Обсуждение: A qsort template
Hello, In another thread[1], I proposed $SUBJECT, but then we found a better solution to that thread's specific problem. The general idea is still good though: it's possible to (1) replace several existing copies of our qsort algorithm with one, and (2) make new specialised versions a bit more easily than the existing Perl generator allows. So, I'm back with a rebased stack of patches. I'll leave specific cases for new worthwhile specialisations for separate proposals; I've heard about several. [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGKMQFVpjr106gRhwk6R-nXv0qOcTreZuQzxgpHESAL6dw%40mail.gmail.com
Вложения
Hi, On 2021-02-18 16:09:49 +1300, Thomas Munro wrote: > In another thread[1], I proposed $SUBJECT, but then we found a better > solution to that thread's specific problem. The general idea is still > good though: it's possible to (1) replace several existing copies of > our qsort algorithm with one, and (2) make new specialised versions a > bit more easily than the existing Perl generator allows. So, I'm back > with a rebased stack of patches. I'll leave specific cases for new > worthwhile specialisations for separate proposals; I've heard about > several. One place that could benefit is the qsort that BufferSync() does at the start. I tried your patch for that, and it does reduce the sort time considerably. For 64GB of mostly dirty shared_buffers from ~1.4s to 0.6s. Now, obviously one can argue that that's not going to be the crucial spot, and wouldn't be entirely wrong. OTOH, in my AIO branch I see checkpointer doing ~10GB/s, leading to the sort being a measurable portion of the overall time. Greetings, Andres Freund
On Mon, Mar 15, 2021 at 1:09 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Sun, Mar 14, 2021 at 5:03 PM Zhihong Yu <zyu@yugabyte.com> wrote: > > + * Remove duplicates from an array. Return the new size. > > + */ > > +ST_SCOPE size_t > > +ST_UNIQUE(ST_ELEMENT_TYPE *array, > > > > The array is supposed to be sorted, right ? > > The comment should mention this. > > Good point, will update. Thanks! Rebased. Also fixed some formatting problems and updated typedefs.list so they don't come back.
Вложения
On Tue, Jun 15, 2021 at 10:55 PM Thomas Munro <thomas.munro@gmail.com> wrote:
On Mon, Mar 15, 2021 at 1:09 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> On Sun, Mar 14, 2021 at 5:03 PM Zhihong Yu <zyu@yugabyte.com> wrote:
> > + * Remove duplicates from an array. Return the new size.
> > + */
> > +ST_SCOPE size_t
> > +ST_UNIQUE(ST_ELEMENT_TYPE *array,
> >
> > The array is supposed to be sorted, right ?
> > The comment should mention this.
>
> Good point, will update. Thanks!
Rebased. Also fixed some formatting problems and updated
typedefs.list so they don't come back.
Hi,
In 0001-Add-bsearch-and-unique-templates-to-sort_template.h.patch :
+ const ST_ELEMENT_TYPE *ST_SORT_PROTO_ARG);
It seems there is no real change in the line above. Better keep the original formation.
*
+ * To say that the comparator returns a type other than int, use:
+ *
+ * - ST_COMPARE_TYPE - an integer type
Since the ST_COMPARE_TYPE is meant to designate the type of the return value, maybe ST_COMPARE_RET_TYPE would be better name.
It also goes with ST_COMPARE_ARG_TYPE preceding this.
- ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data,
- *pa,
- *pb,
- *pc,
- *pd,
- *pl,
- *pm,
- *pn;
+ ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data;
+ ST_POINTER_TYPE *pa;
- *pa,
- *pb,
- *pc,
- *pd,
- *pl,
- *pm,
- *pn;
+ ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data;
+ ST_POINTER_TYPE *pa;
There doesn't seem to be material change for the above hunk.
+ while (left <= right)
+ {
+ size_t mid = (left + right) / 2;
+ {
+ size_t mid = (left + right) / 2;
The computation for midpoint should be left + (right-left)/2.
Cheers
Hi Zhihong,
On Thu, Jun 17, 2021 at 8:13 AM Zhihong Yu <zyu@yugabyte.com> wrote:
> In 0001-Add-bsearch-and-unique-templates-to-sort_template.h.patch :
>
> - const ST_ELEMENT_TYPE * ST_SORT_PROTO_ARG);
> + const ST_ELEMENT_TYPE *ST_SORT_PROTO_ARG);
>
> It seems there is no real change in the line above. Better keep the original formation.
Hmm, well it was only recently damaged by commit def5b065, and that's
because I'd forgotten to put ST_ELEMENT_TYPE into typedefs.list, and I
was correcting that in this patch. (That file is used by
pg_bsd_indent to decide if an identifier is a type or a variable,
which affects whether '*' is formatted like a unary operator/type
syntax or a binary operator.)
> * - ST_COMPARE_ARG_TYPE - type of extra argument
> *
> + * To say that the comparator returns a type other than int, use:
> + *
> + * - ST_COMPARE_TYPE - an integer type
>
> Since the ST_COMPARE_TYPE is meant to designate the type of the return value, maybe ST_COMPARE_RET_TYPE would be
bettername.
> It also goes with ST_COMPARE_ARG_TYPE preceding this.
Good idea, will do.
> - ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data,
> - *pa,
> - *pb,
> - *pc,
> - *pd,
> - *pl,
> - *pm,
> - *pn;
> + ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data;
> + ST_POINTER_TYPE *pa;
>
> There doesn't seem to be material change for the above hunk.
In master, you can't write #define ST_ELEMENT_TYPE some_type *, which
seems like it would be quite useful. You can use pointers as element
types, but only with a typedef name due to C parsing rules. some_type
**a, *pa, ... declares some_type *pa, but we want some_type **pa. I
don't want to have to introduce extra typedefs. The change fixes that
problem by not using C's squirrelly variable declaration list syntax.
> + while (left <= right)
> + {
> + size_t mid = (left + right) / 2;
>
> The computation for midpoint should be left + (right-left)/2.
Right, my way can overflow. Will fix. Thanks!
On Wed, Jun 16, 2021 at 2:54 PM Thomas Munro <thomas.munro@gmail.com> wrote:
Hi Zhihong,
On Thu, Jun 17, 2021 at 8:13 AM Zhihong Yu <zyu@yugabyte.com> wrote:
> In 0001-Add-bsearch-and-unique-templates-to-sort_template.h.patch :
>
> - const ST_ELEMENT_TYPE * ST_SORT_PROTO_ARG);
> + const ST_ELEMENT_TYPE *ST_SORT_PROTO_ARG);
>
> It seems there is no real change in the line above. Better keep the original formation.
Hmm, well it was only recently damaged by commit def5b065, and that's
because I'd forgotten to put ST_ELEMENT_TYPE into typedefs.list, and I
was correcting that in this patch. (That file is used by
pg_bsd_indent to decide if an identifier is a type or a variable,
which affects whether '*' is formatted like a unary operator/type
syntax or a binary operator.)
> * - ST_COMPARE_ARG_TYPE - type of extra argument
> *
> + * To say that the comparator returns a type other than int, use:
> + *
> + * - ST_COMPARE_TYPE - an integer type
>
> Since the ST_COMPARE_TYPE is meant to designate the type of the return value, maybe ST_COMPARE_RET_TYPE would be better name.
> It also goes with ST_COMPARE_ARG_TYPE preceding this.
Good idea, will do.
> - ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data,
> - *pa,
> - *pb,
> - *pc,
> - *pd,
> - *pl,
> - *pm,
> - *pn;
> + ST_POINTER_TYPE *a = (ST_POINTER_TYPE *) data;
> + ST_POINTER_TYPE *pa;
>
> There doesn't seem to be material change for the above hunk.
In master, you can't write #define ST_ELEMENT_TYPE some_type *, which
seems like it would be quite useful. You can use pointers as element
types, but only with a typedef name due to C parsing rules. some_type
**a, *pa, ... declares some_type *pa, but we want some_type **pa. I
don't want to have to introduce extra typedefs. The change fixes that
problem by not using C's squirrelly variable declaration list syntax.
> + while (left <= right)
> + {
> + size_t mid = (left + right) / 2;
>
> The computation for midpoint should be left + (right-left)/2.
Right, my way can overflow. Will fix. Thanks!
Hi,
Thanks for giving me background on typedefs.
The relevant changes look fine to me.
Cheers
Thomas Munro <thomas.munro@gmail.com> writes:
> Hmm, well it was only recently damaged by commit def5b065, and that's
> because I'd forgotten to put ST_ELEMENT_TYPE into typedefs.list, and I
> was correcting that in this patch.
If ST_ELEMENT_TYPE isn't recognized as a typedef by the buildfarm's
typedef collectors, this sort of manual addition to typedefs.list
is not going to survive the next pgindent run. No, I will NOT
promise to manually add it back every time.
We do already have special provision for injecting additional typedefs
in the pgindent script, so one possibility is to add it there:
-my @additional = ("bool\n");
+my @additional = ("bool\nST_ELEMENT_TYPE\n");
On the whole I'm not sure that this is a big enough formatting
issue to justify a special hack, though. Is there any more than
the one line that gets misformatted?
regards, tom lane
On Thu, Jun 17, 2021 at 11:40 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Thomas Munro <thomas.munro@gmail.com> writes:
> > Hmm, well it was only recently damaged by commit def5b065, and that's
> > because I'd forgotten to put ST_ELEMENT_TYPE into typedefs.list, and I
> > was correcting that in this patch.
>
> If ST_ELEMENT_TYPE isn't recognized as a typedef by the buildfarm's
> typedef collectors, this sort of manual addition to typedefs.list
> is not going to survive the next pgindent run. No, I will NOT
> promise to manually add it back every time.
>
> We do already have special provision for injecting additional typedefs
> in the pgindent script, so one possibility is to add it there:
>
> -my @additional = ("bool\n");
> +my @additional = ("bool\nST_ELEMENT_TYPE\n");
>
> On the whole I'm not sure that this is a big enough formatting
> issue to justify a special hack, though. Is there any more than
> the one line that gets misformatted?
Ohh. In that case, I won't bother with that hunk and will live with
the extra space. There are several other lines like this in the tree,
where people use caveman template macrology that is invisible to
whatever analyser is being used for that, and I can see that that's
just going to have to be OK for now. Perhaps one day we could add a
secondary file, not updated by that mechanism, that holds a manually
maintained list for cases like this.
Thomas Munro <thomas.munro@gmail.com> writes:
> Perhaps one day we could add a
> secondary file, not updated by that mechanism, that holds a manually
> maintained list for cases like this.
Yeah, the comments in pgindent already speculate about that. For
now, those include and exclude lists are short enough that keeping
them inside the script seems a lot easier than building tooling
to get them from somewhere else.
The big problem in my mind, which would not be alleviated in the
slightest by having a separate file, is that it'd be easy to miss
removing entries if they ever become obsolete.
regards, tom lane
On Thu, Jun 17, 2021 at 1:14 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > The big problem in my mind, which would not be alleviated in the > slightest by having a separate file, is that it'd be easy to miss > removing entries if they ever become obsolete. I suppose you could invent some kind of declaration syntax in a comment near the use of the pseudo-typename in the source tree that is mechanically extracted.
On Wed, Jun 16, 2021 at 1:55 AM Thomas Munro <thomas.munro@gmail.com> wrote:
[v2 patch]
[v2 patch]
Hi Thomas,
I plan to do some performance testing with VACUUM, ANALYZE etc soon, to see if I can detect any significant differences.
I did a quick check of the MacOS/clang binary size (no debug symbols):
master: 8108408
0001-0009: 8125224
Later, I'll drill down into the individual patches and see if anything stands out.
There were already some comments for v2 upthread about formatting and an overflow hazard, but I did find a few more things to ask about:
- For my curiosity, there are a lot of calls to qsort/qunique in the tree -- without having looked exhaustively, do these patches focus on cases where there are bespoke comparator functions and/or hot code paths?
- Aside from the qsort{_arg} precedence, is there a practical reason for keeping the new global functions in their own files?
- 0002 / 0004
+/* Search and unique functions inline in header. */
The functions are pretty small, but is there some advantage for inlining these?
- 0003
#include "lib/qunique.h" is not needed anymore.
This isn't quite relevant for the current patch perhaps, but I'm wondering why we don't already call bsearch for RelationHasSysCache() and RelationSupportsSysCache().
- 0008
+#define ST_COMPARE(a, b, cxt) \
+ DatumGetInt32(FunctionCall2Coll(&cxt->flinfo, cxt->collation, *a, *b))
This seems like a pretty heavyweight comparison, so I'm not sure inlining buys us much, but it seems also there are fewer branches this way. I'll come up with a test and see what happens.
--
John Naylor
EDB: http://www.enterprisedb.com
I plan to do some performance testing with VACUUM, ANALYZE etc soon, to see if I can detect any significant differences.
I did a quick check of the MacOS/clang binary size (no debug symbols):
master: 8108408
0001-0009: 8125224
Later, I'll drill down into the individual patches and see if anything stands out.
There were already some comments for v2 upthread about formatting and an overflow hazard, but I did find a few more things to ask about:
- For my curiosity, there are a lot of calls to qsort/qunique in the tree -- without having looked exhaustively, do these patches focus on cases where there are bespoke comparator functions and/or hot code paths?
- Aside from the qsort{_arg} precedence, is there a practical reason for keeping the new global functions in their own files?
- 0002 / 0004
+/* Search and unique functions inline in header. */
The functions are pretty small, but is there some advantage for inlining these?
- 0003
#include "lib/qunique.h" is not needed anymore.
This isn't quite relevant for the current patch perhaps, but I'm wondering why we don't already call bsearch for RelationHasSysCache() and RelationSupportsSysCache().
- 0008
+#define ST_COMPARE(a, b, cxt) \
+ DatumGetInt32(FunctionCall2Coll(&cxt->flinfo, cxt->collation, *a, *b))
This seems like a pretty heavyweight comparison, so I'm not sure inlining buys us much, but it seems also there are fewer branches this way. I'll come up with a test and see what happens.
--
John Naylor
EDB: http://www.enterprisedb.com
Hi John,
On Tue, Jun 29, 2021 at 7:13 AM John Naylor
<john.naylor@enterprisedb.com> wrote:
> I plan to do some performance testing with VACUUM, ANALYZE etc soon, to see if I can detect any significant
differences.
Thanks!
> I did a quick check of the MacOS/clang binary size (no debug symbols):
>
> master: 8108408
> 0001-0009: 8125224
Not too bad.
> Later, I'll drill down into the individual patches and see if anything stands out.
>
> There were already some comments for v2 upthread about formatting and an overflow hazard, but I did find a few more
thingsto ask about:
Right, here's an update with fixes discussed earlier with Zhihong and Tom:
* COMPARE_TYPE -> COMPARE_RET_TYPE
* quit fighting with pgindent (I will try to fix this problem generally later)
* fix overflow hazard
> - For my curiosity, there are a lot of calls to qsort/qunique in the tree -- without having looked exhaustively, do
thesepatches focus on cases where there are bespoke comparator functions and/or hot code paths?
Patches 0006-0009 are highly specialised for local usage by a single
module, and require some kind of evidence that they're worth their
bytes, and the onus is on me there of course -- but any ideas and
feedback are welcome. There are other opportunities like these, maybe
better ones. That reminds me: I recently had a perf report from
Andres that showed the qsort in compute_scalar_stats() as quite hot.
That's probably a good candidate, and is not yet done in the current
patch set.
The lower numbered patches are all things that are reused in many
places, and in my humble opinion improve the notation and type safety
and code deduplication generally when working with common types
ItemPtr, BlockNumber, Oid, aside from any performance arguments. At
least the ItemPtr stuff *might* also speed something useful up.
I tried to measure a speedup in vacuum, but so far I have not. I did
learn some things though: While doing that with an uncorrelated index
and a lot of deleted tuples, I found that adding more
maintenance_work_mem doesn't help beyond a few MB, because then cache
misses dominate to the point where it's not better than doing multiple
passes (and this is familiar to me from work on hash joins). If I
turned on huge pages on Linux and set min_dynamic_shared_memory so
that the parallel DSM used by vacuum lives in huge pages, then
parallel vacuum with a large maintenance_work_mem starts to do much
better than non-parallel vacuum by improving the TLB misses (as with
hash joins). I thought that was quite interesting! Perhaps
bsearch_itemptr might help with correlated indexes with a lot of
deleted indexes (so not dominated by cache misses), though?
(I wouldn't be suprised if someone comes up with a much better idea
than bsearch for that anyway... a few ideas have been suggested.)
> - Aside from the qsort{_arg} precedence, is there a practical reason for keeping the new global functions in their
ownfiles?
Better idea for layout welcome. One thing I wondered while trying to
figure out where to put functions that operate on itemptr: why is
itemptr_encode() in src/include/catalog/index.h?!
> - 0002 / 0004
>
> +/* Search and unique functions inline in header. */
>
> The functions are pretty small, but is there some advantage for inlining these?
Glibc's bsearch definition is already in a header for inlining (as is
our qunique), so I thought I should preserve that characteristic on
principle. I don't have any evidence though. Other libcs I looked at
didn't have bsearch in a header. So by doing this we make the
generated code the same across platforms (all other relevant things
being equal). I don't know if it really makes much difference,
especially since in this case the comparator and size would still be
inlined if we defined it in the .c (unlike standard bsearch)...
Probably only lazy_tid_reaped() calls it enough to potentially show
any difference in a non-microbenchmark workload, if anything does.
> - 0003
>
> #include "lib/qunique.h" is not needed anymore.
Fixed.
> This isn't quite relevant for the current patch perhaps, but I'm wondering why we don't already call bsearch for
RelationHasSysCache()and RelationSupportsSysCache().
Right, I missed that. Done. Nice to delete some more code.
> - 0008
>
> +#define ST_COMPARE(a, b, cxt) \
> + DatumGetInt32(FunctionCall2Coll(&cxt->flinfo, cxt->collation, *a, *b))
>
> This seems like a pretty heavyweight comparison, so I'm not sure inlining buys us much, but it seems also there are
fewerbranches this way. I'll come up with a test and see what happens.
I will be very interested to see the results. Thanks!
Вложения
I spotted a mistake in v3: I didn't rename ST_COMPARE_TYPE to ST_COMPARE_RET_TYPE in the 0009 patch (well, I did, but forgot to commit before I ran git format-patch). I won't send another tarball just for that, but will correct it next time.
On Tue, Jun 29, 2021 at 1:11 PM Thomas Munro <thomas.munro@gmail.com> wrote: > I spotted a mistake in v3: I didn't rename ST_COMPARE_TYPE to > ST_COMPARE_RET_TYPE in the 0009 patch (well, I did, but forgot to > commit before I ran git format-patch). I won't send another tarball > just for that, but will correct it next time. Here's a version that includes a rather hackish test module that you might find useful to explore various weird effects. Testing sorting routines is really hard, of course... there's a zillion parameters and things you could do in the data and cache effects etc etc. One of the main things that jumps out pretty clearly though with these simple tests is that sorting 6 byte ItemPointerData objects is *really slow* compared to more natural object sizes (look at the times and the MEMORY values in the scripts). Another is that specialised sort functions are much faster than traditional qsort (being one of the goals of this exercise). Sadly, the 64 bit comparison technique is not looking too good in the output of this test.
Вложения
On Tue, Jun 29, 2021 at 2:56 AM Thomas Munro <thomas.munro@gmail.com> wrote:
> Here's a version that includes a rather hackish test module that you
> might find useful to explore various weird effects. Testing sorting
> routines is really hard, of course... there's a zillion parameters and
> things you could do in the data and cache effects etc etc. One of the
That module is incredibly useful!
Golang uses 12, with an extra tweak:
// Do ShellSort pass with gap 6
// It could be written in this simplified form cause b-a <= 12
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
> Here's a version that includes a rather hackish test module that you
> might find useful to explore various weird effects. Testing sorting
> routines is really hard, of course... there's a zillion parameters and
> things you could do in the data and cache effects etc etc. One of the
That module is incredibly useful!
Yeah, while brushing up on recent findings on sorting, it's clear there's a huge amount of options with different tradeoffs. I did see your tweet last year about the "small sort" threshold that was tested on a VAX machine, but hadn't given it any thought til now. Looking around, I've seen quite a range, always with the caveat of "it depends". A couple interesting variations:
// Do ShellSort pass with gap 6
// It could be written in this simplified form cause b-a <= 12
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
insertionSort(data, a, b)
Andrei Alexandrescu gave a couple talks discussing the small-sort part of quicksort, and demonstrated a ruthlessly-optimized make-heap + unguarded-insertion-sort, using a threshold of 256. He reported a 6% speed-up sorting a million doubles, IIRC:
That might not be workable for us, but it's a fun talk.
> main things that jumps out pretty clearly though with these simple
> tests is that sorting 6 byte ItemPointerData objects is *really slow*
> compared to more natural object sizes (look at the times and the
> MEMORY values in the scripts). Another is that specialised sort
> functions are much faster than traditional qsort (being one of the
> goals of this exercise). Sadly, the 64 bit comparison technique is
> not looking too good in the output of this test.
One of the points of the talk I linked to is "if doing the sensible thing makes things worse, try something silly instead".
> tests is that sorting 6 byte ItemPointerData objects is *really slow*
> compared to more natural object sizes (look at the times and the
> MEMORY values in the scripts). Another is that specialised sort
> functions are much faster than traditional qsort (being one of the
> goals of this exercise). Sadly, the 64 bit comparison technique is
> not looking too good in the output of this test.
One of the points of the talk I linked to is "if doing the sensible thing makes things worse, try something silly instead".
Anyway, I'll play around with the scripts and see if something useful pops out.
--
John Naylor
EDB: http://www.enterprisedb.com
--
John Naylor
EDB: http://www.enterprisedb.com
I wrote:
> One of the points of the talk I linked to is "if doing the sensible thing makes things worse, try something silly instead".
For item pointers, it made sense to try doing math to reduce the number of branches. That made things worse, so let's try the opposite: Increase the number of branches so we do less math. In the attached patch (applies on top of your 0012 and a .txt to avoid confusing the CF bot), I test a new comparator with this approach, and also try a wider range of thresholds. The thresholds don't seem to make any noticeable difference with this data type, but the new comparator (cmp=ids below) gives a nice speedup in this test:
# SELECT test_sort_itemptr();
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=0, time=4.964657
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=1, time=5.185384
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=2, time=5.058179
NOTICE: order=random, threshold=7, cmp=std, test=0, time=2.810627
NOTICE: order=random, threshold=7, cmp=std, test=1, time=2.804940
NOTICE: order=random, threshold=7, cmp=std, test=2, time=2.800677
NOTICE: order=random, threshold=7, cmp=ids, test=0, time=1.692711
NOTICE: order=random, threshold=7, cmp=ids, test=1, time=1.694546
NOTICE: order=random, threshold=7, cmp=ids, test=2, time=1.692839
NOTICE: order=random, threshold=12, cmp=std, test=0, time=2.687033
NOTICE: order=random, threshold=12, cmp=std, test=1, time=2.681974
NOTICE: order=random, threshold=12, cmp=std, test=2, time=2.687833
NOTICE: order=random, threshold=12, cmp=ids, test=0, time=1.666418
NOTICE: order=random, threshold=12, cmp=ids, test=1, time=1.666188
NOTICE: order=random, threshold=12, cmp=ids, test=2, time=1.664176
NOTICE: order=random, threshold=16, cmp=std, test=0, time=2.574147
NOTICE: order=random, threshold=16, cmp=std, test=1, time=2.579981
NOTICE: order=random, threshold=16, cmp=std, test=2, time=2.572861
NOTICE: order=random, threshold=16, cmp=ids, test=0, time=1.699432
NOTICE: order=random, threshold=16, cmp=ids, test=1, time=1.703075
NOTICE: order=random, threshold=16, cmp=ids, test=2, time=1.697173
NOTICE: order=random, threshold=32, cmp=std, test=0, time=2.750040
NOTICE: order=random, threshold=32, cmp=std, test=1, time=2.744138
NOTICE: order=random, threshold=32, cmp=std, test=2, time=2.748026
NOTICE: order=random, threshold=32, cmp=ids, test=0, time=1.677414
NOTICE: order=random, threshold=32, cmp=ids, test=1, time=1.683792
NOTICE: order=random, threshold=32, cmp=ids, test=2, time=1.701309
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=0, time=2.543837
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=1, time=2.290497
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=2, time=2.262956
NOTICE: order=increasing, threshold=7, cmp=std, test=0, time=1.033052
NOTICE: order=increasing, threshold=7, cmp=std, test=1, time=1.032079
NOTICE: order=increasing, threshold=7, cmp=std, test=2, time=1.041836
NOTICE: order=increasing, threshold=7, cmp=ids, test=0, time=0.367355
NOTICE: order=increasing, threshold=7, cmp=ids, test=1, time=0.367428
NOTICE: order=increasing, threshold=7, cmp=ids, test=2, time=0.367384
NOTICE: order=increasing, threshold=12, cmp=std, test=0, time=1.004991
NOTICE: order=increasing, threshold=12, cmp=std, test=1, time=1.008045
NOTICE: order=increasing, threshold=12, cmp=std, test=2, time=1.010778
NOTICE: order=increasing, threshold=12, cmp=ids, test=0, time=0.370944
NOTICE: order=increasing, threshold=12, cmp=ids, test=1, time=0.368669
NOTICE: order=increasing, threshold=12, cmp=ids, test=2, time=0.370100
NOTICE: order=increasing, threshold=16, cmp=std, test=0, time=1.023682
NOTICE: order=increasing, threshold=16, cmp=std, test=1, time=1.025805
NOTICE: order=increasing, threshold=16, cmp=std, test=2, time=1.022005
NOTICE: order=increasing, threshold=16, cmp=ids, test=0, time=0.365398
NOTICE: order=increasing, threshold=16, cmp=ids, test=1, time=0.365586
NOTICE: order=increasing, threshold=16, cmp=ids, test=2, time=0.364807
NOTICE: order=increasing, threshold=32, cmp=std, test=0, time=0.950780
NOTICE: order=increasing, threshold=32, cmp=std, test=1, time=0.949920
NOTICE: order=increasing, threshold=32, cmp=std, test=2, time=0.953239
NOTICE: order=increasing, threshold=32, cmp=ids, test=0, time=0.367866
NOTICE: order=increasing, threshold=32, cmp=ids, test=1, time=0.372179
NOTICE: order=increasing, threshold=32, cmp=ids, test=2, time=0.371115
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=0, time=2.317475
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=1, time=2.323446
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=2, time=2.326714
NOTICE: order=decreasing, threshold=7, cmp=std, test=0, time=1.022270
NOTICE: order=decreasing, threshold=7, cmp=std, test=1, time=1.015133
NOTICE: order=decreasing, threshold=7, cmp=std, test=2, time=1.016367
NOTICE: order=decreasing, threshold=7, cmp=ids, test=0, time=0.386884
NOTICE: order=decreasing, threshold=7, cmp=ids, test=1, time=0.388397
NOTICE: order=decreasing, threshold=7, cmp=ids, test=2, time=0.386328
NOTICE: order=decreasing, threshold=12, cmp=std, test=0, time=0.993594
NOTICE: order=decreasing, threshold=12, cmp=std, test=1, time=0.995031
NOTICE: order=decreasing, threshold=12, cmp=std, test=2, time=0.995320
NOTICE: order=decreasing, threshold=12, cmp=ids, test=0, time=0.391243
NOTICE: order=decreasing, threshold=12, cmp=ids, test=1, time=0.391938
NOTICE: order=decreasing, threshold=12, cmp=ids, test=2, time=0.392478
NOTICE: order=decreasing, threshold=16, cmp=std, test=0, time=1.006240
NOTICE: order=decreasing, threshold=16, cmp=std, test=1, time=1.009817
NOTICE: order=decreasing, threshold=16, cmp=std, test=2, time=1.010281
NOTICE: order=decreasing, threshold=16, cmp=ids, test=0, time=0.386388
NOTICE: order=decreasing, threshold=16, cmp=ids, test=1, time=0.385801
NOTICE: order=decreasing, threshold=16, cmp=ids, test=2, time=0.384484
NOTICE: order=decreasing, threshold=32, cmp=std, test=0, time=0.959647
NOTICE: order=decreasing, threshold=32, cmp=std, test=1, time=0.958833
NOTICE: order=decreasing, threshold=32, cmp=std, test=2, time=0.960234
NOTICE: order=decreasing, threshold=32, cmp=ids, test=0, time=0.403014
NOTICE: order=decreasing, threshold=32, cmp=ids, test=1, time=0.393329
NOTICE: order=decreasing, threshold=32, cmp=ids, test=2, time=0.395659
--
John Naylor
EDB: http://www.enterprisedb.com
> One of the points of the talk I linked to is "if doing the sensible thing makes things worse, try something silly instead".
For item pointers, it made sense to try doing math to reduce the number of branches. That made things worse, so let's try the opposite: Increase the number of branches so we do less math. In the attached patch (applies on top of your 0012 and a .txt to avoid confusing the CF bot), I test a new comparator with this approach, and also try a wider range of thresholds. The thresholds don't seem to make any noticeable difference with this data type, but the new comparator (cmp=ids below) gives a nice speedup in this test:
# SELECT test_sort_itemptr();
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=0, time=4.964657
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=1, time=5.185384
NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=2, time=5.058179
NOTICE: order=random, threshold=7, cmp=std, test=0, time=2.810627
NOTICE: order=random, threshold=7, cmp=std, test=1, time=2.804940
NOTICE: order=random, threshold=7, cmp=std, test=2, time=2.800677
NOTICE: order=random, threshold=7, cmp=ids, test=0, time=1.692711
NOTICE: order=random, threshold=7, cmp=ids, test=1, time=1.694546
NOTICE: order=random, threshold=7, cmp=ids, test=2, time=1.692839
NOTICE: order=random, threshold=12, cmp=std, test=0, time=2.687033
NOTICE: order=random, threshold=12, cmp=std, test=1, time=2.681974
NOTICE: order=random, threshold=12, cmp=std, test=2, time=2.687833
NOTICE: order=random, threshold=12, cmp=ids, test=0, time=1.666418
NOTICE: order=random, threshold=12, cmp=ids, test=1, time=1.666188
NOTICE: order=random, threshold=12, cmp=ids, test=2, time=1.664176
NOTICE: order=random, threshold=16, cmp=std, test=0, time=2.574147
NOTICE: order=random, threshold=16, cmp=std, test=1, time=2.579981
NOTICE: order=random, threshold=16, cmp=std, test=2, time=2.572861
NOTICE: order=random, threshold=16, cmp=ids, test=0, time=1.699432
NOTICE: order=random, threshold=16, cmp=ids, test=1, time=1.703075
NOTICE: order=random, threshold=16, cmp=ids, test=2, time=1.697173
NOTICE: order=random, threshold=32, cmp=std, test=0, time=2.750040
NOTICE: order=random, threshold=32, cmp=std, test=1, time=2.744138
NOTICE: order=random, threshold=32, cmp=std, test=2, time=2.748026
NOTICE: order=random, threshold=32, cmp=ids, test=0, time=1.677414
NOTICE: order=random, threshold=32, cmp=ids, test=1, time=1.683792
NOTICE: order=random, threshold=32, cmp=ids, test=2, time=1.701309
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=0, time=2.543837
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=1, time=2.290497
NOTICE: [traditional qsort] order=increasing, threshold=7, cmp=32, test=2, time=2.262956
NOTICE: order=increasing, threshold=7, cmp=std, test=0, time=1.033052
NOTICE: order=increasing, threshold=7, cmp=std, test=1, time=1.032079
NOTICE: order=increasing, threshold=7, cmp=std, test=2, time=1.041836
NOTICE: order=increasing, threshold=7, cmp=ids, test=0, time=0.367355
NOTICE: order=increasing, threshold=7, cmp=ids, test=1, time=0.367428
NOTICE: order=increasing, threshold=7, cmp=ids, test=2, time=0.367384
NOTICE: order=increasing, threshold=12, cmp=std, test=0, time=1.004991
NOTICE: order=increasing, threshold=12, cmp=std, test=1, time=1.008045
NOTICE: order=increasing, threshold=12, cmp=std, test=2, time=1.010778
NOTICE: order=increasing, threshold=12, cmp=ids, test=0, time=0.370944
NOTICE: order=increasing, threshold=12, cmp=ids, test=1, time=0.368669
NOTICE: order=increasing, threshold=12, cmp=ids, test=2, time=0.370100
NOTICE: order=increasing, threshold=16, cmp=std, test=0, time=1.023682
NOTICE: order=increasing, threshold=16, cmp=std, test=1, time=1.025805
NOTICE: order=increasing, threshold=16, cmp=std, test=2, time=1.022005
NOTICE: order=increasing, threshold=16, cmp=ids, test=0, time=0.365398
NOTICE: order=increasing, threshold=16, cmp=ids, test=1, time=0.365586
NOTICE: order=increasing, threshold=16, cmp=ids, test=2, time=0.364807
NOTICE: order=increasing, threshold=32, cmp=std, test=0, time=0.950780
NOTICE: order=increasing, threshold=32, cmp=std, test=1, time=0.949920
NOTICE: order=increasing, threshold=32, cmp=std, test=2, time=0.953239
NOTICE: order=increasing, threshold=32, cmp=ids, test=0, time=0.367866
NOTICE: order=increasing, threshold=32, cmp=ids, test=1, time=0.372179
NOTICE: order=increasing, threshold=32, cmp=ids, test=2, time=0.371115
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=0, time=2.317475
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=1, time=2.323446
NOTICE: [traditional qsort] order=decreasing, threshold=7, cmp=32, test=2, time=2.326714
NOTICE: order=decreasing, threshold=7, cmp=std, test=0, time=1.022270
NOTICE: order=decreasing, threshold=7, cmp=std, test=1, time=1.015133
NOTICE: order=decreasing, threshold=7, cmp=std, test=2, time=1.016367
NOTICE: order=decreasing, threshold=7, cmp=ids, test=0, time=0.386884
NOTICE: order=decreasing, threshold=7, cmp=ids, test=1, time=0.388397
NOTICE: order=decreasing, threshold=7, cmp=ids, test=2, time=0.386328
NOTICE: order=decreasing, threshold=12, cmp=std, test=0, time=0.993594
NOTICE: order=decreasing, threshold=12, cmp=std, test=1, time=0.995031
NOTICE: order=decreasing, threshold=12, cmp=std, test=2, time=0.995320
NOTICE: order=decreasing, threshold=12, cmp=ids, test=0, time=0.391243
NOTICE: order=decreasing, threshold=12, cmp=ids, test=1, time=0.391938
NOTICE: order=decreasing, threshold=12, cmp=ids, test=2, time=0.392478
NOTICE: order=decreasing, threshold=16, cmp=std, test=0, time=1.006240
NOTICE: order=decreasing, threshold=16, cmp=std, test=1, time=1.009817
NOTICE: order=decreasing, threshold=16, cmp=std, test=2, time=1.010281
NOTICE: order=decreasing, threshold=16, cmp=ids, test=0, time=0.386388
NOTICE: order=decreasing, threshold=16, cmp=ids, test=1, time=0.385801
NOTICE: order=decreasing, threshold=16, cmp=ids, test=2, time=0.384484
NOTICE: order=decreasing, threshold=32, cmp=std, test=0, time=0.959647
NOTICE: order=decreasing, threshold=32, cmp=std, test=1, time=0.958833
NOTICE: order=decreasing, threshold=32, cmp=std, test=2, time=0.960234
NOTICE: order=decreasing, threshold=32, cmp=ids, test=0, time=0.403014
NOTICE: order=decreasing, threshold=32, cmp=ids, test=1, time=0.393329
NOTICE: order=decreasing, threshold=32, cmp=ids, test=2, time=0.395659
--
John Naylor
EDB: http://www.enterprisedb.com
Вложения
On Fri, Jul 2, 2021 at 4:39 AM John Naylor <john.naylor@enterprisedb.com> wrote: > For item pointers, it made sense to try doing math to reduce the number of branches. That made things worse, so let's trythe opposite: Increase the number of branches so we do less math. In the attached patch (applies on top of your 0012 anda .txt to avoid confusing the CF bot), I test a new comparator with this approach, and also try a wider range of thresholds.The thresholds don't seem to make any noticeable difference with this data type, but the new comparator (cmp=idsbelow) gives a nice speedup in this test: > NOTICE: [traditional qsort] order=random, threshold=7, cmp=32, test=0, time=4.964657 > NOTICE: order=random, threshold=7, cmp=std, test=0, time=2.810627 > NOTICE: order=random, threshold=7, cmp=ids, test=0, time=1.692711 Oooh. So, the awkwardness of the 64 maths with unaligned inputs (even though we obtain all inputs with 16 bit loads) was hurting, and you realised the same sort of thing might be happening also with the 32 bit version and went the other way. (It'd be nice to understand exactly why.) I tried your 16 bit comparison version on Intel, AMD and Apple CPUs and the results were all in the same ballpark. For random input, I see something like ~1.7x speedup over traditional qsort from specialising (cmp=std), and ~2.7x from going 16 bit (cmp=ids). For increasing and decreasing input, it's ~2x speedup from specialising and ~4x speedup from going 16 bit. Beautiful. One thing I'm wondering about is whether it's worth having stuff to support future experimentation like ST_SORT_SMALL_THRESHOLD and ST_COMPARE_RET_TYPE in the tree, or whether we should pare it back to the minimal changes that definitely produce results. I think I'd like to keep those changes: even if it may be some time, possibly an infinite amount, before we figure out how to tune the thresholds profitably, giving them names instead of using magic numbers seems like progress. The Alexandrescu talk was extremely entertaining, thanks.
On Thu, Jul 1, 2021 at 6:10 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> One thing I'm wondering about is whether it's worth having stuff to
> support future experimentation like ST_SORT_SMALL_THRESHOLD and
> ST_COMPARE_RET_TYPE in the tree, or whether we should pare it back to
> the minimal changes that definitely produce results. I think I'd like
> to keep those changes: even if it may be some time, possibly an
> infinite amount, before we figure out how to tune the thresholds
> profitably, giving them names instead of using magic numbers seems
> like progress.
I suspect if we experiment on two extremes of type "heaviness" (accessing and comparing trivial or not), such as uint32 and tuplesort, we'll have a pretty good idea what the parameters should be, if anything different. I'll do some testing along those lines.
(BTW, I just realized I lied and sent a .patch file after all, oops)
--
John Naylor
EDB: http://www.enterprisedb.com
On Fri, Jul 2, 2021 at 2:32 PM John Naylor <john.naylor@enterprisedb.com> wrote: > I suspect if we experiment on two extremes of type "heaviness" (accessing and comparing trivial or not), such as uint32and tuplesort, we'll have a pretty good idea what the parameters should be, if anything different. I'll do some testingalong those lines. Cool. Since you are experimenting with tuplesort and likely thinking similar thoughts, here's a patch I've been using to explore that area. I've seen it get, for example, ~1.18x speedup for simple index builds in favourable winds (YMMV, early hacking results only). Currently, it kicks in when the leading column is of type int4, int8, timestamp, timestamptz, date or text + friends (when abbreviatable, currently that means "C" and ICU collations only), while increasing the executable by only 8.5kB (Clang, amd64, -O2, no debug). These types are handled with just three specialisations. Their custom "fast" comparators all boiled down to comparisons of datum bits, varying only in signedness and width, so I tried throwing them away and using 3 new common routines. Then I extended tuplesort_sort_memtuples()'s pre-existing specialisation dispatch to recognise qualifying users of those and select 3 corresponding sort specialisations. It might turn out to be worth burning some more executable size on extra variants (for example, see XXX notes in the code comments for opportunities; one could also go nuts trying smaller things like special cases for not-null, nulls first, reverse sort, ... to kill all those branches), or not.
Вложения
On Sun, Jul 4, 2021 at 9:58 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Jul 2, 2021 at 2:32 PM John Naylor <john.naylor@enterprisedb.com> wrote: > > I suspect if we experiment on two extremes of type "heaviness" (accessing and comparing trivial or not), such as uint32and tuplesort, we'll have a pretty good idea what the parameters should be, if anything different. I'll do some testingalong those lines. > > Cool. > > Since you are experimenting with tuplesort and likely thinking similar > thoughts, here's a patch I've been using to explore that area. I've > seen it get, for example, ~1.18x speedup for simple index builds in > favourable winds (YMMV, early hacking results only). Currently, it > kicks in when the leading column is of type int4, int8, timestamp, > timestamptz, date or text + friends (when abbreviatable, currently > that means "C" and ICU collations only), while increasing the > executable by only 8.5kB (Clang, amd64, -O2, no debug). > > These types are handled with just three specialisations. Their custom > "fast" comparators all boiled down to comparisons of datum bits, > varying only in signedness and width, so I tried throwing them away > and using 3 new common routines. Then I extended > tuplesort_sort_memtuples()'s pre-existing specialisation dispatch to > recognise qualifying users of those and select 3 corresponding sort > specialisations. > > It might turn out to be worth burning some more executable size on > extra variants (for example, see XXX notes in the code comments for > opportunities; one could also go nuts trying smaller things like > special cases for not-null, nulls first, reverse sort, ... to kill all > those branches), or not. The patch does not apply on Head anymore, could you rebase and post a patch. I'm changing the status to "Waiting for Author". Regards, Vignesh
On Thu, Jul 15, 2021 at 7:50 AM vignesh C <vignesh21@gmail.com> wrote:
> The patch does not apply on Head anymore, could you rebase and post a
> patch. I'm changing the status to "Waiting for Author".
The patch set is fine. The error is my fault since I attached an experimental addendum and neglected to name it as .txt. I've set it back to "needs review" and will resume testing shortly.
--
John Naylor
EDB: http://www.enterprisedb.com
> The patch does not apply on Head anymore, could you rebase and post a
> patch. I'm changing the status to "Waiting for Author".
The patch set is fine. The error is my fault since I attached an experimental addendum and neglected to name it as .txt. I've set it back to "needs review" and will resume testing shortly.
--
John Naylor
EDB: http://www.enterprisedb.com
On Thu, Jun 17, 2021 at 1:20 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Thu, Jun 17, 2021 at 1:14 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > The big problem in my mind, which would not be alleviated in the > > slightest by having a separate file, is that it'd be easy to miss > > removing entries if they ever become obsolete. > > I suppose you could invent some kind of declaration syntax in a > comment near the use of the pseudo-typename in the source tree that is > mechanically extracted. What do you think about something like this?
Вложения
On Sun, Jul 4, 2021 at 12:27 AM Thomas Munro <thomas.munro@gmail.com> wrote:
>
> Since you are experimenting with tuplesort and likely thinking similar
> thoughts, here's a patch I've been using to explore that area. I've
> seen it get, for example, ~1.18x speedup for simple index builds in
> favourable winds (YMMV, early hacking results only). Currently, it
> kicks in when the leading column is of type int4, int8, timestamp,
> timestamptz, date or text + friends (when abbreviatable, currently
> that means "C" and ICU collations only), while increasing the
> executable by only 8.5kB (Clang, amd64, -O2, no debug).
>
> These types are handled with just three specialisations. Their custom
> "fast" comparators all boiled down to comparisons of datum bits,
> varying only in signedness and width, so I tried throwing them away
> and using 3 new common routines. Then I extended
> tuplesort_sort_memtuples()'s pre-existing specialisation dispatch to
> recognise qualifying users of those and select 3 corresponding sort
> specialisations.
I got around to getting a benchmark together to serve as a starting point. I based it off something I got from the archives, but don't remember where (I seem to remember Tomas Vondra wrote the original, but not sure). To start I just used types that were there already -- int, text, numeric. The latter two won't be helped by this patch, but I wanted to keep something like that so we can see what kind of noise variation there is. I'll probably cut text out in the future and just keep numeric for that purpose.
I've attached both the script and a crude spreadsheet. I'll try to figure out something nicer for future tests, and maybe some graphs. The "comparison" sheet has the results side by side (min of five). There are 6 distributions of values:
- random
- sorted
- "almost sorted"
- reversed
- organ pipe (first half ascending, second half descending)
- rotated (sorted but then put the smallest at the end)
- random 0s/1s
I included both "select a" and "select *" to make sure we have the recent datum sort optimization represented. The results look pretty good for ints -- about the same speed up master gets going from tuple sorts to datum sorts, and those got faster in turn also.
Next I think I'll run microbenchmarks on int64s with the test harness you attached earlier, and experiment with the qsort parameters a bit.
I'm also attaching your tuplesort patch so others can see what exactly I'm comparing.
--
John Naylor
EDB: http://www.enterprisedb.com
I'm also attaching your tuplesort patch so others can see what exactly I'm comparing.
--
John Naylor
EDB: http://www.enterprisedb.com
Вложения
On Fri, Jul 30, 2021 at 3:34 AM John Naylor <john.naylor@enterprisedb.com> wrote: > I'm also attaching your tuplesort patch so others can see what exactly I'm comparing. If you're going to specialize the sort routine for unsigned integer style abbreviated keys then you might as well cover all relevant opclasses/types. Almost all abbreviated key schemes produce conditioned datums that are designed to use simple 3-way unsigned int comparator. It's not just text. (Actually, the only abbreviated key scheme that doesn't do it that way is numeric.) Offhand I know that UUID, macaddr, and inet all have abbreviated keys that can use your new ssup_datum_binary_cmp() comparator instead of their own duplicated comparator (which will make them use the corresponding specialized sort routine inside tuplesort.c). -- Peter Geoghegan
Em qui., 29 de jul. de 2021 às 21:34, John Naylor <john.naylor@enterprisedb.com> escreveu:
On Sun, Jul 4, 2021 at 12:27 AM Thomas Munro <thomas.munro@gmail.com> wrote:
>
> Since you are experimenting with tuplesort and likely thinking similar
> thoughts, here's a patch I've been using to explore that area. I've
> seen it get, for example, ~1.18x speedup for simple index builds in
> favourable winds (YMMV, early hacking results only). Currently, it
> kicks in when the leading column is of type int4, int8, timestamp,
> timestamptz, date or text + friends (when abbreviatable, currently
> that means "C" and ICU collations only), while increasing the
> executable by only 8.5kB (Clang, amd64, -O2, no debug).
>
> These types are handled with just three specialisations. Their custom
> "fast" comparators all boiled down to comparisons of datum bits,
> varying only in signedness and width, so I tried throwing them away
> and using 3 new common routines. Then I extended
> tuplesort_sort_memtuples()'s pre-existing specialisation dispatch to
> recognise qualifying users of those and select 3 corresponding sort
> specialisations.
I got around to getting a benchmark together to serve as a starting point. I based it off something I got from the archives, but don't remember where (I seem to remember Tomas Vondra wrote the original, but not sure). To start I just used types that were there already -- int, text, numeric. The latter two won't be helped by this patch, but I wanted to keep something like that so we can see what kind of noise variation there is. I'll probably cut text out in the future and just keep numeric for that purpose.I've attached both the script and a crude spreadsheet. I'll try to figure out something nicer for future tests, and maybe some graphs. The "comparison" sheet has the results side by side (min of five). There are 6 distributions of values:- random- sorted- "almost sorted"- reversed- organ pipe (first half ascending, second half descending)- rotated (sorted but then put the smallest at the end)- random 0s/1sI included both "select a" and "select *" to make sure we have the recent datum sort optimization represented. The results look pretty good for ints -- about the same speed up master gets going from tuple sorts to datum sorts, and those got faster in turn also.Next I think I'll run microbenchmarks on int64s with the test harness you attached earlier, and experiment with the qsort parameters a bit.
I'm also attaching your tuplesort patch so others can see what exactly I'm comparing.
The patch attached does not apply cleanly,
please can fix it?
error: patch failed: src/backend/utils/sort/tuplesort.c:4776
error: src/backend/utils/sort/tuplesort.c: patch does not apply
error: src/backend/utils/sort/tuplesort.c: patch does not apply
regards,
Ranier Vilela
On Fri, Jul 30, 2021 at 7:47 AM Ranier Vilela <ranier.vf@gmail.com> wrote:
> The patch attached does not apply cleanly,
> please can fix it?
It applies just fine with "patch", for those wondering.
--
John Naylor
EDB: http://www.enterprisedb.com
> The patch attached does not apply cleanly,
> please can fix it?
It applies just fine with "patch", for those wondering.
--
John Naylor
EDB: http://www.enterprisedb.com
On Fri, Jul 30, 2021 at 7:11 PM Peter Geoghegan <pg@bowt.ie> wrote: > If you're going to specialize the sort routine for unsigned integer > style abbreviated keys then you might as well cover all relevant > opclasses/types. Almost all abbreviated key schemes produce > conditioned datums that are designed to use simple 3-way unsigned int > comparator. It's not just text. (Actually, the only abbreviated key > scheme that doesn't do it that way is numeric.) Right, that was the plan, but this was just experimenting with an idea. Looks like John's also seeing evidence that it may be worth pursuing. (Re numeric, I guess it must be possible to rearrange things so it can use ssup_datum_signed_cmp; maybe something like NaN -> INT64_MAX, +inf -> INT64_MAX - 1, -inf -> INT64_MIN, and then -1 - (whatever we're doing now for normal values).) > Offhand I know that UUID, macaddr, and inet all have abbreviated keys > that can use your new ssup_datum_binary_cmp() comparator instead of > their own duplicated comparator (which will make them use the > corresponding specialized sort routine inside tuplesort.c). Thanks, I've added these ones, and also gist_bbox_zorder_cmp_abbrev. I also renamed that function to ssup_datum_unsigned_cmp(), because "binary" was misleading.
Вложения
On Fri, Jul 30, 2021 at 12:34 PM John Naylor <john.naylor@enterprisedb.com> wrote: > I got around to getting a benchmark together to serve as a starting point. I based it off something I got from the archives,but don't remember where (I seem to remember Tomas Vondra wrote the original, but not sure). To start I just usedtypes that were there already -- int, text, numeric. The latter two won't be helped by this patch, but I wanted to keepsomething like that so we can see what kind of noise variation there is. I'll probably cut text out in the future andjust keep numeric for that purpose. Thanks, that's very useful. > I've attached both the script and a crude spreadsheet. I'll try to figure out something nicer for future tests, and maybesome graphs. The "comparison" sheet has the results side by side (min of five). There are 6 distributions of values: > - random > - sorted > - "almost sorted" > - reversed > - organ pipe (first half ascending, second half descending) > - rotated (sorted but then put the smallest at the end) > - random 0s/1s > > I included both "select a" and "select *" to make sure we have the recent datum sort optimization represented. The resultslook pretty good for ints -- about the same speed up master gets going from tuple sorts to datum sorts, and thosegot faster in turn also. Great! I saw similar sorts of numbers. It's really just a few crumbs, nothing compared to the gains David just found over in the thread "Use generation context to speed up tuplesorts", but on the bright side, these crumbs will be magnified by that work. > Next I think I'll run microbenchmarks on int64s with the test harness you attached earlier, and experiment with the qsortparameters a bit. Cool. I haven't had much luck experimenting with that yet, though I consider the promotion from magic numbers to names as an improvement in any case. > I'm also attaching your tuplesort patch so others can see what exactly I'm comparing. We've been bouncing around quite a few different ideas and patches in this thread; soon I'll try to bring it back to one patch set with the ideas that are looking good so far in a more tidied up form. For the tupesort.c part, I added some TODO notes in v3-0001-WIP-Accelerate-tuple-sorting-for-common-types.patch's commit message (see reply to Peter).
On Mon, Aug 2, 2021 at 12:40 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Great! I saw similar sorts of numbers. It's really just a few > crumbs, nothing compared to the gains David just found over in the > thread "Use generation context to speed up tuplesorts", but on the > bright side, these crumbs will be magnified by that work. (Hmm, that also makes me wonder about using a smaller SortTuple when possible...)
On Sun, Aug 1, 2021 at 5:41 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Fri, Jul 30, 2021 at 12:34 PM John Naylor > <john.naylor@enterprisedb.com> wrote: > > I got around to getting a benchmark together to serve as a starting point. I based it off something I got from the archives,but don't remember where (I seem to remember Tomas Vondra wrote the original, but not sure). To start I just usedtypes that were there already -- int, text, numeric. The latter two won't be helped by this patch, but I wanted to keepsomething like that so we can see what kind of noise variation there is. I'll probably cut text out in the future andjust keep numeric for that purpose. > > Thanks, that's very useful. If somebody wants to get a sense of what the size hit is from all of these specializations, I can recommend the diff feature of bloaty: https://github.com/google/bloaty/blob/master/doc/using.md#size-diffs Obviously you'd approach this by building postgres without the patch, and diffing that baseline to postgres with the patch. And possibly variations of the patch, with less or more sort specializations. -- Peter Geoghegan
On Mon, Jun 28, 2021 at 8:16 PM Thomas Munro <thomas.munro@gmail.com> wrote: [v4 patchset] Hi Thomas, (Sorry for the delay -- I have some time to put into this now.) > The lower numbered patches are all things that are reused in many > places, and in my humble opinion improve the notation and type safety > and code deduplication generally when working with common types I think 0001-0003 have had enough review previously to commit them, as they are mostly notational. There's a small amount of bitrot, but not enough to change the conclusions any. Also 0011 with the missing #undef. On Thu, Aug 5, 2021 at 7:18 PM Peter Geoghegan <pg@bowt.ie> wrote: > > If somebody wants to get a sense of what the size hit is from all of > these specializations, I can recommend the diff feature of bloaty: > > https://github.com/google/bloaty/blob/master/doc/using.md#size-diffs > > Obviously you'd approach this by building postgres without the patch, > and diffing that baseline to postgres with the patch. And possibly > variations of the patch, with less or more sort specializations. Thanks, that's a neat feature! For 0001-0003, the diff shows +700 bytes in memory, so pretty small: $ bloaty -s vm src/backend/postgres -- src/backend/postgres.orig FILE SIZE VM SIZE -------------- -------------- +0.0% +608 +0.0% +608 .text +0.0% +64 +0.0% +64 .eh_frame +0.0% +24 +0.0% +24 .dynsym +0.0% +14 +0.0% +14 .dynstr +0.0% +2 +0.0% +2 .gnu.version +0.0% +58 [ = ] 0 .debug_abbrev +0.1% +48 [ = ] 0 .debug_aranges +0.0% +1.65Ki [ = ] 0 .debug_info +0.0% +942 [ = ] 0 .debug_line +0.1% +26 [ = ] 0 .debug_line_str +0.0% +333 [ = ] 0 .debug_loclists -0.0% -23 [ = ] 0 .debug_rnglists +0.0% +73 [ = ] 0 .debug_str -1.0% -4 [ = ] 0 .shstrtab +0.0% +20 [ = ] 0 .strtab +0.0% +24 [ = ] 0 .symtab +131% +3.30Ki [ = ] 0 [Unmapped] +0.0% +7.11Ki +0.0% +712 TOTAL [back to Thomas] > I tried to measure a speedup in vacuum, but so far I have not. I did > learn some things though: While doing that with an uncorrelated index > and a lot of deleted tuples, I found that adding more > maintenance_work_mem doesn't help beyond a few MB, because then cache > misses dominate to the point where it's not better than doing multiple > passes (and this is familiar to me from work on hash joins). If I > turned on huge pages on Linux and set min_dynamic_shared_memory so > that the parallel DSM used by vacuum lives in huge pages, then > parallel vacuum with a large maintenance_work_mem starts to do much > better than non-parallel vacuum by improving the TLB misses (as with > hash joins). I thought that was quite interesting! Perhaps > bsearch_itemptr might help with correlated indexes with a lot of > deleted indexes (so not dominated by cache misses), though? > > (I wouldn't be suprised if someone comes up with a much better idea > than bsearch for that anyway... a few ideas have been suggested.) That's interesting about the (un)correlated index having such a large effect on cache hit rate! By now there has been some discussion and a benchmark for dead tuple storage [1]. bit there doesn't seem to be recent activity on that thread. We might consider adding the ItemPtr comparator work I did in [2] for v15 if we don't have any of the other proposals in place by feature freeze. My concern there is the speedups I observed were observed when the values were comfortably in L2 cache, IIRC. That would need wider testing. That said, I think what I'll do next is test the v3-0001 standalone patch with tuplesort specializations for more data types. I already have a decent test script that I can build on for this. (this is the one currently in CI) Then, I want to do at least preliminary testing of the qsort boundary parameters. Those two things should be doable for this commitfest. [1] https://www.postgresql.org/message-id/CAD21AoAfOZvmfR0j8VmZorZjL7RhTiQdVttNuC4W-Shdc2a-AA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAFBsxsG_c24CHKA3cWrOP1HynWGLOkLb8hyZfsD9db5g-ZPagA%40mail.gmail.com -- John Naylor EDB: http://www.enterprisedb.com
I wrote: > That said, I think what I'll do next is test the v3-0001 standalone > patch with tuplesort specializations for more data types. I already > have a decent test script that I can build on for this. I've run a test with 10 million records using all types found in the v3 patch "accelerate tuple sorting for common types", using a variety of initial orderings, covering index build (btree only, no gist) and queries (both single value and whole record). Attached is the test script and a spreadsheet with the raw data as well as comparisons of the min runtimes in seconds from 5 runs. This is using gcc 11.1 on fairly recent Intel hardware. Overall, this shows a good improvement for these types. One exception is the "0/1" ordering, which is two values in random order. I'm guessing it's because of the cardinality detector, but some runs have apparent possible regressions. It's a bit high and sporadic to just blow off as noise, but this case might not be telling us anything useful. Other notes: - The inet type seems unnaturally fast in some places, meaning faster than int or date. That's suspicous, but I haven't yet dug deeper into that. - With the patch, the VM binary size increases by ~9kB. I have some hunches on the "future research" comments: XXX Can we avoid repeating the null-handling logic? More templating? ;-) XXX Is it worth specializing for reverse sort? I'll run a limited test on DESC to see if anything stands out, but I wonder if the use case is not common -- I seem to remember seeing DESC less often on the first sort key column. XXX Is it worth specializing for nulls first, nulls last, not null? Editorializing the null position in queries is not very common in my experience. Not null is interesting since it'd be trivial to pass constant false to the same Apply[XYZ]SortComparator() and let the compiler remove all those branches for us. On the other hand, those branches would be otherwise predicted well, so it might make little or no difference. XXX Should we have separate cases for "result is authoritative", "need XXX tiebreaker for atts 1..n (= abbrev case)", "need tie breaker for XXX atts 2..n"? The first one seems to be the only case where the SortTuple could be smaller, since the tuple pointer is null. That sounds like a good avenue to explore. Less memory usage is always good. Not sure what you mean by the third case -- there are 2+ sort keys, but the first is authoritative from the datum, so the full comparison can skip the first key? -- John Naylor EDB: http://www.enterprisedb.com
Вложения
On Tue, Jan 18, 2022 at 6:39 PM John Naylor <john.naylor@enterprisedb.com> wrote: > Editorializing the null position in queries is not very common in my > experience. Not null is interesting since it'd be trivial to pass > constant false to the same Apply[XYZ]SortComparator() and let the > compiler remove all those branches for us. On the other hand, those > branches would be otherwise predicted well, so it might make little or > no difference. If you were going to do this, maybe you could encode NULL directly in an abbreviated key. I think that that could be made to work if it was limited to opclasses with abbreviated keys encoded as unsigned integers. Just a thought. -- Peter Geoghegan
On Tue, Jan 18, 2022 at 9:58 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Jan 18, 2022 at 6:39 PM John Naylor > <john.naylor@enterprisedb.com> wrote: > > Editorializing the null position in queries is not very common in my > > experience. Not null is interesting since it'd be trivial to pass > > constant false to the same Apply[XYZ]SortComparator() and let the > > compiler remove all those branches for us. On the other hand, those > > branches would be otherwise predicted well, so it might make little or > > no difference. > > If you were going to do this, maybe you could encode NULL directly in > an abbreviated key. I think that that could be made to work if it was > limited to opclasses with abbreviated keys encoded as unsigned > integers. Just a thought. Now that you mention that, I do remember reading about this technique in the context of b-tree access, so it does make sense. If we had that capability, it would be trivial to order the nulls how we want while building the sort tuple datums, and the not-null case would be handled automatically. And have a smaller code footprint, I think. -- John Naylor EDB: http://www.enterprisedb.com
Hi, I've run a few tests to get some feel for the effects of various comparators on Datums containing int32. I've attached the full results, as well as the (messy) patch which applies on top of 0012 to run the tests. I'll excerpt some of those results as I go through them here. For now, I only ran input orders of sorted, random, and reversed. 1) Specializing This is a win in all cases, including SQL-callable comparators (the case here is for _bt_sort_array_elements). NOTICE: [traditional qsort] size=8MB, order=random, cmp=arg, test=2, time=0.140526 NOTICE: [inlined] size=8MB, order=random, cmp=inline, test=0, time=0.085023 NOTICE: [SQL arg] size=8MB, order=random, cmp=SQL-arg, test=2, time=0.256708 NOTICE: [SQL inlined] size=8MB, order=random, cmp=SQL-inline, test=0, time=0.192063 2) Branchless operations The int case is for how to perform the comparison, and the SQL case is referring to how to reverse the sort order.Surprisingly, they don't seem to help for direct comparisons, and in fact they seem worse. I'll have to dig a bit deeper to be sure, but it's not looking good now. NOTICE: [inlined] size=8MB, order=random, cmp=inline, test=2, time=0.084781 NOTICE: [branchless] size=8MB, order=random, cmp=branchless, test=0, time=0.091837 NOTICE: [SQL inlined] size=8MB, order=random, cmp=SQL-inline, test=2, time=0.192018 NOTICE: [SQL inlined reverse] size=8MB, order=random, cmp=SQL-inline-rev, test=0, time=0.190797 When the effect is reversing a list, the direct comparisons seem much worse, and the SQL ones aren't helped. NOTICE: [inlined] size=8MB, order=decreasing, cmp=inline, test=2, time=0.024963 NOTICE: [branchless] size=8MB, order=decreasing, cmp=branchless, test=0, time=0.036423 NOTICE: [SQL inlined] size=8MB, order=decreasing, cmp=SQL-inline, test=0, time=0.125182 NOTICE: [SQL inlined reverse] size=8MB, order=increasing, cmp=SQL-inline-rev, test=0, time=0.127051 -- Since I have a couple more planned tests, I'll keep a running tally on the current state of the patch set so that summaries are not scattered over many emails: 0001 - bsearch and unique is good to have, and we can keep the return type pending further tests 0002/3 - I've yet to see a case where branchless comparators win, but other than that, these are good. Notational improvement and not performance sensitive. 0004/5 - Computing the arguments slows it down, but accessing the underlying int16s gives an improvement. [1] Haven't done an in-situ test on VACUUM. Could be worth it for pg15, since I imagine the proposals for dead tuple storage won't be ready this cycle. 0006 - I expect this to be slower too. I also wonder if this could also use the global function in 0004 once it's improved. 0007 - untested 0008 - Good performance in microbenchmarks, no in-situ testing. Inlined reversal is not worth the binary space or notational overhead. 0009 - Based on 0004, I would guess that computing the arguments is too slow. Not sure how to test in-situ to see if specializing helps. 0010 - Thresholds on my TODO list. 0011 - A simple correction -- I'll go ahead and commit this. v3-0001 comparators for abbreviated keys - Clearly a win, especially for the "unsigned" case [2]. There are still possible improvements, but they seem like a pg16 project(s). [1] https://www.postgresql.org/message-id/CA%2BhUKG%2BS5SMoG8Z2PHj0bsK70CxVLgqQR1orQJq6Cjgibu26vA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAFBsxsEFGAJ9eBpQVb5a86BE93WER3497zn2OT5wbjm1HHcqgA%40mail.gmail.com (I just realized in that message I didn't attach the script for that, and also attached an extra draft spreadsheet. I'll improve the tests and rerun later) -- John Naylor EDB: http://www.enterprisedb.com
Вложения
I wrote: > 0010 - Thresholds on my TODO list. I did some basic tests on the insertion sort thresholds, and it looks like we could safely and profitably increase the current value from 7 to 20 or so, in line with other more recent implementations. I've attached an addendum on top of 0012 and the full test results on an Intel Coffee Lake machine with gcc 11.1. I found that the object test setup in 0012 had some kind of bug that was comparing the pointer of the object array. Rather than fix that, I decided to use Datums, but with the two extremes in comparator: simple branching with machine instructions vs. a SQL-callable function. The papers I've read indicate the results for Datum sizes would not be much different for small structs. The largest existing sort element is SortTuple, but that's only 24 bytes and has a bulky comparator as well. The first thing to note is that I rejected outright any testing of a "middle value" where the pivot is simply the middle of the array. Even the Bently and McIlroy paper which is the reference for our implementation says "The range that consists of the single integer 7 could be eliminated, but has been left adjustable because on some machines larger ranges are a few percent better". I tested thresholds up to 64, which is where I guessed results to get worse (most implementations are smaller than that). Here are the best thresholds at a quick glance: - elementary comparator: random: 16 or greater decreasing, rotate: get noticeably better all the way up to 64 organ: little difference, but seems to get better all the way up to 64 0/1: seems to get worse above 20 - SQL-callable comparator: random: between 12 and 20, but slight differences until 32 decreasing, rotate: get noticeably better all the way up to 64 organ: seems best at 12, but slight differences until 32 0/1: slight differences Based on these tests and this machine, it seems 20 is a good default value. I'll repeat this test on one older Intel and one non-Intel platform with older compilers. -- Running tally of patchset: 0001 - bsearch and unique is good to have, and we can keep the return type pending further tests -- if none happen this cycle, suggest committing this without the return type symbol. 0002/3 - I've yet to see a case where branchless comparators win, but other than that, these are good. Notational improvement and not performance sensitive. 0004/5 - Computing the arguments slows it down, but accessing the underlying int16s gives an improvement. [1] Haven't done an in-situ test on VACUUM. Could be worth it for pg15, since I imagine the proposals for dead tuple storage won't be ready this cycle. 0006 - I expect this to be slower too. I also wonder if this could also use the global function in 0004 once it's improved. 0007 - untested 0008 - Good performance in microbenchmarks, no in-situ testing. Inlined reversal is not worth the binary space or notational overhead. 0009 - Based on 0004, I would guess that computing the arguments is too slow. Not sure how to test in-situ to see if specializing helps. 0010 - Suggest leaving out the middle threshold and setting the insertion sort threshold to ~20. Might also name them ST_INSERTION_SORT_THRESHOLD and ST_NINTHER_THRESHOLD. (TODO: test on other platforms) 0011 - Committed. v3-0001 comparators for abbreviated keys - Clearly a win in this state already, especially for the "unsigned" case [2]. (gist untested) There are additional possible improvements mentioned, but they seem like a PG16 project(s). [1] https://www.postgresql.org/message-id/CA%2BhUKG%2BS5SMoG8Z2PHj0bsK70CxVLgqQR1orQJq6Cjgibu26vA%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAFBsxsEFGAJ9eBpQVb5a86BE93WER3497zn2OT5wbjm1HHcqgA%40mail.gmail.com (TODO: refine test) -- John Naylor EDB: http://www.enterprisedb.com
Вложения
I wrote: > > 0010 - Thresholds on my TODO list. > > I did some basic tests on the insertion sort thresholds, and it looks > like we could safely and profitably increase the current value from 7 > to 20 or so, in line with other more recent implementations. I've > attached an addendum on top of 0012 and the full test results on an > Intel Coffee Lake machine with gcc 11.1. I found that the object test > setup in 0012 had some kind of bug that was comparing the pointer of > the object array. Rather than fix that, I decided to use Datums, but > with the two extremes in comparator: simple branching with machine > instructions vs. a SQL-callable function. The papers I've read > indicate the results for Datum sizes would not be much different for > small structs. The largest existing sort element is SortTuple, but > that's only 24 bytes and has a bulky comparator as well. > > The first thing to note is that I rejected outright any testing of a > "middle value" where the pivot is simply the middle of the array. Even > the Bently and McIlroy paper which is the reference for our > implementation says "The range that consists of the single integer 7 > could be eliminated, but has been left adjustable because on some > machines larger ranges are a few percent better". > > I tested thresholds up to 64, which is where I guessed results to get > worse (most implementations are smaller than that). Here are the best > thresholds at a quick glance: > > - elementary comparator: > > random: 16 or greater > decreasing, rotate: get noticeably better all the way up to 64 > organ: little difference, but seems to get better all the way up to 64 > 0/1: seems to get worse above 20 > > - SQL-callable comparator: > > random: between 12 and 20, but slight differences until 32 > decreasing, rotate: get noticeably better all the way up to 64 > organ: seems best at 12, but slight differences until 32 > 0/1: slight differences > > Based on these tests and this machine, it seems 20 is a good default > value. I'll repeat this test on one older Intel and one non-Intel > platform with older compilers. The above was an Intel Comet Lake / gcc 11, and I've run the same test on a Haswell-era Xeon / gcc 8 and a Power8 machine / gcc 4.8. The results on those machines are pretty close to the above (full results attached). The noticeable exception is the Power8 on random input with a slow comparator -- those measurements there are more random than others so we can't draw conclusions from them, but the deviations are small in any case. I'm still thinking 20 or so is about right. I've put a lot out here recently, so I'll take a break now and come back in a few weeks. (no running tally here because the conclusions haven't changed since last message) -- John Naylor EDB: http://www.enterprisedb.com
Вложения
In a couple days I'm going to commit the v3 patch "accelerate tuple sorting for common types" as-is after giving it one more look, barring objections. I started towards incorporating the change in insertion sort threshold (part of 0010), but that caused regression test failures, so that will have to wait for a bit of analysis and retesting. (My earlier tests were done in a separate module.) The rest in this series that I looked at closely were either refactoring or could use some minor tweaks so likely v16 material. -- John Naylor EDB: http://www.enterprisedb.com
On Thu, Mar 31, 2022 at 11:09 PM John Naylor <john.naylor@enterprisedb.com> wrote: > In a couple days I'm going to commit the v3 patch "accelerate tuple > sorting for common types" as-is after giving it one more look, barring > objections. Hi John, Thanks so much for all the work you've done here! I feel bad that I lobbed so many experimental patches in here and then ran away due to lack of cycles. That particular patch (the one cfbot has been chewing on all this time) does indeed seem committable, despite the deficiencies/opportunities listed in comments. It's nice to reduce code duplication, it gives the right answers, and it goes faster. > I started towards incorporating the change in insertion sort threshold > (part of 0010), but that caused regression test failures, so that will > have to wait for a bit of analysis and retesting. (My earlier tests > were done in a separate module.) > > The rest in this series that I looked at closely were either > refactoring or could use some minor tweaks so likely v16 material. Looking forward to it.
On Fri, Apr 1, 2022 at 4:43 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Thu, Mar 31, 2022 at 11:09 PM John Naylor > <john.naylor@enterprisedb.com> wrote: > > In a couple days I'm going to commit the v3 patch "accelerate tuple > > sorting for common types" as-is after giving it one more look, barring > > objections. Pushed. > Hi John, > > Thanks so much for all the work you've done here! I feel bad that I > lobbed so many experimental patches in here and then ran away due to > lack of cycles. That particular patch (the one cfbot has been chewing > on all this time) does indeed seem committable, despite the > deficiencies/opportunities listed in comments. It's nice to reduce > code duplication, it gives the right answers, and it goes faster. Thanks for chiming in! It gives me more confidence that there wasn't anything amiss that may have gone unnoticed. And no worries -- my own review efforts here have been sporadic. ;-) -- John Naylor EDB: http://www.enterprisedb.com
I wrote: > I started towards incorporating the change in insertion sort threshold > (part of 0010), but that caused regression test failures, so that will > have to wait for a bit of analysis and retesting. (My earlier tests > were done in a separate module.) The failures seem to be where sort order is partially specified. E.g. ORDER BY col_a, where there are duplicates there and other columns are different. Insertion sort is stable IIRC, so moving the threshold caused different orders in these cases. Some cases can be conveniently fixed with additional columns in the ORDER BY clause. I'll go through the failures and see how much can be cleaned up as a preparatory refactoring. -- John Naylor EDB: http://www.enterprisedb.com
On Sat, Apr 2, 2022 at 9:38 PM John Naylor <john.naylor@enterprisedb.com> wrote: > On Fri, Apr 1, 2022 at 4:43 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Thu, Mar 31, 2022 at 11:09 PM John Naylor > > <john.naylor@enterprisedb.com> wrote: > > > In a couple days I'm going to commit the v3 patch "accelerate tuple > > > sorting for common types" as-is after giving it one more look, barring > > > objections. > > Pushed. It looks like UBsan sees a problem, per BF animal kestrel: /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/utils/sort/tuplesort.c:722:51: runtime error: load of value 96, which is not a valid value for type 'bool' #5 0x0000000000eb65d4 in qsort_tuple_int32_compare (a=0x4292ce0, b=0x4292cf8, state=0x4280130) at /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/utils/sort/tuplesort.c:722 #6 qsort_tuple_int32 (data=<optimized out>, n=133, arg=arg@entry=0x4280130) at /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/include/lib/sort_template.h:313 #7 0x0000000000eaf747 in tuplesort_sort_memtuples (state=state@entry=0x4280130) at /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/utils/sort/tuplesort.c:3613 #8 0x0000000000eaedcb in tuplesort_performsort (state=state@entry=0x4280130) at /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/utils/sort/tuplesort.c:2154 #9 0x0000000000573d60 in heapam_relation_copy_for_cluster (OldHeap=<optimized out>, NewHeap=<optimized out>, OldIndex=<optimized out>, use_sort=<optimized out>, OldestXmin=11681, xid_cutoff=<optimized out>, multi_cutoff=0x7ffecb0cfa70, num_tuples=0x7ffecb0cfa38, tups_vacuumed=0x7ffecb0cfa20, tups_recently_dead=0x7ffecb0cfa28) at /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/access/heap/heapam_handler.c:955 Reproduced locally, using the same few lines from the cluster.sql test. I'll try to dig more tomorrow...
On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > It looks like UBsan sees a problem, per BF animal kestrel: > > /mnt/resource/bf/build/kestrel/HEAD/pgsql.build/../pgsql/src/backend/utils/sort/tuplesort.c:722:51: > runtime error: load of value 96, which is not a valid value for type > 'bool' Yeah, same with tamandua. Then, skink (a Valgrind animal) shows: ==1940791== VALGRINDERROR-BEGIN ==1940791== Conditional jump or move depends on uninitialised value(s) ==1940791== at 0x73D394: ApplyInt32SortComparator (sortsupport.h:311) ==1940791== by 0x73D394: qsort_tuple_int32_compare (tuplesort.c:722) ==1940791== by 0x73D394: qsort_tuple_int32 (sort_template.h:313) ==1940791== by 0x7409BC: tuplesort_sort_memtuples (tuplesort.c:3613) ==1940791== by 0x742806: tuplesort_performsort (tuplesort.c:2154) ==1940791== by 0x23C109: heapam_relation_copy_for_cluster (heapam_handler.c:955) ==1940791== by 0x35799A: table_relation_copy_for_cluster (tableam.h:1658) ==1940791== by 0x35799A: copy_table_data (cluster.c:913) ==1940791== by 0x359016: rebuild_relation (cluster.c:606) ==1940791== by 0x35914E: cluster_rel (cluster.c:427) ==1940791== by 0x3594EB: cluster (cluster.c:195) ==1940791== by 0x5C73FF: standard_ProcessUtility (utility.c:862) ==1940791== by 0x5C78D0: ProcessUtility (utility.c:530) ==1940791== by 0x5C4C7B: PortalRunUtility (pquery.c:1158) ==1940791== by 0x5C4F78: PortalRunMulti (pquery.c:1315) ==1940791== Uninitialised value was created by a stack allocation ==1940791== at 0x74224E: tuplesort_putheaptuple (tuplesort.c:1800) -- John Naylor EDB: http://www.enterprisedb.com
On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Reproduced locally, using the same few lines from the cluster.sql > test. I'll try to dig more tomorrow... Thanks! Unfortunately I can't reproduce locally with clang 13/gcc 11, with -Og or -O2 with CFLAGS="-fsanitize=undefined,alignment" ... -- John Naylor EDB: http://www.enterprisedb.com
On Sun, Apr 3, 2022 at 12:41 AM John Naylor <john.naylor@enterprisedb.com> wrote: > On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > Reproduced locally, using the same few lines from the cluster.sql > > test. I'll try to dig more tomorrow... > > Thanks! Unfortunately I can't reproduce locally with clang 13/gcc 11, > with -Og or -O2 with CFLAGS="-fsanitize=undefined,alignment" ... Maybe you need to add -fno-sanitize-recover=all to make it crash, otherwise it just prints the warning and keeps going.
On Sat, Apr 02, 2022 at 06:41:30PM +0700, John Naylor wrote:
> On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> > Reproduced locally, using the same few lines from the cluster.sql
> > test. I'll try to dig more tomorrow...
>
> Thanks! Unfortunately I can't reproduce locally with clang 13/gcc 11,
> with -Og or -O2 with CFLAGS="-fsanitize=undefined,alignment" ...
Like Thomas just said, I had to use:
CFLAGS="-Og -fsanitize=undefined,alignment -fno-sanitize-recover=all
I'm a couple few steps out of my league here, but it may be an issue with:
commit 4ea51cdfe85ceef8afabceb03c446574daa0ac23
Author: Robert Haas <rhaas@postgresql.org>
Date: Mon Jan 19 15:20:31 2015 -0500
Use abbreviated keys for faster sorting of text datums.
This is enough to avoid the crash, which might be a useful hint..
@@ -4126,22 +4126,23 @@ copytup_cluster(Tuplesortstate *state, SortTuple *stup, void *tup)
/*
* set up first-column key value, and potentially abbreviate, if it's a
* simple column
*/
+ stup->isnull1 = false;
if (state->indexInfo->ii_IndexAttrNumbers[0] == 0)
return;
original = heap_getattr(tuple,
state->indexInfo->ii_IndexAttrNumbers[0],
state->tupDesc,
&stup->isnull1);
Hi, On 2022-04-03 08:07:58 +1200, Thomas Munro wrote: > On Sun, Apr 3, 2022 at 12:41 AM John Naylor > <john.naylor@enterprisedb.com> wrote: > > On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > Reproduced locally, using the same few lines from the cluster.sql > > > test. I'll try to dig more tomorrow... > > > > Thanks! Unfortunately I can't reproduce locally with clang 13/gcc 11, > > with -Og or -O2 with CFLAGS="-fsanitize=undefined,alignment" ... > > Maybe you need to add -fno-sanitize-recover=all to make it crash, > otherwise it just prints the warning and keeps going. I commented with a few more details on https://postgr.es/m/20220402201557.thanbsxcql5lk6pc%40alap3.anarazel.de and an preliminary analysis in https://www.postgresql.org/message-id/20220402203344.ahup2u5n73cdbbcv%40alap3.anarazel.de Greetings, Andres Freund
On Sun, Apr 3, 2022 at 8:20 AM Justin Pryzby <pryzby@telsasoft.com> wrote: > @@ -4126,22 +4126,23 @@ copytup_cluster(Tuplesortstate *state, SortTuple *stup, void *tup) > + stup->isnull1 = false; Looks like I might have failed to grok the scheme for encoding null into SortTuple objects. It's clearly uninitialised in some paths, with a special 0 value in datum1. Will need to look more closely with more coffee...
Hi, On 2022-04-02 15:20:27 -0500, Justin Pryzby wrote: > On Sat, Apr 02, 2022 at 06:41:30PM +0700, John Naylor wrote: > > On Sat, Apr 2, 2022 at 5:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > Reproduced locally, using the same few lines from the cluster.sql > > > test. I'll try to dig more tomorrow... > > > > Thanks! Unfortunately I can't reproduce locally with clang 13/gcc 11, > > with -Og or -O2 with CFLAGS="-fsanitize=undefined,alignment" ... > > Like Thomas just said, I had to use: > CFLAGS="-Og -fsanitize=undefined,alignment -fno-sanitize-recover=all > > I'm a couple few steps out of my league here, but it may be an issue with: > > commit 4ea51cdfe85ceef8afabceb03c446574daa0ac23 > Author: Robert Haas <rhaas@postgresql.org> > Date: Mon Jan 19 15:20:31 2015 -0500 > > Use abbreviated keys for faster sorting of text datums. > > This is enough to avoid the crash, which might be a useful hint.. > > @@ -4126,22 +4126,23 @@ copytup_cluster(Tuplesortstate *state, SortTuple *stup, void *tup) > /* > * set up first-column key value, and potentially abbreviate, if it's a > * simple column > */ > + stup->isnull1 = false; > if (state->indexInfo->ii_IndexAttrNumbers[0] == 0) > return; > > original = heap_getattr(tuple, > state->indexInfo->ii_IndexAttrNumbers[0], > state->tupDesc, > &stup->isnull1); I don't think that can be correct - the column can be NULL afaics. And I don't think in that patch it's needed, because it always goes through ->comparetup() when state->onlyKey isn't explicitly set. Which tuplesort_begin_cluster() as well as several others don't. And you'd just sort an uninitialized datum immediately after. It's certainly not pretty that copytup_cluster() can use SortTuples without actually using SortTuples. Afaics it basically only computes isnull1/datum1 if state->indexInfo->ii_IndexAttrNumbers[0] == 0. Greetings, Andres Freund
On Sun, Apr 3, 2022 at 9:03 AM Andres Freund <andres@anarazel.de> wrote: > It's certainly not pretty that copytup_cluster() can use SortTuples without > actually using SortTuples. Afaics it basically only computes isnull1/datum1 if > state->indexInfo->ii_IndexAttrNumbers[0] == 0. I think we just need to decide up front if we're in a situation that can't provide datum1/isnull1 (in this case because it's an expression index), and skip the optimised paths. Here's an experimental patch... still looking into whether there are more cases like this... (There's also room to recognise when you don't even need to look at isnull1 for a less branchy optimised sort, but that was already discussed and put off for later.)
Вложения
Hi, On 2022-04-03 09:45:13 +1200, Thomas Munro wrote: > On Sun, Apr 3, 2022 at 9:03 AM Andres Freund <andres@anarazel.de> wrote: > > It's certainly not pretty that copytup_cluster() can use SortTuples without > > actually using SortTuples. Afaics it basically only computes isnull1/datum1 if > > state->indexInfo->ii_IndexAttrNumbers[0] == 0. > > I think we just need to decide up front if we're in a situation that > can't provide datum1/isnull1 (in this case because it's an expression > index), and skip the optimised paths. Here's an experimental patch... > still looking into whether there are more cases like this... That's a lot of redundant checks. How about putting all the checks for optimized paths into one if (state->sortKeys && !state->disable_datum1)? I'm a bit worried that none of the !ubsan tests failed on this... Greetings, Andres Freund
On Sun, Apr 3, 2022 at 11:11 AM Andres Freund <andres@anarazel.de> wrote: > On 2022-04-03 09:45:13 +1200, Thomas Munro wrote: > > I think we just need to decide up front if we're in a situation that > > can't provide datum1/isnull1 (in this case because it's an expression > > index), and skip the optimised paths. Here's an experimental patch... > > still looking into whether there are more cases like this... I didn't find anything else. Maybe it'd be better if we explicitly declared whether datum1 is used in each tuplesort mode's 'begin' function, right next to the code that installs the set of routines that are in control of that? Trying that in this version. Is it clearer what's going on like this? > That's a lot of redundant checks. How about putting all the checks for > optimized paths into one if (state->sortKeys && !state->disabl1e_datum1)? OK, sure. > I'm a bit worried that none of the !ubsan tests failed on this... In accordance with whoever-it-was-that-said-that's law about things that aren't tested, this are turned out to be broken already[1]. Once we fix that we should have a new test in the three that might also eventually have failed under this UB, given enough chaos. [1] https://www.postgresql.org/message-id/CA%2BhUKG%2BbA%2BbmwD36_oDxAoLrCwZjVtST2fqe%3Db4%3DqZcmU7u89A%40mail.gmail.com
Вложения
Hi, On 2022-04-03 17:46:28 +1200, Thomas Munro wrote: > On Sun, Apr 3, 2022 at 11:11 AM Andres Freund <andres@anarazel.de> wrote: > > On 2022-04-03 09:45:13 +1200, Thomas Munro wrote: > > > I think we just need to decide up front if we're in a situation that > > > can't provide datum1/isnull1 (in this case because it's an expression > > > index), and skip the optimised paths. Here's an experimental patch... > > > still looking into whether there are more cases like this... > > I didn't find anything else. > > Maybe it'd be better if we explicitly declared whether datum1 is used > in each tuplesort mode's 'begin' function, right next to the code that > installs the set of routines that are in control of that? Trying that > in this version. Is it clearer what's going on like this? Seems an improvement. > > I'm a bit worried that none of the !ubsan tests failed on this... > > In accordance with whoever-it-was-that-said-that's law about things > that aren't tested, this are turned out to be broken already[1]. Yea :/. Would be good to get this committed soon, so we can see further ubsan violations introduced in the next few days (and so I can unblock my local dev tests :P). Greetings, Andres Freund
On Mon, Apr 4, 2022 at 4:32 AM Andres Freund <andres@anarazel.de> wrote: > Would be good to get this committed soon, so we can see further ubsan > violations introduced in the next few days (and so I can unblock my local dev > tests :P). Pushed (with a minor tweak).
Here is the updated insertion sort threshold patch based on Thomas' experimental v4 0010, with adjusted regression test output. I only found a couple places where it could make sense to add sort keys to test queries, but 1) not enough to make a big difference and 2) the adjustments looked out of place, so I decided to just update all the regression tests in one go. Since the patch here is a bit more (and less) involved than Thomas' 0010, I'm going to refrain from committing until it gets review. If not in the next couple days, I will bring it up at the beginning of the v16 cycle. -- John Naylor EDB: http://www.enterprisedb.com
Вложения
Hi,
David Rowley privately reported a performance regression when sorting
single ints with a lot of duplicates, in a case that previously hit
qsort_ssup() but now hits qsort_tuple_int32() and then has to call the
tiebreaker comparator. Note that this comes up only for sorts in a
query, not for eg index builds which always have to tiebreak on item
ptr. I don't have data right now but that'd likely be due to:
+ * XXX: For now, there is no specialization for cases where datum1 is
+ * authoritative and we don't even need to fall back to a callback at all (that
+ * would be true for types like int4/int8/timestamp/date, but not true for
+ * abbreviations of text or multi-key sorts. There could be! Is it worth it?
Upthread we were discussing which variations it'd be worth investing
extra text segment space on to gain speedup and we put those hard
decisions off for future work, but on reflection, we probably should
tackle this particular point to avoid a regression. I think something
like the attached achieves that (draft, not tested much yet, could
perhaps find a tidier way to code the decision tree). In short:
variants qsort_tuple_{int32,signed,unsigned}() no longer fall back,
but new variants qsort_tuple_{int32,signed,unsigned}_tiebreak() do.
We should perhaps also reconsider the other XXX comment about finding
a way to skip the retest of column 1 in the tiebreak comparator.
Perhaps you'd just install a different comparetup function, eg
comparetup_index_btree_tail (which would sharing code), so no need to
multiply specialisations for that.
Planning to look at this more closely after I've sorted out some other
problems, but thought I'd post this draft/problem report early in case
John or others have thoughts or would like to run some experiments.
Вложения
On Sun, Apr 10, 2022 at 2:44 PM Thomas Munro <thomas.munro@gmail.com> wrote: > David Rowley privately reported a performance regression when sorting > single ints with a lot of duplicates, in a case that previously hit > qsort_ssup() but now hits qsort_tuple_int32() and then has to call the > tiebreaker comparator. That's not good. The B&M quicksort implementation that we adopted is generally extremely fast for that case, since it uses 3 way partitioning (based on the Dutch National Flag algorithm). This essentially makes sorting large groups of duplicates take only linear time (not linearithmic time). -- Peter Geoghegan
On Mon, 11 Apr 2022 at 09:44, Thomas Munro <thomas.munro@gmail.com> wrote: > David Rowley privately reported a performance regression when sorting > single ints with a lot of duplicates, in a case that previously hit > qsort_ssup() but now hits qsort_tuple_int32() and then has to call the > tiebreaker comparator. Note that this comes up only for sorts in a > query, not for eg index builds which always have to tiebreak on item > ptr. I don't have data right now but that'd likely be due to: Yeah, I noticed this when running some sort benchmarks to compare v14 with master (as of Thursday last week). The biggest slowdown I saw was the test that sorted 1 million tuples on a BIGINT column with 100 distinct values. The test in question does sorts on the same column each time, but continually adds columns, which I was doing to check how wider tuples changed the performance (this was for the exercise of 40af10b57 rather than this work). With this particular test, v15 is about 15% *slower* than v14. I didn't know what to blame at first, so I tried commenting out the sort specialisations and got the results in the red bars in the graph. This made it about 7.5% *faster* than v14. So looks like this patch is to blame. I then hacked the comparator function that's used in the specialisations for BIGINT to comment out the tiebreak to remove the indirect function call, which happens to do nothing in this 1 column sort case. The aim here was to get an idea what the performance would be if there was a specialisation for single column sorts. That's the yellow bars, which show about 10% *faster* than master.
Вложения
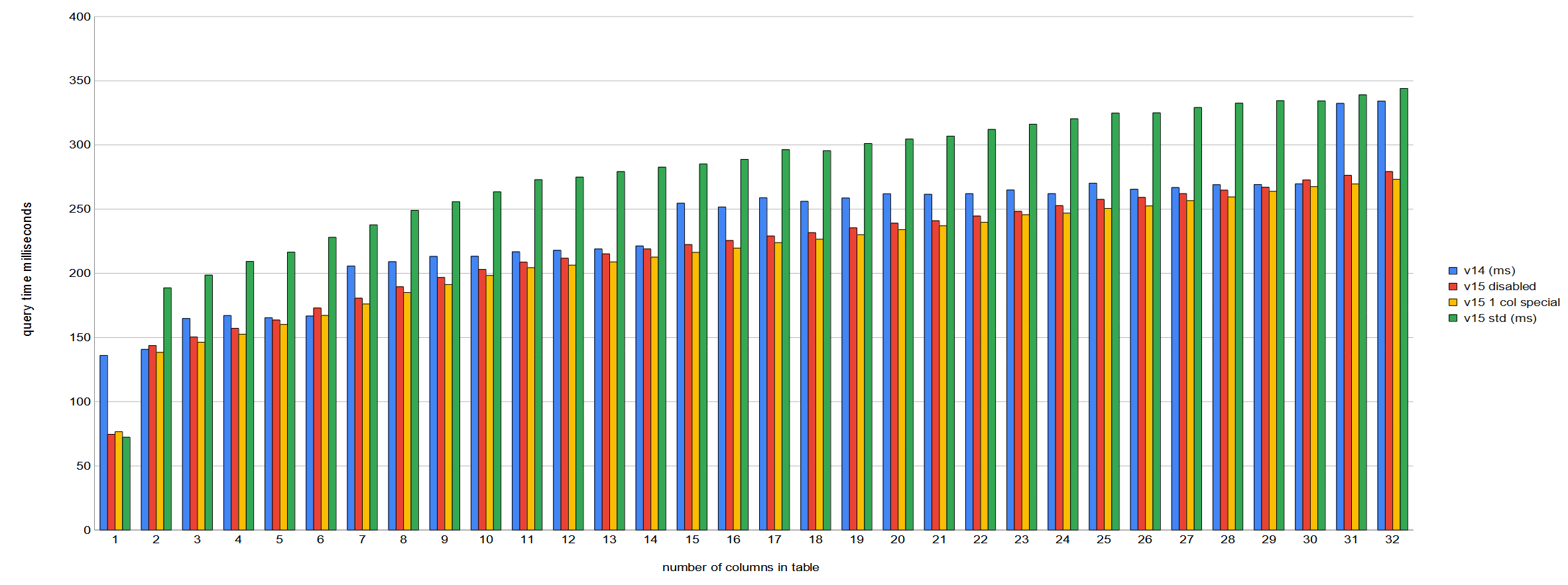{kind=link}
On Mon, 11 Apr 2022 at 09:44, Thomas Munro <thomas.munro@gmail.com> wrote: > David Rowley privately reported a performance regression when sorting > single ints with a lot of duplicates, in a case that previously hit > qsort_ssup() but now hits qsort_tuple_int32() and then has to call the > tiebreaker comparator. Note that this comes up only for sorts in a > query, not for eg index builds which always have to tiebreak on item > ptr. I don't have data right now but that'd likely be due to: I've now added this as an open item for v15. David
On Mon, Apr 11, 2022 at 5:34 AM David Rowley <dgrowleyml@gmail.com> wrote: > With this particular test, v15 is about 15% *slower* than v14. I > didn't know what to blame at first, so I tried commenting out the sort > specialisations and got the results in the red bars in the graph. This > made it about 7.5% *faster* than v14. So looks like this patch is to > blame. I then hacked the comparator function that's used in the > specialisations for BIGINT to comment out the tiebreak to remove the > indirect function call, which happens to do nothing in this 1 column > sort case. The aim here was to get an idea what the performance would > be if there was a specialisation for single column sorts. That's the > yellow bars, which show about 10% *faster* than master. Thanks for investigating! (I assume you meant 10% faster than v14?) On Mon, Apr 11, 2022 at 4:55 AM Peter Geoghegan <pg@bowt.ie> wrote: > The B&M quicksort implementation that we adopted is generally > extremely fast for that case, since it uses 3 way partitioning (based > on the Dutch National Flag algorithm). This essentially makes sorting > large groups of duplicates take only linear time (not linearithmic > time). In the below thread, I wondered if it still counts as extremely fast nowadays. I hope to give an answer to that during next cycle. Relevant to the open item, the paper linked there has a variety of low-cardinality cases. I'll incorporate them in a round of tests soon. https://www.postgresql.org/message-id/CAFBsxsHanJTsX9DNJppXJxwg3bU+YQ6pnmSfPM0uvYUaFdwZdQ@mail.gmail.com On Mon, Apr 11, 2022 at 4:44 AM Thomas Munro <thomas.munro@gmail.com> wrote: > Upthread we were discussing which variations it'd be worth investing > extra text segment space on to gain speedup and we put those hard > decisions off for future work, but on reflection, we probably should > tackle this particular point to avoid a regression. I think something > like the attached achieves that (draft, not tested much yet, could > perhaps find a tidier way to code the decision tree). In short: > variants qsort_tuple_{int32,signed,unsigned}() no longer fall back, > but new variants qsort_tuple_{int32,signed,unsigned}_tiebreak() do. Looks good at a glance, I will get some numbers after modifying my test scripts. > We should perhaps also reconsider the other XXX comment about finding > a way to skip the retest of column 1 in the tiebreak comparator. > Perhaps you'd just install a different comparetup function, eg > comparetup_index_btree_tail (which would sharing code), so no need to > multiply specialisations for that. If we need to add these cases to avoid regression, it makes sense to make them work as well as we reasonably can. -- John Naylor EDB: http://www.enterprisedb.com
On Mon, 11 Apr 2022 at 22:11, John Naylor <john.naylor@enterprisedb.com> wrote: > > On Mon, Apr 11, 2022 at 5:34 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > With this particular test, v15 is about 15% *slower* than v14. I > > didn't know what to blame at first, so I tried commenting out the sort > > specialisations and got the results in the red bars in the graph. This > > made it about 7.5% *faster* than v14. So looks like this patch is to > > blame. I then hacked the comparator function that's used in the > > specialisations for BIGINT to comment out the tiebreak to remove the > > indirect function call, which happens to do nothing in this 1 column > > sort case. The aim here was to get an idea what the performance would > > be if there was a specialisation for single column sorts. That's the > > yellow bars, which show about 10% *faster* than master. > > Thanks for investigating! (I assume you meant 10% faster than v14?) Yes, I did mean to say v14. (I'm too used to comparing everything to master) David
On Mon, 11 Apr 2022 at 09:44, Thomas Munro <thomas.munro@gmail.com> wrote: > Planning to look at this more closely after I've sorted out some other > problems, but thought I'd post this draft/problem report early in case > John or others have thoughts or would like to run some experiments. Thanks for putting the patch together. I had a look at the patch and I wondered if we really need to add an entire dimension of sort functions for just this case. My thought process here is that when I look at a function such as ApplySignedSortComparator(), I think that it might be better to save adding another dimension for a sort case such as a column that does not contain any NULLs. There's quite a bit more branching saved from getting rid of NULL tests there than what we could save by checking if we need to call the tiebreaker function in a function like qsort_tuple_signed_compare(). I didn't really know what the performance implications would be of checking an extra flag would be, so I very quickly put a patch together and ran the benchmarks. The 4GB work_mem 1 million tuple test with values MOD 100 comes out as: Thomas' patch: 10.13% faster than v14 My patch: 9.48% faster than v14 master: 15.62% *slower* than v14 So it does seem like we can fix the regression in a more simple way. We could then maybe do some more meaningful performance tests during the v16 cycle to explore the most useful dimension to add that gains the most performance. Perhaps that's NULLs, or maybe it's something else. I've attached the patch I tested. It was thrown together very quickly just to try out the performance. If it's interesting I can polish it up a bit. If not, I didn't waste too much time. David
Вложения
{kind=link}
As promised, I've done another round of tests (script and spreadsheet
attached) with
- v15 with 6974924347 and cc58eecc5d reverted
- v15 with Thomas' patch
- v15 with David's patch
- v15 as is ("std")
...where v15 is at 7b735f8b52ad. This time I limited it to int,
bigint, and text types.
Since more cases now use random distributions, I also took some
measures to tighten up the measurements:
- Reuse the same random distribution for all tests where the input is
randomized, by invoking the script with/without a second parameter
- For the text case, use lpadded ints so that lexicographic order is
the same as numeric order.
I verified David's mod100 test case and added most test cases from the
Orson Peters paper I mentioned above. I won't explain all of them
here, but the low cardinality ones are randomized sets of:
- mod8
- dupsq: x mod sqrt(n) , for 10 million about 3 thousand distinct values
- dup8: (x**8 + n/2) mod n , for 10 million about 80 thousand distinct
values, about 80% with 64 duplicates and 20% with 256 duplicates
All the clear regressions I can see in v15 are in the above for one or
more query types / data types, and both Thomas and David's patches
restore performance for those.
More broadly than the regression, Thomas' is very often the fastest of
all, at the cost of more binary size. David's is occasionally slower
than v15 or v15 with revert, but much of that is a slight difference
and some is probably noise.
--
John Naylor
EDB: http://www.enterprisedb.com
Вложения
On Wed, 13 Apr 2022 at 23:19, John Naylor <john.naylor@enterprisedb.com> wrote: > More broadly than the regression, Thomas' is very often the fastest of > all, at the cost of more binary size. David's is occasionally slower > than v15 or v15 with revert, but much of that is a slight difference > and some is probably noise. Just to get an opinion from some other hardware, I've run your test script on my AMD 3990x machine. My opinion here is that the best thing we can learn from both of our results is, do the patches fix the regression? I don't believe it should be about if adding the additional specializations performs better than skipping the tie break function call. I think it's pretty obvious that the specializations will be faster. I think if it was decided that v16 would be the version where more work should be done to decide on what should be specialized and what shouldn't be, then we shouldn't let this regression force our hand to make that choice now. It'll be pretty hard to remove any specializations once they've been in a released version of Postgres. David
Вложения
On Thu, Apr 14, 2022 at 1:46 PM David Rowley <dgrowleyml@gmail.com> wrote: > > On Wed, 13 Apr 2022 at 23:19, John Naylor <john.naylor@enterprisedb.com> wrote: > > More broadly than the regression, Thomas' is very often the fastest of > > all, at the cost of more binary size. David's is occasionally slower > > than v15 or v15 with revert, but much of that is a slight difference > > and some is probably noise. To add to my summary of results - the v15 code, with and without extra patches, seems slightly worse on B-tree index creation for very low cardinality keys, but that's not an index that's going to be useful (and therefore common) so that's a good tradeoff in my view. The regression David found is more concerning. > Just to get an opinion from some other hardware, I've run your test > script on my AMD 3990x machine. Thanks for that. I only see 4 non-Btree measurements in your results that are larger than v15-revert, versus 8 in mine (Comet Lake). And overall, most of those seem within the noise level. > My opinion here is that the best thing we can learn from both of our > results is, do the patches fix the regression? I'd say the answer is yes for both. > I don't believe it should be about if adding the additional > specializations performs better than skipping the tie break function > call. I think it's pretty obvious that the specializations will be > faster. I think if it was decided that v16 would be the version where > more work should be done to decide on what should be specialized and > what shouldn't be, then we shouldn't let this regression force our > hand to make that choice now. It'll be pretty hard to remove any > specializations once they've been in a released version of Postgres. I agree that a narrow fix is preferable. I'll take a closer look at your patch soon. -- John Naylor EDB: http://www.enterprisedb.com
On Tue, Apr 12, 2022 at 7:58 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> I've attached the patch I tested. It was thrown together very quickly
> just to try out the performance. If it's interesting I can polish it
> up a bit. If not, I didn't waste too much time.
@@ -959,6 +965,10 @@ tuplesort_begin_batch(Tuplesortstate *state)
state->tapeset = NULL;
+ /* check if specialized sorts can skip calling the tiebreak function */
+ state->oneKeySort = state->nKeys == 1 &&
+ !state->sortKeys[0].abbrev_converter;
+
IIUC, this function is called by tuplesort_begin_common, which in turn
is called by tuplesort_begin_{heap, indexes, etc}. The latter callers
set the onlyKey and now oneKeySort variables as appropriate, and
sometimes hard-coded to false. Is it intentional to set them here
first?
Falling under the polish that you were likely thinking of above:
We might rename oneKeySort to skipTiebreaker to avoid confusion.
SInce the test for these variable is the same, we could consolidate
them into a block and reword this existing comment (which I find a
little confusing anyway):
/*
* The "onlyKey" optimization cannot be used with abbreviated keys, since
* tie-breaker comparisons may be required. Typically, the optimization
* is only of value to pass-by-value types anyway, whereas abbreviated
* keys are typically only of value to pass-by-reference types.
*/
I can take a stab at this, unless you had something else in mind.
--
John Naylor
EDB: http://www.enterprisedb.com
Thanks for looking at this.
On Tue, 19 Apr 2022 at 02:11, John Naylor <john.naylor@enterprisedb.com> wrote:
> IIUC, this function is called by tuplesort_begin_common, which in turn
> is called by tuplesort_begin_{heap, indexes, etc}. The latter callers
> set the onlyKey and now oneKeySort variables as appropriate, and
> sometimes hard-coded to false. Is it intentional to set them here
> first?
>
> Falling under the polish that you were likely thinking of above:
I did put the patch together quickly just for the benchmark and at the
time I was subtly aware that the onlyKey field was being set using a
similar condition as I was using to set the boolean field I'd added.
On reflection today, it should be fine just to check if that field is
NULL or not in the 3 new comparison functions. Similarly to before,
this only needs to be done if the datums compare equally, so does not
add any code to the path where the datums are non-equal. It looks
like the other tuplesort_begin_* functions use a different comparison
function that will never make use of the specialization comparison
functions added by 697492434.
I separated out the "or" condition that I'd added tot he existing "if"
to make it easier to write a comment explaining why we can skip the
tiebreak function call.
Updated patch attached.
David
Вложения
On Tue, Apr 19, 2022 at 12:30 PM David Rowley <dgrowleyml@gmail.com> wrote:
>
> Thanks for looking at this.
>
> On Tue, 19 Apr 2022 at 02:11, John Naylor <john.naylor@enterprisedb.com> wrote:
> > IIUC, this function is called by tuplesort_begin_common, which in turn
> > is called by tuplesort_begin_{heap, indexes, etc}. The latter callers
> > set the onlyKey and now oneKeySort variables as appropriate, and
> > sometimes hard-coded to false. Is it intentional to set them here
> > first?
> >
> > Falling under the polish that you were likely thinking of above:
>
> I did put the patch together quickly just for the benchmark and at the
> time I was subtly aware that the onlyKey field was being set using a
> similar condition as I was using to set the boolean field I'd added.
> On reflection today, it should be fine just to check if that field is
> NULL or not in the 3 new comparison functions. Similarly to before,
> this only needs to be done if the datums compare equally, so does not
> add any code to the path where the datums are non-equal. It looks
> like the other tuplesort_begin_* functions use a different comparison
> function that will never make use of the specialization comparison
> functions added by 697492434.
Okay, this makes logical sense and is a smaller patch to boot. I've
re-run my tests (attached) to make sure we have our bases covered. I'm
sharing the min-of-five, as before, but locally I tried . The
regression is fixed, and most other differences from v15 seem to be
noise. It's possible the naturally fastest cases (pre-sorted ints and
bigints) are slower than v15-revert than expected from noise, but it's
not clear.
I think this is good to go.
--
John Naylor
EDB: http://www.enterprisedb.com
Вложения
> Okay, this makes logical sense and is a smaller patch to boot. I've > re-run my tests (attached) to make sure we have our bases covered. I'm > sharing the min-of-five, as before, but locally I tried . The My sentence there was supposed to read "I tried using median and it was a bit less noisy". -- John Naylor EDB: http://www.enterprisedb.com
I intend to commit David's v2 fix next week, unless there are objections, or unless he beats me to it. -- John Naylor EDB: http://www.enterprisedb.com
On Thu, 21 Apr 2022 at 19:09, John Naylor <john.naylor@enterprisedb.com> wrote: > I intend to commit David's v2 fix next week, unless there are > objections, or unless he beats me to it. I wasn't sure if you wanted to handle it or not, but I don't mind doing it, so I just pushed it after a small adjustment to a comment. Before going ahead with it I did test a 2-key sort where the leading key values were all the same. I wondered if we'd still see any regression from having to re-compare the leading key all over again. I just did: create table ab (a bigint, b bigint); insert into ab select 0,x from generate_series(1,1000000)x; vacuum freeze ab; I then ran: select * from ab order by a,b offset 1000000; 697492434 (Specialize tuplesort routines for different kinds of abbreviated keys) $ pgbench -n -f bench1.sql -T 60 -M prepared postgres tps = 10.651740 (without initial connection time) tps = 10.813647 (without initial connection time) tps = 10.648960 (without initial connection time) 697492434~1 (Remove obsolete comment) $ pgbench -n -f bench1.sql -T 60 -M prepared postgres tps = 9.957163 (without initial connection time) tps = 10.191168 (without initial connection time) tps = 10.145281 (without initial connection time) So it seems there was no regression for that case, at least, not on the AMD machine that I tested on. David
On Fri, Apr 22, 2022 at 11:13 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 21 Apr 2022 at 19:09, John Naylor <john.naylor@enterprisedb.com> wrote: > > I intend to commit David's v2 fix next week, unless there are > > objections, or unless he beats me to it. > > I wasn't sure if you wanted to handle it or not, but I don't mind > doing it, so I just pushed it after a small adjustment to a comment. Thank you! -- John Naylor EDB: http://www.enterprisedb.com
On Fri, Apr 22, 2022 at 4:37 PM John Naylor <john.naylor@enterprisedb.com> wrote: > On Fri, Apr 22, 2022 at 11:13 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 21 Apr 2022 at 19:09, John Naylor <john.naylor@enterprisedb.com> wrote: > > > I intend to commit David's v2 fix next week, unless there are > > > objections, or unless he beats me to it. > > > > I wasn't sure if you wanted to handle it or not, but I don't mind > > doing it, so I just pushed it after a small adjustment to a comment. > > Thank you! Thanks both for working on this. Seems like a good call to defer the choice of further specialisations.
On Fri, Apr 22, 2022 at 11:37:29AM +0700, John Naylor wrote: > On Fri, Apr 22, 2022 at 11:13 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > > On Thu, 21 Apr 2022 at 19:09, John Naylor <john.naylor@enterprisedb.com> wrote: > > > I intend to commit David's v2 fix next week, unless there are > > > objections, or unless he beats me to it. > > > > I wasn't sure if you wanted to handle it or not, but I don't mind > > doing it, so I just pushed it after a small adjustment to a comment. > > Thank you! Should these debug lines be removed ? elog(DEBUG1, "qsort_tuple"); Perhaps if I ask for debug output, I shouldn't be surprised if it changes between major releases - but I still found this surprising. I'm sure it's useful during development and maybe during beta. It could even make sense if it were shown during regression tests (preferably at DEBUG2). But right now it's not. is that ts=# \dt DEBUG: qsort_tuple List of relations -- Justin
On Thu, May 19, 2022 at 1:12 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > Should these debug lines be removed ? > > elog(DEBUG1, "qsort_tuple"); I agree -- DEBUG1 seems too chatty for something like this. DEBUG2 would be more appropriate IMV. Though I don't feel very strongly about it. -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes:
> On Thu, May 19, 2022 at 1:12 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
>> Should these debug lines be removed ?
>>
>> elog(DEBUG1, "qsort_tuple");
> I agree -- DEBUG1 seems too chatty for something like this. DEBUG2
> would be more appropriate IMV. Though I don't feel very strongly about
> it.
Given the lack of context identification, I'd put the usefulness of
these in production at close to zero. +1 for removing them
altogether, or failing that, downgrade to DEBUG5 or so.
regards, tom lane
On Fri, May 20, 2022 at 5:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Peter Geoghegan <pg@bowt.ie> writes: > > On Thu, May 19, 2022 at 1:12 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > >> Should these debug lines be removed ? > >> > >> elog(DEBUG1, "qsort_tuple"); > > > I agree -- DEBUG1 seems too chatty for something like this. DEBUG2 > > would be more appropriate IMV. Though I don't feel very strongly about > > it. > > Given the lack of context identification, I'd put the usefulness of > these in production at close to zero. +1 for removing them > altogether, or failing that, downgrade to DEBUG5 or so. I agree this is only useful in development. Removal sounds fine to me, so I'll do that soon. -- John Naylor EDB: http://www.enterprisedb.com
I wrote: > I agree this is only useful in development. Removal sounds fine to me, > so I'll do that soon. This is done. -- John Naylor EDB: http://www.enterprisedb.com