Обсуждение: WIP: expression evaluation improvements
Hi,
TL;DR: Some performance figures at the end. Lots of details before.
For a while I've been on and off (unfortunately more the latter), been
hacking on improving expression evaluation further.
This is motivated by mainly two factors:
a) Expression evaluation is still often a very significant fraction of
query execution time. Both with and without jit enabled.
b) Currently caching for JITed queries is not possible, as the generated
queries contain pointers that change from query to query
but there are others too (e.g. using less memory, reducing
initialization time).
The main reason why the JITed code is not faster, and why it cannot
really be cached, is that ExprEvalStep's point to memory that's
"outside" of LLVMs view, e.g. via ExprEvalStep->resvalue and the various
FunctionCallInfos. That's currently done by just embedding the raw
pointer value in the generated program (which effectively prevents
caching). LLVM will not really optimize through these memory references,
having difficulty determining aliasing and lifetimes. The fix for that
is to move for on-stack allocations for actually temporary stuff, llvm
can convert that into SSA form, and optimize properly.
In the attached *prototype* patch series there's a lot of incremental
improvements (and some cleanups) (in time, not importance order):
1) A GUC that enables iterating in reverse order over items on a page
during sequential scans. This is mainly to make profiles easier to
read, as the cache misses are otherwise swamping out other effects.
2) A number of optimizations of specific expression evaluation steps:
- reducing the number of aggregate transition steps by "merging"
EEOP_AGG_INIT_TRANS, EEOP_AGG_STRICT_TRANS_CHECK with EEOP_AGG_PLAIN_TRANS{_BYVAL,}
into special case versions for each combination.
- introducing special-case expression steps for common combinations
of steps (EEOP_FUNCEXPR_STRICT_1, EEOP_FUNCEXPR_STRICT_2,
EEOP_AGG_STRICT_INPUT_CHECK_ARGS_1, EEOP_DONE_NO_RETURN).
3) Use NullableDatum for slots and expression evaluation.
This is a small performance win for expression evaluation, and
reduces the number of pointers for each step. The latter is important
for later steps.
4) out-of-line int/float error functions
Right now we have numerous copies of float/int/... error handling
elog()s. That's unnecessary. Instead add functions that issue the
error, not allowing them to be inlined. This is a small win without
jit, and a bigger win with.
5) During expression initialization, compute allocations to be in a
"relative" manner. Each allocation is tracked separately, and
primarily consists out of an 'offset' that initially starts out at
zero, and is increased by the size of each allocation.
For interpreted evaluation, all the memory for these different
allocations is allocated as part of the allocation of the ExprState
itself, following the steps[] array (which now is also
inline). During interpretation it is accessed by basically adding the
offset to a base pointer.
For JIT compiled interpetation the memory is allocated using LLVM's
alloca instruction, which llvm can optimize into SSA form (using the
Mem2Reg or SROA passes). In combination with operator inlining that
enables LLVM to optimize PG function calls away entirely, even
performing common subexpression elimination in some cases.
There's also a few changes that are mainly done as prerequisites:
A) expression eval: Decouple PARAM_CALLBACK interface more strongly from execExpr.c
otherwise too many implementation details are exposed
B) expression eval: Improve ArrayCoerce evaluation implementation.
the recursive evaluation with memory from both the outer and inner
expression step being referenced at the same time makes improvements
harder. And it's not particularly fast either.
C) executor: Move per-call information for aggregates out of AggState.
Right now AggState has elements that we set for each transition
function invocation. That's not particularly fast, requires more
bookkeeping, and is harder for compilers to optimize. Instead
introduce a new AggStatePerCallContext that's passed for each
transition invocation via FunctionCallInfo->context.
D) Add "builder" state objects for ExecInitExpr() and
llvm_compile_expr(). That makes it easier to pass more state around,
and have different representations for the expression currently being
built, and once ready. Also makes it more realistic to break up
llvm_compile_expr() into smaller functions.
E) Improving the naming of JITed basic blocks, including the textual
ExprEvalOp value. Makes it a lot easier to understand the generated
code. Should be used to add a function for some minimal printing of
ExprStates.
F) Add minimal (and very hacky) DWARF output for the JITed
programs. That's useful for debugging, but more importantly makes it
a lot easier to interpret perf profiles.
The patchset leaves a lot of further optimization potential for better
code generation on the floor, but this seems a good enough intermediate
point. The generated code is not *quite* cachable yet,
FunctionCallInfo->{flinfo, context} still point to a pointer constant. I
think this can be solved in the same way as the rest, I just didn't get
to it yet.
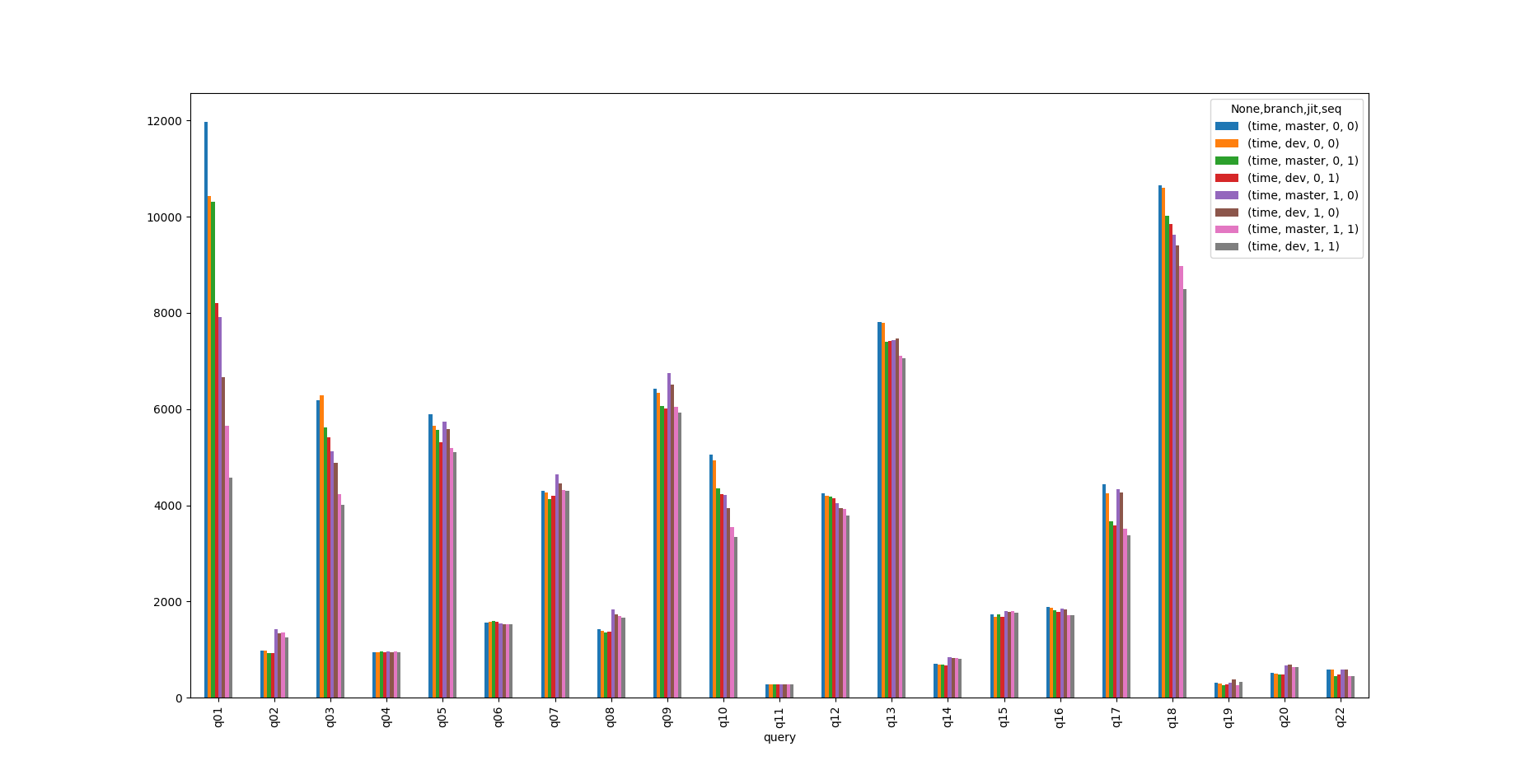
Attached is a graph of tpch query times. branch=master/dev is master
(with just the seqscan patch applied), jit=0/1 is jit enabled or not,
seq=0/1 is whether faster seqscan ordering is enabled or not.
This is just tpch, with scale factor 5, on my laptop. I.e. not to be
taken too serious. I've started a scale 10, but I'm not going to wait
for the results.
Obviously the results are nice for some queries, and meh for others.
For Q01 we get:
time time time time time time time time
branch master dev master dev master dev master dev
jit 0 0 0 0 1 1 1 1
seq 0 0 1 1 0 0 1 1
query
q01 11965.224 10434.316 10309.404 8205.922 7918.81 6661.359 5653.64 4573.794
Which imo is pretty nice. And that's with quite some pessimizations in
the code, without those (which can be removed with just a bit of elbow
grease), the benefit is noticably bigger.
FWIW, for q01 the profile after these changes is:
- 94.29% 2.16% postgres postgres [.] ExecAgg
- 98.97% ExecAgg
- 35.61% lookup_hash_entries
- 95.08% LookupTupleHashEntry
- 60.44% TupleHashTableHash.isra.0
- 99.91% FunctionCall1Coll
+ hashchar
+ 23.34% evalexpr_0_4
+ 11.67% ExecStoreMinimalTuple
+ 4.49% MemoryContextReset
3.64% tts_minimal_clear
1.22% ExecStoreVirtualTuple
+ 34.17% evalexpr_0_7
- 29.38% fetch_input_tuple
- 99.98% ExecSeqScanQual
- 58.15% heap_getnextslot
- 72.70% heapgettup_pagemode
- 99.25% heapgetpage
+ 79.08% ReadBufferExtended
+ 7.08% LockBuffer
+ 6.78% CheckForSerializableConflictOut
+ 3.26% UnpinBuffer.constprop.0
+ 1.94% heap_page_prune_opt
1.80% ReleaseBuffer
+ 0.66% ss_report_location
+ 27.22% ExecStoreBufferHeapTuple
+ 33.00% evalexpr_0_0
+ 5.16% ExecRunCompiledExpr
+ 3.65% MemoryContextReset
+ 0.84% MemoryContextReset
I.e. we spend a significant fraction of the time doing hash computations
(TupleHashTableHash, which is implemented very inefficiently), hash
equality checks (evalexpr_0_4, which is inefficiently done because we do
not cary NOT NULL upwards), the aggregate transition (evalexpr_0_7, now most
bottlenecked by float8_combine()), and fetching/filtering the tuple
(with buffer lookups taking the majority of the time, followed by qual
evaluation (evalexpr_0_0)).
Greetings,
Andres Freund
Вложения
- compare.png
- v2-0001-WIP-GUC-for-enabling-heap-seqscans-to-scan-pages-.patch.gz
- v2-0002-WIP-jit-makefile-improvements.patch.gz
- v2-0003-jit-Minor-code-cleanups.patch.gz
- v2-0004-expression-eval-Minor-code-cleanups.patch.gz
- v2-0005-expression-eval-Don-t-redundantly-keep-track-of-A.patch.gz
- v2-0006-jit-Reference-functions-by-name-in-IOCOERCE-steps.patch.gz
- v2-0007-jit-Don-t-unnecessarily-build-constant-pointer-wh.patch.gz
- v2-0008-expression-eval-Reduce-number-of-operations-for-a.patch.gz
- v2-0009-WIP-expression-eval-Keep-only-necessary-data-in-f.patch.gz
- v2-0010-expression-eval-Add-additional-fast-path-expressi.patch.gz
- v2-0011-WIP-expression-eval-Decouple-PARAM_CALLBACK-inter.patch.gz
- v2-0012-WIP-expression-eval-Improve-ArrayCoerce-evaluatio.patch.gz
- v2-0013-executor-Move-per-call-information-for-aggregates.patch.gz
- v2-0014-WIP-allow-pg_detoast_datum-to-be-inlined.patch.gz
- v2-0015-WIP-jit-increase-inlining-budget.patch.gz
- v2-0016-WIP-Use-NullableDatum-for-slots-and-expression-ev.patch.gz
- v2-0017-WIP-expression-eval-ExprStateBuilder.patch.gz
- v2-0018-WIP-expression-eval-Move-ExprState-into-execExpr..patch.gz
- v2-0019-WIP-out-of-line-int-float-error-functions.patch.gz
- v2-0020-WIP-expression-eval-Add-ExprOpToString.patch.gz
- v2-0021-WIP-jit-Add-ExprCompileState.patch.gz
- v2-0022-WIP-jit-improve-basic-block-naming.patch.gz
- v2-0023-WIP-jit-noalias.patch.gz
- v2-0024-WIP-jit-Use-ExprCompileState-more-widely.patch.gz
- v2-0025-WIP-jit-debuginfo.patch.gz
- v2-0026-WIP-expression-eval-relative-pointer-suppport.patch.gz
- v2-0027-WIP-jit-Initialize-functions-with-local-target-in.patch.gz
- v2-0028-WIP-jit-add-a-few-additional-noinline-markers.patch.gz
- v2-0029-jit-initialization-improvements.patch.gz
- v2-0030-WIP-faster-isinf-check.patch.gz
- v2-0031-executor-replace-most-of-ExecScan-with-custom-rou.patch.gz
{kind=link}
Hey Andres,
After looking at
v2-0006-jit-Reference-functions-by-name-in-IOCOERCE-steps.patch, I was wondering
about other places in the code where we have const pointers to functions outside
LLVM's purview: specially EEOP_FUNCEXPR* for any function call expressions,
EEOP_DISTINCT and EEOP_NULLIF which involve operator specific comparison
function call invocations, deserialization and trans functions for aggregates
etc. All of the above cases involve to some degree some server functions that
can be inlined/optimized.
If we do go down this road, the most immediate solution that comes to mind would
be to populate referenced_functions[] with these. Also, we can replace all
l_ptr_const() calls taking function addresses with calls to
llvm_function_reference() (this is safe as it falls back to a l_pt_const()
call). We could do the l_ptr_const() -> llvm_function_reference() even if we
don't go down this road.
One con with the approach above would be bloating of llvmjit_types.bc but we
would be introducing @declares instead of @defines in the IR...so I think that
is fine.
Let me know your thoughts. I would like to submit a patch here in this thread or
elsewhere.
--
Soumyadeep
After looking at
v2-0006-jit-Reference-functions-by-name-in-IOCOERCE-steps.patch, I was wondering
about other places in the code where we have const pointers to functions outside
LLVM's purview: specially EEOP_FUNCEXPR* for any function call expressions,
EEOP_DISTINCT and EEOP_NULLIF which involve operator specific comparison
function call invocations, deserialization and trans functions for aggregates
etc. All of the above cases involve to some degree some server functions that
can be inlined/optimized.
If we do go down this road, the most immediate solution that comes to mind would
be to populate referenced_functions[] with these. Also, we can replace all
l_ptr_const() calls taking function addresses with calls to
llvm_function_reference() (this is safe as it falls back to a l_pt_const()
call). We could do the l_ptr_const() -> llvm_function_reference() even if we
don't go down this road.
One con with the approach above would be bloating of llvmjit_types.bc but we
would be introducing @declares instead of @defines in the IR...so I think that
is fine.
Let me know your thoughts. I would like to submit a patch here in this thread or
elsewhere.
--
Soumyadeep
Hi, On 2019-10-24 14:59:21 -0700, Soumyadeep Chakraborty wrote: > After looking at > v2-0006-jit-Reference-functions-by-name-in-IOCOERCE-steps.patch, I was > wondering > about other places in the code where we have const pointers to functions > outside > LLVM's purview: specially EEOP_FUNCEXPR* for any function call expressions, > EEOP_DISTINCT and EEOP_NULLIF which involve operator specific comparison > function call invocations, deserialization and trans functions for > aggregates > etc. All of the above cases involve to some degree some server functions > that > can be inlined/optimized. I don't think there's other cases like this, except when we don't have a symbol name. In the normal course that's "just" EEOP_PARAM_CALLBACK IIRC. For EEOP_PARAM_CALLBACK one solution would be to not use a callback specified by pointer, but instead use an SQL level function taking an INTERNAL parameter (to avoid it being called via SQL). There's also a related edge-case where are unable to figure out a symbol name in llvm_function_reference(), and then resort to creating a global variable pointing to the function. This is a somewhat rare case (IIRC it's mostly if not solely around language PL handlers), so I don't think it matters *too* much. We probably should change that to not initialize the global, and instead resolve the symbol during link time. As long as we generate a symbol name that llvm_resolve_symbol() can somehow resolve, we'd be good. I was a bit wary of doing syscache lookups from within llvm_resolve_symbol(), otherwise we could just look look up the function address from within there. So if we went this route I'd probably go for a hashtable of additional symbol resolutions, which llvm_resolve_symbol() would consult. If indeed the only case this is being hit is language PL handlers, it might be better to instead work out the symbol name for that handler - we should be able to get that via pg_language.lanplcallfoid. > If we do go down this road, the most immediate solution that comes to mind > would > be to populate referenced_functions[] with these. Also, we can replace all > l_ptr_const() calls taking function addresses with calls to > llvm_function_reference() (this is safe as it falls back to a l_pt_const() > call). We could do the l_ptr_const() -> llvm_function_reference() even if we > don't go down this road. Which cases are you talking about here? Because I don't think there's any others where would know a symbol name to add to referenced_functions in the first place? I'm also not quite clear what adding to referenced_functions would buy us wrt constants. The benefit of adding a function there is that we get the correct signature of the function, which makes it much harder to accidentally screw up and call with the wrong signature. I don't think there's any benefits around symbol names? I do want to benefit from getting accurate signatures for patch [PATCH v2 26/32] WIP: expression eval: relative pointer suppport I had a number of cases where I passed the wrong parameters, and llvm couldn't tell me... Greetings, Andres Freund
On 10/23/19 6:38 PM, Andres Freund wrote: > In the attached *prototype* patch series there's a lot of incremental > improvements (and some cleanups) (in time, not importance order): You may already know this but your patch set seems to require clang 9. I get the below compilation error which is probably cause by https://github.com/llvm/llvm-project/commit/90868bb0584f first being committed for clang 9 (I run "clang version 7.0.1-8 (tags/RELEASE_701/final)"). In file included from gistutil.c:24: ../../../../src/include/utils/float.h:103:7: error: invalid output constraint '=@ccae' in asm : "=@ccae"(ret), [clobber_reg]"=&x"(clobber_reg) ^ 1 error generated.
Hi, On 2019-10-25 00:43:37 +0200, Andreas Karlsson wrote: > On 10/23/19 6:38 PM, Andres Freund wrote: > > In the attached *prototype* patch series there's a lot of incremental > > improvements (and some cleanups) (in time, not importance order): > > You may already know this but your patch set seems to require clang 9. I didn't, so thanks! > I get the below compilation error which is probably cause by > https://github.com/llvm/llvm-project/commit/90868bb0584f first being > committed for clang 9 (I run "clang version 7.0.1-8 > (tags/RELEASE_701/final)"). > > In file included from gistutil.c:24: > ../../../../src/include/utils/float.h:103:7: error: invalid output > constraint '=@ccae' in asm > : "=@ccae"(ret), [clobber_reg]"=&x"(clobber_reg) > ^ > 1 error generated. I'll probably just drop this patch for now, it's not directly related. I kind of wanted it on the list, so I have I place I can find it if I forget :). I think what really needs to happen instead is to improve the code generated for __builtin_isinf[_sign]() by gcc/clang. They should proce the constants like I did, instead of loading from the constant pool every single time. That adds a fair bit of latency... Greetings, Andres Freund
Hi Andres,
Apologies, I realize my understanding of symbol resolution and the
referenced_functions mechanism wasn't correct. Thank you for your very helpful
explanations.
> There's also a related edge-case where are unable to figure out a symbol
> name in llvm_function_reference(), and then resort to creating a global
> variable pointing to the function.
Indeed.
> If indeed the only case this is being hit is language PL handlers, it
> might be better to instead work out the symbol name for that handler -
> we should be able to get that via pg_language.lanplcallfoid.
I took a stab at this (on top of your patch set):
v1-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch
> Which cases are you talking about here? Because I don't think there's
> any others where would know a symbol name to add to referenced_functions
> in the first place?
I had misunderstood the intent of referenced_functions.
> I do want to benefit from getting accurate signatures for patch
> [PATCH v2 26/32] WIP: expression eval: relative pointer suppport
> I had a number of cases where I passed the wrong parameters, and llvm
> couldn't tell me...
Apologies, I realize my understanding of symbol resolution and the
referenced_functions mechanism wasn't correct. Thank you for your very helpful
explanations.
> There's also a related edge-case where are unable to figure out a symbol
> name in llvm_function_reference(), and then resort to creating a global
> variable pointing to the function.
Indeed.
> If indeed the only case this is being hit is language PL handlers, it
> might be better to instead work out the symbol name for that handler -
> we should be able to get that via pg_language.lanplcallfoid.
I took a stab at this (on top of your patch set):
v1-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch
> Which cases are you talking about here? Because I don't think there's
> any others where would know a symbol name to add to referenced_functions
> in the first place?
I had misunderstood the intent of referenced_functions.
> I do want to benefit from getting accurate signatures for patch
> [PATCH v2 26/32] WIP: expression eval: relative pointer suppport
> I had a number of cases where I passed the wrong parameters, and llvm
> couldn't tell me...
I took a stab:
v1-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch
On a separate note, I had submitted a patch earlier to optimize functions earlier
in accordance to the code comment:
/*
* Do function level optimization. This could be moved to the point where
* functions are emitted, to reduce memory usage a bit.
*/
LLVMInitializeFunctionPassManager(llvm_fpm);
Refer:
https://www.postgresql.org/message-id/flat/CAE-ML+_OE4-sHvn0AA_qakc5qkZvQvainxwb1ztuuT67SPMegw@mail.gmail.com
I have rebased that patch on top of your patch set. Here it is:
v2-0001-Optimize-generated-functions-earlier-to-lower-mem.patch
--
Soumyadeep
v1-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch
On a separate note, I had submitted a patch earlier to optimize functions earlier
in accordance to the code comment:
/*
* Do function level optimization. This could be moved to the point where
* functions are emitted, to reduce memory usage a bit.
*/
LLVMInitializeFunctionPassManager(llvm_fpm);
Refer:
https://www.postgresql.org/message-id/flat/CAE-ML+_OE4-sHvn0AA_qakc5qkZvQvainxwb1ztuuT67SPMegw@mail.gmail.com
I have rebased that patch on top of your patch set. Here it is:
v2-0001-Optimize-generated-functions-earlier-to-lower-mem.patch
--
Soumyadeep
Вложения
Hi, On 2019-10-27 23:46:22 -0700, Soumyadeep Chakraborty wrote: > Apologies, I realize my understanding of symbol resolution and the > referenced_functions mechanism wasn't correct. Thank you for your very > helpful > explanations. No worries! I was just wondering whether I was misunderstanding you. > > If indeed the only case this is being hit is language PL handlers, it > > might be better to instead work out the symbol name for that handler - > > we should be able to get that via pg_language.lanplcallfoid. > > I took a stab at this (on top of your patch set): > v1-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch I think I'd probably try to apply this to master independent of the larger patchset, to avoid a large dependency. > From 07c7ff996706c6f71e00d76894845c1f87956472 Mon Sep 17 00:00:00 2001 > From: soumyadeep2007 <sochakraborty@pivotal.io> > Date: Sun, 27 Oct 2019 17:42:53 -0700 > Subject: [PATCH v1] Resolve PL handler names for JITed code instead of using > const pointers > > Using const pointers to PL handler functions prevents optimization > opportunities in JITed code. Now fmgr_symbol() resolves PL function > references to the corresponding language's handler. > llvm_function_reference() now no longer needs to create the global to > such a function. Did you check whether there's any cases this fails in the tree with your patch applied? The way I usually do that is by running the regression tests like PGOPTIONS='-cjit_above_cost=0' make -s -Otarget check-world (which will take a bit longer if use an optimized LLVM build, and a *lot* longer if you use a debug llvm build) > Discussion: https://postgr.es/m/20191024224303.jvdx3hq3ak2vbit3%40alap3.anarazel.de:wq > --- > src/backend/jit/llvm/llvmjit.c | 29 +++-------------------------- > src/backend/utils/fmgr/fmgr.c | 30 +++++++++++++++++++++++------- > 2 files changed, 26 insertions(+), 33 deletions(-) > > diff --git a/src/backend/jit/llvm/llvmjit.c b/src/backend/jit/llvm/llvmjit.c > index 82c4afb701..69a4167ac9 100644 > --- a/src/backend/jit/llvm/llvmjit.c > +++ b/src/backend/jit/llvm/llvmjit.c > @@ -369,38 +369,15 @@ llvm_function_reference(LLVMJitContext *context, > > fmgr_symbol(fcinfo->flinfo->fn_oid, &modname, &basename); > > - if (modname != NULL && basename != NULL) > + if (modname != NULL) > { > /* external function in loadable library */ > funcname = psprintf("pgextern.%s.%s", modname, basename); > } > - else if (basename != NULL) > - { > - /* internal function */ > - funcname = psprintf("%s", basename); > - } > else > { > - /* > - * Function we don't know to handle, return pointer. We do so by > - * creating a global constant containing a pointer to the function. > - * Makes IR more readable. > - */ > - LLVMValueRef v_fn_addr; > - > - funcname = psprintf("pgoidextern.%u", > - fcinfo->flinfo->fn_oid); > - v_fn = LLVMGetNamedGlobal(mod, funcname); > - if (v_fn != 0) > - return LLVMBuildLoad(builder, v_fn, ""); > - > - v_fn_addr = l_ptr_const(fcinfo->flinfo->fn_addr, TypePGFunction); > - > - v_fn = LLVMAddGlobal(mod, TypePGFunction, funcname); > - LLVMSetInitializer(v_fn, v_fn_addr); > - LLVMSetGlobalConstant(v_fn, true); > - > - return LLVMBuildLoad(builder, v_fn, ""); > + /* internal function or a PL handler */ > + funcname = psprintf("%s", basename); > } Hm. Aren't you breaking things here? If fmgr_symbol returns a basename of NULL, as is the case for all internal functions, you're going to print a NULL pointer, no? > /* check if function already has been added */ > diff --git a/src/backend/utils/fmgr/fmgr.c b/src/backend/utils/fmgr/fmgr.c > index 099ebd779b..71398bb3c1 100644 > --- a/src/backend/utils/fmgr/fmgr.c > +++ b/src/backend/utils/fmgr/fmgr.c > @@ -265,11 +265,9 @@ fmgr_info_cxt_security(Oid functionId, FmgrInfo *finfo, MemoryContext mcxt, > /* > * Return module and C function name providing implementation of functionId. > * > - * If *mod == NULL and *fn == NULL, no C symbol is known to implement > - * function. > - * > * If *mod == NULL and *fn != NULL, the function is implemented by a symbol in > - * the main binary. > + * the main binary. If the function being looked up is not a C language > + * function, it's language handler name is returned. > * > * If *mod != NULL and *fn !=NULL the function is implemented in an extension > * shared object. > @@ -285,6 +283,11 @@ fmgr_symbol(Oid functionId, char **mod, char **fn) > bool isnull; > Datum prosrcattr; > Datum probinattr; > + Oid language; > + HeapTuple languageTuple; > + Form_pg_language languageStruct; > + HeapTuple plHandlerProcedureTuple; > + Form_pg_proc plHandlerProcedureStruct; > > /* Otherwise we need the pg_proc entry */ > procedureTuple = SearchSysCache1(PROCOID, ObjectIdGetDatum(functionId)); > @@ -304,8 +307,9 @@ fmgr_symbol(Oid functionId, char **mod, char **fn) > return; > } > > + language = procedureStruct->prolang; > /* see fmgr_info_cxt_security for the individual cases */ > - switch (procedureStruct->prolang) > + switch (language) > { > case INTERNALlanguageId: > prosrcattr = SysCacheGetAttr(PROCOID, procedureTuple, > @@ -342,9 +346,21 @@ fmgr_symbol(Oid functionId, char **mod, char **fn) > break; > > default: > + languageTuple = SearchSysCache1(LANGOID, > + ObjectIdGetDatum(language)); > + if (!HeapTupleIsValid(languageTuple)) > + elog(ERROR, "cache lookup failed for language %u", language); > + languageStruct = (Form_pg_language) GETSTRUCT(languageTuple); > + plHandlerProcedureTuple = SearchSysCache1(PROCOID, > + ObjectIdGetDatum( > + languageStruct->lanplcallfoid)); > + if (!HeapTupleIsValid(plHandlerProcedureTuple)) > + elog(ERROR, "cache lookup failed for function %u", functionId); > + plHandlerProcedureStruct = (Form_pg_proc) GETSTRUCT(plHandlerProcedureTuple); > *mod = NULL; > - *fn = NULL; /* unknown, pass pointer */ > - break; > + *fn = pstrdup(NameStr(plHandlerProcedureStruct->proname)); > + ReleaseSysCache(languageTuple); > + ReleaseSysCache(plHandlerProcedureTuple); > } > > I do want to benefit from getting accurate signatures for patch > > [PATCH v2 26/32] WIP: expression eval: relative pointer suppport > > I had a number of cases where I passed the wrong parameters, and llvm > > couldn't tell me... > > I took a stab: > v1-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch Cool! I'll probably merge that into my patch (with attribution of course). I wonder if it'd nicer to not have separate C variables for all of these, and instead look them up on-demand from the module loaded in llvm_create_types(). Not sure. > On a separate note, I had submitted a patch earlier to optimize functions > earlier > in accordance to the code comment: > /* > * Do function level optimization. This could be moved to the point where > * functions are emitted, to reduce memory usage a bit. > */ > LLVMInitializeFunctionPassManager(llvm_fpm); > Refer: > https://www.postgresql.org/message-id/flat/CAE-ML+_OE4-sHvn0AA_qakc5qkZvQvainxwb1ztuuT67SPMegw@mail.gmail.com > I have rebased that patch on top of your patch set. Here it is: > v2-0001-Optimize-generated-functions-earlier-to-lower-mem.patch Sorry for not replying to that earlier. I'm not quite sure it's actually worthwhile doing so - did you try to measure any memory / cpu savings? The magnitude of wins aside, I also have a local patch that I'm going to try to publish this or next week, that deduplicates functions more aggressively, mostly to avoid redundant optimizations. It's quite possible that we should run that before the function passes - or even give up entirely on the function pass optimizations. As the module pass manager does the same optimizations it's not that clear in which cases it'd be beneficial to run it, especially if it means we can't deduplicate before optimizations. Greetings, Andres Freund
Hi Andres,
> I think I'd probably try to apply this to master independent of the
> larger patchset, to avoid a large dependency.
Awesome! +1. Attached 2nd version of patch rebased on master.
(v2-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch)
> Did you check whether there's any cases this fails in the tree with your
> patch applied? The way I usually do that is by running the regression
> tests like
> PGOPTIONS='-cjit_above_cost=0' make -s -Otarget check-world
>
> (which will take a bit longer if use an optimized LLVM build, and a
> *lot* longer if you use a debug llvm build)
Great suggestion! I used:
PGOPTIONS='-c jit_above_cost=0' gmake installcheck-world
It all passed except a couple of logical decoding tests that never pass
on my machine for any tree (t/006_logical_decoding.pl and
t/010_logical_decoding_timelines.pl) and point (which seems to be failing even
on master as of: d80be6f2f) I have attached the regression.diffs which captures
the point failure.
> Hm. Aren't you breaking things here? If fmgr_symbol returns a basename
> of NULL, as is the case for all internal functions, you're going to
> print a NULL pointer, no?
For internal functions, it is supposed to return modname = NULL but basename
will be non-NULL right? As things stand, fmgr_symbol can never return a null
basename. I have added an Assert to make that even more explicit.
> Cool! I'll probably merge that into my patch (with attribution of
> course).
>
> I wonder if it'd nicer to not have separate C variables for all of
> these, and instead look them up on-demand from the module loaded in
> llvm_create_types(). Not sure.
Great! It is much nicer indeed. Attached version 2 with your suggested changes.
(v2-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch)
Used the same testing method as above.
> Sorry for not replying to that earlier. I'm not quite sure it's
> actually worthwhile doing so - did you try to measure any memory / cpu
> savings?
No problem, thanks for the reply! Unfortunately, I did not do anything
significant in terms of mem/cpu measurements. However, I have noticed non-trivial
differences between optimized and unoptimized .bc files that were dumped from
time to time.
> The magnitude of wins aside, I also have a local patch that I'm going to
> try to publish this or next week, that deduplicates functions more
> aggressively, mostly to avoid redundant optimizations. It's quite
> possible that we should run that before the function passes - or even
> give up entirely on the function pass optimizations. As the module pass
> manager does the same optimizations it's not that clear in which cases
> it'd be beneficial to run it, especially if it means we can't
> deduplicate before optimizations.
Agreed, excited to see the patch!
--
Soumyadeep
> I think I'd probably try to apply this to master independent of the
> larger patchset, to avoid a large dependency.
Awesome! +1. Attached 2nd version of patch rebased on master.
(v2-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch)
> Did you check whether there's any cases this fails in the tree with your
> patch applied? The way I usually do that is by running the regression
> tests like
> PGOPTIONS='-cjit_above_cost=0' make -s -Otarget check-world
>
> (which will take a bit longer if use an optimized LLVM build, and a
> *lot* longer if you use a debug llvm build)
Great suggestion! I used:
PGOPTIONS='-c jit_above_cost=0' gmake installcheck-world
It all passed except a couple of logical decoding tests that never pass
on my machine for any tree (t/006_logical_decoding.pl and
t/010_logical_decoding_timelines.pl) and point (which seems to be failing even
on master as of: d80be6f2f) I have attached the regression.diffs which captures
the point failure.
> Hm. Aren't you breaking things here? If fmgr_symbol returns a basename
> of NULL, as is the case for all internal functions, you're going to
> print a NULL pointer, no?
For internal functions, it is supposed to return modname = NULL but basename
will be non-NULL right? As things stand, fmgr_symbol can never return a null
basename. I have added an Assert to make that even more explicit.
> Cool! I'll probably merge that into my patch (with attribution of
> course).
>
> I wonder if it'd nicer to not have separate C variables for all of
> these, and instead look them up on-demand from the module loaded in
> llvm_create_types(). Not sure.
Great! It is much nicer indeed. Attached version 2 with your suggested changes.
(v2-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch)
Used the same testing method as above.
> Sorry for not replying to that earlier. I'm not quite sure it's
> actually worthwhile doing so - did you try to measure any memory / cpu
> savings?
No problem, thanks for the reply! Unfortunately, I did not do anything
significant in terms of mem/cpu measurements. However, I have noticed non-trivial
differences between optimized and unoptimized .bc files that were dumped from
time to time.
> The magnitude of wins aside, I also have a local patch that I'm going to
> try to publish this or next week, that deduplicates functions more
> aggressively, mostly to avoid redundant optimizations. It's quite
> possible that we should run that before the function passes - or even
> give up entirely on the function pass optimizations. As the module pass
> manager does the same optimizations it's not that clear in which cases
> it'd be beneficial to run it, especially if it means we can't
> deduplicate before optimizations.
Agreed, excited to see the patch!
--
Soumyadeep
Вложения
Hi, On 2019-10-28 23:58:11 -0700, Soumyadeep Chakraborty wrote: > > Cool! I'll probably merge that into my patch (with attribution of > > course). > > > > I wonder if it'd nicer to not have separate C variables for all of > > these, and instead look them up on-demand from the module loaded in > > llvm_create_types(). Not sure. > > Great! It is much nicer indeed. Attached version 2 with your suggested > changes. > (v2-0001-Rely-on-llvmjit_types-for-building-EvalFunc-calls.patch) > Used the same testing method as above. I've comitted a (somewhat evolved) version of this patch. I think it really improves the code! My changes largely were to get rid of the LLVMGetNamedFunction() added to each opcode implementation, to also convert the ExecEval* functions we were calling directly, to remove the other functions in llvmjit.h, and finally to rebase it onto master, from the patch series in this thread. I do wonder about adding a variadic wrapper like the one introduced here more widely, seems like it could simplify a number of places. If we then redirected all function calls through a common wrapper, for LLVMBuildCall, that also validated parameter count (and perhaps types), I think it'd be easier to develop... Thanks! Andres
Hi, On 2019-10-28 23:58:11 -0700, Soumyadeep Chakraborty wrote: > > Sorry for not replying to that earlier. I'm not quite sure it's > > actually worthwhile doing so - did you try to measure any memory / cpu > > savings? > > No problem, thanks for the reply! Unfortunately, I did not do anything > significant in terms of mem/cpu measurements. However, I have noticed > non-trivial differences between optimized and unoptimized .bc files > that were dumped from time to time. Could you expand on what you mean here? Are you saying that you got significantly better optimization results by doing function optimization early on? That'd be surprising imo? Greetings, Andres Freund
Hi Andres,
> I've comitted a (somewhat evolved) version of this patch. I think it
> really improves the code!Awesome! Thanks for taking it forward!
> I do wonder about adding a variadic wrapper like the one introduced here
> more widely, seems like it could simplify a number of places. If we then
> redirected all function calls through a common wrapper, for LLVMBuildCall,
> that also validated parameter count (and perhaps types), I think it'd be
> easier to develop...
> more widely, seems like it could simplify a number of places. If we then
> redirected all function calls through a common wrapper, for LLVMBuildCall,
> that also validated parameter count (and perhaps types), I think it'd be
> easier to develop...
+1. I was wondering whether such validations should be Asserts instead of
ERRORs.
Regards,
Soumyadeep Chakraborty
Senior Software Engineer
Pivotal Greenplum
Palo Alto
On Thu, Feb 6, 2020 at 10:35 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2019-10-28 23:58:11 -0700, Soumyadeep Chakraborty wrote:
> > Sorry for not replying to that earlier. I'm not quite sure it's
> > actually worthwhile doing so - did you try to measure any memory / cpu
> > savings?
>
> No problem, thanks for the reply! Unfortunately, I did not do anything
> significant in terms of mem/cpu measurements. However, I have noticed
> non-trivial differences between optimized and unoptimized .bc files
> that were dumped from time to time.
Could you expand on what you mean here? Are you saying that you got
significantly better optimization results by doing function optimization
early on? That'd be surprising imo?
Greetings,
Andres Freund
Hi Andres,
> early on? That'd be surprising imo?
if (jit_dump_bitcode)
{
char *filename;
filename = psprintf("%u.%zu.bc",
MyProcPid,
context->module_generation);
LLVMWriteBitcodeToFile(context->module, filename);
pfree(filename);
}
> Could you expand on what you mean here? Are you saying that you got
> significantly better optimization results by doing function optimization> early on? That'd be surprising imo?
Sorry for the ambiguity, I meant that I had observed differences in the sizes
of the bitcode files dumped.
These are the size differences that I observed (for TPCH Q1):
Without my patch:
-rw------- 1 pivotal staff 278K Feb 9 11:59 1021.0.bc
-rw------- 1 pivotal staff 249K Feb 9 11:59 1374.0.bc
-rw------- 1 pivotal staff 249K Feb 9 11:59 1375.0.bc
-rw------- 1 pivotal staff 249K Feb 9 11:59 1374.0.bc
-rw------- 1 pivotal staff 249K Feb 9 11:59 1375.0.bc
With my patch:
-rw------- 1 pivotal staff 245K Feb 9 11:43 88514.0.bc
-rw------- 1 pivotal staff 245K Feb 9 11:43 88515.0.bc
-rw------- 1 pivotal staff 270K Feb 9 11:43 79323.0.bc
-rw------- 1 pivotal staff 245K Feb 9 11:43 88515.0.bc
-rw------- 1 pivotal staff 270K Feb 9 11:43 79323.0.bc
This means that the sizes of the module when execution encountered:
{
char *filename;
filename = psprintf("%u.%zu.bc",
MyProcPid,
context->module_generation);
LLVMWriteBitcodeToFile(context->module, filename);
pfree(filename);
}
were smaller with my patch applied. This means there is less memory
pressure between when the functions were built and when
llvm_compile_module() is called. I don't know if the difference is practically
significant.
Soumyadeep
Hey Andres,
> Awesome! +1. Attached 2nd version of patch rebased on master.
> (v2-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch)
>
>
>
> > Did you check whether there's any cases this fails in the tree with your
> > patch applied? The way I usually do that is by running the regression
> > tests like
> > PGOPTIONS='-cjit_above_cost=0' make -s -Otarget check-world
> >
> > (which will take a bit longer if use an optimized LLVM build, and a
> > *lot* longer if you use a debug llvm build)
>
>
>
> Great suggestion! I used:
> PGOPTIONS='-c jit_above_cost=0' gmake installcheck-world
> It all passed except a couple of logical decoding tests that never pass
> on my machine for any tree (t/006_logical_decoding.pl and
> t/010_logical_decoding_timelines.pl) and point (which seems to be failing
> even
> on master as of: d80be6f2f) I have attached the regression.diffs which
> captures
> the point failure.
I have attached the 3rd version of the patch rebased on master. I made one
slight modification to the previous patch. PL handlers, such as that of plsh,
can be in an external library. So I account for that in modname (earlier
naively I set it to NULL). There are also some minor changes to the comments
and I have rehashed the commit message.
Apart from running the regress tests as you suggested above, I installed plsh
and forced JIT on the following:
CREATE FUNCTION query_plsh (x int) RETURNS text
LANGUAGE plsh
AS $$
#!/bin/sh
psql -At -c "select 1"
$$;
> Awesome! +1. Attached 2nd version of patch rebased on master.
> (v2-0001-Resolve-PL-handler-names-for-JITed-code-instead-o.patch)
>
>
>
> > Did you check whether there's any cases this fails in the tree with your
> > patch applied? The way I usually do that is by running the regression
> > tests like
> > PGOPTIONS='-cjit_above_cost=0' make -s -Otarget check-world
> >
> > (which will take a bit longer if use an optimized LLVM build, and a
> > *lot* longer if you use a debug llvm build)
>
>
>
> Great suggestion! I used:
> PGOPTIONS='-c jit_above_cost=0' gmake installcheck-world
> It all passed except a couple of logical decoding tests that never pass
> on my machine for any tree (t/006_logical_decoding.pl and
> t/010_logical_decoding_timelines.pl) and point (which seems to be failing
> even
> on master as of: d80be6f2f) I have attached the regression.diffs which
> captures
> the point failure.
I have attached the 3rd version of the patch rebased on master. I made one
slight modification to the previous patch. PL handlers, such as that of plsh,
can be in an external library. So I account for that in modname (earlier
naively I set it to NULL). There are also some minor changes to the comments
and I have rehashed the commit message.
Apart from running the regress tests as you suggested above, I installed plsh
and forced JIT on the following:
CREATE FUNCTION query_plsh (x int) RETURNS text
LANGUAGE plsh
AS $$
#!/bin/sh
psql -At -c "select 1"
$$;
SELECT query_plsh(5);
and I also ran plsh's make installcheck with jit_above_cost = 0. Everything
looks good. I think this is ready for another round of review. Thanks!!
Soumyadeep
and I also ran plsh's make installcheck with jit_above_cost = 0. Everything
looks good. I think this is ready for another round of review. Thanks!!
Soumyadeep
Вложения
Hello Andres,
Attached is a patch on top of
v2-0026-WIP-expression-eval-relative-pointer-suppport.patch that eliminates the
const pointer references to fmgrInfo in the generated code.
FmgrInfos are now allocated like the FunctionCallInfos are
(ExprBuilderAllocFunctionMgrInfo()) and are initialized with expr_init_fmgri().
Unfortunately, inside expr_init_fmgri(), I had to emit const pointers to set
fn_addr, fn_extra, fn_mcxt and fn_expr.
fn_addr, fn_mcxt should always be the same const pointer value in between two identical
calls. So this isn't too bad?
fn_extra is NULL most of the time. So not too bad?
fn_expr is very difficult to eliminate because it is allocated way earlier. Is
it something that will have a const pointer value in between two identical
calls? (don't know enough about plan caching..I ran the same query twice and it
seemed to have different pointer values). Eliminating this pointer poses
a similar challenge to that of FunctionCallInfo->context. fn_expr is allocated
quite early on. I had tried writing ExprBuilderAllocNode() to handle the context
field. The trouble with writing something like expr_init_node() or something
even more specific like expr_init_percall() (for the percall context for aggs)
as these structs have lots of pointer references to further pointers and so on
-> so eventually we would have to emit some const pointers.
One naive way to handle this problem may be to emit a call to the _copy*()
functions inside expr_init_node(). It wouldn't be as performant though.
We could decide to live with the const pointers even if our cache key would be
the generated code. The caching layer could be made smart enough to ignore such
pointer references OR we could feed the caching layer with generated code that
has been passed through a custom pass that normalizes all const pointer values
to some predetermined / sentinel value. To help the custom pass we could emit
some metadata when we generate a const pointer (that we know won't have the same
Attached is a patch on top of
v2-0026-WIP-expression-eval-relative-pointer-suppport.patch that eliminates the
const pointer references to fmgrInfo in the generated code.
FmgrInfos are now allocated like the FunctionCallInfos are
(ExprBuilderAllocFunctionMgrInfo()) and are initialized with expr_init_fmgri().
Unfortunately, inside expr_init_fmgri(), I had to emit const pointers to set
fn_addr, fn_extra, fn_mcxt and fn_expr.
fn_addr, fn_mcxt should always be the same const pointer value in between two identical
calls. So this isn't too bad?
fn_extra is NULL most of the time. So not too bad?
fn_expr is very difficult to eliminate because it is allocated way earlier. Is
it something that will have a const pointer value in between two identical
calls? (don't know enough about plan caching..I ran the same query twice and it
seemed to have different pointer values). Eliminating this pointer poses
a similar challenge to that of FunctionCallInfo->context. fn_expr is allocated
quite early on. I had tried writing ExprBuilderAllocNode() to handle the context
field. The trouble with writing something like expr_init_node() or something
even more specific like expr_init_percall() (for the percall context for aggs)
as these structs have lots of pointer references to further pointers and so on
-> so eventually we would have to emit some const pointers.
One naive way to handle this problem may be to emit a call to the _copy*()
functions inside expr_init_node(). It wouldn't be as performant though.
We could decide to live with the const pointers even if our cache key would be
the generated code. The caching layer could be made smart enough to ignore such
pointer references OR we could feed the caching layer with generated code that
has been passed through a custom pass that normalizes all const pointer values
to some predetermined / sentinel value. To help the custom pass we could emit
some metadata when we generate a const pointer (that we know won't have the same
const pointer value) to tell the pass to ignore it.
Soumyadeep
Вложения
> On 3 Mar 2020, at 21:21, Soumyadeep Chakraborty <sochakraborty@pivotal.io> wrote: > Attached is a patch on top of > v2-0026-WIP-expression-eval-relative-pointer-suppport.patch that eliminates the > const pointer references to fmgrInfo in the generated code. Since the CFBot patch tester isn't to apply and test a patchset divided across multiple emails, can you please submit the full patchset for consideration such that we can get it to run in the CI? cheers ./daniel
On Wed, Jul 01, 2020 at 02:50:14PM +0200, Daniel Gustafsson wrote: > Since the CFBot patch tester isn't to apply and test a patchset divided across > multiple emails, can you please submit the full patchset for consideration such > that we can get it to run in the CI? This thread seems to have died a couple of weeks ago, so I have marked it as RwF. -- Michael
Вложения
Andres asked me off-list for comments on 0026, so here goes.
As a general comment, I think the patches could really benefit from
more meaningful commit messages and more comments on individual
functions. It would definitely help me review, and it might help other
people review, or modify the code later. For example, I'm looking at
ExprEvalStep. If the intent here is that we don't want the union
members to point to data that might differ from one execution of the
plan to the next, it's surely important to mention that and explain to
people who are trying to add steps later what they should do instead.
But I'm also not entirely sure that's the intended rule. It kind of
surprises me that the only things that we'd be pointing to here that
would fall into that category would be a bool, a NullableDatum, a
NullableDatum array, and a FunctionCallInfo ... but I've been
surprised by a lot of things that turned out to be true.
I am not a huge fan of the various Rel[Whatever] typedefs. I am not
sure that's really adding any clarity. On the other hand I would be a
big fan of renaming the structure members in some systematic way. This
kind of thing doesn't sit well with me:
- NullableDatum *value; /* value to return */
+ RelNullableDatum value; /* value to return */
Well, if NullableDatum was the value to return, then RelNullableDatum
isn't. It's some kind of thing that lets you find the value to return.
Actually that's not really right either, because before 'value' was a
pointer to the value to return and the corresponding isnull flag, and
now it is a way of finding that stuff. I don't know exactly what to do
here to keep the comment comprehensible and not unreasonably long, but
I don't think not changing at it all is the thing. Nor do I think just
having it be called 'value' when it's clearly not the value, nor even
a pointer to the value, is as clear as I would like to be.
I wonder if ExprBuilderAllocBool ought to be using sizeof(bool) rather
than sizeof(NullableDatum).
Is it true that allocno is only used for, err, some kind of LLVM
thing, and not in the regular interpreted path? As far as I can see,
outside of the LLVM code, we only ever test whether it's 0, and don't
actually care about the specific value.
I hope that the fact that this patch reverses the order of the first
two arguments to ExecInitExprRec is only something you did to make it
so that the compiler would find places you needed to update. Because
otherwise it makes no sense to introduce a new thing called an
ExprStateBuilder in 0017, make it an argument to that function, and
then turn around and change the signature again in 0026. Anyway, a
final patch shouldn't include this kind of churn.
+ offsetof(ExprState, steps) * esb->steps_len * sizeof(ExprEvalStep) +
+ state->mutable_off = offsetof(ExprState, steps) * esb->steps_len *
sizeof(ExprEvalStep);
Well, either I'm confused here, or the first * should be a + in each
case. I wonder how this works at all.
+ /* copy in step data */
+ {
+ ListCell *lc;
+ int off = 0;
+
+ foreach(lc, esb->steps)
+ {
+ memcpy(&state->steps[off], lfirst(lc), sizeof(ExprEvalStep));
+ off++;
+ }
+ }
This seems incredibly pointless to me. Why use a List in the first
place if we're going to have to flatten it using this kind of code?
I think stuff like RelFCIOff() and RelFCIIdx() and RelArrayIdx() is
just pretty much incomprehensible. Now, the executor is full of
badly-named stuff already -- ExecInitExprRec being a fine example of a
name nobody is going to understand on first reading, or maybe ever --
but we ought to try not to make things worse. I also do understand
that anything with relative pointers is bound to involve a bunch of
crappy notation that we're just going to have to accept as the price
of doing business. But it would help to pick names that are not so
heavily abbreviated. Like, if RelFCIIdx() were called
find_function_argument_in_relative_fcinfo() or even
get_fnarg_from_relfcinfo() the casual reader might have a chance of
guessing what it does. Sure, the code might be longer, but if you can
tell what it does without cross-referencing, it's still better.
I would welcome changes that make it clearer which things happen just
once and which things happen at execution time; that said, it seems
like RELPTR_RESOLVE() happens at execution time, and it surprises me a
bit that this is OK from a performance perspective. The pointers can
change from execution to execution, but not within an individual
execution, or so I think. So it doesn't need to be resolved every
time, if somehow that can be avoided. But maybe CPUs are sufficiently
well-optimized for computing a pointer address as a+b*c that it does
not matter.
I'm not sure how helpful any of these comments are, but those are my
initial thoughts.
--
Robert Haas
EDB: http://www.enterprisedb.com
Hi, I pushed a rebased (ugh, that was painul) version of the patches to https://github.com/anarazel/postgres/tree/jit-relative-offsets Besides rebasing I dropped a few patches and did some *minor* cleanup. Besides that there's one substantial improvement, namely that I got rid of one more absolute pointer reference (in the aggregate steps). The main sources for pointers that remain is FunctionCallInfo->{flinfo, context}. There's also WindowFuncExprState->wfuncno (which isn't yet known at "expression compile time"), but that's not too hard to solve differently. On 2021-11-04 12:30:00 -0400, Robert Haas wrote: > As a general comment, I think the patches could really benefit from > more meaningful commit messages and more comments on individual > functions. It would definitely help me review, and it might help other > people review, or modify the code later. Sure. I was mostly exploring what would be necessary to to change expression evaluation so that there's no absolute pointers in it. I still haven't figured out all the necessary bits. > For example, I'm looking at ExprEvalStep. If the intent here is that we > don't want the union members to point to data that might differ from one > execution of the plan to the next, it's surely important to mention that and > explain to people who are trying to add steps later what they should do > instead. But I'm also not entirely sure that's the intended rule. It kind > of surprises me that the only things that we'd be pointing to here that > would fall into that category would be a bool, a NullableDatum, a > NullableDatum array, and a FunctionCallInfo ... but I've been surprised by a > lot of things that turned out to be true. The immediate goal is to be able to generate JITed code/LLVM-IR that doesn't contain any absolute pointer values. If the generated code doesn't change regardless of any of the other contents of ExprEvalStep, we can still cache the JIT optimization / code emission steps - which are the expensive bits. With the exception of what I listed at the top, the types that you listed really are what's needed to avoid such pointer constants. There are more contents in the steps, but either they are constants (and thus just can be embedded into the generated code), the expression step is just passed to ExecEval*, or the data can just be loaded from the ExprStep at runtime (although that makes the generated code slower). There's a "more advanced" version of this where we can avoid recreating ExprStates for e.g. prepared statements. Then we'd need to make a bit more of the data use relative pointers. But that's likely a bit further off. A more moderate version will be to just store the number of steps for expressions inside the expressions - for simple queries the allocation / growing / copying of ExprSteps is quite visible. FWIW interpreted execution does seem to win a bit from the higher density of memory allocations for variable data this provides. > I am not a huge fan of the various Rel[Whatever] typedefs. I am not > sure that's really adding any clarity. On the other hand I would be a > big fan of renaming the structure members in some systematic way. This > kind of thing doesn't sit well with me: I initially had all the Rel* use the same type, and it was much more error prone because the compiler couldn't tell that the types are different. > - NullableDatum *value; /* value to return */ > + RelNullableDatum value; /* value to return */ > > Well, if NullableDatum was the value to return, then RelNullableDatum > isn't.It's some kind of thing that lets you find the value to return. I don't really know what you mean? It's essentially just a different type of pointer? > Is it true that allocno is only used for, err, some kind of LLVM > thing, and not in the regular interpreted path? As far as I can see, > outside of the LLVM code, we only ever test whether it's 0, and don't > actually care about the specific value. I'd expect it to be useful for a few interpreded cases as well, but right now it's not. > I hope that the fact that this patch reverses the order of the first > two arguments to ExecInitExprRec is only something you did to make it > so that the compiler would find places you needed to update. Because > otherwise it makes no sense to introduce a new thing called an > ExprStateBuilder in 0017, make it an argument to that function, and > then turn around and change the signature again in 0026. Anyway, a > final patch shouldn't include this kind of churn. Yes, that definitely needs to go. > + offsetof(ExprState, steps) * esb->steps_len * sizeof(ExprEvalStep) + > + state->mutable_off = offsetof(ExprState, steps) * esb->steps_len * > sizeof(ExprEvalStep); > > Well, either I'm confused here, or the first * should be a + in each > case. I wonder how this works at all. Oh. yes, that doesn't look right. I assume it's just always too big, and that's why it doesn't cause problems... > + /* copy in step data */ > + { > + ListCell *lc; > + int off = 0; > + > + foreach(lc, esb->steps) > + { > + memcpy(&state->steps[off], lfirst(lc), sizeof(ExprEvalStep)); > + off++; > + } > + } > > This seems incredibly pointless to me. Why use a List in the first > place if we're going to have to flatten it using this kind of code? We don't know how many steps an expression is going to require. It turns out that in the current code we spend a good amount of time just growing ->steps. Using a list (even if it's an array of pointers as List now is) during building makes appending fairly cheap. Building a dense array after all steps have been computed keeps the execution time benefit. > I think stuff like RelFCIOff() and RelFCIIdx() and RelArrayIdx() is > just pretty much incomprehensible. Now, the executor is full of > badly-named stuff already -- ExecInitExprRec being a fine example of a > name nobody is going to understand on first reading, or maybe ever -- > but we ought to try not to make things worse. I also do understand > that anything with relative pointers is bound to involve a bunch of > crappy notation that we're just going to have to accept as the price > of doing business. But it would help to pick names that are not so > heavily abbreviated. Like, if RelFCIIdx() were called > find_function_argument_in_relative_fcinfo() or even > get_fnarg_from_relfcinfo() the casual reader might have a chance of > guessing what it does. Yea, they're crappily named. If this were C++ it'd be easy to wrap the relative pointers in something that then makes them behave like normal pointers, but ... > Sure, the code might be longer, but if you can tell what it does without > cross-referencing, it's still better. Unfortunately it's really hard to keep the code legible and keep pgindent happy with long names :(. But I'm sure that we can do better than these. > I would welcome changes that make it clearer which things happen just > once and which things happen at execution time; that said, it seems > like RELPTR_RESOLVE() happens at execution time, and it surprises me a > bit that this is OK from a performance perspective. It's actually fairly cheap, at least on x86, because every relative pointer dereference is just an offset from one base pointer. That base address can be kept in a register. In some initial benchmarking the gains from the higher allocation density of the variable data is bigger than potential losses. > The pointers can change from execution to execution, but not within an > individual execution, or so I think. So it doesn't need to be resolved every > time, if somehow that can be avoided. But maybe CPUs are sufficiently > well-optimized for computing a pointer address as a+b*c that it does not > matter. It should just be a + b, right? Well, for arrays it's more complicated, but it's also more complicated for "normal arrays". > I'm not sure how helpful any of these comments are, but those are my > initial thoughts. It's helpful. The biggest issue I see with getting to the point of actually caching JITed code is the the ->flinfo, ->context thing mentioned above. The best thing I can come up with is moving the allocation of those into the ExprState as well, but my gut says there must be a better approach that I'm not quite seeing. Greetings, Andres Freund
On Thu, Nov 4, 2021 at 7:47 PM Andres Freund <andres@anarazel.de> wrote: > The immediate goal is to be able to generate JITed code/LLVM-IR that doesn't > contain any absolute pointer values. If the generated code doesn't change > regardless of any of the other contents of ExprEvalStep, we can still cache > the JIT optimization / code emission steps - which are the expensive bits. I'm not sure why that requires all of this relative pointer stuff, honestly. Under that problem statement, we don't need everything to be one contiguous allocation. We just need it to have the same lifespan as the JITted code. If you introduced no relative pointers at all, you could still solve this problem: create a new memory context that contains all of the EvalExprSteps and all of the allocations upon which they depend, make sure everything you care about is allocated in that context, and don't destroy any of it until you destroy it all. Or another option would be: instead of having one giant allocation in which we have to place data of every different type, have one allocation per kind of thing. Figure out how many FunctionCallInfo objects we need and make an array of them. Figure out how many NullableDatum objects we need and make a separate array of those. And so on. Then just use pointers. I think that part of your motivation here is unrelated caching the JIT results: you also want to improve performance by increasing memory locality. That's a good goal as far as it goes, but maybe there's a way to be a little less ambitious and still get most of the benefit. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2021-11-05 08:34:26 -0400, Robert Haas wrote: > I'm not sure why that requires all of this relative pointer stuff, > honestly. Under that problem statement, we don't need everything to be > one contiguous allocation. We just need it to have the same lifespan > as the JITted code. If you introduced no relative pointers at all, > you could still solve this problem: create a new memory context that > contains all of the EvalExprSteps and all of the allocations upon > which they depend, make sure everything you care about is allocated in > that context, and don't destroy any of it until you destroy it all. I don't see how that works - the same expression can be evaluated multiple times at once, recursively. So you can't have things like FunctionCallInfoData shared. One key point of separating out the mutable data into something that can be relocated is precisely so that every execution can have its own "mutable" data area, without needing to change anything else. > Or another option would be: instead of having one giant allocation in which > we have to place data of every different type, have one allocation per kind > of thing. Figure out how many FunctionCallInfo objects we need and make an > array of them. Figure out how many NullableDatum objects we need and make a > separate array of those. And so on. Then just use pointers. Without the relative pointer thing you'd still have pointers into those arrays of objects. Which then would make the thing non-shareable. Greetings, Andres Freund
On Fri, Nov 5, 2021 at 12:48 PM Andres Freund <andres@anarazel.de> wrote: > I don't see how that works - the same expression can be evaluated multiple > times at once, recursively. So you can't have things like FunctionCallInfoData > shared. One key point of separating out the mutable data into something that > can be relocated is precisely so that every execution can have its own > "mutable" data area, without needing to change anything else. Oh. That makes it harder. > > Or another option would be: instead of having one giant allocation in which > > we have to place data of every different type, have one allocation per kind > > of thing. Figure out how many FunctionCallInfo objects we need and make an > > array of them. Figure out how many NullableDatum objects we need and make a > > separate array of those. And so on. Then just use pointers. > > Without the relative pointer thing you'd still have pointers into those arrays > of objects. Which then would make the thing non-shareable. Well, I guess you could store indexes into the individual arrays, but then I guess you're not gaining much of anything. It's a pretty annoying problem, really. Somehow it's hard to shake the feeling that there ought to be a better approach than relative pointers. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2021-11-05 13:09:10 -0400, Robert Haas wrote: > On Fri, Nov 5, 2021 at 12:48 PM Andres Freund <andres@anarazel.de> wrote: > > I don't see how that works - the same expression can be evaluated multiple > > times at once, recursively. So you can't have things like FunctionCallInfoData > > shared. One key point of separating out the mutable data into something that > > can be relocated is precisely so that every execution can have its own > > "mutable" data area, without needing to change anything else. > > Oh. That makes it harder. Yes. Optimally we'd do JIT caching across connections as well. One of the biggest issues with the costs of JITing is actually parallel query, where we'll often recreate the same JIT code again and again. For that you really can't have much in the way of pointers... > > > Or another option would be: instead of having one giant allocation in which > > > we have to place data of every different type, have one allocation per kind > > > of thing. Figure out how many FunctionCallInfo objects we need and make an > > > array of them. Figure out how many NullableDatum objects we need and make a > > > separate array of those. And so on. Then just use pointers. > > > > Without the relative pointer thing you'd still have pointers into those arrays > > of objects. Which then would make the thing non-shareable. > > Well, I guess you could store indexes into the individual arrays, but > then I guess you're not gaining much of anything. You'd most likely just loose a bit of locality, because the different types of data are now all on separate cachelines, even if referenced by the one expression step. > It's a pretty annoying problem, really. Somehow it's hard to shake the > feeling that there ought to be a better approach than relative > pointers. Yes. I don't like it much either :(. Basically native code has the same issue, and also largely ended up with making most things relative (see x86-64 which does most addressing relative to the instruction pointer, and binaries pre-relocation, where the addresses aren't resolved yed). Greetings, Andres Freund
Hi,
On 2021-11-05 09:48:16 -0700, Andres Freund wrote:
> On 2021-11-05 08:34:26 -0400, Robert Haas wrote:
> > I'm not sure why that requires all of this relative pointer stuff,
> > honestly. Under that problem statement, we don't need everything to be
> > one contiguous allocation. We just need it to have the same lifespan
> > as the JITted code. If you introduced no relative pointers at all,
> > you could still solve this problem: create a new memory context that
> > contains all of the EvalExprSteps and all of the allocations upon
> > which they depend, make sure everything you care about is allocated in
> > that context, and don't destroy any of it until you destroy it all.
>
> I don't see how that works - the same expression can be evaluated multiple
> times at once, recursively. So you can't have things like FunctionCallInfoData
> shared. One key point of separating out the mutable data into something that
> can be relocated is precisely so that every execution can have its own
> "mutable" data area, without needing to change anything else.
Oh, and the other bit is that the absolute addresses make it much harder to
generate efficient code. If I remove the code setting
FunctionCallInfo->{context,flinfo} to the constant pointers (obviously
incorrect, but works for functions not using either), E.g. TPCH-Q1 gets about
20% faster.
Greetings,
Andres Freund
On Fri, Nov 5, 2021 at 1:20 PM Andres Freund <andres@anarazel.de> wrote: > Yes. Optimally we'd do JIT caching across connections as well. One of the > biggest issues with the costs of JITing is actually parallel query, where > we'll often recreate the same JIT code again and again. For that you really > can't have much in the way of pointers... Well that much is clear, and parallel query also needs relative pointers in some places for other reasons, which reminds me to ask you whether these new relative pointers can't reuse "utils/relptr.h" instead of inventing another way of do it. And if not maybe we should try to first change relptr.h and the one existing client (freepage.c/h) to something better and then use that in both places, because if we're going to be stuck with relative pointers are all over the place it would at least be nice not to have too many different kinds. > > It's a pretty annoying problem, really. Somehow it's hard to shake the > > feeling that there ought to be a better approach than relative > > pointers. > > Yes. I don't like it much either :(. Basically native code has the same issue, > and also largely ended up with making most things relative (see x86-64 which > does most addressing relative to the instruction pointer, and binaries > pre-relocation, where the addresses aren't resolved yed). Yes, but the good thing about those cases is that they're handled by the toolchain. What's irritating about this case is that we're using a just-in-time compiler, and yet somehow it feels like the job that ought to be done by the compiler is having to be done by our code, and the result is a lot of extra notation. I don't know what the alternative is -- if you don't tell the compiler which things it's supposed to assume are constant and which things might vary from execution to execution, it can't know. But it feels a little weird that there isn't some better way to give it that information. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, On 2021-11-05 14:13:38 -0400, Robert Haas wrote: > On Fri, Nov 5, 2021 at 1:20 PM Andres Freund <andres@anarazel.de> wrote: > > Yes. Optimally we'd do JIT caching across connections as well. One of the > > biggest issues with the costs of JITing is actually parallel query, where > > we'll often recreate the same JIT code again and again. For that you really > > can't have much in the way of pointers... > > Well that much is clear, and parallel query also needs relative > pointers in some places for other reasons, which reminds me to ask you > whether these new relative pointers can't reuse "utils/relptr.h" > instead of inventing another way of do it. And if not maybe we should > try to first change relptr.h and the one existing client > (freepage.c/h) to something better and then use that in both places, > because if we're going to be stuck with relative pointers are all over > the place it would at least be nice not to have too many different > kinds. Hm. Yea, that's a fair point. Right now the "allocno" bit would be a problem. Perhaps we can get around that somehow. We could search for allocations by the offset, I guess. > > > It's a pretty annoying problem, really. Somehow it's hard to shake the > > > feeling that there ought to be a better approach than relative > > > pointers. > > > > Yes. I don't like it much either :(. Basically native code has the same issue, > > and also largely ended up with making most things relative (see x86-64 which > > does most addressing relative to the instruction pointer, and binaries > > pre-relocation, where the addresses aren't resolved yed). > > Yes, but the good thing about those cases is that they're handled by > the toolchain. What's irritating about this case is that we're using a > just-in-time compiler, and yet somehow it feels like the job that > ought to be done by the compiler is having to be done by our code, and > the result is a lot of extra notation. I don't know what the > alternative is -- if you don't tell the compiler which things it's > supposed to assume are constant and which things might vary from > execution to execution, it can't know. But it feels a little weird > that there isn't some better way to give it that information. Yes, I feel like there must be something better too. But in the end, I think we want something like this for the non-JIT path too, so that we can avoid the expensive re-creation of expression for every query execution. Which does make referencing at least the mutable data only by offset fairly attractive, imo. Greetings, Andres Freund