Обсуждение: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit)
Good day, every one.
In attempt to improve performance of YCSB on zipfian distribution,
it were found that significant time is spent in XidInMVCCSnapshot in
scanning snapshot->xip array. While overall CPU time is not too
noticable, it has measurable impact on scaleability.
First I tried to sort snapshot->xip in GetSnapshotData, and search in a
sorted array. But since snapshot->xip is not touched if no transaction
contention occurs, sorting xip always is not best option.
Then I sorted xip array on demand in XidInMVCCSnapshot only if
search in snapshot->xip occurs (ie lazy sorting). It performs much
better, but since it is O(NlogN), sort's execution time is noticable
for large number of clients.
Third approach (present in attached patch) is making hash table lazily
on first search in xip array.
Note: hash table is not built if number of "in-progress" xids is less
than 60. Tests shows, there is no big benefit from doing so (at least
on Intel Xeon).
For this letter I've tested with pgbench and random_exponential
updating rows from pgbench_tellers (scale=300, so 3000 rows in a table).
Scripts are in attached archive. With this test configuration, numbers
are quite close to numbers from YCSB benchmark workloada.
Test machine is 4xXeon CPU E7-8890 - 72cores (144HT), fsync=on,
synchronous_commit=off.
Results:
clients | master | hashsnap
--------+----------+----------
25 | 67652 | 70017
50 | 102781 | 102074
75 | 81716 | 79440
110 | 68286 | 69223
150 | 56168 | 60713
200 | 45073 | 48880
250 | 36526 | 40893
325 | 28363 | 32497
400 | 22532 | 26639
500 | 17423 | 21496
650 | 12767 | 16461
800 | 9599 | 13483
(Note: if pgbench_accounts is updated (30000000 rows), then exponential
distribution behaves differently from zipfian with used parameter.)
Remarks:
- it could be combined with "Cache data in GetSnapshotData"
https://commitfest.postgresql.org/14/553/
- if CSN ever landed, then there will be no need in this optimization at
all.
PS.
Excuse me for following little promotion of lwlock patch
https://commitfest.postgresql.org/14/1166/
clients | master | hashsnap | hashsnap+lwlock
--------+----------+----------+--------------
25 | 67652 | 70017 | 127601
50 | 102781 | 102074 | 134545
75 | 81716 | 79440 | 128655
110 | 68286 | 69223 | 110420
150 | 56168 | 60713 | 86715
200 | 45073 | 48880 | 68266
250 | 36526 | 40893 | 56638
325 | 28363 | 32497 | 45704
400 | 22532 | 26639 | 38247
500 | 17423 | 21496 | 32668
650 | 12767 | 16461 | 25488
800 | 9599 | 13483 | 21326
With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On 2017-07-31 18:56, Sokolov Yura wrote: > Good day, every one. > > In attempt to improve performance of YCSB on zipfian distribution, > it were found that significant time is spent in XidInMVCCSnapshot in > scanning snapshot->xip array. While overall CPU time is not too > noticable, it has measurable impact on scaleability. > > First I tried to sort snapshot->xip in GetSnapshotData, and search in a > sorted array. But since snapshot->xip is not touched if no transaction > contention occurs, sorting xip always is not best option. > > Then I sorted xip array on demand in XidInMVCCSnapshot only if > search in snapshot->xip occurs (ie lazy sorting). It performs much > better, but since it is O(NlogN), sort's execution time is noticable > for large number of clients. > > Third approach (present in attached patch) is making hash table lazily > on first search in xip array. > > Note: hash table is not built if number of "in-progress" xids is less > than 60. Tests shows, there is no big benefit from doing so (at least > on Intel Xeon). > > With regards, Here is new, more correct, patch version, and results for pgbench with zipfian distribution (50% read 50% write) (same to Alik's tests at https://www.postgresql.org/message-id/BF3B6F54-68C3-417A-BFAB-FB4D66F2B410@postgrespro.ru ) clients | master | hashsnap2 | hashsnap2_lwlock --------+--------+-----------+------------------ 10 | 203384 | 203813 | 204852 20 | 334344 | 334268 | 363510 40 | 228496 | 231777 | 383820 70 | 146892 | 148173 | 221326 110 | 99741 | 111580 | 157327 160 | 65257 | 81230 | 112028 230 | 38344 | 56790 | 77514 310 | 22355 | 39249 | 55907 400 | 13402 | 26899 | 39742 500 | 8382 | 17855 | 28362 650 | 5313 | 11450 | 17497 800 | 3352 | 7816 | 11030 (Note: I'm not quite sure, why my numbers for master are lower than Alik's one. Probably, our test methodology differs a bit. Perhaps, it is because I don't recreate tables between client number change, but between branch switch). With regards -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
Re: [HACKERS] Lazy hash table for XidInMVCCSnapshot (helps Zipfian a bit)
От
Alexander Korotkov
Дата:
On Thu, Aug 10, 2017 at 3:30 PM, Sokolov Yura <funny.falcon@postgrespro.ru> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
On 2017-07-31 18:56, Sokolov Yura wrote:Good day, every one.
In attempt to improve performance of YCSB on zipfian distribution,
it were found that significant time is spent in XidInMVCCSnapshot in
scanning snapshot->xip array. While overall CPU time is not too
noticable, it has measurable impact on scaleability.
First I tried to sort snapshot->xip in GetSnapshotData, and search in a
sorted array. But since snapshot->xip is not touched if no transaction
contention occurs, sorting xip always is not best option.
Then I sorted xip array on demand in XidInMVCCSnapshot only if
search in snapshot->xip occurs (ie lazy sorting). It performs much
better, but since it is O(NlogN), sort's execution time is noticable
for large number of clients.
Third approach (present in attached patch) is making hash table lazily
on first search in xip array.
Note: hash table is not built if number of "in-progress" xids is less
than 60. Tests shows, there is no big benefit from doing so (at least
on Intel Xeon).
With regards,
Here is new, more correct, patch version, and results for pgbench with
zipfian distribution (50% read 50% write) (same to Alik's tests at
https://www.postgresql.org/message-id/BF3B6F54-68C3-417A-BFA B-FB4D66F2B410@postgrespro.ru )
clients | master | hashsnap2 | hashsnap2_lwlock
--------+--------+-----------+------------------
10 | 203384 | 203813 | 204852
20 | 334344 | 334268 | 363510
40 | 228496 | 231777 | 383820
70 | 146892 | 148173 | 221326
110 | 99741 | 111580 | 157327
160 | 65257 | 81230 | 112028
230 | 38344 | 56790 | 77514
310 | 22355 | 39249 | 55907
400 | 13402 | 26899 | 39742
500 | 8382 | 17855 | 28362
650 | 5313 | 11450 | 17497
800 | 3352 | 7816 | 11030
(Note: I'm not quite sure, why my numbers for master are lower than
Alik's one. Probably, our test methodology differs a bit. Perhaps, it
is because I don't recreate tables between client number change, but
between branch switch).
These results look very cool!
I think CSN is eventually inevitable, but it's a long distance feature. Thus, this optimization could make us a good serve before we would have CSN.
Do you expect there are cases when this patch causes slowdown? What about case when we scan each xip array only once (not sure how to simulate that using pgbench)?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
В Thu, 10 Aug 2017 18:12:34 +0300 Alexander Korotkov <a.korotkov@postgrespro.ru> пишет: > On Thu, Aug 10, 2017 at 3:30 PM, Sokolov Yura > <funny.falcon@postgrespro.ru> wrote: > > > On 2017-07-31 18:56, Sokolov Yura wrote: > > > >> Good day, every one. > >> > >> In attempt to improve performance of YCSB on zipfian distribution, > >> it were found that significant time is spent in XidInMVCCSnapshot > >> in scanning snapshot->xip array. While overall CPU time is not too > >> noticable, it has measurable impact on scaleability. > >> > >> First I tried to sort snapshot->xip in GetSnapshotData, and search > >> in a sorted array. But since snapshot->xip is not touched if no > >> transaction contention occurs, sorting xip always is not best > >> option. > >> > >> Then I sorted xip array on demand in XidInMVCCSnapshot only if > >> search in snapshot->xip occurs (ie lazy sorting). It performs much > >> better, but since it is O(NlogN), sort's execution time is > >> noticable for large number of clients. > >> > >> Third approach (present in attached patch) is making hash table > >> lazily on first search in xip array. > >> > >> Note: hash table is not built if number of "in-progress" xids is > >> less than 60. Tests shows, there is no big benefit from doing so > >> (at least on Intel Xeon). > >> > >> With regards, > >> > > > > Here is new, more correct, patch version, and results for pgbench > > with zipfian distribution (50% read 50% write) (same to Alik's > > tests at > > https://www.postgresql.org/message-id/BF3B6F54-68C3-417A-BFA > > B-FB4D66F2B410@postgrespro.ru ) > > > > > > clients | master | hashsnap2 | hashsnap2_lwlock > > --------+--------+-----------+------------------ > > 10 | 203384 | 203813 | 204852 > > 20 | 334344 | 334268 | 363510 > > 40 | 228496 | 231777 | 383820 > > 70 | 146892 | 148173 | 221326 > > 110 | 99741 | 111580 | 157327 > > 160 | 65257 | 81230 | 112028 > > 230 | 38344 | 56790 | 77514 > > 310 | 22355 | 39249 | 55907 > > 400 | 13402 | 26899 | 39742 > > 500 | 8382 | 17855 | 28362 > > 650 | 5313 | 11450 | 17497 > > 800 | 3352 | 7816 | 11030 > > > > (Note: I'm not quite sure, why my numbers for master are lower than > > Alik's one. Probably, our test methodology differs a bit. Perhaps, > > it is because I don't recreate tables between client number change, > > but between branch switch). > > > > These results look very cool! > I think CSN is eventually inevitable, but it's a long distance > feature. Thus, this optimization could make us a good serve before we > would have CSN. Do you expect there are cases when this patch causes > slowdown? What about case when we scan each xip array only once (not > sure how to simulate that using pgbench)? > Patched version allocates a bit more memory per process (if number of backends is greater than 60), and for copied snapshot (if number of concurrent transactions is greater than 60). I have no strong evidence patch could cause slowdown. Different When xip array is scanned only once, then XidInMVCCSnapshot consumes usually 0.2-0.5% CPU in total, and scanning xip array even less. So even building hash table slows first scan in three-four times, it could increase overall CPU usage just on 0.5-1%, and it is not necessary directly mapped to tps. -- With regards, Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
On Thu, Aug 10, 2017 at 11:12 AM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> These results look very cool!
> I think CSN is eventually inevitable, but it's a long distance feature.
> Thus, this optimization could make us a good serve before we would have CSN.
> Do you expect there are cases when this patch causes slowdown? What about
> case when we scan each xip array only once (not sure how to simulate that
> using pgbench)?
Just a random thought here:
The statements pgbench executes are pretty simple: they touch one row
in one table. You wouldn't expect them to scan the xip array very
many times. If even those statements touch the array enough for this
to win, it seems like it might be hard to construct an even worse
case. I might be missing something, though.
We're not going to accept code like this, though:
+ d = xip[i] >> 6;
+ j = k = xip[i] & mask;
+ while (xiphash[j] != InvalidTransactionId)
+ {
+ j = (k + d) & mask;
+ d = d*5 + 1;
+ }
Single-character variable names, hard-coded constants, and no comments!
I kind of doubt as a general point that we really want another
open-coded hash table -- I wonder if this could be made to use
simplehash.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
В Fri, 11 Aug 2017 14:05:08 -0400
Robert Haas <robertmhaas@gmail.com> пишет:
> On Thu, Aug 10, 2017 at 11:12 AM, Alexander Korotkov
> <a.korotkov@postgrespro.ru> wrote:
> > These results look very cool!
> > I think CSN is eventually inevitable, but it's a long distance
> > feature. Thus, this optimization could make us a good serve before
> > we would have CSN. Do you expect there are cases when this patch
> > causes slowdown? What about case when we scan each xip array only
> > once (not sure how to simulate that using pgbench)?
>
> Just a random thought here:
>
> The statements pgbench executes are pretty simple: they touch one row
> in one table. You wouldn't expect them to scan the xip array very
> many times. If even those statements touch the array enough for this
> to win, it seems like it might be hard to construct an even worse
> case. I might be missing something, though.
With zipfian distribution, many concurrent transactions tries to update
the same row. Every transaction eventually updates this row (may be
after waiting), so there are a lot of concurrent row version, and
transaction scans through its snapshot many times.
>
> We're not going to accept code like this, though:
>
> + d = xip[i] >> 6;
> + j = k = xip[i] & mask;
> + while (xiphash[j] != InvalidTransactionId)
> + {
> + j = (k + d) & mask;
> + d = d*5 + 1;
> + }
>
> Single-character variable names, hard-coded constants, and no
> comments!
I totally agree. First version (which you've cited) was clear POC.
Second version (I've sent in Thursday) looks a bit better, but I agree
there is room for improvement. I'll try to make it prettier.
BTW, I have a question: there is CopySnapshot function, so snapshot is
clearly changed after copy. But I could not follow: is xip and subxip
array changes in a copy, or it remains the same to original, but only
other snapshot fields could be changed?
> I kind of doubt as a general point that we really want another
> open-coded hash table -- I wonder if this could be made to use
> simplehash.
I like simplehash very much (although I'm missing couple of features).
Unfortunately, siplehash is not simple enough for this use case:
- it will use at least twice more memory for hash table itself (cause it have to have 'entry->status' field),
- it has large header (ad-hoc hash-table consumes 1 byte in SnapshotData structure),
- its allocation will be trickier (custom hash-table is co-allocated after xip-array itself),
- its insert algorithm looks to be much more expensive (at least, it is more complex in instructions count).
I thing, using simplehash here will lead to much more invasive patch,
than this ad-hoc table. And I believe it will be slower (and this place
is very performance critical), though I will not bet on.
BTW, ad-hoc hash tables already exist: at least recourse owner uses one.
--
With regards,
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
On Sun, Aug 13, 2017 at 11:05 AM, Sokolov Yura <funny.falcon@postgrespro.ru> wrote: > BTW, ad-hoc hash tables already exist: at least recourse owner uses one. Yeah. :-( -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Simplified a bit and more commented patch version is in attach. Algorithm were switched to linear probing, it makes code simpler and clearer. Flag usages were toggled: now it indicates that hash table were built, it also makes code clearer. XidInXip and some other functions got comments. -- With regards, Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Tue, Aug 22, 2017 at 9:17 PM, Sokolov Yura <funny.falcon@postgrespro.ru> wrote: > Simplified a bit and more commented patch version is in attach. > > Algorithm were switched to linear probing, it makes code simpler and > clearer. > Flag usages were toggled: now it indicates that hash table were built, > it also makes code clearer. > XidInXip and some other functions got comments. This patch still applies but nobody seems interested in it. So moved to next CF. -- Michael
Greetings, * Sokolov Yura (funny.falcon@postgrespro.ru) wrote: > diff --git a/src/backend/utils/time/snapmgr.c b/src/backend/utils/time/snapmgr.c > index 08a08c8e8f..7c3fe7563e 100644 > --- a/src/backend/utils/time/snapmgr.c > +++ b/src/backend/utils/time/snapmgr.c > @@ -662,13 +662,16 @@ CopySnapshot(Snapshot snapshot) > Snapshot newsnap; > Size subxipoff; > Size size; > + int xcnt, subxcnt; > + uint8 xhlog, subxhlog; > > Assert(snapshot != InvalidSnapshot); > > + xcnt = ExtendXipSizeForHash(snapshot->xcnt, &xhlog); > + subxcnt = ExtendXipSizeForHash(snapshot->subxcnt, &subxhlog); > /* We allocate any XID arrays needed in the same palloc block. */ > - size = subxipoff = sizeof(SnapshotData) + > - snapshot->xcnt * sizeof(TransactionId); > - if (snapshot->subxcnt > 0) > + size = subxipoff = sizeof(SnapshotData) + xcnt * sizeof(TransactionId); > + if (subxcnt > 0) > size += snapshot->subxcnt * sizeof(TransactionId); Here you've changed to use xcnt instead of snapshot->xcnt for calculating size, but when it comes to adding in the subxcnt, you calculate a subxcnt but still use snapshot->subxcnt...? That doesn't seem like what you intended to do here. > diff --git a/src/backend/utils/time/tqual.c b/src/backend/utils/time/tqual.c > index f9da9e17f5..a5e7d427b4 100644 > --- a/src/backend/utils/time/tqual.c > +++ b/src/backend/utils/time/tqual.c > @@ -1451,6 +1451,69 @@ HeapTupleIsSurelyDead(HeapTuple htup, TransactionId OldestXmin) > } > > /* > + * XidInXip searches xid in xip array. > + * > + * If xcnt is smaller than SnapshotMinHash (60), or *xhlog is zero, then simple > + * linear scan of xip array used. Looks like there is no benifit in hash table > + * for small xip array. I wouldn't write '60' in there, anyone who is interested could go look up whatever it ends up being set to. I tend to agree with Robert that it'd be nice if simplehash could be used here instead. The insertion is definitely more expensive but that's specifically to try and improve lookup performance, so it might end up not being so bad. I do understand that it would end up using more memory, so that's a fair concern. I do think this could use with more comments and perhaps having some Assert()'s thrown in (and it looks like you're removing one..?). I haven't got a whole lot else to say on this patch, would be good if someone could spend some more time reviewing it more carefully and testing it to see what kind of performance they get. The improvements that you've posted definitely look nice, especially with the lwlock performance work. Thanks! Stephen
Вложения
Hi,
I've done a bit of benchmarking on the last patch version (from 22/8),
using a simple workload:
1) 8 clients doing
SELECT SUM(abalance) FROM pgbench_accounts
with the table truncated to only 10k rows
2) variable number (8, 16, 32, ..., 512) of write clients, doing this
\set aid random(1, 10000 * :scale)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + 1 WHERE aid = :aid;
SELECT pg_sleep(0.005);
COMMIT;
The idea is to measure tps of the read-only clients, with many throttled
write clients (idle in transaction for 5ms after each update). This
should generate snapshots with many XIDs. Scripts attached, of course.
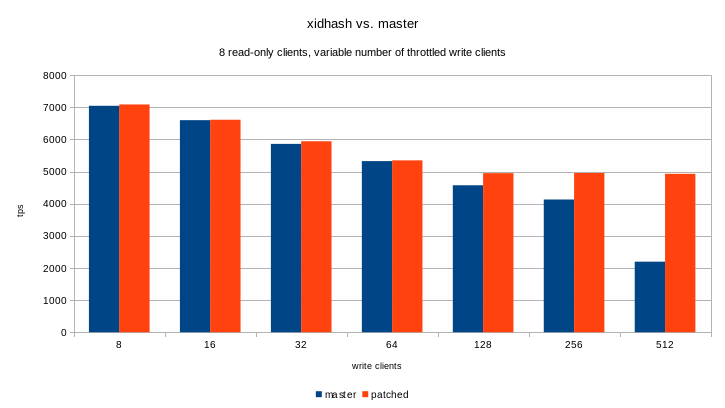
The results look really promising (see the attached chart and .ods):
write clients master patched
8 7048 7089
16 6601 6614
32 5862 5944
64 5327 5349
128 4574 4952
256 4132 4956
512 2196 4930
That being said, I think Stephen is right that there's a bug in
CopySnapshot, and I agree with his other comments too. I think the patch
should have been in WoA, so I'll mark it like that.
simplehash is great, but I'm not sure it's a good fit for this use case.
Seems a bit overkill to me in this case, but maybe I'm wrong.
Snapshots are static (we don't really add new XIDs into existing ones,
right?), so why don't we simply sort the XIDs and then use bsearch to
lookup values? That should fix the linear search, without need for any
local hash table.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
{kind=link}
Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
> Snapshots are static (we don't really add new XIDs into existing ones,
> right?), so why don't we simply sort the XIDs and then use bsearch to
> lookup values? That should fix the linear search, without need for any
> local hash table.
+1 for looking into that, since it would avoid adding any complication
to snapshot copying. In principle, with enough XIDs in the snap, an
O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm
dubious that we are often in the range where that would matter.
We do need to worry about the cost of snapshot copying, too.
regards, tom lane
05.03.2018 18:00, Tom Lane пишет: > Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >> Snapshots are static (we don't really add new XIDs into existing ones, >> right?), so why don't we simply sort the XIDs and then use bsearch to >> lookup values? That should fix the linear search, without need for any >> local hash table. > > +1 for looking into that, since it would avoid adding any complication > to snapshot copying. In principle, with enough XIDs in the snap, an > O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm > dubious that we are often in the range where that would matter. > We do need to worry about the cost of snapshot copying, too. Sorting - is the first thing I've tried. Unfortunately, sorting itself eats too much cpu. Filling hash table is much faster. Can I rely on snapshots being static? May be then there is no need in separate raw representation and hash table. I may try to fill hash table directly in GetSnapshotData instead of lazy filling. Though it will increase time under lock, so it is debatable and should be carefully measured. I'll look at a bug in CopySnapshot soon. Excuse me for delaying. With regards, Sokolov Yura
Вложения
On 03/06/2018 06:23 AM, Yura Sokolov wrote:
> 05.03.2018 18:00, Tom Lane пишет:
>> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes:
>>> Snapshots are static (we don't really add new XIDs into existing ones,
>>> right?), so why don't we simply sort the XIDs and then use bsearch to
>>> lookup values? That should fix the linear search, without need for any
>>> local hash table.
>>
>> +1 for looking into that, since it would avoid adding any complication
>> to snapshot copying. In principle, with enough XIDs in the snap, an
>> O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm
>> dubious that we are often in the range where that would matter.
>> We do need to worry about the cost of snapshot copying, too.
>
> Sorting - is the first thing I've tried. Unfortunately, sorting
> itself eats too much cpu. Filling hash table is much faster.
>
I've been interested in the sort-based approach, so I've spent a bit of
time hacking on it (patch attached). It's much less invasive compared to
the hash-table, but Yura is right the hashtable gives better results.
I've tried to measure the benefits using the same script I shared on
Tuesday, but I kept getting really strange numbers. In fact, I've been
unable to even reproduce the results I shared back then. And after a bit
of head-scratching I think the script is useless - it can't possibly
generate snapshots with many XIDs because all the update threads sleep
for exactly the same time. And first one to sleep is first one to wake
up and commit, so most of the other XIDs are above xmax (and thus not
included in the snapshot). I have no idea why I got the numbers :-/
But with this insight, I quickly modified the script to also consume
XIDs by another thread (which simply calls txid_current). With that I'm
getting snapshots with as many XIDs as there are UPDATE clients (this
time I actually checked that using gdb).
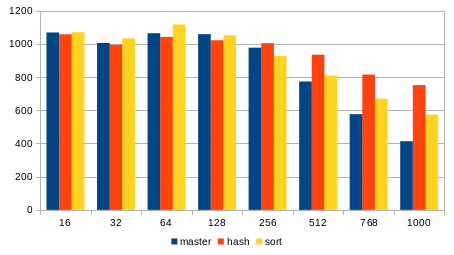
And for a 60-second run the tps results look like this (see the attached
chart, showing the same data):
writers master hash sort
-----------------------------------------
16 1068 1057 1070
32 1005 995 1033
64 1064 1042 1117
128 1058 1021 1051
256 977 1004 928
512 773 935 808
768 576 815 670
1000 413 752 573
The sort certainly does improve performance compared to master, but it's
only about half of the hashtable improvement.
I don't know how much this simple workload resembles the YCSB benchmark,
but I seem to recall it's touching individual rows. In which case it's
likely worse due to the pg_qsort being more expensive than building the
hash table.
So I agree with Yura the sort is not a viable alternative to the hash
table, in this case.
> Can I rely on snapshots being static? May be then there is no need
> in separate raw representation and hash table. I may try to fill hash
> table directly in GetSnapshotData instead of lazy filling. Though it
> will increase time under lock, so it is debatable and should be
> carefully measured.
>
Yes, I think you can rely on snapshots not being modified later. That's
pretty much the definition of a snapshot.
You may do that in GetSnapshotData, but you certainly can't do that in
the for loop there. Not only we don't want to add more work there, but
you don't know the number of XIDs in that loop. And we don't want to
build hash tables for small number of XIDs.
One reason against building the hash table in GetSnapshotData is that
we'd build it even when the snapshot is never queried. Or when it is
queried, but we only need to check xmin/xmax.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
{kind=link}
08.03.2018 03:42, Tomas Vondra пишет: > On 03/06/2018 06:23 AM, Yura Sokolov wrote: >> 05.03.2018 18:00, Tom Lane пишет: >>> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >>>> Snapshots are static (we don't really add new XIDs into existing ones, >>>> right?), so why don't we simply sort the XIDs and then use bsearch to >>>> lookup values? That should fix the linear search, without need for any >>>> local hash table. >>> >>> +1 for looking into that, since it would avoid adding any complication >>> to snapshot copying. In principle, with enough XIDs in the snap, an >>> O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm >>> dubious that we are often in the range where that would matter. >>> We do need to worry about the cost of snapshot copying, too. >> >> Sorting - is the first thing I've tried. Unfortunately, sorting >> itself eats too much cpu. Filling hash table is much faster. >> > > I've been interested in the sort-based approach, so I've spent a bit of > time hacking on it (patch attached). It's much less invasive compared to > the hash-table, but Yura is right the hashtable gives better results. > > I've tried to measure the benefits using the same script I shared on > Tuesday, but I kept getting really strange numbers. In fact, I've been > unable to even reproduce the results I shared back then. And after a bit > of head-scratching I think the script is useless - it can't possibly > generate snapshots with many XIDs because all the update threads sleep > for exactly the same time. And first one to sleep is first one to wake > up and commit, so most of the other XIDs are above xmax (and thus not > included in the snapshot). I have no idea why I got the numbers :-/ > > But with this insight, I quickly modified the script to also consume > XIDs by another thread (which simply calls txid_current). With that I'm > getting snapshots with as many XIDs as there are UPDATE clients (this > time I actually checked that using gdb). > > And for a 60-second run the tps results look like this (see the attached > chart, showing the same data): > > writers master hash sort > ----------------------------------------- > 16 1068 1057 1070 > 32 1005 995 1033 > 64 1064 1042 1117 > 128 1058 1021 1051 > 256 977 1004 928 > 512 773 935 808 > 768 576 815 670 > 1000 413 752 573 > > The sort certainly does improve performance compared to master, but it's > only about half of the hashtable improvement. > > I don't know how much this simple workload resembles the YCSB benchmark, > but I seem to recall it's touching individual rows. In which case it's > likely worse due to the pg_qsort being more expensive than building the > hash table. > > So I agree with Yura the sort is not a viable alternative to the hash > table, in this case. > >> Can I rely on snapshots being static? May be then there is no need >> in separate raw representation and hash table. I may try to fill hash >> table directly in GetSnapshotData instead of lazy filling. Though it >> will increase time under lock, so it is debatable and should be >> carefully measured. >> > > Yes, I think you can rely on snapshots not being modified later. That's > pretty much the definition of a snapshot. > > You may do that in GetSnapshotData, but you certainly can't do that in > the for loop there. Not only we don't want to add more work there, but > you don't know the number of XIDs in that loop. And we don't want to > build hash tables for small number of XIDs. > > One reason against building the hash table in GetSnapshotData is that > we'd build it even when the snapshot is never queried. Or when it is > queried, but we only need to check xmin/xmax. Thank you for analyze, Tomas. Stephen is right about bug in snapmgr.c Attached version fixes bug, and also simplifies XidInXip a bit. With regards, Sokolov Yura.
Вложения
On 03/10/2018 03:11 AM, Yura Sokolov wrote: > 08.03.2018 03:42, Tomas Vondra пишет: >> On 03/06/2018 06:23 AM, Yura Sokolov wrote: >>> 05.03.2018 18:00, Tom Lane пишет: >>>> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >>>>> Snapshots are static (we don't really add new XIDs into existing ones, >>>>> right?), so why don't we simply sort the XIDs and then use bsearch to >>>>> lookup values? That should fix the linear search, without need for any >>>>> local hash table. >>>> >>>> +1 for looking into that, since it would avoid adding any complication >>>> to snapshot copying. In principle, with enough XIDs in the snap, an >>>> O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm >>>> dubious that we are often in the range where that would matter. >>>> We do need to worry about the cost of snapshot copying, too. >>> >>> Sorting - is the first thing I've tried. Unfortunately, sorting >>> itself eats too much cpu. Filling hash table is much faster. >>> >> >> I've been interested in the sort-based approach, so I've spent a bit of >> time hacking on it (patch attached). It's much less invasive compared to >> the hash-table, but Yura is right the hashtable gives better results. >> >> I've tried to measure the benefits using the same script I shared on >> Tuesday, but I kept getting really strange numbers. In fact, I've been >> unable to even reproduce the results I shared back then. And after a bit >> of head-scratching I think the script is useless - it can't possibly >> generate snapshots with many XIDs because all the update threads sleep >> for exactly the same time. And first one to sleep is first one to wake >> up and commit, so most of the other XIDs are above xmax (and thus not >> included in the snapshot). I have no idea why I got the numbers :-/ >> >> But with this insight, I quickly modified the script to also consume >> XIDs by another thread (which simply calls txid_current). With that I'm >> getting snapshots with as many XIDs as there are UPDATE clients (this >> time I actually checked that using gdb). >> >> And for a 60-second run the tps results look like this (see the attached >> chart, showing the same data): >> >> writers master hash sort >> ----------------------------------------- >> 16 1068 1057 1070 >> 32 1005 995 1033 >> 64 1064 1042 1117 >> 128 1058 1021 1051 >> 256 977 1004 928 >> 512 773 935 808 >> 768 576 815 670 >> 1000 413 752 573 >> >> The sort certainly does improve performance compared to master, but it's >> only about half of the hashtable improvement. >> >> I don't know how much this simple workload resembles the YCSB benchmark, >> but I seem to recall it's touching individual rows. In which case it's >> likely worse due to the pg_qsort being more expensive than building the >> hash table. >> >> So I agree with Yura the sort is not a viable alternative to the hash >> table, in this case. >> >>> Can I rely on snapshots being static? May be then there is no need >>> in separate raw representation and hash table. I may try to fill hash >>> table directly in GetSnapshotData instead of lazy filling. Though it >>> will increase time under lock, so it is debatable and should be >>> carefully measured. >>> >> >> Yes, I think you can rely on snapshots not being modified later. That's >> pretty much the definition of a snapshot. >> >> You may do that in GetSnapshotData, but you certainly can't do that in >> the for loop there. Not only we don't want to add more work there, but >> you don't know the number of XIDs in that loop. And we don't want to >> build hash tables for small number of XIDs. >> >> One reason against building the hash table in GetSnapshotData is that >> we'd build it even when the snapshot is never queried. Or when it is >> queried, but we only need to check xmin/xmax. > > Thank you for analyze, Tomas. > > Stephen is right about bug in snapmgr.c > Attached version fixes bug, and also simplifies XidInXip a bit. > OK, a few more comments. 1) The code in ExtendXipSizeForHash seems somewhat redundant with my_log2 (that is, we could just call the existing function). 2) Apparently xhlog/subxhlog fields are used for two purposes - to store log2 of the two XID counts, and to remember if the hash table is built. That's a bit confusing (at least it should be explained in a comment) but most importantly it seems a bit unnecessary. I assume it was done to save space, but I very much doubt that makes any difference. So we could easily keep a separate flag. I'm pretty sure there are holes in the SnapshotData struct, so we could squeeze it the flags in one of those. But do we even need a separate flag? We could just as easily keep the log2 fields set to 0 and only set them after actually building the hash table. Or even better, why not to store the mask so that XidInXip does not need to compute it over and over (granted, that's uint32 instead of just uint8, but I don't think SnapshotData is particularly sensitive to this, especially considering how much larger the xid hash table is). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
16.03.2018 04:23, Tomas Vondra пишет: > > > On 03/10/2018 03:11 AM, Yura Sokolov wrote: >> 08.03.2018 03:42, Tomas Vondra пишет: >>> On 03/06/2018 06:23 AM, Yura Sokolov wrote: >>>> 05.03.2018 18:00, Tom Lane пишет: >>>>> Tomas Vondra <tomas.vondra@2ndquadrant.com> writes: >>>>>> Snapshots are static (we don't really add new XIDs into existing ones, >>>>>> right?), so why don't we simply sort the XIDs and then use bsearch to >>>>>> lookup values? That should fix the linear search, without need for any >>>>>> local hash table. >>>>> >>>>> +1 for looking into that, since it would avoid adding any complication >>>>> to snapshot copying. In principle, with enough XIDs in the snap, an >>>>> O(1) hash probe would be quicker than an O(log N) bsearch ... but I'm >>>>> dubious that we are often in the range where that would matter. >>>>> We do need to worry about the cost of snapshot copying, too. >>>> >>>> Sorting - is the first thing I've tried. Unfortunately, sorting >>>> itself eats too much cpu. Filling hash table is much faster. >>>> >>> >>> I've been interested in the sort-based approach, so I've spent a bit of >>> time hacking on it (patch attached). It's much less invasive compared to >>> the hash-table, but Yura is right the hashtable gives better results. >>> >>> I've tried to measure the benefits using the same script I shared on >>> Tuesday, but I kept getting really strange numbers. In fact, I've been >>> unable to even reproduce the results I shared back then. And after a bit >>> of head-scratching I think the script is useless - it can't possibly >>> generate snapshots with many XIDs because all the update threads sleep >>> for exactly the same time. And first one to sleep is first one to wake >>> up and commit, so most of the other XIDs are above xmax (and thus not >>> included in the snapshot). I have no idea why I got the numbers :-/ >>> >>> But with this insight, I quickly modified the script to also consume >>> XIDs by another thread (which simply calls txid_current). With that I'm >>> getting snapshots with as many XIDs as there are UPDATE clients (this >>> time I actually checked that using gdb). >>> >>> And for a 60-second run the tps results look like this (see the attached >>> chart, showing the same data): >>> >>> writers master hash sort >>> ----------------------------------------- >>> 16 1068 1057 1070 >>> 32 1005 995 1033 >>> 64 1064 1042 1117 >>> 128 1058 1021 1051 >>> 256 977 1004 928 >>> 512 773 935 808 >>> 768 576 815 670 >>> 1000 413 752 573 >>> >>> The sort certainly does improve performance compared to master, but it's >>> only about half of the hashtable improvement. >>> >>> I don't know how much this simple workload resembles the YCSB benchmark, >>> but I seem to recall it's touching individual rows. In which case it's >>> likely worse due to the pg_qsort being more expensive than building the >>> hash table. >>> >>> So I agree with Yura the sort is not a viable alternative to the hash >>> table, in this case. >>> >>>> Can I rely on snapshots being static? May be then there is no need >>>> in separate raw representation and hash table. I may try to fill hash >>>> table directly in GetSnapshotData instead of lazy filling. Though it >>>> will increase time under lock, so it is debatable and should be >>>> carefully measured. >>>> >>> >>> Yes, I think you can rely on snapshots not being modified later. That's >>> pretty much the definition of a snapshot. >>> >>> You may do that in GetSnapshotData, but you certainly can't do that in >>> the for loop there. Not only we don't want to add more work there, but >>> you don't know the number of XIDs in that loop. And we don't want to >>> build hash tables for small number of XIDs. >>> >>> One reason against building the hash table in GetSnapshotData is that >>> we'd build it even when the snapshot is never queried. Or when it is >>> queried, but we only need to check xmin/xmax. >> >> Thank you for analyze, Tomas. >> >> Stephen is right about bug in snapmgr.c >> Attached version fixes bug, and also simplifies XidInXip a bit. >> > > OK, a few more comments. > > 1) The code in ExtendXipSizeForHash seems somewhat redundant with > my_log2 (that is, we could just call the existing function). Yes, I could call my_log2 from ExtendXipSizeForHash. But wouldn't one more call be more expensive than loop itself? > 2) Apparently xhlog/subxhlog fields are used for two purposes - to store > log2 of the two XID counts, and to remember if the hash table is built. > That's a bit confusing (at least it should be explained in a comment) > but most importantly it seems a bit unnecessary. Ok, I'll add comment. > I assume it was done to save space, but I very much doubt that makes any > difference. So we could easily keep a separate flag. I'm pretty sure > there are holes in the SnapshotData struct, so we could squeeze it the > flags in one of those. There's hole just right after xhlog. But it will be a bit strange to move fields around. > But do we even need a separate flag? We could just as easily keep the > log2 fields set to 0 and only set them after actually building the hash > table. There is a need to signal that there is space for hash. It is not always allocated. iirc, I didn't cover the case where snapshot were restored from file, and some other place or two. Only if all places where snapshot is allocated are properly modified to allocate space for hash, then flag could be omitted, and log2 itself used as a flag. > Or even better, why not to store the mask so that XidInXip does > not need to compute it over and over (granted, that's uint32 instead of > just uint8, but I don't think SnapshotData is particularly sensitive to > this, especially considering how much larger the xid hash table is). I don't like unnecessary sizeof struct increase. And I doubt that computation matters. I could be mistaken though, because it is hot place. Do you think it will significantly improve readability? With regards, Sokolov Yura aka funny_falcon.
On 03/17/2018 12:03 AM, Yura Sokolov wrote:
> 16.03.2018 04:23, Tomas Vondra пишет:
>>
>> ...
>>
>> OK, a few more comments.
>>
>> 1) The code in ExtendXipSizeForHash seems somewhat redundant with
>> my_log2 (that is, we could just call the existing function).
>
> Yes, I could call my_log2 from ExtendXipSizeForHash. But wouldn't one
> more call be more expensive than loop itself?
>
I very much doubt it there would be a measurable difference. Firstly,
function calls are not that expensive, otherwise we'd be running around
and removing function calls from the hot paths. Secondly, the call only
happens with many XIDs, and in that case the cost should be out-weighted
by faster lookups. And finally, the function does stuff that seems far
more expensive than a single function call (for example allocation,
which may easily trigger a malloc).
In fact, in the interesting cases it's pretty much guaranteed to hit a
malloc, because the number of backend processes needs to be high enough
(say, 256 or more), which means
GetMaxSnapshotSubxidCount()
will translate to something like
((PGPROC_MAX_CACHED_SUBXIDS + 1) * PROCARRAY_MAXPROCS)
= (64 + 1) * 256
= 16640
and because XIDs are 4B each, that's ~65kB of memory (even ignoring the
ExtendXipSizeForHash business). And aset.c treats chunks larger than 8kB
as separate blocks, that are always malloc-ed independently.
But I may be missing something, and the extra call actually makes a
difference. But I think the onus of proving that is on you, and the
default should be not to duplicate code.
>> 2) Apparently xhlog/subxhlog fields are used for two purposes - to
>> store log2 of the two XID counts, and to remember if the hash table
>> is built. That's a bit confusing (at least it should be explained
>> in a comment) but most importantly it seems a bit unnecessary.
>
> Ok, I'll add comment.
>
>> I assume it was done to save space, but I very much doubt that
>> makes any difference. So we could easily keep a separate flag. I'm
>> pretty sure there are holes in the SnapshotData struct, so we could
>> squeeze it the flags in one of those.
>
> There's hole just right after xhlog. But it will be a bit strange to
> move fields around.
>
Is SnapshotData really that sensitive to size increase? I have my doubts
about that, TBH. The default stance should be to make the code easy to
understand. That is, we should only move fields around if it actually
makes a difference.
>> But do we even need a separate flag? We could just as easily keep
>> the log2 fields set to 0 and only set them after actually building
>> the hash table.
>
> There is a need to signal that there is space for hash. It is not
> always allocated. iirc, I didn't cover the case where snapshot were
> restored from file, and some other place or two.
> Only if all places where snapshot is allocated are properly modified
> to allocate space for hash, then flag could be omitted, and log2
> itself used as a flag.
>
Hmmm, that makes it a bit inconsistent, I guess ... why not to do the
same thing on all those places?
>> Or even better, why not to store the mask so that XidInXip does not
>> need to compute it over and over (granted, that's uint32 instead
>> of just uint8, but I don't think SnapshotData is particularly
>> sensitive to this, especially considering how much larger the xid
>> hash table is).
>
> I don't like unnecessary sizeof struct increase. And I doubt that
> computation matters. I could be mistaken though, because it is hot
> place. Do you think it will significantly improve readability?
>
IMHO the primary goal is to make the code easy to read and understand,
and only optimize struct size if it actually makes a difference. We have
no such proof here, and I very much doubt you'll be able to show any
difference because even with separate flags pahole says this:
struct SnapshotData {
SnapshotSatisfiesFunc satisfies; /* 0 8 */
TransactionId xmin; /* 8 4 */
TransactionId xmax; /* 12 4 */
TransactionId * xip; /* 16 8 */
uint32 xcnt; /* 24 4 */
uint8 xhlog; /* 28 1 */
/* XXX 3 bytes hole, try to pack */
TransactionId * subxip; /* 32 8 */
int32 subxcnt; /* 40 4 */
uint8 subxhlog; /* 44 1 */
bool suboverflowed; /* 45 1 */
bool takenDuringRecovery; /* 46 1 */
bool copied; /* 47 1 */
CommandId curcid; /* 48 4 */
uint32 speculativeToken; /* 52 4 */
uint32 active_count; /* 56 4 */
uint32 regd_count; /* 60 4 */
/* --- cacheline 1 boundary (64 bytes) --- */
pairingheap_node ph_node; /* 64 24 */
TimestampTz whenTaken; /* 88 8 */
XLogRecPtr lsn; /* 96 8 */
/* size: 104, cachelines: 2, members: 19 */
/* sum members: 101, holes: 1, sum holes: 3 */
/* last cacheline: 40 bytes */
};
That is, the whole structure is only 104B - had it got over 128B, it
might have made a difference due to extra cacheline. In fact, even if
you make the xhlog and subxhlog uint32 (which would be enough to store
the mask, which is what simplehash does), it'd be only 120B.
Based on this I'd dare to say neither of those changes would have
negative impact.
So I suggest to split each of the "combined" fields into a simple bool
flag ("hash table built") and a uint32 mask, and see if it simplifies
the code (I believe it will) and what impact it has (I believe there
will be none).
Sorry if this seems like a bikeshedding ...
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Mar 10, 2018 at 7:41 AM, Yura Sokolov <funny.falcon@gmail.com> wrote:
> 08.03.2018 03:42, Tomas Vondra пишет:
>> One reason against building the hash table in GetSnapshotData is that
>> we'd build it even when the snapshot is never queried. Or when it is
>> queried, but we only need to check xmin/xmax.
>
> Thank you for analyze, Tomas.
>
> Stephen is right about bug in snapmgr.c
> Attached version fixes bug, and also simplifies XidInXip a bit.
>
@@ -2167,8 +2175,7 @@ RestoreSnapshot(char *start_address)
/* Copy SubXIDs, if present. */
if (serialized_snapshot.subxcnt > 0)
{
- snapshot->subxip = ((TransactionId *) (snapshot + 1)) +
- serialized_snapshot.xcnt;
+ snapshot->subxip = ((TransactionId *) (snapshot + 1)) + xcnt;
memcpy(snapshot->subxip, serialized_xids + serialized_snapshot.xcnt,
serialized_snapshot.subxcnt * sizeof(TransactionId));
}
It is not clear why you want to change this in RestoreSnapshot when
nothing related is changed in SerializeSnapshot? Can you please add
some comments to clarify it?
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
17.03.2018 03:36, Tomas Vondra пишет:
>
> On 03/17/2018 12:03 AM, Yura Sokolov wrote:
>> 16.03.2018 04:23, Tomas Vondra пишет:
>>>
>>> ...
>>>
>>> OK, a few more comments.
>>>
>>> 1) The code in ExtendXipSizeForHash seems somewhat redundant with
>>> my_log2 (that is, we could just call the existing function).
>>
>> Yes, I could call my_log2 from ExtendXipSizeForHash. But wouldn't one
>> more call be more expensive than loop itself?
>>
>
> I very much doubt it there would be a measurable difference. Firstly,
> function calls are not that expensive, otherwise we'd be running around
> and removing function calls from the hot paths. Secondly, the call only
> happens with many XIDs, and in that case the cost should be out-weighted
> by faster lookups. And finally, the function does stuff that seems far
> more expensive than a single function call (for example allocation,
> which may easily trigger a malloc).
>
> In fact, in the interesting cases it's pretty much guaranteed to hit a
> malloc, because the number of backend processes needs to be high enough
> (say, 256 or more), which means
>
> GetMaxSnapshotSubxidCount()
>
> will translate to something like
>
> ((PGPROC_MAX_CACHED_SUBXIDS + 1) * PROCARRAY_MAXPROCS)
> = (64 + 1) * 256
> = 16640
>
> and because XIDs are 4B each, that's ~65kB of memory (even ignoring the
> ExtendXipSizeForHash business). And aset.c treats chunks larger than 8kB
> as separate blocks, that are always malloc-ed independently.
>
> But I may be missing something, and the extra call actually makes a
> difference. But I think the onus of proving that is on you, and the
> default should be not to duplicate code.
>
>>> 2) Apparently xhlog/subxhlog fields are used for two purposes - to
>>> store log2 of the two XID counts, and to remember if the hash table
>>> is built. That's a bit confusing (at least it should be explained
>>> in a comment) but most importantly it seems a bit unnecessary.
>>
>> Ok, I'll add comment.
>>
>>> I assume it was done to save space, but I very much doubt that
>>> makes any difference. So we could easily keep a separate flag. I'm
>>> pretty sure there are holes in the SnapshotData struct, so we could
>>> squeeze it the flags in one of those.
>>
>> There's hole just right after xhlog. But it will be a bit strange to
>> move fields around.
>>
>
> Is SnapshotData really that sensitive to size increase? I have my doubts
> about that, TBH. The default stance should be to make the code easy to
> understand. That is, we should only move fields around if it actually
> makes a difference.
>
>>> But do we even need a separate flag? We could just as easily keep
>>> the log2 fields set to 0 and only set them after actually building
>>> the hash table.
>>
>> There is a need to signal that there is space for hash. It is not
>> always allocated. iirc, I didn't cover the case where snapshot were
>> restored from file, and some other place or two.
>> Only if all places where snapshot is allocated are properly modified
>> to allocate space for hash, then flag could be omitted, and log2
>> itself used as a flag.
>>
>
> Hmmm, that makes it a bit inconsistent, I guess ... why not to do the
> same thing on all those places?
>
>>> Or even better, why not to store the mask so that XidInXip does not
>>> need to compute it over and over (granted, that's uint32 instead
>>> of just uint8, but I don't think SnapshotData is particularly
>>> sensitive to this, especially considering how much larger the xid
>>> hash table is).
>>
>> I don't like unnecessary sizeof struct increase. And I doubt that
>> computation matters. I could be mistaken though, because it is hot
>> place. Do you think it will significantly improve readability?
>>
>
> IMHO the primary goal is to make the code easy to read and understand,
> and only optimize struct size if it actually makes a difference. We have
> no such proof here, and I very much doubt you'll be able to show any
> difference because even with separate flags pahole says this:
>
> struct SnapshotData {
> SnapshotSatisfiesFunc satisfies; /* 0 8 */
> TransactionId xmin; /* 8 4 */
> TransactionId xmax; /* 12 4 */
> TransactionId * xip; /* 16 8 */
> uint32 xcnt; /* 24 4 */
> uint8 xhlog; /* 28 1 */
>
> /* XXX 3 bytes hole, try to pack */
>
> TransactionId * subxip; /* 32 8 */
> int32 subxcnt; /* 40 4 */
> uint8 subxhlog; /* 44 1 */
> bool suboverflowed; /* 45 1 */
> bool takenDuringRecovery; /* 46 1 */
> bool copied; /* 47 1 */
> CommandId curcid; /* 48 4 */
> uint32 speculativeToken; /* 52 4 */
> uint32 active_count; /* 56 4 */
> uint32 regd_count; /* 60 4 */
> /* --- cacheline 1 boundary (64 bytes) --- */
> pairingheap_node ph_node; /* 64 24 */
> TimestampTz whenTaken; /* 88 8 */
> XLogRecPtr lsn; /* 96 8 */
>
> /* size: 104, cachelines: 2, members: 19 */
> /* sum members: 101, holes: 1, sum holes: 3 */
> /* last cacheline: 40 bytes */
> };
>
> That is, the whole structure is only 104B - had it got over 128B, it
> might have made a difference due to extra cacheline. In fact, even if
> you make the xhlog and subxhlog uint32 (which would be enough to store
> the mask, which is what simplehash does), it'd be only 120B.
>
> Based on this I'd dare to say neither of those changes would have
> negative impact.
>
> So I suggest to split each of the "combined" fields into a simple bool
> flag ("hash table built") and a uint32 mask, and see if it simplifies
> the code (I believe it will) and what impact it has (I believe there
> will be none).
>
> Sorry if this seems like a bikeshedding ...
>
>
> regards
>
I've made version "without bit magic" as you suggested (in attach).
I can't reliably say is there any performance difference with previous
version.
With regards,
Yura.
Вложения
23.03.2018 17:59, Amit Kapila пишет:
> On Sat, Mar 10, 2018 at 7:41 AM, Yura Sokolov <funny.falcon@gmail.com> wrote:
>> 08.03.2018 03:42, Tomas Vondra пишет:
>>> One reason against building the hash table in GetSnapshotData is that
>>> we'd build it even when the snapshot is never queried. Or when it is
>>> queried, but we only need to check xmin/xmax.
>>
>> Thank you for analyze, Tomas.
>>
>> Stephen is right about bug in snapmgr.c
>> Attached version fixes bug, and also simplifies XidInXip a bit.
>>
>
> @@ -2167,8 +2175,7 @@ RestoreSnapshot(char *start_address)
> /* Copy SubXIDs, if present. */
> if (serialized_snapshot.subxcnt > 0)
> {
> - snapshot->subxip = ((TransactionId *) (snapshot + 1)) +
> - serialized_snapshot.xcnt;
> + snapshot->subxip = ((TransactionId *) (snapshot + 1)) + xcnt;
> memcpy(snapshot->subxip, serialized_xids + serialized_snapshot.xcnt,
> serialized_snapshot.subxcnt * sizeof(TransactionId));
> }
>
>
> It is not clear why you want to change this in RestoreSnapshot when
> nothing related is changed in SerializeSnapshot? Can you please add
> some comments to clarify it?
>
I didn't change serialized format. Therefore is no need to change
SerializeSnapshot.
But in-memory representation were changed, so RestoreSnapshot is changed.
With regards,
Sokolov Yura.
> On Sun, 1 Apr 2018 at 19:58, Yura Sokolov <funny.falcon@gmail.com> wrote: > > I didn't change serialized format. Therefore is no need to change > SerializeSnapshot. > But in-memory representation were changed, so RestoreSnapshot is changed. This patch went through the last tree commit fests without any noticeable activity, but cfbot says it still applies and doesn't break any tests. Taking into account potential performance improvements, I believe it would be a pity to stop at this point. Yura, what're your plans about it? If I understand correctly, there are still some commentaries, that were not answered from the last few messages. At the same time can anyone from active reviewers (Tomas, Amit) look at it to agree on what should be done to push it forward?
>On Sun, Nov 4, 2018 at 1:27 PM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > > On Sun, 1 Apr 2018 at 19:58, Yura Sokolov <funny.falcon@gmail.com> wrote: > > > > I didn't change serialized format. Therefore is no need to change > > SerializeSnapshot. > > But in-memory representation were changed, so RestoreSnapshot is changed. > > This patch went through the last tree commit fests without any noticeable > activity, but cfbot says it still applies and doesn't break any tests. Taking > into account potential performance improvements, I believe it would be a pity > to stop at this point. > > Yura, what're your plans about it? If I understand correctly, there are still > some commentaries, that were not answered from the last few messages. At the > same time can anyone from active reviewers (Tomas, Amit) look at it to agree on > what should be done to push it forward? Due to lack of response I'm marking it as "Returned with feedback". Feel free to resubmit a new version though.