Обсуждение: [PROPOSAL] Improvements of Hunspell dictionaries support
Hi. Introduction ============ PostgreSQL full-text search extension uses dictionaries from the various open source spell checker software to perform word normalization. Currently, Ispell, MySpell and Hunspell dictionaries are supported. Dictionaries requires two files: a dictionary file and an affix file. A dictionary file contains a list of words. Each word may be followed by one or more affix flags. An affix file contains a lot of parameters, definitions, prefix and suffix classes used in a dictionary file. Most complete and actively developed are Hunspell dictionaries (http://hunspell.sourceforge.net/). OpenOffice and LibreOffice projects recently switched from MySpell to Hunspell dictionaries. But PostgreSQL is unable to load recent version of Hunsplell dictionaries for several languages. It is because affix files of these dictionaries grow too big. Traditionally affix rules are named by one extended ASCII (8-bit) symbol. And if there is more than 192 rules, some syntax extension is needed. And to handle these dictionaries Hunspell have FLAG parameter with the following values: * FLAG long - sets the double extended ASCII character flag type * FLAG num - sets the decimal number flag type (from 1 to 65000) These flag types are used in affix files of such dictionaries as ar, br_fr, ca, ca_valencia, da_dk, en_ca, en_gb, en_us, fr, gl_es, is, ne_np, nl_nl, si_lk (from http://cgit.freedesktop.org/libreoffice/dictionaries/tree/). But PostgreSQL does not support FLAG parameter and can not load these dictionaries. There is also AF parameter which allows to substitute affix flag sets with ordinal numbers in affix and dictionary files. FLAG and AF parameters are not supported by PostgreSQL. Supporting these parameters allows to load dictionaries listed above into PostgreSQL database and use them in full text search. Proposed Changes ================ Internal representation of the dictionary in the PostgreSQL doesn't impose too strict limits on the number of affix rules. There are a flagval array, which size must be increased from 256 to 65000. All other changes is the changes in the affix file parsing code to properly parse long and numeric flags. I've already implemented support for FLAG long, it require relatively small patch size (60 lines). Support for FLAG num would require comparable amount of code. These changes would allow to use recent versions of Hunspell dictionaries for following dictionaries: br_fr, ca, ca_valencia, da_dk, gl_es, is, ne_np, nl_nl, si_lk. Implementation of AF flag would allow to support also following dictionaries: ar, en_ca, en_gb, en_us, fr, hu_hu. Expected Results ================ These changes would allow to use more recent and complete spelling dictionaries to perform word stemming during full-text indexing. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 10/20/15 9:00 AM, Artur Zakirov wrote: > Internal representation of the dictionary in the PostgreSQL doesn't > impose too strict limits on the number of affix rules. There are a > flagval array, which size must be increased from 256 to 65000. Is that per dictionary entry, fixed at 64k? That seems pretty excessive, if that's the case... -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
21.10.2015 01:37, Jim Nasby пишет: > On 10/20/15 9:00 AM, Artur Zakirov wrote: >> Internal representation of the dictionary in the PostgreSQL doesn't >> impose too strict limits on the number of affix rules. There are a >> flagval array, which size must be increased from 256 to 65000. > > Is that per dictionary entry, fixed at 64k? That seems pretty excessive, > if that's the case... This is per dictionary only. flagval array is used for the all dictionary. And it is not used for every dictionary word. There are also flag field of AFFIX structure, wich size must be increased from 8 bit to 16 bit. This structure is used for every affix in affix file. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
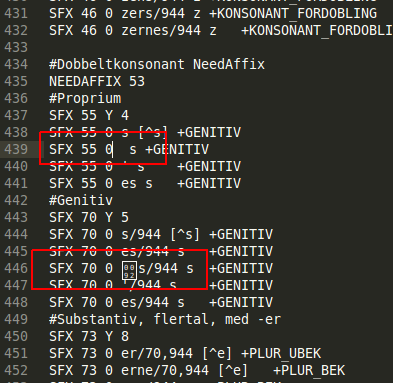
20.10.2015 17:00, Artur Zakirov пишет: > These flag types are used in affix files of such dictionaries as ar, > br_fr, ca, ca_valencia, da_dk, en_ca, en_gb, en_us, fr, gl_es, is, > ne_np, nl_nl, si_lk (from > http://cgit.freedesktop.org/libreoffice/dictionaries/tree/). Now almost all dictionaries are loaded into PostgreSQL. But the da_dk dictionary does not load. I see the following error: ERROR: invalid regular expression: quantifier operand invalid CONTEXT: line 439 of configuration file "/home/artur/progs/pgsql/share/tsearch_data/da_dk.affix": "SFX 55 0 s +GENITIV If you open the affix file in editor you can see that there is incorrect format of the affix 55 in 439 line (screen1.png): SFX 55 0 s +GENITIV SFX parameter should have a 5 fields. There are no field between "0" digit and "s" symbol. "+GENITIV" is the optional morphological field and ignored by PostgreSQL. I think that it is a error of the affix file. I wrote a e-mail to info@stavekontrolden.dk to the dictionary authors about this error. What is the right decision in this case? Should PostgreSQL ignore this error and do not show it? -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
{kind=link}
Hello again! Patches ======= I had implemented support for FLAG long, FLAG num and AF parameters. I attached patch to the e-mail (hunspell-dict.patch). This patch allow to use Hunspell dictionaries listed in the previous e-mail: ar, br_fr, ca, ca_valencia, en_ca, en_gb, en_us, fr, gl_es, hu_hu, is, ne_np, nl_nl, si_lk. The most part of changes was in spell.c in the affix file parsing code. The following are dictionary structures changes: - useFlagAliases and flagMode fields had been added to the IspellDict struct; - flagval array size had been increased from 256 to 65000; - flag field of the AFFIX struct also had been increased. I also had implemented a patch that fixes an error from the e-mail http://www.postgresql.org/message-id/562E1073.8030805@postgrespro.ru This patch just ignore that error. Tests ===== Extention test dictionaries for loading into PostgreSQL and for normalizing with ts_lexize function can be downloaded from https://dl.dropboxusercontent.com/u/15423817/HunspellDictTest.tar.gz It would be nice if somebody can do additional tests of dictionaries of well known languages. Because I do not know many of them. Other Improvements ================== There are also some parameters for compound words. But I am not sure that we want use this parameters. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
06.11.2015 12:33, Artur Zakirov пишет: > Hello again! > > Patches > ======= Link to commitfest: https://commitfest.postgresql.org/8/420/ -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Thank you for working on this.
I tried the patch with a Turkish dictionary [1] I could find on the
Internet. It worked for some words, but not others:
> hasegeli=# create text search dictionary hunspell_tr (template = ispell, dictfile = tr, afffile = tr);
> CREATE TEXT SEARCH DICTIONARY
>
> hasegeli=# select ts_lexize('hunspell_tr', 'tilki'); -- The root "fox"
> -----------
> {tilki}
> (1 row)
>
> hasegeli=# select ts_lexize('hunspell_tr', 'tilkinin'); -- Genitive form, affix 3290
> ts_lexize
> -----------
> {tilki}
> (1 row)
>
> hasegeli=# select ts_lexize('hunspell_tr', 'tilkiler'); -- Plural form, affix 4371
> ts_lexize
> -----------
> {tilki}
> (1 row)
>
> hasegeli=# select ts_lexize('hunspell_tr', 'tilkiyi'); -- Accusative form, affix 2646
> ts_lexize
> -----------
>
> (1 row)
It seems to have something to do with the order of the affixes. It
works, if I move affix 2646 to the beginning of the list.
[1] https://tr-spell.googlecode.com/files/dict_aff_5000_suffix_1130000_words.zip
On 07.11.2015 17:20, Emre Hasegeli wrote: > It seems to have something to do with the order of the affixes. It > works, if I move affix 2646 to the beginning of the list. > > [1] https://tr-spell.googlecode.com/files/dict_aff_5000_suffix_1130000_words.zip Thank you for reply. This was because of the flag field size of the SPELL struct. And long flags were being trancated in the .dict file. I attached new patch. It is temporary patch, not final. It can be done better. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
08.11.2015 14:23, Artur Zakirov пишет: > Thank you for reply. > > This was because of the flag field size of the SPELL struct. And long > flags were being trancated in the .dict file. > > I attached new patch. It is temporary patch, not final. It can be done > better. > I have updated the patch and attached it. Now dynamic memory allocation is used to the flag field of the SPELL struct. I have valued time of a dictionary loading and memory using by a dictionary in the new patch. Dictionary is loaded at the first reference to it. For example, if we execute ts_lexize function. And first ts_lexize executing takes more time than second. The following table shows performance of some dictionaries before patch and after in my computer. ------------------------------------------------- | | loading time, ms | memory, MB | | | before | after | before | after | ------------------------------------------------- |ar | 700 | 300 | 23,7 | 15,7 | |br_fr | 410 | 450 | 27,4 | 27,5 | |ca | 248 | 245 | 14,7 | 15,4 | |en_us | 100 | 100 | 5,4 | 6,2 | |fr | 160 | 178 | 13,7 | 14,1 | |gl_es | 160 | 150 | 9 | 9,4 | |is | 260 | 202 | 16,1 | 16,3 | ------------------------------------------------- As you can see, substantially loading time and memory using before and after the patch are same. Link to patch in commitfest: https://commitfest.postgresql.org/8/420/ Link to regression tests: https://dl.dropboxusercontent.com/u/15423817/HunspellDictTest.tar.gz -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
On 10.11.2015 13:23, Artur Zakirov wrote: > > Link to patch in commitfest: > https://commitfest.postgresql.org/8/420/ > > Link to regression tests: > https://dl.dropboxusercontent.com/u/15423817/HunspellDictTest.tar.gz > Hello! Do you have any remarks or comments about my patch? -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 16.11.2015 15:51, Artur Zakirov wrote: > On 10.11.2015 13:23, Artur Zakirov wrote: >> >> Link to patch in commitfest: >> https://commitfest.postgresql.org/8/420/ >> >> Link to regression tests: >> https://dl.dropboxusercontent.com/u/15423817/HunspellDictTest.tar.gz I have done some changes in documentation in the section "12.6. Dictionaries". I have added some description how to load Ispell and Hunspell dictionaries and description about Ispell and Hunspell formats. Patches for the documentation and for the code are attached separately. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
Artur Zakirov wrote:
> *** 77,83 **** typedef struct spell_struct
>
> typedef struct aff_struct
> {
> ! uint32 flag:8,
> type:1,
> flagflags:7,
> issimple:1,
> --- 74,80 ----
>
> typedef struct aff_struct
> {
> ! uint32 flag:16,
> type:1,
> flagflags:7,
> issimple:1,
By doing this, you're using 40 bits of a 32-bits-wide field. What does
this mean? Are the final 8 bits lost? Does the compiler allocate a
second uint32 member for those additional bits? I don't know, but I
don't think this is a very clean idea.
> typedef struct spell_struct
> {
> ! union
> {
> ! /*
> ! * flag is filled in by NIImportDictionary. After NISortDictionary, d
> ! * is valid and flag is invalid.
> ! */
> ! char flag[MAXFLAGLEN];
> ! struct
> ! {
> ! int affix;
> ! int len;
> ! } d;
> ! } p;
> char word[FLEXIBLE_ARRAY_MEMBER];
> } SPELL;
>
> --- 57,72 ----
>
> typedef struct spell_struct
> {
> ! struct
> {
> ! int affix;
> ! int len;
> ! } d;
> ! /*
> ! * flag is filled in by NIImportDictionary. After NISortDictionary, d
> ! * is valid and flag is invalid.
> ! */
> ! char *flag;
> char word[FLEXIBLE_ARRAY_MEMBER];
> } SPELL;
Here you removed the union, with no rationale for doing so. Why did you
do it? Can it be avoided? Because of the comment, I'd imagine that d
and flag are valid at different times, so at any time we care about only
one of them; but you haven't updated the comment stating the reason for
that no longer to be the case. I suspect you need to keep flag valid
after NISortDictionary has been called, but if so why? If "flag" is
invalid as the comment says, what's the reason for keeping it?
The routines decodeFlag and isAffixFlagInUse could do with more
comments. Your patch adds zero. Actually the whole file has not nearly
enough comments; adding some more would be very good.
Actually, after some more reading, I think this code is pretty terrible.
I have a hard time figuring out how the original works, which makes it
even more difficult to figure out whether your changes make sense. I
would have to take your patch on faith, which doesn't sound so great an
idea.
palloc / cpalloc / tmpalloc make the whole mess even more confusing.
Why does this file have three ways to allocate memory?
Not sure what's a good way to go about this. I am certainly not going
to commit this as is, because if I do whatever bugs you have are going
to become my problem; and with the severe lack of documentation and
given how fiddly this stuff is, I bet there are going to be a bunch of
bugs. I suspect most committers are going to be in the same position.
I think you should start by adding a few comments here and there on top
of the original to explain how it works, then your patch on top. I
suppose it's going to be a lot of work for you but I don't see any other
way.
A top-level overview about it would be good, too. The current comment
at top of file states:
* spell.c* Normalizing word with ISpell
which is, err, somewhat laconic.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Artur Zakirov wrote: > Now almost all dictionaries are loaded into PostgreSQL. But the da_dk > dictionary does not load. I see the following error: > > ERROR: invalid regular expression: quantifier operand invalid > CONTEXT: line 439 of configuration file > "/home/artur/progs/pgsql/share/tsearch_data/da_dk.affix": "SFX 55 0 s > +GENITIV > > If you open the affix file in editor you can see that there is incorrect > format of the affix 55 in 439 line (screen1.png):[ another email ] > I also had implemented a patch that fixes an error from the e-mail > http://www.postgresql.org/message-id/562E1073.8030805@postgrespro.ru > This patch just ignore that error. I think it's a bad idea to just ignore these syntax errors. This affix file is effectively corrupt, after all, so it seems a bad idea that we need to cope with it. I think it would be better to raise the error normally and instruct the user to fix the file; obviously it's better if the upstream provider of the file fixes it. Now, if there is proof somewhere that the file is correct, then the code must cope in some reasonable way. But in any case I don't think this change is acceptable ... it can only cause pain, in the long run. > *** 429,443 **** NIAddAffix(IspellDict *Conf, int flag, char flagflags, const char *mask, const c > err = pg_regcomp(&(Affix->reg.regex), wmask, wmasklen, > REG_ADVANCED | REG_NOSUB, > DEFAULT_COLLATION_OID); > if (err) > ! { > ! char errstr[100]; > ! > ! pg_regerror(err, &(Affix->reg.regex), errstr, sizeof(errstr)); > ! ereport(ERROR, > ! (errcode(ERRCODE_INVALID_REGULAR_EXPRESSION), > ! errmsg("invalid regular expression: %s", errstr))); > ! } > } > > Affix->flagflags = flagflags; > --- 429,437 ---- > err = pg_regcomp(&(Affix->reg.regex), wmask, wmasklen, > REG_ADVANCED | REG_NOSUB, > DEFAULT_COLLATION_OID); > + /* Ignore regular expression error and do not add wrong affix */ > if (err) > ! return; > } > > Affix->flagflags = flagflags; -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thanks for review.
On 09.01.2016 02:04, Alvaro Herrera wrote:
On 09.01.2016 02:04, Alvaro Herrera wrote:
No, 8 bits are not lost. This 8 bits are used if a dictionary uses double extended ASCII character flag type (Conf->flagMode == FM_LONG) or decimal number flag type (Conf->flagMode == FM_NUM). If a dictionary uses single extended ASCII character flag type (Conf->flagMode == FM_CHAR), then 8 bits lost.Artur Zakirov wrote:--- 74,80 ---- typedef struct aff_struct { ! uint32 flag:16, type:1, flagflags:7, issimple:1,By doing this, you're using 40 bits of a 32-bits-wide field. What does this mean? Are the final 8 bits lost? Does the compiler allocate a second uint32 member for those additional bits? I don't know, but I don't think this is a very clean idea.
You can see it in decodeFlag function. This function is used in NIImportOOAffixes function, decode affix flag from string type and store in flag field (flag:16).
Union was removed because the flag field need to be dynamically sized. It had 16 size in the previous version. In this field flag set are stored. For example, if .dict file has the entry:typedef struct spell_struct { ! struct { ! int affix; ! int len; ! } d; ! /* ! * flag is filled in by NIImportDictionary. After NISortDictionary, d ! * is valid and flag is invalid. ! */ ! char *flag; char word[FLEXIBLE_ARRAY_MEMBER]; } SPELL;Here you removed the union, with no rationale for doing so. Why did you do it? Can it be avoided? Because of the comment, I'd imagine that d and flag are valid at different times, so at any time we care about only one of them; but you haven't updated the comment stating the reason for that no longer to be the case. I suspect you need to keep flag valid after NISortDictionary has been called, but if so why? If "flag" is invalid as the comment says, what's the reason for keeping it?
mitigate/NDSGny
Then the "NDSGny" is stored in the flag field.
But in some cases a flag set can have size bigger than 16. I added this changes after this message http://www.postgresql.org/message-id/CAE2gYzwom3=11U9G8ZxMT5PLkZrwb12BWzxh4dB3HUd89FOSrg@mail.gmail.com
In that Turkish dictionary there are can be large flag set. For example:
özek/2240,852,749,5026,2242,4455,2594,2597,4963,1608,494,2409
This flag set has 56 size.
This "flag" is valid all the time. It is used in NISortDictionary and it is not used after NISortDictionary function has been called. Maybe you right and there are no reason for keeping it, and it is necessary to store all flags in separate variable, that will be deleted after NISortDictionary has been called.
I will provide comments and explain how it works in comments. Maybe I will add some explanation about dictionaries structure. I will update the patch soon.The routines decodeFlag and isAffixFlagInUse could do with more comments. Your patch adds zero. Actually the whole file has not nearly enough comments; adding some more would be very good. Actually, after some more reading, I think this code is pretty terrible. I have a hard time figuring out how the original works, which makes it even more difficult to figure out whether your changes make sense. I would have to take your patch on faith, which doesn't sound so great an idea. palloc / cpalloc / tmpalloc make the whole mess even more confusing. Why does this file have three ways to allocate memory? Not sure what's a good way to go about this. I am certainly not going to commit this as is, because if I do whatever bugs you have are going to become my problem; and with the severe lack of documentation and given how fiddly this stuff is, I bet there are going to be a bunch of bugs. I suspect most committers are going to be in the same position. I think you should start by adding a few comments here and there on top of the original to explain how it works, then your patch on top. I suppose it's going to be a lot of work for you but I don't see any other way. A top-level overview about it would be good, too. The current comment at top of file states: * spell.c* Normalizing word with ISpell which is, err, somewhat laconic.
-- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
On 09.01.2016 05:38, Alvaro Herrera wrote:
This error is raised in Danish dictionary because of erroneous entry in the .affix file. I sent a bug-report to developer. He fixed this bug. Corrected dictionary can be downloaded from LibreOffice site.Artur Zakirov wrote:Now almost all dictionaries are loaded into PostgreSQL. But the da_dk dictionary does not load. I see the following error: ERROR: invalid regular expression: quantifier operand invalid CONTEXT: line 439 of configuration file "/home/artur/progs/pgsql/share/tsearch_data/da_dk.affix": "SFX 55 0 s +GENITIV If you open the affix file in editor you can see that there is incorrect format of the affix 55 in 439 line (screen1.png):[ another email ]I also had implemented a patch that fixes an error from the e-mail http://www.postgresql.org/message-id/562E1073.8030805@postgrespro.ru This patch just ignore that error.I think it's a bad idea to just ignore these syntax errors. This affix file is effectively corrupt, after all, so it seems a bad idea that we need to cope with it. I think it would be better to raise the error normally and instruct the user to fix the file; obviously it's better if the upstream provider of the file fixes it. Now, if there is proof somewhere that the file is correct, then the code must cope in some reasonable way. But in any case I don't think this change is acceptable ... it can only cause pain, in the long run.
I undo the changes and the error will be raised. I will update the patch soon.
-- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Artur Zakirov wrote: > I undo the changes and the error will be raised. I will update the patch > soon. I don't think you ever did this. I'm closing it now, but it sounds useful stuff so please do resubmit for 2016-03. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 28.01.2016 14:19, Alvaro Herrera wrote: > Artur Zakirov wrote: > >> I undo the changes and the error will be raised. I will update the patch >> soon. > > I don't think you ever did this. I'm closing it now, but it sounds > useful stuff so please do resubmit for 2016-03. > I'm working on the patch. I wanted to send this changes after all changes. This version of the patch has a top-level comment. Another comments I will provides soon. Also this patch has some changes with ternary operators. > I don't think you ever did this. I'm closing it now, but it sounds > useful stuff so please do resubmit for 2016-03. Moved to next CF. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
Sorry, I don't know why this thread was moved to another thread. I duplicate the patch here. > On 28.01.2016 14:19, Alvaro Herrera wrote: >> Artur Zakirov wrote: >> >>> I undo the changes and the error will be raised. I will update the patch >>> soon. >> >> I don't think you ever did this. I'm closing it now, but it sounds >> useful stuff so please do resubmit for 2016-03. >> > > I'm working on the patch. I wanted to send this changes after all changes. > > This version of the patch has a top-level comment. Another comments I will provides soon. > > Also this patch has some changes with ternary operators. > >> I don't think you ever did this. I'm closing it now, but it sounds >> useful stuff so please do resubmit for 2016-03. > > Moved to next CF. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
> I duplicate the patch here. it's very good thing to update disctionaries to support modern versions. And thank you for improving documentation. Also I've impressed by long description in spell.c header. Som notices about code: 1 struct SPELL. Why do you remove union p? You leave comment about using d struct instead of flag field and as can see it'sright comment. It increases size of SPELL structure. 2 struct AFFIX. I'm agree with Alvaro taht sum of sizes of bit fields should be less or equal to size of integer. In opposite case, suppose, we can get undefined behavior. Please, split bitfields to two integers. 3 unsigned char flagval[65000]; Is it forbidden to use 65555 number? In any case, decodeFlag() doesn't restrict returnvalue. I suggest to enlarge array to 1<<16 and add limit to return value of decodeFlag(). 4 I'd like to see a short comment describing at least new functions 5 Pls, add tests for new code. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
Thank you for the review. On 10.02.2016 19:46, Teodor Sigaev wrote: > >> I duplicate the patch here. > > it's very good thing to update disctionaries to support modern versions. > And thank you for improving documentation. Also I've impressed by long > description in spell.c header. > > Som notices about code: > > 1 > struct SPELL. Why do you remove union p? You leave comment > about using d struct instead of flag field and as can see > it's right comment. It increases size of SPELL structure. I will fix it. I had misunderstood the Alvaro's comment about it. > > 2 struct AFFIX. I'm agree with Alvaro taht sum of sizes of bit fields > should be less or equal to size of integer. In opposite case, suppose, > we can get undefined behavior. Please, split bitfields to two integers. I will fix it. Here I had misunderstood too. > > 3 unsigned char flagval[65000]; > Is it forbidden to use 65555 number? In any case, decodeFlag() doesn't > restrict return value. I suggest to enlarge array to 1<<16 and add limit > to return value of decodeFlag(). I think it can be done. > > 4 > I'd like to see a short comment describing at least new functions Now in spell.c there are more comments. I wanted to send fixed patch after adding all comments that I want to add. But I can send the patch now. Also I will merge this commit http://www.postgresql.org/message-id/E1aTf9o-0001ga-LG@gemulon.postgresql.org > > 5 > Pls, add tests for new code. > > I will add. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
I attached a new version of the patch. On 10.02.2016 19:46, Teodor Sigaev wrote: > >> I duplicate the patch here. > > it's very good thing to update disctionaries to support modern versions. > And thank you for improving documentation. Also I've impressed by long > description in spell.c header. > > Som notices about code: > > 1 > struct SPELL. Why do you remove union p? You leave comment > about using d struct instead of flag field and as can see > it's right comment. It increases size of SPELL structure. Fixed. > > 2 struct AFFIX. I'm agree with Alvaro taht sum of sizes of bit fields > should be less or equal to size of integer. In opposite case, suppose, > we can get undefined behavior. Please, split bitfields to two integers. Fixed. > > 3 unsigned char flagval[65000]; > Is it forbidden to use 65555 number? In any case, decodeFlag() doesn't > restrict return value. I suggest to enlarge array to 1<<16 and add limit > to return value of decodeFlag(). flagval array was enlarged. Added verification of return value of DecodeFlag() for for various FLAG parameter (FM_LONG, FM_NUM and FM_CHAR). > > 4 > I'd like to see a short comment describing at least new functions Added some comments which describe new functions and old functions for loading dictionaries into PostgreSQL. This patch adds new functions and modifies functions which is used for loading dictionaries. At the moment, comments does not describe functions which used for word normalization. But I can add more comments. > > 5 > Pls, add tests for new code. > > Added tests. Old sample dictionaries files was moved to the folder "dicts". New sample dictionaries files was added: - hunspell_sample_long.affix - hunspell_sample_long.dict - hunspell_sample_num.affix - hunspell_sample_num.dict -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company
Вложения
On 16.02.2016 18:14, Artur Zakirov wrote: > I attached a new version of the patch. > Sorry for noise. I attached new version of the patch. I saw mistakes in DecodeFlag(). This patch fix them. -- Artur Zakirov Postgres Professional: http://www.postgrespro.com Russian Postgres Company