Обсуждение: Shrinking SVG (Again)
Our current policy says that we use the two tools Graphviz (drawing Graphs) and Ditaa (drawing ascii art) to generate SVG. The two tools are highly specialized and bound to their original purpose. I strongly believe that we will not be able to visualize more complex situations like this http://1.bp.blogspot.com/--CG_kXBFWzw/UgW5JROpbDI/AAAAAAAAAHc/9V8iwO1qluQ/s1600/arch.bmp or that: https://severalnines.com/sites/default/files/blog/node_5266/image5.jpg without using other tools, which are more flexible. In the past, we had many discussions on this topic and didn't come to a final decision in favor on one single or a few number of such tools. However, we came to the important and very helpful conclusion to store two files per graphic: the original tool-specific (simple to read, diff-able) and the generated SVG version. Out in the wild there is the open source tool SVGO https://github.com/svg/svgo. Its purpose is the generation of a small, easy to read SVG file out of any other SVG file by removing all the clutter, tools typically generate. In my opinion it's not perfect, but it has some strong advantages: the generated files are really small and nearly free of unnecessary information; it is flexible because a lot of parameters control the degree of optimization; it is extensible: missing features may be added by ourselves. The SVGO tool is a node.js application. At Ubuntu you can install it: sudo apt install npm nodejs sudo npm install -g svgo run it, e.g.: svgo test1_ink.svg --pretty --indent=2 --precision=2 --multipass --disable=removeComments \ --output test1_svgo.svg Please test it with your own examples. In contrast to our previous policy the generated file is the diff-able, whereas the original one is hard to read. Jürgen Purtz
{kind=link}
{kind=link}
Вложения
{kind=link}
{kind=link}
I plan to deliver 3 more graphics, see attachment. When creating their textual description in the SGML files I faced a problems: The patch of GSoD https://www.postgresql.org/message-id/flat/CAEkD-mBFQb61gHNWR0cN5K4G4q-i1PRwNn_OKVkKSaaJa5_LbA%40mail.gmail.com#67104a6097e63371c527b14ff43ddafb is not yet committed. But this chapter is a good place for the graphics. Will the GSoD patch become part of the documentation? Furthermore in the last weeks we have seen some initiatives to uniform the wording of our documentation. I appreciate such activities and will deliver a glossary of terms which are used in the description of the graphics. This glossary will focus on PG-specific terms. Well known terms like SQL key words are left out. Any comments? Errors in the graphics? Suggestions? What's about the GSoD patch? Jürgen Purtz
Вложения
{kind=link}
{kind=link}
{kind=link}
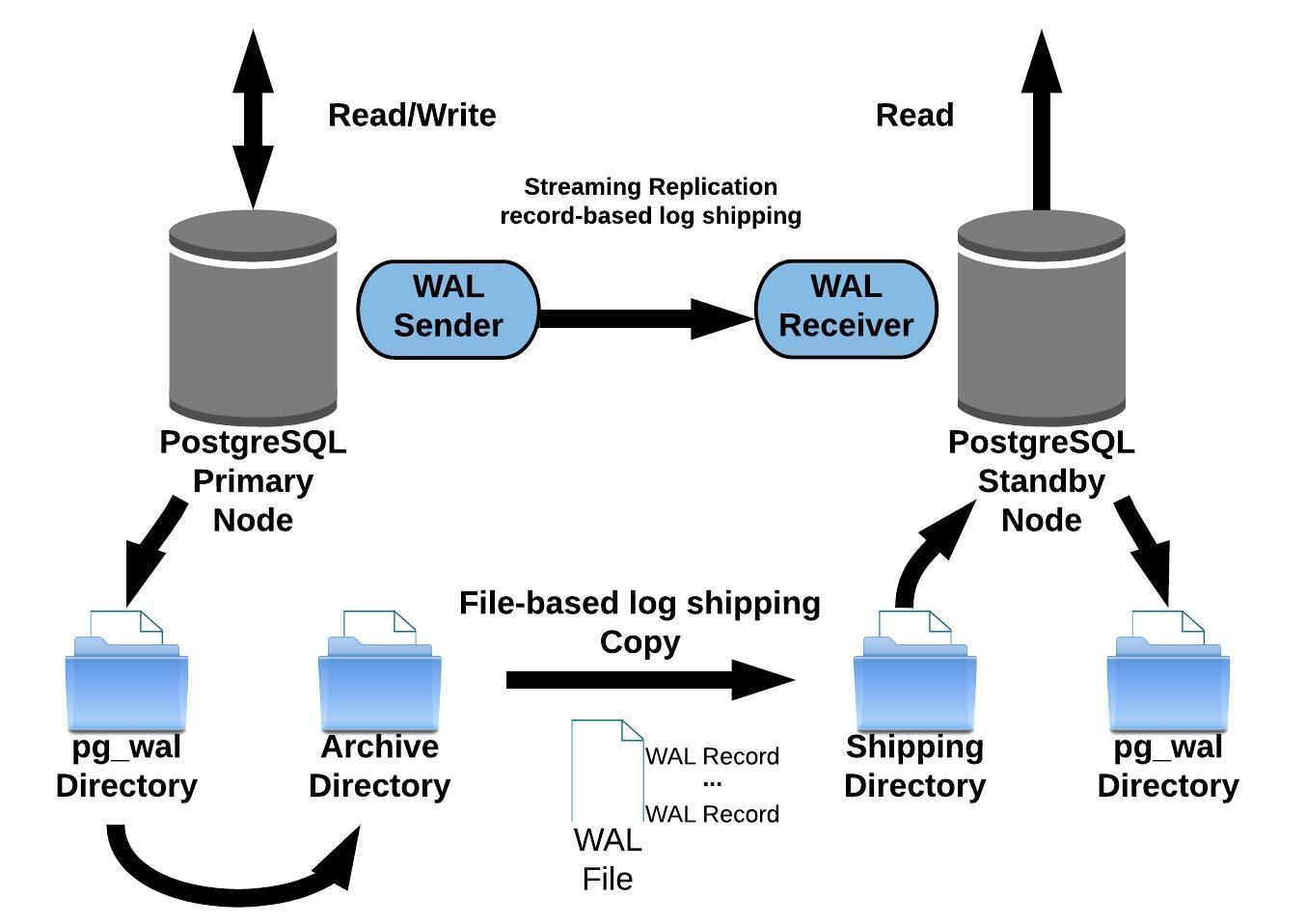
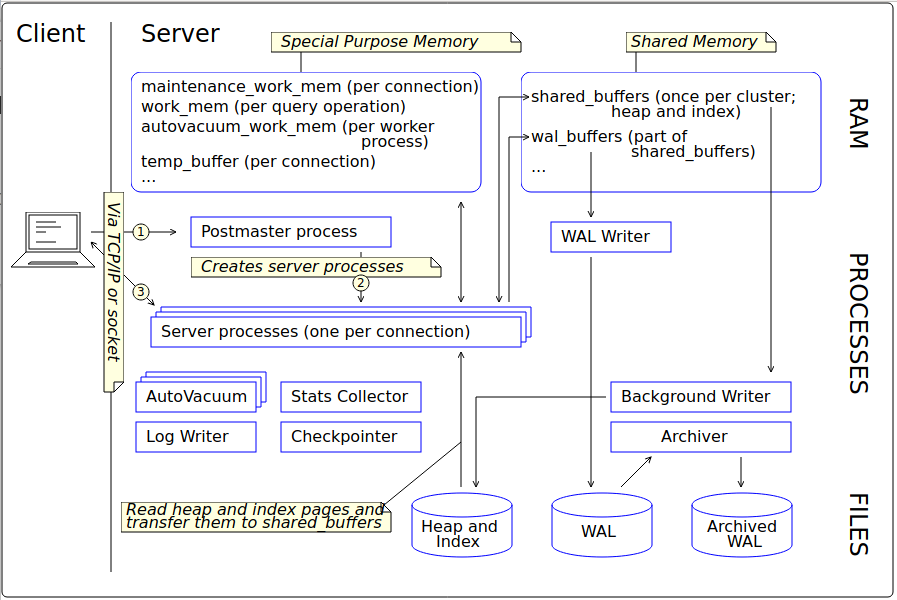
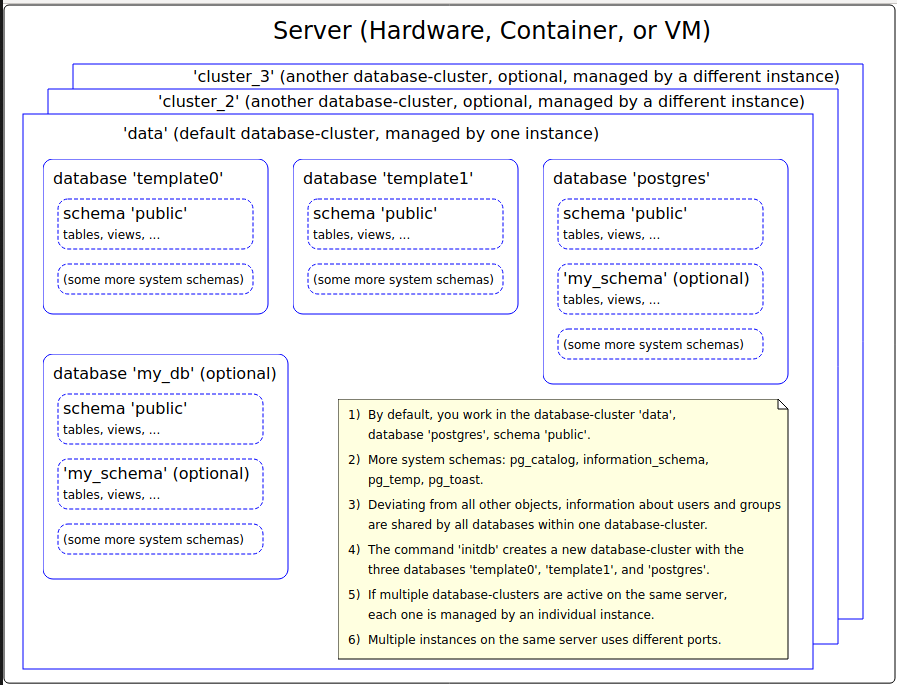
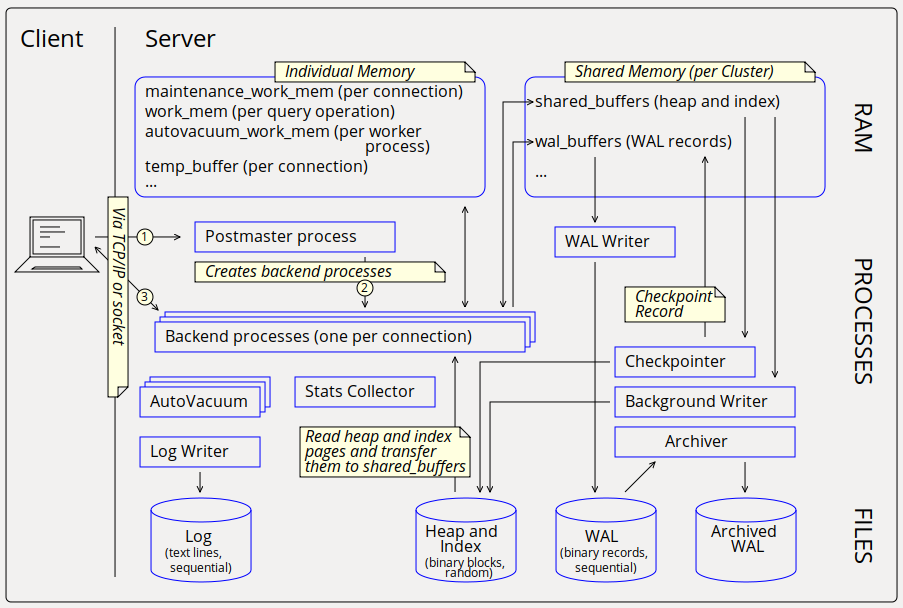
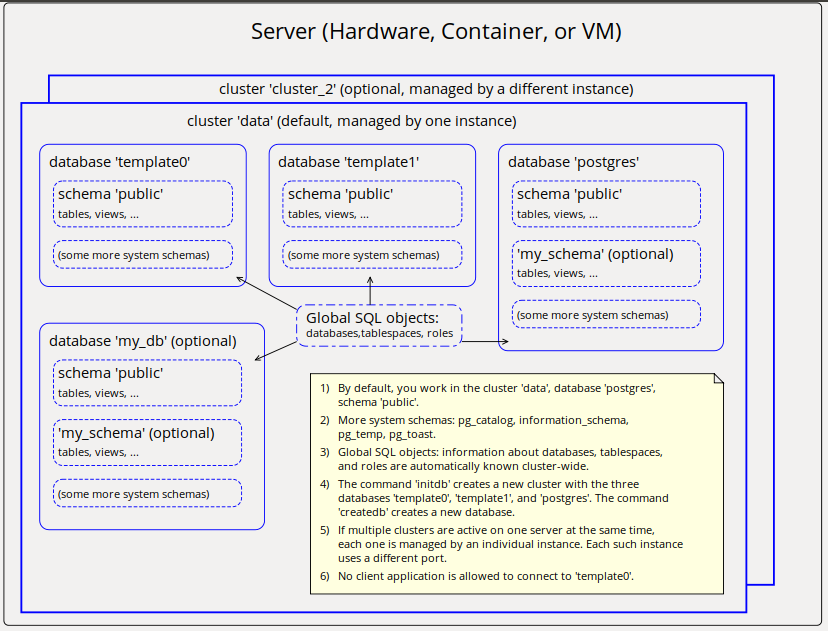
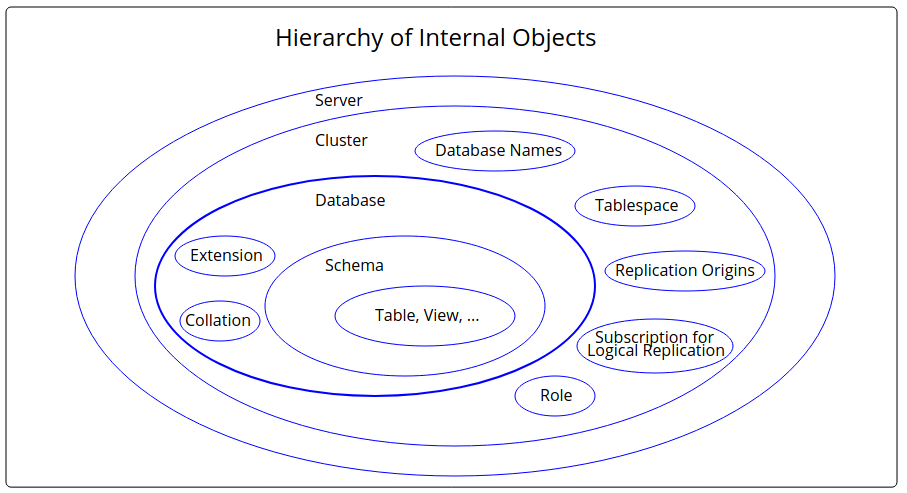
On Wed, 2020-01-15 at 14:56 +0100, Jürgen Purtz wrote: > I plan to deliver 3 more graphics, see attachment. When creating their > textual description in the SGML files I faced a problems: The patch of > GSoD > https://www.postgresql.org/message-id/flat/CAEkD-mBFQb61gHNWR0cN5K4G4q-i1PRwNn_OKVkKSaaJa5_LbA%40mail.gmail.com#67104a6097e63371c527b14ff43ddafb > is not yet committed. But this chapter is a good place for the graphics. > Will the GSoD patch become part of the documentation? Both Tom and me showed interest, and the feedback was that some things could be improved. I have not heard back from the author since; I hope she didn't get discouraged. There were definitely some things there that shouldn't go to waste. > Any comments? Errors in the graphics? Suggestions? What's about the GSoD > patch? I particularly like the first image with the memory and process architecture. Some mistakes: - wal_buffers is shared memory, but it is not a part of shared_buffers - The process that performs most of the writes to the data files is the checkpointer. Sometimes backends also have to write to data files. Minor quibbles: - The "server process" is traditionally called "backend process" - "Special purpose memory" is strange. I thing "private memory" would be better. I don't know how it could be depicted that each of the backends has his own. I liked the "cluster / database / schema" image less. Some problems: - No user data should be stored in the "postgres" database. - "template0" has *no* other schemas or tables. It must be absolutely empty. - I am missing the global objects like roles and tablespaces "outside" the databases. I am fine with the directory layout image, but I wonder what "fluctuating states" may be. Yours, Laurenz Albe
This patch deals with two different topics. First, it creates a glossary with basic PG-terms and second, it supplies new figures with explanations.
a) In our documentation we name some objects inconsistently (e.g.: WAL, WAL file, WAL log, log segment file, WAL segment file, segment file - whereas a 'file segment' is a very different thing) and often without a definition of its meaning. For experienced users this is not a problem, but novice users can get confused easily. In the last months we have seen some more initiatives to clarify the situation. My attempt to introduce such a glossary is focused on fundamental PG-related terms such as CLUSTER or POSTMASTER. Terms with a consistent usage in the database community, such as SELECT, are not part of it.
b) The figures and their explanations are summed up in a new chapter, which is intended as an introduction to the PG architecture directly after the 'Getting Started' chapter. The text makes heavy use of the glossary. Therefore the glossary must be applied before or together with the figures.
The source of the figures do not completely comply to our guidelines and the opinion of the community, which says, that we should use tools (actually ditaa and graphviz) to create SVG files. However, this figures are too complex for the two tools. I provide each figure in 3 variants using a certain name convention: xxx-raw.svg (created in a text- or XML-editor), xxx-ink.svg (created with Inkscape by reading xxx-raw.svg), and xxx-ink-svgo.svg (created out of xxx-ink.svg with the tool SVGO). The 3 variants render to the same output. My personal favorite is 'raw'. If the community prefers 'ink' or 'ink-svgo' it's ok for me. 'ink-svgo' has the advantage over 'ink' that it does not contain Inkscape specific namespaces, elements, or attributes; other elements are reduced in their size (measured in characters). 'ink-svgo' is notable smaller that the original Inkscape file - especially in such situations, where files are really created with the use of Inkscape. The size reduction acts very efficient. Generate the reduced file with:
# disable 'mergePaths' is necessary (bug); 'config' is helpful for readability
svgo xxx-ink.svg --output=xxx-ink-svgo.svg \ --pretty --indent=2 --precision=2 --multipass \ --disable=removeTitle,mergePaths,convertColors,removeViewBox \ --config '{ "plugins": [ { "cleanupIDs": { "force": true, "minify": false} }] }'
The describing sgml files use two different 'role' attributes for 'imageobject' elements. This is necessary in order to keep rendering of font sizes of HTML-text and text inside SVG in correlation when you choose different screen resolutions in the browser.
J. Purtz
Вложения
{kind=link}
{kind=link}
{kind=link}
The attached patch extends the previous one by one more figure, a rework of the old explanations plus additional explanations. J. Purtz
Вложения
{kind=link}
On 2020-Feb-14, Jürgen Purtz wrote: > The attached patch extends the previous one by one more figure, a rework of > the old explanations plus additional explanations. So now we have two glossaries being proposed [1] [2], and they don't have much in common with each other. What to do now? If we can get the authors to agree on what patch to submit, we can move forward. I suggest to make a glossary be 0001, and then the other patches can be 0002 or further. (I also CC Liudmila, who mentioned the topic of a glossary in [3]). [1] https://postgr.es/m/d4175e85-61c6-18d5-65c9-a9e19795f3e2@purtz.de [2] https://postgr.es/m/CADkLM=fx_kNCCz97HSXMBgTSY50Es_czsNZJrdCBtpYiT_VLHA@mail.gmail.com [3] https://postgr.es/m/CAEkD-mBFQb61gHNWR0cN5K4G4q-i1PRwNn_OKVkKSaaJa5_LbA@mail.gmail.com -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> So now we have two glossaries being proposed [1] [2], and they don't > have much in common with each other. What to do now? If we can get the > authors to agree on what patch to submit, we can move forward. > > I suggest to make a glossary be 0001, and then the other patches can be > 0002 or further. Yes, we should work on the glossary with priority because other things depend on it, not only the explanation of figures. The two proposals differs in their nature: [1] is focused on PG-specific terms like WAL, Background Writer, Background Worker, ... and such terms that are broadly used but may differ from the meaning in other DBMS like Segment or Data Dictionary. It's only a starting point. Currently it misses the terms of important features like MVCC, Backup, Replication, ... . [2] also contains fundamental terms but is focused on universal terms of the DBMS community like SELECT, Null, Rollback, ... . It's important to check, whether the existing documentation starts with something like "A <glossary-term> is a ...". In my opinion such redundancies aren't a problem as long as they don't contradict each other. On the contrary, I support this approach. J. Purtz