Обсуждение: Feature request for adoptive indexes
Hi everyone. I want to do some feature request regarding indexes, as far as
I know this kind of functionality doesn't exists in Postgres. Here is my
problem :
I need to create following indexes:
Create index job_nlp_year_scan on ingest_scans_stageing
(`job`,`nlp`,`year`,`scan_id`);
Create index job_nlp_year_issue_flag on ingest_scans_stageing
(`job`,`nlp`,`year`,`issue_flag`);
Create index job_nlp_year_sequence on ingest_scans_stageing
(`job`,`nlp`,`year`,`sequence`);
As you can see the first 3 columns are the same (job, nlp, year). so if I
create 3 different indexes db should manage same job_nlp_year structure 3
times.
The Data Structure that I think which can be efficient in this kind of
scenarios is to have 'Adaptive Index' which will be something like
Create index job_nlp_year on ingest_scans_stageing
(`job`,`nlp`,`year`,(`issue_flag`,`scan_id`, `sequence`));
And depend on query it will use or job_nlp_year_scan or
job_nlp_year_issue_flag , or job_nlp_year_sequence ( job, nlp, year and one
of ( `issue_flag` , `scan_id` , `sequence` )
For more description please feel free to refer me
I know this kind of functionality doesn't exists in Postgres. Here is my
problem :
I need to create following indexes:
Create index job_nlp_year_scan on ingest_scans_stageing
(`job`,`nlp`,`year`,`scan_id`);
Create index job_nlp_year_issue_flag on ingest_scans_stageing
(`job`,`nlp`,`year`,`issue_flag`);
Create index job_nlp_year_sequence on ingest_scans_stageing
(`job`,`nlp`,`year`,`sequence`);
As you can see the first 3 columns are the same (job, nlp, year). so if I
create 3 different indexes db should manage same job_nlp_year structure 3
times.
The Data Structure that I think which can be efficient in this kind of
scenarios is to have 'Adaptive Index' which will be something like
Create index job_nlp_year on ingest_scans_stageing
(`job`,`nlp`,`year`,(`issue_flag`,`scan_id`, `sequence`));
And depend on query it will use or job_nlp_year_scan or
job_nlp_year_issue_flag , or job_nlp_year_sequence ( job, nlp, year and one
of ( `issue_flag` , `scan_id` , `sequence` )
For more description please feel free to refer me
Hi, On 10/25/21 16:07, Hayk Manukyan wrote: > Hi everyone. I want to do some feature request regarding indexes, as far as > I know this kind of functionality doesn't exists in Postgres. Here is my > problem : > I need to create following indexes: > Create index job_nlp_year_scan on ingest_scans_stageing > (`job`,`nlp`,`year`,`scan_id`); > Create index job_nlp_year_issue_flag on ingest_scans_stageing > (`job`,`nlp`,`year`,`issue_flag`); > Create index job_nlp_year_sequence on ingest_scans_stageing > (`job`,`nlp`,`year`,`sequence`); > As you can see the first 3 columns are the same (job, nlp, year). so if I > create 3 different indexes db should manage same job_nlp_year structure 3 > times. > The Data Structure that I think which can be efficient in this kind of > scenarios is to have 'Adaptive Index' which will be something like > Create index job_nlp_year on ingest_scans_stageing > (`job`,`nlp`,`year`,(`issue_flag`,`scan_id`, `sequence`)); > And depend on query it will use or job_nlp_year_scan or > job_nlp_year_issue_flag , or job_nlp_year_sequence ( job, nlp, year and one > of ( `issue_flag` , `scan_id` , `sequence` ) > For more description please feel free to refer me It's not very clear what exactly would the "adaptive index" do, except that it'd have all three columns. Clearly, the three columns can't be considered for ordering etc. but need to be in the index somehow. So why wouldn't it be enough to either to create an index with all six columns? CREATE INDEX ON job_nlp_year_scan (job, nlp, year, scan_id, issue_flag, sequence); or possibly with the columns just "included" in the index: CREATE INDEX ON job_nlp_year_scan (job, nlp, year) INCLUDE (scan_id, issue_flag, sequence); If this does not work, you either need to explain more clearly what exactly the adaptive indexes does, or show queries that can't benefit from these existing features. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
ok. here is the deal if I have the following index with 6 column
CREATE INDEX ON job_nlp_year_scan (job, nlp, year, scan_id, issue_flag, sequence);
I need to specify all 6 columns in where clause in order to fully use this index.
It will not be efficient in cases when I have 4 condition in where clause also I should follow the order of columns.
In case of INCLUDE the 3 columns just will be in index but will not be structured as index so it will have affect only if In select I will have that 6 columns nothing more.
In my case I have table with ~15 columns
In my application I have to do a lot of queries with following where clauses
1. where job = <something> and nlp = <something> and year = <something> and SCAN_ID = <something>
2. where job = <something> and nlp = <something> and year = <something> and ISSUE_FLAG = <something>
3. where job = <something> and nlp = <something> and year = <something> and SEQUENCE = <something>
I don't want to index just on job, nlp, year because for each job, nlp, year I have approximately 5000-7000 rows ,
overall table have ~50m rows so it is partitioned by job as well. So if I build 3 separate indexes it will be huge resource.
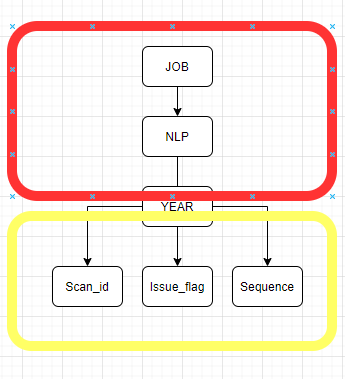
So I am thinking of having one index which will be job, nlp, year and the 4-th layer will be other columns not just included but also in B-tree structure.
To visualize it will be something like this:
The red part is ordinary index with nested b-trees ant the yellow part is adaptive part so depends on
where clause optimizer can decide which direction (leaf, b-tree whatever) to chose.
In this case I will have one index and will manage red part only once for all three cases.
Those it make sense ?
If you need more discussion we can have short call I will try to explain you in more detailed way.
best regards
пн, 25 окт. 2021 г. в 19:33, Tomas Vondra <tomas.vondra@enterprisedb.com>:
Hi,
On 10/25/21 16:07, Hayk Manukyan wrote:
> Hi everyone. I want to do some feature request regarding indexes, as far as
> I know this kind of functionality doesn't exists in Postgres. Here is my
> problem :
> I need to create following indexes:
> Create index job_nlp_year_scan on ingest_scans_stageing
> (`job`,`nlp`,`year`,`scan_id`);
> Create index job_nlp_year_issue_flag on ingest_scans_stageing
> (`job`,`nlp`,`year`,`issue_flag`);
> Create index job_nlp_year_sequence on ingest_scans_stageing
> (`job`,`nlp`,`year`,`sequence`);
> As you can see the first 3 columns are the same (job, nlp, year). so if I
> create 3 different indexes db should manage same job_nlp_year structure 3
> times.
> The Data Structure that I think which can be efficient in this kind of
> scenarios is to have 'Adaptive Index' which will be something like
> Create index job_nlp_year on ingest_scans_stageing
> (`job`,`nlp`,`year`,(`issue_flag`,`scan_id`, `sequence`));
> And depend on query it will use or job_nlp_year_scan or
> job_nlp_year_issue_flag , or job_nlp_year_sequence ( job, nlp, year and one
> of ( `issue_flag` , `scan_id` , `sequence` )
> For more description please feel free to refer me
It's not very clear what exactly would the "adaptive index" do, except
that it'd have all three columns. Clearly, the three columns can't be
considered for ordering etc. but need to be in the index somehow. So why
wouldn't it be enough to either to create an index with all six columns?
CREATE INDEX ON job_nlp_year_scan (job, nlp, year, scan_id, issue_flag,
sequence);
or possibly with the columns just "included" in the index:
CREATE INDEX ON job_nlp_year_scan (job, nlp, year) INCLUDE (scan_id,
issue_flag, sequence);
If this does not work, you either need to explain more clearly what
exactly the adaptive indexes does, or show queries that can't benefit
from these existing features.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On 10/26/21 8:49 AM, Hayk Manukyan wrote: > ok. here is the deal if I have the following index with 6 column > > CREATE INDEX ON job_nlp_year_scan (job, nlp, year, scan_id, issue_flag, > sequence); > > I need to specify all 6 columns in where clause in order to fully use > this index. What do you mean by "fully use this index"? Yes, the query may use just some of the columns and there will be a bit of overhead, but I doubt it'll be measurable. > It will not be efficient in cases when I have 4 condition in where > clause also I should follow the order of columns. So, do some experiments and show us what the difference is. Create an index on the 4 and 6 columns, and measure timings for a query with just the 4 columns. > In case of INCLUDE the 3 columns just will be in index but will not be > structured as index so it will have affect only if In select I will have > that 6 columns nothing more. > > In my case I have table with ~15 columns > In my application I have to do a lot of queries with following where > clauses > > 1. where job = <something> and nlp = <something> and year = <something> > and SCAN_ID = <something> > 2. where job = <something> and nlp = <something> and year = <something> > and ISSUE_FLAG = <something> > 3. where job = <something> and nlp = <something> and year = <something> > and SEQUENCE = <something> > > I don't want to index just on job, nlp, year because for each job, > nlp, year I have approximately 5000-7000 rows , > overall table have ~50m rows so it is partitioned by job as well. So if > I build 3 separate indexes it will be huge resource. > So I am thinking of having one index which will be job, nlp, year and > the 4-th layer will be other columns not just included but also in > B-tree structure. > To visualize it will be something like this: > image.png > The red part is ordinary index with nested b-trees ant the yellow part > is adaptive part so depends on > where clause optimizer can decide which direction (leaf, b-tree > whatever) to chose. > In this case I will have one index and will manage red part only once > for all three cases. > Those it make sense ? If I get what you propose, you want to have a "top" tree for (job, nlp, year), which "splits" the data set into subsets of ~5000-7000 rows. And then for each subset you want a separate "small" trees on each of the other columns, so in this case three trees. Well, the problem with this is pretty obvious - each of the small trees requires separate copies of the leaf pages. And remember, in a btree the internal pages are usually less than 1% of the index, so this pretty much triples the size of the index. And if you insert a row into the index, it has to insert the item pointer into each of the small trees, likely requiring a separate I/O for each. So I'd bet this is not any different from just having three separate indexes - it doesn't save space, doesn't save I/O, nothing. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I've already answered OP but it seems in the wrong thread, so I copy it here:
I think now in many cases you can effectively use covering index to have fast index-only scans without index duplication. It will help if you don't have great selectivity on the last column (most probably you don't). E.g.:
CREATE INDEX ON table_name (`job`,`nlp`,`year`) INCLUDE (`scan_id`, `issue_flag`, `sequence`)
But I consider the feature can be useful when there is a very little selectivity in the first index columns. I.e. if (job`,`nlp`,`year') has many repeats and the most selection is done in the last column. I am not sure how often this can arise but in general, I see it as a useful b-tree generalization.
I'm not sure how it should be done. In my view, we need to add an ordered posting tree as a leaf element if b-tree and now we have index storage only for tuples. The change of on-disk format was previously not easy in nbtree and if we consider the change, we need an extra bit to mark posting trees among index tuples. Maybe it could be done in a way similar to deduplicated tuples if some bits in the tuple header are still could be freed.
Thoughts?
If I get what you propose, you want to have a "top" tree for (job, nlp,
year), which "splits" the data set into subsets of ~5000-7000 rows. And
then for each subset you want a separate "small" trees on each of the
other columns, so in this case three trees.
Well, the problem with this is pretty obvious - each of the small trees
requires separate copies of the leaf pages. And remember, in a btree the
internal pages are usually less than 1% of the index, so this pretty
much triples the size of the index. And if you insert a row into the
index, it has to insert the item pointer into each of the small trees,
likely requiring a separate I/O for each.
So I'd bet this is not any different from just having three separate
indexes - it doesn't save space, doesn't save I/O, nothing.
Tomas, I really think we should not try realizing this feature using existing index pages that contain only tuples. You are right, it will cause large overhead. If instead we decide and succeed in creating "posting trees" as a new on-disk page entry type we can have an index with space comparable to the abovementioned covering index but with sorting of values in these trees (i.e. all values are sorted, and "key" ones).
On 10/26/21 21:39, Pavel Borisov wrote: > I've already answered OP but it seems in the wrong thread, so I copy it > here: > > I think now in many cases you can effectively use covering index to have > fast index-only scans without index duplication. It will help if you > don't have great selectivity on the last column (most probably you > don't). E.g.: > > CREATE INDEX ON table_name (`job`,`nlp`,`year`) INCLUDE (`scan_id`, > `issue_flag`, `sequence`) > > But I consider the feature can be useful when there is a very little > selectivity in the first index columns. I.e. if (job`,`nlp`,`year') has > many repeats and the most selection is done in the last column. I am not > sure how often this can arise but in general, I see it as a useful > b-tree generalization. > > I'm not sure how it should be done. In my view, we need to add an > ordered posting tree as a leaf element if b-tree and now we have index > storage only for tuples. The change of on-disk format was previously not > easy in nbtree and if we consider the change, we need an extra bit to > mark posting trees among index tuples. Maybe it could be done in a way > similar to deduplicated tuples if some bits in the tuple header are > still could be freed. > > Thoughts? > > If I get what you propose, you want to have a "top" tree for (job, nlp, > year), which "splits" the data set into subsets of ~5000-7000 rows. And > then for each subset you want a separate "small" trees on each of the > other columns, so in this case three trees. > > Well, the problem with this is pretty obvious - each of the small trees > requires separate copies of the leaf pages. And remember, in a btree the > internal pages are usually less than 1% of the index, so this pretty > much triples the size of the index. And if you insert a row into the > index, it has to insert the item pointer into each of the small trees, > likely requiring a separate I/O for each. > > So I'd bet this is not any different from just having three separate > indexes - it doesn't save space, doesn't save I/O, nothing. > > Tomas, I really think we should not try realizing this feature using > existing index pages that contain only tuples. You are right, it will > cause large overhead. If instead we decide and succeed in creating > "posting trees" as a new on-disk page entry type we can have an index > with space comparable to the abovementioned covering index but with > sorting of values in these trees (i.e. all values are sorted, and "key" > ones). > Well, there was no explanation about how it could/should be implemented, and maybe there is some elaborate way to handle the "posting trees" that I can't quite think of (at least not in the btree context). I'm still rather skeptical about it - for such feature to be useful the prefix columns must not be very selective, i.e. the posting trees are expected to be fairly large (e.g. 5-7k rows). It pretty much has to to require multiple (many) index pages, in order for the "larger" btree index to be slower. And at that point I'd expect the extra overhead to be worse than simply defining multiple simple indexes. A simple experiment would be to measure timing for queries with a condition on "sequence" using two indexes: 1) (job, nlp, year, sequence) 2) (job, nlp, year, scan_id, issue_flag, sequence) The (1) index is "optimal" i.e. there's unlikely to be a better index for this query, at least no tree-like. (2) is something like the "worst" case index that we can use for this query. For the new feature to be useful, two things would need to be true: * query with (2) is much slower than (1) * the new index would need to be close to (1) Obviously, if the new index is slower than (2), it's mostly useless right off the bat. And it probably can't be faster than (1) in practice, as it still is basically a btree index (at least the top half). So I'd expect the performance to be somewhere between (1) and (2), but if (2) is very close to (1) - which I'd bet it is - then the potential benefit is also pretty small. Perhaps I'm entirely wrong and there's a new type of index, better suited for cases similar to this. The "posting tree" reference actually made me thinking that maybe btree_gin might be applicable here? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
> On Oct 26, 2021, at 1:43 PM, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > I'm still rather skeptical about it - for such feature to be useful the prefix columns must not be very selective, i.e.the posting trees are expected to be fairly large (e.g. 5-7k rows). It pretty much has to to require multiple (many)index pages, in order for the "larger" btree index to be slower. And at that point I'd expect the extra overhead tobe worse than simply defining multiple simple indexes. For three separate indexes, an update or delete of a single row in the indexed table would surely require changing at leastthree pages in the indexes. For some as-yet-ill-defined combined index type, perhaps the three entries in the indexwould fall on the same index page often enough to reduce the I/O cost of the action? This is all hard to contemplatewithout a more precise description of the index algorithm. Perhaps the OP might want to cite a paper describing a particular index algorithm for us to review? — Mark Dilger EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Mark Dilger <mark.dilger@enterprisedb.com> writes:
> For three separate indexes, an update or delete of a single row in the indexed table would surely require changing at
leastthree pages in the indexes. For some as-yet-ill-defined combined index type, perhaps the three entries in the
indexwould fall on the same index page often enough to reduce the I/O cost of the action?
Of course, we have that today from the solution of one index with the
extra columns "included". I think the OP has completely failed to make
any case why that's not a good enough approach.
regards, tom lane
On Tue, Oct 26, 2021 at 3:45 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Of course, we have that today from the solution of one index with the > extra columns "included". I think the OP has completely failed to make > any case why that's not a good enough approach. I think that the design that the OP is talking about (adaptive indexes, AKA merged indexes with master detail clustering) have been the subject of certain research papers. As far as I know nothing like that has ever been implemented in a real DB system. It seems like a daunting project, primarily because of the concurrency control considerations. It's no coincidence that GIN indexes (which have some of the same issues) only support lossy index scans. Lossy scans don't seem to be compatible with adaptive indexes, since the whole point is to have multiple distinct "logical indexes" with a common prefix, but only one physical index, with clustering. I think you'd need something like ARIES KVL for concurrency control, just for starters. Even that is something that won't work with anything like current Postgres. It's roughly the same story that we see with generalizing TIDs at the tableam level. People tend to imagine that it's basically just a matter of coming up with the right index AM data structure, but that's actually just the easy part. -- Peter Geoghegan
It's no coincidence that GIN indexes (which
have some of the same issues) only support lossy index scans.
AFAIK Gin is lossy for phrase queries as we don't store word position in the posting list. For purely logical queries, where position doesn't matter, it's not lossy.
One more consideration against the proposal is that if we want to select with more than one "suffix" columns in the WHERE clause, effectively we will have a join of two separate index scans. And as we consider suffix columns to be highly selective, and prefix columns are weakly selective, then it could be very slow.
Just some ideas on the topic which may not be connected to OP proposal (Not sure whether should we implement them as a part of nbtree) :
1. If prefix columns have low selectivity it may be good if we have some attribute-level deduplication only for prefix columns.
2. If we have several suffix columns, it might be a good idea is to treat them as an n-dimensional space and define some R-tree or Quad-tree on top of them (using GiST, SpGIST).
On Wed, Oct 27, 2021 at 1:02 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > AFAIK Gin is lossy for phrase queries as we don't store word position in the posting list. For purely logical queries,where position doesn't matter, it's not lossy. GIN is always lossy, in the sense that it provides only a gingetbitmap() routine -- there is no gingettuple() routine. I believe that this is fundamental to the overall design of GIN. It would be very difficult to add useful gingettuple() functionality now, since GIN already relies on lossiness to avoid race conditions. Here's an example of the problems that "adding gingettuple()" would run into: Today, an index's pending list entries can be merged concurrently with the entry tree, without worrying about returning the same tuples twice. This is only safe/correct because GIN only supports bitmap index scans. Without that, you need some other mechanism to make it safe -- ISTM you must "logically lock" the index structure, using ARIES/KVL style key value locks, or something along those lines. -- Peter Geoghegan
Hi all
First of all thank you all for fast and rich responses, that is really nice.
I don't have that deep knowledge of how postgres works under the hood so I will try to explain more user side.
I want to refer for some points mentioned above.
- First INCLUDE statement mostly eliminates the necessity to refer to a clustered index or table to get columns that do not exist in the index. So filtering upon columns in INCLUDE statement will not be performant. It can give some very little performance if we include additional columns but it is not in level to compare with indexed one. I believe this not for this case
- Tomas Vondra's Assumption that adaptive should be something between this two
1) (job, nlp, year, sequence)
2) (job, nlp, year, scan_id, issue_flag, sequence)
2) (job, nlp, year, scan_id, issue_flag, sequence)
is completely valid. I have made fairly small demo with this index comparison and as I can see the difference is noticeable. Here is git repo and results , I had no much time to do significant one sorry for that ))
- regarding data structure side of things by Pavel Borisov.
I also think that different data structure will be needed. Not sure exactly at this point which kind of data structure but I will try to explain it here.
best regards
ср, 27 окт. 2021 г. в 20:10, Peter Geoghegan <pg@bowt.ie>:
On Wed, Oct 27, 2021 at 1:02 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote:
> AFAIK Gin is lossy for phrase queries as we don't store word position in the posting list. For purely logical queries, where position doesn't matter, it's not lossy.
GIN is always lossy, in the sense that it provides only a
gingetbitmap() routine -- there is no gingettuple() routine. I believe
that this is fundamental to the overall design of GIN. It would be
very difficult to add useful gingettuple() functionality now, since
GIN already relies on lossiness to avoid race conditions.
Here's an example of the problems that "adding gingettuple()" would
run into: Today, an index's pending list entries can be merged
concurrently with the entry tree, without worrying about returning the
same tuples twice. This is only safe/correct because GIN only supports
bitmap index scans. Without that, you need some other mechanism to
make it safe -- ISTM you must "logically lock" the index structure,
using ARIES/KVL style key value locks, or something along those lines.
--
Peter Geoghegan
On 10/29/21 15:32, Hayk Manukyan wrote: > Hi all > First of all thank you all for fast and rich responses, that is really nice. > I don't have that deep knowledge of how postgres works under the hood > so I will try to explain more user side. > I want to refer for some points mentioned above. > - First INCLUDE statement mostly eliminates the necessity to refer to > a clustered index or table to get columns that do not exist in the > index. So filtering upon columns in INCLUDE statement will not be > performant. It can give some very little performance if we include > additional columns but it is not in level to compare with indexed one. I > believe this not for this case > - Tomas Vondra's Assumption that adaptive should be something between > this two > 1) (job, nlp, year, sequence) > 2) (job, nlp, year, scan_id, issue_flag, sequence) > is completely valid. I have made fairly small demo with this index > comparison and as I can see the difference is noticeable. Here is git > repo and results > <https://github.com/HaykManukyanAvetiky/index_comparition/blob/main/results.md> , > I had no much time to do significant one sorry for that )) I find those results entirely unconvincing, or maybe even suspicious. I used the script to create the objects, and the index sizes are: Name | Size ------------------------------------------+--------- job_nlp_year_scan_id_issue_flag_sequence | 1985 MB job_nlp_year_sequence | 1985 MB So there's no actual difference, most likely due to alignment making up for the two smalling columns. And if I randomize the queries instead of running them with the same parameters over and over (see the attached scripts), then an average of 10 runs, each 60s long, the results are (after a proper warmup) pgbench -n -f q4.sql -T 60 4 columns: 106 ms 6 columns: 109 ms So there's like 3% difference between the two cases, and even that might be just noise. This is consistent with the two indexes being about the same size. This is on machine with i5-2500k CPU and 8GB of RAM, which is just enough to keep everything in RAM. It seems somewhat strange that your machine does this in 10ms, i.e. 10x faster. Seems strange. I'm not sure what is the point of the second query, considering it's not even using an index but parallel seqscan. Anyway, this still fails to demonstrate any material difference between the two indexes, and consequently any potential benefit of the proposed new index type. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
4 columns: 106 ms
6 columns: 109 ms
So there's like 3% difference between the two cases, and even that might
be just noise. This is consistent with the two indexes being about the
same size.
I also don't think we can get great speedup in the mentioned case, so it is not urgently needed of course. My point is that it is just nice to have a multicolumn index constructed on stacked trees constructed on separate columns, not on the index tuples as a whole thing. At least there is a benefit of sparing shared memory if we don't need to cache index tuples of several similar indexes, instead caching one "compound index". So if someone wants to propose this thing I'd support it provided problems with concurrency, which were mentioned by Peter are solved.
These problems could be appear easy though, as we have index tuples constructed in a similar way as heap tuples. Maybe it could be easier if we had another heap am, which stored separate attributes (if so it could be useful as a better JSON storage method than we have today).
--
On 10/31/21 16:48, Pavel Borisov wrote: > 4 columns: 106 ms > 6 columns: 109 ms > > So there's like 3% difference between the two cases, and even that > might > be just noise. This is consistent with the two indexes being about the > same size. > > I also don't think we can get great speedup in the mentioned case, so it > is not urgently needed of course. My point is that it is just nice to > have a multicolumn index constructed on stacked trees constructed on > separate columns, not on the index tuples as a whole thing. Well, I'd say "nice to have" features are pointless unless they actually give tangible benefits (like speedup) to users. I'd bet no one is going to implement and maintain something unless it has such benefit, because they have to weight it against other beneficial features. Maybe there are use cases where this would be beneficial, but so far we haven't seen one. Usually it's the OP who presents such a case, and a plausible way to improve it - but it seems this thread presents a solution and now we're looking for an issue it might solve. > At least there is a benefit of sparing shared memory if we don't need > to cache index tuples of several similar indexes, instead caching one > "compound index". So if someone wants to propose this thing I'd > support it provided problems with concurrency, which were mentioned > by Peter are solved. > The problem with this it assumes the new index would use (significantly) less space than three separate indexes. I find that rather unlikely, but maybe there is a smart way to achieve that (certainly not in detail). I don't want to sound overly pessimistic and if you have an idea how to do this, I'd like to hear it. But it seems pretty tricky, particularly if we assume the suffix columns are more variable (which limits the "compression" ratio etc.). > These problems could be appear easy though, as we have index tuples > constructed in a similar way as heap tuples. Maybe it could be easier if > we had another heap am, which stored separate attributes (if so it could > be useful as a better JSON storage method than we have today). > IMO this just moved the goalposts somewhere outside the solar system. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I agree with the above mentioned.
The only concern I have is that we compare little wrong things.
For read we should compare
(job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag ) VS (job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year INCLUDE(sequence, Scan_ID, issue_flag) )
Because our proposed index for reading should be closer to a combination of those 3 and we have current solutions like index on all or with Include statement.
We should try to find a gap between these three cases.
For DML queries
(job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year INCLUDE(sequence, Scan_ID, issue_flag) ) VS (job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag )
Because again the proposed index should be just one and cover all 3 separate ones.
If you agree with these cases I will try to find a bigger time frame to compare these two cases deeper.
The issue is not high prio but I strongly believe it can help and can be nice feature for even more complicated cases.
Best regards.
вс, 31 окт. 2021 г. в 21:33, Tomas Vondra <tomas.vondra@enterprisedb.com>:
On 10/31/21 16:48, Pavel Borisov wrote:
> 4 columns: 106 ms
> 6 columns: 109 ms
>
> So there's like 3% difference between the two cases, and even that
> might
> be just noise. This is consistent with the two indexes being about the
> same size.
>
> I also don't think we can get great speedup in the mentioned case, so it
> is not urgently needed of course. My point is that it is just nice to
> have a multicolumn index constructed on stacked trees constructed on
> separate columns, not on the index tuples as a whole thing.
Well, I'd say "nice to have" features are pointless unless they actually
give tangible benefits (like speedup) to users. I'd bet no one is going
to implement and maintain something unless it has such benefit, because
they have to weight it against other beneficial features.
Maybe there are use cases where this would be beneficial, but so far we
haven't seen one. Usually it's the OP who presents such a case, and a
plausible way to improve it - but it seems this thread presents a
solution and now we're looking for an issue it might solve.
> At least there is a benefit of sparing shared memory if we don't need
> to cache index tuples of several similar indexes, instead caching one
> "compound index". So if someone wants to propose this thing I'd
> support it provided problems with concurrency, which were mentioned
> by Peter are solved.
>
The problem with this it assumes the new index would use (significantly)
less space than three separate indexes. I find that rather unlikely, but
maybe there is a smart way to achieve that (certainly not in detail).
I don't want to sound overly pessimistic and if you have an idea how to
do this, I'd like to hear it. But it seems pretty tricky, particularly
if we assume the suffix columns are more variable (which limits the
"compression" ratio etc.).
> These problems could be appear easy though, as we have index tuples
> constructed in a similar way as heap tuples. Maybe it could be easier if
> we had another heap am, which stored separate attributes (if so it could
> be useful as a better JSON storage method than we have today).
>
IMO this just moved the goalposts somewhere outside the solar system.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 11/1/21 1:24 PM, Hayk Manukyan wrote: > I agree with the above mentioned. > The only concern I have is that we compare little wrong things. > For read we should compare > (job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, > year, issue_flag ) VS (job, nlp, year, sequence, Scan_ID, issue_flag) > OR (job, nlp, year INCLUDE(sequence, Scan_ID, issue_flag) ) > Because our proposed index for reading should be closer to a combination > of those 3 and we have current solutions like index on all or with > Include statement. I don't follow. The whole point of the experiment was to show the gap between a "best case" and "worst case" alternatives, with the assumption the gap would be substantial and the new index type might get close to the best case. Are you suggesting those are not the actual best/worst cases and we should use some other indexes? If yes, which ones? IMHO those best/worst cases are fine because: 1) best case (job, nlp, year, sequence) I don't see how we could get anything better for queries on "sequence" than this index, because that's literally one of the indexes that would be included in the whole index. Yes, if you need to support queries on additional columns, you might need more indexes, but that's irrelevant - why would anyone define those indexes, when the "worst case" btree index with all the columns is so close to the best case? 2) worst case (job, nlp, year, scan_id, issue_flag, sequence) I think an index with INCLUDE is entirely irrelevant here. The reason to use INCLUDE is to define UNIQUE index on a subset of columns, but that's not what we need here. I repeated the benchmark with such index, and the timing is ~150ms, so about 50% slower than the simple index. Sorting on all columns is clearly beneficial even for the last column. So I still think those best/worst cases are sensible, and the proposed index would need to beat the worst case. Which seems challenging, considering how close it is to the best case. Or it might break the best case, if there's some sort of revolutionary way to store the small indexes or something like that. The fact that there's no size difference between the two cases is mostly a coincidence, due to the columns being just 2B each, and with wider values the difference might be substantial, making the gap larger. But then the new index would have to improve on this, but there's no proposal on how to do that. > We should try to find a gap between these three cases. > For DML queries > (job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year > INCLUDE(sequence, Scan_ID, issue_flag) ) VS (job, nlp, year, sequence) > AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag ) > Because again the proposed index should be just one and cover all 3 > separate ones. > > If you agree with these cases I will try to find a bigger time frame to > compare these two cases deeper. > > The issue is not high prio but I strongly believe it can help and can be > nice feature for even more complicated cases. > You don't need my approval to run benchmarks etc. If you believe this is beneficial then just do the tests and you'll see if it makes sense ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Oct 26, 2021 at 11:11 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > If I get what you propose, you want to have a "top" tree for (job, nlp, > year), which "splits" the data set into subsets of ~5000-7000 rows. And > then for each subset you want a separate "small" trees on each of the > other columns, so in this case three trees. > > Well, the problem with this is pretty obvious - each of the small trees > requires separate copies of the leaf pages. And remember, in a btree the > internal pages are usually less than 1% of the index, so this pretty > much triples the size of the index. And if you insert a row into the > index, it has to insert the item pointer into each of the small trees, > likely requiring a separate I/O for each. > > So I'd bet this is not any different from just having three separate > indexes - it doesn't save space, doesn't save I/O, nothing. I agree. In a lot of cases, it's actually useful to define the index on fewer columns, like (job, nlp, year) or even just (job, nlp) or even just (job) because it makes the index so much smaller and that's pretty important. If you have enough duplicate entries in a (job, nlp, year) index to justify create a (job, nlp, year, sequence) index, the number of distinct (job, nlp, year) tuples has to be small compared to the number of (job, nlp, year, sequence) tuples - and that means that you wouldn't actually save much by combining your (job, nlp, year, sequence) index with a (job, nlp, year, other-stuff) index. As you say, the internal pages aren't the problem. I don't intend to say that there's no possible use for this kind of technology. Peter G. says that people are writing research papers about that and they probably wouldn't be doing that unless they'd found some case where it's a big win. But this example seems extremely unconvincing. -- Robert Haas EDB: http://www.enterprisedb.com
On 11/1/21 21:06, Robert Haas wrote:
> On Tue, Oct 26, 2021 at 11:11 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> If I get what you propose, you want to have a "top" tree for (job, nlp,
>> year), which "splits" the data set into subsets of ~5000-7000 rows. And
>> then for each subset you want a separate "small" trees on each of the
>> other columns, so in this case three trees.
>>
>> Well, the problem with this is pretty obvious - each of the small trees
>> requires separate copies of the leaf pages. And remember, in a btree the
>> internal pages are usually less than 1% of the index, so this pretty
>> much triples the size of the index. And if you insert a row into the
>> index, it has to insert the item pointer into each of the small trees,
>> likely requiring a separate I/O for each.
>>
>> So I'd bet this is not any different from just having three separate
>> indexes - it doesn't save space, doesn't save I/O, nothing.
>
> I agree. In a lot of cases, it's actually useful to define the index
> on fewer columns, like (job, nlp, year) or even just (job, nlp) or
> even just (job) because it makes the index so much smaller and that's
> pretty important. If you have enough duplicate entries in a (job, nlp,
> year) index to justify create a (job, nlp, year, sequence) index, the
> number of distinct (job, nlp, year) tuples has to be small compared to
> the number of (job, nlp, year, sequence) tuples - and that means that
> you wouldn't actually save much by combining your (job, nlp, year,
> sequence) index with a (job, nlp, year, other-stuff) index. As you
> say, the internal pages aren't the problem.
>
> I don't intend to say that there's no possible use for this kind of
> technology. Peter G. says that people are writing research papers
> about that and they probably wouldn't be doing that unless they'd
> found some case where it's a big win. But this example seems extremely
> unconvincing.
>
I actually looked at the use case mentioned by Peter G, i.e. merged
indexes with master-detail clustering (see e.g. [1]), but that seems
like a rather different thing. The master-detail refers to storing rows
from multiple tables, interleaved in a way that allows faster joins. So
it's essentially a denormalization tool.
Perhaps there's something we could learn about efficient storage of the
small trees, but I haven't found any papers describing that (I haven't
spent much time on the search, though).
[1] Algorithms for merged indexes, Goetz Graefe
https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.140.7709
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Tomas Vondra
> Are you suggesting those are not the actual best/worst cases and we
> should use some other indexes? If yes, which ones?I would say yes.
In my case I am not querying only sequence column.
I have the following cases which I want to optimize.
1. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and scan_id = <something>
2. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and Issue_flag = <something>
3. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and sequence = <something>
Those are queries that my app send to db that is why I said that from read perspective our best case is 3 separate indexes for
(job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag) and any other solution like
(job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year ) INCLUDE(sequence, Scan_ID, issue_flag) OR just (job, nlp, year) can be considered as worst case
I will remind that in real world scenario I have ~50m rows and about ~5k rows for each (job, nlp, year )
From write perspective as far as we want to have only one index our best case can be considered any of
(job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year ) INCLUDE(sequence, Scan_ID, issue_flag)
and the worst case will be having 3 separate queries like in read perspective
(job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag)
So I think the comparison that we did is not right because we are comparing different/wrong things.
For right results we need to compare this two cases when we are doing random queries with 1,2,3 and random writes.
вт, 2 нояб. 2021 г. в 01:16, Tomas Vondra <tomas.vondra@enterprisedb.com>:
On 11/1/21 21:06, Robert Haas wrote:
> On Tue, Oct 26, 2021 at 11:11 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
>> If I get what you propose, you want to have a "top" tree for (job, nlp,
>> year), which "splits" the data set into subsets of ~5000-7000 rows. And
>> then for each subset you want a separate "small" trees on each of the
>> other columns, so in this case three trees.
>>
>> Well, the problem with this is pretty obvious - each of the small trees
>> requires separate copies of the leaf pages. And remember, in a btree the
>> internal pages are usually less than 1% of the index, so this pretty
>> much triples the size of the index. And if you insert a row into the
>> index, it has to insert the item pointer into each of the small trees,
>> likely requiring a separate I/O for each.
>>
>> So I'd bet this is not any different from just having three separate
>> indexes - it doesn't save space, doesn't save I/O, nothing.
>
> I agree. In a lot of cases, it's actually useful to define the index
> on fewer columns, like (job, nlp, year) or even just (job, nlp) or
> even just (job) because it makes the index so much smaller and that's
> pretty important. If you have enough duplicate entries in a (job, nlp,
> year) index to justify create a (job, nlp, year, sequence) index, the
> number of distinct (job, nlp, year) tuples has to be small compared to
> the number of (job, nlp, year, sequence) tuples - and that means that
> you wouldn't actually save much by combining your (job, nlp, year,
> sequence) index with a (job, nlp, year, other-stuff) index. As you
> say, the internal pages aren't the problem.
>
> I don't intend to say that there's no possible use for this kind of
> technology. Peter G. says that people are writing research papers
> about that and they probably wouldn't be doing that unless they'd
> found some case where it's a big win. But this example seems extremely
> unconvincing.
>
I actually looked at the use case mentioned by Peter G, i.e. merged
indexes with master-detail clustering (see e.g. [1]), but that seems
like a rather different thing. The master-detail refers to storing rows
from multiple tables, interleaved in a way that allows faster joins. So
it's essentially a denormalization tool.
Perhaps there's something we could learn about efficient storage of the
small trees, but I haven't found any papers describing that (I haven't
spent much time on the search, though).
[1] Algorithms for merged indexes, Goetz Graefe
https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.140.7709
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 11/2/21 13:04, Hayk Manukyan wrote: > Tomas Vondra > > Are you suggesting those are not the actual best/worst cases and we > > should use some other indexes? If yes, which ones? > > I would say yes. > In my case I am not querying only sequence column. > I have the following cases which I want to optimize. > 1. Select * from Some_table where job = <somthing> and nlp = <something> > and year = <something> and *scan_id = <something> * > 2. Select * from Some_table where job = <somthing> and nlp = <something> > and year = <something> and *Issue_flag = <something> * > 3. Select * from Some_table where job = <somthing> and nlp = <something> > and year = <something> and *sequence = <something> * > Those are queries that my app send to db that is why I said that from > *read perspective* our *best case* is 3 separate indexes for > *(job, nlp, year, sequence)* AND *(job, nlp, year, Scan_ID)* and *(job, > nlp, year, issue_flag)* and any other solution like > (job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year ) > INCLUDE(sequence, Scan_ID, issue_flag) OR just (job, nlp, year) can be > considered as*worst case * I already explained why using INCLUDE in this case is the wrong thing to do, it'll harm performance compared to just defining a regular index. > I will remind that in real world scenario I have ~50m rows and about > *~5k rows for each (job, nlp, year )* Well, maybe this is the problem. We have 50M rows, but the three columns have too many distinct values - (job, nlp, year) defines ~50M groups, so there's only a single row per group. That'd explain why the two indexes perform almost equally. So I guess you need to modify the data generator so that the data set is more like the case you're trying to improve. > From *write perspective* as far as we want to have only one index > our*best case* can be considered any of > *(job, nlp, year, sequence, Scan_ID, issue_flag)* OR *(job, nlp, year ) > INCLUDE(sequence, Scan_ID, issue_flag) * > and the*worst case* will be having 3 separate queries like in read > perspective > (job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, > year, issue_flag) > Maybe. It's true a write with three indexes will require modification to three leaf pages (on average). With a single index we have to modify just one leaf page, depending on where the row gets routed. But with the proposed "merged" index, the row will have to be inserted into three smaller trees. If the trees are large enough, they won't fit into a single leaf page (e.g. the 5000 index tuples is guaranteed to need many pages, even if you use some smart encoding). So the write will likely need to modify at least 3 leaf pages, getting much closer to three separate indexes. At which point you could just use three indexes. > So I think the comparison that we did is not right because we are > comparing different/wrong things. > > For right results we need to compare this two cases when we are doing > random queries with 1,2,3 and random writes. > I'm not going to spend any more time on tweaking the benchmark, but if you tweak it to demonstrate the difference / benefits I'll run it again on my machine etc. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
вт, 2 нояб. 2021 г. в 16:04, Hayk Manukyan <manukyantt@gmail.com>:
Tomas Vondra> Are you suggesting those are not the actual best/worst cases and we> should use some other indexes? If yes, which ones?I would say yes.In my case I am not querying only sequence column.I have the following cases which I want to optimize.1. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and scan_id = <something>2. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and Issue_flag = <something>3. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and sequence = <something>Those are queries that my app send to db that is why I said that from read perspective our best case is 3 separate indexes for(job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag) and any other solution like(job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year ) INCLUDE(sequence, Scan_ID, issue_flag) OR just (job, nlp, year) can be considered as worst caseI will remind that in real world scenario I have ~50m rows and about ~5k rows for each (job, nlp, year )
So you get 50M rows /5K rows = 10K times selectivity, when you select on job = <somthing> and nlp = <something> and year = <something> which is enormous. Then you should select some of the 5K rows left, which is expected to be pretty fast on bitmap index scan or INCLUDE column filtering. It confirms Tomas's experiment
pgbench -n -f q4.sql -T 60
106 ms vs 109 ms
106 ms vs 109 ms
fits your case pretty well. You get absolutely negligible difference between best and worst case and certainly you don't need anything more than just plain index for 3 columns, you even don't need INCLUDE index.
From what I read I suppose that this feature indeed doesn't based on the real need. If you suppose it is useful please feel free to make and post here some measurements that proves your point.
Hi All
I did final research and saw that the difference between best and worst cases is indeed really small.
I want to thank you guys for your time and efforts.
Best regards.
вт, 2 нояб. 2021 г. в 18:04, Pavel Borisov <pashkin.elfe@gmail.com>:
вт, 2 нояб. 2021 г. в 16:04, Hayk Manukyan <manukyantt@gmail.com>:Tomas Vondra> Are you suggesting those are not the actual best/worst cases and we> should use some other indexes? If yes, which ones?I would say yes.In my case I am not querying only sequence column.I have the following cases which I want to optimize.1. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and scan_id = <something>2. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and Issue_flag = <something>3. Select * from Some_table where job = <somthing> and nlp = <something> and year = <something> and sequence = <something>Those are queries that my app send to db that is why I said that from read perspective our best case is 3 separate indexes for(job, nlp, year, sequence) AND (job, nlp, year, Scan_ID) and (job, nlp, year, issue_flag) and any other solution like(job, nlp, year, sequence, Scan_ID, issue_flag) OR (job, nlp, year ) INCLUDE(sequence, Scan_ID, issue_flag) OR just (job, nlp, year) can be considered as worst caseI will remind that in real world scenario I have ~50m rows and about ~5k rows for each (job, nlp, year )So you get 50M rows /5K rows = 10K times selectivity, when you select on job = <somthing> and nlp = <something> and year = <something> which is enormous. Then you should select some of the 5K rows left, which is expected to be pretty fast on bitmap index scan or INCLUDE column filtering. It confirms Tomas's experimentpgbench -n -f q4.sql -T 60
106 ms vs 109 msfits your case pretty well. You get absolutely negligible difference between best and worst case and certainly you don't need anything more than just plain index for 3 columns, you even don't need INCLUDE index.From what I read I suppose that this feature indeed doesn't based on the real need. If you suppose it is useful please feel free to make and post here some measurements that proves your point.--