Обсуждение: WIP: "More fair" LWLocks
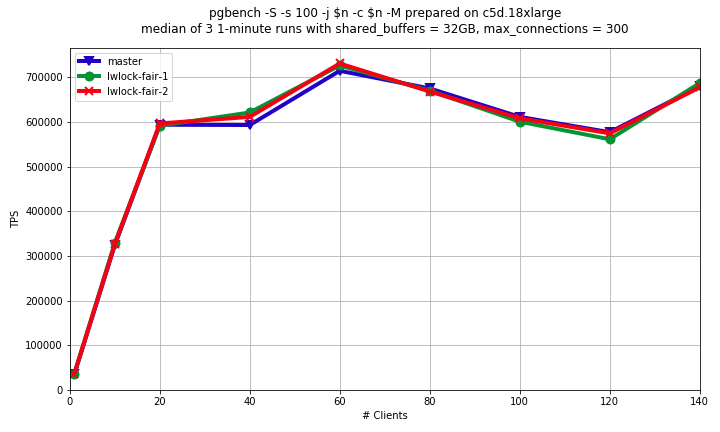
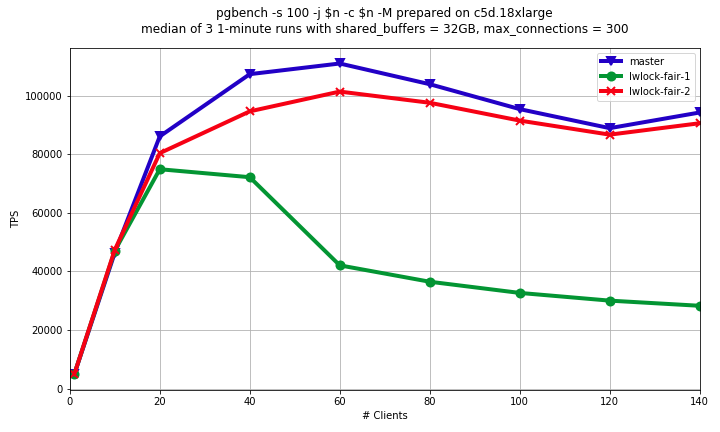
Hi! This subject was already raised multiple times [1], [2], [3]. In short, our LWLock implementation has pathological behavior when shared lockers constitute a continuous flood. In this case exclusive lock waiters are not guaranteed to eventually get the lock. When shared lock is held, other shared lockers goes without any queue. This is why despite individual shared lock durations are small, when flood of shared lockers is high enough then there might be no gap to process exclusive lockers. Such behavior is periodically reported on different LWLocks. And that leads to an idea of making our LWLocks "more fair", which would make infinite starvation of exclusive lock waiters impossible. This idea was a subject of critics. And I can summarize arguments of this critics as following: 1) LWLocks are designed to be unfair. Their unfairness is downside of high performance in majority of scenarios. 2) Attempt to make LWLocks "more fair" would lead to unacceptable general performance regression. 3) If exclusive locks waiters are faced with infinite starvation, then that's not a problem of tLWLocks implementation, but that's a problem of particular use case. So, we need to fix LWLocks use cases, not LWLocks themselves. I see some truth in these arguments. But I can't agree that we shouldn't try to fix LWLocks unfairness. And I see following arguments for that: 1) It doesn't look like we can ever fix all the LWLocks use cases in the way, which would make infinite starvation impossible. Usage of NUMA systems is rising, and more LWLocks use cases are becoming pathological. For instance, there been much efforts placed to reduce ProcArrayLock contention, but on multicore machine with heavy readonly workload it might be still impossible to login or commit transaction. Or another recent example: buffer mapping lock becomes reason of eviction blocking [3]. 2) The situation of infinite exclusive locker starvation is much worse than just bad overall DBMS performance. We are doing our best on removing high contention points in PostgreSQL. It's very good, but it's an infinite race, assuming that new hardware platforms are arriving. But situation when you can't connect to the database when the system have free resources is much worse than situation when PostgreSQL doesn't scale well enough on your brand new hardware. 3) It's not necessary to make LWLocks completely fair in order to exclude infinite starvation of exclusive lockers. So, it's not necessary to put all the shared lockers into the queue. In the majority of cases, shared lockers might still go through directly, but on some event we might decide that it's too much and they should to the queue. So, taking into account all of above I made some experiments with patches making LWLocks "more fair". I'd like to share some intermediate results. I've written two patches for comparison. 1) lwlock-far-1.patch Shared locker goes to the queue if there is already somebody in the queue, otherwise obtains lock immediately. 2) lwlock-far-2.patch New flag LW_FLAG_FAIR is introduced. This flag is set when first shared locker in the row releases the lock. When LW_FLAG_FAIR is set and there is already somebody in the queue, then shared locker goes to the queue. Basically it means that first shared locker "holds the door" for other shared lockers to go without queue. I run pgbench (read-write and read-only benchmarks) on Amazon c5d.18xlarge virtual machine, which has 72 VCPU (approximately same power as 36 physical cores). The results are attached (lwlock-fair-ro.png and lwlock-fair-rw.png). We can see that for read-only scenario there is no difference between master and both of patches. That's expected, because in this scenario no exclusive lock is obtained, so all shared lockers anyway go without queue. For read-write scenario we can see regression in both of patches. 1st version of patch gives dramatic regression in 2.5-3 times. 2nd version of patch behaves better, regression is about 15%, but it's still unacceptable. However, I think idea, that some event triggers path of shared lockers to the queue, is promising. We should just select this triggering event better. I'm going to continue my experiments trying to make "more fair" LWLocks (almost) without performance regression. Any feedback is welcome. Links: 1. https://www.postgresql.org/message-id/0A3221C70F24FB45833433255569204D1F578E83%40G01JPEXMBYT05 2. https://www.postgresql.org/message-id/CAPpHfdsytkTFMy3N-zfSo+kAuUx=u-7JG6q2bYB6Fpuw2cD5DQ@mail.gmail.com 3. https://www.postgresql.org/message-id/CAPpHfdt_HFxNKFbSUaDg5QHxzKcvPBB5OhRengRpVDp6ubdrFg%40mail.gmail.com ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
{kind=link}
{kind=link}
> On Mon, 13 Aug 2018 at 17:36, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > Hi! > > I run pgbench (read-write and read-only benchmarks) on Amazon > c5d.18xlarge virtual machine, which has 72 VCPU (approximately same > power as 36 physical cores). The results are attached > (lwlock-fair-ro.png and lwlock-fair-rw.png). Hi, Thanks for working on that. I haven't read the patch yet, but I think it worth mentioning that with testing locks on AWS we also need to take into account lock holder/waiter preemtion problem and such things as Intel PLE, since I believe they can have significant impact in this case. Right now I'm doing some small research on this topic and I hope soon I'll finish a tool and benchmark setup to test the influence of such factors in virtualized environment. In the meantime I would be glad to review your patches.
> On Mon, 13 Aug 2018 at 17:36, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
>
> 2) lwlock-far-2.patch
> New flag LW_FLAG_FAIR is introduced. This flag is set when first
> shared locker in the row releases the lock. When LW_FLAG_FAIR is set
> and there is already somebody in the queue, then shared locker goes to
> the queue. Basically it means that first shared locker "holds the
> door" for other shared lockers to go without queue.
>
> I run pgbench (read-write and read-only benchmarks) on Amazon
> c5d.18xlarge virtual machine, which has 72 VCPU (approximately same
> power as 36 physical cores). The results are attached
> (lwlock-fair-ro.png and lwlock-fair-rw.png).
I've tested the second patch a bit using my bpf scripts to measure the lock
contention. These scripts are still under the development, so there maybe some
rough edges and of course they make things slower, but so far the
event-by-event tracing correlates quite good with a perf script output. For
highly contented case (I simulated it using random_zipfian) I've even got some
visible improvement in the time distribution, but in an interesting way - there
is almost no difference in the distribution of time for waiting on
exclusive/shared locks, but a similar metric for holding shared locks is
somehow has bigger portion of short time frames:
# without the patch
Shared lock holding time
hold time (us) : count distribution
0 -> 1 : 17897059 |************************** |
2 -> 3 : 27306589 |****************************************|
4 -> 7 : 6386375 |********* |
8 -> 15 : 5103653 |******* |
16 -> 31 : 3846960 |***** |
32 -> 63 : 118039 | |
64 -> 127 : 15588 | |
128 -> 255 : 2791 | |
256 -> 511 : 1037 | |
512 -> 1023 : 137 | |
1024 -> 2047 : 3 | |
# with the patch
Shared lock holding time
hold time (us) : count distribution
0 -> 1 : 20909871 |******************************** |
2 -> 3 : 25453610 |****************************************|
4 -> 7 : 6012183 |********* |
8 -> 15 : 5364837 |******** |
16 -> 31 : 3606992 |***** |
32 -> 63 : 112562 | |
64 -> 127 : 13483 | |
128 -> 255 : 2593 | |
256 -> 511 : 1029 | |
512 -> 1023 : 138 | |
1024 -> 2047 : 7 | |
So looks like the locks, queued as implemented in this patch, are released
faster than without this queue (probably it reduces contention in the less
expected way). I've tested it also using c5d.18xlarge, although with a bit
different options (more pgbench scale, shared_buffers, number of clients is
fixed at 72) and I'll try to make few more rounds with different options.
For the case of uniform distribution (just a normal read-write workload) in the
same environment I don't see yet any significant differences in time
distribution between the patched version and the master, which is a bit
surprising for me. Can you point out some analysis why this kind of "fairness"
introduces significant performance regression?
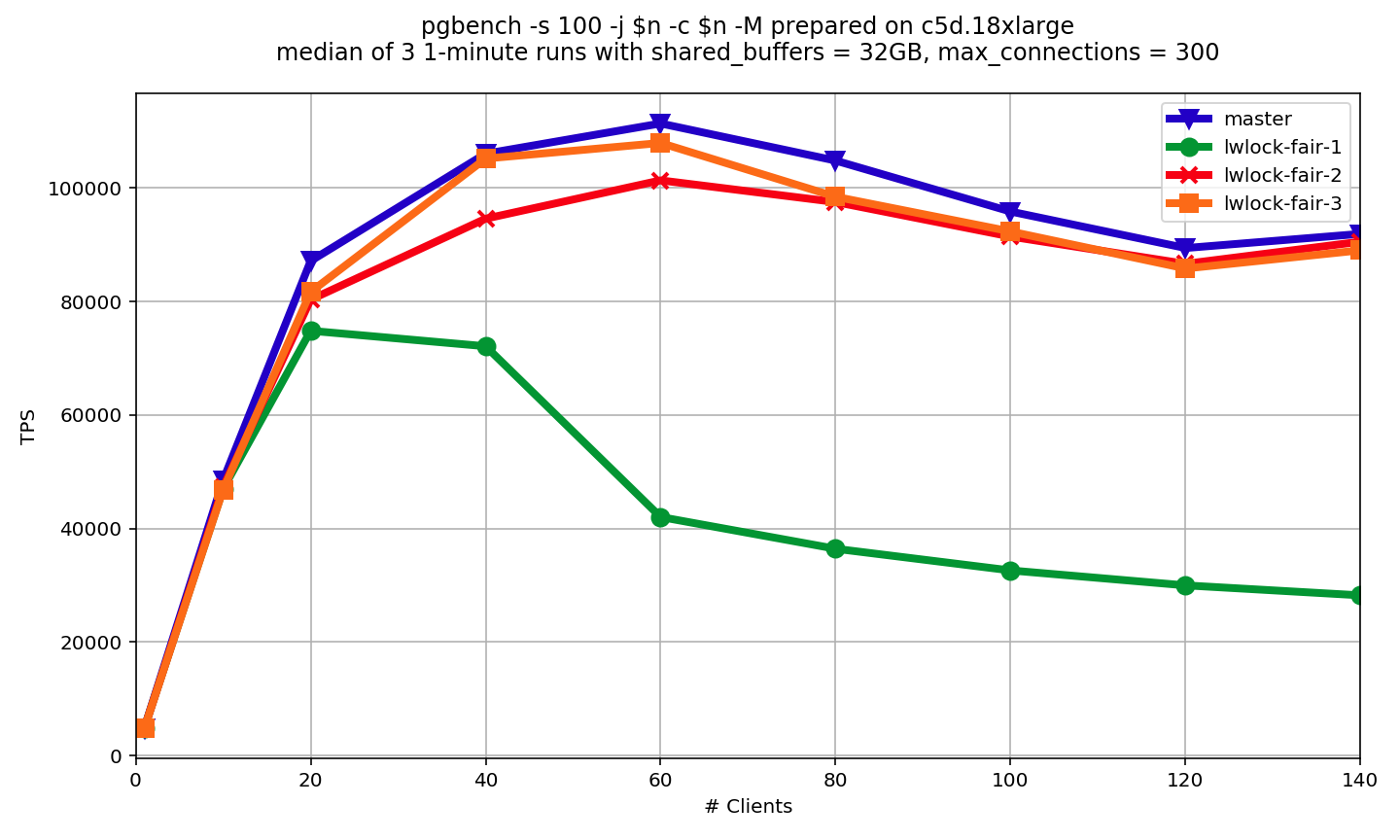
On Sun, Sep 9, 2018 at 7:20 PM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > I've tested the second patch a bit using my bpf scripts to measure the lock > contention. These scripts are still under the development, so there maybe some > rough edges and of course they make things slower, but so far the > event-by-event tracing correlates quite good with a perf script output. For > highly contented case (I simulated it using random_zipfian) I've even got some > visible improvement in the time distribution, but in an interesting way - there > is almost no difference in the distribution of time for waiting on > exclusive/shared locks, but a similar metric for holding shared locks is > somehow has bigger portion of short time frames: > > # without the patch > > Shared lock holding time > > hold time (us) : count distribution > 0 -> 1 : 17897059 |************************** | > 2 -> 3 : 27306589 |****************************************| > 4 -> 7 : 6386375 |********* | > 8 -> 15 : 5103653 |******* | > 16 -> 31 : 3846960 |***** | > 32 -> 63 : 118039 | | > 64 -> 127 : 15588 | | > 128 -> 255 : 2791 | | > 256 -> 511 : 1037 | | > 512 -> 1023 : 137 | | > 1024 -> 2047 : 3 | | > > # with the patch > > Shared lock holding time > hold time (us) : count distribution > 0 -> 1 : 20909871 |******************************** | > 2 -> 3 : 25453610 |****************************************| > 4 -> 7 : 6012183 |********* | > 8 -> 15 : 5364837 |******** | > 16 -> 31 : 3606992 |***** | > 32 -> 63 : 112562 | | > 64 -> 127 : 13483 | | > 128 -> 255 : 2593 | | > 256 -> 511 : 1029 | | > 512 -> 1023 : 138 | | > 1024 -> 2047 : 7 | | > > So looks like the locks, queued as implemented in this patch, are released > faster than without this queue (probably it reduces contention in the less > expected way). I've tested it also using c5d.18xlarge, although with a bit > different options (more pgbench scale, shared_buffers, number of clients is > fixed at 72) and I'll try to make few more rounds with different options. > > For the case of uniform distribution (just a normal read-write workload) in the > same environment I don't see yet any significant differences in time > distribution between the patched version and the master, which is a bit > surprising for me. Can you point out some analysis why this kind of "fairness" > introduces significant performance regression? Dmitry, thank you for your feedback and experiments! Our LWLock allow many shared lockers to take a lock at the same time, while exclusive locker can be only one. On high contended LWLock's flood of shared lockers can be intensive, but all of them are processed in parallel. If we interrupt shared lockers with exclusive lock, then all of them have to wait. If even we do this rarely, shared lockers are many. So, performance impact of this wait is multiplied by the number of shared lockers. Therefore, overall overhead appears to be significant. Thus, I would say that some overhead is inevitable consequence of this patch. My point is that it might be possible to keep overhead negligible in typical use-cases. I made few more versions of this patch. * lwlock-fair-3.patch In lwlock-fair-2.patch we wait for single shared locker to proceed before switching to "fair" mode. Idea of lwlock-fair-3.patch is to extend this period: we wait not for one, but for 7 _sequential_ shared lockers. Free bits of LWLock state are used to hold number of sequential shared lockers processed. Benchmark results are shown on lwlock-fair-3-rw.png. As we can see, there is some win in comparison with 2nd version for 60 and 80 clients. But for 100 clients and more there is almost no effect. So, I think it doesn't worth trying numbers greater than 7. It's better to look for other approaches. I've explained myself why effect lwlock-fair-3.patch was not enough as following. We have group xid clearing and group clog update, which accumulates queue. Once exclusive lock is obtained, all the queue is processed at once. Thus, larger queues are accumulated, higher performance we have. So, 7 (or whatever else fixed number) sequential shared lockers might be not enough to accumulate large enough queue for every number of clients. * lwlock-fair-4-7.patch and lwlock-fair-4-15.patch The idea of 4th version of this patch is to reset counter to zero, when new process is added to exclusive waiters queue. So, we wait exclusive waiters queue to stabilize before switching to "fair" mode. This includes LWLock queue itself and queues of group xid clearing and group clog update. I made experiments with waiting for 7 or 15 sequential shared lockers. In order to implement 15 of them I've to cut one bit from LW_SHARED_MASK (it's not something I propose, but just made for experiment). The results are given on lwlock-fair-4-rw.png. As we can see, overhead is much smaller (and almost no difference between 7 and 15). The thing, which is worrying me is that I've added extra atomic instructions, which can still cause an overhead. I'm going to continue my experiments. I would like to have something like 4th version of patch, but without extra atomic instructions. May be by placing number of sequential shared lockers past into separate (non-atomic) variable. The feedback is welcome. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
{kind=link}
{kind=link}
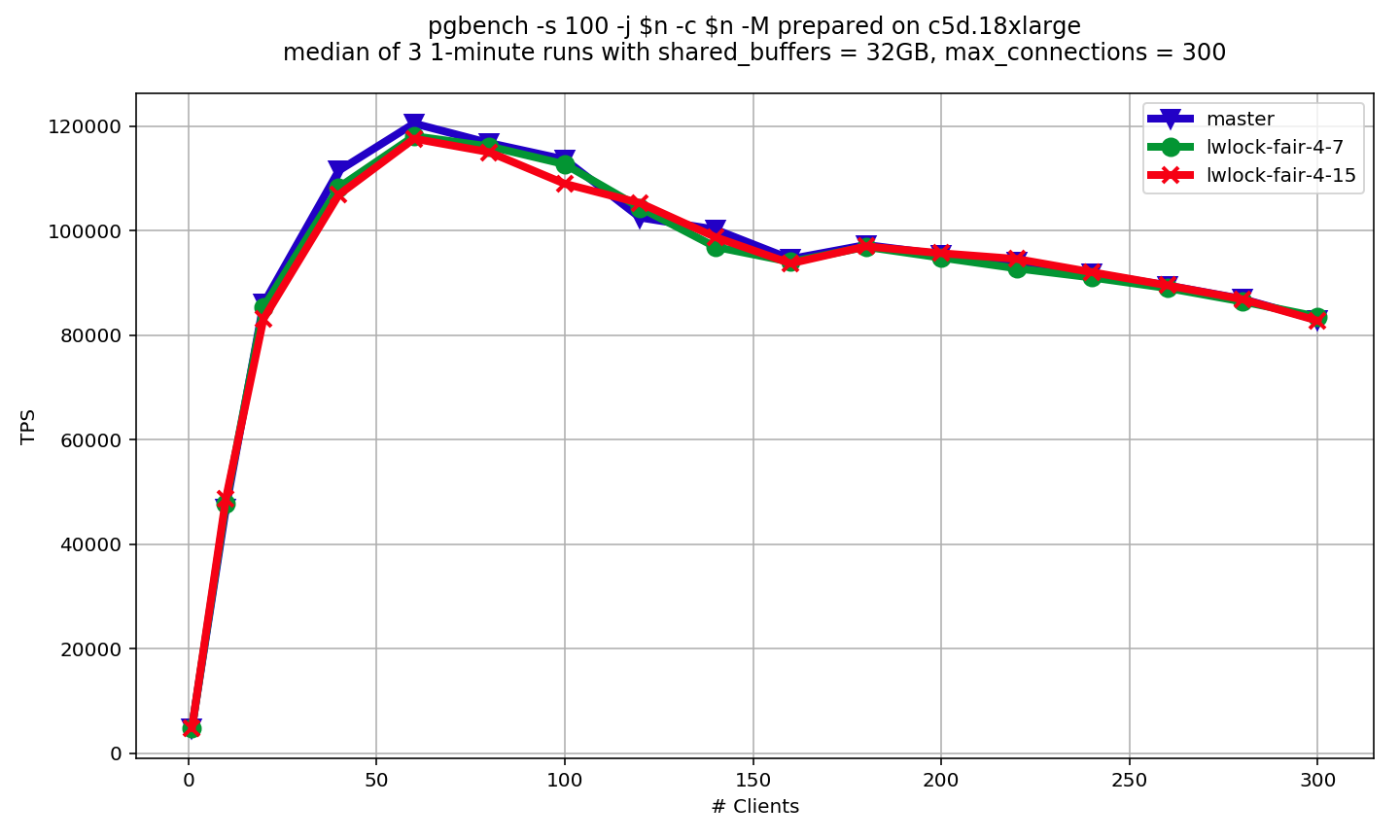
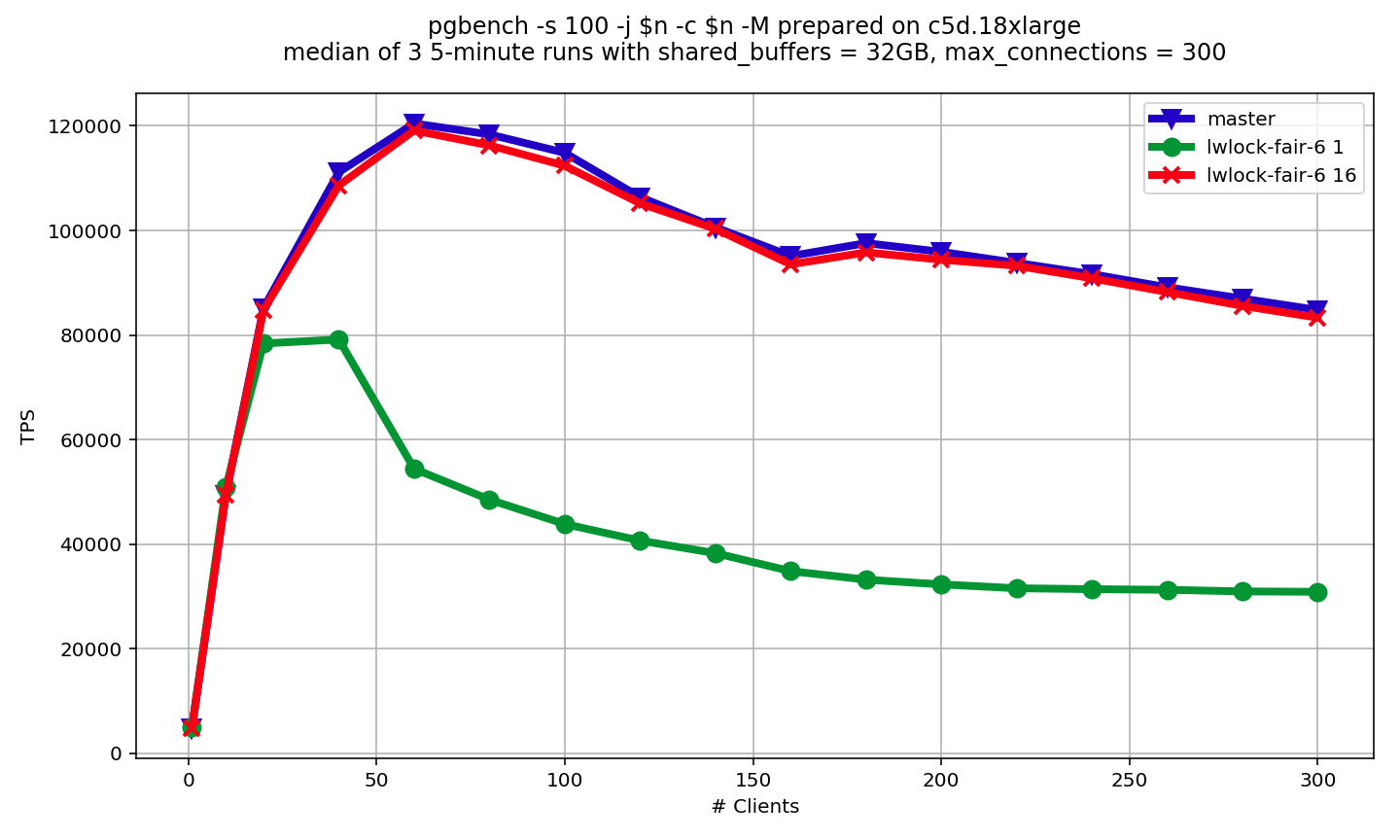
On Mon, Oct 15, 2018 at 7:06 PM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > I'm going to continue my experiments. I would like to have something > like 4th version of patch, but without extra atomic instructions. May > be by placing number of sequential shared lockers past into separate > (non-atomic) variable. The feedback is welcome. I did try this in 6th version of patch. Now number of shared lwlocks taken in a row is stored in usagecount field of LWLock struct. Thus, this patch doesn't introduce more atomic operations, because usagecount field is not atomic. Also, size of LWLock struct didn't grow, because usagecount takes place of struct padding. Since usagecount is not atomic, it might happens that increment and setting to zero operations overlap together. In this case, setting to zero can appear to be ignored. But that's not catastrophic, because in that case LWLock will just switch to fair more sooner than it normally should. Also, I turn number of sequential shared lwlocks taken before switching to fair mode into a lwlock_shared_limit GUC. Zero disables fair mode completely. Results of pgbench scalability benchmark is attached, With lwlock_shared_limit = 16, no LWLocks are switched to fair mode in the benchmark. However, there is still small overhead. I think it's related to extra cacheline invalidation caused by access to usagecount variable. So, I probably did my best in this direction. For now, I don't have any idea of how to make overhead of "fair mode" availability lower. We (Postgres Pro) found this patch useful and integrated it into our proprietary fork. In my opinion PostgreSQL would also benefit from this patch, because it can dramatically improve the situation on some NUMA systems. Also, this feature is controlled by GUC. So, lwlock_shared_limit = 0 completely disables it, and there is no measurable overhead. Any thoughts? ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
{kind=link}