Обсуждение: BufferAlloc: don't take two simultaneous locks
Good day.
I found some opportunity in Buffer Manager code in BufferAlloc
function:
- When valid buffer is evicted, BufferAlloc acquires two partition
lwlocks: for partition for evicted block is in and partition for new
block placement.
It doesn't matter if there is small number of concurrent replacements.
But if there are a lot of concurrent backends replacing buffers,
complex dependency net quickly arose.
It could be easily seen with select-only pgbench with scale 100 and
shared buffers 128MB: scale 100 produces 1.5GB tables, and it certainly
doesn't fit shared buffers. This way performance starts to degrade at
~100 connections. Even with shared buffers 1GB it slowly degrades after
150 connections.
But strictly speaking, there is no need to hold both lock
simultaneously. Buffer is pinned so other processes could not select it
for eviction. If tag is cleared and buffer removed from old partition
then other processes will not find it. Therefore it is safe to release
old partition lock before acquiring new partition lock.
If other process concurrently inserts same new buffer, then old buffer
is placed to bufmanager's freelist.
Additional optimisation: in case of old buffer is reused, there is no
need to put its BufferLookupEnt into dynahash's freelist. That reduces
lock contention a bit more. To acomplish this FreeListData.nentries is
changed to pg_atomic_u32/pg_atomic_u64 and atomic increment/decrement
is used.
Remark: there were bug in the `hash_update_hash_key`: nentries were not
kept in sync if freelist partitions differ. This bug were never
triggered because single use of `hash_update_hash_key` doesn't move
entry between partitions.
There is some tests results.
- pgbench with scale 100 were tested with --select-only (since we want
to test buffer manager alone). It produces 1.5GB table.
- two shared_buffers values were tested: 128MB and 1GB.
- second best result were taken among five runs
Test were made in three system configurations:
- notebook with i7-1165G7 (limited to 2.8GHz to not overheat)
- Xeon X5675 6 core 2 socket NUMA system (12 cores/24 threads).
- same Xeon X5675 but restricted to single socket
(with numactl -m 0 -N 0)
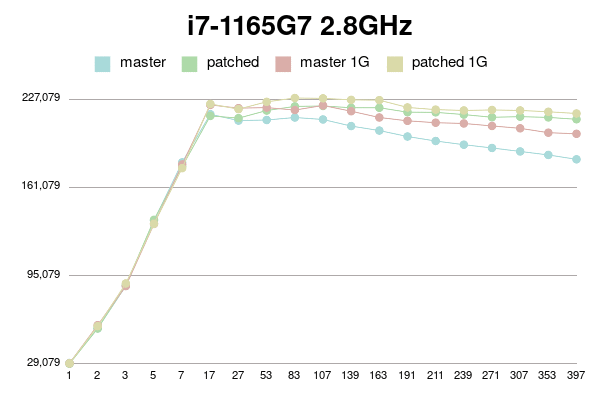
Results for i7-1165G7:
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 29667 | 29079 | 29425 | 29411
2 | 55577 | 55553 | 57974 | 57223
3 | 87393 | 87924 | 87246 | 89210
5 | 136222 | 136879 | 133775 | 133949
7 | 179865 | 176734 | 178297 | 175559
17 | 215953 | 214708 | 222908 | 223651
27 | 211162 | 213014 | 220506 | 219752
53 | 211620 | 218702 | 220906 | 225218
83 | 213488 | 221799 | 219075 | 228096
107 | 212018 | 222110 | 222502 | 227825
139 | 207068 | 220812 | 218191 | 226712
163 | 203716 | 220793 | 213498 | 226493
191 | 199248 | 217486 | 210994 | 221026
211 | 195887 | 217356 | 209601 | 219397
239 | 193133 | 215695 | 209023 | 218773
271 | 190686 | 213668 | 207181 | 219137
307 | 188066 | 214120 | 205392 | 218782
353 | 185449 | 213570 | 202120 | 217786
397 | 182173 | 212168 | 201285 | 216489
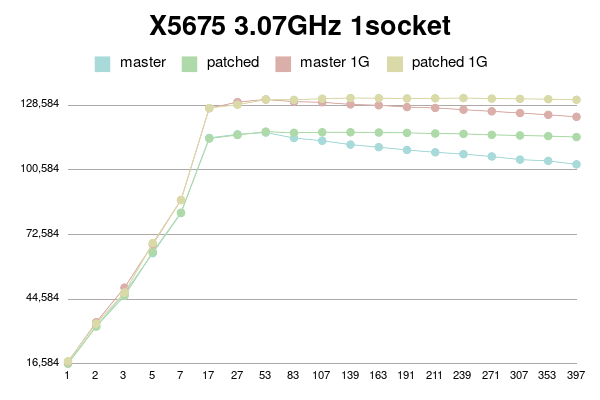
Results for 1 socket X5675
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 16864 | 16584 | 17419 | 17630
2 | 32764 | 32735 | 34593 | 34000
3 | 47258 | 46022 | 49570 | 47432
5 | 64487 | 64929 | 68369 | 68885
7 | 81932 | 82034 | 87543 | 87538
17 | 114502 | 114218 | 127347 | 127448
27 | 116030 | 115758 | 130003 | 128890
53 | 116814 | 117197 | 131142 | 131080
83 | 114438 | 116704 | 130198 | 130985
107 | 113255 | 116910 | 129932 | 131468
139 | 111577 | 116929 | 129012 | 131782
163 | 110477 | 116818 | 128628 | 131697
191 | 109237 | 116672 | 127833 | 131586
211 | 108248 | 116396 | 127474 | 131650
239 | 107443 | 116237 | 126731 | 131760
271 | 106434 | 115813 | 126009 | 131526
307 | 105077 | 115542 | 125279 | 131421
353 | 104516 | 115277 | 124491 | 131276
397 | 103016 | 114842 | 123624 | 131019
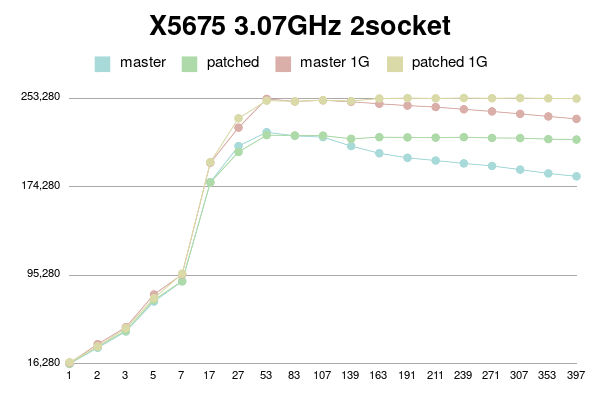
Results for 2 socket x5675
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 16323 | 16280 | 16959 | 17598
2 | 30510 | 31431 | 33763 | 31690
3 | 45051 | 45834 | 48896 | 47991
5 | 71800 | 73208 | 78077 | 74714
7 | 89792 | 89980 | 95986 | 96662
17 | 178319 | 177979 | 195566 | 196143
27 | 210475 | 205209 | 226966 | 235249
53 | 222857 | 220256 | 252673 | 251041
83 | 219652 | 219938 | 250309 | 250464
107 | 218468 | 219849 | 251312 | 251425
139 | 210486 | 217003 | 250029 | 250695
163 | 204068 | 218424 | 248234 | 252940
191 | 200014 | 218224 | 246622 | 253331
211 | 197608 | 218033 | 245331 | 253055
239 | 195036 | 218398 | 243306 | 253394
271 | 192780 | 217747 | 241406 | 253148
307 | 189490 | 217607 | 239246 | 253373
353 | 186104 | 216697 | 236952 | 253034
397 | 183507 | 216324 | 234764 | 252872
As can be seen, patched version degrades much slower than master.
(Or even doesn't degrade with 1G shared buffer on older processor).
PS.
There is a room for further improvements:
- buffer manager's freelist could be partitioned
- dynahash's freelist could be sized/aligned to CPU cache line
- in fact, there is no need in dynahash at all. It is better to make
custom hash-table using BufferDesc as entries. BufferDesc has spare
space for link to next and hashvalue.
regards,
Yura Sokolov
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Вложения
{kind=link}
{kind=link}
{kind=link}
On Fri, Oct 1, 2021 at 3:26 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
Good day.
I found some opportunity in Buffer Manager code in BufferAlloc
function:
- When valid buffer is evicted, BufferAlloc acquires two partition
lwlocks: for partition for evicted block is in and partition for new
block placement.
It doesn't matter if there is small number of concurrent replacements.
But if there are a lot of concurrent backends replacing buffers,
complex dependency net quickly arose.
It could be easily seen with select-only pgbench with scale 100 and
shared buffers 128MB: scale 100 produces 1.5GB tables, and it certainly
doesn't fit shared buffers. This way performance starts to degrade at
~100 connections. Even with shared buffers 1GB it slowly degrades after
150 connections.
But strictly speaking, there is no need to hold both lock
simultaneously. Buffer is pinned so other processes could not select it
for eviction. If tag is cleared and buffer removed from old partition
then other processes will not find it. Therefore it is safe to release
old partition lock before acquiring new partition lock.
If other process concurrently inserts same new buffer, then old buffer
is placed to bufmanager's freelist.
Additional optimisation: in case of old buffer is reused, there is no
need to put its BufferLookupEnt into dynahash's freelist. That reduces
lock contention a bit more. To acomplish this FreeListData.nentries is
changed to pg_atomic_u32/pg_atomic_u64 and atomic increment/decrement
is used.
Remark: there were bug in the `hash_update_hash_key`: nentries were not
kept in sync if freelist partitions differ. This bug were never
triggered because single use of `hash_update_hash_key` doesn't move
entry between partitions.
There is some tests results.
- pgbench with scale 100 were tested with --select-only (since we want
to test buffer manager alone). It produces 1.5GB table.
- two shared_buffers values were tested: 128MB and 1GB.
- second best result were taken among five runs
Test were made in three system configurations:
- notebook with i7-1165G7 (limited to 2.8GHz to not overheat)
- Xeon X5675 6 core 2 socket NUMA system (12 cores/24 threads).
- same Xeon X5675 but restricted to single socket
(with numactl -m 0 -N 0)
Results for i7-1165G7:
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 29667 | 29079 | 29425 | 29411
2 | 55577 | 55553 | 57974 | 57223
3 | 87393 | 87924 | 87246 | 89210
5 | 136222 | 136879 | 133775 | 133949
7 | 179865 | 176734 | 178297 | 175559
17 | 215953 | 214708 | 222908 | 223651
27 | 211162 | 213014 | 220506 | 219752
53 | 211620 | 218702 | 220906 | 225218
83 | 213488 | 221799 | 219075 | 228096
107 | 212018 | 222110 | 222502 | 227825
139 | 207068 | 220812 | 218191 | 226712
163 | 203716 | 220793 | 213498 | 226493
191 | 199248 | 217486 | 210994 | 221026
211 | 195887 | 217356 | 209601 | 219397
239 | 193133 | 215695 | 209023 | 218773
271 | 190686 | 213668 | 207181 | 219137
307 | 188066 | 214120 | 205392 | 218782
353 | 185449 | 213570 | 202120 | 217786
397 | 182173 | 212168 | 201285 | 216489
Results for 1 socket X5675
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 16864 | 16584 | 17419 | 17630
2 | 32764 | 32735 | 34593 | 34000
3 | 47258 | 46022 | 49570 | 47432
5 | 64487 | 64929 | 68369 | 68885
7 | 81932 | 82034 | 87543 | 87538
17 | 114502 | 114218 | 127347 | 127448
27 | 116030 | 115758 | 130003 | 128890
53 | 116814 | 117197 | 131142 | 131080
83 | 114438 | 116704 | 130198 | 130985
107 | 113255 | 116910 | 129932 | 131468
139 | 111577 | 116929 | 129012 | 131782
163 | 110477 | 116818 | 128628 | 131697
191 | 109237 | 116672 | 127833 | 131586
211 | 108248 | 116396 | 127474 | 131650
239 | 107443 | 116237 | 126731 | 131760
271 | 106434 | 115813 | 126009 | 131526
307 | 105077 | 115542 | 125279 | 131421
353 | 104516 | 115277 | 124491 | 131276
397 | 103016 | 114842 | 123624 | 131019
Results for 2 socket x5675
conns | master | patched | master 1G | patched 1G
--------+------------+------------+------------+------------
1 | 16323 | 16280 | 16959 | 17598
2 | 30510 | 31431 | 33763 | 31690
3 | 45051 | 45834 | 48896 | 47991
5 | 71800 | 73208 | 78077 | 74714
7 | 89792 | 89980 | 95986 | 96662
17 | 178319 | 177979 | 195566 | 196143
27 | 210475 | 205209 | 226966 | 235249
53 | 222857 | 220256 | 252673 | 251041
83 | 219652 | 219938 | 250309 | 250464
107 | 218468 | 219849 | 251312 | 251425
139 | 210486 | 217003 | 250029 | 250695
163 | 204068 | 218424 | 248234 | 252940
191 | 200014 | 218224 | 246622 | 253331
211 | 197608 | 218033 | 245331 | 253055
239 | 195036 | 218398 | 243306 | 253394
271 | 192780 | 217747 | 241406 | 253148
307 | 189490 | 217607 | 239246 | 253373
353 | 186104 | 216697 | 236952 | 253034
397 | 183507 | 216324 | 234764 | 252872
As can be seen, patched version degrades much slower than master.
(Or even doesn't degrade with 1G shared buffer on older processor).
PS.
There is a room for further improvements:
- buffer manager's freelist could be partitioned
- dynahash's freelist could be sized/aligned to CPU cache line
- in fact, there is no need in dynahash at all. It is better to make
custom hash-table using BufferDesc as entries. BufferDesc has spare
space for link to next and hashvalue.
regards,
Yura Sokolov
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Hi,
Improvement is impressive.
For BufTableFreeDeleted(), since it only has one call, maybe its caller can invoke hash_return_to_freelist() directly.
For free_list_decrement_nentries():
+ Assert(hctl->freeList[freelist_idx].nentries.value < MAX_NENTRIES);
Is the assertion necessary ? There is similar assertion in free_list_increment_nentries() which would maintain hctl->freeList[freelist_idx].nentries.value <= MAX_NENTRIES.
Cheers
В Пт, 01/10/2021 в 15:46 -0700, Zhihong Yu wrote: > > > On Fri, Oct 1, 2021 at 3:26 PM Yura Sokolov <y.sokolov@postgrespro.ru> > wrote: > > Good day. > > > > I found some opportunity in Buffer Manager code in BufferAlloc > > function: > > - When valid buffer is evicted, BufferAlloc acquires two partition > > lwlocks: for partition for evicted block is in and partition for new > > block placement. > > > > It doesn't matter if there is small number of concurrent > > replacements. > > But if there are a lot of concurrent backends replacing buffers, > > complex dependency net quickly arose. > > > > It could be easily seen with select-only pgbench with scale 100 and > > shared buffers 128MB: scale 100 produces 1.5GB tables, and it > > certainly > > doesn't fit shared buffers. This way performance starts to degrade > > at > > ~100 connections. Even with shared buffers 1GB it slowly degrades > > after > > 150 connections. > > > > But strictly speaking, there is no need to hold both lock > > simultaneously. Buffer is pinned so other processes could not select > > it > > for eviction. If tag is cleared and buffer removed from old > > partition > > then other processes will not find it. Therefore it is safe to > > release > > old partition lock before acquiring new partition lock. > > > > If other process concurrently inserts same new buffer, then old > > buffer > > is placed to bufmanager's freelist. > > > > Additional optimisation: in case of old buffer is reused, there is > > no > > need to put its BufferLookupEnt into dynahash's freelist. That > > reduces > > lock contention a bit more. To acomplish this FreeListData.nentries > > is > > changed to pg_atomic_u32/pg_atomic_u64 and atomic > > increment/decrement > > is used. > > > > Remark: there were bug in the `hash_update_hash_key`: nentries were > > not > > kept in sync if freelist partitions differ. This bug were never > > triggered because single use of `hash_update_hash_key` doesn't move > > entry between partitions. > > > > There is some tests results. > > > > - pgbench with scale 100 were tested with --select-only (since we > > want > > to test buffer manager alone). It produces 1.5GB table. > > - two shared_buffers values were tested: 128MB and 1GB. > > - second best result were taken among five runs > > > > Test were made in three system configurations: > > - notebook with i7-1165G7 (limited to 2.8GHz to not overheat) > > - Xeon X5675 6 core 2 socket NUMA system (12 cores/24 threads). > > - same Xeon X5675 but restricted to single socket > > (with numactl -m 0 -N 0) > > > > Results for i7-1165G7: > > > > conns | master | patched | master 1G | patched 1G > > --------+------------+------------+------------+------------ > > 1 | 29667 | 29079 | 29425 | 29411 > > 2 | 55577 | 55553 | 57974 | 57223 > > 3 | 87393 | 87924 | 87246 | 89210 > > 5 | 136222 | 136879 | 133775 | 133949 > > 7 | 179865 | 176734 | 178297 | 175559 > > 17 | 215953 | 214708 | 222908 | 223651 > > 27 | 211162 | 213014 | 220506 | 219752 > > 53 | 211620 | 218702 | 220906 | 225218 > > 83 | 213488 | 221799 | 219075 | 228096 > > 107 | 212018 | 222110 | 222502 | 227825 > > 139 | 207068 | 220812 | 218191 | 226712 > > 163 | 203716 | 220793 | 213498 | 226493 > > 191 | 199248 | 217486 | 210994 | 221026 > > 211 | 195887 | 217356 | 209601 | 219397 > > 239 | 193133 | 215695 | 209023 | 218773 > > 271 | 190686 | 213668 | 207181 | 219137 > > 307 | 188066 | 214120 | 205392 | 218782 > > 353 | 185449 | 213570 | 202120 | 217786 > > 397 | 182173 | 212168 | 201285 | 216489 > > > > Results for 1 socket X5675 > > > > conns | master | patched | master 1G | patched 1G > > --------+------------+------------+------------+------------ > > 1 | 16864 | 16584 | 17419 | 17630 > > 2 | 32764 | 32735 | 34593 | 34000 > > 3 | 47258 | 46022 | 49570 | 47432 > > 5 | 64487 | 64929 | 68369 | 68885 > > 7 | 81932 | 82034 | 87543 | 87538 > > 17 | 114502 | 114218 | 127347 | 127448 > > 27 | 116030 | 115758 | 130003 | 128890 > > 53 | 116814 | 117197 | 131142 | 131080 > > 83 | 114438 | 116704 | 130198 | 130985 > > 107 | 113255 | 116910 | 129932 | 131468 > > 139 | 111577 | 116929 | 129012 | 131782 > > 163 | 110477 | 116818 | 128628 | 131697 > > 191 | 109237 | 116672 | 127833 | 131586 > > 211 | 108248 | 116396 | 127474 | 131650 > > 239 | 107443 | 116237 | 126731 | 131760 > > 271 | 106434 | 115813 | 126009 | 131526 > > 307 | 105077 | 115542 | 125279 | 131421 > > 353 | 104516 | 115277 | 124491 | 131276 > > 397 | 103016 | 114842 | 123624 | 131019 > > > > Results for 2 socket x5675 > > > > conns | master | patched | master 1G | patched 1G > > --------+------------+------------+------------+------------ > > 1 | 16323 | 16280 | 16959 | 17598 > > 2 | 30510 | 31431 | 33763 | 31690 > > 3 | 45051 | 45834 | 48896 | 47991 > > 5 | 71800 | 73208 | 78077 | 74714 > > 7 | 89792 | 89980 | 95986 | 96662 > > 17 | 178319 | 177979 | 195566 | 196143 > > 27 | 210475 | 205209 | 226966 | 235249 > > 53 | 222857 | 220256 | 252673 | 251041 > > 83 | 219652 | 219938 | 250309 | 250464 > > 107 | 218468 | 219849 | 251312 | 251425 > > 139 | 210486 | 217003 | 250029 | 250695 > > 163 | 204068 | 218424 | 248234 | 252940 > > 191 | 200014 | 218224 | 246622 | 253331 > > 211 | 197608 | 218033 | 245331 | 253055 > > 239 | 195036 | 218398 | 243306 | 253394 > > 271 | 192780 | 217747 | 241406 | 253148 > > 307 | 189490 | 217607 | 239246 | 253373 > > 353 | 186104 | 216697 | 236952 | 253034 > > 397 | 183507 | 216324 | 234764 | 252872 > > > > As can be seen, patched version degrades much slower than master. > > (Or even doesn't degrade with 1G shared buffer on older processor). > > > > PS. > > > > There is a room for further improvements: > > - buffer manager's freelist could be partitioned > > - dynahash's freelist could be sized/aligned to CPU cache line > > - in fact, there is no need in dynahash at all. It is better to make > > custom hash-table using BufferDesc as entries. BufferDesc has > > spare > > space for link to next and hashvalue. > > > > regards, > > Yura Sokolov > > y.sokolov@postgrespro.ru > > funny.falcon@gmail.com > > Hi, > Improvement is impressive. Thank you! > For BufTableFreeDeleted(), since it only has one call, maybe its > caller can invoke hash_return_to_freelist() directly. It will be a dirty break of abstraction. Everywhere we talk with BufTable, and here will be hash ... eugh > For free_list_decrement_nentries(): > > + Assert(hctl->freeList[freelist_idx].nentries.value < > MAX_NENTRIES); > > Is the assertion necessary ? There is similar assertion in > free_list_increment_nentries() which would maintain hctl- > >freeList[freelist_idx].nentries.value <= MAX_NENTRIES. Assertion in free_list_decrement_nentries is absolutely necessary: it is direct translation of Assert(nentries>=0) from signed types to unsigned. (Since there is no signed atomics in pg, I had to convert signed `long nentries` to unsigned `pg_atomic_uXX nentries`). Assertion in free_list_increment_nentries is not necessary. But it doesn't hurt either - it is just Assert that doesn't compile into production code. regards Yura Sokolov y.sokolov@postgrespro.ru funny.falcon@gmail.com
> 21 дек. 2021 г., в 10:23, Yura Sokolov <y.sokolov@postgrespro.ru> написал(а): > > <v1-0001-bufmgr-do-not-acquire-two-partition-lo.patch> Hi Yura! I've took a look into the patch. The idea seems reasonable to me: clearing\evicting old buffer and placing new one seem tobe different units of work, there is no need to couple both partition locks together. And the claimed performance impactis fascinating! Though I didn't verify it yet. On a first glance API change in BufTable does not seem obvious to me. Is void *oldelem actually BufferTag * or maybe BufferLookupEnt*? What if we would like to use or manipulate with oldelem in future? And the name BufTableFreeDeleted() confuses me a bit. You know, in C we usually free(), but in C++ we delete [], and herewe do both... Just to be sure. Thanks! Best regards, Andrey Borodin.
At Sat, 22 Jan 2022 12:56:14 +0500, Andrey Borodin <x4mmm@yandex-team.ru> wrote in > I've took a look into the patch. The idea seems reasonable to me: > clearing\evicting old buffer and placing new one seem to be > different units of work, there is no need to couple both partition > locks together. And the claimed performance impact is fascinating! > Though I didn't verify it yet. The need for having both locks came from, I seems to me, that the function was moving a buffer between two pages, and that there is a moment where buftable holds two entries for one buffer. It seems to me this patch is trying to move a victim buffer to new page via "unallocated" state and to avoid the buftable from having duplicate entries for the same buffer. The outline of the story sounds reasonable. > On a first glance API change in BufTable does not seem obvious to > me. Is void *oldelem actually BufferTag * or maybe BufferLookupEnt > *? What if we would like to use or manipulate with oldelem in > future? > > And the name BufTableFreeDeleted() confuses me a bit. You know, in C > we usually free(), but in C++ we delete [], and here we do > both... Just to be sure. Honestly, I don't like the API change at all as the change allows a dynahash to be in a (even tentatively) broken state and bufmgr touches too much of dynahash details. Couldn't we get a good extent of benefit without that invasive changes? regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Hello, Yura. Test results look promising. But it seems like the naming and dynahash API change is a little confusing. 1) I think it is better to split the main part and atomic nentries optimization into separate commits. 2) Also, it would be nice to also fix hash_update_hash_key bug :) 3) Do we really need a SIZEOF_LONG check? I think pg_atomic_uint64 is fine these days. 4) Looks like hash_insert_with_hash_nocheck could potentially break the hash table. Is it better to replace it with hash_search_with_hash_value with HASH_ATTACH action? 5) In such a case hash_delete_skip_freelist with hash_search_with_hash_value with HASH_DETTACH. 6) And then hash_return_to_freelist -> hash_dispose_dettached_entry? Another approach is a new version of hash_update_hash_key with callbacks. Probably it is the most "correct" way to keep a hash table implementation details closed. It should be doable, I think. Thanks, Michail.
Hello, Yura.
A one additional moment:
> 1332: Assert((oldFlags & (BM_PIN_COUNT_WAITER | BM_IO_IN_PROGRESS)) == 0);
> 1333: CLEAR_BUFFERTAG(buf->tag);
> 1334: buf_state &= ~(BUF_FLAG_MASK | BUF_USAGECOUNT_MASK);
> 1335: UnlockBufHdr(buf, buf_state);
I think there is no sense to unlock buffer here because it will be
locked after a few moments (and no one is able to find it somehow). Of
course, it should be unlocked in case of collision.
BTW, I still think is better to introduce some kind of
hash_update_hash_key and use it.
It may look like this:
// should be called with oldPartitionLock acquired
// newPartitionLock hold on return
// oldPartitionLock and newPartitionLock are not taken at the same time
// if newKeyPtr is present - existingEntry is removed
bool hash_update_hash_key_or_remove(
HTAB *hashp,
void *existingEntry,
const void *newKeyPtr,
uint32 newHashValue,
LWLock *oldPartitionLock,
LWLock *newPartitionLock
);
Thanks,
Michail.
В Вс, 06/02/2022 в 19:34 +0300, Michail Nikolaev пишет: > Hello, Yura. > > A one additional moment: > > > 1332: Assert((oldFlags & (BM_PIN_COUNT_WAITER | BM_IO_IN_PROGRESS)) == 0); > > 1333: CLEAR_BUFFERTAG(buf->tag); > > 1334: buf_state &= ~(BUF_FLAG_MASK | BUF_USAGECOUNT_MASK); > > 1335: UnlockBufHdr(buf, buf_state); > > I think there is no sense to unlock buffer here because it will be > locked after a few moments (and no one is able to find it somehow). Of > course, it should be unlocked in case of collision. UnlockBufHdr actually writes buf_state. Until it called, buffer is in intermediate state and it is ... locked. We have to write state with BM_TAG_VALID cleared before we call BufTableDelete and release oldPartitionLock to maintain consistency. Perhaps, it could be cheated, and there is no harm to skip state write at this point. But I'm not so confident to do it. > > BTW, I still think is better to introduce some kind of > hash_update_hash_key and use it. > > It may look like this: > > // should be called with oldPartitionLock acquired > // newPartitionLock hold on return > // oldPartitionLock and newPartitionLock are not taken at the same time > // if newKeyPtr is present - existingEntry is removed > bool hash_update_hash_key_or_remove( > HTAB *hashp, > void *existingEntry, > const void *newKeyPtr, > uint32 newHashValue, > LWLock *oldPartitionLock, > LWLock *newPartitionLock > ); Interesting suggestion, thanks. I'll think about. It has downside of bringing LWLock knowdlege to dynahash.c . But otherwise looks smart. --------- regards, Yura Sokolov
Hello, all. I thought about patch simplification, and tested version without BufTable and dynahash api change at all. It performs suprisingly well. It is just a bit worse than v1 since there is more contention around dynahash's freelist, but most of improvement remains. I'll finish benchmarking and will attach graphs with next message. Patch is attached here. ------ regards, Yura Sokolov Postgres Professional y.sokolov@postgrespro.ru funny.falcon@gmail.com
Вложения
At Wed, 16 Feb 2022 10:40:56 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > Hello, all. > > I thought about patch simplification, and tested version > without BufTable and dynahash api change at all. > > It performs suprisingly well. It is just a bit worse > than v1 since there is more contention around dynahash's > freelist, but most of improvement remains. > > I'll finish benchmarking and will attach graphs with > next message. Patch is attached here. Thanks for the new patch. The patch as a whole looks fine to me. But some comments needs to be revised. (existing comments) > * To change the association of a valid buffer, we'll need to have > * exclusive lock on both the old and new mapping partitions. ... > * Somebody could have pinned or re-dirtied the buffer while we were > * doing the I/O and making the new hashtable entry. If so, we can't > * recycle this buffer; we must undo everything we've done and start > * over with a new victim buffer. We no longer take a lock on the new partition and have no new hash entry (if others have not yet done) at this point. + * Clear out the buffer's tag and flags. We must do this to ensure that + * linear scans of the buffer array don't think the buffer is valid. We The reason we can clear out the tag is it's safe to use the victim buffer at this point. This comment needs to mention that reason. + * + * Since we are single pinner, there should no be PIN_COUNT_WAITER or + * IO_IN_PROGRESS (flags that were not cleared in previous code). + */ + Assert((oldFlags & (BM_PIN_COUNT_WAITER | BM_IO_IN_PROGRESS)) == 0); It seems like to be a test for potential bugs in other functions. As the comment is saying, we are sure that no other processes are pinning the buffer and the existing code doesn't seem to be care about that condition. Is it really needed? + /* + * Try to make a hashtable entry for the buffer under its new tag. This + * could fail because while we were writing someone else allocated another The most significant point of this patch is the reason that the victim buffer is protected from stealing until it is set up for new tag. I think we need an explanation about the protection here. + * buffer for the same block we want to read in. Note that we have not yet + * removed the hashtable entry for the old tag. Since we have removed the hash table entry for the old tag at this point, the comment got wrong. + * the first place. First, give up the buffer we were planning to use + * and put it to free lists. .. + StrategyFreeBuffer(buf); This is one downside of this patch. But it seems to me that the odds are low that many buffers are freed in a short time by this logic. By the way it would be better if the sentence starts with "First" has a separate comment section. (existing comment) | * Okay, it's finally safe to rename the buffer. We don't "rename" the buffer here. And the safety is already establishsed at the end of the oldPartitionLock section. So it would be just something like "Now allocate the victim buffer for the new tag"? regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On Mon, 21 Feb 2022 at 08:06, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > Good day, Kyotaro Horiguchi and hackers. > > В Чт, 17/02/2022 в 14:16 +0900, Kyotaro Horiguchi пишет: > > At Wed, 16 Feb 2022 10:40:56 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > Hello, all. > > > > > > I thought about patch simplification, and tested version > > > without BufTable and dynahash api change at all. > > > > > > It performs suprisingly well. It is just a bit worse > > > than v1 since there is more contention around dynahash's > > > freelist, but most of improvement remains. > > > > > > I'll finish benchmarking and will attach graphs with > > > next message. Patch is attached here. > > > > Thanks for the new patch. The patch as a whole looks fine to me. But > > some comments needs to be revised. > > Thank you for review and remarks. v3 gets the buffer partition locking right, well done, great results! In v3, the comment at line 1279 still implies we take both locks together, which is not now the case. Dynahash actions are still possible. You now have the BufTableDelete before the BufTableInsert, which opens up the possibility I discussed here: http://postgr.es/m/CANbhV-F0H-8oB_A+m=55hP0e0QRL=RdDDQuSXMTFt6JPrdX+pQ@mail.gmail.com (Apologies for raising a similar topic, I hadn't noticed this thread before; thanks to Horiguchi-san for pointing this out). v1 had a horrible API (sorry!) where you returned the entry and then explicitly re-used it. I think we *should* make changes to dynahash, but not with the API you proposed. Proposal for new BufTable API BufTableReuse() - similar to BufTableDelete() but does NOT put entry back on freelist, we remember it in a private single item cache in dynahash BufTableAssign() - similar to BufTableInsert() but can only be executed directly after BufTableReuse(), fails with ERROR otherwise. Takes the entry from single item cache and re-assigns it to new tag In dynahash we have two new modes that match the above HASH_REUSE - used by BufTableReuse(), similar to HASH_REMOVE, but places entry on the single item cache, avoiding freelist HASH_ASSIGN - used by BufTableAssign(), similar to HASH_ENTER, but uses the entry from the single item cache, rather than asking freelist This last call can fail if someone else already inserted the tag, in which case it adds the single item cache entry back onto freelist Notice that single item cache is not in shared memory, so on abort we should give it back, so we probably need an extra API call for that also to avoid leaking an entry. Doing it this way allows us to * avoid touching freelists altogether in the common path - we know we are about to reassign the entry, so we do remember it - no contention from other backends, no borrowing etc.. * avoid sharing the private details outside of the dynahash module * allows us to use the same technique elsewhere that we have partitioned hash tables This approach is cleaner than v1, but should also perform better because there will be a 1:1 relationship between a buffer and its dynahash entry, most of the time. With these changes, I think we will be able to *reduce* the number of freelists for partitioned dynahash from 32 to maybe 8, as originally speculated by Robert in 2016: https://www.postgresql.org/message-id/CA%2BTgmoZkg-04rcNRURt%3DjAG0Cs5oPyB-qKxH4wqX09e-oXy-nw%40mail.gmail.com since the freelists will be much less contended with the above approach It would be useful to see performance with a higher number of connections, >400. -- Simon Riggs http://www.EnterpriseDB.com/
Hi, On 2022-02-21 11:06:49 +0300, Yura Sokolov wrote: > From 04b07d0627ec65ba3327dc8338d59dbd15c405d8 Mon Sep 17 00:00:00 2001 > From: Yura Sokolov <y.sokolov@postgrespro.ru> > Date: Mon, 21 Feb 2022 08:49:03 +0300 > Subject: [PATCH v3] [PGPRO-5616] bufmgr: do not acquire two partition locks. > > Acquiring two partition locks leads to complex dependency chain that hurts > at high concurrency level. > > There is no need to hold both lock simultaneously. Buffer is pinned so > other processes could not select it for eviction. If tag is cleared and > buffer removed from old partition other processes will not find it. > Therefore it is safe to release old partition lock before acquiring > new partition lock. Yes, the current design is pretty nonsensical. It leads to really absurd stuff like holding the relation extension lock while we write out old buffer contents etc. > + * We have pinned buffer and we are single pinner at the moment so there > + * is no other pinners. Seems redundant. > We hold buffer header lock and exclusive partition > + * lock if tag is valid. Given these statements it is safe to clear tag > + * since no other process can inspect it to the moment. > + */ Could we share code with InvalidateBuffer here? It's not quite the same code, but nearly the same. > + * The usage_count starts out at 1 so that the buffer can survive one > + * clock-sweep pass. > + * > + * We use direct atomic OR instead of Lock+Unlock since no other backend > + * could be interested in the buffer. But StrategyGetBuffer, > + * Flush*Buffers, Drop*Buffers are scanning all buffers and locks them to > + * compare tag, and UnlockBufHdr does raw write to state. So we have to > + * spin if we found buffer locked. So basically the first half of of the paragraph is wrong, because no, we can't? > + * Note that we write tag unlocked. It is also safe since there is always > + * check for BM_VALID when tag is compared. > */ > buf->tag = newTag; > - buf_state &= ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED | > - BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT | > - BUF_USAGECOUNT_MASK); > if (relpersistence == RELPERSISTENCE_PERMANENT || forkNum == INIT_FORKNUM) > - buf_state |= BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > + new_bits = BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > else > - buf_state |= BM_TAG_VALID | BUF_USAGECOUNT_ONE; > - > - UnlockBufHdr(buf, buf_state); > + new_bits = BM_TAG_VALID | BUF_USAGECOUNT_ONE; > > - if (oldPartitionLock != NULL) > + buf_state = pg_atomic_fetch_or_u32(&buf->state, new_bits); > + while (unlikely(buf_state & BM_LOCKED)) I don't think it's safe to atomic in arbitrary bits. If somebody else has locked the buffer header in this moment, it'll lead to completely bogus results, because unlocking overwrites concurrently written contents (which there shouldn't be any, but here there are)... And or'ing contents in also doesn't make sense because we it doesn't work to actually unset any contents? Why don't you just use LockBufHdr/UnlockBufHdr? Greetings, Andres Freund
At Fri, 25 Feb 2022 00:04:55 -0800, Andres Freund <andres@anarazel.de> wrote in > Why don't you just use LockBufHdr/UnlockBufHdr? FWIW, v2 looked fine to me in regards to this point. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Hello, Simon. В Пт, 25/02/2022 в 04:35 +0000, Simon Riggs пишет: > On Mon, 21 Feb 2022 at 08:06, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > Good day, Kyotaro Horiguchi and hackers. > > > > В Чт, 17/02/2022 в 14:16 +0900, Kyotaro Horiguchi пишет: > > > At Wed, 16 Feb 2022 10:40:56 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > > Hello, all. > > > > > > > > I thought about patch simplification, and tested version > > > > without BufTable and dynahash api change at all. > > > > > > > > It performs suprisingly well. It is just a bit worse > > > > than v1 since there is more contention around dynahash's > > > > freelist, but most of improvement remains. > > > > > > > > I'll finish benchmarking and will attach graphs with > > > > next message. Patch is attached here. > > > > > > Thanks for the new patch. The patch as a whole looks fine to me. But > > > some comments needs to be revised. > > > > Thank you for review and remarks. > > v3 gets the buffer partition locking right, well done, great results! > > In v3, the comment at line 1279 still implies we take both locks > together, which is not now the case. > > Dynahash actions are still possible. You now have the BufTableDelete > before the BufTableInsert, which opens up the possibility I discussed > here: > http://postgr.es/m/CANbhV-F0H-8oB_A+m=55hP0e0QRL=RdDDQuSXMTFt6JPrdX+pQ@mail.gmail.com > (Apologies for raising a similar topic, I hadn't noticed this thread > before; thanks to Horiguchi-san for pointing this out). > > v1 had a horrible API (sorry!) where you returned the entry and then > explicitly re-used it. I think we *should* make changes to dynahash, > but not with the API you proposed. > > Proposal for new BufTable API > BufTableReuse() - similar to BufTableDelete() but does NOT put entry > back on freelist, we remember it in a private single item cache in > dynahash > BufTableAssign() - similar to BufTableInsert() but can only be > executed directly after BufTableReuse(), fails with ERROR otherwise. > Takes the entry from single item cache and re-assigns it to new tag > > In dynahash we have two new modes that match the above > HASH_REUSE - used by BufTableReuse(), similar to HASH_REMOVE, but > places entry on the single item cache, avoiding freelist > HASH_ASSIGN - used by BufTableAssign(), similar to HASH_ENTER, but > uses the entry from the single item cache, rather than asking freelist > This last call can fail if someone else already inserted the tag, in > which case it adds the single item cache entry back onto freelist > > Notice that single item cache is not in shared memory, so on abort we > should give it back, so we probably need an extra API call for that > also to avoid leaking an entry. Why there is need for this? Which way backend could be forced to abort between BufTableReuse and BufTableAssign in this code path? I don't see any CHECK_FOR_INTERRUPTS on the way, but may be I'm missing something. > > Doing it this way allows us to > * avoid touching freelists altogether in the common path - we know we > are about to reassign the entry, so we do remember it - no contention > from other backends, no borrowing etc.. > * avoid sharing the private details outside of the dynahash module > * allows us to use the same technique elsewhere that we have > partitioned hash tables > > This approach is cleaner than v1, but should also perform better > because there will be a 1:1 relationship between a buffer and its > dynahash entry, most of the time. Thank you for suggestion. Yes, it is much clearer than my initial proposal. Should I incorporate it to v4 patch? Perhaps, it could be a separate commit in new version. > > With these changes, I think we will be able to *reduce* the number of > freelists for partitioned dynahash from 32 to maybe 8, as originally > speculated by Robert in 2016: > https://www.postgresql.org/message-id/CA%2BTgmoZkg-04rcNRURt%3DjAG0Cs5oPyB-qKxH4wqX09e-oXy-nw%40mail.gmail.com > since the freelists will be much less contended with the above approach > > It would be useful to see performance with a higher number of connections, >400. > > -- > Simon Riggs http://www.EnterpriseDB.com/ ------ regards, Yura Sokolov
On Fri, 25 Feb 2022 at 09:24, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > This approach is cleaner than v1, but should also perform better > > because there will be a 1:1 relationship between a buffer and its > > dynahash entry, most of the time. > > Thank you for suggestion. Yes, it is much clearer than my initial proposal. > > Should I incorporate it to v4 patch? Perhaps, it could be a separate > commit in new version. I don't insist that you do that, but since the API changes are a few hours work ISTM better to include in one patch for combined perf testing. It would be better to put all changes in this area into PG15 than to split it across multiple releases. > Why there is need for this? Which way backend could be forced to abort > between BufTableReuse and BufTableAssign in this code path? I don't > see any CHECK_FOR_INTERRUPTS on the way, but may be I'm missing > something. Sounds reasonable. -- Simon Riggs http://www.EnterpriseDB.com/
Hello, Andres
В Пт, 25/02/2022 в 00:04 -0800, Andres Freund пишет:
> Hi,
>
> On 2022-02-21 11:06:49 +0300, Yura Sokolov wrote:
> > From 04b07d0627ec65ba3327dc8338d59dbd15c405d8 Mon Sep 17 00:00:00 2001
> > From: Yura Sokolov <y.sokolov@postgrespro.ru>
> > Date: Mon, 21 Feb 2022 08:49:03 +0300
> > Subject: [PATCH v3] [PGPRO-5616] bufmgr: do not acquire two partition locks.
> >
> > Acquiring two partition locks leads to complex dependency chain that hurts
> > at high concurrency level.
> >
> > There is no need to hold both lock simultaneously. Buffer is pinned so
> > other processes could not select it for eviction. If tag is cleared and
> > buffer removed from old partition other processes will not find it.
> > Therefore it is safe to release old partition lock before acquiring
> > new partition lock.
>
> Yes, the current design is pretty nonsensical. It leads to really absurd stuff
> like holding the relation extension lock while we write out old buffer
> contents etc.
>
>
>
> > + * We have pinned buffer and we are single pinner at the moment so there
> > + * is no other pinners.
>
> Seems redundant.
>
>
> > We hold buffer header lock and exclusive partition
> > + * lock if tag is valid. Given these statements it is safe to clear tag
> > + * since no other process can inspect it to the moment.
> > + */
>
> Could we share code with InvalidateBuffer here? It's not quite the same code,
> but nearly the same.
>
>
> > + * The usage_count starts out at 1 so that the buffer can survive one
> > + * clock-sweep pass.
> > + *
> > + * We use direct atomic OR instead of Lock+Unlock since no other backend
> > + * could be interested in the buffer. But StrategyGetBuffer,
> > + * Flush*Buffers, Drop*Buffers are scanning all buffers and locks them to
> > + * compare tag, and UnlockBufHdr does raw write to state. So we have to
> > + * spin if we found buffer locked.
>
> So basically the first half of of the paragraph is wrong, because no, we
> can't?
Logically, there are no backends that could be interesting in the buffer.
Physically they do LockBufHdr/UnlockBufHdr just to check they are not interesting.
> > + * Note that we write tag unlocked. It is also safe since there is always
> > + * check for BM_VALID when tag is compared.
>
>
> > */
> > buf->tag = newTag;
> > - buf_state &= ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED |
> > - BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT |
> > - BUF_USAGECOUNT_MASK);
> > if (relpersistence == RELPERSISTENCE_PERMANENT || forkNum == INIT_FORKNUM)
> > - buf_state |= BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE;
> > + new_bits = BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE;
> > else
> > - buf_state |= BM_TAG_VALID | BUF_USAGECOUNT_ONE;
> > -
> > - UnlockBufHdr(buf, buf_state);
> > + new_bits = BM_TAG_VALID | BUF_USAGECOUNT_ONE;
> >
> > - if (oldPartitionLock != NULL)
> > + buf_state = pg_atomic_fetch_or_u32(&buf->state, new_bits);
> > + while (unlikely(buf_state & BM_LOCKED))
>
> I don't think it's safe to atomic in arbitrary bits. If somebody else has
> locked the buffer header in this moment, it'll lead to completely bogus
> results, because unlocking overwrites concurrently written contents (which
> there shouldn't be any, but here there are)...
That is why there is safety loop in the case buf->state were locked just
after first optimistic atomic_fetch_or. 99.999% times this loop will not
have a job. But in case other backend did lock buf->state, loop waits
until it releases lock and retry atomic_fetch_or.
> And or'ing contents in also doesn't make sense because we it doesn't work to
> actually unset any contents?
Sorry, I didn't understand sentence :((
> Why don't you just use LockBufHdr/UnlockBufHdr?
This pair makes two atomic writes to memory. Two writes are heavier than
one write in this version (if optimistic case succeed).
But I thought to use Lock+UnlockBuhHdr instead of safety loop:
buf_state = pg_atomic_fetch_or_u32(&buf->state, new_bits);
if (unlikely(buf_state & BM_LOCKED))
{
buf_state = LockBufHdr(&buf->state);
UnlockBufHdr(&buf->state, buf_state | new_bits);
}
I agree this way code is cleaner. Will do in next version.
-----
regards,
Yura Sokolov
Hi, On 2022-02-25 12:51:22 +0300, Yura Sokolov wrote: > > > + * The usage_count starts out at 1 so that the buffer can survive one > > > + * clock-sweep pass. > > > + * > > > + * We use direct atomic OR instead of Lock+Unlock since no other backend > > > + * could be interested in the buffer. But StrategyGetBuffer, > > > + * Flush*Buffers, Drop*Buffers are scanning all buffers and locks them to > > > + * compare tag, and UnlockBufHdr does raw write to state. So we have to > > > + * spin if we found buffer locked. > > > > So basically the first half of of the paragraph is wrong, because no, we > > can't? > > Logically, there are no backends that could be interesting in the buffer. > Physically they do LockBufHdr/UnlockBufHdr just to check they are not interesting. Yea, but that's still being interested in the buffer... > > > + * Note that we write tag unlocked. It is also safe since there is always > > > + * check for BM_VALID when tag is compared. > > > > > > > */ > > > buf->tag = newTag; > > > - buf_state &= ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED | > > > - BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT | > > > - BUF_USAGECOUNT_MASK); > > > if (relpersistence == RELPERSISTENCE_PERMANENT || forkNum == INIT_FORKNUM) > > > - buf_state |= BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > > > + new_bits = BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > > > else > > > - buf_state |= BM_TAG_VALID | BUF_USAGECOUNT_ONE; > > > - > > > - UnlockBufHdr(buf, buf_state); > > > + new_bits = BM_TAG_VALID | BUF_USAGECOUNT_ONE; > > > > > > - if (oldPartitionLock != NULL) > > > + buf_state = pg_atomic_fetch_or_u32(&buf->state, new_bits); > > > + while (unlikely(buf_state & BM_LOCKED)) > > > > I don't think it's safe to atomic in arbitrary bits. If somebody else has > > locked the buffer header in this moment, it'll lead to completely bogus > > results, because unlocking overwrites concurrently written contents (which > > there shouldn't be any, but here there are)... > > That is why there is safety loop in the case buf->state were locked just > after first optimistic atomic_fetch_or. 99.999% times this loop will not > have a job. But in case other backend did lock buf->state, loop waits > until it releases lock and retry atomic_fetch_or. > > And or'ing contents in also doesn't make sense because we it doesn't work to > > actually unset any contents? > > Sorry, I didn't understand sentence :(( You're OR'ing multiple bits into buf->state. LockBufHdr() only ORs in BM_LOCKED. ORing BM_LOCKED is fine: Either the buffer is not already locked, in which case it just sets the BM_LOCKED bit, acquiring the lock. Or it doesn't change anything, because BM_LOCKED already was set. But OR'ing in multiple bits is *not* fine, because it'll actually change the contents of ->state while the buffer header is locked. > > Why don't you just use LockBufHdr/UnlockBufHdr? > > This pair makes two atomic writes to memory. Two writes are heavier than > one write in this version (if optimistic case succeed). UnlockBufHdr doesn't use a locked atomic op. It uses a write barrier and an unlocked write. Greetings, Andres Freund
В Пт, 25/02/2022 в 09:01 -0800, Andres Freund пишет: > Hi, > > On 2022-02-25 12:51:22 +0300, Yura Sokolov wrote: > > > > + * The usage_count starts out at 1 so that the buffer can survive one > > > > + * clock-sweep pass. > > > > + * > > > > + * We use direct atomic OR instead of Lock+Unlock since no other backend > > > > + * could be interested in the buffer. But StrategyGetBuffer, > > > > + * Flush*Buffers, Drop*Buffers are scanning all buffers and locks them to > > > > + * compare tag, and UnlockBufHdr does raw write to state. So we have to > > > > + * spin if we found buffer locked. > > > > > > So basically the first half of of the paragraph is wrong, because no, we > > > can't? > > > > Logically, there are no backends that could be interesting in the buffer. > > Physically they do LockBufHdr/UnlockBufHdr just to check they are not interesting. > > Yea, but that's still being interested in the buffer... > > > > > > + * Note that we write tag unlocked. It is also safe since there is always > > > > + * check for BM_VALID when tag is compared. > > > > */ > > > > buf->tag = newTag; > > > > - buf_state &= ~(BM_VALID | BM_DIRTY | BM_JUST_DIRTIED | > > > > - BM_CHECKPOINT_NEEDED | BM_IO_ERROR | BM_PERMANENT | > > > > - BUF_USAGECOUNT_MASK); > > > > if (relpersistence == RELPERSISTENCE_PERMANENT || forkNum == INIT_FORKNUM) > > > > - buf_state |= BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > > > > + new_bits = BM_TAG_VALID | BM_PERMANENT | BUF_USAGECOUNT_ONE; > > > > else > > > > - buf_state |= BM_TAG_VALID | BUF_USAGECOUNT_ONE; > > > > - > > > > - UnlockBufHdr(buf, buf_state); > > > > + new_bits = BM_TAG_VALID | BUF_USAGECOUNT_ONE; > > > > > > > > - if (oldPartitionLock != NULL) > > > > + buf_state = pg_atomic_fetch_or_u32(&buf->state, new_bits); > > > > + while (unlikely(buf_state & BM_LOCKED)) > > > > > > I don't think it's safe to atomic in arbitrary bits. If somebody else has > > > locked the buffer header in this moment, it'll lead to completely bogus > > > results, because unlocking overwrites concurrently written contents (which > > > there shouldn't be any, but here there are)... > > > > That is why there is safety loop in the case buf->state were locked just > > after first optimistic atomic_fetch_or. 99.999% times this loop will not > > have a job. But in case other backend did lock buf->state, loop waits > > until it releases lock and retry atomic_fetch_or. > > > And or'ing contents in also doesn't make sense because we it doesn't work to > > > actually unset any contents? > > > > Sorry, I didn't understand sentence :(( > > You're OR'ing multiple bits into buf->state. LockBufHdr() only ORs in > BM_LOCKED. ORing BM_LOCKED is fine: > Either the buffer is not already locked, in which case it just sets the > BM_LOCKED bit, acquiring the lock. Or it doesn't change anything, because > BM_LOCKED already was set. > > But OR'ing in multiple bits is *not* fine, because it'll actually change the > contents of ->state while the buffer header is locked. First, both states are valid: before atomic_or and after. Second, there are no checks for buffer->state while buffer header is locked. All LockBufHdr users uses result of LockBufHdr. (I just checked that). > > > Why don't you just use LockBufHdr/UnlockBufHdr? > > > > This pair makes two atomic writes to memory. Two writes are heavier than > > one write in this version (if optimistic case succeed). > > UnlockBufHdr doesn't use a locked atomic op. It uses a write barrier and an > unlocked write. Write barrier is not free on any platform. Well, while I don't see problem with modifying buffer->state, there is problem with modifying buffer->tag: I missed Drop*Buffers doesn't check BM_TAG_VALID flag. Therefore either I had to add this check to those places, or return to LockBufHdr+UnlockBufHdr pair. For patch simplicity I'll return Lock+UnlockBufHdr pair. But it has measurable impact on low connection numbers on many-sockets. > > Greetings, > > Andres Freund
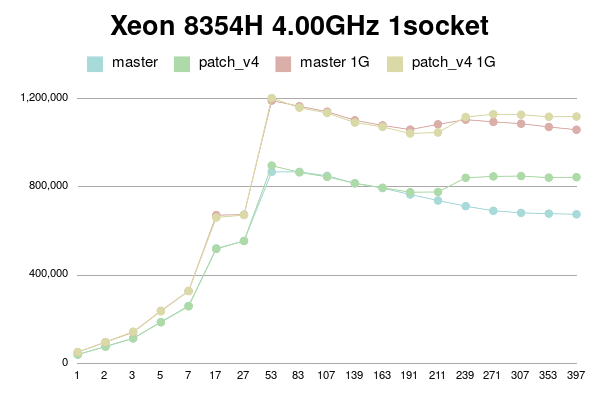
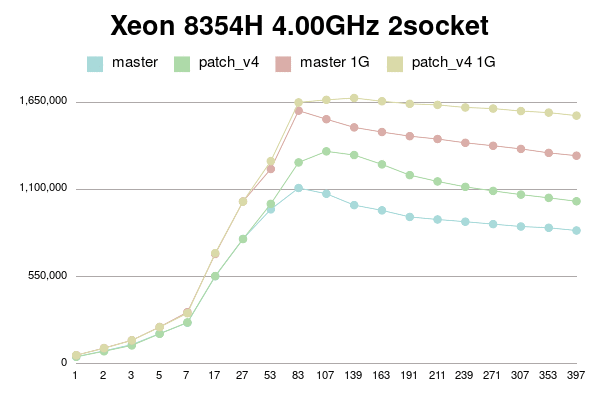
В Пт, 25/02/2022 в 09:38 +0000, Simon Riggs пишет: > On Fri, 25 Feb 2022 at 09:24, Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > > > This approach is cleaner than v1, but should also perform better > > > because there will be a 1:1 relationship between a buffer and its > > > dynahash entry, most of the time. > > > > Thank you for suggestion. Yes, it is much clearer than my initial proposal. > > > > Should I incorporate it to v4 patch? Perhaps, it could be a separate > > commit in new version. > > I don't insist that you do that, but since the API changes are a few > hours work ISTM better to include in one patch for combined perf > testing. It would be better to put all changes in this area into PG15 > than to split it across multiple releases. > > > Why there is need for this? Which way backend could be forced to abort > > between BufTableReuse and BufTableAssign in this code path? I don't > > see any CHECK_FOR_INTERRUPTS on the way, but may be I'm missing > > something. > > Sounds reasonable. Ok, here is v4. It is with two commits: one for BufferAlloc locking change and other for dynahash's freelist avoiding. Buffer locking patch is same to v2 with some comment changes. Ie it uses Lock+UnlockBufHdr For dynahash HASH_REUSE and HASH_ASSIGN as suggested. HASH_REUSE stores deleted element into per-process static variable. HASH_ASSIGN uses this element instead of freelist. If there's no such stored element, it falls back to HASH_ENTER. I've implemented Robert Haas's suggestion to count element in freelists instead of nentries: > One idea is to jigger things so that we maintain a count of the total > number of entries that doesn't change except when we allocate, and > then for each freelist partition we maintain the number of entries in > that freelist partition. So then the size of the hash table, instead > of being sum(nentries) is totalsize - sum(nfree). https://postgr.es/m/CA%2BTgmoZkg-04rcNRURt%3DjAG0Cs5oPyB-qKxH4wqX09e-oXy-nw%40mail.gmail.com It helps to avoid freelist lock just to actualize counters. I made it with replacing "nentries" with "nfree" and adding "nalloced" to each freelist. It also makes "hash_update_hash_key" valid for key that migrates partitions. I believe, there is no need for "nalloced" for each freelist, and instead single such field should be in HASHHDR. More, it seems to me `element_alloc` function needs no acquiring freelist partition lock since it is called only during initialization of shared hash table. Am I right? I didn't go this path in v4 for simplicity, but can put it to v5 if approved. To be honest, "reuse" patch gives little improvement. But still measurable on some connection numbers. I tried to reduce freelist partitions to 8, but it has mixed impact. Most of time performance is same, but sometimes a bit lower. I didn't investigate reasons. Perhaps they are not related to buffer manager. I didn't introduce new functions BufTableReuse and BufTableAssign since there are single call to BufTableInsert and two calls to BufTableDelete. So I reused this functions, just added "reuse" flag to BufTableDelete. Tests simple_select for Xeon 8354H, 128MB and 1G shared buffers for scale 100. 1 socket: conns | master | patch_v4 | master 1G | patch_v4 1G --------+------------+------------+------------+------------ 1 | 41975 | 41540 | 52898 | 52213 2 | 77693 | 77908 | 97571 | 98371 3 | 114713 | 115522 | 142709 | 145226 5 | 188898 | 187617 | 239322 | 237269 7 | 261516 | 260006 | 329119 | 329449 17 | 521821 | 519473 | 672390 | 662106 27 | 555487 | 555697 | 674630 | 672736 53 | 868213 | 896539 | 1190734 | 1202505 83 | 868232 | 866029 | 1164997 | 1158719 107 | 850477 | 845685 | 1140597 | 1134502 139 | 816311 | 816808 | 1101471 | 1091258 163 | 794788 | 796517 | 1078445 | 1071568 191 | 765934 | 776185 | 1059497 | 1041944 211 | 738656 | 777365 | 1083356 | 1046422 239 | 713124 | 841337 | 1104629 | 1116668 271 | 692138 | 847803 | 1094432 | 1128971 307 | 682919 | 849239 | 1086306 | 1127051 353 | 679449 | 842125 | 1071482 | 1117471 397 | 676217 | 844015 | 1058937 | 1118628 2 sockets: conns | master | patch_v4 | master 1G | patch_v4 1G --------+------------+------------+------------+------------ 1 | 44317 | 44034 | 53920 | 53583 2 | 81193 | 78621 | 99138 | 97968 3 | 120755 | 115648 | 148102 | 147423 5 | 190007 | 188943 | 232078 | 231029 7 | 258602 | 260649 | 325545 | 318567 17 | 551814 | 552914 | 692312 | 697518 27 | 787353 | 786573 | 1023509 | 1022891 53 | 973880 | 1008534 | 1228274 | 1278194 83 | 1108442 | 1269777 | 1596292 | 1648156 107 | 1072188 | 1339634 | 1542401 | 1664476 139 | 1000446 | 1316372 | 1490757 | 1676127 163 | 967378 | 1257445 | 1461468 | 1655574 191 | 926010 | 1189591 | 1435317 | 1639313 211 | 909919 | 1149905 | 1417437 | 1632764 239 | 895944 | 1115681 | 1393530 | 1616329 271 | 880545 | 1090208 | 1374878 | 1609544 307 | 865560 | 1066798 | 1355164 | 1593769 353 | 857591 | 1046426 | 1330069 | 1584006 397 | 840374 | 1024711 | 1312257 | 1564872 -------- regards Yura Sokolov Postgres Professional y.sokolov@postgrespro.ru funny.falcon@gmail.com
Вложения
{kind=link}
{kind=link}
В Вт, 01/03/2022 в 10:24 +0300, Yura Sokolov пишет: > Ok, here is v4. And here is v5. First, there was compilation error in Assert in dynahash.c . Excuse me for not checking before sending previous version. Second, I add third commit that reduces HASHHDR allocation size for non-partitioned dynahash: - moved freeList to last position - alloc and memset offset(HASHHDR, freeList[1]) for non-partitioned hash tables. I didn't benchmarked it, but I will be surprised if it matters much in performance sence. Third, I put all three commits into single file to not confuse commitfest application. -------- regards Yura Sokolov Postgres Professional y.sokolov@postgrespro.ru funny.falcon@gmail.com
Вложения
At Thu, 03 Mar 2022 01:35:57 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> В Вт, 01/03/2022 в 10:24 +0300, Yura Sokolov пишет:
> > Ok, here is v4.
>
> And here is v5.
>
> First, there was compilation error in Assert in dynahash.c .
> Excuse me for not checking before sending previous version.
>
> Second, I add third commit that reduces HASHHDR allocation
> size for non-partitioned dynahash:
> - moved freeList to last position
> - alloc and memset offset(HASHHDR, freeList[1]) for
> non-partitioned hash tables.
> I didn't benchmarked it, but I will be surprised if it
> matters much in performance sence.
>
> Third, I put all three commits into single file to not
> confuse commitfest application.
Thanks! I looked into dynahash part.
struct HASHHDR
{
- /*
- * The freelist can become a point of contention in high-concurrency hash
Why did you move around the freeList?
- long nentries; /* number of entries in associated buckets */
+ long nfree; /* number of free entries in the list */
+ long nalloced; /* number of entries initially allocated for
Why do we need nfree? HASH_ASSING should do the same thing with
HASH_REMOVE. Maybe the reason is the code tries to put the detached
bucket to different free list, but we can just remember the
freelist_idx for the detached bucket as we do for hashp. I think that
should largely reduce the footprint of this patch.
-static void hdefault(HTAB *hashp);
+static void hdefault(HTAB *hashp, bool partitioned);
That optimization may work even a bit, but it is not irrelevant to
this patch?
+ case HASH_REUSE:
+ if (currBucket != NULL)
+ {
+ /* check there is no unfinished HASH_REUSE+HASH_ASSIGN pair */
+ Assert(DynaHashReuse.hashp == NULL);
+ Assert(DynaHashReuse.element == NULL);
I think all cases in the switch(action) other than HASH_ASSIGN needs
this assertion and no need for checking both, maybe only for element
would be enough.
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> Thanks! I looked into dynahash part.
>
> struct HASHHDR
> {
> - /*
> - * The freelist can become a point of contention in high-concurrency hash
>
> Why did you move around the freeList?
>
>
> - long nentries; /* number of entries in associated buckets */
> + long nfree; /* number of free entries in the list */
> + long nalloced; /* number of entries initially allocated for
>
> Why do we need nfree? HASH_ASSING should do the same thing with
> HASH_REMOVE. Maybe the reason is the code tries to put the detached
> bucket to different free list, but we can just remember the
> freelist_idx for the detached bucket as we do for hashp. I think that
> should largely reduce the footprint of this patch.
>
> -static void hdefault(HTAB *hashp);
> +static void hdefault(HTAB *hashp, bool partitioned);
>
> That optimization may work even a bit, but it is not irrelevant to
> this patch?
>
> + case HASH_REUSE:
> + if (currBucket != NULL)
> + {
> + /* check there is no unfinished HASH_REUSE+HASH_ASSIGN pair */
> + Assert(DynaHashReuse.hashp == NULL);
> + Assert(DynaHashReuse.element == NULL);
>
> I think all cases in the switch(action) other than HASH_ASSIGN needs
> this assertion and no need for checking both, maybe only for element
> would be enough.
While I looked buf_table part, I came up with additional comments.
BufTableInsert(BufferTag *tagPtr, uint32 hashcode, int buf_id)
{
hash_search_with_hash_value(SharedBufHash,
HASH_ASSIGN,
...
BufTableDelete(BufferTag *tagPtr, uint32 hashcode, bool reuse)
BufTableDelete considers both reuse and !reuse cases but
BufTableInsert doesn't and always does HASH_ASSIGN. That looks
odd. We should use HASH_ENTER here. Thus I think it is more
reasonable that HASH_ENTRY uses the stashed entry if exists and
needed, or returns it to freelist if exists but not needed.
What do you think about this?
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
At Fri, 11 Mar 2022 15:49:49 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > > Thanks! I looked into dynahash part. Then I looked into bufmgr part. It looks fine to me but I have some comments on code comments. > * To change the association of a valid buffer, we'll need to have > * exclusive lock on both the old and new mapping partitions. > if (oldFlags & BM_TAG_VALID) We don't take lock on the new mapping partition here. + * Clear out the buffer's tag and flags. We must do this to ensure that + * linear scans of the buffer array don't think the buffer is valid. We + * also reset the usage_count since any recency of use of the old content + * is no longer relevant. + * + * We are single pinner, we hold buffer header lock and exclusive + * partition lock (if tag is valid). Given these statements it is safe to + * clear tag since no other process can inspect it to the moment. This comment is a merger of the comments from InvalidateBuffer and BufferAlloc. But I think what we need to explain here is why we invalidate the buffer here despite of we are going to reuse it soon. And I think we need to state that the old buffer is now safe to use for the new tag here. I'm not sure the statement is really correct but clearing-out actually looks like safer. > Now it is safe to use victim buffer for new tag. Invalidate the > buffer before releasing header lock to ensure that linear scans of > the buffer array don't think the buffer is valid. It is safe > because it is guaranteed that we're the single pinner of the buffer. > That pin also prevents the buffer from being stolen by others until > we reuse it or return it to freelist. So I want to revise the following comment. - * Now it is safe to use victim buffer for new tag. + * Now reuse victim buffer for new tag. > * Make sure BM_PERMANENT is set for buffers that must be written at every > * checkpoint. Unlogged buffers only need to be written at shutdown > * checkpoints, except for their "init" forks, which need to be treated > * just like permanent relations. > * > * The usage_count starts out at 1 so that the buffer can survive one > * clock-sweep pass. But if you think the current commet is fine, I don't insist on the comment chagnes. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
В Пт, 11/03/2022 в 15:30 +0900, Kyotaro Horiguchi пишет:
> At Thu, 03 Mar 2022 01:35:57 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > В Вт, 01/03/2022 в 10:24 +0300, Yura Sokolov пишет:
> > > Ok, here is v4.
> >
> > And here is v5.
> >
> > First, there was compilation error in Assert in dynahash.c .
> > Excuse me for not checking before sending previous version.
> >
> > Second, I add third commit that reduces HASHHDR allocation
> > size for non-partitioned dynahash:
> > - moved freeList to last position
> > - alloc and memset offset(HASHHDR, freeList[1]) for
> > non-partitioned hash tables.
> > I didn't benchmarked it, but I will be surprised if it
> > matters much in performance sence.
> >
> > Third, I put all three commits into single file to not
> > confuse commitfest application.
>
> Thanks! I looked into dynahash part.
>
> struct HASHHDR
> {
> - /*
> - * The freelist can become a point of contention in high-concurrency hash
>
> Why did you move around the freeList?
>
>
> - long nentries; /* number of entries in associated buckets */
> + long nfree; /* number of free entries in the list */
> + long nalloced; /* number of entries initially allocated for
>
> Why do we need nfree? HASH_ASSING should do the same thing with
> HASH_REMOVE. Maybe the reason is the code tries to put the detached
> bucket to different free list, but we can just remember the
> freelist_idx for the detached bucket as we do for hashp. I think that
> should largely reduce the footprint of this patch.
If we keep nentries, then we need to fix nentries in both old
"freeList" partition and new one. It is two freeList[partition]->mutex
lock+unlock pairs.
But count of free elements doesn't change, so if we change nentries
to nfree, then no need to fix freeList[partition]->nfree counters,
no need to lock+unlock.
>
> -static void hdefault(HTAB *hashp);
> +static void hdefault(HTAB *hashp, bool partitioned);
>
> That optimization may work even a bit, but it is not irrelevant to
> this patch?
>
> + case HASH_REUSE:
> + if (currBucket != NULL)
> + {
> + /* check there is no unfinished HASH_REUSE+HASH_ASSIGN pair */
> + Assert(DynaHashReuse.hashp == NULL);
> + Assert(DynaHashReuse.element == NULL);
>
> I think all cases in the switch(action) other than HASH_ASSIGN needs
> this assertion and no need for checking both, maybe only for element
> would be enough.
Agree.
В Пт, 11/03/2022 в 15:49 +0900, Kyotaro Horiguchi пишет:
> At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> > Thanks! I looked into dynahash part.
> >
> > struct HASHHDR
> > {
> > - /*
> > - * The freelist can become a point of contention in high-concurrency hash
> >
> > Why did you move around the freeList?
> >
> >
> > - long nentries; /* number of entries in associated buckets */
> > + long nfree; /* number of free entries in the list */
> > + long nalloced; /* number of entries initially allocated for
> >
> > Why do we need nfree? HASH_ASSING should do the same thing with
> > HASH_REMOVE. Maybe the reason is the code tries to put the detached
> > bucket to different free list, but we can just remember the
> > freelist_idx for the detached bucket as we do for hashp. I think that
> > should largely reduce the footprint of this patch.
> >
> > -static void hdefault(HTAB *hashp);
> > +static void hdefault(HTAB *hashp, bool partitioned);
> >
> > That optimization may work even a bit, but it is not irrelevant to
> > this patch?
(forgot to answer in previous letter).
Yes, third commit is very optional. But adding `nalloced` to
`FreeListData` increases allocation a lot even for usual
non-shared non-partitioned dynahashes. And this allocation is
quite huge right now for no meaningful reason.
> >
> > + case HASH_REUSE:
> > + if (currBucket != NULL)
> > + {
> > + /* check there is no unfinished HASH_REUSE+HASH_ASSIGN pair */
> > + Assert(DynaHashReuse.hashp == NULL);
> > + Assert(DynaHashReuse.element == NULL);
> >
> > I think all cases in the switch(action) other than HASH_ASSIGN needs
> > this assertion and no need for checking both, maybe only for element
> > would be enough.
>
> While I looked buf_table part, I came up with additional comments.
>
> BufTableInsert(BufferTag *tagPtr, uint32 hashcode, int buf_id)
> {
> hash_search_with_hash_value(SharedBufHash,
> HASH_ASSIGN,
> ...
> BufTableDelete(BufferTag *tagPtr, uint32 hashcode, bool reuse)
>
> BufTableDelete considers both reuse and !reuse cases but
> BufTableInsert doesn't and always does HASH_ASSIGN. That looks
> odd. We should use HASH_ENTER here. Thus I think it is more
> reasonable that HASH_ENTRY uses the stashed entry if exists and
> needed, or returns it to freelist if exists but not needed.
>
> What do you think about this?
Well... I don't like it but I don't mind either.
Code in HASH_ENTER and HASH_ASSIGN cases differs much.
On the other hand, probably it is possible to merge it carefuly.
I'll try.
---------
regards
Yura Sokolov
В Пт, 11/03/2022 в 17:21 +0900, Kyotaro Horiguchi пишет:
> At Fri, 11 Mar 2022 15:49:49 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> > At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> > > Thanks! I looked into dynahash part.
> > >
> > > struct HASHHDR
> > > {
> > > - /*
> > > - * The freelist can become a point of contention in high-concurrency hash
> > >
> > > Why did you move around the freeList?
This way it is possible to allocate just first partition, not all 32 partitions.
>
> Then I looked into bufmgr part. It looks fine to me but I have some
> comments on code comments.
>
> > * To change the association of a valid buffer, we'll need to have
> > * exclusive lock on both the old and new mapping partitions.
> > if (oldFlags & BM_TAG_VALID)
>
> We don't take lock on the new mapping partition here.
Thx, fixed.
> + * Clear out the buffer's tag and flags. We must do this to ensure that
> + * linear scans of the buffer array don't think the buffer is valid. We
> + * also reset the usage_count since any recency of use of the old content
> + * is no longer relevant.
> + *
> + * We are single pinner, we hold buffer header lock and exclusive
> + * partition lock (if tag is valid). Given these statements it is safe to
> + * clear tag since no other process can inspect it to the moment.
>
> This comment is a merger of the comments from InvalidateBuffer and
> BufferAlloc. But I think what we need to explain here is why we
> invalidate the buffer here despite of we are going to reuse it soon.
> And I think we need to state that the old buffer is now safe to use
> for the new tag here. I'm not sure the statement is really correct
> but clearing-out actually looks like safer.
I've tried to reformulate the comment block.
>
> > Now it is safe to use victim buffer for new tag. Invalidate the
> > buffer before releasing header lock to ensure that linear scans of
> > the buffer array don't think the buffer is valid. It is safe
> > because it is guaranteed that we're the single pinner of the buffer.
> > That pin also prevents the buffer from being stolen by others until
> > we reuse it or return it to freelist.
>
> So I want to revise the following comment.
>
> - * Now it is safe to use victim buffer for new tag.
> + * Now reuse victim buffer for new tag.
> > * Make sure BM_PERMANENT is set for buffers that must be written at every
> > * checkpoint. Unlogged buffers only need to be written at shutdown
> > * checkpoints, except for their "init" forks, which need to be treated
> > * just like permanent relations.
> > *
> > * The usage_count starts out at 1 so that the buffer can survive one
> > * clock-sweep pass.
>
> But if you think the current commet is fine, I don't insist on the
> comment chagnes.
Used suggestion.
Fr, 11/03/22 Yura Sokolov wrote:
> В Пт, 11/03/2022 в 15:49 +0900, Kyotaro Horiguchi пишет:
> > BufTableDelete considers both reuse and !reuse cases but
> > BufTableInsert doesn't and always does HASH_ASSIGN. That looks
> > odd. We should use HASH_ENTER here. Thus I think it is more
> > reasonable that HASH_ENTRY uses the stashed entry if exists and
> > needed, or returns it to freelist if exists but not needed.
> >
> > What do you think about this?
>
> Well... I don't like it but I don't mind either.
>
> Code in HASH_ENTER and HASH_ASSIGN cases differs much.
> On the other hand, probably it is possible to merge it carefuly.
> I'll try.
I've merged HASH_ASSIGN into HASH_ENTER.
As in previous letter, three commits are concatted to one file
and could be applied with `git am`.
-------
regards
Yura Sokolov
Postgres Professional
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Вложения
On Sun, Mar 13, 2022 at 3:25 AM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
В Пт, 11/03/2022 в 17:21 +0900, Kyotaro Horiguchi пишет:
> At Fri, 11 Mar 2022 15:49:49 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> > At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in
> > > Thanks! I looked into dynahash part.
> > >
> > > struct HASHHDR
> > > {
> > > - /*
> > > - * The freelist can become a point of contention in high-concurrency hash
> > >
> > > Why did you move around the freeList?
This way it is possible to allocate just first partition, not all 32 partitions.
>
> Then I looked into bufmgr part. It looks fine to me but I have some
> comments on code comments.
>
> > * To change the association of a valid buffer, we'll need to have
> > * exclusive lock on both the old and new mapping partitions.
> > if (oldFlags & BM_TAG_VALID)
>
> We don't take lock on the new mapping partition here.
Thx, fixed.
> + * Clear out the buffer's tag and flags. We must do this to ensure that
> + * linear scans of the buffer array don't think the buffer is valid. We
> + * also reset the usage_count since any recency of use of the old content
> + * is no longer relevant.
> + *
> + * We are single pinner, we hold buffer header lock and exclusive
> + * partition lock (if tag is valid). Given these statements it is safe to
> + * clear tag since no other process can inspect it to the moment.
>
> This comment is a merger of the comments from InvalidateBuffer and
> BufferAlloc. But I think what we need to explain here is why we
> invalidate the buffer here despite of we are going to reuse it soon.
> And I think we need to state that the old buffer is now safe to use
> for the new tag here. I'm not sure the statement is really correct
> but clearing-out actually looks like safer.
I've tried to reformulate the comment block.
>
> > Now it is safe to use victim buffer for new tag. Invalidate the
> > buffer before releasing header lock to ensure that linear scans of
> > the buffer array don't think the buffer is valid. It is safe
> > because it is guaranteed that we're the single pinner of the buffer.
> > That pin also prevents the buffer from being stolen by others until
> > we reuse it or return it to freelist.
>
> So I want to revise the following comment.
>
> - * Now it is safe to use victim buffer for new tag.
> + * Now reuse victim buffer for new tag.
> > * Make sure BM_PERMANENT is set for buffers that must be written at every
> > * checkpoint. Unlogged buffers only need to be written at shutdown
> > * checkpoints, except for their "init" forks, which need to be treated
> > * just like permanent relations.
> > *
> > * The usage_count starts out at 1 so that the buffer can survive one
> > * clock-sweep pass.
>
> But if you think the current commet is fine, I don't insist on the
> comment chagnes.
Used suggestion.
Fr, 11/03/22 Yura Sokolov wrote:
> В Пт, 11/03/2022 в 15:49 +0900, Kyotaro Horiguchi пишет:
> > BufTableDelete considers both reuse and !reuse cases but
> > BufTableInsert doesn't and always does HASH_ASSIGN. That looks
> > odd. We should use HASH_ENTER here. Thus I think it is more
> > reasonable that HASH_ENTRY uses the stashed entry if exists and
> > needed, or returns it to freelist if exists but not needed.
> >
> > What do you think about this?
>
> Well... I don't like it but I don't mind either.
>
> Code in HASH_ENTER and HASH_ASSIGN cases differs much.
> On the other hand, probably it is possible to merge it carefuly.
> I'll try.
I've merged HASH_ASSIGN into HASH_ENTER.
As in previous letter, three commits are concatted to one file
and could be applied with `git am`.
-------
regards
Yura Sokolov
Postgres Professional
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Hi,
In the description:
There is no need to hold both lock simultaneously.
both lock -> both locks
+ * We also reset the usage_count since any recency of use of the old
recency of use -> recent use
+BufTableDelete(BufferTag *tagPtr, uint32 hashcode, bool reuse)
Later on, there is code:
+ reuse ? HASH_REUSE : HASH_REMOVE,
Can flag (such as HASH_REUSE) be passed to BufTableDelete() instead of bool ? That way, flag can be used directly in the above place.
+ long nalloced; /* number of entries initially allocated for
nallocated isn't very long. I think it would be better to name the field nallocated 'nallocated'.
+ sum += hashp->hctl->freeList[i].nalloced;
+ sum -= hashp->hctl->freeList[i].nfree;
+ sum -= hashp->hctl->freeList[i].nfree;
I think it would be better to calculate the difference between nalloced and nfree first, then add the result to sum (to avoid overflow).
Subject: [PATCH 3/3] reduce memory allocation for non-partitioned dynahash
memory allocation -> memory allocations
Cheers
В Вс, 13/03/2022 в 07:05 -0700, Zhihong Yu пишет:
>
> Hi,
> In the description:
>
> There is no need to hold both lock simultaneously.
>
> both lock -> both locks
Thanks.
> + * We also reset the usage_count since any recency of use of the old
>
> recency of use -> recent use
Thanks.
> +BufTableDelete(BufferTag *tagPtr, uint32 hashcode, bool reuse)
>
> Later on, there is code:
>
> + reuse ? HASH_REUSE : HASH_REMOVE,
>
> Can flag (such as HASH_REUSE) be passed to BufTableDelete() instead of bool ? That way, flag can be used directly in
theabove place.
No.
BufTable* functions are created to abstract Buffer Table from dynahash.
Pass of HASH_REUSE directly will break abstraction.
> + long nalloced; /* number of entries initially allocated for
>
> nallocated isn't very long. I think it would be better to name the field nallocated 'nallocated'.
It is debatable.
Why not num_allocated? allocated_count? number_of_allocations?
Same points for nfree.
`nalloced` is recognizable and unambiguous. And there are a lot
of `*alloced` in the postgresql's source, so this one will not
be unusual.
I don't see the need to make it longer.
But if someone supports your point, I will not mind to changing
the name.
> + sum += hashp->hctl->freeList[i].nalloced;
> + sum -= hashp->hctl->freeList[i].nfree;
>
> I think it would be better to calculate the difference between nalloced and nfree first, then add the result to sum
(toavoid overflow).
Doesn't really matter much, because calculation must be valid
even if all nfree==0.
I'd rather debate use of 'long' in dynahash at all: 'long' is
32bit on 64bit Windows. It is better to use 'Size' here.
But 'nelements' were 'long', so I didn't change things. I think
it is place for another patch.
(On the other hand, dynahash with 2**31 elements is at least
512GB RAM... we doubtfully trigger problem before OOM killer
came. Does Windows have an OOM killer?)
> Subject: [PATCH 3/3] reduce memory allocation for non-partitioned dynahash
>
> memory allocation -> memory allocations
For each dynahash instance single allocation were reduced.
I think, 'memory allocation' is correct.
Plural will be
reduce memory allocations for non-partitioned dynahashes
ie both 'allocations' and 'dynahashes'.
Am I wrong?
------
regards
Yura Sokolov
Вложения
On Sun, Mar 13, 2022 at 3:27 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
В Вс, 13/03/2022 в 07:05 -0700, Zhihong Yu пишет:
>
> Hi,
> In the description:
>
> There is no need to hold both lock simultaneously.
>
> both lock -> both locks
Thanks.
> + * We also reset the usage_count since any recency of use of the old
>
> recency of use -> recent use
Thanks.
> +BufTableDelete(BufferTag *tagPtr, uint32 hashcode, bool reuse)
>
> Later on, there is code:
>
> + reuse ? HASH_REUSE : HASH_REMOVE,
>
> Can flag (such as HASH_REUSE) be passed to BufTableDelete() instead of bool ? That way, flag can be used directly in the above place.
No.
BufTable* functions are created to abstract Buffer Table from dynahash.
Pass of HASH_REUSE directly will break abstraction.
> + long nalloced; /* number of entries initially allocated for
>
> nallocated isn't very long. I think it would be better to name the field nallocated 'nallocated'.
It is debatable.
Why not num_allocated? allocated_count? number_of_allocations?
Same points for nfree.
`nalloced` is recognizable and unambiguous. And there are a lot
of `*alloced` in the postgresql's source, so this one will not
be unusual.
I don't see the need to make it longer.
But if someone supports your point, I will not mind to changing
the name.
> + sum += hashp->hctl->freeList[i].nalloced;
> + sum -= hashp->hctl->freeList[i].nfree;
>
> I think it would be better to calculate the difference between nalloced and nfree first, then add the result to sum (to avoid overflow).
Doesn't really matter much, because calculation must be valid
even if all nfree==0.
I'd rather debate use of 'long' in dynahash at all: 'long' is
32bit on 64bit Windows. It is better to use 'Size' here.
But 'nelements' were 'long', so I didn't change things. I think
it is place for another patch.
(On the other hand, dynahash with 2**31 elements is at least
512GB RAM... we doubtfully trigger problem before OOM killer
came. Does Windows have an OOM killer?)
> Subject: [PATCH 3/3] reduce memory allocation for non-partitioned dynahash
>
> memory allocation -> memory allocations
For each dynahash instance single allocation were reduced.
I think, 'memory allocation' is correct.
Plural will be
reduce memory allocations for non-partitioned dynahashes
ie both 'allocations' and 'dynahashes'.
Am I wrong?
Hi,
bq. reduce memory allocation for non-partitioned dynahash
It seems the following is clearer:
reduce one memory allocation for every non-partitioned dynahash
Cheers
At Fri, 11 Mar 2022 11:30:27 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> В Пт, 11/03/2022 в 15:30 +0900, Kyotaro Horiguchi пишет:
> > At Thu, 03 Mar 2022 01:35:57 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > > В Вт, 01/03/2022 в 10:24 +0300, Yura Sokolov пишет:
> > > > Ok, here is v4.
> > >
> > > And here is v5.
> > >
> > > First, there was compilation error in Assert in dynahash.c .
> > > Excuse me for not checking before sending previous version.
> > >
> > > Second, I add third commit that reduces HASHHDR allocation
> > > size for non-partitioned dynahash:
> > > - moved freeList to last position
> > > - alloc and memset offset(HASHHDR, freeList[1]) for
> > > non-partitioned hash tables.
> > > I didn't benchmarked it, but I will be surprised if it
> > > matters much in performance sence.
> > >
> > > Third, I put all three commits into single file to not
> > > confuse commitfest application.
> >
> > Thanks! I looked into dynahash part.
> >
> > struct HASHHDR
> > {
> > - /*
> > - * The freelist can become a point of contention in high-concurrency hash
> >
> > Why did you move around the freeList?
> >
> >
> > - long nentries; /* number of entries in associated buckets */
> > + long nfree; /* number of free entries in the list */
> > + long nalloced; /* number of entries initially allocated for
> >
> > Why do we need nfree? HASH_ASSING should do the same thing with
> > HASH_REMOVE. Maybe the reason is the code tries to put the detached
> > bucket to different free list, but we can just remember the
> > freelist_idx for the detached bucket as we do for hashp. I think that
> > should largely reduce the footprint of this patch.
>
> If we keep nentries, then we need to fix nentries in both old
> "freeList" partition and new one. It is two freeList[partition]->mutex
> lock+unlock pairs.
>
> But count of free elements doesn't change, so if we change nentries
> to nfree, then no need to fix freeList[partition]->nfree counters,
> no need to lock+unlock.
Ah, okay. I missed that bucket reuse chages key in most cases.
But still I don't think its good to move entries around partition
freelists for another reason. I'm afraid that the freelists get into
imbalanced state. get_hash_entry prefers main shmem allocation than
other freelist so that could lead to freelist bloat, or worse
contension than the traditinal way involving more than two partitions.
I'll examine the possibility to resolve this...
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
At Fri, 11 Mar 2022 12:34:32 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > В Пт, 11/03/2022 в 15:49 +0900, Kyotaro Horiguchi пишет: > > At Fri, 11 Mar 2022 15:30:30 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@g> > BufTableDelete(BufferTag *tagPtr, uint32hashcode, bool reuse) > > > > BufTableDelete considers both reuse and !reuse cases but > > BufTableInsert doesn't and always does HASH_ASSIGN. That looks > > odd. We should use HASH_ENTER here. Thus I think it is more > > reasonable that HASH_ENTRY uses the stashed entry if exists and > > needed, or returns it to freelist if exists but not needed. > > > > What do you think about this? > > Well... I don't like it but I don't mind either. > > Code in HASH_ENTER and HASH_ASSIGN cases differs much. > On the other hand, probably it is possible to merge it carefuly. > I'll try. Honestly, I'm not sure it wins on performance basis. It just came from interface consistency (mmm. a bit different, maybe.. convincibility?). regards. -- Kyotaro Horiguchi NTT Open Source Software Center
At Mon, 14 Mar 2022 09:39:48 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > I'll examine the possibility to resolve this... The existence of nfree and nalloc made me confused and I found the reason. In the case where a parittion collects many REUSE-ASSIGN-REMOVEed elemetns from other paritiotns, nfree gets larger than nalloced. This is a strange point of the two counters. nalloced is only referred to as (sum(nalloced[])). So we don't need nalloced per-partition basis and the formula to calculate the number of used elements would be as follows. sum(nalloced - nfree) = <total_nalloced> - sum(nfree) We rarely create fresh elements in shared hashes so I don't think there's additional contention on the <total_nalloced> even if it were a global atomic. So, the remaining issue is the possible imbalancement among partitions. On second thought, by the current way, if there's a bad deviation in partition-usage, a heavily hit partition finally collects elements via get_hash_entry(). By the patch's way, similar thing happens via the REUSE-ASSIGN-REMOVE sequence. But buffers once used for something won't be freed until buffer invalidation. But bulk buffer invalidation won't deviatedly distribute freed buffers among partitions. So I conclude for now that is a non-issue. So my opinion on the counters is: I'd like to ask you to remove nalloced from partitions then add a global atomic for the same use? No need to do something for the possible deviation issue. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет: > At Mon, 14 Mar 2022 09:39:48 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > > I'll examine the possibility to resolve this... > > The existence of nfree and nalloc made me confused and I found the > reason. > > In the case where a parittion collects many REUSE-ASSIGN-REMOVEed > elemetns from other paritiotns, nfree gets larger than nalloced. This > is a strange point of the two counters. nalloced is only referred to > as (sum(nalloced[])). So we don't need nalloced per-partition basis > and the formula to calculate the number of used elements would be as > follows. > > sum(nalloced - nfree) > = <total_nalloced> - sum(nfree) > > We rarely create fresh elements in shared hashes so I don't think > there's additional contention on the <total_nalloced> even if it were > a global atomic. > > So, the remaining issue is the possible imbalancement among > partitions. On second thought, by the current way, if there's a bad > deviation in partition-usage, a heavily hit partition finally collects > elements via get_hash_entry(). By the patch's way, similar thing > happens via the REUSE-ASSIGN-REMOVE sequence. But buffers once used > for something won't be freed until buffer invalidation. But bulk > buffer invalidation won't deviatedly distribute freed buffers among > partitions. So I conclude for now that is a non-issue. > > So my opinion on the counters is: > > I'd like to ask you to remove nalloced from partitions then add a > global atomic for the same use? I really believe it should be global. I made it per-partition to not overcomplicate first versions. Glad you tell it. I thought to protect it with freeList[0].mutex, but probably atomic is better idea here. But which atomic to chose: uint64 or uint32? Based on sizeof(long)? Ok, I'll do in next version. Whole get_hash_entry look strange. Doesn't it better to cycle through partitions and only then go to get_hash_entry? May be there should be bitmap for non-empty free lists? 32bit for 32 partitions. But wouldn't bitmap became contention point itself? > No need to do something for the possible deviation issue. ------- regards Yura Sokolov
At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет: > > I'd like to ask you to remove nalloced from partitions then add a > > global atomic for the same use? > > I really believe it should be global. I made it per-partition to > not overcomplicate first versions. Glad you tell it. > > I thought to protect it with freeList[0].mutex, but probably atomic > is better idea here. But which atomic to chose: uint64 or uint32? > Based on sizeof(long)? > Ok, I'll do in next version. Current nentries is a long (= int64 on CentOS). And uint32 can support roughly 2^32 * 8192 = 32TB shared buffers, which doesn't seem safe enough. So it would be uint64. > Whole get_hash_entry look strange. > Doesn't it better to cycle through partitions and only then go to > get_hash_entry? > May be there should be bitmap for non-empty free lists? 32bit for > 32 partitions. But wouldn't bitmap became contention point itself? The code puts significance on avoiding contention caused by visiting freelists of other partitions. And perhaps thinks that freelist shortage rarely happen. I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on 128kB shared buffers and I saw that get_hash_entry never takes the !element_alloc() path and always allocate a fresh entry, then saturates at 30 new elements allocated at the medium of a 100 seconds run. Then, I tried the same with the patch, and I am surprized to see that the rise of the number of newly allocated elements didn't stop and went up to 511 elements after the 100 seconds run. So I found that my concern was valid. The change in dynahash actually continuously/repeatedly causes lack of free list entries. I'm not sure how much the impact given on performance if we change get_hash_entry to prefer other freelists, though. By the way, there's the following comment in StrategyInitalize. > * Initialize the shared buffer lookup hashtable. > * > * Since we can't tolerate running out of lookup table entries, we must be > * sure to specify an adequate table size here. The maximum steady-state > * usage is of course NBuffers entries, but BufferAlloc() tries to insert > * a new entry before deleting the old. In principle this could be > * happening in each partition concurrently, so we could need as many as > * NBuffers + NUM_BUFFER_PARTITIONS entries. > */ > InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS); "but BufferAlloc() tries to insert a new entry before deleting the old." gets false by this patch but still need that additional room for stashed entries. It seems like needing a fix. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
At Mon, 14 Mar 2022 17:12:48 +0900 (JST), Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote in > Then, I tried the same with the patch, and I am surprized to see that > the rise of the number of newly allocated elements didn't stop and > went up to 511 elements after the 100 seconds run. So I found that my > concern was valid. Which means my last decision was wrong with high odds.. -- Kyotaro Horiguchi NTT Open Source Software Center
В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет: > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет: > > > I'd like to ask you to remove nalloced from partitions then add a > > > global atomic for the same use? > > > > I really believe it should be global. I made it per-partition to > > not overcomplicate first versions. Glad you tell it. > > > > I thought to protect it with freeList[0].mutex, but probably atomic > > is better idea here. But which atomic to chose: uint64 or uint32? > > Based on sizeof(long)? > > Ok, I'll do in next version. > > Current nentries is a long (= int64 on CentOS). And uint32 can support > roughly 2^32 * 8192 = 32TB shared buffers, which doesn't seem safe > enough. So it would be uint64. > > > Whole get_hash_entry look strange. > > Doesn't it better to cycle through partitions and only then go to > > get_hash_entry? > > May be there should be bitmap for non-empty free lists? 32bit for > > 32 partitions. But wouldn't bitmap became contention point itself? > > The code puts significance on avoiding contention caused by visiting > freelists of other partitions. And perhaps thinks that freelist > shortage rarely happen. > > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on > 128kB shared buffers and I saw that get_hash_entry never takes the > !element_alloc() path and always allocate a fresh entry, then > saturates at 30 new elements allocated at the medium of a 100 seconds > run. > > Then, I tried the same with the patch, and I am surprized to see that > the rise of the number of newly allocated elements didn't stop and > went up to 511 elements after the 100 seconds run. So I found that my > concern was valid. The change in dynahash actually > continuously/repeatedly causes lack of free list entries. I'm not > sure how much the impact given on performance if we change > get_hash_entry to prefer other freelists, though. Well, it is quite strange SharedBufHash is not allocated as HASH_FIXED_SIZE. Could you check what happens with this flag set? I'll try as well. Other way to reduce observed case is to remember freelist_idx for reused entry. I didn't believe it matters much since entries migrated netherless, but probably due to some hot buffers there are tention to crowd particular freelist. > By the way, there's the following comment in StrategyInitalize. > > > * Initialize the shared buffer lookup hashtable. > > * > > * Since we can't tolerate running out of lookup table entries, we must be > > * sure to specify an adequate table size here. The maximum steady-state > > * usage is of course NBuffers entries, but BufferAlloc() tries to insert > > * a new entry before deleting the old. In principle this could be > > * happening in each partition concurrently, so we could need as many as > > * NBuffers + NUM_BUFFER_PARTITIONS entries. > > */ > > InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS); > > "but BufferAlloc() tries to insert a new entry before deleting the > old." gets false by this patch but still need that additional room for > stashed entries. It seems like needing a fix. > > > > regards. > > -- > Kyotaro Horiguchi > NTT Open Source Software Center
В Пн, 14/03/2022 в 14:57 +0300, Yura Sokolov пишет:
> В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет:
> > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет:
> > > > I'd like to ask you to remove nalloced from partitions then add a
> > > > global atomic for the same use?
> > >
> > > I really believe it should be global. I made it per-partition to
> > > not overcomplicate first versions. Glad you tell it.
> > >
> > > I thought to protect it with freeList[0].mutex, but probably atomic
> > > is better idea here. But which atomic to chose: uint64 or uint32?
> > > Based on sizeof(long)?
> > > Ok, I'll do in next version.
> >
> > Current nentries is a long (= int64 on CentOS). And uint32 can support
> > roughly 2^32 * 8192 = 32TB shared buffers, which doesn't seem safe
> > enough. So it would be uint64.
> >
> > > Whole get_hash_entry look strange.
> > > Doesn't it better to cycle through partitions and only then go to
> > > get_hash_entry?
> > > May be there should be bitmap for non-empty free lists? 32bit for
> > > 32 partitions. But wouldn't bitmap became contention point itself?
> >
> > The code puts significance on avoiding contention caused by visiting
> > freelists of other partitions. And perhaps thinks that freelist
> > shortage rarely happen.
> >
> > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on
> > 128kB shared buffers and I saw that get_hash_entry never takes the
> > !element_alloc() path and always allocate a fresh entry, then
> > saturates at 30 new elements allocated at the medium of a 100 seconds
> > run.
> >
> > Then, I tried the same with the patch, and I am surprized to see that
> > the rise of the number of newly allocated elements didn't stop and
> > went up to 511 elements after the 100 seconds run. So I found that my
> > concern was valid. The change in dynahash actually
> > continuously/repeatedly causes lack of free list entries. I'm not
> > sure how much the impact given on performance if we change
> > get_hash_entry to prefer other freelists, though.
>
> Well, it is quite strange SharedBufHash is not allocated as
> HASH_FIXED_SIZE. Could you check what happens with this flag set?
> I'll try as well.
>
> Other way to reduce observed case is to remember freelist_idx for
> reused entry. I didn't believe it matters much since entries migrated
> netherless, but probably due to some hot buffers there are tention to
> crowd particular freelist.
Well, I did both. Everything looks ok.
> > By the way, there's the following comment in StrategyInitalize.
> >
> > > * Initialize the shared buffer lookup hashtable.
> > > *
> > > * Since we can't tolerate running out of lookup table entries, we must be
> > > * sure to specify an adequate table size here. The maximum steady-state
> > > * usage is of course NBuffers entries, but BufferAlloc() tries to insert
> > > * a new entry before deleting the old. In principle this could be
> > > * happening in each partition concurrently, so we could need as many as
> > > * NBuffers + NUM_BUFFER_PARTITIONS entries.
> > > */
> > > InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);
> >
> > "but BufferAlloc() tries to insert a new entry before deleting the
> > old." gets false by this patch but still need that additional room for
> > stashed entries. It seems like needing a fix.
Removed whole paragraph because fixed table without extra entries works
just fine.
I lost access to Xeon 8354H, so returned to old Xeon X5675.
128MB and 1GB shared buffers
pgbench with scale 100
select_only benchmark, unix sockets.
Notebook i7-1165G7:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 29614 | 29285 | 32413 | 32784
2 | 58541 | 60052 | 65851 | 65938
3 | 91126 | 90185 | 101404 | 101956
5 | 135809 | 133670 | 143783 | 143471
7 | 155547 | 153568 | 162566 | 162361
17 | 221794 | 218143 | 250562 | 250136
27 | 213742 | 211226 | 241806 | 242594
53 | 216067 | 214792 | 245868 | 246269
83 | 216610 | 218261 | 246798 | 250515
107 | 216169 | 216656 | 248424 | 250105
139 | 208892 | 215054 | 244630 | 246439
163 | 206988 | 212751 | 244061 | 248051
191 | 203842 | 214764 | 241793 | 245081
211 | 201304 | 213997 | 240863 | 246076
239 | 199313 | 211713 | 239639 | 243586
271 | 196712 | 211849 | 236231 | 243831
307 | 194879 | 209813 | 233811 | 241303
353 | 191279 | 210145 | 230896 | 241039
397 | 188509 | 207480 | 227812 | 240637
X5675 1 socket:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 18590 | 18473 | 19652 | 19051
2 | 34899 | 34799 | 37242 | 37432
3 | 51484 | 51393 | 54750 | 54398
5 | 71037 | 70564 | 76482 | 75985
7 | 87391 | 86937 | 96185 | 95433
17 | 122609 | 123087 | 140578 | 140325
27 | 120051 | 120508 | 136318 | 136343
53 | 116851 | 117601 | 133338 | 133265
83 | 113682 | 116755 | 131841 | 132736
107 | 111925 | 116003 | 130661 | 132386
139 | 109338 | 115011 | 128319 | 131453
163 | 107661 | 114398 | 126684 | 130677
191 | 105000 | 113745 | 124850 | 129909
211 | 103607 | 113347 | 123469 | 129302
239 | 101820 | 112428 | 121752 | 128621
271 | 100060 | 111863 | 119743 | 127624
307 | 98554 | 111270 | 117650 | 126877
353 | 97530 | 110231 | 115904 | 125351
397 | 96122 | 109471 | 113609 | 124150
X5675 2 socket:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 17815 | 17577 | 19321 | 19187
2 | 34312 | 35655 | 37121 | 36479
3 | 51868 | 52165 | 56048 | 54984
5 | 81704 | 82477 | 90945 | 90109
7 | 107937 | 105411 | 116015 | 115810
17 | 191339 | 190813 | 216899 | 215775
27 | 236541 | 238078 | 278507 | 278073
53 | 230323 | 231709 | 267226 | 267449
83 | 225560 | 227455 | 261996 | 262344
107 | 221317 | 224030 | 259694 | 259553
139 | 206945 | 219005 | 254817 | 256736
163 | 197723 | 220353 | 251631 | 257305
191 | 193243 | 219149 | 246960 | 256528
211 | 189603 | 218545 | 245362 | 255785
239 | 186382 | 217229 | 240006 | 255024
271 | 183141 | 216359 | 236927 | 253069
307 | 179275 | 215218 | 232571 | 252375
353 | 175559 | 213298 | 227244 | 250534
397 | 172916 | 211627 | 223513 | 248919
Strange thing: both master and patched version has higher
peak tps at X5676 at medium connections (17 or 27 clients)
than in first october version [1]. But lower tps at higher
connections number (>= 191 clients).
I'll try to bisect on master this unfortunate change.
October master was 2d44dee0281a1abf and today's is 7e12256b478b895
(There is small possibility that I tested with TCP sockets
in october and with UNIX sockets today and that gave difference.)
[1] https://postgr.esq/m/1edbb61981fe1d99c3f20e3d56d6c88999f4227c.camel%40postgrespro.ru
-------
regards
Yura Sokolov
Postgres Professional
y.sokolov@postgrespro.ru
Вложения
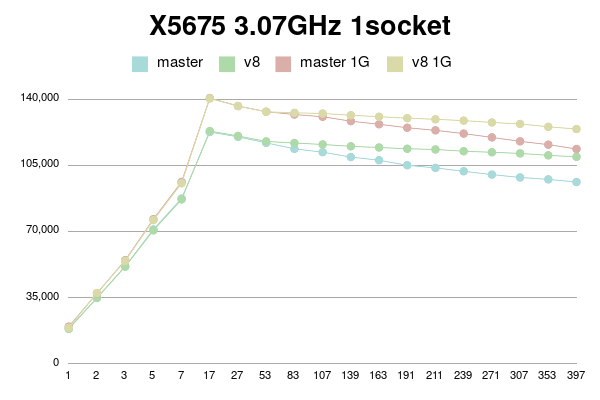{kind=link}
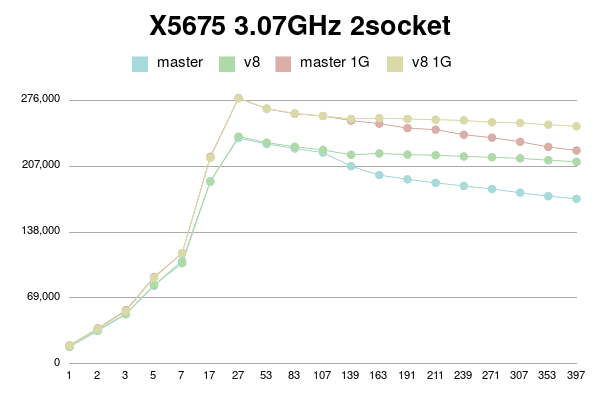{kind=link}
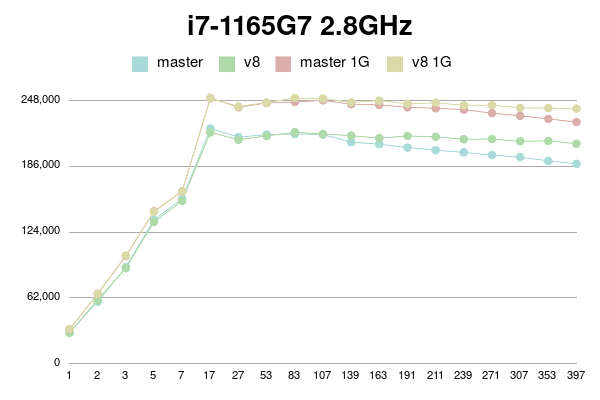{kind=link}
Thanks for the new version.
At Tue, 15 Mar 2022 08:07:39 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> В Пн, 14/03/2022 в 14:57 +0300, Yura Sokolov пишет:
> > В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет:
> > > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет:
> > > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on
> > > 128kB shared buffers and I saw that get_hash_entry never takes the
> > > !element_alloc() path and always allocate a fresh entry, then
> > > saturates at 30 new elements allocated at the medium of a 100 seconds
> > > run.
> > >
> > > Then, I tried the same with the patch, and I am surprized to see that
> > > the rise of the number of newly allocated elements didn't stop and
> > > went up to 511 elements after the 100 seconds run. So I found that my
> > > concern was valid. The change in dynahash actually
> > > continuously/repeatedly causes lack of free list entries. I'm not
> > > sure how much the impact given on performance if we change
> > > get_hash_entry to prefer other freelists, though.
> >
> > Well, it is quite strange SharedBufHash is not allocated as
> > HASH_FIXED_SIZE. Could you check what happens with this flag set?
> > I'll try as well.
> >
> > Other way to reduce observed case is to remember freelist_idx for
> > reused entry. I didn't believe it matters much since entries migrated
> > netherless, but probably due to some hot buffers there are tention to
> > crowd particular freelist.
>
> Well, I did both. Everything looks ok.
Hmm. v8 returns stashed element with original patition index when the
element is *not* reused. But what I saw in the previous test runs is
the REUSE->ENTER(reuse)(->REMOVE) case. So the new version looks like
behaving the same way (or somehow even worse) with the previous
version. get_hash_entry continuously suffer lack of freelist
entry. (FWIW, attached are the test-output diff for both master and
patched)
master finally allocated 31 fresh elements for a 100s run.
> ALLOCED: 31 ;; freshly allocated
v8 finally borrowed 33620 times from another freelist and 0 freshly
allocated (ah, this version changes that..)
Finally v8 results in:
> RETURNED: 50806 ;; returned stashed elements
> BORROWED: 33620 ;; borrowed from another freelist
> REUSED: 1812664 ;; stashed
> ASSIGNED: 1762377 ;; reused
>(ALLOCED: 0) ;; freshly allocated
It contains a huge degradation by frequent elog's so they cannot be
naively relied on, but it should show what is happening sufficiently.
> I lost access to Xeon 8354H, so returned to old Xeon X5675.
...
> Strange thing: both master and patched version has higher
> peak tps at X5676 at medium connections (17 or 27 clients)
> than in first october version [1]. But lower tps at higher
> connections number (>= 191 clients).
> I'll try to bisect on master this unfortunate change.
The reversing of the preference order between freshly-allocation and
borrow-from-another-freelist might affect.
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
diff --git a/src/backend/storage/buffer/buf_table.c b/src/backend/storage/buffer/buf_table.c
index dc439940fa..ac651b98e6 100644
--- a/src/backend/storage/buffer/buf_table.c
+++ b/src/backend/storage/buffer/buf_table.c
@@ -31,7 +31,7 @@ typedef struct
int id; /* Associated buffer ID */
} BufferLookupEnt;
-static HTAB *SharedBufHash;
+HTAB *SharedBufHash;
/*
diff --git a/src/backend/utils/hash/dynahash.c b/src/backend/utils/hash/dynahash.c
index 3babde8d70..294516ef01 100644
--- a/src/backend/utils/hash/dynahash.c
+++ b/src/backend/utils/hash/dynahash.c
@@ -195,6 +195,11 @@ struct HASHHDR
long ssize; /* segment size --- must be power of 2 */
int sshift; /* segment shift = log2(ssize) */
int nelem_alloc; /* number of entries to allocate at once */
+ int alloc;
+ int reuse;
+ int borrow;
+ int assign;
+ int ret;
#ifdef HASH_STATISTICS
@@ -963,6 +968,7 @@ hash_search(HTAB *hashp,
foundPtr);
}
+extern HTAB *SharedBufHash;
void *
hash_search_with_hash_value(HTAB *hashp,
const void *keyPtr,
@@ -1354,6 +1360,8 @@ get_hash_entry(HTAB *hashp, int freelist_idx)
hctl->freeList[freelist_idx].nentries++;
SpinLockRelease(&hctl->freeList[freelist_idx].mutex);
+ if (hashp == SharedBufHash)
+ elog(LOG, "BORROWED: %d", ++hctl->borrow);
return newElement;
}
@@ -1363,6 +1371,8 @@ get_hash_entry(HTAB *hashp, int freelist_idx)
/* no elements available to borrow either, so out of memory */
return NULL;
}
+ else if (hashp == SharedBufHash)
+ elog(LOG, "ALLOCED: %d", ++hctl->alloc);
}
/* remove entry from freelist, bump nentries */
diff --git a/src/backend/storage/buffer/buf_table.c b/src/backend/storage/buffer/buf_table.c
index 55bb491ad0..029bb89f26 100644
--- a/src/backend/storage/buffer/buf_table.c
+++ b/src/backend/storage/buffer/buf_table.c
@@ -31,7 +31,7 @@ typedef struct
int id; /* Associated buffer ID */
} BufferLookupEnt;
-static HTAB *SharedBufHash;
+HTAB *SharedBufHash;
/*
diff --git a/src/backend/utils/hash/dynahash.c b/src/backend/utils/hash/dynahash.c
index 50c0e47643..00159714d1 100644
--- a/src/backend/utils/hash/dynahash.c
+++ b/src/backend/utils/hash/dynahash.c
@@ -199,6 +199,11 @@ struct HASHHDR
int nelem_alloc; /* number of entries to allocate at once */
nalloced_t nalloced; /* number of entries allocated */
+ int alloc;
+ int reuse;
+ int borrow;
+ int assign;
+ int ret;
#ifdef HASH_STATISTICS
/*
@@ -1006,6 +1011,7 @@ hash_search(HTAB *hashp,
foundPtr);
}
+extern HTAB *SharedBufHash;
void *
hash_search_with_hash_value(HTAB *hashp,
const void *keyPtr,
@@ -1143,6 +1149,8 @@ hash_search_with_hash_value(HTAB *hashp,
DynaHashReuse.hashp = hashp;
DynaHashReuse.freelist_idx = freelist_idx;
+ if (hashp == SharedBufHash)
+ elog(LOG, "REUSED: %d", ++hctl->reuse);
/* Caller should call HASH_ASSIGN as the very next step. */
return (void *) ELEMENTKEY(currBucket);
}
@@ -1160,6 +1168,9 @@ hash_search_with_hash_value(HTAB *hashp,
if (likely(DynaHashReuse.element == NULL))
return (void *) ELEMENTKEY(currBucket);
+ if (hashp == SharedBufHash)
+ elog(LOG, "RETURNED: %d", ++hctl->ret);
+
freelist_idx = DynaHashReuse.freelist_idx;
/* if partitioned, must lock to touch nfree and freeList */
if (IS_PARTITIONED(hctl))
@@ -1191,6 +1202,13 @@ hash_search_with_hash_value(HTAB *hashp,
}
else
{
+ if (hashp == SharedBufHash)
+ {
+ hctl->assign++;
+ elog(LOG, "ASSIGNED: %d (%d)",
+ hctl->assign, hctl->reuse - hctl->assign);
+ }
+
currBucket = DynaHashReuse.element;
DynaHashReuse.element = NULL;
DynaHashReuse.hashp = NULL;
@@ -1448,6 +1466,8 @@ get_hash_entry(HTAB *hashp, int freelist_idx)
hctl->freeList[borrow_from_idx].nfree--;
SpinLockRelease(&(hctl->freeList[borrow_from_idx].mutex));
+ if (hashp == SharedBufHash)
+ elog(LOG, "BORROWED: %d", ++hctl->borrow);
return newElement;
}
@@ -1457,6 +1477,10 @@ get_hash_entry(HTAB *hashp, int freelist_idx)
/* no elements available to borrow either, so out of memory */
return NULL;
}
+ else if (hashp == SharedBufHash)
+ elog(LOG, "ALLOCED: %d", ++hctl->alloc);
+
+
}
/* remove entry from freelist, decrease nfree */
В Вт, 15/03/2022 в 16:25 +0900, Kyotaro Horiguchi пишет: > Thanks for the new version. > > At Tue, 15 Mar 2022 08:07:39 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > В Пн, 14/03/2022 в 14:57 +0300, Yura Sokolov пишет: > > > В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет: > > > > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет: > > > > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on > > > > 128kB shared buffers and I saw that get_hash_entry never takes the > > > > !element_alloc() path and always allocate a fresh entry, then > > > > saturates at 30 new elements allocated at the medium of a 100 seconds > > > > run. > > > > > > > > Then, I tried the same with the patch, and I am surprized to see that > > > > the rise of the number of newly allocated elements didn't stop and > > > > went up to 511 elements after the 100 seconds run. So I found that my > > > > concern was valid. The change in dynahash actually > > > > continuously/repeatedly causes lack of free list entries. I'm not > > > > sure how much the impact given on performance if we change > > > > get_hash_entry to prefer other freelists, though. > > > > > > Well, it is quite strange SharedBufHash is not allocated as > > > HASH_FIXED_SIZE. Could you check what happens with this flag set? > > > I'll try as well. > > > > > > Other way to reduce observed case is to remember freelist_idx for > > > reused entry. I didn't believe it matters much since entries migrated > > > netherless, but probably due to some hot buffers there are tention to > > > crowd particular freelist. > > > > Well, I did both. Everything looks ok. > > Hmm. v8 returns stashed element with original patition index when the > element is *not* reused. But what I saw in the previous test runs is > the REUSE->ENTER(reuse)(->REMOVE) case. So the new version looks like > behaving the same way (or somehow even worse) with the previous > version. v8 doesn't differ in REMOVE case neither from master nor from previous version. It differs in RETURNED case only. Or I didn't understand what you mean :( > get_hash_entry continuously suffer lack of freelist > entry. (FWIW, attached are the test-output diff for both master and > patched) > > master finally allocated 31 fresh elements for a 100s run. > > > ALLOCED: 31 ;; freshly allocated > > v8 finally borrowed 33620 times from another freelist and 0 freshly > allocated (ah, this version changes that..) > Finally v8 results in: > > > RETURNED: 50806 ;; returned stashed elements > > BORROWED: 33620 ;; borrowed from another freelist > > REUSED: 1812664 ;; stashed > > ASSIGNED: 1762377 ;; reused > >(ALLOCED: 0) ;; freshly allocated > > It contains a huge degradation by frequent elog's so they cannot be > naively relied on, but it should show what is happening sufficiently. Is there any measurable performance hit cause of borrowing? Looks like "borrowed" happened in 1.5% of time. And it is on 128kb shared buffers that is extremely small. (Or it was 128MB?) Well, I think some spare entries could reduce borrowing if there is a need. I'll test on 128MB with spare entries. If there is profit, I'll return some, but will keep SharedBufHash fixed. Master branch does less freelist manipulations since it tries to insert first and if there is collision it doesn't delete victim buffer. > > I lost access to Xeon 8354H, so returned to old Xeon X5675. > ... > > Strange thing: both master and patched version has higher > > peak tps at X5676 at medium connections (17 or 27 clients) > > than in first october version [1]. But lower tps at higher > > connections number (>= 191 clients). > > I'll try to bisect on master this unfortunate change. > > The reversing of the preference order between freshly-allocation and > borrow-from-another-freelist might affect. `master` changed its behaviour as well. It is not problem of the patch at all. ------ regards Yura.
В Вт, 15/03/2022 в 13:47 +0300, Yura Sokolov пишет: > В Вт, 15/03/2022 в 16:25 +0900, Kyotaro Horiguchi пишет: > > > I lost access to Xeon 8354H, so returned to old Xeon X5675. > > ... > > > Strange thing: both master and patched version has higher > > > peak tps at X5676 at medium connections (17 or 27 clients) > > > than in first october version [1]. But lower tps at higher > > > connections number (>= 191 clients). > > > I'll try to bisect on master this unfortunate change. > > > > The reversing of the preference order between freshly-allocation and > > borrow-from-another-freelist might affect. > > `master` changed its behaviour as well. > It is not problem of the patch at all. Looks like there is no issue: old commmit 2d44dee0281a1abf behaves similar to new one at the moment. I think, something changed in environment. I remember there were maintanance downtime in the autumn. Perhaps kernel were updated or some sysctl tuning changed. ---- regards Yura.
В Вт, 15/03/2022 в 13:47 +0300, Yura Sokolov пишет: > В Вт, 15/03/2022 в 16:25 +0900, Kyotaro Horiguchi пишет: > > Thanks for the new version. > > > > At Tue, 15 Mar 2022 08:07:39 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > В Пн, 14/03/2022 в 14:57 +0300, Yura Sokolov пишет: > > > > В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет: > > > > > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > > > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет: > > > > > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on > > > > > 128kB shared buffers and I saw that get_hash_entry never takes the > > > > > !element_alloc() path and always allocate a fresh entry, then > > > > > saturates at 30 new elements allocated at the medium of a 100 seconds > > > > > run. > > > > > > > > > > Then, I tried the same with the patch, and I am surprized to see that > > > > > the rise of the number of newly allocated elements didn't stop and > > > > > went up to 511 elements after the 100 seconds run. So I found that my > > > > > concern was valid. The change in dynahash actually > > > > > continuously/repeatedly causes lack of free list entries. I'm not > > > > > sure how much the impact given on performance if we change > > > > > get_hash_entry to prefer other freelists, though. > > > > > > > > Well, it is quite strange SharedBufHash is not allocated as > > > > HASH_FIXED_SIZE. Could you check what happens with this flag set? > > > > I'll try as well. > > > > > > > > Other way to reduce observed case is to remember freelist_idx for > > > > reused entry. I didn't believe it matters much since entries migrated > > > > netherless, but probably due to some hot buffers there are tention to > > > > crowd particular freelist. > > > > > > Well, I did both. Everything looks ok. > > > > Hmm. v8 returns stashed element with original patition index when the > > element is *not* reused. But what I saw in the previous test runs is > > the REUSE->ENTER(reuse)(->REMOVE) case. So the new version looks like > > behaving the same way (or somehow even worse) with the previous > > version. > > v8 doesn't differ in REMOVE case neither from master nor from > previous version. It differs in RETURNED case only. > Or I didn't understand what you mean :( > > > get_hash_entry continuously suffer lack of freelist > > entry. (FWIW, attached are the test-output diff for both master and > > patched) > > > > master finally allocated 31 fresh elements for a 100s run. > > > > > ALLOCED: 31 ;; freshly allocated > > > > v8 finally borrowed 33620 times from another freelist and 0 freshly > > allocated (ah, this version changes that..) > > Finally v8 results in: > > > > > RETURNED: 50806 ;; returned stashed elements > > > BORROWED: 33620 ;; borrowed from another freelist > > > REUSED: 1812664 ;; stashed > > > ASSIGNED: 1762377 ;; reused > > > (ALLOCED: 0) ;; freshly allocated > > > > It contains a huge degradation by frequent elog's so they cannot be > > naively relied on, but it should show what is happening sufficiently. > > Is there any measurable performance hit cause of borrowing? > Looks like "borrowed" happened in 1.5% of time. And it is on 128kb > shared buffers that is extremely small. (Or it was 128MB?) > > Well, I think some spare entries could reduce borrowing if there is > a need. I'll test on 128MB with spare entries. If there is profit, > I'll return some, but will keep SharedBufHash fixed. Well, I added GetMaxBackends spare items, but I don't see certain profit. It is probably a bit better at 128MB shared buffers and probably a bit worse at 1GB shared buffers (select_only on scale 100). But it is on old Xeon X5675. Probably things will change on more capable hardware. I just don't have access at the moment. > > Master branch does less freelist manipulations since it tries to > insert first and if there is collision it doesn't delete victim > buffer. > ----- regards Yura
At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> В Вт, 15/03/2022 в 16:25 +0900, Kyotaro Horiguchi пишет:
> > Hmm. v8 returns stashed element with original patition index when the
> > element is *not* reused. But what I saw in the previous test runs is
> > the REUSE->ENTER(reuse)(->REMOVE) case. So the new version looks like
> > behaving the same way (or somehow even worse) with the previous
> > version.
>
> v8 doesn't differ in REMOVE case neither from master nor from
> previous version. It differs in RETURNED case only.
> Or I didn't understand what you mean :(
In v7, HASH_ENTER returns the element stored in DynaHashReuse using
the freelist_idx of the new key. v8 uses that of the old key (at the
time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and
returns the stashed)" case the stashed element is returned to its
original partition. But it is not what I mentioned.
On the other hand, once the stahsed element is reused by HASH_ENTER,
it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow
from old partition) case. I suspect that ththat the frequent freelist
starvation comes from the latter case.
> > get_hash_entry continuously suffer lack of freelist
> > entry. (FWIW, attached are the test-output diff for both master and
> > patched)
> >
> > master finally allocated 31 fresh elements for a 100s run.
> >
> > > ALLOCED: 31 ;; freshly allocated
> >
> > v8 finally borrowed 33620 times from another freelist and 0 freshly
> > allocated (ah, this version changes that..)
> > Finally v8 results in:
> >
> > > RETURNED: 50806 ;; returned stashed elements
> > > BORROWED: 33620 ;; borrowed from another freelist
> > > REUSED: 1812664 ;; stashed
> > > ASSIGNED: 1762377 ;; reused
> > >(ALLOCED: 0) ;; freshly allocated
(I misunderstand that v8 modified get_hash_entry's preference between
allocation and borrowing.)
I re-ran the same check for v7 and it showed different result.
RETURNED: 1
ALLOCED: 15
BORROWED: 0
REUSED: 505435
ASSIGNED: 505462 (-27) ## the counters are not locked.
> Is there any measurable performance hit cause of borrowing?
> Looks like "borrowed" happened in 1.5% of time. And it is on 128kb
> shared buffers that is extremely small. (Or it was 128MB?)
It is intentional set small to get extremely frequent buffer
replacements. The point here was the patch actually can induce
frequent freelist starvation. And as you do, I also doubt the
significance of the performance hit by that. Just I was not usre.
I re-ran the same for v8 and got a result largely different from the
previous trial on the same v8.
RETURNED: 2
ALLOCED: 0
BORROWED: 435
REUSED: 495444
ASSIGNED: 495467 (-23)
Now "BORROWED" happens 0.8% of REUSED.
> Well, I think some spare entries could reduce borrowing if there is
> a need. I'll test on 128MB with spare entries. If there is profit,
> I'll return some, but will keep SharedBufHash fixed.
I don't doubt the benefit of this patch. And now convinced by myself
that the downside is negligible than the benefit.
> Master branch does less freelist manipulations since it tries to
> insert first and if there is collision it doesn't delete victim
> buffer.
>
> > > I lost access to Xeon 8354H, so returned to old Xeon X5675.
> > ...
> > > Strange thing: both master and patched version has higher
> > > peak tps at X5676 at medium connections (17 or 27 clients)
> > > than in first october version [1]. But lower tps at higher
> > > connections number (>= 191 clients).
> > > I'll try to bisect on master this unfortunate change.
> >
> > The reversing of the preference order between freshly-allocation and
> > borrow-from-another-freelist might affect.
>
> `master` changed its behaviour as well.
> It is not problem of the patch at all.
Agreed. So I think we should go on this direction.
There are some last comments on v8.
+ HASH_FIXED_SIZE);
Ah, now I understand that this prevented allocation of new elements.
I think this good to do for SharedBufHash.
====
+ long nfree; /* number of free entries in the list */
HASHELEMENT *freeList; /* chain of free elements */
} FreeListData;
+#if SIZEOF_LONG == 4
+typedef pg_atomic_uint32 nalloced_store_t;
+typedef uint32 nalloced_value_t;
+#define nalloced_read(a) (long)pg_atomic_read_u32(a)
+#define nalloced_add(a, v) pg_atomic_fetch_add_u32((a), (uint32)(v))
====
I don't think nalloced needs to be the same width to long. For the
platforms with 32-bit long, anyway the possible degradation if any by
64-bit atomic there doesn't matter. So don't we always define the
atomic as 64bit and use the pg_atomic_* functions directly?
+ case HASH_REUSE:
+ if (currBucket != NULL)
Don't we need an assertion on (DunaHashReuse.element == NULL) here?
- size = add_size(size, BufTableShmemSize(NBuffers + NUM_BUFFER_PARTITIONS));
+ /* size of lookup hash table */
+ size = add_size(size, BufTableShmemSize(NBuffers));
I was not sure that this is safe, but actually I didn't get "out of
shared memory". On second thought, I realized that when a dynahash
entry is stashed, BufferAlloc always holding a buffer block, too.
So now I'm sure that this is safe.
That's all.
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
В Ср, 16/03/2022 в 12:07 +0900, Kyotaro Horiguchi пишет:
> At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > В Вт, 15/03/2022 в 16:25 +0900, Kyotaro Horiguchi пишет:
> > > Hmm. v8 returns stashed element with original patition index when the
> > > element is *not* reused. But what I saw in the previous test runs is
> > > the REUSE->ENTER(reuse)(->REMOVE) case. So the new version looks like
> > > behaving the same way (or somehow even worse) with the previous
> > > version.
> >
> > v8 doesn't differ in REMOVE case neither from master nor from
> > previous version. It differs in RETURNED case only.
> > Or I didn't understand what you mean :(
>
> In v7, HASH_ENTER returns the element stored in DynaHashReuse using
> the freelist_idx of the new key. v8 uses that of the old key (at the
> time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and
> returns the stashed)" case the stashed element is returned to its
> original partition. But it is not what I mentioned.
>
> On the other hand, once the stahsed element is reused by HASH_ENTER,
> it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow
> from old partition) case. I suspect that ththat the frequent freelist
> starvation comes from the latter case.
Doubtfully. Due to probabilty theory, single partition doubdfully
will be too overflowed. Therefore, freelist.
But! With 128kb shared buffers there is just 32 buffers. 32 entry for
32 freelist partition - certainly some freelist partition will certainly
have 0 entry even if all entries are in freelists.
> > > get_hash_entry continuously suffer lack of freelist
> > > entry. (FWIW, attached are the test-output diff for both master and
> > > patched)
> > >
> > > master finally allocated 31 fresh elements for a 100s run.
> > >
> > > > ALLOCED: 31 ;; freshly allocated
> > >
> > > v8 finally borrowed 33620 times from another freelist and 0 freshly
> > > allocated (ah, this version changes that..)
> > > Finally v8 results in:
> > >
> > > > RETURNED: 50806 ;; returned stashed elements
> > > > BORROWED: 33620 ;; borrowed from another freelist
> > > > REUSED: 1812664 ;; stashed
> > > > ASSIGNED: 1762377 ;; reused
> > > >(ALLOCED: 0) ;; freshly allocated
>
> (I misunderstand that v8 modified get_hash_entry's preference between
> allocation and borrowing.)
>
> I re-ran the same check for v7 and it showed different result.
>
> RETURNED: 1
> ALLOCED: 15
> BORROWED: 0
> REUSED: 505435
> ASSIGNED: 505462 (-27) ## the counters are not locked.
>
> > Is there any measurable performance hit cause of borrowing?
> > Looks like "borrowed" happened in 1.5% of time. And it is on 128kb
> > shared buffers that is extremely small. (Or it was 128MB?)
>
> It is intentional set small to get extremely frequent buffer
> replacements. The point here was the patch actually can induce
> frequent freelist starvation. And as you do, I also doubt the
> significance of the performance hit by that. Just I was not usre.
>
> I re-ran the same for v8 and got a result largely different from the
> previous trial on the same v8.
>
> RETURNED: 2
> ALLOCED: 0
> BORROWED: 435
> REUSED: 495444
> ASSIGNED: 495467 (-23)
>
> Now "BORROWED" happens 0.8% of REUSED
0.08% actually :)
>
> > Well, I think some spare entries could reduce borrowing if there is
> > a need. I'll test on 128MB with spare entries. If there is profit,
> > I'll return some, but will keep SharedBufHash fixed.
>
> I don't doubt the benefit of this patch. And now convinced by myself
> that the downside is negligible than the benefit.
>
> > Master branch does less freelist manipulations since it tries to
> > insert first and if there is collision it doesn't delete victim
> > buffer.
> >
> > > > I lost access to Xeon 8354H, so returned to old Xeon X5675.
> > > ...
> > > > Strange thing: both master and patched version has higher
> > > > peak tps at X5676 at medium connections (17 or 27 clients)
> > > > than in first october version [1]. But lower tps at higher
> > > > connections number (>= 191 clients).
> > > > I'll try to bisect on master this unfortunate change.
> > >
> > > The reversing of the preference order between freshly-allocation and
> > > borrow-from-another-freelist might affect.
> >
> > `master` changed its behaviour as well.
> > It is not problem of the patch at all.
>
> Agreed. So I think we should go on this direction.
I've checked. Looks like something had changed on the server, since
old master commit behaves now same to new one (and differently to
how it behaved in October).
I remember maintainance downtime of the server in november/december.
Probably, kernel were upgraded or some system settings were changed.
> There are some last comments on v8.
>
> + HASH_FIXED_SIZE);
>
> Ah, now I understand that this prevented allocation of new elements.
> I think this good to do for SharedBufHash.
>
>
> ====
> + long nfree; /* number of free entries in the list */
> HASHELEMENT *freeList; /* chain of free elements */
> } FreeListData;
>
> +#if SIZEOF_LONG == 4
> +typedef pg_atomic_uint32 nalloced_store_t;
> +typedef uint32 nalloced_value_t;
> +#define nalloced_read(a) (long)pg_atomic_read_u32(a)
> +#define nalloced_add(a, v) pg_atomic_fetch_add_u32((a), (uint32)(v))
> ====
>
> I don't think nalloced needs to be the same width to long. For the
> platforms with 32-bit long, anyway the possible degradation if any by
> 64-bit atomic there doesn't matter. So don't we always define the
> atomic as 64bit and use the pg_atomic_* functions directly?
Some 32bit platforms has no native 64bit atomics. Then they are
emulated with locks.
Native atomic read/write is quite cheap. So I don't bother with
unlocked read/write for non-partitioned table. (And I don't know
which platform has sizeof(long)>4 without having native 64bit
atomic as well)
(May be I'm wrong a bit? element_alloc invokes nalloc_add, which
is atomic increment. Could it be expensive enough to be problem
in non-shared dynahash instances?)
If patch stick with pg_atomic_uint64 for nalloced, then it have
to separate read+write for partitioned(actually shared) and
non-partitioned cases.
Well, and for 32bit platform long is just enough. Why spend other
4 bytes per each dynahash?
By the way, there is unfortunate miss of PG_HAVE_8BYTE_SINGLE_COPY_ATOMICITY
in port/atomics/arch-arm.h for aarch64 . I'll send patch for
in new thread.
> + case HASH_REUSE:
> + if (currBucket != NULL)
>
> Don't we need an assertion on (DunaHashReuse.element == NULL) here?
Common assert is higher on line 1094:
Assert(action == HASH_ENTER || DynaHashReuse.element == NULL);
I thought it is more accurate than duplicated in each switch case.
> - size = add_size(size, BufTableShmemSize(NBuffers + NUM_BUFFER_PARTITIONS));
> + /* size of lookup hash table */
> + size = add_size(size, BufTableShmemSize(NBuffers));
>
> I was not sure that this is safe, but actually I didn't get "out of
> shared memory". On second thought, I realized that when a dynahash
> entry is stashed, BufferAlloc always holding a buffer block, too.
> So now I'm sure that this is safe.
>
>
> That's all.
Thanks you very much for productive review and discussion.
regards,
Yura Sokolov
Postgres Professional
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
At Wed, 16 Mar 2022 14:11:58 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > В Ср, 16/03/2022 в 12:07 +0900, Kyotaro Horiguchi пишет: > > At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > In v7, HASH_ENTER returns the element stored in DynaHashReuse using > > the freelist_idx of the new key. v8 uses that of the old key (at the > > time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and > > returns the stashed)" case the stashed element is returned to its > > original partition. But it is not what I mentioned. > > > > On the other hand, once the stahsed element is reused by HASH_ENTER, > > it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow > > from old partition) case. I suspect that ththat the frequent freelist > > starvation comes from the latter case. > > Doubtfully. Due to probabilty theory, single partition doubdfully > will be too overflowed. Therefore, freelist. Yeah. I think so generally. > But! With 128kb shared buffers there is just 32 buffers. 32 entry for > 32 freelist partition - certainly some freelist partition will certainly > have 0 entry even if all entries are in freelists. Anyway, it's an extreme condition and the starvation happens only at a neglegible ratio. > > RETURNED: 2 > > ALLOCED: 0 > > BORROWED: 435 > > REUSED: 495444 > > ASSIGNED: 495467 (-23) > > > > Now "BORROWED" happens 0.8% of REUSED > > 0.08% actually :) Mmm. Doesn't matter:p > > > > > I lost access to Xeon 8354H, so returned to old Xeon X5675. > > > > ... > > > > > Strange thing: both master and patched version has higher > > > > > peak tps at X5676 at medium connections (17 or 27 clients) > > > > > than in first october version [1]. But lower tps at higher > > > > > connections number (>= 191 clients). > > > > > I'll try to bisect on master this unfortunate change. ... > I've checked. Looks like something had changed on the server, since > old master commit behaves now same to new one (and differently to > how it behaved in October). > I remember maintainance downtime of the server in november/december. > Probably, kernel were upgraded or some system settings were changed. One thing I have a little concern is that numbers shows 1-2% of degradation steadily for connection numbers < 17. I think there are two possible cause of the degradation. 1. Additional branch by consolidating HASH_ASSIGN into HASH_ENTER. This might cause degradation for memory-contended use. 2. nallocs operation might cause degradation on non-shared dynahasyes? I believe doesn't but I'm not sure. On a simple benchmarking with pgbench on a laptop, dynahash allocation (including shared and non-shared) happend about at 50 times per second with 10 processes and 200 with 100 processes. > > I don't think nalloced needs to be the same width to long. For the > > platforms with 32-bit long, anyway the possible degradation if any by > > 64-bit atomic there doesn't matter. So don't we always define the > > atomic as 64bit and use the pg_atomic_* functions directly? > > Some 32bit platforms has no native 64bit atomics. Then they are > emulated with locks. > > Well, and for 32bit platform long is just enough. Why spend other > 4 bytes per each dynahash? I don't think additional bytes doesn't matter, but emulated atomic operations can matter. However I'm not sure which platform uses that fallback implementations. (x86 seems to have __sync_fetch_and_add() since P4). My opinion in the previous mail is that if that level of degradation caued by emulated atomic operations matters, we shouldn't use atomic there at all since atomic operations on the modern platforms are not also free. In relation to 2 above, if we observe that the degradation disappears by (tentatively) use non-atomic operations for nalloced, we should go back to the previous per-freelist nalloced. I don't have access to such a musculous machines, though.. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
В Чт, 17/03/2022 в 12:02 +0900, Kyotaro Horiguchi пишет: > At Wed, 16 Mar 2022 14:11:58 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > В Ср, 16/03/2022 в 12:07 +0900, Kyotaro Horiguchi пишет: > > > At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > > In v7, HASH_ENTER returns the element stored in DynaHashReuse using > > > the freelist_idx of the new key. v8 uses that of the old key (at the > > > time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and > > > returns the stashed)" case the stashed element is returned to its > > > original partition. But it is not what I mentioned. > > > > > > On the other hand, once the stahsed element is reused by HASH_ENTER, > > > it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow > > > from old partition) case. I suspect that ththat the frequent freelist > > > starvation comes from the latter case. > > > > Doubtfully. Due to probabilty theory, single partition doubdfully > > will be too overflowed. Therefore, freelist. > > Yeah. I think so generally. > > > But! With 128kb shared buffers there is just 32 buffers. 32 entry for > > 32 freelist partition - certainly some freelist partition will certainly > > have 0 entry even if all entries are in freelists. > > Anyway, it's an extreme condition and the starvation happens only at a > neglegible ratio. > > > > RETURNED: 2 > > > ALLOCED: 0 > > > BORROWED: 435 > > > REUSED: 495444 > > > ASSIGNED: 495467 (-23) > > > > > > Now "BORROWED" happens 0.8% of REUSED > > > > 0.08% actually :) > > Mmm. Doesn't matter:p > > > > > > > I lost access to Xeon 8354H, so returned to old Xeon X5675. > > > > > ... > > > > > > Strange thing: both master and patched version has higher > > > > > > peak tps at X5676 at medium connections (17 or 27 clients) > > > > > > than in first october version [1]. But lower tps at higher > > > > > > connections number (>= 191 clients). > > > > > > I'll try to bisect on master this unfortunate change. > ... > > I've checked. Looks like something had changed on the server, since > > old master commit behaves now same to new one (and differently to > > how it behaved in October). > > I remember maintainance downtime of the server in november/december. > > Probably, kernel were upgraded or some system settings were changed. > > One thing I have a little concern is that numbers shows 1-2% of > degradation steadily for connection numbers < 17. > > I think there are two possible cause of the degradation. > > 1. Additional branch by consolidating HASH_ASSIGN into HASH_ENTER. > This might cause degradation for memory-contended use. > > 2. nallocs operation might cause degradation on non-shared dynahasyes? > I believe doesn't but I'm not sure. > > On a simple benchmarking with pgbench on a laptop, dynahash > allocation (including shared and non-shared) happend about at 50 > times per second with 10 processes and 200 with 100 processes. > > > > I don't think nalloced needs to be the same width to long. For the > > > platforms with 32-bit long, anyway the possible degradation if any by > > > 64-bit atomic there doesn't matter. So don't we always define the > > > atomic as 64bit and use the pg_atomic_* functions directly? > > > > Some 32bit platforms has no native 64bit atomics. Then they are > > emulated with locks. > > > > Well, and for 32bit platform long is just enough. Why spend other > > 4 bytes per each dynahash? > > I don't think additional bytes doesn't matter, but emulated atomic > operations can matter. However I'm not sure which platform uses that > fallback implementations. (x86 seems to have __sync_fetch_and_add() > since P4). > > My opinion in the previous mail is that if that level of degradation > caued by emulated atomic operations matters, we shouldn't use atomic > there at all since atomic operations on the modern platforms are not > also free. > > In relation to 2 above, if we observe that the degradation disappears > by (tentatively) use non-atomic operations for nalloced, we should go > back to the previous per-freelist nalloced. Here is version with nalloced being union of appropriate atomic and long. ------ regards Yura Sokolov
Вложения
Good day, Kyotaoro-san.
Good day, hackers.
В Вс, 20/03/2022 в 12:38 +0300, Yura Sokolov пишет:
> В Чт, 17/03/2022 в 12:02 +0900, Kyotaro Horiguchi пишет:
> > At Wed, 16 Mar 2022 14:11:58 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > > В Ср, 16/03/2022 в 12:07 +0900, Kyotaro Horiguchi пишет:
> > > > At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in
> > > > In v7, HASH_ENTER returns the element stored in DynaHashReuse using
> > > > the freelist_idx of the new key. v8 uses that of the old key (at the
> > > > time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and
> > > > returns the stashed)" case the stashed element is returned to its
> > > > original partition. But it is not what I mentioned.
> > > >
> > > > On the other hand, once the stahsed element is reused by HASH_ENTER,
> > > > it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow
> > > > from old partition) case. I suspect that ththat the frequent freelist
> > > > starvation comes from the latter case.
> > >
> > > Doubtfully. Due to probabilty theory, single partition doubdfully
> > > will be too overflowed. Therefore, freelist.
> >
> > Yeah. I think so generally.
> >
> > > But! With 128kb shared buffers there is just 32 buffers. 32 entry for
> > > 32 freelist partition - certainly some freelist partition will certainly
> > > have 0 entry even if all entries are in freelists.
> >
> > Anyway, it's an extreme condition and the starvation happens only at a
> > neglegible ratio.
> >
> > > > RETURNED: 2
> > > > ALLOCED: 0
> > > > BORROWED: 435
> > > > REUSED: 495444
> > > > ASSIGNED: 495467 (-23)
> > > >
> > > > Now "BORROWED" happens 0.8% of REUSED
> > >
> > > 0.08% actually :)
> >
> > Mmm. Doesn't matter:p
> >
> > > > > > > I lost access to Xeon 8354H, so returned to old Xeon X5675.
> > > > > > ...
> > > > > > > Strange thing: both master and patched version has higher
> > > > > > > peak tps at X5676 at medium connections (17 or 27 clients)
> > > > > > > than in first october version [1]. But lower tps at higher
> > > > > > > connections number (>= 191 clients).
> > > > > > > I'll try to bisect on master this unfortunate change.
> > ...
> > > I've checked. Looks like something had changed on the server, since
> > > old master commit behaves now same to new one (and differently to
> > > how it behaved in October).
> > > I remember maintainance downtime of the server in november/december.
> > > Probably, kernel were upgraded or some system settings were changed.
> >
> > One thing I have a little concern is that numbers shows 1-2% of
> > degradation steadily for connection numbers < 17.
> >
> > I think there are two possible cause of the degradation.
> >
> > 1. Additional branch by consolidating HASH_ASSIGN into HASH_ENTER.
> > This might cause degradation for memory-contended use.
> >
> > 2. nallocs operation might cause degradation on non-shared dynahasyes?
> > I believe doesn't but I'm not sure.
> >
> > On a simple benchmarking with pgbench on a laptop, dynahash
> > allocation (including shared and non-shared) happend about at 50
> > times per second with 10 processes and 200 with 100 processes.
> >
> > > > I don't think nalloced needs to be the same width to long. For the
> > > > platforms with 32-bit long, anyway the possible degradation if any by
> > > > 64-bit atomic there doesn't matter. So don't we always define the
> > > > atomic as 64bit and use the pg_atomic_* functions directly?
> > >
> > > Some 32bit platforms has no native 64bit atomics. Then they are
> > > emulated with locks.
> > >
> > > Well, and for 32bit platform long is just enough. Why spend other
> > > 4 bytes per each dynahash?
> >
> > I don't think additional bytes doesn't matter, but emulated atomic
> > operations can matter. However I'm not sure which platform uses that
> > fallback implementations. (x86 seems to have __sync_fetch_and_add()
> > since P4).
> >
> > My opinion in the previous mail is that if that level of degradation
> > caued by emulated atomic operations matters, we shouldn't use atomic
> > there at all since atomic operations on the modern platforms are not
> > also free.
> >
> > In relation to 2 above, if we observe that the degradation disappears
> > by (tentatively) use non-atomic operations for nalloced, we should go
> > back to the previous per-freelist nalloced.
>
> Here is version with nalloced being union of appropriate atomic and
> long.
>
Ok, I got access to stronger server, did the benchmark, found weird
things, and so here is new version :-)
First I found if table size is strictly limited to NBuffers and FIXED,
then under high concurrency get_hash_entry may not find free entry
despite it must be there. It seems while process scans free lists, other
concurrent processes "moves entry around", ie one concurrent process
fetched it from one free list, other process put new entry in other
freelist, and unfortunate process missed it since it tests freelists
only once.
Second, I confirm there is problem with freelist spreading.
If I keep entry's freelist_idx, then one freelist is crowded.
If I use new entry's freelist_idx, then one freelist is emptified
constantly.
Third, I found increased concurrency could harm. When popular block is
evicted for some reason, then thundering herd effect occures: many
backends wants to read same block, they evict many other buffers, but
only one is inserted. Other goes to freelist. Evicted buffers by itself
reduce cache hit ratio and provocates more work. Old version resists
this effect by not removing old buffer before new entry is successfully
inserted.
To fix this issues I made following:
# Concurrency
First, I limit concurrency by introducing other lwlocks tranche -
BufferEvict. It is 8 times larger than BufferMapping tranche (1024 vs
128).
If backend doesn't find buffer in buffer table and wants to introduce
it, it first calls
LWLockAcquireOrWait(newEvictPartitionLock, LW_EXCLUSIVE)
If lock were acquired, then it goes to eviction and replace process.
Otherwise, it waits lock to be released and repeats search.
This greately improve performance for > 400 clients in pgbench.
I tried other variant as well:
- first insert entry with dummy buffer index into buffer table.
- if such entry were already here, then wait it to be filled.
- otherwise find victim buffer and replace dummy index with new one.
Wait were done with shared lock on EvictPartitionLock as well.
This variant performed quite same.
Logically I like that variant more, but there is one gotcha:
FlushBuffer could fail with elog(ERROR). Therefore then there is
a need to reliable remove entry with dummy index.
And after all, I still need to hold EvictPartitionLock to notice
waiters.
I've tried to use ConditionalVariable, but its performance were much
worse.
# Dynahash capacity and freelists.
I returned back buffer table initialization:
- removed FIXES_SIZE restriction introduced in previous version
- returned `NBuffers + NUM_BUFFER_PARTITIONS`.
I really think, there should be more spare items, since almost always
entry_alloc is called at least once (on 128MB shared_buffers). But
let keep it as is for now.
`get_hash_entry` were changed to probe NUM_FREELISTS/4 (==8) freelists
before falling back to `entry_alloc`, and probing is changed from
linear to quadratic. This greately reduces number of calls to
`entry_alloc`, so more shared memory left intact. And I didn't notice
large performance hit from. Probably there is some, but I think it is
adequate trade-off.
`free_reused_entry` now returns entry to random position. It flattens
free entry's spread. Although it is not enough without other changes
(thundering herd mitigation and probing more lists in get_hash_entry).
# Benchmarks
Benchmarked on two socket Xeon(R) Gold 5220 CPU @2.20GHz
18 cores per socket + hyper-threading - upto 72 virtual core total.
turbo-boost disabled
Linux 5.10.103-1 Debian.
pgbench scale 100 simple_select + simple select with 3 keys (sql file
attached).
shared buffers 128MB & 1GB
huge_pages=on
1 socket
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 27882 | 27738 | 32735 | 32439
2 | 54082 | 54336 | 64387 | 63846
3 | 80724 | 81079 | 96387 | 94439
5 | 134404 | 133429 | 160085 | 157399
7 | 185977 | 184502 | 219916 | 217142
17 | 335345 | 338214 | 393112 | 388796
27 | 393686 | 394948 | 447945 | 444915
53 | 572234 | 577092 | 678884 | 676493
83 | 558875 | 561689 | 669212 | 655697
107 | 553054 | 551896 | 654550 | 646010
139 | 541263 | 538354 | 641937 | 633840
163 | 532932 | 531829 | 635127 | 627600
191 | 524647 | 524442 | 626228 | 617347
211 | 521624 | 522197 | 629740 | 613143
239 | 509448 | 554894 | 652353 | 652972
271 | 468190 | 557467 | 647403 | 661348
307 | 454139 | 558694 | 642229 | 657649
353 | 446853 | 554301 | 635991 | 654571
397 | 441909 | 549822 | 625194 | 647973
1 socket 3 keys
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 16677 | 16477 | 22219 | 22030
2 | 32056 | 31874 | 43298 | 43153
3 | 48091 | 47766 | 64877 | 64600
5 | 78999 | 78609 | 105433 | 106101
7 | 108122 | 107529 | 148713 | 145343
17 | 205656 | 209010 | 272676 | 271449
27 | 252015 | 254000 | 323983 | 323499
53 | 317928 | 334493 | 446740 | 449641
83 | 299234 | 327738 | 437035 | 443113
107 | 290089 | 322025 | 430535 | 431530
139 | 277294 | 314384 | 422076 | 423606
163 | 269029 | 310114 | 416229 | 417412
191 | 257315 | 306530 | 408487 | 416170
211 | 249743 | 304278 | 404766 | 416393
239 | 243333 | 310974 | 397139 | 428167
271 | 236356 | 309215 | 389972 | 427498
307 | 229094 | 307519 | 382444 | 425891
353 | 224385 | 305366 | 375020 | 423284
397 | 218549 | 302577 | 364373 | 420846
2 sockets
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 27287 | 27631 | 32943 | 32493
2 | 52397 | 54011 | 64572 | 63596
3 | 76157 | 80473 | 93363 | 93528
5 | 127075 | 134310 | 153176 | 149984
7 | 177100 | 176939 | 216356 | 211599
17 | 379047 | 383179 | 464249 | 470351
27 | 545219 | 546706 | 664779 | 662488
53 | 728142 | 728123 | 857454 | 869407
83 | 918276 | 957722 | 1215252 | 1203443
107 | 884112 | 971797 | 1206930 | 1234606
139 | 822564 | 970920 | 1167518 | 1233230
163 | 788287 | 968248 | 1130021 | 1229250
191 | 772406 | 959344 | 1097842 | 1218541
211 | 756085 | 955563 | 1077747 | 1209489
239 | 732926 | 948855 | 1050096 | 1200878
271 | 692999 | 941722 | 1017489 | 1194012
307 | 668241 | 920478 | 994420 | 1179507
353 | 642478 | 908645 | 968648 | 1174265
397 | 617673 | 893568 | 950736 | 1173411
2 sockets 3 keys
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 16722 | 16393 | 20340 | 21813
2 | 32057 | 32009 | 39993 | 42959
3 | 46202 | 47678 | 59216 | 64374
5 | 78882 | 72002 | 98054 | 103731
7 | 103398 | 99538 | 135098 | 135828
17 | 205863 | 217781 | 293958 | 299690
27 | 283526 | 290539 | 414968 | 411219
53 | 336717 | 356130 | 460596 | 474563
83 | 307310 | 342125 | 419941 | 469989
107 | 294059 | 333494 | 405706 | 469593
139 | 278453 | 328031 | 390984 | 470553
163 | 270833 | 326457 | 384747 | 470977
191 | 259591 | 322590 | 376582 | 470335
211 | 263584 | 321263 | 375969 | 469443
239 | 257135 | 316959 | 370108 | 470904
271 | 251107 | 315393 | 365794 | 469517
307 | 246605 | 311585 | 360742 | 467566
353 | 236899 | 308581 | 353464 | 466936
397 | 249036 | 305042 | 344673 | 466842
I skipped v10 since I used it internally for variant
"insert entry with dummy index then search victim".
------
regards
Yura Sokolov
y.sokolov@postgrespro.ru
funny.falcon@gmail.com
Вложения
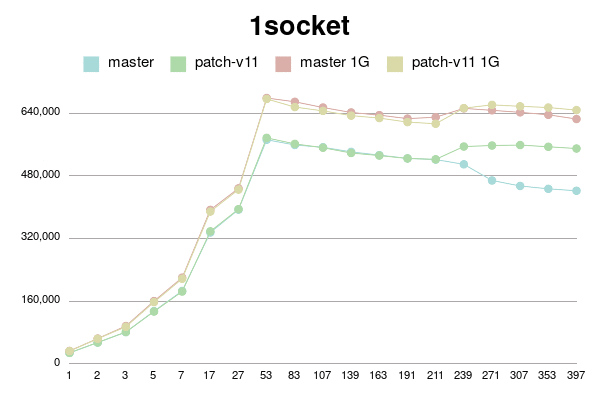{kind=link}
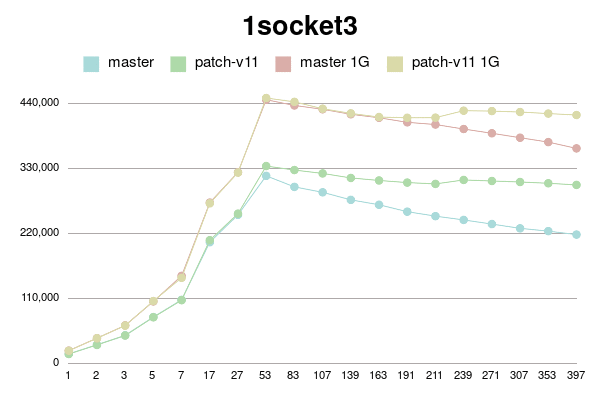{kind=link}
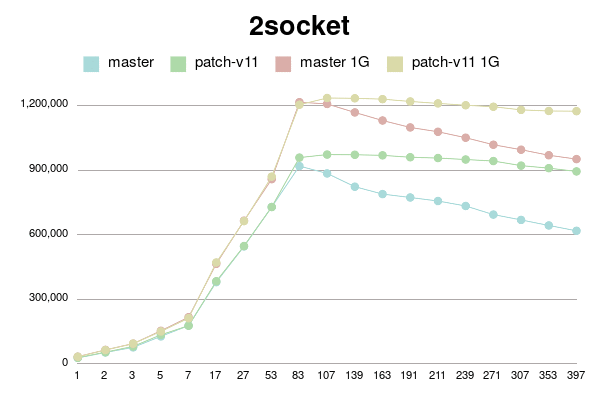{kind=link}
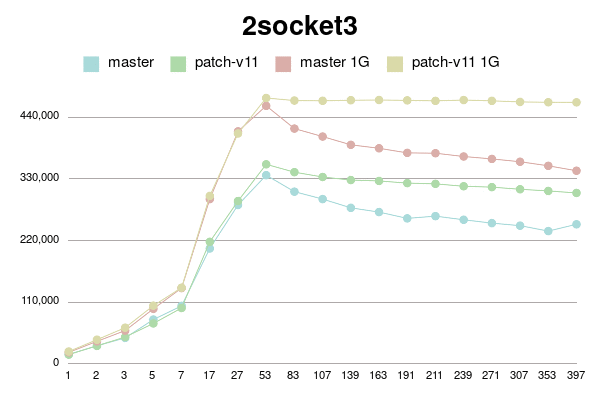{kind=link}
Hi, Yura. At Wed, 06 Apr 2022 16:17:28 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrot e in > Ok, I got access to stronger server, did the benchmark, found weird > things, and so here is new version :-) Thanks for the new version and benchmarking. > First I found if table size is strictly limited to NBuffers and FIXED, > then under high concurrency get_hash_entry may not find free entry > despite it must be there. It seems while process scans free lists, other > concurrent processes "moves etry around", ie one concurrent process > fetched it from one free list, other process put new entry in other > freelist, and unfortunate process missed it since it tests freelists > only once. StrategyGetBuffer believes that entries don't move across freelists and it was true before this patch. > Second, I confirm there is problem with freelist spreading. > If I keep entry's freelist_idx, then one freelist is crowded. > If I use new entry's freelist_idx, then one freelist is emptified > constantly. Perhaps it is what I saw before. I'm not sure about the details of how that happens, though. > Third, I found increased concurrency could harm. When popular block > is evicted for some reason, then thundering herd effect occures: > many backends wants to read same block, they evict many other > buffers, but only one is inserted. Other goes to freelist. Evicted > buffers by itself reduce cache hit ratio and provocates more > work. Old version resists this effect by not removing old buffer > before new entry is successfully inserted. Nice finding. > To fix this issues I made following: > > # Concurrency > > First, I limit concurrency by introducing other lwlocks tranche - > BufferEvict. It is 8 times larger than BufferMapping tranche (1024 vs > 128). > If backend doesn't find buffer in buffer table and wants to introduce > it, it first calls > LWLockAcquireOrWait(newEvictPartitionLock, LW_EXCLUSIVE) > If lock were acquired, then it goes to eviction and replace process. > Otherwise, it waits lock to be released and repeats search. > > This greately improve performance for > 400 clients in pgbench. So the performance difference between the existing code and v11 is the latter has a collision cross section eight times smaller than the former? + * Prevent "thundering herd" problem and limit concurrency. this is something like pressing accelerator and break pedals at the same time. If it improves performance, just increasing the number of buffer partition seems to work? It's also not great that follower backends runs a busy loop on the lock until the top-runner backend inserts the new buffer to the buftable then releases the newParititionLock. > I tried other variant as well: > - first insert entry with dummy buffer index into buffer table. > - if such entry were already here, then wait it to be filled. > - otherwise find victim buffer and replace dummy index with new one. > Wait were done with shared lock on EvictPartitionLock as well. > This variant performed quite same. This one looks better to me. Since a partition can be shared by two or more new-buffers, condition variable seems to work better here... > Logically I like that variant more, but there is one gotcha: > FlushBuffer could fail with elog(ERROR). Therefore then there is > a need to reliable remove entry with dummy index. Perhaps UnlockBuffers can do that. > And after all, I still need to hold EvictPartitionLock to notice > waiters. > I've tried to use ConditionalVariable, but its performance were much > worse. How many CVs did you use? > # Dynahash capacity and freelists. > > I returned back buffer table initialization: > - removed FIXES_SIZE restriction introduced in previous version Mmm. I don't see v10 in this list and v9 doesn't contain FIXES_SIZE.. > - returned `NBuffers + NUM_BUFFER_PARTITIONS`. > I really think, there should be more spare items, since almost always > entry_alloc is called at least once (on 128MB shared_buffers). But > let keep it as is for now. Maybe s/entry_alloc/element_alloc/ ? :p I see it with shared_buffers=128kB (not MB) and pgbench -i on master. The required number of elements are already allocaed to freelists at hash creation. So the reason for the call is imbalanced use among freelists. Even in that case other freelists holds elements. So we don't need to expand the element size. > `get_hash_entry` were changed to probe NUM_FREELISTS/4 (==8) freelists > before falling back to `entry_alloc`, and probing is changed from > linear to quadratic. This greately reduces number of calls to > `entry_alloc`, so more shared memory left intact. And I didn't notice > large performance hit from. Probably there is some, but I think it is > adequate trade-off. I don't think that causes significant performance hit, but I don't understand how it improves freelist hit ratio other than by accident. Could you have some reasoning for it? By the way the change of get_hash_entry looks something wrong. If I understand it correctly, it visits num_freelists/4 freelists at once, then tries element_alloc. If element_alloc() fails (that must happen), it only tries freeList[freelist_idx] and gives up, even though there must be an element in other 3/4 freelists. > `free_reused_entry` now returns entry to random position. It flattens > free entry's spread. Although it is not enough without other changes > (thundering herd mitigation and probing more lists in get_hash_entry). If "thudering herd" means "many backends rush trying to read-in the same page at once", isn't it avoided by the change in BufferAlloc? I feel the random returning method might work. I want to get rid of the randomness here but I don't come up with a better way. Anyway the code path is used only by buftable so it doesn't harm generally. > # Benchmarks # Thanks for benchmarking!! > Benchmarked on two socket Xeon(R) Gold 5220 CPU @2.20GHz > 18 cores per socket + hyper-threading - upto 72 virtual core total. > turbo-boost disabled > Linux 5.10.103-1 Debian. > > pgbench scale 100 simple_select + simple select with 3 keys (sql file > attached). > > shared buffers 128MB & 1GB > huge_pages=on > > 1 socket > conns | master | patch-v11 | master 1G | patch-v11 1G > --------+------------+------------+------------+------------ > 1 | 27882 | 27738 | 32735 | 32439 > 2 | 54082 | 54336 | 64387 | 63846 > 3 | 80724 | 81079 | 96387 | 94439 > 5 | 134404 | 133429 | 160085 | 157399 > 7 | 185977 | 184502 | 219916 | 217142 v11+128MB degrades above here.. > 17 | 335345 | 338214 | 393112 | 388796 > 27 | 393686 | 394948 | 447945 | 444915 > 53 | 572234 | 577092 | 678884 | 676493 > 83 | 558875 | 561689 | 669212 | 655697 > 107 | 553054 | 551896 | 654550 | 646010 > 139 | 541263 | 538354 | 641937 | 633840 > 163 | 532932 | 531829 | 635127 | 627600 > 191 | 524647 | 524442 | 626228 | 617347 > 211 | 521624 | 522197 | 629740 | 613143 v11+1GB degrades above here.. > 239 | 509448 | 554894 | 652353 | 652972 > 271 | 468190 | 557467 | 647403 | 661348 > 307 | 454139 | 558694 | 642229 | 657649 > 353 | 446853 | 554301 | 635991 | 654571 > 397 | 441909 | 549822 | 625194 | 647973 > > 1 socket 3 keys > > conns | master | patch-v11 | master 1G | patch-v11 1G > --------+------------+------------+------------+------------ > 1 | 16677 | 16477 | 22219 | 22030 > 2 | 32056 | 31874 | 43298 | 43153 > 3 | 48091 | 47766 | 64877 | 64600 > 5 | 78999 | 78609 | 105433 | 106101 > 7 | 108122 | 107529 | 148713 | 145343 v11+128MB degrades above here.. > 17 | 205656 | 209010 | 272676 | 271449 > 27 | 252015 | 254000 | 323983 | 323499 v11+1GB degrades above here.. > 53 | 317928 | 334493 | 446740 | 449641 > 83 | 299234 | 327738 | 437035 | 443113 > 107 | 290089 | 322025 | 430535 | 431530 > 139 | 277294 | 314384 | 422076 | 423606 > 163 | 269029 | 310114 | 416229 | 417412 > 191 | 257315 | 306530 | 408487 | 416170 > 211 | 249743 | 304278 | 404766 | 416393 > 239 | 243333 | 310974 | 397139 | 428167 > 271 | 236356 | 309215 | 389972 | 427498 > 307 | 229094 | 307519 | 382444 | 425891 > 353 | 224385 | 305366 | 375020 | 423284 > 397 | 218549 | 302577 | 364373 | 420846 > > 2 sockets > > conns | master | patch-v11 | master 1G | patch-v11 1G > --------+------------+------------+------------+------------ > 1 | 27287 | 27631 | 32943 | 32493 > 2 | 52397 | 54011 | 64572 | 63596 > 3 | 76157 | 80473 | 93363 | 93528 > 5 | 127075 | 134310 | 153176 | 149984 > 7 | 177100 | 176939 | 216356 | 211599 > 17 | 379047 | 383179 | 464249 | 470351 > 27 | 545219 | 546706 | 664779 | 662488 > 53 | 728142 | 728123 | 857454 | 869407 > 83 | 918276 | 957722 | 1215252 | 1203443 v11+1GB degrades above here.. > 107 | 884112 | 971797 | 1206930 | 1234606 > 139 | 822564 | 970920 | 1167518 | 1233230 > 163 | 788287 | 968248 | 1130021 | 1229250 > 191 | 772406 | 959344 | 1097842 | 1218541 > 211 | 756085 | 955563 | 1077747 | 1209489 > 239 | 732926 | 948855 | 1050096 | 1200878 > 271 | 692999 | 941722 | 1017489 | 1194012 > 307 | 668241 | 920478 | 994420 | 1179507 > 353 | 642478 | 908645 | 968648 | 1174265 > 397 | 617673 | 893568 | 950736 | 1173411 > > 2 sockets 3 keys > > conns | master | patch-v11 | master 1G | patch-v11 1G > --------+------------+------------+------------+------------ > 1 | 16722 | 16393 | 20340 | 21813 > 2 | 32057 | 32009 | 39993 | 42959 > 3 | 46202 | 47678 | 59216 | 64374 > 5 | 78882 | 72002 | 98054 | 103731 > 7 | 103398 | 99538 | 135098 | 135828 v11+128MB degrades above here.. > 17 | 205863 | 217781 | 293958 | 299690 > 27 | 283526 | 290539 | 414968 | 411219 > 53 | 336717 | 356130 | 460596 | 474563 > 83 | 307310 | 342125 | 419941 | 469989 > 107 | 294059 | 333494 | 405706 | 469593 > 139 | 278453 | 328031 | 390984 | 470553 > 163 | 270833 | 326457 | 384747 | 470977 > 191 | 259591 | 322590 | 376582 | 470335 > 211 | 263584 | 321263 | 375969 | 469443 > 239 | 257135 | 316959 | 370108 | 470904 > 271 | 251107 | 315393 | 365794 | 469517 > 307 | 246605 | 311585 | 360742 | 467566 > 353 | 236899 | 308581 | 353464 | 466936 > 397 | 249036 | 305042 | 344673 | 466842 > > I skipped v10 since I used it internally for variant > "insert entry with dummy index then search victim". Up to about 15%(?) of gain is great. I'm not sure it is okay that it seems to slow by about 1%.. Ah, I see. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
В Чт, 07/04/2022 в 16:55 +0900, Kyotaro Horiguchi пишет: > Hi, Yura. > > At Wed, 06 Apr 2022 16:17:28 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrot > e in > > Ok, I got access to stronger server, did the benchmark, found weird > > things, and so here is new version :-) > > Thanks for the new version and benchmarking. > > > First I found if table size is strictly limited to NBuffers and FIXED, > > then under high concurrency get_hash_entry may not find free entry > > despite it must be there. It seems while process scans free lists, other > > concurrent processes "moves etry around", ie one concurrent process > > fetched it from one free list, other process put new entry in other > > freelist, and unfortunate process missed it since it tests freelists > > only once. > > StrategyGetBuffer believes that entries don't move across freelists > and it was true before this patch. StrategyGetBuffer knows nothing about dynahash's freelist. It knows about buffer manager's freelist, which is not partitioned. > > > Second, I confirm there is problem with freelist spreading. > > If I keep entry's freelist_idx, then one freelist is crowded. > > If I use new entry's freelist_idx, then one freelist is emptified > > constantly. > > Perhaps it is what I saw before. I'm not sure about the details of > how that happens, though. > > > Third, I found increased concurrency could harm. When popular block > > is evicted for some reason, then thundering herd effect occures: > > many backends wants to read same block, they evict many other > > buffers, but only one is inserted. Other goes to freelist. Evicted > > buffers by itself reduce cache hit ratio and provocates more > > work. Old version resists this effect by not removing old buffer > > before new entry is successfully inserted. > > Nice finding. > > > To fix this issues I made following: > > > > # Concurrency > > > > First, I limit concurrency by introducing other lwlocks tranche - > > BufferEvict. It is 8 times larger than BufferMapping tranche (1024 vs > > 128). > > If backend doesn't find buffer in buffer table and wants to introduce > > it, it first calls > > LWLockAcquireOrWait(newEvictPartitionLock, LW_EXCLUSIVE) > > If lock were acquired, then it goes to eviction and replace process. > > Otherwise, it waits lock to be released and repeats search. > > > > This greately improve performance for > 400 clients in pgbench. > > So the performance difference between the existing code and v11 is the > latter has a collision cross section eight times smaller than the > former? No. Acquiring EvictPartitionLock 1. doesn't block readers, since readers doesn't acquire EvictPartitionLock 2. doesn't form "tree of lock dependency" since EvictPartitionLock is independent from PartitionLock. Problem with existing code: 1. Process A locks P1 and P2 2. Process B (p3-old, p1-new) locks P3 and wants to lock P1 3. Process C (p4-new, p1-old) locks P4 and wants to lock P1 4. Process D (p5-new, p4-old) locks P5 and wants to lock P4 At this moment locks P1, P2, P3, P4 and P5 are all locked and waiting for Process A. And readers can't read from same five partitions. With new code: 1. Process A locks E1 (evict partition) and locks P2, then releases P2 and locks P1. 2. Process B tries to locks E1, waits and retries search. 3. Process C locks E4, locks P1, then releases P1 and locks P4 4. Process D locks E5, locks P4, then releases P4 and locks P5 So, there is no network of locks. Process A doesn't block Process D in any moment: - either A blocks C, but C doesn't block D at this moment - or A doesn't block C. And readers doesn't see simultaneously locked five locks which depends on single Process A. > + * Prevent "thundering herd" problem and limit concurrency. > > this is something like pressing accelerator and break pedals at the > same time. If it improves performance, just increasing the number of > buffer partition seems to work? To be honestly: of cause simple increase of NUM_BUFFER_PARTITIONS does improve average case. But it is better to cure problem than anesthetize. Increase of NUM_BUFFER_PARTITIONS reduces probability and relative weight of lock network, but doesn't eliminate. > It's also not great that follower backends runs a busy loop on the > lock until the top-runner backend inserts the new buffer to the > buftable then releases the newParititionLock. > > > I tried other variant as well: > > - first insert entry with dummy buffer index into buffer table. > > - if such entry were already here, then wait it to be filled. > > - otherwise find victim buffer and replace dummy index with new one. > > Wait were done with shared lock on EvictPartitionLock as well. > > This variant performed quite same. > > This one looks better to me. Since a partition can be shared by two or > more new-buffers, condition variable seems to work better here... > > > Logically I like that variant more, but there is one gotcha: > > FlushBuffer could fail with elog(ERROR). Therefore then there is > > a need to reliable remove entry with dummy index. > > Perhaps UnlockBuffers can do that. Thanks for suggestion. I'll try to investigate and retry this way of patch. > > And after all, I still need to hold EvictPartitionLock to notice > > waiters. > > I've tried to use ConditionalVariable, but its performance were much > > worse. > > How many CVs did you use? I've tried both NUM_PARTITION_LOCKS and NUM_PARTITION_LOCKS*8. It doesn't matter. Looks like use of WaitLatch (which uses epoll) and/or tripple SpinLockAcquire per good case (with two list traversing) is much worse than PgSemaphorLock (which uses futex) and single wait list action. Other probability is while ConditionVariable eliminates thundering nerd effect, it doesn't limit concurrency enough... but that's just theory. In reality, I'd like to try to make BufferLookupEnt->id to be atomic and add LwLock to BufferLookupEnt. I'll test it, but doubt it could be merged, since there is no way to initialize dynahash's entries reliably. > > # Dynahash capacity and freelists. > > > > I returned back buffer table initialization: > > - removed FIXES_SIZE restriction introduced in previous version > > Mmm. I don't see v10 in this list and v9 doesn't contain FIXES_SIZE.. v9 contains HASH_FIXED_SIZE - line 815 of patch, PATCH 3/4 "fixed BufTable". > > - returned `NBuffers + NUM_BUFFER_PARTITIONS`. > > I really think, there should be more spare items, since almost always > > entry_alloc is called at least once (on 128MB shared_buffers). But > > let keep it as is for now. > > Maybe s/entry_alloc/element_alloc/ ? :p :p yes > I see it with shared_buffers=128kB (not MB) and pgbench -i on master. > > The required number of elements are already allocaed to freelists at > hash creation. So the reason for the call is imbalanced use among > freelists. Even in that case other freelists holds elements. So we > don't need to expand the element size. > > > `get_hash_entry` were changed to probe NUM_FREELISTS/4 (==8) freelists > > before falling back to `entry_alloc`, and probing is changed from > > linear to quadratic. This greately reduces number of calls to > > `entry_alloc`, so more shared memory left intact. And I didn't notice > > large performance hit from. Probably there is some, but I think it is > > adequate trade-off. > > I don't think that causes significant performance hit, but I don't > understand how it improves freelist hit ratio other than by accident. > Could you have some reasoning for it? Since free_reused_entry returns entry into random free_list, this probability is quite high. In tests, I see stabilisa > By the way the change of get_hash_entry looks something wrong. > > If I understand it correctly, it visits num_freelists/4 freelists at > once, then tries element_alloc. If element_alloc() fails (that must > happen), it only tries freeList[freelist_idx] and gives up, even > though there must be an element in other 3/4 freelists. No. If element_alloc fails, it tries all NUM_FREELISTS again. - condition: `ntries || !allocFailed`. `!allocFailed` become true, so `ntries` remains. - `ntries = num_freelists;` regardless of `allocFailed`. Therefore, all `NUM_FREELISTS` are retried for partitioned table. > > > `free_reused_entry` now returns entry to random position. It flattens > > free entry's spread. Although it is not enough without other changes > > (thundering herd mitigation and probing more lists in get_hash_entry). > > If "thudering herd" means "many backends rush trying to read-in the > same page at once", isn't it avoided by the change in BufferAlloc? "thundering herd" reduces speed of entries migration a lot. But `simple_select` benchmark is too biased: looks like btree root is evicted from time to time. So entries are slowly migrated to of from freelist of its partition. Without "thundering herd" fix this migration is very fast. > I feel the random returning method might work. I want to get rid of > the randomness here but I don't come up with a better way. > > Anyway the code path is used only by buftable so it doesn't harm > generally. > > > # Benchmarks > > # Thanks for benchmarking!! > > > Benchmarked on two socket Xeon(R) Gold 5220 CPU @2.20GHz > > 18 cores per socket + hyper-threading - upto 72 virtual core total. > > turbo-boost disabled > > Linux 5.10.103-1 Debian. > > > > pgbench scale 100 simple_select + simple select with 3 keys (sql file > > attached). > > > > shared buffers 128MB & 1GB > > huge_pages=on > > > > 1 socket > > conns | master | patch-v11 | master 1G | patch-v11 1G > > --------+------------+------------+------------+------------ > > 1 | 27882 | 27738 | 32735 | 32439 > > 2 | 54082 | 54336 | 64387 | 63846 > > 3 | 80724 | 81079 | 96387 | 94439 > > 5 | 134404 | 133429 | 160085 | 157399 > > 7 | 185977 | 184502 | 219916 | 217142 > > v11+128MB degrades above here.. + 1GB? > > > 17 | 335345 | 338214 | 393112 | 388796 > > 27 | 393686 | 394948 | 447945 | 444915 > > 53 | 572234 | 577092 | 678884 | 676493 > > 83 | 558875 | 561689 | 669212 | 655697 > > 107 | 553054 | 551896 | 654550 | 646010 > > 139 | 541263 | 538354 | 641937 | 633840 > > 163 | 532932 | 531829 | 635127 | 627600 > > 191 | 524647 | 524442 | 626228 | 617347 > > 211 | 521624 | 522197 | 629740 | 613143 > > v11+1GB degrades above here.. > > > 239 | 509448 | 554894 | 652353 | 652972 > > 271 | 468190 | 557467 | 647403 | 661348 > > 307 | 454139 | 558694 | 642229 | 657649 > > 353 | 446853 | 554301 | 635991 | 654571 > > 397 | 441909 | 549822 | 625194 | 647973 > > > > 1 socket 3 keys > > > > conns | master | patch-v11 | master 1G | patch-v11 1G > > --------+------------+------------+------------+------------ > > 1 | 16677 | 16477 | 22219 | 22030 > > 2 | 32056 | 31874 | 43298 | 43153 > > 3 | 48091 | 47766 | 64877 | 64600 > > 5 | 78999 | 78609 | 105433 | 106101 > > 7 | 108122 | 107529 | 148713 | 145343 > > v11+128MB degrades above here.. > > > 17 | 205656 | 209010 | 272676 | 271449 > > 27 | 252015 | 254000 | 323983 | 323499 > > v11+1GB degrades above here.. > > > 53 | 317928 | 334493 | 446740 | 449641 > > 83 | 299234 | 327738 | 437035 | 443113 > > 107 | 290089 | 322025 | 430535 | 431530 > > 139 | 277294 | 314384 | 422076 | 423606 > > 163 | 269029 | 310114 | 416229 | 417412 > > 191 | 257315 | 306530 | 408487 | 416170 > > 211 | 249743 | 304278 | 404766 | 416393 > > 239 | 243333 | 310974 | 397139 | 428167 > > 271 | 236356 | 309215 | 389972 | 427498 > > 307 | 229094 | 307519 | 382444 | 425891 > > 353 | 224385 | 305366 | 375020 | 423284 > > 397 | 218549 | 302577 | 364373 | 420846 > > > > 2 sockets > > > > conns | master | patch-v11 | master 1G | patch-v11 1G > > --------+------------+------------+------------+------------ > > 1 | 27287 | 27631 | 32943 | 32493 > > 2 | 52397 | 54011 | 64572 | 63596 > > 3 | 76157 | 80473 | 93363 | 93528 > > 5 | 127075 | 134310 | 153176 | 149984 > > 7 | 177100 | 176939 | 216356 | 211599 > > 17 | 379047 | 383179 | 464249 | 470351 > > 27 | 545219 | 546706 | 664779 | 662488 > > 53 | 728142 | 728123 | 857454 | 869407 > > 83 | 918276 | 957722 | 1215252 | 1203443 > > v11+1GB degrades above here.. > > > 107 | 884112 | 971797 | 1206930 | 1234606 > > 139 | 822564 | 970920 | 1167518 | 1233230 > > 163 | 788287 | 968248 | 1130021 | 1229250 > > 191 | 772406 | 959344 | 1097842 | 1218541 > > 211 | 756085 | 955563 | 1077747 | 1209489 > > 239 | 732926 | 948855 | 1050096 | 1200878 > > 271 | 692999 | 941722 | 1017489 | 1194012 > > 307 | 668241 | 920478 | 994420 | 1179507 > > 353 | 642478 | 908645 | 968648 | 1174265 > > 397 | 617673 | 893568 | 950736 | 1173411 > > > > 2 sockets 3 keys > > > > conns | master | patch-v11 | master 1G | patch-v11 1G > > --------+------------+------------+------------+------------ > > 1 | 16722 | 16393 | 20340 | 21813 > > 2 | 32057 | 32009 | 39993 | 42959 > > 3 | 46202 | 47678 | 59216 | 64374 > > 5 | 78882 | 72002 | 98054 | 103731 > > 7 | 103398 | 99538 | 135098 | 135828 > > v11+128MB degrades above here.. > > > 17 | 205863 | 217781 | 293958 | 299690 > > 27 | 283526 | 290539 | 414968 | 411219 > > 53 | 336717 | 356130 | 460596 | 474563 > > 83 | 307310 | 342125 | 419941 | 469989 > > 107 | 294059 | 333494 | 405706 | 469593 > > 139 | 278453 | 328031 | 390984 | 470553 > > 163 | 270833 | 326457 | 384747 | 470977 > > 191 | 259591 | 322590 | 376582 | 470335 > > 211 | 263584 | 321263 | 375969 | 469443 > > 239 | 257135 | 316959 | 370108 | 470904 > > 271 | 251107 | 315393 | 365794 | 469517 > > 307 | 246605 | 311585 | 360742 | 467566 > > 353 | 236899 | 308581 | 353464 | 466936 > > 397 | 249036 | 305042 | 344673 | 466842 > > > > I skipped v10 since I used it internally for variant > > "insert entry with dummy index then search victim". > > Up to about 15%(?) of gain is great. Up to 35% in "2 socket 3 key 1GB" case. Up to 44% in "2 socket 1 key 128MB" case. > I'm not sure it is okay that it seems to slow by about 1%.. Well, in fact some degradation is not reproducible. Surprisingly, results change a bit from time to time. I just didn't rerun whole `master` branch bench again after v11 bench, since each whole test run costs me 1.5 hour. But I confirm regression on "1 socket 1 key 1GB" test case between 83 and 211 connections. It were reproducible on more powerful Xeon 8354H, although it were less visible. Other fluctuations close to 1% are not reliable. For example, sometimes I see degradation or improvement with 2GB shared buffers (and even more than 1%). But 2GB is enough for whole test dataset (scale 100 pgbench is 1.5GB on disk). Therefore modified code is not involved in benchmarking at all. How it could be explained? That is why I don't post 2GB benchmark results. (yeah, I'm cheating a bit). > Ah, I see. > > regards. > > -- > Kyotaro Horiguchi > NTT Open Source Software Center > >
At Thu, 07 Apr 2022 14:14:59 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > В Чт, 07/04/2022 в 16:55 +0900, Kyotaro Horiguchi пишет: > > Hi, Yura. > > > > At Wed, 06 Apr 2022 16:17:28 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrot > > e in > > > Ok, I got access to stronger server, did the benchmark, found weird > > > things, and so here is new version :-) > > > > Thanks for the new version and benchmarking. > > > > > First I found if table size is strictly limited to NBuffers and FIXED, > > > then under high concurrency get_hash_entry may not find free entry > > > despite it must be there. It seems while process scans free lists, other > > > concurrent processes "moves etry around", ie one concurrent process > > > fetched it from one free list, other process put new entry in other > > > freelist, and unfortunate process missed it since it tests freelists > > > only once. > > > > StrategyGetBuffer believes that entries don't move across freelists > > and it was true before this patch. > > StrategyGetBuffer knows nothing about dynahash's freelist. > It knows about buffer manager's freelist, which is not partitioned. Yeah, right. I meant get_hash_entry. > > > To fix this issues I made following: > > > > > > # Concurrency > > > > > > First, I limit concurrency by introducing other lwlocks tranche - > > > BufferEvict. It is 8 times larger than BufferMapping tranche (1024 vs > > > 128). > > > If backend doesn't find buffer in buffer table and wants to introduce > > > it, it first calls > > > LWLockAcquireOrWait(newEvictPartitionLock, LW_EXCLUSIVE) > > > If lock were acquired, then it goes to eviction and replace process. > > > Otherwise, it waits lock to be released and repeats search. > > > > > > This greately improve performance for > 400 clients in pgbench. > > > > So the performance difference between the existing code and v11 is the > > latter has a collision cross section eight times smaller than the > > former? > > No. Acquiring EvictPartitionLock > 1. doesn't block readers, since readers doesn't acquire EvictPartitionLock > 2. doesn't form "tree of lock dependency" since EvictPartitionLock is > independent from PartitionLock. > > Problem with existing code: > 1. Process A locks P1 and P2 > 2. Process B (p3-old, p1-new) locks P3 and wants to lock P1 > 3. Process C (p4-new, p1-old) locks P4 and wants to lock P1 > 4. Process D (p5-new, p4-old) locks P5 and wants to lock P4 > At this moment locks P1, P2, P3, P4 and P5 are all locked and waiting > for Process A. > And readers can't read from same five partitions. > > With new code: > 1. Process A locks E1 (evict partition) and locks P2, > then releases P2 and locks P1. > 2. Process B tries to locks E1, waits and retries search. > 3. Process C locks E4, locks P1, then releases P1 and locks P4 > 4. Process D locks E5, locks P4, then releases P4 and locks P5 > So, there is no network of locks. > Process A doesn't block Process D in any moment: > - either A blocks C, but C doesn't block D at this moment > - or A doesn't block C. > And readers doesn't see simultaneously locked five locks which > depends on single Process A. Thansk for the detailed explanation. I see that. > > + * Prevent "thundering herd" problem and limit concurrency. > > > > this is something like pressing accelerator and break pedals at the > > same time. If it improves performance, just increasing the number of > > buffer partition seems to work? > > To be honestly: of cause simple increase of NUM_BUFFER_PARTITIONS > does improve average case. > But it is better to cure problem than anesthetize. > Increase of > NUM_BUFFER_PARTITIONS reduces probability and relative > weight of lock network, but doesn't eliminate. Agreed. > > It's also not great that follower backends runs a busy loop on the > > lock until the top-runner backend inserts the new buffer to the > > buftable then releases the newParititionLock. > > > > > I tried other variant as well: > > > - first insert entry with dummy buffer index into buffer table. > > > - if such entry were already here, then wait it to be filled. > > > - otherwise find victim buffer and replace dummy index with new one. > > > Wait were done with shared lock on EvictPartitionLock as well. > > > This variant performed quite same. > > > > This one looks better to me. Since a partition can be shared by two or > > more new-buffers, condition variable seems to work better here... > > > > > Logically I like that variant more, but there is one gotcha: > > > FlushBuffer could fail with elog(ERROR). Therefore then there is > > > a need to reliable remove entry with dummy index. > > > > Perhaps UnlockBuffers can do that. > > Thanks for suggestion. I'll try to investigate and retry this way > of patch. > > > > And after all, I still need to hold EvictPartitionLock to notice > > > waiters. > > > I've tried to use ConditionalVariable, but its performance were much > > > worse. > > > > How many CVs did you use? > > I've tried both NUM_PARTITION_LOCKS and NUM_PARTITION_LOCKS*8. > It doesn't matter. > Looks like use of WaitLatch (which uses epoll) and/or tripple > SpinLockAcquire per good case (with two list traversing) is much worse > than PgSemaphorLock (which uses futex) and single wait list action. Sure. I unintentionally neglected the overhead of our CV implementation. It cannot be used in such a hot path. > Other probability is while ConditionVariable eliminates thundering > nerd effect, it doesn't limit concurrency enough... but that's just > theory. > > In reality, I'd like to try to make BufferLookupEnt->id to be atomic > and add LwLock to BufferLookupEnt. I'll test it, but doubt it could > be merged, since there is no way to initialize dynahash's entries > reliably. Yeah, that's what came to my mind first (but with not a LWLock but a CV) but gave up for the reason of additional size. The size of BufferLookupEnt is 24 and sizeof(ConditionVariable) is 12. By the way sizeof(LWLock) is 16.. So I think we don't take the per-bufentry approach here for the reason of additional memory usage. > > I don't think that causes significant performance hit, but I don't > > understand how it improves freelist hit ratio other than by accident. > > Could you have some reasoning for it? > > Since free_reused_entry returns entry into random free_list, this > probability is quite high. In tests, I see stabilisa Maybe. Doesn't it improve the efficiency if we prioritize emptied freelist on returning an element? I tried it with an atomic_u32 to remember empty freelist. On the uin32, each bit represents a freelist index. I saw it eliminated calls to element_alloc. I tried to remember a single freelist index in an atomic but there was a case where two freelists are emptied at once and that lead to element_alloc call. > > By the way the change of get_hash_entry looks something wrong. > > > > If I understand it correctly, it visits num_freelists/4 freelists at > > once, then tries element_alloc. If element_alloc() fails (that must > > happen), it only tries freeList[freelist_idx] and gives up, even > > though there must be an element in other 3/4 freelists. > > No. If element_alloc fails, it tries all NUM_FREELISTS again. > - condition: `ntries || !allocFailed`. `!allocFailed` become true, > so `ntries` remains. > - `ntries = num_freelists;` regardless of `allocFailed`. > Therefore, all `NUM_FREELISTS` are retried for partitioned table. Ah, okay. ntries is set to num_freelists after calling element_alloc. I think we (I?) need more comments. By the way, why it is num_freelists / 4 + 1? > > > `free_reused_entry` now returns entry to random position. It flattens > > > free entry's spread. Although it is not enough without other changes > > > (thundering herd mitigation and probing more lists in get_hash_entry). > > > > If "thudering herd" means "many backends rush trying to read-in the > > same page at once", isn't it avoided by the change in BufferAlloc? > > "thundering herd" reduces speed of entries migration a lot. But > `simple_select` benchmark is too biased: looks like btree root is > evicted from time to time. So entries are slowly migrated to of from > freelist of its partition. > Without "thundering herd" fix this migration is very fast. Ah, that observation agree with the seemingly unidirectional migration of free entries. I remember that it is raised in this list several times to prioritize index pages in shared buffers.. > > Up to about 15%(?) of gain is great. > > Up to 35% in "2 socket 3 key 1GB" case. > Up to 44% in "2 socket 1 key 128MB" case. Oh, more great! > > I'm not sure it is okay that it seems to slow by about 1%.. > > Well, in fact some degradation is not reproducible. > Surprisingly, results change a bit from time to time. Yeah. > I just didn't rerun whole `master` branch bench again > after v11 bench, since each whole test run costs me 1.5 hour. Thans for the labor. > But I confirm regression on "1 socket 1 key 1GB" test case > between 83 and 211 connections. It were reproducible on > more powerful Xeon 8354H, although it were less visible. > > Other fluctuations close to 1% are not reliable. I'm glad to hear that. It is not surprising that some fluctuation happens. > For example, sometimes I see degradation or improvement with > 2GB shared buffers (and even more than 1%). But 2GB is enough > for whole test dataset (scale 100 pgbench is 1.5GB on disk). > Therefore modified code is not involved in benchmarking at all. > How it could be explained? > That is why I don't post 2GB benchmark results. (yeah, I'm > cheating a bit). If buffer replacement doesn't happen, theoretically this patch cannot be involved in the fluctuation. I think we can consider it an error. It might come from placement of other variables. I have somethimes got annoyed by such small but steady change of performance that persists until I recompiled the whole tree. But, sorry, I don't have a clear idea of how such performance shift happens.. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
В Пт, 08/04/2022 в 16:46 +0900, Kyotaro Horiguchi пишет: > At Thu, 07 Apr 2022 14:14:59 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > > В Чт, 07/04/2022 в 16:55 +0900, Kyotaro Horiguchi пишет: > > > Hi, Yura. > > > > > > At Wed, 06 Apr 2022 16:17:28 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrot > > > e in > > > > Ok, I got access to stronger server, did the benchmark, found weird > > > > things, and so here is new version :-) > > > > > > Thanks for the new version and benchmarking. > > > > > > > First I found if table size is strictly limited to NBuffers and FIXED, > > > > then under high concurrency get_hash_entry may not find free entry > > > > despite it must be there. It seems while process scans free lists, other > > > > concurrent processes "moves etry around", ie one concurrent process > > > > fetched it from one free list, other process put new entry in other > > > > freelist, and unfortunate process missed it since it tests freelists > > > > only once. > > > > > > StrategyGetBuffer believes that entries don't move across freelists > > > and it was true before this patch. > > > > StrategyGetBuffer knows nothing about dynahash's freelist. > > It knows about buffer manager's freelist, which is not partitioned. > > Yeah, right. I meant get_hash_entry. But entries doesn't move. One backends takes some entry from one freelist, other backend puts other entry to other freelist. > > > I don't think that causes significant performance hit, but I don't > > > understand how it improves freelist hit ratio other than by accident. > > > Could you have some reasoning for it? > > > > Since free_reused_entry returns entry into random free_list, this > > probability is quite high. In tests, I see stabilisa > > Maybe. Doesn't it improve the efficiency if we prioritize emptied > freelist on returning an element? I tried it with an atomic_u32 to > remember empty freelist. On the uin32, each bit represents a freelist > index. I saw it eliminated calls to element_alloc. I tried to > remember a single freelist index in an atomic but there was a case > where two freelists are emptied at once and that lead to element_alloc > call. I thought on bitmask too. But doesn't it return contention which many freelists were against? Well, in case there are enough entries to keep it almost always "all set", it would be immutable. > > > By the way the change of get_hash_entry looks something wrong. > > > > > > If I understand it correctly, it visits num_freelists/4 freelists at > > > once, then tries element_alloc. If element_alloc() fails (that must > > > happen), it only tries freeList[freelist_idx] and gives up, even > > > though there must be an element in other 3/4 freelists. > > > > No. If element_alloc fails, it tries all NUM_FREELISTS again. > > - condition: `ntries || !allocFailed`. `!allocFailed` become true, > > so `ntries` remains. > > - `ntries = num_freelists;` regardless of `allocFailed`. > > Therefore, all `NUM_FREELISTS` are retried for partitioned table. > > Ah, okay. ntries is set to num_freelists after calling element_alloc. > I think we (I?) need more comments. > > By the way, why it is num_freelists / 4 + 1? Well, num_freelists could be 1 or 32. If num_freelists is 1 then num_freelists / 4 == 0 - not good :-) ------ regards Yura Sokolov
On Wed, Apr 6, 2022 at 9:17 AM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > I skipped v10 since I used it internally for variant > "insert entry with dummy index then search victim". Hi, I think there's a big problem with this patch: --- a/src/backend/storage/buffer/freelist.c +++ b/src/backend/storage/buffer/freelist.c @@ -481,10 +481,10 @@ StrategyInitialize(bool init) * * Since we can't tolerate running out of lookup table entries, we must be * sure to specify an adequate table size here. The maximum steady-state - * usage is of course NBuffers entries, but BufferAlloc() tries to insert - * a new entry before deleting the old. In principle this could be - * happening in each partition concurrently, so we could need as many as - * NBuffers + NUM_BUFFER_PARTITIONS entries. + * usage is of course NBuffers entries. But due to concurrent + * access to numerous free lists in dynahash we can miss free entry that + * moved between free lists. So it is better to have some spare free entries + * to reduce probability of entry allocations after server start. */ InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS); With the existing system, there is a hard cap on the number of hash table entries that we can ever need: one per buffer, plus one per partition to cover the "extra" entries that are needed while changing buffer tags. With the patch, the number of concurrent buffer tag changes is no longer limited by NUM_BUFFER_PARTITIONS, because you release the lock on the old buffer partition before acquiring the lock on the new partition, and therefore there can be any number of backends trying to change buffer tags at the same time. But that means, as the comment implies, that there's no longer a hard cap on how many hash table entries we might need. I don't think we can just accept the risk that the hash table might try to allocate after startup. If it tries, it might fail, because all of the extra shared memory that we allocate at startup may already have been consumed, and then somebody's query may randomly error out. That's not OK. It's true that very few users are likely to be affected, because most people won't consume the extra shared memory, and of those who do, most won't hammer the system hard enough to cause an error. However, I don't see us deciding that it's OK to ship something that could randomly break just because it won't do so very often. -- Robert Haas EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> With the existing system, there is a hard cap on the number of hash
> table entries that we can ever need: one per buffer, plus one per
> partition to cover the "extra" entries that are needed while changing
> buffer tags. With the patch, the number of concurrent buffer tag
> changes is no longer limited by NUM_BUFFER_PARTITIONS, because you
> release the lock on the old buffer partition before acquiring the lock
> on the new partition, and therefore there can be any number of
> backends trying to change buffer tags at the same time. But that
> means, as the comment implies, that there's no longer a hard cap on
> how many hash table entries we might need.
I agree that "just hope it doesn't overflow" is unacceptable.
But couldn't you bound the number of extra entries as MaxBackends?
FWIW, I have extremely strong doubts about whether this patch
is safe at all. This particular problem seems resolvable though.
regards, tom lane
On Thu, Apr 14, 2022 at 10:04 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> I agree that "just hope it doesn't overflow" is unacceptable.
> But couldn't you bound the number of extra entries as MaxBackends?
Yeah, possibly ... as long as it can't happen that an operation still
counts against the limit after it's failed due to an error or
something like that.
> FWIW, I have extremely strong doubts about whether this patch
> is safe at all. This particular problem seems resolvable though.
Can you be any more specific?
This existing comment is surely in the running for terrible comment of the year:
* To change the association of a valid buffer, we'll need to have
* exclusive lock on both the old and new mapping partitions.
Anybody with a little bit of C knowledge will have no difficulty
gleaning from the code which follows that we are in fact acquiring
both buffer locks, but whoever wrote this (and I think it was a very
long time ago) did not feel it necessary to explain WHY we will need
to have an exclusive lock on both the old and new mapping partitions,
or more specifically, why we must hold both of those locks
simultaneously. That's unfortunate. It is clear that we need to hold
both locks at some point, just because the hash table is partitioned,
but it is not clear why we need to hold them both simultaneously.
It seems to me that whatever hazards exist must come from the fact
that the operation is no longer fully atomic. The existing code
acquires every relevant lock, then does the work, then releases locks.
Ergo, we don't have to worry about concurrency because there basically
can't be any. Stuff could be happening at the same time in other
partitions that are entirely unrelated to what we're doing, but at the
time we touch the two partitions we care about, we're the only one
touching them. Now, if we do as proposed here, we will acquire one
lock, release it, and then take the other lock, and that means that
some operations could overlap that can't overlap today. Whatever gets
broken must get broken because of that possible overlapping, because
in the absence of concurrency, the end state is the same either way.
So ... how could things get broken by having these operations overlap
each other? The possibility that we might run out of buffer mapping
entries is one concern. I guess there's also the question of whether
the collision handling is adequate: if we fail due to a collision and
handle that by putting the buffer on the free list, is that OK? And
what if we fail midway through and the buffer doesn't end up either on
the free list or in the buffer mapping table? I think maybe that's
impossible, but I'm not 100% sure that it's impossible, and I'm not
sure how bad it would be if it did happen. A permanent "leak" of a
buffer that resulted in it becoming permanently unusable would be bad,
for sure. But all of these issues seem relatively possible to avoid
with sufficiently good coding. My intuition is that the buffer mapping
table size limit is the nastiest of the problems, and if that's
resolvable then I'm not sure what else could be a hard blocker. I'm
not saying there isn't anything, just that I don't know what it might
be.
To put all this another way, suppose that we threw out the way we do
buffer allocation today and always allocated from the freelist. If the
freelist is found to be empty, the backend wanting a buffer has to do
some kind of clock sweep to populate the freelist with >=1 buffers,
and then try again. I don't think that would be performant or fair,
because it would probably happen frequently that a buffer some backend
had just added to the free list got stolen by some other backend, but
I think it would be safe, because we already put buffers on the
freelist when relations or databases are dropped, and we allocate from
there just fine in that case. So then why isn't this safe? It's
functionally the same thing, except we (usually) skip over the
intermediate step of putting the buffer on the freelist and taking it
off again.
--
Robert Haas
EDB: http://www.enterprisedb.com
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Apr 14, 2022 at 10:04 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> FWIW, I have extremely strong doubts about whether this patch
>> is safe at all. This particular problem seems resolvable though.
> Can you be any more specific?
> This existing comment is surely in the running for terrible comment of the year:
> * To change the association of a valid buffer, we'll need to have
> * exclusive lock on both the old and new mapping partitions.
I'm pretty sure that text is mine, and I didn't really think it needed
any additional explanation, because of exactly this:
> It seems to me that whatever hazards exist must come from the fact
> that the operation is no longer fully atomic.
If it's not atomic, then you have to worry about what happens if you
fail partway through, or somebody else changes relevant state while
you aren't holding the lock. Maybe all those cases can be dealt with,
but it will be significantly more fragile and more complicated (and
therefore slower in isolation) than the current code. Is the gain in
potential concurrency worth it? I didn't think so at the time, and
the graphs upthread aren't doing much to convince me otherwise.
regards, tom lane
On Thu, Apr 14, 2022 at 11:27 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > If it's not atomic, then you have to worry about what happens if you > fail partway through, or somebody else changes relevant state while > you aren't holding the lock. Maybe all those cases can be dealt with, > but it will be significantly more fragile and more complicated (and > therefore slower in isolation) than the current code. Is the gain in > potential concurrency worth it? I didn't think so at the time, and > the graphs upthread aren't doing much to convince me otherwise. Those graphs show pretty big improvements. Maybe that's only because what is being done is not actually safe, but it doesn't look like a trivial effect. -- Robert Haas EDB: http://www.enterprisedb.com
At Thu, 14 Apr 2022 11:02:33 -0400, Robert Haas <robertmhaas@gmail.com> wrote in > It seems to me that whatever hazards exist must come from the fact > that the operation is no longer fully atomic. The existing code > acquires every relevant lock, then does the work, then releases locks. > Ergo, we don't have to worry about concurrency because there basically > can't be any. Stuff could be happening at the same time in other > partitions that are entirely unrelated to what we're doing, but at the > time we touch the two partitions we care about, we're the only one > touching them. Now, if we do as proposed here, we will acquire one > lock, release it, and then take the other lock, and that means that > some operations could overlap that can't overlap today. Whatever gets > broken must get broken because of that possible overlapping, because > in the absence of concurrency, the end state is the same either way. > > So ... how could things get broken by having these operations overlap > each other? The possibility that we might run out of buffer mapping > entries is one concern. I guess there's also the question of whether > the collision handling is adequate: if we fail due to a collision and > handle that by putting the buffer on the free list, is that OK? And > what if we fail midway through and the buffer doesn't end up either on > the free list or in the buffer mapping table? I think maybe that's > impossible, but I'm not 100% sure that it's impossible, and I'm not > sure how bad it would be if it did happen. A permanent "leak" of a > buffer that resulted in it becoming permanently unusable would be bad, The patch removes buftable entry frist then either inserted again or returned to freelist. I don't understand how it can be in both buftable and freelist.. What kind of trouble do you have in mind for example? Even if some underlying functions issued ERROR, the result wouldn't differ from the current code. (It seems to me only WARNING or PANIC by a quick look). Maybe to make us sure that it works, we need to make sure the victim buffer is surely isolated. It is described as the following. * We are single pinner, we hold buffer header lock and exclusive * partition lock (if tag is valid). It means no other process can inspect * it at the moment. * * But we will release partition lock and buffer header lock. We must be * sure other backend will not use this buffer until we reuse it for new * tag. Therefore, we clear out the buffer's tag and flags and remove it * from buffer table. Also buffer remains pinned to ensure * StrategyGetBuffer will not try to reuse the buffer concurrently. > for sure. But all of these issues seem relatively possible to avoid > with sufficiently good coding. My intuition is that the buffer mapping > table size limit is the nastiest of the problems, and if that's I believe that still no additional entries are required in buftable. The reason for expansion is explained as the follows. At Wed, 06 Apr 2022 16:17:28 +0300, Yura Sokolov <y.sokolov@postgrespro.ru> wrote in > First I found if table size is strictly limited to NBuffers and FIXED, > then under high concurrency get_hash_entry may not find free entry > despite it must be there. It seems while process scans free lists, other The freelist starvation is caused from almost sigle-directioned inter-freelist migration that this patch introduced. So it is not needed if we neglect the slowdown (I'm not sure how much it is..) caused by walking though all freelists. The inter-freelist migration will stop if we pull out the HASH_REUSE feature from deynahash. > resolvable then I'm not sure what else could be a hard blocker. I'm > not saying there isn't anything, just that I don't know what it might > be. > > To put all this another way, suppose that we threw out the way we do > buffer allocation today and always allocated from the freelist. If the > freelist is found to be empty, the backend wanting a buffer has to do > some kind of clock sweep to populate the freelist with >=1 buffers, > and then try again. I don't think that would be performant or fair, > because it would probably happen frequently that a buffer some backend > had just added to the free list got stolen by some other backend, but > I think it would be safe, because we already put buffers on the > freelist when relations or databases are dropped, and we allocate from > there just fine in that case. So then why isn't this safe? It's > functionally the same thing, except we (usually) skip over the > intermediate step of putting the buffer on the freelist and taking it > off again. So, does this get progressed if someone (maybe Yura?) runs a benchmarking with this method? regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On Fri, Apr 15, 2022 at 4:29 AM Kyotaro Horiguchi <horikyota.ntt@gmail.com> wrote: > The patch removes buftable entry frist then either inserted again or > returned to freelist. I don't understand how it can be in both > buftable and freelist.. What kind of trouble do you have in mind for > example? I'm not sure. I'm just thinking about potential dangers. I was more worried about it ending up in neither place. > So, does this get progressed if someone (maybe Yura?) runs a > benchmarking with this method? I think we're talking about theoretical concerns about safety here, and you can't resolve that by benchmarking. Tom or others may have a different view, but IMHO the issue with this patch isn't that there are no performance benefits, but that the patch needs to be fully safe. He and I may disagree on how likely it is that it can be made safe, but it can be a million times faster and if it's not safe it's still dead. Something clearly needs to be done to plug the specific problem that I mentioned earlier, somehow making it so we never need to grow the hash table at runtime. If anyone can think of other such hazards those also need to be fixed. -- Robert Haas EDB: http://www.enterprisedb.com
At Mon, 18 Apr 2022 09:53:42 -0400, Robert Haas <robertmhaas@gmail.com> wrote in > On Fri, Apr 15, 2022 at 4:29 AM Kyotaro Horiguchi > <horikyota.ntt@gmail.com> wrote: > > The patch removes buftable entry frist then either inserted again or > > returned to freelist. I don't understand how it can be in both > > buftable and freelist.. What kind of trouble do you have in mind for > > example? > > I'm not sure. I'm just thinking about potential dangers. I was more > worried about it ending up in neither place. I think that is more likely to happen. But I think that that can happen also by the current code if it had exits on the way. And the patch does not add a new exit. > > So, does this get progressed if someone (maybe Yura?) runs a > > benchmarking with this method? > > I think we're talking about theoretical concerns about safety here, > and you can't resolve that by benchmarking. Tom or others may have a Yeah.. I didn't mean that benchmarking resolves the concerns. I meant that if benchmarking shows that the safer (or cleaner) way give sufficient gain, we can take that direction. > different view, but IMHO the issue with this patch isn't that there > are no performance benefits, but that the patch needs to be fully > safe. He and I may disagree on how likely it is that it can be made > safe, but it can be a million times faster and if it's not safe it's > still dead. Right. > Something clearly needs to be done to plug the specific problem that I > mentioned earlier, somehow making it so we never need to grow the hash > table at runtime. If anyone can think of other such hazards those also > need to be fixed. - Running out of buffer mapping entries? It seems to me related to "runtime growth of the table mapping hash table". Does the runtime growth of the hash mean that get_hash_entry may call element_alloc even if the hash is created with a sufficient number of elements? If so, it's not the fault of this patch. We can search all freelists before asking element_alloc() (maybe) in exchange of some extent of potential temporary degradation. That being said, I don't think it's good that we call element_alloc for shared hashes after creation. - Is the collision handling correct that just returning the victimized buffer to freelist? Potentially the patch can over-vicitimzie buffers up to max_connections-1. Is this what you are concerned about? A way to preveint over-victimization was raised upthread, that is, we insert a special table mapping entry that signals "this page is going to be available soon." before releasing newPartitionLock. This prevents over-vicitimaztion. - Doesn't buffer-leak or duplicate mapping happen? This patch does not change the order of the required steps, and there's no exit on the way (if the current code doesn't have.). No two processes victimize the same buffer since the victimizing steps are protected by oldPartitionLock (and header lock) same as the current code, and no two processes insert different buffers for the same page since the inserting steps are protected by newPartitionLock. No vicitmized buffer gets orphaned *if* that doesn't happen by the current code. So *I* am at loss how *I* can make it clear that they don't happenX( (Of course Yura might think differently.) regards. -- Kyotaro Horiguchi NTT Open Source Software Center
Good day, hackers. There are some sentences. Sentence one ============ > With the existing system, there is a hard cap on the number of hash > table entries that we can ever need: one per buffer, plus one per > partition to cover the "extra" entries that are needed while changing > buffer tags. As I understand it: current shared buffers implementation doesn't allocate entries after initialization. (I experiment on master 6c0f9f60f1 ) Ok, then it is safe to elog(FATAL) if shared buffers need to allocate? https://pastebin.com/x8arkEdX (all tests were done on base initialized with `pgbench -i -s 100`) $ pgbench -c 1 -T 10 -P 1 -S -M prepared postgres .... pgbench: error: client 0 script 0 aborted in command 1 query 0: FATAL: extend SharedBufHash oops... How many entries are allocated after start? https://pastebin.com/c5z0d5mz (shared_buffers = 128MB . 40/80ht cores on EPYC 7702 (VM on 64/128ht cores)) $ pid=`ps x | awk '/checkpointer/ && !/awk/ { print $1 }'` $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value' $1 = 16512 $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres ... $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value' $1 = 20439 $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres ... $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value' $1 = 20541 It stabilizes at 20541 To be honestly, if we add HASH_FIXED_SIZE to SharedBufHash=ShmemInitHash then it works, but with noticable performance regression. More over, I didn't notice "out of shared memory" starting with 23 spare items instead of 128 (NUM_BUFFER_PARTITIONS). Sentence two: ============= > With the patch, the number of concurrent buffer tag > changes is no longer limited by NUM_BUFFER_PARTITIONS, because you > release the lock on the old buffer partition before acquiring the lock > on the new partition, and therefore there can be any number of > backends trying to change buffer tags at the same time. Lets check. I take v9 branch: - no "thundering nerd" prevention yet - "get_hash_entry" is not modified - SharedBufHash is HASH_FIXED_SIZE (!!!) - no spare items at all, just NBuffers. (!!!) https://www.postgresql.org/message-id/6e6cfb8eea5ccac8e4bc2249fe0614d9f97055ee.camel%40postgrespro.ru I noticed some "out of shared memory" under high connection number (> 350) with this version. But I claimed it is because of race conditions in "get_hash_entry": concurrent backends may take free entries from one slot and but to another. Example: - backend A checks freeList[30] - it is empty - backend B takes entry from freeList[31] - backend C put entry to freeList[30] - backend A checks freeList[31] - it is empty - backend A fails with "out of shared memory" Lets check my claim: set NUM_FREELISTS to 1, therefore there is no possible race condition in "get_hash_entry". .... No single "out of shared memory" for 800 clients for 30 seconds. (well, in fact on this single socket 80 ht-core EPYC I didn't get "out of shared memory" even with NUM_FREELISTS 32. I noticed them on 2 socket 56 ht-core Xeon Gold). At the same time master branch has to have at least 15 spare items with NUM_FREELISTS 1 to work without "out of shared memory" on 800 clients for 30 seconds. Therefore suggested approach reduces real need in hash entries (when there is no races in "get_hash_entry"). If one look into code they see, there is no need in spare item in suggested code: - when backend calls BufTableInsert it already has victim buffer. Victim buffer either: - was uninitialized -- therefore wasn't in hash table --- therefore there is free entry for it in freeList - was just cleaned -- then there is stored free entry in DynaHashReuse --- then there is no need for free entry in freeList. And, not-surprisingly, there is no huge regression from setting NUM_FREELISTS to 1 because we usually Sentence three: =============== (not exact citation) - It is not atomic now therefore fragile. Well, going from "theoretical concerns" to practical, there is new part of control flow: - we clear buffer (but remain it pinned) - delete buffer from hash table if it was there, and store it for reuse - release old partition lock - acquire new partition lock - try insert into new partition - on conflict -- return hash entry to some freelist -- Pin found buffer -- unpin victim buffer -- return victim to Buffer's free list. - without conflict -- reuse saved entry if it was To get some problem one of this action should fail without fail of whole cluster. Therefore it should either elog(ERROR) or elog(FATAL). In any other case whole cluster will stop. Could BufTableDelete elog(ERROR|FATAL)? No. (there is one elog(ERROR), but with comment "shouldn't happen". It really could be changed to PANIC). Could LWLockRelease elog(ERROR|FATAL)? (elog(ERROR, "lock is not held") could not be triggerred since we certainly hold the lock). Could LWLockAcquire elog(ERROR|FATAL)? Well, there is `elog(ERROR, "too many LWLocks taken");` It is not possible becase we just did LWLockRelease. Could BufTableInsert elog(ERROR|FATAL)? There is "out of shared memory" which is avoidable with get_hash_entry modifications or with HASH_FIXED_SIZE + some spare items. Could CHECK_FOR_INTERRUPTS raise something? No: there is single line between LWLockRelease and LWLockAcquire, and it doesn't contain CHECK_FOR_INTERRUPTS. Therefore there is single fixable case of "out of shared memory" (by HASH_FIXED_SIZE or improvements to "get_hash_entry"). May be I'm not quite right at some point. I'd glad to learn. --------- regards Yura Sokolov
On Thu, Apr 21, 2022 at 5:04 AM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
> $ pid=`ps x | awk '/checkpointer/ && !/awk/ { print $1 }'`
> $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
>
> $1 = 16512
>
> $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres
> ...
> $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
>
> $1 = 20439
>
> $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres
> ...
> $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
>
> $1 = 20541
>
> It stabilizes at 20541
Hmm. So is the existing comment incorrect? Remember, I was complaining
about this change:
--- a/src/backend/storage/buffer/freelist.c
+++ b/src/backend/storage/buffer/freelist.c
@@ -481,10 +481,10 @@ StrategyInitialize(bool init)
*
* Since we can't tolerate running out of lookup table entries, we must be
* sure to specify an adequate table size here. The maximum steady-state
- * usage is of course NBuffers entries, but BufferAlloc() tries to insert
- * a new entry before deleting the old. In principle this could be
- * happening in each partition concurrently, so we could need as many as
- * NBuffers + NUM_BUFFER_PARTITIONS entries.
+ * usage is of course NBuffers entries. But due to concurrent
+ * access to numerous free lists in dynahash we can miss free entry that
+ * moved between free lists. So it is better to have some spare free entries
+ * to reduce probability of entry allocations after server start.
*/
InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);
Pre-patch, the comment claims that the maximum number of buffer
entries that can be simultaneously used is limited to NBuffers +
NUM_BUFFER_PARTITIONS, and that's why we make the hash table that
size. The idea is that we normally need more than 1 entry per buffer,
but sometimes we might have 2 entries for the same buffer if we're in
the process of changing the buffer tag, because we make the new entry
before removing the old one. To change the buffer tag, we need the
buffer mapping lock for the old partition and the new one, but if both
are the same, we need only one buffer mapping lock. That means that in
the worst case, you could have a number of processes equal to
NUM_BUFFER_PARTITIONS each in the process of changing the buffer tag
between values that both fall into the same partition, and thus each
using 2 entries. Then you could have every other buffer in use and
thus using 1 entry, for a total of NBuffers + NUM_BUFFER_PARTITIONS
entries. Now I think you're saying we go far beyond that number, and
what I wonder is how that's possible. If the system doesn't work the
way the comment says it does, maybe we ought to start by talking about
what to do about that.
I am a bit confused by your description of having done "p
SharedBufHash->hctl->allocated.value" because SharedBufHash is of type
HTAB and HTAB's hctl member is of type HASHHDR, which has no field
called "allocated". I thought maybe my analysis here was somehow
mistaken, so I tried the debugger, which took the same view of it that
I did:
(lldb) p SharedBufHash->hctl->allocated.value
error: <user expression 0>:1:22: no member named 'allocated' in 'HASHHDR'
SharedBufHash->hctl->allocated.value
~~~~~~~~~~~~~~~~~~~ ^
--
Robert Haas
EDB: http://www.enterprisedb.com
В Чт, 21/04/2022 в 16:24 -0400, Robert Haas пишет:
> On Thu, Apr 21, 2022 at 5:04 AM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
> > $ pid=`ps x | awk '/checkpointer/ && !/awk/ { print $1 }'`
> > $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
> >
> > $1 = 16512
> >
> > $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres
> > ...
> > $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
> >
> > $1 = 20439
> >
> > $ install/bin/pgbench -c 600 -j 800 -T 10 -P 1 -S -M prepared postgres
> > ...
> > $ gdb -p $pid -batch -ex 'p SharedBufHash->hctl->allocated.value'
> >
> > $1 = 20541
> >
> > It stabilizes at 20541
>
> Hmm. So is the existing comment incorrect?
It is correct and incorrect at the same time. Logically it is correct.
And it is correct in practice if HASH_FIXED_SIZE is set for SharedBufHash
(which is not currently). But setting HASH_FIXED_SIZE hurts performance
with low number of spare items.
> Remember, I was complaining
> about this change:
>
> --- a/src/backend/storage/buffer/freelist.c
> +++ b/src/backend/storage/buffer/freelist.c
> @@ -481,10 +481,10 @@ StrategyInitialize(bool init)
> *
> * Since we can't tolerate running out of lookup table entries, we must be
> * sure to specify an adequate table size here. The maximum steady-state
> - * usage is of course NBuffers entries, but BufferAlloc() tries to insert
> - * a new entry before deleting the old. In principle this could be
> - * happening in each partition concurrently, so we could need as many as
> - * NBuffers + NUM_BUFFER_PARTITIONS entries.
> + * usage is of course NBuffers entries. But due to concurrent
> + * access to numerous free lists in dynahash we can miss free entry that
> + * moved between free lists. So it is better to have some spare free entries
> + * to reduce probability of entry allocations after server start.
> */
> InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);
>
> Pre-patch, the comment claims that the maximum number of buffer
> entries that can be simultaneously used is limited to NBuffers +
> NUM_BUFFER_PARTITIONS, and that's why we make the hash table that
> size. The idea is that we normally need more than 1 entry per buffer,
> but sometimes we might have 2 entries for the same buffer if we're in
> the process of changing the buffer tag, because we make the new entry
> before removing the old one. To change the buffer tag, we need the
> buffer mapping lock for the old partition and the new one, but if both
> are the same, we need only one buffer mapping lock. That means that in
> the worst case, you could have a number of processes equal to
> NUM_BUFFER_PARTITIONS each in the process of changing the buffer tag
> between values that both fall into the same partition, and thus each
> using 2 entries. Then you could have every other buffer in use and
> thus using 1 entry, for a total of NBuffers + NUM_BUFFER_PARTITIONS
> entries. Now I think you're saying we go far beyond that number, and
> what I wonder is how that's possible. If the system doesn't work the
> way the comment says it does, maybe we ought to start by talking about
> what to do about that.
At the master state:
- SharedBufHash is not declared as HASH_FIXED_SIZE
- get_hash_entry falls back to element_alloc too fast (just if it doesn't
found free entry in current freelist partition).
- get_hash_entry has races.
- if there are small number of spare items (and NUM_BUFFER_PARTITIONS is
small number) and HASH_FIXED_SIZE is set, it becomes contended and
therefore slow.
HASH_REUSE solves (for shared buffers) most of this issues. Free list
became rare fallback, so HASH_FIXED_SIZE for SharedBufHash doesn't lead
to performance hit. And with fair number of spare items, get_hash_entry
will find free entry despite its races.
> I am a bit confused by your description of having done "p
> SharedBufHash->hctl->allocated.value" because SharedBufHash is of type
> HTAB and HTAB's hctl member is of type HASHHDR, which has no field
> called "allocated".
Previous letter contains links to small patches that I used for
experiments. Link that adds "allocated" is https://pastebin.com/c5z0d5mz
> I thought maybe my analysis here was somehow
> mistaken, so I tried the debugger, which took the same view of it that
> I did:
>
> (lldb) p SharedBufHash->hctl->allocated.value
> error: <user expression 0>:1:22: no member named 'allocated' in 'HASHHDR'
> SharedBufHash->hctl->allocated.value
> ~~~~~~~~~~~~~~~~~~~ ^
-----
regards
Yura Sokolov
Btw, I've runned tests on EPYC (80 cores).
1 key per select
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 29053 | 28959 | 26715 | 25631
2 | 53714 | 53002 | 55211 | 53699
3 | 69796 | 72100 | 72355 | 71164
5 | 118045 | 112066 | 122182 | 119825
7 | 151933 | 156298 | 162001 | 160834
17 | 344594 | 347809 | 390103 | 386676
27 | 497656 | 527313 | 587806 | 598450
53 | 732524 | 853831 | 906569 | 947050
83 | 823203 | 991415 | 1056884 | 1222530
107 | 812730 | 930175 | 1004765 | 1232307
139 | 781757 | 938718 | 995326 | 1196653
163 | 758991 | 969781 | 990644 | 1143724
191 | 774137 | 977633 | 996763 | 1210899
211 | 771856 | 973361 | 1024798 | 1187824
239 | 756925 | 940808 | 954326 | 1165303
271 | 756220 | 940508 | 970254 | 1198773
307 | 746784 | 941038 | 940369 | 1159446
353 | 710578 | 928296 | 923437 | 1189575
397 | 715352 | 915931 | 911638 | 1180688
3 keys per select
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 17448 | 17104 | 18359 | 19077
2 | 30888 | 31650 | 35074 | 35861
3 | 44653 | 43371 | 47814 | 47360
5 | 69632 | 64454 | 76695 | 76208
7 | 96385 | 92526 | 107587 | 107930
17 | 195157 | 205156 | 253440 | 239740
27 | 302343 | 316768 | 386748 | 335148
53 | 334321 | 396359 | 402506 | 486341
83 | 300439 | 374483 | 408694 | 452731
107 | 302768 | 369207 | 390599 | 453817
139 | 294783 | 364885 | 379332 | 459884
163 | 272646 | 344643 | 376629 | 460839
191 | 282307 | 334016 | 363322 | 449928
211 | 275123 | 321337 | 371023 | 445246
239 | 263072 | 341064 | 356720 | 441250
271 | 271506 | 333066 | 373994 | 436481
307 | 261545 | 333489 | 348569 | 466673
353 | 255700 | 331344 | 333792 | 455430
397 | 247745 | 325712 | 326680 | 439245
Вложения
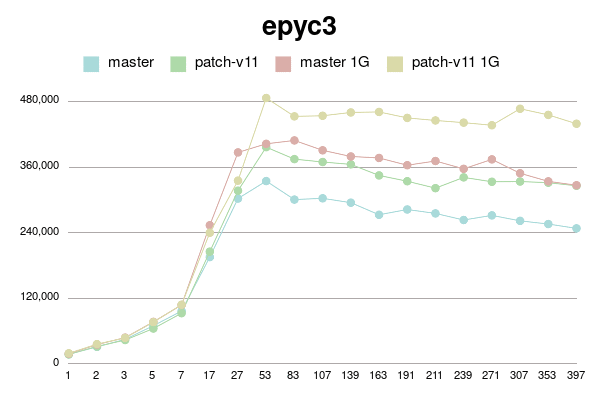{kind=link}
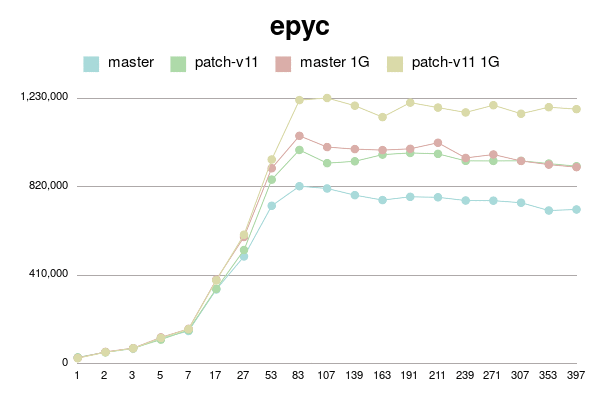{kind=link}
On Thu, Apr 21, 2022 at 6:58 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > At the master state: > - SharedBufHash is not declared as HASH_FIXED_SIZE > - get_hash_entry falls back to element_alloc too fast (just if it doesn't > found free entry in current freelist partition). > - get_hash_entry has races. > - if there are small number of spare items (and NUM_BUFFER_PARTITIONS is > small number) and HASH_FIXED_SIZE is set, it becomes contended and > therefore slow. > > HASH_REUSE solves (for shared buffers) most of this issues. Free list > became rare fallback, so HASH_FIXED_SIZE for SharedBufHash doesn't lead > to performance hit. And with fair number of spare items, get_hash_entry > will find free entry despite its races. Hmm, I see. The idea of trying to arrange to reuse entries rather than pushing them onto a freelist and immediately trying to take them off again is an interesting one, and I kind of like it. But I can't imagine that anyone would commit this patch the way you have it. It's way too much action at a distance. If any ereport(ERROR,...) could happen between the HASH_REUSE operation and the subsequent HASH_ENTER, it would be disastrous, and those things are separated by multiple levels of call stack across different modules, so mistakes would be easy to make. If this could be made into something dynahash takes care of internally without requiring extensive cooperation with the calling code, I think it would very possibly be accepted. One approach would be to have a hash_replace() call that takes two const void * arguments, one to delete and one to insert. Then maybe you propagate that idea upward and have, similarly, a BufTableReplace operation that uses that, and then the bufmgr code calls BufTableReplace instead of BufTableDelete. Maybe there are other better ideas out there... -- Robert Haas EDB: http://www.enterprisedb.com
В Пт, 06/05/2022 в 10:26 -0400, Robert Haas пишет: > On Thu, Apr 21, 2022 at 6:58 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > At the master state: > > - SharedBufHash is not declared as HASH_FIXED_SIZE > > - get_hash_entry falls back to element_alloc too fast (just if it doesn't > > found free entry in current freelist partition). > > - get_hash_entry has races. > > - if there are small number of spare items (and NUM_BUFFER_PARTITIONS is > > small number) and HASH_FIXED_SIZE is set, it becomes contended and > > therefore slow. > > > > HASH_REUSE solves (for shared buffers) most of this issues. Free list > > became rare fallback, so HASH_FIXED_SIZE for SharedBufHash doesn't lead > > to performance hit. And with fair number of spare items, get_hash_entry > > will find free entry despite its races. > > Hmm, I see. The idea of trying to arrange to reuse entries rather than > pushing them onto a freelist and immediately trying to take them off > again is an interesting one, and I kind of like it. But I can't > imagine that anyone would commit this patch the way you have it. It's > way too much action at a distance. If any ereport(ERROR,...) could > happen between the HASH_REUSE operation and the subsequent HASH_ENTER, > it would be disastrous, and those things are separated by multiple > levels of call stack across different modules, so mistakes would be > easy to make. If this could be made into something dynahash takes care > of internally without requiring extensive cooperation with the calling > code, I think it would very possibly be accepted. > > One approach would be to have a hash_replace() call that takes two > const void * arguments, one to delete and one to insert. Then maybe > you propagate that idea upward and have, similarly, a BufTableReplace > operation that uses that, and then the bufmgr code calls > BufTableReplace instead of BufTableDelete. Maybe there are other > better ideas out there... No. While HASH_REUSE is a good addition to overall performance improvement of the patch, it is not required for major gain. Major gain is from not taking two partition locks simultaneously. hash_replace would require two locks, so it is not an option. regards ----- Yura
Good day, hackers.
This is continuation of BufferAlloc saga.
This time I've tried to implement approach:
- if there's no buffer, insert placeholder
- then find victim
- if other backend wants to insert same buffer, it waits on
ConditionVariable.
Patch make separate ConditionVariable per backend, and placeholder
contains backend id. So waiters don't suffer from collision on
partition, they wait exactly for concrete buffer.
This patch doesn't contain any dynahash changes since order of
operation doesn't change: "insert then delete". So there is no way to
"reserve" entry.
But it contains changes to ConditionVariable:
- adds ConditionVariableSleepOnce, which doesn't reinsert process back
on CV's proclist.
This method could not be used in loop as ConditionVariableSleep,
and ConditionVariablePrepareSleep must be called before.
- adds ConditionVariableBroadcastFast - improvement over regular
ConditionVariableBroadcast that awakes processes in batches.
So CVBroadcastFast doesn't acquire/release CV's spinlock mutex for
every proclist entry, but rather for batch of entries.
I believe, it could safely replace ConditionVariableBroadcast. Though
I didn't try yet to replace and check.
Tests:
- tests done on 2 socket Xeon 5220 2.20GHz with turbo bust disabled
(ie max frequency is 2.20GHz)
- runs on 1 socket or 2 sockets using numactl
- pgbench scale 100 - 1.5GB of data
- shared_buffers : 128MB, 1GB (and 2GB)
- variations of simple_select with 1 key per query, 3 keys per query
and 10 keys per query.
1 socket 1 key
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 25670 | 24926 | 29491 | 28858
2 | 50157 | 48894 | 58356 | 57180
3 | 75036 | 72904 | 87152 | 84869
5 | 124479 | 120720 | 143550 | 140799
7 | 168586 | 164277 | 199360 | 195578
17 | 319943 | 314010 | 364963 | 358550
27 | 423617 | 420528 | 491493 | 485139
53 | 491357 | 490994 | 574477 | 571753
83 | 487029 | 486750 | 571057 | 566335
107 | 478429 | 479862 | 565471 | 560115
139 | 467953 | 469981 | 556035 | 551056
163 | 459467 | 463272 | 548976 | 543660
191 | 448420 | 456105 | 540881 | 534556
211 | 440229 | 458712 | 545195 | 535333
239 | 431754 | 471373 | 547111 | 552591
271 | 421767 | 473479 | 544014 | 557910
307 | 408234 | 474285 | 539653 | 556629
353 | 389360 | 472491 | 534719 | 554696
397 | 377063 | 471513 | 527887 | 554383
1 socket 3 keys
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 15277 | 14917 | 20109 | 19564
2 | 29587 | 28892 | 39430 | 36986
3 | 44204 | 43198 | 58993 | 57196
5 | 71471 | 68703 | 96923 | 92497
7 | 98823 | 97823 | 133173 | 130134
17 | 201351 | 198865 | 258139 | 254702
27 | 254959 | 255503 | 338117 | 339044
53 | 277048 | 291923 | 384300 | 390812
83 | 251486 | 287247 | 376170 | 385302
107 | 232037 | 281922 | 365585 | 380532
139 | 210478 | 276544 | 352430 | 373815
163 | 193875 | 271842 | 341636 | 368034
191 | 179544 | 267033 | 334408 | 362985
211 | 172837 | 269329 | 330287 | 366478
239 | 162647 | 272046 | 322646 | 371807
271 | 153626 | 271423 | 314017 | 371062
307 | 144122 | 270540 | 305358 | 370462
353 | 129544 | 268239 | 292867 | 368162
397 | 123430 | 267112 | 284394 | 366845
1 socket 10 keys
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 6824 | 6735 | 10475 | 10220
2 | 13037 | 12628 | 20382 | 19849
3 | 19416 | 19043 | 30369 | 29554
5 | 31756 | 30657 | 49402 | 48614
7 | 42794 | 42179 | 67526 | 65071
17 | 91443 | 89772 | 139630 | 139929
27 | 107751 | 110689 | 165996 | 169955
53 | 97128 | 120621 | 157670 | 184382
83 | 82344 | 117814 | 142380 | 183863
107 | 70764 | 115841 | 134266 | 182426
139 | 57561 | 112528 | 125090 | 180121
163 | 50490 | 110443 | 119932 | 178453
191 | 45143 | 108583 | 114690 | 175899
211 | 42375 | 107604 | 111444 | 174109
239 | 39861 | 106702 | 106253 | 172410
271 | 37398 | 105819 | 102260 | 170792
307 | 35279 | 105355 | 97164 | 168313
353 | 33427 | 103537 | 91629 | 166232
397 | 31778 | 101793 | 87230 | 164381
2 sockets 1 key
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 24839 | 24386 | 29246 | 28361
2 | 46655 | 45265 | 55942 | 54327
3 | 69278 | 68332 | 83984 | 81608
5 | 115263 | 112746 | 139012 | 135426
7 | 159881 | 155119 | 193846 | 188399
17 | 373808 | 365085 | 456463 | 441603
27 | 503663 | 495443 | 600335 | 584741
53 | 708849 | 744274 | 900923 | 908488
83 | 593053 | 862003 | 985953 | 1038033
107 | 431806 | 875704 | 957115 | 1075172
139 | 328380 | 879890 | 881652 | 1069872
163 | 288339 | 874792 | 824619 | 1064047
191 | 255666 | 870532 | 790583 | 1061124
211 | 241230 | 865975 | 764898 | 1058473
239 | 227344 | 857825 | 732353 | 1049745
271 | 216095 | 848240 | 703729 | 1043182
307 | 206978 | 833980 | 674711 | 1031533
353 | 198426 | 803830 | 633783 | 1018479
397 | 191617 | 744466 | 599170 | 1006134
2 sockets 3 keys
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 14688 | 14088 | 18912 | 18905
2 | 26759 | 25925 | 36817 | 35924
3 | 40002 | 38658 | 54765 | 53266
5 | 63479 | 63041 | 90521 | 87496
7 | 88561 | 87101 | 123425 | 121877
17 | 199411 | 196932 | 289555 | 282146
27 | 270121 | 275950 | 386884 | 383019
53 | 202918 | 374848 | 395967 | 501648
83 | 149599 | 363623 | 335815 | 478628
107 | 126501 | 348125 | 311617 | 472473
139 | 106091 | 331350 | 279843 | 466408
163 | 95497 | 321978 | 260884 | 461688
191 | 87427 | 312815 | 241189 | 458252
211 | 82783 | 307261 | 231435 | 454327
239 | 78930 | 299661 | 219655 | 451826
271 | 74081 | 294233 | 211555 | 448412
307 | 71352 | 288133 | 202838 | 446143
353 | 67872 | 279948 | 193354 | 441929
397 | 66178 | 275784 | 185556 | 438330
2 sockets 10 keys
conns | master 128M | v12 128M | master 1G | v12 1G
--------+--------------+--------------+--------------+--------------
1 | 6200 | 6108 | 10163 | 9563
2 | 11196 | 10871 | 18373 | 17827
3 | 16479 | 16129 | 26807 | 26584
5 | 26750 | 26241 | 44291 | 43409
7 | 36501 | 35433 | 60508 | 59379
17 | 77320 | 77451 | 130413 | 128452
27 | 91833 | 105643 | 147259 | 156833
53 | 57138 | 115793 | 119306 | 150647
83 | 44435 | 108850 | 105454 | 148006
107 | 38031 | 105199 | 95108 | 146162
139 | 31697 | 101096 | 84011 | 143281
163 | 28826 | 98255 | 78411 | 141375
191 | 26223 | 96224 | 74256 | 139646
211 | 24933 | 94815 | 71542 | 137834
239 | 23626 | 92849 | 69289 | 137235
271 | 22664 | 90938 | 66431 | 136080
307 | 21691 | 89358 | 64661 | 133166
353 | 20712 | 88239 | 61619 | 133339
397 | 20374 | 86708 | 58937 | 130684
Well, as you see, there is some regression on low connection numbers.
I don't get where it from.
More over, it is even in case of 2GB shared buffers - when all data
fits into buffers cache and new code doesn't work at all.
(except this incomprehensible regression there's no different in
performance with 2GB shared buffers).
For example 2GB shared buffers 1 socket 3 keys:
conns | master 2G | v12 2G
--------+--------------+--------------
1 | 23491 | 22621
2 | 46436 | 44851
3 | 69265 | 66844
5 | 112432 | 108801
7 | 158859 | 150247
17 | 297600 | 291605
27 | 390041 | 384590
53 | 448384 | 447588
83 | 445582 | 442048
107 | 440544 | 438200
139 | 433893 | 430818
163 | 427436 | 424182
191 | 420854 | 417045
211 | 417228 | 413456
Perhaps something changes in memory layout due to array of CV's, or
compiler layouts/optimizes functions differently. I can't find the
reason ;-( I would appreciate help on this.
regards
---
Yura Sokolov
Вложения
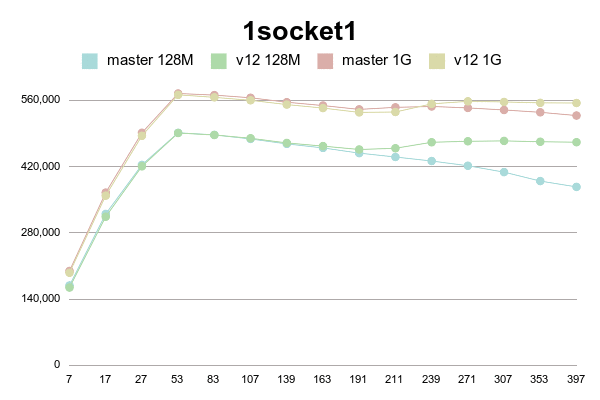{kind=link}
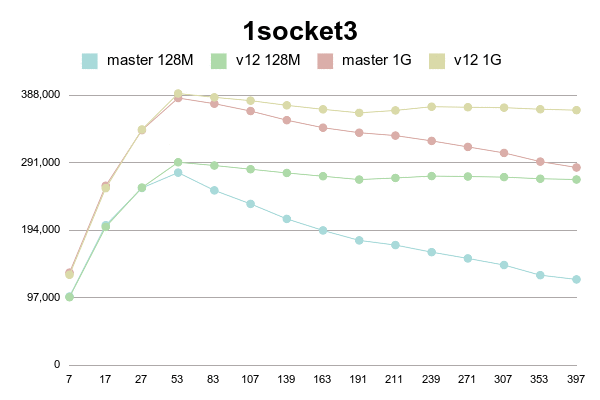{kind=link}
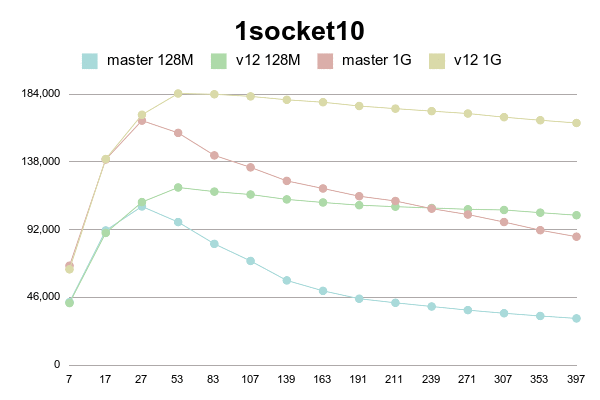{kind=link}
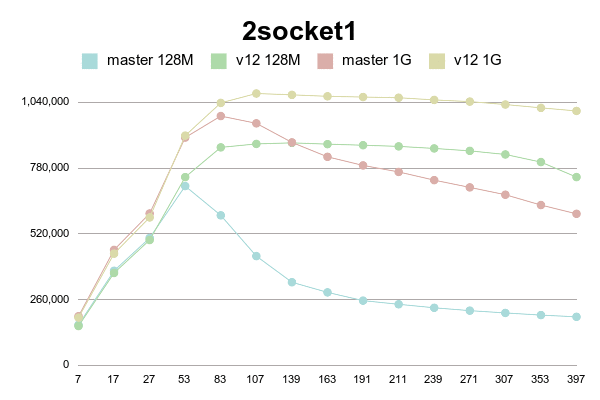{kind=link}
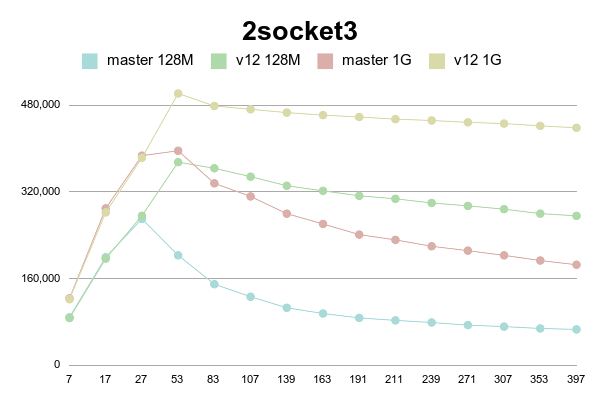{kind=link}
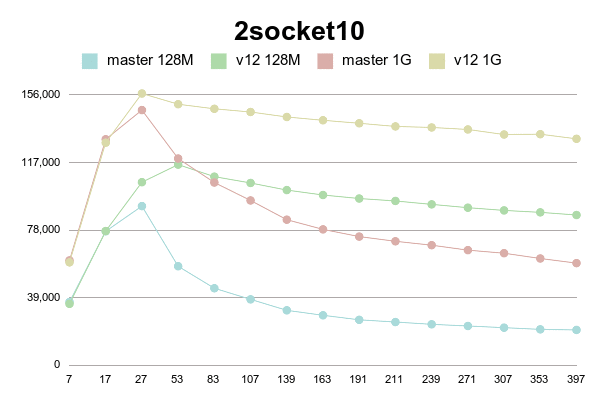{kind=link}
В Вт, 28/06/2022 в 14:13 +0300, Yura Sokolov пишет: > Tests: > - tests done on 2 socket Xeon 5220 2.20GHz with turbo bust disabled > (ie max frequency is 2.20GHz) Forgot to mention: - this time it was Centos7.9.2009 (Core) with Linux mn10 3.10.0-1160.el7.x86_64 Perhaps older kernel describes poor master's performance on 2 sockets compared to my previous results (when this server had Linux 5.10.103-1 Debian). Or there is degradation in PostgreSQL's master branch between. I'll try to check today. regards --- Yura Sokolov
В Вт, 28/06/2022 в 14:26 +0300, Yura Sokolov пишет: > В Вт, 28/06/2022 в 14:13 +0300, Yura Sokolov пишет: > > > Tests: > > - tests done on 2 socket Xeon 5220 2.20GHz with turbo bust disabled > > (ie max frequency is 2.20GHz) > > Forgot to mention: > - this time it was Centos7.9.2009 (Core) with Linux mn10 3.10.0-1160.el7.x86_64 > > Perhaps older kernel describes poor master's performance on 2 sockets > compared to my previous results (when this server had Linux 5.10.103-1 Debian). > > Or there is degradation in PostgreSQL's master branch between. > I'll try to check today. No, old master commit ( 7e12256b47 Sat Mar 12 14:21:40 2022) behaves same. So it is clearly old-kernel issue. Perhaps, futex was much slower than this days.
On Tue, Jun 28, 2022 at 4:50 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote:
В Вт, 28/06/2022 в 14:26 +0300, Yura Sokolov пишет:
> В Вт, 28/06/2022 в 14:13 +0300, Yura Sokolov пишет:
>
> > Tests:
> > - tests done on 2 socket Xeon 5220 2.20GHz with turbo bust disabled
> > (ie max frequency is 2.20GHz)
>
> Forgot to mention:
> - this time it was Centos7.9.2009 (Core) with Linux mn10 3.10.0-1160.el7.x86_64
>
> Perhaps older kernel describes poor master's performance on 2 sockets
> compared to my previous results (when this server had Linux 5.10.103-1 Debian).
>
> Or there is degradation in PostgreSQL's master branch between.
> I'll try to check today.
No, old master commit ( 7e12256b47 Sat Mar 12 14:21:40 2022) behaves same.
So it is clearly old-kernel issue. Perhaps, futex was much slower than this
days.
The patch requires a rebase; please do that.
Hunk #1 FAILED at 231.
Hunk #2 succeeded at 409 (offset 82 lines).
1 out of 2 hunks FAILED -- saving rejects to file src/include/storage/buf_internals.h.rej
Ibrar Ahmed
On Wed, Sep 07, 2022 at 12:53:07PM +0500, Ibrar Ahmed wrote: > Hunk #1 FAILED at 231. > Hunk #2 succeeded at 409 (offset 82 lines). > > 1 out of 2 hunks FAILED -- saving rejects to file > src/include/storage/buf_internals.h.rej With no rebase done since this notice, I have marked this entry as RwF. -- Michael