Обсуждение: 'ERROR: attempted to update invisible tuple' from 'ALTER INDEX ... ATTACH PARTITION' on parent index
Hi,
While testing some use cases, I encountered 'ERROR: attempted to update invisible tuple' when a partitioned index is attached to a parent index which is also a replica identity index.
Below is the reproducible test case. The issue is seen only when the commands are executed inside a transaction.
BEGIN;CREATE TABLE foo ( id INT NOT NULL, ts TIMESTAMP WITH TIME ZONE NOT NULL
) PARTITION BY RANGE (ts);
CREATE TABLE foo_2023 ( id INT NOT NULL, ts TIMESTAMP WITH TIME ZONE NOT NULL
);
ALTER TABLE ONLY foo ATTACH PARTITION foo_2023 FOR VALUES FROM ('2023-01-01 00:00:00+09') TO ('2024-01-01 00:00:00+09');
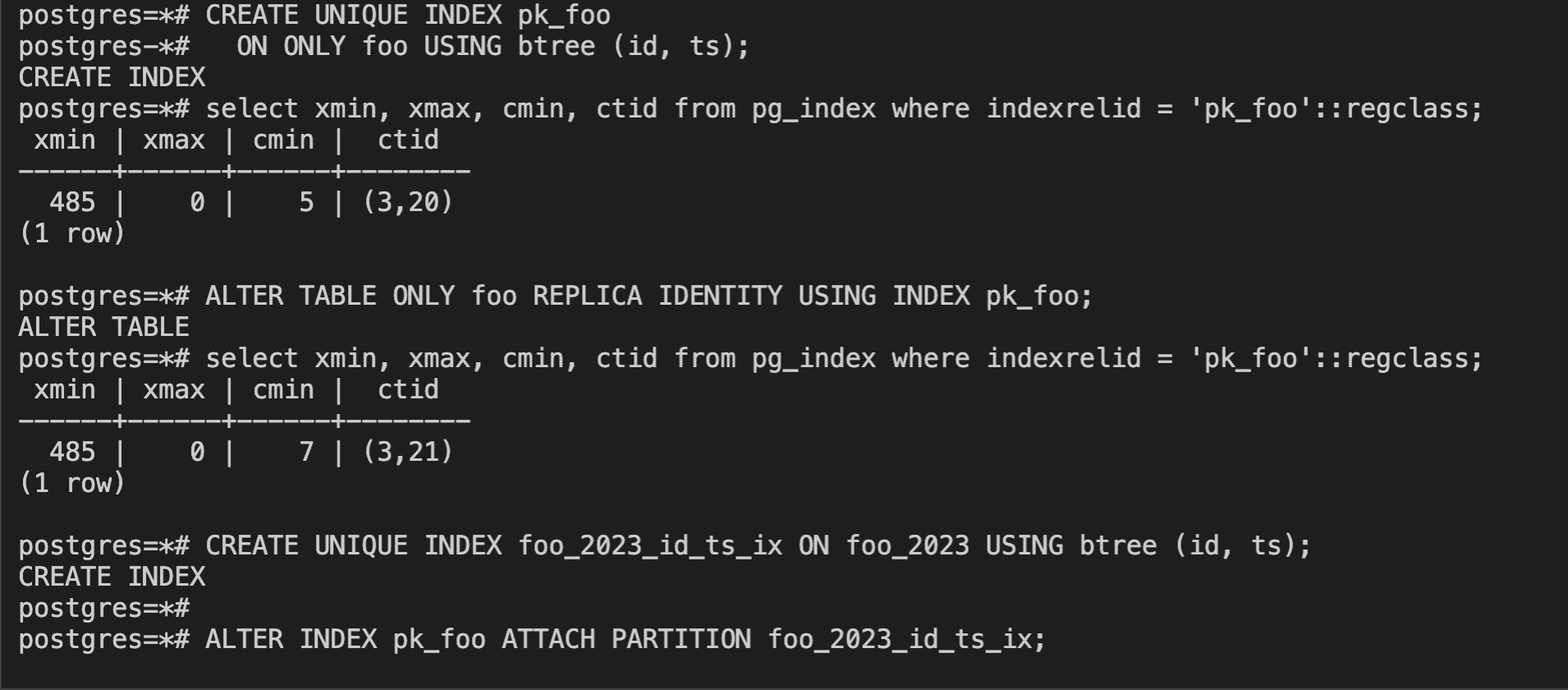
CREATE UNIQUE INDEX pk_foo ON ONLY foo USING btree (id, ts);
ALTER TABLE ONLY foo REPLICA IDENTITY USING INDEX pk_foo;
CREATE UNIQUE INDEX foo_2023_id_ts_ix ON foo_2023 USING btree (id, ts);
ALTER INDEX pk_foo ATTACH PARTITION foo_2023_id_ts_ix;
The 'ALTER INDEX pk_foo ATTACH PARTITION foo_2023_id_ts_ix' returns "ERROR: attempted to update invisible tuple"Below are few observations from debugging:
The error is seen in validatePartitionedIndex() while validating the partition.
This function marks the parent index as VALID if it found as many inherited indexes as the partitioned table has partitions.
The pg_index tuple is fetched from partedIdx->rd_indextuple.Iit looks like the index tuple is not refreshed.
The 'indisreplident' is false, the ctid field value is old and it does not reflect the ctid changes made by 'ALTER TABLE ONLY foo REPLICA IDENTITY USING INDEX pk_foo'.
Any suggestions ?
Regards,
Shruthi KC
EnterpriseDB: http://www.enterprisedb.com
Вложения
On Tue, Jul 11, 2023 at 10:52:16PM +0530, Shruthi Gowda wrote: > While testing some use cases, I encountered 'ERROR: attempted to update > invisible tuple' when a partitioned index is attached to a parent index > which is also a replica identity index. > Below is the reproducible test case. The issue is seen only when the > commands are executed inside a transaction. Thanks for the report, reproduced here. > The 'ALTER INDEX pk_foo ATTACH PARTITION foo_2023_id_ts_ix' returns > "*ERROR: attempted to update invisible tuple"* While working recently on what has led to cfc43ae and fc55c7f, I really got the feeling that there could be some command sequences that lacked some CCIs (or CommandCounterIncrement calls) to make sure that the catalog updates are visible in any follow-up steps in the same transaction. > The 'indisreplident' is false, the ctid field value is old and it does > not reflect the ctid changes made by 'ALTER TABLE ONLY foo REPLICA > IDENTITY USING INDEX pk_foo'. Your report is telling that we are missing a CCI somewhere in this sequence. I would have thought that relation_mark_replica_identity() is the correct place when the pg_index entry is dirtied, but that does not seem correct. Hmm. -- Michael
Вложения
On Wed, Jul 12, 2023 at 09:38:41AM +0900, Michael Paquier wrote:
> While working recently on what has led to cfc43ae and fc55c7f, I
> really got the feeling that there could be some command sequences that
> lacked some CCIs (or CommandCounterIncrement calls) to make sure that
> the catalog updates are visible in any follow-up steps in the same
> transaction.
Wait a minute. The validation of a partitioned index uses a copy of
the pg_index tuple from the relcache, which be out of date:
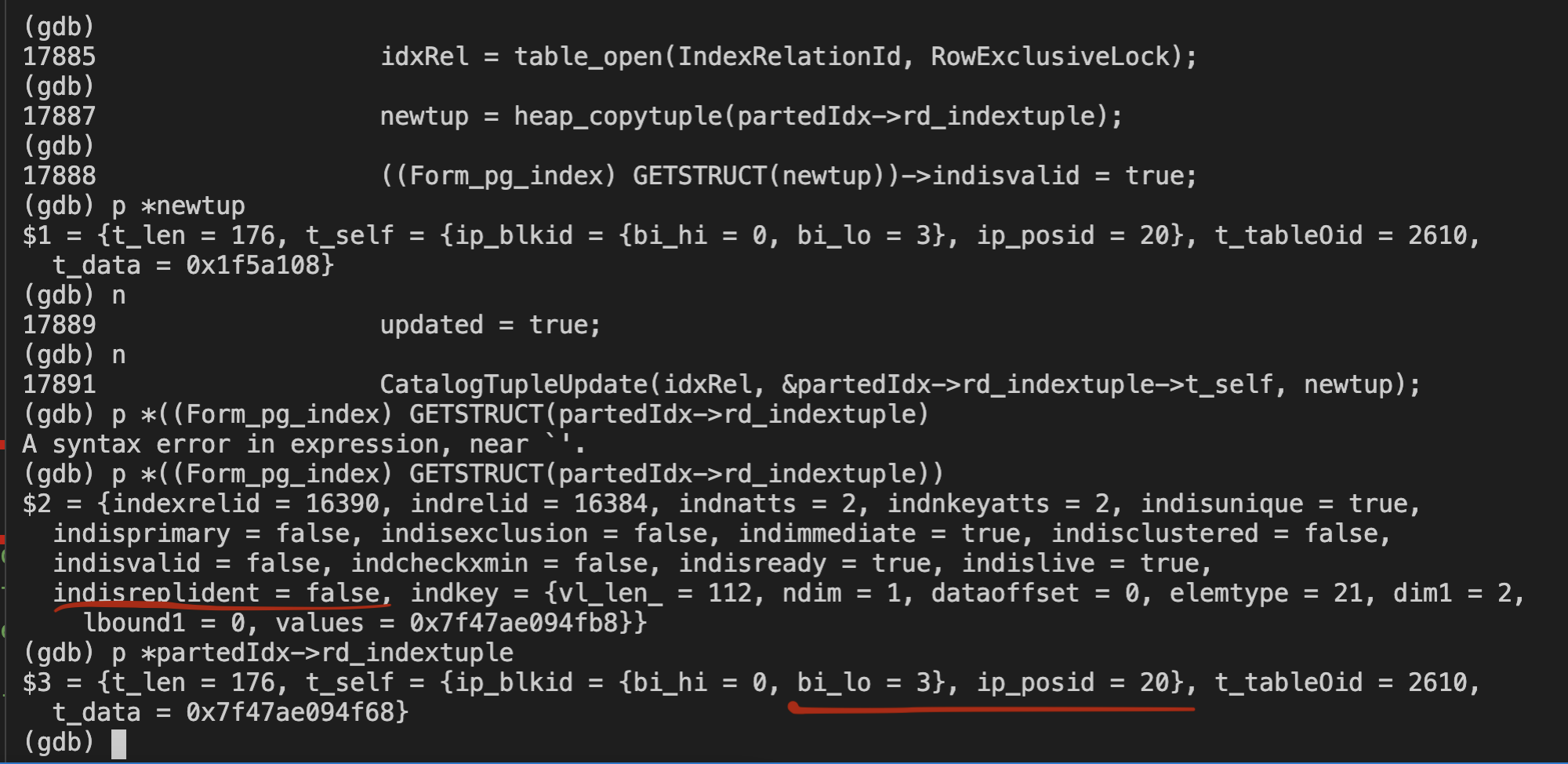
newtup = heap_copytuple(partedIdx->rd_indextuple);
((Form_pg_index) GETSTRUCT(newtup))->indisvalid = true;
And it seems to me that we should do the catalog update based on a
copy of a tuple coming from the syscache, no? Attached is a patch
that fixes your issue with more advanced regression tests that use two
levels of partitioning, looping twice through an update of indisvalid
when attaching the leaf index (the test reproduces the problem on
HEAD, as well).
--
Michael
Вложения
On Wed, Jul 12, 2023 at 11:12 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Wed, Jul 12, 2023 at 09:38:41AM +0900, Michael Paquier wrote: > > While working recently on what has led to cfc43ae and fc55c7f, I > > really got the feeling that there could be some command sequences that > > lacked some CCIs (or CommandCounterIncrement calls) to make sure that > > the catalog updates are visible in any follow-up steps in the same > > transaction. > > Wait a minute. The validation of a partitioned index uses a copy of > the pg_index tuple from the relcache, which be out of date: > newtup = heap_copytuple(partedIdx->rd_indextuple); > ((Form_pg_index) GETSTRUCT(newtup))->indisvalid = true; But why the recache entry is outdated, does that mean that in the previous command, we missed registering the invalidation for the recache entry? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Wed, Jul 12, 2023 at 11:38:05AM +0530, Dilip Kumar wrote: > On Wed, Jul 12, 2023 at 11:12 AM Michael Paquier <michael@paquier.xyz> wrote: >> >> On Wed, Jul 12, 2023 at 09:38:41AM +0900, Michael Paquier wrote: >> > While working recently on what has led to cfc43ae and fc55c7f, I >> > really got the feeling that there could be some command sequences that >> > lacked some CCIs (or CommandCounterIncrement calls) to make sure that >> > the catalog updates are visible in any follow-up steps in the same >> > transaction. >> >> Wait a minute. The validation of a partitioned index uses a copy of >> the pg_index tuple from the relcache, which be out of date: >> newtup = heap_copytuple(partedIdx->rd_indextuple); >> ((Form_pg_index) GETSTRUCT(newtup))->indisvalid = true; > > But why the recache entry is outdated, does that mean that in the > previous command, we missed registering the invalidation for the > recache entry? Yes, something's still a bit off here, even if switching a partitioned index to become valid should use a fresh tuple copy from the syscache. Taking the test case of upthread, from what I can see, the ALTER TABLE .. REPLICA IDENTITY registers two relcache invalidations for pk_foo (via RegisterRelcacheInvalidation), which is the relcache entry whose stuff is messed up. I would have expected a refresh of the cache of pk_foo to happen when doing the ALTER INDEX .. ATTACH PARTITION, but for some reason it does not happen when running the whole in a transaction block. I cannot put my finger on what's wrong for the moment, but based on my current impressions the inval requests are correctly registered when switching the replica identity, but nothing about pk_foo is updated when attaching a partition to it in the last step where the invisible update happens :/ -- Michael
Вложения
On Wed, Jul 12, 2023 at 1:56 PM Michael Paquier <michael@paquier.xyz> wrote:
>
> On Wed, Jul 12, 2023 at 11:38:05AM +0530, Dilip Kumar wrote:
> > On Wed, Jul 12, 2023 at 11:12 AM Michael Paquier <michael@paquier.xyz> wrote:
> >>
> >> On Wed, Jul 12, 2023 at 09:38:41AM +0900, Michael Paquier wrote:
> >> > While working recently on what has led to cfc43ae and fc55c7f, I
> >> > really got the feeling that there could be some command sequences that
> >> > lacked some CCIs (or CommandCounterIncrement calls) to make sure that
> >> > the catalog updates are visible in any follow-up steps in the same
> >> > transaction.
> >>
> >> Wait a minute. The validation of a partitioned index uses a copy of
> >> the pg_index tuple from the relcache, which be out of date:
> >> newtup = heap_copytuple(partedIdx->rd_indextuple);
> >> ((Form_pg_index) GETSTRUCT(newtup))->indisvalid = true;
> >
> > But why the recache entry is outdated, does that mean that in the
> > previous command, we missed registering the invalidation for the
> > recache entry?
>
> Yes, something's still a bit off here, even if switching a partitioned
> index to become valid should use a fresh tuple copy from the syscache.
>
> Taking the test case of upthread, from what I can see, the ALTER TABLE
> .. REPLICA IDENTITY registers two relcache invalidations for pk_foo
> (via RegisterRelcacheInvalidation), which is the relcache entry whose
> stuff is messed up. I would have expected a refresh of the cache of
> pk_foo to happen when doing the ALTER INDEX .. ATTACH PARTITION, but
> for some reason it does not happen when running the whole in a
> transaction block.
I think there is something to do with this code here[1], basically, we
are in a transaction block so while processing the invalidation we
have first cleared the entry for the pk_foo but then we have partially
recreated it using 'RelationReloadIndexInfo', in this function we
haven't build complete relation descriptor but marked
'relation->rd_isvalid' as true and due to that next relation_open in
(ALTER INDEX .. ATTACH PARTITION) will reuse this half backed entry.
I am still not sure what is the purpose of just reloading the index
and marking the entry as valid which is not completely valid.
RelationClearRelation()
{
..
/*
* Even non-system indexes should not be blown away if they are open and
* have valid index support information. This avoids problems with active
* use of the index support information. As with nailed indexes, we
* re-read the pg_class row to handle possible physical relocation of the
* index, and we check for pg_index updates too.
*/
if ((relation->rd_rel->relkind == RELKIND_INDEX ||
relation->rd_rel->relkind == RELKIND_PARTITIONED_INDEX) &&
relation->rd_refcnt > 0 &&
relation->rd_indexcxt != NULL)
{
if (IsTransactionState())
RelationReloadIndexInfo(relation);
return;
}
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
On Tue, Jul 11, 2023 at 1:22 PM Shruthi Gowda <gowdashru@gmail.com> wrote:
BEGIN;CREATE TABLE foo ( id INT NOT NULL, ts TIMESTAMP WITH TIME ZONE NOT NULL ) PARTITION BY RANGE (ts); CREATE TABLE foo_2023 ( id INT NOT NULL, ts TIMESTAMP WITH TIME ZONE NOT NULL ); ALTER TABLE ONLY foo ATTACH PARTITION foo_2023 FOR VALUES FROM ('2023-01-01 00:00:00+09') TO ('2024-01-01 00:00:00+09'); CREATE UNIQUE INDEX pk_foo ON ONLY foo USING btree (id, ts); ALTER TABLE ONLY foo REPLICA IDENTITY USING INDEX pk_foo; CREATE UNIQUE INDEX foo_2023_id_ts_ix ON foo_2023 USING btree (id, ts); ALTER INDEX pk_foo ATTACH PARTITION foo_2023_id_ts_ix;
This example confused me quite a bit when I first read it. I think that the documentation for CREATE INDEX .. ONLY is pretty inadequate. All it says is "Indicates not to recurse creating indexes on partitions, if the table is partitioned. The default is to recurse." But that would just create a permanently empty index, which is of no use to anyone. I think we should somehow explain the intent of this, namely that this creates an initially invalid index which can be made valid by using ALTER INDEX ... ATTACH PARTITION once per partition.
On Wed, Jul 12, 2023 at 4:26 AM Michael Paquier <michael@paquier.xyz> wrote: > Taking the test case of upthread, from what I can see, the ALTER TABLE > .. REPLICA IDENTITY registers two relcache invalidations for pk_foo > (via RegisterRelcacheInvalidation), which is the relcache entry whose > stuff is messed up. I would have expected a refresh of the cache of > pk_foo to happen when doing the ALTER INDEX .. ATTACH PARTITION, but > for some reason it does not happen when running the whole in a > transaction block. I cannot put my finger on what's wrong for the > moment, but based on my current impressions the inval requests are > correctly registered when switching the replica identity, but nothing > about pk_foo is updated when attaching a partition to it in the last > step where the invisible update happens :/ I'm not sure exactly what is happening here, but it looks to me like ATExecReplicaIdentity() only takes ShareLock on the index and nevertheless feels entitled to update the pg_index tuple, which is pretty strange. We normally require AccessExclusiveLock to perform DDL on an object, and in the limited exceptions that we have to that rule - see AlterTableGetLockLevel - it's pretty much always a self-exclusive lock. Otherwise, two backends might try to do the same DDL operation at the same time, which would lead to low-level failures trying to update the same tuple such as the one seen here. But even if that doesn't happen or is prevented by some other mechanism, there's still a synchronization problem. Suppose backend B1 modifies some state via a DDL operation on table T and then afterward backend B2 wants to perform a non-DDL operation that depends on that state. Well, B1 takes some lock on the relation, and B2 takes a lock that would conflict with it, and that guarantees that B2 starts after B1 commits. That means that B2 is guaranteed to see the invalidations that were queued by B1, which means it will flush any state out of its cache that was made stale by the operation performed by B1. If the locks didn't conflict, B2 might start before B1 committed and either fail to update its caches or update them but with a version of the tuples that's about to be made obsolete when B1 commits. So ShareLock doesn't feel like a very safe choice here. But I'm not quite sure exactly what's going wrong, either. Every update is going to call CacheInvalidateHeapTuple(), and updating either an index's pg_class tuple or its pg_index tuple should queue up a relcache invalidation, and CommandEndInvalidationMessages() should cause that to be processed. If this were multiple transactions, the only thing that would be different is that the invalidation messages would be in the shared queue, so maybe there's something going on with the timing of CommandEndInvalidationMessages() vs. AcceptInvalidationMessages() that accounts for the problem occurring in one case but not the other. But I do wonder whether the underlying problem is that what ATExecReplicaIdentity() is doing is not really safe. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Jul 12, 2023 at 5:46 PM Dilip Kumar <dilipbalaut@gmail.com> wrote:
On Wed, Jul 12, 2023 at 1:56 PM Michael Paquier <michael@paquier.xyz> wrote:
>
> On Wed, Jul 12, 2023 at 11:38:05AM +0530, Dilip Kumar wrote:
> > On Wed, Jul 12, 2023 at 11:12 AM Michael Paquier <michael@paquier.xyz> wrote:
> >>
> >> On Wed, Jul 12, 2023 at 09:38:41AM +0900, Michael Paquier wrote:
> >> > While working recently on what has led to cfc43ae and fc55c7f, I
> >> > really got the feeling that there could be some command sequences that
> >> > lacked some CCIs (or CommandCounterIncrement calls) to make sure that
> >> > the catalog updates are visible in any follow-up steps in the same
> >> > transaction.
> >>
> >> Wait a minute. The validation of a partitioned index uses a copy of
> >> the pg_index tuple from the relcache, which be out of date:
> >> newtup = heap_copytuple(partedIdx->rd_indextuple);
> >> ((Form_pg_index) GETSTRUCT(newtup))->indisvalid = true;
> >
> > But why the recache entry is outdated, does that mean that in the
> > previous command, we missed registering the invalidation for the
> > recache entry?
>
> Yes, something's still a bit off here, even if switching a partitioned
> index to become valid should use a fresh tuple copy from the syscache.
>
> Taking the test case of upthread, from what I can see, the ALTER TABLE
> .. REPLICA IDENTITY registers two relcache invalidations for pk_foo
> (via RegisterRelcacheInvalidation), which is the relcache entry whose
> stuff is messed up. I would have expected a refresh of the cache of
> pk_foo to happen when doing the ALTER INDEX .. ATTACH PARTITION, but
> for some reason it does not happen when running the whole in a
> transaction block.
I think there is something to do with this code here[1], basically, we
are in a transaction block so while processing the invalidation we
have first cleared the entry for the pk_foo but then we have partially
recreated it using 'RelationReloadIndexInfo', in this function we
haven't build complete relation descriptor but marked
'relation->rd_isvalid' as true and due to that next relation_open in
(ALTER INDEX .. ATTACH PARTITION) will reuse this half backed entry.
I am still not sure what is the purpose of just reloading the index
and marking the entry as valid which is not completely valid.
RelationClearRelation()
{
..
/*
* Even non-system indexes should not be blown away if they are open and
* have valid index support information. This avoids problems with active
* use of the index support information. As with nailed indexes, we
* re-read the pg_class row to handle possible physical relocation of the
* index, and we check for pg_index updates too.
*/
if ((relation->rd_rel->relkind == RELKIND_INDEX ||
relation->rd_rel->relkind == RELKIND_PARTITIONED_INDEX) &&
relation->rd_refcnt > 0 &&
relation->rd_indexcxt != NULL)
{
if (IsTransactionState())
RelationReloadIndexInfo(relation);
return;
}
I reviewed the function RelationReloadIndexInfo() and observed that the 'indisreplident' field and the SelfItemPointer 't_self' are not refreshed to the pg_index tuple of the index.
Attached is the patch that fixes the above issue.
Вложения
On Wed, Jul 12, 2023 at 12:28 PM Shruthi Gowda <gowdashru@gmail.com> wrote: > I reviewed the function RelationReloadIndexInfo() and observed that the 'indisreplident' field and the SelfItemPointer't_self' are not refreshed to the pg_index tuple of the index. > Attached is the patch that fixes the above issue. Oh, interesting. The fact that indisreplident isn't copied seems like a pretty clear mistake, but I'm guessing that the fact that t_self wasn't refreshed was deliberate and that the author of this code didn't really intend for callers to look at the t_self value. We could change our mind about whether that ought to be allowed, though. But, like, none of the other tuple header fields are copied either... xmax, xvac, infomask, etc. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Jul 12, 2023 at 04:02:23PM -0400, Robert Haas wrote:
> Oh, interesting. The fact that indisreplident isn't copied seems like
> a pretty clear mistake, but I'm guessing that the fact that t_self
> wasn't refreshed was deliberate and that the author of this code
> didn't really intend for callers to look at the t_self value. We could
> change our mind about whether that ought to be allowed, though. But,
> like, none of the other tuple header fields are copied either... xmax,
> xvac, infomask, etc.
See 3c84046 and 8ec9438, mainly, from Tom. I didn't know that this is
used as a shortcut to reload index information in the cache because it
is much cheaper than a full index information rebuild. I agree that
not copying indisreplident in this code path is a mistake as this bug
shows, because any follow-up command run in a transaction that changed
this field would get an incorrect information reference.
Now, I have to admit that I am not completely sure what the
consequences of this addition are when it comes to concurrent index
operations (CREATE/DROP INDEX, REINDEX):
/* Copy xmin too, as that is needed to make sense of indcheckxmin */
HeapTupleHeaderSetXmin(relation->rd_indextuple->t_data,
HeapTupleHeaderGetXmin(tuple->t_data));
+ ItemPointerCopy(&tuple->t_self, &relation->rd_indextuple->t_self);
Anyway, as I have pointed upthread, I think that the craziness is also
in validatePartitionedIndex() where this stuff thinks that it is OK to
use a copy the pg_index tuple coming from the relcache. As this
report proves, it is *not* safe, because we may miss a lot of
information not updated by RelationReloadIndexInfo() that other
commands in the same transaction block may have updated, and the
code would insert into the catalog an inconsistent tuple for a
partitioned index switched to become valid.
I agree that updating indisreplident in this cheap index reload path
is necessary, as well. Does my suggestion of using the syscache not
make sense for somebody here? Note that this is what all the other
code paths do for catalog updates of pg_index when retrieving a copy
of its tuples.
--
Michael
Вложения
On Wed, Jul 12, 2023 at 10:01:49AM -0400, Robert Haas wrote: > I'm not sure exactly what is happening here, but it looks to me like > ATExecReplicaIdentity() only takes ShareLock on the index and > nevertheless feels entitled to update the pg_index tuple, which is > pretty strange. We normally require AccessExclusiveLock to perform DDL > on an object, and in the limited exceptions that we have to that rule > - see AlterTableGetLockLevel - it's pretty much always a > self-exclusive lock. Otherwise, two backends might try to do the same > DDL operation at the same time, which would lead to low-level failures > trying to update the same tuple such as the one seen here. > > But even if that doesn't happen or is prevented by some other > mechanism, there's still a synchronization problem. Suppose backend B1 > modifies some state via a DDL operation on table T and then afterward > backend B2 wants to perform a non-DDL operation that depends on that > state. Well, B1 takes some lock on the relation, and B2 takes a lock > that would conflict with it, and that guarantees that B2 starts after > B1 commits. That means that B2 is guaranteed to see the invalidations > that were queued by B1, which means it will flush any state out of its > cache that was made stale by the operation performed by B1. If the > locks didn't conflict, B2 might start before B1 committed and either > fail to update its caches or update them but with a version of the > tuples that's about to be made obsolete when B1 commits. So ShareLock > doesn't feel like a very safe choice here. Yes, I also got to wonder whether it is OK to hold only a ShareLock for the index being used as a replica identity. We hold an AEL on the parent table, and ShareLock is sufficient to prevent concurrent schema operations until the transaction that took the lock commit. But surely, that feels inconsistent with the common practices in tablecmds.c. -- Michael
Вложения
On Thu, Jul 13, 2023 at 3:56 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Wed, Jul 12, 2023 at 04:02:23PM -0400, Robert Haas wrote: > > Oh, interesting. The fact that indisreplident isn't copied seems like > > a pretty clear mistake, but I'm guessing that the fact that t_self > > wasn't refreshed was deliberate and that the author of this code > > didn't really intend for callers to look at the t_self value. We could > > change our mind about whether that ought to be allowed, though. But, > > like, none of the other tuple header fields are copied either... xmax, > > xvac, infomask, etc. > > See 3c84046 and 8ec9438, mainly, from Tom. I didn't know that this is > used as a shortcut to reload index information in the cache because it > is much cheaper than a full index information rebuild. I agree that > not copying indisreplident in this code path is a mistake as this bug > shows, because any follow-up command run in a transaction that changed > this field would get an incorrect information reference. > > Now, I have to admit that I am not completely sure what the > consequences of this addition are when it comes to concurrent index > operations (CREATE/DROP INDEX, REINDEX): > /* Copy xmin too, as that is needed to make sense of indcheckxmin */ > HeapTupleHeaderSetXmin(relation->rd_indextuple->t_data, > HeapTupleHeaderGetXmin(tuple->t_data)); > + ItemPointerCopy(&tuple->t_self, &relation->rd_indextuple->t_self); > > Anyway, as I have pointed upthread, I think that the craziness is also > in validatePartitionedIndex() where this stuff thinks that it is OK to > use a copy the pg_index tuple coming from the relcache. As this > report proves, it is *not* safe, because we may miss a lot of > information not updated by RelationReloadIndexInfo() that other > commands in the same transaction block may have updated, and the > code would insert into the catalog an inconsistent tuple for a > partitioned index switched to become valid. > > I agree that updating indisreplident in this cheap index reload path > is necessary, as well. Does my suggestion of using the syscache not > make sense for somebody here? Note that this is what all the other > code paths do for catalog updates of pg_index when retrieving a copy > of its tuples. Yeah, It seems that using pg_index tuples from relcache is not safe, at least for updating the catalog tuples. However, are there known rules or do we need to add some comments saying that the pg_index tuple from the relcache cannot be used to update the catalog tuple? Or do we actually need to update all the tuple header information as well in RelationReloadIndexInfo() in order to fix that invariant so that it can be used for catalog tuple updates as well? -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Thu, Jul 13, 2023 at 09:35:17AM +0530, Dilip Kumar wrote: > Yeah, It seems that using pg_index tuples from relcache is not safe, > at least for updating the catalog tuples. However, are there known > rules or do we need to add some comments saying that the pg_index > tuple from the relcache cannot be used to update the catalog tuple? I don't recall an implied rule written in the tree about that, on top of my mind. Perhaps something about that could be done around the declaration of RelationData in rel.h, for instance. > Or do we actually need to update all the tuple header information as > well in RelationReloadIndexInfo() in order to fix that invariant so > that it can be used for catalog tuple updates as well? RelationReloadIndexInfo() is designed to be minimal, so I am not really excited about extending it more than necessary without a case in favor of it. indisreplident is clearly on the list of things to update in this concept. The others would need a more careful evaluation, though we don't really have a case for doing more, IMO, particularly in the score of stable branches. -- Michael
Вложения
On Thu, Jul 13, 2023 at 02:26:42PM +0900, Michael Paquier wrote: > On Thu, Jul 13, 2023 at 09:35:17AM +0530, Dilip Kumar wrote: >> Or do we actually need to update all the tuple header information as >> well in RelationReloadIndexInfo() in order to fix that invariant so >> that it can be used for catalog tuple updates as well? > > RelationReloadIndexInfo() is designed to be minimal, so I am not > really excited about extending it more than necessary without a case > in favor of it. indisreplident is clearly on the list of things to > update in this concept. The others would need a more careful > evaluation, though we don't really have a case for doing more, IMO, > particularly in the score of stable branches. FYI, I was planning to do something about this thread in the shape of two different patches: one for the indisreplident missing from the RelationReloadIndexInfo() and one for the syscache issue in the partitioned index validation. indisreplident use in the backend code is interesting, as, while double-checking the code, I did not find a code path involving a command where indisreplident would be checked from the pg_index tuple in the relcache: all the values are from tuples retrieved from the syscache. -- Michael
Вложения
On Thu, Jul 13, 2023 at 1:40 PM Michael Paquier <michael@paquier.xyz> wrote:
On Thu, Jul 13, 2023 at 02:26:42PM +0900, Michael Paquier wrote:
> On Thu, Jul 13, 2023 at 09:35:17AM +0530, Dilip Kumar wrote:
>> Or do we actually need to update all the tuple header information as
>> well in RelationReloadIndexInfo() in order to fix that invariant so
>> that it can be used for catalog tuple updates as well?
>
> RelationReloadIndexInfo() is designed to be minimal, so I am not
> really excited about extending it more than necessary without a case
> in favor of it. indisreplident is clearly on the list of things to
> update in this concept. The others would need a more careful
> evaluation, though we don't really have a case for doing more, IMO,
> particularly in the score of stable branches.
FYI, I was planning to do something about this thread in the shape of
two different patches: one for the indisreplident missing from the
RelationReloadIndexInfo() and one for the syscache issue in the
partitioned index validation. indisreplident use in the backend code
is interesting, as, while double-checking the code, I did not find a
code path involving a command where indisreplident would be checked
from the pg_index tuple in the relcache: all the values are from
tuples retrieved from the syscache.
Agree with the idea of splitting the patch.
While analyzing the issue I did notice that validatePartitionedIndex() is the only place where the index tuple was copied from rel->rd_indextuple however was not clear about the motive behind it.
Regards,
Shruthi KC
EnterpriseDB: http://www.enterprisedb.com
On Thu, Jul 13, 2023 at 02:01:49PM +0530, Shruthi Gowda wrote: > While analyzing the issue I did notice that validatePartitionedIndex() is > the only place where the index tuple was copied from rel->rd_indextuple > however was not clear about the motive behind it. No idea either. Anyway, I've split this stuff into two parts and applied the whole across the whole set of stable branches. Thanks! -- Michael