On Wed, 25 May 2022 at 04:02, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Here's a draft patch for the other way of doing it. I'd first tried
> to make the side-effects completely local to generation.c, but that
> fails in view of code like
>
> MemoryContextAlloc(GetMemoryChunkContext(x), ...)
>
> Thus we pretty much have to have some explicit awareness of this scheme
> in GetMemoryChunkContext(). There's more than one way it could be
> done, but I thought a clean way is to invent a separate NodeTag type
> to identify the indirection case.
Thanks for coding that up. This seems like a much better idea than mine.
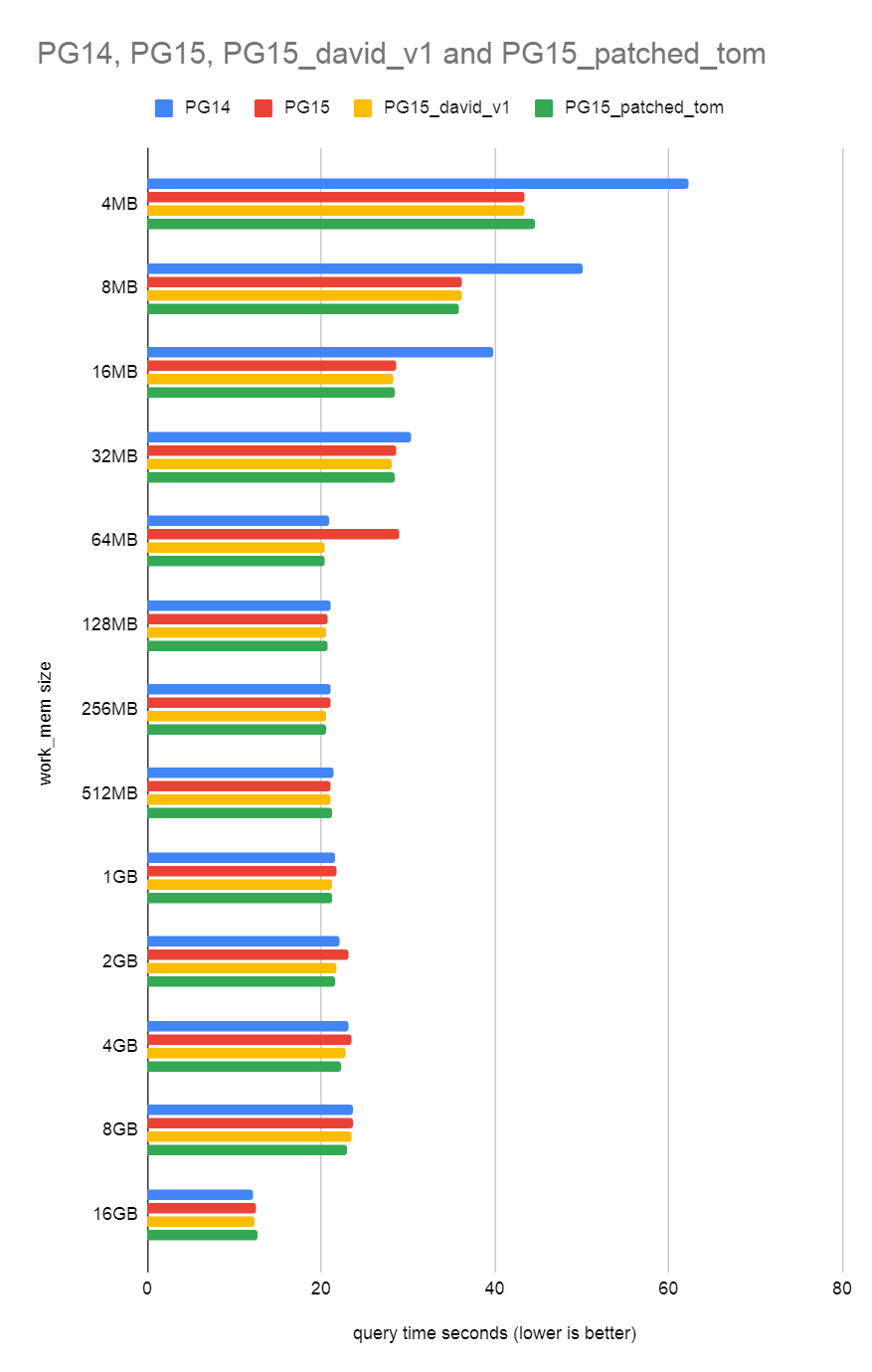
I ran the same benchmark as I did in the blog on your patch and got
the attached sort_bench.png. You can see the patch fixes the 64MB
work_mem performance regression, as we'd expect.
To get an idea of the overhead of this I came up with the attached
allocate_performance_function.patch which basically just adds a
function named pg_allocate_generation_memory() which you can pass a
chunk_size for the number of bytes to allocate at once, and also a
keep_memory to tell the function how much memory to keep around before
starting to pfree previous allocations. The final parameter defines
the total amount of memory to allocate.
The attached script calls the function with varying numbers of chunk
sizes from 8 up to 2048, multiplying by 2 each step. It keeps 1MB of
memory and does a total of 1GB of allocations.
I ran the script against today's master and master + the
invent-MemoryContextLink-1.patch and got the attached tps_results.txt.
The worst-case is the 8-byte allocation size where performance drops
around 7%. For the larger chunk sizes, the drop is much less, mostly
just around <1% to ~6%. For the 2048 byte size chunks, the performance
seems to improve (?). Obviously, the test is pretty demanding as far
as palloc and pfree go. I imagine we don't come close to anything like
that in the actual code. This test was just aimed to give us an idea
of the overhead. It might not be enough information to judge if we
should be concerned about more realistic palloc/pfree workloads.
I didn't test the performance of an aset.c context. I imagine it's
likely to be less overhead due to aset.c being generally slower from
having to jump through a few more hoops during palloc/pfree.
David