Обсуждение: High CPU load caused by the autovacuum launcher process
Hi folks,
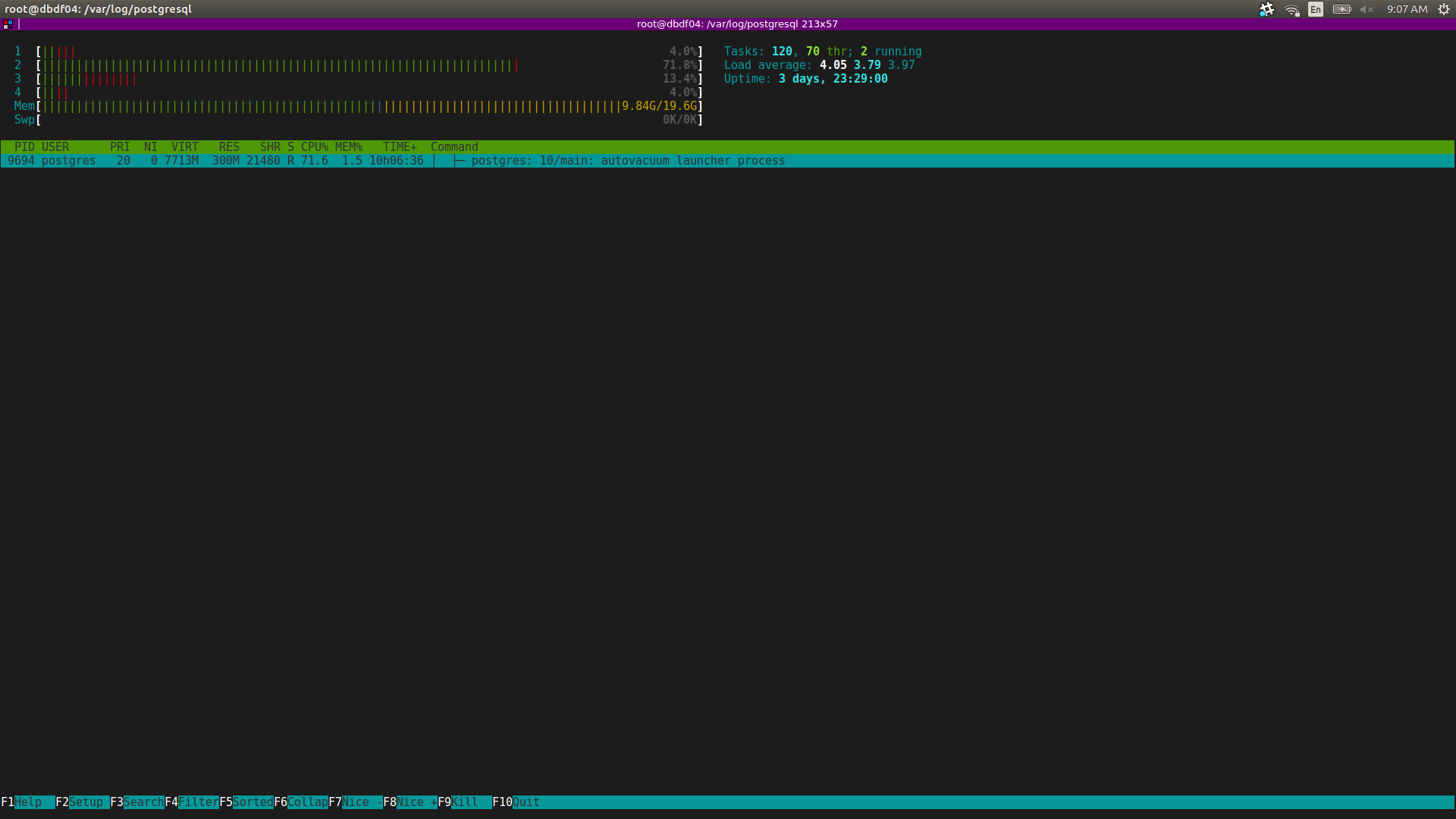
I ran into an issue where, on Postgres instances that have a very large number of databases per cluster (~15K), the autovacuum process seems to have a very high impact on CPU usage. Specifically, it is the autovacuum launcher process, not the workers. The launcher process eats a whole CPU (attached is in screenshot of htop).
I tried to look into what that process is actually doing, below is in output of strace:
# strace -c -p 17252
strace: Process 17252 attached
^Cstrace: Process 17252 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ---------------- 94.16 0.030485 2 18878 read 4.42 0.001431 6 239 brk 0.35 0.000113 1 91 close 0.28 0.000091 4 24 4 epoll_wait 0.19 0.000060 1 60 epoll_ctl 0.15 0.000050 1 60 fstat 0.12 0.000040 1 30 epoll_create1 0.12 0.000039 1 60 open 0.08 0.000026 1 21 4 rt_sigreturn 0.05 0.000017 1 21 lseek 0.05 0.000016 4 4 write 0.01 0.000003 0 10 sendto 0.01 0.000002 0 10 select 0.01 0.000002 2 1 1 futex 0.00 0.000000 0 10 kill
------ ----------- ----------- --------- --------- ----------------
100.00 0.032375 19519 9 totalAll of those reads look like the following:
15:20:12 read(8, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0M\232q\20"..., 4096) = 4096
15:20:12 read(8, "\0\0\314\316\237\275\v\21\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
...That file, happens to be the global.stat file:
# ls -la /proc/17252/fd/8
lr-x------ 1 postgres postgres 64 Jun 7 15:22 /proc/17252/fd/8 -> /mnt/pg_stat_mem_tmp/global.statOn all instances where we have these ~15K huge cluster, this file's size is about 3MB:
# ls -lha /mnt/pg_stat_mem_tmp/global.stat
-rw------- 1 postgres postgres 3.0M Jun 7 15:23 /mnt/pg_stat_mem_tmp/global.statOn instances where we have just one or couple databases per cluster, the file is about one kilobyte in size. This, of course, is to be expected, as I understand that the contents of this file are cluster-wide statistics that are gathered by the stats collector process.
I tried activating DEBUG1 logs and reloaded the postgres server, from the logs it was clear that auto-vacuuming was always going on:
Jun 7 15:16:19 dbdf04 postgres[6455]: [944-1] 2018-06-07 15:16:19 UTC DEBUG: autovacuum: processing database "3c8e81b6-d94a-45c5-9ec2-27ab3192cd3b_db"
Jun 7 15:16:19 dbdf04 postgres[6457]: [944-1] 2018-06-07 15:16:19 UTC DEBUG: autovacuum: processing database "8d7b130a-67ce-47aa-96a6-359d6c14fb24_db"
Jun 7 15:16:20 dbdf04 postgres[6462]: [944-1] 2018-06-07 15:16:20 UTC DEBUG: autovacuum: processing database "134c5c51-a441-46a0-a2ca-15f08f37649e_db"
Jun 7 15:16:20 dbdf04 postgres[6463]: [944-1] 2018-06-07 15:16:20 UTC [unknown] [unknown] [unknown] LOG: incomplete startup packet
Jun 7 15:16:21 dbdf04 postgres[6464]: [944-1] 2018-06-07 15:16:21 UTC DEBUG: autovacuum: processing database "973b7be4-fd06-4c98-a078-f7a5e355d218_db"
Jun 7 15:16:21 dbdf04 postgres[6466]: [944-1] 2018-06-07 15:16:21 UTC DEBUG: autovacuum: processing database "6b831edf-f3e4-4d3b-ae7e-68def59d6c91_db"
Jun 7 15:16:21 dbdf04 postgres[6468]: [944-1] 2018-06-07 15:16:21 UTC DEBUG: autovacuum: processing database "8cfbf388-d30b-4a7d-b9ea-953352c0e947_db"So auto-vacuum never really sleeps. Even changing the autovacuum_naptime and setting it to a much higher value (from 1min to 50min) did not have any effect at all. Both strace and the postgres logs showed a similar behaviour: lots of reads to global.stat file and constantly iterating through all the databases non-stop and executing autovacuum.
Is there anything that I can do to minimize the CPU load impact that this process is having?
Many thanks in advance,
Owayss.
Вложения
{kind=link}
On 06/08/2018 02:24 AM, Owayss Kabtoul wrote: > Hi folks, > > I ran into an issue where, on Postgres instances that have a very large > number of databases per cluster (~15K), the I won't ask why there's a cluster with 15,000 databases... > So auto-vacuum never really sleeps. Even changing the autovacuum_naptime > and setting it to a much higher value (from 1min to 50min) did not have > any effect at all. Both strace and the postgres logs showed a similar > behaviour: lots of reads to global.stat file and constantly iterating > through all the databases non-stop and executing autovacuum. > > > Is there anything that I can do to minimize the CPU load impact that this > process is having? What if you disable autovacuum and run it manually? -- Angular momentum makes the world go 'round.
I guess the Htop captured by you is for a particular instant. You will have to record the cpu utilisation for a longer duration and then analyze.
Deepak
On Fri, Jun 8, 2018 at 12:58 PM, Ron <ronljohnsonjr@gmail.com> wrote:
On 06/08/2018 02:24 AM, Owayss Kabtoul wrote:Hi folks,
I ran into an issue where, on Postgres instances that have a very large number of databases per cluster (~15K), the
I won't ask why there's a cluster with 15,000 databases...So auto-vacuum never really sleeps. Even changing the autovacuum_naptime and setting it to a much higher value (from 1min to 50min) did not have any effect at all. Both strace and the postgres logs showed a similar behaviour: lots of reads to global.stat file and constantly iterating through all the databases non-stop and executing autovacuum.
Is there anything that I can do to minimize the CPU load impact that this process is having?
What if you disable autovacuum and run it manually?
--
Angular momentum makes the world go 'round.
Deepak
"The greatness of a nation can be judged by the way its animals are treated. Please consider stopping the cruelty by becoming a Vegan"
+91 73500 12833
deicool@gmail.com
Facebook: https://www.facebook.com/deicool
LinkedIn: www.linkedin.com/in/deicool
deicool@gmail.com
Facebook: https://www.facebook.com/deicool
LinkedIn: www.linkedin.com/in/deicool
"Plant a Tree, Go Green"
On Fri, Jun 8, 2018 at 1:38 AM, Deepak Goel <deicool@gmail.com> wrote:
I guess the Htop captured by you is for a particular instant. You will have to record the cpu utilisation for a longer duration and then analyze.On Fri, Jun 8, 2018 at 12:58 PM, Ron <ronljohnsonjr@gmail.com> wrote:On 06/08/2018 02:24 AM, Owayss Kabtoul wrote:Hi folks,
I ran into an issue where, on Postgres instances that have a very large number of databases per cluster (~15K), the
I won't ask why there's a cluster with 15,000 databases...So auto-vacuum never really sleeps. Even changing the autovacuum_naptime and setting it to a much higher value (from 1min to 50min) did not have any effect at all. Both strace and the postgres logs showed a similar behaviour: lots of reads to global.stat file and constantly iterating through all the databases non-stop and executing autovacuum.
Is there anything that I can do to minimize the CPU load impact that this process is having?
What if you disable autovacuum and run it manually?
--
Angular momentum makes the world go 'round.
What do you have your
autovacuum_vacuum_cost_limit set to?On Fri, Jun 8, 2018 at 3:24 AM, Owayss Kabtoul <owayssk@gmail.com> wrote:
Hi folks,I ran into an issue where, on Postgres instances that have a very large number of databases per cluster (~15K), the autovacuum process seems to have a very high impact on CPU usage. Specifically, it is the autovacuum launcher process, not the workers. The launcher process eats a whole CPU (attached is in screenshot of htop)....So auto-vacuum never really sleeps. Even changing the autovacuum_naptime and setting it to a much higher value (from 1min to 50min) did not have any effect at all.
After changing autovacuum_naptime, did you give it enough time to stabilize at the new setting? Say, at least 3 * 50 = 150 minutes?
But overall, I would say that if you want to have 15,000 databases, you should just resign yourself to having one CPU dedicated to this task.
Cheers,
Jeff
On Fri, Jun 8, 2018 at 3:24 AM, Owayss Kabtoul <owayssk@gmail.com> wrote:
Hi folks,I ran into an issue where, on Postgres instances that have a very large number of databases per cluster (~15K), the autovacuum process seems to have a very high impact on CPU usage. Specifically, it is the autovacuum launcher process, not the workers. The launcher process eats a whole CPU (attached is in screenshot of htop)....So auto-vacuum never really sleeps. Even changing the autovacuum_naptime and setting it to a much higher value (from 1min to 50min) did not have any effect at all.
After changing autovacuum_naptime, did you give it enough time to stabilize at the new setting? Say, at least 3 * 50 = 150 minutes?
But overall, I would say that if you want to have 15,000 databases, you should just resign yourself to having one CPU dedicated to this task.
Cheers,
Jeff
Owayss Kabtoul <owayssk@gmail.com> writes:
> I ran into an issue where, on Postgres instances that have a very large
> number of databases per cluster (~15K), the autovacuum process seems to
> have a very high impact on CPU usage.
That's, um, not a very reasonable configuration.
> So auto-vacuum never really sleeps. Even changing the autovacuum_naptime
> and setting it to a much higher value (from 1min to 50min) did not have any
> effect at all.
Simple arithmetic says that even at 50min, the launcher will have to
launch one worker every 0.2 seconds in order to visit every database
once per naptime.
You could raise the naptime setting by another factor of 10 and then
the launcher would only have to wake up every other second ... but
these DBs had better all have extremely light workloads, or you're
risking terrible bloat due to tables only getting vacuumed a couple
times per day.
On the whole, I'd revisit why you need so many DBs per cluster.
Quite aside from autovacuum performance issues, you're expending
~100GB just on redundant copies of the system catalogs; that can't
be helping disk cache performance, for instance. (Or, if you've
got a box that's so beefy you just don't care about that, why are
you worried about the launcher?)
regards, tom lane