Обсуждение: High concurrency same row (inventory)
Hello there.
I am not an PG expert, as currently I work as a Enterprise Architect (who believes in OSS and in particular PostgreSQL 😍). So please forgive me if this question is too simple. 🙏
Here it goes:
We have a new Inventory system running on its own database (PG 10 AWS RDS.m5.2xlarge 1TB SSD EBS - Multizone). The DB effective size is less than 10GB at the moment. We provided 1TB to get more IOPS from EBS.
As we don't have a lot of different products in our catalogue it's quite common (especially when a particular product is on sale) to have a high rate of concurrent updates against the same row. There is also a frequent (every 30 minutes) update to all items which changed their current stock/Inventory coming from the warehouses (SAP), the latter is a batch process. We have just installed this system for a new tenant (one of the smallest one) and although it's running great so far, we believe this solution would not scale as we roll out this system to new (and bigger) tenants. Currently there is up to 1.500 transactions per second (mostly SELECTS and 1 particular UPDATE which I believe is the one being aborted/deadlocked some tImes) in this inventory database.
I am not a DBA, but as the DBAs (most of them old school Oracle DBAs who are not happy with the move to POSTGRES) are considering ditching Postgresql without any previous tunning I would like to understand the possibilities.
Considering this is a highly concurrent (same row) system I thought to suggest:
1) Set up Shared_buffer to 25% of the RAM on the RDS instance;
2) Install a pair (HA) of PGBouncers (session) in front of PG and setup it in a way that it would keep only 32 connections (4 per core) open to the database at the same time, but all connections going to PGBouncer (might be thousands) would be queued as soon as there is more than 32 active connections to the Database. We have reached more than 500 concurrent connections so far. But these numbers will grow.
3) set work_mem to 3 times the size of largest temp file;
4) set maintenance_work_mem to 2GB;
5) set effective_cache_size to 50% of total memory.
The most used update is already a HOT UPDATE, as it (or any trigger) doesn't change indexed columns.
It seems to me the kind of problem we have is similar to those systems which sell limited number of tickets to large concerts/events, like googleIO used to be... Where everyone tried to buy the ticket as soon as possible, and the system had to keep a consistent number of available tickets. I believe that's a hard problem to solve. So that's way I am asking for suggestions/ideas from the experts.
Thanks so much!
On Mon, Jul 29, 2019 at 2:16 AM Jean Baro <jfbaro@gmail.com> wrote:
We have a new Inventory system running on its own database (PG 10 AWS RDS.m5.2xlarge 1TB SSD EBS - Multizone). The DB effective size is less than 10GB at the moment. We provided 1TB to get more IOPS from EBS.As we don't have a lot of different products in our catalogue it's quite common (especially when a particular product is on sale) to have a high rate of concurrent updates against the same row. There is also a frequent (every 30 minutes) update to all items which changed their current stock/Inventory coming from the warehouses (SAP), the latter is a batch process. We have just installed this system for a new tenant (one of the smallest one) and although it's running great so far, we believe this solution would not scale as we roll out this system to new (and bigger) tenants. Currently there is up to 1.500 transactions per second (mostly SELECTS and 1 particular UPDATE which I believe is the one being aborted/deadlocked some tImes) in this inventory database.I am not a DBA, but as the DBAs (most of them old school Oracle DBAs who are not happy with the move to POSTGRES) are considering ditching Postgresql without any previous tunning I would like to understand the possibilities.Considering this is a highly concurrent (same row) system I thought to suggest:
Another thing which you might want to investigate is your checkpoint tunables. My hunch is with that many writes, the defaults are probably not going to be ideal.
Consider the WAL tunables documentation: https://www.postgresql.org/docs/10/wal-configuration.html
On Mon, Jul 29, 2019 at 11:46 AM Jean Baro <jfbaro@gmail.com> wrote:
Monitoring the locks and activities, as described here, may help -Hello there.I am not an PG expert, as currently I work as a Enterprise Architect (who believes in OSS and in particular PostgreSQL 😍). So please forgive me if this question is too simple. 🙏Here it goes:We have a new Inventory system running on its own database (PG 10 AWS RDS.m5.2xlarge 1TB SSD EBS - Multizone). The DB effective size is less than 10GB at the moment. We provided 1TB to get more IOPS from EBS.As we don't have a lot of different products in our catalogue it's quite common (especially when a particular product is on sale) to have a high rate of concurrent updates against the same row. There is also a frequent (every 30 minutes) update to all items which changed their current stock/Inventory coming from the warehouses (SAP), the latter is a batch process. We have just installed this system for a new tenant (one of the smallest one) and although it's running great so far, we believe this solution would not scale as we roll out this system to new (and bigger) tenants. Currently there is up to 1.500 transactions per second (mostly SELECTS and 1 particular UPDATE which I believe is the one being aborted/deadlocked some tImes) in this inventory database.
Regards,
Jayadevan
Does pg_stat_user_tables validate that the major updates are indeed "hot updates"? Otherwise, you may be experiencing bloat problems if autovacuum is not set aggressively. Did you change default parameters for autovacuum? You should. They are set very conservatively right outa the box. Also, I wouldn't increase work_mem too much unless you are experiencing query spill over to disk. Turn on "log_temp_files" (=0) and monitor if you have this spillover. If not, don't mess with work_mem. Also, why isn't effective_cache_size set closer to 80-90% of memory instead of 50%? Are there other servers on the same host as postgres? As the other person mentioned, tune checkpoints so that they do not happen too often. Turn on "log_checkpoints" to get more info.
Regards,
Michael Vitale
Rick Otten wrote on 7/29/2019 8:35 AM:
Regards,
Michael Vitale
Rick Otten wrote on 7/29/2019 8:35 AM:
On Mon, Jul 29, 2019 at 2:16 AM Jean Baro <jfbaro@gmail.com> wrote:We have a new Inventory system running on its own database (PG 10 AWS RDS.m5.2xlarge 1TB SSD EBS - Multizone). The DB effective size is less than 10GB at the moment. We provided 1TB to get more IOPS from EBS.As we don't have a lot of different products in our catalogue it's quite common (especially when a particular product is on sale) to have a high rate of concurrent updates against the same row. There is also a frequent (every 30 minutes) update to all items which changed their current stock/Inventory coming from the warehouses (SAP), the latter is a batch process. We have just installed this system for a new tenant (one of the smallest one) and although it's running great so far, we believe this solution would not scale as we roll out this system to new (and bigger) tenants. Currently there is up to 1.500 transactions per second (mostly SELECTS and 1 particular UPDATE which I believe is the one being aborted/deadlocked some tImes) in this inventory database.I am not a DBA, but as the DBAs (most of them old school Oracle DBAs who are not happy with the move to POSTGRES) are considering ditching Postgresql without any previous tunning I would like to understand the possibilities.Considering this is a highly concurrent (same row) system I thought to suggest:Another thing which you might want to investigate is your checkpoint tunables. My hunch is with that many writes, the defaults are probably not going to be ideal.Consider the WAL tunables documentation: https://www.postgresql.org/docs/10/wal-configuration.html
Thanks guys! This is really good and useful information! :)
During the day we can see some exceptions coming from Postgres (alway when the load is the highest), only in the MAIN UPDATE:
- How to overcome the error "current transaction is aborted, commands ignored until end of transaction block"
- Deadlock detected
Thanks
On Mon, Jul 29, 2019 at 9:55 AM MichaelDBA <MichaelDBA@sqlexec.com> wrote:
Does pg_stat_user_tables validate that the major updates are indeed "hot updates"? Otherwise, you may be experiencing bloat problems if autovacuum is not set aggressively. Did you change default parameters for autovacuum? You should. They are set very conservatively right outa the box. Also, I wouldn't increase work_mem too much unless you are experiencing query spill over to disk. Turn on "log_temp_files" (=0) and monitor if you have this spillover. If not, don't mess with work_mem. Also, why isn't effective_cache_size set closer to 80-90% of memory instead of 50%? Are there other servers on the same host as postgres? As the other person mentioned, tune checkpoints so that they do not happen too often. Turn on "log_checkpoints" to get more info.
Regards,
Michael Vitale
Rick Otten wrote on 7/29/2019 8:35 AM:On Mon, Jul 29, 2019 at 2:16 AM Jean Baro <jfbaro@gmail.com> wrote:We have a new Inventory system running on its own database (PG 10 AWS RDS.m5.2xlarge 1TB SSD EBS - Multizone). The DB effective size is less than 10GB at the moment. We provided 1TB to get more IOPS from EBS.As we don't have a lot of different products in our catalogue it's quite common (especially when a particular product is on sale) to have a high rate of concurrent updates against the same row. There is also a frequent (every 30 minutes) update to all items which changed their current stock/Inventory coming from the warehouses (SAP), the latter is a batch process. We have just installed this system for a new tenant (one of the smallest one) and although it's running great so far, we believe this solution would not scale as we roll out this system to new (and bigger) tenants. Currently there is up to 1.500 transactions per second (mostly SELECTS and 1 particular UPDATE which I believe is the one being aborted/deadlocked some tImes) in this inventory database.I am not a DBA, but as the DBAs (most of them old school Oracle DBAs who are not happy with the move to POSTGRES) are considering ditching Postgresql without any previous tunning I would like to understand the possibilities.Considering this is a highly concurrent (same row) system I thought to suggest:Another thing which you might want to investigate is your checkpoint tunables. My hunch is with that many writes, the defaults are probably not going to be ideal.Consider the WAL tunables documentation: https://www.postgresql.org/docs/10/wal-configuration.html
Can you share the schema of the table(s) involved and an example or two of the updates being executed?
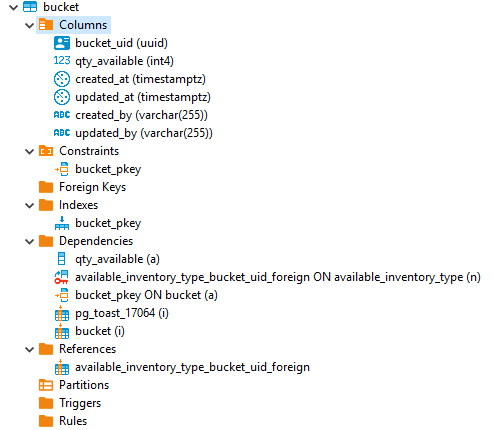
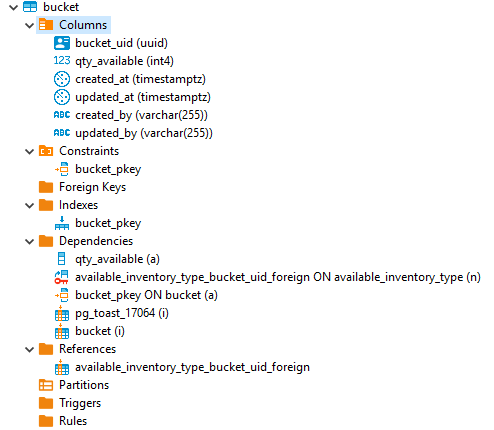
All the failures come from the Bucket Table (see image below).
I don't have access to the DB, neither the code, but last time I was presented to the UPDATE it was changing (incrementing or decrementing) qty_available, but tomorrow morning I can be sure, once the developers and DBAs are back to the office. I know it's quite a simple UPDATE.
{autovacuum_vacuum_scale_factor=0.01}
On Mon, Jul 29, 2019 at 3:12 PM Michael Lewis <mlewis@entrata.com> wrote:
Can you share the schema of the table(s) involved and an example or two of the updates being executed?
Вложения
The UPDATE was something like:
UPDATE bucket SET qty_available = qty_available + 1 WHERE bucket_uid = 0940850938059380590
Thanks for all your help guys!
On Mon, Jul 29, 2019 at 9:04 PM Jean Baro <jfbaro@gmail.com> wrote:
All the failures come from the Bucket Table (see image below).I don't have access to the DB, neither the code, but last time I was presented to the UPDATE it was changing (incrementing or decrementing) qty_available, but tomorrow morning I can be sure, once the developers and DBAs are back to the office. I know it's quite a simple UPDATE.Table is called Bucket:{autovacuum_vacuum_scale_factor=0.01}On Mon, Jul 29, 2019 at 3:12 PM Michael Lewis <mlewis@entrata.com> wrote:Can you share the schema of the table(s) involved and an example or two of the updates being executed?
Вложения

The dead tuples goes up at a high ratio, but then it gets cleaned.
if you guys need any further information, please let me know!
On Mon, Jul 29, 2019 at 9:06 PM Jean Baro <jfbaro@gmail.com> wrote:
The UPDATE was something like:UPDATE bucket SET qty_available = qty_available + 1 WHERE bucket_uid = 0940850938059380590Thanks for all your help guys!On Mon, Jul 29, 2019 at 9:04 PM Jean Baro <jfbaro@gmail.com> wrote:All the failures come from the Bucket Table (see image below).I don't have access to the DB, neither the code, but last time I was presented to the UPDATE it was changing (incrementing or decrementing) qty_available, but tomorrow morning I can be sure, once the developers and DBAs are back to the office. I know it's quite a simple UPDATE.Table is called Bucket:{autovacuum_vacuum_scale_factor=0.01}On Mon, Jul 29, 2019 at 3:12 PM Michael Lewis <mlewis@entrata.com> wrote:Can you share the schema of the table(s) involved and an example or two of the updates being executed?
Вложения
Looks like regular updates not HOT UPDATES
Jean Baro wrote on 7/29/2019 8:26 PM:
Jean Baro wrote on 7/29/2019 8:26 PM:
The dead tuples goes up at a high ratio, but then it gets cleaned.if you guys need any further information, please let me know!On Mon, Jul 29, 2019 at 9:06 PM Jean Baro <jfbaro@gmail.com> wrote:The UPDATE was something like:UPDATE bucket SET qty_available = qty_available + 1 WHERE bucket_uid = 0940850938059380590Thanks for all your help guys!On Mon, Jul 29, 2019 at 9:04 PM Jean Baro <jfbaro@gmail.com> wrote:All the failures come from the Bucket Table (see image below).I don't have access to the DB, neither the code, but last time I was presented to the UPDATE it was changing (incrementing or decrementing) qty_available, but tomorrow morning I can be sure, once the developers and DBAs are back to the office. I know it's quite a simple UPDATE.Table is called Bucket:{autovacuum_vacuum_scale_factor=0.01}On Mon, Jul 29, 2019 at 3:12 PM Michael Lewis <mlewis@entrata.com> wrote:Can you share the schema of the table(s) involved and an example or two of the updates being executed?

Вложения
Michael Vitale --> No, there is only postgreSQL running in this server... it is in fact an RDS server.
FROM pg_stat_user_tables
WHERE schemaname = 'schemaFOO' and relname = 'bucket';
On Mon, Jul 29, 2019 at 9:26 PM Jean Baro <jfbaro@gmail.com> wrote:
The dead tuples goes up at a high ratio, but then it gets cleaned.if you guys need any further information, please let me know!On Mon, Jul 29, 2019 at 9:06 PM Jean Baro <jfbaro@gmail.com> wrote:The UPDATE was something like:UPDATE bucket SET qty_available = qty_available + 1 WHERE bucket_uid = 0940850938059380590Thanks for all your help guys!On Mon, Jul 29, 2019 at 9:04 PM Jean Baro <jfbaro@gmail.com> wrote:All the failures come from the Bucket Table (see image below).I don't have access to the DB, neither the code, but last time I was presented to the UPDATE it was changing (incrementing or decrementing) qty_available, but tomorrow morning I can be sure, once the developers and DBAs are back to the office. I know it's quite a simple UPDATE.Table is called Bucket:{autovacuum_vacuum_scale_factor=0.01}On Mon, Jul 29, 2019 at 3:12 PM Michael Lewis <mlewis@entrata.com> wrote:Can you share the schema of the table(s) involved and an example or two of the updates being executed?

{kind=link}