] > Attached patch realizes this interface, but it has little bit ugly codeing in > executeStatement() and process_commands().. I think it is not too bad. The "ignore extra arguments on the line" is a little pre-existing mess anyway. > What do you think? I'm okay with this UI and its implementation. -- Fabien.
(2014/03/09 1:49), Fabien COELHO wrote: > > Hello Mitsumasa-san, > >> New "\setrandom" interface is here. >> \setrandom var min max [gaussian threshold | exponential threshold] > >> Attached patch realizes this interface, but it has little bit ugly codeing in >> executeStatement() and process_commands().. > > I think it is not too bad. The "ignore extra arguments on the line" is a little > pre-existing mess anyway. All right. >> What do you think? > > I'm okay with this UI and its implementation. OK. Attached patch is updated in the document. I don't like complex sentence, so I use <para> tag a lot. If you like this documents, please mark ready for commiter. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Вложения
On Tue, Mar 11, 2014 at 1:49 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2014/03/09 1:49), Fabien COELHO wrote: >> >> >> Hello Mitsumasa-san, >> >>> New "\setrandom" interface is here. >>> \setrandom var min max [gaussian threshold | exponential threshold] >> >> >>> Attached patch realizes this interface, but it has little bit ugly >>> codeing in >>> executeStatement() and process_commands().. >> >> >> I think it is not too bad. The "ignore extra arguments on the line" is a >> little >> pre-existing mess anyway. > > All right. > > >>> What do you think? >> >> >> I'm okay with this UI and its implementation. > > OK. We should do the same discussion for the UI of command-line option? The patch adds two options --gaussian and --exponential, but this UI seems to be a bit inconsistent with the UI for \setrandom. Instead, we can use something like --distribution=[uniform | gaussian | exponential]. Regards, -- Fujii Masao
On 03/13/2014 03:17 PM, Fujii Masao wrote: > On Tue, Mar 11, 2014 at 1:49 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> (2014/03/09 1:49), Fabien COELHO wrote: >>> >>> I'm okay with this UI and its implementation. >> >> OK. > > We should do the same discussion for the UI of command-line option? > The patch adds two options --gaussian and --exponential, but this UI > seems to be a bit inconsistent with the UI for \setrandom. Instead, > we can use something like --distribution=[uniform | gaussian | exponential]. IMHO we should just implement the \setrandom changes, and not add any of these options to modify the standard test workload. If someone wants to run TPC-B workload with gaussian or exponential distribution, they can implement it as a custom script. The docs include the script for the standard TPC-B workload; just copy-paster that and modify the \setrandom lines. - Heikki
On Thu, Mar 13, 2014 at 10:51 PM, Heikki Linnakangas <hlinnakangas@vmware.com> wrote: > On 03/13/2014 03:17 PM, Fujii Masao wrote: >> >> On Tue, Mar 11, 2014 at 1:49 PM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> >>> (2014/03/09 1:49), Fabien COELHO wrote: >>>> >>>> >>>> I'm okay with this UI and its implementation. >>> >>> >>> OK. >> >> >> We should do the same discussion for the UI of command-line option? >> The patch adds two options --gaussian and --exponential, but this UI >> seems to be a bit inconsistent with the UI for \setrandom. Instead, >> we can use something like --distribution=[uniform | gaussian | >> exponential]. > > > IMHO we should just implement the \setrandom changes, and not add any of > these options to modify the standard test workload. If someone wants to run > TPC-B workload with gaussian or exponential distribution, they can implement > it as a custom script. The docs include the script for the standard TPC-B > workload; just copy-paster that and modify the \setrandom lines. Yeah, I'm OK with this. Regards, -- Fujii Masao
> We should do the same discussion for the UI of command-line option? The > patch adds two options --gaussian and --exponential, but this UI seems > to be a bit inconsistent with the UI for \setrandom. > Instead, we can use something like --distribution=[uniform | gaussian | > exponential]. Hmmm. That is possible, obviously. Note that it does not need to resort to a custom script, if one can do something like "--define=exp_threshold=5.6". If so, maybe one simpler named variable could be used, say "threshold", instead of separate names for each options. However there is a catch: currently the option allows to check that the threshold is large enough so as to avoid loops in the generator. So this mean moving the check in the generator, and doing it over and over. Possibly this is a good idea, because otherwise a custom script could circumvent the check. Well, the current status is that the check can be avoided with --define... Also, a shorter possibly additional name, would be nice, maybe something like: --dist=exp|gauss|uniform? Not sure. I like long options not to be too long. -- Fabien.
Hi, (2014/03/14 4:21), Fabien COELHO wrote: > >> We should do the same discussion for the UI of command-line option? The patch >> adds two options --gaussian and --exponential, but this UI seems to be a bit >> inconsistent with the UI for \setrandom. >> Instead, we can use something like --distribution=[uniform | gaussian | >> exponential]. > > Hmmm. That is possible, obviously. > > Note that it does not need to resort to a custom script, if one can do something > like "--define=exp_threshold=5.6". Yeah, threshold paramter should be needed by generating distribution algorithms in my patch. And it is important that we can control distribution pattern by this paramter. > If so, maybe one simpler named variable could > be used, say "threshold", instead of separate names for each options. If we separate threshold option, I think it is difficult to understand dependency of this parameter. Because "threshold" is very general term, and when we will add other new feature, it is difficult to undestand which parameter is dependent and be needed. > However there is a catch: currently the option allows to check that the threshold > is large enough so as to avoid loops in the generator. So this mean moving the > check in the generator, and doing it over and over. Possibly this is a good idea, > because otherwise a custom script could circumvent the check. Well, the current > status is that the check can be avoided with --define... > > Also, a shorter possibly additional name, would be nice, maybe something like: > --dist=exp|gauss|uniform? Not sure. I like long options not to be too long. Well, if we run standard benchmark in pgbench, we need not set option because it is default benmchmark, and it is same as uniform distribution. And if we run extra benchmarks in pgbench which are like '-S' or '-N', we need to set option. Because they are non-standard benchmark setting, and it is same as gaussian or exponential distribution. So present UI keeps consistency and along the pgbench history. > I like long options not to be too long. Yes, I like so too. Present UI is very simple and useful for combination using such like '-S' and '--gaussian'. So I hope not changing UI. ex) pgbench -S --gaussian=5 pgbench -N --exponential=2 --sampling-rate=0.8 Regards, -- Mitsumasa KONDO NTT Open Source Software Center
(2014/03/13 23:00), Fujii Masao wrote: > On Thu, Mar 13, 2014 at 10:51 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> On 03/13/2014 03:17 PM, Fujii Masao wrote: >>> >>> On Tue, Mar 11, 2014 at 1:49 PM, KONDO Mitsumasa >>> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> >>>> (2014/03/09 1:49), Fabien COELHO wrote: >>>>> >>>>> >>>>> I'm okay with this UI and itsaccess probability of top implementation. >>>> >>>> >>>> OK. >>> >>> >>> We should do the same discussion for the UI of command-line option? >>> The patch adds two options --gaussian and --exponential, but this UI >>> seems to be a bit inconsistent with the UI for \setrandom. Instead, >>> we can use something like --distribution=[uniform | gaussian | >>> exponential]. >> >> >> IMHO we should just implement the \setrandom changes, and not add any of >> these options to modify the standard test workload. If someone wants to run >> TPC-B workload with gaussian or exponential distribution, they can implement >> it as a custom script. The docs include the script for the standard TPC-B >> workload; just copy-paster that and modify the \setrandom lines. Well, when we set '--gaussian=NUM' or '--exponential=NUM' on command line, we can see access probability of top N records in result of final output. This out put is under following, > [mitsu-ko@localhost pgbench]$ ./pgbench --exponential=10 postgres > starting vacuum...end. > transaction type: Exponential distribution TPC-B (sort of) > scaling factor: 1 > exponential threshold: 10.00000 > access probability of top 20%, 10% and 5% records: 0.86466 0.63212 0.39347 > ~ This feature helps user to understand bias of distribution for tuning threshold parameter. If this feature is nothing, it is difficult to understand distribution of access pattern, and it cannot realized on custom script. Because range of distribution (min, max, and SQL pattern) are unknown on custom script. So I think present UI is not bad and should not change. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
> Well, when we set '--gaussian=NUM' or '--exponential=NUM' on command line, we > can see access probability of top N records in result of final output. This > out put is under following, Indeed. I had forgotten this point. This is a significant information that I would not like to loose. > This feature helps user to understand bias of distribution for tuning > threshold parameter. > If this feature is nothing, it is difficult to understand distribution of > access pattern, and it cannot realized on custom script. Because range of > distribution (min, max, and SQL pattern) are unknown on custom script. So I > think present UI is not bad and should not change. Ok. I agree with this argument. -- Fabien.
On 03/13/2014 04:00 PM, Fujii Masao wrote: > On Thu, Mar 13, 2014 at 10:51 PM, Heikki Linnakangas > <hlinnakangas@vmware.com> wrote: >> IMHO we should just implement the \setrandom changes, and not add any of >> these options to modify the standard test workload. If someone wants to run >> TPC-B workload with gaussian or exponential distribution, they can implement >> it as a custom script. The docs include the script for the standard TPC-B >> workload; just copy-paster that and modify the \setrandom lines. > > Yeah, I'm OK with this. So I took a look at the \setrandom parts of this patch to see if that's ready for commit, without any of the changes to modify the standard TPC-B workload. Attached is a patch with just those parts; everyone please focus on this. A couple of comments: * There should be an explicit "\setrandom ... uniform" option too, even though you get that implicitly if you don't specify the distribution * What exactly does the "threshold" mean? The docs informally explain that "the larger the thresold, the more frequent values close to the middle of the interval are drawn", but that's pretty vague. * Does min and max really make sense for gaussian and exponential distributions? For gaussian, I would expect mean and standard deviation as the parameters, not min/max/threshold. * How about setting the variable as a float instead of integer? Would seem more natural to me. At least as an option. - Heikki
Вложения
Hello Heikki, > A couple of comments: > > * There should be an explicit "\setrandom ... uniform" option too, even > though you get that implicitly if you don't specify the distribution Indeed. I agree. I suggested it, but it got lost. > * What exactly does the "threshold" mean? The docs informally explain that > "the larger the thresold, the more frequent values close to the middle of the > interval are drawn", but that's pretty vague. There are explanations and computations as comments in the code. If it is about the documentation, I'm not sure that a very precise mathematical definition will help a lot of people, and might rather hinder understanding, so the doc focuses on an intuitive explanation instead. > * Does min and max really make sense for gaussian and exponential > distributions? For gaussian, I would expect mean and standard deviation as > the parameters, not min/max/threshold. Yes... and no:-) The aim is to draw an integer primary key from a table, so it must be in a specified range. This is approximated by drawing a double value with the expected distribution (gaussian or exponential) and project it carefully onto integers. If it is out of range, there is a loop and another value is drawn. The minimal threshold constraint (2.0) ensures that the probability of looping is low. > * How about setting the variable as a float instead of integer? Would seem > more natural to me. At least as an option. Which variable? The values set by setrandom are mostly used for primary keys. We really want integers in a range. -- Fabien.
Hello Heikki,Indeed. I agree. I suggested it, but it got lost.A couple of comments:
* There should be an explicit "\setrandom ... uniform" option too, even though you get that implicitly if you don't specify the distribution
There are explanations and computations as comments in the code. If it is about the documentation, I'm not sure that a very precise mathematical definition will help a lot of people, and might rather hinder understanding, so the doc focuses on an intuitive explanation instead.* What exactly does the "threshold" mean? The docs informally explain that "the larger the thresold, the more frequent values close to the middle of the interval are drawn", but that's pretty vague.
Yes... and no:-) The aim is to draw an integer primary key from a table, so it must be in a specified range. This is approximated by drawing a double value with the expected distribution (gaussian or exponential) and project it carefully onto integers. If it is out of range, there is a loop and another value is drawn. The minimal threshold constraint (2.0) ensures that the probability of looping is low.* Does min and max really make sense for gaussian and exponential distributions? For gaussian, I would expect mean and standard deviation as the parameters, not min/max/threshold.
Which variable? The values set by setrandom are mostly used for primary keys. We really want integers in a range.* How about setting the variable as a float instead of integer? Would seem more natural to me. At least as an option.
Вложения
Hi2014-03-15 15:53 GMT+09:00 Fabien COELHO <coelho@cri.ensmp.fr>:
Hello Heikki,Indeed. I agree. I suggested it, but it got lost.A couple of comments:
* There should be an explicit "\setrandom ... uniform" option too, even though you get that implicitly if you don't specify the distributionOK. If we keep to the SQL grammar, your saying is right. I will add it.There are explanations and computations as comments in the code. If it is about the documentation, I'm not sure that a very precise mathematical definition will help a lot of people, and might rather hinder understanding, so the doc focuses on an intuitive explanation instead.* What exactly does the "threshold" mean? The docs informally explain that "the larger the thresold, the more frequent values close to the middle of the interval are drawn", but that's pretty vague.Yeah, I think that we had better to only explain necessary infomation for using this feature. If we add mathematical theory in docs, it will be too difficult for user. And it's waste.Yes... and no:-) The aim is to draw an integer primary key from a table, so it must be in a specified range. This is approximated by drawing a double value with the expected distribution (gaussian or exponential) and project it carefully onto integers. If it is out of range, there is a loop and another value is drawn. The minimal threshold constraint (2.0) ensures that the probability of looping is low.* Does min and max really make sense for gaussian and exponential distributions? For gaussian, I would expect mean and standard deviation as the parameters, not min/max/threshold.I think it is difficult to understand from our text... So I create picture that will help you to understand it.Please see it.Which variable? The values set by setrandom are mostly used for primary keys. We really want integers in a range.* How about setting the variable as a float instead of integer? Would seem more natural to me. At least as an option.I think he said threshold parameter. Threshold parameter is very sensitive parameter, so we need to set double in threshold. I think that you can consent it when you see attached picture.regards,--Mitsumasa KONDONTT Open Source Software Center
Nice drawing! >> * How about setting the variable as a float instead of integer? Would >>> seem more natural to me. At least as an option. >> >> Which variable? The values set by setrandom are mostly used for primary >> keys. We really want integers in a range. > > I think he said threshold parameter. Threshold parameter is very sensitive > parameter, so we need to set double in threshold. I think that you can > consent it when you see attached picture. I'm sure that the threshold must be a double, but I thought it was already the case, because of atof, the static variables which are declared double, and the threshold function parameters which are declared double as well, and the putVariable uses a "%lf" format... Possibly I'm missing something? -- Fabien.
Nice drawing!* How about setting the variable as a float instead of integer? Wouldseem more natural to me. At least as an option.
Which variable? The values set by setrandom are mostly used for primary
keys. We really want integers in a range.
I think he said threshold parameter. Threshold parameter is very sensitive
parameter, so we need to set double in threshold. I think that you can
consent it when you see attached picture.
I'm sure that the threshold must be a double, but I thought it was already the case, because of atof, the static variables which are declared double, and the threshold function parameters which are declared double as well, and the putVariable uses a "%lf" format...
Possibly I'm missing something?
(2014/03/15 15:53), Fabien COELHO wrote: > > Hello Heikki, > >> A couple of comments: >> >> * There should be an explicit "\setrandom ... uniform" option too, even though >> you get that implicitly if you don't specify the distribution > > Indeed. I agree. I suggested it, but it got lost. > >> * What exactly does the "threshold" mean? The docs informally explain that "the >> larger the thresold, the more frequent values close to the middle of the >> interval are drawn", but that's pretty vague. > > There are explanations and computations as comments in the code. If it is about > the documentation, I'm not sure that a very precise mathematical definition will > help a lot of people, and might rather hinder understanding, so the doc focuses > on an intuitive explanation instead. > >> * Does min and max really make sense for gaussian and exponential >> distributions? For gaussian, I would expect mean and standard deviation as the >> parameters, not min/max/threshold. > > Yes... and no:-) The aim is to draw an integer primary key from a table, so it > must be in a specified range. This is approximated by drawing a double value with > the expected distribution (gaussian or exponential) and project it carefully onto > integers. If it is out of range, there is a loop and another value is drawn. The > minimal threshold constraint (2.0) ensures that the probability of looping is low. > >> * How about setting the variable as a float instead of integer? Would seem more >> natural to me. At least as an option. > > Which variable? The values set by setrandom are mostly used for primary keys. We > really want integers in a range. Oh, I see. He said about documents. + Moreover, set gaussian or exponential with threshold interger value, + we can get gaussian or exponential random in integer value between + <replaceable>min</> and <replaceable>max</> bounds inclusive. Collectry, + Moreover, set gaussian or exponential with threshold double value, + we can get gaussian or exponential random in integer value between + <replaceable>min</> and <replaceable>max</> bounds inclusive. And I am going to fix the document more easily understanding for user. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Hi Heikki-san, (2014/03/17 14:39), KONDO Mitsumasa wrote: > (2014/03/15 15:53), Fabien COELHO wrote: >> >> Hello Heikki, >> >>> A couple of comments: >>> >>> * There should be an explicit "\setrandom ... uniform" option too, even though >>> you get that implicitly if you don't specify the distribution Fix. We can use "\setrandom val min max uniform" without error messages. >>> * What exactly does the "threshold" mean? The docs informally explain that "the >>> larger the thresold, the more frequent values close to the middle of the >>> interval are drawn", but that's pretty vague. >> >> There are explanations and computations as comments in the code. If it is about >> the documentation, I'm not sure that a very precise mathematical definition will >> help a lot of people, and might rather hinder understanding, so the doc focuses >> on an intuitive explanation instead. Add more detail information in the document. Is it OK? Please confirm it. >>> * Does min and max really make sense for gaussian and exponential >>> distributions? For gaussian, I would expect mean and standard deviation as the >>> parameters, not min/max/threshold. >> >> Yes... and no:-) The aim is to draw an integer primary key from a table, so it >> must be in a specified range. This is approximated by drawing a double value with >> the expected distribution (gaussian or exponential) and project it carefully onto >> integers. If it is out of range, there is a loop and another value is drawn. The >> minimal threshold constraint (2.0) ensures that the probability of looping is low. It make sense. Please see the attached picutre in last day. >>> * How about setting the variable as a float instead of integer? Would seem more >>> natural to me. At least as an option. >> >> Which variable? The values set by setrandom are mostly used for primary keys. We >> really want integers in a range. > Oh, I see. He said about documents. The document was mistaken. Threshold parameter must be double and fix the document. By the way, you seem to want to remove --gaussian=NUM and --exponential=NUM command options. Can you tell me the objective reason? I think pgbench is the benchmark test on PostgreSQL and default benchmark is TPC-B-like benchmark. It is written in documents, and default benchmark wasn't changed by my patch. So we need not remove command options, and they are one of the variety of benchmark options. Maybe you have something misunderstanding about my patch... Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Вложения
On 03/15/2014 08:53 AM, Fabien COELHO wrote: >> >* Does min and max really make sense for gaussian and exponential >> >distributions? For gaussian, I would expect mean and standard deviation as >> >the parameters, not min/max/threshold. > Yes... and no:-) The aim is to draw an integer primary key from a table, > so it must be in a specified range. Well, I don't agree with that aim. It's useful for choosing a primary key, as in the pgbench TPC-B workload, but a gaussian distributed random number could be used for many other things too. For example: \setrandom foo ... gaussian select * from cheese where weight > :foo And :foo should be a float, not an integer. That's what I was trying to say earlier, when I said that the variable should be a float. If you need an integer, just cast or round it in the query. I realize that the current \setrandom sets the variable to an integer, so gaussian/exponential would be different. But so what? An option to generate uniformly distributed floats would be handy too, though. > This is approximated by drawing a > double value with the expected distribution (gaussian or exponential) and > project it carefully onto integers. If it is out of range, there is a loop > and another value is drawn. The minimal threshold constraint (2.0) ensures > that the probability of looping is low. Well, that's one way to do constraint it to the given range, but there are many other ways to do it. Like, clamp it to the min/max if it's out of range. I don't think we need to choose any particular method, you can handle that in the test script. - Heikki
On 03/17/2014 10:40 AM, KONDO Mitsumasa wrote: > By the way, you seem to want to remove --gaussian=NUM and --exponential=NUM > command options. Can you tell me the objective reason? I think pgbench is the > benchmark test on PostgreSQL and default benchmark is TPC-B-like benchmark. > It is written in documents, and default benchmark wasn't changed by my patch. > So we need not remove command options, and they are one of the variety of > benchmark options. Maybe you have something misunderstanding about my patch... There is an infinite number of variants of the TPC-B test that we could include in pgbench. If we start adding every one of them, we're quickly going to have hundreds of options to choose the workload. I'd like to keep pgbench simple. These two new test variants, gaussian and exponential, are not that special that they'd deserve to be included in the program itself. pgbench already has a mechanism for running custom scripts, in which you can specify whatever workload you want. Let's use that. If it's missing something you need to specify the workload you want, let's enhance the script language. The features we're missing, which makes it difficult to write the gaussian and exponential variants as custom scripts, is the capability to create random numbers with a non-uniform distribution. That's the feature we should include in pgbench. (Actually, you could do the Box-Muller transformation as part of the query, to convert the uniform random variable to a gaussian one. Then you wouldn't need any changes to pgbench. But I agree that "\setrandom ... gaussian" would be quite handy) - Heikki
(2014/03/17 17:46), Heikki Linnakangas wrote: > On 03/15/2014 08:53 AM, Fabien COELHO wrote: >>> >* Does min and max really make sense for gaussian and exponential >>> >distributions? For gaussian, I would expect mean and standard deviation as >>> >the parameters, not min/max/threshold. >> Yes... and no:-) The aim is to draw an integer primary key from a table, >> so it must be in a specified range. > > Well, I don't agree with that aim. It's useful for choosing a primary key, as in > the pgbench TPC-B workload, but a gaussian distributed random number could be > used for many other things too. For example: > > \setrandom foo ... gaussian > > select * from cheese where weight > :foo > > And :foo should be a float, not an integer. That's what I was trying to say > earlier, when I said that the variable should be a float. If you need an integer, > just cast or round it in the query. > > I realize that the current \setrandom sets the variable to an integer, so > gaussian/exponential would be different. But so what? An option to generate > uniformly distributed floats would be handy too, though. Well, it seems new feature. If you want to realise it as double, add '\setrandomd' as a double random generator in pgbebch. I will agree with that. >> This is approximated by drawing a >> double value with the expected distribution (gaussian or exponential) and >> project it carefully onto integers. If it is out of range, there is a loop >> and another value is drawn. The minimal threshold constraint (2.0) ensures >> that the probability of looping is low. > > Well, that's one way to do constraint it to the given range, but there are many > other ways to do it. Like, clamp it to the min/max if it's out of range. It's too heavy method.. Client calculation must be light. > I don't > think we need to choose any particular method, you can handle that in the test > script. I think our implementation is the best way to realize it. It is fast and robustness for the probability of looping is low. If you have better idea, please teach us. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
(2014/03/17 18:02), Heikki Linnakangas wrote: > On 03/17/2014 10:40 AM, KONDO Mitsumasa wrote: >> By the way, you seem to want to remove --gaussian=NUM and --exponential=NUM >> command options. Can you tell me the objective reason? I think pgbench is the >> benchmark test on PostgreSQL and default benchmark is TPC-B-like benchmark. >> It is written in documents, and default benchmark wasn't changed by my patch. >> So we need not remove command options, and they are one of the variety of >> benchmark options. Maybe you have something misunderstanding about my patch... > > There is an infinite number of variants of the TPC-B test that we could include > in pgbench. If we start adding every one of them, we're quickly going to have > hundreds of options to choose the workload. I'd like to keep pgbench simple. > These two new test variants, gaussian and exponential, are not that special that > they'd deserve to be included in the program itself. Well, I add only two options, and they are major distribution that are seen in real database system than uniform distiribution. I'm afraid, I think you are too worried and it will not be added hundreds of options. And pgbench is still simple. > pgbench already has a mechanism for running custom scripts, in which you can > specify whatever workload you want. Let's use that. If it's missing something you > need to specify the workload you want, let's enhance the script language. I have not seen user who is using pgbench custom script very much. And gaussian and exponential distribution are much better to measure the real system perfomance, so I'd like to use it command option. In now pgbench, we can only measure about database size, but it isn't realistic situation. We want to forcast the required system from calculating the size of hot spot or distirbution of access pettern. I'd realy like to include it on my heart:) Please... Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Mon, Mar 17, 2014 at 7:07 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > (2014/03/17 18:02), Heikki Linnakangas wrote: >> >> On 03/17/2014 10:40 AM, KONDO Mitsumasa wrote: >>> >>> By the way, you seem to want to remove --gaussian=NUM and >>> --exponential=NUM >>> command options. Can you tell me the objective reason? I think pgbench is >>> the >>> benchmark test on PostgreSQL and default benchmark is TPC-B-like >>> benchmark. >>> It is written in documents, and default benchmark wasn't changed by my >>> patch. >>> So we need not remove command options, and they are one of the variety of >>> benchmark options. Maybe you have something misunderstanding about my >>> patch... >> >> >> There is an infinite number of variants of the TPC-B test that we could >> include >> in pgbench. If we start adding every one of them, we're quickly going to >> have >> hundreds of options to choose the workload. I'd like to keep pgbench >> simple. >> These two new test variants, gaussian and exponential, are not that >> special that >> they'd deserve to be included in the program itself. > > Well, I add only two options, and they are major distribution that are seen > in real database system than uniform distiribution. I'm afraid, I think you > are too worried and it will not be added hundreds of options. And pgbench is > still simple. > > >> pgbench already has a mechanism for running custom scripts, in which you >> can >> specify whatever workload you want. Let's use that. If it's missing >> something you >> need to specify the workload you want, let's enhance the script language. > > I have not seen user who is using pgbench custom script very much. And > gaussian and exponential distribution are much better to measure the real > system perfomance, so I'd like to use it command option. In now pgbench, we > can only measure about database size, but it isn't realistic situation. We > want to forcast the required system from calculating the size of hot spot or > distirbution of access pettern. > > I'd realy like to include it on my heart:) Please... I have no strong opinion about the command-line option for gaussian, but I think that we should focus on \setrandom gaussian first. Even after that's committed, we can implement that commnand-line option later if many people think that's necessary. Regards, -- Fujii Masao
KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> writes:
> (2014/03/17 18:02), Heikki Linnakangas wrote:
>> On 03/17/2014 10:40 AM, KONDO Mitsumasa wrote:
>> There is an infinite number of variants of the TPC-B test that we could include
>> in pgbench. If we start adding every one of them, we're quickly going to have
>> hundreds of options to choose the workload. I'd like to keep pgbench simple.
>> These two new test variants, gaussian and exponential, are not that special that
>> they'd deserve to be included in the program itself.
> Well, I add only two options, and they are major distribution that are seen in
> real database system than uniform distiribution. I'm afraid, I think you are too
> worried and it will not be added hundreds of options. And pgbench is still simple.
FWIW, I concur with Heikki on this. Adding new versions of \setrandom is
useful functionality. Embedding them in the "standard" test is not,
because that just makes it (even) less standard. And pgbench has too darn
many switches already.
regards, tom lane
On Sat, Mar 15, 2014 at 4:50 AM, Mitsumasa KONDO <kondo.mitsumasa@gmail.com> wrote: >> There are explanations and computations as comments in the code. If it is >> about the documentation, I'm not sure that a very precise mathematical >> definition will help a lot of people, and might rather hinder understanding, >> so the doc focuses on an intuitive explanation instead. > > Yeah, I think that we had better to only explain necessary infomation for > using this feature. If we add mathematical theory in docs, it will be too > difficult for user. And it's waste. Well, if you *don't* include at least *some* mathematical description of what the feature does in the documentation, then users who need to understand it will have to read the source code to figure it out, which is going to be even more difficult. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
(2014/03/17 22:37), Tom Lane wrote: > KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> writes: >> (2014/03/17 18:02), Heikki Linnakangas wrote: >>> On 03/17/2014 10:40 AM, KONDO Mitsumasa wrote: >>> There is an infinite number of variants of the TPC-B test that we could include >>> in pgbench. If we start adding every one of them, we're quickly going to have >>> hundreds of options to choose the workload. I'd like to keep pgbench simple. >>> These two new test variants, gaussian and exponential, are not that special that >>> they'd deserve to be included in the program itself. > >> Well, I add only two options, and they are major distribution that are seen in >> real database system than uniform distiribution. I'm afraid, I think you are too >> worried and it will not be added hundreds of options. And pgbench is still simple. > > FWIW, I concur with Heikki on this. Adding new versions of \setrandom is > useful functionality. Embedding them in the "standard" test is not, > because that just makes it (even) less standard. And pgbench has too darn > many switches already. Hmm, I cooled down and see the pgbench option. I can understand his arguments, there are many sitches already and it will become more largear options unless we stop adding new option. However, I think that the man who added the option in the past thought the option will be useful for PostgreSQL performance improvement. But now, they are disturb the new option such like my feature which can create more real system benchmark distribution. I think it is very unfortunate and also tending to stop progress of improvement of PostgreSQL performance, not only pgbench. And if we remove command line option, I think new feature will tend to reject. It is not also good. By the way, if we remove command line option, it is difficult to understand distirbution of gaussian, because threshold parameter is very sensitive and it is also very useful feature. It is difficult and taking labor that analyzing and visualization pgbench_history using SQL. What do you think about this problem? This is not disscussed yet. > [mitsu-ko@pg-rex31 pgbench]$ ./pgbench --gaussian=2 > ~ > access probability of top 20%, 10% and 5% records: 0.32566 0.16608 0.08345 > ~ > [mitsu-ko@pg-rex31 pgbench]$ ./pgbench --gaussian=4 > ~ > access probability of top 20%, 10% and 5% records: 0.57633 0.31086 0.15853 > ~ > [mitsu-ko@pg-rex31 pgbench]$ ./pgbench --gaussian=10 > ~ > access probability of top 20%, 10% and 5% records: 0.95450 0.68269 0.38292 > ~ Regards, -- Mitsumasa KONDO NTT Open Source Software Center
(2014/03/17 23:29), Robert Haas wrote: > On Sat, Mar 15, 2014 at 4:50 AM, Mitsumasa KONDO > <kondo.mitsumasa@gmail.com> wrote: >>> There are explanations and computations as comments in the code. If it is >>> about the documentation, I'm not sure that a very precise mathematical >>> definition will help a lot of people, and might rather hinder understanding, >>> so the doc focuses on an intuitive explanation instead. >> >> Yeah, I think that we had better to only explain necessary infomation for >> using this feature. If we add mathematical theory in docs, it will be too >> difficult for user. And it's waste. > > Well, if you *don't* include at least *some* mathematical description > of what the feature does in the documentation, then users who need to > understand it will have to read the source code to figure it out, > which is going to be even more difficult. I had fixed this problem. Please see the v12 patch. I think it doesn't includ mathematical description, but user will be able to understand intuitive from the explanation of document. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
And I find new useful point of this feature. Under following results are '--gaussian=20' case and '--gaussian=2' case, and postgresql setting is same. > [mitsu-ko@pg-rex31 pgbench]$ ./pgbench -c8 -j4 --gaussian=20 -T30 -P 5 > starting vacuum...end. > progress: 5.0 s, 4285.8 tps, lat 1.860 ms stddev 0.425 > progress: 10.0 s, 4249.2 tps, lat 1.879 ms stddev 0.372 > progress: 15.0 s, 4230.3 tps, lat 1.888 ms stddev 0.430 > progress: 20.0 s, 4247.3 tps, lat 1.880 ms stddev 0.400 > LOG: checkpoints are occurring too frequently (12 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 25.0 s, 4269.0 tps, lat 1.870 ms stddev 0.427 > progress: 30.0 s, 4318.1 tps, lat 1.849 ms stddev 0.415 > transaction type: Gaussian distribution TPC-B (sort of) > scaling factor: 10 > standard deviation threshold: 20.00000 > access probability of top 20%, 10% and 5% records: 0.99994 0.95450 0.68269 > query mode: simple > number of clients: 8 > number of threads: 4 > duration: 30 s > number of transactions actually processed: 128008 > latency average: 1.871 ms > latency stddev: 0.412 ms > tps = 4266.266374 (including connections establishing) > tps = 4267.312022 (excluding connections establishing) > [mitsu-ko@pg-rex31 pgbench]$ ./pgbench -c8 -j4 --gaussian=2 -T30 -P 5 > starting vacuum...end. > LOG: checkpoints are occurring too frequently (13 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (1 second apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 5.0 s, 3927.9 tps, lat 2.030 ms stddev 0.691 > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (1 second apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 10.0 s, 4045.8 tps, lat 1.974 ms stddev 0.835 > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (1 second apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 15.0 s, 4042.5 tps, lat 1.976 ms stddev 0.613 > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 20.0 s, 4103.9 tps, lat 1.946 ms stddev 0.540 > LOG: checkpoints are occurring too frequently (1 second apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 25.0 s, 4003.1 tps, lat 1.995 ms stddev 0.526 > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (1 second apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > LOG: checkpoints are occurring too frequently (2 seconds apart) > HINT: Consider increasing the configuration parameter "checkpoint_segments". > progress: 30.0 s, 4025.5 tps, lat 1.984 ms stddev 0.568 > transaction type: Gaussian distribution TPC-B (sort of) > scaling factor: 10 > standard deviation threshold: 2.00000 > access probability of top 20%, 10% and 5% records: 0.32566 0.16608 0.08345 > query mode: simple > number of clients: 8 > number of threads: 4 > duration: 30 s > number of transactions actually processed: 120752 > latency average: 1.984 ms > latency stddev: 0.638 ms > tps = 4024.823433 (including connections establishing) > tps = 4025.777787 (excluding connections establishing) In '--gaussian=2' benchmark, checkpoint is frequently happen than '--gaussian=20' benchmark. Because former update large range of records so that fullpage write WALs are bigger than later. Former distribution updates large range of records, so that fullpage-write WALs are bigger than later distribution. Such benchmark was not able to come out by the past pgbench at all. I think that this feature will be also useful for survey new buffer-replace algorithm and checkpoint strategy, so on. If we remove this option, it is really dissapointed.. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On 03/18/2014 11:57 AM, KONDO Mitsumasa wrote: > I think that this feature will be also useful for survey new buffer-replace > algorithm and checkpoint strategy, so on. Sure. No doubt about that. > If we remove this option, it is really dissapointed.. As long as we get the \setrandom changes in, you can easily do these tests using a custom script. There's nothing wrong with using a custom script, it will be just as useful for exploring buffer replacement algorithms, checkpoints etc. as a built-in option. - Heikki
Please find attached an updated version "v13" for this patch. I have (I hope) significanlty improved the documentation, including not so helpful mathematical explanation about the actual meaning of the threshold value. If a native English speaker could check the documentation, it would be nice! I have improved the implementation of the exponential distribution so as to avoid a loop, which allows to lift the minimum threshold value constraint, and the exponential pgbench summary displays decile and first/last percent drawing probabilities. However, the same simplification cannot be applied on the gaussian distribution part which must rely on a loop, thus needs a minimal threshold for performance. I have also checked (see the 4 attached scripts) the actual distribution against the computed probabilities. I disagree with the suggestion to remove the included gaussian & exponential tests variants, because (1) it would mean removing the specific summaries as well, which are essential to help feel how the feature works; (2) the corresponding code in the source is rather straightforward; (3) the tests correspond to the schema and data created with -i, so it makes sense that they are stored in pgbench; (4) in order for this feature to be used, it is best that it is available directly and simply from pgbench, and not to be thought for elsewhere. If this is a commit blocker, then the embedded script will have to be removed, but I really think that they add a significant value to pgbench and its "non uniform" features because they make it easy to test. If Mitsumasa-san aggrees with these proposed changes, I would suggest to apply this patch. -- Fabien
generating algorithm. It works fine and less or no overhead than previous version.
And I'm also interested in your "decile percents" output like under followings,
> ~
> decile percents: 86.5% 11.7% 1.6% 0.2% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
> ~
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10
> ~
> decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0%
> ~
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=5
> ~
> decile percents: 39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4%
> ~
in gaussian distribution.
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --gaussian=20
> ~
> decile percents: 0.0% 0.0% 0.0% 0.0% 50.0% 50.0% 0.0% 0.0% 0.0% 0.0%
> ~
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --gaussian=10
> ~
> decile percents: 0.0% 0.0% 0.0% 2.3% 47.7% 47.7% 2.3% 0.0% 0.0% 0.0%
> ~
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --gaussian=5
> ~
> decile percents: 0.0% 0.1% 2.1% 13.6% 34.1% 34.1% 13.6% 2.1% 0.1% 0.0%
with decile percentage for users, and anyone cannot understand this digits.
> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=5
> ~
> decile percents: 39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4%
> highest/lowest percent of the range: 4.9% 0.0%
> ~
So I'd like to remove it if you like. It will be more simple.
Вложения
Hello Mitsumasa-san, > And I'm also interested in your "decile percents" output like under > followings, > decile percents: 39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4% Sure, I'm really fine with that. > I think that it is easier than before. Sum of decile percents is just 100%. That's a good property:-) > However, I don't prefer "highest/lowest percentage" because it will be > confused with decile percentage for users, and anyone cannot understand > this digits. I cannot understand "4.9%, 0.0%" when I see the first time. > Then, I checked the source code, I understood it:( It's not good > design... #Why this parameter use 100? What else? People have ten fingers and like powers of 10, and are used to percents? > So I'd like to remove it if you like. It will be more simple. I think that for the exponential distribution it helps, especially for high threshold, to have the lowest/highest percent density. For low thresholds, the decile is also definitely useful. So I'm fine with both outputs as you have put them. I have just updated the wording so that it may be clearer: decile percents: 69.9% 21.0% 6.3% 1.9% 0.6% 0.2% 0.1% 0.0% 0.0% 0.0% probability of fist/last percent of the range: 11.3%0.0% > Attached patch is fixed version, please confirm it. Attached a v15 which just fixes a typo and the above wording update. I'm validating it for committers. > #Of course, World Cup is being held now. I'm not hurry at all. I'm not a soccer kind of person, so it does not influence my availibility.:-) Suggested commit message: Add drawing random integers with a Gaussian or truncated exponentional distributions to pgbench. Test variants with these distributions are also provided and triggered with options "--gaussian=..." and "--exponential=...". Have a nice day/night, -- Fabien.
> I have just updated the wording so that it may be clearer: Oops, I have sent the wrong patch, without the wording fix. Here is the real updated version, which I tested. > probability of fist/last percent of the range: 11.3% 0.0% -- Fabien.
<div class="moz-cite-prefix">On 02/07/14 21:05, Fabien COELHO wrote:<br /></div><blockquote cite="mid:alpine.DEB.2.10.1407021046080.22369@sto"type="cite"><br /> Hello Mitsumasa-san, <br /><br /><blockquote type="cite">AndI'm also interested in your "decile percents" output like under <br /> followings, <br /> decile percents:39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4% <br /></blockquote><br /> Sure, I'm really fine with that.<br /><br /><blockquote type="cite">I think that it is easier than before. Sum of decile percents is just 100%. <br/></blockquote><br /> That's a good property:-) <br /><br /><blockquote type="cite">However, I don't prefer "highest/lowestpercentage" because it will be confused with decile percentage for users, and anyone cannot understand thisdigits. I cannot understand "4.9%, 0.0%" when I see the first time. Then, I checked the source code, I understood it:(It's not good design... #Why this parameter use 100? <br /></blockquote><br /> What else? People have ten fingers andlike powers of 10, and are used to percents? <br /><br /><blockquote type="cite">So I'd like to remove it if you like.It will be more simple. <br /></blockquote><br /> I think that for the exponential distribution it helps, especiallyfor high threshold, to have the lowest/highest percent density. For low thresholds, the decile is also definitelyuseful. So I'm fine with both outputs as you have put them. <br /><br /> I have just updated the wording so thatit may be clearer: <br /><br /> decile percents: 69.9% 21.0% 6.3% 1.9% 0.6% 0.2% 0.1% 0.0% 0.0% 0.0% <br /> probabilityof fist/last percent of the range: 11.3% 0.0% <br /><br /><blockquote type="cite">Attached patch is fixed version,please confirm it. <br /></blockquote><br /> Attached a v15 which just fixes a typo and the above wording update.I'm validating it for committers. <br /><br /><blockquote type="cite">#Of course, World Cup is being held now. I'mnot hurry at all. <br /></blockquote><br /> I'm not a soccer kind of person, so it does not influence my availibility.:-)<br /><br /><br /> Suggested commit message: <br /><br /> Add drawing random integers with a Gaussian ortruncated exponentional distributions to pgbench. <br /><br /> Test variants with these distributions are also providedand triggered <br /> with options "--gaussian=..." and "--exponential=...". <br /><br /><br /> Have a nice day/night,<br /><br /><br /><fieldset class="mimeAttachmentHeader"></fieldset><br /><pre wrap=""> </pre></blockquote> I would suggest that probabilities should NEVER be expressed in percentages! As a percentage probabilitylooks weird, and is never used for serious statistical work - in my experience at least.<br /><br /> I think probabilitiesshould be expressed in the range 0 ... 1 - i.e. 0.35 rather than 35%.<br /><br /><br /> Cheers,<br /> Gavin<br/>
Hello Gavin, >> decile percents: 69.9% 21.0% 6.3% 1.9% 0.6% 0.2% 0.1% 0.0% 0.0% 0.0% >> probability of fist/last percent of the range: 11.3% 0.0% > I would suggest that probabilities should NEVER be expressed in percentages! > As a percentage probability looks weird, and is never used for serious > statistical work - in my experience at least. > > I think probabilities should be expressed in the range 0 ... 1 - i.e. 0.35 > rather than 35%. I could agree about the mathematics, but ISTM that "11.5%" is more readable and intuitive than "0.115". I could change "probability" and replace it with "frequency" or maybe "occurence", what would you think about that? -- Fabien.
On 03/07/14 20:58, Fabien COELHO wrote: > > Hello Gavin, > >>> decile percents: 69.9% 21.0% 6.3% 1.9% 0.6% 0.2% 0.1% 0.0% 0.0% 0.0% >>> probability of fist/last percent of the range: 11.3% 0.0% > >> I would suggest that probabilities should NEVER be expressed in >> percentages! As a percentage probability looks weird, and is never >> used for serious statistical work - in my experience at least. >> >> I think probabilities should be expressed in the range 0 ... 1 - i.e. >> 0.35 rather than 35%. > > I could agree about the mathematics, but ISTM that "11.5%" is more > readable and intuitive than "0.115". > > I could change "probability" and replace it with "frequency" or maybe > "occurence", what would you think about that? > You may well be hitting a situation, where you meet opposition whatever you do! :-) "frequency" implies a positive integer (though "relative frequency" might be okay) - and if you use "occurrence", someone else is bound to complain... Though, I'd opt for "relative frequency", if you can't use values in the range 0 ... 1 for probabilities, if %'s are used - so long as it does not generate a flame war. I suspect it may not be worth the grief to change. Cheers, Gavin
On Wed, Jul 2, 2014 at 6:05 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: > > Hello Mitsumasa-san, > >> And I'm also interested in your "decile percents" output like under >> followings, >> decile percents: 39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4% > > > Sure, I'm really fine with that. > > >> I think that it is easier than before. Sum of decile percents is just >> 100%. > > > That's a good property:-) > >> However, I don't prefer "highest/lowest percentage" because it will be >> confused with decile percentage for users, and anyone cannot understand this >> digits. I cannot understand "4.9%, 0.0%" when I see the first time. Then, I >> checked the source code, I understood it:( It's not good design... #Why this >> parameter use 100? > > > What else? People have ten fingers and like powers of 10, and are used to > percents? > > >> So I'd like to remove it if you like. It will be more simple. > > > I think that for the exponential distribution it helps, especially for high > threshold, to have the lowest/highest percent density. For low thresholds, > the decile is also definitely useful. So I'm fine with both outputs as you > have put them. > > I have just updated the wording so that it may be clearer: > > decile percents: 69.9% 21.0% 6.3% 1.9% 0.6% 0.2% 0.1% 0.0% 0.0% 0.0% > probability of fist/last percent of the range: 11.3% 0.0% > > >> Attached patch is fixed version, please confirm it. > > > Attached a v15 which just fixes a typo and the above wording update. I'm > validating it for committers. > > >> #Of course, World Cup is being held now. I'm not hurry at all. > > > I'm not a soccer kind of person, so it does not influence my > availibility.:-) > > > Suggested commit message: > > Add drawing random integers with a Gaussian or truncated exponentional > distributions to pgbench. > > Test variants with these distributions are also provided and triggered > with options "--gaussian=..." and "--exponential=...". IIRC we've not reached consensus about whether we should support such options in pgbench. Several hackers disagreed to support them. OTOH, we've almost reached the consensus that supporting gaussian and exponential options in \setrandom. So I think that you should separate those two features into two patches, and we should apply the \setrandom one first. Then we can discuss whether the other patch should be applied or not. Regards, -- Fujii Masao
On 2014-07-03 21:27:53 +0900, Fujii Masao wrote: > > Add drawing random integers with a Gaussian or truncated exponentional > > distributions to pgbench. > > > > Test variants with these distributions are also provided and triggered > > with options "--gaussian=..." and "--exponential=...". > > IIRC we've not reached consensus about whether we should support > such options in pgbench. Several hackers disagreed to support them. Yea. I certainly disagree with the patch in it's current state because it copies the same 15 lines several times with a two word difference. Independent of whether we want those options, I don't think that's going to fly. > OTOH, we've almost reached the consensus that supporting gaussian > and exponential options in \setrandom. So I think that you should > separate those two features into two patches, and we should apply > the \setrandom one first. Then we can discuss whether the other patch > should be applied or not. Sounds like a good plan. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> Yea. I certainly disagree with the patch in it's current state because > it copies the same 15 lines several times with a two word difference. > Independent of whether we want those options, I don't think that's going > to fly. I liked a simple static string for the different variants, which means replication. Factorizing out the (large) common part will mean malloc & sprintf. Well, why not. >> OTOH, we've almost reached the consensus that supporting gaussian >> and exponential options in \setrandom. So I think that you should >> separate those two features into two patches, and we should apply >> the \setrandom one first. Then we can discuss whether the other patch >> should be applied or not. > Sounds like a good plan. Sigh. I'll do that as it seems to be a blocker... The caveat that I have is that without these options there is: (1) no return about the actual distributions in the final summary, which depend on the threshold value, and (2) no included mean to test the feature, so the first patch is less meaningful if the feature cannot be used simply and require a custom script. -- Fabien.
On 2014-07-04 11:59:23 +0200, Fabien COELHO wrote: > > >Yea. I certainly disagree with the patch in it's current state because it > >copies the same 15 lines several times with a two word difference. > >Independent of whether we want those options, I don't think that's going > >to fly. > > I liked a simple static string for the different variants, which means > replication. Factorizing out the (large) common part will mean malloc & > sprintf. Well, why not. It sucks from a maintenance POV. And I don't see the overhead of malloc being relevant here... > >>OTOH, we've almost reached the consensus that supporting gaussian > >>and exponential options in \setrandom. So I think that you should > >>separate those two features into two patches, and we should apply > >>the \setrandom one first. Then we can discuss whether the other patch > >>should be applied or not. > > >Sounds like a good plan. > > Sigh. I'll do that as it seems to be a blocker... I think we also need documentation about the actual mathematical behaviour of the randomness generators. > + <para> > + With the gaussian option, the larger the <replaceable>threshold</>, > + the more frequently values close to the middle of the interval are drawn, > + and the less frequently values close to the <replaceable>min</> and > + <replaceable>max</> bounds. > + In other worlds, the larger the <replaceable>threshold</>, > + the narrower the access range around the middle. > + the smaller the threshold, the smoother the access pattern > + distribution. The minimum threshold is 2.0 for performance. > + </para> The only way to actually understand the distribution here is to create a table, insert random values, and then look at the result. That's not a good thing. > The caveat that I have is that without these options there is: > > (1) no return about the actual distributions in the final summary, which > depend on the threshold value, and > > (2) no included mean to test the feature, so the first patch is less > meaningful if the feature cannot be used simply and require a custom script. I personally agree that we likely want that as an additional feature. Even if just because it makes the results easier to compare. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 2014-07-04 11:59:23 +0200, Fabien COELHO wrote:It sucks from a maintenance POV. And I don't see the overhead of malloc
>
> >Yea. I certainly disagree with the patch in it's current state because it
> >copies the same 15 lines several times with a two word difference.
> >Independent of whether we want those options, I don't think that's going
> >to fly.
>
> I liked a simple static string for the different variants, which means
> replication. Factorizing out the (large) common part will mean malloc &
> sprintf. Well, why not.
being relevant here...
> >>OTOH, we've almost reached the consensus that supporting gaussian
> >>and exponential options in \setrandom. So I think that you should
> >>separate those two features into two patches, and we should apply
> >>the \setrandom one first. Then we can discuss whether the other patch
> >>should be applied or not.
>
> >Sounds like a good plan.
>
> Sigh. I'll do that as it seems to be a blocker...
I think we also need documentation about the actual mathematical
behaviour of the randomness generators.
> + <para>
> + With the gaussian option, the larger the <replaceable>threshold</>,
> + the more frequently values close to the middle of the interval are drawn,
> + and the less frequently values close to the <replaceable>min</> and
> + <replaceable>max</> bounds.
> + In other worlds, the larger the <replaceable>threshold</>,
> + the narrower the access range around the middle.
> + the smaller the threshold, the smoother the access pattern
> + distribution. The minimum threshold is 2.0 for performance.
> + </para>
The only way to actually understand the distribution here is to create a
table, insert random values, and then look at the result. That's not a
good thing.
[nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10
starting vacuum...end.
transaction type: Exponential distribution TPC-B (sort of)
scaling factor: 1
exponential threshold: 10.00000
decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0%
highest/lowest percent of the range: 9.5% 0.0%
[nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=5
starting vacuum...end.
transaction type: Exponential distribution TPC-B (sort of)
scaling factor: 1
exponential threshold: 5.00000
decile percents: 39.6% 24.0% 14.6% 8.8% 5.4% 3.3% 2.0% 1.2% 0.7% 0.4%
highest/lowest percent of the range: 4.9% 0.0%
> The caveat that I have is that without these options there is:I personally agree that we likely want that as an additional
>
> (1) no return about the actual distributions in the final summary, which
> depend on the threshold value, and
>
> (2) no included mean to test the feature, so the first patch is less
> meaningful if the feature cannot be used simply and require a custom script.
feature. Even if just because it makes the results easier to compare.
Actuary, he didn't answer to our proposal about understanding the parametrized distribution...
So I also think it is blocker. Command line feature is also needed.
On Sun, Jul 13, 2014 at 2:27 AM, Mitsumasa KONDO <kondo.mitsumasa@gmail.com> wrote: > I still agree with Fabien-san. I cannot understand why our logical proposal > isn't accepted... Well, I think the feedback has been pretty clear, honestly. Here's what I'm unhappy about: I can't understand what these options are actually doing. And this isn't helping me a bit: > [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10 > starting vacuum...end. > transaction type: Exponential distribution TPC-B (sort of) > scaling factor: 1 > exponential threshold: 10.00000 > > decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0% > highest/lowest percent of the range: 9.5% 0.0% I don't have a clue what that means. None. Here is an example of an explanation that would make sense to me. This is not the actual behavior of your patch, I'm quite sure, so this is just an example of the *kind* of explanation that I think is needed: The --exponential option causes pgbench to select lower-numbered account IDs exponentially more frequently than higher-numbered account IDs. The argument to --exponential controls the strength of the preference for lower-numbered account IDs, with a smaller value indicating a stronger preference. Specifically, it is the percentage of the total number of account IDs which will receive half the total accesses. For example, with --exponential=10, half the accesses will be to the smallest 10 percent of the account IDs; half the remaining accesses will be to the next-smallest 10 percent of account IDs, and so on. --exponential=50 therefore represents a completely flat distribution; larger values are not allowed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Robert, > Well, I think the feedback has been pretty clear, honestly. Here's > what I'm unhappy about: I can't understand what these options are > actually doing. We can try to improve the documentation, once more! However, ISTM that it is not the purpose of pgbench documentation to be a primer about what is an exponential or gaussian distribution, so the idea would yet be to have a relatively compact explanation, and that the interested but clueless reader would document h..self from wikipedia or a text book or a friend or a math teacher (who could be a friend as well:-). >> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10 >> starting vacuum...end. >> transaction type: Exponential distribution TPC-B (sort of) >> scaling factor: 1 >> exponential threshold: 10.00000 >> >> decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0% >> highest/lowest percent of the range: 9.5% 0.0% > > I don't have a clue what that means. None. Maybe we could add in front of the decile/percent "distribution of increasing account key values selected by pgbench:" > Here is an example of an explanation that would make sense to me. > This is not the actual behavior of your patch, I'm quite sure, so this > is just an example of the *kind* of explanation that I think is > needed: This is more or less the approximate behavior of the patch, but for 1% of the range, not 50%. However I'm not sure that the current documentation is so bad. > The --exponential option causes pgbench to select lower-numbered > account IDs exponentially more frequently than higher-numbered account > IDs. The argument to --exponential controls the strength of the > preference for lower-numbered account IDs, with a smaller value > indicating a stronger preference. Specifically, it is the percentage > of the total number of account IDs which will receive half the total > accesses. For example, with --exponential=10, half the accesses will > be to the smallest 10 percent of the account IDs; half the remaining > accesses will be to the next-smallest 10 percent of account IDs, and > so on. --exponential=50 therefore represents a completely flat > distribution; larger values are not allowed. -- Fabien.
pgbench with gaussian & exponential, part 1 of 2. This patch is a subset of the previous patch which only adds the two new \setrandom gaussian and exponantial variants, but not the adapted pgbench test cases, as suggested by Fujii Masao. There is no new code nor code changes. The corresponding documentation has been yet again extended wrt to the initial patch, so that what is achieved is hopefully unambiguous (there are two mathematical formula, tasty!), in answer to Andres Freund comments, and partly to Robert Haas comments as well. This patch also provides several sql/pgbench scripts and a README, so that the feature can be tested. I do not know whether these scripts should make it to postgresql. I would say yes, otherwise there is no way to test... part 2 which provide adapted pgbench test cases will come later. -- Fabien.
On Wed, Jul 16, 2014 at 12:57 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> Well, I think the feedback has been pretty clear, honestly. Here's >> what I'm unhappy about: I can't understand what these options are >> actually doing. > > We can try to improve the documentation, once more! > > However, ISTM that it is not the purpose of pgbench documentation to be a > primer about what is an exponential or gaussian distribution, so the idea > would yet be to have a relatively compact explanation, and that the > interested but clueless reader would document h..self from wikipedia or a > text book or a friend or a math teacher (who could be a friend as well:-). Well, I think it's a balance. I agree that the pgbench documentation shouldn't try to substitute for a text book or a math teacher, but I also think that you shouldn't necessarily need to refer to a text book or a math teacher in order to figure out how to use pgbench. Saying "it's complicated, so we don't have to explain it" would be a cop out; we need to *make* it simple. And if there's no way to do that, then IMHO we should reject the patch in favor of some future patch that implements something that will be easy for users to understand. >>> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10 >>> starting vacuum...end. >>> transaction type: Exponential distribution TPC-B (sort of) >>> scaling factor: 1 >>> exponential threshold: 10.00000 >>> >>> decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0% >>> highest/lowest percent of the range: 9.5% 0.0% >> >> I don't have a clue what that means. None. > > Maybe we could add in front of the decile/percent > > "distribution of increasing account key values selected by pgbench:" I still wouldn't know what that meant. And it misses the point anyway: if the documentation is good, this will be unnecessary. If the documentation is bad, a printout that tries to illustrate it by example is not an acceptable substitute. >> Here is an example of an explanation that would make sense to me. >> This is not the actual behavior of your patch, I'm quite sure, so this >> is just an example of the *kind* of explanation that I think is >> needed: > > This is more or less the approximate behavior of the patch, but for 1% of > the range, not 50%. However I'm not sure that the current documentation is > so bad. I think it isn't, because in the system I described, a larger value indicates a flatter distribution, but in the documentation, a smaller value indicates a flatter distribution. That having been said, I agree the current documentation for the exponential distribution is not too bad. But this part does not make sense: + A crude approximation of the distribution is that the most frequent 1% + values are drawn <replaceable>threshold</>% of the time. + The closer to 0.0 the threshold, the flatter (more uniform) the access + distribution. Given the first statement, I'd expect the lowest possible threshold to be 0.01, not 0. The documentation for the Gaussian distribution is in somewhat worse shape. Unlike the documentation for exponential, it makes no attempt at all to give the user a clear idea what the distribution actually looks like. The closest it comes is this: + In other worlds, the larger the <replaceable>threshold</>, + the narrower the access range around the middle. But that's not really very close - there's no way for a user to judge what impact the threshold parameter actually has except to try it. Unlike the discussion of exponential, which contains a fairly-precise mathematical characterization of the behavior, the Gaussian stuff has nothing except a hand-wavy explanation that a higher threshold skews the distribution more. (Also, the English expression is "in other words" not "in other worlds" - but in fact the phrase has no business in that sentence at all, because it is not reiterating the contents of the previous sentence in different language, but rather making a new point entirely. And the following sentence does not start with a capital letter, though maybe that's because it was intended to be incorporated into this sentence somehow.) I think that you also need to consider which instances of the words "gaussian" and "exponential" are referring to the option and which are referring to the abstract mathematical concept. When you're talking about the option, you should use all lower-case (as you've done) but with <literal> tags or similar. When you're referring to the mathematical distribution, Gaussian should be capitalized. BTW, I agree with both Heikki's suggestion that we make these options to setrandom only and not expose command-line options for them, and with Andres's critique that the documentation of those options is far too repetitive. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>> However, ISTM that it is not the purpose of pgbench documentation to be a
>> primer about what is an exponential or gaussian distribution, so the idea
>> would yet be to have a relatively compact explanation, and that the
>> interested but clueless reader would document h..self from wikipedia or a
>> text book or a friend or a math teacher (who could be a friend as well:-).
>
> Well, I think it's a balance. I agree that the pgbench documentation
> shouldn't try to substitute for a text book or a math teacher, but I
> also think that you shouldn't necessarily need to refer to a text book
> or a math teacher in order to figure out how to use pgbench. Saying
> "it's complicated, so we don't have to explain it" would be a cop out;
> we need to *make* it simple. And if there's no way to do that, then
> IMHO we should reject the patch in favor of some future patch that
> implements something that will be easy for users to understand.
>
>>>> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10
>>>> starting vacuum...end.
>>>> transaction type: Exponential distribution TPC-B (sort of)
>>>> scaling factor: 1
>>>> exponential threshold: 10.00000
>>>>
>>>> decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0%
>>>> highest/lowest percent of the range: 9.5% 0.0%
>>>
>>> I don't have a clue what that means. None.
>>
>> Maybe we could add in front of the decile/percent
>>
>> "distribution of increasing account key values selected by pgbench:"
>
> I still wouldn't know what that meant. And it misses the point
> anyway: if the documentation is good, this will be unnecessary. If
> the documentation is bad, a printout that tries to illustrate it by
> example is not an acceptable substitute.
The decile description is quite classic when discussing statistics.
>>> Here is an example of an explanation that would make sense to me.
>>> This is not the actual behavior of your patch, I'm quite sure, so this
>>> is just an example of the *kind* of explanation that I think is
>>> needed:
>>
>> This is more or less the approximate behavior of the patch, but for 1% of
>> the range, not 50%. However I'm not sure that the current documentation is
>> so bad.
>
> I think it isn't, because in the system I described, a larger value
> indicates a flatter distribution, but in the documentation, a smaller
> value indicates a flatter distribution.
Ok. But the general thrust was ok.
> That having been said, I agree the current documentation for the
> exponential distribution is not too bad. But this part does not make
> sense:
>
> + A crude approximation of the distribution is that the most frequent 1%
> + values are drawn <replaceable>threshold</>% of the time.
I'm trying to be nice to the reader by providing an intuitive
information. I do not seem to succeed:-) I'm attempting to say that when
you draw from a range, say 1 to 1000, the first 1%, i.e. values 1 to 10,
are draw about "threshold"% of the time.
If I draw from one hundred values:
\setrandom x 1 100 exponential 10.0
The 1 will be drawn about 10% of the time, and the 99 next values will
share the remaining 90%.
> + The closer to 0.0 the threshold, the flatter (more uniform) the access
> + distribution.
>
> Given the first statement, I'd expect the lowest possible threshold to
> be 0.01, not 0.
This is in the sense of "epsilon", small number close to 0 but different
from 0. The lowest possible threshold is the smallest
strictly positive representable with a "double".
> The documentation for the Gaussian distribution is in somewhat worse
> shape. Unlike the documentation for exponential, it makes no attempt
> at all to give the user a clear idea what the distribution actually
> looks like. The closest it comes is this:
>
> + In other worlds, the larger the <replaceable>threshold</>,
> + the narrower the access range around the middle.
>
> But that's not really very close - there's no way for a user to judge
> what impact the threshold parameter actually has except to try it.
> Unlike the discussion of exponential, which contains a fairly-precise
> mathematical characterization of the behavior,
I have now added a precise formula for Gaussian. When you see the formula,
maybe you still would want see the decile to have an intuition.
I think that we assumed that the reader would know that a gaussian
distribution is the classic bell-shaped distribution, and if not .?he
would not be interested anyway.
> the Gaussian stuff has
> nothing except a hand-wavy explanation that a higher threshold skews
> the distribution more. (Also, the English expression is "in other
> words" not "in other worlds" - but in fact the phrase has no business
> in that sentence at all, because it is not reiterating the contents of
> the previous sentence in different language, but rather making a new
> point entirely. And the following sentence does not start with a
> capital letter, though maybe that's because it was intended to be
> incorporated into this sentence somehow.)
>
> I think that you also need to consider which instances of the words
> "gaussian" and "exponential" are referring to the option and which are
> referring to the abstract mathematical concept. When you're talking
> about the option, you should use all lower-case (as you've done) but
> with <literal> tags or similar. When you're referring to the
> mathematical distribution, Gaussian should be capitalized.
>
> BTW, I agree with both Heikki's suggestion that we make these options
> to setrandom only and not expose command-line options for them, and
> with Andres's critique that the documentation of those options is far
> too repetitive.
I'll have yet another ago at trying to improve the documentation, esp the
gaussian part. However you must allow that these are Mathematics, and the
user who wants to use these distribution will be expected to understand
what they are somehow beforehand.
Moreover, I cannot make it precise, intuitive and very short.
--
Fabien.
The decile description is quite classic when discussing statistics.However, ISTM that it is not the purpose of pgbench documentation to be a
primer about what is an exponential or gaussian distribution, so the idea
would yet be to have a relatively compact explanation, and that the
interested but clueless reader would document h..self from wikipedia or a
text book or a friend or a math teacher (who could be a friend as well:-).
Well, I think it's a balance. I agree that the pgbench documentation
shouldn't try to substitute for a text book or a math teacher, but I
also think that you shouldn't necessarily need to refer to a text book
or a math teacher in order to figure out how to use pgbench. Saying
"it's complicated, so we don't have to explain it" would be a cop out;
we need to *make* it simple. And if there's no way to do that, then
IMHO we should reject the patch in favor of some future patch that
implements something that will be easy for users to understand.[nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10
starting vacuum...end.
transaction type: Exponential distribution TPC-B (sort of)
scaling factor: 1
exponential threshold: 10.00000
decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0%
highest/lowest percent of the range: 9.5% 0.0%
I don't have a clue what that means. None.
Maybe we could add in front of the decile/percent
"distribution of increasing account key values selected by pgbench:"
I still wouldn't know what that meant. And it misses the point
anyway: if the documentation is good, this will be unnecessary. If
the documentation is bad, a printout that tries to illustrate it by
example is not an acceptable substitute.
> For example, when we set the number of transaction 10,000 (-t 10000), > range of aid is 100,000, > and --exponential is 10, decile percents is under following as you know. > > decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0% > highest/lowest percent of the range: 9.5% 0.0% > > They mean that, > #number of access in range of aid (from decile percents): > 1 to 10,000 => 6,320 times > 10,001 to 20,000 => 2,330 times > 20,001 to 30,000 => 860 times > ... > 90,001 to 10,0000 => 0 times > > #number of access in range of aid (from highest/lowest percent of the > range): > 1 to 1,000 => 950 times > ... > 99,001 to 10,0000 => 0 times > > that's all. > > Their information is easy to understand distribution of access probability, > isn't it? > Maybe I and Fabien-san have a knowledge of mathematics, so we think decile > percentage is common sense. > But if it isn't common sense, I agree with adding about these explanation > in the documents. What we are talking about is the "summary" at the end of the run, which is expected to be compact, hence the terse few lines. I'm not sure how to make it explicit without extending the summary too much, so it would not be a summary anymore:-) My initial assumption is that anyone interested enough in changing the default uniform distribution for a test would know about decile, but that seems to be optimistic. Maybe it would be okay to keep a terse summary but to expand the documentation to explain what it means, as you suggested above... -- Fabien.
Please find attached 2 patches, which are a split of the patch discussed in this thread. (A) add gaussian & exponential options to pgbench \setrandom the patch includes sql test files. There is no change in the *code* from previous already reviewed submissions, so I do not think that it needs another review on that account. However I have (yet again) reworked the *documentation* (for Andres Freund & Robert Haas), in particular both descriptions now follow the same structure (introduction, formula, intuition, rule of thumb and constraint). I have differentiated the concept and the option by putting the later in <literal> tags, and added a link to the corresponding wikipedia pages. Please bear in mind that: 1. English is not my native language. 2. this is not easy reading... this is maths, to read slowly:-)3. word smithing contributions are welcome. I assume somehow that a user interested in gaussian & exponential distributions must know a little bit about probabilities... (B) add pgbench test variants with gauss & exponential. I have reworked the patch so as to avoid copy pasting the 3 test cases, as requested by Andres Freund, thus this is new, although quite simple, code. I have also added explanations in the documentation about how to interpret the "decile" outputs, so as to hopefully address Robert Haas comments. -- Fabien.
> Please find attached 2 patches, which are a split of the patch discussed in > this thread. Please find attached a very minor improvement to apply a code (variable name) simplification directly in patch A so as to avoid a change in patch B. The cumulated patch is the same as previous. > (A) add gaussian & exponential options to pgbench \setrandom > the patch includes sql test files. > > There is no change in the *code* from previous already reviewed submissions, > so I do not think that it needs another review on that account. > > However I have (yet again) reworked the *documentation* (for Andres Freund & > Robert Haas), in particular both descriptions now follow the same structure > (introduction, formula, intuition, rule of thumb and constraint). I have > differentiated the concept and the option by putting the later in <literal> > tags, and added a link to the corresponding wikipedia pages. > > > Please bear in mind that: > 1. English is not my native language. > 2. this is not easy reading... this is maths, to read slowly:-) > 3. word smithing contributions are welcome. > > I assume somehow that a user interested in gaussian & exponential > distributions must know a little bit about probabilities... > > > > (B) add pgbench test variants with gauss & exponential. > > I have reworked the patch so as to avoid copy pasting the 3 test cases, as > requested by Andres Freund, thus this is new, although quite simple, code. I > have also added explanations in the documentation about how to interpret the > "decile" outputs, so as to hopefully address Robert Haas comments. -- Fabien.
On Thu, Jul 17, 2014 at 12:09 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote:
> pgbench with gaussian & exponential, part 1 of 2.
>
> This patch is a subset of the previous patch which only adds the two
> new \setrandom gaussian and exponantial variants, but not the
> adapted pgbench test cases, as suggested by Fujii Masao.
> There is no new code nor code changes.
>
> The corresponding documentation has been yet again extended wrt
> to the initial patch, so that what is achieved is hopefully unambiguous
> (there are two mathematical formula, tasty!), in answer to Andres Freund
> comments, and partly to Robert Haas comments as well.
>
> This patch also provides several sql/pgbench scripts and a README, so
> that the feature can be tested. I do not know whether these scripts
> should make it to postgresql. I would say yes, otherwise there is no way
> to test...
>
> part 2 which provide adapted pgbench test cases will come later.
Some review comments:
1. I suggest that getExponentialrand and getGaussianrand be renamed to
getExponentialRand and getGaussianRand.
2. I suggest that the code be changed so that the branch currently
labeled as /* uniform with extra argument */ become a hard error
instead of a warning.
3. Similarly, I suggest that the use of gaussian or uniform be an
error when argc < 6 OR argc > 6. I also suggest that the
parenthesized distribution type be dropped from the error message in
all cases.
4. This question mark seems like it should be a period:
+ * value fails the test? To be on the safe side, let
us try over.
5. With regards to the following paragraph:
<para>
+ The default random distribution is uniform, that is all values in the
+ range are drawn with equal probability. The gaussian and exponential
+ options allow to change this default. The mandatory
+ <replaceable>threshold</> double value controls the actual distribution
+ with gaussian or exponential.
+ </para>
This paragraph needs a bit of copy-editing. Here's an attempt: "By
default, all values in the range are drawn with equal probability.
The <literal>gaussian</> and <literal>exponential</> options modify
this behavior; each requires a mandatory threshold which determines
the precise shape of the distribution." The following paragraph
should be changed to begin with "For a Gaussian distribution" and the
one after "For an exponential distribution".
6. Overall, I think the documentation here looks much better now, but
I suggest adding one or two example to the Gaussian section. Like
this: for example, if threshold is 2.0, 68% of the values will fall in
the middle third of the interval; with a threshold of 3.0, 99.7% of
the values will fall in the middle third of the interval. These
numbers are fabricated, and the middle third of the interval might not
be the best part to talk about, but you get the idea (I hope).
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hello Robert, > Some review comments: Thanks a lot for your return. Please find attached two new parts of the patch (A for setrandom extension, B for pgbench embedded test case extension). > 1. I suggest that getExponentialrand and getGaussianrand be renamed to > getExponentialRand and getGaussianRand. Done. It was named like that because "getrand" was used for the uniform case. > 2. I suggest that the code be changed so that the branch currently > labeled as /* uniform with extra argument */ become a hard error > instead of a warning. > > 3. Similarly, I suggest that the use of gaussian or uniform be an > error when argc < 6 OR argc > 6. I also suggest that the > parenthesized distribution type be dropped from the error message in > all cases. I wish to agree, but my interpretation of the previous code is that they were ignored before, so ISTM that we are stuck with keeping the same unfortunate behavior. > 4. This question mark seems like it should be a period: > > + * value fails the test? To be on the safe side, let us try over. Indeed. > 5. With regards to the following paragraph: > > <para> > + The default random distribution is uniform, that is all values in the > + range are drawn with equal probability. The gaussian and exponential > + options allow to change this default. The mandatory > + <replaceable>threshold</> double value controls the actual distribution > + with gaussian or exponential. > + </para> > > This paragraph needs a bit of copy-editing. Here's an attempt: "By > default, all values in the range are drawn with equal probability. > The <literal>gaussian</> and <literal>exponential</> options modify > this behavior; each requires a mandatory threshold which determines > the precise shape of the distribution." The following paragraph > should be changed to begin with "For a Gaussian distribution" and the > one after "For an exponential distribution". Ok. I've kept "uniform" in the first sentence, because this is both an option name and it is significant in term of probabilities. > 6. Overall, I think the documentation here looks much better now, but > I suggest adding one or two example to the Gaussian section. Like > this: for example, if threshold is 2.0, 68% of the values will fall in > the middle third of the interval; with a threshold of 3.0, 99.7% of > the values will fall in the middle third of the interval. These > numbers are fabricated, and the middle third of the interval might not > be the best part to talk about, but you get the idea (I hope). Done with threshold value 4.0 so I have a "middle quarter" and a "middle half". -- Fabien.
+ pgbench_account's aid selected with a truncated gaussian distribution
+ standard deviation threshold: 5.00000
+ decile percents: 0.0% 0.1% 2.1% 13.6% 34.1% 34.1% 13.6% 2.1% 0.1% 0.0%
+ probability of max/min percent of the range: 4.0% 0.0%
And I add the explanation about this in the document.
I'm very appreciate for your works!!!
Best regards,
--
Mitsumasa KONDO
Вложения
> Thank you for your grate documentation and fix working!!! > It becomes very helpful for understanding our feature. Hopefully it will help make it, or part of it, pass through. > I add two feature in gauss_B_4.patch. > > 1) Add gaussianProbability() function > It is same as exponentialProbability(). And the feature is as same as > before. Ok, that is better for readability and easy reuse. > 2) Add result of "max/min percent of the range" > It is almost same as --exponential option's result. However, max percent of > the range is center of distribution > and min percent of the range is most side of distribution. > Here is the output example, Ok, good that make it homogeneous with the exponential case. > + pgbench_account's aid selected with a truncated gaussian distribution > + standard deviation threshold: 5.00000 > + decile percents: 0.0% 0.1% 2.1% 13.6% 34.1% 34.1% 13.6% 2.1% 0.1% 0.0% > + probability of max/min percent of the range: 4.0% 0.0% > And I add the explanation about this in the document. This is a definite improvement. I tested these minor changes and everything seems ok. Attached is a very small update. One word removed from the doc, and one redundant declaration removed from the code. I also have a problem with assert & Assert. I finally figured out that Assert is not compiled in by default, thus it is generally ignored. So it is more for debugging purposes when activated than for guarding against some unexpected user errors. -- Fabien.
Fabien COELHO wrote: > I also have a problem with assert & Assert. I finally figured out > that Assert is not compiled in by default, thus it is generally > ignored. So it is more for debugging purposes when activated than > for guarding against some unexpected user errors. Yes, Assert() is for debugging during development. If you need to deal with user error, use regular if () and exit() as appropriate (ereport() in the backend). We mostly avoid assert() in our own code. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
<div dir="ltr"><div class="gmail_extra"><div class="gmail_quote">Thanks for your modify the patch! I confirmed that It seemsto be fine.</div><br /></div><div class="gmail_extra">I think that our latest patch fill all community comment.</div><divclass="gmail_extra">So it is really ready for committer now. </div><div class="gmail_extra"><br /></div><divclass="gmail_extra">Best regards,</div><div class="gmail_extra">--</div><div class="gmail_extra">Mitsumasa KONDO</div></div>
On 07/17/2014 11:13 PM, Fabien COELHO wrote: > >>> However, ISTM that it is not the purpose of pgbench documentation to be a >>> primer about what is an exponential or gaussian distribution, so the idea >>> would yet be to have a relatively compact explanation, and that the >>> interested but clueless reader would document h..self from wikipedia or a >>> text book or a friend or a math teacher (who could be a friend as well:-). >> >> Well, I think it's a balance. I agree that the pgbench documentation >> shouldn't try to substitute for a text book or a math teacher, but I >> also think that you shouldn't necessarily need to refer to a text book >> or a math teacher in order to figure out how to use pgbench. Saying >> "it's complicated, so we don't have to explain it" would be a cop out; >> we need to *make* it simple. And if there's no way to do that, then >> IMHO we should reject the patch in favor of some future patch that >> implements something that will be easy for users to understand. >> >>>>> [nttcom@localhost postgresql]$ contrib/pgbench/pgbench --exponential=10 >>>>> starting vacuum...end. >>>>> transaction type: Exponential distribution TPC-B (sort of) >>>>> scaling factor: 1 >>>>> exponential threshold: 10.00000 >>>>> >>>>> decile percents: 63.2% 23.3% 8.6% 3.1% 1.2% 0.4% 0.2% 0.1% 0.0% 0.0% >>>>> highest/lowest percent of the range: 9.5% 0.0% >>>> >>>> I don't have a clue what that means. None. >>> >>> Maybe we could add in front of the decile/percent >>> >>> "distribution of increasing account key values selected by pgbench:" >> >> I still wouldn't know what that meant. And it misses the point >> anyway: if the documentation is good, this will be unnecessary. If >> the documentation is bad, a printout that tries to illustrate it by >> example is not an acceptable substitute. > > The decile description is quite classic when discussing statistics. IMHO we should include a diagram for each distribution. A diagram would be much more easy to understand than a decile or verbal explanation. The only problem is that the build infrastructure doesn't currently support including images in the docs. That's been discussed before, and I think we even used to have a couple of images there a long time ago. Now would be a good time to bite the bullet and add the support. We got fairly close to a consensus on how to do it in this thread: www.postgresql.org/message-id/flat/20120712181636.GC11063@momjian.us. The biggest problem was choosing an editor that has a fairly stable file format, so that we don't get huge diffs every time someone moves a line in a diagram. One work-around for that is to use graphviz and/or gnuplot as the source format, instead of a graphical editor. - Heikki
On Wed, Jul 23, 2014 at 12:39 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> 3. Similarly, I suggest that the use of gaussian or uniform be an >> error when argc < 6 OR argc > 6. I also suggest that the >> parenthesized distribution type be dropped from the error message in >> all cases. > > I wish to agree, but my interpretation of the previous code is that they > were ignored before, so ISTM that we are stuck with keeping the same > unfortunate behavior. I don't agree. I'm not in a huge hurry to fix all the places where pgbench currently lacks error checks just because I don't have enough to do (hint: I do have enough to do), but when we're adding more complicated syntax in one particular place, bringing the error checks in that portion of the code up to scratch is an eminently sensible thing to do, and we should do it. Also, please stop changing the title of this thread every other post. It breaks threading for me (and anyone else using gmail), and that makes the thread hard to follow. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Robert, >> I wish to agree, but my interpretation of the previous code is that >> they were ignored before, so ISTM that we are stuck with keeping the >> same unfortunate behavior. > > I don't agree. I'm not in a huge hurry to fix all the places where > pgbench currently lacks error checks just because I don't have enough to > do (hint: I do have enough to do), but when we're adding more > complicated syntax in one particular place, bringing the error checks in > that portion of the code up to scratch is an eminently sensible thing to > do, and we should do it. Ok. I'm in favor of that anyway. It is just that was afraid that changing behavior, however poor the said behavior, could be a blocker. > Also, please stop changing the title of this thread every other post. > It breaks threading for me (and anyone else using gmail), and that > makes the thread hard to follow. Sorry. It does not break my mailer which relies on internal headers, but I'll try to be compatible with this gmail "features" in the future. -- Fabien.
Hello Robert, >>> 3. Similarly, I suggest that the use of gaussian or uniform be an >>> error when argc < 6 OR argc > 6. I also suggest that the >>> parenthesized distribution type be dropped from the error message in >>> all cases. >> >> I wish to agree, but my interpretation of the previous code is that they >> were ignored before, so ISTM that we are stuck with keeping the same >> unfortunate behavior. > > I don't agree. Attached B patch does turn incorrect setrandom syntax into errors instead of ignoring extra parameters. First A patch is repeated to help commitfest references. -- Fabien.
> Attached B patch does turn incorrect setrandom syntax into errors instead of > ignoring extra parameters. > > First A patch is repeated to help commitfest references. Oops, I applied the change on the wrong part:-( Here is the change on part A which checks setrandom syntax, and B for completeness. -- Fabien.
On Tue, Jul 29, 2014 at 4:41 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> Attached B patch does turn incorrect setrandom syntax into errors instead >> of ignoring extra parameters. >> >> First A patch is repeated to help commitfest references. > > Oops, I applied the change on the wrong part:-( > > Here is the change on part A which checks setrandom syntax, and B for > completeness. I've committed the changes to pgbench.c and the documentation changes with some further wordsmithing. I don't think including the other changes in patch A is a good idea, nor am I in favor of patch B. But thanks for your and Kondo-san's hard work on this; I think this will be quite useful. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Robert, > I've committed the changes to pgbench.c and the documentation changes > with some further wordsmithing. Ok, thanks a lot for your reviews and your help with improving the documentation. > I don't think including the other changes in patch A is a good idea, Fine. It was mostly for testing and checking purposes. > nor am I in favor of patch B. Yep. Would providing these as additional contrib files be more acceptable? Something like "tpc-b-gauss.sql"... Otherwise there is no example available to show the feature. Thanks again, -- Fabien.
Ok, thanks a lot for your reviews and your help with improving the documentation.I've committed the changes to pgbench.c and the documentation changes with some further wordsmithing.
Fine. It was mostly for testing and checking purposes.I don't think including the other changes in patch A is a good idea,
Yep.nor am I in favor of patch B.
Would providing these as additional contrib files be more acceptable? Something like "tpc-b-gauss.sql"... Otherwise there is no example available to show the feature.
On Wed, Jul 30, 2014 at 4:18 PM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> nor am I in favor of patch B. > > Yep. Would providing these as additional contrib files be more acceptable? > Something like "tpc-b-gauss.sql"... Otherwise there is no example available > to show the feature. To be honest, it just feels like clutter to me. If we added examples for every feature that is as significant as this one is, we'd end up with twice the installation footprint, and most of it would be stuff nobody ever looked at. I think the documentation is good enough that people will be able to understand how to use this feature, which is good enough for me. One thing that might still be worth doing is including the standard pgbench scripts in the pgbench documentation. Then we could say things like "and you could also modify these". Right now I tend to end up cut-and-pasting from the source code, which is fine if you're a hacker but not so user-friendly. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jul 30, 2014 at 9:00 PM, Mitsumasa KONDO <kondo.mitsumasa@gmail.com> wrote: > Hmm... It doesn't have harm for pgbench source code. And, in general, > checking script is useful for avoiding bug. Not if nobody runs it, or if people run it but don't know what the output should look like. I think anyone who knows enough to find bugs by running these scripts probably doesn't need the scripts. > No, patch B is still needed. Please tell me the reason. I don't like > deciding by someones feeling, > and it needs logical reason. Our documentation is better than the past. I > think it can easy to understand decile probability. > This part of the discussion is needed to continue... > >> Would providing these as additional contrib files be more acceptable? >> Something like "tpc-b-gauss.sql"... Otherwise there is no example available >> to show the feature. > > I agree the test script and including command line options. It's not harm, > and it's useful. As to all of this, I simply don't agree that the stuff has enough value to justify including it. Now, of course, that is subjective: one person may think it has enough value, while another person may think that it does not have enough value. So it just comes down to a question of opinion, and we make those judgements of opinion all the time. If we included everything that everyone who works on the code wants included, we'd end up with a bloated mess of stuff that nobody cares about; indeed, we have a significant amount of stuff in the source code that IMHO looks like somebody's debugging leftovers that should have been removed before commit. I don't want to add more unless there is clear and convincing evidence that a significant number of people want it, and that is not the case here. Now, if we get a few reports from people saying, hey, I was doing some benchmarking with pgbench, and I found the new gaussian feature to be really excellent, but it sucked that there was no command-line option for it, we can go back and add one. No problem! But in the meantime, we've added the core of the feature without cluttering up the list of command-line options with things that may or may not prove to be useful. One of the concerns that I have about the proposal of simply slapping a gaussian or exponential modifier onto \setrandom aid 1 :naccounts is that, while it will allow you to make part of the relation hot and another part of the relation cold, you really can't get any more fine-grained than that. If you use exponential, all the hot accounts will be near the beginning of the relation, and if you use gaussian, they'll all be in the middle. I'm not sure exactly will happen after some updating has happened; I'm guessing some of the keys will still be in their original location and others will have been pushed to the end of the relation following relation-extension. But there's no way, with those command line options, to for example have 5 hot spots distributed uniformly through the relation; or even to have the end of the relation rather than the beginning or the middle as the hot spot. You can do those things with the newly-enhanced \setrand *and a custom script* but not with just a command-line option. So that makes me think that people who find these new facilities useful might not get all that much use out of the command-line option anyway; and we can't have a command-line option for every behavior anyone ever wants. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Robert, [...] > One of the concerns that I have about the proposal of simply slapping a > gaussian or exponential modifier onto \setrandom aid 1 :naccounts is > that, while it will allow you to make part of the relation hot and > another part of the relation cold, you really can't get any more > fine-grained than that. If you use exponential, all the hot accounts > will be near the beginning of the relation, and if you use gaussian, > they'll all be in the middle. That is a very good remark. Although I thought of it, I do not have a very good solution yet:-) From a testing perspective, if we assume that keys have no semantics, a reasonable assumption is that the distribution of access for actual realistic workloads is probably exponential (of gaussian, anyway hardly uniform), but without direct correlation between key values. In order to simulate that, we would have to apply a fixed (pseudo-)random permutation to the exponential-drawn key values. This is a non trivial problem. The version zero of solving it is to do nothing... it is the current status;-) Version one is "k' = 1 + (a * k + b) modulo n" with "a" prime with respect to "n", "n" being the number of keys. This is nearly possible, but for the modulo operator which is currently missing, and that I'm planning to submit for this very reason, but probably another time. > I'm not sure exactly will happen after some updating has happened; I'm > guessing some of the keys will still be in their original location and > others will have been pushed to the end of the relation following > relation-extension. This is a not too bad side. What matters most in the long term is not the key value correlation, but the actual storage correlation, i.e. whether two tuples required are in the same page or not. At the beginning of a simulation, with close key numbers being picked up with an exponential distribution, the correlation is more that what would be expected. However, once a significant amount of the table has been updated, this initial artificial correlation is going to fade, and the test should become more realistic. -- Fabien.
On Thu, Jul 31, 2014 at 10:01 AM, Fabien COELHO <coelho@cri.ensmp.fr> wrote: >> One of the concerns that I have about the proposal of simply slapping a >> gaussian or exponential modifier onto \setrandom aid 1 :naccounts is that, >> while it will allow you to make part of the relation hot and another part of >> the relation cold, you really can't get any more fine-grained than that. If >> you use exponential, all the hot accounts will be near the beginning of the >> relation, and if you use gaussian, they'll all be in the middle. > > That is a very good remark. Although I thought of it, I do not have a very > good solution yet:-) > > From a testing perspective, if we assume that keys have no semantics, a > reasonable assumption is that the distribution of access for actual > realistic workloads is probably exponential (of gaussian, anyway hardly > uniform), but without direct correlation between key values. > > In order to simulate that, we would have to apply a fixed (pseudo-)random > permutation to the exponential-drawn key values. This is a non trivial > problem. The version zero of solving it is to do nothing... it is the > current status;-) Version one is "k' = 1 + (a * k + b) modulo n" with "a" > prime with respect to "n", "n" being the number of keys. This is nearly > possible, but for the modulo operator which is currently missing, and that > I'm planning to submit for this very reason, but probably another time. That's pretty crude, although I don't object to a modulo operator. It would be nice to be able to use a truly random permutation, which is not hard to generate but probably requires O(n) storage, likely a problem for large scale factors. Maybe somebody who knows more math than I do (like you, probably!) can come up with something more clever. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello, >> Version one is "k' = 1 + (a * k + b) modulo n" with "a" prime with >> respect to "n", "n" being the number of keys. This is nearly possible, >> but for the modulo operator which is currently missing, and that I'm >> planning to submit for this very reason, but probably another time. > > That's pretty crude, Yep. It is very simple, it is much better than nothing, and for a database test is may be "good enough". > although I don't object to a modulo operator. It would be nice to be > able to use a truly random permutation, which is not hard to generate > but probably requires O(n) storage, likely a problem for large scale > factors. That is indeed the actual issue in my mind. I was thinking of permutations with a formula, which are not so easy to find and may end-up looking like "(a*k+b)%n" anyway. I had the same issue for generating random data for a schema (see http://www.coelho.net/datafiller.html). > Maybe somebody who knows more math than I do (like you, probably!) can > come up with something more clever. I can certainly suggest other formula, but that does not mean beautiful code, thus would probably be rejected. I'll see. An alternative to this whole process may be to hash/modulo a non uniform random value. id = 1 + hash(some-random()) % n But the hashing changes the distribution as it adds collisions, so I have to think about how to be able to control the distribution in that case, and what hash function to use. -- Fabien.
I can certainly suggest other formula, but that does not mean beautiful code, thus would probably be rejected. I'll see.Maybe somebody who knows more math than I do (like you, probably!) can come up with something more clever.
An alternative to this whole process may be to hash/modulo a non uniform random value.
id = 1 + hash(some-random()) % n
But the hashing changes the distribution as it adds collisions, so I have to think about how to be able to control the distribution in that case, and what hash function to use.