Обсуждение: Parallel Apply
Hi,
Background and Motivation
-------------------------------------
In high-throughput systems, where hundreds of sessions generate data
on the publisher, the subscriber's apply process often becomes a
bottleneck due to the single apply worker model. While users can
mitigate this by creating multiple publication-subscription pairs,
this approach has scalability and usability limitations.
Currently, PostgreSQL supports parallel apply only for large streaming
transactions (streaming=parallel). This proposal aims to extend
parallelism to non-streaming transactions, thereby improving
replication performance in workloads dominated by smaller, frequent
transactions.
Design Overview
------------------------
To safely parallelize non-streaming transactions, we must ensure that
transaction dependencies are respected to avoid failures and
deadlocks. Consider the following scenarios to understand it better:
(a) Transaction failures: Say, if we insert a row in the first
transaction and update it in the second transaction on the publisher,
then allowing the subscriber to apply both in parallel can lead to
failure in the update; (b) Deadlocks - allowing transactions that
update the same set of rows in a table in the opposite order in
parallel can lead to deadlocks.
The core idea is that the leader apply worker ensures the following:
a. Identifies dependencies between transactions. b. Coordinates
parallel workers to apply independent transactions concurrently. c.
Ensures correct ordering for dependent transactions.
Dependency Detection
--------------------------------
1. Basic Dependency Tracking: Maintain a hash table keyed by
(RelationId, ReplicaIdentity) with the value as the transaction XID.
Before dispatching a change to a parallel worker, the leader checks
for existing entries: (a) If no match: add the entry and proceed; (b)
If match: instruct the worker to wait until the dependent transaction
completes.
2. Unique Keys
In addition to RI, track unique keys to detect conflicts. Example:
CREATE TABLE tab1(a INT PRIMARY KEY, b INT UNIQUE);
Transactions on publisher:
Txn1: INSERT (1,1)
Txn2: INSERT (2,2)
Txn3: DELETE (2,2)
Txn4: UPDATE (1,1) → (1,2)
If Txn4 is applied before Txn2 and Txn3, it will fail due to a unique
constraint violation. To prevent this, track both RI and unique keys
in the hash table. Compare keys of both old and new tuples to detect
dependencies. Then old_tuple's RI needs to be compared, and new
tuple's, both unique key and RI (new tuple's RI is required to detect
some prior insertion with the same key) needs to be compared with
existing hash table entries to identify transaction dependency.
3. Foreign Keys
Consider FK constraints between tables. Example:
TABLE owner(user_id INT PRIMARY KEY);
TABLE car(car_name TEXT, user_id INT REFERENCES owner);
Transactions:
Txn1: INSERT INTO owner(1)
Txn2: INSERT INTO car('bz', 1)
Applying Txn2 before Txn1 will fail. To avoid this, check if FK values
in new tuples match any RI or unique key in the hash table. If
matched, treat the transaction as dependent.
4. Triggers and Constraints
For the initial version, exclude tables with user-defined triggers or
constraints from parallel apply due to complexity in dependency
detection. We may need some parallel-apply-safe marking to allow this.
Replication Progress Tracking
-----------------------------------------
Parallel apply introduces out-of-order commit application,
complicating replication progress tracking. To handle restarts and
ensure consistency:
Track Three Key Metrics:
lowest_remote_lsn: Starting point for applying transactions.
highest_remote_lsn: Highest LSN that has been applied.
list_remote_lsn: List of commit LSNs applied between the lowest and highest.
Mechanism:
Store these in ReplicationState: lowest_remote_lsn,
highest_remote_lsn, list_remote_lsn. Flush these to disk during
checkpoints similar to CheckPointReplicationOrigin.
After Restart, Start from lowest_remote_lsn and for each transaction,
if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it.
Once commit LSN > highest_remote_lsn, apply without checking the list.
During apply, the leader maintains list_in_progress_xacts in the
increasing commit order. On commit, update highest_remote_lsn. If
commit LSN matches the first in-progress xact of
list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to
list_remote_lsn. After commit, also remove it from the
list_in_progress_xacts. We need to clean up entries below
lowest_remote_lsn in list_remote_lsn while updating its value.
To illustrate how this mechanism works, consider the following four
transactions:
Transaction ID Commit LSN
501 1000
502 1100
503 1200
504 1300
Assume:
Transactions 501 and 502 take longer to apply whereas transactions 503
and 504 finish earlier. Parallel apply workers are assigned as
follows:
pa-1 → 501
pa-2 → 502
pa-3 → 503
pa-4 → 504
Initial state: list_in_progress_xacts = [501, 502, 503, 504]
Step 1: Transaction 503 commits first and in RecordTransactionCommit,
it updates highest_remote_lsn to 1200. In apply_handle_commit, since
503 is not the first in list_in_progress_xacts, add 1200 to
list_remote_lsn. Remove 503 from list_in_progress_xacts.
Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300.
Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts.
ReplicationState now:
lowest_remote_lsn = 0
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [501, 502]
Step 3: Transaction 501 commits. Since 501 is now the first in
list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501
from list_in_progress_xacts. Clean up list_remote_lsn to remove
entries < lowest_remote_lsn (none in this case).
ReplicationState now:
lowest_remote_lsn = 1000
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [502]
Step 4: System crash and restart
Upon restart, Start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502, since it is not present in
list_remote_lsn, apply it. As transactions 503 and 504 are present in
list_remote_lsn, we skip them. Note that each transaction's
end_lsn/commit_lsn has to be compared which the apply worker receives
along with the first transaction command BEGIN. This ensures
correctness and avoids duplicate application of already committed
transactions.
Upon restart, start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502 with commit LSN 1100, since it is not
present in list_remote_lsn, apply it. As transactions 503 and 504's
respective commit LSNs [1200, 1300] are present in list_remote_lsn, we
skip them. This ensures correctness and avoids duplicate application
of already committed transactions.
Now, it is possible that some users may want to parallelize the
transaction but still want to maintain commit order because they don't
explicitly annotate FK, PK for columns but maintain the integrity via
application. So, in such cases as we won't be able to detect
transaction dependencies, it would be better to allow out-of-order
commits optionally.
Thoughts?
--
With Regards,
Amit Kapila.
Hi! On Mon, 11 Aug 2025 at 09:46, Amit Kapila <amit.kapila16@gmail.com> wrote: > > Hi, > > Background and Motivation > ------------------------------------- > In high-throughput systems, where hundreds of sessions generate data > on the publisher, the subscriber's apply process often becomes a > bottleneck due to the single apply worker model. While users can > mitigate this by creating multiple publication-subscription pairs, > this approach has scalability and usability limitations. > > Currently, PostgreSQL supports parallel apply only for large streaming > transactions (streaming=parallel). This proposal aims to extend > parallelism to non-streaming transactions, thereby improving > replication performance in workloads dominated by smaller, frequent > transactions. Sure. > Design Overview > ------------------------ > To safely parallelize non-streaming transactions, we must ensure that > transaction dependencies are respected to avoid failures and > deadlocks. Consider the following scenarios to understand it better: > (a) Transaction failures: Say, if we insert a row in the first > transaction and update it in the second transaction on the publisher, > then allowing the subscriber to apply both in parallel can lead to > failure in the update; (b) Deadlocks - allowing transactions that > update the same set of rows in a table in the opposite order in > parallel can lead to deadlocks. > Build-in subsystem for transaction dependency tracking would be highly beneficial for physical replication speedup projects like[0] > > Thoughts? Surely we need to give it a try. [0] https://github.com/koichi-szk/postgres -- Best regards, Kirill Reshke
On Mon, Aug 11, 2025 at 1:39 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > > > Design Overview > > ------------------------ > > To safely parallelize non-streaming transactions, we must ensure that > > transaction dependencies are respected to avoid failures and > > deadlocks. Consider the following scenarios to understand it better: > > (a) Transaction failures: Say, if we insert a row in the first > > transaction and update it in the second transaction on the publisher, > > then allowing the subscriber to apply both in parallel can lead to > > failure in the update; (b) Deadlocks - allowing transactions that > > update the same set of rows in a table in the opposite order in > > parallel can lead to deadlocks. > > > > Build-in subsystem for transaction dependency tracking would be highly > beneficial for physical replication speedup projects like[0] > I am not sure if that is directly applicable because this work proposes to track dependencies based on logical WAL contents. However, if you can point me to README on the overall design of the work you are pointing to then I can check it once. -- With Regards, Amit Kapila.
On Mon, 11 Aug 2025 at 13:45, Amit Kapila <amit.kapila16@gmail.com> wrote: > > > I am not sure if that is directly applicable because this work > proposes to track dependencies based on logical WAL contents. However, > if you can point me to README on the overall design of the work you > are pointing to then I can check it once. The only doc on this that I am aware of is [0]. The project is however more dead than alive, but I hope this is just a temporary stop of development, not permanent. [0] https://wiki.postgresql.org/wiki/Parallel_Recovery -- Best regards, Kirill Reshke
On 11/8/2025 06:45, Amit Kapila wrote: > The core idea is that the leader apply worker ensures the following: > a. Identifies dependencies between transactions. b. Coordinates > parallel workers to apply independent transactions concurrently. c. > Ensures correct ordering for dependent transactions. Dependency detection may be quite an expensive operation. What about a 'positive' approach - deadlock detection on replica and, restart apply of a record that should be applied later? Have you thought about this way? What are the pros and cons here? Do you envision common cases where such a deadlock will be frequent? -- regards, Andrei Lepikhov
On Tue, Aug 12, 2025 at 12:04 PM Andrei Lepikhov <lepihov@gmail.com> wrote: > > On 11/8/2025 06:45, Amit Kapila wrote: > > The core idea is that the leader apply worker ensures the following: > > a. Identifies dependencies between transactions. b. Coordinates > > parallel workers to apply independent transactions concurrently. c. > > Ensures correct ordering for dependent transactions. > Dependency detection may be quite an expensive operation. What about a > 'positive' approach - deadlock detection on replica and, restart apply > of a record that should be applied later? Have you thought about this > way? What are the pros and cons here? Do you envision common cases where > such a deadlock will be frequent? > It is not only deadlocks but we could also incorrectly apply some transactions which should otherwise fail. For example, consider following case: Pub: t1(c1 int unique key, c2 int) Sub: t1(c1 int unique key, c2 int) On Pub: TXN-1 insert(1,11) TXN-2 update (1,11) --> update (2,12) On Sub: table contains (1,11) before replication. Now, if we allow dependent transactions to go in parallel, instead of giving an ERROR while doing Insert, the update will be successful and next insert will also be successful. This will create inconsistency on the subscriber-side. Similarly consider another set of transactions: On Pub: TXN-1 insert(1,11) TXN-2 Delete (1,11) On subscriber, if we allow TXN-2 before TXN-1, then the subscriber will apply both transactions successfully but will become inconsistent w.r.t publisher. My colleague had already built a POC based on this idea and we did check some initial numbers for non-dependent transactions and the apply speed has improved drastically. We will share the POC patch and numbers in the next few days. For the dependent transactions workload, if we choose to go with the deadlock detection approach, there will be lot of retries which may not lead to good apply improvements. Also, we may choose to enable this form of parallel-apply optionally due to reasons mentioned in my first email, so if there is overhead due to dependency tracking then one can disable parally apply for those particular subscriptions. -- With Regards, Amit Kapila.
On Mon, Aug 11, 2025 at 3:00 PM Kirill Reshke <reshkekirill@gmail.com> wrote: > > On Mon, 11 Aug 2025 at 13:45, Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > I am not sure if that is directly applicable because this work > > proposes to track dependencies based on logical WAL contents. However, > > if you can point me to README on the overall design of the work you > > are pointing to then I can check it once. > > > The only doc on this that I am aware of is [0]. The project is however > more dead than alive, but I hope this is just a temporary stop of > development, not permanent. > > [0] https://wiki.postgresql.org/wiki/Parallel_Recovery > Thanks for sharing the wiki page. After reading, it seems we can't use the exact dependency tracking mechanism as both the projects have different dependency requirements. However, it could be an example to refer to and maybe some parts of the infrastructure could be reused. -- With Regards, Amit Kapila.
Hi,
Background and Motivation
-------------------------------------
In high-throughput systems, where hundreds of sessions generate data
on the publisher, the subscriber's apply process often becomes a
bottleneck due to the single apply worker model. While users can
mitigate this by creating multiple publication-subscription pairs,
this approach has scalability and usability limitations.
Currently, PostgreSQL supports parallel apply only for large streaming
transactions (streaming=parallel). This proposal aims to extend
parallelism to non-streaming transactions, thereby improving
replication performance in workloads dominated by smaller, frequent
transactions.
Design Overview
------------------------
To safely parallelize non-streaming transactions, we must ensure that
transaction dependencies are respected to avoid failures and
deadlocks. Consider the following scenarios to understand it better:
(a) Transaction failures: Say, if we insert a row in the first
transaction and update it in the second transaction on the publisher,
then allowing the subscriber to apply both in parallel can lead to
failure in the update; (b) Deadlocks - allowing transactions that
update the same set of rows in a table in the opposite order in
parallel can lead to deadlocks.
The core idea is that the leader apply worker ensures the following:
a. Identifies dependencies between transactions. b. Coordinates
parallel workers to apply independent transactions concurrently. c.
Ensures correct ordering for dependent transactions.
Dependency Detection
--------------------------------
1. Basic Dependency Tracking: Maintain a hash table keyed by
(RelationId, ReplicaIdentity) with the value as the transaction XID.
Before dispatching a change to a parallel worker, the leader checks
for existing entries: (a) If no match: add the entry and proceed; (b)
If match: instruct the worker to wait until the dependent transaction
completes.
2. Unique Keys
In addition to RI, track unique keys to detect conflicts. Example:
CREATE TABLE tab1(a INT PRIMARY KEY, b INT UNIQUE);
Transactions on publisher:
Txn1: INSERT (1,1)
Txn2: INSERT (2,2)
Txn3: DELETE (2,2)
Txn4: UPDATE (1,1) → (1,2)
If Txn4 is applied before Txn2 and Txn3, it will fail due to a unique
constraint violation. To prevent this, track both RI and unique keys
in the hash table. Compare keys of both old and new tuples to detect
dependencies. Then old_tuple's RI needs to be compared, and new
tuple's, both unique key and RI (new tuple's RI is required to detect
some prior insertion with the same key) needs to be compared with
existing hash table entries to identify transaction dependency.
3. Foreign Keys
Consider FK constraints between tables. Example:
TABLE owner(user_id INT PRIMARY KEY);
TABLE car(car_name TEXT, user_id INT REFERENCES owner);
Transactions:
Txn1: INSERT INTO owner(1)
Txn2: INSERT INTO car('bz', 1)
Applying Txn2 before Txn1 will fail. To avoid this, check if FK values
in new tuples match any RI or unique key in the hash table. If
matched, treat the transaction as dependent.
4. Triggers and Constraints
For the initial version, exclude tables with user-defined triggers or
constraints from parallel apply due to complexity in dependency
detection. We may need some parallel-apply-safe marking to allow this.
Replication Progress Tracking
-----------------------------------------
Parallel apply introduces out-of-order commit application,
complicating replication progress tracking. To handle restarts and
ensure consistency:
Track Three Key Metrics:
lowest_remote_lsn: Starting point for applying transactions.
highest_remote_lsn: Highest LSN that has been applied.
list_remote_lsn: List of commit LSNs applied between the lowest and highest.
Mechanism:
Store these in ReplicationState: lowest_remote_lsn,
highest_remote_lsn, list_remote_lsn. Flush these to disk during
checkpoints similar to CheckPointReplicationOrigin.
After Restart, Start from lowest_remote_lsn and for each transaction,
if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it.
Once commit LSN > highest_remote_lsn, apply without checking the list.
During apply, the leader maintains list_in_progress_xacts in the
increasing commit order. On commit, update highest_remote_lsn. If
commit LSN matches the first in-progress xact of
list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to
list_remote_lsn. After commit, also remove it from the
list_in_progress_xacts. We need to clean up entries below
lowest_remote_lsn in list_remote_lsn while updating its value.
To illustrate how this mechanism works, consider the following four
transactions:
Transaction ID Commit LSN
501 1000
502 1100
503 1200
504 1300
Assume:
Transactions 501 and 502 take longer to apply whereas transactions 503
and 504 finish earlier. Parallel apply workers are assigned as
follows:
pa-1 → 501
pa-2 → 502
pa-3 → 503
pa-4 → 504
Initial state: list_in_progress_xacts = [501, 502, 503, 504]
Step 1: Transaction 503 commits first and in RecordTransactionCommit,
it updates highest_remote_lsn to 1200. In apply_handle_commit, since
503 is not the first in list_in_progress_xacts, add 1200 to
list_remote_lsn. Remove 503 from list_in_progress_xacts.
Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300.
Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts.
ReplicationState now:
lowest_remote_lsn = 0
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [501, 502]
Step 3: Transaction 501 commits. Since 501 is now the first in
list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501
from list_in_progress_xacts. Clean up list_remote_lsn to remove
entries < lowest_remote_lsn (none in this case).
ReplicationState now:
lowest_remote_lsn = 1000
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [502]
Step 4: System crash and restart
Upon restart, Start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502, since it is not present in
list_remote_lsn, apply it. As transactions 503 and 504 are present in
list_remote_lsn, we skip them. Note that each transaction's
end_lsn/commit_lsn has to be compared which the apply worker receives
along with the first transaction command BEGIN. This ensures
correctness and avoids duplicate application of already committed
transactions.
Upon restart, start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502 with commit LSN 1100, since it is not
present in list_remote_lsn, apply it. As transactions 503 and 504's
respective commit LSNs [1200, 1300] are present in list_remote_lsn, we
skip them. This ensures correctness and avoids duplicate application
of already committed transactions.
Now, it is possible that some users may want to parallelize the
transaction but still want to maintain commit order because they don't
explicitly annotate FK, PK for columns but maintain the integrity via
application. So, in such cases as we won't be able to detect
transaction dependencies, it would be better to allow out-of-order
commits optionally.
Thoughts?
Hi,
This is something similar to what I have in mind when starting my experiments with LR apply speed improvements. I think that maintaining a full (RelationId, ReplicaIdentity) hash may be too expensive - there can be hundreds of active transactions updating millions of rows.
I thought about something like a bloom filter. But frankly speaking I didn't go far in thinking about all implementation details. Your proposal is much more concrete.
But I decided to implement first approach with prefetch, which is much more simple, similar with prefetching currently used for physical replication and still provide quite significant improvement:
There is one thing which I do not completely understand with your proposal: do you assume that LR walsender at publisher will use reorder buffer to "serialize" transactions
or you assume that streaming mode will be used (now it is possible to enforce parallel apply of short transactions using `debug_logical_replication_streaming`)?
It seems to be senseless to spend time and memory trying to serialize transactions at the publisher if we in any case want to apply them in parallel at subscriber.
But then there is another problem: at publisher there can be hundreds of concurrent active transactions (limited only by `max_connections`) which records are intermixed in WAL.
If we try to apply them concurrently at subscriber, we need a corresponding number of parallel apply workers. But usually the number of such workers is less than 10 (and default is 2).
So looks like we need to serialize transactions at subscriber side.
Assume that there are 100 concurrent transactions T1..T100, i.e. before first COMMIT record there are mixed records of 100 transactions.
And there are just two parallel apply workers W1 and W2. Main LR apply worker with send T1 record to W1, T2 record to W2 and ... there are not more vacant workers.
It has either to spawn additional ones, but it is not always possible because total number of background workers is limited.
Either serialize all other transactions in memory or on disk, until it reaches COMMIT of T1 or T2.
I afraid that such serialization will eliminate any advantages of parallel apply.
Certainly if we do reordering of transactions at publisher side, then there is no such problem. Subscriber receives all records for T1, then all records for T2, ... If there are no more vacant workers, it can just wait until any of this transactions is completed. But I am afraid that in this case the reorder buffer at the publisher will be a bottleneck.
On Mon, Aug 11, 2025 at 10:15:41AM +0530, Amit Kapila wrote:
> Hi,
>
> Background and Motivation
> -------------------------------------
> In high-throughput systems, where hundreds of sessions generate data
> on the publisher, the subscriber's apply process often becomes a
> bottleneck due to the single apply worker model. While users can
> mitigate this by creating multiple publication-subscription pairs,
> this approach has scalability and usability limitations.
>
> Currently, PostgreSQL supports parallel apply only for large streaming
> transactions (streaming=parallel). This proposal aims to extend
> parallelism to non-streaming transactions, thereby improving
> replication performance in workloads dominated by smaller, frequent
> transactions.
I thought the approach for improving WAL apply speed, for both binary
and logical, was pipelining:
https://en.wikipedia.org/wiki/Instruction_pipelining
rather than trying to do all the steps in parallel.
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EDB https://enterprisedb.com
Do not let urgent matters crowd out time for investment in the future.
On Tue, Aug 12, 2025 at 10:40 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Mon, Aug 11, 2025 at 10:15:41AM +0530, Amit Kapila wrote: > > Hi, > > > > Background and Motivation > > ------------------------------------- > > In high-throughput systems, where hundreds of sessions generate data > > on the publisher, the subscriber's apply process often becomes a > > bottleneck due to the single apply worker model. While users can > > mitigate this by creating multiple publication-subscription pairs, > > this approach has scalability and usability limitations. > > > > Currently, PostgreSQL supports parallel apply only for large streaming > > transactions (streaming=parallel). This proposal aims to extend > > parallelism to non-streaming transactions, thereby improving > > replication performance in workloads dominated by smaller, frequent > > transactions. > > I thought the approach for improving WAL apply speed, for both binary > and logical, was pipelining: > > https://en.wikipedia.org/wiki/Instruction_pipelining > > rather than trying to do all the steps in parallel. > It is not clear to me how the speed for a mix of dependent and independent transactions can be improved using the technique you shared as we still need to follow the commit order for dependent transactions. Can you please elaborate more on the high-level idea of how this technique can be used to improve speed for applying logical WAL records? -- With Regards, Amit Kapila.
On Tue, Aug 12, 2025 at 9:22 PM Константин Книжник <knizhnik@garret.ru> wrote: > > Hi, > This is something similar to what I have in mind when starting my experiments with LR apply speed improvements. I thinkthat maintaining a full (RelationId, ReplicaIdentity) hash may be too expensive - there can be hundreds of active transactionsupdating millions of rows. > I thought about something like a bloom filter. But frankly speaking I didn't go far in thinking about all implementationdetails. Your proposal is much more concrete. > We can surely investigate a different hash_key if that works for all cases. > But I decided to implement first approach with prefetch, which is much more simple, similar with prefetching currentlyused for physical replication and still provide quite significant improvement: > https://www.postgresql.org/message-id/flat/84ed36b8-7d06-4945-9a6b-3826b3f999a6%40garret.ru#70b45c44814c248d3d519a762f528753 > > There is one thing which I do not completely understand with your proposal: do you assume that LR walsender at publisherwill use reorder buffer to "serialize" transactions > or you assume that streaming mode will be used (now it is possible to enforce parallel apply of short transactions using`debug_logical_replication_streaming`)? > The current proposal is based on reorderbuffer serializing transactions as we are doing now. > It seems to be senseless to spend time and memory trying to serialize transactions at the publisher if we in any case wantto apply them in parallel at subscriber. > But then there is another problem: at publisher there can be hundreds of concurrent active transactions (limited onlyby `max_connections`) which records are intermixed in WAL. > If we try to apply them concurrently at subscriber, we need a corresponding number of parallel apply workers. But usuallythe number of such workers is less than 10 (and default is 2). > So looks like we need to serialize transactions at subscriber side. > > Assume that there are 100 concurrent transactions T1..T100, i.e. before first COMMIT record there are mixed records of100 transactions. > And there are just two parallel apply workers W1 and W2. Main LR apply worker with send T1 record to W1, T2 record toW2 and ... there are not more vacant workers. > It has either to spawn additional ones, but it is not always possible because total number of background workers is limited. > Either serialize all other transactions in memory or on disk, until it reaches COMMIT of T1 or T2. > I afraid that such serialization will eliminate any advantages of parallel apply. > Right, I also think so and we will probably end up doing something what we are doing now in publisher. > Certainly if we do reordering of transactions at publisher side, then there is no such problem. Subscriber receives allrecords for T1, then all records for T2, ... If there are no more vacant workers, it can just wait until any of this transactionsis completed. But I am afraid that in this case the reorder buffer at the publisher will be a bottleneck. > This is a point to investigate if we observe so. But till now in our internal testing parallel apply gives good improvement in pgbench kind of workload. -- With Regards, Amit Kapila.
On Monday, August 11, 2025 12:46 PM Amit Kapila <amit.kapila16@gmail.com> wrote:
> Background and Motivation
> -------------------------------------
> In high-throughput systems, where hundreds of sessions generate data
> on the publisher, the subscriber's apply process often becomes a
> bottleneck due to the single apply worker model. While users can
> mitigate this by creating multiple publication-subscription pairs,
> this approach has scalability and usability limitations.
>
> Currently, PostgreSQL supports parallel apply only for large streaming
> transactions (streaming=parallel). This proposal aims to extend
> parallelism to non-streaming transactions, thereby improving
> replication performance in workloads dominated by smaller, frequent
> transactions.
>
> Design Overview
> ------------------------
> To safely parallelize non-streaming transactions, we must ensure that
> transaction dependencies are respected to avoid failures and
> deadlocks. Consider the following scenarios to understand it better:
> (a) Transaction failures: Say, if we insert a row in the first
> transaction and update it in the second transaction on the publisher,
> then allowing the subscriber to apply both in parallel can lead to
> failure in the update; (b) Deadlocks - allowing transactions that
> update the same set of rows in a table in the opposite order in
> parallel can lead to deadlocks.
>
> The core idea is that the leader apply worker ensures the following:
> a. Identifies dependencies between transactions. b. Coordinates
> parallel workers to apply independent transactions concurrently. c.
> Ensures correct ordering for dependent transactions.
>
> Dependency Detection
> --------------------------------
> 1. Basic Dependency Tracking: Maintain a hash table keyed by
> (RelationId, ReplicaIdentity) with the value as the transaction XID.
> Before dispatching a change to a parallel worker, the leader checks
> for existing entries: (a) If no match: add the entry and proceed; (b)
> If match: instruct the worker to wait until the dependent transaction
> completes.
>
> 2. Unique Keys
> In addition to RI, track unique keys to detect conflicts. Example:
> CREATE TABLE tab1(a INT PRIMARY KEY, b INT UNIQUE);
> Transactions on publisher:
> Txn1: INSERT (1,1)
> Txn2: INSERT (2,2)
> Txn3: DELETE (2,2)
> Txn4: UPDATE (1,1) → (1,2)
>
> If Txn4 is applied before Txn2 and Txn3, it will fail due to a unique
> constraint violation. To prevent this, track both RI and unique keys
> in the hash table. Compare keys of both old and new tuples to detect
> dependencies. Then old_tuple's RI needs to be compared, and new
> tuple's, both unique key and RI (new tuple's RI is required to detect
> some prior insertion with the same key) needs to be compared with
> existing hash table entries to identify transaction dependency.
>
> 3. Foreign Keys
> Consider FK constraints between tables. Example:
>
> TABLE owner(user_id INT PRIMARY KEY);
> TABLE car(car_name TEXT, user_id INT REFERENCES owner);
>
> Transactions:
> Txn1: INSERT INTO owner(1)
> Txn2: INSERT INTO car('bz', 1)
>
> Applying Txn2 before Txn1 will fail. To avoid this, check if FK values
> in new tuples match any RI or unique key in the hash table. If
> matched, treat the transaction as dependent.
>
> 4. Triggers and Constraints
> For the initial version, exclude tables with user-defined triggers or
> constraints from parallel apply due to complexity in dependency
> detection. We may need some parallel-apply-safe marking to allow this.
>
> Replication Progress Tracking
> -----------------------------------------
> Parallel apply introduces out-of-order commit application,
> complicating replication progress tracking. To handle restarts and
> ensure consistency:
>
> Track Three Key Metrics:
> lowest_remote_lsn: Starting point for applying transactions.
> highest_remote_lsn: Highest LSN that has been applied.
> list_remote_lsn: List of commit LSNs applied between the lowest and highest.
>
> Mechanism:
> Store these in ReplicationState: lowest_remote_lsn,
> highest_remote_lsn, list_remote_lsn. Flush these to disk during
> checkpoints similar to CheckPointReplicationOrigin.
>
> After Restart, Start from lowest_remote_lsn and for each transaction,
> if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it.
> Once commit LSN > highest_remote_lsn, apply without checking the list.
>
> During apply, the leader maintains list_in_progress_xacts in the
> increasing commit order. On commit, update highest_remote_lsn. If
> commit LSN matches the first in-progress xact of
> list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to
> list_remote_lsn. After commit, also remove it from the
> list_in_progress_xacts. We need to clean up entries below
> lowest_remote_lsn in list_remote_lsn while updating its value.
>
> To illustrate how this mechanism works, consider the following four
> transactions:
>
> Transaction ID Commit LSN
> 501 1000
> 502 1100
> 503 1200
> 504 1300
>
> Assume:
> Transactions 501 and 502 take longer to apply whereas transactions 503
> and 504 finish earlier. Parallel apply workers are assigned as
> follows:
> pa-1 → 501
> pa-2 → 502
> pa-3 → 503
> pa-4 → 504
>
> Initial state: list_in_progress_xacts = [501, 502, 503, 504]
>
> Step 1: Transaction 503 commits first and in RecordTransactionCommit,
> it updates highest_remote_lsn to 1200. In apply_handle_commit, since
> 503 is not the first in list_in_progress_xacts, add 1200 to
> list_remote_lsn. Remove 503 from list_in_progress_xacts.
> Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300.
> Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts.
> ReplicationState now:
> lowest_remote_lsn = 0
> list_remote_lsn = [1200, 1300]
> highest_remote_lsn = 1300
> list_in_progress_xacts = [501, 502]
>
> Step 3: Transaction 501 commits. Since 501 is now the first in
> list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501
> from list_in_progress_xacts. Clean up list_remote_lsn to remove
> entries < lowest_remote_lsn (none in this case).
> ReplicationState now:
> lowest_remote_lsn = 1000
> list_remote_lsn = [1200, 1300]
> highest_remote_lsn = 1300
> list_in_progress_xacts = [502]
>
> Step 4: System crash and restart
> Upon restart, Start replication from lowest_remote_lsn = 1000. First
> transaction encountered is 502, since it is not present in
> list_remote_lsn, apply it. As transactions 503 and 504 are present in
> list_remote_lsn, we skip them. Note that each transaction's
> end_lsn/commit_lsn has to be compared which the apply worker receives
> along with the first transaction command BEGIN. This ensures
> correctness and avoids duplicate application of already committed
> transactions.
>
> Upon restart, start replication from lowest_remote_lsn = 1000. First
> transaction encountered is 502 with commit LSN 1100, since it is not
> present in list_remote_lsn, apply it. As transactions 503 and 504's
> respective commit LSNs [1200, 1300] are present in list_remote_lsn, we
> skip them. This ensures correctness and avoids duplicate application
> of already committed transactions.
>
> Now, it is possible that some users may want to parallelize the
> transaction but still want to maintain commit order because they don't
> explicitly annotate FK, PK for columns but maintain the integrity via
> application. So, in such cases as we won't be able to detect
> transaction dependencies, it would be better to allow out-of-order
> commits optionally.
>
> Thoughts?
Here is the initial POC patch for this idea.
The basic implementation is outlined below. Please note that there are several
TODO items remaining, which we are actively working on; these are also detailed
further down.
The leader worker assigns each non-streaming transaction to a parallel apply
worker. Before dispatching changes to a parallel worker, the leader verifies if
the current modification affects the same row (identitied by replica identity
key) as another ongoing transaction. If so, the leader sends a list of dependent
transaction IDs to the parallel worker, indicating that the parallel apply
worker must wait for these transactions to commit before proceeding. Parallel
apply workers do not maintain commit order; transactions can be committed at any
time provided there are no dependencies.
Each parallel apply worker records the local end LSN of the transaction it
applies in shared memory. Subsequently, the leader gathers these local end LSNs
and logs them in the local 'lsn_mapping' for verifying whether they have been
flushed to disk (following the logic in get_flush_position()).
If no parallel apply worker is available, the leader will apply the transaction
independently.
For further details, please refer to the following:
The leader maintains a local hash table, using the remote change's replica
identity column values and relid as keys, with remote transaction IDs as values.
Before sending changes to the parallel apply worker, the leader computes a hash
using RI key values and the relid of the current change to search the hash
table. If an existing entry is found, the leader tells the parallel worker
to wait for the remote xid in the hash entry, after which the leader updates the
hash entry with the current xid.
If the remote relation lacks a replica identity (RI), it indicates that only
INSERT can be replicated for this table. In such cases, the leader skips
dependency checks, allowing the parallel apply worker to proceed with applying
changes without delay. This is because the only potential conflict could happen
is related to the local unique key or foreign key, which that is yet to be
implemented (see TODO - dependency on local unique key, foreign key.).
In cases of TRUNCATE or remote schema changes affecting the entire table, the
leader retrieves all remote xids touching the same table (via sequential scans
of the hash table) and tells the parallel worker to wait for those transactions
to commit.
Hash entries are cleaned up once the transaction corresponding to the remote xid
in the entry has been committed. Clean-up typically occurs when collecting the
flush position of each transaction, but is forced if the hash table exceeds a
set threshold.
If a transaction is relied upon by others, the leader adds its xid to a shared
hash table. The shared hash table entry is cleared by the parallel apply worker
upon completing the transaction. Workers needing to wait for a transaction check
the shared hash table entry; if present, they lock the transaction ID (using
pa_lock_transaction). If absent, it indicates the transaction has been
committed, negating the need to wait.
--
TODO - replication progress tracking for out of order commit.
TODO - dependency on local unique key, foreign key.
TODO - restrict user defined trigger and constraints.
TODO - enable the parallel apply optionally
TODO - potential improvement to use shared hash table for tracking dependencies.
--
The above TODO items are also included in the initial email[1].
[1] https://www.postgresql.org/message-id/CAA4eK1%2BSEus_6vQay9TF_r4ow%2BE-Q7LYNLfsD78HaOsLSgppxQ%40mail.gmail.com
Best Regards,
Hou zj
Вложения
On Wed, Aug 13, 2025 at 09:50:27AM +0530, Amit Kapila wrote: > On Tue, Aug 12, 2025 at 10:40 PM Bruce Momjian <bruce@momjian.us> wrote: > > > Currently, PostgreSQL supports parallel apply only for large streaming > > > transactions (streaming=parallel). This proposal aims to extend > > > parallelism to non-streaming transactions, thereby improving > > > replication performance in workloads dominated by smaller, frequent > > > transactions. > > > > I thought the approach for improving WAL apply speed, for both binary > > and logical, was pipelining: > > > > https://en.wikipedia.org/wiki/Instruction_pipelining > > > > rather than trying to do all the steps in parallel. > > > > It is not clear to me how the speed for a mix of dependent and > independent transactions can be improved using the technique you > shared as we still need to follow the commit order for dependent > transactions. Can you please elaborate more on the high-level idea of > how this technique can be used to improve speed for applying logical > WAL records? This blog post from February I think has some good ideas for binary replication pipelining: https://www.cybertec-postgresql.com/en/end-of-the-road-for-postgresql-streaming-replication/ Surprisingly, what could be considered the actual replay work seems to be a minority of the total workload. The largest parts involve reading WAL and decoding page references from it, followed by looking up those pages in the cache, and pinning them so they are not evicted while in use. All of this work could be performed concurrently with the replay loop. For example, a separate read-ahead process could handle these tasks, ensuring that the replay process receives a queue of transaction log records with associated cache references already pinned, ready for application. The beauty of the approach is that there is no need for dependency tracking. I have CC'ed the author, Ants Aasma. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Do not let urgent matters crowd out time for investment in the future.
On Wed, Aug 13, 2025 at 8:57 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Wed, Aug 13, 2025 at 09:50:27AM +0530, Amit Kapila wrote: > > On Tue, Aug 12, 2025 at 10:40 PM Bruce Momjian <bruce@momjian.us> wrote: > > > > Currently, PostgreSQL supports parallel apply only for large streaming > > > > transactions (streaming=parallel). This proposal aims to extend > > > > parallelism to non-streaming transactions, thereby improving > > > > replication performance in workloads dominated by smaller, frequent > > > > transactions. > > > > > > I thought the approach for improving WAL apply speed, for both binary > > > and logical, was pipelining: > > > > > > https://en.wikipedia.org/wiki/Instruction_pipelining > > > > > > rather than trying to do all the steps in parallel. > > > > > > > It is not clear to me how the speed for a mix of dependent and > > independent transactions can be improved using the technique you > > shared as we still need to follow the commit order for dependent > > transactions. Can you please elaborate more on the high-level idea of > > how this technique can be used to improve speed for applying logical > > WAL records? > > This blog post from February I think has some good ideas for binary > replication pipelining: > > https://www.cybertec-postgresql.com/en/end-of-the-road-for-postgresql-streaming-replication/ > > Surprisingly, what could be considered the actual replay work > seems to be a minority of the total workload. > This is the biggest difference between physical and logical WAL apply. In the case of logical WAL, the actual replay is the majority of the work. We don't need to read WAL or decode it or find/pin the appropriate pages to apply. Here, you can consider it is almost equivalent to how primary receives insert/update/delete from the user. Firstly, the idea shared in the blog is not applicable for logical replication and even if we try to somehow map with logical apply, I don't see how or why it will be able to match up the speed of applying with multiple workers in case of logical replication. Also, note that dependency calculation is not as tricky for logical replication as we can easily retrieve such information from logical WAL records in most cases. -- With Regards, Amit Kapila.
On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu)
<houzj.fnst@fujitsu.com> wrote:
>
> Here is the initial POC patch for this idea.
>
Thank you Hou-san for the patch.
I did some performance benchmarking for the patch and overall, the
results show substantial performance improvements.
Please find the details as follows:
Source code:
----------------
pgHead (572c0f1b0e) and v1-0001 patch
Setup:
---------
Pub --> Sub
- Two nodes created in pub-sub logical replication setup.
- Both nodes have the same set of pgbench tables created with scale=300.
- The sub node is subscribed to all the changes from the pub node's
pgbench tables.
Workload Run:
--------------------
- Disable the subscription on Sub node
- Run default pgbench(read-write) only on Pub node with #clients=40
and run duration=10 minutes
- Enable the subscription on Sub once pgbench completes and then
measure time taken in replication.
~~~
Test-01: Measure Replication lag
----------------------------------------
Observations:
---------------
- Replication time improved as the number of parallel workers
increased with the patch.
- On pgHead, replicating a 10-minute publisher workload took ~46 minutes.
- With just 2 parallel workers (default), replication time was cut in
half, and with 8 workers it completed in ~13 minutes(3.5x faster).
- With 16 parallel workers, achieved ~3.7x speedup over pgHead.
- With 32 workers, performance gains plateaued slightly, likely due
to more workers running on the machine and work done parallelly is not
that high to see further improvements.
Detailed Result:
-----------------
Case Time_taken_in_replication(sec) rep_time_in_minutes
faster_than_head
1. pgHead 2760.791 46.01318333 -
2. patched_#worker=2 1463.853 24.3975 1.88 times
3. patched_#worker=4 1031.376 17.1896 2.68 times
4. patched_#worker=8 781.007 13.0168 3.54 times
5. patched_#worker=16 741.108 12.3518 3.73 times
6. patched_#worker=32 787.203 13.1201 3.51 times
~~~~
Test-02: Measure number of transactions parallelized
-----------------------------------------------------
- Used a top up patch to LOG the number of transactions applied by
parallel worker, applied by leader, and are depended.
- The LOG output e.g. -
```
LOG: parallelized_nxact: 11497254 dependent_nxact: 0 leader_applied_nxact: 600
```
- parallelized_nxact: gives the number of parallelized transactions
- dependent_nxact: gives the dependent transactions
- leader_applied_nxact: gives the transactions applied by leader worker
(the required top-up v1-002 patch is attached.)
Observations:
----------------
- With 4 to 8 parallel workers, ~80%-98% transactions are parallelized
- As the number of workers increased, the parallelized percentage
increased and reached 99.99% with 32 workers.
Detailed Result:
-----------------
case1: #parallel_workers = 2(default)
#total_pgbench_txns = 24745648
parallelized_nxact = 14439480 (58.35%)
dependent_nxact = 16 (0.00006%)
leader_applied_nxact = 10306153 (41.64%)
case2: #parallel_workers = 4
#total_pgbench_txns = 24776108
parallelized_nxact = 19666593 (79.37%)
dependent_nxact = 212 (0.0008%)
leader_applied_nxact = 5109304 (20.62%)
case3: #parallel_workers = 8
#total_pgbench_txns = 24821333
parallelized_nxact = 24397431 (98.29%)
dependent_nxact = 282 (0.001%)
leader_applied_nxact = 423621 (1.71%)
case4: #parallel_workers = 16
#total_pgbench_txns = 24938255
parallelized_nxact = 24937754 (99.99%)
dependent_nxact = 142 (0.0005%)
leader_applied_nxact = 360 (0.0014%)
case5: #parallel_workers = 32
#total_pgbench_txns = 24769474
parallelized_nxact = 24769135 (99.99%)
dependent_nxact = 312 (0.0013%)
leader_applied_nxact = 28 (0.0001%)
~~~~~
The scripts used for above tests are attached.
Next, I plan to extend the testing to larger workloads by running
pgbench for 20–30 minutes.
We will also benchmark performance across different workload types to
evaluate the improvements once the patch has matured further.
--
Thanks,
Nisha
Вложения
On 18/08/2025 9:56 AM, Nisha Moond wrote: > On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: >> Here is the initial POC patch for this idea. >> > Thank you Hou-san for the patch. > > I did some performance benchmarking for the patch and overall, the > results show substantial performance improvements. > Please find the details as follows: > > Source code: > ---------------- > pgHead (572c0f1b0e) and v1-0001 patch > > Setup: > --------- > Pub --> Sub > - Two nodes created in pub-sub logical replication setup. > - Both nodes have the same set of pgbench tables created with scale=300. > - The sub node is subscribed to all the changes from the pub node's > pgbench tables. > > Workload Run: > -------------------- > - Disable the subscription on Sub node > - Run default pgbench(read-write) only on Pub node with #clients=40 > and run duration=10 minutes > - Enable the subscription on Sub once pgbench completes and then > measure time taken in replication. > ~~~ > > Test-01: Measure Replication lag > ---------------------------------------- > Observations: > --------------- > - Replication time improved as the number of parallel workers > increased with the patch. > - On pgHead, replicating a 10-minute publisher workload took ~46 minutes. > - With just 2 parallel workers (default), replication time was cut in > half, and with 8 workers it completed in ~13 minutes(3.5x faster). > - With 16 parallel workers, achieved ~3.7x speedup over pgHead. > - With 32 workers, performance gains plateaued slightly, likely due > to more workers running on the machine and work done parallelly is not > that high to see further improvements. > > Detailed Result: > ----------------- > Case Time_taken_in_replication(sec) rep_time_in_minutes > faster_than_head > 1. pgHead 2760.791 46.01318333 - > 2. patched_#worker=2 1463.853 24.3975 1.88 times > 3. patched_#worker=4 1031.376 17.1896 2.68 times > 4. patched_#worker=8 781.007 13.0168 3.54 times > 5. patched_#worker=16 741.108 12.3518 3.73 times > 6. patched_#worker=32 787.203 13.1201 3.51 times > ~~~~ > > Test-02: Measure number of transactions parallelized > ----------------------------------------------------- > - Used a top up patch to LOG the number of transactions applied by > parallel worker, applied by leader, and are depended. > - The LOG output e.g. - > ``` > LOG: parallelized_nxact: 11497254 dependent_nxact: 0 leader_applied_nxact: 600 > ``` > - parallelized_nxact: gives the number of parallelized transactions > - dependent_nxact: gives the dependent transactions > - leader_applied_nxact: gives the transactions applied by leader worker > (the required top-up v1-002 patch is attached.) > > Observations: > ---------------- > - With 4 to 8 parallel workers, ~80%-98% transactions are parallelized > - As the number of workers increased, the parallelized percentage > increased and reached 99.99% with 32 workers. > > Detailed Result: > ----------------- > case1: #parallel_workers = 2(default) > #total_pgbench_txns = 24745648 > parallelized_nxact = 14439480 (58.35%) > dependent_nxact = 16 (0.00006%) > leader_applied_nxact = 10306153 (41.64%) > > case2: #parallel_workers = 4 > #total_pgbench_txns = 24776108 > parallelized_nxact = 19666593 (79.37%) > dependent_nxact = 212 (0.0008%) > leader_applied_nxact = 5109304 (20.62%) > > case3: #parallel_workers = 8 > #total_pgbench_txns = 24821333 > parallelized_nxact = 24397431 (98.29%) > dependent_nxact = 282 (0.001%) > leader_applied_nxact = 423621 (1.71%) > > case4: #parallel_workers = 16 > #total_pgbench_txns = 24938255 > parallelized_nxact = 24937754 (99.99%) > dependent_nxact = 142 (0.0005%) > leader_applied_nxact = 360 (0.0014%) > > case5: #parallel_workers = 32 > #total_pgbench_txns = 24769474 > parallelized_nxact = 24769135 (99.99%) > dependent_nxact = 312 (0.0013%) > leader_applied_nxact = 28 (0.0001%) > > ~~~~~ > The scripts used for above tests are attached. > > Next, I plan to extend the testing to larger workloads by running > pgbench for 20–30 minutes. > We will also benchmark performance across different workload types to > evaluate the improvements once the patch has matured further. > > -- > Thanks, > Nisha I also did some benchmarking of the proposed parallel apply patch and compare it with my prewarming approach. And parallel apply is significantly more efficient than prefetch (it is expected). So I had two tests (more details here): https://www.postgresql.org/message-id/flat/84ed36b8-7d06-4945-9a6b-3826b3f999a6%40garret.ru#70b45c44814c248d3d519a762f528753 One is performing random updates and another - inserts with random key. I stop subscriber, apply workload at publisher during 100 seconds and then measure how long time it will take subscriber to caught up. update test (with 8 parallel apply workers): master: 8:30 min prefetch: 2:05 min parallel apply: 1:30 min insert test (with 8 parallel apply workers): master: 9:20 min prefetch: 3:08 min parallel apply: 1:54 min
On Mon, Aug 18, 2025 at 8:20 PM Konstantin Knizhnik <knizhnik@garret.ru> wrote: > > On 18/08/2025 9:56 AM, Nisha Moond wrote: > > On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) > > <houzj.fnst@fujitsu.com> wrote: > >> Here is the initial POC patch for this idea. > >> > > Thank you Hou-san for the patch. > > > > I did some performance benchmarking for the patch and overall, the > > results show substantial performance improvements. > > Please find the details as follows: > > > > Source code: > > ---------------- > > pgHead (572c0f1b0e) and v1-0001 patch > > > > Setup: > > --------- > > Pub --> Sub > > - Two nodes created in pub-sub logical replication setup. > > - Both nodes have the same set of pgbench tables created with scale=300. > > - The sub node is subscribed to all the changes from the pub node's > > pgbench tables. > > > > Workload Run: > > -------------------- > > - Disable the subscription on Sub node > > - Run default pgbench(read-write) only on Pub node with #clients=40 > > and run duration=10 minutes > > - Enable the subscription on Sub once pgbench completes and then > > measure time taken in replication. > > ~~~ > > > > Test-01: Measure Replication lag > > ---------------------------------------- > > Observations: > > --------------- > > - Replication time improved as the number of parallel workers > > increased with the patch. > > - On pgHead, replicating a 10-minute publisher workload took ~46 minutes. > > - With just 2 parallel workers (default), replication time was cut in > > half, and with 8 workers it completed in ~13 minutes(3.5x faster). > > - With 16 parallel workers, achieved ~3.7x speedup over pgHead. > > - With 32 workers, performance gains plateaued slightly, likely due > > to more workers running on the machine and work done parallelly is not > > that high to see further improvements. > > > > Detailed Result: > > ----------------- > > Case Time_taken_in_replication(sec) rep_time_in_minutes > > faster_than_head > > 1. pgHead 2760.791 46.01318333 - > > 2. patched_#worker=2 1463.853 24.3975 1.88 times > > 3. patched_#worker=4 1031.376 17.1896 2.68 times > > 4. patched_#worker=8 781.007 13.0168 3.54 times > > 5. patched_#worker=16 741.108 12.3518 3.73 times > > 6. patched_#worker=32 787.203 13.1201 3.51 times > > ~~~~ > > > > Test-02: Measure number of transactions parallelized > > ----------------------------------------------------- > > - Used a top up patch to LOG the number of transactions applied by > > parallel worker, applied by leader, and are depended. > > - The LOG output e.g. - > > ``` > > LOG: parallelized_nxact: 11497254 dependent_nxact: 0 leader_applied_nxact: 600 > > ``` > > - parallelized_nxact: gives the number of parallelized transactions > > - dependent_nxact: gives the dependent transactions > > - leader_applied_nxact: gives the transactions applied by leader worker > > (the required top-up v1-002 patch is attached.) > > > > Observations: > > ---------------- > > - With 4 to 8 parallel workers, ~80%-98% transactions are parallelized > > - As the number of workers increased, the parallelized percentage > > increased and reached 99.99% with 32 workers. > > > > Detailed Result: > > ----------------- > > case1: #parallel_workers = 2(default) > > #total_pgbench_txns = 24745648 > > parallelized_nxact = 14439480 (58.35%) > > dependent_nxact = 16 (0.00006%) > > leader_applied_nxact = 10306153 (41.64%) > > > > case2: #parallel_workers = 4 > > #total_pgbench_txns = 24776108 > > parallelized_nxact = 19666593 (79.37%) > > dependent_nxact = 212 (0.0008%) > > leader_applied_nxact = 5109304 (20.62%) > > > > case3: #parallel_workers = 8 > > #total_pgbench_txns = 24821333 > > parallelized_nxact = 24397431 (98.29%) > > dependent_nxact = 282 (0.001%) > > leader_applied_nxact = 423621 (1.71%) > > > > case4: #parallel_workers = 16 > > #total_pgbench_txns = 24938255 > > parallelized_nxact = 24937754 (99.99%) > > dependent_nxact = 142 (0.0005%) > > leader_applied_nxact = 360 (0.0014%) > > > > case5: #parallel_workers = 32 > > #total_pgbench_txns = 24769474 > > parallelized_nxact = 24769135 (99.99%) > > dependent_nxact = 312 (0.0013%) > > leader_applied_nxact = 28 (0.0001%) > > > > ~~~~~ > > The scripts used for above tests are attached. > > > > Next, I plan to extend the testing to larger workloads by running > > pgbench for 20–30 minutes. > > We will also benchmark performance across different workload types to > > evaluate the improvements once the patch has matured further. > > > > -- > > Thanks, > > Nisha > > > I also did some benchmarking of the proposed parallel apply patch and > compare it with my prewarming approach. > And parallel apply is significantly more efficient than prefetch (it is > expected). > Thanks to you and Nisha for doing some preliminary performance testing, the results are really encouraging (more than 3 to 4 times improvement in multiple workloads). I hope we keep making progress on this patch and make it ready for the next release. -- With Regards, Amit Kapila.
Hi, I ran tests to compare the performance of logical synchronous replication with parallel-apply against physical synchronous replication. Highlights =============== On pgHead:(current behavior) - With synchronous physical replication set to remote_apply, the Primary’s TPS drops by ~60% (≈2.5x slower than asynchronous). - With synchronous logical replication set to remote_apply, the Publisher’s TPS drops drastically by ~94% (≈16x slower than asynchronous). With proposed Parallel-Apply Patch(v1): - Parallel apply significantly improves logical synchronous replication performance by 5-6×. - With 40 parallel workers on the subscriber, the Publisher achieves 30045.82 TPS, which is 5.5× faster than the no-patch case (5435.46 TPS). - With the patch, the Publisher’s performance is only ~3x slower than asynchronous, bringing it much closer to the physical replication case. Machine details =============== Intel(R) Xeon(R) CPU E7-4890 v2 @ 2.80GHz CPU(s) :88 cores, - 503 GiB RAM Source code: =============== - pgHead(e9a31c0cc60) and v1 patch Test-01: Physical replication: ====================== - To measure the physical synchronous replication performance on pgHead. Setup & Workload: ----------------- Primary --> Standby - Two nodes created in physical (primary-standby) replication setup. - Default pgbench (read-write) was run on the Primary with scale=300, #clients=40, run duration=20 minutes. - The TPS is measured with the synchronous_commit set as "off" vs "remote_apply" on pgHead. Results: --------- synchronous_commit Primary_TPS regression OFF 90466.57743 - remote_apply(run1) 35848.6558 -60% remote_apply(run2) 35306.25479 -61% - on phHead, when synchronous_commit is set to "remote_apply" during physical replication, the Primary experiences a 60–61% reduction in TPS, which is ~2.5 times slower. ~~~ Test-02: Logical replication: ===================== - To measure the logical synchronous replication performance on pgHead and with parallel-apply patch. Setup & Workload: ----------------- Publisher --> Subscriber - Two nodes created in logical (publisher-subscriber) replication setup. - Default pgbench (read-write) was run on the Pub with scale=300, #clients=40, run duration=20 minutes. - The TPS is measured on pgHead and with the parallel-apply v1 patch. - The number of parallel workers was varied as 2, 4, 8, 16, 32, 40. case-01: pgHead ------------------- Results: synchronous_commit Primary_TPS regression pgHead(OFF) 89138.14626 -- pgHead(remote_apply) 5435.464525 -94% - By default(pgHead), the synchronous logical replication sees a 94% drop in TPS which is - a) 16.4 times slower than the logical async case and, b) 6.6 times slower than physical sync replication case. case-02: patched --------------------- - synchronous_commit = 'remote_apply' - measured the performance by varying #parallel workers as 2, 4, 8, 16, 32, 40 Results: #workers Primary_TPS Improvement_with_patch faster_than_no-patch 2 9679.077736 78% 1.78x 4 14329.64073 164% 2.64x 8 21832.04285 302% 4.02x 16 27676.47085 409% 5.09x 32 29718.40090 447% 5.47x 40 30045.82365 453% 5.53x - The TPS on the publisher improves significantly as the number of parallel workers increases. - At 40 workers, the TPS reaches 30045.82, which is about 5.5x higher than the no-patch case.. - With 40 parallel workers, logical sync replication is only about 1.2x slower than physical sync replication. ~~~ The scripts used for the tests are attached. We'll do tests with larger data sets later and share results. -- Thanks, Nisha
Вложения
On Mon, Aug 11, 2025 at 10:16 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> Hi,
>
> Background and Motivation
> -------------------------------------
> In high-throughput systems, where hundreds of sessions generate data
> on the publisher, the subscriber's apply process often becomes a
> bottleneck due to the single apply worker model. While users can
> mitigate this by creating multiple publication-subscription pairs,
> this approach has scalability and usability limitations.
>
> Currently, PostgreSQL supports parallel apply only for large streaming
> transactions (streaming=parallel). This proposal aims to extend
> parallelism to non-streaming transactions, thereby improving
> replication performance in workloads dominated by smaller, frequent
> transactions.
>
> Design Overview
> ------------------------
> To safely parallelize non-streaming transactions, we must ensure that
> transaction dependencies are respected to avoid failures and
> deadlocks. Consider the following scenarios to understand it better:
> (a) Transaction failures: Say, if we insert a row in the first
> transaction and update it in the second transaction on the publisher,
> then allowing the subscriber to apply both in parallel can lead to
> failure in the update; (b) Deadlocks - allowing transactions that
> update the same set of rows in a table in the opposite order in
> parallel can lead to deadlocks.
>
> The core idea is that the leader apply worker ensures the following:
> a. Identifies dependencies between transactions. b. Coordinates
> parallel workers to apply independent transactions concurrently. c.
> Ensures correct ordering for dependent transactions.
>
> Dependency Detection
> --------------------------------
> 1. Basic Dependency Tracking: Maintain a hash table keyed by
> (RelationId, ReplicaIdentity) with the value as the transaction XID.
> Before dispatching a change to a parallel worker, the leader checks
> for existing entries: (a) If no match: add the entry and proceed; (b)
> If match: instruct the worker to wait until the dependent transaction
> completes.
>
> 2. Unique Keys
> In addition to RI, track unique keys to detect conflicts. Example:
> CREATE TABLE tab1(a INT PRIMARY KEY, b INT UNIQUE);
> Transactions on publisher:
> Txn1: INSERT (1,1)
> Txn2: INSERT (2,2)
> Txn3: DELETE (2,2)
> Txn4: UPDATE (1,1) → (1,2)
>
> If Txn4 is applied before Txn2 and Txn3, it will fail due to a unique
> constraint violation. To prevent this, track both RI and unique keys
> in the hash table. Compare keys of both old and new tuples to detect
> dependencies. Then old_tuple's RI needs to be compared, and new
> tuple's, both unique key and RI (new tuple's RI is required to detect
> some prior insertion with the same key) needs to be compared with
> existing hash table entries to identify transaction dependency.
>
> 3. Foreign Keys
> Consider FK constraints between tables. Example:
>
> TABLE owner(user_id INT PRIMARY KEY);
> TABLE car(car_name TEXT, user_id INT REFERENCES owner);
>
> Transactions:
> Txn1: INSERT INTO owner(1)
> Txn2: INSERT INTO car('bz', 1)
>
> Applying Txn2 before Txn1 will fail. To avoid this, check if FK values
> in new tuples match any RI or unique key in the hash table. If
> matched, treat the transaction as dependent.
>
> 4. Triggers and Constraints
> For the initial version, exclude tables with user-defined triggers or
> constraints from parallel apply due to complexity in dependency
> detection. We may need some parallel-apply-safe marking to allow this.
>
> Replication Progress Tracking
> -----------------------------------------
> Parallel apply introduces out-of-order commit application,
> complicating replication progress tracking. To handle restarts and
> ensure consistency:
>
> Track Three Key Metrics:
> lowest_remote_lsn: Starting point for applying transactions.
> highest_remote_lsn: Highest LSN that has been applied.
> list_remote_lsn: List of commit LSNs applied between the lowest and highest.
>
> Mechanism:
> Store these in ReplicationState: lowest_remote_lsn,
> highest_remote_lsn, list_remote_lsn. Flush these to disk during
> checkpoints similar to CheckPointReplicationOrigin.
>
> After Restart, Start from lowest_remote_lsn and for each transaction,
> if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it.
> Once commit LSN > highest_remote_lsn, apply without checking the list.
>
> During apply, the leader maintains list_in_progress_xacts in the
> increasing commit order. On commit, update highest_remote_lsn. If
> commit LSN matches the first in-progress xact of
> list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to
> list_remote_lsn. After commit, also remove it from the
> list_in_progress_xacts. We need to clean up entries below
> lowest_remote_lsn in list_remote_lsn while updating its value.
>
> To illustrate how this mechanism works, consider the following four
> transactions:
>
> Transaction ID Commit LSN
> 501 1000
> 502 1100
> 503 1200
> 504 1300
>
> Assume:
> Transactions 501 and 502 take longer to apply whereas transactions 503
> and 504 finish earlier. Parallel apply workers are assigned as
> follows:
> pa-1 → 501
> pa-2 → 502
> pa-3 → 503
> pa-4 → 504
>
> Initial state: list_in_progress_xacts = [501, 502, 503, 504]
>
> Step 1: Transaction 503 commits first and in RecordTransactionCommit,
> it updates highest_remote_lsn to 1200. In apply_handle_commit, since
> 503 is not the first in list_in_progress_xacts, add 1200 to
> list_remote_lsn. Remove 503 from list_in_progress_xacts.
> Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300.
> Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts.
> ReplicationState now:
> lowest_remote_lsn = 0
> list_remote_lsn = [1200, 1300]
> highest_remote_lsn = 1300
> list_in_progress_xacts = [501, 502]
>
> Step 3: Transaction 501 commits. Since 501 is now the first in
> list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501
> from list_in_progress_xacts. Clean up list_remote_lsn to remove
> entries < lowest_remote_lsn (none in this case).
> ReplicationState now:
> lowest_remote_lsn = 1000
> list_remote_lsn = [1200, 1300]
> highest_remote_lsn = 1300
> list_in_progress_xacts = [502]
>
> Step 4: System crash and restart
> Upon restart, Start replication from lowest_remote_lsn = 1000. First
> transaction encountered is 502, since it is not present in
> list_remote_lsn, apply it. As transactions 503 and 504 are present in
> list_remote_lsn, we skip them. Note that each transaction's
> end_lsn/commit_lsn has to be compared which the apply worker receives
> along with the first transaction command BEGIN. This ensures
> correctness and avoids duplicate application of already committed
> transactions.
>
> Upon restart, start replication from lowest_remote_lsn = 1000. First
> transaction encountered is 502 with commit LSN 1100, since it is not
> present in list_remote_lsn, apply it. As transactions 503 and 504's
> respective commit LSNs [1200, 1300] are present in list_remote_lsn, we
> skip them. This ensures correctness and avoids duplicate application
> of already committed transactions.
>
> Now, it is possible that some users may want to parallelize the
> transaction but still want to maintain commit order because they don't
> explicitly annotate FK, PK for columns but maintain the integrity via
> application. So, in such cases as we won't be able to detect
> transaction dependencies, it would be better to allow out-of-order
> commits optionally.
>
> Thoughts?
+1 for the idea. So I see we already have the parallel apply workers
for the large streaming transaction so I am trying to think what
additional problem we need to solve here. IIUC we are actually
parallely applying the transaction which were actually running
parallel on the publisher and commits are actually applied in serial
order. Whereas now we are trying to parallel apply the small
transactions so we are not controlling the commit apply order at the
leader worker so we need extra handling of dependency and also we need
to track which transaction we need to apply and which we need to skip
after the restarts as well. Is that right?
I am reading the proposal and POC patch in more detail to get the
fundamentals of the design and will share my thoughts.
--
Regards,
Dilip Kumar
Google
On Fri, Sep 5, 2025 at 2:59 PM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Mon, Aug 11, 2025 at 10:16 AM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > +1 for the idea. So I see we already have the parallel apply workers > for the large streaming transaction so I am trying to think what > additional problem we need to solve here. IIUC we are actually > parallely applying the transaction which were actually running > parallel on the publisher and commits are actually applied in serial > order. Whereas now we are trying to parallel apply the small > transactions so we are not controlling the commit apply order at the > leader worker so we need extra handling of dependency and also we need > to track which transaction we need to apply and which we need to skip > after the restarts as well. Is that right? > Right. > I am reading the proposal and POC patch in more detail to get the > fundamentals of the design and will share my thoughts. > Thanks. -- With Regards, Amit Kapila.
Hello, Amit! Amit Kapila <amit.kapila16@gmail.com>: > So, in such cases as we won't be able to detect > transaction dependencies, it would be better to allow out-of-order > commits optionally. I think it is better to enable preserve order by default - for safety reasons. I also checked the patch for potential issues like [0] - seems like it is unaffected, because parallel apply workers sync their concurrent updates and wait for each other to commit. [0]: https://www.postgresql.org/message-id/flat/CADzfLwWC49oanFSGPTf%3D6FJoTw-kAnpPZV8nVqAyR5KL68LrHQ%40mail.gmail.com#5f6b3be849f8d95c166decfae541df09 Best regards, Mikhail.
On Fri, Sep 5, 2025 at 5:15 PM Mihail Nikalayeu <mihailnikalayeu@gmail.com> wrote: > > Hello, Amit! > > Amit Kapila <amit.kapila16@gmail.com>: > > So, in such cases as we won't be able to detect > > transaction dependencies, it would be better to allow out-of-order > > commits optionally. > > I think it is better to enable preserve order by default - for safety reasons. > +1. -- With Regards, Amit Kapila.
On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) <houzj.fnst@fujitsu.com> wrote: > > Here is the initial POC patch for this idea. > > The basic implementation is outlined below. Please note that there are several > TODO items remaining, which we are actively working on; these are also detailed > further down. Thanks for the patch. > Each parallel apply worker records the local end LSN of the transaction it > applies in shared memory. Subsequently, the leader gathers these local end LSNs > and logs them in the local 'lsn_mapping' for verifying whether they have been > flushed to disk (following the logic in get_flush_position()). > > If no parallel apply worker is available, the leader will apply the transaction > independently. I suspect this might not be the most performant default strategy and could frequently cause a performance dip. In general, we utilize parallel apply workers, considering that the time taken to apply changes is much costlier than reading and sending messages to workers. The current strategy involves the leader picking one transaction for itself after distributing transactions to all apply workers, assuming the apply task will take some time to complete. When the leader takes on an apply task, it becomes a bottleneck for complete parallelism. This is because it needs to finish applying previous messages before accepting any new ones. Consequently, even as workers slowly become free, they won't receive new tasks because the leader is busy applying its own transaction. This type of strategy might be suitable in scenarios where users cannot supply more workers due to resource limitations. However, on high-end machines, it is more efficient to let the leader act solely as a message transmitter and allow the apply workers to handle all apply tasks. This could be a configurable parameter, determining whether the leader also participates in applying changes. I believe this should not be the default strategy; in fact, the default should be for the leader to act purely as a transmitter. -- Regards, Dilip Kumar Google
On Sat, Sep 6, 2025 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > Here is the initial POC patch for this idea. > > > > > > If no parallel apply worker is available, the leader will apply the transaction > > independently. > > This type of strategy might be suitable in scenarios where users > cannot supply more workers due to resource limitations. However, on > high-end machines, it is more efficient to let the leader act solely > as a message transmitter and allow the apply workers to handle all > apply tasks. This could be a configurable parameter, determining > whether the leader also participates in applying changes. I believe > this should not be the default strategy; in fact, the default should > be for the leader to act purely as a transmitter. In case the leader encounters an error while applying a transaction, it will have to be restarted. Would that restart all the parallel apply workers? That will be another (minor) risk when letting the leader apply transactions. The probability of hitting an error while applying a transaction is more than when just transmitting messages. -- Best Wishes, Ashutosh Bapat
Hi Amit,
Really interesting proposal! I've been thinking through some of the implementation challenges:
On the memory side: That hash table tracking RelationId and ReplicaIdentity could get pretty hefty under load. Maybe bloom filters could help with the initial screening? Also wondering
about size caps with some kind of LRU cleanup when things get tight.
Worker bottleneck: This is the tricky part - hundreds of active transactions but only a handful of workers. Seems like we'll hit serialization anyway when workers are maxed out. What
about spawning workers dynamically (within limits) or having some smart queuing for when we're worker-starved?
Alternative approach(if it can be consider): Rather than full parallelization, break transaction processing into overlapping stages:
• Stage 1: Parse WAL records
• Stage 2: Analyze dependencies
• Stage 3: Execute changes
• Stage 4: Commit and track progress
This creates a pipeline where Transaction A executes changes while Transaction B analyzes dependencies and Transaction C parses data - all happening simultaneously in different stages.
The out-of-order commit option you mentioned makes sense for apps handling integrity themselves.
Question: What's the fallback behavior when dependency detection fails?
Thanks,
Abhishek Mehta
Hi,
Background and Motivation
-------------------------------------
In high-throughput systems, where hundreds of sessions generate data
on the publisher, the subscriber's apply process often becomes a
bottleneck due to the single apply worker model. While users can
mitigate this by creating multiple publication-subscription pairs,
this approach has scalability and usability limitations.
Currently, PostgreSQL supports parallel apply only for large streaming
transactions (streaming=parallel). This proposal aims to extend
parallelism to non-streaming transactions, thereby improving
replication performance in workloads dominated by smaller, frequent
transactions.
Design Overview
------------------------
To safely parallelize non-streaming transactions, we must ensure that
transaction dependencies are respected to avoid failures and
deadlocks. Consider the following scenarios to understand it better:
(a) Transaction failures: Say, if we insert a row in the first
transaction and update it in the second transaction on the publisher,
then allowing the subscriber to apply both in parallel can lead to
failure in the update; (b) Deadlocks - allowing transactions that
update the same set of rows in a table in the opposite order in
parallel can lead to deadlocks.
The core idea is that the leader apply worker ensures the following:
a. Identifies dependencies between transactions. b. Coordinates
parallel workers to apply independent transactions concurrently. c.
Ensures correct ordering for dependent transactions.
Dependency Detection
--------------------------------
1. Basic Dependency Tracking: Maintain a hash table keyed by
(RelationId, ReplicaIdentity) with the value as the transaction XID.
Before dispatching a change to a parallel worker, the leader checks
for existing entries: (a) If no match: add the entry and proceed; (b)
If match: instruct the worker to wait until the dependent transaction
completes.
2. Unique Keys
In addition to RI, track unique keys to detect conflicts. Example:
CREATE TABLE tab1(a INT PRIMARY KEY, b INT UNIQUE);
Transactions on publisher:
Txn1: INSERT (1,1)
Txn2: INSERT (2,2)
Txn3: DELETE (2,2)
Txn4: UPDATE (1,1) → (1,2)
If Txn4 is applied before Txn2 and Txn3, it will fail due to a unique
constraint violation. To prevent this, track both RI and unique keys
in the hash table. Compare keys of both old and new tuples to detect
dependencies. Then old_tuple's RI needs to be compared, and new
tuple's, both unique key and RI (new tuple's RI is required to detect
some prior insertion with the same key) needs to be compared with
existing hash table entries to identify transaction dependency.
3. Foreign Keys
Consider FK constraints between tables. Example:
TABLE owner(user_id INT PRIMARY KEY);
TABLE car(car_name TEXT, user_id INT REFERENCES owner);
Transactions:
Txn1: INSERT INTO owner(1)
Txn2: INSERT INTO car('bz', 1)
Applying Txn2 before Txn1 will fail. To avoid this, check if FK values
in new tuples match any RI or unique key in the hash table. If
matched, treat the transaction as dependent.
4. Triggers and Constraints
For the initial version, exclude tables with user-defined triggers or
constraints from parallel apply due to complexity in dependency
detection. We may need some parallel-apply-safe marking to allow this.
Replication Progress Tracking
-----------------------------------------
Parallel apply introduces out-of-order commit application,
complicating replication progress tracking. To handle restarts and
ensure consistency:
Track Three Key Metrics:
lowest_remote_lsn: Starting point for applying transactions.
highest_remote_lsn: Highest LSN that has been applied.
list_remote_lsn: List of commit LSNs applied between the lowest and highest.
Mechanism:
Store these in ReplicationState: lowest_remote_lsn,
highest_remote_lsn, list_remote_lsn. Flush these to disk during
checkpoints similar to CheckPointReplicationOrigin.
After Restart, Start from lowest_remote_lsn and for each transaction,
if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it.
Once commit LSN > highest_remote_lsn, apply without checking the list.
During apply, the leader maintains list_in_progress_xacts in the
increasing commit order. On commit, update highest_remote_lsn. If
commit LSN matches the first in-progress xact of
list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to
list_remote_lsn. After commit, also remove it from the
list_in_progress_xacts. We need to clean up entries below
lowest_remote_lsn in list_remote_lsn while updating its value.
To illustrate how this mechanism works, consider the following four
transactions:
Transaction ID Commit LSN
501 1000
502 1100
503 1200
504 1300
Assume:
Transactions 501 and 502 take longer to apply whereas transactions 503
and 504 finish earlier. Parallel apply workers are assigned as
follows:
pa-1 → 501
pa-2 → 502
pa-3 → 503
pa-4 → 504
Initial state: list_in_progress_xacts = [501, 502, 503, 504]
Step 1: Transaction 503 commits first and in RecordTransactionCommit,
it updates highest_remote_lsn to 1200. In apply_handle_commit, since
503 is not the first in list_in_progress_xacts, add 1200 to
list_remote_lsn. Remove 503 from list_in_progress_xacts.
Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300.
Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts.
ReplicationState now:
lowest_remote_lsn = 0
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [501, 502]
Step 3: Transaction 501 commits. Since 501 is now the first in
list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501
from list_in_progress_xacts. Clean up list_remote_lsn to remove
entries < lowest_remote_lsn (none in this case).
ReplicationState now:
lowest_remote_lsn = 1000
list_remote_lsn = [1200, 1300]
highest_remote_lsn = 1300
list_in_progress_xacts = [502]
Step 4: System crash and restart
Upon restart, Start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502, since it is not present in
list_remote_lsn, apply it. As transactions 503 and 504 are present in
list_remote_lsn, we skip them. Note that each transaction's
end_lsn/commit_lsn has to be compared which the apply worker receives
along with the first transaction command BEGIN. This ensures
correctness and avoids duplicate application of already committed
transactions.
Upon restart, start replication from lowest_remote_lsn = 1000. First
transaction encountered is 502 with commit LSN 1100, since it is not
present in list_remote_lsn, apply it. As transactions 503 and 504's
respective commit LSNs [1200, 1300] are present in list_remote_lsn, we
skip them. This ensures correctness and avoids duplicate application
of already committed transactions.
Now, it is possible that some users may want to parallelize the
transaction but still want to maintain commit order because they don't
explicitly annotate FK, PK for columns but maintain the integrity via
application. So, in such cases as we won't be able to detect
transaction dependencies, it would be better to allow out-of-order
commits optionally.
Thoughts?
--
With Regards,
Amit Kapila.
On Sat, Sep 6, 2025 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) > <houzj.fnst@fujitsu.com> wrote: > > > > > Here is the initial POC patch for this idea. > > > > The basic implementation is outlined below. Please note that there are several > > TODO items remaining, which we are actively working on; these are also detailed > > further down. > > Thanks for the patch. > > > Each parallel apply worker records the local end LSN of the transaction it > > applies in shared memory. Subsequently, the leader gathers these local end LSNs > > and logs them in the local 'lsn_mapping' for verifying whether they have been > > flushed to disk (following the logic in get_flush_position()). > > > > If no parallel apply worker is available, the leader will apply the transaction > > independently. > > I suspect this might not be the most performant default strategy and > could frequently cause a performance dip. In general, we utilize > parallel apply workers, considering that the time taken to apply > changes is much costlier than reading and sending messages to workers. > > The current strategy involves the leader picking one transaction for > itself after distributing transactions to all apply workers, assuming > the apply task will take some time to complete. When the leader takes > on an apply task, it becomes a bottleneck for complete parallelism. > This is because it needs to finish applying previous messages before > accepting any new ones. Consequently, even as workers slowly become > free, they won't receive new tasks because the leader is busy applying > its own transaction. > > This type of strategy might be suitable in scenarios where users > cannot supply more workers due to resource limitations. However, on > high-end machines, it is more efficient to let the leader act solely > as a message transmitter and allow the apply workers to handle all > apply tasks. This could be a configurable parameter, determining > whether the leader also participates in applying changes. I believe > this should not be the default strategy; in fact, the default should > be for the leader to act purely as a transmitter. > I see your point but consider a scenario where we have two pa workers. pa-1 is waiting for some backend on unique_key insertion and pa-2 is waiting for pa-1 to complete its transaction as pa-2 has to perform some change which is dependent on pa-1's transaction. So, leader can either simply wait for a third transaction to be distributed or just apply it and process another change. If we follow the earlier then it is quite possible that the sender fills the network queue to send data and simply timed out. -- With Regards, Amit Kapila.
On Sat, Sep 13, 2025 at 9:49 PM Abhi Mehta <abhi15.mehta@gmail.com> wrote: > > Hi Amit, > > > Really interesting proposal! I've been thinking through some of the implementation challenges: > > > On the memory side: That hash table tracking RelationId and ReplicaIdentity could get pretty hefty under load. Maybe bloomfilters could help with the initial screening? Also wondering > > about size caps with some kind of LRU cleanup when things get tight. > Yeah, this is an interesting thought and we should test, if we really hit this case and if we could improve it with your suggestion. > > Worker bottleneck: This is the tricky part - hundreds of active transactions but only a handful of workers. Seems likewe'll hit serialization anyway when workers are maxed out. What > > about spawning workers dynamically (within limits) or having some smart queuing for when we're worker-starved? > Yeah, we would have a GUC or subscription-option max parallel workers. We can consider smart-queuing or any advanced techniques for such cases after the first version is committed as making that work in itself is a big undertaking. > > > Alternative approach(if it can be consider): Rather than full parallelization, break transaction processing into overlappingstages: > > > • Stage 1: Parse WAL records > Hmm, this is already performed by the publisher. > • Stage 2: Analyze dependencies > > • Stage 3: Execute changes > > • Stage 4: Commit and track progress > > > This creates a pipeline where Transaction A executes changes while Transaction B analyzes dependencies > I don't know how to make this work in the current framework of apply. But feel free to propose this with some more details as to how it will work? -- With Regards, Amit Kapila.
On Mon, Sep 8, 2025 at 3:10 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > On Sat, Sep 6, 2025 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Wed, Aug 13, 2025 at 4:17 PM Zhijie Hou (Fujitsu) > > <houzj.fnst@fujitsu.com> wrote: > > > > > > Here is the initial POC patch for this idea. > > > > > > > > > If no parallel apply worker is available, the leader will apply the transaction > > > independently. > > > > This type of strategy might be suitable in scenarios where users > > cannot supply more workers due to resource limitations. However, on > > high-end machines, it is more efficient to let the leader act solely > > as a message transmitter and allow the apply workers to handle all > > apply tasks. This could be a configurable parameter, determining > > whether the leader also participates in applying changes. I believe > > this should not be the default strategy; in fact, the default should > > be for the leader to act purely as a transmitter. > > In case the leader encounters an error while applying a transaction, > it will have to be restarted. Would that restart all the parallel > apply workers? That will be another (minor) risk when letting the > leader apply transactions. The probability of hitting an error while > applying a transaction is more than when just transmitting messages. > I think we have to anyway (irrespective of whether it applies changes by itself or not) let leader restart in this case because otherwise, we may not get the failed transaction again. Also, if one of the pa exits without completing the transaction, it is important to let other pa's also exit otherwise dependency calculation can go wrong. There could be some cases where we could let some pa complete its current ongoing transaction if it is independent of other transactions and has received all its changes. -- With Regards, Amit Kapila.
Hi, 4. Triggers and Constraints For the initial version, exclude tables with user-defined triggers or constraints from parallel apply due to complexity in dependency detection. We may need some parallel-apply-safe marking to allow this.
I think that the problem is wider than just triggers and constrains.
Even if database has no triggers and constraints, there still can be causality violations.
If transactions at subscriber are executed in different order than on publisher, then it is possible to observe some "invalid" database state which is never possible at publisher. Assume very simple example: you withdraw some money in ATM from one account and then deposit them to some other account. There are two different transactions. And there are no any dependencies between them (they update different records). But if second transaction is committed before first, then we can view incorrect report where total number of money at all accounts exceeds real balance. Another case is when you persisting some stream of events (with timestamps). It may be confusing if at subscriber monotony of events is violated.
And there can be many other similar situations when tjere are no "direct" data dependencies between transactions, but there are hidden "indirect"dependencies. The most popular case you have mentioned: foreign keys. Certainly support of referential integrity constraints can be added. But there can be such dependencies without correspondent constraints in database schema.
You have also suggested to add option which will force preserving commit order. But my experiments with `debug_logical_replication_streaming=immediate` shows that in this case for short transactions performance with parallel workers is even worser than with single apply worker.
May be it is possible to enforce some weaker commit order: do not try to commit transactions in exactly the same order as at publisher, but if transaction T1 at publisher is started after T2 is committed, then T2 can not be committed before T1 at subscriber. Unfortunately it is not clear how to enforce such "partial order" - `LogicalRepBeginData` contains `finish_lsn`, but not `start_lsn`.
First time I read your proposal and especially after seen concrete results of it's implementation, I decided than parallel apply approach is definitely better than prefetch approach. But now I am not so sure. Yes, parallel apply is about 2x times faster than parallel prefetch. But still parallel prefetch allows to 2-3 times increase LR speed without causing any problems with deadlock, constraints, triggers,...
Replication Progress Tracking ----------------------------------------- Parallel apply introduces out-of-order commit application, complicating replication progress tracking. To handle restarts and ensure consistency: Track Three Key Metrics: lowest_remote_lsn: Starting point for applying transactions. highest_remote_lsn: Highest LSN that has been applied. list_remote_lsn: List of commit LSNs applied between the lowest and highest. Mechanism: Store these in ReplicationState: lowest_remote_lsn, highest_remote_lsn, list_remote_lsn. Flush these to disk during checkpoints similar to CheckPointReplicationOrigin. After Restart, Start from lowest_remote_lsn and for each transaction, if its commit LSN is in list_remote_lsn, skip it, otherwise, apply it. Once commit LSN > highest_remote_lsn, apply without checking the list. During apply, the leader maintains list_in_progress_xacts in the increasing commit order. On commit, update highest_remote_lsn. If commit LSN matches the first in-progress xact of list_in_progress_xacts, update lowest_remote_lsn, otherwise, add to list_remote_lsn. After commit, also remove it from the list_in_progress_xacts. We need to clean up entries below lowest_remote_lsn in list_remote_lsn while updating its value. To illustrate how this mechanism works, consider the following four transactions: Transaction ID Commit LSN 501 1000 502 1100 503 1200 504 1300 Assume: Transactions 501 and 502 take longer to apply whereas transactions 503 and 504 finish earlier. Parallel apply workers are assigned as follows: pa-1 → 501 pa-2 → 502 pa-3 → 503 pa-4 → 504 Initial state: list_in_progress_xacts = [501, 502, 503, 504] Step 1: Transaction 503 commits first and in RecordTransactionCommit, it updates highest_remote_lsn to 1200. In apply_handle_commit, since 503 is not the first in list_in_progress_xacts, add 1200 to list_remote_lsn. Remove 503 from list_in_progress_xacts. Step 2: Transaction 504 commits, Update highest_remote_lsn to 1300. Add 1300 to list_remote_lsn. Remove 504 from list_in_progress_xacts. ReplicationState now: lowest_remote_lsn = 0 list_remote_lsn = [1200, 1300] highest_remote_lsn = 1300 list_in_progress_xacts = [501, 502] Step 3: Transaction 501 commits. Since 501 is now the first in list_in_progress_xacts, update lowest_remote_lsn to 1000. Remove 501 from list_in_progress_xacts. Clean up list_remote_lsn to remove entries < lowest_remote_lsn (none in this case). ReplicationState now: lowest_remote_lsn = 1000 list_remote_lsn = [1200, 1300] highest_remote_lsn = 1300 list_in_progress_xacts = [502] Step 4: System crash and restart Upon restart, Start replication from lowest_remote_lsn = 1000. First transaction encountered is 502, since it is not present in list_remote_lsn, apply it. As transactions 503 and 504 are present in list_remote_lsn, we skip them. Note that each transaction's end_lsn/commit_lsn has to be compared which the apply worker receives along with the first transaction command BEGIN. This ensures correctness and avoids duplicate application of already committed transactions. Upon restart, start replication from lowest_remote_lsn = 1000. First transaction encountered is 502 with commit LSN 1100, since it is not present in list_remote_lsn, apply it. As transactions 503 and 504's respective commit LSNs [1200, 1300] are present in list_remote_lsn, we skip them. This ensures correctness and avoids duplicate application of already committed transactions. Now, it is possible that some users may want to parallelize the transaction but still want to maintain commit order because they don't explicitly annotate FK, PK for columns but maintain the integrity via application. So, in such cases as we won't be able to detect transaction dependencies, it would be better to allow out-of-order commits optionally. Thoughts?
On Wednesday, September 17, 2025 2:40 AM Konstantin Knizhnik <knizhnik@garret.ru> wrote: > On 11/08/2025 7:45 AM, Amit Kapila wrote: > > 4. Triggers and Constraints For the initial version, exclude tables with > > user-defined triggers or constraints from parallel apply due to complexity in > > dependency detection. We may need some parallel-apply-safe marking to allow > > this. I think that the problem is wider than just triggers and constrains. > > Even if database has no triggers and constraints, there still can be causality > violations. > > If transactions at subscriber are executed in different order than > on publisher, then it is possible to observe some "invalid" database state which > is never possible at publisher. Assume very simple example: you withdraw some > money in ATM from one account and then deposit them to some other account. There > are two different transactions. And there are no any dependencies between them > (they update different records). But if second transaction is committed before > first, then we can view incorrect report where total number of money at all > accounts exceeds real balance. Another case is when you persisting some stream > of events (with timestamps). It may be confusing if at subscriber monotony of > events is violated. > > And there can be many other similar situations when tjere are no "direct" data > dependencies between transactions, but there are hidden "indirect"dependencies. > The most popular case you have mentioned: foreign keys. Certainly support of > referential integrity constraints can be added. But there can be such > dependencies without correspondent constraints in database schema. Yes, I agree with these situations, which is why we suggest allowing out-of-commit options while preserving commit order by default. However, I think not all use cases are affected by non-direct dependencies because we ensure eventual consistency in out-of-order commit anyway. Additionally, databases like Oracle and MySQL support out-of-order parallel apply, IIRC. > > You have also suggested to add option which will force preserving commit order. > But my experiments with `debug_logical_replication_streaming=immediate` shows > that in this case for short transactions performance with parallel workers is > even worser than with single apply worker. I think debug_logical_replication_streaming=immediate differs from real parallel apply . It wasn't designed to simulate genuine parallel application because it restricts parallelism by requiring the leader to wait for each transaction to complete on commit. To achieve in-order parallel apply, each parallel apply worker should wait for the preceding transaction to finish, similar to the dependency wait in the current POC patch. We plan to extend the patch to support in-order parallel apply and will test its performance. Best Regards, Hou zj
I think debug_logical_replication_streaming=immediate differs from real parallel apply . It wasn't designed to simulate genuine parallel application because it restricts parallelism by requiring the leader to wait for each transaction to complete on commit. To achieve in-order parallel apply, each parallel apply worker should wait for the preceding transaction to finish, similar to the dependency wait in the current POC patch. We plan to extend the patch to support in-order parallel apply and will test its performance.
Will be interesting to see such results.
Actually, I have tried to improve parallelism in case of `debug_log And debug_logical_replication_streaming=immediate` mode but faced with deadlock issue: assume that T1 and T2 are updating the same tuples and T1 is committed before T2 at publishers. If we let them execute in parallel, then T2 can update the tuple first and T1 will wait end of T2. But if we want to preserve commit order, we should not allow T2 to commit before T1. And so we will get deadlock.
Certainly if we take in account dependencies between transactions (as in your proposal), then we can avoid such situations. But I am not sure if such deadlock can not happen even if there are conflicts between transactions. Let's assume that T1 and T2 inserting some new records in one table. Can index update in T2 cause obtaining some locks which blocks T1? And T2 is not able to able to complete transaction and release this locks because we want to commit T1 first.
On 17/09/2025 8:18 AM, Zhijie Hou (Fujitsu) wrote: > On Wednesday, September 17, 2025 2:40 AM Konstantin Knizhnik <knizhnik@garret.ru> wrote: > I think debug_logical_replication_streaming=immediate differs from real parallel > apply . It wasn't designed to simulate genuine parallel application because it > restricts parallelism by requiring the leader to wait for each transaction to > complete on commit. To achieve in-order parallel apply, each parallel apply > worker should wait for the preceding transaction to finish, similar to the > dependency wait in the current POC patch. We plan to extend the patch to support > in-order parallel apply and will test its performance. You was right. I tried to preserve commit order with your patch (using my random update test) and was surprised that performance penalty is quite small: I run pgbench performing random updates using 10 clients during 100 seconds and then check how long time it takes subscriber to caught up (seconds): master: 488 parallel-apply no order: 74 parallel-apply preserve order: 88 So looks like serialization of commits adds not so much overhead and it makes it possible to use it by default, avoiding all effects which may be caused by changing commit order at subscriber. Patch is attached (it is based on your patch) and adds preserve_commit_order GUC.
Вложения
Dear hackers,
> TODO - potential improvement to use shared hash table for tracking
> dependencies.
I measured the performance data for the shared hash table approach. Based on the result,
local hash table approach seems better.
Abstract
========
No good performance improvement was observed by the shared hash, it had 1-2% regression.
The trend was not changed by number of parallel apply workers.
Machine details
===============
Intel(R) Xeon(R) CPU E7-4890 v2 @ 2.80GHz CPU(s) :88 cores, - 503 GiB RAM
Used patch
==========
0001 is same as Hou posted on -hackers [1], and 0002 is the patch for shared hash.
0002 introduces a shared hash table dependency_dshash. 0002 introduces a shared
hash table dependency_dshash. Since the length of shared hash key must be fixed
value, it is computed from the replica identity of tuples. When the parallel apply
worker receives changes, it computes the hash key again and remember it by the list.
At the commit time it iterates the list and remove hash entries based on the keys.
0001 has the mechanism to clean up the local hash but it was removed.
Workload
========
Setup:
---------
Pub --> Sub
- Two nodes created in pub-sub synchronous logical replication setup.
- Both nodes have same set of pgbench tables created with scale=100.
- The Sub node is subscribed to all the changes from the Pub's pgbench tables
Workload Run:
--------------------
- Run built-in pgbench(simple-update)[2] only on Pub with #clients=40 and run duration=5 minutes
Results:
--------------------
Number of worker is changed to 4, 8 or 16. In any cases 0001 has better performance.
#worker = 4:
------------
0001 0001+0002 diff
TPS 14499.33387 14097.74469 3%
14361.7166 14359.87781 0%
14467.91344 14153.53934 2%
14451.8596 14381.70987 0%
14646.90346 14239.4712 3%
14530.66788 14298.33845 2%
14733.35987 14189.41794 4%
14543.9252 14373.21266 1%
14945.57568 14249.46787 5%
14638.6342 14125.87626 4%
AVE 14581.988979 14246.865608 2%
MEDIAN 14537.296540 14244.469536 2%
#worker=8
---------
0001 0001+0002 diff
TPS 21531.08712 21443.68765 0%
22337.60439 21383.94778 4%
21806.70504 21097.42874 3%
22192.99695 21424.78921 4%
21721.95472 21470.8714 1%
21450.6779 21265.89539 1%
21397.51433 21606.51486 -1%
21551.09391 21306.97061 1%
21455.89699 21351.38868 0%
21849.52528 21304.42329 3%
AVE 21729.505662 21365.591761 2%
MEDIAN 21636.524316 21367.668229 1%
#worker=16
-----------
0001 0001+0002 diff
TPS 28034.64652 28129.85068 0%
27839.10942 27364.40725 2%
27693.94576 27871.80199 -1%
27717.83971 27129.96132 2%
28453.25381 27439.77526 4%
28083.73208 27201.0004 3%
27842.19262 27226.43813 2%
27729.44205 27459.01256 1%
28103.76727 27385.80016 3%
27688.52482 27485.67209 1%
AVE 27918.645405 27469.371982 2%
MEDIAN 27840.651020 27412.787708 2%
[1]:
https://www.postgresql.org/message-id/OS0PR01MB5716D43CB68DB8FFE73BF65D942AA%40OS0PR01MB5716.jpnprd01.prod.outlook.com
[2]: https://www.postgresql.org/docs/current/pgbench.html#PGBENCH-OPTION-BUILTIN
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
Dear Hackers,
> I measured the performance data for the shared hash table approach. Based on
> the result,
> local hash table approach seems better.
I did analyze bit more detail for tests. Let me share from the beginning...
Background and current implementation
==========
Even if apply worker is being parallelized, some transactions which depend on
other transactions must wait until others are committed.
In the first version of PoC, leader apply worker has a local hash table, which
has the key {txid,replica identity}. When the leader sends a replication message
to one of parallel apply worker, the leader checks for existing entries:
(a) If no match: add the entry and proceed; (b) If match: instruct the worker to
wait until the dependent transaction completes.
One possible downside of the approach is to clean up the dependency tracking hash table.
First PoC does when: a) the leader worker sends feedback to walsender or
b) the number of entries exceeds the limit (1024). Leader worker cannot receive
replication messages to other workers while cleaning up entries thus this might
be a bottleneck.
Proposal
========
Based on above, one possible idea to improve the performance was to make the
dependency hash table shared one. A leader worker and parallel apply workers
assigned from the leader could attach to the same shared hash table.
Leader worker would use the hash table samely when it put replication messages.
One difference was that when parallel apply worker commits a transaction,
it removes the used entry from the shared hash table. This could reduce entries
continuously and leader did not have to maintain the hash.
Downside of the approach was to need additional overhead accessing the hash.
Results and considerations
==========================
As I shared on -hackers, there are no performance improvement by making the hash
shared. I found the reason is the cleanup task is not so expensive.
I did profile leader worker during the benchmark, and I found that that cleanup
function `cleanup_replica_identity_table` wastes only 0.84% CPU time.
(I did try to attach results, but the file was too huge)
Attached histogram (simple_cleanup) shows the spent time in the cleanup for each
patches. The average of elapsed was 1.2 microseconds in the 0001 patch.
The needed time per transaction is around 74 microseconds (from TPS) thus it might
not affect the whole performance.
Another experiment - contains 2000 changes per transaction
===========================================================
First example used the built-in simple-update workload, and there was a possibility
that the trend might be different if each transaction has more changed, because
each cleanup might spend more time.
Based on that, the second workload had the 1000 deletion and 1000 insertions per
transaction.
Below table shows the results (with #worker = 4). They have mostly same TPSs,
same trend as simpler-update workload case. Histogram for the case is also attached.
0001 0001+0002 diff
TPS 10297.58551 10146.71342 1%
10046.75987 9865.730785 2%
9970.800272 9977.835592 0%
9927.863416 9909.675726 0%
10033.03796 9886.181373 1%
AVE 10055.209405 9957.227380 1%
MEDIAN 10033.037957 9909.675726 1%
Overall, I think local hash approach seems enough for now, unless we find better
approaches and corner cases.
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Sorry, I missed to attach files. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
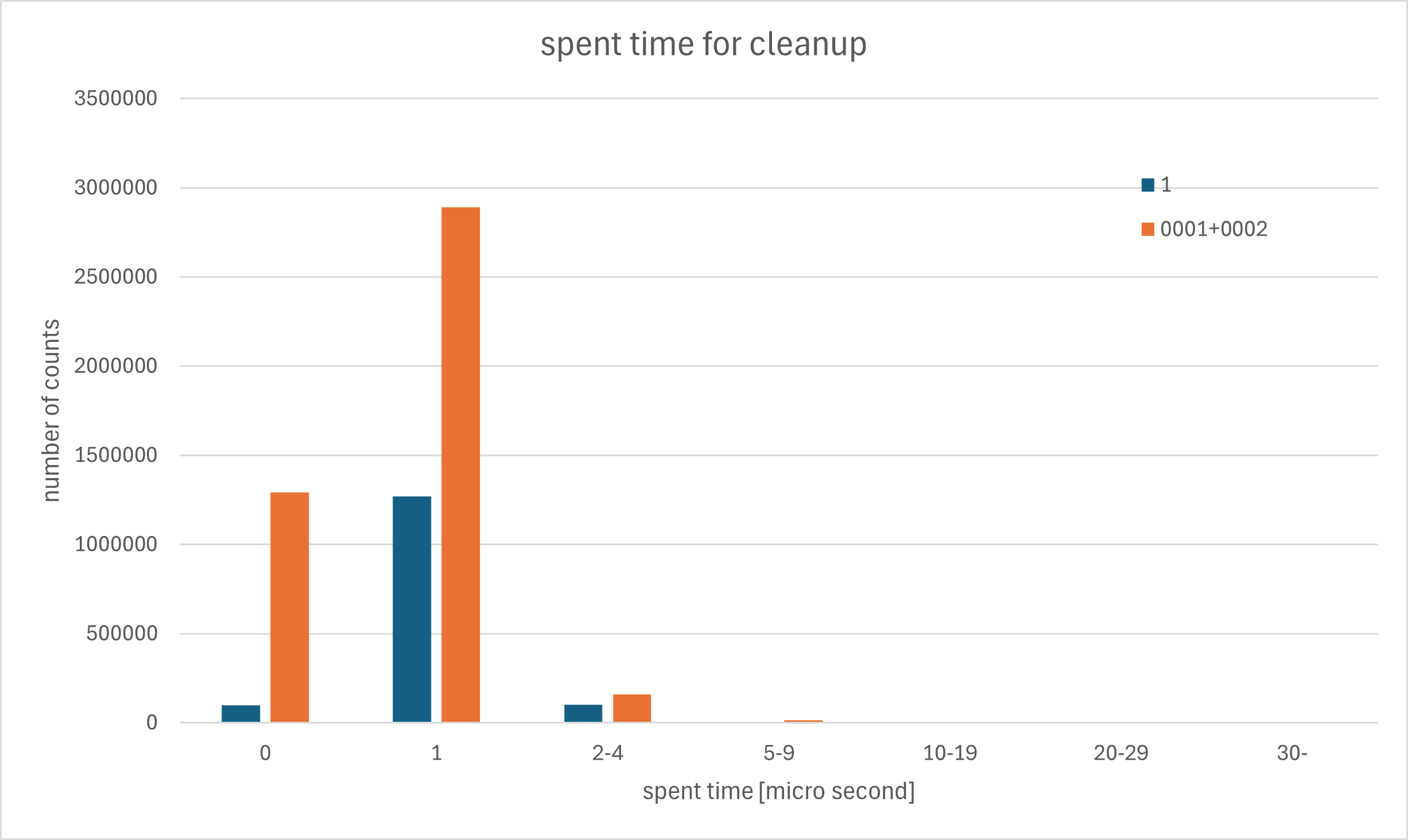{kind=link}
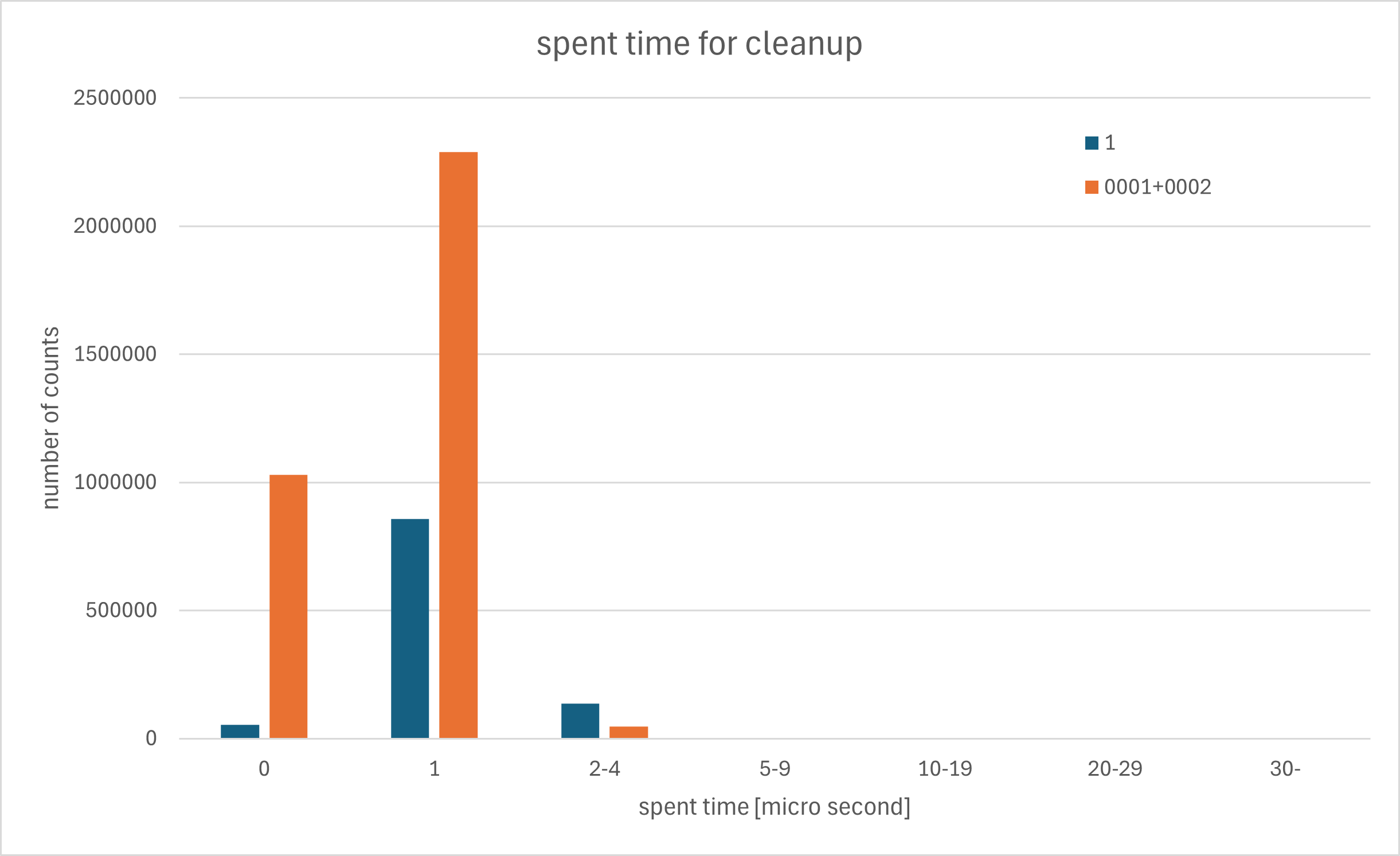{kind=link}
Dear hackers,
> I think it is better to enable preserve order by default - for safety reasons.
Per some discussions on -hackers, I implemented the patch which preserves the
commit ordering on publisher. Let me clarify from the beginning.
Background
==========
Current patch, say v1, does not preserve the commit ordering on the publisher node.
After the leader worker sends a COMMIT message to parallel apply worker, the
leader does not wait to apply the transaction and continue reading messages from
the publisher node. This can cause that a parallel apply worker assigned later may
commit earlier, which breaks the commit ordering on the pub node.
Proposal
========
We decided to preserve the commit ordering by default not to break data between
nodes [1]. The basic idea is that leader apply worker caches the remote_xid when
it sends to commit record to the parallel apply worker. Leader worker sends
INTERNAL_DEPENDENCY message with the cached xid to the parallel apply worker
before the leader sends commit message to p.a. P.a. would read the DEPENDENCY
message and wait until the transaction finishes. The cached xid would be updated
after the leader sends COMMIT.
This approach requires less codes because DEPENDENCY message has already been
introduced by v1, but the number of transaction messages would be increased.
Performance testing
===================
I confirmed that even if we preserve the commit ordering, the parallel apply still
has 2.x improvement compared with the HEAD. Below contains the detail.
Machine details
---------------
Intel(R) Xeon(R) CPU E7-4890 v2 @ 2.80GHz CPU(s) :88 cores, - 503 GiB RAM
Used patch
----------
v1 is same as Hou posted on -hackers [1], and v2 implements preserve-commit-order
part. Attached patch is what I used here.
Workload
-----
Setup:
Pub --> Sub
- Two nodes created in pub-sub synchronous logical replication setup.
- Both nodes have same set of pgbench tables created with scale=100.
- The Sub node is subscribed to all the changes from the Pub's pgbench tables
Workload Run:
- Run built-in pgbench(simple-update)[2] only on Pub with #clients=40 and run duration=5 minutes
This means that same tuples would be rarely modified between transactions.
I can imagine that v1 patch would work mostly without waits, and 0002 would
be slower because it waits until previous commit would be done every time.
Results:
Number of workers is fixed to 4. v2 was 2.1 times faster than HEAD, and
v1 was 2.6 times faster than HEAD. I think it is very good improvement.
I can continue some other benchmarks with different workloads and parameters.
HEAD v1 v2
TPS 6134.7 16194.8 12944.4
6030.5 16303.9 13043.0
6181.9 16251.5 12815.7
6108.1 16173.3 12771.8
6035.6 16180.3 13054.5
AVE 6098.2 16220.8 12925.8
MEDIAN 6108.1 16194.8 12944.4
[1]: https://www.postgresql.org/message-id/CADzfLwXnJ1H4HncFugGPdnm8t%2BaUAU4E-yfi1j3BbiP5VfXD8g%40mail.gmail.com
[2]: https://www.postgresql.org/docs/current/pgbench.html#PGBENCH-OPTION-BUILTIN
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
On Tue, Nov 18, 2025 at 1:46 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > Dear hackers, > > > I think it is better to enable preserve order by default - for safety reasons. > > Per some discussions on -hackers, I implemented the patch which preserves the > commit ordering on publisher. Let me clarify from the beginning. > > Background > ========== > Current patch, say v1, does not preserve the commit ordering on the publisher node. > After the leader worker sends a COMMIT message to parallel apply worker, the > leader does not wait to apply the transaction and continue reading messages from > the publisher node. This can cause that a parallel apply worker assigned later may > commit earlier, which breaks the commit ordering on the pub node. > > Proposal > ======== > We decided to preserve the commit ordering by default not to break data between > nodes [1]. The basic idea is that leader apply worker caches the remote_xid when > it sends to commit record to the parallel apply worker. Leader worker sends > INTERNAL_DEPENDENCY message with the cached xid to the parallel apply worker > before the leader sends commit message to p.a. P.a. would read the DEPENDENCY > message and wait until the transaction finishes. The cached xid would be updated > after the leader sends COMMIT. > This approach requires less codes because DEPENDENCY message has already been > introduced by v1, but the number of transaction messages would be increased. > It seems you haven't sent the patch that preserves commit order or the commit message of the attached patch is wrong. I think the first patch in series should be the one that preserves commit order and then we can build a patch that tracks dependencies and allows parallelization without preserving commit order. I feel it may be better to just discuss preserve commit order patch that also contains some comments as to how to extend it further, once that is done, we can do further discussion of the other patch. -- With Regards, Amit Kapila.
Dear Amit, > It seems you haven't sent the patch that preserves commit order or the > commit message of the attached patch is wrong. I think the first patch > in series should be the one that preserves commit order and then we > can build a patch that tracks dependencies and allows parallelization > without preserving commit order. I think I attached the correct file. Since we are trying to preserve the commit order by default, everything was merged into one patch. One point to clarify is that dependency tracking is essential even if we fully preserve the commit ordering not to violate constrains like PK. Assuming there is a table which has PK, txn1 inserts a tuple and txn2 updates it. UPDATE statement in txn2 must be done after committing txn1. > I feel it may be better to just > discuss preserve commit order patch that also contains some comments > as to how to extend it further, once that is done, we can do further > discussion of the other patch. I do agree, let me implement one by one. Best regards, Hayato Kuroda FUJITSU LIMITED
Hello Kuroda-san, On 11/18/25 12:00, Hayato Kuroda (Fujitsu) wrote: > Dear Amit, > >> It seems you haven't sent the patch that preserves commit order or the >> commit message of the attached patch is wrong. I think the first patch >> in series should be the one that preserves commit order and then we >> can build a patch that tracks dependencies and allows parallelization >> without preserving commit order. > > I think I attached the correct file. Since we are trying to preserve > the commit order by default, everything was merged into one patch. I agree the goal should be preserving the commit order, unless someone can demonstrate (a) clear performance benefits and (b) correctness. It's not clear to me how would that deal e.g. with crashes, where some of the "future" replicated transactions committed. Maybe it's fine, not sure. But keeping the same commit order just makes it easier to think about the consistency model, no? So it seems natural to target the same commit order first, and then maybe explore if relaxing that would be beneficial for some cases. However, the patch seems fairly large (~80kB, although a fair bit of that is comments). Would it be possible to split it into smaller chunks? Is there some "minimal patch", which could be moved to 0001, and then followed by improvements in 0002, 0003, ...? I sometimes do some "infrastructure" first, and the actual patch in the last part (simply using the earlier parts). I'm not saying it has to be split (or how exactly), but I personally find smaller patches easier to review ... > One point to clarify is that dependency tracking is essential even if we fully > preserve the commit ordering not to violate constrains like PK. Assuming there is > a table which has PK, txn1 inserts a tuple and txn2 updates it. UPDATE statement > in txn2 must be done after committing txn1. > Right. I don't see how we could do parallel apply correct in general case without tracking these dependencies. >> I feel it may be better to just >> discuss preserve commit order patch that also contains some comments >> as to how to extend it further, once that is done, we can do further >> discussion of the other patch. > > I do agree, let me implement one by one. > Some comments / questions after looking at the patch today: 1) The way the patch determines dependencies seems to be the "writeset" approach from other replication systems (e.g. MySQL does that). Maybe we should stick to the same naming? 2) If I understand correctly, the patch maintains a "replica_identity" hash table, with replica identity keys for all changes for all concurrent transactions. How expensive can this be, in terms of CPU and memory? What if I have multiple large batch transactions, each updating millions of rows? 3) Would it make sense to use some alternative data structure? A bloom filter, for example. Just a random idea, not sure if that's a good fit. 4) I've seen the benchmarks posted a couple days ago, and I'm running some tests myself. But it's hard to say if the result is good or bad without knowing what fraction of transactions finds a dependency and has to wait for an earlier one. Would it be possible to track this somewhere? Is there a suitable pg_stats_ view? 5) It's not clear to me how did you measure the TPS in your benchmark. Did you measure how long it takes for the standby to catch up, or what did you do? 6) Did you investigate why the speedup is just ~2.1 with 4 workers, i.e. about half of the "ideal" speedup? Is it bottlenecked on WAL, leader having to determine dependencies, or something else? 7) I'm a bit confused about the different types of dependencies, and at which point they make the workers wait. There are the dependencies due to modifying the same row, in which case the worker waits before starting to apply the changes that hits the dependency. And then there's a dependency to enforce commit order, in which case it waits before commit. Right? Or did I get that wrong? 8) The commit message says: > It would be challenge to check the dependency if the table has user > defined trigger or constraints. the most viable solution might be to > disallow parallel apply for relations whose triggers and constraints > are not marked as parallel-safe or immutable. Wouldn't this have similar issues with verifying these features on partitioned tables as the patch that attempted to allow parallelism for INSERT ... SELECT [1]? AFAICS it was too expensive to do with large partitioning hierarchies. 9) I think it'd be good to make sure the "design" comments explain how the new parts work in more detail. For example, the existing comment at the beginning of applyparallelworker.c goes into a lot of detail, but the patch adds only two fairly short paragraphs. Even the commit message has more detail, which seems a bit strange. 10) For example it would be good to explain what "internal dependency" and "internal relation" are for. I think I understand the internal dependency, I'm still not quite sure why we need internal relation (or rather why we didn't need it before). 11) I think it might be good to have TAP tests that stress this out in various ways. Say, a test that randomly restarts the standby during parallel apply, and checks it does not miss any records, etc. In the online checksums patch this was quite useful. It wouldn't be part of regular check-world, of course. Or maybe it'd be for development only? regards [1] https://www.postgresql.org/message-id/flat/E1lJoQ6-0005BJ-DY%40gemulon.postgresql.org -- Tomas Vondra
On Thursday, November 20, 2025 5:31 AM Tomas Vondra <tomas@vondra.me> wrote: > > Hello Kuroda-san, > > On 11/18/25 12:00, Hayato Kuroda (Fujitsu) wrote: > > Dear Amit, > > > >> It seems you haven't sent the patch that preserves commit order or the > >> commit message of the attached patch is wrong. I think the first patch > >> in series should be the one that preserves commit order and then we > >> can build a patch that tracks dependencies and allows parallelization > >> without preserving commit order. > > > > I think I attached the correct file. Since we are trying to preserve > > the commit order by default, everything was merged into one patch. > ... > > However, the patch seems fairly large (~80kB, although a fair bit of > that is comments). Would it be possible to split it into smaller chunks? > Is there some "minimal patch", which could be moved to 0001, and then > followed by improvements in 0002, 0003, ...? I sometimes do some > "infrastructure" first, and the actual patch in the last part (simply > using the earlier parts). > > I'm not saying it has to be split (or how exactly), but I personally > find smaller patches easier to review ... Agreed and thanks for the suggestion, we will try to split the patches into smaller ones. > > > One point to clarify is that dependency tracking is essential even if we fully > > preserve the commit ordering not to violate constrains like PK. Assuming > there is > > a table which has PK, txn1 inserts a tuple and txn2 updates it. UPDATE > statement > > in txn2 must be done after committing txn1. > > > > Right. I don't see how we could do parallel apply correct in general > case without tracking these dependencies. > > >> I feel it may be better to just > >> discuss preserve commit order patch that also contains some comments > >> as to how to extend it further, once that is done, we can do further > >> discussion of the other patch. > > > > I do agree, let me implement one by one. > > > > Some comments / questions after looking at the patch today: Thanks for the comments! > 1) The way the patch determines dependencies seems to be the "writeset" > approach from other replication systems (e.g. MySQL does that). Maybe we > should stick to the same naming? OK, I did not research the design in MySQL in detail but will try to analyze it. > 2) If I understand correctly, the patch maintains a "replica_identity" hash > table, with replica identity keys for all changes for all concurrent > transactions. How expensive can this be, in terms of CPU and memory? What if I > have multiple large batch transactions, each updating millions of rows? In case TPC-B or simple-update the cost of dependency seems trivial (e.g., the data in profile of previous simple-update test shows --1.39%--check_dependency_on_replica_identity), but we will try to analyze more for large transaction cases as suggested. > > 3) Would it make sense to use some alternative data structure? A bloom filter, > for example. Just a random idea, not sure if that's a good fit. It's worth analyzing. We will do some more tests and if we find some bottlenecks due to the current dependency tracking, then we will research more on alternative approaches like bloom filter. > > 4) I've seen the benchmarks posted a couple days ago, and I'm running some > tests myself. But it's hard to say if the result is good or bad without > knowing what fraction of transactions finds a dependency and has to wait for > an earlier one. Would it be possible to track this somewhere? Is there a > suitable pg_stats_ view? Right, we will consider this idea and will try to implement this. > > 5) It's not clear to me how did you measure the TPS in your benchmark. Did you > measure how long it takes for the standby to catch up, or what did you do? The test we shared has enabled synchronous logical replication and then use pgbench (simple-update) to write on the publisher and count the TPS output by pgbench. > > 6) Did you investigate why the speedup is just ~2.1 with 4 workers, i.e. about > half of the "ideal" speedup? Is it bottlenecked on WAL, leader having to > determine dependencies, or something else? > > 7) I'm a bit confused about the different types of dependencies, and at which > point they make the workers wait. There are the dependencies due to modifying > the same row, in which case the worker waits before starting to apply the > changes that hits the dependency. And then there's a dependency to enforce > commit order, in which case it waits before commit. Right? Or did I get that > wrong? Right, your understanding is correct, there are only two dependencies for now (same row modification and commit order) > > 8) The commit message says: > > > It would be challenge to check the dependency if the table has user defined > > trigger or constraints. the most viable solution might be to disallow > > parallel apply for relations whose triggers and constraints are not marked > > as parallel-safe or immutable. > > Wouldn't this have similar issues with verifying these features on partitioned > tables as the patch that attempted to allow parallelism for INSERT ... SELECT > [1]? AFAICS it was too expensive to do with large partitioning hierarchies. By default, since publish_via_partition_root is set to false in the publication, we normally replicate changes to the leaf partition directly. So, for non-partitioned tables, we can directly assess their parallel safety and cache the results. Partitioned tables require additional handling. But unlike INSERT ... SELECT, logical replication provides remote data changes upfront, allowing us to identify the target leaf partition for each change and assess safety for that table. So, we can avoid examining all partition hierarchies for a change. To check the safety for a change on partitioned table, the leader worker could initially perform tuple routing for the remote change and evaluate the user-defined triggers or functions in the target partition before determining whether to parallelize the transaction. Although this approach may introduce some overhead for the leader, we plan to test its impact. If the overhead is unacceptable, we might also consider disallowing parallelism for changes on partitioned tables. > > 9) I think it'd be good to make sure the "design" comments explain how the new > parts work in more detail. For example, the existing comment at the beginning > of applyparallelworker.c goes into a lot of detail, but the patch adds only > two fairly short paragraphs. Even the commit message has more detail, which > seems a bit strange. Agreed, we will add more comments. > > 10) For example it would be good to explain what "internal dependency" and > "internal relation" are for. I think I understand the internal dependency, I'm > still not quite sure why we need internal relation (or rather why we didn't > need it before). The internal relation is used to share relation information (such as the publisher's table name, schema name, relkind, column names, etc) with parallel apply workers. This information is needed for verifying whether the publisher's relation data aligns with the subscriber's data when applying changes. Previously, sharing this information wasn't necessary because parallel apply workers were only tasked with applying streamed replication. In those cases, the relation information for modified relations was always sent within streamed transactions (see maybe_send_schema() for details), eliminating the need for additional sharing. However, in non-streaming transactions, relation information might not be included in every transaction. Therefore, we request the leader to distribute the received relation information to parallel apply workers before assigning them a transaction. > > 11) I think it might be good to have TAP tests that stress this out in various > ways. Say, a test that randomly restarts the standby during parallel apply, > and checks it does not miss any records, etc. In the online checksums patch > this was quite useful. It wouldn't be part of regular check-world, of course. > Or maybe it'd be for development only? We will think more on this. Best Regards, Hou zj
On Thu, Nov 20, 2025 at 3:00 AM Tomas Vondra <tomas@vondra.me> wrote: > > Hello Kuroda-san, > > On 11/18/25 12:00, Hayato Kuroda (Fujitsu) wrote: > > Dear Amit, > > > >> It seems you haven't sent the patch that preserves commit order or the > >> commit message of the attached patch is wrong. I think the first patch > >> in series should be the one that preserves commit order and then we > >> can build a patch that tracks dependencies and allows parallelization > >> without preserving commit order. > > > > I think I attached the correct file. Since we are trying to preserve > > the commit order by default, everything was merged into one patch. > > I agree the goal should be preserving the commit order, unless someone > can demonstrate (a) clear performance benefits and (b) correctness. It's > not clear to me how would that deal e.g. with crashes, where some of the > "future" replicated transactions committed. > Yeah, the key challenge in not-preserving commit order is that the future transactions can be applied when some of the previous transactions were still in the apply phase and the crash happens. With the current replication progress tracking scheme, we won't be able to apply the transactions that were still in-progress when the crash happened. However, I came up with a scheme to change the replication progress tracking mechanism to allow out-of-order commits during apply. See [1] (Replication Progress Tracking). Anyway, as discussed in this thread, it is better to keep that as optional non-default behavior, so we want to focus first on preserving the commit-order part. Thanks for paying attention, your comments/suggestions are helpful. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BSEus_6vQay9TF_r4ow%2BE-Q7LYNLfsD78HaOsLSgppxQ%40mail.gmail.com -- With Regards, Amit Kapila
> 1) The way the patch determines dependencies seems to be the "writeset"
> approach from other replication systems (e.g. MySQL does that). Maybe we
> should stick to the same naming?
> OK, I did not research the design in MySQL in detail but will try to analyze it.
I have some documents for mysql parallel apply binlog event.But after MySQL 8.4, only the writeset mode is available. In scenarios with a primary key or unique key, the replica replay is not ordered, but the data is eventually consistent."
https://dev.mysql.com/worklog/task/?id=9556
https://dev.mysql.com/blog-archive/improving-the-parallel-applier-with-writeset-based-dependency-tracking/
https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with-parallel-replication-and-writeset-based-dependency-tracking-1fc405cf023c
Thanks
On Thu, Nov 20, 2025 at 3:00 AM Tomas Vondra <tomas@vondra.me> wrote:
>
> Hello Kuroda-san,
>
> On 11/18/25 12:00, Hayato Kuroda (Fujitsu) wrote:
> > Dear Amit,
> >
> >> It seems you haven't sent the patch that preserves commit order or the
> >> commit message of the attached patch is wrong. I think the first patch
> >> in series should be the one that preserves commit order and then we
> >> can build a patch that tracks dependencies and allows parallelization
> >> without preserving commit order.
> >
> > I think I attached the correct file. Since we are trying to preserve
> > the commit order by default, everything was merged into one patch.
>
> I agree the goal should be preserving the commit order, unless someone
> can demonstrate (a) clear performance benefits and (b) correctness. It's
> not clear to me how would that deal e.g. with crashes, where some of the
> "future" replicated transactions committed.
>
Yeah, the key challenge in not-preserving commit order is that the
future transactions can be applied when some of the previous
transactions were still in the apply phase and the crash happens. With
the current replication progress tracking scheme, we won't be able to
apply the transactions that were still in-progress when the crash
happened. However, I came up with a scheme to change the replication
progress tracking mechanism to allow out-of-order commits during
apply. See [1] (Replication Progress Tracking). Anyway, as discussed
in this thread, it is better to keep that as optional non-default
behavior, so we want to focus first on preserving the commit-order
part.
Thanks for paying attention, your comments/suggestions are helpful.
[1] - https://www.postgresql.org/message-id/CAA4eK1%2BSEus_6vQay9TF_r4ow%2BE-Q7LYNLfsD78HaOsLSgppxQ%40mail.gmail.com
--
With Regards,
Amit Kapila
On 11/20/25 14:10, wenhui qiu wrote: > Hi >> 1) The way the patch determines dependencies seems to be the "writeset" >> approach from other replication systems (e.g. MySQL does that). Maybe we >> should stick to the same naming? > >> OK, I did not research the design in MySQL in detail but will try to > analyze it. > I have some documents for mysql parallel apply binlog event.But after > MySQL 8.4, only the writeset mode is available. In scenarios with a > primary key or unique key, the replica replay is not ordered, but the > data is eventually consistent." > https://dev.mysql.com/worklog/task/?id=9556 <https://dev.mysql.com/ > worklog/task/?id=9556> > https://dev.mysql.com/blog-archive/improving-the-parallel-applier-with- > writeset-based-dependency-tracking/ <https://dev.mysql.com/blog-archive/ > improving-the-parallel-applier-with-writeset-based-dependency-tracking/> > https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with- > parallel-replication-and-writeset-based-dependency-tracking-1fc405cf023c > <https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with- > parallel-replication-and-writeset-based-dependency-tracking-1fc405cf023c> > FWIW there was a talk about MySQL replication at pgconf.dev 2024 https://www.youtube.com/watch?v=eOfUqh5PltM discussing some of this stuff. I'm not saying we should copy all of this, but it seems like a good source of inspiration what (not) to do. regards -- Tomas Vondra
> this, but it seems like a good source of inspiration what (not) to do.
On 11/20/25 14:10, wenhui qiu wrote:
> Hi
>> 1) The way the patch determines dependencies seems to be the "writeset"
>> approach from other replication systems (e.g. MySQL does that). Maybe we
>> should stick to the same naming?
>
>> OK, I did not research the design in MySQL in detail but will try to
> analyze it.
> I have some documents for mysql parallel apply binlog event.But after
> MySQL 8.4, only the writeset mode is available. In scenarios with a
> primary key or unique key, the replica replay is not ordered, but the
> data is eventually consistent."
> https://dev.mysql.com/worklog/task/?id=9556 <https://dev.mysql.com/
> worklog/task/?id=9556>
> https://dev.mysql.com/blog-archive/improving-the-parallel-applier-with-
> writeset-based-dependency-tracking/ <https://dev.mysql.com/blog-archive/
> improving-the-parallel-applier-with-writeset-based-dependency-tracking/>
> https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with-
> parallel-replication-and-writeset-based-dependency-tracking-1fc405cf023c
> <https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with-
> parallel-replication-and-writeset-based-dependency-tracking-1fc405cf023c>
>
FWIW there was a talk about MySQL replication at pgconf.dev 2024
https://www.youtube.com/watch?v=eOfUqh5PltM
discussing some of this stuff. I'm not saying we should copy all of
this, but it seems like a good source of inspiration what (not) to do.
regards
--
Tomas Vondra
On Thursday, November 20, 2025 10:50 PM Tomas Vondra <tomas@vondra.me> wrote: > > On 11/20/25 14:10, wenhui qiu wrote: > > Hi > >> 1) The way the patch determines dependencies seems to be the "writeset" > >> approach from other replication systems (e.g. MySQL does that). Maybe > >> we should stick to the same naming? > > > >> OK, I did not research the design in MySQL in detail but will try to > > analyze it. > > I have some documents for mysql parallel apply binlog event.But after > > MySQL 8.4, only the writeset mode is available. In scenarios with a > > primary key or unique key, the replica replay is not ordered, but the > > data is eventually consistent." > > https://dev.mysql.com/worklog/task/?id=9556 <https://dev.mysql.com/ > > worklog/task/?id=9556> > > https://dev.mysql.com/blog-archive/improving-the-parallel-applier-with > > - writeset-based-dependency-tracking/ > > <https://dev.mysql.com/blog-archive/ > > improving-the-parallel-applier-with-writeset-based-dependency-tracking > > /> > > https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with- > > parallel-replication-and-writeset-based-dependency-tracking-1fc405cf02 > > 3c > > <https://medium.com/airtable-eng/optimizing-mysql-replication-lag-with > > - > > parallel-replication-and-writeset-based-dependency-tracking- > 1fc405cf023c> > > > > FWIW there was a talk about MySQL replication at pgconf.dev 2024 > > https://www.youtube.com/watch?v=eOfUqh5PltM > > discussing some of this stuff. I'm not saying we should copy all of this, but it > seems like a good source of inspiration what (not) to do. Thank you both for the information. We'll look into these further. Best Regards, Hou zj
On Tue, Sep 16, 2025 at 3:03 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Sat, Sep 6, 2025 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > I suspect this might not be the most performant default strategy and > > could frequently cause a performance dip. In general, we utilize > > parallel apply workers, considering that the time taken to apply > > changes is much costlier than reading and sending messages to workers. > > > > The current strategy involves the leader picking one transaction for > > itself after distributing transactions to all apply workers, assuming > > the apply task will take some time to complete. When the leader takes > > on an apply task, it becomes a bottleneck for complete parallelism. > > This is because it needs to finish applying previous messages before > > accepting any new ones. Consequently, even as workers slowly become > > free, they won't receive new tasks because the leader is busy applying > > its own transaction. > > > > This type of strategy might be suitable in scenarios where users > > cannot supply more workers due to resource limitations. However, on > > high-end machines, it is more efficient to let the leader act solely > > as a message transmitter and allow the apply workers to handle all > > apply tasks. This could be a configurable parameter, determining > > whether the leader also participates in applying changes. I believe > > this should not be the default strategy; in fact, the default should > > be for the leader to act purely as a transmitter. > > > > I see your point but consider a scenario where we have two pa workers. > pa-1 is waiting for some backend on unique_key insertion and pa-2 is > waiting for pa-1 to complete its transaction as pa-2 has to perform > some change which is dependent on pa-1's transaction. So, leader can > either simply wait for a third transaction to be distributed or just > apply it and process another change. If we follow the earlier then it > is quite possible that the sender fills the network queue to send data > and simply timed out. Sorry I took a while to come back to this. I understand your point and agree that it's a valid concern. However, I question whether limiting this to a single choice is the optimal solution. The core issue involves two distinct roles: work distribution and applying changes. Work distribution is exclusively handled by the leader, while any worker can apply the changes. This is essentially a single-producer, multiple-consumer problem. While it might seem efficient for the producer (leader) to assist consumers (workers) when there's a limited number of consumers, I believe this isn't the best design. In such scenarios, it's generally better to allow the producer to focus solely on its primary task, unless there's a severe shortage of processing power. If computing resources are constrained, allowing producers to join consumers in applying changes is acceptable. However, if sufficient processing power is available, the producer should ideally be left to its own duties. The question then becomes: how do we make this decision? My suggestion is to make this a configurable parameter. Users could then decide whether the leader participates in applying changes. This would provide flexibility: If there are enough workers, user can set the leader can focus on its distribution task only OTOH If processing power is limited and only a few apply workers (e.g., two, as in your example) can be set up, users would have the option to configure the leader to also act as an apply worker when needed. -- Regards, Dilip Kumar Google
On Mon, Nov 24, 2025 at 9:56 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Tue, Sep 16, 2025 at 3:03 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Sat, Sep 6, 2025 at 10:33 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > I suspect this might not be the most performant default strategy and > > > could frequently cause a performance dip. In general, we utilize > > > parallel apply workers, considering that the time taken to apply > > > changes is much costlier than reading and sending messages to workers. > > > > > > The current strategy involves the leader picking one transaction for > > > itself after distributing transactions to all apply workers, assuming > > > the apply task will take some time to complete. When the leader takes > > > on an apply task, it becomes a bottleneck for complete parallelism. > > > This is because it needs to finish applying previous messages before > > > accepting any new ones. Consequently, even as workers slowly become > > > free, they won't receive new tasks because the leader is busy applying > > > its own transaction. > > > > > > This type of strategy might be suitable in scenarios where users > > > cannot supply more workers due to resource limitations. However, on > > > high-end machines, it is more efficient to let the leader act solely > > > as a message transmitter and allow the apply workers to handle all > > > apply tasks. This could be a configurable parameter, determining > > > whether the leader also participates in applying changes. I believe > > > this should not be the default strategy; in fact, the default should > > > be for the leader to act purely as a transmitter. > > > > > > > I see your point but consider a scenario where we have two pa workers. > > pa-1 is waiting for some backend on unique_key insertion and pa-2 is > > waiting for pa-1 to complete its transaction as pa-2 has to perform > > some change which is dependent on pa-1's transaction. So, leader can > > either simply wait for a third transaction to be distributed or just > > apply it and process another change. If we follow the earlier then it > > is quite possible that the sender fills the network queue to send data > > and simply timed out. > > Sorry I took a while to come back to this. I understand your point and > agree that it's a valid concern. However, I question whether limiting > this to a single choice is the optimal solution. The core issue > involves two distinct roles: work distribution and applying changes. > Work distribution is exclusively handled by the leader, while any > worker can apply the changes. This is essentially a single-producer, > multiple-consumer problem. > > While it might seem efficient for the producer (leader) to assist > consumers (workers) when there's a limited number of consumers, I > believe this isn't the best design. In such scenarios, it's generally > better to allow the producer to focus solely on its primary task, > unless there's a severe shortage of processing power. > > If computing resources are constrained, allowing producers to join > consumers in applying changes is acceptable. However, if sufficient > processing power is available, the producer should ideally be left to > its own duties. The question then becomes: how do we make this > decision? > > My suggestion is to make this a configurable parameter. Users could > then decide whether the leader participates in applying changes. > We could do this but another possibility is that the leader does distribute some threshold of pending transactions (say 5 or 10) to each of the workers and if none of the workers is still available then it can perform the task by itself. I think this will avoid the system performing poorly when the existing workers are waiting on each other and or backend to finish the current transaction. Having said that, I think this can be done as a separate optimization patch as well. -- With Regards, Amit Kapila.
On Mon, Nov 24, 2025 at 5:07 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > While it might seem efficient for the producer (leader) to assist > > consumers (workers) when there's a limited number of consumers, I > > believe this isn't the best design. In such scenarios, it's generally > > better to allow the producer to focus solely on its primary task, > > unless there's a severe shortage of processing power. > > > > If computing resources are constrained, allowing producers to join > > consumers in applying changes is acceptable. However, if sufficient > > processing power is available, the producer should ideally be left to > > its own duties. The question then becomes: how do we make this > > decision? > > > > My suggestion is to make this a configurable parameter. Users could > > then decide whether the leader participates in applying changes. > > > > We could do this but another possibility is that the leader does > distribute some threshold of pending transactions (say 5 or 10) to > each of the workers and if none of the workers is still available then > it can perform the task by itself. IMHO making the producer (the leader) join as a consumer (an apply worker) is not the best default behavior for a single-producer, multi-consumer design. This design choice is generally not scalable because the producer is a unique resource no other process can handle its job while multiple parallel workers can act as consumers. By keeping the roles separate, a user always has the option to set up a sufficiently high number of dedicated consumer workers. However, in resource constrained environments where maximum resource utilization is prioritized over the most scalable solution, a configuration parameter could be introduced. This parameter would allow the producer to act as a consumer worker whenever it is free and other consumers are busy. This offers a trade-off between resource efficiency and overall scalability. I think this will avoid the system > performing poorly when the existing workers are waiting on each other > and or backend to finish the current transaction. The core issue is that integrating the producer (sender) as an extra consumer (apply worker) just adds an N+1 worker capacity, but doesn't fundamentally solve the problem of all workers eventually becoming busy or blocked (waiting on transactions) or am I missing something? The possibility remains that all N+1 workers could become busy applying or, more commonly, waiting for transactions to commit or resources to free up. Adding one extra worker doesn't resolve the underlying problem if the workload exceeds the total available processing power or if transactions are frequently waiting. Users already have the ability to address this by configuring N+1 or more dedicated consumer workers based on their resource availability and performance needs. Therefore, relying on the producer as an occasional consumer offers only a minor, temporary capacity gain and doesn't resolve the overall scalability limit or the likelihood of full worker saturation. Having said that, I > think this can be done as a separate optimization patch as well. Yeah we could. -- Regards, Dilip Kumar Google
Dear Tomas, Thanks for seeing the thread and sorry for late response. I had a PostgreSQL conference in Japan. > However, the patch seems fairly large (~80kB, although a fair bit of > that is comments). Would it be possible to split it into smaller chunks? > Is there some "minimal patch", which could be moved to 0001, and then > followed by improvements in 0002, 0003, ...? I sometimes do some > "infrastructure" first, and the actual patch in the last part (simply > using the earlier parts). > > I'm not saying it has to be split (or how exactly), but I personally > find smaller patches easier to review ... Yes, smaller patches are always better than huge monolith. I splitted the patch into four patches - three of them introduces a mechanism to track dependencies and wait until other transactions finish, and fourth patch launches parallel workers with them. Each patch can be built and pass tests individually. Two of them might be still large (-800 lines) but I hope this is helpful for reviewers. > Some comments / questions after looking at the patch today: We would answer them after more analysis. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
On Mon, Dec 1, 2025 at 4:16 PM Hayato Kuroda (Fujitsu) <kuroda.hayato@fujitsu.com> wrote: > > Dear Tomas, > > Thanks for seeing the thread and sorry for late response. > I had a PostgreSQL conference in Japan. > > > However, the patch seems fairly large (~80kB, although a fair bit of > > that is comments). Would it be possible to split it into smaller chunks? > > Is there some "minimal patch", which could be moved to 0001, and then > > followed by improvements in 0002, 0003, ...? I sometimes do some > > "infrastructure" first, and the actual patch in the last part (simply > > using the earlier parts). > > > > I'm not saying it has to be split (or how exactly), but I personally > > find smaller patches easier to review ... > > Yes, smaller patches are always better than huge monolith. I splitted the patch > into four patches - three of them introduces a mechanism to track dependencies > and wait until other transactions finish, and fourth patch launches parallel > workers with them. Each patch can be built and pass tests individually. > Two of them might be still large (-800 lines) but I hope this is helpful for > reviewers. > > > Some comments / questions after looking at the patch today: > > We would answer them after more analysis. I was just going through the commit messages of all the patches, I could not understand the last line of below paragraph in v3-0004, what do you mean by the last line which says "after which the leader updates the hash entry with the current xid"? "The leader maintains a local hash table, using the remote change's replica identity column values and relid as keys, with remote transaction IDs as values. Before sending changes to the parallel apply worker, the leader computes a hash using RI key values and the relid of the current change to search the hash table. If an existing entry is found, the leader tells the parallel worker to wait for the remote xid in the hash entry, after which the leader updates the hash entry with the current xid." -- Regards, Dilip Kumar Google
Dear Dilip, > I was just going through the commit messages of all the patches, I > could not understand the last line of below paragraph in v3-0004, what > do you mean by the last line which says "after which the leader > updates the > hash entry with the current xid"? > > "The leader maintains a local hash table, using the remote change's replica > identity column values and relid as keys, with remote transaction IDs as values. > Before sending changes to the parallel apply worker, the leader computes a hash > using RI key values and the relid of the current change to search the hash > table. If an existing entry is found, the leader tells the parallel worker > to wait for the remote xid in the hash entry, after which the leader updates the > hash entry with the current xid." This meant if two transactions had changes for the same RI, lastly committed transaction's XID could be stored here. In other words, each local hash entry always has the latest XID which modifies a key (RI). Assuming that there are three transactions T1->T2->T3 and they modify the same tuple. When subscriber applies T3, it should wait till T2 is committed, not T1. XID of the entry should be updated for implementing it. I tried to rephrase that line a bit, how do you feel? All patches are attached to keep CI happy. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
Dear hackers,
I have been spending time for benchmarking the patch set. Here is an updated
report. Firstly, I want to reply few points raised by Tomas.
> 5) It's not clear to me how did you measure the TPS in your benchmark.
> Did you measure how long it takes for the standby to catch up, or what
> did you do?
Since the approach was not straightforward, we changed the metric - latency
for replication was measured. See the "workload" section for more details.
> 2) If I understand correctly, the patch maintains a "replica_identity"
> hash table, with replica identity keys for all changes for all
> concurrent transactions. How expensive can this be, in terms of CPU and
> memory? What if I have multiple large batch transactions, each updating
> millions of rows?
I have profiled large transaction cases and confirmed that cleanup is not CPU
costly. E.g., the attached .dat file showed the profile for the leader worker,
with 1 M update workload and 16 parallelisms. We can see that the leader worker
spends most of its time reading data from the stream, while the cleanup function
spends only around 5%. Also, I temporary removed the dependency tracking part
then ran tests, but the performance was not changed. Based on that, the CPU
consumption for dependency tracking can be ignored.
I have not attached the profile for other cases, tell me if needed.
We are still analyzing the memory consumption, will share later.
> 6) Did you investigate why the speedup is just ~2.1 with 4 workers, i.e.
> about half of the "ideal" speedup? Is it bottlenecked on WAL, leader
> having to determine dependencies, or something else?
Even in the 1M insert/update workload with the replica identity, parallelism
could not be improved. My theory was that parallel workers were fast enough,
and four workers could finish applying all transactions.
Thus, I did further experiment, which removed a replica identity and used REPLICA
IDENTITY FULL for applying UPDATEs. It increased the application time, and
performance could be improved up to w=16. See "Result" part.
Below contains details of benchmarks.
Abstract
----------
I did benchmarks with two workloads: 1) 1 million tuples are inserted in total,
and 2) 1 million tuples are updated in total. Overall, we can say that parallel
apply can improve performance, especially when transactions are long and
needs time to apply them.
Regarding the INSERT workload, the patch applies changes about 10% faster than
HEAD, but results remain constant regardless of parallelism. IIUC, because
applying transactions was relatively fast, fewer parallel workers could be
launched. Another point is that performance worsens when the number of workers
is set to 0. We may be able to skip additional patches in this case.
Regarding the UPDATE workload, performance could be improved till
max_parallel_apply_workers_per_subscription=4, but it was stable for {8, 16} cases.
This is because four workers are enough to apply all changes. When leader tries to
assign a new transaction, the first parallel worker has already finished its task.
Additionally, I ran UPDATE workload with REPLICA IDENTITY FULL, and this allows us
to improve performance till the w=16 case. This also shows that each parallel
worker spent more time, and the leader assigned workers from the pool.
Machine details
----------------
Intel(R) Xeon(R) CPU E7-4890 v2 @ 2.80GHz CPU(s) :88 cores, - 503 GiB RAM
Source code:
----------------
pgHead (19b966243c) and v4 patch set
Setup:
---------
Pub --> Sub
- Two nodes created in pub-sub logical replication setup.
- both instances had a table " foo (id int PRIMARY KEY, value double precision)"
and it was included in the publication
Workload:
----------------
Two workloads were run:
1. Disabled the subscription on the Sub node
2. ran 1000 transactions. Each transaction inserted 1000 tuples.
I.e., there were 1 million tuples on the publisher.
3. Enabled the subscription on Sub and measured the time taken in replication.
Case 2) UPDATE 1 million tuples
1. Inserted one million tuples on the Pub node
2. Waited until tuples were replicated
3. Disabled the subscription on the Sub node
4. ran 1000 transactions. Each transaction updated 1000 tuples.
Note that each transaction modified different tuples.
5. Enabled the subscription on Sub and measured the time taken in replication.
Furthermore, I ran one additional case that performed a 1 M update without PK.
Result:
---------------------
I measured with varying the parallelism of the apply, max_parallel_apply_workers_per_subscription.
Case 1) 1 M insert
Each cell is the median of 5-time runs. Also, insert 1 million tuples spends
*8.28 second*s on publisher side.
(w means the max_parallel_apply_workers_per_subscription)
Used source elapsed time [s]
------------------------
HEAD 6.750675
patched, w=0 7.215072
patched, w=1 5.674886
patched, w=2 5.566869
patched, w=4 5.491499
patched, w=8 5.541768
patched, w=16 5.556885
We can see a regression if number of workers is set to zero because the leader
worker checks the dependency even in the case. We may be able to discuss optimizing
the part, one idea is to skip them if the parallelism is disabled.
w=1 case has better performance. Because the leader can concentrate receiving
the changes and parallel worker can apply in parallel. This looks like what
streaming replication does.
In case of w=2 and larger, the performance was not changed. I found that after the
benchmark only one parallel apply worker was launched at that time. The reason was
that the launched parallel worker can finish applying a transaction before the
leader worker receives further changes. When the leader worker tries to assign,
it finds the parallel worker has already finished the task thus leader re-uses it.
This scenario means that the parallelism can work effectively if transactions have
dependency or applying transactions need time more than leader receives new ones.
Also, I think it is OK that the performance cannot be improved linearly because such
a workload can be applied very quicky. In this experiment the applying on subscriber
is mostly the same as (or faster than) publisher.
Case 2) 1 M update
Used source elapsed time [s]
------------------------
HEAD 17.180169
patched, w=0 18.284964
patched, w=1 13.390546
patched, w=2 11.978078
patched, w=4 8.906887
patched, w=8 9.004753
patched, w=16 8.974946
Same as the INSERT case w=0 has worse performance than HEAD, and w=1 is better
than it. In case of updates, performance could be improved up to the w=4 case.
Per my analysis, the p.a. could be launched up to 4 in the workload. Before
receiving the 5th transaction, the first p.a. could finish applying the task and
start applying the next one.
Additionally, I ran the same workload with case 2), without PK on both nodes.
REPLICA IDENTITY was set to FULL on publisher node to replicate UPDATE commands.
Since it needs more than 2 hrs for HEAD/w=0 I did not run these cases.
Used source elapsed time [s]
------------------------
patched, w=1 7571.225952
patched, w=2 2688.792047
patched, w=4 1681.862011
patched, w=8 995.177401
patched, w=16 718.488441
Apart from above, performance can be improved for all max_parallel_apply_workers_per_subscription.
This meant that leader fully used the worker pool for all cases. I checked the
perf report at that time and found that leader spent most of time
at RelationFindReplTupleSeq - this meant leader could not assign transactions to
parallel workers and it applied by itself.
Used scripts were attached, you could run to verify the same workload.
Best regards,
Hayato Kuroda
FUJITSU LIMITED
Вложения
On 16/12/25 12:35, Hayato Kuroda (Fujitsu) wrote: > Dear hackers, > > I have been spending time for benchmarking the patch set. Here is an updated > report. > I apologise if my question is incorrect. But what about asynchronous replication? Does this method help to reduce lag? My case is a replica located far from the main instance. There are an inevitable lag exists. Do your benchmarks provide any insights into the lag reduction? Or the WALsender process that decodes WAL records from a hundred actively committing backends, a bottleneck here? -- regards, Andrei Lepikhov, pgEdge
Dear Andrei, > > I have been spending time for benchmarking the patch set. Here is an updated > > report. > > > I apologise if my question is incorrect. But what about asynchronous > replication? Does this method help to reduce lag? > > My case is a replica located far from the main instance. There are an > inevitable lag exists. Do your benchmarks provide any insights into the > lag reduction? Yes, ideally parallel apply can reduce the lag, but note that it affects after changes are reached to the subscriber. It may not be so effective if lag is caused by the network. If your transaction is large and you did not enable the streaming option, changing it to 'on' or 'parallel' can improve the lag. It allows to replicate changes before huge transactions are committed. > Or the WALsender process that decodes WAL records from a > hundred actively committing backends, a bottleneck here? Can you clarify your use case bit more? E.g., how many instances subscribe the change from the same publisher. The cheat sheet [1] may be helpful to distinguish the bottleneck. [1]: https://wiki.postgresql.org/wiki/Operations_cheat_sheet Best regards, Hayato Kuroda FUJITSU LIMITED
On 18/12/25 07:44, Hayato Kuroda (Fujitsu) wrote: > Dear Andrei, > >>> I have been spending time for benchmarking the patch set. Here is an updated >>> report. >>> >> I apologise if my question is incorrect. But what about asynchronous >> replication? Does this method help to reduce lag? >> >> My case is a replica located far from the main instance. There are an >> inevitable lag exists. Do your benchmarks provide any insights into the >> lag reduction? > > Yes, ideally parallel apply can reduce the lag, but note that it affects after > changes are reached to the subscriber. It may not be so effective if lag is > caused by the network. If your transaction is large and you did not enable the > streaming option, changing it to 'on' or 'parallel' can improve the lag. > It allows to replicate changes before huge transactions are committed. Sorry if I was inaccurate. I want to understand the scope of this feature: what benefit does the code provide to the current master in the case of async LR? Of course, it is a prerequisite to enable streaming and parallel apply - without these settings, your code is not working, is it? Put aside transaction sizes - it's usually hard to predict. We may think about a mix, but it would be enough to benchmark two corner cases - very short (single row) and long (let’s say 10% of a table) transactions to be sure we have no degradation. I just wonder if the main use case for this approach is synchronous commit and a good-enough network. Is it correct? > >> Or the WALsender process that decodes WAL records from a >> hundred actively committing backends, a bottleneck here? > > Can you clarify your use case bit more? E.g., how many instances subscribe the > change from the same publisher. The cheat sheet [1] may be helpful to distinguish > the bottleneck. I keep in mind two cases (For simplicity, let’s imagine we have only one publisher-subscriber.): 1. We have a low-latency network. If we add more and more load to the main instance, which process will be the first bottleneck: walsender or subscriber? 2. We have a stable load and walsender cope the WAL decoding and fills the output socket with transactions. In case latency goes down (geographically distributed configuration), may we profit from these new changes in parallel apply feature if the network bandwidth is wide enough? -- regards, Andrei Lepikhov, pgEdge
On Thu, Dec 18, 2025 at 2:14 PM Andrei Lepikhov <lepihov@gmail.com> wrote: > > On 18/12/25 07:44, Hayato Kuroda (Fujitsu) wrote: > > Dear Andrei, > > > >>> I have been spending time for benchmarking the patch set. Here is an updated > >>> report. > >>> > >> I apologise if my question is incorrect. But what about asynchronous > >> replication? Does this method help to reduce lag? > >> > >> My case is a replica located far from the main instance. There are an > >> inevitable lag exists. Do your benchmarks provide any insights into the > >> lag reduction? > > > > Yes, ideally parallel apply can reduce the lag, but note that it affects after > > changes are reached to the subscriber. It may not be so effective if lag is > > caused by the network. If your transaction is large and you did not enable the > > streaming option, changing it to 'on' or 'parallel' can improve the lag. > > It allows to replicate changes before huge transactions are committed. > > Sorry if I was inaccurate. I want to understand the scope of this > feature: what benefit does the code provide to the current master in the > case of async LR? Of course, it is a prerequisite to enable streaming > and parallel apply - without these settings, your code is not working, > is it? > > Put aside transaction sizes - it's usually hard to predict. We may think > about a mix, but it would be enough to benchmark two corner cases - very > short (single row) and long (let’s say 10% of a table) transactions to > be sure we have no degradation. > > I just wonder if the main use case for this approach is synchronous > commit and a good-enough network. Is it correct? > It should help async workload as well, the key criteria is that the apply-worker is not able to deal with load from the publisher. > > > >> Or the WALsender process that decodes WAL records from a > >> hundred actively committing backends, a bottleneck here? > > > > Can you clarify your use case bit more? E.g., how many instances subscribe the > > change from the same publisher. The cheat sheet [1] may be helpful to distinguish > > the bottleneck. > > I keep in mind two cases (For simplicity, let’s imagine we have only one > publisher-subscriber.): > > 1. We have a low-latency network. If we add more and more load to the > main instance, which process will be the first bottleneck: walsender or > subscriber? > Ideally, it should be subscriber because it has to do more work w.r.t applying the changes. So, the proposed feature should help these cases. > 2. We have a stable load and walsender cope the WAL decoding and fills > the output socket with transactions. In case latency goes down > (geographically distributed configuration), may we profit from these new > changes in parallel apply feature if the network bandwidth is wide enough? > I think so. However, it would be helpful if you can measure performance in such cases either now or once the patch is in bit more stabilized shape after some cycles of review. -- With Regards, Amit Kapila.
Dear Andrei, > > Yes, ideally parallel apply can reduce the lag, but note that it affects after > > changes are reached to the subscriber. It may not be so effective if lag is > > caused by the network. If your transaction is large and you did not enable the > > streaming option, changing it to 'on' or 'parallel' can improve the lag. > > It allows to replicate changes before huge transactions are committed. > > Sorry if I was inaccurate. I want to understand the scope of this > feature: what benefit does the code provide to the current master in the > case of async LR? This feature, applying non-streaming transactions in parallel, can improve the performance when many numbers of transactions are committed on the publisher side and apply worker is a bottleneck. Please see the attached primitive diagram. Assuming receiving changes need one time unit and applying changes also need a time unit. If leader does all tasks alone, it needs eight time-units. But if there are parallel workers which apply changes in parallel, leader can concentrate receiving items and reduce the total time. I think this fact is not depends on whether it is the sync LR or not. > Of course, it is a prerequisite to enable streaming > and parallel apply - without these settings, your code is not working, > is it? Let me clarify. A subscription option 'streaming' affects how we handle large transactions. 'on' means that large transactions can be streamed before the commit, and it is stored on the subscriber side. 'parallel' also means transactions can be streamed and it can be applied by the parallel workers. Actually these options are not related with the proposal. This patch focuses on the relatively small ones which are not streamed before committing. > I just wonder if the main use case for this approach is synchronous > commit and a good-enough network. Is it correct? Both (a)-sync replication can work well. But it might not so effective if the transporting data spent 90% of the time. Leader would spend most of the same time with HEAD and the patched case. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
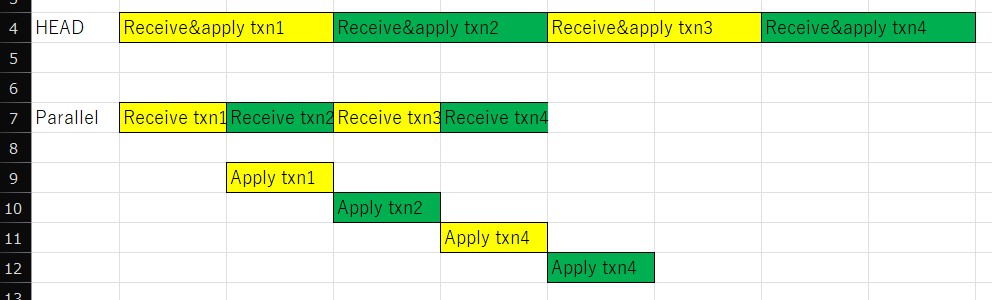{kind=link}
Dear Hackers, I have been spending time for implementing the patch, and I think it's time to share on -hackers. Patches 0001-0004 are largely not changed; some refactoring were done. Now 0004 has a basic test for dependency tracking. Remained patches enhance the parallel apply feature. 0006, 0007 and 0008 contains tests. 0005 was copied from [1]. The patch is needed for applying the prepared transactions correctly. Please post comments at [1] if you have any comments on it. 0006 contains changes for supporting two-phase transactions in parallel. Parallel workers can be assigned when the BEGIN_PREPARE message comes, and released after the PREPARE message. As with normal non-streamed transactions, prepared transactions are marked as parallelized when the leader dispatches a PREPARE message to the parallel workers, and they are removed when the parallel worker finishes preparing. This allows upcoming transactions to not commit transactions till the parallel worker finishes the preparation. Same as streaming transactions, COMMIT/ROLLBACK PREPARED messages are handled by the leader worker. At that time, the leader waits for the last transaction launched to finish. 0007 contains changes to track dependencies for streamed transactions. In streaming=on mode, dependency tracking and waiting are performed while changes are applied. The leader does nothing while serializing changes. In the case of streaming=parallel mode, we must track and wait based on dependencies. Basically, non-streamed transactions do not have to wait for streamed transactions because the leader worker always waits for them to be applied. In contrast, streamed transactions must wait for the lastly dispatched non-streamed transactions. Based on that, streamed transactions won't be marked as parallelized, and the XID of the streamed transaction won't be set for the replica identity hash entry. This means no parallel workers would wait for the streamed transactions. Other than that, dependency tracking is done the same as in a non-streaming case. 0008 contains changes to track dependencies based on subscriber-local indexes. This extends the RI hash table to allow values to be stored based on local indexes. The information, which indexes are defined for the table, is gathered by leader, when the dependency checking for the table is firstly done in a transaction. The detection mechanism is mostly the same as the RI case. How do you feel? [1]: https://www.postgresql.org/message-id/TY4PR01MB169078771FB31B395AB496A6B94B4A%40TY4PR01MB16907.jpnprd01.prod.outlook.com [2]: https://www.postgresql.org/message-id/OS0PR01MB5716D43CB68DB8FFE73BF65D942AA%40OS0PR01MB5716.jpnprd01.prod.outlook.com Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- v5-0001-Introduce-new-type-of-logical-replication-message.patch
- v5-0002-Introduce-a-shared-hash-table-to-store-paralleliz.patch
- v5-0003-Introduce-a-local-hash-table-to-store-replica-ide.patch
- v5-0004-Parallel-apply-non-streaming-transactions.patch
- v5-0005-Fix-unexpected-origin-advancement-during-parallel.patch
- v5-0006-support-2PC.patch
- v5-0007-Track-dependencies-for-streamed-transactions.patch
- v5-0008-Support-dependency-tracking-via-local-unique-inde.patch
Dear Hackers, Here is a rebased version. Since the parallel worker's bug has been fixed, the patch is not attached anymore. 0006 contains changes to handle the case that user-defined triggers are not immutable. Some triggers may change their behaviors based on the number of tuples and other internal states. To keep the result consistent with the non-parallel case, parallel workers wait to apply changes till the previous transaction is committed if the target relation has such triggers. Note that we assume CHECK constraints are immutable, so they are not checked. I think it is a reasonable assumption because it has already been described in the doc [1]. (This does not contain tests yet) 0007 contains changes for track dependencies by local indexes. It was mostly the same as v5-0008. Since I cannot find a reasonable way to compute a hash for expression indexes, these indexes are no longer used for tracking. Instead, the parallel worker waits to apply changes till the previous transaction is committed if the target relation has such indexes. [1]: https://www.postgresql.org/docs/current/ddl-constraints.html Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- v6-0001-Introduce-a-shared-hash-table-to-store-paralleliz.patch
- v6-0002-Introduce-a-local-hash-table-to-store-replica-ide.patch
- v6-0003-Parallel-apply-non-streaming-transactions.patch
- v6-0004-support-2PC.patch
- v6-0005-Track-dependencies-for-streamed-transactions.patch
- v6-0006-Wait-applying-transaction-if-one-of-user-defined-.patch
- v6-0007-Support-dependency-tracking-via-local-unique-inde.patch
> Here is a rebased version. Oh, I mistook run the git format-patch command. Here is a correct set. the sequence number is incremented. > 0006 contains changes to handle the case that user-defined triggers are not... It should be 0007. > 0007 contains changes for track dependencies by local indexes. It was mostly the... It should be 0008. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- v6_2-0001-Introduce-new-type-of-logical-replication-messa.patch
- v6_2-0002-Introduce-a-shared-hash-table-to-store-parallel.patch
- v6_2-0003-Introduce-a-local-hash-table-to-store-replica-i.patch
- v6_2-0004-Parallel-apply-non-streaming-transactions.patch
- v6_2-0005-support-2PC.patch
- v6_2-0006-Track-dependencies-for-streamed-transactions.patch
- v6_2-0007-Wait-applying-transaction-if-one-of-user-define.patch
- v6_2-0008-Support-dependency-tracking-via-local-unique-in.patch
Happy new year hackers, I found that CFbot sometimes failed tests. Per my analysis, there were two issues in the 0005 patch. The following describes two changes. 1) Took care of the case where an empty prepared transaction was replicated. The leader worker would gather even such transactions in get_flush_position() and try to clean up a replica identity hash. If the empty transaction is firstly replicated after the worker is launched, however, the replica identity hash is not yet initialized, which causes the segmentation fault. To address the issue, a guard was added to the cleanup function. As far as I know, an empty prepared transaction can happen if a) the prepared transaction has already been rolled back while decoding, or b) all changes are skipped. Added test sometimes meets a) due to the timing issue. 2) Fixed a timing issue in 050_parallel_apply.pl. The test sets the two_phase option to true, but sometimes it fails if the apply workers are not yet finished after the subscription is disabled. Now the test ensures there are no apply workers. Best regards, Hayato Kuroda FUJITSU LIMITED
Вложения
- v7-0001-Introduce-new-type-of-logical-replication-message.patch
- v7-0002-Introduce-a-shared-hash-table-to-store-paralleliz.patch
- v7-0003-Introduce-a-local-hash-table-to-store-replica-ide.patch
- v7-0004-Parallel-apply-non-streaming-transactions.patch
- v7-0005-support-2PC.patch
- v7-0006-Track-dependencies-for-streamed-transactions.patch
- v7-0007-Wait-applying-transaction-if-one-of-user-defined-.patch
- v7-0008-Support-dependency-tracking-via-local-unique-inde.patch