Обсуждение: Speed up COPY FROM text/CSV parsing using SIMD
Hi hackers,
I have implemented SIMD optimization for the COPY FROM (FORMAT {csv,
text}) command and observed approximately a 5% performance
improvement. Please see the detailed test results below.
Idea
====
The current text/CSV parser processes input byte-by-byte, checking
whether each byte is a special character (\n, \r, quote, escape) or a
regular character, and transitions states in a state machine. This
sequential processing is inefficient and likely causes frequent branch
mispredictions due to the many if statements.
I thought this problem could be addressed by leveraging SIMD and
vectorized operations for faster processing.
Implementation Overview
=======================
1. Create a vector of special characters (e.g., Vector8 nl =
vector8_broadcast('\n');).
2. Load the input buffer into a Vector8 variable called chunk.
3. Perform vectorized operations between chunk and the special
character vectors to check if the buffer contains any special
characters.
4-1. If no special characters are found, advance the input_buf_ptr by
sizeof(Vector8).
4-2. If special characters are found, advance the input_buf_ptr as far
as possible, then fall back to the original text/CSV parser for
byte-by-byte processing.
Test
====
I tested the performance by measuring the time it takes to load a CSV
file created using the attached SQL script with the following COPY
command:
=# COPY t FROM '/tmp/t.csv' (FORMAT csv);
Environment
-----------
OS: Rocky Linux 9.6
CPU: Intel Core i7-10710U (6 Cores / 12 Threads, 1.1 GHz Base / 4.7
GHz Boost, AVX2 & FMA supported)
Time
----
master: 02.44.943
patch applied: 02:36.878 (about 5% faster)
Perf
----
Each call graphs are attached and the rates of CopyReadLineText are:
master: 12.15%
patch applied: 8.04%
Thought?
I would appreciate feedback on the implementation and any suggestions
for further improvement.
--
Best regards,
Shinya Kato
NTT OSS Center
Вложения
{kind=link}
{kind=link}
Hi,
Thank you for working on this!
On Thu, 7 Aug 2025 at 04:49, Shinya Kato <shinya11.kato@gmail.com> wrote:
>
> Hi hackers,
>
> I have implemented SIMD optimization for the COPY FROM (FORMAT {csv,
> text}) command and observed approximately a 5% performance
> improvement. Please see the detailed test results below.
I have been working on the same idea. I was not moving input_buf_ptr
as far as possible, so I think your approach is better.
Also, I did a benchmark on text format. I created a benchmark for line
length in a table being from 1 byte to 1 megabyte.The peak improvement
is line length being 4096 and the improvement is more than 20% [1], I
saw no regression on your patch.
> Idea
> ====
> The current text/CSV parser processes input byte-by-byte, checking
> whether each byte is a special character (\n, \r, quote, escape) or a
> regular character, and transitions states in a state machine. This
> sequential processing is inefficient and likely causes frequent branch
> mispredictions due to the many if statements.
>
> I thought this problem could be addressed by leveraging SIMD and
> vectorized operations for faster processing.
>
> Implementation Overview
> =======================
> 1. Create a vector of special characters (e.g., Vector8 nl =
> vector8_broadcast('\n');).
> 2. Load the input buffer into a Vector8 variable called chunk.
> 3. Perform vectorized operations between chunk and the special
> character vectors to check if the buffer contains any special
> characters.
> 4-1. If no special characters are found, advance the input_buf_ptr by
> sizeof(Vector8).
> 4-2. If special characters are found, advance the input_buf_ptr as far
> as possible, then fall back to the original text/CSV parser for
> byte-by-byte processing.
>
...
> Thought?
> I would appreciate feedback on the implementation and any suggestions
> for further improvement.
I have a couple of ideas that I was working on:
---
+ * However, SIMD optimization cannot be applied in the following cases:
+ * - Inside quoted fields, where escape sequences and closing quotes
+ * require sequential processing to handle correctly.
I think you can continue SIMD inside quoted fields. Only important
thing is you need to set last_was_esc to false when SIMD skipped the
chunk.
---
+ * - When the remaining buffer size is smaller than the size of a SIMD
+ * vector register, as SIMD operations require processing data in
+ * fixed-size chunks.
You run SIMD when 'copy_buf_len - input_buf_ptr >= sizeof(Vector8)'
but you only call CopyLoadInputBuf() when 'input_buf_ptr >=
copy_buf_len || need_data' so basically you need to wait at least the
sizeof(Vector8) character to pass for the next SIMD. And in the worst
case; if CopyLoadInputBuf() puts one character less than
sizeof(Vector8), then you can't ever run SIMD. I think we need to make
sure that CopyLoadInputBuf() loads at least the sizeof(Vector8)
character to the input_buf so we do not encounter that problem.
---
What do you think about adding SIMD to CopyReadAttributesText() and
CopyReadAttributesCSV() functions? When I add your SIMD approach to
CopyReadAttributesText() function, the improvement on the 4096 byte
line length input [1] goes from 20% to 30%.
---
I shared my ideas as a Feedback.txt file (.txt to stay off CFBot's
radar for this thread). I hope these help, please let me know if you
have any questions.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Вложения
Hi,
On Thu, 7 Aug 2025 at 14:15, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> On Thu, 7 Aug 2025 at 04:49, Shinya Kato <shinya11.kato@gmail.com> wrote:
> >
> > I have implemented SIMD optimization for the COPY FROM (FORMAT {csv,
> > text}) command and observed approximately a 5% performance
> > improvement. Please see the detailed test results below.
>
> Also, I did a benchmark on text format. I created a benchmark for line
> length in a table being from 1 byte to 1 megabyte.The peak improvement
> is line length being 4096 and the improvement is more than 20% [1], I
> saw no regression on your patch.
I did the same benchmark for the CSV format. The peak improvement is
line length being 4096 and the improvement is more than 25% [1]. I saw
a 5% regression on the 1 byte benchmark, there are no other
regressions.
> What do you think about adding SIMD to CopyReadAttributesText() and
> CopyReadAttributesCSV() functions? When I add your SIMD approach to
> CopyReadAttributesText() function, the improvement on the 4096 byte
> line length input [1] goes from 20% to 30%.
I wanted to try using SIMD in CopyReadAttributesCSV() as well. The
improvement on the 4096 byte line length input [1] goes from 25% to
35%, the regression on the 1 byte input is the same.
CopyReadAttributesCSV() changes are attached as feedback v2.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Вложения
On Thu, Aug 7, 2025 at 8:15 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> Thank you for working on this!
>
> On Thu, 7 Aug 2025 at 04:49, Shinya Kato <shinya11.kato@gmail.com> wrote:
> >
> > Hi hackers,
> >
> > I have implemented SIMD optimization for the COPY FROM (FORMAT {csv,
> > text}) command and observed approximately a 5% performance
> > improvement. Please see the detailed test results below.
>
> I have been working on the same idea. I was not moving input_buf_ptr
> as far as possible, so I think your approach is better.
Great. I'm looking forward to working with you on this feature implementation.
> Also, I did a benchmark on text format. I created a benchmark for line
> length in a table being from 1 byte to 1 megabyte.The peak improvement
> is line length being 4096 and the improvement is more than 20% [1], I
> saw no regression on your patch.
Thank you for the additional benchmarks.
> I have a couple of ideas that I was working on:
> ---
>
> + * However, SIMD optimization cannot be applied in the following cases:
> + * - Inside quoted fields, where escape sequences and closing quotes
> + * require sequential processing to handle correctly.
>
> I think you can continue SIMD inside quoted fields. Only important
> thing is you need to set last_was_esc to false when SIMD skipped the
> chunk.
That's a clever point that last_was_esc should be reset to false when
a SIMD chunk is skipped. You're right about that specific case.
However, the core challenge is not what happens when we skip a chunk,
but what happens when a chunk contains special characters like quotes
or escapes. The main reason we avoid SIMD inside quoted fields is that
the parsing logic becomes fundamentally sequential and
context-dependent.
To correctly parse a "" as a single literal quote, we must perform a
lookahead to check the next character. This is an inherently
sequential operation that doesn't map well to SIMD's parallel nature.
Trying to handle this stateful logic with SIMD would lead to
significant implementation complexity, especially with edge cases like
an escape character falling on the last byte of a chunk.
> + * - When the remaining buffer size is smaller than the size of a SIMD
> + * vector register, as SIMD operations require processing data in
> + * fixed-size chunks.
>
> You run SIMD when 'copy_buf_len - input_buf_ptr >= sizeof(Vector8)'
> but you only call CopyLoadInputBuf() when 'input_buf_ptr >=
> copy_buf_len || need_data' so basically you need to wait at least the
> sizeof(Vector8) character to pass for the next SIMD. And in the worst
> case; if CopyLoadInputBuf() puts one character less than
> sizeof(Vector8), then you can't ever run SIMD. I think we need to make
> sure that CopyLoadInputBuf() loads at least the sizeof(Vector8)
> character to the input_buf so we do not encounter that problem.
I think you're probably right, but we only need to account for
sizeof(Vector8) when USE_NO_SIMD is not defined.
> What do you think about adding SIMD to CopyReadAttributesText() and
> CopyReadAttributesCSV() functions? When I add your SIMD approach to
> CopyReadAttributesText() function, the improvement on the 4096 byte
> line length input [1] goes from 20% to 30%.
Agreed, I will.
> I shared my ideas as a Feedback.txt file (.txt to stay off CFBot's
> radar for this thread). I hope these help, please let me know if you
> have any questions.
Thanks a lot!
On Mon, Aug 11, 2025 at 5:52 PM Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> On Thu, 7 Aug 2025 at 14:15, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:
> >
> > On Thu, 7 Aug 2025 at 04:49, Shinya Kato <shinya11.kato@gmail.com> wrote:
> > >
> > > I have implemented SIMD optimization for the COPY FROM (FORMAT {csv,
> > > text}) command and observed approximately a 5% performance
> > > improvement. Please see the detailed test results below.
> >
> > Also, I did a benchmark on text format. I created a benchmark for line
> > length in a table being from 1 byte to 1 megabyte.The peak improvement
> > is line length being 4096 and the improvement is more than 20% [1], I
> > saw no regression on your patch.
>
> I did the same benchmark for the CSV format. The peak improvement is
> line length being 4096 and the improvement is more than 25% [1]. I saw
> a 5% regression on the 1 byte benchmark, there are no other
> regressions.
Thank you. I'm not too concerned about a regression when there's only
one byte per line.
> > What do you think about adding SIMD to CopyReadAttributesText() and
> > CopyReadAttributesCSV() functions? When I add your SIMD approach to
> > CopyReadAttributesText() function, the improvement on the 4096 byte
> > line length input [1] goes from 20% to 30%.
>
> I wanted to try using SIMD in CopyReadAttributesCSV() as well. The
> improvement on the 4096 byte line length input [1] goes from 25% to
> 35%, the regression on the 1 byte input is the same.
Yes, I'm on it. I'm currently adding the SIMD logic to
CopyReadAttributesCSV() as you suggested. I'll share the new version
of the patch soon.
--
Best regards,
Shinya Kato
NTT OSS Center
On Tue, Aug 12, 2025 at 4:25 PM Shinya Kato <shinya11.kato@gmail.com> wrote: > > + * However, SIMD optimization cannot be applied in the following cases: > > + * - Inside quoted fields, where escape sequences and closing quotes > > + * require sequential processing to handle correctly. > > > > I think you can continue SIMD inside quoted fields. Only important > > thing is you need to set last_was_esc to false when SIMD skipped the > > chunk. > > That's a clever point that last_was_esc should be reset to false when > a SIMD chunk is skipped. You're right about that specific case. > > However, the core challenge is not what happens when we skip a chunk, > but what happens when a chunk contains special characters like quotes > or escapes. The main reason we avoid SIMD inside quoted fields is that > the parsing logic becomes fundamentally sequential and > context-dependent. > > To correctly parse a "" as a single literal quote, we must perform a > lookahead to check the next character. This is an inherently > sequential operation that doesn't map well to SIMD's parallel nature. > > Trying to handle this stateful logic with SIMD would lead to > significant implementation complexity, especially with edge cases like > an escape character falling on the last byte of a chunk. Ah, you're right. My apologies, I misunderstood the implementation. It appears that SIMD can be used even within quoted strings. I think it would be better not to use the SIMD path when last_was_esc is true. The next character is likely to be a special character, and handling this case outside the SIMD loop would also improve readability by consolidating the last_was_esc toggle logic in one place. Furthermore, when inside a quote (in_quote) in CSV mode, the detection of \n and \r can be disabled. + last_was_esc = false; Regarding the implementation, I believe we must set last_was_esc to false when advancing input_buf_ptr, as shown in the code below. For this reason, I think it’s best to keep the current logic for toggling last_was_esc. + int advance = pg_rightmost_one_pos32(mask); + input_buf_ptr += advance; I've attached a new patch that includes these changes. Further modifications are still in progress. -- Best regards, Shinya Kato NTT OSS Center
Вложения
Results for a 1/3 of line length of special characters:
~43.9% slower copy in TEXT format
~16.7% slower copy in CSV format
On Tue, Aug 12, 2025 at 4:25 PM Shinya Kato <shinya11.kato@gmail.com> wrote:
> > + * However, SIMD optimization cannot be applied in the following cases:
> > + * - Inside quoted fields, where escape sequences and closing quotes
> > + * require sequential processing to handle correctly.
> >
> > I think you can continue SIMD inside quoted fields. Only important
> > thing is you need to set last_was_esc to false when SIMD skipped the
> > chunk.
>
> That's a clever point that last_was_esc should be reset to false when
> a SIMD chunk is skipped. You're right about that specific case.
>
> However, the core challenge is not what happens when we skip a chunk,
> but what happens when a chunk contains special characters like quotes
> or escapes. The main reason we avoid SIMD inside quoted fields is that
> the parsing logic becomes fundamentally sequential and
> context-dependent.
>
> To correctly parse a "" as a single literal quote, we must perform a
> lookahead to check the next character. This is an inherently
> sequential operation that doesn't map well to SIMD's parallel nature.
>
> Trying to handle this stateful logic with SIMD would lead to
> significant implementation complexity, especially with edge cases like
> an escape character falling on the last byte of a chunk.
Ah, you're right. My apologies, I misunderstood the implementation. It
appears that SIMD can be used even within quoted strings.
I think it would be better not to use the SIMD path when last_was_esc
is true. The next character is likely to be a special character, and
handling this case outside the SIMD loop would also improve
readability by consolidating the last_was_esc toggle logic in one
place.
Furthermore, when inside a quote (in_quote) in CSV mode, the detection
of \n and \r can be disabled.
+ last_was_esc = false;
Regarding the implementation, I believe we must set last_was_esc to
false when advancing input_buf_ptr, as shown in the code below. For
this reason, I think it’s best to keep the current logic for toggling
last_was_esc.
+ int advance = pg_rightmost_one_pos32(mask);
+ input_buf_ptr += advance;
I've attached a new patch that includes these changes. Further
modifications are still in progress.
--
Best regards,
Shinya Kato
NTT OSS Center
Hi, On Thu, 14 Aug 2025 at 05:25, KAZAR Ayoub <ma_kazar@esi.dz> wrote: > > Following Nazir's findings about 4096 bytes being the performant line length, I did more benchmarks from my side on bothTEXT and CSV formats with two different cases of normal data (no special characters) and data with many special characters. > > Results are con good as expected and similar to previous benchmarks > ~30.9% faster copy in TEXT format > ~32.4% faster copy in CSV format > 20%-30% reduces cycles per instructions > > In the case of doing a lot of special characters in the lines (e.g., tables with large numbers of columns maybe), we obviouslyexpect regressions here because of the overhead of many fallbacks to scalar processing. > Results for a 1/3 of line length of special characters: > ~43.9% slower copy in TEXT format > ~16.7% slower copy in CSV format > So for even less occurrences of special characters or wider distance between there might still be some regressions in thiscase, a non-significant case maybe, but can be treated in other patches if we consider to not use SIMD path sometimes. > > I hope this helps more and confirms the patch. Thanks for running that benchmark! Would you mind sharing a reproducer for the regression you observed? -- Regards, Nazir Bilal Yavuz Microsoft
Hi,
On Thu, 14 Aug 2025 at 05:25, KAZAR Ayoub <ma_kazar@esi.dz> wrote:
>
> Following Nazir's findings about 4096 bytes being the performant line length, I did more benchmarks from my side on both TEXT and CSV formats with two different cases of normal data (no special characters) and data with many special characters.
>
> Results are con good as expected and similar to previous benchmarks
> ~30.9% faster copy in TEXT format
> ~32.4% faster copy in CSV format
> 20%-30% reduces cycles per instructions
>
> In the case of doing a lot of special characters in the lines (e.g., tables with large numbers of columns maybe), we obviously expect regressions here because of the overhead of many fallbacks to scalar processing.
> Results for a 1/3 of line length of special characters:
> ~43.9% slower copy in TEXT format
> ~16.7% slower copy in CSV format
> So for even less occurrences of special characters or wider distance between there might still be some regressions in this case, a non-significant case maybe, but can be treated in other patches if we consider to not use SIMD path sometimes.
>
> I hope this helps more and confirms the patch.
Thanks for running that benchmark! Would you mind sharing a reproducer
for the regression you observed?
--
Regards,
Nazir Bilal Yavuz
Microsoft
Вложения
On Thu, 7 Aug 2025 at 14:15, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > I have a couple of ideas that I was working on: > --- > > + * However, SIMD optimization cannot be applied in the following cases: > + * - Inside quoted fields, where escape sequences and closing quotes > + * require sequential processing to handle correctly. > > I think you can continue SIMD inside quoted fields. Only important > thing is you need to set last_was_esc to false when SIMD skipped the > chunk. There is a trick with doing carryless multiplication with -1 that can be used to SIMD process transitions between quoted/not-quoted. [1] This is able to convert a bitmask of unescaped quote character positions to a quote mask in a single operation. I last looked at it 5 years ago, but I remember coming to the conclusion that it would work for implementing PostgreSQL's interpretation of CSV. [1] https://github.com/geofflangdale/simdcsv/blob/master/src/main.cpp#L76 -- Ants
Hi, On Thu, 14 Aug 2025 at 18:00, KAZAR Ayoub <ma_kazar@esi.dz> wrote: >> Thanks for running that benchmark! Would you mind sharing a reproducer >> for the regression you observed? > > Of course, I attached the sql to generate the text and csv test files. > If having a 1/3 of line length of special characters can be an exaggeration, something lower might still reproduce someregressions of course for the same idea. Thank you so much! I am able to reproduce the regression you mentioned but both regressions are %20 on my end. I found that (by experimenting) SIMD causes a regression if it advances less than 5 characters. So, I implemented a small heuristic. It works like that: - If advance < 5 -> insert a sleep penalty (n cycles). - Each time advance < 5, n is doubled. - Each time advance ≥ 5, n is halved. I am sharing a POC patch to show heuristic, it can be applied on top of v1-0001. Heuristic version has the same performance improvements with the v1-0001 but the regression is %5 instead of %20 compared to the master. -- Regards, Nazir Bilal Yavuz Microsoft
Вложения
Hi, On Tue, 19 Aug 2025 at 15:33, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > > I am able to reproduce the regression you mentioned but both > regressions are %20 on my end. I found that (by experimenting) SIMD > causes a regression if it advances less than 5 characters. > > So, I implemented a small heuristic. It works like that: > > - If advance < 5 -> insert a sleep penalty (n cycles). 'sleep' might be a poor word choice here. I meant skipping SIMD for n number of times. -- Regards, Nazir Bilal Yavuz Microsoft
On 2025-08-19 Tu 10:14 AM, Nazir Bilal Yavuz wrote: > Hi, > > On Tue, 19 Aug 2025 at 15:33, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: >> I am able to reproduce the regression you mentioned but both >> regressions are %20 on my end. I found that (by experimenting) SIMD >> causes a regression if it advances less than 5 characters. >> >> So, I implemented a small heuristic. It works like that: >> >> - If advance < 5 -> insert a sleep penalty (n cycles). > 'sleep' might be a poor word choice here. I meant skipping SIMD for n > number of times. > I was thinking a bit about that this morning. I wonder if it might be better instead of having a constantly applied heuristic like this, it might be better to do a little extra accounting in the first, say, 1000 lines of an input file, and if less than some portion of the input is found to be special characters then switch to the SIMD code. What that portion should be would need to be determined by some experimentation with a variety of typical workloads, but given your findings 20% seems like a good starting point. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Thu, 14 Aug 2025 at 18:00, KAZAR Ayoub <ma_kazar@esi.dz> wrote:
>> Thanks for running that benchmark! Would you mind sharing a reproducer
>> for the regression you observed?
>
> Of course, I attached the sql to generate the text and csv test files.
> If having a 1/3 of line length of special characters can be an exaggeration, something lower might still reproduce some regressions of course for the same idea.
Thank you so much!
I am able to reproduce the regression you mentioned but both
regressions are %20 on my end. I found that (by experimenting) SIMD
causes a regression if it advances less than 5 characters.
So, I implemented a small heuristic. It works like that:
- If advance < 5 -> insert a sleep penalty (n cycles).
- Each time advance < 5, n is doubled.
- Each time advance ≥ 5, n is halved.
I am sharing a POC patch to show heuristic, it can be applied on top
of v1-0001. Heuristic version has the same performance improvements
with the v1-0001 but the regression is %5 instead of %20 compared to
the master.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Hi, On Thu, 21 Aug 2025 at 18:47, Andrew Dunstan <andrew@dunslane.net> wrote: > > > On 2025-08-19 Tu 10:14 AM, Nazir Bilal Yavuz wrote: > > Hi, > > > > On Tue, 19 Aug 2025 at 15:33, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > >> I am able to reproduce the regression you mentioned but both > >> regressions are %20 on my end. I found that (by experimenting) SIMD > >> causes a regression if it advances less than 5 characters. > >> > >> So, I implemented a small heuristic. It works like that: > >> > >> - If advance < 5 -> insert a sleep penalty (n cycles). > > 'sleep' might be a poor word choice here. I meant skipping SIMD for n > > number of times. > > > > I was thinking a bit about that this morning. I wonder if it might be > better instead of having a constantly applied heuristic like this, it > might be better to do a little extra accounting in the first, say, 1000 > lines of an input file, and if less than some portion of the input is > found to be special characters then switch to the SIMD code. What that > portion should be would need to be determined by some experimentation > with a variety of typical workloads, but given your findings 20% seems > like a good starting point. I implemented a heuristic something similar to this. It is a mix of previous heuristic and your idea, it works like that: Overall logic is that we will not run SIMD for the entire line and we decide if it is worth it to run SIMD for the next lines. 1 - We will try SIMD and decide if it is worth it to run SIMD. 1.1 - If it is worth it, we will continue to run SIMD and we will halve the simd_last_sleep_cycle variable. 1.2 - If it is not worth it, we will double the simd_last_sleep_cycle and we will not run SIMD for these many lines. 1.3 - After skipping simd_last_sleep_cycle lines, we will go back to the #1. Note: simd_last_sleep_cycle can not pass 1024, so we will run SIMD for each 1024 lines at max. With this heuristic the regression is limited by %2 in the worst case. Patches are attached, the first patch is v2-0001 from Shinya with the '-Werror=maybe-uninitialized' fixes and the pgindent changes. 0002 is the actual heuristic patch. -- Regards, Nazir Bilal Yavuz Microsoft
Вложения
I’ve rebenchmarked the new heuristic patch, We still have the previous improvements ranging from 15% to 30%. For regressions i see at maximum 3% or 4% in the worst case, so this is solid.
I'm also trying the idea of doing SIMD inside quotes with prefix XOR using carry less multiplication avoiding the slow path in all cases even with weird looking input, but it needs to take into consideration the availability of PCLMULQDQ instruction set with <wmmintrin.h> and here we go, it quickly starts to become dirty OR we can wait for the decision to start requiring x86-64-v2 or v3 which has SSE4.2 and AVX2.
Regards,
Ayoub Kazar
Hi, On Thu, 16 Oct 2025 at 17:29, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote: > > Overall logic is that we will not run SIMD for the entire line and we > decide if it is worth it to run SIMD for the next lines. I had a typo there, correct sentence is that: "Overall logic is that we *will* run SIMD for the entire line and we decide if it is worth it to run SIMD for the next lines." -- Regards, Nazir Bilal Yavuz Microsoft
Hi, On Sat, 18 Oct 2025 at 21:46, KAZAR Ayoub <ma_kazar@esi.dz> wrote: > > Hello, > > I’ve rebenchmarked the new heuristic patch, We still have the previous improvements ranging from 15% to 30%. For regressionsi see at maximum 3% or 4% in the worst case, so this is solid. Thank you so much for doing this! The results look nice, do you think there are any other benchmarks that might be interesting to try? > I'm also trying the idea of doing SIMD inside quotes with prefix XOR using carry less multiplication avoiding the slowpath in all cases even with weird looking input, but it needs to take into consideration the availability of PCLMULQDQinstruction set with <wmmintrin.h> and here we go, it quickly starts to become dirty OR we can wait for the decisionto start requiring x86-64-v2 or v3 which has SSE4.2 and AVX2. I can not quite picture this, would you mind sharing a few examples or patches? -- Regards, Nazir Bilal Yavuz Microsoft
Hi, On Thu, 21 Aug 2025 at 18:47, Andrew Dunstan <andrew@dunslane.net> wrote:On 2025-08-19 Tu 10:14 AM, Nazir Bilal Yavuz wrote:Hi, On Tue, 19 Aug 2025 at 15:33, Nazir Bilal Yavuz <byavuz81@gmail.com> wrote:I am able to reproduce the regression you mentioned but both regressions are %20 on my end. I found that (by experimenting) SIMD causes a regression if it advances less than 5 characters. So, I implemented a small heuristic. It works like that: - If advance < 5 -> insert a sleep penalty (n cycles).'sleep' might be a poor word choice here. I meant skipping SIMD for n number of times.I was thinking a bit about that this morning. I wonder if it might be better instead of having a constantly applied heuristic like this, it might be better to do a little extra accounting in the first, say, 1000 lines of an input file, and if less than some portion of the input is found to be special characters then switch to the SIMD code. What that portion should be would need to be determined by some experimentation with a variety of typical workloads, but given your findings 20% seems like a good starting point.I implemented a heuristic something similar to this. It is a mix of previous heuristic and your idea, it works like that: Overall logic is that we will not run SIMD for the entire line and we decide if it is worth it to run SIMD for the next lines. 1 - We will try SIMD and decide if it is worth it to run SIMD. 1.1 - If it is worth it, we will continue to run SIMD and we will halve the simd_last_sleep_cycle variable. 1.2 - If it is not worth it, we will double the simd_last_sleep_cycle and we will not run SIMD for these many lines. 1.3 - After skipping simd_last_sleep_cycle lines, we will go back to the #1. Note: simd_last_sleep_cycle can not pass 1024, so we will run SIMD for each 1024 lines at max. With this heuristic the regression is limited by %2 in the worst case.
My worry is that the worst case is actually quite common. Sparse data sets dominated by a lot of null values (and hence lots of special characters) are very common. Are people prepared to accept a 2% regression on load times for such data sets?
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
On Mon, Oct 20, 2025 at 10:02:23AM -0400, Andrew Dunstan wrote: > On 2025-10-16 Th 10:29 AM, Nazir Bilal Yavuz wrote: >> With this heuristic the regression is limited by %2 in the worst case. > > My worry is that the worst case is actually quite common. Sparse data sets > dominated by a lot of null values (and hence lots of special characters) are > very common. Are people prepared to accept a 2% regression on load times for > such data sets? Without knowing how common it is, I think it's difficult to judge whether 2% is a reasonable trade-off. If <5% of workloads might see a small regression while the other >95% see double-digit percentage improvements, then I might argue that it's fine. But I'm not sure we have any way to know those sorts of details at the moment. I'm also at least a little skeptical about the 2% number. IME that's generally within the noise range and can vary greatly between machines and test runs. -- nathan
On Mon, Oct 20, 2025 at 10:02:23AM -0400, Andrew Dunstan wrote:On 2025-10-16 Th 10:29 AM, Nazir Bilal Yavuz wrote:With this heuristic the regression is limited by %2 in the worst case.My worry is that the worst case is actually quite common. Sparse data sets dominated by a lot of null values (and hence lots of special characters) are very common. Are people prepared to accept a 2% regression on load times for such data sets?Without knowing how common it is, I think it's difficult to judge whether 2% is a reasonable trade-off. If <5% of workloads might see a small regression while the other >95% see double-digit percentage improvements, then I might argue that it's fine. But I'm not sure we have any way to know those sorts of details at the moment.
I guess what I don't understand is why we actually need to do the test continuously, even using an adaptive algorithm. Data files in my experience usually have lines with fairly similar shapes. It's highly unlikely that you will get the the first 1000 (say) lines of a file that are rich in special characters and then some later significant section that isn't, or vice versa. Therefore, doing the test once should yield the correct answer that can be applied to the rest of the file. That should reduce the worst case regression to ~0% without sacrificing any of the performance gains. I appreciate the elegance of what Bilal has done here, but it does seem like overkill.
I'm also at least a little skeptical about the 2% number. IME that's generally within the noise range and can vary greatly between machines and test runs.
Fair point.
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
Hi, On Mon, 20 Oct 2025 at 23:32, Andrew Dunstan <andrew@dunslane.net> wrote: > > > On 2025-10-20 Mo 1:04 PM, Nathan Bossart wrote: > > On Mon, Oct 20, 2025 at 10:02:23AM -0400, Andrew Dunstan wrote: > > On 2025-10-16 Th 10:29 AM, Nazir Bilal Yavuz wrote: > > With this heuristic the regression is limited by %2 in the worst case. > > My worry is that the worst case is actually quite common. Sparse data sets > dominated by a lot of null values (and hence lots of special characters) are > very common. Are people prepared to accept a 2% regression on load times for > such data sets? > > Without knowing how common it is, I think it's difficult to judge whether > 2% is a reasonable trade-off. If <5% of workloads might see a small > regression while the other >95% see double-digit percentage improvements, > then I might argue that it's fine. But I'm not sure we have any way to > know those sorts of details at the moment. > > > I guess what I don't understand is why we actually need to do the test continuously, even using an adaptive algorithm.Data files in my experience usually have lines with fairly similar shapes. It's highly unlikely that you will getthe the first 1000 (say) lines of a file that are rich in special characters and then some later significant section thatisn't, or vice versa. Therefore, doing the test once should yield the correct answer that can be applied to the restof the file. That should reduce the worst case regression to ~0% without sacrificing any of the performance gains. Iappreciate the elegance of what Bilal has done here, but it does seem like overkill. I think the problem is deciding how many lines to process before deciding for the rest. 1000 lines could work for the small sized data but it might not work for the big sized data. Also, it might cause a worse regressions for the small sized data. Because of this reason, I tried to implement a heuristic that will work regardless of the size of the data. The last heuristic I suggested will run SIMD for approximately (#number_of_lines / 1024 [1024 is the max number of lines to sleep before running SIMD again]) lines if all characters in the data are special characters. -- Regards, Nazir Bilal Yavuz Microsoft
Thank you so much for doing this! The results look nice, do you think
there are any other benchmarks that might be interesting to try?
> I'm also trying the idea of doing SIMD inside quotes with prefix XOR using carry less multiplication avoiding the slow path in all cases even with weird looking input, but it needs to take into consideration the availability of PCLMULQDQ instruction set with <wmmintrin.h> and here we go, it quickly starts to become dirty OR we can wait for the decision to start requiring x86-64-v2 or v3 which has SSE4.2 and AVX2.
I can not quite picture this, would you mind sharing a few examples or patches?
[1] https://branchfree.org/2019/03/06/code-fragment-finding-quote-pairs-with-carry-less-multiply-pclmulqdq/
[2] https://github.com/AyoubKaz07/postgres/commit/73c6ecfedae4cce5c3f375fd6074b1ca9dfe1daf
Currently we are at 200-400Mbps which isn't that terrible compared to production and non production grade parsers (of course we don't only parse in our case), also we are using SSE2 only so theoretically if we add support for avx later on we'll have even better numbers.Maybe more micro optimizations to the current heuristic can squeeze it more.
[1] https://branchfree.org/2019/03/06/code-fragment-finding-quote-pairs-with-carry-less-multiply-pclmulqdq/
[2] https://github.com/AyoubKaz07/postgres/commit/73c6ecfedae4cce5c3f375fd6074b1ca9dfe1dafRegards,Ayoub Kazar.
On Tue, Oct 21, 2025 at 12:09:27AM +0300, Nazir Bilal Yavuz wrote: > I think the problem is deciding how many lines to process before > deciding for the rest. 1000 lines could work for the small sized data > but it might not work for the big sized data. Also, it might cause a > worse regressions for the small sized data. IMHO we have some leeway with smaller amounts of data. If COPY FROM for 1000 rows takes 19 milliseconds as opposed to 11 milliseconds, it seems unlikely users would be inconvenienced all that much. (Those numbers are completely made up in order to illustrate my point.) > Because of this reason, I > tried to implement a heuristic that will work regardless of the size > of the data. The last heuristic I suggested will run SIMD for > approximately (#number_of_lines / 1024 [1024 is the max number of > lines to sleep before running SIMD again]) lines if all characters in > the data are special characters. I wonder if we could mitigate the regression further by spacing out the checks a bit more. It could be worth comparing a variety of values to identify what works best with the test data. -- nathan
On Tue, Oct 21, 2025 at 08:17:01AM +0200, KAZAR Ayoub wrote: >>> I'm also trying the idea of doing SIMD inside quotes with prefix XOR >>> using carry less multiplication avoiding the slow path in all cases even >>> with weird looking input, but it needs to take into consideration the >>> availability of PCLMULQDQ instruction set with <wmmintrin.h> and here we >>> go, it quickly starts to become dirty OR we can wait for the decision to >>> start requiring x86-64-v2 or v3 which has SSE4.2 and AVX2. > > [...] > > Currently we are at 200-400Mbps which isn't that terrible compared to > production and non production grade parsers (of course we don't only parse > in our case), also we are using SSE2 only so theoretically if we add > support for avx later on we'll have even better numbers. > Maybe more micro optimizations to the current heuristic can squeeze it more. I'd greatly prefer that we stick with SSE2/Neon (i.e., simd.h) unless the gains are extraordinary. Beyond the inherent complexity of using architecture-specific intrinsics, you also have to deal with configure-time checks, runtime checks, and function pointer overhead juggling. That tends to be a lot of work for the amount of gain. -- nathan
Hi, On Tue, 21 Oct 2025 at 21:40, Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Tue, Oct 21, 2025 at 12:09:27AM +0300, Nazir Bilal Yavuz wrote: > > I think the problem is deciding how many lines to process before > > deciding for the rest. 1000 lines could work for the small sized data > > but it might not work for the big sized data. Also, it might cause a > > worse regressions for the small sized data. > > IMHO we have some leeway with smaller amounts of data. If COPY FROM for > 1000 rows takes 19 milliseconds as opposed to 11 milliseconds, it seems > unlikely users would be inconvenienced all that much. (Those numbers are > completely made up in order to illustrate my point.) > > > Because of this reason, I > > tried to implement a heuristic that will work regardless of the size > > of the data. The last heuristic I suggested will run SIMD for > > approximately (#number_of_lines / 1024 [1024 is the max number of > > lines to sleep before running SIMD again]) lines if all characters in > > the data are special characters. > > I wonder if we could mitigate the regression further by spacing out the > checks a bit more. It could be worth comparing a variety of values to > identify what works best with the test data. Do you mean that instead of doubling the SIMD sleep, we should multiply it by 3 (or another factor)? Or are you referring to increasing the maximum sleep from 1024? Or possibly both? -- Regards, Nazir Bilal Yavuz Microsoft
On Wed, Oct 22, 2025 at 03:33:37PM +0300, Nazir Bilal Yavuz wrote: > On Tue, 21 Oct 2025 at 21:40, Nathan Bossart <nathandbossart@gmail.com> wrote: >> I wonder if we could mitigate the regression further by spacing out the >> checks a bit more. It could be worth comparing a variety of values to >> identify what works best with the test data. > > Do you mean that instead of doubling the SIMD sleep, we should > multiply it by 3 (or another factor)? Or are you referring to > increasing the maximum sleep from 1024? Or possibly both? I'm not sure of the precise details, but the main thrust of my suggestion is to assume that whatever sampling you do to determine whether to use SIMD is good for a larger chunk of data. That is, if you are sampling 1K lines and then using the result to choose whether to use SIMD for the next 100K lines, we could instead bump the latter number to 1M lines (or something). That way we minimize the regression for relatively uniform data sets while retaining some ability to adapt in case things change halfway through a large table. -- nathan
On 2025-10-22 We 3:24 PM, Nathan Bossart wrote: > On Wed, Oct 22, 2025 at 03:33:37PM +0300, Nazir Bilal Yavuz wrote: >> On Tue, 21 Oct 2025 at 21:40, Nathan Bossart <nathandbossart@gmail.com> wrote: >>> I wonder if we could mitigate the regression further by spacing out the >>> checks a bit more. It could be worth comparing a variety of values to >>> identify what works best with the test data. >> Do you mean that instead of doubling the SIMD sleep, we should >> multiply it by 3 (or another factor)? Or are you referring to >> increasing the maximum sleep from 1024? Or possibly both? > I'm not sure of the precise details, but the main thrust of my suggestion > is to assume that whatever sampling you do to determine whether to use SIMD > is good for a larger chunk of data. That is, if you are sampling 1K lines > and then using the result to choose whether to use SIMD for the next 100K > lines, we could instead bump the latter number to 1M lines (or something). > That way we minimize the regression for relatively uniform data sets while > retaining some ability to adapt in case things change halfway through a > large table. > I'd be ok with numbers like this, although I suspect the numbers of cases where we see shape shifts like this in the middle of a data set would be vanishingly small. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On 2025-10-22 We 3:24 PM, Nathan Bossart wrote:
> On Wed, Oct 22, 2025 at 03:33:37PM +0300, Nazir Bilal Yavuz wrote:
>> On Tue, 21 Oct 2025 at 21:40, Nathan Bossart <nathandbossart@gmail.com> wrote:
>>> I wonder if we could mitigate the regression further by spacing out the
>>> checks a bit more. It could be worth comparing a variety of values to
>>> identify what works best with the test data.
>> Do you mean that instead of doubling the SIMD sleep, we should
>> multiply it by 3 (or another factor)? Or are you referring to
>> increasing the maximum sleep from 1024? Or possibly both?
> I'm not sure of the precise details, but the main thrust of my suggestion
> is to assume that whatever sampling you do to determine whether to use SIMD
> is good for a larger chunk of data. That is, if you are sampling 1K lines
> and then using the result to choose whether to use SIMD for the next 100K
> lines, we could instead bump the latter number to 1M lines (or something).
> That way we minimize the regression for relatively uniform data sets while
> retaining some ability to adapt in case things change halfway through a
> large table.
>
I'd be ok with numbers like this, although I suspect the numbers of
cases where we see shape shifts like this in the middle of a data set
would be vanishingly small.
cheers
andrew
--
Andrew Dunstan
EDB: https://www.enterprisedb.com
Hello!I wanted reproduce the results using files attached by Shinya Kato and Ayoub Kazar. I installed a postgres compiled from master, and then I installed a postgres built from master plus Nazir Bilal Yavuz's v3 patches applied.The master+v3patches postgres naturally performed better on copying into the database: anywhere from 11% better for the t.csv file produced by Shinyo's test.sql, to 35% better copying in the t_4096_none.csv file created by Ayoub Kazar's simd-copy-from-bench.sql.But here's where it gets weird. The two files created by Ayoub Kazar's simd-copy-from-bench.sql that are supposed to be slower, t_4096_escape.txt, and t_4096_quote.csv, actually ran faster on my machine, by 11% and 5% respectively.This seems impossible.A few things I should note:I timed the commands using the Unix time command, like so:time psql -X -U mwood -h localhost -d postgres -c '\copy t from /tmp/t_4096_escape.txt'For each file, I timed the copy 6 times and took the average.This was done on my work Linux machine while also running Chrome and an Open Office spreadsheet; not a dedicated machine only running postgres.
All of the copy results took between 4.5 seconds (Shinyo's t.csv copied into postgres compiled from master) to 2 seconds (Ayoub Kazar's t_4096_none.csv copied into postgres compiled from master plus Nazir's v3 patches).Perhaps I need to fiddle with the provided SQL to produce larger files to get longer run times? Maybe sub-second differences won't tell as interesting a story as minutes-long copy commands?
On Tue, Nov 11, 2025 at 11:23 PM Manni Wood <manni.wood@enterprisedb.com> wrote:Hello!I wanted reproduce the results using files attached by Shinya Kato and Ayoub Kazar. I installed a postgres compiled from master, and then I installed a postgres built from master plus Nazir Bilal Yavuz's v3 patches applied.The master+v3patches postgres naturally performed better on copying into the database: anywhere from 11% better for the t.csv file produced by Shinyo's test.sql, to 35% better copying in the t_4096_none.csv file created by Ayoub Kazar's simd-copy-from-bench.sql.But here's where it gets weird. The two files created by Ayoub Kazar's simd-copy-from-bench.sql that are supposed to be slower, t_4096_escape.txt, and t_4096_quote.csv, actually ran faster on my machine, by 11% and 5% respectively.This seems impossible.A few things I should note:I timed the commands using the Unix time command, like so:time psql -X -U mwood -h localhost -d postgres -c '\copy t from /tmp/t_4096_escape.txt'For each file, I timed the copy 6 times and took the average.This was done on my work Linux machine while also running Chrome and an Open Office spreadsheet; not a dedicated machine only running postgres.Hello,I think if you do a perf benchmark (if it still reproduces) it would probably be possible to explain why it's performing like that looking at the CPI and other metrics and compare it to my findings.What i also suggest is to make the data close even closer to the worst case i.e: more special characters where it hurts the switching between SIMD and scalar processing (in simd-copy-from-bench.sql file), if still does a good job then there's something to look at.All of the copy results took between 4.5 seconds (Shinyo's t.csv copied into postgres compiled from master) to 2 seconds (Ayoub Kazar's t_4096_none.csv copied into postgres compiled from master plus Nazir's v3 patches).Perhaps I need to fiddle with the provided SQL to produce larger files to get longer run times? Maybe sub-second differences won't tell as interesting a story as minutes-long copy commands?I did try it on some GBs (around 2-5GB only), the differences were not that much, but if you can run this on more GBs (at least 10GB) it would be good to look at, although i don't suspect anything interesting since the shape of data is the same for the totality of the COPY.Thanks for the info.Regards,Ayoub Kazar.
I'd like to mark myself as the committer this one, but I noticed that the commitfest entry [0] has been marked as Withdrawn. Could someone either reopen it or create a new one as appropriate (assuming there is a desire to continue with it)? I'm hoping to start spending more time on it soon. [0] https://commitfest.postgresql.org/patch/5952/ -- nathan
I'd like to mark myself as the committer this one, but I noticed that the
commitfest entry [0] has been marked as Withdrawn. Could someone either
reopen it or create a new one as appropriate (assuming there is a desire to
continue with it)? I'm hoping to start spending more time on it soon.
[0] https://commitfest.postgresql.org/patch/5952/
Hi, On Tue, 18 Nov 2025 at 01:53, Shinya Kato <shinya11.kato@gmail.com> wrote: > > > On Tue, Nov 18, 2025, 07:16 Nathan Bossart <nathandbossart@gmail.com> wrote: >> >> I'd like to mark myself as the committer this one, but I noticed that the >> commitfest entry [0] has been marked as Withdrawn. Could someone either >> reopen it or create a new one as appropriate (assuming there is a desire to >> continue with it)? I'm hoping to start spending more time on it soon. >> >> [0] https://commitfest.postgresql.org/patch/5952/ > > > I closed this entry because I currently don't have enough time to continue developing this patch. It is fine if someoneelse reopens it; I will do my best to see the patch whenever I can. Thank you for all your work on this patch. I would like to continue working on this but I am not sure what are the correct steps to reopen this commitfest entry. Do I just need to change commitfest entry's status to 'Needs review'? -- Regards, Nazir Bilal Yavuz Microsoft
On 2025-11-18 Tu 3:04 AM, Nazir Bilal Yavuz wrote: > Hi, > > On Tue, 18 Nov 2025 at 01:53, Shinya Kato <shinya11.kato@gmail.com> wrote: >> >> On Tue, Nov 18, 2025, 07:16 Nathan Bossart <nathandbossart@gmail.com> wrote: >>> I'd like to mark myself as the committer this one, but I noticed that the >>> commitfest entry [0] has been marked as Withdrawn. Could someone either >>> reopen it or create a new one as appropriate (assuming there is a desire to >>> continue with it)? I'm hoping to start spending more time on it soon. >>> >>> [0] https://commitfest.postgresql.org/patch/5952/ >> >> I closed this entry because I currently don't have enough time to continue developing this patch. It is fine if someoneelse reopens it; I will do my best to see the patch whenever I can. > Thank you for all your work on this patch. > > I would like to continue working on this but I am not sure what are > the correct steps to reopen this commitfest entry. Do I just need to > change commitfest entry's status to 'Needs review'? That should do it, I believe. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Hi, On Tue, 18 Nov 2025 at 17:01, Andrew Dunstan <andrew@dunslane.net> wrote: > > > On 2025-11-18 Tu 3:04 AM, Nazir Bilal Yavuz wrote: > > Hi, > > > > On Tue, 18 Nov 2025 at 01:53, Shinya Kato <shinya11.kato@gmail.com> wrote: > >> > >> On Tue, Nov 18, 2025, 07:16 Nathan Bossart <nathandbossart@gmail.com> wrote: > >>> I'd like to mark myself as the committer this one, but I noticed that the > >>> commitfest entry [0] has been marked as Withdrawn. Could someone either > >>> reopen it or create a new one as appropriate (assuming there is a desire to > >>> continue with it)? I'm hoping to start spending more time on it soon. > >>> > >>> [0] https://commitfest.postgresql.org/patch/5952/ > >> > >> I closed this entry because I currently don't have enough time to continue developing this patch. It is fine if someoneelse reopens it; I will do my best to see the patch whenever I can. > > Thank you for all your work on this patch. > > > > I would like to continue working on this but I am not sure what are > > the correct steps to reopen this commitfest entry. Do I just need to > > change commitfest entry's status to 'Needs review'? > > That should do it, I believe. Thanks, done. -- Regards, Nazir Bilal Yavuz Microsoft
(assuming there is a desire to
continue with it)?
I'm hoping to start spending more time on it soon.
Somethings worth noting for future reference (so someone else wouldn't waste time thinking about it), previously I tried extra several micro optimizations inside and around CopyReadLineText:
SIMD alignment: Forcing 16-byte aligned buffers so we could use aligned memory instructions (_mm_load_si128 vs _mm_loadu_si128) provided no measurable benefit on modern CPUs (there's definitely a thread somewhere talking about it that i didn't encounter yet). This likely explains why simd.h exclusively uses unaligned load intrinsics the performance difference has become negligible since Nehalem processors.
Memory prefetching: Explicit prefetch instructions for the COPY buffer pipeline (copy_raw_buf, input buffers, etc.) either showed no improvement or slight regression. Multiple chunks are already within a cache line, other buffers are too far to prefetch and the next part of the buffer is easily prefetched, nothing special, so it turns out to be not worth having more uops.
Instruction-level parallelism: Spreading too many independent vector operations to increase ILP eventually degrades performance, likely due to backend saturation observed through perf (execution port and execution units contention most likely ?)
.....
This simply suggests that further optimization work should focus on the pipeline as a whole for large benefits (parallel copy[0], maybe ?).
[0] https://www.postgresql.org/message-id/CAA4eK1+kpddvvLxWm4BuG_AhVvYz8mKAEa7osxp_X0d4ZEiV=g@mail.gmail.com
--
Regards,
Ayoub Kazar
On Tue, Nov 18, 2025 at 05:20:05PM +0300, Nazir Bilal Yavuz wrote:
> Thanks, done.
I took a look at the v3 patches. Here are my high-level thoughts:
+ /*
+ * Parse data and transfer into line_buf. To get benefit from inlining,
+ * call CopyReadLineText() with the constant boolean variables.
+ */
+ if (cstate->simd_continue)
+ result = CopyReadLineText(cstate, is_csv, true);
+ else
+ result = CopyReadLineText(cstate, is_csv, false);
I'm curious whether this actually generates different code, and if it does,
if it's actually faster. We're already branching on cstate->simd_continue
here.
+ /* Load a chunk of data into a vector register */
+ vector8_load(&chunk, (const uint8 *) ©_input_buf[input_buf_ptr]);
In other places, processing 2 or 4 vectors of data at a time has proven
faster. Have you tried that here?
+ /* \n and \r are not special inside quotes */
+ if (!in_quote)
+ match = vector8_or(vector8_eq(chunk, nl), vector8_eq(chunk, cr));
+
+ if (is_csv)
+ {
+ match = vector8_or(match, vector8_eq(chunk, quote));
+ if (escapec != '\0')
+ match = vector8_or(match, vector8_eq(chunk, escape));
+ }
+ else
+ match = vector8_or(match, vector8_eq(chunk, bs));
The amount of branching here catches my eye. Some branching might be
unavoidable, but in general we want to keep these SIMD paths as branch-free
as possible.
+ /*
+ * Found a special character. Advance up to that point and let
+ * the scalar code handle it.
+ */
+ int advance = pg_rightmost_one_pos32(mask);
+
+ input_buf_ptr += advance;
+ simd_total_advance += advance;
Do we actually need to advance here? Or could we just fall through to the
scalar path? My suspicion is that this extra code doesn't gain us much.
+ if (simd_last_sleep_cycle == 0)
+ simd_last_sleep_cycle = 1;
+ else if (simd_last_sleep_cycle >= SIMD_SLEEP_MAX / 2)
+ simd_last_sleep_cycle = SIMD_SLEEP_MAX;
+ else
+ simd_last_sleep_cycle <<= 1;
+ cstate->simd_current_sleep_cycle = simd_last_sleep_cycle;
+ cstate->simd_last_sleep_cycle = simd_last_sleep_cycle;
IMHO we should be looking for ways to simplify this should-we-use-SIMD
code. For example, perhaps we could just disable the SIMD path for 10K or
100K lines any time a special character is found. I'm dubious that a lot
of complexity is warranted.
--
nathan
Hi,
Thank you for looking into this!
On Thu, 20 Nov 2025 at 00:01, Nathan Bossart <nathandbossart@gmail.com> wrote:
>
> On Tue, Nov 18, 2025 at 05:20:05PM +0300, Nazir Bilal Yavuz wrote:
> > Thanks, done.
>
> I took a look at the v3 patches. Here are my high-level thoughts:
>
> + /*
> + * Parse data and transfer into line_buf. To get benefit from inlining,
> + * call CopyReadLineText() with the constant boolean variables.
> + */
> + if (cstate->simd_continue)
> + result = CopyReadLineText(cstate, is_csv, true);
> + else
> + result = CopyReadLineText(cstate, is_csv, false);
>
> I'm curious whether this actually generates different code, and if it does,
> if it's actually faster. We're already branching on cstate->simd_continue
> here.
I had the same doubts before but my benchmark shows nice speedup. I
used a test which is full of delimiters. The current code gives 2700
ms but when I changed these lines with the 'result =
CopyReadLineText(cstate, is_csv, cstate->simd_continue);', the result
was 2920 ms. I compiled code with both -O3 and -O2 and the results
were similar.
>
> + /* Load a chunk of data into a vector register */
> + vector8_load(&chunk, (const uint8 *) ©_input_buf[input_buf_ptr]);
>
> In other places, processing 2 or 4 vectors of data at a time has proven
> faster. Have you tried that here?
Sorry, I could not find the related code piece. I only saw the
vector8_load() inside of hex_decode_safe() function and its comment
says:
/*
* We must process 2 vectors at a time since the output will be half the
* length of the input.
*/
But this does not mention any speedup from using 2 vectors at a time.
Could you please show the related code?
>
> + /* \n and \r are not special inside quotes */
> + if (!in_quote)
> + match = vector8_or(vector8_eq(chunk, nl), vector8_eq(chunk, cr));
> +
> + if (is_csv)
> + {
> + match = vector8_or(match, vector8_eq(chunk, quote));
> + if (escapec != '\0')
> + match = vector8_or(match, vector8_eq(chunk, escape));
> + }
> + else
> + match = vector8_or(match, vector8_eq(chunk, bs));
>
> The amount of branching here catches my eye. Some branching might be
> unavoidable, but in general we want to keep these SIMD paths as branch-free
> as possible.
You are right, I will check these branches and will try to remove as
many branches as possible.
>
> + /*
> + * Found a special character. Advance up to that point and let
> + * the scalar code handle it.
> + */
> + int advance = pg_rightmost_one_pos32(mask);
> +
> + input_buf_ptr += advance;
> + simd_total_advance += advance;
>
> Do we actually need to advance here? Or could we just fall through to the
> scalar path? My suspicion is that this extra code doesn't gain us much.
My testing shows that if we advance more than ~5 characters then SIMD
is worth it, but if we advance less than ~5; then code causes a
regression. I used this information while writing a heuristic.
>
> + if (simd_last_sleep_cycle == 0)
> + simd_last_sleep_cycle = 1;
> + else if (simd_last_sleep_cycle >= SIMD_SLEEP_MAX / 2)
> + simd_last_sleep_cycle = SIMD_SLEEP_MAX;
> + else
> + simd_last_sleep_cycle <<= 1;
> + cstate->simd_current_sleep_cycle = simd_last_sleep_cycle;
> + cstate->simd_last_sleep_cycle = simd_last_sleep_cycle;
>
> IMHO we should be looking for ways to simplify this should-we-use-SIMD
> code. For example, perhaps we could just disable the SIMD path for 10K or
> 100K lines any time a special character is found. I'm dubious that a lot
> of complexity is warranted.
I think this is a bit too harsh since SIMD is still worth it if SIMD
can advance more than ~5 character average. I am trying to use SIMD as
much as possible when it is worth it but what you said can remove the
regression completely, perhaps that is the correct way.
--
Regards,
Nazir Bilal Yavuz
Microsoft
On 2025-11-20 Th 7:55 AM, Nazir Bilal Yavuz wrote: > Hi, > > Thank you for looking into this! > > On Thu, 20 Nov 2025 at 00:01, Nathan Bossart <nathandbossart@gmail.com> wrote: > >> IMHO we should be looking for ways to simplify this should-we-use-SIMD >> code. For example, perhaps we could just disable the SIMD path for 10K or >> 100K lines any time a special character is found. I'm dubious that a lot >> of complexity is warranted. > I think this is a bit too harsh since SIMD is still worth it if SIMD > can advance more than ~5 character average. I am trying to use SIMD as > much as possible when it is worth it but what you said can remove the > regression completely, perhaps that is the correct way. > Perhaps a very small regression (say under 1%) in the worst case would be OK. But the closer you can get that to zero the more acceptable this will be. Very large loads of sparse data, which will often have lots of special characters AIUI, are very common, so we should not dismiss the worst case as an outlier. I still like the idea of testing, say, a thousand lines every million, or something like that. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Thu, Nov 20, 2025 at 03:55:43PM +0300, Nazir Bilal Yavuz wrote: > On Thu, 20 Nov 2025 at 00:01, Nathan Bossart <nathandbossart@gmail.com> wrote: >> + /* Load a chunk of data into a vector register */ >> + vector8_load(&chunk, (const uint8 *) ©_input_buf[input_buf_ptr]); >> >> In other places, processing 2 or 4 vectors of data at a time has proven >> faster. Have you tried that here? > > Sorry, I could not find the related code piece. I only saw the > vector8_load() inside of hex_decode_safe() function and its comment > says: > > /* > * We must process 2 vectors at a time since the output will be half the > * length of the input. > */ > > But this does not mention any speedup from using 2 vectors at a time. > Could you please show the related code? See pg_lfind32(). -- nathan
On Thu, Nov 20, 2025 at 03:55:43PM +0300, Nazir Bilal Yavuz wrote:
> On Thu, 20 Nov 2025 at 00:01, Nathan Bossart <nathandbossart@gmail.com> wrote:
>> + /* Load a chunk of data into a vector register */
>> + vector8_load(&chunk, (const uint8 *) ©_input_buf[input_buf_ptr]);
>>
>> In other places, processing 2 or 4 vectors of data at a time has proven
>> faster. Have you tried that here?
>
> Sorry, I could not find the related code piece. I only saw the
> vector8_load() inside of hex_decode_safe() function and its comment
> says:
>
> /*
> * We must process 2 vectors at a time since the output will be half the
> * length of the input.
> */
>
> But this does not mention any speedup from using 2 vectors at a time.
> Could you please show the related code?
See pg_lfind32().
--
nathan
On Tue, Nov 18, 2025 at 05:20:05PM +0300, Nazir Bilal Yavuz wrote:I've compiled both versions with -O2 and confirmed they generate different code. When simd_continue is passed as a constant to CopyReadLineText, the compiler optimizes out the condition checks from the SIMD path.
> Thanks, done.
I took a look at the v3 patches. Here are my high-level thoughts:
+ /*
+ * Parse data and transfer into line_buf. To get benefit from inlining,
+ * call CopyReadLineText() with the constant boolean variables.
+ */
+ if (cstate->simd_continue)
+ result = CopyReadLineText(cstate, is_csv, true);
+ else
+ result = CopyReadLineText(cstate, is_csv, false);
I'm curious whether this actually generates different code, and if it does,
if it's actually faster. We're already branching on cstate->simd_continue
here.
A small benchmark on a 1GB+ file shows the expected benefit which is around 6% performance improvement.
I've attached the assembly outputs in case someone wants to check something else.
Вложения
On Tue, Nov 18, 2025 at 05:20:05PM +0300, Nazir Bilal Yavuz wrote:I've compiled both versions with -O2 and confirmed they generate different code. When simd_continue is passed as a constant to CopyReadLineText, the compiler optimizes out the condition checks from the SIMD path.
> Thanks, done.
I took a look at the v3 patches. Here are my high-level thoughts:
+ /*
+ * Parse data and transfer into line_buf. To get benefit from inlining,
+ * call CopyReadLineText() with the constant boolean variables.
+ */
+ if (cstate->simd_continue)
+ result = CopyReadLineText(cstate, is_csv, true);
+ else
+ result = CopyReadLineText(cstate, is_csv, false);
I'm curious whether this actually generates different code, and if it does,
if it's actually faster. We're already branching on cstate->simd_continue
here.
A small benchmark on a 1GB+ file shows the expected benefit which is around 6% performance improvement.
I've attached the assembly outputs in case someone wants to check something else.Regards,Ayoub Kazar
On Wed, Nov 26, 2025 at 5:51 AM KAZAR Ayoub <ma_kazar@esi.dz> wrote:On Tue, Nov 18, 2025 at 05:20:05PM +0300, Nazir Bilal Yavuz wrote:I've compiled both versions with -O2 and confirmed they generate different code. When simd_continue is passed as a constant to CopyReadLineText, the compiler optimizes out the condition checks from the SIMD path.
> Thanks, done.
I took a look at the v3 patches. Here are my high-level thoughts:
+ /*
+ * Parse data and transfer into line_buf. To get benefit from inlining,
+ * call CopyReadLineText() with the constant boolean variables.
+ */
+ if (cstate->simd_continue)
+ result = CopyReadLineText(cstate, is_csv, true);
+ else
+ result = CopyReadLineText(cstate, is_csv, false);
I'm curious whether this actually generates different code, and if it does,
if it's actually faster. We're already branching on cstate->simd_continue
here.
A small benchmark on a 1GB+ file shows the expected benefit which is around 6% performance improvement.
I've attached the assembly outputs in case someone wants to check something else.Regards,Ayoub KazarCorrection to my last post:I also tried files that alternated lines with no special characters and lines with 1/3rd special characters, thinking I could force the algorithm to continually check whether or not it should use simd and therefore force more overhead in the try-simd/don't-try-simd housekeeping code. The text file was still 20% faster (not 50% faster as I originally stated --- that was a typo). The CSV file was still 13% faster.Also, apologies for posting at the top in my last e-mail.---- Manni Wood EDB: https://www.enterprisedb.com
Вложения
Hi,
On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> Hello, all.
>
> Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth using.
Attachedare v4 versions of the patches showing a first attempt at doing that.
Thank you for doing this!
> I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations
introducedby Ayub Kazar.
>
> The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text with
1/3rdescapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
>
> This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of the
fileand then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion of
maybechecking again every million lines or so.
My input-generation script is not ready to share yet, but the inputs
follow this format: text_${n}.input, where n represents the number of
normal characters before the delimiter. For example:
n = 0 -> "\n\n\n\n\n..." (no normal characters)
n = 1 -> "a\n..." (1 normal character before the delimiter)
...
n = 5 -> "aaaaa\n..."
… continuing up to n = 32.
Each line has 4096 chars and there are a total of 100000 lines in each
input file.
I only benchmarked the text format. I compared the latest heuristic I
shared [1] with the current method. The benchmarks show roughly a ~16%
regression at the worst case (n = 2), with regressions up to n = 5.
For the remaining values, performance was similar.
Actual comparison of timings (in ms):
current method / heuristic
n = 0 -> 3252.7253 / 2856.2753 (%12)
n = 1 -> 2910.321 / 2520.7717 (%13)
n = 2 -> 2865.008 / 2403.2017 (%16)
n = 3 -> 2608.649 / 2353.1477 (%9)
n = 4 -> 2460.74 / 2300.1783 (%6)
n = 5 -> 2451.696 / 2362.1573 (%3)
No difference for the rest.
Side note: Sorry for the delay in responding, I will continue working
on this next week.
[1] https://postgr.es/m/CAN55FZ1KF7XNpm2XyG%3DM-sFUODai%3D6Z8a11xE3s4YRBeBKY3tA%40mail.gmail.com
--
Regards,
Nazir Bilal Yavuz
Microsoft
Hi,
On Sat, 6 Dec 2025 at 10:55, Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> > Hello, all.
> >
> > Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth
using.Attached are v4 versions of the patches showing a first attempt at doing that.
>
> Thank you for doing this!
>
> > I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations
introducedby Ayub Kazar.
> >
> > The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text with
1/3rdescapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
> >
> > This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of
thefile and then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion
ofmaybe checking again every million lines or so.
>
> My input-generation script is not ready to share yet, but the inputs
> follow this format: text_${n}.input, where n represents the number of
> normal characters before the delimiter. For example:
>
> n = 0 -> "\n\n\n\n\n..." (no normal characters)
> n = 1 -> "a\n..." (1 normal character before the delimiter)
> ...
> n = 5 -> "aaaaa\n..."
> … continuing up to n = 32.
>
> Each line has 4096 chars and there are a total of 100000 lines in each
> input file.
>
> I only benchmarked the text format. I compared the latest heuristic I
> shared [1] with the current method. The benchmarks show roughly a ~16%
> regression at the worst case (n = 2), with regressions up to n = 5.
> For the remaining values, performance was similar.
I tried to improve the v4 patchset. My changes are:
1 - I changed CopyReadLineText() to an inline function and sent the
use_simd variable as an argument to get help from inlining.
2 - A main for loop in the CopyReadLineText() function is called many
times, so I moved the use_simd check to the CopyReadLine() function.
3 - Instead of 'bytes_processed', I used 'chars_processed' because
cstate->bytes_processed is increased before we process them and this
can cause wrong results.
4 - Because of #2 and #3, instead of having
'SPECIAL_CHAR_SIMD_THRESHOLD', I used the ratio of 'chars_processed /
special_chars_encountered' to determine whether we want to use SIMD.
5 - cstate->special_chars_encountered is incremented wrongly for the
CSV case. It is not incremented for the quote and escape delimiters. I
moved all increments of cstate->special_chars_encountered to the
central place and tried to optimize it but it still causes a
regression as it creates one more branching.
With these changes, I am able to decrease the regression to %10 from
%16. Regression decreases to %7 if I modify #5 for the only text input
but I did not do that.
My changes are in the 0003.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Вложения
Hi,
On Sat, 6 Dec 2025 at 10:55, Bilal Yavuz <byavuz81@gmail.com> wrote:
>
> Hi,
>
> On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> > Hello, all.
> >
> > Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth using. Attached are v4 versions of the patches showing a first attempt at doing that.
>
> Thank you for doing this!
>
> > I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations introduced by Ayub Kazar.
> >
> > The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text with 1/3rd escapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
> >
> > This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of the file and then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion of maybe checking again every million lines or so.
>
> My input-generation script is not ready to share yet, but the inputs
> follow this format: text_${n}.input, where n represents the number of
> normal characters before the delimiter. For example:
>
> n = 0 -> "\n\n\n\n\n..." (no normal characters)
> n = 1 -> "a\n..." (1 normal character before the delimiter)
> ...
> n = 5 -> "aaaaa\n..."
> … continuing up to n = 32.
>
> Each line has 4096 chars and there are a total of 100000 lines in each
> input file.
>
> I only benchmarked the text format. I compared the latest heuristic I
> shared [1] with the current method. The benchmarks show roughly a ~16%
> regression at the worst case (n = 2), with regressions up to n = 5.
> For the remaining values, performance was similar.
I tried to improve the v4 patchset. My changes are:
1 - I changed CopyReadLineText() to an inline function and sent the
use_simd variable as an argument to get help from inlining.
2 - A main for loop in the CopyReadLineText() function is called many
times, so I moved the use_simd check to the CopyReadLine() function.
3 - Instead of 'bytes_processed', I used 'chars_processed' because
cstate->bytes_processed is increased before we process them and this
can cause wrong results.
4 - Because of #2 and #3, instead of having
'SPECIAL_CHAR_SIMD_THRESHOLD', I used the ratio of 'chars_processed /
special_chars_encountered' to determine whether we want to use SIMD.
5 - cstate->special_chars_encountered is incremented wrongly for the
CSV case. It is not incremented for the quote and escape delimiters. I
moved all increments of cstate->special_chars_encountered to the
central place and tried to optimize it but it still causes a
regression as it creates one more branching.
With these changes, I am able to decrease the regression to %10 from
%16. Regression decreases to %7 if I modify #5 for the only text input
but I did not do that.
My changes are in the 0003.
--
Regards,
Nazir Bilal Yavuz
Microsoft
Hi, On Wed, 10 Dec 2025 at 01:13, Manni Wood <manni.wood@enterprisedb.com> wrote: > > Bilal Yavuz (Nazir Bilal Yavuz?), It is Nazir Bilal Yavuz, I changed some settings on my phone and it seems that it affected my mail account, hopefully it should be fixed now. > I did not get a chance to do any work on this today, but wanted to thank you for finding my logic errors in counting specialchars for CSV, and hacking on my naive solution to make it faster. By attempting Andrew Dunstan's suggestion, I gota better feel for the reality that the "housekeeping" code produces a significant amount of overhead. You are welcome! v4.1 has some problems with in_quote case in SIMD handling code and counting cstate->chars_processed variable. I fixed them in v4.2. -- Regards, Nazir Bilal Yavuz Microsoft
Вложения
Hi everyone,
On Tue, Dec 09, 2025 at 04:40:19PM +0300, Bilal Yavuz wrote:
> Hi,
>
> On Sat, 6 Dec 2025 at 10:55, Bilal Yavuz <byavuz81@gmail.com> wrote:
> >
> > Hi,
> >
> > On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> > > Hello, all.
> > >
> > > Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth
using.Attached are v4 versions of the patches showing a first attempt at doing that.
> >
> > Thank you for doing this!
> >
> > > I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations
introducedby Ayub Kazar.
> > >
> > > The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text
with1/3rd escapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
> > >
> > > This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of
thefile and then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion
ofmaybe checking again every million lines or so.
> >
> > My input-generation script is not ready to share yet, but the inputs
> > follow this format: text_${n}.input, where n represents the number of
> > normal characters before the delimiter. For example:
> >
> > n = 0 -> "\n\n\n\n\n..." (no normal characters)
> > n = 1 -> "a\n..." (1 normal character before the delimiter)
> > ...
> > n = 5 -> "aaaaa\n..."
> > … continuing up to n = 32.
> >
> > Each line has 4096 chars and there are a total of 100000 lines in each
> > input file.
> >
> > I only benchmarked the text format. I compared the latest heuristic I
> > shared [1] with the current method. The benchmarks show roughly a ~16%
> > regression at the worst case (n = 2), with regressions up to n = 5.
> > For the remaining values, performance was similar.
>
> I tried to improve the v4 patchset. My changes are:
>
> 1 - I changed CopyReadLineText() to an inline function and sent the
> use_simd variable as an argument to get help from inlining.
>
> 2 - A main for loop in the CopyReadLineText() function is called many
> times, so I moved the use_simd check to the CopyReadLine() function.
>
> 3 - Instead of 'bytes_processed', I used 'chars_processed' because
> cstate->bytes_processed is increased before we process them and this
> can cause wrong results.
>
> 4 - Because of #2 and #3, instead of having
> 'SPECIAL_CHAR_SIMD_THRESHOLD', I used the ratio of 'chars_processed /
> special_chars_encountered' to determine whether we want to use SIMD.
>
> 5 - cstate->special_chars_encountered is incremented wrongly for the
> CSV case. It is not incremented for the quote and escape delimiters. I
> moved all increments of cstate->special_chars_encountered to the
> central place and tried to optimize it but it still causes a
> regression as it creates one more branching.
>
> With these changes, I am able to decrease the regression to %10 from
> %16. Regression decreases to %7 if I modify #5 for the only text input
> but I did not do that.
>
> My changes are in the 0003.
I was helping collect some data, but I'm a little behind sharing what I
ran against the v4.1 patches (on commit 07961ef8) with the v4.2 version
out there...
I hope it's still helpfule that I share what I collected even though
they are not quite as nice, but maybe it's more about how/where I ran
them.
My laptop has a Intel(R) Core(TM) Ultra 7 165H, where most of these
tests were using up 95%+ of one of the cores (I have hyperthreading
disabled), and using about 10% the ssd's capacity.
Summarizing my results from the same script Manni ran, I didn't see as
much as an improvement in the positive tests, and then saw more negative
results in the other tests.
text copy with no special chars: 18% improvement of 15s from 80s before
the patch
CSV copy with no special chars: 23% improvement of 23s from 96s before
the patch
text with 1/3rd escapes: 6% slower, an additional 5s to 85 seconds
before the patch
CSV with 1/3rd quotes: 7% slower, an additional 10 seconds to 129
seconds before the patch
I'm wondering if my laptop/processor isn't the best test bed for this...
Regards,
Mark
--
Mark Wong <markwkm@gmail.com>
EDB https://enterprisedb.com
Hi everyone,
On Tue, Dec 09, 2025 at 04:40:19PM +0300, Bilal Yavuz wrote:
> Hi,
>
> On Sat, 6 Dec 2025 at 10:55, Bilal Yavuz <byavuz81@gmail.com> wrote:
> >
> > Hi,
> >
> > On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> > > Hello, all.
> > >
> > > Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth using. Attached are v4 versions of the patches showing a first attempt at doing that.
> >
> > Thank you for doing this!
> >
> > > I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations introduced by Ayub Kazar.
> > >
> > > The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text with 1/3rd escapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
> > >
> > > This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of the file and then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion of maybe checking again every million lines or so.
> >
> > My input-generation script is not ready to share yet, but the inputs
> > follow this format: text_${n}.input, where n represents the number of
> > normal characters before the delimiter. For example:
> >
> > n = 0 -> "\n\n\n\n\n..." (no normal characters)
> > n = 1 -> "a\n..." (1 normal character before the delimiter)
> > ...
> > n = 5 -> "aaaaa\n..."
> > … continuing up to n = 32.
> >
> > Each line has 4096 chars and there are a total of 100000 lines in each
> > input file.
> >
> > I only benchmarked the text format. I compared the latest heuristic I
> > shared [1] with the current method. The benchmarks show roughly a ~16%
> > regression at the worst case (n = 2), with regressions up to n = 5.
> > For the remaining values, performance was similar.
>
> I tried to improve the v4 patchset. My changes are:
>
> 1 - I changed CopyReadLineText() to an inline function and sent the
> use_simd variable as an argument to get help from inlining.
>
> 2 - A main for loop in the CopyReadLineText() function is called many
> times, so I moved the use_simd check to the CopyReadLine() function.
>
> 3 - Instead of 'bytes_processed', I used 'chars_processed' because
> cstate->bytes_processed is increased before we process them and this
> can cause wrong results.
>
> 4 - Because of #2 and #3, instead of having
> 'SPECIAL_CHAR_SIMD_THRESHOLD', I used the ratio of 'chars_processed /
> special_chars_encountered' to determine whether we want to use SIMD.
>
> 5 - cstate->special_chars_encountered is incremented wrongly for the
> CSV case. It is not incremented for the quote and escape delimiters. I
> moved all increments of cstate->special_chars_encountered to the
> central place and tried to optimize it but it still causes a
> regression as it creates one more branching.
>
> With these changes, I am able to decrease the regression to %10 from
> %16. Regression decreases to %7 if I modify #5 for the only text input
> but I did not do that.
>
> My changes are in the 0003.
I was helping collect some data, but I'm a little behind sharing what I
ran against the v4.1 patches (on commit 07961ef8) with the v4.2 version
out there...
I hope it's still helpfule that I share what I collected even though
they are not quite as nice, but maybe it's more about how/where I ran
them.
My laptop has a Intel(R) Core(TM) Ultra 7 165H, where most of these
tests were using up 95%+ of one of the cores (I have hyperthreading
disabled), and using about 10% the ssd's capacity.
Summarizing my results from the same script Manni ran, I didn't see as
much as an improvement in the positive tests, and then saw more negative
results in the other tests.
text copy with no special chars: 18% improvement of 15s from 80s before
the patch
CSV copy with no special chars: 23% improvement of 23s from 96s before
the patch
text with 1/3rd escapes: 6% slower, an additional 5s to 85 seconds
before the patch
CSV with 1/3rd quotes: 7% slower, an additional 10 seconds to 129
seconds before the patch
I'm wondering if my laptop/processor isn't the best test bed for this...
Regards,
Mark
--
Mark Wong <markwkm@gmail.com>
EDB https://enterprisedb.com
Вложения
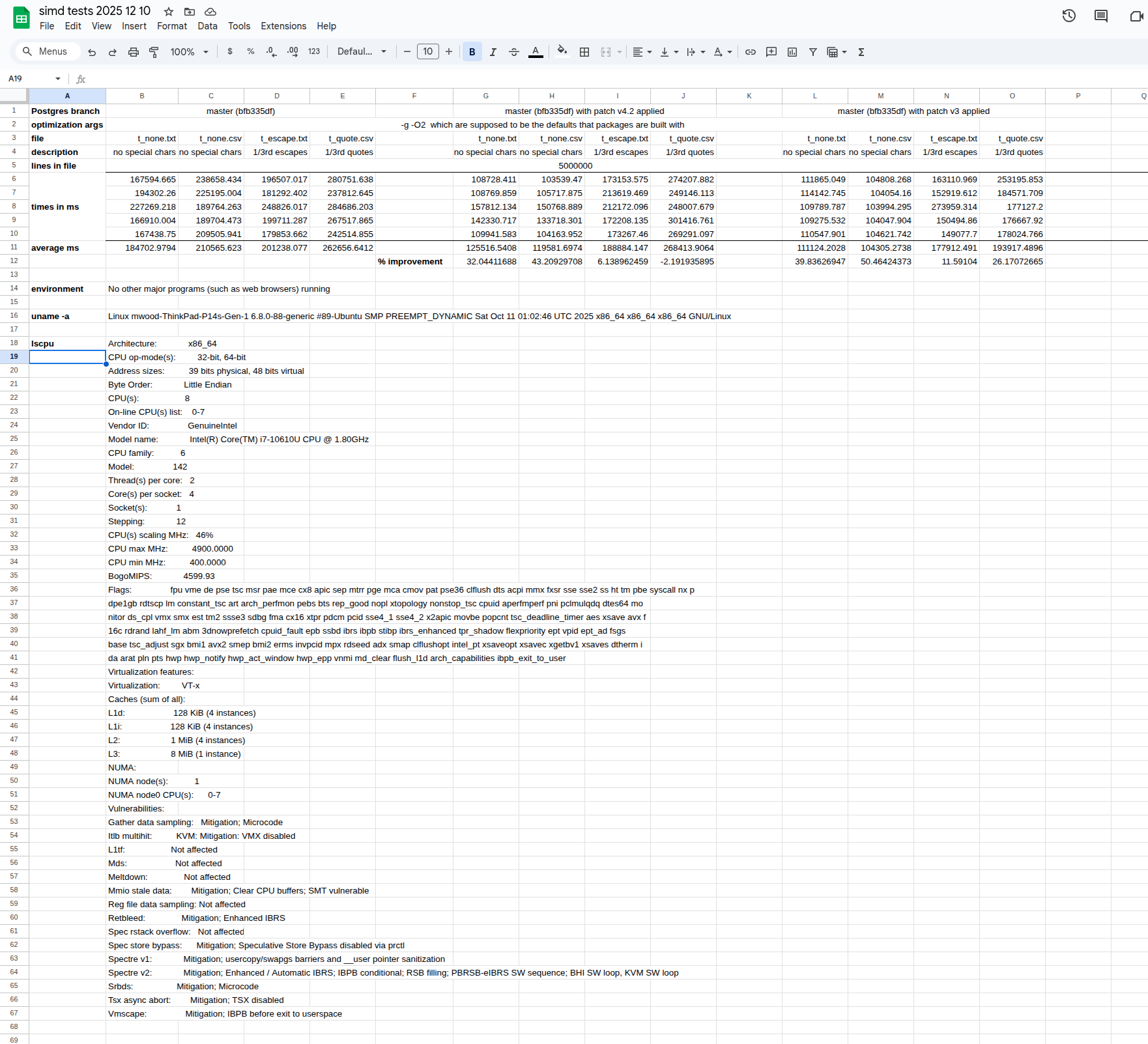{kind=link}
Hi,
On Sat, 13 Dec 2025 at 02:09, Manni Wood <manni.wood@enterprisedb.com> wrote:
>
> Hello, Everyone!
>
> I have attached two files. 1) the shell script that Mark and I have been using to get our test results, and 2) a
screenshotof a spreadsheet of my latest test results. (Please let me know if there's a different format than a
screenshotthat I could share my spreadsheet in.)
>
> I took greater care this time to compile all three variants of Postgres (master at bfb335df, master at bfb335df with
v4.2patches installed, master at bfb335df with v3 patches installed) with the same gcc optimization flags that would be
usedto build Postgres packages. To the best of my knowledge, the two gcc flags of greatest interest would be -g and
-O2.I built all three variants of Postgres using meson like so:
>
> BRANCH=$(git branch --show-current)
> meson setup build --prefix=/home/mwood/compiled-pg-instances/${BRANCH} --buildtype=debugoptimized
>
> It occurred to me that in addition to end users only caring about 1) wall clock time (is the speedup noticeable in
"realtime" or just technically faster / uses less CPU?) and 2) Postgres binaries compiled with the same optimization
levelone would get when installing Postgres from packages like .deb or .rpm; in other words, will the user see speedups
withouthaving do manually compile postgres.
>
> My interesting finding, on my laptop (ThinkPad P14s Gen 1 running Ubuntu 24.04.3), is different from Mark Wong's. On
mylaptop, using three Postgres installations all compiled with the -O2 optimization flag, I see speedups with the v4.2
patchexcept for a 2% slowdown with CSV with 1/3rd quotes (a 2% slowdown). But with Nazir's proposed v3 patch, I see
improvementsacross the board. So even for a text file with 1/3rd escape characters, and even with a CSV file with 1/3rd
quotes,I see speedups of 11% and 26% respectively.
>
> The format of these test files originally comes from Ayoub Kazar's test scripts; all Mark and I have done in playing
withthem is make them much larger: 5,000,000 rows, based on the assumption that longer tests are better tests.
>
> I find my results interesting enough that I'd be curious to know if anybody else can reproduce them. It is very
interestingthat Mark's results are noticeably different from mine.
Thank you for sharing the benchmark script! I ran the benchmarks using
your script with --buildtype=debugoptimized. My results are below:
master: 85ddcc2f4c
text, no special: 102294
text, 1/3 special: 108946
csv, no special: 121831
csv, 1/3 special: 140063
v3
text, no special: 88890 (13.1% speedup)
text, 1/3 special: 110463 (1.4% regression)
csv, no special: 89781 (26.3% speedup)
csv, 1/3 special: 147094 (5.0% regression)
v4.2
text, no special: 87785 (14.2% speedup)
text, 1/3 special: 127008 (16.6% regression)
csv, no special: 88093 (27.7% speedup)
csv, 1/3 special: 164487 (17.4% regression)
One thing I noticed is that your benchmark timings appear to have some
variance. In my runs, I did not observe differences greater than one
second between runs. It is possible that this variance is affecting
your results.
Before running the benchmarks, I use the these commands [1] to improve
result stability; they might be helpful if you are not already using
something similar:
I did this benchmark on my local and my specs are Intel i5 13600k,
32GB Memory and SATA SSD.
[1]
sudo cpupower frequency-set --governor=performance
sudo cpupower idle-set -D 0 # disable idle
echo "1" | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo (intel only)
--
Regards,
Nazir Bilal Yavuz
Microsoft
Regards,