Re: Speed up COPY FROM text/CSV parsing using SIMD
| От | Manni Wood |
|---|---|
| Тема | Re: Speed up COPY FROM text/CSV parsing using SIMD |
| Дата | |
| Msg-id | CAKWEB6r=axZsG-s7zyWURZ-s9-s1dTV9ohkZXO0ynfLEU5ha3Q@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Speed up COPY FROM text/CSV parsing using SIMD (Mark Wong <markwkm@gmail.com>) |
| Список | pgsql-hackers |
On Fri, Dec 12, 2025 at 2:42 PM Mark Wong <markwkm@gmail.com> wrote:
Hi everyone,
On Tue, Dec 09, 2025 at 04:40:19PM +0300, Bilal Yavuz wrote:
> Hi,
>
> On Sat, 6 Dec 2025 at 10:55, Bilal Yavuz <byavuz81@gmail.com> wrote:
> >
> > Hi,
> >
> > On Sat, 6 Dec 2025 at 04:40, Manni Wood <manni.wood@enterprisedb.com> wrote:
> > > Hello, all.
> > >
> > > Andrew, I tried your suggestion of just reading the first chunk of the copy file to determine if SIMD is worth using. Attached are v4 versions of the patches showing a first attempt at doing that.
> >
> > Thank you for doing this!
> >
> > > I attached test.sh.txt to show how I've been testing, with 5 million lines of the various copy file variations introduced by Ayub Kazar.
> > >
> > > The text copy with no special chars is 30% faster. The CSV copy with no special chars is 48% faster. The text with 1/3rd escapes is 3% slower. The CSV with 1/3rd quotes is 0.27% slower.
> > >
> > > This set of patches follows the simplest suggestion of just testing the first N lines (actually first N bytes) of the file and then deciding whether or not to enable SIMD. This set of patches does not follow Andrew's later suggestion of maybe checking again every million lines or so.
> >
> > My input-generation script is not ready to share yet, but the inputs
> > follow this format: text_${n}.input, where n represents the number of
> > normal characters before the delimiter. For example:
> >
> > n = 0 -> "\n\n\n\n\n..." (no normal characters)
> > n = 1 -> "a\n..." (1 normal character before the delimiter)
> > ...
> > n = 5 -> "aaaaa\n..."
> > … continuing up to n = 32.
> >
> > Each line has 4096 chars and there are a total of 100000 lines in each
> > input file.
> >
> > I only benchmarked the text format. I compared the latest heuristic I
> > shared [1] with the current method. The benchmarks show roughly a ~16%
> > regression at the worst case (n = 2), with regressions up to n = 5.
> > For the remaining values, performance was similar.
>
> I tried to improve the v4 patchset. My changes are:
>
> 1 - I changed CopyReadLineText() to an inline function and sent the
> use_simd variable as an argument to get help from inlining.
>
> 2 - A main for loop in the CopyReadLineText() function is called many
> times, so I moved the use_simd check to the CopyReadLine() function.
>
> 3 - Instead of 'bytes_processed', I used 'chars_processed' because
> cstate->bytes_processed is increased before we process them and this
> can cause wrong results.
>
> 4 - Because of #2 and #3, instead of having
> 'SPECIAL_CHAR_SIMD_THRESHOLD', I used the ratio of 'chars_processed /
> special_chars_encountered' to determine whether we want to use SIMD.
>
> 5 - cstate->special_chars_encountered is incremented wrongly for the
> CSV case. It is not incremented for the quote and escape delimiters. I
> moved all increments of cstate->special_chars_encountered to the
> central place and tried to optimize it but it still causes a
> regression as it creates one more branching.
>
> With these changes, I am able to decrease the regression to %10 from
> %16. Regression decreases to %7 if I modify #5 for the only text input
> but I did not do that.
>
> My changes are in the 0003.
I was helping collect some data, but I'm a little behind sharing what I
ran against the v4.1 patches (on commit 07961ef8) with the v4.2 version
out there...
I hope it's still helpfule that I share what I collected even though
they are not quite as nice, but maybe it's more about how/where I ran
them.
My laptop has a Intel(R) Core(TM) Ultra 7 165H, where most of these
tests were using up 95%+ of one of the cores (I have hyperthreading
disabled), and using about 10% the ssd's capacity.
Summarizing my results from the same script Manni ran, I didn't see as
much as an improvement in the positive tests, and then saw more negative
results in the other tests.
text copy with no special chars: 18% improvement of 15s from 80s before
the patch
CSV copy with no special chars: 23% improvement of 23s from 96s before
the patch
text with 1/3rd escapes: 6% slower, an additional 5s to 85 seconds
before the patch
CSV with 1/3rd quotes: 7% slower, an additional 10 seconds to 129
seconds before the patch
I'm wondering if my laptop/processor isn't the best test bed for this...
Regards,
Mark
--
Mark Wong <markwkm@gmail.com>
EDB https://enterprisedb.com
Hello, Everyone!
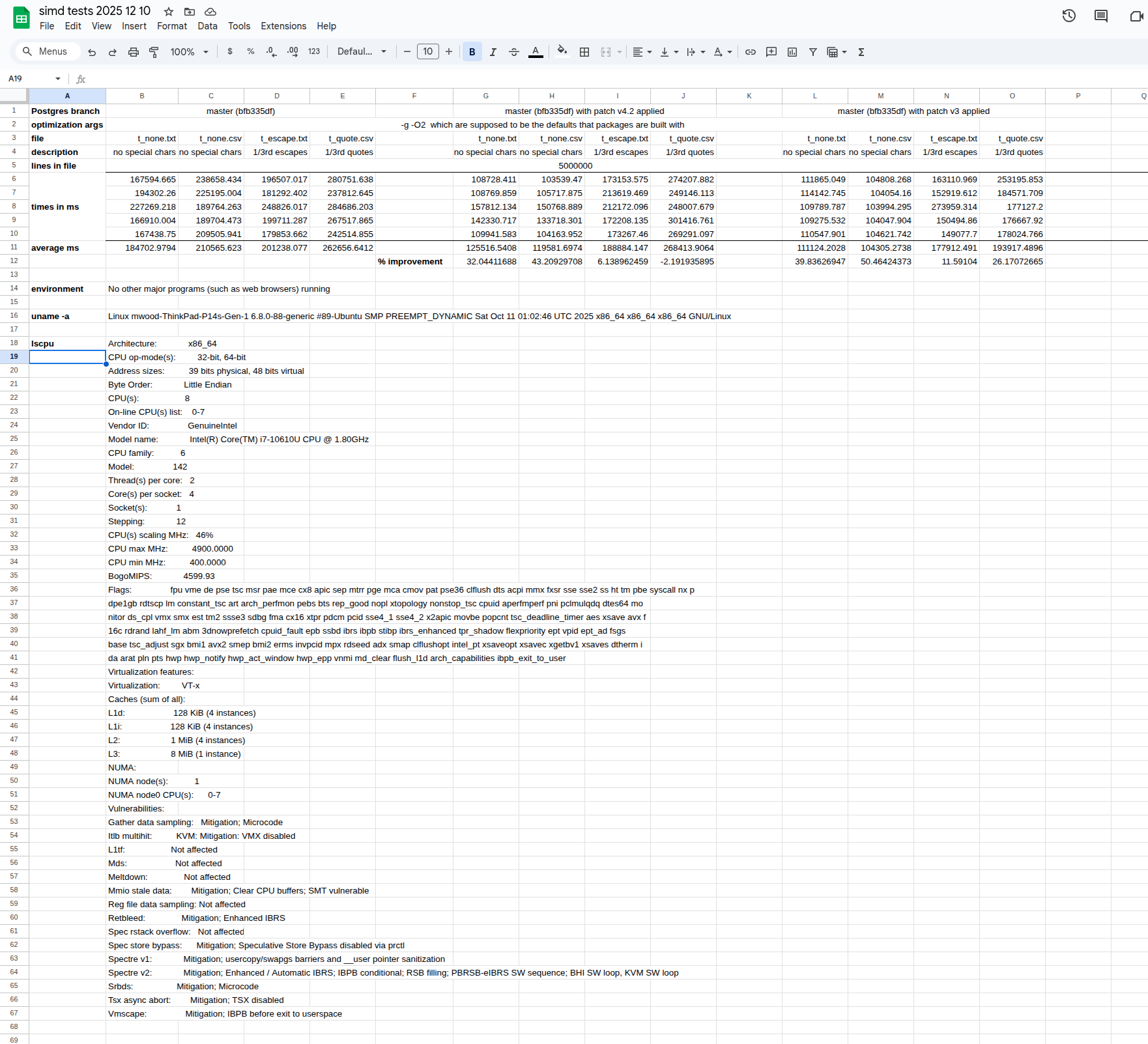
I have attached two files. 1) the shell script that Mark and I have been using to get our test results, and 2) a screenshot of a spreadsheet of my latest test results. (Please let me know if there's a different format than a screenshot that I could share my spreadsheet in.)
I took greater care this time to compile all three variants of Postgres (master at bfb335df, master at bfb335df with v4.2 patches installed, master at bfb335df with v3 patches installed) with the same gcc optimization flags that would be used to build Postgres packages. To the best of my knowledge, the two gcc flags of greatest interest would be -g and -O2. I built all three variants of Postgres using meson like so:
BRANCH=$(git branch --show-current)
meson setup build --prefix=/home/mwood/compiled-pg-instances/${BRANCH} --buildtype=debugoptimized
It occurred to me that in addition to end users only caring about 1) wall clock time (is the speedup noticeable in "real time" or just technically faster / uses less CPU?) and 2) Postgres binaries compiled with the same optimization level one would get when installing Postgres from packages like .deb or .rpm; in other words, will the user see speedups without having do manually compile postgres.
My interesting finding, on my laptop (ThinkPad P14s Gen 1 running Ubuntu 24.04.3), is different from Mark Wong's. On my laptop, using three Postgres installations all compiled with the -O2 optimization flag, I see speedups with the v4.2 patch except for a 2% slowdown with CSV with 1/3rd quotes (a 2% slowdown). But with Nazir's proposed v3 patch, I see improvements across the board. So even for a text file with 1/3rd escape characters, and even with a CSV file with 1/3rd quotes, I see speedups of 11% and 26% respectively.
The format of these test files originally comes from Ayoub Kazar's test scripts; all Mark and I have done in playing with them is make them much larger: 5,000,000 rows, based on the assumption that longer tests are better tests.
I find my results interesting enough that I'd be curious to know if anybody else can reproduce them. It is very interesting that Mark's results are noticeably different from mine.
--
-- Manni Wood EDB: https://www.enterprisedb.com
Вложения
В списке pgsql-hackers по дате отправления: