Hi,
I've done some initial benchmarking on the branch over the last couple
of days, focusing on analytics workloads using the DBT-3 benchmark.
Attached are two spreadsheets with results from two machines (the same
two I use for all benchmarks), and a couple of charts illustrating the
impact of enabling different JIT options.
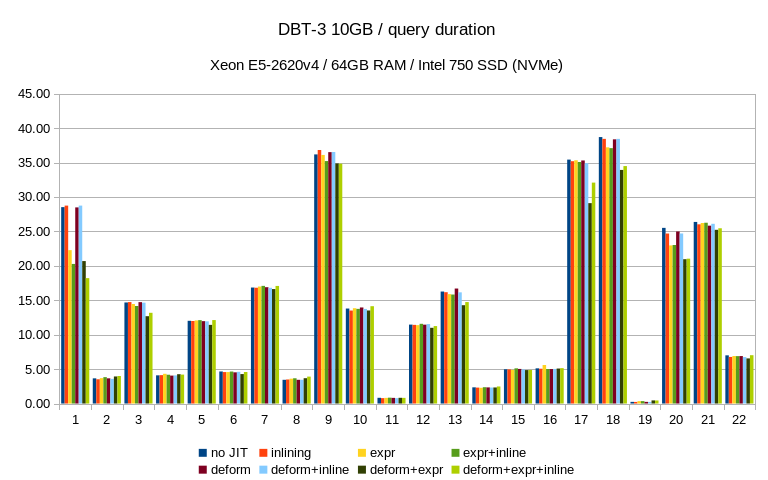
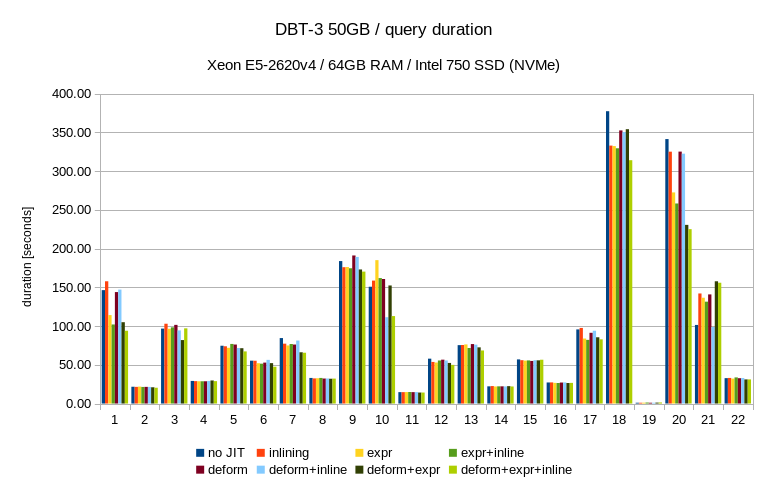
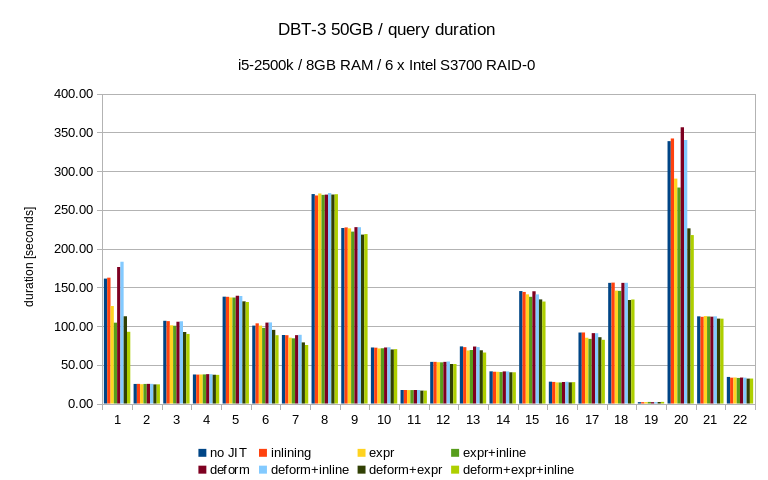
I did the tests with 10GB and 50GB data sets (load into database
generally increases the size by a factor of 2-3x). So at least on the
larger machine the 10GB dataset should be fully in memory. The numbers
are medians for 10 consecutive runs of each query, so the data tends to
be well cached.
In this round of tests I've disabled parallelism. Based on discussion
with Andres I've decided to repeat the tests with parallel queries
enabled - that's running now, and will take some time to complete.
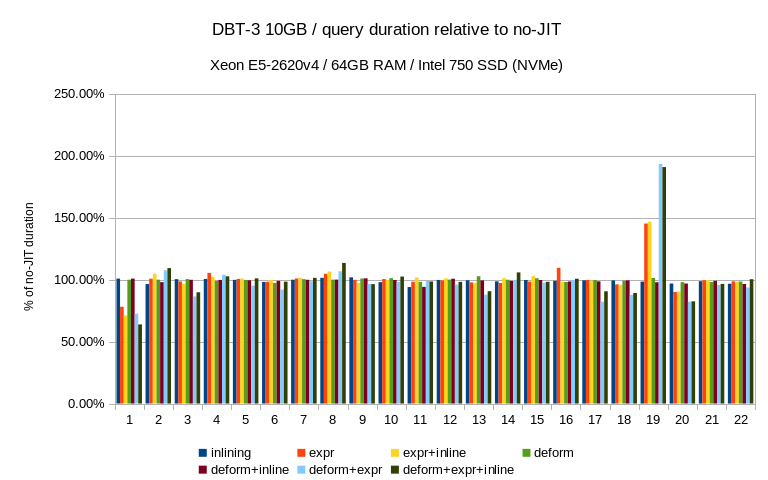
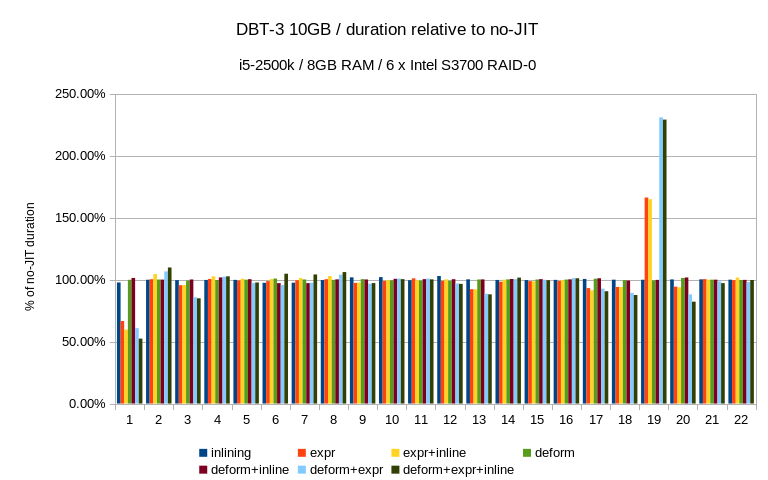
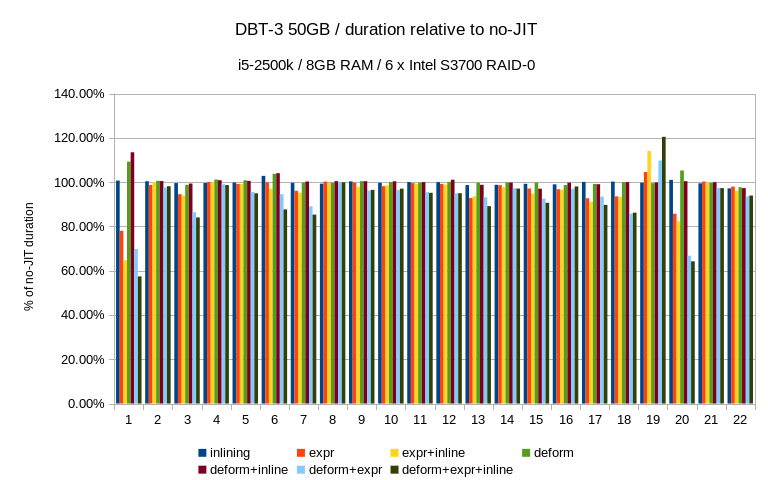
According to the results, most of the DBT-3 queries see slight
improvement in the 5-10% range, but the JIT options vary depending on
the query. What surprised me quite a bit is that the improvement is way
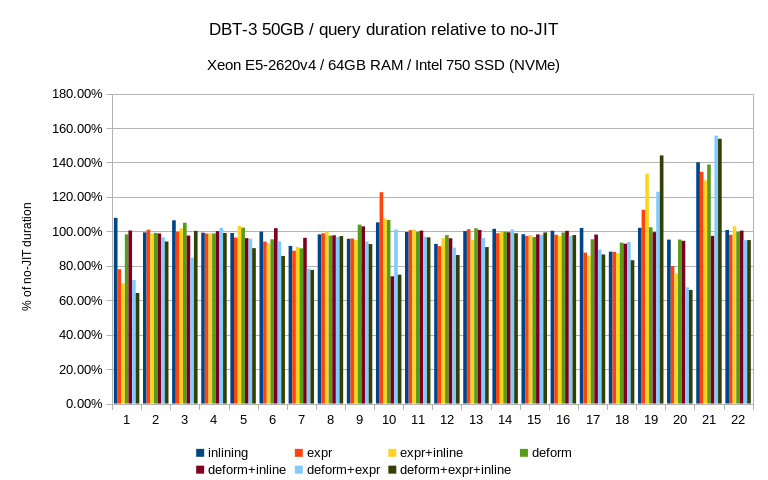
more significant on the 50GB dataset (on both machines). I have expected
the opposite behavior, i.e. that the JIT impact will be more obvious on
the small dataset and then will diminish as I/O becomes more prominent.
Yet that's not the case, apparently. One possible explanation is that on
the 50GB data set the queries switch to plans that are more sensitive to
the JIT optimizations.
A couple of queries saw much more significant improvements - Q1 and Q20
got about 30%-40% faster, and I have no problem believing that other
queries may see even more significant benefits.
Other queries (Q19 and Q21) saw regressions - for Q19 it's relatively
harmless, I think. It's a short query and so the relative slowdown seems
somewhat worse that in absolute terms. Not sure what's going on for Q21,
though. But I think we'll need to look at the costing model, and try
tweaking it to make the right decision in those cases.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services