Обсуждение: PG15 beta1 sort performance regression due to Generation context change
Hackers, Over the past few days I've been gathering some benchmark results together to show the sort performance improvements in PG15 [1]. One of the test cases I did was to demonstrate Heikki's change to use a k-way merge (65014000b). The test I did to try this out was along the lines of: set max_parallel_workers_per_gather = 0; create table t (a bigint not null, b bigint not null, c bigint not null, d bigint not null, e bigint not null, f bigint not null); insert into t select x,x,x,x,x,x from generate_Series(1,140247142) x; -- 10GB! vacuum freeze t; The query I ran was: select * from t order by a offset 140247142; I tested various sizes of work_mem starting at 4MB and doubled that all the way to 16GB. For many of the smaller values of work_mem the performance is vastly improved by Heikki's change, however for work_mem = 64MB I detected quite a large slowdown. PG14 took 20.9 seconds and PG15 beta 1 took 29 seconds! I've been trying to get to the bottom of this today and finally have discovered this is due to the tuple size allocations in the sort being exactly 64 bytes. Prior to 40af10b57 (Use Generation memory contexts to store tuples in sorts) the tuple for the sort would be stored in an aset context. After 40af10b57 we'll use a generation context. The idea with that change is that the generation context does no power-of-2 round ups for allocations, so we save memory in most cases. However, due to this particular test having a tuple size of 64-bytes, there was no power-of-2 wastage with aset. The problem is that generation chunks have a larger chunk header than aset do due to having to store the block pointer that the chunk belongs to so that GenerationFree() can increment the nfree chunks in the block. aset.c does not require this as freed chunks just go onto a freelist that's global to the entire context. Basically, for my test query, the slowdown is because instead of being able to store 620702 tuples per tape over 226 tapes with an aset context, we can now only store 576845 tuples per tape resulting in requiring 244 tapes when using the generation context. If I had added column "g" to make the tuple size 72 bytes causing aset's code to round allocations up to 128 bytes and generation.c to maintain the 72 bytes then the sort would have stored 385805 tuples over 364 batches for aset and 538761 tuples over 261 batches using the generation context. That would have been a huge win. So it basically looks like I discovered a very bad case that causes a significant slowdown. Yet other cases that are not an exact power of 2 stand to gain significantly from this change. One thing 40af10b57 does is stops those terrible performance jumps when the tuple size crosses a power-of-2 boundary. The performance should be more aligned to the size of the data being sorted now... Unfortunately, that seems to mean regressions for large sorts with power-of-2 sized tuples. I'm unsure exactly what I should do about this right now. David [1] https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-sort-performance-in-postgres-15/ba-p/3396953#change4
Re: PG15 beta1 sort performance regression due to Generation context change
On 20/05/2022 08:56, David Rowley wrote: > The problem is that generation chunks have a larger chunk header than > aset do due to having to store the block pointer that the chunk > belongs to so that GenerationFree() can increment the nfree chunks in > the block. aset.c does not require this as freed chunks just go onto a > freelist that's global to the entire context. Could the 'context' field be moved from GenerationChunk to GenerationBlock? - Heikki
Hi David,
>Over the past few days I've been gathering some benchmark results
>together to show the sort performance improvements in PG15 [1].
>One of the test cases I did was to demonstrate Heikki's change to use
>a k-way merge (65014000b).
>The test I did to try this out was along the lines of:
>set max_parallel_workers_per_gather = 0;
>create table t (a bigint not null, b bigint not null, c bigint not
>null, d bigint not null, e bigint not null, f bigint not null);
>insert into t select x,x,x,x,x,x from generate_Series(1,140247142) x; -- 10GB!
>vacuum freeze t;
>The query I ran was:
>select * from t order by a offset 140247142;I redid this test here:
Windows 10 64 bits
msvc 2019 64 bits
RAM 8GB
SSD 256 GB
>I tested various sizes of work_mem starting at 4MB and doubled that
>all the way to 16GB. For many of the smaller values of work_mem the
>performance is vastly improved by Heikki's change, however for
>work_mem = 64MB I detected quite a large slowdown. PG14 took 20.9
>seconds and PG15 beta 1 took 29 seconds!
>I've been trying to get to the bottom of this today and finally have
>discovered this is due to the tuple size allocations in the sort being
>exactly 64 bytes. Prior to 40af10b57 (Use Generation memory contexts
>to store tuples in sorts) the tuple for the sort would be stored in an
>aset context. After 40af10b57 we'll use a generation context. The
>idea with that change is that the generation context does no
>power-of-2 round ups for allocations, so we save memory in most cases.
>However, due to this particular test having a tuple size of 64-bytes,
>there was no power-of-2 wastage with aset.
>The problem is that generation chunks have a larger chunk header than
>aset do due to having to store the block pointer that the chunk
>belongs to so that GenerationFree() can increment the nfree chunks in
>the block. aset.c does not require this as freed chunks just go onto a
>freelist that's global to the entire context.
>Basically, for my test query, the slowdown is because instead of being
>able to store 620702 tuples per tape over 226 tapes with an aset
>context, we can now only store 576845 tuples per tape resulting in
>requiring 244 tapes when using the generation context.
>If I had added column "g" to make the tuple size 72 bytes causing
>aset's code to round allocations up to 128 bytes and generation.c to
>maintain the 72 bytes then the sort would have stored 385805 tuples
>over 364 batches for aset and 538761 tuples over 261 batches using the
>generation context. That would have been a huge win.
>So it basically looks like I discovered a very bad case that causes a
>significant slowdown. Yet other cases that are not an exact power of
>2 stand to gain significantly from this change.
>One thing 40af10b57 does is stops those terrible performance jumps
>when the tuple size crosses a power-of-2 boundary. The performance
>should be more aligned to the size of the data being sorted now...
>Unfortunately, that seems to mean regressions for large sorts with
>power-of-2 sized tuples.
It seems to me that the solution would be to use aset allocations
when the size of the tuples is power-of-2?
if (state->sortopt & TUPLESORT_ALLOWBOUNDED ||
(state->memtupsize & (state->memtupsize - 1)) == 0)
state->tuplecontext = AllocSetContextCreate(state->sortcontext,
"Caller tuples", ALLOCSET_DEFAULT_SIZES);
else
state->tuplecontext = GenerationContextCreate(state->sortcontext,
"Caller tuples", ALLOCSET_DEFAULT_SIZES);
I took a look and tried some improvements to see if I had a better result.
Would you mind taking a look and testing?
regards,
Ranier Vilela
Вложения
On 5/20/22 12:01, Heikki Linnakangas wrote: > On 20/05/2022 08:56, David Rowley wrote: >> The problem is that generation chunks have a larger chunk header than >> aset do due to having to store the block pointer that the chunk >> belongs to so that GenerationFree() can increment the nfree chunks in >> the block. aset.c does not require this as freed chunks just go onto a >> freelist that's global to the entire context. > > Could the 'context' field be moved from GenerationChunk to GenerationBlock? > Not easily, because GetMemoryChunkContext() expects the context to be stored right before the chunk. In principle we could add "get context" callback to MemoryContextMethods, so that different implementations can override that. I wonder how expensive the extra redirect would be, but probably not much because the places touching chunk->context deal with the block too (e.g. GenerationFree has to tweak block->nfree). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> On 5/20/22 12:01, Heikki Linnakangas wrote:
>> Could the 'context' field be moved from GenerationChunk to GenerationBlock?
> Not easily, because GetMemoryChunkContext() expects the context to be
> stored right before the chunk. In principle we could add "get context"
> callback to MemoryContextMethods, so that different implementations can
> override that.
How would you know which context type to consult for that?
regards, tom lane
On Tue, 24 May 2022 at 08:32, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 5/20/22 12:01, Heikki Linnakangas wrote: > > Could the 'context' field be moved from GenerationChunk to GenerationBlock? > > > > Not easily, because GetMemoryChunkContext() expects the context to be > stored right before the chunk. In principle we could add "get context" > callback to MemoryContextMethods, so that different implementations can > override that. hmm, but we need to know the context first before we can know which callback to call. David
On 5/23/22 22:47, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> On 5/20/22 12:01, Heikki Linnakangas wrote: >>> Could the 'context' field be moved from GenerationChunk to GenerationBlock? > >> Not easily, because GetMemoryChunkContext() expects the context to be >> stored right before the chunk. In principle we could add "get context" >> callback to MemoryContextMethods, so that different implementations can >> override that. > > How would you know which context type to consult for that? > D'oh! I knew there has to be some flaw in that idea, but I forgot about this chicken-or-egg issue. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
FYI not sure why, but your responses seem to break threading quite often, due to missing headers identifying the message you're responding to (In-Reply-To, References). Not sure why or how to fix it, but this makes it much harder to follow the discussion. On 5/22/22 21:11, Ranier Vilela wrote: > Hi David, > >>Over the past few days I've been gathering some benchmark results >>together to show the sort performance improvements in PG15 [1]. > >>One of the test cases I did was to demonstrate Heikki's change to use >>a k-way merge (65014000b). > >>The test I did to try this out was along the lines of: > >>set max_parallel_workers_per_gather = 0; >>create table t (a bigint not null, b bigint not null, c bigint not >>null, d bigint not null, e bigint not null, f bigint not null); > >>insert into t select x,x,x,x,x,x from generate_Series(1,140247142) x; > -- 10GB! >>vacuum freeze t; > >>The query I ran was: > >>select * from t order by a offset 140247142; > > I redid this test here: > Windows 10 64 bits > msvc 2019 64 bits > RAM 8GB > SSD 256 GB > > HEAD (default configuration) > Time: 229396,551 ms (03:49,397) > PATCHED: > Time: 220887,346 ms (03:40,887) > This is 10x longer than reported by David. Presumably David used a machine a lot of RAM, while your system has 8GB and so is I/O bound. Also, what exactly does "patched" mean? The patch you attached? >>I tested various sizes of work_mem starting at 4MB and doubled that >>all the way to 16GB. For many of the smaller values of work_mem the >>performance is vastly improved by Heikki's change, however for >>work_mem = 64MB I detected quite a large slowdown. PG14 took 20.9 >>seconds and PG15 beta 1 took 29 seconds! > >>I've been trying to get to the bottom of this today and finally have >>discovered this is due to the tuple size allocations in the sort being >>exactly 64 bytes. Prior to 40af10b57 (Use Generation memory contexts >>to store tuples in sorts) the tuple for the sort would be stored in an >>aset context. After 40af10b57 we'll use a generation context. The >>idea with that change is that the generation context does no >>power-of-2 round ups for allocations, so we save memory in most cases. >>However, due to this particular test having a tuple size of 64-bytes, >>there was no power-of-2 wastage with aset. > >>The problem is that generation chunks have a larger chunk header than >>aset do due to having to store the block pointer that the chunk >>belongs to so that GenerationFree() can increment the nfree chunks in >>the block. aset.c does not require this as freed chunks just go onto a >>freelist that's global to the entire context. > >>Basically, for my test query, the slowdown is because instead of being >>able to store 620702 tuples per tape over 226 tapes with an aset >>context, we can now only store 576845 tuples per tape resulting in >>requiring 244 tapes when using the generation context. > >>If I had added column "g" to make the tuple size 72 bytes causing >>aset's code to round allocations up to 128 bytes and generation.c to >>maintain the 72 bytes then the sort would have stored 385805 tuples >>over 364 batches for aset and 538761 tuples over 261 batches using the >>generation context. That would have been a huge win. > >>So it basically looks like I discovered a very bad case that causes a >>significant slowdown. Yet other cases that are not an exact power of >>2 stand to gain significantly from this change. > >>One thing 40af10b57 does is stops those terrible performance jumps >>when the tuple size crosses a power-of-2 boundary. The performance >>should be more aligned to the size of the data being sorted now... >>Unfortunately, that seems to mean regressions for large sorts with >>power-of-2 sized tuples. > > It seems to me that the solution would be to use aset allocations > > when the size of the tuples is power-of-2? > > if (state->sortopt & TUPLESORT_ALLOWBOUNDED || > (state->memtupsize & (state->memtupsize - 1)) == 0) > state->tuplecontext = AllocSetContextCreate(state->sortcontext, > "Caller tuples", ALLOCSET_DEFAULT_SIZES); > else > state->tuplecontext = GenerationContextCreate(state->sortcontext, > "Caller tuples", ALLOCSET_DEFAULT_SIZES); > I'm pretty sure this is pointless, because memtupsize is the size of the memtuples array. But the issue is about size of the tuples. After all, David was talking about 64B chunks, but the array is always at least 1024 elements, so it obviously can't be the same thing. How would we even know how large the tuples will be at this point, before we even see the first of them? > I took a look and tried some improvements to see if I had a better result. > IMHO special-casing should be the last resort, because it makes the behavior much harder to follow. Also, we're talking about sort, but don't other places using Generation context have the same issue? Treating prefferrable to find a fix addressing all those places, regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, 24 May 2022 at 08:52, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > On 5/23/22 22:47, Tom Lane wrote: > > How would you know which context type to consult for that? > > > > D'oh! I knew there has to be some flaw in that idea, but I forgot about > this chicken-or-egg issue. Handy wavy idea: It's probably too complex for now, and it also might be too much overhead, but having GenerationPointerGetChunk() do a binary search on a sorted-by-memory-address array of block pointers might be a fast enough way to find the block that the pointer belongs to. There should be far fewer blocks now since generation.c now grows the block sizes. N in O(log2 N) the search complexity should never be excessively high. However, it would mean a binary search for every pfree, which feels pretty horrible. My feeling is that it seems unlikely that saving 8 bytes by not storing the GenerationBlock would be a net win here. There may be something to claw back as for the tuplesort.c case as I think the heap_free_minimal_tuple() call in writetup_heap() is not needed in many cases as we reset the tuple context directly afterward writing the tuples out. David
David Rowley <dgrowleyml@gmail.com> writes:
> Handy wavy idea: It's probably too complex for now, and it also might
> be too much overhead, but having GenerationPointerGetChunk() do a
> binary search on a sorted-by-memory-address array of block pointers
> might be a fast enough way to find the block that the pointer belongs
> to. There should be far fewer blocks now since generation.c now grows
> the block sizes. N in O(log2 N) the search complexity should never be
> excessively high.
> However, it would mean a binary search for every pfree, which feels
> pretty horrible. My feeling is that it seems unlikely that saving 8
> bytes by not storing the GenerationBlock would be a net win here.
I think probably that could be made to work, since a Generation
context should not contain all that many live blocks at any one time.
However, here's a different idea: how badly do we need the "size"
field in GenerationChunk? We're not going to ever recycle the
chunk, IIUC, so it doesn't matter exactly how big it is. When
doing MEMORY_CONTEXT_CHECKING we'll still want requested_size,
but that's not relevant to performance-critical cases.
regards, tom lane
On Tue, 24 May 2022 at 09:36, Tom Lane <tgl@sss.pgh.pa.us> wrote: > However, here's a different idea: how badly do we need the "size" > field in GenerationChunk? We're not going to ever recycle the > chunk, IIUC, so it doesn't matter exactly how big it is. When > doing MEMORY_CONTEXT_CHECKING we'll still want requested_size, > but that's not relevant to performance-critical cases. Interesting idea. However, I do see a couple of usages of the "size" field away from MEMORY_CONTEXT_CHECKING builds: GenerationRealloc: uses "size" to figure out if the new size is smaller than the old size. Maybe we could just always move to a new chunk regardless of if the new size is smaller or larger than the old size. GenerationGetChunkSpace: Uses "size" to figure out the amount of memory is used by the chunk. I'm not sure how we'd work around the fact that USEMEM() uses that extensively in tuplesort.c to figure out how much memory we're using. David
FYI not sure why, but your responses seem to break threading quite
often, due to missing headers identifying the message you're responding
to (In-Reply-To, References). Not sure why or how to fix it, but this
makes it much harder to follow the discussion.
On 5/22/22 21:11, Ranier Vilela wrote:
> Hi David,
>
>>Over the past few days I've been gathering some benchmark results
>>together to show the sort performance improvements in PG15 [1].
>
>>One of the test cases I did was to demonstrate Heikki's change to use
>>a k-way merge (65014000b).
>
>>The test I did to try this out was along the lines of:
>
>>set max_parallel_workers_per_gather = 0;
>>create table t (a bigint not null, b bigint not null, c bigint not
>>null, d bigint not null, e bigint not null, f bigint not null);
>
>>insert into t select x,x,x,x,x,x from generate_Series(1,140247142) x;
> -- 10GB!
>>vacuum freeze t;
>
>>The query I ran was:
>
>>select * from t order by a offset 140247142;
>
> I redid this test here:
> Windows 10 64 bits
> msvc 2019 64 bits
> RAM 8GB
> SSD 256 GB
>
> HEAD (default configuration)
> Time: 229396,551 ms (03:49,397)
> PATCHED:
> Time: 220887,346 ms (03:40,887)
>
This is 10x longer than reported by David. Presumably David used a
machine a lot of RAM, while your system has 8GB and so is I/O bound.
Also, what exactly does "patched" mean? The patch you attached?
>>I tested various sizes of work_mem starting at 4MB and doubled that
>>all the way to 16GB. For many of the smaller values of work_mem the
>>performance is vastly improved by Heikki's change, however for
>>work_mem = 64MB I detected quite a large slowdown. PG14 took 20.9
>>seconds and PG15 beta 1 took 29 seconds!
>
>>I've been trying to get to the bottom of this today and finally have
>>discovered this is due to the tuple size allocations in the sort being
>>exactly 64 bytes. Prior to 40af10b57 (Use Generation memory contexts
>>to store tuples in sorts) the tuple for the sort would be stored in an
>>aset context. After 40af10b57 we'll use a generation context. The
>>idea with that change is that the generation context does no
>>power-of-2 round ups for allocations, so we save memory in most cases.
>>However, due to this particular test having a tuple size of 64-bytes,
>>there was no power-of-2 wastage with aset.
>
>>The problem is that generation chunks have a larger chunk header than
>>aset do due to having to store the block pointer that the chunk
>>belongs to so that GenerationFree() can increment the nfree chunks in
>>the block. aset.c does not require this as freed chunks just go onto a
>>freelist that's global to the entire context.
>
>>Basically, for my test query, the slowdown is because instead of being
>>able to store 620702 tuples per tape over 226 tapes with an aset
>>context, we can now only store 576845 tuples per tape resulting in
>>requiring 244 tapes when using the generation context.
>
>>If I had added column "g" to make the tuple size 72 bytes causing
>>aset's code to round allocations up to 128 bytes and generation.c to
>>maintain the 72 bytes then the sort would have stored 385805 tuples
>>over 364 batches for aset and 538761 tuples over 261 batches using the
>>generation context. That would have been a huge win.
>
>>So it basically looks like I discovered a very bad case that causes a
>>significant slowdown. Yet other cases that are not an exact power of
>>2 stand to gain significantly from this change.
>
>>One thing 40af10b57 does is stops those terrible performance jumps
>>when the tuple size crosses a power-of-2 boundary. The performance
>>should be more aligned to the size of the data being sorted now...
>>Unfortunately, that seems to mean regressions for large sorts with
>>power-of-2 sized tuples.
>
> It seems to me that the solution would be to use aset allocations
>
> when the size of the tuples is power-of-2?
>
> if (state->sortopt & TUPLESORT_ALLOWBOUNDED ||
> (state->memtupsize & (state->memtupsize - 1)) == 0)
> state->tuplecontext = AllocSetContextCreate(state->sortcontext,
> "Caller tuples", ALLOCSET_DEFAULT_SIZES);
> else
> state->tuplecontext = GenerationContextCreate(state->sortcontext,
> "Caller tuples", ALLOCSET_DEFAULT_SIZES);
>
I'm pretty sure this is pointless, because memtupsize is the size of the
memtuples array. But the issue is about size of the tuples. After all,
David was talking about 64B chunks, but the array is always at least
1024 elements, so it obviously can't be the same thing.
How would we even know how large the tuples will be at this point,
before we even see the first of them?
> I took a look and tried some improvements to see if I had a better result.
>
IMHO special-casing should be the last resort, because it makes the
behavior much harder to follow.
Also, we're talking about sort, but
don't other places using Generation context have the same issue?
Treating prefferrable to find a fix addressing all those places,
I wrote:
> However, here's a different idea: how badly do we need the "size"
> field in GenerationChunk? We're not going to ever recycle the
> chunk, IIUC, so it doesn't matter exactly how big it is. When
> doing MEMORY_CONTEXT_CHECKING we'll still want requested_size,
> but that's not relevant to performance-critical cases.
Refining that a bit: we could provide the size field only when
MEMORY_CONTEXT_CHECKING and/or CLOBBER_FREED_MEMORY are defined.
That would leave us with GenerationRealloc and GenerationGetChunkSpace
not being supportable operations, but I wonder how much we need either.
BTW, shouldn't GenerationCheck be ifdef'd out if MEMORY_CONTEXT_CHECKING
isn't set? aset.c does things that way.
regards, tom lane
David Rowley <dgrowleyml@gmail.com> writes:
> GenerationRealloc: uses "size" to figure out if the new size is
> smaller than the old size. Maybe we could just always move to a new
> chunk regardless of if the new size is smaller or larger than the old
> size.
I had the same idea ... but we need to know the old size to know how much
to copy.
> GenerationGetChunkSpace: Uses "size" to figure out the amount of
> memory is used by the chunk. I'm not sure how we'd work around the
> fact that USEMEM() uses that extensively in tuplesort.c to figure out
> how much memory we're using.
Ugh, that seems like a killer.
regards, tom lane
On Tue, 24 May 2022 at 10:02, Tom Lane <tgl@sss.pgh.pa.us> wrote: > BTW, shouldn't GenerationCheck be ifdef'd out if MEMORY_CONTEXT_CHECKING > isn't set? aset.c does things that way. Isn't it done in generation.c:954? David
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 24 May 2022 at 10:02, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> BTW, shouldn't GenerationCheck be ifdef'd out if MEMORY_CONTEXT_CHECKING
>> isn't set? aset.c does things that way.
> Isn't it done in generation.c:954?
Ah, sorry, didn't look that far up ...
regards, tom lane
I had another, possibly-crazy idea. I think that the API requirement
that the word before a chunk's start point to a MemoryContext is
overly strong. What we need is that it point to something in which
a MemoryContextMethods pointer can be found (at a predefined offset).
Thus, if generation.c is willing to add the overhead of a
MemoryContextMethods pointer in GenerationBlock, it could dispense
with the per-chunk context field and just have the GenerationBlock
link there. I guess most likely we'd also need a back-link to
the GenerationContext from GenerationBlock. Still, two more
pointers per GenerationBlock is an easy tradeoff to make to save
one pointer per GenerationChunk.
I've not trawled the code to make sure that *only* the methods
pointer is touched by context-type-independent code, but it
seems like we could get to that even if we're not there today.
Whether this idea is something we could implement post-beta,
I'm not sure. I'm inclined to think that we can't change the layout
of MemoryContextData post-beta, as people may already be building
extensions for production use. We could bloat GenerationBlock even
more so that the methods pointer is at the right offset for today's
layout of MemoryContextData, though obviously going forward it'd be
better if there wasn't extra overhead needed to make this happen.
regards, tom lane
Re: PG15 beta1 sort performance regression due to Generation context change
On 5/20/22 1:56 AM, David Rowley wrote: > Hackers, > > Over the past few days I've been gathering some benchmark results > together to show the sort performance improvements in PG15 [1]. > So it basically looks like I discovered a very bad case that causes a > significant slowdown. Yet other cases that are not an exact power of > 2 stand to gain significantly from this change. > > I'm unsure exactly what I should do about this right now. While this is being actively investigated, I added this into open items. Thanks, Jonathan
Вложения
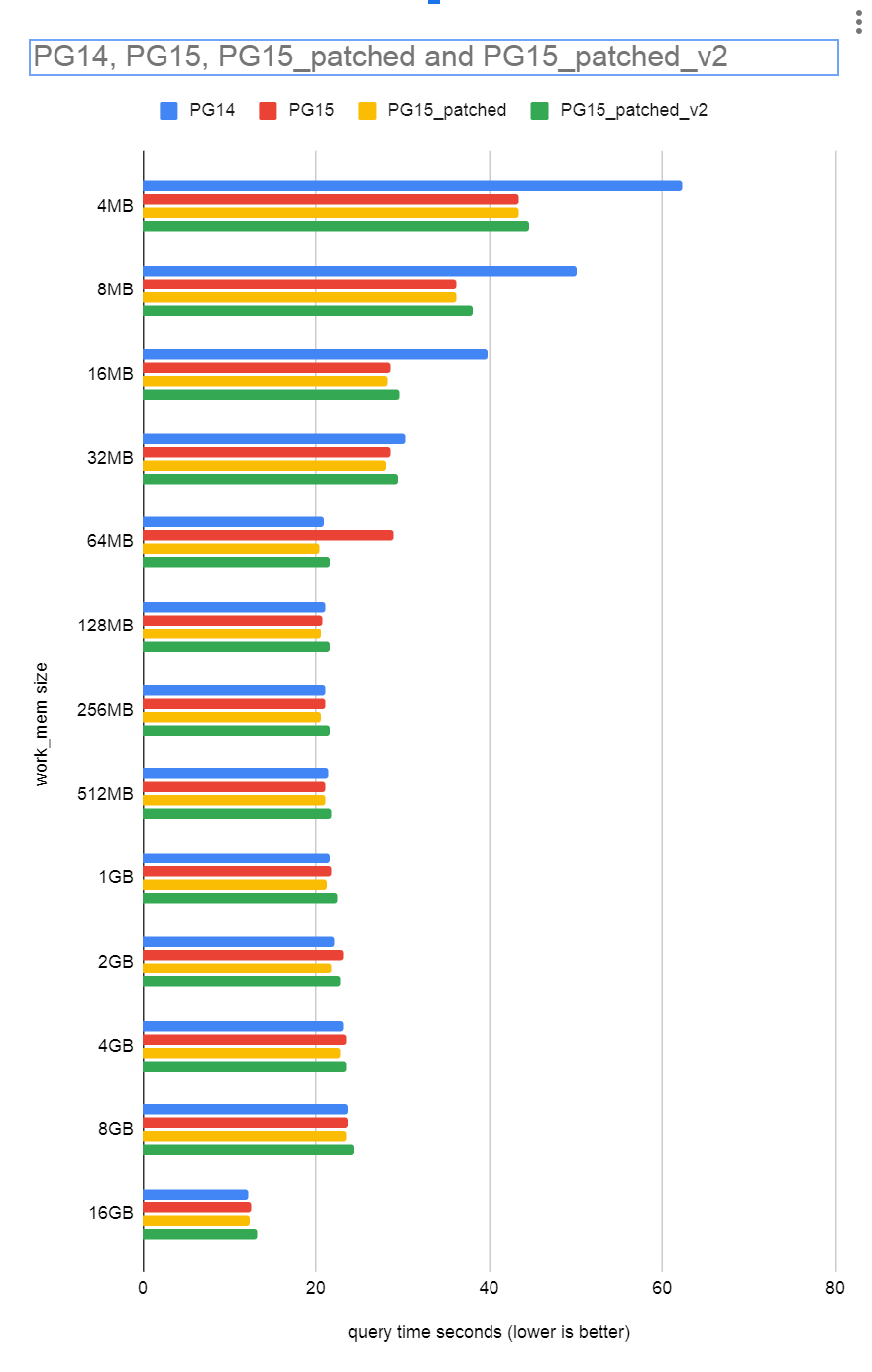
On Tue, 24 May 2022 at 09:36, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Handy wavy idea: It's probably too complex for now, and it also might > > be too much overhead, but having GenerationPointerGetChunk() do a > > binary search on a sorted-by-memory-address array of block pointers > > might be a fast enough way to find the block that the pointer belongs > > to. There should be far fewer blocks now since generation.c now grows > > the block sizes. N in O(log2 N) the search complexity should never be > > excessively high. > > > However, it would mean a binary search for every pfree, which feels > > pretty horrible. My feeling is that it seems unlikely that saving 8 > > bytes by not storing the GenerationBlock would be a net win here. > > I think probably that could be made to work, since a Generation > context should not contain all that many live blocks at any one time. I've done a rough cut implementation of this and attached it here. I've not done that much testing yet, but it does seem to fix the performance regression that I mentioned in the blog post that I linked in the initial post on this thread. There are a couple of things to note about the patch: 1. I quickly realised that there's no good place to store the sorted-by-memory-address array of GenerationBlocks. In the patch, I've had to malloc() this array and also had to use a special case so that I didn't try to do another malloc() inside GenerationContextCreate(). It's possible that the malloc() / repalloc of this array fails. In which case, I think I've coded things in such a way that there will be no memory leaks of the newly added block. 2. I did see GenerationFree() pop up in perf top a little more than it used to. I considered that we might want to have GenerationGetBlockFromChunk() cache the last found block for the set and then check that one first. We expect generation contexts to pfree() in an order that would likely make us hit this case most of the time. I added a few lines to the attached v2 patch to add a last_pfree_block field to the context struct. However, this seems to hinder performance more than it helps. It can easily be removed from the v2 patch. In the results you can see the PG14 + PG15 results the same as I reported on the blog post I linked earlier. It seems that for PG15_patched virtually all work_mem sizes produce results that are faster than PG14. The exception here is the 16GB test where PG15_patched is 0.8% slower, which seems within the noise threshold. David
Вложения
{kind=link}
David Rowley <dgrowleyml@gmail.com> writes:
> On Tue, 24 May 2022 at 09:36, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I think probably that could be made to work, since a Generation
>> context should not contain all that many live blocks at any one time.
> I've done a rough cut implementation of this and attached it here.
> I've not done that much testing yet, but it does seem to fix the
> performance regression that I mentioned in the blog post that I linked
> in the initial post on this thread.
Here's a draft patch for the other way of doing it. I'd first tried
to make the side-effects completely local to generation.c, but that
fails in view of code like
MemoryContextAlloc(GetMemoryChunkContext(x), ...)
Thus we pretty much have to have some explicit awareness of this scheme
in GetMemoryChunkContext(). There's more than one way it could be
done, but I thought a clean way is to invent a separate NodeTag type
to identify the indirection case.
So this imposes a distributed overhead of one additional test-and-branch
per pfree or repalloc. I'm inclined to think that that's negligible,
but I've not done performance testing to try to prove it.
For back-patching into v14, we could put the new NodeTag type at the
end of that enum list. The change in the inline GetMemoryChunkContext
is probably an acceptable hazard.
regards, tom lane
diff --git a/src/backend/utils/mmgr/README b/src/backend/utils/mmgr/README
index 221b4bd343..c932f88639 100644
--- a/src/backend/utils/mmgr/README
+++ b/src/backend/utils/mmgr/README
@@ -397,12 +397,14 @@ precede the MemoryContext. This means the only overhead implied by
the memory context mechanism is a pointer to its context, so we're not
constraining context-type designers very much.
-Given this, routines like pfree determine their corresponding context
-with an operation like (although that is usually encapsulated in
-GetMemoryChunkContext())
-
- MemoryContext context = *(MemoryContext*) (((char *) pointer) - sizeof(void *));
-
+Furthermore, context allocators can make the pointer preceding an
+allocated chunk be a pointer to a "MemoryContextLink" rather than
+directly to the owning context. This allows chunks to be associated
+with a subsidiary data structure, such as a sub-group of allocations,
+at relatively low cost.
+
+Given this, routines like pfree determine their target context
+with GetMemoryChunkContext() or equivalent code,
and then invoke the corresponding method for the context
context->methods->free_p(pointer);
diff --git a/src/backend/utils/mmgr/generation.c b/src/backend/utils/mmgr/generation.c
index e530e272e0..bf1acc13c7 100644
--- a/src/backend/utils/mmgr/generation.c
+++ b/src/backend/utils/mmgr/generation.c
@@ -85,9 +85,15 @@ typedef struct GenerationContext
*
* GenerationBlock is the header data for a block --- the usable space
* within the block begins at the next alignment boundary.
+ *
+ * To make it cheap to identify the GenerationBlock containing a given
+ * chunk, a GenerationBlock starts with a MemoryContextLink. This
+ * allows us to make GenerationChunk's required overhead pointer point to
+ * the containing GenerationBlock rather than directly to the context.
*/
struct GenerationBlock
{
+ MemoryContextLink link; /* link to owning context */
dlist_node node; /* doubly-linked list of blocks */
Size blksize; /* allocated size of this block */
int nchunks; /* number of chunks in the block */
@@ -101,7 +107,7 @@ struct GenerationBlock
* The prefix of each piece of memory in a GenerationBlock
*
* Note: to meet the memory context APIs, the payload area of the chunk must
- * be maxaligned, and the "context" link must be immediately adjacent to the
+ * be maxaligned, and the "block" link must be immediately adjacent to the
* payload area (cf. GetMemoryChunkContext). We simplify matters for this
* module by requiring sizeof(GenerationChunk) to be maxaligned, and then
* we can ensure things work by adding any required alignment padding before
@@ -128,17 +134,16 @@ struct GenerationChunk
#endif
GenerationBlock *block; /* block owning this chunk */
- GenerationContext *context; /* owning context, or NULL if freed chunk */
/* there must not be any padding to reach a MAXALIGN boundary here! */
};
/*
- * Only the "context" field should be accessed outside this module.
+ * Only the "block" field should be accessed outside this module.
* We keep the rest of an allocated chunk's header marked NOACCESS when using
* valgrind. But note that freed chunk headers are kept accessible, for
* simplicity.
*/
-#define GENERATIONCHUNK_PRIVATE_LEN offsetof(GenerationChunk, context)
+#define GENERATIONCHUNK_PRIVATE_LEN offsetof(GenerationChunk, block)
/*
* GenerationIsValid
@@ -152,7 +157,8 @@ struct GenerationChunk
((GenerationPointer *)(((char *)(chk)) + Generation_CHUNKHDRSZ))
/* Inlined helper functions */
-static inline void GenerationBlockInit(GenerationBlock *block, Size blksize);
+static inline void GenerationBlockInit(GenerationBlock *block,
+ MemoryContext context, Size blksize);
static inline bool GenerationBlockIsEmpty(GenerationBlock *block);
static inline void GenerationBlockMarkEmpty(GenerationBlock *block);
static inline Size GenerationBlockFreeBytes(GenerationBlock *block);
@@ -226,7 +232,7 @@ GenerationContextCreate(MemoryContext parent,
/* Assert we padded GenerationChunk properly */
StaticAssertStmt(Generation_CHUNKHDRSZ == MAXALIGN(Generation_CHUNKHDRSZ),
"sizeof(GenerationChunk) is not maxaligned");
- StaticAssertStmt(offsetof(GenerationChunk, context) + sizeof(MemoryContext) ==
+ StaticAssertStmt(offsetof(GenerationChunk, block) + sizeof(void *) ==
Generation_CHUNKHDRSZ,
"padding calculation in GenerationChunk is wrong");
@@ -278,7 +284,7 @@ GenerationContextCreate(MemoryContext parent,
block = (GenerationBlock *) (((char *) set) + MAXALIGN(sizeof(GenerationContext)));
/* determine the block size and initialize it */
firstBlockSize = allocSize - MAXALIGN(sizeof(GenerationContext));
- GenerationBlockInit(block, firstBlockSize);
+ GenerationBlockInit(block, (MemoryContext) set, firstBlockSize);
/* add it to the doubly-linked list of blocks */
dlist_push_head(&set->blocks, &block->node);
@@ -413,6 +419,10 @@ GenerationAlloc(MemoryContext context, Size size)
context->mem_allocated += blksize;
+ /* set up standard GenerationBlock header */
+ block->link.type = T_MemoryContextLink;
+ block->link.link = context;
+
/* block with a single (used) chunk */
block->blksize = blksize;
block->nchunks = 1;
@@ -423,7 +433,6 @@ GenerationAlloc(MemoryContext context, Size size)
chunk = (GenerationChunk *) (((char *) block) + Generation_BLOCKHDRSZ);
chunk->block = block;
- chunk->context = set;
chunk->size = chunk_size;
#ifdef MEMORY_CONTEXT_CHECKING
@@ -516,7 +525,7 @@ GenerationAlloc(MemoryContext context, Size size)
context->mem_allocated += blksize;
/* initialize the new block */
- GenerationBlockInit(block, blksize);
+ GenerationBlockInit(block, context, blksize);
/* add it to the doubly-linked list of blocks */
dlist_push_head(&set->blocks, &block->node);
@@ -544,7 +553,6 @@ GenerationAlloc(MemoryContext context, Size size)
Assert(block->freeptr <= block->endptr);
chunk->block = block;
- chunk->context = set;
chunk->size = chunk_size;
#ifdef MEMORY_CONTEXT_CHECKING
@@ -574,8 +582,11 @@ GenerationAlloc(MemoryContext context, Size size)
* mem_allocated field.
*/
static inline void
-GenerationBlockInit(GenerationBlock *block, Size blksize)
+GenerationBlockInit(GenerationBlock *block, MemoryContext context, Size blksize)
{
+ block->link.type = T_MemoryContextLink;
+ block->link.link = context;
+
block->blksize = blksize;
block->nchunks = 0;
block->nfree = 0;
@@ -685,9 +696,6 @@ GenerationFree(MemoryContext context, void *pointer)
wipe_mem(pointer, chunk->size);
#endif
- /* Reset context to NULL in freed chunks */
- chunk->context = NULL;
-
#ifdef MEMORY_CONTEXT_CHECKING
/* Reset requested_size to 0 in freed chunks */
chunk->requested_size = 0;
@@ -979,6 +987,12 @@ GenerationCheck(MemoryContext context)
total_allocated += block->blksize;
+ /* Sanity-check the block header. */
+ if (block->link.type != T_MemoryContextLink ||
+ block->link.link != context)
+ elog(WARNING, "problem in Generation %s: invalid link in block %p",
+ name, block);
+
/*
* nfree > nchunks is surely wrong. Equality is allowed as the block
* might completely empty if it's the freeblock.
@@ -1004,21 +1018,11 @@ GenerationCheck(MemoryContext context)
nchunks += 1;
- /* chunks have both block and context pointers, so check both */
+ /* verify the block pointer */
if (chunk->block != block)
elog(WARNING, "problem in Generation %s: bogus block link in block %p, chunk %p",
name, block, chunk);
- /*
- * Check for valid context pointer. Note this is an incomplete
- * test, since palloc(0) produces an allocated chunk with
- * requested_size == 0.
- */
- if ((chunk->requested_size > 0 && chunk->context != gen) ||
- (chunk->context != gen && chunk->context != NULL))
- elog(WARNING, "problem in Generation %s: bogus context link in block %p, chunk %p",
- name, block, chunk);
-
/* now make sure the chunk size is correct */
if (chunk->size < chunk->requested_size ||
chunk->size != MAXALIGN(chunk->size))
@@ -1026,7 +1030,7 @@ GenerationCheck(MemoryContext context)
name, block, chunk);
/* is chunk allocated? */
- if (chunk->context != NULL)
+ if (chunk->requested_size > 0)
{
/* check sentinel, but only in allocated blocks */
if (chunk->requested_size < chunk->size &&
@@ -1041,7 +1045,7 @@ GenerationCheck(MemoryContext context)
* If chunk is allocated, disallow external access to private part
* of chunk header.
*/
- if (chunk->context != NULL)
+ if (chunk->requested_size > 0)
VALGRIND_MAKE_MEM_NOACCESS(chunk, GENERATIONCHUNK_PRIVATE_LEN);
}
diff --git a/src/include/nodes/memnodes.h b/src/include/nodes/memnodes.h
index bbbe151e39..e0f87a612e 100644
--- a/src/include/nodes/memnodes.h
+++ b/src/include/nodes/memnodes.h
@@ -95,6 +95,20 @@ typedef struct MemoryContextData
/* utils/palloc.h contains typedef struct MemoryContextData *MemoryContext */
+/*
+ * MemoryContextLink
+ * An indirect linkage to a MemoryContext.
+ *
+ * Some context types prefer to make the pointer preceding each chunk
+ * point to one of these, rather than directly to the owning MemoryContext.
+ */
+typedef struct MemoryContextLink
+{
+ NodeTag type; /* == T_MemoryContextLink */
+ MemoryContext link; /* owning context */
+} MemoryContextLink;
+
+
/*
* MemoryContextIsValid
* True iff memory context is valid.
diff --git a/src/include/nodes/nodes.h b/src/include/nodes/nodes.h
index b3b407579b..f01ad58a20 100644
--- a/src/include/nodes/nodes.h
+++ b/src/include/nodes/nodes.h
@@ -301,6 +301,7 @@ typedef enum NodeTag
T_AllocSetContext,
T_SlabContext,
T_GenerationContext,
+ T_MemoryContextLink,
/*
* TAGS FOR VALUE NODES (value.h)
diff --git a/src/include/utils/memutils.h b/src/include/utils/memutils.h
index 495d1af201..1a51fce193 100644
--- a/src/include/utils/memutils.h
+++ b/src/include/utils/memutils.h
@@ -105,9 +105,10 @@ extern bool MemoryContextContains(MemoryContext context, void *pointer);
*
* All chunks allocated by any memory context manager are required to be
* preceded by the corresponding MemoryContext stored, without padding, in the
- * preceding sizeof(void*) bytes. A currently-allocated chunk must contain a
- * backpointer to its owning context. The backpointer is used by pfree() and
- * repalloc() to find the context to call.
+ * preceding sizeof(void*) bytes. This pointer is used by pfree() and
+ * repalloc() to find the context to call. The only exception is that the
+ * pointer might point to a MemoryContextLink rather than directly to the
+ * owning context.
*/
#ifndef FRONTEND
static inline MemoryContext
@@ -128,6 +129,12 @@ GetMemoryChunkContext(void *pointer)
*/
context = *(MemoryContext *) (((char *) pointer) - sizeof(void *));
+ /*
+ * It might be a link rather than the context itself.
+ */
+ if (IsA(context, MemoryContextLink))
+ context = ((MemoryContextLink *) context)->link;
+
AssertArg(MemoryContextIsValid(context));
return context;
Hi, On 2022-05-24 12:01:58 -0400, Tom Lane wrote: > David Rowley <dgrowleyml@gmail.com> writes: > > On Tue, 24 May 2022 at 09:36, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> I think probably that could be made to work, since a Generation > >> context should not contain all that many live blocks at any one time. > > > I've done a rough cut implementation of this and attached it here. > > I've not done that much testing yet, but it does seem to fix the > > performance regression that I mentioned in the blog post that I linked > > in the initial post on this thread. > > Here's a draft patch for the other way of doing it. I'd first tried > to make the side-effects completely local to generation.c, but that > fails in view of code like > > MemoryContextAlloc(GetMemoryChunkContext(x), ...) > > Thus we pretty much have to have some explicit awareness of this scheme > in GetMemoryChunkContext(). There's more than one way it could be > done, but I thought a clean way is to invent a separate NodeTag type > to identify the indirection case. That's interesting - I actually needed something vaguely similar recently. For direct IO support we need to allocate memory with pagesize alignment (otherwise DMA doesn't work). Several places allocating such buffers also pfree them. The easiest way I could see to deal with that was to invent a different memory context node type that handles allocation / freeing by over-allocating sufficiently to ensure alignment, backed by an underlying memory context. A variation on your patch would be to only store the offset to the block header - that should always fit into 32bit (huge allocations being their own block, which is why this wouldn't work for storing an offset to the context). With a bit of care that'd allow aset.c to half it's overhead, by using 4 bytes of space for all non-huge allocations. Of course, it'd increase the cost of pfree() of small allocations, because AllocSetFree() currently doesn't need to access the block for those. But I'd guess that'd be outweighed by the reduced memory usage. Sorry for the somewhat off-topic musing - I was trying to see if the MemoryContextLink approach could be generalized or has disadvantages aside from the branch in GetMemoryChunkContext(). > For back-patching into v14, we could put the new NodeTag type at the > end of that enum list. The change in the inline GetMemoryChunkContext > is probably an acceptable hazard. Why would we backpatch this to 14? I don't think we have any regressions there? Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2022-05-24 12:01:58 -0400, Tom Lane wrote:
>> For back-patching into v14, we could put the new NodeTag type at the
>> end of that enum list. The change in the inline GetMemoryChunkContext
>> is probably an acceptable hazard.
> Why would we backpatch this to 14? I don't think we have any regressions
> there?
Oh, sorry, I meant v15. I'm operating on the assumption that we have
at least a weak ABI freeze in v15 already.
regards, tom lane
On Wed, 25 May 2022 at 04:02, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Here's a draft patch for the other way of doing it. I'd first tried > to make the side-effects completely local to generation.c, but that > fails in view of code like > > MemoryContextAlloc(GetMemoryChunkContext(x), ...) > > Thus we pretty much have to have some explicit awareness of this scheme > in GetMemoryChunkContext(). There's more than one way it could be > done, but I thought a clean way is to invent a separate NodeTag type > to identify the indirection case. Thanks for coding that up. This seems like a much better idea than mine. I ran the same benchmark as I did in the blog on your patch and got the attached sort_bench.png. You can see the patch fixes the 64MB work_mem performance regression, as we'd expect. To get an idea of the overhead of this I came up with the attached allocate_performance_function.patch which basically just adds a function named pg_allocate_generation_memory() which you can pass a chunk_size for the number of bytes to allocate at once, and also a keep_memory to tell the function how much memory to keep around before starting to pfree previous allocations. The final parameter defines the total amount of memory to allocate. The attached script calls the function with varying numbers of chunk sizes from 8 up to 2048, multiplying by 2 each step. It keeps 1MB of memory and does a total of 1GB of allocations. I ran the script against today's master and master + the invent-MemoryContextLink-1.patch and got the attached tps_results.txt. The worst-case is the 8-byte allocation size where performance drops around 7%. For the larger chunk sizes, the drop is much less, mostly just around <1% to ~6%. For the 2048 byte size chunks, the performance seems to improve (?). Obviously, the test is pretty demanding as far as palloc and pfree go. I imagine we don't come close to anything like that in the actual code. This test was just aimed to give us an idea of the overhead. It might not be enough information to judge if we should be concerned about more realistic palloc/pfree workloads. I didn't test the performance of an aset.c context. I imagine it's likely to be less overhead due to aset.c being generally slower from having to jump through a few more hoops during palloc/pfree. David
Вложения
{kind=link}
On Wed, 25 May 2022 at 15:09, David Rowley <dgrowleyml@gmail.com> wrote: > I didn't test the performance of an aset.c context. I imagine it's > likely to be less overhead due to aset.c being generally slower from > having to jump through a few more hoops during palloc/pfree. I've attached the results from doing the same test with a standard allocset context. With the exception of the 8 byte chunk size test, there just seems to be a 3-4% slowdown on my machine. David
Вложения
В Вт, 24/05/2022 в 17:39 -0700, Andres Freund пишет:
>
> A variation on your patch would be to only store the offset to the block
> header - that should always fit into 32bit (huge allocations being their own
> block, which is why this wouldn't work for storing an offset to the
> context). With a bit of care that'd allow aset.c to half it's overhead, by
> using 4 bytes of space for all non-huge allocations. Of course, it'd increase
> the cost of pfree() of small allocations, because AllocSetFree() currently
> doesn't need to access the block for those. But I'd guess that'd be outweighed
> by the reduced memory usage.
I'm +1 for this.
And with this change every memory context kind can have same header:
typedef struct MemoryChunk {
#ifdef MEMORY_CONTEXT_CHECKING
Size requested_size;
#endif
uint32 encoded_size; /* encoded allocation size */
uint32 offset_to_block; /* backward offset to block header */
}
Allocated size always could be encoded into uint32 since it is rounded
for large allocations (I believe, large allocations certainly rounded
to at least 4096 bytes):
encoded_size = size < (1u<<31) ? size : (1u<<31)|(size>>12);
/* and reverse */
size = (encoded_size >> 31) ? ((Size)(encoded_size<<1)<<12) :
(Size)encoded_size;
There is a glitch with Aset since it currently reuses `aset` pointer
for freelist link. With such change this link had to be encoded in
chunk-body itself instead of header. I was confused with this, since
there are valgrind hooks, and I was not sure how to change it (I'm
not good at valgrind hooks). But after thinking more about I believe
it is doable.
regards
-------
Yura Sokolov
Yura Sokolov <y.sokolov@postgrespro.ru> writes:
> В Вт, 24/05/2022 в 17:39 -0700, Andres Freund пишет:
>> A variation on your patch would be to only store the offset to the block
>> header - that should always fit into 32bit (huge allocations being their own
>> block, which is why this wouldn't work for storing an offset to the
>> context).
> I'm +1 for this.
Given David's results in the preceding message, I don't think I am.
A scheme like this would add more arithmetic and at least one more
indirection to GetMemoryChunkContext(), and we already know that
adding even a test-and-branch there has measurable cost. (I wonder
if using unlikely() on the test would help? But it's not unlikely
in a generation-context-heavy use case.) There would also be a good
deal of complication and ensuing slowdown created by the need for
oversize chunks to be a completely different kind of animal with a
different header.
I'm also not very happy about this:
> And with this change every memory context kind can have same header:
IMO that's a bug not a feature. It puts significant constraints on how
context types can be designed.
regards, tom lane
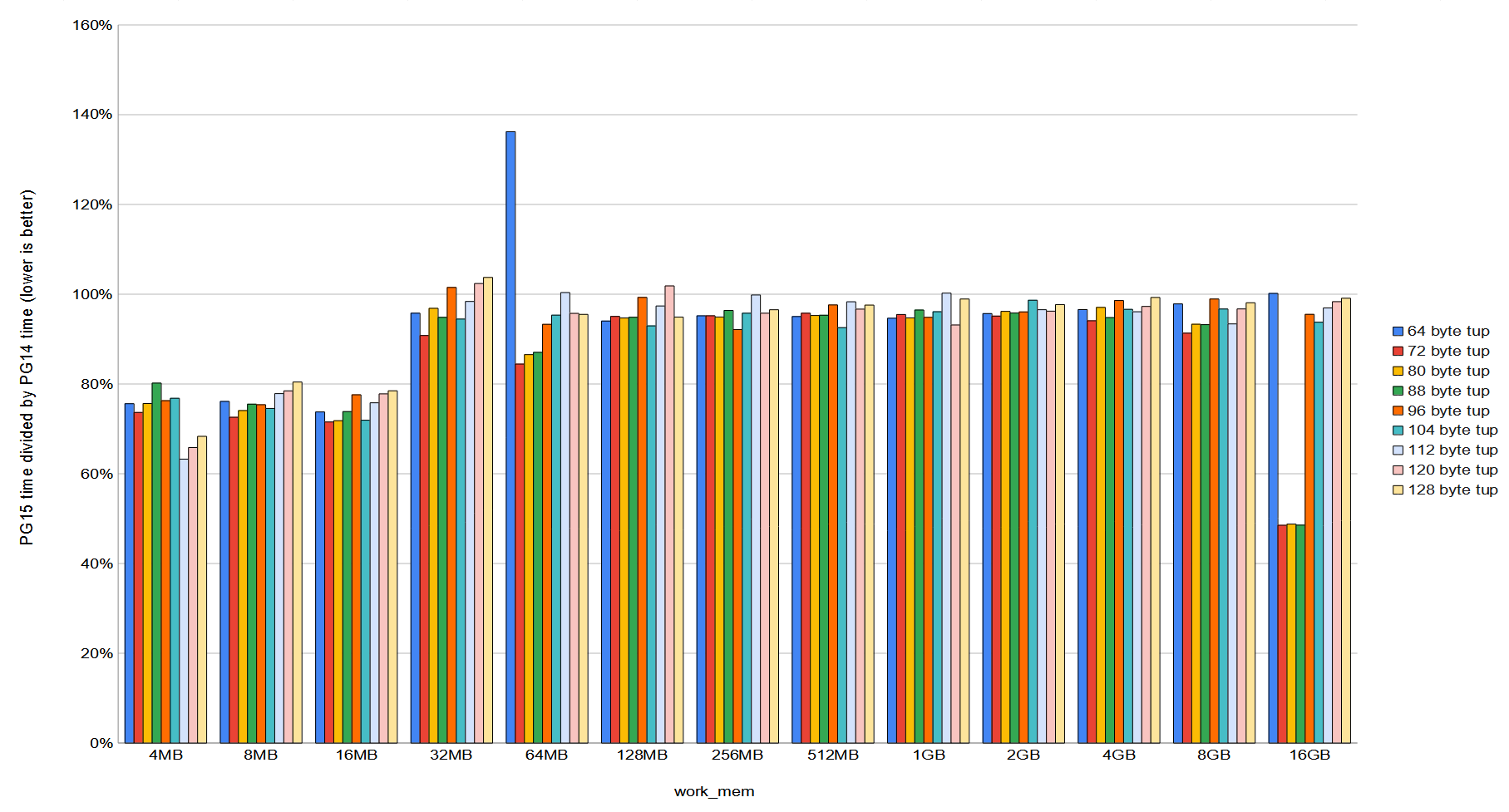
On Sat, 28 May 2022 at 02:51, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Given David's results in the preceding message, I don't think I am. > A scheme like this would add more arithmetic and at least one more > indirection to GetMemoryChunkContext(), and we already know that > adding even a test-and-branch there has measurable cost. I also ran the same tests on my patch to binary search for the generation block and the performance is worse than with the MemoryContextLink patch, albeit, limited to generation contexts only. Also disheartening. See attached bsearch_gen_blocks.txt I decided to run some more extensive benchmarking with the 10GB table with varying numbers of BIGINT columns from 6 up to 14. 6 columns means 64-byte pallocs in the generation context and 14 means 128 bytes. Once again, I tested work_mem values starting at 4MB and doubled that each test until I got to 16GB. The results are attached both in chart format and I've also included the complete results in a spreadsheet along with the script I ran to get the results. The results compare PG14 @ 0adff38d against master @ b3fb16e8b. In the chart, anything below 100% is a performance improvement over PG14 and anything above 100% means PG15 is slower. You can see there's only the 64-byte / 64MB work_mem test that gets significantly slower and that there are only a small amount of other tests that are slightly slower. Most are faster and on average PG15 takes 90% of the time that PG14 took. Likely it would have been more relevant to have tested this against master with 40af10b57 reverted. I'm running those now. David
Вложения
{kind=link}
Re: PG15 beta1 sort performance regression due to Generation context change
On Mon, May 30, 2022 at 2:37 PM David Rowley <dgrowleyml@gmail.com> wrote: > The results compare PG14 @ 0adff38d against master @ b3fb16e8b. In > the chart, anything below 100% is a performance improvement over PG14 > and anything above 100% means PG15 is slower. You can see there's > only the 64-byte / 64MB work_mem test that gets significantly slower > and that there are only a small amount of other tests that are > slightly slower. Most are faster and on average PG15 takes 90% of the > time that PG14 took. Shouldn't this be using the geometric mean rather than the arithmetic mean? That's pretty standard practice when summarizing a set of benchmark results that are expressed as ratios to some baseline. If I tweak your spreadsheet to use the geometric mean, the patch looks slightly better -- 89%. -- Peter Geoghegan
On Tue, 31 May 2022 at 09:48, Peter Geoghegan <pg@bowt.ie> wrote: > Shouldn't this be using the geometric mean rather than the arithmetic > mean? That's pretty standard practice when summarizing a set of > benchmark results that are expressed as ratios to some baseline. Maybe just comparing the SUM of the seconds of each version is the best way. That comes out to 86.6% David
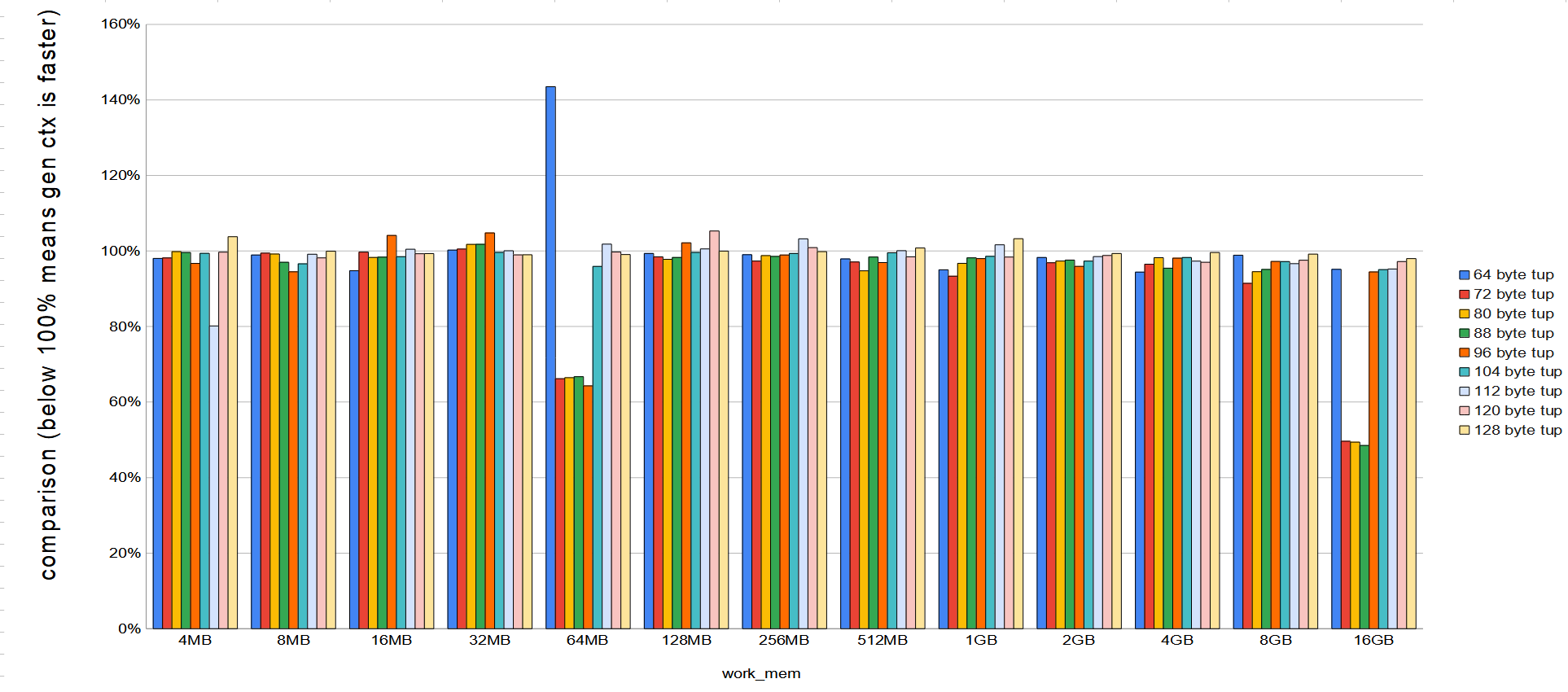
On Tue, 31 May 2022 at 09:37, David Rowley <dgrowleyml@gmail.com> wrote: > Likely it would have been more relevant to have tested this against > master with 40af10b57 reverted. I'm running those now. My machine just finished running the tests on master with the generation context in tuplesort.c commented out so that it always uses the allocset context. In the attached graph, anything below 100% means that using the generation context performs better than without. In the test, each query runs 5 times. If I sum the average run time of each query, master takes 41 min 43.8 seconds and without the use of generation context it takes 43 mins 31.3 secs. So it runs in 95.88% with the generation context. Looking at the graph, you can easily see the slower performance for the 64-byte tuples with 64MB of work_mem. That's the only regression of note. Many other cases are much faster. I'm wondering if we should just do nothing about this. Any thoughts? David
Вложения
{kind=link}
On Fri, May 27, 2022 at 10:52 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Given David's results in the preceding message, I don't think I am. > A scheme like this would add more arithmetic and at least one more > indirection to GetMemoryChunkContext(), and we already know that > adding even a test-and-branch there has measurable cost. I think you're being too negative here. It's a 7% regression on 8-byte allocations in a tight loop. In real life, people allocate memory because they want to do something with it, and the allocation overhead therefore figures to be substantially less. They also nearly always allocate memory more than 8 bytes at a time, since there's very little of interest that can fit into an 8 byte allocation, and if you're dealing with one of the things that can, you're likely to allocate an array rather than each item individually. I think it's quite plausible that saving space is going to be more important for performance than the tiny cost of a test-and-branch here. I don't want to take the position that we ought necessarily to commit your patch, because I don't really have a clear sense of what the wins and losses actually are. But, I am worried that our whole memory allocation infrastructure is stuck at a local maximum, and I think your patch pushes in a generally healthy direction: let's optimize for wasting less space, instead of for the absolute minimum number of CPU cycles consumed. aset.c's approach is almost unbeatable for small numbers of allocations in tiny contexts, and PostgreSQL does a lot of that. But when you do have cases where a lot of data needs to be stored in memory, it starts to look pretty lame. To really get out from under that problem, we'd need to find a way to remove the requirement of a per-allocation header altogether, and I don't think this patch really helps us see how we could ever get all the way to that point. Nonetheless, I like the fact that it puts more flexibility into the mechanism seemingly at very little real cost, and that it seems to mean less memory spent on header information rather than user data. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> I don't want to take the position that we ought necessarily to commit
> your patch, because I don't really have a clear sense of what the wins
> and losses actually are.
Yeah, we don't have any hard data here. It could be that it's a win to
switch to a rule that chunks must present an offset (instead of a pointer)
back to a block header, which'd then be required to contain a link to the
actual context, meaning that every context has to do something like what
I proposed for generation.c. But nobody's coded that up let alone done
any testing on it, and I feel like it's too late in the v15 cycle for
changes as invasive as that. Quite aside from that change in itself,
you wouldn't get any actual space savings in aset.c contexts unless
you did something with the chunk-size field too, and that seems a lot
messier.
Right now my vote would be to leave things as they stand for v15 ---
the performance loss that started this thread occurs in a narrow
enough set of circumstances that I don't feel too much angst about
it being the price of winning in most other circumstances. We can
investigate these options at leisure for v16 or later.
regards, tom lane
On Tue, May 31, 2022 at 11:09 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Yeah, we don't have any hard data here. It could be that it's a win to > switch to a rule that chunks must present an offset (instead of a pointer) > back to a block header, which'd then be required to contain a link to the > actual context, meaning that every context has to do something like what > I proposed for generation.c. But nobody's coded that up let alone done > any testing on it, and I feel like it's too late in the v15 cycle for > changes as invasive as that. Quite aside from that change in itself, > you wouldn't get any actual space savings in aset.c contexts unless > you did something with the chunk-size field too, and that seems a lot > messier. > > Right now my vote would be to leave things as they stand for v15 --- > the performance loss that started this thread occurs in a narrow > enough set of circumstances that I don't feel too much angst about > it being the price of winning in most other circumstances. We can > investigate these options at leisure for v16 or later. I don't think it's all that narrow a case, but I think it's narrow enough that I agree that we can live with it if we don't feel like the risk-reward trade-offs are looking favorable. I don't think tuples whose size, after rounding to a multiple of 8, is exactly a power of 2 are going to be terribly uncommon. It is not very likely that many people will have tuples between 25 and 31 bytes, but tables with lots of 57-64 byte tuples are probably pretty common, and tables with lots of 121-128 and 249-256 byte tuples are somewhat plausible as well. I think we will win more than we lose, but I think we will lose often enough that I wouldn't be very surprised if we get >0 additional complaints about this over the next 5 years. While it may seem risky to do something about that now, it will certainly seem a lot riskier once the release is out, and there is some risk in doing nothing, because we don't know how many people are going to run into the bad cases or how severely they might be impacted. I think the biggest risk in your patch as presented is that slowing down pfree() might suck in some set of workloads upon which we can't easily identify now. I don't really know how to rule out that possibility. In general terms, I think we're not doing ourselves any favors by relying partly on memory context cleanup and partly on pfree. The result is that pfree() has to work for every memory context type and can't be unreasonably slow, which rules out a lot of really useful ideas, both in terms of how to make allocation faster, and also in terms of how to make it denser. If you're ever of a mind to put some efforts into really driving things forward in this area, I think figuring out some way to break that hard dependence would be effort really well-spent. -- Robert Haas EDB: http://www.enterprisedb.com
I ran a shorter version of David's script with just 6-9 attributes to try to reproduce the problem area (spreadsheet with graph attached). My test is also different in that I compare HEAD with just reverting 40af10b57. This shows a 60% increase in HEAD in runtime for 64MB workmem and 64 byte tuples. It also shows a 20% regression for 32MB workmem and 64 byte tuples. I don't have anything to add to the discussion about whether something needs to be done here for PG15. If anything, changing work_mem is an easy to understand (although sometimes not practical) workaround. -- John Naylor EDB: http://www.enterprisedb.com
Вложения
Fr, 27/05/2022 в 10:51 -0400, Tom Lane writes: > Yura Sokolov <y.sokolov@postgrespro.ru> writes: > > В Вт, 24/05/2022 в 17:39 -0700, Andres Freund пишет: > > > A variation on your patch would be to only store the offset to the block > > > header - that should always fit into 32bit (huge allocations being their own > > > block, which is why this wouldn't work for storing an offset to the > > > context). > > I'm +1 for this. > > Given David's results in the preceding message, I don't think I am. But David did the opposite: he removed pointer to block and remain pointer to context. Then code have to do bsearch to find actual block. > A scheme like this would add more arithmetic and at least one more > indirection to GetMemoryChunkContext(), and we already know that > adding even a test-and-branch there has measurable cost. (I wonder > if using unlikely() on the test would help? But it's not unlikely > in a generation-context-heavy use case.) Well, it should be tested. > There would also be a good > deal of complication and ensuing slowdown created by the need for > oversize chunks to be a completely different kind of animal with a > different header. Why? encoded_size could handle both small sizes and larges sizes given actual (not requested) allocation size is rounded to page size. There's no need to different chunk header. > I'm also not very happy about this: > > > And with this change every memory context kind can have same header: > > IMO that's a bug not a feature. It puts significant constraints on how > context types can be designed. Nothing prevents to add additional data before common header. regards Yura
On Thu, 2 Jun 2022 at 20:20, John Naylor <john.naylor@enterprisedb.com> wrote: > If anything, changing work_mem is an > easy to understand (although sometimes not practical) workaround. I had a quick look at that for the problem case and we're very close in terms of work_mem size to better performance. A work_mem of just 64.3MB brings the performance back to better than PG14. postgres=# set work_mem = '64.2MB'; postgres=# \i bench.sql c1 | c2 | c3 | c4 | c5 | c6 ----+----+----+----+----+---- (0 rows) Time: 28949.942 ms (00:28.950) postgres=# set work_mem = '64.3MB'; postgres=# \i bench.sql c1 | c2 | c3 | c4 | c5 | c6 ----+----+----+----+----+---- (0 rows) Time: 19759.552 ms (00:19.760) David
On Thu, Jun 2, 2022 at 5:37 PM David Rowley <dgrowleyml@gmail.com> wrote: > I had a quick look at that for the problem case and we're very close > in terms of work_mem size to better performance. A work_mem of just > 64.3MB brings the performance back to better than PG14. This is one of the things that I find super-frustrating about work_mem and sorting. I mean, we all know that work_mem is hard to tune because it's per-node rather than per-query or per-backend, but on top of that, sort performance doesn't change smoothly as you vary it. I've seen really different work_mem settings produce only slightly different performance, and here you have the opposite: only slightly different work_mem settings produce significantly different performance. It's not even the case that more memory is necessarily better than less. I have no idea what to do about this, and even if I did, it's too late to redesign v15. But I somehow feel like the whole model is just wrong. Sorting shouldn't use more memory unless it's actually going to speed things up -- and not just any speed-up, but one that's significant compared to the additional expenditure of memory. But the fact that the sorting code just treats the memory budget as an input, and is not adaptive in any way, seems pretty bad. It means we use up all that memory even if a much smaller amount of memory would deliver the same performance, or even better performance. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, 1 Jun 2022 at 03:09, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Right now my vote would be to leave things as they stand for v15 --- > the performance loss that started this thread occurs in a narrow > enough set of circumstances that I don't feel too much angst about > it being the price of winning in most other circumstances. We can > investigate these options at leisure for v16 or later. I've been hesitating a little to put my views here as I wanted to see what the other views were first. My thoughts are generally in agreement with you, i.e., to do nothing for PG15 about this. My reasoning is: 1. Most cases are faster as a result of using generation contexts for sorting. 2. The slowdown cases seem rare and the speedup cases are much more common. 3. There were performance cliffs in PG14 if a column was added to a table to make the tuple size cross a power-of-2 boundary which I don't recall anyone complaining about. PG15 makes the performance drop more gradual as tuple sizes increase. Performance is more predictable as a result. 4. As I just demonstrated in [1], if anyone is caught by this and has a problem, the work_mem size increase required seems very small to get performance back to better than in PG14. I found that setting work_mem to 64.3MB makes PG15 faster than PG14 for the problem case. If anyone happened to hit this case and find the performance regression unacceptable then they have a way out... increase work_mem a little. Also, in terms of what we might do to improve this situation for PG16: I was also discussing this off-list with Andres which resulted in him prototyping a patch [2] to store the memory context type in 3-bits in the 64-bits prior to the pointer which is used to lookup a memory context method table so that we can call the correct function. I've been hacking around with this and I've added some optimisations and got the memory allocation test [3] (modified to use aset.c rather than generation.c) showing very promising results when comparing this patch to master. There are still a few slowdowns, but 16-byte allocations up to 256-bytes allocations are looking pretty good. Up to ~10% faster compared to master. (lower is better) size compare 8 114.86% 16 89.04% 32 90.95% 64 94.17% 128 93.36% 256 96.57% 512 101.25% 1024 109.88% 2048 100.87% There's quite a bit more work to do for deciding how to handle large allocations and there's also likely more than can be done to further shrink the existing chunk headers for each of the 3 existing memory allocators. David [1] https://www.postgresql.org/message-id/CAApHDvq8MoEMxHN+f=RcCfwCfr30An1w3uOKruUnnPLVRR3c_A@mail.gmail.com [2] https://github.com/anarazel/postgres/tree/mctx-chunk [3] https://www.postgresql.org/message-id/attachment/134021/allocate_performance_function.patch
On Fri, Jun 3, 2022 at 10:14 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Wed, 1 Jun 2022 at 03:09, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Right now my vote would be to leave things as they stand for v15 --- > > the performance loss that started this thread occurs in a narrow > > enough set of circumstances that I don't feel too much angst about > > it being the price of winning in most other circumstances. We can > > investigate these options at leisure for v16 or later. > > I've been hesitating a little to put my views here as I wanted to see > what the other views were first. My thoughts are generally in > agreement with you, i.e., to do nothing for PG15 about this. My > reasoning is: > > 1. Most cases are faster as a result of using generation contexts for sorting. > 2. The slowdown cases seem rare and the speedup cases are much more common. > 3. There were performance cliffs in PG14 if a column was added to a > table to make the tuple size cross a power-of-2 boundary which I don't > recall anyone complaining about. PG15 makes the performance drop more > gradual as tuple sizes increase. Performance is more predictable as a > result. > 4. As I just demonstrated in [1], if anyone is caught by this and has > a problem, the work_mem size increase required seems very small to get > performance back to better than in PG14. I found that setting work_mem > to 64.3MB makes PG15 faster than PG14 for the problem case. If anyone > happened to hit this case and find the performance regression > unacceptable then they have a way out... increase work_mem a little. Since #4 is such a small lift, I'd be comfortable with closing the open item. -- John Naylor EDB: http://www.enterprisedb.com
On Fri, 3 Jun 2022 at 16:03, John Naylor <john.naylor@enterprisedb.com> wrote: > > On Fri, Jun 3, 2022 at 10:14 AM David Rowley <dgrowleyml@gmail.com> wrote: > > 4. As I just demonstrated in [1], if anyone is caught by this and has > > a problem, the work_mem size increase required seems very small to get > > performance back to better than in PG14. I found that setting work_mem > > to 64.3MB makes PG15 faster than PG14 for the problem case. If anyone > > happened to hit this case and find the performance regression > > unacceptable then they have a way out... increase work_mem a little. > > Since #4 is such a small lift, I'd be comfortable with closing the open item. I also think that we should close off this open item for PG15. The majority of cases are faster now and it is possible for anyone who does happen to hit a bad case to raise work_mem by some fairly small fraction. I posted a WIP patch on [1] that we aim to get into PG16 to improve the situation here further. I'm hoping the fact that we do have some means to fix this for PG16 might mean we can leave this as a known issue for PG15. So far only Robert has raised concerns with this regression for PG15 (see [2]). Tom voted for leaving things as they are for PG15 in [3]. John agrees, as quoted above. Does anyone else have any opinion? David [1] https://www.postgresql.org/message-id/CAApHDvpjauCRXcgcaL6+e3eqecEHoeRm9D-kcbuvBitgPnW=vw@mail.gmail.com [2] https://www.postgresql.org/message-id/CA+TgmoZoYxFBN+AEJGfjJCCbeW8MMkHfFVcC61kP2OncmeYDWA@mail.gmail.com [3] https://www.postgresql.org/message-id/180278.1654009751@sss.pgh.pa.us
On Tue, 12 Jul 2022 at 17:15, David Rowley <dgrowleyml@gmail.com> wrote: > So far only Robert has raised concerns with this regression for PG15 > (see [2]). Tom voted for leaving things as they are for PG15 in [3]. > John agrees, as quoted above. Does anyone else have any opinion? Let me handle this slightly differently. I've moved the open item for this into the "won't fix" section. If nobody shouts at me for that then I'll let that end the debate. Otherwise, we can consider the argument when it arrives. David
Re: PG15 beta1 sort performance regression due to Generation context change
Hi David, On 7/13/22 12:13 AM, David Rowley wrote: > On Tue, 12 Jul 2022 at 17:15, David Rowley <dgrowleyml@gmail.com> wrote: >> So far only Robert has raised concerns with this regression for PG15 >> (see [2]). Tom voted for leaving things as they are for PG15 in [3]. >> John agrees, as quoted above. Does anyone else have any opinion? > > Let me handle this slightly differently. I've moved the open item for > this into the "won't fix" section. If nobody shouts at me for that > then I'll let that end the debate. Otherwise, we can consider the > argument when it arrives. The RMT discussed this issue at its meeting today (and a few weeks back -- apologies for not writing sooner). While we agree with your analysis that 1/ this issue does appear to be a corner case and 2/ the benefits outweigh the risks, we still don't know how prevalent it may be in the wild and the general impact to user experience. The RMT suggests that you make one more pass at attempting to solve it. If there does not appear to be a clear path forward, we should at least document how a user can detect and resolve the issue. Thanks, Jonathan
Вложения
Hi, On 2022-07-13 09:23:00 -0400, Jonathan S. Katz wrote: > On 7/13/22 12:13 AM, David Rowley wrote: > > On Tue, 12 Jul 2022 at 17:15, David Rowley <dgrowleyml@gmail.com> wrote: > > > So far only Robert has raised concerns with this regression for PG15 > > > (see [2]). Tom voted for leaving things as they are for PG15 in [3]. > > > John agrees, as quoted above. Does anyone else have any opinion? > > > > Let me handle this slightly differently. I've moved the open item for > > this into the "won't fix" section. If nobody shouts at me for that > > then I'll let that end the debate. Otherwise, we can consider the > > argument when it arrives. > > The RMT discussed this issue at its meeting today (and a few weeks back -- > apologies for not writing sooner). While we agree with your analysis that 1/ > this issue does appear to be a corner case and 2/ the benefits outweigh the > risks, we still don't know how prevalent it may be in the wild and the > general impact to user experience. > > The RMT suggests that you make one more pass at attempting to solve it. I think without a more concrete analysis from the RMT that's not really actionable. What risks are we willing to accept to resolve this? This is mostly a question of tradeoffs. Several "senior" postgres hackers looked at this and didn't find any solution that makes sense to apply to 15. I don't think having David butt his head further against this code is likely to achieve much besides a headache. Note that David already has a patch to address this for 16. > If there does not appear to be a clear path forward, we should at least > document how a user can detect and resolve the issue. To me that doesn't really make sense. We have lots of places were performance changes once you cross some threshold, and lots of those are related to work_mem. We don't, e.g., provide tooling to detect when performance in aggregation regresses due to crossing work_mem and could be fixed by a tiny increase in work_mem. Greetings, Andres Freund
On 7/13/22 17:32, Andres Freund wrote: > Hi, > > On 2022-07-13 09:23:00 -0400, Jonathan S. Katz wrote: >> On 7/13/22 12:13 AM, David Rowley wrote: >>> On Tue, 12 Jul 2022 at 17:15, David Rowley <dgrowleyml@gmail.com> wrote: >>>> So far only Robert has raised concerns with this regression for PG15 >>>> (see [2]). Tom voted for leaving things as they are for PG15 in [3]. >>>> John agrees, as quoted above. Does anyone else have any opinion? >>> >>> Let me handle this slightly differently. I've moved the open item for >>> this into the "won't fix" section. If nobody shouts at me for that >>> then I'll let that end the debate. Otherwise, we can consider the >>> argument when it arrives. >> >> The RMT discussed this issue at its meeting today (and a few weeks back -- >> apologies for not writing sooner). While we agree with your analysis that 1/ >> this issue does appear to be a corner case and 2/ the benefits outweigh the >> risks, we still don't know how prevalent it may be in the wild and the >> general impact to user experience. >> >> The RMT suggests that you make one more pass at attempting to solve it. > > I think without a more concrete analysis from the RMT that's not really > actionable. What risks are we willing to accept to resolve this? This is > mostly a question of tradeoffs. > > Several "senior" postgres hackers looked at this and didn't find any solution > that makes sense to apply to 15. I don't think having David butt his head > further against this code is likely to achieve much besides a headache. Note > that David already has a patch to address this for 16. > I agree with this. It's not clear to me how we'd asses how prevalent it really is (reports on a mailing list surely are not a very great way to measure this). My personal opinion is that it's a rare regression. Other optimization patches have similar rare regressions, except that David spent so much time investigating this one it seems more serious. I think it's fine to leave this as is. If we feel we have to fix this for v15, it's probably best to just apply the v16. I doubt we'll find anything simpler. > >> If there does not appear to be a clear path forward, we should at least >> document how a user can detect and resolve the issue. > > To me that doesn't really make sense. We have lots of places were performance > changes once you cross some threshold, and lots of those are related to > work_mem. > > We don't, e.g., provide tooling to detect when performance in aggregation > regresses due to crossing work_mem and could be fixed by a tiny increase in > work_mem. > Yeah. I find it entirely reasonable to tell people to increase work_mem a bit to fix this. The problem is knowing you're affected :-( regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Re: PG15 beta1 sort performance regression due to Generation context change
On 7/15/22 4:36 PM, Tomas Vondra wrote: > > > On 7/13/22 17:32, Andres Freund wrote: >> Hi, >> >> On 2022-07-13 09:23:00 -0400, Jonathan S. Katz wrote: >>> On 7/13/22 12:13 AM, David Rowley wrote: >>>> On Tue, 12 Jul 2022 at 17:15, David Rowley <dgrowleyml@gmail.com> wrote: >>>>> So far only Robert has raised concerns with this regression for PG15 >>>>> (see [2]). Tom voted for leaving things as they are for PG15 in [3]. >>>>> John agrees, as quoted above. Does anyone else have any opinion? >>>> >>>> Let me handle this slightly differently. I've moved the open item for >>>> this into the "won't fix" section. If nobody shouts at me for that >>>> then I'll let that end the debate. Otherwise, we can consider the >>>> argument when it arrives. >>> >>> The RMT discussed this issue at its meeting today (and a few weeks back -- >>> apologies for not writing sooner). While we agree with your analysis that 1/ >>> this issue does appear to be a corner case and 2/ the benefits outweigh the >>> risks, we still don't know how prevalent it may be in the wild and the >>> general impact to user experience. >>> >>> The RMT suggests that you make one more pass at attempting to solve it. >> >> I think without a more concrete analysis from the RMT that's not really >> actionable. What risks are we willing to accept to resolve this? This is >> mostly a question of tradeoffs. >> >> Several "senior" postgres hackers looked at this and didn't find any solution >> that makes sense to apply to 15. I don't think having David butt his head >> further against this code is likely to achieve much besides a headache. Note >> that David already has a patch to address this for 16. >> > > I agree with this. It's not clear to me how we'd asses how prevalent it > really is (reports on a mailing list surely are not a very great way to > measure this). My personal opinion is that it's a rare regression. Other > optimization patches have similar rare regressions, except that David > spent so much time investigating this one it seems more serious. > > I think it's fine to leave this as is. If we feel we have to fix this > for v15, it's probably best to just apply the v16. I doubt we'll find > anything simpler. I think the above is reasonable. >>> If there does not appear to be a clear path forward, we should at least >>> document how a user can detect and resolve the issue. >> >> To me that doesn't really make sense. We have lots of places were performance >> changes once you cross some threshold, and lots of those are related to >> work_mem. Yes, but in this case this is nonobvious to a user. A sort that may be performing just fine on a pre-PG15 version is suddenly degraded, and the user has no guidance as to why or how to remediate. >> We don't, e.g., provide tooling to detect when performance in aggregation >> regresses due to crossing work_mem and could be fixed by a tiny increase in >> work_mem. >> > > Yeah. I find it entirely reasonable to tell people to increase work_mem > a bit to fix this. The problem is knowing you're affected :-( This is the concern the RMT discussed. Yes it is reasonable to say "increase work_mem to XYZ", but how does a user know how to detect and apply that? This is the part that is worrisome, especially because we don't have any sense of what the overall impact will be. Maybe it's not much, but we should document that there is the potential for a regression. Jonathan
Вложения
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> ... My personal opinion is that it's a rare regression. Other
> optimization patches have similar rare regressions, except that David
> spent so much time investigating this one it seems more serious.
Yeah, this. I fear we're making a mountain out of a molehill. We have
committed many optimizations that win on average but possibly lose
in edge cases, and not worried too much about it.
regards, tom lane
Hi, On 2022-07-15 16:42:14 -0400, Jonathan S. Katz wrote: > On 7/15/22 4:36 PM, Tomas Vondra wrote: > > > > If there does not appear to be a clear path forward, we should at least > > > > document how a user can detect and resolve the issue. > > > > > > To me that doesn't really make sense. We have lots of places were performance > > > changes once you cross some threshold, and lots of those are related to > > > work_mem. > > Yes, but in this case this is nonobvious to a user. A sort that may be > performing just fine on a pre-PG15 version is suddenly degraded, and the > user has no guidance as to why or how to remediate. We make minor changes affecting thresholds at which point things spill to disk etc *all the time*. Setting the standard that all of those need to be documented seems not wise to me. Both because of the effort for us, and because it'll end up being a morass of documentation that nobody can make use off, potentially preventing people from upgrading because some minor perf changes in some edge cases sound scary. I'm fairly certain there were numerous other changes with such effects. We just don't know because there wasn't as careful benchmarking. > > > We don't, e.g., provide tooling to detect when performance in aggregation > > > regresses due to crossing work_mem and could be fixed by a tiny increase in > > > work_mem. > > > > > > > Yeah. I find it entirely reasonable to tell people to increase work_mem > > a bit to fix this. The problem is knowing you're affected :-( > > This is the concern the RMT discussed. Yes it is reasonable to say "increase > work_mem to XYZ", but how does a user know how to detect and apply that? The won't. Nor will they with any reasonable documentation we can give. Nor will they know in any of the other cases some threshold is crossed. > This is the part that is worrisome, especially because we don't have any > sense of what the overall impact will be. > > Maybe it's not much, but we should document that there is the potential for > a regression. -1 Greetings, Andres Freund
Re: PG15 beta1 sort performance regression due to Generation context change
On 7/15/22 4:54 PM, Tom Lane wrote: > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> ... My personal opinion is that it's a rare regression. Other >> optimization patches have similar rare regressions, except that David >> spent so much time investigating this one it seems more serious. > > Yeah, this. I fear we're making a mountain out of a molehill. We have > committed many optimizations that win on average but possibly lose > in edge cases, and not worried too much about it. I disagree with the notion of this being a "mountain out of a molehill." The RMT looked at the situation, asked if we should make one more pass. There were logical argument as to why not to (e.g. v16 efforts). I think that is reasonable, and we can move on from any additional code changes for v15. What I find interesting is the resistance to adding any documentation around this feature to guide users in case they hit the regression. I understand it can be difficult to provide guidance on issues related to adjusting work_mem, but even just a hint in the release notes to say "if you see a performance regression you may need to adjust work_mem" would be helpful. This would help people who are planning upgrades to at least know what to watch out for. If that still seems unreasonable, I'll agree to disagree so we can move on with other parts of the release. Jonathan
Вложения
Re: PG15 beta1 sort performance regression due to Generation context change
On 7/15/22 6:40 PM, Jonathan S. Katz wrote: > On 7/15/22 4:54 PM, Tom Lane wrote: >> Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >>> ... My personal opinion is that it's a rare regression. Other >>> optimization patches have similar rare regressions, except that David >>> spent so much time investigating this one it seems more serious. >> >> Yeah, this. I fear we're making a mountain out of a molehill. We have >> committed many optimizations that win on average but possibly lose >> in edge cases, and not worried too much about it. > > I disagree with the notion of this being a "mountain out of a molehill." > The RMT looked at the situation, asked if we should make one more pass. > There were logical argument as to why not to (e.g. v16 efforts). I think > that is reasonable, and we can move on from any additional code changes > for v15. > > What I find interesting is the resistance to adding any documentation > around this feature to guide users in case they hit the regression. I > understand it can be difficult to provide guidance on issues related to > adjusting work_mem, but even just a hint in the release notes to say "if > you see a performance regression you may need to adjust work_mem" would > be helpful. This would help people who are planning upgrades to at least > know what to watch out for. > > If that still seems unreasonable, I'll agree to disagree so we can move > on with other parts of the release. For completeness, I marked the open item as closed. Jonathan
Вложения
Hi, On 2022-07-15 18:40:11 -0400, Jonathan S. Katz wrote: > What I find interesting is the resistance to adding any documentation around > this feature to guide users in case they hit the regression. I understand it > can be difficult to provide guidance on issues related to adjusting > work_mem, but even just a hint in the release notes to say "if you see a > performance regression you may need to adjust work_mem" would be helpful. > This would help people who are planning upgrades to at least know what to > watch out for. If we want to add that as boilerplate for every major release - ok, although it's not really actionable. What I'm against is adding it specifically for this release - we have stuff like this *all the time*, we just often don't bother to carefully find the specific point at which an optimization might hurt. Honestly, if this thread teaches anything, it's to hide relatively minor corner case regressions. Which isn't good. Greetings, Andres Freund
On Sat, 16 Jul 2022 at 10:40, Jonathan S. Katz <jkatz@postgresql.org> wrote: > What I find interesting is the resistance to adding any documentation > around this feature to guide users in case they hit the regression. I > understand it can be difficult to provide guidance on issues related to > adjusting work_mem, but even just a hint in the release notes to say "if > you see a performance regression you may need to adjust work_mem" would > be helpful. This would help people who are planning upgrades to at least > know what to watch out for. Looking back at the final graph in the blog [1], l see that work_mem is a pretty surprising GUC. I'm sure many people would expect that setting work_mem to some size that allows the sort to be entirely done in RAM would be the fastest way. And that does appear to be the case, as 16GB was the only setting which allowed that. However, I bet it would surprise many people to see that 8GB wasn't 2nd fastest. Even 128MB was faster than 8GB! Most likely that's because the machine I tested that on has lots of RAM spare for kernel buffers which would allow all that disk activity for batching not actually to cause physical reads or writes. I bet that would have looked different if I'd run a few concurrent sorts with 128MB of work_mem. They'd all be competing for kernel buffers in that case. So I agree with Andres here. It seems weird to me to try to document this new thing that I caused when we don't really make any attempt to document all the other weird stuff with work_mem. I think the problem can actually be worse with work_mem sizes in regards to hash tables. The probing phase of a hash join causes memory access patterns that the CPU cannot determine which can result in poor performance when the hash table size is larger than the CPU's L3 cache size. If you have fast enough disks, it seems realistic that given the right workload (most likely much more than 1 probe per bucket) that you could also get better performance by having lower values of work_mem. If we're going to document the generic context anomaly then we should go all out and document all of the above, plus all the other weird stuff I've not thought of. However, I think, short of having an actual patch to review, it might be better to leave it until someone can come up with some text that's comprehensive enough to be worthy of reading. I don't think I could do the topic justice. I'm also not sure any wisdom we write about this would be of much use in the real world given that its likely concurrency has a larger effect, and we don't have much ability to control that. FWIW, I think it would be better for us just to solve these problems in code instead. Having memory gating to control the work_mem from a pool and teaching sort about CPU caches might be better than explaining to users that tuning work_mem is hard. David [1] https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-sort-performance-in-postgres-15/ba-p/3396953
Re: PG15 beta1 sort performance regression due to Generation context change
Thank you for the very detailed analysis. Comments inline. On 7/15/22 7:12 PM, David Rowley wrote: > On Sat, 16 Jul 2022 at 10:40, Jonathan S. Katz <jkatz@postgresql.org> wrote: >> What I find interesting is the resistance to adding any documentation >> around this feature to guide users in case they hit the regression. I >> understand it can be difficult to provide guidance on issues related to >> adjusting work_mem, but even just a hint in the release notes to say "if >> you see a performance regression you may need to adjust work_mem" would >> be helpful. This would help people who are planning upgrades to at least >> know what to watch out for. > > Looking back at the final graph in the blog [1], l see that work_mem > is a pretty surprising GUC. I'm sure many people would expect that > setting work_mem to some size that allows the sort to be entirely done > in RAM would be the fastest way. And that does appear to be the case, > as 16GB was the only setting which allowed that. However, I bet it > would surprise many people to see that 8GB wasn't 2nd fastest. Even > 128MB was faster than 8GB! Yeah that is interesting. And while some of those settings are less likely in the wild, I do think we are going to see larger and larger "work_mem" settings as instance sizes continue to grow. That said, your PG15 benchmarks are overall faster than the PG14, and that is what I am looking at in the context of this release. > Most likely that's because the machine I tested that on has lots of > RAM spare for kernel buffers which would allow all that disk activity > for batching not actually to cause physical reads or writes. I bet > that would have looked different if I'd run a few concurrent sorts > with 128MB of work_mem. They'd all be competing for kernel buffers in > that case. > > So I agree with Andres here. It seems weird to me to try to document > this new thing that I caused when we don't really make any attempt to > document all the other weird stuff with work_mem. I can't argue with this. My note on the documentation was primarily around to seeing countless user issues post-upgrade where queries that "once performed well no longer do so." I want to ensure that our users at least have a starting point to work on resolving the issues, even if they end up being very nuanced. Perhaps a next step (and a separate step from this) is to assess the guidance we give on the upgrade page[1] about some common things they should check for. Then we can have the "boilerplate" there. > I think the problem can actually be worse with work_mem sizes in > regards to hash tables. The probing phase of a hash join causes > memory access patterns that the CPU cannot determine which can result > in poor performance when the hash table size is larger than the CPU's > L3 cache size. If you have fast enough disks, it seems realistic that > given the right workload (most likely much more than 1 probe per > bucket) that you could also get better performance by having lower > values of work_mem. > > If we're going to document the generic context anomaly then we should > go all out and document all of the above, plus all the other weird > stuff I've not thought of. However, I think, short of having an > actual patch to review, it might be better to leave it until someone > can come up with some text that's comprehensive enough to be worthy of > reading. I don't think I could do the topic justice. I'm also not > sure any wisdom we write about this would be of much use in the real > world given that its likely concurrency has a larger effect, and we > don't have much ability to control that. Understood. I don't think that is fair to ask for this release, but don't sell your short on explaining the work_mem nuances. > FWIW, I think it would be better for us just to solve these problems > in code instead. Having memory gating to control the work_mem from a > pool and teaching sort about CPU caches might be better than > explaining to users that tuning work_mem is hard. +1. Again thank you for taking the time for the thorough explanation and of course, working on the patch and fixes. Jonathan [1] https://www.postgresql.org/docs/current/upgrading.html
Вложения
Re: PG15 beta1 sort performance regression due to Generation context change
On 7/15/22 6:52 PM, Andres Freund wrote: > Hi, > > On 2022-07-15 18:40:11 -0400, Jonathan S. Katz wrote: >> What I find interesting is the resistance to adding any documentation around >> this feature to guide users in case they hit the regression. I understand it >> can be difficult to provide guidance on issues related to adjusting >> work_mem, but even just a hint in the release notes to say "if you see a >> performance regression you may need to adjust work_mem" would be helpful. >> This would help people who are planning upgrades to at least know what to >> watch out for. > > If we want to add that as boilerplate for every major release - ok, although > it's not really actionable. What I'm against is adding it specifically for > this release - we have stuff like this *all the time*, we just often don't > bother to carefully find the specific point at which an optimization might > hurt. > > Honestly, if this thread teaches anything, it's to hide relatively minor > corner case regressions. Which isn't good. I think it's OK to discuss ways we can better help our users. It's also OK to be wrong; I have certainly been so plenty of times. Jonathan
Вложения
On Fri, Jul 15, 2022 at 07:27:47PM -0400, Jonathan S. Katz wrote: > > So I agree with Andres here. It seems weird to me to try to document > > this new thing that I caused when we don't really make any attempt to > > document all the other weird stuff with work_mem. > > I can't argue with this. > > My note on the documentation was primarily around to seeing countless user > issues post-upgrade where queries that "once performed well no longer do > so." I want to ensure that our users at least have a starting point to work > on resolving the issues, even if they end up being very nuanced. > > Perhaps a next step (and a separate step from this) is to assess the > guidance we give on the upgrade page[1] about some common things they should > check for. Then we can have the "boilerplate" there. I assume that if you set a GUC, you should also review and maintain it into the future. Non-default settings should be re-evaluated (at least) during major upgrades. That's typically more important than additionally fidding with any newly-added GUCs. For example, in v13, I specifically re-evaluated shared_buffers everywhere due to de-duplication. In v13, hash agg was updated to spill to disk, and hash_mem_multiplier was added to mitigate any performance issues (and documented as such in the release notes). I've needed to disable JIT since it was enabled by default in v12, since it 1) doesn't help; and 2) leaks memory enough to cause some customers' DBs to be killed every 1-2 days. (The change in default was documented, so there's no more documentation needed). I'm sure some people should/have variously revisted the parallel and "asynchronous" GUCs, if they changed the defaults. (When parallel query was enabled by default in v10, the change wasn't initially documented, which was a problem). I'm suppose checkpoint_* and *wal* should be/have been revisited at various points. Probably effective_cache_size too. Those are just the most common ones to change. -- Justin