Обсуждение: Update with last known location?
Dear all, I have a large table of data which has about 75,000 people's locations per minute of the day for a 24 hour period. The columns are: ppid (person ID) point_time (timestamp) the_geom (geometry point) My problem is that some (alot) of the info from the location (the_geom) column is missing. This column needs updating with the last known location of the person. The attached screenshot explains a bit better than I am managing too in writing. In the attached image, the_geom column from 14:41 to 14:51 would be updated with the data from the 14:40. I'm struggling conceptually as to how to do this. Some sort of self-join on the table I think. But how to get the right data for the update? Does anyone have any clever ideas? Thanks JDS
Вложения
{kind=link}
--As of January 27, 2014 1:02:05 PM +0000, James David Smith is alleged to have said: > ppid (person ID) > point_time (timestamp) > the_geom (geometry point) > > My problem is that some (alot) of the info from the location > (the_geom) column is missing. This column needs updating with the last > known location of the person. The attached screenshot explains a bit > better than I am managing too in writing. In the attached image, > the_geom column from 14:41 to 14:51 would be updated with the data > from the 14:40. > > I'm struggling conceptually as to how to do this. Some sort of > self-join on the table I think. But how to get the right data for the > update? > > Does anyone have any clever ideas? --As for the rest, it is mine. Is this a one-time thing, or something ongoing? If this is something you need regularly, I'd write in a trigger or something to fill in the location at record creation. (And I'd probably write a program to go through and fill in the locations on historic data, if needed.) Anyway, the select for the data is probably something along the lines of: SELECT the_geom FROM table WHERE ppid = current_ppid AND point_time < current_time ORDER BY point_time DESC NULLS LAST LIMIT 1; Daniel T. Staal --------------------------------------------------------------- This email copyright the author. Unless otherwise noted, you are expressly allowed to retransmit, quote, or otherwise use the contents for non-commercial purposes. This copyright will expire 5 years after the author's death, or in 30 years, whichever is longer, unless such a period is in excess of local copyright law. ---------------------------------------------------------------
On 27 January 2014 19:26, Daniel Staal <DStaal@usa.net> wrote: > --As of January 27, 2014 1:02:05 PM +0000, James David Smith is alleged to > have said: > >> ppid (person ID) >> point_time (timestamp) >> the_geom (geometry point) >> >> My problem is that some (alot) of the info from the location >> (the_geom) column is missing. This column needs updating with the last >> known location of the person. The attached screenshot explains a bit >> better than I am managing too in writing. In the attached image, >> the_geom column from 14:41 to 14:51 would be updated with the data >> from the 14:40. >> >> I'm struggling conceptually as to how to do this. Some sort of >> self-join on the table I think. But how to get the right data for the >> update? >> >> Does anyone have any clever ideas? > > > --As for the rest, it is mine. > > Is this a one-time thing, or something ongoing? If this is something you > need regularly, I'd write in a trigger or something to fill in the location > at record creation. (And I'd probably write a program to go through and > fill in the locations on historic data, if needed.) > > Anyway, the select for the data is probably something along the lines of: > > SELECT the_geom FROM table WHERE ppid = current_ppid AND point_time < > current_time ORDER BY point_time DESC NULLS LAST LIMIT 1; > > Daniel T. Staal Hi Daniel, This is a one-time thing. I'm afraid the select you wrote above doesn't do what I need it to do. Maybe I didn't explain my issue well enough. I was playing around a bit yesterday and thought maybe I need to do some sort of loop. In pseudo-code it would work something like this: 1) Order the table by ppid and then point_time 2) Iterate through the table. 3) When you come to a row that has a blank 'the_geom' column, take 'the_geom' from the row above and copy it to this row, but only if they have the same ppid. 4) Move to the next row i.e. keep iterating through the table. 5) Repeat 3 as necessary. What do you think? I've not done much with LOOPS in postgreSQL. I'm going to do some reading today and see if I can figure it out! Thanks James
On 28 January 2014 10:42, James David Smith <james.david.smith@gmail.com> wrote:
> On 27 January 2014 19:26, Daniel Staal <DStaal@usa.net> wrote:
>> --As of January 27, 2014 1:02:05 PM +0000, James David Smith is alleged to
>> have said:
>>
>>> ppid (person ID)
>>> point_time (timestamp)
>>> the_geom (geometry point)
>>>
>>> My problem is that some (alot) of the info from the location
>>> (the_geom) column is missing. This column needs updating with the last
>>> known location of the person. The attached screenshot explains a bit
>>> better than I am managing too in writing. In the attached image,
>>> the_geom column from 14:41 to 14:51 would be updated with the data
>>> from the 14:40.
>>>
>>> I'm struggling conceptually as to how to do this. Some sort of
>>> self-join on the table I think. But how to get the right data for the
>>> update?
>>>
>>> Does anyone have any clever ideas?
>>
>>
>> --As for the rest, it is mine.
>>
>> Is this a one-time thing, or something ongoing? If this is something you
>> need regularly, I'd write in a trigger or something to fill in the location
>> at record creation. (And I'd probably write a program to go through and
>> fill in the locations on historic data, if needed.)
>>
>> Anyway, the select for the data is probably something along the lines of:
>>
>> SELECT the_geom FROM table WHERE ppid = current_ppid AND point_time <
>> current_time ORDER BY point_time DESC NULLS LAST LIMIT 1;
>>
>> Daniel T. Staal
>
> Hi Daniel,
>
> This is a one-time thing.
>
> I'm afraid the select you wrote above doesn't do what I need it to do.
> Maybe I didn't explain my issue well enough.
>
> I was playing around a bit yesterday and thought maybe I need to do
> some sort of loop. In pseudo-code it would work something like this:
>
> 1) Order the table by ppid and then point_time
> 2) Iterate through the table.
> 3) When you come to a row that has a blank 'the_geom' column, take
> 'the_geom' from the row above and copy it to this row, but only if
> they have the same ppid.
> 4) Move to the next row i.e. keep iterating through the table.
> 5) Repeat 3 as necessary.
>
> What do you think? I've not done much with LOOPS in postgreSQL. I'm
> going to do some reading today and see if I can figure it out!
>
> Thanks
>
> James
Hi,
Bad form to reply to oneself I guess, but hey ho. I've been working on
trying to do this in a LOOP, but haven't managed to get it to work.
But I thought that posting my progress so far might help people
understand what I'm trying to do.
DROP TABLE test;
-- Create a table which is a join on itself. The join is offset by one minute .
CREATE TABLE test AS (SELECT a.ppid as a_ppid, a.point_time as
a_point_time, a.the_geom as a_the_geom, b.ppid as b_ppid, b.point_time
as b_point_time, b.the_geom as b_the_geom FROM hybrid_location a LEFT
JOIN hybrid_location b ON a.ppid = b.ppid AND a.point_time =
b.point_time + INTERVAL '1 MINUTE' ORDER BY a.ppid, a_point_time);
---Now create a function which is going to go through this table row
by row, and copy the data from b_the_geom to a_the_geom IF a_the_geom
is null.
DROP FUNCTION update_locations();
CREATE FUNCTION update_locations() RETURNS integer AS $$
DECLARE
mviews RECORD;
BEGIN
FOR mviews IN SELECT a_the_geom, b_the_geom FROM test ORDER BY
a_ppid, a_point_time LOOP
-- Now "mviews" has one record from the above query.
EXECUTE 'UPDATE test SET a_the_geom = ' || b_the_geom || '
WHERE a_the_geom IS NULL AND WHERE a_ppid = ' ||
quote_literal(b_ppid);
END LOOP;
RETURN 1;
END;
$$ LANGUAGE plpgsql;
SELECT update_locations();
So this doesn't work, but maybe it shows what I'm trying to do?
Thanks
James
--As of January 28, 2014 10:42:45 AM +0000, James David Smith is alleged to have said: > This is a one-time thing. > > I'm afraid the select you wrote above doesn't do what I need it to do. > Maybe I didn't explain my issue well enough. > > I was playing around a bit yesterday and thought maybe I need to do > some sort of loop. In pseudo-code it would work something like this: > > 1) Order the table by ppid and then point_time > 2) Iterate through the table. > 3) When you come to a row that has a blank 'the_geom' column, take > 'the_geom' from the row above and copy it to this row, but only if > they have the same ppid. > 4) Move to the next row i.e. keep iterating through the table. > 5) Repeat 3 as necessary. > > What do you think? I've not done much with LOOPS in postgreSQL. I'm > going to do some reading today and see if I can figure it out! --As for the rest, it is mine. If it's strictly a one-time thing, I personally would write it in Perl, not SQL. ;) (Or whatever your scripting language of choice is.) Which would allow you to change step 3 to 'If the_geom is blank, take stored recent value for ppid and fill, then insert back into database. Else, overwrite the_geom for this ppid.' (A bit less convoluted than yours, and avoids the problems with multiple nulls in a row, as well as allowing you to only sort by point_time.) Daniel T. Staal --------------------------------------------------------------- This email copyright the author. Unless otherwise noted, you are expressly allowed to retransmit, quote, or otherwise use the contents for non-commercial purposes. This copyright will expire 5 years after the author's death, or in 30 years, whichever is longer, unless such a period is in excess of local copyright law. ---------------------------------------------------------------
On 28 January 2014 16:57, Daniel Staal <DStaal@usa.net> wrote: > --As of January 28, 2014 10:42:45 AM +0000, James David Smith is alleged to > have said: > >> This is a one-time thing. >> >> I'm afraid the select you wrote above doesn't do what I need it to do. >> Maybe I didn't explain my issue well enough. >> >> I was playing around a bit yesterday and thought maybe I need to do >> some sort of loop. In pseudo-code it would work something like this: >> >> 1) Order the table by ppid and then point_time >> 2) Iterate through the table. >> 3) When you come to a row that has a blank 'the_geom' column, take >> 'the_geom' from the row above and copy it to this row, but only if >> they have the same ppid. >> 4) Move to the next row i.e. keep iterating through the table. >> 5) Repeat 3 as necessary. >> >> What do you think? I've not done much with LOOPS in postgreSQL. I'm >> going to do some reading today and see if I can figure it out! > > > --As for the rest, it is mine. > > If it's strictly a one-time thing, I personally would write it in Perl, not > SQL. ;) (Or whatever your scripting language of choice is.) > > Which would allow you to change step 3 to 'If the_geom is blank, take stored > recent value for ppid and fill, then insert back into database. Else, > overwrite the_geom for this ppid.' (A bit less convoluted than yours, and > avoids the problems with multiple nulls in a row, as well as allowing you to > only sort by point_time.) > > > Daniel T. Staal Hi Daniel, Given the data is so large I don't want to be taking the data out to a CSV or whatever and then loading it back in. I'd like to do this within the database using SQL. I thought I would be able to do this using a LOOP to be honest. Thanks for your thoughts anyway. James
--As of January 28, 2014 5:07:16 PM +0000, James David Smith is alleged to have said: >> If it's strictly a one-time thing, I personally would write it in Perl, >> not SQL. ;) (Or whatever your scripting language of choice is.) >> >> Which would allow you to change step 3 to 'If the_geom is blank, take >> stored recent value for ppid and fill, then insert back into database. >> Else, overwrite the_geom for this ppid.' (A bit less convoluted than >> yours, and avoids the problems with multiple nulls in a row, as well as >> allowing you to only sort by point_time.) >> >> >> Daniel T. Staal > > Hi Daniel, > > Given the data is so large I don't want to be taking the data out to a > CSV or whatever and then loading it back in. I'd like to do this > within the database using SQL. I thought I would be able to do this > using a LOOP to be honest. --As for the rest, it is mine. I haven't played with LOOP, it might be able to do what you need. But I'm not saying pull the data into a CSV or anything: Perl's DBI has the ability to iterate over a result set, pulling each value out of the database as needed. I'm sure other scripting languages have something similar. Daniel T. Staal --------------------------------------------------------------- This email copyright the author. Unless otherwise noted, you are expressly allowed to retransmit, quote, or otherwise use the contents for non-commercial purposes. This copyright will expire 5 years after the author's death, or in 30 years, whichever is longer, unless such a period is in excess of local copyright law. ---------------------------------------------------------------
On 28 January 2014 16:57, Daniel Staal <DStaal@usa.net> wrote:
> --As of January 28, 2014 10:42:45 AM +0000, James David Smith is alleged to
> have said:
>
>> This is a one-time thing.
>>
>> I'm afraid the select you wrote above doesn't do what I need it to do.
>> Maybe I didn't explain my issue well enough.
>>
>> I was playing around a bit yesterday and thought maybe I need to do
>> some sort of loop. In pseudo-code it would work something like this:
>>
>> 1) Order the table by ppid and then point_time
>> 2) Iterate through the table.
>> 3) When you come to a row that has a blank 'the_geom' column, take
>> 'the_geom' from the row above and copy it to this row, but only if
>> they have the same ppid.
>> 4) Move to the next row i.e. keep iterating through the table.
>> 5) Repeat 3 as necessary.
>>
>> What do you think? I've not done much with LOOPS in postgreSQL. I'm
>> going to do some reading today and see if I can figure it out!
>
>
> --As for the rest, it is mine.
>
> If it's strictly a one-time thing, I personally would write it in Perl, not
> SQL. ;) (Or whatever your scripting language of choice is.)
>
> Which would allow you to change step 3 to 'If the_geom is blank, take stored
> recent value for ppid and fill, then insert back into database. Else,
> overwrite the_geom for this ppid.' (A bit less convoluted than yours, and
> avoids the problems with multiple nulls in a row, as well as allowing you to
> only sort by point_time.)
>
>
> Daniel T. Staal
Hi Daniel,
Given the data is so large I don't want to be taking the data out to a
CSV or whatever and then loading it back in. I'd like to do this
within the database using SQL. I thought I would be able to do this
using a LOOP to be honest.
Thanks for your thoughts anyway.
James
--
Sent via pgsql-novice mailing list (pgsql-novice@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-novice
James David Smith <james.david.smith@gmail.com> wrote: > Given the data is so large I don't want to be taking the data out > to a CSV or whatever and then loading it back in. I'd like to do > this within the database using SQL. I thought I would be able to > do this using a LOOP to be honest. I would be amazed if you couldn't do this with a single UPDATE statement. I've generally found declarative forms of such work to be at least one order of magnitude faster than going to either a PL or a script approach. I would start by putting together a SELECT query using window functions and maybe a CTE or two to list all the primary keys which need updating and the new values they should have. Once that SELECT was looking good, I would put it in the FROM clause of an UPDATE statement. That should work, but if you are updating a large percentage of the table, I would go one step further before running this against the production tables. I would put a LIMIT on the above-mentioned SELECT of something like 10000 rows, and script a loop that alternates between the UPDATE and a VACUUM ANALYZE on the table. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 29/01/14 11:00, Kevin Grittner wrote: > James David Smith <james.david.smith@gmail.com> wrote: > >> Given the data is so large I don't want to be taking the data out >> to a CSV or whatever and then loading it back in. I'd like to do >> this within the database using SQL. I thought I would be able to >> do this using a LOOP to be honest. > I would be amazed if you couldn't do this with a single UPDATE > statement. I've generally found declarative forms of such work to > be at least one order of magnitude faster than going to either a PL > or a script approach. I would start by putting together a SELECT > query using window functions and maybe a CTE or two to list all the > primary keys which need updating and the new values they should > have. Once that SELECT was looking good, I would put it in the > FROM clause of an UPDATE statement. > > That should work, but if you are updating a large percentage of the > table, I would go one step further before running this against the > production tables. I would put a LIMIT on the above-mentioned > SELECT of something like 10000 rows, and script a loop that > alternates between the UPDATE and a VACUUM ANALYZE on the table. > > -- > Kevin Grittner > EDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company > > James, you might consider dropping as many indexes on the table as you safely can, and rebuilding them after the mass update. If you have lots of such indexes, you will find this apprtoach to be a lot faster. Cheers, Gavin
On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz> wrote: > On 29/01/14 11:00, Kevin Grittner wrote: >> >> James David Smith <james.david.smith@gmail.com> wrote: >> >>> Given the data is so large I don't want to be taking the data out >>> to a CSV or whatever and then loading it back in. I'd like to do >>> this within the database using SQL. I thought I would be able to >>> do this using a LOOP to be honest. >> >> I would be amazed if you couldn't do this with a single UPDATE >> statement. I've generally found declarative forms of such work to >> be at least one order of magnitude faster than going to either a PL >> or a script approach. I would start by putting together a SELECT >> query using window functions and maybe a CTE or two to list all the >> primary keys which need updating and the new values they should >> have. Once that SELECT was looking good, I would put it in the >> FROM clause of an UPDATE statement. >> >> That should work, but if you are updating a large percentage of the >> table, I would go one step further before running this against the >> production tables. I would put a LIMIT on the above-mentioned >> SELECT of something like 10000 rows, and script a loop that >> alternates between the UPDATE and a VACUUM ANALYZE on the table. >> >> -- >> Kevin Grittner >> EDB: http://www.enterprisedb.com >> The Enterprise PostgreSQL Company >> >> > James, you might consider dropping as many indexes on the table as you > safely can, and rebuilding them after the mass update. If you have lots of > such indexes, you will find this apprtoach to be a lot faster. > > > Cheers, > Gavin Hi all, Thanks for your help and assistance. I think that window functions, and inparticular the PARTITION function, is 100% the way to go. I've been concentrating on a SELECT statement for now and am close but not quite close enough. The below query gets all the data I want, but *too* much. What I've essentially done is: - Select all the rows that don't have any geom information - Join them with all rows before this point that *do* have geom information. - Before doing this join, use partition to generate row numbers. The attached screen grab shows the result of my query below. Unfortunately this is generating alot of joins that I don't want. This won't be practical when doing it with 75,000 people. Thoughts and code suggestions very much appreciated... if needed I could put together some SQL to create an example table? Thanks SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY test.point_time) as test_row, test.ppid as test_ppid, test.point_time as test_point_time, test.the_geom as test_the_geom, a.ppid as a_ppid, a.point_time as a_point_time, a.the_geom as a_the_geom, a.a_row FROM test LEFT JOIN ( SELECT the_geom, ppid, point_time, row_number() OVER (ORDER BY ppid, point_time) as a_row FROM test WHERE the_geom IS NOT NULL) a ON a.point_time < test.point_time AND a.ppid = test.ppid WHERE test.the_geom IS NULL ORDER BY test.point_time)
Вложения
{kind=link}
I would try partitioning the second time you call row_number, perhaps by ID, and then selecting the MAX() from that, since I think the too much data you're referring to is coming from the right side of your join.
On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz> wrote:
> On 29/01/14 11:00, Kevin Grittner wrote:
>>
>> James David Smith <james.david.smith@gmail.com> wrote:
>>
>>> Given the data is so large I don't want to be taking the data out
>>> to a CSV or whatever and then loading it back in. I'd like to do
>>> this within the database using SQL. I thought I would be able to
>>> do this using a LOOP to be honest.
>>
>> I would be amazed if you couldn't do this with a single UPDATE
>> statement. I've generally found declarative forms of such work to
>> be at least one order of magnitude faster than going to either a PL
>> or a script approach. I would start by putting together a SELECT
>> query using window functions and maybe a CTE or two to list all the
>> primary keys which need updating and the new values they should
>> have. Once that SELECT was looking good, I would put it in the
>> FROM clause of an UPDATE statement.
>>
>> That should work, but if you are updating a large percentage of the
>> table, I would go one step further before running this against the
>> production tables. I would put a LIMIT on the above-mentioned
>> SELECT of something like 10000 rows, and script a loop that
>> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>>
>> --
>> Kevin Grittner
>> EDB: http://www.enterprisedb.com
>> The Enterprise PostgreSQL Company
>>
>>
> James, you might consider dropping as many indexes on the table as you
> safely can, and rebuilding them after the mass update. If you have lots of
> such indexes, you will find this apprtoach to be a lot faster.
>
>
> Cheers,
> Gavin
Hi all,
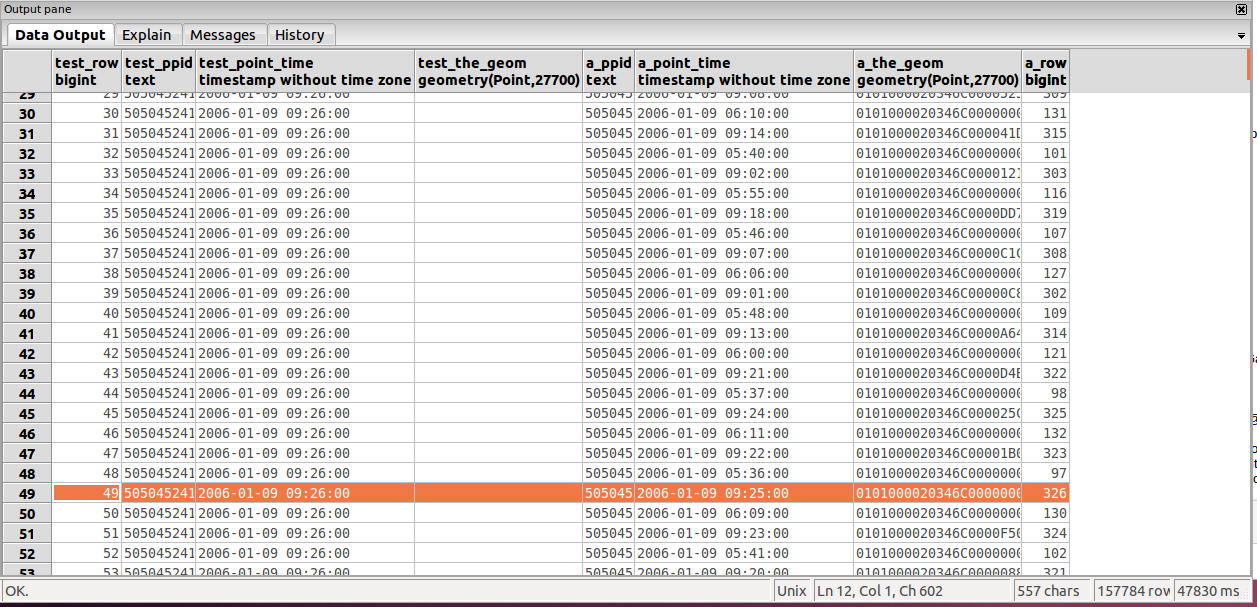
Thanks for your help and assistance. I think that window functions,
and inparticular the PARTITION function, is 100% the way to go. I've
been concentrating on a SELECT statement for now and am close but not
quite close enough. The below query gets all the data I want, but
*too* much. What I've essentially done is:
- Select all the rows that don't have any geom information
- Join them with all rows before this point that *do* have geom information.
- Before doing this join, use partition to generate row numbers.
The attached screen grab shows the result of my query below.
Unfortunately this is generating alot of joins that I don't want. This
won't be practical when doing it with 75,000 people.
Thoughts and code suggestions very much appreciated... if needed I
could put together some SQL to create an example table?
Thanks
SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
test.point_time) as test_row,
test.ppid as test_ppid,
test.point_time as test_point_time,
test.the_geom as test_the_geom,
a.ppid as a_ppid,
a.point_time as a_point_time,
a.the_geom as a_the_geom,
a.a_row
FROM test
LEFT JOIN (
SELECT the_geom,
ppid,
point_time,
row_number() OVER (ORDER BY ppid, point_time) as a_row
FROM test
WHERE the_geom IS NOT NULL) a
ON a.point_time < test.point_time
AND a.ppid = test.ppid
WHERE test.the_geom IS NULL
ORDER BY test.point_time)
--
Sent via pgsql-novice mailing list (pgsql-novice@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-novice
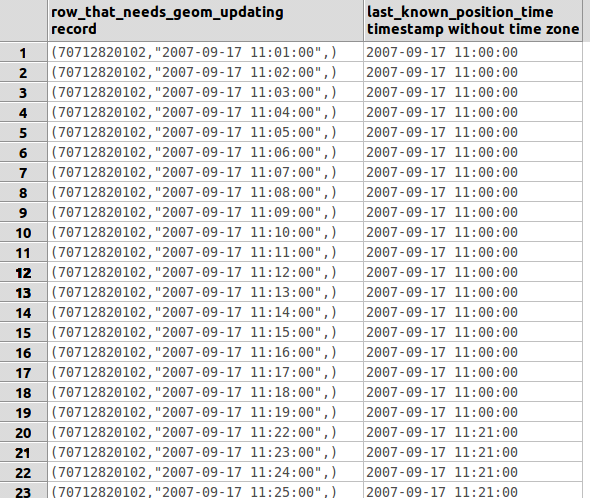
Hi Erik/all, I just tried that, but it's tricky. The 'extra' data is indeed coming from the right side of the join, but it's hard to select only the max from it. Maybe it's possible but I've not managed to do it. Here is where I am, which is so very close. SELECT DISTINCT(a.ppid, a.point_time, a.the_geom) as row_that_needs_geom_updating, max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as last_known_position_time FROM test a INNER JOIN (SELECT ppid, point_time, the_geom FROM test WHERE the_geom IS NOT NULL) b ON b.point_time < a.point_time AND a.ppid = b.ppid WHERE a.the_geom IS NULL; If you see attached screen-print, the output is the rows that I want. However I've had to use DISTINCT to stop the duplication. Also I've not managed to pull through 'the_geom' from the JOIN. I'm not sure how. Anyone? But it's kind of working. :-) Worst case if I can't figure out how to solve this in one query I'll have to store the result of the above, and then use it as a basis for another query I think. Thanks James On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote: > I would try partitioning the second time you call row_number, perhaps by ID, > and then selecting the MAX() from that, since I think the too much data > you're referring to is coming from the right side of your join. > > On Jan 29, 2014 7:23 AM, "James David Smith" <james.david.smith@gmail.com> > wrote: >> >> On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz> >> wrote: >> > On 29/01/14 11:00, Kevin Grittner wrote: >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote: >> >> >> >>> Given the data is so large I don't want to be taking the data out >> >>> to a CSV or whatever and then loading it back in. I'd like to do >> >>> this within the database using SQL. I thought I would be able to >> >>> do this using a LOOP to be honest. >> >> >> >> I would be amazed if you couldn't do this with a single UPDATE >> >> statement. I've generally found declarative forms of such work to >> >> be at least one order of magnitude faster than going to either a PL >> >> or a script approach. I would start by putting together a SELECT >> >> query using window functions and maybe a CTE or two to list all the >> >> primary keys which need updating and the new values they should >> >> have. Once that SELECT was looking good, I would put it in the >> >> FROM clause of an UPDATE statement. >> >> >> >> That should work, but if you are updating a large percentage of the >> >> table, I would go one step further before running this against the >> >> production tables. I would put a LIMIT on the above-mentioned >> >> SELECT of something like 10000 rows, and script a loop that >> >> alternates between the UPDATE and a VACUUM ANALYZE on the table. >> >> >> >> -- >> >> Kevin Grittner >> >> EDB: http://www.enterprisedb.com >> >> The Enterprise PostgreSQL Company >> >> >> >> >> > James, you might consider dropping as many indexes on the table as you >> > safely can, and rebuilding them after the mass update. If you have lots >> > of >> > such indexes, you will find this apprtoach to be a lot faster. >> > >> > >> > Cheers, >> > Gavin >> >> Hi all, >> >> Thanks for your help and assistance. I think that window functions, >> and inparticular the PARTITION function, is 100% the way to go. I've >> been concentrating on a SELECT statement for now and am close but not >> quite close enough. The below query gets all the data I want, but >> *too* much. What I've essentially done is: >> >> - Select all the rows that don't have any geom information >> - Join them with all rows before this point that *do* have geom >> information. >> - Before doing this join, use partition to generate row numbers. >> >> The attached screen grab shows the result of my query below. >> Unfortunately this is generating alot of joins that I don't want. This >> won't be practical when doing it with 75,000 people. >> >> Thoughts and code suggestions very much appreciated... if needed I >> could put together some SQL to create an example table? >> >> Thanks >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY >> test.point_time) as test_row, >> test.ppid as test_ppid, >> test.point_time as test_point_time, >> test.the_geom as test_the_geom, >> a.ppid as a_ppid, >> a.point_time as a_point_time, >> a.the_geom as a_the_geom, >> a.a_row >> FROM test >> LEFT JOIN ( >> SELECT the_geom, >> ppid, >> point_time, >> row_number() OVER (ORDER BY ppid, point_time) as a_row >> FROM test >> WHERE the_geom IS NOT NULL) a >> ON a.point_time < test.point_time >> AND a.ppid = test.ppid >> WHERE test.the_geom IS NULL >> ORDER BY test.point_time) >> >> >> -- >> Sent via pgsql-novice mailing list (pgsql-novice@postgresql.org) >> To make changes to your subscription: >> http://www.postgresql.org/mailpref/pgsql-novice >> >
Вложения
{kind=link}
Hi Erik/all,
I just tried that, but it's tricky. The 'extra' data is indeed coming
from the right side of the join, but it's hard to select only the max
from it. Maybe it's possible but I've not managed to do it. Here is
where I am, which is so very close.
SELECT
DISTINCT(a.ppid, a.point_time, a.the_geom) as row_that_needs_geom_updating,
max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
last_known_position_time
FROM
test a
INNER JOIN
(SELECT ppid,
point_time,
the_geom
FROM test
WHERE the_geom IS NOT NULL) b
ON b.point_time < a.point_time
AND a.ppid = b.ppid
WHERE a.the_geom IS NULL;
If you see attached screen-print, the output is the rows that I want.
However I've had to use DISTINCT to stop the duplication. Also I've
not managed to pull through 'the_geom' from the JOIN. I'm not sure
how. Anyone?
But it's kind of working. :-)
Worst case if I can't figure out how to solve this in one query I'll
have to store the result of the above, and then use it as a basis for
another query I think.
Thanks
James
On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
> I would try partitioning the second time you call row_number, perhaps by ID,
> and then selecting the MAX() from that, since I think the too much data
> you're referring to is coming from the right side of your join.
>
> On Jan 29, 2014 7:23 AM, "James David Smith" <james.david.smith@gmail.com>
> wrote:
>>
>> On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz>
>> wrote:
>> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >>
>> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >>
>> >>> Given the data is so large I don't want to be taking the data out
>> >>> to a CSV or whatever and then loading it back in. I'd like to do
>> >>> this within the database using SQL. I thought I would be able to
>> >>> do this using a LOOP to be honest.
>> >>
>> >> I would be amazed if you couldn't do this with a single UPDATE
>> >> statement. I've generally found declarative forms of such work to
>> >> be at least one order of magnitude faster than going to either a PL
>> >> or a script approach. I would start by putting together a SELECT
>> >> query using window functions and maybe a CTE or two to list all the
>> >> primary keys which need updating and the new values they should
>> >> have. Once that SELECT was looking good, I would put it in the
>> >> FROM clause of an UPDATE statement.
>> >>
>> >> That should work, but if you are updating a large percentage of the
>> >> table, I would go one step further before running this against the
>> >> production tables. I would put a LIMIT on the above-mentioned
>> >> SELECT of something like 10000 rows, and script a loop that
>> >> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>> >>
>> >> --
>> >> Kevin Grittner
>> >> EDB: http://www.enterprisedb.com
>> >> The Enterprise PostgreSQL Company
>> >>
>> >>
>> > James, you might consider dropping as many indexes on the table as you
>> > safely can, and rebuilding them after the mass update. If you have lots
>> > of
>> > such indexes, you will find this apprtoach to be a lot faster.
>> >
>> >
>> > Cheers,
>> > Gavin
>>
>> Hi all,
>>
>> Thanks for your help and assistance. I think that window functions,
>> and inparticular the PARTITION function, is 100% the way to go. I've
>> been concentrating on a SELECT statement for now and am close but not
>> quite close enough. The below query gets all the data I want, but
>> *too* much. What I've essentially done is:
>>
>> - Select all the rows that don't have any geom information
>> - Join them with all rows before this point that *do* have geom
>> information.
>> - Before doing this join, use partition to generate row numbers.
>>
>> The attached screen grab shows the result of my query below.
>> Unfortunately this is generating alot of joins that I don't want. This
>> won't be practical when doing it with 75,000 people.
>>
>> Thoughts and code suggestions very much appreciated... if needed I
>> could put together some SQL to create an example table?
>>
>> Thanks
>>
>> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
>> test.point_time) as test_row,
>> test.ppid as test_ppid,
>> test.point_time as test_point_time,
>> test.the_geom as test_the_geom,
>> a.ppid as a_ppid,
>> a.point_time as a_point_time,
>> a.the_geom as a_the_geom,
>> a.a_row
>> FROM test
>> LEFT JOIN (
>> SELECT the_geom,
>> ppid,
>> point_time,
>> row_number() OVER (ORDER BY ppid, point_time) as a_row
>> FROM test
>> WHERE the_geom IS NOT NULL) a
>> ON a.point_time < test.point_time
>> AND a.ppid = test.ppid
>> WHERE test.the_geom IS NULL
>> ORDER BY test.point_time)
>>
>>
>> --
>> Sent via pgsql-novice mailing list (pgsql-novice@postgresql.org)
>> To make changes to your subscription:
>> http://www.postgresql.org/mailpref/pgsql-novice
>>
>
On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote: > I would re-suggest using a CTE to contain each dataset to ensure your > selects are distilling them correctly, and then using a final query to join > them. You can then either update your data directly through the CTE(s), or > insert the results to another table to do some further testing. I think > you'll find this method presents the data a bit more ergonomically for > analysis. > > http://www.postgresql.org/docs/9.3/static/queries-with.html > > > > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith > <james.david.smith@gmail.com> wrote: >> >> Hi Erik/all, >> >> I just tried that, but it's tricky. The 'extra' data is indeed coming >> from the right side of the join, but it's hard to select only the max >> from it. Maybe it's possible but I've not managed to do it. Here is >> where I am, which is so very close. >> >> SELECT >> DISTINCT(a.ppid, a.point_time, a.the_geom) as >> row_that_needs_geom_updating, >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as >> last_known_position_time >> FROM >> test a >> INNER JOIN >> (SELECT ppid, >> point_time, >> the_geom >> FROM test >> WHERE the_geom IS NOT NULL) b >> ON b.point_time < a.point_time >> AND a.ppid = b.ppid >> WHERE a.the_geom IS NULL; >> >> If you see attached screen-print, the output is the rows that I want. >> However I've had to use DISTINCT to stop the duplication. Also I've >> not managed to pull through 'the_geom' from the JOIN. I'm not sure >> how. Anyone? >> >> But it's kind of working. :-) >> >> Worst case if I can't figure out how to solve this in one query I'll >> have to store the result of the above, and then use it as a basis for >> another query I think. >> >> Thanks >> >> James >> >> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote: >> > I would try partitioning the second time you call row_number, perhaps by >> > ID, >> > and then selecting the MAX() from that, since I think the too much data >> > you're referring to is coming from the right side of your join. >> > >> > On Jan 29, 2014 7:23 AM, "James David Smith" >> > <james.david.smith@gmail.com> >> > wrote: >> >> >> >> On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz> >> >> wrote: >> >> > On 29/01/14 11:00, Kevin Grittner wrote: >> >> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote: >> >> >> >> >> >>> Given the data is so large I don't want to be taking the data out >> >> >>> to a CSV or whatever and then loading it back in. I'd like to do >> >> >>> this within the database using SQL. I thought I would be able to >> >> >>> do this using a LOOP to be honest. >> >> >> >> >> >> I would be amazed if you couldn't do this with a single UPDATE >> >> >> statement. I've generally found declarative forms of such work to >> >> >> be at least one order of magnitude faster than going to either a PL >> >> >> or a script approach. I would start by putting together a SELECT >> >> >> query using window functions and maybe a CTE or two to list all the >> >> >> primary keys which need updating and the new values they should >> >> >> have. Once that SELECT was looking good, I would put it in the >> >> >> FROM clause of an UPDATE statement. >> >> >> >> >> >> That should work, but if you are updating a large percentage of the >> >> >> table, I would go one step further before running this against the >> >> >> production tables. I would put a LIMIT on the above-mentioned >> >> >> SELECT of something like 10000 rows, and script a loop that >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the table. >> >> >> >> >> >> -- >> >> >> Kevin Grittner >> >> >> EDB: http://www.enterprisedb.com >> >> >> The Enterprise PostgreSQL Company >> >> >> >> >> >> >> >> > James, you might consider dropping as many indexes on the table as >> >> > you >> >> > safely can, and rebuilding them after the mass update. If you have >> >> > lots >> >> > of >> >> > such indexes, you will find this apprtoach to be a lot faster. >> >> > >> >> > >> >> > Cheers, >> >> > Gavin >> >> >> >> Hi all, >> >> >> >> Thanks for your help and assistance. I think that window functions, >> >> and inparticular the PARTITION function, is 100% the way to go. I've >> >> been concentrating on a SELECT statement for now and am close but not >> >> quite close enough. The below query gets all the data I want, but >> >> *too* much. What I've essentially done is: >> >> >> >> - Select all the rows that don't have any geom information >> >> - Join them with all rows before this point that *do* have geom >> >> information. >> >> - Before doing this join, use partition to generate row numbers. >> >> >> >> The attached screen grab shows the result of my query below. >> >> Unfortunately this is generating alot of joins that I don't want. This >> >> won't be practical when doing it with 75,000 people. >> >> >> >> Thoughts and code suggestions very much appreciated... if needed I >> >> could put together some SQL to create an example table? >> >> >> >> Thanks >> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY >> >> test.point_time) as test_row, >> >> test.ppid as test_ppid, >> >> test.point_time as test_point_time, >> >> test.the_geom as test_the_geom, >> >> a.ppid as a_ppid, >> >> a.point_time as a_point_time, >> >> a.the_geom as a_the_geom, >> >> a.a_row >> >> FROM test >> >> LEFT JOIN ( >> >> SELECT the_geom, >> >> ppid, >> >> point_time, >> >> row_number() OVER (ORDER BY ppid, point_time) as a_row >> >> FROM test >> >> WHERE the_geom IS NOT NULL) a >> >> ON a.point_time < test.point_time >> >> AND a.ppid = test.ppid >> >> WHERE test.the_geom IS NULL >> >> ORDER BY test.point_time) >> >> Hi Erik / all, So I think I've managed to re-write my queries using CTEs. The below code now does get me the data that I want from this. But to do so it is going to create a frankly huge table in the bit of the SQL where it makes the table called 'partitioned'. My rough guess is that it'll have to make a table of about 100 billion rows in order to get data I need ( about 108 million rows). Could someone please glance through it for me and suggest how to write it more efficiently? Thanks James WITH missing_geoms AS ( SELECT ppid, point_time, the_geom FROM hybrid_location WHERE the_geom IS NULL) ----------------- ,filled_geoms AS ( SELECT ppid, point_time, the_geom FROM hybrid_location WHERE the_geom IS NOT NULL) ---------------- ,partitioned AS ( SELECT missing_geoms.ppid, missing_geoms.point_time, missing_geoms.the_geom, filled_geoms.ppid, filled_geoms.point_time, filled_geoms.the_geom, row_number() OVER ( PARTITION BY missing_geoms.ppid, missing_geoms.point_time ORDER BY missing_geoms.ppid, missing_geoms.point_time, filled_geoms.ppid, filled_geoms.point_time DESC) FROM missing_geoms LEFT JOIN filled_geoms ON filled_geoms.point_time < missing_geoms.point_time AND filled_geoms.ppid = missing_geoms.ppid) -------------- SELECT * FROM partitioned WHERE row_number = 1; James
Hi Erik / all,On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote:
> I would re-suggest using a CTE to contain each dataset to ensure your
> selects are distilling them correctly, and then using a final query to join
> them. You can then either update your data directly through the CTE(s), or
> insert the results to another table to do some further testing. I think
> you'll find this method presents the data a bit more ergonomically for
> analysis.
>
> http://www.postgresql.org/docs/9.3/static/queries-with.html
>
>
>
> On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> Hi Erik/all,
>>
>> I just tried that, but it's tricky. The 'extra' data is indeed coming
>> from the right side of the join, but it's hard to select only the max
>> from it. Maybe it's possible but I've not managed to do it. Here is
>> where I am, which is so very close.
>>
>> SELECT
>> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> row_that_needs_geom_updating,
>> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> last_known_position_time
>> FROM
>> test a
>> INNER JOIN
>> (SELECT ppid,
>> point_time,
>> the_geom
>> FROM test
>> WHERE the_geom IS NOT NULL) b
>> ON b.point_time < a.point_time
>> AND a.ppid = b.ppid
>> WHERE a.the_geom IS NULL;
>>
>> If you see attached screen-print, the output is the rows that I want.
>> However I've had to use DISTINCT to stop the duplication. Also I've
>> not managed to pull through 'the_geom' from the JOIN. I'm not sure
>> how. Anyone?
>>
>> But it's kind of working. :-)
>>
>> Worst case if I can't figure out how to solve this in one query I'll
>> have to store the result of the above, and then use it as a basis for
>> another query I think.
>>
>> Thanks
>>
>> James
>>
>>
>>
>> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
>> > I would try partitioning the second time you call row_number, perhaps by
>> > ID,
>> > and then selecting the MAX() from that, since I think the too much data
>> > you're referring to is coming from the right side of your join.
>> >
>> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> > <james.david.smith@gmail.com>
>> > wrote:
>> >>
>> >> On 28 January 2014 23:15, Gavin Flower <GavinFlower@archidevsys.co.nz>
>> >> wrote:
>> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >> >>
>> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >> >>
>> >> >>> Given the data is so large I don't want to be taking the data out
>> >> >>> to a CSV or whatever and then loading it back in. I'd like to do
>> >> >>> this within the database using SQL. I thought I would be able to
>> >> >>> do this using a LOOP to be honest.
>> >> >>
>> >> >> I would be amazed if you couldn't do this with a single UPDATE
>> >> >> statement. I've generally found declarative forms of such work to
>> >> >> be at least one order of magnitude faster than going to either a PL
>> >> >> or a script approach. I would start by putting together a SELECT
>> >> >> query using window functions and maybe a CTE or two to list all the
>> >> >> primary keys which need updating and the new values they should
>> >> >> have. Once that SELECT was looking good, I would put it in the
>> >> >> FROM clause of an UPDATE statement.
>> >> >>
>> >> >> That should work, but if you are updating a large percentage of the
>> >> >> table, I would go one step further before running this against the
>> >> >> production tables. I would put a LIMIT on the above-mentioned
>> >> >> SELECT of something like 10000 rows, and script a loop that
>> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>> >> >>
>> >> >> --
>> >> >> Kevin Grittner
>> >> >> EDB: http://www.enterprisedb.com
>> >> >> The Enterprise PostgreSQL Company
>> >> >>
>> >> >>
>> >> > James, you might consider dropping as many indexes on the table as
>> >> > you
>> >> > safely can, and rebuilding them after the mass update. If you have
>> >> > lots
>> >> > of
>> >> > such indexes, you will find this apprtoach to be a lot faster.
>> >> >
>> >> >
>> >> > Cheers,
>> >> > Gavin
>> >>
>> >> Hi all,
>> >>
>> >> Thanks for your help and assistance. I think that window functions,
>> >> and inparticular the PARTITION function, is 100% the way to go. I've
>> >> been concentrating on a SELECT statement for now and am close but not
>> >> quite close enough. The below query gets all the data I want, but
>> >> *too* much. What I've essentially done is:
>> >>
>> >> - Select all the rows that don't have any geom information
>> >> - Join them with all rows before this point that *do* have geom
>> >> information.
>> >> - Before doing this join, use partition to generate row numbers.
>> >>
>> >> The attached screen grab shows the result of my query below.
>> >> Unfortunately this is generating alot of joins that I don't want. This
>> >> won't be practical when doing it with 75,000 people.
>> >>
>> >> Thoughts and code suggestions very much appreciated... if needed I
>> >> could put together some SQL to create an example table?
>> >>
>> >> Thanks
>> >>
>> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
>> >> test.point_time) as test_row,
>> >> test.ppid as test_ppid,
>> >> test.point_time as test_point_time,
>> >> test.the_geom as test_the_geom,
>> >> a.ppid as a_ppid,
>> >> a.point_time as a_point_time,
>> >> a.the_geom as a_the_geom,
>> >> a.a_row
>> >> FROM test
>> >> LEFT JOIN (
>> >> SELECT the_geom,
>> >> ppid,
>> >> point_time,
>> >> row_number() OVER (ORDER BY ppid, point_time) as a_row
>> >> FROM test
>> >> WHERE the_geom IS NOT NULL) a
>> >> ON a.point_time < test.point_time
>> >> AND a.ppid = test.ppid
>> >> WHERE test.the_geom IS NULL
>> >> ORDER BY test.point_time)
>> >>
So I think I've managed to re-write my queries using CTEs. The below
code now does get me the data that I want from this. But to do so it
is going to create a frankly huge table in the bit of the SQL where it
makes the table called 'partitioned'. My rough guess is that it'll
have to make a table of about 100 billion rows in order to get data I
need ( about 108 million rows).
Could someone please glance through it for me and suggest how to write
it more efficiently?
Thanks
James
WITH missing_geoms AS (
SELECT ppid,
point_time,
the_geom
FROM hybrid_location
WHERE the_geom IS NULL)
-----------------
,filled_geoms AS (
SELECT ppid,
point_time,
the_geom
FROM hybrid_locationWHERE the_geom IS NOT NULL)----------------
,partitioned AS (
SELECT missing_geoms.ppid,
missing_geoms.point_time,
missing_geoms.the_geom,
filled_geoms.ppid,
filled_geoms.point_time,
filled_geoms.the_geom,
row_number() OVER ( PARTITION BY missing_geoms.ppid,
missing_geoms.point_time
ORDER BY missing_geoms.ppid,
missing_geoms.point_time,
filled_geoms.ppid,
filled_geoms.point_time DESC)
FROM missing_geoms
LEFT JOIN filled_geoms
ON filled_geoms.point_time < missing_geoms.point_time
AND filled_geoms.ppid = missing_geoms.ppid)
--------------
SELECT *
FROM partitioned
WHERE row_number = 1;
James
Hi Erik,
Do you mean in this section of the SQL?
.....
filled_geoms AS (
SELECT
ppid,
point_time,
the_geom
FROM
hybrid_location
WHERE
the_geom IS NOT NULL)
...
Thanks
James
On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
> Hi James,
>
> I think you're still stuck with sort of unnecessary ('too much' ) data
> coming from the right side of your left join. If so, one option I would
> consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
> filled_geoms table. If you partition by id and order by date descending, you
> can do an additional d_rank = 1 filter to only get the most recent activity.
> I believe this is what you want to set your NULL values to, no?
>
>
>
>
> On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote:
>> > I would re-suggest using a CTE to contain each dataset to ensure your
>> > selects are distilling them correctly, and then using a final query to
>> > join
>> > them. You can then either update your data directly through the CTE(s),
>> > or
>> > insert the results to another table to do some further testing. I think
>> > you'll find this method presents the data a bit more ergonomically for
>> > analysis.
>> >
>> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>> >
>> >
>> >
>> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>> > <james.david.smith@gmail.com> wrote:
>> >>
>> >> Hi Erik/all,
>> >>
>> >> I just tried that, but it's tricky. The 'extra' data is indeed coming
>> >> from the right side of the join, but it's hard to select only the max
>> >> from it. Maybe it's possible but I've not managed to do it. Here is
>> >> where I am, which is so very close.
>> >>
>> >> SELECT
>> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> >> row_that_needs_geom_updating,
>> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> >> last_known_position_time
>> >> FROM
>> >> test a
>> >> INNER JOIN
>> >> (SELECT ppid,
>> >> point_time,
>> >> the_geom
>> >> FROM test
>> >> WHERE the_geom IS NOT NULL) b
>> >> ON b.point_time < a.point_time
>> >> AND a.ppid = b.ppid
>> >> WHERE a.the_geom IS NULL;
>> >>
>> >> If you see attached screen-print, the output is the rows that I want.
>> >> However I've had to use DISTINCT to stop the duplication. Also I've
>> >> not managed to pull through 'the_geom' from the JOIN. I'm not sure
>> >> how. Anyone?
>> >>
>> >> But it's kind of working. :-)
>> >>
>> >> Worst case if I can't figure out how to solve this in one query I'll
>> >> have to store the result of the above, and then use it as a basis for
>> >> another query I think.
>> >>
>> >> Thanks
>> >>
>> >> James
>> >>
>> >>
>> >>
>> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
>> >> > I would try partitioning the second time you call row_number, perhaps
>> >> > by
>> >> > ID,
>> >> > and then selecting the MAX() from that, since I think the too much
>> >> > data
>> >> > you're referring to is coming from the right side of your join.
>> >> >
>> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> >> > <james.david.smith@gmail.com>
>> >> > wrote:
>> >> >>
>> >> >> On 28 January 2014 23:15, Gavin Flower
>> >> >> <GavinFlower@archidevsys.co.nz>
>> >> >> wrote:
>> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >> >> >>
>> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >> >> >>
>> >> >> >>> Given the data is so large I don't want to be taking the data
>> >> >> >>> out
>> >> >> >>> to a CSV or whatever and then loading it back in. I'd like to do
>> >> >> >>> this within the database using SQL. I thought I would be able to
>> >> >> >>> do this using a LOOP to be honest.
>> >> >> >>
>> >> >> >> I would be amazed if you couldn't do this with a single UPDATE
>> >> >> >> statement. I've generally found declarative forms of such work
>> >> >> >> to
>> >> >> >> be at least one order of magnitude faster than going to either a
>> >> >> >> PL
>> >> >> >> or a script approach. I would start by putting together a SELECT
>> >> >> >> query using window functions and maybe a CTE or two to list all
>> >> >> >> the
>> >> >> >> primary keys which need updating and the new values they should
>> >> >> >> have. Once that SELECT was looking good, I would put it in the
>> >> >> >> FROM clause of an UPDATE statement.
>> >> >> >>
>> >> >> >> That should work, but if you are updating a large percentage of
>> >> >> >> the
>> >> >> >> table, I would go one step further before running this against
>> >> >> >> the
>> >> >> >> production tables. I would put a LIMIT on the above-mentioned
>> >> >> >> SELECT of something like 10000 rows, and script a loop that
>> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>> >> >> >>
>> >> >> >> --
>> >> >> >> Kevin Grittner
>> >> >> >> EDB: http://www.enterprisedb.com
>> >> >> >> The Enterprise PostgreSQL Company
>> >> >> >>
>> >> >> >>
>> >> >> > James, you might consider dropping as many indexes on the table as
>> >> >> > you
>> >> >> > safely can, and rebuilding them after the mass update. If you
>> >> >> > have
>> >> >> > lots
>> >> >> > of
>> >> >> > such indexes, you will find this apprtoach to be a lot faster.
>> >> >> >
>> >> >> >
>> >> >> > Cheers,
>> >> >> > Gavin
>> >> >>
>> >> >> Hi all,
>> >> >>
>> >> >> Thanks for your help and assistance. I think that window functions,
>> >> >> and inparticular the PARTITION function, is 100% the way to go.
>> >> >> I've
>> >> >> been concentrating on a SELECT statement for now and am close but
>> >> >> not
>> >> >> quite close enough. The below query gets all the data I want, but
>> >> >> *too* much. What I've essentially done is:
>> >> >>
>> >> >> - Select all the rows that don't have any geom information
>> >> >> - Join them with all rows before this point that *do* have geom
>> >> >> information.
>> >> >> - Before doing this join, use partition to generate row numbers.
>> >> >>
>> >> >> The attached screen grab shows the result of my query below.
>> >> >> Unfortunately this is generating alot of joins that I don't want.
>> >> >> This
>> >> >> won't be practical when doing it with 75,000 people.
>> >> >>
>> >> >> Thoughts and code suggestions very much appreciated... if needed I
>> >> >> could put together some SQL to create an example table?
>> >> >>
>> >> >> Thanks
>> >> >>
>> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
>> >> >> test.point_time) as test_row,
>> >> >> test.ppid as test_ppid,
>> >> >> test.point_time as test_point_time,
>> >> >> test.the_geom as test_the_geom,
>> >> >> a.ppid as a_ppid,
>> >> >> a.point_time as a_point_time,
>> >> >> a.the_geom as a_the_geom,
>> >> >> a.a_row
>> >> >> FROM test
>> >> >> LEFT JOIN (
>> >> >> SELECT the_geom,
>> >> >> ppid,
>> >> >> point_time,
>> >> >> row_number() OVER (ORDER BY ppid, point_time) as a_row
>> >> >> FROM test
>> >> >> WHERE the_geom IS NOT NULL) a
>> >> >> ON a.point_time < test.point_time
>> >> >> AND a.ppid = test.ppid
>> >> >> WHERE test.the_geom IS NULL
>> >> >> ORDER BY test.point_time)
>> >> >>
>>
>>
>> Hi Erik / all,
>>
>> So I think I've managed to re-write my queries using CTEs. The below
>> code now does get me the data that I want from this. But to do so it
>> is going to create a frankly huge table in the bit of the SQL where it
>> makes the table called 'partitioned'. My rough guess is that it'll
>> have to make a table of about 100 billion rows in order to get data I
>> need ( about 108 million rows).
>>
>> Could someone please glance through it for me and suggest how to write
>> it more efficiently?
>>
>> Thanks
>>
>> James
>>
>> WITH missing_geoms AS (
>> SELECT ppid,
>> point_time,
>> the_geom
>> FROM hybrid_location
>> WHERE the_geom IS NULL)
>> -----------------
>> ,filled_geoms AS (
>> SELECT ppid,
>> point_time,
>> the_geom
>> FROM hybrid_location
>> WHERE the_geom IS NOT NULL)
>> ----------------
>> ,partitioned AS (
>> SELECT missing_geoms.ppid,
>> missing_geoms.point_time,
>> missing_geoms.the_geom,
>> filled_geoms.ppid,
>> filled_geoms.point_time,
>> filled_geoms.the_geom,
>> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>> missing_geoms.point_time
>> ORDER BY missing_geoms.ppid,
>> missing_geoms.point_time,
>> filled_geoms.ppid,
>> filled_geoms.point_time DESC)
>> FROM missing_geoms
>> LEFT JOIN filled_geoms
>> ON filled_geoms.point_time < missing_geoms.point_time
>> AND filled_geoms.ppid = missing_geoms.ppid)
>> --------------
>> SELECT *
>> FROM partitioned
>> WHERE row_number = 1;
>>
>> James
>
>
Hi Erik,
Do you mean in this section of the SQL?
.....filled_geoms AS (...
SELECT
ppid,
point_time,
the_geom
FROM
hybrid_location
WHERE
the_geom IS NOT NULL)
Thanks
James
On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
> Hi James,
>
> I think you're still stuck with sort of unnecessary ('too much' ) data
> coming from the right side of your left join. If so, one option I would
> consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
> filled_geoms table. If you partition by id and order by date descending, you
> can do an additional d_rank = 1 filter to only get the most recent activity.
> I believe this is what you want to set your NULL values to, no?
>
>
>
>
> On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote:
>> > I would re-suggest using a CTE to contain each dataset to ensure your
>> > selects are distilling them correctly, and then using a final query to
>> > join
>> > them. You can then either update your data directly through the CTE(s),
>> > or
>> > insert the results to another table to do some further testing. I think
>> > you'll find this method presents the data a bit more ergonomically for
>> > analysis.
>> >
>> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>> >
>> >
>> >
>> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>> > <james.david.smith@gmail.com> wrote:
>> >>
>> >> Hi Erik/all,
>> >>
>> >> I just tried that, but it's tricky. The 'extra' data is indeed coming
>> >> from the right side of the join, but it's hard to select only the max
>> >> from it. Maybe it's possible but I've not managed to do it. Here is
>> >> where I am, which is so very close.
>> >>
>> >> SELECT
>> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> >> row_that_needs_geom_updating,
>> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> >> last_known_position_time
>> >> FROM
>> >> test a
>> >> INNER JOIN
>> >> (SELECT ppid,
>> >> point_time,
>> >> the_geom
>> >> FROM test
>> >> WHERE the_geom IS NOT NULL) b
>> >> ON b.point_time < a.point_time
>> >> AND a.ppid = b.ppid
>> >> WHERE a.the_geom IS NULL;
>> >>
>> >> If you see attached screen-print, the output is the rows that I want.
>> >> However I've had to use DISTINCT to stop the duplication. Also I've
>> >> not managed to pull through 'the_geom' from the JOIN. I'm not sure
>> >> how. Anyone?
>> >>
>> >> But it's kind of working. :-)
>> >>
>> >> Worst case if I can't figure out how to solve this in one query I'll
>> >> have to store the result of the above, and then use it as a basis for
>> >> another query I think.
>> >>
>> >> Thanks
>> >>
>> >> James
>> >>
>> >>
>> >>
>> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
>> >> > I would try partitioning the second time you call row_number, perhaps
>> >> > by
>> >> > ID,
>> >> > and then selecting the MAX() from that, since I think the too much
>> >> > data
>> >> > you're referring to is coming from the right side of your join.
>> >> >
>> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> >> > <james.david.smith@gmail.com>
>> >> > wrote:
>> >> >>
>> >> >> On 28 January 2014 23:15, Gavin Flower
>> >> >> <GavinFlower@archidevsys.co.nz>
>> >> >> wrote:
>> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >> >> >>
>> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >> >> >>
>> >> >> >>> Given the data is so large I don't want to be taking the data
>> >> >> >>> out
>> >> >> >>> to a CSV or whatever and then loading it back in. I'd like to do
>> >> >> >>> this within the database using SQL. I thought I would be able to
>> >> >> >>> do this using a LOOP to be honest.
>> >> >> >>
>> >> >> >> I would be amazed if you couldn't do this with a single UPDATE
>> >> >> >> statement. I've generally found declarative forms of such work
>> >> >> >> to
>> >> >> >> be at least one order of magnitude faster than going to either a
>> >> >> >> PL
>> >> >> >> or a script approach. I would start by putting together a SELECT
>> >> >> >> query using window functions and maybe a CTE or two to list all
>> >> >> >> the
>> >> >> >> primary keys which need updating and the new values they should
>> >> >> >> have. Once that SELECT was looking good, I would put it in the
>> >> >> >> FROM clause of an UPDATE statement.
>> >> >> >>
>> >> >> >> That should work, but if you are updating a large percentage of
>> >> >> >> the
>> >> >> >> table, I would go one step further before running this against
>> >> >> >> the
>> >> >> >> production tables. I would put a LIMIT on the above-mentioned
>> >> >> >> SELECT of something like 10000 rows, and script a loop that
>> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the table.
>> >> >> >>
>> >> >> >> --
>> >> >> >> Kevin Grittner
>> >> >> >> EDB: http://www.enterprisedb.com
>> >> >> >> The Enterprise PostgreSQL Company
>> >> >> >>
>> >> >> >>
>> >> >> > James, you might consider dropping as many indexes on the table as
>> >> >> > you
>> >> >> > safely can, and rebuilding them after the mass update. If you
>> >> >> > have
>> >> >> > lots
>> >> >> > of
>> >> >> > such indexes, you will find this apprtoach to be a lot faster.
>> >> >> >
>> >> >> >
>> >> >> > Cheers,
>> >> >> > Gavin
>> >> >>
>> >> >> Hi all,
>> >> >>
>> >> >> Thanks for your help and assistance. I think that window functions,
>> >> >> and inparticular the PARTITION function, is 100% the way to go.
>> >> >> I've
>> >> >> been concentrating on a SELECT statement for now and am close but
>> >> >> not
>> >> >> quite close enough. The below query gets all the data I want, but
>> >> >> *too* much. What I've essentially done is:
>> >> >>
>> >> >> - Select all the rows that don't have any geom information
>> >> >> - Join them with all rows before this point that *do* have geom
>> >> >> information.
>> >> >> - Before doing this join, use partition to generate row numbers.
>> >> >>
>> >> >> The attached screen grab shows the result of my query below.
>> >> >> Unfortunately this is generating alot of joins that I don't want.
>> >> >> This
>> >> >> won't be practical when doing it with 75,000 people.
>> >> >>
>> >> >> Thoughts and code suggestions very much appreciated... if needed I
>> >> >> could put together some SQL to create an example table?
>> >> >>
>> >> >> Thanks
>> >> >>
>> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER BY
>> >> >> test.point_time) as test_row,
>> >> >> test.ppid as test_ppid,
>> >> >> test.point_time as test_point_time,
>> >> >> test.the_geom as test_the_geom,
>> >> >> a.ppid as a_ppid,
>> >> >> a.point_time as a_point_time,
>> >> >> a.the_geom as a_the_geom,
>> >> >> a.a_row
>> >> >> FROM test
>> >> >> LEFT JOIN (
>> >> >> SELECT the_geom,
>> >> >> ppid,
>> >> >> point_time,
>> >> >> row_number() OVER (ORDER BY ppid, point_time) as a_row
>> >> >> FROM test
>> >> >> WHERE the_geom IS NOT NULL) a
>> >> >> ON a.point_time < test.point_time
>> >> >> AND a.ppid = test.ppid
>> >> >> WHERE test.the_geom IS NULL
>> >> >> ORDER BY test.point_time)
>> >> >>
>>
>>
>> Hi Erik / all,
>>
>> So I think I've managed to re-write my queries using CTEs. The below
>> code now does get me the data that I want from this. But to do so it
>> is going to create a frankly huge table in the bit of the SQL where it
>> makes the table called 'partitioned'. My rough guess is that it'll
>> have to make a table of about 100 billion rows in order to get data I
>> need ( about 108 million rows).
>>
>> Could someone please glance through it for me and suggest how to write
>> it more efficiently?
>>
>> Thanks
>>
>> James
>>
>> WITH missing_geoms AS (
>> SELECT ppid,
>> point_time,
>> the_geom
>> FROM hybrid_location
>> WHERE the_geom IS NULL)
>> -----------------
>> ,filled_geoms AS (
>> SELECT ppid,
>> point_time,
>> the_geom
>> FROM hybrid_location
>> WHERE the_geom IS NOT NULL)
>> ----------------
>> ,partitioned AS (
>> SELECT missing_geoms.ppid,
>> missing_geoms.point_time,
>> missing_geoms.the_geom,
>> filled_geoms.ppid,
>> filled_geoms.point_time,
>> filled_geoms.the_geom,
>> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>> missing_geoms.point_time
>> ORDER BY missing_geoms.ppid,
>> missing_geoms.point_time,
>> filled_geoms.ppid,
>> filled_geoms.point_time DESC)
>> FROM missing_geoms
>> LEFT JOIN filled_geoms
>> ON filled_geoms.point_time < missing_geoms.point_time
>> AND filled_geoms.ppid = missing_geoms.ppid)
>> --------------
>> SELECT *
>> FROM partitioned
>> WHERE row_number = 1;
>>
>> James
>
>
Hi Erik / all,
I don't think that will work, as what happens if one of the people has
two missing periods of time within their day?
I've made a self-contained example of my problem below. Would you mind
trying to produce in the code below what you think I should do? Or if
anyone else fancies having a go then please do.
I very much appreciate your help by the way. Thank you. I'm really at
a loss with this. :-(
James
--------------------------------------
DROP TABLE test_data;
CREATE TABLE test_data(
ppid integer,
point_time timestamp without time zone,
the_geom integer);
INSERT INTO test_data VALUES
('1', '2012-01-01 07:00', '1'),
('1', '2012-01-01 07:01', '1'),
('1', '2012-01-01 07:02', '1'),
('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1
('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1
('1', '2012-01-01 07:05', '5'),
('1', '2012-01-01 07:06', '5'),
('1', '2012-01-01 07:07', '5'),
('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5
('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5
('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5
('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5
('2', '2013-05-02 07:12', '24'),
('2', '2013-05-02 07:13', '24'),
('2', '2013-05-02 07:14', '24'),
('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24
('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24
('2', '2013-05-02 07:17', '44'),
('2', '2013-05-02 07:18', '44'),
('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44
('2', '2013-05-02 07:20', '4'),
('2', '2013-05-02 07:21', '4'),
('2', '2013-05-02 07:22', '4');
WITH missing_geoms AS (
SELECT ppid,
point_time,
the_geom
FROM test_data
WHERE the_geom IS NULL)
---
,filled_geoms AS (
SELECT ppid,
point_time,
the_geom
FROM test_data
WHERE the_geom IS NOT NULL)
---
,partitioned AS (
SELECT missing_geoms.ppid as missing_geoms_ppid,
missing_geoms.point_time as missing_geoms_point_time,
missing_geoms.the_geom as missing_geoms_the_geom,
filled_geoms.ppid as filled_geoms_ppid,
filled_geoms.point_time as filled_geoms_point_time,
filled_geoms.the_geom as filled_geoms_the_geom
FROM missing_geoms
LEFT JOIN filled_geoms
ON filled_geoms.point_time < missing_geoms.point_time
AND filled_geoms.ppid = missing_geoms.ppid
ORDER BY missing_geoms_ppid,
missing_geoms_point_time)
---
SELECT *
FROM partitioned;
On 29 January 2014 22:10, Erik Darling <edarling80@gmail.com> wrote:
> Hi James,
>
> Yeah, that looks like the right place to me.
>
>
> On Wed, Jan 29, 2014 at 1:14 PM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> Hi Erik,
>>
>> Do you mean in this section of the SQL?
>> .....
>> filled_geoms AS (
>> SELECT
>> ppid,
>> point_time,
>> the_geom
>> FROM
>> hybrid_location
>> WHERE
>> the_geom IS NOT NULL)
>> ...
>>
>> Thanks
>>
>> James
>>
>> On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
>> > Hi James,
>> >
>> > I think you're still stuck with sort of unnecessary ('too much' ) data
>> > coming from the right side of your left join. If so, one option I would
>> > consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
>> > filled_geoms table. If you partition by id and order by date descending,
>> > you
>> > can do an additional d_rank = 1 filter to only get the most recent
>> > activity.
>> > I believe this is what you want to set your NULL values to, no?
>> >
>> >
>> >
>> >
>> > On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
>> > <james.david.smith@gmail.com> wrote:
>> >>
>> >> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote:
>> >> > I would re-suggest using a CTE to contain each dataset to ensure your
>> >> > selects are distilling them correctly, and then using a final query
>> >> > to
>> >> > join
>> >> > them. You can then either update your data directly through the
>> >> > CTE(s),
>> >> > or
>> >> > insert the results to another table to do some further testing. I
>> >> > think
>> >> > you'll find this method presents the data a bit more ergonomically
>> >> > for
>> >> > analysis.
>> >> >
>> >> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>> >> >
>> >> >
>> >> >
>> >> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>> >> > <james.david.smith@gmail.com> wrote:
>> >> >>
>> >> >> Hi Erik/all,
>> >> >>
>> >> >> I just tried that, but it's tricky. The 'extra' data is indeed
>> >> >> coming
>> >> >> from the right side of the join, but it's hard to select only the
>> >> >> max
>> >> >> from it. Maybe it's possible but I've not managed to do it. Here is
>> >> >> where I am, which is so very close.
>> >> >>
>> >> >> SELECT
>> >> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> >> >> row_that_needs_geom_updating,
>> >> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> >> >> last_known_position_time
>> >> >> FROM
>> >> >> test a
>> >> >> INNER JOIN
>> >> >> (SELECT ppid,
>> >> >> point_time,
>> >> >> the_geom
>> >> >> FROM test
>> >> >> WHERE the_geom IS NOT NULL) b
>> >> >> ON b.point_time < a.point_time
>> >> >> AND a.ppid = b.ppid
>> >> >> WHERE a.the_geom IS NULL;
>> >> >>
>> >> >> If you see attached screen-print, the output is the rows that I
>> >> >> want.
>> >> >> However I've had to use DISTINCT to stop the duplication. Also I've
>> >> >> not managed to pull through 'the_geom' from the JOIN. I'm not sure
>> >> >> how. Anyone?
>> >> >>
>> >> >> But it's kind of working. :-)
>> >> >>
>> >> >> Worst case if I can't figure out how to solve this in one query I'll
>> >> >> have to store the result of the above, and then use it as a basis
>> >> >> for
>> >> >> another query I think.
>> >> >>
>> >> >> Thanks
>> >> >>
>> >> >> James
>> >> >>
>> >> >>
>> >> >>
>> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
>> >> >> > I would try partitioning the second time you call row_number,
>> >> >> > perhaps
>> >> >> > by
>> >> >> > ID,
>> >> >> > and then selecting the MAX() from that, since I think the too much
>> >> >> > data
>> >> >> > you're referring to is coming from the right side of your join.
>> >> >> >
>> >> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> >> >> > <james.david.smith@gmail.com>
>> >> >> > wrote:
>> >> >> >>
>> >> >> >> On 28 January 2014 23:15, Gavin Flower
>> >> >> >> <GavinFlower@archidevsys.co.nz>
>> >> >> >> wrote:
>> >> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >> >> >> >>
>> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >> >> >> >>
>> >> >> >> >>> Given the data is so large I don't want to be taking the data
>> >> >> >> >>> out
>> >> >> >> >>> to a CSV or whatever and then loading it back in. I'd like to
>> >> >> >> >>> do
>> >> >> >> >>> this within the database using SQL. I thought I would be able
>> >> >> >> >>> to
>> >> >> >> >>> do this using a LOOP to be honest.
>> >> >> >> >>
>> >> >> >> >> I would be amazed if you couldn't do this with a single
>> >> >> >> >> UPDATE
>> >> >> >> >> statement. I've generally found declarative forms of such
>> >> >> >> >> work
>> >> >> >> >> to
>> >> >> >> >> be at least one order of magnitude faster than going to either
>> >> >> >> >> a
>> >> >> >> >> PL
>> >> >> >> >> or a script approach. I would start by putting together a
>> >> >> >> >> SELECT
>> >> >> >> >> query using window functions and maybe a CTE or two to list
>> >> >> >> >> all
>> >> >> >> >> the
>> >> >> >> >> primary keys which need updating and the new values they
>> >> >> >> >> should
>> >> >> >> >> have. Once that SELECT was looking good, I would put it in
>> >> >> >> >> the
>> >> >> >> >> FROM clause of an UPDATE statement.
>> >> >> >> >>
>> >> >> >> >> That should work, but if you are updating a large percentage
>> >> >> >> >> of
>> >> >> >> >> the
>> >> >> >> >> table, I would go one step further before running this against
>> >> >> >> >> the
>> >> >> >> >> production tables. I would put a LIMIT on the above-mentioned
>> >> >> >> >> SELECT of something like 10000 rows, and script a loop that
>> >> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the
>> >> >> >> >> table.
>> >> >> >> >>
>> >> >> >> >> --
>> >> >> >> >> Kevin Grittner
>> >> >> >> >> EDB: http://www.enterprisedb.com
>> >> >> >> >> The Enterprise PostgreSQL Company
>> >> >> >> >>
>> >> >> >> >>
>> >> >> >> > James, you might consider dropping as many indexes on the table
>> >> >> >> > as
>> >> >> >> > you
>> >> >> >> > safely can, and rebuilding them after the mass update. If you
>> >> >> >> > have
>> >> >> >> > lots
>> >> >> >> > of
>> >> >> >> > such indexes, you will find this apprtoach to be a lot faster.
>> >> >> >> >
>> >> >> >> >
>> >> >> >> > Cheers,
>> >> >> >> > Gavin
>> >> >> >>
>> >> >> >> Hi all,
>> >> >> >>
>> >> >> >> Thanks for your help and assistance. I think that window
>> >> >> >> functions,
>> >> >> >> and inparticular the PARTITION function, is 100% the way to go.
>> >> >> >> I've
>> >> >> >> been concentrating on a SELECT statement for now and am close but
>> >> >> >> not
>> >> >> >> quite close enough. The below query gets all the data I want, but
>> >> >> >> *too* much. What I've essentially done is:
>> >> >> >>
>> >> >> >> - Select all the rows that don't have any geom information
>> >> >> >> - Join them with all rows before this point that *do* have geom
>> >> >> >> information.
>> >> >> >> - Before doing this join, use partition to generate row numbers.
>> >> >> >>
>> >> >> >> The attached screen grab shows the result of my query below.
>> >> >> >> Unfortunately this is generating alot of joins that I don't want.
>> >> >> >> This
>> >> >> >> won't be practical when doing it with 75,000 people.
>> >> >> >>
>> >> >> >> Thoughts and code suggestions very much appreciated... if needed
>> >> >> >> I
>> >> >> >> could put together some SQL to create an example table?
>> >> >> >>
>> >> >> >> Thanks
>> >> >> >>
>> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER
>> >> >> >> BY
>> >> >> >> test.point_time) as test_row,
>> >> >> >> test.ppid as test_ppid,
>> >> >> >> test.point_time as test_point_time,
>> >> >> >> test.the_geom as test_the_geom,
>> >> >> >> a.ppid as a_ppid,
>> >> >> >> a.point_time as a_point_time,
>> >> >> >> a.the_geom as a_the_geom,
>> >> >> >> a.a_row
>> >> >> >> FROM test
>> >> >> >> LEFT JOIN (
>> >> >> >> SELECT the_geom,
>> >> >> >> ppid,
>> >> >> >> point_time,
>> >> >> >> row_number() OVER (ORDER BY ppid, point_time) as
>> >> >> >> a_row
>> >> >> >> FROM test
>> >> >> >> WHERE the_geom IS NOT NULL) a
>> >> >> >> ON a.point_time < test.point_time
>> >> >> >> AND a.ppid = test.ppid
>> >> >> >> WHERE test.the_geom IS NULL
>> >> >> >> ORDER BY test.point_time)
>> >> >> >>
>> >>
>> >>
>> >> Hi Erik / all,
>> >>
>> >> So I think I've managed to re-write my queries using CTEs. The below
>> >> code now does get me the data that I want from this. But to do so it
>> >> is going to create a frankly huge table in the bit of the SQL where it
>> >> makes the table called 'partitioned'. My rough guess is that it'll
>> >> have to make a table of about 100 billion rows in order to get data I
>> >> need ( about 108 million rows).
>> >>
>> >> Could someone please glance through it for me and suggest how to write
>> >> it more efficiently?
>> >>
>> >> Thanks
>> >>
>> >> James
>> >>
>> >> WITH missing_geoms AS (
>> >> SELECT ppid,
>> >> point_time,
>> >> the_geom
>> >> FROM hybrid_location
>> >> WHERE the_geom IS NULL)
>> >> -----------------
>> >> ,filled_geoms AS (
>> >> SELECT ppid,
>> >> point_time,
>> >> the_geom
>> >> FROM hybrid_location
>> >> WHERE the_geom IS NOT NULL)
>> >> ----------------
>> >> ,partitioned AS (
>> >> SELECT missing_geoms.ppid,
>> >> missing_geoms.point_time,
>> >> missing_geoms.the_geom,
>> >> filled_geoms.ppid,
>> >> filled_geoms.point_time,
>> >> filled_geoms.the_geom,
>> >> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>> >> missing_geoms.point_time
>> >> ORDER BY missing_geoms.ppid,
>> >> missing_geoms.point_time,
>> >> filled_geoms.ppid,
>> >> filled_geoms.point_time DESC)
>> >> FROM missing_geoms
>> >> LEFT JOIN filled_geoms
>> >> ON filled_geoms.point_time < missing_geoms.point_time
>> >> AND filled_geoms.ppid = missing_geoms.ppid)
>> >> --------------
>> >> SELECT *
>> >> FROM partitioned
>> >> WHERE row_number = 1;
>> >>
>> >> James
>> >
>> >
>
>
All, Here's a SQL fiddle of my problem: http://sqlfiddle.com/#!15/77157 Thanks James On 30 January 2014 11:19, James David Smith <james.david.smith@gmail.com> wrote: > Hi Erik / all, > > I don't think that will work, as what happens if one of the people has > two missing periods of time within their day? > > I've made a self-contained example of my problem below. Would you mind > trying to produce in the code below what you think I should do? Or if > anyone else fancies having a go then please do. > > I very much appreciate your help by the way. Thank you. I'm really at > a loss with this. :-( > > James > -------------------------------------- > > DROP TABLE test_data; > > CREATE TABLE test_data( > ppid integer, > point_time timestamp without time zone, > the_geom integer); > > INSERT INTO test_data VALUES > ('1', '2012-01-01 07:00', '1'), > ('1', '2012-01-01 07:01', '1'), > ('1', '2012-01-01 07:02', '1'), > ('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1 > ('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1 > ('1', '2012-01-01 07:05', '5'), > ('1', '2012-01-01 07:06', '5'), > ('1', '2012-01-01 07:07', '5'), > ('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5 > ('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5 > ('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5 > ('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5 > ('2', '2013-05-02 07:12', '24'), > ('2', '2013-05-02 07:13', '24'), > ('2', '2013-05-02 07:14', '24'), > ('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24 > ('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24 > ('2', '2013-05-02 07:17', '44'), > ('2', '2013-05-02 07:18', '44'), > ('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44 > ('2', '2013-05-02 07:20', '4'), > ('2', '2013-05-02 07:21', '4'), > ('2', '2013-05-02 07:22', '4'); > > WITH missing_geoms AS ( > SELECT ppid, > point_time, > the_geom > FROM test_data > WHERE the_geom IS NULL) > --- > ,filled_geoms AS ( > SELECT ppid, > point_time, > the_geom > FROM test_data > WHERE the_geom IS NOT NULL) > --- > ,partitioned AS ( > SELECT missing_geoms.ppid as missing_geoms_ppid, > missing_geoms.point_time as missing_geoms_point_time, > missing_geoms.the_geom as missing_geoms_the_geom, > filled_geoms.ppid as filled_geoms_ppid, > filled_geoms.point_time as filled_geoms_point_time, > filled_geoms.the_geom as filled_geoms_the_geom > FROM missing_geoms > LEFT JOIN filled_geoms > ON filled_geoms.point_time < missing_geoms.point_time > AND filled_geoms.ppid = missing_geoms.ppid > ORDER BY missing_geoms_ppid, > missing_geoms_point_time) > --- > SELECT * > FROM partitioned; > > > > > > On 29 January 2014 22:10, Erik Darling <edarling80@gmail.com> wrote: >> Hi James, >> >> Yeah, that looks like the right place to me. >> >> >> On Wed, Jan 29, 2014 at 1:14 PM, James David Smith >> <james.david.smith@gmail.com> wrote: >>> >>> Hi Erik, >>> >>> Do you mean in this section of the SQL? >>> ..... >>> filled_geoms AS ( >>> SELECT >>> ppid, >>> point_time, >>> the_geom >>> FROM >>> hybrid_location >>> WHERE >>> the_geom IS NOT NULL) >>> ... >>> >>> Thanks >>> >>> James >>> >>> On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote: >>> > Hi James, >>> > >>> > I think you're still stuck with sort of unnecessary ('too much' ) data >>> > coming from the right side of your left join. If so, one option I would >>> > consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the >>> > filled_geoms table. If you partition by id and order by date descending, >>> > you >>> > can do an additional d_rank = 1 filter to only get the most recent >>> > activity. >>> > I believe this is what you want to set your NULL values to, no? >>> > >>> > >>> > >>> > >>> > On Wed, Jan 29, 2014 at 12:41 PM, James David Smith >>> > <james.david.smith@gmail.com> wrote: >>> >> >>> >> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote: >>> >> > I would re-suggest using a CTE to contain each dataset to ensure your >>> >> > selects are distilling them correctly, and then using a final query >>> >> > to >>> >> > join >>> >> > them. You can then either update your data directly through the >>> >> > CTE(s), >>> >> > or >>> >> > insert the results to another table to do some further testing. I >>> >> > think >>> >> > you'll find this method presents the data a bit more ergonomically >>> >> > for >>> >> > analysis. >>> >> > >>> >> > http://www.postgresql.org/docs/9.3/static/queries-with.html >>> >> > >>> >> > >>> >> > >>> >> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith >>> >> > <james.david.smith@gmail.com> wrote: >>> >> >> >>> >> >> Hi Erik/all, >>> >> >> >>> >> >> I just tried that, but it's tricky. The 'extra' data is indeed >>> >> >> coming >>> >> >> from the right side of the join, but it's hard to select only the >>> >> >> max >>> >> >> from it. Maybe it's possible but I've not managed to do it. Here is >>> >> >> where I am, which is so very close. >>> >> >> >>> >> >> SELECT >>> >> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as >>> >> >> row_that_needs_geom_updating, >>> >> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as >>> >> >> last_known_position_time >>> >> >> FROM >>> >> >> test a >>> >> >> INNER JOIN >>> >> >> (SELECT ppid, >>> >> >> point_time, >>> >> >> the_geom >>> >> >> FROM test >>> >> >> WHERE the_geom IS NOT NULL) b >>> >> >> ON b.point_time < a.point_time >>> >> >> AND a.ppid = b.ppid >>> >> >> WHERE a.the_geom IS NULL; >>> >> >> >>> >> >> If you see attached screen-print, the output is the rows that I >>> >> >> want. >>> >> >> However I've had to use DISTINCT to stop the duplication. Also I've >>> >> >> not managed to pull through 'the_geom' from the JOIN. I'm not sure >>> >> >> how. Anyone? >>> >> >> >>> >> >> But it's kind of working. :-) >>> >> >> >>> >> >> Worst case if I can't figure out how to solve this in one query I'll >>> >> >> have to store the result of the above, and then use it as a basis >>> >> >> for >>> >> >> another query I think. >>> >> >> >>> >> >> Thanks >>> >> >> >>> >> >> James >>> >> >> >>> >> >> >>> >> >> >>> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote: >>> >> >> > I would try partitioning the second time you call row_number, >>> >> >> > perhaps >>> >> >> > by >>> >> >> > ID, >>> >> >> > and then selecting the MAX() from that, since I think the too much >>> >> >> > data >>> >> >> > you're referring to is coming from the right side of your join. >>> >> >> > >>> >> >> > On Jan 29, 2014 7:23 AM, "James David Smith" >>> >> >> > <james.david.smith@gmail.com> >>> >> >> > wrote: >>> >> >> >> >>> >> >> >> On 28 January 2014 23:15, Gavin Flower >>> >> >> >> <GavinFlower@archidevsys.co.nz> >>> >> >> >> wrote: >>> >> >> >> > On 29/01/14 11:00, Kevin Grittner wrote: >>> >> >> >> >> >>> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote: >>> >> >> >> >> >>> >> >> >> >>> Given the data is so large I don't want to be taking the data >>> >> >> >> >>> out >>> >> >> >> >>> to a CSV or whatever and then loading it back in. I'd like to >>> >> >> >> >>> do >>> >> >> >> >>> this within the database using SQL. I thought I would be able >>> >> >> >> >>> to >>> >> >> >> >>> do this using a LOOP to be honest. >>> >> >> >> >> >>> >> >> >> >> I would be amazed if you couldn't do this with a single >>> >> >> >> >> UPDATE >>> >> >> >> >> statement. I've generally found declarative forms of such >>> >> >> >> >> work >>> >> >> >> >> to >>> >> >> >> >> be at least one order of magnitude faster than going to either >>> >> >> >> >> a >>> >> >> >> >> PL >>> >> >> >> >> or a script approach. I would start by putting together a >>> >> >> >> >> SELECT >>> >> >> >> >> query using window functions and maybe a CTE or two to list >>> >> >> >> >> all >>> >> >> >> >> the >>> >> >> >> >> primary keys which need updating and the new values they >>> >> >> >> >> should >>> >> >> >> >> have. Once that SELECT was looking good, I would put it in >>> >> >> >> >> the >>> >> >> >> >> FROM clause of an UPDATE statement. >>> >> >> >> >> >>> >> >> >> >> That should work, but if you are updating a large percentage >>> >> >> >> >> of >>> >> >> >> >> the >>> >> >> >> >> table, I would go one step further before running this against >>> >> >> >> >> the >>> >> >> >> >> production tables. I would put a LIMIT on the above-mentioned >>> >> >> >> >> SELECT of something like 10000 rows, and script a loop that >>> >> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the >>> >> >> >> >> table. >>> >> >> >> >> >>> >> >> >> >> -- >>> >> >> >> >> Kevin Grittner >>> >> >> >> >> EDB: http://www.enterprisedb.com >>> >> >> >> >> The Enterprise PostgreSQL Company >>> >> >> >> >> >>> >> >> >> >> >>> >> >> >> > James, you might consider dropping as many indexes on the table >>> >> >> >> > as >>> >> >> >> > you >>> >> >> >> > safely can, and rebuilding them after the mass update. If you >>> >> >> >> > have >>> >> >> >> > lots >>> >> >> >> > of >>> >> >> >> > such indexes, you will find this apprtoach to be a lot faster. >>> >> >> >> > >>> >> >> >> > >>> >> >> >> > Cheers, >>> >> >> >> > Gavin >>> >> >> >> >>> >> >> >> Hi all, >>> >> >> >> >>> >> >> >> Thanks for your help and assistance. I think that window >>> >> >> >> functions, >>> >> >> >> and inparticular the PARTITION function, is 100% the way to go. >>> >> >> >> I've >>> >> >> >> been concentrating on a SELECT statement for now and am close but >>> >> >> >> not >>> >> >> >> quite close enough. The below query gets all the data I want, but >>> >> >> >> *too* much. What I've essentially done is: >>> >> >> >> >>> >> >> >> - Select all the rows that don't have any geom information >>> >> >> >> - Join them with all rows before this point that *do* have geom >>> >> >> >> information. >>> >> >> >> - Before doing this join, use partition to generate row numbers. >>> >> >> >> >>> >> >> >> The attached screen grab shows the result of my query below. >>> >> >> >> Unfortunately this is generating alot of joins that I don't want. >>> >> >> >> This >>> >> >> >> won't be practical when doing it with 75,000 people. >>> >> >> >> >>> >> >> >> Thoughts and code suggestions very much appreciated... if needed >>> >> >> >> I >>> >> >> >> could put together some SQL to create an example table? >>> >> >> >> >>> >> >> >> Thanks >>> >> >> >> >>> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER >>> >> >> >> BY >>> >> >> >> test.point_time) as test_row, >>> >> >> >> test.ppid as test_ppid, >>> >> >> >> test.point_time as test_point_time, >>> >> >> >> test.the_geom as test_the_geom, >>> >> >> >> a.ppid as a_ppid, >>> >> >> >> a.point_time as a_point_time, >>> >> >> >> a.the_geom as a_the_geom, >>> >> >> >> a.a_row >>> >> >> >> FROM test >>> >> >> >> LEFT JOIN ( >>> >> >> >> SELECT the_geom, >>> >> >> >> ppid, >>> >> >> >> point_time, >>> >> >> >> row_number() OVER (ORDER BY ppid, point_time) as >>> >> >> >> a_row >>> >> >> >> FROM test >>> >> >> >> WHERE the_geom IS NOT NULL) a >>> >> >> >> ON a.point_time < test.point_time >>> >> >> >> AND a.ppid = test.ppid >>> >> >> >> WHERE test.the_geom IS NULL >>> >> >> >> ORDER BY test.point_time) >>> >> >> >> >>> >> >>> >> >>> >> Hi Erik / all, >>> >> >>> >> So I think I've managed to re-write my queries using CTEs. The below >>> >> code now does get me the data that I want from this. But to do so it >>> >> is going to create a frankly huge table in the bit of the SQL where it >>> >> makes the table called 'partitioned'. My rough guess is that it'll >>> >> have to make a table of about 100 billion rows in order to get data I >>> >> need ( about 108 million rows). >>> >> >>> >> Could someone please glance through it for me and suggest how to write >>> >> it more efficiently? >>> >> >>> >> Thanks >>> >> >>> >> James >>> >> >>> >> WITH missing_geoms AS ( >>> >> SELECT ppid, >>> >> point_time, >>> >> the_geom >>> >> FROM hybrid_location >>> >> WHERE the_geom IS NULL) >>> >> ----------------- >>> >> ,filled_geoms AS ( >>> >> SELECT ppid, >>> >> point_time, >>> >> the_geom >>> >> FROM hybrid_location >>> >> WHERE the_geom IS NOT NULL) >>> >> ---------------- >>> >> ,partitioned AS ( >>> >> SELECT missing_geoms.ppid, >>> >> missing_geoms.point_time, >>> >> missing_geoms.the_geom, >>> >> filled_geoms.ppid, >>> >> filled_geoms.point_time, >>> >> filled_geoms.the_geom, >>> >> row_number() OVER ( PARTITION BY missing_geoms.ppid, >>> >> missing_geoms.point_time >>> >> ORDER BY missing_geoms.ppid, >>> >> missing_geoms.point_time, >>> >> filled_geoms.ppid, >>> >> filled_geoms.point_time DESC) >>> >> FROM missing_geoms >>> >> LEFT JOIN filled_geoms >>> >> ON filled_geoms.point_time < missing_geoms.point_time >>> >> AND filled_geoms.ppid = missing_geoms.ppid) >>> >> -------------- >>> >> SELECT * >>> >> FROM partitioned >>> >> WHERE row_number = 1; >>> >> >>> >> James >>> > >>> > >> >>
SELECT ppid, point_time, the_geom,
dense_rank() over (partition by ppid, the_geom order by ppid, point_time) as dr
FROM test_data
)
SELECT id, pt, gm,
CASE WHEN gm IS NULL THEN
LAG(gm, cast(c.DR as int) ) OVER (PARTITION BY id ORDER BY id, pt)
ELSE gm END as gm2
FROM C
ORDER BY id, pt, gm
All,
Here's a SQL fiddle of my problem:
http://sqlfiddle.com/#!15/77157
Thanks
James
On 30 January 2014 11:19, James David Smith <james.david.smith@gmail.com> wrote:
> Hi Erik / all,
>
> I don't think that will work, as what happens if one of the people has
> two missing periods of time within their day?
>
> I've made a self-contained example of my problem below. Would you mind
> trying to produce in the code below what you think I should do? Or if
> anyone else fancies having a go then please do.
>
> I very much appreciate your help by the way. Thank you. I'm really at
> a loss with this. :-(
>
> James
> --------------------------------------
>
> DROP TABLE test_data;
>
> CREATE TABLE test_data(
> ppid integer,
> point_time timestamp without time zone,
> the_geom integer);
>
> INSERT INTO test_data VALUES
> ('1', '2012-01-01 07:00', '1'),
> ('1', '2012-01-01 07:01', '1'),
> ('1', '2012-01-01 07:02', '1'),
> ('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1
> ('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1
> ('1', '2012-01-01 07:05', '5'),
> ('1', '2012-01-01 07:06', '5'),
> ('1', '2012-01-01 07:07', '5'),
> ('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5
> ('2', '2013-05-02 07:12', '24'),
> ('2', '2013-05-02 07:13', '24'),
> ('2', '2013-05-02 07:14', '24'),
> ('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24
> ('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24
> ('2', '2013-05-02 07:17', '44'),
> ('2', '2013-05-02 07:18', '44'),
> ('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44
> ('2', '2013-05-02 07:20', '4'),
> ('2', '2013-05-02 07:21', '4'),
> ('2', '2013-05-02 07:22', '4');
>
> WITH missing_geoms AS (
> SELECT ppid,
> point_time,
> the_geom
> FROM test_data
> WHERE the_geom IS NULL)
> ---
> ,filled_geoms AS (
> SELECT ppid,
> point_time,
> the_geom
> FROM test_data
> WHERE the_geom IS NOT NULL)
> ---
> ,partitioned AS (
> SELECT missing_geoms.ppid as missing_geoms_ppid,
> missing_geoms.point_time as missing_geoms_point_time,
> missing_geoms.the_geom as missing_geoms_the_geom,
> filled_geoms.ppid as filled_geoms_ppid,
> filled_geoms.point_time as filled_geoms_point_time,
> filled_geoms.the_geom as filled_geoms_the_geom
> FROM missing_geoms
> LEFT JOIN filled_geoms
> ON filled_geoms.point_time < missing_geoms.point_time
> AND filled_geoms.ppid = missing_geoms.ppid
> ORDER BY missing_geoms_ppid,
> missing_geoms_point_time)
> ---
> SELECT *
> FROM partitioned;
>
>
>
>
>
> On 29 January 2014 22:10, Erik Darling <edarling80@gmail.com> wrote:
>> Hi James,
>>
>> Yeah, that looks like the right place to me.
>>
>>
>> On Wed, Jan 29, 2014 at 1:14 PM, James David Smith
>> <james.david.smith@gmail.com> wrote:
>>>
>>> Hi Erik,
>>>
>>> Do you mean in this section of the SQL?
>>> .....
>>> filled_geoms AS (
>>> SELECT
>>> ppid,
>>> point_time,
>>> the_geom
>>> FROM
>>> hybrid_location
>>> WHERE
>>> the_geom IS NOT NULL)
>>> ...
>>>
>>> Thanks
>>>
>>> James
>>>
>>> On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
>>> > Hi James,
>>> >
>>> > I think you're still stuck with sort of unnecessary ('too much' ) data
>>> > coming from the right side of your left join. If so, one option I would
>>> > consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
>>> > filled_geoms table. If you partition by id and order by date descending,
>>> > you
>>> > can do an additional d_rank = 1 filter to only get the most recent
>>> > activity.
>>> > I believe this is what you want to set your NULL values to, no?
>>> >
>>> >
>>> >
>>> >
>>> > On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
>>> > <james.david.smith@gmail.com> wrote:
>>> >>
>>> >> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com> wrote:
>>> >> > I would re-suggest using a CTE to contain each dataset to ensure your
>>> >> > selects are distilling them correctly, and then using a final query
>>> >> > to
>>> >> > join
>>> >> > them. You can then either update your data directly through the
>>> >> > CTE(s),
>>> >> > or
>>> >> > insert the results to another table to do some further testing. I
>>> >> > think
>>> >> > you'll find this method presents the data a bit more ergonomically
>>> >> > for
>>> >> > analysis.
>>> >> >
>>> >> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>>> >> >
>>> >> >
>>> >> >
>>> >> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>>> >> > <james.david.smith@gmail.com> wrote:
>>> >> >>
>>> >> >> Hi Erik/all,
>>> >> >>
>>> >> >> I just tried that, but it's tricky. The 'extra' data is indeed
>>> >> >> coming
>>> >> >> from the right side of the join, but it's hard to select only the
>>> >> >> max
>>> >> >> from it. Maybe it's possible but I've not managed to do it. Here is
>>> >> >> where I am, which is so very close.
>>> >> >>
>>> >> >> SELECT
>>> >> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>>> >> >> row_that_needs_geom_updating,
>>> >> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>>> >> >> last_known_position_time
>>> >> >> FROM
>>> >> >> test a
>>> >> >> INNER JOIN
>>> >> >> (SELECT ppid,
>>> >> >> point_time,
>>> >> >> the_geom
>>> >> >> FROM test
>>> >> >> WHERE the_geom IS NOT NULL) b
>>> >> >> ON b.point_time < a.point_time
>>> >> >> AND a.ppid = b.ppid
>>> >> >> WHERE a.the_geom IS NULL;
>>> >> >>
>>> >> >> If you see attached screen-print, the output is the rows that I
>>> >> >> want.
>>> >> >> However I've had to use DISTINCT to stop the duplication. Also I've
>>> >> >> not managed to pull through 'the_geom' from the JOIN. I'm not sure
>>> >> >> how. Anyone?
>>> >> >>
>>> >> >> But it's kind of working. :-)
>>> >> >>
>>> >> >> Worst case if I can't figure out how to solve this in one query I'll
>>> >> >> have to store the result of the above, and then use it as a basis
>>> >> >> for
>>> >> >> another query I think.
>>> >> >>
>>> >> >> Thanks
>>> >> >>
>>> >> >> James
>>> >> >>
>>> >> >>
>>> >> >>
>>> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com> wrote:
>>> >> >> > I would try partitioning the second time you call row_number,
>>> >> >> > perhaps
>>> >> >> > by
>>> >> >> > ID,
>>> >> >> > and then selecting the MAX() from that, since I think the too much
>>> >> >> > data
>>> >> >> > you're referring to is coming from the right side of your join.
>>> >> >> >
>>> >> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>>> >> >> > <james.david.smith@gmail.com>
>>> >> >> > wrote:
>>> >> >> >>
>>> >> >> >> On 28 January 2014 23:15, Gavin Flower
>>> >> >> >> <GavinFlower@archidevsys.co.nz>
>>> >> >> >> wrote:
>>> >> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>>> >> >> >> >>
>>> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>>> >> >> >> >>
>>> >> >> >> >>> Given the data is so large I don't want to be taking the data
>>> >> >> >> >>> out
>>> >> >> >> >>> to a CSV or whatever and then loading it back in. I'd like to
>>> >> >> >> >>> do
>>> >> >> >> >>> this within the database using SQL. I thought I would be able
>>> >> >> >> >>> to
>>> >> >> >> >>> do this using a LOOP to be honest.
>>> >> >> >> >>
>>> >> >> >> >> I would be amazed if you couldn't do this with a single
>>> >> >> >> >> UPDATE
>>> >> >> >> >> statement. I've generally found declarative forms of such
>>> >> >> >> >> work
>>> >> >> >> >> to
>>> >> >> >> >> be at least one order of magnitude faster than going to either
>>> >> >> >> >> a
>>> >> >> >> >> PL
>>> >> >> >> >> or a script approach. I would start by putting together a
>>> >> >> >> >> SELECT
>>> >> >> >> >> query using window functions and maybe a CTE or two to list
>>> >> >> >> >> all
>>> >> >> >> >> the
>>> >> >> >> >> primary keys which need updating and the new values they
>>> >> >> >> >> should
>>> >> >> >> >> have. Once that SELECT was looking good, I would put it in
>>> >> >> >> >> the
>>> >> >> >> >> FROM clause of an UPDATE statement.
>>> >> >> >> >>
>>> >> >> >> >> That should work, but if you are updating a large percentage
>>> >> >> >> >> of
>>> >> >> >> >> the
>>> >> >> >> >> table, I would go one step further before running this against
>>> >> >> >> >> the
>>> >> >> >> >> production tables. I would put a LIMIT on the above-mentioned
>>> >> >> >> >> SELECT of something like 10000 rows, and script a loop that
>>> >> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the
>>> >> >> >> >> table.
>>> >> >> >> >>
>>> >> >> >> >> --
>>> >> >> >> >> Kevin Grittner
>>> >> >> >> >> EDB: http://www.enterprisedb.com
>>> >> >> >> >> The Enterprise PostgreSQL Company
>>> >> >> >> >>
>>> >> >> >> >>
>>> >> >> >> > James, you might consider dropping as many indexes on the table
>>> >> >> >> > as
>>> >> >> >> > you
>>> >> >> >> > safely can, and rebuilding them after the mass update. If you
>>> >> >> >> > have
>>> >> >> >> > lots
>>> >> >> >> > of
>>> >> >> >> > such indexes, you will find this apprtoach to be a lot faster.
>>> >> >> >> >
>>> >> >> >> >
>>> >> >> >> > Cheers,
>>> >> >> >> > Gavin
>>> >> >> >>
>>> >> >> >> Hi all,
>>> >> >> >>
>>> >> >> >> Thanks for your help and assistance. I think that window
>>> >> >> >> functions,
>>> >> >> >> and inparticular the PARTITION function, is 100% the way to go.
>>> >> >> >> I've
>>> >> >> >> been concentrating on a SELECT statement for now and am close but
>>> >> >> >> not
>>> >> >> >> quite close enough. The below query gets all the data I want, but
>>> >> >> >> *too* much. What I've essentially done is:
>>> >> >> >>
>>> >> >> >> - Select all the rows that don't have any geom information
>>> >> >> >> - Join them with all rows before this point that *do* have geom
>>> >> >> >> information.
>>> >> >> >> - Before doing this join, use partition to generate row numbers.
>>> >> >> >>
>>> >> >> >> The attached screen grab shows the result of my query below.
>>> >> >> >> Unfortunately this is generating alot of joins that I don't want.
>>> >> >> >> This
>>> >> >> >> won't be practical when doing it with 75,000 people.
>>> >> >> >>
>>> >> >> >> Thoughts and code suggestions very much appreciated... if needed
>>> >> >> >> I
>>> >> >> >> could put together some SQL to create an example table?
>>> >> >> >>
>>> >> >> >> Thanks
>>> >> >> >>
>>> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time ORDER
>>> >> >> >> BY
>>> >> >> >> test.point_time) as test_row,
>>> >> >> >> test.ppid as test_ppid,
>>> >> >> >> test.point_time as test_point_time,
>>> >> >> >> test.the_geom as test_the_geom,
>>> >> >> >> a.ppid as a_ppid,
>>> >> >> >> a.point_time as a_point_time,
>>> >> >> >> a.the_geom as a_the_geom,
>>> >> >> >> a.a_row
>>> >> >> >> FROM test
>>> >> >> >> LEFT JOIN (
>>> >> >> >> SELECT the_geom,
>>> >> >> >> ppid,
>>> >> >> >> point_time,
>>> >> >> >> row_number() OVER (ORDER BY ppid, point_time) as
>>> >> >> >> a_row
>>> >> >> >> FROM test
>>> >> >> >> WHERE the_geom IS NOT NULL) a
>>> >> >> >> ON a.point_time < test.point_time
>>> >> >> >> AND a.ppid = test.ppid
>>> >> >> >> WHERE test.the_geom IS NULL
>>> >> >> >> ORDER BY test.point_time)
>>> >> >> >>
>>> >>
>>> >>
>>> >> Hi Erik / all,
>>> >>
>>> >> So I think I've managed to re-write my queries using CTEs. The below
>>> >> code now does get me the data that I want from this. But to do so it
>>> >> is going to create a frankly huge table in the bit of the SQL where it
>>> >> makes the table called 'partitioned'. My rough guess is that it'll
>>> >> have to make a table of about 100 billion rows in order to get data I
>>> >> need ( about 108 million rows).
>>> >>
>>> >> Could someone please glance through it for me and suggest how to write
>>> >> it more efficiently?
>>> >>
>>> >> Thanks
>>> >>
>>> >> James
>>> >>
>>> >> WITH missing_geoms AS (
>>> >> SELECT ppid,
>>> >> point_time,
>>> >> the_geom
>>> >> FROM hybrid_location
>>> >> WHERE the_geom IS NULL)
>>> >> -----------------
>>> >> ,filled_geoms AS (
>>> >> SELECT ppid,
>>> >> point_time,
>>> >> the_geom
>>> >> FROM hybrid_location
>>> >> WHERE the_geom IS NOT NULL)
>>> >> ----------------
>>> >> ,partitioned AS (
>>> >> SELECT missing_geoms.ppid,
>>> >> missing_geoms.point_time,
>>> >> missing_geoms.the_geom,
>>> >> filled_geoms.ppid,
>>> >> filled_geoms.point_time,
>>> >> filled_geoms.the_geom,
>>> >> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>>> >> missing_geoms.point_time
>>> >> ORDER BY missing_geoms.ppid,
>>> >> missing_geoms.point_time,
>>> >> filled_geoms.ppid,
>>> >> filled_geoms.point_time DESC)
>>> >> FROM missing_geoms
>>> >> LEFT JOIN filled_geoms
>>> >> ON filled_geoms.point_time < missing_geoms.point_time
>>> >> AND filled_geoms.ppid = missing_geoms.ppid)
>>> >> --------------
>>> >> SELECT *
>>> >> FROM partitioned
>>> >> WHERE row_number = 1;
>>> >>
>>> >> James
>>> >
>>> >
>>
>>
You're a star Erik. Thanks again. I'll see how this goes.
I posted the question on stack-exchange earlier too by the way and
someone replied with the below code. So I'm going to try both. Cheers
again.
SELECT
data.ppid,
data.point_time,
CASE
WHEN data.the_geom IS NULL
THEN (
--Get all locations with an earlier time stamp for that ppid
SELECT geom.the_geom
FROM test_data geom
WHERE data.ppid = geom.ppid
AND geom.point_time < data.point_time
AND geom.the_geom IS NOT NULL
AND NOT EXISTS (
-- Cull all but the most recent one
SELECT *
FROM test_data cull
WHERE cull.ppid = geom.ppid
AND geom.the_geom IS NOT NULL
AND cull.point_time < data.point_time
AND cull.point_time > geom.point_time
AND cull.the_geom IS NOT NULL
)
)
ELSE data.the_geom
end
FROM test_data data
On 30 January 2014 15:24, Erik Darling <edarling80@gmail.com> wrote:
> Hi James,
>
> This is pretty close, but I have to get back to work for the time being.
> Feel free to mess with it. If you don't come up with a fully working
> solution, I can look at it later tonight (US EST). From your test data, only
> one row is missing the correct geom.
>
> WITH C (id, pt, gm, dr) as (
> SELECT ppid, point_time, the_geom,
> dense_rank() over (partition by ppid, the_geom order by ppid,
> point_time) as dr
> FROM test_data
> )
> SELECT id, pt, gm,
> CASE WHEN gm IS NULL THEN
> LAG(gm, cast(c.DR as int) ) OVER (PARTITION BY id ORDER BY id, pt)
> ELSE gm END as gm2
> FROM C
> ORDER BY id, pt, gm
>
>
>
> On Thu, Jan 30, 2014 at 8:58 AM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> All,
>>
>> Here's a SQL fiddle of my problem:
>>
>> http://sqlfiddle.com/#!15/77157
>>
>> Thanks
>>
>> James
>>
>> On 30 January 2014 11:19, James David Smith <james.david.smith@gmail.com>
>> wrote:
>> > Hi Erik / all,
>> >
>> > I don't think that will work, as what happens if one of the people has
>> > two missing periods of time within their day?
>> >
>> > I've made a self-contained example of my problem below. Would you mind
>> > trying to produce in the code below what you think I should do? Or if
>> > anyone else fancies having a go then please do.
>> >
>> > I very much appreciate your help by the way. Thank you. I'm really at
>> > a loss with this. :-(
>> >
>> > James
>> > --------------------------------------
>> >
>> > DROP TABLE test_data;
>> >
>> > CREATE TABLE test_data(
>> > ppid integer,
>> > point_time timestamp without time zone,
>> > the_geom integer);
>> >
>> > INSERT INTO test_data VALUES
>> > ('1', '2012-01-01 07:00', '1'),
>> > ('1', '2012-01-01 07:01', '1'),
>> > ('1', '2012-01-01 07:02', '1'),
>> > ('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1
>> > ('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1
>> > ('1', '2012-01-01 07:05', '5'),
>> > ('1', '2012-01-01 07:06', '5'),
>> > ('1', '2012-01-01 07:07', '5'),
>> > ('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5
>> > ('2', '2013-05-02 07:12', '24'),
>> > ('2', '2013-05-02 07:13', '24'),
>> > ('2', '2013-05-02 07:14', '24'),
>> > ('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24
>> > ('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24
>> > ('2', '2013-05-02 07:17', '44'),
>> > ('2', '2013-05-02 07:18', '44'),
>> > ('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44
>> > ('2', '2013-05-02 07:20', '4'),
>> > ('2', '2013-05-02 07:21', '4'),
>> > ('2', '2013-05-02 07:22', '4');
>> >
>> > WITH missing_geoms AS (
>> > SELECT ppid,
>> > point_time,
>> > the_geom
>> > FROM test_data
>> > WHERE the_geom IS NULL)
>> > ---
>> > ,filled_geoms AS (
>> > SELECT ppid,
>> > point_time,
>> > the_geom
>> > FROM test_data
>> > WHERE the_geom IS NOT NULL)
>> > ---
>> > ,partitioned AS (
>> > SELECT missing_geoms.ppid as missing_geoms_ppid,
>> > missing_geoms.point_time as missing_geoms_point_time,
>> > missing_geoms.the_geom as missing_geoms_the_geom,
>> > filled_geoms.ppid as filled_geoms_ppid,
>> > filled_geoms.point_time as filled_geoms_point_time,
>> > filled_geoms.the_geom as filled_geoms_the_geom
>> > FROM missing_geoms
>> > LEFT JOIN filled_geoms
>> > ON filled_geoms.point_time < missing_geoms.point_time
>> > AND filled_geoms.ppid = missing_geoms.ppid
>> > ORDER BY missing_geoms_ppid,
>> > missing_geoms_point_time)
>> > ---
>> > SELECT *
>> > FROM partitioned;
>> >
>> >
>> >
>> >
>> >
>> > On 29 January 2014 22:10, Erik Darling <edarling80@gmail.com> wrote:
>> >> Hi James,
>> >>
>> >> Yeah, that looks like the right place to me.
>> >>
>> >>
>> >> On Wed, Jan 29, 2014 at 1:14 PM, James David Smith
>> >> <james.david.smith@gmail.com> wrote:
>> >>>
>> >>> Hi Erik,
>> >>>
>> >>> Do you mean in this section of the SQL?
>> >>> .....
>> >>> filled_geoms AS (
>> >>> SELECT
>> >>> ppid,
>> >>> point_time,
>> >>> the_geom
>> >>> FROM
>> >>> hybrid_location
>> >>> WHERE
>> >>> the_geom IS NOT NULL)
>> >>> ...
>> >>>
>> >>> Thanks
>> >>>
>> >>> James
>> >>>
>> >>> On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
>> >>> > Hi James,
>> >>> >
>> >>> > I think you're still stuck with sort of unnecessary ('too much' )
>> >>> > data
>> >>> > coming from the right side of your left join. If so, one option I
>> >>> > would
>> >>> > consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
>> >>> > filled_geoms table. If you partition by id and order by date
>> >>> > descending,
>> >>> > you
>> >>> > can do an additional d_rank = 1 filter to only get the most recent
>> >>> > activity.
>> >>> > I believe this is what you want to set your NULL values to, no?
>> >>> >
>> >>> >
>> >>> >
>> >>> >
>> >>> > On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
>> >>> > <james.david.smith@gmail.com> wrote:
>> >>> >>
>> >>> >> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com>
>> >>> >> wrote:
>> >>> >> > I would re-suggest using a CTE to contain each dataset to ensure
>> >>> >> > your
>> >>> >> > selects are distilling them correctly, and then using a final
>> >>> >> > query
>> >>> >> > to
>> >>> >> > join
>> >>> >> > them. You can then either update your data directly through the
>> >>> >> > CTE(s),
>> >>> >> > or
>> >>> >> > insert the results to another table to do some further testing. I
>> >>> >> > think
>> >>> >> > you'll find this method presents the data a bit more
>> >>> >> > ergonomically
>> >>> >> > for
>> >>> >> > analysis.
>> >>> >> >
>> >>> >> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>> >>> >> >
>> >>> >> >
>> >>> >> >
>> >>> >> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>> >>> >> > <james.david.smith@gmail.com> wrote:
>> >>> >> >>
>> >>> >> >> Hi Erik/all,
>> >>> >> >>
>> >>> >> >> I just tried that, but it's tricky. The 'extra' data is indeed
>> >>> >> >> coming
>> >>> >> >> from the right side of the join, but it's hard to select only
>> >>> >> >> the
>> >>> >> >> max
>> >>> >> >> from it. Maybe it's possible but I've not managed to do it. Here
>> >>> >> >> is
>> >>> >> >> where I am, which is so very close.
>> >>> >> >>
>> >>> >> >> SELECT
>> >>> >> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> >>> >> >> row_that_needs_geom_updating,
>> >>> >> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> >>> >> >> last_known_position_time
>> >>> >> >> FROM
>> >>> >> >> test a
>> >>> >> >> INNER JOIN
>> >>> >> >> (SELECT ppid,
>> >>> >> >> point_time,
>> >>> >> >> the_geom
>> >>> >> >> FROM test
>> >>> >> >> WHERE the_geom IS NOT NULL) b
>> >>> >> >> ON b.point_time < a.point_time
>> >>> >> >> AND a.ppid = b.ppid
>> >>> >> >> WHERE a.the_geom IS NULL;
>> >>> >> >>
>> >>> >> >> If you see attached screen-print, the output is the rows that I
>> >>> >> >> want.
>> >>> >> >> However I've had to use DISTINCT to stop the duplication. Also
>> >>> >> >> I've
>> >>> >> >> not managed to pull through 'the_geom' from the JOIN. I'm not
>> >>> >> >> sure
>> >>> >> >> how. Anyone?
>> >>> >> >>
>> >>> >> >> But it's kind of working. :-)
>> >>> >> >>
>> >>> >> >> Worst case if I can't figure out how to solve this in one query
>> >>> >> >> I'll
>> >>> >> >> have to store the result of the above, and then use it as a
>> >>> >> >> basis
>> >>> >> >> for
>> >>> >> >> another query I think.
>> >>> >> >>
>> >>> >> >> Thanks
>> >>> >> >>
>> >>> >> >> James
>> >>> >> >>
>> >>> >> >>
>> >>> >> >>
>> >>> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com>
>> >>> >> >> wrote:
>> >>> >> >> > I would try partitioning the second time you call row_number,
>> >>> >> >> > perhaps
>> >>> >> >> > by
>> >>> >> >> > ID,
>> >>> >> >> > and then selecting the MAX() from that, since I think the too
>> >>> >> >> > much
>> >>> >> >> > data
>> >>> >> >> > you're referring to is coming from the right side of your
>> >>> >> >> > join.
>> >>> >> >> >
>> >>> >> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> >>> >> >> > <james.david.smith@gmail.com>
>> >>> >> >> > wrote:
>> >>> >> >> >>
>> >>> >> >> >> On 28 January 2014 23:15, Gavin Flower
>> >>> >> >> >> <GavinFlower@archidevsys.co.nz>
>> >>> >> >> >> wrote:
>> >>> >> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >>> >> >> >> >>
>> >>> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >>> >> >> >> >>
>> >>> >> >> >> >>> Given the data is so large I don't want to be taking the
>> >>> >> >> >> >>> data
>> >>> >> >> >> >>> out
>> >>> >> >> >> >>> to a CSV or whatever and then loading it back in. I'd
>> >>> >> >> >> >>> like to
>> >>> >> >> >> >>> do
>> >>> >> >> >> >>> this within the database using SQL. I thought I would be
>> >>> >> >> >> >>> able
>> >>> >> >> >> >>> to
>> >>> >> >> >> >>> do this using a LOOP to be honest.
>> >>> >> >> >> >>
>> >>> >> >> >> >> I would be amazed if you couldn't do this with a single
>> >>> >> >> >> >> UPDATE
>> >>> >> >> >> >> statement. I've generally found declarative forms of such
>> >>> >> >> >> >> work
>> >>> >> >> >> >> to
>> >>> >> >> >> >> be at least one order of magnitude faster than going to
>> >>> >> >> >> >> either
>> >>> >> >> >> >> a
>> >>> >> >> >> >> PL
>> >>> >> >> >> >> or a script approach. I would start by putting together a
>> >>> >> >> >> >> SELECT
>> >>> >> >> >> >> query using window functions and maybe a CTE or two to
>> >>> >> >> >> >> list
>> >>> >> >> >> >> all
>> >>> >> >> >> >> the
>> >>> >> >> >> >> primary keys which need updating and the new values they
>> >>> >> >> >> >> should
>> >>> >> >> >> >> have. Once that SELECT was looking good, I would put it
>> >>> >> >> >> >> in
>> >>> >> >> >> >> the
>> >>> >> >> >> >> FROM clause of an UPDATE statement.
>> >>> >> >> >> >>
>> >>> >> >> >> >> That should work, but if you are updating a large
>> >>> >> >> >> >> percentage
>> >>> >> >> >> >> of
>> >>> >> >> >> >> the
>> >>> >> >> >> >> table, I would go one step further before running this
>> >>> >> >> >> >> against
>> >>> >> >> >> >> the
>> >>> >> >> >> >> production tables. I would put a LIMIT on the
>> >>> >> >> >> >> above-mentioned
>> >>> >> >> >> >> SELECT of something like 10000 rows, and script a loop
>> >>> >> >> >> >> that
>> >>> >> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the
>> >>> >> >> >> >> table.
>> >>> >> >> >> >>
>> >>> >> >> >> >> --
>> >>> >> >> >> >> Kevin Grittner
>> >>> >> >> >> >> EDB: http://www.enterprisedb.com
>> >>> >> >> >> >> The Enterprise PostgreSQL Company
>> >>> >> >> >> >>
>> >>> >> >> >> >>
>> >>> >> >> >> > James, you might consider dropping as many indexes on the
>> >>> >> >> >> > table
>> >>> >> >> >> > as
>> >>> >> >> >> > you
>> >>> >> >> >> > safely can, and rebuilding them after the mass update. If
>> >>> >> >> >> > you
>> >>> >> >> >> > have
>> >>> >> >> >> > lots
>> >>> >> >> >> > of
>> >>> >> >> >> > such indexes, you will find this apprtoach to be a lot
>> >>> >> >> >> > faster.
>> >>> >> >> >> >
>> >>> >> >> >> >
>> >>> >> >> >> > Cheers,
>> >>> >> >> >> > Gavin
>> >>> >> >> >>
>> >>> >> >> >> Hi all,
>> >>> >> >> >>
>> >>> >> >> >> Thanks for your help and assistance. I think that window
>> >>> >> >> >> functions,
>> >>> >> >> >> and inparticular the PARTITION function, is 100% the way to
>> >>> >> >> >> go.
>> >>> >> >> >> I've
>> >>> >> >> >> been concentrating on a SELECT statement for now and am close
>> >>> >> >> >> but
>> >>> >> >> >> not
>> >>> >> >> >> quite close enough. The below query gets all the data I want,
>> >>> >> >> >> but
>> >>> >> >> >> *too* much. What I've essentially done is:
>> >>> >> >> >>
>> >>> >> >> >> - Select all the rows that don't have any geom information
>> >>> >> >> >> - Join them with all rows before this point that *do* have
>> >>> >> >> >> geom
>> >>> >> >> >> information.
>> >>> >> >> >> - Before doing this join, use partition to generate row
>> >>> >> >> >> numbers.
>> >>> >> >> >>
>> >>> >> >> >> The attached screen grab shows the result of my query below.
>> >>> >> >> >> Unfortunately this is generating alot of joins that I don't
>> >>> >> >> >> want.
>> >>> >> >> >> This
>> >>> >> >> >> won't be practical when doing it with 75,000 people.
>> >>> >> >> >>
>> >>> >> >> >> Thoughts and code suggestions very much appreciated... if
>> >>> >> >> >> needed
>> >>> >> >> >> I
>> >>> >> >> >> could put together some SQL to create an example table?
>> >>> >> >> >>
>> >>> >> >> >> Thanks
>> >>> >> >> >>
>> >>> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time
>> >>> >> >> >> ORDER
>> >>> >> >> >> BY
>> >>> >> >> >> test.point_time) as test_row,
>> >>> >> >> >> test.ppid as test_ppid,
>> >>> >> >> >> test.point_time as test_point_time,
>> >>> >> >> >> test.the_geom as test_the_geom,
>> >>> >> >> >> a.ppid as a_ppid,
>> >>> >> >> >> a.point_time as a_point_time,
>> >>> >> >> >> a.the_geom as a_the_geom,
>> >>> >> >> >> a.a_row
>> >>> >> >> >> FROM test
>> >>> >> >> >> LEFT JOIN (
>> >>> >> >> >> SELECT the_geom,
>> >>> >> >> >> ppid,
>> >>> >> >> >> point_time,
>> >>> >> >> >> row_number() OVER (ORDER BY ppid, point_time) as
>> >>> >> >> >> a_row
>> >>> >> >> >> FROM test
>> >>> >> >> >> WHERE the_geom IS NOT NULL) a
>> >>> >> >> >> ON a.point_time < test.point_time
>> >>> >> >> >> AND a.ppid = test.ppid
>> >>> >> >> >> WHERE test.the_geom IS NULL
>> >>> >> >> >> ORDER BY test.point_time)
>> >>> >> >> >>
>> >>> >>
>> >>> >>
>> >>> >> Hi Erik / all,
>> >>> >>
>> >>> >> So I think I've managed to re-write my queries using CTEs. The
>> >>> >> below
>> >>> >> code now does get me the data that I want from this. But to do so
>> >>> >> it
>> >>> >> is going to create a frankly huge table in the bit of the SQL where
>> >>> >> it
>> >>> >> makes the table called 'partitioned'. My rough guess is that it'll
>> >>> >> have to make a table of about 100 billion rows in order to get data
>> >>> >> I
>> >>> >> need ( about 108 million rows).
>> >>> >>
>> >>> >> Could someone please glance through it for me and suggest how to
>> >>> >> write
>> >>> >> it more efficiently?
>> >>> >>
>> >>> >> Thanks
>> >>> >>
>> >>> >> James
>> >>> >>
>> >>> >> WITH missing_geoms AS (
>> >>> >> SELECT ppid,
>> >>> >> point_time,
>> >>> >> the_geom
>> >>> >> FROM hybrid_location
>> >>> >> WHERE the_geom IS NULL)
>> >>> >> -----------------
>> >>> >> ,filled_geoms AS (
>> >>> >> SELECT ppid,
>> >>> >> point_time,
>> >>> >> the_geom
>> >>> >> FROM hybrid_location
>> >>> >> WHERE the_geom IS NOT NULL)
>> >>> >> ----------------
>> >>> >> ,partitioned AS (
>> >>> >> SELECT missing_geoms.ppid,
>> >>> >> missing_geoms.point_time,
>> >>> >> missing_geoms.the_geom,
>> >>> >> filled_geoms.ppid,
>> >>> >> filled_geoms.point_time,
>> >>> >> filled_geoms.the_geom,
>> >>> >> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>> >>> >> missing_geoms.point_time
>> >>> >> ORDER BY missing_geoms.ppid,
>> >>> >> missing_geoms.point_time,
>> >>> >> filled_geoms.ppid,
>> >>> >> filled_geoms.point_time DESC)
>> >>> >> FROM missing_geoms
>> >>> >> LEFT JOIN filled_geoms
>> >>> >> ON filled_geoms.point_time < missing_geoms.point_time
>> >>> >> AND filled_geoms.ppid = missing_geoms.ppid)
>> >>> >> --------------
>> >>> >> SELECT *
>> >>> >> FROM partitioned
>> >>> >> WHERE row_number = 1;
>> >>> >>
>> >>> >> James
>> >>> >
>> >>> >
>> >>
>> >>
>
>
SELECT
data.ppid,
data.point_time,
CASE
WHEN data.the_geom IS NULL
THEN (
--Get all locations ...
ERROR: This type of correlated subquery pattern is not supported yet [SQL State=0A000]
You're a star Erik. Thanks again. I'll see how this goes.
I posted the question on stack-exchange earlier too by the way and
someone replied with the below code. So I'm going to try both. Cheers
again.
SELECT
data.ppid,
data.point_time,
CASE
WHEN data.the_geom IS NULL
THEN (
--Get all locations with an earlier time stamp for that ppid
SELECT geom.the_geom
FROM test_data geom
WHERE data.ppid = geom.ppid
AND geom.point_time < data.point_time
AND geom.the_geom IS NOT NULL
AND NOT EXISTS (
-- Cull all but the most recent one
SELECT *
FROM test_data cull
WHERE cull.ppid = geom.ppid
AND geom.the_geom IS NOT NULL
AND cull.point_time < data.point_time
AND cull.point_time > geom.point_time
AND cull.the_geom IS NOT NULL
)
)
ELSE data.the_geom
end
FROM test_data data
On 30 January 2014 15:24, Erik Darling <edarling80@gmail.com> wrote:
> Hi James,
>
> This is pretty close, but I have to get back to work for the time being.
> Feel free to mess with it. If you don't come up with a fully working
> solution, I can look at it later tonight (US EST). From your test data, only
> one row is missing the correct geom.
>
> WITH C (id, pt, gm, dr) as (
> SELECT ppid, point_time, the_geom,
> dense_rank() over (partition by ppid, the_geom order by ppid,
> point_time) as dr
> FROM test_data
> )
> SELECT id, pt, gm,
> CASE WHEN gm IS NULL THEN
> LAG(gm, cast(c.DR as int) ) OVER (PARTITION BY id ORDER BY id, pt)
> ELSE gm END as gm2
> FROM C
> ORDER BY id, pt, gm
>
>
>
> On Thu, Jan 30, 2014 at 8:58 AM, James David Smith
> <james.david.smith@gmail.com> wrote:
>>
>> All,
>>
>> Here's a SQL fiddle of my problem:
>>
>> http://sqlfiddle.com/#!15/77157
>>
>> Thanks
>>
>> James
>>
>> On 30 January 2014 11:19, James David Smith <james.david.smith@gmail.com>
>> wrote:
>> > Hi Erik / all,
>> >
>> > I don't think that will work, as what happens if one of the people has
>> > two missing periods of time within their day?
>> >
>> > I've made a self-contained example of my problem below. Would you mind
>> > trying to produce in the code below what you think I should do? Or if
>> > anyone else fancies having a go then please do.
>> >
>> > I very much appreciate your help by the way. Thank you. I'm really at
>> > a loss with this. :-(
>> >
>> > James
>> > --------------------------------------
>> >
>> > DROP TABLE test_data;
>> >
>> > CREATE TABLE test_data(
>> > ppid integer,
>> > point_time timestamp without time zone,
>> > the_geom integer);
>> >
>> > INSERT INTO test_data VALUES
>> > ('1', '2012-01-01 07:00', '1'),
>> > ('1', '2012-01-01 07:01', '1'),
>> > ('1', '2012-01-01 07:02', '1'),
>> > ('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1
>> > ('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1
>> > ('1', '2012-01-01 07:05', '5'),
>> > ('1', '2012-01-01 07:06', '5'),
>> > ('1', '2012-01-01 07:07', '5'),
>> > ('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5
>> > ('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5
>> > ('2', '2013-05-02 07:12', '24'),
>> > ('2', '2013-05-02 07:13', '24'),
>> > ('2', '2013-05-02 07:14', '24'),
>> > ('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24
>> > ('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24
>> > ('2', '2013-05-02 07:17', '44'),
>> > ('2', '2013-05-02 07:18', '44'),
>> > ('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44
>> > ('2', '2013-05-02 07:20', '4'),
>> > ('2', '2013-05-02 07:21', '4'),
>> > ('2', '2013-05-02 07:22', '4');
>> >
>> > WITH missing_geoms AS (
>> > SELECT ppid,
>> > point_time,
>> > the_geom
>> > FROM test_data
>> > WHERE the_geom IS NULL)
>> > ---
>> > ,filled_geoms AS (
>> > SELECT ppid,
>> > point_time,
>> > the_geom
>> > FROM test_data
>> > WHERE the_geom IS NOT NULL)
>> > ---
>> > ,partitioned AS (
>> > SELECT missing_geoms.ppid as missing_geoms_ppid,
>> > missing_geoms.point_time as missing_geoms_point_time,
>> > missing_geoms.the_geom as missing_geoms_the_geom,
>> > filled_geoms.ppid as filled_geoms_ppid,
>> > filled_geoms.point_time as filled_geoms_point_time,
>> > filled_geoms.the_geom as filled_geoms_the_geom
>> > FROM missing_geoms
>> > LEFT JOIN filled_geoms
>> > ON filled_geoms.point_time < missing_geoms.point_time
>> > AND filled_geoms.ppid = missing_geoms.ppid
>> > ORDER BY missing_geoms_ppid,
>> > missing_geoms_point_time)
>> > ---
>> > SELECT *
>> > FROM partitioned;
>> >
>> >
>> >
>> >
>> >
>> > On 29 January 2014 22:10, Erik Darling <edarling80@gmail.com> wrote:
>> >> Hi James,
>> >>
>> >> Yeah, that looks like the right place to me.
>> >>
>> >>
>> >> On Wed, Jan 29, 2014 at 1:14 PM, James David Smith
>> >> <james.david.smith@gmail.com> wrote:
>> >>>
>> >>> Hi Erik,
>> >>>
>> >>> Do you mean in this section of the SQL?
>> >>> .....
>> >>> filled_geoms AS (
>> >>> SELECT
>> >>> ppid,
>> >>> point_time,
>> >>> the_geom
>> >>> FROM
>> >>> hybrid_location
>> >>> WHERE
>> >>> the_geom IS NOT NULL)
>> >>> ...
>> >>>
>> >>> Thanks
>> >>>
>> >>> James
>> >>>
>> >>> On 29 January 2014 17:57, Erik Darling <edarling80@gmail.com> wrote:
>> >>> > Hi James,
>> >>> >
>> >>> > I think you're still stuck with sort of unnecessary ('too much' )
>> >>> > data
>> >>> > coming from the right side of your left join. If so, one option I
>> >>> > would
>> >>> > consider is using DENSE_RANK() the way you use ROW_NUMBER(), in the
>> >>> > filled_geoms table. If you partition by id and order by date
>> >>> > descending,
>> >>> > you
>> >>> > can do an additional d_rank = 1 filter to only get the most recent
>> >>> > activity.
>> >>> > I believe this is what you want to set your NULL values to, no?
>> >>> >
>> >>> >
>> >>> >
>> >>> >
>> >>> > On Wed, Jan 29, 2014 at 12:41 PM, James David Smith
>> >>> > <james.david.smith@gmail.com> wrote:
>> >>> >>
>> >>> >> On 29 January 2014 16:02, Erik Darling <edarling80@gmail.com>
>> >>> >> wrote:
>> >>> >> > I would re-suggest using a CTE to contain each dataset to ensure
>> >>> >> > your
>> >>> >> > selects are distilling them correctly, and then using a final
>> >>> >> > query
>> >>> >> > to
>> >>> >> > join
>> >>> >> > them. You can then either update your data directly through the
>> >>> >> > CTE(s),
>> >>> >> > or
>> >>> >> > insert the results to another table to do some further testing. I
>> >>> >> > think
>> >>> >> > you'll find this method presents the data a bit more
>> >>> >> > ergonomically
>> >>> >> > for
>> >>> >> > analysis.
>> >>> >> >
>> >>> >> > http://www.postgresql.org/docs/9.3/static/queries-with.html
>> >>> >> >
>> >>> >> >
>> >>> >> >
>> >>> >> > On Wed, Jan 29, 2014 at 10:45 AM, James David Smith
>> >>> >> > <james.david.smith@gmail.com> wrote:
>> >>> >> >>
>> >>> >> >> Hi Erik/all,
>> >>> >> >>
>> >>> >> >> I just tried that, but it's tricky. The 'extra' data is indeed
>> >>> >> >> coming
>> >>> >> >> from the right side of the join, but it's hard to select only
>> >>> >> >> the
>> >>> >> >> max
>> >>> >> >> from it. Maybe it's possible but I've not managed to do it. Here
>> >>> >> >> is
>> >>> >> >> where I am, which is so very close.
>> >>> >> >>
>> >>> >> >> SELECT
>> >>> >> >> DISTINCT(a.ppid, a.point_time, a.the_geom) as
>> >>> >> >> row_that_needs_geom_updating,
>> >>> >> >> max(b.point_time) OVER (PARTITION BY a.ppid, a.point_time) as
>> >>> >> >> last_known_position_time
>> >>> >> >> FROM
>> >>> >> >> test a
>> >>> >> >> INNER JOIN
>> >>> >> >> (SELECT ppid,
>> >>> >> >> point_time,
>> >>> >> >> the_geom
>> >>> >> >> FROM test
>> >>> >> >> WHERE the_geom IS NOT NULL) b
>> >>> >> >> ON b.point_time < a.point_time
>> >>> >> >> AND a.ppid = b.ppid
>> >>> >> >> WHERE a.the_geom IS NULL;
>> >>> >> >>
>> >>> >> >> If you see attached screen-print, the output is the rows that I
>> >>> >> >> want.
>> >>> >> >> However I've had to use DISTINCT to stop the duplication. Also
>> >>> >> >> I've
>> >>> >> >> not managed to pull through 'the_geom' from the JOIN. I'm not
>> >>> >> >> sure
>> >>> >> >> how. Anyone?
>> >>> >> >>
>> >>> >> >> But it's kind of working. :-)
>> >>> >> >>
>> >>> >> >> Worst case if I can't figure out how to solve this in one query
>> >>> >> >> I'll
>> >>> >> >> have to store the result of the above, and then use it as a
>> >>> >> >> basis
>> >>> >> >> for
>> >>> >> >> another query I think.
>> >>> >> >>
>> >>> >> >> Thanks
>> >>> >> >>
>> >>> >> >> James
>> >>> >> >>
>> >>> >> >>
>> >>> >> >>
>> >>> >> >> On 29 January 2014 12:56, Erik Darling <edarling80@gmail.com>
>> >>> >> >> wrote:
>> >>> >> >> > I would try partitioning the second time you call row_number,
>> >>> >> >> > perhaps
>> >>> >> >> > by
>> >>> >> >> > ID,
>> >>> >> >> > and then selecting the MAX() from that, since I think the too
>> >>> >> >> > much
>> >>> >> >> > data
>> >>> >> >> > you're referring to is coming from the right side of your
>> >>> >> >> > join.
>> >>> >> >> >
>> >>> >> >> > On Jan 29, 2014 7:23 AM, "James David Smith"
>> >>> >> >> > <james.david.smith@gmail.com>
>> >>> >> >> > wrote:
>> >>> >> >> >>
>> >>> >> >> >> On 28 January 2014 23:15, Gavin Flower
>> >>> >> >> >> <GavinFlower@archidevsys.co.nz>
>> >>> >> >> >> wrote:
>> >>> >> >> >> > On 29/01/14 11:00, Kevin Grittner wrote:
>> >>> >> >> >> >>
>> >>> >> >> >> >> James David Smith <james.david.smith@gmail.com> wrote:
>> >>> >> >> >> >>
>> >>> >> >> >> >>> Given the data is so large I don't want to be taking the
>> >>> >> >> >> >>> data
>> >>> >> >> >> >>> out
>> >>> >> >> >> >>> to a CSV or whatever and then loading it back in. I'd
>> >>> >> >> >> >>> like to
>> >>> >> >> >> >>> do
>> >>> >> >> >> >>> this within the database using SQL. I thought I would be
>> >>> >> >> >> >>> able
>> >>> >> >> >> >>> to
>> >>> >> >> >> >>> do this using a LOOP to be honest.
>> >>> >> >> >> >>
>> >>> >> >> >> >> I would be amazed if you couldn't do this with a single
>> >>> >> >> >> >> UPDATE
>> >>> >> >> >> >> statement. I've generally found declarative forms of such
>> >>> >> >> >> >> work
>> >>> >> >> >> >> to
>> >>> >> >> >> >> be at least one order of magnitude faster than going to
>> >>> >> >> >> >> either
>> >>> >> >> >> >> a
>> >>> >> >> >> >> PL
>> >>> >> >> >> >> or a script approach. I would start by putting together a
>> >>> >> >> >> >> SELECT
>> >>> >> >> >> >> query using window functions and maybe a CTE or two to
>> >>> >> >> >> >> list
>> >>> >> >> >> >> all
>> >>> >> >> >> >> the
>> >>> >> >> >> >> primary keys which need updating and the new values they
>> >>> >> >> >> >> should
>> >>> >> >> >> >> have. Once that SELECT was looking good, I would put it
>> >>> >> >> >> >> in
>> >>> >> >> >> >> the
>> >>> >> >> >> >> FROM clause of an UPDATE statement.
>> >>> >> >> >> >>
>> >>> >> >> >> >> That should work, but if you are updating a large
>> >>> >> >> >> >> percentage
>> >>> >> >> >> >> of
>> >>> >> >> >> >> the
>> >>> >> >> >> >> table, I would go one step further before running this
>> >>> >> >> >> >> against
>> >>> >> >> >> >> the
>> >>> >> >> >> >> production tables. I would put a LIMIT on the
>> >>> >> >> >> >> above-mentioned
>> >>> >> >> >> >> SELECT of something like 10000 rows, and script a loop
>> >>> >> >> >> >> that
>> >>> >> >> >> >> alternates between the UPDATE and a VACUUM ANALYZE on the
>> >>> >> >> >> >> table.
>> >>> >> >> >> >>
>> >>> >> >> >> >> --
>> >>> >> >> >> >> Kevin Grittner
>> >>> >> >> >> >> EDB: http://www.enterprisedb.com
>> >>> >> >> >> >> The Enterprise PostgreSQL Company
>> >>> >> >> >> >>
>> >>> >> >> >> >>
>> >>> >> >> >> > James, you might consider dropping as many indexes on the
>> >>> >> >> >> > table
>> >>> >> >> >> > as
>> >>> >> >> >> > you
>> >>> >> >> >> > safely can, and rebuilding them after the mass update. If
>> >>> >> >> >> > you
>> >>> >> >> >> > have
>> >>> >> >> >> > lots
>> >>> >> >> >> > of
>> >>> >> >> >> > such indexes, you will find this apprtoach to be a lot
>> >>> >> >> >> > faster.
>> >>> >> >> >> >
>> >>> >> >> >> >
>> >>> >> >> >> > Cheers,
>> >>> >> >> >> > Gavin
>> >>> >> >> >>
>> >>> >> >> >> Hi all,
>> >>> >> >> >>
>> >>> >> >> >> Thanks for your help and assistance. I think that window
>> >>> >> >> >> functions,
>> >>> >> >> >> and inparticular the PARTITION function, is 100% the way to
>> >>> >> >> >> go.
>> >>> >> >> >> I've
>> >>> >> >> >> been concentrating on a SELECT statement for now and am close
>> >>> >> >> >> but
>> >>> >> >> >> not
>> >>> >> >> >> quite close enough. The below query gets all the data I want,
>> >>> >> >> >> but
>> >>> >> >> >> *too* much. What I've essentially done is:
>> >>> >> >> >>
>> >>> >> >> >> - Select all the rows that don't have any geom information
>> >>> >> >> >> - Join them with all rows before this point that *do* have
>> >>> >> >> >> geom
>> >>> >> >> >> information.
>> >>> >> >> >> - Before doing this join, use partition to generate row
>> >>> >> >> >> numbers.
>> >>> >> >> >>
>> >>> >> >> >> The attached screen grab shows the result of my query below.
>> >>> >> >> >> Unfortunately this is generating alot of joins that I don't
>> >>> >> >> >> want.
>> >>> >> >> >> This
>> >>> >> >> >> won't be practical when doing it with 75,000 people.
>> >>> >> >> >>
>> >>> >> >> >> Thoughts and code suggestions very much appreciated... if
>> >>> >> >> >> needed
>> >>> >> >> >> I
>> >>> >> >> >> could put together some SQL to create an example table?
>> >>> >> >> >>
>> >>> >> >> >> Thanks
>> >>> >> >> >>
>> >>> >> >> >> SELECT row_number() OVER (PARTITION BY test.point_time
>> >>> >> >> >> ORDER
>> >>> >> >> >> BY
>> >>> >> >> >> test.point_time) as test_row,
>> >>> >> >> >> test.ppid as test_ppid,
>> >>> >> >> >> test.point_time as test_point_time,
>> >>> >> >> >> test.the_geom as test_the_geom,
>> >>> >> >> >> a.ppid as a_ppid,
>> >>> >> >> >> a.point_time as a_point_time,
>> >>> >> >> >> a.the_geom as a_the_geom,
>> >>> >> >> >> a.a_row
>> >>> >> >> >> FROM test
>> >>> >> >> >> LEFT JOIN (
>> >>> >> >> >> SELECT the_geom,
>> >>> >> >> >> ppid,
>> >>> >> >> >> point_time,
>> >>> >> >> >> row_number() OVER (ORDER BY ppid, point_time) as
>> >>> >> >> >> a_row
>> >>> >> >> >> FROM test
>> >>> >> >> >> WHERE the_geom IS NOT NULL) a
>> >>> >> >> >> ON a.point_time < test.point_time
>> >>> >> >> >> AND a.ppid = test.ppid
>> >>> >> >> >> WHERE test.the_geom IS NULL
>> >>> >> >> >> ORDER BY test.point_time)
>> >>> >> >> >>
>> >>> >>
>> >>> >>
>> >>> >> Hi Erik / all,
>> >>> >>
>> >>> >> So I think I've managed to re-write my queries using CTEs. The
>> >>> >> below
>> >>> >> code now does get me the data that I want from this. But to do so
>> >>> >> it
>> >>> >> is going to create a frankly huge table in the bit of the SQL where
>> >>> >> it
>> >>> >> makes the table called 'partitioned'. My rough guess is that it'll
>> >>> >> have to make a table of about 100 billion rows in order to get data
>> >>> >> I
>> >>> >> need ( about 108 million rows).
>> >>> >>
>> >>> >> Could someone please glance through it for me and suggest how to
>> >>> >> write
>> >>> >> it more efficiently?
>> >>> >>
>> >>> >> Thanks
>> >>> >>
>> >>> >> James
>> >>> >>
>> >>> >> WITH missing_geoms AS (
>> >>> >> SELECT ppid,
>> >>> >> point_time,
>> >>> >> the_geom
>> >>> >> FROM hybrid_location
>> >>> >> WHERE the_geom IS NULL)
>> >>> >> -----------------
>> >>> >> ,filled_geoms AS (
>> >>> >> SELECT ppid,
>> >>> >> point_time,
>> >>> >> the_geom
>> >>> >> FROM hybrid_location
>> >>> >> WHERE the_geom IS NOT NULL)
>> >>> >> ----------------
>> >>> >> ,partitioned AS (
>> >>> >> SELECT missing_geoms.ppid,
>> >>> >> missing_geoms.point_time,
>> >>> >> missing_geoms.the_geom,
>> >>> >> filled_geoms.ppid,
>> >>> >> filled_geoms.point_time,
>> >>> >> filled_geoms.the_geom,
>> >>> >> row_number() OVER ( PARTITION BY missing_geoms.ppid,
>> >>> >> missing_geoms.point_time
>> >>> >> ORDER BY missing_geoms.ppid,
>> >>> >> missing_geoms.point_time,
>> >>> >> filled_geoms.ppid,
>> >>> >> filled_geoms.point_time DESC)
>> >>> >> FROM missing_geoms
>> >>> >> LEFT JOIN filled_geoms
>> >>> >> ON filled_geoms.point_time < missing_geoms.point_time
>> >>> >> AND filled_geoms.ppid = missing_geoms.ppid)
>> >>> >> --------------
>> >>> >> SELECT *
>> >>> >> FROM partitioned
>> >>> >> WHERE row_number = 1;
>> >>> >>
>> >>> >> James
>> >>> >
>> >>> >
>> >>
>> >>
>
>
James David Smith wrote
> INSERT INTO test_data VALUES
> ('1', '2012-01-01 07:00', '1'),
> ('1', '2012-01-01 07:01', '1'),
> ('1', '2012-01-01 07:02', '1'),
> ('1', '2012-01-01 07:03', NULL), -- null should be replaced with 1
> ('1', '2012-01-01 07:04', NULL), -- null should be replaced with 1
> ('1', '2012-01-01 07:05', '5'),
> ('1', '2012-01-01 07:06', '5'),
> ('1', '2012-01-01 07:07', '5'),
> ('1', '2012-01-01 07:08', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:09', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:10', NULL), -- null should be replaced with 5
> ('1', '2012-01-01 07:11', NULL), -- null should be replaced with 5
> ('2', '2013-05-02 07:12', '24'),
> ('2', '2013-05-02 07:13', '24'),
> ('2', '2013-05-02 07:14', '24'),
> ('2', '2013-05-02 07:15', NULL), -- null should be replaced with 24
> ('2', '2013-05-02 07:16', NULL), -- null should be replaced with 24
> ('2', '2013-05-02 07:17', '44'),
> ('2', '2013-05-02 07:18', '44'),
> ('2', '2013-05-02 07:19', NULL), -- null should be replaced with 44
> ('2', '2013-05-02 07:20', '4'),
> ('2', '2013-05-02 07:21', '4'),
> ('2', '2013-05-02 07:22', '4');
This specific problem has two solutions.
1. Create a custom aggregate that maintains the last non-null value
encountered and returns it as a final value.
2. More slowly, but less complexly, use array_agg to capture all prior
values of the data in question. Then pass that array into a function that
unnests the array, removes the Nulls, reverses the order, and applies limit
1.
For both solutions you will need to construct a window clause with an order
by.
Examples exists in the mailing list archive. Recently I can recall Merlin
and myself posting these but cannot go find them at this moment.
David J.
--
View this message in context:
http://postgresql.1045698.n5.nabble.com/Update-with-last-known-location-tp5788966p5789708.html
Sent from the PostgreSQL - novice mailing list archive at Nabble.com.
James David Smith <james.david.smith@gmail.com> wrote: > I've made a self-contained example of my problem below. It is always easier to provide advice on this sort of thing with a self-contained test case. Looking at that, I think I would approach it this way, at least as a first attempt, to see if performance is good enough: update test_data x set the_geom = y.the_geom from test_data y where x.the_geom is null and y.ppid = x.ppid and y.the_geom is not null and y.point_time < x.point_time and not exists ( select * from test_data z where z.ppid = y.ppid and z.the_geom is not null and z.point_time > y.point_time and z.point_time < x.point_time ) ; To my eye, that is simple and straightforward. On my machine, it runs in less than 1 ms with the provided test data; the question is whether it scales OK. If it does not, we will need a description of your hardware, OS, and your configuration to figure out why not. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 30 January 2014 16:45, Kevin Grittner <kgrittn@ymail.com> wrote: > James David Smith <james.david.smith@gmail.com> wrote: > >> I've made a self-contained example of my problem below. > > It is always easier to provide advice on this sort of thing with a > self-contained test case. Looking at that, I think I would > approach it this way, at least as a first attempt, to see if > performance is good enough: > > update test_data x > set the_geom = y.the_geom > from test_data y > where x.the_geom is null > and y.ppid = x.ppid > and y.the_geom is not null > and y.point_time < x.point_time > and not exists > ( > select * from test_data z > where z.ppid = y.ppid > and z.the_geom is not null > and z.point_time > y.point_time > and z.point_time < x.point_time > ) > ; > > To my eye, that is simple and straightforward. On my machine, it > runs in less than 1 ms with the provided test data; the question is > whether it scales OK. If it does not, we will need a description > of your hardware, OS, and your configuration to figure out why not. > > -- > Kevin Grittner > EDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company Hi Kevin et al, Thanks for the code. I've just ran it. It completed in 0.730 ms. Speedy. I can't run it on my actual data at the moment, or rather I don't want too, as I set the below query going an hour or so ago and thought I should let it finish really. If it hasn't finished when I come into work tomorrow (I'm leaving the office shortly) then I'll cancel it and give yours a crack instead. To my novice eye, your code looks like it'll be quicker than the below anyway. Cheers James SELECT data.ppid, data.point_time, CASE WHEN data.the_geom IS NULL THEN ( --Get all locations with an earlier time stamp for that ppid SELECT geom.the_geom FROM hybrid_location geom WHERE data.ppid = geom.ppid AND geom.point_time < data.point_time AND geom.the_geom IS NOT NULL AND NOT EXISTS ( -- Cull all but the most recent one SELECT * FROM hybrid_location cull WHERE cull.ppid = geom.ppid AND geom.the_geom IS NOT NULL AND cull.point_time < data.point_time AND cull.point_time > geom.point_time AND cull.the_geom IS NOT NULL ) ) ELSE data.the_geom end FROM hybrid_location data;
James David Smith <james.david.smith@gmail.com> wrote: > On 30 January 2014 16:45, Kevin Grittner <kgrittn@ymail.com> wrote: >> update test_data x >> set the_geom = y.the_geom >> from test_data y >> where x.the_geom is null >> and y.ppid = x.ppid >> and y.the_geom is not null >> and y.point_time < x.point_time >> and not exists >> ( >> select * from test_data z >> where z.ppid = y.ppid >> and z.the_geom is not null >> and z.point_time > y.point_time >> and z.point_time < x.point_time >> ) >> ; > I can't run it on my actual data at the moment, or rather I don't want > too, as I set the below query going an hour or so ago and thought I > should let it finish really. > > If it hasn't finished when I come into work tomorrow (I'm leaving the > office shortly) then I'll cancel it and give yours a crack instead. To > my novice eye, your code looks like it'll be quicker than the below > anyway. > SELECT > data.ppid, > data.point_time, > CASE > WHEN data.the_geom IS NULL > THEN ( > --Get all locations with an earlier time stamp for that ppid > SELECT geom.the_geom > FROM hybrid_location geom > WHERE data.ppid = geom.ppid > AND geom.point_time < data.point_time > AND geom.the_geom IS NOT NULL > AND NOT EXISTS ( > -- Cull all but the most recent one > SELECT * > FROM hybrid_location cull > WHERE cull.ppid = geom.ppid > AND geom.the_geom IS NOT NULL > AND cull.point_time < data.point_time > AND cull.point_time > geom.point_time > AND cull.the_geom IS NOT NULL > ) > ) > ELSE data.the_geom > end > FROM hybrid_location data; Yeah, that's basically the same approach, but it uses a subquery which I don't think can get pulled up -- so I think it will need to do a lot of the work once for each row with a NULL the_geom column where my version can do it once, period. If you haven't tuned your configuration, you can probably speed up any of these versions with a few tweaks to memory allocation and cost factors. The most significant for this query would probably be to set work_mem to something around 25% of machine RAM divided by the number of active connections you can have. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Kevin / all, I tried to run the update with your code but got the following error (which I realise is now diverging from my original question): ERROR: could not write to hash-join temporary file: No space left on device ********** Error ********** Any thoughts? I didn't tweak the memory allocation or cost factors before I ran it - maybe that would help? I didn't bother doing it initially as I wasn't too fussed if it took say 4 hours instead of 3 etc. I'm not in a huge rush. Regarding the system, it's a virtual Ubuntu 12.04 desktop with PostgreSQL 9.3 and PostGIS 2.0. I asked our IT guy for the details about it and he gave the below. I'm the only user of the visualization set-up at the moment, so all the resource *should* be available to me he says: 20 cores of Intel Xeon E-2690 v2 processor @ 3GHz 48GB of memory at 1866 MHz Hard drive based on 10 x 15K RPM SAS hard disks Cheers James On 30 January 2014 20:08, Kevin Grittner <kgrittn@ymail.com> wrote: > James David Smith <james.david.smith@gmail.com> wrote: >> On 30 January 2014 16:45, Kevin Grittner <kgrittn@ymail.com> wrote: > >>> update test_data x >>> set the_geom = y.the_geom >>> from test_data y >>> where x.the_geom is null >>> and y.ppid = x.ppid >>> and y.the_geom is not null >>> and y.point_time < x.point_time >>> and not exists >>> ( >>> select * from test_data z >>> where z.ppid = y.ppid >>> and z.the_geom is not null >>> and z.point_time > y.point_time >>> and z.point_time < x.point_time >>> ) >>> ; > >> I can't run it on my actual data at the moment, or rather I don't want >> too, as I set the below query going an hour or so ago and thought I >> should let it finish really. >> >> If it hasn't finished when I come into work tomorrow (I'm leaving the >> office shortly) then I'll cancel it and give yours a crack instead. To >> my novice eye, your code looks like it'll be quicker than the below >> anyway. > >> SELECT >> data.ppid, >> data.point_time, >> CASE >> WHEN data.the_geom IS NULL >> THEN ( >> --Get all locations with an earlier time stamp for that ppid >> SELECT geom.the_geom >> FROM hybrid_location geom >> WHERE data.ppid = geom.ppid >> AND geom.point_time < data.point_time >> AND geom.the_geom IS NOT NULL >> AND NOT EXISTS ( >> -- Cull all but the most recent one >> SELECT * >> FROM hybrid_location cull >> WHERE cull.ppid = geom.ppid >> AND geom.the_geom IS NOT NULL >> AND cull.point_time < data.point_time >> AND cull.point_time > geom.point_time >> AND cull.the_geom IS NOT NULL >> ) >> ) >> ELSE data.the_geom >> end >> FROM hybrid_location data; > > Yeah, that's basically the same approach, but it uses a subquery > which I don't think can get pulled up -- so I think it will need to > do a lot of the work once for each row with a NULL the_geom column > where my version can do it once, period. > > If you haven't tuned your configuration, you can probably speed up > any of these versions with a few tweaks to memory allocation and > cost factors. The most significant for this query would probably > be to set work_mem to something around 25% of machine RAM divided > by the number of active connections you can have. > > -- > Kevin Grittner > EDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company
On 31 Jan 2014 4:51 PM, "James David Smith" <james.david.smith@gmail.com> wrote:
>
> Hi Kevin / all,
>
> I tried to run the update with your code but got the following error
> (which I realise is now diverging from my original question):
>
> ERROR: could not write to hash-join temporary file: No space left on device
> ********** Error **********
Just a guess, but maybe it's writing to a temporary table and ran out of disk space?
> Any thoughts? I didn't tweak the memory allocation or cost factors
> before I ran it - maybe that would help? I didn't bother doing it
> initially as I wasn't too fussed if it took say 4 hours instead of 3
> etc. I'm not in a huge rush.
>
> Regarding the system, it's a virtual Ubuntu 12.04 desktop with
> PostgreSQL 9.3 and PostGIS 2.0. I asked our IT guy for the details
> about it and he gave the below. I'm the only user of the visualization
> set-up at the moment, so all the resource *should* be available to me
> he says:
>
> 20 cores of Intel Xeon E-2690 v2 processor @ 3GHz
> 48GB of memory at 1866 MHz
> Hard drive based on 10 x 15K RPM SAS hard disks
>
> Cheers
>
> James
--
Michael Wood
Yes, that was it Michael. I increased my working memory which helped (although it was still writing to a temp table), and also split the query into smaller bits. THanks. On 5 February 2014 20:39, Michael Wood <esiotrot@gmail.com> wrote: > On 31 Jan 2014 4:51 PM, "James David Smith" <james.david.smith@gmail.com> > wrote: >> >> Hi Kevin / all, >> >> I tried to run the update with your code but got the following error >> (which I realise is now diverging from my original question): >> >> ERROR: could not write to hash-join temporary file: No space left on >> device >> ********** Error ********** > > Just a guess, but maybe it's writing to a temporary table and ran out of > disk space? > >> Any thoughts? I didn't tweak the memory allocation or cost factors >> before I ran it - maybe that would help? I didn't bother doing it >> initially as I wasn't too fussed if it took say 4 hours instead of 3 >> etc. I'm not in a huge rush. >> >> Regarding the system, it's a virtual Ubuntu 12.04 desktop with >> PostgreSQL 9.3 and PostGIS 2.0. I asked our IT guy for the details >> about it and he gave the below. I'm the only user of the visualization >> set-up at the moment, so all the resource *should* be available to me >> he says: >> >> 20 cores of Intel Xeon E-2690 v2 processor @ 3GHz >> 48GB of memory at 1866 MHz >> Hard drive based on 10 x 15K RPM SAS hard disks >> >> Cheers >> >> James > > -- > Michael Wood