Обсуждение: Slowness of extended protocol
Hi all. I know this has been discussed before, I'd like to know what's the current position on this.
Comparing the performance of the simple vs. extended protocols with pgbench yields some extreme results:
$ ./pgbench -T 10 -S -M simple -f /tmp/pgbench.sql pgbench
tps = 14739.803253 (excluding connections establishing)
$ ./pgbench -T 10 -S -M extended -f /tmp/pgbench.sql pgbench
tps = 11407.012679 (excluding connections establishing)
(pgbench.sql contains a minimal SELECT 1, I'm running against localhost)
I was aware that there's some overhead associated with the extended protocol, but not that it was a 30% difference... My question is whether there are good reasons why this should be so, or rather that this simply hasn't been optimized yet. If it's the latter, are there plans to do so?
To give some context, I maintain Npgsql, the open-source .NET driver for PostgreSQL. Since recent version Npgsql uses the extended protocol almost exclusively, mainly because it does binary data rather than text. Even if that weren't the case, imposing such a performance penalty on extended-only features (parameters, prepared statements) seems problematic.
I'm aware that testing against localhost inflates the performance issue - taking into account the latency of a remote server, the simple/extended difference would be much less significant. But the issue still seems to be relevant.
> Hi all. I know this has been discussed before, I'd like to know what's the
> current position on this.
>
> Comparing the performance of the simple vs. extended protocols with pgbench
> yields some extreme results:
>
> $ ./pgbench -T 10 -S -M simple -f /tmp/pgbench.sql pgbench
> tps = 14739.803253 (excluding connections establishing)
>
> $ ./pgbench -T 10 -S -M extended -f /tmp/pgbench.sql pgbench
> tps = 11407.012679 (excluding connections establishing)
>
> (pgbench.sql contains a minimal SELECT 1, I'm running against localhost)
>
> I was aware that there's some overhead associated with the extended
> protocol, but not that it was a 30% difference... My question is whether
> there are good reasons why this should be so, or rather that this simply
> hasn't been optimized yet. If it's the latter, are there plans to do so?
>
> To give some context, I maintain Npgsql, the open-source .NET driver for
> PostgreSQL. Since recent version Npgsql uses the extended protocol almost
> exclusively, mainly because it does binary data rather than text. Even if
> that weren't the case, imposing such a performance penalty on extended-only
> features (parameters, prepared statements) seems problematic.
>
> I'm aware that testing against localhost inflates the performance issue -
> taking into account the latency of a remote server, the simple/extended
> difference would be much less significant. But the issue still seems to be
> relevant.
Without re-using prepared statements or portals, extended protocol is
always slow because it requires more messages exchanges than simple
protocol. In pgbench case, it always sends parse, bind, describe,
execute and sync message in each transaction even if each transaction
involves identical statement ("SELECT 1" in your case).
See the manual for the protocol details.
Best regards,
--
Tatsuo Ishii
SRA OSS, Inc. Japan
English: http://www.sraoss.co.jp/index_en.php
Japanese:http://www.sraoss.co.jp
Without re-using prepared statements or portals, extended protocol is
always slow because it requires more messages exchanges than simple
protocol. In pgbench case, it always sends parse, bind, describe,
execute and sync message in each transaction even if each transaction
involves identical statement ("SELECT 1" in your case).
See the manual for the protocol details.
I'm well aware of how the extended protocol works, but it seems odd for a 30% increase in processing time to be the result exclusively of processing 5 messages instead of just 1 - it doesn't seem like that big a deal (although I may be mistaken). I was imagining that there's something more fundamental in how the protocol or PostgreSQL state is managed internally, that would be responsible for the slowdown.
Shay Rojansky <roji@roji.org>:
I'm well aware of how the extended protocol works, but it seems odd for a 30% increase in processing time to be the result exclusively of processing 5 messages instead of just 1 - it doesn't seem like that big a deal (although I may be mistaken). I was imagining that there's something more fundamental in how the protocol or PostgreSQL state is managed internally, that would be responsible for the slowdown.
Hi, have you tried to use a profiler to identify the _cause_ of the difference in performance?
Here's relevant read: https://shipilev.net/blog/2015/voltmeter/#_english_version
Vladimir
Shay Rojansky <roji@roji.org>:I'm well aware of how the extended protocol works, but it seems odd for a 30% increase in processing time to be the result exclusively of processing 5 messages instead of just 1 - it doesn't seem like that big a deal (although I may be mistaken). I was imagining that there's something more fundamental in how the protocol or PostgreSQL state is managed internally, that would be responsible for the slowdown.Hi, have you tried to use a profiler to identify the _cause_ of the difference in performance?Here's relevant read: https://shipilev.net/blog/2015/voltmeter/#_english_version
I'm definitely not a stage where I'm interested in the cause of the difference. I'm not a PostgreSQL hacker, and I'm not going into the source code to try and optimize anything (not yet anyway). For now, I'm just looking to get a high-level picture of the situation and to inform people that there may be an issue.
Or in terms of your article, I'm plugging a light bulb into the wall socket and the light is dim, so I'm trying to ask the building electricity team if they're aware of it, if if it's a fixable situation and if there are plans to fix it - before pushing any fingers into some electricity cabinet I don't know.
On Sun, Jul 31, 2016 at 4:05 PM, Shay Rojansky <roji@roji.org> wrote: > I'm well aware of how the extended protocol works, but it seems odd for a > 30% increase in processing time to be the result exclusively of processing 5 > messages instead of just 1 - it doesn't seem like that big a deal (although > I may be mistaken). I was imagining that there's something more fundamental > in how the protocol or PostgreSQL state is managed internally, that would be > responsible for the slowdown. I think you're looking at this the wrong way around. 30% of what? You're doing these simple read-only selects on a database that obviously is entirely in RAM. If you do the math on the numbers you gave above the simple protocol took 678 microseconds per transaction and the extended protocol took 876 microseconds. The difference is 198 microseconds. I'm not sure exactly where those 200us are going and perhaps it could be lower but in what real-world query is it going to have a measurable impact on the total time? The other danger in unrealistic test cases is that you're probably measuring work that doesn't scale and in fact optimizing based on it could impose a cost that *does* scale. For example if 150us of that time is being spent in the prepare and we cut that down by a factor of 10 to 15us then it would be only a 10% penalty over the simple protocol in your test. But if that optimization added any overhead to the execute stage then when it's executed thousands of times that could add milliseconds to the total runtime. -- greg
On 2016-07-31 22:26:00 +0100, Greg Stark wrote: > I think you're looking at this the wrong way around. 30% of what? > You're doing these simple read-only selects on a database that > obviously is entirely in RAM. If you do the math on the numbers you > gave above the simple protocol took 678 microseconds per transaction > and the extended protocol took 876 microseconds. The difference is 198 > microseconds. I'm not sure exactly where those 200us are going and > perhaps it could be lower but in what real-world query is it going to > have a measurable impact on the total time? FWIW, I've observed the same with (a bit) more complicated queries. A part of this is that the extended protocol simply does more. PQsendQueryGuts() sends Parse/Bind/Describe/Execute/Sync - that's simply more work and data over the wire than a single Q message. Whether that matters for a given workload or not, is a different question, but I think it's pretty clear that it can for some. Shay, are you using unnamed or named portals? There's already a shortcut path for the former in some places. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> FWIW, I've observed the same with (a bit) more complicated queries. A
> part of this is that the extended protocol simply does
> more. PQsendQueryGuts() sends Parse/Bind/Describe/Execute/Sync - that's
> simply more work and data over the wire than a single Q message.
Yeah. The extended query protocol was designed to offer a lot of
functionality that people had asked for, like plan re-use and
introspection of the data types assigned to query parameters, but that
doesn't come at zero cost. I think the tie-in to the plan cache is a
significant part of the added overhead, and so is the fact that we have to
iterate the per-message loop in PostgresMain five times not once, with
overheads like updating the process title incurred several times in that.
In hindsight it seems clear that what a lot of apps want out of extended
protocol is only the ability to send parameter values out-of-line instead
of having to quote/escape them into SQL literals. Maybe an idea for the
fabled V4 protocol update is some compromise query type that corresponds
precisely to PQexecParams's feature set: you can send parameter values
out-of-line, and you can specify text or binary results, but there's no
notion of any persistent state being created and no feedback about
parameter data types.
regards, tom lane
Greg wrote:
> iterate the per-message loop in PostgresMain five times not once, with
> overheads like updating the process title incurred several times in that.
> I think you're looking at this the wrong way around. 30% of what?
> You're doing these simple read-only selects on a database that
> obviously is entirely in RAM. If you do the math on the numbers you
> gave above the simple protocol took 678 microseconds per transaction
> and the extended protocol took 876 microseconds. The difference is 198
> microseconds. I'm not sure exactly where those 200us are going and
> perhaps it could be lower but in what real-world query is it going to
> have a measurable impact on the total time?
> You're doing these simple read-only selects on a database that
> obviously is entirely in RAM. If you do the math on the numbers you
> gave above the simple protocol took 678 microseconds per transaction
> and the extended protocol took 876 microseconds. The difference is 198
> microseconds. I'm not sure exactly where those 200us are going and
> perhaps it could be lower but in what real-world query is it going to
> have a measurable impact on the total time?
That's a valid question, but as Andres said, it may not matter for most workloads but I think such a significant difference would matter to some... Keep in mind that I'm writing from the point of view of a driver developer, and not of a specific app - I know there are some point executing against a local database and trying to get extremely high throughput, for RAM reading queries or otherwise.
> The other danger in unrealistic test cases is that you're probably
> measuring work that doesn't scale and in fact optimizing based on it
> could impose a cost that *does* scale. For example if 150us of that
> time is being spent in the prepare and we cut that down by a factor of
> 10 to 15us then it would be only a 10% penalty over the simple
> protocol in your test. But if that optimization added any overhead to
> the execute stage then when it's executed thousands of times that
> could add milliseconds to the total runtime.
> measuring work that doesn't scale and in fact optimizing based on it
> could impose a cost that *does* scale. For example if 150us of that
> time is being spent in the prepare and we cut that down by a factor of
> 10 to 15us then it would be only a 10% penalty over the simple
> protocol in your test. But if that optimization added any overhead to
> the execute stage then when it's executed thousands of times that
> could add milliseconds to the total runtime.
I think it's a bit too early to say that... We're not discussing any proposed optimizations yet, just discussing what may or may not be a problem... Of course any proposed optimization would have to be carefully studied to make sure it doesn't cause performance degradation elsewhere.
Andres wrote:
> Shay, are you using unnamed or named portals? There's already a shortcut
> path for the former in some places.The benchmarks I posted are simply pgbench doing SELECT 1 with extended vs. simple, so I'm assuming unnamed portals. Npgsql itself only uses the unnamed portal, I think it's documented somewhere that this is better for performance.
Tom wrote:
> In hindsight it seems clear that what a lot of apps want out of extended
> protocol is only the ability to send parameter values out-of-line instead
> of having to quote/escape them into SQL literals. Maybe an idea for the
> fabled V4 protocol update is some compromise query type that corresponds
> precisely to PQexecParams's feature set: you can send parameter values
> out-of-line, and you can specify text or binary results, but there's no
> notion of any persistent state being created and no feedback about
> parameter data types.
> protocol is only the ability to send parameter values out-of-line instead
> of having to quote/escape them into SQL literals. Maybe an idea for the
> fabled V4 protocol update is some compromise query type that corresponds
> precisely to PQexecParams's feature set: you can send parameter values
> out-of-line, and you can specify text or binary results, but there's no
> notion of any persistent state being created and no feedback about
> parameter data types.
That seems like a good way forward. It may be possible to generalize this into a more "pay-per-play" protocol. You currently have a binary choice between a simple but fast protocol supporting very little, and an extended but slow protocol supporting everything. Making things more "pick and choose" could help here: if you want to actually use plan reuse, you pay for that. If you actually send parameters, you pay for that. It would be a pretty significant protocol change but it would make things more modular that way.
> I think the tie-in to the plan cache is a
> significant part of the added overhead, and so is the fact that we have to> iterate the per-message loop in PostgresMain five times not once, with
> overheads like updating the process title incurred several times in that.
I was thinking that something like that may be the cause. Is it worth looking into the loop and trying to optimize? For example, updating the process title doesn't seem to make sense for every single extended message...
Tom> I think the tie-in to the plan cache is a
Tom> significant part of the added overhead, and so is the fact that we have toTom> iterate the per-message loop in PostgresMain five times not once, with
Tom> overheads like updating the process title incurred several times in that.
Shay>I was thinking that something like that may be the cause. Is it worth looking into the loop and trying to optimize? For example, updating the
Shay>process title doesn't seem to make sense for every single extended message...
Shay> just discussing what may or may not be a problem...
Shay, why don't you use a profiler? Seriously.
I'm afraid "iterate the per-message loop in PostgresMain five times not once" /"just discussing what may or may not be a problem..." is just hand-waving.
Come on, it is not that hard.
Here's what I get with Instruments, OS X 10.11.5, Intel(R) Core(TM) i7-4960HQ CPU @ 2.60GHz, running with power plugged in. There are lots of applications running, however I believe it should not matter much since I'm using just 1 load thread and the 5-second averages are consistent and CPU is not overloaded.
test.sql:
SELECT 1;
PostgreSQL 9.5.3 on x86_64-apple-darwin15.4.0, compiled by Apple LLVM version 7.0.2 (clang-700.1.81), 64-bit
Command line:
/opt/local/lib/postgresql95/bin/pgbench -M extended -f test.sql -j 1 -P 5 -T 120
Profiler is activated at seconds 30...60
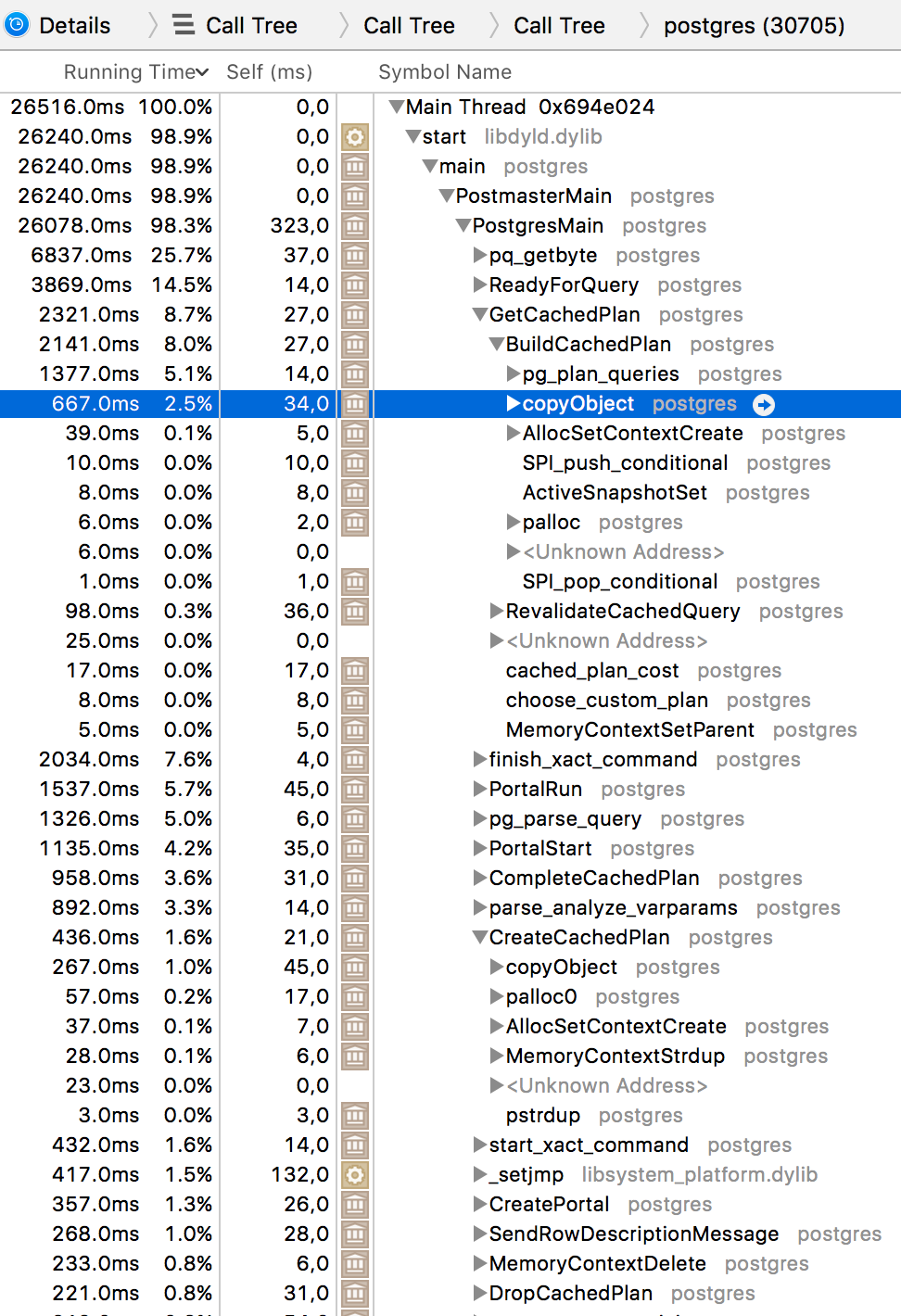
It looks strange to see copyObject calls from within BuildCachedPlan/CreateCachedPlan.
I would expect one-shot plan to be reused without copying, however exec_parse_message does not seem to bother setting is_oneshot=true flag on a CachedPlanSource.
It it a bug? It think exec_parse_message should set is_oneshot=true for parse message with empty statement names.

Here's the detailed list for the run:
postgres$ /opt/local/lib/postgresql95/bin/pgbench -M extended -f test.sql -j 1 -P 5 -T 120
starting vacuum...ERROR: relation "pgbench_branches" does not exist
(ignoring this error and continuing anyway)
ERROR: relation "pgbench_tellers" does not exist
(ignoring this error and continuing anyway)
ERROR: relation "pgbench_history" does not exist
(ignoring this error and continuing anyway)
end.
progress: 5.0 s, 30061.1 tps, lat 0.033 ms stddev 0.013
progress: 10.0 s, 31407.4 tps, lat 0.032 ms stddev 0.008
progress: 15.0 s, 31332.4 tps, lat 0.032 ms stddev 0.008
progress: 20.0 s, 31812.3 tps, lat 0.031 ms stddev 0.007
progress: 25.0 s, 31560.9 tps, lat 0.031 ms stddev 0.008
progress: 30.0 s, 31492.3 tps, lat 0.031 ms stddev 0.008
vvv profiler activated
progress: 35.0 s, 29972.2 tps, lat 0.033 ms stddev 0.011
progress: 40.0 s, 28965.8 tps, lat 0.034 ms stddev 0.010
progress: 45.0 s, 29127.0 tps, lat 0.034 ms stddev 0.011
progress: 50.0 s, 29464.0 tps, lat 0.034 ms stddev 0.008
progress: 55.0 s, 29072.2 tps, lat 0.034 ms stddev 0.011
progress: 60.0 s, 29405.2 tps, lat 0.034 ms stddev 0.008
^^^ profiler deactivated
progress: 65.0 s, 28848.0 tps, lat 0.034 ms stddev 0.013
progress: 70.0 s, 31175.8 tps, lat 0.032 ms stddev 0.010
progress: 75.0 s, 32042.8 tps, lat 0.031 ms stddev 0.007
progress: 80.0 s, 31277.8 tps, lat 0.032 ms stddev 0.008
progress: 85.0 s, 31373.3 tps, lat 0.032 ms stddev 0.009
progress: 90.0 s, 31171.0 tps, lat 0.032 ms stddev 0.008
Vladimir
Вложения
>It it a bug? It think exec_parse_message should set is_oneshot=true for parse message with empty statement names.
I've tried "build from git as of 74d8c95b7456faefdd4244acf854361711fb42ce", and it produced PostgreSQL 9.6beta3 on x86_64-apple-darwin15.5.0, compiled by Apple LLVM version 7.0.0 (clang-700.1.76), 64-bit
The attached patch passes `make check` and it gains 31221 -> 33547 improvement for "extended pgbench of SELECT 1".
The same version gains 35682 in "simple" mode, and "prepared" mode achieves 46367 (just in case).
Вложения
{kind=link}
On Mon, Aug 1, 2016 at 12:12 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
> The attached patch passes `make check` and it gains 31221 -> 33547 improvement for "extended pgbench of SELECT 1".
>
> The same version gains 35682 in "simple" mode, and "prepared" mode achieves 46367 (just in case).
That's great, thanks for looking into it! I hope your patch gets merged.
> Shay, why don't you use a profiler? Seriously.
> I'm afraid "iterate the per-message loop in PostgresMain five times not once" /"just discussing what may or may not be a problem..." is just hand-waving.
>
> Come on, it is not that hard.
I really don't get what's problematic with posting a message on a mailing list about a potential performance issue, to try to get people's reactions, without diving into profiling right away. I'm not a PostgreSQL developer, have other urgent things to do and don't even spend most of my programming time in C.
I really don't get what's problematic with posting a message on a mailing list about a potential performance issue, to try to get people's reactions, without diving into profiling right away
"Benchmark data is a perfect substitute for benchmarking results. Data is easy to misinterpret, so try not to do that." (see [1], and slide 73 of [2])
The key points are:
0) It is extremely easy to take a wrong way unless you analyze the benchmark results.
1) If you (or someone else) thinks that "ok, the original email did meet its goal, as Vladimir did provide a patch with measurements", then I failed.
The only reason for me doing the benchmark and patch was to teach you how to do that.
2) Have you seen recent discussion "TODO item: Implement Boyer-Moore searching in LIKE queries" on the list?
It does include relevant details right from the start.
I'm not a PostgreSQL developer
Neither am I.
I have other urgent things to do
So do I.
and don't even spend most of my programming time in C.
Java and SQL covers 99% of my time.
Vladimir
Doesn't this patch break an existing behavior of unnamed statements? That is, an unnamed statement shall exist until next parse message using unnamed statement received. It is possible to use the same unnamed statement multiple times in a transaction. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
On Sun, Jul 31, 2016 at 05:57:12PM -0400, Tom Lane wrote: > In hindsight it seems clear that what a lot of apps want out of extended > protocol is only the ability to send parameter values out-of-line instead > of having to quote/escape them into SQL literals. Maybe an idea for the > fabled V4 protocol update is some compromise query type that corresponds > precisely to PQexecParams's feature set: you can send parameter values > out-of-line, and you can specify text or binary results, but there's no > notion of any persistent state being created and no feedback about > parameter data types. Do you want this on the TODO list? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Bruce Momjian <bruce@momjian.us> writes:
> On Sun, Jul 31, 2016 at 05:57:12PM -0400, Tom Lane wrote:
>> In hindsight it seems clear that what a lot of apps want out of extended
>> protocol is only the ability to send parameter values out-of-line instead
>> of having to quote/escape them into SQL literals. Maybe an idea for the
>> fabled V4 protocol update is some compromise query type that corresponds
>> precisely to PQexecParams's feature set: you can send parameter values
>> out-of-line, and you can specify text or binary results, but there's no
>> notion of any persistent state being created and no feedback about
>> parameter data types.
> Do you want this on the TODO list?
I didn't hear anyone say it was a silly idea, so sure.
regards, tom lane
Tom Lane <tgl@sss.pgh.pa.us>:
Bruce Momjian <bruce@momjian.us> writes:
> On Sun, Jul 31, 2016 at 05:57:12PM -0400, Tom Lane wrote:
>> In hindsight it seems clear that what a lot of apps want out of extended
>> protocol is only the ability to send parameter values out-of-line instead
>> of having to quote/escape them into SQL literals. Maybe an idea for the
>> fabled V4 protocol update is some compromise query type that corresponds
>> precisely to PQexecParams's feature set: you can send parameter values
>> out-of-line, and you can specify text or binary results, but there's no
>> notion of any persistent state being created and no feedback about
>> parameter data types.
> Do you want this on the TODO list?
I didn't hear anyone say it was a silly idea, so sure.
Frankly speaking, it is not clear what this change buys.
Are you sure v3 cannot be tuned to reach comparable performance?
I do not like very much having a variety of "query modes".
For instance, when working with logical replication, extended queries are not supported over the wire, that complicates client.
This particular issue delays merge of logical repilcation support to the JDBC driver: https://github.com/pgjdbc/pgjdbc/pull/550#issuecomment-236418614
If adding one more "execute flavor" the things would get only worse, not better.
Reusing parse state does indeed improve the performance in real-life applications, so I would wonder if we can make current "extended" query faster rather than implementing yet another protocol.
So while the request itself would definitely make sense if we had no "v2/v3" protocols at all, however as we do have v2 and v3, it adding "PQexecParams's feature set" looks not that important.
Just in case, here are "protocol wanted features" as seen by client applications (e.g. JDBC client): https://github.com/pgjdbc/pgjdbc/blob/master/backend_protocol_v4_wanted_features.md
Vladimir
Tatsuo Ishii <ishii@postgresql.org>:
Doesn't this patch break an existing behavior of unnamed statements?
That is, an unnamed statement shall exist until next parse message
using unnamed statement received. It is possible to use the same
unnamed statement multiple times in a transaction.
>Doesn't this patch break an existing behavior of unnamed statements?
As it was expected, the behavior for unnamed statements is broken (some tests from make check-world fail with segmentation fault).
So some more sophisticated patch is required.
For those who are interested, I've created a Github-Travis mirror that automatically runs several regression suites for the given postgresql patch: https://github.com/vlsi/postgres
I think it will simplify running regression tests for postgresql patches against multiple suites.
Current tests include: make check, make check-world, and pgjdbc test suite (except XA and SSL).
For instance, here's the link to my patch https://github.com/vlsi/postgres/pull/1
Feel free to file PRs for travis branch of https://github.com/vlsi/postgres so the patch gets tested.
Vladimir
On Wed, Aug 3, 2016 at 10:02:39AM -0400, Tom Lane wrote: > Bruce Momjian <bruce@momjian.us> writes: > > On Sun, Jul 31, 2016 at 05:57:12PM -0400, Tom Lane wrote: > >> In hindsight it seems clear that what a lot of apps want out of extended > >> protocol is only the ability to send parameter values out-of-line instead > >> of having to quote/escape them into SQL literals. Maybe an idea for the > >> fabled V4 protocol update is some compromise query type that corresponds > >> precisely to PQexecParams's feature set: you can send parameter values > >> out-of-line, and you can specify text or binary results, but there's no > >> notion of any persistent state being created and no feedback about > >> parameter data types. > > > Do you want this on the TODO list? > > I didn't hear anyone say it was a silly idea, so sure. Done: Create a more efficient way to handle out-of-line parameters -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
On Wed, Aug 3, 2016 at 7:35 PM, Bruce Momjian <bruce@momjian.us> wrote: > On Wed, Aug 3, 2016 at 10:02:39AM -0400, Tom Lane wrote: >> Bruce Momjian <bruce@momjian.us> writes: >> > On Sun, Jul 31, 2016 at 05:57:12PM -0400, Tom Lane wrote: >> >> In hindsight it seems clear that what a lot of apps want out of extended >> >> protocol is only the ability to send parameter values out-of-line instead >> >> of having to quote/escape them into SQL literals. Maybe an idea for the >> >> fabled V4 protocol update is some compromise query type that corresponds >> >> precisely to PQexecParams's feature set: you can send parameter values >> >> out-of-line, and you can specify text or binary results, but there's no >> >> notion of any persistent state being created and no feedback about >> >> parameter data types. >> >> > Do you want this on the TODO list? >> >> I didn't hear anyone say it was a silly idea, so sure. > > Done: > > Create a more efficient way to handle out-of-line parameters FWIW, I agree with this idea. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 2, 2016 at 2:00 PM, Shay Rojansky <roji@roji.org> wrote: >> Shay, why don't you use a profiler? Seriously. >> I'm afraid "iterate the per-message loop in PostgresMain five times not >> once" /"just discussing what may or may not be a problem..." is just >> hand-waving. >> >> Come on, it is not that hard. > > I really don't get what's problematic with posting a message on a mailing > list about a potential performance issue, to try to get people's reactions, > without diving into profiling right away. I'm not a PostgreSQL developer, > have other urgent things to do and don't even spend most of my programming > time in C. There's absolutely nothing wrong with that. I find your questions helpful and interesting and I hope you will keep asking them. I think that they are a valuable contribution to the discussion on this list. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
> I really don't get what's problematic with posting a message on a mailing
> list about a potential performance issue, to try to get people's reactions,
> without diving into profiling right away. I'm not a PostgreSQL developer,
> have other urgent things to do and don't even spend most of my programming
> time in C.
There's absolutely nothing wrong with that. I find your questions
helpful and interesting and I hope you will keep asking them. I think
that they are a valuable contribution to the discussion on this list.
Thanks for the positive feedback Robert.
I'm glad reducing the overhead of out-of-line parameters seems like an important goal. FWIW, if as Vladimir seems to suggest, it's possible to bring down the overhead of the v3 extended protocol to somewhere near the simple protocol, that would obviously be a better solution - it would mean things work faster here and now, rather than waiting for the v4 protocol. I have no idea if that's possible though, I'll see if I can spend some time on understand where the slowdown comes from.
On Fri, Aug 5, 2016 at 8:07 PM, Shay Rojansky <roji@roji.org> wrote: >> > I really don't get what's problematic with posting a message on a >> > mailing >> > list about a potential performance issue, to try to get people's >> > reactions, >> > without diving into profiling right away. I'm not a PostgreSQL >> > developer, >> > have other urgent things to do and don't even spend most of my >> > programming >> > time in C. >> >> There's absolutely nothing wrong with that. I find your questions >> helpful and interesting and I hope you will keep asking them. I think >> that they are a valuable contribution to the discussion on this list. > > Thanks for the positive feedback Robert. > > I'm glad reducing the overhead of out-of-line parameters seems like an > important goal. FWIW, if as Vladimir seems to suggest, it's possible to > bring down the overhead of the v3 extended protocol to somewhere near the > simple protocol, that would obviously be a better solution - it would mean > things work faster here and now, rather than waiting for the v4 protocol. I > have no idea if that's possible though, I'll see if I can spend some time on > understand where the slowdown comes from. I think that's a fine thing to work on, but I don't hold out a lot of hope. If we ask the question "can you reduce the overhead vs. the status quo?" I will wager that the answer is "yes". But if you ask the question "can you make it as efficient as we could be given a protocol change?" I will wager that the answer is "no". That having been said, I don't really see a reason why we couldn't introduce a new protocol message for this without bumping the protocol version. Clients who don't know about the new message type just won't use it; nothing breaks. Clients who do know about the new message need to be careful not to send it to older servers, but since the server reports its version to the client before the first opportunity to send queries, that shouldn't be too hard. We could add a new interface to libpq that uses the new protocol message on new servers and falls back to the existing extended protocol on older servers. In general, it seems to me that we only need to bump the protocol version if there will be server-initiated communication that is incompatible with existing clients. Anything that the client can choose to initiate (or not) based on the server version should be OK. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Aug 7, 2016 at 6:11 PM, Robert Haas <robertmhaas@gmail.com> wrote:
That having been said, I don't really see a reason why we couldn't> I'm glad reducing the overhead of out-of-line parameters seems like an
> important goal. FWIW, if as Vladimir seems to suggest, it's possible to
> bring down the overhead of the v3 extended protocol to somewhere near the
> simple protocol, that would obviously be a better solution - it would mean
> things work faster here and now, rather than waiting for the v4 protocol. I
> have no idea if that's possible though, I'll see if I can spend some time on
> understand where the slowdown comes from.
introduce a new protocol message for this without bumping the protocol
version. Clients who don't know about the new message type just won't
use it; nothing breaks. Clients who do know about the new message
need to be careful not to send it to older servers, but since the
server reports its version to the client before the first opportunity
to send queries, that shouldn't be too hard. We could add a new
interface to libpq that uses the new protocol message on new servers
and falls back to the existing extended protocol on older servers. In
general, it seems to me that we only need to bump the protocol version
if there will be server-initiated communication that is incompatible
with existing clients. Anything that the client can choose to
initiate (or not) based on the server version should be OK.
That sounds right to me. As you say, the server version is sent early in the startup phase, before any queries are sent to the backend, so frontends know which server they're communicating with.
We could call this "protocol 3.1" since it doesn't break backwards compatibility (no incompatible server-initiated message changes, but it does include a feature that won't be supported by servers which only support 3.0. This could be a sort of "semantic versioning" for the protocol - optional new client-initiated features are a minor version bump, others are a major version bump...
This new client-initiated message would be similar to query, except that it would include the parameter and result-related fields from Bind. The responses would be identical to the responses for the Query message.
Does this make sense?
On Sun, Aug 7, 2016 at 7:46 PM, Shay Rojansky <roji@roji.org> wrote: > We could call this "protocol 3.1" since it doesn't break backwards > compatibility (no incompatible server-initiated message changes, but it does > include a feature that won't be supported by servers which only support 3.0. > This could be a sort of "semantic versioning" for the protocol - optional > new client-initiated features are a minor version bump, others are a major > version bump... I wouldn't try to do that; we've done nothing similar in past instances where we've added new protocol or sub-protocol messages, which has happened at least for COPY BOTH mode within recent memory. See d3d414696f39e2b57072fab3dd4fa11e465be4ed. > This new client-initiated message would be similar to query, except that it > would include the parameter and result-related fields from Bind. The > responses would be identical to the responses for the Query message. > > Does this make sense? I think so. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Shay Rojansky <roji@roji.org>:
That sounds right to me. As you say, the server version is sent early in the startup phase, before any queries are sent to the backend, so frontends know which server they're communicating with.We could call this "protocol 3.1" since it doesn't break backwards compatibility (no incompatible server-initiated message changes, but it does include a feature that won't be supported by servers which only support 3.0. This could be a sort of "semantic versioning" for the protocol - optional new client-initiated features are a minor version bump, others are a major version bump...
Adding a new message is not backward compatible since it will fail in pgbouncer kind of deployments.
Suppose there's "new backend", "old pgbouncer", "new client" deployment.
If the client tries to send the new message, it will fail since pgbouncer would have no idea what to do with that new message.
On the other hand, usage of some well-defined statement name to trigger the special case would be fine: all pgbouncer versions would pass those parse/bind/exec message as if it were regular messages.
Vladimir
We could call this "protocol 3.1" since it doesn't break backwards compatibility (no incompatible server-initiated message changes, but it does include a feature that won't be supported by servers which only support 3.0. This could be a sort of "semantic versioning" for the protocol - optional new client-initiated features are a minor version bump, others are a major version bump...Adding a new message is not backward compatible since it will fail in pgbouncer kind of deployments.Suppose there's "new backend", "old pgbouncer", "new client" deployment.If the client tries to send the new message, it will fail since pgbouncer would have no idea what to do with that new message.
That's definitely a valid point. But do you think it's a strong enough argument to avoid ever adding new messages?
On the other hand, usage of some well-defined statement name to trigger the special case would be fine: all pgbouncer versions would pass those parse/bind/exec message as if it were regular messages.
Can you elaborate on what that means exactly? Are you proposing to somehow piggyback on an existing message (e.g. Parse) but use some special statement name that would make PostgreSQL interpret it as a different message type? Apart from being a pretty horrible hack, it would still break pgbouncer, which has to actually inspect and understand SQL being sent to the database (e.g. to know when transactions start and stop).
Shay Rojansky <roji@roji.org>:
That's definitely a valid point. But do you think it's a strong enough argument to avoid ever adding new messages?
The point is "adding a message to current v3 protocol is not a backward compatible change".
The problem with adding new message types is not only "client support", but deployment issues as well: new message would require simultaneous upgrade of both backend, client, and pgbouncer.
It could make sense to add some kind of transparent extensibility to the protocol, so clients can just ignore unknown message types.
For instance, consider a new message "ExtensibleMessage" is added: '#', int16 (message id), int32 (message length), contents.
For the pgbouncer case above, pgbouncer could just proxy "unknown requests" as is and it would cover many of the cases out of the box.
That message has a well-defined message length, so it is easy to skip.
If new "messages" required, a new message_id can be allocated and assigned to the new message type. Old clients would be able to skip the message as they know its length.
Of course, adding that '#' message does require support from pgbouncer, etc, etc, however I'm sure it would simplify protocol evolution in the future.
Of course there might appear a need for a message that cannot be ignored by the client, but I think "even a bit of flexibility" is better than no flexibility at all.
Technically speaking, there's a "NotificationResponse" message, however it is not that good since it cannot have 0 bytes in the contents.
Shay Rojansky <roji@roji.org>:
On the other hand, usage of some well-defined statement name to trigger the special case would be fine: all pgbouncer versions would pass those parse/bind/exec message as if it were regular messages.Can you elaborate on what that means exactly? Are you proposing to somehow piggyback on an existing message (e.g. Parse) but use some special statement name that would make PostgreSQL interpret it as a different message type?
Exactly.
For instance: if client sends Parse(statementName=I_swear_the_statement_will_be_used_only_once), then the subsequent message must be BindMessage, and the subsequent must be ExecMessage for exactly the same statement id.
Then backend could recognize the pattern and perform the optimization.
Note: it is quite easy to invent a name that is not yet used in the wild, so it is safe.
From security point of view (e.g. if a client would want to exploit use-after-free kind of issues), backend could detect deviations from this parse-bind-exec sequence and just drop the mic off.
Shay Rojansky <roji@roji.org>:
Apart from being a pretty horrible hack,
I would not call it a horrible hack. That is just a clever use of existing bits, and it does not break neither backward nor forward compatibility.
Backward compatibility: new clients would be compatible with old PG versions (even 8.4).
Forward compatibility: even if the support of that special statement name would get dropped for some reason, there will be no application issues (it would just result in a slight performance degradation).
Shay Rojansky <roji@roji.org>:
it would still break pgbouncer, which has to actually inspect and understand SQL being sent to the database (e.g. to know when transactions start and stop).
Note: I do not suggest to change message formats. The message itself is just fine and existing pgbouncer versions can inspect the SQL. The difference is a special statementName, and I see no reasons for that kind of change to break pgbouncer.
Vladimir
Vladimir Sitnikov <sitnikov.vladimir@gmail.com> writes:
> The point is "adding a message to current v3 protocol is not a backward
> compatible change".
> The problem with adding new message types is not only "client support", but
> deployment issues as well: new message would require simultaneous upgrade
> of both backend, client, and pgbouncer.
Right ...
> It could make sense to add some kind of transparent extensibility to the
> protocol, so clients can just ignore unknown message types.
I'm not really sure what use that particular behavior would be. We
certainly want to try to have some incremental extensibility in there
when we do v4, but I think it would more likely take the form of a way
for client and server to agree on which extensions they support.
> On the other hand, usage of some well-defined statement name to trigger
> the special case would be fine: all pgbouncer versions would pass those
> parse/bind/exec message as if it were regular messages.
I do not accept this idea that retroactively defining special semantics
for certain statement names is not a protocol break. If it causes any
change in what the server's response would be, then it is a protocol
break.
> Note: it is quite easy to invent a name that is not yet used in the wild,
> so it is safe.
Sir, that is utter nonsense. And even if it were true, why is it that
this way would safely pass through existing releases of pgbouncer when
other ways would not? Either pgbouncer needs to understand what it's
passing through, or it doesn't.
regards, tom lane
Vladimir wrote:
On the other hand, usage of some well-defined statement name to trigger the special case would be fine: all pgbouncer versions would pass those parse/bind/exec message as if it were regular messages.Can you elaborate on what that means exactly? Are you proposing to somehow piggyback on an existing message (e.g. Parse) but use some special statement name that would make PostgreSQL interpret it as a different message type?Exactly.For instance: if client sends Parse(statementName=I_swear_the_statement_will_be_used_ only_once), then the subsequent message must be BindMessage, and the subsequent must be ExecMessage for exactly the same statement id.
Ah, I understand the proposal better now - you're not proposing encoding a new message type in an old one, but rather a magic statement name in Parse which triggers an optimized processing path in PostgreSQL, that wouldn't go through the query cache etc.
If so, isn't that what the empty statement is already supposed to do? I know there's already some optimizations in place around the scenario of empty statement name (and empty portal).
Also, part of the point here is to reduce the number of protocol messages needed in order to send a parameterized query - not to have to do Parse/Describe/Bind/Execute/Sync - since part of the slowdown comes from that (although I'm not sure how much). Your proposal keeps the 5 messages.
Again, if it's possible to make "Parse/Describe/Bind/Execute/Sync" perform close to Query, e.g. when specifying empty statement/portal, that's obviously the best thing here. But people seem to be suggesting that a significant part of the overhead comes from the fact that there are 5 messages, meaning there's no way to optimize this without a new message type.
Note: it is quite easy to invent a name that is not yet used in the wild, so it is safe.
That's problematic, how do you know what's being used in the wild and what isn't? The protocol has a specification, it's very problematic to get up one day and to change it retroactively. But again, the empty statement seems to already be there for that.
Shay Rojansky <roji@roji.org> writes:
> Ah, I understand the proposal better now - you're not proposing encoding a
> new message type in an old one, but rather a magic statement name in Parse
> which triggers an optimized processing path in PostgreSQL, that wouldn't go
> through the query cache etc.
> If so, isn't that what the empty statement is already supposed to do? I
> know there's already some optimizations in place around the scenario of
> empty statement name (and empty portal).
Right, but the problem is that per the current protocol spec, those
optimizations are not allowed to change any protocol-visible behavior.
We might be able to do a bit more optimization than we're doing now, but
we still have to be able to cache the statement in case it's executed more
than once, we still have to do planning in response to a separate 'bind'
message, etc. AFAICT most of the added overhead comes from having to
allow for the possibility of re-execution: that forces at least one extra
copy of the parse tree to be made, as well as adding manipulations of the
plan cache. We can't get out from under that without a protocol change.
> Again, if it's possible to make "Parse/Describe/Bind/Execute/Sync" perform
> close to Query, e.g. when specifying empty statement/portal, that's
> obviously the best thing here. But people seem to be suggesting that a
> significant part of the overhead comes from the fact that there are 5
> messages, meaning there's no way to optimize this without a new message
> type.
The rather crude measurements I've done put most of the blame on the
cacheing part, although the number of messages might matter more on
platforms with slow process-title-update support (I'm looking at you,
Windows).
regards, tom lane
Shay Rojansky <roji@roji.org>:
Ah, I understand the proposal better now - you're not proposing encoding a new message type in an old one, but rather a magic statement name in Parse which triggers an optimized processing path in PostgreSQL, that wouldn't go through the query cache etc.
Exactly.
If so, isn't that what the empty statement is already supposed to do? I know there's already some optimizations in place around the scenario of empty statement name (and empty portal).
The problem with "empty statement name" is statements with empty name can be reused (for instance, for batch insert executions), so the server side has to do a defensive copy (it cannot predict how many times this unnamed statement will be used).
Also, part of the point here is to reduce the number of protocol messages needed in order to send a parameterized query - not to have to do Parse/Describe/Bind/Execute/Sync - since part of the slowdown comes from that (although I'm not sure how much). Your proposal keeps the 5 messages.
As my benchmarks show, notable overhead is due to "defensive copying of the execution plan". So I would measure first, and only then would claim where the overhead is.
Some more profiling is required to tell which part is a main time consumer.
Technically speaking, I would prefer to have a more real-life looking example instead of SELECT 1.
Do you have something in mind?
For instance, for more complex queries, "Parse/Plan" could cost much more than we shave by adding "a special non-cached statement name" or by reducing "5 messages into 1".
There's a side problem: describe message requires full roundtrip since there are cases when client needs to know how to encode parameters. Additional roundtrip hurts much worse than just an additional message that is pipelined (e.g. sent in the same TCP packet).
But people seem to be suggesting that a significant part of the overhead comes from the fact that there are 5 messages, meaning there's no way to optimize this without a new message type.
Of course 5 messages are slower than 1 message.
However, that does not mean "there's no way to optimize without a new message type".
Profiling can easily reveal time consumer parts, then we can decide if there's a solution.
Note: if we improve "SELECT 1" by 10%, it does not mean we improved statement execution by 10%. Real-life statements matter for proper profiling/discussion.
Shay Rojansky <roji@roji.org>:
Note: it is quite easy to invent a name that is not yet used in the wild, so it is safe.That's problematic, how do you know what's being used in the wild and what isn't? The protocol has a specification, it's very problematic to get up one day and to change it retroactively. But again, the empty statement seems to already be there for that.
Empty statement has different semantics, and it is wildly used.
For instance, pgjdbc uses unnamed statements a lot.
On the other hand, statement name of "!pq@#!@#42" is rather safe to use as a special case.
Note: statement names are not typically created by humans (statement name is not a SQL), and very little PG clients do support named statements.
Vladimir
I'm sorry, we are discussing technical details with no real-life use case to cover that.
I do not want to suck time for no reason. Please accept my sincere apologies for not asking the real-life case earlier.
Shay, can you come up with a real-life use case when those "I claim the statement will be used only once" is would indeed improve performance?
Or, to put it in another way: "do you have a real-life case when simple protocol is faster than extended protocol with statement reuse"?
I do have a couple of java applications and it turns out there's a huge win of reusing server-prepared statements.
There's a problem that "generic plan after 5th execution might be much worse than a specific one", however those statements are not often and I just put hints to the SQL (limit 0, +0, CTE, those kind of things).
Tom Lane <tgl@sss.pgh.pa.us>:
I do not accept this idea that retroactively defining special semantics
for certain statement names is not a protocol break.
Sir, any new SQL keyword is what you call a "retroactively defining special semantics".
It's obvious that very little current clients do use named server-prepared statements.
Statement names are not something that is provided by the end-user in a web page, so it is not a rocket science to come up with a statement name that is both short and "never ever used in the wild".
Tom Lane <tgl@sss.pgh.pa.us>:
If it causes any
change in what the server's response would be, then it is a protocol
break.
I see no changes except "backend would report a protocol violation for the case when special statement is used and message sequence is wrong".
> Note: it is quite easy to invent a name that is not yet used in the wild,
> so it is safe.
Sir, that is utter nonsense.
Tom Lane <tgl@sss.pgh.pa.us>:
And even if it were true, why is it that
this way would safely pass through existing releases of pgbouncer when
other ways would not? Either pgbouncer needs to understand what it's
passing through, or it doesn't.
Once again: exiting pgbouncer versions know how to parse Parse/Bind/Exec/Deallocate messages, so if we bless some well-defined statement name with a semantics that "it is forbidden to reuse that name for multiple executions in a row", then that is completely transparent for pgbouncer. Pgbouncer would just think that "the application is dumb since it reparses the same statement again and againt", but it would work just fine.
On contrary, if a new statement name is added, then pgbouncer would fail to understand the new message.
Vladimir
>> On the other hand, usage of some well-defined statement name to trigger >> the special case would be fine: all pgbouncer versions would pass those >> parse/bind/exec message as if it were regular messages. > > I do not accept this idea that retroactively defining special semantics > for certain statement names is not a protocol break. If it causes any > change in what the server's response would be, then it is a protocol > break. +1. It definitely is a protocol break. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
On Mon, Aug 8, 2016 at 6:44 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
The problem with "empty statement name" is statements with empty name can be reused (for instance, for batch insert executions), so the server side has to do a defensive copy (it cannot predict how many times this unnamed statement will be used).
That seems right.
Also, part of the point here is to reduce the number of protocol messages needed in order to send a parameterized query - not to have to do Parse/Describe/Bind/Execute/Sync - since part of the slowdown comes from that (although I'm not sure how much). Your proposal keeps the 5 messages. As my benchmarks show, notable overhead is due to "defensive copying of the execution plan". So I would measure first, and only then would claim where the overhead is.
Some more profiling is required to tell which part is a main time consumer.
Tom also pointed to the caching as the main culprit, although there seems to be some message-related overhead as well. It seems that things like process title changes may be fixable easily - do we really need a process title change on every message (as opposed to, say, execute messages only). This profiling and optimization effort can happen in parallel to the discussion on what to do with the execution plan caching.
Technically speaking, I would prefer to have a more real-life looking example instead of SELECT 1.Do you have something in mind?For instance, for more complex queries, "Parse/Plan" could cost much more than we shave by adding "a special non-cached statement name" or by reducing "5 messages into 1".There's a side problem: describe message requires full roundtrip since there are cases when client needs to know how to encode parameters. Additional roundtrip hurts much worse than just an additional message that is pipelined (e.g. sent in the same TCP packet).
This is true, but there doesn't seem to be anything we can do about it - if your usage relies on describe to get information on parameters (as opposed to results), you're stuck with an extra roundtrip no matter what. So it seems you have to use the extended protocol anyway.
FYI in Npgsql specifically describe isn't used to get any knowledge about parameters - users must populate the correct parameters or query execution fails.
Note: it is quite easy to invent a name that is not yet used in the wild, so it is safe.That's problematic, how do you know what's being used in the wild and what isn't? The protocol has a specification, it's very problematic to get up one day and to change it retroactively. But again, the empty statement seems to already be there for that.Empty statement has different semantics, and it is wildly used.For instance, pgjdbc uses unnamed statements a lot.On the other hand, statement name of "!pq@#!@#42" is rather safe to use as a special case.Note: statement names are not typically created by humans (statement name is not a SQL), and very little PG clients do support named statements.
IMHO this simply isn't the kind of thing one does in a serious protocol of a widely-used product, others seem to agree on this.
> Sir, any new SQL keyword is what you call a "retroactively defining special semantics".
> It's obvious that very little current clients do use named server-prepared statements.
> Statement names are not something that is provided by the end-user in a web page, so it is not a rocket science to come up with a
> statement name that is both short and "never ever used in the wild".
The difference is that before the new SQL keyword is added, trying to use it results in an error. What you're proposing is taking something that already works in one way and changing its behavior.
> Shay, can you come up with a real-life use case when those "I claim the statement will be used only once" is would indeed improve performance?
> Or, to put it in another way: "do you have a real-life case when simple protocol is faster than extended protocol with statement reuse"?
> I do have a couple of java applications and it turns out there's a huge win of reusing server-prepared statements.
> There's a problem that "generic plan after 5th execution might be much worse than a specific one", however those statements are not often
> and I just put hints to the SQL (limit 0, +0, CTE, those kind of things).
I maintain Npgsql, which is a general-purpose database driver and not a specific application. The general .NET database API (ADO.NET), like most (all?) DB APIs, allows users to send a simple statement to the database (ExecuteReader, ExecuteScalar, ExecuteNonQuery). Every time a user uses these APIs without preparing, they pay a performance penalty because the extended protocol has more overhead than the simple one.
Obviously smart use of prepared statements is a great idea, but it doesn't work everywhere. There are many scenarios where connections are very short-lived (think about webapps where a pooled connection is allocated per-request and reset in between), and the extra roundtrip that preparing entails is too much. There are also many scenarios where you're not necessarily going to send the same query multiple times in a single connection lifespan, so preparing is again out of the question. And more generally, there's no reason for a basic, non-prepared execution to be slower than it can be.
Of course we can choose a different query to benchmark instead of SELECT 1 - feel free to propose one (or several).
FWIW I do agree at this stage we should probably benchmark a bit more and see where we can get by optimizing the extended protocol itself (which is a good idea regardless). If it becomes clear that it's impossible to reach performance that's similar to the simple query, we can look into adding a new protocol message (as I think the special-statement-name solution has generally been rejected). I'm not sure I'll have the time to go into this in the very near future (and it would be my first time really diving into PostgreSQL internals) but if nobody else wants to I'll try.
Shay>There are many scenarios where connections are very short-lived (think about webapps where a pooled connection is allocated per-request and reset in between)
Why the connection is reset in between in the first place?
In pgjdbc we do not reset per-connection statement cache, thus we easily reuse named statements for pooled connections.
Shay>and the extra roundtrip that preparing entails is too much.
When server-prepared statement gets reused, neither parse neither describe are used.
Shay>There are also many scenarios where you're not necessarily going to send the same query multiple times in a single connection lifespan, so preparing is again out of the question.
Can you list at least one scenario of that kind, so we can code it into pgbench (or alike) and validate "simple vs prepared" performance?
Shay>And more generally, there's no reason for a basic, non-prepared execution to be slower than it can be.
That's too generic. If the performance for "end-to-end cases" is just fine, then it is not worth optimizing further. Typical application best practice is to reuse SQL text (for both security and performance point of views), so in typical applications I've seen, query text was reused, thus it naturally was handled by server-prepared logic.
Let me highlight another direction: current execution of server-prepared statement requires some copying of "parse tree" (or whatever). I bet it would be much better investing in removal of that copying rather than investing into "make one-time queries faster" thing. If we could make "Exec" processing faster, it would immediately improve tons of applications.
Shay>Of course we can choose a different query to benchmark instead of SELECT 1 - feel free to propose one (or several).
I've tried pgbench -M prepared, and it is way faster than pgbench -M simple.
Once again: all cases I have in mind would benefit from reusing server-prepared statements. In other words, after some warmup the appication would use just Bind-Execute-Sync kind of messages, and it would completely avoid Parse/Describe ones.
If a statement is indeed "one-time" statement, then I do not care much how long it would take to execute.
Shay>FYI in Npgsql specifically describe isn't used to get any knowledge about parameters - users must populate the correct parameters or query execution fails.
I think the main reason to describe for pgjdbc is to get result oids. pgjdbc is not "full binary", thus it has to be careful which fields it requests in binary format.
That indeed slows down "unknown queries", but as the query gets reused, pgjdbc switches to server-prepared execution, and eliminates parse-describe overheads completely.
Vladimir
On Tue, Aug 9, 2016 at 8:50 AM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Shay>There are many scenarios where connections are very short-lived (think about webapps where a pooled connection is allocated per-request and reset in between)Why the connection is reset in between in the first place?In pgjdbc we do not reset per-connection statement cache, thus we easily reuse named statements for pooled connections.
A DISCARD ALL is sent when the connection is returned to the pool, the prevent state leakage etc. You make a valid comment though - there's already a new feature in the Npgsql dev branch which allows prepared statements to be persisted across open/close on pooled connections, it's interesting to learn that it is standard behavior in pgjdbc. At least up to now, the logic was not to implcitly keep holding server-side resources across a pooled connection close, because these may become a drain on the server etc.
More important, unless I'm mistaken pgbouncer also sends DISCARD ALL to clean the connection state, as will other pooling solutions. That unfortunately means that you can't always depend on prepared statements to persist after closing the connection.
Shay>There are also many scenarios where you're not necessarily going to send the same query multiple times in a single connection lifespan, so preparing is again out of the question.
Can you list at least one scenario of that kind, so we can code it into pgbench (or alike) and validate "simple vs prepared" performance?
Again, in a world where prepared statements aren't persisted across connections (e.g. pgbouncer), this scenario is extremely common. Any scenario where you open a relatively short-lived connection and execute something once is problematic - imagine a simple web service which needs to insert a single record into a table.
Shay>And more generally, there's no reason for a basic, non-prepared execution to be slower than it can be.That's too generic. If the performance for "end-to-end cases" is just fine, then it is not worth optimizing further. Typical application best practice is to reuse SQL text (for both security and performance point of views), so in typical applications I've seen, query text was reused, thus it naturally was handled by server-prepared logic.
I don't see how reusing SQL text affects security in any way.
But here's the more important general point. We're driver developers, not application developers. I don't really know what performance is "just fine" for each of my users, and what is not worth optimizing further. Users may follow best practices, or they may not for various reasons. They may be porting code over from SqlServer, where prepare is almost never used (because SqlServer caches plans implicitly), or they may simply not be very good programmers. The API for executing non-prepared statements is there, we support it and PostgreSQL supports it - it just happens to not be very fast. Of course we can say "screw everyone not preparing statements", but that doesn't seem like a very good way to treat users. Especially since the fix isn't that hard.
Let me highlight another direction: current execution of server-prepared statement requires some copying of "parse tree" (or whatever). I bet it would be much better investing in removal of that copying rather than investing into "make one-time queries faster" thing. If we could make "Exec" processing faster, it would immediately improve tons of applications.
I don't understand what exactly you're proposing here, but if you have some unrelated optimization that would speed up prepared statements, by all means that's great. It's just unrelated to this thread.
Shay>Of course we can choose a different query to benchmark instead of SELECT 1 - feel free to propose one (or several).I've tried pgbench -M prepared, and it is way faster than pgbench -M simple.Once again: all cases I have in mind would benefit from reusing server-prepared statements. In other words, after some warmup the appication would use just Bind-Execute-Sync kind of messages, and it would completely avoid Parse/Describe ones.
Of course that's the ideal scenario. It's just not the *only* scenario for all users - they may either not have prepared statements persisting across open/close as detailed above, or their code may simply not be preparing statements at the moment. Why not help them out for free?
Shay>FYI in Npgsql specifically describe isn't used to get any knowledge about parameters - users must populate the correct parameters or query execution fails.I think the main reason to describe for pgjdbc is to get result oids. pgjdbc is not "full binary", thus it has to be careful which fields it requests in binary format.That indeed slows down "unknown queries", but as the query gets reused, pgjdbc switches to server-prepared execution, and eliminates parse-describe overheads completely.
Npgsql has a very different architecture. It does not attempt to decide on its own when to prepare statements and when not to - it's a very simple driver that does exactly what the user requests. If the user requests that a statement is prepared, it's prepared, otherwise it's not prepared.
FYI, if it's *result* OIDs you're concerned with, the Npgsql solution is to always request binary results, unless the user explicitly requests certain fields in text (via a special API). This means Npgsql never breaks the query into two roundtrips - Parse/Bind/Describe/Execute/Sync are always sent in a single roundtrip.
Shay>But here's the more important general point. We're driver developers, not application developers. I don't really know what performance is "just fine" for each of my users, and what is not worth optimizing further. Users may follow best practices, or they may not for various reasons.
Of course we cannot benchmark all the existing applications, however we should at lest try to use "close to production" benchmarks.
Let me recap: even "select 1" shows clear advantage of reusing server-prepared statements.
My machine shows the following results for "select 1 pgbench":
simple: 38K ops/sec (~26us/op)
extended: 32K ops/sec (~31us/op)
prepared: 47K ops/sec (~21us/op)
Note: reusing server-prepared statements shaves 10us (out of 31us), while "brand new ParseBindExecDeallocate" message would not able to perform better than 26us/op (that is 5 us worse than the prepared one). So it makes much more sense investing time in "server-prepared statement reuse" at the client side and "improving Bind/Exec performance" at the backend side.
For more complex queries the gap (prepared vs simple) would be much bigger since parse/validate/plan for a complex query is much harder operation than the one for "select 1"
Note: I do not mean "look, prepared always win". I mean: "if your environment does not allow reuse of prepared statements for some reason, you lose huge amount of time on re-parsing the queries, and it is worth fixing that obvious issue first".
Reusing SQL text makes application more secure as "build SQL on the fly" is prone to SQL injection security issues.
So reusing SQL text makes application more secure and it enables server-prepared statements that improve performance considerably. It is a win-win.
Shay>a new feature in the Npgsql dev branch which allows prepared statements to be persisted across open/close on pooled connections
Do you have some benchmark results for "reusing server-prepared statements across open/close on pooled"? I would expect that feature to be a great win.
Once again, I'd like to focus on real-life cases, not artificial ones.
For example, the major part of my performance fixes to pgjdbc were made as a part of improving my java application that was suffering from performance issues when talking to PostgreSQL.
For instance, there were queries that took 20ms to plan and 0.2ms to execute (the query is like where id=? but the SQL text was more involved).
As transparent server-side statement was implemented at pgjdbc side, it shaved those 20ms by eliminating Parse messages on the hot path.
In other words, it was not just "lets optimize pgjdbc". It was driven by the need to optimize the client application, and the profiling results were pointing to pgjdbc issues.
Shay>Again, in a world where prepared statements aren't persisted across connections (e.g. pgbouncer)
pgbouncer does not properly support named statements, and that is pbgouncer's issue.
Here's the issue for pgbouncer project: https://github.com/pgbouncer/pgbouncer/issues/126#issuecomment-200900171
The response from pgbouncer team is "all the protocol bits are there, it is just implementation from pgbouncer that is missing".
By the way: I do not use pgbouncer, thus there's no much interest for me to invest time in fixing pgbouncer's issues.
Shay>Any scenario where you open a relatively short-lived connection and execute something once is problematic - imagine a simple web service which needs to insert a single record into a table.
I would assume the application does not use random string for a table name (and columns/aliases), thus it would result in typical SQL text reuse, thus it should trigger "server-side statement prepare" logic. In other way, that kind of application does not need the "new ParseBindExecDeallocate message we are talking about".
In other words, if an application is using "select name from objects where id=$1" kind of queries, the driver should be using extended protocol (Bind/Exec) behind the scenes if it does aim to get high performance.
Vladimir
On Tue, Aug 9, 2016 at 3:42 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Shay>But here's the more important general point. We're driver developers, not application developers. I don't really know what performance is "just fine" for each of my users, and what is not worth optimizing further. Users may follow best practices, or they may not for various reasons.Of course we cannot benchmark all the existing applications, however we should at lest try to use "close to production" benchmarks.Let me recap: even "select 1" shows clear advantage of reusing server-prepared statements.My machine shows the following results for "select 1 pgbench":simple: 38K ops/sec (~26us/op)extended: 32K ops/sec (~31us/op)prepared: 47K ops/sec (~21us/op)Note: reusing server-prepared statements shaves 10us (out of 31us), while "brand new ParseBindExecDeallocate" message would not able to perform better than 26us/op (that is 5 us worse than the prepared one). So it makes much more sense investing time in "server-prepared statement reuse" at the client side and "improving Bind/Exec performance" at the backend side.For more complex queries the gap (prepared vs simple) would be much bigger since parse/validate/plan for a complex query is much harder operation than the one for "select 1"
You seem to be misunderstanding the fundamental point here. Nobody is saying that prepared statements aren't a huge performance booster - they are. I recommend them to anyone who asks. But you're saying "let's not optimize anything else", whereas there are many programs out there *not* using prepared statements for various reasons (e.g. pgbouncer, or simply an existing codebase). If your opinion is that nothing should be done for these users, fine - nobody's forcing you to do anything. I simply don't see why *not* optimize the very widely-used single-statement execution path.
Note: I do not mean "look, prepared always win". I mean: "if your environment does not allow reuse of prepared statements for some reason, you lose huge amount of time on re-parsing the queries, and it is worth fixing that obvious issue first".
Maybe it's worth fixing it, maybe not - that's going to depend on the application. Some applications may be huge/legacy and hard to change, others may depend on something like pgbouncer which doesn't allow it. Other drivers out there probably don't persist prepared statements across close/open, making prepared statements useless for short-lived scenarios. Does the Python driver persist prepared statements? Does the Go driver do so? If not the single-execution flow is very relevant for optimization.
Shay>I don't see how reusing SQL text affects security in any way.Reusing SQL text makes application more secure as "build SQL on the fly" is prone to SQL injection security issues.So reusing SQL text makes application more secure and it enables server-prepared statements that improve performance considerably. It is a win-win.
We've all understood that server-prepared statements are good for performance. But they aren't more or less vulnerable to SQL injection - developers can just as well concatenate user-provided strings into a prepared SQL text.
[deleting more comments trying to convince that prepared statements are great for performance, which they are]
Shay>Again, in a world where prepared statements aren't persisted across connections (e.g. pgbouncer)pgbouncer does not properly support named statements, and that is pbgouncer's issue.Here's the issue for pgbouncer project: https://github.com/pgbouncer/pgbouncer/issues/ 126#issuecomment-200900171 The response from pgbouncer team is "all the protocol bits are there, it is just implementation from pgbouncer that is missing".By the way: I do not use pgbouncer, thus there's no much interest for me to invest time in fixing pgbouncer's issues.
Um, OK... So you're not at all bothered by the fact that the (probably) most popular PostgreSQL connection pool is incompatible with your argument? I'm trying to think about actual users and the actual software they use, so pgbouncer is very relevant.
Shay>Any scenario where you open a relatively short-lived connection and execute something once is problematic - imagine a simple web service which needs to insert a single record into a table.I would assume the application does not use random string for a table name (and columns/aliases), thus it would result in typical SQL text reuse, thus it should trigger "server-side statement prepare" logic. In other way, that kind of application does not need the "new ParseBindExecDeallocate message we are talking about".
I wouldn't assume anything. Maybe the application does want to change column names (which can't be parameterized). Maybe it needs the extended protocol simply because it wants to do binary encoding, which isn't possible with the simple protocol (that's the case with Npgsql). There are many types of applications out there, I try in general not to assume things about them.
It would be great to get some external opinions on this debate (and apologies about the email volume here too).
On Tue, Aug 9, 2016 at 4:50 AM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote: > I've tried pgbench -M prepared, and it is way faster than pgbench -M simple. That's true, but it's also testing something completely different from what Shay is concerned about. -M prepared creates a prepared statement once, and then executes it many times. That is, as you say, faster. But what Shay is concerned about is the case where you are using the extended query protocol to send out-of-line parameters but for some reason you can't use prepared statements, for example because the queries are dynamically generated and you have to keep sending a different query text every time. That case is analogous to -M extended, not -M prepared. And -M extended is well-known to be SLOWER than -M simple. Here's a quick test on my laptop demonstrating this: [rhaas ~]$ pgbench -M simple -S -T 10 starting vacuum...end. transaction type: <builtin: select only> scaling factor: 1 query mode: simple number of clients: 1 number of threads: 1 duration: 10 s number of transactions actually processed: 119244 latency average: 0.084 ms tps = 11919.440321 (including connections establishing) tps = 11923.229139 (excluding connections establishing) [rhaas ~]$ pgbench -M prepared -S -T 10 starting vacuum...end. transaction type: <builtin: select only> scaling factor: 1 query mode: prepared number of clients: 1 number of threads: 1 duration: 10 s number of transactions actually processed: 192100 latency average: 0.052 ms tps = 19210.341944 (including connections establishing) tps = 19214.820999 (excluding connections establishing) [rhaas ~]$ pgbench -M extended -S -T 10 starting vacuum...end. transaction type: <builtin: select only> scaling factor: 1 query mode: extended number of clients: 1 number of threads: 1 duration: 10 s number of transactions actually processed: 104275 latency average: 0.096 ms tps = 10425.510813 (including connections establishing) tps = 10427.725239 (excluding connections establishing) Shay is not worried about the people who are getting 19.2k TPS instead of 11.9k TPS. Those people are already happy. He is worried about the people who are getting 10.4k TPS instead of 11.9k TPS. People who can't use prepared statements because their query text varies - and I have personally written multiple web applications that have exactly that profile - suffer a big penalty if they choose to use the extended query protocol to pass parameters. Here, it's about a 13% performance loss. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas:
but for some reason you can't use prepared statements, for example because
the queries are dynamically generated and . That case is analogous to -M
extended, not -M prepared. And -M extended is well-known to be SLOWER
I do not buy that "dynamically generated queries defeat server-prepared usage" argument. It is just not true (see below).
Do you mean "in language X, where X != Java it is impossible to implement a query cache"?
That is just ridiculus.
At the end of the day, there will be a finite number of hot queries that are important.
Here's relevant pgjdbc commit: https://github.com/pgjdbc/pgjdbc/pull/319
It works completely transparent to the application, and it does use server-prepared statements even though application builds "brand new" sql text every time.
It is not something theoretical, but it is something that is already implemented and battle-tested. The application does build SQL texts based on the names of tables and columns that are shown in the browser, and pgjdbc uses query cache (to map user SQL to backend statement name), thus it benefits from server-prepared statements automatically.
Not a single line change was required at the application side.
Am I missing something?
I cannot imagine a real life case when an application throws 10'000+ UNIQUE SQL texts per second at the database.
Cases like "where id=1", "where id=2", "where id=3" do not count as they should be written with bind variables, thus it represents a single SQL text like "where id=$1".
Robert>you have to keep sending a different query text every time
Do you agree that the major part would be some hot queries, the rest will be much less frequently used ones (e.g. one time queries)?
In OLTP applications the number of queries is high, and almost all the queries are reused.
server-prepared to rescue here.
"protocol optimization" would not be noticeable.
In DWH applications the queries might be unique, however the number of queries is much less, thus the "protocol optimization" would be invisible as the query plan/process time would be much higher than the gain from "protocol optimization".
Vladimir
On Tue, Aug 9, 2016 at 5:07 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote: > I do not buy that "dynamically generated queries defeat server-prepared > usage" argument. It is just not true (see below). > > Do you mean "in language X, where X != Java it is impossible to implement a > query cache"? > That is just ridiculus. Well, multiple experienced users are telling you that this is a real problem. You certainly don't have to agree, but when a bunch of other people who are smart and experienced think that something is a problem, I think you should consider the possibility that those people know what they are talking about. > Do you agree that the major part would be some hot queries, the rest will be > much less frequently used ones (e.g. one time queries)? Sure, but I don't want the application to have to know about that, and I don't really think the driver should need to know about that either. Your point, as I understand it, is that sufficiently good query caching in the driver can ameliorate the problem, and I agree with that. But that makes it the job of every driver to implement some sort of cache, which IMHO isn't a very reasonable position. When there's a common need that affects users of many different programming languages, the server should make it easy to meet that need, not require every driver to implement query caching. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> Sure, but I don't want the application to have to know about that, and
> I don't really think the driver should need to know about that either.
> Your point, as I understand it, is that sufficiently good query
> caching in the driver can ameliorate the problem, and I agree with
> that.
I don't, actually. If a particular application has a query mix that gets
a good win from caching query plans, it should already be using prepared
statements. The fact that that's not a particularly popular thing to do
isn't simply because people are lazy, it's because they've found out that
it isn't worth the trouble for them. Putting query caching logic into
drivers isn't going to improve performance for such cases, and it could
very possibly make things worse. The driver is the place with the
absolute least leverage for implementing caching; it has no visibility
into either the application or the server.
regards, tom lane
On Wed, Aug 10, 2016 at 11:50 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> Sure, but I don't want the application to have to know about that, and >> I don't really think the driver should need to know about that either. >> Your point, as I understand it, is that sufficiently good query >> caching in the driver can ameliorate the problem, and I agree with >> that. > > I don't, actually. If a particular application has a query mix that gets > a good win from caching query plans, it should already be using prepared > statements. The fact that that's not a particularly popular thing to do > isn't simply because people are lazy, it's because they've found out that > it isn't worth the trouble for them. Putting query caching logic into > drivers isn't going to improve performance for such cases, and it could > very possibly make things worse. The driver is the place with the > absolute least leverage for implementing caching; it has no visibility > into either the application or the server. I didn't mean to imply, in any way, that it is an ideal solution - just that people use it successfully. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
* Vladimir Sitnikov (sitnikov.vladimir@gmail.com) wrote: > It works completely transparent to the application, and it does use > server-prepared statements even though application builds "brand new" sql > text every time. And is the source of frequent complaints on various mailing lists along the lines of "why did my query suddently get slow the 6th time it was run?!". I encourage you to look through the archives and read up on how and why that can happen. Thanks! Stephen
Robert>But that makes it the job of every driver to implement some
sort of cache, which IMHO isn't a very reasonable position
languages
sort of cache, which IMHO isn't a very reasonable position
Let's wait what Shay decides on implementing query cache in npgsql ?
Here's the issue: https://github.com/npgsql/npgsql/issues/1237
He could change his mind when it comes to the need of "new ParseBindExecuteDeallocate message".
Robert>I think you should consider the possibility that those people
know what they are talking about.I do appreciate all the inputs, however, all the performance-related complaints in this thread I've seen can trivially be solved by adding a query cache at the driver level + fixing pgbouncer's issue.
Unfortunately, client-side SQL parsing is inevitable evil (see below on '?'), so any sane driver would cache queries any way. The ones that do not have query cache will perform badly anyway.
As far as I can understand, the alternative solution is "to add ParseBindExecDeallocateInOneGo message to the protocol". This new message would require changes from all the drivers, and all the pgbouncers. This new message would be slower than proper query cache, so why should we all spend time on a half-baked solution?
Of course, I might miss some use cases, that is why keep asking: please provide close to production scenario that does require the new protocol message we are talking about.
Note: examples (by Robert and Shay) like "typical web application that fetches a single row from DB and prints it to the browser" were already presented, and they are easily covered by the query cache.
To be fair, implementing a cache is a trivial thing when compared with hard-coding binary/text formats for all the datatypes in each and every language.
Remember, each driver has to implement its own set of procedures to input/output values in text/binary format, and that is a way harder than implementing the cache we are talking about.
If only there was some ability to have language-independent binary transfer format (protobuf, avro, kryo, whatever)....
Regarding query cache: each language has its own notion how bind variables are represented in SQL text.
For instance, in Go language (as well as in Java), bind placeholders are represented as '?' character.
Of course, PostgreSQL does not support that (it wants $1, $2, etc), so Go driver has to parse SQL text at the driver side in order to convert it into PostgreSQL-compatible flavor. This parser has to support comments, string literals, etc, etc. It is just natural thing to have a cache there so the driver does not repeat the same parsing logic again and again (typical applications are known to use the same query text multiple times).
Robert>When
there's a common need that affects users of many different programminglanguages
You are right. No questions here.
Ok, what is a need? What problem does "new message" solve?
From what I see there is no performance need to introduce "ParseBindExecDeallocateInOneGo" message. The thread is performance-related, so I naturally object spending everybody's time on implementing a useless feature.
Vladimir>Do you agree that the major part would be some hot queries, the rest will be
Vladimir> much less frequently used ones (e.g. one time queries)?
Vladimir> much less frequently used ones (e.g. one time queries)?
Robert>Sure, but I don't want the application to have to know about that
Application does not need to know that. It is like "branch prediction in the CPU". Application does not need to know there is a branch predictor in the CPU. The same goes for query cache. Application should just continue to execute SQLs in a sane manner, and the query cache would pick up the pattern (server-prepare hot-used queries).
Vladimir
Stephen>I encourage you to look through the archives
The thing is pl/pgsql suffers from exactly the same problem.
pl/pgsql is not a typical language of choice (e.g. see Tiobe index and alike), so the probability of running into "prepared statement issues" was low.
As more languages would use server-prepared statements, the rate of the issues would naturally increase.
JFYI: I did participate in those conversations, so I do not get which particular point are you asking for me to "look through" there.
Stephen Frost:
And is the source of frequent complaints on various mailing lists along
the lines of "why did my query suddently get slow the 6th time it was
run?!".
I claim the following:
1) People run into such problems with pl/pgsql as well. pl/pgsql does exactly the same server-prepared logic. So what? Pl/pgsql does have a query cache, but other languages are forbidden from having one?
2) Those problematic queries are not that often
3) "suddently get slow the 6th time" is a PostgreSQL bug that both fails to estimate cardinality properly, and it does not provide administrator a way to disable the feature (generic vs specific plan).
4) Do you have better solution? Of course, the planner is not perfect. Of course it will have issues with wrong cardinality estimations. So what? Should we completely abandon the optimizer?
I do not think so.
Query cache does have very good results for the overall web page times, and problems like "6th execution" are not that often.
By the way, other common problems are:
"cached plan cannot change result type" -- PostgreSQL just fails to execute the server-prepared statement if a table was altered.
"prepared statement does not exist" -- the applications might use "deallocate all" for some unknown reason, so the driver has to keep eye on that.
"set search_path" vs "prepared statement" -- the prepared statement binds by oids, so "search_path changes" should be accompanied by "deallocate all" or alike.
Vladimir
* Vladimir Sitnikov (sitnikov.vladimir@gmail.com) wrote: > 3) "suddently get slow the 6th time" is a PostgreSQL bug that both fails to > estimate cardinality properly, and it does not provide administrator a way > to disable the feature (generic vs specific plan). Dropping and recreating the prepared statement is how that particular issue is addressed. > Query cache does have very good results for the overall web page times, and > problems like "6th execution" are not that often. While it may have good results in many cases, it's not accurate to say that using prepared statements will always be faster than not. Thanks! Stephen
Stephen> While it may have good results in many cases, it's not accurate to say that using prepared statements will always be faster than not.
There's no silver bullet. <-- that is accurate, but it is useless for end-user applications
I've never claimed that "server prepared statement" is a silver bullet.
I just claim that "PrepareBindExecuteDeallocate" message does have justification from performance point of view.
Stephen Frost> Dropping and recreating the prepared statement is how that particular issue is addressed.
Stephen,
The original problem is: "extended query execution is slow"
I recommend "let's just add a query cache"
You mention: "that does not work since one query in a year might get slower on 6th execution"
I ask: "what should be done _instead_ of a query cache?"
You say: "the same query cache, but execute 5 times at most"
Does that mean you agree that "query cache is a way to go"?
I do not follow that. Of course, I could add "yet another debugger switch" to pgjdbc so it executes server-prepared statements 5 times maximum, however I do consider it to be a PostgreSQL's issue.
I do not like to hard-code "5" into the driver logic.
I do not like making "5 times maximum" a default mode.
Vladimir
Some comments...
For the record, I do find implicit/transparent driver-level query preparation interesting and potentially useful, and have opened https://github.com/
One interesting case where implicit preparation is unbeatable, though, is when users aren't coding against the driver directly but are using some layer, e.g. an ORM. For example, the Entity Framework ORM simply does not prepare statements (see https://github.com/aspnet/EntityFramework/issues/5459 which I opened). This is one reason I find it a valuable feature to have, although probably as opt-in and not opt-out.
Regarding driver-level SQL parsing, Vladimir wrote:
> Unfortunately, client-side SQL parsing is inevitable evil (see below on '?'), so any sane driver would cache queries any way. The ones that do not have query cache will perform badly anyway.
First, it's a very different thing to have a query cache in the driver, and to implicitly prepare statements.
Second, I personally hate the idea that drivers parse SQL and rewrite queries. It's true that in many languages database APIs have "standardized" parameter placeholders, and therefore drivers have no choice but to rewrite. ADO.NET (the .NET database API) actually does not do this - parameter placeholders are completely database-dependent (see https://msdn.microsoft.com/en-us/library/yy6y35y8%28v=vs.110%29.aspx?f=255&MSPPError=-2147217396). Npgsql does rewrite queries to provide named parameters, but the next version is going to have a "raw query" mode in which no parsing/rewriting happens whatsoever. It simply takes your string, packs it into a Parse (or Query), and sends it off. This is not necessarily going to be the main way users use Npgsql, but it's important to note that query parsing and rewriting isn't an "inevitable evil".
Vladimir wrote:
> This new message would be slower than proper query cache, so why should we all spend time on a half-baked solution?
The cases where the prepared statement path doesn't work have already been listed many times - pgbouncer (and other pools), drivers which don't support persisting prepared statement across pooled connection open/close, and people (like many in this conversation) who don't appreciate their drivers doing magic under the hood. This is why I thing both proposals are great - there's nothing wrong with query caching (or more precisely, implicit statement preparation by the driver), especially if it's opt-in, but that doesn't mean we shouldn't optimize things for people who don't, can't or won't go for that.
> To be fair, implementing a cache is a trivial thing when compared with hard-coding binary/text formats for all the datatypes in each and every language.
> Remember, each driver has to implement its own set of procedures to input/output values in text/binary format, and that is a way harder than implementing the cache we are talking about.
I agree with that, but it's not a question of how easy it is to implement implicit preparation. It's a question of whether driver developers choose to do this, based on other considerations as well - many people here think it's not the job of the driver to decide for you whether to prepare or not, for example. It has nothing to do with implementation complexity.
> "cached plan cannot change result type" -- PostgreSQL just fails to execute the server-prepared statement if a table was altered.
That alone seems to be a good reason to make implicit preparation opt-in at best. How exactly do users cope with this in pgjdbc? Do they have some special API to flush (i.e. deallocate) prepared statements which they're supposed to use after a DDL? Do you look at the command tag in the CommandComplete to know whether a command was DDL or not?
Shay> it's important to note that query parsing and rewriting isn't an "inevitable evil".
Ok, I stay corrected. ADO.NET have raw mode in the API. That's interesting.
Let's say "lots of heavily used languages do have their own notion of bind placeholders".
And for the reset, it is still not that hard to prepare on the go.
Shay> As Tom said, if an application can benefit from preparing, the developer has the responsibility (and also the best knowledge) to manage preparation, not the driver. Magical behavior under the hood causes surprises, hard-to-diagnose bugs etc.
Why do you do C# then?
Aren't you supposed to love machine codes as the least magical thing?
Even x86 does not describe "the exact way the code should be executed".
All the CPUs shuffle the instructions to make it faster.
Shay>As Tom said, if an application can benefit from preparing, the developer has the responsibility
Does developer have the responsibility to choose between "index scan" and "table seq scan"? So your "developer has the responsibility" is like building on sand.
Even "SQL execution on PostgreSQL is a magical behavior under the hood". Does that mean we should drop the optimizer and implement "fully static hint-based execution mode"? I do not buy that.
My experience shows, that people are very bad at predicting where the performance problem would be.
For 80% (or even 99%) of the cases, they just do not care thinking if a particular statement should be server-prepared or not.
They have absolutely no idea how much resources it would take and so on.
ORMs have no that notion of "this query must be server-prepared, while that one must not be".
And so on.
It is somewhat insane to assume people would use naked SQL. Of course they would use ORMs and alike, so they just would not be able to pass that additional parameter telling if a particular query out of thousands should be server-prepared or not.
Vladimir> "cached plan cannot change result type" -- PostgreSQL just fails to execute the server-prepared statement if a table was altered.
Shay>How exactly do users cope with this in pgjdbc? Do they have some special API to flush (i.e. deallocate) prepared statements which they're supposed to use after a DDL?
First of all, pgjdbc does report those problems to hackers.
Unfortunately, it is still "not implemented".
Then, a workaround at pgjdbc side is made.
Here's relevant pgjdbc fix: https://github.com/pgjdbc/pgjdbc/pull/451
It analyzes error code, and if it finds "not_implemented from RevalidateCachedQuery", then it realizes it should re-prepare. Unfortunately, there is no dedicated error code, but at least there's a routine name.
On top of that, each pgjdbc commit is tested against HEAD PostgreSQL revision, so if the routine will get renamed for some reason, we'll know that right away.
There will be some more parsing to cover "deallocate all" case.
Shay>it have been listed many times - pgbouncer
Let's stop discussing pgbouncer issue here?
It has absolutely nothing to do with pgsql-hackers.
Thanks.
Vladimir
Shay> As Tom said, if an application can benefit from preparing, the developer has the responsibility (and also the best knowledge) to manage preparation, not the driver. Magical behavior under the hood causes surprises, hard-to-diagnose bugs etc.Why do you do C# then?Aren't you supposed to love machine codes as the least magical thing?Even x86 does not describe "the exact way the code should be executed".All the CPUs shuffle the instructions to make it faster.
These are valid questions. I have several answers to that.
First, it depends on the extent to which the "under the hood" activity may have visible side-effects. CPU instruction reordering is 100% invisible, having no effect whatsoever on the application apart from speeding it up. Prepared statements can have very visible effects apart from the speedup they provide (e.g. failure because of schema changes). It's not that these effects can't be worked around - they can be - but programmers can be surprised by these effects, which can cause difficult-to-diagnose issues. Nobody needs to be really aware of CPU instruction reordering because it will never cause an application issue (barring a CPU bug).
Another important visible effect of preparing a statement is server-side cost (i.e. memory). I'm not sure what the overhead is, but it is there and an irresponsible "prepare everything everywhere" can create a significant resource drain on your server. I know pgjdbc has knobs for controlling how many statements are prepared, but in a large-scale performance-sensitive app a programmer may want to manually decide, on a per-query basis, whether they want to prepare or not.
But the most important question is that this is a choice that should be left to the developer, rather than imposed. In some cases developers *do* drop down to assembly, or prefer to call system calls directly to be in control of exactly what's happening. They should be able to do this. Now, of course you can provide an option which disables implicit preparing, but if you refuse to optimize non-prepared paths you're effectively forcing the programmer to go down the prepared statement path.
Shay>As Tom said, if an application can benefit from preparing, the developer has the responsibilityDoes developer have the responsibility to choose between "index scan" and "table seq scan"? So your "developer has the responsibility" is like building on sand.
I'm very glad you raised that point. The programmers indeed outsources that decision to the database, because the database has the most *knowledge* on optimal execution (e.g. which indices are defined). Implicit preparing, on the other hand, has nothing to do with knowledge: as Tom said, the driver knows absolutely nothing about the application, and doesn't have any advantage over the programmer in making that decision.
But note that the DBA *does* have to decide which indices exist and which don't. Would you accept a database that automatically creates indices based on use, i.e. "x queries caused full table scans, so I'll silently create an index here"? I wouldn't, it would be utter nonsense and create lots of unpredictability in terms of performance and resource drain.
My experience shows, that people are very bad at predicting where the performance problem would be.For 80% (or even 99%) of the cases, they just do not care thinking if a particular statement should be server-prepared or not.They have absolutely no idea how much resources it would take and so on.
And for those people it's great to have an implicit preparation feature, most probably opt-in. But that shouldn't mean we shouldn't optimize things for the rest.
ORMs have no that notion of "this query must be server-prepared, while that one must not be".And so on.It is somewhat insane to assume people would use naked SQL. Of course they would use ORMs and alike, so they just would not be able to pass that additional parameter telling if a particular query out of thousands should be server-prepared or not.
Uh, I really wouldn't make statements like that if you want to be taken seriously. Tons of applications use naked SQL and avoid ORMs for many reasons (e.g. performance benefits of hand-crafted SQL), such general statements on what applications do in the world are, well, silly. Again, ORMs are an argument for why implicit preparation should exist (I made that argument myself above), but they're not an argument for why optimizing other paths should be excluded.
Vladimir> "cached plan cannot change result type" -- PostgreSQL just fails to execute the server-prepared statement if a table was altered.Shay>How exactly do users cope with this in pgjdbc? Do they have some special API to flush (i.e. deallocate) prepared statements which they're supposed to use after a DDL?First of all, pgjdbc does report those problems to hackers.Unfortunately, it is still "not implemented".Then, a workaround at pgjdbc side is made.Here's relevant pgjdbc fix: https://github.com/pgjdbc/pgjdbc/pull/451 It analyzes error code, and if it finds "not_implemented from RevalidateCachedQuery", then it realizes it should re-prepare. Unfortunately, there is no dedicated error code, but at least there's a routine name.
That's exactly the kind of behavior I don't like in libraries/drivers - implicit behavior which may trigger errors, which the library than has to (transparently!) recover from. It makes applications very brittle. What happens if you happen to be in a transaction when this error occurs? When an error occurs, PostgreSQL puts the ongoing transaction in state "failed" and requires you to rollback - how can you possibly recover from that?
Shay>it have been listed many times - pgbouncerLet's stop discussing pgbouncer issue here?It has absolutely nothing to do with pgsql-hackers.
You have the right to think so, but I disagree. PostgreSQL is part of an ecosystem, and pgbouncer is a big part of that ecosystem (as are other potential pools).
Shay:
Prepared statements can have very visible effects apart from the speedup they provide (e.g. failure because of schema changes) It's not that these effects can't be worked around - they can be - but programmers can be surprised by these effects, which can cause difficult-to-diagnose issues.
The specific effect of "cached plan cannot change return type" can be solved by cooperation of backend and frontend (~driver) developers.
I find that solving that kind of issues is more important than investing into "ParseBindExecDeallocateInOneGo" message.
I hope you would forgive me if I just stop the discussion here.
I find I'd better spent that time on just fixing pgbouncer issue rather than discussing if it is pgbouncer's or postgresql's issue.
I'm sorry for being impolite if I was ever.
Vladimir
On Thu, Aug 11, 2016 at 8:39 AM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Shay:Prepared statements can have very visible effects apart from the speedup they provide (e.g. failure because of schema changes) It's not that these effects can't be worked around - they can be - but programmers can be surprised by these effects, which can cause difficult-to-diagnose issues.The specific effect of "cached plan cannot change return type" can be solved by cooperation of backend and frontend (~driver) developers.
I really don't see how. As I said, an error is going to kill the ongoing transaction, how can this be solved without application logic? Unless you propose keeping track of all statements executed in the query and resend them?
I'm asking this out of genuine interest (I might be missing something), since I'm seriously considering implementing implicit query preparation in Npgsql.
I find that solving that kind of issues is more important than investing into "ParseBindExecDeallocateInOneGo " message.
I don't think it's solvable. But regardless, it's totally to invest in two things, I think it's totally legitimate to invest in implicit query preparation.
I hope you would forgive me if I just stop the discussion here.
Of course, no problem.
I find I'd better spent that time on just fixing pgbouncer issue rather than discussing if it is pgbouncer's or postgresql's issue.
The point is that it's not just a pgbouncer "bug". Connection pools like pgbouncer (there are others) usually send DISCARD ALL on connection close, which makes prepared statements useless for short-lived connection scenarios (since you have to reprepare). I don't know if that's changeable across pool implementations in general, and even if so, requires significant user understanding for tweaking the pool. So the general point is that the existence of pools is problematic for the argument "always prepare for recurring statements".
I'm sorry for being impolite if I was ever.
I don't think you were impolite, I personally learned a few things from the conversation and will probably implement opt-in implicit query preparation thanks to it.
Shay>As I said, an error is going to kill the ongoing transaction, how can this be solved without application logic?
1) At least, some well-defined error code should be created for that kind of matter.
2) The driver can use safepoints and autorollback to the good "right before failure" state in case of a known failure. Here's the implementation: https://github.com/pgjdbc/pgjdbc/pull/477
As far as I can remember, performance overheads are close to zero (no extra roundtrips to create a safepoint)
3) Backend could somehow invalidate prepared statements, and notify clients accordingly. Note: the problem is hard in a generic case, however it might be not that hard if we fix well-known often-used cases like "a column is added". That however, would add memory overheads to store additional maps like "table_oid -> statement_names[]"
4) Other. For instance, new message flow so frontend and backend could re-negotiate "binary vs text formats for the new resulting type". Or "ValidatePreparedStatement" message that would just validate the statement and avoid killing the transaction if the statement is invalid. Or whatever else there can be invented.
Shay>So the general point is that the existence of pools is problematic for the argument "always prepare for recurring statements".
So what?
Don't use pools that issue "discard all" or configure them accordingly. That's it.
In Java world, no wildly used pool defaults to "discard everything" strategy.
Please stop saying "pgbouncer" as its issue is confirmed, and pgbouncer developers did acknowledge they would prefer to solve "prepared statement issue" right inside pgbouncer without any cooperation from driver developers.
Do you mean in C# world major connection pools default to "discard all" setup? That sounds strange to me.
Vladimir
On Thu, Aug 11, 2016 at 1:22 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
2) The driver can use safepoints and autorollback to the good "right before failure" state in case of a known failure. Here's the implementation: https://github.com/pgjdbc/pgjdbc/pull/ 477
As far as I can remember, performance overheads are close to zero (no extra roundtrips to create a safepoint)
What? Do you mean you do implicit savepoints and autorollback too? How does the driver decide when to do a savepoint? Is it on every single command? If not, commands can get lost when an error is raised and you automatically roll back? If you do a savepoint on every single command, that surely would impact performance even without extra roundtrips...?
You seem to have a very "unique" idea of what a database driver should do under-the-hood for its users. At the very least I can say that your concept is very far from almost any database driver I've seen up to now (PostgreSQL JDBC, psycopg, Npgsql, libpq...). I'm not aware of other drivers that implicitly prepare statements, and definitely of no drivers that internally create savepoints and roll the back without explicit user APIs. At the very least you should be aware (and also clearly admit!) that you're doing something very different - not necessarily wrong - and not attempt to impose your ideas on everyone as if it's the only true way to write a db driver.
3) Backend could somehow invalidate prepared statements, and notify clients accordingly. Note: the problem is hard in a generic case, however it might be not that hard if we fix well-known often-used cases like "a column is added". That however, would add memory overheads to store additional maps like "table_oid -> statement_names[]"
Assuming your driver supports batching/pipelining (and I hope it does), that doesn't make sense. Say I send a 2-statement batch, with the first one a DDL and with the second one some prepared query invalidated by the first. When your DDL is executed by PostgreSQL your hypothetical notification is sent. But the second query, which should be invalidated, has already been sent to the server (because of batching), and boom.
4) Other. For instance, new message flow so frontend and backend could re-negotiate "binary vs text formats for the new resulting type". Or "ValidatePreparedStatement" message that would just validate the statement and avoid killing the transaction if the statement is invalid. Or whatever else there can be invented.
When would you send this ValidatePreparedStatement? Before each execution as a separate roundtrip? That would kill performance. Would you send it in the same packet before Execute? In that case you still get the error when Execute is evaluated...
There really is no solution to this problem within the current PostgreSQL way of doing things - although of course we could reinvent the entire PostgreSQL protocol here to accommodate for your special driver...
The basic truth is this... In every db driver I'm familiar with programmers are expected to manage query preparation on their own. They're supposed to do it based on knowledge only they have, weighing pros and cons. They have responsibility over their own code and they don't outsource major decisions like this to their driver. When they get an error from PostgreSQL, it's triggered by something they did in a very explicit and clear way - and they therefore have a good chance to understand what's going on. They generally don't get errors triggered by some under-the-hood magic their driver decided to do for them, and which are hard to diagnose and understand. Their drivers are simple, predictable and lean, and they don't have to include complex healing logic to deal with errors they themselves triggered with under-the-hood logic (e.g. implicit savepoints).
Shay>So the general point is that the existence of pools is problematic for the argument "always prepare for recurring statements".So what?Don't use pools that issue "discard all" or configure them accordingly. That's it.In Java world, no wildly used pool defaults to "discard everything" strategy.
I don't know much about the Java world, but both pgbouncer and pgpool (the major pools?) send DISCARD ALL by default. That is a fact, and it has nothing to do with any bugs or issues pgbouncer may have. I'm tempted to go look at other pools in other languages but frankly I don't think that would have any effect in this conversation...
Shay>I don't know much about the Java world, but both pgbouncer and pgpool (the major pools?)
In Java world, https://github.com/brettwooldridge/HikariCP is a very good connection pool.
Neither pgbouncer nor pgpool is required.
The architecture is: application <=> HikariCP <=> pgjdbc <=> PostgreSQL
The idea is HikariCP pools pgjdbc connections, and server-prepared statements are per-pgjdbc connection, so there is no reason to "discard all" or "deallocate all" or whatever.
Shay>send DISCARD ALL by default. That is a fact, and it has nothing to do with any bugs or issues pgbouncer may have.
That is configurable. If pgbouncer/pgpool defaults to "wrong configuration", why should we (driver developers, backend developers) try to accommodate that?
Shay> What? Do you mean you do implicit savepoints and autorollback too?
I mean that.
On top of that it enables opt-in psql-like ON_ERROR_ROLLBACK functionality so it could automatically roll back the latest statement if it failed.
For instance, that might simplify migration from other DBs that have the same "rollback just one statement on error" semantics by default.
Shay>How does the driver decide when to do a savepoint?
By default it would set a savepoint in a case when there's open transaction, and the query to be executed has been previously described.
In other words, the default mode is to protect user from "cached plan cannot change result type" error.
Shay>Is it on every single command?
Exactly (modulo the above). If user manually sets "autosave=always", every command would get prepended with a savepoint and rolled back.
Shay>f you do a savepoint on every single command, that surely would impact performance even without extra roundtrips...?
My voltmeter says me that the overhead is just 3us for a simple "SELECT" statement (see https://github.com/pgjdbc/pgjdbc/pull/477#issuecomment-239579547 ).
I think it is acceptable to have it enabled by default, however it would be nice if the database did not require a savepoint dance to heal its "not implemented" "cache query cannot change result type" error.
Shay>I'm not aware of other drivers that implicitly prepare statements,
Shay >and definitely of no drivers that internally create savepoints and
Shay> roll the back without explicit user APIs
Glad to hear that.
Are you aware of other drivers that translate "insert into table(a,b,c) values(?,?,?)" =into=> "insert into table(a,b,c) values(?,?,?),(?,?,?),...,(?,?,?)" statement on the fly?
That gives 2-3x performance boost (that includes client result processing as well!) for batched inserts since "bind/exec" message processing is not that fast. That is why I say that investing into "bind/exec performance" makes more sense than investing into "improved execution of non-prepared statements".
Shay>you're doing something very different - not necessarily wrong - and not
Shay>attempt to impose your ideas on everyone as if it's the only true way
Shay>to write a db driver.
1) Feel free to pick ideas you like
2) I don't say "it is the only true way". I would change my mind if someone would suggest better solution. Everybody makes mistakes, and I have no problem with admitting that "I made a mistake" and moving forward.
They say: "Don't cling to a mistake just because you spent a lot of time making it"
However, no-one did suggest a case when application issues lots of unique SQL statements.
The suggested alternative "a new message for non-prepared extended query" might shave 5-10us per query for those who are lazy to implement a query cache. However, that is just 5-10ms per 1000 queries. Would that be noticeable by the end-users? I don't think so.
Having a query cache can easily shave 5-10+ms for each query, that is why I suggest driver developers to implement a query cache first, and only then ask for new performance-related messages.
3) For "performance related" issues, a business case and a voltmeter is required to prove there's an issue.
Shay>But the second query, which should be invalidated, has already been
Shay>sent to the server (because of batching), and boom
-- Doctor, it hurts me when I do that
-- Don't do that
When doing batched SQL, some of the queries might fail with "duplicate key", or "constraint violation". There's already API that covers those kind of cases and reports which statements did succeed (if any).
In the case as you described (one query in a batch somehow invalidates the subsequent one) it would just resort to generic error handling.
Shay>When would you send this ValidatePreparedStatement?
Shay>Before each execution as a separate roundtrip?
Shay>That would kill performance.
Why do you think the performance would degrade? Once again: the current problem is the client thinks it knows "which columns will be returned by a particular server-prepared statement" but the table might get change behind the scenes (e.g. online schema upgrade), so the error occurs. That "return type" is already validated by the database (the time is already spent on validation), so there's is virtually no additional work.
So it could be fine if a separate validate message was invented or just some connection property that would make "cached query cannot change result type" a non-fatal error (as in "it would not kill the transaction").
For instance: "in case of cached query cannot change result type error the backend would skip processing the subsequent bind/exec kind of messages for the problematic statement, and it will keep the transaction in open state. The client would have to re-send relevant prepare/bind/execute". That would prevent user from receiving the error and that approach does not require savepoints.
This particular topic "how to fix <<cannot change result type>> error" might be better to be split into its own conversation.
Vladimir
On 11 August 2016 at 10:18, Shay Rojansky <roji@roji.org> wrote:
On Thu, Aug 11, 2016 at 1:22 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:2) The driver can use safepoints and autorollback to the good "right before failure" state in case of a known failure. Here's the implementation: https://github.com/pgjdbc/pgjdbc/pull/477 As far as I can remember, performance overheads are close to zero (no extra roundtrips to create a safepoint)What? Do you mean you do implicit savepoints and autorollback too? How does the driver decide when to do a savepoint? Is it on every single command? If not, commands can get lost when an error is raised and you automatically roll back? If you do a savepoint on every single command, that surely would impact performance even without extra roundtrips...?You seem to have a very "unique" idea of what a database driver should do under-the-hood for its users. At the very least I can say that your concept is very far from almost any database driver I've seen up to now (PostgreSQL JDBC, psycopg, Npgsql, libpq...). I'm not aware of other drivers that implicitly prepare statements, and definitely of no drivers that internally create savepoints and roll the back without explicit user APIs. At the very least you should be aware (and also clearly admit!) that you're doing something very different - not necessarily wrong - and not attempt to impose your ideas on everyone as if it's the only true way to write a db driver.
A number of other drivers default to this behaviour, including at least MS-SQL and Oracle. psqlODBC also supports this behaviour with statement rollback mode. And obviously PostgreSQL JDBC which Vladimir is referring to.
Shay>I don't know much about the Java world, but both pgbouncer and pgpool (the major pools?)In Java world, https://github.com/brettwooldridge/HikariCP is a very good connection pool. Neither pgbouncer nor pgpool is required.The architecture is: application <=> HikariCP <=> pgjdbc <=> PostgreSQLThe idea is HikariCP pools pgjdbc connections, and server-prepared statements are per-pgjdbc connection, so there is no reason to "discard all" or "deallocate all" or whatever.Shay>send DISCARD ALL by default. That is a fact, and it has nothing to do with any bugs or issues pgbouncer may have.That is configurable. If pgbouncer/pgpool defaults to "wrong configuration", why should we (driver developers, backend developers) try to accommodate that?
In a nutshell, that sentence represents much of the problem I have with this conversation: you simply consider that anything that's different from your approach is simply "wrong".
Shay>f you do a savepoint on every single command, that surely would impact performance even without extra roundtrips...?My voltmeter says me that the overhead is just 3us for a simple "SELECT" statement (see https://github.com/pgjdbc/pgjdbc/pull/477# issuecomment-239579547 ). I think it is acceptable to have it enabled by default, however it would be nice if the database did not require a savepoint dance to heal its "not implemented" "cache query cannot change result type" error.
That's interesting (I don't mean that ironically). Aside from simple client-observed speed which you're measuring, are you sure there aren't "hidden" costs on the PostgreSQL side for generating so many implicit savepoints? I don't know anything about PostgreSQL transaction/savepoint internals, but adding savepoints to each and every statement in a transaction seems like it would have some impact. It would be great to have the confirmation of someone who really knows the internals.
Shay>I'm not aware of other drivers that implicitly prepare statements,Shay >and definitely of no drivers that internally create savepoints andShay> roll the back without explicit user APIsGlad to hear that.Are you aware of other drivers that translate "insert into table(a,b,c) values(?,?,?)" =into=> "insert into table(a,b,c) values(?,?,?),(?,?,?),...,(?,?,?)" statement on the fly? That gives 2-3x performance boost (that includes client result processing as well!) for batched inserts since "bind/exec" message processing is not that fast. That is why I say that investing into "bind/exec performance" makes more sense than investing into "improved execution of non-prepared statements".
I'm not aware of any, but I also don't consider that part of the driver's job. There's nothing your driver is doing that the application developer can't do themselves - so your driver isn't faster than other drivers. It's faster only when used by lazy programmers.
What you're doing is optimizing developer code, with the assumption that developers can't be trusted to code efficiently - they're going to write bad SQL and forget to prepare their statements. That's your approach, and that's fine. The other approach, which is also fine, is that each software component has its own role, and that clearly-defined boundaries of responsibility should exist - that writing SQL is the developer's job, and that delivering it to the database is the driver's job. To me this separation of layers/roles is key part of software engineering: it results in simpler, leaner components which interact in predictable ways, and when there's a problem it's easier to know exactly where it originated. To be honest, the mere idea of having an SQL parser inside my driver makes me shiver.
The HikariCP page you sent (thanks, didn't know it) contains a great Dijkstra quote that summarizes what I think about this - "Simplicity is prerequisite for reliability.". IMHO you're going the opposite way by implicitly rewriting SQL, preparing statements and creating savepoints.
But at the end of the day it's two different philosophies. All I ask is that you respect the one that isn't yours, which means accepting the optimization of non-prepared statements. There's no mutual exclusion.
2) I don't say "it is the only true way". I would change my mind if someone would suggest better solution. Everybody makes mistakes, and I have no problem with admitting that "I made a mistake" and moving forward.They say: "Don't cling to a mistake just because you spent a lot of time making it"
:)
So your way isn't the only true way, but others are just clinging to their mistakes... :)
However, no-one did suggest a case when application issues lots of unique SQL statements.
We did, you just dismissed or ignored them.
3) For "performance related" issues, a business case and a voltmeter is required to prove there's an issue.Shay>But the second query, which should be invalidated, has already beenShay>sent to the server (because of batching), and boom
When doing batched SQL, some of the queries might fail with "duplicate key", or "constraint violation". There's already API that covers those kind of cases and reports which statements did succeed (if any).In the case as you described (one query in a batch somehow invalidates the subsequent one) it would just resort to generic error handling.
You claimed that this condition could be handled transparently between the driver and the backend, without disrupting the application with an error. You proposed some new invalidation protocol between the client and the server, but for batches this fails and the application does get an error. That's all I wanted to say - that transparent handling of this error is difficult, probably impossible without serious changes to the PostgreSQL protocol...
This is very different from failure because of "duplicate key" or "constraint violation" - your error is a result of something the driver did implicitly, after 5 executions, without the user's request or knowledge.
From my side, I think this conversation has definitely reached a dead end (although I can continue responding if you think it would be of any value). There are two software design philosophies here, and the discussion isn't really even about databases or drivers. For the record, I do recognize that your approach has some merit (even if in the grand scheme of things I think it isn't the right way to design software components).
Also for the record, I do intend to implement implicit query preparation, but as an opt-in mechanism. I'm going to so not because I think developers shouldn't be trusted to code efficiently, but because there are situations outside of the developers control which could greatly benefit from it (i.e. ORMs, large existing codebase that can't easily be changed to use prepare). I'm going to recommend developers keep this feature off, unless they have no other choice.
Shay>To be honest, the mere idea of having an SQL parser inside my driver makes me shiver.
Same for me.
However I cannot wait for PostgreSQL 18 that does not need client-side parsing.
Shay>We did, you just dismissed or ignored them
Please prove me wrong, but I did provide a justified answer to both
yours: https://www.postgresql.org/message-id/CAB%3DJe-FHSwrbJiTcTDeT4J3y_%2BWvN1d%2BS%2B26aesr85swocb7EA%40mail.gmail.com (starting with "Why the connection is reset")
and Robert's examples: https://www.postgresql.org/message-id/CAB%3DJe-GSAs_340dqdrJoTtP6KO6xxN067CtB6Y0ea5c8LRHC9Q%40mail.gmail.com
Shay>so your driver isn't faster than other drivers. It's faster only when used by lazy programmers.
I'm afraid you do not get the point.
ORMs like Hibernate, EclipseLink, etc send regular "insert ... values" via batch API.
For the developer the only way to make use of "multivalues" is to implement either "ORM fix" or "the driver fix" or "postgresql fix".
So the feature has very little to do with laziness of the programmers. Application developer just does not have full control of each SQL when working though ORM.
Do you suggest "stop using ORMs"? Do you suggest fixing all the ORMs so it uses optimal for each DB insert statement?
Do you suggest fixing postgresql?
Once again "multivalues rewrite at pgjdbc level" enables the feature transparently for all the users. If PostgreSQL 10/11 would improve bind/exec performance, we could even drop that rewrite at pgjdbc level and revert to the regular flow. That would again be transparent to the application.
Shay>are you sure there aren't "hidden" costs on the PostgreSQL side for generating so many implicit savepoints?
Technically speaking I use the same savepoint name through bind/exec message.
Shay>What you're doing is optimizing developer code, with the assumption that developers can't be trusted to code efficiently - they're going to write bad SQL and forget to prepare their statements
Please, be careful. "you are completely wrong here" he-he. Well, you list the wrong assumption. Why do you think my main assumption is "developers can't be trusted"?
The proper assumption is: I follow Java database API specification, and I optimize pgjdbc for the common use case (e.g. ORM or ORM-like).
For instance, if Java application wants to use bind values (e.g. to prevent security issues), then the only way is to go through java.sql.PreparedStatement.
Here's the documentation: https://docs.oracle.com/javase/8/docs/api/java/sql/Connection.html#prepareStatement-java.lang.String-
Here's a quote:
Javadoc> Note: This method is optimized for handling parametric SQL statements that benefit from precompilation. If the driver supports precompilation, the method
prepareStatement will send the statement to the database for precompilation. Some drivers may not support precompilation. In this case, the statement may not be sent to the database until the PreparedStatement object is executed. This has no direct effect on users; however, it does affect which methods throw certainSQLException objects.The most important part is "if the driver supports precompilation..."
There's no API to enable/disable precompilation at all.
So, when using Java, there is no such thing as "statement.enableServerPrepare=true".
It is expected, that "driver" would "optimize" the handling somehow in the best possible way.
It is Java API specification that enables me (as a driver developer) to be flexible, and leverage database features so end user gets best experience.
Vladimir
> Shay>I don't know much about the Java world, but both pgbouncer and pgpool > (the major pools?) > > In Java world, https://github.com/brettwooldridge/HikariCP is a very good > connection pool. > Neither pgbouncer nor pgpool is required. > The architecture is: application <=> HikariCP <=> pgjdbc <=> PostgreSQL > > The idea is HikariCP pools pgjdbc connections, and server-prepared > statements are per-pgjdbc connection, so there is no reason to "discard > all" or "deallocate all" or whatever. Interesting. What would happen if a user changes some of GUC parameters? Subsequent session accidentally inherits the changed GUC parameter? > Shay>send DISCARD ALL by default. That is a fact, and it has nothing to do > with any bugs or issues pgbouncer may have. That is correct for pgpool as well. > That is configurable. If pgbouncer/pgpool defaults to "wrong > configuration", why should we (driver developers, backend developers) try > to accommodate that? There's nothing wrong with DICARD ALL. It's just not suitable for your program (and HikariCP?). I don't know about pgbouncer but pgpool has been created for a general purpose connection pooler, which means it must behave as much as similarly to PostgreSQL backend from frontend's point of view. "DISCARD ALL" is needed to simulate the behavior of backend: it discards all properties set by a frontend including prepared statements when a session terminates. "DISCARD ALL" is perfect for this goal. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Tatsuo>Interesting. What would happen if a user changes some of GUC
parameters? Subsequent session accidentally inherits the changed GUC
parameter?
parameters? Subsequent session accidentally inherits the changed GUC
parameter?
Yes, that is what happens.
The idea is not to mess with gucs.
Tatsuo>There's nothing wrong with DICARD ALL
Tatsuo>"DISCARD ALL" is perfect for this goal.
It looks like you mean: "let's reset the connection state just in case".
I see where it might help: e.g. when providing database access to random people who might screw a connection in every possible way.
Just in case: do you think one should reset CPU caches, OS filesystem caches, DNS caches, bounce the application, and bounce the OS in addition to "discard all"?
Why reset only "connection properties" when we can reset everything to its pristine state?
Just in case: PostgreSQL does not execute "discard all" on its own.
If you mean "pgpool is exactly like reconnect to postgresql but faster since connection is already established", then OK, that might work in some cases (e.g. when response times/throughput are not important), however why forcing "you must always start from scratch" execution model?
Developers are not that dumb, and they can understand that "changing gucs at random is bad".
When a connection pool is dedicated to a particular application (or a set of applications), then it makes sense to reuse statement cache for performance reasons.
Of course, it requires some discipline like "don't mess with gucs", however that is acceptable and it is easily understandable by developers.
My application cannot afford re-parsing hot SQL statements as hurts performance. It is very visible in the end-to-end performance tests, so "discard all" is not used, and developers know not to mess with gucs.
Vladimir
> Tatsuo>Interesting. What would happen if a user changes some of GUC > parameters? Subsequent session accidentally inherits the changed GUC > parameter? > > Yes, that is what happens. Ouch. > The idea is not to mess with gucs. > > Tatsuo>There's nothing wrong with DICARD ALL > Tatsuo>"DISCARD ALL" is perfect for this goal. > > It looks like you mean: "let's reset the connection state just in case". > I see where it might help: e.g. when providing database access to random > people who might screw a connection in every possible way. Yes, that's what clients of pgpool is expecting. Clients do not want to change their applications which were working with PostgreSQL without pgpool. > Just in case: do you think one should reset CPU caches, OS filesystem > caches, DNS caches, bounce the application, and bounce the OS in addition > to "discard all"? Aparently no, because that is different from what PostgreSQL is doing when backend exits. > Why reset only "connection properties" when we can reset everything to its > pristine state? You can propose that kind of variants of DISCARD command. PostgreSQL is an open source project. > Just in case: PostgreSQL does not execute "discard all" on its own. > If you mean "pgpool is exactly like reconnect to postgresql but faster > since connection is already established", then OK, that might work in some > cases (e.g. when response times/throughput are not important), however why > forcing "you must always start from scratch" execution model? I'm not doing that. I do not ask all the people to use pgpool. People can choose whatever tools he/she thinks suitable for their purpose. > Developers are not that dumb, and they can understand that "changing gucs > at random is bad". > > When a connection pool is dedicated to a particular application (or a set > of applications), then it makes sense to reuse statement cache for > performance reasons. > Of course, it requires some discipline like "don't mess with gucs", however > that is acceptable and it is easily understandable by developers. I'm not against such a developer's way. If you like it, you can do it. Nobody disturbs you. I just want to say that not all the client want that way. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Apologies, I accidentally replied off-list, here's the response I sent. Vladimir, I suggest you reply to this message with your own response...
Shay>To be honest, the mere idea of having an SQL parser inside my driver makes me shiver.Same for me.However I cannot wait for PostgreSQL 18 that does not need client-side parsing.
I'm glad we agree on something. For me the problem has nothing to do with PostgreSQL or performance - it has to do with database APIs that impose uniform parameter placeholder formats, and therefore force drivers to rewrite user SQL queries. AFAIK rewriting a user's SQL for optimization is totally out of the scope of the driver's work.
Shay>There's nothing your driver is doing that the application developer can't do themselves -Shay>so your driver isn't faster than other drivers. It's faster only when used by lazy programmers.I'm afraid you do not get the point.ORMs like Hibernate, EclipseLink, etc send regular "insert ... values" via batch API.For the developer the only way to make use of "multivalues" is to implement either "ORM fix" or "the driver fix" or "postgresql fix".
So the feature has very little to do with laziness of the programmers. Application developer just does not have full control of each SQL when working though ORM.Do you suggest "stop using ORMs"? Do you suggest fixing all the ORMs so it uses optimal for each DB insert statement?Do you suggest fixing postgresql?Once again "multivalues rewrite at pgjdbc level" enables the feature transparently for all the users. If PostgreSQL 10/11 would improve bind/exec performance, we could even drop that rewrite at pgjdbc level and revert to the regular flow. That would again be transparent to the application.
I do get the point, and in fact I myself mentioned the ORM case above as an advantage of implicit query preparation.
First, there's nothing stopping an ORM from optimizing multiple inserts into a single multivalue insert. I do admit I'm not aware of any who do this, but it's a good idea for an optimization - I happen to maintain the Entity Framework Core provider for Npgsql, I might take a look at this optimization (so again thanks for the idea).
Second, it's well-known that using an ORM almost always implies a performance sacrifice - it's a tradeoff that's chosen when going with an ORM. It's great that you optimize multiple inserts, but there are a myriad of other cases where an ORM generates less efficient SQL that what would be possible - but I don't think it makes sense for the driver to actually contain an SQL optimizer. Slightly worse performance isn't in itself a reason to drop ORMs: it's frequent practice to drop down to raw SQL for performance-critical operations, etc.
But all that isn't really important - I'm going to repeat what I said before and it would be good to get some reaction to this. Every software component in the stack has a role, and maintaining those separations is what keeps things simple and sane. Just for fun, we could imagine a kernel network-stack feature which analyzes outgoing messages and optimizes them; we could even implement your multiple insert -> multivalue insert optimization there. This would have the advantage of working out-of-the-box for every driver and every language out there (just like your driver does provides it transparently for all ORMs) But nobody in their right mind would think of doing something like this, and for good reason.
The programmer's task is to write SQL, the driver's task is to communicate that SQL via the database-specific protocol, the kernel's networking stack's task is to transmit that protocol via TCP, etc. etc. If an ORM is used, the programmer effectively outsources the task of writing SQL to another component, which is supposed to do a good job about it. Once you go about blurring all the lines here, everything becomes more complicated, brittle and hard to debug.
For what it's worth, I can definitely imagine your kind of optimizations occurring at some additional layer which the user would choose to use - an intermediate SQL optimizer between application code (or ORM) and the driver. This "SQL optimizer" layer would keep the driver itself lean and simple (for users who *don't* want all the magic), while allowing for transparent optimizations for ORMs. Or if the magic is implemented at the driver leve, it should be opt-in, or at least easy to disable entirely.
Shay>are you sure there aren't "hidden" costs on the PostgreSQL side for generating so many implicit savepoints?Technically speaking I use the same savepoint name through bind/exec message.
Out of curiosity, I whipped up a quick benchmark (voltmeter) of the impact of adding a savepoint before every command. Each iteration creates a transaction, sends one Bind/Execute for "SELECT 1" (which was prepared during setup), then sends one Bind/Execute for "SAVEPOINT x; SELECT 1", then commits. The baseline simply sends "SELECT 1" twice (two Bind/Execute roundtrips) in the transaction. Here are the results against localhost (PG 9.5):
Method | Median | StdDev | Scaled | Op/s |
-------- |------------ |---------- |------- |-------- |
With | 268.0387 us | 9.4800 us | 1.06 | 3678.32 |
Without | 252.9685 us | 8.3573 us | 1.00 | 3896.9 |
The benchmark source code is https://gist.github.com/
Shay>What you're doing is optimizing developer code, with the assumption that developers can't be trusted to code efficiently - they're going to write bad SQL and forget to prepare their statementsPlease, be careful. "you are completely wrong here" he-he. Well, you list the wrong assumption. Why do you think my main assumption is "developers can't be trusted"?
Because you said so above (Wed, Aug 10, 2016 at 8:37 PM):
> My experience shows, that people are very bad at predicting where the performance problem would be.
> For 80% (or even 99%) of the cases, they just do not care thinking if a particular statement should be server-prepared or not.
> They have absolutely no idea how much resources it would take and so on.
Maybe you're even right saying these things, I don't know. But that doesn't mean I as a driver should solve their problems for them. And I also get that you have an additional argument here besides programmer laziness/stupidity - the ORM argument - which makes more sense.
The proper assumption is: I follow Java database API specification, and I optimize pgjdbc for the common use case (e.g. ORM or ORM-like).
Do you have any evidence that ORM or ORM-like is the common use case?
For instance, if Java application wants to use bind values (e.g. to prevent security issues), then the only way is to go through java.sql.PreparedStatement.Here's the documentation: https://docs.oracle.com/javase/8/docs/api/jav a/sql/Connection.html#prepareS tatement-java.lang.String- Here's a quote:Javadoc> Note: This method is optimized for handling parametric SQL statements that benefit from precompilation. If the driver supports precompilation, the methodprepareStatementwill send the statement to the database for precompilation. Some drivers may not support precompilation. In this case, the statement may not be sent to the database until thePreparedStatementobject is executed. This has no direct effect on users; however, it does affect which methods throw certainSQLExceptionobjects.The most important part is "if the driver supports precompilation..."There's no API to enable/disable precompilation at all.So, when using Java, there is no such thing as "statement.enableServerPrepare=true". It is expected, that "driver" would "optimize" the handling somehow in the best possible way.
What? I really didn't understand your point here. All the doc is saying is that if the driver doesn't support prepared statements, then using them wouldn't provide any benefit etc. The very fact that the Java API *has* a PreparedStatement class means that statement preparation is exposed to the developer - the API provides methods to the developer, allowing them to choose *themselves* what to prepare. You chose to implicitly prepare statements even if PreparedStatement *isn't* used, you really can't claim that this is expected behavior (and indeed, most drivers I know don't do it).
It is Java API specification that enables me (as a driver developer) to be flexible, and leverage database features so end user gets best experience.
In my opinion, the API neither enables nor prohibits what you're doing. But again, the very fact that the API includes PreparedStatement shows that the JDBC considers preparation a programmer concern/decision and not an implicit driver decision.
Shay> What? I really didn't understand your point here. All the doc is saying is Shay> that if the driver doesn't support prepared statements, then using them Please read again. PreparedStatement is the only way to execute statements in JDBC API. There's no API that allows user to specify "use server-prepared here". Well, there's non-prepared API in JDBC, however it misses "bind variables" support, so if bind variables required, developer would use PreparedStatement. Java's PreparedStatement does not have an option to distinguish which statements should be server-prepared and which should not. Vladimir>> My experience shows, that people are very bad at predicting where the Vladimir>> performance problem would be. Vladimir>> For 80% (or even 99%) of the cases, they just do not care thinking if a Vladimir>> particular statement should be server-prepared or not. Vladimir>> They have absolutely no idea how much resources it would take and so on. Shay> Maybe you're even right saying these things, I don't know. But that doesn't Shay> mean I as a driver should solve their problems for them. And I also get Shay> that you have an additional argument here besides programmer Shay> laziness/stupidity - the ORM argument - which makes more sense. Suppose backend can handle 20 server-prepared statements at most (if using more it would run out of memory). Suppose an application has 100 statements with ".prepare()" call. I think it is reasonable for the DB driver to figure out which statements are most important and server-prepare just "20 most important ones", and leave the rest 80 as regular non-prepared statements. Do you think the DB driver should just follow developer's advice and server-prepare all the 100 statements causing backend crash? Do you think application developer should have a single list of all the statements ever used in the application and make sure there's no more than 20 queries in it? My main point is not "developers are stupid", but "people often have wrong guess when it comes to performance". There are too many moving parts, so it is hard to predict performance implications. Often it is much easier to execute a series of benchmarks that validate certain hypothesis. For instance, as Tatsuo says, savepoint overhead for DML is higher than savepoint overhead for SELECT, so I plan to have that benchmark as well. Shay> First, there's nothing stopping an ORM from optimizing multiple inserts Shay> into a single multivalue insert. I do admit I'm not aware of any who do Shay> this, but it's a good idea for an optimization - I happen to maintain the Shay> Entity Framework Core provider for Npgsql, I might take a look at this Shay> optimization (so again thanks for the idea). Nothings stops, but M framework times N database drivers results in M*N effort for each feature. As you say: application should just use batch API, and it's driver's job to convert that into suitable for the database sequence of bytes. Same for Npgsql: if you implement rewrite at Npgsql level, that would automatically improve all the framework/applications running on top of Npgsql. Shay> I'm going to repeat what I said Shay> before and it would be good to get some reaction to this. Every software Shay> component in the stack has a role, and maintaining those separations is Shay> what keeps things simple and sane You might be missing my comments on CPU, x86, etc. My reaction is: almost every existing component is extremely hard to reason about. For instance: CPU has certain number of registers, it has certain amount of L1/L2/... caches and so on. Do you mean each and every developer should explicitly specify which program variable should use register and which one should go into L2 cache? This is a counter-example to your "sane" "separation". CPU is free to reorder instruction stream as long as the net result complies to the specification. In the same way, CPU is free to use L1/L2 caches in whatever way it thinks is the best. Note: typical DB driver developer does not try to maintain a set of "optimal assembly instructions". Driver developer relies on the compiler and the CPU so they would optimize driver's code into the best machine code. Of course driver might have inline assembly, but that is not how mainstream drivers are written. Another example: TCP stack. When DB driver sends some data, kernel is free to reorder packets, it is free to interleave, delay them, or even send even use multiple network cards to send a single TCP stream. Windows 10 includes several performance improvements to the TCP stack, and it is nowhere near to "kernel is doing exactly what application/driver coded". Once again: application/driver developer does not optimize for a specific hardware (e.g. network card). Developers just use common API and it is kernel's job to use best optimizations for the particular HW. The same goes to ORM-DB combo. ORM uses DB driver's API, and it's drivers job to use optimal command sequence for the specific database. Note: of course ORM might use vendor specific features for a good reason, however simple cases like "batch insert" are both common, and they are not top priority from "ORM developer" perspective. The same goes for application-driver-DB. Application just uses driver's API, and it is not application's business which bytes to send over the wire. Neither application should specify which particular packets to use. Note: I do not suggest to rewite SELECTs at the driver level yet. I do not know a common pattern there. For "insert multivalues" the pattern is simple: user sends insert statements via batch API. It happens quite often as it is the standard way of inserting data in bulks. It is recommended in all the books and articles on JDBC API. Not all the databases support multivaleus, so a cross-database application would likely just use "insert single values through batch API" and rely on the DB driver and database to do the right thing. Of course having that fix at network stack level would automatically improve all the postgresql drivers, however 1) It is NOT possible since multivalues have different SEMANTICS. When sending indivisual inserts, each individual response would have "number of rows inserted" field. When using multivalues insert, there will be just one insert with the total number of rows inserted. If application logic did expect separate row counts, then kernel stack is in trouble: it cannot recover individual counts out of a combined response. That is why multivalues rewrite at TCP level is impossible. So, PostgreSQL network protocol v3 prohibits kernel from doing automatic multivalues optimization. Let me show you how JDBC API enables PgJDBC to do that optimization: when application is using JDBC batch API, it does receive "per statement row count" as a batch result. However, there's a special result code that says "statement did succeed, but the row count is not known". Developers are prepared that DB driver can return "not known" for all the rows, so PgJDBC is free o use multivalues or copy or whatever makes most sense for a particular batch. 2) There are other implications of doing that optimization at kernel level (e.g. overhead for mysql users), but since "the optimization is not possible due to semantics", other reasons are not important. Shay> Or if the magic is implemented at the Shay> driver leve, it should be opt-in, or at least easy to disable entirely. "Optimizations in the CPU should be opt-in or at least easy to disable". Does that sound right to you? For debugging purposes, it could make sense. However, for regular production usage, optimizations should be enabled by default. Regular Intel CPUs come with optimizations enabled by default. Multivalues rewrite does comply with JDBC batch API, so it makes no surprise even if the optimization is enabled by default. Shay> So the Shay> several-microsecond difference translates to a 6% performance degradation. Shay> This is probably due to the slowness of processing the extra Bind/Execute Shay> pair for the savepoint, which maybe can be improved in PostgreSQL. Shay> Regardless, you may say there's no business case or that SELECT 1 against Shay> localhost means nothing, or that posting data is somehow wrong, but I don't Shay> find this very acceptable. In this particular case the purpose is to measure the overhead. In your particular case savepoint seems to cost 15us. It costs 3us for me, but that does not matter much. If each and every query is prefixed with a savepoint, then it will be like 15ms overhead for 1000 queries. I think if application issues 1000 queries, it would anyway spend much more time on processing the results and figuring out "which query to issue/which values to pass". However, that voltmeter is broken as Tatsuo have pointed out. He chimed in a pgdbc issue tracker and pointed out that "savepoint-DML-savepoint-DML-..." scenario would allocate extra xid for each savepoint. The more the xid allocation rate, the harder for vacuum the case is. So we need to measure 1) "savepoint-DML-savepoint-DML-..." in order to find "savepoint overhead in case of DML". Note: pgjdbc's autosave=conservative would not issue savepoint before regular DMLs as DML cannot fail with "cached plan ... result type" error. So "DML-select-DML-select" scenario is required. 2) "real life applications" in order to find how extra savepoints affect xid allocation rate. Vladimir
On Sat, Aug 13, 2016 at 11:20 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Tatsuo>Interesting. What would happen if a user changes some of GUC
parameters? Subsequent session accidentally inherits the changed GUC
parameter?Yes, that is what happens.The idea is not to mess with gucs.
Wow... That is... insane...
Tatsuo>There's nothing wrong with DICARD ALLTatsuo>"DISCARD ALL" is perfect for this goal.It looks like you mean: "let's reset the connection state just in case".I see where it might help: e.g. when providing database access to random people who might screw a connection in every possible way.
It's not about random people screwing up connections, it's about maintaining isolation between different connections... When using an out-of-process pool (e.g. pgbouncer/pgpool), it's entirely reasonable for more than one app to use use the same pool. It's entirely possible for one app to change a GUC and then the other app goes boom. It's especially hard to debug too, because it depends on who got the physical connection before you.
Even with in-process pools it's standard practice (and a good idea) to reset state. The idea is that pooling, much like a cache (see below!), is supposed to speed up your application without having any other visible effects. In other words, running your app with or without a pool should be identical except for performance aspects. If some part of a big complex application modified state, and then some other part happens to get that physical connection, it's extremely hard to make sense of things.
One note - in Npgsql's implementation of persistent prepared statements, instead of sending DISCARD ALL Npgsql sends the commands listed in https://www.postgresql.org/docs/current/static/sql-discard.html, except for DEALLOCATE ALL. This cleans up state changes but leaves prepared statements in place.
Just in case: do you think one should reset CPU caches, OS filesystem caches, DNS caches, bounce the application, and bounce the OS in addition to "discard all"?Why reset only "connection properties" when we can reset everything to its pristine state?
Um, because all the caches you mention are, well, caches - by definition they're not supposed to have any visible impact on any application, except for making it faster. This is somewhat similar to the CPU reordering you keep coming back to - it's totally invisible. GUCs are the exact opposite - you use them to modify how PostgreSQL behaves. So it makes perfect sense to reset them.
Just in case: PostgreSQL does not execute "discard all" on its own.
Of course it doesn't - it doesn't know anything about connection pooling, it only knows about physical connections. When would it execute "discard all" on its own?
If you mean "pgpool is exactly like reconnect to postgresql but faster since connection is already established", then OK, that might work in some cases (e.g. when response times/throughput are not important), however why forcing "you must always start from scratch" execution model?
To enforce isolation, which is maybe the most important way for programs to be reliable - but this is a general theme which you don't seem to agree with. Regardless, resetting state doesn't have to have a necessary effect on response times/throughput.
Developers are not that dumb, and they can understand that "changing gucs at random is bad".
This has nothing to do with random, developers may have a legitimate reason to modify a GUC. In fact, GUCs are there precisely so that developers can change them...
Also, session state is not only about GUCs. DISCARD ALL also releases locks, resets authorization, resets sequence state (currval/nextval), etc. etc. All these things should not leak across connections.
> Please read again. PreparedStatement is the only way to execute statements
> in JDBC API. There's no API that allows user to specify "use
> server-prepared here".
> Well, there's non-prepared API in JDBC, however it misses "bind
> variables" support,
> so if bind variables required, developer would use PreparedStatement.
> Java's PreparedStatement does not have an option to distinguish which statements
> should be server-prepared and which should not.
> server-prepared here".
> Well, there's non-prepared API in JDBC, however it misses "bind
> variables" support,
> so if bind variables required, developer would use PreparedStatement.
> Java's PreparedStatement does not have an option to distinguish which statements
> should be server-prepared and which should not.
This is something new - maybe it's part of the misunderstanding here. To me, the term "prepared statements" always means "server-prepared statements"; this seems to be supported by the documentation you quote: "If the driver supports precompilation, the method prepareStatement will send the statement to the database for precompilation". I don't understand the concept of a prepared statements which isn't server-prepared - do you have some sort of driver-only prepared statements, which
Regardless of any optimizations you may be doing, in every database driver I've ever seen in my life, "prepared" simply means "server-prepared". And in every driver I've ever seen, there's an explicit API for that. Therefore server-prepare is something that's exposed to the developer, rather than some internal detail left to the driver.
> Suppose backend can handle 20 server-prepared statements at most (if using more it would run out of memory).
> Suppose an application has 100 statements with ".prepare()" call.
> I think it is reasonable for the DB driver to figure out which statements are most important and server-prepare just "20 most important ones", > and leave the rest 80 as regular non-prepared statements.
> Suppose an application has 100 statements with ".prepare()" call.
> I think it is reasonable for the DB driver to figure out which statements are most important and server-prepare just "20 most important ones", > and leave the rest 80 as regular non-prepared statements.
I seriously don't find it reasonable at all. LRU caching sometimes works well, and sometimes works very badly. That depends on the application and on the domain. Here's an example. Imagine two applications running against the same pool (or two large components within the same application). Each one has its set of "hot" statements, but unfortunately not all of them can fit prepared statement quota (20 in your example). Each connection fills the cache, ejecting the other component's prepared statements from the cache. As we switch between the two components, statements have to be reprepared.
Manual work here would allow picking truly hottest statements from each app/component, and preparing those - allowing the hottest statements across both components to always remain live. This is exactly what is meant by "programmer knowledge" which the driver doesn't have - it only has its recently-used logic which sometimes breaks down.
> Shay> I'm going to repeat what I said
> Shay> before and it would be good to get some reaction to this. Every software
> Shay> component in the stack has a role, and maintaining those separations is
> Shay> what keeps things simple and sane
> Shay> before and it would be good to get some reaction to this. Every software
> Shay> component in the stack has a role, and maintaining those separations is
> Shay> what keeps things simple and sane
>
> You might be missing my comments on CPU, x86, etc.
> My reaction is: almost every existing component is extremely hard to
> reason about.
> For instance: CPU has certain number of registers, it has certain
> amount of L1/L2/...
> caches and so on.
> Do you mean each and every developer should explicitly specify which
> program variable should use register and which one should go into L2 cache?
> You might be missing my comments on CPU, x86, etc.
> My reaction is: almost every existing component is extremely hard to
> reason about.
> For instance: CPU has certain number of registers, it has certain
> amount of L1/L2/...
> caches and so on.
> Do you mean each and every developer should explicitly specify which
> program variable should use register and which one should go into L2 cache?
You keep making this mistaken analogy... Caches (and CPU reordering) are invisible, prepared statements aren't - they can trigger bugs (because of DDL), and much more importantly, they take up resources on the PostgreSQL side. Period. The L2 cache is already there and takes no additional resources whether you use it or not. It's invisible.
Vladimir>> Yes, that is what happens. Vladimir>> The idea is not to mess with gucs. Shay:> Wow... That is... insane... Someone might say that "programming languages that enable side-effects are insane". Lots of connection pools work by sharing the connections and it is up to developer if he can behave well (see "It is not" below) Shay> it's entirely reasonable for Shay> more than one app to use use the same pool Sharing connections between different applications might be not that good idea. However, I would not agree that "having out-of-process connection pool" is the only sane way to go. I do admit there might be valid cases for out of process pooling, however I do not agree it is the only way to go. Not only "inprocess" is one of the ways, "in-process" way is wildly used in at least one of the top enterprise languages. If you agree with that, you might agree that "in-process connection pool that serves exactly one application" might work in a reasonable fashion even without DISCARD ALL. Shay> Even with in-process pools it's standard practice (and a good idea) to Shay> reset state. It is not. Can you quote where did you get that "standard practice is to reset state" from? Oracle Weblogic application server does not reset connections. JBoss WildFly application server does not reset connections. HikariCP connection pool does not reset connections. I can easily continue the list. The above are heavily used java servers (Hikari is a pool to be exact). Shay> If some part of a big complex Shay> application modified state, and then some other part happens to get that Shay> physical connection, it's extremely hard to make sense of things. Let's not go into "functional programming" vs "imperative programming" discussion? Of course you might argue that "programming in Haskell or OCaml or F#" makes "extremely easy to make sense of things", but that's completely another discussion. Shay> One note - in Npgsql's implementation of persistent prepared statements, Shay> instead of sending DISCARD ALL Npgsql sends the commands listed in Shay> https://www.postgresql.org/docs/current/static/sql-discard.html, except for Shay> DEALLOCATE ALL. This cleans up state changes but leaves prepared statements Shay> in place. Ok. At least you consider that "always discarding all the state" might be bad. Shay> This is somewhat similar to the CPU reordering you Shay> keep coming back to - it's totally invisible I would disagree. CPU reordering is easily visible if you are dealing with multithreaded case. It can easily result in application bugs if application misses some synchronization. CPU reordering is very visible to regular programmers, and it is a compromise: 1) Developers enable compiler and CPU do certain "reorderings" 2) Developers agree to follow the rules like "missing synchronization might screw things up" 3) In the result, the code gets executed faster. Vladimir> Just in case: PostgreSQL does not execute "discard all" on its own. Shay> Of course it doesn't - it doesn't know anything about connection pooling, Shay> it only knows about physical connections. When would it execute "discard Shay> all" on its own? That my point was for "pgpool aiming to look like a regular postgresql connection". The point was: "postgresql does not discard on its own, so pgpool should not discard". Shay> To enforce isolation, which is maybe the most important way for programs to Shay> be reliable - but this is a general theme which you don't seem to agree Shay> with. If you want to isolate something, you might better have a per-application connection pool. That way, if a particular application consumes all the connections, it would not impact other applications. If all the applications use the same out-of-process pool, there might be trouble of resource hogging. Shay> Regardless, resetting state doesn't have to have a necessary effect Shay> on response times/throughput. Even if you do not reset prepared statements, "reset query" takes time. For instance: there's a common problem to "validate connections before use". That is the pooler should ensure the connection is working before handling it to the application. Both Weblogic server, and HikariCP have those connection validation built in and the validation is enabled by default. However, it turns out that "connection validation" takes too much time, it is visible in the application response times, etc, so they both implement a grace period. That is "if the connection was recently used, it is assumed to be fine". Weblogic trusts 15 seconds by default, so if you borrow connections each 10 seconds, then they will not be tested. Well, there's additional background validation, but my main point is "even select 1" is visible on the application response times. Shay> This is something new - maybe it's part of the misunderstanding here. To Shay> me, the term "prepared statements" always means "server-prepared Shay> statements"; this seems to be supported by the documentation you quote: "If Shay> the driver supports precompilation, the method prepareStatement will send Shay> the statement to the database for precompilation". I don't understand the Shay> concept of a prepared statements which isn't server-prepared - do you have Shay> some sort of driver-only prepared statements, which The concept is "the implementation of PreparedStatement interface is free to chose how it will execute the queries". It can go with "server-prepare on each execution", it can go with "cache server-prepared statements", etc, etc. The whole purpose of having that "vague API" is to enable database vendors to make most sense of their databases. Shay> Regardless of any optimizations you may be doing, in every database driver Shay> I've ever seen in my life, "prepared" simply means "server-prepared". And Shay> in every driver I've ever seen, there's an explicit API for that. Therefore Shay> server-prepare is something that's exposed to the developer, rather than Shay> some internal detail left to the driver. Please, take CPU example (or TCP example) seriously. Seriously. CPU did not always had a L2 cache. L2 was invented to improve the performance of existing and future applications. The same applies to "prepared statement cache at the database driver level". It is implemented in pgjdbc to improve the performance of existing and future applications. Vladimir>> Suppose backend can handle 20 server-prepared statements at most (if Vladimir> using more it would run out of memory). Vladimir>> Suppose an application has 100 statements with ".prepare()" call. Vladimir>> I think it is reasonable for the DB driver to figure out which statements Vladimir> are most important and server-prepare just "20 most important ones", > and Vladimir> leave the rest 80 as regular non-prepared statements. Shay> I seriously don't find it reasonable at all. Would you please answer to "should db driver silently server-prepare all the 100 statements and crash the DB" question? Shay> Each connection fills Shay> the cache, ejecting the other component's prepared statements from the Shay> cache. As we switch between the two components, statements have to be Shay> reprepared. This is exactly what happens when several applications use the same CPU. L2/L3 can be shared between cores, so if one cares on the performance of a particular application, he should isolate the critical task to its own CPU (or set of cores). The same principle applies to connection pool. Either multiple pools should be used, or cache size increased, or more sophisticated algorithms should be used to provide better hit rate. Shay> Manual work here would allow picking truly hottest statements from each Shay> app/component, and preparing those - allowing the hottest statements across Shay> both components to always remain live. Shay> This is exactly what is meant by Shay> "programmer knowledge" which the driver doesn't have - it only has its Shay> recently-used logic which sometimes breaks down. Let me exaggerate a bit. Compiler optimizations sometimes break down (they produce not that well performing code), so all the optimizations should be disabled by default, and every developer should manually examine each line of code, identify hottest statements from each app/component and assign variables to CPU registers. This is exactly "programmer knowledge" which the compiler doesn't have. Does it sound good to you? Come on. Suppose you are writing a framework (ORM or whatever) that happens to execute queries into the database. Should that API have a special parameter "should_use_server_prepared" for each and every method? How should framework developer tell which statements should be server-prepared and which should not? Should framework use server-prepared statements at all? What if framework should support PostgreSQL, MySQL, and Oracle? Should there be three parameters? Just the same in another direction: can you show some github library that allows user (the developer) to control which statements should be server-prepared and which should not? Shay> You keep making this mistaken analogy... Caches (and CPU reordering) are Shay> invisible, prepared statements aren't - they can trigger bugs (because of Shay> DDL), Note: "the cache of server-prepared statements" is invisible to the end user. Well, when it comes to DDL it might trigger "PostgreSQL's not_implemented" issues, however those cases are not often, and those cases can be solved (in no particular order): 1) For instance, it can be solved by manual intervention: reset the connection pool after DDL. 2) It can be solved by "automatic savepointing" at the driver level. 3) It can be solved by fixing "not_implemented" at the database level. For instance, if "cached plan must not change state" error did not kill transaction, driver would be able just resend the full parse/describe/bind sequence and avoid throwing "cached plan" at user. 4) I'm sure there are other solutions. They might be even better than all the three above, but the point is reusing server-prepared statements is a way to go, so let's try fixing the database/protocol instead of reverting to "each connection should be taken through DISCARD ALL" Shay> and much more importantly, they take up resources on the PostgreSQL Shay> side. Period. The L2 cache is already there and takes no additional Shay> resources whether you use it or not. It's invisible. CPU caches take resources as well. L2 cache drains power, it costs money to produce. CPUs without L2/L3 would be cheaper. "it takes resources" does not justify that "the feature must not exist". "statement cache" is not completely invisible partially due to current database limitations, and partially due to "strange maintenance techniques end-users are using". Vladimir
On Mon, Aug 15, 2016 at 3:16 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Vladimir>> Yes, that is what happens.
Vladimir>> The idea is not to mess with gucs.
Shay:> Wow... That is... insane...
Someone might say that "programming languages that enable side-effects
are insane".
Lots of connection pools work by sharing the connections and it is up
to developer
if he can behave well (see "It is not" below)
The insane part is that there's really almost no reason to allow these side-effects... It's possible to efficiently reset connection state with a truly negligible impact on
Shay> it's entirely reasonable for
Shay> more than one app to use use the same pool
Sharing connections between different applications might be not that good idea.
Not sure why... It seems like a bad idea mostly if your pool is leaking state.
However, I would not agree that "having out-of-process connection
pool" is the only sane
way to go.
I do admit there might be valid cases for out of process pooling,
however I do not agree
it is the only way to go. Not only "inprocess" is one of the ways,
"in-process" way is wildly used
in at least one of the top enterprise languages.
If you agree with that, you might agree that "in-process connection
pool that serves
exactly one application" might work in a reasonable fashion even
without DISCARD ALL.
I never said out-of-process pooling is the way to go - in the .NET world in-process pooling is very valid. But as I carefully said in my last email, the same problems you have with multiple applications can occur with multiple components within the same application. The process boundary isn't very important here - in some scenarios programmers choose process separation, in others they choose threads. The same basic problems that occur in one model can occur in the other, including usage strategies which make LRU caching very bad.
Shay> Even with in-process pools it's standard practice (and a good idea) to
Shay> reset state.
It is not. Can you quote where did you get that "standard practice is
to reset state" from?
I guess I take that back, I haven't actually made a thorough comparison here.
Shay> If some part of a big complex
Shay> application modified state, and then some other part happens to get that
Shay> physical connection, it's extremely hard to make sense of things.
Let's not go into "functional programming" vs "imperative programming"
discussion?
Of course you might argue that "programming in Haskell or OCaml or F#" makes
"extremely easy to make sense of things", but that's completely
another discussion.
I'm not sure what this is referring to... If you're talking about my comment that "isolation/separation of layers is a good thing in programming", then I don't think it's the function vs. imperative kind of argument.
Shay> One note - in Npgsql's implementation of persistent prepared statements,
Shay> instead of sending DISCARD ALL Npgsql sends the commands listed in
Shay> https://www.postgresql.org/docs/current/static/sql- discard.html,
except for
Shay> DEALLOCATE ALL. This cleans up state changes but leaves prepared
statements
Shay> in place.
Ok. At least you consider that "always discarding all the state" might be bad.
Yes I do. I actually implemented persistent prepared statements before this conversation started - I think it's a great performance booster. I'm still not sure if it should be opt-in or default, although I admit I'm leaning towards default. But that feature has very little to do with *implicit* preparation.
Shay> This is somewhat similar to the CPU reordering you
Shay> keep coming back to - it's totally invisible
I would disagree. CPU reordering is easily visible if you are dealing
with multithreaded case.
It can easily result in application bugs if application misses some
synchronization.
CPU reordering is very visible to regular programmers, and it is a compromise:
1) Developers enable compiler and CPU do certain "reorderings"
2) Developers agree to follow the rules like "missing synchronization
might screw things up"
3) In the result, the code gets executed faster.
The point is that AFAIK the same bugs that can result from reordering can also result from other basic conditions as well. If you're writing multithreaded code then you must handle synchronization - this is not a reordering-specific problem. Therefore if your program is multithreaded but doesn't do proper synchronization you have a bug - regardless of whether its manifestation is triggered by CPU reordering or not. I admit I'm not an expert on this and may be wrong (it would be interesting to know).
Vladimir> Just in case: PostgreSQL does not execute "discard all" on its own.
Shay> Of course it doesn't - it doesn't know anything about connection pooling,
Shay> it only knows about physical connections. When would it execute "discard
Shay> all" on its own?
That my point was for "pgpool aiming to look like a regular postgresql
connection".
The point was: "postgresql does not discard on its own, so pgpool
should not discard".
That makes no sense at all... PostgreSQL is not a pool, nor is it a driver. Within this conversation, DISCARD ALL is only relevant in the context of connection pooling. PostgreSQL only deals with physical connections, so there's no possible relevance here.
Shay> To enforce isolation, which is maybe the most important way for
programs to
Shay> be reliable - but this is a general theme which you don't seem to agree
Shay> with.
If you want to isolate something, you might better have a
per-application connection pool.
That way, if a particular application consumes all the connections, it
would not impact
other applications. If all the applications use the same
out-of-process pool, there might
be trouble of resource hogging.
Sometimes that's true, sometimes it's not... Different scenarios require different degrees of isolation. That's the thing about writing infrastructure like drivers and pools - it's not a good idea to assume too much about how people will use your component, and it's especially bad to impose things on them. It's perfectly reasonable to have two applications using the same pool - this removes pressure from PostgreSQL. Of course some attention has to be paid to resource hogging, but that doesn't mean pools should always be per-application.
Shay> Regardless, resetting state doesn't have to have a necessary effect
Shay> on response times/throughput.
Even if you do not reset prepared statements, "reset query" takes time.
It does only if you do it in a roundtrip of its own. When you close a pooled connection in Npgsql, the reset query is written to an internal buffer but not sent. The first query that actually gets sent by the user after opening will therefore have the reset query prepended to it (basically the reset query is batched). You can argue there's still some overhead there because of the extra PostgreSQL message, but that really seems like a negligible price to pay for the isolation advantages. And I accept that there should be an option for performance-hungry programmers to remove the reset query for extreme situations.
For instance: there's a common problem to "validate connections before use".
That is the pooler should ensure the connection is working before handling it
to the application.
Both Weblogic server, and HikariCP have those connection validation built in
and the validation is enabled by default.
However, it turns out that "connection validation" takes too much time,
it is visible in the application response times, etc, so they both implement a
grace period. That is "if the connection was recently used, it is
assumed to be fine".
Weblogic trusts 15 seconds by default, so if you borrow connections
each 10 seconds, then
they will not be tested.
Well, there's additional background validation, but my main point is
"even select 1"
is visible on the application response times.
That's all very true. When I started contributing to Npgsql (back in the 2.x days), it did a SELECT 1 validation roundtrip on each pooled connection open. This is obviously a very bad idea. It also doesn't make much sense, because connections can break at any point in time - why check only when a connection is returned from a pool? One thing Npgsql does to help, is to have an opt-in keepalive feature, which sends SELECT 1 after X seconds of inactivity. Aside from preventing nosy routers from killing connections after inactivity, it performs something like what you describe with the grace period, but the keepalive isn't tied to the actual open in any way.
But this interesting subject has nothing to do with the reset query, which can be done without an extra roundtrip as I said above.
The concept is "the implementation of PreparedStatement interface is
free to chose
how it will execute the queries". It can go with "server-prepare on
each execution",
it can go with "cache server-prepared statements", etc, etc.
The whole purpose of having that "vague API" is to enable database vendors to
make most sense of their databases.
What exactly does "server-prepare on each execution" means? Sending Parse on each execution? How can that be considered prepared at all? In my mind there's basically 2 possibilities:
1. You send Parse/Describe/Bind/Execute/Sync (or a single Query). This is the non-prepared mode (which I proposed to optimize originally).
2. You send Parse/Describe/Sync when prepareStatement is called (when the PreparedStatement instance is created, you'll forgive me if I'm too familiar with the JDBC API). Then, when the prepared statement is executed, you send Bind/Execute/Sync. This is a server-prepared (or simply prepared) statement.
Do you see some other mode of query execution? Does pgjdbc consider something "prepared" without it being the 2nd option above? Note that I'm genuinely interested in case I'm missing something.
Shay> Regardless of any optimizations you may be doing, in every database driver
Shay> I've ever seen in my life, "prepared" simply means "server-prepared". And
Shay> in every driver I've ever seen, there's an explicit API for
that. Therefore
Shay> server-prepare is something that's exposed to the developer, rather than
Shay> some internal detail left to the driver.
Please, take CPU example (or TCP example) seriously. Seriously.
CPU did not always had a L2 cache. L2 was invented to improve the performance
of existing and future applications.
The same applies to "prepared statement cache at the database driver level".
It is implemented in pgjdbc to improve the performance of existing and
future applications.
I really am listening to you, but I'm really not agreeing with you, so I'm going to repeat myself. CPU caching is an even clearer case than instruction reordering, in that it's totally invisible - and that is why your analogy breaks down. Of course L2 was invented to improve performance, but that doesn't mean that all caches are the same. More precisely, what I find objectionable about your approach is not any caching - it's the implicit or automatic preparation of statements. This practice isn't invisible in that a) it may cause errors that wouldn't have been there otherwise (e.g. because of DDL), and b) it imposes a resource drain on the server. The second point is very important: the L2 cache doesn't impose a resource drain on anyone - it's just there, speeding up your application. I hope that point makes it across - it's why I don't accept your analogy.
Vladimir>> Suppose backend can handle 20 server-prepared statements at most (if
Vladimir> using more it would run out of memory).
Vladimir>> Suppose an application has 100 statements with ".prepare()" call.
Vladimir>> I think it is reasonable for the DB driver to figure out
which statements
Vladimir> are most important and server-prepare just "20 most
important ones", > and
Vladimir> leave the rest 80 as regular non-prepared statements.
Shay> I seriously don't find it reasonable at all.
Would you please answer to "should db driver silently server-prepare
all the 100 statements
and crash the DB" question?
Sure, the answer is no. A driver shouldn't silently server-prepare anything. This is what I've been arguing all along (I'm starting to think we might have some communication failure here). But the way I understand the database APIs (including JDBC), if the programmer calls .prepare() on 100 statements this overloads the database, then that's expected behavior, because there's nothing silent about it. Calling .prepare() means "please server-prepare my statement". I really don't understand how it can have any other meaning.
Shay> Each connection fills
Shay> the cache, ejecting the other component's prepared statements from the
Shay> cache. As we switch between the two components, statements have to be
Shay> reprepared.
This is exactly what happens when several applications use the same CPU.
L2/L3 can be shared between cores, so if one cares on the performance of
a particular application, he should isolate the critical task to its
own CPU (or set of cores).
The same principle applies to connection pool.
Either multiple pools should be used, or cache size increased, or more
sophisticated algorithms
should be used to provide better hit rate.
You're absolutely right that it happens with CPU caching, but that doesn't mean that it should be the same at the database driver level (see below).
Shay> Manual work here would allow picking truly hottest statements from each
Shay> app/component, and preparing those - allowing the hottest
statements across
Shay> both components to always remain live.
Shay> This is exactly what is meant by
Shay> "programmer knowledge" which the driver doesn't have - it only has its
Shay> recently-used logic which sometimes breaks down.
Let me exaggerate a bit.
Compiler optimizations sometimes break down (they produce not that
well performing code),
so all the optimizations should be disabled by default, and every
developer should
manually examine each line of code, identify hottest statements from each
app/component and assign variables to CPU registers.
This is exactly "programmer knowledge" which the compiler doesn't have.
Does it sound good to you?
Of course not. But I don't think it's a very valid analogy.
Here's how I see things, we have a pretty well-defined stack in the database world. ORMs exist on top of drivers as a way of allowing users to write higher-level code. It's possible to loosely see a database driver as, say, C, whereas using an ORM would be something like Java or C#, where you delegate memory management to the language runtime. You can even decide to drop down to "assembly", dumping the database driver and communicating with PostgreSQL in TCP to squeeze out some more performance (extreme scenario obviously).
All these are valid choices, and programmers should be able to choose at what layer they want to operate. By including all the high-level functionality (e.g. silent server preparation) in the driver layer, you're effectively saying that C shouldn't exist - there's no reason a programmer should ever choose a low-level approach.
And the thing I find hardest to understand here, if we leave ORMs aside for a minute, is that it's really trivial for programmers to explicit server-prepare their statements - as database APIs universally allow and encourage. Simply calling prepare on your statements is nowhere near the complexity that a compiler optimizer provides. Whereas it's totally unreasonable to expect programmers to do the work of the compiler optimizer, it seems really reasonable to ask them to think about server preparation, and even about multivalue inserts (at least if performance is important in the application).
The silent server preparation simply doesn't contribute that much, except when working with an ORM that doesn't support preparation. I've already said that for that case I think silent preparation is a *great* opt-in feature (and intend to implement it), but it's an exceptional thing that should be part of the ORM, not the driver.
Come on. Suppose you are writing a framework (ORM or whatever) that
happens to execute queries into the database.
Should that API have a special parameter "should_use_server_prepared"
for each and every method?
How should framework developer tell which statements should be
server-prepared and which should not?
As I said above, I think this is a critical point of misunderstand between us. The developers tells the driver which statements should be server-prepared by calling .prepareStatement(). I'm guessing you have a totally different understanding here.
I'm not going to respond to the part about dealing with prepared statements errors, since I think we've already covered that and there's nothing new being said. I don't find automatic savepointing acceptable, and a significant change of the PostgreSQL protocol to support this doesn't seem reasonable (but you can try proposing).
I'm not going to respond to the part about dealing with prepared statements errors, since I think we've already covered that and there's nothing new being said. I don't find automatic savepointing acceptable, and a significant change of the PostgreSQL protocol to support this doesn't seem reasonable (but you can try proposing).
As mentioned before. JDBC is not the only postgres driver to do this the ODBC driver does this as well. This is a requested feature by users. We didn't just decide to do it on our own.
One thing to keep in mind is that both JDBC and ODBC are not exclusively PostgreSQL drivers and as such we sometimes have to jump through hoops to provide the semantics requested by the API.
I'm not going to respond to the part about dealing with prepared statements errors, since I think we've already covered that and there's nothing new being said. I don't find automatic savepointing acceptable, and a significant change of the PostgreSQL protocol to support this doesn't seem reasonable (but you can try proposing).As mentioned before. JDBC is not the only postgres driver to do this the ODBC driver does this as well. This is a requested feature by users. We didn't just decide to do it on our own.One thing to keep in mind is that both JDBC and ODBC are not exclusively PostgreSQL drivers and as such we sometimes have to jump through hoops to provide the semantics requested by the API.
I don't have anything in particular against automatic savepointing when requested directly by users (especially if it's opt-in). My problem is more with automatic savepointing as a solution to a problem created by doing automatic prepared statements... Way too much automatic stuff going on there for my taste...
Shay> your analogy breaks down. Of course L2 was invented to improve performance, Shay> but that doesn't mean that all caches are the same. More precisely, what I Shay> find objectionable about your approach is not any caching - it's the Shay> implicit or automatic preparation of statements. This practice isn't Shay> invisible in that a) it may cause errors that wouldn't have been there Shay> otherwise (e.g. because of DDL), Long-lived named server-prepared statements cause problems even if server-prepared statements are created manually by developers. Could you please stop saying "automatic preparation causes ~DDL issues"? Those errors are not inherent to "automatic preparation of statements" Those are just database defects that need to be cured. Automatic savepointing is just a workaround for current DB limitation, and it provides users with a simplified migration path. Please, don't try to tell me that "IDbCommand.Prepare()" documentation says that "prepared statement might fail for no reason just because it is prepared". Shay> As I said above, I think this is a critical point of misunderstand between Shay> us. The developers tells the driver which statements should be Shay> server-prepared by calling .prepareStatement(). I'm guessing you have a Shay> totally different understanding here. Please, quote the document you got that "developers tell the driver which statements should be server-prepared by calling ..." from. It never works like that. Neither in Java, nor in C#. I would admit I've no C# experience, but I did find documentation on IDbCommand.Prepare() and examined it. The proper way to say is "by calling .Prepare() developer passes the intention that he might be using the same query multiple times". That is it. It never means "driver must absolutely use server-prepare in the response to .Prepare() call". The same goes for Java's PreparedStatement. It never means "the driver must use server-prepared features". As Microsoft lists in the .Prepare() documentation, modern versions of MSSQL just ignore .Prepare() and cache statements automatically. It is not a developer's business which statements should be in the database cache. Neither developer should care which statements reside in the driver cache. Shay> What exactly does "server-prepare on each execution" means? Sending Parse Shay> on each execution? How can that be considered prepared at all? Remember, java.sql.PreparedStatement interface is NOT bound to PostgreSQL in any manner. It is a generic database API. Thus the word "prepared" does not mean anything specific there. It gives no promise whether the statement will use "parseOnce, execMany" PostgreSQL's feature or not. A compliant implementation (that is a driver) could just assemble full SQL by concatenating the parameters on each execution and send it via 'Q' simple execute message. Shay> Does pgjdbc consider Shay> something "prepared" without it being the 2nd option above? Note that I'm Shay> genuinely interested in case I'm missing something. Currently the first 5 executions of PreparedStatement use unnamed statements (Parse/Bind/Exec). Then pgjdbc assigns a name and uses just Bind/Exec. So if a particular SQL is rare, then it would not get its own server-prepared name even though it is "java.sql.PreparedStatement". What pgjdbc does is it picks the most used queries and enables them to be cached at the database level. Vladimir>> app/component and assign variables to CPU registers. Vladimir>> This is exactly "programmer knowledge" which the compiler doesn't have. Vladimir>> Does it sound good to you? Shay> Of course not. But I don't think it's a very valid analogy. The analogy was not supposed to play in a way you twisted it with ORM=Java, driver=C, etc. Here's more detailed explanation: 1) You claim that programmers should manually examine all the SQL statements, and put ".prepare()" call if and only if the specific SQL should be server-prepared. 2) My analogy: programmers should manually examine all the variables (think of C# variables, or Java variables, or C variables, it does not matter), and assign which variables should use CPU registers, and which ones should go into the memory. Named server-prepared statements == CPU registers SQL statements in the code == variables in the code (e.g. C# variables) That is very valid analogy. What you say is "programmer has full visibility over the meaning of the code, thus it knows better which statements should be server-prepared and which should not". Well, register allocation is a bit harder problem that "statement name allocation", but the essence is the same: there's limited number of registers/named statements, so someone (or something) should decide which statements deserve a name. Just in case: you definitely know what CPU registers are and what is "register allocation" problem, don't you? You seem to pick up that "application developer != compiler engineer", however then you slipped into "nevertheless application developer should decide if each SQL should be server-prepared on a case-by-case basis". In ideal world that might work. However, that does not work in practice: 0) Microsoft's documentation on ".Prepare()" says "prepare call does not have any effect since sql server optimizes the statements automatically". So applications ported from MSSQL might miss ".Prepare()" altogether, thus it will under-perform and blame PostgreSQL for no reason. Does it sound fair? I do not think so. Do you see lots of complaints for "MSSQL doing automatic statement caching"? I'm not into MSSQL, but I know Oracle does automatic statement caching as well, and no one ever raises questions like "my precious statement was evicted". 1) What if the database RAM is increased, so the application can ".prepare()" not 20, but 2000 statements? Should developer add more ".prepare()" calls and recompile the application just to accommodate RAM increase? That sounds crazy. I think the way to go should be just increase "statement cache size". 2) Do you really expect each project to have a list of all the used SQL along with "should server-prepare" flags? 3) What if the application is composed of 5 components? How should one split the budget of server-prepared statements? (remember, we cannot prepare all of them otherwise the DB would crash) 4) Database driver does see all the SQLs executed within a connection. Of course, driver's automatic cache cannot beat "ideal pick", however that automatic statement can easily be "just fine" and automatic caching saves enormous amount of development time. Remember, C# compiler often is "just fine" at CPU register allocation, and you don't need to control how the code is actually executed. That spare time would better be spent on SQL tuning (that is "explain analyze...") rather than deciding which statements should be server-prepared and which should not. 5) When porting from other database, the application might already be full of "con.prepareStatement(String sql)" calls. As I said, there is NO NonPreparedStatement in Java. Does that mean an application ported from say Oracle should crash when running against PostgreSQL? That does not sound right. Shay> Whereas it's totally Shay> unreasonable to expect programmers to do the work of the compiler Shay> optimizer, it seems really reasonable to ask them to think about server Shay> preparation, and even about multivalue inserts (at least if performance is Shay> important in the application). a) They don't even know that multivalues in PostgreSQL gives such a boost b) By the time all the ORMs implement that feature, PostgreSQL might fix that defect so the optimization will become obsolete. Once again: I do not suggest rewriting SELECTs on the fly yet. What I suggest is to decide "which are the most important SQLs and which of them deserve their own server-prepared name" at the driver level. Remember: it is very close to what compiler is doing. It assigns registers automatically based on some heuristics. For typical applications it is just fine. No-one is trying to Shay> and b) it imposes a resource drain on the Shay> server. The second point is very important: the L2 cache doesn't impose a Shay> resource drain on anyone - it's just there, speeding up your application. I Shay> hope that point makes it across - it's why I don't accept your analogy. Oh. You might be not into a chip design either, that is why that analogy plays so bad. Just in case: if L2 cache was just there, and if L2 cache didn't impose a resource drain, why don't we have 1GiB L2 caches? Of course L2 drains lots of resources: 1) It drains money, as L2 costs valuable on-die space 2) L2 drains power, that is naturally drains your battery Of course there are good reasons to have L2 even though it drains resources, but the statement of "it is just there for free" is plain wrong. Shay> I'm still Shay> not sure if it should be opt-in or default, although I admit I'm leaning Shay> towards default. But that feature has very little to do with *implicit* Shay> preparation. Shay> The point is that AFAIK the same bugs that can result from reordering can Shay> also result from other basic conditions as well. If you're writing Shay> multithreaded code then you must handle synchronization - this is not a Shay> reordering-specific problem. Therefore if your program is multithreaded but Shay> doesn't do proper synchronization you have a bug - regardless of whether Shay> its manifestation is triggered by CPU reordering or not. I admit I'm not an Shay> expert on this and may be wrong (it would be interesting to know). Regarding "regardless...by CPU or not", you are off. I've listed a link to a concurrency bug in Linux kernel. It manifested itself only on some recent Intel CPUs. In other words, the kernel was fine otherwise, but if running modern CPU, it might hang. Of course it was bug in the kernel, but the trigger condition was "smarter CPU" that was able to do more "reorderings" that were possible with older ones. There are good articles by Alexey Shipilev where he describes what are the typical concurrency problems, and why do compiler engineers allow them to appear. The articles are java-related, however I think they are good read anyway: https://shipilev.net/blog/2014/jmm-pragmatics https://shipilev.net/blog/2016/close-encounters-of-jmm-kind Shay> It does only if you do it in a roundtrip of its own. When you close a Shay> pooled connection in Npgsql, the reset query is written to an internal Shay> buffer but not sent. The first query that actually gets sent by the user Shay> after opening will therefore have the reset query prepended to it Shay> (basically the reset query is batched) That is clever. Is it something specific to Npgsql pool? Does it work with all poolers that operate on top of Npgsql connections? Vladimir
Halfway through this mail I suddenly understood something, please read all the way down before responding...
On Tue, Aug 16, 2016 at 2:16 PM, Vladimir Sitnikov <sitnikov.vladimir@gmail.com> wrote:
Shay> your analogy breaks down. Of course L2 was invented to improve
performance,
Shay> but that doesn't mean that all caches are the same. More precisely, what I
Shay> find objectionable about your approach is not any caching - it's the
Shay> implicit or automatic preparation of statements. This practice isn't
Shay> invisible in that a) it may cause errors that wouldn't have been there
Shay> otherwise (e.g. because of DDL),
Long-lived named server-prepared statements cause problems even if
server-prepared statements are created manually by developers.
Could you please stop saying "automatic preparation causes ~DDL issues"?
I never said that... As I've said many times, the problem is errors caused by something the user never asked for. If I server-prepare a statement and then get an error, it's a result of my own action.
Shay> As I said above, I think this is a critical point of misunderstand between
Shay> us. The developers tells the driver which statements should be
Shay> server-prepared by calling .prepareStatement(). I'm guessing you have a
Shay> totally different understanding here.
Please, quote the document you got that "developers tell the driver which
statements should be server-prepared by calling ..." from. It never
works like that.
Neither in Java, nor in C#. I would admit I've no C# experience, but I did
find documentation on IDbCommand.Prepare() and examined it.
The proper way to say is "by calling .Prepare() developer passes the
intention that
he might be using the same query multiple times".
That is it. It never means "driver must absolutely use server-prepare
in the response
to .Prepare() call".
The same goes for Java's PreparedStatement.
It never means "the driver must use server-prepared features".
As Microsoft lists in the .Prepare() documentation, modern versions of
MSSQL just ignore .Prepare() and cache statements automatically.
It is not a developer's business which statements should be in the
database cache.
Neither developer should care which statements reside in the driver cache.
I'm really baffled here.
First, I never said prepared statements *must* be server-prepared. You're completely correct that databases APIs don't *require* this, because they by definition cover many databases and drivers. In Sqlite there's no server, so there can be no server-prepared statement.
However, where there *is* a server which supports prepared statements as an optimization, it's completely unthinkable to me that a driver wouldn't implement prepare as server-prepare. Nobody forces you to do it - it just seems unthinkable to do otherwise. This reason for this is that if server-prepared statements are supported by your database, we expect them to be a significant optimization (otherwise why would they exist), and therefore not using them when the user calls "prepare" seems like... foolishness. In other words, whatever client-side "precompilation" or other optimization is possible is probably going to be negligible when compared to server-preparation (this seems to be the case with PostgreSQL at the very least), so why *not* map the database API's prepare method to server-prepared statements?
I'm going to requote the API note which you quoted above on Connection.prepareStatement (https://docs.oracle.com/javase/7/docs/api/java/sql/Connection.html):
> This method is optimized for handling parametric SQL statements that benefit from precompilation. If the driver supports precompilation, the method prepareStatement will send the statement to the database for precompilation. Some drivers may not support precompilation.
Again, my understanding of English may be flawed, or maybe my logic circuits are malfunctioning. But I read this the following way:
1. preparedStatement is about precompilation.
2. If a driver supports precompilation (i.e. preparation), "prepareStatement will send the statement to the *database* for precompilation". Note that the API explicitly mentioned sending *to the database* - server preparation...
3. A driver may not support precompilation (i.e. preparation). This could be because it simply hasn't implemented it yet, or because the backend doesn't support it, or for any other reason. In this case it's a noop, which doesn't really change anything in this discussion.
A compliant implementation (that is a driver) could just assemble full SQL
by concatenating the parameters on each execution and send it via 'Q' simple
execute message.
I think I may have understood the problem here - there's definitely a Java vs. C# issue difference this conversation.
From reading the Java docs, I now realize that JDBC only seems to support parameters in prepared statements. In other words, the parameters capability is coupled with the capability of precompilation, i.e. the ability to execute the same query multiple times with better performance. In ADO.NET things are different. You can use parameters on a statement regardless of whether it's prepared or not. In other words, the *only* use of preparation is to speed up frequently-used statements - this makes it very natural to understand preparation as "server preparation".
So I now understand why in JDBC it could make sense for some prepared statements to be server-prepared, and for others not to. The JDBC API design seems very problematic to me - there are perfectly good reasons to use parameters without preparation (prevent SQL injection) and also the other way around, so coupling them doesn't seem like a good idea. But that isn't really relevant to this conversation.
I hope this also makes you understand why, at least in ADO.NET, it makes perfect sense to simply understand preparation as server-preparation - the only reason prepare exists is to improve performance.
I'm going to skip most of the CPU reordering/caching arguments here as I don't think they're relevant. Not everything is the same as CPU registers, and we can find different behaviors depending on the components and layer we choose to compare with. There are many scenarios in which programmers are expected to specify caching explicitly. I'm going to leave this behind.
0) Microsoft's documentation on ".Prepare()" says "prepare call does not have
any effect since sql server optimizes the statements automatically".
So applications ported from MSSQL might miss ".Prepare()" altogether,
thus it will
under-perform and blame PostgreSQL for no reason.
Does it sound fair? I do not think so.
Of course it's fair. They're porting code from one database to another, it's their responsibility to do the work. There are many other aspects besides preparation which would perform better in one database and worst in another. SQL itself differs from database to database, so it's totally unrealistic to expect the same code to simply run. The same goes for your Oracle example.
Regarding "regardless...by CPU or not", you are off.
I've listed a link to a concurrency bug in Linux kernel.
It manifested itself only on some recent Intel CPUs.
In other words, the kernel was fine otherwise, but if running modern
CPU, it might hang.
Of course it was bug in the kernel, but the trigger condition was
"smarter CPU" that
was able to do more "reorderings" that were possible with older ones.
Again, as I wrote, the bug was already there. Reordering just made it manifest - it could in theory have been manifested otherwise. You need to separate between a problem the programmer is responsible for, and a problem someone else is responsible for, regardless of why it's manifested.
Shay> It does only if you do it in a roundtrip of its own. When you close a
Shay> pooled connection in Npgsql, the reset query is written to an internal
Shay> buffer but not sent. The first query that actually gets sent by the user
Shay> after opening will therefore have the reset query prepended to it
Shay> (basically the reset query is batched)
That is clever.
Is it something specific to Npgsql pool? Does it work with all poolers
that operate
on top of Npgsql connections?
Thanks. It's specific to the Npgsql pool, which is also in-process. ADO.NET tends heavily to in-process pools, and also couples the pool to the driver - I'm not aware of driver-independent pools which you can use with any driver, like in Java. Basically if you use Npgsql, you use the Npgsql pool.
On 2016-07-31 17:57:12 -0400, Tom Lane wrote:
> Andres Freund <andres@anarazel.de> writes:
> > FWIW, I've observed the same with (a bit) more complicated queries. A
> > part of this is that the extended protocol simply does
> > more. PQsendQueryGuts() sends Parse/Bind/Describe/Execute/Sync - that's
> > simply more work and data over the wire than a single Q message.
>
> Yeah. The extended query protocol was designed to offer a lot of
> functionality that people had asked for, like plan re-use and
> introspection of the data types assigned to query parameters, but that
> doesn't come at zero cost. I think the tie-in to the plan cache is a
> significant part of the added overhead, and so is the fact that we have to
> iterate the per-message loop in PostgresMain five times not once, with
> overheads like updating the process title incurred several times in that.
One approach to solving this, without changing the protocol, would be to
"fuse" parse/bind/execute/sync together, by peeking ahead in the
protocol stream. When that combination is seen looking ahead (without
blocking), optimize it by handing it to something closer to
exec_simple_query() which also handles parameters. Even if we don't
recognize that pattern everytime, e.g. because later messages are in
different, not yet arrived, tcp packets, that'd speed up the common
case. As our client socket is nearly always is in non-blocking mode
these days, that shouldn't be too expensive.
Not that that analogy is fitting perfectl;y, but the above approach
seems to work quite well on the CPU level ("macro op fusion"), to
increase execution throughput...
Andres
Andres Freund <andres@anarazel.de> writes:
> On 2016-07-31 17:57:12 -0400, Tom Lane wrote:
>> Yeah. The extended query protocol was designed to offer a lot of
>> functionality that people had asked for, like plan re-use and
>> introspection of the data types assigned to query parameters, but that
>> doesn't come at zero cost. I think the tie-in to the plan cache is a
>> significant part of the added overhead, and so is the fact that we have to
>> iterate the per-message loop in PostgresMain five times not once, with
>> overheads like updating the process title incurred several times in that.
> One approach to solving this, without changing the protocol, would be to
> "fuse" parse/bind/execute/sync together, by peeking ahead in the
> protocol stream.
I do not think that would move the needle noticeably, because we'd still
have to do basically all the same work, due to not knowing whether the
statement is going to be used over again. If we'd specified that the
unnamed statement could be used only once, and that the unnamed portal
had to be executed to completion on first use, there would be more room
for optimization. The joys of hindsight :-(
regards, tom lane
On 2016-08-16 21:40:32 -0400, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2016-07-31 17:57:12 -0400, Tom Lane wrote: > >> Yeah. The extended query protocol was designed to offer a lot of > >> functionality that people had asked for, like plan re-use and > >> introspection of the data types assigned to query parameters, but that > >> doesn't come at zero cost. I think the tie-in to the plan cache is a > >> significant part of the added overhead, and so is the fact that we have to > >> iterate the per-message loop in PostgresMain five times not once, with > >> overheads like updating the process title incurred several times in that. > > > One approach to solving this, without changing the protocol, would be to > > "fuse" parse/bind/execute/sync together, by peeking ahead in the > > protocol stream. > > I do not think that would move the needle noticeably, because we'd still > have to do basically all the same work, due to not knowing whether the > statement is going to be used over again. If we'd specified that the > unnamed statement could be used only once, and that the unnamed portal > had to be executed to completion on first use, there would be more room > for optimization. The joys of hindsight :-( ISTM that with the current prepared statement search path behaviour (i.e. we replan on relevant changes anyway), we can store the unnamed statement's sql for that case.
BTW, there seem to be a room to enhance JDBC driver performance. In my understanding it always uses unnamed portal even if the SQL is like "BEGIN" or "COMMIT" (no parameters). They are too often used. Why not doing like this? Prepare(stmt=S1,query="BEGIN") Bind(stmt=S1,portal=P1) Execute(portal=P1) : : Execute(portal=P1) : : Execute(portal=P1) Instead of: Prepare(stmt=S1,query="BEGIN") Bind(stmt=S1,portal=null) Execute(portal=null) : : Bind(stmt=s1,portal=null) Execute(portal=null) : : Bind(stmt=s1,portal=null) Execute(portal=null) This way, we could save bunch of Bind messages. I don't know what other drivers do though. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Tatsuo>understanding it always uses unnamed portal even if the SQL is like
"BEGIN" or "COMMIT" (no parameters). They are too often used. Why not
doing like this?
Does it actually work?
"BEGIN" or "COMMIT" (no parameters). They are too often used. Why not
doing like this?
Does it actually work?
The documentation says named portals last till the end of the transaction:
https://www.postgresql.org/docs/9.5/static/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY
doc>If successfully created, a named portal object lasts till the end of the current transaction, unless explicitly destroyed
https://www.postgresql.org/docs/9.5/static/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY
doc>If successfully created, a named portal object lasts till the end of the current transaction, unless explicitly destroyed
Vladimir
> Tatsuo>understanding it always uses unnamed portal even if the SQL is like > "BEGIN" or "COMMIT" (no parameters). They are too often used. Why not > doing like this? > > Does it actually work? > > The documentation says named portals last till the end of the transaction: > > https://www.postgresql.org/docs/9.5/static/protocol-flow.html#PROTOCOL-FLOW-EXT-QUERY > > > doc>If successfully created, a named portal object lasts till the end of > the current transaction, unless explicitly destroyed Oh, ok. I misunderstood that named portals survive beyond transaction boundary. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
On Tue, Aug 16, 2016 at 4:48 PM, Andres Freund <andres@anarazel.de> wrote: > One approach to solving this, without changing the protocol, would be to > "fuse" parse/bind/execute/sync together, by peeking ahead in the > protocol stream. When that combination is seen looking ahead (without > blocking), optimize it by handing it to something closer to > exec_simple_query() which also handles parameters. Even if we don't > recognize that pattern everytime, e.g. because later messages are in > different, not yet arrived, tcp packets, that'd speed up the common > case. As our client socket is nearly always is in non-blocking mode > these days, that shouldn't be too expensive. I think this could possibly be done, but it seems a lot better to me to just bite the bullet and add a new protocol message. That was proposed by Tom Lane on July 31st and I think it's still by far the best and easiest idea proposed, except I think we could introduce it without waiting for a bigger rework of the protocol if we design the libpq APIs carefully. Most of the rest of this thread seems to have devolved into an argument about whether this is really necessary, which IMHO is a pretty silly argument, instead of focusing on how it might be done, which I think would be a much more productive conversation. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2016-08-23 11:42:53 -0400, Robert Haas wrote: > I think this could possibly be done, but it seems a lot better to me > to just bite the bullet and add a new protocol message. That was > proposed by Tom Lane on July 31st and I think it's still by far the > best and easiest idea proposed, except I think we could introduce it > without waiting for a bigger rework of the protocol if we design the > libpq APIs carefully. Most of the rest of this thread seems to have > devolved into an argument about whether this is really necessary, > which IMHO is a pretty silly argument, instead of focusing on how it > might be done, which I think would be a much more productive > conversation. I agree about the odd course of the further discussion, especially the tone was rather odd. But I do think it's valuable to think about a path that fixes the issue without requiring version-dependant adaptions in all client drivers. Greetings, Andres Freund
Just a note from me - I also agree this thread evolved (or rather devolved) in a rather unproductive and strange way.
One important note that came out, though, is that adding a new client message does have a backwards compatibility issue - intelligent proxies such as pgbouncer/pgpool will probably break once they see an unknown client message. Even if they don't, they may miss potentially important information being transmitted to the server. Whether this is a deal-breaker for introducing new messages is another matter (I personally don't think so).
On Tue, Aug 23, 2016 at 4:54 PM, Andres Freund <andres@anarazel.de> wrote:
On 2016-08-23 11:42:53 -0400, Robert Haas wrote:
> I think this could possibly be done, but it seems a lot better to me
> to just bite the bullet and add a new protocol message. That was
> proposed by Tom Lane on July 31st and I think it's still by far the
> best and easiest idea proposed, except I think we could introduce it
> without waiting for a bigger rework of the protocol if we design the
> libpq APIs carefully. Most of the rest of this thread seems to have
> devolved into an argument about whether this is really necessary,
> which IMHO is a pretty silly argument, instead of focusing on how it
> might be done, which I think would be a much more productive
> conversation.
I agree about the odd course of the further discussion, especially the
tone was rather odd. But I do think it's valuable to think about a path
that fixes the issue without requiring version-dependant adaptions in
all client drivers.
Greetings,
Andres Freund