Обсуждение: Gin indexes on intarray is fast when value in array does not exists, and slow, when value exists
I increased rows limit from 50 to 500, because now, difference visible much better, so query is:
explain analyze SELECT * FROM table_name WHERE my_array @> '{x}'::integer[] ORDER BY id desc LIMIT 500
with GIN index:
"Limit (cost=107.83..109.08 rows=500 width=905) (actual time=978.256..978.293 rows=500 loops=1)"
" -> Sort (cost=107.83..109.16 rows=533 width=905) (actual time=978.254..978.272 rows=500 loops=1)"
" Sort Key: id DESC"
" Sort Method: top-N heapsort Memory: 589kB"
" -> Bitmap Heap Scan on table_name (cost=23.93..83.69 rows=533 width=905) (actual time=50.612..917.422 rows=90049 loops=1)"
" Recheck Cond: (my_array @> '{8}'::integer[])"
" Heap Blocks: exact=46525"
" -> Bitmap Index Scan on idx (cost=0.00..23.80 rows=533 width=0) (actual time=35.054..35.054 rows=90052 loops=1)"
" Index Cond: (my_array @> '{8}'::integer[])"
"Planning time: 0.202 ms"
"Execution time: 978.718 ms"
Without index:
"Limit (cost=7723.12..7724.37 rows=500 width=122) (actual time=184.041..184.102 rows=500 loops=1)"
" -> Sort (cost=7723.12..7724.45 rows=534 width=122) (actual time=184.039..184.052 rows=500 loops=1)"
" Sort Key: id DESC"
" Sort Method: top-N heapsort Memory: 157kB"
" -> Seq Scan on table_name (cost=0.00..7698.93 rows=534 width=122) (actual time=0.020..176.079 rows=84006 loops=1)"
" Filter: (my_array @> '{14}'::integer[])"
" Rows Removed by Filter: 450230"
"Planning time: 0.165 ms"
"Execution time: 184.155 ms"
Postgres version: 9.5; OS: Windows 7; RAM: 8GB
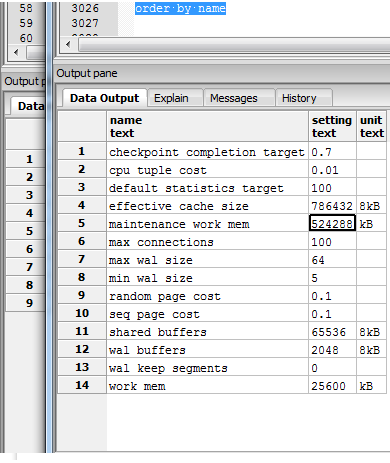
In picture is some config current values.
p.s. In "pg_stats" really many values (long lists in "most_common_vals", "most_common_freqs") and in another columns
Which one columns should I show you? All?
Вложения
{kind=link}
otar shavadze <oshavadze@gmail.com> writes:
> " -> Bitmap Index Scan on idx (cost=0.00..23.80 rows=533
> width=0) (actual time=35.054..35.054 rows=90052 loops=1)"
> " Index Cond: (my_array @> '{8}'::integer[])"
Seems like your problem here is that the planner has no idea about the
selectivity of this condition --- if it did, I think it would have
made the right choice, because it would have made a much higher estimate
for the cost of the indexscan.
AFAICT, Postgres 9.5 does make a reasonably correct guess when given
up-to-date stats. I speculate that you need to ANALYZE this table.
If there are a lot of distinct possible values in the arrays, increasing
the statistics target for the column might be needed.
regards, tom lane
On Tue, Nov 8, 2016 at 12:27 PM, otar shavadze <oshavadze@gmail.com> wrote:
p.s. In "pg_stats" really many values (long lists in "most_common_vals", "most_common_freqs") and in another columnsWhich one columns should I show you? All?
most_common_elems. Is it empty, or is it not empty? If not empty, does it contain the specific values you used in your queries?
Cheers,
Jeff
I wrote:
> Seems like your problem here is that the planner has no idea about the
> selectivity of this condition --- if it did, I think it would have
> made the right choice, because it would have made a much higher estimate
> for the cost of the indexscan.
> AFAICT, Postgres 9.5 does make a reasonably correct guess when given
> up-to-date stats. I speculate that you need to ANALYZE this table.
Hmmm ... actually, I wonder if maybe '@>' here is the contrib/intarray
operator not the core operator? The intarray operator didn't get plugged
into any real estimation logic until 9.6.
regards, tom lane
@Jeff
most_common_elems. Is it empty, or is it not empty? If not empty, does it contain the specific values you used in your queries?
No, most_common_elems is not empty. it contain the specific values I used in queries.
@Tom
Hmmm ... actually, I wonder if maybe '@>' here is the contrib/intarray
operator not the core operator? The intarray operator didn't get plugged
into any real estimation logic until 9.6.
So, you mean that better would be go to version 9.6 ?
On Wed, Nov 9, 2016 at 8:35 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
I wrote:
> Seems like your problem here is that the planner has no idea about the
> selectivity of this condition --- if it did, I think it would have
> made the right choice, because it would have made a much higher estimate
> for the cost of the indexscan.
> AFAICT, Postgres 9.5 does make a reasonably correct guess when given
> up-to-date stats. I speculate that you need to ANALYZE this table.
Hmmm ... actually, I wonder if maybe '@>' here is the contrib/intarray
operator not the core operator? The intarray operator didn't get plugged
into any real estimation logic until 9.6.
regards, tom lane
otar shavadze <oshavadze@gmail.com> writes:
>> Hmmm ... actually, I wonder if maybe '@>' here is the contrib/intarray
>> operator not the core operator? The intarray operator didn't get plugged
>> into any real estimation logic until 9.6.
> So, you mean that better would be go to version 9.6 ?
If you are using that contrib module, and it's capturing this operator
reference, that would probably explain the bad estimate. You could
drop the extension if you're not depending on its other features, or you
could explicitly qualify the operator name ("operator(pg_catalog.@>)"),
or you could upgrade to 9.6 (don't forget to do ALTER EXTENSION ... UPDATE
afterwards).
regards, tom lane
On Thu, Nov 10, 2016 at 7:11 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
otar shavadze <oshavadze@gmail.com> writes:
>> Hmmm ... actually, I wonder if maybe '@>' here is the contrib/intarray
>> operator not the core operator? The intarray operator didn't get plugged
>> into any real estimation logic until 9.6.
> So, you mean that better would be go to version 9.6 ?
If you are using that contrib module, and it's capturing this operator
reference, that would probably explain the bad estimate. You could
drop the extension if you're not depending on its other features, or you
could explicitly qualify the operator name ("operator(pg_catalog.@>)"),
or you could upgrade to 9.6 (don't forget to do ALTER EXTENSION ... UPDATE
afterwards).
Isn't the operator determined at index build time? If he doesn't want to update to 9.6, I think he would need to rebuild the index, removing the "gin__int_ops" specification.
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> On Thu, Nov 10, 2016 at 7:11 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> If you are using that contrib module, and it's capturing this operator
>> reference, that would probably explain the bad estimate. You could
>> drop the extension if you're not depending on its other features, or you
>> could explicitly qualify the operator name ("operator(pg_catalog.@>)"),
>> or you could upgrade to 9.6 (don't forget to do ALTER EXTENSION ... UPDATE
>> afterwards).
> Isn't the operator determined at index build time? If he doesn't want to
> update to 9.6, I think he would need to rebuild the index, removing
> the "gin__int_ops" specification.
The operator in the query isn't. But yes, if he's using an index that's
built on the extension's opclass, he'd need to rebuild that too in order
to still use the index with the core @> operator.
regards, tom lane
Tried
OPERATOR(pg_catalog.@>)
as Tom mentioned, but still, don't get fast performance when value does not existed in any array.
Also "played" with many different ways, gin, gist indexes (gin with and without gin__int_ops) but, always, there was some situation, where search in array was slow.
I don't know exactly, may be I am wrong, but what I understood after several day "trying", is that, I never will use arrays, with tables more than 500 000-1000 000 rows, because then searching in this array is somehow problematic.
I rebuild my structure and added another table (instead of using array) and then used join's instead of searching in array.
That's works perfectly, joining works fast as hell, even for several millions rows in each table.
On Fri, Nov 11, 2016 at 12:58 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Jeff Janes <jeff.janes@gmail.com> writes:
> On Thu, Nov 10, 2016 at 7:11 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> If you are using that contrib module, and it's capturing this operator
>> reference, that would probably explain the bad estimate. You could
>> drop the extension if you're not depending on its other features, or you
>> could explicitly qualify the operator name ("operator(pg_catalog.@>)"),
>> or you could upgrade to 9.6 (don't forget to do ALTER EXTENSION ... UPDATE
>> afterwards).
> Isn't the operator determined at index build time? If he doesn't want to
> update to 9.6, I think he would need to rebuild the index, removing
> the "gin__int_ops" specification.
The operator in the query isn't. But yes, if he's using an index that's
built on the extension's opclass, he'd need to rebuild that too in order
to still use the index with the core @> operator.
regards, tom lane
On Sat, Nov 12, 2016 at 5:33 PM, otar shavadze <oshavadze@gmail.com> wrote:
TriedOPERATOR(pg_catalog.@>)as Tom mentioned, but still, don't get fast performance when value does not existed in any array.
Did you build the correct index?
Also "played" with many different ways, gin, gist indexes (gin with and without gin__int_ops) but, always, there was some situation, where search in array was slow.
Yes. There will always be some situation when the array search is slow. Is that situation one that a specific person cares about? Hard to tell, since you have not given us any additional useful information.
I don't know exactly, may be I am wrong, but what I understood after several day "trying", is that, I never will use arrays, with tables more than 500 000-1000 000 rows, because then searching in this array is somehow problematic.I rebuild my structure and added another table (instead of using array) and then used join's instead of searching in array.That's works perfectly, joining works fast as hell, even for several millions rows in each table.
"Properly" normalizing your data is a wonderful thing, no doubt about it, if you are prepared to deal with the consequences of doing so. But not everyone has that luxury. Which is why there is more than one way of doing things.
Cheers,
Jeff