Обсуждение: POC and rebased patch for CSN based snapshots
Hello hackers,
I have read the community mail from 'postgrespro' which the link
below ①, a summary for the patch, it generals a CSN by timestamp
when a transaction is committed and assigns a special value as CSN
for abort transaction, and record them in CSN SLRU file. Now we can
judge if a xid available in a snapshot with a CSN value instead of by
xmin,xmax and xip array so that if we hold CSN as a snapshot which
can be export and import.
CSN may be a correct direction and an important part to implement
distributed of PostgreSQL because it delivers few data among cross-nodes
for snapshot, so the patch is meant to do some research.
We want to implement Clock-SI base on the patch.However the patch
is too old, and I rebase the infrastructure part of the patch to recently
commit(7dc37ccea85).
The origin patch does not support csn alive among database restart
because it will clean csnlog at every time the database restart, it works
well until a prepared transaction occurs due to the csn of prepare
transaction cleaned by a database restart. So I add wal support for
csnlog then csn can alive all the time, and move the csnlog clean work
to auto vacuum.
It comes to another issue, now it can't switch from a xid-base snapshot
to csn-base snapshot if a prepare transaction exists because it can not
find csn for the prepare transaction produced during xid-base snapshot.
To solve it, if the database restart with snapshot change to csn-base I
record an 'xmin_for_csn' where start to check with csn snapshot.
Some issues known about the current patch:
1. The CSN-snapshot support repeatable read isolation level only, we
should try to support other isolation levels.
2. We can not switch fluently from xid-base->csn-base, if there be prepared
transaction in database.
What do you think about it, I want try to test and improve the patch step by step.
-----------
Regards,
Highgo Software (Canada/China/Pakistan)
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
Вложения
Hello hackers,
Currently, I do some changes based on the last version:
1. Catch up to the current commit (c2bd1fec32ab54).
2. Add regression and document.
3. Add support to switch from xid-base snapshot to csn-base snapshot,
and the same with standby side.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
Вложения
On Fri, Jun 12, 2020 at 3:11 PM movead.li@highgo.ca <movead.li@highgo.ca> wrote: > > Hello hackers, > > Currently, I do some changes based on the last version: > 1. Catch up to the current commit (c2bd1fec32ab54). > 2. Add regression and document. > 3. Add support to switch from xid-base snapshot to csn-base snapshot, > and the same with standby side. > AFAIU, this patch is to improve scalability and also will be helpful for Global Snapshots stuff, is that right? If so, how much performance/scalability benefit this patch will have after Andres's recent work on scalability [1]? [1] - https://www.postgresql.org/message-id/20200301083601.ews6hz5dduc3w2se%40alap3.anarazel.de -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 2020/06/12 18:41, movead.li@highgo.ca wrote: > Hello hackers, > > Currently, I do some changes based on the last version: > 1. Catch up to the current commit (c2bd1fec32ab54). > 2. Add regression and document. > 3. Add support to switch from xid-base snapshot to csn-base snapshot, > and the same with standby side. Andrey also seems to be proposing the similar patch [1] that introduces CSN into core. Could you tell me what the difference between his patch and yours? If they are almost the same, we should focus on one together rather than working separately? Regards, [1] https://www.postgresql.org/message-id/9964cf46-9294-34b9-4858-971e9029f5c7@postgrespro.ru -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
On 2020/06/15 16:48, Fujii Masao wrote: > > > On 2020/06/12 18:41, movead.li@highgo.ca wrote: >> Hello hackers, >> >> Currently, I do some changes based on the last version: >> 1. Catch up to the current commit (c2bd1fec32ab54). >> 2. Add regression and document. >> 3. Add support to switch from xid-base snapshot to csn-base snapshot, >> and the same with standby side. Probably it's not time to do the code review yet, but when I glanced the patch, I came up with one question. 0002 patch changes GenerateCSN() so that it generates CSN-related WAL records (and inserts it into WAL buffers). Which means that new WAL record is generated whenever CSN is assigned, e.g., in GetSnapshotData(). Is this WAL generation really necessary for CSN? BTW, GenerateCSN() is called while holding ProcArrayLock. Also it inserts new WAL record in WriteXidCsnXlogRec() while holding spinlock. Firstly this is not acceptable because spinlocks are intended for *very* short-term locks. Secondly, I don't think that WAL generation during ProcArrayLock is good design because ProcArrayLock is likely to be bottleneck and its term should be short for performance gain. Regards, -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
Thanks for reply.
>Probably it's not time to do the code review yet, but when I glanced the patch,
>I came up with one question.
>0002 patch changes GenerateCSN() so that it generates CSN-related WAL records
>(and inserts it into WAL buffers). Which means that new WAL record is generated
>whenever CSN is assigned, e.g., in GetSnapshotData(). Is this WAL generation
>really necessary for CSN?
This is designed for crash recovery, here we record our most new lsn in wal so it
will not use a history lsn after a restart. It will not write into wal every time, but with
a gap which you can see CSNAddByNanosec() function.
>BTW, GenerateCSN() is called while holding ProcArrayLock. Also it inserts new
>WAL record in WriteXidCsnXlogRec() while holding spinlock. Firstly this is not
>acceptable because spinlocks are intended for *very* short-term locks.
>Secondly, I don't think that WAL generation during ProcArrayLock is good
>design because ProcArrayLock is likely to be bottleneck and its term should
>be short for performance gain.
Thanks for point out which may help me deeply, I will reconsider that.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
Thanks for reply.
>AFAIU, this patch is to improve scalability and also will be helpful
>for Global Snapshots stuff, is that right? If so, how much
>performance/scalability benefit this patch will have after Andres's
>recent work on scalability [1]?
The patch focus on to be an infrastructure of sharding feature, according
to my test almost has the same performance with and without the patch.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
On 2020/06/19 12:12, movead.li@highgo.ca wrote: > > Thanks for reply. > > >Probably it's not time to do the code review yet, but when I glanced the patch, >>I came up with one question. >>0002 patch changes GenerateCSN() so that it generates CSN-related WAL records >>(and inserts it into WAL buffers). Which means that new WAL record is generated >>whenever CSN is assigned, e.g., in GetSnapshotData(). Is this WAL generation >>really necessary for CSN? > This is designed for crash recovery, here we record our most new lsn in wal so it > will not use a history lsn after a restart. It will not write into wal every time, but with > a gap which you can see CSNAddByNanosec() function. You mean that the last generated CSN needs to be WAL-logged because any smaller CSN than the last one should not be reused after crash recovery. Right? If right, that WAL-logging seems not necessary because CSN mechanism assumes CSN is increased monotonically. IOW, even without that WAL-logging, CSN afer crash recovery must be larger than that before. No? >>BTW, GenerateCSN() is called while holding ProcArrayLock. Also it inserts new >>WAL record in WriteXidCsnXlogRec() while holding spinlock. Firstly this is not >>acceptable because spinlocks are intended for *very* short-term locks. >>Secondly, I don't think that WAL generation during ProcArrayLock is good >>design because ProcArrayLock is likely to be bottleneck and its term should >>be short for performance gain. > Thanks for point out which may help me deeply, I will reconsider that. Thanks for working on this! Regards, -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
>You mean that the last generated CSN needs to be WAL-logged because any smaller
>CSN than the last one should not be reused after crash recovery. Right?
Yes that's it.
>If right, that WAL-logging seems not necessary because CSN mechanism assumes
>CSN is increased monotonically. IOW, even without that WAL-logging, CSN afer
>crash recovery must be larger than that before. No?
CSN collected based on time of system in this patch, but time is not reliable all the
time. And it designed for Global CSN(for sharding) where it may rely on CSN from
other node , which generated from other machine.
So monotonically is not reliable and it need to keep it's largest CSN in wal in case
of crash.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
On 2020/06/19 13:36, movead.li@highgo.ca wrote: > > >You mean that the last generated CSN needs to be WAL-logged because any smaller >>CSN than the last one should not be reused after crash recovery. Right? > Yes that's it. > >>If right, that WAL-logging seems not necessary because CSN mechanism assumes >>CSN is increased monotonically. IOW, even without that WAL-logging, CSN afer >>crash recovery must be larger than that before. No? > > CSN collected based on time of system in this patch, but time is not reliable all the > time. And it designed for Global CSN(for sharding) where it may rely on CSN from > other node , which generated from other machine. > > So monotonically is not reliable and it need to keep it's largest CSN in wal in case > of crash. Thanks for the explanaion! Understood. Regards, -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
On 6/12/20 2:41 PM, movead.li@highgo.ca wrote: > Hello hackers, > > Currently, I do some changes based on the last version: > 1. Catch up to the current commit (c2bd1fec32ab54). > 2. Add regression and document. > 3. Add support to switch from xid-base snapshot to csn-base snapshot, > and the same with standby side. Some remarks on your patch: 1. The variable last_max_csn can be an atomic variable. 2. GenerateCSN() routine: in the case than csn < csnState->last_max_csn This is the case when someone changed the value of the system clock. I think it is needed to write a WARNING to the log file. (May be we can do synchronization with a time server. 3. That about global snapshot xmin? In the pgpro version of the patch we had GlobalSnapshotMapXmin() routine to maintain circular buffer of oldestXmins for several seconds in past. This buffer allows to shift oldestXmin in the past when backend is importing global transaction. Otherwise old versions of tuples that were needed for this transaction can be recycled by other processes (vacuum, HOT, etc). How do you implement protection from local pruning? I saw SNAP_DESYNC_COMPLAIN, but it is not used anywhere. 4. The current version of the patch is not applied clearly with current master. -- regards, Andrey Lepikhov Postgres Professional
Thanks for the remarks,
>Some remarks on your patch:
>1. The variable last_max_csn can be an atomic variable.
Yes will consider.
>2. GenerateCSN() routine: in the case than csn < csnState->last_max_csn
>This is the case when someone changed the value of the system clock. I
>think it is needed to write a WARNING to the log file. (May be we can do
>synchronization with a time server.
Yes good point, I will work out a way to report the warning, it should exist a
report gap rather than report every time it generates CSN.
If we really need a correct time? What's the inferiority if one node generate
csn by monotonically increasing?
>3. That about global snapshot xmin? In the pgpro version of the patch we
>had GlobalSnapshotMapXmin() routine to maintain circular buffer of
>oldestXmins for several seconds in past. This buffer allows to shift
>oldestXmin in the past when backend is importing global transaction.
>Otherwise old versions of tuples that were needed for this transaction
>can be recycled by other processes (vacuum, HOT, etc).
>How do you implement protection from local pruning? I saw
>SNAP_DESYNC_COMPLAIN, but it is not used anywhere.
I have researched your patch which is so great, in the patch only data
out of 'global_snapshot_defer_time' can be vacuum, and it keep dead
tuple even if no snapshot import at all,right?
I am thanking about a way if we can start remain dead tuple just before
we import a csn snapshot.
Base on Clock-SI paper, we should get local CSN then send to shard nodes,
because we do not known if the shard nodes' csn bigger or smaller then
master node, so we should keep some dead tuple all the time to support
snapshot import anytime.
Then if we can do a small change to CLock-SI model, we do not use the
local csn when transaction start, instead we touch every shard node for
require their csn, and shard nodes start keep dead tuple, and master node
choose the biggest csn to send to shard nodes.
By the new way, we do not need to keep dead tuple all the time and do
not need to manage a ring buf, we can give to ball to 'snapshot too old'
feature. But for trade off, almost all shard node need wait.
I will send more detail explain in few days.
>4. The current version of the patch is not applied clearly with current
>master.
Maybe it's because of the release of PG13, it cause some conflict, I will
rebase it.
---
Regards,
Highgo Software (Canada/China/Pakistan)
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
On 7/2/20 7:31 PM, Movead Li wrote: > Thanks for the remarks, > > >Some remarks on your patch: > >1. The variable last_max_csn can be an atomic variable. > Yes will consider. > > >2. GenerateCSN() routine: in the case than csn < csnState->last_max_csn > >This is the case when someone changed the value of the system clock. I > >think it is needed to write a WARNING to the log file. (May be we can do > >synchronization with a time server. > Yes good point, I will work out a way to report the warning, it should > exist a > report gap rather than report every time it generates CSN. > If we really need a correct time? What's the inferiority if one node > generate > csn by monotonically increasing? Changes in time values can lead to poor effects, such as old snapshot. Adjusting the time can be a kind of defense. > > >3. That about global snapshot xmin? In the pgpro version of the patch we > >had GlobalSnapshotMapXmin() routine to maintain circular buffer of > >oldestXmins for several seconds in past. This buffer allows to shift > >oldestXmin in the past when backend is importing global transaction. > >Otherwise old versions of tuples that were needed for this transaction > >can be recycled by other processes (vacuum, HOT, etc). > >How do you implement protection from local pruning? I saw > >SNAP_DESYNC_COMPLAIN, but it is not used anywhere. > I have researched your patch which is so great, in the patch only data > out of 'global_snapshot_defer_time' can be vacuum, and it keep dead > tuple even if no snapshot import at all,right? > > I am thanking about a way if we can start remain dead tuple just before > we import a csn snapshot. > > Base on Clock-SI paper, we should get local CSN then send to shard nodes, > because we do not known if the shard nodes' csn bigger or smaller then > master node, so we should keep some dead tuple all the time to support > snapshot import anytime. > > Then if we can do a small change to CLock-SI model, we do not use the > local csn when transaction start, instead we touch every shard node for > require their csn, and shard nodes start keep dead tuple, and master node > choose the biggest csn to send to shard nodes. > > By the new way, we do not need to keep dead tuple all the time and do > not need to manage a ring buf, we can give to ball to 'snapshot too old' > feature. But for trade off, almost all shard node need wait. > I will send more detail explain in few days. I think, in the case of distributed system and many servers it can be bottleneck. Main idea of "deferred time" is to reduce interference between DML queries in the case of intensive OLTP workload. This time can be reduced if the bloationg of a database prevails over the frequency of transaction aborts. > > > >4. The current version of the patch is not applied clearly with current > >master. > Maybe it's because of the release of PG13, it cause some conflict, I will > rebase it. Ok > > --- > Regards, > Highgo Software (Canada/China/Pakistan) > URL : www.highgo.ca <http://www.highgo.ca/> > EMAIL: mailto:movead(dot)li(at)highgo(dot)ca > > -- regards, Andrey Lepikhov Postgres Professional
Hello Andrey
>> I have researched your patch which is so great, in the patch only data>> out of 'global_snapshot_defer_time' can be vacuum, and it keep dead>> tuple even if no snapshot import at all,right?>>>> I am thanking about a way if we can start remain dead tuple just before>> we import a csn snapshot.>>>> Base on Clock-SI paper, we should get local CSN then send to shard nodes,>> because we do not known if the shard nodes' csn bigger or smaller then>> master node, so we should keep some dead tuple all the time to support>> snapshot import anytime.>>>> Then if we can do a small change to CLock-SI model, we do not use the>> local csn when transaction start, instead we touch every shard node for>> require their csn, and shard nodes start keep dead tuple, and master node>> choose the biggest csn to send to shard nodes.>>>> By the new way, we do not need to keep dead tuple all the time and do>> not need to manage a ring buf, we can give to ball to 'snapshot too old'>> feature. But for trade off, almost all shard node need wait.>> I will send more detail explain in few days.>I think, in the case of distributed system and many servers it can be>bottleneck.>Main idea of "deferred time" is to reduce interference between DML>queries in the case of intensive OLTP workload. This time can be reduced>if the bloationg of a database prevails over the frequency of>transaction aborts.OK there maybe a performance issue, and I have another question about Clock-SI.For example we have three nodes, shard1(as master), shard2, shard3, which(time of node2) > (time of node2) > (time of node3), and you can see a picture:http://movead.gitee.io/picture/blog_img_bad/csn/clock_si_question.png
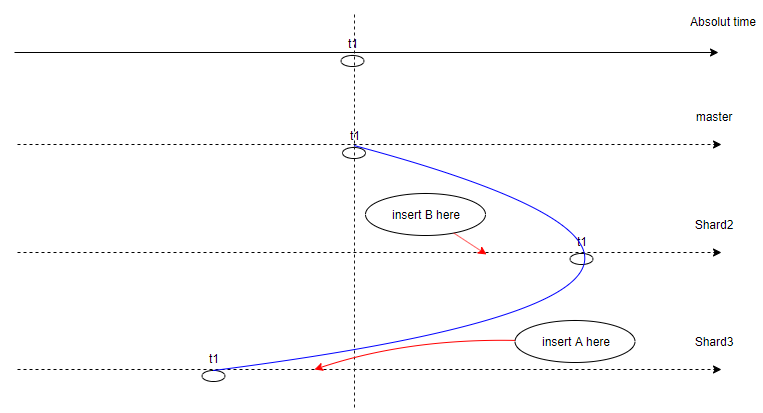{kind=link}
As far as I know about Clock-SI, left part of the blue line will setup as a snapshot
if master require a snapshot at time t1. But in fact data A should in snapshot but
not and data B should out of snapshot but not.
If this scene may appear in your origin patch? Or something my understand about
Clock-SI is wrong?
On 7/4/20 7:56 PM, movead.li@highgo.ca wrote: > > > As far as I know about Clock-SI, left part of the blue line will > setup as a snapshot > > if master require a snapshot at time t1. But in fact data A should > in snapshot but > > not and data B should out of snapshot but not. > > > If this scene may appear in your origin patch? Or something my > understand about > > Clock-SI is wrong? > > > Sorry for late answer. I have doubts that I fully understood your question, but still. What real problems do you see here? Transaction t1 doesn't get state of shard2 until time at node with shard2 won't reach start time of t1. If transaction, that inserted B wants to know about it position in time relatively to t1 it will generate CSN, attach to node1 and will see, that t1 is not started yet. Maybe you are saying about the case that someone who has a faster data channel can use the knowledge from node1 to change the state at node2? If so, i think it is not a problem, or you can explain your idea. -- regards, Andrey Lepikhov Postgres Professional
>I have doubts that I fully understood your question, but still.
>What real problems do you see here? Transaction t1 doesn't get state of
>shard2 until time at node with shard2 won't reach start time of t1.
>If transaction, that inserted B wants to know about it position in time
>relatively to t1 it will generate CSN, attach to node1 and will see,
>that t1 is not started yet.
>Maybe you are saying about the case that someone who has a faster data
>channel can use the knowledge from node1 to change the state at node2?
>If so, i think it is not a problem, or you can explain your idea.
Sorry, I think this is my wrong understand about Clock-SI. At first I expect
we can get a absolutly snapshot, for example B should not include in the
snapshot because it happened after time t1. How ever Clock-SI can not guarantee
that and no design guarantee that at all.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
On 2020/06/19 14:54, Fujii Masao wrote: > > > On 2020/06/19 13:36, movead.li@highgo.ca wrote: >> >> >You mean that the last generated CSN needs to be WAL-logged because any smaller >>> CSN than the last one should not be reused after crash recovery. Right? >> Yes that's it. >> >>> If right, that WAL-logging seems not necessary because CSN mechanism assumes >>> CSN is increased monotonically. IOW, even without that WAL-logging, CSN afer >>> crash recovery must be larger than that before. No? >> >> CSN collected based on time of system in this patch, but time is not reliable all the >> time. And it designed for Global CSN(for sharding) where it may rely on CSN from >> other node , which generated from other machine. >> >> So monotonically is not reliable and it need to keep it's largest CSN in wal in case >> of crash. > > Thanks for the explanaion! Understood. I have another question about this patch; When checking each tuple visibility, we always have to get the CSN corresponding to XMIN or XMAX from CSN SLRU. In the past discussion, there was the suggestion that CSN should be stored in the tuple header or somewhere (like hint bit) to avoid the overhead by very frequehntly lookup for CSN SLRU. I'm not sure the conclusion of this discussion. But this patch doesn't seem to adopt that idea. So did you confirm that such performance overhead by lookup for CSN SLRU is negligible? Of course I know that idea has big issue, i.e., there is no enough space to store CSN in a tuple header if CSN is 64 bits. If CSN is 32 bits, we may be able to replace XMIN or XMAX with CSN corresponding to them. But it means that we have to struggle with one more wraparound issue (CSN wraparound issue). So it's not easy to adopt that idea... Sorry if this was already discussed and concluded... Regards, -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
>When checking each tuple visibility, we always have to get the CSN
>corresponding to XMIN or XMAX from CSN SLRU. In the past discussion,
>there was the suggestion that CSN should be stored in the tuple header
>or somewhere (like hint bit) to avoid the overhead by very frequehntly
>lookup for CSN SLRU. I'm not sure the conclusion of this discussion.
>But this patch doesn't seem to adopt that idea. So did you confirm that
>such performance overhead by lookup for CSN SLRU is negligible?
This patch came from postgrespro's patch which shows a good performance,
I have simple test on current patch and result no performance decline.
And not everytime we do a tuple visibility need lookup forCSN SLRU, only xid
large than 'TransactionXmin' need that. Maybe we have not touch the case
which cause bad performance, so it shows good performance temporary.
>Of course I know that idea has big issue, i.e., there is no enough space
>to store CSN in a tuple header if CSN is 64 bits. If CSN is 32 bits, we may
>be able to replace XMIN or XMAX with CSN corresponding to them. But
>it means that we have to struggle with one more wraparound issue
>(CSN wraparound issue). So it's not easy to adopt that idea...
>Sorry if this was already discussed and concluded...
I think your point with CSN in tuple header is a exciting approach, but I have
not seen the discussion, can you show me the discussion address?
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
On 2020/07/14 11:02, movead.li@highgo.ca wrote: > >>When checking each tuple visibility, we always have to get the CSN >>corresponding to XMIN or XMAX from CSN SLRU. In the past discussion, >>there was the suggestion that CSN should be stored in the tuple header >>or somewhere (like hint bit) to avoid the overhead by very frequehntly >>lookup for CSN SLRU. I'm not sure the conclusion of this discussion. >>But this patch doesn't seem to adopt that idea. So did you confirm that >>such performance overhead by lookup for CSN SLRU is negligible? > This patch came from postgrespro's patch which shows a good performance, > I have simple test on current patch and result no performance decline. This is good news! When I read the past discussions about CSN, my impression was that the performance overhead by CSN SLRU lookup might become one of show-stopper for CSN. So I was worring about this issue... > And not everytime we do a tuple visibility need lookup forCSN SLRU, only xid > large than 'TransactionXmin' need that. Maybe we have not touch the case > which cause bad performance, so it shows good performance temporary. Yes, we would need more tests in several cases. >>Of course I know that idea has big issue, i.e., there is no enough space >>to store CSN in a tuple header if CSN is 64 bits. If CSN is 32 bits, we may >>be able to replace XMIN or XMAX with CSN corresponding to them. But >>it means that we have to struggle with one more wraparound issue >>(CSN wraparound issue). So it's not easy to adopt that idea... > >>Sorry if this was already discussed and concluded... > I think your point with CSN in tuple header is a exciting approach, but I have > not seen the discussion, can you show me the discussion address? Probably you can find the discussion by searching with the keywords "CSN" and "hint bit". For example, https://www.postgresql.org/message-id/CAPpHfdv7BMwGv=OfUg3S-jGVFKqHi79pR_ZK1Wsk-13oZ+cy5g@mail.gmail.com Regards, -- Fujii Masao Advanced Computing Technology Center Research and Development Headquarters NTT DATA CORPORATION
On 7/13/20 11:46 AM, movead.li@highgo.ca wrote: I continue to see your patch. Some code improvements see at the attachment. Questions: * csnSnapshotActive is the only member of the CSNshapshotShared struct. * The WriteAssignCSNXlogRec() routine. I din't understand why you add 20 nanosec to current CSN and write this into the WAL. For simplify our communication, I rewrote this routine in accordance with my opinion (see patch in attachment). At general, maybe we will add your WAL writing CSN machinery + TAP tests to the patch from the thread [1] and work on it together? [1] https://www.postgresql.org/message-id/flat/07b2c899-4ed0-4c87-1327-23c750311248%40postgrespro.ru -- regards, Andrey Lepikhov Postgres Professional
Вложения
Currently, we are developing and test global snapshot on branch[2] created by
Andrey, I want to keep a latest patch set on this thread so that hackers can easily
catch every change on this area.
This time it change little point come up by Fujii Masao about WriteXidCsnXlogRec()
should out of spinlocks, and add comments for CSNAddByNanosec(), and other
fine tunings.
[1]
https://github.com/danolivo/pgClockSI
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
Вложения
I find an issue with snapshot switch part of last patch, the xmin_for_csn value is
wrong in TransactionIdGetCSN() function. I try to hold xmin_for_csn in pg_control
and add a UnclearCSN statue for transactionid. And new patches attached.
Regards,
Highgo Software (Canada/China/Pakistan)
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca
URL : www.highgo.ca
EMAIL: mailto:movead(dot)li(at)highgo(dot)ca