Обсуждение: [Patch][WiP] Tweaked LRU for shared buffers
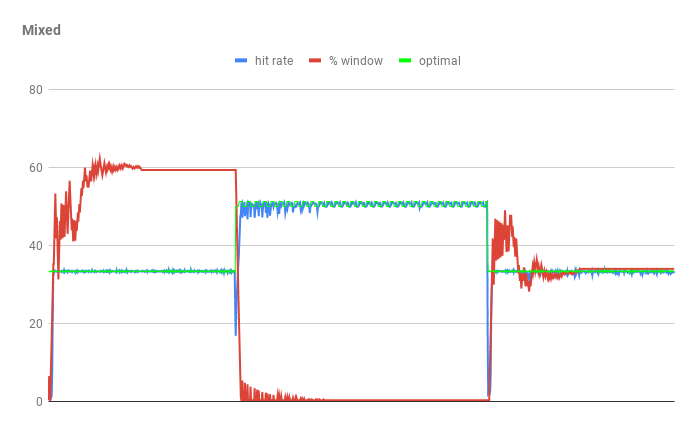
Hi, hackers! We have held education project at Sirius edu center (Sochi, Russia) with mentors from Yandex. The group of 5 students wasworking on improving the shared buffers eviction algorithm: Andrey Chausov, Yuriy Skakovskiy, Ivan Edigaryev, Arslan Gumerov,Daria Filipetskaya. I’ve been a mentor for the group. For two weeks we have been looking into known caching algorithmsand tried to adapt some of them for PostgreSQL codebase. While a lot of algorithms appeared to be too complex to be hacked in 2 weeks, we decided to implement and test the workingversion of tweaked LRU eviction algorithm. ===How it works=== Most of the buffers are organized into the linked list. Firstly admitted pages jump into 5/8th of the queue. The last ⅛ ofthe queue is governed by clock sweep algorithm to improve concurrency. ===So how we tested the patch=== We used sampling on 4 Yandex.Cloud compute instances with 16 vCPU cores, 8GB of RAM, 200GB database in 30-minute YCSB-likeruns with Zipf distribution. We found that on read-only workload our algorithm is showing consistent improvementover the current master branch. On read-write workloads we haven’t found performance improvements yet, there wastoo much noise from checkpoints and bgwriter (more on it in TODO section). Charts are here: [0,1] We used this config: [2] ===TODO=== We have taken some ideas expressed by Ben Manes in the pgsql-hackers list. But we could not implement all of them duringthe time of the program. For example, we tried to make LRU bumps less write-contentious by storing them in a circularbuffer. But this feature was not stable enough. The patch in its current form also requires improvements. So, we shall reduce the number of locks at all (in this way wehave tried bufferization, but not only it). “Clock sweep” algorithm at the last ⅛ part of the logical sequence should beimproved too (see ClockSweepTickAtTheAnd() and places of its usage). Unfortunately, we didn’t have more time to bring CAR and W-TinyLFU to testing-ready state. We have a working implementation of frequency sketch [3] to make a transition between the admission cycle and LRU more concisewith TinyLFU filter. Most probably, work in this direction will be continued. Also, the current patch does not change bgwriter behavior: with a piece of knowledge from LRU, we can predict that some pageswill not be changed in the nearest future. This information should be used to schedule the background writes better. We also think that with proper eviction algorithm shared buffers should be used instead of specialized buffer rings. We will be happy to hear your feedback on our work! Thank you :) [0] LRU TPS https://yadi.sk/i/wNNmNw3id22nMQ [1] LRU hitrate https://yadi.sk/i/l1o710C3IX6BiA [2] Benchmark config https://yadi.sk/d/L-PIVq--ujw6NA [3] Frequency sketch code https://github.com/heyfaraday/postgres/commit/a684a139a72cd50dd0f9d031a8aa77f998607cf1 With best regards, almost serious cache group.
Вложения
Hi, On 2/13/19 3:37 PM, Andrey Borodin wrote: > Hi, hackers! > > We have held education project at Sirius edu center (Sochi, Russia) > with mentors from Yandex. The group of 5 students was working on > improving the shared buffers eviction algorithm: Andrey Chausov, Yuriy > Skakovskiy, Ivan Edigaryev, Arslan Gumerov, Daria Filipetskaya. I’ve > been a mentor for the group. For two weeks we have been looking into > known caching algorithms and tried to adapt some of them for PostgreSQL > codebase. > > While a lot of algorithms appeared to be too complex to be hacked in > 2 weeks, we decided to implement and test the working version of > tweaked LRU eviction algorithm. > > ===How it works=== > Most of the buffers are organized into the linked list. Firstly > admitted pages jump into 5/8th of the queue. The last ⅛ of the queue is > governed by clock sweep algorithm to improve concurrency. > Interesting. Where do these numbers (5/8 and 1/8) come from? > ===So how we tested the patch=== > We used sampling on 4 Yandex.Cloud compute instances with 16 vCPU > cores, 8GB of RAM, 200GB database in 30-minute YCSB-like runs with Zipf > distribution. We found that on read-only workload our algorithm is > showing consistent improvement over the current master branch. On > read-write workloads we haven’t found performance improvements yet, > there was too much noise from checkpoints and bgwriter (more on it in > TODO section). > Charts are here: [0,1] That TPS chart looks a bit ... wild. How come the master jumps so much up and down? That's a bit suspicious, IMHO. How do I reproduce this benchmark? I'm aware of pg_ycsb, but maybe you've used some other tools? Also, have you tried some other benchmarks (like, regular TPC-B as implemented by pgbench, or read-only pgbench)? We need such benchmarks with a range of access patterns to check for regressions. BTW what do you mean by "sampling"? > We used this config: [2] > That's only half the information - it doesn't say how many clients were running the benchmark etc. > ===TODO=== > We have taken some ideas expressed by Ben Manes in the pgsql-hackers > list. But we could not implement all of them during the time of the > program. For example, we tried to make LRU bumps less write-contentious > by storing them in a circular buffer. But this feature was not stable > enough. Can you point us to the thread/email discussing those ideas? I have tried searching through archives, but I haven't found anything :-( This message does not really explain the algorithms, and combined with the absolute lack of comments in the linked commit, it'd somewhat difficult to form an opinion. > The patch in its current form also requires improvements. So, we > shall reduce the number of locks at all (in this way we have tried > bufferization, but not only it). “Clock sweep” algorithm at the last > ⅛ part of the logical sequence should be improved too (see > ClockSweepTickAtTheAnd() and places of its usage). OK > Unfortunately, we didn’t have more time to bring CAR and W-TinyLFU > to testing-ready state. What is CAR? Did you mean ARC, perhaps? > We have a working implementation of frequency sketch [3] to make a > transition between the admission cycle and LRU more concise with TinyLFU > filter. Most probably, work in this direction will be continued. OK > Also, the current patch does not change bgwriter behavior: with a > piece of knowledge from LRU, we can predict that some pages will not be > changed in the nearest future. This information should be used to > schedule the background writes better. Sounds interesting. > We also think that with proper eviction algorithm shared buffers > should be used instead of specialized buffer rings. > Are you suggesting to get rid of the buffer rings we use for sequential scans, for example? IMHO that's going to be tricky, e.g. because of synchronized sequential scans. > We will be happy to hear your feedback on our work! Thank you :) > > [0] LRU TPS https://yadi.sk/i/wNNmNw3id22nMQ > [1] LRU hitrate https://yadi.sk/i/l1o710C3IX6BiA > [2] Benchmark config https://yadi.sk/d/L-PIVq--ujw6NA > [3] Frequency sketch code https://github.com/heyfaraday/postgres/commit/a684a139a72cd50dd0f9d031a8aa77f998607cf1 > > With best regards, almost serious cache group. > cheers -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Feb 15, 2019 at 3:30 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > That TPS chart looks a bit ... wild. How come the master jumps so much > up and down? That's a bit suspicious, IMHO. Somebody should write a patch to make buffer eviction completely random, without aiming to get it committed. That isn't as bad of a strategy as it sounds, and it would help with assessing improvements in this area. We know that the cache replacement algorithm behaves randomly when there is extreme contention, while also slowing everything down due to maintaining the clock. A unambiguously better caching algorithm would at a minimum be able to beat our "cheap random replacement" prototype as well as the existing clocksweep algorithm in most or all cases. That seems like a reasonably good starting point, at least. -- Peter Geoghegan
On 2/16/19 12:51 AM, Peter Geoghegan wrote: > On Fri, Feb 15, 2019 at 3:30 PM Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> That TPS chart looks a bit ... wild. How come the master jumps so much >> up and down? That's a bit suspicious, IMHO. > > Somebody should write a patch to make buffer eviction completely > random, without aiming to get it committed. That isn't as bad of a > strategy as it sounds, and it would help with assessing improvements > in this area. > > We know that the cache replacement algorithm behaves randomly when > there is extreme contention, while also slowing everything down due > to maintaining the clock. Possibly, although I still find it strange that the throughput first grows, then at shared_buffers 1GB it drops, and then at 3GB it starts growing again. Considering this is on 200GB data set, I doubt the pressure/contention is much different with 1GB and 3GB, but maybe it is. > A unambiguously better caching algorithm would at a minimum be able > to beat our "cheap random replacement" prototype as well as the > existing clocksweep algorithm in most or all cases. That seems like a > reasonably good starting point, at least. > Yes, comparison to cheap random replacement would be an interesting experiment. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
If you mean "synchronized" in terms of multi-threading and locks, then this is a solved problem in terms of caching. My limited understanding is that the buffer rings are used to protect the cache from being polluted by scans which flush the LRU-like algorithms. This allows those policies to capture more frequent items. It also avoids lock contention on the cache due to writes caused by misses, where Clock allows lock-free reads but uses a global lock on writes. A smarter cache eviction policy and concurrency model can handle this without needing buffer rings to compensate.
I was not involved with Andrey and his team's work, which looks like a very promising first pass. I can try to clarify a few minor details.
What is CAR? Did you mean ARC, perhaps?
CAR is the Clock variants of ARC: CAR: Clock with Adaptive Replacement
I believe the main interest in ARC is its claim of adaptability with high hit rates. Unfortunately the reality is less impressive as it fails to handle many frequency workloads, e.g. poor scan resistance, and the adaptivity is poor due to the accesses being quite noisy. For W-TinyLFU, we have recent improvements which show near perfect adaptivity in our stress case that results in double the hit rate of ARC and is less than 1% from optimal.
{kind=link}
Can you point us to the thread/email discussing those ideas? I have tried searching through archives, but I haven't found anything :-(
This thread doesn't explain Andrey's work, but includes my minor contribution. The longer thread discusses the interest in CAR, et al.
Are you suggesting to get rid of the buffer rings we use for sequential scans, for example? IMHO that's going to be tricky, e.g. because of synchronized sequential scans.
Somebody should write a patch to make buffer eviction completely random, without aiming to get it committed. That isn't as bad of a strategy as it sounds, and it would help with assessing improvements in this area.
A related and helpful patch would be to capture the access log and provide anonymized traces. We have a simulator with dozens of policies to quickly provide a breakdown. That would let you know the hit rates before deciding on the policy to adopt.
Cheers.
On Fri, Feb 15, 2019 at 4:22 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 2/16/19 12:51 AM, Peter Geoghegan wrote:
> On Fri, Feb 15, 2019 at 3:30 PM Tomas Vondra
> <tomas.vondra@2ndquadrant.com> wrote:
>> That TPS chart looks a bit ... wild. How come the master jumps so much
>> up and down? That's a bit suspicious, IMHO.
>
> Somebody should write a patch to make buffer eviction completely
> random, without aiming to get it committed. That isn't as bad of a
> strategy as it sounds, and it would help with assessing improvements
> in this area.
>
> We know that the cache replacement algorithm behaves randomly when
> there is extreme contention, while also slowing everything down due
> to maintaining the clock.
Possibly, although I still find it strange that the throughput first
grows, then at shared_buffers 1GB it drops, and then at 3GB it starts
growing again. Considering this is on 200GB data set, I doubt the
pressure/contention is much different with 1GB and 3GB, but maybe it is.
> A unambiguously better caching algorithm would at a minimum be able
> to beat our "cheap random replacement" prototype as well as the
> existing clocksweep algorithm in most or all cases. That seems like a
> reasonably good starting point, at least.
>
Yes, comparison to cheap random replacement would be an interesting
experiment.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2/16/19 1:48 AM, Benjamin Manes wrote: > Hi, > > I was not involved with Andrey and his team's work, which looks like a > very promising first pass. I can try to clarify a few minor details. > > What is CAR? Did you mean ARC, perhaps? > > > CAR is the Clock variants of ARC: CAR: Clock with Adaptive Replacement > <https://www.usenix.org/legacy/publications/library/proceedings/fast04/tech/full_papers/bansal/bansal.pdf> > Thanks, will check. > I believe the main interest in ARC is its claim of adaptability with > high hit rates. Unfortunately the reality is less impressive as it fails > to handle many frequency workloads, e.g. poor scan resistance, and the > adaptivity is poor due to the accesses being quite noisy. For W-TinyLFU, > we have recent improvements which show near perfect adaptivity > <https://user-images.githubusercontent.com/378614/52891655-2979e380-3141-11e9-91b3-00002a3cc80b.png> in > our stress case that results in double the hit rate of ARC and is less > than 1% from optimal. > Interesting. > Can you point us to the thread/email discussing those ideas? I have > tried searching through archives, but I haven't found anything :-( > > > This thread > <https://www.postgresql.org/message-id/1526057854777-0.post%40n3.nabble.com> > doesn't explain Andrey's work, but includes my minor contribution. The > longer thread discusses the interest in CAR, et al. > Thanks. > Are you suggesting to get rid of the buffer rings we use for > sequential scans, for example? IMHO that's going to be tricky, e.g. > because of synchronized sequential scans. > > > If you mean "synchronized" in terms of multi-threading and locks, then > this is a solved problem > <http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html> in > terms of caching. No, I "synchronized scans" are an optimization to reduce I/O when multiple processes do sequential scan on the same table. Say one process is half-way through the table, when another process starts another scan. Instead of scanning it from block #0 we start at the position of the first process (at which point they "synchronize") and then wrap around to read the beginning. I was under the impression that this somehow depends on the small circular buffers, but I've now checked the code and I see that's bogus. > My limited understanding is that the buffer rings are > used to protect the cache from being polluted by scans which flush the > LRU-like algorithms. This allows those policies to capture more frequent > items. It also avoids lock contention on the cache due to writes caused > by misses, where Clock allows lock-free reads but uses a global lock on > writes. A smarter cache eviction policy and concurrency model can handle > this without needing buffer rings to compensate. > Right - that's the purpose of circular buffers. > Somebody should write a patch to make buffer eviction completely > random, without aiming to get it committed. That isn't as bad of a > strategy as it sounds, and it would help with assessing improvements > in this area. > > > A related and helpful patch would be to capture the access log and > provide anonymized traces. We have a simulator > <https://github.com/ben-manes/caffeine/wiki/Simulator> with dozens of > policies to quickly provide a breakdown. That would let you know the hit > rates before deciding on the policy to adopt. > Interesting. I assume the trace is essentially a log of which blocks were requested? Is there some trace format specification somewhere? cheers -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
{kind=link}
No, I "synchronized scans" are an optimization to reduce I/O when multiple processes do sequential scan on the same table.
Oh, very neat. Thanks!
Interesting. I assume the trace is essentially a log of which blocks were requested? Is there some trace format specification somewhere?
Yes, whatever constitutes a cache key (block address, item hash, etc). We write parsers for each trace so there isn't a format requirement. The parsers produce a 64-bit int stream of keys, which are broadcasted to each policy via an actor framework. The trace files can be text or binary, optionally compressed (xz preferred). The ARC traces are block I/O and this is their format description, so perhaps something similar? That parser is only 5 lines of custom code.
On Fri, Feb 15, 2019 at 5:51 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 2/16/19 1:48 AM, Benjamin Manes wrote:
> Hi,
>
> I was not involved with Andrey and his team's work, which looks like a
> very promising first pass. I can try to clarify a few minor details.
>
> What is CAR? Did you mean ARC, perhaps?
>
>
> CAR is the Clock variants of ARC: CAR: Clock with Adaptive Replacement
> <https://www.usenix.org/legacy/publications/library/proceedings/fast04/tech/full_papers/bansal/bansal.pdf>
>
Thanks, will check.
> I believe the main interest in ARC is its claim of adaptability with
> high hit rates. Unfortunately the reality is less impressive as it fails
> to handle many frequency workloads, e.g. poor scan resistance, and the
> adaptivity is poor due to the accesses being quite noisy. For W-TinyLFU,
> we have recent improvements which show near perfect adaptivity
> <https://user-images.githubusercontent.com/378614/52891655-2979e380-3141-11e9-91b3-00002a3cc80b.png> in
> our stress case that results in double the hit rate of ARC and is less
> than 1% from optimal.
>
Interesting.
> Can you point us to the thread/email discussing those ideas? I have
> tried searching through archives, but I haven't found anything :-(
>
>
> This thread
> <https://www.postgresql.org/message-id/1526057854777-0.post%40n3.nabble.com>
> doesn't explain Andrey's work, but includes my minor contribution. The
> longer thread discusses the interest in CAR, et al.
>
Thanks.
> Are you suggesting to get rid of the buffer rings we use for
> sequential scans, for example? IMHO that's going to be tricky, e.g.
> because of synchronized sequential scans.
>
>
> If you mean "synchronized" in terms of multi-threading and locks, then
> this is a solved problem
> <http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html> in
> terms of caching.
No, I "synchronized scans" are an optimization to reduce I/O when
multiple processes do sequential scan on the same table. Say one process
is half-way through the table, when another process starts another scan.
Instead of scanning it from block #0 we start at the position of the
first process (at which point they "synchronize") and then wrap around
to read the beginning.
I was under the impression that this somehow depends on the small
circular buffers, but I've now checked the code and I see that's bogus.
> My limited understanding is that the buffer rings are
> used to protect the cache from being polluted by scans which flush the
> LRU-like algorithms. This allows those policies to capture more frequent
> items. It also avoids lock contention on the cache due to writes caused
> by misses, where Clock allows lock-free reads but uses a global lock on
> writes. A smarter cache eviction policy and concurrency model can handle
> this without needing buffer rings to compensate.
>
Right - that's the purpose of circular buffers.
> Somebody should write a patch to make buffer eviction completely
> random, without aiming to get it committed. That isn't as bad of a
> strategy as it sounds, and it would help with assessing improvements
> in this area.
>
>
> A related and helpful patch would be to capture the access log and
> provide anonymized traces. We have a simulator
> <https://github.com/ben-manes/caffeine/wiki/Simulator> with dozens of
> policies to quickly provide a breakdown. That would let you know the hit
> rates before deciding on the policy to adopt.
>
Interesting. I assume the trace is essentially a log of which blocks
were requested? Is there some trace format specification somewhere?
cheers
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Benjamin> A related and helpful patch would be to capture the access log and
Benjamin> provide anonymized traces.
The traces can be captured via DTrace scripts, so no patch is required here.
For instance:
https://www.postgresql.org/message-id/CAB%3DJe-F_BhGfBu1sO1H7u_XMtvak%3DBQtuJFyv8cfjGBRp7Q_yA%40mail.gmail.com
or
https://www.postgresql.org/message-id/CAH2-WzmbUWKvCqjDycpCOSF%3D%3DPEswVf6WtVutgm9efohH0NfHA%40mail.gmail.com
Benjamin> provide anonymized traces.
The traces can be captured via DTrace scripts, so no patch is required here.
For instance:
https://www.postgresql.org/message-id/CAB%3DJe-F_BhGfBu1sO1H7u_XMtvak%3DBQtuJFyv8cfjGBRp7Q_yA%40mail.gmail.com
or
https://www.postgresql.org/message-id/CAH2-WzmbUWKvCqjDycpCOSF%3D%3DPEswVf6WtVutgm9efohH0NfHA%40mail.gmail.com
The missing bit is a database with more-or-less relevant workload.
Vladimir
On 2/16/19 10:36 AM, Vladimir Sitnikov wrote: > Benjamin> A related and helpful patch would be to capture the access log and > Benjamin> provide anonymized traces. > > The traces can be captured via DTrace scripts, so no patch is required here. > Right. Or a BPF on reasonably new linux kernels. > For instance: > https://www.postgresql.org/message-id/CAB%3DJe-F_BhGfBu1sO1H7u_XMtvak%3DBQtuJFyv8cfjGBRp7Q_yA%40mail.gmail.com > or > https://www.postgresql.org/message-id/CAH2-WzmbUWKvCqjDycpCOSF%3D%3DPEswVf6WtVutgm9efohH0NfHA%40mail.gmail.com > > The missing bit is a database with more-or-less relevant workload. > I think it'd be sufficient (or at least reasonable first step) to get traces from workloads regularly used for benchmarking (different flavors of pgbench workload, YCSB, TPC-H/TPC-DS and perhaps something else). A good algorithm has to perform well in those anyway, and applications generally can be modeled as a mix of those simple workloads. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi there. I was responsible for the benchmarks, and I would be glad to make clear that part for you. On Sat, 16 Feb 2019 at 02:30, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > Interesting. Where do these numbers (5/8 and 1/8) come from? The first number came from MySQL realization of LRU algorithm <https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html> and the second from simple tuning, we've tried to change 1/8 a little, but it didn't change metrics significantly. > That TPS chart looks a bit ... wild. How come the master jumps so much > up and down? That's a bit suspicious, IMHO. Yes, it is. It would be great if someone will try to reproduce those results. > How do I reproduce this benchmark? I'm aware of pg_ycsb, but maybe > you've used some other tools? Yes, we used pg_ycsb, but nothing more than that and pgbench, it's just maybe too simple. I attach the example of the sh script that has been used to generate database and measure each point on the chart. Build was generated without any additional debug flags in configuration. Database was mad by initdb with --data-checksums enabled and generated by initialization step in pgbench with --scale=11000. > Also, have you tried some other benchmarks (like, regular TPC-B as > implemented by pgbench, or read-only pgbench)? We need such benchmarks > with a range of access patterns to check for regressions. Yes, we tried all builtin pgbench benchmarks and YCSB-A,B,C from pg_ycsb with unoform and zipfian distribution. I also attach some other charts that we did, they are not as statistically significant as could because we used less time in them but hope that it will help. > BTW what do you mean by "sampling"? I meant that we measure tps and hit rate on several virtual machines for our and master build in order to neglect the influence that came from the difference between them. > > We used this config: [2] > > > > That's only half the information - it doesn't say how many clients were > running the benchmark etc. Yes, sorry for that missing, we've had virtual machines with configuration mentioned in the initial letter, with 16 jobs and 16 clients in pgbench configuration. [0] Scripts https://yadi.sk/d/PHICP0N6YrN5Cw [1] Measurements for other workloads https://yadi.sk/d/6G0e09Drf0ygag I will be looking forward if you have any other questions about measurement or code. Please note me if you have them. Best regards. -- Ivan Edigaryev
On 2/17/19 2:14 PM, Едигарьев, Иван Григорьевич wrote: > Hi there. I was responsible for the benchmarks, and I would be glad to > make clear that part for you. > > On Sat, 16 Feb 2019 at 02:30, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >> Interesting. Where do these numbers (5/8 and 1/8) come from? > > The first number came from MySQL realization of LRU algorithm > <https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html> > and the second from simple tuning, we've tried to change 1/8 a little, > but it didn't change metrics significantly. > >> That TPS chart looks a bit ... wild. How come the master jumps so much >> up and down? That's a bit suspicious, IMHO. > > Yes, it is. It would be great if someone will try to reproduce those results. > I'll try. >> How do I reproduce this benchmark? I'm aware of pg_ycsb, but maybe >> you've used some other tools? > > Yes, we used pg_ycsb, but nothing more than that and pgbench, it's > just maybe too simple. I attach the example of the sh script that has > been used to generate database and measure each point on the chart. > OK. I see the measurement script is running plain select-only test (so with uniform distribution). So how did you do the zipfian test? Also, I see the test is resetting all stats regularly - that may not be quite a good thing, because it also resets stats used by autovacuum for example. It's better to query the values before the run, and compute the delta. OTOH it should affect all tests about the same, I guess. > Build was generated without any additional debug flags in > configuration. Database was mad by initdb with --data-checksums > enabled and generated by initialization step in pgbench with > --scale=11000. > Sounds reasonable. >> Also, have you tried some other benchmarks (like, regular TPC-B as >> implemented by pgbench, or read-only pgbench)? We need such benchmarks >> with a range of access patterns to check for regressions. > > Yes, we tried all builtin pgbench benchmarks and YCSB-A,B,C from > pg_ycsb with unoform and zipfian distribution. I also attach some > other charts that we did, they are not as statistically significant as > could because we used less time in them but hope that it will help. > OK. Notice that the random_zipfian function is quite expensive in terms of CPU, and it may significantly skew the results particularly with large data sets / short runs. I've posted a message earlier, as I ran into the issue while trying to reproduce the behavior. >> BTW what do you mean by "sampling"? > > I meant that we measure tps and hit rate on several virtual machines > for our and master build in order to neglect the influence that came > from the difference between them. > OK >>> We used this config: [2] >>> >> >> That's only half the information - it doesn't say how many clients were >> running the benchmark etc. > > Yes, sorry for that missing, we've had virtual machines with > configuration mentioned in the initial letter, with 16 jobs and 16 > clients in pgbench configuration. > > [0] Scripts https://yadi.sk/d/PHICP0N6YrN5Cw > [1] Measurements for other workloads https://yadi.sk/d/6G0e09Drf0ygag > > I will be looking forward if you have any other questions about > measurement or code. Please note me if you have them. > Thanks. I'll try running some tests on my machines, I'll see if I manage to reproduce the suspicious behavior. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2/17/19 2:53 PM, Tomas Vondra wrote: > On 2/17/19 2:14 PM, Едигарьев, Иван Григорьевич wrote: >> Hi there. I was responsible for the benchmarks, and I would be glad to >> make clear that part for you. >> >> On Sat, 16 Feb 2019 at 02:30, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: >>> Interesting. Where do these numbers (5/8 and 1/8) come from? >> >> The first number came from MySQL realization of LRU algorithm >> <https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html> >> and the second from simple tuning, we've tried to change 1/8 a little, >> but it didn't change metrics significantly. >> >>> That TPS chart looks a bit ... wild. How come the master jumps so much >>> up and down? That's a bit suspicious, IMHO. >> >> Yes, it is. It would be great if someone will try to reproduce those results. >> > > I'll try. > I've tried to reproduce this behavior, and I've done a quite extensive set of tests on two different (quite different) machines, but so far I have not observed anything like that. The results are attached, along with the test scripts used. I wonder if this might be due to pg_ycsb using random_zipfian, which has somewhat annoying behavior for some parameters (as I've mentioned in a separate thread). But that should affect all the runs, not just some shared_buffers sizes. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
Hi Tomas,
If you are on a benchmarking binge and feel like generating some trace files (as mentioned earlier), I'd be happy to help in regards to running them through simulations to show how different policies behave. We can add more types to match this patch / Postgres' GClock as desired, too.
On Tue, Feb 26, 2019 at 3:04 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 2/17/19 2:53 PM, Tomas Vondra wrote:
> On 2/17/19 2:14 PM, Едигарьев, Иван Григорьевич wrote:
>> Hi there. I was responsible for the benchmarks, and I would be glad to
>> make clear that part for you.
>>
>> On Sat, 16 Feb 2019 at 02:30, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
>>> Interesting. Where do these numbers (5/8 and 1/8) come from?
>>
>> The first number came from MySQL realization of LRU algorithm
>> <https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html>
>> and the second from simple tuning, we've tried to change 1/8 a little,
>> but it didn't change metrics significantly.
>>
>>> That TPS chart looks a bit ... wild. How come the master jumps so much
>>> up and down? That's a bit suspicious, IMHO.
>>
>> Yes, it is. It would be great if someone will try to reproduce those results.
>>
>
> I'll try.
>
I've tried to reproduce this behavior, and I've done a quite extensive
set of tests on two different (quite different) machines, but so far I
have not observed anything like that. The results are attached, along
with the test scripts used.
I wonder if this might be due to pg_ycsb using random_zipfian, which has
somewhat annoying behavior for some parameters (as I've mentioned in a
separate thread). But that should affect all the runs, not just some
shared_buffers sizes.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services