Обсуждение: Bitmap table scan cost per page formula
Hi hackers,
This is Haisheng Yuan from Greenplum Database.
We had some query in production showing that planner favors seqscan over bitmapscan, and the execution of seqscan is 5x slower than using bitmapscan, but the cost of bitmapscan is 2x the cost of seqscan. The statistics were updated and quite accurate.
Bitmap table scan uses a formula to interpolate between random_page_cost and seq_page_cost to determine the cost per page. In Greenplum Database, the default value of random_page_cost is 100, the default value of seq_page_cost is 1. With the original cost formula, random_page_cost dominates in the final cost result, even the formula is declared to be non-linear. However, it is still more like linear, which can't reflect the real cost per page when a majority of pages are fetched. Therefore, the cost formula is updated to real non-linear function to reflect both random_page_cost and seq_page_cost for different percentage of pages fetched.
Even though PostgreSQL has much smaller default value of random_page_cost (4), the same problem exists there if we change the default value.
Old cost formula:
cost_per_page = random_page_cost - (random_page_cost - seq_page_cost) * sqrt(pages_fetched / T);
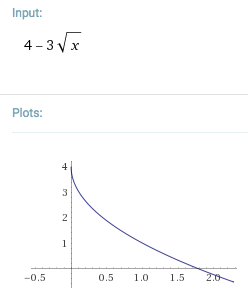
New cost formula:
cost_per_page = seq_page_cost * pow(random_page_cost / seq_page_cost, 1 - sqrt(pages_fetched / T));
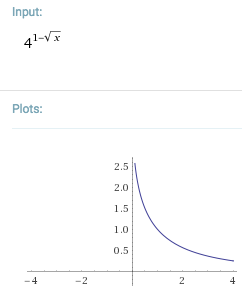
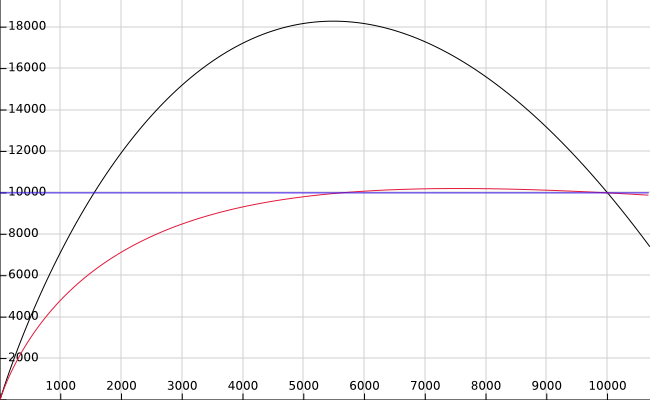
Below is the graph (credit to Heikki) that plots the total estimated cost of a bitmap heap scan, where table size is 10000 pages, and random_page_cost=10 and seq_page_cost=1. X axis is the number of pages fetche. I.e. on the left, no pages are fetched, and on the right end, at 10000, all pages are fetched. The original formula is in black, the new formula in red, and the horizontal line, in blue, shows the cost of a Seq Scan.
Thoughts? Any better ideas?
Thanks!
Haisheng Yuan
Вложения
On Tue, Dec 19, 2017 at 07:55:32PM +0000, Haisheng Yuan wrote: > Hi hackers, > > This is Haisheng Yuan from Greenplum Database. > > We had some query in production showing that planner favors seqscan over > bitmapscan, and the execution of seqscan is 5x slower than using > bitmapscan, but the cost of bitmapscan is 2x the cost of seqscan. The > statistics were updated and quite accurate. > > Bitmap table scan uses a formula to interpolate between random_page_cost > and seq_page_cost to determine the cost per page. In Greenplum Database, > the default value of random_page_cost is 100, the default value of > seq_page_cost is 1. With the original cost formula, random_page_cost > dominates in the final cost result, even the formula is declared to be > non-linear. However, it is still more like linear, which can't reflect the > real cost per page when a majority of pages are fetched. Therefore, the > cost formula is updated to real non-linear function to reflect both > random_page_cost and seq_page_cost for different percentage of pages > fetched. > > Even though PostgreSQL has much smaller default value of random_page_cost > (4), the same problem exists there if we change the default value. > > Old cost formula: > cost_per_page = random_page_cost - (random_page_cost - seq_page_cost) * > sqrt(pages_fetched / T); > [image: Inline image 1] > > New cost formula: > cost_per_page = seq_page_cost * pow(random_page_cost / seq_page_cost, 1 - > sqrt(pages_fetched / T)); > [image: Inline image 2] > > Below is the graph (credit to Heikki) that plots the total estimated cost > of a bitmap heap scan, where table size is 10000 pages, and > random_page_cost=10 and seq_page_cost=1. X axis is the number of pages > fetche. I.e. on the left, no pages are fetched, and on the right end, at > 10000, all pages are fetched. The original formula is in black, the new > formula in red, and the horizontal line, in blue, shows the cost of a Seq > Scan. > [image: Inline image 3] Thanks for caring about bitmap scans ;) There's a couple earlier/ongoing discussions on this: In this old thread: https://www.postgresql.org/message-id/CAGTBQpZ%2BauG%2BKhcLghvTecm4-cGGgL8vZb5uA3%3D47K7kf9RgJw%40mail.gmail.com ..Claudio Freire <klaussfreire(at)gmail(dot)com> wrote: > Correct me if I'm wrong, but this looks like the planner not > accounting for correlation when using bitmap heap scans. > > Checking the source, it really doesn't. ..which I think is basically right: the formula does distinguish between the cases of small or large fraction of pages, but doesn't use correlation. Our issue in that case seems to be mostly a failure of cost_index to account for fine-scale deviations from large-scale correlation; but, if cost_bitmap accounted for our high correlation metric (>0.99), it might've helped our case. Note costsize.c: * Save amcostestimate's results for possible use in bitmap scan planning. * We don't bother to save indexStartupCost or indexCorrelation, because a * BITMAP SCAN DOESN'T CARE ABOUT EITHER. See more at this recent/ongoing discussion (involving several issues, only one of which is bitmap cost vs index cost): https://www.postgresql.org/message-id/flat/20171206214652.GA13889%40telsasoft.com#20171206214652.GA13889@telsasoft.com Consider the bitmap scans in the two different cases: 1) In Vitaliy's case, bitmap was being chosen in preference to index scan (due in part to random_page_cost>1), but performed poorly, partially because bitmap component must complete before the heap reads can begin. And also because the heap reads for the test case involving modular division would've read pages across the entire length of the table, incurring maximum lseek costs. 2) In my case from ~16 months ago, index scan was being chosen in preference to bitmap, but index scan was incurring high seek cost. We would've been happy if the planner would've done a bitmap scan on a weekly-partitioned child table (with 7 days data), while querying one day's data (1/7th of the table), 99% of which would been strictly sequential page reads, so incurring low lseek costs (plus some component of random costs for the remaining 1% "long tail"). It seems clear to me that sequentially reading 1/7th of the tightly clustered pages in a table ought to be costed differently than reading 1/7th of the pages evenly distributed accross its entire length. I started playing with this weeks ago (probably during Vitaliy's problem report). Is there any reason cost_bitmap_heap_scan shouldn't interpolate based on correlation from seq_page_cost to rand_page_cost, same as cost_index ? Justin
On Tue, Dec 19, 2017 at 10:25 PM, Justin Pryzby <pryzby@telsasoft.com> wrote: > In this old thread: https://www.postgresql.org/message-id/CAGTBQpZ%2BauG%2BKhcLghvTecm4-cGGgL8vZb5uA3%3D47K7kf9RgJw%40mail.gmail.com > ..Claudio Freire <klaussfreire(at)gmail(dot)com> wrote: >> Correct me if I'm wrong, but this looks like the planner not >> accounting for correlation when using bitmap heap scans. >> >> Checking the source, it really doesn't. > > ..which I think is basically right: the formula does distinguish between the > cases of small or large fraction of pages, but doesn't use correlation. Our > issue in that case seems to be mostly a failure of cost_index to account for > fine-scale deviations from large-scale correlation; but, if cost_bitmap > accounted for our high correlation metric (>0.99), it might've helped our case. I think this is a different and much harder problem than the one Haisheng Yuan is attempting to fix. His data shows that the cost curve has a nonsensical shape even when the assumption that pages are spread uniformly is correct. That should surely be fixed. Now, being able to figure out whether the assumption of uniform spread is correct on a particular table would be nice too, but it seems like a much harder problem. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Dec 19, 2017 at 2:55 PM, Haisheng Yuan <hyuan@pivotal.io> wrote:
Below is the graph (credit to Heikki) that plots the total estimated cost of a bitmap heap scan, where table size is 10000 pages, and random_page_cost=10 and seq_page_cost=1. X axis is the number of pages fetche. I.e. on the left, no pages are fetched, and on the right end, at 10000, all pages are fetched. The original formula is in black, the new formula in red, and the horizontal line, in blue, shows the cost of a Seq Scan.Thoughts? Any better ideas?
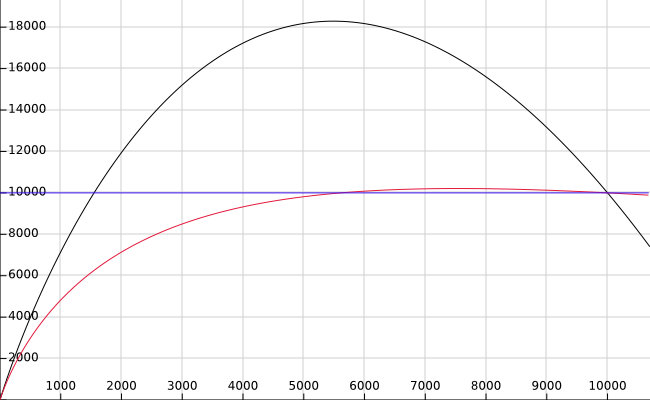
The parabola-shape curve we're getting at present is clearly wrong; approaching a horizontal line as an asymptote seems much better. However, shouldn't the red line level off at some level *above* the blue line rather than *at* the blue line? Reading the index pages isn't free, so a sequential scan should be preferred when we're going to read the whole table anyway.
Вложения
On Wed, Dec 20, 2017 at 12:29 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Dec 19, 2017 at 2:55 PM, Haisheng Yuan <hyuan@pivotal.io> wrote:Below is the graph (credit to Heikki) that plots the total estimated cost of a bitmap heap scan, where table size is 10000 pages, and random_page_cost=10 and seq_page_cost=1. X axis is the number of pages fetche. I.e. on the left, no pages are fetched, and on the right end, at 10000, all pages are fetched. The original formula is in black, the new formula in red, and the horizontal line, in blue, shows the cost of a Seq Scan.Thoughts? Any better ideas?The parabola-shape curve we're getting at present is clearly wrong; approaching a horizontal line as an asymptote seems much better. However, shouldn't the red line level off at some level *above* the blue line rather than *at* the blue line? Reading the index pages isn't free, so a sequential scan should be preferred when we're going to read the whole table anyway.
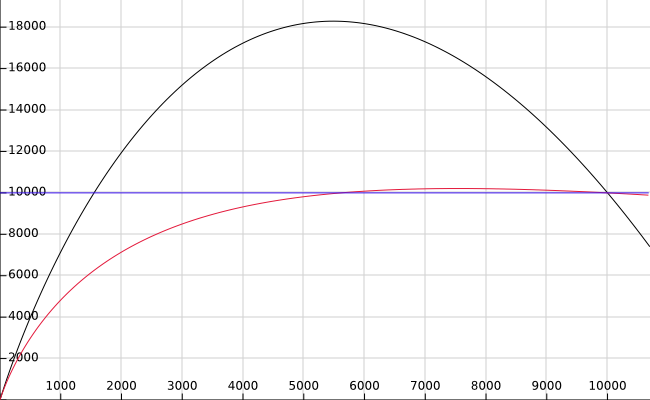
It is not obvious to me that the parabola is wrong. I've certainly seen cases where reading every 2nd or 3rd block (either stochastically, or modulus) actually does take longer than reading every block, because it defeats read-ahead. But it depends on a lot on your kernel version and your kernel settings and your file system and probably other things as well.
Cheers,
Jeff
Вложения
On Wed, Dec 20, 2017 at 4:20 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
-- It is not obvious to me that the parabola is wrong. I've certainly seen cases where reading every 2nd or 3rd block (either stochastically, or modulus) actually does take longer than reading every block, because it defeats read-ahead. But it depends on a lot on your kernel version and your kernel settings and your file system and probably other things as well.
Well, that's an interesting point, too. Maybe we need another graph that also shows the actual runtime of a bitmap scan and a sequential scan.
Robert, you are right. The new formula serves Greenplum better than the original formula, because our default random page cost is much higher than Postgres. We don't want random cost always dominates in the final cost per page.
~ ~ ~
Haisheng Yuan
On Wed, Dec 20, 2017 at 12:25 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Dec 19, 2017 at 10:25 PM, Justin Pryzby <pryzby@telsasoft.com> wrote:
> In this old thread: https://www.postgresql.org/message-id/CAGTBQpZ%2BauG% 2BKhcLghvTecm4-cGGgL8vZb5uA3% 3D47K7kf9RgJw%40mail.gmail.com
> ..Claudio Freire <klaussfreire(at)gmail(dot)com> wrote:
>> Correct me if I'm wrong, but this looks like the planner not
>> accounting for correlation when using bitmap heap scans.
>>
>> Checking the source, it really doesn't.
>
> ..which I think is basically right: the formula does distinguish between the
> cases of small or large fraction of pages, but doesn't use correlation. Our
> issue in that case seems to be mostly a failure of cost_index to account for
> fine-scale deviations from large-scale correlation; but, if cost_bitmap
> accounted for our high correlation metric (>0.99), it might've helped our case.
I think this is a different and much harder problem than the one
Haisheng Yuan is attempting to fix. His data shows that the cost
curve has a nonsensical shape even when the assumption that pages are
spread uniformly is correct. That should surely be fixed. Now, being
able to figure out whether the assumption of uniform spread is correct
on a particular table would be nice too, but it seems like a much
harder problem.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Dec 20, 2017 at 4:20 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
>> It is not obvious to me that the parabola is wrong. I've certainly seen
>> cases where reading every 2nd or 3rd block (either stochastically, or
>> modulus) actually does take longer than reading every block, because it
>> defeats read-ahead. But it depends on a lot on your kernel version and
>> your kernel settings and your file system and probably other things as well.
> Well, that's an interesting point, too.
Yes. I think the proposed new curve is flat wrong: for areas near the
middle of the graph, the estimated I/O cost for a bitmap scan should
*substantially* exceed the cost of a seqscan, because in that regime
you're reading a lot of pages but you are probably failing to activate
the kernel's readahead heuristics. This is especially true if you
consider that random_page_cost >> seq_page_cost as the Greenplum folk
seem to want.
The parabola is probably wrong in detail --- its behavior as we approach
reading all of the pages ought to be more asymptotic, seems like.
I suppose that the reason it appears to go below the seqscan cost at the
right is that even the rightmost end of the curve doesn't reflect reading
all of the *tuples*, just one tuple per page, so that there's some CPU
savings from not inspecting all the tuples. Once you approach needing to
read all the tuples, the curve ought to go back higher than seqscan cost.
The point upthread about perhaps wanting to consider index correlation is
interesting too. I think that correlation as currently defined is the
wrong stat for that purpose: what we are interested in for a bitmap scan
is clumping, not ordering. If reading 10% of the index is likely to
result in accessing a tightly packed 10% of the table, rather than
roughly-one-page-in-10, then we ideally ought to be costing that as
sequential access not random access. It's true that perfect correlation
would guarantee good clumping as well as good ordering, but it seems like
that's too strong an assumption. An index with almost zero correlation
might still have pretty good clumping behavior.
regards, tom lane
On Wed, Dec 20, 2017 at 2:18 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Wed, Dec 20, 2017 at 4:20 PM, Jeff Janes <jeff.janes@gmail.com> wrote:It is not obvious to me that the parabola is wrong. I've certainly seen cases where reading every 2nd or 3rd block (either stochastically, or modulus) actually does take longer than reading every block, because it defeats read-ahead. But it depends on a lot on your kernel version and your kernel settings and your file system and probably other things as well.Well, that's an interesting point, too. Maybe we need another graph that also shows the actual runtime of a bitmap scan and a sequential scan.
I've did some low level IO benchmarking, and I actually get 13 times slower to read every 3rd block than every block using CentOS6.9 with ext4 and the setting:
blockdev --setra 8192 /dev/sdb1
On some virtualized storage which I don't know the details of, but it behaves as if it were RAID/JBOD with around 6 independent spindles..
If I pick the 1/3 of the blocks to read stochastically rather than by modulus, it is only 2 times slower than reading all of them, I assume because having occasional reads which are adjacent to each other does make read-ahead kick in, while evenly spaced never-adjacent reads does not. This is probably a better model of how bitmap table scans actually work, as there is no general reason to think they would be evenly spaced and non-adjacent. So this result is in reasonable agreement with how the current cost estimation works, the parabola peaks at about twice the cost as the sequence scan.
I used a file of about 10GB, because I happened to have one laying around.
## read every block ($_%3>5 is never true)
sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
time perl -le 'open my $fh, "rand" or die; foreach (1..1300000) {$x=""; next if $_%3>5; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh, $x,8*1024; print length $x} '|uniq -c
1295683 8192
4317 0
real 0m38.329s
## read every 3rd block
sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
time perl -le 'open my $fh, "rand" or die; foreach (1..1300000) {$x=""; next if $_%3>0; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh, $x,8*1024; print length $x} '|uniq -c
431894 8192
1439 0
real 8m54.698s
time perl -wle 'open my $fh, "rand" or die; foreach (1..1300000) {$x=""; next if rand()>0.3333; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh, $x,8*1024; print length $x} '|uniq -c
431710 8192
1434 0
real 1m23.130s
Dropping the caches is a reasonable way to do this type of benchmark, because it simulates what would happen if your data set was much larger than RAM, without needing to actually use a data set much larger than RAM.
It would be interesting to see what other people get for similar low level tests, as well actual bitmap scans.
Cheers,
Jeff
On Tue, Dec 19, 2017 at 11:55 AM, Haisheng Yuan <hyuan@pivotal.io> wrote:
Hi hackers,This is Haisheng Yuan from Greenplum Database.We had some query in production showing that planner favors seqscan over bitmapscan, and the execution of seqscan is 5x slower than using bitmapscan, but the cost of bitmapscan is 2x the cost of seqscan. The statistics were updated and quite accurate.Bitmap table scan uses a formula to interpolate between random_page_cost and seq_page_cost to determine the cost per page. In Greenplum Database, the default value of random_page_cost is 100, the default value of seq_page_cost is 1. With the original cost formula, random_page_cost dominates in the final cost result, even the formula is declared to be non-linear.
My first inclination would be take this as evidence that 100 is a poor default for random_page_cost, rather than as evidence that the bitmap heap scan IO cost model is wrong.
Could you try the low level benchmark I posted elsewhere in the thread on your hardware for reading 1/3 or 1/2 of the pages, in order? Maybe your kernel/system does a better job of predicting read ahead.
Cheers,
Jeff
On Tue, Dec 19, 2017 at 7:25 PM, Justin Pryzby <pryzby@telsasoft.com> wrote:
I started playing with this weeks ago (probably during Vitaliy's problem
report). Is there any reason cost_bitmap_heap_scan shouldn't interpolate based
on correlation from seq_page_cost to rand_page_cost, same as cost_index ?
I think that doing something like that is a good idea in general, but someone has to implement the code, and so far no one seems enthused to do so. You seem pretty interested in the topic, so....
It is not obvious to me how to pass the correlation from the cost_index up to the bitmap heap scan, especially not if it has to go through a BitmapAnd or a BitmapOr to get there. Maybe the optimization would only be used in the case where there are no BitmapAnd or BitmapOr, at least for a proof of concept?
I haven't been able to reproduce your test case, but I have not had the hardware or the time to try very hard. I think next year I'll have more time, but I don't know about the hardware.
Cheers,
Jeff
On Wed, Dec 20, 2017 at 5:03 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
The parabola is probably wrong in detail --- its behavior as we approach
reading all of the pages ought to be more asymptotic, seems like.
I suppose that the reason it appears to go below the seqscan cost at the
right is that even the rightmost end of the curve doesn't reflect reading
all of the *tuples*, just one tuple per page, so that there's some CPU
savings from not inspecting all the tuples.
I think that the graph is only about the IO costs of the heap scan, and the CPU costs are an independent issue.
The reason it drops below the seqscan on the far right edge is much simpler. 10,000 is the point where 100% of the pages are being read, so the two scans converge to the same value. The graph continues above 10,000 but it is meaningless as a bitmap heap scan will never read more than 100% of the table pages and so the math no longer represents a reality.
Cheers,
Jeff
Hi Jeff,
The issue happens on our customer's production environment, I don't have access to their hardware. But I agree, the default value 100 is indeed a poor value. After I change the default value to 30 or less, the query starts generating plan with bitmap scan as expected.
~ ~ ~
Haisheng Yuan
On Wed, Dec 20, 2017 at 9:43 PM, Jeff Janes <jeff.janes@gmail.com> wrote:
On Tue, Dec 19, 2017 at 11:55 AM, Haisheng Yuan <hyuan@pivotal.io> wrote:Hi hackers,This is Haisheng Yuan from Greenplum Database.We had some query in production showing that planner favors seqscan over bitmapscan, and the execution of seqscan is 5x slower than using bitmapscan, but the cost of bitmapscan is 2x the cost of seqscan. The statistics were updated and quite accurate.Bitmap table scan uses a formula to interpolate between random_page_cost and seq_page_cost to determine the cost per page. In Greenplum Database, the default value of random_page_cost is 100, the default value of seq_page_cost is 1. With the original cost formula, random_page_cost dominates in the final cost result, even the formula is declared to be non-linear.My first inclination would be take this as evidence that 100 is a poor default for random_page_cost, rather than as evidence that the bitmap heap scan IO cost model is wrong.Could you try the low level benchmark I posted elsewhere in the thread on your hardware for reading 1/3 or 1/2 of the pages, in order? Maybe your kernel/system does a better job of predicting read ahead.Cheers,Jeff
Moin,
On Wed, December 20, 2017 11:51 pm, Jeff Janes wrote:
> On Wed, Dec 20, 2017 at 2:18 PM, Robert Haas <robertmhaas@gmail.com>
> wrote:
>
>> On Wed, Dec 20, 2017 at 4:20 PM, Jeff Janes <jeff.janes@gmail.com>
>> wrote:
>>>
>>> It is not obvious to me that the parabola is wrong. I've certainly
>>> seen
>>> cases where reading every 2nd or 3rd block (either stochastically, or
>>> modulus) actually does take longer than reading every block, because it
>>> defeats read-ahead. But it depends on a lot on your kernel version and
>>> your kernel settings and your file system and probably other things as
>>> well.
>>>
>>
>> Well, that's an interesting point, too. Maybe we need another graph
>> that
>> also shows the actual runtime of a bitmap scan and a sequential scan.
>>
>
> I've did some low level IO benchmarking, and I actually get 13 times
> slower
> to read every 3rd block than every block using CentOS6.9 with ext4 and the
> setting:
> blockdev --setra 8192 /dev/sdb1
> On some virtualized storage which I don't know the details of, but it
> behaves as if it were RAID/JBOD with around 6 independent spindles..
Repeated this here on my desktop, linux-image-4.10.0-42 with a Samsung SSD
850 EVO 500 Gbyte, on an encrypted / EXT4 partition:
$ dd if=/dev/zero of=zero.dat count=1300000 bs=8192
1300000+0 records in
1300000+0 records out
10649600000 bytes (11 GB, 9,9 GiB) copied, 22,1993 s, 480 MB/s
All blocks:
$ sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
$ time perl -le 'open my $fh, "rand" or die; foreach (1..1300000)
{$x="";next if $_%3>5; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh,
$x,8*1024; print length $x} ' | uniq -c
1299999 8192
real 0m20,841s
user 0m0,960s
sys 0m2,516s
Every 3rd block:
$ sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
$ time perl -le 'open my $fh, "rand" or die; foreach (1..1300000) {$x="";
next if $_%3>0; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh,
$x,8*1024; print length $x} '|uniq -c
433333 8192
real 0m50,504s
user 0m0,532s
sys 0m2,972s
Every 3rd block random:
$ sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
$ time perl -le 'open my $fh, "rand" or die; foreach (1..1300000) {$x="";
next if rand()> 0.3333; sysseek $fh,$_*8*1024,0 or die $!; sysread $fh,
$x,8*1024; print length $x} ' | uniq -c
432810 8192
real 0m26,575s
user 0m0,540s
sys 0m2,200s
So it does get slower, but only about 2.5 times respectively about 30%.
Hope this helps,
Tels