Re: Should we update the random_page_cost default value?
| От | Tomas Vondra |
|---|---|
| Тема | Re: Should we update the random_page_cost default value? |
| Дата | |
| Msg-id | a72f0e7f-5ef7-4809-9bcc-aa4a43fd77d2@vondra.me обсуждение исходный текст |
| Ответ на | Re: Should we update the random_page_cost default value? (David Rowley <dgrowleyml@gmail.com>) |
| Список | pgsql-hackers |
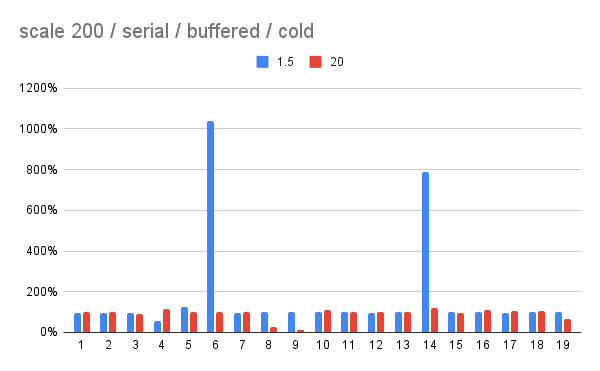
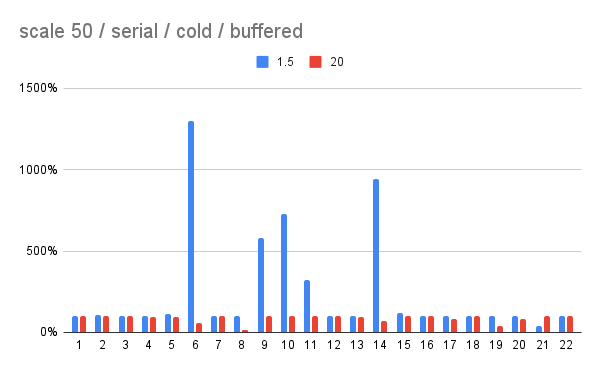
On 10/6/25 07:26, David Rowley wrote: > On Mon, 6 Oct 2025 at 13:59, Tomas Vondra <tomas@vondra.me> wrote: >> Unless I did some silly mistakes, these results suggest the current 4.0 >> value is a bit too low, and something like ~20 would be better even on >> SSDs. This is not the first time it was suggested a higher default might >> be better - see this 2008 post [3]. Of course, that's from before SSDs >> became a thing, it's about evolution in hard disks and our code. > > Thanks for going to all that effort to calculate that. It was an > interesting read and also very interesting that you found the opposite > to the typical advice that people typically provide. > > I don't have any HDDs around to run the script to check the results. I > do have a machine with 2 SSDs, one PCIe3 and one PCIe4. I'll see if I > can get you some results from that. > > It would be interesting to see how your calculated values fare when > given a more realistic workload. Say TPC-H or Join Order Benchmark. I > recall that TPCH has both a power and a throughput result, one to test > concurrency and one for single query throughput. I wonder if the same > random_page_cost setting would be preferred in both scenarios. I can > imagine that it might be more useful to have more index pages in > shared buffers when there's strong contention for buffers. It would be > interesting to run some pg_buffercache queries with GROUP BY relkind > to see how much of an effect changing random_page_cost has on the > number of buffers per relkind after each query. > Here's a couple results from TPC-H on scales 50 and 200 (from two different systems). I ran the test with/without parallel query, with buffered and direct I/O. And I ran each query with random_page_cost set to 4.0, 1.5 and 20, to get some comparison. Each query was executed twice - once from cold state (nothing in RAM), then from warmed state (from the first execution). Attached are PDFs with more complete results, and charts for "cold" runs without parallel query, with buffered I/O. The charts are comparing the timing to random_page_cost = 4.0, used as a baseline. Note: The scale 200 results are incomplete - I only have 19 queries for buffered/serial setup now. In all the runs, setting random_page_cost = 1.5 causes significant regressions for a number of queries. This is more visible on scale 50, with ~5 clear regressions (and maybe one improvement for Q21). On scale 200 there are only 2 regressions of similar scale. The random_page_cost = 20 doesn't have such regressions, and a couple queries get much faster (Q8 or Q19 or scale 50, and Q9 on scale 200). There are some regressions, either with parallel query enabled (not sure why), or when the warm run doesn't get faster (while the other rpc values seem to benefit from caching more). I don't have time for thorough analysis of the plans, but I did check a couple queries with significant changes in timing, and the estimates seem very accurate. So it doesn't seem to be a matter of luck, with bad estimates and "bogus" rpc value compensating for that. regards -- Tomas Vondra
Вложения
В списке pgsql-hackers по дате отправления: