Обсуждение: [PATCH] reduce page overlap of GiST indexes built using sorted method
Hey!
Postgres 14 introduces an option to create a GiST index using a sort method. It allows to create indexes much faster but as it had been mentioned in sort support patch discussion the faster build performance comes at cost of higher degree of overlap between pages than for indexes built with regular method.
Sort support was implemented for GiST opclass in PostGIS but eventually got removed as default behaviour in latest 3.2 release because as it had been discovered by Paul Ramsey https://lists.osgeo.org/pipermail/postgis-devel/2021-November/029225.html performance of queries might degrade by 50%.
Together with Darafei Praliaskouski, Andrey Borodin and me we tried several approaches to solve query performance degrade:
- The first attempt was try to decide whether to make a split depending on direction of curve (Z-curve for Postgres geometry type, Hilbert curve for PostGIS). It was implemented by filling page until fillfactor / 2 and then checking penalty for every next item and keep inserting in current page if penalty is 0 or start new page if penalty is not 0. It turned out that with this approach index becomes significantly larger whereas pages overlap still remains high.
- Andrey Borodin implemented LRU + split: a fixed amount of pages are kept in memory and the best candidate page to insert the next item in is selected by minimum penalty among these pages. If the best page for insertion is full, it gets splited into multiple pages, and if the amount of candidate pages after split exceeds the limit, the pages insertion to which has not happened recently are flushed. https://github.com/x4m/postgres_g/commit/0f2ed5f32a00f6c3019048e0c145b7ebda629e73. We made some tests and while query performance speed using index built with this approach is fine a size of index is extremely large.
Eventually we made implementation of an idea outlined in sort support patch discussion here https://www.postgresql.org/message-id/flat/08173bd0-488d-da76-a904-912c35da446b@iki.fi#09ac9751a4cde897c99b99b2170faf3a that several pages can be collected and then divided into actual index pages by calling picksplit. My benchmarks with data provided in postgis-devel show that query performance using index built with patched sort support is comparable with performance of query using index built with regular method. The size of index is also matches size of index built with non-sorting method.
It should be noted that with the current implementation of the sorting build method, pages are always filled up to fillfactor. This patch changes this behavior to what it would be if using a non-sorting method, and pages are not always filled to fillfactor for the sake of query performance. I'm interested in improving it and I wonder if there are any ideas on this.
Benchmark summary:
create index roads_rdr_idx on roads_rdr using gist (geom);
with sort support before patch / CREATE INDEX 76.709 ms
with sort support after patch / CREATE INDEX 225.238 ms
without sort support / CREATE INDEX 446.071 ms
select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
with sort support before patch / SELECT 5766.526 ms
with sort support after patch / SELECT 2646.554 ms
without sort support / SELECT 2721.718 ms
index size
with sort support before patch / IDXSIZE 2940928 bytes
with sort support after patch / IDXSIZE 4956160 bytes
without sort support / IDXSIZE 5447680 bytes
More detailed:
Before patch using sorted method:
postgres=# create index roads_rdr_geom_idx_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 76.709 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5766.526 ms (00:05.767)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5880.142 ms (00:05.880)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5778.437 ms (00:05.778)
postgres=# select gist_stat('roads_rdr_geom_idx_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 359 +
Number of leaf pages: 356 +
Number of tuples: 93034 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2609260 bytes+
Total size of leaf tuples: 2599200 bytes+
Total size of index: 2940928 bytes+
(1 row)
After patch using sorted method:
postgres=# create index roads_rdr_geom_idx_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 225.238 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2646.554 ms (00:02.647)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2499.107 ms (00:02.499)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2519.815 ms (00:02.520)
postgres=# select gist_stat('roads_rdr_geom_idx_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 605 +
Number of leaf pages: 600 +
Number of tuples: 93280 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2619100 bytes+
Total size of leaf tuples: 2602128 bytes+
Total size of index: 4956160 bytes+
(1 row)
With index built using default method:
postgres=# create index roads_rdr_geom_idx_no_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 446.071 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2721.718 ms (00:02.722)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 3549.549 ms (00:03.550)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
postgres=# select gist_stat('roads_rdr_geom_idx_no_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 665 +
Number of leaf pages: 660 +
Number of tuples: 93340 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2621500 bytes+
Total size of leaf tuples: 2602848 bytes+
Total size of index: 5447680 bytes+
(1 row)
Вложения
Re: [PATCH] reduce page overlap of GiST indexes built using sorted method
Hi Aliaksandr!
Thanks for working on this!
> Benchmark summary:
>
> create index roads_rdr_idx on roads_rdr using gist (geom);
>
> with sort support before patch / CREATE INDEX 76.709 ms
>
> with sort support after patch / CREATE INDEX 225.238 ms
>
> without sort support / CREATE INDEX 446.071 ms
>
> select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
>
> with sort support before patch / SELECT 5766.526 ms
>
> with sort support after patch / SELECT 2646.554 ms
>
> without sort support / SELECT 2721.718 ms
>
> index size
>
> with sort support before patch / IDXSIZE 2940928 bytes
>
> with sort support after patch / IDXSIZE 4956160 bytes
>
> without sort support / IDXSIZE 5447680 bytes
The numbers are impressive, newly build index is actually performing better!
I've conducted some tests over points, not PostGIS geometry. For points build is 2x slower now, but this is the cost of faster scans.
Some strong points of this index building technology.
The proposed algorithm is not randomly chosen as anything that performs better than the original sorting build. We actually researched every idea we knew from literature and intuition. Although we consciously limited the search area by existing GiST API.
Stuff like penalty-based choose-subtree and split in equal halves seriously limit possible solutions. If anyone knows an any better way to build GiST faster or with better scan performance - please let us know.
The proposed algorithm contains the current algorithm as a special case: there is a parameter - the number of buffers accumulated before calling Split. If this parameter is 1 proposed algorithm will produce exactly the same output.
At this stage, we would like to hear some feedback from Postgres and PostGIS community. What other performance aspects should we test?
Current patch implementation has some known deficiencies:
1. We need a GUC instead of the hard-coded buffer of 8 pages.
2. Is GiST sorting build still deterministic? If not - we should add a fixed random seed into pageinspect tests.
3. It would make sense to check the resulting indexes with amcheck [0], although it's not committed.
4. We cannot make an exact fillfactor due to the behavior of picksplit. But can we improve anything here? I think if not - it's still OK.
5. GistSortedBuildPageState is no more page state. It's Level state or something like that.
6. The patch desperately needs comments.
Thanks!
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/59D0DA6B-1652-4D44-B0EF-A582D5824F83%40yandex-team.ru
Вложения
Hi, here are some benchmark results for GiST patch: https://gist.github.com/mngr777/88ae200c9c30ba5656583d92e8d2cf9e Code used for benchmarking: https://github.com/mngr777/pg_index_bm2, see README for the list of test queries. Results show query performance close to indexes built with no sortsupport function, with index creation time reduced approx. by half. On 1/8/22 10:20 PM, Aliaksandr Kalenik wrote: > After further testing, here is v2 where the issue that rightlink can be > set when an index page is already flushed is fixed. > > On Sat, Dec 25, 2021 at 4:35 PM Andrey Borodin <x4mmm@yandex-team.ru > <mailto:x4mmm@yandex-team.ru>> wrote: > > > Hi Aliaksandr! > > Thanks for working on this! > > > Benchmark summary: > > > > create index roads_rdr_idx on roads_rdr using gist (geom); > > > > with sort support before patch / CREATE INDEX 76.709 ms > > > > with sort support after patch / CREATE INDEX 225.238 ms > > > > without sort support / CREATE INDEX 446.071 ms > > > > select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom; > > > > with sort support before patch / SELECT 5766.526 ms > > > > with sort support after patch / SELECT 2646.554 ms > > > > without sort support / SELECT 2721.718 ms > > > > index size > > > > with sort support before patch / IDXSIZE 2940928 bytes > > > > with sort support after patch / IDXSIZE 4956160 bytes > > > > without sort support / IDXSIZE 5447680 bytes > > The numbers are impressive, newly build index is actually performing > better! > I've conducted some tests over points, not PostGIS geometry. For > points build is 2x slower now, but this is the cost of faster scans. > > Some strong points of this index building technology. > The proposed algorithm is not randomly chosen as anything that > performs better than the original sorting build. We actually > researched every idea we knew from literature and intuition. > Although we consciously limited the search area by existing GiST API. > Stuff like penalty-based choose-subtree and split in equal halves > seriously limit possible solutions. If anyone knows an any better > way to build GiST faster or with better scan performance - please > let us know. > The proposed algorithm contains the current algorithm as a special > case: there is a parameter - the number of buffers accumulated > before calling Split. If this parameter is 1 proposed algorithm will > produce exactly the same output. > > At this stage, we would like to hear some feedback from Postgres and > PostGIS community. What other performance aspects should we test? > > Current patch implementation has some known deficiencies: > 1. We need a GUC instead of the hard-coded buffer of 8 pages. > 2. Is GiST sorting build still deterministic? If not - we should add > a fixed random seed into pageinspect tests. > 3. It would make sense to check the resulting indexes with amcheck > [0], although it's not committed. > 4. We cannot make an exact fillfactor due to the behavior of > picksplit. But can we improve anything here? I think if not - it's > still OK. > 5. GistSortedBuildPageState is no more page state. It's Level state > or something like that. > 6. The patch desperately needs comments. > > > Thanks! > > Best regards, Andrey Borodin. > > [0] > https://www.postgresql.org/message-id/flat/59D0DA6B-1652-4D44-B0EF-A582D5824F83%40yandex-team.ru > <https://www.postgresql.org/message-id/flat/59D0DA6B-1652-4D44-B0EF-A582D5824F83%40yandex-team.ru> >
Hey!
Postgres 14 introduces an option to create a GiST index using a sort method. It allows to create indexes much faster but as it had been mentioned in sort support patch discussion the faster build performance comes at cost of higher degree of overlap between pages than for indexes built with regular method.
Sort support was implemented for GiST opclass in PostGIS but eventually got removed as default behaviour in latest 3.2 release because as it had been discovered by Paul Ramsey https://lists.osgeo.org/pipermail/postgis-devel/2021-November/029225.html performance of queries might degrade by 50%.
Together with Darafei Praliaskouski, Andrey Borodin and me we tried several approaches to solve query performance degrade:
- The first attempt was try to decide whether to make a split depending on direction of curve (Z-curve for Postgres geometry type, Hilbert curve for PostGIS). It was implemented by filling page until fillfactor / 2 and then checking penalty for every next item and keep inserting in current page if penalty is 0 or start new page if penalty is not 0. It turned out that with this approach index becomes significantly larger whereas pages overlap still remains high.
- Andrey Borodin implemented LRU + split: a fixed amount of pages are kept in memory and the best candidate page to insert the next item in is selected by minimum penalty among these pages. If the best page for insertion is full, it gets splited into multiple pages, and if the amount of candidate pages after split exceeds the limit, the pages insertion to which has not happened recently are flushed. https://github.com/x4m/postgres_g/commit/0f2ed5f32a00f6c3019048e0c145b7ebda629e73. We made some tests and while query performance speed using index built with this approach is fine a size of index is extremely large.
Eventually we made implementation of an idea outlined in sort support patch discussion here https://www.postgresql.org/message-id/flat/08173bd0-488d-da76-a904-912c35da446b@iki.fi#09ac9751a4cde897c99b99b2170faf3a that several pages can be collected and then divided into actual index pages by calling picksplit. My benchmarks with data provided in postgis-devel show that query performance using index built with patched sort support is comparable with performance of query using index built with regular method. The size of index is also matches size of index built with non-sorting method.
It should be noted that with the current implementation of the sorting build method, pages are always filled up to fillfactor. This patch changes this behavior to what it would be if using a non-sorting method, and pages are not always filled to fillfactor for the sake of query performance. I'm interested in improving it and I wonder if there are any ideas on this.
Benchmark summary:
create index roads_rdr_idx on roads_rdr using gist (geom);
with sort support before patch / CREATE INDEX 76.709 ms
with sort support after patch / CREATE INDEX 225.238 ms
without sort support / CREATE INDEX 446.071 ms
select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
with sort support before patch / SELECT 5766.526 ms
with sort support after patch / SELECT 2646.554 ms
without sort support / SELECT 2721.718 ms
index size
with sort support before patch / IDXSIZE 2940928 bytes
with sort support after patch / IDXSIZE 4956160 bytes
without sort support / IDXSIZE 5447680 bytes
More detailed:Before patch using sorted method:
postgres=# create index roads_rdr_geom_idx_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 76.709 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5766.526 ms (00:05.767)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5880.142 ms (00:05.880)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 5778.437 ms (00:05.778)
postgres=# select gist_stat('roads_rdr_geom_idx_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 359 +
Number of leaf pages: 356 +
Number of tuples: 93034 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2609260 bytes+
Total size of leaf tuples: 2599200 bytes+
Total size of index: 2940928 bytes+
(1 row)
After patch using sorted method:postgres=# create index roads_rdr_geom_idx_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 225.238 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2646.554 ms (00:02.647)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2499.107 ms (00:02.499)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2519.815 ms (00:02.520)
postgres=# select gist_stat('roads_rdr_geom_idx_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 605 +
Number of leaf pages: 600 +
Number of tuples: 93280 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2619100 bytes+
Total size of leaf tuples: 2602128 bytes+
Total size of index: 4956160 bytes+
(1 row)
With index built using default method:
postgres=# create index roads_rdr_geom_idx_no_sortsupport on roads_rdr using gist(geom);
CREATE INDEX
Time: 446.071 ms
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 2721.718 ms (00:02.722)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
Time: 3549.549 ms (00:03.550)
postgres=# select count(*) from roads_rdr a, roads_rdr b where a.geom && b.geom;
count
--------
505806
(1 row)
postgres=# select gist_stat('roads_rdr_geom_idx_no_sortsupport');
gist_stat
------------------------------------------
Number of levels: 3 +
Number of pages: 665 +
Number of leaf pages: 660 +
Number of tuples: 93340 +
Number of invalid tuples: 0 +
Number of leaf tuples: 92676 +
Total size of tuples: 2621500 bytes+
Total size of leaf tuples: 2602848 bytes+
Total size of index: 5447680 bytes+
(1 row)
> 18 янв. 2022 г., в 03:54, Björn Harrtell <bjorn.harrtell@gmail.com> написал(а): > > There might be some deep reason in the architecture that I'm unaware of that could make it difficult to affect the nodesize but regardless, I believe there could be a substantial win if node size could be controlled. That's kind of orthogonal development path. Some years ago I had posted "GiST intrapage indexing" patch [0], that was aimingto make a tree with fanout that is Sqrt(Items on page). But for now decreasing fillfactor == wasting a lot of space,both in shared_buffers and on disk... Thank you for raising this topic, I think I should rebase and refresh that patch too... Best regards, Andrey Borodin. [0] https://www.postgresql.org/message-id/flat/7780A07B-4D04-41E2-B228-166B41D07EEE%40yandex-team.ru
Hi, I've addressed Andrey Borodin's concerns about v2 of this patch by Aliaksandr Kalenik in attached version. Change list: * Number of pages to collect moved to GUC parameter "gist_sorted_build_page_buffer_size". * GistSortedBuildPageState type renamed to GistSortedBuildLevelState. * Comments added. Sorted build remaind deterministic as long as picksplit implementation for given opclass is, which seem to be true for builtin types, so setting random seed is not required for testing. Andrey Borodin's GiST support patch for amcheck was used to verify built indexes: https://commitfest.postgresql.org/25/1800/ PSA modified version working with current Postgres code (btree functions removed).
Вложения
Re: [PATCH] reduce page overlap of GiST indexes built using sorted method
Hi,
I've addressed Andrey Borodin's concerns about v2 of this patch by
Aliaksandr
Kalenik in attached version.
[snip]
This patchset got some attention in the PostGIS development channel, as it is important to really enable the fast GiST build there for the end user. The reviews are positive, it saves build time and performs as well as original non-sorting build on tested workloads.
Darafei.
> 19 янв. 2022 г., в 01:26, sergei sh. <sshoulbakov@kontur.io> написал(а): > > Hi, > > I've addressed Andrey Borodin's concerns about v2 of this patch by Aliaksandr > Kalenik in attached version. Thank you! I'll make a new iteration of review. From a first glance everything looks good, but gist_sorted_build_page_buffer_sizehaven't any documentation.... Best regards, Andrey Borodin.
> 19 янв. 2022 г., в 09:31, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): >> >> I've addressed Andrey Borodin's concerns about v2 of this patch by Aliaksandr >> Kalenik in attached version. > > Thank you! I'll make a new iteration of review. From a first glance everything looks good, but gist_sorted_build_page_buffer_sizehaven't any documentation.... I've made one more iteration. The code generally looks OK to me. Some nitpicking: 1. gist_sorted_build_page_buffer_size is not documented yet 2. Comments correctly state that check for interrupts is done once per whatever. Let's make "whatever" == "1 page flush"again. 3. There is "Size i" in a loop. I haven't found usage of Size, but many size_t-s. For the same purpose in the same file mostly"int i" is used. 4. Many multiline comments are formatted in an unusual manner. Besides this I think the patch is ready for committer. Thanks! Best regards, Andrey Borodin.
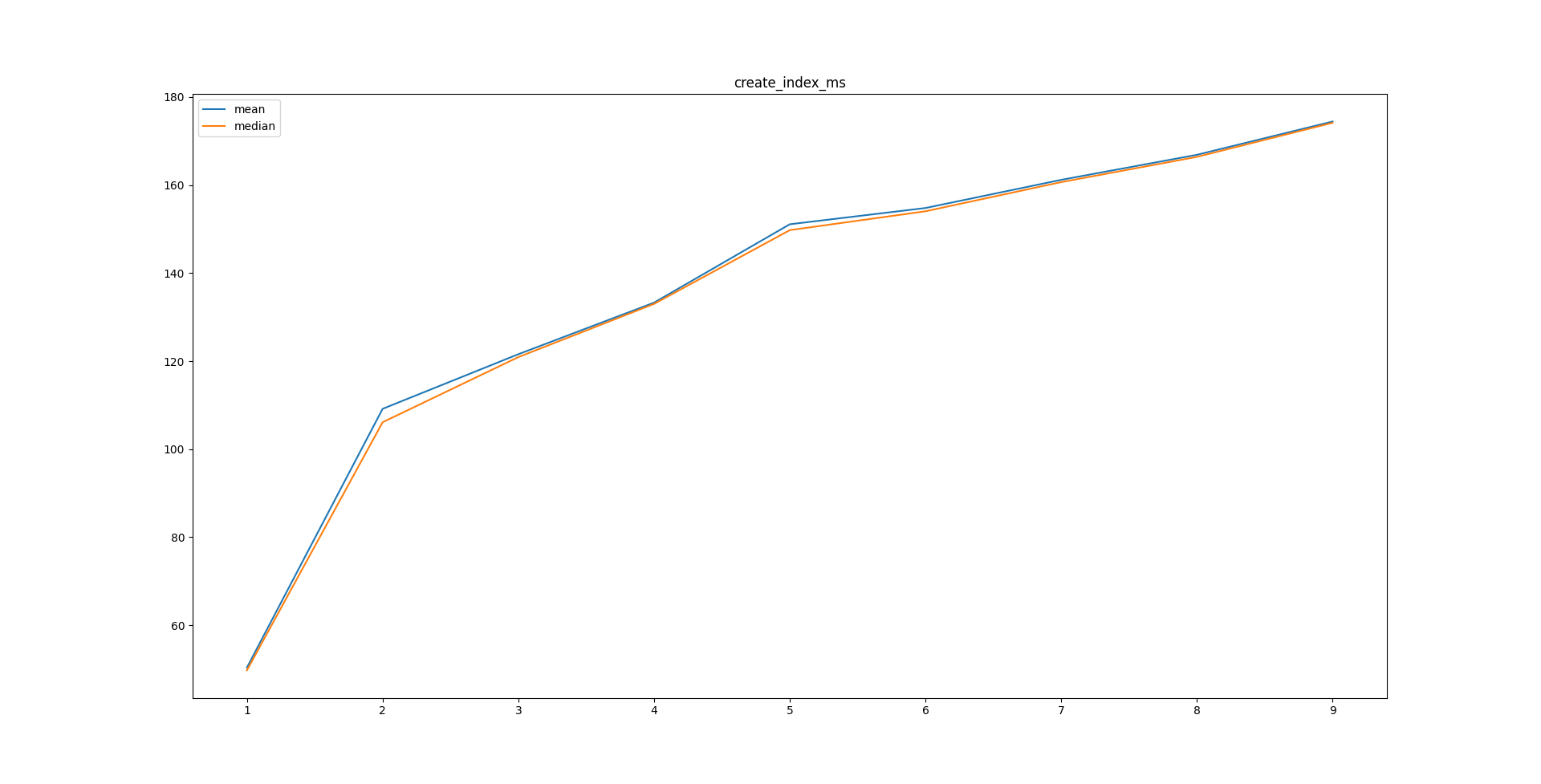
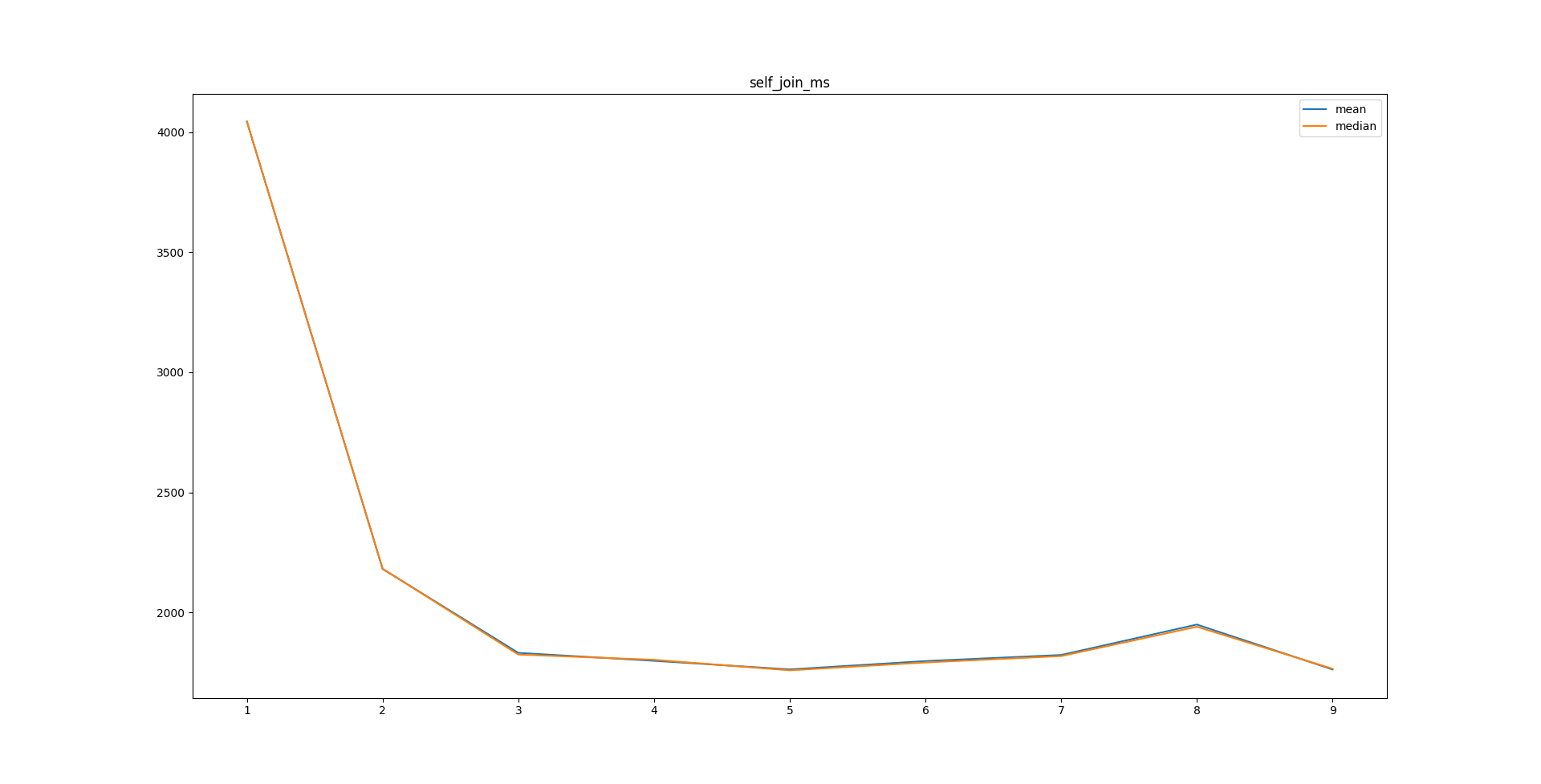
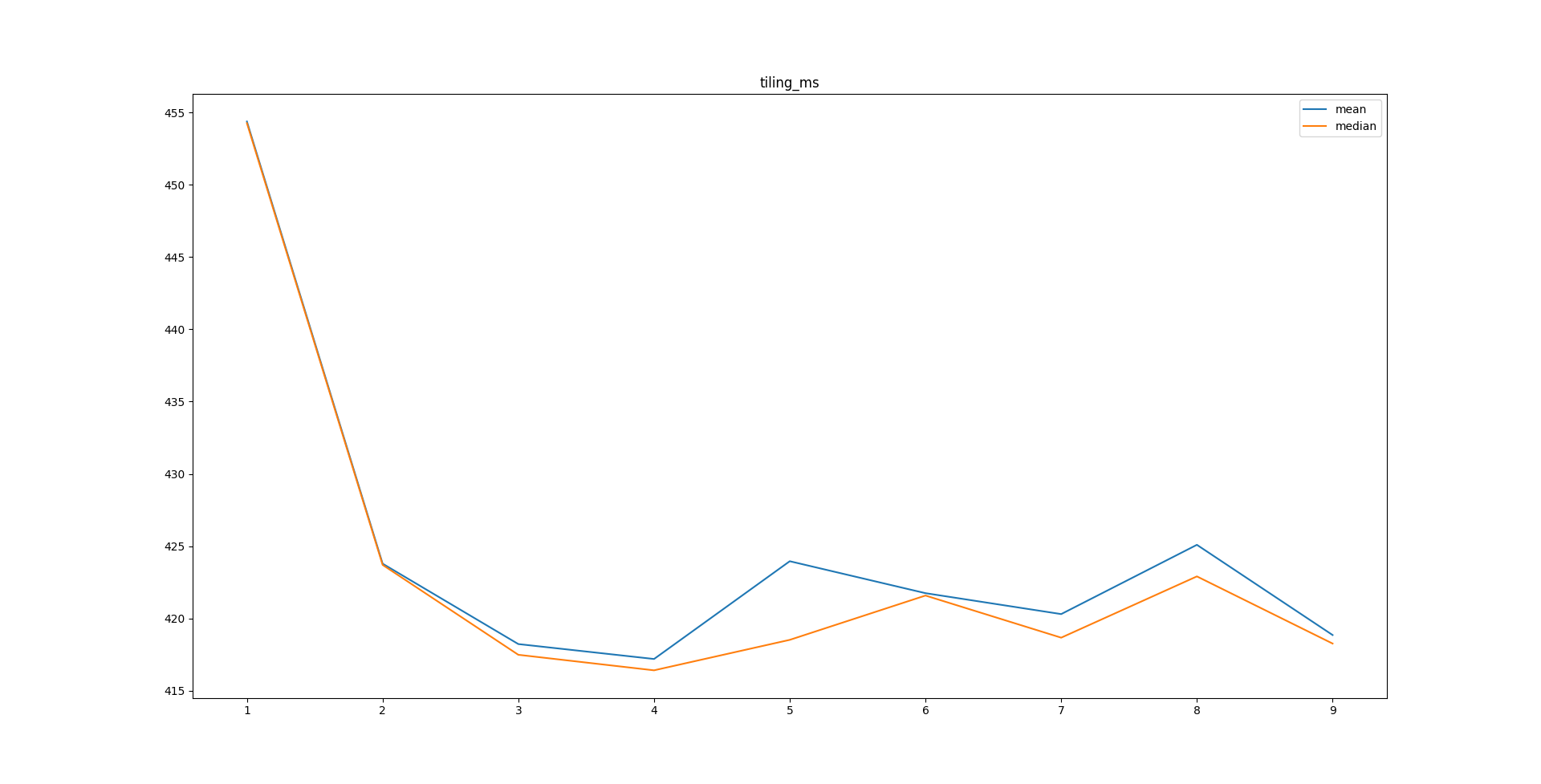
On 1/23/22 12:33, Andrey Borodin wrote: > > >> 19 янв. 2022 г., в 09:31, Andrey Borodin <x4mmm@yandex-team.ru> написал(а): >>> >>> I've addressed Andrey Borodin's concerns about v2 of this patch by Aliaksandr >>> Kalenik in attached version. >> >> Thank you! I'll make a new iteration of review. From a first glance everything looks good, but gist_sorted_build_page_buffer_sizehaven't any documentation.... > > I've made one more iteration. The code generally looks OK to me. > > Some nitpicking: > 1. gist_sorted_build_page_buffer_size is not documented yet > 2. Comments correctly state that check for interrupts is done once per whatever. Let's make "whatever" == "1 page flush"again. > 3. There is "Size i" in a loop. I haven't found usage of Size, but many size_t-s. For the same purpose in the same filemostly "int i" is used. > 4. Many multiline comments are formatted in an unusual manner. > > Besides this I think the patch is ready for committer. > > Thanks! > > Best regards, Andrey Borodin. > Hi, I've fixed issues 2 -- 4 in attached version. GUC parameter has been removed for the number of pages to collect before splitting and fixed value of 4 is used instead, as discussed off-list with Andrey Borodin, Aliaksandr Kalenik, Darafei Praliaskouski. Benchmarking shows that using higher values has almost no effect on query efficiency while increasing index building time. PSA graphs for index creation and query time, "tiling" and "self-join" refer to queries used in previous benchmarks: https://github.com/mngr777/pg_index_bm2 Sorted build method description has been added in GiST README.
Вложения
{kind=link}
{kind=link}
{kind=link}
Re: [PATCH] reduce page overlap of GiST indexes built using sorted method
Hi! On Wed, Jan 26, 2022 at 7:07 PM sergei sh. <sshoulbakov@kontur.io> wrote: > I've fixed issues 2 -- 4 in attached version. > > GUC parameter has been removed for the number of pages to collect > before splitting and fixed value of 4 is used instead, as discussed > off-list with Andrey Borodin, Aliaksandr Kalenik, Darafei > Praliaskouski. Benchmarking shows that using higher values has almost > no effect on query efficiency while increasing index building time. > > PSA graphs for index creation and query time, "tiling" and "self-join" > refer to queries used in previous benchmarks: > https://github.com/mngr777/pg_index_bm2 > > Sorted build method description has been added in GiST README. Thank you for the revision. This patch looks good to me. I've slightly adjusted comments and formatting and wrote the commit message. I'm going to push this if no objections. ------ Regards, Alexander Korotkov
Вложения
Hi,
04.02.2022 03:52, Alexander Korotkov wrote:
> Thank you for the revision. This patch looks good to me. I've
> slightly adjusted comments and formatting and wrote the commit
> message.
>
> I'm going to push this if no objections.
While exploring the gist test coverage (that is discussed in [1])
I've found that this block in regress/sql/gist.sql:
-- rebuild the index with a different fillfactor
alter index gist_pointidx SET (fillfactor = 40);
reindex index gist_pointidx;
doesn't do what is declared.
In fact fillfactor is ignored by default now. I've added:
select pg_relation_size('gist_pointidx');
after reindex and get the same size with any fillfactor.
fillfactor = 40: pg_relation_size = 122880
fillfactor = 100: pg_relation_size = 122880
Though size of the index really changes on REL_14_STABLE:
fillfactor = 40: pg_relation_size = 294912
fillfactor = 100: pg_relation_size = 122880
I've found that the behavior changed after f1ea98a79. I see a comment there:
/* fillfactor ignored */
but maybe this change should be reflected on higher levels (tests, docs [2],
RN) too?
For now the fillfactor option still works for the buffering build, but maybe
it could be just made unsupported as it is not supported for gist, brin...
[1] https://www.postgresql.org/message-id/flat/20230331050726.agslrnb7e7sqtpw2%40awork3.anarazel.de
[2] https://www.postgresql.org/docs/devel/sql-createindex.html
Best regards,
Alexander