Обсуждение: [PATCH] CRC32C optimizations using SVE2 on ARM.
Hello,
This email aims to discuss the contribution of an optimized CRC32C implementation for ARM (aarch64) machines. The CRC32C function is widely used throughout PostgreSQL for checksum workloads such as WAL generation and data integrity validation.
The current CRC32C implementation on ARM relies on scalar hardware instructions (
__crc32cb/ch/cw/cd) which process 1, 2, 4, or 8 bytes per iteration. While correct and efficient for smaller inputs, this scalar design becomes a bottleneck for large buffer sizes, leading to noticeable performance degradation. With the introduction of an SVE2�Cbased implementation, we leverage wide vector intrinsics to process up to 128 bytes per iteration using 8 vectors in parallel. This design significantly accelerates CRC32C execution by reducing the total number of loop iterations, minimizing serial dependency chains, and improving compute and memory throughput.
We have implemented this feature to ensure correctness, compatibility, and safe integration. It includes compile-time and runtime checks to detect SVE2 support on both the compiler and underlying hardware. When SVE2 is unavailable, the function safely falls back to the existing scalar CRC32C path to ensure consistent results across systems.
For architecture-specific functions, we use
pg_attribute_target("arch=armv9-a+sve2-aes") to ensure precise compilation control without modifying global CFLAGS, enabling a clean integration within PostgreSQL’s build system.System Configuration
Machine: AWS EC2 c8g.4xlarge (16 cores, 30 GB RAM)
OS: Ubuntu 22.04.5 LTS
GCC: 13.1.0
Machine: AWS EC2 c8g.4xlarge (16 cores, 30 GB RAM)
OS: Ubuntu 22.04.5 LTS
GCC: 13.1.0
Benchmark and Results
Setup:
We used the CRC32C microbenchmark SQL function published on the PostgreSQL mailing list [0] to evaluate the performance of the SVE2 implementation against the existing scalar ARM version across multiple buffer sizes.
Setup:
We used the CRC32C microbenchmark SQL function published on the PostgreSQL mailing list [0] to evaluate the performance of the SVE2 implementation against the existing scalar ARM version across multiple buffer sizes.
Query:
The experiment was executed for input sizes ranging from 8 bytes up to 32 MB.
time SELECT drive_crc32c(1000000, bytes);The experiment was executed for input sizes ranging from 8 bytes up to 32 MB.
Results:
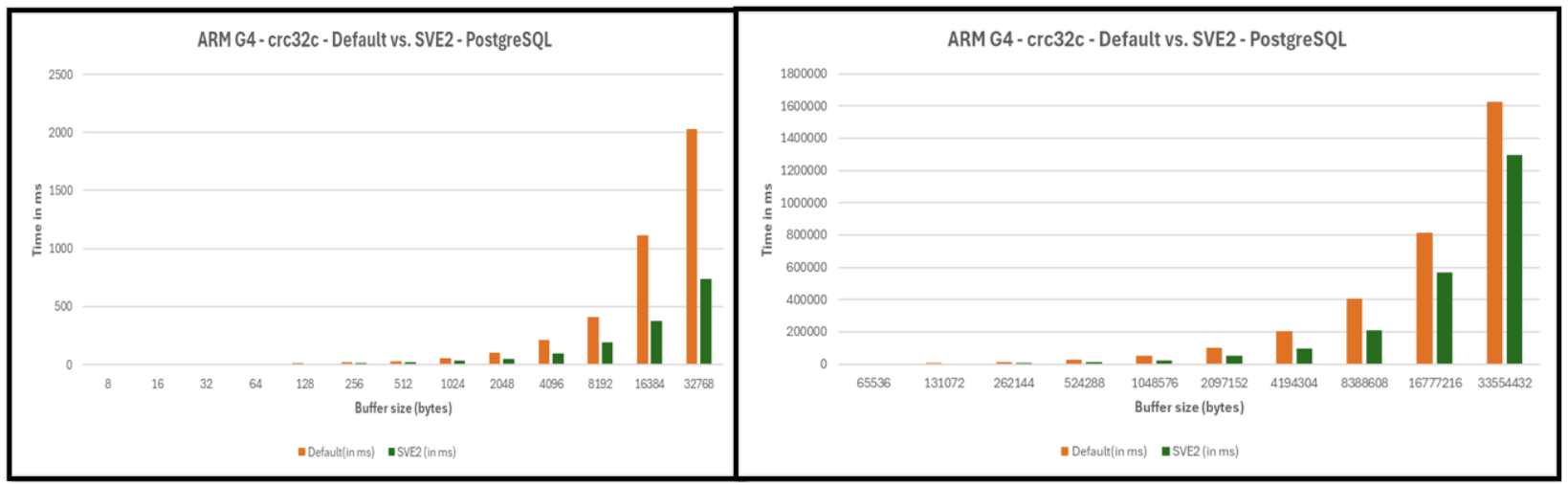
Significant performance gains are observed starting from 128 bytes. For larger buffer sizes (≥ 1 KB), the SVE2 implementation achieves approximately 2�C3 times speed-ups, with peak improvements observed for multi-megabyte inputs due to parallel folding and polynomial carry-less multiplication using 8 SVE2 vectors.
Significant performance gains are observed starting from 128 bytes. For larger buffer sizes (≥ 1 KB), the SVE2 implementation achieves approximately 2�C3 times speed-ups, with peak improvements observed for multi-megabyte inputs due to parallel folding and polynomial carry-less multiplication using 8 SVE2 vectors.
These improvements make CRC32C computation substantially faster for real PostgreSQL workloads involving large data blocks or WAL buffers.
We would like to contribute this work so that it becomes available to the PostgreSQL community. As part of the process, we are following the guidelines provided in Submitting a Patch - PostgreSQL wiki. Please find the attachment for the patches and performance results.
Please let us know if you have any queries or suggestions.
Thanks & Regards,
Susmitha Devanga.
[0]
postgresql.org/message-id/attachment/169378/v10-0001-Add-a-Postgres-SQL-function-for-crc32c-benchmark.patch
Susmitha Devanga.
[0]
postgresql.org/message-id/attachment/169378/v10-0001-Add-a-Postgres-SQL-function-for-crc32c-benchmark.patch
Вложения
{kind=link}
On Fri, Dec 19, 2025 at 4:20 AM Devanga.Susmitha@fujitsu.com
<Devanga.Susmitha@fujitsu.com> wrote:
> For architecture-specific functions, we use pg_attribute_target("arch=armv9-a+sve2-aes")
There was already a proposal to use armv8-a+crypto, which is more
widely available and works on smaller inputs. Perhaps you'd be
interested in reviewing and testing?
https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
> to ensure precise compilation control without modifying global CFLAGS, enabling a clean integration within
PostgreSQL’sbuild system.
I think the reason we continue to use CFLAGS here was that clang
support for target attributes on Arm is fairly recent. It's probably
too soon to reconsider that.
--
John Naylor
Amazon Web Services
>There was already a proposal to use armv8-a+crypto, which is more
widely available and works on smaller inputs.
Our implementation with SVE2 is able to gain better performance than
https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
I've benchmarked our SVE2 implementation against armv8-a+crypto, and the results show substantial improvements.
widely available and works on smaller inputs.
Our implementation with SVE2 is able to gain better performance than
https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
I've benchmarked our SVE2 implementation against armv8-a+crypto, and the results show substantial improvements.
Buffer size (bytes) | armv8+crypto (in ms) | armv9+SVE2 (in ms) | Improvement |
512 | 28.491 | 19.37 | 32.0% faster |
1024 | 47.145 | 29.962 | 36.5% faster |
2048 | 86.717 | 52.841 | 39.1% faster |
4096 | 165.205 | 105.626 | 36.1% faster |
8192 | 318.103 | 226.437 | 28.8% faster |
These buffer sizes are particularly relevant for PostgreSQL workloads:
- 8KB: Default page size (28.8% faster checksumming)
- 4KB: Alternative page size configuration (36.1% faster)
- 512B-2KB: Typical WAL record sizes (32-39% faster)
- 2KB: TOAST chunk size (39% faster)
While armv8-a+crypto has broader current deployment, SVE2 is already available in production cloud infrastructure: AWS Graviton 4, Ampere AmpereOne, and NVIDIA Grace (all released 2023). As ARMv9 adoption continues, these gains become increasingly relevant.
Rather than choosing one approach over the other, perhaps we could implement both with runtime CPU detection? Since we already perform runtime detection for crypto extension availability, adding an additional check for SVE2 introduces no performance degradation on systems without SVE2, while providing significant performance gains (28-39%) on systems that do support it. This would provide optimal performance on capable hardware while maintaining broad compatibility. Please let me know your thoughts.
static pg_crc32c (*pg_comp_crc32c_armv8)(pg_crc32c crc, const void *data, size_t len);
static pg_crc32c (*pg_comp_crc32c_armv8)(pg_crc32c crc, const void *data, size_t len);
void pg_comp_crc32c_choose_armv8(void)
{
if (pg_cpu_has_sve2())
pg_comp_crc32c_armv8 = pg_comp_crc32c_armv8_sve2;
else if (pg_cpu_has_crypto())
pg_comp_crc32c_armv8 = pg_comp_crc32c_armv8_crypto;
else
pg_comp_crc32c_armv8 = pg_comp_crc32c_sb8; // scalar fallback
}
Thanks,
Susmitha Devanga.
Susmitha Devanga.
From: John Naylor <johncnaylorls@gmail.com>
Sent: Friday, December 19, 2025 08:27
To: Susmitha, Devanga <Devanga.Susmitha@fujitsu.com>
Cc: pgsql-hackers <pgsql-hackers@postgresql.org>; Hajela, Ragesh <Ragesh.Hajela@fujitsu.com>; Bhattacharya, Chiranmoy <Chiranmoy.Bhattacharya@fujitsu.com>
Subject: Re: [PATCH] CRC32C optimizations using SVE2 on ARM.
Sent: Friday, December 19, 2025 08:27
To: Susmitha, Devanga <Devanga.Susmitha@fujitsu.com>
Cc: pgsql-hackers <pgsql-hackers@postgresql.org>; Hajela, Ragesh <Ragesh.Hajela@fujitsu.com>; Bhattacharya, Chiranmoy <Chiranmoy.Bhattacharya@fujitsu.com>
Subject: Re: [PATCH] CRC32C optimizations using SVE2 on ARM.
On Fri, Dec 19, 2025 at 4:20 AM Devanga.Susmitha@fujitsu.com
<Devanga.Susmitha@fujitsu.com> wrote:
> For architecture-specific functions, we use pg_attribute_target("arch=armv9-a+sve2-aes")
There was already a proposal to use armv8-a+crypto, which is more
widely available and works on smaller inputs. Perhaps you'd be
interested in reviewing and testing?
https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
> to ensure precise compilation control without modifying global CFLAGS, enabling a clean integration within PostgreSQL’s build system.
I think the reason we continue to use CFLAGS here was that clang
support for target attributes on Arm is fairly recent. It's probably
too soon to reconsider that.
--
John Naylor
Amazon Web Services
<Devanga.Susmitha@fujitsu.com> wrote:
> For architecture-specific functions, we use pg_attribute_target("arch=armv9-a+sve2-aes")
There was already a proposal to use armv8-a+crypto, which is more
widely available and works on smaller inputs. Perhaps you'd be
interested in reviewing and testing?
https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
> to ensure precise compilation control without modifying global CFLAGS, enabling a clean integration within PostgreSQL’s build system.
I think the reason we continue to use CFLAGS here was that clang
support for target attributes on Arm is fairly recent. It's probably
too soon to reconsider that.
--
John Naylor
Amazon Web Services
On Mon, Jan 5, 2026 at 4:02 PM Devanga.Susmitha@fujitsu.com <Devanga.Susmitha@fujitsu.com> wrote:
>
> >There was already a proposal to use armv8-a+crypto, which is more
> widely available and works on smaller inputs.
>
> Our implementation with SVE2 is able to gain better performance than
> https://www.postgresql.org/message-id/CANWCAZaKhE%2BRD5KKouUFoxx1EbUNrNhcduM1VQ%3DDkSDadNEFng%40mail.gmail.com
>
> I've benchmarked our SVE2 implementation against armv8-a+crypto, and the results show substantial improvements.
Thanks for testing! For future reference, please don't top post. We prefer to reply in-line to relevant points.
> These buffer sizes are particularly relevant for PostgreSQL workloads:
>
> 8KB: Default page size (28.8% faster checksumming)
> 4KB: Alternative page size configuration (36.1% faster)
We don't use CRC for page checksums. Did you mean FPI in WAL?
> 512B-2KB: Typical WAL record sizes (32-39% faster)
That seems on the high end, but your mileage may vary. Even if it were typical, the difference isn't that impressive, given that the patch seems to use double the number of (twice as wide?) accumulators. In any case, I suspect going from (say) 3x to 4x won't make much difference in profiles for those workloads, aside from having less portability. Plus, it seems more widely useful to allow a cutoff at 64 bytes, rather than 128.
> While armv8-a+crypto has broader current deployment, SVE2 is already available in production cloud infrastructure: AWS Graviton 4, Ampere AmpereOne, and NVIDIA Grace (all released 2023). As ARMv9 adoption continues, these gains become increasingly relevant.
That's pretty recent.
> Rather than choosing one approach over the other, perhaps we could implement both with runtime CPU detection?
That's bad for maintainability.
The broader point is I've already found something that seems good enough (and can be configured differently if necessary), portable enough, and is already used for our x86 vectorized implementation. I just wasn't going to make it a priority until someone showed up with enough interest to test and review it.
--
John Naylor
Amazon Web Services