Обсуждение: WIP Patch: Add a function that returns binary JSONB as a bytea
database=# SELECT jsonb_raw_bytes('{"b":12345}'::jsonb);
jsonb_raw_bytes
----------------------------------------------------------
\x0101000020010000800d0000106200000028000000018001002909
(1 row)
database=# SELECT jsonb_raw_bytes('{"a":{"b":12345}}'::jsonb->'a');
jsonb_raw_bytes
----------------------------------------------------------
\x0101000020010000800d0000106200000028000000018001002909
(1 row)
Some preliminary testing on my own machine shows me that this change has a significant impact on performance.
I used psql to select a jsonb column from all the rows in a table (about 1 million rows) where the json data was roughly 400-500 bytes per record.
database=# \timing
Timing is on.
database=# \o /tmp/raw_bytes_out.txt;
database=# SELECT jsonb_raw_bytes(data) FROM datatable;
Time: 2582.545 ms (00:02.583)
database=# \o /tmp/json_out.txt;
database=# SELECT data FROM datatable;
Time: 5653.235 ms (00:05.653)
Of note is that the size of raw_bytes_out.txt in the example is roughly twice that of json_out.txt so the timing difference is not due to less data being transferred.
Вложения
Kevin Van <kevinvan@shift.com> writes: > This patch adds a new function that allows callers to receive binary jsonb. > This change was proposed in the discussion here: > https://www.postgresql.org/message-id/CAOsiKEL7%2BKkV0C_hAJWxqwTg%2BPYVfiGPQ0yjFww7ECtqwBjb%2BQ%40mail.gmail.com > and the primary motivation is to reduce database load by skipping jsonb to > string conversion (with the expectation that the application can parse > binary jsonb). I dunno, I do not think it's a great idea to expose jsonb's internal format to the world. We intentionally did not do that when the type was first defined --- that's why its binary I/O format isn't already like this --- and I don't see that the tradeoffs have changed since then. The format is complex, and specific to Postgres' needs, and we might wish to change it in future. regards, tom lane
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Kevin Van <kevinvan@shift.com> writes: > > This patch adds a new function that allows callers to receive binary jsonb. > > This change was proposed in the discussion here: > > https://www.postgresql.org/message-id/CAOsiKEL7%2BKkV0C_hAJWxqwTg%2BPYVfiGPQ0yjFww7ECtqwBjb%2BQ%40mail.gmail.com > > and the primary motivation is to reduce database load by skipping jsonb to > > string conversion (with the expectation that the application can parse > > binary jsonb). > > I dunno, I do not think it's a great idea to expose jsonb's internal > format to the world. We intentionally did not do that when the type > was first defined --- that's why its binary I/O format isn't already > like this --- and I don't see that the tradeoffs have changed since then. > The format is complex, and specific to Postgres' needs, and we might wish > to change it in future. I disagree- it's awfully expensive to go back and forth between string and a proper representation. If we did decide to change the on-disk format, we'd likely be able to translate that format into the wire-protocol format and that'd still be much better than going to strings. As I recall, we did end up making changes to jsonb right before we released it and so, at the time, it was definitely a good thing that we hadn't exposed that format, but we're quite a few years in now (by the time 12 comes out, every supported release will have jsonb) and the format hasn't changed further. If we really did want to go to a new format in the future, we'd probably end up wanting to do so in a way which allowed us to avoid a full dump/restore of the database too, so we'd need code to be able to at least convert from the old format into the new format and it'd hopefully not be too bad to have code to go the other way too. Even if we didn't though, I expect library authors would deal with the update across a major version change- it's not like we don't do other things that require them to update (SCRAM being my current favorite) and they've been pretty good about getting things updated. As always, there'll be the fallback option of going back to text format too. Thanks! Stephen
Вложения
Stephen Frost <sfrost@snowman.net> writes:
> * Tom Lane (tgl@sss.pgh.pa.us) wrote:
>> I dunno, I do not think it's a great idea to expose jsonb's internal
>> format to the world. We intentionally did not do that when the type
>> was first defined --- that's why its binary I/O format isn't already
>> like this --- and I don't see that the tradeoffs have changed since then.
> I disagree- it's awfully expensive to go back and forth between string
> and a proper representation.
Has anyone put any effort into making jsonb_out() faster? I think that
that would be way more productive. Nobody is going to want to write
code to convert jsonb's internal form into whatever their application
uses; particularly not dealing with numeric fields.
In any case, the approach proposed in this patch seems like the worst
of all possible worlds: it's inconsistent and we get zero benefit from
having thrown away our information-hiding. If we're going to expose the
internal format, let's just change the definition of the type's binary
I/O format, thereby getting a win for purposes like COPY BINARY as well.
We'd need to ensure that jsonb_recv could tell whether it was seeing the
old or new format, but at worst that'd require prepending a header of
some sort. (In practice, I suspect we'd end up with a wire-format
definition that isn't exactly the bits-on-disk, but something easily
convertible to/from that and more easily verifiable by jsonb_recv.
Numeric subfields, for instance, ought to match the numeric wire
format, which IIRC isn't exactly the bits-on-disk either.)
regards, tom lane
On 10/31/2018 10:21 AM, Tom Lane wrote: > Stephen Frost <sfrost@snowman.net> writes: >> * Tom Lane (tgl@sss.pgh.pa.us) wrote: >>> I dunno, I do not think it's a great idea to expose jsonb's internal >>> format to the world. We intentionally did not do that when the type >>> was first defined --- that's why its binary I/O format isn't already >>> like this --- and I don't see that the tradeoffs have changed since then. >> I disagree- it's awfully expensive to go back and forth between string >> and a proper representation. > Has anyone put any effort into making jsonb_out() faster? I think that > that would be way more productive. Nobody is going to want to write > code to convert jsonb's internal form into whatever their application > uses; particularly not dealing with numeric fields. > > In any case, the approach proposed in this patch seems like the worst > of all possible worlds: it's inconsistent and we get zero benefit from > having thrown away our information-hiding. If we're going to expose the > internal format, let's just change the definition of the type's binary > I/O format, thereby getting a win for purposes like COPY BINARY as well. > We'd need to ensure that jsonb_recv could tell whether it was seeing the > old or new format, but at worst that'd require prepending a header of > some sort. (In practice, I suspect we'd end up with a wire-format > definition that isn't exactly the bits-on-disk, but something easily > convertible to/from that and more easily verifiable by jsonb_recv. > Numeric subfields, for instance, ought to match the numeric wire > format, which IIRC isn't exactly the bits-on-disk either.) > > jsonb_send() sends a version number byte, currently 1. So if we invent a new version we would send 2 and teach jsonb_recv to be able to handle both. This was kinda anticipated. I agree that just sending a blob of the internal format isn't a great idea. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Stephen Frost <sfrost@snowman.net> writes: > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > >> I dunno, I do not think it's a great idea to expose jsonb's internal > >> format to the world. We intentionally did not do that when the type > >> was first defined --- that's why its binary I/O format isn't already > >> like this --- and I don't see that the tradeoffs have changed since then. > > > I disagree- it's awfully expensive to go back and forth between string > > and a proper representation. > > Has anyone put any effort into making jsonb_out() faster? I think that > that would be way more productive. Nobody is going to want to write > code to convert jsonb's internal form into whatever their application > uses; particularly not dealing with numeric fields. I'm all for making jsonb_out() faster, but even a faster jsonb_out() isn't going to be faster than shoveling the jsonb across. The concern over the application question seems like a complete red herring to me- people will bake into the various libraries the ability to convert from our jsonb format to the language's preferred json data structure, and even if that doesn't happen, we clearly have someone here who is saying they'd write code to convert from our jsonb format to whatever their application or language uses, and we've heard that multiple times on this list. > In any case, the approach proposed in this patch seems like the worst > of all possible worlds: it's inconsistent and we get zero benefit from > having thrown away our information-hiding. If we're going to expose the > internal format, let's just change the definition of the type's binary > I/O format, thereby getting a win for purposes like COPY BINARY as well. I hadn't looked at the patch, so I'm not surprised it has issues. I recall there was some prior discussion about what a good approach was to implementing this and that changing the binary i/o format was the way to go, but certainly a review of the threads should be done by whomever wants to implement this or review the patch. > We'd need to ensure that jsonb_recv could tell whether it was seeing the > old or new format, but at worst that'd require prepending a header of > some sort. (In practice, I suspect we'd end up with a wire-format > definition that isn't exactly the bits-on-disk, but something easily > convertible to/from that and more easily verifiable by jsonb_recv. > Numeric subfields, for instance, ought to match the numeric wire > format, which IIRC isn't exactly the bits-on-disk either.) Agreed, that'd certainly be a good idea. Thanks! Stephen
Вложения
Hi, On 2018-10-31 11:13:13 -0400, Andrew Dunstan wrote: > I agree that just sending a blob of the internal format isn't a great idea. It's entirely unacceptable afaict. Besides the whole "exposing internals" issue, it's also at least not endianess safe, depends on the local alignment requirements (which differ both between platforms and 32/64 bit), numeric's internal encoding and probably more. Greetings, Andres Freund
If we're going to expose the
internal format, let's just change the definition of the type's binary
I/O format, thereby getting a win for purposes like COPY BINARY as well.
We'd need to ensure that jsonb_recv could tell whether it was seeing the
old or new format, but at worst that'd require prepending a header of
some sort. (In practice, I suspect we'd end up with a wire-format
definition that isn't exactly the bits-on-disk, but something easily
convertible to/from that and more easily verifiable by jsonb_recv.
Numeric subfields, for instance, ought to match the numeric wire
format, which IIRC isn't exactly the bits-on-disk either.)
Applications currently receive JSON strings when reading JSONB data, and the driver presumably has to stay compatible with that. Does that mean the driver transparently converts JSONB to JSON before handing it to the application? That scales better than doing it in Postgres itself, but is still the kind of inefficiency we're trying to avoid.
So, AFAICS, when the application requests JSONB data, the driver has to hand it the raw JSONB bytes. But that's incompatible with what currently happens. To preserve compatibility, does the application have to opt in by setting some out-of-band per-query per-result-column flags to tell the driver how it wants the JSONB data returned? That's workable in principle but bloats every driver's API with some rarely-used performance feature. Seems much simpler to put this into the query.
The idea behind the proposal is to improve efficiency by avoiding conversions, and the most straightforward way to do that is for every layer to pass through the raw bytes. With an explicit conversion to BYTEA in the query, this is automatic without any changes to drivers, since every layer already knows to leave BYTEAs untouched.
Christian Ohler <ohler@shift.com> writes:
> On Wed, Oct 31, 2018 at 7:22 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> If we're going to expose the
>> internal format, let's just change the definition of the type's binary
>> I/O format, thereby getting a win for purposes like COPY BINARY as well.
> How would this work from the driver's and application's perspective? What
> does the driver do when receiving JSONB data?
Well, upthread it was posited that applications that read binary JSONB
data would be willing to track changes in that format (or else have no
need to, because they don't do anything with it except feed it back to the
server). If that isn't the case, then this entire thread is a waste of
time. I certainly don't buy that exposing the internal format via some
other mechanism than binary I/O would be a sufficient excuse for not
worrying about cross-version compatibility.
> The idea behind the proposal is to improve efficiency by avoiding
> conversions, and the most straightforward way to do that is for every layer
> to pass through the raw bytes.
This argument is, frankly, as bogus as it could possibly be. In the first
place, you're essentially saying that ignoring version compatibility
considerations entirely is the way to avoid future version compatibility
problems. I don't buy it. In the second place, you already admitted
that format conversion *is* necessary; what PG finds best internally is
unlikely to be exactly what some other piece of software will want.
So we'd be better off agreeing on some common interchange format.
I'm still bemused by the proposition that that common interchange format
shouldn't be, um, JSON. We've already seen BSON, BJSON, etc die
well-deserved deaths. Why would jsonb internal format, which was never
for one second intended to be seen anywhere outside PG, be a better
interchange-format design than those were?
(In short, I remain unconvinced that we'd not be better off spending
our effort on making json_out faster...)
regards, tom lane
Greetings, * Tom Lane (tgl@sss.pgh.pa.us) wrote: > Christian Ohler <ohler@shift.com> writes: > > On Wed, Oct 31, 2018 at 7:22 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> If we're going to expose the > >> internal format, let's just change the definition of the type's binary > >> I/O format, thereby getting a win for purposes like COPY BINARY as well. > > > How would this work from the driver's and application's perspective? What > > does the driver do when receiving JSONB data? > > Well, upthread it was posited that applications that read binary JSONB > data would be willing to track changes in that format (or else have no > need to, because they don't do anything with it except feed it back to the > server). If that isn't the case, then this entire thread is a waste of > time. I certainly don't buy that exposing the internal format via some > other mechanism than binary I/O would be a sufficient excuse for not > worrying about cross-version compatibility. Yes, I agree that the applications/libraries would need to be expecting and able to handle changes to the format, though, of course, we'd only change the format across major versions- we wouldn't do it in a point release. There might be some argument for supporting multiple versions also, though we don't really have support for anything like that today, unfortunately. > > The idea behind the proposal is to improve efficiency by avoiding > > conversions, and the most straightforward way to do that is for every layer > > to pass through the raw bytes. > > This argument is, frankly, as bogus as it could possibly be. In the first > place, you're essentially saying that ignoring version compatibility > considerations entirely is the way to avoid future version compatibility > problems. I don't buy it. In the second place, you already admitted > that format conversion *is* necessary; what PG finds best internally is > unlikely to be exactly what some other piece of software will want. > So we'd be better off agreeing on some common interchange format. There will definitely need to be *some* kind of conversion happening, the point of doing this would be to give us similar benefits as we have when passing binary data with the PG protocol today- sure, the data as the application gets it back probably isn't exactly in the format the application would like, but at least it's just moving bytes around typically (network byte order to host byte order, putting things into some application-side structure, etc). Today, with jsonb, we have the data stored as binary, but we have to go through the binary->text->binary conversion for every binary value and that's far from free. > I'm still bemused by the proposition that that common interchange format > shouldn't be, um, JSON. We've already seen BSON, BJSON, etc die > well-deserved deaths. Why would jsonb internal format, which was never > for one second intended to be seen anywhere outside PG, be a better > interchange-format design than those were? I'd suggest that it's because our jsonb format doesn't have the limitations that the others had. That said, I also agree that we wouldn't stream out the *exact* format that's on disk, but the point, at least to me, is to avoid bouncing back and forth between binary and text representation of things like integers, floats, timestamps, etc, where we already support binary-format results being sent out of PG to an application. Thanks! Stephen
Вложения
> On 2 Nov 2018, at 04:21, Tom Lane <tgl@sss.pgh.pa.us> wrote: > (In short, I remain unconvinced that we'd not be better off spending > our effort on making json_out faster...) Shooting wildly from the hip, isn't this a case where we can potentially utilize the JIT infrastructure to speed it up? cheers ./daniel
On 11/02/2018 01:42 PM, Daniel Gustafsson wrote: >> On 2 Nov 2018, at 04:21, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> (In short, I remain unconvinced that we'd not be better off spending >> our effort on making json_out faster...) > > Shooting wildly from the hip, isn't this a case where we can > potentially utilize the JIT infrastructure to speed it up? > I don't see how could it help here. The crucial idea of JIT is that if you postpone the compilation, you may provide additional information that may allow eliminating parts of the code. For example, we don't know anything about table structure in general, so the tuple deforming code had to assume any attribute may be NULL etc. making the code rather complex with many branches, loops etc. But at runtime we have the tuple descriptor, so with JIT we may eliminate some of the branches. But we don't have anything like that for jsonb - every value may be an arbitrary json document, etc. And each value (even if stored in the same column) may be entirely different. Maybe it's just lack of imagination on my side, but I don't see how could this benefit from JIT :-( regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Oct 31, 2018 at 10:23 AM Andres Freund <andres@anarazel.de> wrote: > > Hi, > > On 2018-10-31 11:13:13 -0400, Andrew Dunstan wrote: > > I agree that just sending a blob of the internal format isn't a great idea. > > It's entirely unacceptable afaict. Besides the whole "exposing > internals" issue, it's also at least not endianess safe, depends on the > local alignment requirements (which differ both between platforms and > 32/64 bit), numeric's internal encoding and probably more. Binary format consuming applications already have to deal with these kinds of issues. We already expose internal structures in the other functions -- not sure why jsonb is held to a different standard. For other data types where format changes were made, the standard of 'caveat version' was in place to protect the user. For jsonb we decided to implement a version flag within the type itself, which I thought mistake at the time -- better to have a version header in the COPY BINARY if needed. People using binary format are basically interested one one thing, performance. It's really the fastest way to get data in an out of the database. For my part, I'd like to see some observed demonstrable benefit in terms of performance to justify making the change. merlin
Merlin Moncure <mmoncure@gmail.com> writes:
> On Wed, Oct 31, 2018 at 10:23 AM Andres Freund <andres@anarazel.de> wrote:
>> It's entirely unacceptable afaict. Besides the whole "exposing
>> internals" issue, it's also at least not endianess safe, depends on the
>> local alignment requirements (which differ both between platforms and
>> 32/64 bit), numeric's internal encoding and probably more.
> Binary format consuming applications already have to deal with these
> kinds of issues. We already expose internal structures in the other
> functions -- not sure why jsonb is held to a different standard.
I don't think it's being held to a different standard at all. Even for
data as simple as integers/floats, we convert to uniform endianness on the
wire. Moreover, we do not expose the exact bits for anything more complex
than machine floats. Numeric, for instance, gets disassembled into fields
rather than showing the exact header format (let alone several different
header formats, as actually found on disk).
Andres' point about alignment is a pretty good one as well, if it applies
here --- I don't recall just what internal alignment requirements jsonb
has. We have not historically expected clients to have to deal with that.
I agree that in any particular use-case one could argue for a different
set of trade-offs in choosing the exposed binary format. But this is the
set that the project has chosen, and one would need to make a FAR stronger
case than has been made here to let jsonb be an exception.
regards, tom lane
On Fri, Nov 2, 2018 at 10:53 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Merlin Moncure <mmoncure@gmail.com> writes: > > On Wed, Oct 31, 2018 at 10:23 AM Andres Freund <andres@anarazel.de> wrote: > >> It's entirely unacceptable afaict. Besides the whole "exposing > >> internals" issue, it's also at least not endianess safe, depends on the > >> local alignment requirements (which differ both between platforms and > >> 32/64 bit), numeric's internal encoding and probably more. > > > Binary format consuming applications already have to deal with these > > kinds of issues. We already expose internal structures in the other > > functions -- not sure why jsonb is held to a different standard. > > I don't think it's being held to a different standard at all. Even for > data as simple as integers/floats, we convert to uniform endianness on the > wire. Moreover, we do not expose the exact bits for anything more complex > than machine floats. Numeric, for instance, gets disassembled into fields > rather than showing the exact header format (let alone several different > header formats, as actually found on disk). > > Andres' point about alignment is a pretty good one as well, if it applies > here --- I don't recall just what internal alignment requirements jsonb > has. We have not historically expected clients to have to deal with that. I see your (and Andres') point; the binary wire format ought to lay on top of the basic contracts established by other types. It can be binary; just not a straight memcpy out of the server. The array and composite type serializers should give some inspiration there on serialization. I'll still stand other point I made though; I'd really want to see some benchmarks demonstrating benefit over competing approaches that work over the current formats. That should frame the argument as to whether this is a good idea. merlin
Greetings, * Merlin Moncure (mmoncure@gmail.com) wrote: > On Fri, Nov 2, 2018 at 10:53 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Andres' point about alignment is a pretty good one as well, if it applies > > here --- I don't recall just what internal alignment requirements jsonb > > has. We have not historically expected clients to have to deal with that. > > I see your (and Andres') point; the binary wire format ought to lay on > top of the basic contracts established by other types. It can be > binary; just not a straight memcpy out of the server. The array and > composite type serializers should give some inspiration there on > serialization. Right- I agree w/ Tom and Andres on this part also. > I'll still stand other point I made though; I'd > really want to see some benchmarks demonstrating benefit over > competing approaches that work over the current formats. That should > frame the argument as to whether this is a good idea. What are the 'competing approaches' you're alluding to here? Sending text-format json across as we do today? Is there something else you're thinking would be appropriate in this kind of a performance bake-off...? I'm having a hard time seeing what else would actually have the flexibility that JSON does without being clearly worse (xml?). Thanks! Stephen
Вложения
On Fri, Nov 2, 2018 at 11:15 AM Stephen Frost <sfrost@snowman.net> wrote: > > Greetings, > > * Merlin Moncure (mmoncure@gmail.com) wrote: > > On Fri, Nov 2, 2018 at 10:53 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > Andres' point about alignment is a pretty good one as well, if it applies > > > here --- I don't recall just what internal alignment requirements jsonb > > > has. We have not historically expected clients to have to deal with that. > > > > I see your (and Andres') point; the binary wire format ought to lay on > > top of the basic contracts established by other types. It can be > > binary; just not a straight memcpy out of the server. The array and > > composite type serializers should give some inspiration there on > > serialization. > > Right- I agree w/ Tom and Andres on this part also. > > > I'll still stand other point I made though; I'd > > really want to see some benchmarks demonstrating benefit over > > competing approaches that work over the current formats. That should > > frame the argument as to whether this is a good idea. > > What are the 'competing approaches' you're alluding to here? Sending > text-format json across as we do today? Yep -- exactly. For example, write a C client program that recursed the structure and dumped it to stdout or assigned to dummy variables (being mindful of compiler optimizations). I'd be contrasting this to a C parsed json that did essentially the same thing, and rigging a high scale test on the back of that. The assumption here is that the ultimate consumer is not, say, a browser, but some client app that can actually exploit the performance advantages (else, why bother?). In my experience with arrays and composites, you can see significant performance reduction and throughput increase in certain classes of queries. However, some of the types that were the worst offenders (like timestamps) have been subsequently optimized and/or are irrelevant to json since they'd be passed as test anyways. merlin
Greetings, * Merlin Moncure (mmoncure@gmail.com) wrote: > On Fri, Nov 2, 2018 at 11:15 AM Stephen Frost <sfrost@snowman.net> wrote: > > * Merlin Moncure (mmoncure@gmail.com) wrote: > > > I'll still stand other point I made though; I'd > > > really want to see some benchmarks demonstrating benefit over > > > competing approaches that work over the current formats. That should > > > frame the argument as to whether this is a good idea. > > > > What are the 'competing approaches' you're alluding to here? Sending > > text-format json across as we do today? > > Yep -- exactly. For example, write a C client program that recursed > the structure and dumped it to stdout or assigned to dummy variables > (being mindful of compiler optimizations). I'd be contrasting this to > a C parsed json that did essentially the same thing, and rigging a > high scale test on the back of that. The assumption here is that the > ultimate consumer is not, say, a browser, but some client app that can > actually exploit the performance advantages (else, why bother?). If transferring the data in binary doesn't show a performance improvement then I could agree that it wouldn't be sensible to do- but I also find that very unlikely to be the case. As for what language it's written in- I don't think that matters much. I'd very much expect it to be more performant to use binary if you're working in C, of course, but there's no point comparing C-parsed json into some C structure vs. psycopg2 injesting binary data and building a Python json object- what matters is if it'd be faster for psycopg2 to pull in binary-json data and put it into a Python json object, or if it'd be faster to parse the text-json data and put the result into the same Python object. In my view, there's something clearly quite wrong if the text-json data format is faster at that. > In my experience with arrays and composites, you can see significant > performance reduction and throughput increase in certain classes of > queries. However, some of the types that were the worst offenders > (like timestamps) have been subsequently optimized and/or are > irrelevant to json since they'd be passed as test anyways. I've had very good success transferring timestamps as binary, so I'm not quite sure what you're getting at here. Thanks! Stephen
Вложения
On Fri, Nov 2, 2018 at 2:34 PM Stephen Frost <sfrost@snowman.net> wrote: > * Merlin Moncure (mmoncure@gmail.com) wrote: > As for what language it's written in- I don't think that matters much. > I'd very much expect it to be more performant to use binary if you're > working in C, of course, but there's no point comparing C-parsed json > into some C structure vs. psycopg2 injesting binary data and building a > Python json object- what matters is if it'd be faster for psycopg2 to > pull in binary-json data and put it into a Python json object, or if > it'd be faster to parse the text-json data and put the result into the > same Python object. In my view, there's something clearly quite wrong > if the text-json data format is faster at that. Yeah, I figure the language would be C or another language with drivers smart enough to speak the binary protocol. > > In my experience with arrays and composites, you can see significant > > performance reduction and throughput increase in certain classes of > > queries. However, some of the types that were the worst offenders > > (like timestamps) have been subsequently optimized and/or are > > irrelevant to json since they'd be passed as test anyways. > > I've had very good success transferring timestamps as binary, so I'm not > quite sure what you're getting at here. Er, yes, timestamps are much faster in binary -- that is what I'd observed and was the point I was trying to make. They are slightly less faster with recent optimizations but still faster. In the old days I saw as much as +50% throughput binary vs text in certain contrived situations; that may no longer be true today. merlin
On 11/02/2018 11:34 AM, Merlin Moncure wrote: > > Binary format consuming applications already have to deal with these > kinds of issues. We already expose internal structures in the other > functions -- not sure why jsonb is held to a different standard. For > other data types where format changes were made, the standard of > 'caveat version' was in place to protect the user. For jsonb we > decided to implement a version flag within the type itself, which I > thought mistake at the time -- better to have a version header in the > COPY BINARY if needed. > jsonb_send does output a version header, as I pointed out upthread. cheers andrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-11-02 10:34:07 -0500, Merlin Moncure wrote: > On Wed, Oct 31, 2018 at 10:23 AM Andres Freund <andres@anarazel.de> wrote: > > > > Hi, > > > > On 2018-10-31 11:13:13 -0400, Andrew Dunstan wrote: > > > I agree that just sending a blob of the internal format isn't a great idea. > > > > It's entirely unacceptable afaict. Besides the whole "exposing > > internals" issue, it's also at least not endianess safe, depends on the > > local alignment requirements (which differ both between platforms and > > 32/64 bit), numeric's internal encoding and probably more. > > Binary format consuming applications already have to deal with these > kinds of issues. Uh, which? We have some that are affected by configure flags, but otherwise we should be endianess & alignment independent. And *even if* that were the case, that's not a good reason to continue a bad practice. > For jsonb we decided to implement a version flag within the type > itself, which I thought mistake at the time -- better to have a > version header in the COPY BINARY if needed. What's the problem with the version? How does a COPY BINARY flag address normal clients? Greetings, Andres Freund
Hi,
On 2018-11-02 11:52:59 -0400, Tom Lane wrote:
> Andres' point about alignment is a pretty good one as well, if it applies
> here --- I don't recall just what internal alignment requirements jsonb
> has. We have not historically expected clients to have to deal with that.
Certainly looks like it takes it into account:
static void
fillJsonbValue(JsonbContainer *container, int index,
char *base_addr, uint32 offset,
JsonbValue *result)
...
else if (JBE_ISNUMERIC(entry))
{
result->type = jbvNumeric;
result->val.numeric = (Numeric) (base_addr + INTALIGN(offset));
}
...
else
{
Assert(JBE_ISCONTAINER(entry));
result->type = jbvBinary;
/* Remove alignment padding from data pointer and length */
result->val.binary.data = (JsonbContainer *) (base_addr + INTALIGN(offset));
result->val.binary.len = getJsonbLength(container, index) -
(INTALIGN(offset) - offset);
}
...
Greetings,
Andres Freund
Hi, On 2018-11-02 17:02:24 -0400, Andrew Dunstan wrote: > On 11/02/2018 11:34 AM, Merlin Moncure wrote: > > > > Binary format consuming applications already have to deal with these > > kinds of issues. We already expose internal structures in the other > > functions -- not sure why jsonb is held to a different standard. For > > other data types where format changes were made, the standard of > > 'caveat version' was in place to protect the user. For jsonb we > > decided to implement a version flag within the type itself, which I > > thought mistake at the time -- better to have a version header in the > > COPY BINARY if needed. > > > > > jsonb_send does output a version header, as I pointed out upthread. That's Merlin's point I think. For reasons I don't quite understand he doesn't like that. Yes, a global solution would have been prettier than per-datum version flag, but that obvioulsy wasn't realistic to introduce around the feature freeze of the version that introduced jsonb. Greetings, Andres Freund
On 11/02/2018 05:20 PM, Andres Freund wrote: > Hi, > > On 2018-11-02 17:02:24 -0400, Andrew Dunstan wrote: >> On 11/02/2018 11:34 AM, Merlin Moncure wrote: >>> Binary format consuming applications already have to deal with these >>> kinds of issues. We already expose internal structures in the other >>> functions -- not sure why jsonb is held to a different standard. For >>> other data types where format changes were made, the standard of >>> 'caveat version' was in place to protect the user. For jsonb we >>> decided to implement a version flag within the type itself, which I >>> thought mistake at the time -- better to have a version header in the >>> COPY BINARY if needed. >>> >> >> jsonb_send does output a version header, as I pointed out upthread. > That's Merlin's point I think. For reasons I don't quite understand he > doesn't like that. Yes, a global solution would have been prettier than > per-datum version flag, but that obvioulsy wasn't realistic to introduce > around the feature freeze of the version that introduced jsonb. > > > Oh, hmm. It would have been a big change of little value, ISTM. One byte of overhead per jsonb datum for a version indicator doesn't seem a huge price to pay. cheers andtrew -- Andrew Dunstan https://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Oct 31, 2018 at 11:18:46AM -0400, Stephen Frost wrote: > Greetings, > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > Stephen Frost <sfrost@snowman.net> writes: > > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > >> I dunno, I do not think it's a great idea to expose jsonb's internal > > >> format to the world. We intentionally did not do that when the type > > >> was first defined --- that's why its binary I/O format isn't already > > >> like this --- and I don't see that the tradeoffs have changed since then. > > > > > I disagree- it's awfully expensive to go back and forth between string > > > and a proper representation. > > > > Has anyone put any effort into making jsonb_out() faster? I think that > > that would be way more productive. Nobody is going to want to write > > code to convert jsonb's internal form into whatever their application > > uses; particularly not dealing with numeric fields. > > I'm all for making jsonb_out() faster, but even a faster jsonb_out() > isn't going to be faster than shoveling the jsonb across. Would it be completely batty to try store JSONB on disk in wire format and optimize accesses, indexing, etc. around that? Best, David. -- David Fetter <david(at)fetter(dot)org> http://fetter.org/ Phone: +1 415 235 3778 Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On 2018-11-02 23:24:35 +0100, David Fetter wrote: > On Wed, Oct 31, 2018 at 11:18:46AM -0400, Stephen Frost wrote: > > Greetings, > > > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > > Stephen Frost <sfrost@snowman.net> writes: > > > > * Tom Lane (tgl@sss.pgh.pa.us) wrote: > > > >> I dunno, I do not think it's a great idea to expose jsonb's internal > > > >> format to the world. We intentionally did not do that when the type > > > >> was first defined --- that's why its binary I/O format isn't already > > > >> like this --- and I don't see that the tradeoffs have changed since then. > > > > > > > I disagree- it's awfully expensive to go back and forth between string > > > > and a proper representation. > > > > > > Has anyone put any effort into making jsonb_out() faster? I think that > > > that would be way more productive. Nobody is going to want to write > > > code to convert jsonb's internal form into whatever their application > > > uses; particularly not dealing with numeric fields. > > > > I'm all for making jsonb_out() faster, but even a faster jsonb_out() > > isn't going to be faster than shoveling the jsonb across. > > Would it be completely batty to try store JSONB on disk in wire format > and optimize accesses, indexing, etc. around that? It doesn't seem to make any sense whatsoever. For one, the current wire format is text. If that's your argument, uh, yes, we have jsonb over json for a reason. If you're talking about a hypothetical future wire format, that seems unlikely as well - for one there's obviously on-disk compat issues, for another, the on-disk format is already kind of optimized to store what it stores. And on-wire and on-disk concerns are different. Greetings, Andres Freund
On Fri, Nov 2, 2018 at 5:15 PM Andrew Dunstan <andrew.dunstan@2ndquadrant.com> wrote: > On 11/02/2018 05:20 PM, Andres Freund wrote: > > Hi, > > > > On 2018-11-02 17:02:24 -0400, Andrew Dunstan wrote: > >> On 11/02/2018 11:34 AM, Merlin Moncure wrote: > >>> Binary format consuming applications already have to deal with these > >>> kinds of issues. We already expose internal structures in the other > >>> functions -- not sure why jsonb is held to a different standard. For > >>> other data types where format changes were made, the standard of > >>> 'caveat version' was in place to protect the user. For jsonb we > >>> decided to implement a version flag within the type itself, which I > >>> thought mistake at the time -- better to have a version header in the > >>> COPY BINARY if needed. > >>> > >> > >> jsonb_send does output a version header, as I pointed out upthread. > > That's Merlin's point I think. For reasons I don't quite understand he > > doesn't like that. Yes, a global solution would have been prettier than > > per-datum version flag, but that obvioulsy wasn't realistic to introduce > > around the feature freeze of the version that introduced jsonb. > > > Oh, hmm. It would have been a big change of little value, ISTM. One byte > of overhead per jsonb datum for a version indicator doesn't seem a huge > price to pay. Yeah -- it really isn't. My concern was more that it seemed odd to protect one type with a version flag where others aren't; format agreement strikes me as more of a protocol negotiation thing than an aspect of each individual data point. It also makes for slightly odd (IMO) client side coding. The contract is of concern, not the overhead. It works well enough though...we discussed this a bit when the header was introduced and the discussion ended exactly the same way :-). merlin
(reviving an old thread) On Thu, 23 Jun 2022 at 13:29, Merlin Moncure <mmoncure@gmail.com> wrote: > I'll still stand other point I made though; I'd > really want to see some benchmarks demonstrating benefit over > competing approaches that work over the current formats. That should > frame the argument as to whether this is a good idea. I tried to use COPY BINARY to copy data recently from one Postgres server to another and it was much slower than I expected. The backend process on the receiving side was using close to 100% of a CPU core. So the COPY command was clearly CPU bound in this case. After doing a profile it became clear that 50% of the CPU time was spent on parsing JSON. This seems extremely excessive to me. I'm pretty sure any semi-decent binary format would be able to outperform this. FYI: The table being copied contained large JSONB blobs in one of the columns. These blobs were around 15kB for each row.
(attached is the flamegraph of the profile, in case others are interested) On Thu, 23 Jun 2022 at 13:33, Jelte Fennema <me@jeltef.nl> wrote: > > (reviving an old thread) > > On Thu, 23 Jun 2022 at 13:29, Merlin Moncure <mmoncure@gmail.com> wrote: > > I'll still stand other point I made though; I'd > > really want to see some benchmarks demonstrating benefit over > > competing approaches that work over the current formats. That should > > frame the argument as to whether this is a good idea. > > I tried to use COPY BINARY to copy data recently from one Postgres > server to another and it was much slower than I expected. The backend > process on the receiving side was using close to 100% of a CPU core. > So the COPY command was clearly CPU bound in this case. After doing a > profile it became clear that 50% of the CPU time was spent on parsing > JSON. This seems extremely excessive to me. I'm pretty sure any > semi-decent binary format would be able to outperform this. > > FYI: The table being copied contained large JSONB blobs in one of the > columns. These blobs were around 15kB for each row.
Вложения
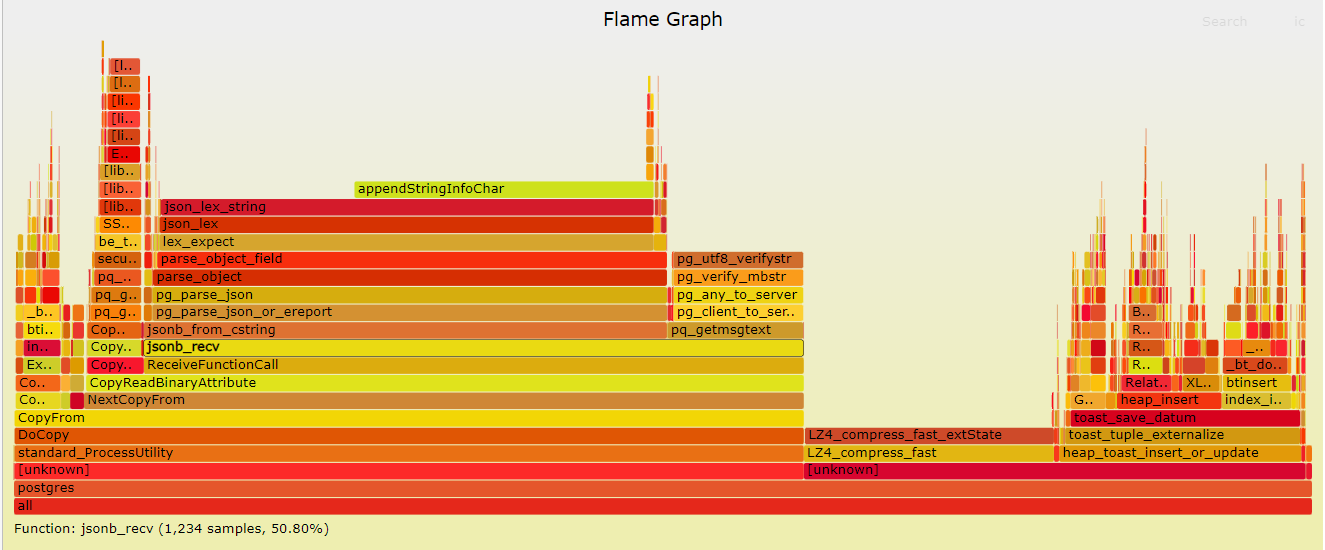{kind=link}
Hi, On 2022-06-23 13:33:24 +0200, Jelte Fennema wrote: > (reviving an old thread) > > On Thu, 23 Jun 2022 at 13:29, Merlin Moncure <mmoncure@gmail.com> wrote: > > I'll still stand other point I made though; I'd > > really want to see some benchmarks demonstrating benefit over > > competing approaches that work over the current formats. That should > > frame the argument as to whether this is a good idea. > > I tried to use COPY BINARY to copy data recently from one Postgres > server to another and it was much slower than I expected. The backend > process on the receiving side was using close to 100% of a CPU core. > So the COPY command was clearly CPU bound in this case. After doing a > profile it became clear that 50% of the CPU time was spent on parsing > JSON. This seems extremely excessive to me. It looks like there's quite a bit of low hanging fruits to optimize... > I'm pretty sure any semi-decent binary format would be able to outperform > this. Sure. It's a decent amount of work to define one though... It's clearly not acceptable to just dump out the internal representation, as already discussed in this thread. Greetings, Andres Freund
On Thu, Jun 23, 2022 at 9:06 PM Andres Freund <andres@anarazel.de> wrote: > It looks like there's quite a bit of low hanging fruits to optimize... Yeah, if escapes and control characters are rare, adding an SSE2 fast path would give a boost to json_lex_string: check 16 bytes at a time for those chars (plus the ending double-quote). We can also shave a few percent by having pg_utf8_verifystr use SSE2 for the ascii path. I can look into this. -- John Naylor EDB: http://www.enterprisedb.com
> It's a decent amount of work to define one though... It's clearly not > acceptable to just dump out the internal representation, as already discussed > in this thread. I totally agree that it should be a well-defined format that doesn't leak stuff like endianness and alignment of the underlying database. With a bit of googling I found the UBJSON specification: https://ubjson.org/#data_format It seems like it would be possible to transform between JSONB and UBJSON efficiently. As an example: For my recent use case the main thing that was slow was parsing JSON strings, because of the escape characters. That's not needed with UBJSON, because strings are simply UTF-8 encoded binary data, that are prefixed with their length. So all that would be needed is checking if the binary data is valid UTF-8. Also there seem to be implementations in many languages for this spec: https://ubjson.org/libraries/ So, that should make it easy for Postgres client libraries to support this binary format. > I'm still bemused by the proposition that that common interchange format > shouldn't be, um, JSON. We've already seen BSON, BJSON, etc die > well-deserved deaths. @Tom Lane: UBJSON calls explicitly lists these specific failed attempts at a binary encoding for JSON as the reason for why it was created, aiming to fix the issues those specs have: https://github.com/ubjson/universal-binary-json#why Jelte
Hi, On 2022-06-24 14:33:00 +0700, John Naylor wrote: > On Thu, Jun 23, 2022 at 9:06 PM Andres Freund <andres@anarazel.de> wrote: > > It looks like there's quite a bit of low hanging fruits to optimize... > > Yeah, if escapes and control characters are rare, adding an SSE2 fast > path would give a boost to json_lex_string: check 16 bytes at a time > for those chars (plus the ending double-quote). The biggest thing I see is building the string in bigger chunks. Doing a separate appendStringInfoChar() for each input character is obviously bad for performance. I'd bet a good chunk of the time attributed to json_lex_string() in Jelte's flamegraph is actually setting up the external function call to appendStringInfoChar(). Which then proceeds to do a check whether the buffer needs to be enlarged and maintains the trailing null byte on every call. Greetings, Andres Freund
I wrote: > We can also shave a > few percent by having pg_utf8_verifystr use SSE2 for the ascii path. I > can look into this. Here's a patch for that. If the input is mostly ascii, I'd expect that part of the flame graph to shrink by 40-50% and give a small boost overall. -- John Naylor EDB: http://www.enterprisedb.com