SSI performance
| От | Heikki Linnakangas |
|---|---|
| Тема | SSI performance |
| Дата | |
| Msg-id | 4D4C0D3A.90709@enterprisedb.com обсуждение исходный текст |
| Ответы |
Re: SSI performance
Re: SSI performance |
| Список | pgsql-hackers |
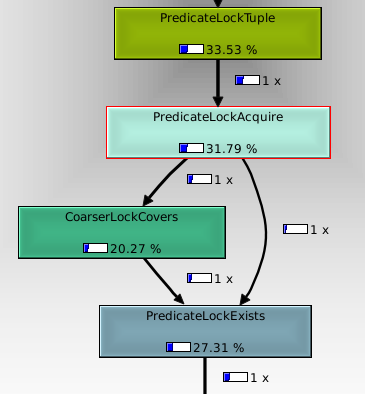
We know that the predicate locking introduced by the serializable snapshot isolation patch adds a significant amount of overhead, when it's used. It was fixed for sequential scans by acquiring a relation level lock upfront and skipping the locking after that, but the general problem for index scans and bitmap index scans remains. I ran a little benchmark of that: postgres=# begin isolation level repeatable read; BEGIN Time: 0,262 ms postgres=# SELECT COUNT(*) FROM foo WHERE id < 400000; count -------- 399999 (1 row) Time: 204,571 ms postgres=# begin isolation level serializable; BEGIN Time: 0,387 ms postgres=# SELECT COUNT(*) FROM foo WHERE id < 400000; count -------- 399999 (1 row) Time: 352,293 ms These numbers are fairly repeatable. I ran oprofile to see where the time is spent, and fed the output to kcachegrind to get a better breakdown. Attached is a screenshot of that (I don't know how to get this information in a nice text format, sorry). As you might expect, about 1/3 of the CPU time is spent in PredicateLockTuple(), which matches with the 50% increase in execution time compared to repeatable read. IOW, all the overhead comes from PredicateLockTuple. The interesting thing is that CoarserLockCovers() accounts for 20% of the overall CPU time, or 2/3 of the overhead. The logic of PredicateLockAcquire is: 1. Check if we already have a lock on the tuple. 2. Check if we already have a lock on the page. 3. Check if we already have a lock on the relation. So if you're accessing a lot of rows, so that your lock is promoted to a relation lock, you perform three hash table lookups on every PredicateLockAcquire() call to notice that you already have the lock. I was going to put a note at the beginning of this mail saying upfront that this is 9.2 materila, but it occurs to me that we could easily just reverse the order of those tests. That would cut the overhead of the case where you already have a relation lock by 2/3, but make the case where you already have a tuple lock slower. Would that be a good tradeoff? For 9.2, perhaps a tree would be better than a hash table for this.. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Вложения
В списке pgsql-hackers по дате отправления: