Обсуждение: Resurrected thread: Speed improvement - Group batch Insert - Rewrite the INSERT at the driver level (using a parameter)
Hi, I see this conversation [1] occurred back in 2009. I'd like to resurrect the thread. In response to the questions by J. W. Ulbts I have some performances results demonstrating the benefit. Also a response to his suggestion for using COPY. "Where exactly is the performance benefit that you see coming from?" To answer this question a simple java JDBC project [2] was created to demonstrate the benefit. In the project are several benchmarks grouped by individual statements (IndividualStatementsTest) or re-written multi-insert (MultiInsertStatementTest). Each group has 3 different statement/row sizes (2/5/51) which are configurable. Named "SMALL", "MEDIUM" and "LARGE" respectively. The default sizes are not intended to be representative of any particular use case. As everyone has differing opinions of what is appropriate. The project is easy to set up and run. Details are in the README file. The attached normalized graph of ops/sec demonstrating the benefit at different levels of concurrency. The results are for a client machine and a dedicated server system. Details of the db system are: 32 core @2.90GHz, 283GB memory, couple of enterprise SSD for db storage. WAL and tablespace are on separate devices. "If your use case is just "I want to do bulk inserts as fast as possible" then perhaps the newly merged COPY suport is a better way to go." For use cases involving applications using an ORM like Hibernate COPY isn't supported nor likely to. Hibernate doesn't have any concept of handling files on the database system. What are the thoughts for having this optimization introduced into pgjdbc driver ? Regards, Jeremy [1] http://www.postgresql.org/message-id/828427796@web.de [2] https://github.com/whitingjr/batch-rewrite-statements-perf -- Jeremy Whiting Senior Software Engineer, JBoss Performance Team Red Hat ------------------------------------------------------------ Registered Address: RED HAT UK LIMITED, 64 Baker Street, 4th Floor, Paddington. London. United Kingdom W1U 7DF Registered in UK and Wales under Company Registration No. 3798903 Directors: Michael Cunningham (US), Charles Peters (US),Matt Parson (US) and Michael O'Neill(Ireland)
Вложения
{kind=link}
{kind=link}
{kind=link}
Hi Jeremy,
As Oliver pointed out in the response to [1] this would require parsing the query which we avoid.
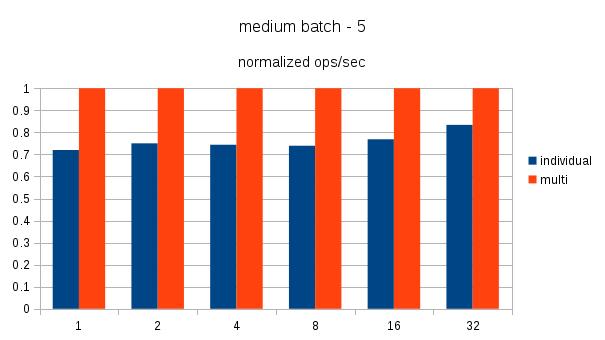
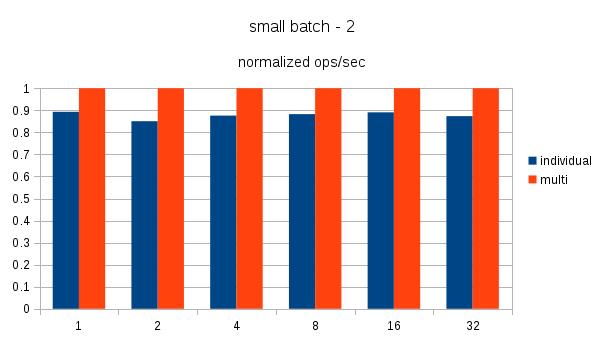
I also note that this approach isn't much of an improvement for small batches. I am curious what is your real world use case that prompted this experiment ?
Dave
On 25 March 2015 at 15:34, Jeremy Whiting <jwhiting@redhat.com> wrote:
Hi,
I see this conversation [1] occurred back in 2009. I'd like to resurrect the thread.
In response to the questions by J. W. Ulbts I have some performances results demonstrating the benefit. Also a response to his suggestion for using COPY.
"Where exactly is the performance benefit that you see coming from?"
To answer this question a simple java JDBC project [2] was created to demonstrate the benefit. In the project are several benchmarks grouped by individual statements (IndividualStatementsTest) or re-written multi-insert (MultiInsertStatementTest). Each group has 3 different statement/row sizes (2/5/51) which are configurable. Named "SMALL", "MEDIUM" and "LARGE" respectively. The default sizes are not intended to be representative of any particular use case. As everyone has differing opinions of what is appropriate.
The project is easy to set up and run. Details are in the README file.
The attached normalized graph of ops/sec demonstrating the benefit at different levels of concurrency. The results are for a client machine and a dedicated server system. Details of the db system are: 32 core @2.90GHz, 283GB memory, couple of enterprise SSD for db storage. WAL and tablespace are on separate devices.
"If your use case is just "I want to do bulk inserts as fast as possible" then perhaps the newly merged COPY suport is a better way to go."
For use cases involving applications using an ORM like Hibernate COPY isn't supported nor likely to. Hibernate doesn't have any concept of handling files on the database system.
What are the thoughts for having this optimization introduced into pgjdbc driver ?
Regards,
Jeremy
[1] http://www.postgresql.org/message-id/828427796@web.de
[2] https://github.com/whitingjr/batch-rewrite-statements-perf
--
Jeremy Whiting
Senior Software Engineer, JBoss Performance Team
Red Hat
------------------------------------------------------------
Registered Address: RED HAT UK LIMITED, 64 Baker Street, 4th Floor, Paddington. London. United Kingdom W1U 7DF
Registered in UK and Wales under Company Registration No. 3798903 Directors: Michael Cunningham (US), Charles Peters (US), Matt Parson (US) and Michael O'Neill(Ireland)
--
Sent via pgsql-jdbc mailing list (pgsql-jdbc@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-jdbc
Hi Dave, Yes I noticed query parsing doesn't occur in the code base. I do hope avoiding query parsing is not going to be avoided outright ;) I suggest an optimization like this should be enabled only through configuration. Using a connection parameter. So the default driver behaviour will continue to avoid query parsing. I agree the small batch size is a meagre improvement. Putting on my red hat I have customers and community users seeking any improvement possible using batching. They see the optimization in the MySQL jdbc driver and want to have some of that too as they are using PostgreSQL/EnterpriseDB and do not have the option to change. Having investigated this optimization and the issues in Git there is a particular case I wish to avoid/de-scope. That is INSERT statements with RETURNING. I see there are a number of open issues that Craig Ringer is investigating. At the moment I am coding changes to the driver [3] with the intention of proposing they be added. Along with test cases to add coverage for existing default behaviour and expected behaviour when the optimization is enabled. Jeremy [3] https://github.com/whitingjr/pgjdbc/tree/batched-insert-rewrite On 28/03/15 18:01, Dave Cramer wrote: > Hi Jeremy, > > As Oliver pointed out in the response to [1] this would require > parsing the query which we avoid. > > I also note that this approach isn't much of an improvement for small > batches. I am curious what is your real world use case that prompted > this experiment ? > > Dave > > Dave Cramer > > dave.cramer(at)credativ(dot)ca > http://www.credativ.ca
On 30 March 2015 at 07:29, Jeremy Whiting <jwhiting@redhat.com> wrote:
Hi Dave,
Yes I noticed query parsing doesn't occur in the code base. I do hope avoiding query parsing is not going to be avoided outright ;)
As a matter of fact query parsing has been avoided outright. We do not want to parse the query. This will have a fairly high barrier to entry, as you are now going to slow every query down.
I suggest an optimization like this should be enabled only through configuration. Using a connection parameter. So the default driver behaviour will continue to avoid query parsing.
I agree the small batch size is a meagre improvement. Putting on my red hat I have customers and community users seeking any improvement possible using batching. They see the optimization in the MySQL jdbc driver and want to have some of that too as they are using PostgreSQL/EnterpriseDB and do not have the option to change.
Comparing PostgreSQL to MySQL even at the driver level would be hard to prove where the efficiency would be realized. How can you prove whether the problem is the driver or the backend, or even the network ?
Can you provide references to said users ?
Having investigated this optimization and the issues in Git there is a particular case I wish to avoid/de-scope. That is INSERT statements with RETURNING. I see there are a number of open issues that Craig Ringer is investigating.
At the moment I am coding changes to the driver [3] with the intention of proposing they be added. Along with test cases to add coverage for existing default behaviour and expected behaviour when the optimization is enabled.
Jeremy
[3] https://github.com/whitingjr/pgjdbc/tree/batched-insert-rewrite
Look forward to seeing it.
On 28/03/15 18:01, Dave Cramer wrote:Hi Jeremy,
As Oliver pointed out in the response to [1] this would require parsing the query which we avoid.
I also note that this approach isn't much of an improvement for small batches. I am curious what is your real world use case that prompted this experiment ?
Dave
Dave Cramer
dave.cramer(at)credativ(dot)ca
http://www.credativ.ca
Jeremy Whiting schrieb am 25.03.2015 um 20:34: > "If your use case is just "I want to do bulk inserts as fast as possible" then perhaps the newly merged COPY suport isa better way to go." I wonder if it is possible to silently "rewrite" a batched statement to use the CopyManager. Very(!) roughly speaking: when the first call to addBatch() is made, initialize the CopyManager and provide a a Reader implementationthat acts as a bridge between the PreparedStatement.setXXX()/addBatch() statements and the CopyManager. Somethinglike a producer/consumer pattern. The setXXX() calls would prepare a single "line" and the addBatch() would then"send" this to the CopyManager which is blocked on the Read.readLine() call. But I have no clue if this would even be possible (blocking Reader.readLine() but sill allowing calls to addBatch() in thesame Thread seems a major roadblock to me) or - if possible - how much work it would be. It would definitely require parsing the insert statement passed to the prepareStatement() clause, but as the syntax of aplain insert statement isn't that complicated, I think that should be doable - especially because we wouldn't need to worryabout literals as only placeholders will be (must be?) used. Thomas
On 30 March 2015 at 08:23, Thomas Kellerer <spam_eater@gmx.net> wrote:
Jeremy Whiting schrieb am 25.03.2015 um 20:34:
> "If your use case is just "I want to do bulk inserts as fast as possible" then perhaps the newly merged COPY suport is a better way to go."
I wonder if it is possible to silently "rewrite" a batched statement to use the CopyManager.
copy doesn't invoke rules... not that I think rules are a great thing. I imagine some folks might have an issue.
Very(!) roughly speaking: when the first call to addBatch() is made, initialize the CopyManager and provide a a Reader implementation that acts as a bridge between the PreparedStatement.setXXX()/addBatch() statements and the CopyManager. Something like a producer/consumer pattern. The setXXX() calls would prepare a single "line" and the addBatch() would then "send" this to the CopyManager which is blocked on the Read.readLine() call.
But I have no clue if this would even be possible (blocking Reader.readLine() but sill allowing calls to addBatch() in the same Thread seems a major roadblock to me) or - if possible - how much work it would be.
It would definitely require parsing the insert statement passed to the prepareStatement() clause, but as the syntax of a plain insert statement isn't that complicated, I think that should be doable - especially because we wouldn't need to worry about literals as only placeholders will be (must be?) used.
Thomas
--
Sent via pgsql-jdbc mailing list (pgsql-jdbc@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-jdbc
On 26 March 2015 at 03:34, Jeremy Whiting <jwhiting@redhat.com> wrote:
For use cases involving applications using an ORM like Hibernate COPY isn't supported nor likely to. Hibernate doesn't have any concept of handling files on the database system.
There is no need for a file on the database system. It's just a stream of rows in CSV-like form, sent from the client to the server over the PostgreSQL wire protocol. PgJDBC's COPY protocol support uses the server-side COPY ... FROM STDIN command to implement this
Nonetheless, it's extension API, not something that's part of the JDBC interfaces, and it's not likely an ORM would adopt it.
What are the thoughts for having this optimization introduced into pgjdbc driver ?
IMO: Use batching. The JDBC API provides batching features, and PgJDBC implements them. A PreparedStatement batch does a single Parse, then repeated Bind/Describe/Execute statements, and will perform very well.
Failure to use such APIs is a bug in the ORM.
There's room for improvement in PgJDBC's current batching support though. For one thing it does its buffer management totally backwards (see github issues), meaning it has to force round-trips more often than it would ideally need to. Further improvement would involve reading replies in a separate thread so we didn't have to force Sync at all.
To further improve things (in sane ways that didn't involve some scary query-parsing hacks) would involve a PostgreSQL protocol enhancement to let PostgreSQL accept parameter arrays via table-valued Bind messages. So we could essentially send "INSERT INTO ... VALUES $TABLE" . I'd love to have this, but I don't really see it being implemented when we already have COPY; someone would have to provide a really compelling argument and a solid implementation.