Обсуждение: LWLock contention: I think I understand the problem
After some further experimentation, I believe I understand the reason for
the reports we've had of 7.2 producing heavy context-swap activity where
7.1 didn't. Here is an extract from tracing lwlock activity for one
backend in a pgbench run:
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): awakened
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): excl 1 shared 0 head 0x422c27d4
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): release waiter
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(300): excl 0 shared 0 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(300): excl 0 shared 1 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): excl 1 shared 0 head 0x422c2bfc
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): waiting
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): awakened
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): excl 1 shared 0 head 0x422c27d4
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): release waiter
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(232): excl 0 shared 0 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(232): excl 0 shared 1 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(300): excl 0 shared 0 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(300): excl 0 shared 1 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): excl 1 shared 0 head 0x422c2bfc
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): waiting
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): awakened
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): excl 1 shared 0 head 0x422c27d4
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): release waiter
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(232): excl 0 shared 0 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(232): excl 0 shared 1 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(300): excl 0 shared 0 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(300): excl 0 shared 1 head (nil)
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): excl 1 shared 0 head 0x422c2bfc
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): waiting
2001-12-29 13:30:30 [31442] DEBUG: LWLockAcquire(0): awakened
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): excl 1 shared 0 head 0x422c27d4
2001-12-29 13:30:30 [31442] DEBUG: LWLockRelease(0): release waiter
LWLock 0 is the BufMgrLock, while the locks with numbers like 232 and
300 are context locks for individual buffers. At the beginning of this
trace we see the process awoken after having been granted the
BufMgrLock. It does a small amount of processing (probably a ReadBuffer
operation) and releases the BufMgrLock. At that point, someone else is
already waiting for BufMgrLock, and the line about "release waiter"
means that ownership of BufMgrLock has been transferred to that other
someone. Next, the context lock 300 is acquired and released (there's no
contention for it). Next we need to get the BufMgrLock again (probably
to do a ReleaseBuffer). Since we've already granted the BufMgrLock to
someone else, we are forced to block here. When control comes back,
we do the ReleaseBuffer and then release the BufMgrLock --- again,
immediately granting it to someone else. That guarantees that our next
attempt to acquire BufMgrLock will cause us to block. The cycle repeats
for every attempt to lock BufMgrLock.
In essence, what we're seeing here is a "tag team" behavior: someone is
always waiting on the BufMgrLock, and so each LWLockRelease(BufMgrLock)
transfers lock ownership to someone else; then the next
LWLockAcquire(BufMgrLock) in the same process is guaranteed to block;
and that means we have a new waiter on BufMgrLock, so that the cycle
repeats. Net result: a process context swap for *every* entry to the
buffer manager.
In previous versions, since BufMgrLock was only a spinlock, releasing it
did not cause ownership of the lock to be immediately transferred to
someone else. Therefore, the releaser would be able to re-acquire the
lock if he wanted to do another bufmgr operation before his time quantum
expired. This made for many fewer context swaps.
It would seem, therefore, that lwlock.c's behavior of immediately
granting the lock to released waiters is not such a good idea after all.
Perhaps we should release waiters but NOT grant them the lock; when they
get to run, they have to loop back, try to get the lock, and possibly go
back to sleep if they fail. This apparent waste of cycles is actually
beneficial because it saves context swaps overall.
Comments?
regards, tom lane
...
> It would seem, therefore, that lwlock.c's behavior of immediately
> granting the lock to released waiters is not such a good idea after all.
> Perhaps we should release waiters but NOT grant them the lock; when they
> get to run, they have to loop back, try to get the lock, and possibly go
> back to sleep if they fail. This apparent waste of cycles is actually
> beneficial because it saves context swaps overall.
Hmm. Seems reasonable. In some likely scenerios, it would seem that the
waiters *could* grab the lock when they are next scheduled, since the
current locker would have finished at least one
grab/release/grab/release cycle in the meantime.
How hard will it be to try this out?
- Thomas
> It would seem, therefore, that lwlock.c's behavior of immediately > granting the lock to released waiters is not such a good idea after all. > Perhaps we should release waiters but NOT grant them the lock; when they > get to run, they have to loop back, try to get the lock, and possibly go > back to sleep if they fail. This apparent waste of cycles is actually > beneficial because it saves context swaps overall. I still need to think about this, but the above idea doesn't seem good. Right now, we wake only one waiting process who gets the lock while other waiters stay sleeping, right? If we don't give them the lock, don't we have to wake up all the waiters? If there are many, that sounds like lots of context switches no? I am still thinking. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> It would seem, therefore, that lwlock.c's behavior of immediately > granting the lock to released waiters is not such a good idea after all. > Perhaps we should release waiters but NOT grant them the lock; when they > get to run, they have to loop back, try to get the lock, and possibly go > back to sleep if they fail. This apparent waste of cycles is actually > beneficial because it saves context swaps overall. Another question: Is there a way to release buffer locks without aquiring the master lock? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> I still need to think about this, but the above idea doesn't seem good.
> Right now, we wake only one waiting process who gets the lock while
> other waiters stay sleeping, right? If we don't give them the lock,
> don't we have to wake up all the waiters?
No. We'll still wake up the same processes as now: either one would-be
exclusive lock holder, or multiple would-be shared lock holders.
But what I'm proposing is that they don't get granted the lock at that
instant; they have to try to get the lock once they actually start to
run.
Once in a while, they'll fail to get the lock, either because the
original releaser reacquired the lock, and then ran out of his time
quantum before releasing it, or because some third process came along
and acquired the lock. In either of these scenarios they'd have to
block again, and we'd have wasted a process dispatch cycle. The
important thing though is that the current arrangement wastes a process
dispatch cycle for every acquisition of a contended-for lock.
What I had not really focused on before, but it's now glaringly obvious,
is that on modern machines one process time quantum (0.01 sec typically)
is enough time for a LOT of computation, in particular an awful lot of
trips through the buffer manager or other modules with shared state.
We want to be sure that a process can repeatedly acquire and release
the shared lock for as long as its time quantum holds out, even if there
are other processes waiting for the lock. Otherwise we'll be swapping
processes too often.
regards, tom lane
Thomas Lockhart <lockhart@fourpalms.org> writes:
> How hard will it be to try this out?
It's a pretty minor rearrangement of the logic in lwlock.c, I think.
Working on it now.
regards, tom lane
> No. We'll still wake up the same processes as now: either one would-be > exclusive lock holder, or multiple would-be shared lock holders. > But what I'm proposing is that they don't get granted the lock at that > instant; they have to try to get the lock once they actually start to > run. > > Once in a while, they'll fail to get the lock, either because the > original releaser reacquired the lock, and then ran out of his time > quantum before releasing it, or because some third process came along > and acquired the lock. In either of these scenarios they'd have to > block again, and we'd have wasted a process dispatch cycle. The > important thing though is that the current arrangement wastes a process > dispatch cycle for every acquisition of a contended-for lock. > > What I had not really focused on before, but it's now glaringly obvious, > is that on modern machines one process time quantum (0.01 sec typically) > is enough time for a LOT of computation, in particular an awful lot of > trips through the buffer manager or other modules with shared state. > We want to be sure that a process can repeatedly acquire and release > the shared lock for as long as its time quantum holds out, even if there > are other processes waiting for the lock. Otherwise we'll be swapping > processes too often. OK, I understand what you are saying now. You are not talking about the SysV semaphore but a level above that. What you are saying is that when we release a lock, we are currently automatically giving it to another process that is asleep and may not be scheduled to run for some time. We then continue processing, and when we need that lock again, we can't get it because the sleeper is holding it. We go to sleep and the sleeper wakes up, gets the lock, and continues. What you want to do is to wake up the sleeper but not give them the lock until they are actually running and can aquire it themselves. Seems like a no-brainer win to me. Giving the lock to a process that is not currently running seems quite bad to me. It would be one thing if we were trying to do some real-time processing, but throughput is the key for us. If you code up a patch, I will test it on my SMP machine using pgbench. Hopefully this will help Tatsuo's 4-way AIX machine too, and Linux. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> Another question: Is there a way to release buffer locks without
> aquiring the master lock?
We might want to think about making bufmgr locking more fine-grained
... in a future release. For 7.2 I don't really want to mess around
with the bufmgr logic at this late hour. Too risky.
regards, tom lane
> Bruce Momjian <pgman@candle.pha.pa.us> writes: > > Another question: Is there a way to release buffer locks without > > aquiring the master lock? > > We might want to think about making bufmgr locking more fine-grained > ... in a future release. For 7.2 I don't really want to mess around > with the bufmgr logic at this late hour. Too risky. You want a TODO item on this? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> What you want to do is to wake up the sleeper but not give them the lock
> until they are actually running and can aquire it themselves.
Yeah. Essentially this is a partial reversion to the idea of a
spinlock. But it's more efficient than our old implementation with
timed waits between retries, because (a) a process will not be awoken
unless it has a chance at getting the lock, and (b) when a contended-for
lock is freed, a waiting process will be made ready immediately, rather
than waiting for a time tick to elapse. So, if the lock-releasing
process does block before the end of its quantum, the released process
is available to run immediately. Under the old scheme, a process that
had failed to get a spinlock couldn't run until its select wait timed
out, even if the lock were now available. So I think it's still a net
win to have the LWLock mechanism in there, rather than just changing
them back to spinlocks.
> If you code up a patch, I will test it on my SMP machine using pgbench.
> Hopefully this will help Tatsuo's 4-way AIX machine too, and Linux.
Attached is a proposed patch (against the current-CVS version of
lwlock.c). I haven't committed this yet, but it seems to be a win on
a single CPU. Can people try it on multi CPUs?
regards, tom lane
*** src/backend/storage/lmgr/lwlock.c.orig Fri Dec 28 18:26:04 2001
--- src/backend/storage/lmgr/lwlock.c Sat Dec 29 15:20:08 2001
***************
*** 195,201 ****
LWLockAcquire(LWLockId lockid, LWLockMode mode)
{
volatile LWLock *lock = LWLockArray + lockid;
! bool mustwait;
PRINT_LWDEBUG("LWLockAcquire", lockid, lock);
--- 195,202 ----
LWLockAcquire(LWLockId lockid, LWLockMode mode)
{
volatile LWLock *lock = LWLockArray + lockid;
! PROC *proc = MyProc;
! int extraWaits = 0;
PRINT_LWDEBUG("LWLockAcquire", lockid, lock);
***************
*** 206,248 ****
*/
HOLD_INTERRUPTS();
! /* Acquire mutex. Time spent holding mutex should be short! */
! SpinLockAcquire_NoHoldoff(&lock->mutex);
!
! /* If I can get the lock, do so quickly. */
! if (mode == LW_EXCLUSIVE)
{
! if (lock->exclusive == 0 && lock->shared == 0)
{
! lock->exclusive++;
! mustwait = false;
}
else
- mustwait = true;
- }
- else
- {
- /*
- * If there is someone waiting (presumably for exclusive access),
- * queue up behind him even though I could get the lock. This
- * prevents a stream of read locks from starving a writer.
- */
- if (lock->exclusive == 0 && lock->head == NULL)
{
! lock->shared++;
! mustwait = false;
}
- else
- mustwait = true;
- }
! if (mustwait)
! {
! /* Add myself to wait queue */
! PROC *proc = MyProc;
! int extraWaits = 0;
/*
* If we don't have a PROC structure, there's no way to wait. This
* should never occur, since MyProc should only be null during
* shared memory initialization.
--- 207,263 ----
*/
HOLD_INTERRUPTS();
! /*
! * Loop here to try to acquire lock after each time we are signaled
! * by LWLockRelease.
! *
! * NOTE: it might seem better to have LWLockRelease actually grant us
! * the lock, rather than retrying and possibly having to go back to
! * sleep. But in practice that is no good because it means a process
! * swap for every lock acquisition when two or more processes are
! * contending for the same lock. Since LWLocks are normally used to
! * protect not-very-long sections of computation, a process needs to
! * be able to acquire and release the same lock many times during a
! * single process dispatch cycle, even in the presence of contention.
! * The efficiency of being able to do that outweighs the inefficiency of
! * sometimes wasting a dispatch cycle because the lock is not free when a
! * released waiter gets to run. See pgsql-hackers archives for 29-Dec-01.
! */
! for (;;)
{
! bool mustwait;
!
! /* Acquire mutex. Time spent holding mutex should be short! */
! SpinLockAcquire_NoHoldoff(&lock->mutex);
!
! /* If I can get the lock, do so quickly. */
! if (mode == LW_EXCLUSIVE)
{
! if (lock->exclusive == 0 && lock->shared == 0)
! {
! lock->exclusive++;
! mustwait = false;
! }
! else
! mustwait = true;
}
else
{
! if (lock->exclusive == 0)
! {
! lock->shared++;
! mustwait = false;
! }
! else
! mustwait = true;
}
! if (!mustwait)
! break; /* got the lock */
/*
+ * Add myself to wait queue.
+ *
* If we don't have a PROC structure, there's no way to wait. This
* should never occur, since MyProc should only be null during
* shared memory initialization.
***************
*** 267,275 ****
*
* Since we share the process wait semaphore with the regular lock
* manager and ProcWaitForSignal, and we may need to acquire an
! * LWLock while one of those is pending, it is possible that we
! * get awakened for a reason other than being granted the LWLock.
! * If so, loop back and wait again. Once we've gotten the lock,
* re-increment the sema by the number of additional signals
* received, so that the lock manager or signal manager will see
* the received signal when it next waits.
--- 282,290 ----
*
* Since we share the process wait semaphore with the regular lock
* manager and ProcWaitForSignal, and we may need to acquire an
! * LWLock while one of those is pending, it is possible that we get
! * awakened for a reason other than being signaled by LWLockRelease.
! * If so, loop back and wait again. Once we've gotten the LWLock,
* re-increment the sema by the number of additional signals
* received, so that the lock manager or signal manager will see
* the received signal when it next waits.
***************
*** 287,309 ****
LOG_LWDEBUG("LWLockAcquire", lockid, "awakened");
! /*
! * The awakener already updated the lock struct's state, so we
! * don't need to do anything more to it. Just need to fix the
! * semaphore count.
! */
! while (extraWaits-- > 0)
! IpcSemaphoreUnlock(proc->sem.semId, proc->sem.semNum);
! }
! else
! {
! /* Got the lock without waiting */
! SpinLockRelease_NoHoldoff(&lock->mutex);
}
/* Add lock to list of locks held by this backend */
Assert(num_held_lwlocks < MAX_SIMUL_LWLOCKS);
held_lwlocks[num_held_lwlocks++] = lockid;
}
/*
--- 302,322 ----
LOG_LWDEBUG("LWLockAcquire", lockid, "awakened");
! /* Now loop back and try to acquire lock again. */
}
+ /* We are done updating shared state of the lock itself. */
+ SpinLockRelease_NoHoldoff(&lock->mutex);
+
/* Add lock to list of locks held by this backend */
Assert(num_held_lwlocks < MAX_SIMUL_LWLOCKS);
held_lwlocks[num_held_lwlocks++] = lockid;
+
+ /*
+ * Fix the process wait semaphore's count for any absorbed wakeups.
+ */
+ while (extraWaits-- > 0)
+ IpcSemaphoreUnlock(proc->sem.semId, proc->sem.semNum);
}
/*
***************
*** 344,355 ****
}
else
{
! /*
! * If there is someone waiting (presumably for exclusive access),
! * queue up behind him even though I could get the lock. This
! * prevents a stream of read locks from starving a writer.
! */
! if (lock->exclusive == 0 && lock->head == NULL)
{
lock->shared++;
mustwait = false;
--- 357,363 ----
}
else
{
! if (lock->exclusive == 0)
{
lock->shared++;
mustwait = false;
***************
*** 427,446 ****
if (lock->exclusive == 0 && lock->shared == 0)
{
/*
! * Remove the to-be-awakened PROCs from the queue, and update
! * the lock state to show them as holding the lock.
*/
proc = head;
! if (proc->lwExclusive)
! lock->exclusive++;
! else
{
- lock->shared++;
while (proc->lwWaitLink != NULL &&
!proc->lwWaitLink->lwExclusive)
{
proc = proc->lwWaitLink;
- lock->shared++;
}
}
/* proc is now the last PROC to be released */
--- 435,451 ----
if (lock->exclusive == 0 && lock->shared == 0)
{
/*
! * Remove the to-be-awakened PROCs from the queue. If the
! * front waiter wants exclusive lock, awaken him only.
! * Otherwise awaken as many waiters as want shared access.
*/
proc = head;
! if (!proc->lwExclusive)
{
while (proc->lwWaitLink != NULL &&
!proc->lwWaitLink->lwExclusive)
{
proc = proc->lwWaitLink;
}
}
/* proc is now the last PROC to be released */
Bruce Momjian <pgman@candle.pha.pa.us> writes:
>> We might want to think about making bufmgr locking more fine-grained
>> ... in a future release. For 7.2 I don't really want to mess around
>> with the bufmgr logic at this late hour. Too risky.
> You want a TODO item on this?
Sure. But don't phrase it as just a bufmgr problem. Maybe:
* Make locking of shared data structures more fine-grained
regards, tom lane
> Bruce Momjian <pgman@candle.pha.pa.us> writes: > > What you want to do is to wake up the sleeper but not give them the lock > > until they are actually running and can aquire it themselves. > > Yeah. Essentially this is a partial reversion to the idea of a > spinlock. But it's more efficient than our old implementation with > timed waits between retries, because (a) a process will not be awoken > unless it has a chance at getting the lock, and (b) when a contended-for > lock is freed, a waiting process will be made ready immediately, rather > than waiting for a time tick to elapse. So, if the lock-releasing > process does block before the end of its quantum, the released process > is available to run immediately. Under the old scheme, a process that > had failed to get a spinlock couldn't run until its select wait timed > out, even if the lock were now available. So I think it's still a net > win to have the LWLock mechanism in there, rather than just changing > them back to spinlocks. > > > If you code up a patch, I will test it on my SMP machine using pgbench. > > Hopefully this will help Tatsuo's 4-way AIX machine too, and Linux. > > Attached is a proposed patch (against the current-CVS version of > lwlock.c). I haven't committed this yet, but it seems to be a win on > a single CPU. Can people try it on multi CPUs? OK, here are the results on BSD/OS 4.2 on a 2-cpu system. The first is before the patch, the second after. Both average 14tps, so the patch has no negative effect on my system. Of course, it has no positive effect either. :-) -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000 + If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania 19026 transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 1 number of transactions per client: 1000 number of transactions actually processed: 1000/1000 tps = 15.755389(including connections establishing) tps = 15.765396(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 10 number of transactions per client: 1000 number of transactions actually processed: 10000/10000 tps = 16.926562(including connections establishing) tps = 16.935963(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 25 number of transactions per client: 1000 number of transactions actually processed: 25000/25000 tps = 16.219866(including connections establishing) tps = 16.228470(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 50 number of transactions per client: 1000 number of transactions actually processed: 50000/50000 tps = 12.071730(including connections establishing) tps = 12.076470(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 1 number of transactions per client: 1000 number of transactions actually processed: 1000/1000 tps = 13.784963(including connections establishing) tps = 13.792893(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 10 number of transactions per client: 1000 number of transactions actually processed: 10000/10000 tps = 16.287374(including connections establishing) tps = 16.296349(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 25 number of transactions per client: 1000 number of transactions actually processed: 25000/25000 tps = 15.810789(including connections establishing) tps = 15.819153(excluding connections establishing) transaction type: TPC-B (sort of) scaling factor: 50 number of clients: 50 number of transactions per client: 1000 number of transactions actually processed: 50000/50000 tps = 12.030432(including connections establishing) tps = 12.035500(excluding connections establishing)
> > > On Sat, 29 Dec 2001, Bruce Momjian wrote: > > > OK, here are the results on BSD/OS 4.2 on a 2-cpu system. The first is > > before the patch, the second after. Both average 14tps, so the patch > > has no negative effect on my system. Of course, it has no positive > > effect either. :-) > > Actually it looks slighty worse with the patch. What about CPU usage? Yes, slightly, but I have better performance on 2 cpu's than 1, so I didn't expect to see any major change, partially because the context switching overhead problem doesn't see to exist on this OS. If we find that it helps single-cpu machines, and perhaps helps machines that had worse performance on SMP than single-cpu, my guess is it would be a win, in general. Let me tell you what I did to test it. I ran /contrib/pgbench. I had the postmaster configured with 1000 buffers, and ran pgbench with a scale of 50. I then ran it with 1, 10, 25, and 50 clients using 1000 transactions. The commands were: $ createdb pgbench$ pgbench -i -s 50 $ for CLIENT in 1 10 25 50do pgbench -c $CLIENT -t 1000 pgbenchdone | tee -a pgbench2_7.2 -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> OK, here are the results on BSD/OS 4.2 on a 2-cpu system. The first is
> before the patch, the second after. Both average 14tps, so the patch
> has no negative effect on my system. Of course, it has no positive
> effect either. :-)
I am also having a hard time measuring any difference using pgbench.
However, pgbench is almost entirely I/O bound on my hardware (CPU is
typically 70-80% idle) so this is not very surprising.
I can confirm that the patch accomplishes the intended goal of reducing
context swaps. Using pgbench with 64 clients, a profile of the old code
showed about 7% of LWLockAcquire calls blocking (invoking
IpcSemaphoreLock). A profile of the new code shows 0.1% of the calls
blocking.
I suspect that we need something less I/O-bound than pgbench to really
tell whether this patch is worthwhile or not. Jeffrey, what are you
seeing in your application?
And btw, what are you using to count context swaps?
regards, tom lane
> > > On Sat, 29 Dec 2001, Bruce Momjian wrote: > > > OK, here are the results on BSD/OS 4.2 on a 2-cpu system. The first is > > before the patch, the second after. Both average 14tps, so the patch > > has no negative effect on my system. Of course, it has no positive > > effect either. :-) > > Actually it looks slighty worse with the patch. What about CPU usage? For 5 clients, CPU's are 96% idle. Load average is around 5. Seems totally I/O bound. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> > If you code up a patch, I will test it on my SMP machine using pgbench. > > Hopefully this will help Tatsuo's 4-way AIX machine too, and Linux. > > Attached is a proposed patch (against the current-CVS version of > lwlock.c). I haven't committed this yet, but it seems to be a win on > a single CPU. Can people try it on multi CPUs? Your patches seem lightly enhanced 7.2 performance on AIX 5L (still slower than 7.1, however).
Tatsuo Ishii <t-ishii@sra.co.jp> writes:
> Your patches seem lightly enhanced 7.2 performance on AIX 5L (still
> slower than 7.1, however).
It's awfully hard to see what's happening near the left end of that
chart. May I suggest plotting the x-axis on a log scale?
regards, tom lane
I have thought of a further refinement to the patch I produced
yesterday. Assume that there are multiple waiters blocked on (eg)
BufMgrLock. After we release the first one, we want the currently
running process to be able to continue acquiring and releasing the lock
for as long as its time quantum holds out. But in the patch as given,
each acquire/release cycle releases another waiter. This is probably
not good.
Attached is a modification that prevents additional waiters from being
released until the first releasee has a chance to run and acquire the
lock. Would you try this and see if it's better or not in your test
cases? It doesn't seem to help on a single CPU, but maybe on multiple
CPUs it'll make a difference.
To try to make things simple, I've attached the mod in two forms:
as a diff from current CVS, and as a diff from the previous patch.
regards, tom lane
*** src/backend/storage/lmgr/lwlock.c.orig Sat Dec 29 19:48:03 2001
--- src/backend/storage/lmgr/lwlock.c Sun Dec 30 12:11:47 2001
***************
*** 30,35 ****
--- 30,36 ----
typedef struct LWLock
{
slock_t mutex; /* Protects LWLock and queue of PROCs */
+ bool releaseOK; /* T if ok to release waiters */
char exclusive; /* # of exclusive holders (0 or 1) */
int shared; /* # of shared holders (0..MaxBackends) */
PROC *head; /* head of list of waiting PROCs */
***************
*** 67,75 ****
PRINT_LWDEBUG(const char *where, LWLockId lockid, const volatile LWLock *lock)
{
if (Trace_lwlocks)
! elog(DEBUG, "%s(%d): excl %d shared %d head %p",
where, (int) lockid,
! (int) lock->exclusive, lock->shared, lock->head);
}
inline static void
--- 68,77 ----
PRINT_LWDEBUG(const char *where, LWLockId lockid, const volatile LWLock *lock)
{
if (Trace_lwlocks)
! elog(DEBUG, "%s(%d): excl %d shared %d head %p rOK %d",
where, (int) lockid,
! (int) lock->exclusive, lock->shared, lock->head,
! (int) lock->releaseOK);
}
inline static void
***************
*** 153,158 ****
--- 155,161 ----
for (id = 0, lock = LWLockArray; id < numLocks; id++, lock++)
{
SpinLockInit(&lock->mutex);
+ lock->releaseOK = true;
lock->exclusive = 0;
lock->shared = 0;
lock->head = NULL;
***************
*** 195,201 ****
LWLockAcquire(LWLockId lockid, LWLockMode mode)
{
volatile LWLock *lock = LWLockArray + lockid;
! bool mustwait;
PRINT_LWDEBUG("LWLockAcquire", lockid, lock);
--- 198,206 ----
LWLockAcquire(LWLockId lockid, LWLockMode mode)
{
volatile LWLock *lock = LWLockArray + lockid;
! PROC *proc = MyProc;
! bool retry = false;
! int extraWaits = 0;
PRINT_LWDEBUG("LWLockAcquire", lockid, lock);
***************
*** 206,248 ****
*/
HOLD_INTERRUPTS();
! /* Acquire mutex. Time spent holding mutex should be short! */
! SpinLockAcquire_NoHoldoff(&lock->mutex);
!
! /* If I can get the lock, do so quickly. */
! if (mode == LW_EXCLUSIVE)
{
! if (lock->exclusive == 0 && lock->shared == 0)
{
! lock->exclusive++;
! mustwait = false;
}
else
- mustwait = true;
- }
- else
- {
- /*
- * If there is someone waiting (presumably for exclusive access),
- * queue up behind him even though I could get the lock. This
- * prevents a stream of read locks from starving a writer.
- */
- if (lock->exclusive == 0 && lock->head == NULL)
{
! lock->shared++;
! mustwait = false;
}
- else
- mustwait = true;
- }
! if (mustwait)
! {
! /* Add myself to wait queue */
! PROC *proc = MyProc;
! int extraWaits = 0;
/*
* If we don't have a PROC structure, there's no way to wait. This
* should never occur, since MyProc should only be null during
* shared memory initialization.
--- 211,271 ----
*/
HOLD_INTERRUPTS();
! /*
! * Loop here to try to acquire lock after each time we are signaled
! * by LWLockRelease.
! *
! * NOTE: it might seem better to have LWLockRelease actually grant us
! * the lock, rather than retrying and possibly having to go back to
! * sleep. But in practice that is no good because it means a process
! * swap for every lock acquisition when two or more processes are
! * contending for the same lock. Since LWLocks are normally used to
! * protect not-very-long sections of computation, a process needs to
! * be able to acquire and release the same lock many times during a
! * single process dispatch cycle, even in the presence of contention.
! * The efficiency of being able to do that outweighs the inefficiency of
! * sometimes wasting a dispatch cycle because the lock is not free when a
! * released waiter gets to run. See pgsql-hackers archives for 29-Dec-01.
! */
! for (;;)
{
! bool mustwait;
!
! /* Acquire mutex. Time spent holding mutex should be short! */
! SpinLockAcquire_NoHoldoff(&lock->mutex);
!
! /* If retrying, allow LWLockRelease to release waiters again */
! if (retry)
! lock->releaseOK = true;
!
! /* If I can get the lock, do so quickly. */
! if (mode == LW_EXCLUSIVE)
{
! if (lock->exclusive == 0 && lock->shared == 0)
! {
! lock->exclusive++;
! mustwait = false;
! }
! else
! mustwait = true;
}
else
{
! if (lock->exclusive == 0)
! {
! lock->shared++;
! mustwait = false;
! }
! else
! mustwait = true;
}
! if (!mustwait)
! break; /* got the lock */
/*
+ * Add myself to wait queue.
+ *
* If we don't have a PROC structure, there's no way to wait. This
* should never occur, since MyProc should only be null during
* shared memory initialization.
***************
*** 267,275 ****
*
* Since we share the process wait semaphore with the regular lock
* manager and ProcWaitForSignal, and we may need to acquire an
! * LWLock while one of those is pending, it is possible that we
! * get awakened for a reason other than being granted the LWLock.
! * If so, loop back and wait again. Once we've gotten the lock,
* re-increment the sema by the number of additional signals
* received, so that the lock manager or signal manager will see
* the received signal when it next waits.
--- 290,298 ----
*
* Since we share the process wait semaphore with the regular lock
* manager and ProcWaitForSignal, and we may need to acquire an
! * LWLock while one of those is pending, it is possible that we get
! * awakened for a reason other than being signaled by LWLockRelease.
! * If so, loop back and wait again. Once we've gotten the LWLock,
* re-increment the sema by the number of additional signals
* received, so that the lock manager or signal manager will see
* the received signal when it next waits.
***************
*** 287,309 ****
LOG_LWDEBUG("LWLockAcquire", lockid, "awakened");
! /*
! * The awakener already updated the lock struct's state, so we
! * don't need to do anything more to it. Just need to fix the
! * semaphore count.
! */
! while (extraWaits-- > 0)
! IpcSemaphoreUnlock(proc->sem.semId, proc->sem.semNum);
! }
! else
! {
! /* Got the lock without waiting */
! SpinLockRelease_NoHoldoff(&lock->mutex);
}
/* Add lock to list of locks held by this backend */
Assert(num_held_lwlocks < MAX_SIMUL_LWLOCKS);
held_lwlocks[num_held_lwlocks++] = lockid;
}
/*
--- 310,331 ----
LOG_LWDEBUG("LWLockAcquire", lockid, "awakened");
! /* Now loop back and try to acquire lock again. */
! retry = true;
}
+ /* We are done updating shared state of the lock itself. */
+ SpinLockRelease_NoHoldoff(&lock->mutex);
+
/* Add lock to list of locks held by this backend */
Assert(num_held_lwlocks < MAX_SIMUL_LWLOCKS);
held_lwlocks[num_held_lwlocks++] = lockid;
+
+ /*
+ * Fix the process wait semaphore's count for any absorbed wakeups.
+ */
+ while (extraWaits-- > 0)
+ IpcSemaphoreUnlock(proc->sem.semId, proc->sem.semNum);
}
/*
***************
*** 344,355 ****
}
else
{
! /*
! * If there is someone waiting (presumably for exclusive access),
! * queue up behind him even though I could get the lock. This
! * prevents a stream of read locks from starving a writer.
! */
! if (lock->exclusive == 0 && lock->head == NULL)
{
lock->shared++;
mustwait = false;
--- 366,372 ----
}
else
{
! if (lock->exclusive == 0)
{
lock->shared++;
mustwait = false;
***************
*** 419,451 ****
/*
* See if I need to awaken any waiters. If I released a non-last
! * shared hold, there cannot be anything to do.
*/
head = lock->head;
if (head != NULL)
{
! if (lock->exclusive == 0 && lock->shared == 0)
{
/*
! * Remove the to-be-awakened PROCs from the queue, and update
! * the lock state to show them as holding the lock.
*/
proc = head;
! if (proc->lwExclusive)
! lock->exclusive++;
! else
{
- lock->shared++;
while (proc->lwWaitLink != NULL &&
!proc->lwWaitLink->lwExclusive)
{
proc = proc->lwWaitLink;
- lock->shared++;
}
}
/* proc is now the last PROC to be released */
lock->head = proc->lwWaitLink;
proc->lwWaitLink = NULL;
}
else
{
--- 436,469 ----
/*
* See if I need to awaken any waiters. If I released a non-last
! * shared hold, there cannot be anything to do. Also, do not awaken
! * any waiters if someone has already awakened waiters that haven't
! * yet acquired the lock.
*/
head = lock->head;
if (head != NULL)
{
! if (lock->exclusive == 0 && lock->shared == 0 && lock->releaseOK)
{
/*
! * Remove the to-be-awakened PROCs from the queue. If the
! * front waiter wants exclusive lock, awaken him only.
! * Otherwise awaken as many waiters as want shared access.
*/
proc = head;
! if (!proc->lwExclusive)
{
while (proc->lwWaitLink != NULL &&
!proc->lwWaitLink->lwExclusive)
{
proc = proc->lwWaitLink;
}
}
/* proc is now the last PROC to be released */
lock->head = proc->lwWaitLink;
proc->lwWaitLink = NULL;
+ /* prevent additional wakeups until retryer gets to run */
+ lock->releaseOK = false;
}
else
{
*** src/backend/storage/lmgr/lwlock.c.try1 Sat Dec 29 15:20:08 2001
--- src/backend/storage/lmgr/lwlock.c Sun Dec 30 12:11:47 2001
***************
*** 30,35 ****
--- 30,36 ----
typedef struct LWLock
{
slock_t mutex; /* Protects LWLock and queue of PROCs */
+ bool releaseOK; /* T if ok to release waiters */
char exclusive; /* # of exclusive holders (0 or 1) */
int shared; /* # of shared holders (0..MaxBackends) */
PROC *head; /* head of list of waiting PROCs */
***************
*** 67,75 ****
PRINT_LWDEBUG(const char *where, LWLockId lockid, const volatile LWLock *lock)
{
if (Trace_lwlocks)
! elog(DEBUG, "%s(%d): excl %d shared %d head %p",
where, (int) lockid,
! (int) lock->exclusive, lock->shared, lock->head);
}
inline static void
--- 68,77 ----
PRINT_LWDEBUG(const char *where, LWLockId lockid, const volatile LWLock *lock)
{
if (Trace_lwlocks)
! elog(DEBUG, "%s(%d): excl %d shared %d head %p rOK %d",
where, (int) lockid,
! (int) lock->exclusive, lock->shared, lock->head,
! (int) lock->releaseOK);
}
inline static void
***************
*** 153,158 ****
--- 155,161 ----
for (id = 0, lock = LWLockArray; id < numLocks; id++, lock++)
{
SpinLockInit(&lock->mutex);
+ lock->releaseOK = true;
lock->exclusive = 0;
lock->shared = 0;
lock->head = NULL;
***************
*** 196,201 ****
--- 199,205 ----
{
volatile LWLock *lock = LWLockArray + lockid;
PROC *proc = MyProc;
+ bool retry = false;
int extraWaits = 0;
PRINT_LWDEBUG("LWLockAcquire", lockid, lock);
***************
*** 230,235 ****
--- 234,243 ----
/* Acquire mutex. Time spent holding mutex should be short! */
SpinLockAcquire_NoHoldoff(&lock->mutex);
+ /* If retrying, allow LWLockRelease to release waiters again */
+ if (retry)
+ lock->releaseOK = true;
+
/* If I can get the lock, do so quickly. */
if (mode == LW_EXCLUSIVE)
{
***************
*** 303,308 ****
--- 311,317 ----
LOG_LWDEBUG("LWLockAcquire", lockid, "awakened");
/* Now loop back and try to acquire lock again. */
+ retry = true;
}
/* We are done updating shared state of the lock itself. */
***************
*** 427,438 ****
/*
* See if I need to awaken any waiters. If I released a non-last
! * shared hold, there cannot be anything to do.
*/
head = lock->head;
if (head != NULL)
{
! if (lock->exclusive == 0 && lock->shared == 0)
{
/*
* Remove the to-be-awakened PROCs from the queue. If the
--- 436,449 ----
/*
* See if I need to awaken any waiters. If I released a non-last
! * shared hold, there cannot be anything to do. Also, do not awaken
! * any waiters if someone has already awakened waiters that haven't
! * yet acquired the lock.
*/
head = lock->head;
if (head != NULL)
{
! if (lock->exclusive == 0 && lock->shared == 0 && lock->releaseOK)
{
/*
* Remove the to-be-awakened PROCs from the queue. If the
***************
*** 451,456 ****
--- 462,469 ----
/* proc is now the last PROC to be released */
lock->head = proc->lwWaitLink;
proc->lwWaitLink = NULL;
+ /* prevent additional wakeups until retryer gets to run */
+ lock->releaseOK = false;
}
else
{
Several people complained that my email client was not properly attributing quotations to the people who made them. I figured out the elmrc option and I have it working now, as you can see: --> Tom Lane wrote:> I have thought of a further refinement to the patch I produced> yesterday. Assume that there aremultiple waiters blocked on (eg) -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> I have thought of a further refinement to the patch I produced > yesterday. Assume that there are multiple waiters blocked on (eg) > BufMgrLock. After we release the first one, we want the currently > running process to be able to continue acquiring and releasing the lock > for as long as its time quantum holds out. But in the patch as given, > each acquire/release cycle releases another waiter. This is probably > not good. > > Attached is a modification that prevents additional waiters from being > released until the first releasee has a chance to run and acquire the > lock. Would you try this and see if it's better or not in your test > cases? It doesn't seem to help on a single CPU, but maybe on multiple > CPUs it'll make a difference. > > To try to make things simple, I've attached the mod in two forms: > as a diff from current CVS, and as a diff from the previous patch. Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way). "7.2 with patch" is for the previous patch. "7.2 with patch (revised)" is for the this patch. I see virtually no improvement. Please note that xy axis are now in log scale.
Tom Lane wrote: > I have thought of a further refinement to the patch I produced > yesterday. Assume that there are multiple waiters blocked on (eg) > BufMgrLock. After we release the first one, we want the currently > running process to be able to continue acquiring and releasing the lock > for as long as its time quantum holds out. But in the patch as given, > each acquire/release cycle releases another waiter. This is probably > not good. > > Attached is a modification that prevents additional waiters from being > released until the first releasee has a chance to run and acquire the > lock. Would you try this and see if it's better or not in your test > cases? It doesn't seem to help on a single CPU, but maybe on multiple > CPUs it'll make a difference. > > To try to make things simple, I've attached the mod in two forms: > as a diff from current CVS, and as a diff from the previous patch. This does seem like a nice optimization. I will try to test it tomorrow but I doubt I will see any change on BSD/OS. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tatsuo Ishii wrote:
> > I have thought of a further refinement to the patch I produced
> > yesterday. Assume that there are multiple waiters blocked on (eg)
> > BufMgrLock. After we release the first one, we want the currently
> > running process to be able to continue acquiring and releasing the lock
> > for as long as its time quantum holds out. But in the patch as given,
> > each acquire/release cycle releases another waiter. This is probably
> > not good.
> >
> > Attached is a modification that prevents additional waiters from being
> > released until the first release has a chance to run and acquire the
> > lock. Would you try this and see if it's better or not in your test
> > cases? It doesn't seem to help on a single CPU, but maybe on multiple
> > CPUs it'll make a difference.
> >
> > To try to make things simple, I've attached the mod in two forms:
> > as a diff from current CVS, and as a diff from the previous patch.
>
> Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way).
>
> "7.2 with patch" is for the previous patch. "7.2 with patch (revised)"
> is for the this patch. I see virtually no improvement. Please note
> that xy axis are now in log scale.
Well, there is clearly some good news in that graph. The unpatched 7.2
had _terrible_ performance for a few users. The patch clearly helped
that.
Both the 7.2 with patch tests show much better performance, close to
7.1. Interestingly the first 7.2 patch shows better performance than
the later one, perhaps because it is a 4-way system and maybe it is
faster to start up more waiting backends on such a system, but the
performance difference is minor.
I guess what really bothers me now is why the select() in 7.1 wasn't
slower than it was. We made 7.2 especially for multicpu systems, and
here we have identical performance to 7.1. Tatsuo, is AIX capable of
<10 millisecond sleeps? I see there is such a program in the archives
from Tom Lane:
http://fts.postgresql.org/db/mw/msg.html?mid=1217731
Tatsuo, can you run that program on the AIX box and tell us what it
reports? It would not surprise me if AIX supported sub-10ms select()
timing because I have heard AIX is a mixing of Unix and IBM mainframe
code.
I have attached a clean version of the code because the web mail archive
munged the C code. I called it tst1.c. If you compile it and run it
like this:
#$ time tst1 1
real 0m10.013s
user 0m0.000s
sys 0m0.004s
This runs select(1) 1000 times, meaning 10ms per select for BSD/OS.
--
Bruce Momjian | http://candle.pha.pa.us
pgman@candle.pha.pa.us | (610) 853-3000
+ If your life is a hard drive, | 830 Blythe Avenue
+ Christ can be your backup. | Drexel Hill, Pennsylvania 19026
#include <sys/types.h>
#include <sys/time.h>
#include <sys/select.h>
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv)
{
struct timeval delay;
int i, del;
del = atoi(argv[1]);
for (i = 0; i < 1000; i++) {
delay.tv_sec = 0;
delay.tv_usec = del;
(void) select(0, NULL, NULL, NULL, &delay);
}
return 0;
}
> I guess what really bothers me now is why the select() in 7.1 wasn't > slower than it was. We made 7.2 especially for multicpu systems, and > here we have identical performance to 7.1. Tatsuo, is AIX capable of > <10 millisecond sleeps? I see there is such a program in the archives > from Tom Lane: > > http://fts.postgresql.org/db/mw/msg.html?mid=1217731 > > Tatsuo, can you run that program on the AIX box and tell us what it > reports? It would not surprise me if AIX supported sub-10ms select() > timing because I have heard AIX is a mixing of Unix and IBM mainframe > code. > > I have attached a clean version of the code because the web mail archive > munged the C code. I called it tst1.c. If you compile it and run it > like this: > > #$ time tst1 1 > > real 0m10.013s > user 0m0.000s > sys 0m0.004s > > This runs select(1) 1000 times, meaning 10ms per select for BSD/OS. Bingo. It seems AIX 5L can run select() at 1ms timing. bash-2.04$ time ./a.out 1 real 0m1.027s user 0m0.000s sys 0m0.000s -- Tatsuo Ishii
> Tatsuo, is AIX capable of <10 millisecond sleeps? Yes, the select granularity is 1 ms for non root users on AIX. AIX is able to actually sleep micro seconds with select as user root (non root users can use usleep for the same result). AIX also has yield. I already reported this once, but a patch was not welcomed, maybe I failed to properly describe ... Andreas
On Sat, 29 Dec 2001, Tom Lane wrote: > After some further experimentation, I believe I understand the reason for > the reports we've had of 7.2 producing heavy context-swap activity where > 7.1 didn't. Here is an extract from tracing lwlock activity for one > backend in a pgbench run: ... > It would seem, therefore, that lwlock.c's behavior of immediately > granting the lock to released waiters is not such a good idea after all. > Perhaps we should release waiters but NOT grant them the lock; when they > get to run, they have to loop back, try to get the lock, and possibly go > back to sleep if they fail. This apparent waste of cycles is actually > beneficial because it saves context swaps overall. Sounds reasonable enough, but there seems to be a possibility of a process starving. For example, if A releases the lock, B and C wake up, B gets the lock. Then B releases the lock, A and C wake, and A gets the lock back. C gets CPU time but never gets the lock. BTW I am not on this list. -jwb
On Sat, 29 Dec 2001, Bruce Momjian wrote: > OK, here are the results on BSD/OS 4.2 on a 2-cpu system. The first is > before the patch, the second after. Both average 14tps, so the patch > has no negative effect on my system. Of course, it has no positive > effect either. :-) Actually it looks slighty worse with the patch. What about CPU usage? -jwb
Tatsuo Ishii <t-ishii@sra.co.jp> writes:
> Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way).
> "7.2 with patch" is for the previous patch. "7.2 with patch (revised)"
> is for the this patch. I see virtually no improvement.
If anything, the revised patch seems to make things slightly worse :-(.
That agrees with my measurement on a single CPU.
I am inclined to use the revised patch anyway, though, because I think
it will be less prone to starvation (ie, a process repeatedly being
awoken but failing to get the lock). The original form of lwlock.c
guaranteed that a writer could not be locked out by large numbers of
readers, but I had to abandon that goal in the first version of the
patch. The second version still doesn't keep the writer from being
blocked by active readers, but it does ensure that readers queued up
behind the writer won't be released. Comments?
> Please note that xy axis are now in log scale.
Seems much easier to read this way. Thanks.
regards, tom lane
Tom Lane wrote: > Tatsuo Ishii <t-ishii@sra.co.jp> writes: > > Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way). > > "7.2 with patch" is for the previous patch. "7.2 with patch (revised)" > > is for the this patch. I see virtually no improvement. > > If anything, the revised patch seems to make things slightly worse :-(. > That agrees with my measurement on a single CPU. > > I am inclined to use the revised patch anyway, though, because I think > it will be less prone to starvation (ie, a process repeatedly being > awoken but failing to get the lock). The original form of lwlock.c > guaranteed that a writer could not be locked out by large numbers of > readers, but I had to abandon that goal in the first version of the > patch. The second version still doesn't keep the writer from being > blocked by active readers, but it does ensure that readers queued up > behind the writer won't be released. Comments? Yes, I agree with the later patch. > > > Please note that xy axis are now in log scale. > > Seems much easier to read this way. Thanks. Yes, good idea. I want to read up on gnuplot. I knew how to use it long ago. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom Lane wrote: > Tatsuo Ishii <t-ishii@sra.co.jp> writes: > > Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way). > > "7.2 with patch" is for the previous patch. "7.2 with patch (revised)" > > is for the this patch. I see virtually no improvement. > > If anything, the revised patch seems to make things slightly worse :-(. > That agrees with my measurement on a single CPU. > > I am inclined to use the revised patch anyway, though, because I think > it will be less prone to starvation (ie, a process repeatedly being > awoken but failing to get the lock). The original form of lwlock.c > guaranteed that a writer could not be locked out by large numbers of > readers, but I had to abandon that goal in the first version of the > patch. The second version still doesn't keep the writer from being > blocked by active readers, but it does ensure that readers queued up > behind the writer won't be released. Comments? OK, so now we know that while the new lock code handles the select(1) problem better, we also know that on AIX the old select(1) code wasn't as bad as we thought. As to why we don't see better numbers on AIX, we are getting 100tps, which seems pretty good to me. Tatsuo, were you expecting higher than 100tps on that machine? My hardware is at listed at http://candle.pha.pa.us/main/hardware.html and I don't get over 16tps. I believe we don't see improvement on SMP machines using pgbench because pgbench, at least at high scaling factors, is really testing disk i/o, not backend processing speed. It would be interesting to test pgbench using scaling factors that allowed most of the tables to sit in shared memory buffers. Then, we wouldn't be testing disk i/o and would be testing more backend processing throughput. (Tom, is that true?) -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> OK, so now we know that while the new lock code handles the select(1)
> problem better, we also know that on AIX the old select(1) code wasn't
> as bad as we thought.
It still seems that the select() blocking method should be a loser.
I notice that for AIX, s_lock.h defines TAS() as a call on a system
routine cs(). I wonder what cs() actually does and how long it takes.
Tatsuo or Andreas, any info? It might be interesting to try the pgbench
tests on AIX with s_lock.c's SPINS_PER_DELAY set to different values
(try 10 and 1000 instead of the default 100).
> I believe we don't see improvement on SMP machines using pgbench because
> pgbench, at least at high scaling factors, is really testing disk i/o,
> not backend processing speed.
Good point. I suspect this is even more true on the PC-hardware setups
that most of the rest of us are using: we've got these ridiculously fast
processors and consumer-grade disks (with IDE interfaces, yet).
Tatsuo's AIX setup might have a better CPU-to-IO throughput balance,
but it's probably still ultimately I/O bound in this test. Tatsuo,
can you report anything about CPU idle time percentage while you are
running these tests?
> It would be interesting to test pgbench
> using scaling factors that allowed most of the tables to sit in shared
> memory buffers. Then, we wouldn't be testing disk i/o and would be
> testing more backend processing throughput. (Tom, is that true?)
Unfortunately, at low scaling factors pgbench is guaranteed to look
horrible because of contention for the "branches" rows. I think that
it'd be necessary to adjust the ratios of branches, tellers, and
accounts rows to make it possible to build a small pgbench database
that didn't show a lot of contention.
BTW, I realized over the weekend that the reason performance tails off
for more clients is that if you hold tx/client constant, more clients
means more total updates executed, which means more dead rows, which
means more time spent in unique-index duplicate checks. We know we want
to change the way that works, but not for 7.2. At the moment, the only
way to make a pgbench run that accurately reflects the impact of
multiple clients and not the inefficiency of dead index entries is to
scale tx/client down as #clients increases, so that the total number of
transactions is the same for all test runs.
regards, tom lane
Tom Lane wrote:
>Attached is a modification that prevents additional waiters from being
>released until the first releasee has a chance to run and acquire the
>lock. Would you try this and see if it's better or not in your test
>cases? It doesn't seem to help on a single CPU, but maybe on multiple
>CPUs it'll make a difference.
>
Here are some results for Linux 2.2 on a Dual PentiumPro 200MHz, SCSI
disks and way too litte RAM
(just 128MB). I observed the loadavg. with the three different 7.2
versions and 50 clients, without patch
the load stayed low (2-3), with patch no1 very high (12-14) and with
patch no2 between the two others
(6-8). Any of the patches seem to be a big win with the second version
being slightly better. I could run
benchmarks on 7.1 if that would be interesting. I used the same
benchmark database with a
VACUUM FULL between each version of the backend tested. I also re-run
some of the tests on the same
database after I tested all loads on the different versions, and numbers
stayed very simmilar (difference:
0.1-0.3 tps).
Best regrds
Fredrik Estreen
--------------------------------------
7.2 CVS without patch
--------------------------------------
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 1
number of transactions per client: 1000
number of transactions actually processed: 1000/1000
tps = 16.169579(including connections establishing)
tps = 16.180891(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 2
number of transactions per client: 1000
number of transactions actually processed: 2000/2000
tps = 17.392394(including connections establishing)
tps = 17.404734(excluding connections establishing)
scaling factor: 50
transaction type: TPC-B (sort of)
number of clients: 5
number of transactions per client: 1000
number of transactions actually processed: 5000/5000
tps = 18.648499(including connections establishing)
tps = 18.661991(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 10
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
tps = 15.405974(including connections establishing)
tps = 15.416244(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 25
number of transactions per client: 1000
number of transactions actually processed: 25000/25000
tps = 10.421300(including connections establishing)
tps = 10.425750(excluding connections establishing)
scaling factor: 50
number of clients: 50
number of transactions per client: 1000
number of transactions actually processed: 50000/50000
tps = 5.370482(including connections establishing)
tps = 5.371573(excluding connections establishing)
-------------------------------------
7.2 CVS with patch no1
--------------------------------------
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 1
number of transactions per client: 1000
number of transactions actually processed: 1000/1000
tps = 15.614858(including connections establishing)
tps = 15.625053(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 2
number of transactions per client: 1000
number of transactions actually processed: 2000/2000
tps = 18.165989(including connections establishing)
tps = 18.179211(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 5
number of transactions per client: 1000
number of transactions actually processed: 5000/5000
tps = 18.979070(including connections establishing)
tps = 18.993031(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 10
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
tps = 19.809421(including connections establishing)
tps = 19.836396(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 25
number of transactions per client: 1000
number of transactions actually processed: 25000/25000
tps = 19.927333(including connections establishing)
tps = 19.942641(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 50
number of transactions per client: 1000
number of transactions actually processed: 50000/50000
tps = 16.888624(including connections establishing)
tps = 16.900136(excluding connections establishing)
--------------------------------------
7.2 CVS with patch no 2
--------------------------------------
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 1
number of transactions per client: 1000
number of transactions actually processed: 1000/1000
tps = 16.653249(including connections establishing)
tps = 16.664507(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 2
number of transactions per client: 1000
number of transactions actually processed: 2000/2000
tps = 18.773602(including connections establishing)
tps = 18.787637(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 5
number of transactions per client: 1000
number of transactions actually processed: 5000/5000
tps = 19.325495(including connections establishing)
tps = 19.339827(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 10
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
tps = 20.251957(including connections establishing)
tps = 20.267558(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 25
number of transactions per client: 1000
number of transactions actually processed: 25000/25000
tps = 20.466319(including connections establishing)
tps = 20.482390(excluding connections establishing)
transaction type: TPC-B (sort of)
scaling factor: 50
number of clients: 50
number of transactions per client: 1000
number of transactions actually processed: 50000/50000
tps = 17.742367(including connections establishing)
tps = 17.754473(excluding connections establishing)
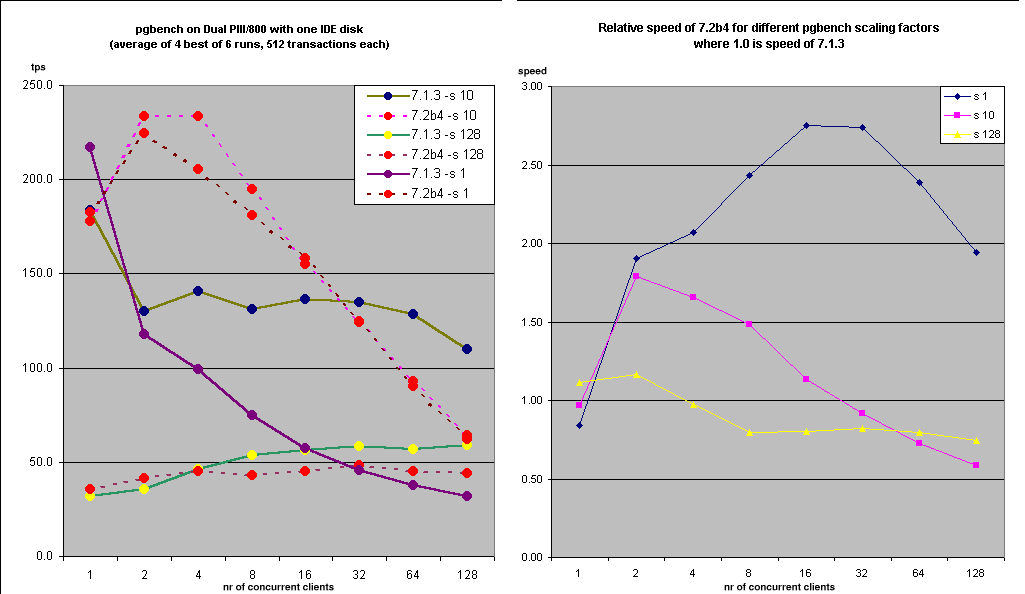
Bruce Momjian wrote: >Tom Lane wrote: > >>Tatsuo Ishii <t-ishii@sra.co.jp> writes: >> >>>Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way). >>>"7.2 with patch" is for the previous patch. "7.2 with patch (revised)" >>>is for the this patch. I see virtually no improvement. >>> >>If anything, the revised patch seems to make things slightly worse :-(. >>That agrees with my measurement on a single CPU. >> >>I am inclined to use the revised patch anyway, though, because I think >>it will be less prone to starvation (ie, a process repeatedly being >>awoken but failing to get the lock). The original form of lwlock.c >>guaranteed that a writer could not be locked out by large numbers of >>readers, but I had to abandon that goal in the first version of the >>patch. The second version still doesn't keep the writer from being >>blocked by active readers, but it does ensure that readers queued up >>behind the writer won't be released. Comments? >> > >OK, so now we know that while the new lock code handles the select(1) >problem better, we also know that on AIX the old select(1) code wasn't >as bad as we thought. > >As to why we don't see better numbers on AIX, we are getting 100tps, >which seems pretty good to me. Tatsuo, were you expecting higher than >100tps on that machine? My hardware is at listed at >http://candle.pha.pa.us/main/hardware.html and I don't get over 16tps. > What scaling factor do you use ? What OS ? I got from ~40 tps for -s 128 up to 50-230 tps for -s 1 or 10 on dual PIII 800 on IDE disk (Model=IBM-DTLA-307045) with hdparm -t the following /dev/hda: Timing buffered disk reads: 64 MB in 3.10 seconds = 20.65 MB/sec The only difference from Tom's hdparm is unmaskirq = 1 (on) (the -u 1 switch that enables interrupts during IDE processing - there is an ancient warning about it being a risk, but I have been running so for years on very different configurations with no problems) I'll reattach the graph (old one, without either Tom's 7.2b4 patches). This is on RedHat 7.2 >I believe we don't see improvement on SMP machines using pgbench because >pgbench, at least at high scaling factors, is really testing disk i/o, >not backend processing speed. It would be interesting to test pgbench >using scaling factors that allowed most of the tables to sit in shared >memory buffers. Then, we wouldn't be testing disk i/o and would be >testing more backend processing throughput. > I suspect that we should run at about same level of disk i/o for same TPS level regardless of number of clients, so pgbench is measuring ability to run concurrently in this scenario. ----------------- Hannu
Вложения
{kind=link}
Tom Lane wrote: >>It would be interesting to test pgbench >>using scaling factors that allowed most of the tables to sit in shared >>memory buffers. >> Thats why I recommended testing on ram disk ;) >>Then, we wouldn't be testing disk i/o and would be >>testing more backend processing throughput. (Tom, is that true?) >> > >Unfortunately, at low scaling factors pgbench is guaranteed to look >horrible because of contention for the "branches" rows. > Not really! See graph in my previous post - the database size affects performance much more ! -s 1 is faster than -s 128 for all cases except 7.1.3 where it becomse slower when nr of clients is > 16 >I think that >it'd be necessary to adjust the ratios of branches, tellers, and >accounts rows to make it possible to build a small pgbench database >that didn't show a lot of contention. > My understanding is that pgbench is meant to have some level of contention and should be tested up to ( -c = 10 times -s ), as each test client should emulate a real "teller" and there are 10 tellers per -s. >BTW, I realized over the weekend that the reason performance tails off >for more clients is that if you hold tx/client constant, more clients >means more total updates executed, which means more dead rows, which >means more time spent in unique-index duplicate checks. > Thats the point I tried to make by modifying Tatsuos script to do what you describe. I'm not smart enough to attribute it directly to index lookups but my gut feeling told me that dead tuples must be the culprit ;) I first tried to counter the slowdown by running a concurrent new-type vacuum process but it made things 2X slower still (38 --> 20 tps for -s 100 with original nr for -t ) > We know we want >to change the way that works, but not for 7.2. At the moment, the only >way to make a pgbench run that accurately reflects the impact of >multiple clients and not the inefficiency of dead index entries is to >scale tx/client down as #clients increases, so that the total number of >transactions is the same for all test runs. > Yes. My test also showed that the impact of per-client startup costs is much smaller than the impact of increased numer of transactions. I posted the modified script that does exactly that (512 total transactions for 1-2-4-8-16-32-64-128 concurrent clients ) about a week ago together with a graph of results. ------------------------ Hannu
Hannu Krosing <hannu@tm.ee> writes:
> Tom Lane wrote:
>> Unfortunately, at low scaling factors pgbench is guaranteed to look
>> horrible because of contention for the "branches" rows.
>>
> Not really! See graph in my previous post - the database size affects
> performance much more !
But the way that pgbench is currently set up, you can't really tell the
difference between database size effects and contention effects, because
you can't vary one while holding the other constant.
I based my comments on having done profiles that show most of the CPU
time going into attempts to acquire row locks for updates and/or
checking of dead tuples in _bt_check_unique. So at least in the
conditions I was using (single CPU) I think those are the bottlenecks.
I don't have any profiles for SMP machines, yet.
regards, tom lane
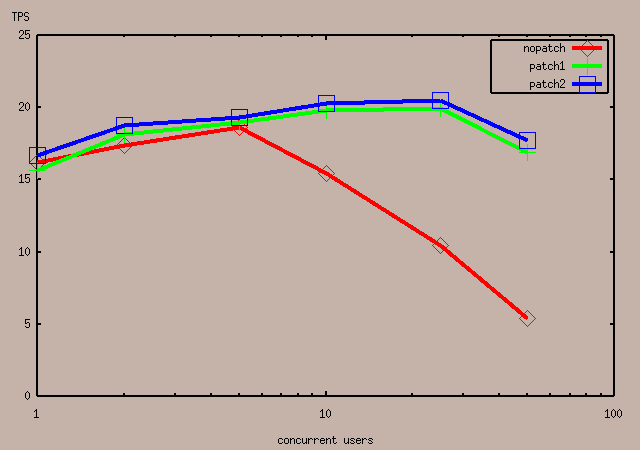
Fredrik Estreen <estreen@algonet.se> writes:
> Here are some results for Linux 2.2 on a Dual PentiumPro 200MHz, SCSI
> disks and way too litte RAM (just 128MB).
Many thanks for the additional datapoints! I converted the data into
a plot (attached) to make it easier to interpret.
> I observed the loadavg. with the three different 7.2 versions and 50
> clients, without patch the load stayed low (2-3), with patch no1 very
> high (12-14) and with patch no2 between the two others (6-8).
That makes sense. The first patch would release more processes than
it probably should, which would translate to more processes in the
kernel's run queue = higher load average. This would only make a
difference if the additional processes were not able to get the lock
when they finally get a chance to run; which would happen sometimes
but not always. So the small improvement for patch2 is pretty much
what I would've expected.
> I could run benchmarks on 7.1 if that would be interesting.
Yes, if you have the time to run the same test conditions on 7.1, it
would be good.
Also, per recent discussions, it would probably be better to try to keep
the total number of transactions the same for all runs (maybe about
10000 transactions total, so -t would vary between 10000 and 200 as
-c ranges from 1 to 50).
regards, tom lane
Вложения
{kind=link}
On Thu, Jan 03, 2002 at 11:17:04PM +0100, Fredrik Estreen wrote: Fredrik:Not sure who or where this should go to, but here is what I did,hope it makes some sense.. The box normally runsoracle, its notbusy at the moment.. I sent a copy to pgsql-hackers@postgresql.org,I think that is the correct address. For the SMP test (I think it was using pgbench)downloaded the 7.2b4 sourcebuild postgres from source into /usr/local treemanuallystarted the db with defaults build pgbench hardware is a 2-processor Dell box, 1.2 GZ Zeon processors4G memory with RAID SCSI disksLinux seti 2.4.7-10smp #1 SMP ThuSep 6 17:09:31 EDT 2001 i686 unknown setup pgbench with : pgbench -i testdb -c 50 -t 40 -s 10changed postgresql.conf parameters wal_files = 4 # range0-64 shared_buffers = 200 # 2*max_connections, min 16test run as pgbench testdb -- output follows: [kklatt@seti pgbench]$ pgbench testdb -c 50 -t 40 -s 10 starting vacuum...end. transaction type: TPC-B (sort of) scaling factor: 10 number of clients: 50 number of transactions per client: 40 number of transactions actually processed: 2000/2000 tps = 101.847384(including connections establishing) tps = 104.345472(excluding connections establishing) Hope this makes some sense.. Kenny Klatt Data Architect / Oracle DBA University of Wisconsin Milwaukee
Hannu Krosing wrote: > > > Bruce Momjian wrote: > > >Tom Lane wrote: > > > >>Tatsuo Ishii <t-ishii@sra.co.jp> writes: > >> > >>>Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way). > >>>"7.2 with patch" is for the previous patch. "7.2 with patch (revised)" > >>>is for the this patch. I see virtually no improvement. > >>> > >>If anything, the revised patch seems to make things slightly worse :-(. > >>That agrees with my measurement on a single CPU. > >> > >>I am inclined to use the revised patch anyway, though, because I think > >>it will be less prone to starvation (ie, a process repeatedly being > >>awoken but failing to get the lock). The original form of lwlock.c > >>guaranteed that a writer could not be locked out by large numbers of > >>readers, but I had to abandon that goal in the first version of the > >>patch. The second version still doesn't keep the writer from being > >>blocked by active readers, but it does ensure that readers queued up > >>behind the writer won't be released. Comments? > >> > > > >OK, so now we know that while the new lock code handles the select(1) > >problem better, we also know that on AIX the old select(1) code wasn't > >as bad as we thought. > > > >As to why we don't see better numbers on AIX, we are getting 100tps, > >which seems pretty good to me. Tatsuo, were you expecting higher than > >100tps on that machine? My hardware is at listed at > >http://candle.pha.pa.us/main/hardware.html and I don't get over 16tps. > > > What scaling factor do you use ? > What OS ? > > I got from ~40 tps for -s 128 up to 50-230 tps for -s 1 or 10 on dual > PIII 800 on IDE > disk (Model=IBM-DTLA-307045) with hdparm -t the following Scale 50, transactions 1000, clients 1, 5, 10, 25, 50, all around 15tps. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom Lane wrote: > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > OK, so now we know that while the new lock code handles the select(1) > > problem better, we also know that on AIX the old select(1) code wasn't > > as bad as we thought. > > It still seems that the select() blocking method should be a loser. No question the new locking code is better. It just frustrates me we can't get something to show that. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
>> It still seems that the select() blocking method should be a loser.
> No question the new locking code is better. It just frustrates me we
> can't get something to show that.
pgbench may not be the setting in which that can be shown. It's I/O
bound to start with, and it exercises some of our other weak spots
(viz duplicate-key checking). So I'm not really surprised that it's
not showing any improvement from 7.1 to 7.2.
But yeah, it'd be nice to get some cross-version comparisons on other
test cases.
regards, tom lane
> > > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > > > OK, so now we know that while the new lock code handles the select(1) > > > > problem better, we also know that on AIX the old select(1) code wasn't > > > > as bad as we thought. > > > > > > It still seems that the select() blocking method should be a loser. > > > > No question the new locking code is better. It just frustrates me we > > can't get something to show that. > > Even though I haven't completed controlled benchmarks yet, 7.2b4 was using > all of my CPU time, whereas a patched version is using around half of CPU > time, all in user space. > > I think not pissing away all our time in the scheduler is a big > improvement! Yes, the new patch is clearly better than 7.2b4. We are really hoping to see the patched version beat 7.1. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom Lane wrote: >Fredrik Estreen <estreen@algonet.se> writes: > >>I could run benchmarks on 7.1 if that would be interesting. >> > >Yes, if you have the time to run the same test conditions on 7.1, it >would be good. > >Also, per recent discussions, it would probably be better to try to keep >the total number of transactions the same for all runs (maybe about >10000 transactions total, so -t would vary between 10000 and 200 as >-c ranges from 1 to 50). > I'll test my original series on 7.1 and also test the constant number of transactions this weekend. A quick test with 20 transactions and 50 clients gave ca 25 tps with the latest patch, but I'm not sure that point is good, other loads etc. Regards Fredrik Estreen
Tom Lane wrote: > > Hannu Krosing <hannu@tm.ee> writes: > > Tom Lane wrote: > >> Unfortunately, at low scaling factors pgbench is guaranteed to look > >> horrible because of contention for the "branches" rows. > >> > > Not really! See graph in my previous post - the database size affects > > performance much more ! > > But the way that pgbench is currently set up, you can't really tell the > difference between database size effects and contention effects, because > you can't vary one while holding the other constant. What I meant was that a small -s (lot of contention and small database) runs much faster than tham big -s (low contention and big database) > I based my comments on having done profiles that show most of the CPU > time going into attempts to acquire row locks for updates and/or > checking of dead tuples in _bt_check_unique. So at least in the > conditions I was using (single CPU) I think those are the bottlenecks. > I don't have any profiles for SMP machines, yet. You have good theoretical grounds for your claim - it just does not fit with real-world tests. It may be due to contention in some other places but not on the branches table (i.e small scale factor) -------------- Hannu
I have gotten my hands on a Linux 4-way SMP box (courtesy of my new
employer Red Hat), and have obtained pgbench results that look much
more promising than Tatsuo's. It seems the question is not so much
"why is 7.2 bad?" as "why is it bad on AIX?"
The test machine has 4 550MHz Pentium III CPUs, 5Gb RAM, and a passel
of SCSI disks hanging off ultra-wide controllers. It's presently
running Red Hat 7.1 enterprise release, kernel version 2.4.2-2enterprise
#1 SMP. (Not the latest thing, but perhaps representative of what
people are running in production situations. I can get it rebooted with
other kernel versions if anyone thinks the results will be interesting.)
For the tests, the postmasters were started with parameters
postmaster -F -N 100 -B 3800
(the -B setting chosen to fit within 32Mb, which is the shmmax setting
on stock Linux). -F is not very representative of production use,
but I thought it was appropriate since we are trying to measure CPU
effects not disk I/O. pgbench scale factor is 50; xacts/client varied
so that each run executes 10000 transactions, per this script:
#! /bin/sh
DB=bench
totxacts=10000
for c in 1 2 3 4 5 6 10 25 50 100
do
t=`expr $totxacts / $c`
psql -c 'vacuum' $DB
psql -c 'checkpoint' $DB
echo "===== sync ======" 1>&2
sync;sync;sync;sleep 10
echo $c concurrent users... 1>&2
pgbench -n -t $t -c $c $DB
done
The results are shown in the attached plot. Interesting, hmm?
The "sweet spot" at 3 processes might be explained by assuming that
pgbench itself chews up the fourth CPU.
This still leaves me undecided whether to apply the first or second
version of the LWLock patch.
regards, tom lane
Вложения
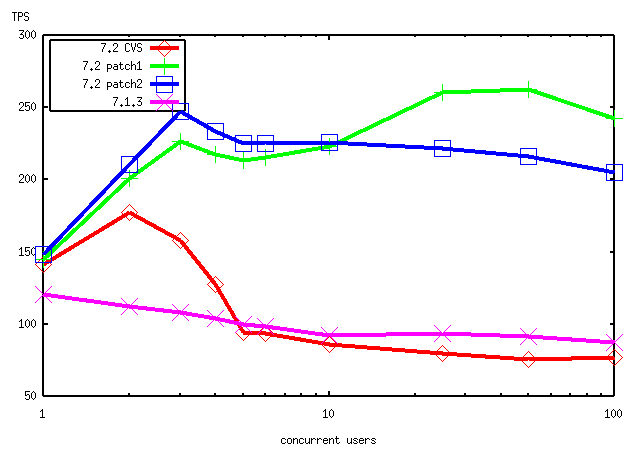{kind=link}
> This still leaves me undecided whether to apply the first or second > version of the LWLock patch. I vote for the second. Logically it makes more sense, and my guess is that the first patch wins only if there are enough CPU's available to run all the newly-awoken processes. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> The results are shown in the attached plot. Interesting, hmm? > The "sweet spot" at 3 processes might be explained by assuming that > pgbench itself chews up the fourth CPU. To probe the theory, you could run pgbench on a different machine. BTW, could you run the test with changing the number of CPUs? I'm interested in how 7.2 is scale with # of processors. -- Tatsuo Ishii
Tatsuo Ishii <t-ishii@sra.co.jp> writes:
> BTW, could you run the test with changing the number of CPUs?
I'm not sure how to do that (and I don't have root on that machine,
so probably couldn't do it myself anyway). Maybe I can arrange
something with the admins next week.
BTW, I am currently getting some interesting results from adjusting
SPINS_PER_DELAY in s_lock.c. Will post results when I finish the
set of test runs.
regards, tom lane
Tom Lane wrote: >I have gotten my hands on a Linux 4-way SMP box (courtesy of my new >employer Red Hat), and have obtained pgbench results that look much >more promising than Tatsuo's. It seems the question is not so much >"why is 7.2 bad?" as "why is it bad on AIX?" > Could you rerun some of the tests on the same hardware but with uniprocesor kernel to get another reference point ? There were some reports about very poor insert performance on 4way vs 1way processors. You could also try timing pgbench -i to compare raw inser performance. >The test machine has 4 550MHz Pentium III CPUs, 5Gb RAM, and a passel >of SCSI disks hanging off ultra-wide controllers. It's presently >running Red Hat 7.1 enterprise release, kernel version 2.4.2-2enterprise >#1 SMP. (Not the latest thing, but perhaps representative of what >people are running in production situations. I can get it rebooted with >other kernel versions if anyone thinks the results will be interesting.) > > >For the tests, the postmasters were started with parameters > postmaster -F -N 100 -B 3800 >(the -B setting chosen to fit within 32Mb, which is the shmmax setting >on stock Linux). -F is not very representative of production use, >but I thought it was appropriate since we are trying to measure CPU >effects not disk I/O. pgbench scale factor is 50; xacts/client varied >so that each run executes 10000 transactions, per this script: > >#! /bin/sh > >DB=bench >totxacts=10000 > >for c in 1 2 3 4 5 6 10 25 50 100 >do > t=`expr $totxacts / $c` > psql -c 'vacuum' $DB > Should this not be 'vacuum full' ? > > psql -c 'checkpoint' $DB > echo "===== sync ======" 1>&2 > sync;sync;sync;sleep 10 > echo $c concurrent users... 1>&2 > pgbench -n -t $t -c $c $DB >done > ----------- Hannu
Hannu Krosing <hannu@tm.ee> writes:
> Could you rerun some of the tests on the same hardware but with
> uniprocesor kernel
I don't have root on that machine, but will see what I can arrange next
week.
> There were some reports about very poor insert performance on 4way vs 1way
> processors.
IIRC, that was fixed for 7.2. (As far as I can tell from profiling,
contention for the shared free-space-map is a complete nonissue, at
least in this test. That was something I was a tad worried about
when I wrote the FSM code, but the tactic of locally caching a current
insertion page seems to have sidestepped the problem nicely.)
>> psql -c 'vacuum' $DB
>>
> Should this not be 'vacuum full' ?
Don't see why I should expend the extra time to do a vacuum full.
The point here is just to ensure a comparable starting state for all
the runs.
regards, tom lane
This maybe of interest on this topic.. http://kerneltrap.org/article.php?sid=461 Most of this is way above my head, but it's still interesting and ties in with possible current bad performance of smp under linux..[?] Anyways.. apologies if this is spam.. Ashley Cambrell
Hannu Krosing <hannu@krosing.net> writes:
> Should this not be 'vacuum full' ?
>>
>> Don't see why I should expend the extra time to do a vacuum full.
>> The point here is just to ensure a comparable starting state for all
>> the runs.
> Ok. I thought that you would also want to compare performance for different
> concurrency levels where the number of dead tuples matters more as shown by
> the attached graph. It is for Dual PIII 800 on RH 7.2 with IDE hdd, scale 5,
> 1-25 concurrent backends and 10000 trx per run
VACUUM and VACUUM FULL will provide the same starting state as far as
number of dead tuples goes: none. So that doesn't explain the
difference you see. My guess is that VACUUM FULL looks better because
all the new tuples will get added at the end of their tables; possibly
that improves I/O locality to some extent. After a plain VACUUM the
system will tend to allow each backend to drop new tuples into a
different page of a relation, at least until the partially-empty pages
all fill up.
What -B setting were you using?
regards, tom lane
Hannu Krosing <hannu@krosing.net> writes:
> I misinterpreted the fact that new VACUUM will skip locked pages
Huh? There is no such "fact".
regards, tom lane
Tom Lane wrote: > > Hannu Krosing <hannu@krosing.net> writes: > > I misinterpreted the fact that new VACUUM will skip locked pages > > Huh? There is no such "fact". > > regards, tom lane Was it not the case that instead of locking whole tables the new vacuum locks only one page at a time. If it can't lock that page it just moves to next one instead of waiting for other backend to release its lock. At least I remember that this was the (proposed?) behaviour once. --------------- Hannu
Hannu Krosing <hannu@tm.ee> writes:
> Was it not the case that instead of locking whole tables the new
> vacuum locks only one page at a time. If it can't lock that page it
> just moves to next one instead of waiting for other backend to release
> its lock.
No, it just waits till it can get the page lock.
The only conditional part of the new vacuum algorithm is truncation of
the relation file (releasing empty end pages back to the OS). That
requires exclusive lock on the relation, which it will not be able to
get if there are any other users of the relation. In that case it
forgets about truncation and just leaves the empty pages as free space.
regards, tom lane
On Mon, 2002-01-07 at 06:37, Tom Lane wrote: > Hannu Krosing <hannu@krosing.net> writes: > > Should this not be 'vacuum full' ? > >> > >> Don't see why I should expend the extra time to do a vacuum full. > >> The point here is just to ensure a comparable starting state for all > >> the runs. > > > Ok. I thought that you would also want to compare performance for different > > concurrency levels where the number of dead tuples matters more as shown by > > the attached graph. It is for Dual PIII 800 on RH 7.2 with IDE hdd, scale 5, > > 1-25 concurrent backends and 10000 trx per run > > VACUUM and VACUUM FULL will provide the same starting state as far as > number of dead tuples goes: none. I misinterpreted the fact that new VACUUM will skip locked pages - here are none if run independently. > So that doesn't explain the > difference you see. My guess is that VACUUM FULL looks better because > all the new tuples will get added at the end of their tables; possibly > that improves I/O locality to some extent. After a plain VACUUM the > system will tend to allow each backend to drop new tuples into a > different page of a relation, at least until the partially-empty pages > all fill up. > > What -B setting were you using? I had the following in the postgresql.conf shared_buffers = 4096 -------------- Hannu I attach similar run, only with scale 50, from my desktop computer (uniprocessor Athlon 850MHz, RedHat 7.1) BTW, both were running unpatched postgreSQL 7.2b4. -------------- Hannu
Вложения
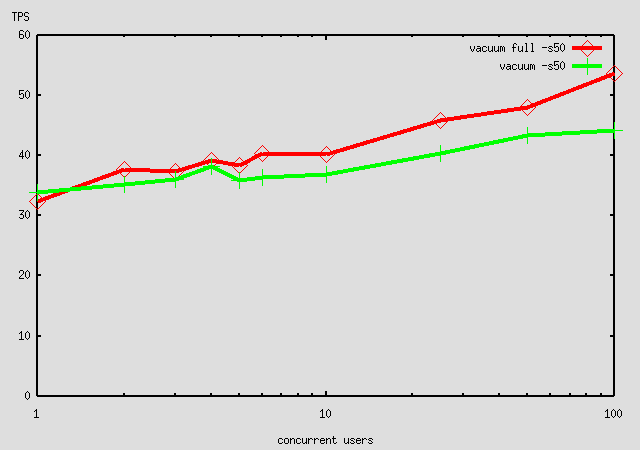{kind=link}
On Sun, 2002-01-06 at 02:44, Tom Lane wrote: > Hannu Krosing <hannu@tm.ee> writes: > > Could you rerun some of the tests on the same hardware but with > > uniprocesor kernel > > I don't have root on that machine, but will see what I can arrange next > week. > > > There were some reports about very poor insert performance on 4way vs 1way > > processors. > > IIRC, that was fixed for 7.2. (As far as I can tell from profiling, > contention for the shared free-space-map is a complete nonissue, at > least in this test. That was something I was a tad worried about > when I wrote the FSM code, but the tactic of locally caching a current > insertion page seems to have sidestepped the problem nicely.) > > >> psql -c 'vacuum' $DB > >> > > Should this not be 'vacuum full' ? > > Don't see why I should expend the extra time to do a vacuum full. > The point here is just to ensure a comparable starting state for all > the runs. Ok. I thought that you would also want to compare performance for different concurrency levels where the number of dead tuples matters more as shown by the attached graph. It is for Dual PIII 800 on RH 7.2 with IDE hdd, scale 5, 1-25 concurrent backends and 10000 trx per run
Вложения
{kind=link}
On Thu, 3 Jan 2002, Bruce Momjian wrote: > Tom Lane wrote: > > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > > OK, so now we know that while the new lock code handles the select(1) > > > problem better, we also know that on AIX the old select(1) code wasn't > > > as bad as we thought. > > > > It still seems that the select() blocking method should be a loser. > > No question the new locking code is better. It just frustrates me we > can't get something to show that. Even though I haven't completed controlled benchmarks yet, 7.2b4 was using all of my CPU time, whereas a patched version is using around half of CPU time, all in user space. I think not pissing away all our time in the scheduler is a big improvement! -jwb
I know it's a bit too late, but here are unpatched 7.2b3 and patched 7.2b4 results for pgbench scale factor 50 on a 8 MIPS r10000 sgi-Irix machine with 1Gb hope it helps
Вложения
Tom Lane wrote: > Hannu Krosing <hannu@tm.ee> writes: > > Was it not the case that instead of locking whole tables the new > > vacuum locks only one page at a time. If it can't lock that page it > > just moves to next one instead of waiting for other backend to release > > its lock. > > No, it just waits till it can get the page lock. > > The only conditional part of the new vacuum algorithm is truncation of > the relation file (releasing empty end pages back to the OS). That > requires exclusive lock on the relation, which it will not be able to > get if there are any other users of the relation. In that case it > forgets about truncation and just leaves the empty pages as free space. If we have one page with data, and 100 empty pages, and another page with data on the end, will VACUUM shrink that to two pages if no one is accessing the table, or does it do _only_ intra-page moves. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> If we have one page with data, and 100 empty pages, and another page
> with data on the end, will VACUUM shrink that to two pages if no one is
> accessing the table, or does it do _only_ intra-page moves.
The only way to shrink that is VACUUM FULL.
regards, tom lane