Обсуждение: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate.
Please add the attached patch and this discussion to the open commit fest. The
original bugs thread is here: 20180111111254.1408.8342@wrigleys.postgresql.org.
Bug reference: 15005
Logged by: David Gould
Email address: daveg@sonic.net
PostgreSQL version: 10.1 and earlier
Operating system: Linux
Description:
ANALYZE can make pg_class.reltuples wildly inaccurate compared to the actual
row counts for tables that are larger than the default_statistics_target.
Example from one of a clients production instances:
# analyze verbose pg_attribute;
INFO: analyzing "pg_catalog.pg_attribute"
INFO: "pg_attribute": scanned 30000 of 24519424 pages, containing 6475 live rows and 83 dead rows; 6475 rows in
sample,800983035 estimated total rows.
This is a large complex database - pg_attribute actually has about five
million rows and needs about one hundred thouand pages. However it has
become extremely bloated and is taking 25 million pages (192GB!), about 250
times too much. This happened despite aggressive autovacuum settings and a
periodic bloat monitoring script. Since pg_class.reltuples was 800 million,
the bloat monitoring script did not detect that this table was bloated and
autovacuum did not think it needed vacuuming.
When reltuples is very large compared to the actual row count it causes a
number of problems:
- Bad input to the query planner.
- Prevents autovacuum from processing large bloated tables because
autovacuum_scale_factor * reltuples is large enough the threshold is
rarely reached.
- Decieves bloat checking tools that rely on the relationship of relpages
to reltuples*average_row_size.
I've tracked down how this happens and created a reproduction script and a
patch. Attached:
- analyze_reltuples_bug-v1.patch Patch against master
- README.txt Instructions for testing
- analyze_reltuples_bug.sql Reproduction script
- analyze_counts.awk Helper for viewing results of test
- test_standard.txt Test output for unpatched postgresql 10.1
- test_patched.txt Test output with patch
The patch applies cleanly, with some offsets, to 9.4.15, 9.5.10, 9.6.6 and 10.1.
Note that this is not the same as the reltuples calculation bug discussed in the
thread at 16db4468-edfa-830a-f921-39a50498e77e@2ndquadrant.com. That one is
mainly concerned with vacuum, this with analyze. The two bugs do amplify each
other though.
Analysis:
---------
Analyze and vacuum calculate the new value for pg_class.reltuples in
vacuum.c:vac_estimate_reltuples():
old_density = old_rel_tuples / old_rel_pages;
new_density = scanned_tuples / scanned_pages;
multiplier = (double) scanned_pages / (double) total_pages;
updated_density = old_density + (new_density - old_density) * multiplier;
return floor(updated_density * total_pages + 0.5);
The comments talk about the difference between VACUUM and ANALYZE and explain
that VACUUM probably only scanned changed pages so the density of the scanned
pages is not representative of the rest of the unchanged table. Hence the new
overall density of the table should be adjusted proportionaly to the scanned
pages vs total pages. Which makes sense. However despite the comment noteing
that ANALYZE and VACUUM are different, the code actually does the same
calculation for both.
The problem is that it dilutes the impact of ANALYZE on reltuples for large
tables:
- For a table of 3000000 pages an analyze can only change the reltuples
value by 1%.
- When combined with changes in relpages due to bloat the new computed
reltuples can end up far from reality.
Reproducing the reltuples analyze estimate bug.
-----------------------------------------------
The script "reltuples_analyze_bug.sql" creates a table that is large
compared to the analyze sample size and then repeatedly updates about
10% of it followed by an analyze each iteration. The bug is that the
calculation analyze uses to update pg_class.reltuples will tend to
increase each time even though the actual rowcount does not change.
To run:
Given a postgresql 10.x server with >= 1GB of shared buffers:
createdb test
psql --no-psqlrc -f analyze_reltuples_bug.sql test > test_standard.out 2>&1
awk -f analyze_counts.awk test_standard.out
To verify the fix, restart postgres with a patched binary and repeat
the above.
Here are the results with an unpatched server:
After 10 interations of:
update 10% of rows;
analyze
reltuples has almost doubled.
/ estimated rows / / pages / /sampled rows/
relname current proposed total scanned live dead
reltuples_test 10000001 10000055 153847 3000 195000 0
reltuples_test 10981367 9951346 169231 3000 176410 18590
reltuples_test 11948112 10039979 184615 3000 163150 31850
reltuples_test 12900718 10070666 200000 3000 151060 43940
reltuples_test 13835185 9739305 215384 3000 135655 59345
reltuples_test 14758916 9864947 230768 3000 128245 66755
reltuples_test 15674572 10138631 246153 3000 123565 71435
reltuples_test 16576847 9910944 261537 3000 113685 81315
reltuples_test 17470388 10019961 276922 3000 108550 86450
reltuples_test 18356707 10234607 292306 3000 105040 89960
reltuples_test 19228409 9639927 307690 3000 93990 101010
-dg
--
David Gould daveg@sonic.net
If simplicity worked, the world would be overrun with insects.
Вложения
Hi David, I was able to reproduce the problem using your script. analyze_counts.awk is missing, though. The idea of using the result of ANALYZE as-is, without additional averaging, was discussed when vac_estimate_reltuples() was introduced originally. Ultimately, it was decided not to do so. You can find the discussion in this thread: https://www.postgresql.org/message-id/flat/BANLkTinL6QuAm_Xf8teRZboG2Mdy3dR_vw%40mail.gmail.com#BANLkTinL6QuAm_Xf8teRZboG2Mdy3dR_vw@mail.gmail.com The core problem here seems to be that this calculation of moving average does not converge in your scenario. It can be shown that when the number of live tuples is constant and the number of pages grows, the estimated number of tuples will increase at each step. Do you think we can use some other formula that would converge in this scenario, but still filter the noise in ANALYZE results? I couldn't think of one yet. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Wed, 28 Feb 2018 15:55:19 +0300 Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > Hi David, > > I was able to reproduce the problem using your script. > analyze_counts.awk is missing, though. Attached now I hope. I think I also added it to the commitfest page. > The idea of using the result of ANALYZE as-is, without additional > averaging, was discussed when vac_estimate_reltuples() was introduced > originally. Ultimately, it was decided not to do so. You can find the > discussion in this thread: > https://www.postgresql.org/message-id/flat/BANLkTinL6QuAm_Xf8teRZboG2Mdy3dR_vw%40mail.gmail.com#BANLkTinL6QuAm_Xf8teRZboG2Mdy3dR_vw@mail.gmail.com Well that was a long discussion. I'm not sure I would agree that there was a firm conclusion on what to do about ANALYZE results. There was some recognition that the case of ANALYZE is different than VACUUM and that is reflected in the original code comments too. However the actual code ended up being the same for both ANALYZE and VACUUM. This patch is about that. See messages: https://www.postgresql.org/message-id/BANLkTimVhdO_bKQagRsH0OLp7MxgJZDryg%40mail.gmail.com https://www.postgresql.org/message-id/BANLkTimaDj950K-298JW09RrmG0eJ_C%3DqQ%40mail.gmail.com https://www.postgresql.org/message-id/28116.1306609295%40sss.pgh.pa.us > The core problem here seems to be that this calculation of moving > average does not converge in your scenario. It can be shown that when > the number of live tuples is constant and the number of pages grows, the > estimated number of tuples will increase at each step. Do you think we > can use some other formula that would converge in this scenario, but > still filter the noise in ANALYZE results? I couldn't think of one yet. Besides the test data generated with the script I have parsed the analyze verbose output for several large production systems running complex applications and have found that for tables larger than the statistics sample size (300*default_statistics_target) the row count you can caculate from (pages/sample_pages) * live_rows is pretty accurate, within a few percent of the value from count(*). In theory the sample pages analyze uses should represent the whole table fairly well. We rely on this to generate pg_statistic and it is a key input to the planner. Why should we not believe in it as much only for reltuples? If the analyze sampling does not work, the fix would be to improve that, not to disregard it piecemeal. My motivation is that I have seen large systems fighting mysterious run-away bloat for years no matter how aggressively autovacuum is tuned. The fact that an inflated reltuples can cause autovacuum to simply ignore tables forever seems worth fixing. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
Вложения
On 01.03.2018 06:23, David Gould wrote: > In theory the sample pages analyze uses should represent the whole table > fairly well. We rely on this to generate pg_statistic and it is a key > input to the planner. Why should we not believe in it as much only for > reltuples? If the analyze sampling does not work, the fix would be to improve > that, not to disregard it piecemeal. Well, that sounds reasonable. But the problem with the moving average calculation remains. Suppose you run vacuum and not analyze. If the updates are random enough, vacuum won't be able to reclaim all the pages, so the number of pages will grow. Again, we'll have the same thing where the number of pages grows, the real number of live tuples stays constant, and the estimated reltuples grows after each vacuum run. I did some more calculations on paper to try to understand this. If we average reltuples directly, instead of averaging tuple density, it converges like it should. The error with this density calculation seems to be that we're effectively multiplying the old density by the new number of pages. I'm not sure why we even work with tuple density. We could just estimate the number of tuples based on analyze/vacuum, and then apply moving average to it. The calculations would be shorter, too. What do you think? -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> writes:
> On 01.03.2018 06:23, David Gould wrote:
>> In theory the sample pages analyze uses should represent the whole table
>> fairly well. We rely on this to generate pg_statistic and it is a key
>> input to the planner. Why should we not believe in it as much only for
>> reltuples? If the analyze sampling does not work, the fix would be to improve
>> that, not to disregard it piecemeal.
> Well, that sounds reasonable. But the problem with the moving average
> calculation remains. Suppose you run vacuum and not analyze. If the
> updates are random enough, vacuum won't be able to reclaim all the
> pages, so the number of pages will grow. Again, we'll have the same
> thing where the number of pages grows, the real number of live tuples
> stays constant, and the estimated reltuples grows after each vacuum run.
You claimed that before, with no more evidence than this time, and I still
don't follow your argument. The number of pages may indeed bloat but the
number of live tuples per page will fall. Ideally, at least, the estimate
would remain on-target. If it doesn't, there's some other effect that
you haven't explained. It doesn't seem to me that the use of a moving
average would prevent that from happening. What it *would* do is smooth
out errors from the inevitable sampling bias in any one vacuum or analyze
run, and that seems like a good thing.
> I did some more calculations on paper to try to understand this. If we
> average reltuples directly, instead of averaging tuple density, it
> converges like it should. The error with this density calculation seems
> to be that we're effectively multiplying the old density by the new
> number of pages. I'm not sure why we even work with tuple density. We
> could just estimate the number of tuples based on analyze/vacuum, and
> then apply moving average to it. The calculations would be shorter, too.
> What do you think?
I think you're reinventing the way we used to do it. Perhaps consulting
the git history in the vicinity of this code would be enlightening.
regards, tom lane
On 01.03.2018 18:09, Tom Lane wrote: > Ideally, at least, the estimate would remain on-target. The test shows that under this particular scenario the estimated number of tuples grows after each ANALYZE. I tried to explain how this happens in the attached pdf. The direct averaging of the number of tuples, not using the density, doesn't have this problem, so I suppose it could help. > I think you're reinventing the way we used to do it. Perhaps consulting > the git history in the vicinity of this code would be enlightening. I see that before vac_estimate_reltuples was introduced, the results of analyze and vacuum were used directly, without averaging. What I am suggesting is to use a different way of averaging, not to remove it. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
On Thu, 1 Mar 2018 17:25:09 +0300 Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > Well, that sounds reasonable. But the problem with the moving average > calculation remains. Suppose you run vacuum and not analyze. If the > updates are random enough, vacuum won't be able to reclaim all the > pages, so the number of pages will grow. Again, we'll have the same > thing where the number of pages grows, the real number of live tuples > stays constant, and the estimated reltuples grows after each vacuum run. I agree VACUUM's moving average may be imperfect, but the rationale makes sense and I don't have a plan to improve it now. This patch only intends to improve the behavior of ANALYZE by using the estimated row density time relpages to get reltuples. It does not change VACUUM. The problem with the moving average for ANALYZE is that it prevents ANALYZE from changing the reltuples estimate enough for large tables. Consider this based on the test setup from the patch: create table big as select id*p, ten, hun, thou, tenk, lahk, meg, padding from reltuples_test, generate_series(0,9) g(p); -- SELECT 100000000 alter table big set (autovacuum_enabled=false); select count(*) from big; -- count -- 100000000 select reltuples::int, relpages from pg_class where relname = 'big'; -- reltuples | relpages -- 0 | 0 analyze verbose big; -- INFO: analyzing "public.big" -- INFO: "big": scanned 30000 of 1538462 pages, containing 1950000 live rows and 0 dead rows; -- 30000 rows in sample, 100000030 estimated total rows select reltuples::int, relpages from pg_class where relname = 'big'; -- reltuples | relpages -- 100000032 | 1538462 delete from big where ten > 1; -- DELETE 80000000 select count(*) from big; -- count -- 20000000 select reltuples::int, relpages from pg_class where relname = 'big'; -- reltuples | relpages -- 100000032 | 1538462 analyze verbose big; -- INFO: analyzing "public.big" -- INFO: "big": scanned 30000 of 1538462 pages, containing 388775 live rows and 1561225 dead rows; -- 30000 rows in sample, 98438807 estimated total rows select reltuples::int, relpages from pg_class where relname = 'big'; reltuples | relpages 98438808 | 1538462 select count(*) from big; -- count -- 20000000 analyze verbose big; -- INFO: analyzing "public.big" -- INFO: "big": scanned 30000 of 1538462 pages, containing 390885 live rows and 1559115 dead rows; -- 30000 rows in sample, 96910137 estimated total rows select reltuples::int, relpages from pg_class where relname = 'big'; reltuples | relpages 96910136 | 1538462 Table big has 1.5 million pages. ANALYZE samples 30 thousand. No matter how many rows we change in T, ANALYZE can only change the reltuples estimate by old_estimate + new_estimate * (30000/1538462), ie about 1.9 percent. With the patch on this same table we get: select count(*) from big; -- count -- 20000000 select reltuples::int, relpages from pg_class where relname = 'big'; reltuples | relpages 96910136 | 1538462 analyze verbose big; -- INFO: analyzing "public.big" -- INFO: "big": scanned 30000 of 1538462 pages, containing 390745 live rows and 1559255 dead rows; -- 30000 rows in sample, 20038211 estimated total rows select reltuples::int, relpages from pg_class where relname = 'big'; -- reltuples | relpages -- 20038212 | 1538462 -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> writes:
> On 01.03.2018 18:09, Tom Lane wrote:
>> Ideally, at least, the estimate would remain on-target.
> The test shows that under this particular scenario the estimated number
> of tuples grows after each ANALYZE. I tried to explain how this happens
> in the attached pdf.
I looked at this and don't think it really answers the question. What
happens is that, precisely because we only slowly adapt our estimate of
density towards the new measurement, we will have an overestimate of
density if the true density is decreasing (even if the new measurement is
spot-on), and that corresponds exactly to an overestimate of reltuples.
No surprise there. The question is why it fails to converge to reality
over time.
I think part of David's point is that because we only allow ANALYZE to
scan a limited number of pages even in a very large table, that creates
an artificial limit on the slew rate of the density estimate; perhaps
what's happening in his tables is that the true density is dropping
faster than that limit allows us to adapt. Still, if there's that
much going on in his tables, you'd think VACUUM would be touching
enough of the table that it would keep the estimate pretty sane.
So I don't think we yet have a convincing explanation of why the
estimates drift worse over time.
Anyway, I find myself semi-persuaded by his argument that we are
already assuming that ANALYZE has taken a random sample of the table,
so why should we not believe its estimate of density too? Aside from
simplicity, that would have the advantage of providing a way out of the
situation when the existing reltuples estimate has gotten drastically off.
The sticking point in my mind right now is, if we do that, what to do with
VACUUM's estimates. If you believe the argument in the PDF that we'll
necessarily overshoot reltuples in the face of declining true density,
then it seems like that argument applies to VACUUM as well. However,
VACUUM has the issue that we should *not* believe that it looked at a
random sample of pages. Maybe the fact that it looks exactly at the
changed pages causes it to see something less than the overall density,
cancelling out the problem, but that seems kinda optimistic.
Anyway, as I mentioned in the 2011 thread, the existing computation is
isomorphic to the rule "use the old density estimate for the pages we did
not look at, and the new density estimate --- ie, exactly scanned_tuples
--- for the pages we did look at". That still has a lot of intuitive
appeal, especially for VACUUM where there's reason to believe those page
populations aren't alike. We could recast the code to look like it's
doing that rather than doing a moving-average, although the outcome
should be the same up to roundoff error.
regards, tom lane
Re: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate.
От
Alexander Kuzmenkov
Дата:
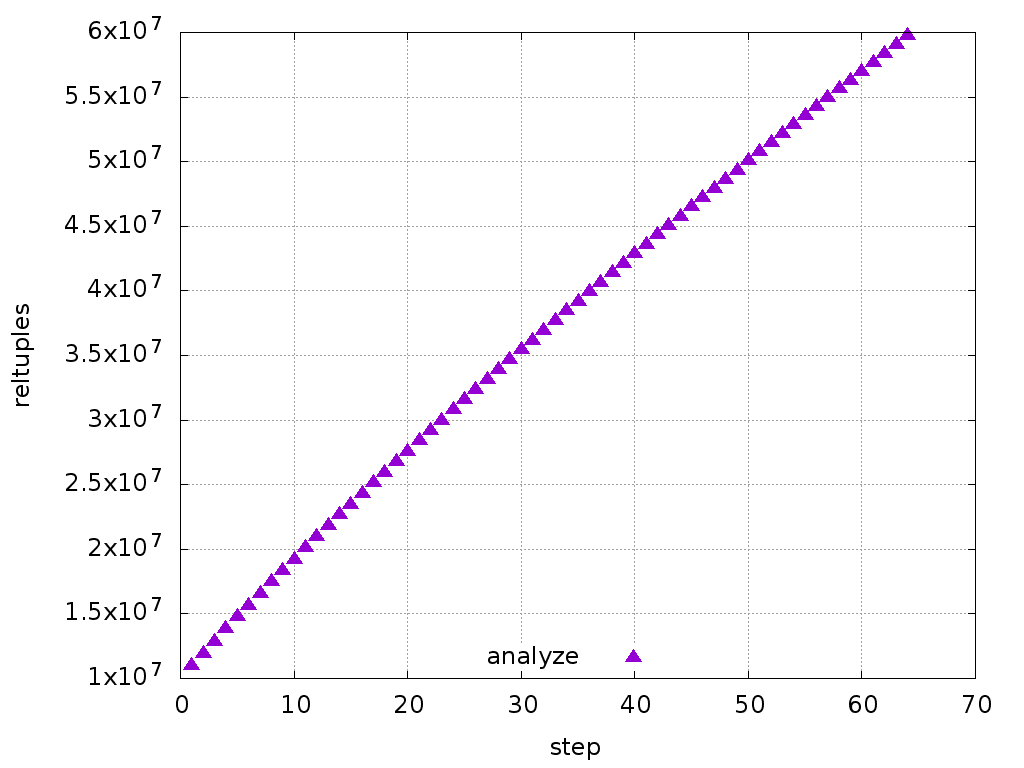
On 02.03.2018 02:49, Tom Lane wrote: > I looked at this and don't think it really answers the question. What > happens is that, precisely because we only slowly adapt our estimate of > density towards the new measurement, we will have an overestimate of > density if the true density is decreasing (even if the new measurement is > spot-on), and that corresponds exactly to an overestimate of reltuples. > No surprise there. The question is why it fails to converge to reality > over time. The calculation I made for the first step applies to the next steps too, with minor differences. So, the estimate increases at each step. Just out of interest, I plotted the reltuples for 60 steps, and it doesn't look like it's going to converge anytime soon (see attached). Looking at the formula, this overshoot term is created when we multiply the old density by the new number of pages. I'm not sure how to fix this. I think we could average the number of tuples, not the densities. The attached patch demonstrates what I mean. -- Alexander Kuzmenkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Вложения
{kind=link}
On Fri, 2 Mar 2018 18:47:44 +0300 Alexander Kuzmenkov <a.kuzmenkov@postgrespro.ru> wrote: > The calculation I made for the first step applies to the next steps too, > with minor differences. So, the estimate increases at each step. Just > out of interest, I plotted the reltuples for 60 steps, and it doesn't > look like it's going to converge anytime soon (see attached). > Looking at the formula, this overshoot term is created when we multiply > the old density by the new number of pages. I'm not sure how to fix > this. I think we could average the number of tuples, not the densities. > The attached patch demonstrates what I mean. I'm confused at this point, I provided a patch that addresses this and a test case. We seem to be discussing everything as if we first noticed the issue. Have you reviewed the patch and and attached analysis and tested it? Please commment on that? Thanks. Also, here is a datapoint that I found just this morning on a clients production system: INFO: "staging_xyz": scanned 30000 of pages, containing 63592 live rows and 964346 dead rows; 30000 rows in sample, 1959918155 estimated total rows # select (50000953.0/30000*63592)::int as nrows; nrows ----------- 105988686 This tables reltuples is 18 times the actual row count. It will never converge because with 50000953 pages analyze can only adjust reltuples by 0.0006 each time. It will also almost never get vacuumed because the autovacuum threshold of 0.2 * 1959918155 = 391983631 about 3.7 times larger than the actual row count. The submitted patch is makes analyze effective in setting reltuples to within a few percent of the count(*) value. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
David Gould <daveg@sonic.net> writes:
> I'm confused at this point, I provided a patch that addresses this and a
> test case. We seem to be discussing everything as if we first noticed the
> issue. Have you reviewed the patch and and attached analysis and tested it?
> Please commment on that?
I've looked at the patch. The questions in my mind are
(1) do we really want to go over to treating ANALYZE's tuple density
result as gospel, contradicting the entire thrust of the 2011 discussion?
(2) what should we do in the VACUUM case? Alexander's argument seems
to apply with just as much force to the VACUUM case, so either you
discount that or you conclude that VACUUM needs adjustment too.
> This tables reltuples is 18 times the actual row count. It will never converge
> because with 50000953 pages analyze can only adjust reltuples by 0.0006 each time.
But by the same token, analyze only looked at 0.0006 of the pages. It's
nice that for you, that's enough to get a robust estimate of the density
everywhere; but I have a nasty feeling that that won't hold good for
everybody. The whole motivation of the 2011 discussion, and the issue
that is also seen in some other nearby discussions, is that the density
can vary wildly.
regards, tom lane
On Thu, 01 Mar 2018 18:49:20 -0500
Tom Lane <tgl@sss.pgh.pa.us> wrote:
> The sticking point in my mind right now is, if we do that, what to do with
> VACUUM's estimates. If you believe the argument in the PDF that we'll
> necessarily overshoot reltuples in the face of declining true density,
> then it seems like that argument applies to VACUUM as well. However,
> VACUUM has the issue that we should *not* believe that it looked at a
> random sample of pages. Maybe the fact that it looks exactly at the
> changed pages causes it to see something less than the overall density,
> cancelling out the problem, but that seems kinda optimistic.
For what it's worth, I think the current estimate formula for VACUUM is
pretty reasonable. Consider a table T with N rows and P pages clustered
on serial key k. Assume reltuples is initially correct.
Then after:
delete from T where k < 0.2 * (select max k from T);
vacuum T;
Vacuum will touch the first 20% of the pages due to visibility map, the sample
will have 0 live rows, scanned pages will be 0.2 * P.
Then according to the current code:
old_density = old_rel_tuples / old_rel_pages;
new_density = scanned_tuples / scanned_pages;
multiplier = (double) scanned_pages / (double) total_pages;
updated_density = old_density + (new_density - old_density) * multiplier;
return floor(updated_density * total_pages + 0.5);
the new density will be:
N/P + (0/0.2*P - N/P) * 0.2
= N/P - N/P * 0.2
= 0.8 * N/P
New reltuples estimate will be 0.8 * old_reltuples. Which is what we wanted.
If we evenly distribute the deletes across the table:
delete from T where rand() < 0.2;
Then vacuum will scan all the pages, the sample will have 0.8 * N live rows,
scanned pages will be 1.0 * P. The new density will be
N/P + (0.8 * N/1.0*P - N/P) * 1.0
= N/P + (0.8 N/P - N/P)
= N/P - 0.2 * N/P
= 0.8 * N/P
Which again gives new reltuples as 0.8 * old_reltuples and is again correct.
I believe that given a good initial estimate of reltuples and relpages and
assuming that the pages vacuum does not scan do not change density then the
vacuum calculation does the right thing.
However, for ANALYZE the case is different.
-dg
--
David Gould daveg@sonic.net
If simplicity worked, the world would be overrun with insects.
On Fri, 02 Mar 2018 17:17:29 -0500 Tom Lane <tgl@sss.pgh.pa.us> wrote: > But by the same token, analyze only looked at 0.0006 of the pages. It's > nice that for you, that's enough to get a robust estimate of the density > everywhere; but I have a nasty feeling that that won't hold good for > everybody. My grasp of statistics is somewhat weak, so please inform me if I've got this wrong, but every time I've looked into it I've found that one can get pretty good accuracy and confidence with fairly small samples. Typically 1000 samples will serve no matter the population size if the desired margin of error is 5%. Even with 99% confidence and a 1% margin of error it takes less than 20,000 samples. See the table at: http://www.research-advisors.com/tools/SampleSize.htm Since we have by default 30000 sample pages and since ANALYZE takes some trouble to get a random sample I think we really can rely on the results of extrapolating reltuples from analyze. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On Wed, Jan 17, 2018 at 4:49 PM, David Gould <daveg@sonic.net> wrote:
Please add the attached patch and this discussion to the open commit fest. The
original bugs thread is here: 20180111111254.1408.8342@wrigleys.postgresql.org.
Bug reference: 15005
Logged by: David Gould
Email address: daveg@sonic.net
PostgreSQL version: 10.1 and earlier
Operating system: Linux
Description:
ANALYZE can make pg_class.reltuples wildly inaccurate compared to the actual
row counts for tables that are larger than the default_statistics_target.
Example from one of a clients production instances:
# analyze verbose pg_attribute;
INFO: analyzing "pg_catalog.pg_attribute"
INFO: "pg_attribute": scanned 30000 of 24519424 pages, containing 6475 live rows and 83 dead rows; 6475 rows in sample, 800983035 estimated total rows.
This is a large complex database - pg_attribute actually has about five
million rows and needs about one hundred thouand pages. However it has
become extremely bloated and is taking 25 million pages (192GB!), about 250
times too much. This happened despite aggressive autovacuum settings and a
periodic bloat monitoring script. Since pg_class.reltuples was 800 million,
the bloat monitoring script did not detect that this table was bloated and
autovacuum did not think it needed vacuuming.
I can see how this issue would prevent ANALYZE from fixing the problem, but I don't see how it could have caused the problem in the first place. In your demonstration case, you had to turn off autovac in order to get it to happen, and then when autovac is turned back on, it is all primed for an autovac to launch, go through, touch almost all of the pages, and fix it for you. How did your original table get into a state where this wouldn't happen?
Maybe a well-timed crash caused n_dead_tup to get reset to zero and that is why autovac is not kicking in? What are the pg_stat_user_table number and the state of the visibility map for your massively bloated table, if you still have them?
In any event, I agree with your analysis that ANALYZE should set the number of tuples from scratch. After all, it sets the other estimates, such as MCV, from scratch, and those are much more fragile to sampling than just the raw number of tuples are. But if the default target is set to 1, that would scan only 300 pages. I think that that is a little low of a sample size to base an estimate on, but it isn't clear to that using 300 pages plus whacking them around with an exponential averaging is really going to be much better. And if you set your default target to 1, that is more-or-less what you signed up for.
It is little weird to have VACUUM incrementally update and then ANALYZE compute from scratch and discard the previous value, but no weirder than what we currently do of having ANALYZE incrementally update despite that it is specifically designed to representatively sample the entire table. So I don't think we need to decide what to do about VACUUM before we can do something about ANALYZE.
So I support your patch. There is probably more investigation and work that could be done in this area, but those could be different patches, not blocking this one.
Cheers,
Jeff
On Sun, 4 Mar 2018 07:49:46 -0800 Jeff Janes <jeff.janes@gmail.com> wrote: > On Wed, Jan 17, 2018 at 4:49 PM, David Gould <daveg@sonic.net> wrote: > > # analyze verbose pg_attribute; > > INFO: "pg_attribute": scanned 30000 of 24519424 pages, containing 6475 > > live rows and 83 dead rows; 6475 rows in sample, 800983035 estimated total > > rows. > > I can see how this issue would prevent ANALYZE from fixing the problem, but > I don't see how it could have caused the problem in the first place. In > your demonstration case, you had to turn off autovac in order to get it to > happen, and then when autovac is turned back on, it is all primed for an > autovac to launch, go through, touch almost all of the pages, and fix it > for you. How did your original table get into a state where this wouldn't > happen? > > Maybe a well-timed crash caused n_dead_tup to get reset to zero and that is > why autovac is not kicking in? What are the pg_stat_user_table number and > the state of the visibility map for your massively bloated table, if you > still have them? We see this sort of thing pretty routinely on more than just catalogs, but catalogs are where it really hurts. These systems are 40 cores/80 threads, 1 TB memory, Fusion IO. Databases are 5 to 10 TB with 100,000 to 200,000 tables. Tables are updated in batches every few minutes 100 threads at a time. There are also some long running queries that don't help. Due to the large number of tables and high rate of mutation it can take a long time between visits from autovacuum, especially since autovacuum builds a list of pending work and then processes it to completion so new tables in need of vacuum can't even be seen until all the old work is done. For what it is worth, streaming replication doesn't work either as the single threaded recovery can't keep up with the 80 thread mutator. We tried relying on external scripts to address the most bloated tables, but those also depended on reltuples to detect bloat so they missed out a lot. For a long time we simply had recurring crisis. Once I figured out that ANALYZE could not set reltuples effectively we worked around it by running ANALYZE VERBOSE on all the large tables and parsing the notices to calculate the rowcount the same way as in the patch. This works, but is a nuisance. The main pain points are that when reltuples gets inflated there is no way to fix it, auto vacuum stops looking at the table and hand run ANALYZE can't reset the reltuples. The only cure is VACUUM FULL, but that is not really practical without unacceptable amounts of downtime. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On Sun, 4 Mar 2018 07:49:46 -0800 Jeff Janes <jeff.janes@gmail.com> wrote: > In any event, I agree with your analysis that ANALYZE should set the number > of tuples from scratch. After all, it sets the other estimates, such as > MCV, from scratch, and those are much more fragile to sampling than just > the raw number of tuples are. But if the default target is set to 1, that > would scan only 300 pages. I think that that is a little low of a sample > size to base an estimate on, but it isn't clear to that using 300 pages > plus whacking them around with an exponential averaging is really going to > be much better. And if you set your default target to 1, that is > more-or-less what you signed up for. > > It is little weird to have VACUUM incrementally update and then ANALYZE > compute from scratch and discard the previous value, but no weirder than > what we currently do of having ANALYZE incrementally update despite that it > is specifically designed to representatively sample the entire table. So I > don't think we need to decide what to do about VACUUM before we can do > something about ANALYZE. Thanks. I was going to add the point about trusting ANALYZE for the statistics but not for reltuples, but you beat me to it. 300 samples would be on the small side, as you say that's asking for it. Even the old default target of 10 gives 3000 samples which is probably plenty. I think the method VACUUM uses is appropriate and probably correct for VACUUM. But not for ANALYZE. Which is actually hinted at in the original comments but not in the code. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On Sun, 4 Mar 2018 07:49:46 -0800 Jeff Janes <jeff.janes@gmail.com> wrote: > I don't see how it could have caused the problem in the first place. In > your demonstration case, you had to turn off autovac in order to get it to > happen, and then when autovac is turned back on, it is all primed for an > autovac to launch, go through, touch almost all of the pages, and fix it > for you. How did your original table get into a state where this wouldn't > happen? One more way for this to happen, vacuum was including the dead tuples in the estimate in addition to the live tuples. This is a separate bug that tends to aggravate the one I'm trying to fix. See the thread re BUG #15005 at: https://www.postgresql.org/message-id/16db4468-edfa-830a-f921-39a50498e77e%402ndquadrant.com > It seems to me that VACUUM and ANALYZE somewhat disagree on what exactly > reltuples means. VACUUM seems to be thinking that > > reltuples = live + dead > > while ANALYZE apparently believes that > > reltuples = live There is a patch for this one from Tomas Vondra/Tom Lane that I hope it will land in the next set of releases. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
David Gould <daveg@sonic.net> writes:
> On Sun, 4 Mar 2018 07:49:46 -0800
> Jeff Janes <jeff.janes@gmail.com> wrote:
>> I don't see how it could have caused the problem in the first place. In
>> your demonstration case, you had to turn off autovac in order to get it to
>> happen, and then when autovac is turned back on, it is all primed for an
>> autovac to launch, go through, touch almost all of the pages, and fix it
>> for you. How did your original table get into a state where this wouldn't
>> happen?
> One more way for this to happen, vacuum was including the dead tuples in the
> estimate in addition to the live tuples.
FWIW, I've been continuing to think about this and poke at your example,
and I am having the same difficulty as Jeff. While it's clear that if you
managed to get into a state with wildly inflated reltuples, ANALYZE would
fail to get out of it, it's not clear how you could get to such a state
without additional contributing factors. This ANALYZE behavior only seems
to result in an incremental increase in reltuples per run, and so that
shouldn't prevent autovacuum from happening and fixing the estimate ---
maybe not as quickly as it should happen, but it'd happen.
The reasons I'm harping on this are (a) if there are additional bugs
contributing to the problem, we need to identify them and fix them;
(b) we need to understand what the triggering conditions are in some
detail, so that we can decide whether this bug is bad enough to justify
back-patching a behavioral change. I remain concerned that the proposed
fix is too simplistic and will have some unforeseen side-effects, so
I'd really rather just put it in HEAD and let it go through a beta test
cycle before it gets loosed on the world.
Another issue I have after thinking more is that we need to consider
what should happen during a combined VACUUM+ANALYZE. In this situation,
with the proposed patch, we'd overwrite VACUUM's result with an estimate
derived from ANALYZE's sample ... even though VACUUM's result might've
come from a full-table scan and hence be exact. In the existing code
a small ANALYZE sample can't do a lot of damage to VACUUM's result, but
that would no longer be true with this. I'm inclined to feel that we
should trust VACUUM's result for reltuples more than ANALYZE's, on the
grounds that if there actually was any large change in reltuples, VACUUM
would have looked at most of the pages and hence have a more reliable
number. Hence I think we should skip the pg_class update for ANALYZE if
it's in a combined VACUUM+ANALYZE, at least unless ANALYZE looked at all
(most of?) the pages. That could be mechanized with something like
- if (!inh)
+ if (!inh && !(options & VACOPT_VACUUM))
controlling do_analyze_rel's call to vac_update_relstats, maybe with a
check on scanned_pages vs total_pages. Perhaps the call to
pgstat_report_analyze needs to be filtered similarly (or maybe we still
want to report that an analyze happened, but somehow tell the stats
collector not to change its counts?)
Also, as a stylistic matter, I'd be inclined not to touch
vac_estimate_reltuples' behavior. The place where the rubber is meeting
the road is
*totalrows = vac_estimate_reltuples(onerel, true,
totalblocks,
bs.m,
liverows);
if (bs.m > 0)
*totaldeadrows = floor((deadrows / bs.m) * totalblocks + 0.5);
else
*totaldeadrows = 0.0;
and it seems to me it'd make more sense to abandon the use of
vac_estimate_reltuples entirely, and just calculate totalrows in a fashion
exactly parallel to totaldeadrows. (I think that's how the code used to
look here ...)
In HEAD, we could then drop vac_estimate_reltuples' is_analyze argument
altogether, though that would be unwise in the back branches (if we
back-patch) since we have no idea whether any third party code is calling
this function.
regards, tom lane
David Gould <daveg@sonic.net> writes:
> On Thu, 01 Mar 2018 18:49:20 -0500
> Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The sticking point in my mind right now is, if we do that, what to do with
>> VACUUM's estimates.
> For what it's worth, I think the current estimate formula for VACUUM is
> pretty reasonable. Consider a table T with N rows and P pages clustered
> on serial key k. Assume reltuples is initially correct.
If the starting condition involves uniform tuple density throughout the
table, with matching reltuples/relpages ratio, then any set of changes
followed by one VACUUM will produce the right reltuples (to within
roundoff error) at the end. This can be seen by recognizing that VACUUM
will visit every changed page, and the existing calculation is equivalent
to "assume the old tuple density is correct for the unvisited pages, and
then add on the measured tuple count within the visited pages". I'm a bit
inclined to reformulate and redocument the calculation that way, in hopes
that people would find it more convincing.
However, things get less good if the initial state is nonuniform and
we do a set of updates that line up with the nonuniformity. For
example, start with a uniformly full table, and update 50% of the
rows lying within the first 20% of the pages. Now those 20% are
only half full of live tuples, and the table has grown by 10%, with
all those added pages full. Do a VACUUM. It will process the first
20% and the new 10% of pages, and arrive at a correct reltuples count
per the above argument. But now, reltuples/relpages reflects an average
tuple density that's only about 90% of maximum. Next, delete the
surviving tuples in the first 20% of pages, and again VACUUM. VACUUM
will examine only the first 20% of pages, and find that they're devoid
of live tuples. It will then update reltuples using the 90% density
figure as the estimate of what's in the remaining pages, and that's
too small, so that reltuples will drop to about 90% of the correct
value.
Lacking an oracle (small "o"), I do not think there's much we can do
about this, without resorting to very expensive measures such as
scanning the whole table. (It's somewhat interesting to speculate
about whether scanning the table's FSM could yield useful data, but
I'm unsure that I'd trust the results much.) The best we can do is
hope that correlated update patterns like this are uncommon.
Maybe this type of situation is an argument for trusting an ANALYZE-based
estimate more than the VACUUM-based estimate. I remain uncomfortable with
that in cases where VACUUM looked at much more of the table than ANALYZE
did, though. Maybe we need some heuristic based on the number of pages
actually visited by each pass?
regards, tom lane
On Tue, 06 Mar 2018 11:16:04 -0500 Tom Lane <tgl@sss.pgh.pa.us> wrote: > so that we can decide whether this bug is bad enough to justify > back-patching a behavioral change. I remain concerned that the proposed > fix is too simplistic and will have some unforeseen side-effects, so > I'd really rather just put it in HEAD and let it go through a beta test > cycle before it gets loosed on the world. It happens to us fairly regularly and causes lots of problems. However, I'm agreeable to putting it in head for now, my client can build from source to pick up this patch until that ships, but doesn't want to maintain their own fork forever. That said, if it does get though beta I'd hope we could back-patch at that time. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
On Fri, Mar 2, 2018 at 5:17 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > (1) do we really want to go over to treating ANALYZE's tuple density > result as gospel, contradicting the entire thrust of the 2011 discussion? > >> This tables reltuples is 18 times the actual row count. It will never converge >> because with 50000953 pages analyze can only adjust reltuples by 0.0006 each time. > > But by the same token, analyze only looked at 0.0006 of the pages. It's > nice that for you, that's enough to get a robust estimate of the density > everywhere; but I have a nasty feeling that that won't hold good for > everybody. The whole motivation of the 2011 discussion, and the issue > that is also seen in some other nearby discussions, is that the density > can vary wildly. I think that viewing ANALYZE's result as fairly authoritative is probably a good idea. If ANALYZE looked at only 0.0006 of the pages, that's because we decided that 0.0006 of the pages were all it needed to look at in order to come up with good estimates. Having decided that, we should turn around and decide that they are 99.94% bunk. Now, it could be that there are data sets out there were the number of tuples per page varies widely between different parts of the table, and therefore sampling 0.0006 of the pages can return quite different estimates depending on which ones we happen to pick. However, that's a lot like saying that 0.0006 of the pages isn't really enough, and maybe the solution is to sample more. Still, it doesn't seem unreasonable to do some kind of smoothing, where we set the new estimate = (newly computed estimate * X) + (previous estimate * (1 - X)) where X might be 0.25 or whatever; perhaps X might even be configurable. One thing to keep in mind is that VACUUM will, in many workloads, tend to scan the same parts of the table over and over again. For example, consider a database of chess players which is regularly updated with new ratings information. The records for active players will be updated frequently, but the ratings for deceased players will rarely change. Living but inactive players may occasionally become active again, or may be updated occasionally for one reason or another. So, VACUUM will keep scanning the pages that contain records for active players but will rarely or never be asked to scan the pages for dead players. If it so happens that these different groups of players have rows of varying width -- perhaps we store more detailed data about newer players but don't have full records for older ones -- then the overall tuple density estimate will come to resemble more and more the density of the rows that are actively being updated, rather than the overall density of the whole table. Even if all the tuples are the same width, it might happen in some workload that typically insert a record, update it N times, and then it stays fixed after that. Suppose we can fit 100 tuples into a page. On pages were all of the records have reached their final state, there will be 100 tuples. But on pages where updates are still happening there will -- after VACUUM -- be fewer than 100 tuples per page, because some fraction of the tuples on the page were dead row versions. That's why we were vacuuming them. Suppose typically half the tuples on each page are getting removed by VACUUM. Then, over time, as the table grows, if only VACUUM is ever run, our estimate of tuples per page will converge to 50, but in reality, as the table grows, the real number is converging to 100. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, Mar 4, 2018 at 3:18 PM, David Gould <daveg@sonic.net> wrote:
On Sun, 4 Mar 2018 07:49:46 -0800
Jeff Janes <jeff.janes@gmail.com> wrote:
> On Wed, Jan 17, 2018 at 4:49 PM, David Gould <daveg@sonic.net> wrote:
...
>
> Maybe a well-timed crash caused n_dead_tup to get reset to zero and that is
> why autovac is not kicking in? What are the pg_stat_user_table number and
> the state of the visibility map for your massively bloated table, if you
> still have them?
...
The main pain points are that when reltuples gets inflated there is no way
to fix it, auto vacuum stops looking at the table and hand run ANALYZE can't
reset the reltuples. The only cure is VACUUM FULL, but that is not really
practical without unacceptable amounts of downtime.
But why won't an ordinary manual VACUUM (not FULL) fix it? That seems like that is a critical thing to figure out.
As for preventing it in the first place, based on your description of your hardware and operations, I was going to say you need to increase the max number of autovac workers, but then I remembered you from "Autovacuum slows down with large numbers of tables. More workers makes it slower" (https://www.postgresql.org/message-id/20151030133252.3033.4249%40wrigleys.postgresql.org). So you are probably still suffering from that? Your patch from then seemed to be pretty invasive and so controversial. I had a trivial but fairly effective patch at the time, but it now less trivial because of how shared catalogs are dealt with (commit 15739393e4c3b64b9038d75) and I haven't rebased it over that issue.
Cheers,
Jeff
On Wed, 7 Mar 2018 21:39:08 -0800 Jeff Janes <jeff.janes@gmail.com> wrote: > As for preventing it in the first place, based on your description of your > hardware and operations, I was going to say you need to increase the max > number of autovac workers, but then I remembered you from "Autovacuum slows > down with large numbers of tables. More workers makes it slower" ( > https://www.postgresql.org/message-id/20151030133252.3033.4249%40wrigleys.postgresql.org). > So you are probably still suffering from that? Your patch from then seemed > to be pretty invasive and so controversial. We have been building from source using that patch for the worker contention since then. It's very effective, there is no way we could have continued to rely on autovacuum without it. It's sort of a nuisance to keep updating it for each point release that touches autovacuum, but here we are. The current patch is motivated by the fact that even with effective workers we still regularly find tables with inflated reltuples. I have some theories about why, but not really proof. Mainly variants on "all the vacuum workers were busy making their way through a list of 100,000 tables and did not get back to the problem table before it became a problem." I do have a design in mind for a larger more principled patch that fixes the same issue and some others too, but given the reaction to the earlier one I hesitate to spend a lot of time on it. I'd be happy to discuss a way to try to move forward though if any one is interested. Your patch helped, but mainly was targeted at the lock contention part of the problem. The other part of the problem was that autovacuum workers will force a rewrite of the stats file every time they try to choose a new table to work on. With large numbers of tables and many autovacuum workers this is a significant extra workload. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
David Gould <daveg@sonic.net> writes: > On Wed, 7 Mar 2018 21:39:08 -0800 > Jeff Janes <jeff.janes@gmail.com> wrote: >> As for preventing it in the first place, based on your description of your >> hardware and operations, I was going to say you need to increase the max >> number of autovac workers, but then I remembered you from "Autovacuum slows >> down with large numbers of tables. More workers makes it slower" ( >> https://www.postgresql.org/message-id/20151030133252.3033.4249%40wrigleys.postgresql.org). >> So you are probably still suffering from that? Your patch from then seemed >> to be pretty invasive and so controversial. > We have been building from source using that patch for the worker contention > since then. It's very effective, there is no way we could have continued to > rely on autovacuum without it. It's sort of a nuisance to keep updating it > for each point release that touches autovacuum, but here we are. Re-reading that thread, it seems like we should have applied Jeff's initial trivial patch[1] (to not hold AutovacuumScheduleLock across table_recheck_autovac) rather than waiting around for a super duper improvement to get agreed on. I'm a bit tempted to go do that; if nothing else, it seems simple enough to back-patch, unlike most of the rest of what was discussed. regards, tom lane [1] https://www.postgresql.org/message-id/CAMkU%3D1zQUAV6Zv3O7R5BO8AfJO%2BLAw7satHYfd%2BV2t5MO3Bp4w%40mail.gmail.com
I wrote:
> Maybe this type of situation is an argument for trusting an ANALYZE-based
> estimate more than the VACUUM-based estimate. I remain uncomfortable with
> that in cases where VACUUM looked at much more of the table than ANALYZE
> did, though. Maybe we need some heuristic based on the number of pages
> actually visited by each pass?
I looked into doing something like that. It's possible, but it's fairly
invasive; there's no clean way to compare those page counts without
altering the API of acquire_sample_rows() to pass back the number of pages
it visited. That would mean a change in FDW-visible APIs. We could do
that, but I don't want to insist on it when there's nothing backing it up
except a fear that *maybe* ANALYZE's estimate will be wrong often enough
to worry about.
So at this point I'm prepared to go forward with your patch, though not
to risk back-patching it. Field experience will tell us if we need to
do more. I propose the attached cosmetic refactoring, though.
regards, tom lane
diff --git a/contrib/pgstattuple/pgstatapprox.c b/contrib/pgstattuple/pgstatapprox.c
index 3cfbc08..474c3bd 100644
*** a/contrib/pgstattuple/pgstatapprox.c
--- b/contrib/pgstattuple/pgstatapprox.c
*************** statapprox_heap(Relation rel, output_typ
*** 184,190 ****
stat->table_len = (uint64) nblocks * BLCKSZ;
! stat->tuple_count = vac_estimate_reltuples(rel, false, nblocks, scanned,
stat->tuple_count + misc_count);
/*
--- 184,190 ----
stat->table_len = (uint64) nblocks * BLCKSZ;
! stat->tuple_count = vac_estimate_reltuples(rel, nblocks, scanned,
stat->tuple_count + misc_count);
/*
diff --git a/src/backend/commands/analyze.c b/src/backend/commands/analyze.c
index 5f21fcb..ef93fb4 100644
*** a/src/backend/commands/analyze.c
--- b/src/backend/commands/analyze.c
*************** acquire_sample_rows(Relation onerel, int
*** 1249,1267 ****
qsort((void *) rows, numrows, sizeof(HeapTuple), compare_rows);
/*
! * Estimate total numbers of rows in relation. For live rows, use
! * vac_estimate_reltuples; for dead rows, we have no source of old
! * information, so we have to assume the density is the same in unseen
! * pages as in the pages we scanned.
*/
- *totalrows = vac_estimate_reltuples(onerel, true,
- totalblocks,
- bs.m,
- liverows);
if (bs.m > 0)
*totaldeadrows = floor((deadrows / bs.m) * totalblocks + 0.5);
else
*totaldeadrows = 0.0;
/*
* Emit some interesting relation info
--- 1249,1270 ----
qsort((void *) rows, numrows, sizeof(HeapTuple), compare_rows);
/*
! * Estimate total numbers of live and dead rows in relation, extrapolating
! * on the assumption that the average tuple density in pages we didn't
! * scan is the same as in the pages we did scan. Since what we scanned is
! * a random sample of the pages in the relation, this should be a good
! * assumption.
*/
if (bs.m > 0)
+ {
+ *totalrows = floor((liverows / bs.m) * totalblocks + 0.5);
*totaldeadrows = floor((deadrows / bs.m) * totalblocks + 0.5);
+ }
else
+ {
+ *totalrows = 0.0;
*totaldeadrows = 0.0;
+ }
/*
* Emit some interesting relation info
diff --git a/src/backend/commands/vacuum.c b/src/backend/commands/vacuum.c
index 7aca69a..b50c554 100644
*** a/src/backend/commands/vacuum.c
--- b/src/backend/commands/vacuum.c
*************** vacuum_set_xid_limits(Relation rel,
*** 766,781 ****
* vac_estimate_reltuples() -- estimate the new value for pg_class.reltuples
*
* If we scanned the whole relation then we should just use the count of
! * live tuples seen; but if we did not, we should not trust the count
! * unreservedly, especially not in VACUUM, which may have scanned a quite
! * nonrandom subset of the table. When we have only partial information,
! * we take the old value of pg_class.reltuples as a measurement of the
* tuple density in the unscanned pages.
- *
- * This routine is shared by VACUUM and ANALYZE.
*/
double
! vac_estimate_reltuples(Relation relation, bool is_analyze,
BlockNumber total_pages,
BlockNumber scanned_pages,
double scanned_tuples)
--- 766,779 ----
* vac_estimate_reltuples() -- estimate the new value for pg_class.reltuples
*
* If we scanned the whole relation then we should just use the count of
! * live tuples seen; but if we did not, we should not blindly extrapolate
! * from that number, since VACUUM may have scanned a quite nonrandom
! * subset of the table. When we have only partial information, we take
! * the old value of pg_class.reltuples as a measurement of the
* tuple density in the unscanned pages.
*/
double
! vac_estimate_reltuples(Relation relation,
BlockNumber total_pages,
BlockNumber scanned_pages,
double scanned_tuples)
*************** vac_estimate_reltuples(Relation relation
*** 783,791 ****
BlockNumber old_rel_pages = relation->rd_rel->relpages;
double old_rel_tuples = relation->rd_rel->reltuples;
double old_density;
! double new_density;
! double multiplier;
! double updated_density;
/* If we did scan the whole table, just use the count as-is */
if (scanned_pages >= total_pages)
--- 781,788 ----
BlockNumber old_rel_pages = relation->rd_rel->relpages;
double old_rel_tuples = relation->rd_rel->reltuples;
double old_density;
! double unscanned_pages;
! double total_tuples;
/* If we did scan the whole table, just use the count as-is */
if (scanned_pages >= total_pages)
*************** vac_estimate_reltuples(Relation relation
*** 809,839 ****
/*
* Okay, we've covered the corner cases. The normal calculation is to
! * convert the old measurement to a density (tuples per page), then update
! * the density using an exponential-moving-average approach, and finally
! * compute reltuples as updated_density * total_pages.
! *
! * For ANALYZE, the moving average multiplier is just the fraction of the
! * table's pages we scanned. This is equivalent to assuming that the
! * tuple density in the unscanned pages didn't change. Of course, it
! * probably did, if the new density measurement is different. But over
! * repeated cycles, the value of reltuples will converge towards the
! * correct value, if repeated measurements show the same new density.
! *
! * For VACUUM, the situation is a bit different: we have looked at a
! * nonrandom sample of pages, but we know for certain that the pages we
! * didn't look at are precisely the ones that haven't changed lately.
! * Thus, there is a reasonable argument for doing exactly the same thing
! * as for the ANALYZE case, that is use the old density measurement as the
! * value for the unscanned pages.
! *
! * This logic could probably use further refinement.
*/
old_density = old_rel_tuples / old_rel_pages;
! new_density = scanned_tuples / scanned_pages;
! multiplier = (double) scanned_pages / (double) total_pages;
! updated_density = old_density + (new_density - old_density) * multiplier;
! return floor(updated_density * total_pages + 0.5);
}
--- 806,819 ----
/*
* Okay, we've covered the corner cases. The normal calculation is to
! * convert the old measurement to a density (tuples per page), then
! * estimate the number of tuples in the unscanned pages using that figure,
! * and finally add on the number of tuples in the scanned pages.
*/
old_density = old_rel_tuples / old_rel_pages;
! unscanned_pages = (double) total_pages - (double) scanned_pages;
! total_tuples = old_density * unscanned_pages + scanned_tuples;
! return floor(total_tuples + 0.5);
}
diff --git a/src/backend/commands/vacuumlazy.c b/src/backend/commands/vacuumlazy.c
index cf7f5e1..9ac84e8 100644
*** a/src/backend/commands/vacuumlazy.c
--- b/src/backend/commands/vacuumlazy.c
*************** lazy_scan_heap(Relation onerel, int opti
*** 1286,1292 ****
vacrelstats->new_dead_tuples = nkeep;
/* now we can compute the new value for pg_class.reltuples */
! vacrelstats->new_rel_tuples = vac_estimate_reltuples(onerel, false,
nblocks,
vacrelstats->tupcount_pages,
num_tuples);
--- 1286,1292 ----
vacrelstats->new_dead_tuples = nkeep;
/* now we can compute the new value for pg_class.reltuples */
! vacrelstats->new_rel_tuples = vac_estimate_reltuples(onerel,
nblocks,
vacrelstats->tupcount_pages,
num_tuples);
diff --git a/src/include/commands/vacuum.h b/src/include/commands/vacuum.h
index 797b6df..85d472f 100644
*** a/src/include/commands/vacuum.h
--- b/src/include/commands/vacuum.h
*************** extern void vacuum(int options, List *re
*** 162,168 ****
extern void vac_open_indexes(Relation relation, LOCKMODE lockmode,
int *nindexes, Relation **Irel);
extern void vac_close_indexes(int nindexes, Relation *Irel, LOCKMODE lockmode);
! extern double vac_estimate_reltuples(Relation relation, bool is_analyze,
BlockNumber total_pages,
BlockNumber scanned_pages,
double scanned_tuples);
--- 162,168 ----
extern void vac_open_indexes(Relation relation, LOCKMODE lockmode,
int *nindexes, Relation **Irel);
extern void vac_close_indexes(int nindexes, Relation *Irel, LOCKMODE lockmode);
! extern double vac_estimate_reltuples(Relation relation,
BlockNumber total_pages,
BlockNumber scanned_pages,
double scanned_tuples);
I wrote:
> Re-reading that thread, it seems like we should have applied Jeff's
> initial trivial patch[1] (to not hold AutovacuumScheduleLock across
> table_recheck_autovac) rather than waiting around for a super duper
> improvement to get agreed on. I'm a bit tempted to go do that;
> if nothing else, it seems simple enough to back-patch, unlike most
> of the rest of what was discussed.
Jeff mentioned that that patch wasn't entirely trivial to rebase over
15739393e, and I now see why: in the code structure as it stands,
we don't know soon enough whether the table is shared. In the
attached rebase, I solved that with the brute-force method of just
reading the pg_class tuple an extra time. I think this is probably
good enough, really. I thought about having do_autovacuum pass down
the tuple to table_recheck_autovac so as to not increase the net
number of syscache fetches, but I'm slightly worried about whether
we could be passing a stale pg_class tuple to table_recheck_autovac
if we do it like that. OTOH, that just raises the question of why
we are doing any of this while holding no lock whatever on the target
table :-(. I'm content to leave that question to the major redesign
that was speculated about in the bug #13750 thread.
This also corrects the inconsistency that at the bottom, do_autovacuum
clears wi_tableoid while taking AutovacuumLock, not AutovacuumScheduleLock
as is the documented lock for that field. There's no actual bug there,
but cleaning this up might provide a slight improvement in concurrency
for operations that need AutovacuumLock but aren't looking at other
processes' wi_tableoid. (Alternatively, we could decide that there's
no real need anymore for the separate AutovacuumScheduleLock, but that's
more churn than I wanted to deal with here.)
I think this is OK to commit/backpatch --- any objections?
regards, tom lane
diff --git a/src/backend/postmaster/autovacuum.c b/src/backend/postmaster/autovacuum.c
index 21f5e2c..639bd71 100644
*** a/src/backend/postmaster/autovacuum.c
--- b/src/backend/postmaster/autovacuum.c
*************** typedef struct autovac_table
*** 212,220 ****
* wi_launchtime Time at which this worker was launched
* wi_cost_* Vacuum cost-based delay parameters current in this worker
*
! * All fields are protected by AutovacuumLock, except for wi_tableoid which is
! * protected by AutovacuumScheduleLock (which is read-only for everyone except
! * that worker itself).
*-------------
*/
typedef struct WorkerInfoData
--- 212,220 ----
* wi_launchtime Time at which this worker was launched
* wi_cost_* Vacuum cost-based delay parameters current in this worker
*
! * All fields are protected by AutovacuumLock, except for wi_tableoid and
! * wi_sharedrel which are protected by AutovacuumScheduleLock (note these
! * two fields are read-only for everyone except that worker itself).
*-------------
*/
typedef struct WorkerInfoData
*************** do_autovacuum(void)
*** 2317,2323 ****
--- 2317,2325 ----
foreach(cell, table_oids)
{
Oid relid = lfirst_oid(cell);
+ HeapTuple classTup;
autovac_table *tab;
+ bool isshared;
bool skipit;
int stdVacuumCostDelay;
int stdVacuumCostLimit;
*************** do_autovacuum(void)
*** 2342,2350 ****
}
/*
! * hold schedule lock from here until we're sure that this table still
! * needs vacuuming. We also need the AutovacuumLock to walk the
! * worker array, but we'll let go of that one quickly.
*/
LWLockAcquire(AutovacuumScheduleLock, LW_EXCLUSIVE);
LWLockAcquire(AutovacuumLock, LW_SHARED);
--- 2344,2366 ----
}
/*
! * Find out whether the table is shared or not. (It's slightly
! * annoying to fetch the syscache entry just for this, but in typical
! * cases it adds little cost because table_recheck_autovac would
! * refetch the entry anyway. We could buy that back by copying the
! * tuple here and passing it to table_recheck_autovac, but that
! * increases the odds of that function working with stale data.)
! */
! classTup = SearchSysCache1(RELOID, ObjectIdGetDatum(relid));
! if (!HeapTupleIsValid(classTup))
! continue; /* somebody deleted the rel, forget it */
! isshared = ((Form_pg_class) GETSTRUCT(classTup))->relisshared;
! ReleaseSysCache(classTup);
!
! /*
! * Hold schedule lock from here until we've claimed the table. We
! * also need the AutovacuumLock to walk the worker array, but that one
! * can just be a shared lock.
*/
LWLockAcquire(AutovacuumScheduleLock, LW_EXCLUSIVE);
LWLockAcquire(AutovacuumLock, LW_SHARED);
*************** do_autovacuum(void)
*** 2381,2386 ****
--- 2397,2412 ----
}
/*
+ * Store the table's OID in shared memory before releasing the
+ * schedule lock, so that other workers don't try to vacuum it
+ * concurrently. (We claim it here so as not to hold
+ * AutovacuumScheduleLock while rechecking the stats.)
+ */
+ MyWorkerInfo->wi_tableoid = relid;
+ MyWorkerInfo->wi_sharedrel = isshared;
+ LWLockRelease(AutovacuumScheduleLock);
+
+ /*
* Check whether pgstat data still says we need to vacuum this table.
* It could have changed if something else processed the table while
* we weren't looking.
*************** do_autovacuum(void)
*** 2396,2414 ****
if (tab == NULL)
{
/* someone else vacuumed the table, or it went away */
LWLockRelease(AutovacuumScheduleLock);
continue;
}
/*
- * Ok, good to go. Store the table in shared memory before releasing
- * the lock so that other workers don't vacuum it concurrently.
- */
- MyWorkerInfo->wi_tableoid = relid;
- MyWorkerInfo->wi_sharedrel = tab->at_sharedrel;
- LWLockRelease(AutovacuumScheduleLock);
-
- /*
* Remember the prevailing values of the vacuum cost GUCs. We have to
* restore these at the bottom of the loop, else we'll compute wrong
* values in the next iteration of autovac_balance_cost().
--- 2422,2435 ----
if (tab == NULL)
{
/* someone else vacuumed the table, or it went away */
+ LWLockAcquire(AutovacuumScheduleLock, LW_EXCLUSIVE);
+ MyWorkerInfo->wi_tableoid = InvalidOid;
+ MyWorkerInfo->wi_sharedrel = false;
LWLockRelease(AutovacuumScheduleLock);
continue;
}
/*
* Remember the prevailing values of the vacuum cost GUCs. We have to
* restore these at the bottom of the loop, else we'll compute wrong
* values in the next iteration of autovac_balance_cost().
*************** deleted:
*** 2522,2531 ****
* settings, so we don't want to give up our share of I/O for a very
* short interval and thereby thrash the global balance.
*/
! LWLockAcquire(AutovacuumLock, LW_EXCLUSIVE);
MyWorkerInfo->wi_tableoid = InvalidOid;
MyWorkerInfo->wi_sharedrel = false;
! LWLockRelease(AutovacuumLock);
/* restore vacuum cost GUCs for the next iteration */
VacuumCostDelay = stdVacuumCostDelay;
--- 2543,2552 ----
* settings, so we don't want to give up our share of I/O for a very
* short interval and thereby thrash the global balance.
*/
! LWLockAcquire(AutovacuumScheduleLock, LW_EXCLUSIVE);
MyWorkerInfo->wi_tableoid = InvalidOid;
MyWorkerInfo->wi_sharedrel = false;
! LWLockRelease(AutovacuumScheduleLock);
/* restore vacuum cost GUCs for the next iteration */
VacuumCostDelay = stdVacuumCostDelay;
On Mon, 12 Mar 2018 10:43:36 -0400 Tom Lane <tgl@sss.pgh.pa.us> wrote: > Re-reading that thread, it seems like we should have applied Jeff's > initial trivial patch[1] (to not hold across > table_recheck_autovac) rather than waiting around for a super duper > improvement to get agreed on. I'm a bit tempted to go do that; > if nothing else, it seems simple enough to back-patch, unlike most > of the rest of what was discussed. This will help. In my testing it reduced the lock contention considerably. I think a lot of users with lots of tables will benefit from it. However it does nothing about the bigger issue which is that autovacuum flaps the stats temp files. I have attached the patch we are currently using. It applies to 9.6.8. I have versions for older releases in 9.4, 9.5, 9.6. I fails to apply to 10, and presumably head but I can update it if there is any interest. The patch has three main features: - Impose an ordering on the autovacuum workers worklist to avoid the need for rechecking statistics to skip already vacuumed tables. - Reduce the frequency of statistics refreshes - Remove the AutovacuumScheduleLock The patch is aware of the shared relations fix. It is subject to the problem Alvero noted in the original discussion: if the last table to be autovacuumed is large new workers will exit instead of choosing an earlier table. Not sure this is really a big problem in practice, but I agree it is a corner case. My patch does not do what I believe really needs doing: Schedule autovacuum more intelligently. Currently autovacuum collects all the tables in the physical order of pg_class and visits them one by one. With many tables it can take too long to respond to urgent vacuum needs, eg heavily updated tables or wraparound. There is a patch in the current commit fest that allows prioritizing tables manually. I don't like that idea much, but it does recognize that the current scheme is not adequate for databases with large numbers of tables. -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.
Вложения
On Mon, 12 Mar 2018 12:21:34 -0400
Tom Lane <tgl@sss.pgh.pa.us> wrote:
> I wrote:
> > Maybe this type of situation is an argument for trusting an ANALYZE-based
> > estimate more than the VACUUM-based estimate. I remain uncomfortable with
> > that in cases where VACUUM looked at much more of the table than ANALYZE
> > did, though. Maybe we need some heuristic based on the number of pages
> > actually visited by each pass?
>
> I looked into doing something like that. It's possible, but it's fairly
> invasive; there's no clean way to compare those page counts without
> altering the API of acquire_sample_rows() to pass back the number of pages
> it visited. That would mean a change in FDW-visible APIs. We could do
> that, but I don't want to insist on it when there's nothing backing it up
> except a fear that *maybe* ANALYZE's estimate will be wrong often enough
> to worry about.
>
> So at this point I'm prepared to go forward with your patch, though not
> to risk back-patching it. Field experience will tell us if we need to
> do more. I propose the attached cosmetic refactoring, though.
I like the re-factor. Making vac_estimate_reltuples() specific to the
special case of vacuum and having the normal analyze case just in analyze
seems like an improvement overall.
It it helps I have been experimenting with your thought experiment (update
first 20% of rows, then delete 50% of those) to try to trick analyze. I
built test scripts and generate data and found the the current system
after vacuum is usually about 8% to 10% off on reltuples. Analyze moves it
very slowly closer to the true count. With the patch analyze nails it
immediately.
To see how this was affected by the relationship of table size and sample
I created another test setup just to iterate analyze runs and compare to
the true count. fter a couple thousand analyzes with various table mutations
and table sizes up to 100 M rows, (1.8 M pages) and
default_statistics_targets ranging from 1 to 1000 I am pretty confident that
we can get 2% accuracy for any size table even with the old statistics
target. The table size does not really matter much, the error drops and
clusters more tightly as sample size increases but past 10000 or so it's well
into diminishing returns.
Summary of 100 analyze runs for each line below.
Errors and sample fraction are in percent for easy reading.
/ ----------- percent ---------------/
testcase | Mrows | stats | pages | sample | fraction | maxerr | avgerr | stddev
-----------+-------+-------+---------+--------+----------+--------+--------+---------
first-last | 10 | 1 | 163935 | 300 | 0.001830 | 6.6663 | 2.3491 | 2.9310
first-last | 10 | 3 | 163935 | 900 | 0.005490 | 3.8886 | 1.2451 | 1.5960
first-last | 10 | 10 | 163935 | 3000 | 0.018300 | 2.8337 | 0.7539 | 0.9657
first-last | 10 | 33 | 163935 | 9900 | 0.060390 | 1.4903 | 0.3723 | 0.4653
first-last | 10 | 100 | 163935 | 30000 | 0.182999 | 0.6580 | 0.2221 | 0.2707
first-last | 10 | 333 | 163935 | 99900 | 0.609388 | 0.1960 | 0.0758 | 0.0897
first-last | 100 | 1 | 1639345 | 300 | 0.000183 | 8.7500 | 2.2292 | 2.8685
first-last | 100 | 3 | 1639345 | 900 | 0.000549 | 5.4166 | 1.1695 | 1.5431
first-last | 100 | 10 | 1639345 | 3000 | 0.001830 | 1.7916 | 0.6258 | 0.7593
first-last | 100 | 33 | 1639345 | 9900 | 0.006039 | 1.8182 | 0.4141 | 0.5433
first-last | 100 | 100 | 1639345 | 30000 | 0.018300 | 0.9417 | 0.2464 | 0.3098
first-last | 100 | 333 | 1639345 | 99900 | 0.060939 | 0.4642 | 0.1206 | 0.1542
first-last | 100 | 1000 | 1639345 | 300000 | 0.183000 | 0.2192 | 0.0626 | 0.0776
un-updated | 10 | 1 | 180328 | 300 | 0.001664 | 7.9259 | 2.2845 | 2.7806
un-updated | 10 | 3 | 180328 | 900 | 0.004991 | 4.2964 | 1.2923 | 1.5990
un-updated | 10 | 10 | 180328 | 3000 | 0.016636 | 2.2593 | 0.6734 | 0.8271
un-updated | 10 | 33 | 180328 | 9900 | 0.054900 | 0.9260 | 0.3305 | 0.3997
un-updated | 10 | 100 | 180328 | 30000 | 0.166364 | 1.0162 | 0.2024 | 0.2691
un-updated | 10 | 333 | 180328 | 99900 | 0.553991 | 0.2058 | 0.0683 | 0.0868
un-updated | 100 | 1 | 1803279 | 300 | 0.000166 | 7.1111 | 1.8793 | 2.3820
un-updated | 100 | 3 | 1803279 | 900 | 0.000499 | 3.8889 | 1.0586 | 1.3265
un-updated | 100 | 10 | 1803279 | 3000 | 0.001664 | 2.1407 | 0.6710 | 0.8376
un-updated | 100 | 33 | 1803279 | 9900 | 0.005490 | 1.1728 | 0.3779 | 0.4596
un-updated | 100 | 100 | 1803279 | 30000 | 0.016636 | 0.6256 | 0.1983 | 0.2551
un-updated | 100 | 333 | 1803279 | 99900 | 0.055399 | 0.3454 | 0.1181 | 0.1407
un-updated | 100 | 1000 | 1803279 | 300000 | 0.166364 | 0.1738 | 0.0593 | 0.0724
I also thought about the theory and am confident that there really is no way
to trick it. Basically if there are enough pages that are different to affect
the overall density, say 10% empty or so, there is no way a random sample
larger than a few hundred probes can miss them no matter how big the table is.
If there are few enough pages to "hide" from the sample, then they are so few
they don't matter anyway.
After all this my vote is for back patching too. I don't see any case where
the patched analyze is or could be worse than what we are doing. I'm happy to
provide my test cases if anyone is interested.
Thanks
-dg
--
David Gould daveg@sonic.net
If simplicity worked, the world would be overrun with insects.
David Gould <daveg@sonic.net> writes:
> I also thought about the theory and am confident that there really is no way
> to trick it. Basically if there are enough pages that are different to affect
> the overall density, say 10% empty or so, there is no way a random sample
> larger than a few hundred probes can miss them no matter how big the table is.
> If there are few enough pages to "hide" from the sample, then they are so few
> they don't matter anyway.
> After all this my vote is for back patching too. I don't see any case where
> the patched analyze is or could be worse than what we are doing. I'm happy to
> provide my test cases if anyone is interested.
Yeah, you have a point. I'm still worried about unexpected side-effects,
but it seems like overall this is very unlikely to hurt anyone. I'll
back-patch (minus the removal of the unneeded vac_estimate_reltuples
argument).
regards, tom lane
David Gould <daveg@sonic.net> writes:
> I have attached the patch we are currently using. It applies to 9.6.8. I
> have versions for older releases in 9.4, 9.5, 9.6. I fails to apply to 10,
> and presumably head but I can update it if there is any interest.
> The patch has three main features:
> - Impose an ordering on the autovacuum workers worklist to avoid
> the need for rechecking statistics to skip already vacuumed tables.
> - Reduce the frequency of statistics refreshes
> - Remove the AutovacuumScheduleLock
As per the earlier thread, the first aspect of that needs more work to
not get stuck when the worklist has long tasks near the end. I don't
think you're going to get away with ignoring that concern.
Perhaps we could sort the worklist by decreasing table size? That's not
an infallible guide to the amount of time that a worker will need to
spend, but it's sure safer than sorting by OID.
Alternatively, if we decrease the frequency of stats refreshes, how
much do we even need to worry about reordering the worklist?
In any case, I doubt anyone will have any appetite for back-patching
such a change. I'd recommend that you clean up your patch and rebase
to HEAD, then submit it into the September commitfest (either on a
new thread or a continuation of the old #13750 thread, not this one).
regards, tom lane
On Tue, 13 Mar 2018 11:29:03 -0400 Tom Lane <tgl@sss.pgh.pa.us> wrote: > David Gould <daveg@sonic.net> writes: > > I have attached the patch we are currently using. It applies to 9.6.8. I > > have versions for older releases in 9.4, 9.5, 9.6. I fails to apply to 10, > > and presumably head but I can update it if there is any interest. > > > The patch has three main features: > > - Impose an ordering on the autovacuum workers worklist to avoid > > the need for rechecking statistics to skip already vacuumed tables. > > - Reduce the frequency of statistics refreshes > > - Remove the AutovacuumScheduleLock > > As per the earlier thread, the first aspect of that needs more work to > not get stuck when the worklist has long tasks near the end. I don't > think you're going to get away with ignoring that concern. I agree that the concern needs to be addressed. The other concern is that sorting by oid is fairly arbitrary, the essential part is that there is some determinate order. > Perhaps we could sort the worklist by decreasing table size? That's not > an infallible guide to the amount of time that a worker will need to > spend, but it's sure safer than sorting by OID. That is better. I'll modify it to also prioritize tables that have relpages and reltuples = 0 which usually means the table has no stats at all. Maybe use oid to break ties. > Alternatively, if we decrease the frequency of stats refreshes, how > much do we even need to worry about reordering the worklist? The stats refresh in the current scheme is needed to make sure that two different workers don't vacuum the same table in close succession. It doesn't actually work, and it costs the earth. The patch imposes an ordering to prevent workers trying to claim recently vacuumed tables. This removes the need for the stats refresh. > In any case, I doubt anyone will have any appetite for back-patching > such a change. I'd recommend that you clean up your patch and rebase > to HEAD, then submit it into the September commitfest (either on a > new thread or a continuation of the old #13750 thread, not this one). I had in mind to make a more comprehensive patch to try to make utovacuum more responsive when there are lots of tables, but was a bit shy of the reception. I'll try again with this one (in a new thread) based on the suggestions. Thanks! -dg -- David Gould daveg@sonic.net If simplicity worked, the world would be overrun with insects.