Обсуждение: [PATCH] Reuse Workers and Replication Slots during Logical Replication
Hi hackers,
I created a patch to reuse tablesync workers and their replication slots for more tables that are not synced yet. So that overhead of creating and dropping workers/replication slots can be reduced.
Current version of logical replication has two steps: tablesync and apply.
In tablesync step, apply worker creates a tablesync worker for each table and those tablesync workers are killed when they're done with their associated table. (the number of tablesync workers running at the same time is limited by "max_sync_workers_per_subscription")
Each tablesync worker also creates a replication slot on publisher during its lifetime and drops the slot before exiting.
The purpose of this patch is getting rid of the overhead of creating/killing a new worker (and replication slot) for each table.
It aims to reuse tablesync workers and their replication slots so that tablesync workers can copy multiple tables from publisher to subscriber during their lifetime.
The benefits of reusing tablesync workers can be significant if tables are empty or close to empty.
In an empty table case, spawning tablesync workers and handling replication slots are where the most time is spent since the actual copy phase takes too little time.
The changes in the behaviour of tablesync workers with this patch as follows:
1- After tablesync worker is done with syncing the current table, it takes a lock and fetches tables in init state
2- it looks for a table that is not already being synced by another worker from the tables with init state
3- If it founds one, updates its state for the new table and loops back to beginning to start syncing
4- If no table found, it drops the replication slot and exits
With those changes, I did some benchmarking to see if it improves anything.
This results compares this patch with the latest version of master branch. "max_sync_workers_per_subscription" is set to 2 as default.
Got some results simply averaging timings from 5 consecutive runs for each branch.
First, tested logical replication with empty tables.
10 tables
----------------
- master: 286.964 ms
- the patch: 116.852 ms
100 tables
----------------
- master: 2785.328 ms
- the patch: 706.817 ms
10K tables
----------------
- master: 39612.349 ms
- the patch: 12526.981 ms
Also tried replication tables with some data
10 tables loaded with 10MB data
----------------
- master: 1517.714 ms
- the patch: 1399.965 ms
100 tables loaded with 10MB data
----------------
- master: 16327.229 ms
- the patch: 11963.696 ms
Then loaded more data
10 tables loaded with 100MB data
----------------
- master: 13910.189 ms
- the patch: 14770.982 ms
100 tables loaded with 100MB data
----------------
- master: 146281.457 ms
- the patch: 156957.512
If tables are mostly empty, the improvement can be significant - up to 3x faster logical replication.
With some data loaded, it can still be faster to some extent.
When the table size increases more, the advantage of reusing workers becomes insignificant.
I would appreciate your comments and suggestions.Thanks in advance for reviewing.
Best,
Melih
Вложения
On Tue, Jul 5, 2022 at 7:20 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > I created a patch to reuse tablesync workers and their replication slots for more tables that are not synced yet. So thatoverhead of creating and dropping workers/replication slots can be reduced. > > Current version of logical replication has two steps: tablesync and apply. > In tablesync step, apply worker creates a tablesync worker for each table and those tablesync workers are killed when they'redone with their associated table. (the number of tablesync workers running at the same time is limited by "max_sync_workers_per_subscription") > Each tablesync worker also creates a replication slot on publisher during its lifetime and drops the slot before exiting. > > The purpose of this patch is getting rid of the overhead of creating/killing a new worker (and replication slot) for eachtable. > It aims to reuse tablesync workers and their replication slots so that tablesync workers can copy multiple tables frompublisher to subscriber during their lifetime. > > The benefits of reusing tablesync workers can be significant if tables are empty or close to empty. > In an empty table case, spawning tablesync workers and handling replication slots are where the most time is spent sincethe actual copy phase takes too little time. > > > The changes in the behaviour of tablesync workers with this patch as follows: > 1- After tablesync worker is done with syncing the current table, it takes a lock and fetches tables in init state > 2- it looks for a table that is not already being synced by another worker from the tables with init state > 3- If it founds one, updates its state for the new table and loops back to beginning to start syncing > 4- If no table found, it drops the replication slot and exits > How would you choose the slot name for the table sync, right now it contains the relid of the table for which it needs to perform sync? Say, if we ignore to include the appropriate identifier in the slot name, we won't be able to resue/drop the slot after restart of table sync worker due to an error. > > With those changes, I did some benchmarking to see if it improves anything. > This results compares this patch with the latest version of master branch. "max_sync_workers_per_subscription" is set to2 as default. > Got some results simply averaging timings from 5 consecutive runs for each branch. > > First, tested logical replication with empty tables. > 10 tables > ---------------- > - master: 286.964 ms > - the patch: 116.852 ms > > 100 tables > ---------------- > - master: 2785.328 ms > - the patch: 706.817 ms > > 10K tables > ---------------- > - master: 39612.349 ms > - the patch: 12526.981 ms > > > Also tried replication tables with some data > 10 tables loaded with 10MB data > ---------------- > - master: 1517.714 ms > - the patch: 1399.965 ms > > 100 tables loaded with 10MB data > ---------------- > - master: 16327.229 ms > - the patch: 11963.696 ms > > > Then loaded more data > 10 tables loaded with 100MB data > ---------------- > - master: 13910.189 ms > - the patch: 14770.982 ms > > 100 tables loaded with 100MB data > ---------------- > - master: 146281.457 ms > - the patch: 156957.512 > > > If tables are mostly empty, the improvement can be significant - up to 3x faster logical replication. > With some data loaded, it can still be faster to some extent. > These results indicate that it is a good idea, especially for very small tables. > When the table size increases more, the advantage of reusing workers becomes insignificant. > It seems from your results that performance degrades for large relations. Did you try to investigate the reasons for the same? -- With Regards, Amit Kapila.
On Wed, Jul 6, 2022 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > How would you choose the slot name for the table sync, right now it > contains the relid of the table for which it needs to perform sync? > Say, if we ignore to include the appropriate identifier in the slot > name, we won't be able to resue/drop the slot after restart of table > sync worker due to an error. I had a quick look into the patch and it seems it is using the worker array index instead of relid while forming the slot name, and I think that make sense, because now whichever worker is using that worker index can reuse the slot created w.r.t that index. > > > > With those changes, I did some benchmarking to see if it improves anything. > > This results compares this patch with the latest version of master branch. "max_sync_workers_per_subscription" is setto 2 as default. > > Got some results simply averaging timings from 5 consecutive runs for each branch. > > > > First, tested logical replication with empty tables. > > 10 tables > > ---------------- > > - master: 286.964 ms > > - the patch: 116.852 ms > > > > 100 tables > > ---------------- > > - master: 2785.328 ms > > - the patch: 706.817 ms > > > > 10K tables > > ---------------- > > - master: 39612.349 ms > > - the patch: 12526.981 ms > > > > > > Also tried replication tables with some data > > 10 tables loaded with 10MB data > > ---------------- > > - master: 1517.714 ms > > - the patch: 1399.965 ms > > > > 100 tables loaded with 10MB data > > ---------------- > > - master: 16327.229 ms > > - the patch: 11963.696 ms > > > > > > Then loaded more data > > 10 tables loaded with 100MB data > > ---------------- > > - master: 13910.189 ms > > - the patch: 14770.982 ms > > > > 100 tables loaded with 100MB data > > ---------------- > > - master: 146281.457 ms > > - the patch: 156957.512 > > > > > > If tables are mostly empty, the improvement can be significant - up to 3x faster logical replication. > > With some data loaded, it can still be faster to some extent. > > > > These results indicate that it is a good idea, especially for very small tables. > > > When the table size increases more, the advantage of reusing workers becomes insignificant. > > > > It seems from your results that performance degrades for large > relations. Did you try to investigate the reasons for the same? Yeah, that would be interesting to know that why there is a drop in some cases. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jul 6, 2022 at 1:47 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Jul 6, 2022 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > How would you choose the slot name for the table sync, right now it > > contains the relid of the table for which it needs to perform sync? > > Say, if we ignore to include the appropriate identifier in the slot > > name, we won't be able to resue/drop the slot after restart of table > > sync worker due to an error. > > I had a quick look into the patch and it seems it is using the worker > array index instead of relid while forming the slot name, and I think > that make sense, because now whichever worker is using that worker > index can reuse the slot created w.r.t that index. > I think that won't work because each time on restart the slot won't be fixed. Now, it is possible that we may drop the wrong slot if that state of copying rel is SUBREL_STATE_DATASYNC. Also, it is possible that while creating a slot, we fail because the same name slot already exists due to some other worker which has created that slot has been restarted. Also, what about origin_name, won't that have similar problems? Also, if the state is already SUBREL_STATE_FINISHEDCOPY, if the slot is not the same as we have used in the previous run of a particular worker, it may start WAL streaming from a different point based on the slot's confirmed_flush_location. -- With Regards, Amit Kapila.
On Wed, Jul 6, 2022 at 2:48 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jul 6, 2022 at 1:47 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > On Wed, Jul 6, 2022 at 9:06 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > How would you choose the slot name for the table sync, right now it > > > contains the relid of the table for which it needs to perform sync? > > > Say, if we ignore to include the appropriate identifier in the slot > > > name, we won't be able to resue/drop the slot after restart of table > > > sync worker due to an error. > > > > I had a quick look into the patch and it seems it is using the worker > > array index instead of relid while forming the slot name, and I think > > that make sense, because now whichever worker is using that worker > > index can reuse the slot created w.r.t that index. > > > > I think that won't work because each time on restart the slot won't be > fixed. Now, it is possible that we may drop the wrong slot if that > state of copying rel is SUBREL_STATE_DATASYNC. So it will drop the previous slot the worker at that index was using, so it is possible that on that slot some relation was at SUBREL_STATE_FINISHEDCOPY or so and we will drop that slot. Because now relid and replication slot association is not 1-1 so it would be wrong to drop based on the relstate which is picked by this worker. In short it makes sense what you have pointed out. Also, it is possible > that while creating a slot, we fail because the same name slot already > exists due to some other worker which has created that slot has been > restarted. Also, what about origin_name, won't that have similar > problems? Also, if the state is already SUBREL_STATE_FINISHEDCOPY, if > the slot is not the same as we have used in the previous run of a > particular worker, it may start WAL streaming from a different point > based on the slot's confirmed_flush_location. Yeah this is also true, when a tablesync worker has to do catch up after completing the copy then it might stream from the wrong lsn. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Hi Amit and Dilip,
Thanks for the replies.
> I had a quick look into the patch and it seems it is using the worker
> array index instead of relid while forming the slot name
Yes, I changed the slot names so they include slot index instead of relation id.
This was needed because I aimed to separate replication slots from relations.
I think that won't work because each time on restart the slot won't be
fixed. Now, it is possible that we may drop the wrong slot if that
state of copying rel is SUBREL_STATE_DATASYNC. Also, it is possible
that while creating a slot, we fail because the same name slot already
exists due to some other worker which has created that slot has been
restarted. Also, what about origin_name, won't that have similar
problems? Also, if the state is already SUBREL_STATE_FINISHEDCOPY, if
the slot is not the same as we have used in the previous run of a
particular worker, it may start WAL streaming from a different point
based on the slot's confirmed_flush_location.
You're right Amit. In case of a failure, tablesync phase of a relation may continue with different worker and replication slot due to this change in naming.
Seems like the same replication slot should be used from start to end for a relation during tablesync. However, creating/dropping replication slots can be a major overhead in some cases.
It would be nice if these slots are somehow reused.
To overcome this issue, I've been thinking about making some changes in my patch.
So far, my proposal would be as follows:
Slot naming can be like pg_<sub_id>_<worker_pid> instead of pg_<sub_id>_<slot_index>. This way each worker can use the same replication slot during their lifetime.
But if a worker is restarted, then it will switch to a new replication slot since its pid has changed.
pg_subscription_rel catalog can store replication slot name for each non-ready relation. Then we can find the slot needed for that particular relation to complete tablesync.
If a worker syncs a relation without any error, everything works well and this new replication slot column from the catalog will not be needed.
However if a worker is restarted due to a failure, the previous run of that worker left its slot behind since it did not exit properly.
And the restarted worker (with a different pid) will see that the relation is actually in SUBREL_STATE_FINISHEDCOPY and want to proceed for the catchup step.
Then the worker can look for that particular relation's replication slot from pg_subscription_rel catalog (slot name should be there since relation state is not ready). And tablesync can proceed with that slot.
There might be some cases where some replication slots are left behind. An example to such cases would be when the slot is removed from pg_subscription_rel catalog and detached from any relation, but tha slot actually couldn't be dropped for some reason. For such cases, a slot cleanup logic is needed. This cleanup can also be done by tablesync workers.
Whenever a tablesync worker is created, it can look for existing replication slots that do not belong to any relation and any worker (slot name has pid for that), and drop those slots if it finds any.
What do you think about this new way of handling slots? Do you see any points of concern?
I'm currently working on adding this change into the patch. And would appreciate any comment.
Thanks,
Melih
It seems from your results that performance degrades for large
relations. Did you try to investigate the reasons for the same?
I have not tried to investigate the performance degradation for large relations yet.
Once I'm done with changes for the slot usage, I'll look into this and come with more findings.
Thanks,
Melih
On Fri, Jul 8, 2022 at 10:26 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > >> I think that won't work because each time on restart the slot won't be >> fixed. Now, it is possible that we may drop the wrong slot if that >> state of copying rel is SUBREL_STATE_DATASYNC. Also, it is possible >> that while creating a slot, we fail because the same name slot already >> exists due to some other worker which has created that slot has been >> restarted. Also, what about origin_name, won't that have similar >> problems? Also, if the state is already SUBREL_STATE_FINISHEDCOPY, if >> the slot is not the same as we have used in the previous run of a >> particular worker, it may start WAL streaming from a different point >> based on the slot's confirmed_flush_location. > > > You're right Amit. In case of a failure, tablesync phase of a relation may continue with different worker and replicationslot due to this change in naming. > Seems like the same replication slot should be used from start to end for a relation during tablesync. However, creating/droppingreplication slots can be a major overhead in some cases. > It would be nice if these slots are somehow reused. > > To overcome this issue, I've been thinking about making some changes in my patch. > So far, my proposal would be as follows: > > Slot naming can be like pg_<sub_id>_<worker_pid> instead of pg_<sub_id>_<slot_index>. This way each worker can use thesame replication slot during their lifetime. > But if a worker is restarted, then it will switch to a new replication slot since its pid has changed. > I think using worker_pid also has similar risks of mixing slots from different workers because after restart same worker_pid could be assigned to a totally different worker. Can we think of using a unique 64-bit number instead? This will be allocated when each workers started for the very first time and after that we can refer catalog to find it as suggested in the idea below. > pg_subscription_rel catalog can store replication slot name for each non-ready relation. Then we can find the slot neededfor that particular relation to complete tablesync. > Yeah, this is worth investigating. However, instead of storing the slot_name, we can store just the unique number (as suggested above). We should use the same for the origin name as well. > If a worker syncs a relation without any error, everything works well and this new replication slot column from the catalogwill not be needed. > However if a worker is restarted due to a failure, the previous run of that worker left its slot behind since it did notexit properly. > And the restarted worker (with a different pid) will see that the relation is actually in SUBREL_STATE_FINISHEDCOPY andwant to proceed for the catchup step. > Then the worker can look for that particular relation's replication slot from pg_subscription_rel catalog (slot name shouldbe there since relation state is not ready). And tablesync can proceed with that slot. > > There might be some cases where some replication slots are left behind. An example to such cases would be when the slotis removed from pg_subscription_rel catalog and detached from any relation, but tha slot actually couldn't be droppedfor some reason. For such cases, a slot cleanup logic is needed. This cleanup can also be done by tablesync workers. > Whenever a tablesync worker is created, it can look for existing replication slots that do not belong to any relation andany worker (slot name has pid for that), and drop those slots if it finds any. > This sounds tricky. Why not first drop slot/origin and then detach it from pg_subscription_rel? On restarts, it is possible that we may error out after dropping the slot or origin but before updating the catalog entry but in such case we can ignore missing slot/origin and detach them from pg_subscription_rel. Also, if we use the unique number as suggested above, I think even if we don't remove it after the relation state is ready, it should be okay. > What do you think about this new way of handling slots? Do you see any points of concern? > > I'm currently working on adding this change into the patch. And would appreciate any comment. > Thanks for making progress! -- With Regards, Amit Kapila.
Hi Amit,
I updated the patch in order to prevent the problems that might be caused by using different replication slots for syncing a table.
As suggested in previous emails, replication slot names are stored in the catalog. So slot names can be reached later and it is ensured
that same replication slot is used during tablesync step of a table.
With the current version of the patch:
-. "srrelslotname" column is introduced into pg_subscibtion_rel catalog. It stores the slot name for tablesync
-. Tablesync worker logic is now as follows:
1. Tablesync worker is launched by apply worker for a table.
2. Worker generates a default replication slot name for itself. Slot name includes subid and worker pid for tracking purposes.
3. If table has a slot name value in the catalog:
i. If the table state is DATASYNC, drop the replication slot from the catalog and proceed tablesync with a new slot.
4. Before worker moves to new table, drop any replication slot that are retrieved from the catalog and used.ii. If the table state is FINISHEDCOPY, use the replicaton slot from the catalog, do not create a new slot.
5. In case of no table left to sync, drop the replication slot of that sync worker with worker pid if it exists. (It's possible that a sync worker do not create a replication slot for itself but uses slots read from the catalog in each iteration)
I think using worker_pid also has similar risks of mixing slots from
different workers because after restart same worker_pid could be
assigned to a totally different worker. Can we think of using a unique
64-bit number instead? This will be allocated when each workers
started for the very first time and after that we can refer catalog to
find it as suggested in the idea below.
I'm not sure how likely to have colliding pid's for different tablesync workers in the same subscription.
Though ,having pid in slot name makes it easier to track which slot belongs to which worker. That's why I kept using pid in slot names.
But I think it should be simple to switch to using a unique 64-bit number. So I can remove pid's from slot names, if you think that it would be better.
We should use the same for the origin name as well.
I did not really change anything related to origin names. Origin names are still the same and include relation id. What do you think would be an issue with origin names in this patch?
This sounds tricky. Why not first drop slot/origin and then detach it
from pg_subscription_rel? On restarts, it is possible that we may
error out after dropping the slot or origin but before updating the
catalog entry but in such case we can ignore missing slot/origin and
detach them from pg_subscription_rel. Also, if we use the unique
number as suggested above, I think even if we don't remove it after
the relation state is ready, it should be okay.
Right, I did not add an additional slot cleanup step. The patch now drops the slot when we're done with it and then removes it from the catalog.
Thanks,
Melih
Вложения
On Wed, Jul 27, 2022 at 3:56 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi Amit, > > I updated the patch in order to prevent the problems that might be caused by using different replication slots for syncinga table. > As suggested in previous emails, replication slot names are stored in the catalog. So slot names can be reached later andit is ensured > that same replication slot is used during tablesync step of a table. > > With the current version of the patch: > -. "srrelslotname" column is introduced into pg_subscibtion_rel catalog. It stores the slot name for tablesync > > -. Tablesync worker logic is now as follows: > 1. Tablesync worker is launched by apply worker for a table. > 2. Worker generates a default replication slot name for itself. Slot name includes subid and worker pid for tracking purposes. > 3. If table has a slot name value in the catalog: > > i. If the table state is DATASYNC, drop the replication slot from the catalog and proceed tablesync with a new slot. > > ii. If the table state is FINISHEDCOPY, use the replicaton slot from the catalog, do not create a new slot. > > 4. Before worker moves to new table, drop any replication slot that are retrieved from the catalog and used. > Why after step 4, do you need to drop the replication slot? Won't just clearing the required info from the catalog be sufficient? > 5. In case of no table left to sync, drop the replication slot of that sync worker with worker pid if it exists. (It'spossible that a sync worker do not create a replication slot for itself but uses slots read from the catalog in eachiteration) > > >> I think using worker_pid also has similar risks of mixing slots from >> different workers because after restart same worker_pid could be >> assigned to a totally different worker. Can we think of using a unique >> 64-bit number instead? This will be allocated when each workers >> started for the very first time and after that we can refer catalog to >> find it as suggested in the idea below. > > > I'm not sure how likely to have colliding pid's for different tablesync workers in the same subscription. > Hmm, I think even if there is an iota of a chance which I think is there, we can't use worker_pid. Assume, that if the same worker_pid is assigned to another worker once the worker using it got an error out, the new worker will fail as soon as it will try to create a replication slot. > Though ,having pid in slot name makes it easier to track which slot belongs to which worker. That's why I kept using pidin slot names. > But I think it should be simple to switch to using a unique 64-bit number. So I can remove pid's from slot names, if youthink that it would be better. > I feel it would be better or maybe we need to think of some other identifier but one thing we need to think about before using a 64-bit unique identifier here is how will we retrieve its last used value after restart of server. We may need to store it in a persistent way somewhere. >> >> We should use the same for the origin name as well. > > > I did not really change anything related to origin names. Origin names are still the same and include relation id. Whatdo you think would be an issue with origin names in this patch? > The problems will be similar to the slot name. The origin is used to track the progress of replication, so, if we use the wrong origin name after the restart, it can send the wrong start_streaming position to the publisher. -- With Regards, Amit Kapila.
Why after step 4, do you need to drop the replication slot? Won't just
clearing the required info from the catalog be sufficient?
The replication slots that we read from the catalog will not be used for anything else after we're done with syncing the table which the rep slot belongs to.
It's removed from the catalog when the sync is completed and it basically becomes a slot that is not linked to any table or worker. That's why I think it should be dropped rather than left behind.
Note that if a worker dies and its replication slot continues to exist, that slot will only be used to complete the sync process of the one table that the dead worker was syncing but couldn't finish.
When that particular table is synced and becomes ready, the replication slot has no use anymore.
Hmm, I think even if there is an iota of a chance which I think is
there, we can't use worker_pid. Assume, that if the same worker_pid is
assigned to another worker once the worker using it got an error out,
the new worker will fail as soon as it will try to create a
replication slot.
Right. If something like that happens, worker will fail without doing anything. Then a new one will be launched and that one will continue to do the work.
The worst case might be having conflicting pid over and over again while also having replication slots whose name includes one of those pids still exist.
It seems unlikely but possible, yes.
I feel it would be better or maybe we need to think of some other
identifier but one thing we need to think about before using a 64-bit
unique identifier here is how will we retrieve its last used value
after restart of server. We may need to store it in a persistent way
somewhere.
We might consider storing this info in a catalog again. Since this last used value will be different for each subscription, pg_subscription can be a good place to keep that.
The problems will be similar to the slot name. The origin is used to
track the progress of replication, so, if we use the wrong origin name
after the restart, it can send the wrong start_streaming position to
the publisher.
I understand. But origin naming logic is still the same. Its format is like pg_<subid>_<relid> .
I did not need to change this since it seems to me origins should belong to only one table. The patch does not reuse origins.
So I don't think this change introduces an issue with origin. What do you think?
Thanks,
Melih
On Thu, Jul 28, 2022 at 9:32 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: >> >> Why after step 4, do you need to drop the replication slot? Won't just >> clearing the required info from the catalog be sufficient? > > > The replication slots that we read from the catalog will not be used for anything else after we're done with syncing thetable which the rep slot belongs to. > It's removed from the catalog when the sync is completed and it basically becomes a slot that is not linked to any tableor worker. That's why I think it should be dropped rather than left behind. > > Note that if a worker dies and its replication slot continues to exist, that slot will only be used to complete the syncprocess of the one table that the dead worker was syncing but couldn't finish. > When that particular table is synced and becomes ready, the replication slot has no use anymore. > Why can't it be used to sync the other tables if any? >> >> Hmm, I think even if there is an iota of a chance which I think is >> there, we can't use worker_pid. Assume, that if the same worker_pid is >> assigned to another worker once the worker using it got an error out, >> the new worker will fail as soon as it will try to create a >> replication slot. > > > Right. If something like that happens, worker will fail without doing anything. Then a new one will be launched and thatone will continue to do the work. > The worst case might be having conflicting pid over and over again while also having replication slots whose name includesone of those pids still exist. > It seems unlikely but possible, yes. > >> >> I feel it would be better or maybe we need to think of some other >> identifier but one thing we need to think about before using a 64-bit >> unique identifier here is how will we retrieve its last used value >> after restart of server. We may need to store it in a persistent way >> somewhere. > > > We might consider storing this info in a catalog again. Since this last used value will be different for each subscription,pg_subscription can be a good place to keep that. > This sounds reasonable. Let's do this unless we get some better idea. >> >> The problems will be similar to the slot name. The origin is used to >> track the progress of replication, so, if we use the wrong origin name >> after the restart, it can send the wrong start_streaming position to >> the publisher. > > > I understand. But origin naming logic is still the same. Its format is like pg_<subid>_<relid> . > I did not need to change this since it seems to me origins should belong to only one table. The patch does not reuse origins. > So I don't think this change introduces an issue with origin. What do you think? > There is no such restriction that origins should belong to only one table. What makes you think like that? -- With Regards, Amit Kapila.
Hi Amit,
>> Why after step 4, do you need to drop the replication slot? Won't just
>> clearing the required info from the catalog be sufficient?
>
>
> The replication slots that we read from the catalog will not be used for anything else after we're done with syncing the table which the rep slot belongs to.
> It's removed from the catalog when the sync is completed and it basically becomes a slot that is not linked to any table or worker. That's why I think it should be dropped rather than left behind.
>
> Note that if a worker dies and its replication slot continues to exist, that slot will only be used to complete the sync process of the one table that the dead worker was syncing but couldn't finish.
> When that particular table is synced and becomes ready, the replication slot has no use anymore.
>
Why can't it be used to sync the other tables if any?
It can be used. But I thought it would be better not to, for example in the following case:
Let's say a sync worker starts with a table in INIT state. The worker creates a new replication slot to sync that table.
When sync of the table is completed, it will move to the next one. This time the new table may be in FINISHEDCOPY state, so the worker may need to use the new table's existing replication slot.
Before the worker will move to the next table again, there will be two replication slots used by the worker. We might want to keep one and drop the other.
At this point, I thought it would be better to keep the replication slot created by this worker in the first place. I think it's easier to track slots this way since we know how to generate the rep slots name.
Otherwise we would need to store the replication slot name somewhere too.
This sounds reasonable. Let's do this unless we get some better idea.
I updated the patch to use an unique id for replication slot names and store the last used id in the catalog.
Can you look into it again please?
There is no such restriction that origins should belong to only one
table. What makes you think like that?
I did not reuse origins since I didn't think it would significantly improve the performance as reusing replication slots does.
So I just kept the origins as they were, even if it was possible to reuse them. Does that make sense?
Best,
Melih
Вложения
On Fri, Aug 5, 2022 at 7:25 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: >> >> Why can't it be used to sync the other tables if any? > > > It can be used. But I thought it would be better not to, for example in the following case: > Let's say a sync worker starts with a table in INIT state. The worker creates a new replication slot to sync that table. > When sync of the table is completed, it will move to the next one. This time the new table may be in FINISHEDCOPY state,so the worker may need to use the new table's existing replication slot. > Before the worker will move to the next table again, there will be two replication slots used by the worker. We might wantto keep one and drop the other. > At this point, I thought it would be better to keep the replication slot created by this worker in the first place. I thinkit's easier to track slots this way since we know how to generate the rep slots name. > Otherwise we would need to store the replication slot name somewhere too. > I think there is some basic flaw in slot reuse design. Currently, we copy the table by starting a repeatable read transaction (BEGIN READ ONLY ISOLATION LEVEL REPEATABLE READ) and create a slot that establishes a snapshot which is first used for copy and then LSN returned by it is used in the catchup phase after the copy is done. The patch won't establish such a snapshot before a table copy as it won't create a slot each time. If this understanding is correct, I think we need to use ExportSnapshot/ImportSnapshot functionality to achieve it or do something else to avoid the problem mentioned. > >> >> This sounds reasonable. Let's do this unless we get some better idea. > > >> There is no such restriction that origins should belong to only one >> table. What makes you think like that? > > > I did not reuse origins since I didn't think it would significantly improve the performance as reusing replication slotsdoes. > So I just kept the origins as they were, even if it was possible to reuse them. Does that make sense? > For small tables, it could have a visible performance difference as it involves database write operations to each time create and drop the origin. But if we don't want to reuse then also you need to set its origin_lsn appropriately. Currently (without this patch), after creating the slot, we directly use the origin_lsn returned by create_slot API whereas now it won't be the same case as the patch doesn't create a slot every time. -- With Regards, Amit Kapila.
Hi Amit,
Amit Kapila <amit.kapila16@gmail.com>, 6 Ağu 2022 Cmt, 16:01 tarihinde şunu yazdı:
I think there is some basic flaw in slot reuse design. Currently, we
copy the table by starting a repeatable read transaction (BEGIN READ
ONLY ISOLATION LEVEL REPEATABLE READ) and create a slot that
establishes a snapshot which is first used for copy and then LSN
returned by it is used in the catchup phase after the copy is done.
The patch won't establish such a snapshot before a table copy as it
won't create a slot each time. If this understanding is correct, I
think we need to use ExportSnapshot/ImportSnapshot functionality to
achieve it or do something else to avoid the problem mentioned.
I did not really think about the snapshot created by replication slot while making this change. Thanks for pointing it out.
I've been thinking about how to fix this issue. There are some points I'm still not sure about.
If the worker will not create a new replication slot, which snapshot should we actually export and then import?
At the line where the worker was supposed to create replication slot but now will reuse an existing slot instead, calling pg_export_snapshot() can export the snapshot instead of CREATE_REPLICATION_SLOT.
However, importing that snapshot into the current transaction may not make any difference since we exported that snapshot from the same transaction. I think this wouldn't make sense.
How else an export/import snapshot logic can be placed in this change?
LSN also should be set accurately. The current change does not handle LSN properly.
I see that CREATE_REPLICATION_SLOT returns consistent_point which indicates the earliest location which streaming can start from. And this consistent_point is used as origin_startpos.
If that's the case, would it make sense to use "confirmed_flush_lsn" of the replication slot in case the slot is being reused?
Since confirmed_flush_lsn can be considered as the safest, earliest location which streaming can start from, I think it would work.
And at this point, with the correct LSN, I'm wondering whether this export/import logic is really necessary if the worker does not create a replication slot. What do you think?
For small tables, it could have a visible performance difference as it
involves database write operations to each time create and drop the
origin. But if we don't want to reuse then also you need to set its
origin_lsn appropriately. Currently (without this patch), after
creating the slot, we directly use the origin_lsn returned by
create_slot API whereas now it won't be the same case as the patch
doesn't create a slot every time.
Correct. For this issue, please consider the LSN logic explained above.
Thanks,
Melih
On Mon, Aug 15, 2022 at 4:56 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi Amit, > > Amit Kapila <amit.kapila16@gmail.com>, 6 Ağu 2022 Cmt, 16:01 tarihinde şunu yazdı: >> >> I think there is some basic flaw in slot reuse design. Currently, we >> copy the table by starting a repeatable read transaction (BEGIN READ >> ONLY ISOLATION LEVEL REPEATABLE READ) and create a slot that >> establishes a snapshot which is first used for copy and then LSN >> returned by it is used in the catchup phase after the copy is done. >> The patch won't establish such a snapshot before a table copy as it >> won't create a slot each time. If this understanding is correct, I >> think we need to use ExportSnapshot/ImportSnapshot functionality to >> achieve it or do something else to avoid the problem mentioned. > > > I did not really think about the snapshot created by replication slot while making this change. Thanks for pointing itout. > I've been thinking about how to fix this issue. There are some points I'm still not sure about. > If the worker will not create a new replication slot, which snapshot should we actually export and then import? > Can we (export/import) use the snapshot we used the first time when a slot is created for future transactions that copy other tables? Because if we can do that then I think we can use the same LSN as returned for the slot when it was created for all other table syncs. -- With Regards, Amit Kapila.
Re: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
Ian Lawrence Barwick
Дата:
2022年8月5日(金) 22:55 Melih Mutlu <m.melihmutlu@gmail.com>: > > Hi Amit, > >> >> Why after step 4, do you need to drop the replication slot? Won't just >> >> clearing the required info from the catalog be sufficient? >> > >> > >> > The replication slots that we read from the catalog will not be used for anything else after we're done with syncingthe table which the rep slot belongs to. >> > It's removed from the catalog when the sync is completed and it basically becomes a slot that is not linked to any tableor worker. That's why I think it should be dropped rather than left behind. >> > >> > Note that if a worker dies and its replication slot continues to exist, that slot will only be used to complete thesync process of the one table that the dead worker was syncing but couldn't finish. >> > When that particular table is synced and becomes ready, the replication slot has no use anymore. >> > >> >> Why can't it be used to sync the other tables if any? > > > It can be used. But I thought it would be better not to, for example in the following case: > Let's say a sync worker starts with a table in INIT state. The worker creates a new replication slot to sync that table. > When sync of the table is completed, it will move to the next one. This time the new table may be in FINISHEDCOPY state,so the worker may need to use the new table's existing replication slot. > Before the worker will move to the next table again, there will be two replication slots used by the worker. We might wantto keep one and drop the other. > At this point, I thought it would be better to keep the replication slot created by this worker in the first place. I thinkit's easier to track slots this way since we know how to generate the rep slots name. > Otherwise we would need to store the replication slot name somewhere too. > > >> >> This sounds reasonable. Let's do this unless we get some better idea. > > > I updated the patch to use an unique id for replication slot names and store the last used id in the catalog. > Can you look into it again please? > > >> There is no such restriction that origins should belong to only one >> table. What makes you think like that? > > > I did not reuse origins since I didn't think it would significantly improve the performance as reusing replication slotsdoes. > So I just kept the origins as they were, even if it was possible to reuse them. Does that make sense? Hi cfbot reports the patch no longer applies [1]. As CommitFest 2022-11 is currently underway, this would be an excellent time to update the patch. [1] http://cfbot.cputube.org/patch_40_3784.log Thanks Ian Barwick
Hi hackers,
I've been working on/struggling with this patch for a while. But I haven't updated this thread regularly.
So sharing what I did with this patch so far.
> Amit Kapila <amit.kapila16@gmail.com>, 6 Ağu 2022 Cmt, 16:01 tarihinde şunu yazdı:
>>
>> I think there is some basic flaw in slot reuse design. Currently, we
>> copy the table by starting a repeatable read transaction (BEGIN READ
>> ONLY ISOLATION LEVEL REPEATABLE READ) and create a slot that
>> establishes a snapshot which is first used for copy and then LSN
>> returned by it is used in the catchup phase after the copy is done.
>> The patch won't establish such a snapshot before a table copy as it
>> won't create a slot each time. If this understanding is correct, I
>> think we need to use ExportSnapshot/ImportSnapshot functionality to
>> achieve it or do something else to avoid the problem mentioned.
This issue that Amit mentioned causes some problems such as duplicated rows in the subscriber.
Basically, with this patch, tablesync worker creates a replication slot only in its first run. To ensure table copy and sync are consistent with each other, the worker needs the correct snapshot and LSN which both are returned by slot create operation.
Since this patch does not create a rep. slot in each table copy and instead reuses the one created in the beginning, we do not get a new snapshot and LSN for each table anymore. Snapshot gets lost right after the transaction is committed, but the patch continues to use the same LSN for next tables without the proper snapshot.
In the end, for example, the worker might first copy some rows, then apply changes from rep. slot and inserts those rows again for the tables in later iterations.
I discussed some possible ways to resolve this with Amit offline:
1- Copy all tables in one transaction so that we wouldn't need to deal with snapshots.
Not easy to keep track of the progress. If the transaction fails, we would need to start all over again.
2- Don't lose the first snapshot (by keeping a transaction open with the snapshot imported or some other way) and use the same snapshot and LSN for all tables.
I'm not sure about the side effects of keeping a transaction open that long or using a snapshot that might be too old after some time.
Still seems like it might work.
3- For each table, get a new snapshot and LSN by using an existing replication slot.
Even though this approach wouldn't create a new replication slot, preparing the slot for snapshot and then taking the snapshot may be costly.
Need some numbers here to see how much this approach would improve the performance.
I decided to go with approach 3 (creating a new snapshot with an existing replication slot) for now since it would require less change in the tablesync worker logic than the other options would.
To achieve this, this patch introduces a new command for Streaming Replication Protocol.
The new REPLICATION_SLOT_SNAPSHOT command basically mimics how CREATE_REPLICATION_SLOT creates a snapshot, but without actually creating a new replication slot.
Later the tablesync worker calls this command if it decides not to create a new rep. slot, uses the snapshot created and LSN returned by the command.
Also;
After the changes discussed here [1], concurrent replication origin drops by apply worker and tablesync workers may hold each other on wait due to locks taken by replorigin_drop_by_name.
I see that this harms the performance of logical replication quite a bit in terms of speed.
Even though reusing replication origins was discussed in this thread before, the patch didn't include any change to do so.
The updated version of the patch now also reuses replication origins too. Seems like even only changes to reuse origins by itself improves the performance significantly.
Attached two patches:
0001: adds REPLICATION_SLOT_SNAPSHOT command for replication protocol.
0002: Reuses workers/replication slots and origins for tablesync
I would appreciate any feedback/review/thought on the approach and both patches.
I will also share some numbers to compare performances of the patch and master branch soon.
Best,
--
Melih Mutlu
Microsoft
Вложения
On Mon, Dec 5, 2022 at 6:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Attached two patches: > 0001: adds REPLICATION_SLOT_SNAPSHOT command for replication protocol. > 0002: Reuses workers/replication slots and origins for tablesync > > I would appreciate any feedback/review/thought on the approach and both patches. > I will also share some numbers to compare performances of the patch and master branch soon. > It would be interesting to see the numbers differently for resue of replication slots and origins. This will let us know how much each of those optimizations helps with the reuse of workers. -- With Regards, Amit Kapila.
Hi,
Attached new versions of the patch with some changes/fixes.
Here also some numbers to compare the performance of log. rep. with this patch against the current master branch.
My method of benchmarking is the same with what I did earlier in this thread. (on a different environment, so not compare the result from this email with the ones from earlier emails)
With those changes, I did some benchmarking to see if it improves anything.
This results compares this patch with the latest version of master branch. "max_sync_workers_per_subscription" is set to 2 as default.
Got some results simply averaging timings from 5 consecutive runs for each branch.
Since this patch is expected to improve log. rep. of empty/close-to-empty tables, started with measuring performance with empty tables.
| 10 tables | 100 tables | 1000 tables
------------------------------------------------------------------------------
master | 283.430 ms | 22739.107 ms | 105226.177 ms
------------------------------------------------------------------------------
patch | 189.139 ms | 1554.802 ms | 23091.434 ms
After the changes discussed here [1], concurrent replication origin drops by apply worker and tablesync workers may hold each other on wait due to locks taken by replorigin_drop_by_name.
I see that this harms the performance of logical replication quite a bit in terms of speed.
[1] https://www.postgresql.org/message-id/flat/20220714115155.GA5439%40depesz.com
Firstly, as I mentioned, replication origin drops made things worse for the master branch.
Locks start being a more serious issue when the number of tables increases.
The patch reuses the origin so does not need to drop them in each iteration. That's why the difference between the master and the patch is more significant now than it was when I first sent the patch.
To just show that the improvement is not only the result of reuse of origins, but also reuse of rep. slots and workers, I just reverted those commits which causes the origin drop issue.
| 10 tables | 100 tables | 1000 tables
-----------------------------------------------------------------------------
reverted | 270.012 ms | 2483.907 ms | 31660.758 ms
-----------------------------------------------------------------------------
patch | 189.139 ms | 1554.802 ms | 23091.434 ms
With this patch, logical replication is still faster, even if we wouldn't have an issue with rep. origin drops.
Also here are some numbers with 10 tables loaded with some data :
| 10 MB | 100 MB
----------------------------------------------------------
master | 2868.524 ms | 14281.711 ms
----------------------------------------------------------
patch | 1750.226 ms | 14592.800 ms
The difference between the master and the patch is getting close when the size of tables increase, as expected.
I would appreciate any feedback/thought on the approach/patch/numbers etc.
Thanks,
-- Melih Mutlu
Microsoft
Вложения
On Thu, Dec 15, 2022 at 5:33 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Also here are some numbers with 10 tables loaded with some data : > > | 10 MB | 100 MB > ---------------------------------------------------------- > master | 2868.524 ms | 14281.711 ms > ---------------------------------------------------------- > patch | 1750.226 ms | 14592.800 ms > > The difference between the master and the patch is getting close when the size of tables increase, as expected. > Right, but when the size is 100MB, it seems to be taking a bit more time. Do we want to evaluate with different sizes to see how it looks? Other than that all the numbers are good. -- With Regards, Amit Kapila.
Hi Amit,
Amit Kapila <amit.kapila16@gmail.com>, 16 Ara 2022 Cum, 05:46 tarihinde şunu yazdı:
Right, but when the size is 100MB, it seems to be taking a bit more
time. Do we want to evaluate with different sizes to see how it looks?
Other than that all the numbers are good.
I did a similar testing with again 100MB and also 1GB this time.
| 100 MB | 1 GB
----------------------------------------------------------
master | 14761.425 ms | 160932.982 ms
----------------------------------------------------------
patch | 14398.408 ms | 160593.078 ms
This time, it seems like the patch seems slightly faster than the master.
Not sure if we can say the patch slows things down (or speeds up) if the size of tables increases.
The difference may be something arbitrary or caused by other factors. What do you think?
I also wondered what happens when "max_sync_workers_per_subscription" is set to 1.
Which means tablesync will be done sequentially in both cases but the patch will use only one worker and one replication slot during the whole tablesync process.
Here are the numbers for that case:
| 100 MB | 1 GB
----------------------------------------------------------
master | 27751.463 ms | 312424.999 ms
----------------------------------------------------------
patch | 27342.760 ms | 310021.767 ms
Best,
Melih Mutlu
Microsoft
On Tue, Dec 20, 2022 at 8:14 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Amit Kapila <amit.kapila16@gmail.com>, 16 Ara 2022 Cum, 05:46 tarihinde şunu yazdı: >> >> Right, but when the size is 100MB, it seems to be taking a bit more >> time. Do we want to evaluate with different sizes to see how it looks? >> Other than that all the numbers are good. > > > I did a similar testing with again 100MB and also 1GB this time. > > | 100 MB | 1 GB > ---------------------------------------------------------- > master | 14761.425 ms | 160932.982 ms > ---------------------------------------------------------- > patch | 14398.408 ms | 160593.078 ms > > This time, it seems like the patch seems slightly faster than the master. > Not sure if we can say the patch slows things down (or speeds up) if the size of tables increases. > The difference may be something arbitrary or caused by other factors. What do you think? > Yes, I agree with you as I also can't see an obvious reason for any slowdown with this patch's idea. -- With Regards, Amit Kapila.
Hi hackers,
Sending an updated version of this patch to get rid of compiler warnings.
I would highly appreciate any feedback.
Thanks,
-- Melih Mutlu
Microsoft
Вложения
Hi hackers,
Rebased the patch to resolve conflicts.
Best,
-- Melih Mutlu
Microsoft
Вложения
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"shiy.fnst@fujitsu.com"
Дата:
On Wed, Jan 11, 2023 4:31 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi hackers,
>
> Rebased the patch to resolve conflicts.
>
Thanks for your patch. Here are some comments.
0001 patch
============
1. walsender.c
+ /* Create a tuple to send consisten WAL location */
"consisten" should be "consistent" I think.
2. logical.c
+ if (need_full_snapshot)
+ {
+ LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE);
+
+ SpinLockAcquire(&slot->mutex);
+ slot->effective_catalog_xmin = xmin_horizon;
+ slot->data.catalog_xmin = xmin_horizon;
+ slot->effective_xmin = xmin_horizon;
+ SpinLockRelease(&slot->mutex);
+
+ xmin_horizon = GetOldestSafeDecodingTransactionId(!need_full_snapshot);
+ ReplicationSlotsComputeRequiredXmin(true);
+
+ LWLockRelease(ProcArrayLock);
+ }
It seems that we should first get the safe decoding xid, then inform the slot
machinery about the new limit, right? Otherwise the limit will be
InvalidTransactionId and that seems inconsistent with the comment.
3. doc/src/sgml/protocol.sgml
+ is used in the currenct transaction. This command is currently only supported
+ for logical replication.
+ slots.
We don't need to put "slots" in a new line.
0002 patch
============
1.
In pg_subscription_rel.h, I think the type of "srrelslotname" can be changed to
NameData, see "subslotname" in pg_subscription.h.
2.
+ * Find the logical replication sync worker if exists store
+ * the slot number for dropping associated replication slots
+ * later.
Should we add comma after "if exists"?
3.
+ PG_FINALLY();
+ {
+ pfree(cmd.data);
+ }
+ PG_END_TRY();
+ \
+ return tablelist;
+}
Do we need the backslash?
4.
+ /*
+ * Advance to the LSN got from walrcv_create_slot. This is WAL
+ * logged for the purpose of recovery. Locks are to prevent the
+ * replication origin from vanishing while advancing.
"walrcv_create_slot" should be changed to
"walrcv_create_slot/walrcv_slot_snapshot" I think.
5.
+ /* Replication drop might still exist. Try to drop */
+ replorigin_drop_by_name(originname, true, false);
Should "Replication drop" be "Replication origin"?
6.
I saw an assertion failure in the following case, could you please look into it?
The backtrace is attached.
-- pub
CREATE TABLE tbl1 (a int, b text);
CREATE TABLE tbl2 (a int primary key, b text);
create publication pub for table tbl1, tbl2;
insert into tbl1 values (1, 'a');
insert into tbl1 values (1, 'a');
-- sub
CREATE TABLE tbl1 (a int primary key, b text);
CREATE TABLE tbl2 (a int primary key, b text);
create subscription sub connection 'dbname=postgres port=5432' publication pub;
Subscriber log:
2023-01-17 14:47:10.054 CST [1980841] LOG: logical replication apply worker for subscription "sub" has started
2023-01-17 14:47:10.060 CST [1980843] LOG: logical replication table synchronization worker for subscription "sub",
table"tbl1" has started
2023-01-17 14:47:10.070 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub",
table"tbl2" has started
2023-01-17 14:47:10.073 CST [1980843] ERROR: duplicate key value violates unique constraint "tbl1_pkey"
2023-01-17 14:47:10.073 CST [1980843] DETAIL: Key (a)=(1) already exists.
2023-01-17 14:47:10.073 CST [1980843] CONTEXT: COPY tbl1, line 2
2023-01-17 14:47:10.074 CST [1980821] LOG: background worker "logical replication worker" (PID 1980843) exited with
exitcode 1
2023-01-17 14:47:10.083 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub",
table"tbl2" has finished
2023-01-17 14:47:10.083 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub" has
movedto sync table "tbl1".
TRAP: failed Assert("node != InvalidRepOriginId"), File: "origin.c", Line: 892, PID: 1980845
Regards,
Shi yu
Вложения
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"wangw.fnst@fujitsu.com"
Дата:
On Wed, Jan 11, 2023 4:31 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > Rebased the patch to resolve conflicts. Thanks for your patch set. Here are some comments: v3-0001* patch =============== 1. typedefs.list I think we also need to add "walrcv_slot_snapshot_fn" to this file. v7-0002* patch =============== 1. About function ReplicationOriginNameForLogicalRep() Do we need to modify the API of this function? I think the original API could also meet the current needs. Since this is not a static function, I think it seems better to keep the original API if there is no reason. Please let me know if I'm missing something. ----- 2. Comment atop the function GetSubscriptionRelReplicationSlot +/* + * Get replication slot name of subscription table. + * + * Returns null if the subscription table does not have a replication slot. + */ Since this function always returns NULL, I think it would be better to say the value in "slotname" here instead of the function's return value. If you agree with this, please also kindly modify the comment atop the function GetSubscriptionRelOrigin. ----- 3. typo + * At this point, there shouldn't be any existing replication + * origin wit the same name. wit -> with ----- 4. In function CreateSubscription + values[Anum_pg_subscription_sublastusedid - 1] = Int64GetDatum(1); I think it might be better to initialize this field to NULL or 0 here. Because in the patch, we always ignore the initialized value when launching the sync worker in the function process_syncing_tables_for_apply. And I think we could document in pg-doc that this value means that no tables have been synced yet. ----- 5. New member "created_slot" in structure LogicalRepWorker + /* + * Indicates if the sync worker created a replication slot or it reuses an + * existing one created by another worker. + */ + bool created_slot; I think the second half of the sentence looks inaccurate. Because I think this flag could be false even when we reuse an existing slot created by another worker. Assuming the first run for the worker tries to sync a table which is synced by another sync worker before, and the relstate is set to SUBREL_STATE_FINISHEDCOPY by another sync worker, I think this flag will not be set to true. (see function LogicalRepSyncTableStart) So, what if we simplify the description here and just say that this worker already has it's default slot? If I'm not missing something and you agree with this, please also kindly modify the relevant comment atop the if-statement (!MyLogicalRepWorker->created_slot) in the function LogicalRepSyncTableStart. Regards, Wang Wei
Hi,
Thanks for your review.
Attached updated versions of the patches.
On Wed, Jan 11, 2023 4:31 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
v3-0001* patch
===============
1. typedefs.list
I think we also need to add "walrcv_slot_snapshot_fn" to this file.
Done.
v7-0002* patch
===============
1. About function ReplicationOriginNameForLogicalRep()
Do we need to modify the API of this function? I think the original API could
also meet the current needs. Since this is not a static function, I think it
seems better to keep the original API if there is no reason. Please let me know
if I'm missing something.
You're right.
I still need to modify ReplicationOriginNameForLogicalRep. Origin names are not tied to relations anymore, so their name doesn't need to include relation id.
But I didn't really need to change the function signature. I reverted that part of the change in the updated version of the patch.
2. Comment atop the function GetSubscriptionRelReplicationSlot
Done
3. typo
+ * At this point, there shouldn't be any existing replication
+ * origin wit the same name.
Done.
4. In function CreateSubscription
+ values[Anum_pg_subscription_sublastusedid - 1] = Int64GetDatum(1);
I think it might be better to initialize this field to NULL or 0 here.
Because in the patch, we always ignore the initialized value when launching
the sync worker in the function process_syncing_tables_for_apply. And I think
we could document in pg-doc that this value means that no tables have been
synced yet.
I changed it to start from 0 and added a line into the related doc to indicate that 0 means that no table has been synced yet.
5. New member "created_slot" in structure LogicalRepWorker
+ /*
+ * Indicates if the sync worker created a replication slot or it reuses an
+ * existing one created by another worker.
+ */
+ bool created_slot;
I think the second half of the sentence looks inaccurate.
Because I think this flag could be false even when we reuse an existing slot
created by another worker. Assuming the first run for the worker tries to sync
a table which is synced by another sync worker before, and the relstate is set
to SUBREL_STATE_FINISHEDCOPY by another sync worker, I think this flag will not
be set to true. (see function LogicalRepSyncTableStart)
So, what if we simplify the description here and just say that this worker
already has it's default slot?
If I'm not missing something and you agree with this, please also kindly modify
the relevant comment atop the if-statement (!MyLogicalRepWorker->created_slot)
in the function LogicalRepSyncTableStart.
This "created_slot" indicates whether the current worker has created a replication slot for its own use. If so, created_slot will be true, otherwise false.
Let's say the tablesync worker has not created its own slot yet in its previous runs or this is its first run. And the worker decides to reuse an existing replication slot (which created by another tablesync worker). Then created_slot is expected to be false. Because this particular tablesync worker has not created its own slot yet in either of its runs.
In your example, the worker is in its first run and begin to sync a table whose state is FINISHEDCOPY. If the table's state is FINISHEDCOPY then the table should already have a replication slot created for its own sync process. The worker will want to reuse that existing replication slot for this particular table and it will not create a new replication slot. So created_slot will be false, because the worker has not actually created any replication slot yet.
Basically, created_slot is set to true only if "walrcv_create_slot" is called by the tablesync worker any time during its lifetime. Otherwise, it's possible that the worker can use existing replication slots for each table it syncs. (e.g. if all the tables that the worker has synced were in FINISHEDCOPY state, then the worker will not need to create a new slot).
Does it make sense now? Maybe I need to improve comments to make it clearer.
Best,
Melih Mutlu
Microsoft
Вложения
On Mon, Jan 23, 2023 at 6:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
> Thanks for your review.
> Attached updated versions of the patches.
>
Hello,
I am still in the process of reviewing the patch, before that I tried
to run below test:
--publisher
create table tab1(id int , name varchar);
create table tab2(id int primary key , name varchar);
create table tab3(id int primary key , name varchar);
Insert into tab1 values(10, 'a');
Insert into tab1 values(20, 'b');
Insert into tab1 values(30, 'c');
Insert into tab2 values(10, 'a');
Insert into tab2 values(20, 'b');
Insert into tab2 values(30, 'c');
Insert into tab3 values(10, 'a');
Insert into tab3 values(20, 'b');
Insert into tab3 values(30, 'c');
create publication mypub for table tab1, tab2, tab3;
--subscriber
create table tab1(id int , name varchar);
create table tab2(id int primary key , name varchar);
create table tab3(id int primary key , name varchar);
create subscription mysub connection 'dbname=postgres host=localhost
user=shveta port=5432' publication mypub;
--I see initial data copied, but new catalog columns srrelslotname
and srreloriginname are not updated:
postgres=# select sublastusedid from pg_subscription;
sublastusedid
---------------
2
postgres=# select * from pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn | srrelslotname | srreloriginname
---------+---------+------------+-----------+---------------+-----------------
16409 | 16384 | r | 0/15219E0 | |
16409 | 16389 | r | 0/15219E0 | |
16409 | 16396 | r | 0/15219E0 | |
When are these supposed to be updated? I thought the slotname created
will be updated here. Am I missing something here?
Also the v8 patch does not apply on HEAD, giving merge conflicts.
thanks
Shveta
Hi Shveta,
Thanks for reviewing.
shveta malik <shveta.malik@gmail.com>, 25 Oca 2023 Çar, 16:02 tarihinde şunu yazdı:
On Mon, Jan 23, 2023 at 6:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
--I see initial data copied, but new catalog columns srrelslotname
and srreloriginname are not updated:
postgres=# select sublastusedid from pg_subscription;
sublastusedid
---------------
2
postgres=# select * from pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn | srrelslotname | srreloriginname
---------+---------+------------+-----------+---------------+-----------------
16409 | 16384 | r | 0/15219E0 | |
16409 | 16389 | r | 0/15219E0 | |
16409 | 16396 | r | 0/15219E0 | |
When are these supposed to be updated? I thought the slotname created
will be updated here. Am I missing something here?
If a relation is currently being synced by a tablesync worker and uses a replication slot/origin for that operation, then srrelslotname and srreloriginname fields will have values.
When a relation is done with its replication slot/origin, their info gets removed from related catalog row, so that slot/origin can be reused for another table or dropped if not needed anymore.
In your case, all relations are in READY state so it's expected that srrelslotname and srreloriginname are empty. READY relations do not need a replication slot/origin anymore.
Tables are probably synced so quickly that you're missing the moments when a tablesync worker copies a relation and stores its rep. slot/origin in the catalog.
If initial sync is long enough, then you should be able to see the columns get updated. I follow [1] to make it longer and test if the patch really updates the catalog.
Also the v8 patch does not apply on HEAD, giving merge conflicts.
Rebased and resolved conflicts. Please check the new version
---
[1]
publisher:
SELECT 'CREATE TABLE table_'||i||'(i int);' FROM generate_series(1, 100) g(i) \gexec
SELECT 'INSERT INTO table_'||i||' SELECT x FROM generate_series(1, 10000) x' FROM generate_series(1, 100) g(i) \gexec
CREATE PUBLICATION mypub FOR ALL TABLES;
subscriber:
SELECT 'CREATE TABLE table_'||i||'(i int);' FROM generate_series(1, 100) g(i) \gexec
CREATE SUBSCRIPTION mysub CONNECTION 'dbname=postgres port=5432 ' PUBLICATION mypub;
select * from pg_subscription_rel where srrelslotname <> ''; \watch 0.5
Thanks,
Melih Mutlu
Microsoft
Вложения
On Thu, Jan 26, 2023 at 7:53 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> If a relation is currently being synced by a tablesync worker and uses a replication slot/origin for that operation,
thensrrelslotname and srreloriginname fields will have values.
> When a relation is done with its replication slot/origin, their info gets removed from related catalog row, so that
slot/origincan be reused for another table or dropped if not needed anymore.
> In your case, all relations are in READY state so it's expected that srrelslotname and srreloriginname are empty.
READYrelations do not need a replication slot/origin anymore.
>
> Tables are probably synced so quickly that you're missing the moments when a tablesync worker copies a relation and
storesits rep. slot/origin in the catalog.
> If initial sync is long enough, then you should be able to see the columns get updated. I follow [1] to make it
longerand test if the patch really updates the catalog.
>
Thank You for the details. It is clear now.
>
>
> Rebased and resolved conflicts. Please check the new version
>
Please find my suggestions on v9:
1.
--Can we please add a few more points to the Summary to make it more clear.
a) something telling that reusability of workers is for tables under
one subscription and not across multiple subscriptions.
b) Since we are reusing both workers and slots, can we add:
--when do we actually end up spawning a new worker
--when do we actually end up creating a new slot in a worker rather
than using existing one.
--if we reuse existing slots, what happens to the snapshot?
2.
+ The last used ID for tablesync workers. This ID is used to
+ create replication slots. The last used ID needs to be stored
+ to make logical replication can safely proceed after any interruption.
+ If sublastusedid is 0, then no table has been synced yet.
--typo:
to make logical replication can safely proceed ==> to make logical
replication safely proceed
--Also, does it sound better:
The last used ID for tablesync workers. It acts as an unique
identifier for replication slots
which are created by table-sync workers. The last used ID needs to be
persisted...
3.
is_first_run;
move_to_next_rel;
--Do you think one variable is enough here as we do not get any extra
info by using 2 variables? Can we have 1 which is more generic like
'ready_to_reuse'. Otherwise, please let me know if we must use 2.
4.
/* missin_ok = true, since the origin might be already dropped. */
typo: missing_ok
5. GetReplicationSlotNamesBySubId:
errmsg("not tuple returned."));
Can we have a better error msg:
ereport(ERROR,
errmsg("could not receive list of slots
associated with subscription %d, error: %s", subid, res->err));
6.
static void
clean_sync_worker(void)
--can we please add introductory comment for this function.
7.
/*
* Pick the table for the next run if there is not another worker
* already picked that table.
*/
Pick the table for the next run if it is not already picked up by
another worker.
8.
process_syncing_tables_for_sync()
/* Cleanup before next run or ending the worker. */
--can we please improve this comment:
if there is no more work left for this worker, stop the worker
gracefully, else do clean-up and make it ready for the next
relation/run.
9.
LogicalRepSyncTableStart:
* Read previous slot name from the catalog, if exists.
*/
prev_slotname = (char *) palloc0(NAMEDATALEN);
Do we need to free this at the end?
10.
if (strlen(prev_slotname) == 0)
{
elog(ERROR, "Replication slot could not be
found for relation %u",
MyLogicalRepWorker->relid);
}
shall we mention subid also in error msg.
I am reviewing further...
thanks
Shveta
On Thu, 26 Jan 2023 at 19:53, Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi Shveta, > > Thanks for reviewing. > > shveta malik <shveta.malik@gmail.com>, 25 Oca 2023 Çar, 16:02 tarihinde şunu yazdı: >> >> On Mon, Jan 23, 2023 at 6:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: >> --I see initial data copied, but new catalog columns srrelslotname >> and srreloriginname are not updated: >> postgres=# select sublastusedid from pg_subscription; >> sublastusedid >> --------------- >> 2 >> >> postgres=# select * from pg_subscription_rel; >> srsubid | srrelid | srsubstate | srsublsn | srrelslotname | srreloriginname >> ---------+---------+------------+-----------+---------------+----------------- >> 16409 | 16384 | r | 0/15219E0 | | >> 16409 | 16389 | r | 0/15219E0 | | >> 16409 | 16396 | r | 0/15219E0 | | >> >> When are these supposed to be updated? I thought the slotname created >> will be updated here. Am I missing something here? > > > If a relation is currently being synced by a tablesync worker and uses a replication slot/origin for that operation, thensrrelslotname and srreloriginname fields will have values. > When a relation is done with its replication slot/origin, their info gets removed from related catalog row, so that slot/origincan be reused for another table or dropped if not needed anymore. > In your case, all relations are in READY state so it's expected that srrelslotname and srreloriginname are empty. READYrelations do not need a replication slot/origin anymore. > > Tables are probably synced so quickly that you're missing the moments when a tablesync worker copies a relation and storesits rep. slot/origin in the catalog. > If initial sync is long enough, then you should be able to see the columns get updated. I follow [1] to make it longerand test if the patch really updates the catalog. > > >> >> Also the v8 patch does not apply on HEAD, giving merge conflicts. > > > Rebased and resolved conflicts. Please check the new version CFBot shows some compilation errors as in [1], please post an updated version for the same: [14:38:38.392] [827/1808] Compiling C object src/backend/postgres_lib.a.p/replication_logical_tablesync.c.o [14:38:38.392] ../src/backend/replication/logical/tablesync.c: In function ‘LogicalRepSyncTableStart’: [14:38:38.392] ../src/backend/replication/logical/tablesync.c:1629:3: warning: implicit declaration of function ‘walrcv_slot_snapshot’ [-Wimplicit-function-declaration] [14:38:38.392] 1629 | walrcv_slot_snapshot(LogRepWorkerWalRcvConn, slotname, &options, origin_startpos); [14:38:38.392] | ^~~~~~~~~~~~~~~~~~~~ [14:38:45.125] FAILED: src/backend/postgres [14:38:45.125] cc @src/backend/postgres.rsp [14:38:45.125] /usr/bin/ld: src/backend/postgres_lib.a.p/replication_logical_tablesync.c.o: in function `LogicalRepSyncTableStart': [14:38:45.125] /tmp/cirrus-ci-build/build/../src/backend/replication/logical/tablesync.c:1629: undefined reference to `walrcv_slot_snapshot' [14:38:45.125] collect2: error: ld returned 1 exit status [1] - https://cirrus-ci.com/task/4897131543134208?logs=build#L1236 Regards, Vignesh
On Fri, Jan 27, 2023 at 3:41 PM shveta malik <shveta.malik@gmail.com> wrote:
>
>
> I am reviewing further...
> thanks
> Shveta
Few more comments:
v4-0001:
1)
REPLICATION_SLOT_SNAPSHOT
--Do we need 'CREATE' prefix with it i.e. CREATE_REPLICATION_SNAPSHOT
(or some other brief one with CREATE?). 'REPLICATION_SLOT_SNAPSHOT'
does not look like a command/action and thus is confusing.
2)
is used in the currenct transaction. This command is currently only supported
for logical replication.
slots.
--typo: currenct-->current
--slots can be moved to previous line
3)
/*
* Signal that we don't need the timeout mechanism. We're just creating
* the replication slot and don't yet accept feedback messages or send
* keepalives. As we possibly need to wait for further WAL the walsender
* would otherwise possibly be killed too soon.
*/
We're just creating the replication slot --> We're just creating the
replication snapshot
4)
I see XactReadOnly check in CreateReplicationSlot, do we need the same
in ReplicationSlotSnapshot() as well?
===============
v9-0002:
5)
/* We are safe to drop the replication trackin origin after this
--typo: tracking
6)
slot->data.catalog_xmin = xmin_horizon;
slot->effective_xmin = xmin_horizon;
SpinLockRelease(&slot->mutex);
xmin_horizon =
GetOldestSafeDecodingTransactionId(!need_full_snapshot);
ReplicationSlotsComputeRequiredXmin(true);
--do we need to set xmin_horizon in slot after
'GetOldestSafeDecodingTransactionId' call, otherwise it will be set to
InvalidId in slot. Is that intentional? I see that we do set this
correct xmin_horizon in builder->initial_xmin_horizon but the slot is
carrying Invalid one.
thanks
Shveta
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"wangw.fnst@fujitsu.com"
Дата:
On Mon, Jan 23, 2023 21:00 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > Hi, > > Thanks for your review. > Attached updated versions of the patches. Thanks for updating the patch set. > > 5. New member "created_slot" in structure LogicalRepWorker > > + /* > > + * Indicates if the sync worker created a replication slot or it reuses an > > + * existing one created by another worker. > > + */ > > + bool created_slot; > > > > I think the second half of the sentence looks inaccurate. > > Because I think this flag could be false even when we reuse an existing slot > > created by another worker. Assuming the first run for the worker tries to sync > > a table which is synced by another sync worker before, and the relstate is set > > to SUBREL_STATE_FINISHEDCOPY by another sync worker, I think this flag will > not > > be set to true. (see function LogicalRepSyncTableStart) > > > > So, what if we simplify the description here and just say that this worker > > already has it's default slot? > > > > If I'm not missing something and you agree with this, please also kindly modify > > the relevant comment atop the if-statement (!MyLogicalRepWorker- > >created_slot) > > in the function LogicalRepSyncTableStart. > > This "created_slot" indicates whether the current worker has created a > replication slot for its own use. If so, created_slot will be true, otherwise false. > Let's say the tablesync worker has not created its own slot yet in its previous > runs or this is its first run. And the worker decides to reuse an existing > replication slot (which created by another tablesync worker). Then created_slot > is expected to be false. Because this particular tablesync worker has not created > its own slot yet in either of its runs. > > In your example, the worker is in its first run and begin to sync a table whose > state is FINISHEDCOPY. If the table's state is FINISHEDCOPY then the table > should already have a replication slot created for its own sync process. The > worker will want to reuse that existing replication slot for this particular table > and it will not create a new replication slot. So created_slot will be false, because > the worker has not actually created any replication slot yet. > > Basically, created_slot is set to true only if "walrcv_create_slot" is called by the > tablesync worker any time during its lifetime. Otherwise, it's possible that the > worker can use existing replication slots for each table it syncs. (e.g. if all the > tables that the worker has synced were in FINISHEDCOPY state, then the > worker will not need to create a new slot). > > Does it make sense now? Maybe I need to improve comments to make it > clearer. Yes, I think it makes sense. Thanks for the detailed explanation. I think I misunderstood the second half of the comment. I previously thought it meant that it was also true when reusing an existing slot. I found one typo in v9-0002, but it seems already mentioned by Shi in [1].#5 before. Maybe you can have a look at that email for this and some other comments. Regards, Wang Wei
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"wangw.fnst@fujitsu.com"
Дата:
On Tues, Jan 31, 2023 18:27 PM I wrote: > I found one typo in v9-0002, but it seems already mentioned by Shi in [1].#5 > before. Maybe you can have a look at that email for this and some other > comments. Sorry, I forgot to add the link to the email. Please refer to [1]. [1] - https://www.postgresql.org/message-id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpnprd01.prod.outlook.com Regards, Wang Wei
On Tue, Jan 31, 2023 at 3:57 PM wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com> wrote: > > On Mon, Jan 23, 2023 21:00 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi, > > > > Thanks for your review. > > Attached updated versions of the patches. > > Thanks for updating the patch set. > > > > 5. New member "created_slot" in structure LogicalRepWorker > > > + /* > > > + * Indicates if the sync worker created a replication slot or it reuses an > > > + * existing one created by another worker. > > > + */ > > > + bool created_slot; > > > > Yes, I think it makes sense. Thanks for the detailed explanation. > I think I misunderstood the second half of the comment. I previously thought it > meant that it was also true when reusing an existing slot. > I agree with Wang-san that the comment is confusing, I too misunderstood it initially during my first run of the code. Maybe it can be improved. 'Indicates if the sync worker created a replication slot for itself; set to false if sync worker reuses an existing one created by another worker' thanks Shveta
Hi,
Please see attached patches for the below changes.
shveta malik <shveta.malik@gmail.com>, 27 Oca 2023 Cum, 13:12 tarihinde şunu yazdı:
On Thu, Jan 26, 2023 at 7:53 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
1.
--Can we please add a few more points to the Summary to make it more clear.
a) something telling that reusability of workers is for tables under
one subscription and not across multiple subscriptions.
b) Since we are reusing both workers and slots, can we add:
--when do we actually end up spawning a new worker
--when do we actually end up creating a new slot in a worker rather
than using existing one.
--if we reuse existing slots, what happens to the snapshot?
I modified the commit message if that's what you mean by the Summary.
2.
+ The last used ID for tablesync workers. This ID is used to
+ create replication slots. The last used ID needs to be stored
+ to make logical replication can safely proceed after any interruption.
+ If sublastusedid is 0, then no table has been synced yet.
--typo:
to make logical replication can safely proceed ==> to make logical
replication safely proceed
Done
3.
is_first_run;
move_to_next_rel;
--Do you think one variable is enough here as we do not get any extra
info by using 2 variables? Can we have 1 which is more generic like
'ready_to_reuse'. Otherwise, please let me know if we must use 2.
Right. Removed is_first_run and renamed move_to_next_rel as ready_to_reuse.
4.
/* missin_ok = true, since the origin might be already dropped. */
typo: missing_ok
Done.
5. GetReplicationSlotNamesBySubId:
errmsg("not tuple returned."));
Can we have a better error msg:
ereport(ERROR,
errmsg("could not receive list of slots
associated with subscription %d, error: %s", subid, res->err));
Done.
6.
static void
clean_sync_worker(void)
--can we please add introductory comment for this function.
Done.
7.
/*
* Pick the table for the next run if there is not another worker
* already picked that table.
*/
Pick the table for the next run if it is not already picked up by
another worker.
Done.
8.
process_syncing_tables_for_sync()
/* Cleanup before next run or ending the worker. */
--can we please improve this comment:
if there is no more work left for this worker, stop the worker
gracefully, else do clean-up and make it ready for the next
relation/run.
Done
9.
LogicalRepSyncTableStart:
* Read previous slot name from the catalog, if exists.
*/
prev_slotname = (char *) palloc0(NAMEDATALEN);
Do we need to free this at the end?
Pfree'd prev_slotname after we're done with it.
10.
if (strlen(prev_slotname) == 0)
{
elog(ERROR, "Replication slot could not be
found for relation %u",
MyLogicalRepWorker->relid);
}
shall we mention subid also in error msg.
Done.
Thanks for reviewing,
Melih Mutlu
Microsoft
Вложения
Hi,
I mistakenly attached v9 in my previous email.
Please see attached v6 and v10 for the previous and below changes.
shveta malik <shveta.malik@gmail.com>, 31 Oca 2023 Sal, 12:59 tarihinde şunu yazdı:
On Fri, Jan 27, 2023 at 3:41 PM shveta malik <shveta.malik@gmail.com> wrote:
1)
REPLICATION_SLOT_SNAPSHOT
--Do we need 'CREATE' prefix with it i.e. CREATE_REPLICATION_SNAPSHOT
(or some other brief one with CREATE?). 'REPLICATION_SLOT_SNAPSHOT'
does not look like a command/action and thus is confusing.
Renamed it as CREATE_REPLICATION_SNAPSHOT
2)
is used in the currenct transaction. This command is currently only supported
for logical replication.
slots.
--typo: currenct-->current
--slots can be moved to previous line
Done.
3)
/*
* Signal that we don't need the timeout mechanism. We're just creating
* the replication slot and don't yet accept feedback messages or send
* keepalives. As we possibly need to wait for further WAL the walsender
* would otherwise possibly be killed too soon.
*/
We're just creating the replication slot --> We're just creating the
replication snapshot
Done.
4)
I see XactReadOnly check in CreateReplicationSlot, do we need the same
in ReplicationSlotSnapshot() as well?
Added this check too.
===============
v9-0002:
5)
/* We are safe to drop the replication trackin origin after this
--typo: tracking
Done.
6)
slot->data.catalog_xmin = xmin_horizon;
slot->effective_xmin = xmin_horizon;
SpinLockRelease(&slot->mutex);
xmin_horizon =
GetOldestSafeDecodingTransactionId(!need_full_snapshot);
ReplicationSlotsComputeRequiredXmin(true);
--do we need to set xmin_horizon in slot after
'GetOldestSafeDecodingTransactionId' call, otherwise it will be set to
InvalidId in slot. Is that intentional? I see that we do set this
correct xmin_horizon in builder->initial_xmin_horizon but the slot is
carrying Invalid one.
I think you're right. Moved GetOldestSafeDecodingTransactionId call before xmin_horizon assignment.
Thanks,
Melih Mutlu
Microsoft
Вложения
On Wed, Feb 1, 2023 at 5:05 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
> Please see attached patches for the below changes.
>
> Thanks for reviewing,
> --
> Melih Mutlu
> Microsoft
Hello Melih,
Thank you for making the changes.
I have few more comments:
1)
src/backend/replication/logical/worker.c: (errmsg("logical replication
table synchronization worker for subscription \"%s\", table \"%s\" has
started",
src/backend/replication/logical/worker.c: (errmsg("logical replication
table synchronization worker for subscription \"%s\" has moved to sync
table \"%s\".",
src/backend/replication/logical/tablesync.c: (errmsg("logical
replication table synchronization worker for subscription \"%s\",
table \"%s\" has finished",
In above can we have rep_slot_id as well in trace message, else it is
not clear which worker moved to next relation. We may have:
logical replication table synchronization worker_%d for subscription
\"%s\" has moved to sync table, rep_slot_id,....
Overall we need to improve the tracing. I will give my suggestions on
this later (in detail).
2) I found a crash in the previous patch (v9), but have not tested it
on the latest yet. Crash happens when all the replication slots are
consumed and we are trying to create new. I tweaked the settings like
below so that it can be reproduced easily:
max_sync_workers_per_subscription=3
max_replication_slots = 2
and then ran the test case shared by you. I think there is some memory
corruption happening. (I did test in debug mode, have not tried in
release mode). I tried to put some traces to identify the root-cause.
I observed that worker_1 keeps on moving from 1 table to another table
correctly, but at some point, it gets corrupted i.e. origin-name
obtained for it is wrong and it tries to advance that and since that
origin does not exist, it asserts and then something else crashes.
From log: (new trace lines added by me are prefixed by shveta, also
tweaked code to have my comment 1 fixed to have clarity on worker-id).
form below traces, it is clear that worker_1 was moving from one
relation to another, always getting correct origin 'pg_16688_1', but
at the end it got 'pg_16688_49' which does not exist. Second part of
trace shows who updated 'pg_16688_49', it was done by worker_49 which
even did not get chance to create this origin due to max_rep_slot
reached.
==============================
..............
2023-02-01 16:01:38.041 IST [9243] LOG: logical replication table
synchronization worker_1 for subscription "mysub", table "table_93"
has finished
2023-02-01 16:01:38.047 IST [9243] LOG: logical replication table
synchronization worker_1 for subscription "mysub" has moved to sync
table "table_98".
2023-02-01 16:01:38.055 IST [9243] LOG: shveta-
LogicalRepSyncTableStart- worker_1 get-origin-id2 originid:2,
originname:pg_16688_1
2023-02-01 16:01:38.055 IST [9243] LOG: shveta-
LogicalRepSyncTableStart- Worker_1 reusing
slot:pg_16688_sync_1_7195132648087016333, originid:2,
originname:pg_16688_1
2023-02-01 16:01:38.094 IST [9243] LOG: shveta-
LogicalRepSyncTableStart- worker_1 updated-origin2
originname:pg_16688_1
2023-02-01 16:01:38.096 IST [9243] LOG: logical replication table
synchronization worker_1 for subscription "mysub", table "table_98"
has finished
2023-02-01 16:01:38.096 IST [9243] LOG: logical replication table
synchronization worker_1 for subscription "mysub" has moved to sync
table "table_60".
2023-02-01 16:01:38.099 IST [9243] LOG: shveta-
LogicalRepSyncTableStart- worker_1 get-origin originid:0,
originname:pg_16688_49
2023-02-01 16:01:38.099 IST [9243] LOG: could not drop replication
slot "pg_16688_sync_49_7195132648087016333" on publisher: ERROR:
replication slot "pg_16688_sync_49_7195132648087016333" does not exist
2023-02-01 16:01:38.103 IST [9243] LOG: shveta-
LogicalRepSyncTableStart- Worker_1 reusing
slot:pg_16688_sync_1_7195132648087016333, originid:0,
originname:pg_16688_49
TRAP: failed Assert("node != InvalidRepOriginId"), File: "origin.c",
Line: 892, PID: 9243
postgres: logical replication worker for subscription 16688 sync 16384
(ExceptionalCondition+0xbb)[0x56019194d3b7]
postgres: logical replication worker for subscription 16688 sync 16384
(replorigin_advance+0x6d)[0x5601916b53d4]
postgres: logical replication worker for subscription 16688 sync 16384
(LogicalRepSyncTableStart+0xbb4)[0x5601916cb648]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x5d25e2)[0x5601916d35e2]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x5d282c)[0x5601916d382c]
postgres: logical replication worker for subscription 16688 sync 16384
(ApplyWorkerMain+0x17b)[0x5601916d4078]
postgres: logical replication worker for subscription 16688 sync 16384
(StartBackgroundWorker+0x248)[0x56019167f943]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x589ad3)[0x56019168aad3]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x589ee3)[0x56019168aee3]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x588d8d)[0x560191689d8d]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x584604)[0x560191685604]
postgres: logical replication worker for subscription 16688 sync 16384
(PostmasterMain+0x14f1)[0x560191684f1e]
postgres: logical replication worker for subscription 16688 sync 16384
(+0x446e05)[0x560191547e05]
/lib/x86_64-linux-gnu/libc.so.6(+0x29d90)[0x7f048cc58d90]
==============================
'pg_16688_49' updated by worker_49:
2023-02-01 16:01:37.083 IST [9348] LOG: shveta-
LogicalRepSyncTableStart- worker_49 get-origin originid:0,
originname:pg_16688_49
2023-02-01 16:01:37.083 IST [9348] LOG: shveta-
LogicalRepSyncTableStart- worker_49 updated-origin
originname:pg_16688_49
2023-02-01 16:01:37.083 IST [9348] LOG: shveta-
LogicalRepSyncTableStart- worker_49 get-origin-id2 originid:0,
originname:pg_16688_49
2023-02-01 16:01:37.083 IST [9348] ERROR: could not create
replication slot "pg_16688_sync_49_7195132648087016333": ERROR: all
replication slots are in use
HINT: Free one or increase max_replication_slots.
==============================
Rest of the workers keep on exiting and getting recreated since they
could not create slot. The last_used_id kept on increasing on every
restart of subscriber until we kill it. In my case it reached 2k+.
thanks
Shveta
Hi,
wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com>, 31 Oca 2023 Sal, 13:40 tarihinde şunu yazdı:
Sorry, I forgot to add the link to the email. Please refer to [1].
[1] - https://www.postgresql.org/message-id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpnprd01.prod.outlook.com
Thanks for pointing out this review. I somehow skipped that, sorry.
Please see attached patches.
On Wed, Jan 11, 2023 4:31 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
0001 patch
============
1. walsender.c
+ /* Create a tuple to send consisten WAL location */
"consisten" should be "consistent" I think.
Done.
2. logical.c
+ if (need_full_snapshot)
+ {
+ LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE);
+
+ SpinLockAcquire(&slot->mutex);
+ slot->effective_catalog_xmin = xmin_horizon;
+ slot->data.catalog_xmin = xmin_horizon;
+ slot->effective_xmin = xmin_horizon;
+ SpinLockRelease(&slot->mutex);
+
+ xmin_horizon = GetOldestSafeDecodingTransactionId(!need_full_snapshot);
+ ReplicationSlotsComputeRequiredXmin(true);
+
+ LWLockRelease(ProcArrayLock);
+ }
It seems that we should first get the safe decoding xid, then inform the slot
machinery about the new limit, right? Otherwise the limit will be
InvalidTransactionId and that seems inconsistent with the comment.
You're right. Moved that call before assigning xmin_horizon.
3. doc/src/sgml/protocol.sgml
+ is used in the currenct transaction. This command is currently only supported
+ for logical replication.
+ slots.
We don't need to put "slots" in a new line.
Done.
0002 patch
============
1.
In pg_subscription_rel.h, I think the type of "srrelslotname" can be changed to
NameData, see "subslotname" in pg_subscription.h.
2.
+ * Find the logical replication sync worker if exists store
+ * the slot number for dropping associated replication slots
+ * later.
Should we add comma after "if exists"?
Done.
3.
+ PG_FINALLY();
+ {
+ pfree(cmd.data);
+ }
+ PG_END_TRY();
+ \
+ return tablelist;
+}
Do we need the backslash?
Removed it.
4.
+ /*
+ * Advance to the LSN got from walrcv_create_slot. This is WAL
+ * logged for the purpose of recovery. Locks are to prevent the
+ * replication origin from vanishing while advancing.
"walrcv_create_slot" should be changed to
"walrcv_create_slot/walrcv_slot_snapshot" I think.
Right, done.
5.
+ /* Replication drop might still exist. Try to drop */
+ replorigin_drop_by_name(originname, true, false);
Should "Replication drop" be "Replication origin"?
Done.
6.
I saw an assertion failure in the following case, could you please look into it?
The backtrace is attached.
-- pub
CREATE TABLE tbl1 (a int, b text);
CREATE TABLE tbl2 (a int primary key, b text);
create publication pub for table tbl1, tbl2;
insert into tbl1 values (1, 'a');
insert into tbl1 values (1, 'a');
-- sub
CREATE TABLE tbl1 (a int primary key, b text);
CREATE TABLE tbl2 (a int primary key, b text);
create subscription sub connection 'dbname=postgres port=5432' publication pub;
Subscriber log:
2023-01-17 14:47:10.054 CST [1980841] LOG: logical replication apply worker for subscription "sub" has started
2023-01-17 14:47:10.060 CST [1980843] LOG: logical replication table synchronization worker for subscription "sub", table "tbl1" has started
2023-01-17 14:47:10.070 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub", table "tbl2" has started
2023-01-17 14:47:10.073 CST [1980843] ERROR: duplicate key value violates unique constraint "tbl1_pkey"
2023-01-17 14:47:10.073 CST [1980843] DETAIL: Key (a)=(1) already exists.
2023-01-17 14:47:10.073 CST [1980843] CONTEXT: COPY tbl1, line 2
2023-01-17 14:47:10.074 CST [1980821] LOG: background worker "logical replication worker" (PID 1980843) exited with exit code 1
2023-01-17 14:47:10.083 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub", table "tbl2" has finished
2023-01-17 14:47:10.083 CST [1980845] LOG: logical replication table synchronization worker for subscription "sub" has moved to sync table "tbl1".
TRAP: failed Assert("node != InvalidRepOriginId"), File: "origin.c", Line: 892, PID: 1980845
I'm not able to reproduce this yet. Will look into it further.
Thanks,
Melih Mutlu
Microsoft
Вложения
Hi Shveta,
shveta malik <shveta.malik@gmail.com>, 1 Şub 2023 Çar, 15:01 tarihinde şunu yazdı:
On Wed, Feb 1, 2023 at 5:05 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
2) I found a crash in the previous patch (v9), but have not tested it
on the latest yet. Crash happens when all the replication slots are
consumed and we are trying to create new. I tweaked the settings like
below so that it can be reproduced easily:
max_sync_workers_per_subscription=3
max_replication_slots = 2
and then ran the test case shared by you. I think there is some memory
corruption happening. (I did test in debug mode, have not tried in
release mode). I tried to put some traces to identify the root-cause.
I observed that worker_1 keeps on moving from 1 table to another table
correctly, but at some point, it gets corrupted i.e. origin-name
obtained for it is wrong and it tries to advance that and since that
origin does not exist, it asserts and then something else crashes.
From log: (new trace lines added by me are prefixed by shveta, also
tweaked code to have my comment 1 fixed to have clarity on worker-id).
form below traces, it is clear that worker_1 was moving from one
relation to another, always getting correct origin 'pg_16688_1', but
at the end it got 'pg_16688_49' which does not exist. Second part of
trace shows who updated 'pg_16688_49', it was done by worker_49 which
even did not get chance to create this origin due to max_rep_slot
reached.
Thanks for investigating this error. I think it's the same error as the one Shi reported earlier. [1]
I couldn't reproduce it yet but will apply your tweaks and try again.
Looking into this.
Thanks,
Melih Mutlu
Microsoft
On Wed, Feb 1, 2023 at 5:42 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > Thanks for investigating this error. I think it's the same error as the one Shi reported earlier. [1] > I couldn't reproduce it yet but will apply your tweaks and try again. > Looking into this. > > [1] https://www.postgresql.org/message-id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpnprd01.prod.outlook.com I tried Shi-san's testcase earlier but I too could not reproduce it, so I assumed that it is fixed in one of your patches already and thus thought that the current issue is a new one. thanks Shveta
On Wed, Feb 1, 2023 at 5:42 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi Shveta, > > shveta malik <shveta.malik@gmail.com>, 1 Şub 2023 Çar, 15:01 tarihinde şunu yazdı: >> >> On Wed, Feb 1, 2023 at 5:05 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: >> 2) I found a crash in the previous patch (v9), but have not tested it >> on the latest yet. Crash happens when all the replication slots are >> consumed and we are trying to create new. I tweaked the settings like >> below so that it can be reproduced easily: >> max_sync_workers_per_subscription=3 >> max_replication_slots = 2 >> and then ran the test case shared by you. I think there is some memory >> corruption happening. (I did test in debug mode, have not tried in >> release mode). I tried to put some traces to identify the root-cause. >> I observed that worker_1 keeps on moving from 1 table to another table >> correctly, but at some point, it gets corrupted i.e. origin-name >> obtained for it is wrong and it tries to advance that and since that >> origin does not exist, it asserts and then something else crashes. >> From log: (new trace lines added by me are prefixed by shveta, also >> tweaked code to have my comment 1 fixed to have clarity on worker-id). >> >> form below traces, it is clear that worker_1 was moving from one >> relation to another, always getting correct origin 'pg_16688_1', but >> at the end it got 'pg_16688_49' which does not exist. Second part of >> trace shows who updated 'pg_16688_49', it was done by worker_49 which >> even did not get chance to create this origin due to max_rep_slot >> reached. > > > Thanks for investigating this error. I think it's the same error as the one Shi reported earlier. [1] > I couldn't reproduce it yet but will apply your tweaks and try again. > Looking into this. > > [1] https://www.postgresql.org/message-id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpnprd01.prod.outlook.com > Hi Melih, I think I am able to identify the root cause. It is not memory corruption, but the way origin-names are stored in system-catalog mapped to a particular relation-id before even those are created. After adding few more logs: [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 constructed originname :pg_16684_49, relid:16540 [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 updated-origin in system catalog:pg_16684_49, slot:pg_16684_sync_49_7195149685251088378, relid:16540 [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 get-origin-id2 originid:0, originname:pg_16684_49 [4227] ERROR: could not create replication slot "pg_16684_sync_49_7195149685251088378": ERROR: all replication slots are in use HINT: Free one or increase max_replication_slots. [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 constructed originname :pg_16684_49, relid:16540 [4428] LOG: could not drop replication slot "pg_16684_sync_49_7195149685251088378" on publisher: ERROR: replication slot "pg_16684_sync_49_7195149 685251088378" does not exist [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 drop-origin originname:pg_16684_49 [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 updated-origin:pg_16684_49, slot:pg_16684_sync_148_7195149685251088378, relid:16540 So from above, worker_49 came and picked up relid:16540, constructed origin-name and slot-name and updated in system-catalog and then it tried to actually create that slot and origin but since max-slot count was reached, it failed and exited, but did not do cleanup from system catalog for that relid. Then worker_148 came and also picked up table 16540 since it was not completed/started by previous worker, but this time it found that origin and slot entry present in system-catalog against this relid, so it picked the same names and started processing, but since those do not exist, it asserted while advancing the origin. The assert is only reproduced when an already running worker (say worker_1) who has 'created=true' set, gets to sync the relid for which a previously failed worker has tried and updated origin-name w/o creating it. In such a case worker_1 (with created=true) will try to reuse the origin and thus will try to advance it and will end up asserting. That is why you might not see the assertion always. The condition 'created' is set to true for that worker and it goes to reuse the origin updated by the previous worker. So to fix this, I think either we update origin and slot entries in the system catalog after the creation has passed or we clean-up the system catalog in case of failure. What do you think? thanks Shveta
On Thu, Feb 2, 2023 at 9:18 AM shveta malik <shveta.malik@gmail.com> wrote: > > > Hi Melih, > I think I am able to identify the root cause. It is not memory > corruption, but the way origin-names are stored in system-catalog > mapped to a particular relation-id before even those are created. > Apart from the problem mentioned in my earlier email, I think there is one more issue here as seen by the same assert causing testcase. The 'lastusedid' stored in system-catalog kept on increasing w/o even slot and origin getting created. 2 workers worked well with max_replication_slots=2 and then since all slots were consumed 3rd one could not create any slot and exited but it increased lastusedid. Then another worker came, incremented lastusedId in system-catalog and failed to create slot and exited and so on. This makes lastUsedId incremented continuously until you kill the subscriber or free any slot used previously. If you keep subscriber running long enough, it will make lastUsedId go beyond its limit. Shouldn't lastUsedId be incremented only after making sure that worker has created a slot and origin corresponding to that particular rep_slot_id (derived using lastUsedId). Please let me know if my understanding is not correct. thanks Shveta
On Wed, Feb 1, 2023 at 5:37 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
> Please see attached patches.
>
> Thanks,
> --
> Melih Mutlu
> Microsoft
Hi Melih,
Few suggestions on v10-0002-Reuse patch
1)
for (int64 i = 1; i <= lastusedid; i++)
{
char originname_to_drop[NAMEDATALEN] = {0};
snprintf(originname_to_drop,
sizeof(originname_to_drop), "pg_%u_%lld", subid, (long long) i);
.......
}
--Is it better to use the function
'ReplicationOriginNameForLogicalRep' here instead of sprintf, just to
be consistent everywhere to construct origin-name?
2)
pa_launch_parallel_worker:
launched = logicalrep_worker_launch(MyLogicalRepWorker->dbid,
MySubscription->oid,
MySubscription->name,
MyLogicalRepWorker->userid,
InvalidOid,
dsm_segment_handle(winfo->dsm_seg),
0);
--Can we please define 'InvalidRepSlotId' macro and pass it here as
the last arg to make it more readable.
#define InvalidRepSlotId 0
Same in ApplyLauncherMain where we are passing 0 as last arg to
logicalrep_worker_launch.
3)
We are safe to drop the replication trackin origin after this
--typo: trackin -->tracking
4)
process_syncing_tables_for_sync:
if (MyLogicalRepWorker->slot_name && strcmp(syncslotname,
MyLogicalRepWorker->slot_name) != 0)
{
..............
ReplicationOriginNameForLogicalRep(MyLogicalRepWorker->subid,
MyLogicalRepWorker->relid,
originname,
sizeof(originname));
/* Drop replication origin */
replorigin_drop_by_name(originname, true, false);
}
--Are we passing missing_ok as true (second arg) intentionally here in
replorigin_drop_by_name? Once we fix the issue reported in my earlier
email (ASSERT), do you think it makes sense to pass missing_ok as
false here?
5)
process_syncing_tables_for_sync:
foreach(lc, rstates)
{
rstate = (SubscriptionRelState *)
palloc(sizeof(SubscriptionRelState));
memcpy(rstate, lfirst(lc),
sizeof(SubscriptionRelState));
/*
* Pick the table for the next run if it is
not already picked up
* by another worker.
*/
LWLockAcquire(LogicalRepWorkerLock, LW_SHARED);
if (rstate->state != SUBREL_STATE_SYNCDONE &&
!logicalrep_worker_find(MySubscription->oid, rstate->relid, false))
{
.........
}
LWLockRelease(LogicalRepWorkerLock);
}
--Do we need to palloc for each relation separately? Shall we do it
once outside the loop and reuse it? Also pfree is not done for rstate
here.
6)
LogicalRepSyncTableStart:
1385 slotname = (char *) palloc(NAMEDATALEN);
1413 prev_slotname = (char *) palloc(NAMEDATALEN);
1481 slotname = prev_slotname;
1502 pfree(prev_slotname);
1512 UpdateSubscriptionRel(MyLogicalRepWorker->subid,
1513
MyLogicalRepWorker->relid,
1514
MyLogicalRepWorker->relstate,
1515
MyLogicalRepWorker->relstate_lsn,
1516 slotname,
1517 originname);
Can you please review the above flow (I have given line# along with),
I think it could be problematic. We alloced prev_slotname, assigned it
to slotname, freed prev_slotname and used slotname after freeing the
prev_slotname.
Also slotname is allocated some memory too, that is not freed.
Reviewing further....
JFYI, I get below while applying patch:
========================
shveta@shveta-vm:~/repos/postgres1/postgres$ git am
~/Desktop/shared/reuse/v10-0002-Reuse-Logical-Replication-Background-worker.patch
Applying: Reuse Logical Replication Background worker
.git/rebase-apply/patch:142: trailing whitespace.
values[Anum_pg_subscription_rel_srrelslotname - 1] =
.git/rebase-apply/patch:692: indent with spaces.
errmsg("could not receive list of slots associated
with the subscription %u, error: %s",
.git/rebase-apply/patch:1055: trailing whitespace.
/*
.git/rebase-apply/patch:1057: trailing whitespace.
* relations.
.git/rebase-apply/patch:1059: trailing whitespace.
* and origin. Then stop the worker gracefully.
warning: 5 lines add whitespace errors.
========================
thanks
Shveta
On Thu, Feb 2, 2023 at 5:01 PM shveta malik <shveta.malik@gmail.com> wrote:
>
> Reviewing further....
>
Few more comments for v10-0002 and v7-0001:
1)
+ * need_full_snapshot
+ * if true, create a snapshot able to read all tables,
+ * otherwise do not create any snapshot.
+ *
CreateDecodingContext(..,CreateDecodingContext,..)
--Is the comment correct? Shall we have same comment here as that of
'CreateDecodingContext'
* need_full_snapshot -- if true, must obtain a snapshot able to read all
* tables; if false, one that can read only catalogs is acceptable.
This function is not going to create a snapshot anyways. It is just a
pre-step and then the caller needs to call 'SnapBuild' functions to
build a snapshot. Here need_full_snapshot decides whether we need all
tables or only catalog tables changes only and thus the comment change
is needed.
==========
2)
Can we please add more logging:
2a)
when lastusedId is incremented and updated in pg_* table
ereport(DEBUG2,
(errmsg("[subid:%d] Incremented lastusedid
to:%ld",MySubscription->oid, MySubscription->lastusedid)));
Comments for LogicalRepSyncTableStart():
2b ) After every UpdateSubscriptionRel:
ereport(DEBUG2,
(errmsg("[subid:%d] LogicalRepSyncWorker_%ld updated origin to %s and
slot to %s for relid %d",
MyLogicalRepWorker->subid, MyLogicalRepWorker->rep_slot_id,
originname, slotname, MyLogicalRepWorker->relid)));
2c )
After walrcv_create_slot:
ereport(DEBUG2,
(errmsg("[subid:%d] LogicalRepSyncWorker_%ld created slot %s",
MyLogicalRepWorker->subid, MyLogicalRepWorker->rep_slot_id, slotname)));
2d)
After replorigin_create:
ereport(DEBUG2,
(errmsg("[subid:%d] LogicalRepSyncWorker_%ld created origin %s [id: %d]",
MyLogicalRepWorker->subid, MyLogicalRepWorker->rep_slot_id,
originname, originid)));
2e)
When it goes to reuse flow (i.e. before walrcv_slot_snapshot), if
needed we can dump newly obtained origin_startpos also:
ereport(DEBUG2,
(errmsg("[subid:%d] LogicalRepSyncWorker_%ld reusing slot %s and origin %s",
MyLogicalRepWorker->subid, MyLogicalRepWorker->rep_slot_id, slotname,
originname)));
2f)
Also in existing comment:
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has moved to sync table \"%s\".",
+ MySubscription->name, get_rel_name(MyLogicalRepWorker->relid))));
we can add relid also along with relname. relid is the one stored in
pg_subscription_rel and thus it becomes easy to map. Also we can
change 'logical replication table synchronization worker' to
'LogicalRepSyncWorker_%ld'.
Same change needed in other similar log lines where we say that worker
started and finished.
Please feel free to change the above log lines as you find
appropriate. I have given just a sample sort of thing.
thanks
Shveta
On Fri, Feb 3, 2023 at 11:50 AM shveta malik <shveta.malik@gmail.com> wrote:
>
> On Thu, Feb 2, 2023 at 5:01 PM shveta malik <shveta.malik@gmail.com> wrote:
> >
>
> 2e)
> When it goes to reuse flow (i.e. before walrcv_slot_snapshot), if
> needed we can dump newly obtained origin_startpos also:
>
> ereport(DEBUG2,
> (errmsg("[subid:%d] LogicalRepSyncWorker_%ld reusing slot %s and origin %s",
> MyLogicalRepWorker->subid, MyLogicalRepWorker->rep_slot_id, slotname,
> originname)));
>
One addition, I think it will be good to add relid as well in above so
that we can get info as in we are reusing old slot for which relid.
Once we have all the above in log-file, it makes it very easy to
diagnose reuse-sync worker related problems just by looking at the
logfile.
thanks
Shveta
On Thu, Feb 2, 2023 at 5:01 PM shveta malik <shveta.malik@gmail.com> wrote: > > Reviewing further.... > Hi Melih, int64 rep_slot_id; int64 lastusedid; int64 sublastusedid --Should all of the above be unsigned integers? thanks Shveta
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"shiy.fnst@fujitsu.com"
Дата:
On Thu, Feb 2, 2023 11:48 AM shveta malik <shveta.malik@gmail.com> wrote: > > On Wed, Feb 1, 2023 at 5:42 PM Melih Mutlu <m.melihmutlu@gmail.com> > wrote: > > > > Hi Shveta, > > > > shveta malik <shveta.malik@gmail.com>, 1 Şub 2023 Çar, 15:01 tarihinde > şunu yazdı: > >> > >> On Wed, Feb 1, 2023 at 5:05 PM Melih Mutlu <m.melihmutlu@gmail.com> > wrote: > >> 2) I found a crash in the previous patch (v9), but have not tested it > >> on the latest yet. Crash happens when all the replication slots are > >> consumed and we are trying to create new. I tweaked the settings like > >> below so that it can be reproduced easily: > >> max_sync_workers_per_subscription=3 > >> max_replication_slots = 2 > >> and then ran the test case shared by you. I think there is some memory > >> corruption happening. (I did test in debug mode, have not tried in > >> release mode). I tried to put some traces to identify the root-cause. > >> I observed that worker_1 keeps on moving from 1 table to another table > >> correctly, but at some point, it gets corrupted i.e. origin-name > >> obtained for it is wrong and it tries to advance that and since that > >> origin does not exist, it asserts and then something else crashes. > >> From log: (new trace lines added by me are prefixed by shveta, also > >> tweaked code to have my comment 1 fixed to have clarity on worker-id). > >> > >> form below traces, it is clear that worker_1 was moving from one > >> relation to another, always getting correct origin 'pg_16688_1', but > >> at the end it got 'pg_16688_49' which does not exist. Second part of > >> trace shows who updated 'pg_16688_49', it was done by worker_49 > which > >> even did not get chance to create this origin due to max_rep_slot > >> reached. > > > > > > Thanks for investigating this error. I think it's the same error as the one Shi > reported earlier. [1] > > I couldn't reproduce it yet but will apply your tweaks and try again. > > Looking into this. > > > > [1] https://www.postgresql.org/message- > id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpn > prd01.prod.outlook.com > > > > Hi Melih, > I think I am able to identify the root cause. It is not memory > corruption, but the way origin-names are stored in system-catalog > mapped to a particular relation-id before even those are created. > > After adding few more logs: > > [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 constructed > originname :pg_16684_49, relid:16540 > [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 > updated-origin in system catalog:pg_16684_49, > slot:pg_16684_sync_49_7195149685251088378, relid:16540 > [4227] LOG: shveta- LogicalRepSyncTableStart- worker_49 > get-origin-id2 originid:0, originname:pg_16684_49 > [4227] ERROR: could not create replication slot > "pg_16684_sync_49_7195149685251088378": ERROR: all replication slots > are in use > HINT: Free one or increase max_replication_slots. > > > [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 constructed > originname :pg_16684_49, relid:16540 > [4428] LOG: could not drop replication slot > "pg_16684_sync_49_7195149685251088378" on publisher: ERROR: > replication slot "pg_16684_sync_49_7195149 685251088378" does not > exist > [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 drop-origin > originname:pg_16684_49 > [4428] LOG: shveta- LogicalRepSyncTableStart- worker_148 > updated-origin:pg_16684_49, > slot:pg_16684_sync_148_7195149685251088378, relid:16540 > > So from above, worker_49 came and picked up relid:16540, constructed > origin-name and slot-name and updated in system-catalog and then it > tried to actually create that slot and origin but since max-slot count > was reached, it failed and exited, but did not do cleanup from system > catalog for that relid. > > Then worker_148 came and also picked up table 16540 since it was not > completed/started by previous worker, but this time it found that > origin and slot entry present in system-catalog against this relid, so > it picked the same names and started processing, but since those do > not exist, it asserted while advancing the origin. > > The assert is only reproduced when an already running worker (say > worker_1) who has 'created=true' set, gets to sync the relid for which > a previously failed worker has tried and updated origin-name w/o > creating it. In such a case worker_1 (with created=true) will try to > reuse the origin and thus will try to advance it and will end up > asserting. That is why you might not see the assertion always. The > condition 'created' is set to true for that worker and it goes to > reuse the origin updated by the previous worker. > > So to fix this, I think either we update origin and slot entries in > the system catalog after the creation has passed or we clean-up the > system catalog in case of failure. What do you think? > I think the first way seems better. I reproduced the problem I reported before with latest patch (v7-0001, v10-0002), and looked into this problem. It is caused by a similar reason. Here is some analysis for the problem I reported [1].#6. First, a tablesync worker (worker-1) started for "tbl1", its originname is "pg_16398_1". And it exited because of unique constraint. In LogicalRepSyncTableStart(), originname in pg_subscription_rel is updated when updating table state to DATASYNC, and the origin is created when updating table state to FINISHEDCOPY. So when it exited with state DATASYNC , the origin is not created but the originname has been updated in pg_subscription_rel. Then a tablesync worker (worker-2) started for "tbl2", its originname is "pg_16398_2". After tablesync of "tbl2" finished, this worker moved to sync table "tbl1". In LogicalRepSyncTableStart(), it got the originname of "tbl1" - "pg_16398_1", by calling ReplicationOriginNameForLogicalRep(), and tried to drop the origin (although it is not actually created before). After that, it called replorigin_by_name to get the originid whose name is "pg_16398_1" and the result is InvalidOid. Origin won't be created in this case because the sync worker has created a replication slot (when it synced tbl2), so the originid was still invalid and it caused an assertion failure when calling replorigin_advance(). It seems we don't need to drop previous origin in worker-2 because the previous origin was not created in worker-1. I think one way to fix it is to not update originname of pg_subscription_rel when setting state to DATASYNC, and only do that when setting state to FINISHEDCOPY. If so, the originname in pg_subscription_rel will be set at the same time the origin is created. (Besides, the slotname seems need to be updated when setting state to DATASYNC, because the previous slot might have been created successfully and we need to get the previous slotname and drop that.) [1] https://www.postgresql.org/message-id/OSZPR01MB631013C833C98E826B3CFCB9FDC69%40OSZPR01MB6310.jpnprd01.prod.outlook.com Regards, Shi yu
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"wangw.fnst@fujitsu.com"
Дата:
On Wed, Feb 1, 2023 20:07 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> Thanks for pointing out this review. I somehow skipped that, sorry.
>
> Please see attached patches.
Thanks for updating the patch set.
Here are some comments.
1. In the function ApplyWorkerMain.
+ /* This is main apply worker */
+ run_apply_worker(&options, myslotname, originname, sizeof(originname), &origin_startpos);
I think we need to keep the worker name as "leader apply worker" in the comment
like the current HEAD.
---
2. In the function LogicalRepApplyLoop.
+ * can be reused, we need to take care of memory contexts here
+ * before moving to sync a table.
+ */
+ if (MyLogicalRepWorker->ready_to_reuse)
+ {
+ MemoryContextResetAndDeleteChildren(ApplyMessageContext);
+ MemoryContextSwitchTo(TopMemoryContext);
+ return;
+ }
I think in this case we also need to pop the error context stack before
returning. Otherwise, I think we might use the wrong callback
(apply error_callback) after we return from this function.
---
3. About the function UpdateSubscriptionRelReplicationSlot.
This newly introduced function UpdateSubscriptionRelReplicationSlot does not
seem to be invoked. Do we need this function?
Regards,
Wang Wei
On Tue, Feb 7, 2023 at 8:18 AM shiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com> wrote: > > > On Thu, Feb 2, 2023 11:48 AM shveta malik <shveta.malik@gmail.com> wrote: > > > > > > So to fix this, I think either we update origin and slot entries in > > the system catalog after the creation has passed or we clean-up the > > system catalog in case of failure. What do you think? > > > > I think the first way seems better. Yes, I agree. > > I reproduced the problem I reported before with latest patch (v7-0001, > v10-0002), and looked into this problem. It is caused by a similar reason. Here > is some analysis for the problem I reported [1].#6. > > First, a tablesync worker (worker-1) started for "tbl1", its originname is > "pg_16398_1". And it exited because of unique constraint. In > LogicalRepSyncTableStart(), originname in pg_subscription_rel is updated when > updating table state to DATASYNC, and the origin is created when updating table > state to FINISHEDCOPY. So when it exited with state DATASYNC , the origin is not > created but the originname has been updated in pg_subscription_rel. > > Then a tablesync worker (worker-2) started for "tbl2", its originname is > "pg_16398_2". After tablesync of "tbl2" finished, this worker moved to sync > table "tbl1". In LogicalRepSyncTableStart(), it got the originname of "tbl1" - > "pg_16398_1", by calling ReplicationOriginNameForLogicalRep(), and tried to drop > the origin (although it is not actually created before). After that, it called > replorigin_by_name to get the originid whose name is "pg_16398_1" and the result > is InvalidOid. Origin won't be created in this case because the sync worker has > created a replication slot (when it synced tbl2), so the originid was still > invalid and it caused an assertion failure when calling replorigin_advance(). > > It seems we don't need to drop previous origin in worker-2 because the previous > origin was not created in worker-1. I think one way to fix it is to not update > originname of pg_subscription_rel when setting state to DATASYNC, and only do > that when setting state to FINISHEDCOPY. If so, the originname in > pg_subscription_rel will be set at the same time the origin is created. +1. Update of system-catalog needs to be done carefully and only when origin is created. thanks Shveta
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"wangw.fnst@fujitsu.com"
Дата:
On Thur, Feb 7, 2023 15:29 PM I wrote:
> On Wed, Feb 1, 2023 20:07 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> > Thanks for pointing out this review. I somehow skipped that, sorry.
> >
> > Please see attached patches.
>
> Thanks for updating the patch set.
> Here are some comments.
Hi, here are some more comments on patch v7-0001*:
1. The new comments atop the function CreateDecodingContext
+ * need_full_snapshot
+ * if true, create a snapshot able to read all tables,
+ * otherwise do not create any snapshot.
I think if 'need_full_snapshot' is false, it means we will create a snapshot
that can read only catalogs. (see SnapBuild->building_full_snapshot)
===
2. This are two questions I'm not sure about.
2a.
Because pg-doc has the following description in [1]: (option "SNAPSHOT 'use'")
```
'use' will use the snapshot for the current transaction executing the command.
This option must be used in a transaction, and CREATE_REPLICATION_SLOT must be
the first command run in that transaction.
```
So I think in the function CreateDecodingContext, when "need_full_snapshot" is
true, we seem to need the following check, just like in the function
CreateInitDecodingContext:
```
if (IsTransactionState() &&
GetTopTransactionIdIfAny() != InvalidTransactionId)
ereport(ERROR,
(errcode(ERRCODE_ACTIVE_SQL_TRANSACTION),
errmsg("cannot create logical replication slot in transaction that has performed writes")));
```
2b.
It seems that we also need to invoke the function
CheckLogicalDecodingRequirements in the new function CreateReplicationSnapshot,
just like the function CreateReplicationSlot and the function
StartLogicalReplication.
Is there any reason not to do these two checks? Please let me know if I missed
something.
===
3. The invocation of startup_cb_wrapper in the function CreateDecodingContext.
I think we should change the third input parameter to true when invoke function
startup_cb_wrapper for CREATE_REPLICATION_SNAPSHOT. BTW, after applying patch
v10-0002*, these settings will be inconsistent when sync workers use
"CREATE_REPLICATION_SLOT" and "CREATE_REPLICATION_SNAPSHOT" to take snapshots.
This input parameter (true) will let us disable streaming and two-phase
transactions in function pgoutput_startup. See the last paragraph of the commit
message for 4648243 for more details.
[1] - https://www.postgresql.org/docs/devel/protocol-replication.html
Regards,
Wang Wei
Hi Shveta and Shi,
Thanks for your investigations.
shveta malik <shveta.malik@gmail.com>, 8 Şub 2023 Çar, 16:49 tarihinde şunu yazdı:
On Tue, Feb 7, 2023 at 8:18 AM shiy.fnst@fujitsu.com
<shiy.fnst@fujitsu.com> wrote:
> I reproduced the problem I reported before with latest patch (v7-0001,
> v10-0002), and looked into this problem. It is caused by a similar reason. Here
> is some analysis for the problem I reported [1].#6.
>
> First, a tablesync worker (worker-1) started for "tbl1", its originname is
> "pg_16398_1". And it exited because of unique constraint. In
> LogicalRepSyncTableStart(), originname in pg_subscription_rel is updated when
> updating table state to DATASYNC, and the origin is created when updating table
> state to FINISHEDCOPY. So when it exited with state DATASYNC , the origin is not
> created but the originname has been updated in pg_subscription_rel.
>
> Then a tablesync worker (worker-2) started for "tbl2", its originname is
> "pg_16398_2". After tablesync of "tbl2" finished, this worker moved to sync
> table "tbl1". In LogicalRepSyncTableStart(), it got the originname of "tbl1" -
> "pg_16398_1", by calling ReplicationOriginNameForLogicalRep(), and tried to drop
> the origin (although it is not actually created before). After that, it called
> replorigin_by_name to get the originid whose name is "pg_16398_1" and the result
> is InvalidOid. Origin won't be created in this case because the sync worker has
> created a replication slot (when it synced tbl2), so the originid was still
> invalid and it caused an assertion failure when calling replorigin_advance().
>
> It seems we don't need to drop previous origin in worker-2 because the previous
> origin was not created in worker-1. I think one way to fix it is to not update
> originname of pg_subscription_rel when setting state to DATASYNC, and only do
> that when setting state to FINISHEDCOPY. If so, the originname in
> pg_subscription_rel will be set at the same time the origin is created.
+1. Update of system-catalog needs to be done carefully and only when
origin is created.
I see that setting originname in the catalog before actually creating it causes issues. My concern with setting originname when setting the state to FINISHEDCOPY is that if worker waits until FINISHEDCOPY to update slot/origin name but it fails somewhere before reaching FINISHEDCOPY and after creating slot/origin, then this new created slot/origin will be left behind. It wouldn't be possible to find and drop them since their names are not stored in the catalog. Eventually, this might also cause hitting the max_replication_slots limit in case of such failures between origin creation and FINISHEDCOPY.
One fix I can think is to update the catalog right after creating a new origin. But this would also require commiting the current transaction to actually persist the originname. I guess this action of commiting the transaction in the middle of initial sync could hurt the copy process.
What do you think?
Also; working on an updated patch to address your other comments. Thanks again.
Best,
Melih Mutlu
Microsoft
Hi,
Melih Mutlu <m.melihmutlu@gmail.com>, 16 Şub 2023 Per, 14:37 tarihinde şunu yazdı:
I see that setting originname in the catalog before actually creating it causes issues. My concern with setting originname when setting the state to FINISHEDCOPY is that if worker waits until FINISHEDCOPY to update slot/origin name but it fails somewhere before reaching FINISHEDCOPY and after creating slot/origin, then this new created slot/origin will be left behind. It wouldn't be possible to find and drop them since their names are not stored in the catalog. Eventually, this might also cause hitting the max_replication_slots limit in case of such failures between origin creation and FINISHEDCOPY.One fix I can think is to update the catalog right after creating a new origin. But this would also require commiting the current transaction to actually persist the originname. I guess this action of commiting the transaction in the middle of initial sync could hurt the copy process.
Here are more thoughts on this:
I still believe that updating originname when setting state to FINISHEDCOPY is not a good idea since any failure before FINISHEDCOPY prevent us to store originname in the catalog. If an origin or slot is not in the catalog, it's not easily possible to find and drop origins/slot that are left behind. And we definitely do not want to keep unnecessary origins/slots since we would hit max_replication_slots limit.
It's better to be safe and update origin/slot names when setting state to DATASYNC. At this point, the worker must be sure that it writes correct origin/slot names into the catalog.
Following part actually cleans up the catalog if a table is left behind in DATASYNC state and its slot and origin cannot be used for sync.
ReplicationSlotDropAtPubNode(LogRepWorkerWalRcvConn, prev_slotname, true);
StartTransactionCommand();
/* Replication origin might still exist. Try to drop */
replorigin_drop_by_name(originname, true, false);
/*
* Remove replication slot and origin name from the relation's
* catalog record
*/
UpdateSubscriptionRel(MyLogicalRepWorker->subid,
MyLogicalRepWorker->relid,
MyLogicalRepWorker->relstate,
MyLogicalRepWorker->relstate_lsn,
NULL,
NULL);
The patch needs to refresh the origin name before it begins copying the table. It will try to read from the catalog but won't find any slot/origin since they are cleaned. Then, it will move on with the correct origin name which is the one created/will be created for the current sync worker.
I tested refetching originname and seems like it fixes the errors you reported.
Thanks,
Melih Mutlu
Microsoft
Hi Shveta,
Thanks for reviewing.
Please see attached patches.
shveta malik <shveta.malik@gmail.com>, 2 Şub 2023 Per, 14:31 tarihinde şunu yazdı:
On Wed, Feb 1, 2023 at 5:37 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
for (int64 i = 1; i <= lastusedid; i++)
{
char originname_to_drop[NAMEDATALEN] = {0};
snprintf(originname_to_drop,
sizeof(originname_to_drop), "pg_%u_%lld", subid, (long long) i);
.......
}
--Is it better to use the function
'ReplicationOriginNameForLogicalRep' here instead of sprintf, just to
be consistent everywhere to construct origin-name?
ReplicationOriginNameForLogicalRep creates a slot name with current "lastusedid" and doesn't accept that id as parameter. Here the patch needs to check all possible id's.
/* Drop replication origin */
replorigin_drop_by_name(originname, true, false);
}
--Are we passing missing_ok as true (second arg) intentionally here in
replorigin_drop_by_name? Once we fix the issue reported in my earlier
email (ASSERT), do you think it makes sense to pass missing_ok as
false here?
Yes, missing_ok is intentional. The user might be concurrently refreshing the sub or the apply worker might already drop the origin at that point. So, missing_ok is set to true.
This is also how origin drops before the worker exits are handled on HEAD too. I only followed the same approach.
--Do we need to palloc for each relation separately? Shall we do it
once outside the loop and reuse it? Also pfree is not done for rstate
here.
Removed palloc from the loop. No need to pfree here since the memory context will be deleted with the next CommitTransactionCommand call.
Can you please review the above flow (I have given line# along with),
I think it could be problematic. We alloced prev_slotname, assigned it
to slotname, freed prev_slotname and used slotname after freeing the
prev_slotname.
Also slotname is allocated some memory too, that is not freed.
Right, I used memcpy instead of assigning prev_slotname to slotname. slotname is returned in the end and pfree'd later [1]
I also addressed your other reviews that I didn't explicitly mention in this email. I simply applied the changes you pointed out. Also added some more logs as well. I hope it's more useful now.
Thanks,
Melih Mutlu
Microsoft
Вложения
Hi Wang,
Thanks for reviewing.
Please see updated patches. [1]
wangw.fnst@fujitsu.com <wangw.fnst@fujitsu.com>, 7 Şub 2023 Sal, 10:28 tarihinde şunu yazdı:
1. In the function ApplyWorkerMain.
I think we need to keep the worker name as "leader apply worker" in the comment
like the current HEAD.
Done.
I think in this case we also need to pop the error context stack before
returning. Otherwise, I think we might use the wrong callback
(apply error_callback) after we return from this function.
Done.
3. About the function UpdateSubscriptionRelReplicationSlot.
This newly introduced function UpdateSubscriptionRelReplicationSlot does not
seem to be invoked. Do we need this function?
Removed.
I think if 'need_full_snapshot' is false, it means we will create a snapshot
that can read only catalogs. (see SnapBuild->building_full_snapshot)
Fixed.
```
'use' will use the snapshot for the current transaction executing the command.
This option must be used in a transaction, and CREATE_REPLICATION_SLOT must be
the first command run in that transaction.
```
So I think in the function CreateDecodingContext, when "need_full_snapshot" is
true, we seem to need the following check, just like in the function
CreateInitDecodingContext:
```
if (IsTransactionState() &&
GetTopTransactionIdIfAny() != InvalidTransactionId)
ereport(ERROR,
(errcode(ERRCODE_ACTIVE_SQL_TRANSACTION),
errmsg("cannot create logical replication slot in transaction that has performed writes")));
```
You're right to "use" the snapshot, it must be the first command in the transaction. And that check happens here [2]. CreateReplicationSnapshot has also similar check.
I think the check you're referring to is needed to actually create a replication slot and it performs whether the snapshot will be "used" or "exported". This is not the case for CreateReplicationSnapshot.
It seems that we also need to invoke the function
CheckLogicalDecodingRequirements in the new function CreateReplicationSnapshot,
just like the function CreateReplicationSlot and the function
StartLogicalReplication.
Added this check.
3. The invocation of startup_cb_wrapper in the function CreateDecodingContext.
I think we should change the third input parameter to true when invoke function
startup_cb_wrapper for CREATE_REPLICATION_SNAPSHOT. BTW, after applying patch
v10-0002*, these settings will be inconsistent when sync workers use
"CREATE_REPLICATION_SLOT" and "CREATE_REPLICATION_SNAPSHOT" to take snapshots.
This input parameter (true) will let us disable streaming and two-phase
transactions in function pgoutput_startup. See the last paragraph of the commit
message for 4648243 for more details.
I'm not sure if "is_init" should be set to true. CreateDecodingContext only creates a context for an already existing logical slot and does not initialize new one.
I think inconsistencies between "CREATE_REPLICATION_SLOT" and "CREATE_REPLICATION_SNAPSHOT" are expected since one creates a new replication slot and the other does not.
CreateDecodingContext is also used in other places as well. Not sure how this change would affect those places. I'll look into this more. Please let me know if I'm missing something.
Thanks,
-- Melih Mutlu
Microsoft
Re: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
Melanie Plageman
Дата:
On Wed, Feb 22, 2023 at 8:04 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi Wang,
>
> Thanks for reviewing.
> Please see updated patches. [1]
This is cool! Thanks for working on this.
I had a chance to review your patchset and I had some thoughts and
questions.
I notice that you've added a new user-facing option to make a snapshot.
I think functionality to independently make a snapshot for use elsewhere
has been discussed in the past for the implementation of different
features (e.g. [1] pg_dump but they ended up using replication slots for
this I think?), but I'm not quite sure I understand all the implications
for providing a user-visible create snapshot command. Where can it be
used? When can the snapshot be used? In your patch's case, you know that
you can use the snapshot you are creating, but I just wonder if any
restrictions or caveats need be taken for its general use.
For the worker reuse portion of the code, could it be a separate patch
in the set? It could be independently committable and would be easier to
review (separate from repl slot reuse).
Given table sync worker reuse, I think it is worth considering a more
explicit structure for the table sync worker code now -- i.e. having a
TableSyncWorkerMain() function. Though they still do the
LogicalRepApplyLoop(), much of what else they do is different than the
apply leader.
Apply worker leader does:
ApplyWorkerMain()
walrcv_startstreaming()
LogicalRepApplyLoop()
launch table sync workers
walrcv_endstreaming()
proc_exit()
Table Sync workers master:
ApplyWorkerMain()
start_table_sync()
walrcv_create_slot()
copy_table()
walrcv_startstreaming()
start_apply()
LogicalRepApplyLoop()
walrcv_endstreaming()
proc_exit()
Now table sync workers need to loop back and do start_table_sync() again
for their new table.
You have done this in ApplyWorkerMain(). But I think that this could be
a separate main function since their main loop is effectively totally
different now than an apply worker leader.
Something like:
TableSyncWorkerMain()
TableSyncWorkerLoop()
start_table_sync()
walrcv_startstreaming()
LogicalRepApplyLoop()
walrcv_endstreaming()
wait_for_new_rel_assignment()
proc_exit()
You mainly have this structure, but it is a bit hidden and some of the
shared functions that previously may have made sense for table sync
worker and apply workers to share don't really make sense to share
anymore.
The main thing that table sync workers and apply workers share is the
logic in LogicalRepApplyLoop() (table sync workers use when they do
catchup), so perhaps we should make the other code separate?
Also on the topic of worker reuse, I was wondering if having workers
find their own next table assignment (as you have done in
process_syncing_tables_for_sync()) makes sense.
The way the whole system would work now (with your patch applied), as I
understand it, the apply leader would loop through the subscription rel
states and launch workers up to max_sync_workers_per_subscription for
every candidate table needing sync. The apply leader will continue to do
this, even though none of those workers would exit unless they die
unexpectedly. So, once it reaches max_sync_workers_per_subscription, it
won't launch any more workers.
When one of these sync workers is finished with a table (it is synced
and caught up), it will search through the subscription rel states
itself looking for a candidate table to work on.
It seems it would be common for workers to be looking through the
subscription rel states at the same time, and I don't really see how you
prevent races in who is claiming a relation to work on. Though you take
a shared lock on the LogicalRepWorkerLock, what if in between
logicalrep_worker_find() and updating my MyLogicalRepWorker->relid,
someone else also updates their relid to that relid. I don't think you
can update LogicalRepWorker->relid with only a shared lock.
I wonder if it is not better to have the apply leader, in
process_syncing_tables_for_apply(), first check for an existing worker
for the rel, then check for an available worker without an assignment,
then launch a worker?
Workers could then sleep after finishing their assignment and wait for
the leader to give them a new assignment.
Given an exclusive lock on LogicalRepWorkerLock, it may be okay for
workers to find their own table assignments from the subscriptionrel --
and perhaps this will be much more efficient from a CPU perspective. It
feels just a bit weird to have the code doing that buried in
process_syncing_tables_for_sync(). It seems like it should at least
return out to a main table sync worker loop in which workers loop
through finding a table and assigning it to themselves, syncing the
table, and catching the table up.
- Melanie
[1]
https://www.postgresql.org/message-id/flat/CA%2BU5nMLRjGtpskUkYSzZOEYZ_8OMc02k%2BO6FDi4una3mB4rS1w%40mail.gmail.com#45692f75a1e79d4ce2d4f6a0e3ccb853
Re: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Gregory Stark (as CFM)"
Дата:
On Sun, 26 Feb 2023 at 19:11, Melanie Plageman <melanieplageman@gmail.com> wrote: > > This is cool! Thanks for working on this. > I had a chance to review your patchset and I had some thoughts and > questions. It looks like this patch got a pretty solid review from Melanie Plageman in February just before the CF started. It was never set to Waiting on Author but I think that may be the right state for it. -- Gregory Stark As Commitfest Manager
Hi Melanie,
Thanks for reviewing.
Melanie Plageman <melanieplageman@gmail.com>, 27 Şub 2023 Pzt, 03:10 tarihinde şunu yazdı:
>
> I notice that you've added a new user-facing option to make a snapshot.
> I think functionality to independently make a snapshot for use elsewhere
> has been discussed in the past for the implementation of different
> features (e.g. [1] pg_dump but they ended up using replication slots for
> this I think?), but I'm not quite sure I understand all the implications
> for providing a user-visible create snapshot command. Where can it be
> used? When can the snapshot be used? In your patch's case, you know that
> you can use the snapshot you are creating, but I just wonder if any
> restrictions or caveats need be taken for its general use.
I can't say a use-case, other than this patch, that needs this user-facing command. The main reason why I added this command as it is in the patch is because that's already how other required communication between publisher and subscriber is done for other operations in logical replication. Even though it may sound similar to the case in pg_dump discussion, I think the main difference is that calling CREATE_REPLICATION_SNAPSHOT creates a snapshot and imports it to wherever it's called (i.e. the same transaction which invoked CREATE_REPLICATION_SNAPSHOT ), and not used anywhere else.
But I agree that this part of the patch needs more thoughts and reviews. Honestly, I'm not also sure if this is the ideal way to fix the "snapshot issue" introduced by reusing the same replication slot.
>
> For the worker reuse portion of the code, could it be a separate patch
> in the set? It could be independently committable and would be easier to
> review (separate from repl slot reuse).
I did this, please see the patch 0001.
>
> You mainly have this structure, but it is a bit hidden and some of the
> shared functions that previously may have made sense for table sync
> worker and apply workers to share don't really make sense to share
> anymore.
>
> The main thing that table sync workers and apply workers share is the
> logic in LogicalRepApplyLoop() (table sync workers use when they do
> catchup), so perhaps we should make the other code separate?
You're right that apply and tablesync worker's paths are unnecessarily intertwined. With the reusing workers/replication slots logic, I guess it became worse.
I tried to change the structure to something similar to what you explained.
Tablesync workers have different starting point now and it simply runs as follows:
TableSyncWorkerMain()
loop:
start_table_sync()
walrcv_startstreaming()
LogicalRepApplyLoop()
check if there is a table with INIT state
if there is such table: // reuse case
clean_sync_worker()
else: // exit case
walrcv_endstreaming()
ReplicationSlotDropAtPubNode()
replorigin_drop_by_name
break
proc_exit()
> It seems it would be common for workers to be looking through the
> subscription rel states at the same time, and I don't really see how you
> prevent races in who is claiming a relation to work on. Though you take
> a shared lock on the LogicalRepWorkerLock, what if in between
> logicalrep_worker_find() and updating my MyLogicalRepWorker->relid,
> someone else also updates their relid to that relid. I don't think you
> can update LogicalRepWorker->relid with only a shared lock.
>
>
> I wonder if it is not better to have the apply leader, in
> process_syncing_tables_for_apply(), first check for an existing worker
> for the rel, then check for an available worker without an assignment,
> then launch a worker?
>
> Workers could then sleep after finishing their assignment and wait for
> the leader to give them a new assignment.
I'm not sure if we should rely on a single apply worker for the assignment of several tablesync workers. I suspect that moving the assignment responsibility to the apply worker may bring some overhead. But I agree that shared lock on LogicalRepWorkerLock is not good. Changed it to exclusive lock.
>
> Given an exclusive lock on LogicalRepWorkerLock, it may be okay for
> workers to find their own table assignments from the subscriptionrel --
> and perhaps this will be much more efficient from a CPU perspective. It
> feels just a bit weird to have the code doing that buried in
> process_syncing_tables_for_sync(). It seems like it should at least
> return out to a main table sync worker loop in which workers loop
> through finding a table and assigning it to themselves, syncing the
> table, and catching the table up.
Right, it shouldn't be process_syncing_tables_for_sync()'s responsibility. I moved it into the TableSyncWorkerMain loop.
Also;
I did some benchmarking like I did a couple of times previously [1].
Here are the recent numbers:
With empty tables:
+--------+------------+-------------+--------------+
| | 10 tables | 100 tables | 1000 tables |
+--------+------------+-------------+--------------+
| master | 296.689 ms | 2579.154 ms | 41753.043 ms |
+--------+------------+-------------+--------------+
| patch | 210.580 ms | 1724.230 ms | 36247.061 ms |
+--------+------------+-------------+--------------+
With 10 tables loaded with some data:
Thanks for reviewing.
Melanie Plageman <melanieplageman@gmail.com>, 27 Şub 2023 Pzt, 03:10 tarihinde şunu yazdı:
>
> I notice that you've added a new user-facing option to make a snapshot.
> I think functionality to independently make a snapshot for use elsewhere
> has been discussed in the past for the implementation of different
> features (e.g. [1] pg_dump but they ended up using replication slots for
> this I think?), but I'm not quite sure I understand all the implications
> for providing a user-visible create snapshot command. Where can it be
> used? When can the snapshot be used? In your patch's case, you know that
> you can use the snapshot you are creating, but I just wonder if any
> restrictions or caveats need be taken for its general use.
I can't say a use-case, other than this patch, that needs this user-facing command. The main reason why I added this command as it is in the patch is because that's already how other required communication between publisher and subscriber is done for other operations in logical replication. Even though it may sound similar to the case in pg_dump discussion, I think the main difference is that calling CREATE_REPLICATION_SNAPSHOT creates a snapshot and imports it to wherever it's called (i.e. the same transaction which invoked CREATE_REPLICATION_SNAPSHOT ), and not used anywhere else.
But I agree that this part of the patch needs more thoughts and reviews. Honestly, I'm not also sure if this is the ideal way to fix the "snapshot issue" introduced by reusing the same replication slot.
>
> For the worker reuse portion of the code, could it be a separate patch
> in the set? It could be independently committable and would be easier to
> review (separate from repl slot reuse).
I did this, please see the patch 0001.
>
> You mainly have this structure, but it is a bit hidden and some of the
> shared functions that previously may have made sense for table sync
> worker and apply workers to share don't really make sense to share
> anymore.
>
> The main thing that table sync workers and apply workers share is the
> logic in LogicalRepApplyLoop() (table sync workers use when they do
> catchup), so perhaps we should make the other code separate?
You're right that apply and tablesync worker's paths are unnecessarily intertwined. With the reusing workers/replication slots logic, I guess it became worse.
I tried to change the structure to something similar to what you explained.
Tablesync workers have different starting point now and it simply runs as follows:
TableSyncWorkerMain()
loop:
start_table_sync()
walrcv_startstreaming()
LogicalRepApplyLoop()
check if there is a table with INIT state
if there is such table: // reuse case
clean_sync_worker()
else: // exit case
walrcv_endstreaming()
ReplicationSlotDropAtPubNode()
replorigin_drop_by_name
break
proc_exit()
> It seems it would be common for workers to be looking through the
> subscription rel states at the same time, and I don't really see how you
> prevent races in who is claiming a relation to work on. Though you take
> a shared lock on the LogicalRepWorkerLock, what if in between
> logicalrep_worker_find() and updating my MyLogicalRepWorker->relid,
> someone else also updates their relid to that relid. I don't think you
> can update LogicalRepWorker->relid with only a shared lock.
>
>
> I wonder if it is not better to have the apply leader, in
> process_syncing_tables_for_apply(), first check for an existing worker
> for the rel, then check for an available worker without an assignment,
> then launch a worker?
>
> Workers could then sleep after finishing their assignment and wait for
> the leader to give them a new assignment.
I'm not sure if we should rely on a single apply worker for the assignment of several tablesync workers. I suspect that moving the assignment responsibility to the apply worker may bring some overhead. But I agree that shared lock on LogicalRepWorkerLock is not good. Changed it to exclusive lock.
>
> Given an exclusive lock on LogicalRepWorkerLock, it may be okay for
> workers to find their own table assignments from the subscriptionrel --
> and perhaps this will be much more efficient from a CPU perspective. It
> feels just a bit weird to have the code doing that buried in
> process_syncing_tables_for_sync(). It seems like it should at least
> return out to a main table sync worker loop in which workers loop
> through finding a table and assigning it to themselves, syncing the
> table, and catching the table up.
Right, it shouldn't be process_syncing_tables_for_sync()'s responsibility. I moved it into the TableSyncWorkerMain loop.
Also;
I did some benchmarking like I did a couple of times previously [1].
Here are the recent numbers:
With empty tables:
+--------+------------+-------------+--------------+
| | 10 tables | 100 tables | 1000 tables |
+--------+------------+-------------+--------------+
| master | 296.689 ms | 2579.154 ms | 41753.043 ms |
+--------+------------+-------------+--------------+
| patch | 210.580 ms | 1724.230 ms | 36247.061 ms |
+--------+------------+-------------+--------------+
With 10 tables loaded with some data:
+--------+------------+-------------+--------------+
| | 1 MB | 10 MB | 100 MB |
+--------+------------+-------------+--------------+
| master | 568.072 ms | 2074.557 ms | 16995.399 ms |
+--------+------------+-------------+--------------+
| patch | 470.700 ms | 1923.386 ms | 16980.686 ms |
+--------+------------+-------------+--------------+
It seems that even though master has improved since the last time I did a similar experiment, the patch still improves the time spent in table sync for empty/small tables.
| | 1 MB | 10 MB | 100 MB |
+--------+------------+-------------+--------------+
| master | 568.072 ms | 2074.557 ms | 16995.399 ms |
+--------+------------+-------------+--------------+
| patch | 470.700 ms | 1923.386 ms | 16980.686 ms |
+--------+------------+-------------+--------------+
It seems that even though master has improved since the last time I did a similar experiment, the patch still improves the time spent in table sync for empty/small tables.
Also there is a decrease in the performance of the patch, compared with the previous results [1]. Some portion of it might be caused by switching from shared locks to exclusive locks. I'll look into that a bit more though.
Best,
-- Melih Mutlu
Microsoft
Вложения
Hi, and thanks for the patch! It is an interesting idea. I have not yet fully read this thread, so below are only my first impressions after looking at patch 0001. Sorry if some of these were already discussed earlier. TBH the patch "reuse-workers" logic seemed more complicated than I had imagined it might be. 1. IIUC with patch 0001, each/every tablesync worker (a.k.a. TSW) when it finishes dealing with one table then goes looking to find if there is some relation that it can process next. So now every TSW has a loop where it will fight with every other available TSW over who will get to process the next relation. Somehow this seems all backwards to me. Isn't it strange for the TSW to be the one deciding what relation it would deal with next? IMO it seems more natural to simply return the finished TSW to some kind of "pool" of available workers and the main Apply process can just grab a TSW from that pool instead of launching a brand new one in the existing function process_syncing_tables_for_apply(). Or, maybe those "available" workers can be returned to a pool maintained within the launcher.c code, which logicalrep_worker_launch() can draw from instead of launching a whole new process? (I need to read the earlier posts to see if these options were already discussed and rejected) ~~ 2. AFAIK the thing that identifies a tablesync worker is the fact that only TSW will have a 'relid'. But it feels very awkward to me to have a TSW marked as "available" and yet that LogicalRepWorker must still have some OLD relid field value lurking (otherwise it will forget that it is a "tablesync" worker!). IMO perhaps it is time now to introduce some enum 'type' to the LogicalRepWorker. Then an "in_use" type=TSW would have a valid 'relid' whereas an "available" type=TSW would have relid == InvalidOid. ~~ 3. Maybe I am mistaken, but it seems the benchmark results posted are only using quite a small/default values for "max_sync_workers_per_subscription", so I wondered how those results are affected by increasing that GUC. I think having only very few workers would cause more sequential processing, so conveniently the effect of the patch avoiding re-launch might be seen in the best possible light. OTOH, using more TSW in the first place might reduce the overall tablesync time because the subscriber can do more work in parallel. So I'm not quite sure what the goal is here. E.g. if the user doesn't care much about how long tablesync phase takes then there is maybe no need for this patch at all. OTOH, I thought if a user does care about the subscription startup time, won't those users be opting for a much larger "max_sync_workers_per_subscription" in the first place? Therefore shouldn't the benchmarking be using a larger number too? ====== Here are a few other random things noticed while looking at patch 0001: 1. Commit message 1a. typo /sequantially/sequentially/ 1b. Saying "killed" and "killing" seemed a bit extreme and implies somebody else is killing the process. But I think mostly tablesync is just ending by a normal proc exit, so maybe reword this a bit. ~~~ 2. It seemed odd that some -- clearly tablesync specific -- functions are in the worker.c instead of in tablesync.c. 2a. e.g. clean_sync_worker 2b. e.g. sync_worker_exit ~~~ 3. process_syncing_tables_for_sync + /* + * Sync worker is cleaned at this point. It's ready to sync next table, + * if needed. + */ + SpinLockAcquire(&MyLogicalRepWorker->relmutex); + MyLogicalRepWorker->ready_to_reuse = true; SpinLockRelease(&MyLogicalRepWorker->relmutex); + } + + SpinLockRelease(&MyLogicalRepWorker->relmutex); Isn't there a double release of that mutex happening there? ------ Kind Regards, Peter Smith. Fujitsu Australia
Hi,
Peter Smith <smithpb2250@gmail.com>, 24 May 2023 Çar, 05:59 tarihinde şunu yazdı:
Hi, and thanks for the patch! It is an interesting idea.
I have not yet fully read this thread, so below are only my first
impressions after looking at patch 0001. Sorry if some of these were
already discussed earlier.
TBH the patch "reuse-workers" logic seemed more complicated than I had
imagined it might be.
If you mean patch 0001 by the patch "reuse-workers", most of the complexity comes with some refactoring to split apply worker and tablesync worker paths. [1]
If you mean the whole patch set, then I believe it's because reusing replication slots also requires having a proper snapshot each time the worker moves to a new table. [2]
1.
IIUC with patch 0001, each/every tablesync worker (a.k.a. TSW) when it
finishes dealing with one table then goes looking to find if there is
some relation that it can process next. So now every TSW has a loop
where it will fight with every other available TSW over who will get
to process the next relation.
Somehow this seems all backwards to me. Isn't it strange for the TSW
to be the one deciding what relation it would deal with next?
IMO it seems more natural to simply return the finished TSW to some
kind of "pool" of available workers and the main Apply process can
just grab a TSW from that pool instead of launching a brand new one in
the existing function process_syncing_tables_for_apply(). Or, maybe
those "available" workers can be returned to a pool maintained within
the launcher.c code, which logicalrep_worker_launch() can draw from
instead of launching a whole new process?
(I need to read the earlier posts to see if these options were already
discussed and rejected)
I think ([3]) relying on a single apply worker for the assignment of several tablesync workers might bring some overhead, it's possible that some tablesync workers wait in idle until the apply worker assigns them something. OTOH yes, the current approach makes tablesync workers race for a new table to sync.
TBF both ways might be worth discussing/investigating more, before deciding which way to go.
2.
AFAIK the thing that identifies a tablesync worker is the fact that
only TSW will have a 'relid'.
But it feels very awkward to me to have a TSW marked as "available"
and yet that LogicalRepWorker must still have some OLD relid field
value lurking (otherwise it will forget that it is a "tablesync"
worker!).
IMO perhaps it is time now to introduce some enum 'type' to the
LogicalRepWorker. Then an "in_use" type=TSW would have a valid 'relid'
whereas an "available" type=TSW would have relid == InvalidOid.
Hmm, relid will be immediately updated when the worker moves to a new table. And the time between finishing sync of a table and finding a new table to sync should be minimal. I'm not sure how having an old relid for such a small amount of time can do any harm.
3.
Maybe I am mistaken, but it seems the benchmark results posted are
only using quite a small/default values for
"max_sync_workers_per_subscription", so I wondered how those results
are affected by increasing that GUC. I think having only very few
workers would cause more sequential processing, so conveniently the
effect of the patch avoiding re-launch might be seen in the best
possible light. OTOH, using more TSW in the first place might reduce
the overall tablesync time because the subscriber can do more work in
parallel.
So I'm not quite sure what the goal is here. E.g. if the user doesn't
care much about how long tablesync phase takes then there is maybe no
need for this patch at all. OTOH, I thought if a user does care about
the subscription startup time, won't those users be opting for a much
larger "max_sync_workers_per_subscription" in the first place?
Therefore shouldn't the benchmarking be using a larger number too?
Regardless of how many tablesync workers there are, reusing workers will speed things up if a worker has a chance to sync more than one table. Increasing the number of tablesync workers, of course, improves the tablesync performance. But if it doesn't make 100% parallel ( meaning that # of sync workers != # of tables to sync), then reusing workers can bring an additional improvement.
Here are some benchmarks similar to earlier, but with 100 tables and different number of workers:
+--------+-------------+-------------+-------------+------------+
| | 2 workers | 4 workers | 6 workers | 8 workers |
+--------+-------------+-------------+-------------+------------+
| master | 2579.154 ms | 1383.153 ms | 1001.559 ms | 911.758 ms |
+--------+-------------+-------------+-------------+------------+
| patch | 1724.230 ms | 853.894 ms | 601.176 ms | 496.395 ms |
+--------+-------------+-------------+-------------+------------+
| | 2 workers | 4 workers | 6 workers | 8 workers |
+--------+-------------+-------------+-------------+------------+
| master | 2579.154 ms | 1383.153 ms | 1001.559 ms | 911.758 ms |
+--------+-------------+-------------+-------------+------------+
| patch | 1724.230 ms | 853.894 ms | 601.176 ms | 496.395 ms |
+--------+-------------+-------------+-------------+------------+
So yes, increasing the number of workers makes it faster. But reusing workers can still improve more.
Best,
Melih Mutlu
Microsoft
On Thu, May 25, 2023 at 6:59 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
>
> Peter Smith <smithpb2250@gmail.com>, 24 May 2023 Çar, 05:59 tarihinde şunu yazdı:
>>
>> Hi, and thanks for the patch! It is an interesting idea.
>>
>> I have not yet fully read this thread, so below are only my first
>> impressions after looking at patch 0001. Sorry if some of these were
>> already discussed earlier.
>>
>> TBH the patch "reuse-workers" logic seemed more complicated than I had
>> imagined it might be.
>
>
> If you mean patch 0001 by the patch "reuse-workers", most of the complexity comes with some refactoring to split
applyworker and tablesync worker paths. [1]
> If you mean the whole patch set, then I believe it's because reusing replication slots also requires having a proper
snapshoteach time the worker moves to a new table. [2]
>
Yes, I was mostly referring to the same as point 1 below about patch
0001. I guess I just found the concept of mixing A) launching TSW (via
apply worker) with B) reassigning TSW to another relation (by the TSW
battling with its peers) to be a bit difficult to understand. I
thought most of the refactoring seemed to arise from choosing to do it
that way.
>>
>>
>> 1.
>> IIUC with patch 0001, each/every tablesync worker (a.k.a. TSW) when it
>> finishes dealing with one table then goes looking to find if there is
>> some relation that it can process next. So now every TSW has a loop
>> where it will fight with every other available TSW over who will get
>> to process the next relation.
>>
>> Somehow this seems all backwards to me. Isn't it strange for the TSW
>> to be the one deciding what relation it would deal with next?
>>
>> IMO it seems more natural to simply return the finished TSW to some
>> kind of "pool" of available workers and the main Apply process can
>> just grab a TSW from that pool instead of launching a brand new one in
>> the existing function process_syncing_tables_for_apply(). Or, maybe
>> those "available" workers can be returned to a pool maintained within
>> the launcher.c code, which logicalrep_worker_launch() can draw from
>> instead of launching a whole new process?
>>
>> (I need to read the earlier posts to see if these options were already
>> discussed and rejected)
>
>
> I think ([3]) relying on a single apply worker for the assignment of several tablesync workers might bring some
overhead,it's possible that some tablesync workers wait in idle until the apply worker assigns them something. OTOH
yes,the current approach makes tablesync workers race for a new table to sync.
Yes, it might be slower than the 'patched' code because "available"
workers might be momentarily idle while they wait to be re-assigned to
the next relation. We would need to try it to find out.
> TBF both ways might be worth discussing/investigating more, before deciding which way to go.
+1. I think it would be nice to see POC of both ways for benchmark
comparison because IMO performance is not the only consideration --
unless there is an obvious winner, then they need to be judged also by
the complexity of the logic, the amount of code that needed to be
refactored, etc.
>
>>
>> 2.
>> AFAIK the thing that identifies a tablesync worker is the fact that
>> only TSW will have a 'relid'.
>>
>> But it feels very awkward to me to have a TSW marked as "available"
>> and yet that LogicalRepWorker must still have some OLD relid field
>> value lurking (otherwise it will forget that it is a "tablesync"
>> worker!).
>>
>> IMO perhaps it is time now to introduce some enum 'type' to the
>> LogicalRepWorker. Then an "in_use" type=TSW would have a valid 'relid'
>> whereas an "available" type=TSW would have relid == InvalidOid.
>
>
> Hmm, relid will be immediately updated when the worker moves to a new table. And the time between finishing sync of a
tableand finding a new table to sync should be minimal. I'm not sure how having an old relid for such a small amount of
timecan do any harm.
There is no "harm", but it just didn't feel right to make the
LogicalRepWorker to transition through some meaningless state
("available" for re-use but still assigned some relid), just because
it was easy to do it that way. I think it is more natural for the
'relid' to be valid only when it is valid for the worker and to be
InvalidOid when it is not valid. --- Maybe this gripe would become
more apparent if the implementation use the "free-list" idea because
then you would have a lot of bogus relids assigned to the workers of
that list for longer than just a moment.
>
>>
>> 3.
>> Maybe I am mistaken, but it seems the benchmark results posted are
>> only using quite a small/default values for
>> "max_sync_workers_per_subscription", so I wondered how those results
>> are affected by increasing that GUC. I think having only very few
>> workers would cause more sequential processing, so conveniently the
>> effect of the patch avoiding re-launch might be seen in the best
>> possible light. OTOH, using more TSW in the first place might reduce
>> the overall tablesync time because the subscriber can do more work in
>> parallel.
>>
>>
>>
>> So I'm not quite sure what the goal is here. E.g. if the user doesn't
>>
>> care much about how long tablesync phase takes then there is maybe no
>> need for this patch at all. OTOH, I thought if a user does care about
>> the subscription startup time, won't those users be opting for a much
>> larger "max_sync_workers_per_subscription" in the first place?
>> Therefore shouldn't the benchmarking be using a larger number too?
>
>
> Regardless of how many tablesync workers there are, reusing workers will speed things up if a worker has a chance to
syncmore than one table. Increasing the number of tablesync workers, of course, improves the tablesync performance. But
ifit doesn't make 100% parallel ( meaning that # of sync workers != # of tables to sync), then reusing workers can
bringan additional improvement.
>
> Here are some benchmarks similar to earlier, but with 100 tables and different number of workers:
>
> +--------+-------------+-------------+-------------+------------+
> | | 2 workers | 4 workers | 6 workers | 8 workers |
> +--------+-------------+-------------+-------------+------------+
> | master | 2579.154 ms | 1383.153 ms | 1001.559 ms | 911.758 ms |
> +--------+-------------+-------------+-------------+------------+
> | patch | 1724.230 ms | 853.894 ms | 601.176 ms | 496.395 ms |
> +--------+-------------+-------------+-------------+------------+
>
> So yes, increasing the number of workers makes it faster. But reusing workers can still improve more.
>
Thanks for the benchmark results! There is no denying they seem pretty
good numbers.
But it is difficult to get an overall picture of the behaviour. Mostly
when benchmarks were posted you hold one variable fixed and show only
one other varying. It always leaves me wondering -- what about not
empty tables, or what about different numbers of tables etc. Is it
possible to make some script to gather a bigger set of results so we
can see everything at once? Perhaps then it will become clear there is
some "sweet spot" where the patch is really good but beyond that it
degrades (actually, who knows what it might show).
For example:
=== empty tables
workers:2 workers:4 workers:8 workers:16
tables:10 tables:10 tables:10 tables:10
data:0 data:0 data:0 data:0
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:100 tables:100 tables:100 tables:100
data:0 data:0 data:0 data:0
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:1000 tables:1000 tables:1000 tables:1000
data:0 data:0 data:0 data:0
master/patch master/patch master/patch master/patch
=== 1M data
workers:2 workers:4 workers:8 workers:16
tables:10 tables:10 tables:10 tables:10
data:1M data:1M data:1M data:1M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:100 tables:100 tables:100 tables:100
data:1M data:1M data:1M data:1M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:1000 tables:1000 tables:1000 tables:1000
data:1M data:1M data:1M data:1M
master/patch master/patch master/patch master/patch
=== 10M data
workers:2 workers:4 workers:8 workers:16
tables:10 tables:10 tables:10 tables:10
data:10M data:10M data:10M data:10M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:100 tables:100 tables:100 tables:100
data:10M data:10M data:10M data:10M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:1000 tables:1000 tables:1000 tables:1000
data:10M data:10M data:10M data:10M
master/patch master/patch master/patch master/patch
== 100M data
workers:2 workers:4 workers:8 workers:16
tables:10 tables:10 tables:10 tables:10
data:100M data:100M data:100M data:100M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:100 tables:100 tables:100 tables:100
data:100M data:100M data:100M data:100M
master/patch master/patch master/patch master/patch
workers:2 workers:4 workers:8 workers:16
tables:1000 tables:1000 tables:1000 tables:1000
data:100M data:100M data:100M data:100M
master/patch master/patch master/patch master/patch
------
Kind Regards,
Peter Smith
Fujitsu Australia
Hi, I rebased the patch and addressed the following reviews. Peter Smith <smithpb2250@gmail.com>, 24 May 2023 Çar, 05:59 tarihinde şunu yazdı: > Here are a few other random things noticed while looking at patch 0001: > > 1. Commit message > > 1a. typo /sequantially/sequentially/ > > 1b. Saying "killed" and "killing" seemed a bit extreme and implies > somebody else is killing the process. But I think mostly tablesync is > just ending by a normal proc exit, so maybe reword this a bit. > Fixed the type and reworded a bit. > > 2. It seemed odd that some -- clearly tablesync specific -- functions > are in the worker.c instead of in tablesync.c. > > 2a. e.g. clean_sync_worker > > 2b. e.g. sync_worker_exit > Honestly, the distinction between worker.c and tablesync.c is not that clear to me. Both seem like they're doing some work for tablesync and apply. But yes, you're right. Those functions fit better to tablesync.c. Moved them. > > 3. process_syncing_tables_for_sync > > + /* > + * Sync worker is cleaned at this point. It's ready to sync next table, > + * if needed. > + */ > + SpinLockAcquire(&MyLogicalRepWorker->relmutex); > + MyLogicalRepWorker->ready_to_reuse = true; > SpinLockRelease(&MyLogicalRepWorker->relmutex); > + } > + > + SpinLockRelease(&MyLogicalRepWorker->relmutex); > > Isn't there a double release of that mutex happening there? Fixed. Thanks, -- Melih Mutlu Microsoft
Вложения
Hi Peter, Peter Smith <smithpb2250@gmail.com>, 26 May 2023 Cum, 10:30 tarihinde şunu yazdı: > > On Thu, May 25, 2023 at 6:59 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > Yes, I was mostly referring to the same as point 1 below about patch > 0001. I guess I just found the concept of mixing A) launching TSW (via > apply worker) with B) reassigning TSW to another relation (by the TSW > battling with its peers) to be a bit difficult to understand. I > thought most of the refactoring seemed to arise from choosing to do it > that way. No, the refactoring is not related to the way of assigning a new table. In fact, the patch did not include such refactoring a couple versions earlier [1] and was still assigning tables the same way. It was suggested here [2]. Then, I made the patch 0001 which includes some refactoring and only reuses the worker and nothing else. Also I find it more understandable this way, maybe it's a bit subjective. I feel that logical replication related files are getting more and more complex and hard to understand with each change. IMHO, even without reusing anything, those need some refactoring anyway. But for this patch, refactoring some places made it simpler to reuse workers and/or replication slots, regardless of how tables are assigned to TSW's. > +1. I think it would be nice to see POC of both ways for benchmark > comparison because IMO performance is not the only consideration -- > unless there is an obvious winner, then they need to be judged also by > the complexity of the logic, the amount of code that needed to be > refactored, etc. Will try to do that. But, like I mentioned above, I don't think that such a change would reduce the complexity or number of lines changed. > But it is difficult to get an overall picture of the behaviour. Mostly > when benchmarks were posted you hold one variable fixed and show only > one other varying. It always leaves me wondering -- what about not > empty tables, or what about different numbers of tables etc. Is it > possible to make some script to gather a bigger set of results so we > can see everything at once? Perhaps then it will become clear there is > some "sweet spot" where the patch is really good but beyond that it > degrades (actually, who knows what it might show). I actually shared the benchmarks with different numbers of tables and sizes. But those were all with 2 workers. I guess you want a similar benchmark with different numbers of workers. Will work on this and share soon. [1] https://www.postgresql.org/message-id/CAGPVpCQmEE8BygXr%3DHi2N2t2kOE%3DPJwofn9TX0J9J4crjoXarQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAAKRu_YKGyF%2BsvRQqe1th-mG9xLdzneWgh9H1z1DtypBkawkkw%40mail.gmail.com Thanks, -- Melih Mutlu Microsoft
On Thu, Jun 1, 2023 at 7:22 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi Peter, > > Peter Smith <smithpb2250@gmail.com>, 26 May 2023 Cum, 10:30 tarihinde > şunu yazdı: > > > > On Thu, May 25, 2023 at 6:59 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Yes, I was mostly referring to the same as point 1 below about patch > > 0001. I guess I just found the concept of mixing A) launching TSW (via > > apply worker) with B) reassigning TSW to another relation (by the TSW > > battling with its peers) to be a bit difficult to understand. I > > thought most of the refactoring seemed to arise from choosing to do it > > that way. > > No, the refactoring is not related to the way of assigning a new > table. In fact, the patch did not include such refactoring a couple > versions earlier [1] and was still assigning tables the same way. It > was suggested here [2]. Then, I made the patch 0001 which includes > some refactoring and only reuses the worker and nothing else. Also I > find it more understandable this way, maybe it's a bit subjective. > > I feel that logical replication related files are getting more and > more complex and hard to understand with each change. IMHO, even > without reusing anything, those need some refactoring anyway. But for > this patch, refactoring some places made it simpler to reuse workers > and/or replication slots, regardless of how tables are assigned to > TSW's. If refactoring is wanted anyway (regardless of the chosen "reuse" logic), then will it be better to split off a separate 0001 patch just to get that part out of the way first? ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Yu Shi (Fujitsu)"
Дата:
On Thu, Jun 1, 2023 6:54 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
> I rebased the patch and addressed the following reviews.
>
Thanks for updating the patch. Here are some comments on 0001 patch.
1.
- ereport(LOG,
- (errmsg("logical replication table synchronization worker for subscription \"%s\", table \"%s\" has
finished",
- MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
Could we move this to somewhere else instead of removing it?
2.
+ if (!OidIsValid(originid))
+ originid = replorigin_create(originname);
+ replorigin_session_setup(originid, 0);
+ replorigin_session_origin = originid;
+ *origin_startpos = replorigin_session_get_progress(false);
+ CommitTransactionCommand();
+
+ /* Is the use of a password mandatory? */
+ must_use_password = MySubscription->passwordrequired &&
+ !superuser_arg(MySubscription->owner);
+ LogRepWorkerWalRcvConn = walrcv_connect(MySubscription->conninfo, true,
+ must_use_password,
+ MySubscription->name, &err);
It seems that there is a problem when refactoring.
See commit e7e7da2f8d5.
3.
+ /* Set this to false for safety, in case we're already reusing the worker */
+ MyLogicalRepWorker->ready_to_reuse = false;
+
I am not sure do we need to lock when setting it.
4.
+ /*
+ * Allocate the origin name in long-lived context for error context
+ * message.
+ */
+ StartTransactionCommand();
+ ReplicationOriginNameForLogicalRep(MySubscription->oid,
+ MyLogicalRepWorker->relid,
+ originname,
+ originname_size);
+ CommitTransactionCommand();
Do we need the call to StartTransactionCommand() and CommitTransactionCommand()
here? Besides, the comment here is the same as the comment atop
set_apply_error_context_origin(), do we need it?
5.
I saw a segmentation fault when debugging.
It happened when calling sync_worker_exit() called (see the code below in
LogicalRepSyncTableStart()). In the case that this is not the first table the
worker synchronizes, clean_sync_worker() has been called before (in
TablesyncWorkerMain()), and LogRepWorkerWalRcvConn has been set to NULL. Then, a
segmentation fault happened because LogRepWorkerWalRcvConn is a null pointer.
switch (relstate)
{
case SUBREL_STATE_SYNCDONE:
case SUBREL_STATE_READY:
case SUBREL_STATE_UNKNOWN:
sync_worker_exit(); /* doesn't return */
}
Here is the backtrace.
#0 0x00007fc8a8ce4c95 in libpqrcv_disconnect (conn=0x0) at libpqwalreceiver.c:757
#1 0x000000000092b8c0 in clean_sync_worker () at tablesync.c:150
#2 0x000000000092b8ed in sync_worker_exit () at tablesync.c:164
#3 0x000000000092d8f6 in LogicalRepSyncTableStart (origin_startpos=0x7ffd50f30f08) at tablesync.c:1293
#4 0x0000000000934f76 in start_table_sync (origin_startpos=0x7ffd50f30f08, myslotname=0x7ffd50f30e80) at
worker.c:4457
#5 0x000000000093513b in run_tablesync_worker (options=0x7ffd50f30ec0, slotname=0x0, originname=0x7ffd50f30f10
"pg_16394_16395",
originname_size=64, origin_startpos=0x7ffd50f30f08) at worker.c:4532
#6 0x0000000000935a3a in TablesyncWorkerMain (main_arg=1) at worker.c:4853
#7 0x00000000008e97f6 in StartBackgroundWorker () at bgworker.c:864
#8 0x00000000008f350b in do_start_bgworker (rw=0x12fc1a0) at postmaster.c:5762
#9 0x00000000008f38b7 in maybe_start_bgworkers () at postmaster.c:5986
#10 0x00000000008f2975 in process_pm_pmsignal () at postmaster.c:5149
#11 0x00000000008ee98a in ServerLoop () at postmaster.c:1770
#12 0x00000000008ee3bb in PostmasterMain (argc=3, argv=0x12c4af0) at postmaster.c:1463
#13 0x00000000007b6d3a in main (argc=3, argv=0x12c4af0) at main.c:198
The steps to reproduce:
Worker1, in TablesyncWorkerMain(), the relstate of new table to sync (obtained
by GetSubscriptionRelations) is SUBREL_STATE_INIT, and in the foreach loop,
before the following Check (it needs a breakpoint before locking),
LWLockAcquire(LogicalRepWorkerLock, LW_EXCLUSIVE);
if (rstate->state != SUBREL_STATE_SYNCDONE &&
!logicalrep_worker_find(MySubscription->oid, rstate->relid, false))
{
/* Update worker state for the next table */
MyLogicalRepWorker->relid = rstate->relid;
MyLogicalRepWorker->relstate = rstate->state;
MyLogicalRepWorker->relstate_lsn = rstate->lsn;
LWLockRelease(LogicalRepWorkerLock);
break;
}
LWLockRelease(LogicalRepWorkerLock);
let this table to be synchronized by another table sync worker (Worker2), and
Worker2 has finished before logicalrep_worker_find was called(). Then Worker1
tried to sync a table whose state is SUBREL_STATE_READY and the segmentation
fault happened.
Regards,
Shi Yu
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Melih,
Thank you for making the patch!
I'm also interested in the patchset. Here are the comments for 0001.
Some codes are not suit for our coding conventions, but followings do not contain them
because patches seems in the early statge.
Moreover, 0003 needs rebase.
01. general
Why do tablesync workers have to disconnect from publisher for every iterations?
I think connection initiation overhead cannot be negligible in the postgres's basic
architecture. I have not checked yet, but could we add a new replication message
like STOP_STREAMING or CLEANUP? Or, engineerings for it is quite larger than the benefit?
02. logicalrep_worker_launch()
```
- else
+ else if (!OidIsValid(relid))
snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyWorkerMain");
+ else
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "TablesyncWorkerMain");
```
You changed the entry point of tablesync workers, but bgw_type is still the same.
Do you have any decisions about it?
03. process_syncing_tables_for_sync()
```
+ /*
+ * Sync worker is cleaned at this point. It's ready to sync next table,
+ * if needed.
+ */
+ SpinLockAcquire(&MyLogicalRepWorker->relmutex);
+ MyLogicalRepWorker->ready_to_reuse = true;
+ SpinLockRelease(&MyLogicalRepWorker->relmutex);
```
Maybe acquiring the lock for modifying ready_to_reuse is not needed because all
the sync workers check only the own attribute. Moreover, other processes do not read.
04. sync_worker_exit()
```
+/*
+ * Exit routine for synchronization worker.
+ */
+void
+pg_attribute_noreturn()
+sync_worker_exit(void)
```
I think we do not have to rename the function from finish_sync_worker().
05. LogicalRepApplyLoop()
```
+ if (MyLogicalRepWorker->ready_to_reuse)
+ {
+ endofstream = true;
+ }
```
We should add comments here to clarify the reason.
06. stream_build_options()
I think we can set twophase attribute here.
07. TablesyncWorkerMain()
```
+ ListCell *lc;
```
This variable should be declared inside the loop.
08. TablesyncWorkerMain()
```
+ /*
+ * If a relation with INIT state is assigned, clean up the worker for
+ * the next iteration.
+ *
+ * If there is no more work left for this worker, break the loop to
+ * exit.
+ */
+ if ( MyLogicalRepWorker->relstate == SUBREL_STATE_INIT)
+ clean_sync_worker();
```
The sync worker sends a signal to its leader per the iteration, but it may be too
often. Maybe it is added for changing the rstate to READY, however, it is OK to
change it when the next change have come because should_apply_changes_for_rel()
returns true even if rel->state == SUBREL_STATE_SYNCDONE. I think the notification
should be done only at the end of sync workers. How do you think?
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Here are some review comments for the patch v2-0001.
======
Commit message
1. General
Better to use consistent terms in this message. Either "relations" or
"tables" -- not a mixture of both.
~~~
2.
Before this commit, tablesync workers were capable of syncing only one
relation. For each table, a new sync worker was launched and the worker
would exit when the worker is done with the current table.
~
SUGGESTION (2nd sentence)
For each table, a new sync worker was launched and that worker would
exit when done processing the table.
~~~
3.
Now, tablesync workers are not only limited with one relation and can
move to another relation in the same subscription. This reduces the
overhead of launching a new background worker and exiting from that
worker for each relation.
~
SUGGESTION (1st sentence)
Now, tablesync workers are not limited to processing only one
relation. When done, they can move to processing another relation in
the same subscription.
~~~
4.
A new tablesync worker gets launched only if the number of tablesync
workers for the subscription does not exceed
max_sync_workers_per_subscription. If there is a table needs to be synced,
a tablesync worker picks that up and syncs it.The worker continues to
picking new tables to sync until there is no table left for synchronization
in the subscription.
~
This seems to be missing the point that only "available" workers go
looking for more tables to process. Maybe reword something like below:
SUGGESTION
If there is a table that needs to be synced, an "available" tablesync
worker picks up that table and syncs it. Each tablesync worker
continues to pick new tables to sync until there are no tables left
requiring synchronization. If there was no "available" worker to
process the table, then a new tablesync worker will be launched,
provided the number of tablesync workers for the subscription does not
exceed max_sync_workers_per_subscription.
======
src/backend/replication/logical/launcher.c
5. logicalrep_worker_launch
@@ -460,8 +461,10 @@ retry:
if (is_parallel_apply_worker)
snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ParallelApplyWorkerMain");
- else
+ else if (!OidIsValid(relid))
snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyWorkerMain");
+ else
+ snprintf(bgw.bgw_function_name, BGW_MAXLEN, "TablesyncWorkerMain");
if (OidIsValid(relid))
snprintf(bgw.bgw_name, BGW_MAXLEN,
~
5a.
I felt at least these conditions can be rearranged, so you can use
OidIsValid(relid) instead of !OidIsValid(relid).
~
5b.
Probably it can all be simplified, if you are happy to do it in one line:
snprintf(bgw.bgw_function_name, BGW_MAXLEN,
OidIsValid(relid) ? "TablesyncWorkerMain" :
is_parallel_apply_worker ? "ParallelApplyWorkerMain" :
"ApplyWorkerMain");
======
src/backend/replication/logical/tablesync.c
6. finish_sync_worker
This function is removed/renamed but there are still commenting in
this file referring to 'finish-sync_worker'
~~~
7. clean_sync_worker
I agree with comment from Shi-san. There should still be logging
somewhere that say this tablesync worker has completed the processing
of the current table.
~~~
8. sync_worker_exit
There is inconsistent function naming for clean_sync_worker versus
sync_worker_exit.
How about: clean_sync_worker/exit_sync_worker?
Or: sync_worker_clean/sync_worker_exit?
~~~
9. process_syncing_tables_for_sync
@@ -378,7 +387,13 @@ process_syncing_tables_for_sync(XLogRecPtr current_lsn)
*/
replorigin_drop_by_name(originname, true, false);
- finish_sync_worker();
+ /*
+ * Sync worker is cleaned at this point. It's ready to sync next table,
+ * if needed.
+ */
+ SpinLockAcquire(&MyLogicalRepWorker->relmutex);
+ MyLogicalRepWorker->ready_to_reuse = true;
+ SpinLockRelease(&MyLogicalRepWorker->relmutex);
9a.
I did not quite follow the logic. It says "Sync worker is cleaned at
this point", but who is doing that? -- more details are needed. But,
why not just call clean_sync_worker() right here like it use to call
finish_sync_worker?
~
9b.
Shouldn't this "ready_to_use" flag be assigned within the
clean_sync_worker() function, since that is the function making is
clean for next re-use. The function comment even says so: "Prepares
the synchronization worker for reuse or exit."
======
src/backend/replication/logical/worker.c
10. General -- run_tablesync_worker, TablesyncWorkerMain
IMO these functions would be more appropriately reside in the
tablesync.c instead of the (common) worker.c. Was there some reason
why they cannot be put there?
~~~
11. LogicalRepApplyLoop
+ /*
+ * apply_dispatch() may have gone into apply_handle_commit()
+ * which can go into process_syncing_tables_for_sync early.
+ * Before we were able to reuse tablesync workers, that
+ * process_syncing_tables_for_sync call would exit the worker
+ * instead of preparing for reuse. Now that tablesync workers
+ * can be reused and process_syncing_tables_for_sync is not
+ * responsible for exiting. We need to take care of memory
+ * contexts here before moving to sync the nex table or exit.
+ */
11a.
IMO it does not seem good to explain the reason by describing how the
logic USED to work, with code that is removed (e.g. "Before we
were..."). It's better to describe why this is needed here based on
all the CURRENT code logic.
~
11b.
/nex table/next table/
~
12.
+ if (MyLogicalRepWorker->ready_to_reuse)
+ {
+ endofstream = true;
+ }
Unnecessary parentheses.
~
13.
+ /*
+ * If it's still not ready to reuse, this is probably an apply worker.
+ * End streaming before exiting.
+ */
+ if (!MyLogicalRepWorker->ready_to_reuse)
+ {
+ /* All done */
+ walrcv_endstreaming(LogRepWorkerWalRcvConn, &tli);
+ }
How can we not be 100% sure of the kind of worker we are dealing with?
E.g. "probably" ??
Should this code be using macros like am_tablesync_worker() to have
some certainty what it is dealing with here?
~~~
14. stream_build_options
+ /* stream_build_options
+ * Build logical replication streaming options.
+ *
+ * This function sets streaming options including replication slot name
+ * and origin start position. Workers need these options for logical
replication.
+ */
+static void
+stream_build_options(WalRcvStreamOptions *options, char *slotname,
XLogRecPtr *origin_startpos)
The function name seem a bit strange -- it's not really "building"
anything. How about something like SetStreamOptions, or
set_stream_options.
~~~
15. run_tablesync_worker
+static void
+run_tablesync_worker(WalRcvStreamOptions *options,
+ char *slotname,
+ char *originname,
+ int originname_size,
+ XLogRecPtr *origin_startpos)
+{
+ /* Set this to false for safety, in case we're already reusing the worker */
+ MyLogicalRepWorker->ready_to_reuse = false;
Maybe reword the comment so it does not say set 'this' to false.
~
16.
+ /* Start applying changes to catcup. */
+ start_apply(*origin_startpos);
typo: catcup
~~~
17. run_apply_worker
+static void
+run_apply_worker(WalRcvStreamOptions *options,
+ char *slotname,
+ char *originname,
+ int originname_size,
+ XLogRecPtr *origin_startpos)
+{
+ /* This is the leader apply worker */
+ RepOriginId originid;
+ TimeLineID startpointTLI;
+ char *err;
+ bool must_use_password;
The comment above the variable declarations seems redundant/misplaced.
~~
18. InitializeLogRepWorker
if (am_tablesync_worker())
ereport(LOG,
- (errmsg("logical replication table synchronization worker for
subscription \"%s\", table \"%s\" has started",
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\", relation \"%s\" with relid %u has started",
MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
else
I felt this code could be using get_worker_name() function like the
"else" does instead of the hardwired: "logical replication table
synchronization worker" string
~~~
19. TablesyncWorkerMain
+TablesyncWorkerMain(Datum main_arg)
+{
+ int worker_slot = DatumGetInt32(main_arg);
+ char originname[NAMEDATALEN];
+ XLogRecPtr origin_startpos = InvalidXLogRecPtr;
+ char *myslotname = NULL;
+ WalRcvStreamOptions options;
+ List *rstates;
+ SubscriptionRelState *rstate;
+ ListCell *lc;
- /* Setup replication origin tracking. */
- StartTransactionCommand();
- ReplicationOriginNameForLogicalRep(MySubscription->oid, InvalidOid,
- originname, sizeof(originname));
- originid = replorigin_by_name(originname, true);
- if (!OidIsValid(originid))
- originid = replorigin_create(originname);
- replorigin_session_setup(originid, 0);
- replorigin_session_origin = originid;
- origin_startpos = replorigin_session_get_progress(false);
-
- /* Is the use of a password mandatory? */
- must_use_password = MySubscription->passwordrequired &&
- !superuser_arg(MySubscription->owner);
-
- /* Note that the superuser_arg call can access the DB */
- CommitTransactionCommand();
+ elog(LOG, "logical replication table synchronization worker has started");
Would it be better if that elog was using the common function get_worker_name()?
~~~
20.
+ if (MyLogicalRepWorker->ready_to_reuse)
+ {
+ /* This transaction will be committed by clean_sync_worker. */
+ StartTransactionCommand();
The indentation is broken.
~~~
21.
+ * Check if any table whose relation state is still INIT. If a table
+ * in INIT state is found, the worker will not be finished, it will be
+ * reused instead.
*/
First sentence is not meaningful. Should it say: "Check if there is
any table whose relation state is still INIT." ??
~~~
22.
+ /*
+ * Pick the table for the next run if it is not already picked up
+ * by another worker.
+ *
+ * Take exclusive lock to prevent any other sync worker from picking
+ * the same table.
+ */
+ LWLockAcquire(LogicalRepWorkerLock, LW_EXCLUSIVE);
+ if (rstate->state != SUBREL_STATE_SYNCDONE &&
+ !logicalrep_worker_find(MySubscription->oid, rstate->relid, false))
+ {
+ /* Update worker state for the next table */
+ MyLogicalRepWorker->relid = rstate->relid;
+ MyLogicalRepWorker->relstate = rstate->state;
+ MyLogicalRepWorker->relstate_lsn = rstate->lsn;
+ LWLockRelease(LogicalRepWorkerLock);
+ break;
+ }
+ LWLockRelease(LogicalRepWorkerLock);
}
+
+ /*
+ * If a relation with INIT state is assigned, clean up the worker for
+ * the next iteration.
+ *
+ * If there is no more work left for this worker, break the loop to
+ * exit.
+ */
+ if ( MyLogicalRepWorker->relstate == SUBREL_STATE_INIT)
+ clean_sync_worker();
else
- {
- walrcv_startstreaming(LogRepWorkerWalRcvConn, &options);
- }
+ break;
I was unsure about this logic, but shouldn't the
MyLogicalRepWorker->relstate be assigned a default value prior to all
these loops, so that there can be no chance for it to be
SUBREL_STATE_INIT by accident.
~
23.
+ /* If not exited yet, then the worker will sync another table. */
+ StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has moved to sync table \"%s\" with relid %u.",
+ MySubscription->name, get_rel_name(MyLogicalRepWorker->relid),
MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
23a
This code seems strangely structured. Why is the "not exited yet" part
not within the preceding "if" block where the clean_sync_worker was
done?
~~~
23b.
Wont it be better for that errmsg to use the common function
get_worker_name() instead of having the hardcoded string?
======
src/include/replication/worker_internal.h
24.
+ /*
+ * Used to indicate whether sync worker is ready for being reused
+ * to sync another relation.
+ */
+ bool ready_to_reuse;
+
IIUC this field has no meaning except for a tablesync worker, but the
fieldname give no indication of that at all.
To make this more obvious it might be better to put this with the
other tablesync fields:
/* Used for initial table synchronization. */
Oid relid;
char relstate;
XLogRecPtr relstate_lsn;
slock_t relmutex;
And maybe rename it according to that convention relXXX -- e.g.
'relworker_available' or something
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi hackers, You can find the updated patchset attached. I worked to address the reviews and made some additional changes. Let me first explain the new patchset. 0001: Refactors the logical replication code, mostly worker.c and tablesync.c. Although this patch makes it easier to reuse workers, I believe that it's useful even by itself without other patches. It does not improve performance or anything but aims to increase readability and such. 0002: This is only to reuse worker processes, everything else stays the same (replication slots/origins etc.). 0003: Adds a new command for streaming replication protocol to create a snapshot by an existing replication slot. 0004: Reuses replication slots/origins together with workers. Even only 0001 and 0002 are enough to improve table sync performance at the rates previously shared on this thread. This also means that currently 0004 (reusing replication slots/origins) does not improve as much as I would expect, even though it does not harm either. I just wanted to share what I did so far, while I'm continuing to investigate it more to see what I'm missing in patch 0004. Thanks, -- Melih Mutlu Microsoft
Вложения
Hi, Thanks for your reviews. Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 13 Haz 2023 Sal, 13:06 tarihinde şunu yazdı: > 01. general > > Why do tablesync workers have to disconnect from publisher for every iterations? > I think connection initiation overhead cannot be negligible in the postgres's basic > architecture. I have not checked yet, but could we add a new replication message > like STOP_STREAMING or CLEANUP? Or, engineerings for it is quite larger than the benefit? This actually makes sense. I quickly try to do that without adding any new replication message. As you would expect, it did not work. I don't really know what's needed to make a connection to last for more than one iteration. Need to look into this. Happy to hear any suggestions and thoughts. > The sync worker sends a signal to its leader per the iteration, but it may be too > often. Maybe it is added for changing the rstate to READY, however, it is OK to > change it when the next change have come because should_apply_changes_for_rel() > returns true even if rel->state == SUBREL_STATE_SYNCDONE. I think the notification > should be done only at the end of sync workers. How do you think? I tried to move the logicalrep_worker_wakeup call from clean_sync_worker (end of an iteration) to finish_sync_worker (end of sync worker). I made table sync much slower for some reason, then I reverted that change. Maybe I should look a bit more into the reason why that happened some time. Thanks, -- Melih Mutlu Microsoft
Hi Peter, Thanks for your reviews. I tried to apply most of them. I just have some comments below for some of them. Peter Smith <smithpb2250@gmail.com>, 14 Haz 2023 Çar, 08:45 tarihinde şunu yazdı: > > 9. process_syncing_tables_for_sync > > @@ -378,7 +387,13 @@ process_syncing_tables_for_sync(XLogRecPtr current_lsn) > */ > replorigin_drop_by_name(originname, true, false); > > - finish_sync_worker(); > + /* > + * Sync worker is cleaned at this point. It's ready to sync next table, > + * if needed. > + */ > + SpinLockAcquire(&MyLogicalRepWorker->relmutex); > + MyLogicalRepWorker->ready_to_reuse = true; > + SpinLockRelease(&MyLogicalRepWorker->relmutex); > > 9a. > I did not quite follow the logic. It says "Sync worker is cleaned at > this point", but who is doing that? -- more details are needed. But, > why not just call clean_sync_worker() right here like it use to call > finish_sync_worker? I agree that these explanations at places where the worker decides to not continue with the current table were confusing. Even the name of ready_to_reuse was misleading. I renamed it and tried to improve comments in such places. Can you please check if those make more sense now? > ====== > src/backend/replication/logical/worker.c > > 10. General -- run_tablesync_worker, TablesyncWorkerMain > > IMO these functions would be more appropriately reside in the > tablesync.c instead of the (common) worker.c. Was there some reason > why they cannot be put there? I'm not really against moving those functions to tablesync.c. But what's not clear to me is worker.c. Is it the places to put common functions for all log. rep. workers? Then, what about apply worker? Should we consider a separate file for apply worker too? Thanks, -- Melih Mutlu Microsoft
On Fri, Jun 23, 2023 at 11:50 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > src/backend/replication/logical/worker.c > > > > 10. General -- run_tablesync_worker, TablesyncWorkerMain > > > > IMO these functions would be more appropriately reside in the > > tablesync.c instead of the (common) worker.c. Was there some reason > > why they cannot be put there? > > I'm not really against moving those functions to tablesync.c. But > what's not clear to me is worker.c. Is it the places to put common > functions for all log. rep. workers? Then, what about apply worker? > Should we consider a separate file for apply worker too? IIUC - tablesync.c = for tablesync only - applyparallelworker = for parallel apply worker only - worker.c = for both normal apply worker, plus "common" worker code Regarding making another file (e.g. applyworker.c). It sounds sensible, but I guess you would need to first demonstrate the end result will be much cleaner to get support for such a big refactor. ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Melih,
Thank you for updating the patch! I have not reviewed yet, but I wanted
to reply your comments.
> This actually makes sense. I quickly try to do that without adding any
> new replication message. As you would expect, it did not work.
> I don't really know what's needed to make a connection to last for
> more than one iteration. Need to look into this. Happy to hear any
> suggestions and thoughts.
I have analyzed how we handle this. Please see attached the patch (0003) which
allows reusing connection. The patchset passed tests on my CI.
To make cfbot happy I reassigned the patch number.
In this patch, the tablesync worker does not call clean_sync_worker() at the end
of iterations, and the establishment of the connection is done only once.
The creation of memory context is also suppressed.
Regarding the walsender, streamingDone{Sending|Receiving} is now initialized
before executing StartLogicalReplication(). These flags have been used to decide
when the process exits copy mode. The default value is false, and they are set
to true when the copy mode is finished.
I think there was no use-case that the same walsender executes START_REPLICATION
replication twice so there were no codes for restoring flags. Please tell me if any other
reasons.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
On Fri, Jun 23, 2023 at 7:03 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > You can find the updated patchset attached. > I worked to address the reviews and made some additional changes. > > Let me first explain the new patchset. > 0001: Refactors the logical replication code, mostly worker.c and > tablesync.c. Although this patch makes it easier to reuse workers, I > believe that it's useful even by itself without other patches. It does > not improve performance or anything but aims to increase readability > and such. > 0002: This is only to reuse worker processes, everything else stays > the same (replication slots/origins etc.). > 0003: Adds a new command for streaming replication protocol to create > a snapshot by an existing replication slot. > 0004: Reuses replication slots/origins together with workers. > > Even only 0001 and 0002 are enough to improve table sync performance > at the rates previously shared on this thread. This also means that > currently 0004 (reusing replication slots/origins) does not improve as > much as I would expect, even though it does not harm either. > I just wanted to share what I did so far, while I'm continuing to > investigate it more to see what I'm missing in patch 0004. > I think the reason why you don't see the benefit of the 0004 patches is that it still pays the cost of disconnect/connect and we haven't saved much on network transfer costs because of the new snapshot you are creating in patch 0003. Is it possible to avoid disconnect/connect each time the patch needs to reuse the same tablesync worker? Once, we do that and save the cost of drop_slot and associated network round trip, you may see the benefit of 0003 and 0004 patches. -- With Regards, Amit Kapila.
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Melih,
Thanks for updating the patch. Followings are my comments.
Note that some lines exceeds 80 characters and some other lines seem too short.
And comments about coding conventions were skipped.
0001
01. logicalrep_worker_launch()
```
if (is_parallel_apply_worker)
+ {
snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ParallelApplyWorkerMain");
- else
- snprintf(bgw.bgw_function_name, BGW_MAXLEN, "ApplyWorkerMain");
-
- if (OidIsValid(relid))
snprintf(bgw.bgw_name, BGW_MAXLEN,
- "logical replication worker for subscription %u sync %u", subid, relid);
- else if (is_parallel_apply_worker)
+ "logical replication parallel apply worker for subscription %u", subid);
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication parallel apply worker for subscription %u", subid);
```
Latter snprintf(bgw.bgw_name...) should be snprintf(bgw.bgw_type, BGW_MAXLEN, "logical replication worker").
02. ApplyWorkerMain
```
/*
* Setup callback for syscache so that we know when something changes in
- * the subscription relation state.
+ * the subscription relation state. Do this outside the loop to avoid
+ * exceeding MAX_SYSCACHE_CALLBACKS
*/
```
I'm not sure this change is really needed. CacheRegisterSyscacheCallback() must
be outside the loop to avoid duplicated register, and it seems trivial.
0002
03. TablesyncWorkerMain()
Regarding the inner loop, the exclusive lock is acquired even if the rstate is
SUBREL_STATE_SYNCDONE. Moreover, palloc() and memcpy() for rstate seemsed not
needed. How about following?
```
for (;;)
{
List *rstates;
- SubscriptionRelState *rstate;
ListCell *lc;
...
- rstate = (SubscriptionRelState *) palloc(sizeof(SubscriptionRelState));
foreach(lc, rstates)
{
- memcpy(rstate, lfirst(lc), sizeof(SubscriptionRelState));
+ SubscriptionRelState *rstate =
+ (SubscriptionRelState *) lfirst(lc);
+
+ if (rstate->state == SUBREL_STATE_SYNCDONE)
+ continue;
/*
- * Pick the table for the next run if it is not already picked up
- * by another worker.
- *
- * Take exclusive lock to prevent any other sync worker from picking
- * the same table.
- */
+ * Take exclusive lock to prevent any other sync worker from
+ * picking the same table.
+ */
LWLockAcquire(LogicalRepWorkerLock, LW_EXCLUSIVE);
- if (rstate->state != SUBREL_STATE_SYNCDONE &&
- !logicalrep_worker_find(MySubscription->oid, rstate->relid, false))
+
+ /*
+ * Pick the table for the next run if it is not already picked up
+ * by another worker.
+ */
+ if (!logicalrep_worker_find(MySubscription->oid,
+ rstate->relid, false))
```
04. TablesyncWorkerMain
I think rstates should be pfree'd at the end of the outer loop, but it's OK
if other parts do not.
05. repsponse for for post
>
I tried to move the logicalrep_worker_wakeup call from
clean_sync_worker (end of an iteration) to finish_sync_worker (end of
sync worker). I made table sync much slower for some reason, then I
reverted that change. Maybe I should look a bit more into the reason
why that happened some time.
>
I want to see the testing method to reproduce the same issue, could you please
share it to -hackers?
0003, 0004
I did not checked yet but I could say same as above:
I want to see the testing method to reproduce the same issue.
Could you please share it to -hackers?
My previous post (an approach for reuse connection) may help the performance.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
On Tue, Jun 27, 2023 at 1:12 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > > This actually makes sense. I quickly try to do that without adding any > > new replication message. As you would expect, it did not work. > > I don't really know what's needed to make a connection to last for > > more than one iteration. Need to look into this. Happy to hear any > > suggestions and thoughts. > It is not clear to me what exactly you tried here which didn't work. Can you please explain a bit more? > I have analyzed how we handle this. Please see attached the patch (0003) which > allows reusing connection. > Why did you change the application name during the connection? -- With Regards, Amit Kapila.
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Amit, > > > This actually makes sense. I quickly try to do that without adding any > > > new replication message. As you would expect, it did not work. > > > I don't really know what's needed to make a connection to last for > > > more than one iteration. Need to look into this. Happy to hear any > > > suggestions and thoughts. > > > > It is not clear to me what exactly you tried here which didn't work. > Can you please explain a bit more? Just to confirm, this is not my part. Melih can answer this... > > I have analyzed how we handle this. Please see attached the patch (0003) which > > allows reusing connection. > > > > Why did you change the application name during the connection? It was because the lifetime of tablesync worker is longer than slots's one and tablesync worker creates temporary replication slots many times, per the target relation. The name of each slots has relid, so I thought that it was not suitable. But in the later patch the tablesync worker tries to reuse the slot during the synchronization, so in this case the application_name should be same as slotname. I added comment in 0003, and new file 0006 file to use slot name as application_name again. Note again that the separation was just for specifying changes, Melih can include them to one part of files if needed. Best Regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- 0005-Reuse-Replication-Slot-and-Origin-in-Tablesync.patch
- 0006-Use-slot-name-as-application_name-again.patch
- 0001-Refactor-to-split-Apply-and-Tablesync-Workers.patch
- 0002-Reuse-Tablesync-Workers.patch
- 0003-reuse-connection-when-tablesync-workers-change-the-t.patch
- 0004-Add-replication-protocol-cmd-to-create-a-snapshot.patch
On Wed, Jun 28, 2023 at 12:02 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > > > I have analyzed how we handle this. Please see attached the patch (0003) which > > > allows reusing connection. > > > > > > > Why did you change the application name during the connection? > > It was because the lifetime of tablesync worker is longer than slots's one and > tablesync worker creates temporary replication slots many times, per the target > relation. The name of each slots has relid, so I thought that it was not suitable. > Okay, but let's try to give a unique application name to each tablesync worker for the purpose of pg_stat_activity and synchronous replication (as mentioned in existing comments as well). One idea is to generate a name like pg_<sub_id>_sync_<worker_slot> but feel free to suggest if you have any better ideas. > But in the later patch the tablesync worker tries to reuse the slot during the > synchronization, so in this case the application_name should be same as slotname. > Fair enough. I am slightly afraid that if we can't show the benefits with later patches then we may need to drop them but at this stage I feel we need to investigate why those are not helping? -- With Regards, Amit Kapila.
On Mon, Jul 3, 2023 at 9:42 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jun 28, 2023 at 12:02 PM Hayato Kuroda (Fujitsu) > <kuroda.hayato@fujitsu.com> wrote: > > > But in the later patch the tablesync worker tries to reuse the slot during the > > synchronization, so in this case the application_name should be same as slotname. > > > > Fair enough. I am slightly afraid that if we can't show the benefits > with later patches then we may need to drop them but at this stage I > feel we need to investigate why those are not helping? > On thinking about this, I think the primary benefit we were expecting by saving network round trips for slot drop/create but now that we anyway need an extra round trip to establish a snapshot, so such a benefit was not visible. This is just a theory so we should validate it. The another idea as discussed before [1] could be to try copying multiple tables in a single transaction. Now, keeping a transaction open for a longer time could have side-effects on the publisher node. So, we probably need to ensure that we don't perform multiple large syncs and even for smaller tables (and later sequences) perform it only for some threshold number of tables which we can figure out by some tests. Also, the other safety-check could be that anytime we need to perform streaming (sync with apply worker), we won't copy more tables in same transaction. Thoughts? [1] - https://www.postgresql.org/message-id/CAGPVpCRWEVhXa7ovrhuSQofx4to7o22oU9iKtrOgAOtz_%3DY6vg%40mail.gmail.com -- With Regards, Amit Kapila.
On Wed, 28 Jun 2023 at 12:02, Hayato Kuroda (Fujitsu)
<kuroda.hayato@fujitsu.com> wrote:
>
> Dear Amit,
>
> > > > This actually makes sense. I quickly try to do that without adding any
> > > > new replication message. As you would expect, it did not work.
> > > > I don't really know what's needed to make a connection to last for
> > > > more than one iteration. Need to look into this. Happy to hear any
> > > > suggestions and thoughts.
> > >
> >
> > It is not clear to me what exactly you tried here which didn't work.
> > Can you please explain a bit more?
>
> Just to confirm, this is not my part. Melih can answer this...
>
> > > I have analyzed how we handle this. Please see attached the patch (0003) which
> > > allows reusing connection.
> > >
> >
> > Why did you change the application name during the connection?
>
> It was because the lifetime of tablesync worker is longer than slots's one and
> tablesync worker creates temporary replication slots many times, per the target
> relation. The name of each slots has relid, so I thought that it was not suitable.
> But in the later patch the tablesync worker tries to reuse the slot during the
> synchronization, so in this case the application_name should be same as slotname.
>
> I added comment in 0003, and new file 0006 file to use slot name as application_name
> again. Note again that the separation was just for specifying changes, Melih can
> include them to one part of files if needed.
Few comments:
1) Should these error messages say "Could not create a snapshot by
replication slot":
+ if (!pubnames_str)
+ ereport(ERROR,
+ (errcode(ERRCODE_OUT_OF_MEMORY),
/* likely guess */
+ errmsg("could not start WAL streaming: %s",
+
pchomp(PQerrorMessage(conn->streamConn)))));
+ pubnames_literal = PQescapeLiteral(conn->streamConn, pubnames_str,
+
strlen(pubnames_str));
+ if (!pubnames_literal)
+ ereport(ERROR,
+ (errcode(ERRCODE_OUT_OF_MEMORY),
/* likely guess */
+ errmsg("could not start WAL streaming: %s",
+
pchomp(PQerrorMessage(conn->streamConn)))));
+ appendStringInfo(&cmd, ", publication_names %s", pubnames_literal);
+ PQfreemem(pubnames_literal);
+ pfree(pubnames_str);
2) These checks are present in CreateReplicationSlot too, can we have
a common function to check these for both CreateReplicationSlot and
CreateReplicationSnapshot:
+ if (!IsTransactionBlock())
+ ereport(ERROR,
+ (errmsg("%s must be called inside a
transaction",
+
"CREATE_REPLICATION_SNAPSHOT ...")));
+
+ if (XactIsoLevel != XACT_REPEATABLE_READ)
+ ereport(ERROR,
+ (errmsg("%s must be called in
REPEATABLE READ isolation mode transaction",
+
"CREATE_REPLICATION_SNAPSHOT ...")));
+
+ if (!XactReadOnly)
+ ereport(ERROR,
+ (errmsg("%s must be called in a read
only transaction",
+
"CREATE_REPLICATION_SNAPSHOT ...")));
+
+ if (FirstSnapshotSet)
+ ereport(ERROR,
+ (errmsg("%s must be called before any query",
+
"CREATE_REPLICATION_SNAPSHOT ...")));
+
+ if (IsSubTransaction())
+ ereport(ERROR,
+ (errmsg("%s must not be called in a
subtransaction",
+
"CREATE_REPLICATION_SNAPSHOT ...")));
3) Probably we can add the function header at this point of time:
+/*
+ * TODO
+ */
+static void
+libpqrcv_slot_snapshot(WalReceiverConn *conn,
+ char *slotname,
+ const WalRcvStreamOptions *options,
+ XLogRecPtr *lsn)
4) Either or relation name or relid should be sufficient here, no need
to print both:
StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("%s
for subscription \"%s\" has moved to sync table \"%s\" with relid
%u.",
+
get_worker_name(),
+
MySubscription->name,
+
get_rel_name(MyLogicalRepWorker->relid),
+
MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
5) Why is this check of logicalrep_worker_find is required required,
will it not be sufficient to pick the relations that are in
SUBREL_STATE_INIT state?
+ /*
+ * Pick the table for the next run if
it is not already picked up
+ * by another worker.
+ *
+ * Take exclusive lock to prevent any
other sync worker from picking
+ * the same table.
+ */
+ LWLockAcquire(LogicalRepWorkerLock,
LW_EXCLUSIVE);
+ if (rstate->state != SUBREL_STATE_SYNCDONE &&
+
!logicalrep_worker_find(MySubscription->oid, rstate->relid, false))
+ {
+ /* Update worker state for the
next table */
6) This comment is missed while refactoring:
- /* Build logical replication streaming options. */
- options.logical = true;
- options.startpoint = origin_startpos;
- options.slotname = myslotname;
7) We could keep twophase and origin as the same order as it was
earlier so that it is easy to review that the existing code is kept as
is in this case:
+ options->proto.logical.publication_names = MySubscription->publications;
+ options->proto.logical.binary = MySubscription->binary;
+ options->proto.logical.twophase = false;
+ options->proto.logical.origin = pstrdup(MySubscription->origin);
+
+ /*
+ * Assign the appropriate option value for streaming option according to
+ * the 'streaming' mode and the publisher's ability to support
that mode.
+ */
+ if (server_version >= 160000 &&
8) There are few indentation issues, we could run pgindent once:
8.a)
+ /* Sync worker has completed synchronization of the
current table. */
+ MyLogicalRepWorker->is_sync_completed = true;
+
+ ereport(LOG,
+ (errmsg("logical replication table synchronization
worker for subscription \"%s\", relation \"%s\" with relid %u has
finished",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
8.b)
+ ereport(DEBUG2,
+ (errmsg("process_syncing_tables_for_sync:
updated originname: %s, slotname: %s, state: %c for relation \"%u\" in
subscription \"%u\".",
+ "NULL", "NULL",
MyLogicalRepWorker->relstate,
+ MyLogicalRepWorker->relid,
MyLogicalRepWorker->subid)));
+ CommitTransactionCommand();
+ pgstat_report_stat(false);
Regards,
Vignesh
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Amit, > > > > I have analyzed how we handle this. Please see attached the patch (0003) > which > > > > allows reusing connection. > > > > > > > > > > Why did you change the application name during the connection? > > > > It was because the lifetime of tablesync worker is longer than slots's one and > > tablesync worker creates temporary replication slots many times, per the target > > relation. The name of each slots has relid, so I thought that it was not suitable. > > > > Okay, but let's try to give a unique application name to each > tablesync worker for the purpose of pg_stat_activity and synchronous > replication (as mentioned in existing comments as well). One idea is > to generate a name like pg_<sub_id>_sync_<worker_slot> but feel free > to suggest if you have any better ideas. Good point. The slot id is passed as an argument of TablesyncWorkerMain(), so I passed it to LogicalRepSyncTableStart(). PSA new set. > > But in the later patch the tablesync worker tries to reuse the slot during the > > synchronization, so in this case the application_name should be same as > slotname. > > > > Fair enough. I am slightly afraid that if we can't show the benefits > with later patches then we may need to drop them but at this stage I > feel we need to investigate why those are not helping? Agreed. Now I'm planning to do performance testing independently. We can discuss based on that or Melih's one. Best Regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- v2-0001-Refactor-to-split-Apply-and-Tablesync-Workers.patch
- v2-0002-Reuse-Tablesync-Workers.patch
- v2-0003-reuse-connection-when-tablesync-workers-change-th.patch
- v2-0004-Add-replication-protocol-cmd-to-create-a-snapshot.patch
- v2-0005-Reuse-Replication-Slot-and-Origin-in-Tablesync.patch
- v2-0006-Use-slot-name-as-application_name-again.patch
Hi,
Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 27 Haz 2023 Sal,
10:42 tarihinde şunu yazdı:
>
> Dear Melih,
>
> Thank you for updating the patch! I have not reviewed yet, but I wanted
> to reply your comments.
>
> > This actually makes sense. I quickly try to do that without adding any
> > new replication message. As you would expect, it did not work.
> > I don't really know what's needed to make a connection to last for
> > more than one iteration. Need to look into this. Happy to hear any
> > suggestions and thoughts.
>
> I have analyzed how we handle this. Please see attached the patch (0003) which
> allows reusing connection. The patchset passed tests on my CI.
> To make cfbot happy I reassigned the patch number.
>
> In this patch, the tablesync worker does not call clean_sync_worker() at the end
> of iterations, and the establishment of the connection is done only once.
> The creation of memory context is also suppressed.
>
> Regarding the walsender, streamingDone{Sending|Receiving} is now initialized
> before executing StartLogicalReplication(). These flags have been used to decide
> when the process exits copy mode. The default value is false, and they are set
> to true when the copy mode is finished.
> I think there was no use-case that the same walsender executes START_REPLICATION
> replication twice so there were no codes for restoring flags. Please tell me if any other
> reasons.
Thanks for the 0003 patch. But it did not work for me. Can you create
a subscription successfully with patch 0003 applied?
I get the following error: " ERROR: table copy could not start
transaction on publisher: another command is already in progress".
I think streaming needs to be ended before moving to another table. So
I changed the patch a little bit and also addressed the reviews from
recent emails. Please see the attached patch set.
I'm still keeping the reuse connection patch separate for now to see
what is needed clearly.
Thanks,
Melih
Вложения
Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 4 Tem 2023 Sal, 08:42 tarihinde şunu yazdı: > > > But in the later patch the tablesync worker tries to reuse the slot during the > > > synchronization, so in this case the application_name should be same as > > slotname. > > > > > > > Fair enough. I am slightly afraid that if we can't show the benefits > > with later patches then we may need to drop them but at this stage I > > feel we need to investigate why those are not helping? > > Agreed. Now I'm planning to do performance testing independently. We can discuss > based on that or Melih's one. Here I attached what I use for performance testing of this patch. I only benchmarked the patch set with reusing connections very roughly so far. But seems like it improves quite significantly. For example, it took 611 ms to sync 100 empty tables, it was 1782 ms without reusing connections. First 3 patches from the set actually bring a good amount of improvement, but not sure about the later patches yet. Amit Kapila <amit.kapila16@gmail.com>, 3 Tem 2023 Pzt, 08:59 tarihinde şunu yazdı: > On thinking about this, I think the primary benefit we were expecting > by saving network round trips for slot drop/create but now that we > anyway need an extra round trip to establish a snapshot, so such a > benefit was not visible. This is just a theory so we should validate > it. The another idea as discussed before [1] could be to try copying > multiple tables in a single transaction. Now, keeping a transaction > open for a longer time could have side-effects on the publisher node. > So, we probably need to ensure that we don't perform multiple large > syncs and even for smaller tables (and later sequences) perform it > only for some threshold number of tables which we can figure out by > some tests. Also, the other safety-check could be that anytime we need > to perform streaming (sync with apply worker), we won't copy more > tables in same transaction. > > Thoughts? Yeah, maybe going to the publisher for creating a slot or only a snapshot does not really make enough difference. I was hoping that creating only snapshot by an existing replication slot would help the performance. I guess I was either wrong or am missing something in the implementation. The tricky bit with keeping a long transaction to copy multiple tables is deciding how many tables one transaction can copy. Thanks, -- Melih Mutlu Microsoft
Вложения
On Wed, Jul 5, 2023 at 1:48 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 4 Tem 2023 Sal, > 08:42 tarihinde şunu yazdı: > > > > But in the later patch the tablesync worker tries to reuse the slot during the > > > > synchronization, so in this case the application_name should be same as > > > slotname. > > > > > > > > > > Fair enough. I am slightly afraid that if we can't show the benefits > > > with later patches then we may need to drop them but at this stage I > > > feel we need to investigate why those are not helping? > > > > Agreed. Now I'm planning to do performance testing independently. We can discuss > > based on that or Melih's one. > > Here I attached what I use for performance testing of this patch. > > I only benchmarked the patch set with reusing connections very roughly > so far. But seems like it improves quite significantly. For example, > it took 611 ms to sync 100 empty tables, it was 1782 ms without > reusing connections. > First 3 patches from the set actually bring a good amount of > improvement, but not sure about the later patches yet. > I suggest then we should focus first on those 3, get them committed and then look at the remaining. > Amit Kapila <amit.kapila16@gmail.com>, 3 Tem 2023 Pzt, 08:59 tarihinde > şunu yazdı: > > On thinking about this, I think the primary benefit we were expecting > > by saving network round trips for slot drop/create but now that we > > anyway need an extra round trip to establish a snapshot, so such a > > benefit was not visible. This is just a theory so we should validate > > it. The another idea as discussed before [1] could be to try copying > > multiple tables in a single transaction. Now, keeping a transaction > > open for a longer time could have side-effects on the publisher node. > > So, we probably need to ensure that we don't perform multiple large > > syncs and even for smaller tables (and later sequences) perform it > > only for some threshold number of tables which we can figure out by > > some tests. Also, the other safety-check could be that anytime we need > > to perform streaming (sync with apply worker), we won't copy more > > tables in same transaction. > > > > Thoughts? > > Yeah, maybe going to the publisher for creating a slot or only a > snapshot does not really make enough difference. I was hoping that > creating only snapshot by an existing replication slot would help the > performance. I guess I was either wrong or am missing something in the > implementation. > > The tricky bit with keeping a long transaction to copy multiple tables > is deciding how many tables one transaction can copy. > Yeah, I was thinking that we should not allow copying some threshold data in one transaction. After every copy, we will check the size of the table and add it to the previously copied table size in the same transaction. Once the size crosses a certain threshold, we will end the transaction. This may not be a very good scheme but I think it this helps then it would be much simpler than creating-only-snapshot approach. -- With Regards, Amit Kapila.
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Melih,
> Thanks for the 0003 patch. But it did not work for me. Can you create
> a subscription successfully with patch 0003 applied?
> I get the following error: " ERROR: table copy could not start
> transaction on publisher: another command is already in progress".
You got the ERROR when all the patches (0001-0005) were applied, right?
I have focused on 0001 and 0002 only, so I missed something.
If it was not correct, please attach the logfile and test script what you did.
As you might know, the error is output when the worker executs walrcv_endstreaming()
before doing walrcv_startstreaming().
> I think streaming needs to be ended before moving to another table. So
> I changed the patch a little bit
Your modification seemed not correct. I applied only first three patches (0001-0003), and
executed attached script. Then I got following error on subscriber (attached as N2.log):
> ERROR: could not send end-of-streaming message to primary: no COPY in progress
IIUC the tablesync worker has been already stopped streaming without your modification.
Please see process_syncing_tables_for_sync():
```
if (MyLogicalRepWorker->relstate == SUBREL_STATE_CATCHUP &&
current_lsn >= MyLogicalRepWorker->relstate_lsn)
{
TimeLineID tli;
char syncslotname[NAMEDATALEN] = {0};
char originname[NAMEDATALEN] = {0};
MyLogicalRepWorker->relstate = SUBREL_STATE_SYNCDONE;
...
/*
* End streaming so that LogRepWorkerWalRcvConn can be used to drop
* the slot.
*/
walrcv_endstreaming(LogRepWorkerWalRcvConn, &tli);
```
This means that following changes should not be in the 0003, should be at 0005.
PSA fixed patches.
```
+ /*
+ * If it's already connected to the publisher, end streaming before using
+ * the same connection for another iteration
+ */
+ if (LogRepWorkerWalRcvConn != NULL)
+ {
+ TimeLineID tli;
+ walrcv_endstreaming(LogRepWorkerWalRcvConn, &tli);
+ }
```
Besides, cfbot could not apply your patch set [1]. According to the log, the
bot tried to apply 0004 and 0005 first and got error. IIUC you should assign
same version number within the same mail, like v16-0001, v16-0002,....
[1]: http://cfbot.cputube.org/patch_43_3784.log
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
- N2.log
- test.sh
- v16-0001-Refactor-to-split-Apply-and-Tablesync-Workers.patch
- v16-0002-Reuse-Tablesync-Workers.patch
- v16-0003-reuse-connection-when-tablesync-workers-change-t.patch
- v16-0004-Add-replication-protocol-cmd-to-create-a-snapsho.patch
- v16-0005-Reuse-Replication-Slot-and-Origin-in-Tablesync.patch
Hi. Here are some review comments for the patch v16-0001 ====== Commit message. 1. Also; most of the code shared by both worker types are already combined in LogicalRepApplyLoop(). There is no need to combine the rest in ApplyWorkerMain() anymore. ~ /are already/is already/ /Also;/Also,/ ~~~ 2. This commit introduces TablesyncWorkerMain() as a new entry point for tablesync workers and separates both type of workers from each other. This aims to increase code readability and help to maintain logical replication workers separately. 2a. /This commit/This patch/ ~ 2b. "and separates both type of workers from each other" Maybe that part can all be removed. The following sentence says the same again anyhow. ====== src/backend/replication/logical/worker.c 3. static void stream_write_change(char action, StringInfo s); static void stream_open_and_write_change(TransactionId xid, char action, StringInfo s); static void stream_close_file(void); +static void set_stream_options(WalRcvStreamOptions *options, + char *slotname, + XLogRecPtr *origin_startpos); ~ Maybe a blank line was needed here because this static should not be grouped with the other functions that are grouped for "Serialize and deserialize changes for a toplevel transaction." comment. ~~~ 4. set_stream_options + /* set_stream_options + * Set logical replication streaming options. + * + * This function sets streaming options including replication slot name and + * origin start position. Workers need these options for logical replication. + */ +static void +set_stream_options(WalRcvStreamOptions *options, The indentation is not right for this function comment. ~~~ 5. set_stream_options + /* + * Even when the two_phase mode is requested by the user, it remains as + * the tri-state PENDING until all tablesyncs have reached READY state. + * Only then, can it become ENABLED. + * + * Note: If the subscription has no tables then leave the state as + * PENDING, which allows ALTER SUBSCRIPTION ... REFRESH PUBLICATION to + * work. + */ + if (MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_PENDING && + AllTablesyncsReady()) + options->proto.logical.twophase = true; +} This part of the refactoring seems questionable... IIUC this new function was extracted from code in originally in function ApplyWorkerMain() But in that original code, this fragment above was guarded by the condition if (!am_tablesync_worker()) But now where is that condition? e.g. What is stopping tablesync working from getting into this code it previously would not have executed? ~~~ 6. AbortOutOfAnyTransaction(); - pgstat_report_subscription_error(MySubscription->oid, !am_tablesync_worker()); + pgstat_report_subscription_error(MySubscription->oid, + !am_tablesync_worker()); Does this change have anything to do with this patch? Is it a quirk of running pg_indent? ~~~ 7. run_tablesync_worker Since the stated intent of the patch is the separation of apply and tablesync workers then shouldn't this function belong in the tablesync.c file? ~~~ 8. run_tablesync_worker + * Runs the tablesync worker. + * It starts syncing tables. After a successful sync, sets streaming options + * and starts streaming to catchup. + */ +static void +run_tablesync_worker(WalRcvStreamOptions *options, Nicer to have a blank line after the first sentence of that function comment? ~~~ 9. run_apply_worker +/* + * Runs the leader apply worker. + * It sets up replication origin, streaming options and then starts streaming. + */ +static void +run_apply_worker(WalRcvStreamOptions *options, Nicer to have a blank line after the first sentence of that function comment? ~~~ 10. InitializeLogRepWorker +/* + * Common initialization for logical replication workers; leader apply worker, + * parallel apply worker and tablesync worker. * * Initialize the database connection, in-memory subscription and necessary * config options. */ void -InitializeApplyWorker(void) +InitializeLogRepWorker(void) typo: /workers;/workers:/ ~~~ 11. TablesyncWorkerMain Since the stated intent of the patch is the separation of apply and tablesync workers then shouldn't this function belong in the tablesync.c file? ====== src/include/replication/worker_internal.h 12. #define isParallelApplyWorker(worker) ((worker)->leader_pid != InvalidPid) +extern void finish_sync_worker(void); ~ I think the macro isParallelApplyWorker is associated with the am_XXX inline functions that follow it, so it doesn’t seem the best place to jam this extern in the middle of that. ------ Kind Regards, Peter Smith. Fujitsu Australia
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear hackers, Hi, I did a performance testing for v16 patch set. Results show that patches significantly improves the performance in most cases. # Method Following tests were done 10 times per condition, and compared by median. do_one_test.sh was used for the testing. 1. Create tables on publisher 2. Insert initial data on publisher 3. Create tables on subscriber 4. Create a replication slot (mysub_slot) on publisher 5. Create a publication on publisher 6. Create tables on subscriber --- timer on --- 7. Create subscription with pre-existing replication slot (mysub_slot) 8. Wait until all srsubstate in pg_subscription_rel becomes 'r' --- timer off --- # Tested sources I used three types of sources * HEAD (f863d82) * HEAD + 0001 + 0002 * HEAD + 0001 + 0002 + 0003 # Tested conditions Following parameters were changed during the measurement. ### table size * empty * around 10kB ### number of tables * 10 * 100 * 1000 * 2000 ### max_sync_workers_per_subscription * 2 * 4 * 8 * 16 ## Results Please see the attached image file. Each cell shows the improvement percentage of measurement comapred with HEAD, HEAD + 0001 + 0002, and HEAD + 0001 + 0002 + 0003. According to the measurement, we can say following things: * In any cases the performance was improved from the HEAD. * The improvement became more significantly if number of synced tables were increased. * 0003 basically improved performance from first two patches * Increasing workers could sometimes lead to lesser performance due to contention. This was occurred when the number of tables were small. Moreover, this was not only happen by patchset - it happened evenif we used HEAD. Detailed analysis will be done later. Mored deital, please see the excel file. It contains all the results of measurement. ## Detailed configuration * Powerful machine was used: - Number of CPU: 120 - Memory: 755 GB * Both publisher and subscriber were on the same machine. * Following GUC settings were used for both pub/sub: ``` wal_level = logical shared_buffers = 40GB max_worker_processes = 32 max_parallel_maintenance_workers = 24 max_parallel_workers = 32 synchronous_commit = off checkpoint_timeout = 1d max_wal_size = 24GB min_wal_size = 15GB autovacuum = off max_wal_senders = 200 max_replication_slots = 200 ``` Best Regards, Hayato Kuroda FUJITSU LIMITED
Вложения
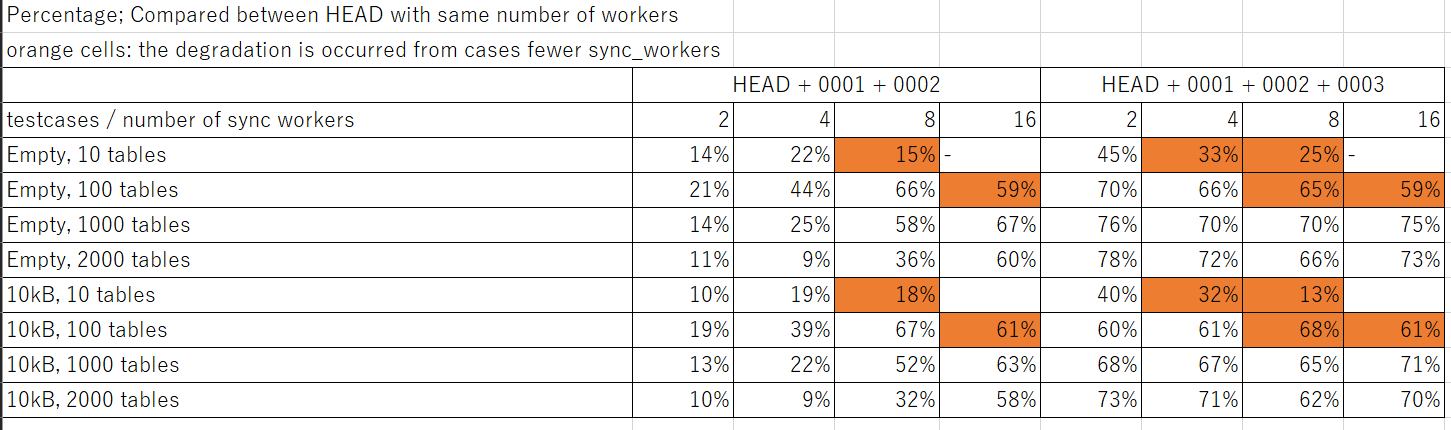{kind=link}
Hi, here are some review comments for patch v16-0002.
======
Commit message
1.
This commit allows reusing tablesync workers for syncing more than one
table sequentially during their lifetime, instead of exiting after
only syncing one table.
Before this commit, tablesync workers were capable of syncing only one
table. For each table, a new sync worker was launched and that worker would
exit when done processing the table.
Now, tablesync workers are not limited to processing only one
table. When done, they can move to processing another table in
the same subscription.
~
IMO that first paragraph can be removed because AFAIK the other
paragraphs are saying exactly the same thing but worded differently.
======
src/backend/replication/logical/tablesync.c
2. General -- for clean_sync_worker and finish_sync_worker
TBH, I found the separation of clean_sync_worker() and
finish_sync_worker() to be confusing. Can't it be rearranged to keep
the same function but just pass a boolean to tell it to exit or not
exit?
e.g.
finish_sync_worker(bool reuse_worker) { ... }
~~~
3. clean_sync_worker
/*
- * Commit any outstanding transaction. This is the usual case, unless
- * there was nothing to do for the table.
+ * Commit any outstanding transaction. This is the usual case, unless there
+ * was nothing to do for the table.
*/
The word wrap seems OK, except the change seemed unrelated to this patch (??)
~~~
4.
+ /*
+ * Disconnect from publisher. Otherwise reused sync workers causes
+ * exceeding max_wal_senders
+ */
Missing period, and not an English sentence.
SUGGESTION (??)
Disconnect from the publisher otherwise reusing the sync worker can
error due to exceeding max_wal_senders.
~~~
5. finish_sync_worker
+/*
+ * Exit routine for synchronization worker.
+ */
+void
+pg_attribute_noreturn()
+finish_sync_worker(void)
+{
+ clean_sync_worker();
+
/* And flush all writes. */
XLogFlush(GetXLogWriteRecPtr());
StartTransactionCommand();
ereport(LOG,
- (errmsg("logical replication table synchronization worker for
subscription \"%s\", table \"%s\" has finished",
- MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
+ MySubscription->name)));
CommitTransactionCommand();
In the original code, the XLogFlush was in a slightly different order
than in this refactored code. E.g. it came before signalling the apply
worker. Is it OK to be changed?
Keeping one function (suggested in #2) can maybe remove this potential issue.
======
src/backend/replication/logical/worker.c
6. LogicalRepApplyLoop
+ /*
+ * apply_dispatch() may have gone into apply_handle_commit()
+ * which can call process_syncing_tables_for_sync.
+ *
+ * process_syncing_tables_for_sync decides whether the sync of
+ * the current table is completed. If it is completed,
+ * streaming must be already ended. So, we can break the loop.
+ */
+ if (MyLogicalRepWorker->is_sync_completed)
+ {
+ endofstream = true;
+ break;
+ }
+
and
+ /*
+ * If is_sync_completed is true, this means that the tablesync
+ * worker is done with synchronization. Streaming has already been
+ * ended by process_syncing_tables_for_sync. We should move to the
+ * next table if needed, or exit.
+ */
+ if (MyLogicalRepWorker->is_sync_completed)
+ endofstream = true;
~
Instead of those code fragments above assigning 'endofstream' as a
side-effect, would it be the same (but tidier) to just modify the
other "breaking" condition below:
BEFORE:
/* Check if we need to exit the streaming loop. */
if (endofstream)
break;
AFTER:
/* Check if we need to exit the streaming loop. */
if (endofstream || MyLogicalRepWorker->is_sync_completed)
break;
~~~
7. LogicalRepApplyLoop
+ /*
+ * Tablesync workers should end streaming before exiting the main loop to
+ * drop replication slot. Only end streaming here for apply workers.
+ */
+ if (!am_tablesync_worker())
+ walrcv_endstreaming(LogRepWorkerWalRcvConn, &tli);
This comment does not seem very clear. Maybe it can be reworded:
SUGGESTION
End streaming here only for apply workers. Ending streaming for
tablesync workers is deferred until ... because ...
~~~
8. TablesyncWorkerMain
+ StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("%s for subscription \"%s\" has moved to sync table \"%s\"
with relid %u.",
+ get_worker_name(),
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
The "has moved to..." terminology is unusual. If you say something
"will be reused to..." then it matches better the commit message etc.
~~~
9.
+ if (!is_table_found)
+ break;
Instead of an infinite loop that is exited by this 'break' it might be
better to rearrange the logic slightly so the 'for' loop can exit
normally:
BEFORE:
for (;;)
AFTER
for (; !done;)
======
src/include/replication/worker_internal.h
10.
XLogRecPtr relstate_lsn;
slock_t relmutex;
+ /*
+ * Indicates whether tablesync worker has completed sycning its assigned
+ * table. If true, no need to continue with that table.
+ */
+ bool is_sync_completed;
+
10a.
Typo /sycning/syncing/
~
10b.
All the other tablesync-related fields of this struct are named as
relXXX, so I wonder if is better for this to follow the same pattern.
e.g. 'relsync_completed'
~
10c.
"If true, no need to continue with that table.".
I am not sure if this sentence is adding anything useful.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi, Amit Kapila <amit.kapila16@gmail.com>, 6 Tem 2023 Per, 06:56 tarihinde şunu yazdı: > > On Wed, Jul 5, 2023 at 1:48 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 4 Tem 2023 Sal, > > 08:42 tarihinde şunu yazdı: > > > > > But in the later patch the tablesync worker tries to reuse the slot during the > > > > > synchronization, so in this case the application_name should be same as > > > > slotname. > > > > > > > > > > > > > Fair enough. I am slightly afraid that if we can't show the benefits > > > > with later patches then we may need to drop them but at this stage I > > > > feel we need to investigate why those are not helping? > > > > > > Agreed. Now I'm planning to do performance testing independently. We can discuss > > > based on that or Melih's one. > > > > Here I attached what I use for performance testing of this patch. > > > > I only benchmarked the patch set with reusing connections very roughly > > so far. But seems like it improves quite significantly. For example, > > it took 611 ms to sync 100 empty tables, it was 1782 ms without > > reusing connections. > > First 3 patches from the set actually bring a good amount of > > improvement, but not sure about the later patches yet. > > > > I suggest then we should focus first on those 3, get them committed > and then look at the remaining. > That sounds good. I'll do my best to address any review/concern from reviewers now for the first 3 patches and hopefully those can get committed first. I'll continue working on the remaining patches later. -- Melih Mutlu Microsoft
Hi, Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 6 Tem 2023 Per, 12:47 tarihinde şunu yazdı: > > Dear Melih, > > > Thanks for the 0003 patch. But it did not work for me. Can you create > > a subscription successfully with patch 0003 applied? > > I get the following error: " ERROR: table copy could not start > > transaction on publisher: another command is already in progress". > > You got the ERROR when all the patches (0001-0005) were applied, right? > I have focused on 0001 and 0002 only, so I missed something. > If it was not correct, please attach the logfile and test script what you did. Yes, I did get an error with all patches applied. But with only 0001 and 0002, your version seems like working and mine does not. What do you think about combining 0002 and 0003? Or should those stay separate? > Hi, I did a performance testing for v16 patch set. > Results show that patches significantly improves the performance in most cases. > > # Method > > Following tests were done 10 times per condition, and compared by median. > do_one_test.sh was used for the testing. > > 1. Create tables on publisher > 2. Insert initial data on publisher > 3. Create tables on subscriber > 4. Create a replication slot (mysub_slot) on publisher > 5. Create a publication on publisher > 6. Create tables on subscriber > --- timer on --- > 7. Create subscription with pre-existing replication slot (mysub_slot) > 8. Wait until all srsubstate in pg_subscription_rel becomes 'r' > --- timer off --- > Thanks for taking the time to do testing and sharing the results. This is also how I've been doing the testing since, but the process was half scripted, half manual work. > According to the measurement, we can say following things: > > * In any cases the performance was improved from the HEAD. > * The improvement became more significantly if number of synced tables were increased. Yes, I believe it becomes more significant when workers spend less time with actually copying data but more with other stuff like launching workers, opening connections etc. > * 0003 basically improved performance from first two patches Agree, 0003 is definitely a good addition which was missing earlier. Thanks, -- Melih Mutlu Microsoft
Here are some review comments for patch v16-00003
======
1. Commit Message.
The patch description is missing.
======
2. General.
+LogicalRepSyncTableStart(XLogRecPtr *origin_startpos, int worker_slot)
and
+start_table_sync(XLogRecPtr *origin_startpos,
+ char **myslotname,
+ int worker_slot)
and
@@ -4548,12 +4552,13 @@ run_tablesync_worker(WalRcvStreamOptions *options,
char *slotname,
char *originname,
int originname_size,
- XLogRecPtr *origin_startpos)
+ XLogRecPtr *origin_startpos,
+ int worker_slot)
It seems the worker_slot is being passed all over the place as an
additional function argument so that it can be used to construct an
application_name. Is it possible/better to introduce a new
'MyLogicalRepWorker' field for the 'worker_slot' so it does not have
to be passed like this?
======
src/backend/replication/logical/tablesync.c
3.
+ /*
+ * Disconnect from publisher. Otherwise reused sync workers causes
+ * exceeding max_wal_senders.
+ */
+ if (LogRepWorkerWalRcvConn != NULL)
+ {
+ walrcv_disconnect(LogRepWorkerWalRcvConn);
+ LogRepWorkerWalRcvConn = NULL;
+ }
+
Why is this comment mentioning anything about "reused workers" at all?
The worker process exits in this function, right?
~~~
4. LogicalRepSyncTableStart
/*
- * Here we use the slot name instead of the subscription name as the
- * application_name, so that it is different from the leader apply worker,
- * so that synchronous replication can distinguish them.
+ * Connect to publisher if not yet. The application_name must be also
+ * different from the leader apply worker because synchronous replication
+ * must distinguish them.
*/
I felt all the details in the 2nd part of this comment belong inside
the condition, not outside.
SUGGESTION
/* Connect to the publisher if haven't done so already. */
~~~
5.
+ if (LogRepWorkerWalRcvConn == NULL)
+ {
+ char application_name[NAMEDATALEN];
+
+ /*
+ * FIXME: set appropriate application_name. Previously, the slot name
+ * was used becasue the lifetime of the tablesync worker was same as
+ * that, but now the tablesync worker handles many slots during the
+ * synchronization so that it is not suitable. So what should be?
+ * Note that if the tablesync worker starts to reuse the replication
+ * slot during synchronization, we should use the slot name as
+ * application_name again.
+ */
+ snprintf(application_name, NAMEDATALEN, "pg_%u_sync_%i",
+ MySubscription->oid, worker_slot);
+ LogRepWorkerWalRcvConn =
+ walrcv_connect(MySubscription->conninfo, true,
+ must_use_password,
+ application_name, &err);
+ }
5a.
/becasue/because/
~
5b.
I am not sure about what name this should ideally use, but anyway for
uniqueness doesn't it still need to include the GetSystemIdentifier()
same as function ReplicationSlotNameForTablesync() was doing?
Maybe this can use the same function ReplicationSlotNameForTablesync()
can be used but just pass the worker_slot instead of the relid?
======
src/backend/replication/logical/worker.c
6. LogicalRepApplyLoop
/*
* Init the ApplyMessageContext which we clean up after each replication
- * protocol message.
+ * protocol message, if needed.
*/
- ApplyMessageContext = AllocSetContextCreate(ApplyContext,
- "ApplyMessageContext",
- ALLOCSET_DEFAULT_SIZES);
+ if (!ApplyMessageContext)
+ ApplyMessageContext = AllocSetContextCreate(ApplyContext,
+ "ApplyMessageContext",
+
Maybe slightly reword the comment.
BEFORE:
Init the ApplyMessageContext which we clean up after each replication
protocol message, if needed.
AFTER:
Init the ApplyMessageContext if needed. This context is cleaned up
after each replication protocol message.
======
src/backend/replication/walsender.c
7.
+ /*
+ * Initialize the flag again because this streaming may be
+ * second time.
+ */
+ streamingDoneSending = streamingDoneReceiving = false;
Isn't this only possible to be 2nd time because the "reuse tablesync
worker" might re-issue a START_REPLICATION again to the same
WALSender? So, should this flag reset ONLY be done for the logical
replication ('else' part), otherwise it should be asserted false?
e.g. Would it be better to be like this?
if (cmd->kind == REPLICATION_KIND_PHYSICAL)
{
Assert(!streamingDoneSending && !streamingDoneReceiving)
StartReplication(cmd);
}
else
{
/* Reset flags because reusing tablesync workers can mean this is the
second time here. */
streamingDoneSending = streamingDoneReceiving = false;
StartLogicalReplication(cmd);
}
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Tue, Jul 11, 2023 at 12:31 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi, > > Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 6 Tem 2023 Per, > 12:47 tarihinde şunu yazdı: > > > > Dear Melih, > > > > > Thanks for the 0003 patch. But it did not work for me. Can you create > > > a subscription successfully with patch 0003 applied? > > > I get the following error: " ERROR: table copy could not start > > > transaction on publisher: another command is already in progress". > > > > You got the ERROR when all the patches (0001-0005) were applied, right? > > I have focused on 0001 and 0002 only, so I missed something. > > If it was not correct, please attach the logfile and test script what you did. > > Yes, I did get an error with all patches applied. But with only 0001 > and 0002, your version seems like working and mine does not. > What do you think about combining 0002 and 0003? Or should those stay separate? > Even if patches 0003 and 0002 are to be combined, I think that should not happen until after the "reuse" design is confirmed which way is best. e.g. IMO it might be easier to compare the different PoC designs for patch 0002 if there is no extra logic involved. PoC design#1 -- each tablesync decides for itself what to do next after it finishes PoC design#2 -- reuse tablesync using a "pool" of available workers ------ Kind Regards, Peter Smith. Fujitsu Australia
On Mon, Jul 10, 2023 at 8:01 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 6 Tem 2023 Per, > 12:47 tarihinde şunu yazdı: > > > > Dear Melih, > > > > > Thanks for the 0003 patch. But it did not work for me. Can you create > > > a subscription successfully with patch 0003 applied? > > > I get the following error: " ERROR: table copy could not start > > > transaction on publisher: another command is already in progress". > > > > You got the ERROR when all the patches (0001-0005) were applied, right? > > I have focused on 0001 and 0002 only, so I missed something. > > If it was not correct, please attach the logfile and test script what you did. > > Yes, I did get an error with all patches applied. But with only 0001 > and 0002, your version seems like working and mine does not. > What do you think about combining 0002 and 0003? Or should those stay separate? > I am fine either way but I think one minor advantage of keeping 0003 separate is that we can focus on some of the problems specific to that patch. For example, the following comment in the 0003 patch: "FIXME: set appropriate application_name...". I have given a suggestion to address it in [1] and Kuroda-San seems to have addressed the same but I am not sure if all of us agree with that or if there is any better way to address it. What do you think? > > > * 0003 basically improved performance from first two patches > > Agree, 0003 is definitely a good addition which was missing earlier. > +1. [1] - https://www.postgresql.org/message-id/CAA4eK1JOZHmy2o2F2wTCPKsjpwDiKZPOeTa_jt%3Dwm2JLbf-jsg%40mail.gmail.com -- With Regards, Amit Kapila.
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Melih, > > > Thanks for the 0003 patch. But it did not work for me. Can you create > > > a subscription successfully with patch 0003 applied? > > > I get the following error: " ERROR: table copy could not start > > > transaction on publisher: another command is already in progress". > > > > You got the ERROR when all the patches (0001-0005) were applied, right? > > I have focused on 0001 and 0002 only, so I missed something. > > If it was not correct, please attach the logfile and test script what you did. > > Yes, I did get an error with all patches applied. But with only 0001 > and 0002, your version seems like working and mine does not. Hmm, really? IIUC I did not modify 0001 and 0002 patches, I just re-assigned the version number. I compared between yours and mine, but no meaningful differences were found. E.g., following command compared v4-0002 and v16-0002: ``` diff --git a/../reuse_workers/v4-0002-Reuse-Tablesync-Workers.patch b/../reuse_workers/hayato/v16-0002-Reuse-Tablesync-Workers.patch index 5350216e98..7785a573e4 100644 --- a/../reuse_workers/v4-0002-Reuse-Tablesync-Workers.patch +++ b/../reuse_workers/hayato/v16-0002-Reuse-Tablesync-Workers.patch @@ -1,7 +1,7 @@ -From d482022b40e0a5ce1b74fd0e320cb5b45da2f671 Mon Sep 17 00:00:00 2001 +From db3e8e2d7aadea79126c5816bce8b06dc82f33c2 Mon Sep 17 00:00:00 2001 From: Melih Mutlu <m.melihmutlu@gmail.com> Date: Tue, 4 Jul 2023 22:04:46 +0300 -Subject: [PATCH 2/5] Reuse Tablesync Workers +Subject: [PATCH v16 2/5] Reuse Tablesync Workers This commit allows reusing tablesync workers for syncing more than one table sequentially during their lifetime, instead of exiting after @@ -324,5 +324,5 @@ index 7aba034774..1e9f8e6e72 100644 static inline bool am_tablesync_worker(void) -- -2.25.1 +2.27.0 ``` For confirmation, please attach the logfile and test script what you did if you could reproduce? > What do you think about combining 0002 and 0003? Or should those stay > separate? I have no strong opinion, but it may be useful to keep them pluggable. Best Regards, Hayato Kuroda FUJITSU LIMITED
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Hayato Kuroda (Fujitsu)"
Дата:
Dear Peter,
Thanks for reviewing! I'm not sure what should be, but I modified only my part - 0003.
PSA new patchset. Other patches were not changed.
(I attached till 0005 just in case, but I did not consider about 0004 and 0005)
> ======
> 1. Commit Message.
>
> The patch description is missing.
Briefly added.
> 2. General.
>
> +LogicalRepSyncTableStart(XLogRecPtr *origin_startpos, int worker_slot)
>
> and
>
> +start_table_sync(XLogRecPtr *origin_startpos,
> + char **myslotname,
> + int worker_slot)
>
> and
>
> @@ -4548,12 +4552,13 @@ run_tablesync_worker(WalRcvStreamOptions
> *options,
> char *slotname,
> char *originname,
> int originname_size,
> - XLogRecPtr *origin_startpos)
> + XLogRecPtr *origin_startpos,
> + int worker_slot)
>
>
> It seems the worker_slot is being passed all over the place as an
> additional function argument so that it can be used to construct an
> application_name. Is it possible/better to introduce a new
> 'MyLogicalRepWorker' field for the 'worker_slot' so it does not have
> to be passed like this?
I'm not sure it should be, but I did. How do you think?
> src/backend/replication/logical/tablesync.c
>
> 3.
> + /*
> + * Disconnect from publisher. Otherwise reused sync workers causes
> + * exceeding max_wal_senders.
> + */
> + if (LogRepWorkerWalRcvConn != NULL)
> + {
> + walrcv_disconnect(LogRepWorkerWalRcvConn);
> + LogRepWorkerWalRcvConn = NULL;
> + }
> +
>
> Why is this comment mentioning anything about "reused workers" at all?
> The worker process exits in this function, right?
I considered that code again, and I found this part is not needed anymore.
Initially it was added in 0002, this is because workers established new connections
without exiting and walsenders on publisher might be remained. So This was correct
for 0002 patch.
But now, in 0003 patch, workers reuse connections, which means that no need to call
walrcv_disconnect() explicitly. It is done when processes are exit.
> 4. LogicalRepSyncTableStart
>
> /*
> - * Here we use the slot name instead of the subscription name as the
> - * application_name, so that it is different from the leader apply worker,
> - * so that synchronous replication can distinguish them.
> + * Connect to publisher if not yet. The application_name must be also
> + * different from the leader apply worker because synchronous replication
> + * must distinguish them.
> */
>
> I felt all the details in the 2nd part of this comment belong inside
> the condition, not outside.
>
> SUGGESTION
> /* Connect to the publisher if haven't done so already. */
Changed.
> 5.
> + if (LogRepWorkerWalRcvConn == NULL)
> + {
> + char application_name[NAMEDATALEN];
> +
> + /*
> + * FIXME: set appropriate application_name. Previously, the slot name
> + * was used becasue the lifetime of the tablesync worker was same as
> + * that, but now the tablesync worker handles many slots during the
> + * synchronization so that it is not suitable. So what should be?
> + * Note that if the tablesync worker starts to reuse the replication
> + * slot during synchronization, we should use the slot name as
> + * application_name again.
> + */
> + snprintf(application_name, NAMEDATALEN, "pg_%u_sync_%i",
> + MySubscription->oid, worker_slot);
> + LogRepWorkerWalRcvConn =
> + walrcv_connect(MySubscription->conninfo, true,
> + must_use_password,
> + application_name, &err);
> + }
>
> 5a.
> /becasue/because/
Modified. Also, comments were moved atop ApplicationNameForTablesync.
I was not sure when it is removed, but I kept it.
>
> 5b.
> I am not sure about what name this should ideally use, but anyway for
> uniqueness doesn't it still need to include the GetSystemIdentifier()
> same as function ReplicationSlotNameForTablesync() was doing?
>
> Maybe this can use the same function ReplicationSlotNameForTablesync()
> can be used but just pass the worker_slot instead of the relid?
Good point. ApplicationNameForTablesync() was defined and used.
> src/backend/replication/logical/worker.c
>
> 6. LogicalRepApplyLoop
>
> /*
> * Init the ApplyMessageContext which we clean up after each replication
> - * protocol message.
> + * protocol message, if needed.
> */
> - ApplyMessageContext = AllocSetContextCreate(ApplyContext,
> - "ApplyMessageContext",
> - ALLOCSET_DEFAULT_SIZES);
> + if (!ApplyMessageContext)
> + ApplyMessageContext = AllocSetContextCreate(ApplyContext,
> + "ApplyMessageContext",
> +
>
> Maybe slightly reword the comment.
>
> BEFORE:
> Init the ApplyMessageContext which we clean up after each replication
> protocol message, if needed.
>
> AFTER:
> Init the ApplyMessageContext if needed. This context is cleaned up
> after each replication protocol message.
Changed.
> src/backend/replication/walsender.c
>
> 7.
> + /*
> + * Initialize the flag again because this streaming may be
> + * second time.
> + */
> + streamingDoneSending = streamingDoneReceiving = false;
>
> Isn't this only possible to be 2nd time because the "reuse tablesync
> worker" might re-issue a START_REPLICATION again to the same
> WALSender? So, should this flag reset ONLY be done for the logical
> replication ('else' part), otherwise it should be asserted false?
>
> e.g. Would it be better to be like this?
>
> if (cmd->kind == REPLICATION_KIND_PHYSICAL)
> {
> Assert(!streamingDoneSending && !streamingDoneReceiving)
> StartReplication(cmd);
> }
> else
> {
> /* Reset flags because reusing tablesync workers can mean this is the
> second time here. */
> streamingDoneSending = streamingDoneReceiving = false;
> StartLogicalReplication(cmd);
> }
>
It's OK to modify the comment. But after considering more, I started to think that
any specification for physical replication should not be changed.
So I accepted comments only for the logical rep.
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
Hi Peter,
Peter Smith <smithpb2250@gmail.com>, 11 Tem 2023 Sal, 05:59 tarihinde şunu yazdı:
> Even if patches 0003 and 0002 are to be combined, I think that should
> not happen until after the "reuse" design is confirmed which way is
> best.
>
> e.g. IMO it might be easier to compare the different PoC designs for
> patch 0002 if there is no extra logic involved.
>
> PoC design#1 -- each tablesync decides for itself what to do next
> after it finishes
> PoC design#2 -- reuse tablesync using a "pool" of available workers
Right. I made a patch 0003 to change 0002 so that tables will be assigned to sync workers by apply worker.
It's a rough POC and ignores some edge cases. But this is what I think how apply worker would take the responsibility of table assignments. Hope the implementation makes sense and I'm not missing anything that may cause degraded perforrmance.
PoC design#1 --> apply only patch 0001 and 0002
PoC design#2 --> apply all patches, 0001, 0002 and 0003
Here are some quick numbers with 100 empty tables.
+--------------+----------------+----------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync workers |
+--------------+----------------+----------------+----------------+
| POC design#1 | 1909.873 ms | 986.261 ms | 552.404 ms |
+--------------+----------------+----------------+----------------+
| POC design#2 | 4962.208 ms | 1240.503 ms | 1165.405 ms |
+--------------+----------------+----------------+----------------+
| master | 2666.008 ms | 1462.012 ms | 986.848 ms |
+--------------+----------------+----------------+----------------+
Peter Smith <smithpb2250@gmail.com>, 11 Tem 2023 Sal, 05:59 tarihinde şunu yazdı:
> Even if patches 0003 and 0002 are to be combined, I think that should
> not happen until after the "reuse" design is confirmed which way is
> best.
>
> e.g. IMO it might be easier to compare the different PoC designs for
> patch 0002 if there is no extra logic involved.
>
> PoC design#1 -- each tablesync decides for itself what to do next
> after it finishes
> PoC design#2 -- reuse tablesync using a "pool" of available workers
Right. I made a patch 0003 to change 0002 so that tables will be assigned to sync workers by apply worker.
It's a rough POC and ignores some edge cases. But this is what I think how apply worker would take the responsibility of table assignments. Hope the implementation makes sense and I'm not missing anything that may cause degraded perforrmance.
PoC design#1 --> apply only patch 0001 and 0002
PoC design#2 --> apply all patches, 0001, 0002 and 0003
Here are some quick numbers with 100 empty tables.
+--------------+----------------+----------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync workers |
+--------------+----------------+----------------+----------------+
| POC design#1 | 1909.873 ms | 986.261 ms | 552.404 ms |
+--------------+----------------+----------------+----------------+
| POC design#2 | 4962.208 ms | 1240.503 ms | 1165.405 ms |
+--------------+----------------+----------------+----------------+
| master | 2666.008 ms | 1462.012 ms | 986.848 ms |
+--------------+----------------+----------------+----------------+
Seems like design#1 is better than both design#2 and master overall. It's surprising to see that even master beats design#2 in some cases though. Not sure if that is expected or there are some places to improve design#2 even more.
What do you think?
PS: I only attached the related patches and not the whole patch set. 0001 and 0002 may contain some of your earlier reviews, but I'll send a proper updated set soon.
Thanks,
-- Melih Mutlu
Microsoft
Вложения
On Fri, Jul 14, 2023 at 1:58 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Here are some quick numbers with 100 empty tables. > > +--------------+----------------+----------------+----------------+ > | | 2 sync workers | 4 sync workers | 8 sync workers | > +--------------+----------------+----------------+----------------+ > | POC design#1 | 1909.873 ms | 986.261 ms | 552.404 ms | > +--------------+----------------+----------------+----------------+ > | POC design#2 | 4962.208 ms | 1240.503 ms | 1165.405 ms | > +--------------+----------------+----------------+----------------+ > | master | 2666.008 ms | 1462.012 ms | 986.848 ms | > +--------------+----------------+----------------+----------------+ > > Seems like design#1 is better than both design#2 and master overall. It's surprising to see that even master beats design#2in some cases though. Not sure if that is expected or there are some places to improve design#2 even more. > Yeah, it is quite surprising that Design#2 is worse than master. I suspect there is something wrong going on with your Design#2 patch. One area to check is whether apply worker is able to quickly assign the new relations to tablesync workers. Note that currently after the first time assigning the tables to workers, the apply worker may wait before processing the next set of tables in the main loop of LogicalRepApplyLoop(). The other minor point about design#2 implementation is that you may want to first assign the allocated tablesync workers before trying to launch a new worker. > > PS: I only attached the related patches and not the whole patch set. 0001 and 0002 may contain some of your earlier reviews,but I'll send a proper updated set soon. > Yeah, that would be helpful. -- With Regards, Amit Kapila.
Hi Kuroda-san.
Here are some review comments for the v17-0003 patch. They are all minor.
======
Commit message
1.
Previously tablesync workers establish new connections when it changes
the syncing
table, but this might have additional overhead. This patch allows to
reuse connections
instead.
~
/This patch allows to reuse connections instead./This patch allows the
existing connection to be reused./
~~~
2.
As for the publisher node, this patch allows to reuse logical
walsender processes
after the streaming is done once.
~
Is this paragraph even needed? Since the connection is reused then it
already implies the other end (the Wlasender) is being reused, right?
======
src/backend/replication/logical/tablesync.c
3.
+ * FIXME: set appropriate application_name. Previously, the slot name was used
+ * because the lifetime of the tablesync worker was same as that, but now the
+ * tablesync worker handles many slots during the synchronization so that it is
+ * not suitable. So what should be? Note that if the tablesync worker starts to
+ * reuse the replication slot during synchronization, we should use the slot
+ * name as application_name again.
+ */
+static void
+ApplicationNameForTablesync(Oid suboid, int worker_slot,
+ char *application_name, Size szapp)
3a.
I felt that most of this FIXME comment belongs with the calling code,
not here.
3b.
Also, maybe it needs some rewording -- I didn't understand exactly
what it is trying to say.
~~~
4.
- /*
- * Here we use the slot name instead of the subscription name as the
- * application_name, so that it is different from the leader apply worker,
- * so that synchronous replication can distinguish them.
- */
- LogRepWorkerWalRcvConn =
- walrcv_connect(MySubscription->conninfo, true,
- must_use_password,
- slotname, &err);
+ /* Connect to the publisher if haven't done so already. */
+ if (LogRepWorkerWalRcvConn == NULL)
+ {
+ char application_name[NAMEDATALEN];
+
+ /*
+ * The application_name must be also different from the leader apply
+ * worker because synchronous replication must distinguish them.
+ */
+ ApplicationNameForTablesync(MySubscription->oid,
+ MyLogicalRepWorker->worker_slot,
+ application_name,
+ NAMEDATALEN);
+ LogRepWorkerWalRcvConn =
+ walrcv_connect(MySubscription->conninfo, true,
+ must_use_password,
+ application_name, &err);
+ }
+
Should the comment mention the "subscription name" as it did before?
SUGGESTION
The application_name must differ from the subscription name (used by
the leader apply worker) because synchronous replication has to be
able to distinguish this worker from the leader apply worker.
======
src/backend/replication/logical/worker.c
5.
-start_table_sync(XLogRecPtr *origin_startpos, char **myslotname)
+start_table_sync(XLogRecPtr *origin_startpos,
+ char **myslotname)
This is a wrapping change only. It looks like an unnecessary hangover
from a previous version of 0003.
======
src/backend/replication/walsender.c
6. exec_replication_command
+
if (cmd->kind == REPLICATION_KIND_PHYSICAL)
StartReplication(cmd);
~
The extra blank line does not belong in this patch.
======
src/include/replication/worker_internal.h
+ /* Indicates the slot number which corresponds to this LogicalRepWorker. */
+ int worker_slot;
+
6a
I think this field is very fundamental, so IMO it should be defined at
the top of the struct, maybe nearby the other 'in_use' and
'generation' fields.
~
6b.
Also, since this is already a "worker" struct so there is no need to
have "worker" in the field name again -- just "slot_number" or
"slotnum" might be a better name.
And then the comment can also be simplified.
SUGGESTION
/* Slot number of this worker. */
int slotnum;
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi,
Amit Kapila <amit.kapila16@gmail.com>, 14 Tem 2023 Cum, 11:11 tarihinde şunu yazdı:
Yeah, it is quite surprising that Design#2 is worse than master. I
suspect there is something wrong going on with your Design#2 patch.
One area to check is whether apply worker is able to quickly assign
the new relations to tablesync workers. Note that currently after the
first time assigning the tables to workers, the apply worker may wait
before processing the next set of tables in the main loop of
LogicalRepApplyLoop(). The other minor point about design#2
implementation is that you may want to first assign the allocated
tablesync workers before trying to launch a new worker.
It's not actually worse than master all the time. It seems like it's just unreliable.
Here are some consecutive runs for both designs and master.
design#1 = 1621,527 ms, 1788,533 ms, 1645,618 ms, 1702,068 ms, 1745,753 ms
design#2 = 2089,077 ms, 1864,571 ms, 4574,799 ms, 5422,217 ms, 1905,944 ms
master = 2815,138 ms, 2481,954 ms , 2594,413 ms, 2620,690 ms, 2489,323 ms
And apply worker was not busy with applying anything during these experiments since there were not any writes to the publisher. I'm not sure how that would also affect the performance if there were any writes.
Thanks,
Melih Mutlu
Microsoft
On Fri, Jul 14, 2023 at 3:07 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Amit Kapila <amit.kapila16@gmail.com>, 14 Tem 2023 Cum, 11:11 tarihinde şunu yazdı: >> >> Yeah, it is quite surprising that Design#2 is worse than master. I >> suspect there is something wrong going on with your Design#2 patch. >> One area to check is whether apply worker is able to quickly assign >> the new relations to tablesync workers. Note that currently after the >> first time assigning the tables to workers, the apply worker may wait >> before processing the next set of tables in the main loop of >> LogicalRepApplyLoop(). The other minor point about design#2 >> implementation is that you may want to first assign the allocated >> tablesync workers before trying to launch a new worker. > > > It's not actually worse than master all the time. It seems like it's just unreliable. > Here are some consecutive runs for both designs and master. > > design#1 = 1621,527 ms, 1788,533 ms, 1645,618 ms, 1702,068 ms, 1745,753 ms > design#2 = 2089,077 ms, 1864,571 ms, 4574,799 ms, 5422,217 ms, 1905,944 ms > master = 2815,138 ms, 2481,954 ms , 2594,413 ms, 2620,690 ms, 2489,323 ms > > And apply worker was not busy with applying anything during these experiments since there were not any writes to the publisher.I'm not sure how that would also affect the performance if there were any writes. > Yeah, this is a valid point. I think this is in favor of the Design#1 approach we are discussing here. One thing I was thinking whether we can do anything to alleviate the contention at the higher worker count. One possibility is to have some kind of available worker list which can be used to pick up the next worker instead of checking all the workers while assigning the next table. We can probably explore it separately once the first three patches are ready because anyway, this will be an optimization atop the Design#1 approach. -- With Regards, Amit Kapila.
Hi,
PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small comments below.
Peter Smith <smithpb2250@gmail.com>, 10 Tem 2023 Pzt, 10:09 tarihinde şunu yazdı:
6. LogicalRepApplyLoop
+ /*
+ * apply_dispatch() may have gone into apply_handle_commit()
+ * which can call process_syncing_tables_for_sync.
+ *
+ * process_syncing_tables_for_sync decides whether the sync of
+ * the current table is completed. If it is completed,
+ * streaming must be already ended. So, we can break the loop.
+ */
+ if (MyLogicalRepWorker->is_sync_completed)
+ {
+ endofstream = true;
+ break;
+ }
+
and
+ /*
+ * If is_sync_completed is true, this means that the tablesync
+ * worker is done with synchronization. Streaming has already been
+ * ended by process_syncing_tables_for_sync. We should move to the
+ * next table if needed, or exit.
+ */
+ if (MyLogicalRepWorker->is_sync_completed)
+ endofstream = true;
~
Instead of those code fragments above assigning 'endofstream' as a
side-effect, would it be the same (but tidier) to just modify the
other "breaking" condition below:
BEFORE:
/* Check if we need to exit the streaming loop. */
if (endofstream)
break;
AFTER:
/* Check if we need to exit the streaming loop. */
if (endofstream || MyLogicalRepWorker->is_sync_completed)
break;
First place you mentioned also breaks the infinite loop. Such an if statement is needed there with or without endofstream assignment.
I think if there is a flag to break a loop, using that flag to indicate that we should exit the loop seems more appropriate to me. I see that it would be a bit tidier without endofstream = true lines, but I feel like it would also be less readable.
I don't have a strong opinion though. I'm just keeping them as they are for now, but I can change them if you disagree.
10b.
All the other tablesync-related fields of this struct are named as
relXXX, so I wonder if is better for this to follow the same pattern.
e.g. 'relsync_completed'
Aren't those start with rel because they're related to the relation that the tablesync worker is syncing? is_sync_completed is not a relation specific field. I'm okay with changing the name but feel like relsync_completed would be misleading.
Thanks,
Melih Mutlu
Microsoft
Вложения
On Tue, Jul 18, 2023 at 1:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi, > > PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small commentsbelow. > Thanks, I will take another look at these soon. FYI, the 0001 patch does not apply cleanly. It needs to be rebased again because get_worker_name() function was recently removed from HEAD. replication/logical/worker.o: In function `InitializeLogRepWorker': /home/postgres/oss_postgres_misc/src/backend/replication/logical/worker.c:4605: undefined reference to `get_worker_name' ------ Kind Regards, Peter Smith. Fujitsu Australia
On Tue, Jul 18, 2023 at 11:25 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Tue, Jul 18, 2023 at 1:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > Hi, > > > > PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small commentsbelow. > > > > Thanks, I will take another look at these soon. FYI, the 0001 patch > does not apply cleanly. It needs to be rebased again because > get_worker_name() function was recently removed from HEAD. > Sorry, to be more correct -- it applied OK, but failed to build. > replication/logical/worker.o: In function `InitializeLogRepWorker': > /home/postgres/oss_postgres_misc/src/backend/replication/logical/worker.c:4605: > undefined reference to `get_worker_name' > > ------ > Kind Regards, > Peter Smith. > Fujitsu Australia
Hi Peter,
Peter Smith <smithpb2250@gmail.com>, 18 Tem 2023 Sal, 04:33 tarihinde şunu yazdı:
On Tue, Jul 18, 2023 at 11:25 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Tue, Jul 18, 2023 at 1:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> >
> > Hi,
> >
> > PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small comments below.
> >
>
> Thanks, I will take another look at these soon. FYI, the 0001 patch
> does not apply cleanly. It needs to be rebased again because
> get_worker_name() function was recently removed from HEAD.
>
Sorry, to be more correct -- it applied OK, but failed to build.
Attached the fixed patchset.
Thanks,
Melih Mutlu
Microsoft
Вложения
On Tue, Jul 18, 2023 at 2:33 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Attached the fixed patchset.
>
Few comments on 0001
====================
1.
+ logicalrep_worker_attach(worker_slot);
+
+ /* Setup signal handling */
+ pqsignal(SIGHUP, SignalHandlerForConfigReload);
+ pqsignal(SIGTERM, die);
+ BackgroundWorkerUnblockSignals();
+
+ /*
+ * We don't currently need any ResourceOwner in a walreceiver process, but
+ * if we did, we could call CreateAuxProcessResourceOwner here.
+ */
+
+ /* Initialise stats to a sanish value */
+ MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
+ MyLogicalRepWorker->reply_time = GetCurrentTimestamp();
+
+ /* Load the libpq-specific functions */
+ load_file("libpqwalreceiver", false);
+
+ InitializeLogRepWorker();
+
+ /* Connect to the origin and start the replication. */
+ elog(DEBUG1, "connecting to publisher using connection string \"%s\"",
+ MySubscription->conninfo);
+
+ /*
+ * Setup callback for syscache so that we know when something changes in
+ * the subscription relation state.
+ */
+ CacheRegisterSyscacheCallback(SUBSCRIPTIONRELMAP,
+ invalidate_syncing_table_states,
+ (Datum) 0);
It seems this part of the code is the same for ApplyWorkerMain() and
TablesyncWorkerMain(). So, won't it be better to move it into a common
function?
2. Can LogicalRepSyncTableStart() be static function?
3. I think you don't need to send 0004, 0005 each time till we are
able to finish patches till 0003.
4. In 0001's commit message, you can say that it will help the
upcoming reuse tablesync worker patch.
--
With Regards,
Amit Kapila.
On Tue, 11 Jul 2023 at 08:30, Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Tue, Jul 11, 2023 at 12:31 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> >
> > Hi,
> >
> > Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com>, 6 Tem 2023 Per,
> > 12:47 tarihinde şunu yazdı:
> > >
> > > Dear Melih,
> > >
> > > > Thanks for the 0003 patch. But it did not work for me. Can you create
> > > > a subscription successfully with patch 0003 applied?
> > > > I get the following error: " ERROR: table copy could not start
> > > > transaction on publisher: another command is already in progress".
> > >
> > > You got the ERROR when all the patches (0001-0005) were applied, right?
> > > I have focused on 0001 and 0002 only, so I missed something.
> > > If it was not correct, please attach the logfile and test script what you did.
> >
> > Yes, I did get an error with all patches applied. But with only 0001
> > and 0002, your version seems like working and mine does not.
> > What do you think about combining 0002 and 0003? Or should those stay separate?
> >
>
> Even if patches 0003 and 0002 are to be combined, I think that should
> not happen until after the "reuse" design is confirmed which way is
> best.
>
> e.g. IMO it might be easier to compare the different PoC designs for
> patch 0002 if there is no extra logic involved.
>
> PoC design#1 -- each tablesync decides for itself what to do next
> after it finishes
> PoC design#2 -- reuse tablesync using a "pool" of available workers
I did a POC for design#2 for implementing a worker pool to synchronize
the tables for a subscriber. The core design is the same as what Melih
had implemented at [1]. I had already started the implementation of
POC based on one of the earlier e-mail [2] Peter had shared.
The POC has been implemented like:
a) Apply worker will check the tablesync pool and see if any tablesync
worker is free:
i) If there are no free workers in the pool, start a table sync
worker and add it to the table sync pool.
ii) If there are free workers in the pool, re-use the tablesync
worker for synchronizing another table.
b) Apply worker will check if the tables are synchronized, if all the
tables are synchronized apply worker will release all the workers from
the tablesync pool
c) Apply worker and tablesync worker has shared memory to share the
following relation data and execution state between the apply worker
and the tablesync worker
d) The apply worker and tablesync worker's pid are also stored in the
shared memory so that we need not take a lock on LogicalRepWorkerLock
and loop on max_logical_replication_workers every time. We use the pid
stored in shared memory to wake up the apply worker and tablesync
worker whenever needed.
While I was implementing the POC I found one issue in the POC
patch(there is no problem with the HEAD code, issue was only with the
POC):
1) Apply worker was waiting for the table to be set to SYNCDONE.
2) Mean time tablesync worker sets the table to SYNCDONE and sets
apply worker's latch.
3) Apply worker will reset the latch set by tablesync and go to main
loop and wait in main loop latch(since tablesync worker's latch was
already reset, apply worker will wait for 1 second)
To fix this I had to set apply worker's latch once in 1ms in this case
alone which is not a good solution as it will consume a lot of cpu
cycles. A better fix for this would be to introduce a new subscription
relation state.
Attached patch has the changes for the same. 001, 0002 and 0003 are
the patches shared by Melih and Kuroda-san earlier. 0004 patch has the
changes for the POC of Tablesync worker pool implementation.
POC design 1: Tablesync worker identifies the tables that should be
synced and reuses the connection.
POC design 2: Tablesync worker pool with apply worker scheduling the
work to tablesync workers in the tablesync pool and reusing the
connection.
Performance results for 10 empty tables:
+-------------------+--------------------+--------------------+----------------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync
workers | 16 sync workers|
+-------------------+--------------------+--------------------+----------------------+----------------+
| HEAD | 128.4685 ms | 121.271 ms | 136.5455 ms
| N/A |
+-------------------+--------------------+--------------------+----------------------+----------------+
| POC design#1| 70.7095 ms | 80.9805 ms | 102.773 ms |
N/A |
+-------------------+--------------------+--------------------+----------------------+----------------+
| POC design#2| 70.858 ms | 83.0845 ms | 112.505 ms |
N/A |
+-------------------+--------------------+--------------------+----------------------+----------------+
Performance results for 100 empty tables:
+-------------------+--------------------+--------------------+----------------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync
workers | 16 sync workers|
+-------------------+--------------------+--------------------+----------------------+----------------+
| HEAD | 1039.89 ms | 860.88 ms | 1112.312 ms
| 1122.52 ms |
+-------------------+--------------------+--------------------+----------------------+----------------+
| POC design#1| 310.920 ms | 293.14 ms | 385.698 ms |
456.64 ms |
+-------------------+--------------------+--------------------+----------------------+----------------+
| POC design#2 | 318.464 ms | 313.98 ms | 352.316 ms |
441.53 ms |
+-------------------+--------------------+--------------------+----------------------+----------------+
Performance results for 1000 empty tables:
+-------------------+--------------------+--------------------+----------------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync
workers | 16 sync workers|
+------------------+---------------------+---------------------+---------------------+----------------+
| HEAD | 16327.96 ms | 10253.65 ms | 9741.986 ms
| 10278.98 ms |
+-------------------+--------------------+---------------------+---------------------+----------------+
| POC design#1| 3598.21 ms | 3099.54 ms | 2944.386 ms |
2588.20 ms |
+-------------------+--------------------+---------------------+---------------------+----------------+
| POC design#2| 4131.72 ms | 2840.36 ms | 3001.159 ms |
5461.82 ms |
+-------------------+--------------------+---------------------+--------------------+----------------+
Performance results for 2000 empty tables:
+-------------------+--------------------+--------------------+----------------------+----------------+
| | 2 sync workers | 4 sync workers | 8 sync
workers | 16 sync workers|
+-------------------+--------------------+--------------------+----------------------+----------------+
| HEAD | 47210.92 ms | 25239.90 ms | 19171.48 ms
| 19556.46 ms |
+-------------------+--------------------+--------------------+---------------------+----------------+
| POC design#1| 10598.32 ms | 6995.61 ms | 6507.53 ms |
5295.72 ms |
+-------------------+--------------------+--------------------+-------------------------------------+
| POC design#2| 11121.00 ms | 6659.74 ms | 6253.66 ms |
15433.81 ms |
+-------------------+--------------------+--------------------+-------------------------------------+
The performance result execution for the same is attached in
Perftest_Results.xlsx.
Also testing with a) table having data and b) apply worker applying
changes while table sync in progress is not done. One of us will do
and try to share the results for these too.
It is noticed that performance of POC design #1 and POC design #2 are
good but POC design #2's performance degrades when there are a greater
number of workers and more tables. In POC design #2, when there are a
greater number of workers and tables, apply worker is becoming a
bottleneck as it must allocate work for all the workers.
Based on the test results, POC design #1 is better.
Thanks to Kuroda-san for helping me in running the performance tests.
[1] - https://www.postgresql.org/message-id/CAGPVpCSk4v-V1WbFDy8a5dL7Es5z8da6hoQbuVyrqP5s3Yh6Cg%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CAHut%2BPs8gWP9tCPK9gdMnxyshRKgVP3pJnAnaJto_T07uR9xUA%40mail.gmail.com
Regards,
Vignesh
Вложения
Some review comments for v19-0001
======
src/backend/replication/logical/tablesync.c
1. run_tablesync_worker
+run_tablesync_worker(WalRcvStreamOptions *options,
+ char *slotname,
+ char *originname,
+ int originname_size,
+ XLogRecPtr *origin_startpos)
+{
+ /* Start table synchronization. */
+ start_table_sync(origin_startpos, &slotname);
There was no such comment ("/* Start table synchronization. */") in
the original HEAD code, so I didn't see that it adds much value by
adding it in the refactored code.
~~~
2. LogicalRepSyncTableStart
/*
* Finally, wait until the leader apply worker tells us to catch up and
* then return to let LogicalRepApplyLoop do it.
*/
wait_for_worker_state_change(SUBREL_STATE_CATCHUP);
~
Should LogicalRepApplyLoop still be mentioned here, since that is
static in worker.c? Maybe it is better to refer instead to the common
'start_apply' wrapper? (see also #5a below)
======
src/backend/replication/logical/worker.c
3. set_stream_options
+/*
+ * Sets streaming options including replication slot name and origin start
+ * position. Workers need these options for logical replication.
+ */
+void
+set_stream_options(WalRcvStreamOptions *options,
I'm not sure if the last sentence of the comment is adding anything useful.
~~~
4. start_apply
/*
* Run the apply loop with error handling. Disable the subscription,
* if necessary.
*
* Note that we don't handle FATAL errors which are probably because
* of system resource error and are not repeatable.
*/
void
start_apply(XLogRecPtr origin_startpos)
~
4a.
Somehow I found the function names to be confusing. Intuitively (IMO)
'start_apply' is for apply worker and 'start_tablesync' is for
tablesync worker. But actually, the start_apply() function is the
*common* function for both kinds of worker. Might be easier to
understand if start_apply function name can be changed to indicate it
is really common -- e.g. common_apply_loop(), or similar.
~
4b.
If adverse to changing the function name, it might be helpful anyway
if the function comment can emphasize this function is shared by
different worker types. e.g. "Common function to run the apply
loop..."
~~~
5. run_apply_worker
+ ReplicationOriginNameForLogicalRep(MySubscription->oid, InvalidOid,
+ originname, originname_size);
+
+ /* Setup replication origin tracking. */
+ StartTransactionCommand();
Even if you wish ReplicationOriginNameForLogicalRep() to be outside of
the transaction I thought it should still come *after* the comment,
same as it does in the HEAD code.
~~~
6. ApplyWorkerMain
- /* Run the main loop. */
- start_apply(origin_startpos);
+ /* This is leader apply worker */
+ run_apply_worker(&options, myslotname, originname,
sizeof(originname), &origin_startpos);
proc_exit(0);
}
~
6a.
The comment "/* This is leader apply worker */" is redundant now. This
function is the entry point for leader apply workers so it can't be
anything else.
~
6b.
Caller parameter wrapping differs from the similar code in
TablesyncWorkerMain. Shouldn't they be similar?
e.g.
+ run_apply_worker(&options, myslotname, originname,
sizeof(originname), &origin_startpos);
versus
+ run_tablesync_worker(&options,
+ myslotname,
+ originname,
+ sizeof(originname),
+ &origin_startpos);
======
src/include/replication/worker_internal.h
7.
+
+extern void set_stream_options(WalRcvStreamOptions *options,
+ char *slotname,
+ XLogRecPtr *origin_startpos);
+extern void start_apply(XLogRecPtr origin_startpos);
+extern void DisableSubscriptionAndExit(void);
+
Maybe all the externs belong together? It doesn't seem right for just
these 3 externs to be separated from all the others, with those static
inline functions in-between.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Jul 19, 2023 at 8:38 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Some review comments for v19-0001 > ... > ====== > src/backend/replication/logical/worker.c > > 3. set_stream_options > > +/* > + * Sets streaming options including replication slot name and origin start > + * position. Workers need these options for logical replication. > + */ > +void > +set_stream_options(WalRcvStreamOptions *options, > > I'm not sure if the last sentence of the comment is adding anything useful. > Personally, I find it useful as at a high-level it tells the purpose of setting these options. > ~~~ > > 4. start_apply > /* > * Run the apply loop with error handling. Disable the subscription, > * if necessary. > * > * Note that we don't handle FATAL errors which are probably because > * of system resource error and are not repeatable. > */ > void > start_apply(XLogRecPtr origin_startpos) > > ~ > > 4a. > Somehow I found the function names to be confusing. Intuitively (IMO) > 'start_apply' is for apply worker and 'start_tablesync' is for > tablesync worker. But actually, the start_apply() function is the > *common* function for both kinds of worker. Might be easier to > understand if start_apply function name can be changed to indicate it > is really common -- e.g. common_apply_loop(), or similar. > > ~ > > 4b. > If adverse to changing the function name, it might be helpful anyway > if the function comment can emphasize this function is shared by > different worker types. e.g. "Common function to run the apply > loop..." > I would prefer to change the comments as suggested by you in 4b because both the workers (apply and tablesync) need to perform apply, so it seems logical for both of them to invoke start_apply. -- With Regards, Amit Kapila.
On Tue, Jul 18, 2023 at 1:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
> PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small
commentsbelow.
>
> Peter Smith <smithpb2250@gmail.com>, 10 Tem 2023 Pzt, 10:09 tarihinde şunu yazdı:
>>
>> 6. LogicalRepApplyLoop
>>
>> + /*
>> + * apply_dispatch() may have gone into apply_handle_commit()
>> + * which can call process_syncing_tables_for_sync.
>> + *
>> + * process_syncing_tables_for_sync decides whether the sync of
>> + * the current table is completed. If it is completed,
>> + * streaming must be already ended. So, we can break the loop.
>> + */
>> + if (MyLogicalRepWorker->is_sync_completed)
>> + {
>> + endofstream = true;
>> + break;
>> + }
>> +
>>
>> and
>>
>> + /*
>> + * If is_sync_completed is true, this means that the tablesync
>> + * worker is done with synchronization. Streaming has already been
>> + * ended by process_syncing_tables_for_sync. We should move to the
>> + * next table if needed, or exit.
>> + */
>> + if (MyLogicalRepWorker->is_sync_completed)
>> + endofstream = true;
>>
>> ~
>>
>> Instead of those code fragments above assigning 'endofstream' as a
>> side-effect, would it be the same (but tidier) to just modify the
>> other "breaking" condition below:
>>
>> BEFORE:
>> /* Check if we need to exit the streaming loop. */
>> if (endofstream)
>> break;
>>
>> AFTER:
>> /* Check if we need to exit the streaming loop. */
>> if (endofstream || MyLogicalRepWorker->is_sync_completed)
>> break;
>
>
> First place you mentioned also breaks the infinite loop. Such an if statement is needed there with or without
endofstreamassignment.
>
> I think if there is a flag to break a loop, using that flag to indicate that we should exit the loop seems more
appropriateto me. I see that it would be a bit tidier without endofstream = true lines, but I feel like it would also
beless readable.
>
> I don't have a strong opinion though. I'm just keeping them as they are for now, but I can change them if you
disagree.
>
I felt it was slightly sneaky to re-use the existing variable as a
convenient way to do what you want. But, I don’t feel strongly enough
on this point to debate it -- maybe see later if others have an
opinion about this.
>>
>>
>> 10b.
>> All the other tablesync-related fields of this struct are named as
>> relXXX, so I wonder if is better for this to follow the same pattern.
>> e.g. 'relsync_completed'
>
>
> Aren't those start with rel because they're related to the relation that the tablesync worker is syncing?
is_sync_completedis not a relation specific field. I'm okay with changing the name but feel like relsync_completed
wouldbe misleading.
My reading of the code is slightly different: Only these fields have
the prefix ‘rel’ and they are all grouped under the comment “/* Used
for initial table synchronization. */” because AFAIK only these fields
are TWS specific (not used for other kinds of workers).
Since this new flag field is also TWS-specific, therefore IMO it
should follow the same consistent name pattern. But, if you are
unconvinced, maybe see later if others have an opinion about it.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Some review comments for patch v20-0002
======
src/backend/replication/logical/tablesync.c
1. finish_sync_worker
/*
* Exit routine for synchronization worker.
*
* If reuse_worker is false, the worker will not be reused and exit.
*/
~
IMO the "will not be reused" part doesn't need saying -- it is
self-evident from the fact "reuse_worker is false".
SUGGESTION
If reuse_worker is false, at the conclusion of this function the
worker process will exit.
~~~
2. finish_sync_worker
- StartTransactionCommand();
- ereport(LOG,
- (errmsg("logical replication table synchronization worker for
subscription \"%s\", table \"%s\" has finished",
- MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
- CommitTransactionCommand();
-
/* Find the leader apply worker and signal it. */
logicalrep_worker_wakeup(MyLogicalRepWorker->subid, InvalidOid);
- /* Stop gracefully */
- proc_exit(0);
+ if (!reuse_worker)
+ {
+ StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
+ MySubscription->name)));
+ CommitTransactionCommand();
+
+ /* Stop gracefully */
+ proc_exit(0);
+ }
In the HEAD code the log message came *before* it signalled to the
apply leader. Won't it be better to keep the logic in that same order?
~~~
3. process_syncing_tables_for_sync
- finish_sync_worker();
+ /* Sync worker has completed synchronization of the current table. */
+ MyLogicalRepWorker->is_sync_completed = true;
+
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\", relation \"%s\" with relid %u has finished",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
IIUC it is only the " table synchronization" part that is finished
here; not the whole "table synchronization worker" (compared to
finish_sync_worker function), so maybe the word "worker" should not
be in this message.
~~~
4. TablesyncWorkerMain
+ if (MyLogicalRepWorker->is_sync_completed)
+ {
+ /* tablesync is done unless a table that needs syncning is found */
+ done = true;
SUGGESTION (Typo "syncning" and minor rewording.)
This tablesync worker is 'done' unless another table that needs
syncing is found.
~
5.
+ /* Found a table for next iteration */
+ finish_sync_worker(true);
+
+ StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("logical replication worker for subscription \"%s\" will be
reused to sync table \"%s\" with relid %u.",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
+
+ done = false;
+ break;
+ }
+ LWLockRelease(LogicalRepWorkerLock);
5a.
IMO it seems better to put this ereport *inside* the
finish_sync_worker() function alongside the similar log for when the
worker is not reused.
~
5b.
Isn't there a missing call to that LWLockRelease, if the 'break' happens?
======
src/backend/replication/logical/worker.c
6. LogicalRepApplyLoop
Refer to [1] for my reply to a previous review comment
~~~
7. InitializeLogRepWorker
if (am_tablesync_worker())
ereport(LOG,
- (errmsg("logical replication worker for subscription \"%s\", table
\"%s\" has started",
+ (errmsg("logical replication worker for subscription \"%s\", table
\"%s\" with relid %u has started",
MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
But this is certainly a tablesync worker so the message here should
say "logical replication table synchronization worker" like the HEAD
code used to do.
It seems this mistake was introduced in patch v20-0001.
======
src/include/replication/worker_internal.h
8.
Refer to [1] for my reply to a previous review comment
------
[1] Replies to previous 0002 comments --
https://www.postgresql.org/message-id/CAHut%2BPtiAtGJC52SGNdobOah5ctYDDhWWKd%3DuP%3DrkRgXzg5rdg%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Jul 20, 2023 at 8:02 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Tue, Jul 18, 2023 at 1:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> >
> > Hi,
> >
> > PFA updated patches. Rebased 0003 with minor changes. Addressed Peter's reviews for 0001 and 0002 with some small
commentsbelow.
> >
> > Peter Smith <smithpb2250@gmail.com>, 10 Tem 2023 Pzt, 10:09 tarihinde şunu yazdı:
> >>
> >> 6. LogicalRepApplyLoop
> >>
> >> + /*
> >> + * apply_dispatch() may have gone into apply_handle_commit()
> >> + * which can call process_syncing_tables_for_sync.
> >> + *
> >> + * process_syncing_tables_for_sync decides whether the sync of
> >> + * the current table is completed. If it is completed,
> >> + * streaming must be already ended. So, we can break the loop.
> >> + */
> >> + if (MyLogicalRepWorker->is_sync_completed)
> >> + {
> >> + endofstream = true;
> >> + break;
> >> + }
> >> +
> >>
> >> and
> >>
> >> + /*
> >> + * If is_sync_completed is true, this means that the tablesync
> >> + * worker is done with synchronization. Streaming has already been
> >> + * ended by process_syncing_tables_for_sync. We should move to the
> >> + * next table if needed, or exit.
> >> + */
> >> + if (MyLogicalRepWorker->is_sync_completed)
> >> + endofstream = true;
> >>
> >> ~
> >>
> >> Instead of those code fragments above assigning 'endofstream' as a
> >> side-effect, would it be the same (but tidier) to just modify the
> >> other "breaking" condition below:
> >>
> >> BEFORE:
> >> /* Check if we need to exit the streaming loop. */
> >> if (endofstream)
> >> break;
> >>
> >> AFTER:
> >> /* Check if we need to exit the streaming loop. */
> >> if (endofstream || MyLogicalRepWorker->is_sync_completed)
> >> break;
> >
> >
> > First place you mentioned also breaks the infinite loop. Such an if statement is needed there with or without
endofstreamassignment.
> >
> > I think if there is a flag to break a loop, using that flag to indicate that we should exit the loop seems more
appropriateto me. I see that it would be a bit tidier without endofstream = true lines, but I feel like it would also
beless readable.
> >
> > I don't have a strong opinion though. I'm just keeping them as they are for now, but I can change them if you
disagree.
> >
>
> I felt it was slightly sneaky to re-use the existing variable as a
> convenient way to do what you want. But, I don’t feel strongly enough
> on this point to debate it -- maybe see later if others have an
> opinion about this.
>
I feel it is okay to use the existing variable 'endofstream' here but
shall we have an assertion that it is a tablesync worker?
> >>
> >>
> >> 10b.
> >> All the other tablesync-related fields of this struct are named as
> >> relXXX, so I wonder if is better for this to follow the same pattern.
> >> e.g. 'relsync_completed'
> >
> >
> > Aren't those start with rel because they're related to the relation that the tablesync worker is syncing?
is_sync_completedis not a relation specific field. I'm okay with changing the name but feel like relsync_completed
wouldbe misleading.
>
> My reading of the code is slightly different: Only these fields have
> the prefix ‘rel’ and they are all grouped under the comment “/* Used
> for initial table synchronization. */” because AFAIK only these fields
> are TWS specific (not used for other kinds of workers).
>
> Since this new flag field is also TWS-specific, therefore IMO it
> should follow the same consistent name pattern. But, if you are
> unconvinced, maybe see later if others have an opinion about it.
>
+1 to use the prefix 'rel' here as the sync is specific to the
relation. Even during apply phase, we will apply the relation-specific
changes. See should_apply_changes_for_rel().
--
With Regards,
Amit Kapila.
Hi, I had a look at the latest 00003 patch (v20-0003). Although this patch was recently modified, the updates are mostly only to make it compatible with the updated v20-0002 patch. Specifically, the v20-0003 updates did not yet address my review comments from v17-0003 [1]. Anyway, this post is just a reminder so the earlier review doesn't get forgotten. ------ [1] v17-0003 review - https://www.postgresql.org/message-id/CAHut%2BPuMAiO_X_Kw6ud-jr5WOm%2Brpkdu7CppDU6mu%3DgY7UVMzQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Hi Peter,
Peter Smith <smithpb2250@gmail.com>, 20 Tem 2023 Per, 07:10 tarihinde şunu yazdı:
Hi, I had a look at the latest 00003 patch (v20-0003).
Although this patch was recently modified, the updates are mostly only
to make it compatible with the updated v20-0002 patch. Specifically,
the v20-0003 updates did not yet address my review comments from
v17-0003 [1].
Yes, I only addressed your reviews for 0001 and 0002, and rebased 0003 in latest patches as stated here [1].
I'll update the patch soon according to recent reviews, including yours for 0003.
Thanks for the reminder.
Melih Mutlu
Microsoft
Hi,
Peter Smith <smithpb2250@gmail.com>, 20 Tem 2023 Per, 05:41 tarihinde şunu yazdı:
7. InitializeLogRepWorker
if (am_tablesync_worker())
ereport(LOG,
- (errmsg("logical replication worker for subscription \"%s\", table
\"%s\" has started",
+ (errmsg("logical replication worker for subscription \"%s\", table
\"%s\" with relid %u has started",
MySubscription->name,
- get_rel_name(MyLogicalRepWorker->relid))));
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
But this is certainly a tablesync worker so the message here should
say "logical replication table synchronization worker" like the HEAD
code used to do.
It seems this mistake was introduced in patch v20-0001.
I'm a bit confused here. Isn't it decided to use "logical replication worker" regardless of the worker's type [1]. That's why I made this change. If that's not the case here, I'll put it back.
Thanks,
Melih Mutlu
Microsoft
On Thu, Jul 20, 2023 at 5:12 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Peter Smith <smithpb2250@gmail.com>, 20 Tem 2023 Per, 05:41 tarihinde şunu yazdı:
>>
>> 7. InitializeLogRepWorker
>>
>> if (am_tablesync_worker())
>> ereport(LOG,
>> - (errmsg("logical replication worker for subscription \"%s\", table
>> \"%s\" has started",
>> + (errmsg("logical replication worker for subscription \"%s\", table
>> \"%s\" with relid %u has started",
>> MySubscription->name,
>> - get_rel_name(MyLogicalRepWorker->relid))));
>> + get_rel_name(MyLogicalRepWorker->relid),
>> + MyLogicalRepWorker->relid)));
>>
>> But this is certainly a tablesync worker so the message here should
>> say "logical replication table synchronization worker" like the HEAD
>> code used to do.
>>
>> It seems this mistake was introduced in patch v20-0001.
>
>
> I'm a bit confused here. Isn't it decided to use "logical replication worker" regardless of the worker's type [1].
That'swhy I made this change. If that's not the case here, I'll put it back.
>
I feel where the worker type is clear, it is better to use it unless
the same can lead to translation issues.
--
With Regards,
Amit Kapila.
Hi,
Attached the updated patches with recent reviews addressed.
See below for my comments:
Peter Smith <smithpb2250@gmail.com>, 19 Tem 2023 Çar, 06:08 tarihinde şunu yazdı:
Some review comments for v19-0001
2. LogicalRepSyncTableStart
/*
* Finally, wait until the leader apply worker tells us to catch up and
* then return to let LogicalRepApplyLoop do it.
*/
wait_for_worker_state_change(SUBREL_STATE_CATCHUP);
~
Should LogicalRepApplyLoop still be mentioned here, since that is
static in worker.c? Maybe it is better to refer instead to the common
'start_apply' wrapper? (see also #5a below)
Isn't' LogicalRepApplyLoop static on HEAD and also mentioned in the exact comment in tablesync.c while the common "start_apply" function also exists? I'm not sure how such a change would be related to this patch.
---
5.
+ /* Found a table for next iteration */
+ finish_sync_worker(true);
+
+ StartTransactionCommand();
+ ereport(LOG,
+ (errmsg("logical replication worker for subscription \"%s\" will be
reused to sync table \"%s\" with relid %u.",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ CommitTransactionCommand();
+
+ done = false;
+ break;
+ }
+ LWLockRelease(LogicalRepWorkerLock);
5b.
Isn't there a missing call to that LWLockRelease, if the 'break' happens?
Lock is already released before break, if that's the lock you meant:
/* Update worker state for the next table */
MyLogicalRepWorker->relid = rstate->relid;
MyLogicalRepWorker->relstate = rstate->state;
MyLogicalRepWorker->relstate_lsn = rstate->lsn;
LWLockRelease(LogicalRepWorkerLock);
/* Found a table for next iteration */
finish_sync_worker(true);
done = false;
break;
---
2.
As for the publisher node, this patch allows to reuse logical
walsender processes
after the streaming is done once.
~
Is this paragraph even needed? Since the connection is reused then it
already implies the other end (the Wlasender) is being reused, right?
I actually see no harm in explaining this explicitly.
Thanks,
-- Melih Mutlu
Microsoft
Вложения
On Thu, Jul 20, 2023 at 11:41 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > Hi, > > Attached the updated patches with recent reviews addressed. > > See below for my comments: > > Peter Smith <smithpb2250@gmail.com>, 19 Tem 2023 Çar, 06:08 tarihinde şunu yazdı: >> >> Some review comments for v19-0001 >> >> 2. LogicalRepSyncTableStart >> >> /* >> * Finally, wait until the leader apply worker tells us to catch up and >> * then return to let LogicalRepApplyLoop do it. >> */ >> wait_for_worker_state_change(SUBREL_STATE_CATCHUP); >> >> ~ >> >> Should LogicalRepApplyLoop still be mentioned here, since that is >> static in worker.c? Maybe it is better to refer instead to the common >> 'start_apply' wrapper? (see also #5a below) > > > Isn't' LogicalRepApplyLoop static on HEAD and also mentioned in the exact comment in tablesync.c while the common "start_apply"function also exists? I'm not sure how such a change would be related to this patch. > Fair enough. I thought it was questionable for one module to refer to another module's static functions, but you are correct - it is not really related to your patch. Sorry for the noise. ------ Kind Regards, Peter Smith. Fujitsu Australia
Some review comments for v21-0001
======
src/backend/replication/logical/worker.c
1. InitializeLogRepWorker
if (am_tablesync_worker())
ereport(LOG,
- (errmsg("logical replication table synchronization worker for
subscription \"%s\", table \"%s\" has started",
+ (errmsg("logical replication worker for subscription \"%s\", table
\"%s\" has started",
MySubscription->name,
get_rel_name(MyLogicalRepWorker->relid))));
I think this should not be changed. IIUC that decision for using the
generic worker name for translations was only when the errmsg was in
shared code where the worker type was not clear from existing
conditions. See also previous review comments [1].
~~~
2. StartLogRepWorker
/* Common function to start the leader apply or tablesync worker. */
void
StartLogRepWorker(int worker_slot)
{
/* Attach to slot */
logicalrep_worker_attach(worker_slot);
/* Setup signal handling */
pqsignal(SIGHUP, SignalHandlerForConfigReload);
pqsignal(SIGTERM, die);
BackgroundWorkerUnblockSignals();
/*
* We don't currently need any ResourceOwner in a walreceiver process, but
* if we did, we could call CreateAuxProcessResourceOwner here.
*/
/* Initialise stats to a sanish value */
MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
MyLogicalRepWorker->reply_time = GetCurrentTimestamp();
/* Load the libpq-specific functions */
load_file("libpqwalreceiver", false);
InitializeLogRepWorker();
/* Connect to the origin and start the replication. */
elog(DEBUG1, "connecting to publisher using connection string \"%s\"",
MySubscription->conninfo);
/*
* Setup callback for syscache so that we know when something changes in
* the subscription relation state.
*/
CacheRegisterSyscacheCallback(SUBSCRIPTIONRELMAP,
invalidate_syncing_table_states,
(Datum) 0);
}
~
2a.
The function name seems a bit misleading because it is not really
"starting" anything here - it is just more "initialization" code,
right? Nor is it common to all kinds of LogRepWorker. Maybe the
function could be named something else like 'InitApplyOrSyncWorker()'.
-- see also #2c
~
2b.
Should this have Assert to ensure this is only called from leader
apply or tablesync? -- see also #2c
~
2c.
IMO maybe the best/tidiest way to do this is not to introduce a new
function at all. Instead, just put all this "common init" code into
the existing "common init" function ('InitializeLogRepWorker') and
execute it only if (am_tablesync_worker() || am_leader_apply_worker())
{ }.
======
src/include/replication/worker_internal.h
3.
extern void pa_xact_finish(ParallelApplyWorkerInfo *winfo,
XLogRecPtr remote_lsn);
+extern void set_stream_options(WalRcvStreamOptions *options,
+ char *slotname,
+ XLogRecPtr *origin_startpos);
+
+extern void start_apply(XLogRecPtr origin_startpos);
+extern void DisableSubscriptionAndExit(void);
+extern void StartLogRepWorker(int worker_slot);
This placement (esp. with the missing whitespace) seems to be grouping
the set_stream_options with the other 'pa' externs, which are all
under the comment "/* Parallel apply worker setup and interactions
*/".
Putting all these up near the other "extern void
InitializeLogRepWorker(void)" might be less ambiguous.
------
[1] worker name in errmsg -
https://www.postgresql.org/message-id/CAA4eK1%2B%2BwkxxMjsPh-z2aKa9ZjNhKsjv0Tnw%2BTVX-hCBkDHusw%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Some review comments for v21-0002.
On Thu, Jul 20, 2023 at 11:41 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi,
>
> Attached the updated patches with recent reviews addressed.
>
> See below for my comments:
>
> Peter Smith <smithpb2250@gmail.com>, 19 Tem 2023 Çar, 06:08 tarihinde şunu yazdı:
>>
>> 5.
>> + /* Found a table for next iteration */
>> + finish_sync_worker(true);
>> +
>> + StartTransactionCommand();
>> + ereport(LOG,
>> + (errmsg("logical replication worker for subscription \"%s\" will be
>> reused to sync table \"%s\" with relid %u.",
>> + MySubscription->name,
>> + get_rel_name(MyLogicalRepWorker->relid),
>> + MyLogicalRepWorker->relid)));
>> + CommitTransactionCommand();
>> +
>> + done = false;
>> + break;
>> + }
>> + LWLockRelease(LogicalRepWorkerLock);
>>
>>
>> 5b.
>> Isn't there a missing call to that LWLockRelease, if the 'break' happens?
>
>
> Lock is already released before break, if that's the lock you meant:
>
>> /* Update worker state for the next table */
>> MyLogicalRepWorker->relid = rstate->relid;
>> MyLogicalRepWorker->relstate = rstate->state;
>> MyLogicalRepWorker->relstate_lsn = rstate->lsn;
>> LWLockRelease(LogicalRepWorkerLock);
>>
>>
>> /* Found a table for next iteration */
>> finish_sync_worker(true);
>> done = false;
>> break;
>
>
Sorry, I misread the code. You are right.
======
src/backend/replication/logical/tablesync.c
1.
+ if (!reuse_worker)
+ {
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
+ MySubscription->name)));
+ }
+ else
+ {
+ ereport(LOG,
+ (errmsg("logical replication worker for subscription \"%s\" will be
reused to sync table \"%s\" with relid %u.",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ }
1a.
We know this must be a tablesync worker, so I think that second errmsg
should also be saying "logical replication table synchronization
worker".
~
1b.
Since this is if/else anyway, is it simpler to be positive and say "if
(reuse_worker)" instead of the negative "if (!reuse_worker)"
~~~
2. run_tablesync_worker
{
+ MyLogicalRepWorker->relsync_completed = false;
+
+ /* Start table synchronization. */
start_table_sync(origin_startpos, &slotname);
This still contains the added comment that I'd previously posted I
thought was adding anything useful. Also, I didn't think this comment
exists in the HEAD code.
======
src/backend/replication/logical/worker.c
3. LogicalRepApplyLoop
+ /*
+ * apply_dispatch() may have gone into apply_handle_commit()
+ * which can call process_syncing_tables_for_sync.
+ *
+ * process_syncing_tables_for_sync decides whether the sync of
+ * the current table is completed. If it is completed,
+ * streaming must be already ended. So, we can break the loop.
+ */
+ if (am_tablesync_worker() &&
+ MyLogicalRepWorker->relsync_completed)
+ {
+ endofstream = true;
+ break;
+ }
+
Maybe just personal taste, but IMO it is better to rearrange like
below because then there is no reason to read the long comment except
for tablesync workers.
if (am_tablesync_worker())
{
/*
* apply_dispatch() may have gone into apply_handle_commit()
* which can call process_syncing_tables_for_sync.
*
* process_syncing_tables_for_sync decides whether the sync of
* the current table is completed. If it is completed,
* streaming must be already ended. So, we can break the loop.
*/
if (MyLogicalRepWorker->relsync_completed)
{
endofstream = true;
break;
}
}
~~~
4. LogicalRepApplyLoop
+
+ /*
+ * If relsync_completed is true, this means that the tablesync
+ * worker is done with synchronization. Streaming has already been
+ * ended by process_syncing_tables_for_sync. We should move to the
+ * next table if needed, or exit.
+ */
+ if (am_tablesync_worker() &&
+ MyLogicalRepWorker->relsync_completed)
+ endofstream = true;
Ditto the same comment about rearranging the condition, as #3 above.
======
src/include/replication/worker_internal.h
5.
+ /*
+ * Indicates whether tablesync worker has completed syncing its assigned
+ * table.
+ */
+ bool relsync_completed;
+
Isn't it better to arrange this to be adjacent to other relXXX fields,
so they all clearly belong to that "Used for initial table
synchronization." group?
For example, something like:
/* Used for initial table synchronization. */
Oid relid;
char relstate;
XLogRecPtr relstate_lsn;
slock_t relmutex;
bool relsync_completed; /* has tablesync finished syncing
the assigned table? */
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Fri, Jul 21, 2023 at 7:30 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> ~~~
>
> 2. StartLogRepWorker
>
> /* Common function to start the leader apply or tablesync worker. */
> void
> StartLogRepWorker(int worker_slot)
> {
> /* Attach to slot */
> logicalrep_worker_attach(worker_slot);
>
> /* Setup signal handling */
> pqsignal(SIGHUP, SignalHandlerForConfigReload);
> pqsignal(SIGTERM, die);
> BackgroundWorkerUnblockSignals();
>
> /*
> * We don't currently need any ResourceOwner in a walreceiver process, but
> * if we did, we could call CreateAuxProcessResourceOwner here.
> */
>
> /* Initialise stats to a sanish value */
> MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
> MyLogicalRepWorker->reply_time = GetCurrentTimestamp();
>
> /* Load the libpq-specific functions */
> load_file("libpqwalreceiver", false);
>
> InitializeLogRepWorker();
>
> /* Connect to the origin and start the replication. */
> elog(DEBUG1, "connecting to publisher using connection string \"%s\"",
> MySubscription->conninfo);
>
> /*
> * Setup callback for syscache so that we know when something changes in
> * the subscription relation state.
> */
> CacheRegisterSyscacheCallback(SUBSCRIPTIONRELMAP,
> invalidate_syncing_table_states,
> (Datum) 0);
> }
>
> ~
>
> 2a.
> The function name seems a bit misleading because it is not really
> "starting" anything here - it is just more "initialization" code,
> right? Nor is it common to all kinds of LogRepWorker. Maybe the
> function could be named something else like 'InitApplyOrSyncWorker()'.
> -- see also #2c
>
How about SetupLogRepWorker? The other thing I noticed is that we
don't seem to be consistent in naming functions in these files. For
example, shall we make all exposed functions follow camel case (like
InitializeLogRepWorker) and static functions follow _ style (like
run_apply_worker) or the other possibility is to use _ style for all
functions except may be the entry functions like ApplyWorkerMain()? I
don't know if there is already a pattern but if not then let's form it
now, so that code looks consistent.
> ~
>
> 2b.
> Should this have Assert to ensure this is only called from leader
> apply or tablesync? -- see also #2c
>
> ~
>
> 2c.
> IMO maybe the best/tidiest way to do this is not to introduce a new
> function at all. Instead, just put all this "common init" code into
> the existing "common init" function ('InitializeLogRepWorker') and
> execute it only if (am_tablesync_worker() || am_leader_apply_worker())
> { }.
>
I don't like 2c much because it will make InitializeLogRepWorker()
have two kinds of initializations.
> ======
> src/include/replication/worker_internal.h
>
> 3.
> extern void pa_xact_finish(ParallelApplyWorkerInfo *winfo,
> XLogRecPtr remote_lsn);
> +extern void set_stream_options(WalRcvStreamOptions *options,
> + char *slotname,
> + XLogRecPtr *origin_startpos);
> +
> +extern void start_apply(XLogRecPtr origin_startpos);
> +extern void DisableSubscriptionAndExit(void);
> +extern void StartLogRepWorker(int worker_slot);
>
> This placement (esp. with the missing whitespace) seems to be grouping
> the set_stream_options with the other 'pa' externs, which are all
> under the comment "/* Parallel apply worker setup and interactions
> */".
>
> Putting all these up near the other "extern void
> InitializeLogRepWorker(void)" might be less ambiguous.
>
+1. Also, note that they should be in the same order as they are in .c files.
--
With Regards,
Amit Kapila.
On Fri, Jul 21, 2023 at 3:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Jul 21, 2023 at 7:30 AM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > ~~~
> >
> > 2. StartLogRepWorker
> >
> > /* Common function to start the leader apply or tablesync worker. */
> > void
> > StartLogRepWorker(int worker_slot)
> > {
> > /* Attach to slot */
> > logicalrep_worker_attach(worker_slot);
> >
> > /* Setup signal handling */
> > pqsignal(SIGHUP, SignalHandlerForConfigReload);
> > pqsignal(SIGTERM, die);
> > BackgroundWorkerUnblockSignals();
> >
> > /*
> > * We don't currently need any ResourceOwner in a walreceiver process, but
> > * if we did, we could call CreateAuxProcessResourceOwner here.
> > */
> >
> > /* Initialise stats to a sanish value */
> > MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
> > MyLogicalRepWorker->reply_time = GetCurrentTimestamp();
> >
> > /* Load the libpq-specific functions */
> > load_file("libpqwalreceiver", false);
> >
> > InitializeLogRepWorker();
> >
> > /* Connect to the origin and start the replication. */
> > elog(DEBUG1, "connecting to publisher using connection string \"%s\"",
> > MySubscription->conninfo);
> >
> > /*
> > * Setup callback for syscache so that we know when something changes in
> > * the subscription relation state.
> > */
> > CacheRegisterSyscacheCallback(SUBSCRIPTIONRELMAP,
> > invalidate_syncing_table_states,
> > (Datum) 0);
> > }
> >
> > ~
> >
> > 2a.
> > The function name seems a bit misleading because it is not really
> > "starting" anything here - it is just more "initialization" code,
> > right? Nor is it common to all kinds of LogRepWorker. Maybe the
> > function could be named something else like 'InitApplyOrSyncWorker()'.
> > -- see also #2c
> >
>
> How about SetupLogRepWorker?
The name is better than StartXXX, but still, SetupXXX seems a synonym
of InitXXX. That is why I thought it is a bit awkward having 2
functions with effectively the same name and the same
initialization/setup purpose (the only difference is one function
excludes parallel workers, and the other function is common to all
workers).
> The other thing I noticed is that we
> don't seem to be consistent in naming functions in these files. For
> example, shall we make all exposed functions follow camel case (like
> InitializeLogRepWorker) and static functions follow _ style (like
> run_apply_worker) or the other possibility is to use _ style for all
> functions except may be the entry functions like ApplyWorkerMain()? I
> don't know if there is already a pattern but if not then let's form it
> now, so that code looks consistent.
>
+1 for using some consistent rule, but I think this may result in
*many* changes, so it would be safer to itemize all the changes first,
just to make sure everybody is OK with it first before updating
everything.
------
Kind Regards,
Peter Smith
On Fri, Jul 21, 2023 at 12:05 PM Peter Smith <smithpb2250@gmail.com> wrote:
>
> On Fri, Jul 21, 2023 at 3:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> >
> > On Fri, Jul 21, 2023 at 7:30 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > ~~~
> > >
> > > 2. StartLogRepWorker
> > >
> > > /* Common function to start the leader apply or tablesync worker. */
> > > void
> > > StartLogRepWorker(int worker_slot)
> > > {
> > > /* Attach to slot */
> > > logicalrep_worker_attach(worker_slot);
> > >
> > > /* Setup signal handling */
> > > pqsignal(SIGHUP, SignalHandlerForConfigReload);
> > > pqsignal(SIGTERM, die);
> > > BackgroundWorkerUnblockSignals();
> > >
> > > /*
> > > * We don't currently need any ResourceOwner in a walreceiver process, but
> > > * if we did, we could call CreateAuxProcessResourceOwner here.
> > > */
> > >
> > > /* Initialise stats to a sanish value */
> > > MyLogicalRepWorker->last_send_time = MyLogicalRepWorker->last_recv_time =
> > > MyLogicalRepWorker->reply_time = GetCurrentTimestamp();
> > >
> > > /* Load the libpq-specific functions */
> > > load_file("libpqwalreceiver", false);
> > >
> > > InitializeLogRepWorker();
> > >
> > > /* Connect to the origin and start the replication. */
> > > elog(DEBUG1, "connecting to publisher using connection string \"%s\"",
> > > MySubscription->conninfo);
> > >
> > > /*
> > > * Setup callback for syscache so that we know when something changes in
> > > * the subscription relation state.
> > > */
> > > CacheRegisterSyscacheCallback(SUBSCRIPTIONRELMAP,
> > > invalidate_syncing_table_states,
> > > (Datum) 0);
> > > }
> > >
> > > ~
> > >
> > > 2a.
> > > The function name seems a bit misleading because it is not really
> > > "starting" anything here - it is just more "initialization" code,
> > > right? Nor is it common to all kinds of LogRepWorker. Maybe the
> > > function could be named something else like 'InitApplyOrSyncWorker()'.
> > > -- see also #2c
> > >
> >
> > How about SetupLogRepWorker?
>
> The name is better than StartXXX, but still, SetupXXX seems a synonym
> of InitXXX. That is why I thought it is a bit awkward having 2
> functions with effectively the same name and the same
> initialization/setup purpose (the only difference is one function
> excludes parallel workers, and the other function is common to all
> workers).
>
I can't know of a better way. We can probably name it as
SetupApplyOrSyncWorker or something like that if you find that better.
> > The other thing I noticed is that we
> > don't seem to be consistent in naming functions in these files. For
> > example, shall we make all exposed functions follow camel case (like
> > InitializeLogRepWorker) and static functions follow _ style (like
> > run_apply_worker) or the other possibility is to use _ style for all
> > functions except may be the entry functions like ApplyWorkerMain()? I
> > don't know if there is already a pattern but if not then let's form it
> > now, so that code looks consistent.
> >
>
> +1 for using some consistent rule, but I think this may result in
> *many* changes, so it would be safer to itemize all the changes first,
> just to make sure everybody is OK with it first before updating
> everything.
>
Fair enough. We can do that as a first patch and then work on the
refactoring patch to avoid introducing more inconsistencies or we can
do the refactoring patch first but keep all the new function names to
follow _ style.
Apart from this, few more comments on 0001:
1.
+run_apply_worker(WalRcvStreamOptions *options,
+ char *slotname,
+ char *originname,
+ int originname_size,
+ XLogRecPtr *origin_startpos)
The caller neither uses nor passes the value of origin_startpos. So,
isn't it better to make origin_startpos local to run_apply_worker()?
It seems the same is true for some of the other parameters slotname,
originname, originname_size. Is there a reason to keep these as
arguments in this function?
2.
+static void
+run_tablesync_worker(WalRcvStreamOptions *options,
+ char *slotname,
+ char *originname,
+ int originname_size,
+ XLogRecPtr *origin_startpos)
The comments in the previous point seem to apply to this as well.
3.
+ set_stream_options(options, slotname, origin_startpos);
+
+ walrcv_startstreaming(LogRepWorkerWalRcvConn, options);
+
+ if (MySubscription->twophasestate == LOGICALREP_TWOPHASE_STATE_PENDING &&
+ AllTablesyncsReady())
This last check is done in set_stream_options() and here as well. I
don't see any reason to give different answers at both places but
before the patch, we were not relying on any such assumption that this
check will always give the same answer considering the answer could be
different due to AllTablesyncsReady(). Can we move this check outside
set_stream_options()?
--
With Regards,
Amit Kapila.
Amit Kapila <amit.kapila16@gmail.com>, 21 Tem 2023 Cum, 08:39 tarihinde şunu yazdı:
On Fri, Jul 21, 2023 at 7:30 AM Peter Smith <smithpb2250@gmail.com> wrote:
How about SetupLogRepWorker? The other thing I noticed is that we
don't seem to be consistent in naming functions in these files. For
example, shall we make all exposed functions follow camel case (like
InitializeLogRepWorker) and static functions follow _ style (like
run_apply_worker) or the other possibility is to use _ style for all
functions except may be the entry functions like ApplyWorkerMain()? I
don't know if there is already a pattern but if not then let's form it
now, so that code looks consistent.
I agree that these files have inconsistencies in naming things.
Most of the time I can't really figure out which naming convention I should use. I try to name things by looking at other functions with similar responsibilities.
> 3.
> extern void pa_xact_finish(ParallelApplyWorkerInfo *winfo,
> XLogRecPtr remote_lsn);
> +extern void set_stream_options(WalRcvStreamOptions *options,
> + char *slotname,
> + XLogRecPtr *origin_startpos);
> +
> +extern void start_apply(XLogRecPtr origin_startpos);
> +extern void DisableSubscriptionAndExit(void);
> +extern void StartLogRepWorker(int worker_slot);
>
> This placement (esp. with the missing whitespace) seems to be grouping
> the set_stream_options with the other 'pa' externs, which are all
> under the comment "/* Parallel apply worker setup and interactions
> */".
>
> Putting all these up near the other "extern void
> InitializeLogRepWorker(void)" might be less ambiguous.
>
+1. Also, note that they should be in the same order as they are in .c files.
I did not realize the order is the same with .c files. Good to know. I'll fix it along with other comments.
Thanks,
Melih Mutlu
Microsoft
On Fri, Jul 21, 2023 at 5:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Jul 21, 2023 at 12:05 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > On Fri, Jul 21, 2023 at 3:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > > > The other thing I noticed is that we > > > don't seem to be consistent in naming functions in these files. For > > > example, shall we make all exposed functions follow camel case (like > > > InitializeLogRepWorker) and static functions follow _ style (like > > > run_apply_worker) or the other possibility is to use _ style for all > > > functions except may be the entry functions like ApplyWorkerMain()? I > > > don't know if there is already a pattern but if not then let's form it > > > now, so that code looks consistent. > > > > > > > +1 for using some consistent rule, but I think this may result in > > *many* changes, so it would be safer to itemize all the changes first, > > just to make sure everybody is OK with it first before updating > > everything. > > > > Fair enough. We can do that as a first patch and then work on the > refactoring patch to avoid introducing more inconsistencies or we can > do the refactoring patch first but keep all the new function names to > follow _ style. > Fixing the naming inconsistency will be more far-reaching than just a few functions affected by these "reuse" patches. There are plenty of existing functions already inconsistently named in the HEAD code. So perhaps this topic should be moved to a separate thread? For example, here are some existing/proposed names: === worker.c (HEAD) static functions DisableSubscriptionAndExit -> disable_subscription_and_exit FindReplTupleInLocalRel -> find_repl_tuple_in_local_rel TwoPhaseTransactionGid -> two_phase_transaction_gid TargetPrivilegesCheck -> target_privileges_check UpdateWorkerStats -> update_worker_stats LogicalRepApplyLoop -> logical_rep_apply_loop non-static functions stream_stop_internal -> StreamStopInternal apply_spooled_messages -> ApplySpooledMessages apply_dispatch -> ApplyDispatch store_flush_position -> StoreFlushPosition set_apply_error_context_origin -> SetApplyErrorContextOrigin === tablesync.c (HEAD) static functions FetchTableStates -> fetch_table_states non-static functions invalidate_syncing_table_states -> InvalidateSyncingTableStates ------ Kind Regards, Peter Smith. Fujitsu Australia
Peter Smith <smithpb2250@gmail.com>, 21 Tem 2023 Cum, 12:48 tarihinde şunu yazdı:
On Fri, Jul 21, 2023 at 5:24 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Jul 21, 2023 at 12:05 PM Peter Smith <smithpb2250@gmail.com> wrote:
> >
> > On Fri, Jul 21, 2023 at 3:39 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > The other thing I noticed is that we
> > > don't seem to be consistent in naming functions in these files. For
> > > example, shall we make all exposed functions follow camel case (like
> > > InitializeLogRepWorker) and static functions follow _ style (like
> > > run_apply_worker) or the other possibility is to use _ style for all
> > > functions except may be the entry functions like ApplyWorkerMain()? I
> > > don't know if there is already a pattern but if not then let's form it
> > > now, so that code looks consistent.
> > >
> >
> > +1 for using some consistent rule, but I think this may result in
> > *many* changes, so it would be safer to itemize all the changes first,
> > just to make sure everybody is OK with it first before updating
> > everything.
> >
>
> Fair enough. We can do that as a first patch and then work on the
> refactoring patch to avoid introducing more inconsistencies or we can
> do the refactoring patch first but keep all the new function names to
> follow _ style.
>
Fixing the naming inconsistency will be more far-reaching than just a
few functions affected by these "reuse" patches. There are plenty of
existing functions already inconsistently named in the HEAD code. So
perhaps this topic should be moved to a separate thread?
+1 for moving it to a separate thread. This is not something particularly introduced by this patch.
Thanks,
Melih Mutlu
Microsoft
Hi,
Melih Mutlu <m.melihmutlu@gmail.com>, 21 Tem 2023 Cum, 12:47 tarihinde şunu yazdı:
I did not realize the order is the same with .c files. Good to know. I'll fix it along with other comments.
Addressed the recent reviews and attached the updated patches.
Thanks,
Melih Mutlu
Microsoft
Вложения
Here are some comments for patch v22-0001.
======
1. General -- naming conventions
There is quite a lot of inconsistency with variable/parameter naming
styles in this patch. I understand in most cases the names are copied
unchanged from the original functions. Still, since this is a big
refactor anyway, it can also be a good opportunity to clean up those
inconsistencies instead of just propagating them to different places.
IIUC, the usual reluctance to rename things because it would cause
backpatch difficulties doesn't apply here (since everything is being
refactored anyway).
E.g. Consider using use snake_case names more consistently in the
following places:
~
1a. start_table_sync
+static void
+start_table_sync(XLogRecPtr *origin_startpos, char **myslotname)
+{
+ char *syncslotname = NULL;
origin_startpos -> (no change)
myslotname -> my_slot_name (But, is there a better name for this than
calling it "my" slot name)
syncslotname -> sync_slot_name
~
1b. run_tablesync_worker
+static void
+run_tablesync_worker()
+{
+ char originname[NAMEDATALEN];
+ XLogRecPtr origin_startpos = InvalidXLogRecPtr;
+ char *slotname = NULL;
+ WalRcvStreamOptions options;
originname -> origin_name
origin_startpos -> (no change)
slotname -> slot_name
~
1c. set_stream_options
+void
+set_stream_options(WalRcvStreamOptions *options,
+ char *slotname,
+ XLogRecPtr *origin_startpos)
+{
+ int server_version;
options -> (no change)
slotname -> slot_name
origin_startpos -> (no change)
server_version -> (no change)
~
1d. run_apply_worker
static void
-start_apply(XLogRecPtr origin_startpos)
+run_apply_worker()
{
- PG_TRY();
+ char originname[NAMEDATALEN];
+ XLogRecPtr origin_startpos = InvalidXLogRecPtr;
+ char *slotname = NULL;
+ WalRcvStreamOptions options;
+ RepOriginId originid;
+ TimeLineID startpointTLI;
+ char *err;
+ bool must_use_password;
originname -> origin_name
origin_startpos => (no change)
slotname -> slot_name
originid -> origin_id
======
src/backend/replication/logical/worker.c
2. SetupApplyOrSyncWorker
-ApplyWorkerMain(Datum main_arg)
+SetupApplyOrSyncWorker(int worker_slot)
{
- int worker_slot = DatumGetInt32(main_arg);
- char originname[NAMEDATALEN];
- XLogRecPtr origin_startpos = InvalidXLogRecPtr;
- char *myslotname = NULL;
- WalRcvStreamOptions options;
- int server_version;
-
- InitializingApplyWorker = true;
-
/* Attach to slot */
logicalrep_worker_attach(worker_slot);
+ Assert(am_tablesync_worker() || am_leader_apply_worker());
+
Why is the Assert not the very first statement of this function?
======
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, Jul 26, 2023 at 10:10 AM Peter Smith <smithpb2250@gmail.com> wrote: > > Here are some comments for patch v22-0001. > > ====== > 1. General -- naming conventions > > There is quite a lot of inconsistency with variable/parameter naming > styles in this patch. I understand in most cases the names are copied > unchanged from the original functions. Still, since this is a big > refactor anyway, it can also be a good opportunity to clean up those > inconsistencies instead of just propagating them to different places. > I am not against improving consistency in the naming of existing variables but I feel it would be better to do as a separate patch along with improving the consistency function names. For new functions/variables, it would be good to follow a consistent style. -- With Regards, Amit Kapila.
Here are some review comments for v22-0002
======
1. General - errmsg
AFAIK, the errmsg part does not need to be enclosed by extra parentheses.
e.g.
BEFORE
ereport(LOG,
(errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
MySubscription->name)));
AFTER
ereport(LOG,
errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
MySubscription->name));
~
The patch has multiple cases similar to that example.
======
src/backend/replication/logical/tablesync.c
2.
+ if (reuse_worker)
+ {
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" will be reused to sync table \"%s\" with relid
%u.",
+ MySubscription->name,
+ get_rel_name(MyLogicalRepWorker->relid),
+ MyLogicalRepWorker->relid)));
+ }
+ else
+ {
+ ereport(LOG,
+ (errmsg("logical replication table synchronization worker for
subscription \"%s\" has finished",
+ MySubscription->name)));
+ }
These brackets { } are not really necessary.
~~~
3. TablesyncWorkerMain
+ for (;!done;)
+ {
+ List *rstates;
+ ListCell *lc;
+
+ run_tablesync_worker();
+
+ if (IsTransactionState())
+ CommitTransactionCommand();
+
+ if (MyLogicalRepWorker->relsync_completed)
+ {
+ /*
+ * This tablesync worker is 'done' unless another table that needs
+ * syncing is found.
+ */
+ done = true;
Those variables 'rstates' and 'lc' do not need to be declared at this
scope -- they can be declared further down, closer to where they are
needed.
=====
src/backend/replication/logical/worker.c
4. LogicalRepApplyLoop
+
+ if (am_tablesync_worker())
+ /*
+ * If relsync_completed is true, this means that the tablesync
+ * worker is done with synchronization. Streaming has already been
+ * ended by process_syncing_tables_for_sync. We should move to the
+ * next table if needed, or exit.
+ */
+ if (MyLogicalRepWorker->relsync_completed)
+ endofstream = true;
Here I think it is better to use bracketing { } for the outer "if",
instead of only relying on the indentation for readability. YMMV.
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Here are some review comments for v22-0003
======
1. ApplicationNameForTablesync
+/*
+ * Determine the application_name for tablesync workers.
+ *
+ * Previously, the replication slot name was used as application_name. Since
+ * it's possible to reuse tablesync workers now, a tablesync worker can handle
+ * several different replication slots during its lifetime. Therefore, we
+ * cannot use the slot name as application_name anymore. Instead, the slot
+ * number of the tablesync worker is used as a part of the application_name.
+ *
+ * FIXME: if the tablesync worker starts to reuse the replication slot during
+ * synchronization, we should again use the replication slot name as
+ * application_name.
+ */
+static void
+ApplicationNameForTablesync(Oid suboid, int worker_slot,
+ char *application_name, Size szapp)
+{
+ snprintf(application_name, szapp, "pg_%u_sync_%i_" UINT64_FORMAT, suboid,
+ worker_slot, GetSystemIdentifier());
+}
1a.
The intent of the "FIXME" comment was not clear. Is this some existing
problem that needs addressing, or is this really more like just an
"XXX" warning/note for the future, in case the tablesync logic
changes?
~
1b.
Since this is a new function, should it be named according to the
convention for static functions?
e.g.
ApplicationNameForTablesync -> app_name_for_tablesync
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Thu, Jul 27, 2023 at 6:46 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
> Here are some review comments for v22-0003
>
> ======
>
> 1. ApplicationNameForTablesync
> +/*
> + * Determine the application_name for tablesync workers.
> + *
> + * Previously, the replication slot name was used as application_name. Since
> + * it's possible to reuse tablesync workers now, a tablesync worker can handle
> + * several different replication slots during its lifetime. Therefore, we
> + * cannot use the slot name as application_name anymore. Instead, the slot
> + * number of the tablesync worker is used as a part of the application_name.
> + *
> + * FIXME: if the tablesync worker starts to reuse the replication slot during
> + * synchronization, we should again use the replication slot name as
> + * application_name.
> + */
> +static void
> +ApplicationNameForTablesync(Oid suboid, int worker_slot,
> + char *application_name, Size szapp)
> +{
> + snprintf(application_name, szapp, "pg_%u_sync_%i_" UINT64_FORMAT, suboid,
> + worker_slot, GetSystemIdentifier());
> +}
>
> 1a.
> The intent of the "FIXME" comment was not clear. Is this some existing
> problem that needs addressing, or is this really more like just an
> "XXX" warning/note for the future, in case the tablesync logic
> changes?
>
This seems to be a Note for the future, so better to use XXX notation here.
> ~
>
> 1b.
> Since this is a new function, should it be named according to the
> convention for static functions?
>
> e.g.
> ApplicationNameForTablesync -> app_name_for_tablesync
>
I think for now let's follow the style for similar functions like
ReplicationOriginNameForLogicalRep() and
ReplicationSlotNameForTablesync().
--
With Regards,
Amit Kapila.
Hi Peter,
Peter Smith <smithpb2250@gmail.com>, 26 Tem 2023 Çar, 07:40 tarihinde şunu yazdı:
Here are some comments for patch v22-0001.
======
1. General -- naming conventions
There is quite a lot of inconsistency with variable/parameter naming
styles in this patch. I understand in most cases the names are copied
unchanged from the original functions. Still, since this is a big
refactor anyway, it can also be a good opportunity to clean up those
inconsistencies instead of just propagating them to different places.
IIUC, the usual reluctance to rename things because it would cause
backpatch difficulties doesn't apply here (since everything is being
refactored anyway).
E.g. Consider using use snake_case names more consistently in the
following places:
I can simply change the places you mentioned, that seems okay to me.
The reason why I did not change the namings in existing variables/functions is because I did (and still do) not get what's the naming conventions in those files. Is snake_case the convention for variables in those files (or in general)?
2. SetupApplyOrSyncWorker
-ApplyWorkerMain(Datum main_arg)
+SetupApplyOrSyncWorker(int worker_slot)
{
- int worker_slot = DatumGetInt32(main_arg);
- char originname[NAMEDATALEN];
- XLogRecPtr origin_startpos = InvalidXLogRecPtr;
- char *myslotname = NULL;
- WalRcvStreamOptions options;
- int server_version;
-
- InitializingApplyWorker = true;
-
/* Attach to slot */
logicalrep_worker_attach(worker_slot);
+ Assert(am_tablesync_worker() || am_leader_apply_worker());
+
Why is the Assert not the very first statement of this function?
I would also prefer to assert in the very beginning but am_tablesync_worker and am_leader_apply_worker require MyLogicalRepWorker to be not NULL. And MyLogicalRepWorker is assigned in logicalrep_worker_attach. I can change this if you think there is a better way to check the worker type.
Thanks,
Melih Mutlu
Microsoft
On Thu, Jul 27, 2023 at 11:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi Peter,
>
> Peter Smith <smithpb2250@gmail.com>, 26 Tem 2023 Çar, 07:40 tarihinde şunu yazdı:
>>
>> Here are some comments for patch v22-0001.
>>
>> ======
>> 1. General -- naming conventions
>>
>> There is quite a lot of inconsistency with variable/parameter naming
>> styles in this patch. I understand in most cases the names are copied
>> unchanged from the original functions. Still, since this is a big
>> refactor anyway, it can also be a good opportunity to clean up those
>> inconsistencies instead of just propagating them to different places.
>> IIUC, the usual reluctance to rename things because it would cause
>> backpatch difficulties doesn't apply here (since everything is being
>> refactored anyway).
>>
>> E.g. Consider using use snake_case names more consistently in the
>> following places:
>
>
> I can simply change the places you mentioned, that seems okay to me.
> The reason why I did not change the namings in existing variables/functions is because I did (and still do) not get
what'sthe naming conventions in those files. Is snake_case the convention for variables in those files (or in general)?
>
TBH, I also don't know if there is a specific Postgres coding
guideline to use snake_case or not (and Chat-GPT did not know either
when I asked about it). I only assumed snake_case in my previous
review comment because the mentioned vars were already all lowercase.
Anyway, the point was that whatever style is chosen, it ought to be
used *consistently* because having a random mixture of styles in the
same function (e.g. worker_slot, originname, origin_startpos,
myslotname, options, server_version) seems messy. Meanwhile, I think
Amit suggested [1] that for now, we only need to worry about the name
consistency in new code.
>> 2. SetupApplyOrSyncWorker
>>
>> -ApplyWorkerMain(Datum main_arg)
>> +SetupApplyOrSyncWorker(int worker_slot)
>> {
>> - int worker_slot = DatumGetInt32(main_arg);
>> - char originname[NAMEDATALEN];
>> - XLogRecPtr origin_startpos = InvalidXLogRecPtr;
>> - char *myslotname = NULL;
>> - WalRcvStreamOptions options;
>> - int server_version;
>> -
>> - InitializingApplyWorker = true;
>> -
>> /* Attach to slot */
>> logicalrep_worker_attach(worker_slot);
>>
>> + Assert(am_tablesync_worker() || am_leader_apply_worker());
>> +
>>
>> Why is the Assert not the very first statement of this function?
>
>
> I would also prefer to assert in the very beginning but am_tablesync_worker and am_leader_apply_worker require
MyLogicalRepWorkerto be not NULL. And MyLogicalRepWorker is assigned in logicalrep_worker_attach. I can change this if
youthink there is a better way to check the worker type.
>
I see. In that case your Assert LGTM.
------
[1] https://www.postgresql.org/message-id/CAA4eK1%2Bh9hWDAKupsoiw556xqh7uvj_F1pjFJc4jQhL89HdGww%40mail.gmail.com
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi Melih, BACKGROUND ---------- We wanted to compare performance for the 2 different reuse-worker designs, when the apply worker is already busy handling other replications, and then simultaneously the test table tablesyncs are occurring. To test this scenario, some test scripts were written (described below). For comparisons, the scripts were then run using a build of HEAD; design #1 (v21); design #2 (0718). HOW THE TEST WORKS ------------------ Overview: 1. The apply worker is made to subscribe to a 'busy_tbl'. 2. After the SUBSCRIPTION is created, the publisher-side then loops (forever) doing INSERTS into that busy_tbl. 3. While the apply worker is now busy, the subscriber does an ALTER SUBSCRIPTION REFRESH PUBLICATION to subscribe to all the other test tables. 4. We time how long it takes for all tablsyncs to complete 5. Repeat above for different numbers of empty tables (10, 100, 1000, 2000) and different numbers of sync workers (2, 4, 8, 16) Scripts ------- (PSA 4 scripts to implement this logic) testrun script - this does common setup (do_one_test_setup) and then the pub/sub scripts (do_one_test_PUB and do_one_test_SUB -- see below) are run in parallel - repeat 10 times do_one_test_setup script - init and start instances - ipc setup tables and procedures do_one_test_PUB script - ipc setup pub/sub - table setup - publishes the "busy_tbl", but then waits for the subscriber to subscribe to only this one - alters the publication to include all other tables (so subscriber will see these only after the ALTER SUBSCRIPTION PUBLICATION REFRESH) - enter a busy INSERT loop until it informed by the subscriber that the test is finished do_one_test_SUB script - ipc setup pub/sub - table setup - subscribes only to "busy_tbl", then informs the publisher when that is done (this will cause the publisher to commence the stay_busy loop) - after it knows the publishing busy loop has started it does - ALTER SUBSCRIPTION REFRESH PUBLICATION - wait until all the tablesyncs are ready <=== This is the part that is timed for the test RESULT PROBLEM ------- Looking at the output files (e.g. *.dat_PUB and *.dat_SUB) they seem to confirm the tests are working how we wanted. Unfortunately, there is some slot problem for the patched builds (both designs #1 and #2). e.g. Search "ERROR" in the *.log files and see many slot-related errors. Please note - running these same scripts with HEAD build gave no such errors. So it appears to be a patch problem. ------ Kind Regards Peter Smith. Fujitsu Australia
Вложения
On Fri, Jul 28, 2023 at 5:22 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Melih, > > BACKGROUND > ---------- > > We wanted to compare performance for the 2 different reuse-worker > designs, when the apply worker is already busy handling other > replications, and then simultaneously the test table tablesyncs are > occurring. > > To test this scenario, some test scripts were written (described > below). For comparisons, the scripts were then run using a build of > HEAD; design #1 (v21); design #2 (0718). > > HOW THE TEST WORKS > ------------------ > > Overview: > 1. The apply worker is made to subscribe to a 'busy_tbl'. > 2. After the SUBSCRIPTION is created, the publisher-side then loops > (forever) doing INSERTS into that busy_tbl. > 3. While the apply worker is now busy, the subscriber does an ALTER > SUBSCRIPTION REFRESH PUBLICATION to subscribe to all the other test > tables. > 4. We time how long it takes for all tablsyncs to complete > 5. Repeat above for different numbers of empty tables (10, 100, 1000, > 2000) and different numbers of sync workers (2, 4, 8, 16) > > Scripts > ------- > > (PSA 4 scripts to implement this logic) > > testrun script > - this does common setup (do_one_test_setup) and then the pub/sub > scripts (do_one_test_PUB and do_one_test_SUB -- see below) are run in > parallel > - repeat 10 times > > do_one_test_setup script > - init and start instances > - ipc setup tables and procedures > > do_one_test_PUB script > - ipc setup pub/sub > - table setup > - publishes the "busy_tbl", but then waits for the subscriber to > subscribe to only this one > - alters the publication to include all other tables (so subscriber > will see these only after the ALTER SUBSCRIPTION PUBLICATION REFRESH) > - enter a busy INSERT loop until it informed by the subscriber that > the test is finished > > do_one_test_SUB script > - ipc setup pub/sub > - table setup > - subscribes only to "busy_tbl", then informs the publisher when that > is done (this will cause the publisher to commence the stay_busy loop) > - after it knows the publishing busy loop has started it does > - ALTER SUBSCRIPTION REFRESH PUBLICATION > - wait until all the tablesyncs are ready <=== This is the part that > is timed for the test RESULT > > PROBLEM > ------- > > Looking at the output files (e.g. *.dat_PUB and *.dat_SUB) they seem > to confirm the tests are working how we wanted. > > Unfortunately, there is some slot problem for the patched builds (both > designs #1 and #2). e.g. Search "ERROR" in the *.log files and see > many slot-related errors. > > Please note - running these same scripts with HEAD build gave no such > errors. So it appears to be a patch problem. > Hi FYI, here is some more information about ERRORs seen. The patches were re-tested -- applied in stages (and also against the different scripts) to identify where the problem was introduced. Below are the observations: ~~~ Using original test scripts 1. Using only patch v21-0001 - no errors 2. Using only patch v21-0001+0002 - no errors 3. Using patch v21-0001+0002+0003 - no errors ~~~ Using the "busy loop" test scripts for long transactions 1. Using only patch v21-0001 - no errors 2. Using only patch v21-0001+0002 - gives errors for "no copy in progress issue" e.g. ERROR: could not send data to WAL stream: no COPY in progress 3. Using patch v21-0001+0002+0003 - gives the same "no copy in progress issue" errors as above e.g. ERROR: could not send data to WAL stream: no COPY in progress - and also gives slot consistency point errors e.g. ERROR: could not create replication slot "pg_16700_sync_16514_7261998170966054867": ERROR: could not find logical decoding starting point e.g. LOG: could not drop replication slot "pg_16700_sync_16454_7261998170966054867" on publisher: ERROR: replication slot "pg_16700_sync_16454_7261998170966054867" does not exist ------ Kind Regards, Peter Smith. Fujitsu Australia
On Tue, 1 Aug 2023 at 09:44, Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Jul 28, 2023 at 5:22 PM Peter Smith <smithpb2250@gmail.com> wrote: > > > > Hi Melih, > > > > BACKGROUND > > ---------- > > > > We wanted to compare performance for the 2 different reuse-worker > > designs, when the apply worker is already busy handling other > > replications, and then simultaneously the test table tablesyncs are > > occurring. > > > > To test this scenario, some test scripts were written (described > > below). For comparisons, the scripts were then run using a build of > > HEAD; design #1 (v21); design #2 (0718). > > > > HOW THE TEST WORKS > > ------------------ > > > > Overview: > > 1. The apply worker is made to subscribe to a 'busy_tbl'. > > 2. After the SUBSCRIPTION is created, the publisher-side then loops > > (forever) doing INSERTS into that busy_tbl. > > 3. While the apply worker is now busy, the subscriber does an ALTER > > SUBSCRIPTION REFRESH PUBLICATION to subscribe to all the other test > > tables. > > 4. We time how long it takes for all tablsyncs to complete > > 5. Repeat above for different numbers of empty tables (10, 100, 1000, > > 2000) and different numbers of sync workers (2, 4, 8, 16) > > > > Scripts > > ------- > > > > (PSA 4 scripts to implement this logic) > > > > testrun script > > - this does common setup (do_one_test_setup) and then the pub/sub > > scripts (do_one_test_PUB and do_one_test_SUB -- see below) are run in > > parallel > > - repeat 10 times > > > > do_one_test_setup script > > - init and start instances > > - ipc setup tables and procedures > > > > do_one_test_PUB script > > - ipc setup pub/sub > > - table setup > > - publishes the "busy_tbl", but then waits for the subscriber to > > subscribe to only this one > > - alters the publication to include all other tables (so subscriber > > will see these only after the ALTER SUBSCRIPTION PUBLICATION REFRESH) > > - enter a busy INSERT loop until it informed by the subscriber that > > the test is finished > > > > do_one_test_SUB script > > - ipc setup pub/sub > > - table setup > > - subscribes only to "busy_tbl", then informs the publisher when that > > is done (this will cause the publisher to commence the stay_busy loop) > > - after it knows the publishing busy loop has started it does > > - ALTER SUBSCRIPTION REFRESH PUBLICATION > > - wait until all the tablesyncs are ready <=== This is the part that > > is timed for the test RESULT > > > > PROBLEM > > ------- > > > > Looking at the output files (e.g. *.dat_PUB and *.dat_SUB) they seem > > to confirm the tests are working how we wanted. > > > > Unfortunately, there is some slot problem for the patched builds (both > > designs #1 and #2). e.g. Search "ERROR" in the *.log files and see > > many slot-related errors. > > > > Please note - running these same scripts with HEAD build gave no such > > errors. So it appears to be a patch problem. > > > > Hi > > FYI, here is some more information about ERRORs seen. > > The patches were re-tested -- applied in stages (and also against the > different scripts) to identify where the problem was introduced. Below > are the observations: > > ~~~ > > Using original test scripts > > 1. Using only patch v21-0001 > - no errors > > 2. Using only patch v21-0001+0002 > - no errors > > 3. Using patch v21-0001+0002+0003 > - no errors > > ~~~ > > Using the "busy loop" test scripts for long transactions > > 1. Using only patch v21-0001 > - no errors > > 2. Using only patch v21-0001+0002 > - gives errors for "no copy in progress issue" > e.g. ERROR: could not send data to WAL stream: no COPY in progress > > 3. Using patch v21-0001+0002+0003 > - gives the same "no copy in progress issue" errors as above > e.g. ERROR: could not send data to WAL stream: no COPY in progress > - and also gives slot consistency point errors > e.g. ERROR: could not create replication slot > "pg_16700_sync_16514_7261998170966054867": ERROR: could not find > logical decoding starting point > e.g. LOG: could not drop replication slot > "pg_16700_sync_16454_7261998170966054867" on publisher: ERROR: > replication slot "pg_16700_sync_16454_7261998170966054867" does not > exist I agree that "no copy in progress issue" issue has nothing to do with 0001 patch. This issue is present with the 0002 patch. In the case when the tablesync worker has to apply the transactions after the table is synced, the tablesync worker sends the feedback of writepos, applypos and flushpos which results in "No copy in progress" error as the stream has ended already. Fixed it by exiting the streaming loop if the tablesync worker is done with the synchronization. The attached 0004 patch has the changes for the same. The rest of v22 patches are the same patch that were posted by Melih in the earlier mail. Regards, Vignesh
Вложения
On Tue, Aug 1, 2023 at 9:44 AM Peter Smith <smithpb2250@gmail.com> wrote:
>
>
> FYI, here is some more information about ERRORs seen.
>
> The patches were re-tested -- applied in stages (and also against the
> different scripts) to identify where the problem was introduced. Below
> are the observations:
>
> ~~~
>
> Using original test scripts
>
> 1. Using only patch v21-0001
> - no errors
>
> 2. Using only patch v21-0001+0002
> - no errors
>
> 3. Using patch v21-0001+0002+0003
> - no errors
>
> ~~~
>
> Using the "busy loop" test scripts for long transactions
>
> 1. Using only patch v21-0001
> - no errors
>
> 2. Using only patch v21-0001+0002
> - gives errors for "no copy in progress issue"
> e.g. ERROR: could not send data to WAL stream: no COPY in progress
>
> 3. Using patch v21-0001+0002+0003
> - gives the same "no copy in progress issue" errors as above
> e.g. ERROR: could not send data to WAL stream: no COPY in progress
> - and also gives slot consistency point errors
> e.g. ERROR: could not create replication slot
> "pg_16700_sync_16514_7261998170966054867": ERROR: could not find
> logical decoding starting point
> e.g. LOG: could not drop replication slot
> "pg_16700_sync_16454_7261998170966054867" on publisher: ERROR:
> replication slot "pg_16700_sync_16454_7261998170966054867" does not
> exist
>
I think we are getting the error (ERROR: could not find logical
decoding starting point) because we wouldn't have waited for WAL to
become available before reading it. It could happen due to the
following code:
WalSndWaitForWal()
{
...
if (streamingDoneReceiving && streamingDoneSending &&
!pq_is_send_pending())
break;
..
}
Now, it seems that in 0003 patch, instead of resetting flags
streamingDoneSending, and streamingDoneReceiving before start
replication, we should reset before create logical slots because we
need to read the WAL during that time as well to find the consistent
point.
--
With Regards,
Amit Kapila.
Hi,
Amit Kapila <amit.kapila16@gmail.com>, 2 Ağu 2023 Çar, 12:01 tarihinde şunu yazdı:
I think we are getting the error (ERROR: could not find logical
decoding starting point) because we wouldn't have waited for WAL to
become available before reading it. It could happen due to the
following code:
WalSndWaitForWal()
{
...
if (streamingDoneReceiving && streamingDoneSending &&
!pq_is_send_pending())
break;
..
}
Now, it seems that in 0003 patch, instead of resetting flags
streamingDoneSending, and streamingDoneReceiving before start
replication, we should reset before create logical slots because we
need to read the WAL during that time as well to find the consistent
point.
Thanks for the suggestion Amit. I've been looking into this recently and couldn't figure out the cause until now.
I quickly made the fix in 0003. Seems like it resolved the "could not find logical decoding starting point" errors.
vignesh C <vignesh21@gmail.com>, 1 Ağu 2023 Sal, 09:32 tarihinde şunu yazdı:
I agree that "no copy in progress issue" issue has nothing to do with
0001 patch. This issue is present with the 0002 patch.
In the case when the tablesync worker has to apply the transactions
after the table is synced, the tablesync worker sends the feedback of
writepos, applypos and flushpos which results in "No copy in progress"
error as the stream has ended already. Fixed it by exiting the
streaming loop if the tablesync worker is done with the
synchronization. The attached 0004 patch has the changes for the same.
The rest of v22 patches are the same patch that were posted by Melih
in the earlier mail.
Thanks for the fix. I placed it into 0002 with a slight change as follows:
- send_feedback(last_received, false, false);
+ if (!MyLogicalRepWorker->relsync_completed)
+ send_feedback(last_received, false, false);
IMHO relsync_completed means simply the same with streaming_done, that's why I wanted to check that flag instead of an additional goto statement. Does it make sense to you as well?
Thanks,
Melih Mutlu
Microsoft
Вложения
Hi,
PFA an updated version with some of the earlier reviews addressed.
Forgot to include them in the previous email.
Thanks,
-- Melih Mutlu
Microsoft
Вложения
On Wed, Aug 2, 2023 at 4:09 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > PFA an updated version with some of the earlier reviews addressed. > Forgot to include them in the previous email. > It is always better to explicitly tell which reviews are addressed but anyway, I have done some minor cleanup in the 0001 patch including removing includes which didn't seem necessary, modified a few comments, and ran pgindent. I also thought of modifying some variable names based on suggestions by Peter Smith in an email [1] but didn't find many of them any better than the current ones so modified just a few of those. If you guys are okay with this then let's commit it and then we can focus more on the remaining patches. [1] - https://www.postgresql.org/message-id/CAHut%2BPs3Du9JFmhecWY8%2BVFD11VLOkSmB36t_xWHHQJNMpdA-A%40mail.gmail.com -- With Regards, Amit Kapila.
Вложения
On Wed, Aug 2, 2023 at 11:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Aug 2, 2023 at 4:09 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > PFA an updated version with some of the earlier reviews addressed. > > Forgot to include them in the previous email. > > > > It is always better to explicitly tell which reviews are addressed but > anyway, I have done some minor cleanup in the 0001 patch including > removing includes which didn't seem necessary, modified a few > comments, and ran pgindent. I also thought of modifying some variable > names based on suggestions by Peter Smith in an email [1] but didn't > find many of them any better than the current ones so modified just a > few of those. If you guys are okay with this then let's commit it and > then we can focus more on the remaining patches. > I checked the latest patch v25-0001. LGTM. ~~ BTW, I have re-tested many cases of HEAD versus HEAD+v25-0001 (using current test scripts previously mentioned in this thread). Because v25-0001 is only a refactoring patch we expect that the results should be the same as for HEAD, and that is what I observed. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Aug 3, 2023 at 9:35 AM Peter Smith <smithpb2250@gmail.com> wrote: > > On Wed, Aug 2, 2023 at 11:19 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Wed, Aug 2, 2023 at 4:09 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > > > PFA an updated version with some of the earlier reviews addressed. > > > Forgot to include them in the previous email. > > > > > > > It is always better to explicitly tell which reviews are addressed but > > anyway, I have done some minor cleanup in the 0001 patch including > > removing includes which didn't seem necessary, modified a few > > comments, and ran pgindent. I also thought of modifying some variable > > names based on suggestions by Peter Smith in an email [1] but didn't > > find many of them any better than the current ones so modified just a > > few of those. If you guys are okay with this then let's commit it and > > then we can focus more on the remaining patches. > > > > I checked the latest patch v25-0001. > > LGTM. > Thanks, I have pushed 0001. Let's focus on the remaining patches. -- With Regards, Amit Kapila.
Hi Melih, Now that v25-0001 has been pushed, can you please rebase the remaining patches? ------ Kind Regards, Peter Smith. Fujitsu Australia
Just to clarify my previous post, I meant we will need new v26* patches v24-0001 -> not needed because v25-0001 pushed v24-0002 -> v26-0001 v24-0003 -> v26-0002 On Thu, Aug 3, 2023 at 6:19 PM Peter Smith <smithpb2250@gmail.com> wrote: > > Hi Melih, > > Now that v25-0001 has been pushed, can you please rebase the remaining patches? > > ------ > Kind Regards, > Peter Smith. > Fujitsu Australia
Hi,
Amit Kapila <amit.kapila16@gmail.com>, 3 Ağu 2023 Per, 09:22 tarihinde şunu yazdı:
On Thu, Aug 3, 2023 at 9:35 AM Peter Smith <smithpb2250@gmail.com> wrote:
> I checked the latest patch v25-0001.
>
> LGTM.
>
Thanks, I have pushed 0001. Let's focus on the remaining patches.
Thanks!
Peter Smith <smithpb2250@gmail.com>, 3 Ağu 2023 Per, 12:06 tarihinde şunu yazdı:
Just to clarify my previous post, I meant we will need new v26* patches
Right. I attached the v26 as you asked.
Thanks,
Melih Mutlu
Microsoft
Вложения
FWIW, I confirmed that my review comments for v22* have all been addressed in the latest v26* patches. Thanks! ------ Kind Regards, Peter Smith. Fujitsu Australia
Hi Melih. Now that the design#1 ERRORs have been fixed, we returned to doing performance measuring of the design#1 patch versus HEAD. Unfortunately, we observed that under some particular conditions (large transactions of 1000 inserts/tx for a busy apply worker, 100 empty tables to be synced) the performance was worse with the design#1 patch applied. ~~ RESULTS Below are some recent measurements (for 100 empty tables to be synced when apply worker is already busy). We vary the size of the published transaction for the "busy" table, and you can see that for certain large transaction sizes (1000 and 2000 inserts/tx) the design#1 performance was worse than HEAD: ~ The publisher "busy" table does commit every 10 inserts: 2w 4w 8w 16w HEAD 3945 1138 1166 1205 HEAD+v24-0002 3559 886 355 490 %improvement 10% 22% 70% 59% ~ The publisher "busy" table does commit every 100 inserts: 2w 4w 8w 16w HEAD 2363 1357 1354 1355 HEAD+v24-0002 2077 1358 762 756 %improvement 12% 0% 44% 44% ~ Publisher "busy" table does commit every 1000 inserts: 2w 4w 8w 16w HEAD 11898 5855 1868 1631 HEAD+v24-0002 21905 8254 3531 1626 %improvement -84% -41% -89% 0% ^ Note - design#1 was slower than HEAD here ~ Publisher "busy" table does commit every 2000 inserts: 2w 4w 8w 16w HEAD 21740 7109 3454 1703 HEAD+v24-0002 21585 10877 4779 2293 %improvement 1% -53% -38% -35% ^ Note - design#1 was slower than HEAD here ~ The publisher "busy" table does commit every 5000 inserts: 2w 4w 8w 16w HEAD 36094 18105 8595 3567 HEAD+v24-0002 36305 18199 8151 3710 %improvement -1% -1% 5% -4% ~ The publisher "busy" table does commit every 10000 inserts: 2w 4w 8w 16w HEAD 38077 18406 9426 5559 HEAD+v24-0002 36763 18027 8896 4166 %improvement 3% 2% 6% 25% ------ TEST SCRIPTS The "busy apply" test scripts are basically the same as already posted [1], but I have reattached the latest ones again anyway. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPuNVNK2%2BA%2BR6eV8rKPNBHemCFE4NDtEYfpXbYr6SsvvBg%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Вложения
RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
От
"Zhijie Hou (Fujitsu)"
Дата:
On Thursday, August 3, 2023 7:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> Right. I attached the v26 as you asked.
Thanks for posting the patches.
While reviewing the patch, I noticed one rare case that it's possible that there
are two table sync worker for the same table in the same time.
The patch relies on LogicalRepWorkerLock to prevent concurrent access, but the
apply worker will start a new worker after releasing the lock. So, at the point[1]
where the lock is released and the new table sync worker has not been started,
it seems possible that another old table sync worker will be reused for the
same table.
/* Now safe to release the LWLock */
LWLockRelease(LogicalRepWorkerLock);
*[1]
/*
* If there are free sync worker slot(s), start a new sync
* worker for the table.
*/
if (nsyncworkers < max_sync_workers_per_subscription)
...
logicalrep_worker_launch(MyLogicalRepWorker->dbid,
I can reproduce it by using gdb.
Steps:
1. set max_sync_workers_per_subscription to 1 and setup pub/sub which publishes
two tables(table A and B).
2. when the table sync worker for the table A started, use gdb to block it
before being reused for another table.
3. set max_sync_workers_per_subscription to 2 and use gdb to block the apply
worker at the point after releasing the LogicalRepWorkerLock and before
starting another table sync worker for table B.
4. release the blocked table sync worker, then we can see the table sync worker
is also reused for table B.
5. release the apply worker, then we can see the apply worker will start
another table sync worker for the same table(B).
I think it would be better to prevent this case from happening as this case
will give some unexpected ERROR or LOG. Note that I haven't checked if it would
cause worse problems like duplicate copy or others.
Best Regards,
Hou zj
Hi Melih,
Here is a patch to help in getting the execution at various phases
like: a) replication slot creation time, b) Wal reading c) Number of
WAL records read d) subscription relation state change etc
Couple of observation while we tested with this patch:
1) We noticed that the patch takes more time for finding the decoding
start point.
2) Another observation was that the number of XLOG records read for
identify the consistent point was significantly high with the v26_0001
patch.
HEAD
postgres=# select avg(counttime)/1000 "avgtime(ms)",
median(counttime)/1000 "median(ms)", min(counttime)/1000
"mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
group by logtype;
avgtime(ms) | median(ms) | mintime(ms) |
maxtime(ms) | logtype
------------------------+------------------------+-------------+-------------+--------------------------
0.00579245283018867920 | 0.00200000000000000000 | 0 |
1 | SNAPSHOT_BUILD
1.2246811320754717 | 0.98550000000000000000 | 0 |
37 | LOGICAL_SLOT_CREATION
171.0863283018867920 | 183.9120000000000000 | 0 |
408 | FIND_DECODING_STARTPOINT
2.0699433962264151 | 1.4380000000000000 | 1 |
49 | INIT_DECODING_CONTEXT
(4 rows)
HEAD + v26-0001 patch
postgres=# select avg(counttime)/1000 "avgtime(ms)",
median(counttime)/1000 "median(ms)", min(counttime)/1000
"mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
group by logtype;
avgtime(ms) | median(ms) | mintime(ms) |
maxtime(ms) | logtype
------------------------+------------------------+-------------+-------------+--------------------------
0.00588113207547169810 | 0.00500000000000000000 | 0 |
0 | SNAPSHOT_BUILD
1.1270962264150943 | 1.1000000000000000 | 0 |
2 | LOGICAL_SLOT_CREATION
301.1745528301886790 | 410.4870000000000000 | 0 |
427 | FIND_DECODING_STARTPOINT
1.4814660377358491 | 1.4530000000000000 | 1 |
9 | INIT_DECODING_CONTEXT
(4 rows)
In the above FIND_DECODING_STARTPOINT is very much higher with V26-0001 patch.
HEAD
FIND_DECODING_XLOG_RECORD_COUNT
- average = 2762
- median = 3362
HEAD + reuse worker patch(v26_0001 patch)
Where FIND_DECODING_XLOG_RECORD_COUNT
- average = 4105
- median = 5345
Similarly Number of xlog records read is higher with v26_0001 patch.
Steps to calculate the timing:
-- first collect the necessary LOG from subscriber's log.
cat *.log | grep -E
'(LOGICAL_SLOT_CREATION|INIT_DECODING_CONTEXT|FIND_DECODING_STARTPOINT|SNAPSHOT_BUILD|FIND_DECODING_XLOG_RECORD_COUNT|LOGICAL_XLOG_READ|LOGICAL_DECODE_PROCESS_RECORD|LOGICAL_WAIT_TRANSACTION)'
> grep.dat
create table testv26(logtime varchar, pid varchar, level varchar,
space varchar, logtype varchar, counttime int);
-- then copy these datas into db table to count the avg number.
COPY testv26 FROM '/home/logs/grep.dat' DELIMITER ' ';
-- Finally, use the SQL to analyze the data:
select avg(counttime)/1000 "avgtime(ms)", logtype from testv26 group by logtype;
--- To get the number of xlog records read:
select avg(counttime) from testv26 where logtype
='FIND_DECODING_XLOG_RECORD_COUNT' and counttime != 1;
Thanks to Peter and Hou-san who helped in finding these out. We are
parallely analysing this, @Melih Mutlu posting this information so
that it might help you too in analysing this issue.
Regards,
Vignesh
Вложения
On Wed, Aug 9, 2023 at 8:28 AM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > On Thursday, August 3, 2023 7:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > Right. I attached the v26 as you asked. > > Thanks for posting the patches. > > While reviewing the patch, I noticed one rare case that it's possible that there > are two table sync worker for the same table in the same time. > > The patch relies on LogicalRepWorkerLock to prevent concurrent access, but the > apply worker will start a new worker after releasing the lock. So, at the point[1] > where the lock is released and the new table sync worker has not been started, > it seems possible that another old table sync worker will be reused for the > same table. > > /* Now safe to release the LWLock */ > LWLockRelease(LogicalRepWorkerLock); > *[1] > /* > * If there are free sync worker slot(s), start a new sync > * worker for the table. > */ > if (nsyncworkers < max_sync_workers_per_subscription) > ... > logicalrep_worker_launch(MyLogicalRepWorker->dbid, > Yeah, this is a problem. I think one idea to solve this is by extending the lock duration till we launch the tablesync worker but we should also consider changing this locking scheme such that there is a better way to indicate that for a particular rel, tablesync is in progress. Currently, the code in TablesyncWorkerMain() also acquires the lock in exclusive mode even though the tablesync for a rel is in progress which I guess could easily heart us for larger values of max_logical_replication_workers. So, that could be another motivation to think for a different locking scheme. -- With Regards, Amit Kapila.
Hi Melih,
FYI -- The same testing was repeated but this time PG was configured
to say synchronous_commit=on. Other factors and scripts were the same
as before --- busy apply, 5 runs, 4 workers, 1000 inserts/tx, 100
empty tables, etc.
There are still more xlog records seen for the v26 patch, but now the
v26 performance was better than HEAD.
RESULTS (synchronous_commit=on)
---------------------------------------------------
Xlog Counts
HEAD
postgres=# select avg(counttime) "avg", median(counttime) "median",
min(counttime) "min", max(counttime) "max", logtype from test_head
group by logtype;
avg | median | min | max |
logtype
-----------------------+-----------------------+-----+------+-----------
-----------------------+-----------------------+-----+------+-----------
-----------------------+-----------------------+-----+------+-----------
1253.7509433962264151 | 1393.0000000000000000 | 1 | 2012 |
FIND_DECODING_XLOG_RECORD_COUNT
(1 row)
HEAD+v26-0001
postgres=# select avg(counttime) "avg", median(counttime) "median",
min(counttime) "min", max(counttime) "max", logtype from test_v26
group by logtype;
avg | median | min | max |
logtype
-----------------------+-----------------------+-----+------+-----------
-----------------------+-----------------------+-----+------+-----------
-----------------------+-----------------------+-----+------+-----------
1278.4075471698113208 | 1423.5000000000000000 | 1 | 2015 |
FIND_DECODING_XLOG_RECORD_COUNT
(1 row)
~~~~~~
Performance
HEAD
[peter@localhost res_0809_vignesh_timing_sync_head]$ cat *.dat_SUB |
grep RESULT | grep -v duration | awk '{print $3}'
4014.266
3892.089
4195.318
3571.862
4312.183
HEAD+v26-0001
[peter@localhost res_0809_vignesh_timing_sync_v260001]$ cat *.dat_SUB
| grep RESULT | grep -v duration | awk '{print $3}'
3326.627
3213.028
3433.611
3299.803
3258.821
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Hi Peter and Vignesh,
Peter Smith <smithpb2250@gmail.com>, 7 Ağu 2023 Pzt, 09:25 tarihinde şunu yazdı:
Hi Melih.
Now that the design#1 ERRORs have been fixed, we returned to doing
performance measuring of the design#1 patch versus HEAD.
Thanks a lot for taking the time to benchmark the patch. It's really helpful.
Publisher "busy" table does commit every 1000 inserts:
2w 4w 8w 16w
HEAD 11898 5855 1868 1631
HEAD+v24-0002 21905 8254 3531 1626
%improvement -84% -41% -89% 0%
^ Note - design#1 was slower than HEAD here
~
Publisher "busy" table does commit every 2000 inserts:
2w 4w 8w 16w
HEAD 21740 7109 3454 1703
HEAD+v24-0002 21585 10877 4779 2293
%improvement 1% -53% -38% -35%
I assume you meant HEAD+v26-0002 and not v24. I wanted to quickly reproduce these two cases where the patch was significantly worse. Interestingly my results are a bit different than yours.
Publisher "busy" table does commit every 1000 inserts:
2w 4w 8w 16w
HEAD 22405 10335 5008 3304
HEAD+v26 19954 8037 4068 2761
%improvement 1% 2% 2% 1%
2w 4w 8w 16w
HEAD 22405 10335 5008 3304
HEAD+v26 19954 8037 4068 2761
%improvement 1% 2% 2% 1%
Publisher "busy" table does commit every 2000 inserts:
2w 4w 8w 16w
HEAD 33122 14220 7251 4279
HEAD+v26 34248 16213 7356 3914
%improvement 0% -1% 0% 1%
2w 4w 8w 16w
HEAD 33122 14220 7251 4279
HEAD+v26 34248 16213 7356 3914
%improvement 0% -1% 0% 1%
If I'm not doing something wrong in testing (or maybe the patch doesn't perform reliable yet for some reason), I don't see a drastic change in performance. But I guess the patch is supposed to perform better than HEAD in these both cases anyway. right?. I would expect the performance of the patch to converge to HEAD's performance with large tables. But I'm not sure what to expect when apply worker is busy with large transactions.
However, I need to investigate a bit more what Vignesh shared earlier [1]. It makes sense that those issues can cause this problem here.
It just takes a bit of time for me to figure out these things, but I'm working on it.
Thanks,
Melih Mutlu
Microsoft
On Fri, Aug 11, 2023 at 12:54 AM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Hi Peter and Vignesh,
>
> Peter Smith <smithpb2250@gmail.com>, 7 Ağu 2023 Pzt, 09:25 tarihinde şunu yazdı:
>>
>> Hi Melih.
>>
>> Now that the design#1 ERRORs have been fixed, we returned to doing
>> performance measuring of the design#1 patch versus HEAD.
>
>
> Thanks a lot for taking the time to benchmark the patch. It's really helpful.
>
>> Publisher "busy" table does commit every 1000 inserts:
>> 2w 4w 8w 16w
>> HEAD 11898 5855 1868 1631
>> HEAD+v24-0002 21905 8254 3531 1626
>> %improvement -84% -41% -89% 0%
>>
>>
>> ^ Note - design#1 was slower than HEAD here
>>
>>
>> ~
>>
>>
>> Publisher "busy" table does commit every 2000 inserts:
>> 2w 4w 8w 16w
>> HEAD 21740 7109 3454 1703
>> HEAD+v24-0002 21585 10877 4779 2293
>> %improvement 1% -53% -38% -35%
>
>
> I assume you meant HEAD+v26-0002 and not v24. I wanted to quickly reproduce these two cases where the patch was
significantlyworse. Interestingly my results are a bit different than yours.
>
No, I meant what I wrote there. When I ran the tests the HEAD included
the v25-0001 refactoring patch, but v26 did not yet exist.
For now, we are only performance testing the first
"Reuse-Tablesyc-Workers" patch, but not yet including the second patch
("Reuse connection when...").
Note that those "Reuse-Tablesyc-Workers" patches v24-0002 and v26-0001
are equivalent because there are only cosmetic log message differences
between them.
So, my testing was with HEAD+v24-0002 (but not including v24-0003).
Your same testing should be with HEAD+v26-0001 (but not including v26-0002).
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Wed, 9 Aug 2023 at 09:51, vignesh C <vignesh21@gmail.com> wrote:
>
> Hi Melih,
>
> Here is a patch to help in getting the execution at various phases
> like: a) replication slot creation time, b) Wal reading c) Number of
> WAL records read d) subscription relation state change etc
> Couple of observation while we tested with this patch:
> 1) We noticed that the patch takes more time for finding the decoding
> start point.
> 2) Another observation was that the number of XLOG records read for
> identify the consistent point was significantly high with the v26_0001
> patch.
>
> HEAD
> postgres=# select avg(counttime)/1000 "avgtime(ms)",
> median(counttime)/1000 "median(ms)", min(counttime)/1000
> "mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
> group by logtype;
> avgtime(ms) | median(ms) | mintime(ms) |
> maxtime(ms) | logtype
> ------------------------+------------------------+-------------+-------------+--------------------------
> 0.00579245283018867920 | 0.00200000000000000000 | 0 |
> 1 | SNAPSHOT_BUILD
> 1.2246811320754717 | 0.98550000000000000000 | 0 |
> 37 | LOGICAL_SLOT_CREATION
> 171.0863283018867920 | 183.9120000000000000 | 0 |
> 408 | FIND_DECODING_STARTPOINT
> 2.0699433962264151 | 1.4380000000000000 | 1 |
> 49 | INIT_DECODING_CONTEXT
> (4 rows)
>
> HEAD + v26-0001 patch
> postgres=# select avg(counttime)/1000 "avgtime(ms)",
> median(counttime)/1000 "median(ms)", min(counttime)/1000
> "mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
> group by logtype;
> avgtime(ms) | median(ms) | mintime(ms) |
> maxtime(ms) | logtype
> ------------------------+------------------------+-------------+-------------+--------------------------
> 0.00588113207547169810 | 0.00500000000000000000 | 0 |
> 0 | SNAPSHOT_BUILD
> 1.1270962264150943 | 1.1000000000000000 | 0 |
> 2 | LOGICAL_SLOT_CREATION
> 301.1745528301886790 | 410.4870000000000000 | 0 |
> 427 | FIND_DECODING_STARTPOINT
> 1.4814660377358491 | 1.4530000000000000 | 1 |
> 9 | INIT_DECODING_CONTEXT
> (4 rows)
>
> In the above FIND_DECODING_STARTPOINT is very much higher with V26-0001 patch.
>
> HEAD
> FIND_DECODING_XLOG_RECORD_COUNT
> - average = 2762
> - median = 3362
>
> HEAD + reuse worker patch(v26_0001 patch)
> Where FIND_DECODING_XLOG_RECORD_COUNT
> - average = 4105
> - median = 5345
>
> Similarly Number of xlog records read is higher with v26_0001 patch.
>
> Steps to calculate the timing:
> -- first collect the necessary LOG from subscriber's log.
> cat *.log | grep -E
>
'(LOGICAL_SLOT_CREATION|INIT_DECODING_CONTEXT|FIND_DECODING_STARTPOINT|SNAPSHOT_BUILD|FIND_DECODING_XLOG_RECORD_COUNT|LOGICAL_XLOG_READ|LOGICAL_DECODE_PROCESS_RECORD|LOGICAL_WAIT_TRANSACTION)'
> > grep.dat
>
> create table testv26(logtime varchar, pid varchar, level varchar,
> space varchar, logtype varchar, counttime int);
> -- then copy these datas into db table to count the avg number.
> COPY testv26 FROM '/home/logs/grep.dat' DELIMITER ' ';
>
> -- Finally, use the SQL to analyze the data:
> select avg(counttime)/1000 "avgtime(ms)", logtype from testv26 group by logtype;
>
> --- To get the number of xlog records read:
> select avg(counttime) from testv26 where logtype
> ='FIND_DECODING_XLOG_RECORD_COUNT' and counttime != 1;
>
> Thanks to Peter and Hou-san who helped in finding these out. We are
> parallely analysing this, @Melih Mutlu posting this information so
> that it might help you too in analysing this issue.
I analysed further on why it needs to read a larger number of XLOG
records in some cases while creating the replication slot, here are my
thoughts:
Note: Tablesync worker needs to connect to the publisher and create
consistent point for the slots by reading the XLOG records. This
requires that all the open transactions and the transactions that are
created while creating consistent point should be committed.
I feel the creation of slots is better in few cases in Head because:
Publisher | Subscriber
------------------------------------------------------------
Begin txn1 transaction |
Insert 1..1000 records |
Commit |
Begin txn2 transaction |
Insert 1..1000 records | Apply worker applies transaction txn1
| Start tablesync table t2
| create consistent point in
| publisher before transaction txn3 is
| started
commit | We just need to wait till
| transaction txn2 is finished.
Begin txn3 transaction |
Insert 1..1000 records |
commit |
In V26, this is happening in some cases:
Publisher | Subscriber
------------------------------------------------------------
Begin txn1 transaction |
Insert 1..1000 records |
Commit |
Begin txn2 transaction |
Insert 1..1000 records | Apply worker applies transaction txn1
| Start tablesync table t2
commit | Create consistent point
Begin txn3 transaction | (since transaction txn2 is committed
| and txn3 is started, we will
| need to wait
| for transaction txn3 to be
| committed)
Insert 1..1000 records |
commit |
This is because In HEAD the tablesync worker will be started after one
commit, so we are able to create the consistent point before a new
transaction is started in some cases.
Create slot will be fastest if the tablesync worker is able to connect
to the publisher and create a consistent point before the new
transaction is started. The probability of this is better in HEAD for
this scenario as the new tablesync worker is started after commit and
the tablesync worker in HEAD has a better time window(because the
current transaction has just started) before another new transaction
is started. This probability is slightly lower with the V26 version.
I felt this issue is purely a timing issue in a few cases because of
the timing of the new transactions being created while creating the
slot.
Regards,
Vignesh
On Fri, 11 Aug 2023 at 16:26, vignesh C <vignesh21@gmail.com> wrote:
>
> On Wed, 9 Aug 2023 at 09:51, vignesh C <vignesh21@gmail.com> wrote:
> >
> > Hi Melih,
> >
> > Here is a patch to help in getting the execution at various phases
> > like: a) replication slot creation time, b) Wal reading c) Number of
> > WAL records read d) subscription relation state change etc
> > Couple of observation while we tested with this patch:
> > 1) We noticed that the patch takes more time for finding the decoding
> > start point.
> > 2) Another observation was that the number of XLOG records read for
> > identify the consistent point was significantly high with the v26_0001
> > patch.
> >
> > HEAD
> > postgres=# select avg(counttime)/1000 "avgtime(ms)",
> > median(counttime)/1000 "median(ms)", min(counttime)/1000
> > "mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
> > group by logtype;
> > avgtime(ms) | median(ms) | mintime(ms) |
> > maxtime(ms) | logtype
> > ------------------------+------------------------+-------------+-------------+--------------------------
> > 0.00579245283018867920 | 0.00200000000000000000 | 0 |
> > 1 | SNAPSHOT_BUILD
> > 1.2246811320754717 | 0.98550000000000000000 | 0 |
> > 37 | LOGICAL_SLOT_CREATION
> > 171.0863283018867920 | 183.9120000000000000 | 0 |
> > 408 | FIND_DECODING_STARTPOINT
> > 2.0699433962264151 | 1.4380000000000000 | 1 |
> > 49 | INIT_DECODING_CONTEXT
> > (4 rows)
> >
> > HEAD + v26-0001 patch
> > postgres=# select avg(counttime)/1000 "avgtime(ms)",
> > median(counttime)/1000 "median(ms)", min(counttime)/1000
> > "mintime(ms)", max(counttime)/1000 "maxtime(ms)", logtype from test
> > group by logtype;
> > avgtime(ms) | median(ms) | mintime(ms) |
> > maxtime(ms) | logtype
> > ------------------------+------------------------+-------------+-------------+--------------------------
> > 0.00588113207547169810 | 0.00500000000000000000 | 0 |
> > 0 | SNAPSHOT_BUILD
> > 1.1270962264150943 | 1.1000000000000000 | 0 |
> > 2 | LOGICAL_SLOT_CREATION
> > 301.1745528301886790 | 410.4870000000000000 | 0 |
> > 427 | FIND_DECODING_STARTPOINT
> > 1.4814660377358491 | 1.4530000000000000 | 1 |
> > 9 | INIT_DECODING_CONTEXT
> > (4 rows)
> >
> > In the above FIND_DECODING_STARTPOINT is very much higher with V26-0001 patch.
> >
> > HEAD
> > FIND_DECODING_XLOG_RECORD_COUNT
> > - average = 2762
> > - median = 3362
> >
> > HEAD + reuse worker patch(v26_0001 patch)
> > Where FIND_DECODING_XLOG_RECORD_COUNT
> > - average = 4105
> > - median = 5345
> >
> > Similarly Number of xlog records read is higher with v26_0001 patch.
> >
> > Steps to calculate the timing:
> > -- first collect the necessary LOG from subscriber's log.
> > cat *.log | grep -E
> >
'(LOGICAL_SLOT_CREATION|INIT_DECODING_CONTEXT|FIND_DECODING_STARTPOINT|SNAPSHOT_BUILD|FIND_DECODING_XLOG_RECORD_COUNT|LOGICAL_XLOG_READ|LOGICAL_DECODE_PROCESS_RECORD|LOGICAL_WAIT_TRANSACTION)'
> > > grep.dat
> >
> > create table testv26(logtime varchar, pid varchar, level varchar,
> > space varchar, logtype varchar, counttime int);
> > -- then copy these datas into db table to count the avg number.
> > COPY testv26 FROM '/home/logs/grep.dat' DELIMITER ' ';
> >
> > -- Finally, use the SQL to analyze the data:
> > select avg(counttime)/1000 "avgtime(ms)", logtype from testv26 group by logtype;
> >
> > --- To get the number of xlog records read:
> > select avg(counttime) from testv26 where logtype
> > ='FIND_DECODING_XLOG_RECORD_COUNT' and counttime != 1;
> >
> > Thanks to Peter and Hou-san who helped in finding these out. We are
> > parallely analysing this, @Melih Mutlu posting this information so
> > that it might help you too in analysing this issue.
>
> I analysed further on why it needs to read a larger number of XLOG
> records in some cases while creating the replication slot, here are my
> thoughts:
> Note: Tablesync worker needs to connect to the publisher and create
> consistent point for the slots by reading the XLOG records. This
> requires that all the open transactions and the transactions that are
> created while creating consistent point should be committed.
> I feel the creation of slots is better in few cases in Head because:
> Publisher | Subscriber
> ------------------------------------------------------------
> Begin txn1 transaction |
> Insert 1..1000 records |
> Commit |
> Begin txn2 transaction |
> Insert 1..1000 records | Apply worker applies transaction txn1
> | Start tablesync table t2
> | create consistent point in
> | publisher before transaction txn3 is
> | started
> commit | We just need to wait till
> | transaction txn2 is finished.
> Begin txn3 transaction |
> Insert 1..1000 records |
> commit |
>
> In V26, this is happening in some cases:
> Publisher | Subscriber
> ------------------------------------------------------------
> Begin txn1 transaction |
> Insert 1..1000 records |
> Commit |
> Begin txn2 transaction |
> Insert 1..1000 records | Apply worker applies transaction txn1
> | Start tablesync table t2
> commit | Create consistent point
> Begin txn3 transaction | (since transaction txn2 is committed
> | and txn3 is started, we will
> | need to wait
> | for transaction txn3 to be
> | committed)
> Insert 1..1000 records |
> commit |
>
> This is because In HEAD the tablesync worker will be started after one
> commit, so we are able to create the consistent point before a new
> transaction is started in some cases.
> Create slot will be fastest if the tablesync worker is able to connect
> to the publisher and create a consistent point before the new
> transaction is started. The probability of this is better in HEAD for
> this scenario as the new tablesync worker is started after commit and
> the tablesync worker in HEAD has a better time window(because the
> current transaction has just started) before another new transaction
> is started. This probability is slightly lower with the V26 version.
> I felt this issue is purely a timing issue in a few cases because of
> the timing of the new transactions being created while creating the
> slot.
I used the following steps to analyse this issue:
Logs can be captured by applying the patches at [1].
-- first collect the necessary information about from publisher's log
from the execution of HEAD:
cat *.log | grep FIND_DECODING_XLOG_RECORD_COUNT > grep_head.dat
-- first collect the necessary information about from publisher's log
from the execution of v26:
cat *.log | grep FIND_DECODING_XLOG_RECORD_COUNT > grep_v26.dat
-- then copy these datas into HEAD's db table to count the avg number.
COPY test_head FROM '/home/logs/grep_head.dat' DELIMITER ' ';
-- then copy these datas into the v26 db table to count the avg number.
COPY test_v26 FROM '/home/logs/grep_v26.dat' DELIMITER ' ';
Find the average of XLOG records read in HEAD:
postgres=# select avg(counttime) from test_head where logtype
='FIND_DECODING_XLOG_RECORD_COUNT' and counttime != 1;
avg
-----------------------
1394.1100000000000000
(1 row)
Find the average of XLOG records read in V26:
postgres=# select avg(counttime) from test_v26 where logtype
='FIND_DECODING_XLOG_RECORD_COUNT' and counttime != 1;
avg
-----------------------
1900.4100000000000000
(1 row)
When analysing why create replication slot needs to read more records
in a few cases, I found a very interesting observation. I found that
with HEAD about 29% (29 out of 100 tables) of tables could find the
consistent point by reading the WAL records up to the next subsequent
COMMIT, whereas with V26 patch only 5% of tables could find the
consistent point by reading the WAL records up to next subsequent
commit. In these cases V26 patch had to read another transaction of
approximately > 1000 WAL records to reach the consistent point which
results in an increase of average for more records to be read with V26
version. For these I got the start lsn and consistent lsn from the log
files by matching the corresponding FIND_DECODING_XLOG_RECORD_COUNT, I
did a waldump of the WAL file and searched the records between start
lsn and consistent LSN in the WAL dump and confirmed that only one
COMMIT record had to be read to reach the consistent point. Details of
this information from the log of HEAD and V26 is attached.
The number of tables required to read less than 1 commit can be found
by the following:
-- I checked for 1000 WAL records because we are having 1000 inserts
in each transaction.
select count(counttime) from test_head where logtype
='FIND_DECODING_XLOG_RECORD_COUNT' and counttime < 1000;
count
-------
29
(1 row)
select count(counttime) from test_v26 where logtype
='FIND_DECODING_XLOG_RECORD_COUNT' and counttime < 1000;
count
-------
5
(1 row)
Apart from these there were other instances where the V26 had to read
more COMMIT record in few cases.
The above is happening because as mentioned in [2]. i.e. in HEAD the
tablesync worker will be started after one commit, so we are able to
create the consistent point before a new transaction is started in
some cases. Create slot will be fastest if the tablesync worker is
able to connect to the publisher and create a consistent point before
the new transaction is started. The probability of this is better in
HEAD for this scenario as the new tablesync worker is started after
commit and the tablesync worker in HEAD has a better time
window(because the current transaction has just started) before
another new transaction is started. This probability is slightly
lower with the V26 version. I felt this issue is purely a timing issue
in a few cases because of the timing of the new transactions being
created while creating the slot.
Since this is purely a timing issue as explained above in a few cases
because of the timing of the new transactions being created while
creating the slot, I felt we can ignore this.
[1] - https://www.postgresql.org/message-id/CALDaNm1TA068E2niJFUR9ig%2BYz3-ank%3Dj5%3Dj-2UocbzaDnQPrA%40mail.gmail.com
[2] - https://www.postgresql.org/message-id/CALDaNm2k2z3Hpa3Omb_tpxWkyHnUvsWjJMbqDs-2uD2eLzemJQ%40mail.gmail.com
Regards,
Vignesh
Вложения
Hi Peter,
Peter Smith <smithpb2250@gmail.com>, 11 Ağu 2023 Cum, 01:26 tarihinde şunu yazdı:
No, I meant what I wrote there. When I ran the tests the HEAD included
the v25-0001 refactoring patch, but v26 did not yet exist.
For now, we are only performance testing the first
"Reuse-Tablesyc-Workers" patch, but not yet including the second patch
("Reuse connection when...").
Note that those "Reuse-Tablesyc-Workers" patches v24-0002 and v26-0001
are equivalent because there are only cosmetic log message differences
between them.
Ok, that's fair.
So, my testing was with HEAD+v24-0002 (but not including v24-0003).
Your same testing should be with HEAD+v26-0001 (but not including v26-0002).
That's actually what I did. I should have been more clear about what I included in my previous email.With v26-0002, results are noticeably better anyway.
I just rerun the test again against HEAD, HEAD+v26-0001 and additionally HEAD+v26-0001+v26-0002 this time, for better comparison.
Here are my results with the same scripts you shared earlier (I obviously only changed the number of inserts before each commit. ).
Note that this is when synchronous_commit = off.
100 inserts/tx
+-------------+-------+------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+------+------+------+
| v26-0002 | 10421 | 6472 | 6656 | 6566 |
+-------------+-------+------+------+------+
| improvement | 31% | 12% | 0% | 5% |
+-------------+-------+------+------+------+
| v26-0001 | 14585 | 7386 | 7129 | 7274 |
+-------------+-------+------+------+------+
| improvement | 9% | 5% | 12% | 7% |
+-------------+-------+------+------+------+
| HEAD | 16130 | 7785 | 8147 | 7827 |
+-------------+-------+------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+------+------+------+
| v26-0002 | 10421 | 6472 | 6656 | 6566 |
+-------------+-------+------+------+------+
| improvement | 31% | 12% | 0% | 5% |
+-------------+-------+------+------+------+
| v26-0001 | 14585 | 7386 | 7129 | 7274 |
+-------------+-------+------+------+------+
| improvement | 9% | 5% | 12% | 7% |
+-------------+-------+------+------+------+
| HEAD | 16130 | 7785 | 8147 | 7827 |
+-------------+-------+------+------+------+
1000 inserts/tx
+-------------+-------+------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+------+------+------+
| v26-0002 | 13796 | 6848 | 5942 | 6315 |
+-------------+-------+------+------+------+
| improvement | 9% | 7% | 10% | 8% |
+-------------+-------+------+------+------+
| v26-0001 | 14685 | 7325 | 6675 | 6719 |
+-------------+-------+------+------+------+
| improvement | 3% | 0% | 0% | 2% |
+-------------+-------+------+------+------+
| HEAD | 15118 | 7354 | 6644 | 6890 |
+-------------+-------+------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+------+------+------+
| v26-0002 | 13796 | 6848 | 5942 | 6315 |
+-------------+-------+------+------+------+
| improvement | 9% | 7% | 10% | 8% |
+-------------+-------+------+------+------+
| v26-0001 | 14685 | 7325 | 6675 | 6719 |
+-------------+-------+------+------+------+
| improvement | 3% | 0% | 0% | 2% |
+-------------+-------+------+------+------+
| HEAD | 15118 | 7354 | 6644 | 6890 |
+-------------+-------+------+------+------+
2000 inserts/tx
+-------------+-------+-------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+-------+------+------+
| v26-0002 | 22442 | 9944 | 6034 | 5829 |
+-------------+-------+-------+------+------+
| improvement | 5% | 2% | 4% | 10% |
+-------------+-------+-------+------+------+
| v26-0001 | 23632 | 10164 | 6311 | 6480 |
+-------------+-------+-------+------+------+
| improvement | 0% | 0% | 0% | 0% |
+-------------+-------+-------+------+------+
| HEAD | 23667 | 10157 | 6285 | 6470 |
+-------------+-------+-------+------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+-------+------+------+
| v26-0002 | 22442 | 9944 | 6034 | 5829 |
+-------------+-------+-------+------+------+
| improvement | 5% | 2% | 4% | 10% |
+-------------+-------+-------+------+------+
| v26-0001 | 23632 | 10164 | 6311 | 6480 |
+-------------+-------+-------+------+------+
| improvement | 0% | 0% | 0% | 0% |
+-------------+-------+-------+------+------+
| HEAD | 23667 | 10157 | 6285 | 6470 |
+-------------+-------+-------+------+------+
5000 inserts/tx
+-------------+-------+-------+-------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+-------+-------+------+
| v26-0002 | 41443 | 21385 | 10832 | 6146 |
+-------------+-------+-------+-------+------+
| improvement | 0% | 0% | 1% | 16% |
+-------------+-------+-------+-------+------+
| v26-0001 | 41293 | 21226 | 10814 | 6158 |
+-------------+-------+-------+-------+------+
| improvement | 0% | 1% | 1% | 15% |
+-------------+-------+-------+-------+------+
| HEAD | 41503 | 21466 | 10943 | 7292 |
+-------------+-------+-------+-------+------+
| | 2w | 4w | 8w | 16w |
+-------------+-------+-------+-------+------+
| v26-0002 | 41443 | 21385 | 10832 | 6146 |
+-------------+-------+-------+-------+------+
| improvement | 0% | 0% | 1% | 16% |
+-------------+-------+-------+-------+------+
| v26-0001 | 41293 | 21226 | 10814 | 6158 |
+-------------+-------+-------+-------+------+
| improvement | 0% | 1% | 1% | 15% |
+-------------+-------+-------+-------+------+
| HEAD | 41503 | 21466 | 10943 | 7292 |
+-------------+-------+-------+-------+------+
Again, I couldn't reproduce the cases where you saw significantly degraded performance. I wonder if I'm missing something. Did you do anything not included in the test scripts you shared? Do you think v26-0001 will perform 84% worse than HEAD, if you try again? I just want to be sure that it was not a random thing.
Interestingly, I also don't see an improvement in above results as big as in your results when inserts/tx ratio is smaller. Even though it certainly is improved in such cases.
Thanks,
Melih Mutlu
Microsoft
On Fri, Aug 11, 2023 at 7:15 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Peter Smith <smithpb2250@gmail.com>, 11 Ağu 2023 Cum, 01:26 tarihinde şunu yazdı:
>>
>> No, I meant what I wrote there. When I ran the tests the HEAD included
>> the v25-0001 refactoring patch, but v26 did not yet exist.
>>
>> For now, we are only performance testing the first
>> "Reuse-Tablesyc-Workers" patch, but not yet including the second patch
>> ("Reuse connection when...").
>>
>> Note that those "Reuse-Tablesyc-Workers" patches v24-0002 and v26-0001
>> are equivalent because there are only cosmetic log message differences
>> between them.
>
>
> Ok, that's fair.
>
>
>>
>> So, my testing was with HEAD+v24-0002 (but not including v24-0003).
>> Your same testing should be with HEAD+v26-0001 (but not including v26-0002).
>
>
> That's actually what I did. I should have been more clear about what I included in my previous email.With v26-0002,
resultsare noticeably better anyway.
> I just rerun the test again against HEAD, HEAD+v26-0001 and additionally HEAD+v26-0001+v26-0002 this time, for better
comparison.
>
> Here are my results with the same scripts you shared earlier (I obviously only changed the number of inserts before
eachcommit. ).
> Note that this is when synchronous_commit = off.
>
> 100 inserts/tx
> +-------------+-------+------+------+------+
> | | 2w | 4w | 8w | 16w |
> +-------------+-------+------+------+------+
> | v26-0002 | 10421 | 6472 | 6656 | 6566 |
> +-------------+-------+------+------+------+
> | improvement | 31% | 12% | 0% | 5% |
> +-------------+-------+------+------+------+
> | v26-0001 | 14585 | 7386 | 7129 | 7274 |
> +-------------+-------+------+------+------+
> | improvement | 9% | 5% | 12% | 7% |
> +-------------+-------+------+------+------+
> | HEAD | 16130 | 7785 | 8147 | 7827 |
> +-------------+-------+------+------+------+
>
> 1000 inserts/tx
> +-------------+-------+------+------+------+
> | | 2w | 4w | 8w | 16w |
> +-------------+-------+------+------+------+
> | v26-0002 | 13796 | 6848 | 5942 | 6315 |
> +-------------+-------+------+------+------+
> | improvement | 9% | 7% | 10% | 8% |
> +-------------+-------+------+------+------+
> | v26-0001 | 14685 | 7325 | 6675 | 6719 |
> +-------------+-------+------+------+------+
> | improvement | 3% | 0% | 0% | 2% |
> +-------------+-------+------+------+------+
> | HEAD | 15118 | 7354 | 6644 | 6890 |
> +-------------+-------+------+------+------+
>
> 2000 inserts/tx
> +-------------+-------+-------+------+------+
> | | 2w | 4w | 8w | 16w |
> +-------------+-------+-------+------+------+
> | v26-0002 | 22442 | 9944 | 6034 | 5829 |
> +-------------+-------+-------+------+------+
> | improvement | 5% | 2% | 4% | 10% |
> +-------------+-------+-------+------+------+
> | v26-0001 | 23632 | 10164 | 6311 | 6480 |
> +-------------+-------+-------+------+------+
> | improvement | 0% | 0% | 0% | 0% |
> +-------------+-------+-------+------+------+
> | HEAD | 23667 | 10157 | 6285 | 6470 |
> +-------------+-------+-------+------+------+
>
> 5000 inserts/tx
> +-------------+-------+-------+-------+------+
> | | 2w | 4w | 8w | 16w |
> +-------------+-------+-------+-------+------+
> | v26-0002 | 41443 | 21385 | 10832 | 6146 |
> +-------------+-------+-------+-------+------+
> | improvement | 0% | 0% | 1% | 16% |
> +-------------+-------+-------+-------+------+
> | v26-0001 | 41293 | 21226 | 10814 | 6158 |
> +-------------+-------+-------+-------+------+
> | improvement | 0% | 1% | 1% | 15% |
> +-------------+-------+-------+-------+------+
> | HEAD | 41503 | 21466 | 10943 | 7292 |
> +-------------+-------+-------+-------+------+
>
>
> Again, I couldn't reproduce the cases where you saw significantly degraded performance.
>
I am not surprised to see that you don't see regression because as per
Vignesh's analysis, this is purely a timing issue where sometimes
after the patch the slot creation can take more time because there is
a constant inflow of transactions on the publisher. I think we are
seeing it because this workload is predominantly just creating and
destroying slots. We can probably improve it later as discussed
earlier by using a single for multiple copies (especially for small
tables) or something like that.
--
With Regards,
Amit Kapila.
On Thu, Aug 10, 2023 at 10:15 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Aug 9, 2023 at 8:28 AM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > On Thursday, August 3, 2023 7:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > > Right. I attached the v26 as you asked. > > > > Thanks for posting the patches. > > > > While reviewing the patch, I noticed one rare case that it's possible that there > > are two table sync worker for the same table in the same time. > > > > The patch relies on LogicalRepWorkerLock to prevent concurrent access, but the > > apply worker will start a new worker after releasing the lock. So, at the point[1] > > where the lock is released and the new table sync worker has not been started, > > it seems possible that another old table sync worker will be reused for the > > same table. > > > > /* Now safe to release the LWLock */ > > LWLockRelease(LogicalRepWorkerLock); > > *[1] > > /* > > * If there are free sync worker slot(s), start a new sync > > * worker for the table. > > */ > > if (nsyncworkers < max_sync_workers_per_subscription) > > ... > > logicalrep_worker_launch(MyLogicalRepWorker->dbid, > > > > Yeah, this is a problem. I think one idea to solve this is by > extending the lock duration till we launch the tablesync worker but we > should also consider changing this locking scheme such that there is a > better way to indicate that for a particular rel, tablesync is in > progress. Currently, the code in TablesyncWorkerMain() also acquires > the lock in exclusive mode even though the tablesync for a rel is in > progress which I guess could easily heart us for larger values of > max_logical_replication_workers. So, that could be another motivation > to think for a different locking scheme. > Yet another problem is that currently apply worker maintains a hash table for 'last_start_times' to avoid restarting the tablesync worker immediately upon error. The same functionality is missing while reusing the table sync worker. One possibility is to use a shared hash table to remember start times but I think it may depend on what we decide to solve the previous problem reported by Hou-San. -- With Regards, Amit Kapila.
On Thu, 10 Aug 2023 at 10:16, Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Aug 9, 2023 at 8:28 AM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > On Thursday, August 3, 2023 7:30 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote: > > > > > Right. I attached the v26 as you asked. > > > > Thanks for posting the patches. > > > > While reviewing the patch, I noticed one rare case that it's possible that there > > are two table sync worker for the same table in the same time. > > > > The patch relies on LogicalRepWorkerLock to prevent concurrent access, but the > > apply worker will start a new worker after releasing the lock. So, at the point[1] > > where the lock is released and the new table sync worker has not been started, > > it seems possible that another old table sync worker will be reused for the > > same table. > > > > /* Now safe to release the LWLock */ > > LWLockRelease(LogicalRepWorkerLock); > > *[1] > > /* > > * If there are free sync worker slot(s), start a new sync > > * worker for the table. > > */ > > if (nsyncworkers < max_sync_workers_per_subscription) > > ... > > logicalrep_worker_launch(MyLogicalRepWorker->dbid, > > > > Yeah, this is a problem. I think one idea to solve this is by > extending the lock duration till we launch the tablesync worker but we > should also consider changing this locking scheme such that there is a > better way to indicate that for a particular rel, tablesync is in > progress. Currently, the code in TablesyncWorkerMain() also acquires > the lock in exclusive mode even though the tablesync for a rel is in > progress which I guess could easily heart us for larger values of > max_logical_replication_workers. So, that could be another motivation > to think for a different locking scheme. There are couple of ways in which this issue can be solved: Approach #1) check that the reuse worker has not picked up this table for table sync from logicalrep_worker_launch while holding a lock on LogicalRepWorkerLock, if the reuse worker has already picked it up for processing, simply ignore it and return, nothing has to be done by the launcher in this case. Approach #2) a) Applyworker to create a shared memory of all the relations that need to be synced, b) tablesync worker to take a lock on this shared memory and pick the next table to be processed(tablesync worker need not get the subscription relations again and again) c) tablesync worker to update the status in shared memory for the relation(since the lock is held there will be no concurrency issues), also mark the start time in the shared memory, this will help in not to restart the failed table before wal_retrieve_retry_interval has expired d) tablesync worker to sync the table e) subscription relation will be marked as ready and the tablesync worker to remove the entry from shared memory f) Applyworker will periodically synchronize the shared memory relations to keep it in sync with the fetched subscription relation tables g) when apply worker exits, the shared memory will be cleared. Approach #2) will also help in solving the other issue reported by Amit at [1]. I felt we can use Approach #2 to solve the problem as it solves both the reported issues and also there is an added advantage where the re-use table sync worker need not scan the pg_subscription_rel to get the non-ready table for every run, instead we can use the list prepared by apply worker. Thoughts? [1] - https://www.postgresql.org/message-id/CAA4eK1KyHfVOVeio28p8CHDnuyKuej78cj_7U9mHAB4ictVQwQ%40mail.gmail.com Regards, Vignesh
Here is another review comment about patch v26-0001.
The tablesync worker processes include the 'relid' as part of their
name. See launcher.c:
snprintf(bgw.bgw_name, BGW_MAXLEN,
"logical replication tablesync worker for subscription %u sync %u",
subid,
relid);
~~
And if that worker is "reused" by v26-0001 to process another relation
there is a LOG
if (reuse_worker)
ereport(LOG,
errmsg("logical replication table synchronization worker for
subscription \"%s\" will be reused to sync table \"%s\" with relid
%u.",
MySubscription->name,
get_rel_name(MyLogicalRepWorker->relid),
MyLogicalRepWorker->relid));
AFAICT, when being "reused" the original process name remains
unchanged, and so I think it will continue to appear to any user
looking at it that the tablesync process is just taking a very long
time handling the original 'relid'.
Won't the stale process name cause confusion to the users?
------
Kind Regards,
Peter Smith.
Fujitsu Australia
On Fri, Aug 11, 2023 at 11:45 PM Melih Mutlu <m.melihmutlu@gmail.com> wrote:
>
> Again, I couldn't reproduce the cases where you saw significantly degraded performance. I wonder if I'm missing
something.Did you do anything not included in the test scripts you shared? Do you think v26-0001 will perform 84% worse
thanHEAD, if you try again? I just want to be sure that it was not a random thing.
> Interestingly, I also don't see an improvement in above results as big as in your results when inserts/tx ratio is
smaller.Even though it certainly is improved in such cases.
>
TEST ENVIRONMENTS
I am running the tests on a high-spec machine:
-- NOTE: Nobody else is using this machine during our testing, so
there are no unexpected influences messing up the results.
Linix
Architecture: x86_64
CPU(s): 120
Thread(s) per core: 2
Core(s) per socket: 15
total used free shared buff/cache available
Mem: 755G 5.7G 737G 49M 12G 748G
Swap: 4.0G 0B 4.0G
~~~
The results I am seeing are not random. HEAD+v26-0001 is consistently
worse than HEAD but only for some settings. With these settings, I see
bad results (i.e. worse than HEAD) consistently every time using the
dedicated test machine.
Hou-san also reproduced bad results using a different high-spec machine
Vignesh also reproduced bad results using just his laptop but in his
case, it did *not* occur every time. As discussed elsewhere the
problem is timing-related, so sometimes you may be lucky and sometimes
not.
~
I expect you are running everything correctly, but if you are using
just a laptop (like Vignesh) then like him you might need to try
multiple times before you can hit the problem happening in your
environment.
Anyway, in case there is some other reason you are not seeing the bad
results I have re-attached scripts and re-described every step below.
======
BUILDING
-- NOTE: I have a very minimal configuration without any
optimization/debug flags etc. See config.log
$ ./configure --prefix=/home/peter/pg_oss
-- NOTE: Of course, make sure to be running using the correct Postgres:
echo 'set environment variables for OSS work'
export PATH=/home/peter/pg_oss/bin:$PATH
-- NOTE: Be sure to do git stash or whatever so don't accidentally
build a patched version thinking it is the HEAD version
-- NOTE: Be sure to do a full clean build and apply (or don't apply
v26-0001) according to the test you wish to run.
STEPS
1. sudo make clean
2. make
3. sudo make install
======
SCRIPTS & STEPS
SCRIPTS
testrun.sh
do_one_test_setup.sh
do_one_test_PUB.sh
do_one_test_SUB.sh
---
STEPS
Step-1. Edit the testrun.sh
tables=( 100 )
workers=( 2 4 8 16 )
size="0"
prefix="0816headbusy" <-- edit to differentiate each test run
~
Step-2. Edit the do_one_test_PUB.sh
IF commit_counter = 1000 THEN <-- edit this if needed. I wanted 1000
inserts/tx so nothing to do
~
Step-3: Check nothing else is running. If yes, then clean it up
[peter@localhost testing_busy]$ ps -eaf | grep postgres
peter 111924 100103 0 19:31 pts/0 00:00:00 grep --color=auto postgres
~
Step-4: Run the tests
[peter@localhost testing_busy]$ ./testrun.sh
num_tables=100, size=0, num_workers=2, run #1 <-- check the echo
matched the config you set in the Setp-1
waiting for server to shut down.... done
server stopped
waiting for server to shut down.... done
server stopped
num_tables=100, size=0, num_workers=2, run #2
waiting for server to shut down.... done
server stopped
waiting for server to shut down.... done
server stopped
num_tables=100, size=0, num_workers=2, run #3
...
~
Step-5: Sanity check
When the test completes the current folder will be full of .log and .dat* files.
Check for sanity that no errors happened
[peter@localhost testing_busy]$ cat *.log | grep ERROR
[peter@localhost testing_busy]$
~
Step-6: Collect the results
The results are output (by the do_one_test_SUB.sh) into the *.dat_SUB files
Use grep to extract them
[peter@localhost testing_busy]$ cat 0816headbusy_100t_0_2w_*.dat_SUB |
grep RESULT | grep -v duration | awk '{print $3}'
11742.019
12157.355
11773.807
11582.981
12220.962
12546.325
12210.713
12614.892
12015.489
13527.05
Repeat grep for other files:
$ cat 0816headbusy_100t_0_4w_*.dat_SUB | grep RESULT | grep -v
duration | awk '{print $3}'
$ cat 0816headbusy_100t_0_8w_*.dat_SUB | grep RESULT | grep -v
duration | awk '{print $3}'
$ cat 0816headbusy_100t_0_16w_*.dat_SUB | grep RESULT | grep -v
duration | awk '{print $3}'
~
Step-7: Summarise the results
Now I just cut/paste the results from Step-6 into a spreadsheet and
report the median of the runs.
For example, for the above HEAD run, it was:
2w 4w 8w 16w
1 11742 5996 1919 1582
2 12157 5960 1871 1469
3 11774 5926 2101 1571
4 11583 6155 1883 1671
5 12221 6310 1895 1707
6 12546 6166 1900 1470
7 12211 6114 2477 1587
8 12615 6173 2610 1715
9 12015 5869 2110 1673
10 13527 5913 2144 1227
Median 12184 6055 2010 1584
~
Step-8: REPEAT
-- repeat all above for different size transactions (editing do_one_test_PUB.sh)
-- repeat all above after rebuilding again with HEAD+v26-0001
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Вложения
Hi Melih,
Last week we revisited your implementation of design#2. Vignesh rebased it, and then made a few other changes.
PSA v28*
The patch changes include:
* changed the logic slightly by setting recv_immediately(new variable), if this variable is set the main apply worker loop will not wait in this case.
* setting the relation state to ready immediately if there are no more incremental changes to be synced.
* receive the incremental changes if applicable and set the relation state to ready without waiting.
* reuse the worker if the worker is free before trying to start a new table sync worker
* restarting the tablesync worker only after wal_retrieve_retry_interval
~
FWIW, we just wanted to share with you the performance measurements seen using this design#2 patch set:
======
RESULTS (not busy tests)
------
10 empty tables
2w 4w 8w 16w
HEAD: 125 119 140 133
HEAD+v28*: 92 93 123 134
%improvement: 27% 22% 12% -1%
------
100 empty tables
2w 4w 8w 16w
HEAD: 1037 843 1109 1155
HEAD+v28*: 591 625 2616 2569
%improvement: 43% 26% -136% -122%
------
1000 empty tables
2w 4w 8w 16w
HEAD: 15874 10047 9919 10338
HEAD+v28*: 33673 12199 9094 9896
%improvement: -112% -21% 8% 4%
------
2000 empty tables
2w 4w 8w 16w
HEAD: 45266 24216 19395 19820
HEAD+v28*: 88043 21550 21668 22607
%improvement: -95% 11% -12% -14%
~~~
Note - the results were varying quite a lot in comparison to the HEAD
e.g. HEAD results are very consistent, but the v28* results observed are not
HEAD 1000 (2w): 15861, 15777, 16007, 15950, 15886, 15740, 15846, 15740, 15908, 15940
v28* 1000 (2w): 34214, 13679, 8792, 33289, 31976, 56071, 57042, 56163, 34058, 11969
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Last week we revisited your implementation of design#2. Vignesh rebased it, and then made a few other changes.
PSA v28*
The patch changes include:
* changed the logic slightly by setting recv_immediately(new variable), if this variable is set the main apply worker loop will not wait in this case.
* setting the relation state to ready immediately if there are no more incremental changes to be synced.
* receive the incremental changes if applicable and set the relation state to ready without waiting.
* reuse the worker if the worker is free before trying to start a new table sync worker
* restarting the tablesync worker only after wal_retrieve_retry_interval
~
FWIW, we just wanted to share with you the performance measurements seen using this design#2 patch set:
======
RESULTS (not busy tests)
------
10 empty tables
2w 4w 8w 16w
HEAD: 125 119 140 133
HEAD+v28*: 92 93 123 134
%improvement: 27% 22% 12% -1%
------
100 empty tables
2w 4w 8w 16w
HEAD: 1037 843 1109 1155
HEAD+v28*: 591 625 2616 2569
%improvement: 43% 26% -136% -122%
------
1000 empty tables
2w 4w 8w 16w
HEAD: 15874 10047 9919 10338
HEAD+v28*: 33673 12199 9094 9896
%improvement: -112% -21% 8% 4%
------
2000 empty tables
2w 4w 8w 16w
HEAD: 45266 24216 19395 19820
HEAD+v28*: 88043 21550 21668 22607
%improvement: -95% 11% -12% -14%
~~~
Note - the results were varying quite a lot in comparison to the HEAD
e.g. HEAD results are very consistent, but the v28* results observed are not
HEAD 1000 (2w): 15861, 15777, 16007, 15950, 15886, 15740, 15846, 15740, 15908, 15940
v28* 1000 (2w): 34214, 13679, 8792, 33289, 31976, 56071, 57042, 56163, 34058, 11969
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Oops - now with attachments
On Mon, Aug 21, 2023 at 5:56 PM Peter Smith <smithpb2250@gmail.com> wrote:
Hi Melih,
Last week we revisited your implementation of design#2. Vignesh rebased it, and then made a few other changes.
PSA v28*
The patch changes include:
* changed the logic slightly by setting recv_immediately(new variable), if this variable is set the main apply worker loop will not wait in this case.
* setting the relation state to ready immediately if there are no more incremental changes to be synced.
* receive the incremental changes if applicable and set the relation state to ready without waiting.
* reuse the worker if the worker is free before trying to start a new table sync worker
* restarting the tablesync worker only after wal_retrieve_retry_interval
~
FWIW, we just wanted to share with you the performance measurements seen using this design#2 patch set:
======
RESULTS (not busy tests)
------
10 empty tables
2w 4w 8w 16w
HEAD: 125 119 140 133
HEAD+v28*: 92 93 123 134
%improvement: 27% 22% 12% -1%
------
100 empty tables
2w 4w 8w 16w
HEAD: 1037 843 1109 1155
HEAD+v28*: 591 625 2616 2569
%improvement: 43% 26% -136% -122%
------
1000 empty tables
2w 4w 8w 16w
HEAD: 15874 10047 9919 10338
HEAD+v28*: 33673 12199 9094 9896
%improvement: -112% -21% 8% 4%
------
2000 empty tables
2w 4w 8w 16w
HEAD: 45266 24216 19395 19820
HEAD+v28*: 88043 21550 21668 22607
%improvement: -95% 11% -12% -14%
~~~
Note - the results were varying quite a lot in comparison to the HEAD
e.g. HEAD results are very consistent, but the v28* results observed are not
HEAD 1000 (2w): 15861, 15777, 16007, 15950, 15886, 15740, 15846, 15740, 15908, 15940
v28* 1000 (2w): 34214, 13679, 8792, 33289, 31976, 56071, 57042, 56163, 34058, 11969
------
Kind Regards,
Peter Smith.
Fujitsu Australia
Вложения
Hi, This patch is not applying on the HEAD. Please rebase and share the updated patch. Thanks and Regards Shlok Kyal On Wed, 10 Jan 2024 at 14:55, Peter Smith <smithpb2250@gmail.com> wrote: > > Oops - now with attachments > > On Mon, Aug 21, 2023 at 5:56 PM Peter Smith <smithpb2250@gmail.com> wrote: >> >> Hi Melih, >> >> Last week we revisited your implementation of design#2. Vignesh rebased it, and then made a few other changes. >> >> PSA v28* >> >> The patch changes include: >> * changed the logic slightly by setting recv_immediately(new variable), if this variable is set the main apply workerloop will not wait in this case. >> * setting the relation state to ready immediately if there are no more incremental changes to be synced. >> * receive the incremental changes if applicable and set the relation state to ready without waiting. >> * reuse the worker if the worker is free before trying to start a new table sync worker >> * restarting the tablesync worker only after wal_retrieve_retry_interval >> >> ~ >> >> FWIW, we just wanted to share with you the performance measurements seen using this design#2 patch set: >> >> ====== >> >> RESULTS (not busy tests) >> >> ------ >> 10 empty tables >> 2w 4w 8w 16w >> HEAD: 125 119 140 133 >> HEAD+v28*: 92 93 123 134 >> %improvement: 27% 22% 12% -1% >> ------ >> 100 empty tables >> 2w 4w 8w 16w >> HEAD: 1037 843 1109 1155 >> HEAD+v28*: 591 625 2616 2569 >> %improvement: 43% 26% -136% -122% >> ------ >> 1000 empty tables >> 2w 4w 8w 16w >> HEAD: 15874 10047 9919 10338 >> HEAD+v28*: 33673 12199 9094 9896 >> %improvement: -112% -21% 8% 4% >> ------ >> 2000 empty tables >> 2w 4w 8w 16w >> HEAD: 45266 24216 19395 19820 >> HEAD+v28*: 88043 21550 21668 22607 >> %improvement: -95% 11% -12% -14% >> >> ~~~ >> >> Note - the results were varying quite a lot in comparison to the HEAD >> e.g. HEAD results are very consistent, but the v28* results observed are not >> HEAD 1000 (2w): 15861, 15777, 16007, 15950, 15886, 15740, 15846, 15740, 15908, 15940 >> v28* 1000 (2w): 34214, 13679, 8792, 33289, 31976, 56071, 57042, 56163, 34058, 11969 >> >> ------ >> Kind Regards, >> Peter Smith. >> Fujitsu Australia
On Wed, Jan 10, 2024 at 2:59 PM Shlok Kyal <shlok.kyal.oss@gmail.com> wrote: > > This patch is not applying on the HEAD. Please rebase and share the > updated patch. > IIRC, there were some regressions observed with this patch. So, one needs to analyze those as well. I think we should mark it as "Returned with feedback". -- With Regards, Amit Kapila.
On Wed, 10 Jan 2024 at 15:04, Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Wed, Jan 10, 2024 at 2:59 PM Shlok Kyal <shlok.kyal.oss@gmail.com> wrote: > > > > This patch is not applying on the HEAD. Please rebase and share the > > updated patch. > > > > IIRC, there were some regressions observed with this patch. So, one > needs to analyze those as well. I think we should mark it as "Returned > with feedback". Thanks, I have updated the status to "Returned with feedback". Feel free to post an updated version with the fix for the regression and start a new entry for the same. Regards, Vignesh