Обсуждение: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Xuneng Zhou
Дата:
Hi Hackers, The SnapBuildPurgeOlderTxn function previously used a suboptimal method to remove old XIDs from the committed.xip array. It allocated a temporary workspace array, copied the surviving elements into it, and then copied them back, incurring unnecessary memory allocation and multiple data copies. This patch refactors the logic to use a standard two-pointer, in-place compaction algorithm. The new approach filters the array in a single pass with no extra memory allocation, improving both CPU and memory efficiency. No behavioral changes are expected. This resolves a TODO comment expecting a more efficient algorithm. Best, Xuneng
Вложения
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Kirill Reshke
Дата:
On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi Hackers, Hi! > The SnapBuildPurgeOlderTxn function previously used a suboptimal > method to remove old XIDs from the committed.xip array. It allocated a > temporary workspace array, copied the surviving elements into it, and > then copied them back, incurring unnecessary memory allocation and > multiple data copies. > > This patch refactors the logic to use a standard two-pointer, in-place > compaction algorithm. The new approach filters the array in a single > pass with no extra memory allocation, improving both CPU and memory > efficiency. > > No behavioral changes are expected. This resolves a TODO comment > expecting a more efficient algorithm. > Indeed, these changes look correct. I wonder why b89e151054a0 did this place this way, hope we do not miss anything here. Can we construct a microbenchmark here which will show some benefit? -- Best regards, Kirill Reshke
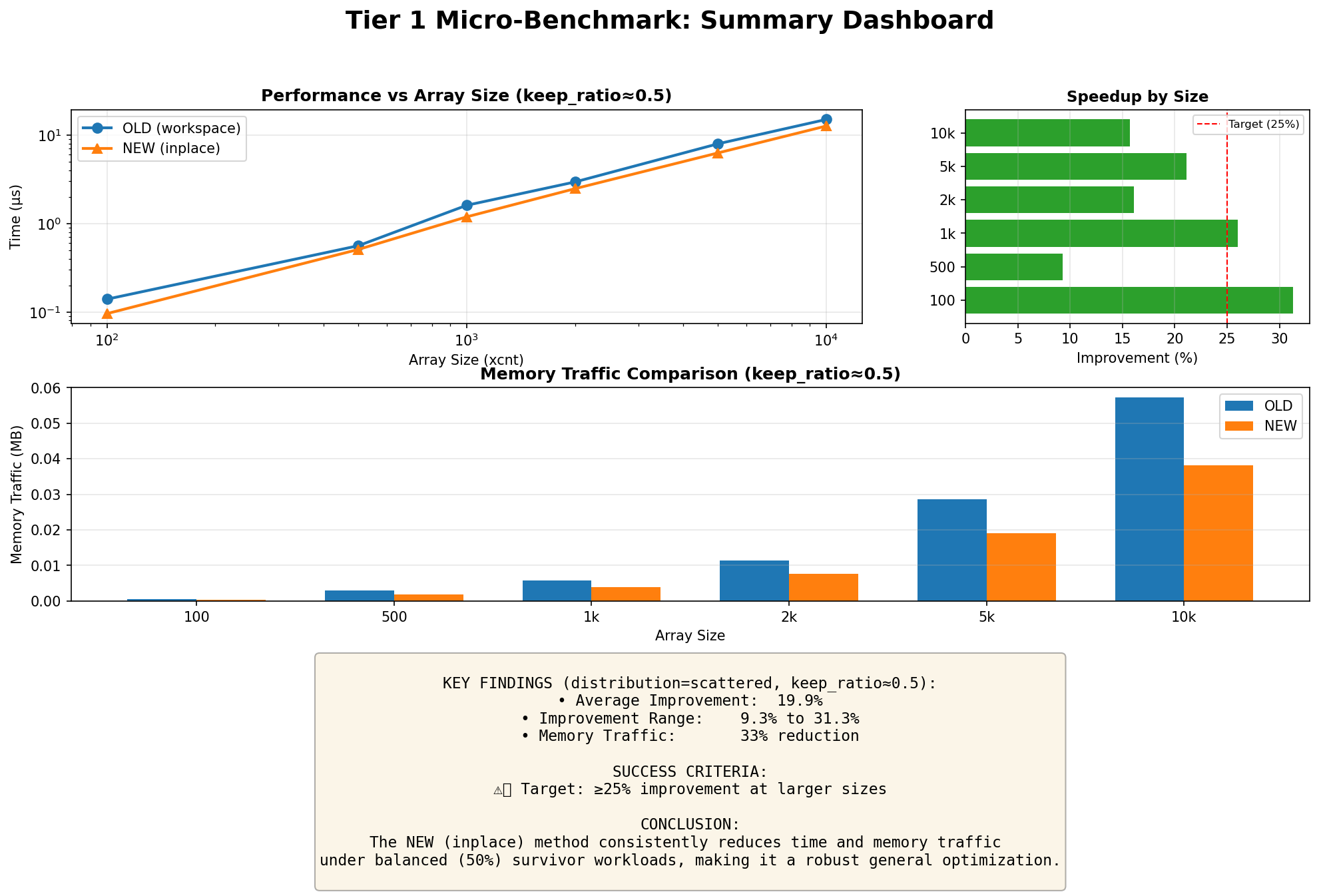
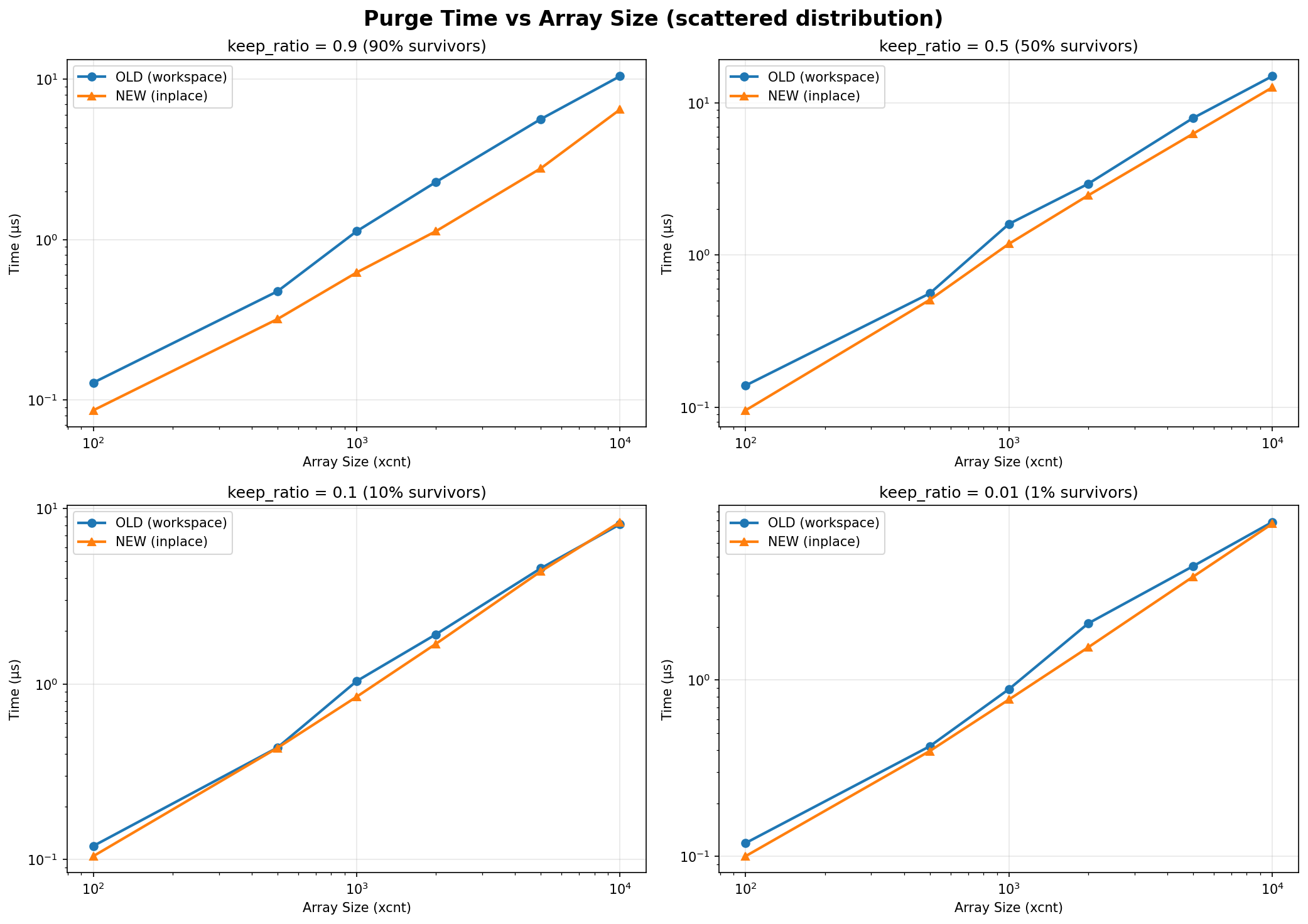
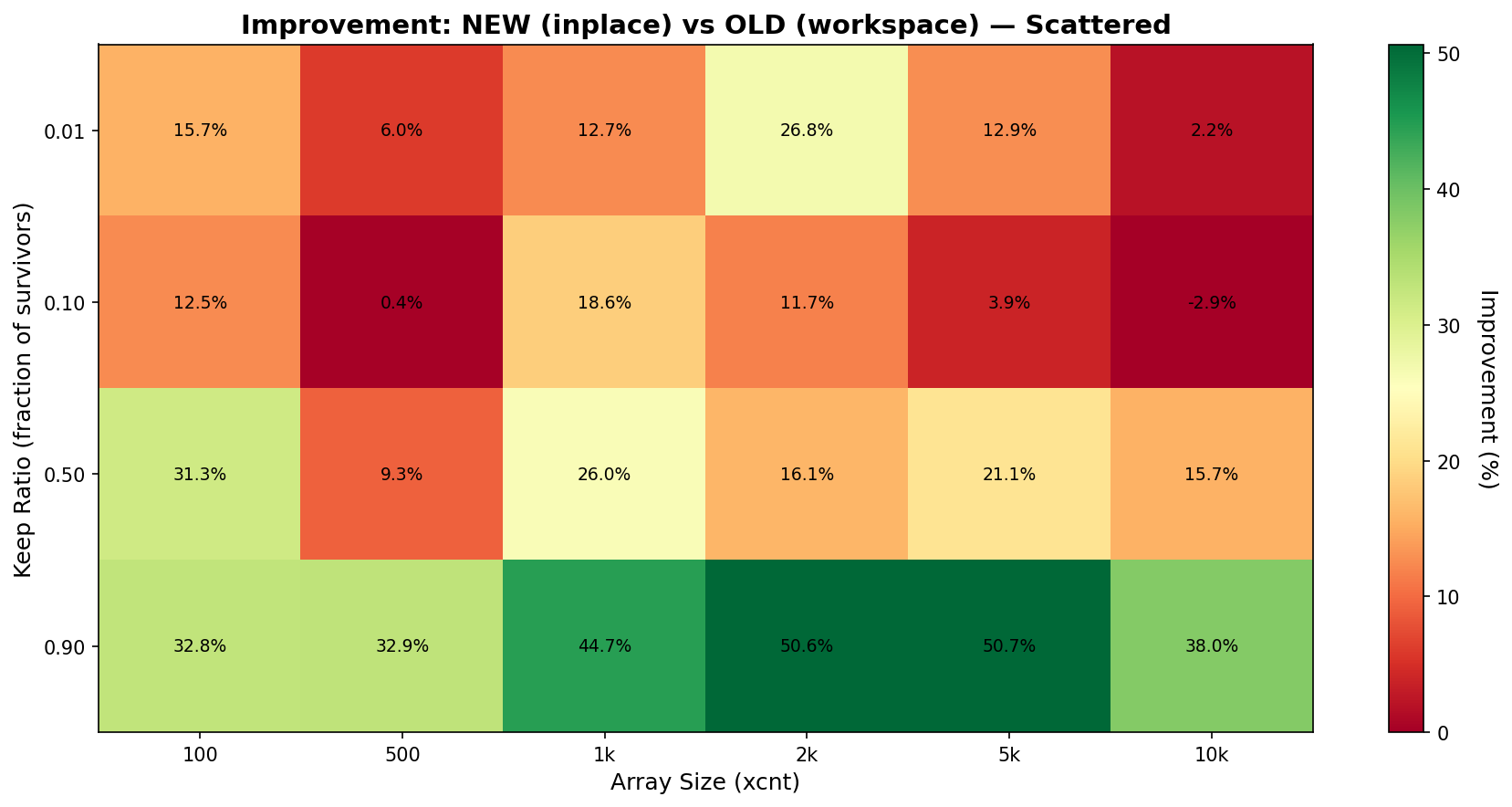
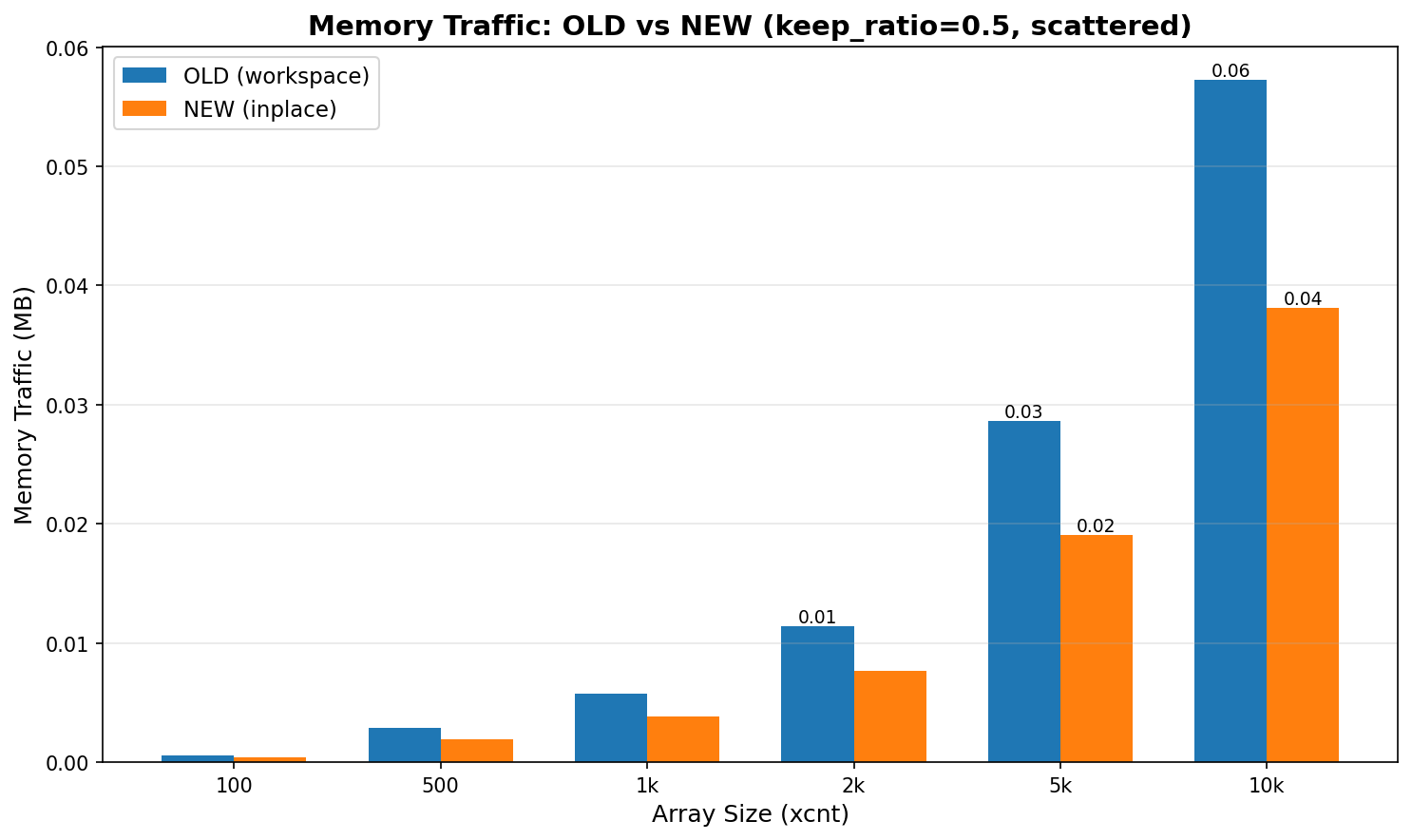
Hi, thanks for looking into this. On Sat, Oct 18, 2025 at 4:59 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi Hackers, > > Hi! > > > The SnapBuildPurgeOlderTxn function previously used a suboptimal > > method to remove old XIDs from the committed.xip array. It allocated a > > temporary workspace array, copied the surviving elements into it, and > > then copied them back, incurring unnecessary memory allocation and > > multiple data copies. > > > > This patch refactors the logic to use a standard two-pointer, in-place > > compaction algorithm. The new approach filters the array in a single > > pass with no extra memory allocation, improving both CPU and memory > > efficiency. > > > > No behavioral changes are expected. This resolves a TODO comment > > expecting a more efficient algorithm. > > > > Indeed, these changes look correct. > I wonder why b89e151054a0 did this place this way, hope we do not miss > anything here. I think this small refactor does not introduce behavioral changes or breaks given constraints. > Can we construct a microbenchmark here which will show some benefit? > I prepared a simple microbenchmark to evaluate the impact of the algorithm replacement. The attached results summarize the findings. An end-to-end benchmark was not included, as this function is unlikely to be a performance hotspot in typical decoding workloads—the array being cleaned is expected to be relatively small under normal operating conditions. However, its impact could become more noticeable in scenarios with long-running transactions and a large number of catalog-modifying DML or DDL operations. Hardware: AMD EPYC™ Genoa 9454P 48-core 4th generation DDR5 ECC reg NVMe SSD Datacenter Edition (Gen 4) Best, Xuneng
Вложения
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Kirill Reshke
Дата:
On Mon, 20 Oct 2025 at 08:08, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, thanks for looking into this. > > On Sat, Oct 18, 2025 at 4:59 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > > > Hi Hackers, > > > > Hi! > > > > > The SnapBuildPurgeOlderTxn function previously used a suboptimal > > > method to remove old XIDs from the committed.xip array. It allocated a > > > temporary workspace array, copied the surviving elements into it, and > > > then copied them back, incurring unnecessary memory allocation and > > > multiple data copies. > > > > > > This patch refactors the logic to use a standard two-pointer, in-place > > > compaction algorithm. The new approach filters the array in a single > > > pass with no extra memory allocation, improving both CPU and memory > > > efficiency. > > > > > > No behavioral changes are expected. This resolves a TODO comment > > > expecting a more efficient algorithm. > > > > > > > Indeed, these changes look correct. > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > anything here. > > I think this small refactor does not introduce behavioral changes or > breaks given constraints. > > > Can we construct a microbenchmark here which will show some benefit? > > > > I prepared a simple microbenchmark to evaluate the impact of the > algorithm replacement. The attached results summarize the findings. > An end-to-end benchmark was not included, as this function is unlikely > to be a performance hotspot in typical decoding workloads—the array > being cleaned is expected to be relatively small under normal > operating conditions. However, its impact could become more noticeable > in scenarios with long-running transactions and a large number of > catalog-modifying DML or DDL operations. > > Hardware: > AMD EPYC™ Genoa 9454P 48-core 4th generation > DDR5 ECC reg > NVMe SSD Datacenter Edition (Gen 4) > > Best, > Xuneng At first glance these results look satisfactory. Can you please describe, how did you get your numbers? Maybe more script or steps to reproduce, if anyone will be willing to... -- Best regards, Kirill Reshke
Hi, On Mon, Oct 20, 2025 at 11:36 AM Kirill Reshke <reshkekirill@gmail.com> wrote: > > On Mon, 20 Oct 2025 at 08:08, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi, thanks for looking into this. > > > > On Sat, Oct 18, 2025 at 4:59 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > > > On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > > > > > Hi Hackers, > > > > > > Hi! > > > > > > > The SnapBuildPurgeOlderTxn function previously used a suboptimal > > > > method to remove old XIDs from the committed.xip array. It allocated a > > > > temporary workspace array, copied the surviving elements into it, and > > > > then copied them back, incurring unnecessary memory allocation and > > > > multiple data copies. > > > > > > > > This patch refactors the logic to use a standard two-pointer, in-place > > > > compaction algorithm. The new approach filters the array in a single > > > > pass with no extra memory allocation, improving both CPU and memory > > > > efficiency. > > > > > > > > No behavioral changes are expected. This resolves a TODO comment > > > > expecting a more efficient algorithm. > > > > > > > > > > Indeed, these changes look correct. > > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > > anything here. > > > > I think this small refactor does not introduce behavioral changes or > > breaks given constraints. > > > > > Can we construct a microbenchmark here which will show some benefit? > > > > > > > I prepared a simple microbenchmark to evaluate the impact of the > > algorithm replacement. The attached results summarize the findings. > > An end-to-end benchmark was not included, as this function is unlikely > > to be a performance hotspot in typical decoding workloads—the array > > being cleaned is expected to be relatively small under normal > > operating conditions. However, its impact could become more noticeable > > in scenarios with long-running transactions and a large number of > > catalog-modifying DML or DDL operations. > > > > Hardware: > > AMD EPYC™ Genoa 9454P 48-core 4th generation > > DDR5 ECC reg > > NVMe SSD Datacenter Edition (Gen 4) > > > > Best, > > Xuneng > > At first glance these results look satisfactory. > > Can you please describe, how did you get your numbers? Maybe more > script or steps to reproduce, if anyone will be willing to... > Sure. Here is a brief description of this experiential benchmark: 1) what Tier 1 measures Function under test: committed.xip purge in SnapBuild (OLD=workspace+memcpy vs NEW=in-place compaction). Inputs: Array sizes: 100, 500, 1000, 2000, 5000, 10000 Keep ratios: 0.9, 0.5, 0.1, 0.01 Distributions: scattered (Fisher–Yates shuffle), contiguous Repetitions: 30 per scenario RNG and determinism: pg_prng_state with seed 42 per dataset ensures reproducibility. Metrics recorded per scenario: Time (ns): mean, median, p95 Survivors (count) Memory traffic (bytes): bytes_read, bytes_written, bytes_total OLD: reads = (xcnt + survivors) × sizeof(XID); writes = 2 × survivors × sizeof(XID) NEW: reads = xcnt × sizeof(XID); writes = survivors × sizeof(XID) 2) The core components # C Extension (snapbuild_bench.c) - The actual benchmark implementation The C extension contains the actual benchmark implementation that runs inside the PostgreSQL backend process. It's designed to: - Mimic real PostgreSQL code paths** as closely as possible - Use actual PostgreSQL data structures** (`TransactionId`, `MemoryContext`) - Call real PostgreSQL functions** (`NormalTransactionIdPrecedes`) - Measure with nanosecond precision** using PostgreSQL's timing infrastructure # SQL Wrapper (snapbuild_bench--1.0.sql) - function definitions # Orchestration Scripts - Automated benchmark execution and analysis run_snapbuild_purge_bench 3) Execution Flow 1. Extension Installation # Build and install export PG_CONFIG=$HOME/pg/vanilla/bin/pg_config make -C contrib_extension/snapbuild_bench clean install # Create extension in database CREATE EXTENSION snapbuild_bench; 3. Run full benchmark suite ./run_snapbuild_purge_bench.sh --clean --with-baseline <patch> 4. Data Analysis # Generate plots python3 plot_tier1_results.py --csv results/unit/base_unit.csv --out plots/ # Compare baseline vs patched python3 compare_snapbuild_results.py vanilla/ patched/ TBH, the performance improvement from this refactor is fairly straightforward, and it’s unlikely to introduce regressions. The experimental benchmark is therefore more complex than necessary. Still, I treated it as a learning exercise — an opportunity to practice benchmarking methodology and hopefully to reuse some of these techniques when evaluating more performance-critical paths in the future. If anyone has suggestions or spots issues, I’d greatly appreciate your feedback as well. Best, Xuneng
Вложения
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Kirill Reshke
Дата:
On Mon, 20 Oct 2025 at 13:47, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > On Mon, Oct 20, 2025 at 11:36 AM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > On Mon, 20 Oct 2025 at 08:08, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > > > Hi, thanks for looking into this. > > > > > > On Sat, Oct 18, 2025 at 4:59 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > > > > > On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > > > > > > > Hi Hackers, > > > > > > > > Hi! > > > > > > > > > The SnapBuildPurgeOlderTxn function previously used a suboptimal > > > > > method to remove old XIDs from the committed.xip array. It allocated a > > > > > temporary workspace array, copied the surviving elements into it, and > > > > > then copied them back, incurring unnecessary memory allocation and > > > > > multiple data copies. > > > > > > > > > > This patch refactors the logic to use a standard two-pointer, in-place > > > > > compaction algorithm. The new approach filters the array in a single > > > > > pass with no extra memory allocation, improving both CPU and memory > > > > > efficiency. > > > > > > > > > > No behavioral changes are expected. This resolves a TODO comment > > > > > expecting a more efficient algorithm. > > > > > > > > > > > > > Indeed, these changes look correct. > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > > > anything here. > > > > > > I think this small refactor does not introduce behavioral changes or > > > breaks given constraints. > > > > > > > Can we construct a microbenchmark here which will show some benefit? > > > > > > > > > > I prepared a simple microbenchmark to evaluate the impact of the > > > algorithm replacement. The attached results summarize the findings. > > > An end-to-end benchmark was not included, as this function is unlikely > > > to be a performance hotspot in typical decoding workloads—the array > > > being cleaned is expected to be relatively small under normal > > > operating conditions. However, its impact could become more noticeable > > > in scenarios with long-running transactions and a large number of > > > catalog-modifying DML or DDL operations. > > > > > > Hardware: > > > AMD EPYC™ Genoa 9454P 48-core 4th generation > > > DDR5 ECC reg > > > NVMe SSD Datacenter Edition (Gen 4) > > > > > > Best, > > > Xuneng > > > > At first glance these results look satisfactory. > > > > Can you please describe, how did you get your numbers? Maybe more > > script or steps to reproduce, if anyone will be willing to... > > > > Sure. Here is a brief description of this experiential benchmark: > > 1) what Tier 1 measures > > Function under test: committed.xip purge in SnapBuild > (OLD=workspace+memcpy vs NEW=in-place compaction). > > Inputs: > Array sizes: 100, 500, 1000, 2000, 5000, 10000 > Keep ratios: 0.9, 0.5, 0.1, 0.01 > Distributions: scattered (Fisher–Yates shuffle), contiguous > Repetitions: 30 per scenario > > RNG and determinism: pg_prng_state with seed 42 per dataset ensures > reproducibility. > > Metrics recorded per scenario: > Time (ns): mean, median, p95 > Survivors (count) > Memory traffic (bytes): bytes_read, bytes_written, bytes_total > OLD: reads = (xcnt + survivors) × sizeof(XID); writes = 2 × survivors > × sizeof(XID) > NEW: reads = xcnt × sizeof(XID); writes = survivors × sizeof(XID) > > 2) The core components > > # C Extension (snapbuild_bench.c) - The actual benchmark implementation > > The C extension contains the actual benchmark implementation that runs > inside the PostgreSQL backend process. It's designed to: > - Mimic real PostgreSQL code paths** as closely as possible > - Use actual PostgreSQL data structures** (`TransactionId`, `MemoryContext`) > - Call real PostgreSQL functions** (`NormalTransactionIdPrecedes`) > - Measure with nanosecond precision** using PostgreSQL's timing infrastructure > > # SQL Wrapper (snapbuild_bench--1.0.sql) - function definitions > > # Orchestration Scripts - Automated benchmark execution and analysis > run_snapbuild_purge_bench > > 3) Execution Flow > > 1. Extension Installation > # Build and install > export PG_CONFIG=$HOME/pg/vanilla/bin/pg_config > make -C contrib_extension/snapbuild_bench clean install > # Create extension in database > CREATE EXTENSION snapbuild_bench; > > 3. Run full benchmark suite > ./run_snapbuild_purge_bench.sh --clean --with-baseline <patch> > > 4. Data Analysis > # Generate plots > python3 plot_tier1_results.py --csv results/unit/base_unit.csv --out plots/ > # Compare baseline vs patched > python3 compare_snapbuild_results.py vanilla/ patched/ Thank you. > TBH, the performance improvement from this refactor is fairly > straightforward, and it’s unlikely to introduce regressions. Sure. > The > experimental benchmark is therefore more complex than necessary. > Still, I treated it as a learning exercise — an opportunity to > practice benchmarking methodology and hopefully to reuse some of these > techniques when evaluating more performance-critical paths in the > future. If anyone has suggestions or spots issues, I’d greatly > appreciate your feedback as well. > > Best, > Xuneng I think this patch is in committable state, should we change its CF entry accordingly? -- Best regards, Kirill Reshke
Hi,
Kirill Reshke <reshkekirill@gmail.com> 于 2025年10月20日周一 下午6:07写道:
On Mon, 20 Oct 2025 at 13:47, Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Hi,
>
> On Mon, Oct 20, 2025 at 11:36 AM Kirill Reshke <reshkekirill@gmail.com> wrote:
> >
> > On Mon, 20 Oct 2025 at 08:08, Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > >
> > > Hi, thanks for looking into this.
> > >
> > > On Sat, Oct 18, 2025 at 4:59 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > >
> > > > On Sat, 18 Oct 2025 at 12:50, Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > > >
> > > > > Hi Hackers,
> > > >
> > > > Hi!
> > > >
> > > > > The SnapBuildPurgeOlderTxn function previously used a suboptimal
> > > > > method to remove old XIDs from the committed.xip array. It allocated a
> > > > > temporary workspace array, copied the surviving elements into it, and
> > > > > then copied them back, incurring unnecessary memory allocation and
> > > > > multiple data copies.
> > > > >
> > > > > This patch refactors the logic to use a standard two-pointer, in-place
> > > > > compaction algorithm. The new approach filters the array in a single
> > > > > pass with no extra memory allocation, improving both CPU and memory
> > > > > efficiency.
> > > > >
> > > > > No behavioral changes are expected. This resolves a TODO comment
> > > > > expecting a more efficient algorithm.
> > > > >
> > > >
> > > > Indeed, these changes look correct.
> > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > anything here.
> > >
> > > I think this small refactor does not introduce behavioral changes or
> > > breaks given constraints.
> > >
> > > > Can we construct a microbenchmark here which will show some benefit?
> > > >
> > >
> > > I prepared a simple microbenchmark to evaluate the impact of the
> > > algorithm replacement. The attached results summarize the findings.
> > > An end-to-end benchmark was not included, as this function is unlikely
> > > to be a performance hotspot in typical decoding workloads—the array
> > > being cleaned is expected to be relatively small under normal
> > > operating conditions. However, its impact could become more noticeable
> > > in scenarios with long-running transactions and a large number of
> > > catalog-modifying DML or DDL operations.
> > >
> > > Hardware:
> > > AMD EPYC™ Genoa 9454P 48-core 4th generation
> > > DDR5 ECC reg
> > > NVMe SSD Datacenter Edition (Gen 4)
> > >
> > > Best,
> > > Xuneng
> >
> > At first glance these results look satisfactory.
> >
> > Can you please describe, how did you get your numbers? Maybe more
> > script or steps to reproduce, if anyone will be willing to...
> >
>
> Sure. Here is a brief description of this experiential benchmark:
>
> 1) what Tier 1 measures
>
> Function under test: committed.xip purge in SnapBuild
> (OLD=workspace+memcpy vs NEW=in-place compaction).
>
> Inputs:
> Array sizes: 100, 500, 1000, 2000, 5000, 10000
> Keep ratios: 0.9, 0.5, 0.1, 0.01
> Distributions: scattered (Fisher–Yates shuffle), contiguous
> Repetitions: 30 per scenario
>
> RNG and determinism: pg_prng_state with seed 42 per dataset ensures
> reproducibility.
>
> Metrics recorded per scenario:
> Time (ns): mean, median, p95
> Survivors (count)
> Memory traffic (bytes): bytes_read, bytes_written, bytes_total
> OLD: reads = (xcnt + survivors) × sizeof(XID); writes = 2 × survivors
> × sizeof(XID)
> NEW: reads = xcnt × sizeof(XID); writes = survivors × sizeof(XID)
>
> 2) The core components
>
> # C Extension (snapbuild_bench.c) - The actual benchmark implementation
>
> The C extension contains the actual benchmark implementation that runs
> inside the PostgreSQL backend process. It's designed to:
> - Mimic real PostgreSQL code paths** as closely as possible
> - Use actual PostgreSQL data structures** (`TransactionId`, `MemoryContext`)
> - Call real PostgreSQL functions** (`NormalTransactionIdPrecedes`)
> - Measure with nanosecond precision** using PostgreSQL's timing infrastructure
>
> # SQL Wrapper (snapbuild_bench--1.0.sql) - function definitions
>
> # Orchestration Scripts - Automated benchmark execution and analysis
> run_snapbuild_purge_bench
>
> 3) Execution Flow
>
> 1. Extension Installation
> # Build and install
> export PG_CONFIG=$HOME/pg/vanilla/bin/pg_config
> make -C contrib_extension/snapbuild_bench clean install
> # Create extension in database
> CREATE EXTENSION snapbuild_bench;
>
> 3. Run full benchmark suite
> ./run_snapbuild_purge_bench.sh --clean --with-baseline <patch>
>
> 4. Data Analysis
> # Generate plots
> python3 plot_tier1_results.py --csv results/unit/base_unit.csv --out plots/
> # Compare baseline vs patched
> python3 compare_snapbuild_results.py vanilla/ patched/
Thank you.
> TBH, the performance improvement from this refactor is fairly
> straightforward, and it’s unlikely to introduce regressions.
Sure.
> The
> experimental benchmark is therefore more complex than necessary.
> Still, I treated it as a learning exercise — an opportunity to
> practice benchmarking methodology and hopefully to reuse some of these
> techniques when evaluating more performance-critical paths in the
> future. If anyone has suggestions or spots issues, I’d greatly
> appreciate your feedback as well.
>
> Best,
> Xuneng
I think this patch is in committable state, should we change its CF
entry accordingly?
Feel free to do so if you agree. Thanks again for your review!
Best,
Xuneng
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Michael Paquier
Дата:
On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote: > Indeed, these changes look correct. > I wonder why b89e151054a0 did this place this way, hope we do not miss > anything here. Perhaps a lack of time back in 2014? It feels like an item where we would need to research a bit some of the past threads, and see if this has been discussed, or if there were other potential alternatives discussed. This is not saying that what you are doing in this proposal is actually bad, but it's a bit hard to say what an "algorithm" should look like in this specific code path with XID manipulations. Perhaps since 2014, we may have other places in the tree that share similar characteristics as what's done here. So it feels like this needs a bit more historical investigation first, rather than saying that your proposal is the best choice on the table. -- Michael
Вложения
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Kirill Reshke
Дата:
On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote: > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote: > > Indeed, these changes look correct. > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > anything here. > > Perhaps a lack of time back in 2014? It feels like an item where we > would need to research a bit some of the past threads, and see if this > has been discussed, or if there were other potential alternatives > discussed. This is not saying that what you are doing in this > proposal is actually bad, but it's a bit hard to say what an > "algorithm" should look like in this specific code path with XID > manipulations. Perhaps since 2014, we may have other places in the > tree that share similar characteristics as what's done here. > > So it feels like this needs a bit more historical investigation first, > rather than saying that your proposal is the best choice on the table. > -- > Michael Sure Commit b89e151054a0 comes from [0] Comment of SnapBuildPurgeCommittedTxn tracks to [1] (it was in form "XXX: Neater algorithm?") Between these two messages, it was not disucccesseed... I will also study other related threads like [2], but i don't think they will give more insight here. [0] https://www.postgresql.org/message-id/20140303162652.GB16654%40awork2.anarazel.de [1] https://www.postgresql.org/message-id/20140115002223.GA17204%40awork2.anarazel.de [2] https://www.postgresql.org/message-id/flat/20130914204913.GA4071%40awork2.anarazel.de#:~:text=20130914204913.GA4071%40awork2.anarazel.de -- Best regards, Kirill Reshke
Hi, Thanks for looking into this. On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote: > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote: > > > Indeed, these changes look correct. > > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > > anything here. > > > > Perhaps a lack of time back in 2014? It feels like an item where we > > would need to research a bit some of the past threads, and see if this > > has been discussed, or if there were other potential alternatives > > discussed. This is not saying that what you are doing in this > > proposal is actually bad, but it's a bit hard to say what an > > "algorithm" should look like in this specific code path with XID > > manipulations. Perhaps since 2014, we may have other places in the > > tree that share similar characteristics as what's done here. > > > > So it feels like this needs a bit more historical investigation first, > > rather than saying that your proposal is the best choice on the table. > > -- > > Michael > > Sure > > Commit b89e151054a0 comes from [0] > Comment of SnapBuildPurgeCommittedTxn tracks to [1] (it was in form > "XXX: Neater algorithm?") > > Between these two messages, it was not disucccesseed... > > I will also study other related threads like [2], but i don't think > they will give more insight here. > > [0] https://www.postgresql.org/message-id/20140303162652.GB16654%40awork2.anarazel.de > [1] https://www.postgresql.org/message-id/20140115002223.GA17204%40awork2.anarazel.de > [2] https://www.postgresql.org/message-id/flat/20130914204913.GA4071%40awork2.anarazel.de#:~:text=20130914204913.GA4071%40awork2.anarazel.de Introducing logical decoding was a major feature, and I assume there were more critical design decisions and trade-offs to consider at that time. I proposed this refactor not because it is the most significant optimization, but because it seems to be a low-hanging fruit with clear benefits. By using an in-place two-pointer compaction, we can eliminate the extra memory allocation and copy-back step without introducing risks to this well-tested code path. A comparable optimization exists in KnownAssignedXidsCompress() which uses the same algorithm to remove stale XIDs without workspace allocation. That implementation also adds a lazy compaction heuristic that delays compaction until a threshold of removed entries is reached, amortizing the O(N) cost across multiple operations. The comment above the data structure mentions the trade-off of keeping the committed.xip array sorted versus unsorted. If the array were sorted, we could use a binary search combined with memmove to compact it efficiently, achieving O(log n + n) complexity for purging. However, that design would increase the complexity of SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt wraparound". /* * Array of committed transactions that have modified the catalog. * * As this array is frequently modified we do *not* keep it in * xidComparator order. Instead we sort the array when building & * distributing a snapshot. * * TODO: It's unclear whether that reasoning has much merit. Every * time we add something here after becoming consistent will also * require distributing a snapshot. Storing them sorted would * potentially also make it easier to purge (but more complicated wrt * wraparound?). Should be improved if sorting while building the * snapshot shows up in profiles. */ TransactionId *xip; } committed; /* * Keep track of a new catalog changing transaction that has committed. */ static void SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid) { Assert(TransactionIdIsValid(xid)); if (builder->committed.xcnt == builder->committed.xcnt_space) { builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1; elog(DEBUG1, "increasing space for committed transactions to %u", (uint32) builder->committed.xcnt_space); builder->committed.xip = repalloc(builder->committed.xip, builder->committed.xcnt_space * sizeof(TransactionId)); } /* * TODO: It might make sense to keep the array sorted here instead of * doing it every time we build a new snapshot. On the other hand this * gets called repeatedly when a transaction with subtransactions commits. */ builder->committed.xip[builder->committed.xcnt++] = xid; } It might be worth profiling this function to evaluate whether maintaining a sorted array could bring potential benefits, although accurately measuring its end-to-end impact could be difficult if it isn’t a known hotspot. I also did a brief search on the mailing list and found no reports of performance concerns or related proposals to optimize this part of the code. [1] https://www.postgresql.org/search/?m=1&q=SnapBuildPurgeOlderTxn&l=1&d=-1&s=r [2] https://www.postgresql.org/search/?m=1&q=committed.xip&l=1&d=-1&s=r&p=2 Best, Xuneng
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Masahiko Sawada
Дата:
On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > Thanks for looking into this. > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote: > > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote: > > > > Indeed, these changes look correct. > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > > > anything here. > > > > > > Perhaps a lack of time back in 2014? It feels like an item where we > > > would need to research a bit some of the past threads, and see if this > > > has been discussed, or if there were other potential alternatives > > > discussed. This is not saying that what you are doing in this > > > proposal is actually bad, but it's a bit hard to say what an > > > "algorithm" should look like in this specific code path with XID > > > manipulations. Perhaps since 2014, we may have other places in the > > > tree that share similar characteristics as what's done here. > > > > > > So it feels like this needs a bit more historical investigation first, > > > rather than saying that your proposal is the best choice on the table. > > > -- > > > Michael > > > > Sure > > > > Commit b89e151054a0 comes from [0] > > Comment of SnapBuildPurgeCommittedTxn tracks to [1] (it was in form > > "XXX: Neater algorithm?") > > > > Between these two messages, it was not disucccesseed... > > > > I will also study other related threads like [2], but i don't think > > they will give more insight here. > > > > [0] https://www.postgresql.org/message-id/20140303162652.GB16654%40awork2.anarazel.de > > [1] https://www.postgresql.org/message-id/20140115002223.GA17204%40awork2.anarazel.de > > [2] https://www.postgresql.org/message-id/flat/20130914204913.GA4071%40awork2.anarazel.de#:~:text=20130914204913.GA4071%40awork2.anarazel.de > > Introducing logical decoding was a major feature, and I assume there > were more critical design decisions and trade-offs to consider at that > time. > > I proposed this refactor not because it is the most significant > optimization, but because it seems to be a low-hanging fruit with > clear benefits. By using an in-place two-pointer compaction, we can > eliminate the extra memory allocation and copy-back step without > introducing risks to this well-tested code path. I agree the proposed in-pace update is better than the current copy-and-iterating approach. While the benefit might not be visible as it's not a known hot-path, I find that the proposed patch makes sense to improve the current codes. It could help some workloads where there are many DDLs (e.g., creating temporary tables in many transactions). > > A comparable optimization exists in KnownAssignedXidsCompress() which > uses the same algorithm to remove stale XIDs without workspace > allocation. That implementation also adds a lazy compaction heuristic > that delays compaction until a threshold of removed entries is > reached, amortizing the O(N) cost across multiple operations. > > The comment above the data structure mentions the trade-off of keeping > the committed.xip array sorted versus unsorted. If the array were > sorted, we could use a binary search combined with memmove to compact > it efficiently, achieving O(log n + n) complexity for purging. > However, that design would increase the complexity of > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt > wraparound". > > /* > * Array of committed transactions that have modified the catalog. > * > * As this array is frequently modified we do *not* keep it in > * xidComparator order. Instead we sort the array when building & > * distributing a snapshot. > * > * TODO: It's unclear whether that reasoning has much merit. Every > * time we add something here after becoming consistent will also > * require distributing a snapshot. Storing them sorted would > * potentially also make it easier to purge (but more complicated wrt > * wraparound?). Should be improved if sorting while building the > * snapshot shows up in profiles. > */ > TransactionId *xip; > } committed; > > /* > * Keep track of a new catalog changing transaction that has committed. > */ > static void > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid) > { > Assert(TransactionIdIsValid(xid)); > > if (builder->committed.xcnt == builder->committed.xcnt_space) > { > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1; > > elog(DEBUG1, "increasing space for committed transactions to %u", > (uint32) builder->committed.xcnt_space); > > builder->committed.xip = repalloc(builder->committed.xip, > builder->committed.xcnt_space * sizeof(TransactionId)); > } > > /* > * TODO: It might make sense to keep the array sorted here instead of > * doing it every time we build a new snapshot. On the other hand this > * gets called repeatedly when a transaction with subtransactions commits. > */ > builder->committed.xip[builder->committed.xcnt++] = xid; > } > > It might be worth profiling this function to evaluate whether > maintaining a sorted array could bring potential benefits, although > accurately measuring its end-to-end impact could be difficult if it > isn’t a known hotspot. I also did a brief search on the mailing list > and found no reports of performance concerns or related proposals to > optimize this part of the code. It might also be worth researching what kind of workloads would need a better algorithm in terms of storing/updating xip and subxip arrays since it would be the primary motivation. Also, otherwise we cannot measure the real-world impact of a new algorithm. Having said that, I find that it would be discussed and developed separately from the proposed patch on this thread. Regards, -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Hi Sawada-san, Michael, Thanks for your comments on this patch. On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi, > > > > Thanks for looking into this. > > > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote: > > > > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote: > > > > > Indeed, these changes look correct. > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss > > > > > anything here. > > > > > > > > Perhaps a lack of time back in 2014? It feels like an item where we > > > > would need to research a bit some of the past threads, and see if this > > > > has been discussed, or if there were other potential alternatives > > > > discussed. This is not saying that what you are doing in this > > > > proposal is actually bad, but it's a bit hard to say what an > > > > "algorithm" should look like in this specific code path with XID > > > > manipulations. Perhaps since 2014, we may have other places in the > > > > tree that share similar characteristics as what's done here. > > > > > > > > So it feels like this needs a bit more historical investigation first, > > > > rather than saying that your proposal is the best choice on the table. Following these suggestions, I carefully searched the mailing list archives and found no reports of performance issues directly related to this code path. I also examined other parts of the codebase for similar patterns. Components like integerset might share some characteristics with SnapBuildPurgeOlderTxn, but they have constraints that make them not directly applicable here. I am not very familiar with the whole tree, so the investigation might not be exhaustive. > > > > > > Commit b89e151054a0 comes from [0] > > > Comment of SnapBuildPurgeCommittedTxn tracks to [1] (it was in form > > > "XXX: Neater algorithm?") > > > > > > Between these two messages, it was not disucccesseed... > > > > > > I will also study other related threads like [2], but i don't think > > > they will give more insight here. > > > > > > [0] https://www.postgresql.org/message-id/20140303162652.GB16654%40awork2.anarazel.de > > > [1] https://www.postgresql.org/message-id/20140115002223.GA17204%40awork2.anarazel.de > > > [2] https://www.postgresql.org/message-id/flat/20130914204913.GA4071%40awork2.anarazel.de#:~:text=20130914204913.GA4071%40awork2.anarazel.de > > > > Introducing logical decoding was a major feature, and I assume there > > were more critical design decisions and trade-offs to consider at that > > time. > > > > I proposed this refactor not because it is the most significant > > optimization, but because it seems to be a low-hanging fruit with > > clear benefits. By using an in-place two-pointer compaction, we can > > eliminate the extra memory allocation and copy-back step without > > introducing risks to this well-tested code path. > > I agree the proposed in-pace update is better than the current > copy-and-iterating approach. While the benefit might not be visible as > it's not a known hot-path, I find that the proposed patch makes sense > to improve the current codes. It could help some workloads where there > are many DDLs (e.g., creating temporary tables in many transactions). > I also agree this approach offers better efficiency within the scope of current SnapBuildPurgeOlderTxn. > > > > A comparable optimization exists in KnownAssignedXidsCompress() which > > uses the same algorithm to remove stale XIDs without workspace > > allocation. That implementation also adds a lazy compaction heuristic > > that delays compaction until a threshold of removed entries is > > reached, amortizing the O(N) cost across multiple operations. > > > > The comment above the data structure mentions the trade-off of keeping > > the committed.xip array sorted versus unsorted. If the array were > > sorted, we could use a binary search combined with memmove to compact > > it efficiently, achieving O(log n + n) complexity for purging. > > However, that design would increase the complexity of > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt > > wraparound". > > > > /* > > * Array of committed transactions that have modified the catalog. > > * > > * As this array is frequently modified we do *not* keep it in > > * xidComparator order. Instead we sort the array when building & > > * distributing a snapshot. > > * > > * TODO: It's unclear whether that reasoning has much merit. Every > > * time we add something here after becoming consistent will also > > * require distributing a snapshot. Storing them sorted would > > * potentially also make it easier to purge (but more complicated wrt > > * wraparound?). Should be improved if sorting while building the > > * snapshot shows up in profiles. > > */ > > TransactionId *xip; > > } committed; > > > > /* > > * Keep track of a new catalog changing transaction that has committed. > > */ > > static void > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid) > > { > > Assert(TransactionIdIsValid(xid)); > > > > if (builder->committed.xcnt == builder->committed.xcnt_space) > > { > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1; > > > > elog(DEBUG1, "increasing space for committed transactions to %u", > > (uint32) builder->committed.xcnt_space); > > > > builder->committed.xip = repalloc(builder->committed.xip, > > builder->committed.xcnt_space * sizeof(TransactionId)); > > } > > > > /* > > * TODO: It might make sense to keep the array sorted here instead of > > * doing it every time we build a new snapshot. On the other hand this > > * gets called repeatedly when a transaction with subtransactions commits. > > */ > > builder->committed.xip[builder->committed.xcnt++] = xid; > > } > > > > It might be worth profiling this function to evaluate whether > > maintaining a sorted array could bring potential benefits, although > > accurately measuring its end-to-end impact could be difficult if it > > isn’t a known hotspot. I also did a brief search on the mailing list > > and found no reports of performance concerns or related proposals to > > optimize this part of the code. > > It might also be worth researching what kind of workloads would need a > better algorithm in terms of storing/updating xip and subxip arrays > since it would be the primary motivation. Also, otherwise we cannot > measure the real-world impact of a new algorithm. Having said that, > find that it would be discussed and developed separately from the > proposed patch on this thread. +1 for researching the workloads that might need a sorted array and more efficient algorithm. This exploration isn’t limited to the scope of SnapBuildPurgeOlderTxn but relates more broadly to the overall snapbuild process, which might be worth discussing in a separate thread as suggested. * TODO: It's unclear whether that reasoning has much merit. Every * time we add something here after becoming consistent will also * require distributing a snapshot. Storing them sorted would * potentially also make it easier to purge (but more complicated wrt * wraparound?). Should be improved if sorting while building the * snapshot shows up in profiles. I also constructed an artificial workload to try to surface the qsort call in SnapBuildBuildSnapshot, though such a scenario seems very unlikely to occur in production. for ((c=1; c<=DDL_CLIENTS; c++)); do ( local seq=1 while (( $(date +%s) < tB_end )); do local tbl="hp_ddl_${c}_$seq" "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c " BEGIN; CREATE TABLE ${tbl} (id int, data text); CREATE INDEX idx_${tbl} ON ${tbl} (id); INSERT INTO ${tbl} VALUES ($seq, 'd'); DROP TABLE ${tbl}; COMMIT;" >/dev/null 2>&1 || true seq=$((seq+1)) done ) 97.02% 0.00% postgres postgres [.] postmaster_child_launch | ---postmaster_child_launch | |--94.93%--BackendMain | PostgresMain | exec_replication_command | StartLogicalReplication | | | --94.92%--WalSndLoop | | | |--92.24%--XLogSendLogical | | | | | --91.63%--LogicalDecodingProcessRecord | | | | | |--89.55%--xact_decode | | | | | | | --89.23%--DecodeCommit | | | | | | | |--64.64%--SnapBuildCommitTxn | | | | | | | | | |--62.60%--SnapBuildBuildSnapshot | | | | | | | | | | | --62.33%--pg_qsort | | | | | | | | | | | |--56.84%--pg_qsort Best, Xuneng
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Masahiko Sawada
Дата:
On Thu, Oct 23, 2025 at 1:17 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Hi Sawada-san, Michael,
>
> Thanks for your comments on this patch.
>
> On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > >
> > > Hi,
> > >
> > > Thanks for looking into this.
> > >
> > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > >
> > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote:
> > > > >
> > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote:
> > > > > > Indeed, these changes look correct.
> > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > > > anything here.
> > > > >
> > > > > Perhaps a lack of time back in 2014? It feels like an item where we
> > > > > would need to research a bit some of the past threads, and see if this
> > > > > has been discussed, or if there were other potential alternatives
> > > > > discussed. This is not saying that what you are doing in this
> > > > > proposal is actually bad, but it's a bit hard to say what an
> > > > > "algorithm" should look like in this specific code path with XID
> > > > > manipulations. Perhaps since 2014, we may have other places in the
> > > > > tree that share similar characteristics as what's done here.
> > > > >
> > > > > So it feels like this needs a bit more historical investigation first,
> > > > > rather than saying that your proposal is the best choice on the table.
>
> Following these suggestions, I carefully searched the mailing list
> archives and found no reports of performance issues directly related
> to this code path. I also examined other parts of the codebase for
> similar patterns. Components like integerset might share some
> characteristics with SnapBuildPurgeOlderTxn, but they have constraints
> that make them not directly applicable here. I am not very familiar
> with the whole tree, so the investigation might not be exhaustive.
Thank you for looking through the archives. In logical replication,
performance problems typically show up as replication delays. Since
logical replication involves many different components and processes,
it's quite rare for investigations to trace problems back to this
specific piece of code. However, I still believe it's important to
optimize the performance of logical decoding itself.
>
> > >
> > > A comparable optimization exists in KnownAssignedXidsCompress() which
> > > uses the same algorithm to remove stale XIDs without workspace
> > > allocation. That implementation also adds a lazy compaction heuristic
> > > that delays compaction until a threshold of removed entries is
> > > reached, amortizing the O(N) cost across multiple operations.
> > >
> > > The comment above the data structure mentions the trade-off of keeping
> > > the committed.xip array sorted versus unsorted. If the array were
> > > sorted, we could use a binary search combined with memmove to compact
> > > it efficiently, achieving O(log n + n) complexity for purging.
> > > However, that design would increase the complexity of
> > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt
> > > wraparound".
> > >
> > > /*
> > > * Array of committed transactions that have modified the catalog.
> > > *
> > > * As this array is frequently modified we do *not* keep it in
> > > * xidComparator order. Instead we sort the array when building &
> > > * distributing a snapshot.
> > > *
> > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > * time we add something here after becoming consistent will also
> > > * require distributing a snapshot. Storing them sorted would
> > > * potentially also make it easier to purge (but more complicated wrt
> > > * wraparound?). Should be improved if sorting while building the
> > > * snapshot shows up in profiles.
> > > */
> > > TransactionId *xip;
> > > } committed;
> > >
> > > /*
> > > * Keep track of a new catalog changing transaction that has committed.
> > > */
> > > static void
> > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid)
> > > {
> > > Assert(TransactionIdIsValid(xid));
> > >
> > > if (builder->committed.xcnt == builder->committed.xcnt_space)
> > > {
> > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1;
> > >
> > > elog(DEBUG1, "increasing space for committed transactions to %u",
> > > (uint32) builder->committed.xcnt_space);
> > >
> > > builder->committed.xip = repalloc(builder->committed.xip,
> > > builder->committed.xcnt_space * sizeof(TransactionId));
> > > }
> > >
> > > /*
> > > * TODO: It might make sense to keep the array sorted here instead of
> > > * doing it every time we build a new snapshot. On the other hand this
> > > * gets called repeatedly when a transaction with subtransactions commits.
> > > */
> > > builder->committed.xip[builder->committed.xcnt++] = xid;
> > > }
> > >
> > > It might be worth profiling this function to evaluate whether
> > > maintaining a sorted array could bring potential benefits, although
> > > accurately measuring its end-to-end impact could be difficult if it
> > > isn’t a known hotspot. I also did a brief search on the mailing list
> > > and found no reports of performance concerns or related proposals to
> > > optimize this part of the code.
> >
> > It might also be worth researching what kind of workloads would need a
> > better algorithm in terms of storing/updating xip and subxip arrays
> > since it would be the primary motivation. Also, otherwise we cannot
> > measure the real-world impact of a new algorithm. Having said that,
> > find that it would be discussed and developed separately from the
> > proposed patch on this thread.
>
> +1 for researching the workloads that might need a sorted array and
> more efficient algorithm. This exploration isn’t limited to the scope
> of SnapBuildPurgeOlderTxn but relates more broadly to the overall
> snapbuild process, which might be worth discussing in a separate
> thread as suggested.
>
> * TODO: It's unclear whether that reasoning has much merit. Every
> * time we add something here after becoming consistent will also
> * require distributing a snapshot. Storing them sorted would
> * potentially also make it easier to purge (but more complicated wrt
> * wraparound?). Should be improved if sorting while building the
> * snapshot shows up in profiles.
>
> I also constructed an artificial workload to try to surface the qsort
> call in SnapBuildBuildSnapshot, though such a scenario seems very
> unlikely to occur in production.
>
> for ((c=1; c<=DDL_CLIENTS; c++)); do
> (
> local seq=1
> while (( $(date +%s) < tB_end )); do
> local tbl="hp_ddl_${c}_$seq"
> "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c "
> BEGIN;
> CREATE TABLE ${tbl} (id int, data text);
> CREATE INDEX idx_${tbl} ON ${tbl} (id);
> INSERT INTO ${tbl} VALUES ($seq, 'd');
> DROP TABLE ${tbl};
> COMMIT;" >/dev/null 2>&1 || true
> seq=$((seq+1))
> done
> )
Interesting. To be honest, I think this scenario might actually occur
in practice, especially in cases where users frequently use CREATE
TEMP TABLE ... ON COMMIT DROP.
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Hi,
On Sat, Oct 25, 2025 at 2:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Thu, Oct 23, 2025 at 1:17 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Hi Sawada-san, Michael,
> >
> > Thanks for your comments on this patch.
> >
> > On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > >
> > > > Hi,
> > > >
> > > > Thanks for looking into this.
> > > >
> > > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > > >
> > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote:
> > > > > >
> > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote:
> > > > > > > Indeed, these changes look correct.
> > > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > > > > anything here.
> > > > > >
> > > > > > Perhaps a lack of time back in 2014? It feels like an item where we
> > > > > > would need to research a bit some of the past threads, and see if this
> > > > > > has been discussed, or if there were other potential alternatives
> > > > > > discussed. This is not saying that what you are doing in this
> > > > > > proposal is actually bad, but it's a bit hard to say what an
> > > > > > "algorithm" should look like in this specific code path with XID
> > > > > > manipulations. Perhaps since 2014, we may have other places in the
> > > > > > tree that share similar characteristics as what's done here.
> > > > > >
> > > > > > So it feels like this needs a bit more historical investigation first,
> > > > > > rather than saying that your proposal is the best choice on the table.
> >
> > Following these suggestions, I carefully searched the mailing list
> > archives and found no reports of performance issues directly related
> > to this code path. I also examined other parts of the codebase for
> > similar patterns. Components like integerset might share some
> > characteristics with SnapBuildPurgeOlderTxn, but they have constraints
> > that make them not directly applicable here. I am not very familiar
> > with the whole tree, so the investigation might not be exhaustive.
>
> Thank you for looking through the archives. In logical replication,
> performance problems typically show up as replication delays. Since
> logical replication involves many different components and processes,
> it's quite rare for investigations to trace problems back to this
> specific piece of code. However, I still believe it's important to
> optimize the performance of logical decoding itself.
>
> >
> > > >
> > > > A comparable optimization exists in KnownAssignedXidsCompress() which
> > > > uses the same algorithm to remove stale XIDs without workspace
> > > > allocation. That implementation also adds a lazy compaction heuristic
> > > > that delays compaction until a threshold of removed entries is
> > > > reached, amortizing the O(N) cost across multiple operations.
> > > >
> > > > The comment above the data structure mentions the trade-off of keeping
> > > > the committed.xip array sorted versus unsorted. If the array were
> > > > sorted, we could use a binary search combined with memmove to compact
> > > > it efficiently, achieving O(log n + n) complexity for purging.
> > > > However, that design would increase the complexity of
> > > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt
> > > > wraparound".
> > > >
> > > > /*
> > > > * Array of committed transactions that have modified the catalog.
> > > > *
> > > > * As this array is frequently modified we do *not* keep it in
> > > > * xidComparator order. Instead we sort the array when building &
> > > > * distributing a snapshot.
> > > > *
> > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > * time we add something here after becoming consistent will also
> > > > * require distributing a snapshot. Storing them sorted would
> > > > * potentially also make it easier to purge (but more complicated wrt
> > > > * wraparound?). Should be improved if sorting while building the
> > > > * snapshot shows up in profiles.
> > > > */
> > > > TransactionId *xip;
> > > > } committed;
> > > >
> > > > /*
> > > > * Keep track of a new catalog changing transaction that has committed.
> > > > */
> > > > static void
> > > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid)
> > > > {
> > > > Assert(TransactionIdIsValid(xid));
> > > >
> > > > if (builder->committed.xcnt == builder->committed.xcnt_space)
> > > > {
> > > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1;
> > > >
> > > > elog(DEBUG1, "increasing space for committed transactions to %u",
> > > > (uint32) builder->committed.xcnt_space);
> > > >
> > > > builder->committed.xip = repalloc(builder->committed.xip,
> > > > builder->committed.xcnt_space * sizeof(TransactionId));
> > > > }
> > > >
> > > > /*
> > > > * TODO: It might make sense to keep the array sorted here instead of
> > > > * doing it every time we build a new snapshot. On the other hand this
> > > > * gets called repeatedly when a transaction with subtransactions commits.
> > > > */
> > > > builder->committed.xip[builder->committed.xcnt++] = xid;
> > > > }
> > > >
> > > > It might be worth profiling this function to evaluate whether
> > > > maintaining a sorted array could bring potential benefits, although
> > > > accurately measuring its end-to-end impact could be difficult if it
> > > > isn’t a known hotspot. I also did a brief search on the mailing list
> > > > and found no reports of performance concerns or related proposals to
> > > > optimize this part of the code.
> > >
> > > It might also be worth researching what kind of workloads would need a
> > > better algorithm in terms of storing/updating xip and subxip arrays
> > > since it would be the primary motivation. Also, otherwise we cannot
> > > measure the real-world impact of a new algorithm. Having said that,
> > > find that it would be discussed and developed separately from the
> > > proposed patch on this thread.
> >
> > +1 for researching the workloads that might need a sorted array and
> > more efficient algorithm. This exploration isn’t limited to the scope
> > of SnapBuildPurgeOlderTxn but relates more broadly to the overall
> > snapbuild process, which might be worth discussing in a separate
> > thread as suggested.
> >
> > * TODO: It's unclear whether that reasoning has much merit. Every
> > * time we add something here after becoming consistent will also
> > * require distributing a snapshot. Storing them sorted would
> > * potentially also make it easier to purge (but more complicated wrt
> > * wraparound?). Should be improved if sorting while building the
> > * snapshot shows up in profiles.
> >
> > I also constructed an artificial workload to try to surface the qsort
> > call in SnapBuildBuildSnapshot, though such a scenario seems very
> > unlikely to occur in production.
> >
> > for ((c=1; c<=DDL_CLIENTS; c++)); do
> > (
> > local seq=1
> > while (( $(date +%s) < tB_end )); do
> > local tbl="hp_ddl_${c}_$seq"
> > "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c "
> > BEGIN;
> > CREATE TABLE ${tbl} (id int, data text);
> > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > DROP TABLE ${tbl};
> > COMMIT;" >/dev/null 2>&1 || true
> > seq=$((seq+1))
> > done
> > )
>
> Interesting. To be honest, I think this scenario might actually occur
> in practice, especially in cases where users frequently use CREATE
> TEMP TABLE ... ON COMMIT DROP.
The attached file shows the flamegraph for this workload.
for ((c=1; c<=CLIENTS_DDL; c++)); do
(
local seq=1
while (( $(date +%s) < tB_end )); do
local tbl="hp_temp_${c}_$seq"
$psql_cmd -d postgres -c "
BEGIN;
CREATE TEMP TABLE ${tbl} (id int, data text) ON COMMIT DROP;
CREATE INDEX idx_${tbl} ON ${tbl} (id);
INSERT INTO ${tbl} VALUES ($seq, 'd');
COMMIT;" >/dev/null 2>&1 || true
seq=$((seq+1))
done
) &
pidsB+=($!)
done
I’ve been thinking about possible ways to maintain a sorted array to
optimize this case and purge function. Below are some preliminary
ideas. If any of them seem reasonable, I’d like to start a new thread
and prepare a patch based on this direction.
1) Batch insertion with globally sorted array (raw uint32 order)
Goal: Maintain committed.xip sorted and deduplicated to eliminate
repeated qsorts.
Mechanism:
In SnapBuildCommitTxn, collect all XIDs/subxids to be tracked into a
local vector (length m)
Sort and deduplicate the batch: O(m log m)
Reverse-merge the batch into the global array: O(N + m), deduplicating
on the fly
Invariant: committed.xip[0..xcnt) is always raw-sorted (xidComparator
order) and deduplicated
Complexity improvement:
Before: O((N+m) log (N+m)) per build
After: O(m log m + N) per commit; snapshot build can skip qsort entirely
Purge:
Remains O(N) linear scan. Raw sorting doesn't enable binary search
because the purge predicate uses wraparound-aware semantics
(NormalTransactionIdPrecedes), and committed.xip can span epochs, so
numeric order ≠ logical XID order.
2) Adopt FullTransactionId for sublinear purge (theoretically possible)
Rationale:
To make purge O(log N), the array needs to be sorted under the same
ordering relation as the purge predicate. Wraparound-aware comparison
of 32-bit XIDs is not a total order when the set spans epochs.
FullTransactionId (epoch<<32 | xid) could provide a true total order.
Mechanism:
Store FullTransactionId *fxip instead of TransactionId *xip
struct
{
size_t xcnt;
size_t xcnt_space;
bool includes_all_transactions;
FullTransactionId *fxip; /* Changed from TransactionId *xip */
} committed;
Insertion: Map each 32-bit XID to FullTransactionId using a snapshot
of nextFullXid (same logic as hot standby feedback); sort/dedup batch;
reverse-merge O(N + m)
Purge: Compute xmin_full using the same snapshot; binary search for
lower bound O(log N) + memmove suffix
/*
* xidLogicalComparator
* qsort comparison function for XIDs
*
* This is used to compare only XIDs from the same epoch (e.g. for backends
* running at the same time). So there must be only normal XIDs, so there's
* no issue with triangle inequality.
*/
int
xidLogicalComparator(const void *arg1, const void *arg2)
Trade-offs:
Downcasting a logically sorted FullTransactionId array can break raw
uint32 ordering if the set spans an epoch boundary. Still need a qsort
on snapshot->xip after copying xids from committed.xip at worst case.
Memory/I/O: 2× bytes for committed array (4→8 bytes per entry)
Purge improves from O(N) to O(log N + move); merge complexity unchanged
Best,
Xuneng
Вложения
{kind=link}
Hi,
On Wed, Oct 29, 2025 at 8:17 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Hi,
>
> On Sat, Oct 25, 2025 at 2:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Thu, Oct 23, 2025 at 1:17 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > >
> > > Hi Sawada-san, Michael,
> > >
> > > Thanks for your comments on this patch.
> > >
> > > On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > >
> > > > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > > >
> > > > > Hi,
> > > > >
> > > > > Thanks for looking into this.
> > > > >
> > > > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > > > >
> > > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote:
> > > > > > >
> > > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote:
> > > > > > > > Indeed, these changes look correct.
> > > > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > > > > > anything here.
> > > > > > >
> > > > > > > Perhaps a lack of time back in 2014? It feels like an item where we
> > > > > > > would need to research a bit some of the past threads, and see if this
> > > > > > > has been discussed, or if there were other potential alternatives
> > > > > > > discussed. This is not saying that what you are doing in this
> > > > > > > proposal is actually bad, but it's a bit hard to say what an
> > > > > > > "algorithm" should look like in this specific code path with XID
> > > > > > > manipulations. Perhaps since 2014, we may have other places in the
> > > > > > > tree that share similar characteristics as what's done here.
> > > > > > >
> > > > > > > So it feels like this needs a bit more historical investigation first,
> > > > > > > rather than saying that your proposal is the best choice on the table.
> > >
> > > Following these suggestions, I carefully searched the mailing list
> > > archives and found no reports of performance issues directly related
> > > to this code path. I also examined other parts of the codebase for
> > > similar patterns. Components like integerset might share some
> > > characteristics with SnapBuildPurgeOlderTxn, but they have constraints
> > > that make them not directly applicable here. I am not very familiar
> > > with the whole tree, so the investigation might not be exhaustive.
> >
> > Thank you for looking through the archives. In logical replication,
> > performance problems typically show up as replication delays. Since
> > logical replication involves many different components and processes,
> > it's quite rare for investigations to trace problems back to this
> > specific piece of code. However, I still believe it's important to
> > optimize the performance of logical decoding itself.
> >
> > >
> > > > >
> > > > > A comparable optimization exists in KnownAssignedXidsCompress() which
> > > > > uses the same algorithm to remove stale XIDs without workspace
> > > > > allocation. That implementation also adds a lazy compaction heuristic
> > > > > that delays compaction until a threshold of removed entries is
> > > > > reached, amortizing the O(N) cost across multiple operations.
> > > > >
> > > > > The comment above the data structure mentions the trade-off of keeping
> > > > > the committed.xip array sorted versus unsorted. If the array were
> > > > > sorted, we could use a binary search combined with memmove to compact
> > > > > it efficiently, achieving O(log n + n) complexity for purging.
> > > > > However, that design would increase the complexity of
> > > > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt
> > > > > wraparound".
> > > > >
> > > > > /*
> > > > > * Array of committed transactions that have modified the catalog.
> > > > > *
> > > > > * As this array is frequently modified we do *not* keep it in
> > > > > * xidComparator order. Instead we sort the array when building &
> > > > > * distributing a snapshot.
> > > > > *
> > > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > > * time we add something here after becoming consistent will also
> > > > > * require distributing a snapshot. Storing them sorted would
> > > > > * potentially also make it easier to purge (but more complicated wrt
> > > > > * wraparound?). Should be improved if sorting while building the
> > > > > * snapshot shows up in profiles.
> > > > > */
> > > > > TransactionId *xip;
> > > > > } committed;
> > > > >
> > > > > /*
> > > > > * Keep track of a new catalog changing transaction that has committed.
> > > > > */
> > > > > static void
> > > > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid)
> > > > > {
> > > > > Assert(TransactionIdIsValid(xid));
> > > > >
> > > > > if (builder->committed.xcnt == builder->committed.xcnt_space)
> > > > > {
> > > > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1;
> > > > >
> > > > > elog(DEBUG1, "increasing space for committed transactions to %u",
> > > > > (uint32) builder->committed.xcnt_space);
> > > > >
> > > > > builder->committed.xip = repalloc(builder->committed.xip,
> > > > > builder->committed.xcnt_space * sizeof(TransactionId));
> > > > > }
> > > > >
> > > > > /*
> > > > > * TODO: It might make sense to keep the array sorted here instead of
> > > > > * doing it every time we build a new snapshot. On the other hand this
> > > > > * gets called repeatedly when a transaction with subtransactions commits.
> > > > > */
> > > > > builder->committed.xip[builder->committed.xcnt++] = xid;
> > > > > }
> > > > >
> > > > > It might be worth profiling this function to evaluate whether
> > > > > maintaining a sorted array could bring potential benefits, although
> > > > > accurately measuring its end-to-end impact could be difficult if it
> > > > > isn’t a known hotspot. I also did a brief search on the mailing list
> > > > > and found no reports of performance concerns or related proposals to
> > > > > optimize this part of the code.
> > > >
> > > > It might also be worth researching what kind of workloads would need a
> > > > better algorithm in terms of storing/updating xip and subxip arrays
> > > > since it would be the primary motivation. Also, otherwise we cannot
> > > > measure the real-world impact of a new algorithm. Having said that,
> > > > find that it would be discussed and developed separately from the
> > > > proposed patch on this thread.
> > >
> > > +1 for researching the workloads that might need a sorted array and
> > > more efficient algorithm. This exploration isn’t limited to the scope
> > > of SnapBuildPurgeOlderTxn but relates more broadly to the overall
> > > snapbuild process, which might be worth discussing in a separate
> > > thread as suggested.
> > >
> > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > * time we add something here after becoming consistent will also
> > > * require distributing a snapshot. Storing them sorted would
> > > * potentially also make it easier to purge (but more complicated wrt
> > > * wraparound?). Should be improved if sorting while building the
> > > * snapshot shows up in profiles.
> > >
> > > I also constructed an artificial workload to try to surface the qsort
> > > call in SnapBuildBuildSnapshot, though such a scenario seems very
> > > unlikely to occur in production.
> > >
> > > for ((c=1; c<=DDL_CLIENTS; c++)); do
> > > (
> > > local seq=1
> > > while (( $(date +%s) < tB_end )); do
> > > local tbl="hp_ddl_${c}_$seq"
> > > "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c "
> > > BEGIN;
> > > CREATE TABLE ${tbl} (id int, data text);
> > > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > > DROP TABLE ${tbl};
> > > COMMIT;" >/dev/null 2>&1 || true
> > > seq=$((seq+1))
> > > done
> > > )
> >
> > Interesting. To be honest, I think this scenario might actually occur
> > in practice, especially in cases where users frequently use CREATE
> > TEMP TABLE ... ON COMMIT DROP.
>
> The attached file shows the flamegraph for this workload.
>
> for ((c=1; c<=CLIENTS_DDL; c++)); do
> (
> local seq=1
> while (( $(date +%s) < tB_end )); do
> local tbl="hp_temp_${c}_$seq"
> $psql_cmd -d postgres -c "
> BEGIN;
> CREATE TEMP TABLE ${tbl} (id int, data text) ON COMMIT DROP;
> CREATE INDEX idx_${tbl} ON ${tbl} (id);
> INSERT INTO ${tbl} VALUES ($seq, 'd');
> COMMIT;" >/dev/null 2>&1 || true
> seq=$((seq+1))
> done
> ) &
> pidsB+=($!)
> done
>
> I’ve been thinking about possible ways to maintain a sorted array to
> optimize this case and purge function. Below are some preliminary
> ideas. If any of them seem reasonable, I’d like to start a new thread
> and prepare a patch based on this direction.
>
> 1) Batch insertion with globally sorted array (raw uint32 order)
>
> Goal: Maintain committed.xip sorted and deduplicated to eliminate
> repeated qsorts.
>
> Mechanism:
> In SnapBuildCommitTxn, collect all XIDs/subxids to be tracked into a
> local vector (length m)
> Sort and deduplicate the batch: O(m log m)
> Reverse-merge the batch into the global array: O(N + m), deduplicating
> on the fly
> Invariant: committed.xip[0..xcnt) is always raw-sorted (xidComparator
> order) and deduplicated
>
> Complexity improvement:
> Before: O((N+m) log (N+m)) per build
> After: O(m log m + N) per commit; snapshot build can skip qsort entirely
>
> Purge:
> Remains O(N) linear scan. Raw sorting doesn't enable binary search
> because the purge predicate uses wraparound-aware semantics
> (NormalTransactionIdPrecedes), and committed.xip can span epochs, so
> numeric order ≠ logical XID order.
>
> 2) Adopt FullTransactionId for sublinear purge (theoretically possible)
>
> Rationale:
> To make purge O(log N), the array needs to be sorted under the same
> ordering relation as the purge predicate. Wraparound-aware comparison
> of 32-bit XIDs is not a total order when the set spans epochs.
> FullTransactionId (epoch<<32 | xid) could provide a true total order.
>
> Mechanism:
> Store FullTransactionId *fxip instead of TransactionId *xip
> struct
> {
> size_t xcnt;
> size_t xcnt_space;
> bool includes_all_transactions;
> FullTransactionId *fxip; /* Changed from TransactionId *xip */
> } committed;
>
> Insertion: Map each 32-bit XID to FullTransactionId using a snapshot
> of nextFullXid (same logic as hot standby feedback); sort/dedup batch;
> reverse-merge O(N + m)
>
> Purge: Compute xmin_full using the same snapshot; binary search for
> lower bound O(log N) + memmove suffix
>
> /*
> * xidLogicalComparator
> * qsort comparison function for XIDs
> *
> * This is used to compare only XIDs from the same epoch (e.g. for backends
> * running at the same time). So there must be only normal XIDs, so there's
> * no issue with triangle inequality.
> */
> int
> xidLogicalComparator(const void *arg1, const void *arg2)
>
> Trade-offs:
> Downcasting a logically sorted FullTransactionId array can break raw
> uint32 ordering if the set spans an epoch boundary. Still need a qsort
> on snapshot->xip after copying xids from committed.xip at worst case.
>
> Memory/I/O: 2× bytes for committed array (4→8 bytes per entry)
>
> Purge improves from O(N) to O(log N + move); merge complexity unchanged
I’ve implemented an experimental version that maintains the
committed.xip array in numeric sorted order and profiled it on the
previous workload. The overhead observed earlier has now been
eliminated.
Before starting a discussion thread and proposing the patch, I plan to
run additional pgbench workloads to verify that there are no
performance regressions. Once the results look stable, I’ll polish and
share the patch for review.
Best,
Xuneng
Вложения
{kind=link}
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Masahiko Sawada
Дата:
On Thu, Oct 30, 2025 at 9:21 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
>
> Hi,
>
> On Wed, Oct 29, 2025 at 8:17 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Hi,
> >
> > On Sat, Oct 25, 2025 at 2:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Thu, Oct 23, 2025 at 1:17 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > >
> > > > Hi Sawada-san, Michael,
> > > >
> > > > Thanks for your comments on this patch.
> > > >
> > > > On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > > >
> > > > > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > > > >
> > > > > > Hi,
> > > > > >
> > > > > > Thanks for looking into this.
> > > > > >
> > > > > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > > > > >
> > > > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote:
> > > > > > > >
> > > > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote:
> > > > > > > > > Indeed, these changes look correct.
> > > > > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > > > > > > anything here.
> > > > > > > >
> > > > > > > > Perhaps a lack of time back in 2014? It feels like an item where we
> > > > > > > > would need to research a bit some of the past threads, and see if this
> > > > > > > > has been discussed, or if there were other potential alternatives
> > > > > > > > discussed. This is not saying that what you are doing in this
> > > > > > > > proposal is actually bad, but it's a bit hard to say what an
> > > > > > > > "algorithm" should look like in this specific code path with XID
> > > > > > > > manipulations. Perhaps since 2014, we may have other places in the
> > > > > > > > tree that share similar characteristics as what's done here.
> > > > > > > >
> > > > > > > > So it feels like this needs a bit more historical investigation first,
> > > > > > > > rather than saying that your proposal is the best choice on the table.
> > > >
> > > > Following these suggestions, I carefully searched the mailing list
> > > > archives and found no reports of performance issues directly related
> > > > to this code path. I also examined other parts of the codebase for
> > > > similar patterns. Components like integerset might share some
> > > > characteristics with SnapBuildPurgeOlderTxn, but they have constraints
> > > > that make them not directly applicable here. I am not very familiar
> > > > with the whole tree, so the investigation might not be exhaustive.
> > >
> > > Thank you for looking through the archives. In logical replication,
> > > performance problems typically show up as replication delays. Since
> > > logical replication involves many different components and processes,
> > > it's quite rare for investigations to trace problems back to this
> > > specific piece of code. However, I still believe it's important to
> > > optimize the performance of logical decoding itself.
> > >
> > > >
> > > > > >
> > > > > > A comparable optimization exists in KnownAssignedXidsCompress() which
> > > > > > uses the same algorithm to remove stale XIDs without workspace
> > > > > > allocation. That implementation also adds a lazy compaction heuristic
> > > > > > that delays compaction until a threshold of removed entries is
> > > > > > reached, amortizing the O(N) cost across multiple operations.
> > > > > >
> > > > > > The comment above the data structure mentions the trade-off of keeping
> > > > > > the committed.xip array sorted versus unsorted. If the array were
> > > > > > sorted, we could use a binary search combined with memmove to compact
> > > > > > it efficiently, achieving O(log n + n) complexity for purging.
> > > > > > However, that design would increase the complexity of
> > > > > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt
> > > > > > wraparound".
> > > > > >
> > > > > > /*
> > > > > > * Array of committed transactions that have modified the catalog.
> > > > > > *
> > > > > > * As this array is frequently modified we do *not* keep it in
> > > > > > * xidComparator order. Instead we sort the array when building &
> > > > > > * distributing a snapshot.
> > > > > > *
> > > > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > > > * time we add something here after becoming consistent will also
> > > > > > * require distributing a snapshot. Storing them sorted would
> > > > > > * potentially also make it easier to purge (but more complicated wrt
> > > > > > * wraparound?). Should be improved if sorting while building the
> > > > > > * snapshot shows up in profiles.
> > > > > > */
> > > > > > TransactionId *xip;
> > > > > > } committed;
> > > > > >
> > > > > > /*
> > > > > > * Keep track of a new catalog changing transaction that has committed.
> > > > > > */
> > > > > > static void
> > > > > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid)
> > > > > > {
> > > > > > Assert(TransactionIdIsValid(xid));
> > > > > >
> > > > > > if (builder->committed.xcnt == builder->committed.xcnt_space)
> > > > > > {
> > > > > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1;
> > > > > >
> > > > > > elog(DEBUG1, "increasing space for committed transactions to %u",
> > > > > > (uint32) builder->committed.xcnt_space);
> > > > > >
> > > > > > builder->committed.xip = repalloc(builder->committed.xip,
> > > > > > builder->committed.xcnt_space * sizeof(TransactionId));
> > > > > > }
> > > > > >
> > > > > > /*
> > > > > > * TODO: It might make sense to keep the array sorted here instead of
> > > > > > * doing it every time we build a new snapshot. On the other hand this
> > > > > > * gets called repeatedly when a transaction with subtransactions commits.
> > > > > > */
> > > > > > builder->committed.xip[builder->committed.xcnt++] = xid;
> > > > > > }
> > > > > >
> > > > > > It might be worth profiling this function to evaluate whether
> > > > > > maintaining a sorted array could bring potential benefits, although
> > > > > > accurately measuring its end-to-end impact could be difficult if it
> > > > > > isn’t a known hotspot. I also did a brief search on the mailing list
> > > > > > and found no reports of performance concerns or related proposals to
> > > > > > optimize this part of the code.
> > > > >
> > > > > It might also be worth researching what kind of workloads would need a
> > > > > better algorithm in terms of storing/updating xip and subxip arrays
> > > > > since it would be the primary motivation. Also, otherwise we cannot
> > > > > measure the real-world impact of a new algorithm. Having said that,
> > > > > find that it would be discussed and developed separately from the
> > > > > proposed patch on this thread.
> > > >
> > > > +1 for researching the workloads that might need a sorted array and
> > > > more efficient algorithm. This exploration isn’t limited to the scope
> > > > of SnapBuildPurgeOlderTxn but relates more broadly to the overall
> > > > snapbuild process, which might be worth discussing in a separate
> > > > thread as suggested.
> > > >
> > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > * time we add something here after becoming consistent will also
> > > > * require distributing a snapshot. Storing them sorted would
> > > > * potentially also make it easier to purge (but more complicated wrt
> > > > * wraparound?). Should be improved if sorting while building the
> > > > * snapshot shows up in profiles.
> > > >
> > > > I also constructed an artificial workload to try to surface the qsort
> > > > call in SnapBuildBuildSnapshot, though such a scenario seems very
> > > > unlikely to occur in production.
> > > >
> > > > for ((c=1; c<=DDL_CLIENTS; c++)); do
> > > > (
> > > > local seq=1
> > > > while (( $(date +%s) < tB_end )); do
> > > > local tbl="hp_ddl_${c}_$seq"
> > > > "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c "
> > > > BEGIN;
> > > > CREATE TABLE ${tbl} (id int, data text);
> > > > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > > > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > > > DROP TABLE ${tbl};
> > > > COMMIT;" >/dev/null 2>&1 || true
> > > > seq=$((seq+1))
> > > > done
> > > > )
> > >
> > > Interesting. To be honest, I think this scenario might actually occur
> > > in practice, especially in cases where users frequently use CREATE
> > > TEMP TABLE ... ON COMMIT DROP.
> >
> > The attached file shows the flamegraph for this workload.
> >
> > for ((c=1; c<=CLIENTS_DDL; c++)); do
> > (
> > local seq=1
> > while (( $(date +%s) < tB_end )); do
> > local tbl="hp_temp_${c}_$seq"
> > $psql_cmd -d postgres -c "
> > BEGIN;
> > CREATE TEMP TABLE ${tbl} (id int, data text) ON COMMIT DROP;
> > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > COMMIT;" >/dev/null 2>&1 || true
> > seq=$((seq+1))
> > done
> > ) &
> > pidsB+=($!)
> > done
> >
> > I’ve been thinking about possible ways to maintain a sorted array to
> > optimize this case and purge function. Below are some preliminary
> > ideas. If any of them seem reasonable, I’d like to start a new thread
> > and prepare a patch based on this direction.
> >
> > 1) Batch insertion with globally sorted array (raw uint32 order)
> >
> > Goal: Maintain committed.xip sorted and deduplicated to eliminate
> > repeated qsorts.
> >
> > Mechanism:
> > In SnapBuildCommitTxn, collect all XIDs/subxids to be tracked into a
> > local vector (length m)
> > Sort and deduplicate the batch: O(m log m)
> > Reverse-merge the batch into the global array: O(N + m), deduplicating
> > on the fly
> > Invariant: committed.xip[0..xcnt) is always raw-sorted (xidComparator
> > order) and deduplicated
> >
> > Complexity improvement:
> > Before: O((N+m) log (N+m)) per build
> > After: O(m log m + N) per commit; snapshot build can skip qsort entirely
> >
> > Purge:
> > Remains O(N) linear scan. Raw sorting doesn't enable binary search
> > because the purge predicate uses wraparound-aware semantics
> > (NormalTransactionIdPrecedes), and committed.xip can span epochs, so
> > numeric order ≠ logical XID order.
> >
> > 2) Adopt FullTransactionId for sublinear purge (theoretically possible)
> >
> > Rationale:
> > To make purge O(log N), the array needs to be sorted under the same
> > ordering relation as the purge predicate. Wraparound-aware comparison
> > of 32-bit XIDs is not a total order when the set spans epochs.
> > FullTransactionId (epoch<<32 | xid) could provide a true total order.
> >
> > Mechanism:
> > Store FullTransactionId *fxip instead of TransactionId *xip
> > struct
> > {
> > size_t xcnt;
> > size_t xcnt_space;
> > bool includes_all_transactions;
> > FullTransactionId *fxip; /* Changed from TransactionId *xip */
> > } committed;
> >
> > Insertion: Map each 32-bit XID to FullTransactionId using a snapshot
> > of nextFullXid (same logic as hot standby feedback); sort/dedup batch;
> > reverse-merge O(N + m)
> >
> > Purge: Compute xmin_full using the same snapshot; binary search for
> > lower bound O(log N) + memmove suffix
> >
> > /*
> > * xidLogicalComparator
> > * qsort comparison function for XIDs
> > *
> > * This is used to compare only XIDs from the same epoch (e.g. for backends
> > * running at the same time). So there must be only normal XIDs, so there's
> > * no issue with triangle inequality.
> > */
> > int
> > xidLogicalComparator(const void *arg1, const void *arg2)
> >
> > Trade-offs:
> > Downcasting a logically sorted FullTransactionId array can break raw
> > uint32 ordering if the set spans an epoch boundary. Still need a qsort
> > on snapshot->xip after copying xids from committed.xip at worst case.
> >
> > Memory/I/O: 2× bytes for committed array (4→8 bytes per entry)
> >
> > Purge improves from O(N) to O(log N + move); merge complexity unchanged
>
> I’ve implemented an experimental version that maintains the
> committed.xip array in numeric sorted order and profiled it on the
> previous workload. The overhead observed earlier has now been
> eliminated.
> Before starting a discussion thread and proposing the patch, I plan to
> run additional pgbench workloads to verify that there are no
> performance regressions. Once the results look stable, I’ll polish and
> share the patch for review.
+1. I've not reviewed the patch yet. I think we need to evaluate how
much the patch makes logical decoding performance better and how much
potential regressions it could have (in the base and worst cases for
each).
Regards,
--
Masahiko Sawada
Amazon Web Services: https://aws.amazon.com
Hi,
On Fri, Oct 31, 2025 at 6:08 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Thu, Oct 30, 2025 at 9:21 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> >
> > Hi,
> >
> > On Wed, Oct 29, 2025 at 8:17 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > >
> > > Hi,
> > >
> > > On Sat, Oct 25, 2025 at 2:36 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > >
> > > > On Thu, Oct 23, 2025 at 1:17 AM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > > >
> > > > > Hi Sawada-san, Michael,
> > > > >
> > > > > Thanks for your comments on this patch.
> > > > >
> > > > > On Thu, Oct 23, 2025 at 8:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > > > >
> > > > > > On Mon, Oct 20, 2025 at 11:13 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
> > > > > > >
> > > > > > > Hi,
> > > > > > >
> > > > > > > Thanks for looking into this.
> > > > > > >
> > > > > > > On Tue, Oct 21, 2025 at 1:05 PM Kirill Reshke <reshkekirill@gmail.com> wrote:
> > > > > > > >
> > > > > > > > On Tue, 21 Oct 2025 at 04:31, Michael Paquier <michael@paquier.xyz> wrote:
> > > > > > > > >
> > > > > > > > > On Sat, Oct 18, 2025 at 01:59:40PM +0500, Kirill Reshke wrote:
> > > > > > > > > > Indeed, these changes look correct.
> > > > > > > > > > I wonder why b89e151054a0 did this place this way, hope we do not miss
> > > > > > > > > > anything here.
> > > > > > > > >
> > > > > > > > > Perhaps a lack of time back in 2014? It feels like an item where we
> > > > > > > > > would need to research a bit some of the past threads, and see if this
> > > > > > > > > has been discussed, or if there were other potential alternatives
> > > > > > > > > discussed. This is not saying that what you are doing in this
> > > > > > > > > proposal is actually bad, but it's a bit hard to say what an
> > > > > > > > > "algorithm" should look like in this specific code path with XID
> > > > > > > > > manipulations. Perhaps since 2014, we may have other places in the
> > > > > > > > > tree that share similar characteristics as what's done here.
> > > > > > > > >
> > > > > > > > > So it feels like this needs a bit more historical investigation first,
> > > > > > > > > rather than saying that your proposal is the best choice on the table.
> > > > >
> > > > > Following these suggestions, I carefully searched the mailing list
> > > > > archives and found no reports of performance issues directly related
> > > > > to this code path. I also examined other parts of the codebase for
> > > > > similar patterns. Components like integerset might share some
> > > > > characteristics with SnapBuildPurgeOlderTxn, but they have constraints
> > > > > that make them not directly applicable here. I am not very familiar
> > > > > with the whole tree, so the investigation might not be exhaustive.
> > > >
> > > > Thank you for looking through the archives. In logical replication,
> > > > performance problems typically show up as replication delays. Since
> > > > logical replication involves many different components and processes,
> > > > it's quite rare for investigations to trace problems back to this
> > > > specific piece of code. However, I still believe it's important to
> > > > optimize the performance of logical decoding itself.
> > > >
> > > > >
> > > > > > >
> > > > > > > A comparable optimization exists in KnownAssignedXidsCompress() which
> > > > > > > uses the same algorithm to remove stale XIDs without workspace
> > > > > > > allocation. That implementation also adds a lazy compaction heuristic
> > > > > > > that delays compaction until a threshold of removed entries is
> > > > > > > reached, amortizing the O(N) cost across multiple operations.
> > > > > > >
> > > > > > > The comment above the data structure mentions the trade-off of keeping
> > > > > > > the committed.xip array sorted versus unsorted. If the array were
> > > > > > > sorted, we could use a binary search combined with memmove to compact
> > > > > > > it efficiently, achieving O(log n + n) complexity for purging.
> > > > > > > However, that design would increase the complexity of
> > > > > > > SnapBuildAddCommittedTxn from O(1) to O(n) and "more complicated wrt
> > > > > > > wraparound".
> > > > > > >
> > > > > > > /*
> > > > > > > * Array of committed transactions that have modified the catalog.
> > > > > > > *
> > > > > > > * As this array is frequently modified we do *not* keep it in
> > > > > > > * xidComparator order. Instead we sort the array when building &
> > > > > > > * distributing a snapshot.
> > > > > > > *
> > > > > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > > > > * time we add something here after becoming consistent will also
> > > > > > > * require distributing a snapshot. Storing them sorted would
> > > > > > > * potentially also make it easier to purge (but more complicated wrt
> > > > > > > * wraparound?). Should be improved if sorting while building the
> > > > > > > * snapshot shows up in profiles.
> > > > > > > */
> > > > > > > TransactionId *xip;
> > > > > > > } committed;
> > > > > > >
> > > > > > > /*
> > > > > > > * Keep track of a new catalog changing transaction that has committed.
> > > > > > > */
> > > > > > > static void
> > > > > > > SnapBuildAddCommittedTxn(SnapBuild *builder, TransactionId xid)
> > > > > > > {
> > > > > > > Assert(TransactionIdIsValid(xid));
> > > > > > >
> > > > > > > if (builder->committed.xcnt == builder->committed.xcnt_space)
> > > > > > > {
> > > > > > > builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1;
> > > > > > >
> > > > > > > elog(DEBUG1, "increasing space for committed transactions to %u",
> > > > > > > (uint32) builder->committed.xcnt_space);
> > > > > > >
> > > > > > > builder->committed.xip = repalloc(builder->committed.xip,
> > > > > > > builder->committed.xcnt_space * sizeof(TransactionId));
> > > > > > > }
> > > > > > >
> > > > > > > /*
> > > > > > > * TODO: It might make sense to keep the array sorted here instead of
> > > > > > > * doing it every time we build a new snapshot. On the other hand this
> > > > > > > * gets called repeatedly when a transaction with subtransactions commits.
> > > > > > > */
> > > > > > > builder->committed.xip[builder->committed.xcnt++] = xid;
> > > > > > > }
> > > > > > >
> > > > > > > It might be worth profiling this function to evaluate whether
> > > > > > > maintaining a sorted array could bring potential benefits, although
> > > > > > > accurately measuring its end-to-end impact could be difficult if it
> > > > > > > isn’t a known hotspot. I also did a brief search on the mailing list
> > > > > > > and found no reports of performance concerns or related proposals to
> > > > > > > optimize this part of the code.
> > > > > >
> > > > > > It might also be worth researching what kind of workloads would need a
> > > > > > better algorithm in terms of storing/updating xip and subxip arrays
> > > > > > since it would be the primary motivation. Also, otherwise we cannot
> > > > > > measure the real-world impact of a new algorithm. Having said that,
> > > > > > find that it would be discussed and developed separately from the
> > > > > > proposed patch on this thread.
> > > > >
> > > > > +1 for researching the workloads that might need a sorted array and
> > > > > more efficient algorithm. This exploration isn’t limited to the scope
> > > > > of SnapBuildPurgeOlderTxn but relates more broadly to the overall
> > > > > snapbuild process, which might be worth discussing in a separate
> > > > > thread as suggested.
> > > > >
> > > > > * TODO: It's unclear whether that reasoning has much merit. Every
> > > > > * time we add something here after becoming consistent will also
> > > > > * require distributing a snapshot. Storing them sorted would
> > > > > * potentially also make it easier to purge (but more complicated wrt
> > > > > * wraparound?). Should be improved if sorting while building the
> > > > > * snapshot shows up in profiles.
> > > > >
> > > > > I also constructed an artificial workload to try to surface the qsort
> > > > > call in SnapBuildBuildSnapshot, though such a scenario seems very
> > > > > unlikely to occur in production.
> > > > >
> > > > > for ((c=1; c<=DDL_CLIENTS; c++)); do
> > > > > (
> > > > > local seq=1
> > > > > while (( $(date +%s) < tB_end )); do
> > > > > local tbl="hp_ddl_${c}_$seq"
> > > > > "$psql" -h 127.0.0.1 -p "$PORT" -d postgres -c "
> > > > > BEGIN;
> > > > > CREATE TABLE ${tbl} (id int, data text);
> > > > > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > > > > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > > > > DROP TABLE ${tbl};
> > > > > COMMIT;" >/dev/null 2>&1 || true
> > > > > seq=$((seq+1))
> > > > > done
> > > > > )
> > > >
> > > > Interesting. To be honest, I think this scenario might actually occur
> > > > in practice, especially in cases where users frequently use CREATE
> > > > TEMP TABLE ... ON COMMIT DROP.
> > >
> > > The attached file shows the flamegraph for this workload.
> > >
> > > for ((c=1; c<=CLIENTS_DDL; c++)); do
> > > (
> > > local seq=1
> > > while (( $(date +%s) < tB_end )); do
> > > local tbl="hp_temp_${c}_$seq"
> > > $psql_cmd -d postgres -c "
> > > BEGIN;
> > > CREATE TEMP TABLE ${tbl} (id int, data text) ON COMMIT DROP;
> > > CREATE INDEX idx_${tbl} ON ${tbl} (id);
> > > INSERT INTO ${tbl} VALUES ($seq, 'd');
> > > COMMIT;" >/dev/null 2>&1 || true
> > > seq=$((seq+1))
> > > done
> > > ) &
> > > pidsB+=($!)
> > > done
> > >
> > > I’ve been thinking about possible ways to maintain a sorted array to
> > > optimize this case and purge function. Below are some preliminary
> > > ideas. If any of them seem reasonable, I’d like to start a new thread
> > > and prepare a patch based on this direction.
> > >
> > > 1) Batch insertion with globally sorted array (raw uint32 order)
> > >
> > > Goal: Maintain committed.xip sorted and deduplicated to eliminate
> > > repeated qsorts.
> > >
> > > Mechanism:
> > > In SnapBuildCommitTxn, collect all XIDs/subxids to be tracked into a
> > > local vector (length m)
> > > Sort and deduplicate the batch: O(m log m)
> > > Reverse-merge the batch into the global array: O(N + m), deduplicating
> > > on the fly
> > > Invariant: committed.xip[0..xcnt) is always raw-sorted (xidComparator
> > > order) and deduplicated
> > >
> > > Complexity improvement:
> > > Before: O((N+m) log (N+m)) per build
> > > After: O(m log m + N) per commit; snapshot build can skip qsort entirely
> > >
> > > Purge:
> > > Remains O(N) linear scan. Raw sorting doesn't enable binary search
> > > because the purge predicate uses wraparound-aware semantics
> > > (NormalTransactionIdPrecedes), and committed.xip can span epochs, so
> > > numeric order ≠ logical XID order.
> > >
> > > 2) Adopt FullTransactionId for sublinear purge (theoretically possible)
> > >
> > > Rationale:
> > > To make purge O(log N), the array needs to be sorted under the same
> > > ordering relation as the purge predicate. Wraparound-aware comparison
> > > of 32-bit XIDs is not a total order when the set spans epochs.
> > > FullTransactionId (epoch<<32 | xid) could provide a true total order.
> > >
> > > Mechanism:
> > > Store FullTransactionId *fxip instead of TransactionId *xip
> > > struct
> > > {
> > > size_t xcnt;
> > > size_t xcnt_space;
> > > bool includes_all_transactions;
> > > FullTransactionId *fxip; /* Changed from TransactionId *xip */
> > > } committed;
> > >
> > > Insertion: Map each 32-bit XID to FullTransactionId using a snapshot
> > > of nextFullXid (same logic as hot standby feedback); sort/dedup batch;
> > > reverse-merge O(N + m)
> > >
> > > Purge: Compute xmin_full using the same snapshot; binary search for
> > > lower bound O(log N) + memmove suffix
> > >
> > > /*
> > > * xidLogicalComparator
> > > * qsort comparison function for XIDs
> > > *
> > > * This is used to compare only XIDs from the same epoch (e.g. for backends
> > > * running at the same time). So there must be only normal XIDs, so there's
> > > * no issue with triangle inequality.
> > > */
> > > int
> > > xidLogicalComparator(const void *arg1, const void *arg2)
> > >
> > > Trade-offs:
> > > Downcasting a logically sorted FullTransactionId array can break raw
> > > uint32 ordering if the set spans an epoch boundary. Still need a qsort
> > > on snapshot->xip after copying xids from committed.xip at worst case.
> > >
> > > Memory/I/O: 2× bytes for committed array (4→8 bytes per entry)
> > >
> > > Purge improves from O(N) to O(log N + move); merge complexity unchanged
> >
> > I’ve implemented an experimental version that maintains the
> > committed.xip array in numeric sorted order and profiled it on the
> > previous workload. The overhead observed earlier has now been
> > eliminated.
> > Before starting a discussion thread and proposing the patch, I plan to
> > run additional pgbench workloads to verify that there are no
> > performance regressions. Once the results look stable, I’ll polish and
> > share the patch for review.
>
> +1. I've not reviewed the patch yet. I think we need to evaluate how
> much the patch makes logical decoding performance better and how much
> potential regressions it could have (in the base and worst cases for
> each).
>
I conducted several benchmark tests on this patch, and here are some
observations:
1) Workloads & settings
# Workload MIXED - Realistic mix of DDL and DML
create_mixed_workload() {
local ROOT="$1"
cat >"$ROOT/mixed_ddl.sql" <<'SQL'
-- DDL workload (catalog changes)
DO $$
DECLARE
tbl text := format('t_%s_%s',
current_setting('application_name', true),
floor(random()*1e9)::int);
BEGIN
EXECUTE format('CREATE TABLE %I (id int, data text) ON COMMIT DROP', tbl);
EXECUTE format('INSERT INTO %I VALUES (1, ''x'')', tbl);
END$$;
SQL
cat >"$ROOT/mixed_dml.sql" <<'SQL'
-- DML workload (no catalog changes)
INSERT INTO app_data (id, data)
VALUES (floor(random()*1e6)::int, repeat('x', 100))
ON CONFLICT (id) DO UPDATE SET data = repeat('y', 100);
SQL
}
# Workload CONTROL - Pure DML, no catalog changes
create_control_workload() {
local ROOT="$1"
cat >"$ROOT/control.sql" <<'SQL'
-- Pure DML, no catalog changes
-- Should show no difference between baseline and patched
INSERT INTO control_data (id, data)
VALUES (floor(random()*1e6)::int, repeat('x', 100))
ON CONFLICT (id) DO UPDATE SET data = repeat('y', 100);
SQL
}
# Start workload 100 clients, duration 40s, 1 run
local pids=()
for ((c=1; c<=CLIENTS; c++)); do
(
local end=$(($(date +%s) + DURATION))
while (( $(date +%s) < end )); do
"$psql" -h 127.0.0.1 -p "$PORT" -d postgres \
-v ON_ERROR_STOP=0 \
-f "$SQL_FILE" >/dev/null 2>&1 || true
done
) &
pids+=($!)
done
"SELECT pg_create_logical_replication_slot('$SLOT', 'test_decoding',
false, true);" \
"SELECT COALESCE(total_txns, 0), COALESCE(total_bytes, 0) FROM
pg_stat_replication_slots WHERE slot_name='$SLOT';")
shared_buffers = '4GB'
wal_level = logical
max_replication_slots = 10
max_wal_senders = 10
log_min_messages = warning
max_connections = 600
autovacuum = off
checkpoint_timeout = 15min
max_wal_size = 4GB
2) Performance results
=== Workload: mixed ===
Client commits/sec:
Baseline: 7845.82 commits/sec
Patched: 7747.88 commits/sec
Decoder throughput (from pg_stat_replication_slots):
Baseline: 750.10 txns/sec (646.80 MB/s)
Patched: 2440.03 txns/sec (2052.32 MB/s)
Transaction efficiency (decoded vs committed):
Baseline: 313833 committed → 30004 decoded (9.56%)
Patched: 309915 committed → 97601 decoded (31.49%)
Total decoded (all reps):
Baseline: 30004 txns (25872.01 MB)
Patched: 97601 txns (82092.83 MB)
Decoder improvement: +225.00% (txns/sec)
Decoder improvement: +217.00% (MB/s)
Efficiency improvement: +21.93% points (more transactions decoded per committed)
=== Workload: control ===
Client commits/sec:
Baseline: 6756.80 commits/sec
Patched: 6643.95 commits/sec
Decoder throughput (from pg_stat_replication_slots):
Baseline: 3373.28 txns/sec (0.29 MB/s)
Patched: 3316.15 txns/sec (0.28 MB/s)
Transaction efficiency (decoded vs committed):
Baseline: 270272 committed → 134931 decoded (49.92%)
Patched: 265758 committed → 132646 decoded (49.91%)
Total decoded (all reps):
Baseline: 134931 txns (11.56 MB)
Patched: 132646 txns (11.37 MB)
3) Potential regression
The potential regression point could be before the slot reaches the
CONSISTENT state, particularly when building_full_snapshot is set to
true. In this phase, all transactions including those that don’t
modify the catalog — must be added to the committed.xip array. These
XIDs don’t require later snapshot builds or sorting, so the
batch-insert logic increases the per-insert cost from O(1) to O(m + n)
without providing a direct benefit.
However, the impact of this regression could be limited. The system
remains in the pre-CONSISTENT phase only briefly during initial
snapshot building, and the building_full_snapshot = true case is rare,
mainly used when creating replication slots with the EXPORT_SNAPSHOT
option.
Once the slot becomes CONSISTENT, only catalog-modifying transactions
are tracked in committed.xip, and the patch reduces overall
snapshot-building overhead by eliminating repeated full-array sorts.
We could also adopt a two-phase approach — keeping the current
behavior before reaching the CONSISTENT state and maintaining a sorted
array only after that point. This would preserve the performance
benefits while avoiding potential regressions. However, it would
introduce additional complexity and potential risks in handling the
state transitions.
if (builder->state < SNAPBUILD_CONSISTENT)
{
/* ensure that only commits after this are getting replayed */
if (builder->start_decoding_at <= lsn)
builder->start_decoding_at = lsn + 1;
/*
* If building an exportable snapshot, force xid to be tracked, even
* if the transaction didn't modify the catalog.
*/
if (builder->building_full_snapshot)
{
needs_timetravel = true;
}
}
It also occurs to me that we can optimize the purge operation by using
two binary searches to locate the interval to keep when the array is
sorted.
Best,
Xuneng
Hi,
> I conducted several benchmark tests on this patch, and here are some
> observations:
>
> 1) Workloads & settings
> # Workload MIXED - Realistic mix of DDL and DML
> create_mixed_workload() {
> local ROOT="$1"
> cat >"$ROOT/mixed_ddl.sql" <<'SQL'
> -- DDL workload (catalog changes)
> DO $$
> DECLARE
> tbl text := format('t_%s_%s',
> current_setting('application_name', true),
> floor(random()*1e9)::int);
> BEGIN
> EXECUTE format('CREATE TABLE %I (id int, data text) ON COMMIT DROP', tbl);
> EXECUTE format('INSERT INTO %I VALUES (1, ''x'')', tbl);
> END$$;
>
> SQL
> cat >"$ROOT/mixed_dml.sql" <<'SQL'
> -- DML workload (no catalog changes)
> INSERT INTO app_data (id, data)
> VALUES (floor(random()*1e6)::int, repeat('x', 100))
> ON CONFLICT (id) DO UPDATE SET data = repeat('y', 100);
> SQL
> }
>
> # Workload CONTROL - Pure DML, no catalog changes
> create_control_workload() {
> local ROOT="$1"
> cat >"$ROOT/control.sql" <<'SQL'
>
> -- Pure DML, no catalog changes
> -- Should show no difference between baseline and patched
> INSERT INTO control_data (id, data)
> VALUES (floor(random()*1e6)::int, repeat('x', 100))
> ON CONFLICT (id) DO UPDATE SET data = repeat('y', 100);
> SQL
> }
>
> # Start workload 100 clients, duration 40s, 1 run
> local pids=()
> for ((c=1; c<=CLIENTS; c++)); do
> (
> local end=$(($(date +%s) + DURATION))
> while (( $(date +%s) < end )); do
> "$psql" -h 127.0.0.1 -p "$PORT" -d postgres \
> -v ON_ERROR_STOP=0 \
> -f "$SQL_FILE" >/dev/null 2>&1 || true
> done
> ) &
> pids+=($!)
> done
>
> "SELECT pg_create_logical_replication_slot('$SLOT', 'test_decoding',
> false, true);" \
>
> "SELECT COALESCE(total_txns, 0), COALESCE(total_bytes, 0) FROM
> pg_stat_replication_slots WHERE slot_name='$SLOT';")
>
> shared_buffers = '4GB'
> wal_level = logical
> max_replication_slots = 10
> max_wal_senders = 10
> log_min_messages = warning
> max_connections = 600
> autovacuum = off
> checkpoint_timeout = 15min
> max_wal_size = 4GB
>
> 2) Performance results
>
> === Workload: mixed ===
> Client commits/sec:
> Baseline: 7845.82 commits/sec
> Patched: 7747.88 commits/sec
>
> Decoder throughput (from pg_stat_replication_slots):
> Baseline: 750.10 txns/sec (646.80 MB/s)
> Patched: 2440.03 txns/sec (2052.32 MB/s)
>
> Transaction efficiency (decoded vs committed):
> Baseline: 313833 committed → 30004 decoded (9.56%)
> Patched: 309915 committed → 97601 decoded (31.49%)
>
> Total decoded (all reps):
> Baseline: 30004 txns (25872.01 MB)
> Patched: 97601 txns (82092.83 MB)
>
> Decoder improvement: +225.00% (txns/sec)
> Decoder improvement: +217.00% (MB/s)
> Efficiency improvement: +21.93% points (more transactions decoded per committed)
>
> === Workload: control ===
> Client commits/sec:
> Baseline: 6756.80 commits/sec
> Patched: 6643.95 commits/sec
>
> Decoder throughput (from pg_stat_replication_slots):
> Baseline: 3373.28 txns/sec (0.29 MB/s)
> Patched: 3316.15 txns/sec (0.28 MB/s)
>
> Transaction efficiency (decoded vs committed):
> Baseline: 270272 committed → 134931 decoded (49.92%)
> Patched: 265758 committed → 132646 decoded (49.91%)
>
> Total decoded (all reps):
> Baseline: 134931 txns (11.56 MB)
> Patched: 132646 txns (11.37 MB)
>
> 3) Potential regression
>
> The potential regression point could be before the slot reaches the
> CONSISTENT state, particularly when building_full_snapshot is set to
> true. In this phase, all transactions including those that don’t
> modify the catalog — must be added to the committed.xip array. These
> XIDs don’t require later snapshot builds or sorting, so the
> batch-insert logic increases the per-insert cost from O(1) to O(m + n)
> without providing a direct benefit.
>
> However, the impact of this regression could be limited. The system
> remains in the pre-CONSISTENT phase only briefly during initial
> snapshot building, and the building_full_snapshot = true case is rare,
> mainly used when creating replication slots with the EXPORT_SNAPSHOT
> option.
>
> Once the slot becomes CONSISTENT, only catalog-modifying transactions
> are tracked in committed.xip, and the patch reduces overall
> snapshot-building overhead by eliminating repeated full-array sorts.
>
> We could also adopt a two-phase approach — keeping the current
> behavior before reaching the CONSISTENT state and maintaining a sorted
> array only after that point. This would preserve the performance
> benefits while avoiding potential regressions. However, it would
> introduce additional complexity and potential risks in handling the
> state transitions.
>
>
> if (builder->state < SNAPBUILD_CONSISTENT)
> {
> /* ensure that only commits after this are getting replayed */
> if (builder->start_decoding_at <= lsn)
> builder->start_decoding_at = lsn + 1;
>
> /*
> * If building an exportable snapshot, force xid to be tracked, even
> * if the transaction didn't modify the catalog.
> */
> if (builder->building_full_snapshot)
> {
> needs_timetravel = true;
> }
> }
>
> It also occurs to me that we can optimize the purge operation by using
> two binary searches to locate the interval to keep when the array is
> sorted.
The result of mixed workload in this email is that of the pure DDL
workload. Sorry for the noise here.
I started a new thread for the discussion of maintaining a sorted
committed.xip array. Please
see [1].
[1] https://www.postgresql.org/message-id/CABPTF7XiwbA38OZBj5Y2F-q%2BfZ%3D03YFN9iFnb_406F4SfE-f4w%40mail.gmail.com
Best,
Xuneng
Hi,
With a sorted commited.xip array, we could replace the iteration with
two binary searches to find the interval to keep.
Proposed Optimization
---------------------
Use binary search to locate the boundaries of XIDs to remove, then
compact with a single memmove. The key insight requires understanding
how XID precedence relates to numeric ordering.
XID Precedence Definition
~~~~~~~~~~~~~~~~~~~~~~~~~~
PostgreSQL defines XID precedence as:
/* compare two XIDs already known to be normal; this is a macro for speed */
#define NormalTransactionIdPrecedes(id1, id2) \
(AssertMacro(TransactionIdIsNormal(id1) && TransactionIdIsNormal(id2)), \
(int32) ((id1) - (id2)) < 0)
This means: id1 precedes id2 if (int32)(id1 - id2) < 0.
Equivalently, this identifies all XIDs in the modular interval
[id2 - 2^31, id2) on the 32-bit ring as "preceding id2". So XIDs
preceding xmin are exactly those in [xmin - 2^31, xmin).
From Modular Interval to Array Positions
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The arrays are sorted in numeric uint32 order (xip[i] <= xip[i+1] in
unsigned sense), which is a total order—not wraparound-aware. Therefore,
the modular interval we want to remove may appear as one or two numeric
blocks in the sorted array.
Let boundary = xmin - 2^31 (mod 2^32). The modular interval [boundary, xmin)
contains all XIDs to remove (half-open: xmin itself is kept, matching
NormalTransactionIdPrecedes). Where does it appear in the numerically sorted
array?
Case A: (uint32)boundary <= (uint32)xmin (numeric no wrap)
Example: xmin = 3,000,000,000
boundary = 3,000,000,000 - 2,147,483,648 = 852,516,352
Here, (uint32)boundary < (uint32)xmin, so the interval does not cross
0 numerically. In the sorted array, XIDs to remove form one contiguous
block: [idx_boundary, idx_xmin).
Array layout:
[... keep ...][=== remove ===][... keep ...]
0 ............ idx_boundary ... idx_xmin ...... n
Action: Keep prefix [0, idx_boundary) and suffix [idx_xmin, n).
Case B: (uint32)boundary > (uint32)xmin (numeric wrap)
Example: xmin = 100
boundary = 100 - 2^31 (mod 2^32) = 2,147,483,748
Since (uint32)boundary > (uint32)xmin, the interval wraps through 0
numerically. In the sorted array, XIDs to remove form two blocks:
[0, idx_xmin) and [idx_boundary, n).
Array layout:
[= remove =][... keep ...][= remove =]
0 ......... idx_xmin .... idx_boundary ......... n
Action: Keep only the middle [idx_xmin, idx_boundary).
Note: Case B often occurs when xmin is "small" (e.g., right after
startup), making xmin - 2^31 wrap numerically. This is purely about
positions in the numeric order; it does not imply the cluster has
"wrapped" XIDs operationally.
In both cases, we locate idx_boundary and idx_xmin using binary search
in O(log n) time, then use one memmove to compact
The algorithm:
1. Compute boundary = xmin - 2^31
2. Binary search for idx_boundary (first index with xip[i] >= boundary)
3. Binary search for idx_xmin (first index with xip[i] >= xmin)
4. Use memmove to compact based on case A or B above
Benefits
--------
1. Performance: O(log n) binary search vs O(n) linear scan
2. Memory: No workspace allocation needed
3. Simplicity: One memmove instead of allocate + two copies + free
The same logic is applied to both committed.xip and catchange.xip arrays.
Faster binary search
--------
While faster binary search variants exist, the current code already
introduces more complexity than the original. It’s uncertain that
further optimization would deliver a meaningful performance gain.
Best,
Xuneng
Вложения
On Mon, Nov 10, 2025 at 11:22 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > Hi, > > With a sorted commited.xip array, we could replace the iteration with > two binary searches to find the interval to keep. > > Proposed Optimization > --------------------- > > Use binary search to locate the boundaries of XIDs to remove, then > compact with a single memmove. The key insight requires understanding > how XID precedence relates to numeric ordering. > > XID Precedence Definition > ~~~~~~~~~~~~~~~~~~~~~~~~~~ > > PostgreSQL defines XID precedence as: > > /* compare two XIDs already known to be normal; this is a macro for speed */ > #define NormalTransactionIdPrecedes(id1, id2) \ > (AssertMacro(TransactionIdIsNormal(id1) && TransactionIdIsNormal(id2)), \ > (int32) ((id1) - (id2)) < 0) > > This means: id1 precedes id2 if (int32)(id1 - id2) < 0. > > Equivalently, this identifies all XIDs in the modular interval > [id2 - 2^31, id2) on the 32-bit ring as "preceding id2". So XIDs > preceding xmin are exactly those in [xmin - 2^31, xmin). > > From Modular Interval to Array Positions > ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ > > The arrays are sorted in numeric uint32 order (xip[i] <= xip[i+1] in > unsigned sense), which is a total order—not wraparound-aware. Therefore, > the modular interval we want to remove may appear as one or two numeric > blocks in the sorted array. > > Let boundary = xmin - 2^31 (mod 2^32). The modular interval [boundary, xmin) > contains all XIDs to remove (half-open: xmin itself is kept, matching > NormalTransactionIdPrecedes). Where does it appear in the numerically sorted > array? > > Case A: (uint32)boundary <= (uint32)xmin (numeric no wrap) > Example: xmin = 3,000,000,000 > boundary = 3,000,000,000 - 2,147,483,648 = 852,516,352 > > Here, (uint32)boundary < (uint32)xmin, so the interval does not cross > 0 numerically. In the sorted array, XIDs to remove form one contiguous > block: [idx_boundary, idx_xmin). > > Array layout: > [... keep ...][=== remove ===][... keep ...] > 0 ............ idx_boundary ... idx_xmin ...... n > > Action: Keep prefix [0, idx_boundary) and suffix [idx_xmin, n). > > Case B: (uint32)boundary > (uint32)xmin (numeric wrap) > Example: xmin = 100 > boundary = 100 - 2^31 (mod 2^32) = 2,147,483,748 > > Since (uint32)boundary > (uint32)xmin, the interval wraps through 0 > numerically. In the sorted array, XIDs to remove form two blocks: > [0, idx_xmin) and [idx_boundary, n). > > Array layout: > [= remove =][... keep ...][= remove =] > 0 ......... idx_xmin .... idx_boundary ......... n > > Action: Keep only the middle [idx_xmin, idx_boundary). > > Note: Case B often occurs when xmin is "small" (e.g., right after > startup), making xmin - 2^31 wrap numerically. This is purely about > positions in the numeric order; it does not imply the cluster has > "wrapped" XIDs operationally. > > In both cases, we locate idx_boundary and idx_xmin using binary search > in O(log n) time, then use one memmove to compact > > The algorithm: > 1. Compute boundary = xmin - 2^31 > 2. Binary search for idx_boundary (first index with xip[i] >= boundary) > 3. Binary search for idx_xmin (first index with xip[i] >= xmin) > 4. Use memmove to compact based on case A or B above > > Benefits > -------- > > 1. Performance: O(log n) binary search vs O(n) linear scan > 2. Memory: No workspace allocation needed > 3. Simplicity: One memmove instead of allocate + two copies + free > > The same logic is applied to both committed.xip and catchange.xip arrays. > > Faster binary search > -------- > > While faster binary search variants exist, the current code already > introduces more complexity than the original. It’s uncertain that > further optimization would deliver a meaningful performance gain. > Adapt the patch with two-phase optimization: - Pre-CONSISTENT: Use in-place compaction O(n) since committed.xip is unsorted during this phase. - Post-CONSISTENT: Use binary search O(log n) since committed.xip is maintained in sorted order after reaching consistency. -- Best, Xuneng
Вложения
Hi, On Tue, Dec 16, 2025 at 6:29 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > On Mon, Nov 10, 2025 at 11:22 AM Xuneng Zhou <xunengzhou@gmail.com> wrote: > > > > Hi, > > > > With a sorted commited.xip array, we could replace the iteration with > > two binary searches to find the interval to keep. > > > > Proposed Optimization > > --------------------- > > > > Use binary search to locate the boundaries of XIDs to remove, then > > compact with a single memmove. The key insight requires understanding > > how XID precedence relates to numeric ordering. > > > > XID Precedence Definition > > ~~~~~~~~~~~~~~~~~~~~~~~~~~ > > > > PostgreSQL defines XID precedence as: > > > > /* compare two XIDs already known to be normal; this is a macro for speed */ > > #define NormalTransactionIdPrecedes(id1, id2) \ > > (AssertMacro(TransactionIdIsNormal(id1) && TransactionIdIsNormal(id2)), \ > > (int32) ((id1) - (id2)) < 0) > > > > This means: id1 precedes id2 if (int32)(id1 - id2) < 0. > > > > Equivalently, this identifies all XIDs in the modular interval > > [id2 - 2^31, id2) on the 32-bit ring as "preceding id2". So XIDs > > preceding xmin are exactly those in [xmin - 2^31, xmin). > > > > From Modular Interval to Array Positions > > ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ > > > > The arrays are sorted in numeric uint32 order (xip[i] <= xip[i+1] in > > unsigned sense), which is a total order—not wraparound-aware. Therefore, > > the modular interval we want to remove may appear as one or two numeric > > blocks in the sorted array. > > > > Let boundary = xmin - 2^31 (mod 2^32). The modular interval [boundary, xmin) > > contains all XIDs to remove (half-open: xmin itself is kept, matching > > NormalTransactionIdPrecedes). Where does it appear in the numerically sorted > > array? > > > > Case A: (uint32)boundary <= (uint32)xmin (numeric no wrap) > > Example: xmin = 3,000,000,000 > > boundary = 3,000,000,000 - 2,147,483,648 = 852,516,352 > > > > Here, (uint32)boundary < (uint32)xmin, so the interval does not cross > > 0 numerically. In the sorted array, XIDs to remove form one contiguous > > block: [idx_boundary, idx_xmin). > > > > Array layout: > > [... keep ...][=== remove ===][... keep ...] > > 0 ............ idx_boundary ... idx_xmin ...... n > > > > Action: Keep prefix [0, idx_boundary) and suffix [idx_xmin, n). > > > > Case B: (uint32)boundary > (uint32)xmin (numeric wrap) > > Example: xmin = 100 > > boundary = 100 - 2^31 (mod 2^32) = 2,147,483,748 > > > > Since (uint32)boundary > (uint32)xmin, the interval wraps through 0 > > numerically. In the sorted array, XIDs to remove form two blocks: > > [0, idx_xmin) and [idx_boundary, n). > > > > Array layout: > > [= remove =][... keep ...][= remove =] > > 0 ......... idx_xmin .... idx_boundary ......... n > > > > Action: Keep only the middle [idx_xmin, idx_boundary). > > > > Note: Case B often occurs when xmin is "small" (e.g., right after > > startup), making xmin - 2^31 wrap numerically. This is purely about > > positions in the numeric order; it does not imply the cluster has > > "wrapped" XIDs operationally. > > > > In both cases, we locate idx_boundary and idx_xmin using binary search > > in O(log n) time, then use one memmove to compact > > > > The algorithm: > > 1. Compute boundary = xmin - 2^31 > > 2. Binary search for idx_boundary (first index with xip[i] >= boundary) > > 3. Binary search for idx_xmin (first index with xip[i] >= xmin) > > 4. Use memmove to compact based on case A or B above > > > > Benefits > > -------- > > > > 1. Performance: O(log n) binary search vs O(n) linear scan > > 2. Memory: No workspace allocation needed > > 3. Simplicity: One memmove instead of allocate + two copies + free > > > > The same logic is applied to both committed.xip and catchange.xip arrays. > > > > Faster binary search > > -------- > > > > While faster binary search variants exist, the current code already > > introduces more complexity than the original. It’s uncertain that > > further optimization would deliver a meaningful performance gain. > > > > Adapt the patch with two-phase optimization: > > - Pre-CONSISTENT: Use in-place compaction O(n) since committed.xip is > unsorted during this phase. > > - Post-CONSISTENT: Use binary search O(log n) since committed.xip is > maintained in sorted order after reaching consistency. > v3-0001 fixes a critical issue where the snapshot->xip array in SnapBuildBuildSnapshot might not be sorted before reaching the consistent state. Sorry for the noise here. -- Best, Xuneng
Вложения
Hi Xuneng,
On Thu, Jan 8, 2026 at 4:15 PM Xuneng Zhou <xunengzhou@gmail.com> wrote:
v3-0001 fixes a critical issue where the snapshot->xip array in
SnapBuildBuildSnapshot might not be sorted before reaching the
consistent state. Sorry for the noise here.
I’ve given this patch a cursory review, and it looks good overall.
Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure the correctness of the modification?
I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness is fully guaranteed.
Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure the correctness of the modification?
I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness is fully guaranteed.
Hi Xuneng,
On Thu, Jan 8, 2026 at 4:15 PM Xuneng Zhou <xunengzhou(at)gmail(dot)com> wrote:
>
> v3-0001 fixes a critical issue where the snapshot->xip array in
> SnapBuildBuildSnapshot might not be sorted before reaching the
> consistent state. Sorry for the noise here.
>
>
I just reviewed the v3 and I got a few comment
in function `SnapBuildAddCommittedTxns`
`builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1`
Wouldn't it be more appropriate to use:
`builder->committed.cnt_space = builder->committed.xcnt_space * 2`
Best regards,
Hi Neil, On Thu, Jan 8, 2026 at 4:49 PM Neil Chen <carpenter.nail.cz@gmail.com> wrote: > > Hi Xuneng, > > On Thu, Jan 8, 2026 at 4:15 PM Xuneng Zhou <xunengzhou@gmail.com> wrote: >> >> >> v3-0001 fixes a critical issue where the snapshot->xip array in >> SnapBuildBuildSnapshot might not be sorted before reaching the >> consistent state. Sorry for the noise here. >> > > I’ve given this patch a cursory review, and it looks good overall. > Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure the correctnessof the modification? > I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness is fullyguaranteed. Thanks for your review. I think we can add a tap test for it. -- Best, Xuneng
Hi Dewei, On Thu, Jan 8, 2026 at 6:42 PM Dewei Dai <daidewei1970@163.com> wrote: > > Hi Xuneng, > > On Thu, Jan 8, 2026 at 4:15 PM Xuneng Zhou <xunengzhou(at)gmail(dot)com> wrote: > > > > v3-0001 fixes a critical issue where the snapshot->xip array in > > SnapBuildBuildSnapshot might not be sorted before reaching the > > consistent state. Sorry for the noise here. > > > > > I just reviewed the v3 and I got a few comment > in function `SnapBuildAddCommittedTxns` > `builder->committed.xcnt_space = builder->committed.xcnt_space * 2 + 1` > > Wouldn't it be more appropriate to use: > `builder->committed.cnt_space = builder->committed.xcnt_space * 2` > > > Best regards, > Thanks for looking into this. Yeah, we don't need the +1 in the while loop. I'll remove it. -- Best, Xuneng
Xuneng Zhou <xunengzhou@gmail.com> writes: > On Thu, Jan 8, 2026 at 4:49 PM Neil Chen <carpenter.nail.cz@gmail.com> wrote: >> I’ve given this patch a cursory review, and it looks good overall. >> Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure the correctnessof the modification? >> I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness is fullyguaranteed. > Thanks for your review. I think we can add a tap test for it. What makes you think this code isn't adequately tested already? The coverage report at https://coverage.postgresql.org/src/backend/replication/logical/snapbuild.c.gcov.html shows SnapBuildPurgeOlderTxn as pretty fully exercised. A more interesting question is whether it's worth bothering with at all. This code only runs when we receive a running-xacts WAL record, which is infrequent. So it seems pretty likely to me that nobody could ever detect any performance difference from saving a palloc/pfree here. Perhaps the patch is worth applying on the grounds that it makes the function shorter and clearer, but that's pretty much in the eye of the beholder. On the whole, I think we've got bigger fish to fry. regards, tom lane
Re: Optimize SnapBuildPurgeOlderTxn: use in-place compaction instead of temporary array
От
Masahiko Sawada
Дата:
On Thu, Jan 8, 2026 at 8:05 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Xuneng Zhou <xunengzhou@gmail.com> writes: > > On Thu, Jan 8, 2026 at 4:49 PM Neil Chen <carpenter.nail.cz@gmail.com> wrote: > >> I’ve given this patch a cursory review, and it looks good overall. > >> Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure thecorrectness of the modification? > >> I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness isfully guaranteed. > > > Thanks for your review. I think we can add a tap test for it. > > What makes you think this code isn't adequately tested already? > The coverage report at > > https://coverage.postgresql.org/src/backend/replication/logical/snapbuild.c.gcov.html > > shows SnapBuildPurgeOlderTxn as pretty fully exercised. > > A more interesting question is whether it's worth bothering with > at all. This code only runs when we receive a running-xacts WAL > record, which is infrequent. So it seems pretty likely to me that > nobody could ever detect any performance difference from saving > a palloc/pfree here. Perhaps the patch is worth applying on the > grounds that it makes the function shorter and clearer, but that's > pretty much in the eye of the beholder. The 0001 patch optimizes the management of catalog-modifying XIDs during the decoding of COMMIT records. Instead of doing qsort() for every snapshot building, the patch maintains committed.xip in sorted order. While this accelerates logical decoding in scenarios with frequent DDL execution, I share Tom's concern: the added complexity seems disproportionate for such an infrequent use case. I am also not sure that the optimization regarding the CONSISTENT state is necessary. Furthermore, the patch introduces a palloc()/pfree() overhead for every COMMIT record to replace qsort(). As indicated by the results[1], this appears to cause a slight regression in common workloads dominated by DML. Regards, [1] https://www.postgresql.org/message-id/CABPTF7USnHTLLzg%2BKsNTb0dCONM%3DcrM5tdH5HUZr4kNOq7tqAw%40mail.gmail.com -- Masahiko Sawada Amazon Web Services: https://aws.amazon.com
Hi, On Fri, Jan 9, 2026 at 7:59 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Jan 8, 2026 at 8:05 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > Xuneng Zhou <xunengzhou@gmail.com> writes: > > > On Thu, Jan 8, 2026 at 4:49 PM Neil Chen <carpenter.nail.cz@gmail.com> wrote: > > >> I’ve given this patch a cursory review, and it looks good overall. > > >> Considering the impact of this change, should we add a regression test for it, or provide a unit test to ensure thecorrectness of the modification? > > >> I think it would be more receptive to merging such a "subtle performance optimization" only when its correctness isfully guaranteed. > > > > > Thanks for your review. I think we can add a tap test for it. > > > > What makes you think this code isn't adequately tested already? > > The coverage report at > > > > https://coverage.postgresql.org/src/backend/replication/logical/snapbuild.c.gcov.html > > > > shows SnapBuildPurgeOlderTxn as pretty fully exercised. I was unaware of this site before. Thanks for informing me. > > A more interesting question is whether it's worth bothering with > > at all. This code only runs when we receive a running-xacts WAL > > record, which is infrequent. So it seems pretty likely to me that > > nobody could ever detect any performance difference from saving > > a palloc/pfree here. Perhaps the patch is worth applying on the > > grounds that it makes the function shorter and clearer, but that's > > pretty much in the eye of the beholder. > > The 0001 patch optimizes the management of catalog-modifying XIDs > during the decoding of COMMIT records. Instead of doing qsort() for > every snapshot building, the patch maintains committed.xip in sorted > order. > > While this accelerates logical decoding in scenarios with frequent DDL > execution, I share Tom's concern: the added complexity seems > disproportionate for such an infrequent use case. I am also not sure > that the optimization regarding the CONSISTENT state is necessary. > > Furthermore, the patch introduces a palloc()/pfree() overhead for > every COMMIT record to replace qsort(). As indicated by the > results[1], this appears to cause a slight regression in common > workloads dominated by DML. > Yes, the current patch feels more like an algorithmic optimization on its own. If SnapBuildPurgeOlderTxn is not a known hot spot, the added complexity may outweigh marginal performance benefit from using a more sophisticated approach such as binary search. With respect to measuring regression in a CONSISTENT state, my understanding is that in the presence of a long-running transaction and a high volume of concurrent DML activity, the time to create a replication slot is already dominated by the long-running transaction. In that situation, slot-creation latency is not a reliable metric for evaluating this change. A sensible way to assess impact would be to look at CPU-level metrics using tools like perf. The palloc()/pfree() overhead could potentially be reduced by techniques such as lazy allocation—only allocating once the first XID is actually needed—or by using a small fixed-size stack array initially and falling back to heap allocation only when the capacity is exceeded. However, both approaches would introduce additional complexity into the code. I am more inclined to the simpler approach of in-place compaction given it is an easy win. WDYT. -- Best, Xuneng
Hi Tom,
On Fri, Jan 9, 2026 at 12:05 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
What makes you think this code isn't adequately tested already?
The coverage report at
https://coverage.postgresql.org/src/backend/replication/logical/snapbuild.c.gcov.html
shows SnapBuildPurgeOlderTxn as pretty fully exercised.
Actually, this patch evolved from a tiny, "casual" quick-fix patch in its very first version. I agree that the current effort invested in it possible has outweighed the potential benefits it may bring.
On a side note, I’m a beginner with PostgreSQL and trying to take on some simple tasks while deepening my understanding of the system. I noticed that many items in the coverage tests you provided have rather low coverage rates (< 75%). Do you think it would be worthwhile to add more test cases to improve their test coverage? I’d appreciate any advice the community can offer on this.
Hi, On Fri, Jan 9, 2026 at 10:18 AM Neil Chen <carpenter.nail.cz@gmail.com> wrote: > > Hi Tom, > > On Fri, Jan 9, 2026 at 12:05 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: >> >> >> What makes you think this code isn't adequately tested already? >> The coverage report at >> >> https://coverage.postgresql.org/src/backend/replication/logical/snapbuild.c.gcov.html >> >> shows SnapBuildPurgeOlderTxn as pretty fully exercised. >> > > I wasn’t aware of this website before, so thank you for sharing it. > Actually, this patch evolved from a tiny, "casual" quick-fix patch in its very first version. I agree that the currenteffort invested in it possible has outweighed the potential benefits it may bring. > > On a side note, I’m a beginner with PostgreSQL and trying to take on some simple tasks while deepening my understandingof the system. I noticed that many items in the coverage tests you provided have rather low coverage rates (<75%). Do you think it would be worthwhile to add more test cases to improve their test coverage? I’d appreciate any advicethe community can offer on this. I think improving test coverage is generally beneficial and also helps build familiarity with the codebase. -- Best, Xuneng