Обсуждение: SSI performance
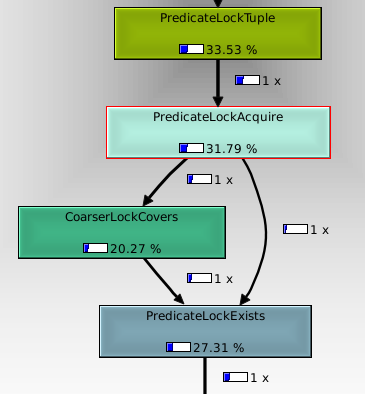
We know that the predicate locking introduced by the serializable snapshot isolation patch adds a significant amount of overhead, when it's used. It was fixed for sequential scans by acquiring a relation level lock upfront and skipping the locking after that, but the general problem for index scans and bitmap index scans remains. I ran a little benchmark of that: postgres=# begin isolation level repeatable read; BEGIN Time: 0,262 ms postgres=# SELECT COUNT(*) FROM foo WHERE id < 400000; count -------- 399999 (1 row) Time: 204,571 ms postgres=# begin isolation level serializable; BEGIN Time: 0,387 ms postgres=# SELECT COUNT(*) FROM foo WHERE id < 400000; count -------- 399999 (1 row) Time: 352,293 ms These numbers are fairly repeatable. I ran oprofile to see where the time is spent, and fed the output to kcachegrind to get a better breakdown. Attached is a screenshot of that (I don't know how to get this information in a nice text format, sorry). As you might expect, about 1/3 of the CPU time is spent in PredicateLockTuple(), which matches with the 50% increase in execution time compared to repeatable read. IOW, all the overhead comes from PredicateLockTuple. The interesting thing is that CoarserLockCovers() accounts for 20% of the overall CPU time, or 2/3 of the overhead. The logic of PredicateLockAcquire is: 1. Check if we already have a lock on the tuple. 2. Check if we already have a lock on the page. 3. Check if we already have a lock on the relation. So if you're accessing a lot of rows, so that your lock is promoted to a relation lock, you perform three hash table lookups on every PredicateLockAcquire() call to notice that you already have the lock. I was going to put a note at the beginning of this mail saying upfront that this is 9.2 materila, but it occurs to me that we could easily just reverse the order of those tests. That would cut the overhead of the case where you already have a relation lock by 2/3, but make the case where you already have a tuple lock slower. Would that be a good tradeoff? For 9.2, perhaps a tree would be better than a hash table for this.. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Вложения
{kind=link}
On Fri, Feb 4, 2011 at 9:29 AM, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > The interesting thing is that CoarserLockCovers() accounts for 20% of the > overall CPU time, or 2/3 of the overhead. The logic of PredicateLockAcquire > is: > > 1. Check if we already have a lock on the tuple. > 2. Check if we already have a lock on the page. > 3. Check if we already have a lock on the relation. > > So if you're accessing a lot of rows, so that your lock is promoted to a > relation lock, you perform three hash table lookups on every > PredicateLockAcquire() call to notice that you already have the lock. > > I was going to put a note at the beginning of this mail saying upfront that > this is 9.2 materila, but it occurs to me that we could easily just reverse > the order of those tests. That would cut the overhead of the case where you > already have a relation lock by 2/3, but make the case where you already > have a tuple lock slower. Would that be a good tradeoff? Not sure. How much benefit do we get from upgrading tuple locks to page locks? Should we just upgrade from tuple locks to full-relation locks? It also seems like there might be some benefit to caching the knowledge that we have a full-relation lock somewhere, so that once we get one we needn't keep checking that. Not sure if that actually makes sense... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 04.02.2011 15:37, Robert Haas wrote: > Not sure. How much benefit do we get from upgrading tuple locks to > page locks? Should we just upgrade from tuple locks to full-relation > locks? Hmm, good question. Page-locks are the coarsest level for the b-tree locks, but maybe that would make sense for the heap. > It also seems like there might be some benefit to caching the > knowledge that we have a full-relation lock somewhere, so that once we > get one we needn't keep checking that. Not sure if that actually > makes sense... Well, if you reverse the order of the hash table lookups, that's effectively what you get. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Fri, Feb 4, 2011 at 11:07 AM, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 04.02.2011 15:37, Robert Haas wrote: >> >> Not sure. How much benefit do we get from upgrading tuple locks to >> page locks? Should we just upgrade from tuple locks to full-relation >> locks? > > Hmm, good question. Page-locks are the coarsest level for the b-tree locks, > but maybe that would make sense for the heap. > >> It also seems like there might be some benefit to caching the >> knowledge that we have a full-relation lock somewhere, so that once we >> get one we needn't keep checking that. Not sure if that actually >> makes sense... > > Well, if you reverse the order of the hash table lookups, that's effectively > what you get. I was wondering if it could be cached someplace that was cheaper to examine, though, like (stabs wildly) the executor scan state. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > The logic of PredicateLockAcquire is: > > 1. Check if we already have a lock on the tuple. > 2. Check if we already have a lock on the page. > 3. Check if we already have a lock on the relation. > > So if you're accessing a lot of rows, so that your lock is > promoted to a relation lock, you perform three hash table lookups > on every PredicateLockAcquire() call to notice that you already > have the lock. > > I was going to put a note at the beginning of this mail saying > upfront that this is 9.2 materila, but it occurs to me that we > could easily just reverse the order of those tests. That would cut > the overhead of the case where you already have a relation lock by > 2/3, but make the case where you already have a tuple lock slower. > Would that be a good tradeoff? The problem with that is that we'd need to figure out how to handle LW locking. The target at each level may be protected by a different partition lock, so locks must be released and acquired for each level checked. When we promote granularity we add to the higher level first and then remove from the lower level, again protected by potentially different partition locks. To avoid having a search miss during concurrent promotion, we did the searches from the finer to the coarser granularity. In early benchmarks we were held up mostly by LW lock contention, and went to some effort to rearrange locking to minimize that; we'd need to be very careful trying to go the other direction here. I just had a thought -- we already have the LocalPredicateLockHash HTAB to help with granularity promotion issues without LW locking. Offhand, I can't see any reason we couldn't use this for an initial check for a relation level lock, before going through the more rigorous pass under cover of the locks. We won't have a relation lock showing in the local table if it never was taken out, and it won't go away until the end of transaction (unless the whole transaction is deamed safe from SSI conflicts and everything is cleaned up early). Dan, does that look sane to you, or am I having another "senior moment" here? If this works, it would be a very minor change, which might eliminate a lot of that overhead for many common cases. -Kevin
I wrote: > I just had a thought -- we already have the LocalPredicateLockHash > HTAB to help with granularity promotion issues without LW > locking. Offhand, I can't see any reason we couldn't use this for > an initial check for a relation level lock, before going through > the more rigorous pass under cover of the locks. We won't have a > relation lock showing in the local table if it never was taken > out, and it won't go away until the end of transaction (unless the > whole transaction is deamed safe from SSI conflicts and everything > is cleaned up early). > > Dan, does that look sane to you, or am I having another "senior > moment" here? > > If this works, it would be a very minor change, which might > eliminate a lot of that overhead for many common cases. To make this more concrete: http://git.postgresql.org/gitweb?p=users/kgrittn/postgres.git;a=commitdiff;h=91d93734b8a84cf54e77f8d30b26afde7cc43218 I *think* we should be able to do this with the page lock level, too; but I'd like Dan to weigh in on that before putting something out there for that. He did the local lock table work, and will be in a better position to know how safe this is. Also, while it's pretty clear this should be a win at the relation level, it's not as clear to me whether adding this for the page level will be a net gain. -Kevin
I wrote: >> If this works, it would be a very minor change, which might >> eliminate a lot of that overhead for many common cases. With that change in place, I loaded actual data from one county for our most heavily searched table and searched it on the most heavily searched index. I returned actual data rather than a count, from 3654 rows. On a less trivial and more common query like this, the overhead of SSI tends to be lost in the noise: select "nameL", "nameF", "nameM", "suffix", "countyNo", "caseNo", "sex" from "Party" where "searchName" like 'WILLIAMS,%'order by "countyNo", "caseNo"; repeatable read Time: 51.150 ms Time: 54.809 ms Time: 53.495 ms Time: 51.458 ms Time: 82.656 ms serializable Time: 54.105 ms Time: 52.765 ms Time: 52.852 ms Time: 69.449 ms Time: 52.089 ms Unfortunately for those who rely on count(*), it is about the worst case possible for highlighting SSI predicate locking overhead. -Kevin
I wrote: > repeatable read > [best] Time: 51.150 ms > serializable > [best] Time: 52.089 ms It occurred to me that taking the best time from each was likely to give a reasonable approximation of the actual overhead of SSI in this situation. That came out to about 1.8% in this (small) set of tests, which is right where earlier benchmarks of a heavy read load against fully-cached data put the SSI predicate locking overhead. That previous benchmarking involved letting things run overnight for several days in a row to accumulate hundreds of runs of decent length. While today's little test doesn't prove much, because of its size, the fact that it matches the numbers from the earlier, more rigorous tests suggests that we're probably still in the same ballpark. If you get into a load where there's actual disk access, I suspect that this overhead will be very hard to spot; the transaction rollback rate is going to become the dominant performance issue. -Kevin