Обсуждение: HA Setup Review
Hello Team,
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
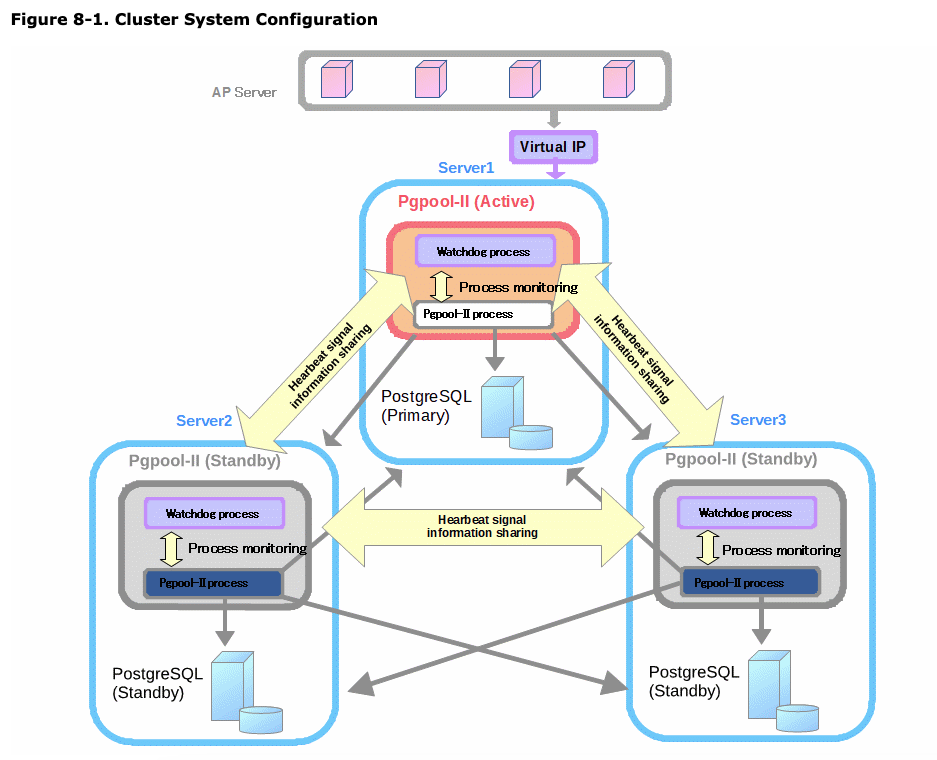
https://www.pgpool.net/docs/42/en/html/example-cluster.html
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
https://www.pgpool.net/docs/42/en/html/example-cluster.html
- Basically a 3 node PostgreSQL Cluster, running 3 processes i.e. PostgreSQL DB, PGPool and WatchDog.
- These 3 nodes will be distributed across 3 availability zones/data centers for resilience and use a synchronous replication between Primary and Stand-by.
- Synchronous option will be Any One, so that the DB availability is not impacted if 1 Stand-by is down for even planned outage i.e. Patching of DB or Virtual Machine.
We see a lot of benefits of this setup in terms of availability and managing less infrastructure v/s setting up separate machines for PGPool.
However, I wanted to know if there are any Cons/Downsides of this setup and any suggestion to improve this setup.
Any views would be highly appreciated.
Thanks & Regards,
Akshay
Вложения
{kind=link}
On Tue, Apr 30, 2024 at 3:41 AM akshay polji <akshay.polji@gmail.com> wrote:
Hello Team,
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
https://www.pgpool.net/docs/42/en/html/example-cluster.html
- Basically a 3 node PostgreSQL Cluster, running 3 processes i.e. PostgreSQL DB, PGPool and WatchDog.
- These 3 nodes will be distributed across 3 availability zones/data centers for resilience and use a synchronous replication between Primary and Stand-by.
You're describing HA+DR, not just HA,
Also, I wouldn't do synchronous replication across the WAN. Not only is the latency too high for decent performance, but any fault in the network freezes the DB.
- Synchronous option will be Any One, so that the DB availability is not impacted if 1 Stand-by is down for even planned outage i.e. Patching of DB or Virtual Machine.
You can switch from async to sync replication just before patching, and then switch back to async when it's completed.
That's pretty much what we do for HA, except only two DB instances (but still three PgPool instances), and they are local and asynchronously replicated. DR is handled by VMware SRM.
Watchdog and heartbeat are built into PgPool. Is that what you're using for WD and HB?
Hi Ron,
Thanks for the details.
Kindly share how we can achieve HA in postgresql, basically my requirement is zero downtime for the application and the database.
In this scenario we have to do failover and in that time there will be outage, kindly correct me if I am wrong.
Also share how can we achieve zero downtime of database (primary write available always) in PG.
Thanks Deepak
From: Ron Johnson <ronljohnsonjr@gmail.com>
Sent: Tuesday, April 30, 2024 8:22:36 PM
To: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup Review
Sent: Tuesday, April 30, 2024 8:22:36 PM
To: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup Review
On Tue, Apr 30, 2024 at 3:41 AM akshay polji <akshay.polji@gmail.com> wrote:
Hello Team,
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
https://www.pgpool.net/docs/42/en/html/example-cluster.html
- Basically a 3 node PostgreSQL Cluster, running 3 processes i.e. PostgreSQL DB, PGPool and WatchDog.
- These 3 nodes will be distributed across 3 availability zones/data centers for resilience and use a synchronous replication between Primary and Stand-by.
You're describing HA+DR, not just HA,
Also, I wouldn't do synchronous replication across the WAN. Not only is the latency too high for decent performance, but any fault in the network freezes the DB.
- Synchronous option will be Any One, so that the DB availability is not impacted if 1 Stand-by is down for even planned outage i.e. Patching of DB or Virtual Machine.
You can switch from async to sync replication just before patching, and then switch back to async when it's completed.
That's pretty much what we do for HA, except only two DB instances (but still three PgPool instances), and they are local and asynchronously replicated. DR is handled by VMware SRM.
Watchdog and heartbeat are built into PgPool. Is that what you're using for WD and HB?
You're confusing HA with DR.
A 3-node cluster, with two in the primary DC and the third (asynchronously replicated) in the remote DC will give you both.
ZERO downtime is -- to my knowledge -- impossible with master-slave replication. There will always be some seconds of lag while the secondary-that-was is promoted to new-primary, and the applications that were forcibly disconnected from the old primary are connected to the new-primary.
Heck, even in a master-master DB cluster, any connections on the master that dies will be down until they can connect to the other master.
On Tue, Apr 30, 2024 at 8:58 AM Deepak Pahuja . <deepakpahuja@hotmail.com> wrote:
Hi Ron,Thanks for the details.Kindly share how we can achieve HA in postgresql, basically my requirement is zero downtime for the application and the database.In this scenario we have to do failover and in that time there will be outage, kindly correct me if I am wrong.Also share how can we achieve zero downtime of database (primary write available always) in PG.Thanks DeepakSent from Outlook for AndroidFrom: Ron Johnson <ronljohnsonjr@gmail.com>
Sent: Tuesday, April 30, 2024 8:22:36 PM
To: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup ReviewOn Tue, Apr 30, 2024 at 3:41 AM akshay polji <akshay.polji@gmail.com> wrote:Hello Team,
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
https://www.pgpool.net/docs/42/en/html/example-cluster.html
- Basically a 3 node PostgreSQL Cluster, running 3 processes i.e. PostgreSQL DB, PGPool and WatchDog.
- These 3 nodes will be distributed across 3 availability zones/data centers for resilience and use a synchronous replication between Primary and Stand-by.
You're describing HA+DR, not just HA,Also, I wouldn't do synchronous replication across the WAN. Not only is the latency too high for decent performance, but any fault in the network freezes the DB.
- Synchronous option will be Any One, so that the DB availability is not impacted if 1 Stand-by is down for even planned outage i.e. Patching of DB or Virtual Machine.
You can switch from async to sync replication just before patching, and then switch back to async when it's completed.That's pretty much what we do for HA, except only two DB instances (but still three PgPool instances), and they are local and asynchronously replicated. DR is handled by VMware SRM.Watchdog and heartbeat are built into PgPool. Is that what you're using for WD and HB?
> On Apr 30, 2024, at 8:20 AM, Ron Johnson <ronljohnsonjr@gmail.com> wrote: > > ZERO downtime is -- to my knowledge -- impossible with master-slave replication. There will always be some seconds oflag while the secondary-that-was is promoted to new-primary, and the applications that were forcibly disconnected fromthe old primary are connected to the new-primary. > > Heck, even in a master-master DB cluster, any connections on the master that dies will be down until they can connect tothe other master. This is true. However, with a secondary that is up to date, and applications accessing through pgbouncer, client connectionsto pgbouncer are not broken, and pgbouncer connections to postgres can be reestablished quickly enough that usersonly observe a slightly slow response.
Thanks a lot Ron and Scott for sharing your insights.
As per Azure documentation "https://learn.microsoft.com/en-us/azure/reliability/availability-zones-overview?tabs=azure-cli"
--- Point - 1 ------
"Watchdog and heartbeat are built into PgPool. Is that what you're using for WD and HB?" --> Yes.
I completely agree with you that with Synchronous Replication across the data center any network glitch would freeze the primary database.
However, in the context cloud e.g., Azure we are planning to place the 3 Nodes the cluster in all different Availability Zones but still in the Same Region.
As per Azure documentation "https://learn.microsoft.com/en-us/azure/reliability/availability-zones-overview?tabs=azure-cli"
"Availability zones are close enough to have low-latency connections to other availability zones. They're connected by a high-performance network with a round-trip latency of less than 2ms."
So do you think that even such a cluster with 3 node pgpool + postgresql (running on the same machine) Synchronous Replication (Any one out of the two replicas) would mean Primary DB will be at risk of degraded performance?
---- Point - 2
For DR, we would add another Stand-by in a different region. But that would be Asynchronous Replication.
---- Point - 3
"You can switch from async to sync replication just before patching, and then switch back to async when it's completed." --> I am a little confused here. What benefit do we get by switching from async to sync replication before patching? I mean that would block the transactions on the primary DB right? What am I missing?
--- Point - 4
" There will always be some seconds of lag while the secondary-that-was is promoted to new-primary, and the applications that were forcibly disconnected from the old primary are connected to the new-primary. "
Agree - 100% .. But that's where the application needs a Retry Logic to handle transient failures to avoid direct impact.
So to Deepak's questions, IMO true ZERO downtime needs to be solved from both App and DB teams together and it's not really DB's problem to solve independently.
"Easier said than done" :D.
Thanks,
Akshay.
On Tue, Apr 30, 2024 at 7:51 PM Ron Johnson <ronljohnsonjr@gmail.com> wrote:
You're confusing HA with DR.A 3-node cluster, with two in the primary DC and the third (asynchronously replicated) in the remote DC will give you both.ZERO downtime is -- to my knowledge -- impossible with master-slave replication. There will always be some seconds of lag while the secondary-that-was is promoted to new-primary, and the applications that were forcibly disconnected from the old primary are connected to the new-primary.Heck, even in a master-master DB cluster, any connections on the master that dies will be down until they can connect to the other master.On Tue, Apr 30, 2024 at 8:58 AM Deepak Pahuja . <deepakpahuja@hotmail.com> wrote:Hi Ron,Thanks for the details.Kindly share how we can achieve HA in postgresql, basically my requirement is zero downtime for the application and the database.In this scenario we have to do failover and in that time there will be outage, kindly correct me if I am wrong.Also share how can we achieve zero downtime of database (primary write available always) in PG.Thanks DeepakSent from Outlook for AndroidFrom: Ron Johnson <ronljohnsonjr@gmail.com>
Sent: Tuesday, April 30, 2024 8:22:36 PM
To: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup ReviewOn Tue, Apr 30, 2024 at 3:41 AM akshay polji <akshay.polji@gmail.com> wrote:Hello Team,
I am looking for some feedback on the HA Setup that we are finalizing for running our business critical workloads.
We are planning to follow this Setup,
https://www.pgpool.net/docs/42/en/html/example-cluster.html
- Basically a 3 node PostgreSQL Cluster, running 3 processes i.e. PostgreSQL DB, PGPool and WatchDog.
- These 3 nodes will be distributed across 3 availability zones/data centers for resilience and use a synchronous replication between Primary and Stand-by.
You're describing HA+DR, not just HA,Also, I wouldn't do synchronous replication across the WAN. Not only is the latency too high for decent performance, but any fault in the network freezes the DB.
- Synchronous option will be Any One, so that the DB availability is not impacted if 1 Stand-by is down for even planned outage i.e. Patching of DB or Virtual Machine.
You can switch from async to sync replication just before patching, and then switch back to async when it's completed.That's pretty much what we do for HA, except only two DB instances (but still three PgPool instances), and they are local and asynchronously replicated. DR is handled by VMware SRM.Watchdog and heartbeat are built into PgPool. Is that what you're using for WD and HB?
> On Apr 30, 2024, at 10:29 AM, akshay polji <akshay.polji@gmail.com> wrote: > > So do you think that even such a cluster with 3 node pgpool + postgresql (running on the same machine) Synchronous Replication(Any one out of the two replicas) would mean Primary DB will be at risk of degraded performance? All cloud providers have downtime and outages. Maybe this is reliable enough for you, but just don't treat it as a guarantee.The point is: if a network glitch, or failure of a replica, can cascade to cause failure of primary, is that reallyHA?
"All cloud providers have downtime and outages. Maybe this is reliable enough for you, but just don't treat it as a guarantee." --> Very true!!
Unless there's a middle ground that I am not aware of but would love to know more.
"if a network glitch, or failure of a replica, can cascade to cause failure of primary, is that really HA?" --> Absolutely not.
But then for HA you need a replica, so now the question is if you want to do Async or Sync.
Sync would mean impact to Primary due to n/w issues or failures but guarantee no-to-minimum data loss,
Async would mean no impact to Primary due to n/w issues or failures but can cause data loss due to replication lag.
If you ask the applications, they will need both .. Neither impact to primary nor data loss. How to weigh the options in this case?
Unless there's a middle ground that I am not aware of but would love to know more.
Thanks,
Akshay
On Tue, Apr 30, 2024 at 10:08 PM Scott Ribe <scott_ribe@elevated-dev.com> wrote:
> On Apr 30, 2024, at 10:29 AM, akshay polji <akshay.polji@gmail.com> wrote:
>
> So do you think that even such a cluster with 3 node pgpool + postgresql (running on the same machine) Synchronous Replication (Any one out of the two replicas) would mean Primary DB will be at risk of degraded performance?
All cloud providers have downtime and outages. Maybe this is reliable enough for you, but just don't treat it as a guarantee. The point is: if a network glitch, or failure of a replica, can cascade to cause failure of primary, is that really HA?
Thank you guys for your inputs and suggestions.
I completely agree that zero downtime is not 100% achievable hence distributed database solutions are quite popular too .
Thanks Deepak
Sent from Outlook for Android
From: akshay polji <akshay.polji@gmail.com>
Sent: Wednesday, May 1, 2024 1:08:48 AM
To: Scott Ribe <scott_ribe@elevated-dev.com>
Cc: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup Review
Sent: Wednesday, May 1, 2024 1:08:48 AM
To: Scott Ribe <scott_ribe@elevated-dev.com>
Cc: pgsql-admin <pgsql-admin@postgresql.org>
Subject: Re: HA Setup Review
"All cloud providers have downtime and outages. Maybe this is reliable enough for you, but just don't treat it as a guarantee." --> Very true!!
Unless there's a middle ground that I am not aware of but would love to know more.
"if a network glitch, or failure of a replica, can cascade to cause failure of primary, is that really HA?" --> Absolutely not.
But then for HA you need a replica, so now the question is if you want to do Async or Sync.
Sync would mean impact to Primary due to n/w issues or failures but guarantee no-to-minimum data loss,
Async would mean no impact to Primary due to n/w issues or failures but can cause data loss due to replication lag.
If you ask the applications, they will need both .. Neither impact to primary nor data loss. How to weigh the options in this case?
Unless there's a middle ground that I am not aware of but would love to know more.
Thanks,
Akshay
On Tue, Apr 30, 2024 at 10:08 PM Scott Ribe <scott_ribe@elevated-dev.com> wrote:
> On Apr 30, 2024, at 10:29 AM, akshay polji <akshay.polji@gmail.com> wrote:
>
> So do you think that even such a cluster with 3 node pgpool + postgresql (running on the same machine) Synchronous Replication (Any one out of the two replicas) would mean Primary DB will be at risk of degraded performance?
All cloud providers have downtime and outages. Maybe this is reliable enough for you, but just don't treat it as a guarantee. The point is: if a network glitch, or failure of a replica, can cascade to cause failure of primary, is that really HA?
On Tue, Apr 30, 2024 at 12:30 PM akshay polji <akshay.polji@gmail.com> wrote:
---- Point - 3"You can switch from async to sync replication just before patching, and then switch back to async when it's completed." --> I am a little confused here. What benefit do we get by switching from async to sync replication before patching?
The guarantee that all transactions committed on the primary have been written to the secondary just before shutting down Primary.
I mean that would block the transactions on the primary DB right?
Wrong 99.99% of the time. It blocks the transaction IFF the network/WAN link is down.
When the WAN link is up, you "just" get cascading transaction slowness because of WAN latency.
Thus... you leave replication to the remote DR site in asynchronous mode until that very specific point when you need to guarantee remote consistency: just before you shut down the Primary for patching.
Once the Primary is patched, and replication is restored, then you can change back to async mode.
Thank you for your response Ron and apologies for delayed response.
"The guarantee that all transactions committed on the primary have been written to the secondary just before shutting down Primary." -> Is this for SYNC or ASYNC?
Thanks for clarifying that the transactions would be blocked if the network/WAN link is down.
"Thus... you leave replication to the remote DR site in asynchronous mode until that very specific point when you need to guarantee remote consistency: just before you shut down the Primary for patching.
Once the Primary is patched, and replication is restored, then you can change back to async mode." -- Makes sense now. Thanks a lot for clarifying.
On Fri, May 3, 2024 at 8:55 AM Ron Johnson <ronljohnsonjr@gmail.com> wrote:
On Tue, Apr 30, 2024 at 12:30 PM akshay polji <akshay.polji@gmail.com> wrote:---- Point - 3"You can switch from async to sync replication just before patching, and then switch back to async when it's completed." --> I am a little confused here. What benefit do we get by switching from async to sync replication before patching?The guarantee that all transactions committed on the primary have been written to the secondary just before shutting down Primary.I mean that would block the transactions on the primary DB right?Wrong 99.99% of the time. It blocks the transaction IFF the network/WAN link is down.When the WAN link is up, you "just" get cascading transaction slowness because of WAN latency.Thus... you leave replication to the remote DR site in asynchronous mode until that very specific point when you need to guarantee remote consistency: just before you shut down the Primary for patching.Once the Primary is patched, and replication is restored, then you can change back to async mode.