Re: [PERFORM] Slow query: bitmap scan troubles
| От | Tom Lane |
|---|---|
| Тема | Re: [PERFORM] Slow query: bitmap scan troubles |
| Дата | |
| Msg-id | 13967.1357866454@sss.pgh.pa.us обсуждение |
| Ответ на | Re: [PERFORM] Slow query: bitmap scan troubles (Tom Lane <tgl@sss.pgh.pa.us>) |
| Ответы |
Re: [PERFORM] Slow query: bitmap scan troubles
|
| Список | pgsql-hackers |
I wrote:
> I'm fairly happy with the general shape of this formula: it has a
> principled explanation and the resulting numbers appear to be sane.
> The specific cost multipliers obviously are open to improvement based
> on future evidence. (In particular, I intend to code it in a way that
> doesn't tie the "startup overhead" and "cost per page" numbers to be
> equal, even though I'm setting them equal for the moment for lack of a
> better idea.)
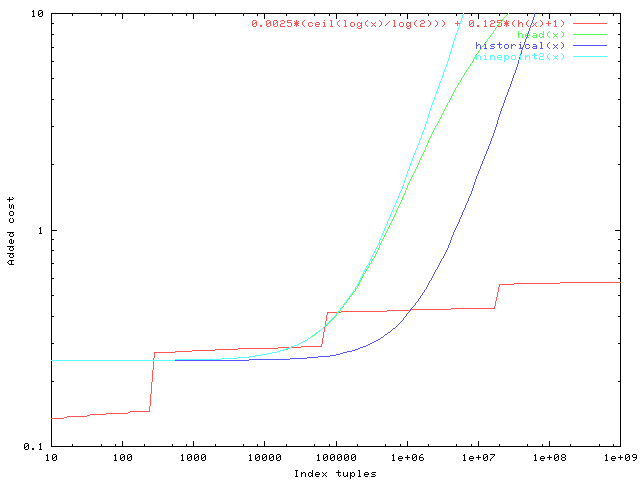
I realized that there was a rather serious error in the graphs I showed
before: they were computing the old cost models as #tuples/10000 or
#tuples/100000, but really it's #pages. So naturally that moves those
curves down quite a lot. After some playing around I concluded that the
best way to avoid any major increases in the attributed cost is to drop
the constant "costs of indexscan setup" charge that I proposed before.
(That was a little weird anyway since we don't model any similar cost
for any other sort of executor setup.) The attached graph shows the
corrected old cost curves and the proposed new one.
> One issue that needs some thought is that the argument for this formula
> is based entirely on thinking about b-trees. I think it's probably
> reasonable to apply it to gist, gin, and sp-gist as well, assuming we
> can get some estimate of tree height for those, but it's obviously
> hogwash for hash indexes. We could possibly just take H=0 for hash,
> and still apply the log2(N) part ... not so much because that is right
> as because it's likely too small to matter.
In the attached patch, I use the proposed formula for btree, gist, and
spgist indexes. For btree we read out the actual tree height from the
metapage and use that. For gist and spgist there's not a uniquely
determinable tree height, but I propose taking log100(#pages) as a
first-order estimate. For hash, I think we actually don't need any
corrections, for the reasons set out in the comment added to
hashcostestimate. I left the estimate for GIN alone; I've not studied
it enough to know whether it ought to be fooled with, but in any case it
behaves very little like btree.
A big chunk of the patch diff comes from redesigning the API of
genericcostestimate so that it can cheaply pass back some additional
values, so we don't have to recompute those values at the callers.
Other than that and the new code to let btree report out its tree
height, this isn't a large patch. It basically gets rid of the two
ad-hoc calculations in genericcostestimate() and inserts substitute
calculations in the per-index-type functions.
I've verified that this patch results in no changes in the regression
tests. It's worth noting though that there is now a small nonzero
startup-cost charge for indexscans, for example:
regression=# explain select * from tenk1 where unique1 = 42;
QUERY PLAN
-----------------------------------------------------------------------------
Index Scan using tenk1_unique1 on tenk1 (cost=0.29..8.30 rows=1 width=244)
Index Cond: (unique1 = 42)
(2 rows)
where in 9.2 the cost estimate was 0.00..8.28. I personally think this
is a good idea, but we'll have to keep our eyes open to see if it
changes any plans in ways we don't like.
This is of course much too large a change to consider back-patching.
What I now recommend we do about 9.2 is just revert it to the historical
fudge factor (#pages/100000).
Comments?
regards, tom lane
set terminal png small color
set output 'newer_costs.png'
set xlabel "Index tuples"
set ylabel "Added cost"
set logscale x
set logscale y
fo = 256.0
h(x) = (x <= fo) ? 0 : (x <= fo*fo) ? 1 : (x <= fo*fo*fo) ? 2 : (x <= fo*fo*fo*fo) ? 3 : (x <= fo*fo*fo*fo*fo) ? 4 : 5
head(x) = 4*log(1 + (x/fo)/10000) + 0.25
historical(x) = 4 * (x/fo)/100000 + 0.25
ninepoint2(x) = 4 * (x/fo)/10000 + 0.25
plot [10:1e9][0.1:10] 0.0025*(ceil(log(x)/log(2))) + 0.125*(h(x)+1), head(x), historical(x), ninepoint2(x)
Вложения
В списке pgsql-hackers по дате отправления: