Re: Questions about btree_gin vs btree_gist for low cardinality columns
| От | Morris de Oryx |
|---|---|
| Тема | Re: Questions about btree_gin vs btree_gist for low cardinality columns |
| Дата | |
| Msg-id | CAKqncciJrdpbioGtUVMa0fgXPdaU8U_HckK2mo-hYPq0pc6Diw@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Questions about btree_gin vs btree_gist for low cardinality columns (Morris de Oryx <morrisdeoryx@gmail.com>) |
| Список | pgsql-general |
From what Peter showed, the answer to (part of) the original questions seems to be that yes, a B-tree GIN can be quite appealing. The test times aren't too worrisome, and the index size is about 1/12th of a B-tree. I added on the sizes, and divided each index size by a full B-tree:
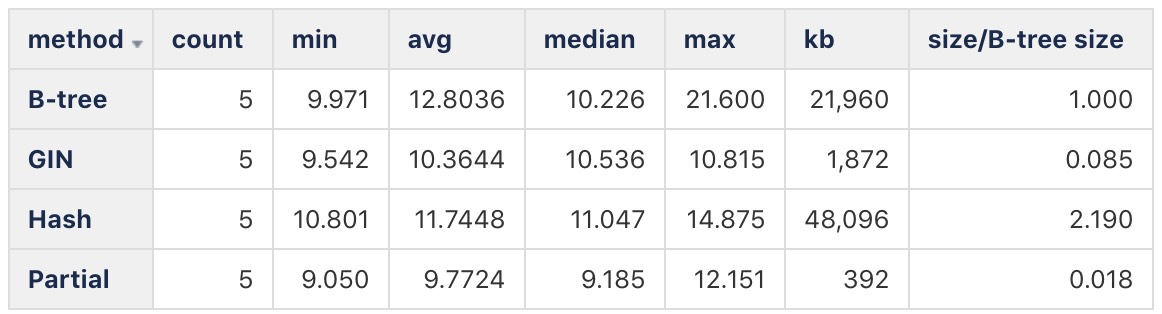
Method Count Min Avg Median Max KB KB/B-Tree
Partial 5 9.050 9.7724 9.185 12.151 392 0.018
B-tree 5 9.971 12.8036 10.226 21.600 21,960 1.000
GIN 5 9.542 10.3644 10.536 10.815 1,872 0.085
Hash 5 10.801 11.7448 11.047 14.875 48,096 2.190
I'm not great at ASCII tables, I'm attaching a picture...don't know if that works here.
I guess I'd say at this point:
* The test case I set up is kind of silly and definitely not representative of a variety of data distributions.
* Hash index is not well-matched to low-cardinality (=== "high collision") values.
* Partial B-trees aren't going to save space if you need one for each distinct value. And there's an overhead to index maintenance, so there's that. (But partial indexes in Postgres are fantastic in the right situations....this probably isn't one.)
* A B-tree GIN index performs well and is space-efficient.
Might be overriding a bit here from an artificial/toy test, but I find the results Peter offered pretty encouraging. It really feels wrong to use a standard B-tree for low-cardinality columns. It's just a badly matched data structure. Hash too....there you see the results quite dramatically, but it's a closely related problem. A GIN index seems like it's well-matched to low-cardinality indexing.
Now that this is all in my head a bit, I'm hoping for more feedback and real-world observations. Any commentary appreciated.
On Sun, Jun 2, 2019 at 9:10 AM Morris de Oryx <morrisdeoryx@gmail.com> wrote:
Peter, thanks a lot for picking up on what I started, improving it, and reporting back. I thought I was providing timing estimates from the EXPLAIN cost dumps. Seems not. Well, there's another thing that I've learned.Your explanation of why the hash index bloats out makes complete sense, I ought to have thought that.Can you tell me how you get timing results into state_test_times? I know how to turn on time display in psql, but I much prefer to use straight SQL. The reason for that is my production code is always run through a SQL session, not typing things into psql.On Sat, Jun 1, 2019 at 11:53 PM Peter J. Holzer <hjp-pgsql@hjp.at> wrote:On 2019-06-01 17:44:00 +1000, Morris de Oryx wrote:
> Since I've been wondering about this subject, I figured I'd take a bit of time
> and try to do some tests. I'm not new to databases or coding, but have been
> using Postgres for less than two years. I haven't tried to generate large
> blocks of test data directly in Postgres before, so I'm sure that there are
> better ways to do what I've done here. No worries, this gave me a chance to
> work through at least some of the questions/problems in setting up and running
> tests.
>
> Anyway, I populated a table with 1M rows of data with very little in them, just
> a two-character state abbreviation. There are only 59 values, and the
> distribution is fairly even as I used random() without any tricks to shape the
> distribution. So, each value is roughly 1/60th of the total row count. Not
> realistic, but what I've got.
>
> For this table, I built four different kind of index and tried each one out
> with a count(*) query on a single exact match. I also checked out the size of
> each index.
>
> Headline results:
>
> Partial index: Smaller (as expeced), fast.
> B-tree index: Big, fast.
> GIN: Small, slow.
> Hash: Large, slow. ("Large" may be exaggerated in comparison with a B-tree
> because of my test data.)
You didn't post any times (or the queries you timed), so I don't know
what "fast" and "slow" mean.
I used your setup to time
select sum(num) from state_test where abbr = 'MA';
on my laptop (i5-7Y54, 16GB RAM, SSD, Pgsql 10.8) and here are the
results:
hjp=> select method, count(*),
min(time_ms),
avg(time_ms),
percentile_cont(0.5) within group (order by time_ms) as median,
max(time_ms)
from state_test_times
group by method
order by 5;
method | count | min | avg | median | max
---------+-------+--------+---------+--------+--------
Partial | 5 | 9.05 | 9.7724 | 9.185 | 12.151
B tree | 5 | 9.971 | 12.8036 | 10.226 | 21.6
GIN | 5 | 9.542 | 10.3644 | 10.536 | 10.815
Hash | 5 | 10.801 | 11.7448 | 11.047 | 14.875
All the times are pretty much the same. GIN is third by median, but the
difference is tiny, and it is secondy by minium and average and even
first by maximum.
In this case all the queries do a bitmap scan, so the times are probably
dominated by reading the heap, not the index.
> method pg_table_size kb
> Partial 401408 392 Kb
> B tree 22487040 21960 Kb
> GIN 1916928 1872 Kb
> Hash 49250304 48096 Kb
I get the same sizes.
> Okay, so the partial index is smaller, basically proportional to the fraction
> of the file it's indexing. So that makes sense, and is good to know.
Yeah. But to cover all values you would need 59 partial indexes, which
gets you back to the size of the full btree index. My test shows that it
might be faster, though, which might make the hassle of having to
maintain a large number of indexes worthwhile.
> The hash index size is...harder to explain...very big. Maybe my tiny
> strings? Not sure what size Postgres hashes to. A hash of a two
> character string is likely about worst-case.
I think that a hash index is generally a poor fit for low cardinality
indexes: You get a lot of equal values, which are basically hash
collisions. Unless the index is specifically designed to handle this
(e.g. by storing the key only once and then a tuple list per key, like a
GIN index does) it will balloon out trying to reduce the number of
collisions.
hp
--
_ | Peter J. Holzer | we build much bigger, better disasters now
|_|_) | | because we have much more sophisticated
| | | hjp@hjp.at | management tools.
__/ | http://www.hjp.at/ | -- Ross Anderson <https://www.edge.org/>
Вложения
В списке pgsql-general по дате отправления: